
Improve model card: Update pipeline tag, add library name, and update news section
#1
by nielsr HF Staff - opened
README.md
CHANGED
|
@@ -1,37 +1,88 @@
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
-
pipeline_tag:
|
|
|
|
| 4 |
---
|
| 5 |
|
| 6 |
<h2 align="center"> <a href="https://arxiv.org/abs/2405.14297">Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models</a></h2>
|
| 7 |
<h5 align="center"> If our project helps you, please give us a star ⭐ on <a href="https://github.com/LINs-lab/DynMoE">GitHub</a> and cite our paper!</h2>
|
| 8 |
<h5 align="center">
|
| 9 |
|
| 10 |
-
|
|
|
|
|
|
|
| 11 |
|
| 12 |
-
|
| 13 |
-
- **[
|
| 14 |
-
- **[2024.05.
|
|
|
|
| 15 |
|
| 16 |
-
##
|
| 17 |
|
| 18 |
-
|
| 19 |
|
| 20 |
-
|
| 21 |
|
| 22 |
-
|
| 23 |
|
| 24 |
-
##
|
| 25 |
|
| 26 |
-
|
| 27 |
|
| 28 |
-
|
| 29 |
|
| 30 |
-
|
| 31 |
-
- 🚀 Our DynMoE-StableLM-1.6B has totally 2.9B parameters, but **only 1.8B are activated!** (average top-k = 1.25)
|
| 32 |
-
- ⌛ With the DynMoE tuning stage, we can complete training on 8 A100 GPUs **within 40 hours.**
|
| 33 |
|
| 34 |
-
##
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
|
| 36 |
We are grateful for the following awesome projects:
|
| 37 |
|
|
@@ -42,19 +93,21 @@ We are grateful for the following awesome projects:
|
|
| 42 |
- [MoE-LLaVA](https://github.com/PKU-YuanGroup/MoE-LLaVA)
|
| 43 |
- [GLUE-X](https://github.com/YangLinyi/GLUE-X)
|
| 44 |
|
| 45 |
-
##
|
| 46 |
-
|
| 47 |
-
This project is released under the Apache-2.0 license as found in the [LICENSE](https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/mit.md) file.
|
| 48 |
|
| 49 |
-
|
| 50 |
|
| 51 |
-
```
|
| 52 |
-
@
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
archivePrefix={arXiv},
|
| 58 |
-
primaryClass={cs.LG}
|
| 59 |
}
|
| 60 |
-
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
+
pipeline_tag: text-generation
|
| 4 |
+
library_name: transformers
|
| 5 |
---
|
| 6 |
|
| 7 |
<h2 align="center"> <a href="https://arxiv.org/abs/2405.14297">Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models</a></h2>
|
| 8 |
<h5 align="center"> If our project helps you, please give us a star ⭐ on <a href="https://github.com/LINs-lab/DynMoE">GitHub</a> and cite our paper!</h2>
|
| 9 |
<h5 align="center">
|
| 10 |
|
| 11 |
+
[](https://huggingface.co/papers/2405.14297)
|
| 12 |
+
[](https://arxiv.org/abs/2405.14297)
|
| 13 |
+
[](https://hits.seeyoufarm.com)
|
| 14 |
|
| 15 |
+
## News
|
| 16 |
+
- **[2025.01.23]**: 🎉 Our paper is accepted to ICLR 2025!
|
| 17 |
+
- **[2024.05.25]** Our [checkpoints](https://huggingface.co/collections/LINs-lab/dynmoe-family-665ed5a331a7e84463cab01a) are available now!
|
| 18 |
+
- **[2024.05.23]** Our [paper](https://arxiv.org/abs/2405.14297) is released!
|
| 19 |
|
| 20 |
+
## Why Do We Need DynMoE?
|
| 21 |
|
| 22 |
+
Sparse MoE (SMoE) has an unavoidable drawback: *the performance of SMoE heavily relies on the choice of hyper-parameters, such as the number of activated experts per token (top-k) and the number of experts.*
|
| 23 |
|
| 24 |
+
Also, *identifying the optimal hyper-parameter without a sufficient number of ablation studies is challenging.* As the size of the models continues to grow, this limitation could result in a significant waste of computational resources, and in turn, could hinder the efficiency of training MoE-based models in practice.
|
| 25 |
|
| 26 |
+
Now, our **DynMoE** addresses these challenges through the two components introduced in [Dynamic Mixture of Experts (DynMoE)](#dynamic-mixture-of-experts-dynmoe).
|
| 27 |
|
| 28 |
+
## Dynamic Mixture of Experts (DynMoE)
|
| 29 |
|
| 30 |
+
## Top-Any Gating
|
| 31 |
|
| 32 |
+

|
| 33 |
|
| 34 |
+
We first introduce a novel gating method that enables each token to **automatically determine the number of experts to activate**.
|
|
|
|
|
|
|
| 35 |
|
| 36 |
+
## Adaptive Training Process
|
| 37 |
+
|
| 38 |
+
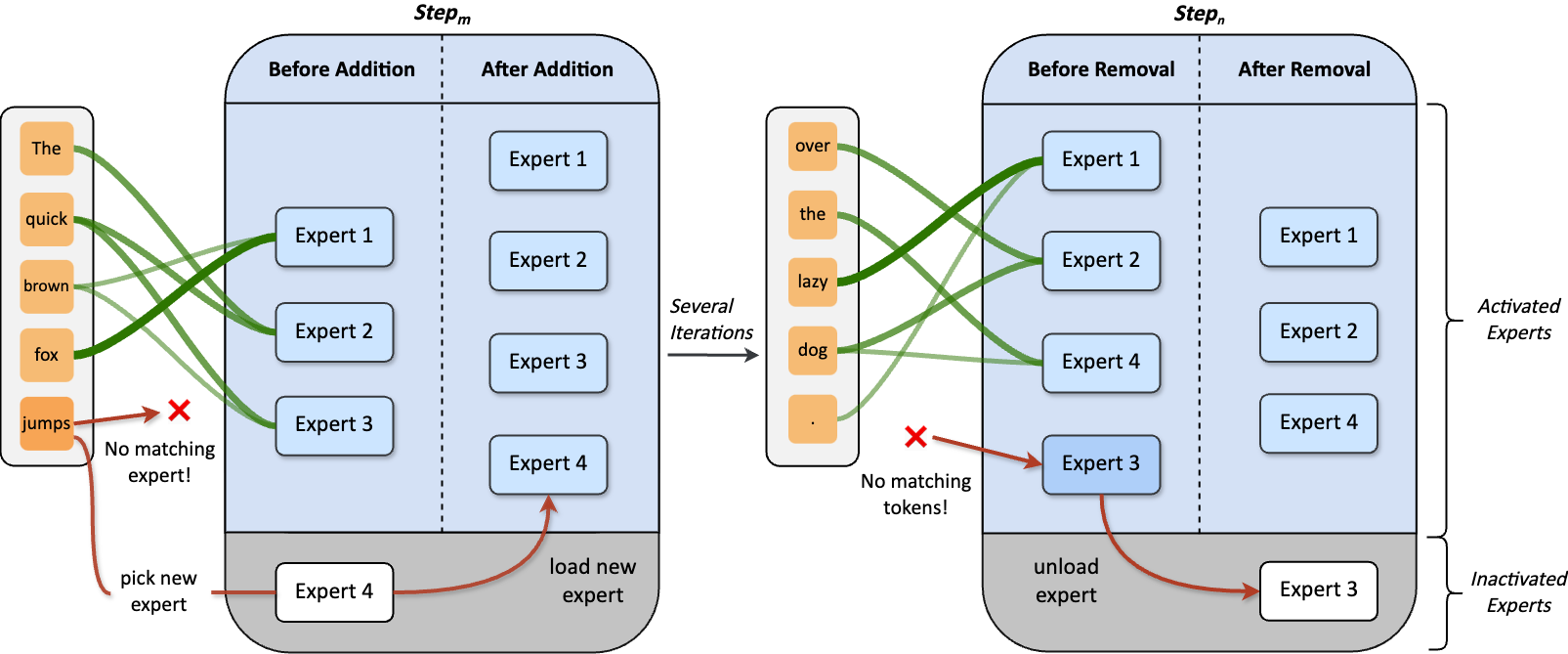
|
| 39 |
+
|
| 40 |
+
Our method also includes an adaptive process **automatically adjusts the number of experts** during training.
|
| 41 |
+
|
| 42 |
+
## Can We Trust DynMoE? Yes!
|
| 43 |
+
|
| 44 |
+
- On language tasks, **DynMoE surpasses the average performance among various MoE settings.**
|
| 45 |
+
- **Effectiveness of DynMoE remains consistent** in both Vision and Vision-Language tasks.
|
| 46 |
+
- Although sparsity is not enforced in DynMoE, it **maintains efficiency by activating even less parameters!**
|
| 47 |
+
|
| 48 |
+
## Model Zoo
|
| 49 |
+
|
| 50 |
+
| Model | Activated Params / Total Params| Transformers(HF) |
|
| 51 |
+
| ----- | --------------- | ---------------- |
|
| 52 |
+
| DynMoE-StableLM-1.6B | 1.8B / 2.9B | [LINs-lab/DynMoE-StableLM-1.6B](https://huggingface.co/LINs-lab/DynMoE-StableLM-1.6B)
|
| 53 |
+
| DynMoE-Qwen-1.8B | 2.2B / 3.1B | [LINs-lab/DynMoE-Qwen-1.8B](https://huggingface.co/LINs-lab/DynMoE-Qwen-1.8B)
|
| 54 |
+
| DynMoE-Phi-2-2.7B | 3.4B / 5.3B| [LINs-lab/DynMoE-Phi-2-2.7B](https://huggingface.co/LINs-lab/DynMoE-Phi-2-2.7B)
|
| 55 |
+
|
| 56 |
+
## Directory Specification
|
| 57 |
+
|
| 58 |
+
### Experiment Code
|
| 59 |
+
|
| 60 |
+
- `EMoE/` contains experiments on language and vision tasks, which uses tutel-based DynMoE.
|
| 61 |
+
- `MoE-LLaVA/` contains experiments on language-vision tasks, which uses deepspeed-0.9.5-based DynMoE.
|
| 62 |
+
|
| 63 |
+
### DynMoE Implementations
|
| 64 |
+
|
| 65 |
+
- `Deepspeed/` provides DynMoE-Deepspeed implementation. **(Recommend)**
|
| 66 |
+
- `EMoE/tutel/` provides DynMoE-Tutel implementation.
|
| 67 |
+
|
| 68 |
+
## Environment Setup
|
| 69 |
+
|
| 70 |
+
Please refer to instructions under `EMoE/` and `MoE-LLaVA/`.
|
| 71 |
+
|
| 72 |
+
## Usage
|
| 73 |
+
|
| 74 |
+
### Tutel Examples
|
| 75 |
+
|
| 76 |
+
Please refer to `EMoE/Language/README.md` and `EMoE/Language/Vision.md`.
|
| 77 |
+
|
| 78 |
+
### DeepSpeed Examples (Recommend)
|
| 79 |
+
|
| 80 |
+
We give a minimal example to train DynMoE-ViT on ImageNet-1K from scratch at `Examples/DeepSpeed-MoE`.
|
| 81 |
+
|
| 82 |
+
- Check `Examples/DeepSpeed-MoE/dynmoe_vit.py` for how to use DynMoE in model implementation.
|
| 83 |
+
- Check `Examples/DeepSpeed-MoE/train.py` for how to train model with DynMoE.
|
| 84 |
+
|
| 85 |
+
## Acknowledgement
|
| 86 |
|
| 87 |
We are grateful for the following awesome projects:
|
| 88 |
|
|
|
|
| 93 |
- [MoE-LLaVA](https://github.com/PKU-YuanGroup/MoE-LLaVA)
|
| 94 |
- [GLUE-X](https://github.com/YangLinyi/GLUE-X)
|
| 95 |
|
| 96 |
+
## Citation
|
|
|
|
|
|
|
| 97 |
|
| 98 |
+
If you find this project helpful, please consider citing our work:
|
| 99 |
|
| 100 |
+
```bibtex
|
| 101 |
+
@article{guo2024dynamic,
|
| 102 |
+
title={Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models},
|
| 103 |
+
author={Guo, Yongxin and Cheng, Zhenglin and Tang, Xiaoying and Lin, Tao},
|
| 104 |
+
journal={arXiv preprint arXiv:2405.14297},
|
| 105 |
+
year={2024}
|
|
|
|
|
|
|
| 106 |
}
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
## Star History
|
| 110 |
+
|
| 111 |
+
[](https://star-history.com/#LINs-lab/DynMoE&Date)
|
| 112 |
+
|
| 113 |
+
Code: https://github.com/LINs-lab/DynMoE
|