| | --- |
| | license: mit |
| | datasets: |
| | - OffSeeker/DeepForge |
| | language: |
| | - en |
| | - zh |
| | base_model: |
| | - Qwen/Qwen3-8B |
| | tags: |
| | - agent |
| | --- |
| | |
| |
|
| | # OffSeeker: Online Reinforcement Learning Is Not All You Need for Deep Research Agents |
| |
|
| | <a href="https://arxiv.org/abs/2601.18467"><b>Paper</b></a> | <a href="https://github.com/Ralph-Zhou/OffSeeker/tree/main"><b>Github</b></a> |
| |
|
| | <!-- [](https://arxiv.org/abs/2601.18467) [](https://huggingface.co/OffSeeker/OffSeeker-8B-DPO) [](https://huggingface.co/datasets/OffSeeker/DeepForge) [](LICENSE) --> |
| |
|
| | ## 🌟 Abstract |
| |
|
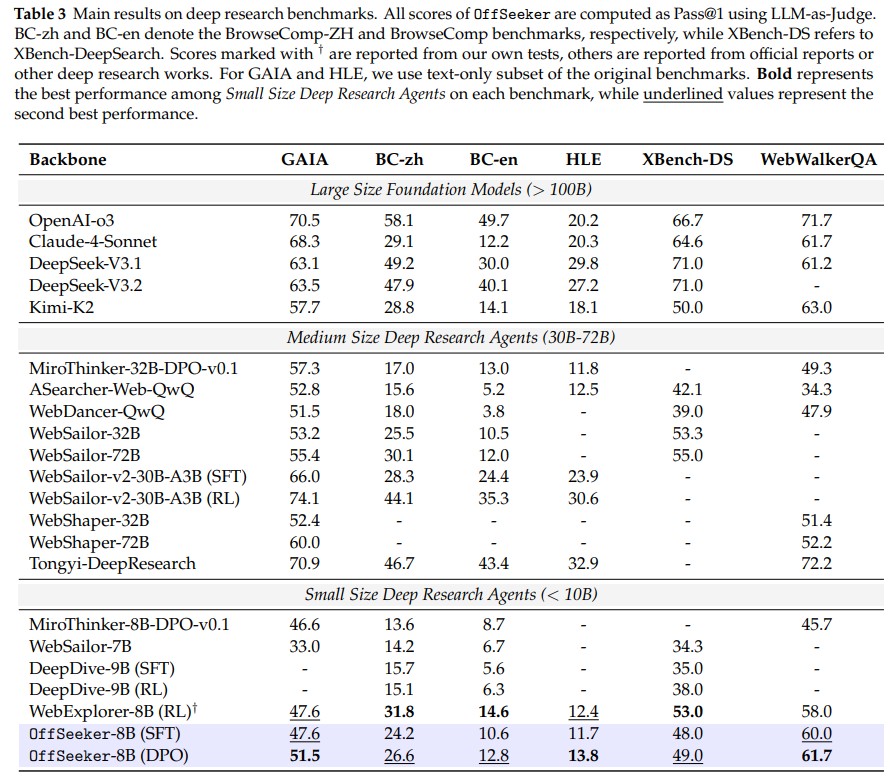
| | We introduce a fully open-source suite designed for effective offline training. Our core contributions include DeepForge, a ready-to-use task synthesis framework that generates large-scale research queries without heavy preprocessing; and a curated collection of 66k QA pairs, 33k SFT trajectories, and 21k DPO pairs. Leveraging these resources, we train OffSeeker (8B), a model developed entirely offline. Extensive evaluations across six benchmarks show that OffSeeker not only leads among similar-sized agents but also remains competitive with 30B-parameter systems trained via heavy online RL. |
| |
|
| |  |
| |
|
| |
|
| | ## 📊 Resources & Datasets |
| |
|
| |
|
| | We are releasing our complete dataset to support the research community in offline agent training. |
| |
|
| | | Resource | Quantity | Description | |
| | | :--- | :--- | :--- | |
| | | **Research QA Pairs** | 66,000 | Complex questions requiring multi-hop search | |
| | | **SFT Trajectories** | 33,000 | Step-by-step reasoning and tool-use paths | |
| | | **DPO Pairs** | 21,000 | Preference pairs for refining agent behavior | |
| | | **OffSeeker Model** | 8B | Competitive with 30B-parameter online RL models | |
| |
|
| | ## 📖 Citation |
| |
|
| | If you find this work useful for your research, please cite our paper: |
| |
|
| | ```bibtex |
| | @article{zhou2026offseeker, |
| | title={OffSeeker: Online Reinforcement Learning Is Not All You Need for Deep Research Agents}, |
| | author={Zhou, Yuhang and Zheng, Kai and Chen, Qiguang and Hu, Mengkang and Sun, Qingfeng and Xu, Can and Chen, Jingjing}, |
| | journal={arXiv preprint arXiv:2601.18467}, |
| | year={2026} |
| | } |
| | ``` |
