
zRzRzRzRzRzRzR
commited on
Commit
·
1a68bb7
1
Parent(s):
baee9b2
init2
Browse files
README.md
CHANGED
|
@@ -10,10 +10,10 @@ pipeline_tag: text-generation
|
|
| 10 |
# GLM-5
|
| 11 |
|
| 12 |
<div align="center">
|
| 13 |
-
<img src=https://raw.githubusercontent.com/zai-org/GLM-
|
| 14 |
</div>
|
| 15 |
<p align="center">
|
| 16 |
-
👋 Join our <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community.
|
| 17 |
<br>
|
| 18 |
📖 Check out the GLM-5 <a href="https://z.ai/blog/glm-4.7" target="_blank">technical blog</a>.
|
| 19 |
<br>
|
|
@@ -28,16 +28,6 @@ We are launching GLM-5, targeting complex systems engineering and long-horizon a
|
|
| 28 |
|
| 29 |
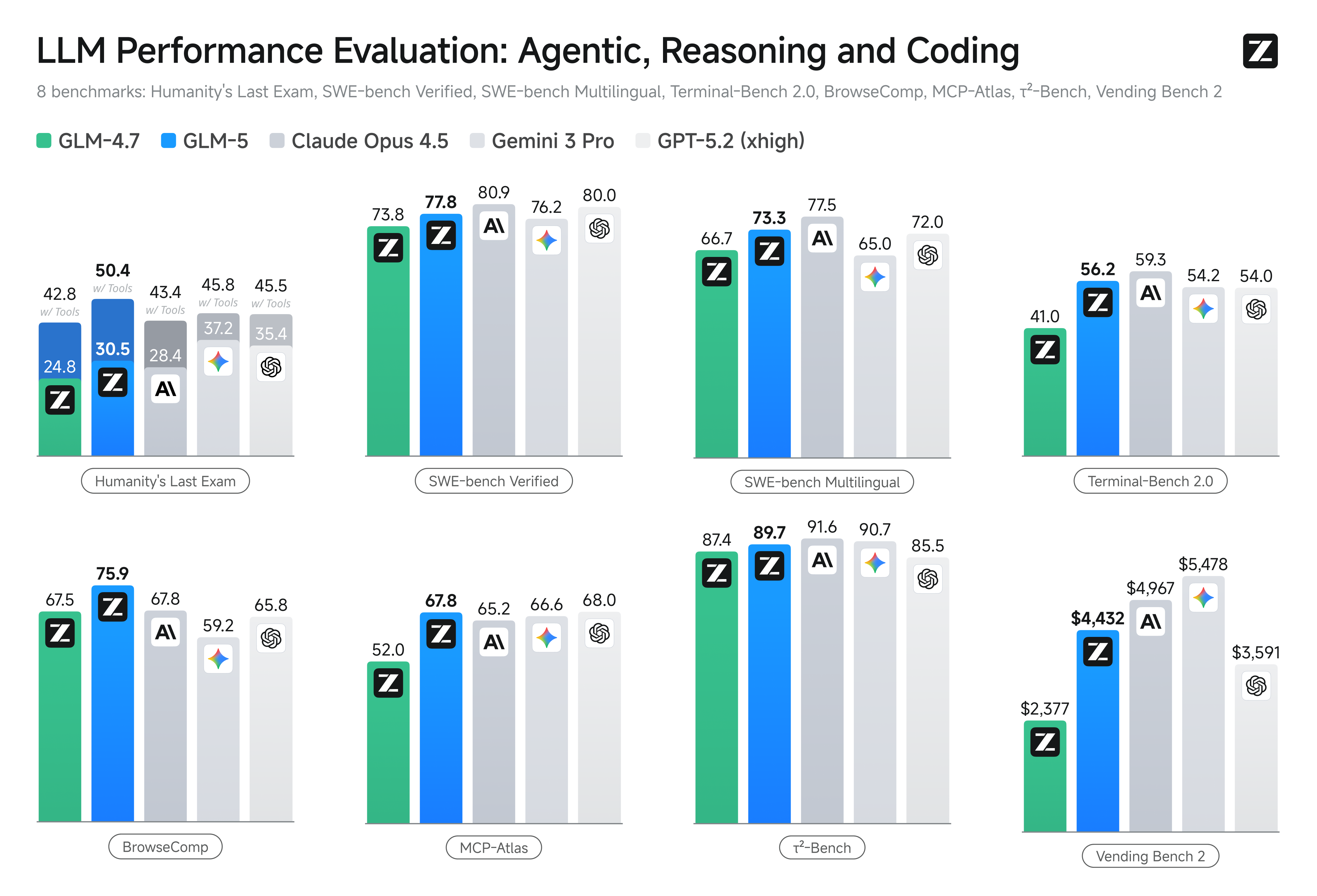
Reinforcement learning aims to bridge the gap between competence and excellence in pre-trained models. However, deploying it at scale for LLMs is a challenge due to the RL training inefficiency. To this end, we developed [slime](https://github.com/THUDM/slime), a novel **asynchronous RL infrastructure** that substantially improves training throughput and efficiency, enabling more fine-grained post-training iterations. With advances in both pre-training and post-training, GLM-5 delivers significant improvement compared to GLM-4.7 across a wide range of academic benchmarks and achieves best-in-class performance among all open-source models in the world on reasoning, coding, and agentic tasks, closing the gap with frontier models.
|
| 30 |
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
GLM-5 is purpose-built for complex systems engineering and long-horizon agentic tasks. On our internal evaluation suite CC-Bench-V2, GLM-5 significantly outperforms GLM-4.7 across frontend, backend, and long-horizon tasks, narrowing the gap to Claude Opus 4.5.
|
| 34 |
-
|
| 35 |
-

|
| 36 |
-
|
| 37 |
-
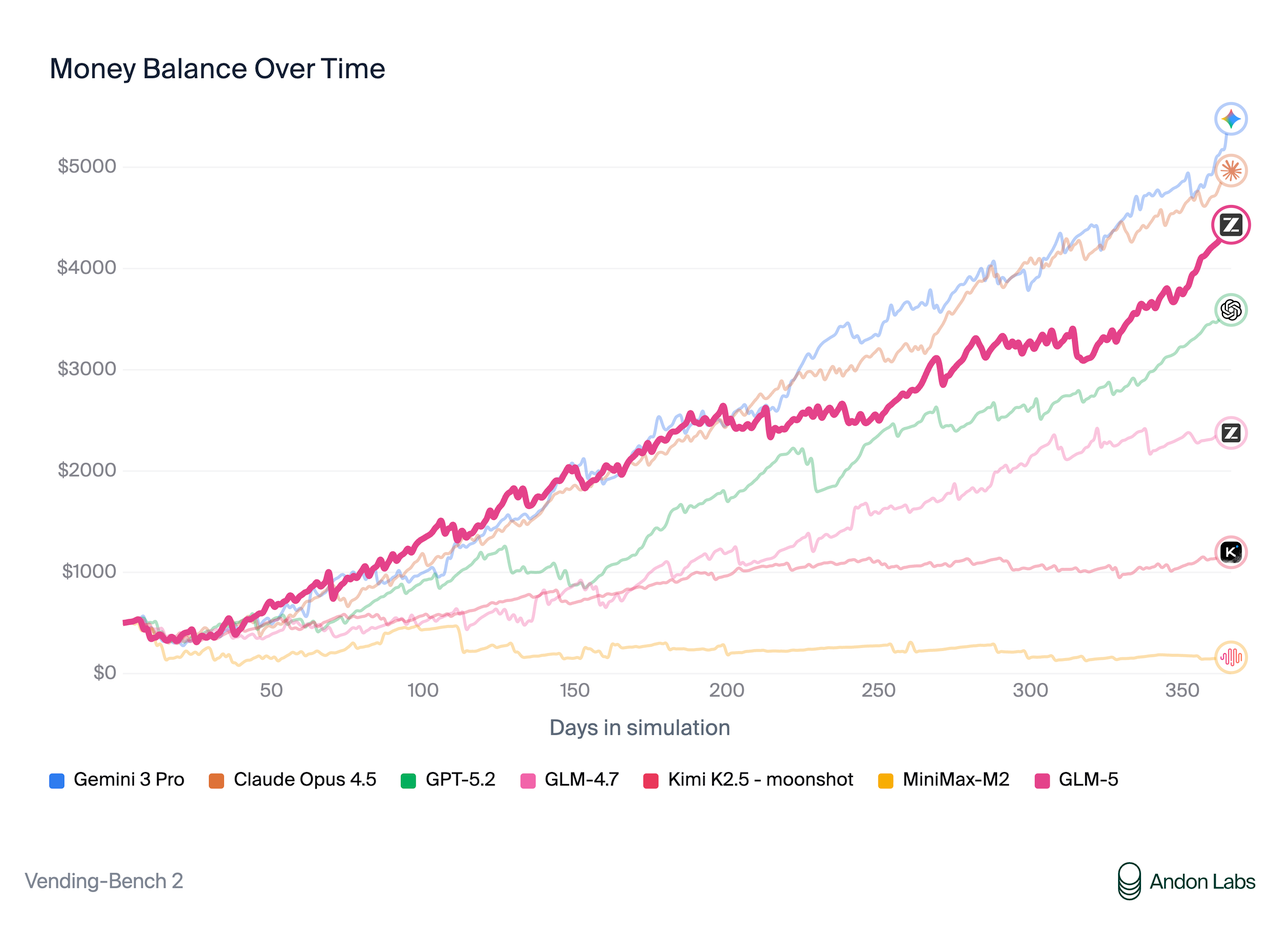
On [Vending Bench 2](https://andonlabs.com/evals/vending-bench-2), a benchmark that measures long-term operational capability, GLM-5 ranks \#1 among open-source models. Vending Bench 2 requires the model to run a simulated vending machine business over a one-year horizon; GLM-5 finishes with a final account balance of $4,432, approaching Claude Opus 4.5 and demonstrating strong long-term planning and resource management.
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
## Benchmark
|
| 42 |
|
| 43 |
| | GLM-5 | GLM-4.7 | DeepSeek-V3.2 | Kimi K2.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (xhigh) |
|
|
|
|
| 10 |
# GLM-5
|
| 11 |
|
| 12 |
<div align="center">
|
| 13 |
+
<img src=https://raw.githubusercontent.com/zai-org/GLM-5/refs/heads/main/resources/logo.svg width="15%"/>
|
| 14 |
</div>
|
| 15 |
<p align="center">
|
| 16 |
+
👋 Join our <a href="https://raw.githubusercontent.com/zai-org/GLM-5/refs/heads/main/resources/wechat.png" target="_blank">WeChat</a> or <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community.
|
| 17 |
<br>
|
| 18 |
📖 Check out the GLM-5 <a href="https://z.ai/blog/glm-4.7" target="_blank">technical blog</a>.
|
| 19 |
<br>
|
|
|
|
| 28 |
|
| 29 |
Reinforcement learning aims to bridge the gap between competence and excellence in pre-trained models. However, deploying it at scale for LLMs is a challenge due to the RL training inefficiency. To this end, we developed [slime](https://github.com/THUDM/slime), a novel **asynchronous RL infrastructure** that substantially improves training throughput and efficiency, enabling more fine-grained post-training iterations. With advances in both pre-training and post-training, GLM-5 delivers significant improvement compared to GLM-4.7 across a wide range of academic benchmarks and achieves best-in-class performance among all open-source models in the world on reasoning, coding, and agentic tasks, closing the gap with frontier models.
|
| 30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 31 |
## Benchmark
|
| 32 |
|
| 33 |
| | GLM-5 | GLM-4.7 | DeepSeek-V3.2 | Kimi K2.5 | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.2 (xhigh) |
|