
Upload README.md with huggingface_hub
Browse files
README.md
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
tags:
|
| 4 |
+
- audio
|
| 5 |
+
- codec
|
| 6 |
+
- speech
|
| 7 |
+
- rvq
|
| 8 |
+
language:
|
| 9 |
+
- en
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
# nano-codec 🔊
|
| 13 |
+
|
| 14 |
+
A minimal neural audio codec. 16kHz mono • 128x compression • 10.2 kbps • 24M parameters.
|
| 15 |
+
|
| 16 |
+
Trained on LibriSpeech train-clean-100 (~100 hours) for ~180k steps.
|
| 17 |
+
|
| 18 |
+
📝 [Blog Post]() — in-depth walkthrough of the architecture, training, and lessons learned
|
| 19 |
+
|
| 20 |
+
🤗 [Model Weights](https://huggingface.co/taresh18/nano-codec) — pretrained model on HuggingFace
|
| 21 |
+
|
| 22 |
+
💻 [GitHub](https://github.com/taresh18/nano-codec) — full training and inference code
|
| 23 |
+
|
| 24 |
+
## 🏗️ Architecture
|
| 25 |
+
|
| 26 |
+
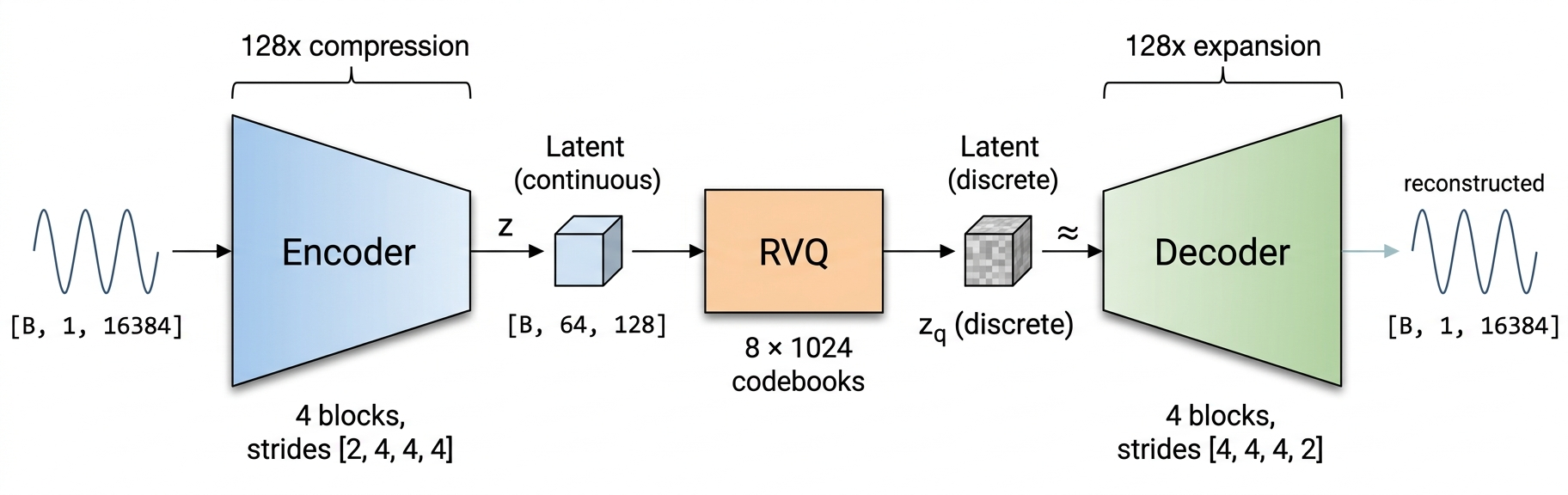
|
| 27 |
+
|
| 28 |
+
Inspired by [DAC](https://arxiv.org/abs/2306.06546) (Descript Audio Codec). Strided convolutional encoder, 8-level RVQ with factorized L2-normalized codebooks, mirror decoder.
|
| 29 |
+
|
| 30 |
+
## 🎧 Samples
|
| 31 |
+
|
| 32 |
+
| | Original | Reconstructed |
|
| 33 |
+
|---|---|---|
|
| 34 |
+
| Sample 1 | [aud_2_original.wav](https://raw.githubusercontent.com/taresh18/nano-codec/main/assets/aud_2_original.wav) | [aud_2_recon.wav](https://raw.githubusercontent.com/taresh18/nano-codec/main/assets/aud_2_recon.wav) |
|
| 35 |
+
| Sample 2 | [aud_6_original.wav](https://raw.githubusercontent.com/taresh18/nano-codec/main/assets/aud_6_original.wav) | [aud_6_recon.wav](https://raw.githubusercontent.com/taresh18/nano-codec/main/assets/aud_6_recon.wav) |
|
| 36 |
+
| Sample 3 | [aud_7_original.wav](https://raw.githubusercontent.com/taresh18/nano-codec/main/assets/aud_7_original.wav) | [aud_7_recon.wav](https://raw.githubusercontent.com/taresh18/nano-codec/main/assets/aud_7_recon.wav) |
|
| 37 |
+
| Sample 4 | [aud_8_original.wav](https://raw.githubusercontent.com/taresh18/nano-codec/main/assets/aud_8_original.wav) | [aud_8_recon.wav](https://raw.githubusercontent.com/taresh18/nano-codec/main/assets/aud_8_recon.wav) |
|
| 38 |
+
|
| 39 |
+
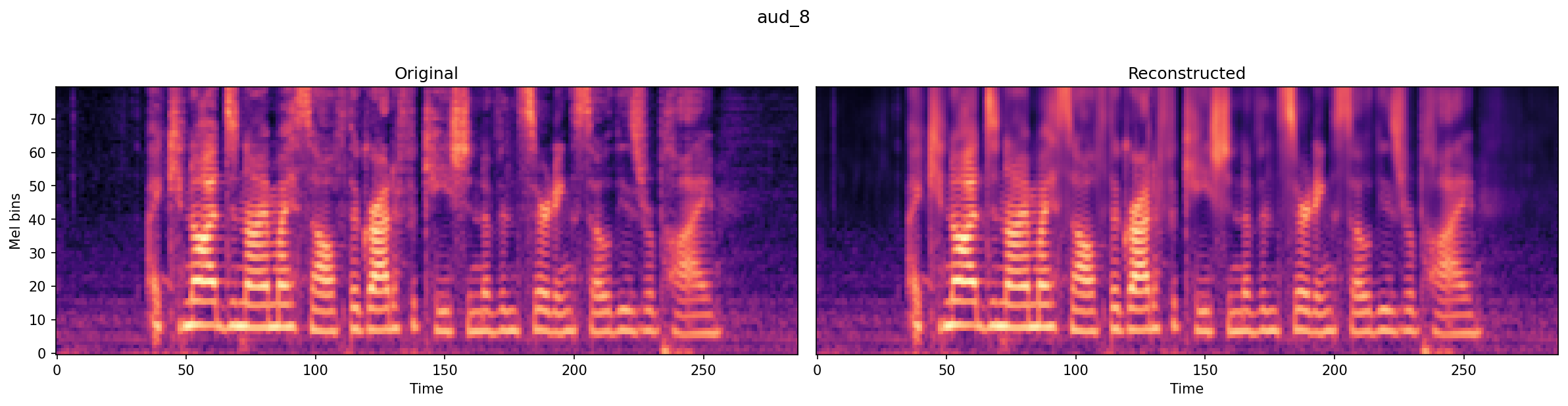
|
| 40 |
+
|
| 41 |
+
## 🏃 Quick Start
|
| 42 |
+
|
| 43 |
+
**1. Clone & Install**
|
| 44 |
+
```bash
|
| 45 |
+
git clone https://github.com/taresh18/nano-codec.git
|
| 46 |
+
cd nano-codec
|
| 47 |
+
uv sync
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
**2. Reconstruct Audio**
|
| 51 |
+
```bash
|
| 52 |
+
cd nano_codec
|
| 53 |
+
python inference.py --input audio.wav --output reconstructed.wav
|
| 54 |
+
```
|
| 55 |
+
Downloads model weights from HuggingFace on first run. Resamples to 16kHz if needed.
|
| 56 |
+
|
| 57 |
+
**3. Train Your Own**
|
| 58 |
+
```bash
|
| 59 |
+
cd nano_codec
|
| 60 |
+
python prepare_data.py # download LibriSpeech, chunk into shards
|
| 61 |
+
python train.py # config in configs/config.yaml
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
## 🏗️ Project Structure
|
| 65 |
+
|
| 66 |
+
```
|
| 67 |
+
nano-codec/
|
| 68 |
+
├── configs/
|
| 69 |
+
│ └── config.yaml # Training & model config
|
| 70 |
+
├── nano_codec/
|
| 71 |
+
│ ├── model.py # RVQCodec, VQ, RVQ, encoder/decoder
|
| 72 |
+
│ ├── loss.py # Multi-scale spectral losses
|
| 73 |
+
│ ├── loader.py # Dataset loading (in-memory + streaming)
|
| 74 |
+
│ ├── train.py # Training loop
|
| 75 |
+
│ ├── inference.py # Reconstruct audio from trained model
|
| 76 |
+
│ ├── prepare_data.py # Preprocess LibriSpeech into chunks
|
| 77 |
+
│ └── utils.py # Checkpointing, logging, profiling
|
| 78 |
+
└── assets/ # Audio samples, images
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
## 📚 References
|
| 82 |
+
|
| 83 |
+
- [Audio Codec Explainer (Kyutai)](https://kyutai.org/codec-explainer)
|
| 84 |
+
- [High-Fidelity Audio Compression with Improved RVQGAN (DAC)](https://arxiv.org/abs/2306.06546)
|
| 85 |
+
- [Neural Discrete Representation Learning (VQ-VAE)](https://arxiv.org/abs/1711.00937)
|