

pipeline_tag: video-text-to-text
library_name: transformers
license: apache-2.0
VideoSSR: Video Self-Supervised Reinforcement Learning
VideoSSR-8B is a multimodal large language model (MLLM) fine-tuned from Qwen-VL-8B-Instruct for enhanced video understanding. It is trained using a novel Video Self-Supervised Reinforcement Learning (VideoSSR) framework, which generates its own high-quality training data directly from videos, eliminating the need for manual annotation.
- Base Model:
Qwen-VL-8B-Instruct - Paper: VideoSSR: Video Self-Supervised Reinforcement Learning
- Code/Project Page: https://github.com/lcqysl/VideoSSR
Paper Abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has substantially advanced the video understanding capabilities of Multimodal Large Language Models (MLLMs). However, the rapid progress of MLLMs is outpacing the complexity of existing video datasets, while the manual annotation of new, high-quality data remains prohibitively expensive. This work investigates a pivotal question: Can the rich, intrinsic information within videos be harnessed to self-generate high-quality, verifiable training data? To investigate this, we introduce three self-supervised pretext tasks: Anomaly Grounding, Object Counting, and Temporal Jigsaw. We construct the Video Intrinsic Understanding Benchmark (VIUBench) to validate their difficulty, revealing that current state-of-the-art MLLMs struggle significantly on these tasks. Building upon these pretext tasks, we develop the VideoSSR-30K dataset and propose VideoSSR, a novel video self-supervised reinforcement learning framework for RLVR. Extensive experiments across 17 benchmarks, spanning four major video domains (General Video QA, Long Video QA, Temporal Grounding, and Complex Reasoning), demonstrate that VideoSSR consistently enhances model performance, yielding an average improvement of over 5%. These results establish VideoSSR as a potent foundational framework for developing more advanced video understanding in MLLMs. The code is available at this https URL .
Authors: Zefeng He, Xiaoye Qu, Yafu Li, Siyuan Huang, Daizong Liu, Yu Cheng
Related Hugging Face Resources
- Dataset: VideoSSR-30K
- Benchmark: VIUBench
Model Details
VideoSSR is a novel framework designed to enhance the video understanding capabilities of Multimodal Large Language Models (MLLMs). Instead of relying on prohibitively expensive manually annotated data or biased model-annotated data, VideoSSR harnesses the rich, intrinsic information within videos to generate high-quality, verifiable training data. We introduce three self-supervised pretext tasks: Anomaly Grounding, Object Counting, and Temporal Jigsaw. Building upon these tasks, we construct the VideoSSR-30K dataset and train models with Reinforcement Learning with Verifiable Rewards (RLVR), establishing a potent foundational framework for developing more advanced video understanding in MLLMs.
Pretext Tasks

VIUBench
To rigorously test the capabilities of modern MLLMs on fundamental video understanding, we introduce the Video Intrinsic Understanding Benchmark (VIUBench). This benchmark is systematically constructed from our three self-supervised pretext tasks: Anomaly Grounding, Object Counting, and Temporal Jigsaw. It specifically evaluates a model's ability to reason about intrinsic video properties—such as temporal coherence and fine-grained details—independent of external annotations. Our results show that VIUBench poses a significant challenge even for the most advanced models, highlighting a critical area for improvement and validating the effectiveness of our approach.
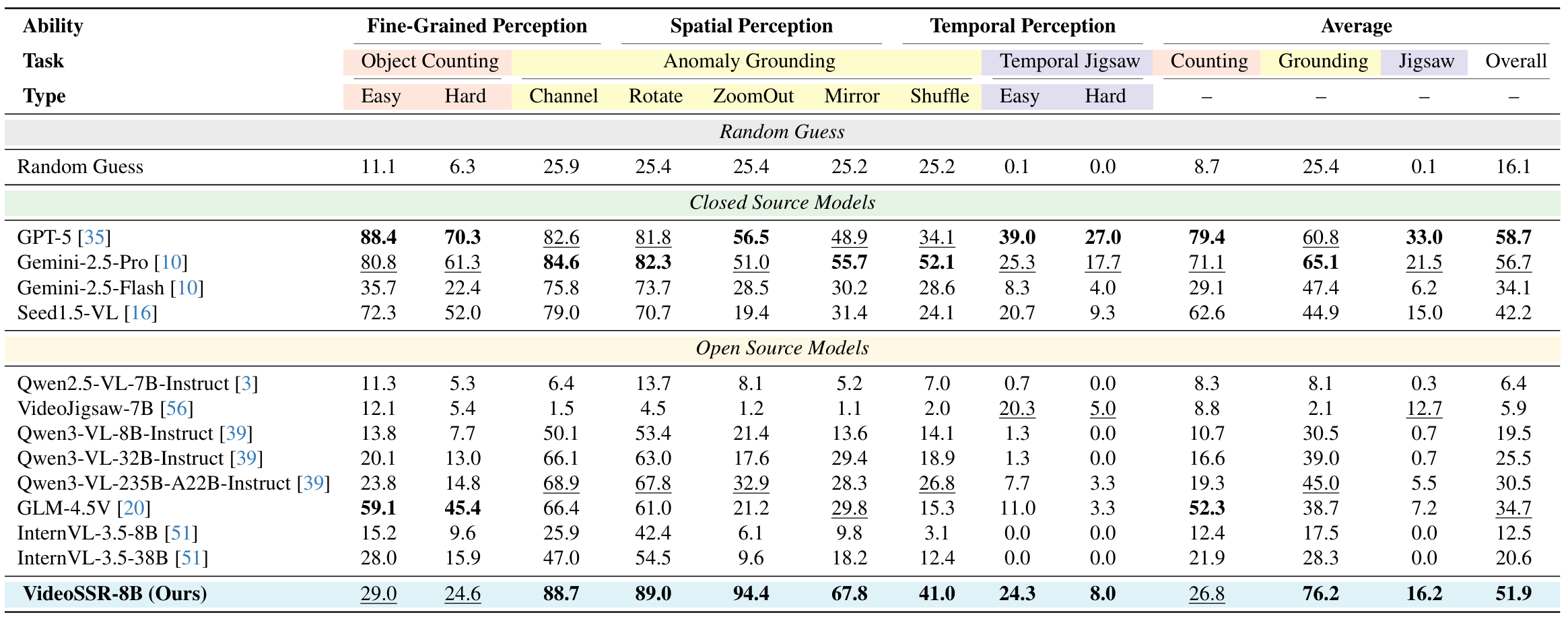
Performance Highlights
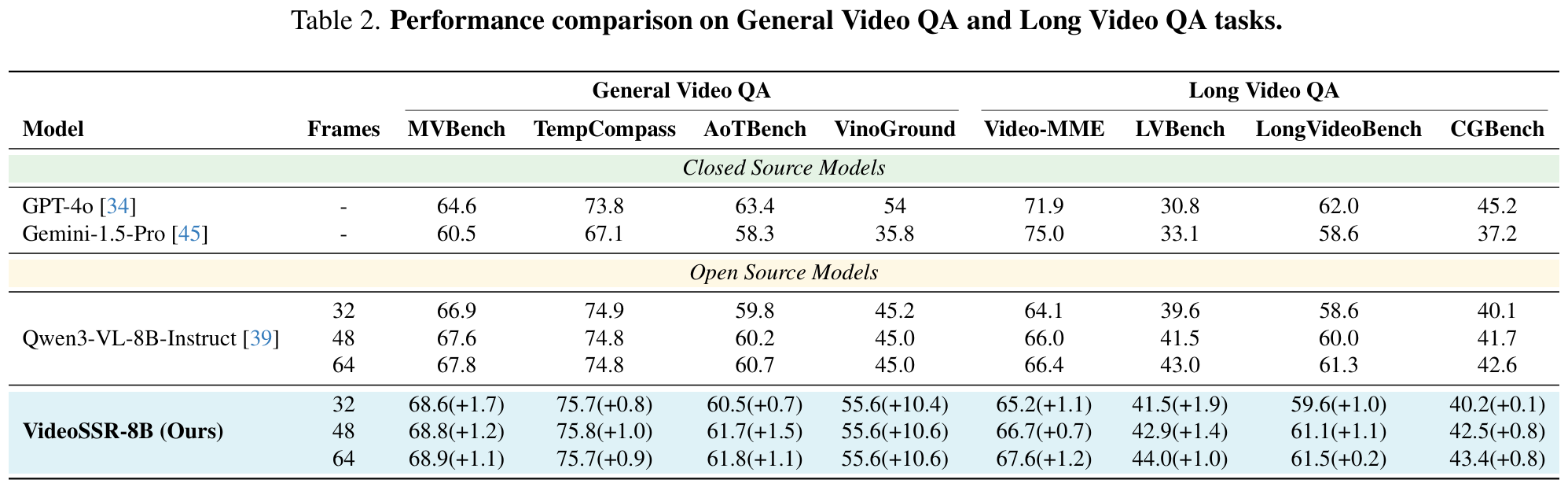
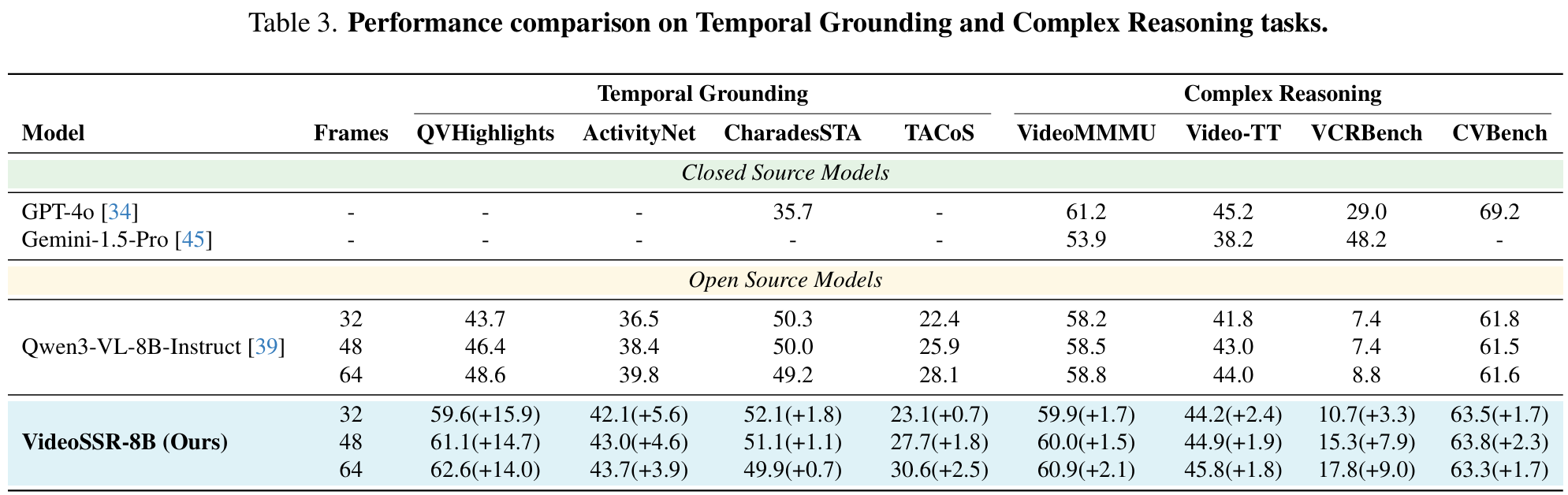
Acknowledgement
This work was developed upon verl. We also thank the great work of Visual Jigsaw for the inspiration.