
the model is not working in LM studio
#2
by rail123 - opened

Getting following error when sending the prompt and in model settings
Failed to parse Jinja template: Parser Error: Expected closing statement token. OpenSquareBracket !== CloseStatement.
Error rendering prompt with jinja template: "Parser Error: Expected closing statement token. OpenSquareBracket !== CloseStatement.". This is usually an issue with the model's prompt template. If you are using a popular model, you can try to search the model under lmstudio-community, which will have fixed prompt templates. If you cannot find one, you are welcome to post this issue to our discord or issue tracker on GitHub. Alternatively, if you know how to write jinja templates, you can override the prompt template in My Models > model settings > Prompt Template
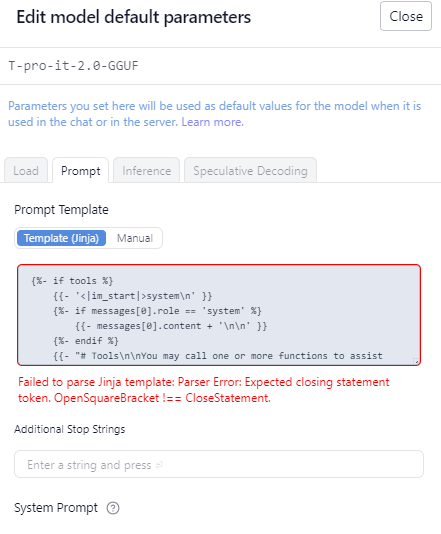

Got the same error. As I can see, this is because of focus on tools usage. Model works well after deleting template. As a workaround.