
File size: 4,811 Bytes
4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d 65ef268 4dfe26d | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 | ---
language:
- en
license: other
pipeline_tag: image-text-to-text
tags:
- robotics
- vision-language-model
- embodied-ai
- manipulation
- qwen2-vl
library_name: transformers
---
# Embodied-R1-3B-v1
**Embodied-R1: Reinforced Embodied Reasoning for General Robotic Manipulation (ICLR 2026)**
[[🌐 Project Website](https://embodied-r1.github.io)] [[📄 Paper](http://arxiv.org/abs/2508.13998)] [[🏆 ICLR2026 Version](https://openreview.net/forum?id=i5wlozMFsQ)] [[🎯 Dataset](https://huggingface.co/datasets/IffYuan/Embodied-R1-Dataset)] [[📦 Code](https://github.com/pickxiguapi/Embodied-R1)]
---
## Model Details
### Model Description
**Embodied-R1** is a 3B vision-language model (VLM) for general robotic manipulation.
It introduces a **Pointing** mechanism and uses **Reinforced Fine-tuning (RFT)** to bridge perception and action, with strong zero-shot generalization in embodied tasks.
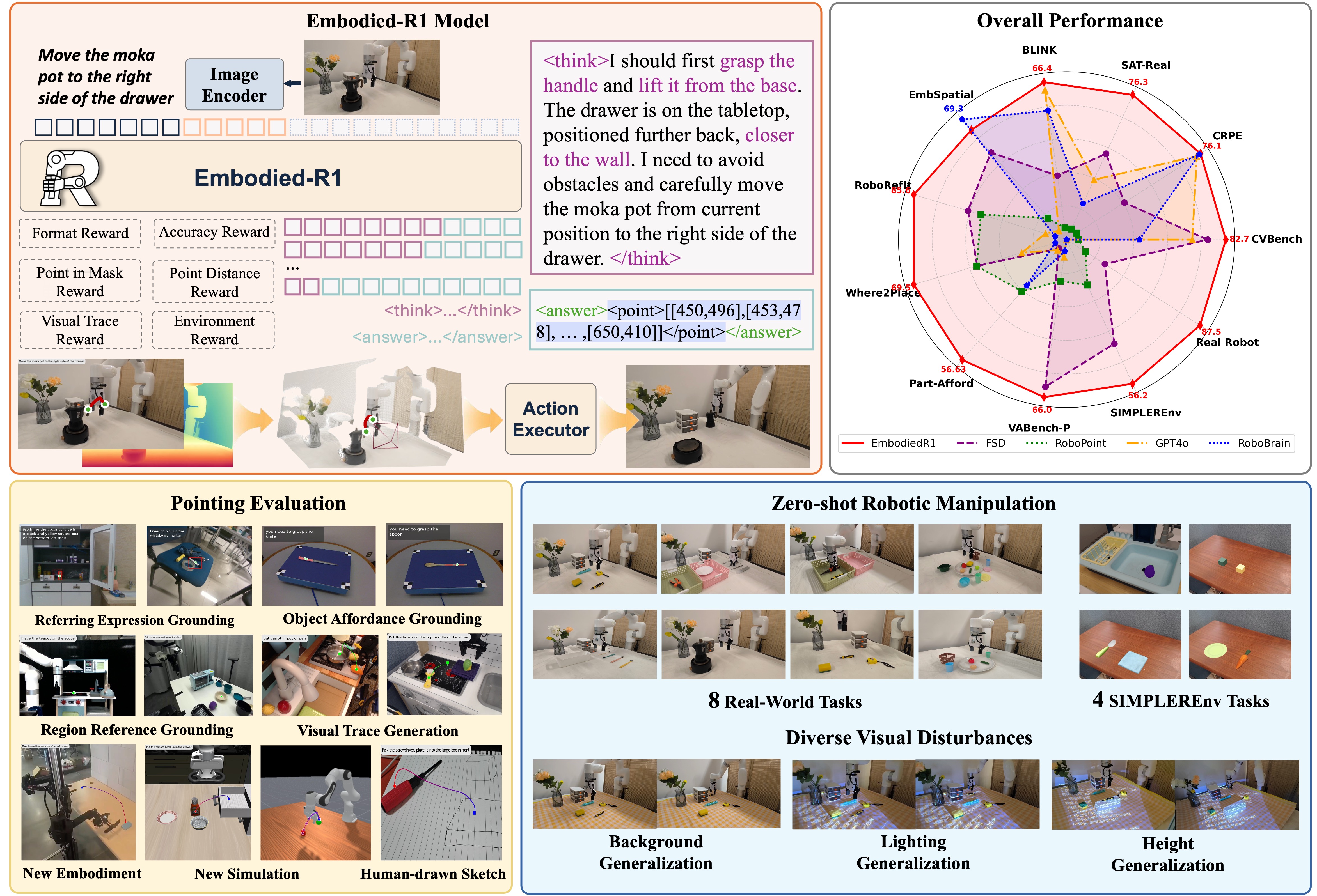
*Figure: Embodied-R1 framework, performance overview, and zero-shot manipulation demos.*
### Model Sources
- **Repository:** https://github.com/pickxiguapi/Embodied-R1
- **Paper:** http://arxiv.org/abs/2508.13998
- **OpenReview:** https://openreview.net/forum?id=i5wlozMFsQ
### Updates
- **[2026-03]** VABench-P / VABench-V released:
[VABench-P](https://huggingface.co/datasets/IffYuan/VABench-P), [VABench-V](https://huggingface.co/datasets/IffYuan/vabench-v)
- **[2026-03-03]** Embodied-R1 dataset released:
https://huggingface.co/datasets/IffYuan/Embodied-R1-Dataset
- **[2026-01-27]** Accepted by ICLR 2026
- **[2025-08-22]** Embodied-R1-3B-v1 checkpoint released
---
## Intended Uses
### Direct Use
This model is intended for **research and benchmarking** in embodied reasoning and robotic manipulation tasks, including:
- Visual target grounding (VTG)
- Referring region grounding (RRG/REG-style tasks)
- Open-form grounding (OFG)
### Out-of-Scope Use
- Safety-critical real-world deployment without additional safeguards and validation
- Decision-making in high-risk domains
- Any use requiring guaranteed robustness under distribution shift
---
## How to Use
### Setup
```bash
git clone https://github.com/pickxiguapi/Embodied-R1.git
cd Embodied-R1
conda create -n embodied_r1 python=3.11 -y
conda activate embodied_r1
pip install transformers==4.51.3 accelerate
pip install qwen-vl-utils[decord]
```
### Inference
```bash
python inference_example.py
```
### Example Tasks
- VTG: *put the red block on top of the yellow block*
- RRG: *put pepper in pan*
- REG: *bring me the camel model*
- OFG: *loosening stuck bolts*
(Visualization examples are available in the project repo: `assets/`)
---
## Evaluation
```bash
cd eval
python hf_inference_where2place.py
python hf_inference_vabench_point.py
...
```
Related benchmarks:
- [Embodied-R1-Dataset](https://huggingface.co/datasets/IffYuan/Embodied-R1-Dataset)
- [VABench-P](https://huggingface.co/datasets/IffYuan/VABench-P)
- [VABench-V](https://huggingface.co/datasets/IffYuan/vabench-v)
---
## Training
Training scripts are available at:
https://github.com/pickxiguapi/Embodied-R1/tree/main/scripts
```bash
# Stage 1 training
bash scripts/stage_1_embodied_r1.sh
# Stage 2 training
bash scripts/stage_2_embodied_r1.sh
```
Key files:
- `scripts/config_stage1.yaml`
- `scripts/config_stage2.yaml`
- `scripts/stage_1_embodied_r1.sh`
- `scripts/stage_2_embodied_r1.sh`
- `scripts/model_merger.py` (checkpoint merging + HF export)
---
## Limitations
- Performance may vary across environments, camera viewpoints, and unseen object domains.
- Outputs are generated from visual-language reasoning and may include localization/action errors.
- Additional system-level constraints (calibration, motion planning, safety checks) are required for real robot deployment.
---
## Citation
```bibtex
@article{yuan2026embodied,
title={Embodied-r1: Reinforced embodied reasoning for general robotic manipulation},
author={Yuan, Yifu and Cui, Haiqin and Huang, Yaoting and Chen, Yibin and Ni, Fei and Dong, Zibin and Li, Pengyi and Zheng, Yan and Tang, Hongyao and Hao, Jianye},
journal={The Fourteenth International Conference on Learning Representations},
year={2026}
}
@article{yuan2026seeing,
title={From seeing to doing: Bridging reasoning and decision for robotic manipulation},
author={Yuan, Yifu and Cui, Haiqin and Chen, Yibin and Dong, Zibin and Ni, Fei and Kou, Longxin and Liu, Jinyi and Li, Pengyi and Zheng, Yan and Hao, Jianye},
journal={The Fourteenth International Conference on Learning Representations},
year={2026}
}
```
---
## Acknowledgements
If this model or resources are useful for your research, please consider citing our work and starring the repository.
|