
Improve model card: Add pipeline tag, abstract summary, and usage info
#1
by
nielsr HF Staff - opened
README.md
CHANGED
|
@@ -1,8 +1,11 @@
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
|
|
|
| 3 |
---
|
| 4 |
-
## DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
|
| 5 |
|
|
|
|
|
|
|
|
|
|
| 6 |
Arxiv: https://arxiv.org/abs/2511.19365
|
| 7 |
|
| 8 |
Project Page: https://zehong-ma.github.io/DeCo
|
|
@@ -11,29 +14,112 @@ Code Repository: https://github.com/Zehong-Ma/DeCo
|
|
| 11 |
|
| 12 |
Huggingface Space: https://14467288703cf06a3c.gradio.live/
|
| 13 |
|
|
|
|
|
|
|
|
|
|
| 14 |
|
| 15 |
## 🖼️ Background
|
| 16 |
|
| 17 |
+ Pixel diffusion aims to generate images directly in pixel space in an end-to-end fashion. This avoids the two-stage training and inevitable low-level artifacts of VAE.
|
| 18 |
-
+ Current pixel diffusion models suffer from slow training
|
| 19 |
-
+ JiT proposes that high-dimensional noise may distract the model from learning low-dimensional data, which is also a form of high-frequency interference. Additionaly, the intrinsic noise (e.g., camera noise) in the clean image is also high-frequency noise that requires modeling. Our DeCO can jointly models these high-frequency signals (gaussian noise in JiT,
|
| 20 |
+ **Motivation**: **The paper proposes the frequency-DeCoupled (DeCo) framework to separate the modeling of high and low-frequency components.** A lightweight Pixel Decoder is introduced to model the high-frequency components , thereby freeing the DiT to specialize in modeling low-frequency semantics.
|
| 21 |
|
| 22 |
### 💡Method
|
| 23 |
|
| 24 |
+ The DiT operates on a downsampled, low-resolution input to generate low-frequency semantic conditions. The Pixel Decoder then takes the full-resolution input, and use the DiT's semantic condition as guidance to predict the velocity. The AdaLN-Zero interaction mechanism is used to modulate the dense features in the Pixel Decoder with the DiT output.
|
| 25 |
-
+ The paper also propose a frequency-aware flow-matching loss
|
| 26 |
|
| 27 |
### 📈Experiments
|
| 28 |
|
| 29 |
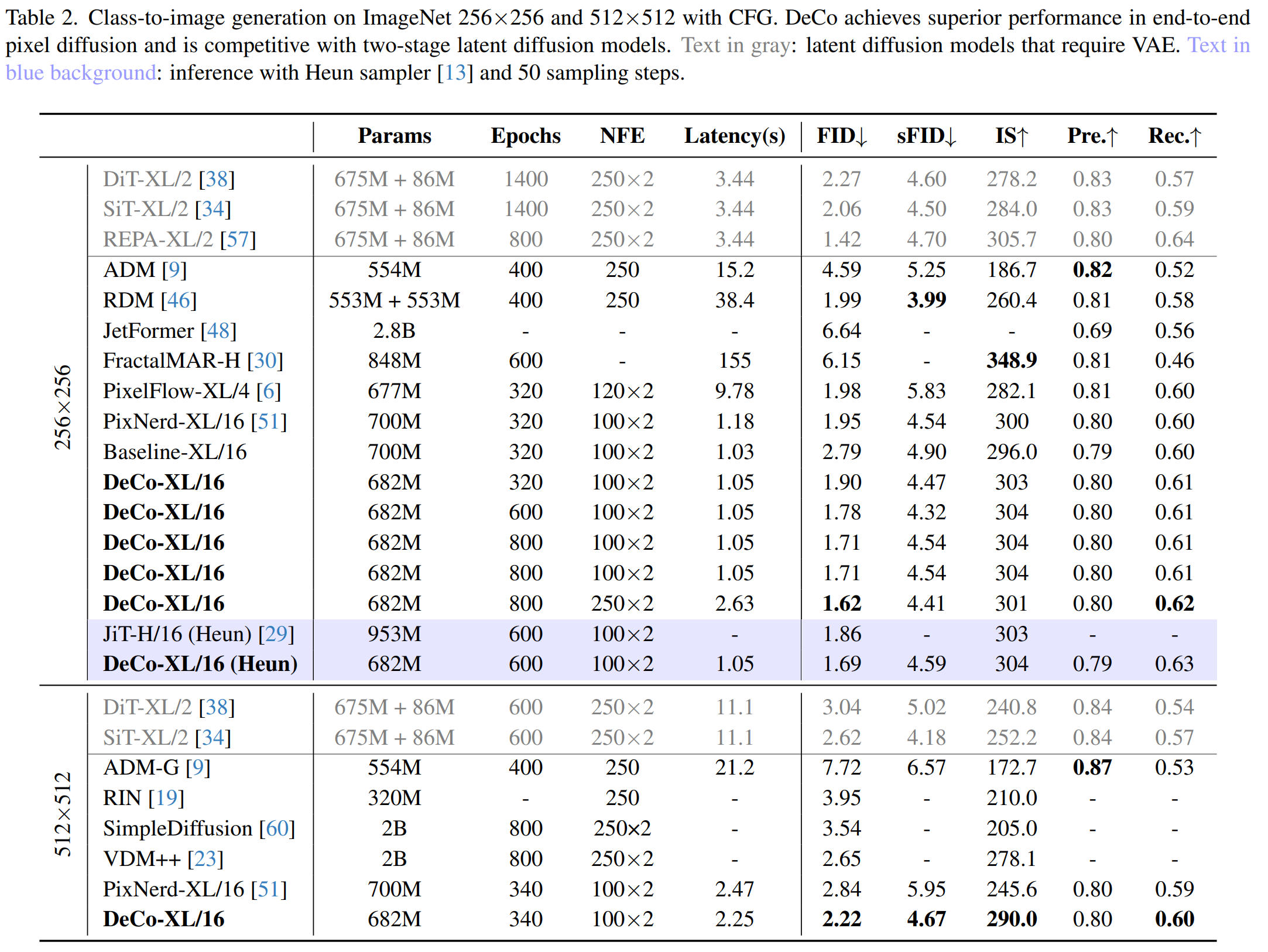
+ The authors trained the DeCo-XL model with a DiT patch size of 16 on the ImageNet 256x256 and 512x512. DeCo-XL achieves a leading FID of **1.62** on ImageNet 256x256 and **2.22** on ImageNet 512x512. With the same 50 Heun steps at 600 epochs, DeCo's FID of 1.69 is superior to JiT's FID of 1.86.
|
| 30 |
-
+ For scaling ability in text-to-image generation, a DeCo-XXL model was trained on the BLIP3o dataset (36M pretraining images + 60k instruction-tuning data). It achieves an overall score of **0.86** on GenEval
|
| 31 |
|
| 32 |
|
| 33 |
|
| 34 |
|
| 35 |
|
| 36 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
```
|
| 38 |
@misc{ma2025decofrequencydecoupledpixeldiffusion,
|
| 39 |
title={DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation},
|
|
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
+
pipeline_tag: text-to-image
|
| 4 |
---
|
|
|
|
| 5 |
|
| 6 |
+
# DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
|
| 7 |
+
|
| 8 |
+
Paper: https://huggingface.co/papers/2511.19365
|
| 9 |
Arxiv: https://arxiv.org/abs/2511.19365
|
| 10 |
|
| 11 |
Project Page: https://zehong-ma.github.io/DeCo
|
|
|
|
| 14 |
|
| 15 |
Huggingface Space: https://14467288703cf06a3c.gradio.live/
|
| 16 |
|
| 17 |
+
## Abstract Summary
|
| 18 |
+
|
| 19 |
+
DeCo introduces a frequency-decoupled pixel diffusion framework for end-to-end image generation. It addresses slow training and inference in existing pixel diffusion models by using a lightweight pixel decoder for high-frequency details, allowing the Diffusion Transformer (DiT) to focus on low-frequency semantics. Combined with a frequency-aware flow-matching loss, DeCo achieves state-of-the-art performance, with FID scores of 1.62 (256x256) and 2.22 (512x512) on ImageNet, and a leading overall score of 0.86 on GenEval for text-to-image generation.
|
| 20 |
|
| 21 |
## 🖼️ Background
|
| 22 |
|
| 23 |
+ Pixel diffusion aims to generate images directly in pixel space in an end-to-end fashion. This avoids the two-stage training and inevitable low-level artifacts of VAE.
|
| 24 |
+
+ Current pixel diffusion models suffer from slow training since a single Diffusion Transformer (DiT) is required to jointly model complex high-frequency signals and low-frequency semantics. Modeling complex high-frequency signals, especially high-frequency noise, can distract the DiT from learning low-frequency semantics.
|
| 25 |
+
+ JiT proposes that high-dimensional noise may distract the model from learning low-dimensional data, which is also a form of high-frequency interference. Additionaly, the intrinsic noise (e.g., camera noise) in the clean image is also high-frequency noise that requires modeling. Our DeCO can jointly models these high-frequency signals (gaussian noise in JiT, intrinsic camera noise, high-frequency details) in an end-to-end manner.
|
| 26 |
+ **Motivation**: **The paper proposes the frequency-DeCoupled (DeCo) framework to separate the modeling of high and low-frequency components.** A lightweight Pixel Decoder is introduced to model the high-frequency components , thereby freeing the DiT to specialize in modeling low-frequency semantics.
|
| 27 |
|
| 28 |
### 💡Method
|
| 29 |
|
| 30 |
+ The DiT operates on a downsampled, low-resolution input to generate low-frequency semantic conditions. The Pixel Decoder then takes the full-resolution input, and use the DiT's semantic condition as guidance to predict the velocity. The AdaLN-Zero interaction mechanism is used to modulate the dense features in the Pixel Decoder with the DiT output.
|
| 31 |
+
+ The paper also propose a frequency-aware flow-matching loss. It applies adaptive weights for different frequency components. These weights are derived from normalized reciprocal of JPEG quantization tables , which assign higher weights to perceptually more important low-frequency components and suppress insignificant high-frequency noise.
|
| 32 |
|
| 33 |
### 📈Experiments
|
| 34 |
|
| 35 |
+ The authors trained the DeCo-XL model with a DiT patch size of 16 on the ImageNet 256x256 and 512x512. DeCo-XL achieves a leading FID of **1.62** on ImageNet 256x256 and **2.22** on ImageNet 512x512. With the same 50 Heun steps at 600 epochs, DeCo's FID of 1.69 is superior to JiT's FID of 1.86.
|
| 36 |
+
+ For scaling ability in text-to-image generation, a DeCo-XXL model was trained on the BLIP3o dataset (36M pretraining images + 60k instruction-tuning data). It achieves an overall score of **0.86** on GenEval in system-level comparison.
|
| 37 |
|
| 38 |

|
| 39 |
|
| 40 |

|
| 41 |
|
| 42 |
+
## <img src="data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHZpZXdCb3g9IjAgMCAyNCAyNCIgZmlsbD0iIzg4OCI+PHBhdGggZD0iTTEyLDJBNy45LDcuOSwwLDAsMCw0LjEsOS45LDcuOCw3LjgsMCwwLDAsMiwxN2gzYTEsMSwwLDAsMCwxLDFoM3YyYTEsMSwwLDAsMCwxLDFoNHYwYTEsMSwwLDAsMCwxLTFWMThoM2ExLDEsMCwwLDAsMS0xaDNjMC0zLjgtMS42LTcuNS01LjgtOS4yQTguMSw4LjEsMCwwLDAsMTIsMlpNMTQsMTMuNWwtLjUuOGExLDEsMCwwLDEtLjkuNWgtMS4yYTEsMSwwLDAsMS0uOS0uNWwtLjUtLjhDOS4zLDEzLDksMTIuNyw5LDEyLjRzLjMtLjYsLjktMWwuNS0uOGExLDEsMCwwLDEsLjktLjVoMS4yYTEsMSwwLDAsMSwuOS41bC41LjhjLjYuNC45LjcuOSwxUzE0LjYsMTMuMSwxNCwxMy41WiIvPjwvc3ZnPg==" width="20" style="vertical-align: middle;"/> DCT Spectral Analysis
|
| 43 |
+
|
| 44 |
+
<div class="content">
|
| 45 |
+
<img src="./docs/static/images/dct_and_FID_comparison.jpg" style="width: 95%;"><br>
|
| 46 |
+
<span style="font-size: 0.8em; width: 100%; display: inline-block;">DCT energy distribution of DiT outputs and predicted pixel velocities. Compared with baseline, DeCo suppresses high-frequency signals in DiT outputs while preserving strong high-frequency energy in pixel velocity, confirming effective frequency decoupling. The distribution is computed on 10K images across all diffusion steps using DCT transform with 8x8 block size. (b) FID comparison between our DeCo and baseline. DeCo reaches 2.57 FID in 400k iterations, 10× faster than the baseline.
|
| 47 |
+
</span>
|
| 48 |
+
</div>
|
| 49 |
+
|
| 50 |
+
## 🧩 Visualizations
|
| 51 |
+
+ Visualization of more images generated by our text-to-image DeCo.
|
| 52 |
+
<div class="content">
|
| 53 |
+
<img src="./docs/static/images/appendix_t2i_figures.jpg" style="width: 100%;"><br>
|
| 54 |
+
</div>
|
| 55 |
+
|
| 56 |
+
+ Visualization of 256*256 images generated by our class-to-image DeCo.
|
| 57 |
+
<div class="content">
|
| 58 |
+
<img src="./docs/static/images/c2i_imagenet256.jpg" style="width: 100%;"><br>
|
| 59 |
+
</div>
|
| 60 |
+
|
| 61 |
+
## 🎉 Checkpoints
|
| 62 |
+
|
| 63 |
+
| Dataset | Epoch | Model | Params | FID | HuggingFace |
|
| 64 |
+
|---------------|-------|---------------|--------|-------|---------------------------------------|
|
| 65 |
+
| ImageNet256 | 320 | DeCo-XL/16 | 682M | 1.90 | [🤗](https://huggingface.co/zehongma/DeCo/blob/main/imagenet256_epoch320.ckpt) |
|
| 66 |
+
| ImageNet256 | 600 | DeCo-XL/16 | 682M | 1.78 | [🤗](https://huggingface.co/zehongma/DeCo/blob/main/imagenet256_epoch600.ckpt) |
|
| 67 |
+
| ImageNet256 | 800 | DeCo-XL/16 | 682M | 1.62 | [🤗](https://huggingface.co/zehongma/DeCo/blob/main/imagenet256_epoch800.ckpt) |
|
| 68 |
+
| ImageNet512 | 340 | DeCo-XL/16 | 682M | 2.22 | [🤗](https://huggingface.co/zehongma/DeCo/blob/main/imagenet512_epoch340.ckpt) |
|
| 69 |
+
|
| 70 |
+
| Dataset | Model | Params | GenEval | DPG | HuggingFace |
|
| 71 |
+
|---------------|---------------|--------|------|------|----------------------------------------------------------|
|
| 72 |
+
| Text-to-Image | DeCo-XXL/16| 1.1B | 0.86 | 81.4| [🤗](https://huggingface.co/zehongma/DeCo/blob/main/t2i_DeCo.ckpt) |
|
| 73 |
+
## 🔥 Online Demos
|
| 74 |
+

|
| 75 |
+
We provide online demos for DeCo-XXL/16(text-to-image) on HuggingFace Spaces.
|
| 76 |
+
|
| 77 |
+
HF spaces: [https://14467288703cf06a3c.gradio.live](https://14467288703cf06a3c.gradio.live)
|
| 78 |
+
|
| 79 |
+
To host the local gradio demo, run the following command:
|
| 80 |
+
```bash
|
| 81 |
+
# for text-to-image applications
|
| 82 |
+
python app.py --config configs_t2i/inference_heavydecoder.yaml --ckpt_path=./ckpts/t2i_DeCo.ckpt
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
## 🤖 Usages
|
| 86 |
+
In class-to-image(ImageNet) experiments, We use [ADM evaluation suite](https://github.com/openai/guided-diffusion/tree/main/evaluations) to report FID.
|
| 87 |
+
In text-to-image experiments, we use BLIP3o dataset as training set and utilize GenEval and DPG to collect metrics.
|
| 88 |
+
|
| 89 |
+
+ Environments
|
| 90 |
+
```bash
|
| 91 |
+
# for installation (recommend python 3.10)
|
| 92 |
+
pip install -r requirements.txt
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
+ Inference
|
| 96 |
+
```bash
|
| 97 |
+
# for inference
|
| 98 |
+
python main.py predict -c ./configs_c2i/DeCo_XL.yaml --ckpt_path=XXX.ckpt
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
+ Train
|
| 102 |
+
```bash
|
| 103 |
+
# for c2i training
|
| 104 |
+
# Please modify the ImageNet1k path in the config file before training.
|
| 105 |
+
python main.py fit -c ./configs_c2i/DeCo_XL.yaml
|
| 106 |
+
|
| 107 |
+
# for 512*512 continuing pretraining
|
| 108 |
+
python main.py fit -c ./configs_c2i/DeCo_XL_512.yaml --ckpt_path=/path/to/256/checkpoint/at/320/epochs
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
```bash
|
| 112 |
+
# for t2i training
|
| 113 |
+
python main.py fit -c ./configs_t2i/pretraining_res256.yaml
|
| 114 |
+
python main.py fit -c ./configs_t2i/pretraining_res512.yaml --ckpt_path=./ckpts/pretrain256.ckpt
|
| 115 |
+
python main.py fit -c ./configs_t2i/sft_res512.yaml --ckpt_path=./ckpts/pretrain512.ckpt
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
## 💐 Acknowledgement
|
| 119 |
+
|
| 120 |
+
This repository is built based on [PixNerd](https://github.com/MCG-NJU/PixNerd) and [DDT](https://github.com/MCG-NJU/DDT). Thanks for their contributions and [Shuai Wang](https://github.com/WANGSSSSSSS)'s support!
|
| 121 |
+
|
| 122 |
+
### 📖 Citation
|
| 123 |
```
|
| 124 |
@misc{ma2025decofrequencydecoupledpixeldiffusion,
|
| 125 |
title={DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation},
|