
llm.create_chat_completion(
messages = "No input example has been defined for this model task."
)Separability of Intelligence in Mixture-of-Experts: Slicing Qwen3-Coder into Independent Domain Specialists
Author: J. Thomas Context: College of Experts Architecture Validation — Proof of Principle Date: March 2026
Abstract
Recent experiments with the Qwen3-Coder-Next-80B-A3B Mixture-of-Experts (MoE) model provide compelling empirical evidence that intelligence and domain knowledge are physically separable within MoE architectures. By slicing the expert layers of a pre-trained 80B parameter model in half (from 512 to 256 routed experts) based on histographic activation profiles, we successfully decoupled "Backend Logic" from "Frontend Web Design", generating two specialized 40B models: a Python Specialist and a Web Specialist.
The results confirm the absence of holographic entanglement:
- The base 80B:q4_K_M model scores 94.0% on HumanEval (Python).
- The surgically derived 256-expert Python Specialist scores 93.0% on HumanEval, retaining nearly all algorithmic capability despite losing 50% of its expert parameters.
- The 256-expert Web Specialist scores just 29.0% on HumanEval, proving that the python-specific logic gates were successfully excised from its weights.
- Conversely, in a qualitative benchmark of complex, single-file modern Web applications (HTML/CSS/JS), the Web Specialist nearly matches the Base Model's high fidelity output, while the Python Specialist fails completely (emitting non-HTML or broken output).
These findings validate the core "College of Experts" hypothesis: an MoE model's individual experts act as discrete logic modules that can be surgically extracted into highly efficient, domain-specific models. This establishes a direct pathway to running frontier-level intelligence on localized consumer hardware by splitting monolithic MoE files into smaller, loadable "lobes." It should be noted that these models underwent no post surgery training or fine-tuning.
1. Introduction
A major barrier to local AI deployment is the monolithic nature of Large Language Models. While state-of-the-art architectures like Qwen3-Coder-Next-80B-A3B are heavily sparse (activating only ~3B parameters per token), they still require the user to load all 80B parameters into memory/disk.
Because traditional dense models holographically entangle their knowledge across the entire parameter space, they cannot be split apart without catastrophic brain damage. This proof of principle set out to discover if sparse MoE models behave differently. Can we isolate the "lobes" of an artificial brain that code Python from the "lobes" that write HTML/JS/CSS?
Run with Ollama
Fastest — pull directly from this repo (no separate download needed):
ollama run hf.co/JThomas-CoE/CoE-python2-40b-A3b-GGUF:Q4_K_M
Or, if you have already downloaded the GGUF file, recreate locally:
ollama create CoE-WEB2-40b-A3b -f Modelfile-python2
ollama run CoE-python2-40b-A3b
2. Experimental Design
2.1 The Parent Model
The target model was the GGUF quantized representation of Qwen3-coder-next:q4_K_M.
- Total Parameters: ~80 Billion
- Architecture: Hybrid MoE, 512 total experts
- Active Parameters: ~3 Billion per token
2.2 The Custom Quantization Constraint
Slicing was performed directly on the GGUF format via Python. Due to the strict power-of-2 hardware threading constraints of existing GGUF and llama.cpp kernels, we were constrained to targeting exactly 256 experts across the board.
2.3 The Histographic Slice
By using profile_lru_moe.py, we gathered activation heatmaps by running a forward pass of prompt and answer pairs on the full fp16 model using disk offload of 10 separate data corpora: Python, C++, Rust, Go, Typescript, Java, SQL, JS, power shell and WEB(combined HTML/CSS/JS) front-end type tasks. After viewing the histographic data we devised a bias function that adjusted the raw expert activation ranking per layer depending on how many languages an expert activated for along a spectrum of one language(i.e. only activated during the forward pass for the given language in question) to all ten languages. The bias function overweighted generalist experts in early layers, specialist experts in mid layers then gradually transitions back to a neutral bias by the final layer. We did not do an exhaustive sweep of the bias function but tried two variants based on discussion and logical inference and picked the best one, hence the "2" designation in the published model names. We then assembled experts per layer based on the expert bias adjusted activation ranks up to the 256 expert budget per layer for the python and WEB domains, mapped the router, and saved two new GGUF files and registered them to run on Ollama:
CoE-python2-40b-A3b:q4_K_MCoE-WEB2-40b-A3b:q4_K_M
3. Quantitative Results: Back-end Algorithms
We utilized the industry-standard HumanEval benchmark to measure pure algorithmic python logic and syntax correctness.
| Model | Experts Fired | HumanEval (Pass@1) | Delta from Base |
|---|---|---|---|
| Base Model (Qwen3) | 512 pool | 94.0% (94/100) | --------------- |
| CoE Python Specialist | 256 pool | 93.0% (93/100) | -1.0% |
| CoE Web Specialist | 256 pool | 29.0% (29/100) | -65.0% |
Analysis: The Python specialist retained within 1% of the baseline model’s accuracy. By excising the 256 experts dedicated to unrelated tasks, we did not cause any structural reasoning degradation. The severe failure of the Web specialist confirms that algorithmic Python capability lives inside specific, targetable parameter subsets.
4. Qualitative Results: Front-end Web UI Generation
To test the inverse capability, we built the CoE Web Visual Benchmark mapping single-file zero-dependency UI prompt generation across 5 tasks: Task Manager, Movie Tracker, SaaS Landing Page, Expense Tracker, and a Pomodoro Timer.
Each model was tasked with producing a unified HTML file with inline CSS, aesthetic dark themes, and functional JavaScript logic.
| Task | Base Model (Qwen3) | CoE Web Specialist | CoE Python Specialist |
|---|---|---|---|
| Task Manager | ✓ Full HTML+CSS+JS | ✓ Full HTML+CSS+JS | ✗ Non-HTML response |
| Movie Tracker | ✓ Full HTML+CSS+JS | ✓ Full HTML+CSS+JS | ⚠ HTML (partial) |
| SaaS Landing | ✓ Full HTML+CSS+JS | ✓ Full HTML+CSS+JS | ✗ Non-HTML response |
| Expense Tracker | ✓ Full HTML+CSS+JS | ✓ Full HTML+CSS+JS | ✗ Non-HTML response |
| Pomodoro Timer | ✓ Full HTML+CSS+JS | ✓ Full HTML+CSS+JS | ✓ Full HTML+CSS+JS* |
* In the one instance in which the Python specialist produced something close to a full HTML file, the side-by-side comparison below (left: CoE Web Specialist, centre: CoE Python Specialist, right: base Qwen3) makes clear that the rendered output was nonetheless a complete fail.
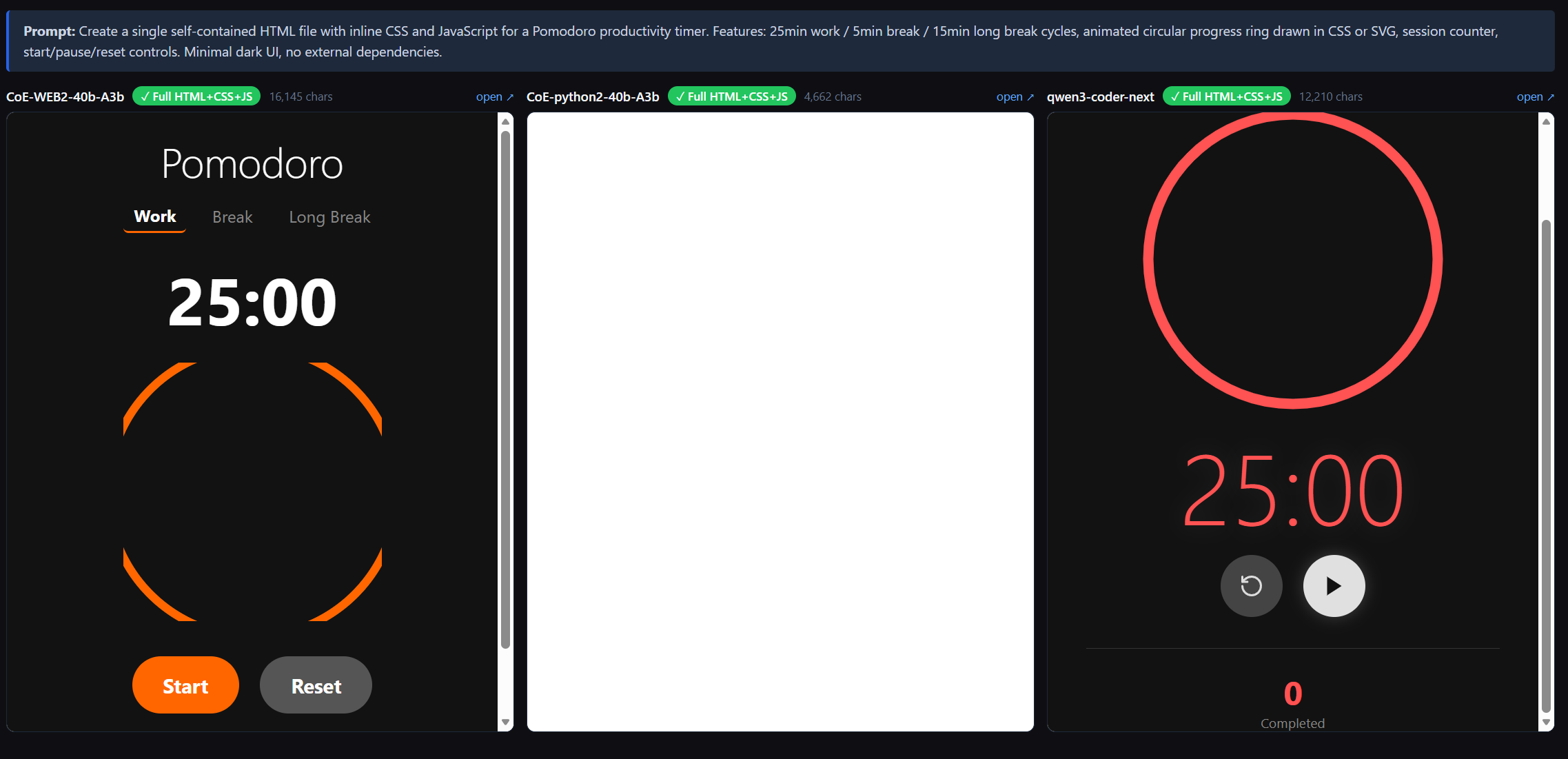
Analysis: The CoE Web Specialist successfully mirrored the full base model on all 5 visual tasks, generating tens of thousands of characters of functional design code. Conversely, the Python specialist was functionally lobotomized for DOM generation; 4 out of 5 tests resulted in severe un-renderable syntax errors or refused to output HTML entirely.
5. Architectural Implications
5.1 Physical Separability Validated
These empirical results prove conclusively that Mixture-of-Experts layers behave fundamentally differently than Dense FFNs. Domain knowledge is clearly separable so long as sufficient generalist backbone intelligence is included. We have physically extracted a frontend Web Developer and separately a python specialist from the parent monolithic brain while retaining nearly all the parent models capability in the focused domain and done this WITHOUT ANY POST SURGERY TRAINING!
5.2 Breaking the VRAM Bottleneck
The base model requires ~48GB+ of memory to run. The resulting sliced specialists each require approximately half of that. But crucially, because 50% of the model is shared attention and embedding layers, future iterations of this framework may be able to be engineered to load a shared backbone into persistent VRAM alongside "hot swappable" 10-15GB expert lobes based on task heuristics. This was not possible given the constraints of the Ollama runtime and more generally the architectural constraints of the model in the GGUF framework. The 93% Python performance was achieved within the GGUF constraint forcing us to keep exactly 256 experts. Histographic analysis suggests that the vast majority of Python capability likely resides in fewer experts and future work in non GGUF formats, (native PyTorch transformers and compiling with the ONNX Runtime (DirectML)), may allow us to explore a different memory footprint to performance landscape and also more efficient post surgery training to further elevate performance to memory metrics.
5.3 Future directions
We next plan to create a full suite of domain specialist models based on the qwen3.5-35B-A3B model. We feel this is the ideal testbed for a more general proof of principle for the "College of Experts" paradigm(https://github.com/JThomas-CoE/College-of-Experts-AI/blob/main/CoE-Demo-v1.5). If this proves successful, then an enterprise scale effort adapting the full qwen3.5-400B-A17B model may be justified, leading to a true local SOTA model runtime on reasonably accessible consumer/prosumer grade hardware which would have the added benefit of allowing piecewise upgradability. Each domain specialist could be independently fine tuned/trained or otherwise upgraded without touching the other domain specialist models.
- Downloads last month
- 22
4-bit
# !pip install llama-cpp-python from llama_cpp import Llama llm = Llama.from_pretrained( repo_id="JThomas-CoE/CoE-python2-40b-A3b-GGUF", filename="CoE-python2-40b-A3b-q4_K_M.gguf", )