

base_model:
- THUDM/GLM-4-9B-0414
language:
- en
- zh
library_name: transformers
license: mit
pipeline_tag: image-text-to-text
tags:
- reasoning
- multimodal
- video
- gui-agent
- grounding
GLM-4.1V-9B-Base
📖 View the GLM-4.1V-9B-Thinking paper.
💡 Try the Hugging Face or ModelScope online demo for GLM-4.1V-9B-Thinking.
📍 Using GLM-4.1V-9B-Thinking API at Zhipu Foundation Model Open Platform
Model Introduction
Vision-Language Models (VLMs) have become foundational components of intelligent systems. As real-world AI tasks grow increasingly complex, VLMs must evolve beyond basic multimodal perception to enhance their reasoning capabilities in complex tasks. This involves improving accuracy, comprehensiveness, and intelligence, enabling applications such as complex problem solving, long-context understanding, and multimodal agents.
Based on the GLM-4-9B-0414 foundation model, we present the new open-source VLM model GLM-4.1V-9B-Thinking, designed to explore the upper limits of reasoning in vision-language models. By introducing a "thinking paradigm" and leveraging reinforcement learning, the model significantly enhances its capabilities. It achieves state-of-the-art performance among 10B-parameter VLMs, matching or even surpassing the 72B-parameter Qwen-2.5-VL-72B on 18 benchmark tasks. We are also open-sourcing the base model GLM-4.1V-9B-Base to support further research into the boundaries of VLM capabilities.
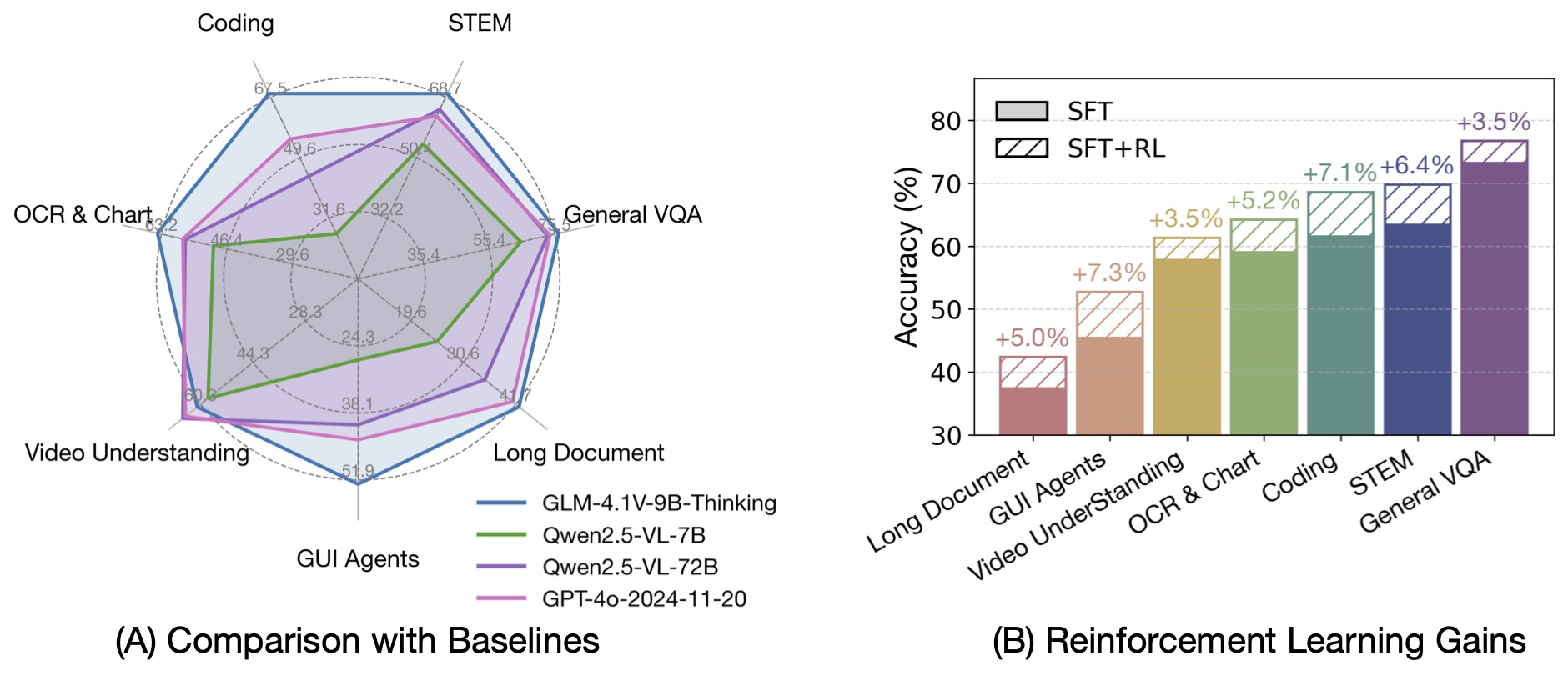
Compared to the previous generation models CogVLM2 and the GLM-4V series, GLM-4.1V-Thinking offers the following improvements:
- The first reasoning-focused model in the series, achieving world-leading performance not only in mathematics but also across various sub-domains.
- Supports 64k context length.
- Handles arbitrary aspect ratios and up to 4K image resolution.
- Provides an open-source version supporting both Chinese and English bilingual usage.
Benchmark Performance
By incorporating the Chain-of-Thought reasoning paradigm, GLM-4.1V-9B-Thinking significantly improves answer accuracy, richness, and interpretability. It comprehensively surpasses traditional non-reasoning visual models. Out of 28 benchmark tasks, it achieved the best performance among 10B-level models on 23 tasks, and even outperformed the 72B-parameter Qwen-2.5-VL-72B on 18 tasks.

For video reasoning, web demo deployment, and more code, please check our GitHub.
Sample Usage
You can use the model with the transformers library as follows:
from transformers import AutoProcessor, AutoModelForConditionalGeneration
from PIL import Image
import torch
model_id = "THUDM/GLM-4.1V-9B-Base" # This model
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForConditionalGeneration.from_pretrained(model_id, trust_remote_code=True, torch_dtype=torch.bfloat16).to("cuda")
# Example image (replace with your image path or load from URL)
# Example image from the GitHub repo's resources (for illustrative purposes)
# import requests
# from io import BytesIO
# img_url = "https://raw.githubusercontent.com/THUDM/GLM-4.1V-Thinking/refs/heads/main/resources/rl.jpeg"
# response = requests.get(img_url)
# image = Image.open(BytesIO(response.content)).convert("RGB")
image_path = "./path/to/your/image.jpg" # Replace with your actual image path
image = Image.open(image_path).convert("RGB")
# Example prompt
prompt = "Describe this image in detail."
# Prepare messages for chat template
messages = [
{"role": "user", "content": f"<image>
{prompt}"}
]
# Apply chat template and get inputs
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
)
inputs = inputs.to(model.device)
# Process image inputs separately
image_inputs = processor(images=image, return_tensors="pt").pixel_values.to(model.device)
# Generate response
generated_ids = model.generate(
input_ids=inputs.input_ids,
images=image_inputs,
max_new_tokens=512,
do_sample=True, # Set to False for greedy decoding
temperature=0.7,
top_p=0.9,
num_beams=1, # Set to >1 for beam search
)
# Decode and print the generated text
generated_text = processor.decode(generated_ids[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
print(generated_text)
Citation
If you use this model, please cite the following paper:
@misc{vteam2025glm45vglm41vthinkingversatilemultimodal,
title={GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning},
author={V Team and Wenyi Hong and Wenmeng Yu and Xiaotao Gu and Guo Wang and Guobing Gan and Haomiao Tang and Jiale Cheng and Ji Qi and Junhui Ji and Lihang Pan and Shuaiqi Duan and Weihan Wang and Yan Wang and Yean Cheng and Zehai He and Zhe Su and Zhen Yang and Ziyang Pan and Aohan Zeng and Baoxu Wang and Bin Chen and Boyan Shi and Changyu Pang and Chenhui Zhang and Da Yin and Fan Yang and Guoqing Chen and Jiazheng Xu and Jiale Zhu and Jiali Chen and Jing Chen and Jinhao Chen and Jinghao Lin and Jinjiang Wang and Junjie Chen and Leqi Lei and Letian Gong and Leyi Pan and Mingdao Liu and Mingde Xu and Mingzhi Zhang and Qinkai Zheng and Sheng Yang and Shi Zhong and Shiyu Huang and Shuyuan Zhao and Siyan Xue and Shangqin Tu and Shengbiao Meng and Tianshu Zhang and Tianwei Luo and Tianxiang Hao and Tianyu Tong and Wenkai Li and Wei Jia and Xiao Liu and Xiaohan Zhang and Xin Lyu and Xinyue Fan and Xuancheng Huang and Yanling Wang and Yadong Xue and Yanfeng Wang and Yanzi Wang and Yifan An and Yifan Du and Yiming Shi and Yiheng Huang and Yilin Niu and Yuan Wang and Yuanchang Yue and Yuchen Li and Yutao Zhang and Yuting Wang and Yu Wang and Yuxuan Zhang and Zhao Xue and Zhenyu Hou and Zhengxiao Du and Zihan Wang and Peng Zhang and Debing Liu and Bin Xu and Juanzi Li and Minlie Huang and Yuxiao Dong and Jie Tang},
year={2025},
eprint={2507.01006},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.01006},
}