| --- |
| language: |
| - en |
| license: apache-2.0 |
| base_model: Qwen/Qwen3.5-0.8B |
| datasets: |
| - google/MapTrace |
| pipeline_tag: image-text-to-text |
| tags: |
| - qwen3.5 |
| - vision-language |
| - path-planning |
| - maptrace |
| - fine-tuned |
| - partial-fine-tuning |
| --- |
| |
|  |
|
|
| # Qwen3.5-0.8B — MapTrace Path Planning (Partial Fine-Tune) |
|
|
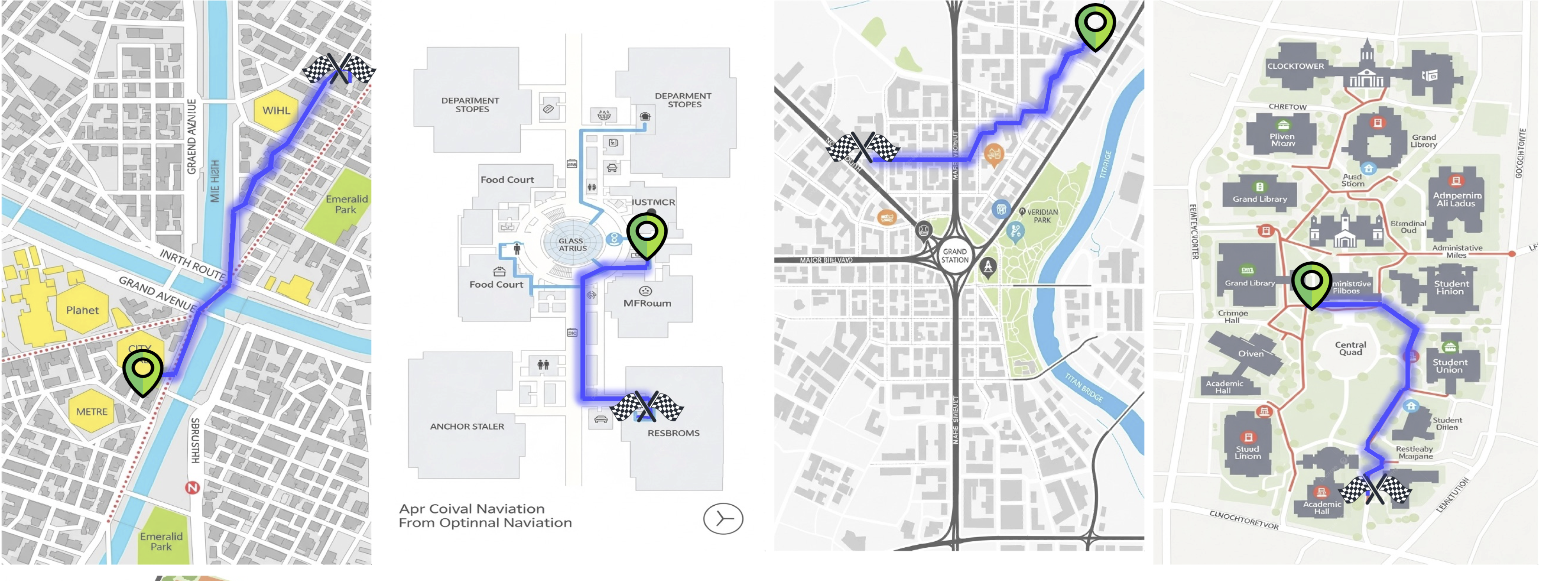
| This model is a **Partial Fine-Tune** of [`Qwen/Qwen3.5-0.8B`](https://huggingface.co/Qwen/Qwen3.5-0.8B) specifically trained for **visual path planning** on indoor and outdoor maps. Given an image of a traversable map with marked start (green) and end (red) locations, the model predicts a sequence of normalized (x, y) waypoints that connect the two locations while staying on traversable paths. |
|
|
| --- |
|
|
| ## 🗺️ Task Description |
|
|
| **MapTrace** is a visual navigation benchmark that requires a model to: |
| 1. Understand a map image with a marked **start location (green dot)** and **end location (red dot)**. |
| 2. Trace a realistic, traversable path between the two points. |
| 3. Output the path as a list of **normalized (x, y) coordinates**: `[(x1, y1), (x2, y2), ...]` |
|
|
| ### Example Input |
| ``` |
| You are provided an image of a path with a start location denoted in green |
| and an end location denoted in red. |
| The normalized xy-coordinates of the start location are (0.77, 0.47) and |
| of the end location (0.54, 0.54). |
| Output a list of normalized coordinates in the form of a list [(x1,y1), (x2,y2)...] |
| of the path between the start and end location. |
| Ensure that the path follows the traversable locations of the map. |
| ``` |
|
|
| ### Example Output |
| ```python |
| [(0.7695, 0.4727), (0.7344, 0.5156), (0.5898, 0.5234), (0.543, 0.543)] |
| ``` |
|
|
| --- |
|
|
| ## 🏋️ Training Strategy |
|
|
| The model was trained using a **Partial Fine-Tuning** approach to balance quality and computational efficiency: |
|
|
| | Setting | Value | |
| |---|---| |
| | **Base Model** | `Qwen/Qwen3.5-0.8B` | |
| | **Strategy** | Partial Fine-Tuning (Last 6 of 24 layers) | |
| | **Dataset** | `google/MapTrace (maptrace_20k subset)` | |
| | **Vision Encoder** | ✅ Trained (not frozen) | |
| | **Effective Batch Size** | 128 (`1 per GPU × 32 grad_accum × 4 GPUs`) | |
| | **Learning Rate** | `1e-5` with Warmup (100 steps) | |
| | **Max Sequence Length** | `2048` tokens | |
| | **Mixed Precision** | `bf16` | |
| | **Gradient Checkpointing** | ✅ Enabled | |
| | **Image Resolution Cap** | `1024 × 768` pixels (VRAM safety) | |
| | **Hardware** | 4× NVIDIA RTX 4090 24GB | |
|
|
| ### Why Partial Fine-Tuning? |
| Instead of full fine-tuning or LoRA, we opted for **unlocking the last 6 transformer layers and the visual encoder** for gradient updates. This approach: |
| - Preserves the model's general language understanding from the foundation weights. |
| - Directly adapts the "reasoning" layers to the spatial coordinate prediction task. |
| - Avoids LoRA's approximation error — weights are modified directly. |
|
|
| ### Training Highlights |
| - Resumed from `checkpoint-50 → checkpoint-100 → final` across multiple sessions. |
| - VRAM stability was achieved by setting `max_pixels=1024x768` as a safety cap, preventing OOM spikes from high-resolution map images. |
| - Loss masking was applied so the model only learns from the **assistant's coordinate response**, not the user's prompt or image tokens. |
| - Final **Token Accuracy: ~~84.5%**, Final **Loss: ~0.37**. |
|
|
| --- |
|
|
| ## 🚀 Inference |
|
|
| ```python |
| import torch |
| from transformers import AutoModelForImageTextToText, AutoProcessor |
| from PIL import Image |
| |
| model_id = "TurkishCodeMan/Qwen3.5-0.8B-MapTrace-PartialFT" |
| |
| processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True) |
| model = AutoModelForImageTextToText.from_pretrained( |
| model_id, |
| torch_dtype=torch.bfloat16, |
| device_map="auto", |
| trust_remote_code=True, |
| ) |
| model.eval() |
| |
| def predict_path(image_path: str, start_xy: tuple, end_xy: tuple) -> str: |
| image = Image.open(image_path).convert("RGB") |
| |
| prompt_text = ( |
| f"You are provided an image of a path with a start location denoted in green " |
| f"and an end location denoted in red. \n" |
| f"The normalized xy-coordinates of the start location are ({start_xy[0]}, {start_xy[1]}) " |
| f"and of the end location ({end_xy[0]}, {end_xy[1]}). \n" |
| f"Output a list of normalized coordinates in the form of a list [(x1,y1), (x2,y2)...] " |
| f"of the path between the start and end location. \n" |
| f"Ensure that the path follows the traversable locations of the map." |
| ) |
| |
| messages = [ |
| { |
| "role": "user", |
| "content": [ |
| {"type": "image"}, |
| {"type": "text", "text": prompt_text}, |
| ], |
| } |
| ] |
| |
| text = processor.apply_chat_template( |
| messages, |
| tokenize=False, |
| add_generation_prompt=True, |
| ) |
| |
| inputs = processor( |
| text=[text], |
| images=[image], |
| return_tensors="pt", |
| padding=True, |
| min_pixels=256 * 28 * 28, |
| max_pixels=1024 * 768, |
| ).to(model.device) |
| |
| with torch.no_grad(): |
| generated_ids = model.generate( |
| **inputs, |
| max_new_tokens=512, |
| do_sample=False, |
| temperature=0.0, |
| ) |
| |
| output = processor.decode( |
| generated_ids[0][inputs.input_ids.shape[1]:], |
| skip_special_tokens=True |
| ) |
| return output.strip() |
| |
| |
| # Example usage |
| result = predict_path( |
| image_path="map.png", |
| start_xy=(0.7695, 0.4727), |
| end_xy=(0.543, 0.543), |
| ) |
| print(result) |
| # Expected: [(0.7695, 0.4727), (0.7344, 0.5156), (0.5898, 0.5234), (0.543, 0.543)] |
| ``` |
|
|
| > **Important:** Use the **raw prompt format** shown above (not `apply_chat_template` with `add_generation_prompt=True`). Since the training data did not include `<think>` tokens, applying the default Qwen3.5 template would inject thinking tags and cause degraded output. |
|
|
| --- |
|
|
| ## 📊 Training Metrics |
|
|
| | Epoch | Step | Loss | Token Accuracy | Learning Rate | |
| |---|---|---|---|---| |
| | 0.50 | 71 | 0.5044 | 70.35% | 6.9e-06 | |
| ... |
| | 0.71 | 100 | 0.4614 | 81.57% | 9.9e-06 | |
| | 0.85 | 120 | 0.4294 | 82.71% | 9.73e-06 | |
| | 1.00 | 141 | 0.4147 | 83.29% | 9.39e-06 | |
| | 1.42 | 200 | 0.3841 | 84.32% | 4.31e-06 | |
| | 1.50 | 211 | 0.3741 | 84.50% | 3.47e-06 | |
| | 1.63 | 224 | 0.3669 | 84.82% | 1.95e-06 | |
|
|
| --- |
|
|
| ## 🗂️ Dataset |
|
|
| The model was trained on [google/MapTrace](https://huggingface.co/datasets/google/MapTrace) (the `maptrace_20k` subset), a dataset containing 20,000 map images paired with path annotations from start to end locations. |
|
|
| --- |
|
|
| ## ⚠️ Limitations |
|
|
| - **Map-Specific:** The model is trained exclusively for top-down map images; it is not a general path planner. |
| - **Coordinate Precision:** Predictions are in normalized [0, 1] space and may have small pixel-level deviations. |
| - **Resolution Cap:** Images larger than `1024×768` will be downscaled to this resolution during inference to match training conditions. |
|
|
| --- |
|
|
| ## 📜 License |
|
|
| This model is released under the [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0) license, consistent with the base model. |
|
|
