Buckets:

| Title: How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use | |
| URL Source: https://arxiv.org/html/2602.00528 | |
| Published Time: Tue, 03 Feb 2026 01:29:19 GMT | |
| Markdown Content: | |
| Minhua Lin 1 Enyan Dai 2 Hui Liu 3 Xianfeng Tang 3 Yuliang Yan 2 Zhenwei Dai 3 | |
| Jingying Zeng 3 Zhiwei Zhang 1 Fali Wang 1 Hongcheng Gao 4 Chen Luo 2 | |
| Xiang Zhang 1 Qi He 5 Suhang Wang 1 | |
| 1 The Pennsylvania State University 2 HKUST (GZ) 3 Amazon 4 Tsinghua University 5 Microsoft | |
| ###### Abstract | |
| As Large Language Models (LLMs) are increasingly applied in high-stakes domains, their ability to reason strategically under uncertainty becomes critical. Poker provides a rigorous testbed, requiring not only strong actions but also principled, game-theoretic reasoning. In this paper, we conduct a systematic study of LLMs in multiple realistic poker tasks, evaluating both gameplay outcomes and reasoning traces. Our analysis reveals LLMs fail to compete against traditional algorithms and identifies three recurring flaws: reliance on heuristics, factual misunderstandings, and a “knowing–doing” gap where actions diverge from reasoning. An initial attempt with behavior cloning and step-level reinforcement learning improves reasoning style but remains insufficient for accurate game-theoretic play. Motivated by these limitations, we propose ToolPoker, a tool-integrated reasoning framework that combines external solvers for GTO-consistent actions with more precise professional-style explanations. Experiments demonstrate that ToolPoker achieves state-of-the-art gameplay while producing reasoning traces that closely reflect game-theoretic principles. | |
| 1 Introduction | |
| -------------- | |
| Large Language Models (LLMs) are increasingly deployed in high-stakes domains such as cybersecurity(Ameri et al., [2021](https://arxiv.org/html/2602.00528v1#bib.bib48 "CyBERT: cybersecurity claim classification by fine-tuning the bert language model")) and strategic decision-making(Jiang et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib49 "Large language model for causal decision making")), where success requires not only factual recall but also reasoning under uncertainty and informed decision-making. A natural testbed for these abilities is _game-playing_, which combines reasoning, planning, and opponent modeling. Poker is especially suitable as a canonical incomplete-information game(Harsanyi, [1995](https://arxiv.org/html/2602.00528v1#bib.bib23 "Games with incomplete information")), requiring players to act with hidden information, estimate opponents’ ranges, and anticipate future outcomes. Importantly, professional players succeed not only by choosing strong actions, but by _reasoning in a game-theoretic manner_(Brown and Sandholm, [2019](https://arxiv.org/html/2602.00528v1#bib.bib44 "Superhuman ai for multiplayer poker")), grounding decisions in equilibrium principles while adapting to opponents. Thus, to play like professionals, one must not only act optimally but also _think strategically_. Evaluating LLMs in poker requires going beyond win rate and examining whether their _reasoning traces_ reflect principled strategic thinking. | |
| Motivated by this, we ask: How far are LLMs from professional poker players? Several recent studies have explored LLMs in such game-theoretic games. For instance, GTBench(Duan et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib21 "Gtbench: uncovering the strategic reasoning capabilities of llms via game-theoretic evaluations")) and PokerBench(Zhuang et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib20 "Pokerbench: training large language models to become professional poker players")) focus on gameplay outcomes and show that LLMs struggle to compete. Suspicion-Agent(Guo et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib6 "Suspicion-agent: playing imperfect information games with theory of mind aware gpt-4")) uses theory-of-mind prompting in Leduc Hold’em, with GPT-4 surpassing neural baselines such as NFSP(Heinrich and Silver, [2016](https://arxiv.org/html/2602.00528v1#bib.bib8 "Deep reinforcement learning from self-play in imperfect-information games")), but still falls short of equilibrium-based methods like CFR+(Zinkevich et al., [2007](https://arxiv.org/html/2602.00528v1#bib.bib12 "Regret minimization in games with incomplete information")). GameBot(Lin et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib22 "GAMEBoT: transparent assessment of LLM reasoning in games")) examines reasoning steps but only measures correctness. While insightful, these works focus narrowly on outcomes, offering limited understandings of _why_ LLMs succeed or fail. | |
| To fill this gap, we conduct a systematic study of LLMs in poker, analyzing both gameplay and reasoning traces. Our analysis shows that LLMs consistently underperform traditional baselines, such as NFSP(Heinrich and Silver, [2016](https://arxiv.org/html/2602.00528v1#bib.bib8 "Deep reinforcement learning from self-play in imperfect-information games")) and CFR+Tammelin ([2014](https://arxiv.org/html/2602.00528v1#bib.bib19 "Solving large imperfect information games using cfr+")), ranging from reinforcement learning (RL) to equilibrium-based solvers, due to three key reasoning flaws: (i) _Heuristic reasoning_: LLMs often rely on shallow heuristics rather than rigorous game-theoretic principles. (ii) _Factual misunderstanding_: LLMs sometimes misjudge fundamental aspects of the game, such as hand strength, pot odds, or opponent range estimation, leading to systematically flawed reasoning and (iii) _Knowing–doing gap_: even when LLMs articulate sound reasoning, their final actions often deviate from it, exposing a gap between knowledge expression and decision execution. | |
| To investigate whether these flaws can be mitigated internally, we attempt a two-stage framework: (i) behavior cloning (BC) on expert reasoning traces to instill game-theoretic principles, and (ii) RL fine-tuning with step-level rewards. While this improves fluency and expert-like reasoning style, it remains insufficient for precise derivations or competitive gameplay, underscoring LLMs’ fundamental limitations in game-theoretic tasks. | |
| 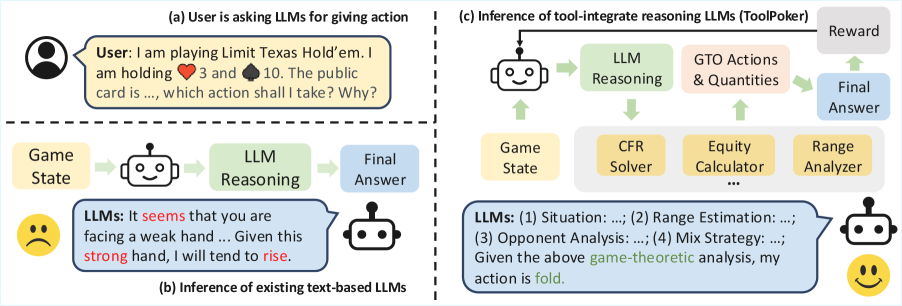 | |
| Figure 1: Illustration of ToolPoker and its advantages over LLMs using internal policies. | |
| Motivated by these limitations, we pursue an alternative direction: leveraging LLMs’ strength in _tool use_. However, achieving this integration in poker is non-trivial and challenging: (i) _Multi-tool dependency_. Accurate game-theoretic reasoning often requires multiple solvers (e.g., action and equity solvers), and naively teaching LLMs to invoke these tools across multi-turn poker scenarios leads to error propagation and unstable training. (ii) _High data cost_. Collecting large-scale reasoning traces augmented with solver calls requires expensive LLM annotation and careful domain-specific tool invocation, making it prohibitively costly to build. | |
| To address these challenges, we introduce ToolPoker, the first tool-integrated reasoning (TIR) framework for _imperfect-information games_ (Fig.[1](https://arxiv.org/html/2602.00528v1#S1.F1 "Figure 1 ‣ 1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use")), which teaches LLMs to call external poker solvers to provide game-theoretic optimal (GTO) actions and supporting quantities such as equity and hand ranges for accurate expert-level explanations. (i) We design a _unified tool interface_ that consolidates solver functionalities into a single API, returning all quantities in one query to simplify tool use and stabilize training. (ii) We construct a _small-scale expert-level_ reasoning dataset (Sec.[4.1](https://arxiv.org/html/2602.00528v1#S4.SS1 "4.1 Behavior Cloning ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use")) inspired by the thought process of professional players, and programmatically augment it with standardized tool invocation templates and execution outputs, ensuring high-quality and reducing annotation cost. This also provides a robust foundation for the following RL training in TIR. By combining GTO-guaranteed computation with human-like reasoning, ToolPoker overcomes fundamental weaknesses of policy-only training and moves LLMs closer to professional-level play. Experiments across multiple poker tasks demonstrate that ToolPoker achieves both state-of-the-art gameplay performance and produces reasoning traces that align much more closely with game-theoretic principles. | |
| Our main contributions are summarized as follows: (i) We conduct the first systematic study of LLMs in poker, revealing fundamental reasoning flaws such as _heuristic bias_, _factual misunderstanding_, and _knowing–doing gaps_. (ii) We make an initial attempt to improve LLMs’ internal policies through a two-stage RL framework. While effective at improving reasoning style, this approach remains insufficient for GTO reasoning and accurate game-theoretic derivation. (iii) We introduce ToolPoker, a tool-integrated reasoning framework that leverages external solvers to guarantee GTO-consistent actions while enabling LLMs to generate precise, professional-style explanations. (iv) Extensive experiments show that ToolPoker achieves state-of-the-art gameplay performance and produces reasoning traces that align closely with professional game-theoretic principles. | |
| 2 Backgrounds and Preliminaries | |
| ------------------------------- | |
| Two-Player Imperfect Information Poker Games. In this paper, we explore using LLMs to play poker with imperfect information. Following prior work(Guo et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib6 "Suspicion-agent: playing imperfect information games with theory of mind aware gpt-4"); Huang et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib33 "PokerGPT: an end-to-end lightweight solver for multi-player texas hold’em via large language model")), we focus on three widely studied two-player variants of increasing complexity: Kuhn Poker, Leduc Hold’em, and Limit Texas Hold’em, where their backgrounds and rules are in Appendix[B](https://arxiv.org/html/2602.00528v1#A2 "Appendix B Background and Rules of Poker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| Game-theoretic Reasoning. In poker, professional players go beyond heuristics or pattern recognition by systematically evaluating equity, ranges, and pot odds within a game-theoretic framework, guiding them toward actions that converge to Nash equilibrium. An example of such professional-style reasoning is in Appendix[B.6](https://arxiv.org/html/2602.00528v1#A2.SS6 "B.6 Professional Players in Poker ‣ Appendix B Background and Rules of Poker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), with further details on Nash equilibrium in Appendix[B.5](https://arxiv.org/html/2602.00528v1#A2.SS5 "B.5 Game-theoretic Reasoning ‣ Appendix B Background and Rules of Poker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| Problem Statement. We model a two-player poker game as a partially observable Markov decision process (POMDP) (𝒮,𝒜,𝒯,ℛ,Ω,O)(\mathcal{S},\mathcal{A},\mathcal{T},\mathcal{R},\Omega,O), where 𝒮={s t:1≤t≤T}\mathcal{S}=\{s^{t}:1\leq t\leq T\} is the set of true states, T T is the maximum turns, 𝒜\mathcal{A} is the action space, 𝒯\mathcal{T} is the transition function, ℛ\mathcal{R} is the reward function, Ω\Omega denotes the observation space, and O O represents the observation function. At time t t, the state is s t={s pub t,s pri(i)t,s pri(¬i)t}s^{t}=\{s^{t}_{{pub}},s^{t}_{{pri}(i)},s^{t}_{{pri}(\neg i)}\}, where s pub t s^{t}_{{pub}} denotes public information (e.g., community cards, betting), and s pri(i)t s^{t}_{{pri}(i)} and s pri(¬i)t s^{t}_{{pri}(\neg i)} are the private cards of player i i and the opponent, respectively. Each player i i partially observes o i t=(s pub t,s pri(i)t)∈Ω o_{i}^{t}=(s^{t}_{{pub}},s^{t}_{{pri}(i)})\in\Omega and conditions on its history h i t=(o i 1,a i 1,…,o i t)h_{i}^{t}=(o_{i}^{1},a_{i}^{1},\ldots,o_{i}^{t}) to choose an action a i t∼μ θ i(⋅∣f(h i t))a_{i}^{t}\sim\mu_{\theta}^{i}(\cdot\mid f(h_{i}^{t})), where f f is a prompt template that converts game states into natural language task descriptions. A full trajectory is τ=(s 1,a 1 1,a 2 1,r 1 1,r 2 1,…,s T,a 1 T,a 2 T,r 1 T,r 2 T)\tau=(s^{1},a_{1}^{1},a_{2}^{1},r_{1}^{1},r_{2}^{1},\ldots,s^{T},a_{1}^{T},a_{2}^{T},r_{1}^{T},r_{2}^{T}). The objective for player i i is to learn a policy μ θ i\mu_{\theta}^{i} that maximizes the cumulative reward ∑t=1 T r i t\sum_{t=1}^{T}r_{i}^{t} in the game. | |
| 3 Are LLMs Good at Poker? A Preliminary Analysis | |
| ------------------------------------------------ | |
| In this section, to understand the capabilities of LLMs in playing poker games, we conduct a preliminary analysis to provide initial evidence regarding the strengths and weaknesses of LLMs compared to traditional algorithms for imperfect-information games. | |
| ### 3.1 Experimental Setup | |
| Tasks. To quantitatively evaluate the performance of LLMs in poker, we consider two widely studied and popular poker games, Leduc Hold’em and Limit Texas Hold’em(Brown et al., [2019](https://arxiv.org/html/2602.00528v1#bib.bib5 "Deep counterfactual regret minimization"); Steinberger, [2019](https://arxiv.org/html/2602.00528v1#bib.bib7 "Single deep counterfactual regret minimization"); Guo et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib6 "Suspicion-agent: playing imperfect information games with theory of mind aware gpt-4")), both implemented in the RLCard environment(Zha et al., [2021a](https://arxiv.org/html/2602.00528v1#bib.bib4 "RLCard: a platform for reinforcement learning in card games")). | |
| Comparison Methods. Following(Guo et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib6 "Suspicion-agent: playing imperfect information games with theory of mind aware gpt-4")), we consider four traditional baselines for imperfect information games: NFSP(Heinrich and Silver, [2016](https://arxiv.org/html/2602.00528v1#bib.bib8 "Deep reinforcement learning from self-play in imperfect-information games")), DQN(Mnih et al., [2015](https://arxiv.org/html/2602.00528v1#bib.bib10 "Human-level control through deep reinforcement learning")), DMC(Zha et al., [2021b](https://arxiv.org/html/2602.00528v1#bib.bib11 "Douzero: mastering doudizhu with self-play deep reinforcement learning")), and CFR+(Tammelin, [2014](https://arxiv.org/html/2602.00528v1#bib.bib19 "Solving large imperfect information games using cfr+")). NFSP and DMC are self-play RL methods tailored to imperfect information games, while CFR+ provides a game-theoretic guarantee of convergence to the Nash equilibrium. For the more complex Limit Texas Hold’em environment, where CFR+ is computationally prohibitive, we instead adopt DeepCFR(Brown et al., [2019](https://arxiv.org/html/2602.00528v1#bib.bib5 "Deep counterfactual regret minimization")), a scalable neural extension of CFR+. These baselines cover diverse strategic paradigms, allowing us to assess LLMs against a broad range of opponent types. Details are provided in Appendix[C.1](https://arxiv.org/html/2602.00528v1#A3.SS1 "C.1 Comparison Methods ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| Evaluation Protocol. To ensure the robustness of our evaluation metrics, in our experiment, we run a series of 50 50 games with fixed random seeds and fixed player positions We then rerun the 50 50 games with the same fixed random seeds but switched positions for the compared methods. To evaluate the gameplay performance in poker games, we choose the earned chips as the evaluation metric. Specifically, for each individual poker game, each player starts with 100 100 chips, the small blind is 1 1 chip, and the big blind is 2 2 chips. | |
| ### 3.2 Comparison with Traditional Method | |
| Setting. We evaluate a suite of representative LLMs spanning a wide range of parameter scales, including Qwen2.5-3B, Qwen2.5-7B, Qwen2.5-72B(Qwen, [2024](https://arxiv.org/html/2602.00528v1#bib.bib28 "Qwen2.5: a party of foundation models")), Qwen3-8B(Yang et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib31 "Qwen3 technical report")), Llama3-8B(Grattafiori et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib30 "The llama 3 herd of models")), GPT-4.1-mini(OpenAI, [2025](https://arxiv.org/html/2602.00528v1#bib.bib29 "Gpt-4.1 system card")), GPT-4o Hurst et al. ([2024](https://arxiv.org/html/2602.00528v1#bib.bib27 "Gpt-4o system card")), and o4-mini(OpenAI, [2024](https://arxiv.org/html/2602.00528v1#bib.bib32 "OpenAI o3 and o4-mini system card")), where the instruction-following versions of these open-source models are adopted. These models are evaluated against the aforementioned traditional baselines. | |
| Results Analysis. Table[1](https://arxiv.org/html/2602.00528v1#S3.T1 "Table 1 ‣ 3.2 Comparison with Traditional Method ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") reports the average chip gain of different LLMs against traditional methods in both Leduc Hold’em and Limit Texas Hold’em. From the table, we observe that (i) Most vanilla LLMs, particularly open-source models with smaller scales, underperform relative to traditional methods. This highlights the limited effectiveness of state-of-the-art LLMs in poker. (ii) CFR+ consistently outperforms all LLMs, including strong closed-source models such as GPT-4o and o4-mini. This is expected, as CFR+ explicitly targets Nash equilibrium strategies, underscoring the importance of game-theoretic reasoning in imperfect-information games. (iii) Against non-equilibrium baselines (i.e., NFSP, DQN, DMC), some large-scale and closed-source LLMs demonstrate competitive or superior performance. For instance, GPT-4o achieves +41.5+41.5, +60.5+60.5, and −22-22 chip outcomes against NFSP, DQN, and DMC, respectively. In contrast, small open-source LLMs (e.g., Qwen2.5-3B) exhibit severe losses across all baselines (e.g., −143.5-143.5, −161-161, and −124-124 chips). These results suggest that while LLMs cannot approximate Nash equilibrium strategies, sufficiently large models can exploit non-equilibrium opponents. | |
| Table 1: Comparison of various vanilla LLMs against different traditional algorithms trained in Leduc Hold’em and Limit Texas Hold’em environments. Each method plays 100 games with varying random seeds and alternated player positions. Results report net chip gains. In Leduc Hold’em, values range from 1 1 to 14 14 chips; in Limit Texas Hold’em, they range from 1 1 to 99 99 chips. Bold and underline indicate the best and worst performance in each column, respectively. The “Avg.” columns summarize LLMs’ mean performance across the four traditional baselines. | |
| ### 3.3 In-depth Analysis: Decomposing Reasoning Flaws of LLMs | |
| To understand why LLMs fail to compete with traditional methods in poker, we conduct an in-depth analysis of their reasoning processes. Specifically, we first present several case studies that highlight three key flaws in LLM reasoning, followed by a quantitative analysis to further validate and interpret these observations. | |
| Case Study of LLMs’ Reasoning Flaw. To probe LLMs’ decision-making, we examine their reasoning traces in specific scenarios against baseline opponents. Representative cases from Qwen2.5-3B and GPT-4o are shown in Table[13](https://arxiv.org/html/2602.00528v1#A10.T13 "Table 13 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") and[14](https://arxiv.org/html/2602.00528v1#A10.T14 "Table 14 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") in Appendix[C.2](https://arxiv.org/html/2602.00528v1#A3.SS2 "C.2 Case Studies of LLMs’ Reasoning Flaws ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). From these examples, we identify three recurrent flaws: (i) _Heuristic Reasoning_. LLMs frequently rely on heuristic-driven reasoning, making decisions based on surface-level patterns or intuitive analogies rather than on rigorous game-theoretic principles. In contrast, the Nash-equilibrium algorithm CFR+ consistently achieves the strongest performance, underscoring the value of game-theoretic reasoning in imperfect-information games like poker. The absence of such equilibrium-oriented reasoning substantially constrains the gameplay performance of LLMs. These two findings indicate that while LLMs are capable of articulating plausible strategic reasoning, their actual decision-making remains constrained by executional inconsistencies and heuristic biases. These limitations ultimately hinder their effectiveness in complex poker games that require advanced strategic reasoning capabilities. (ii) _Factual Misunderstanding_. LLMs often ground their reasoning in intuitive analogies, making them prone to misjudging fundamental aspects of the game, such as hand strength or opponent range estimation. These factual inaccuracies can cascade into flawed reasoning chains and ultimately suboptimal actions. For example, as shown in Tab.[14](https://arxiv.org/html/2602.00528v1#A10.T14 "Table 14 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), GPT-4o incorrectly judged (♠K,♣10)(\spadesuit\text{K},\clubsuit\text{10}) as weak and preferred folding. However, an equity calculator shows this hand has about 60%60\% equity, indicating it is relatively strong. (iii) _Knowing–Doing Gap._ LLMs often exhibit a mismatch between articulated reasoning and final actions. For instance, in Tab.[13](https://arxiv.org/html/2602.00528v1#A10.T13 "Table 13 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), Qwen2.5-3B correctly reasons that (♣3♡10\clubsuit\text{3}\ \heartsuit\text{10}) is not a strong hand and fold is optimal, while it yet proceeds to raise. Such inconsistencies reveal a breakdown between reasoning and execution. Additional case studies are provided in Appendix[C.2](https://arxiv.org/html/2602.00528v1#A3.SS2 "C.2 Case Studies of LLMs’ Reasoning Flaws ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| Quantitative Analysis of LLMs’ Reasoning Flaws. To validate the reasoning flaws observed in case studies, we adopt the LLM-as-a-Judge framework(Dubois et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib41 "AlpacaFarm: a simulation framework for methods that learn from human feedback")). We design three metrics: heuristic reasoning (HR), factual alignment (FA), and action–reasoning consistency (AC), and score each reasoning trace on a 0–2 2 scale using GPT-4.1-mini as the judge. Metric definitions, judge prompts, and human–LLM agreement are in Appendix[C.3](https://arxiv.org/html/2602.00528v1#A3.SS3 "C.3 Evaluation Metrics of the LLM-as-a-Judge for LLMs’ Reasoning ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") and[C.5](https://arxiv.org/html/2602.00528v1#A3.SS5 "C.5 Human-in-the-Loop Evaluation for LLMs’ Reasoning ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). For each model, we sample 20 20 traces and evaluate Qwen2.5-3B/7B/72B, GPT-4.1-mini, and o4-mini. To ensure reliability of LLM-based judging, we manually curate 20 20 professional-style reasoning traces and score them by LLMs. We observe high agreement with human judgement and include it as a reference (see Appendix[C.5](https://arxiv.org/html/2602.00528v1#A3.SS5 "C.5 Human-in-the-Loop Evaluation for LLMs’ Reasoning ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use")). | |
| Table 2: LLM-as-a-Judge score (0-2 2) evaluating reasoning traces of various LLMs in Leduc Hold’em and Limit Texas Hold’em. Bold and underlined numbers indicate the best and worst performance, respectively. | |
| We report results in Tab.[2](https://arxiv.org/html/2602.00528v1#S3.T2 "Table 2 ‣ 3.3 In-depth Analysis: Decomposing Reasoning Flaws of LLMs ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). Three key findings are observed: (i) Reasoning flaws persist across all models. Qwen2.5-3B scores only 0.53 0.53 HR, 0.18 0.18 FA, and 1.53 1.53 AC, while o4-mini, the strongest model, reaches 1.80 1.80/1.56 1.56/1.85 1.85, still below perfect consistency. This shows systemic heuristic, factual, and knowing–doing flaws in LLMs. (ii) Scaling improves but does not eliminate flaws. Larger models (Qwen2.5-72B, o4-mini) improve all metrics, but significant FA and AC gaps remain, showing scale alone cannot achieve professional-level reasoning. (iii) Action–reasoning consistency remains imperfect. AC stabilizes around 1.53 1.53–1.87 1.87, below the professional baseline of 2.0 2.0, with o4-mini still exhibiting knowing–doing mismatches. Full details are in Appendix[C.4](https://arxiv.org/html/2602.00528v1#A3.SS4 "C.4 Full Details of Quantitative Analysis ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| Overall, these findings quantitatively reinforce our case studies: despite improvements in scale and instruction tuning, current LLMs remain far from professional-level poker reasoning. They continue to exhibit heuristic biases, factual misunderstandings, and executional inconsistencies that fundamentally limit their game-theoretic reasoning capabilities. | |
| 4 Can We Improve LLMs in Poker? Failures and Insights | |
| ----------------------------------------------------- | |
| Building on the preliminary analysis of LLM limitations in poker, we next explore how to improve their ability to both _act_ and _reason_ like professional players. A natural starting point is supervised fine-tuning (SFT) on expert gameplay. However, while obtaining expert actions is straightforward using established solvers such as CFR+, constructing large-scale datasets with high-quality reasoning traces is extremely costly, making pure SFT impractical at scale. For instance, Wang et al. ([2025](https://arxiv.org/html/2602.00528v1#bib.bib61 "Can large language models master complex card games?")) report that mastering even simplified poker games like Leduc Hold’em requires at least 400 400 k action-only instances. Adding reasoning traces would multiply both time and financial costs, rendering such datasets infeasible to construct. To address this, inspired by recent progress in RL for enhancing LLM reasoning(Guo et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib24 "Deepseek-r1: incentivizing reasoning capability in llms via reinforcement learning")) and by traditional RL for poker(Heinrich and Silver, [2016](https://arxiv.org/html/2602.00528v1#bib.bib8 "Deep reinforcement learning from self-play in imperfect-information games")), we make an initial attempt to propose a two-stage framework, BC-RIRL, that combines behavior cloning (BC) with regret-inspired policy optimization (RIRL). In the first stage, BC aims to provide a small but valuable foundation of expert play and reasoning. In the second stage, RIRL refines these policies toward GTO play under Nash–equilibrium–based supervision. | |
| ### 4.1 Behavior Cloning | |
| We first leverage BC to expose LLMs to professional-style reasoning. Following recent advances in reasoning-augmented datasets(Muennighoff et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib18 "S1: simple test-time scaling")) and inspired by professional players’s thought process (Appendix[B.6](https://arxiv.org/html/2602.00528v1#A2.SS6 "B.6 Professional Players in Poker ‣ Appendix B Background and Rules of Poker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use")), we curate a dataset of professional-level trajectories 𝒟 b={(h t,a t,r t)}\mathcal{D}_{b}=\{(h^{t},a^{t},r^{t})\}, where h t h^{t} is the full interaction history up to time t t and a t a^{t} is the corresponding expert response. Expert actions a t a^{t} are obtained by querying the state-of-the-art CFR+ solver(Tammelin, [2014](https://arxiv.org/html/2602.00528v1#bib.bib19 "Solving large imperfect information games using cfr+")) with h t h^{t}, ensuring alignment with Nash-equilibrium play. Reasoning traces r t r^{t} are generated using an LLM guided by domain-specific prompt templates covering key concepts such as hand equity, pot odds, and opponent ranges, to mimic the explanatory style of professional players. The construction prompts and dataset examples are in Appendix[D.3](https://arxiv.org/html/2602.00528v1#A4.SS3 "D.3 Additional Details of Behavior Cloning ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). To ensure dataset quality, we implement an automated pipeline that (i) checks consistency between the annotated actions and CFR+ outputs, and (ii) filters out low-quality samples using our HR/FA/AC metrics. After filtering, we obtain a compact dataset of approximately 5 5 k reasoning-augmented samples, which is then used to fine-tune the LLM policy π θ\pi_{\theta} via supervised fine-tuning (SFT) to imitate expert responses: | |
| ℒ BC=−𝔼(h t,a t)∼𝒟 b[logπ θ(a t|h t)].\mathcal{L}_{\text{BC}}=-\mathbb{E}_{(h^{t},a^{t})\sim\mathcal{D}_{b}}[\log\pi_{\theta}(a^{t}|h^{t})].(1) | |
| This imitation phase grounds the LLM in domain knowledge and equips it with basic game-theoretic reasoning capability. As shown in Sec.[4.3](https://arxiv.org/html/2602.00528v1#S4.SS3 "4.3 Experiment Analysis ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), BC primarily serves as a warm start, providing a crucial foundation for the subsequent RL stage. | |
| ### 4.2 Regret-Inspired RL Fine-Tuning | |
| As an initial attempt to refine policies beyond imitation, we attempt a regret-inspired reinforcement learning (RIRL) framework. To overcome the sparse and noisy outcome-based rewards in multi-turn poker games such as Leduc Hold’em and Texas Hold’em, we experiment with a step-level regret-guided reward that leverages signals from a pre-trained CFR solver to guild LLMs minimize cumulative regret and convergence to the Nash equilibrium. Full details of RIRL are in Appendix[D.1](https://arxiv.org/html/2602.00528v1#A4.SS1 "D.1 Full details of Regret-Inspired RL Fine-Tuning ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| Regret-guided Reward Design. Motivated by CFR’s success in poker playing by approaching Nash equilibrium from Sec.[3.2](https://arxiv.org/html/2602.00528v1#S3.SS2 "3.2 Comparison with Traditional Method ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), we optimize LLMs via regret minimization. Our key idea is to compute cumulative regrets from a pre-trained CFR solver and normalize them into fine-grained reward signals that capture each action’s relative contribution. For a policy π θ\pi_{\theta} as player i i, the reward of action a i t a_{i}^{t} is defined as: | |
| R(a i t)=R t(a i t)−mean({r t(a j)}j=1|𝒜|)F norm({r t(a j)}j=1|𝒜|),R(a^{t}_{i})\;=\;\frac{R_{t}(a^{t}_{i})-\text{mean}(\{r_{t}(a_{j})\}_{j=1}^{|\mathcal{A}|})}{F_{\text{norm}}(\{r_{t}(a_{j})\}_{j=1}^{|\mathcal{A}|})},(2) | |
| where F norm F_{\text{norm}} denotes a normalization factor, chosen as the standard deviation in our implementation. r t(a i t)r_{t}(a_{i}^{t}) is the cumulative regret of action a i t a_{i}^{t}, indicating how much better or worse it performs compared to the current mixture strategy across time. | |
| Fine-tuning Objective. Based on this signal, we fine-tune LLM policy via PPO(Schulman et al., [2017](https://arxiv.org/html/2602.00528v1#bib.bib13 "Proximal policy optimization algorithms")) with the following clipped RL objective: | |
| ℒ PPO\displaystyle\mathcal{L}_{\text{PPO}}(θ)=−𝔼 x∼𝒟 s,y∼π old(⋅|x)\displaystyle(\theta)=-\mathbb{E}_{x\sim\mathcal{D}_{s},y\sim\pi_{{old}}(\cdot|x)}(3) | |
| [min(π θ(y|x)π old(y|x)A,clip(π θ(y|x)π old(y|x),1−ϵ,1+ϵ))−β 𝔻 KL(π θ(⋅|c)||π ref(y|x))],\displaystyle\left[\min\left(\frac{\pi_{\theta}(y|x)}{\pi_{{old}}(y|x)}A,\text{clip}\left(\frac{\pi_{\theta}(y|x)}{\pi_{{old}}(y|x)},1-\epsilon,1+\epsilon\right)\right)-\beta\mathbb{D}_{\text{KL}}(\pi_{\theta}(\cdot|c)||\pi_{ref}(y|x))\right], | |
| where π θ\pi_{\theta} and π old\pi_{old} denote the current and previous policy models, respectively. ϵ\epsilon is the clipping threshold. π ref\pi_{ref} is the reference policy that regularizes π θ\pi_{\theta} update via a KL-divergence penalty, measured and weighted by 𝔻 KL\mathbb{D}_{KL} and β\beta, respectively. Generalized Advantage Estimation (GAE)(Schulman et al., [2015](https://arxiv.org/html/2602.00528v1#bib.bib9 "High-dimensional continuous control using generalized advantage estimation")) is used for advantage estimate A A. x x denotes the input samples drawn from 𝒟\mathcal{D}, which is composed of trajectories generated by the current policy π θ\pi_{\theta}. y y is the generated outputs via policy LLMs π θ(⋅|x)\pi_{\theta}(\cdot|x). The trajectory collection procedure is introduced in Appendix[D.4](https://arxiv.org/html/2602.00528v1#A4.SS4 "D.4 Trajectory Collection Procedure ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| ### 4.3 Experiment Analysis | |
| Experimental Setup. Following the settings in Sec.[3.1](https://arxiv.org/html/2602.00528v1#S3.SS1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), we implement BC-RIRL by fine-tuning LLMs with both BC and RIRL, and compare against traditional algorithms as well as LLM-based approaches. For traditional baselines, we adopt NFSP, DQN, DMC, and CFR+, consistent with Sec.[3.1](https://arxiv.org/html/2602.00528v1#S3.SS1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). For LLM-based baselines, in addition to direct prompting without fine-tuning, we consider two variants: (i) BC-SPRL, which fine-tunes LLMs through BC and self-play RL with sparse outcome-based rewards, and (ii) RIRL, which fine-tunes LLMs with RIRL alone, without the BC stage. Further details of SPRL are in Appendix[E](https://arxiv.org/html/2602.00528v1#A5 "Appendix E Methodology of SPRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). Other settings follow these in Sec.[3.1](https://arxiv.org/html/2602.00528v1#S3.SS1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), including the evaluation metrics. The implementation details are in Appendix[D.5](https://arxiv.org/html/2602.00528v1#A4.SS5 "D.5 Implementation Details of BC-RIRL ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| Comparison Results. We fine-tune Qwen2.5-7B with BC-RIRL and compare against traditional algorithms and vanilla LLMs. The gameplay and reasoning results are reported in Tab.[3](https://arxiv.org/html/2602.00528v1#S4.T3 "Table 3 ‣ 4.3 Experiment Analysis ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") and Tab.[4](https://arxiv.org/html/2602.00528v1#S4.T4 "Table 4 ‣ 4.3 Experiment Analysis ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| _Gameplay_. (i) All RL-based fine-tuning variants improve performance in Kuhn Poker, showing that both outcome- and regret-based feedback provide useful signals in simple environments. (ii) BC-RIRL outperforms direct prompting and BC-SPRL (e.g., +17.0+17.0 chips vs. GPT-4.1-mini) but still trails CFR+ (−34.0-34.0 chips) In Leduc Hold’em, indicating dense regret feedback is more effective than sparse outcome rewards in complex poker games, yet insufficient for equilibrium-level play. (iii) Pure RIRL without the BC stage does not yield improvements in Leduc Hold’em (−64.5-64.5 chips vs. GPT-4.1-mini), highlighting BC as a necessary foundation. | |
| _Reasoning_. (i) RIRL consistently improves HR and AC (e.g., 1.93 1.93 HR and 1.90 1.90 AC in Leduc Hold’em vs. 1.80 1.80/1.85 1.85 for o4-mini), reducing heuristic flaws and the knowing–doing gap. (ii) RIRL gains only marginal improvement in FA (1.12 1.12, 0.87 0.87 and 1.65 1.65 for RIRL, Qwen2.5-7B and o4-mini), showing that factual misunderstandings remain the main limitation. Together with the case studies, these results indicate that while BC-RIRL improves strategic reasoning and action–reasoning alignment, factual misunderstandings remain a notable challenge. Full analysis are in Appendix[D.2](https://arxiv.org/html/2602.00528v1#A4.SS2 "D.2 Full Details of Comparison Results ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| Takeaway. Our experiments validate that current LLMs are inherently weak at strategic reasoning in game-theoretic tasks. RL fine-tuning with step-level or outcome-based rewards yields modest gameplay gains but still lags behind traditional methods like CFR. Importantly, while our two-stage approach helps LLMs imitate professional reasoning styles, they continue to struggle with precise derivation such as equity and hand ranges. This reveals a fundamental _limitation_: LLMs alone cannot yet achieve both GTO actions and precise reasoning. To bridge this gap, we next explore augmenting LLMs with _tool use_, leveraging their natural strength in tool invocation to support GTO-consistent actions and precise game-theoretic reasoning. | |
| Table 3: Results of comparison fine-tuning methods against various traditional-based and vanilla LLMs in Kuhn and Leduc Hold’em environment. Other settings follow these in Tab.[1](https://arxiv.org/html/2602.00528v1#S3.T1 "Table 1 ‣ 3.2 Comparison with Traditional Method ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). Bold and underlined numbers indicate the best and worst performance, respectively. | |
| Traditional Methods Vanilla LLMs | |
| Method NFSP DQN DMC CFR+Qwen2.5-3B Qwen2.5-7B GPT-4.1-mini o4-mini Avg. | |
| _Kuhn_ | |
| Qwen2.5-7B-22.0-53.0-33.0-36.0+26--41-43-28.8 | |
| Qwen2.5-7B RIRL{}_{\text{RIRL}}-14.0+3.0+10.0-5.0+43.0+8.0-1.0-11.0+4.1 | |
| Qwen2.5-7B BC-SPRL{}_{\text{BC-SPRL}}+6.0-6.0+13.0-14.0+32.0+23.0+22.0+10.0+10.7 | |
| Qwen2.5-7B BC-RIRL{}_{\text{BC-RIRL}}+4.0+8.0+11.0-2.0+57.0+27.0+21.0+11.0+17.1 | |
| _Leduc Hold’em_ | |
| Qwen2.5-7B-57.5-93.0-73.0-68.5+48.5--59.5-32.5-47.9 | |
| Qwen2.5-7B RIRL{}_{\text{RIRL}}-42.5-80-59.5-55.0+52.0+12.0+2.5-18.5-23.6 | |
| Qwen2.5-7B BC-SPRL{}_{\text{BC-SPRL}}-93.0-154.5-95.5-103.5+2.0-18.0-64.5-54.5-72.6 | |
| Qwen2.5-7B BC-RIRL{}_{\text{BC-RIRL}}-37.0-64.5-43.5-34.0+54.0+28.5+17.0+1.0-9.8 | |
| Table 4: LLM-as-a-Judge score (0-2 2) evaluating reasoning traces of various LLMs in two realistic poker tasks. Bold and underlined numbers indicate the best and worst performance, respectively. | |
| 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use | |
| ----------------------------------------------------------- | |
| Table 5: Comparison of various LLM-based methods against different traditional algorithms trained in Leduc Hold’em and Limit Texas Hold’em environments. Other settings follow these in Tab.[1](https://arxiv.org/html/2602.00528v1#S3.T1 "Table 1 ‣ 3.2 Comparison with Traditional Method ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). Bold and underline indicate the best and worst performance in each column, respectively. | |
| Building on our analysis in Sec.[4](https://arxiv.org/html/2602.00528v1#S4 "4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), which highlights the limitations of LLMs in producing GTO actions and precise game-theoretic reasoning, we propose ToolPoker, a tool-integrated reasoning (TIR) framework to leverage LLMs’ strength in _tool use_ to empower LLMs to leverage external poker solvers to refine their actions and reasoning qualities, which is shown in Fig.[1](https://arxiv.org/html/2602.00528v1#S1.F1 "Figure 1 ‣ 1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). To make this tool usage stable and effective, we introduce a unified tool interface that consolidates multiple poker solvers (e.g., CFR and equity calculators) into a single API to simplify this into a single-turn tool use. On the training side, we adopt a two-stage strategy: first, behavior cloning on a code-augmented dataset to teach the model when and how to call external tools; and second, reinforcement learning with a composite reward to further optimize solver integration and reasoning quality. | |
| ### 5.1 Tool-Integrated Game-theoretic Reasoning in Poker | |
| Rollout Process. To enable GTO-consistent TIR, we design a structured prompt template in Tab.[21](https://arxiv.org/html/2602.00528v1#A10.T21 "Table 21 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") to guide LLM to leverage external poker solvers for game-theoretic reasoning. Concretely, given a policy LLM π θ\pi_{\theta} as player i i at time t t, π θ\pi_{\theta} generates a reasoning trace enclosed in <think></think> tags. To obtain GTO actions and other quantities, π θ\pi_{\theta} issues a query in <tool></tool> tags, which calls the unified solver interface and returns results wrapped in <output></output> tags. These outputs are then incorporated into the reasoning trace before π θ\pi_{\theta} produces the final action a i t a_{i}^{t} within <answer></answer> tags. | |
| Unified Tool Inference. Obtaining GTO actions and supporting quantities (e.g., equity, pot odds, and range distributions) often requires multiple tool calls, such as a CFR solver and an equity calculator. To simplify and stabilize training, we unify these functionalities into a single standardized interface that provides both the solver’s actions and auxiliary statistics for game-theoretic reasoning. | |
| ### 5.2 Training Algorithm | |
| BC for TIR. To construct high-quality TIR data without incurring prohibitive annotation cost, we build an automated pipeline that programmatically augments the reasoning dataset from Sec.[4.1](https://arxiv.org/html/2602.00528v1#S4.SS1 "4.1 Behavior Cloning ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") with standardized tool invocation templates (e.g., <tool></tool>) and execution outputs (e.g., <output></output>). This resulting dataset 𝒟 c\mathcal{D}_{c} is then used to train ToolPoker via SFT, providing a foundation for LLMs to know how to invoke tools for game-theoretic reasoning. The realistic example and the details of the automatic pipeline are in Tab.[22](https://arxiv.org/html/2602.00528v1#A10.T22 "Table 22 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") in Appendix[G.2](https://arxiv.org/html/2602.00528v1#A7.SS2 "G.2 TIR BC Reasoning Dataset Curation ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| RL Fine-tuning. We train ToolPoker with PPO(Schulman et al., [2017](https://arxiv.org/html/2602.00528v1#bib.bib13 "Proximal policy optimization algorithms")), where the objective function is defined in Eq.([8](https://arxiv.org/html/2602.00528v1#A4.E8 "In D.1 Full details of Regret-Inspired RL Fine-Tuning ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use")). To better support TIR, we follow ReTool(Feng et al., [2025a](https://arxiv.org/html/2602.00528v1#bib.bib38 "Retool: reinforcement learning for strategic tool use in llms")) and integrate external poker solvers into the LLM policy π θ\pi_{\theta}, enabling multi-turn real-time tool use that provides GTO-consistent actions and supporting quantities from external tools. To guide the training, we design a composite reward function. Formally, given player i i at time step t t, the reward is defined as | |
| R(a i t,a^i t,ρ i t)=R answer(a i t,a^i t)+α f⋅R format(ρ i t)+α t⋅R tool(ρ i t),R(a_{i}^{t},\hat{a}_{i}^{t},\rho_{i}^{t})=R_{\text{answer}}(a_{i}^{t},\hat{a}_{i}^{t})+\alpha_{f}\cdot R_{\text{format}}(\rho_{i}^{t})+\alpha_{t}\cdot R_{\text{tool}}(\rho_{i}^{t}),(4) | |
| where a i t a_{i}^{t} is the ground-truth action from the CFR solver, a^i t\hat{a}i^{t} is the model-predicted action, and ρ i t\rho_{i}^{t} is the generated reasoning trace. Here, R answer R_{\text{answer}}, R format R_{\text{format}}, and R tool R_{\text{tool}} correspond to the answer reward, format reward, and tool-execution reward, respectively, ensuring that ToolPoker not only outputs GTO-consistent actions but also generates structured reasoning traces with effective tool usage. α f\alpha_{f} and α t\alpha_{t} are the weights to balance the impact of format and tool execution rewards. More details of these reward functions are in Appendix[G.3](https://arxiv.org/html/2602.00528v1#A7.SS3 "G.3 Reward Design ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). The fine-tuning algorithm is in Alg.[1](https://arxiv.org/html/2602.00528v1#alg1 "Algorithm 1 ‣ F.1 Case Studies of BC-RIRL ‣ Appendix F Additional Details of Initial Attempt in Sec. 4 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") of Appendix[G.4](https://arxiv.org/html/2602.00528v1#A7.SS4 "G.4 RL Fine-tuning Algorithm for TIR ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| ### 5.3 Experimental Results | |
| 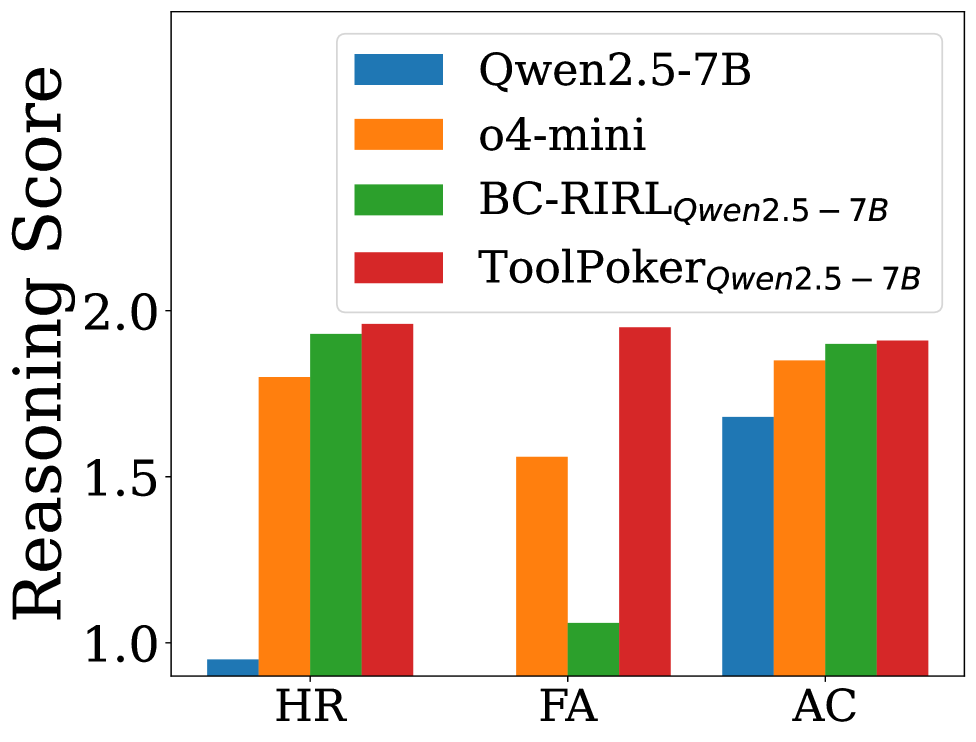 | |
| (a) Reasoning - Leduc | |
| 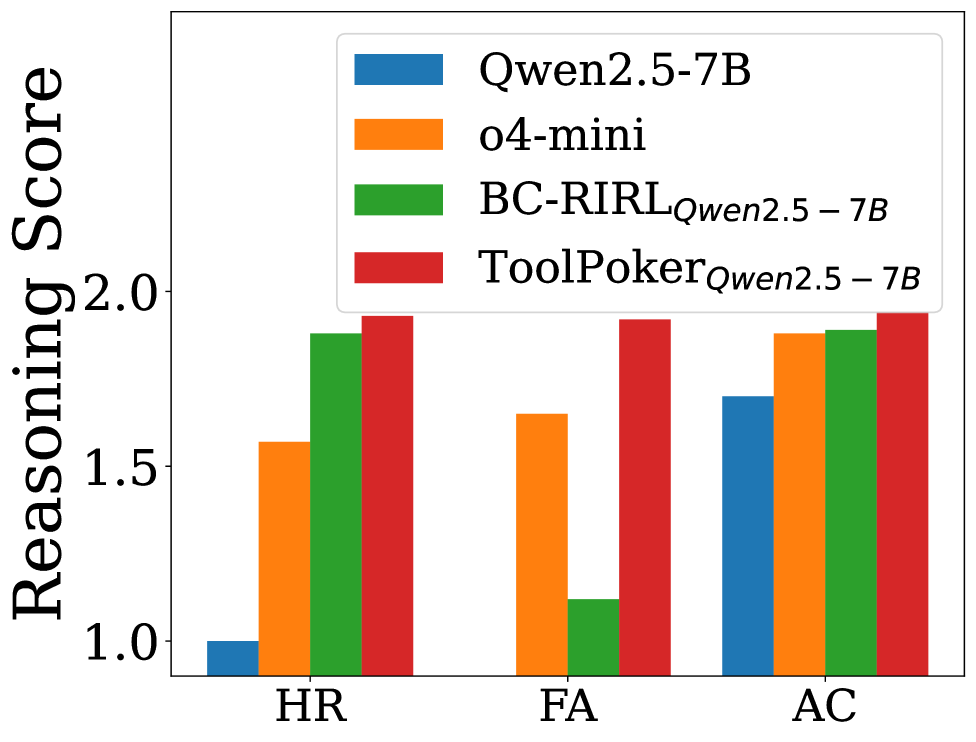 | |
| (b) Reasoning - Limit | |
| 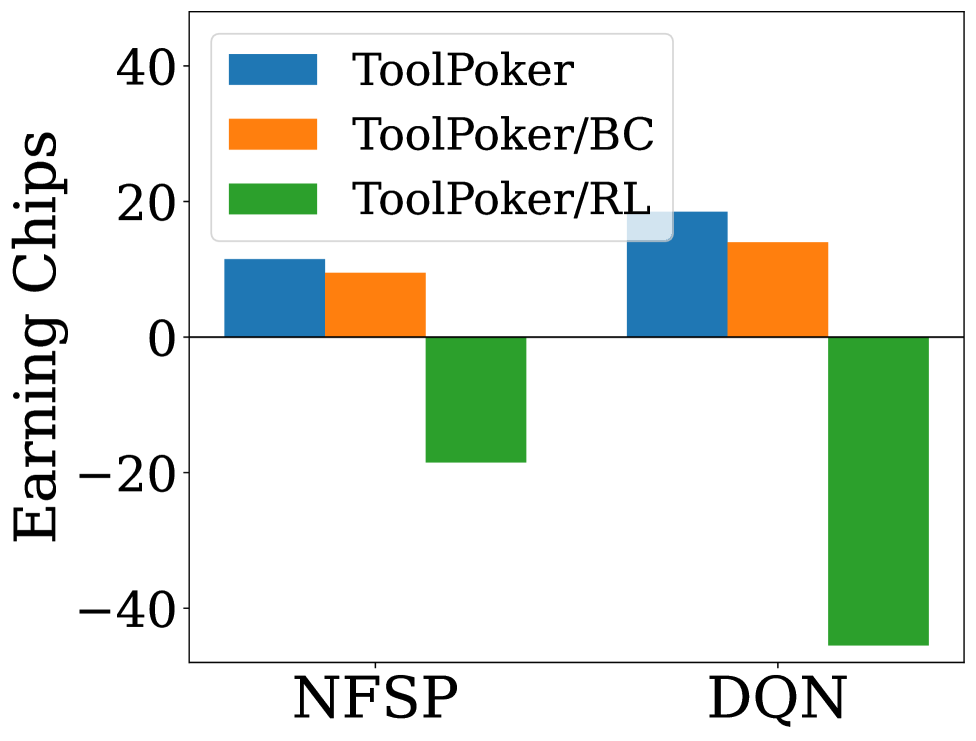 | |
| (c) Ablation - Gameplay | |
|  | |
| (d) Ablation - Reasoning | |
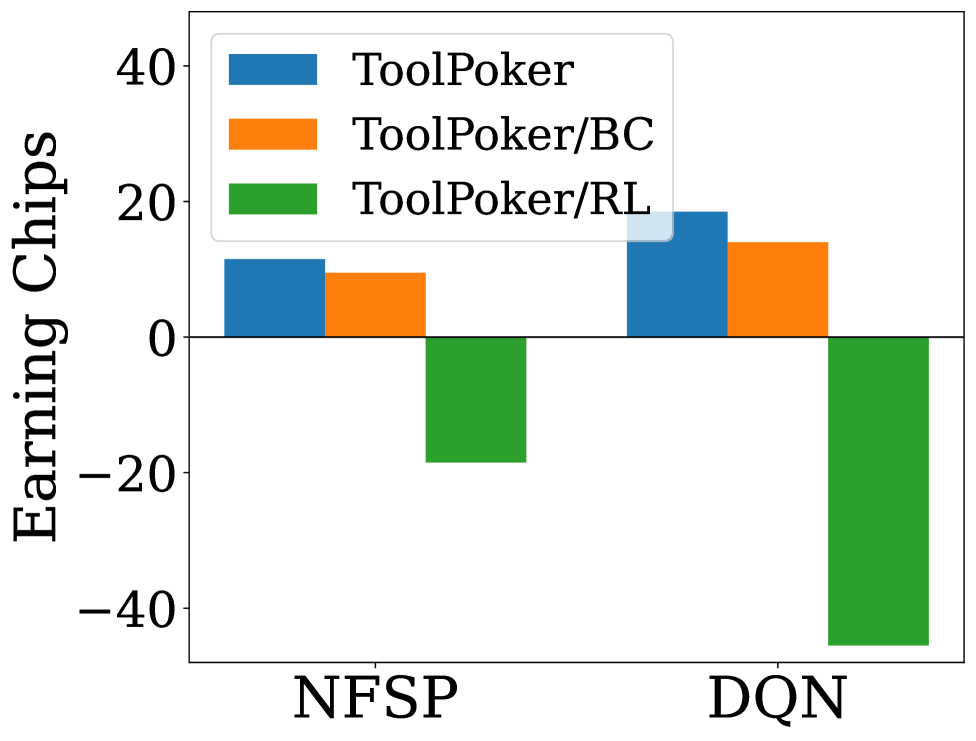
| Figure 2: Results for ToolPoker: (a) and (b) present reasoning analysis in Leduc Hold’em and Limit Texas Hold’em; (c) and (d) show ablation studies on gameplay and reasoning in Leduc Hold’em. | |
| Evaluation Setup. We conduct evaluations on two realistic and complex poker tasks, Leduc Hold’em and Limit Texas Hold’em. We compare ToolPoker with the following baselines: (i) Traditional algorithms: NFSP, DQN, DMC, and CFR; (ii) Vanilla LLMs: Qwen2.5-7B, Qwen2.5-72B, and o4-mini; (iii) Fine-tuning-based baseline: BC-RIRL. Other settings follow these in Sec.[4.3](https://arxiv.org/html/2602.00528v1#S4.SS3 "4.3 Experiment Analysis ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). More Implementation details of ToolPoker are in Appendix[G.5](https://arxiv.org/html/2602.00528v1#A7.SS5 "G.5 Implementation Details ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| Gameplay Performance. We first explore the gameplay performance of ToolPoker. Qwen2.5-7B is the base model for fine-tuning. We compare ToolPoker with BC-RIRL and three vanilla LLMs, Qwen2.5-7B, Qwen2.5-72B and o4-mini, where the comparison results are reported in Tab.[5](https://arxiv.org/html/2602.00528v1#S5.T5 "Table 5 ‣ 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). Two key findings emerge: (i) _ToolPoker achieve state-of-the-art gameplay perfomrance against traditional algorithms_. For instance, ToolPoker gains +60.5+60.5, +63.0+63.0 and +61.5+61.5 chips against NFSP, DQN and DMC in Limit Texas Hold’em, while BC-RIRL gains −77.5-77.5, −82.5-82.5 and −80.5-80.5 chips against them. This indicates the effectiveness of ToolPoker in calling CFR solver to obtain GTO-consistent actions. (ii) _ToolPoker slightly underperforms CFR but is still comparable in both poker environments_. Specifically, ToolPoker gain −3.0-3.0 and −5.0-5.0 chips against CFR+ and DeepCFR in both Leduc Hold’em and Limit Texas Hold’em, which are minor. We analyze the reason is that while ToolPoker provides a high success rate in executing the CFR solver to provide GTO-consistent action, it is inevitable that occasional errors occur in tool calling. | |
| Reasoning Quality. To assess whether ToolPoker also improves _reasoning_, we employ the LLM-as-a-Judge framework following the settings in Sec.[4.3](https://arxiv.org/html/2602.00528v1#S4.SS3 "4.3 Experiment Analysis ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). Fig.[2](https://arxiv.org/html/2602.00528v1#S5.F2 "Figure 2 ‣ 5.3 Experimental Results ‣ 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") (a) and (b) summarize the results across three metrics. Two observations emerge: (i) _ToolPoker achieves near-perfect across all three scores_, outperforming all baselines and approaching professional levels. This indicates that, beyond delivering state-of-the-art gameplay performance, ToolPoker also enables LLMs to generate precise and logically consistent reasoning traces grounded in game-theoretic principles. (ii) Compared with BC-RIRL, _ToolPoker yields substantially higher FA scores_. This demonstrates the importance of leveraging external solvers: while BC-RIRL can articulate plausible reasoning, it often lacks accurate auxiliary quantities (e.g., equities, ranges). In contrast, ToolPoker grounds its reasoning in solver-derived calculations, ensuring rigor and internal consistency. | |
| Ablation Studies. To understand the impact of each component in ToolPoker, we implement two ablated variants: (i) ToolPoker/BC: removes BC and learns tool use only via RL; (ii) ToolPoker/RL: discards RL fine-tuning and relies solely on BC. We measure both gameplay performance (against NFSP and DQN) and reasoning quality in Leduc Hold’em, with results shown in Fig.[2](https://arxiv.org/html/2602.00528v1#S5.F2 "Figure 2 ‣ 5.3 Experimental Results ‣ 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") (c) and (d). The full ToolPoker achieves the strongest overall performance, while the variants reveal complementary weaknesses. Specifically: (i) _ToolPoker/BC suffers from lower HR and weaker gameplay_, suggesting it can query the solver but fails to internalize game-theoretic reasoning patterns; (ii) _ToolPoker/RL attains higher HR but performs poorly in gameplay and FA/AC_, indicating it imitates reasoning superficially without aligning with GTO-consistent actions. These results highlight that BC provides the foundation for TIR, while RL fine-tuning aligns solver execution with GTO actions and precise derivation. Together, they enable ToolPoker to learn not only how to call the solver, but also how to integrate outputs into coherent, professional-style reasoning traces. More discussions are in Appendix[G.6](https://arxiv.org/html/2602.00528v1#A7.SS6 "G.6 Additional Discussion ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| 6 Related Work | |
| -------------- | |
| Strategic Reasoning in LLMs. Recent studies have examined LLMs in game-theoretic settings, including poker(Duan et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib21 "Gtbench: uncovering the strategic reasoning capabilities of llms via game-theoretic evaluations"); Zhai et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib64 "Fine-tuning large vision-language models as decision-making agents via reinforcement learning"); Zhuang et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib20 "Pokerbench: training large language models to become professional poker players"); Wang et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib61 "Can large language models master complex card games?")). Unlike prior work that primarily evaluates gameplay outcomes, we also analyze the _reasoning process_, identifying why LLMs fail to achieve GTO play. Moreover, we introduce the first TIR framework that leverages poker solvers for professional-level gameplay. Further discussion is in Appendix[A.1](https://arxiv.org/html/2602.00528v1#A1.SS1 "A.1 Strategic Reasoning in LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| Tool Learning on LLMs. TIR equips LLMs with external tools for domains such as math and web search(Gao et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib50 "Pal: program-aided language models"); Jin et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib26 "Search-r1: training llms to reason and leverage search engines with reinforcement learning")), which are typically fully observed and single-agent. In contrast, ToolPoker extends TIR to imperfect-information games, integrating poker solvers to ensure GTO actions and rigorous reasoning. Full details on RL and TIR are in Appendix[A.2](https://arxiv.org/html/2602.00528v1#A1.SS2 "A.2 Reinforcement Learning ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") and[A.3](https://arxiv.org/html/2602.00528v1#A1.SS3 "A.3 Tool-Integrated Reasoning of LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| 7 Conclusions and Future Works | |
| ------------------------------ | |
| In this paper, we revisit strategic reasoning in LLMs through poker with imperfect information. Our analysis shows that current LLMs fall short of professional-level play, exhibiting heuristic biases, factual misunderstandings, and a knowing–doing gap between their reasoning and actions. An initial attempt with BC and RIRL partially reduces heuristic flaws but is still not enough for precise game-theoretic derivations or competitive gameplay. To address this, we introduce ToolPoker, a TIR framework that leverages LLMs’ strength in tool use to incorporate external poker solvers. ToolPoker enables models not only to call solvers for GTO actions but also to ground their rigorous and accurate game-theoretic reasoning in solver outputs. Experiments across multiple poker tasks show that ToolPoker achieves state-of-the-art gameplay performance and produces reasoning traces that align closely with professional game-theoretic principles. Our research paves the way for further exploration of TIR in more complex strategic settings, shifting the focus beyond solely improving models’ internal policies. Further discussion of future works is provided in Appendix[I](https://arxiv.org/html/2602.00528v1#A9 "Appendix I Discussion of Future Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| 8 Ethics Statement | |
| ------------------ | |
| This paper studies LLMs in the context of poker as a rigorous benchmark for strategic reasoning under uncertainty. While poker involves gambling in practice, our experiments are conducted entirely in simulated environments without any financial transactions or human participants. Thus, this research does not pose risks related to gambling addiction or monetary harm. | |
| Our contributions focus on methodology and evaluation. We study the reasoning capabilities of LLMs, propose new training frameworks, and benchmark them against both traditional algorithms and LLM-based methods. These findings aim to deepen understanding of LLM reasoning in imperfect-information games, with potential implications for broader domains such as cybersecurity and negotiation. We acknowledge that advanced poker agents could, if misused, be deployed in real-money contexts. To mitigate this risk, we release code and datasets solely for research purposes, emphasizing their use as benchmarks for safe and reproducible evaluation. | |
| Finally, we ensured that no personally identifiable or sensitive human data were used in this work. All datasets are synthetically generated using poker solvers or LLMs. We believe the potential benefits of this paper, including advancing understanding of the limitations of LLMs’ reasoning, improving the design of tool-augmented AI, and supporting safer deployment in high-stakes domains, clearly outweigh the minimal risks. | |
| 9 Reproducibility Statement | |
| --------------------------- | |
| We have made every effort to ensure reproducibility. The details of our proposed methods, including model architectures, training objectives, and hyperparameters, are provided in Sec.[4](https://arxiv.org/html/2602.00528v1#S4 "4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") and Sec.[5](https://arxiv.org/html/2602.00528v1#S5 "5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). Experimental setups, including datasets, preprocessing steps, and evaluation protocols, are described in Sec.[3.1](https://arxiv.org/html/2602.00528v1#S3.SS1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), Sec.[4.3](https://arxiv.org/html/2602.00528v1#S4.SS3 "4.3 Experiment Analysis ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), and Sec.[5.3](https://arxiv.org/html/2602.00528v1#S5.SS3 "5.3 Experimental Results ‣ 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), with additional details in the Appendix. Our code is publicly available at [https://anonymous.4open.science/r/ToolPoker-797E](https://anonymous.4open.science/r/ToolPoker-797E). | |
| References | |
| ---------- | |
| * CyBERT: cybersecurity claim classification by fine-tuning the bert language model. Journal of Cybersecurity and Privacy, pp.615–637. Cited by: [§1](https://arxiv.org/html/2602.00528v1#S1.p1.1 "1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * M. Bowling, N. Burch, M. Johanson, and O. Tammelin (2015)Heads-up limit hold’em poker is solved. Science 347 (6218), pp.145–149. Cited by: [§B.3](https://arxiv.org/html/2602.00528v1#A2.SS3.p1.1 "B.3 Limit Texas Hold’em ‣ Appendix B Background and Rules of Poker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * N. Brown, A. Lerer, S. Gross, and T. Sandholm (2019)Deep counterfactual regret minimization. In International conference on machine learning, pp.793–802. Cited by: [5th item](https://arxiv.org/html/2602.00528v1#A3.I1.i5.p1.1 "In C.1 Comparison Methods ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§3.1](https://arxiv.org/html/2602.00528v1#S3.SS1.p1.1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§3.1](https://arxiv.org/html/2602.00528v1#S3.SS1.p2.1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * N. Brown and T. Sandholm (2019)Superhuman ai for multiplayer poker. Science 365 (6456), pp.885–890. Cited by: [5th item](https://arxiv.org/html/2602.00528v1#A3.I1.i5.p1.1 "In C.1 Comparison Methods ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§1](https://arxiv.org/html/2602.00528v1#S1.p1.1 "1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * W. Chen, X. Ma, X. Wang, and W. W. Cohen (2022)Program of thoughts prompting: disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588. Cited by: [§A.3](https://arxiv.org/html/2602.00528v1#A1.SS3.p1.1 "A.3 Tool-Integrated Reasoning of LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * Y. Chen, Y. Liu, J. Zhou, Y. Hao, J. Wang, Y. Zhang, and C. Fan (2025)R1-code-interpreter: training llms to reason with code via supervised and reinforcement learning. arXiv preprint arXiv:2505.21668. Cited by: [§A.2](https://arxiv.org/html/2602.00528v1#A1.SS2.p1.1 "A.2 Reinforcement Learning ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * A. Costarelli, M. Allen, R. Hauksson, G. Sodunke, S. Hariharan, C. Cheng, W. Li, J. Clymer, and A. Yadav (2024)Gamebench: evaluating strategic reasoning abilities of llm agents. arXiv preprint arXiv:2406.06613. Cited by: [§A.1](https://arxiv.org/html/2602.00528v1#A1.SS1.p1.1 "A.1 Strategic Reasoning in LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * D. Das, D. Banerjee, S. Aditya, and A. Kulkarni (2024)MATHSENSEI: a tool-augmented large language model for mathematical reasoning. arXiv preprint arXiv:2402.17231. Cited by: [§A.3](https://arxiv.org/html/2602.00528v1#A1.SS3.p1.1 "A.3 Tool-Integrated Reasoning of LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * J. Duan, R. Zhang, J. Diffenderfer, B. Kailkhura, L. Sun, E. Stengel-Eskin, M. Bansal, T. Chen, and K. Xu (2024)Gtbench: uncovering the strategic reasoning capabilities of llms via game-theoretic evaluations. Advances in Neural Information Processing Systems 37, pp.28219–28253. Cited by: [§A.1](https://arxiv.org/html/2602.00528v1#A1.SS1.p1.1 "A.1 Strategic Reasoning in LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§H.1](https://arxiv.org/html/2602.00528v1#A8.SS1.p1.1 "H.1 Transferability & Scalability ‣ Appendix H In-depth Analysis of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§1](https://arxiv.org/html/2602.00528v1#S1.p2.1 "1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§6](https://arxiv.org/html/2602.00528v1#S6.p1.1 "6 Related Work ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * Y. Dubois, X. Li, R. Taori, T. Zhang, I. Gulrajani, J. Ba, C. Guestrin, P. Liang, and T. Hashimoto (2023)AlpacaFarm: a simulation framework for methods that learn from human feedback. In Thirty-seventh Conference on Neural Information Processing Systems, External Links: [Link](https://openreview.net/forum?id=4hturzLcKX)Cited by: [§C.4](https://arxiv.org/html/2602.00528v1#A3.SS4.p1.2 "C.4 Full Details of Quantitative Analysis ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§3.3](https://arxiv.org/html/2602.00528v1#S3.SS3.p3.4 "3.3 In-depth Analysis: Decomposing Reasoning Flaws of LLMs ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * J. Feng, S. Huang, X. Qu, G. Zhang, Y. Qin, B. Zhong, C. Jiang, J. Chi, and W. Zhong (2025a)Retool: reinforcement learning for strategic tool use in llms. arXiv preprint arXiv:2504.11536. Cited by: [§A.3](https://arxiv.org/html/2602.00528v1#A1.SS3.p1.1 "A.3 Tool-Integrated Reasoning of LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§G.5](https://arxiv.org/html/2602.00528v1#A7.SS5.p1.2 "G.5 Implementation Details ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§G.7.1](https://arxiv.org/html/2602.00528v1#A7.SS7.SSS1.p2.1 "G.7.1 Relation to Existing Tool-use Framework ‣ G.7 Comparison with Existing Tool-use Framework ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§G.7.1](https://arxiv.org/html/2602.00528v1#A7.SS7.SSS1.p3.1 "G.7.1 Relation to Existing Tool-use Framework ‣ G.7 Comparison with Existing Tool-use Framework ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§G.7.2](https://arxiv.org/html/2602.00528v1#A7.SS7.SSS2.p1.1 "G.7.2 Empirical Comparison with ReTool ‣ G.7 Comparison with Existing Tool-use Framework ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§5.2](https://arxiv.org/html/2602.00528v1#S5.SS2.p2.4 "5.2 Training Algorithm ‣ 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * L. Feng, Z. Xue, T. Liu, and B. An (2025b)Group-in-group policy optimization for llm agent training. arXiv preprint arXiv:2505.10978. Cited by: [§A.2](https://arxiv.org/html/2602.00528v1#A1.SS2.p1.1 "A.2 Reinforcement Learning ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y. Yang, J. Callan, and G. Neubig (2023)Pal: program-aided language models. In International Conference on Machine Learning, pp.10764–10799. Cited by: [§A.3](https://arxiv.org/html/2602.00528v1#A1.SS3.p1.1 "A.3 Tool-Integrated Reasoning of LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§6](https://arxiv.org/html/2602.00528v1#S6.p2.1 "6 Related Work ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * Z. Gou, Z. Shao, Y. Gong, yelong shen, Y. Yang, M. Huang, N. Duan, and W. Chen (2024)ToRA: a tool-integrated reasoning agent for mathematical problem solving. In The Twelfth International Conference on Learning Representations, Cited by: [§A.3](https://arxiv.org/html/2602.00528v1#A1.SS3.p1.1 "A.3 Tool-Integrated Reasoning of LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. (2024)The llama 3 herd of models. arXiv preprint arXiv:2407.21783. Cited by: [§3.2](https://arxiv.org/html/2602.00528v1#S3.SS2.p1.1 "3.2 Comparison with Traditional Method ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. (2025)Deepseek-r1: incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948. Cited by: [§A.2](https://arxiv.org/html/2602.00528v1#A1.SS2.p1.1 "A.2 Reinforcement Learning ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§D.1](https://arxiv.org/html/2602.00528v1#A4.SS1.p1.1 "D.1 Full details of Regret-Inspired RL Fine-Tuning ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§4](https://arxiv.org/html/2602.00528v1#S4.p1.2 "4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * J. Guo, B. Yang, P. Yoo, B. Y. Lin, Y. Iwasawa, and Y. Matsuo (2023)Suspicion-agent: playing imperfect information games with theory of mind aware gpt-4. arXiv preprint arXiv:2309.17277. Cited by: [§A.1](https://arxiv.org/html/2602.00528v1#A1.SS1.p1.1 "A.1 Strategic Reasoning in LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [2nd item](https://arxiv.org/html/2602.00528v1#A3.I1.i2.p1.1 "In C.1 Comparison Methods ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [3rd item](https://arxiv.org/html/2602.00528v1#A3.I1.i3.p1.1 "In C.1 Comparison Methods ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§H.1](https://arxiv.org/html/2602.00528v1#A8.SS1.p1.1 "H.1 Transferability & Scalability ‣ Appendix H In-depth Analysis of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§1](https://arxiv.org/html/2602.00528v1#S1.p2.1 "1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§2](https://arxiv.org/html/2602.00528v1#S2.p1.1 "2 Backgrounds and Preliminaries ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§3.1](https://arxiv.org/html/2602.00528v1#S3.SS1.p1.1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§3.1](https://arxiv.org/html/2602.00528v1#S3.SS1.p2.1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * A. Gupta (2023)Are chatgpt and gpt-4 good poker players?–a pre-flop analysis. arXiv preprint arXiv:2308.12466. Cited by: [§A.1](https://arxiv.org/html/2602.00528v1#A1.SS1.p1.1 "A.1 Strategic Reasoning in LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * J. C. Harsanyi (1995)Games with incomplete information. The American Economic Review, pp.291–303. Cited by: [§1](https://arxiv.org/html/2602.00528v1#S1.p1.1 "1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * J. Heinrich and D. Silver (2016)Deep reinforcement learning from self-play in imperfect-information games. arXiv preprint arXiv:1603.01121. Cited by: [§A.1](https://arxiv.org/html/2602.00528v1#A1.SS1.p1.1 "A.1 Strategic Reasoning in LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [1st item](https://arxiv.org/html/2602.00528v1#A3.I1.i1.p1.1 "In C.1 Comparison Methods ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§D.1](https://arxiv.org/html/2602.00528v1#A4.SS1.p1.1 "D.1 Full details of Regret-Inspired RL Fine-Tuning ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [Appendix E](https://arxiv.org/html/2602.00528v1#A5.p1.13 "Appendix E Methodology of SPRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§1](https://arxiv.org/html/2602.00528v1#S1.p2.1 "1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§1](https://arxiv.org/html/2602.00528v1#S1.p3.1 "1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§3.1](https://arxiv.org/html/2602.00528v1#S3.SS1.p2.1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§4](https://arxiv.org/html/2602.00528v1#S4.p1.2 "4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * [21]N. Herr, F. Acero, R. Raileanu, M. Perez-Ortiz, and Z. Li Large language models are bad game theoretic reasoners: evaluating performance and bias in two-player non-zero-sum games. In ICML 2024 Workshop on LLMs and Cognition, Cited by: [§A.1](https://arxiv.org/html/2602.00528v1#A1.SS1.p1.1 "A.1 Strategic Reasoning in LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * C. Huang, Y. Cao, Y. Wen, T. Zhou, and Y. Zhang (2024)PokerGPT: an end-to-end lightweight solver for multi-player texas hold’em via large language model. arXiv preprint arXiv:2401.06781. Cited by: [§A.1](https://arxiv.org/html/2602.00528v1#A1.SS1.p1.1 "A.1 Strategic Reasoning in LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§2](https://arxiv.org/html/2602.00528v1#S2.p1.1 "2 Backgrounds and Preliminaries ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. (2024)Gpt-4o system card. arXiv preprint arXiv:2410.21276. Cited by: [§3.2](https://arxiv.org/html/2602.00528v1#S3.SS2.p1.1 "3.2 Comparison with Traditional Method ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * H. Jiang, L. Ge, Y. Gao, J. Wang, and R. Song (2023)Large language model for causal decision making. arXiv preprint arXiv:2312.17122. Cited by: [§1](https://arxiv.org/html/2602.00528v1#S1.p1.1 "1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * B. Jin, H. Zeng, Z. Yue, J. Yoon, S. Arik, D. Wang, H. Zamani, and J. Han (2025)Search-r1: training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516. Cited by: [§A.3](https://arxiv.org/html/2602.00528v1#A1.SS3.p1.1 "A.3 Tool-Integrated Reasoning of LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§G.5](https://arxiv.org/html/2602.00528v1#A7.SS5.p1.2 "G.5 Implementation Details ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§6](https://arxiv.org/html/2602.00528v1#S6.p2.1 "6 Related Work ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * H. W. Kuhn (2016)A simplified two-person poker. Contributions to the Theory of Games 1, pp.97–103. Cited by: [§B.1](https://arxiv.org/html/2602.00528v1#A2.SS1.p1.1 "B.1 Kuhn Poker ‣ Appendix B Background and Rules of Poker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * W. Lin, J. Roberts, Y. Yang, S. Albanie, Z. Lu, and K. Han (2025)GAMEBoT: transparent assessment of LLM reasoning in games. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), W. Che, J. Nabende, and M. T. Pilehvar (Eds.), pp.7656–7682. Cited by: [§1](https://arxiv.org/html/2602.00528v1#S1.p2.1 "1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * Y. Meng, M. Xia, and D. Chen (2024)Simpo: simple preference optimization with a reference-free reward. Advances in Neural Information Processing Systems 37, pp.124198–124235. Cited by: [§A.2](https://arxiv.org/html/2602.00528v1#A1.SS2.p1.1 "A.2 Reinforcement Learning ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al. (2015)Human-level control through deep reinforcement learning. nature 518 (7540), pp.529–533. Cited by: [2nd item](https://arxiv.org/html/2602.00528v1#A3.I1.i2.p1.1 "In C.1 Comparison Methods ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§3.1](https://arxiv.org/html/2602.00528v1#S3.SS1.p2.1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * N. Muennighoff, Z. Yang, W. Shi, X. L. Li, L. Fei-Fei, H. Hajishirzi, L. Zettlemoyer, P. Liang, E. Candès, and T. Hashimoto (2025)S1: simple test-time scaling. arXiv preprint arXiv:2501.19393. Cited by: [§4.1](https://arxiv.org/html/2602.00528v1#S4.SS1.p1.9 "4.1 Behavior Cloning ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * J. F. Nash Jr (1950)Equilibrium points in n-person games. Proceedings of the national academy of sciences 36 (1), pp.48–49. Cited by: [Definition B.1](https://arxiv.org/html/2602.00528v1#A2.Thmdefinition1 "Definition B.1 (Nash Equilibrium (Nash Jr, 1950)). ‣ B.5 Game-theoretic Reasoning ‣ Appendix B Background and Rules of Poker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * OpenAI (2024)OpenAI o3 and o4-mini system card. External Links: [Link](https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf)Cited by: [§3.2](https://arxiv.org/html/2602.00528v1#S3.SS2.p1.1 "3.2 Comparison with Traditional Method ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * OpenAI (2025)Gpt-4.1 system card. External Links: [Link](https://platform.openai.com/docs/models/gpt-4.1)Cited by: [§C.4](https://arxiv.org/html/2602.00528v1#A3.SS4.p1.2 "C.4 Full Details of Quantitative Analysis ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§3.2](https://arxiv.org/html/2602.00528v1#S3.SS2.p1.1 "3.2 Comparison with Traditional Method ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * Qwen (2024)Qwen2.5: a party of foundation models. External Links: [Link](https://qwenlm.github.io/blog/qwen2.5/)Cited by: [§3.2](https://arxiv.org/html/2602.00528v1#S3.SS2.p1.1 "3.2 Comparison with Traditional Method ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn (2023)Direct preference optimization: your language model is secretly a reward model. Advances in neural information processing systems 36, pp.53728–53741. Cited by: [§A.2](https://arxiv.org/html/2602.00528v1#A1.SS2.p1.1 "A.2 Reinforcement Learning ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom (2023)Toolformer: language models can teach themselves to use tools. Advances in Neural Information Processing Systems 36, pp.68539–68551. Cited by: [§G.7.1](https://arxiv.org/html/2602.00528v1#A7.SS7.SSS1.p2.1 "G.7.1 Relation to Existing Tool-use Framework ‣ G.7 Comparison with Existing Tool-use Framework ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§G.7.1](https://arxiv.org/html/2602.00528v1#A7.SS7.SSS1.p3.1 "G.7.1 Relation to Existing Tool-use Framework ‣ G.7 Comparison with Existing Tool-use Framework ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel (2015)High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438. Cited by: [§D.1](https://arxiv.org/html/2602.00528v1#A4.SS1.p3.13 "D.1 Full details of Regret-Inspired RL Fine-Tuning ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [Appendix E](https://arxiv.org/html/2602.00528v1#A5.p2.13 "Appendix E Methodology of SPRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§G.4](https://arxiv.org/html/2602.00528v1#A7.SS4.p2.12 "G.4 RL Fine-tuning Algorithm for TIR ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§4.2](https://arxiv.org/html/2602.00528v1#S4.SS2.p3.13 "4.2 Regret-Inspired RL Fine-Tuning ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov (2017)Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347. Cited by: [§A.2](https://arxiv.org/html/2602.00528v1#A1.SS2.p1.1 "A.2 Reinforcement Learning ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§D.1](https://arxiv.org/html/2602.00528v1#A4.SS1.p3.14 "D.1 Full details of Regret-Inspired RL Fine-Tuning ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [Appendix E](https://arxiv.org/html/2602.00528v1#A5.p2.9 "Appendix E Methodology of SPRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§4.2](https://arxiv.org/html/2602.00528v1#S4.SS2.p3.14 "4.2 Regret-Inspired RL Fine-Tuning ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§5.2](https://arxiv.org/html/2602.00528v1#S5.SS2.p2.4 "5.2 Training Algorithm ‣ 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu, et al. (2024)Deepseekmath: pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300. Cited by: [Appendix E](https://arxiv.org/html/2602.00528v1#A5.p2.13 "Appendix E Methodology of SPRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y. Peng, H. Lin, and C. Wu (2024)HybridFlow: a flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256. Cited by: [§G.5](https://arxiv.org/html/2602.00528v1#A7.SS5.p1.2 "G.5 Implementation Details ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * E. Steinberger (2019)Single deep counterfactual regret minimization. arXiv preprint arXiv:1901.07621. Cited by: [§3.1](https://arxiv.org/html/2602.00528v1#S3.SS1.p1.1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * O. Tammelin (2014)Solving large imperfect information games using cfr+. arXiv preprint arXiv:1407.5042. Cited by: [4th item](https://arxiv.org/html/2602.00528v1#A3.I1.i4.p1.1 "In C.1 Comparison Methods ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§D.5](https://arxiv.org/html/2602.00528v1#A4.SS5.p1.1 "D.5 Implementation Details of BC-RIRL ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§1](https://arxiv.org/html/2602.00528v1#S1.p3.1 "1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§3.1](https://arxiv.org/html/2602.00528v1#S3.SS1.p2.1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§4.1](https://arxiv.org/html/2602.00528v1#S4.SS1.p1.9 "4.1 Behavior Cloning ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * T. Vu, M. Iyyer, X. Wang, N. Constant, J. Wei, J. Wei, C. Tar, Y. Sung, D. Zhou, Q. Le, et al. (2023)Freshllms: refreshing large language models with search engine augmentation. arXiv preprint arXiv:2310.03214. Cited by: [§A.3](https://arxiv.org/html/2602.00528v1#A1.SS3.p1.1 "A.3 Tool-Integrated Reasoning of LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * W. Wang, F. Bie, J. Chen, D. Zhang, S. Huang, E. Kharlamov, and J. Tang (2025)Can large language models master complex card games?. arXiv preprint arXiv:2509.01328. Cited by: [§A.1](https://arxiv.org/html/2602.00528v1#A1.SS1.p1.1 "A.1 Strategic Reasoning in LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§G.5](https://arxiv.org/html/2602.00528v1#A7.SS5.p1.2 "G.5 Implementation Details ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§H.1](https://arxiv.org/html/2602.00528v1#A8.SS1.p1.1 "H.1 Transferability & Scalability ‣ Appendix H In-depth Analysis of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§4](https://arxiv.org/html/2602.00528v1#S4.p1.2 "4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§6](https://arxiv.org/html/2602.00528v1#S6.p1.1 "6 Related Work ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * Z. Wei, W. Yao, Y. Liu, W. Zhang, Q. Lu, L. Qiu, C. Yu, P. Xu, C. Zhang, B. Yin, et al. (2025)Webagent-r1: training web agents via end-to-end multi-turn reinforcement learning. arXiv preprint arXiv:2505.16421. Cited by: [§A.2](https://arxiv.org/html/2602.00528v1#A1.SS2.p1.1 "A.2 Reinforcement Learning ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * T. Xiao, Y. Yuan, Z. Chen, M. Li, S. Liang, Z. Ren, and V. G. Honavar (2025)SimPER: a minimalist approach to preference alignment without hyperparameters. arXiv preprint arXiv:2502.00883. Cited by: [§A.2](https://arxiv.org/html/2602.00528v1#A1.SS2.p1.1 "A.2 Reinforcement Learning ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * Z. Xu, Z. Wu, Y. Zhou, A. Feng, K. Zhou, S. Woo, K. Ramnath, Y. Tian, X. Qi, W. Qiu, et al. (2025)Beyond correctness: rewarding faithful reasoning in retrieval-augmented generation. arXiv preprint arXiv:2510.13272. Cited by: [1st item](https://arxiv.org/html/2602.00528v1#A8.I4.i1.p1.1 "In H.2 Error analysis in ToolPoker ‣ Appendix H In-depth Analysis of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. (2025)Qwen3 technical report. arXiv preprint arXiv:2505.09388. Cited by: [§3.2](https://arxiv.org/html/2602.00528v1#S3.SS2.p1.1 "3.2 Comparison with Traditional Method ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y. Cao (2022)React: synergizing reasoning and acting in language models. In The eleventh international conference on learning representations, Cited by: [§G.7.1](https://arxiv.org/html/2602.00528v1#A7.SS7.SSS1.p2.1 "G.7.1 Relation to Existing Tool-use Framework ‣ G.7 Comparison with Existing Tool-use Framework ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * T. Zaciragic, A. Plaat, and K. J. Batenburg (2025)Analysis of bluffing by dqn and cfr in leduc hold’em poker. arXiv preprint arXiv:2509.04125. Cited by: [§B.2](https://arxiv.org/html/2602.00528v1#A2.SS2.p1.1 "B.2 Leduc Hold’em ‣ Appendix B Background and Rules of Poker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * D. Zha, K. Lai, S. Huang, Y. Cao, K. Reddy, J. Vargas, A. Nguyen, R. Wei, J. Guo, and X. Hu (2021a)RLCard: a platform for reinforcement learning in card games. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Cited by: [§3.1](https://arxiv.org/html/2602.00528v1#S3.SS1.p1.1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * D. Zha, J. Xie, W. Ma, S. Zhang, X. Lian, X. Hu, and J. Liu (2021b)Douzero: mastering doudizhu with self-play deep reinforcement learning. In international conference on machine learning, pp.12333–12344. Cited by: [2nd item](https://arxiv.org/html/2602.00528v1#A3.I1.i2.p1.1 "In C.1 Comparison Methods ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [3rd item](https://arxiv.org/html/2602.00528v1#A3.I1.i3.p1.1 "In C.1 Comparison Methods ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§3.1](https://arxiv.org/html/2602.00528v1#S3.SS1.p2.1 "3.1 Experimental Setup ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * S. Zhai, H. Bai, Z. Lin, J. Pan, P. Tong, Y. Zhou, A. Suhr, S. Xie, Y. LeCun, Y. Ma, et al. (2024)Fine-tuning large vision-language models as decision-making agents via reinforcement learning. Advances in neural information processing systems 37, pp.110935–110971. Cited by: [§A.1](https://arxiv.org/html/2602.00528v1#A1.SS1.p1.1 "A.1 Strategic Reasoning in LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§6](https://arxiv.org/html/2602.00528v1#S6.p1.1 "6 Related Work ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * R. Zhang, Z. Xu, C. Ma, C. Yu, W. Tu, W. Tang, S. Huang, D. Ye, W. Ding, Y. Yang, et al. (2024)A survey on self-play methods in reinforcement learning. arXiv preprint arXiv:2408.01072. Cited by: [Appendix E](https://arxiv.org/html/2602.00528v1#A5.p1.13 "Appendix E Methodology of SPRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * E. Zhao, R. Yan, J. Li, K. Li, and J. Xing (2022)Alphaholdem: high-performance artificial intelligence for heads-up no-limit poker via end-to-end reinforcement learning. In Proceedings of the AAAI conference on artificial intelligence, Vol. 36, pp.4689–4697. Cited by: [§D.1](https://arxiv.org/html/2602.00528v1#A4.SS1.p1.1 "D.1 Full details of Regret-Inspired RL Fine-Tuning ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * Y. Zheng, D. Fu, X. Hu, X. Cai, L. Ye, P. Lu, and P. Liu (2025)Deepresearcher: scaling deep research via reinforcement learning in real-world environments. arXiv preprint arXiv:2504.03160. Cited by: [§A.3](https://arxiv.org/html/2602.00528v1#A1.SS3.p1.1 "A.3 Tool-Integrated Reasoning of LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * R. Zhuang, A. Gupta, R. Yang, A. Rahane, Z. Li, and G. Anumanchipalli (2025)Pokerbench: training large language models to become professional poker players. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39, pp.26175–26182. Cited by: [§A.1](https://arxiv.org/html/2602.00528v1#A1.SS1.p1.1 "A.1 Strategic Reasoning in LLMs ‣ Appendix A Full Details of Related Works ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§H.1](https://arxiv.org/html/2602.00528v1#A8.SS1.p1.1 "H.1 Transferability & Scalability ‣ Appendix H In-depth Analysis of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§1](https://arxiv.org/html/2602.00528v1#S1.p2.1 "1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§6](https://arxiv.org/html/2602.00528v1#S6.p1.1 "6 Related Work ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * M. Zinkevich, M. Johanson, M. Bowling, and C. Piccione (2007)Regret minimization in games with incomplete information. Advances in neural information processing systems 20. Cited by: [§B.2](https://arxiv.org/html/2602.00528v1#A2.SS2.p2.1 "B.2 Leduc Hold’em ‣ Appendix B Background and Rules of Poker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [4th item](https://arxiv.org/html/2602.00528v1#A3.I1.i4.p1.1 "In C.1 Comparison Methods ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), [§1](https://arxiv.org/html/2602.00528v1#S1.p2.1 "1 Introduction ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| Appendix A Full Details of Related Works | |
| ---------------------------------------- | |
| ### A.1 Strategic Reasoning in LLMs | |
| With the rapid progress of LLMs’ cognitive capabilities, recent studies have begun to investigate their potential for strategic reasoning in game-theoretic settings(Duan et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib21 "Gtbench: uncovering the strategic reasoning capabilities of llms via game-theoretic evaluations"); Gupta, [2023](https://arxiv.org/html/2602.00528v1#bib.bib60 "Are chatgpt and gpt-4 good poker players?–a pre-flop analysis"); Huang et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib33 "PokerGPT: an end-to-end lightweight solver for multi-player texas hold’em via large language model"); Zhuang et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib20 "Pokerbench: training large language models to become professional poker players"); Wang et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib61 "Can large language models master complex card games?")). GTBench(Duan et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib21 "Gtbench: uncovering the strategic reasoning capabilities of llms via game-theoretic evaluations")) introduces a comprehensive benchmark covering a variety of games to assess LLMs’ ability to follow equilibrium principles. Gupta ([2023](https://arxiv.org/html/2602.00528v1#bib.bib60 "Are chatgpt and gpt-4 good poker players?–a pre-flop analysis")) provide one of the first empirical evaluations of GPT-4 and ChatGPT in poker, revealing systematic deviations from GTO gameplay. Guo et al. ([2023](https://arxiv.org/html/2602.00528v1#bib.bib6 "Suspicion-agent: playing imperfect information games with theory of mind aware gpt-4")) explore theory-of-mind (ToM) prompting in Leduc Hold’em, showing that GPT-4 with ToM reasoning can outperform neural baselines such as NFSP(Heinrich and Silver, [2016](https://arxiv.org/html/2602.00528v1#bib.bib8 "Deep reinforcement learning from self-play in imperfect-information games")). PokerGPT(Huang et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib33 "PokerGPT: an end-to-end lightweight solver for multi-player texas hold’em via large language model")) fine-tunes LLMs on poker-specific data and observes improvements in gameplay, while PokerBench(Zhuang et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib20 "Pokerbench: training large language models to become professional poker players")) constructs a benchmark on No-Limit Hold’em. More recently, Wang et al. ([2025](https://arxiv.org/html/2602.00528v1#bib.bib61 "Can large language models master complex card games?")) curate large-scale action-only datasets (more than 400k+ examples) and demonstrate gains in card games by fine-tuning LLMs on such data. Additional works(Costarelli et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib62 "Gamebench: evaluating strategic reasoning abilities of llm agents"); [Herr et al.,](https://arxiv.org/html/2602.00528v1#bib.bib63 "Large language models are bad game theoretic reasoners: evaluating performance and bias in two-player non-zero-sum games")) also investigate gameplay performance and biases of LLMs in other strategic games, such as Tic-Tac-Toe and Prisoner’s Dilemma. In addition to exploring strategic reasoning in text-based settings, Zhai et al. ([2024](https://arxiv.org/html/2602.00528v1#bib.bib64 "Fine-tuning large vision-language models as decision-making agents via reinforcement learning")) extend this line of work to the multimodal domain by fine-tuning large vision–language models (VLMs) with RL. This paper leverages CoT-style intermediate reasoning to guide VLMs through multi-step decision-making tasks, including poker. This demonstrates that RL can enable VLMs to effectively explore and execute visual–textual reasoning sequences. | |
| Our work differs in two key aspects: (i) unlike prior works that mainly evaluate or improve LLMs’ _actions_, we further analyze their _reasoning process_, asking how LLMs think before acting and why they fail to achieve GTO play; and (ii) rather than relying on internal policies alone, we propose the first tool-integrated reasoning framework that leverages poker solvers, enabling both equilibrium-consistent actions and professional-style game-theoretic reasoning. | |
| ### A.2 Reinforcement Learning | |
| Reinforcement Learning (RL) has emerged as a powerful mechanism for enhancing the reasoning abilities of LLMs. In context of LLMs, RL was first introduced through Reinforcement Learning from Human Feedback (RLHF) to align outputs with human preferences via algorithms such as Proximal Policy Optimization (PPO)(Schulman et al., [2017](https://arxiv.org/html/2602.00528v1#bib.bib13 "Proximal policy optimization algorithms")). Subsequent works proposed more advanced techniques such as Direct Preference Optimization (DPO)(Rafailov et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib55 "Direct preference optimization: your language model is secretly a reward model")), SimPO(Meng et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib54 "Simpo: simple preference optimization with a reference-free reward")), and SimPER(Xiao et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib57 "SimPER: a minimalist approach to preference alignment without hyperparameters")), which improve the stability and efficiency of RL training. More recently, researchers have explored both outcome-based rewards(Guo et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib24 "Deepseek-r1: incentivizing reasoning capability in llms via reinforcement learning")) and step-level rewards(Feng et al., [2025b](https://arxiv.org/html/2602.00528v1#bib.bib16 "Group-in-group policy optimization for llm agent training")) to improve problem-solving in domains such as mathematical reasoning(Guo et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib24 "Deepseek-r1: incentivizing reasoning capability in llms via reinforcement learning")), code generation(Chen et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib58 "R1-code-interpreter: training llms to reason with code via supervised and reinforcement learning")), and web retrieval(Wei et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib59 "Webagent-r1: training web agents via end-to-end multi-turn reinforcement learning")). In this work, we investigate RL for imperfect-information games, where sparse outcomes, hidden states, and adversarial dynamics make reward design particularly challenging. Our analysis shows that _both outcome-based and step-level RL signals are ineffective at improving LLMs’ internal policies in poker_, motivating the use of solver-derived, regret-inspired signals as more reliable feedback. | |
| ### A.3 Tool-Integrated Reasoning of LLMs | |
| Tool-integrated reasoning (TIR) has emerged as a promising approach to extend the capabilities of LLMs. Prior works demonstrate improvements in domains requiring precise computation or external knowledge, including mathematical calculation(Das et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib47 "MATHSENSEI: a tool-augmented large language model for mathematical reasoning")), programming(Chen et al., [2022](https://arxiv.org/html/2602.00528v1#bib.bib45 "Program of thoughts prompting: disentangling computation from reasoning for numerical reasoning tasks")), and web search(Vu et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib46 "Freshllms: refreshing large language models with search engine augmentation")). Early studies such as PAL(Gao et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib50 "Pal: program-aided language models")) prompt LLMs to generate code for execution, while ToRA(Gou et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib53 "ToRA: a tool-integrated reasoning agent for mathematical problem solving")) curate tool-use trajectories and apply imitation learning to train tool invocation. More recently, RL has been explored as an effective framework to improve TIR(Jin et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib26 "Search-r1: training llms to reason and leverage search engines with reinforcement learning"); Feng et al., [2025a](https://arxiv.org/html/2602.00528v1#bib.bib38 "Retool: reinforcement learning for strategic tool use in llms"); Zheng et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib51 "Deepresearcher: scaling deep research via reinforcement learning in real-world environments")). For instance, Search-R1(Jin et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib26 "Search-r1: training llms to reason and leverage search engines with reinforcement learning")) enables search-engine queries for QA, ReTool(Feng et al., [2025a](https://arxiv.org/html/2602.00528v1#bib.bib38 "Retool: reinforcement learning for strategic tool use in llms")) improves mathematical reasoning with a code sandbox, and DeepResearcher(Zheng et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib51 "Deepresearcher: scaling deep research via reinforcement learning in real-world environments")) scales multi-hop retrieval and tool orchestration. Despite these advances, existing TIR research largely targets fully observed, single-agent tasks. In contrast, poker involves stochasticity, hidden information, and adversarial dynamics, where tools must compute equilibrium-consistent strategies and counterfactual values rather than deterministic answers. To the best of our knowledge, ToolPoker is the first TIR framework for imperfect-information games. It integrates external poker solvers into LLMs, teaching them how to invoke solvers, and grounding their reasoning traces in solver outputs. This ensures rigorous, precise game-theoretic reasoning and GTO-consistent play, bridging prior works on strategic reasoning, RL, and TIR. | |
| Appendix B Background and Rules of Poker | |
| ---------------------------------------- | |
| In this section, we introduce the poker variants studied in our work. These games are widely used in the literature as benchmarks for imperfect-information reasoning because they balance tractability with the core challenges of hidden information, sequential decision-making, and stochasticity. | |
| ### B.1 Kuhn Poker | |
| Kuhn poker(Kuhn, [2016](https://arxiv.org/html/2602.00528v1#bib.bib35 "A simplified two-person poker")) is a minimalistic poker game designed to capture the essence of imperfect-information decision-making in a tractable form. The game is played with only three cards (e.g., Jack, Queen, King) and two players. Each player antes one chip, and a single betting round follows. Each player receives one private card, and the third card remains hidden. | |
| Players can either check/bet (if no bet has been made) or call/fold (if a bet has been made). Because of its small size—only a handful of information sets—Kuhn poker admits closed-form solutions, including simple Nash equilibrium strategies that mix between bluffing with weak hands and value betting with strong hands. Despite its simplicity, it highlights the central strategic dilemma of poker: balancing deception and value extraction under hidden information. | |
| ### B.2 Leduc Hold’em | |
| Leduc Hold’em(Zaciragic et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib37 "Analysis of bluffing by dqn and cfr in leduc hold’em poker")) is a widely studied poker variant that extends Kuhn by introducing multiple betting rounds and public information. The game is played with a small deck of six cards consisting of two suits and three ranks. Each player antes one chip and receives a single private card. A first round of betting occurs, after which a single public card is revealed. A second round of betting then follows. | |
| The addition of the public card dramatically increases strategic depth: players must update beliefs about opponents’ ranges as new information is revealed, balance bluffing and value bets across streets, and plan actions that maximize long-term expected value. Although still small enough for exact or approximate equilibrium computation (e.g., via CFR(Zinkevich et al., [2007](https://arxiv.org/html/2602.00528v1#bib.bib12 "Regret minimization in games with incomplete information"))), Leduc captures essential poker phenomena such as semi-bluffing, slow-playing, and range narrowing, making it a standard benchmark for algorithmic and LLM-based poker research. | |
| ### B.3 Limit Texas Hold’em | |
| Limit Texas Hold’em Bowling et al. ([2015](https://arxiv.org/html/2602.00528v1#bib.bib36 "Heads-up limit hold’em poker is solved")) is a more realistic and complex poker variant that is closely related to the full game of Texas Hold’em, which is the most popular poker format in practice. The deck consists of 52 52 standard playing cards. Each player is dealt two private hole cards, and up to five public community cards are revealed in stages: the flop (three cards), the turn (one card), and the river (one card). At each stage, players take turns acting in one of several betting rounds. | |
| Unlike No-Limit Hold’em, bet sizes in Limit Hold’em are fixed and restricted to small or big bets depending on the round. Each hand therefore unfolds as a sequence of structured betting decisions, but the state space remains extremely large compared to Kuhn or Leduc. The presence of multiple streets, large range interactions, and complex pot-odds considerations make Limit Hold’em a significantly more challenging testbed for LLMs and reinforcement learning algorithms. Professional-level play in this environment demands mastery of equilibrium-based reasoning as well as opponent exploitation—skills that current LLMs struggle to replicate. | |
| ### B.4 Additional Details of Background and Preliminary | |
| ### B.5 Game-theoretic Reasoning | |
| In poker, game-theoretic reasoning grounded in Nash Equilibrium is essential for professional-level play. A Nash Equilibrium represents a stable outcome in which each player’s strategy is an optimal response to the others. Formally: | |
| ###### Definition B.1(Nash Equilibrium(Nash Jr, [1950](https://arxiv.org/html/2602.00528v1#bib.bib42 "Equilibrium points in n-person games"))). | |
| A Nash Equilibrium is a strategy profile in a game where no player can unilaterally improve their payoff by deviating from their current strategy, assuming the other players’ strategies remain unchanged. Formally, a strategy profile (a 1∗,a 2∗,…,a n∗)(a_{1}^{*},a_{2}^{*},\ldots,a_{n}^{*}) is a Nash Equilibrium if, for every player i i: | |
| U i(a i∗,a−i∗)≥U i(a i,a−i∗),∀a i∈A i U_{i}(a_{i}^{*},a_{-i}^{*})\geq U_{i}(a_{i},a_{-i}^{*}),\quad\forall a_{i}\in A_{i}(5) | |
| where A i A_{i} denotes the set of feasible actions for player i i, U i U_{i} is the utility function (expected payoff) of player i i, and a−i∗a_{-i}^{*} represents the equilibrium strategies of all players other than i i. | |
| Rather than relying solely on heuristics or pattern recognition, professional players systematically evaluate equity, ranges, and pot odds within a game-theoretic framework, thereby providing an optimal action. An illustrative example of such game-theoretic reasoning in practice is in Appendix[B.6](https://arxiv.org/html/2602.00528v1#A2.SS6 "B.6 Professional Players in Poker ‣ Appendix B Background and Rules of Poker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| ### B.6 Professional Players in Poker | |
| To illustrate how professional poker players think, we provide a real example from the blog of a well-known Texas Hold’em professional player 1 1 1[https://www.partypoker.com/blog/en/its-the-same-game-but-it-isnt.html](https://www.partypoker.com/blog/en/its-the-same-game-but-it-isnt.html). Unlike casual players who rely on intuition, professionals systematically evaluate a wide range of factors before acting, including: | |
| * •Game context: What are the stack sizes, pot size, and stack-to-pot ratio? | |
| * •Ranges: What range of hands should I continue with? What range does my opponent have? How does the board interact with these ranges, and which player benefits most? | |
| * •Board texture and big hands: Who holds the larger share of strong hands in this spot? | |
| * •Mixed strategies: What is my optimal mix between actions (e.g., 3-betting vs. calling, check-calling vs. check-raising)? | |
| * •Bet sizing: How many bet sizes do I need here (e.g., two sizes such as 30% pot and 90% pot)? Which size does my hand prefer relative to my overall range? | |
| * •Randomization: How do I randomize between actions to stay balanced (e.g., using a chip marker to decide frequencies)? | |
| * •Opponent modeling: What is my opponent’s likely response to my bet? What physical tells, history, or reads do I have? At what strategic level are they operating, and what exploits should I consider? | |
| This example shows that professional play is grounded in equilibrium-based reasoning, probabilistic mixing, and careful opponent modeling, far beyond heuristic or surface-level decision making. | |
| Our behavior datasets are designed with these principles in mind, encouraging LLMs to reason through such questions. Details of the text-only BC dataset curation and TIR-enable BC dataset curation are provided in Appendix[D.3](https://arxiv.org/html/2602.00528v1#A4.SS3 "D.3 Additional Details of Behavior Cloning ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") and Appendix[G.2](https://arxiv.org/html/2602.00528v1#A7.SS2 "G.2 TIR BC Reasoning Dataset Curation ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), respectively. | |
| Appendix C Additional Details of Preliminary Analysis in Sec.[3](https://arxiv.org/html/2602.00528v1#S3 "3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") | |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |
| ### C.1 Comparison Methods | |
| To comprehensively evaluate the performance of LLMs in playing poker, we consider both _traditional RL-based baselines_ and _rule-based solver baselines_. RL methods serve as learning-based references that have been widely applied to imperfect-information games, while rule-based solvers provide near-equilibrium strategies that approximate ground truth. Specifically, we include the following methods: | |
| * •NFSP(Heinrich and Silver, [2016](https://arxiv.org/html/2602.00528v1#bib.bib8 "Deep reinforcement learning from self-play in imperfect-information games")): Neural Fictitious Self-Play is a pioneering framework for learning approximate Nash equilibria in imperfect-information games. It combines reinforcement learning to approximate best responses with supervised learning to approximate average strategies, enabling agents to learn directly from self-play experience. | |
| * •DQN Mnih et al. ([2015](https://arxiv.org/html/2602.00528v1#bib.bib10 "Human-level control through deep reinforcement learning")): Deep Q-Network was one of the first breakthroughs in deep RL for sequential decision-making. Although originally designed for perfect-information environments such as Atari, subsequent works(Zha et al., [2021b](https://arxiv.org/html/2602.00528v1#bib.bib11 "Douzero: mastering doudizhu with self-play deep reinforcement learning"); Guo et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib6 "Suspicion-agent: playing imperfect information games with theory of mind aware gpt-4")) have adopted it as a baseline for imperfect-information games, including poker. | |
| * •DMC Zha et al. ([2021b](https://arxiv.org/html/2602.00528v1#bib.bib11 "Douzero: mastering doudizhu with self-play deep reinforcement learning")): The Deep Monte Carlo (DMC) algorithm is originally proposed for the Chinese card game DouDizhu. It leverages large-scale self-play with Monte Carlo policy optimization and demonstrates strong performance in complex imperfect-information card games. Following prior works(Zha et al., [2021b](https://arxiv.org/html/2602.00528v1#bib.bib11 "Douzero: mastering doudizhu with self-play deep reinforcement learning"); Guo et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib6 "Suspicion-agent: playing imperfect information games with theory of mind aware gpt-4")), we adapt DMC as a baseline for poker. | |
| * •CFR+(Tammelin, [2014](https://arxiv.org/html/2602.00528v1#bib.bib19 "Solving large imperfect information games using cfr+")): Counterfactual Regret Minimization (CFR)(Zinkevich et al., [2007](https://arxiv.org/html/2602.00528v1#bib.bib12 "Regret minimization in games with incomplete information")) is a foundational algorithm for solving imperfect-information games, converging to Nash equilibrium by iteratively minimizing counterfactual regret at each information set. CFR+ enhances CFR with linear regret updates and warm-start averaging, greatly accelerating convergence. It has become the de facto standard solver in large-scale poker domains and serves as a strong rule-based baseline in our evaluation. | |
| * •DeepCFR Brown et al. ([2019](https://arxiv.org/html/2602.00528v1#bib.bib5 "Deep counterfactual regret minimization")): Building on CFR, DeepCFR employs neural function approximation to replace tabular regret tables, thereby generalizing across information sets. While CFR+ is provably effective, its computational cost grows prohibitively in large games such as Texas Hold’em. DeepCFR addresses this limitation by learning regret values via neural networks, making it applicable to larger domains and forming the basis of superhuman agents such as Libratus(Brown and Sandholm, [2019](https://arxiv.org/html/2602.00528v1#bib.bib44 "Superhuman ai for multiplayer poker")). | |
| ### C.2 Case Studies of LLMs’ Reasoning Flaws | |
| We provide the examples from Qwen2.5-3B and GPT-4o in Tab.[13](https://arxiv.org/html/2602.00528v1#A10.T13 "Table 13 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") and[14](https://arxiv.org/html/2602.00528v1#A10.T14 "Table 14 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") to illustrate why LLMs fail in playing poker. From these tables, we consistently observe three limitations of LLMs in playing poker: (1) Heuristic Reasoning; (ii) Factual Misunderstanding; and (iii) Knowing-Doing Gap. The detailed analysis of these case studies can be found in Sec.[3.3](https://arxiv.org/html/2602.00528v1#S3.SS3 "3.3 In-depth Analysis: Decomposing Reasoning Flaws of LLMs ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| ### C.3 Evaluation Metrics of the LLM-as-a-Judge for LLMs’ Reasoning | |
| In the LLM-as-a-Judge approach used in quantitative analysis of LLMs’ reasoning traces in Sec.[3.3](https://arxiv.org/html/2602.00528v1#S3.SS3 "3.3 In-depth Analysis: Decomposing Reasoning Flaws of LLMs ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), we use the following three metrics to validate the identified three reasoning flaws: | |
| * •Heuristic Reasoning Score (HR): The judge prompt template is provided in Tab.[15](https://arxiv.org/html/2602.00528v1#A10.T15 "Table 15 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * •Factual Alignment Score (FA): The judge prompt template is provided in Tab.[16](https://arxiv.org/html/2602.00528v1#A10.T16 "Table 16 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| * •Action-reasoning Consistency Score (AC): The judge prompt template is provided in Tab.[17](https://arxiv.org/html/2602.00528v1#A10.T17 "Table 17 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| ### C.4 Full Details of Quantitative Analysis | |
| To further validate the reasoning flaws observed in case studies, we adopt an LLM-as-a-Judge framework(Dubois et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib41 "AlpacaFarm: a simulation framework for methods that learn from human feedback")). Specifically, we design three metrics: heuristic reasoning (HR), factual alignment (FA), and action–reasoning consistency (AC). Each generated reasoning trace is scored by three independent LLM judges on a 0–2 2 scale for each metric. GPT-4.1-mini(OpenAI, [2025](https://arxiv.org/html/2602.00528v1#bib.bib29 "Gpt-4.1 system card")) is used as the judge model. The metric definitions and judge prompts are in Appendix[C.3](https://arxiv.org/html/2602.00528v1#A3.SS3 "C.3 Evaluation Metrics of the LLM-as-a-Judge for LLMs’ Reasoning ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| From the table, we observe that (i) Reasoning flaws persist across all models. All evaluated LLMs demonstrate varying degrees of heuristic reasoning, factual misunderstanding, and knowing–doing gaps. For instance, Qwen2.5-3B obtains only 0.53 0.53 HR, 0.18 0.18 FA, and 1.53 1.53 AC, indicating weak factual grounding and limited strategic reasoning. Even the strongest model, o4-mini, while achieving the 1.80 1.80 HR, 1.56 1.56 FA, and 1.85 1.85 AC, still falls short of perfect action–reasoning consistency (1.85 1.85). This confirms that these flaws are systemic and persist across models. (ii) Scaling improves but does not eliminate reasoning flaws. Large and more powerful models, such as Qwen2.5-72B and o4-mini, generally achieve higher scores across all these metrics compared to their lightweight variants. This suggests that increased scale and instruction tuning enhance the ability of LLMs to approximate game-theoretic reasoning and avoid factual mistakes. Nevertheless, the persistence of non-trivial gaps, particularly in FA and AC, indicates that scaling alone is insufficient to reach professional-level game-theoretic reasoning. (iii) Action-reasoning consistency remains imperfect. AC scores are stable across models (1.53 1.53–1.87 1.87) yet below the professional baseline of 2.0 2.0. Even the strongest model, o4-mini, reaches 1.85 1.85 but still shows knowing–doing gaps where reasoning diverges from action. To directly assess this, we compute mismatch proportions in Appendix[C.5](https://arxiv.org/html/2602.00528v1#A3.SS5 "C.5 Human-in-the-Loop Evaluation for LLMs’ Reasoning ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), which align with AC values and confirm it as both a valid proxy for and evidence of the knowing–doing gap. | |
| ### C.5 Human-in-the-Loop Evaluation for LLMs’ Reasoning | |
| To validate the reliability of LLM-based judging, we conduct a human-in-the-loop evaluation. Drawing on professional-style reasoning (Appendix[B.6](https://arxiv.org/html/2602.00528v1#A2.SS6 "B.6 Professional Players in Poker ‣ Appendix B Background and Rules of Poker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use")) and our behavior cloning prompt template (Appendix[D.3](https://arxiv.org/html/2602.00528v1#A4.SS3 "D.3 Additional Details of Behavior Cloning ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use")), we use GPT-5 to curate 20 20 reasoning traces and have them scored by LLMs. These traces achieve perfect scores (all achieve maximum 2 2), showing strong alignment with human judgments, which we include as a reference for our analysis. | |
| ### C.6 Calibration and Validation of our LLM-as-a-Judge Score | |
| In this subsection, we provide the details of how to calibrate and validate our LLM-as-a-Judge Score. Judge calibration. In Appendix[C.3](https://arxiv.org/html/2602.00528v1#A3.SS3 "C.3 Evaluation Metrics of the LLM-as-a-Judge for LLMs’ Reasoning ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), we apply the LLM-as-a-Judge approach and use three metrics: _Heuristic Reasoning (HR)_, _Factual Alignment (FA)_, and _Action–reasoning Consistency (AC)_ in the scale of 0-2. To calibrate this scale, we iteratively refined the HR/FA/AC rubrics and judge prompts using a small pilot set of representative hands. | |
| * •General procedure. We collect a small set of clearly _good_, _medium_, and _poor_ reasoning traces for each dimension, manually assign target scores (0/1/2), and refine the textual criteria until the judge consistently reproduces the correct scores. | |
| * •HR calibration. We anchor the “0/1/2” rubric using examples that are (i) purely heuristic, (ii) partially grounded but inconsistent, and (iii) strongly aligned with game-theoretic principles (e.g., pot odds, range interactions). | |
| * •FA calibration. We provide objective poker quantities (equities, ranges, pot odds) from external solvers and instruct the judge to score _only factual correctness_. | |
| * •AC calibration. We explicitly instruct the judge to verify that the reasoning logically implies the same action as the final decision. | |
| Judge validation. Following the protocol in Sec.[3.3](https://arxiv.org/html/2602.00528v1#S3.SS3 "3.3 In-depth Analysis: Decomposing Reasoning Flaws of LLMs ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), we manually curate 20 professional-style reasoning traces to use them and score them by LLMs. These traces achieve perfect scores (all achieve maximum 2), showing strong alignment with human judgments. | |
| Sensitivity and inter-rater LLM agreement. Our LLM-as-a-Judge results in Tab.[2](https://arxiv.org/html/2602.00528v1#S3.T2 "Table 2 ‣ 3.3 In-depth Analysis: Decomposing Reasoning Flaws of LLMs ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), Tab.[4](https://arxiv.org/html/2602.00528v1#S4.T4 "Table 4 ‣ 4.3 Experiment Analysis ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), and Fig.[2](https://arxiv.org/html/2602.00528v1#S5.F2 "Figure 2 ‣ 5.3 Experimental Results ‣ 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") are consistent across two distinct poker environments (Leduc and Limit Hold’em), indicating that the judge is _not domain-sensitive_. | |
| To further assess inter-rater agreement, we re-evaluate ToolPoker’s Limit Hold’em reasoning traces using GPT-5 as the judge (instead of the GPT-4.1-mini judge used in the main paper). All settings follow Section 5.3. The results are reported in Tab.[6](https://arxiv.org/html/2602.00528v1#A3.T6 "Table 6 ‣ C.6 Calibration and Validation of our LLM-as-a-Judge Score ‣ Appendix C Additional Details of Preliminary Analysis in Sec. 3 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). From the table, we observe close agreement between the two judge models, validating the robustness of our evaluation and reducing concerns about prompt sensitivity or model-specific bias. | |
| Table 6: Inter-rater agreement: LLM-as-a-Judge scores (0–2) on ToolPoker’s reasoning traces in Limit Texas Hold’em. We compare the original judge (GPT-4.1-mini) with another judge (GPT-5). | |
| Appendix D Full Details of BC-RIRL | |
| ---------------------------------- | |
| ### D.1 Full details of Regret-Inspired RL Fine-Tuning | |
| While BC helps LLMs imitate expert play, its limited dataset size and imitation-based nature make it insufficient for professional-level performance. As an initial attempt to refine policies beyond imitation, we explore a regret-inspired reinforcement learning (RIRL) framework. Prior approaches in both traditional RL(Heinrich and Silver, [2016](https://arxiv.org/html/2602.00528v1#bib.bib8 "Deep reinforcement learning from self-play in imperfect-information games"); Zhao et al., [2022](https://arxiv.org/html/2602.00528v1#bib.bib15 "Alphaholdem: high-performance artificial intelligence for heads-up no-limit poker via end-to-end reinforcement learning")) and LLM-based RL(Guo et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib24 "Deepseek-r1: incentivizing reasoning capability in llms via reinforcement learning")) typically rely on outcome-based rewards (e.g., win/loss). However, in poker, especially in multi-round games such as Leduc Hold’em and Texas Hold’em—these sparse and noisy signals fail to capture the contribution of individual actions. To address this, we experiment with a step-level regret-guided reward that leverages signals from a pre-trained CFR solver, aligning fine-tuning with the principle that minimizing cumulative regret drives convergence to the Nash equilibrium. | |
| Regret-guided Reward Design. Inspired by our analysis in Sec.[3.2](https://arxiv.org/html/2602.00528v1#S3.SS2 "3.2 Comparison with Traditional Method ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), which highlights CFR as the state-of-the-art algorithm for approaching Nash equilibrium in imperfect-information games, we explore optimizing LLMs through regret minimization. Our key idea is to compute cumulative regrets with CFR and transform them into fine-grained reward signals that estimate each action’s contribution. For a policy π θ\pi_{\theta} as player i i, the cumulative regret of action a i t a_{i}^{t} at time t t is defined as: | |
| r t(a i t)=r t−1(a i t)+I t(a i t),I t(a i t)=u(σ t a i t,σ t−a i t)−u(σ t),r_{t}(a^{t}_{i})=r_{t-1}(a^{t}_{i})+I_{t}(a^{t}_{i}),\quad I_{t}(a^{t}_{i})=u(\sigma_{t}^{a^{t}_{i}},\sigma_{t}^{-a^{t}_{i}})-u(\sigma_{t}),(6) | |
| where σ t\sigma_{t} denotes the strategy profile at time t t, σ t−i\sigma_{t}^{-i} is the opponents’ strategy, u(σ t)u(\sigma_{t}) the expected utility under σ t\sigma_{t}, and u(σ t a i t,σ t−i)u(\sigma_{t}^{a_{i}^{t}},\sigma_{t}^{-i}) is the utility when player i i deviates to action a i t a_{i}^{t}. The instantaneous regret I t(a i t)I_{t}(a_{i}^{t}) measures how much better or worse a i t a_{i}^{t} performs relative to the current mixture strategy, while R t(a i t)R_{t}(a_{i}^{t}) aggregates this over time. To compare actions within the same decision point, we normalize regrets into a relative reward signal: | |
| R(a i t)=R t(a i t)−mean({r t(a j)}j=1|𝒜|)F norm({r t(a j)}j=1|𝒜|),R(a^{t}_{i})\;=\;\frac{R_{t}(a^{t}_{i})-\text{mean}(\{r_{t}(a_{j})\}_{j=1}^{|\mathcal{A}|})}{F_{\text{norm}}(\{r_{t}(a_{j})\}_{j=1}^{|\mathcal{A}|})},(7) | |
| where F norm F_{\text{norm}} denotes a normalization factor, chosen as the standard deviation in our implementation. | |
| Fine-tuning Objective. Based on this signal, we fine-tune LLM policy via PPO(Schulman et al., [2017](https://arxiv.org/html/2602.00528v1#bib.bib13 "Proximal policy optimization algorithms")) with the following clipped RL objective: | |
| ℒ PPO\displaystyle\mathcal{L}_{\text{PPO}}(θ)=−𝔼 x∼𝒟 s,y∼π old(⋅|x)\displaystyle(\theta)=-\mathbb{E}_{x\sim\mathcal{D}_{s},y\sim\pi_{{old}}(\cdot|x)}(8) | |
| [min(π θ(y|x)π old(y|x)A,clip(π θ(y|x)π old(y|x),1−ϵ,1+ϵ))−β 𝔻 KL(π θ(⋅|c)||π ref(y|x))],\displaystyle\left[\min\left(\frac{\pi_{\theta}(y|x)}{\pi_{{old}}(y|x)}A,\text{clip}\left(\frac{\pi_{\theta}(y|x)}{\pi_{{old}}(y|x)},1-\epsilon,1+\epsilon\right)\right)-\beta\mathbb{D}_{\text{KL}}(\pi_{\theta}(\cdot|c)||\pi_{ref}(y|x))\right], | |
| where π θ\pi_{\theta} and π old\pi_{old} denote the current and previous policy models, respectively. ϵ\epsilon is the clipping-related hyperparameter. π ref\pi_{ref} is the reference policy that regularizes π θ\pi_{\theta} update via a KL-divergence penalty, measured and weighted by 𝔻 KL\mathbb{D}_{KL} and β\beta, respectively. Generalized Advantage Estimation (GAE)(Schulman et al., [2015](https://arxiv.org/html/2602.00528v1#bib.bib9 "High-dimensional continuous control using generalized advantage estimation")) is used as the advantage estimate A A. x x denotes the input samples drawn from 𝒟\mathcal{D}, which is composed of trajectories generated by the current policy π θ\pi_{\theta}. y y is the generated outputs via policy LLMs π θ(⋅|x)\pi_{\theta}(\cdot|x). The procedures of trajectory collection are detailed in Appendix[D.4](https://arxiv.org/html/2602.00528v1#A4.SS4 "D.4 Trajectory Collection Procedure ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| ### D.2 Full Details of Comparison Results | |
| We evaluate whether BC-RIRL improves LLMs’ poker performance by fine-tuning Qwen2.5-7B and comparing against both traditional methods and vanilla LLMs. Results in Kuhn and Leduc Hold’em are reported in Tab.[3](https://arxiv.org/html/2602.00528v1#S4.T3 "Table 3 ‣ 4.3 Experiment Analysis ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). We highlight three key findings: (i) _All RL-based fine-tuning variants improve performance in Kuhn Poker_. This suggests that both outcome-based and regret-guided feedback provide useful learning signals in simple environments with limited strategy space. (ii) _BC-RIRL surpasses direct prompting and BC-SPRL in Leduc Hold’em, though it still trails traditional algorithms such as CFR+_. For example, BC-RIRL gains 17.0 17.0 chips against GPT-4.1-mini, while still losing 34.0 34.0 chips against CFR+. This indicates that regret-guided dense feedback is more effective than sparse outcome-based rewards in complex tasks, but is sufficient to reach equilibrium-level play. (iii) _Pure RIRL without the BC stage does not yield improvements in Leduc Hold’em_. For instance, BC-RIRL and BC-SPRL gain +17.0+17.0 and −64.5-64.5 chips against GPT-4.1-mini, respectively. This underscores the importance of BC in establishing a strong foundation of expert-like reasoning before RL fine-tuning. | |
| To further assess whether BC-RIRL enhances reasoning quality, we adopt the LLM-as-a-Judge protocol from Sec.[3.3](https://arxiv.org/html/2602.00528v1#S3.SS3 "3.3 In-depth Analysis: Decomposing Reasoning Flaws of LLMs ‣ 3 Are LLMs Good at Poker? A Preliminary Analysis ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") and compute three reasoning-trace scores. Results in Leduc Hold’em and Limit Texas Hold’em are reported in Tab.[4](https://arxiv.org/html/2602.00528v1#S4.T4 "Table 4 ‣ 4.3 Experiment Analysis ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), with additional case studies provided in Appendix[F.1](https://arxiv.org/html/2602.00528v1#A6.SS1 "F.1 Case Studies of BC-RIRL ‣ Appendix F Additional Details of Initial Attempt in Sec. 4 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). Two findings are observed: (i) _RIRL consistently surpasses the baselines on HR and AC_. For example, BC-RIRL fine-tuned on Qwen2.5-7B reaches 1.93 1.93 HR and 1.90 1.90 AC in Leduc Hold’em, outperforming the strongest vanilla LLM, o4-mini, which achieves 1.80 1.80 HR and 1.85 1.85 AC. This shows that BC-RIRL effectively mitigates heuristic reasoning flaws and reduces the knowing–doing gap. (ii) _RIRL yields only marginal improvements in FA._ For instance, in Limit Texas Hold’em, BC-RIRL achieves 1.12 1.12 FA, only slightly higher than vanilla Qwen2.5-7B (0.87 0.87 FA) and still far behind o4-mini (1.65 1.65 FA). Together with the case studies, these results indicate that while BC-RIRL improves strategic reasoning and action–reasoning alignment, factual misunderstandings remain a notable challenge. | |
| ### D.3 Additional Details of Behavior Cloning | |
| We provide the BC data construct prompt template, which is shown in Tab.[18](https://arxiv.org/html/2602.00528v1#A10.T18 "Table 18 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). GPT-5-mini is used as the target model for annotation. The detailed actions and other auxiliary quantities (e.g., winning probability and hand range) are obtained from a pre-trained CFR solver, equity calculator and other tools. These tools are implemented in Python. | |
| ### D.4 Trajectory Collection Procedure | |
| To collect trajectories for RL fine-tuning, we adopt an on-policy setting where the LLM policy competes against a random agent. At each iteration, the LLM plays a batch of N N games against the random agent (N=64 N=64 in our setting). The LLM’s actions from each round are stored as individual data samples. Formally, for an LLM policy π θ\pi_{\theta} with partial observation o i t o_{i}^{t} and action history h i t h_{i}^{t} at time step t t, a sample is represented as (o i t,h i t,a i t)(o_{i}^{t},h_{i}^{t},a_{i}^{t}), where a i t a_{i}^{t} is the chosen action of player i i. After each batch, the collected trajectories are used to fine-tune the LLM policy π θ\pi_{\theta}, producing an updated policy π θ′\pi_{\theta}^{\prime} that is then used for subsequent data collection. | |
| ### D.5 Implementation Details of BC-RIRL | |
| In the behavior cloning stage, we construct 5,000 5,000 data samples with both reasoning traces and actions for behavior cloning. Specifically, to generate actions, we use CFR+Tammelin ([2014](https://arxiv.org/html/2602.00528v1#bib.bib19 "Solving large imperfect information games using cfr+")) to compete against a random player that randomly selects actions from the action space, and extract the actions from CFR+ as the ground-truth actions. The GPT-5-mini is then used to generate reasoning traces of these actions, where the prompt is provided in Appendix[D.3](https://arxiv.org/html/2602.00528v1#A4.SS3 "D.3 Additional Details of Behavior Cloning ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). In the RL stage, we set Qwen2.5-7B-Instruct as the base model for fine-tuning. | |
| Appendix E Methodology of SPRL | |
| ------------------------------ | |
| Inspired by traditional RL in imperfect-information games(Heinrich and Silver, [2016](https://arxiv.org/html/2602.00528v1#bib.bib8 "Deep reinforcement learning from self-play in imperfect-information games"); Zhang et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib34 "A survey on self-play methods in reinforcement learning")), we conduct δ\delta-uniform self-play by letting a single policy LLM π θ\pi_{\theta} play both sides. In each round, we (i) clone the current policy to obtain a fixed opponent π θ¯\pi_{\bar{\theta}}; (ii) sample N N self-play games between π θ(⋅∣f(o 1 t))\pi_{\theta}(\cdot\mid f(o_{1}^{t})) and π θ¯(⋅∣f(o 2 t))\pi_{\bar{\theta}}(\cdot\mid f(o_{2}^{t})), alternating positions and random seeds, to collect trajectories 𝒯 θ\mathcal{T}_{\theta}; (iii) update π θ\pi_{\theta} with RL on 𝒯 θ\mathcal{T}_{\theta} for δ\delta steps while keeping π θ¯\pi_{\bar{\theta}} fixed; and (iv) refresh π θ¯\pi_{\bar{\theta}} with the latest π θ\pi_{\theta} to start the next cycle. | |
| Fine-tuning Objective. To fine-tune LLMs via RL, we then formulate the RL objective function as follows: | |
| max θ 𝔼 x∼𝒟 s,y∼π θ(⋅|x)[r ϕ(x,y)]−β 𝔻 KL[π θ(y|x)||π ref(y|x)],\max_{\theta}\mathbb{E}_{x\sim{\mathcal{D}_{s}},y\sim{\pi_{\theta(\cdot|x)}}}[r_{\phi}(x,y)]-\beta\mathbb{D}_{KL}[\pi_{\theta}(y|x)||\pi_{ref}(y|x)],(9) | |
| where π θ\pi_{\theta} is the policy LLM being trained. π ref\pi_{ref} is the reference LLM (typically the initial pretrained LLM) that regularizes the policy update via a KL-divergence penalty, measured and weighted by 𝔻 KL\mathbb{D}_{KL} and β\beta, respectively. x x denotes the input samples drawn from 𝒟 s\mathcal{D}_{s}, which is composed of trajectories generated by the current policy π θ\pi_{\theta} in a self-play setting. y y represents the generated outputs via policy LLMs π θ(⋅|x)\pi_{\theta}(\cdot|x). In this paper, we choose a commonly used Proximal Policy Optimization (PPO)(Schulman et al., [2017](https://arxiv.org/html/2602.00528v1#bib.bib13 "Proximal policy optimization algorithms")) as the backbone RL algorithm, which optimizes LLMs by maximizing the following objective: | |
| ℒ PPO\displaystyle\mathcal{L}_{\text{PPO}}(θ)=−𝔼 x∼𝒟 s,y∼π old(⋅|x)\displaystyle(\theta)=-\mathbb{E}_{x\sim\mathcal{D}_{s},y\sim\pi_{{old}}(\cdot|x)}(10) | |
| [min(π θ(y|x)π old(y|x)A adv,c l i p(π θ(y|x)π old(y|x),1−ϵ,1+ϵ)A adv)−β 𝔻 KL(π θ(⋅|c)||π ref(y|x))],\displaystyle\left[\min\left(\frac{\pi_{\theta}(y|x)}{\pi_{{old}}(y|x)}A_{adv},{clip}\left(\frac{\pi_{\theta}(y|x)}{\pi_{{old}}(y|x)},1-\epsilon,1+\epsilon\right)A_{adv}\right)-\beta\mathbb{D}_{KL}(\pi_{\theta}(\cdot|c)||\pi_{ref}(y|x))\right], | |
| where π θ\pi_{\theta} and π old\pi_{old} denote the current and previous policy models, respectively. ϵ\epsilon is the clipping-related hyperparameter. The advantage estimate A adv A_{adv} is computed using Generalized Advantage Estimation (GAE)(Schulman et al., [2015](https://arxiv.org/html/2602.00528v1#bib.bib9 "High-dimensional continuous control using generalized advantage estimation")). We also investigate the performance of other commonly used RL algorithms, such as GRPO Shao et al. ([2024](https://arxiv.org/html/2602.00528v1#bib.bib14 "Deepseekmath: pushing the limits of mathematical reasoning in open language models")). | |
| Reward Design. Poker is a sequential decision-making task with multiple turns. The reward for player i i at time step t t is defined as the discounted cumulative return from t t until the end of the game: | |
| R i t=∑k=t T γ k−tr i k,R_{i}^{t}=\sum_{k=t}^{T}\gamma^{\,k-t}r_{i}^{k},(11) | |
| where γ∈(0,1]\gamma\in(0,1] is the discount factor balancing immediate and long-term outcomes. Because players only observe payoffs after a hand is completed, the task is characterized by sparse rewards: intermediate steps yield r i k=0 r_{i}^{k}=0, while the terminal step provides r i T r_{i}^{T}. We consider two types of terminal signals: (i) _binary outcome_ reward, where r i T=1 r_{i}^{T}=1 if the player wins the hand and r i T=0 r_{i}^{T}=0 otherwise; and (ii) _normalized earnings_ reward, where r i T=c earn/c init r_{i}^{T}=c_{\text{earn}}/c_{\text{init}}, with c earn c_{\text{earn}} the final net chip gain (or loss) and c init c_{\text{init}} the initial chip count. | |
| Appendix F Additional Details of Initial Attempt in Sec.[4](https://arxiv.org/html/2602.00528v1#S4 "4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") | |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | |
| ### F.1 Case Studies of BC-RIRL | |
| We present case studies of Qwen2.5-7B fine-tuned with BC-RIRL in Leduc Hold’em (Tab.[19](https://arxiv.org/html/2602.00528v1#A10.T19 "Table 19 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") and Tab.[20](https://arxiv.org/html/2602.00528v1#A10.T20 "Table 20 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use")). The results show that after fine-tuning, the model can produce reasoning traces that resemble those of professional players. However, closer inspection reveals persistent factual misunderstandings. For example, the model claims that calling is the optimal CFR action, even though the prompt explicitly states that calling is not a legal move. This supports our conclusion in Sec.[4.3](https://arxiv.org/html/2602.00528v1#S4.SS3 "4.3 Experiment Analysis ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"): while BC-RIRL improves action–reasoning consistency and professional-style imitation, factual inaccuracies remain a significant challenge, highlighting the limitations of BC-RIRL. | |
| Algorithm 1 Fine-tuning Algorithm of ToolPoker for TIR. | |
| Policy model | |
| π θ\pi_{\theta} | |
| , old policy | |
| π old\pi_{\text{old}} | |
| , task dataset | |
| 𝒟 t\mathcal{D}_{t} | |
| , masking function | |
| ℳ\mathcal{M} | |
| for each training iteration do | |
| for each task | |
| x x | |
| in | |
| 𝒟 t\mathcal{D}_{t} | |
| do | |
| Sample ground-truth GTO action | |
| a^\hat{a} | |
| of | |
| x x | |
| Sample a rollout | |
| y y | |
| from | |
| π old\pi_{\text{old}} | |
| for | |
| x x | |
| : | |
| Initialize reasoning chain | |
| while not end of episode do | |
| Generate next segment: `<think>` or `<tool>` | |
| if tool is invoked then | |
| Interact with external poker solvers, obtain `<output>` | |
| Append output to reasoning chain | |
| end if | |
| end while | |
| Extract model-predicted action | |
| a{a} | |
| from final response | |
| p p | |
| Compute the composite reward | |
| R(a,a^,p)R(a,\hat{a},p) | |
| Compute GAE advantages | |
| A^\hat{A} | |
| for | |
| y y | |
| Apply loss masking | |
| ℳ\mathcal{M} | |
| to exclude tool output tokens | |
| Compute PPO loss | |
| ℒ PPO\mathcal{L}_{\text{PPO}} | |
| in Eq.[10](https://arxiv.org/html/2602.00528v1#A5.E10 "In Appendix E Methodology of SPRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") and update | |
| π θ\pi_{\theta} | |
| end for | |
| end for | |
| Appendix G Additional Detail of ToolPoker | |
| ----------------------------------------- | |
| ### G.1 TIR Rollout Prompt Template | |
| The TIR rollout prompt template for poker is provided in Tab.[21](https://arxiv.org/html/2602.00528v1#A10.T21 "Table 21 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| ### G.2 TIR BC Reasoning Dataset Curation | |
| To construct high-quality TIR data without incurring prohibitive annotation cost, instead of building a TIR reasoning-augmented dataset from scratch, we build an automated pipeline to programmatically augments the reasoning dataset from Sec.[4.1](https://arxiv.org/html/2602.00528v1#S4.SS1 "4.1 Behavior Cloning ‣ 4 Can We Improve LLMs in Poker? Failures and Insights ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") with standardized tool invocation templates (e.g., <tool></tool>) and execution outputs (e.g., <output></output>). A detailed example of the appended tool invocation templates is provided in Tab.[22](https://arxiv.org/html/2602.00528v1#A10.T22 "Table 22 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| ### G.3 Reward Design | |
| Our hybrid reward function contain the following components: | |
| * •Answer reward: This reward enforces the alignment of LLMs’ final action with the GTO-guarantee action from the CFR solver. Formally, given an LLM policy π θ\pi_{\theta} as the player i i with partial observation o i t o_{i}^{t} and action history h i t h_{i}^{t} at time step t t, the answer reward is denoted as: | |
| R answer(a i t,a^i t)={1,if is_equivalent(a i t,a^i t),−1,otherwise,R_{\text{answer}}(a_{i}^{t},\hat{a}_{i}^{t})=\begin{cases}1,&\text{if }\texttt{is\_equivalent}(a_{i}^{t},\hat{a}_{i}^{t}),\\ -1,&\text{otherwise},\end{cases}(12) | |
| where a i t a_{i}^{t} and a^i t\hat{a}_{i}^{t} denote π θ\pi_{\theta}’s predicted action and CFR solver’s action at time step t t. is_equivalent(⋅)\texttt{is\_equivalent}(\cdot) checks whether the model’s final action matches the CFR solver’s action as the ground-truth action. | |
| * •Format reward: R format(ρ i t)∈{0,1}R_{\text{format}}(\rho_{i}^{t})\in\{0,1\}, which evaluates whether the reasoning trace follows the required structured schema with special tokens in the correct order: reasoning `<think></think>`, tool calling `<tool></tool>`, feedback output `<output></output>`, and final action `<answer></answer>`. | |
| * •Tool execution reward: R tool(ρ i t)=Tool suc/Tool tot R_{\text{tool}}(\rho_{i}^{t})={\text{Tool}_{\text{suc}}}/{\text{Tool}_{\text{tot}}}, which measures the fraction of successful tool calls in the reasoning trace, encouraging the model to invoke external tools effectively and integrate their outputs into subsequent reasoning. | |
| ### G.4 RL Fine-tuning Algorithm for TIR | |
| Alg.[1](https://arxiv.org/html/2602.00528v1#alg1 "Algorithm 1 ‣ F.1 Case Studies of BC-RIRL ‣ Appendix F Additional Details of Initial Attempt in Sec. 4 ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") summarizes the fine-tuning procedure of ToolPoker for enabling TIR in poker. Given a task dataset 𝒟 t\mathcal{D}_{t}, where construction details are in Appendix[G.5](https://arxiv.org/html/2602.00528v1#A7.SS5 "G.5 Implementation Details ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), the algorithm proceeds as follows. | |
| For each task x∈𝒟 t x\in\mathcal{D}_{t} with a corresponding ground-truth action a^\hat{a} from a CFR solver, we first obtain G G rollouts y y from the old policy π old\pi_{\text{old}}. Each rollout is generated step by step, where the model produces either a <think> segment (internal reasoning) or a <tool> call. If a tool is invoked, the model interacts with the external poker solver, retrieves the <output>, and appends it to the reasoning chain. This iterative process continues until the end of the episode. At the end of the rollout, we extract the model-predicted action a a from the final response p p. A composite reward R(a,a^,p)R(a,\hat{a},p) is then computed, combining answer accuracy, reasoning format, and tool-execution quality (see Appendix[G.3](https://arxiv.org/html/2602.00528v1#A7.SS3 "G.3 Reward Design ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use")). Using this reward, we estimate advantages A^\hat{A} with Generalized Advantage Estimation (GAE)(Schulman et al., [2015](https://arxiv.org/html/2602.00528v1#bib.bib9 "High-dimensional continuous control using generalized advantage estimation")). To ensure tool outputs do not dominate training, we apply a masking function ℳ\mathcal{M} that excludes solver outputs from the loss. Finally, we compute the PPO loss ℒ PPO\mathcal{L}_{\text{PPO}} (Eq.[8](https://arxiv.org/html/2602.00528v1#A4.E8 "In D.1 Full details of Regret-Inspired RL Fine-Tuning ‣ Appendix D Full Details of BC-RIRL ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use")) and update the policy π θ\pi_{\theta}. | |
| Through this iterative process, the model learns not only to query solvers for GTO-consistent actions and other auxiliary quantities but also to integrate solver outputs into coherent reasoning traces, thereby aligning action selection with rigorous game-theoretic principles. | |
| ### G.5 Implementation Details | |
| We follow existing works(Feng et al., [2025a](https://arxiv.org/html/2602.00528v1#bib.bib38 "Retool: reinforcement learning for strategic tool use in llms"); Jin et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib26 "Search-r1: training llms to reason and leverage search engines with reinforcement learning")) to train ToolPoker with the VeRL(Sheng et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib39 "HybridFlow: a flexible and efficient rlhf framework")) framework. For RL fine-tuning, based on the existing work(Wang et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib61 "Can large language models master complex card games?")), we build an automated pipeline to curate an action-only dataset with 400,000 400,000 samples for both Leduc Hold’em and Limit Texas Hold’em. Specifically, we use a pretrained CFR solver to compete against a random agent and collect the game states and actions of CFR to build such a dataset. Note that | |
| Qwen2.5-7B-Instruct model is the base model. The max response length is set as 8,192 8,192 tokens. The rollout model’s temperature is 0.7 0.7 and top-p is 0.6 0.6. For behavior cloning, we curate a TIR dataset with 5,000 5,000 samples with both actions and tool-integrated reasoning traces. During RL fine-tuning, the rollout batch size is set to 64 64, and the mini update size is 16 16. An AdamW optimizer is utilized with an initial learning rate 1e−6 1e-6. | |
| ### G.6 Additional Discussion | |
| Generalization without solvers. In realistic settings, external tools may be unavailable or only intermittently accessible. To examine this, we ablate ToolPoker by removing RL fine-tuning and retaining only BC (Sec.[5.3](https://arxiv.org/html/2602.00528v1#S5.SS3 "5.3 Experimental Results ‣ 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use")). This variant shows weaker tool-use capability than full ToolPoker, and under intermittent tool access we find that HR and AC remain relatively high while FA degrades first. These results suggest that ToolPoker internalizes core strategic structures (e.g., range-based reasoning and mixed strategies), while solvers primarily supply precise numerical quantities—supporting our view that LLMs provide the reasoning framework whereas external tools ensure the accuracy of game-theoretic computations. | |
| ### G.7 Comparison with Existing Tool-use Framework | |
| #### G.7.1 Relation to Existing Tool-use Framework | |
| While ToolPoker follows the general “LLM+ tools” paradigm, it is designed specifically for imperfect-information poker games with game-theoretic principles, whereas prior frameworks focus on general tasks (e.g., math, QA, web search). This difference leads to several important challenges that make existing methods difficult to directly apply. | |
| Task difference: game-theoretic reasoning. Prior TIR methods(Yao et al., [2022](https://arxiv.org/html/2602.00528v1#bib.bib66 "React: synergizing reasoning and acting in language models"); Schick et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib65 "Toolformer: language models can teach themselves to use tools"); Feng et al., [2025a](https://arxiv.org/html/2602.00528v1#bib.bib38 "Retool: reinforcement learning for strategic tool use in llms")) typically aim to obtain factual answers or execute deterministic API calls. In contrast, ToolPoker targets _strategic reasoning_ in games where (i) the agent must reason under imperfect information, and optimal play requires _Nash-equilibrium (GTO) reasoning_, and (ii) explanations must reflect game-theoretic principles rather than surface-level logic. This setting requires multi-step strategic reasoning that goes substantially beyond previous tool-use scenarios. | |
| Existing frameworks cannot be directly adapted. Unstable interleaved reasoning and tool use. Poker reasoning requires LLMs to generate game-theoretic explanations while coordinating multiple solver calls for diverse quantities (e.g., actions, equities, ranges). Directly applying a ReTool-style framework(Feng et al., [2025a](https://arxiv.org/html/2602.00528v1#bib.bib38 "Retool: reinforcement learning for strategic tool use in llms")) to teach LLMs to invoke multiple tools during reasoning would (i) force the model to call and integrate several specialized solvers for each hand, (ii) introduce error propagation from tool calls across multi-step game-theoretic reasoning trajectories, and (iii) lead to inaccurate explanations and degraded gameplay. High data cost. Toolformer-style approaches(Schick et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib65 "Toolformer: language models can teach themselves to use tools")) usually require large-scale reasoning traces augmented with solver calls to fine-tune LLMs. For game-theoretic reasoning tasks, generating such traces demands expensive LLM annotation and careful domain-specific tool invocation, making it prohibitively costly to scale to expert-level poker play. | |
| ToolPoker: a design specifically addressing these challenges. To overcome these issues, ToolPoker introduces two key design choices. Equilibrium-oriented simplified interface. Rather than asking the LLM to orchestrate multiple tools, ToolPoker consolidates all solver functionalities into a single API call that returns GTO actions as well as auxiliary quantities (e.g., equities, strategic ranges, hand distributions). This equilibrium-oriented interface stabilizes TIR–RL training and allows the LLM to focus on producing accurate, professional-level reasoning instead of managing complex tool orchestration. Low-cost, expert-level TIR dataset. Instead of relying on a large-scale reasoning dataset, ToolPoker deliberately constructs a small curated expert reasoning dataset aligned with game-theoretic principles, and augments it with tool-calling templates and solver outputs. This provides a cost-efficient way to perform behavior cloning from expert-level play, followed by reinforcement learning fine-tuning. | |
| #### G.7.2 Empirical Comparison with ReTool | |
| We then empirically compare ToolPoker with ReTool Feng et al. ([2025a](https://arxiv.org/html/2602.00528v1#bib.bib38 "Retool: reinforcement learning for strategic tool use in llms")) to validate the effectiveness of ToolPoker in our poker games with imperfect information. Specifically, we implement ReTool in Leduc Hold’em (same solver, same backbone LLM). We modify our BC dataset following the original ReTool protocol to teach the model to call multiple poker tools during reasoning, and keep the RL stage consistent with ReTool. | |
| We compare both methods under the same settings as Section[5.3](https://arxiv.org/html/2602.00528v1#S5.SS3 "5.3 Experimental Results ‣ 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") using Qwen2.5-7B-Instruct. Gameplay and Reasoning results are shown in Tab.[7](https://arxiv.org/html/2602.00528v1#A7.T7 "Table 7 ‣ G.7.2 Empirical Comparison with ReTool ‣ G.7 Comparison with Existing Tool-use Framework ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") and[8](https://arxiv.org/html/2602.00528v1#A7.T8 "Table 8 ‣ G.7.2 Empirical Comparison with ReTool ‣ G.7 Comparison with Existing Tool-use Framework ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), respectively. These results show that while ReTool improves over prompting-only LLMs, ToolPoker achieves higher gameplay performance and expert-level reasoning quality, demonstrating the advantages of our simple but effective design in ToolPoker for game-theoretic reasoning tasks. | |
| Table 7: Gameplay comparison results of ToolPoker and ReTool in Leduc Hold’em. Qwen2.5-7B-Instruct is the backbone model. | |
| Table 8: Reasoning quality comparison results of ToolPoker and ReTool in Leduc Hold’em. Qwen2.5-7B-Instruct is the backbone model. | |
| ### G.8 Impact of Reward Component in R R | |
| To study the contribution of each component in the composite reward, we implement three ablative variants of ToolPoker in Leduc Hold’em (Qwen2.5-7B-Instruct backbone), each removing one component from the composite reward in Eq.[4](https://arxiv.org/html/2602.00528v1#S5.E4 "In 5.2 Training Algorithm ‣ 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). All other settings follow Section[5.3](https://arxiv.org/html/2602.00528v1#S5.SS3 "5.3 Experimental Results ‣ 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). We report both gameplay performance and reasoning quality in Table[9](https://arxiv.org/html/2602.00528v1#A7.T9 "Table 9 ‣ G.8 Impact of Reward Component in 𝑅 ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") and[10](https://arxiv.org/html/2602.00528v1#A7.T10 "Table 10 ‣ G.8 Impact of Reward Component in 𝑅 ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). From these tables, we observe: | |
| * •R answer R_{\text{answer}} is the main driver of improvement. Removing it will make reasoning traces and final decisions less tightly aligned with solvers’ outputs (e.g., GTO-consistent action), leading to worse gameplay performance and reasoning quality (e.g, AC). | |
| * •R format R_{\text{format}} mainly stabilizes format and structure, with a smaller but positive effect on performance. Removing R format R_{\text{format}} keeps gameplay competitive. | |
| * •R tool R_{\text{tool}} benefits reliable tool use. Removing it leads to a slight drop in gameplay performance and FA/AC scores. | |
| Table 9: Gameplay performance of ToolPoker and ablations in Leduc Hold’em. Qwen2.5-7B-Instruct is the backbone model. | |
| Table 10: Reasoning quality metrics across ablations in Leduc Hold’em. Qwen2.5-7B-Instruct is the backbone model. | |
| ### G.9 Reward Visualization | |
| We plot the per-component reward trajectories of ToolPoker in Leduc Hold’em in Fig.[3](https://arxiv.org/html/2602.00528v1#A7.F3 "Figure 3 ‣ G.9 Reward Visualization ‣ Appendix G Additional Detail of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). Qwen2.5-7B-Instruct is the backbone model. From the figure, we can observe: | |
| * •R format R_{format} and R tool R_{tool} rapidly approach near 1, indicating that the model can learn to produce correct formats and tool invocation quickly. | |
| * •R answer R_{answer} gradually increases over training with some variance but no signs of instability or collapse. | |
|  | |
| (a) R R | |
|  | |
| (b) R answer R_{\text{answer}} | |
|  | |
| (c) R format R_{\text{format}} | |
|  | |
| (d) R tool R_{\text{tool}} | |
| Figure 3: Reward visualization of ToolPoker in Leduc Hold’em. Qwen2.5-7B-Instruct is the backbone model. (a) is the overall composite reward R R, (b)-(d) shows the R answer R_{\text{answer}}, R format R_{\text{format}} and R tool R_{\text{tool}}, respectively. | |
| Appendix H In-depth Analysis of ToolPoker | |
| ----------------------------------------- | |
| ### H.1 Transferability & Scalability | |
| Extending to Other Imperfect-information Games. Although ToolPoker is empirically evaluated on poker in the main paper, the framework itself is not poker-specific. We choose poker as our primary testbed because it is a canonical benchmark for imperfect-information, game-theoretic reasoning: it has mature equilibrium solvers (e.g., CFR+), well-established evaluation protocols, and is widely used in prior works(Guo et al., [2023](https://arxiv.org/html/2602.00528v1#bib.bib6 "Suspicion-agent: playing imperfect information games with theory of mind aware gpt-4"); Wang et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib61 "Can large language models master complex card games?"); Zhuang et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib20 "Pokerbench: training large language models to become professional poker players"); Duan et al., [2024](https://arxiv.org/html/2602.00528v1#bib.bib21 "Gtbench: uncovering the strategic reasoning capabilities of llms via game-theoretic evaluations")) to study strategic reasoning. | |
| ToolPoker is architecturally game-agnostic and only requires access to a solver that, given a state description, returns equilibrium quantities (e.g., optimal actions, values, strategy distributions). To instantiate ToolPoker for another imperfect-information game, the required modifications are minimal: | |
| * •Build solver API. In a new game, collect required solvers for game-theoretic reasoning, and build a unified solver API that returns all supporting quantities from these solvers. | |
| * •State encoding. The game history, private information, and public observations of the new game must be encoded into text suitable for the LLM and for the unified solver API. | |
| * •TIR reasoning dataset construction. Similar to poker, we create a small-scale expert reasoning dataset containing high-quality reasoning traces augmented with solver outputs. This teaches the model how to read and interpret solver quantities and how to produce game-theoretic explanations. | |
| * •Two-stage training pipeline. We apply the same training procedure used in Section 5.2, which contains SFT on the solver-augmented reasoning dataset, followed by RL fine-tuning with our composite reward to refine tool-use behavior and action quality. | |
| As an illustrative example, consider extending ToolPoker to an imperfect-information game, Mahjong. We would: | |
| * •encode each player’s private hand, open melds, discards, and round context into text | |
| * •build an unified API such that the LLM can query this API to interface with external Mahjong solver to obtain actions (e.g., discard, call) and other supporting quantities (e.g., shanten count, tile-efficiency metrics, expected value, defensive risk), which are similar to equities and ranges in poker | |
| * •build a small solver-augmented reasoning set grounding explanations in strategic principles of Mahjong (e.g., tile efficiency, defense, hand value) | |
| * •apply the same two-stage training pipeline to finetune LLMs | |
| Empirical Results of ToolPoker in Extending to Three-player Leduc Hold’em. To further demonstrate scalability, we adapted ToolPoker to a three-player Limit Texas Hold’em. We follow the steps above to fine-tune Qwen2.5-7B-Instruct using ToolPoker. We choose GPT-4.1-mini and vanilla Qwen2.5-7B-Instruct as the opponents, and compare the gameplay performance of the resulting model under the same settings in Section[5.3](https://arxiv.org/html/2602.00528v1#S5.SS3 "5.3 Experimental Results ‣ 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). The gameplay and reasoning quality results are reported in Tab.[11](https://arxiv.org/html/2602.00528v1#A8.T11 "Table 11 ‣ H.1 Transferability & Scalability ‣ Appendix H In-depth Analysis of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use") and[12](https://arxiv.org/html/2602.00528v1#A8.T12 "Table 12 ‣ H.1 Transferability & Scalability ‣ Appendix H In-depth Analysis of ToolPoker ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). | |
| Table 11: Gameplay performance comparison across models in 3-player Leduc Hold’em. | |
| Table 12: LM-as-a-Judge score (0-2) evaluating reasoning traces of various LLMs in 3-player Leduc Hold’em. | |
| From these tables, we observe that ToolPoker consistently outperforms vanilla LLM across both gameplay performance and expert-level reasoning scores in this new game, providing empirical evidence that ToolPoker generalizes beyond poker to other imperfect-information domains. | |
| ### H.2 Error analysis in ToolPoker | |
| In this subsection, we provide an in-depth error analysis of ToolPoker. | |
| Error patterns discussion. As shown in Tab.[5](https://arxiv.org/html/2602.00528v1#S5.T5 "Table 5 ‣ 5 ToolPoker: Game-theoretic Reasoning with Agentic Tool Use ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"), ToolPoker slightly underperforms CFR by 3 3 chips per 100 100 games, while still achieving comparable overall gameplay. To better understand this phenomenon, we conduct an error analysis and observe the following error patterns | |
| * •State mis-specification. The model may sometimes encode the game state (e.g., hand card, public card) imperfectly before querying the solver, which can lead to suboptimal actions and quantities from solvers. | |
| * •Misalignment between solvers’ outputs and final actions. In some cases, the LLM may correctly receive solvers’ outputs (e.g., action) but does not faithfully follow them in the final answer. | |
| Potential Mitigation. To mitigate these errors, we consider several potential methods: | |
| * •Additional faithfulness reward term: Inspired by recent work on faithful agentic search(Xu et al., [2025](https://arxiv.org/html/2602.00528v1#bib.bib67 "Beyond correctness: rewarding faithful reasoning in retrieval-augmented generation")), we can train a reward model to score how faithfully the reasoning aligns with solver outputs, and use this as an auxiliary reward during RL fine-tune. | |
| * •Consistency-aware signal: Similarly, we can add an auxiliary reward during RL fine-tuning to encourage correctly querying the external solvers with accurate states. | |
| ### H.3 Robustness of ToolPoker | |
| Robustness to noisy or human-style inputs. A natural question is how ToolPoker handles inputs that deviate from clean CFR-style play, such as suboptimal, noisy, or human-generated trajectories. Although our main experiments rely on solver-labeled data, we emphasize that ToolPoker is already trained and evaluated in settings that include substantial off-equilibrium and non-expert behavior. | |
| (i) Training already includes noisy, off-equilibrium states. As described in Appendix G.5, our RL dataset is constructed by letting a pretrained CFR agent play against a _random_ opponent in both Leduc and Limit Texas Hold’em. We record all states but only use the CFR agent’s actions as labels. Because the random agent frequently deviates from equilibrium play, the resulting trajectories contain diverse and imperfect state distributions far from idealized CFR self-play. Thus, ToolPoker is trained on a broad range of noisy, non-CFR game patterns rather than purely clean solver trajectories. | |
| (ii) Evaluation already involves diverse, non-expert opponents. In online evaluation, ToolPoker plays against several traditional imperfect-information algorithms (NFSP, DQN, DMC) and LLM-based agents (e.g., prompting-only, BC+RIRL). These opponents generate highly variable and often non-equilibrium strategies. ToolPoker’s consistent superiority across these settings demonstrates that it does not overfit to synthetic solver traces and can robustly respond to suboptimal or noisy play. | |
| (iii) Why ToolPoker is expected to generalize to human gameplay. At inference time, ToolPoker does not rely on imitation of historical actions. Instead, it queries the unified solver API to retrieve equilibrium-oriented quantities (e.g., optimal action, equities, ranges) for the _current_ state. Because solver outputs depend only on the observed state—regardless of whether the trajectory arose from CFR, heuristics, or human mistakes—ToolPoker can consistently anchor its reasoning to accurate game-theoretic guidance. This design inherently promotes robustness to out-of-distribution human-style inputs. | |
| While we have not yet evaluated ToolPoker on real human gameplay, extending our assessment to human or crowd-sourced datasets is an exciting direction for future work. | |
| Appendix I Discussion of Future Works | |
| ------------------------------------- | |
| Our research paves the way for further exploration of TIR in more complex strategic settings, shifting the focus beyond solely improving models’ internal policies. Future work may explore richer tool ecosystems, multi-agent interactions, and principled frameworks for balancing internal reasoning with external computation, ultimately advancing the development of reliable AI systems for high-stakes decision making. | |
| Appendix J LLM Usage | |
| -------------------- | |
| We used an OpenAI LLM (GPT-5) as a writing and formatting assistant. In particular, it helped refine grammar and phrasing, improve clarity, and suggest edits to figure/table captions and layout (e.g., column alignment, caption length, placement). The LLM did not contribute to research ideation, experimental design, implementation, data analysis, or technical content beyond surface-level edits. All outputs were reviewed and edited by the authors, who take full responsibility for the final text and visuals. | |
| Table 13: Realistic Examples of Qwen2.5-3B-Instruct in playing Limit Texas Hold’em. It demonstrates three limitations of LLMs in playing poker: (i) Heuristic reasoning; (ii) Factual Misunderstanding; (iii) Knowing-Doing Gap. Errors identified during reasoning are highlighted in red. | |
| Table 14: Realistic Examples of GPT-4o in playing Limit Texas Hold’em. It demonstrates three limitations of LLMs in playing poker: (i) Heuristic reasoning; (ii) Factual Misunderstanding. Errors identified during reasoning are highlighted in red. | |
| Table 15: Heuristic Reasoning (HR) Judge Prompt. | |
| Table 16: Factual Alignment (FA) Judge Prompt Template. | |
| Table 17: Action-reasoning Consistency Judge Prompt Template. | |
| Table 18: Behavior Cloning Dataset Construction Template. | |
| Table 19: Case Study of BC-RIRL fine-tuned Qwen2.5-7B in Leduc Hold’em (Part I). Errors identified during reasoning are highlighted in red. | |
| Table 20: Case study of BC-RIRL fine-tuned Qwen2.5-7B in Leduc Hold’em (Part II), which is continued from Tab.[19](https://arxiv.org/html/2602.00528v1#A10.T19 "Table 19 ‣ Appendix J LLM Usage ‣ How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use"). Errors identified during reasoning are highlighted in red. | |
| Table 21: TIR rollout structured prompt template. | |
| Table 22: Example of tool-integrated behavior cloning data | |
Xet Storage Details
- Size:
- 182 kB
- Xet hash:
- 22e0fcd8af1bf61c184d63a03567050c3e4198289f6ecb4fcbe62ecc66b3ff67
·
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.