
High-Fidelity Audio Compression with Improved RVQGAN
Paper • 2306.06546 • Published • 12
A minimal neural audio codec. 16kHz mono • 128x compression • 10.2 kbps • 24M parameters.
Trained on LibriSpeech train-clean-100 (~100 hours) for ~180k steps.
📝 Blog Post — in-depth walkthrough of the architecture, training, and lessons learned
🤗 Model Weights — pretrained model on HuggingFace
💻 GitHub — full training and inference code
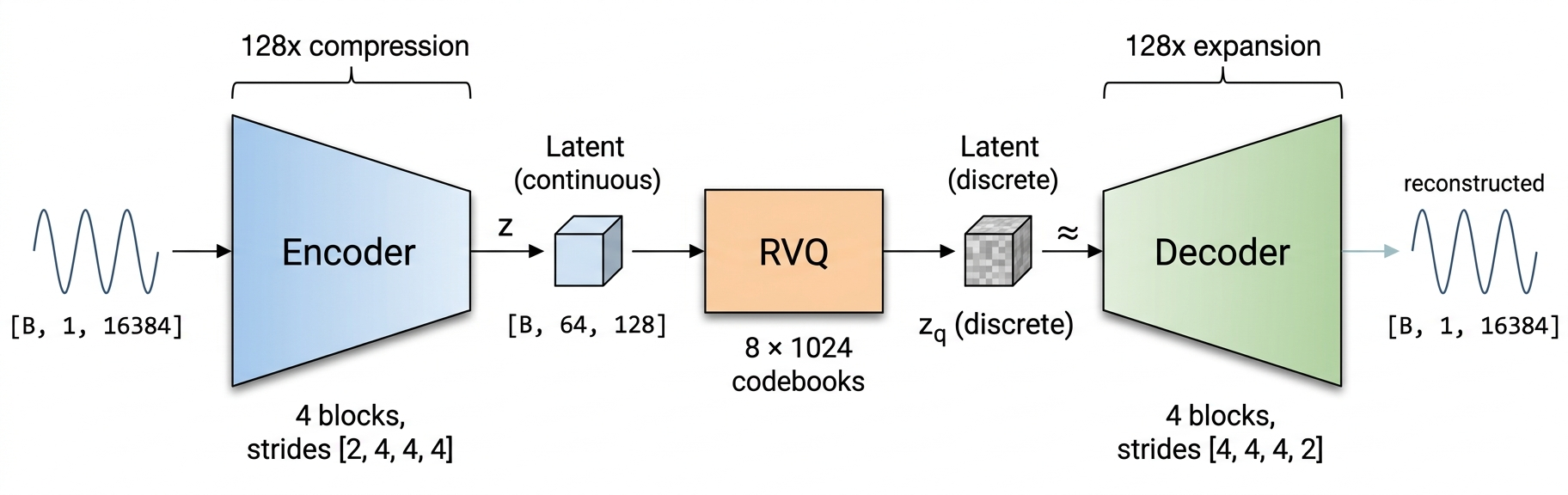
Inspired by DAC (Descript Audio Codec). Strided convolutional encoder, 8-level RVQ with factorized L2-normalized codebooks, mirror decoder.
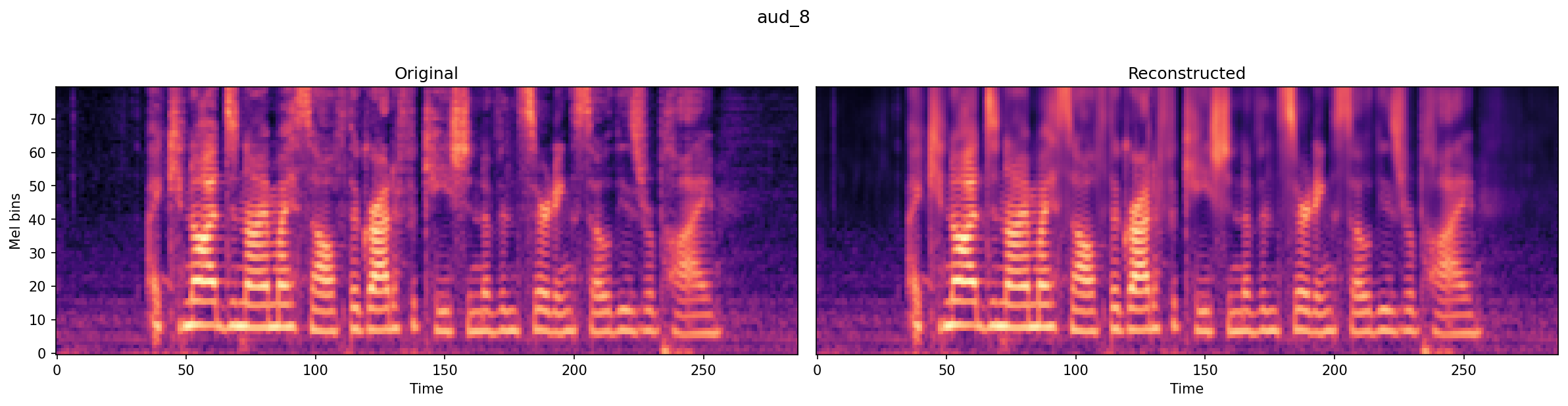
Sample 1 — Original:
Reconstructed:
Sample 2 — Original:
Reconstructed:
Sample 3 — Original:
Reconstructed:
Sample 4 — Original:
Reconstructed:
from huggingface_hub import hf_hub_download
import torch, yaml, soundfile as sf, torchaudio
from model import RVQCodec
# load model
model_path = hf_hub_download("taresh18/nano-codec", "model.pt")
config_path = hf_hub_download("taresh18/nano-codec", "config.yaml")
with open(config_path) as f:
cfg = yaml.safe_load(f)
model = RVQCodec(in_ch=1, latent_ch=cfg['latent_dim'], K=cfg['codebook_size'],
num_rvq_levels=cfg['num_rvq_levels'], codebook_dim=cfg.get('codebook_dim', 8))
model.load_state_dict(torch.load(model_path, map_location="cpu", weights_only=True))
model.eval()
# reconstruct audio
audio, sr = sf.read("input.wav", dtype="float32")
waveform = torch.from_numpy(audio).unsqueeze(0).unsqueeze(0) # [1, 1, T]
if sr != 16000:
waveform = torchaudio.functional.resample(waveform, sr, 16000)
with torch.no_grad():
recon, _, _, _ = model(waveform)
sf.write("reconstructed.wav", recon[0, 0].numpy(), 16000)
Or use the inference script from the GitHub repo:
python inference.py --input audio.wav --output reconstructed.wav