
Update README: add video results, new DOI, fix genome table
Browse files
README.md
CHANGED
|
@@ -1,132 +1,157 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: mit
|
| 3 |
-
tags:
|
| 4 |
-
- sparse-networks
|
| 5 |
-
- neural-architecture-search
|
| 6 |
-
- network-growing
|
| 7 |
-
- genome
|
| 8 |
-
- topology-learning
|
| 9 |
-
- pytorch
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
-
|
| 13 |
-
-
|
| 14 |
-
-
|
| 15 |
-
|
| 16 |
-
--
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
](https://doi.org/10.5281/zenodo.19248389)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
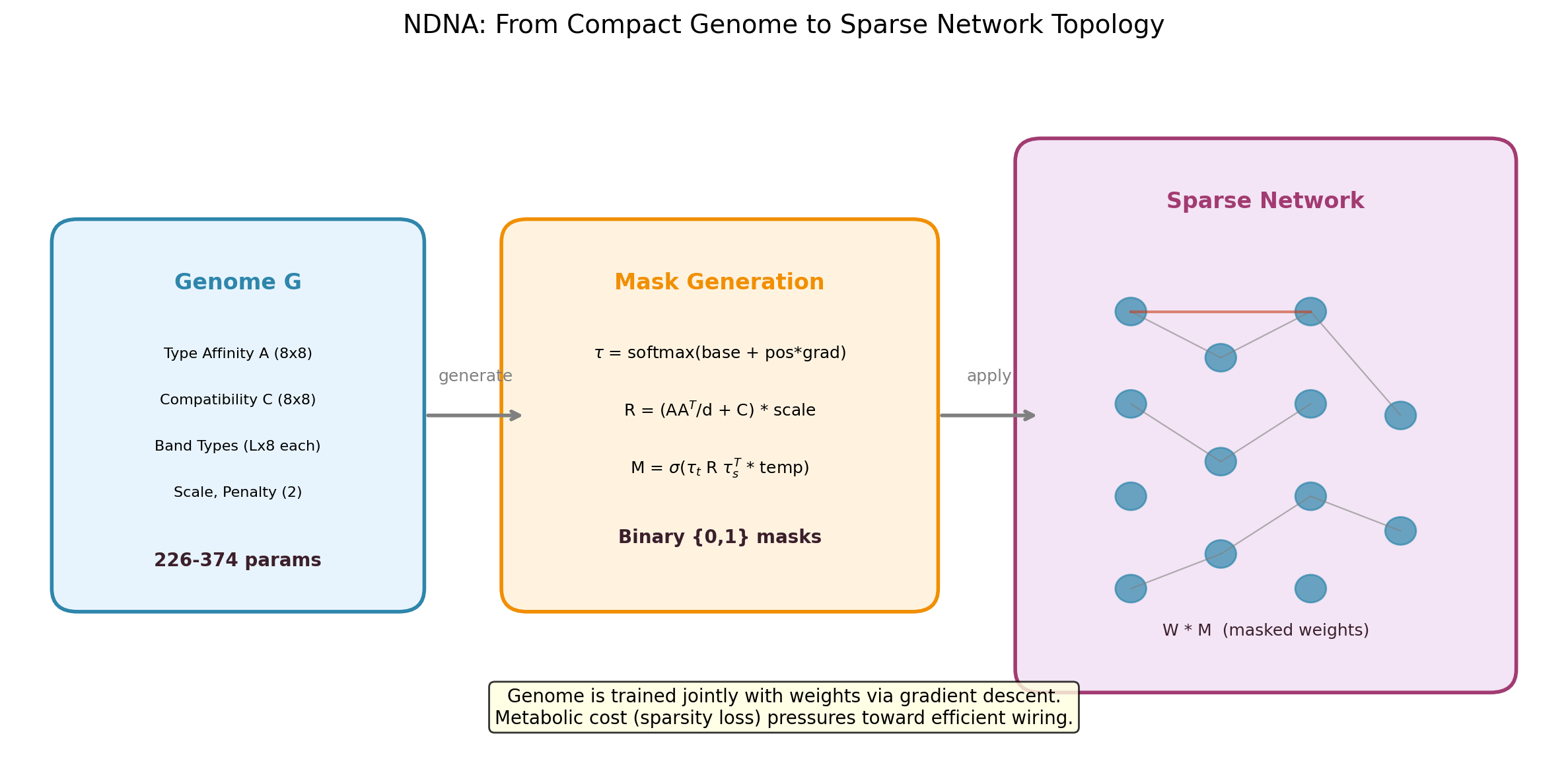
## What is NDNA?
|
| 29 |
+
|
| 30 |
+
Neural networks typically use fixed, fully-connected layers. NDNA asks: what if a small "genome" could learn *which* connections should exist?
|
| 31 |
+
|
| 32 |
+
The genome encodes cell type embeddings and a compatibility matrix. During growth, it compares source and target types for every potential connection and decides whether to wire it or not. A metabolic cost penalty forces selectivity, so only useful connections survive.
|
| 33 |
+
|
| 34 |
+
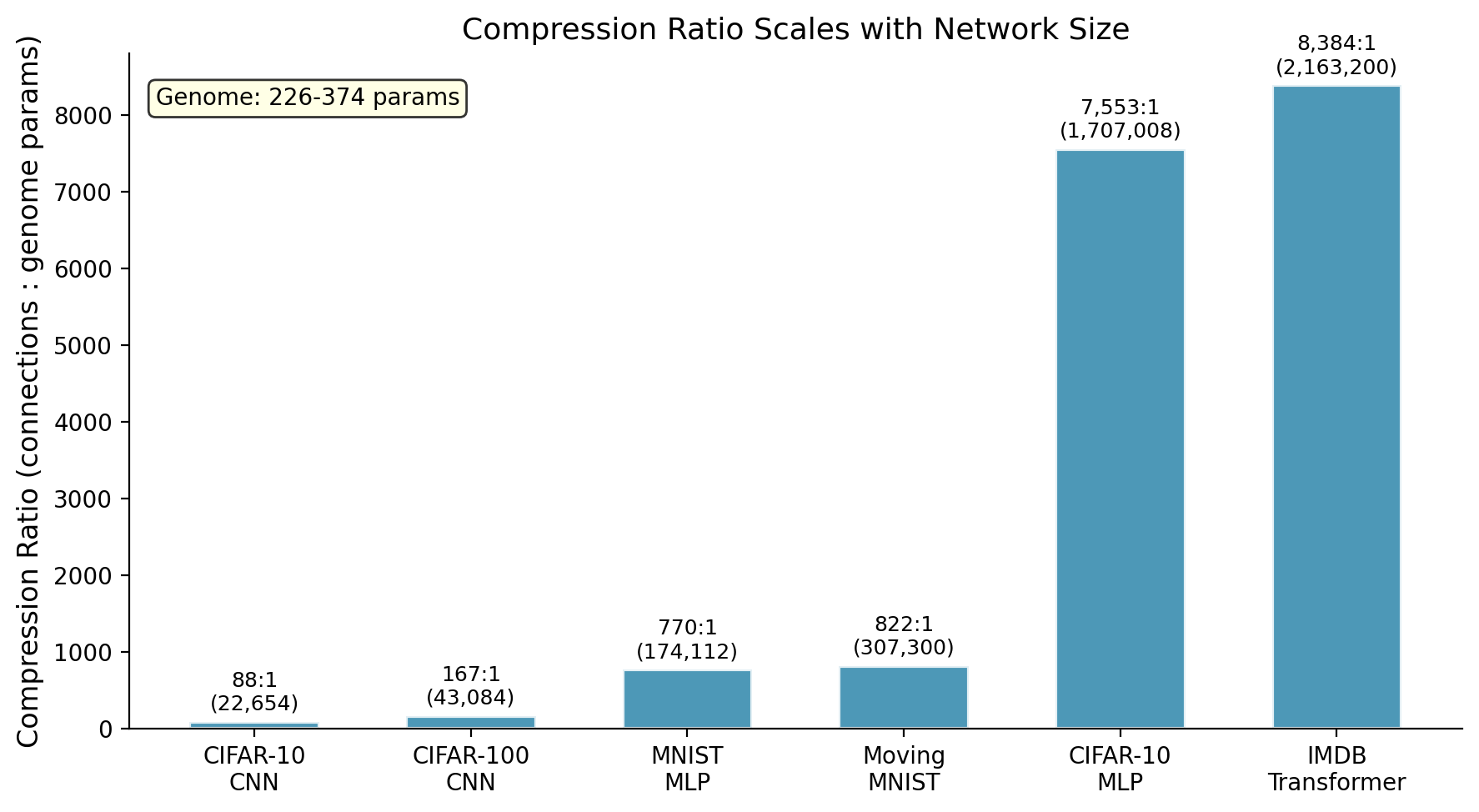
**The result:** 226 to 374 genome parameters control up to 2.2 million connections (8,384:1 compression on our benchmarks, likely higher on larger networks). The grown networks are sparse but structured, and they consistently beat randomly-wired sparse networks.
|
| 35 |
+
|
| 36 |
+
## How It Works
|
| 37 |
+
|
| 38 |
+
1. **Genome** encodes cell type embeddings (8 types, 8 dimensions) and a compatibility matrix
|
| 39 |
+
2. **Growth**: for each potential connection, source and target type embeddings are compared via the compatibility matrix to produce a connection probability
|
| 40 |
+
3. **Binary mask**: probabilities are thresholded to produce hard 0/1 masks (straight-through estimator for gradient flow)
|
| 41 |
+
4. **Metabolic cost**: a sparsity loss penalizes total connection strength, forcing the genome to be selective
|
| 42 |
+
5. **Default disconnected**: compatibility is initialized negative, so the genome must actively grow every connection
|
| 43 |
+
|
| 44 |
+
The genome and network weights are trained jointly with standard backpropagation.
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
## Key Results
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
| Experiment | Genome | Random Sparse | Dense Baseline | Genome vs Random |
|
| 53 |
+
|---|---|---|---|---|
|
| 54 |
+
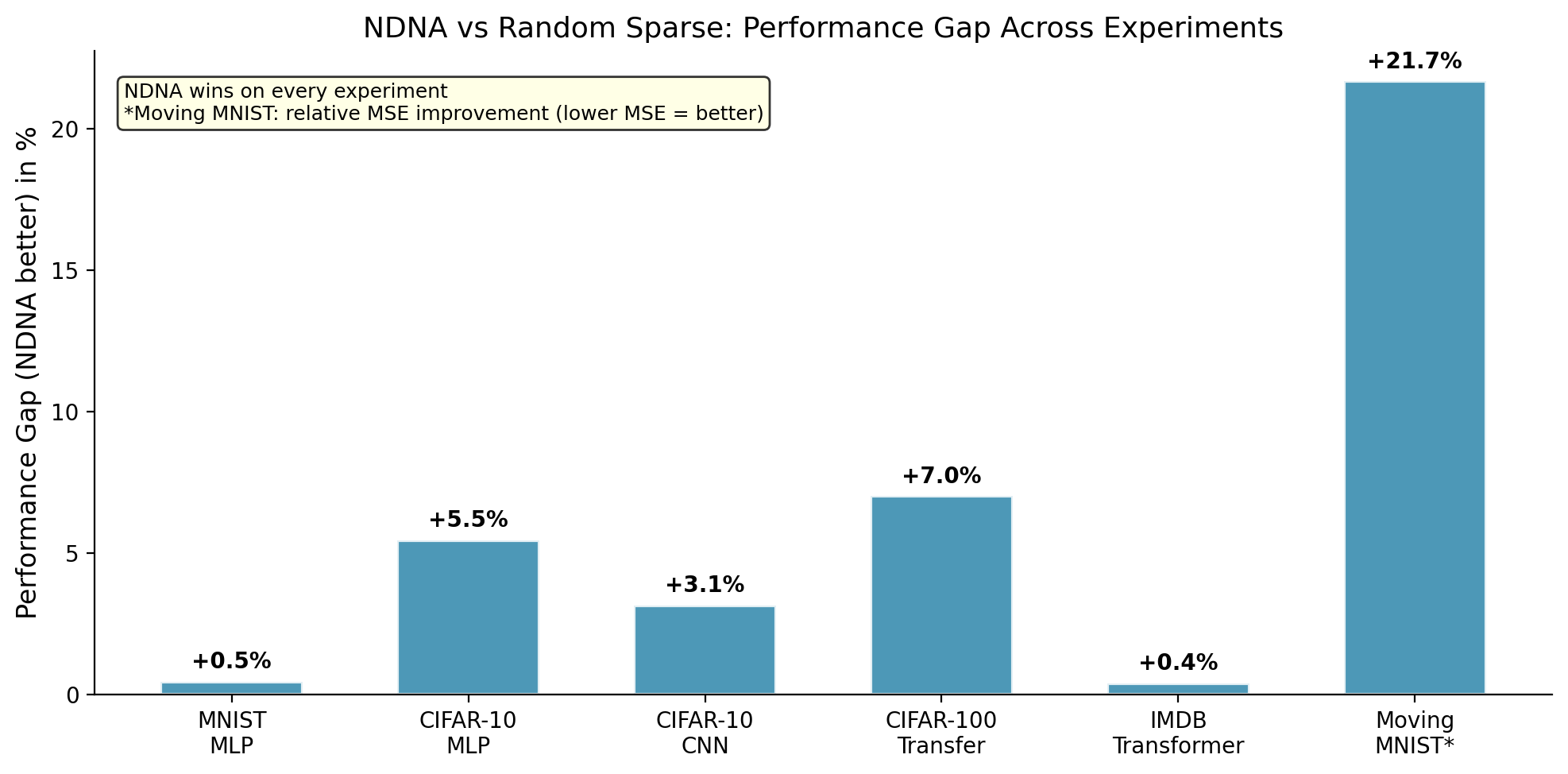
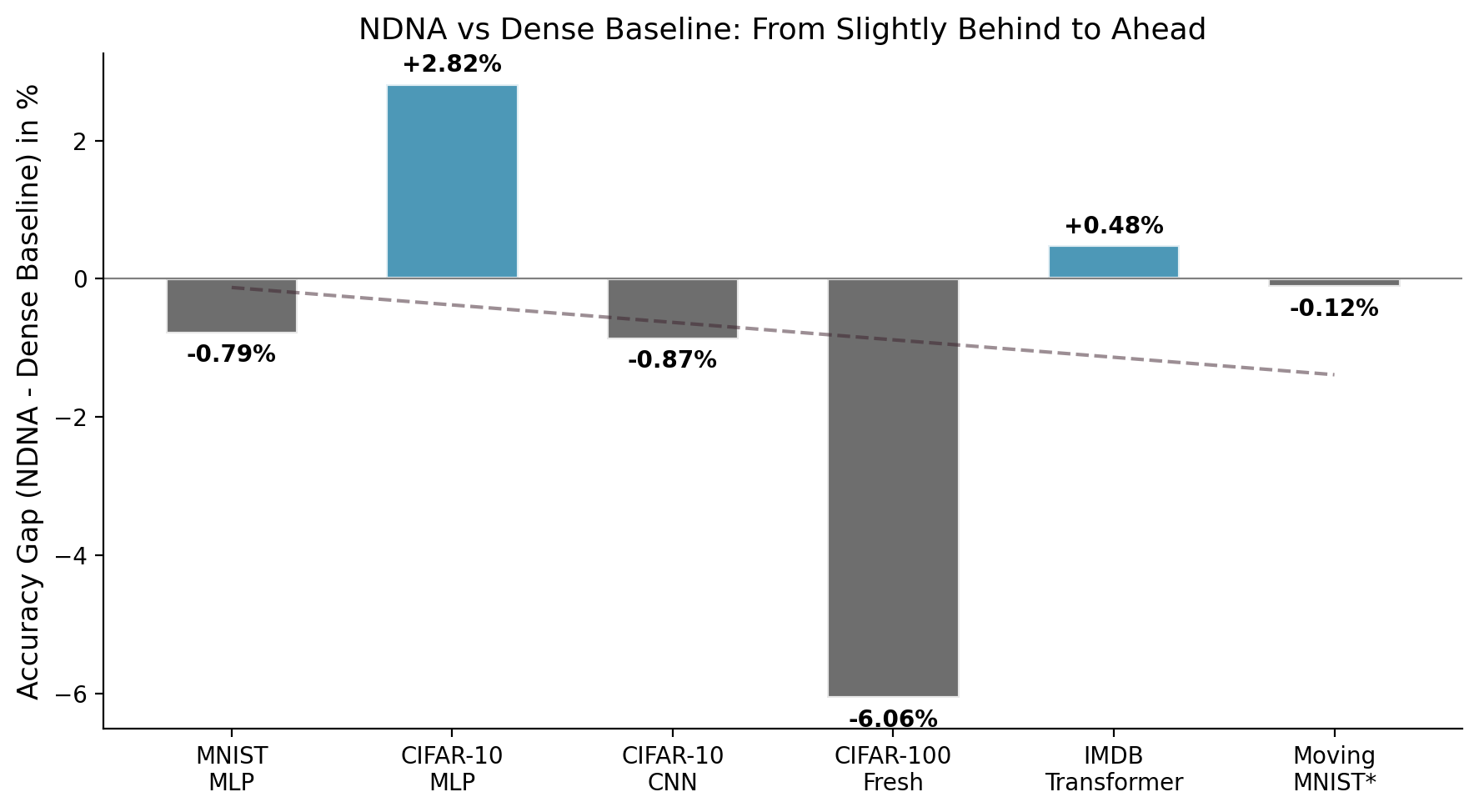
| MNIST (MLP) | 97.54% | 97.09% | 98.33% | +0.45% |
|
| 55 |
+
| CIFAR-10 (MLP) | 57.14% | 51.68% | 54.32% | +5.46% |
|
| 56 |
+
| CIFAR-10 (CNN) | 88.93% | 85.78% | 89.80% | +3.15% |
|
| 57 |
+
| CIFAR-100 (Transfer) | 60.92% | 53.91% | 67.16% | +7.01% |
|
| 58 |
+
| IMDB (Transformer) | 85.05% | 84.66% | 84.57% | +0.39% |
|
| 59 |
+
| Moving MNIST (Video)* | 62.23 | 79.44 | 62.15 | +21.7% |
|
| 60 |
+
|
| 61 |
+
*\*Moving MNIST uses MSE (lower is better). The +21.7% is relative improvement.*
|
| 62 |
+
|
| 63 |
+
The genome beats random sparse wiring on every experiment. The largest gap is on video prediction (+21.7%), where random wiring completely falls apart but genome-grown wiring matches the dense baseline.
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
## Video: Factored Spatiotemporal Genome
|
| 68 |
+
|
| 69 |
+
The video experiment uses a factored genome: temporal (74 params) + spatial (74 params) + depth (226 params) = 374 total. The temporal genome discovers temporal recency (recent frames get strong connections, distant frames get almost none). The spatial genome discovers spatial locality (nearby patches connect strongly, distant patches barely connect).
|
| 70 |
+
|
| 71 |
+
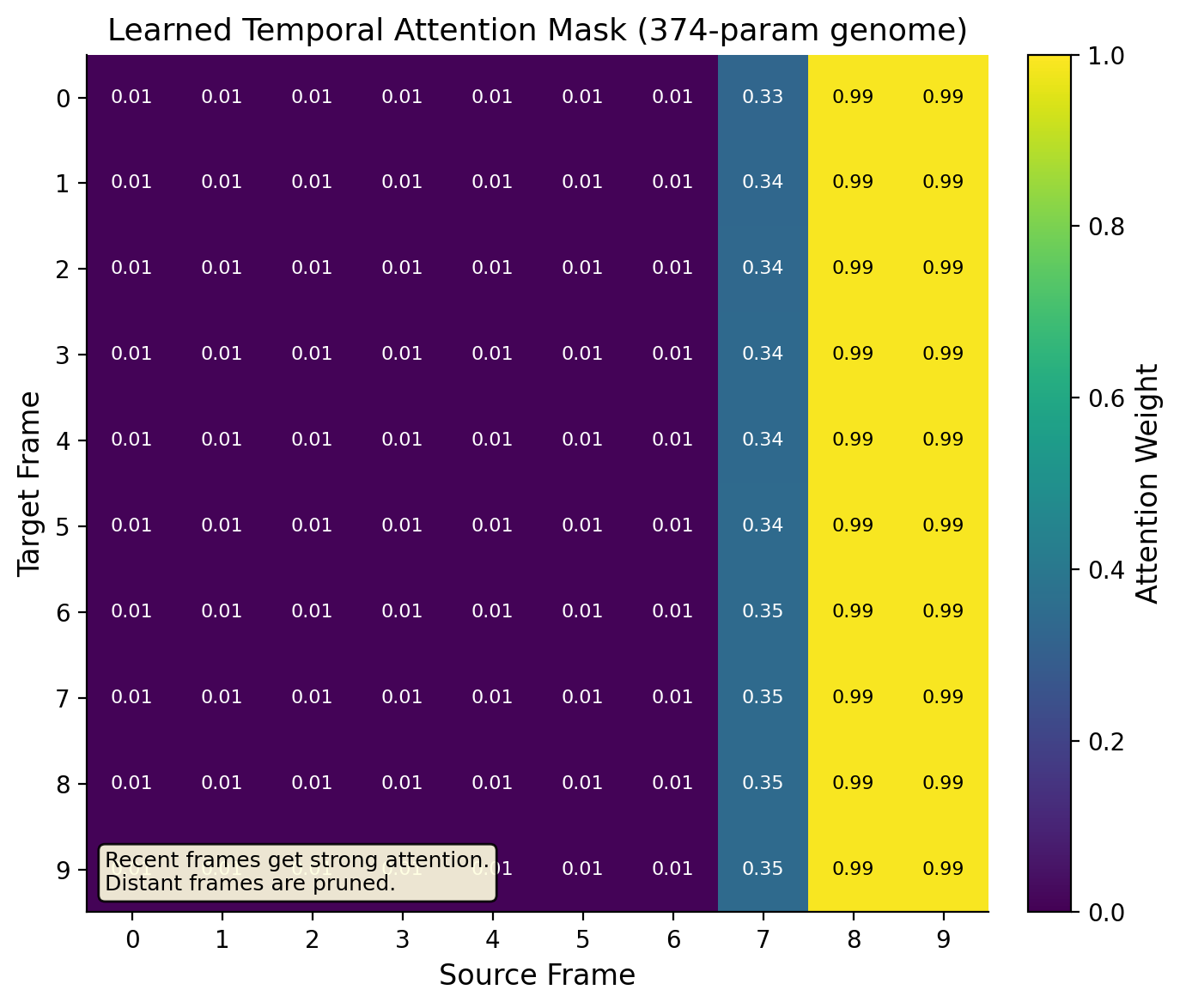
|
| 72 |
+
|
| 73 |
+
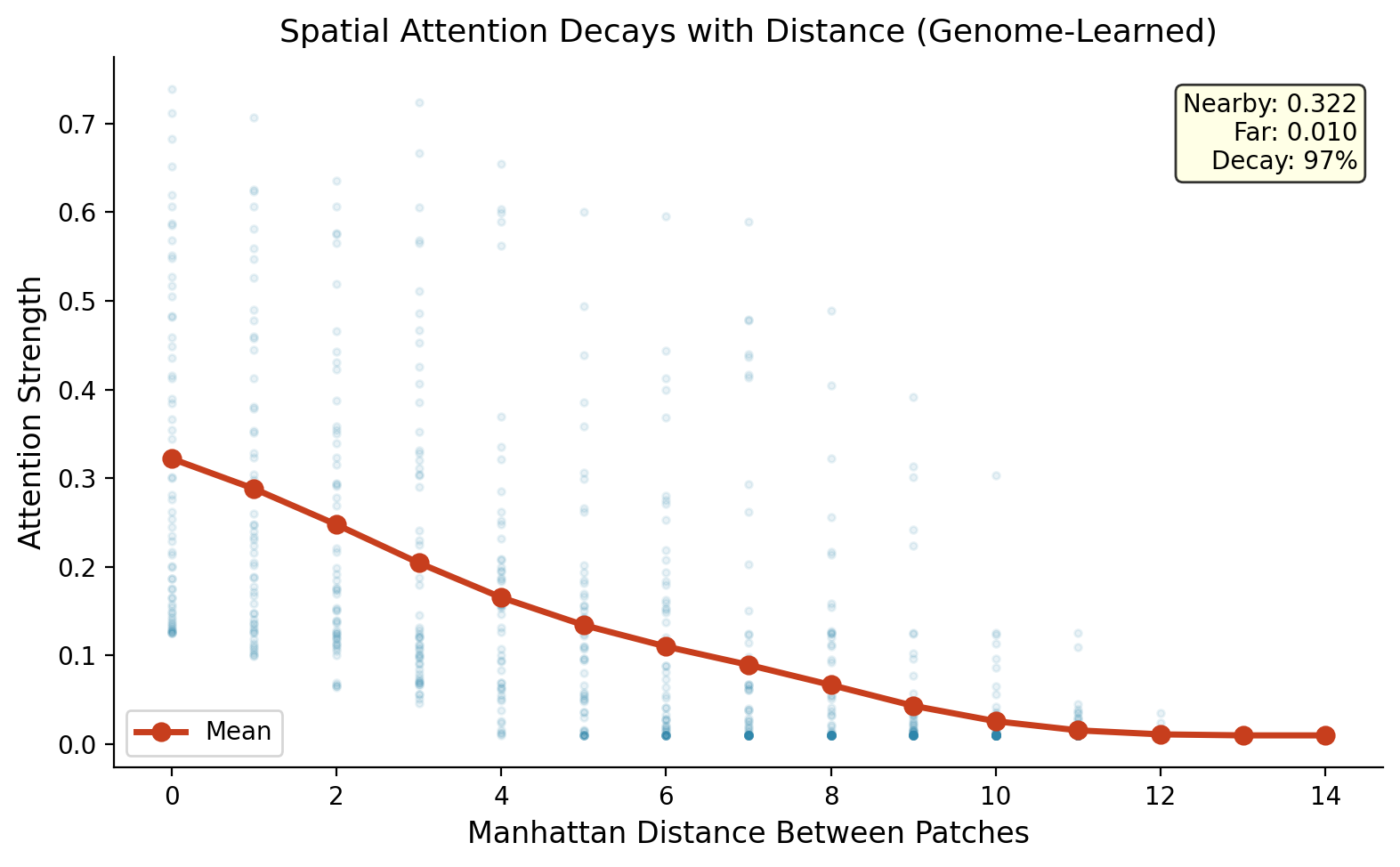
|
| 74 |
+
|
| 75 |
+
## Pre-trained Genomes
|
| 76 |
+
|
| 77 |
+
These are the trained genome files. Each genome is tiny but controls the full network topology.
|
| 78 |
+
|
| 79 |
+
| File | Architecture | Task | Params | Connections | Compression | Result |
|
| 80 |
+
|---|---|---|---|---|---|---|
|
| 81 |
+
| `genome_mnist.pt` | MLP | MNIST | 226 | 174,240 | 770:1 | 97.54% |
|
| 82 |
+
| `genome_cifar10_mlp.pt` | MLP | CIFAR-10 | 226 | 1,706,240 | 7,553:1 | 57.14% |
|
| 83 |
+
| `genome_cifar10_cnn.pt` | CNN | CIFAR-10 | 258 | 165,888 | 643:1 | 88.93% |
|
| 84 |
+
| `genome_cifar100_fresh.pt` | MLP | CIFAR-100 (transfer) | 226 | 1,706,240 | 7,553:1 | 60.92% |
|
| 85 |
+
| `genome_transformer.pt` | Transformer | IMDB | 258 | 2,162,688 | 8,384:1 | 85.05% |
|
| 86 |
+
| `genome_video.pt` | Video Transformer | Moving MNIST | 374 | 307,300 | 821:1 | MSE 62.23 |
|
| 87 |
+
|
| 88 |
+
## Cross-Task Transfer
|
| 89 |
+
|
| 90 |
+
The CIFAR-100 genome was not trained on CIFAR-100. It is the CIFAR-10 genome applied directly to CIFAR-100 without retraining the topology. Only the network weights were retrained. The genome's learned connectivity pattern transferred across tasks and still beat random sparse wiring by +7.01%.
|
| 91 |
+
|
| 92 |
+
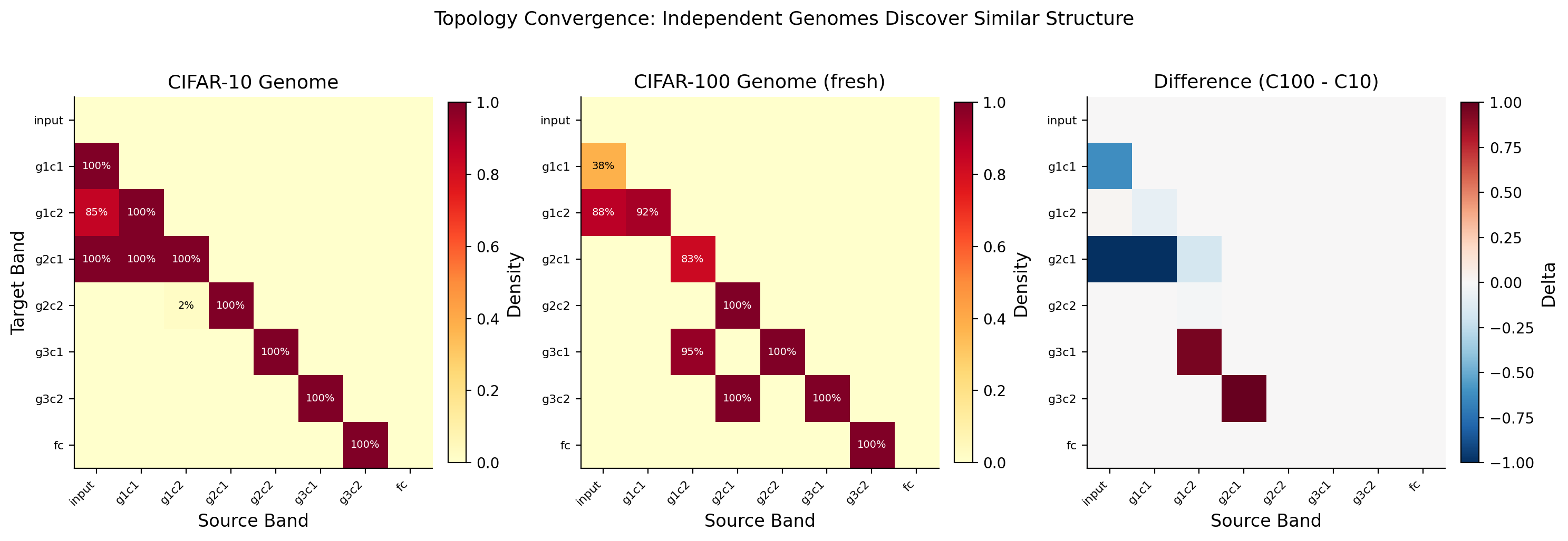
|
| 93 |
+
|
| 94 |
+
## Transformer Attention Patterns
|
| 95 |
+
|
| 96 |
+
The genome also works on transformers. On IMDB sentiment analysis, the grown transformer beats both random sparse and dense baselines.
|
| 97 |
+
|
| 98 |
+
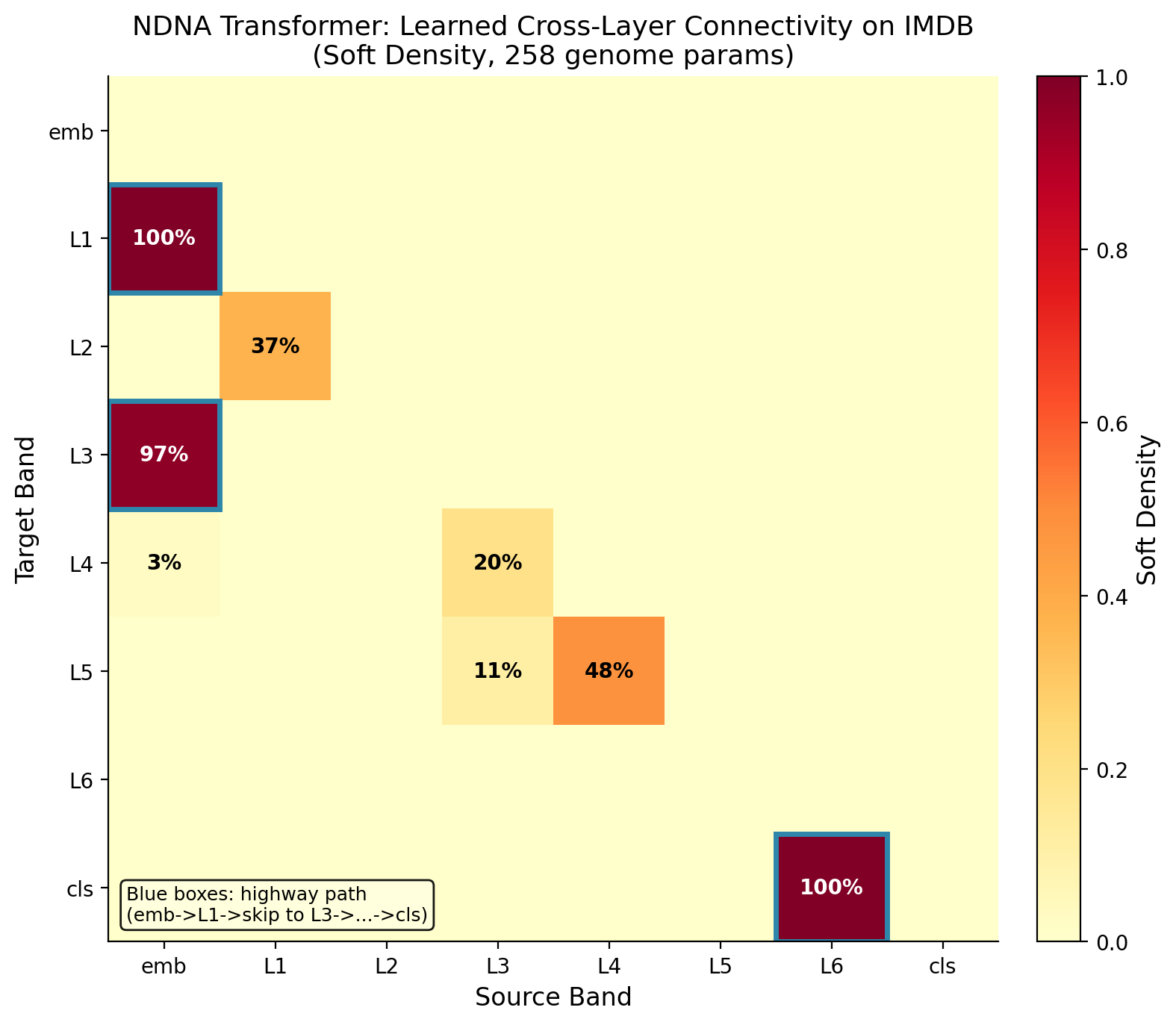
|
| 99 |
+
|
| 100 |
+
## How to Use
|
| 101 |
+
|
| 102 |
+
```python
|
| 103 |
+
import torch
|
| 104 |
+
from genome.model import Genome, GrownNetwork, GrownConvNetwork, GrownTransformer
|
| 105 |
+
|
| 106 |
+
# --- MLP (MNIST) ---
|
| 107 |
+
genome = Genome(n_types=8, type_dim=8, n_bands=6)
|
| 108 |
+
genome.load_state_dict(torch.load("genome_mnist.pt", weights_only=True))
|
| 109 |
+
model = GrownNetwork(genome, input_dim=784, hidden_bands=[48, 48, 48, 48], output_dim=10)
|
| 110 |
+
|
| 111 |
+
# --- MLP (CIFAR-10) ---
|
| 112 |
+
genome = Genome(n_types=8, type_dim=8, n_bands=6)
|
| 113 |
+
genome.load_state_dict(torch.load("genome_cifar10_mlp.pt", weights_only=True))
|
| 114 |
+
model = GrownNetwork(genome, input_dim=3072, hidden_bands=[128, 128, 128, 128], output_dim=10)
|
| 115 |
+
|
| 116 |
+
# --- CNN (CIFAR-10) ---
|
| 117 |
+
genome = Genome(n_types=8, type_dim=8, n_bands=8)
|
| 118 |
+
genome.load_state_dict(torch.load("genome_cifar10_cnn.pt", weights_only=True))
|
| 119 |
+
model = GrownConvNetwork(genome, num_classes=10)
|
| 120 |
+
|
| 121 |
+
# --- Transformer (IMDB) ---
|
| 122 |
+
genome = Genome(n_types=8, type_dim=8, n_bands=8)
|
| 123 |
+
genome.load_state_dict(torch.load("genome_transformer.pt", weights_only=True))
|
| 124 |
+
model = GrownTransformer(genome, vocab_size=20000, embed_dim=128, num_heads=4, num_layers=2, num_classes=2)
|
| 125 |
+
|
| 126 |
+
# --- Video Transformer (Moving MNIST) ---
|
| 127 |
+
from experiments.rung4_video import SpatiotemporalGenome, GenomeVideoTransformer
|
| 128 |
+
stg = SpatiotemporalGenome()
|
| 129 |
+
stg.load_state_dict(torch.load("genome_video.pt", weights_only=True))
|
| 130 |
+
model = GenomeVideoTransformer(stg, d_model=64, nhead=4, num_layers=2, n_frames=10, patch_size=8, img_size=64)
|
| 131 |
+
|
| 132 |
+
# --- Transfer (CIFAR-10 genome -> CIFAR-100) ---
|
| 133 |
+
genome = Genome(n_types=8, type_dim=8, n_bands=6)
|
| 134 |
+
genome.load_state_dict(torch.load("genome_cifar100_fresh.pt", weights_only=True))
|
| 135 |
+
model = GrownNetwork(genome, input_dim=3072, hidden_bands=[128, 128, 128, 128], output_dim=100)
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
## Links
|
| 139 |
+
|
| 140 |
+
- **Paper**: [Zenodo (DOI: 10.5281/zenodo.19248389)](https://doi.org/10.5281/zenodo.19248389)
|
| 141 |
+
- **Code**: [github.com/tejassudsfp/ndna](https://github.com/tejassudsfp/ndna)
|
| 142 |
+
- **Author**: [Tejas Parthasarathi Sudarshan](https://tejassuds.com) (tejas@fandesk.ai)
|
| 143 |
+
|
| 144 |
+
## Citation
|
| 145 |
+
|
| 146 |
+
```bibtex
|
| 147 |
+
@article{sudarshan2026ndna,
|
| 148 |
+
title={Neural DNA: A Compact Genome for Growing Network Architecture},
|
| 149 |
+
author={Sudarshan, Tejas Parthasarathi},
|
| 150 |
+
year={2026},
|
| 151 |
+
doi={10.5281/zenodo.19248389}
|
| 152 |
+
}
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
## License
|
| 156 |
+
|
| 157 |
+
[MIT](https://opensource.org/licenses/MIT)
|