
Unleashing the Potential of Large Language Models for Text-to-Image Generation through Autoregressive Representation Alignment
Paper
•
2503.07334
•
Published
•
16
This model xing0916/ARRA-Adapt-MIMIC-7B is trained on the MIMIC-CXR dataset for X-ray generation, as presented in the paper Unleashing the Potential of Large Language Models for Text-to-Image Generation through Autoregressive Representation Alignment.
Code: https://github.com/xiexing0916/ARRA
![]()
![]()
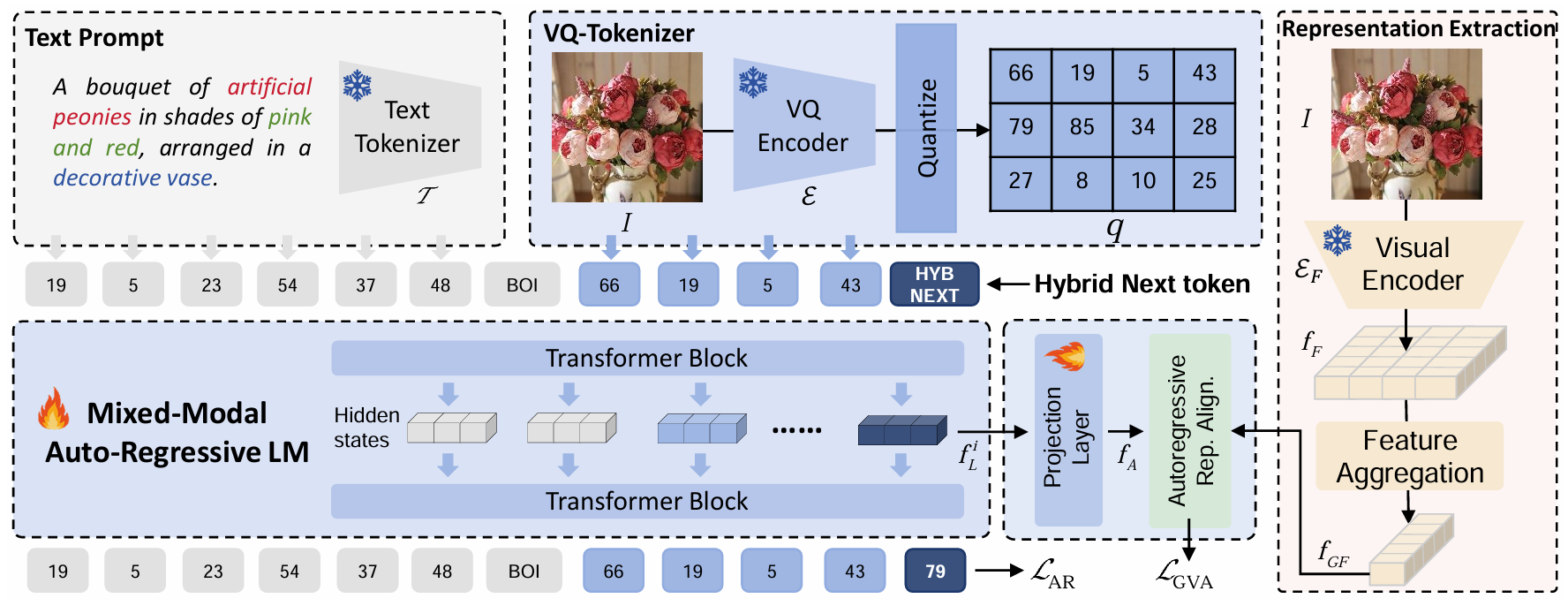
ARRA (Autoregressive Representation Alignment) is a novel training framework that enables autoregressive LLMs to perform high-quality text-to-image generation without architectural modifications. The key designs include:
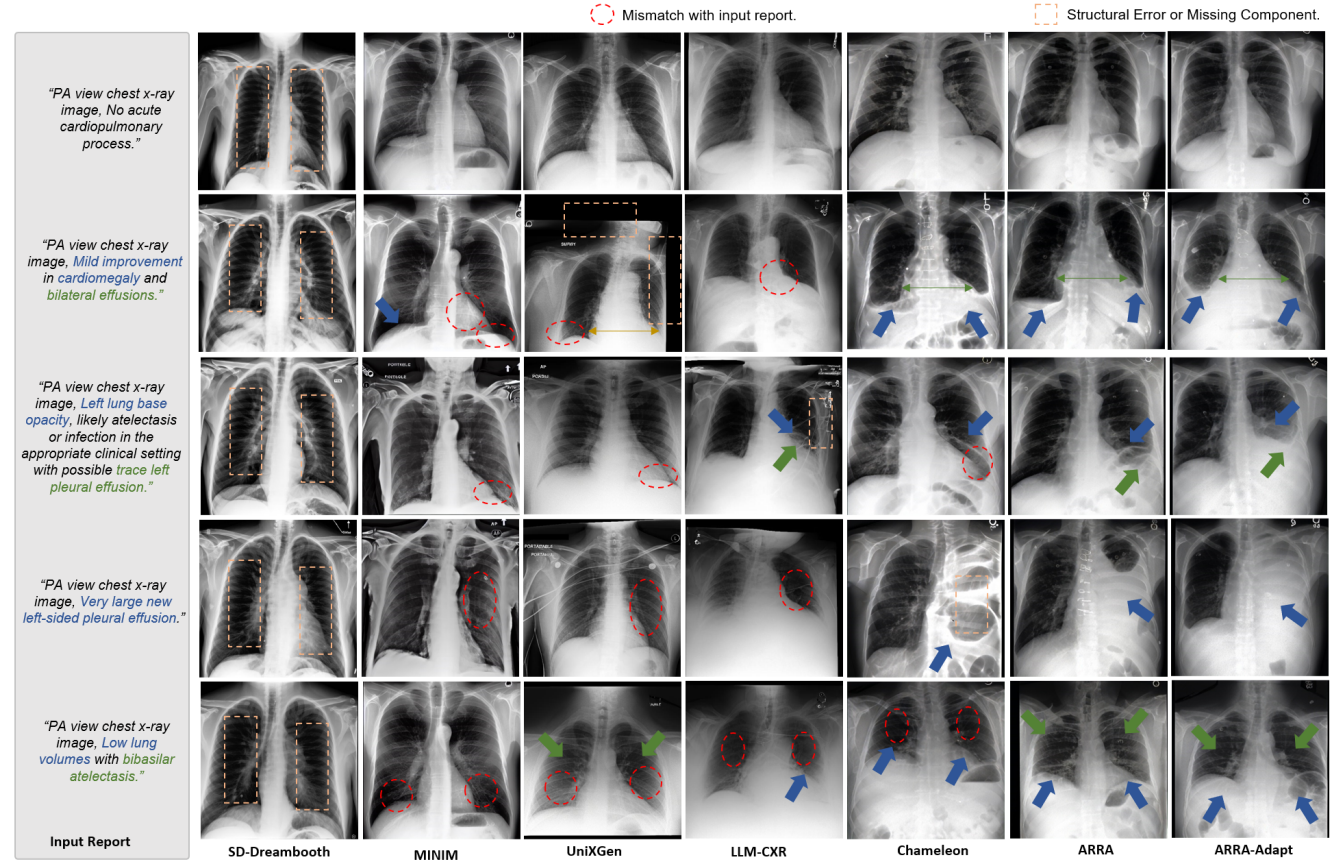
<HYBNEXT> token (enforcing dual local-global constraints)We present Autoregressive Representation Alignment (ARRA), a new training framework that unlocks global-coherent text-to-image generation in autoregressive LLMs without architectural modifications. Different from prior works that require complex architectural redesigns, ARRA aligns LLM's hidden states with visual representations from external visual foundational models via a global visual alignment loss and a hybrid token, <HYBNEXT>. This token enforces dual constraints: local next-token prediction and global semantic distillation, enabling LLMs to implicitly learn spatial and contextual coherence while retaining their original autoregressive paradigm. Extensive experiments validate ARRA's plug-and-play versatility. When training T2I LLMs from scratch, ARRA reduces FID by 16.6% (ImageNet), 12.0% (LAION-COCO) for autoregressive LLMs like LlamaGen, without modifying original architecture and inference mechanism. For training from text-generation-only LLMs, ARRA reduces FID by 25.5% (MIMIC-CXR), 8.8% (DeepEyeNet) for advanced LLMs like Chameleon. For domain adaptation, ARRA aligns general-purpose LLMs with specialized models (e.g., BioMedCLIP), achieving an 18.6% FID reduction over direct fine-tuning on medical imaging (MIMIC-CXR). These results demonstrate that training objective redesign, rather than architectural modifications, can resolve cross-modal global coherence challenges. ARRA offers a complementary paradigm for advancing autoregressive models.
To generate an X-ray image from a text prompt, you can use the FlexARInferenceSolver from the ARRA GitHub repository:
import torch
from PIL import Image
from arra.models.inference_solver import FlexARInferenceSolver # Requires installing ARRA as a Python package, see GitHub repo
# ******************** Image Generation ********************
inference_solver = FlexARInferenceSolver(
model_path="xing0916/ARRA-Adapt-MIMIC-7B", # This model
precision="bf16",
target_size=512,
)
q1 = "PA view chest x-ray image, Mild interstitial pulmonary edema and bilateral pleural effusions, increased on the right."
# generated: tuple of (generated response, list of generated images)
generated = inference_solver.generate(
images=[],
qas=[[q1, None]],
max_gen_len=8192,
temperature=1.0,
logits_processor=inference_solver.create_logits_processor(cfg=4.0, image_top_k=2000),
)
a1, new_image = generated[0], generated[1][0]
new_image.save("generated_xray.jpg")
print(f"Generated image saved to generated_xray.jpg")