
Provence: efficient and robust context pruning for retrieval-augmented generation
Paper • 2501.16214 • Published • 1
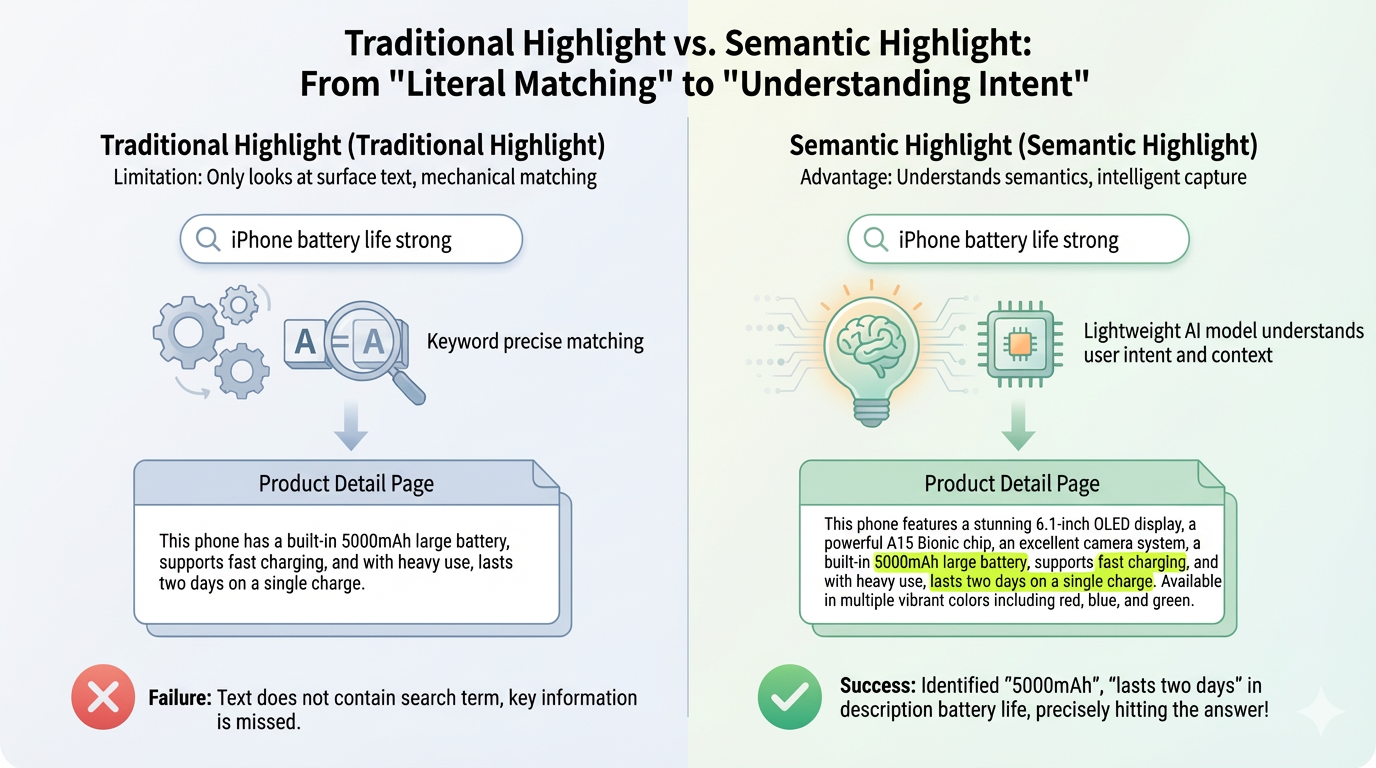 Traditional search highlighting works by matching keywords. When you search for "iPhone performance" on an e-commerce site, only the words "iPhone" and "performance" get highlighted in the results. But what if the product description says "Powered by A15 Bionic chip, scores over 1 million in benchmarks, smooth performance with no lag"? This clearly answers the performance question, yet nothing gets highlighted because it doesn't contain the exact word "performance".
Traditional search highlighting works by matching keywords. When you search for "iPhone performance" on an e-commerce site, only the words "iPhone" and "performance" get highlighted in the results. But what if the product description says "Powered by A15 Bionic chip, scores over 1 million in benchmarks, smooth performance with no lag"? This clearly answers the performance question, yet nothing gets highlighted because it doesn't contain the exact word "performance".
Semantic Highlight solves this problem by understanding meaning, not just matching words. It highlights text segments that are semantically relevant to your query, even if they don't contain the exact keywords. This is crucial in RAG (Retrieval-Augmented Generation) scenarios where users need to quickly identify relevant information in long retrieved documents.
For more technical details, check out our blog here: https://huggingface.co/blog/zilliz/zilliz-semantic-highlight-model
Highlighting happens on every search query - it needs to be fast and cost-effective. Large language models would be too slow and expensive for this real-time task. This model is designed to be:
pip install transformers torch
from transformers import AutoModel
model = AutoModel.from_pretrained(
"zilliz/semantic-highlight-bilingual-v1",
trust_remote_code=True
)
question = "What are the symptoms of dehydration?"
context = """
Dehydration occurs when your body loses more fluid than you take in.
Common signs include feeling thirsty and having a dry mouth.
The human body is composed of about 60% water.
Dark yellow urine and infrequent urination are warning signs.
Water is essential for many bodily functions.
Dizziness, fatigue, and headaches can indicate severe dehydration.
Drinking 8 glasses of water daily is often recommended.
"""
result = model.process(
question=question,
context=context,
threshold=0.5,
# language="en", # Language can be auto-detected, or explicitly specified
return_sentence_metrics=True, # Enable sentence probabilities
)
highlighted = result["highlighted_sentences"]
print(f"Highlighted {len(highlighted)} sentences:")
for i, sent in enumerate(highlighted, 1):
print(f" {i}. {sent}")
print(f"\nTotal sentences in context: {len(context.strip().split('.')) - 1}")
# Print sentence probabilities if available
if "sentence_probabilities" in result:
probs = result["sentence_probabilities"]
print(f"\nSentence probabilities: {probs}")
Highlighted 3 sentences:
1. Common signs include feeling thirsty and having a dry mouth.
2. Dark yellow urine and infrequent urination are warning signs.
3. Dizziness, fatigue, and headaches can indicate severe dehydration.
Total sentences in context: 7
Sentence probabilities: [0.01702437922358513, 0.9901671409606934, 0.002306025242432952, 0.9472107887268066, 0.0009636427275836468, 0.9724337458610535, 0.0009910146472975612]
from transformers import AutoModel
model = AutoModel.from_pretrained(
"zilliz/semantic-highlight-bilingual-v1",
trust_remote_code=True
)
question = "北京有什么好吃的?"
context = """
北京烤鸭是北京最著名的特色美食,皮酥肉嫩,配上薄饼和甜面酱。
故宫是明清两代的皇家宫殿,也是世界上现存规模最大的木质结构古建筑群。
炸酱面是北京的传统面食,用黄酱配上黄瓜丝和豆芽菜。
长城是中国古代的军事防御工程,绵延数千公里。
老北京涮羊肉以铜锅为特色,羊肉鲜嫩,蘸料丰富。
天坛是明清两代皇帝祭天的场所,建筑精美。
豆汁儿是北京独特的传统小吃,口味特别,配上焦圈最地道。
颐和园是清朝的皇家园林,以昆明湖和万寿山为主体。
"""
result = model.process(
question=question,
context=context,
threshold=0.5,
# language="zh", # Language can be auto-detected, or explicitly specified
return_sentence_metrics=True, # Enable sentence probabilities
)
highlighted = result["highlighted_sentences"]
print(f"高亮了 {len(highlighted)} 个句子:")
for i, sent in enumerate(highlighted, 1):
print(f" {i}. {sent}")
print(f"\n上下文总句子数: {len([s for s in context.strip().split('。') if s.strip()])}")
# Print sentence probabilities if available
if "sentence_probabilities" in result:
probs = result["sentence_probabilities"]
print(f"\n句子概率: {probs}")
高亮了 4 个句子:
1. 北京烤鸭是北京最著名的特色美食,皮酥肉嫩,配上薄饼和甜面酱。
2. 炸酱面是北京的传统面食,用黄酱配上黄瓜丝和豆芽菜。
3. 老北京涮羊肉以铜锅为特色,羊肉鲜嫩,蘸料丰富。
4. 豆汁儿是北京独特的传统小吃,口味特别,配上焦圈最地道。
上下文总句子数: 8
句子概率: [0.9885324239730835, 0.2653350234031677, 0.9058853983879089, 0.13888002932071686, 0.9659912586212158, 0.39620667695999146, 0.968794584274292, 0.23973196744918823]
question: Query textcontext: Document text to highlightthreshold: Relevance threshold (0-1), default 0.5. Lower values include more sentences.language: Language code ("en", "zh", or "auto"). If not specified, language will be auto-detected.return_sentence_metrics: Return per-sentence relevance scoreshighlighted_sentences: List of highlighted sentences (relevant sentences only)compression_rate: Percentage of text removedsentence_probabilities: Relevance score for each sentence (if return_sentence_metrics=True)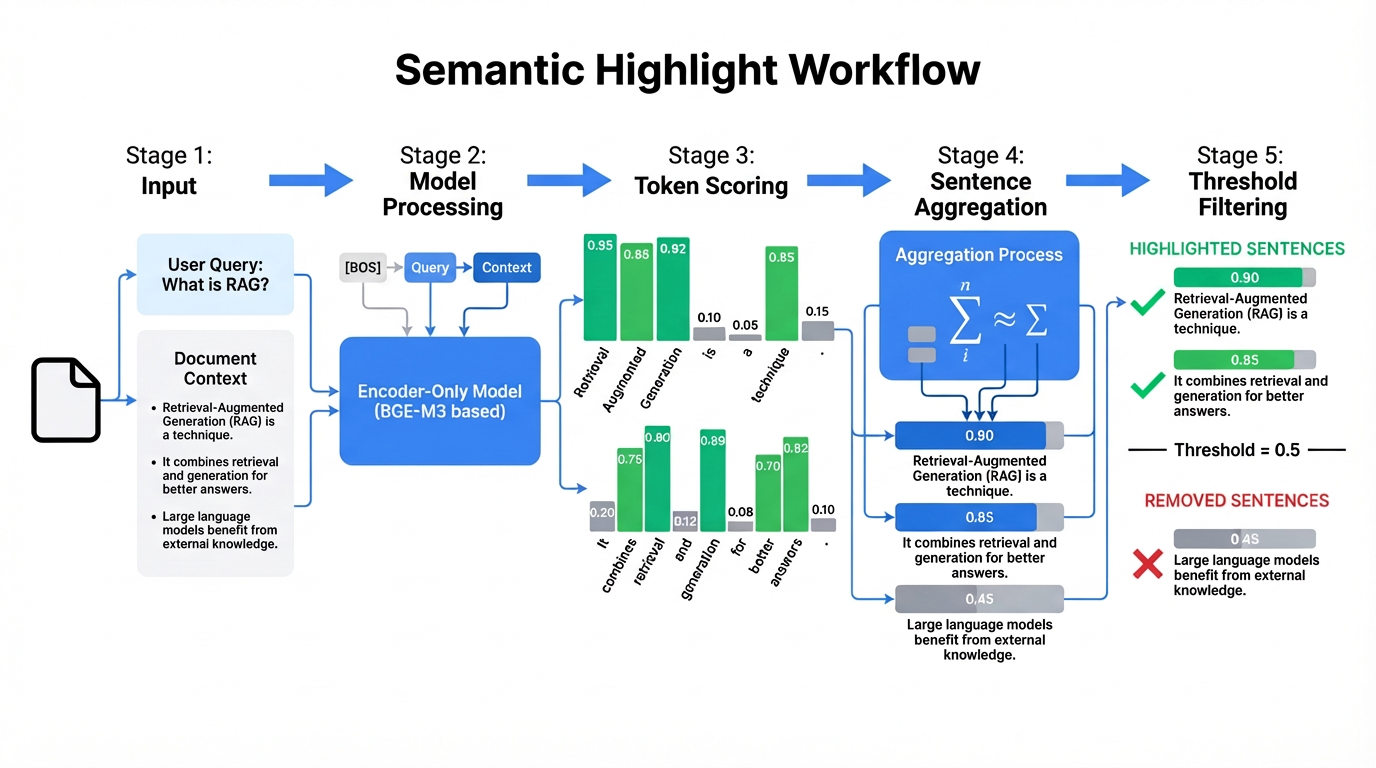 The input consists of a query and a text passage, and the output is a relevance score for each token position in the text. Token scores are then aggregated into sentence scores, and a threshold is applied to highlight or remove sentences accordingly.
The input consists of a query and a text passage, and the output is a relevance score for each token position in the text. Token scores are then aggregated into sentence scores, and a threshold is applied to highlight or remove sentences accordingly.
Specifically, the model concatenates inputs as [BOS] + Query + Context, scores each token in the context (between 0 and 1), averages token scores within each sentence to obtain sentence scores, and finally highlights sentences with high scores while removing those with low scores. The model essentially performs a single pass over the context, using scores to indicate which parts merit attention.
 The model ranks SOTA across all four evaluation datasets. Notably, it’s the only model that demonstrates strong performance on both Chinese and English datasets. Other models either support only English or show significant performance degradation on Chinese text.
The model ranks SOTA across all four evaluation datasets. Notably, it’s the only model that demonstrates strong performance on both Chinese and English datasets. Other models either support only English or show significant performance degradation on Chinese text.
This work draws its core ideas and theoretical underpinnings from Provence (https://arxiv.org/abs/2501.16214), whose seminal research laid the essential groundwork for our exploration.
For the practical implementation of code and training strategies, we build entirely upon the exceptional efforts of the Open Provence project (https://github.com/hotchpotch/open_provence). We extend our sincere gratitude to the Open Provence team for generously open-sourcing the complete framework—including the high-quality dataset and toolkit for model training—thus making this valuable resource accessible to the broader research community.
This model stands firmly on the shoulders of these foundational contributions, while we have tailored it to better align with specific business needs: we enhanced data generation and training quality for bilingual datasets, and removed the rerank head to optimize its applicability to our use case. Our sincere thanks go to all the researchers and developers behind these remarkable works.
MIT License
@misc{chirkova2025provenceefficientrobustcontext,
title={Provence: efficient and robust context pruning for retrieval-augmented generation},
author={Nadezhda Chirkova and Thibault Formal and Vassilina Nikoulina and Stéphane Clinchant},
year={2025},
eprint={2501.16214},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.16214},
}
@misc{yuichi-tateno-2025-open-provence,
url = {https://github.com/hotchpotch/open_provence},
title = {OpenProvence: An Open-Source Implementation of Efficient and Robust Context Pruning for Retrieval-Augmented Generation},
author = {Yuichi Tateno},
year = {2025}
}
@misc{chen2024bge,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Jianlv Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu},
year={2024},
eprint={2402.03216},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
For more information, check out the blog here: https://huggingface.co/blog/zilliz/zilliz-semantic-highlight-model
Base model
BAAI/bge-reranker-v2-m3