| --- |
| language: |
| - en |
| - zh |
| library_name: transformers |
| license: mit |
| pipeline_tag: text-generation |
| tags: |
| - heretic |
| - uncensored |
| - decensored |
| - abliterated |
| - compressed-tensors |
| - nvfp4 |
| - 4-bit |
| base_model: zai-org/GLM-4.7 |
| --- |
| # GLM-4.7-heretic-NVFP4 |
|
|
| NVFP4 (W4A4) quantized version of [trohrbaugh/GLM-4.7-heretic](https://huggingface.co/trohrbaugh/GLM-4.7-heretic) — a decensored [zai-org/GLM-4.7](https://huggingface.co/zai-org/GLM-4.7), made using [Heretic](https://github.com/p-e-w/heretic) v1.2.0+custom. |
|
|
| > **Requires NVIDIA Blackwell GPUs** (B200, GB200, RTX 5090, RTX PRO 6000 Blackwell). Hopper/Ampere GPUs do not have native FP4 tensor cores. See the [FP8 version](https://huggingface.co/trohrbaugh/GLM-4.7-heretic-fp8) for broader GPU compatibility. |
|
|
| ## Abliteration parameters |
|
|
| | Parameter | Value | |
| | :-------- | :---: | |
| | **direction_index** | per layer | |
| | **attn.o_proj.max_weight** | 1.84 | |
| | **attn.o_proj.max_weight_position** | 49.16 | |
| | **attn.o_proj.min_weight** | 1.64 | |
| | **attn.o_proj.min_weight_distance** | 26.42 | |
| | **mlp.down_proj.max_weight** | 1.02 | |
| | **mlp.down_proj.max_weight_position** | 53.46 | |
| | **mlp.down_proj.min_weight** | 0.97 | |
| | **mlp.down_proj.min_weight_distance** | 45.98 | |
| |
| ## Abliteration performance |
| |
| | Metric | This model | Original model ([zai-org/GLM-4.7](https://huggingface.co/zai-org/GLM-4.7)) | |
| | :----- | :--------: | :---------------------------: | |
| | **KL divergence** | 0.0748 | 0 *(by definition)* | |
| | **Refusals** | 0/100 | 99/100 | |
| |
| ## NVFP4 Quantization |
| |
| Quantized using [llm-compressor](https://github.com/vllm-project/llm-compressor) (v0.10.1-dev, main branch) to produce a **compressed-tensors** format checkpoint natively supported by vLLM — no `--quantization` flag or patches needed. |
| |
| ### Why compressed-tensors instead of ModelOpt? |
| |
| Earlier versions of this model were quantized with NVIDIA ModelOpt, which produced a `modelopt_fp4` format checkpoint. This caused multiple issues with vLLM: |
| |
| - `k_scale`/`v_scale` KeyError due to missing name remapping in vLLM's GLM-4 MoE weight loader |
| - Garbled output with the FlashInfer TRTLLM MoE backend |
| - Required manual patches to `glm4_moe.py` |
| |
| The compressed-tensors format produced by llm-compressor avoids all of these issues and loads natively in vLLM without any modifications. |
| |
| ### Quantization recipe |
| |
| - **Scheme:** NVFP4 (W4A4) — 4-bit floating point (E2M1) with two-level scaling: FP8 micro-block scale per 16 values + FP32 tensor-level global scale |
| - **Calibration:** 1024 samples from [fineweb-edu-score-2](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu-score-2), max sequence length 4096 |
| - **SmoothQuant:** Not used (can interfere with MoE expert routing) |
| - **Format:** `compressed-tensors` (auto-detected by vLLM) |
| |
| ### Precision map |
| |
| | Component | Precision | Rationale | |
| | :-------- | :-------: | :-------- | |
| | Routed expert weights (160 experts × 89 MoE layers) | NVFP4 E2M1 | Bulk of model — two-level scaling via calibration | |
| | Attention projections (q/k/v/o) | NVFP4 E2M1 | GQA with 96Q / 8KV heads, head_dim=128 | |
| | Shared expert weights | NVFP4 E2M1 | Active every token, well-calibrated | |
| | Dense MLP (layers 0–2) | NVFP4 E2M1 | Only 3 dense layers | |
| | Attention biases (q/k/v) | BF16 | Small tensors, sensitive to precision loss | |
| | Router/gate weights | BF16 | Routing errors cascade through all downstream computation | |
| | MoE e_score_correction_bias | BF16 | Critical for expert load balancing | |
| | RMSNorm / QK norms | BF16 | Negligible size, high sensitivity | |
| | Embeddings / LM head | BF16 | Standard practice for quantized models | |
| | MTP head (layer 92: enorm, hnorm, eh_proj) | BF16 | Speculative decoding head, kept full precision | |
| |
| ### Ignore patterns used |
| |
| ```python |
| IGNORE_PATTERNS = [ |
| "re:.*embed_tokens.*", |
| "lm_head", |
| "re:.*layernorm.*", |
| "re:.*q_norm.*", |
| "re:.*k_norm.*", |
| "model.norm", |
| "re:.*self_attn\\.q_proj\\.bias", |
| "re:.*self_attn\\.k_proj\\.bias", |
| "re:.*self_attn\\.v_proj\\.bias", |
| "re:.*mlp\\.gate$", |
| "re:.*mlp\\.gate\\.weight", |
| "re:.*mlp\\.gate\\.e_score_correction_bias", |
| "re:.*\\.enorm", |
| "re:.*\\.hnorm", |
| "re:.*\\.eh_proj", |
| "re:.*shared_head\\.norm", |
| ] |
| ``` |
| |
| ## Serving |
| |
| ### vLLM (recommended) |
| |
| vLLM auto-detects the compressed-tensors NVFP4 format from config.json. No `--quantization` flag required. |
| |
| ```shell |
| vllm serve trohrbaugh/GLM-4.7-heretic-NVFP4 \ |
| --tensor-parallel-size 4 \ |
| --max-model-len 131072 \ |
| --tool-call-parser glm47 \ |
| --reasoning-parser glm45 \ |
| --enable-auto-tool-choice |
| ``` |
| |
| To disable thinking mode (shorter, faster responses): |
| |
| ```shell |
| vllm serve trohrbaugh/GLM-4.7-heretic-NVFP4 \ |
| --tensor-parallel-size 4 \ |
| --max-model-len 131072 \ |
| --tool-call-parser glm47 \ |
| --reasoning-parser glm45 \ |
| --enable-auto-tool-choice \ |
| --default-chat-template-kwargs '{"enable_thinking": false}' |
| ``` |
| |
| Or disable per-request: |
| |
| ```json |
| { |
| "model": "trohrbaugh/GLM-4.7-heretic-NVFP4", |
| "messages": [{"role": "user", "content": "Hello"}], |
| "chat_template_kwargs": {"enable_thinking": false} |
| } |
| ``` |
| |
| ### VRAM requirements |
| |
| | Configuration | Approx. VRAM | Example hardware | |
| | :------------ | :----------: | :--------------- | |
| | TP=4 | ~200 GB | 4× RTX PRO 6000 96GB (Blackwell) | |
| | TP=2 | ~200 GB | 2× B200 192GB | |
| |
| > **Note:** NVFP4 requires Blackwell FP4 tensor cores (SM100+). This model will not run on Hopper (H100/A100) or earlier GPUs. Use the [FP8 version](https://huggingface.co/trohrbaugh/GLM-4.7-heretic-fp8) for those GPUs. |
|
|
| ## Related models |
|
|
| | Variant | Size | Format | GPU requirement | Link | |
| | :------ | :--: | :----- | :-------------- | :--- | |
| | BF16 (full precision) | ~706 GB | safetensors | Any | [trohrbaugh/GLM-4.7-heretic](https://huggingface.co/trohrbaugh/GLM-4.7-heretic) | |
| | FP8 W8A8 | ~362 GB | compressed-tensors | Hopper+ | [trohrbaugh/GLM-4.7-heretic-fp8](https://huggingface.co/trohrbaugh/GLM-4.7-heretic-fp8) | |
| | NVFP4 W4A4 (this model) | ~200 GB | compressed-tensors | Blackwell only | [trohrbaugh/GLM-4.7-heretic-NVFP4](https://huggingface.co/trohrbaugh/GLM-4.7-heretic-NVFP4) | |
|
|
| ## Quantization environment |
|
|
| - **GPU:** 8× NVIDIA RTX PRO 6000 Blackwell Server Edition |
| - **CUDA:** 13.1 |
| - **torch:** 2.11.0+cu130 |
| - **transformers:** 4.57.6 |
| - **llm-compressor:** 0.10.1-dev (main branch) |
| - **compressed-tensors:** 0.14.0.1 |
|
|
| ## Credits |
|
|
| - [Z.ai / THUDM](https://huggingface.co/zai-org) for GLM-4.7 |
| - [P-E-W](https://github.com/p-e-w/heretic) for the Heretic abliteration engine |
| - [vLLM team](https://github.com/vllm-project/llm-compressor) for llm-compressor |
|
|
| --- |
|
|
| # GLM-4.7 |
|
|
| <div align="center"> |
| <img src=https://raw.githubusercontent.com/zai-org/GLM-4.5/refs/heads/main/resources/logo.svg width="15%"/> |
| </div> |
| <p align="center"> |
| 👋 Join our <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community. |
| <br> |
| 📖 Check out the GLM-4.7 <a href="https://z.ai/blog/glm-4.7" target="_blank">technical blog</a>, <a href="https://arxiv.org/abs/2508.06471" target="_blank">technical report(GLM-4.5)</a>. |
| <br> |
| 📍 Use GLM-4.7 API services on <a href="https://docs.z.ai/guides/llm/glm-4.7">Z.ai API Platform. </a> |
| <br> |
| 👉 One click to <a href="https://chat.z.ai">GLM-4.7</a>. |
| </p> |
| |
| ## Introduction |
|
|
| **GLM-4.7**, your new coding partner, is coming with the following features: |
|
|
| - **Core Coding**: GLM-4.7 brings clear gains, compared to its predecessor GLM-4.6, in multilingual agentic coding and terminal-based tasks, including (73.8%, +5.8%) on SWE-bench, (66.7%, +12.9%) on SWE-bench Multilingual, and (41%, +16.5%) on Terminal Bench 2.0. GLM-4.7 also supports thinking before acting, with significant improvements on complex tasks in mainstream agent frameworks such as Claude Code, Kilo Code, Cline, and Roo Code. |
| - **Vibe Coding**: GLM-4.7 takes a big step forward in improving UI quality. It produces cleaner, more modern webpages and generates better-looking slides with more accurate layout and sizing. |
| - **Tool Using**: GLM-4.7 achieves significantly improvements in Tool using. Significant better performances can be seen on benchmarks such as τ^2-Bench and on web browsing via BrowseComp. |
| - **Complex Reasoning**: GLM-4.7 delivers a substantial boost in mathematical and reasoning capabilities, achieving (42.8%, +12.4%) on the HLE (Humanity's Last Exam) benchmark compared to GLM-4.6. |
|
|
| You can also see significant improvements in many other scenarios such as chat, creative writing, and role-play scenario. |
|
|
|  |
|
|
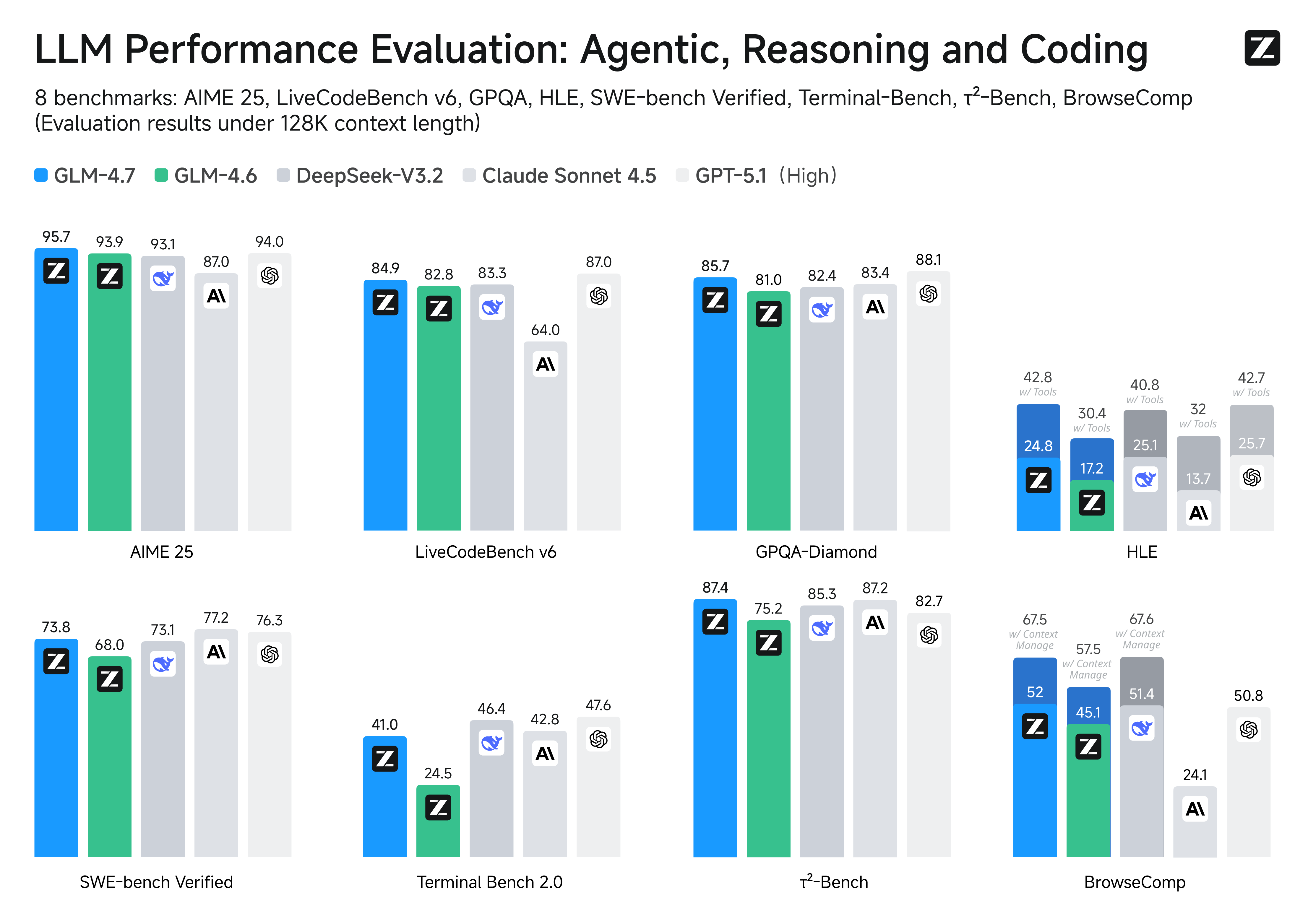
| **Performances on Benchmarks.** More detailed comparisons of GLM-4.7 with other models GPT-5-High, GPT-5.1-High, Claude Sonnet 4.5, Gemini 3.0 Pro, DeepSeek-V3.2, Kimi K2 Thinking, on 17 benchmarks (including 8 reasoning, 5 coding, and 3 agents benchmarks) can be seen in the below table. |
|
|
| | Benchmark | GLM-4.7 | GLM-4.6 | Kimi K2 Thinking | DeepSeek-V3.2 | Gemini 3.0 Pro | Claude Sonnet 4.5 | GPT-5-High | GPT-5.1-High | |
| |:------------------------------ |:-------:|:-------:|:----------------:|:-------------:|:--------------:|:-----------------:|:----------:|:------------:| |
| | MMLU-Pro | 84.3 | 83.2 | 84.6 | 85.0 | 90.1 | 88.2 | 87.5 | 87.0 | |
| | GPQA-Diamond | 85.7 | 81.0 | 84.5 | 82.4 | 91.9 | 83.4 | 85.7 | 88.1 | |
| | HLE | 24.8 | 17.2 | 23.9 | 25.1 | 37.5 | 13.7 | 26.3 | 25.7 | |
| | HLE (w/ Tools) | 42.8 | 30.4 | 44.9 | 40.8 | 45.8 | 32.0 | 35.2 | 42.7 | |
| | AIME 2025 | 95.7 | 93.9 | 94.5 | 93.1 | 95.0 | 87.0 | 94.6 | 94.0 | |
| | HMMT Feb. 2025 | 97.1 | 89.2 | 89.4 | 92.5 | 97.5 | 79.2 | 88.3 | 96.3 | |
| | HMMT Nov. 2025 | 93.5 | 87.7 | 89.2 | 90.2 | 93.3 | 81.7 | 89.2 | - | |
| | IMOAnswerBench | 82.0 | 73.5 | 78.6 | 78.3 | 83.3 | 65.8 | 76.0 | - | |
| | LiveCodeBench-v6 | 84.9 | 82.8 | 83.1 | 83.3 | 90.7 | 64.0 | 87.0 | 87.0 | |
| | SWE-bench Verified | 73.8 | 68.0 | 71.3 | 73.1 | 76.2 | 77.2 | 74.9 | 76.3 | |
| | SWE-bench Multilingual | 66.7 | 53.8 | 61.1 | 70.2 | - | 68.0 | 55.3 | - | |
| | Terminal Bench Hard | 33.3 | 23.6 | 30.6 | 35.4 | 39.0 | 33.3 | 30.5 | 43.0 | |
| | Terminal Bench 2.0 | 41.0 | 24.5 | 35.7 | 46.4 | 54.2 | 42.8 | 35.2 | 47.6 | |
| | BrowseComp | 52.0 | 45.1 | - | 51.4 | - | 24.1 | 54.9 | 50.8 | |
| | BrowseComp (w/ Context Manage) | 67.5 | 57.5 | 60.2 | 67.6 | 59.2 | - | - | - | |
| | BrowseComp-Zh | 66.6 | 49.5 | 62.3 | 65.0 | - | 42.4 | 63.0 | - | |
| | τ²-Bench | 87.4 | 75.2 | 74.3 | 85.3 | 90.7 | 87.2 | 82.4 | 82.7 | |
|
|
| > **Coding:** AGI is a long journey, and benchmarks are only one way to evaluate performance. While the metrics provide necessary checkpoints, the most important thing is still how it *feels*. True intelligence isn't just about acing a test or processing data faster; ultimately, the success of AGI will be measured by how seamlessly it integrates into our lives-**"coding"** this time. |
|
|
| ## Getting started with GLM-4.7 |
|
|
| ### Interleaved Thinking & Preserved Thinking |
|
|
|  |
|
|
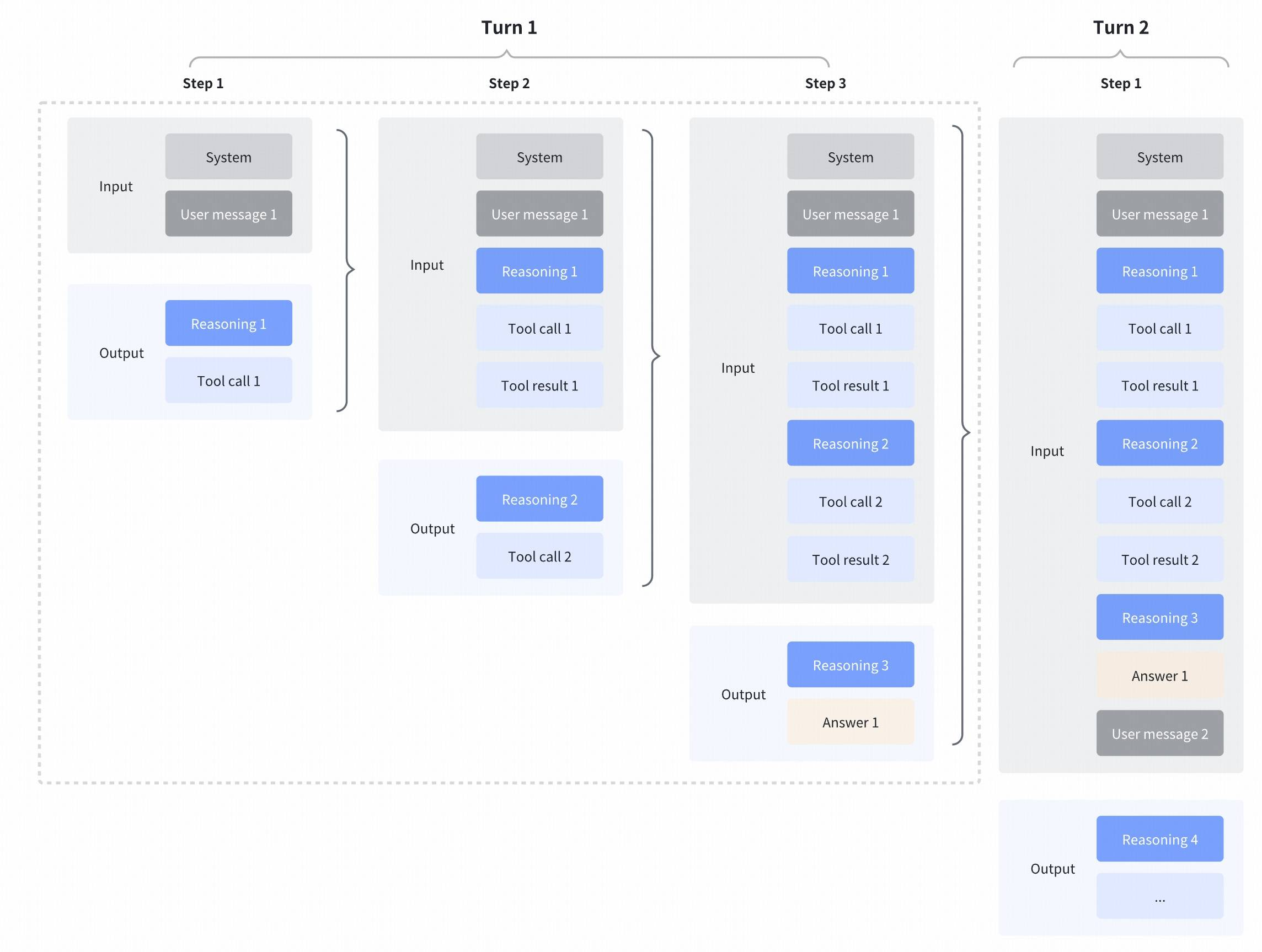
| GLM-4.7 further enhances **Interleaved Thinking** (a feature introduced since GLM-4.5) and introduces **Preserved Thinking** and **Turn-level Thinking**. By thinking between actions and staying consistent across turns, it makes complex tasks more stable and more controllable: |
|
|
| - **Interleaved Thinking**: The model thinks before every response and tool calling, improving instruction following and the quality of generation. |
| - **Preserved Thinking**: In coding agent scenarios, the model automatically retains all thinking blocks across multi-turn conversations, reusing the existing reasoning instead of re-deriving from scratch. This reduces information loss and inconsistencies, and is well-suited for long-horizon, complex tasks. |
| - **Turn-level Thinking**: The model supports per-turn control over reasoning within a session—disable thinking for lightweight requests to reduce latency/cost, enable it for complex tasks to improve accuracy and stability. |
|
|
| More details: https://docs.z.ai/guides/capabilities/thinking-mode |
|
|
| ### Evaluation Parameters |
|
|
| **Default Settings (Most Tasks)** |
|
|
| * temperature: `1.0` |
| * top-p: `0.95` |
| * max new tokens: `131072` |
|
|
| For multi-turn agentic tasks (τ²-Bench and Terminal Bench 2), please turn on [Preserved Thinking mode](https://docs.z.ai/guides/capabilities/thinking-mode). |
|
|
| **Terminal Bench, SWE Bench Verified** |
|
|
| * temperature: `0.7` |
| * top-p: `1.0` |
| * max new tokens: `16384` |
|
|
| **τ^2-Bench** |
|
|
| * Temperature: `0` |
| * Max new tokens: `16384` |
|
|
| For τ^2-Bench evaluation, we added an additional prompt to the Retail and Telecom user interaction to avoid failure modes caused by users ending the interaction incorrectly. For the Airline domain, we applied the domain fixes as proposed in the [Claude Opus 4.5](https://assets.anthropic.com/m/64823ba7485345a7/Claude-Opus-4-5-System-Card.pdf) release report. |
|
|
| ## Serve GLM-4.7 Locally |
|
|
| For local deployment, GLM-4.7 supports inference frameworks including vLLM and SGLang. Comprehensive deployment instructions are available in the official [Github](https://github.com/zai-org/GLM-4.5) repository. |
|
|
| vLLM and SGLang only support GLM-4.7 on their main branches. You can use their official docker images for inference. |
|
|
| ### vLLM |
|
|
| Using Docker: |
|
|
| ```shell |
| docker pull vllm/vllm-openai:nightly |
| ``` |
|
|
| or using pip (must use pypi.org as the index url): |
|
|
| ```shell |
| pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly |
| ``` |
|
|
| ### SGLang |
|
|
| Using Docker: |
|
|
| ```shell |
| docker pull lmsysorg/sglang:dev |
| ``` |
|
|
| or using pip install sglang from source. |
|
|
| ### Parameter Instructions |
|
|
| - For agentic tasks of GLM-4.7, please turn on [Preserved Thinking mode](https://docs.z.ai/guides/capabilities/thinking-mode) by adding the following config (only sglang support): |
|
|
| ```json |
| "chat_template_kwargs": { |
| "enable_thinking": true, |
| "clear_thinking": false |
| } |
| ``` |
|
|
| - When using `vLLM` and `SGLang`, thinking mode is enabled by default when sending requests. If you want to disable the thinking switch, you need to add the `"chat_template_kwargs": {"enable_thinking": false}` parameter. |
|
|
| - Both support tool calling. Please use OpenAI-style tool description format for calls. |
|
|
| ## Citation |
|
|
| ```bibtex |
| @misc{5team2025glm45agenticreasoningcoding, |
| title={GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models}, |
| author={GLM Team and Aohan Zeng and Xin Lv and others}, |
| year={2025}, |
| eprint={2508.06471}, |
| archivePrefix={arXiv}, |
| primaryClass={cs.CL}, |
| url={https://arxiv.org/abs/2508.06471}, |
| } |
| ``` |
|
|

