| | --- |
| | license: apache-2.0 |
| | --- |
| | ## DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation |
| |
|
| | Arxiv: https://arxiv.org/abs/2511.19365 |
| |
|
| | Project Page: https://zehong-ma.github.io/DeCo |
| |
|
| | Code Repository: https://github.com/Zehong-Ma/DeCo |
| |
|
| | Huggingface Space: https://14467288703cf06a3c.gradio.live/ |
| |
|
| |
|
| | ## 🖼️ Background |
| |
|
| | + Pixel diffusion aims to generate images directly in pixel space in an end-to-end fashion. This avoids the two-stage training and inevitable low-level artifacts of VAE. |
| | + Current pixel diffusion models suffer from slow training since a single Diffusion Transformer (DiT) is required to jointly model complex high-frequency signals and low-frequency semantics. Modeling complex high-frequency signals, especially high-frequency noise, can distract the DiT from learning low-frequency semantics. |
| | + JiT proposes that high-dimensional noise may distract the model from learning low-dimensional data, which is also a form of high-frequency interference. Additionaly, the intrinsic noise (e.g., camera noise) in the clean image is also high-frequency noise that requires modeling. Our DeCO can jointly models these high-frequency signals (gaussian noise in JiT, intrinsic camera noise, high-frequency details) in an end-to-end manner. |
| | + **Motivation**: **The paper proposes the frequency-DeCoupled (DeCo) framework to separate the modeling of high and low-frequency components.** A lightweight Pixel Decoder is introduced to model the high-frequency components , thereby freeing the DiT to specialize in modeling low-frequency semantics. |
| |
|
| | ### 💡Method |
| |
|
| | + The DiT operates on a downsampled, low-resolution input to generate low-frequency semantic conditions. The Pixel Decoder then takes the full-resolution input, and use the DiT's semantic condition as guidance to predict the velocity. The AdaLN-Zero interaction mechanism is used to modulate the dense features in the Pixel Decoder with the DiT output. |
| | + The paper also propose a frequency-aware flow-matching loss。It applies adaptive weights for different frequency components. These weights are derived from normalized reciprocal of JPEG quantization tables , which assign higher weights to perceptually more important low-frequency components and suppress insignificant high-frequency noise. |
| |
|
| | ### 📈Experiments |
| |
|
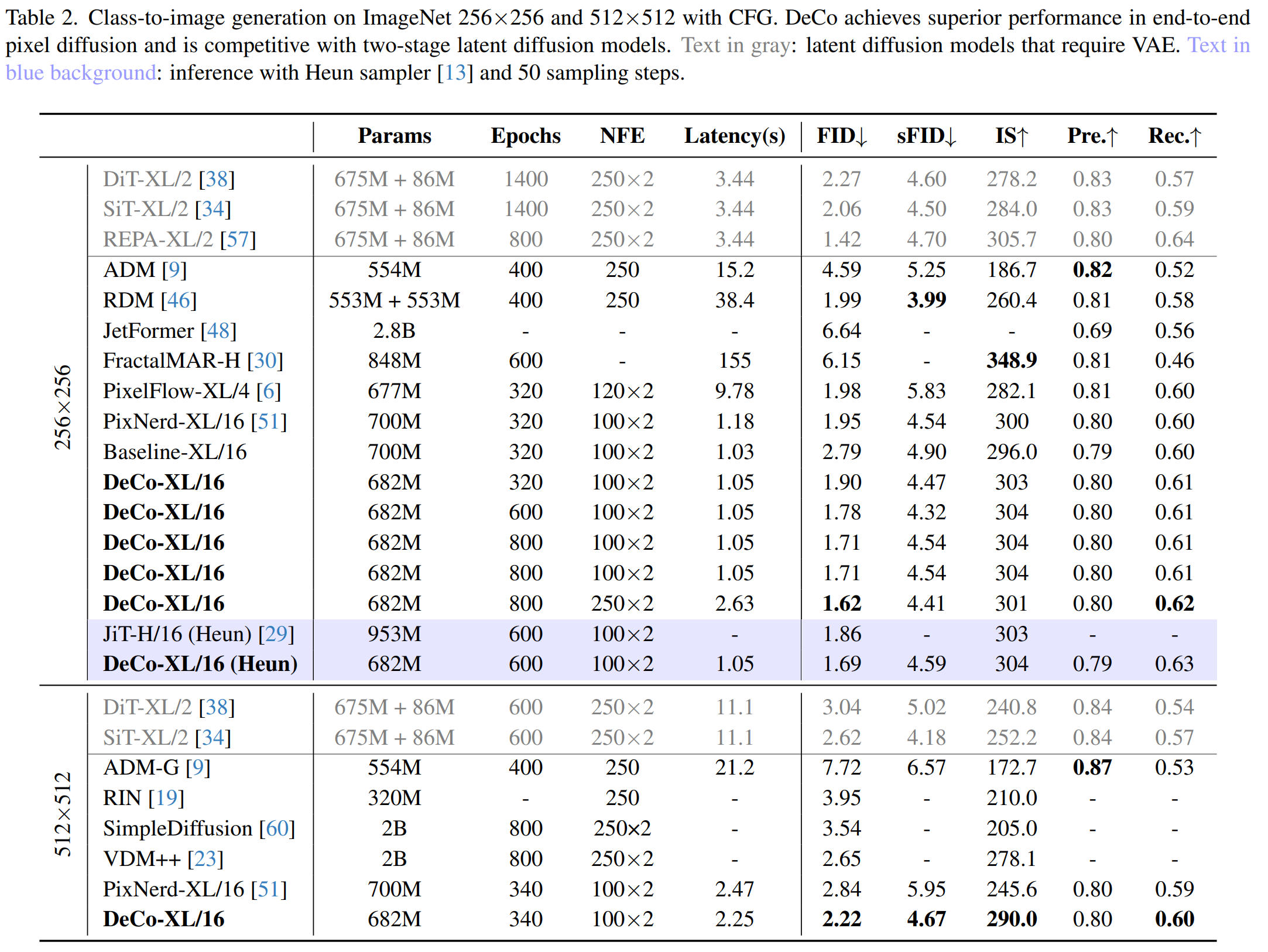
| | + The authors trained the DeCo-XL model with a DiT patch size of 16 on the ImageNet 256x256 and 512x512. DeCo-XL achieves a leading FID of **1.62** on ImageNet 256x256 and **2.22** on ImageNet 512x512. With the same 50 Heun steps at 600 epochs, DeCo's FID of 1.69 is superior to JiT's FID of 1.86. |
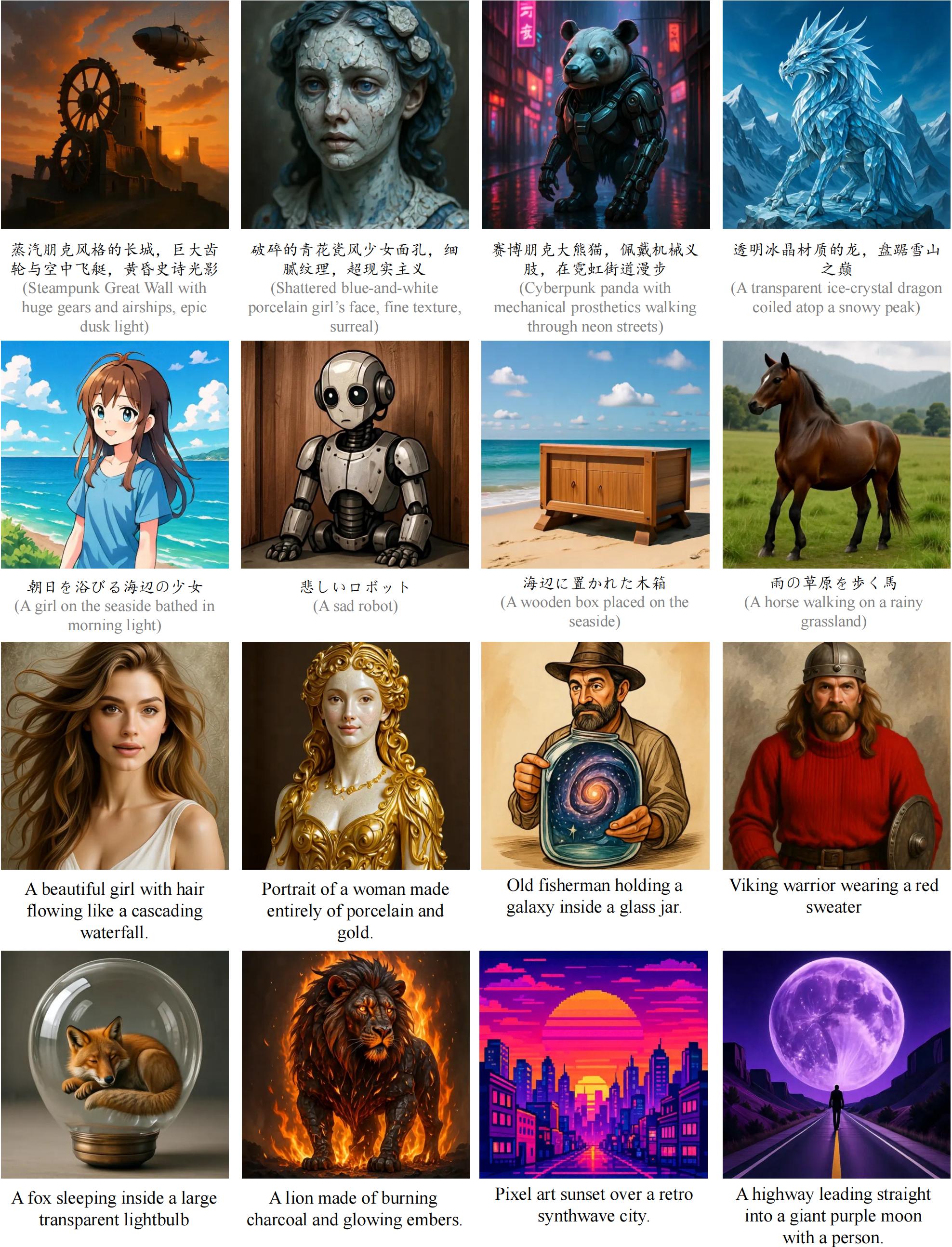
| | + For scaling ability in text-to-image generation, a DeCo-XXL model was trained on the BLIP3o dataset (36M pretraining images + 60k instruction-tuning data). It achieves an overall score of **0.86** on GenEval and a competitive average score of 81.4 on DPG-Bench. |
| |
|
| |  |
| |
|
| |  |
| |
|
| | ### 📖Citation |
| | ``` |
| | @misc{ma2025decofrequencydecoupledpixeldiffusion, |
| | title={DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation}, |
| | author={Zehong Ma and Longhui Wei and Shuai Wang and Shiliang Zhang and Qi Tian}, |
| | year={2025}, |
| | eprint={2511.19365}, |
| | archivePrefix={arXiv}, |
| | primaryClass={cs.CV}, |
| | url={https://arxiv.org/abs/2511.19365}, |
| | } |
| | ``` |
