
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91
values | source stringclasses 1
value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
Introduction
SQL 2000 Server provided T-SQL language extensions to operate bi-directionally with relational and XML sources. It also provided two system stored procedures, sp_XML_preparedocument and sp_XML_removedocument, that assist the XML to Relational transformation. This support for returning XML data from relational data using the For XML clause is continued in SQL Server 2005 and SQL Server 2008 although the support for XML is lot more extensive. The shape of the data returned by the For XML clause is further modified by choosing the following modes, raw, auto, explicit, or path. As a preparation for this article we will be creating an XML document starting from the PrincetonTemp table used in a previous article, Binding MS Chart Control to LINQ Data Source Control, on this site.
Creating an XML document from an SQL Table
Open the SQL Server Management and create a new query [SELECT * from PrincetonTemp for XML auto]. You can use the For XML Auto clause to create a XML document (actually what you create is a fragment - a root-less XML without a processing directive) as shown in Figure 01.
Figure 01: For XML Auto clause of a SELECT statement
The result shown in a table has essentially two columns with the second column containing the document fragment shown in the next listing.
Listing 01:
<PrincetonTemp Id="1" Month="Jan " Temperature="4.000000000000000e+001" RecordHigh="6.000000000000000e+001"/>
<PrincetonTemp Id="2" Month="Feb " Temperature="3.200000000000000e+001" RecordHigh="5.000000000000000e+001"/>
<PrincetonTemp Id="3"Month="Mar " Temperature="4.300000000000000e+001" RecordHigh="6.500000000000000e+001"/>
<PrincetonTemp Id="4" Month="Apr " Temperature="5.000000000000000e+001" RecordHigh="7.000000000000000e+001"/>
<PrincetonTemp Id="5" Month="May " Temperature="5.300000000000000e+001" RecordHigh="7.400000000000000e+001"/>
<PrincetonTemp Id="6" Month="Jun " Temperature="6.000000000000000e+001" RecordHigh="7.800000000000000e+001"/>
<PrincetonTemp Id="7" Month="Jul " Temperature="6.800000000000000e+001" RecordHigh="7.000000000000000e+001"/>
<PrincetonTemp Id="8" Month="Aug " Temperature="7.100000000000000e+001" RecordHigh="7.000000000000000e+001"/>
<PrincetonTemp Id="9" Month="Sep " Temperature="6.000000000000000e+001" RecordHigh="8.200000000000000e+001"/>
<PrincetonTemp Id="10" Month="Oct " Temperature="5.500000000000000e+001" RecordHigh="6.700000000000000e+001"/>
<PrincetonTemp Id="11" Month="Nov " Temperature="4.500000000000000e+001" RecordHigh="5.500000000000000e+001"/>
<PrincetonTemp Id="12" Month="Dec " Temperature="4.000000000000000e+001" RecordHigh="6.200000000000000e+001"/>
This result is attribute-centric as each row of data corresponds to a row in the relational table with each column represented as an XML attribute.
The same data can be extracted in an element centric manner by using the directive elements in the SELECT statement as shown in the next figure.
Figure 02: For XML auto, Elements clause of a Select statement
This would still give us an XML fragment but now it is displayed with element nodes as shown in the next listing (only two nodes 1 and 12 are shown).
Listing 02:
<PrincetonTemp><Id>1</Id><Month>Jan </Month><Temperature>4.000000000000000e+001</Temperature>
<RecordHigh>6.000000000000000e+001</RecordHigh> </PrincetonTemp>
...
<PrincetonTemp><Id>12</Id><Month>Dec </Month><Temperature>4.000000000000000e+001</Temperature>
<RecordHigh>6.200000000000000e+001 </RecordHigh></PrincetonTemp>
To make a clear distinction between the results returned by the two select statements the first row of data is shown in blue. This has returned elements and not attributes. As you can see the returned XML still lacks a root element as well as the XML processing directive.
To continue with displaying this data in MS Chart Save Listing 2 as PrincetonXMLDOC.xml to a location of your choice.
Create a Framework 3.5 Web Site project
Let us create a web site project and display the chart on the Default.aspx page. Open Visual Studio 2008 from its shortcut on the desktop. Click File New | Web Site...|(or Shift+Alt+N) to open the New Web Site window. Change the default name of the site to a name of your choice (herein Chart_XMLWeb) as shown. Make sure you are creating a .NET Framework 3.5 web site as shown here.
Figure 03: New Framework 3.5 Web Site Project
Click on APP_Data folder in the solution explorer as shown in the next figure and click on Add Existing Item… menu item.
Figure 04: Add an existing item to the web site folder
In the interactive window that gets displayed browse to the location where you saved the PrincetonXMLDOC.xml file and click Add button. This will add the XML file to the ADD_Data folder of the web site project.
Double click PrincetonXMLDOC.xml in the web site project folder to display and verify its contents as shown in the next figure. Only nodes 1 and 12 are shown expanded. As mentioned previously this is an XML fragment.
Figure 05: Imported PrincetonXMLDOC.xml
Modify this document by adding the <root/> as well as the XML processing instruction as shown in the next figure. Build the project.
Figure 06: Modified PrincetonXMLDOX.xml (valid XML document)
Binding the chart to XML data
Drag and drop a Microsoft Chart control from Toolbox under Data to the Default.aspx page as in the previous cited article. Drag and drop a button and change its Text property to Display Chart as shown.
Figure 07: Chart1 on Default.aspx page
Double click the button and to the button's click event insert the listing shown in the page's code.
Listing 03: Code for the button's click event
Imports System.Data
Partial Class _Default
Inherits System.Web.UI.Page
Protected Sub Button1_Click(ByVal sender As Object, _
ByVal e As System.EventArgs) Handles Button1.Click
Dim ds As New DataSet
'Read xml data to the dataset
ds.ReadXml("C:Documents and SettingsJayaram Krishnaswamy" & _
"My DocumentsVisual Studio 2008Chart_XMLWeb" & _
"App_DataPrincetonXMLDOC.xml")
'code used for verifying necessary strings
'Response.Write(ds.Tables(0).Columns(0).ColumnName.ToString())
'Response.Write(ds.Tables(0).Columns(1).ColumnName.ToString())
'Response.Write(ds.Tables(0).Columns(2).ColumnName.ToString())
'Response.Write(ds.Tables(0).Columns(3).ColumnName.ToString())
Chart1.DataSource = ds
Chart1.Series("Series1").XValueMember = _
ds.Tables(0).Columns(1).ColumnName.ToString()
Chart1.Series("Series1").YValueMembers = _
ds.Tables(0).Columns(2).ColumnName.ToString()
Chart1.Series.Add("Series2")
Chart1.Series("Series2").XValueMember = _
ds.Tables(0).Columns(1).ColumnName.ToString()
Chart1.Series("Series2").YValueMembers = _
ds.Tables(0).Columns(3).ColumnName.ToString()
Chart1.Series(0).Color = Drawing.Color.DarkRed
Chart1.Series(1).Color = Drawing.Color.RoyalBlue
Chart1.ChartAreas("ChartArea1").AxisX.Interval = 1
Chart1.DataBind()
End Sub
End Class
Build the web site project and browse the page on the browser. In the web page that gets displayed click on the Display Chart button. The chart gets displayed as shown in the next figure.
The dataset gets the XML document using ReadXML(). All you need to do is to point to the correct location of the XML Document. The information is parsed and provided to the proper components of the chart(Series and Columns). The commented code was used to verify that the proper association is made to the chart components.
Figure 08: PrincetonTemp Chart
While modifying the imported XML file make sure that you add the <root/> element otherwise you will encounter an XML exception as shown.
Figure 09: XML Exception
Although we started off with an element-centric XML the ReadXML() method provides the proper nodes of the XML for the chart even for attribute-centric XML Documents.
Adding titles to chart
Although data is central to a chart,titles are absoutely necessary. They can be added at design time using the properties of the chart. They can be added at run time so as to customize them. In the next subsections we will add a title to the chart and the axes as well as set the minimum and maximum values for the Y-axis.
Adding a title to the chart
The chart's title belongs to the titles collection. You first need to add the title element and then format the same providing a text; positional and size information. The following listing shows code used to add a title to the chart. The chart size was increased to 400x400 from its default 300x300 size.
Listing 4: Adding X and Y axes titles to basic chart
Chart1.Height = 400
Chart1.Width = 400
Chart1.ChartAreas("ChartArea1").AxisY.Minimum = 30
Chart1.ChartAreas("ChartArea1").AxisY.Maximum = 90
Chart1.Titles.Add("Title1")
With Chart1.Titles("Title1")
.Text = "Princeton Temperature"
.ForeColor = Drawing.Color.BlueViolet
.TextStyle = DataVisualization.Charting.TextStyle.Emboss
.Font = New Drawing.Font("Broadway", 14, Drawing.FontStyle.Bold)
.Alignment = Drawing.ContentAlignment.TopCenter
.Position.Width = 100
.Position.Height = 25
End With
Adding titles to X and Y axis (shown for X axis)
Chart axes titles are essential for any chart. The chart axes are a property of the chart areas in the MS Chart Control. All axes properties are easily accessible as shown in the next figure. For a Column type chart there are two X and two Y axes.
Figure 10: Chart axes properties
Code for adding and formatting the axes
The code shown in the following listing will add the titles for the X and Y axes for the basic columnar chart of Figure 09. The code snippet can be inserted in the click event of the button.
Listing 5: Adding X and Y axes titles to basic chart
With Chart1.ChartAreas("ChartArea1")
.AxisX.Title = "Month"
.AxisX.TitleFont = New Drawing.Font("Broadway", 12, Drawing.FontStyle.Bold)
.AxisX.TitleForeColor = Drawing.Color.DarkMagenta
.AxisY.Title = "Temperature in Deg F"
.AxisY.TitleFont = New Drawing.Font("Verdana", 12, Drawing.FontStyle.Bold)
.AxisY.TitleForeColor = Drawing.Color.DarkMagenta
End With
Setting the maximum and minimum values for an axis
Sometimes it may be necessary to change the displayed maximum and minimum values for the axes in order to better bring out the details and reduce the chart size. For example the program has used the default of 0 and 100 as the minimum and maximum values for the graph in Figure 08. This could be changed using the Maximum and Minimum properties of the axes as shown in the next listing.
Listing 6:Maximum and Minimum of the axes
Chart1.ChartAreas("ChartArea1").AxisY.Minimum = 30
Chart1.ChartAreas("ChartArea1").AxisY.Maximum = 90
Adding all the titles and setting the minimum and maximum as above the chart gets rendered as shown in the next figure.
Figure 11: Chart with axes and chart titles added
Basic Chart Code in C#
Add a web page SharpChart.aspx with language attribute for the page as C#. Use the existing PrincetonXMLDOC.xml file as the source of data. Add a MS Chart control from the Toolbox on to the SharpChart.aspx page. Add a button control as well. To the click event of the button add the code shown in Listing 6.
Listing 7:SharpChart.aspx.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.Web.UI;
using System.Web.UI.WebControls;
using System.Data;
public partial class SharpChart : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
}
protected void Button1_Click(object sender, EventArgs e)
{
DataSet ds = new DataSet();
ds.ReadXml("C:Documents and SettingsJayaram KrishnaswamyMy DocumentsVisual Studio 2008Chart_XMLWebApp_DataPrincetonXMLDOC.xml");
//Response.Write(Convert.ToString(ds.Tables[0].Columns[0].ColumnName));
Chart1.Series.Add("Series2");
Chart1.Series[0].XValueMember=Convert.ToString(ds.Tables[0].Columns[1].ColumnName);
string colname = Convert.ToString(ds.Tables[0].Columns[1].ColumnName);
Chart1.Series["Series1"].XValueMember = colname;
Chart1.Series["Series2"].XValueMember = colname;
Chart1.Series["Series1"].YValueMembers = Convert.ToString(ds.Tables[0].Columns[2].ColumnName);
Chart1.Series["Series2"].YValueMembers = Convert.ToString(ds.Tables[0].Columns[3].ColumnName);
Chart1.ChartAreas[0].AxisX.Interval = 1;
Chart1.ToolTip=("Princeton's current year and record high temperatures");
Chart1.DataSource = ds;
}
}
The extra item you see in this code is Chart's tooltip property that displays "Princeton's current year and record high temperatures" when you hover over the chart.
Summary
Binding the MS Chart Control to XML data was carried out using code. Creating a dataset is all that is necessary. The XML data is obtained from an XML Document which is read with the ReadXML() method. Chart area's properties were explored while adding X and Y axes titles to the chart. Also the chart title and the range of Y axis values were set using code.
If you have read this article you may be interested to view :
- Binding MS Chart Control to LINQ Data Source Control
- Displaying SQL Server Data using a Linq Data Source
- MySQL Linked Server on SQL Server 2008
- Displaying MySQL data on an ASP.NET Web Page
- Exporting data from MS Access 2003 to MySQL
- Transferring Data from MS Access 2003 to SQL Server 2008 | https://www.packtpub.com/books/content/microsoft-chart-xml-data | CC-MAIN-2016-36 | refinedweb | 2,093 | 50.94 |
Event-driven integration on Kubernetes with Camel & KEDA
Can we develop apps in Kubernetes that autoscale based on events? Perhaps, with this example using KEDA, ActiveMQ and Apache Camel
Tags: Apache ActiveMQ, Apache Camel, Kubernetes • Comments
I’ve been working with a team this week who are investigating how they could use AWS Lambda for data processing. The process is vaguely something like this:
write some data processing logic
spin it up when an event happens (e.g. a message arrives on an SQS queue)
terminate when finished.
So they want to use AWS Lambda for this, to make it scalable and serverless. These are going to create lightweight bits of data transformation logic, driven by events, that use minimal compute power. Sounds good so far..
KEDA: Kubernetes Event-Driven Autoscaling
After digging around for a little while, I found KEDA - Kubernetes Event-Driven Autoscaling. This is quite new and backed by Microsoft (Azure).
KEDA is a way of auto-scaling applications in Kubernetes based on an external metric. The metrics are collected by a set of Scalers which support things like:
ActiveMQ Artemis
Apache Kafka
Amazon SQS
Azure Service Bus
and lots more….
The basic idea is that a KEDA Scaler monitors one of these objects for a metric. The metric is usually something like the number of messages on a queue.
When the metric goes above a certain threshold, KEDA can scale up a Deployment automatically (called “Scaling Deployments”), or create a Job (called “Scaling Jobs”). It can also scale down Deployments when the metric goes down.
It does this by creating a Horizontal Pod Autoscaler (HPA)..
And when I think of messaging, of course I immediately think of ActiveMQ and Camel and how KEDA could be used. I think I feel an example coming on….
KEDA example: Apache Camel and ActiveMQ.
About the demo app
I’ve created an example Camel app which uses Quarkus as the runtime. I’ve published the image to Docker Hub and I use that in the steps further below. But if you’re interested in how it was created, read on.
Get the code on GitHub Get the image on Docker Hub
I decided to use Quarkus because it boasts super-fast startup times, way faster than Spring Boot. When we’re reacting to events, we want to be able to start up quickly and not wait 30-60 seconds for the app to start.
To create the app, I used the Quarkus app generator.
As Quarkus is configured using extensions, I needed to find a Quarkus extension which would help me create a connection factory to talk to ActiveMQ Artemis. So I’m using the Qpid JMS Extension for Quarkus, which wraps up the Apache Qpid JMS client for Quarkus applications. This allows me to talk to ActiveMQ Artemis using the nice, open AMQP 1.0 protocol.
The Qpid JMS extension creates a connection factory to ActiveMQ when it finds certain config properties. You only need to set the properties
quarkus.qpid-jms.url,
quarkus.qpid-jms.username and
quarkus.qpid-jms.password. The Extension will do the rest automatically, as it says in the docs:
Then, I use Camel’s AMQP component to actually consume the messages. This will detect and use the connection factory created by the extension.
I’ve compiled and packaged the application into a native binary, not a JAR. This will help it to start up very fast. You need GraalVM to be able to do this.
./mvnw package -Pnative
Or, if you don’t want to install GraalVM, you can tell Quarkus to use a helper container with GraalVM baked in, in order to build the native image. You’ll need Docker running for this, of course:
./mvnw package -Pnative -Dquarkus.native.container-build=true
The output from this is a native binary which should start up faster than a typical JVM-based application. Nice. Good for rapid scale-up when we receive a message!
Finally, I built a container image with Docker and pushed it up to Docker Hub. There’s a Dockerfile provided with the Quarkus quickstart to do the build, and then it’s an easy
docker push:
docker build -f src/main/docker/Dockerfile.native -t monodot/camel-amqp-quarkus . docker push monodot/camel-amqp-quarkus
Now we’re ready to deploy the app, deploy KEDA and configure it to auto-scale the app.
Deploying KEDA and the demo app
First, install KEDA on your Kubernetes cluster. You’ll probably need to have cluster-admin permissions to be able to do this.
If you need a Kubernetes cluster of your own, you can use Minikube or a cloud offering like Amazon’s EKS. Read about my experiences with EKS on AWS).
To install KEDA, you should probably follow the instructions on the KEDA web site, but I installed it with Helm like this:
$ helm repo add kedacore $ helm repo update $ kubectl create namespace keda $ helm install keda kedacore/keda --namespace keda
Create a namespace for our demo.
kubectl create namespace keda-demo
Now we need to deploy an ActiveMQ Artemis message broker.
Here’s some YAML to create a Service and Deployment for it in Kubernetes. It uses the
vromero/activemq-artemiscommunity image of Artemis on Docker Hub, and exposes its console and amqp ports. I’m customising it by adding a ConfigMap which:
Changes the internal name of the broker to a static name:
keda-demo-broker
Defines one queue, called
ALEX.HONKING. If we don’t do this, then the queue will be created when a consumer connects to it, but it will be removed again when the consumer disappears, and so KEDA will just get confused. So we define the queue first.
$
Next, we deploy the demo Camel Quarkus AMQP consumer application, and add some configuration.
So we create a Deployment. I’m deploying my demo image
monodot/camel-amqp-quarkusfrom Docker Hub. You can also deploy my image, or you can build and deploy your own image if you want.
We use the environment variables
QUARKUS_QPID_JMS_*to set the URL, username and password for the ActiveMQ Artemis broker. These will override the properties
quarkus.qpid-jms.*in my application’s properties
Now we tell KEDA to scale the pod down when there are no messages, and back up when there are messages.
We do this by creating a
ScaledObject. This tells KEDA which Deployment to scale, and when to scale it.
$
By the way, to get the credentials to use the Artemis API, KEDA will look for any environment variables on the Deployment pods of the Camel app This means you don’t have to specify the credentials twice :-) So here, I’m using
QUARKUS_QPID_JMS_USERNAMEand
_PASSWORD. They reference the environment variables on the demo app’s Deployment.
Now let’s put some test messages onto the queue.
You can do this in a couple of different ways: either point and click using the Artemis web console, or use the Jolokia REST API.
Either way, we need to be able to reach the
artemisK
localhostport
8161:
kubectl port-forward -n keda-demo svc/artemis 8161:8161
Leave that running in the background.
Now, in a different terminal, hit the Artemis Jolokia API with
curl, via the kubectl port-forwarding proxy. We want to send a message to an Artemis queue called ALEX.HONKING.
This part requires a ridiculously long API call, so I’ve added some line breaks here to make it easier to read. This uses ActiveMQ’s Jolokia REST API to put a message in the Artemis queue:\"]}"
(If you have any issues with this, just use the Artemis web UI to send a message, it’s at)
All good!
You put messages in the queue, you should see the Camel app pod starting up and consuming the messages.
After all messages are consumed, there will be no messages left on the queue. KEDA waits for the cooldown period (in this demo I’ve used 30 seconds as an example), and then scales down the deployment back to zero, so there are no pods running.
This is autoscaling… in action!
Epilogue: You forgot Knative
So you’ve probably noticed that I didn’t mention Knative.
I started my research by looking at Knative. Knative is a beast of a project. It was announced a couple of years ago and is backed by Google.
There are a couple of major parts to Knative, but the interesting ones to me are:
Knative Serving -.
Knative Eventing - is the other half of the project, which is about making “events” a native concept in Kubernetes, and decoupling producers and consumers. You can then write apps which respond to these events.:
I think that means that Knative is out of the running. For now….
What do you think? You can use Markdown in your comment. To write code, indent each line with 4 spaces. | https://tomd.xyz/kubernetes-event-driven-keda/ | CC-MAIN-2021-49 | refinedweb | 1,483 | 72.46 |
shouldn't be a problem...
your internal namespace can share components of your internet facing namespace... it would be preferable to have something like...
yourcompany.com for external (then)
create a place holder such as ad.yourcompany.com (do not put any objects or anything like that in this domain)
then create for example sitename.ad.yourcompany.com for internal... all our internal domains will be children of ad.yourcompany.com.
You can then manage your DNS and have separation of internal/external records, also you can place your firewalls, etc., between ad.yourcompany.com and yourcompany.com
dns and active directory
on my active directory. i have to get to dns to cheqe if one of my costomer is on the domain list.
I have done it before by pasting the second
name on the sytem and clik find and it will bring the list names out,this inlude list of similat names and family name of other costomers.
Please help me hou to acces to this information from my desk.
Regards
Gbollu
Active Directory - Domain Names and Split DNS
(Split DNS). We are not currently using Exchange but will be moving to it soon.
My question is should I consider changing our internal domain name to something else before we bring Exchange into the picture.
We are only at one site currently and about 100 users. Everything works fine and with the exception of a having to create a few additional internal DNS entries, we are happy.
What is the concensus on this configuration vs having differing domain names. Is there a preference or do many companies use this setup.
Thanks,
HM
This conversation is currently closed to new comments. | https://www.techrepublic.com/forums/discussions/active-directory-domain-names-and-split-dns/ | CC-MAIN-2018-34 | refinedweb | 282 | 58.48 |
Learn how to build a container image from source code and use the image to schedule your PostgreSQL backups using IBM Cloud Code Engine.
Following the instructions in this post, you can schedule the backup to run hourly, daily, weekly, monthly, yearly or even every minute, if you want.
Before jumping into the technical how-to instructions, let's understand a bit about IBM Cloud Databases for PostgreSQL and IBM Cloud Code Engine with quick introductions below
What is IBM Cloud Databases for PostgreSQL?
IBM Cloud Databases for PostgreSQL is a serverless cloud database service that is fully integrated into the IBM Cloud environment. This offering lets users access and use a cloud database system without purchasing and setting up their own hardware, installing their own database software or managing the database themselves.
IBM Cloud Databases for PostgreSQL requires no software, infrastructure, network or OS administration. IBM continuously provides fully automated updates to the service, such as security patches and minor version upgrades. A database instance is deployed by default as highly available across multiple data centers in an IBM Cloud Multi-Zone region with synchronous replication. Customers need only connect to a single database endpoint and IBM automatically manages the failover between Availability Zones.
IBM Cloud Databases for PostgreSQL provides the ability to horizontally scale the PostgreSQL instance with Read Replicas in region or cross-regionally. IBM Cloud Databases for PostgreSQL Read Replicas can be easily transformed into fully functioning IBM Cloud Databases for PostgreSQL instances, an especially useful feature for online cross-regional disaster recovery strategies.
What is IBM Cloud Code Engine?
IBM Cloud:
Before you begin
- Create an IBM Cloud API key.
- Create an IBM Cloud Code Engine project.
- Create an IBM Cloud Databases for PostgreSQL service instance. Copy and Save the CRN (deployment ID) from the service Overview page for quick reference.
- Create an IBM Cloud Container Registry namespace.
Create a job from source code
You can create your job from source code. Find out what advantages are available when you build your image with Code Engine.
A job runs one or more instances of your executable code. Unlike applications, which include an HTTP Server to handle incoming requests, jobs are designed to run one time and exit.
IBM Cloud Code Engine can automatically push images to Container Registry namespaces in your account and even create a namespace for you. To push images to a different Container Registry account or to a private Docker Hub account, see Accessing container registries.
- Open the Code Engine console.
- Under Start from source code, enter as the source URL and click Start creating.
- Select Job.
- Enter a name for the job or leave the default. Use a name for your job that is unique within the project.
- Select the project you created from the list of available projects. You can also create a new one. Note that you must have a selected project to create a job.
- Select Source code under Choose the code to run.
- Click Specify build details:
- Check the source repository Click Next.
- Select Dockerfile as the strategy for your build and resources for your build. Click Next. For more information about build options, see Planning your build.
- Provide registry information about where to store the image of your build output. Select a container registry location, such as IBM Registry Dallas.
- Select an existing Registry access secret or create a new one. If you are building your image to a Container Registry instance that is in your account, you can select Code Engine-managed secret and let Code Engine create and manage the secret for you.
- Select a namespace, name and a tag for your image. Click Done.
- Add environment variables by clicking Add under the Environment Variables (optional) section. Select Literal value:
- Environment variable name: IBM_CLOUD_API_KEY. Provide the API key under Value and click Done
- Repeat the steps and add POSTGRES_DEPLOYMENT_ID. Use the CRN (deployment ID) from the PostgreSQL overview page. Click Done
- Click Create.
Create an event subscription
In distributed environments, you'll often want your applications or jobs to react to messages (events) that are generated from other components, which are usually called event producers. With Code Engine, your applications or jobs can receive events of interest by subscribing to event producers. Event information is received as POST HTTP requests for applications and as environment variables for jobs.
The cron event producer is based on cron and generates an event at regular intervals. You will use a cron event producer when an action needs to be taken at well-defined intervals or at specific times.
- Once the image build is successful, click on the project name in the navigation menu.
- Click on Event subscriptions and then Create.
- Select Periodic timer, provide a name and click Next.
- Under cron expression, add */60 * * * * to schedule backup every hour and click Next. You can schedule the backup to run hourly, daily, weekly, monthly, yearly or even every minute, if you want:
- Skip custom event data and click Next.
- Under the Event consumer page:
- Select Component type: Job
- Name: <Name of the Job created earlier using the source code>
- Click Next.
- Check the Summary and click Create.
Check the backup status
You can check the backup status either on the PostgreSQL service page or under the Code Engine job runs tab:
- Navigate to the resource list and under Services, click on the name of the PostgreSQL service.
- Click on Backups and restore to see the automatic and on-demand backups under the Available backups section.
- You can also check the Job run that initiates the job to see the status:
- Navigate to the Code Engine project page.
- Click on the name of the project and then click Jobs.
- Click on the Job name > Job runs > Check the status in the table:
What's next?
- Instead of using environment variables as literal values, learn how to bind Cloud services to an application and a job: Tutorial: Text Analysis with IBM Cloud Code Engine
- Image Classification with IBM Cloud Code Engine and TensorFlow
Conclusion
Following the steps in this post, you learned how to create a container image directly from the source code on a Git repository, push the image to a private container registry and then create a cron job from the container image to automate the PostgreSQL backups using IBM Cloud Code Engine.
Along with the IBM Cloud console, you can also use the IBM Cloud CLI with Code Engine and cloud-databases plugins to achieve what's shown above. Remember, PostgreSQL deployments come with free backup storage equal to the service total disk space. If your backup storage usage is greater than total disk space, each gigabyte is charged. Backups are compressed, so even if you use on-demand backups, most deployments will not exceed the allotted credit.
If you have any queries, feel free to reach out to me on Twitter or on LinkedIn.
Follow IBM Cloud
Be the first to hear about news, product updates, and innovation from IBM Cloud.Email subscribeRSS | https://www.ibm.com/cloud/blog/automate-postgresql-backups-with-ibm-cloud-code-engine | CC-MAIN-2022-21 | refinedweb | 1,167 | 62.68 |
From: David Abrahams (david.abrahams_at_[hidden])
Date: 2002-01-15 00:06:09
A request: please leave a blank line between text you quote and your new
text. I have trouble separating them otherwise. Thanks.
----- Original Message -----
From: "Brad King" <brad.king_at_[hidden]>
>
> > I hope we can also have "jam test1", which runs the test by the user's
> > preferred testing means.
> That should be easy to add. All we need to do is have a rule that checks
> if an environment variable is set with the preferred testing module and
> add a target "test1" that depends on "preferred-test.test1" for every
> test. This should pass through the rule invocations automatically.
We're not going to rely on environment variables. There are simply too many
things that a user would want to configure. Instead, we'll have
user-config.jam and site-config.jam in the BOOST_BUILD_PATH, which can
import modules and invoke rules to set preferences:
test.default-backend superdupertester ;
> > > To see what a particular test entails, the user can also list a
specific
> > > test:
> > > jam list-tests.test1
> > > jam list-tests.test2
> >
> > What's that going to tell you? The command-line that will get executed
> > perhaps?
> Right now it just prints out the line used to declare the test, but
> without the "test." prefix. That support was mostly just there for
> checking my own code, but turned out to be a useful feature in the end.
> It may be tricky to get the command line that will be executed unless the
> testing back-end supports it because I don't know if there is a way to get
> the string back from an action without actualy invoking it (perhaps this
> is a feature worth adding to jam if it doesn't exist??).
...my answer to this is too complicated to type at this late hour... ;-)
> > Some other features supported by the current system:
> >
> > "jam <testname>.run" will run the test even if there's an up-to-date
record
> > of its success. Now that I think of it, I wonder if it woulnd't be
better if
> > "jam <testname>" had that behavior, while "jam test" or "jam
test-update"
> > would only run outdated tests.
> Okay, that was something I hadn't considered. Actually having a record
> marking a test as up-to-date is a good idea. I would think a good choice
> for this mark would be a file containing the test's output.
Please examine the stuff Joerg is working on, or status/Jamfile. It already
does exactly that.
> I agree that
> the default behavior when a specific test name is requested is to run it
> even if it appears up-to-date. For the run-all-tests targets, there
> should be one that always runs all tests, and one that runs out-of-date
> tests.
>
> Fortunately, there is an individual target for each test with each
> back-end, and its name is well defined. This makes it easy to add new
> rules that can group the tests in any combination. Perhaps having a rule
> similar to the test-suite rule in the current system would be useful.
> How does this look (just off the top of my head):
>
> test.suite suite-name : test1 test2 ... ;
>
> This would create a target for each back-end called
> "back-end-name.suite-name" to run all the tests in the suite. Again, the
> default back-end idea would allow a target called "suite-name" to run the
> tests with the default back-end.
>
> Also, as far as running a test versus compiling, how does this sound to
> you:
>
> "compile", "compile-fail", "link", and "link-fail" tests are actually
> built when they are run since the compile/link steps are the test itself.
We might want to throw away the product and leave a simple file marker
instead, just to save space. But that's an optimization that can wait.
> "run" and "run-fail" tests have targets that will build them without
> actually running them in addition to the normal test execution targets.
> The targets that actually run them will simply depend on the build
> versions. This way the test will not be re-built if the executable is
> up-to-date and the user requests that the test be run.
AFAICT, that's what we're already doing.
> It will also allow
> nightly testing to build the run and run-fail tests as part of the normal
> build so that any errors show up in the normal build log. This will
> provide a means of distinguishing the output from building the run-* tests
> and the output from actually running them.
I was thinking that we always need a way to capture run output directly from
Jam anyway, so all build actions might end with something like
>$(STDOUT) >2$(STDERR)
or possibly
>>$(STDOUT) >>2$(STDERR)
If the build set the variables on the target, the output would go to the
specified place. This feature needs some consideration; it might be a
candidate for core language support.
> > If you look at the python.jam file, you'll see that there's a
> > PYTHON_LAUNCH variable which can be used to say how python is invoked.
> > I commonly use this to run a debugger in the same context in which the
> > test needs to be run.
> I'll look at that. It sound's useful...then the user won't have to figure
> out what command line to run just to bring the failed test up in a
> debugger.
very important, especially where shared libs are concerned.
> > While your approach is basically sound, it will need some adjustment to
be
> > compatible with the planned rewrite. Some things I noticed:
> >
> > 1. We don't write "module" explicitly, except in low-level code. See the
> > contents of tools/build/new, and especially modules.jam
> I was looking at that a bit. I take it that the name of the .jam file
> becomes the name of the module automatically? I also see that there is a
> nearly empty test.jam file. Should I write the testing front-end under
> the assumption that it will be placed into that file (since the module
> will probably be called "test" anyway)?
Oh, you can replace the contents of test.jam. I'm just using
with -sBOOST_BUILD_TEST=1 to run the unit tests of the new code. I can use a
differenly-named file.
> > 2. Part of the plan is to delay generation of targets (meaning the use
> > of DEPENDS and action rules) until after the Jamfile has been
> > completely read in. There are lots of good reasons for this, which you
> > can read about in the message history. So, your initial level of
> > indirection/delay will have to be extended.
> I'm pretty sure this is the behavior of the current implementation unless
> I'm misunderstanding your request. The only DEPENDS rules and action
> invokations are in the "test.invoke" and "test.list" rules, which are not
> called until after all the user jamfiles have been processed. All the
> "test.*" declaration rules merely save their arguments in module-local
> variables.
The user calls "demo.invoke demo-test" in the Jamfile itself, which calls
test.invoke. So the Jamfile isn't finished yet. The way the system will work
is:
1. import the Jamfile
2. Jamfile rules record data about user-level targets, etc., much like in
your example
3. After the Jamfile is completely processed, go through the record of
user-level targets and generate actual targets.
To make your system fit, you'd just have demo.invoke make some more records
about targets. But we don't have the framework to do that yet, so don't
worry about it ;-)
-Dave
Boost-Build list run by bdawes at acm.org, david.abrahams at rcn.com, gregod at cs.rpi.edu, cpdaniel at pacbell.net, john at johnmaddock.co.uk | https://lists.boost.org/boost-build/2002/01/0186.php | CC-MAIN-2020-24 | refinedweb | 1,313 | 75.4 |
I'd like to post some code of an app I wrote to spit out large files, and sort them, and finally reassemble them. I'm new to Python, and the 'object' way in general.
If you feel like it, would you please tell me how it should have been written 'properly'. For instance, I don't get the whole 'self' thing, and I don't 'quite' get the modularity. I'm not looking for a lesson so much as just 'you could have done this here', or, 'this is sloppy, it should be done like this'..
Please look at it, and if you have the time, let me know how I 'should' have done it, or at least a tip or two. I'm glad I found this group, you guys are awesome.
Code:
import csv import time import sys import os def main(): pass def sortAndWrite(fname, ziploc): try: T = csv.reader(open(fname, 'rb'), quoting = csv.QUOTE_ALL) To = open('Sorted_' + fn,'ab') Tw = csv.writer(To, quoting = csv.QUOTE_ALL) #add all of the rows to a temporary array for row in T: tmpTable.append(row) #sort the data tmpTable.sort(lambda a,b: cmp(a[ziploc][0:5],b[ziploc][0:5]) ) #write the table print "Building Sorted file, adding: " + fname if header == 1: # Have we written it? Tw.writerow(h) # No, write it first header == 0 # Now, it's written # Write the contents of the temp list after sorting to the master output file for row in tmpTable: Tw.writerow(row) #empty the temp table tmpTable[:] = [] if fname == 'temp6.tmp': To.flush() To.close() except: print ("Unexpected error:", sys.exc_info()[0]) # Start App ==================================================================== os.system("cls") # Clear the screen # Define the help menu should they type Zipsort.py --help helptext="""\nUsage: Zipsort.py [filename -h | -c ] Zipsort.py is is a small program that will sort your file by Zip Code. -h No header [default, assumes file has a header] -c New Zip Code column (zero based) [default is column 76] Example: Zipsort.py MyFile.csv -h -c In the above example, the file to be sorted is 'MyFile.csv', the file does not have a header record and the column that contains the zip code needs to be overridden. """ print "" # Force a print line so the text isn't wedged against the top of the # DOS window. # Do they need help? if sys.argv.count("--help")>0: print helptext sys.exit() try: fn = sys.argv[1] # The filename is the first argument on the command line print "Filename is: " + fn if os.path.exists(fn) == False: print "File does not exist, try again." exit() except: # rather than mess with indexes, I just catch the exception print "You must define a valid file to sort. Ex: Zipsort.py MyFile.cvs" exit() # is there no header? if sys.argv.count("-h")>0: header = 0 print "File has no header" else: header = 1 print "File has a header" # Do they want to change the zip code location? if sys.argv.count("-c")>0: z = raw_input("What is the new Zip Code column?: ") print "Zip code is now located at: " + str(z) else: z = 76 print "Zip code is located at: " + str(z) # Define the working table we will use to hold the temp file(s) records # for sorting, and other working variables tmpTable = [] h = '' # This will hold the header for later # Delete the Sorted out file before we start if os.path.exists('Sorted_' + fn) == True: YN = raw_input("Sorted file already exists, delete it?: ") if YN == 'y' or YN == 'Y': os.remove('Sorted_' + fn) print "Sorted file removed" else: Q = raw_input( "Quit?, or Continue (Q/C)?") if Q == 'q' or Q == 'Q': print "Exiting.." exit() #Open input file and split it into (6) temp files for processing #if there's a header, we will capture it at run time start = time.clock() #start the timer I = open(fn, 'rb') r = csv.reader(I, quoting = csv.QUOTE_ALL) O1 = open('temp1.tmp', 'w+b') w1 = csv.writer(O1, quoting = csv.QUOTE_ALL) O2 = open('temp2.tmp', 'w+b') w2 = csv.writer(O2, quoting = csv.QUOTE_ALL) O3 = open('temp3.tmp', 'w+b') w3 = csv.writer(O3, quoting = csv.QUOTE_ALL) O4 = open('temp4.tmp', 'w+b') w4 = csv.writer(O4, quoting = csv.QUOTE_ALL) O5 = open('temp5.tmp', 'w+b') w5 = csv.writer(O5, quoting = csv.QUOTE_ALL) O6 = open('temp6.tmp', 'w+b') w6 = csv.writer(O6, quoting = csv.QUOTE_ALL) if header == 1: h = r.next() # store the header print "" print "Splitting out the input file" try: for row in r: Zip = int(row[z][0:5]) if Zip <= 20000: w1.writerow(row) if Zip > 20000 and Zip <= 35000: w2.writerow(row) if Zip > 35000 and Zip <= 45000: w3.writerow(row) if Zip > 45000 and Zip <= 65000: w4.writerow(row) if Zip > 65000 and Zip <= 85000: w5.writerow(row) if Zip > 85000: w6.writerow(row) except: w6.writerow(row) print "Error in this record, bad zip: " + row[z][0:5] #close the temp files so we don't have contention issues later O1.close() O2.close() O3.close() O4.close() O5.close() O6.close() #once the file are separated, we need to sort them for f in range(1,7): tmpFile = 'temp' + str(f) + '.tmp' print "Sorting: " + tmpFile sortAndWrite(tmpFile, z) os.remove(tmpFile) # End of app.... end = time.clock() print "Finished" print "Time elapsed = ", end - start, "seconds" if __name__ == '__main__': main() | https://www.daniweb.com/programming/software-development/threads/298947/help-with-python-design | CC-MAIN-2017-34 | refinedweb | 898 | 86.81 |
1.1 anton 1: \ Etags support for GNU Forth.: : tags-file-name ( -- c-addr u ) 41: \ for now I use just TAGS; this may become more flexible in the 42: \ future 43: s" TAGS" ; 44: 45: variable tags-file 0 tags-file ! 46: 47: create tags-line 128 chars allot 48: 49: : skip-tags ( file-id -- ) 50: \ reads in file until it finds the end or the loadfilename 51: drop ; 52: 53: : tags-file-id ( -- file-id ) 54: tags-file @ 0= if 55: tags-file-name w/o create-file throw 56: \ 2dup file-status 57: \ if \ the file does not exist 58: \ drop w/o create-file throw 59: \ else 60: \ drop r/w open-file throw 61: \ dup skip-tags 62: \ endif 63: tags-file ! 64: endif 65: tags-file @ ; 66: 67: create emit-file-char 0 c, 68: 69: : emit-file ( c file-id -- ) 70: swap emit-file-char c! 71: emit-file-char 1 chars rot write-file ; 72: 73: 2variable last-loadfilename 0 0 last-loadfilename 2! 74: 75: : put-load-file-name ( file-id -- ) 76: >r 1.4 anton 77: sourcefilename last-loadfilename 2@ d<> 1.1 anton 78: if 79: #ff r@ emit-file throw 80: #lf r@ emit-file throw 1.4 anton 81: sourcefilename 2dup 1.1 anton 82: r@ write-file throw 83: last-loadfilename 2! 84: s" ,0" r@ write-line throw 85: endif 86: rdrop ; 87: 88: : put-tags-entry ( -- ) 89: \ write the entry for the last name to the TAGS file 90: \ if the input is from a file and it is not a local name 91: source-id dup 0<> swap -1 <> and \ input from a file 1.5 ! anton 92: current @ locals-list <> and \ not a local name 1.1 anton 93: last @ 0<> and \ not an anonymous (i.e. noname) header 94: if 95: tags-file-id >r 96: r@ put-load-file-name 97: source drop >in @ r@ write-file throw 98: 127 r@ emit-file throw 1.2 pazsan 99: bl r@ emit-file throw 1.1 anton 100: last @ name>string r@ write-file throw 1.2 pazsan 101: bl r@ emit-file throw 1.1 anton 102: 1 r@ emit-file throw 1.4 anton 103: base @ decimal sourceline# 0 <# #s #> r@ write-file throw base ! 1.1 anton 104: s" ,0" r@ write-line throw 105: \ the character position in the file; not strictly necessary AFAIK 106: \ instead of using 0, we could use file-position and subtract 107: \ the line length 108: rdrop 1.5 ! anton 109: endif ; 1.1 anton 110: 111: : (tags-header) ( -- ) 112: defers header 113: put-tags-entry ; 114: 115: ' (tags-header) IS header | http://www.complang.tuwien.ac.at/cvsweb/cgi-bin/cvsweb/gforth/etags.fs?annotate=1.5;sortby=log;f=h;only_with_tag=MAIN | CC-MAIN-2019-39 | refinedweb | 450 | 80.01 |
In this Python Tkinter Tutorial, we will discuss the usage and inner workings behind the “mainloop” function.
We use this function on our Tkinter window, typically called “root”, in every single Tkinter program. But often the actual working and purpose of this function is forgotten. This tutorial aims to explain this, so you have a better idea of what’s going on behind the scenes.
Understanding Tkinter MainLoop
If you remember correctly, the mainloop function is called as shown below. And until it is called, the Tkinter window will not appear.
import tkinter as tk root = tk.Tk() root.mainloop()
Think about how code is executed for a moment. Normally, your programs will begin executing and finish within a fraction of a second. But this does not happened with games or GUI windows, which last indefinetly. Have you ever wondered why?
This is because they must run infinitely, until they are ordered to be closed, either by the program or by a manual action by the user. So how is this possible? With Loops of course. With the right condition, a loop can run indefinitely, repeating the same chunk of code over and over again.
Event Loop
If we take a deeper look into this, there are several more elements to it. There is what we call an “event loop” (within the infinite loop) that “listens” for certain actions that the user may take (such as clicking a button). Once an event has been detected, a corresponding action is taken (such as closing the window when the quite button is pressed)
Without an event loop, GUI windows would remain static, and unable to change or be interactive like they normally are. You may not realize it, but Tkinter has one of these too.
If you want to visualize the Tkinter MainLoop function a bit, the below code should give you a little idea.
while True: event = wait_for_event() event.process() if main_window_has_been_destroyed(): break
Game Loop in Pygame
In order to better understand the Tkinter
MainLoop() function, let’s take a look at another popular Python Library called Pygame.
Pygame is a game library used to create simple 2D games in Python. And as I said earlier, games also run infinitely, hence the also need an infinite loop, commonly referred to as the game loop.
One big difference between Tkinter and Pygame, is that you have to make your own (infinite) Game loop in Pygame. This actually helps build up your understanding alot, and makes things much more flexible and under your control.
Shown below is the code for a Game Loop in Pygame. You don’t need to focus on the syntax much, rather just o the concept.
entities = pygame.sprite.Group() entities.add(Player) entities.add(Enemy) while True: # Event Loop for event in pygame.event.get(): if event.type == pygame.QUIT: pygame.quit() sys.exit() if event.type == pygame.KEYDOWN: if event.key == pygame.K_M: print("M-key was pressed") # Updating for entity in entities: entity.update() # Rendering display.render(background) for entity in entities: display.render(entity) pygame.display.update()
A brief description of some important elements in the above code:
- There is an infinite while loop, that only breaks once the QUIT event is detected.
- Within the While loop, there is a for loop that we call the event loop. (Implementation will vary from library to library, but all have an event loop that continuously listens for events, and then acts accordingly)
- Update function is being called on all entities in every iteration of the loop.
- All entities are re-drawn to the screen in every iteration of the loop.
These features can be said to be very similar to those found within the Tkinter mainloop. Hence it should serve as a good reference.
This marks the end of the Python Tkinter MainLoop Function Tutorial. Any suggestions or contributions for CodersLegacy are more than welcome. Questions regarding the tutorial content can be asked in the comments section below. | https://coderslegacy.com/python/tkinter-mainloop-function/ | CC-MAIN-2022-40 | refinedweb | 661 | 65.42 |
@starry-abyss , That helped me find it once I turned on my "show hidden files".
Thanks Lee
Ferrari177
@Ferrari177
Currently building an great game in HaxeFlixel.
Posts made by Ferrari177
- RE: FlxSave file location ??
@starry-abyss , That helped me find it once I turned on my "show hidden files".
- FlxSave file location ??
My code seems to work fine when compiling to Neko locally, but I can't work out where it is saving the save file. Help please, Would like to delete it so I can test properly.
Thanks Lee
var _gameSave = new FlxSave(); // initialize _gameSave.bind("score"); _gameSave.data.score = score; _gameSave.flush();
- RE: Download and play audio files from Server
- RE: Download and play audio files from Server
Yes, I already have this line in my project.XML, but still no luck.
- Download and play audio files from Server
Hi guys, I am trying to download an audio file from my server and play it. Sound simple (get it?).
I have got it working find on neko, but I have a problem when I make an android version.
when I try to write to the assets/music folder the app crashes. I think maybe its to do with the fact is compiled to an APK file and no longer sees this a an accessible folder. ??
I have tried making a another folder, but crashes it as well.
Does anyone have experience of this. Thanks Lee
import sys.FileSystem; import Sys; import sys.io.File; var content : String = haxe.Http.requestUrl(""); sys.io.File.write("assets/music/054377431-halloween.ogg", true).writeString(content); trace(content.length + " bytes downloaded"); FlxG.sound.playMusic("assets/music/054377431-halloween.ogg",0.5);
- RE: Fading a sprite in a tween
Thank you, IT works. very quick! Lee
- Fading a sprite in a tween
I am trying to simply fade a sprite object ( a coin ) to transparent over a couple of seconds.
I managed to get it to fade, but it goes black first. I think I need alpha i there somewere!
This is the line I used, I think I am close but, help please. Thanks Lee
var tween1 = FlxTween.color(sprite, 5, FlxColor.BLACK, FlxColor.fromRGB(255, 255, 50, 0));
- RE: 2 Tweens at once?
Ahh nice, so you can put this one after another and they work together. Perfect . Thanks for that. Lee
- RE: Fixing your problems in HaxeFlixel
Thanks for That, Look like it could be promising. I will book mark this and look to see whats been added from time to time.
- 2 Tweens at once?
Hi Guys, I am trying to have a arrow pointing at an object and it cycles back and forth. So far so good, but at the same time I would like the scale of the arrow to change to give it more of a squishy feel.
Thanks Lee
var arrow:FlxSprite = new FlxSprite(670,200); arrow.loadGraphic("assets/donotuse/arrow.png"); arrow.scale.y*= -1; add(arrow); FlxTween.tween(arrow, { x: 670, y: 150 }, .3, { type: FlxTween.PINGPONG, ease: FlxEase.quadInOut, onComplete: changeColor, startDelay: 0, loopDelay: 0 });
// need another tween to run at the same time as the tween above to effect scale. ??? | http://forum.haxeflixel.com/user/ferrari177 | CC-MAIN-2020-34 | refinedweb | 529 | 77.23 |
In this chapter, we are going to discuss the number of ways the database connections could be created with the MySQL database.
* Connection using MySQL 5.7 command line client: You can start the MySQL 5.7 command line client by simply clicking on the desktop icon or opening it from the Window’s Program Menu. Once MySQL 5.7 command line client opens, you can see the following command line window which will be asking you to enter the root password (i.e. mysqldb). Once the password is entered, you will be successfully able to establish database connection with the MySQL database.
* JDBC Connection with MySQL database: You can perform various database operations on MySQL database by simply establishing JDBC (“Java Database Connectivity”) connection. Before we jump to MySQL JDBC connection. Let’s understand what actually JDBC is.
JDBC (Java Database Connectivity)
JDBC is a Java API (Application Programming Interface) that interacts with the backend database after obtaining a database connection and allows you to execute various SQL statements through this database connection. JDBC API supports database connection to multiple databases through their database drivers. Therefore, we require MySQL connector driver in order to establish JDBC connection with MySQL. Following are the classes and interfaces that are provided by the JDBC API.
• Driver Manager Driver Manager class helps to return a database connection object. It accepts three parameters. They are DB connection URL, username and password.
• Driver Driver is nothing but a database specific driver e.g. com.mysql.jdbc.Driver. It helps to create a JDBC connection with the MySQL database.
• Connection Connection is an interface. It helps to provide database information such as table descriptions, SQL grammar supported by the database, associated stored procedures, and the various connection capabilities, etc.
• Statement Statement is an interface. It helps to pre-compile the object and use it to execute SQL statements efficiently into MySQL database.
• ResultSet ResultSet is an interface to the object. It maintains a cursor that points to its current row of data. At the start, the cursor is always positioned at the top of the first row. The cursor keeps on rotating to the next row and returns a Boolean value only if the fetched rows from database actually exists.
• SQLException SQLException is an exception class in Java. It defines the various SQL exceptions that could be thrown during the run time. Whenever, we attempt to execute any SQL statement through JDBC connection, it is compulsory to catch the SQL exception or declare this class with throws statement at the method level.
STEPS to create JDBC Connection using MySQL database
As we discussed earlier, that we require a MySQL connector driver. The Driver class helps to create a JDBC connection with MySQL database. We can download SQL connector driver API through the link below.
When you browse above link in the web browser, you will notice the following download links on the web page as shown below.
Click on the ‘Download’ link which offers the ZIP Archive. The downloaded zip file has the name as ‘mysql-connector-java-5.1.39.zip’, you can unzip this archive file to procure the jar or connector API that acts as our actual driver API. The following are the steps to make JDBC connection using SQL connector JAR just downloaded and eclipse as IDE (Integrated Development Environment).
Step 1: – Create a new project using the name as ‘mysql-jdbc-connection-demo’ in eclipse. Next, add class ‘MySqlJdbcConnector.java’ to this project.
Step 2: – On the left hand side from Package Explorer, right click on the project and navigate as ‘Build Path’ ‘Configure Build Path…’ as shown below.
Step 3: – Next, click on the ‘Libraries’ tab followed by clicking on the ‘Add External JARs…’ button. Select the path where you have placed unzipped SQL Connector API (i.e. ‘mysql-connector-java-5.1.39.jar’) which was downloaded earlier. Lastly, click on the Open button in order to complete this step.
Step 4: – Next, click on the ‘OK’ button to complete the build path set up as shown below.
Step 5: – Once SQL connecter JAR is available at the project build path, you can write the following JAVA program to establish JDBC Connection with MySQL database as shown below.
package com.eduonix.mysql.jdbc; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; /** * * @author Aparajita * */ public class MySqlJdbcConnector { public static final String QUERY = "select * from USER;"; public static void main(String[] args) throws ClassNotFoundException, SQLException{ // TODO Auto-generated method stub String host = ""; String user = ""; /** * Load MySQL JDBC driver */ Class.forName("com.mysql.jdbc.Driver"); /** * Create Connection to DB */ Connection con = DriverManager.getConnection("jdbc:mysql://localhost:3306/mysql","root","mysqldb"); /** * Create Statement Object. */ Statement stmt = con.createStatement(); /** * Execute the SQL Query. Store results in ResultSet. */ ResultSet rs= stmt.executeQuery(QUERY); /** * While Loop iterates through all data present in a table. */ while (rs.next()){ host = rs.getString(1); user = rs.getString("User"); System.out.println("Host: "+host); System.out.println("Username: "+user); } con.close(); } }
Output: –
When we execute the above program as a JAVA application in eclipse IDE, then we can observe the following output. The output has printed the host and user name of three records from the user table.
Host: localhost Username: root Host: localhost Username: mysql.session Host: localhost Username: mysql.sys
Explanation of JAVA Program
1) Creation of a Database connection: You are creating the MySQL DB connection after loading the JDBC driver through the DriverManager class. This class requires the following parameters viz. URL, username and password i.e. (jdbc: mysql://localhost:3306/mysql”, “root”, “mysqldb).
2) Execution of the SQL queries in MySQL Database via JDBC connection: You have to create a SQL query that can select the records from User table (here we are displaying just Host and user name from USER table) present in the mysql database. The Statement interface and the ‘createStatement’ method of the Connection interface prepare the SQL in the pre-compiled state.
3) Processing of the result set returned from database: At this execution point, we executes the pre-compiled SQL and with the help of the ‘executeQuery’ method, the database will return a result set that contains three records for user as displayed in the program output (i.e. host and user name for each user). We iterate over the returned result, set and print the values on the console.
Conclusion
In this chapter, we have demonstrated two ways using which we can connect to MySQL database along with the suitable examples. | https://blog.eduonix.com/web-programming-tutorials/learn-jdbc-connection-mysql-database/ | CC-MAIN-2020-45 | refinedweb | 1,094 | 58.48 |
with 1 problem left to go im stuck on a solution for my username blacklist checker.
it can find an exact item like admin or webmaster but if wanted to look for:
siteadmin it will not block that.
i want to be able to block any occurance of admin.
I've troied several things but none seem to do it. her is the code im using:
function blacklisted_usernames($value){ $q = mysql_query("SELECT * FROM ebb_blacklist") or die(mysql_error()); while ($row = mysql_fetch_assoc($q)){ if (strstr($row['blacklisted_username'], $value) !== false){ $blklist = 1; }else{ $blklist = 0; } } return ($blklist); }
I've tried several other things but nothing has worked, any input is welcomed. | https://forums.phpfreaks.com/topic/18365-resolved-username-blacklist-error/ | CC-MAIN-2018-09 | refinedweb | 108 | 62.98 |
Re: Wrong overload resolution ?
- From: "Vladimir Granitsky" <vl_granitsky@xxxxxxxxxxx>
- Date: Tue, 12 Apr 2005 19:28:35 +0300
Hi James,
Thanks for the interesting response. I agree that the question is - Is this a C# compiler bug or a specification design issue. Will look forward for someone to answer. My comment are below.
"James Curran" <jamescurran@xxxxxxxx> wrote in message news:uU3DCO3PFHA.3668@xxxxxxxxxxxxxxxxxxxx...
> Well, I'm gonna guess that it's working according to the C# spec, but
>.
Yes, I know, This is bacause if the method is declared vurtual in the base class, the latest override will be invoked, even if the object is cast to the base type. Currently I resolve this issue by calling ((Class1)o2).Method1(s);
> Now, replace the "override" with "new" (or just delete it). Now,
> o2.Method1() is correct, while o1.Method1() is wrong.
I think we can't say wrong here. The "new" keyword prevents Class2.Method1(string s) from being an override of Class1.Method1(string s) and the rule i mentioned above do not apply. So if you have a variable of type Class1 pointing to an instance of Class2, the method of Class1 will be invoked. I think, this is normal behaviour.
>
> So, what I THOUGHT was happening was that Method1(object) was hiding the
> Class1.Method1() (including hiding it's override).
> BUT, now change Method1(object o) to Method1(int o). Now, both o2.Method1()
> & o1.Method1() are correct. So, it's only hiding it if the parameters are
> similar (C++ would hide it based on just the name)
I think this is because string cannot cast to int and the compiler takes the right way.
>
>
> "Vladimir Granitsky" <vl_granitsky@xxxxxxxxxxx> wrote in message
> news:##2N1G1PFHA.2788@xxxxxxxxxxxxxxxxxxxx...
> Hi guys,
>
> Please, look at the code below and try to step into it. The compiled code
> calls the loosely typed method public void Method1(object o) !?!?
>
> Am I right that C# compiler does wrong overload resolution ?
>
> I've used parameters of type object and string here, just to illustrate the
> problem. Really I have a bit more deep inheritance graph, and the things get
> more interesting if the strongly typed overload is like override public void
> Method1(BaseType x). When I call it with parameter of type SubType (that
> inherits BaseType) the right method is called.
>
> Thanks for any useful points.
>
> Regadrs,
> Vladimir Granitsky
> using System;using System.Diagnostics;namespace OverloadResolution{
> public class Class1 { virtual public void Method1(string s)
> { Trace.WriteLine("Class1.Method1"); } } public
> class Class2 : Class1 { override public void Method1(string s)
> { Trace.WriteLine("Class2.Method1a"); } public void
> Method1(object o) {
> Trace.WriteLine("Class2.Method1b"); } } class Client
> { [STAThread] static void Main(string[] args)
> { string s = "blah"; Class2 o2 = new Class2();
> o2.Method1(s); } }}
>
>
- References:
- Wrong overload resolution ?
- From: Vladimir Granitsky
- Re: Wrong overload resolution ?
- From: James Curran
- Prev by Date: RE: TrackMouseEvent in C#?
- Next by Date: Re: static library in c# library control
- Previous by thread: Re: Wrong overload resolution ?
- Next by thread: RE: Wrong overload resolution ?
- Index(es): | http://www.tech-archive.net/Archive/DotNet/microsoft.public.dotnet.languages.csharp/2005-04/msg02787.html | crawl-002 | refinedweb | 503 | 69.07 |
annonhall12,247 Points
How do you Import flash from Flask?
Oh dear I think I'm asking a stupid question But if someone helps me that would REALLY help Thanks! :D
from flask import Flask, redirect, url_for, render_template app = Flask(__name__) @app.route('/') def index(): return render_template("index.html") @app.route('/fishy') def fishy(): return redirect(url_for('index')) import flash
1 Answer
William LiCourses Plus Student 26,865 Points
To do that, just add flash to the end of the import statement
from flask import Flask, redirect, url_for, render_template, flash
channonhall12,247 Points
channonhall12,247 Points
Thanks Again william! It's always the Tiny stuff that I get stuck on. | https://teamtreehouse.com/community/how-do-you-import-flash-from-flask | CC-MAIN-2022-27 | refinedweb | 110 | 63.7 |
Refactoring - Pull Members Up and Push Members Down
Go Up to Refactoring Procedures Index
Moving members assumes that the member is either moved to the target location being deleted from the original location, or created in the target location being preserved on the original one.
To move a member:
- Select member in the Code Editor or the Modeling's Diagram View or Model View.
Tip: In the editor, place the mouse cursor on the member name.
- Choose Refactor > Pull Members Up/Push Members Down on the context menu or on the main menu.
- In the resulting dialog box, specify additional information required to make the move.
- In the top pane of the dialog box, check the members to be moved.
- In the bottom pane of the dialog box, that shows the class hierarchy tree, select the target class.
- Click OK.
- In the Refactoring window that opens, review the refactoring before committing to it. Click the Perform refactoring button to complete the move.
Tip: Moving members is more complicated than moving classes among namespaces, because class members often contain references to each other. A warning message is issued when Pull Members Up > or Push Members Down has the potential for corrupting the syntax if the member being moved references other class members. You can choose to move the class member and correct the resulting code manually. | http://docwiki.embarcadero.com/RADStudio/Rio/en/Refactoring_-_Pull_Members_Up_and_Push_Members_Down | CC-MAIN-2020-24 | refinedweb | 225 | 52.6 |
doublerather than
inthere. Not only will that allow the input and output of decimal values, it also reduces rounding errors.
intI now use
double, along with writing the code so that if the user inputs 0 for the degrees in Celsius, the program will quit, and I believe making the buffer clear in every iteration of the loop. Updated code is below.
system("ls");
#include <iostream>, and then had to spend 20 minutes trying to figure out why cout and cin didn't work. This is merely the first program i've made that did something remotely useful. Also, I don't have a Unix system, just Windows 7. Don't know how much that actually changes anything in relation to programming. | http://www.cplusplus.com/forum/beginner/93858/ | CC-MAIN-2015-14 | refinedweb | 122 | 65.12 |
My solution from contest with minimal cleanup. For each end point search for the first start point that is equal or higher in a previously constructed ordered list of start points. If there is one then return its index. If not return -1:
def findRightInterval(self, intervals): l = sorted((e.start, i) for i, e in enumerate(intervals)) res = [] for e in intervals: r = bisect.bisect_left(l, (e.end,)) res.append(l[r][1] if r < len(l) else -1) return res
Nice solution! My idea is the same as yours, but my code is more verbose. I did not know that bisect can be used in that way. I have a quick question: how does bisect work when you give it a tuple like in your code? Thank you!
def findRightInterval(self, intervals): """ :type intervals: List[Interval] :rtype: List[int] """ intvl = sorted([(x.start, i) for i, x in enumerate(intervals)], key=lambda x: x[0]) starts, idx = [x[0] for x in intvl], [x[1] for x in intvl] res = [] for x in intervals: pos = bisect.bisect_left(starts, x.end) if pos == len(starts): res.append(-1) else: res.append(idx[pos]) return res
Hi @WKVictor, sequences are compared item by item. See here for more details. So you don't need to specify a key for the sorted function, because the default sort function is similar already.
I have the same idea, but I didn't know that bisect can use like this. So I use the same code from bisect, and change it to compare the tuple with index, like this,
lo = 0 hi = len(intervals) while lo < hi: mid = (lo + hi) // 2 if sorted_start[mid][0] < end: lo = lo+1 else: hi = mid
But it has TLE at 11/17 test cases.
My complete code is,
def findRightInterval(self, intervals): sorted_start = [(interval.start, index) for (index, interval) in enumerate(intervals)] sorted_start.sort() result = [] for interval in intervals: end = interval.end lo = 0 hi = len(intervals) while lo < hi: mid = (lo + hi) // 2 if sorted_start[mid][0] < end: lo = lo+1 else: hi = mid if lo == len(intervals): result.append(-1) else: result.append(sorted_start[lo][1]) return result
Does anyone know why this is much slower than using bisect.bisect_left, although they are almost the same?
I tried the super long 11/17 test case, which has 11000 intervals. By using bisect.bisect_left, it takes about 0.11 seconds to run. On the other hand, the above code takes about 15 seconds to run.
Is it because the bisect module actually has an optimized C module version?
@NoAnyLove "Does anyone know why this is much slower" - looks like your problem is in the line:
> if sorted_start[mid][0] < end: > lo = lo+1
Instead of halving the search interval by setting 'lo = mid' and solving in O(log_2(n)) time, you are crawling up in single increments in O(n) time! That's a big problem.
For comparison, in my code (for which I implemented my own bisection search, for practice) had the equivalent lines:
if sortedStartPairs[jMid][1] < end: jLower = jMid
@gor.rennie Ah, I see. How fool I am~! I was mean to use binary search, but I mistook
lo and
mid. Thanks for point that out.
The correct snippet should be,
while lo < hi: mid = (lo + hi) // 2 if sorted_start[mid][0] < end: lo = mid+1 else: hi = mid
Looks like your connection to LeetCode Discuss was lost, please wait while we try to reconnect. | https://discuss.leetcode.com/topic/65596/python-o-nlogn-short-solution-with-explanation | CC-MAIN-2017-43 | refinedweb | 582 | 66.64 |
J:
- Visual Studio "Whidbey" (VS2005) moving towards lifecycle management features, designed to reduce complexity and improve the communication process around the software produced from Visual Studio. VS2005 is still focused on providing a platform for ISV partners to build additional plug-ins to support lifecycle management in Visual Studio.
- EDT tools include Static Analysis and Profiling (dev) and Test Authoring and Test Execution (test).
- VS Test product features to include the ability to author tests, with UI extensions leveraging existing windows and some new windows in VS2005.
- Test execution is support via the new Test Explorer window in Visual Studio. This window shows views by "All Tests" and by "Categories" with a customized hierarchy. The results of a test shows up in the Results window, and by double-clicking on a specific test you can drill down to the details.
- A Test Types construct exists to support simplified test development and to support test extensions. The types consists of Web, Manual, Load, Unit, and 3rd Party tests (in Tech Ed bits). (Aside- the Load test type sounds amazing! I can't wait to try this- I've wanted to see something like this in a VS tool for a LONG time.) In later bits the Automated, Generic, and Ordered test types will be supported.
- Jason did a demo (major league unscripted) of writing a unit test in VS2005. By building a simple test class and adding attributes for a declarative programming model for testing. This is really simple, and is similar to NUnit. The test run configuration feature is very cool- it allows you to run the test on remote machines, set parameters for code coverage, and to script deployment of supporting files. The test results upon build is also avaliable in a series of XML files that can be read independently for purposes of build verification testing. Very cool stuff.
- Default unit code test generation can yield basic level of coverage with skeleton code that would yield "Inconclusive" test results. This enables you to mitigate human errors associated with unit testing, in the form of missed classes or methods.
- Tom did a demo on unit test code generation. At the namespace, class, or method level you can generate unit test code with various configuration options that enable you to set various properties for the generated unit testing code. For an unscripted demo, this went very smoothly, with only a glitch or two. They also demonstrated how private methods can be covered through the unit testing code, with the reflection code generated automatically.
- TDD processes with VS2005 were discussed, and a demo was performed. It was very fun stuff, even with a minor glitch when generating the stub code for a method that wasn't yet written but was referenced in a test method. Jason and Tom were pretty fearless, running stuff ad hoc out of yesterday's build.
- Tom demo'd the support for Manual test types (more useful than I thought it would be) and the Web test types. The Web test type launches an instance of IE with a panel that can record your actions in the browser, and save the results as a test script back in VS2005. Interesting tool. The Load test type is amazing. Again, I would have killed for something like this a few years ago when I was working more in the web space. Very useful.
- I'm tired of writing notes... trust me, this is cool stuff.
Overall, there were a bunch of cool questions and discussions about specific features for the V1 version of the product, along with lots of ideas and comments related to potential VNext features. This was an awesome discussion- and WELL worth the time. Thanks to Jason and Tom for staying with us until nearly midnight tonight to go over this stuff. | http://blogs.msdn.com/b/rholloway/archive/2004/06/22/162134.aspx | CC-MAIN-2015-18 | refinedweb | 636 | 62.27 |
bps_event_get_code()
Get the code of an event.
Synopsis:
#include <bps/event.h>
BPS_API unsigned int bps_event_get_code(bps_event_t *event)
Since:
BlackBerry 10.0.0
Arguments:
- event
The event to get the code of.
Library:libbps (For the qcc command, use the -l bps option to link against this library)
Description:
The bps_event_get_code() function gets the code of a BPS event. In addition to being associated with a domain, each event in BPS has a code, which represents the specific type of event that occurred. For example, the virtual keyboard service includes event codes that indicate when the keyboard becomes visible, when the keyboard becomes hidden, and so on.
Returns:
The code of the event.
Last modified: 2014-05-14
Got questions about leaving a comment? Get answers from our Disqus FAQ.comments powered by Disqus | http://developer.blackberry.com/native/reference/core/com.qnx.doc.bps.lib_ref/topic/bps_event_get_code.html | CC-MAIN-2014-35 | refinedweb | 134 | 59.9 |
NAME
VOP_ACLCHECK - check an access control list for a vnode
SYNOPSIS
#include <sys/param.h> #include <sys/vnode.h> #include <sys/acl.h> int VOP_ACLCHECK(struct vnode *vp, acl_type_t type, struct acl *aclp, struct ucred *cred, struct thread *td);
DESCRIPTION
This vnode call may be used to determine the validity of a particular access control list (ACL) for a particular file or directory. Its arguments are:. The cred pointer may be NULL to indicate that access control checks are not to be performed, if possible. This cred setting might be used to allow the kernel to authorize ACL verification that the active process might not be permitted to do. The vnode ACL interface defines the syntax, and not semantics, of file and directory ACL interfaces. More information about ACL management in kernel may be found in acl(9).
LOCKS
No locks are required to call this vnode method, and any locks held on entry will be held on exit.
RETURN VALUES
If the aclp pointer points to a valid ACL of type type for the object vp, then zero is returned. Otherwise, an appropriate error code is returned.
ERRORS
. | http://manpages.ubuntu.com/manpages/intrepid/man9/VOP_ACLCHECK.9freebsd.html | CC-MAIN-2014-10 | refinedweb | 189 | 64.61 |
It has been more than 2 years since I’ve written anything over here. Feels great to write again! This is Part-1 of my series on data-driven A/B testing of Facebook ads using Python.
I’ve run thousands of campaigns from scratch, and often ideation and scalabilty was just one part of it. The other part that marketers underrate is quantitative and qualitative assessment of success/failure metrics.
A/B testing and subjectivity
Questions like “What if you’d selected a green coloured CTA as opposed to a blue one?” often bring subjectivity. And, most of the conversion frameworks that we have bounce around the idea of subjectivity (Emotional SWOT analysis for image selection).
There’s nothing wrong with looking at heatmaps, scrollmaps, and other generic KPIs or metrics that most marketers use. But, it gets subjective. And rather pushes the load of A/B testing on the observer. If observer choses to be extremely subjective and vague, the entire campaign could fail due to a subjectively poor decision making.
Over the course of time, data has helped us split monolithic, compartmentalised marketing into domain driven, collaborative and attributable marketing.
A huge factor for marketers getting in probablistic, domain driven marketing was the ability to understand data. With probabilistic marketing, we reduce the clutter by filtering out low volume marketing initiatives, divide them into various domains and use data driven metrics to determine success and failure metrics.
I plan to cover these things in detail in a future blog post with 3-5 actionable examples. But, for this blog post, let’s stick to A/B testing with Facebook ads using Python and kick start data driven A/B testing.
Getting started with A/B Testing on Facebook ads
If you wish to understand A/B testing beyond the “this color or that color” theory, Rohan Kohavi of Microsoft’s paper on A/B testing Fundamentals is a pure gold. He also gets into Multivariate testing with Facebook ads, which is also on my list of blogs to cover in future.
Our goal here is to be able to do A/B testing without using expensive tools. And, Python is an excellent programming language for that!
Why the hell should a marketer learn programming?
Because growth hacking isn’t driven by templates. The tools that are around you are extremely limited in terms of what they can do. Even if they are helpful, they cost you $,$$$s to show you generic stuff. Sure, they integrate well with your automation tools and CRMs, but they limit your creativity and what you can do with them.
Another reason for you learn programming is to become a true data driven marketer. You often run your ads and other campaigns in isolation. For those that are involved in high end B2B marketing, integrating A/B test results with what’s happening in real time would provide insights that otherwise requires subjective decision making (which is often flawed).
A/B testing is just an example, but learning programming can help you extend your marketing capabilities by:
– Automated benchmarking of competitors
– Determining precise segments
– Identify the best audience for creating a lookalike audience
– Identifying customer intents by leveraging social data
and much more.
Coming back to A/B testing, we will use Python here to determine which one of our ads should continue and expand for ebook’s promotion.
Our Goal
Our goal here is to generate and increase signups for an e-Book. This is a fairly common strategy in B2B/B2C marketing where single touch attribution no longer can help convert customers. You should your target audience a piece of locked content, ask them to sign up and push them to down to your automation driven funnels and nurture them to conversion.
We have two landing pages with different coloured Call to Actions. One follows an aggressive approach towards increasing conversion, other takes an authority driven approach. We want to understand which one of these would lead to a better conversion. We have been running one ad before and the conversion rate we’ve observed is around 10%.
Our goal is to understand if we make a switch to colour theme suggestive of aggression, would it lead to higher conversions?
Setting up A/B testing with Facebook ads using Python – Framework
Here’s what we are going to do here:
- Setup up the experiment (Treatment and Control groups)
- Run the ads and get data from Facebook Ads Manager
- Evaluate distribution between these two ads
- Evaluate statistical variables
- See how sample size impacts the A/B test results
Note: This data is from an actual A/B test we ran. So, I won’t be able to share the plan for actual ads, but, I will shared highly anonymized information from my Facebook Ad Manager.
I am assuming you’ve already done a great job in identifying your target audience and you are not playing around. Still, there are a few things that you should have before we can leverage A/B tests to drive empirical data:
- Optimized ad copies for maximum impact – No point in running Facebook ads with a generic “We are so awesome, download my eBook” ad. Identify real pains and talk about how this eBook with help them resolve that.
- Make sure to have one design that you can A/B test on color theories. But at the same time, your Ad image should be very impactful.
- Encrypt your UTM tags – Some marketers keep their UTM tags so identifiable that it gets easy for someone to write an Python script and generate whole hierarchy of their marketing automation. Don’t do that!
- At the end, don’t just blindly launch your ads, use and see if the text to image ratio is appropriate.
Getting back to this Facebook Ad, our goal is to see if we can achieve a 13% conversion rate as opposed to a 10% conversion rate that we’ve already observed from an Ad campaign that was never A/B tested.
The way we want to achieve this is by changing the ebook landing page b we are using for these ads. This is a Middle of the Funnel exercise where we have a deeply intent filtered audience and we want to see how well we push them down increasing their predictive lead scores. The goal is to eventually make them a SQL (Sales Qualified lead).
Data after run A/B tests
So, here’s an export from my Facebook Ads using two variants of the eBook landing pages.
Jargon aside, let’s load this data into Python.
In order to use this code, just rename the file you’ve downloaded to “ab_testsplit.csv” so that it works perfectly with the code.
To load this data in Python, use the following commands
import pandas as pd
ab_testsplit = pd.read_csv(“ab_testdata.csv”)
ab_testdata.csv is your csv file that you get after exporting data from your ads manager.
Now, when you enter ab_testdata.csv on your Python console, you will get the output of data table as I’ve show at the start of the column.
Great! That’s your first step towards being a data driven marketer.
Let’s now run an exploratory data analysis over these ad results and check the following group-wise:
- Total converted
- Total landing page views
- Effective conversion rate
But, how would you generate a table that can so quickly show you the number of conversions?
If you have done this excel or SQL before, you would know that you need to generate a pivot table. But, if you haven’t done it before, there’s no need to worry about anything. Pivot table of a data is basically a summary. And, it takes less than 3 lines to generate them.
Let’s build a pivot table with three columns: Converted, total, and conversion rates.
Here’s the code that you can use
ab_testsummary = ab_testdata.pivot_table(values='converted', index='group', aggfunc=np.sum) # add additional columns to the pivot table ab_testsummary['total'] = ab_testdata.pivot_table(values='converted', index='group', aggfunc=lambda x: len(x)) ab_testsummary['rate'] = ab_testdata.pivot_table(values='converted', index='group') ab_testsummary
The code above generates the following pivot table
Note that our actual test results with the variant were lower than the original conversion rate of 12%. The modified landing page converted to ~ 11%.
Now, don’t just jump on the bandwagon to kill your ad yet!
Although we see that our conversion rates are actually down by 1%, our goal is to generate enough evidence to say that one design is better than the other.
If we try to take a look at our data, we have three different options to evaluate statistical significance:
- Evaluate assuming a Normal distribution
- Evaluate assuming a Poisson distribution
- Evaluate assuming Binomial distribution
Normal distribution vs binomial vs Poisson distribution for A/B testing?
If you are new to it, here’s what a normal distribution looks like
We call it a normal distribution because, it represents the nature of distribution that we commonly see occurring naturally. IQ distribution, height distribution, etc are a really good examples of where you can actually use normal distribution to establish statistical significance.
Clearly, we can’t use Normal distribution in our situation as it has nothing to do with dual outcome scenarios (click or no click).
Poisson distribution on the other hand focuses more on time intervals and rarity of events. But the focus of approximation between zero to infinity.
In this case, as we have finite number of clicks (events), we need a distribution that can be approximated for zero and the number of trials we have in our dataset – i.e. Binomial distribution.
So clearly, you can go ahead with Binomial distribution that helps you get a much more clearer picture of the AB testing.
There’s an entire science behind deciding how to understand this, which starts from the distribution and goes all the way to statistical tests.
So far, we learned two very important fundamentals of A/B testing facebook ads:
– How to import ads data using Python
– How to select the right distribution for A/B testing assessment
I will end part 1 here, and will cover rest of the testing in future blogs.
Meanwhile, if you have any questions, feel free to reach out to me on Twitter (I’m @parinfuture).
3 Comments
Very interesting stuff about this whole process !
A Straightforward approach, backed up with relevancy.
Thanks you for the learning,
Jérémie
Thanks for the helpful article! I’m wondering how you were able to export the data from Facebook Ad Managers in that individual-level format you have in the screen-shot, with columns for treatment group, user-id etc. I’ve tried and also looked online but can’t seem to find any indication of how to go from the default ad-level metrics (aggregate) to the individual/user level that we would want for analysis.
Thanks so much !
Basically fuse multiple data sources together. If you don’t have that as an option, you can also leverage your own internal analytics to help shape some of this data, all you have to do is to pull up relevant UTMs, and get timestamp + page variant + conversion data. | http://parikshit-joshi.com/python/ab-testing-facebook-ads-python/ | CC-MAIN-2021-31 | refinedweb | 1,880 | 60.85 |
Found a solution by myself.
since I installed Unity 5.1 I can't use UnityEnigne anymore.
I get this error message in Visual Studio:
The type or namespace name 'UnityEditor' could not be found (are you missing a using directive or an assembly reference?)
The type or namespace name 'UnityEditor' could not be found (are you missing a using directive or an assembly reference?)
Answer by DiebeImDunkeln
·
Jun 11, 2015 at 08:16 AM
I found the problem. A scriptable object was missing.
Answer by Kiwasi
·
Jun 11, 2015 at 08:06 AM
Is the script in the Editor folder? You can only use UnityEditor from the editor folder.
yes, it is in the Editor folder. I have a corresponding script outside the Editor folder and there I get no error message. I get the error only from the script within the Editor folder. timer
0
Answers
How do you get the R1 and R2 buttons to work on the PS4?
0
Answers
Need to Include a file in the build and use it in the runtime
0
Answers
UnityEngine.MovieTexure is required access, Help?
1
Answer
Different sizes of jump when Android device
1
Answer | https://answers.unity.com/questions/984396/unity-51-using-unityeditor-is-throwing-error-messa.html | CC-MAIN-2021-04 | refinedweb | 197 | 67.76 |
Hello Forums!
I'm so sorry to bother you, but I recently bought three Teensy 3.0 boards. I have a sketch which compiles fine and works on Teensy 2.0, but when I try to compile it for Teensy 3.0, it won't work. I am using it with the latest Teensyuino version, and Arduino 1.0.5.
Here is the error info the Arduino software provides:
Aug_22_2013_GOOD.cpp.o: In function `readFloat(int)':
C:\Program Files (x86)\Arduino/Aug_22_2013_GOOD.ino:396: undefined reference to `eeprom_read_block'
Aug_22_2013_GOOD.cpp.o: In function `writeFloat(float, int)':
C:\Program Files (x86)\Arduino/Aug_22_2013_GOOD.ino:401: undefined reference to `eeprom_write_block'
collect2.exe: error: ld returned 1 exit status
I wish I was experienced enough at this to handle this myself, but sadly I am new and in over my head. I do notice that in my sketch is this line:
#include <avr/EEPROM.h>
And there is no "avr" folder in libraries. However, changing the line does not fix the problem. I think it must be including the EEPROM library buried in subfolders for AVR. So, the problem must be something to do with the new 32-bit chip, right?
Sketch is attached below. I hope the problem is reproducible. Any ideas?
Aug_22_2013_GOOD.ino | https://forum.pjrc.com/threads/24379-New-Teensies-do-not-show-same-info-work-with-drivers-the-same?s=2d37684cea3e7473192572af5c93127b&goto=nextnewest | CC-MAIN-2021-04 | refinedweb | 212 | 69.58 |
formler
Simple form data parser.
Features:
- Handles multipart/form-data content.
- Handles x-www-urlencoded form content.
- Annotated source code
Getting Started
Pubspec
pub.dartlang.org: (you can use 'any' instead of a version if you just want the latest always)
dependencies: formler: 0.1.2
import 'package:formler/formler.dart';
Start parsing ...
// Parse a Multipart form Formler formler = new Formler(bytes, "--someBoundaryStuff"); Map form = formler.parse(); // -> {fieldName: .... } // Parse a UrlEncoded form Formler.parseUrlEncoded("username=someValue+other%26val&password=eqwdawd9"); // -> { "username": "someValue other&val", "password": "eqwdawd9" }
API
new Formler(List<int> bytes, String boundary)
Creates a new Formler instance with the byte contents of the request and the boundary from the contentType.
bytes- (List<int>) A list of bytes respresnting the POST form data.
Returns the new instance of
Formler.
formler.parse()
Actually does the parsing of the data and creates the data map of the contents.
Returns
Map representation of the parsed data.
(static) Formler.parseUrlEncoded(String postBody,
bool printErrors = true)
Parses a UrlEncoded post body string.
postBody- (String) A string of key/urlencoded value pairs.
printErrors- (Bool) Set to false if you don't want Formler to print warnings to STDOUT. Default is true.
Returns
Map representation of the parsed Data
Example: Encode a hex string.
Testing
In dartvm
dart test\formler_test.dart
In Browser
At the moment, this package does not work client-side as it uses server-side only UInt8Lists. I might have to wait till UInt8Arrays and UInt8Lists are merged into 1
Release notes
v0.1.2 - Pull Request accepted to fix package versions for increased compatibility.
v0.1.1 - Fix empty string and handle malformed urlencoded strings gracefully.
v0.1.0 - Dart 1.0 Readiness
v0.0.8 - Fixing analyzer complaints.
v0.0.7 - Fixing package changes for Crypto and URI
v0.0.6 - Including fixes for TypedData and Regex and also switched to useing the Base64 Decode built into Crypto now.
v0.0.5 - Accepted pull request to add multi-file support. Must have overlooked this in my excitement to get this parser working.
v0.0.4 - Fixing an import/part issue that affected Fukiya.
v0.0.3 - Binary file upload parsing bug fixed.
v0.0.2 - Parsing Bugs.
v0.0.1 - Initial Release | https://www.dartdocs.org/documentation/formler/0.1.2/index.html | CC-MAIN-2017-13 | refinedweb | 371 | 53.98 |
A:
function randomColor() { return "#" + Math.floor((1 + Math.random()) * 4096).toString(16).substr(1); }
Those samples in the first link belong on TheDailyWTF. It'd be so much easier if JavaScript had a printf-style format function or operator. In Python, it'd look something like this:
def randomColor(): return "#%06x" % random.randint(0, 16777216)
Or the Python 3-preferred way:
def randomColor(): return "#{0:06x}".format(random.randint(0, 16777216))
You can also drop the Math.floor by noting that bitwise operators force an integer conversion. The smallest bitwise operator you can choose is OR 0. If you're looking for saving characters instead of saving operations, you can also drop the constant into a shift:
function randomColor() {
return "#"+((1+Math.random())*1<<24)|0).toString(16).substr(1);
}
Nice little 3-line function. But the real question is, is Math.Random() /truly/ random? My years developing high-grade crypto hardware makes me that it is not. (Nitpicking? Maybe.)
There's some discussion of Math.Random here: stackoverflow.com/…/how-random-is-javascripts-math-random
Brian_EE you develop HIGH level crypto hardware and don't know how random math.random is? scary
@BrianEE.
No. It's not truly random (by Cryptographic standards or by Quantum randomness standards). It's implementation defined how it actually works under the hood, but generally it's just a PRNG seeded by the system time (although in IE the seed is a 32-bit cryptographically random seed XORed with the PID and the process start time, so you have at least 32-bits of "real" randomness in the first call to Math.random() in the process).
Math.Random() is required to be random up to PRNG standards, that is to say that it should be loosely unpredictable, it should be evenly distributed over the range, and it should have a period substantially larger than the range.
Math.random() is NOT required (but also not forbidden) from being cryptographically random or quantumly random, so you should not rely on it being so.
Moral of the store: Don't use Random() for cryptographically important functions. (But you weren't doing that anyway, right?)
@Brian
The link on stackoverflow you gave is about the randomness of digits scale, not the randomness of the numbers generated. As stated there by jwoolard answer 9/10 number will have the same number of digits. And to answer your question : NO. There is nothing, repeat nothing, in software that is truly random, everything is pseudo-random. If you need a true random generator you have to resort to a hardware generator to be your source (no matter if is quantifying the noise in a transistor gate or "catching" the background cosmic noise, courtesy of Big Bang)
Possibly I'm missing the point, but I think the original code is actually broken.
padZero(Math.floor(Math.random() * 256)).toString(16)
will convert a zero-padded base-10 string to base 16 (assuming it works at all, since numbers have no length property). The closing parenthesis of padZero should be moved to the end for correct behavior.
Of course, this kind of algorithm will result in a lot of muddy gray and brown colors, since that makes up a large portion by 'volume' of the sRGB colorspace. If I wanted to generate a "random color", I'd pick a random hue angle and use some sort of weighted probability for the S/V or S/L components.
"Math.Random() is required to be random up to PRNG standards, that is to say that it should be loosely unpredictable, it should be evenly distributed over the range, and it should have a period substantially larger than the range."
IIRC, PRNGs in general are not guaranteed not to have multi-variable correlations (e.g. treating every three subsequent values as a coordinate gets you a set of point that's can't be outside of 11 possible planes).
It's a random 24-bit (and later 12-bit) color being chosen on the client for use in CSS, why would it need to be securely random? It just needs to be reasonably unpredictable to a human.
@Random832:
I assume you're talking about the 15 possible planes in LCG(2^31, 65539, 0, 1), but yes, you're right – PRNGs don't have any guarantees about multi-variable analysis, other than the distance between consecutive numbers is non-linear.
Note that the limitation of LCG as a PRNG implementation is not systemic. Other PRNGs don't suffer this limitation.
Darn, I was hoping for a discussion of human sensitivity to different frequencies and intensities. For example, note that the colors of the form #0x0y0z look very much more similar to each other than do the corresponding colors #x0y0z0.
When I first saw "can you do better", I immediately started thinking along Random832's line of thinking: pick a random hue, etc.
Then I figured that maybe you just wanted a way to simplify the given method, which led me thinking along the same lines as you. I just came up with a different way to implement padding:
return "#" + ("00000" + Math.floor(Math.random() * 16777216).toString(16)).slice(-6);
I'd probably just do something simple like:
function randomColor() {
____var color = "#";
____for (var i = 1; i <= 6; i++) {
________color += Math.floor(Math.random() * 16).toString(16);
____}
____return color;
}
function randomColor(){
return "#000004" // chosen by fair dice roll
// guaranteed to be random
}
Well somebody had to do it…
@AndyCadley – You should always give xkcd credit.
If you only need good enough you could probably get away with this:
return "#"+new Date().getTime().toString(16).slice(-3);
Too complicated, not good enough for enterprise usage. I'd use HTML5 technologies to outsource the problem to some SaaS solution running on the cloud, to promote an agile development process and leverage the synergy between function prosumers and bleeding-edge platform providers.
Of course the server would be written in node.js, so I'd need to use one of those things too, but that's just an implementation detail.
The only problem with that implementation is that you're going to end up with the colour of mud a lot of the time. If you want to pick a random colour that is pleasing then you probably want to use the HSV approach (en.wikipedia.org/…/HSV_color_space) where you limit the desaturation and value layers so that you always end up with a vibrant colour. Or if your mood ring is a bit cold then a sad colour that is not mostly grey.
@Anon – Not sure if you are baiting, but why would I know whether a javascript library software is truly random? I can assure you that high-grade crypto hardware does not run any JS whatsoever. Go learn about TRUE random number generators – i.e. custom chips with a high number of asynchronous ring oscillators (each a different length/frequency) that are summed together. These chips go through extensive testing and characterization to get <govt agency> approvals.
Back on topic, as a part-time web developer, I can see Ray's function as useful for a banner & button generating site. Something where you only need the *perception* of random.
@The MAZZTer has it right, don't bother with trying to make a hex number and just write out an rgb()-style color triplet. They're supported by every browser (even IE6!) to there's no real drawback to using them.
That's what I've always done in the past for dynamic colors via JavaScript.
My contribution:
function randomColor(includeAlpha) {
return "rgba(" + Math.floor(Math.random() * 256) + ", " + Math.floor(Math.random() * 256) + ", " + Math.floor(Math.random() * 256) + ", " + (includeAlpha ? Math.random() : 1) + ")";
}
Yeah yeah I took all the hexadecimal fun out of it. rgb(rr, gg, bb) syntax is also valid, btw.
@Adam not really much of a WTF. Although Raymond's solution of 0 padding by adding and them removing an extra digit is a bit odd, though it might be nicer than padding manually it's also more difficult to read without a comment to help.
@AndyCadley. Yup.
And that's probably the shortest and most time efficient way of generating a random number on the client computer. The only problem is that it fails to perform very well for more than 1 page load, and is downright out for more than 2. One obvious fix would be to have the javascript come from the server when the page is loaded. The server-side would invoke a C++ program that builds and outputs the javascript function. Why C++? Well because template metaprogramming would be used to dynamically generate the hard-coded random number of course. So the server-side program would first run a C++ toolchain, then use the resulting program to generate the javascript. As a pre-build step, the C++ project might need to generate a seed to use for the TMP code. One obvious solution would be to run a program that changes the system clock to a random value so that TIME could be the seed. This would imply that only one page at a time could be
generated to web clients (to avoid duplicate seeds), but this bottleneck could be ameliorated by having the compilation done 'before-hand'. (ie: have a dedicated server farm or cloud that constantly runs the C++ step, so that the web-server-side script or whatever would just grab a pre-built executable then delete it once done (this is the only part that would have to be done inside a lock).
function randomColor() {
return "#" +
Math.random().toString(16).substr(-6);
}
Note: negative start numbers in substr() requires IE9 or later.
Tod, you're on The Old New Thing, not The Daily Worse Than Failure.
and while the original version was easily understandable ven for the layman the final version needs an added comment so you know why it works. As if JS wasn't easily enough obfuscated without even trying…
on another note: while the original version got three (most likely consecutive) numbers the other versions just get one. So the "randomness" of the resulting color (and additionally the "randomness" of all generated colors if more than one is needed) changes, depending on implementation of the PRNG. Of course, in a perfect RNG this would not matter, but… :-)
I agree, simplicity is the key to success. ;-)
You could replace(!) "#" + str.substr(1) with str.replace(/./, "#").
@Henry
That won't work. The random number could be "0.1"
Just for fun I looked up the ECMAScript specification for Math.random():
— begin quote —
15.8.2.14 random ( )
Returns a Number value with positive sign, greater than or equal to 0 but less than 1, chosen randomly or pseudo randomly with approximately uniform distribution over that range, using an implementation-dependent algorithm or strategy. This function takes no arguments.
— end quote —
@sugendran: Dang you, I followed the link you gave to the Wikipedia article, then followed its footnotes to some fascinating documents that I skimmed and downloaded to read later. More stuff to do. It's all your fault. :-)
function randomColor() {
return "#444"; // Chosen by fair dice rolls.
// Guaranteed to be random.
}
return "peachpuff";
My friends all agree that "peachpuff" is quite a random color. | https://blogs.msdn.microsoft.com/oldnewthing/20121023-00/?p=6273/ | CC-MAIN-2017-22 | refinedweb | 1,879 | 63.49 |
Hi, I am trying to figure out how to write a program that will allow the user to enter as many numbers as they want, and store them in a vector<t>. I am using a FOR () loop to accept the input (since I wouldn't know beforehand how many numbers they might want to input). To break out of the loop I am using an if statement that I want to check for the newline character. Of course, the input type is integer, and I recognize that the newline is type character so I am not totally shocked that this isn't working. I just don't know what to do about it. I did verify that if the loop would end, the rest of the code does what I want it to (by using a counting loop). So my question is, what syntax might I use to get the FOR loop to break when the user presses enter?
Thanks!
Here is what I have so far:
Code:#include <iostream> #include <vector> using namespace std; int main() { cout << "Hello.\n"; vector<int> num1; int bigNum; cout << "Enter a large number, seperated by spaces such as 987 393 903\n"; for(;;) { cin >> bigNum; if (bigNum == '\n') break; // This is not breaking when "enter" is pressed. num1.push_back(bigNum); } cout << "You entered: "; for (unsigned i = 0; i < num1.size(); i++) cout << num1[i] << endl; } | http://cboard.cprogramming.com/cplusplus-programming/52854-comparing-int-newline-character.html | CC-MAIN-2015-18 | refinedweb | 233 | 76.45 |
To first approximation, Earth is a sphere. A more accurate description is that the earth is an oblate spheroid, the polar axis being a little shorter than the equatorial diameter. See details here. Other planets are also oblate spheroids as well. Jupiter is further from spherical than the earth is more oblate.
The general equation for the surface of an ellipsoid is
An ellipsoid has three semi-axes: a, b, and c. For a sphere, all three are equal to the radius. For a spheroid, two are equal. In an oblate spheroid, like Earth and Jupiter, a = b > c. For a prolate spheroid like Saturn’s moon Enceladus, a = b < c.
The dwarf planet Haumea is far from spherical. It’s not even a spheroid. It’s a general (tri-axial) ellipsoid, with a, b, and c being quite distinct. It’s three semi-axes are approximately 1000, 750, and 500 kilometers. The dimensions are not known very accurately. The image above is an artists conception of Haumea and its ring, via Astronomy Picture of the Day.
This post explains how to compute the volume and surface area of an ellipsoid. See that post for details. Here we’ll just copy the Python code from that post.
from math import sin, cos, acos, sqrt, pi from scipy.special import ellipkinc, ellipeinc def volume(a, b, c): return 4*pi*a*b*c/3) a, b, c = 1000, 750, 500 print(volume(a, b, c)) print(area(a, b, c))
Related post: Planets evenly spaced on a log scale
One thought on “Ellipsoid geometry and Haumea”
I was surprised by the statement that Enceladus is a prolate spheroid. I found the following, which seems to say it is triaxial, like (but less extremely than) Haumea, but closer to an oblate spheroid with the polar semimajor axis less than either of the equatorial semimajor axes: “Limb profiles from Cassini images show that Enceladus is well represented by a triaxial ellipsoid whose principal axes are a = 256.6 ± 0.3 km, b = 251.4 ± 0.2 km, and c = 248.3 ± 0.2 km” (c being the polar semimajor axis; see figure 1) at . | https://www.johndcook.com/blog/2018/05/15/ellipsoid-geometry-haumea/ | CC-MAIN-2021-17 | refinedweb | 361 | 74.79 |
Tutorials > C++ > Dynamic Arrays
You may have noticed that you cannot create an array unless the exact size is known.
If you tried to create an array eg. int nums[50], all would
be fine. If however, you tried to create an array eg. int nums[i],
you would get errors.
The array above is known as a dynamic array. If you would like
to create a dynamic array, you need to allocate memory as
was shown in the previous tutorial.
Contents of main.cpp :
#include <iostream>
#include <stdlib.h>
#include <fstream>
using namespace std;
int main()
{
Below we declare 2 pointers to integers. We have dealt with pointers to an integer before.
A pointer can also point to the first integer in an array of values.
int *cnums = NULL;
int *cppnums = NULL;
The code below opens a text file. The first line of the file indicates how many numbers
are in the array and each successive line holds a number to place in the array.
int numNums;
ifstream fin("in.txt");
fin >> numNums >> ws;
In C, you use the malloc function, but instead of specifying the amount of memory
to allocate as sizeof(int), you specify the amount of bytes
as the size of the data type multiplied by the amount of items you want in the array.
// C Dynamic Array
//-----------------
cnums = (int *)malloc(sizeof(int) * numNums);
In C++, you still use the new keyword followed by the data
type that you are wanting to create the array for, but this time you place square
brackets containing the size of the array. The size of the array is given as how many
items you would like, not the number of bytes.
// C++ Dynamic Array
//-------------------
cppnums = new int[numNums];
The arrays can now be used as per normal.
int temp = 0;
for (int i = 0; i < numNums; i++)
{
fin >> temp >> ws;
cnums[i] = temp;
cppnums[i] = temp;
}
fin.close();
for (int i = 0; i < numNums; i++)
cout << "c : " << cnums[i]
<< " cpp : " << cppnums[i] << endl;
Arithmetic can also be done on pointers. If you add 2 to
the cppnums array and dereference the pointer position to
access the data, you will receive 87, being the number in position
2.
cout << *(cppnums + 2) << endl;
In C, there is no change in how you deallocate the memory previously allocated. You simply
use the free function and pass the pointer as a parameter.
// C Release of Array
//--------------------
free(cnums);
In C++, the deallocation mechanism is slightly different. When you are reclaiming memory
from an array, you need to place square brackets straight after the delete
keyword. This indicates that an entire array must be deallocated. If you left out these
square brackets, only the memory for the first item would be released.
// C++ Release of Array
//----------------------
delete[] cppnums;
system("pause");
return 0;
}
Well done. You should now be able to create dynamic arrays. This is very useful as you will
normally find that you do not know the size of an array at compile time.
Please let me know of any comments you may have : Contact Me
Back to Top
Read the Disclaimer | http://www.zeuscmd.com/tutorials/cplusplus/41-DynamicArrays.php | CC-MAIN-2016-50 | refinedweb | 519 | 72.46 |
10 April 2013 15:59 [Source: ICIS news]
CAMPINAS, Brazil (ICIS)--Brazilian petrochemical producer Braskem will begin training about 400 people to work at its Braskem Idesa Ethylene XXI project in the Nanchital region of Mexico's Veracruz state, the company said on Wednesday.
The employees will work directly at the plant on the production of ethylene and polyethylene (PE), it said.
Braskem said it will bring a training model that it uses in ?xml:namespace>
It also plans to work with Universidad Tecnológica Del Sureste de Veracruz (UTSV) to promote better training for its employees in the region.
"Our goal is to develop a local expertise and contribute with the generation of jobs in
The Ethylene XXI complex is being built by Braskem Idesa, a partnership between Braskem and Mexico-based Grupo Idesa.
The project is expected.
Ethylene XXI should begin operations in the second half | http://www.icis.com/Articles/2013/04/10/9657794/brazil-braskem-to-train-400-people-to-work-at-ethylene-xxi-project.html | CC-MAIN-2015-14 | refinedweb | 147 | 50.87 |
Jim O'Neil
Technology Evangelist
Looking to dive into coding with Windows 7? The RC Training Kit is a great resource for developers, with hands-on labs and presentation materials covering many of the Windows 7 features, including:
There’s also the Windows® API Code Pack for Microsoft® .NET Framework, currently at version 0.90, which provides a namespace of managed code wrappers for many, but not yet all, of the COM and C++ interfaces exposed by the new Windows 7 features.
You’ll note that the examples in the RC Training Kit use a different set of managed code wrappers from what’s in the API Code Pack. There’s an on-going plan to port most of the older Vista Bridge code (in the training kit) to the API Code Pack, but until the Code Pack reaches its version 1.0 RTM milestone, you may end up dealing with one (or both) managed code layers depending on what features of Windows 7 you’re working with and what code samples you’re consulting. | http://blogs.msdn.com/b/jimoneil/archive/2009/06/19/windows-7-rc-training-kit-for-developers.aspx | CC-MAIN-2013-48 | refinedweb | 175 | 64.64 |
ConnectCode .Net DLL IntegrationConnectCode Barcode Fonts package includes a .Net 2.0/4.0 Dynamic Link Library (DLL) that you can bundle with your .Net application. This DLL helps you translate input data to barcode output characters, generate check digit and ensure that the data complies with industry specifications. The DLL can be redistributed with a Distribution or Unlimited Distribution License from ConnectCode.
The Resource\Net DLL Integration Samples directory of the installation package includes the .Net DLL and samples that demonstrate the use of the DLL.
Strong-Name .Net Barcode Dynamic Link Library (DLL)
ConnectCode Barcode Fonts package also provides a Strong-Name DLL signed using a cryptographic key pair. This allows the barcode DLL to be deployed to the Global Assembly Cache and you can enjoy all the benefits of a strong name DLL.
Location of the Strong-Name Barcode DLL
The Strong-Name DLL is stored in a subdirectory of the ConnectCode Barcode Fonts package.
...\Resource\Net DLL Integration Samples\DLL\StrongName
Integration Topics
- Tutorial on using the .Net DLL with ConnectCode Barcode Fonts
- C# Sample on using the .Net DLL with ConnectCode Barcode Fonts
- ConnectCode Barcode Fonts .Net DLL Application Programming Interface
Tutorial on using the .Net DLLIn this tutorial, we are going to create a Windows Forms Application that contains a TextBox that uses ConnectCode Barcode Fonts. The application will use the .Net DLL to verify the input and generate a check digit. The application will then set the appropriate fonts to generate the final barcode.
1. Launch Visual Studio 2005 (or VS2008/VS2010/VS2012/VS2015) to create a new project.
2. Goto File->New->Project. Select Visual C#->Windows Application. You can also choose to create a Visual Basic or Visual C++ application. The ConnectCodeBarcodeFonts.dll is .Net 2.0 (and onwards) compliant and can be used in any of the .Net languages project.
Name the project MyWindowsApplication.
3. Next, add a reference to the ConnectCode Barcode Fonts Library. The ConnectCodeBarcodeFonts.dll library can be found in the Resource\Net DLL Intergration Samples\DLL directory. This can be achieved by right clicking the References object in the Solution Explorer and selecting Add Reference.
4. The Add Reference Dialog will appear as below. Click on the Browse tab and navigate to the Resource\Net DLL Intergration Samples\DLL directory. Select ConnectCodeBarcodeFonts.dll and click ok.
5. The DLL is now ready to be used by the application. We will first add the namespace to the Form1.cs class. This can be carried out by right clicking on the Form1.cs class and selecting View Code. At the top of the Form1.cs class, you will see many "using System..." statements.
Add the statement
"using Net.ConnectCode.Barcode;"
In Visual Basic, you can add
"Imports Net.ConnectCode.Barcode"
6. We will next add the TextBox object to our application. Double click on Form1.cs in the Solution Explorer. Notice that Form1.cs [Design] tab will appear.
Click on the menu item View->Toolbox. In the Common Controls of the Toolbox, select the TextBox object. Next goto Form1 and drop the TextBox object.
Right click on TextBox and click on Properties. Set the Multiline property to True. Change the name of the TextBox to "textBoxOutput".
Next drop a button onto Form1. You Form1 should look like the following:
7. We will now make use of the ConnectCodeBarcodeFonts.dll in our application. Double click on the "button1" object in Form1. The following will appear in the source code editor.
private void button1_Click(object sender, EventArgs e) { }8. Add the following code below
private void button1_Click(object sender, EventArgs e) { //Add Code Start BarcodeFonts barcode = new BarcodeFonts(); barcode.BarcodeType = BarcodeFonts.BarcodeEnum.Code39; barcode.Data = "1234567"; barcode.CheckDigit = BarcodeFonts.YesNoEnum.Yes; barcode.encode(); textBoxOutput.Text = barcode.EncodedData; Font fontz = new Font("CCode39_S3_Trial", 24); textBoxOutput.Font = fontz; //Add Code End }
9. Compile and run the application. You should see the following:
Note :
If you are compiling the projects in Vista, you may need to copy them into a folder that does not require elevated privilege for writing into.
Application SamplesThe Resource\Net DLL Integration Samples\MyWindowsApplication directory contains the complete C# sample of the above tutorial.
Application Programming InterfaceThe following section illustrates how to generate the ConnectCode Barcode Fonts characters using the .Net DLL. Each of the attributes are explained below and the font to use for each barcode is shown in the following table.
BarcodeType - Barcode symbology. The complete list of barcodes is listed in the table below.
Data - Input Data.
CheckDigit - Specifies whether you will like the check digit to be appended to the barcode.
Values : BarcodeFonts.YesNoEnum.Yes, BarcodeFonts.YesNoEnum.No
Extended - Specifies whether to use the extended style of the barcode. This option is only applicable to the EAN13, EAN8, UPCA and UPCE barcodes.
Values : BarcodeFonts.YesNoEnum.Yes, BarcodeFonts.YesNoEnum.No
EANStandards - This option is only used with the EAN13 barcode. It is used to specify whether the EANText will return the
ISBN - International Standard Book Number
ISBN13 - International Standard Book Number (Sunrise Compliance)
ISSN - International Standard Serial Number
Values :
BarcodeFonts.EANStandardsEnum.ISBN, BarcodeFonts.EANStandardsEnum.ISBN13, BarcodeFonts.EANStandardsEnum.ISSN, BarcodeFonts.EANStandardsEnum.None
HumanText - Returns the Human Readable Text of the barcode.
EANText - Returns the EAN text as specified in EANStandards.
Note :
The default font size for most barcodes is set to 24 (Except for POSTNET which is set to 9 and GS1 Databar Stacked Omni/GS1 Databar Expanded Stacked which is set to 48. But it can be adjusted to be slightly bigger or smaller. The font name needs to be appended with _Trial for Trial fonts.
If you are using the trial copy of ConnectCode Barcode fonts, the font name that is chosen when an input string is encoded will be appended with the word _Trial. As a consequence, the barcode sample that is displayed will be marked with horizontal lines at the top for some digits. | http://www.barcoderesource.com/dotNetDLLBarcodeFonts.shtml | CC-MAIN-2017-13 | refinedweb | 981 | 51.34 |
Im trying to figure out the mouse classes for a larger project im working on. This is a really simple applet i wrote, and based off of the sun micro systems tutorial it seems like it should work. The program should simply redraw the square where ever the mouse clicks. However it doesnt do it. As i undersatnd the applet should draw, wait for a mouse command, then redraw right? but in my program my mouseUp fires (i have console out to tell me every time it fires) but then it does fire paint again, so i must be mistaken about the way applets work. What am i missing, how do i get it to redraw? and how would i get this app to work?
/////////
import java.awt.*; import javax.swing.*; import java.applet.*; public class MovingSquare extends Applet { private int xPos = 0; private int yPos = 0; private Color currentColor = Color.BLACK; public void init() { addMouseListener(this); xPos = 200; yPos = 200; setBackground(Color.GRAY); } public void paint(Graphics g) { g.setColor(currentColor); g.fillRect(xPos,yPos,30,30); System.out.println("RUN_PAINT"); } public boolean mouseUp (Event event, int x, int y) { System.out.println(x); System.out.println(y); xPos = x; yPos = y; return true; } } | http://www.javaprogrammingforums.com/java-applets/793-simple-problem-w-appelets-i-cant-figure-out.html | CC-MAIN-2015-35 | refinedweb | 205 | 65.83 |
Hi Konrad, Konrad Hinsen <address@hidden> skribis: > Here is a first complete draft: > > > > > Feedback welcome, be it by mail or as issues on GitHub. I’ve read it entirely and I think it’s perfect. It’s a pleasant read, it covers many aspects in a pedagogical way (if I’m able to judge that!), and it always shows how these nitty-gritty details relate to reproducible computations. I like how you explain that it’s human interpretation that leads us to split “inputs” and “outputs” into more specific categories (I had already enjoyed that in one of your talks). Minor comments: • You write “Build systems are packages as well”. This could be slightly misleading: build systems are (1) a set of packages, and (2) a build procedure. Dunno if it makes sense to clarify that. • In the ‘guix pack’ example, you could perhaps omit all the -S flags except for /bin, and mention ‘--save-provenance’. • Would it make sense to mention MPFR in the paragraph about IEEE 754? • Regarding ‘--container’, you write that namespaces “may not be present on your system, or may be disabled by default”, which is a bit strong; “may be present on your system, but perhaps disabled by default” would be more accurate. :-) > Also, what is the procedure for submitting blog posts? What are the > right formats for text and graphics? The format we use is Markdown fed to Haunt: (which is sad because your Org file with Babel sessions is much nicer…). I think Pierre had something to convert Org to Markdown. To syntax-highlight Scheme code, you must start Scheme blocks with “```scheme” in Markdown. PNGs for graphics are good. You can post a patch against the guix-artwork.git repo here when you’re ready. If you want we can publish it next Tuesday or Thursday. We could have it on both hpc.guix.info and guix.gnu.org, with one saying that it’s a re-post of the other. Thank you for the great article! Ludo’. | https://lists.gnu.org/archive/html/guix-devel/2020-01/msg00188.html | CC-MAIN-2022-33 | refinedweb | 336 | 74.9 |
This post shows how to use the Dual Analogue Radio Transmitter (DART) and the Universal Radio Receiver (URR) to monitor the temperature of one or more freezer.
The DART collects data from 2 analogue inputs and transmits this to a receiver using a 433 MHz FM radio module. (FM radio modules gives gives significantly better range and noise performance when compared to AM modules). More information on the DART and URR can be found here.
The TMP36 is very easy to use. The relationship between the temperature and analogue voltage output is as follows:
Temp (in deg C) = voltage (in mv) divided by 10 minus 50
So for example if the TMP36 output volts was 800 mV the temperature would be 800/10 = 80 mnus 50 would be 30 deg C.
The DART has 2 sets of screw terminals. The TMP36 temperature sesnor can be connected directlty to these. The timing of the temperature measurement and transmission can be set to 1 every minute or 1 every 10 minutes.
On this project uses 2 TMP36 devices. One is connected directlty to the screw terminals and the other is on a cable of approximately 1 metre in length. The TMP36 at the end of this is housed in a plastic tube for protection.
The image below shows the DART in pace with one of the TMP36 device inside the freezer and one outside. This way we can monitor the temperature inside and outside the freezer (which in this case is in the garage).
The Universal Radio REceiver is connected to a Raspberry Pi, using A Custard Pi 1A breakout board. (This has easy connection points and also has 0.1A fuses on the 5V and 3.3V rails to prevent too much current being drawn from the RPi.)
The Python code to receive the data on the serial port is listedat the end of this post. Please read this document for more comprehensive instructions on using the UART on the Raspberry Pi.
The data displayed on the HDMI monitor connected to the Raspberry Pi is hsown here.
The data is received every minute and is interpreted as follows.
1st digit = device type )always 1 for a DART)
2nd digit = address set on this DART
3rd digit = data count (goes from 0 to 15 and then starts again. Each data set is sent twice)
4th digit = temp 1 = -21 deg C (inside the freezer)
5th digit = temp 2 = 12 deg C (in the garage)
6th digit = batt voltage = 4.417 V
PROJECT IDEA #1: Send an e-mail from the Raspberry Pi if the temperature inside the freezer rises by 5 degrees.
PROJECT IDEA #2: Log the temperature from a number of freezers for food hygiene purposes. (One URR can receive data from a number of DART devices).
Summary: The DART and URR devices allow remote temperature monitoring to be set up very quickly.
Appendix: Python code to recive and display data from the serial port.
#!/usr/bin/env python
import time
import serial
ser = serial.Serial(
port='/dev/ttyAMA0',
baudrate = 9600,
parity=serial.PARITY_NONE,
stopbits=serial.STOPBITS_ONE,
bytesize=serial.EIGHTBITS,
timeout=0
)
ser.flushInput()
while True:
data1 = ser.read(1)
data2 = ser.read(1)
data3 = ser.read(1)
data4 = ser.read(1)
data5 = ser.read(1)
data6 = ser.read(1)
if len(data1) >0:
localtime = time.asctime( time.localtime(time.time()))
print localtime
temp1 = (1024*ord(data4)/2550)-50
temp2 = (1024*ord(data5)/2550)-50
battv = (1024 * ord(data6) * 11)/255
print ord(data2), ord(data3), ord(data1),
print "Temp1 = ", temp1,
print "Temp2 = ", temp2,
print "BattV", battv
time.sleep (0.5)
ser.close()
Top Comments
I don't see a CE mark (or any reference to WEE) on the DART or its documentation - did I miss them or do they not exist ?
MK
Good - I asked because I couldn't see them on the pictures. Your stuff is a lot more expensive than similar little boards from unknown sources in China via Ebay or Aliexpress (which generally are not… | https://community.element14.com/products/raspberry-pi/b/blog/posts/remote-temperature-monitoring | CC-MAIN-2022-21 | refinedweb | 668 | 65.42 |
Interfacing with C
NOTE! Have to do some spell checking, verify text, code and filenames.
ForewordThis is a tiny basic tutorial on how to write a simple library in C and then use it in FreeBASIC. The tutorial should be possible to follow without to much knowledge of C or FreeBASIC. After doing this tutorial you should be able to compile a static and a dynamically linked C library. Translate the necessary header files to FreeBASIC header files and understand how to use the libraries in a FreeBASIC project.
What is a library
PrerequisiteThis tutorial was written and tested with FreeBASIC 0.16b and the latest Current release of MinGW32 at the time. As a note Dev-cpp uses MinGW32 as it's compiler tool chain. You also get code::blocks with a mingw32 bundle.
Formal description of the task at handTo demonstrate usage of a C library in FreeBASIC we need to create the simplest possible library with a few functions. A test file in C to demonstrate that our library works as intended. Then we have to translate the library header file to a FreeBASIC header file (*.bi) and finally create a test project in FreeBASIC using the library.
Creating the filesSo our file list will look like this:
myClib.c: C file implementing our library.
myClib.h: C header file describing the libraries interface.
myClibCTest.c: C file implementing our test program in C.
myClib.bi: FreeBASIC header file. A translation of myClib.h.
myClibFBTest.bas: FreeBASIC
make.cmd: A sample shell script compiling the library and test files.
The C file to become a static library. myClib.c
/* A function adding two integers and returning the result */ #include "myClib.h" int SampleAddInt(int i1, int i2) { return i1 + i2; } /* A function doing nothing ;) */ void SampleFunction1() { /* insert code here */ } /* A function always returning zero */ int SampleFunction2() { /* insert code here */ return 10; }
The header file myClib.h
int SampleAddInt(int i1, int i2); void SampleFunction1(); int SampleFunction2();
A C test project to verify that the static lib is C compatible. myClibCTest.c:
#include <stdio.h> #include <stdlib.h> #include "myClib.h" int main(int argc, char *argv[]) { printf("SampleAddInt(5, 5):=%d\n", SampleAddInt(5, 5)); system("PAUSE"); return 0; }
Translating the C header file to a FreeBASIC header filemyClib.bi: To interface the static library and automatically include it (#inclib "myClib" ) i have this file.
''include file for libmyClib.a
And finally the FreeBASIC file using the librarymyClibFBTest.bas:
''Testing functions in myClib.bi
#include "myClib.bi"
''
Print "SampleAddInt(10, 10):=", SampleAddInt(10, 10)
'' Just a dumy call
SampleFunction1()
''
Print "SampleFunction2():=", SampleFunction2()
#include "myClib.bi"
''
Print "SampleAddInt(10, 10):=", SampleAddInt(10, 10)
'' Just a dumy call
SampleFunction1()
''
Print "SampleFunction2():=", SampleFunction2()
The make file: make.cmdI have created a batch file to compile all the files. Including a sample in C using the static library. Note the config lines at the top which has to be modified to suite your setup.
@REM TODO: Set PATH's for this session. SET PATH=C:\mingw32\bin;c:\mingw32\mingw32\bin SET MINGW_INCLUDE="C:/MinGW32/include" SET MINGW_LIB="C:/MinGW32/lib" @REM @REM fbc testing SET fbc="C:\portableapps\FreeBASIC\fbc.exe" SET fbc="C:\FreeBasic16b\fbc.exe" @echo *** Verify pat's to compilers @pause @echo off @REM @REM Remove old files DEL /F *.o *.a myClibFBTest.exe @REM @REM Create static lib from c source gcc.exe -c myClib.c -o myClib.o -I%MINGW_INCLUDE% @REM @REM ar: creating libstatictest.a ar r libmyClib.a myClib.o @REM @REM No nead for ranlib anymore? ar is supposed to take care of it ranlib libmyClib.a @REM @REM Create a test with a C file gcc.exe -c myClibCTest.c -o myClibCTest.o -I%MINGW_INCLUDE% gcc.exe myClibCTest.o -o "myClibCTest.exe" -L%MINGW_LIB% libmyClib.a echo ===================================== echo RUnning C sample echo ===================================== myClibCTest.exe echo ===================================== echo Creating FreeBASIC sample echo ===================================== REM I thought this explicit reference is unnecessary as I use #inclib SET fbcop= -I myClib SET fbcfl="myClibFBTest.bas" %fbc% %fbcop% %fbcfl% echo ===================================== echo RUnning FreeBASIC sample echo ===================================== myClibFBTest.exe @pause
Encountered error messages and their solutions
undefined reference toTrying to link against the static C library without using the cdecl alias "functionname" in the FreeBASIC header file results in errors like this.
C:\code>"C:\FreeBasic16b\fbc.exe" "myClibFBTest.bas" myClibFBTest.o:fake:(.text+0x3d): undefined reference to `SAMPLEADDINT@8' myClibFBTest.o:fake:(.text+0x4a): undefined reference to `SAMPLEFUNCTION1@0' myClibFBTest.o:fake:(.text+0x67): undefined reference to `SAMPLEFUNCTION2@0' Press any key to continue . . .
To resolve this you will have to locate function declarations in a *.bi file that look like this:
Declare Function SampleAddInt(ByVal i1 As Integer, ByVal i2 As Integer) As Integer
And change it to something like this:
Declare Function SampleAddInt CDecl Alias "SampleAddInt" (ByVal i1 As Integer, ByVal i2 As Integer) As Integer
Appendix A: linksThe basis for this tutorial is several threads in the forum.
When it evolves and can stand alone the links to the threads might be removed.
Some interesting links containing information on interfacing libraries created in FreeBASIC and used by other languages or visa versa.
How do I compile a C project as a static lib for inclusion.. | https://www.freebasic.net/wiki/wikka.php?wakka=TutInterfacingWithC | CC-MAIN-2018-09 | refinedweb | 870 | 51.75 |
Bugzilla – Bug 12212
iPhoneOSGameView.Run throws "An element with the same key already exists in the dictionary."
Last modified: 2013-06-14 04:41:57 EDT
Rarely, I get this error when calling Run:
System.ArgumentException: An element with the same key already exists in the
dictionary.
at
System.Collections.Generic.Dictionary`2[OpenTK.ContextHandle,System.WeakReference].Add
(ContextHandle key, System.WeakReference value) [0x00000] in <filename
unknown>:0
at OpenTK.Graphics.GraphicsContext..ctor (OpenTK.Graphics.GraphicsMode
mode, IWindowInfo window, Int32 major, Int32 minor, GraphicsContextFlags flags)
[0x00000] in <filename unknown>:0
at OpenTK.Platform.Utilities.CreateGraphicsContext
(OpenTK.Graphics.GraphicsMode mode, IWindowInfo window, Int32 major, Int32
minor, GraphicsContextFlags flags) [0x00000] in <filename unknown>:0
at OpenTK.Platform.Utilities.CreateGraphicsContext (EAGLRenderingAPI
version) [0x00000] in <filename unknown>:0
at OpenTK.Platform.iPhoneOS.iPhoneOSGameView.CreateFrameBuffer ()
[0x00000] in <filename unknown>:0
at OpenTK.Platform.iPhoneOS.iPhoneOSGameView.RunWithFrameInterval (Int32
frameInterval) [0x00000] in <filename unknown>:0
at OpenTK.Platform.iPhoneOS.iPhoneOSGameView.Run () [0x00000] in
<filename unknown>:0
at WAML.IOS.RenderBoxImplementation.Start () [0x00000] in <filename
unknown>:0
I haven't been able to repro it, but it's happened quite a few times. It seems
to be random. Saw in mtouch 6.2.3.0 (8d98f5e).
Googling it showed someone else that ran into this problem too, but his post to
the forums did not receive any replies:
Hello Randy,
Would you happen to have a test case we can use to reproduce this?
Reading the source code, and based on your comment that this happens randomly,
I wonder if you are using threads in your application, and just two threads try
to create the GraphcisConext at once?
Okay, I spent some more time on this, and I can now provide a repro. See
attachment.
And no, it doesn't appear to be related to multi-threading. My app only ever
calls Run from the UI thread, as does the attached sample.
The attached sample is just a simple app that creates and destroys
iPhoneOSGameViews rapidly. If you let it run long enough on an actual device,
the above error happens (usually within 15-30 seconds for me.)
Created attachment 3982 [details]
Repro
Randy,
Notice that NSTimer runs on a parallel thread to the UI thread, so this means
that you are calling the new UIViewController from a background thread.
Can you rename your Tick () function with Tick2 (), and then make Tick () be:
Tick ()
{
BeginInvokeOnMainThread (() => Tick2 ());
}
I don't believe that is true. If I write out the
Thread.CurrentThread.ManagedThreadID from a NSTimer callback, it always shows
it's on the UI thread.
Nevertheless, I tried using BeginInvokeOnMainThread anyway as you suggested and
I still got the same error.
Sebastien, would you mind researching this issue?
I can duplicate it and it does not seems to be threading related.
The sample creates a lot of new GraphicContext and the same context pointer can
be (re)used.
Right now the code does not check if the WeakReference is alive before adding
it to the dictionary. If it's not alive it should replace the existing entry.
That's the "direct" cause of the exception.
Now if the WeakReference is not alive then it must have been disposed - and
that should have removed the entry from available_contexts. OTOH my breakpoint
on Dispose was not hit - and that's likely the "real" bug.
The main dispose issue is the lack of a finalizer, making instance freed by the
GC (and not manually disposed), not removed from the dictionary.
So adding
~GraphicsContext ()
{
this.Dispose(false);
}
removes entries from `available_contexts`. That makes the situation better but
it's still possible that the pointer is part of the dictionary (but it's weak
reference will be alive). Looking into that...
The old, still in the dictionary, `implementation` seems invalid (disposed?)
and that's where the Context handle comes from (not from the object instance
`this` on which the weak reference is kept).
So it seems the tracking is not done on the "correct" data and can introduce a
race situation like this one, i.e. the inner `implementation` is disposed but
it's parent is not (yet). So the handle can be (and is) reused and fails to be
added.
One "hacky" solution would be to ignore it, IOW replace any existing
(half-disposed) instance with the new (fresh) one.
The "right" one would be to track the right data, the `implementation`, but
might be more invasive. Looking into it...
Sometime the GraphicsContext dispose of the EAGLContext (in it's Dispose
method) and sometime the EAGLContext is disposed before (e.g. when
DestroyFrameBuffer is called).
That means the previous (accessed thru the WeakReference) `implementation`,
which is a iPhoneOSGraphicsContext, has it's EAGLContext (it's Handle is 0x0).
Now `implementation.Context` is a *copy* of `contextHandle` - the original
Handle value (IntPtr).
So that makes it possible, on the native side, to reuse the same handle (it's
been freed) while the managed side still as a copy of the value
(contextHandle). That happens when the GraphicsContext has not yet been
disposed and it means it's possible to re-add the same handle value into the
dictionary.
Cleaning that `contextHandle` (when disposed) value does not work since it's
used to remove entries from the dictionary (so the problem remains).
The second bug seems to dispappear when we ensure the dispose order remains
identical everywhere (I'm well over 10k instances).
Part's of GraphicsContext Dispose job is to call EAGLContext.Dispose so this
ensure they get released in the "right" order (so the dictionary is kept in
sync).
OTOH maybe I'm missing the point why only the EAGLContext was disposed and the
GraphicsContext only null'ed ?!?
diff --git a/src/OpenGLES/OpenTK_1.0/Platform/iPhoneOS/iPhoneOSGameView.cs
b/src/OpenGLES/OpenTK_1.0/Platform/iPhoneOS/iPhoneOSGameView.cs
index 7bb7d03..e757940 100644
--- a/src/OpenGLES/OpenTK_1.0/Platform/iPhoneOS/iPhoneOSGameView.cs
+++ b/src/OpenGLES/OpenTK_1.0/Platform/iPhoneOS/iPhoneOSGameView.cs
@@ -557,7 +557,7 @@ namespace OpenTK.Platform.iPhoneOS
else
EAGLContext.SetCurrentContext(null);
- EAGLContext.Dispose();
+ GraphicsContext.Dispose();
GraphicsContext = null;
gl = null;
}
The first bug (missing finalizer), inside opentk, has been filled as
Fixes for the two issues are now fixed in
938cf69518205d26fe4243dca1a0b6cdf8dbb46a (master)
Today I have checked this issue with following builds:
X.S 4.0.8-1
Xamarin.iOS 6.3.6-76
Mono 3.0.11
And we have run the attached project, It deployed and launched successfully on
both Simulator and device.
Changing the status to Verified.
An Update to Comment#15
I have run this application for 15 minutes on physical device and I am not
seeing any crash. | https://bugzilla.xamarin.com/show_bug.cgi?id=12212 | CC-MAIN-2014-15 | refinedweb | 1,098 | 57.37 |
vimal_Parthan + 8 comments
My Java Solution
Queue queue=new LinkedList();
queue.add(root);
while(!queue.isEmpty())
{
Node tempNode=queue.poll();
System.out.print(tempNode.data+" ");
if(tempNode.left!=null)
queue.add(tempNode.left);
if(tempNode.right!=null)
queue.add(tempNode.right);
}
h4ck3rviv3k + 3 comments
You need to type cast "queue.poll()" because it will give you an object so you need to type cast it to Node object "(Node)queue.poll()".
- II
inno_irving_est1 + 2 comments
omg i was getting frustrated with this one. Its weird it works if I instantiate the queue as a linked list, but it doesnt work with PriorityQueue. Shouldnt PriorityQueue work also? I almost had the same solution as vimal_Parthan but I had it initialized Queue queue = PriorityQueue() but this didnt work
- D
- AP
anirudh_pratap22 + 1 comment
or you can define the Queue using generics
miere00 + 1 comment
@aniruth_prata22 was right. I don't understand why someone have down voted his answer....
void levelOrder(Node root) { Queue<Node> queue=new LinkedList<>(); queue.add(root); while(!queue.isEmpty()) { Node tempNode=queue.poll(); System.out.print(tempNode.data+" "); if(tempNode.left!=null) queue.add(tempNode.left); if(tempNode.right!=null) queue.add(tempNode.right); } }
- MB
mvbelgaonkar + 0 comments[deleted]
- SV
enmar + 1 comment
Just a note for anyone reading, you should never use raw types; always use generics. The ability to use raw types only exists to support legacy Java code.
Queue<Node> q = new LinkedList<Node>();
is the proper way of instantiating your LinkedList in this case.
From Effective Java, 2nd ed..
- JS
jscupc + 0 comments
- OB
orionsongs + 1 comment
Not a good comment! You could provide constructive feedback or a better example, instead of just a negative opinion.
abhinavgolum97 + 6 comments
Can anyone tell me what is the problem here ?
C solution :
void levelOrder(node * root) { static int i=0; if(i==0){ printf("%d ",root->data); i++; } if(root==NULL) return; if(root->left==NULL && root->right==NULL); return; if(root->left!=NULL) printf("%d ",root->left->data); if(root->right!=NULL) printf("%d ",root->right->data); levelOrder(root->left); levelOrder(root->right); }
Thanks!
- DY
wallah + 1 comment
i think u did i just like first question in trees . if u test it on copy on simple example u will find it
abhinavgolum97 + 2 comments
what is wrong here ? I got right answer when i traced it using an example.
meraz_zatin + 0 comments
That you are thinking actually happens to the left subtree first and then goes further left. so the first line of traversal is fine. However when it traverses down it goes left first. what you actually are thinking is hapening in left subtree and then the same thing occurs int he lower trees.
akscool100 + 0 comments
the operation here on right patr of the tree is happening only after the operation getting finished on the left part. thats why you are getting error as it should happen at once.
- SA
shaif_ansari22 + 0 comments
you are traversing the left subtree then right subtree and because of that the order is not coming properly.
kasa_pranay9 + 0 comments
Absolutely ur program is wrong because ur program is first printing the left subtree node values then its coming to right but u need to print left and right which are in same level
surajkumar_cse + 0 comments
It will traverse through all branches of left first then it will come to right.
hammeramr + 1 comment
Solution with generics
void levelOrder(Node root) { Queue<Node> Q = new LinkedList<Node>(); Q.add(root); while(!Q.isEmpty()) { Node n = Q.poll(); System.out.print(n.data + " "); if(n.left != null) Q.add(n.left); if(n.right != null) Q.add(n.right); } }
- JS
jscupc + 0 comments
Hi @hammeramr,
- TR
reasonet + 1 comment
Python solution:
import sys def levelOrder(root): if root is None: return q = [root] while(len(q) > 0): sys.stdout.write(str(q[0].data) + ' ') n = q.pop(0) if not n.left is None: q.append(n.left) if not n.right is None: q.append(n.right)
sayanarijit + 2 comments
Great... Little modified version:
def levelOrder(root): if root is None: return q = [root] while(len(q) > 0): n = q.pop(0) print n.data, if n.left: q.append(n.left) if n.right: q.append(n.right)
AffineStructure + 0 comments
def levelOrder(root): deck = deque() if not root: return None else: deck.append(root) while deck: x = deck.popleft() print x.data, if x.left: deck.append(x.left) if x.right: deck.append(x.right)
- FK
farhadkeramatim + 0 comments
Little more modification (shortest version I could do):
def levelOrder(root): q = [root] while q: n = q.pop(0) print n.data, if n.left: q.append(n.left) if n.right: q.append(n.right)
priyeshu + 14 comments
Here's simplest C++ solution I could write
#include<queue> void LevelOrder(node * root) { queue<node*> q; node *temp = root; while(temp!=NULL) { cout<<temp->data<<" "; if(temp->left!=NULL) q.push(temp->left); if(temp->right!=NULL) q.push(temp->right); temp = q.front(); q.pop(); }
- AK
anvitakamat + 1 comment
# include<queue> void LevelOrder(node * root) { queue<node *> q; node *temp=root; if(root != NULL) { q.push(root); } while(!q.empty()) { cout<<temp->data<<" "; if(temp->left != NULL) { q.push(temp->left); } if(temp->right != NULL) { q.push(temp->right); } q.pop(); temp= q.front(); } }
- E
pavitra_ag + 1 comment
- HR
hardikrana437 + 0 comments
check for 1 element in tree.
Scent_Leader + 1 comment
Wow I really need to work more Object-like... My solution works but is not be optimal... I like yours.
void LevelOrder(node * root){ static int depth = 1; static int level = 1; static bool next = false; if(level == depth){ cout << root->data << " "; } if((root->left || root->right || next) && level == depth) next = true; else next = false; ++depth; if(root->left && depth <= level) LevelOrder(root->left); if(root->right && depth <= level) LevelOrder(root->right); --depth; if(next && depth == 1){ ++level; next = false; LevelOrder(root); } }
- AK
rk3102882_ak + 1 comment
can anyone explain last two code of the program i didn't get it.
Scent_Leader + 0 comments
I think I can explain. First the push() function insert always at the end of an array. Second the pop() function delete the first element in an array.
For the program of anvitakamat:
// Basically he creates an array queue<node *> q; // q = [] // ...then a pointer to the root tree node *temp = root; //insert the root value into the array q.push(root); // q = [root] // We arrive to the while loop and q is not empty while(!q.empty()){ // ... now we are in ... }
Now is the tricky part...
cout<<temp->data<<" "; // it print the root's data value since temp points to root if(temp->left != NULL) // if left branch available q.push(temp->left); // ... it stacks left branch // q = [root, root->left] if(temp->right != NULL) // if right branch available q.push(temp->right); // ... it stacks right branch // q = [root, root->left, root->right] q.pop(); // q = [root->left, root->right] temp= q.front(); // temp points now to root->left // and it starts over again // and it will stacks all left and right sides but print one data at a time
Hope it's been helpful. If you have more questions go on.
- KS
kashish25798 + 1 comment
Here's my code for level order but its showing some error i couldnt find plz help
int rear=0,front=-1;
struct queue { node* value; }s[50];
int isFull() { if(rear==50) return 1; else return 0; }
int isEmpty() { if(front==-1) return 1; else return 0; }
void push(node * root) { if(!isFull()) {queue[rear].value=root; rear++;} }
node* pop() { node* temp; if(!isEmpty()) { temp=queue[front].value; front++;} return temp; }
void LevelOrder(node * root) { node* temp=root; while(temp) { printf("%d",temp->data); if(temp->left) push(temp->left); if(temp->right) push(temp->right); temp=pop(); }
Scent_Leader + 0 comments
First your answer is in C not C++ which is different. By looking at your code I guess you're a beginner so I suggest you to read this : C Programming (second edition) by Brian and Dennis
And for pointers exclusively : Better understand of advanced pointers (C)
As for the solution I mimick the C++ solution of this comment section.
Side Note: This is my solution in C and this is not the complete code to run it but only the interesting part. (I highly recommend to be able to deal with pointers)
#include<stdio.h> // Library for basic functions #include<stdlib.h> // String functions and memory allocations function // The presuming structure used in this exercise typedef struct node { char *data; struct node *left; struct node *right; } node; // Example of memory allocation function node *getNodeSpace(void){ node *s = NULL; if((s = (node *) malloc(sizeof(node))) == NULL) exit(1); return s; } // The function in C void LevelOrder(node *root){ int i = 0; // allow to go through the storing array int x = 0; // count the number of node node *temp; // node holder node **base; // pointer to storing array node **s; // storing array if(root != NULL){ *s = root; base = s; ++x; } while((temp = *(base+i)) != NULL && x){ printf("%s\n", temp->data); if(temp->left) if(*++s = getNodeSpace()){ (*s)->data = temp->left->data; (*s)->left = temp->left->left; (*s)->right = temp->left->right; ++x; } if(temp->right) if(*++s = getNodeSpace()){ (*s)->data = temp->right->data; (*s)->left = temp->right->left; (*s)->right = temp->right->right; ++x; } ++i; --x; } }
See ya!
- CQ
himanhsu54 + 1 comment
gives "abort called " on two test cases. but when i run a similar solution (pasted below ) from @anvitakamat it runs sucessfully.
# include<queue> void LevelOrder(node * root) { queue<node *> q; node *temp=root; if(root != NULL) { q.push(root); } while(!q.empty()) { cout<<temp->data<<" "; if(temp->left != NULL) { q.push(temp->left); } if(temp->right != NULL) { q.push(temp->right); } q.pop(); temp= q.front(); } }
can you figure out what is going wrong.?
- AB
akshaybapat04 + 0 comments
I wrote a similar code.. Both of our solutions fail testcases 3 and 5..
- E
pavitra_ag + 0 comments
your solution gives abort called error
sm_khan2010 + 3 comments
Without using any other data structure
public void LevelOrder(Node root){ int i = 0; int h = height(root); for(i=1; i<=h; i++){ printTreeLevelRec(root, i); } } int height(Node n){ if(n==null) return 0; if(n.left==null && n.right==null) return 1; int lheight = height(n.left); int rheight = height(n.right); return Math.max(lheight, rheight) + 1; } void printTreeLevelRec(Node node, int desired){ if(node==null) return; if (desired == 1) System.out.print(node.data+ " "); printTreeLevelRec(node.left, desired-1); printTreeLevelRec(node.right, desired-1); }
- AP
19soumikrakshi96 + 0 comments
This is exactly how the problem is given in GeeksForGeeks. But how do I count the number of nodes in each level using this algo???
jonmcclung + 3 comments
This was a fun problem where I got to make use of the linked lists we learned in the last chapter (:
#include <list> void LevelOrder(node * root) { list<node*> nodes; if (root) { nodes.push_back(root); } for (list<node*>::iterator it = nodes.begin(); it != nodes.end(); it++) { printf("%d ", (*it)->data); if ((*it)->left) { nodes.push_back((*it)->left); } if ((*it)->right) { nodes.push_back((*it)->right); } } }
- RG
IntidSammers + 0 comments[deleted] tomlankhorst + 1 comment
I tried just the same but with vectors instead of lists. Why would I get a segmentation fault like i do?
void LevelOrder(node * root) { std::vector<node*> N; if( root ) { N.push_back( root ); for( std::vector<node*>::iterator i = N.begin(); i != N.end(); i++ ) { std::cout << (*i)->data << " "; if( (*i)->left ) N.push_back( (*i)->left ); if( (*i)->right ) N.push_back( (*i)->right ); } } }
dgodfrey + 1 comment
Because unlike linked list (std::list), vector iterators become invalidated when you insert. So i++ is causing a segmentation fault. You need to do this:
for (...; /* delete i++ */) { if ((*i)->left || (*i)->right) { if ((*i)->left) N.push_back(...) if ((*i)->right) N.push_back(...) } else { i++; } }
tomlankhorst + 2 comments
Is that because of the relocation of data when the original allocated size does not suffice?
- IR
isanrivkin + 0 comments
Thanks for that man !
HuangZhenyang + 1 comment
I don't quit understand why should use
nodes.push_back(root);
dgodfrey + 1 comment
The first node we need to visit is the root, then it will be its children (inside the loop).
HuangZhenyang + 1 comment
Er,sorry,I just cann't know why use list....... And about the loop,does the loop will get the same level node?
dgodfrey + 0 comments
Using
listis optional. The fact is that we need a First-In First-Out (FIFO) data structure. This is what a
queueis normally used for. tomlankhorst figured out a way to emulate FIFO with a linked list.
The loop will first start with the
rootnode that was added before it started. It will print the root node and then add the left node and the right node and do the same thing starting with the left node. Then the left node's children will be added.
- PV
pverardi + 0 comments
Java Solution. Simple Breadth First Solution. The key is to remember to use a Queue and the rest will fall in line.
void LevelOrder(Node root) { if (root == null) return;
Queue<Node> q = new LinkedList<>(); q.add(root); while (!q.isEmpty()){ Node temp = q.poll(); System.out.print(temp.data + " "); if (temp.left != null) q.offer(temp.left); if (temp.right != null) q.offer(temp.right); } }
- GD
return_void + 1 comment
Simple with a queue
#include <queue> void LevelOrder(node * root) { queue<node*> nodes; if (root) nodes.push(root); for (; !nodes.empty(); nodes.pop()) { cout<<nodes.front()->data<<' '; if (nodes.front()->left) nodes.push(nodes.front()->left); if (nodes.front()->right) nodes.push(nodes.front()->right); } }
runcy + 2 comments
When can we see support for python? It's already part of the 30-Days-Code tutorial (in day 23) with python support
- AK
CodeMunkey + 0 comments
If you're familiar with Breadth-First Search, the solution is quite simple. I'm not sure why the editorial states that this is recursive, when it is in fact iterative.
- PJ
ThecoolKid + 2 comments
void LevelOrder(Node root) { java.util.LinkedList<Node> q = new java.util.LinkedList<Node>(); if(root!=null) q.add(root); while(q.peekFirst() != null ){ Node current = q.poll(); System.out.print(current.data + " "); if(current.left!=null) q.add(current.left); if(current.right!=null) q.add(current.right); }
etayluz + 3 comments
C solution:
void LevelOrder(node * root) { node * nodeList[10000]; int n = 1; int i = 0; nodeList[0] = root; while (i < n) { node *thisNode = nodeList[i]; if (thisNode->left) { nodeList[n++] = thisNode->left; } if (thisNode->right) { nodeList[n++] = thisNode->right; } i++; } for (int i = 0; i < n; i++) { node *thisNode = nodeList[i]; printf("%d ", thisNode->data); } }
- P
prendergast + 0 comments
Better use a dynamic data structure like a "linked list" or "queue" to avoid the hardcoded size of an array.
positivedeist_07 + 0 comments
Hey!! I just walked through ur solution and man, was that brilliant! :) so very thoughtful of you. I have a couple of doubts, though.
Isn't "*thisnode" will be created everytime the loop runs? Wouldn't that have a slightly more effect on space complexity? Also, The while loop runs even though there are no nodes left in the tree (i.e., when both the if conditions return false). It runs few times just to prove the while condition false (so that i becomes equal to n). Is that really necessary? Can't we stop as soon as both the if conditions fails with another "else if" of "if" statement?
I'd be really grateful if u helped me out. Thankyou.
Sort 232 Discussions, By:
Please Login in order to post a comment | https://www.hackerrank.com/challenges/tree-level-order-traversal/forum | CC-MAIN-2018-26 | refinedweb | 2,610 | 67.15 |
Java Reference
In-Depth Information
Java Compared to C
• Java is object oriented; C is procedural.
• Java is portable as class files; C needs to be recompiled.
• Java provides extensive instrumentation as part of the runtime.
• Java has no pointers and no equivalent of pointer arithmetic.
• Java provides automatic memory management via garbage collection.
• Java has no ability to lay out memory at a low level (no structs).
• Java has no preprocessor.
Java Compared to C++
• Java has a simplified object model compared to C++.
• Java's dispatch is virtual by default.
• Java is always pass-by-value (but one of the possibilities for Java's values are
object references).
• Java does not support full multiple inheritance.
• Java's generics are less powerful (but also less dangerous) than C++ templates.
• Java has no operator overloading.
Java Compared to PHP
• Java is statically typed; PHP is dynamically typed.
• Java has a JIT; PHP does not (but might in version 6).
• Java is a general-purpose language; PHP is rarely found outside of websites.
• Java is multithreaded; PHP is not.
Java Compared to JavaScript
• Java is statically typed; JavaScript is dynamically typed.
• Java uses class-based objects; JavaScript is prototype based.
• Java provides good object encapsulation; Javascript does not.
• Java has namespaces; JavaScript does not.
• Java is multithreaded; JavaScript is not.
Search WWH ::
Custom Search | http://what-when-how.com/Tutorial/topic-5244o10/Java-in-a-Nutshell-30.html | CC-MAIN-2019-04 | refinedweb | 223 | 53.58 |
Tkinter Windows
In this tutorial, we will learn about Tkinter Windows in Python which is the main Window of the GUI application inside which every other component runs. We have covered the basic Tkinter GUI application Components in which we have explained how Tkinter Windows, Widgets, and Frames are building blocks of a Tkinter App.
Tkinter Windows
The Tkinter window is the foundational element of the Tkinter GUI. Tkinter window is a container in which all other GUI elements(widgets) live.
Here is the syntax for creating a basic Tkinter Window:
win = Tk()
Yes, we use the Tk() function to create our Tkinter app window in which all the other components are added.
Tkinter Windows Example:
Here is a simple example,
from tkinter import * win = Tk() # run the app window win.mainloop()
In the above example, the
mainloop() function is used to run the GUI application.
Tkinter Customized Window
Let us now cover a basic example where we will create a Basic GUI Application using properties like title and geometry.
Here we have the code to demonstrate the steps used in the creation of a customized Tkinter Window:
from tkinter import * window = Tk() # You can add your widgets here window.title('Hello StudyTonight') window.geometry("300x200+10+20") window.mainloop()
Here is what we have done in the code:
The first step is to import the Tkinter module in the code.
After importing, the second step is to set up the application object by calling the
Tk()function. This will create a top-level window (root) having a frame with a title bar and control box with the minimize and close buttons, and a client area to hold other widgets.
After that, you can add the widgets you might want to add in your code like buttons, textbox, scrollbar, labels, and many more.
The
window.title()function is used to provide the title to the user interface as you can see in the output.
In the line
window.geometry("300x200+10+20); the
geometry()method defines the width, height, and coordinates of the top left corner of the frame as follows (all values are generally in pixels) in the same way. Here is the syntax:
window.geometry("widthxheight+XPOS+YPOS")
After that, the application object enters an event listening loop by calling the
mainloop()method. In this way, the application is now constantly waiting for any event generated on the elements in it. There could be an event like text entered in a text field, a selection made from the dropdown or radio button, single/double click actions of the mouse, etc.
The application's functionality involves executing appropriate callback functions in response to a particular type of event.
The event loop will terminate as soon as there is a click made on the close button on the title bar.
Summary:
In this tutorial, we learned how to create a Tkinter window to create a GUI application. The Tkinter window contains all the widgets that make the application. | https://www.studytonight.com/tkinter/tkinter-windows | CC-MAIN-2021-04 | refinedweb | 498 | 52.29 |
Now that Gitlab reduced the CI/CD minutes for free plans to 400. It's possible you might run out of CI/CD time. You can upgrade to higher plans, or you have the option to host your own runner.
We use our own runners since we migrated to Gitlab from Github. There are various benefits for running the Gitlab runner in your own environment. A few of the important features are:
- You are no more concerned about accidentally exposing credentials since you are not using shared infrastructures.
- You can leverage instance role-based credentials to authenticate to your cloud provider.
- No more limits on the CI/CD minutes you can use.
- In terms of operational overhead, since we use Kubernetes, it was just a click of a button for us to deploy the runner.
We were using Docker in Docker workflow described here to build our docker images. On every build, GitLab starts a pod with 3 containers, one of them being a Docker dind container running the docker daemon. The build container would connect to the Docker daemon running on the same pod. Since all containers in a pod share the same network. Docker client building the image was able to connect to the daemon API over the localhost.
The problem we were facing that there was no caching of docker layers. This was because a fresh pod with a fresh docker daemon service was spun up on every build. This increased our build time significantly.
The solution to this problem is very simple. There were many options. We chose the simplest one. Instead of running Docker dind as a service for every pod, let's just run one Docker dind container. All Docker clients building the containers would connect to that same Docker daemon thus docker layer caching will also work. There is an option to bind the runner pod to the docker socket, running on the host itself, but we shouldn't do that for obvious reasons.
Create the PVC to store the persistent data of Docker.
# PVC for storing dind data apiVersion: v1 kind: PersistentVolumeClaim metadata: labels: app: docker-dind name: docker-dind-data namespace: gitlab-managed-apps spec: accessModes: - ReadWriteOnce resources: requests: storage: 100Gi
We are using a managed GKE cluster, so our Persistent volume is automatically created by controllers.
Here's the deployment spec for the Docker Dind pod which is going to provide docker services to Gitlab docker runner.
## Deployment for docker-dind apiVersion: apps/v1 kind: Deployment metadata: labels: app: docker-dind name: docker-dind namespace: gitlab-managed-apps spec: replicas: 1 selector: matchLabels: app: docker-dind template: metadata: labels: app: docker-dind spec: containers: - image: docker:19.03-dind name: docker-dind env: - name: DOCKER_HOST value: tcp://0.0.0.0:2375 - name: DOCKER_TLS_CERTDIR #Disable TLS as traffic is not going outside of network. value: "" volumeMounts: - name: docker-dind-data-vol #Persisting the docker data mountPath: /var/lib/docker/ ports: - name: daemon-port containerPort: 2375 protocol: TCP securityContext: privileged: true #Required for dind container to work. volumes: - name: docker-dind-data-vol persistentVolumeClaim: claimName: docker-dind-data
Now, expose the service, so Gitlab runners can connect with it.
## Service for exposing docker-dind apiVersion: v1 kind: Service metadata: labels: app: docker-dind name: docker-dind namespace: gitlab-managed-apps spec: ports: - port: 2375 protocol: TCP targetPort: 2375 selector: app: docker-dind
Once this is done, you can use the docker daemon in a Gitlab CI job spec file like this.
stages: - image create_image: stage: image image: docker:git variables: DOCKER_HOST: tcp://docker-dind:2375 #IMPORTANT, this tells docker client to connect to docker-dind service we created script: - docker info - docker build -t yourorg/app:${CI_COMMIT_TAG} . - docker push yourorg/app:${CI_COMMIT_TAG} only: - tags
Our build time is now significantly reduced, thanks to docker layer caching.
One last thing, here's a Cronjob that clears the cache every week. So we can start fresh.
# Cronjob to clear docker cache every monday so we start fresh apiVersion: batch/v1beta1 kind: CronJob metadata: labels: app: docker-dind namespace: gitlab-managed-apps name: docker-dind-clear-cache spec: jobTemplate: metadata: labels: app: docker-dind name: docker-dind-clear-cache spec: template: spec: containers: - command: - docker - system - prune - -af image: docker:git name: docker-dind-clear-cache env: - name: DOCKER_HOST value: tcp://docker-dind:2375 restartPolicy: OnFailure schedule: 0 0 * * 0
That's it.
Discussion (4)
Doesn't this limit to at most one build at a time?
What are the potential downsides of this approach?
Worked pretty well for me. Take it for a spin and if you find some, you can post here.
Thanks for your short tutorial - saved me a lot of time! 👍🏼 | https://practicaldev-herokuapp-com.global.ssl.fastly.net/liptanbiswas/gitlab-docker-layer-caching-for-kubernetes-executor-39ch | CC-MAIN-2021-21 | refinedweb | 781 | 54.42 |
Tracing in Microservices With Spring Cloud Sleuth
Tracing in Microservices With Spring Cloud Sleuth
Follow along to gain some insight into tracing requests that span multiple microservices in the Spring Cloud ecosystem.
Join the DZone community and get the full member experience.Join For Free
Verify, standardize, and correct the Big 4 + more– name, email, phone and global addresses – try our Data Quality APIs now at Melissa Developer Portal!
One of the problems developers encounter as their microservice apps grow is tracing requests that propagate from one microservice to the next. It can quite daunting to try and figure out how a requests travels through the app, especially when you may not have any insight into the implementation of the microservice you are calling.
Spring Cloud Sleuth is meant to help with this exact problem. It introduces unique IDs to your logging which are consistent between microservice calls which makes it possible to find how a single request travels from one microservice to the next.
Spring Cloud Sleuth adds two types of IDs to your logging, one called a trace ID and the other called a span ID. The span ID represents a basic unit of work, for example sending an HTTP request. The trace ID contains a set of span IDs, forming a tree-like structure. The trace ID will remain the same as one microservice calls the next. Let's take a look at a simple example which uses Spring Cloud Sleuth to trace a request.
Start out by going to start.spring.io and create a new Spring Boot app that has a dependency on Sleuth (
spring-cloud-starter-slueth). Generate the project to download the code. It is good practice to give your application a name and also necessary to have meaningful tracing from Sleuth. Create a file called
bootstrap.yml in
src/main/resources. Within that file add the property
spring.application.name and set it to whatever you would like to call your application. The name you give your application will show up as part of the tracing produced by Sleuth.
Now let's add some logging to your application so you can see what the tracing will look like. Open the application file for your application (where the
main method is) and create a method called
home which returns a
String.
public String home() { return "Hello World"; }
Let's have this method called when you hit the root of your web app. Add the
@RestController annotation at the class level, and then add
@RequestMapping("/") to your
home method.
@SpringBootApplication @RestController public class SleuthSampleApplication { public static void main(String[] args) { SpringApplication.run(SleuthSampleApplication.class, args); } @RequestMapping("/") public String home() { LOG.log(Level.INFO, "you called home"); return "Hello World"; } }
If you start the app at this point and hit you should see
Hello World returned. Up until this point, all we have is a basic Spring Boot app. Let's add some logging to our app to see the tracing information from Sleuth.
Add the following variable to your application class.
private static final Logger LOG = Logger.getLogger(SleuthSampleApplication.class.getName());
Make sure you change the application class name to whatever your application class name is. In your
home method add the following log statement.
@RequestMapping("/") public String home() { LOG.log(Level.INFO, "you called home"); return "Hello World"; }
Now if you run the application and hit you should see your logging statement printed in the console.
2016-06-15 16:55:56.334 INFO [slueth-sample,44462edc42f2ae73,44462edc42f2ae73,false] 13978 --- [nio-8080-exec-1] com.example.SleuthSampleApplication : calling home
The portion of the log statement that Sleuth adds is
[slueth-sample,44462edc42f2ae73,44462edc42f2ae73,false]. What do all these values mean? The first part is the application name (whatever you set
spring.application.name to in
bootstrap.yml). The second value is the trace id. The third value is the span id. Finally the last value indicates whether the span should be exported to Zipkin (more on Zipkin later).
Besides adding additional tracing information to logging statements, Spring Cloud Sleuth also provides some important benefits when calling other microservices. Remember the real problem here is not identifying logs within a single microservice but instead tracing a chain of requests across multiple microservices. Microservices typically interact with each other synchronously using REST APIs and asynchronously via message hubs. Sleuth can provide tracing information in either scenario but in this example, we will take a look at how REST API calls work. (Sleuth also supports other microservice communication scenarios, see the documentation for more info.)
A simple example to see how this works is to have our application call itself using a
RestTemplate. Let's modify the code in our application class to do just that.
private static final Logger LOG = Logger.getLogger(SleuthSampleApplication.class.getName()); @Autowired private RestTemplate restTemplate; public static void main(String[] args) { SpringApplication.run(SleuthSampleApplication.class, args); } @Bean public RestTemplate getRestTemplate() { return new RestTemplate(); } @RequestMapping("/") public String home() { LOG.log(Level.INFO, "you called home"); return "Hello World"; } @RequestMapping("/callhome") public String callHome() { LOG.log(Level.INFO, "calling home"); return restTemplate.getForObject("", String.class); }
Looking at the code above the first thing you might ask is “Why do we have a
RestTemplate bean?” This is necessary because Spring Cloud Sleuth adds the trace id and span id via headers in the request. The headers can then be used by other Spring Cloud Sleuth enabled microservices to trace the request. In order to do this, the starter needs the
RestTemplate object you will be using. By having a bean for our
RestTemplate it allows Spring Cloud Sleuth to use dependency injection to obtain that object and add the headers.
We have also added a new method and endpoint called
callhome, which just makes a request to the root of the app.
If you run the app now and hit, you will see two logging statements appear in the console that look like:
2016-06-17 16:12:36.902 INFO [slueth-sample,432943172b958030,432943172b958030,false] 12157 --- [nio-8080-exec-2] com.example.SleuthSampleApplication : calling home 2016-06-17 16:12:36.940 INFO [slueth-sample,432943172b958030,b4d88156bc6a49ec,false] 12157 --- [nio-8080-exec-3] com.example.SleuthSampleApplication : you called home
Notice in the logging statements that.
If you open your browsers debug tools and look at the headers for the request to
/callhome you will see two headers returned in the response.
X-B3-SpanId: fbf39ca6e571f294 X-B3-TraceId: fbf39ca6e571f294
These headers are what allows Sleuth to trace requests between microservices.
While this is a very basic example you can easily imagine how this would work similarly if one Sleuth enabled app was calling another passing the trace and span ids in the headers.
If you are using Feign from Spring Cloud Netflix, tracing information will also be added to those requests. In addition Zuul from Spring Cloud Netflix will also forward along the trace and span headers through the proxy to other services.
Zipkin
All this additional information in your logs is great but making sense of it all can be quite cumbersome. Using something like the ELK stack to collect and analyze the logs from your microservices can be quite helpful. By using the trace id you can easily search across all the collected logs and see how the request passed from one microservice to the next.
However what if you want to see timing information? You could certainly calculate how long a request took from one microservice to the next but that is quite a pain to do yourself. The good news is that there is a project called Zipkin which can help us out. Spring Cloud Sleuth will send tracing information to any Zipkin server you point it to when you include the dependency
spring-cloud-sleuth-zipkin in your project. By default Sleuth assumes your Zipkin server is running at. The location can be configured by setting
spring.zipkin.baseUrl in your application properties.
We can use Zipkin to collect the tracing information from our simple example above. Go to start.spring.io and create a new Boot project that has the
Zipkin UI and
Zipkin Server dependencies. In the application properties file for this new project. set
server.port to
9411. If you start this application and head to you will see the Zipkin UI. Of course there aren’t any applications sending information to the Zipkin server so there is nothing to show.
Let's enable our sample Sleuth app from above to send tracing information to our Zipkin server. Open the POM file and add
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin</artifactId> </dependency>
In addition, we need to tell our application how often we want to sample our logs to be exported to Zipkin. Since this is a demo, lets tell our app that we want to sample everything. We can do this by creating a bean for the
AlwaysSampler. Add the following code to your application class.
@Bean public AlwaysSampler defaultSampler() { return new AlwaysSampler(); }
Once you add the sampler bean, restart the application. If you now hit in your browser you should notice that the export flag in the sleuth logging has changed from
false to
true.
2016-06-20 09:03:44.939 INFO [slueth-sample,380c24fd1e5f89df,380c24fd1e5f89df,true] 19263 --- [nio-8080-exec-1] com.example.SleuthSampleApplication : calling home 2016-06-20 09:03:44.966 INFO [slueth-sample,380c24fd1e5f89df,fc50a65582b7b845,true] 19263 --- [nio-8080-exec-2] com.example.SleuthSampleApplication : you called home
This indicates that the tracing information is being sent to your Zipkin server. If you open another browser tab and go to you should see the Zipkin UI. From here you can query Zipkin to find the tracing information you are looking for. Make sure you set the date range correctly and click
Find Taces. You should see tracing information for the
/callhome endpoint returned. Clicking on it will show you all the details collected from the Sleuth logs including timing information for the request.
If you want to learn more about Spring Cloud Sleuth, I suggest you read through the documentation. There is lots of good information in the docs and it contains a ton of additional information for more complicated use Ryan Baxter , DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}{{ parent.urlSource.name }} | https://dzone.com/articles/tracing-in-microservices-with-spring-cloud-sleuth | CC-MAIN-2018-30 | refinedweb | 1,736 | 56.86 |
So we are done with Service, let us consume it in a client.
Consuming Service:
Create a Console Application and right click on References and click Add Service Reference,
This opens a new window, click on Discover to find the Service as shown below and provide Namespace:
Click OK, now we are ready to consume the service. Copy the following code, myTest is the namespace and TestSoapClient is proxy to the service which helps us for communication with service.
Output
Let us see the app.config of console application. WebService uses only basicHttpBinding, that’s the reason Bindings have been mentioned as basicHttpBinding.
View All | https://www.c-sharpcorner.com/UploadFile/sreeelectrons/web-services-interview-questions/ | CC-MAIN-2018-13 | refinedweb | 105 | 62.48 |
This tutorial brings you a docker command cheat list in a printable A4 size and also in a pdf format for your quick reference. Please keep us posted if you need us to add more commands. Commands are categorized in 7 sections as listed below.
Contents of Docker Cheat sheet
PART 1
- 1. Containers
- 1.1. Lifecycle
- 1.2. Starting and Stopping
- 1.3. CPU Constraints
- 1.4. Memory Constraints
- 1.5. Capabilities
- 1.6. Info
- 1.7. Import / Export
- 1.8. Executing Commands
- 2. Images
- 2.1. Lifecycle
- 2.2. Info
- 2.3. Cleaning up
- 2.4. Load/Save image
- 2.5. Import/Export container
PART 2
- 3. Networks
- 3.1. Lifecycle
- 3.2. Info
- 3.3. Connection
- 4. Registry & Repository
- 5. Volumes
- 5.1. Lifecycle
- 5.2. Info
- 6. Exposing ports
- 7. Tips
- 7.1. Get IP address
- 7.2. Get port mapping
- 7.3. Find containers by regular expression
- 7.4. Get Environment Settings
- 7.5. Kill running containers
- 7.6. Delete old containers
- 7.7. Delete stopped containers
- 7.8. Delete dangling images
- 7.9. Delete all images
- 7.10. Delete dangling volumes
You can download docker commands cheat sheet pdf , Part 1 and Part 2 image A4 format.
Conclusion
The idea of using container was made possible by the namespaces feature added to Linux kernel version 2.6.24. Namespaces allows to create an isolated container that has no visibility or access to objects outside the container. LXC, LXD, systemd-nspawn, Linux-VServer, OpenVZ and Docker are some of the management tools for Linux containers.
The main difference between native virtual machine and container is that in VM isolation is achieved by each VM have their own copies of Operating System files, libraries and application code. Whereas containers simply share the host operating system, including the kernel and libraries. | https://linoxide.com/linux-how-to/docker-commands-cheat-sheet/ | CC-MAIN-2020-10 | refinedweb | 304 | 62.04 |
Friday Fun: Envirophat Colour Detector
I'm back at Picademy...yay!!!
You may have seen that this week I was back at Picademy! Yay! Two days of learning, sharing and making.
One.
.
Envirophat?
I recently bought a few Envirophats (£16 from Pimoroni) for a week long Code Camp in Manchester. They did a brilliant job, but why? Well they are easy to use, thanks to a very simple Python library, and the Envirophat comes with plenty of sensors.
- BMP280 temperature/pressure sensor
- TCS3472 light and RGB colour sensor <-- We use this :D
- Two LEDs for illumination <-- And this!
- LSM303D accelerometer/magnetometer sensor
- ADS1015 4-channel 3.3v, analog to digital sensor (ADC)
Installing the software for Envirophat is a simple one line install script, run from the Terminal.
So in our project we will use the Envirophat along with a Raspberry Pi 3, but a Pi Zero W could be used instead.
Bill of Materials
- A Raspberry Pi 3 / Zero W
- Envirophat
All of the code for this project can be downloaded from my Github page.
Building the hardware
The hardest part of this project is to solder the GPIO header on to the Envirophat board. Then just put on top of the Raspberry Pi insert your accessories and power up.
Lets start coding
I used a standard Raspbian Stretch installation, and coded the project in IDLE3, but this can also be written in Thonny. You will need to create a new blank file called
envirophat-colour-checker.py
As always in Python, I start by importing the libraries of code that will be used in our project. First I import the
pygame library, used to create a simple GUI window showing the colour of the item. The second library is for the
envirophat. Lastly I imported two libraries in one line, the
time library to control the update rate of the GUI, and the
sys library used to exit the application. The code looks like this.
import pygame import envirophat import time, sys
Next up lets turn on the LEDs that are either side of the Envirophat's TCS3472 light and RGB colour sensor. Why? Well it will provide us with a better result when trying to detect the colour of the item. Then I need to initiate Pygame, in other words turn it on ready for use. I also started the Pygame Font method, as I would like to use text in the GUI.
Add this to the code :)
envirophat.leds.on() pygame.init() pygame.font.init()
Moving on and the standard Pygame GUI window has a boring name, so lets change that name and tell the user what the application is about. To do this add this code.
pygame.display.set_caption('Envirophat Colour Sensor Output')
Okay so now we get to the main body of the code! Using a
while True loop to constantly run the code contained within, the first step is to create a variable,
background which is used to store the sensor data gathered from the Envirophat's colour sensor. The sensor data is saved as individual RED, GREEN and BLUE values in an object called a
tuple Add this to the code.
while True: background = envirophat.light.rgb()
So what's a tuple?
A tuple is a sequence of data that is stored in a list like format. Tuples can be created and destroyed, but cannot be updated as they are immutable.
So now that we have the sensor data, our goal now is to display it, and to do that the Pygame library is used. Creating an object
screen which us used to store the width and height of the window. Then the
screen object is called with the
fill function and to that I passed the
background variable which contains the sensor data. Add this to the code.
screen = pygame.display.set_mode((400,400)) screen.fill((background))
Moving on and now I want to add text to the GUI, this text is rendered using the Pygame Font method. In this case I used the default font and set it to 45pt. Now to show the sensor data in the application I created a new object called
colour and this contained the sensor data, converted from a tuple to a
string using str(background). Also the text colour is set to
(0,0,0) the RGB value for black. Add this to the code.
myfont = pygame.font.Font(None, 45) colour = myfont.render(str(background),1,(0,0,0))
In order to see the changes to the GUI background colour and see the RGB values update, the
screen object needs to be updated, this is called
blitting and it means that the screen data is loaded into memory. Once that is complete the screen is then updated, before the code waits for 0.1 seconds before repeating the entire loop. Add this to the code.
screen.blit(colour, (0,0)) pygame.display.update() time.sleep(0.1)
Exiting the application
The final four lines of code are a way to exit the application using the X. For this I once again use Pygame but this time I focus on it's event handling framework. In order to detect an event I use a
for loop. This will look for any
event such as exiting the app, moving the mouse, clicking buttons, pressing keys etc. This event is then stored in a variable called
event and then using a
nested if test I check to see if the
event.type is
pygame.QUIT if that is correct then I close the Pygame window and then exit the application. Add this to the code.
for event in pygame.event.get(): if event.type == pygame.QUIT: pygame.quit() sys.exit()
Complete Code Listing
Here is all the code for this project.
import pygame import envirophat import time, sys envirophat.leds.on() pygame.init() pygame.font.init() pygame.display.set_caption('Envirophat Colour Sensor Output') while True: background = envirophat.light.rgb() screen = pygame.display.set_mode((400,400)) screen.fill((background)) myfont = pygame.font.Font(None, 45) colour = myfont.render(str(background),1,(0,0,0)) screen.blit(colour, (0,0)) pygame.display.update() time.sleep(0.1) for event in pygame.event.get(): if event.type == pygame.QUIT: pygame.quit() sys.exit()
Give it a test!
Run your code
In Thonny click on the play button
In IDLE click on Run >> Run Module or Press F5
You will see a window pop up, this is a live preview of the colour that the Envirophat colour sensor can see.
Now just show the items to the sensor, between the two LEDs. You may need to work out the best angle to reproduce the colour correctly. | http://bigl.es/friday-fun-envirophat-colour-detector/ | CC-MAIN-2018-26 | refinedweb | 1,117 | 74.08 |
table of contents
NAME¶pmnsmerge - merge multiple versions of a Performance Co-Pilot PMNS
SYNOPSIS¶$PCP_BINADM_DIR/pmnsmerge [-adfxv] infile [...] outfile
DESCRIPTION¶pmnsmerge merges multiple instances of a Performance Metrics Name Space (PMNS), as used by the components of the Performance Co-Pilot (PCP).
Each infile argument names a file that includes the root of a PMNS, of the form
root { /* arbitrary stuff */ }
The order in which the infile files are processed is determined by the presence or absence of embedded control lines of the form #define _DATESTAMP YYYYMMDD
Files without a control line are processed first and in the order they appear on the command line. The other files are then processed in order of ascending _DATESTAMP.
The -a option suppresses the argument re-ordering and processes all files in the order they appear on the command line.
The merging proceeds by matching names in PMNS, only those new names in each PMNS are considered, and these are added after any existing metrics with the longest possible matching prefix in their names. For example, merging these two input PMNS
root { root { surprise 1:1:3 mine 1:1:1 mine 1:1:1 foo foo yawn yours 1:1:2 } } foo { foo { fumble 1:2:1 mumble 1:2:3 stumble 1:2:2 stumble 1:2:2 } } yawn { sleepy 1:3:1 }
Produces the resulting PMNS in out.
root { mine 1:1:1 foo yours 1:1:2 surprise 1:1:3 yawn } foo { fumble 1:2:1 stumble 1:2:2 mumble 1:2:3 } yawn { sleepy 1:3:1 }
To avoid accidental over-writing of PMNS files, outfile is expected to not exist when pmnsmerge starts. The -f option allows an existing outfile to be unlinked (if possible) and truncated before writing starts.
Normally duplicate names for the same Performance Metric Identifier (PMID) in a PMNS are allowed. The -d option is the default option and is included for backwards compatibility. The -x option reverses the default and pmnsmerge will report an error and exit with a non-zero status if a duplicate name is found for a PMID in any of the input PMNS files or in the merged output PMNS.
The -v option produces one line of diagnostic output as each infile is processed.
Once all of the merging has been completed, pmnsmerge will attempt to load the resultant namespace using pmLoadASCIINameSpace(3) - if this fails for any reason, outfile will still be created, but pmnsmerge will report the problem and exit with non-zero status.
Using pmnsmerge with a single input argument allows that PMNS file to be checked. In addition to syntactic checking, specifying -x will also enable a check for duplicate names for all PMIDs. | https://manpages.debian.org/buster/pcp/pmnsmerge.1.en.html | CC-MAIN-2021-17 | refinedweb | 453 | 53.95 |
25 September 2009 06:59 [Source: ICIS news]
By Pearl Bantillo
SINGAPORE (ICIS news)--Asian petrochemical stocks tumbled on Friday, in line with regional bourses, on concerns that fiscal stimulus will be withdrawn too soon and derail the ongoing economic recovery.
“What has happened so far in the economies and the markets was the result of the governments’ massive stimulus packages from ?xml:namespace>
“Taking this away now is naturally a source of concern, especially if there are no clear signs that private sector is ready to spend,” he said.
In recent weeks, regional petrochemicals trade has substantially thinned down ahead of week-long National Day celebrations in
At 11.36am Singapore time (0336 GMT), Japanese petrochemical majors were down, with Mitsui Chemicals slipping 0.85%, Mitsubishi Chemical 2.95% lower and Asahi Kasei down 1.47% as the benchmark Nikkei 225 index fell 2.48% at 10,282.27.
In
Heavy pump-priming across the globe has achieved its desired effects – major economies like
In emerging Asia,
But when the effects of the stimulus packages wear off and there were no follow-through spending, investors were worried that economic activities would again lose steam, paving the way for a double-dip or a W-shaped recovery, analysts said.
“If you take the money out now, we may risk all these different (letters of) alphabets that are being thrown about,” said Song of CIMB-GK.
“As long as the stimulus packages support the economies and governments continue to keep a watchful eye, then the risk of a W-shaped recovery is minimized,” | http://www.icis.com/Articles/2009/09/25/9250213/asian-petchem-stocks-fall-on-stimulus-withdrawal-fears.html | CC-MAIN-2013-48 | refinedweb | 262 | 59.23 |
0
I am a beginner but my problem with this game is that when i enter east it said it going to north.
here my code for my main and parser also when i enter a word then it quit the game so how do i make it stay open to allow me to enter other words
Main.CPP
#include <iostream> #include <fstream> #ifndef Parse_h #define Parse_h #include "Parser.h" #endif using namespace std; int main() { Parser textparser; char word[20]; cout<<" Welcome To Text Adventure Game! "<<endl; cout <<"To move in the game, You will need to type in north, east, south, west"; cout <<"\nThere another command you can use in the game.\nWhich are : 'pick', 'open', 'read', 'drop', 'eat', 'close', 'look', 'search "; cout <<""<<endl; cout <<""<<endl; cout <<"\nYou Woke up and found yourself in Deep Dark Forest and you need to get out" << endl; cout <<"\nNow what you going to type in > " ; cin >> word; textparser.IsWordinCommands(word); textparser.IsWordinObjects(word); const char cmds[] = "north"; if ("north") { cout <<"\nYou Went North and found yourself in similar postion"; cout <<"\nWhat should you do now? > "; } else if ("east") { cout <<"\nYou went East and saw House"; cout <<"\nWhat should you do now? > "; } else if("south") { cout <<"\nYou cannot go backward beacuse there a wall blocking the path"; cout <<"\nWhat should you do now? > "; } else if("west") { cout <<"\nYou went to west but there are nothing in there."; cout <<"\nWhat should you do now? > "; } system("pause"); return 0; }
Parser.h
#ifndef parse_h #define parse_h #include <string> //Class definition for Parser Class class Parser { char* commands [50]; char* objects[50]; //how many commands can be used int numcommands; //how many objects can be used int numobjects; public: Parser() { numcommands = 12; numobjects = 12; //a word to do something char* cmds[] = {"north", "east", "south", "west", "pick", "open", "read", "drop", "eat", "close", "look", "search"}; //an object that can be used to intract with object. char* objs[] = {"fork", "knife", "sword", "enemy", "monster", "shield", "armour", "spoon", "table", "door", "room", "key"}; //initialise commands array with these valid command words for(int i=0 ; i<numcommands ; i++) { commands[i] = cmds[i]; } //initialise objects array with these valid object words for(int i=0 ; i<numobjects ; i++) { objects[i] = objs[i]; } } char* LowerCase (char* st); char* RemoveThe(char* sen); char* GetVerb(char* sen); char* GetObject(char* sen); void SortCommands(); void SortObjects(); void PrintCommands(); void PrintObjects(); bool IsWordinCommands(char* target); bool IsWordinObjects(char* target); }; #endif | https://www.daniweb.com/programming/software-development/threads/454398/text-adventure-game | CC-MAIN-2016-50 | refinedweb | 402 | 61.29 |
Last year, I attended the EuroPython 2006 conference. The conference was good, the organization perfect, the talks of very high level, the people extremely nice. Nonetheless, I noticed something of a disturbing trend in the Python community that prompted this article. Almost simultaneously, my co-author David Mertz was reflecting on a similar issue with some submitted patches to Gnosis Utilities. The trend at issue is the trend towards cleverness. Unfortunately, whereas cleverness in the Python community was once largely confined to Zope and Twisted, it now is appearing everywhere.
We have nothing against cleverness in experimental projects and learning exercises. Our gripe is with cleverness in production frameworks that we are forced to cope with as users. In this article, we hope to make a small contribution away from cleverness, at least in an area where we have some expertise, that being metaclass abuses.
For this article, we take a ruthless stance: we consider metaclass abuse any usage of a metaclass where you could have solved the same problem equally well without a custom metaclass. Of course, the guilt of the authors is obvious here: our earlier installments on metaclasses in Python helped popularize their usage. Nostra culpa.
One of the most common metaprogramming scenarios is the creation of classes with attributes and methods that are dynamically generated. Contrary to popular belief, this is a job where most of the time you do not need and you do not want a custom metaclass.
This article is intended for two sets of readers: average programmers who would benefit from knowing a few meta-programming tricks but are scared off by brain-melting concepts; and clever programmers who are too clever and should know better. The problem for the latter is that it is easy to be clever, whereas it takes a lot of time to become unclever. For instance, it took us a few months to understand how to use metaclasses, but a few years to understand how not to use them.
About class initialization
During class creation, attributes and methods of classes are set once and for all. Or rather, in Python, methods and attributes can be changed at nearly any point, but only if naughty programmers sacrifice transparency.
In various common situations, you may want to create classes in more dynamic ways than simply running static code for their creation. For instance, you may want to set some default class attributes according to parameters read from a configuration file; or you may want to set class properties according to the fields in a database table. The easiest way to dynamically customize class behavior uses an imperative style: first create the class, then add methods and attributes.
For example, an excellent programmer of our
acquaintance, Anand Pillai, has proposed a path to Gnosis Utilities' subpackage
gnosis.xml.objectify that does exactly this. A base
class called
gnosis.xml.objectify._XO_ that is
specialized (at runtime) to hold "xml node objects" is "decorated" with a number
of enhanced behaviors, like so:
Listing 1. Dynamic enhancement of a base class
You might think, reasonably enough, that the same enhancement can be accomplished simply by subclassing the XO base class. True, in one sense, but Anand has provided about two dozen possible enhancements, and particular users might want some of them, but not others. There are too many permutations to easily create subclasses for every enhancement scenario. Still, the above code is not exactly pretty. You could accomplish the above sort of job with a custom metaclass, attached to XO, but with behavior determined dynamically. But that brings us back to the excessive cleverness (and opacity) that we hope to avoid.
A clean, and non-ugly, solution to the above need might be to add class decorators to Python. If we had those, we might write code similar to this:
Listing 2. Adding class decorators to Python
That syntax, however, is a thing of the future, if it becomes available at all.
When metaclasses become complicated
It might seem like all the fuss in this paper so far is about nothing. Why not,
for example, just define the metaclass of XO as
Enhance, and be done with it.
Enhance.__init__() can happily add whatever
capabilities are needed for the particular use in question. This might look like
so:
Listing 3. Defining XO as Enhance
Unfortunately, things are not so simple once you start to worry about inheritance. Once you have defined a custom metaclass for your base class, all the derived classes will inherit the metaclass, so the initialization code will be run on all derived classes, magically and implicitly. This may be fine in specific circumstances (for instance, suppose you have to register in your framework all the classes you define: using a metaclass ensures that you cannot forget to register a derived class), however, in many cases you may not like this behavior because:
- You believe that explicit is better than implicit.
- The derived classes have the same dynamic class attributes of the base class. Setting them again for each derived class is a waste, since they would be available anyway by inheritance. This may be an especially significant issue if the initialization code is slow or computationally expensive. You might add a check in the metaclass code to see if the attributes were already set in a parent class, but this adds plumbing and it does not give real control on a per-class basis.
- A custom metaclass will make your classes somewhat magic and nonstandard: you may not want to increase your chances to incur in metaclass conflicts, issues with "__slots__", fights with (Zope) extension classes, and other guru-level intricacies. Metaclasses are more fragile than many people realize. We have rarely used them for production code, even after four years of usage in experimental code.
- You feel that a custom metaclasses is overkill for the simple job of class initialization, and you would rather use a simpler solution.
In other words, you should use a custom metaclass only when your real intention is to have code running on derived classes without users of those classes noticing it. If this is not your case, skip the metaclass and make your life (and that of your users) happier.
The classinitializer decorator
What we present in the rest of this paper might be accused of cleverness. But the cleverness need not burden users, just us authors. Readers can do something much akin to the hypothetical (non-ugly) class decorator we propose, but without encountering the inheritance and metaclass conflict issues the metaclass approach raises. The "deep magic" decorator we give in full later generally just enhances the straightforward (but slightly ugly) imperative approach, and is "morally equivalent" to this:
Listing 4. Imperative approach
The above imperative enhancer is not so bad. But it has a few drawbacks: it make you repeat the class name; readability is suboptimal since class definition and class initialization are separated -- for long class definitions you can miss the last line; and it feels wrong to first define something and then immediately mutate it.
The
classinitializer decorator provides a declarative
solution. The decorator converts
Enhance(cls,**kw) into
a method that can be used in a class definition:
Listing 5. The magic decorator in basic operation
If you have used Zope interfaces, you may have seen examples of class
initializers (
zope.interface.implements). In fact,
classinitializer is implemented by using a trick copied
from
zope.interface.advice, which credits Phillip J.
Eby. The trick uses the "__metaclass__" hook, but it does not use a custom
metaclass.
ClassToBeInitialized keeps its original
metaclass, i.e. the plain built-in metaclass
type of
new style classes:
In principle, the trick also works for old style classes, and it would be easy to write an implementation keeping old style classes old style. However, since according to Guido "old style classes are morally deprecated", the current implementation converts old style classes into new style classes:
Listing 6. Promotion to newstyle
One of the motivations for the
classinitializer
decorator is to hide the plumbing and to make mere mortals able to implement their
own class initializers in an easy way, without knowing the details of how class
creation works and the secrets of the _metaclass_ hook. The other motivation is
that even for Python wizards it is very inconvenient to rewrite the code managing
the _metaclass_ hook every time one writes a new class initializer.
As a final note, let us point out that the decorated version of
Enhance is smart enough to continue to work as a
non-decorated version outside a class scope, provided that you pass to it an
explicit class argument:
Here is the code for
classinitializer. You do not
need to understand it to use the decorator:
Listing 7. The classinitializer decorator
From the implementation it is clear how class initializers work: when you call a
class initializer inside a class, your are actually defining a _metaclass_ hook
that will be called by the class' metaclass (typically
type). The metaclass will create the class (as a new
style one) and will pass it to the class initializer procedure.
Tricky points and caveats
Since class initializers (re)define the _metaclass_ hook, they don't play well with classes that define a _metaclass_ hook explicitly (as opposed to implicitly inheriting one). If a _metaclass_ hook is defined after the class initializer, it silently overrides it.
Listing 8. table project index.html home
While unfortunate, there is no general solution to this issue; we simply document it. On the other hand, if you call a class initializer after the _metaclass_ hook, you will get an exception:
Listing 9. Local metaclass raises an error
Raising an error is preferable to silently overriding your explicit _metaclass_ hook. As a consequence, you will get an error if you try to use two class initializers at the same time, or if you call the same one twice:
Listing 10. Doubled enhancement creates a problem
On the plus side, all issues for inherited _metaclass_ hooks and for custom metaclasses are handled:
Listing 11. Happy to enhance inherited metaclass
The class initializer does not disturb the metaclass of
C, which is the one inherited by base
B, and the inherited metaclass does not disturb the
class initializer, which does its job just fine. You would have run into trouble,
instead, if you tried to call
Enhance directly in the
base class.
With all this machinery defined, customizing class initialization becomes rather straightforward, and elegant looking. It might be something as simple as:
Listing 12. Simplest form enhancement
This example still uses the "injection" which is somewhat superfluous to the
general case; i.e. we put the enhanced class back into a specific name in the
module namespace. It is necessary for the particular module, but will not be
needed most of the time. In any case, the argument to to
Enhance() need not be fixed in code as above, you can
equally use
Enhance(**feature_set) for something
completely dynamic.
The other point to keep in mind is that your
Enhance() function can do rather more than the simple
version suggested above. The decorator is more than happy to tweak more
sophisticated enhancement functions. For example, here is one that adds "records"
to a class:
Listing 13. Variations on class enhancement
The differing concerns of (a) what is enhanced; (b) how the magic works; and (c) what the basic class itself does are kept orthogonal:
Listing 14. Customizing a record class
Learn
- The first installment of "Metaclass programming in Python" (developerWorks, February 2003) introduces metaclass programming concepts as compared to object-oriented concepts.
- "Metaclass programming in Python, Part 2" (developerWorks, August 2003) goes into more detail on the subtleties of Python metaclasses.
- "Charming Python: Decorators make magic easy" (developerWorks, December 2006) takes a look at the newest Python facility for meta-programming.
- Read Michele's "A simple and useful doctester for your documentation".
-. . | http://www.ibm.com/developerworks/linux/library/l-pymeta3.html | crawl-002 | refinedweb | 1,986 | 50.77 |
# 286 and the network
*Author of the original post in Russian: [old\_gamer](https://habr.com/en/users/old_gamer/)*

I'm a ragman. I have a closet full of old hardware. From Boolean logic microchips in DIP-cases to Voodoo5. Of course, there's no practical value in all of this, but some people enjoy messing with old hardware. If you are one of them, I invite you under the cut, where I will tell you how the computer based on AMD 286 processor worked with a modern network, and what came out of it.
The idea to connect the network to the 286th was born a long time ago, because the easiest way to transfer the data to a computer is via the network, and indeed, it's interesting. Will TCP/IP work? Will the web browser work? Although the browsers for DOS have already been launched on the 286th, but I've never seen the 286th under Windows on the Internet. Well, and the main purpose is to connect to the domestic NAS on which all the software for my old hardware is stored. And NAS is more or less modern, and «knows» only TCP/IP.
I've already had experience in connecting the old computers to this drive. Including while writing the previous articles about the old hardware. But in the previous articles, I've only reviewed the 32-bit processors, and it's pretty easy: Windows 95 works even on 386SX-16 (yes, terribly slowly, yes, installation takes more than 9 hours, but it works), which has a native TCP/IP stack and a heap of drivers for various network cards in a set. If you want quicker, there is Windows **for Workgroups** 3.11, on which it's possible to roll a native TCP/IP stack after installation of Win32s. And, although it won't be able to log on to a modern file server, open folders without a password are quite currently available for the PC even in this configuration. And Internet Explorer 5 runs even on 386SX, having enough memory!
*This picture is from Google*
But alas, all this is not applicable to 286. The main difficulty is that the 286 processor is a 16-bit processor, and Windows for Workgroups 3.11 is not available for it, since the Standard mode that allowed its predecessor 3.1 to run on 16-bit processors was cut from 3.11. The Win32s extension is not available on 286 as well (for obvious reasons), and, accordingly, you won't be able to install the native Microsoft TCP/IP stack.
Thus, we return to DOS.
After a brief thoughtful googling, the picture with TCP/IP for DOS has become much less clear than it was before. Basically, it all came down to the fact that a normally running DOS application itself has its own stack, and all it needs is a package network card driver. But I couldn't find an application that allows to mount remote disks.
However, I came across as much as 2 different network clients for DOS from Microsoft (MS Client and MS LAN Manager), and another very strange beast called Windows for Workgroups 3.1. Yes, it is 3.1, not 3.11, and this meant that, perhaps, everything will work in the standard mode.
Which would be very interesting. Of course, I didn't expect to see the TCP/IP stack in 3.1, but I also came across a description of the 16-bit TCP/IP stack from Microsoft in Google. That's interesting.
Having bought the distribution 3.1 on eBay, I started the installation.

*The picture is from Google*
The system was a slightly modified 3.1 with a built-in network interface for DOS, very similar to the stripped-down MS LAN Manager. All the difference from the traditional 3.1 was reduced to existence of the only button «to connect a network drive» in the File Manager and the corresponding dialog box. Setting up the network from under Windows itself was impossible. How to perform the configuration from under the DOS wasn't clear. Although after installing the system, it identified my network card as NE1000 or compatible, which was not far from the truth, because I used the Genius GR1222 card and it reallly was compatible. But I had a native disk with drivers for this card, including the ones for DOS. It was still unclear, however, how to configure the driver for the interruption and the i/o address of the card.
Moreover, after reading the articles on Google it turned out that the driver for MS LAN Manager and the batch driver are two different things.
The situation with drivers for DOS began to clear up a little.
So, there were 3 big standards:
1. ODI. This driver model was used by Novell to communicate with its Netware servers. I don't have NetWare, so it won't work.
2. NDIS. This is the Microsoft model, for their LAN Manager and Windows. It's supposed to be the right thing.
3. Packet driver, which is used by many DOS-applications.
So, let's start with Microsoft products. I have had both MS Client and MS LAN Manager for a long time, since very old days. But, according to Google, TCP / IP stack MS Client didn't work with Windows for Workgroups, so I started my experiments with MS LAN Manager.
The network card was defined as NE1000, which didn't surprise me, and the program showed me the network Protocol selection screen.
In the version 2.2c the program supported TCP/IP!!! My joy knew no bounds. I just saw myself there in 5-7 minutes, writing article on Habr on the 286th. But the reality turned out to be more complicated. At first, I chose to configure the Protocol using DHCP, but after rebooting the machine got stuck at the stage of getting the address.
ОК. Let's configure manually.
Now when you restart the machine, it swears at the wrong characters in the file PROTOCOL.INI
It's weird. I won't torment the reader with all my inventions, I will only say that in the LAN Manager settings the IP address is written not through a dot, but through a space, like this:
`192 168 1 101`
When I understood it, the computer ceased to swear at wrong settings at loading, and began to load all the protocols, but after loading LAN Manager reported that it doesn't see any servers. It doesn't matter, but neither ping, nor NET USE didn't work. That's a trouble.
Having thought, I decided that problem must be in the settings of the network card.
After a brief search in the .INI files, I found the lines indicating the interrupt value and the i/o addresses of the network card. They were wrong. Corrected. Reload.
Same again.
Okay, maybe Windows for Workgroups will help.
The first thing that has changed in Windows is the network login window.
But in the end, Windows said the same thing that the DOS said: servers not found. Okay, I thought, this is all due to the fact that it knocks on the Windows NT domain and doesn't see it. By the way, it is weird that Windows for Workgroups wants into the domain, but okay.
But the File Manager window couldn't find the network drive either.
It's just not meant to be.
Okay, let's try to change the network adapter. I have a few different ones and I decided to try using D-Link DE-220P. After configuring the card in MS LAN Manager and rebooting, a miracle happened:
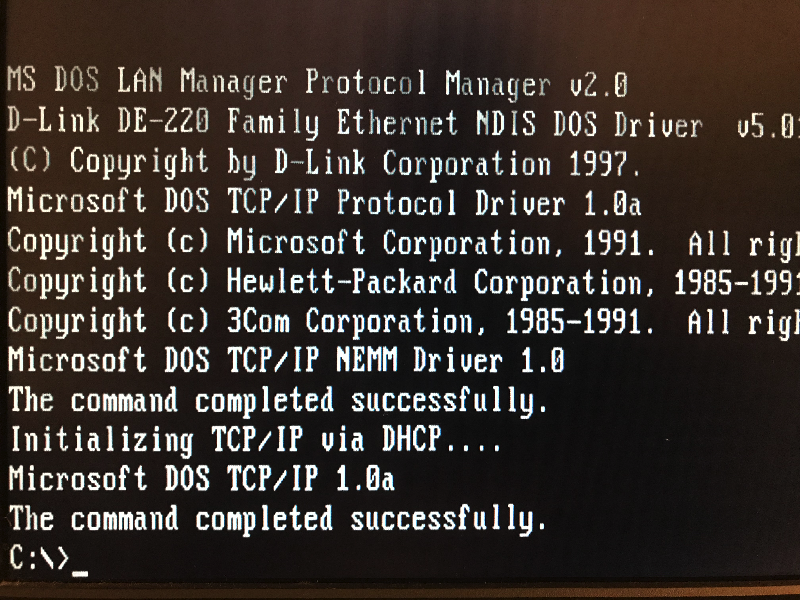
The computer received the address via DHCP. Great, moving on.
File Manager found the network drive:
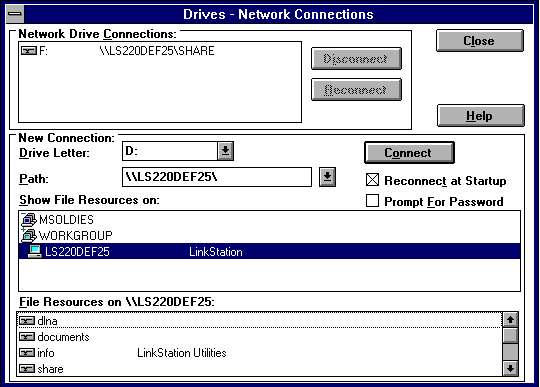
It's alright in DOS, too,
`NET USE Z: \\HOSTNAME\SHARENAME`
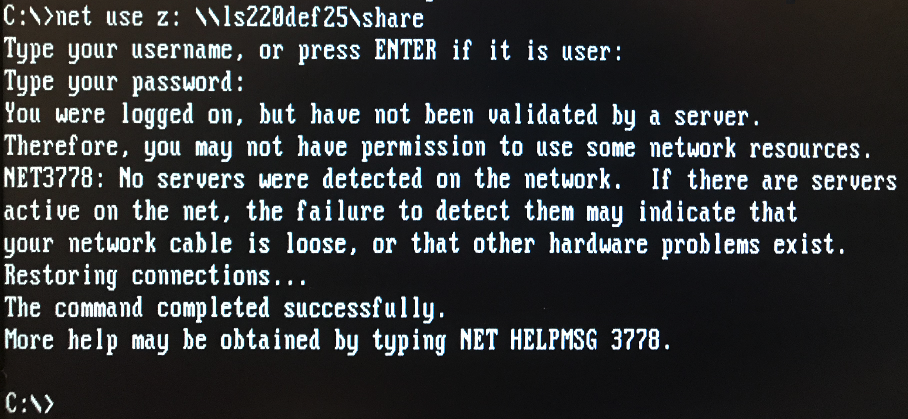
Great! What's inside?
`DIR Z:`
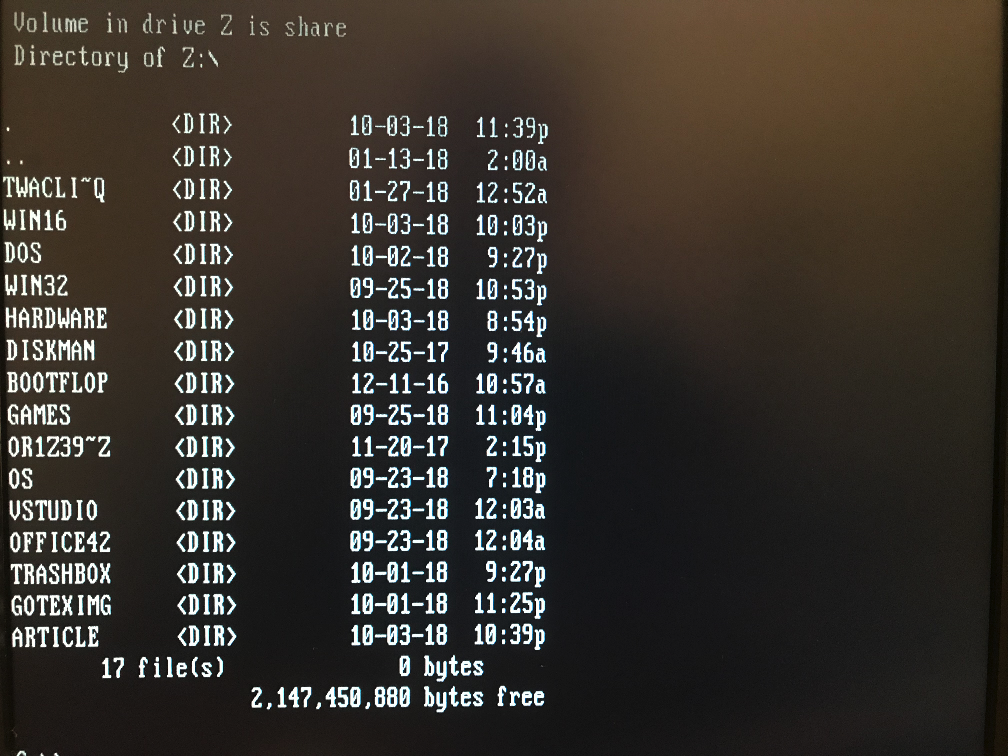
So, why I've been describing all the failures with the previous network card if everything was so simple, changed the card, and everything is okay…
Because with old hardware it's always this way. Something always doesn't work. Never, not once have I been able to build up an old system from the first time from the fully working components. That isn't possible.
But now everything works. However, you won't be able to play games from the network drive: without EMM386 all the software of LAN Manager is loaded in the bottom 640KB, and for the programs there is a very little space:
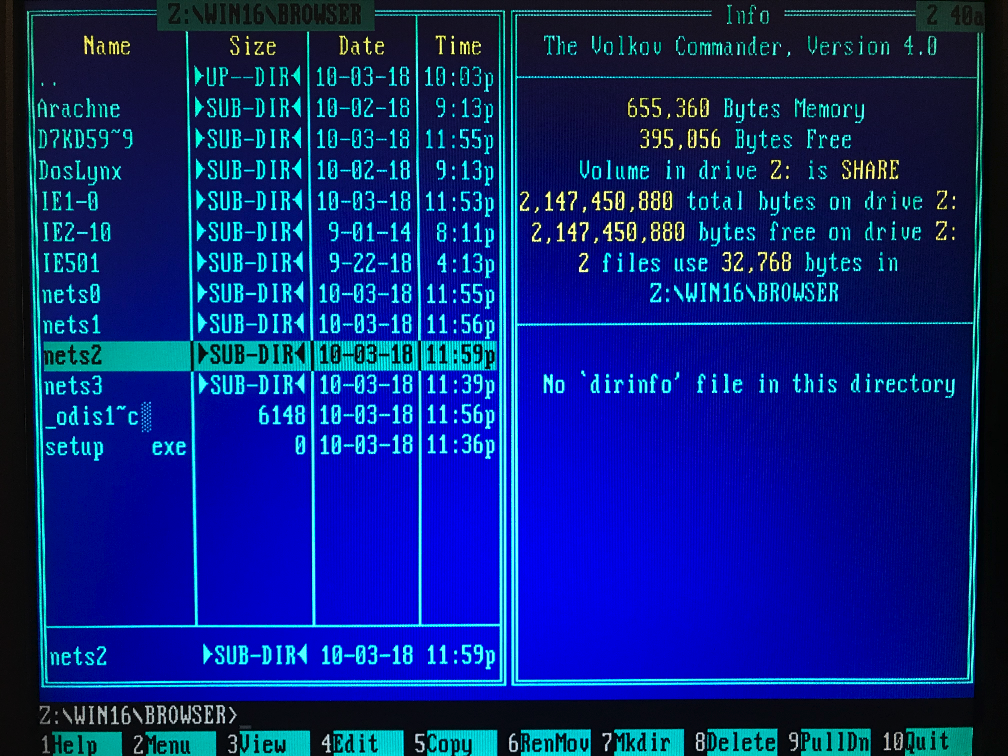
With the Browsers for Windows, too, it has not yet happened, neither Netscape Navigator nor MS Internet Explorer haven't agreed to run on 286, and NCSA Mosaic old versions didn't want to work with the stack of TCP/IP LAN Manager. Which is probably not so important, because I wanted to have access to the online storage, and I have it. And there are browsers for DOS, too, and they work on 286. But still, it hurts a little.
And, of course, the 286th computer with as much of the «lower» memory, as it is now, is absolutely useless. The fact is that the software that uses the «top» memory for the DOS requires 386 processor or higher, since the 286th with memory above 1 MB is very specific… even in the protected mode, the processor is 16-bit, and there is no linear addressing, and to return to the real mode, the 286th processor would require a hardware reset. Of course, there is a bug with the A20 line in real mode, and it was even used, but still, almost all the software for the 286th «rests» in the lower 640 KB, and I will have to do the boot menu in the DOS: either the network or the normal amount of memory, the third is not given. And, as the network under Windows starts from under the DOS, at the choice of the normal memory there won't no network also under Windows. That, of course, doesn't matter for such an ancient machine, but you need to make it possible to choose the boot configuration. Fortunately, DOS 6.22 supports the boot menu. Let's take advantage of this.
I decided to make a menu with 3 items:
1. Boot without network drivers. This gives the maximum of the «lower» memory. For the DOS-applications and games.
2. Boot with the NDIS-drivers. There's almost no memory for the DOS-applications left, so we immediately boot Windows.
3. Boot with the batch driver.
Here is the batch driver and it allows you to run many applications that use the network under the DOS. Such driver was in the set with D-Link DE220, however, there are many drivers for a large number of cards on the Internet, especially for the ISA bus. There should be no problems with any more or less common card problems. And the ones that weren't common were mostly NE2000 clones, so there shouldn't be any problems with them, but that’s as lucky as that.
In order to use TCP/IP with the packet driver, you need some other TCP/IP stack. There is [mTCP](http://www.brutman.com/mTCP/mTCP.html) for DOS, for example, and [Trumpet Winsock](https://thanksfortrumpetwinsock.com/) for Windows, the 1st version of which I still have since the modem times.
It started, but I don't know if it worked. At least, now at the start of the old NCSA Mosaic the message on absence of the TCP/IP stack was not given, but the browser tightly hung up the computer, without finishing loading.
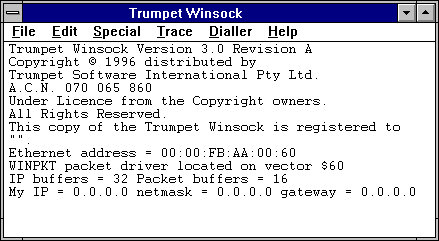
*The image from Google*
The old 16-bit TCP/IP stack for Windows was left. How to install it in the already installed system was unclear. Unlike WFWG 3.11, the 3.1 version doesn't allow you to change network settings directly from Windows. I couldn't figure out how to do it from under the DOS, and there's no installer stack in the installation package.
So, then we reset Windows. At a later stage of installation, it determines the network card (this time as NE2000-compatible, and it doesn't give the option of choosing another), and allows you to configure the Protocol… Select «Unlisted or updated protocol»
and slip the 16-bit stack distribution… Found and installed. That's a good start. But it did not go any further: neither under the DOS, nor under Windows the TCP/IP stack didn't work. That's a pity.
All right, I give up for now. In any case, I got a lot of fun from the mess with this piece of hardware, it's cool. Even though it's a very low fee for the 286. It was released in the days of 386, it uses a large chip Headland instead of a scattering of discrete logic, has SIMM slots, the processor operates at a frequency of 16 MHz, at a time when Intel left the 286x market with 12 MHz. By the way, it will be necessary to change the oscillator to 24 MHz to get 12 on the CPU… and anyway, the fee is small and even seems inexpensive. But it's nice and very fast. It takes less than a second from the moment the computer is turned on until the start of the memory check. And even though the board is quite young, it can work with memory in DIP-cases. However, only with 1 MB, while Windows still need more…

Some nostalgic screenshots of Windows:
Windows 286 only works in Standard mode. In this mode, any DOS application running under Windows runs in full screen mode and completely blocks all other Windows applications. These are the features of 16 bit.
 | https://habr.com/ru/post/436006/ | null | null | 2,509 | 64.91 |
I am in the process of rewriting a big integer class. the older version is fast but makes some non-portable assumptions (inline assembly). the new class takes an additional Traits template parameter that allows customization of the internal adding functionality, etc.
what I'm working on right now is a generic function that will work with any unsigned type to use with the default Traits.
here's what I've come up with:
my concern is the efficiency of the algorithm. is there a better/faster way to do this?my concern is the efficiency of the algorithm. is there a better/faster way to do this?Code:template <typename Unsigned> static Unsigned adc(Unsigned * dst, Unsigned src, Unsigned carry = 0) { static Unsigned one = 1, half = (std::numeric_limits<Unsigned>::max)() >> one; Unsigned tmp = *dst; *dst += src + carry; return (src >> one) + (tmp >> one) + (((src & one) + (tmp & one) + carry) >> one) > half; } | http://cboard.cprogramming.com/cplusplus-programming/95550-generic-add-carry.html | CC-MAIN-2015-06 | refinedweb | 150 | 64.51 |
My thoughts on React
I’ve been playing with React for some time now. React is:
“A JavaScript library for building user interfaces”.
Unlike other libraries something about React just clicked with me. Back in October a client project came along that presented a golden opportunity to develop a web app. I decided to use React, and I now consider myself comfortable in its ecosystem.
Below this huge logo are some of my thoughts on React.
React has its own JSX syntax for writing components. JSX tightly couples HTML with JavaScript in a readable fashion. It does not adhere to a ‘separation of concerns’ in that regard. Rather, it fully embraces the alternative.
This isn’t a React tutorial but here are two contrived examples that hopefully illustrate my thoughts later. I present a simple button and toolbar:
const Button = props => { return ( <button className="button" onClick={props.onClick}>{props.label}</button> ); };
const Toolbar = props => { return ( <nav className="toolbar"> <Button onClick={props.undo} <Button onClick={props.redo} </nav> ); };
Apologies for the lack of syntax highlighting.
There are imperfections to JSX for sure. The
class HTML attributes become
className for example (the former is a reserved keyword in JavaScript). Components without children must use self-closing tags — flashback to the days of XHTML.
By the way, if you’ve never used React, the components you define like
<Toolbar/> can be re-used like HTML elements in other components. They exist in JSX-world only. When React writes to the DOM it uses your semantic HTML underneath.
Despite the quirks I’ve fostered a preference for using JSX over HTML templating used by other libraries. Writing stateless functional components that are presentational-only further satisfies my fondness for readable code. (I’m using Redux to manage state. A topic for another day.)
Transpiling
JSX is not native JavaScript so it must be transpiled. For this I’m using Babel. And with Babel as a dependency comes
an excuse the ability to use new JavaScript features. I’ve fallen in love with arrow functions and the rest/spread operator. These things may not be supported in web browsers but we can transpile them away.
So the necessity to transpile code before it can run is a bit iffy. But it’s trivial for me to write Gulp watch tasks to do this in the background.
I was flirting with the idea of using TypeScript (or Flow). Decided against it. Too much new tech at once and I’d be one of ‘those’ developers.
Dependencies
I suspect a few readers are already balking over the number of names and acronyms I’ve already dropped. A year ago I wrote “I don’t do Angular, is that OK?”. I deliberated over what I should know as a professional front-end developer.
The piece “How it feels to learn JavaScript in 2016” by Jose Aguinaga sums up this quandary from an amusing, if cynical, perspective shared by many.
As with all tools and technology some amount of prerequisite knowledge is required. Efficient development of React requires a bit of transpiling and automation know-how. Coding in plain JavaScript requires understanding of web standards. That, in turn, requires computer literacy — and so on up and down the dependency chain. Obviously knowing how to turn on a computer is assumed but to me it seems somewhat arbitrary, or at least highly subjective, where to draw the line.
I still don’t “do Angular” but now I do do React.
That’s the worst sentence I’ve ever written.
Anyway, my point is that rejecting new technology on the premise that it introduces complexity is simply wrong if said tech proves to make life easy for those involved (not drive-by Githubers). For me — and I
hope plan for those reading my documentation — React make coding web apps a delightful experience.
What makes React special is its singular focus on user interface. It doesn’t box you into a framework. It doesn’t force you to solve app architecture problems too early. From my own usage I believe this makes React the most approachable library of its ilk.
One last thing…
It would be criminal not to give a shout-out to Preact. A magical “fast 3kB alternative to React with the same ES6 API” written by Jason Miller.
Vue and Inferno are also on my radar. | https://dbushell.com/2016/12/02/my-thoughts-on-react/ | CC-MAIN-2022-40 | refinedweb | 727 | 67.15 |
Wikiversity:Colloquium
Contents
- 1 Newsletter
- 2 New request for custodianship
- 3 Doesn't this page violate our Wikiversity:Privacy policy?
- 4 Global AbuseFilter
- 5 Top 1000 Requests By Month
- 6 Hello forum members
- 7 VisualEditor coming to this wiki as a Beta Feature
- 8 VisualEditor coming to this wiki as a Beta Feature (errata)
- 9 Colloquium image
- 10 About opening visual editor for IP access
- 11 What are we suppose to do with accounts with the name "bot" when they aren't even a bot?
- 12 TAO
- 13 Compare law and administration in different jurisdictions?
- 14 The process of converting classic talk pages to Flow
- 15 A less cluttered way to include multiple sister links.
Newsletter[edit]
Hi all, here an update regarding the Dutch wikiversity. As you may or may not know, this year all 5000 pages on the Dutch wikiversity were removed. The people who removed the pages had another vision on what a wikiversity should be. After the removal it became quit again, no content creation. This month Wikimedia Nederland asked me to write about the Dutch wikiversity in there newsletter. What should I write about? My plan for 2015 is to find more people who want to join me in starting the Dutch wikiversity 2.0. How can I set up some guidelines to prevent a mass deletion again? I think I should find other people besides the Wikipedians who deleted the content, but unfortunately they are the only ones who are active? Can somebody help me? Give me some tips in how to establish a new community? Regards, Tim, Timboliu (discuss • contribs) 11:06, 2 November 2014 (UTC)
- Start with a mission and vision. But also recognize that you, by yourself, can't establish anything. It needs to be a community, and the community has to support the vision. Think about what works here on en.wikiversity. How do we avoid mass deletions of questionable content? Two approaches that help are to organize content by learning project rather than individual page, and to focus on the learning rather than the content. Ask those who are interested in Dutch Wikiversity for their ideas. Are they willing to focus on learning, or are they only concerned with content? You might find that the issue isn't the content itself, but the format that is troublesome. You may need to get everyone to agree on a design template for what a course, lesson, and activity look like and go from there. That would be highly proscriptive and somewhat restrictive, but it might get agreement from those who couldn't support the previous work. -- Dave Braunschweig (discuss • contribs) 14:20, 2 November 2014 (UTC)
- I agree with Dave Braunschweig. The key strategy is to allow students to write. They are the future writers of Wikipedia (and everything else that will be written). Don't worry about quality control, just let them write. Then, if a page is neither visited nor edited for a sufficiently long period of time, remove it from namespace so that others will have good names for their projects. Don't worry about Wikiversity being cluttered with bad material. The good stuff will eventually be found by Google or through interwiki links. Teachers who find useful resources on Wikiversity can make permalinks so that they need not worry about misguided edits made in the future. Wikiversity, Wikibooks and Wiktionary will all grow. It just takes time.--guyvan52 (discuss • contribs) 18:11, 2 November 2014 (UTC)
- I'm amazed that someone would bother to remove so much material and then not put something new in its place! But I can quite understand it. There is such a feeling, with Wikiversity, to get some structure in place before adding one's own material (at least, this has been my feeling from time to time with the English Wikiversity) that it's easy to never get to the real work. I rather suspect there's some parallel with traditional university procrastination here!
What was the quality of the deleted pages like? I assume mostly it was not very good?
But yes, those above have it right: the way forward surely is to succinctly define what Wikiversity actually is and then encourage people to write about whatever they're interested in! :-)
— Sam Wilson ( Talk • Contribs ) … 00:55, 6 November 2014 (UTC)
- I just noticed that is not a wiki. Has it been closed completely? — Sam Wilson ( Talk • Contribs ) … 06:20, 7 November 2014 (UTC)
- The Dutch Wikiversity is at. -- Dave Braunschweig (discuss • contribs) 14:34, 7 November 2014 (UTC)
- Thanks for the advice. Cheers, Tim, 77.171.140.130 (discuss) 21:38, 7 November 2014 (UTC)
- Ah, I see. :) Cool. I'll have a read of what's going on over there. I've never really noticed Beta Wikiversity much. :) — Sam Wilson ( Talk • Contribs ) … 05:07, 10 November 2014 (UTC)
New request for custodianship[edit]
Just like to inform you. --Goldenburg111 16:37, 11 November 2014 (UTC)
Doesn't this page violate our Wikiversity:Privacy policy?[edit]
The <hidden> userpage shows:
1. Her full name 2. Her birthdate 3. Ancestry 4. Religion 5. Father, date of birth and place of birth. 6. Mother, date of birth and place of birth. 7. Residence.
I say this violates the privacy policy, as I said, she revealed her full name, her birthdate, ancestry, father (date of birth and place of birth), mother (date of birth and place of birth), and residence. --Goldenburg111 14:55, 13 November 2014 (UTC)
- Yes, the page you noted appears to be a violation of Wikiversity:Privacy policy. But be careful, as drawing attention to it is more likely to cause a violation of that person's privacy than the page itself does. I have hidden the page link here, and will hide your revision to protect the privacy of this minor user. If you find more privacy violations like this, it would be better to use the Email this user feature to contact a custodian for review. -- Dave Braunschweig (discuss • contribs) 15:06, 13)
Top 1000 Requests By Month[edit]
I automated a process to download page request statistics from. I've posted monthly totals for the top 1000 articles from the last three months at:
Those looking for a place to help and wondering where their efforts would have the greatest impact should focus on the projects and pages in highest demand.
Dave Braunschweig (discuss • contribs) 20:43, 17 November 2014 (UTC)
- I am puzzled that Torque_and_angular_acceleration got so many hits. We almost deleted that article about a month ago. See the discussion at Wikiversity:Colloquium#Wikipedia_copies --guyvan52 (discuss • contribs) 23:48, 17 November 2014 (UTC)
- It is possible for a single individual to mess with page counts. Just hitting purge on a page forces it to refresh. There are also some pages on the list that are clearly influenced by a bot driving up the counts. But overall, it makes more sense to focus on pages on the list before working on some random project that may never be viewed. I did notice that there are a number of mechanics / physics pages that might go together well as a learning project. It's out of my area of expertise, but something to consider. I'm also working on a list of the top 100 learning projects (adding up subpage counts to get a total per project). I'll post when I have something useful to share. -- Dave Braunschweig (discuss • contribs) 23:53, 17 November 2014 (UTC)
- It was fascinating to see how much is being done in fields closely related to mine. I was planning to strengthen the electronics sections of Physics equations, but now realize that I should instead let others do the work for me.--guyvan52 (discuss • contribs) 00:18, 18 November 2014 (UTC)
- Keep in mind that this shows page hits or views, not edits. I have several projects on the list that never see an edit from anyone else. They're popular, but they don't draw updates. I keep telling myself it's because the quality is so good that they don't need updates. :-) I'm not entirely sure I believe that, but it sounds good. If you have something high on the list, you should work on it anyway, or make it very clear to visitors that they can update and improve. -- Dave Braunschweig (discuss • contribs) 01:46, 18 November 2014 (UTC)
Hello forum members[edit]
I'm new to greet you need in August. Sorry for my english)
Colloquium image[edit]
A while back we were considering replacing the colloquium image with something a bit more universal and perhaps appropriate. May I suggest the following image, which may need some cropping of the ceiling:
- Where are the kids in the pic? or <SOME COLOR>-colored people? (not that the current one has it either ;-)) ----Erkan Yilmaz 09:55, 24 November 2014 (UTC)
- Two good points! At least it has men and women, improvement number one. There is an Asian Indian or Pakistani center back I believe, and an oriental on the right. I'll keep looking. --Marshallsumter (discuss • contribs) 16:19, 24 November 2014 (UTC)
About opening visual editor for IP access[edit]
Hello every body,
I'm a Belgian contributor in French Wikiversity and I just come here to ask if this Wikiversity community can agree to the idea of opening the use of the visual editor for IP contributor which is concretely a simple switch on the php code but which need a consensus from the community before leave a request on bugzilla.
Access to the visual editor by IP address is some thing vital for me who a not English native speaker. By the way, I can ask to my English friends who are not registered and who don't wan to be, to go to my research pages for correcting English for of the contain.
Thanks a lot for your attention. I will waiting reaction community to know how to star the consensus process.
A nice day for every one.
--Lionel Scheepmans (✉) , le 04:53, 3 December 2014 (UTC)
- I would encourage everyone to try the VisualEditor, and also see Wikipedia: Wikipedia:VisualEditor and Wikipedia: Wikipedia:VisualEditor/Feedback regarding issues and concerns. I noticed that Wikipedia tried having this feature available to all users by default last summer, and then turned it off after six weeks. -- Dave Braunschweig (discuss • contribs) 14:53, 3 December 2014 (UTC)
What are we suppose to do with accounts with the name "bot" when they aren't even a bot?[edit]
I found one: - in the recent changes pretending to be a bot. Aren't we suppose to block accounts that have the name "bot" in it when it isn't even a bot? --Goldenburg111 14:46, 4 December 2014 (UTC)
- How do you know it isn't a bot? Or is it just that the edits weren't correctly tagged as bot? But besides that, there was a long debate here several months ago regarding the blocking of bots. It was the community's consensus that we only block bots operating at faster than sixty seconds per edit without prior approval. In other words, we only block bots based on their activity, the same way we only block users based on their activity. So far, Csdc-bot appears to be an opportunity for education rather than a need to block. Would you like to leave this user/bot a message explaining your concerns? -- Dave Braunschweig (discuss • contribs) 14:58, 4 December 2014 (UTC)
TAO[edit]
The resource TAO, or Third Age Online, has its own category, Category:TAO, and about a hundred resources at Wikiversity. That's the good news! The not-so-good news is that the project was concluded in December 2013, the website is a deadlink, and its category has no category. I was thinking about putting them all up for deletion as they are abandoned for over a year, with the only recent additions coming from bots. What would the community like to do with these?
The easy solution is to put their category into a higher category associated with the internet and leave them as they are. --Marshallsumter (discuss • contribs) 02:25, 9 December 2014 (UTC)
- Since there are no other comments, I'd recommend adding a category and preserving the content. I have many pages myself that haven't had updates for more than a year. I keep thinking it's because the quality is already there. -- Dave Braunschweig (discuss • contribs) 00:40, 12 December 2014 (UTC)
Compare law and administration in different jurisdictions?[edit]
What tools might exist to facilitate the comparison of law and administration in different jurisdictions?
I'd like to find a home and a structure to facilitate crowdsourcing research to compare current law and practices in issues related to the w:American Anti-Corruption Act (AACA). Wikiversity seemed to me like a reasonable home, because it supports research forbidden on Wikiversity, while sharing the Wikimedia policies of writing from a neutral point of view and citing credible sources.
However, I'd also like the capability to flag material with different subject matter, e.g., the eleven "provisions" of the AACA. I'd like to allow a volunteer to write a summary of the law and administration in a particular jurisdiction (e.g., California or San Jose, CA) with some kind of markup language to identify the which subject, e.g., conflicts of interest, to which a section, sentence or paragraph belongs, and eventually perhaps a score on some scale like the Freedom Scores assigned by Freedom House. This would be combined with some ability for a user to compare the material entered on a given subject for different jurisdictions -- either text or scores.
Suggestions? Thanks, DavidMCEddy (discuss • contribs) 11:29, 11 December 2014 (UTC)
- Thank you for your interest! The School:Law has a series of resources listed under "Law by Jurisdiction" that may be of help. I tried looking up the AACA under both "American Anti-Corruption Act" and AACA on Wikisource and Wikiquote, nada. Wikipedia does have an entry at AACA. The summary you propose is likely to be welcomed by our law department. I hope this helps. --Marshallsumter (discuss • contribs) 23:06, 11 December 2014 (UTC)
- Depending on the complexity of your structure, you might experiment with categories and subcategories. For example the category Category:Physics_equations has several subcategories, including Category:Physics equations/Quizzes. I am not sure how many categories you need. If the categories are subcategories of a page I don't think there is a problem with polluting category namespace, but that needs to be looked into.
- I even have the template category Category:Template:Physeq, which I developed when I discovered myself writing the same equation in various places (and having to make multiple changes when I changed something). But note: I think I violated Wikiversity policy when I put the template Template:Physeq1 into mainspace. Either nobody noticed, or they didn't care, or it's OK to do that. In fact, I need a second edit of all my equation templates, and I will now post an inquiry about that right now. --guyvan52 (discuss • contribs) 23:19, 11 December 2014 (UTC)
- Technically, anything starting with Template: is in Template space rather than main space. The colon designates namespace, which is why colons should be avoided in mainspace titles. We don't have any stated guidelines on template placement, but what I go by when creating or moving content is templates that are only used in a single project are better as subpages of that project, and templates used by multiple projects are best in the Template: namespace. -- Dave Braunschweig (discuss • contribs) 00:47, 12 December 2014 (UTC)
- Thank you all very much. I've looked some in School:Law including "Law by Jurisdiction", as suggested by User:Marshallsumter. I may also experiment with categories, as suggested by User:Guy vandegrift. First, however, I think I'll study School:Law a bit more. Thanks again. DavidMCEddy (discuss • contribs) 07:11, 17 December 2014 (UTC)
- I don't fully understand it, but w:Wikipedia:Categorization#Category_tree_organization looks useful. There seems to be two entirely different meanings of the word "subcategory". Wikipedia defines it as placing a child category into a parent category by inserting [[Category:parentname]], usually at the bottom of the child. But you can also define a subcategory a la Wikiversity's subpage system by creating the page in namespace Category:parent/child. Then when you look at the child category a link to the parent appears at the top in the usual way. --guyvan52 (discuss • contribs) 13:24, 17 December 2014 (UTC)
The process of converting classic talk pages to Flow[edit]
(BG: Flow). There are various ways to convert talk pages to Flow. Discussed at this page. I would like to know what we would like to have. Please join the discussion and spread it to other language village pumps. Gryllida 23:59, 11 December 2014 (UTC)
A less cluttered way to include multiple sister links.[edit]
I spent the morning knocking myself out trying to create a better template for multiple wikilinks. With more than 4 or 5 links, the boxes on the right look tacky. Finally it dawned on me that using a template to do the job is like cracking a peanut with a sledgehammer. The links to left are just captions to a figure.
If anybody wants to me add another sister, I can easily modify this image on commons.
--guyvan52 (discuss • contribs) 20:09, 13 December 2014 (UTC) | http://en.wikiversity.org/wiki/Wikiversity:C | CC-MAIN-2014-52 | refinedweb | 2,937 | 62.88 |
Use this procedure to detach a storage array from a single cluster node, in a cluster that has three-node or four-node connectivity..
Back up all database tables, data services, and volumes that are associated with the storage array that you are removing.
Determine the resource groups and device groups that are running on the node to be disconnected.
If necessary, move all resource groups and device groups off the node to be disconnected.
If your cluster is running Oracle RAC software, shut down the Oracle RAC database instance that is running on the node before you move the groups off the node. For instructions, see the Oracle Database Administration Guide.
The clnode evacuate command switches over all device groups from the specified node to the next-preferred node. The command also switches all resource groups from voting or non-voting nodes on the specified node to the next-preferred voting or non-voting node.
Put the device groups into maintenance state.
For the procedure on acquiescing I/O activity to Veritas shared disk groups, see your VxVM documentation.
For the procedure on putting a device group in maintenance state, see How to Put a Node Into Maintenance State.
Remove the node from the device groups.
If you use VxVM or a raw disk, use the cldevicegroup(1CL) command to remove the device groups.
If you use Solstice DiskSuite, use the metaset command to remove the device groups.
For each resource group that contains an HAStoragePlus resource, remove the node from the resource group's node list.
The name of the node.
The name of the non-voting node that can master the resource group. Specify zone only if you specified a non-voting node when you created the resource group.
See the Sun Cluster Data Services Planning and Administration Guide for Solaris OS for more information about changing a resource group's node list.
Resource type, resource group, and resource property names are case sensitive when clresourcegroup is executed.
If the storage array that you are removing is the last storage array that is connected to the node, disconnect the fiber-optic cable between the node and the hub or switch that is connected to this storage array (otherwise, skip this step).
If you are removing the host adapter from the node that you are disconnecting, and power off the node. If you are removing the host adapter from the node that you are disconnecting, skip to Step 11.
Remove the host adapter from the node.
For the procedure on removing host adapters, see the documentation for the node.
Without booting the node, power on the node.
If Oracle RAC software has been installed, remove the Oracle RAC software package from the node that you are disconnecting.
If you do not remove the Oracle RAC software from the node that you disconnected, the node panics when the node is reintroduced to the cluster and potentially causes a loss of data availability.
Boot the node in cluster mode.
On SPARC based systems, run the following command.
On x86 based systems, run the following commands.
When the GRUB menu is displayed, select the appropriate Solaris entry and press Enter. The GRUB menu appears similar to the following:
On the node, update the device namespace by updating the /devices and /dev entries.
Bring the device groups back online.
For procedures about bringing a Veritas shared disk group online, see your Veritas Volume Manager documentation.
For information about bringing a device group online, see How to Bring a Node Out of Maintenance State. | http://docs.oracle.com/cd/E19575-01/820-7358/babgecdb/index.html | CC-MAIN-2014-42 | refinedweb | 591 | 63.59 |
Today, AOP is starting to get attention in the .NET community, and right now, there are a lot of frameworks and compilers for .NET to allow programmers to create .NET applications using AOP.
In this article, I will be talking about the NKalore Compiler. NKalore is a compiler based on MCS (Mono C# Compiler), which allows the use of AOP in your C# code with a very simple and intuitive syntax. So, when developing with NKalore, you will use keywords as
ASPECT,
POINTCUT,
AFTER,
BEFORE,
AROUND, etc.
To start using NKalore, I recommend downloading the latest version at SourceForge. The product is still in an Alpha state, but we already can start to play with NKalore and use AOP in C#.
To compile our samples, we will run NKalore in the command-line mode. At the moment, integration with Visual Studio is not available. It is possible to have a basic integration with #Develop, but it�s a subject for another article.
In this first sample, I will demonstrate the use of the
BEFORE advice, so we can imagine that each time before a specified method is called out, the
BEFORE advice will be called.
For this, we create a class that has a method called
Sum, as you see below:
using System; namespace Namespace { public class MainClass { public void Sum(int a, int b) { Console.WriteLine("Sum = {0}", a + b); } public static void Main() { new MainClass().Sum(2,3); } } }
Now, we are going to create an
aspect so every time the "
Sum" method is called, it writes a message into the console. Check it out:
using System; namespace Namespace { public aspect MyAspect { pointcut SumPointCut void MainClass.Sum(int a, int b); before SumPointCut(int a, int b) { Console.WriteLine( "The sum of numbers {0} and {1} will be calculated.", a, b); } } }
At first, the pointcut is created to identify which methods to "capture". We have put the full name (class name and method name), but we can also use the �%� character to specify the pointcut like a mask.
Then, the
BEFORE advice is created. This advice runs every time the
Sum method is called. To compile the application, run NKalore in the command window passing the .cs file as a parameter, for example:
mcs before.cs
Here, mcs in the binary name of NKalore.
When you run the application, you will see the following in the console window:
The
BEFORE and
AFTER advices bring with them some information about the method that is being "captured", all this information is inside the "
thisJoinPoint" variable. Now, we are going to use these advices to log every code that is executed in our code.
First, we need a class that has a flow built with methods calling a method, just to demonstrate the use of the log:
namespace Namespace { public class MainCls { public MainCls() { a(2); } void a(int a) { b("paul", 14); } void b(string name, double age) { c(true); } void c(bool someFlag) { return; } public static void Main() { new MainCls(); } } }
And now, the aspect that captures all methods, with any name, returning type, or parameter, and logs every thing into the console with information that is in the "
thisJointPoint" variable. See the aspect implemented below:
using System; using System.Reflection; namespace Namespace { public aspect LoggingAspect { pointcut LogPointcut % %(...); int level = 0; void log(NKalore.Model.JoinPoint joinPoint, string prefix, bool showParams) { string pad = new string('�', level - 1); Console.WriteLine(pad + prefix + " - " + joinPoint.MethodInfo); if (showParams) { ParameterInfo[] pis = joinPoint.MethodInfo.GetParameters(); for (int i = 0; i < pis.Length; i++) { Console.WriteLine(pad + "\t{0} {1} = {2}", pis[i].ParameterType, pis[i].Name, joinPoint.ParamsData[i]); } } } after LogPointcut() { log(thisJoinPoint, "after", false); level--; } before LogPointcut() { level++; log(thisJoinPoint, "before", true); } } }
In the aspect, the
AFTER and
BEFORE advices increment or decrement the "level" variable to keep the level of the stack. And call the "
log" method to show in the console, information about
thisJointPoint. The output of the application is the following:
Another very interesting advice is the
AROUND advice. This advice is executed during the execution of the method. So, in reality, when you use this advice, when the method "captured" by the pointcut is executed, your aspect code is executed, and to execute the real method implementation, you need to use the
proceed keyword.
To illustrate, we are going to create an aspect with the
AROUND advice that calls the implementation of a method (using the
proceed keyword). The use of "
proceed" is inside a
try/
catch block, to protect the execution from errors. Take a look at our sample implementation:
using System; using System.Reflection; namespace AroundSample { public aspect AroundAspect { pointcut DoMethods void %.Do%(...); around void DoMethods() { try { Console.WriteLine("Before: {0}", thisJoinPoint.MethodInfo); proceed(...); Console.WriteLine("After: {0}", thisJoinPoint.MethodInfo); } catch (Exception ex) { Console.WriteLine("Error in {0}: {1} ", thisJoinPoint.MethodInfo, ex.InnerException.Message); } } } public class MainCls { public void DoSum(int a, int b) { Console.WriteLine(a + " + " + b + " = " + (a + b)); } public void DoMinus(int a) { Console.WriteLine(a + " - 1 = " + ( a - 1 )); } public void DoDiv(int a, int b) { Console.WriteLine(a + " / " + b + " = " + (a / b)); } public static void Main() { MainCls mainCs = new MainCls(); mainCs.DoSum(7,3); mainCs.DoMinus(5); mainCs.DoDiv(5,0); } } }
Every method that starts with "Do" is handled by the
AROUND advice. First, we log into the console the method that is being executed, writing "before..." and "after...", when the call to the original method is done using
proceed keyword. This is made inside a
try/
catch, block, so if any errors occur (a division by zero will occur in our samples), it will write in the console. The output of this program is:
Another possible use of
AROUND, is to cache the results of the function into a hash table, and avoid running the same method twice.
* Note that if you only whish to handle the exception, you can use the
THROWING advice.
NKalore offers a very simple way to implement AOP into C#, and it�s very intuitive. The project is still in the Alpha stage, but for a while, we can make little programs with it. As roadmap of NKalore says, in the future, probably we will have some more AOP features and integration with Visual Studio, which would be very nice.
General
News
Question
Answer
Joke
Rant
Admin | http://www.codeproject.com/KB/cs/UsingAOPInCSharp.aspx | crawl-002 | refinedweb | 1,046 | 64.91 |
Heroes of Newerth 0.5.11
Sponsored Links
Heroes of Newerth 0.5.11 Ranking & Summary
RankingClick at the star to rank
Ranking Level
Heroes of Newerth 0.5.11 description
Heroes of Newerth 0.5.11 is launched to be a sophisticated and innovative Libpurple protocol plugin for Heroes of Newerth chat server. You can now connect to Heroes of Newerth service and stay in touch with your gaming buddies. Give it a try and improve your gaming experience!
Requirements:
- Windows XP / Vista / 7
Heroes of Newerth 0.5.11 Screenshot
Heroes of Newerth 0.5.11 Keywords
Bookmark Heroes of Newerth 0.5.11
Heroes of Newerth 0.5.11 Copyright
WareSeeker.com do not provide cracks, serial numbers etc for Heroes of Newerth 0.5.11. Any sharing links from rapidshare.com, yousendit.com or megaupload.com are also prohibited.
Featured Software
Want to place your software product here?
Please contact us for consideration.
Contact WareSeeker.com
Related Software
You arrive at the Kingdom of Kot with your brave peasants and loyal dogs. The land is overrun with bandits and enemy forces keep invading the kingdom. You raise fame, collect gold and items Free Download
Heroes of First Star is the first of its kind: A party-based online role playing game. Now you can work on (up to) 5 warriors at a time (rather than one, as youll find in other online games). Train up Free Download
Someone has stolen the scepter with which Zeus controls Heaven and Earth. As you progress, the greatest heroes of ancient times, including Hercules, Perseus and others, will lend a hand Free Download
Mirror comes as a sophisticated and functional program with the power to provide both compile-time and run-time meta-data describing C++ constructs like namespaces, types typedef-ined types, enums, classes with their base classes, member variables, constructors, member functions, etc. and to provide uniform and generic interfaces for their introspection. Free Download
Enchanting scenes and characters from the game Heroes of the Might & Magic V.... Free Download
Heroes of Hellas 2 Olympia gives you the chance to enjoy such an attractive and interesting game to drag your mouse across chains of identical items to remove obstacles, activate bonus items and collect valuable objects. Free Download
Update Soldiers: Heroes of World War II to version 1.12.2. Free Download
Sonic Heroes gives you the opportunity to enjoy such an interesting and fascinating game iwhere you get to help Sonic collect all the gold rings. Free Download
Latest Software
Popular Software
Favourite Software
- Heroes of Might and Magic IV 1.3 to 2.0 patch
- Bionicle Heroes 1
- Forever In Our Hearts 911 WTC Heroes 3.1.1
- Heroes of Might and Magic III: Shadow of Death 3.1 patch
- Star Wars: Battlefront II Battle of Heroes mod
- Wik and the Fable of Souls 1
- Heroes of Might and Magic IV Equilibris Mod
- Worlds of Heroes & Tyrants Epic Adventure Game Introductuctory Edition | http://wareseeker.com/Communications/heroes-of-newerth-0.5.11.zip/3a3dbbab5 | CC-MAIN-2015-06 | refinedweb | 496 | 66.13 |
Tech Off Thread1 post
Forum Read Only
This forum has been made read only by the site admins. No new threads or comments can be added.
XAML + XLinq + VB.Net's XML Literals Equals Classic ASP For WinForms?
Conversation locked
This conversation has been locked by the site admins. No new comments can be made.
The following is a reprint of my blog entry:
You may want to leave comments there, so they are all in one place.
Disclaimer:.
The final version of.Net 2.0 is just about to be released, and we are already starting to get bits and pieces of what they are toying with for the next version with the announcement of the LINQ project during the PDC. LINQ is the code name for extensions to the .Net framework that extends C# and VB with native language syntax for queries and other functional style programming constructs. XLinq is an implementation of Linq designed around creating a new API around XML. The idea is to create a more natural API for creating and manipulating XML. Think of it as a more modern version of the XML DOM. Here are some examples from the XLinq documentation:
Your typical DOM based approach to building an XML document:
The XLinq way:
You can see how the XLinq code has a more natural feel to the API, than the older XML-DOM (side note: yes, these examples are lame, because they do not have the one thing that all good XML fragments should have, namespaces. Part of the reason is that the way namespaces are declared in the current version of XLinq doesn’t feel as natural as the rest of the API (IMHO). So for now, just ignore the namespace issue. I’m sure that with the help of folks like us, XLinq will have an implementation of namespaces that feels as natural as the rest of the API).
The VB Team has taken XLinq one step further in their desire to create a more natural XML API, and add something called XML Literals. Instead of having to actually explicitly declare the object types using the VB constructs, they have simplified to just having to place the actual XML inline with your code:
This is the exact same code as in the other examples, except that the VB compiler “sees” the XML, and then creates the equivilant XLinq commands for you. The net result is that a VB programmer doesn’t even have to know how to create the XLinq objects by hand. The VB compiler handles it for them, thus making it easier for the VB developer to create XML. But what if you didn’t have static XML, and just needed templates to help you generate the final XML. Well, they have you cover there too, with the concept of expression holes that can reside within your XML declarations:
I don’t know about you, but that sure looks a little familiar. Once I saw that little bit of code, well my mind started to add other little pieces of existing knowledge.
Since VB XLinq XML Literals look a lot like old school ASP programming, and that was so sucessful, why not bring it into the 21st century, and instead of generating sloppy HTML, do something more useful. No, I’m not talking about XHTML (but close). I’m talking about using VB XLinq XML Literals to generate XAML. XAML is just a declarative way to wire up .Net objects, and the most popular use of XAML has been the Windows UI realm (aka Windows Presentation Foundation, aka Avalon). In the future, could we see VB programmers writing classic ASP style code to generate Windows applications? Classic ASP was a very easy (and fast) way to generate websites. I’m not saying that I’d want to do that in an enterprise environment, but I could definitely see the “Hobbyist Programmer” doing something like this. And it would also solve “where is Microsoft’s replacement for classic VB” question.
I don’t know if all of this is 100% possible, but it sure looks probable. Don’t even get me started on using something like this in combination with Monad (the new Windows Command Shell). Combined together, it could be all that Windows Scripting Hosting wanted to be, but never was. | https://channel9.msdn.com/Forums/TechOff/124086-XAML--XLinq--VBNets-XML-Literals-Equals-Classic-ASP-For-WinForms | CC-MAIN-2017-34 | refinedweb | 723 | 69.01 |
Data types¶
AiiDA already ships with a number of useful data types. This section details the most common, and some handy features/functionalities to work with them.
The different data types can be accessed through the
DataFactory() function (also exposed from
aiida.plugins) by passing the corresponding entry point as an argument, for example when working in the
verdi shell:
In [1]: ArrayData = DataFactory('array')
重要
Many of the examples in this section will assume you are working inside the
verdi shell.
If this is not the case, you will have to first load e.g. the
DataFactory() function:
from aiida.plugins import DataFactory ArrayData = DataFactory('array')
A list of all the data entry points can be obtain running the command
verdi plugin list aiida.data.
For all data types, you can follow the link to the corresponding data class in the API reference to read more about the class and its methods. We also detail what is stored in the database (mostly as attributes, so the information can be easily queried e.g. with the QueryBuilder) and what is stored as a raw file in the AiiDA file repository (providing access to the file contents, but not efficiently queryable: this is useful for e.g. big data files that don’t need to be queried for).
If you need to work with some specific type of data, first check the list of data types/plugins below, and if you don’t find what you need, give a look to Adding support for custom data types.
Core data types¶
Below is a list of the core data types already provided with AiiDA, along with their entry point and where the data is stored once the node is stored in the AiiDA database.
Base types¶
There are a number of useful classes that wrap base Python data types (
Int,
Float,
Str,
Bool) so they can be stored in the provenance.
These are automatically loaded with the
verdi shell, and also directly exposed from
aiida.orm.
They are particularly useful when you need to provide a single parameter to e.g. a
workfunction.
Each of these classes can most often be used in a similar way as their corresponding base type:
In [1]: total = Int(2) + Int(3)
If you need to access the bare value and not the whole AiiDA class, use the
.value property:
In [2]: total.value Out[2]: 5
警告
While this is convenient if you need to do simple manipulations like multiplying two numbers, be very careful not to pass such nodes instead of the corresponding Python values to libraries that perform heavy computations with them. In fact, any operation on the value would be replaced with an operation creating new AiiDA nodes, that however can be orders of magnitude slower (see this discussion on GitHub). In this case, remember to pass the node.value to the mathematical function instead.
AiiDA has also implemented data classes for two basic Python iterables:
List and
Dict. They can store any list or dictionary where elements can be a base python type (strings, floats, integers, booleans, None type):
In [1]: l = List(list=[1, 'a', False])
Note the use of the keyword argument
list, this is required for the constructor of the
List class.
You can also store lists or dictionaries within the iterable, at any depth level.
For example, you can create a dictionary where a value is a list of dictionaries:
In [2]: d = Dict(dict={'k': 0.1, 'l': [{'m': 0.2}, {'n': 0.3}]})
To obtain the Python
list or
dictionary from a
List or
Dict instance, you have to use the
get_list() or
get_dict() methods:
In [3]: l.get_list() Out[3]: [1, 'a', False] In [4]: d.get_dict() Out[4]: {'k': 0.1, 'l': [{'m': 0.2}, {'n': 0.3}]}
However, you can also use the list index or dictionary key to extract specific values:
In [5]: l[1] Out[5]: 'a' In [6]: d['k'] Out[6]: 0.1
You can also use many methods of the corresponding Python base type, for example:
In [7]: l.append({'b': True}) In [8]: l.get_list() Out[8]: [1, 'a', False, {'b': True}]
For all of the base data types, their value is stored in the database in the attributes column once you store the node using the
store() method.
ArrayData¶
The
ArrayData class can be used to represent numpy arrays in the provenance.
Each array is assigned to a name specified by the user using the
set_array() method:
In [1]: ArrayData = DataFactory('array'); import numpy as np In [2]: array = ArrayData() In [3]: array.set_array('matrix', np.array([[1, 2], [3, 4]]))
Note that one
ArrayData instance can store multiple arrays under different names:
In [4]: array.set_array('vector', np.array([[1, 2, 3, 4]]))
To see the list of array names stored in the
ArrayData instance, you can use the
get_arraynames() method:
In [5]: array.get_arraynames() Out[5]: ['matrix', 'vector']
If you want the array corresponding to a certain name, simply supply the name to the
get_array() method:
In [6]: array.get_array('matrix') Out[6]: array([[1, 2], [3, 4]])
As with all nodes, you can store the
ArrayData node using the
store() method. However, only the names and shapes of the arrays are stored to the database, the content of the arrays is stored to the repository in the numpy format (
.npy).
XyData¶
In case you are working with arrays that have a relationship with each other, i.e.
y as a function of
x, you can use the
XyData class:
In [1]: XyData = DataFactory('array.xy'); import numpy as np In [2]: xy = XyData()
This class is equipped with setter and getter methods for the
x and
y values specifically, and takes care of some validation (e.g. check that they have the same shape).
The user also has to specify the units for both
x and
y:
In [3]: xy.set_x(np.array([10, 20, 30, 40]), 'Temperate', 'Celsius') In [4]: xy.set_y(np.array([1, 2, 3, 4]), 'Volume Expansion', '%')
Note that you can set multiple
y values that correspond to the
x grid.
Same as for the
ArrayData, the names and shapes of the arrays are stored to the database, the content of the arrays is stored to the repository in the numpy format (
.npy).
SinglefileData¶
In order to include a single file in the provenance, you can use the
SinglefileData class.
This class can be initialized via the absolute path to the file you want to store:
In [1]: SinglefileData = DataFactory('singlefile') In [2]: single_file = SinglefileData('/absolute/path/to/file')
The contents of the file in string format can be obtained using the
get_content() method:
In [3]: single_file.get_content() Out[3]: 'The file content'
When storing the node, the filename is stored in the database and the file itself is copied to the repository.
FolderData¶
The
FolderData class stores sets of files and folders (including its subfolders).
To store a complete directory, simply use the
tree keyword:
In [1]: FolderData = DataFactory('folder') In [2]: folder = FolderData(tree='/absolute/path/to/directory')
Alternatively, you can construct the node first and then use the various repository methods to add objects from directory and file paths:
In [1]: folder = FolderData() In [2]: folder.put_object_from_tree('/absolute/path/to/directory') In [3]: folder.put_object_from_file('/absolute/path/to/file1.txt', path='file1.txt')
or from file-like objects:
In [4]: folder.put_object_from_filelike(filelike_object, path='file2.txt')
Inversely, the content of the files stored in the
FolderData node can be accessed using the
get_object_content() method:
In [5]: folder.get_object_content('file1.txt') Out[5]: 'File 1 content\n'
To see the files that are stored in the
FolderData, you can use the
list_object_names() method:
In [6]: folder.list_object_names() Out[6]: ['subdir', 'file1.txt', 'file2.txt']
In this example,
subdir was a sub directory of
/absolute/path/to/directory, whose contents where added above.
to list the contents of the
subdir directory, you can pass its path to the
list_object_names() method:
In [7]: folder.list_object_names('subdir') Out[7]: ['file3.txt', 'module.py']
The content can once again be shown using the
get_object_content() method by passing the correct path:
In [8]: folder.get_object_content('subdir/file3.txt') Out[8]: 'File 3 content\n'
Since the
FolderData node is simply a collection of files, it simply stores these files in the repository.
RemoteData¶
The
RemoteData node represents a “symbolic link” to a specific folder on a remote computer.
Its main use is to allow users to persist the provenance when e.g. a calculation produces data in a raw/scratch folder, and the whole folder needs to be provided to restart/continue.
To create a
RemoteData instance, simply pass the remote path to the folder and the computer on which it is stored:
In [1]: RemoteData = DataFactory('remote') In [2]: computer = load_computer(label='computer_label') In [3]: remote = RemoteData(remote_path='/absolute/path/to/remote/directory' computer=local)
You can see the contents of the remote folder by using the
listdir() method:
In [4]: remote.listdir() Out[4]: ['file2.txt', 'file1.txt', 'subdir']
To see the contents of a subdirectory, pass the relative path to the
listdir() method:
In [5]: remote.listdir('subdir') Out[5]: ['file3.txt', 'module.py']
Materials science data types¶
Since AiiDA was first developed within the computational materials science community, aiida-core still contains several data types specific to this field. This sections lists these data types and provides some important examples of their usage.
StructureData¶
The
StructureData data type represents a structure, i.e. a collection of sites defined in a cell.
The boundary conditions are periodic by default, but can be set to non-periodic in any direction.
As an example, say you want to create a
StructureData instance for bcc Li.
Let’s begin with creating the instance by defining its unit cell:
In [1]: StructureData = DataFactory('structure') In [2]: unit_cell = [[3.0, 0.0, 0.0], [0.0, 3.0, 0.0], [0.0, 0.0, 3.0]] In [3]: structure = StructureData(cell=unit_cell)
注解
Default units for crystal structure cell and atomic coordinates in AiiDA are Å (Ångström).
Next, you can add the Li atoms to the structure using the
append_atom() method:
In [4]: structure.append_atom(position=(0.0, 0.0, 0.0), symbols="Li") In [5]: structure.append_atom(position=(1.5, 1.5, 1.5), symbols="Li")
You can check if the cell and sites have been set up properly by checking the
cell and
sites properties:
In [6]: structure.cell Out[6]: [[3.5, 0.0, 0.0], [0.0, 3.5, 0.0], [0.0, 0.0, 3.5]] In [7]: structure.sites Out[7]: [<Site: kind name 'Li' @ 0.0,0.0,0.0>, <Site: kind name 'Li' @ 1.5,1.5,1.5>]
From the
StructureData node you can also obtain the formats of well-known materials science Python libraries such as the Atomic Simulation Environment (ASE) and pymatgen:
In [8]: structure.get_ase() Out[8]: Atoms(symbols='Li2', pbc=True, cell=[3.5, 3.5, 3.5], masses=...) In [9]: structure.get_pymatgen() Out[9]: Structure Summary Lattice abc : 3.5 3.5 3.5 angles : 90.0 90.0 90.0 volume : 42.875 A : 3.5 0.0 0.0 B : 0.0 3.5 0.0 C : 0.0 0.0 3.5 PeriodicSite: Li (0.0000, 0.0000, 0.0000) [0.0000, 0.0000, 0.0000] PeriodicSite: Li (1.5000, 1.5000, 1.5000) [0.4286, 0.4286, 0.4286]
Exporting¶
The following export formats are available for
StructureData:
xsf(format supported by e.g. XCrySDen and other visualization software; supports periodic cells)
xyz(classical xyz format, does not typically support periodic cells (even if the cell is indicated in the comment line)
cif(export to CIF format, without symmetry reduction, i.e. always storing the structure as P1 symmetry)
The node can be exported using the verdi CLI, for example:
$ verdi data structure export --format xsf <IDENTIFIER> > Li.xsf
Where
<IDENTIFIER> is one of the possible identifiers of the node, e.g. its PK or UUID.
This outputs the structure in
xsf format and writes it to a file.
TrajectoryData¶
The
TrajectoryData data type represents a sequences of StructureData objects, where the number of atomic kinds and sites does not change over time.
Beside the coordinates, it can also optionally store velocities.
If you have a list of
StructureData instances called
structure_list that represent the trajectory of your system, you can create a
TrajectoryData instance from this list:
In [1]: TrajectoryData = DataFactory('array.trajectory') In [2]: trajectory = TrajectoryData(structure_list)
Note that contrary with the
StructureData data type, the cell and atomic positions are stored a
numpy array in the repository and not in the database.
Exporting¶
You can export the py:class:~aiida.orm.nodes.data.array.trajectory.TrajectoryData node with
verdi data trajectory export, which accepts a number of formats including
xsf and
cif, and additional parameters like
--step NUM (to choose to export only a given trajectory step).
The following export formats are available:
xsf(format supported by e.g. XCrySDen and other visualization software; supports periodic cells)
cif(export to CIF format, without symmetry reduction, i.e. always storing the structures as P1 symmetry)
UpfData¶
The
UpfData data type represents a pseudopotential in the .UPF format (e.g. used by Quantum ESPRESSO - see also the AiiDA Quantum ESPRESSO plugin).
Usually these will be installed as part of a pseudopotential family, for example via the aiida-pseudo package.
To see the pseudopotential families that have been installed in your AiiDA profile, you can use the verdi CLI:
$ verdi data upf listfamilies Success: * SSSP_v1.1_precision_PBE [85 pseudos] Success: * SSSP_v1.1_efficiency_PBE [85 pseudos]
KpointsData¶
The
KpointsData data type represents either a grid of k-points (in reciprocal space, for crystal structures), or explicit list of k-points (optionally with a weight associated to each one).
To create a
KpointsData instance that describes a regular (2 x 2 x 2) mesh of k-points, execute the following set of commands in the
verdi shell:
In [1]: KpointsData = DataFactory('array.kpoints') ...: kpoints_mesh = KpointsData() ...: kpoints_mesh.set_kpoints_mesh([2, 2, 2])
This will create a (2 x 2 x 2) mesh centered at the Gamma point (i.e. without offset).
Alternatively, you can also define a
KpointsData node from a list of k-points using the
set_kpoints() method:
In [2]: kpoints_list = KpointsData() ...: kpoints_list.set_kpoints([[0, 0, 0], [0.5, 0.5, 0.5]])
In this case, you can also associate labels to (some of the) points, which is very useful for generating plots of the band structure (and storing them in a
BandsData instance):
In [3]: kpoints_list.labels = [[0, "G"]] In [4]: kpoints_list.labels Out[4]: [(0, 'G')]
Automatic computation of k-point paths¶
AiiDA provides a number of tools and wrappers to automatically compute k-point paths given a cell or a crystal structure.
The main interface is provided by the two methods
aiida.tools.data.array.kpoints.get_kpoints_path() and
aiida.tools.data.array.kpoints.get_explicit_kpoints_path().
These methods are also conveniently exported directly as, e.g.,
aiida.tools.get_kpoints_path.
The difference between the two methods is the following:
get_kpoints_path()returns a dictionary of k-point coordinates (e.g.
{'GAMMA': [0. ,0. ,0. ], 'X': [0.5, 0., 0.], 'L': [0.5, 0.5, 0.5]}, and then a list of tuples of endpoints of each segment, e.g.
[('GAMMA', 'X'), ('X', 'L'), ('L', 'GAMMA')]for the \(\Gamma-X-L-\Gamma\) path.
get_explicit_kpoints_path(), instead, returns a list of kpoints that follow that path, with some predefined (but user-customizable) distance between points, e.g. something like
[[0., 0., 0.], [0.05, 0., 0.], [0.1, 0., 0.], ...].
Depending on how the underlying code works, one method might be preferred on the other.
The docstrings of the methods describe the expected parameters.
The general interface requires always a
StructureData as the first parameter
structure, as well as a string for the method to use (by default this is seekpath, but also the
legacy method implemented in earlier versions of AiiDA is available; see description below).
Additional parameters are passed as
kwargs to the underlying implementation, that often accepts a different number of parameters.
Seekpath implementation¶
When specifying
method='seekpath', the seekpath library is used to generate the path.
Note that this requires
seekpath to be installed (this is not available by default, in order to reduce the dependencies of AiiDA core, but can be easily installed using
pip install seekpath).
For a full description of the accepted parameters, we refer to the docstring of the underlying methods
aiida.tools.data.array.kpoints.seekpath.get_explicit_kpoints_path() and
aiida.tools.data.array.kpoints.seekpath.get_kpoints_path(), and for more general information to the seekpath documentation.
If you use this implementation, please cite the Hinuma paper:
Y. Hinuma, G. Pizzi, Y. Kumagai, F. Oba, I. Tanaka, Band structure diagram paths based on crystallography, Comp. Mat. Sci. 128, 140 (2017) DOI: 10.1016/j.commatsci.2016.10.015
Legacy implementation
This refers to the implementation that has been available since the early versions of AiiDA.
注解
In the 3D case (all three directions have periodic boundary conditions), this implementation expects that the structure is already standardized according to the Setyawan paper (see journal reference below). If this is not the case, the kpoints and band structure returned will be incorrect. The only case that is dealt correctly by the library is the case when axes are swapped, where the library correctly takes this swapping/rotation into account to assign kpoint labels and coordinates.
We therefore suggest that you use the seekpath implementation, that is able to automatically correctly identify the standardized crystal structure (primitive and conventional) as described in the Hinuma paper.
For a full description of the accepted parameters, we refer to the docstring of the underlying methods
aiida.tools.data.array.kpoints.legacy.get_explicit_kpoints_path() and
aiida.tools.data.array.kpoints.legacy.get_kpoints_path(), and for more general information to the seekpath documentation.
If you use this implementation, please cite the correct reference from the following ones:
The 3D implementation is based on the Setyawan paper:
W. Setyawan, S. Curtarolo, High-throughput electronic band structure calculations: Challenges and tools, Comp. Mat. Sci. 49, 299 (2010) DOI: 10.1016/j.commatsci.2010.05.010
The 2D implementation is based on the Ramirez paper:
R. Ramirez and M. C. Bohm, Simple geometric generation of special points in brillouin-zone integrations. Two-dimensional bravais lattices Int. J. Quant. Chem., XXX, 391-411 (1986) DOI: 10.1002/qua.560300306
BandsData¶
The
BandsData data type is dedicated to store band structures of different types (electronic bands, phonons, or any other band-structure-like quantity that is a function of the k-points in the Brillouin zone).
In this section we describe the usage of the
BandsData to store the electronic band structure of silicon and some logic behind its methods.
The dropdown panels below explain some expanded use cases on how to create a
BandsData node and plot the band structure.
Creating a
BandsData instance manually
To start working with the
BandsData data type we should import it using the
DataFactory and create an object of type
BandsData:
from aiida.plugins import DataFactory BandsData = DataFactory('array.bands') bands_data = BandsData()
To import the bands we need to make sure to have two arrays: one containing kpoints and another containing bands.
The shape of the kpoints object should be
nkpoints * 3, while the shape of the bands should be
nkpoints * nstates.
Let’s assume the number of kpoints is 12, and the number of states is 5.
So the kpoints and the bands array will look as follows:
import numpy as np kpoints = np.array( [[0. , 0. , 0. ], # array shape is 12 * 3 [0.1 , 0. , 0.1 ], [0.2 , 0. , 0.2 ], [0.3 , 0. , 0.3 ], [0.4 , 0. , 0.4 ], [0.5 , 0. , 0.5 ], [0.5 , 0. , 0.5 ], [0.525 , 0.05 , 0.525 ], [0.55 , 0.1 , 0.55 ], [0.575 , 0.15 , 0.575 ], [0.6 , 0.2 , 0.6 ], [0.625 , 0.25 , 0.625 ]]) bands = np.array( [[-5.64024889, 6.66929678, 6.66929678, 6.66929678, 8.91047649], # array shape is 12 * 5, where 12 is the size of the kpoints mesh [-5.46976726, 5.76113772, 5.97844699, 5.97844699, 8.48186734], # and 5 is the numbe of states [-4.93870761, 4.06179965, 4.97235487, 4.97235488, 7.68276008], [-4.05318686, 2.21579935, 4.18048674, 4.18048675, 7.04145185], [-2.83974972, 0.37738276, 3.69024464, 3.69024465, 6.75053465], [-1.34041116, -1.34041115, 3.52500177, 3.52500178, 6.92381041], [-1.34041116, -1.34041115, 3.52500177, 3.52500178, 6.92381041], [-1.34599146, -1.31663872, 3.34867603, 3.54390139, 6.93928289], [-1.36769345, -1.24523403, 2.94149041, 3.6004033 , 6.98809593], [-1.42050683, -1.12604118, 2.48497007, 3.69389815, 7.07537154], [-1.52788845, -0.95900776, 2.09104321, 3.82330632, 7.20537566], [-1.71354964, -0.74425095, 1.82242466, 3.98697455, 7.37979746]])
To insert kpoints and bands in the
bands_data object we should employ
set_kpoints() and
set_bands() methods:
bands_data.set_kpoints(kpoints) bands_data.set_bands(bands, units='eV')
Plotting the band structure
Next we want to visualize the band structure. Before doing so, one thing that we may want to add is the array of kpoint labels:
labels = [(0, 'GAMMA'), (5, 'X'), (6, 'X'), (11, 'U')] bands_data.labels = labels bands_data.show_mpl() # to visualize the bands
The resulting band structure will look as follows
警告
As with any AiiDA node, once the
bands_data object is stored (
bands_data.store()) it won’t accept any modifications.
You may notice that depending on how you assign the kpoints labels the output of the
show_mpl() method looks different.
Please compare:
bands_data.labels = [(0, 'GAMMA'), (5, 'X'), (6, 'Y'), (11, 'U')] bands_data.show_mpl() bands_data.labels = [(0, 'GAMMA'), (5, 'X'), (7, 'Y'), (11, 'U')] bands_data.show_mpl()
In the first case two neighboring kpoints with
X and
Y labels will look like
X|Y, while in the second case they will be separated by a certain distance.
The logic behind such a difference is the following.
In the first case the plotting method discovers the two neighboring kpoints and assumes them to be a discontinuity point in the band structure (e.g. Gamma-X|Y-U).
In the second case the kpoints labelled
X and
Y are not neighbors anymore, so they are plotted with a certain distance between them.
The intervals between the kpoints on the X axis are proportional to the cartesian distance between them.
Dealing with spins
The
BandsData object can also deal with the results of spin-polarized calculations.
Two provide different bands for two different spins you should just merge them in one array and import them again using the
set_bands() method:
bands_spins = [bands, bands-0.3] # to distinguish the bands of different spins we subtract 0.3 from the second band structure bands_data.set_bands(bands_spins, units='eV') bands_data.show_mpl()
Now the shape of the bands array becomes
nspins * nkpoints * nstates
Exporting
The
BandsData data type can be exported with
verdi data bands export, which accepts a number of formats including (see also below) and additional parameters like
--prettify-format FORMATNAME, see valid formats below, or
--y-min-lim,
--y-max-lim to specify the
y-axis limits.
The following export formats are available:
agr: export a Xmgrace .agr file with the band plot
agr_batch: export a Xmgrace batch file together with an independent .dat file
dat_blocks: export a .dat file, where each line has a data point (xy) and bands are separated in blocks with empty lines.
dat_multicolumn: export a .dat file, where each line has all the values for a given x coordinate:
x y1 y2 y3 y4 ...(
xbeing a linear coordinate along the band path and
yNbeing the band energies).
gnuplot: export a gnuplot file, together with a .dat file.
json: export a json file with the bands divided into segments.
mpl_singlefile: export a python file that when executed shows a plot using the
matplotlibmodule. All data is included in the same python file as a multiline string containing the data in json format.
mpl_withjson: As above, but the json data is stored separately in a different file.
mpl_pdf: As above, but after creating the .py file it runs it to export the band structure in a PDF file (vectorial). NOTE: it requires that you have the python
matplotlibmodule installed. If
use_latexis true, it requires that you have LaTeX installed on your system to typeset the labels, as well as the
dvipngbinary.
mpl_png: As above, but after creating the .py file it runs it to export the band structure in a PDF file (vectorial). NOTE: this format has the same dependencies as the
mpl_pdfformat above.
AiiDA provides a number of functions to “prettify” the labels of band structures (if labels are present in the data node), i.e., replace
GAMMA with \(\Gamma\) or
K_1 with \(K_{1}\) for instance.
This makes sense for some output formats (e.g. Xmgrace, Gnuplot, matplotlib).
The prettifier functions are defined as methods of the
Prettifier class and can be obtained calling
Prettifier.get_prettifiers().
The prettifiers should be chosen depending on two aspects:
How the raw labels are stored in the database. Two types exist currently:
seekpath, as used in the
seekpathmodule, where Greek letters are written explicitly (e.g.
GAMMA) and underscores are used to indicate a subscript (
K_1); and the “old”
simpleformat, where \(\Gamma\) is indicated with
Gand there is no underscore symbol).
Depending on the output format: xmgrace has a specific syntax for Greek letters and subscripts, matplotlib uses LaTeX syntax, etc.
Most export formats already decide which prettifier is best to use, but if you need
to change it, you can do it passing the
prettify_format parameter to the
export() method.
Valid prettifiers include:
agr_seekpath: format for Xmgrace, using
seekpathraw label syntax.
agr_simple: format for Xmgrace, using
simpleraw label syntax.
latex_simple: format for LaTeX (including dollar signs), using
seekpathraw label syntax.
latex_seekpath: format for LaTeX (including dollar signs), using
simpleraw label syntax.
gnuplot_simple: format for GNUPlot (Unicode for Greek letters, LaTeX syntax without dollar signs for underscores), using
seekpathraw label syntax.
gnuplot_seekpath: format for GNUPlot (Unicode for Greek letters, LaTeX syntax without dollar signs for underscores), using
simpleraw label syntax.
pass: no-op prettifier: leaves all strings unchanged to their raw value.
Exporting data nodes¶
Next to the CLI commands described above, each data node has a
export() method that allows to export the given data node to file in a variety of available formats, e.g. to pass it to a visualization software.
The
export() method asks for a filename, and it will write to file the result.
It is possible that more than one file is written (for example, if you produce a gnuplot script, the data will typically be in a different .dat file).
The return value of the function is a list of files that have been created.
The list of export formats depends on the specific Data plugin.
The export format is typically inferred from the file extension, but if this is not possible (or you want to specify a given format), you can pass an additional
fileformat parameter to
export().
The list of all valid export formats can be obtained calling
Data.get_export_formats() method, that returns a list of strings with all valid formats.
If you don’t want to export directly to a file, but want to get simply the content of the file as a string, then you can call the
_exportcontent() method, passing also a
fileformat parameter.
The return value is a tuple of length 2: the first element is a string with the content of the “main” file, while the second is a dictionary (possibly empty) with a list of additional files that should be created/needed: the keys are filenames, and the values are the files content.
Adding support for custom data types¶
The nodes in the provenance graph that are the inputs and outputs of processes are referred to as data and are represented by
Data nodes.
Since data can come in all shapes and forms, the
Data class can be sub classed.
AiiDA ships with some basic data types such as the
Int which represents a simple integer and the
Dict, representing a dictionary of key-value pairs.
There are also more complex data types such as the
ArrayData which can store multidimensional arrays of numbers.
These basic data types serve most needs for the majority of applications, but more specific solutions may be useful or even necessary.
In the next sections, we will explain how a new data type can be created and what guidelines should ideally be observed during the design process.
Creating a data plugin¶
Creating a new data type is as simple as creating a new sub class of the base
Data class.
from aiida.orm import Data class NewData(Data): """A new data type that wraps a single value."""
At this point, our new data type does nothing special.
Typically, one creates a new data type to represent a specific type of data.
For the purposes of this example, let’s assume that the goal of our
NewData type is to store a single numerical value.
To allow one to construct a new
NewData data node with the desired
value, for example:
node = NewData(value=5)
we need to allow passing that value to the constructor of the node class.
Therefore, we have to override the constructor
__init__():
from aiida.orm import Data class NewData(Data): """A new data type that wraps a single value.""" def __init__(self, **kwargs): value = kwargs.pop('value') super().__init__(**kwargs) self.set_attribute('value', value)
警告
For the class to function properly, the signature of the constructor cannot be changed and the constructor of the parent class has to be called.
Before calling the constructor of the base class, we have to remove the
value keyword from the keyword arguments
kwargs, because the base class will not expect it and will raise an exception if left in the keyword arguments.
The final step is to actually store the value that is passed by the caller of the constructor.
A new node has two locations to permanently store any of its properties:
-
the database
-
the file repository
The section on design guidelines will go into more detail what the advantages and disadvantages of each option are and when to use which.
For now, since we are storing only a single value, the easiest and best option is to use the database.
Each node has attributes that can store any key-value pair, as long as the value is JSON serializable.
By adding the value to the node’s attributes, they will be queryable in the database once an instance of the
NewData node is stored.
node = NewData(value=5) # Creating new node instance in memory node.set_attribute('value', 6) # While in memory, node attributes can be changed node.store() # Storing node instance in the database
After storing the node instance in the database, its attributes are frozen, and
node.set_attribute('value', 7) will fail.
By storing the
value in the attributes of the node instance, we ensure that that
value can be retrieved even when the node is reloaded at a later point in time.
Besides making sure that the content of a data node is stored in the database or file repository, the data type class can also provide useful methods for users to retrieve that data.
For example, with the current state of the
NewData class, in order to retrieve the
value of a stored
NewData node, one needs to do:
node = load_node(<IDENTIFIER>) node.get_attribute('value')
In other words, the user of the
NewData class needs to know that the
value is stored as an attribute with the name ‘value’.
This is not easy to remember and therefore not very user-friendly.
Since the
NewData type is a class, we can give it useful methods.
Let’s introduce one that will return the value that was stored for it:
from aiida.orm import Data class NewData(Data): """A new data type that wraps a single value.""" ... @property def value(self): """Return the value stored for this instance.""" return self.get_attribute('value')
The addition of the instance property
value makes retrieving the value of a
NewData node a lot easier:
node = load_node(<IDENTIFIER) value = node.value
As said before, in addition to their attributes, data types can also store their properties in the file repository. Here is an example for a custom data type that needs to wrap a single text file:
import os from aiida.orm import Data class TextFileData(Data): """Data class that can be used to wrap a single text file by storing it in its file repository.""" def __init__(self, filepath, **kwargs): """Construct a new instance and set the contents to that of the file. :param file: an absolute filepath of the file to wrap """ super().__init__(**kwargs) filename = os.path.basename(filepath) # Get the filename from the absolute path self.put_object_from_file(filepath, filename) # Store the file in the repository under the given filename self.set_attribute('filename', filename) # Store in the attributes what the filename is def get_content(self): """Return the content of the single file stored for this data node. :return: the content of the file as a string """ filename = self.get_attribute('filename') return self.get_object_content(filename)
To create a new instance of this data type and get its content:
node = TextFileData(filepath='/some/absolute/path/to/file.txt') node.get_content() # This will return the content of the file
This example is a simplified version of the
SinglefileData data class that ships with
aiida-core.
If this happens to be your use case (or very close to it), it is of course better to use that class, or you can sub class it and adapt it where needed.
The just presented examples for new data types are of course trivial, but the concept is always the same and can easily be extended to more complex custom data types. The following section will provide useful guidelines on how to optimally design new data types.
Database or repository?¶
When deciding where to store a property of a data type, one has the option to choose between the database and the file repository.
All node properties that are stored in the database (such as the attributes), are directly searchable as part of a database query, whereas data stored in the file repository cannot be queried for.
What this means is that, for example, it is possible to search for all nodes where a particular database-stored integer attribute falls into a certain value range, but the same value stored in a file within the file repository would not be directly searchable in this way.
However, storing large amounts of data within the database comes at the cost of slowing down database queries.
Therefore, big data (think large files), whose content does not necessarily need to be queried for, is better stored in the file repository.
A data type may safely use both the database and file repository in parallel for individual properties.
Properties stored in the database are stored as attributes of the node.
The node class has various methods to set these attributes, such as
set_attribute() and
set_attribute_many(). | https://aiida.readthedocs.io/projects/aiida-core/zh_CN/latest/topics/data_types.html | CC-MAIN-2022-21 | refinedweb | 5,862 | 53.92 |
These changes are in more-or-less reverse chronological order, with the most recent changes first.
See also the list of Qexo (XQuery)-specific changes.
The
(? name::type value) operator
supports conditional binding.
More efficient implementation of
call-with-values:
If either argument is a fixed-arity lambda expression it is inlined.
Better type-checking of both
call-with-values and
values.
New
define-alias can define aliases for
static class members.
The treatment of keywords is changing to not be self-evaluating (in Scheme). If you want a literal keyword, you should quote it. Unquoted keywords should only be used for keyword arguments. (This will be enforced in a future release.) The compiler now warns about badly formed keyword arguments, for example if a value is missing following a keyword.
The default is now Java 7, rather than Java 6. This means the checked-in source code is pre-processed for Java 7, and future binary releases will require Java 7.
The behavior of parameters and fluid variables has changed. Setting a parameter no longer changes its value in already-running sub-threads. The implementation is simpler and should be more efficient.
The form
define-early-constant is similar to
define-constant, but it is evaluated in a module's
class initializer (or constructor in the case of a non-static definition).
Almost all of R7RS is now working:
Importing a SRFI library can now use the syntax
(import (srfi N [name]))
The various standard libraries such as
(scheme base) are implemented.
The functions
eval and
load
can now take an environment-specifier.
Implemented the
environment function.
Extended
numerator,
denominator,
gcd, and
lcm to inexacts.
The full R7RS library functionality is working,
including
define-library
The keyword
export is now a synonym for
module-export,
and both support the
rename keyword.
The
prefix option of
import now works.
The
cond-expand form now supports the
library clause.
Implemented
make-promise and
delay-force
(equivalent to the older name
lazy).
Changed
include so that by default it first seaches the
directory containing the included file, so by default it has the
same effect as
include-relative. However, you can
override the search path with the
-Dkawa.include.path property.
Also implemented
include-ci.
Implemented
define-values.
Fixed
string->number to correctly handle a
radix specifier in the string.
The
read procedure now returns mutable pairs.
If you need to use
... in a
syntax-rules
template you can use
(... template), which disables
the special meaning of
... in
template.
(This is an extension of the older
(... ...).)
Alternatively, you can can write
(syntax-rules dots (literals) rules). The symbol
dots replaces the functionality of
... in the
rules.
An underscore
_ in a
syntax-rules pattern
matches anything, and is ignored.
The
syntax-error syntax
(renamed from
%syntax-error) allows error reporting in
syntax-rules macros.
(The older Kawa-specific
syntax-error procedure was renamed
to
report-syntax-error.)
Implemented and documented R7RS exception handling:
The syntax
guard and the procedures
with-exception-handler,
raise, and
raise-continuable all work.
The
error procedure is R7RS-compatible, and the
procedures
error-object?,
error-object-message,
error-object-irritants,
file-error?,
and
read-error? were implemented.
Implemented
emergency-exit, and modified
exit
so finally-blocks are executed.
Implemented
exact-integer?,
floor/,
floor-quotient,
floor-remainder,
truncate/,
truncate-quotient,
and
truncate-remainder.
The
letrec* syntax is now supported.
(It works the same as
letrec, which is an
allowed extension of
letrec.)
The functions
utf8->string
and
string->utf8 are now documented in the manual.
The changes to characters and strings are worth covering separately:
The
character type is now a new primitive type
(implemented as
int). This can avoid boxing (object allocation)
There is also a new Functions like Implemented a Optimized Implemented New function New function The SRFI-13 function
character-or-eof.
(A union of
character and the EOF value, except the
latter is encoded as -1, thus avoiding object allocation.)
The functions
peek-char now
return a
character-or-eof value.
string-ref that take a character
index would not take into account non-BMP characters (those whose value
is greater than
#xffff, thus requiring two surrogate characters).
This was contrary to R6RS/R7RS. This has been fixed, though at some
performance cost . (For example
string-ref and
string-length are no longer constant-time.)
string-cursor API (based on Chibi Scheme).
Thes allow efficient indexing, based on opaque cursors (actually
counts of 16-bits
chars).
string-for-each, which is now the
preferred way to iterate through a string.
string-map.
string-append! for in-place
appending to a mutable string.
string-replace! for replacing a
substring of a string with some other string.
string-append/shared
is no longer automatically visible; you have to
(import (srfi :13 strings)) or similar.
Functions like
Implemented a
Optimized
Implemented
New function
New function
The SRFI-13 function
The
module-name form allows the name to be a list,
as in a R6RS/R7RS-style library name.
The syntax
@expression is a splicing form.
The
expression must evaluate to a sequence
(vector, list, array, etc). The function application or
constructor form is equivalent to all the elements of the sequence.
The parameter object
current-path returns (or sets)
the default directory of the current thread.
Add convenience procedures and syntax for
working with processes:
run-process,
process-exit-wait,
process-exit-ok?,
&cmd,
&`,
&sh.
The functions
path-bytes, and
path-data can
read or write the entire contents of a file.
Alternatively, you can use the short-hand syntax:
&<{pname}
&>{pname}
&>>{pname}.
These work with "blobs" which may be text or binary depending on context.
The initial values of
(current-output-port)
and
(current-error-port) are now hybrid textual/binary ports.
This means you can call
write-bytevector
and
write-u8 on them, making it possible for an application
to write binary data to standard output.
Similarly, initial value of
(current-input-port)
is a hybrid textual/binary port, but only if there is no console
(standard input is not a tty).
Jamison Hope contributed support for quaternions, a generalization of complex numbers containing 4 real components.
Andrea Bernardini contributed an optimized implementation
of
case expressions. He was sponsored by Google Summer of Code.
The
kawa.sh shell script (which is installed
as
kawa when not configuring with
--enable-kawa-frontend now handles
-D
and
-J options.
The
kawa.sh script is now also built when usint Ant.
The
cond-expand features
java-6
though
java-9 are now set based on the
System property
"java.version"
(rather than how Kawa was configured).
An Emacs-style
coding declaration allows you
to specify the encoding of a Scheme source file.
The command-line option
--debug-syntax-pattern-match
prints logging importation to standard error when a
syntax-rules
or
syntax-case pattern matches.
SRFI-60 (Integers as Bits) is now fully implemented.
Ported SRFI-101. These are.
The class
kawa.lib.kawa.expressions
contains an experimental Scheme API for manipulating and validating expressions.
Internal: Changed representation used for multiple values to an abstract class with multiple implementations.
Internal: Started converting to more standard Java code formatting and indentation conventions, rather than GNU conventions. Some files converted; this is ongoing work.
Internal: Various I/O-related classes moved to new
package
gnu.kawa.io.
Various changes to the
configure+make build framework:
A C compiler is now only needed if you configure with
--enable-kawa-frontend.
Improved support for building under Windows (using MinGW/MSYS).
Support for building with GCJ was removed.
You can pass flags from the
kawa front-end to the
java launcher using
-J and
-D flags.
The
kawa front-end now passes the
kawa.command.line property to Java; this is
used by the
(command-line) procedure.
Various improvements to the shell-script handling, including re-written documentation.
Some initial support for Java 8.
More of R7RS is now working:
make-list,
list-copy,
list-set!all the R7RS list procedures are implemented.
square,
boolean=?,
string-copy!,
digit-value,
get-environment-variable,
get-environment-variables,
current-second,
current-jiffy,
jiffies-per-second, and
features.
finite?,
infinite?, and
nan?are generalized to complex numbers.
write,
write-simple, and
write-sharedare now consistent with R7RS.
string-copy,
string->list, and
string-fill!now take optional (start,end)-bounds. All of the R7RS string functions are now implemented.
=>syntax in
caseform.
'|Hello\nworld|.
Added
define-private-alias keyword.
Extended string quasi-literals
(templates) as specified by SRFI-109. For example,
if
name has the value
"John", then:
&{Hello &[name]!}evaluates to:
"Hello John!".
Named quasi-literal constructors as specified by SRFI-108.
A symbol having the form
->type is a type
conversion function that converts a value to
type.
New and improved check for void-valued expressions in a
context requiring a value.
This is controlled by the new option
--warn-void-used,
which defaults to true.
The
datum->syntax procedure takes an
optional third parameter to specify the source location.
See
testsuite/srfi-108-test.scm for an example.
Instead of specifying
--main the command line,
you can now specify
(module-compile-options: main: #t) in
the Scheme file. This makes it easier to compile one or more
application (main) modules along with other modules.
A change to the data structure used to detect never-returning
procedure uses a lot less memory. (Kawa 1.13 implemented a
conservative detection of when a procedure cannot return.
This analysis would sometimes cause the Kawa compiler to run out of memory.
The improved analysis uses the same basic algorithm, but
with a more space-efficient
inverted data structure.)
Multiple fixes to get Emacs Lisp (JEmacs) working (somewhat) again.
We now do a simple (conservative) analysis of when a procedure cannot return. This is combined with earlier and more precise analysis of reachable code. Not only does this catch programmer errors better, but it also avoids some internal compiler errors, because Kawa could get confused by unreachable code.
Implement 2-argument version of
log function,
as specified by R6RS and R7RS (and, prematurely, the Kawa documentation).
Implement the R7RS
bytevector functions.
The
bytevector type is a synonym for older
u8vector type.
Implement R7RS
vector procedures.
Various procedures now take (start,end)-bounds.
Implement most of the R7RS input/output proecdures. Most significant enhancement is support for R7RS-conforming binary ports.
Various enhancements to the manual, including merging in lots of text from R7RS.
Improved Android support, including a more convenient Ant script contributed by Julien Rousseau. Also, documentation merged into manual.
Implement a compile-time data-flow framework, similar to Single Static Assignment. This enables better type inference, improves some warnings/errors, and enables some optimizations.
Jamison Hope added support for co-variant return types and bridge methods for generics.
datum->syntaxand
syntax->datumare preferred names for
datum->syntax-objectand
syntax-object->datum.
Implemented
bound-identifier=?
and re-wrote implementation of
free-identifier=?.
unsyntaxand
unsyntax-splicing, along with the reader prefixes
#,and
#,@.
New and improved lazy evaluation functionality:
Lazy values (resulting from
delay or
future)
are implicitly forced as needed.
This makes
lazy programming more convenient.
New type
promise.
The semantics of promises (
delay etc) is now compatible with
SRFI 45.
Blank promises are useful for passing data between processes,
logic programmming, and more.
New functions
promise-set-value!,
promise-set-alias!,
promise-set-exception!, and
promise-set-thunk!.
The stream functions of SRFI-41 were re-implemented to use the new promise functionality.
Different functions in the same module can be compiled with or
without full tailcall support. You can control this by using
full-tailcalls in
with-compile-options.
You can also control
full-tailcalls using
module-compile-options.
Charles Turner (sponsored by Google's Summer of Code) enhanced the printer with support for SRFI-38: External Representation for Data With Shared Structure.
Optimize tail-recursion in module-level procedures. (We used to only do this for internal functions, for reasons that are no longer relevant.)
Add support for building Kawa on Windows using configure+make (autotools) and Cygwin.
Some support for parameterized (generic) types:
Type[Arg1 Arg2 ... ArgN]is more-or-less equivalent to Java's:
Type<Arg1, Arg2, ..., ArgN>
New language options
--r5rs,
--r6rs,
and
--r7rs provide better compatibility with those
Scheme standards. (This is a work-in-progress.)
For example
--r6rs aims to disable Kawa extensions
that conflict with R6RS. It does not aim to disable all extensions,
only incompatible extensions.
So far these extensions disable the colon operator and keyword literals.
Selecting
--r5rs makes symbols by default
case-insensitive.
The special tokens
#!fold-case and
#!no-fold-case act like comments except they
enable or disable case-folding of symbols.
The old
symbol-read-case global is now only checked
when a LispReader is created, not each time a symbol is read.
You can now use square brackets to construct immutable sequences (vectors).
A record type defined using
define-record-type
is now compiled to a class that is a member of the module class.
Annotations are now supported. This example shows how to use JAXB annotations to automatically convert between between Java objects and XML files.
Prevent mutation of vector literals.
More R6RS procedures:
vector-map,
vector-for-each,
string-for-each,
real-valued?,
rational-valued?,
integer-valued?,
finite?,
infinite?,
nan?,
exact-integer-sqrt.
SRFI-14 ("character sets") and SRFI-41 ("streams") are now supported, thanks to porting done by Jamison Hope.
Kawa now runs under JDK 1.7. This mostly involved fixing some
errors in
StackMapTable generation.
You can now have a class created by
define-simple-class
with the same name as the module class. For example
(define-simple-class foo ...) in a file
foo.scm. The defined class will
serve dual-purpose as the module class.
Improvements in separating compile-time from run-time code, reducing the size of the runtime jar used for compiled code.
In the
cond-expand conditional form you can
now use
class-exists:ClassName as a
feature
name to tests that
ClassName exists.
A new Kawa logo, contributed by Jakub Jankiewicz.
A new
--warn-unknown-member option, which generalizes
--warn-invoke-unknown-method to fields as well as methods.
A new
kawac task, useful for Ant
build.xml files, contributed by Jamison Hope.
New
define-enum macro contributed by Jamison Hope.
Access specifiers
'final and
'enum are now allowed in
define-class and related forms.
Optimized
odd? and
even?.
If you specify the type of a
#!rest parameter
as an array type, that will now be used for the "varargs" method parameter.
(Before only object arrays did this.)
When constructing an object and there is no matching
constructor method, look for "
add" methods in addition
to "
set" methods. Also, allow passing constructor args
as well as keyword setters.
See here for the gory details.
New
expand function (contributed by Helmut Eller,
and enabled by
(require 'syntax-utils)) for
converting Scheme expressions to macro-expanded forms.
SAM-conversion: In a context that expects a Single Abstract Method (SAM) type
(for example
java.lang.Runnable), if you pass a lambda
you will get an
object where the lambda implements
the abstract method.
In interactive mode allow dynamic rebinding of procedures. I.e. if you re-define a procedure, the old procedure objects gets modified in-place and re-used, rather than creating a new procedure object. Thus calls in existing procedures will call the new version.
Fix various threading issues related to compilation and eval.
When
format returns a string, return a
java.lang.String rather than a
gnu.lists.FString.
Also, add some minor optimization.
Inheritance of environments and fluid variables now work properly
for all child threads, not just ones created using
future.
Now defaults to using Java 6, when compiling from source.
The pre-built
jar works with Java 5, but makes
use of some Java 6 features (
javax.script, built-in HTTP server) if available.
You can write XML literals in Scheme code prefixed by a
#, for example:
#<p>The result is &{result}.</p>
New functions
element-name
and
attribute-name.
Various Web server improvements.
You have the option of using JDK 6's builtin
web-server
for auto-configued web pages.
Automatic import of web server functions, so
you should not need to
(import 'http) any more.
Kawa hashtables now extend
java.util.Map.
If a source file is specified on the
kawa command line
without any options, it is read and compiled as a whole module
before it is run. In contrast, if you want to read and evaluate a
source file line-by-line you must use the
-f flag.
You can specify a class name on the
kawa command line:
$ kawa fully.qualified.nameThis is like the
javacommand. but you don't need to specify the path to the Kawa runtime library, and you don't need a
mainmethod (as long as the class is
Runnable).
The usual bug-fixes, including better handling of the
~F
format directive; and fix in handling of macro hygiene of the
lambda (bug #27042).
Spaces are now optional before and after the '::' in type specifiers. The preferred syntax leave no space after the '::', as in:
(define xx ::int 1)
define-for-syntax and
begin-for-syntax work.
You can now use
car,
cdr etc to work with
syntax objects that wrap lists, as in SRFI-72.
You can now define a package alias:
(define-alias jutil java.util) (define mylist :: jutil:List (jutil:ArrayList))
--module-static is now the default.
A new
--module-nonstatic (or
--no-module-static)
option can be used to get the old behavior.
You can use
access: to specify that a field
is
'volatile or
'transient.
You can now have type-specifiers for multiple variables
in a
do.
Imported variables are read-only.
Exported variables are only made into Locations when needed.
The letter used for the exponent in a floating-point literal
determines its type:
12s2 is a
java.lang.Float,
12d2 is a
java.lang.Double,
12l2 is a
java.math.BigInteger,
12e2 is a
gnu.math.DFloat.
Internal: Asking for a
.class file using
getResourceAsStream on an
ArrayClassLoader
will now open a
ByteArrayInputStream on the class bytes.
A new
disassemble function.
If
exp1 has type
int,
the type of
(+ exp1 1) is now (32-bit)
int,
rather than (unlimited-precision)
integer.
Similar for
long expressions, other arithmetic operations
(as appropriate), and other untyped integer literals
(as long as they fit in 32/64 bits respectively).
Many more oprimization/specializations of arithmetic, especially when argument types are known.
Top-level bindings in a module compiled with
--main
are now implicitly module-private, unless there is an explicit
module-export.
SRFI-2 (
and-let*: an
and with local bindings, a guarded
* special form) is now supported.
The reader now supports shared sub-objects,
as in SRFI-38
and Common Lisp:
(#2=(3 4) 9 #2# #2#).
(Writing shared sub-objects is not yet implemented.)
A module compiled with
--main by default exports no
bindings (unless overriden by an explicit
module-export).
Factor out compile-time only code from run-time code.
The new
kawart-version.jar
is smaller because it has less compile-time only code. (Work in progress.)
More changes for R6RS compatibility:
The reader now recognizes
+nan.0,
+inf.0 and variations.
The
div,
mod,
div0,
mod0,
div-and-mod,
div0-and-mod0,
inexact
and
exact functions were implemented.
command-line and
exit.
Support for
javax.script.
Support for regular expressions.
Performance improvements:
Emit
iinc instruction (to increment a local
int by a constant).
Inline the
not function if the argument is constant.
If
call-with-current-continuation is only used to exit
a block in the current method, optimize to a
goto.
Generate
StackMapTable attributes when targeting Java 6.
Kawa can now inline a function with multiple calls (without
code duplication) if all call sites have the same return location
(continuation). For example:
(if p (f a) (f b)).
Also mutually tail-recursive functions are inlined, so you get constant
stack space even without
--full-tailcalls.
(Thanks for Helmut Eller for a prototype.)
A number of changes for R6RS compatibility:
The
char-titlecase,
char-foldcase,
char-title-case? library functions are implemented.
Imported variables are read-only.
Support the R6RS
import keyword, including
support for renaming.
Support the R6RS
export keyword (though
without support for renaming).
Implemented the
(rnrs hashtables) library.
Implemented the
(rnrs sorting) library.
CommonLisp-style keyword syntax is no longer supported (for Scheme): A colon followed by an identifier is no longer a keyword (though an identifier followed by a colon is still a keyword). (One reason for this change is to support SRFI-97.)
The character names
#\delete,
#\alarm,
#\vtab are now supported.
The old names
#\del,
#\rubout, and
#\bel are deprecated.
Hex escapes in character literals are supported. These are now printed where we before printed octal escapes.
A hex escape in a string literal should be terminated by a semi-colon, but for compatibily any other non-hex-digit will also terminate the escape. (A terminating semi-colon will be skipped, though a different terminator will be included in the string.)
A backslash-whitespace escape in a string literal will not only ignore the whitespace through the end of the line, but also any initial whitespace at the start of the following line.
The comment prefix
#; skips the following
S-expression, as specified by
SRFI-62.
All the R6RS exact bitwise arithmetic functions are
now implemented and documented in the manual.
The new standard functions (for example
bitwise-and)
are now preferred over the old functions (for example
logand).
If
delete-file fails, throws an
exception instead of returning
#f.
The code-base now by default assumes Java 5 (JDK 1.5 or newer),
and pre-built
jar files will require Java 5.
Also, the Kawa source code now uses generics, so you need to
use a generics-aware
javac,
passing it the appropriate
--target flag.
New SRFIs supported:
SRFI-62 - S-expression comments.
SRFI-64 - Scheme API for test suites.
SRFI-95 - Sorting and Merging.
SRFI-97 - Names for SRFI Libraries. This is a naming convention for R6RS
import statements to reference SRFI libraries.
In BRL text outside square brackets (or nested like
]this[)
now evaluates to
UnescapedData, which a Scheme quoted string
evaluates to
String, rather than an
FString.
(All of the mentioned types implement
java.lang.CharSequence.)
You can now run Kawa Scheme programs on Android, Google's mobile-phone operating system.
The macro
resource-url is useful for accessing resources.
A new command-line option
--target (or
-target)
similar to
javac's
-target option.
If there is no console, by default create a window
as if
-w was specificed.
If a class method (defined in
define-class,
define-simple-class or
object) does not have
its parameter or return type specified, search the super-classes/interfaces
for matching methods (same name and number of parameters), and if these
are consistent, use that type.
Trying to modify the
car or
cdr of a
literal list now throws an exception.
The
.zip archive created by
compile-file
is now compressed.
Java5-style varargs-methods are recognized as such.
When evaluating or loading a source file, we now always
compile to bytecode, rather than interpreting
simple
expressions. This makes semantics and performance more consistent,
and gives us better exception stack traces.
The Scheme type specifier
<integer>
now handles automatic conversion from
java.math.BigInteger
and the
java.lang classes
Long,
Integer,
Short, and
Byte.
The various standard functions that work on
<integer>
(for example
gcd and
arithmetic-shift)
can be passed (say) a
java.lang.Integer.
The generic functions such as
+ and the real
function
modulo should also work.
(The result is still a
gnu.math.IntNum.)
If a name such as (
java.util) is lexically
unbound, and there is a known package with that name, return the
java.lang.Package instance. Also, the colon operator
is extended so that
package:name
evaluates to the
Class for
package.name.
`prefix:,expression works
- it finds a symbol in
prefix's package (aka namespace),
whose local-name is the value of
expression.
A quantity
3.0cm is now syntactic sugar for
(* 3.0 unit:cm).
Similarly:
(define-unit name value)
is equivalent to:
(define-constant unit:name value)
This means that unit names follow normal name-lookup rules (except being in the
unit
package), so for example you can
have local unit definitions.
You can specify whether a class has public or package access, and whether it is translated to an interface or class.
You can declare an abstract method
by writing
#!abstract as its body.
If a name of the form
type? is undefined,
but
type is defined, then
treat the former as
(lambda (x) (instance? x type)).
A major incompatible (but long-sought) change:
Java strings (i.e.
java.lang.String values) are
now Scheme strings, rather than Scheme symbols.
Since Scheme strings are mutable, while Java
Strings are
not, we use a different type for mutable strings:
gnu.lists.FString (this is not a change).
Scheme string literals are
java.lang.String values.
The common type for Scheme string is
java.lang.CharSequence
(which was introducted in JDK 1.4).
Scheme symbols are now instances of
gnu.mapping.Symbol, specifically the
SimpleSymbol class.
A fully-qualified class name such as
java.lang.Integer
now evaluates to the corresponding
java.lang.Class object.
I.e. it is equivalent to the Java term
java.lang.Integer.class.
This assumes that the name does not have a lexical binding,
and that it exists in the class-path at compile time.
Array class names (such as
java.lang.Integer[])
and primitive types (such as
int) also work.
The older angle-bracket syntax
<java.lang.Integer>
also works and has the same meaning.
It also evaluates to a
Class.
It used to evaluate to a
Type, so this is a change.
The name bound by a
define-simple-class now evaluates to a
Class, rather than a
ClassType. A
define-simple-class is not allowed
to reference non-static module-level bindings; for that
use
define-class.
New convenience macro
define-syntax-case.
Fix some problems building Kawa from
source using
configure+make.
New types and functions for working with paths and URIs.
Reader macros URI, namespace, duration.
Simplified build using gcj, and added configure flag --with-gcj-dbtool.
If two
word values are written, a space is written between them.
A word is most Scheme values, including numbers and lists.
A Scheme string is treated as a word by
write but by not
display.
A new
--pedantic command-line flag.
It currently only affects the XQuery parser.
The
load-compile procedure was removed.
The string printed by the
--version switch
now includes the Subversion revision and date
(but only if Kawa was built using
make rather than
ant from a checked-out Subversion tree).
Kawa development now uses the Subversion (svn) version control system instead of CVS.
Show file/line/column on unbound symbols (both when interpreted and when compiled).
Cycles are now allowed between
require'd modules.
Also, compiling at set of modules that depend on each other can now
specified on the compilation command line in any order, as long as
needed
require forms are given.
The
colon notation has been generalized..
The syntax
object:name
generally means to extract a component with a given
name
from
object, which may be an object, a class,
or a namespace.
New command-line options
--debug-error-prints-stack-trace
and
--debug-warning-prints-stack-trace provide stack trace
on static error messages.
The license for the Kawa software has been changed to the X11/MIT license.
A much more convenient syntax for working with Java arrays.
The same function-call syntax also works for Scheme vectors, uniform
vectors, strings, lists - and anything else that implements
java.util.List.
The fields and methods of a class and its bases classes are in scope within methods of the class.
Unnamed procedures (such as lambda expressions) are printed with the source filename and line.
The numeric compare functions (
=,
<=, etc)
and
number->string now work when passed standard Java
Number objects (such as
java.lang.Long
or
java.math.BigDecimal).
SRFI-10
is now implemented, providing the
#,(name args ...) form.
Predefined constructor
names so far are
URI
and
namespace.
The
define-reader-ctor function is available
if you
(require 'srfi-10).
A new
--script option makes it easier to write
Unix shell scripts.
Allow general URLs for loading (including the
-f flag),
compilation and
open-input-file, if the
file name starts with a URL
scheme like
http:.
Classes defined (e.g. with
define-simple-class) in
a module can now mutually reference each other.
On the other hand, you can no longer
define-class if the
class extends a class rather than an interface; you must use
define-simple-class.
KawaPageServlet now automatically selects language.
provide macro.
quasisyntax and the convenience syntax
#`,
from SRFI-72.
define-for-syntax,
syntax-source,
syntax-line, and
syntax-column,
for better compatibility with mzscheme.
SRFI-34
(Exception Handling for Programs), which implements
with-exception-handler,
guard, and
raise, is now available,
if you
(require 'srfi-34).
Also, SRFI-35 (Conditions) is available, if you
(require 'srfi-35).
The
case-lambda form from SRFI-16 is now implemented more efficiently.
SRFI-69
Basic hash tables is now available, if you
(require 'hash-table) or
(require 'srfi-69).
This is an optimized and Java-compatible port whose default
hash function calls the standard
hashCode method.
A
define-simple-class can now have one (or more)
explicit constructor methods. These have the spcial name
*init*.
You can call superclass constructors or sibling constructors
(
this constructor calls) using the (admittedly verbose but
powerful)
invoke-special form.
The
runnable function creates
a
Runnable from a
Procedure.
It is implemented using the new class
RunnableClosure,
which is now also used to implement
future.
The
kawa command can now be run
in-place from
the build directory:
$build_dir/bin/kawa.
The special field name
class in
(static-name type 'class) or
(prefix:.class) returns the
java.lang.Class
object corresponding to the
type or
prefix. This is similar to the Java syntax.
Contructing an instance (perhaps using
make) of a class
defined using
define-simple-class in the current module
is much more efficient, since it no longer uses reflection.
(Optimizing classes defined using
define-class is
more difficult.)
The constructor function defined by the
define-record-type macro is also optimized.
You can now access instance methods using this short-hand:
(*:methodname instance arg ...)
This is equivalent to:
(invoke instance 'methodname arg ...)
You can now also access a fields using the same colon-notation as used for
accessing methods, except you write a dot before the field name:
(type:.fieldname)
;; is like:
(static-field type 'fieldname).
(*:.fieldname instance)
;; is like:
(field 'fieldname instance)
(type:.fieldname instance)
;; is like:
(*:.fieldname (as instance type))
These all work with
set! - for example:
(set! (*:.fieldname instance) value).
In the above uses of colon-notation, a
type can
be any one of:
- a namespace prefix bound using
define-namespace to a namespace
uri of the form
"class:classname";
- a namespace prefix using
define-namespace bound to a
<classname> name, which can be
a fully-qualified class name or a locally-declared class, or an alias
(which might be an imported class);
- a fully qualified name of a class (that exists at compile-time), as in
(java.lang.Integer:toHexString 123); or
- a
<classname> variable, for example:
(<list>:list3 11 12 13).
New fluid variables
*print-base*,
*print-radix*,
*print-right-margin*, and
*print-miser-width*
can control output formatting. (These are based on Common Lisp.)
You can new emit elipsis (
...) in the output of a
syntax template using the syntax
(... ...),
as in other
syntax-case implementations.
The
args-fold program-argument processor from
SRFI-37
is available after you
(require 'args-fold) or
(require 'srfi-37).
The
fluid-let form now works with lexical bindings, and should
be more compatible with other Scheme implementations.
(module-export namespace:prefix) can be used to export a namespace prefix.
Static modules are now implemented more similarly to non-static modules.
Specifically, the module body is not automatically run by the class
initializer.
To get the old behavior, use the new
--module-static-run flag.
Alternatively, instead of
(module-static #t) use
(module-static 'init-run).
Implement SRFI-39
"Parameter-objects". These are like anonymous
fluid values and use the same implementation.
current-input-port,
current-output-port,
and
current-error-port
are now parameters.
Infer types of variables declared with a
let.
Character comparisons (such as
char-=?,
char-ci<?)
implemented
much more efficiently — and (if using Java5) work for characters not
in the Basic Multilingual Plane.
Major re-write of symbol and namespace handling.
A
Symbol is now
immutable,
consisting of a "print-name" and a pointer to
a
Namespace (package).
An
Environment
is a mapping from
Symbol
to
Location.
Rename
Interpreter
to
Language and
LispInterpreter
to
LispLanguage.
Constant-time property list operations.
Namespace-prefixes are now always resolved at compile-time, never at run-time.
(define-namespace PREFIX <CLASS>) is loosely the same as
(define-namespace PREFIX "class:CLASS") but does the right thing
for classes defined in this module, including nested or non-simple classes.
Macros capture proper scope automatically, not just when using require. This allows some internal macros to become private.
Major re-write of the macro-handling and hygiene framework.
Usable support for
syntax-case; in fact some of the primitives
(such as
if) are now implemented using
syntax-case.
(syntax form) (or the
short-cut
#!form) evaluates to a syntax object.
(define-syntax (mac x) tr)
same as
(define-syntax mac (lambda (x) tr)).
The following non-hygienic forms are equivalent:
(define-macro (macro-name (param ...) transformer) (define-macro macro-name (lambda (param ...) transformer)) (defmacro macro-name (PARAM ...) transformer)Allow vectors and more general ellipsis-forms in patterns and templates.
A new configure switch
--with-java-source=version
allows you to tweak
the Kawa sources to match Java compiler and libraries you're using.
The default (and how the sources are distributed)
is
2 (for "Java 2" – jdk 1.2 or better),
but you can also select "
1" (for jdk 1.1.x), and
"
5" for Java 5 (jdk 1.5). You can also specify a jdk version number:
"
1.4.1" is equivalent to "2" (for now). Note the default source-base
is incompatible with Java 5 (or more generally JAXB 1.3 or DOM 3),
unless you also
--disable-xml.
Configure argument
--with-servlet[
=servlet-api.jar] replaces
--enable-servlet.
Function argument in error message are now numbered starting at one. Type errors now give better error messages.
A new function calling convention, used for
--full-tailcalls.
A function call is split up in two parts: A
match0/.../
matchN
method checks that the actual arguments match the expected
formal arguments, and leaves them in the per-thread
CallContext.
Then after the calling function returns, a zero-argument
apply()
methods evaluates the function body. This new convention has
long-term advantages (performance, full continuations), but the
most immediate benefit is better handling of generic (otherloaded)
functions. There are also improved error messages.
Real numbers, characters, Lisp/Scheme strings
(
FString) and symbols
all now implement the
Comparable interface.
In
define-class/
define-simple-class:
[Most of this work was funded by Merced Systems.]
access:[
'private|
'protected|
'public|
'package] to set the Java access permissions of fields and methods.
access: 'staticspecifier.
invoke,
field,
static-field,
slot-ref,
slot-set!can now access non-public methods/fields when appropriate.
exprin
init-form: expris now evaluated in the outer scope.
init: exprevalues
exprin the inner scope.
allocation:can now be a string literal or a quoted symbol. The latter is preferred:
allocation: 'class.
'staticas a synonym for
'classfollowing
allocation:.
allocation: 'class init: expr) now works, and is performed at class initialization time.
dummy fieldsto add initialization-time actions not tied to a field:
(define-simple-class Foo () (:init (perform-some-action)))
Various fixes and better error messages in number parsing. Some optimizations for the divide function.
New framework for controlling compiler warnings and other features,
supporting command-line flags, and the Scheme forms
with-compile-options
and
module-compile-options. The flag
--warn-undefined-variable is
useful for catching typos. Implementation funded by Merced Systems.
New
invoke-special syntax form (implemented by Chris Dean).
New
define-variable form (similar to Common Lisp's
defvar).
KawaPageServlet allows automatic loading and on-the-fly compilation in a
servlet engine. See.
The default source-base requires various Java 2 features, such as collection.
However,
make-select1 will comment out Java2 dependencies, allowing you
to build Kawa with an older Java implementation.
The
-f flag and the load function can take an absolute URL.
New Scheme functions
load-relative and
base-uri.
Imported implementation of cut and cute from SRFI-26 (Notation for Specializing Parameters without Currying).
The way top-level definitions (including Scheme procedures) are mapped into Java fields is changed to use a mostly reversible mapping. (The mapping to method names remains more natural but non-reversible.)
define-alias of types can now be exported from a module.
New
--no-inline and
--inline=none options.
You can use
define-namespace to define
namespace aliases.
This is used for the new short-hard syntax for method invocation:
(define-namespace Int32 "class:java.lang.Integer")
(Int32:toHexString 255) =>
"ff"
(Int32:toString (Int32:new "00255")) =>
"255"
Alternatively, you can write:
(java.lang.Integer:toHexString 255) =>
"ff"
SRFI-9 (define-record-type) has been implemented, and compiled to a
define-class, with efficient code.
The configure option
--with-collections is now the default.
Unknowns are no longer automatically static.
If type not specified in a declaration, don't infer it from it initial value.
If no return type is specified for a function, default to
Object,
rather than the return type of the body. (The latter leads to
undesirable different behaviour if definitions are re-arranged.)
You can now define and use classes defined using
object,
define-class, and
define-simple-class
from the
interpreter, as well as the compiler.
Also, a bug where inherited fields did not get initialized has been fixed.
There are several new procedures useful for servlets.
Numerical comparisions (
<,
<=, etc) now generates optimized bytecode
if the types of the operands have certain known types. including
efficient code for
<int>,
<long>,
<double>, and
<integer>.
Much more code can now (with type declaration) be written just as
efficiently in Scheme as in Java.
There have been some internal re-arranging of how Expressions are processed. The Scheme-specific Translator type now inherits from Compilation, which replaces the old Parser class. A Complation is now allocated much earlier, as part of parsing, and includes a SourceMessages object. SourcesMessages now includes (default) line number, which is used by Compilation for the "current" line numbers. The ExpWalker class includes a SourceMessages instance (which it gets from the Compilation). CanInline.inline method now takes ExpWalker parameter. Checking of the number or parameters, and mapping known procedures to Java methods are now both done during the inlining pass.
The user-visible effect is that Kawa can now emit error mesages more cleanly more places; the inlining pass can be more agressive, and can emit better error messages, which yields better type information. This gives us better code with fewer warnings about unknown methods.
A new language front-end handles a tiny subset of XSLT. An example is the check-format-users test in gnu/xquery/testsuite/Makefile.
There are now converters between SAX2 and Consumer events, and a basic implementation of XMLReader based on XMLParser.
The function as-xml prints a value in XML format.
Srfi-0 (cond-expand), srfi-8 (receive), and srfi-25 (multi-dimensional arrays) are now implemented. So is srfi-1 (list library), though that requires doing (require 'list-lib).
The JEmacs code is being re-organized, splitting out the Swing-dependent code into a separate gnu.jemacs.swing package. This should make it easier to add JEmacs implementation without Swing.
The class gnu.expr.Interpreter has various new 'eval' methods that are useful for evaluating Scheme/BRL/XQuery/... expressions from Java.
Kawa now uses current versions of autoconf, autoamke, and libtool, allowing the use of automake file inclusion.
The comparisons
<<,
<=,
-,
>, and
=> now compile to optimized Java
arithmetic if both operands are
<int> or a literal that fits in
<int>.
Generated HTML and Postscrpt documents are no longer included in the
source distribution. Get
kawa-doc-version.tar.gz instead.
(format #t ...) and (format PORT ...) now returns #!void instead of #t.
Support fluid bindings (fluid-let) for any thread, not just Future and main.
A Unix script header
#!/PROGRAM is ignored.
You can now take the same Kawa "web" program (written in Scheme, KRL/BRL, or XQuery) and run it as either a servlet or a CGI script.
There are a number of new functions for accessing HTTP requests and generating HTTP responses.
Kawa now supports a new experimental programming KRL (the "Kawa Report Language"). You select this language using --krl on the Kawa command link. It allows Scheme code to be inside template files, like HTML pages, using a syntax based on BRL (brl.sourceforge.net). However, KRL has soem experimental changes to both BRL and standard Scheme. There is also a BRL-compatibile mode, selected using --brl, though that currently only supports a subset of BRL functions.
If language is not explicitly specified and you're running a source file (e.g. "java kawa.repl myscript.xql"), Kawa tried to derive the language from the the filename extension (e.g. "xql"). It still defaults to Scheme if there is no extension or the extension is unrecognized.
New command-line option --output-format alias --format can be used to over-ride the format used to write out top-level (repl, load) values.
XMLPrinter can now print in (non-well-formed-XML) HTML.
Changed lots of error messages to use pairs of single quotes rather than starting with a backquote (accent grave): 'name' instead of `name'. Many newer fonts make the latter look bad, so it is now discouraged.
The types
<String> and
<java.lang.String> new behave differently. The
type
<java.lang.String> now works just like (say)
<java.util.Hashtable>.
Converting an object to a
<java.lang.String> is done by a simple
coercion, so the incoming value must be a java.lang.String reference
or null. The special type
<String> converts any object to a
java.string.String by calling toString; it also handles null by
specially testing for it.
For convenience (and backwards compatibility) Kawa uses the type
<String> (rather than
<java.lang.String>) when it sees the Java
type
java.lang.String, for example in the argument to an
invoke.
The default behaviour of '[' and '] was changed back to be token (word) constituents, matching R5RS and Common Lisp. However, you can easily change this behaviour using the new setBrackMode method or the defaultBracketMode static field in ReadTable.
You can now build Kawa from source using the Ant build system (from Apache's Jakarta project), as an alternative to using the traditional configure+make system. An advantage of Ant is that it works on most Java systems, without requiring a Unix shell and commands. Specifically, this makes it easy to build Kawa under MS-Windows. Thanks to James White for contributing this support.
Added (current-error-port) which does the obvious.
The new let-values and let-values* macros from srfi-11 provide a more convenient way to use multiple values.
All the abstract apply* and eval* methods now specify 'throws Throwable'. A bunch of code was changed to match. The main visible advantage is that the throw and primitive-throw procedures work for any Throwable without requiring it to be (confusingly) wrapped.
A new compilation flag --servlet generates a Servlet which can be deployed in a servlet engin like Tomcat. This is experimental, but it seesm to work for both Scheme source and XQuery source.
The interface gnu.lists.CharSequence was renamed to avoid conflitcs with the (similar) interface java.lang.CharSequence in JDK 1.4beta.
New --help option (contributed by Andreas Schlapbach).
Changed the code generation used when --full-tailcalls. It now is closer to that used by default, in that we don't generate a class for each non-inlined procedure. In both cases calling an unknown procedure involves executing a switch statement to select a method. In addition to generating fewer classes and simplifying one of the more fragile parts of Kawa, it is also a step towards how full continuations will be implemented.
Changed the convention for name "mangling" - i.e. how Scheme names are
mapped into Java names. Now, if a Scheme name is a valid Java name it
is used as is; otherwise a reversible mangling using "$" characters is
used. Thus the Scheme names
'< and
'$Leq are
both mapped into the same Java name
"$Leq".
However, other names not containing "
$" should
no longer clash, including pairs like "
char-letter?" and
"
charLetter?"
and "
isCharLetter" which used to be all mapped to
"
isCharLetter". Now
only names containing "
$" can be ambiguous.
If the compiler can determine that all the operands of (+ ...) or (- ...) are floating-point, then it will generate optimized code using Java primitive arithmetic.
Guile-style keyword syntax '#:KEYWORD' is recognized. (Note this conflicts with Common Lisp syntax for uninterned symbols.)
New syntax forms define-class and define-simple-class allow you to define classes more easily. define-class supports true multiple inheritance and first class class values, where each Scheme class is compiled to a pair of an inteface and a class. define-simple-class generates more efficient and Java-compatible classes.
A new language "xquery" implements a (so far small subset of) XQuery, the draft XML Query languaage.
Various internal (Java API) changes: Changes to gnu.expr.Interpreter to make it easier to add non-Lisp-like languages; gnu.lists.Consumer now has an endAttribute method that need to be called after each attribute, rather than endAttributes that was called after all of them.
If configured with --with-gcj, Kawa builds and intalls a 'gckawa' script to simlify linking with needed libraries.
The
setter function is now inlined, and
(set! (field X 'N) V) and
(set! (static-field <T> "N) V) are now inlined.
If configured
--with-gcj, then a
gckawa helper
script is installed, to make it easier to link Kawa+gcj-compiled applications.
The JEmacs code now depends on CommonLisp, rather than vice versa, which means Commonlisp no longer depends on Swing, and can be built with GCJ. CommonLisp and JEmacs symbols are now implemented using Binding, not String.
Kawa now installs as a .jar file (kawa.jar symlinked to kawa-VERSION.jar), rather than a collection of .class files.
The Kawa manual includes instructions for how to build Kawa using GCJ, and how to compile Scheme code to a native executable using GCJ.
Kawa now has builtin pretty-printer support, using an algorithm from Steel Bank Common Lisp converted from Lisp to Java. The high-level Common Lisp pretty-printing features are mostly not yet implemented, but the low-level support is there. The standard output and error ports default to pretty-printing.
A new formatting framework uses the Consumer interface from gnu.lists. You can associate a format with an output port. Common Lisp and JEmacs finally print using their respective syntaxes.
All output ports (OutPort instances) are now automatically flushed on program exit, using a new WriterManager helper class.
The new commmand-line option --debug-print-expr causes the Expression for each expression to be printed. The option --debug-print-final-expr is similar, but prints Expressions after optimization and just before compilation. They are printed using the new pretty-printer.
Changed calling convention for --full-tailcalls to write results to a Consumer, usually a TreeList or something to be printed. A top-level ModuleBody now uses the same CpsProcedure convention. This is useful for generating xml or html.
New libtool support allows kawa to be built as a shared library.
The new configure flag --with-gcj uses gcj to compile Kawa to both .class files and native code. This is experimental.
The reader (for Scheme and Lisp) has been re-written to be table-driven, based on the design of Common Lisp readtables.
The new gnu.lists package has new implementations of sequence-related classes. It replaces most of gnu.kawa.util. See the package.html file.
If the expected type of a non-unary
+ or
- is
<int> or
<long> and
the operands are integeral types, then the operands will converted to
the primitive integer type and the addition or subtraction done
using primitive arithmetic. Similarly if the expected type is
<float>
or
<long> and the operands have appropriate type. This optimization
an make a big performance difference. (We still need to also optimize
compare operations like
(< x y) to really benefit from
<int> declarations
of loop variables.)
The implementation of procedure closures has been changed to basically be the same as top-level procedures (except when --full-tailcalls is specified): Each procedure is now an instance of a ModuleMethod, which each "frame" is an instance of ModuleBody, just like for top-level functions. This sometimes reduces the number of classes generated, but more importantly it simplifies the implementation.
A new
gnu.xml package contains XML-related code, currently an XML
parser and printer, plus some XPath support. The class
gnu.lists.TreeList
(alias
<document>) is useful for compactly
representing nested structures, including XML documents.
If you
(require 'xml) you will get Scheme interfaces
(
print-as-xml and
parse-xml-from-url) to
these classes.
New package gnu.kawa.functions, for primitive functions (written in Java).
The map and for-each procedure is now inlined. This is most especially beneficial when it allows the mapped-over procedure to also be inlined, such as when that procedure is a lambda expression.
Added documentation on compiling with Jikes. Renamed some classes to avoid warning when compiling with Jikes.
The reverse! procedure was added.
Internal changes: * If a variable reference is unknown, create a Declaration instance with the IS_UNKNOWN flag to represent an imported binding. * The ExpWalker framework for "tree walking" Expressions had a bit of reorganization. * New package gnu.kawa.functions, for primitive functions (written in Java).
Added a hook for constant-folding and other optimization/inlining at traversal (ExpWalker) time. Optimization of + and - procedures to use primitive Java operations when the operands are primitive types.
Implementation of SRFI-17. Change the definitions of (set! (f x ...) val) to ((setter f) x ... val), rather then the old ((setter f) val x ...). You can now associate a setter with a procedure, either using make-procedure or set-procedure-property!. Also, (setter f) is now inlined, when possible.
Internally, Syntax (and hence Macro) no longer extend Declaration.
Various Java-level changes, which may be reflected in Scheme later: * gnu.kawa.util.Consumer interface is similar to ObjectOutput and SAX's ContentHandler interfaces. * A gnu.expr.ConsumerTarget is used when evaluating to an implicit Consumer. * These interfaces will make it easy to write functional-style but efficient code for transforming data streams, including XML. * gnu.kawa.util.FString is now variable-size.
The bare beginnings of Common Lisp support, enabled by the --commonlisp (or --clisp) command line option. This is so far little more than a hack of the EmacsLisp support, but with lexical scoping and CL-style format.
JEmacs news:
You can now specify in
define and
define-private the
type of a variable. If the variable is module-level,
(define name :: <type> value) creates a field named
having the specified type and initial value. (If type is not
specified, the default is not
name
Object,
but rather a
Binding
that contains the variable's value.)
You can now define the type of a module-level variable: In (define[-private] :: type expression) New (define-constant name [:: type] expression) definition form.
A procedure can now have arbitrary properties associated with it. Use procedure-property and set-procedure-property! to get and set them.
The new procedure make-procedure creates a generic procedure that may contain one or more methods, as well as specified properties.
New declaration form define-base-unit. Both it and define-unit have been re-implemented to be module-safe. Basically '(define-unit ft 12in)' is sugar for '(define-constant ft$unit (... (* 12 in$unit)))', where ft$unit and in$unit are standard identifiers managed by the module system. Also, the output syntax for units and quantities is cleaner.
The new declaration (module-export name ...) allows control over the names exported from a module. The new declaration (module-static ...) allows control over which definitions are static and which are non-static. This makes it easier to use a module as a Java class.
Procedures names that accidentally clash with inherited method names (such as "run") are now re-named.
Simple aliases (define-aliases defining an alias for a variable name) are implemented more efficiently.
The package hierarchy is getter cleaner, with fewer cyclic dependencies: The gnu.math package no longer has any dependencies on kawa.* or gnu.*. Two classes were moved from gnu.text to other classes, avoiding another cyclic package dependency between gnu.text and gnu.mapping. The new gnu.kawa.lispexpr is for compile-time handling of Lisp-like languages.
Compliation of literals has been re-done. A class that can be used in a literal no longer needs to be declared as Compilable. Instead, you declare it as implementaing java.io.Externalizable, and make sure it has appropriate methods.
All the standard "data" types (i.e. not procedures or ports) now implement java.io.Externalizable, and can thus be serialized. If they appear in literals, they can also be compiled.
Created a new class gnu.kawa.util.AbstractString, with the Scheme
alias
<abstract-string>. The old gnu.kawa.util.FString now
extends AbstractString. A new class CharBuffer provides an
growable buffer, with markers (automatically-adjusted positions).
Many of the Scheme
<string> procedures now work
on
<abstract-string>.
The JEmacs BufferContnat class (contains the characters of a buffer)
now extends CharBuffer.
Some JEmacs changes to support a "mode" concept, as well as preliminary support for inferior-process and telnet modes.
New section in manual / web page for projects using Kawa.
The record feasture (make-record-type etc) how handles "funny" type and fields names that need to be "mangled" to Java names.
Re-did implementation of define-alias. For example, you can
define type-aliases:
(define-alias <marker> <gnu.jemacs.buffer.Marker>)
and then use <marker> instead of <gnu.jemacs.buffer.Marker>.
(field array 'length) now works.
Added documentation to the manual for Homogeneous numeric vector datatypes (SRFI-4).
You can now specify characters using their Unicode value: #\u05d0 is alef.
Kawa now uses a more mnemonic name mangling Scheme. For example,
a Scheme function named
<= would get compiled to
method
$Ls$Eq.
There is now working and useful module support, thought not all
features are implemented. The basic idea is that a module can be any
class that has a default constructor (or all of whose fields and
methods are static); the public fields and methods of such a
class are its exported definitions. Compiling a Scheme file
produces such a module. Doing:
(require <classname>)
will create an anonymous instance of
<classname> (if needed), and add
all its exported definitions to the current environment. Note that if
you import a class in a module you are compiling, then an instance of
the module will be created at compile-time, and imported definitions
are not re-imported.
(For now you must compile a module, you cannot just load it.)
The define-private keyword creates a module-local definition.
New syntax to override some properties of the current module:
(module-name <name>) overrides the default name for a module.
(module-extends <class>) specifies the super-class.
(module-implements <interface> ...) specfies the implemented interfaces.
The syntax: (require 'keyword) is syntactic sugar for (require <classname>) where the classname is find is a "module catalog" (currently hard-wired). This provides compatibility with Slib. The Slib "features" gen-write, pretty-print, pprint-file, and printf are now available in Kawa; more will be added, depending on time and demand. See the package directory gnu/kawa/slib for what is available.
A lot of improvements to JEmacs (see JEmacs.SourceForge.net).
kawa-compiled-VERSION.zip is replaced by kawa-compiled-VERSION.jar.
You can now use Kawa to generate applets, using the new --applet switch, Check the "Applet compilation" section in the manual. Generating an application using the --main flag should work again. Neither --applet nor --main has Scheme hard-wired any more.
A new macro `(this)' evaluates to the "this object" - the current instance of the current class. The current implementation is incomplete, and buggy, but it will have to do for now.
The command-line argument -f FILENAME will load the same files types as load.
When a source file is compiled, the top-level definitions (procedures, variables, and macros) are compiled to final fields on the resulting class. This are not automatically entered into the current environment; instead that is the responsibility of whoever loads the compiled class. This is a major step towards a module system for Kawa.
There is a new form define-private which is like define, except that the defined name is not exported from the current module.
A procedure that has optional arguments is now typically compiled into multiple methods. If it's a top-level procedure, these will be methods in the modules "ModuleBody" class, with the same (mangled) name. The compiler can in many cases call the appropriate method directly. Usually, each method takes a fixed number of arguments, which means we save the overhead of creating an array for the arguments.
A top-level procedure declared using the form (define (NAME ARS ...) BODY ..) is assumed to be "constant" if it isn't assigned to in the current compilation unit. A call in the same compilation unit will now be implemented as a direct method call. This is not done if the prcedure is declared with the form: (define NAME (lambda (ARGS ,,,) BODY ...)
gnu.expr.Declaration no longer inherits from gnu.bytecode.Variable.
A gnu.mapping.Environment now resolves hash index collisions using "double hashing" and "open addressing" instead of "chaining" through Binding. This allows a Binding to appear in multiple Environments.
The classes Sequence, Pair, PairWithPosition, FString, and Char were moved from kawa.lang to the new package gnu.kawa.util. It seems that these classes (except perhaps Char) belong together. The classes List and Vector were also moved, and at the same time renamed to LList and FVector, respectively, to avoid clashed with classes in java.util.
New data types and procedures for "uniform vectors" of primitive types were implemented. These follow the SRFI-4 specification, which you can find at .
You can now use the syntax
name :: type to specify the type of a parameter.
For example:
(define (vector-length x :: <vector>) (invoke x 'length))
The following also works:
(define (vector-length (x :: <vector>)) ...).
(define-member-alias name object [fname]) is new syntactic sugar
for
(define-alias name (field object fname)), where the default for
fname is the mangling of
name.
The new function `invoke' allows you to call a Java method. All of `invoke', `invoke-static' and `make' now select the bets method. They are also inlined at compile time in many cases. Specifically, if there is a method known to be definitely applicable, based on compile-time types of the argument expressions, the compiler will choose the most specific such method.
The functions slot-ref, slot-set!, field, and static-field are now inlined by the compiler when it can.
Added open-input-string, open-output-string, get-output-string from SRFI-6. See.
The manual has a new section "Mapping Scheme names to Java names", and a new chapter "Types". The chapters "Extensions", "Objects and Classes", and "Low-level functions" have been extensivley re-organized.
The Kawa license has been simplified. There used to be two licenses: One for the packages gnu.*, and one for the packages kawa.*. There latter has been replaced by the former. The "License" section of the manual was also improved.
There is a new package gnu.kawa.reflect. Some classes that used to be in kawa.lang or kawa.standard are now there.
The procedures slot-ref and slot-set! are now available. They are equivalent to the existing `field', but reading a field `x' will look for `getX' method if there is no public `x' field; writing to a field will look for `setX'.
The procedure `make' makes it convenient to create new objects.
There is now a teaser screen snapshot of "JEmacs" at.
The html version of the manual now has a primitive index. The manual has been slightly re-organized, with a new "Classes and Objects" chapter.
The new functions invoke-static and class-methods allow you to call an arbitary Java method. They both take a class specification and a method name. The result of class-methods is a generic procedure consisting of those methods whose names match. (Instance methods are also matched; they are treated the asme as class methods with an extra initial argument.) The invoke-static function also takes extra arguments, and actually calls the "best"-matching method. An example:
(invoke-static <java.lang.Thread> 'sleep 100)
Many fewer classes are now generated when compiling a Scheme file. It used to be that each top-level procedure got compiled to its own class; that is no longer the case. The change should lead to faster startup and less resource use, but procedure application will probably be noticably slower (though not so much slower as when reflection is used). The reason for the slowdown is that we in the general case now do an extra method call, plus a not-yet-optimized switch statement. This change is part of the new Kawa module system. That will allow the compiler to substitute direct methods calls in more cases, which I hope will more than make up for the slowdown.
A Scheme procedure is now in general compiled to a Java method whose name is a "mangling" of the Scheme procedure's name. If the procedure takes a variable number of parameters, then "$V" is added to the name; this indicates that the last argument is a Java array containing the rest of the arguments. Conversely, calling a Java method whose name ends in "$V" passes any excess arguments in the last argument, which must be an array type.
Many changes to the "Emacs-emulation" library in gnu.jemacs.buffer: * Implemented commands to read and save files. * We ask for file and buffer names using a dialog pop-up window. * Split windows correctly, so that the windows that are not split keep their sizes, the windows being split gets split as specified, and the frame does not change size. Now also handles horizonal splits. * Fairly good support for buffer-local keymaps and Emacs-style keymap search order. A new class BufferKeymap manages the active keymaps of a buffer. Multi-key key-sequences are handled. Pending prefix keys are remembered on a per-buffer basis (whereas Emacs does it globally).
There is now some low-level support for generic procedures.
The R5RS primitives let-syntax and letrec-syntax for defining local syntax extensions (macros) should now work. Also define-syntax works as an internal definition. All of these should now be properly "hygienic". (There is one known exception: symbols listed among the literals lists are matched as raw symbols, rather that checking that the symbol has the same binding, if any, as at the defining site.) The plan is to support general functions as hygienic rewriters, as in the Chez Scheme "syntax-case" system; as one part of that plan, the syntax-case primitive is available, but so far without any of the supporting machinary to support hygiene.
The read-line procedure was added. This allows you to efficiently read a line from an input port. The interface is the same as scsh and Guile.
define-alias now works both top-level and inside a function.
Optimized eqv? so if one of the arguments is constant and not Char or Numeric, inline it the same way eq? is. (This helps case when the labels are symbols, which help the "lattice" benchmark.) ???
The Emacs-related packages are now grouped under a new gnu.jemacs package.
Improved framework for catching errors. This means improved error messages when passing a parameter of the wrong type. Many standard procedures have been improved.
Simplified, documented, and tested (!) procedure for building Kawa from source under Windows (95/98/NT).
New macros trace and untrace for tracing procedures. After executing (trace PROCEDURE), debugging output will be written (to the standard error port) every time PROCEDURE is called, with the parameters and return value. Use (untrace PROCEDURE) to turn tracing off.
New utility functions (system-tmpdir) and (make-temporary-file [format]).
A new (unfinished) framework supports multiple languages. The command-line option --elisp selects Emacs Lisp, while --scheme (the default) selects Scheme. (The only difference so far is the reader syntax; that will change.)
The `format' function now provides fairly complete functionality
for CommonLisp-style formatting. (See the Comon Lisp hyperspec at.)
The floating point formatters (~F, ~E, ~G, ~$) now pass the formatst.scm
test (from Slib, but with some "fixes"; in the testsuite directory). Also,
output ports now track column numbers, so
~T and
~& also work correctly.
A new package gnu.emacs provides various building blocks for building an Emacs-like text editor. These classes are only compiled when Kawa is configured with the new --with-swing configuration option. This is a large initial step towards "JEmacs" - an Emacs re-implemented to use Kawa, Java, and Swing, but with full support (using gnu.elisp) for traditional Emacs Lisp. For more imformation see gnu/emacs/overview.html.
A new configuration option --with-swing can be used if Swing is available. It is currently only used in gnu.emacs, but that may change.
Kawa is now "properly tail-recursive" if you invoke it with the --full-tail-calls flag. (Exception: the eval procedure does not perform proper tail calls, in violation of R5RS. This will be fixed in a future release.) Code compiled when --full-tail-calls is in effect is also properly tail-recursive. Procedures compiled with --full-tail-calls can call procedures compiled without it, and vice versa (but of course without doing proper tail calls). The default is still --no-full-tail-calls, partly because of performance concerns, partly because that provides better compatibility with Java conventions and tools.
The keywords let (including named let), let*, and letrec support type specifiers for the declared variables For example:
(let ((lst :: <list> (foo x))) (reverse lst))
Square brackets [ ... ] are allowed as a synonym of parentheses ( ... ).
A new command-line flag --server PORT specifies that Kawa should run as a telnet server on the specified PORT, creating a new read-eval-print loop for each connection. This allows you to connect using any telnet client program to a remote "Kawa server".
A new front-end program, written in C, that provides editing of input lines, using the GNU readline library. This is a friendlier interface than the plain "java kawa.repl". However, because kawa.c needs readline and suitable networking library support, it is not built by default, but only when you configure Kawa with the --enable-kawa-frontend flag.
The way Scheme names are mapped ("mangled") into Java identifiers is now more natural. E.g. "foo-bar?" now is mapped to "isFooBar".
New syntax (object (SUPERS ...) FIELD-AND-METHODS ...) for creating a new object instance of an anonymous class. Now fairly powerful.
New procedures field and static-field for more convenient field access.
Syntactic sugar:
(lambda args <type> body) ->
(lambda args (as <type> body)).
This is especially useful for declaring methods in classes.
A new synchonized form allows you to synchronize on an arbitrary Java object, and execute some forms while having an exclusive lock on the object. (The syntax matches that used by Skij.)
New --debug-dump-zip option writes out a .zip file for compilation. (Useful for debugging Kawa.)
You can now declare parameter types.
Lot of work on more efficient procedure representation and calling convention: Inlining, directly callable statics method, plus some procedures no longer generate a separate Class.
Local functions that are only called from one locations, except for tail-recursion, are now inlined. This inlines do loops, and most "named let" loops.
New representation of closures (closures with captured local variables). We no longer use an array for the closure. Instead we store the captured variables in the Procedure itself. This should be faster (since we can use field accesses rather than array indexing, which requires bounds checking), and avoids a separate environment object.
If the compiler sees a function call whose (non-lexically-bound) name matches an existing (globally-defined) procedure, and that procedure instance has a static method named either "apply" or the mangled procedure name, them the compiler emits a direct call to that method. This can make a very noticable speed difference, though it may violate strict Scheme sementics, and some code may break.
Partial support for first-class "location" variables.
Created new packages gnu.mapping and gnu.expr. Many classes were moved from kawa.lang to the new packages. (This is part of the long-term process of splitting Kawa into more manageable chunks, separating the Scheme-specific code from the language-independent code, and moving classes under the gnu hierarchy.)
You can now write keywords with the colon first (e.g. :KEYWORD), which has exactly the same effect and meaning as putting the colon last (e.g. KEYWORD:). The latter is preferred is being more consistent with normal English use of punctuation, but the former is allowed for compatibility with soem other Scheme implementations and Common Lisp.
The new package gnu.text contains facilities for reading, formatting, and manipulating text. Some classes in kawa.lang where moved to there.
Added string-upcase!, string-downcase!, string-capitalize!, string-upcase, string-downcase, and string-capitalize; compatible with Slib.
Character constants can now use octal notation (as in Guile). Writing a character uses octal format when that seems best.
A format function, similar to that in Common Lisp (and Slib) has been added.
The default parameter of a #!optional or #!key parameter can now be #!null.
The "record" feature has been changed to that a "record-type descriptor"
is now a gnu.bytecode.ClassType (a
<record-type>), rather than a
java.lang.Class. Thus make-record-type now returns a
<record-typee>,
not a Class, and
record-type-descriptor takes a
<record-typee>,
not a Class.
More robust Eval interfaces.
New Lexer abstract class. New ScmRead class (which extends Lexer) now contains the Scheme reader (moved from Inport). Now read errors are kept in queue, and can be recovered from.
Comparing an exact rational and an inexact real (double) is now done as if by first converting the double to exact, to satisfy R5RS.
The compile virtual method in Expression now takes a Target object, representing the "destination". The special ConditionalTarget is used to evaluate the test of an 'if expression. This allows us to generate much better code for and, or, eq?, not and nested if inside an if.
Added port-line, port-column, and set-port-line! to match Guile.
The Makefiles have been written so all out-of-date .java (or .scm). files in a directory are compiled using a single invocation of javac (or kawa). Building Kawa should now be much faster. (But note that this depends on unreleased recent autoamke changes.)
How the Kawa version number is compiled into Kawa was changed to make it easier for people who want to build from source on non-Unix-like systems.
A new gnu.ecmascript package contains an extremely incomplete implementation of ECMSScript, the ECMA standardized version of JavaScript. It includes an ECMAScript lexer (basically complete), parser (the framework is there but most of the language is missing), incomplete expression evaluation, and a read-eval-print-loop (for testing only).
Improved Kawa home page with extra links, pointer to Java-generated api docs, and homepages for gnu.math and gnu.bytecode.
Implemented system, make-process, and some related procedures.
Added macros for primitive access to object fields, static fields, and Java arrays. Added constant-fold syntax, and used it for the other macros.
The --main flag compiles Scheme code to an application (containing a main method), which can be be invoked directly by a Java interpreter.
Implemented --version (following GNU standards) as kawa.repl command-line flag.
Adding make procedure to create new objects/records.
Extended (set! (f . args) value) to be equivalent to ((setter f) value . args). Implemented setter, as well as (setter car) and (setter cdr).
Can now get and set a record field value using an application: (rec 'fname) gets the value of the field named fname in record rec. (set! (rec 'fname) value) sets the value of the field named fname in rec.
A partial re-write of the implementation of input ports and the Scheme reader, to fix some problems, add some features, and improve performance.
Compiled .class files are now installed in $(datadir)/java, rather than $(prefix)/java. By default, that means they are installed in /usr/local/shared/java, rather than /usr/local/java.
There is now internal infrastructure to support inlining of procedures, and general procedure-specific optimized code generation.
There is better testing that the right number of arguments are passed to a procedure, and better error messages when you don't. If the procedure is inlined, you get a compile-time error message.
The functions created by primitive-constructor, primitive-virtual-method, primitive-static-method, and primitive-interface-method are now first-class procedure values. They use the Java reflection facily, except when the compiler can directly inline them (in which case it generates the same efficient bytecodes as before).
New functions instance? (tests type membership) and as (converts).
The kawa.html is now split into several files, one per chapter. The table of contents is now kawa_toc.html.
The syntactic form try-catch provides low-level exception handler support. It is basically the same as Java's try/catch form, but in Scheme syntax. The new procedure primitive-throw throws an exception object.
The higher-level catch and throw procedures implement exception handling where the handler is specified with a "key" (a symbol). These functions were taken from Guile.
The error function has been generalized to take multiple arguments (as in Guile). It is now a wrapper around (throw 'misc-error ...).
There is a new "friendly" GUI access to the Kawa command-line. If you invoke kawa.repl with the -w flag, a new interaction window is created. This is uses the AWT TextArea class. You can create multiple "consoles". They can either share top-level enevironments, or have separate environments. This window interface has some nice features, including editing. Added a scheme-window procedure, which is another way to create a window.
The default prompt now shows continuations lines differently.
The copy-file function was added.
The variable port-char-encoding controls how external files are converted to/from internal Unicode characters. It also controls whether CR and CR-LF are converted to LF.
The reader by default no longer down-cases letters in symbols. A new variable symbol-read-case control how case is handled: 'P (the default) preserves case; 'U upper-cases letters; 'D or -" down-cases letters; and 'I inverts case.
The gnu.bytecode package now supports exception handlers. The new syntactic form try-finally supports a cleanup hook that is run after some other code finishes (normally or abnormally). Try-finally is used to implement dynamic-wind and fluid-let.
The environment handling has been improved to support thread-specific environments, a thread-safe fluid-let, and multiple top-levels. (The latter still needs a bit of work.)
The gnu.bytecode package has been extensively changed. There are new classes representing the various standard Attributes, and data associated with an attribute is now stored there.
Added new procedures environment-bound? and scheme-implementation-version.
Scheme symbols are represented as java.lang.String objects. Interned symbols are interned Strings; uninterned symbols are uninterned Strings. Note that Java strings literals are automatically interned in JDK 1.1. This change makes symbols slightly more efficient, and moves Kawa closer to Java.
Ports now use the JDK 1.1 character-based Reader and Writer classes, rather than the byte-oriented InputStream and OutputStream classes. This supports different reading and writing different character encodings [in theory - there is no support yet for other than Ascii or binary files].
An interactive input port now has a prompt function associated with it. It is settable with set-input-port-prompter!. The prompt function takes one argument (the input port), and returns a prompt string. There are also user functions for inquiring about the current line and column number of an input port.
The R4RS procedures transcript-on and transcript-off are implemented.
Standard types can be referred to using syntax similar to RScheme.
For example Scheme strings now have the type
<string> which is
preferred to "
kawa.lang.FString" (which in addition to being longer,
is also more suspectible to changes in internal implementation).
Though these types are first-class values, this is so far mainly
useful for invoking primitive methods.
Execute a ~/.kawarc.scm file on startup, if it exists.
Add a number of functions for testing, renaming, and deleting files. These are meant to be compatible with scsh, Guile, and MIT Scheme: file-exists?, file-directory?, file-readable?, file-writable?, delete-file, rename-file, create-diretory, and the variable home-directory.
Fixed some small bugs, mainly in gnu.math and in load.
Generalize apply to accept an arbitrary Sequence, or a primitive Java array.
The codegen package has been renamed gnu.bytecode. The kawa.math package has been moved to gnu.math. Both packages have new license: No restrictions if you use an unmodified release, but GNU General Public License. Let me know if that causes problems. The rest of Kawa still has the old license.
Implement defmacro and gentemp.
Implement make-record-type and related functions to create and use new record types. A record type is implemented as a java.lang.Class object, and this feature depends on the new reflection features of JDK 1.1.
Implement keywords, and extend lambda parameter lists to support #!optional #!rest and #!keyword parameters (following DSSSL).
Added more primitives to call arbitrary interface and constructor methods.
Added primitives to make it easy to call arbitrary Java methods from Scheme.
Exact rational arithetic is now fully implemented. All integer functions now believed to correctly handle bignums. Logical operations on exact integers have been implemented. These include all the logical functions from Guile.
Complex numbers are implemented (except {,a}{sin,cos,tan}). Quantities (with units) are implemented (as in DSSSL).
Eval is available, as specified for R5RS. Also implemented are scheme-report-environment, null-environment, and interaction-environment.
Internal define is implemented.
Rough support for multiple threads is implemented.
Moved kawa class to kawa/repl. Merged in kawac (compiler) functionality. A 'kawa' shell-script is now created. This is now the preferred interface to both the interactive evaluator and the compiler (on Unix-like systems).
Now builds "without a snag" using Cafe 1.51 under Win95.
(Symantec JIT (ver 2.00b19) requires disabling JIT -
JAVA_COMPCMD=disable.)
Compiles under JDK 1.1 beta (with some warnings).
A testsuite (and testing framework) was added.
Documentation moved to doc directory. There is now an internals overview, in doc/kawa-tour.ps.
The numeric classes have been re-written. There is partial support for bignums (infinite-precision integers), but divide (for example) has not been implemented yet. The representation of bignums uses 2's complement, where the "big digits" are laid out so as to be compatible with the mpn functions of the GNU Multi-Precision library (gmp). (The intent is that a future version of Kawa will support an option to use gmp native functions for speed.)
The kawa application takes a number of useful command-line switches.
Basically all of R4RS has been implemented. All the essential forms and functions are implemented. Almost all of the optional forms are implemented. The exceptions are transcript-on, transcript-off, and the functions for complex numbers, and fractions (exact non-integer rationals).
Loading a source file with load now wraps the entire file in a lambda (named "atFileLevel"). This is for better error reporting, and consistency with compile-file.
The hygienic macros described in the appendix to R4RS are now impemented (but only the define-syntax form). They are used to implement the standard "do" form.
The R5RS multiple value functions
values and
call-with-values are implemented.
Macros (and primitive syntax) can now be autoloaded as well as procedures.
New kawac application compiles to one or more .class files.
Compile time errors include line numbers. Uncaught exceptions cause a stack trace that includes .scm line numbers. This makes it more practical to debug Kawa with a Java debugger.
Quasiquotation is implemented.
Various minor bug fixes and optimizations.
The biggest single change is that Scheme procedures are now compiled to Java bytecodes. This is mainly for efficiency, but it also allows us to do tail-recursion-elimination in some cases.
The "codegen" library is included. This is a toolkit that handles most of the details needed to generate Java bytecode (.class) files.
The internal structure of Kawa has been extensively re-written, especially how syntax transforms, eval, and apply are done, largely due to the needs for compilation.
Almost all the R4RS procedures are now implemented, except that there are still large gaps in Section 6.5 "Numbers". | https://www.gnu.org/software/kawa/news.html | CC-MAIN-2015-11 | refinedweb | 13,665 | 51.34 |
This site uses strictly necessary cookies. More Information
Hi, I have some UI Buttons in my game. Now they work perfectly when clicked one time. But I want that they should work continuously if the Button is pressed and held for some time. Like, for the Fire Button. Where is change needed, in the script or in the Inspector?? Please help! Thanks!!
Edit - I have tried the two previous answers, but they all doesn't made any difference. thank you for them though.
Answer by LeonmFF
·
Aug 21, 2018 at 07:48 PM
Hi o/ I'll help you because you're a cool budy.
Go to your button in the Hierarchy, and in the inspector go to "Add Component" -> Event Trigger -> "Add New Event Type" and there you go!
If I'm not mistaken, the event "PointerDown" is the one you want, it's like a "hold event".
The rest is just like OnClick() that you already know your way around it.
haha..yeah it resembles my personality. But this method is also shooting only one time. Thank You for helping though. Even I tried PointerClick, PointerEnter, etc... but they all are working same, one time shoot only.
Answer by Ahsanhabibrafy
·
Jul 18, 2020 at 09:15 AM
As I found no solution on the internet I finally came with one. To continuously shoot on Ui Button hold use this script.Add this script in ur Ui ShootButton.` using System.Collections; using System.Collections.Generic; using UnityEngine; using UnityEngine.EventSystems;
public class ShootHandler : MonoBehaviour,IUpdateSelectedHandler,IPointerDownHandler,IPointerUpHandler
{
public bool isPressed;
// Start is called before the first frame update
public void OnUpdateSelected(BaseEventData data)
{
if (isPressed)
{
Shoot();
}
}
public void OnPointerDown(PointerEventData data)
{
isPressed = true;
}
public void OnPointerUp(PointerEventData data)
{
isPressed = false;
}
}
Answer by Vicarian
·
Aug 21, 2018 at 07:46 PM
I'd use the inspector and add an EventTrigger component, then implement PointerDown. If you're unsure how, visit .
Thank You but it is still shooting only one time.
Answer by HardyForce
·
Jan 24, 2020 at 06:37 PM
Set a bool to true on PointerDown, and false on PointerUp. Then in your Update function, check if the bool is true before your code executes
Answer by venomjadhav
·
Jul 03, 2020 at 06:12 AM
I think I have a solution. Even my character behaved the same when I tried to move it with buttons, with the PointerDown Event added. I added another one called UpdateSelected. To do that, click "Add New Event Type", and click UpdateSelected. Do your thing by adding the necessary gameobject and panel and you're good to go..
Buttons on mobile activating OnHighlight Animation without touching them.
0
Answers
How to Change Menu Button Rollover States with GameObjects
1
Answer
UI button mobile - want a button drag to register as a click
0
Answers
How do I highlight multiple buttons at once?
1
Answer
Tapping a button and screen interference
0
Answers
EnterpriseSocial Q&A | https://answers.unity.com/questions/1544787/how-to-make-the-button-respond-to-touch-and-hold-f.html | CC-MAIN-2021-49 | refinedweb | 491 | 66.03 |
Introduction
Hello everyone, my name is Dustin. Today I'd like to talk about my experience working with Telescope project.
Progress
As I was going through issues in Telescope project, I found an issue that was not very difficult so that I can get to know the project a bit more and learn something out of it. So I chose to go with this issue, which is about adding border for github avatars.
Looking at the issue and thinking about it, It'd be easy to do as I only had to add a couple lines css code, but no. Because telescope has 2 different theme colors which are dark and light. So I had to add another interface to the PaletteOptions
import * as createPalette from '@material-ui/core/styles/createPalettes'; declare module '@material-ui/core/styles/createPalette' { interface PaletteOptions { border?: PaletteColorOptions; } interface Palette { border: PaletteColor; } }
So that I could make my own border attribute in createTheme object
for light theme
border: { main: 'rgba(27,31,36,0.15)', },
for dark theme
border: { main: 'rgba(240,246,252,0.1)', },
However, there was an embarrassing moment where I didn't notice that github isn't using
border: for the border around their avatars but a
box-shadow. I literally stoled their color code but it still didn't show as github. It took me a decent amount of time to realize it.
Wrapup
This is a beginner-friendly issue so it's totally easy but gives me a bit more foundation to try something bigger and harder in this project. Of course, this is a very small thing in a humongous project but I got it working and merged into the main branch, I'm very happy for that.
You can find my pr right here
Discussion (0) | https://dev.to/tuanthanh2067/osd600-release-03-first-pull-request-2jgi | CC-MAIN-2022-21 | refinedweb | 298 | 70.02 |
#include <xvid.h>
#include <unistd.h>
#include "avcodec.h"
#include "internal.h"
#include "libavutil/file.h"
#include "libavutil/cpu.h"
#include "libavutil/intreadwrite.h"
#include "libavutil/mathematics.h"
#include "libxvid_internal.h"
#include "mpegvideo.h"
Go to the source code of this file.
Definition in file libxvidff.c.
Definition at line 44 of file libxvidff.c.
Referenced by xvid_ff_2pass_after(), and xvid_ff_2pass_create().
Definition at line 43 of file libxvidff.c.
Referenced by xvid_ff_2pass_after(), and xvid_ff_2pass_create().
Buffer management macros.
Definition at line 42 of file libxvidff.c. 296 of file libxvidff.c.
Referenced by xvid_encode_init().
Destroy the private context for the encoder.
All buffers are freed, and the Xvid encoder context is destroyed.
Definition at line 758 of file libxvidff.c.
Encode a single frame.
Definition at line 634 of file libxvidff.c.
Create the private context for the encoder.
All buffers are allocated, settings are loaded from the user, and the encoder context created.
Definition at line 354 of file libxvidff.c.
Dispatch function for our custom plugin.
This handles the dispatch for the Xvid plugin. It passes data on to other functions for actual processing.
Definition at line 219 of file libxvidff.c.
Referenced by xvid_encode_init().
Capture statistic data and write it during first pass.
Definition at line 183 of file libxvidff.c.
Referenced by xvid_ff_2pass().
Enable fast encode mode during the first pass.
Definition at line 140 of file libxvidff.c.
Referenced by xvid_ff_2pass().
Initialize the two-pass plugin and context.
Definition at line 93 of file libxvidff.c.
Referenced by xvid_ff_2pass().
Destroy the two-pass plugin context.
Definition at line 124 of file libxvidff.c.
Referenced by xvid_ff_2pass(). 256 of file libxvidff.c.
Referenced by xvid_encode_frame().
Initial value:
{ .name = "libxvid", .type = AVMEDIA_TYPE_VIDEO, .id = CODEC_ID_MPEG4, .priv_data_size = sizeof(struct xvid_context), .init = xvid_encode_init, .encode2 = xvid_encode_frame, .close = xvid_encode_close, .pix_fmts = (const enum PixelFormat[]){ PIX_FMT_YUV420P, PIX_FMT_NONE }, .long_name = NULL_IF_CONFIG_SMALL("libxvidcore MPEG-4 part 2"), }
Definition at line 779 of file libxvidff.c. | http://www.ffmpeg.org//doxygen/trunk/libxvidff_8c.html | crawl-003 | refinedweb | 316 | 57.13 |
Containers are collection of Operating System technologies that allows you to run a process. Containers are themselves a very old technology, but after introduction of Docker and the software system they built to create, deploy and ship containers, it has made containers to be opted widely. We will look at atomic units needed to build a container without docker so that you can get past the definitions like "light weight VM", "something to do with docker", "poor man's virtualization".
So what technologies do we need to create our own containers?
Well, let's first look at what an OS does for us essentially. An OS runs processes, an entity which represents the basic unit of work to be implemented in the system. There is a Process Control Block which is a table maintained by OS in which it identifies each process with the help of a special number known as PID (process ID). It also has status of process along with privileges, memory information, environment variables, path, child processes etc. Every process has a certain root directory in which process executes. You can actually find this information in a folder called
/proc in the file system or by running a command:
ps aux
Here's what it looks like in my machine:
There's a lot more to each of this, but we're gonna stay focused on high level overview of Linux systems.
Now if we are able to create a process and isolate it such that it run somewhere else too without installing the whole operating system, we can call it a container. To isolate this process, i.e. make it impossible for it to look outside it's own folder, we need to "jail" it. We can do it using the following command:
chroot /path/to/new/root command
It will change the root folder for this process and it's children, hence the process will not be able to access anything outside this folder. let's follow some steps as super user:
mkdir my-new-root chroot my-new-root bash
Here we have created a new folder and then using
chroot command to “change the root” and run command
bash in it.
You should see some error like bash is not found or command not recognized. Refer following screenshot:
Since command bash is running inside my-new-root and it cannot access anything outside it's new root, it is unable to find program that runs the bash shell.
To fix this, use ‘ldd’.
ldd prints the shared other objects required by an program to run.
ldd /bin/bash
This command outputs dependencies for a certain program needed to run:
let's copy these in their respective folders inside my-new-root.
mkdir my-new-root/{bin,lib64,lib} cp /bin/bash my-new-root/bin cp /lib/x86_64-linux-gnu/libtinfo.so.5 /lib/x86_64-linux-gnu/libdl.so.2 /lib/x86_64-linux-gnu/libc.so.6 my-new-root/lib cp /lib64/ld-linux-x86-64.so.2 my-new-root/lib64
Here we have created 3 folders in which shared libraries that are required by bash reside (under lib and lib64). Then we are copying those objects into them.
Now if we run
chroot my-new-root bash it will open up a bash shell inside my-new-root. You can verify it by
pwd it should output
/
Why don't you try enabling
lscommand in this too?
Even though our new root cannot access files outside, it can see still running processes on host container. This won't work for us if we want to run multiple containers on the same host. To achieve true isolation, we also need to hide the processes from other processes. If it’s not done then one container can kill PID of process, unmount a filesystem or change network setting for other containers. Each process lie in one of 7 namespaces defined in UNIX world. We can use a command called
unshare to see those:
We can see the important 7 namespaces above. We can use unshare command to restrict those namespaces.
unshare --mount --uts --ipc --net --pid --fork --user --map-root-user chroot my-new-root bash
Now our new root has restricted access to processes from any of these namespaces. They can now get duplicate PID too! That's true isolation.
One last thing left, namespace don't help us limit physical resources like memory limits. For them we have
cgroups, which essentially is a file in which we can collect PIDs and define limits for cpu, memory or network bandwidth. The reason it is important because one container can starve the resources (like by fork bomb attack) of host environment for use by other containers.
Note: Windows operating systems are not vulnerable to a traditional fork bomb attack, as they are unable to fork other processes.
Here's how we'd do it (Don't worry about commands, we're just learning things that containers are made from)
# outside of unshare'd environment get the tools we'll need here apt-get install -y cgroup-tools htop # create new cgroups cgcreate -g cpu,memory,blkio,devices,freezer:/sandbox # add our unshare'd env to our cgroup ps aux # grab the bash PID that's right after the unshare one cgclassify -g cpu,memory,blkio,devices,freezer:sandbox <PID> # Set a limit of 80M cgset -r memory.limit_in_bytes=80M sandbox
You can learn more about cgroups here
That's it! Now we have created our own container.
Let's create images without docker
Images
Images are essentially the premade containers packages as a file object.
We can use the following command to package this container as a compressed file:
tar cvf dockercontainer.tar my-new-root
Now we can ship it somewhere else and we would create a folder to decompress it:
# make container-root directory, export contents of container into it mkdir container-root tar xf dockercontainer.tar -C container-root/ # make a contained user, mount in name spaces unshare --mount --uts --ipc --net --pid --fork --user --map-root-user chroot $PWD/container-root ash # change root to it # mount needed things # change cgroup settings # etc
That's it? Means we can go around and use containers like this. Not really, docker does a lot more than this for you. It provides us an awesome registry of pre baked images, networking, import, export, running, tag, list, kill these images etc.
Benefits of Docker Containers
- Runtime: docker engine allows us to use different packages compiled and run same across various OS. It's runtime provides good workflow benefits too
- Images: Great portability, image registry, image diffs
- Automation: Your containers can flow through local computer to jenkins all with a file which contains config. It also enables caching and multi stage builds for containers. Hence image builds are very fast
An example of above process written in go programming language can be found here and it's accompanying video.
We'll look at all of this in coming posts. Thank you for making it to end of the post.
Please share it if helped you learn something new. You can drop me a hello on twitter. Take care :)
Posted on by:
Deepak Ahuja 👨💻
Lifelong learner, Software Engineer. Not in Forbes 30 under 30.
Discussion
This is helpful! Nice work 🎉
Hey, Thanks for reading!
I am glad you liked it. Please checkout other posts on generalized concepts of full stack development I've done in past, I spend lot of time in streamline text, picture, language and concepts to minimize struggle of learning as less as possible.
Pretty good read.
Hey thanks for reading!
I am glad it made you learn something new. Keep looking for more. I do my best in each post.
nice 11
Hey buddy :p
Thanks for the read. Icici.
Amazing explanation about very confusing topic -what is container- Thank you.
Hey, Thanks for reading!
Please checkout my other work too. I put in lot of work to find balance between text, pictures and diagrams to make things easy which i had myself struggled to understand.
We all are in the same boat! Let’s do this together :) | https://practicaldev-herokuapp-com.global.ssl.fastly.net/dpkahuja/a-docker-free-intro-to-containers-write-your-own-containers-and-images-3pk4 | CC-MAIN-2020-29 | refinedweb | 1,368 | 63.19 |
We can now set up the Chart in XAML, or we can do it in the code behind. Let’s see how we can do this in the code behind below.
In the code behind of the MainPage, using the Telerik.XamarinForms.Chart namespace, create a RadCartesianChart instance and add a categorical axis making it the horizontal axis, and a numerical axis making it the vertical axis. Add a Bar series, and set the content of the page to be the Chart:
What this chart would be without data? Let’s fill it with the sample data we created in the view-model:
One could get better interpretation for data if its shown on a grid background, so let’s add a grid using the Xamarin.Forms namespace:
For pointing out specific metrics that the chart gives, we can use band and line annotations. In this case, let’s take the data average and display it on the chart:
This is it! You can download demo project from Github. Note, that it needs the UI for Xamarin product to run.
Download UI for Xamarin from here, if you haven’t done so already. In the UI for Xamarin package, you will find a complimentary demo project with many examples demonstrating the Telerik Chart for Xamarin.. | https://www.telerik.com/blogs/building-a-mobile-cross-platform-app-from-a-shared-c-code-base-with-ui-for-xamarin | CC-MAIN-2022-40 | refinedweb | 215 | 70.94 |
Lock Management
A process can apply (lock) and release (unlock) locks using the LOCK command. A lock controls access to a data resource, such as a global variable. This access control is by convention; a lock and its corresponding variable may (and commonly do) have the same name, but are independent of each other. Changing a lock does not affect the variable with the same name; changing a variable does not affect the lock with the same name.
By itself a lock does not prevent another process from modifying the associated data because Caché does not enforce unilateral locking. Locking works only by convention: it requires that mutually competing processes all implement locking on the same variables.
A lock can be a local (accessible only by the current process) or a global (accessible by all processes). Lock naming conventions are the same as local variable and global variable naming conventions.
A lock remains in effect until it is unlocked by the process that locked it, is unlocked by a system administrator, or is automatically unlocked when the process terminates.
This chapter describes the following topics:
Management Portal Lock Table, which displays all held locks system-wide, and all lock requests waiting for the release of a held lock. The lock table can also be used to release held locks.
^LOCKTAB utility, which returns the same information as the Lock Table.
Waiting lock requests. How Caché queues lock requests waiting for the release of a held lock.
Avoiding deadlock (mutually blocking lock requests).
For further information on developing a locking strategy, refer to the article Locking and Concurrency Control.
Managing Current Locks System-wide
Caché maintains a system-wide lock table that records all locks that are in effect and the processes that have locked them, and all waiting lock requests. The system manager can display the existing locks in the Lock Table or remove selected locks using the Management Portal interface or the ^LOCKTAB utility. You can also use the %SYS.LockQuery
class to read lock table information. From the %SYS namespace you can use the SYS.Lock
class to manage the lock table.
Viewing Locks Using the Lock Table
You can view all of the locks currently held or requested (waiting) system-wide using the Management Portal. From the Management Portal, select System Operation, select Locks, then select View Locks. The View Locks window displays a list of locks (and lock requests) in alphabetical order by directory (Directory) and within each directory in collation sequence by lock name (Reference). Each lock is identified by its process id (Owner) and has a ModeCount (lock mode and lock increment count). You may need to use the Refresh icon to view the most current list of locks and lock requests. For further details on this interface see Monitoring Locks in the “Monitoring Caché Using the Management Portal” chapter of Caché Monitoring Guide.
ModeCount can indicate a held lock by a specific Owner process on a specific Reference. The following are examples of ModeCount values for held locks:
A held lock ModeCount can, of course, represent any combination of shared or exclusive, escalating or non-escalating locks — with or without increments. An Exclusive lock or a Shared lock (escalating or non-escalating ) can be in a Delock state.
ModeCount can indicate a process waiting for a lock, such as WaitExclusiveExact. The following are ModeCount values for waiting lock requests:
ModeCount indicates the lock (or lock request) that is blocking this lock request. This is not necessarily the same as Reference, which specifies the currently held lock that is at the head of the lock queue on which this lock request is waiting. Reference does not necessarily indicate the requested lock that is immediately blocking this lock request.
ModeCount can indicate other lock status values for a specific Owner process on a specific Reference. The following are these other ModeCount status values:
The Routine column provides the current line number and routine that the owner process is executing.
The View Locks window cannot be used to remove locks.
Removing Locks Using the Lock Table cconsole.log.
^LOCKTAB Utility
You can also view and delete (remove) locks using the Caché ^LOCKTAB utility from the %SYS namespace. You can execute ^LOCKTAB in either of the following forms:
DO ^LOCKTAB: allows you to view and delete locks. It provides letter code commands for deleting an individual lock, deleting all locks owned by a specified process, or deleting all locks on the system.
DO View^LOCKTAB: allows you to view locks. It does not provide options for deleting locks.
Note that these utility names are case-sensitive.
The following Terminal session example shows how ^LOCKTAB displays the current locks:
%SYS>DO ^LOCKTAB Node Name: MYCOMPUTER LOCK table entries at 07:22AM 12/05/2016 1167408 bytes usable, 1174080 bytes available. Entry Process X# S# Flg W# Item Locked 1) 4900 1 ^["^^c:\intersystems\cache151\mgr\"]%SYS("CSP","Daemon") 2) 4856 1 ^["^^c:\intersystems\cache151\mgr\"]ISC.LMFMON("License Monitor") 3) 5016 1 ^["^^c:\intersystems\cache151\mgr\"]ISC.Monitor.System 4) 5024 1 ^["^^c:\intersystems\cache151\mgr\"]TASKMGR 5) 6796 1 ^["^^c:\intersystems\cache151\mgr\user\"]a(1) 6) 6796 1e ^["^^c:\intersystems\cache151\mgr\user\"]a(1,1) 7) 6796 2 1 ^["^^c:\intersystems\cache151\mgr\user\"]b(1)Waiters: 3120(XC) 8) 3120 2 ^["^^c:\intersystems\cache151\mgr\user\"]c(1) 9) 2024 1 1 ^["^^c:\intersystems\cache151\mgr\user\"]d(1) Command=>
In the ^LOCKTAB display, the X# column lists exclusive locks held, the S# column lists shared locks held. The X# or S# number indicates the lock increment count. An “e” suffix indicates that the lock is defined as escalating. A “D” suffix indicates that the lock is in a delock state; the lock has been unlocked, but is not available to another process until the end of the current transaction. The W# column lists number of waiting lock requests. As shown in the above display, process 6796 holds an incremented shared lock ^b(1). Process 3120 has one lock request waiting this lock. The lock request is for an exclusive (X) lock on a child (C) of ^b(1).
Enter a question mark (?) at the Command=> prompt to display the help for this utility. This includes further description of how to read this display and letter code commands to delete locks (if available).
You cannot delete a lock that is in a lock pending state, as indicated by the Flg column value.
Enter Q to exit the ^LOCKTAB utility.
Waiting Lock Requests
When a process holds an exclusive lock, it causes a wait condition for any other process that attempts to acquire the same lock, or a lock on a higher level node or lower level node of the held lock. When locking subscripted globals (array nodes) it is important to make the distinction between what you lock, and what other processes can lock:
What you lock: you only have an explicit lock on the node you specify, not its higher or lower level nodes. For example, if you lock ^student(1,2) you only have an explicit lock on ^student(1,2). You cannot release this node by releasing a higher level node (such as ^student(1)) because you don’t have an explicit lock on that node. You can, of course, explicitly lock higher or lower nodes in any sequence.
What they can lock: the node that you lock bars other processes from locking that exact node or a higher or lower level node (a parent or child of that node). They cannot lock the parent ^student(1) because to do so would also implicitly lock the child ^student(1,2), which your process has already explicitly locked. They cannot lock the child ^student(1,2,3) because your process has locked the parent ^student(1,2). These other processes wait on the lock queue in the order specified. They are listed in the lock table as waiting on the highest level node specified ahead of them in the queue. This may be a locked node, or a node waiting to be locked.
For example:
Process A locks ^student(1,2).
Process B attempts to lock ^student(1), but is barred. This is because if Process B locked ^student(1), it would also (implicitly) lock ^student(1,2). But Process A holds a lock on ^student(1,2). The lock Table lists it as WaitExclusiveParent ^student(1,2).
Process C attempts to lock ^student(1,2,3), but is barred. The lock Table lists it as WaitExclusiveParent ^student(1,2). Process A holds a lock on ^student(1,2) and thus an implicit lock on ^student(1,2,3). However, because Process C is lower in the queue than Process B, Process C must wait for Process B to lock and then release ^student(1).
Process A locks ^student(1,2,3). The waiting locks remain unchanged.
Process A locks ^student(1). The waiting locks change:
Process B is listed as WaitExclusiveExact ^student(1). Process B is waiting to lock the exact lock (^student(1)) that Process A holds.
Process C is listed as WaitExclusiveChild ^student(1). Process C is lower in the queue than Process B, so it is waiting for Process B to lock and release its requested lock. Then Process C will be able to lock the child of the Process B lock. Process B, in turn, is waiting for Process A to release ^student(1).
Process A unlocks ^student(1). The waiting locks change back to WaitExclusiveParent ^student(1,2). (Same conditions as steps 2 and 3.)
Process A unlocks ^student(1,2). The waiting locks change to WaitExclusiveParent ^student(1,2,3). Process B is waiting to lock ^student(1), the parent of the current Process A lock ^student(1,2,3). Process C is waiting for Process B to lock then unlock ^student(1), the parent of the ^student(1,2,3) lock requested by Process C.
Process A unlocks ^student(1,2,3). Process B locks ^student(1). Process C is now barred by Process B. Process C is listed as WaitExclusiveChild ^student(1). Process C is waiting to lock ^student(1,2,3), the child of the current Process B lock.
Queuing of Array Node Lock Requests
The Caché queuing algorithm for array locks is to queue lock requests for the same resource strictly in the order received, even when there is no direct resource contention. As this may differ from expectations, or from implementations of lock queuing on other databases, some clarification is provided here.
Consider the case where three locks on the same global array are requested by three different processes:
Process A: LOCK ^x(1,1) Process B: LOCK ^x(1) Process C: LOCK ^x(1,2)
In this case, Process A gets a lock on ^x(1,1). Process B must wait for Process A to release ^x(1,1) before locking ^x(1). But what about Process C? The lock granted to Process A blocks Process B, but no held lock blocks the Process C lock request. It is the fact that Process B is waiting to explicitly lock ^x(1) and thus implicitly lock ^x(1,2) — which is the node that Process C wants to lock — that blocks Process C. In Caché, Process C must wait for Process B to lock and unlock.
The Caché lock queuing algorithm is fairest for Process B. Other database implementations that allowed Process C to jump the queue can speed Process C, but could (especially if there are many jobs such as Process C) result in an unacceptable delay for Process B.
This strict process queuing algorithm applies to all subscripted lock requests. However, a process releasing a non-subscripted lock (such as LOCK -^abc) when there are both non-subscripted (LOCK +^abc) and subscripted (LOCK +^abc(1,1)) waiting lock requests is a special case. In this case, which lock request is serviced is unpredictable and may not follow strict process queuing.
ECP Local and Remote Lock Requests
When releasing a lock, an ECP client may donate the lock to a local waiter in preference to waiters on other systems in order to improve performance. The number of times this is allowed to happen is limited in order to prevent unacceptable delays for remote lock waiters.
Avoiding Deadlock
Requesting a (+) exclusive lock when you hold an existing shared lock is potentially dangerous because it can lead to a situation known as "deadlock". This situation occurs when two processes each request an exclusive lock on a lock name already locked as a shared lock by the other process. As a result, each process hangs while waiting for the other process to release the existing shared lock.
The following example shows how this can occur (numbers indicate the sequence of operations):
This is the simplest form of deadlock. Deadlock can also occur when a process is requesting a lock on the parent node or child node of a held lock.
To prevent deadlocks, you should either request the exclusive lock without the plus sign (thus unlocking your shared lock). In the following example both processes release their prior locks when requesting an exclusive lock to avoid deadlock (numbers indicate the sequence of operations). Note which process acquires the exclusive lock:
Another way to avoid deadlocks is to follow a strict protocol for the order in which you issue LOCK + and LOCK - commands. Deadlocks cannot occur as long as all processes follow the same order. A simple protocol is for all processes to apply and release locks in collating sequence order.
To minimize the impact of a deadlock situation, you should always include the timeout argument when using plus sign locks. For example, LOCK +^a(1):10.
If a deadlock occurs, you can resolve it by using the Management Portal or the LOCKTAB utility to remove one of the locks in question. From the Management Portal, open the Locks window, then select the Remove option for the deadlocked process. | https://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCOS_LOCKTABLE | CC-MAIN-2021-43 | refinedweb | 2,336 | 63.09 |
Interesting C Puzzle
#include <stdio.h>
float puzzle( float inp )
{
const float ths = 1.5F;
const long k = 21*76069667;
float a, b;
int c;
a = inp * 0.5F;
b = inp;
c = *( long *) &b;
c = k - ( c >> 1 ) ;
b = *( float *) &c;
b = b * ( ths - ( a * b * b ) ) ;
return 1/b;
}
Answer on Saturday!
I suppose it calculates “sqrt” approximately.
The program will return the negative of the cube root of the ‘inp’ variable….!(approx. value)…
suppose we pass inp =2.4 from the main function,
then return value will be -0.076989
It returns the approximate square root of ‘inp’.
It gives an approximation of the square root of inp. But I really can’t say how in the world does it work !!
The result of this program is undefined. It shall behave differently depending of the byte order of the processor, size of a float and size of a long.
Very interesting problem. i have to think few time to get answer. | http://cplus.about.com/b/2008/10/02/interesting-c-puzzle.htm | crawl-002 | refinedweb | 163 | 77.94 |
A static class member can be used independently of any object of that class.
A static member that can be used by itself, without reference to a specific instance.
Here shows how to declare
static method and
static variable.
static int intValue; static void aStaticMethod(){ }
Methods declared as static have several restrictions:
All instances of the class share the same static variable. You can declare a static block to initialize your static variables. The static block gets only called once when the class is first loaded.
The following example shows a class that has a static method
public class Main { static int a = 3; static int b; /*from ww w. j ava 2s . c om*/ static void meth(int x) { System.out.println("x = " + x); System.out.println("a = " + a); System.out.println("b = " + b); } public static void main(String args[]) { Main.meth(42); } }
The output:
The following example shows a class that has the static variables.
public class Main { static int a = 3; static int b; }
We can reference the static variables defined above as follows:
Main.a
The following example shows a class that has a static initialization block.
public class Main { static int a = 3; static int b; static { System.out.println("Static block initialized."); b = a * 4; } }
A final variable cannot be modified. You must initialize a final variable when it is declared. A final variable is essentially a constant.
public class Main { final int FILE_NEW = 1; final int FILE_OPEN = 2; }
Methods declared as final cannot be overridden.
class Base {/*from w w w . ja v a 2 s. c o m*/ final void meth() { System.out.println("This is a final method."); } } class B extends A { void meth() { // ERROR! Can't override. System.out.println("Illegal!"); } }
If you try to compile the code above, the following error will be generated by the compiler. | http://www.java2s.com/Tutorials/Java/Java_Language/5110__Java_static_final.htm | CC-MAIN-2017-43 | refinedweb | 308 | 60.82 |
Getting controller_manager to recognize new controller
Hello everyone,
I am trying to write a new controller as simply as possible and get it working with Gazebo, but now that I have everything set up, my new controller does not seem to register with controller_manager. I am new to ROS, ros_control, and cmake, so I am struggling to troubleshoot.
When launching my controller, parameters load successfully, but I receive an error for each controller:
Could not load controller 'joint1_position_controller' because controller type 'artbot_control_new/CustomController' does not exist.
What is necessary for controller_manager to recognize the new class? In my workspace I have:
1) Robot description and gazebo packages for a robot very similar to this tutorial. Works correctly with existing ros_controllers examples.
2) A control package with the following:
- CMakeLists.txt and package.xml files specifying controller_interface, hardware_interface, pluginlib.
- In src, a controller class .cpp file based on this example, with the namespace, class name, and pluginlib arguments updated.
- A .yaml config file and launchfile specifying this package and the new controller.
I could be missing something very basic, but I am not sure where to look next. Let me know what information I can provide.
I'm using ROS Indigo on Ubuntu 14.04.
Thanks in advance! | https://answers.ros.org/question/207745/getting-controller_manager-to-recognize-new-controller/?answer=207749 | CC-MAIN-2019-47 | refinedweb | 207 | 50.23 |
03 September 2012 08:25 [Source: ICIS news]
SINGAPORE (ICIS)--?xml:namespace>
The cargo will be loaded on 2-4 October, they added.
The tender closes on 5 September, with bids to stay valid until 6 September, traders said.
In its latest tender award, BPCL sold 11,000 tonnes of naphtha to Glencore at a premium of $3/tonne (€2/tonne) to Middle East FOB (free on board) quotes for loading from Haldia on 18-22 September. The naphtha supply is only suitable for gasoline production and hence the premium was lower.
BPCL previously sold by tender 18,000 tonnes of naphtha to Chinese trader Unipec at a premium of $17/tonne to Middle East FOB quotes, for loading from
In an earlier tender, BPCL sold a 10,000 tonne naphtha cargo for 24-28 August loading from Haldia to trading firm Vitol at a premium of $12/tonne to Middle East FOB quotes.
( | http://www.icis.com/Articles/2012/09/03/9591969/indias-bpcl-offers-35000-tonnes-naphtha-for-early-oct.html | CC-MAIN-2014-52 | refinedweb | 154 | 56.08 |
import "github.com/colinmarc/hdfs"
Package hdfs provides a native, idiomatic interface to HDFS. Where possible, it mimics the functionality and signatures of the standard `os` package.
Example:
client, _ := hdfs.New("namenode:8020") file, _ := client.Open("/mobydick.txt") buf := make([]byte, 59) file.ReadAt(buf, 48847) fmt.Println(string(buf)) // => Abominable are the tumblers into which he pours his poison.
client.go content_summary.go error.go file_reader.go file_writer.go hdfs.go mkdir.go perms.go readdir.go remove.go rename.go stat.go stat_fs.go walk.go
A Client represents a connection to an HDFS cluster
New returns Client connected to the namenode(s) specified by address, or an error if it can't connect. Multiple namenodes can be specified by separating them with commas, for example "nn1:9000,nn2:9000".
The user will be the current system user. Any other relevant options (including the address(es) of the namenode(s), if an empty string is passed) will be loaded from the Hadoop configuration present at HADOOP_CONF_DIR or HADOOP_HOME, as specified by hadoopconf.LoadFromEnvironment and ClientOptionsFromConf.
Note, however, that New will not attempt any Kerberos authentication; use NewClient if you need that.
func NewClient(options ClientOptions) (*Client, error)
NewClient returns a connected Client for the given options, or an error if the client could not be created.
func (c *Client) Append(name string) (*FileWriter, error)
Append opens an existing file in HDFS and returns an io.WriteCloser for writing to it. Because of the way that HDFS writes are buffered and acknowledged asynchronously, it is very important that Close is called after all data has been written.
Chmod changes the mode of the named file to mode.
Chown changes the user and group of the file. Unlike os.Chown, this takes a string username and group (since that's what HDFS uses.)
If an empty string is passed for user or group, that field will not be changed remotely.
Chtimes changes the access and modification times of the named file.
Close terminates all underlying socket connections to remote server.
CopyToLocal copies the HDFS file specified by src to the local file at dst. If dst already exists, it will be overwritten.
CopyToRemote copies the local file specified by src to the HDFS file at dst.
func (c *Client) Create(name string) (*FileWriter, error)
Create opens a new file in HDFS with the default replication, block size, and permissions (0644), and returns an io.WriteCloser for writing to it. Because of the way that HDFS writes are buffered and acknowledged asynchronously, it is very important that Close is called after all data has been written.
CreateEmptyFile creates a empty file at the given name, with the permissions 0644.
func (c *Client) CreateFile(name string, replication int, blockSize int64, perm os.FileMode) (*FileWriter, error)
CreateFile opens a new file in HDFS with the given replication, block size, and permissions, and returns an io.WriteCloser for writing to it. Because of the way that HDFS writes are buffered and acknowledged asynchronously, it is very important that Close is called after all data has been written.
func (c *Client) GetContentSummary(name string) (*ContentSummary, error)
GetContentSummary returns a ContentSummary representing the named file or directory. The summary contains information about the entire tree rooted in the named file; for instance, it can return the total size of all
Mkdir creates a new directory with the specified name and permission bits.
MkdirAll creates a directory for dirname, along with any necessary parents, and returns nil, or else returns an error. The permission bits perm are used for all directories that MkdirAll creates. If dirname is already a directory, MkdirAll does nothing and returns nil.
func (c *Client) Open(name string) (*FileReader, error)
Open returns an FileReader which can be used for reading.
ReadDir reads the directory named by dirname and returns a list of sorted directory entries.
The os.FileInfo values returned will not have block location attached to the struct returned by Sys().
ReadFile reads the file named by filename and returns the contents.
Remove removes the named file or (empty) directory.
RemoveAll removes path and any children it contains. It removes everything it can but returns the first error it encounters. If the path does not exist, RemoveAll returns nil (no error).
Rename renames (moves) a file.
Stat returns an os.FileInfo describing the named file or directory.
User returns the user that the Client is acting under. This is either the current system user or the kerberos principal. ClientOptions struct { // Addresses specifies the namenode(s) to connect to. Addresses []string // User specifies which HDFS user the client will act as. It is required // unless kerberos authentication is enabled, in which case it will be // determined from the provided credentials if empty. User string // UseDatanodeHostname specifies whether the client should connect to the // datanodes via hostname (which is useful in multi-homed setups) or IP // address, which may be required if DNS isn't available. UseDatanodeHostname bool // NamenodeDialFunc is used to connect to the datanodes. If nil, then // (&net.Dialer{}).DialContext is used. NamenodeDialFunc func(ctx context.Context, network, addr string) (net.Conn, error) // DatanodeDialFunc is used to connect to the datanodes. If nil, then // (&net.Dialer{}).DialContext is used. DatanodeDialFunc func(ctx context.Context, network, addr string) (net.Conn, error) // KerberosClient is used to connect to kerberized HDFS clusters. If provided, // the client will always mutually athenticate when connecting to the // namenode(s). KerberosClient *krb.Client // KerberosServicePrincipleName specifies the Service Principle Name // (<SERVICE>/<FQDN>) for the namenode(s). Like in the // dfs.namenode.kerberos.principal property of core-site.xml, the special // string '_HOST' can be substituted for the address of the namenode in a // multi-namenode setup (for example: 'nn/_HOST'). It is required if // KerberosClient is provided. KerberosServicePrincipleName string }
ClientOptions represents the configurable options for a client. The NamenodeDialFunc and DatanodeDialFunc options can be used to set connection timeouts:
dialFunc := (&net.Dialer{ Timeout: 30 * time.Second, KeepAlive: 30 * time.Second, DualStack: true, }).DialContext options := ClientOptions{ Addresses: []string{"nn1:9000"}, NamenodeDialFunc: dialFunc, DatanodeDialFunc: dialFunc, }
func ClientOptionsFromConf(conf hadoopconf.HadoopConf) ClientOptions
ClientOptionsFromConf attempts to load any relevant configuration options from the given Hadoop configuration and create a ClientOptions struct suitable for creating a Client. Currently this sets the following fields on the resulting ClientOptions:
// Determined by fs.defaultFS (or the deprecated fs.default.name), or // fields beginning with dfs.namenode.rpc-address. Addresses []string // Determined by dfs.client.use.datanode.hostname. UseDatanodeHostname bool // Set to a non-nil but empty client (without credentials) if the value of // hadoop.security.authentication is 'kerberos'. It must then be replaced // with a credentialed Kerberos client. KerberosClient *krb.Client // Determined by dfs.namenode.kerberos.principal, with the realm // (everything after the first '@') chopped off. KerberosServicePrincipleName string
Because of the way Kerberos can be forced by the Hadoop configuration but not actually configured, you should check for whether KerberosClient is set in the resulting ClientOptions before proceeding:
options := ClientOptionsFromConf(conf) if options.KerberosClient != nil { // Replace with a valid credentialed client. options.KerberosClient = getKerberosClient() }
ContentSummary represents a set of information about a file or directory in HDFS. It's provided directly by the namenode, and has no unix filesystem analogue.
func (cs *ContentSummary) DirectoryCount() int
DirectoryCount returns the number of directories under the named one, including any subdirectories, and including the root directory itself. If the named path is a file, this returns 0.
func (cs *ContentSummary) FileCount() int
FileCount returns the number of files under the named path, including any subdirectories. If the named path is a file, FileCount returns 1.
func (cs *ContentSummary) NameQuota() int
NameQuota returns the HDFS configured "name quota" for the named path. The name quota is a hard limit on the number of directories and files inside a directory; see for more information.
func (cs *ContentSummary) Size() int64
Size returns the total size of the named path, including any subdirectories.
func (cs *ContentSummary) SizeAfterReplication() int64
SizeAfterReplication returns the total size of the named path, including any subdirectories. Unlike Size, it counts the total replicated size of each file, and represents the total on-disk footprint for a tree in HDFS.
func (cs *ContentSummary) SpaceQuota() int64
SpaceQuota returns the HDFS configured "name quota" for the named path. The name quota is a hard limit on the number of directories and files inside a directory; see for more information.
type Error interface { // Method returns the RPC method that encountered an error. Method() string // Desc returns the long form of the error code (for example ERROR_CHECKSUM). Desc() string // Exception returns the java exception class name (for example // java.io.FileNotFoundException). Exception() string // Message returns the full error message, complete with java exception // traceback. Message() string }
Error represents a remote java exception from an HDFS namenode or datanode.
FileInfo implements os.FileInfo, and provides information about a file or directory in HDFS.
AccessTime returns the last time the file was accessed. It's not part of the os.FileInfo interface.
Owner returns the name of the user that owns the file or directory. It's not part of the os.FileInfo interface.
OwnerGroup returns the name of the group that owns the file or directory. It's not part of the os.FileInfo interface.
Sys returns the raw *hadoop_hdfs.HdfsFileStatusProto message from the namenode.
A FileReader represents an existing file or directory in HDFS. It implements io.Reader, io.ReaderAt, io.Seeker, and io.Closer, and can only be used for reads. For writes, see FileWriter and Client.Create.
func (f *FileReader) Checksum() ([]byte, error)
Checksum returns HDFS's internal "MD5MD5CRC32C" checksum for a given file.
Internally to HDFS, it works by calculating the MD5 of all the CRCs (which are stored alongside the data) for each block, and then calculating the MD5 of all of those.
func (f *FileReader) Close() error
Close implements io.Closer.
func (f *FileReader) Name() string
Name returns the name of the file.
func (f *FileReader) Read(b []byte) (int, error)
Read implements io.Reader.
ReadAt implements io.ReaderAt.
Readdir reads the contents of the directory associated with file and returns a slice of up to n os.FileInfo values, as would be returned by Stat, in directory order. Subsequent calls on the same file will yield further os.FileInfos.
If n > 0, Readdir returns at most n os.FileInfo values. In this case, if Readdir returns an empty slice, it will return a non-nil error explaining why. At the end of a directory, the error is io.EOF.
If n <= 0, Readdir returns all the os.FileInfo from the directory in a single slice. In this case, if Readdir succeeds (reads all the way to the end of the directory), it returns the slice and a nil error. If it encounters an error before the end of the directory, Readdir returns the os.FileInfo read until that point and a non-nil error.
The os.FileInfo values returned will not have block location attached to the struct returned by Sys(). To fetch that information, make a separate call to Stat.
Note that making multiple calls to Readdir with a smallish n (as you might do with the os version) is slower than just requesting everything at once. That's because HDFS has no mechanism for limiting the number of entries returned; whatever extra entries it returns are simply thrown away.
func (f *FileReader) Readdirnames(n int) ([]string,.
Seek implements io.Seeker.
The seek is virtual - it starts a new block read at the new position.
func (f *FileReader) SetDeadline(t time.Time) error
SetDeadline sets the deadline for future Read, ReadAt, and Checksum calls. A zero value for t means those calls will not time out.
func (f *FileReader) Stat() os.FileInfo
Stat returns the FileInfo structure describing file.
A FileWriter represents a writer for an open file in HDFS. It implements Writer and Closer, and can only be used for writes. For reads, see FileReader and Client.Open.
func (f *FileWriter) Close() error
Close closes the file, writing any remaining data out to disk and waiting for acknowledgements from the datanodes. It is important that Close is called after all data has been written.
func (f *FileWriter) Flush() error
Flush flushes any buffered data out to the datanodes. Even immediately after a call to Flush, it is still necessary to call Close once all data has been written.
func (f *FileWriter) SetDeadline(t time.Time) error
SetDeadline sets the deadline for future Write, Flush, and Close calls. A zero value for t means those calls will not time out.
Note that because of buffering, Write calls that do not result in a blocking network call may still succeed after the deadline.
func (f *FileWriter) Write(b []byte) (int, error)
Write implements io.Writer for writing to a file in HDFS. Internally, it writes data to an internal buffer first, and then later out to HDFS. Because of this, it is important that Close is called after all data has been written.
type FsInfo struct { Capacity uint64 Used uint64 Remaining uint64 UnderReplicated uint64 CorruptBlocks uint64 MissingBlocks uint64 MissingReplOneBlocks uint64 BlocksInFuture uint64 PendingDeletionBlocks uint64 }
FsInfo provides information about HDFS
Package hdfs imports 20 packages (graph) and is imported by 41 packages. Updated 2018-12-08. Refresh now. Tools for package owners. | https://godoc.org/github.com/colinmarc/hdfs | CC-MAIN-2019-13 | refinedweb | 2,203 | 50.73 |
From: Peter Dimov (pdimov_at_[hidden])
Date: 2004-12-29 09:33:05
Jonathan Turkanis wrote:
> The occurence of boost::io::put in the above example has to be
> qualified, since otherwise it will refer to the member function being
> defined.
What I have to say has nothing to do with namespaces or directory placement,
but...
Given that in the documentation you speak of user-defined overloads of
boost::io::read et al, it might be worthwhile to point out that two-phase
lookup will not see these user overloads. If you want to have an overload
customization point in a template, you have to use an unqualified call. And
choose the identifiers wisely. :-)
Boost list run by bdawes at acm.org, gregod at cs.rpi.edu, cpdaniel at pacbell.net, john at johnmaddock.co.uk | https://lists.boost.org/Archives/boost/2004/12/78149.php | CC-MAIN-2021-21 | refinedweb | 135 | 66.64 |
To my very great annoyance, I realized today that I managed to ship a broken version of JSON Feed with this version of my site.
For those of you who don’t care about any of the details: it’s fixed now!
For those of you who do care about the details, the rest of this post is a deep dive into what went wrong and why, and how I fixed]):
-
input: The absolute or relative input URL to parse. If
inputis relative, then
baseis required. If
inputis absolute, the
baseis ignored.
-:
class URL { static withBase(base: string | URL, relativePath: string): URL; static fromAbsolute(path: string): URL; }:
import { Result } from 'true-myth' import { URL } from 'url' import { logErr, toString } from './utils' const absoluteUrl = (path: string, baseUrl: string): string => Result.tryOrElse(logErr, () => new URL(path, baseUrl)) .map(toString) .unwrapOr(path):
type Components = { path: string, baseUrl: string | URL } const absoluteUrl = ({ path, baseUrl }: Components): string => // .... | https://v5.chriskrycho.com/journal/json-feed-apology-and-explanation/ | CC-MAIN-2020-16 | refinedweb | 152 | 72.36 |
So a couple of weeks ago I create a thread here for feedback on my Roslyn code generator wrapper (can find it here). I got a lot of very nice feedback and also a couple of people that asked for examples on why and how you can use code generation.
So I started to work a bit on a “unit test generator” to show how you can use code generation in a fun way:
It’s far from finish and I think you can call it “SetUp generator” more than “unit test generator” right now. So here is how it work:
- You select your assembly
- The framework will look through your assembly for exported types (that is not static or abstract)
- For each type it find it will generate a unit test file
- In the unit test file it will generate a set up that that initialize the type by looking at the first constructor of the type.
- If the constructor requires any argument it will either mock them, initialize them or set default values.
And well that’s mostly it for now. I tried it on a project from work and it manage to generate at least 700 unit test files that matched the same directory/namespace structur as our regular project.
So if anyone would like to try it or have some funny ideas it would be fun to hear them. I worked on it most as an example at first but it’s actually pretty fun and I think you can do a lot more with it. We also only support MsTest or NUnit as test framework and Moq as mocking framework.
submitted by /u/Meeii
[link] [comments] | https://howtocode.net/2017/02/simple-unit-test-generator/ | CC-MAIN-2019-26 | refinedweb | 281 | 71.38 |
I have stumbled across an issue with FormHelper#text_field and thought
it was worth a patch. The ticket (with patch) is here
It seems like my solution can’t be applied because the form helper
methods really needs to use the *_before_type_cast methods because
of numerical attributes. (By the way, the actionpack tests do not show
that yet)
The thing is that the problem hit something inside me and I got
thinking:
should we really try to override the default attribute accessors? I
mean,
there are .read and .write_attributes for those of us who want to, but
should we?
What I was originally trying to have was something like
def title
result = read_attribute(:title)
return title_from_name || PLACE_HOLDER_TITLE.t if result.nil? ||
result.empty?
return result
end
(Rough translation: in case there isn’t a title, generate a default one
based on the name)
But, because of the before_type_cast issue, I had to use something
along
these lines
def title; title_before_type_cast; end
def title_before_type_cast
result = read_attribute(:title)
return title_from_name || PLACE_HOLDER_TITLE.t if result.nil? ||
result.empty?
return result
end
…and that hurts. A lot! Not to mention that it may have introduced
some
subtle bugs that will come back to haunt me in the future.
I could also have tried renaming the db column to db_title or
something, but
that doesn’t seem right either. I thought about using something like
validates_*,
but this isn’t really a validation. We are just providing some sample
data that
would be tedious for the user to enter in many cases.
Is there any idiomatic solution for that?
Cheers,
Thiago A. | https://www.ruby-forum.com/t/should-we-override-model-accessors/80913 | CC-MAIN-2018-47 | refinedweb | 267 | 63.8 |
Sub-projects are a bad idea.
Been following this thread for awhile without being able to put my
concerns into small sentences. Each time I think about it I think
about how rapidly CouchDB is growing and how much that would hurt
sub-projects that are trying to keep up. And as others have said, we
should make sure that CouchDB doesn't turn into a namespace for
sub-projects.
Personally, I think CouchApp should be very frightened of becoming an
ASF project of any sort. My guess is that the stability/agility trade
off is just too serious. I think adding a CouchApp page on would be good, but adding CouchApp traffic
to the bug tracker or mailing lists would make me want to throw twice
as much stuff.
couchdb-lounge should never be a sub-project. Implementing it in
Erlang is going to touch more bits than most people consider. It'll
end up being unavoidable not having it part of the default
distribution. Trying to pull in the entire project as it is and the
replace it piece by piece is not going to work. We should keep it like
it is, a reference implementation that we hope to achieve in the
default CouchDB distribution.
The only project I could even consider being a sub-project is
couchdb-lucene. Though for roughly the same reasons as CouchApp I'd
probably rather see it as a separate project and just include it on
our website ecosystem. Both projects are public-api compatibile and as
others have stated, they'll either stay compatible or die.
And with all that, we're an Alpha (or Beta), pre-1.0 software project.
Now is not the time for adding bureaucracy to release procedures. We
should be focused on removing obstacles to making good software and
adding sub-projects seems like a good way to cause us a crap load of
pain in the future.
Faster not slower.
Paul Davis
On Fri, Aug 14, 2009 at 2:52 AM, Chris Anderson<jchris@apache.org>
>
>
> | http://mail-archives.apache.org/mod_mbox/couchdb-dev/200908.mbox/%3Ce2111bbb0908162312w414c3f0cmbbd847c6ca8b2754@mail.gmail.com%3E | CC-MAIN-2015-18 | refinedweb | 342 | 72.87 |
First solution in Clear category for Moria Doors by Sim0000
def find_word(message):
def f(s1, s2):
point = 10 * ((s1[0] == s2[0]) + (s1[-1] == s2[-1]))
point += 30 * min(len(s1), len(s2)) / max(len(s1), len(s2))
point += 50 * len(set(s1) & set(s2)) / len(set(s1 + s2))
return point
m = ''.join(c if c.islower() else ' ' for c in message.lower()).split()
score = {}
for i, w1 in enumerate(m):
score[i] = sum(f(w1, w2) for j, w2 in enumerate(m) if i != j)
return m[max(reversed(range(len(m))), key=score.get)]. 24, 2014
Forum
Global Activity
Jobs
Class Manager
Leaderboard
Coding games
Python programming for beginners | https://py.checkio.org/mission/gate-puzzles/publications/Sim0000/python-3/first/share/effe0df39535b5a6e75ce36c9762dd31/ | CC-MAIN-2018-30 | refinedweb | 112 | 58.08 |
Member Since 10 Months Ago
520 Search For Accented Words
'charset' => 'utf8mb4', 'collation' => 'utf8mb4_unicode_ci',
Started a new Conversation Search For Accented Words
I have the following code to search:
$resultContato = Contato::where(function ($q) use ($terms) { foreach ($terms as $key) { $q->orWhere('nome', 'like', "{$key} %"); $q->orWhere('nome', 'like', "{$key}: %"); $q->orWhere('nome', 'like', "% {$key} %"); $q->orWhere('nome', 'like', "% {$key}"); $q->orWhere('nome', 'like', "%{$key}"); } })->get();
It works well if the search is done with mixed or capitalized words. However it does not work with accented words.
Even if I remove the accent when searching, still no results are returned.
How can I solve this?
Replied to How To Hide The Props
The point is that my esoteric tarot has 157 variables that are generated dynamically when a user clicks on the card. So the result displayed is not the problem. What I don't want to display is the 157 variables that are included in the translation file. Because if they see the whole file, they can do something similar
Replied to How To Hide The Props
so the best solution would be to store it in the database, right?
Started a new Conversation How To Hide The Props
I receive some translation data regarding an esoteric tarot through props. But I would like to hide this information, as I don't want the competition to be able to identify how I generate the tarot results.
Currently I do this:
<tarot :</tarot>
Is there any way to hide this from the source code?
If not, how could I get the translation data from laravel without it being exposed in the code?
Started a new Conversation How To Guarantee Only One Record In The Database
After passing validation, I need to ensure that the data is saved only once. I need to guarantee this, because in some cases 2 or more records are saved even preventing this in the frontend with javascript.
My controller looks like this:
public function salvarRelato(Request $request) { $rules = [ 'titulo' => 'required|string|min:4|max:60', 'sonho' => 'required|string|min:20', ]; $messages = [ 'required' => 'Campo obrigatório', 'titulo.min' => 'O título deve ter entre 4 e 60 caracteres.', 'titulo.max' => 'O título deve ter no máximo 60 caracteres.', 'sonho.min' => 'O relato deve ter no mínimo 20 caracteres.', ]; $this->validate($request, $rules, $messages); $novo = new Relato; $novo->grupo_id = $request->id; $novo->user_id = \Auth::user()->id; $novo->lang = 'pt-br'; $novo->titulo = $request->titulo; $novo->slug = mt_rand(1000000, 9999999).'-'.str_slug($novo->titulo, '-'); $novo->relato = $request->sonho; $novo->resumo = $request->resumo; $novo->lastMsg = \Auth::user()->username; $novo->q1 = $request->q1; $novo->q2 = $request->q2; $novo->q3 = $request->q3; $novo->q4 = $request->q4; $novo->q5 = $request->q5; $novo->q6 = $request->q6; $novo->q7 = $request->q7; $novo->q8 = $request->q8; $novo->q9 = $request->q9; $novo->chakra1 = $request->ck1; $novo->chakra2 = $request->ck2; $novo->chakra3 = $request->ck3; $novo->chakra4 = $request->ck4; $novo->chakra5 = $request->ck5; $novo->chakra6 = $request->ck6; $novo->chakra7 = $request->ck7; $novo->exist = $request->exist; $novo->save()
How can I check again if the validation was successful and ensure that the restriction is saved only once in the database?
Started a new Conversation How To Set Canonical Url To Another Language
I have a multi-language website in which only two versions will be identified in content: pt-br and pt
When users access the path "pt" I need to set the canonical url to "pt-br" to prevent google from seeing duplicate content.
But I don't know how to do this.
I could only think about it:
@if(app()->getLocale() === 'pt') <link rel="canonical" href="{{Request::url()}}" /> @endif
But this returns the url of the "pt" pages. How could I change from "pt" to "pt-br"?
Replied to Inserting More Than One Record Improperly
Any suggestion ?
I need to resolve this urgently.
Started a new Conversation Inserting More Than One Record Improperly
My website users complete a personality test that is stored in a database. However, even preventing the user from entering more than one record, in some cases there are users who can send more than one.
I really don't understand the reason for this, because when the user clicks publish once, the save action is removed from the button.
Look my button:
<button class="btn btn-green" @<span>Publicar</span></button>
My data and function:
data(){ return { clicouSave: false, } }, salvarRelato(e) { this.clicouSave = true; this.relato.loading = true; axios.post('/sonhos/novo', { id: this.grupoid, titulo: this.relato.titulo, sonho: this.relato.sonho, resumo: this.relato.resumo, ck1: this.relato.ck.c1, ck2: this.relato.ck.c2, ck3: this.relato.ck.c3, ck4: this.relato.ck.c4, ck5: this.relato.ck.c5, ck6: this.relato.ck.c6, ck7: this.relato.ck.c7, }) .then(response => { }) .catch( error => { this.clicouSave = false; }); },
That is, when the user first clicks "Publicar",
clicouSave is set to true and consequently the button stops calling the
salvarRelato() function.
In practice this works perfectly. But for some reason some users are managing to send more than one.
Can anyone tell me why this is happening?
Replied to Prevent White Space In The Input Not Working
thanks ::)))
Started a new Conversation Prevent White Space In The Input Not Working
I need to prevent my users from placing the "username" with spaces between words.
I solved it this way:
<input @keydown.space.prevent
But
@keydown.space.prevent doesn't work on mobile devices or when the user copies and pastes a text.
What better way to solve this?
Started a new Conversation How Remove Update_at Automatic
I have a forum where there is a visit counter, however, the topics are sorted by the updated_at column, so that the user enters the topic, the number of views is increased by +1. and this ends up updating the updated_at column, changing the display order unnecessarily.
I found this solution (
$relato->timestamps = false;):
$relato = Relato::where([ ['slug', $titulo], ['grupo_id', $grupo->id] ])->first(); $Key = 'relato_' . $relato->id; if (!\Session::has($Key)) { $relato->timestamps = false; $relato->increment('views', 1); \Session::put($Key, 1); }
This works in a way, but when I enter the topic I end up getting this error:
Call to a member function format() on string
I need to continue using the data in the created_at and updated_at column, but not change the date when I call
$report->increment('views', 1);
How could I do that?
Replied to How To Remove App.js From The Cache?
Yes, I use
npm run prod on my personal computer. Then, I access the app.js file on my personal computer and copy the code (ctrl + c), go to the hosting service, click on edit the app.js file and paste (ctrl + v) my new code.
Then I save. But when I enter the site the change does not occur, so I need to rename the app.js file, and finally everything works again.
Replied to How To Remove App.js From The Cache?
I do not upload, just change what I need and save directly to the hosting. Then just rename
Replied to How To Remove App.js From The Cache?
Strange, because I clear the browser's cache, tested it on other devices and cell phones, and even in anonymous mode the file is displayed
I change the code and rename it, so the old one ceases to exist.
Started a new Conversation How To Remove App.js From The Cache?
I have already contacted the support of my hosting service believing that the problem was with them, but everything indicates that the laravel itself is creating a cached app.js file.
I had to rename the file for the code changes to take effect on the website.
For example, if you enter this link:
You will see that the app.js file is displayed, but it no longer exists, it has been deleted.
For every adjustment I make to the code, I need to rename the file. Is the laravel really doing this?
How do I solve it?
Awarded Best Reply on How To Enable Php Artisan Queue:work On Shared Hosting?
My shared hosting é Hostinger, and i solved it like this:
php /home/u216892564/public_html/artisan queue:work --daemon
Replied to How To Enable Php Artisan Queue:work On Shared Hosting?
My shared hosting é Hostinger, and i solved it like this:
php /home/u216892564/public_html/artisan queue:work --daemon
Started a new Conversation How To Enable Php Artisan Queue:work On Shared Hosting?
I have read several topics and articles on the internet on the subject, but this is my first contact with Cron Jobs and I am unable to make it work. I need to keep the php artisan queue: work running. In my hosting it has this:
I've tried it in a few ways, but the two most recent were these:
This does not seem to work, as I am not receiving an account verification email.
Can someone help me ?
Replied to How To Make 9 Digit Counter With Number_format
Very thanks ::))))
Started a new Conversation How To Make 9 Digit Counter With Number_format
In a previous topic, I was given the number_format to do what I need. But I couldn't solve it, because I need to invert the data, and I couldn't do it with
number_format.
I need to take the total of topics in the forum and generate a 9 digit counter.
For example, if I have 65 topics: 000,000,065 If I have 1322 topics: 000,001,322
And so on.
I was unable to do this using only
number_format. Can you help me ?
Started a new Conversation How To Create Counter In 100,000,000 Format
I need to display the number of topics on my forum in the format 100,000,000
That is, if there are 50 topics, the result should be: 000,000,050. And so on
How can I do this?
Awarded Best Reply?
it is a group table, where each row stores the information of a group a specific group. That is, it has ID, the age group columns mentioned before and many other information that I hid to make it easier and cleaner.
But in summary I get the group like this:
$grupo = Grupo::where('id', $request->id)->first();
And inside it I have the columns:
Hence I need to calculate the percentage of each column using the equation:
{{100/$grupo->totalRespostas*$grupo->column}}
And display only the result with the highest percentage
Replied to How To Get A Result With A Higher Percentage?
But the data is stored on a single line. So I would need to group the columns of that row, not the column of several rows. So groupby will not work in my case
Started a new Conversation How To Get A Result With A Higher Percentage?
I have a questionnaire that stores the ages of all users who answered it. So for each age range, I have a column, for example:
When generating the result of all people who responded, I need to display only the age group with the highest percentage.
I don't know how best to solve this, without filling my blade with @if and @elseif.
The equation I'm using is:
{{100/$grupo->totalRespostas*$grupo->19to25}}
But how can I compare all the results and return only the one with the highest percentage? What is the most efficient way to solve this?
Replied to Json_decode Return Null
Started a new Conversation Json_decode Return Null
I can't use my json file on @foreach, because json_decode returns null. Look:
My perguntas.json file:
{ "questions": [ { "ck": ["c1", "c6"], "id": 1, "text": "Você se sente \"desligado\" ou \"aéreo\"?" }, { "ck": ["c1", "c2"], "id": 2, "text": "Tem tendências adictas compulsivas " }, { "ck": ["c1"], "id": 3, "text": "Sente-se abatido e com pouca energia?" }, { "ck": ["c1"], "id": 4, "text": "Sente-se apreensivo ou ansioso sem motivo aparente?" }, ] }
My Controller:
$perguntas = file_get_contents(resource_path('lang/pt-br/perguntas.json')); $getperguntas = json_decode($perguntas);
This does not work, as I get NULL. If I print on the screen without doing the decode, my json looks like this:
Why doesn't it work and how do I solve it?
Started a new Conversation I Need Help With Math Solution
Friends, I suck at math, and even looking on the internet, I couldn't safely solve my problem.
Because you are more familiar with these types of situations, I think you can help me.
You see, I have a personality test site that has 72 questions.
The individual test result I already solved. But I also need a result from several users in the same category. For example, I want to gather the result of people who are 50 years old, for this to work, I need to make the right equation, so that I receive the result (and the personality type) proportional to a particular group. And I can't solve this equation.
Let's take a real example. The following database structure consists of responses from a group of users:
totalUser would be the number of people who answered the questionnaire. Because of this, each question column can contain a different number, since the answers "YES" is equal to 1, and the answers "NO" is equal to 0.
CK is the personality type, and each time the user submits the questionnaire, if CK1 is given as true, then 1 will be added in this column
To summarize imagine the scenario: 10 people answered the questionnaire:
Therefore, I need to display the result in proportion to the number of people who responded. So that if the result of 10 users gave "CK1" as a personality type, I need to show it as true.
In short, I don't know what calculation to do, multiplication, division, percentage. it may seem simple, but this is very confusing to me, and I am afraid of generating wrong results due to an inappropriate equation.
Can you help me ?
Replied to How To Remove Columns With NULL Using Where
Replied to How To Remove Columns With NULL Using Where
Replied to How To Remove Columns With NULL Using Where
public function novoRelato($slug) { $grupo = Grupo::where('slug', $slug)->first(); $pextra = Pextra::where('grupo_id', $grupo->id)->first(); $pextra->makeHidden('grupo_id')->toArray(); $pextra = $pextra->filter(function ($value) { return !is_null($value); }); return view('novoRelato', compact(['grupo','pextra'])); }
Replied to How To Remove Columns With NULL Using Where
Replied to How To Remove Columns With NULL Using Where
Started a new Conversation How To Remove Columns With NULL Using Where
I have a table where extra questions for a questionnaire will be stored. I need to get only the columns that have questions filled out.
I'm doing this:
public function novoRelato($slug) { $grupo = Grupo::where('slug', $slug)->first(); $pextra = Pextra::where('grupo_id', $grupo->id)->first(); $pextra->makeHidden('grupo_id')->toArray(); return view('novoRelato', compact(['grupo','pextra'])); }
Data received:
{"q73":"Oi, tudo bem ?","q74":"Como vai ?","q75":"Seu sonho foi legal ?","q76":null,"q77":null,"q78":null,"q79":null,"q80":null}
I'm using
makeHidden to hide the
grupo_id column, as I need to get only the extra questions for a particular group.
The extra questions table has 10 columns ranging from
q73 to
q80. But not all are filled, so I need to remove the
NULL columns from this collection and get only the columns that have information.
How can I do this ?
Replied to How To Convert Birth Date String To Age
Thanks for the sugestion. But because it is a multi-language site, the date format can also change. May be 05/12/1990 or 05/12/1990
How could I configure this?
Started a new Conversation How To Convert Birth Date String To Age
When the user registers on the website, the date of birth is stored in a string format, like this: 12/05/1990
I need to calculate the age of the user whenever he submits a new post on the site.
I saw that this function exists:
STR_TO_DATE(str, format)
But I can't use it in laravel, and I also don't know how I could get the age using
STR_TO_DATE(str, format)
How can I do this ?
Started a new Conversation Transition Group With Slice Not Working As Expected
I have a dynamic paging that displays 10 items at a time, but the
<transition-group> does not work as expected. While the previous listing disappears, the new one is added to the page, making the behavior a little strange, see:
I tried using
mode="out-in" and
mode="in-out", but that doesn't solve the problem.
I read all the documentation but found nothing to solve it.
Can you help me ?
Started a new Conversation How To Make V-for Display 10 Items At A Time
I have a questionnaire with 60 questions, and I need to display 10 questions at a time.
But, I'm having trouble making it work even though I see some references on the internet.
The way I am doing, each time I click
next(), 10 items are added to the
v-for, but the previous 10 items remain on the page.
I'm doing this:
<div class="test-questions comp"> <div class="question" v- <div class="statement"> {{q.id}}. {{q.text}} </div> <div class="options yes-no"> <div class="caption option yes">Sim</div> <div class="caption option no">Não</div> </div> </div> </div> <div class="action-row"> <button v-<span>Publicar</span></button> <button v-<span>Anterior</span></button> <button v-<span>Próximo</span></button> </div>
My data:
props: ['perguntas'], data(){ return { perpage: 10, } }, methods: { next(){ this.perpage = this.perpage + 10; }, previous(){ this.perpage = this.perpage - 10; }, }
Can you help me ?
Started a new Conversation How To Get Json File
I need to get the questions.json file that is inside the language folder. In other words, inside
lang/pt-br there is the file
questions.json.
I need to include the data from this file inside a vuejs component to perform the
v-for. However, I tried in a few ways but I was unable to capture this file.
My last attempt went like this:
<novo-relato</novo-relato>
How do I get this json file?
Replied to How To Get Range Of Columns In Array?
@automica The answers themselves will not be stored, only the personality type. When answering the 60 questions, the calculation will be done at the end and the database will store only the personality.
So there will be no relationship between questions and answers.
As a multi-language site, I only need one place to capture and display these questions according to the user's language
Replied to How To Get Range Of Columns In Array?
@automica It is a personality test, and the responses will be captured with @click and then stored only the test result. So there will be no relationship between questions and answers in the database.
At the moment I just need to display the questions. I'm thinking of creating a single "questions" column, and storing an array of questions in that single column.
But would that be recommended?
Started a new Conversation How To Get Range Of Columns In Array?
I have a table of questions like this:
public function up() { Schema::create('perguntas', function (Blueprint $table) { $table->increments('id')->unsigned(); $table->string('lang', 5); $table->string('q01'); $table->string('q02'); $table->string('q03'); $table->string('q04'); .... $table->string('q58'); $table->string('q59'); $table->string('q60'); }); }
And I am capturing such questions with axios like this:
mounted() { axios .get(this.getperguntas) .then(response => { this.perguntas = response.data; }) },
I need to use
v-for to display only the questions, which are the columns from
q01 to
q60.
How can I do this ??
The controller looks like this:
public function getPerguntas() { $perguntas = Pergunta::where('lang', app()->getLocale())->get(); return response()->json($perguntas); }
Any tips ?
Started a new Conversation Anonymous Users After Deleting Account
I have a discussion forum and I want to keep the topics even after the user deletes the account.
So that the photo and username show "Anonymous User".
What is the logic for doing this?
I need suggestions, because I'm having trouble choosing the best path for this problem.
Started a new Conversation Verify Email With Locale
I need to redirect the email verification link to the home page according to the language
I am using a package for routes in several languages. Because of this, I need to pass a parameter in the verification url with the user's language. For example, currently the url is generated like this:
I need to insert this in this url
?locale=pt-br
So that in the
VerificationController.php file, I can redirect to the home page of the user's language.
Example...
protected $redirectTo = localized_route('home', $request->locale);
So that in the
VerificationController.php file, I can redirect to the home page of the user's language.
Where should I configure to insert this variable
?Locale=pt-br in the Email verification URL?
And how can I capture it in
VerificationController.php?
Any suggestion or tip is welcome.
Replied to How To Pick Up As A User's Conversations
Thanks for the suggestions.
But I ended up doing it like this...
Model User:
public function deUser() { return $this->hasMany('App\Conversation','de_user_id'); } public function paraUser() { return $this->hasMany('App\Conversation','para_user_id'); } public function conversations() { return $this->deUser()->union($this->paraUser()->toBase())->orderBy('updated_at', 'desc'); }
Model Conversations:
public function deUser() { return $this->belongsTo('App\User', 'de_user_id'); } public function paraUser() { return $this->belongsTo('App\User', 'para_user_id'); }
My Blade:
@foreach(Auth::user()->conversations as $c) @if($c->deUser->username !== Auth::user()->username) <a href="{{localized_route('chat', $c->deUser->username)}}" class="conversation "> <div class="avatar"><img src="{{$c->deUser->avatar}}"></div> <div class="info"> <div class="name "> {{$c->deUser->username}} </div> <div class="body"> Howdy! Hows it going? </div> </div> <div class="date"><span aria-</span> 3 months ago </div> </a> @endif @if($c->paraUser->username !== Auth::user()->username) <a href="{{localized_route('chat', $c->paraUser->username)}}" class="conversation "> <div class="avatar"><img src="{{$c->paraUser->avatar}}"></div> <div class="info"> <div class="name "> {{$c->paraUser->username}} </div> <div class="body"> Howdy! Hows it going? </div> </div> <div class="date"><span aria-</span> 3 months ago </div> </a> @endif @endforeach
Started a new Conversation How To Pick Up As A User's Conversations
I'm having trouble capturing all the messages that the authenticated user has. Look:
Conversations table:
public function up() { Schema::create('conversations', function (Blueprint $table) { $table->increments('id')->unsigned(); $table->integer('de_user_id')->unsigned(); $table->foreign('de_user_id')->references('id')->on('users'); $table->integer('para_user_id')->unsigned(); $table->foreign('para_user_id')->references('id')->on('users'); $table->timestamps(); }); }
Messages table:
public function up() { Schema::create('messages', function (Blueprint $table) { $table->increments('id')->unsigned(); $table->integer('conversation_id')->unsigned(); $table->foreign('conversation_id')->references('id')->on('conversations'); $table->integer('user_id')->unsigned(); $table->foreign('user_id')->references('id')->on('users'); $table->text('message'); $table->timestamps(); }); }
As I'm doing in Controller
public function msgs(Request $request) { $conversas = Conversation::where('de_user_id', $request->user()->id) ->orWhere('para_user_id', $request->user()->id)->with(['deUser','paraUser'])->get(); return view('msgs', compact('conversas')); }
Conversations Model:
class Conversation extends Model { public function deUser() { return $this->belongsTo('App\User', 'de_user_id'); } public function paraUser() { return $this->belongsTo('App\User', 'para_user_id'); } }
This is all too confusing. Because I need to check de_user_id and para_user_id, because the values depend on who starts the chat.
And the solutions I have been thinking are too exaggerated, as I simply need to show the chats that the authenticated user is part of, like this:
The way I'm doing it doesn't seem to be the best solution, because when it comes to displaying the conversations, I need to check whether
de_user_id or
para_user_id correspond to the authenticated user so that the username of the sender is displayed and not of the user.
Can you give me a cleaner and simpler solution?
Replied to ->each Function With Relationship
I understand what's going on, buddy.
I'm using the package: chinleung / laravel-multilingual-routes
And I didn't define the Api route to use it, so it didn't return the correct language.
Now I managed to solve it.
Thank you very much for your attention.
(Y)
Replied to ->each Function With Relationship
Does not work!
It always returns
en, and the request was made in
pt-br | https://laracasts.com/@mvnobrega | CC-MAIN-2020-50 | refinedweb | 4,058 | 54.63 |
Going.
By the end of this tutorial, you’ll be able to:
- Understand common data engineer interview questions
- Distinguish between relational and non-relational databases
- Set up databases using Python
- Use Python for querying data
Free Download: Get a sample chapter from Python Tricks: The Book that shows you Python’s best practices with simple examples you can apply instantly to write more beautiful + Pythonic code.
Becoming a Data Engineer
The data engineering role can be a vast and varied one. You’ll need to have a working knowledge of multiple technologies and concepts. Data engineers are flexible in their thinking. As a result, they can be proficient in multiple topics, such as databases, software development, DevOps, and big data.
What Does a Data Engineer Do?
Given its varied skill set, a data engineering role can span many different job descriptions. A data engineer can be responsible for database design, schema design, and creating multiple database solutions. This work might also involve a Database Administrator.
As a data engineer, you might act as a bridge between the database and the data science teams. In that case, you’ll be responsible for data cleaning and preparation, as well. If big data is involved, then it’s your job to come up with an efficient solution for that data. This work can overlap with the DevOps role.
You’ll also need to make efficient data queries for reporting and analysis. You might need to interact with multiple databases or write Stored Procedures. For many solutions like high-traffic websites or services, there may be more than one database present. In these cases, the data engineer is responsible for setting up the databases, maintaining them, and transferring data between them.
How Can Python Help Data Engineers?
Python is known for being the swiss army knife of programming languages. It’s especially useful in data science, backend systems, and server-side scripting. That’s because Python has strong typing, simple syntax, and an abundance of third-party libraries to use. Pandas, SciPy, Tensorflow, SQLAlchemy, and NumPy are some of the most widely used libraries in production across different industries.
Most importantly, Python decreases development time, which means fewer expenses for companies. For a data engineer, most code execution is database-bound, not CPU-bound. Because of this, it makes sense to capitalize on Python’s simplicity, even at the cost of slower performance when compared to compiled languages such as C# and Java.
Answering Data Engineer Interview Questions
Now that you know what your role might consist of, it’s time to learn how to answer some data engineer interview questions! While there’s a lot of ground to cover, you’ll see practical Python examples throughout the tutorial to guide you along the way.
Questions on Relational Databases
Databases are one of the most crucial components in a system. Without them, there can be no state and no history. While you may not have considered database design to be a priority, know that it can have a significant impact on how quickly your page loads. In the past few years, several large corporations have introduced several new tools and techniques:
- NoSQL
- Cache databases
- Graph databases
- NoSQL support in SQL databases
These and other techniques were invented to try and increase the speed at which databases process requests. You’ll likely need to talk about these concepts in your data engineer interview, so let’s go over some questions!
Q1: Relational vs Non-Relational Databases
A relational database is one where data is stored in the form of a table. Each table has a schema, which is the columns and types a record is required to have. Each schema must have at least one primary key that uniquely identifies that record. In other words, there are no duplicate rows in your database. Moreover, each table can be related to other tables using foreign keys.
One important aspect of relational databases is that a change in a schema must be applied to all records. This can sometimes cause breakages and big headaches during migrations. Non-relational databases tackle things in a different way. They are inherently schema-less, which means that records can be saved with different schemas and with a different, nested structure. Records can still have primary keys, but a change in the schema is done on an entry-by-entry basis.
You would need to perform a speed comparison test based on the type of function being performed. You can choose
INSERT,
UPDATE,
DELETE, or another function. Schema design, indices, the number of aggregations, and the number of records will also affect this analysis, so you’ll need to test thoroughly. You’ll learn more about how to do this later on.
Databases also differ in scalability. A non-relational database may be less of a headache to distribute. That’s because a collection of related records can be easily stored on a particular node. On the other hand, relational databases require more thought and usually make use of a master-slave system.
A SQLite Example
Now that you’ve answered what relational databases are, it’s time to dig into some Python! SQLite is a convenient database that you can use on your local machine. The database is a single file, which makes it ideal for prototyping purposes. First, import the required Python library and create a new database:
import sqlite3 db = sqlite3.connect(':memory:') # Using an in-memory database cur = db.cursor()
You’re now connected to an in-memory database and have your cursor object ready to go.
Next, you’ll create the following three tables:
- Customer: This table will contain a primary key as well as the customer’s first and last names.
- Items: This table will contain a primary key, the item name, and the item price.
- Items Bought: This table will contain an order number, date, and price. It will also connect to the primary keys in the Items and Customer tables.
Now that you have an idea of what your tables will look like, you can go ahead and create them:
cur.execute('''CREATE TABLE IF NOT EXISTS Customer ( id integer PRIMARY KEY, firstname varchar(255), lastname varchar(255) )''') cur.execute('''CREATE TABLE IF NOT EXISTS Item ( id integer PRIMARY KEY, title varchar(255), price decimal )''') cur.execute('''CREATE TABLE IF NOT EXISTS BoughtItem ( ordernumber integer PRIMARY KEY, customerid integer, itemid integer, price decimal, CONSTRAINT customerid FOREIGN KEY (customerid) REFERENCES Customer(id), CONSTRAINT itemid FOREIGN KEY (itemid) REFERENCES Item(id) )''')
You’ve passed a query to
cur.execute() to create your three tables.
The last step is to populate your tables with data:
cur.execute('''INSERT INTO Customer(firstname, lastname) VALUES ('Bob', 'Adams'), ('Amy', 'Smith'), ('Rob', 'Bennet');''') cur.execute('''INSERT INTO Item(title, price) VALUES ('USB', 10.2), ('Mouse', 12.23), ('Monitor', 199.99);''') cur.execute('''INSERT INTO BoughtItem(customerid, itemid, price) VALUES (1, 1, 10.2), (1, 2, 12.23), (1, 3, 199.99), (2, 3, 180.00), (3, 2, 11.23);''') # Discounted price
Now that there are a few records in each table, you can use this data to answer a few more data engineer interview questions.
Q2: SQL Aggregation Functions
Aggregation functions are those that perform a mathematical operation on a result set. Some examples include
AVG,
COUNT,
MIN,
MAX, and
SUM. Often, you’ll need
GROUP BY and
HAVING clauses to complement these aggregations. One useful aggregation function is
AVG, which you can use to compute the mean of a given result set:
>>> cur.execute('''SELECT itemid, AVG(price) FROM BoughtItem GROUP BY itemid''') >>> print(cur.fetchall()) [(1, 10.2), (2, 11.73), (3, 189.995)]
Here, you’ve retrieved the average price for each of the items bought in your database. You can see that the item with an
itemid of
1 has an average price of $10.20.
To make the above output easier to understand, you can display the item name instead of the
itemid:
>>> cur.execute('''SELECT item.title, AVG(boughtitem.price) FROM BoughtItem as boughtitem ... INNER JOIN Item as item on (item.id = boughtitem.itemid) ... GROUP BY boughtitem.itemid''') ... >>> print(cur.fetchall()) [('USB', 10.2), ('Mouse', 11.73), ('Monitor', 189.995)]
Now, you see more easily that the item with an average price of $10.20 is the
USB.
Another useful aggregation is
SUM. You can use this function to display the total amount of money that each customer spent:
>>> cur.execute('''SELECT customer.firstname, SUM(boughtitem.price) FROM BoughtItem as boughtitem ... INNER JOIN Customer as customer on (customer.id = boughtitem.customerid) ... GROUP BY customer.firstname''') ... >>> print(cur.fetchall()) [('Amy', 180), ('Bob', 222.42000000000002), ('Rob', 11.23)]
On average, the customer named Amy spent about $180, while Rob only spent $11.23!
If your interviewer likes databases, then you might want to brush up on nested queries, join types, and the steps a relational database takes to perform your query.
Q3: Speeding Up SQL Queries
Speed depends on various factors, but is mostly affected by how many of each of the following are present:
- Joins
- Aggregations
- Traversals
- Records
The greater the number of joins, the higher the complexity and the larger the number of traversals in tables. Multiple joins are quite expensive to perform on several thousands of records involving several tables because the database also needs to cache the intermediate result! At this point, you might start to think about how to increase your memory size.
Speed is also affected by whether or not there are indices present in the database. Indices are extremely important and allow you to quickly search through a table and find a match for some column specified in the query.
Indices sort the records at the cost of higher insert time, as well as some storage. Multiple columns can be combined to create a single index. For example, the columns
date and
price might be combined because your query depends on both conditions.
Q4: Debugging SQL Queries
Most databases include an
EXPLAIN QUERY PLAN that describes the steps the database takes to execute the query. For SQLite, you can enable this functionality by adding
EXPLAIN QUERY PLAN in front of a
SELECT statement:
>>> cur.execute('''EXPLAIN QUERY PLAN SELECT customer.firstname, item.title, ... item.price, boughtitem.price FROM BoughtItem as boughtitem ... INNER JOIN Customer as customer on (customer.id = boughtitem.customerid) ... INNER JOIN Item as item on (item.id = boughtitem.itemid)''') ... >>> print(cur.fetchall()) [(4, 0, 0, 'SCAN TABLE BoughtItem AS boughtitem'), (6, 0, 0, 'SEARCH TABLE Customer AS customer USING INTEGER PRIMARY KEY (rowid=?)'), (9, 0, 0, 'SEARCH TABLE Item AS item USING INTEGER PRIMARY KEY (rowid=?)')]
This query tries to list the first name, item title, original price, and bought price for all the bought items.
Here’s what the query plan itself looks like:
SCAN TABLE BoughtItem AS boughtitem SEARCH TABLE Customer AS customer USING INTEGER PRIMARY KEY (rowid=?) SEARCH TABLE Item AS item USING INTEGER PRIMARY KEY (rowid=?)
Note that fetch statement in your Python code only returns the explanation, but not the results. That’s because
EXPLAIN QUERY PLAN is not intended to be used in production.
Questions on Non-Relational Databases
In the previous section, you laid out the differences between relational and non-relational databases and used SQLite with Python. Now you’re going to focus on NoSQL. Your goal is to highlight its strengths, differences, and use cases.
A MongoDB Example
You’ll use the same data as before, but this time your database will be MongoDB. This NoSQL database is document-based and scales very well. First things first, you’ll need to install the required Python library:
$ pip install pymongo
You also might want to install the MongoDB Compass Community. It includes a local IDE that’s perfect for visualizing the database. With it, you can see the created records, create triggers, and act as visual admin for the database.
Note: To run the code in this section, you’ll need a running database server. To learn more about how to set it up, check out Introduction to MongoDB and Python.
Here’s how you create the database and insert some data:
import pymongo client = pymongo.MongoClient("mongodb://localhost:27017/") # Note: This database is not created until it is populated by some data db = client["example_database"] customers = db["customers"] items = db["items"] customers_data = [{ "firstname": "Bob", "lastname": "Adams" }, { "firstname": "Amy", "lastname": "Smith" }, { "firstname": "Rob", "lastname": "Bennet" },] items_data = [{ "title": "USB", "price": 10.2 }, { "title": "Mouse", "price": 12.23 }, { "title": "Monitor", "price": 199.99 },] customers.insert_many(customers_data) items.insert_many(items_data)
As you might have noticed, MongoDB stores data records in collections, which are the equivalent to a list of dictionaries in Python. In practice, MongoDB stores BSON documents.
Q5: Querying Data With MongoDB
Let’s try to replicate the
BoughtItem table first, as you did in SQL. To do this, you must append a new field to a customer. MongoDB’s documentation specifies that the keyword operator set can be used to update a record without having to write all the existing fields:
# Just add "boughtitems" to the customer where the firstname is Bob bob = customers.update_many( {"firstname": "Bob"}, { "$set": { "boughtitems": [ { "title": "USB", "price": 10.2, "currency": "EUR", "notes": "Customer wants it delivered via FedEx", "original_item_id": 1 } ] }, } )
Notice how you added additional fields to the
customer without explicitly defining the schema beforehand. Nifty!
In fact, you can update another customer with a slightly altered schema:
amy = customers.update_many( {"firstname": "Amy"}, { "$set": { "boughtitems":[ { "title": "Monitor", "price": 199.99, "original_item_id": 3, "discounted": False } ] } , } ) print(type(amy)) # pymongo.results.UpdateResult
Similar to SQL, document-based databases also allow queries and aggregations to be executed. However, the functionality can differ both syntactically and in the underlying execution. In fact, you might have noticed that MongoDB reserves the
$ character to specify some command or aggregation on the records, such as
$group. You can learn more about this behavior in the official docs.
You can perform queries just like you did in SQL. To start, you can create an index:
>>> customers.create_index([("name", pymongo.DESCENDING)])
This is optional, but it speeds up queries that require name lookups.
Then, you can retrieve the customer names sorted in ascending order:
>>> items = customers.find().sort("name", pymongo.ASCENDING)
You can also iterate through and print the bought items:
>>> for item in items: ... print(item.get('boughtitems')) ... None [{'title': 'Monitor', 'price': 199.99, 'original_item_id': 3, 'discounted': False}] [{'title': 'USB', 'price': 10.2, 'currency': 'EUR', 'notes': 'Customer wants it delivered via FedEx', 'original_item_id': 1}]
You can even retrieve a list of unique names in the database:
>>> customers.distinct("firstname") ['Bob', 'Amy', 'Rob']
Now that you know the names of the customers in your database, you can create a query to retrieve information about them:
>>> for i in customers.find({"$or": [{'firstname':'Bob'}, {'firstname':'Amy'}]}, ... {'firstname':1, 'boughtitems':1, '_id':0}): ... print(i) ... {'firstname': 'Bob', 'boughtitems': [{'title': 'USB', 'price': 10.2, 'currency': 'EUR', 'notes': 'Customer wants it delivered via FedEx', 'original_item_id': 1}]} {'firstname': 'Amy', 'boughtitems': [{'title': 'Monitor', 'price': 199.99, 'original_item_id': 3, 'discounted': False}]}
Here’s the equivalent SQL query:
SELECT firstname, boughtitems FROM customers WHERE firstname LIKE ('Bob', 'Amy')
Note that even though the syntax may differ only slightly, there’s a drastic difference in the way queries are executed underneath the hood. This is to be expected because of the different query structures and use cases between SQL and NoSQL databases.
Q6: NoSQL vs SQL
If you have a constantly changing schema, such as financial regulatory information, then NoSQL can modify the records and nest related information. Imagine the number of joins you’d have to do in SQL if you had eight orders of nesting! However, this situation is more common than you would think.
Now, what if you want to run reports, extract information on that financial data, and infer conclusions? In this case, you need to run complex queries, and SQL tends to be faster in this respect.
Note: SQL databases, particularly PostgreSQL, have also released a feature that allows queryable JSON data to be inserted as part of a record. While this can combine the best of both worlds, speed may be of concern.
It’s faster to query unstructured data from a NoSQL database than it is to query JSON fields from a JSON-type column in PostgreSQL. You can always do a speed comparison test for a definitive answer.
Nonetheless, this feature might reduce the need for an additional database. Sometimes, pickled or serialized objects are stored in records in the form of binary types, and then de-serialized on read.
Speed isn’t the only metric, though. You’ll also want to take into account things like transactions, atomicity, durability, and scalability. Transactions are important in financial applications, and such features take precedence.
Since there’s a wide range of databases, each with its own features, it’s the data engineer’s job to make an informed decision on which database to use in each application. For more information, you can read up on ACID properties relating to database transactions.
You may also be asked what other databases you know of in your data engineer interview. There are several other relevant databases that are used by many companies:
- Elastic Search is highly efficient in text search. It leverages its document-based database to create a powerful search tool.
- Newt DB combines ZODB and the PostgreSQL JSONB feature to create a Python-friendly NoSQL database.
- InfluxDB is used in time-series applications to store events.
The list goes on, but this illustrates how a wide variety of available databases all cater to their niche industry.
Questions on Cache Databases
Cache databases hold frequently accessed data. They live alongside the main SQL and NoSQL databases. Their aim is to alleviate load and serve requests faster.
A Redis Example
You’ve covered SQL and NoSQL databases for long-term storage solutions, but what about faster, more immediate storage? How can a data engineer change how fast data is retrieved from a database?
Typical web-applications retrieve commonly-used data, like a user’s profile or name, very often. If all of the data is contained in one database, then the number of hits the database server gets is going to be over the top and unnecessary. As such, a faster, more immediate storage solution is needed.
While this reduces server load, it also creates two headaches for the data engineer, backend team, and DevOps team. First, you’ll now need some database that has a faster read time than your main SQL or NoSQL database. However, the contents of both databases must eventually match. (Welcome to the problem of state consistency between databases! Enjoy.)
The second headache is that DevOps now needs to worry about scalability, redundancy, and so on for the new cache database. In the next section, you’ll dive into issues like these with the help of Redis.
Q7: How to Use Cache Databases
You may have gotten enough information from the introduction to answer this question! A cache database is a fast storage solution used to store short-lived, structured, or unstructured data. It can be partitioned and scaled according to your needs, but it’s typically much smaller in size than your main database. Because of this, your cache database can reside in memory, allowing you to bypass the need to read from a disk.
Note: If you’ve ever used dictionaries in Python, then Redis follows the same structure. It’s a key-value store, where you can
SET and
GET data just like a Python
dict.
When a request comes in, you first check the cache database, then the main database. This way, you can prevent any unnecessary and repetitive requests from reaching the main database’s server. Since a cache database has a lower read time, you also benefit from a performance increase!
You can use pip to install the required library:
$ pip install redis
Now, consider a request to get the user’s name from their ID:
import redis from datetime import timedelta # In a real web application, configuration is obtained from settings or utils r = redis.Redis() # Assume this is a getter handling a request def get_name(request, *args, **kwargs): id = request.get('id') if id in r: return r.get(id) # Assume that we have an {id: name} store else: # Get data from the main DB here, assume we already did it name = 'Bob' # Set the value in the cache database, with an expiration time r.setex(id, timedelta(minutes=60), value=name) return name
This code checks if the name is in Redis using the
id key. If not, then the name is set with an expiration time, which you use because the cache is short-lived.
Now, what if your interviewer asks you what’s wrong with this code? Your response should be that there’s no exception handling! Databases can have many problems, like dropped connections, so it’s always a good idea to try and catch those exceptions.
Questions on Design Patterns and ETL Concepts
In large applications, you’ll often use more than one type of database. In fact, it’s possible to use PostgreSQL, MongoDB, and Redis all within just one application! One challenging problem is dealing with state changes between databases, which exposes the developer to issues of consistency. Consider the following scenario:
- A value in Database #1 is updated.
- That same value in Database #2 is kept the same (not updated).
- A query is run on Database #2.
Now, you’ve got yourself an inconsistent and outdated result! The results returned from the second database won’t reflect the updated value in the first one. This can happen with any two databases, but it’s especially common when the main database is a NoSQL database, and information is transformed into SQL for query purposes.
Databases may have background workers to tackle such problems. These workers extract data from one database, transform it in some way, and load it into the target database. When you’re converting from a NoSQL database to a SQL one, the Extract, transform, load (ETL) process takes the following steps:
- Extract: There is a MongoDB trigger whenever a record is created, updated, and so on. A callback function is called asynchronously on a separate thread.
- Transform: Parts of the record are extracted, normalized, and put into the correct data structure (or row) to be inserted into SQL.
- Load: The SQL database is updated in batches, or as a single record for high volume writes.
This workflow is quite common in financial, gaming, and reporting applications. In these cases, the constantly-changing schema requires a NoSQL database, but reporting, analysis, and aggregations require a SQL database.
Q8: ETL Challenges
There are several challenging concepts in ETL, including the following:
- Big data
- Stateful problems
- Asynchronous workers
- Type-matching
The list goes on! However, since the steps in the ETL process are well-defined and logical, the data and backend engineers will typically worry more about performance and availability rather than implementation.
If your application is writing thousands of records per second to MongoDB, then your ETL worker needs to keep up with transforming, loading, and delivering the data to the user in the requested form. Speed and latency can become an issue, so these workers are typically written in fast languages. You can use compiled code for the transform step to speed things up, as this part is usually CPU-bound.
Note: Multi-processing and separation of workers are other solutions that you might want to consider.
If you’re dealing with a lot of CPU-intensive functions, then you might want to check out Numba. This library compiles functions to make them faster on execution. Best of all, this is easily implemented in Python, though there are some limitations on what functions can be used in these compiled functions.
Q9: Design Patterns in Big Data
Imagine Amazon needs to create a recommender system to suggest suitable products to users. The data science team needs data and lots of it! They go to you, the data engineer, and ask you to create a separate staging database warehouse. That’s where they’ll clean up and transform the data.
You might be shocked to receive such a request. When you have terabytes of data, you’ll need multiple machines to handle all of that information. A database aggregation function can be a very complex operation. How can you query, aggregate, and make use of relatively big data in an efficient way?
Apache had initially introduced MapReduce, which follows the map, shuffle, reduce workflow. The idea is to map different data on separate machines, also called clusters. Then, you can perform work on the data, grouped by a key, and finally, aggregate the data in the final stage.
This workflow is still used today, but it’s been fading recently in favor of Spark. The design pattern, however, forms the basis of most big data workflows and is a highly intriguing concept. You can read more on MapReduce at IBM Analytics.
Q10: Common Aspects of the ETL Process and Big Data Workflows
You might think this a rather odd question, but it’s simply a check of your computer science knowledge, as well as your overall design knowledge and experience.
Both workflows follow the Producer-Consumer pattern. A worker (the Producer) produces data of some kind and outputs it to a pipeline. This pipeline can take many forms, including network messages and triggers. After the Producer outputs the data, the Consumer consumes and makes use of it. These workers typically work in an asynchronous manner and are executed in separate processes.
You can liken the Producer to the extract and transform steps of the ETL process. Similarly, in big data, the mapper can be seen as the Producer, while the reducer is effectively the Consumer. This separation of concerns is extremely important and effective in the development and architecture design of applications.
Conclusion
Congratulations! You’ve covered a lot of ground and answered several data engineer interview questions. You now understand a bit more about the many different hats a data engineer can wear, as well as what your responsibilities are with respect to databases, design, and workflow.
Armed with this knowledge, you can now:
- Use Python with SQL, NoSQL, and cache databases
- Use Python in ETL and query applications
- Plan projects ahead of time, keeping design and workflow in mind
While interview questions can be varied, you’ve been exposed to multiple topics and learned to think outside the box in many different areas of computer science. Now you’re ready to have an awesome interview! | https://realpython.com/data-engineer-interview-questions-python/ | CC-MAIN-2021-39 | refinedweb | 4,437 | 64.51 |
Jul 01, 2015 04:51 PM|dolot|LINK
Still struggling with EF and LINQ...
So I have this list of objects taken from the database. There are several properties on each object. Let me talk about just a couple of them - Id and Distance.
The list will have several objects with the same Id. So you may have 6 objects with an Id of "1", 7 with an Id of "2", and so on. The distance value within each group may be the same from some of the objects and different for others.
What I'm trying to do is pull out a sub-list that contains just one object from each group that contains the max(Distance). So one object with Id of "1", one object with Id of "2", and so on. If there is more than one object within the Id group that has the same maximum number for Distance, that's OK. Any one will do for my purposes.
Can this be done with just one statement? I've stumbled around trying to figure out the right combination and tripped every time.
All-Star
37628 Points
Microsoft
Jul 02, 2015 05:40 AM|Fei Han - MSFT|LINK
Hi dolot,
Please refer to the following sample.
<asp:GridView</asp:GridView>
protected void Page_Load(object sender, EventArgs e) { if (!IsPostBack) { DataTable dt = new DataTable(); dt.Columns.Add("Id", typeof(int)); dt.Columns.Add("distance", typeof(int)); dt.Rows.Add(1, 3); dt.Rows.Add(2, 4); dt.Rows.Add(1, 6); dt.Rows.Add(2, 5); dt.Rows.Add(3, 3); var records = from d in dt.AsEnumerable() group d by d.Field<int>("Id") into newGroup select new maxdistance { Id = newGroup.Key, distance = newGroup.Select(dd => dd.Field<int>("distance")).Max() }; GridView1.DataSource = records; GridView1.DataBind(); } } public class maxdistance { public int Id { get; set; } public int distance { get; set; } }
Best Regards,
Fei Han
Jul 02, 2015 08:29 AM|dolot|LINK
Another wrinkle that I forgot to mention. This sublist needs to be a strongly typed object. I'm going to use it as part of a model that will be passed to a razor view.
Jul 02, 2015 04:54 PM|dolot|LINK
Wenushka
Hi,
Try as follows,var max = from t in db.Tables group t by t.Id into grp select new { Id = grp.Key, Distance = grp.Select(item => item.Distance).Max() }; var resultList = max.ToList();
Thanks,
Wenushka
So will I have to manually add all the other properties of the object to this list?
Jul 03, 2015 11:01 AM|dolot|LINK
I ended up following a somewhat different route. This is what I came up with:
public List<Analysis.QdAnalyzerResult> PesEsResults { get { List<Analysis.QdAnalyzerResult> Results = new List<Analysis.QdAnalyzerResult>(); foreach (Guid Id in this.QdResults.Select(q => q.EsId).Distinct().ToList()) { int MaxDistance = this.QdResults.Where(q => q.EsId == Id).Max(q => q.QdRequiredDistance); Results.Add(this.QdResults.Where(q => q.EsId == Id && q.QdRequiredDistance == MaxDistance).FirstOrDefault()); } return Results; } }
Jul 03, 2015 04:10 PM|dolot|LINK
I want to extend my thanks to both of you for taking a shot at answering my question.
6 replies
Last post Jul 03, 2015 04:10 PM by dolot | https://forums.asp.net/t/2057113.aspx?Getting+a+list+of+objects+with+max+values+ | CC-MAIN-2017-34 | refinedweb | 536 | 70.19 |
07 October 2013 18:25 [Source: ICIS news]
HOUSTON (ICIS)--US polyethylene (PE) margins for low density polyethylene (LDPE) fell by 0.5% last week, following an increase in ethane costs, the ICIS margin report showed on Monday.?xml:namespace>
Integrated domestic PE margins were assessed at 68.95 cents/lb ($1,520/tonne, €1,125/tonne) for LDPE and 59.59 cents/lb for high density polyethylene (HDPE) blow moulding in the week that ended 4 October. That represents a 0.35 cent/lb decrease on average for LDPE and 0.35 cent/lb decrease on average for HDPE from a week earlier, using ethane as a feedstock.
The PE margin increased due to a 3.6% rise in ethane feedstock costs, while co-product credits rose 1.2%.
Co-product credits are the price at which products - such as propylene, butadiene (BD) and benzene, which are made along with ethylene in the cracking process - can be sold.
Integrated LDPE export margins rose by 0.63 cents/lb for LDPE on lower feedstock costs. LDPE export prices rose by 1 cent | http://www.icis.com/Articles/2013/10/07/9713062/us-ldpe-margins-fell-0.5-on-rise-in-ethane.html | CC-MAIN-2015-22 | refinedweb | 182 | 68.36 |
libnfsclient
Contents
libnfsclient is a userland, NFS client ops library. It can be used by user space programs to send NFS client operations like lookup, mount, read, write, etc. This is done by providing a layer over the Sockets interface thereby avoiding the need to go through the file system. Among other usage scenarios, I use it for my NFS benchmarking tool called nfsreplay.
The NFS benchmarking project page is here: NFSBenchmarking
I can be reached at <shehjart AT gelato DOT NO SPAM unsw DOT edu GREEBLIES DOT au>
News
March 13, 2008, Interface stabilized months back.
April 5, 2007, nfsreplay svn is up
March 31, 2007 libnfsclient is still pre-alpha. Expect breakage due to interface changes.
Interface
See AsyncRPC also since libnfsclient is a layer on top of that library.
Client Context: nfs_ctx
Connection to each NFS server is represented by a structure called nfs_ctx. This is opaque to the users and is to be used only as a handle or identifier for:
- The particular mount, if the connection was initiated by a MOUNT
- or the TCP connection, if the connection was initiated without performing a MOUNT call.
All interface functions need to be passed the nfs_ctx handle that connects to a particular server.
Initializing the nfs client context is always the first step.
nfs_init
#include <nfsclient.h> nfs_ctx *nfs_init(struct sockaddr_in *srv, int proto, int connflags);
Returns the handle for the connection to the server in srv, NULL on failure.
srv - Pointer to the socket which contains the server IP address. The port member in struct sockaddr_in is optional. If srv->sin_port is 0, the portmapper is internally used to look up the NFS port on the server in srv.
proto - The underlying transport layer protocol. The two values are:
IPPROTO_TCP - Transmission Control Protocol, the only protocol currently supported.
IPPROTO_UDP - User Datagram Protocol, not supported at present..
connflags - Flags to customize this TCP connection to the server. Flags supported at present:
NFSC_CFL_NONBLOCKING - Create a non-blocking connection to the server. This ensures that the transmission of nfs requests and reception replies does not block in the system calls. In case the system call will block, libnfsclient makes copies of the buffers so they can transmitted later.
NFSC_CFL_BLOCKING - Create a blocking socket so that transmission and reception is synchronous.
NFSC_CFL_DISABLE_NAGLE - Disable Nagle's algorithm for this connection.
Operations
At present, libnfsclient only implements NFSv3 and MOUNT protocol. The interface is described in nfs3Interface.
Error Handling
#include <nfsclient.h> char * nfsstat3_strerror(int stat);
nfsstat3_strerror is a helper function that allow translating NFS 3 status numbers into the corresponding status messages.
stat is the value of the status in NFS 3 response structures. See test/nfs_errno.c.
XDR Translation
The message structures passed to the nfs3_* functions described in nfs3Interface, are converted internally into XDR format before being transmitted.
The message buffers, read from the socket and passed to the callbacks are in XDR format. These have to be first converted into the required message-specific structure. This implies that each callback somehow know what type of reply it will be processing. Again, see examples of how reply messages are converted into message structures, in the callbacks sources in the test/ directory.
For the interface for translating reply message buffers in XDR format to reply-message specific structures, see XDRInterface.
MOUNT and NFS integration
Generally, a client looks up the file handle of an exported file system(..by connecting to the mountd service..) on a server before it proceeds to operate on it. In cases, where the exported file system's filehandle is already known, clients can proceed directly to connect to the NFS service. Both modes are supported.
The Mount protocol interface is synchronous and returns only after a reply is received. This is not true for the NFS 3 protocol. There,a call function will return after atleast sending the request. Before returning, it'll check if a reply was received and if so, the callback for it will be executed, otherwise it just returns. So yes, there is no guarantee that the callback is executed before returning.
Though, this is the default behaviour, it can be changed, i.e. made blocking by setting the flag argument to nfs_init as NFSC_CFL_BLOCKING. In this case, the call functions will behave like the mount interface, i.e. return only after the reply was received and its callback executed.
Handling Callbacks
Callback should be of the following type.
typedef void (*user_cb)(void *msg_buf, int bufsz, void *priv);
msg_buf - Message in XDR format.
bufsz - Size of message buffer.
priv - is the pointer to private data, passed to nfs3_* call functions.
Callbacks are called by the library whenever a complete reply is received. The message buffers passed to the callbacks are freed after the callback returns so copy anything out of the buffer if persistence is needed. See AsyncRPC for more info.
Completion Notification
In case, user programs need to explicitly have the pending socket buffers processed and any callbacks executed, the following function can be used.
int nfs_complete(nfs_ctx * ctx, int flag);
ctx - The nfs client context.
flag - Specifies the behaviour of the call. The two values for flag are:
RPC_BLOCKING_WAIT - Blocks on the read to a socket, even if the socket was created as non-blocking using the connection flag. If any replies are received the corresponding callbacks are run.
RPC_NONBLOCKING_WAIT - Attempts a read of the socket. If there are pending replies, processes them and runs the corresponding callbacks, otherwise, returns to the user program.
- The interaction between flag and connection flag is shown in the table below:
- When there are pending replies(..libnfsclient keeps a count of these..). In this case, nfs_complete will behave according to the matrix above. Keep in mind that the number of replies processed,i.e. the number of callbacks executed by libnfsclient depends on the amount of data available in the socket buffers and not on the number of replies pending.
- When there are no pending replies, it will simply return with a count of zero without blocking on the socket.
Multi-Threading with libnfsclient
All libnfsclient operations take place on the specified nfs client context so separate threads operating on their own nfs_ctxs will work just fine. A synchronisation mechanism will need to be implemented by the user program if sending requests from multiple threads., over a shared nfs_ctx.
Code
libnfsclient and AsyncRPC are part of the nfsreplay source package. See nfsreplay page for instructions.
Building
Building instructions are in the BUILD file in nfsreplay package.
Examples
For examples on usage of the library, see the sources in test/ subdirectory of the nfsreplay source.
Support
Use nfsreplay lists for support and discussion. | http://www.gelato.unsw.edu.au/IA64wiki/libnfsclient | crawl-002 | refinedweb | 1,108 | 57.57 |
Building a Restful Service using Jersey in Eclipse (Mars 4.2)
This is a kickoff blog post for AllThingsContainer. This blog post is all about container-based workloads in the cloud. We will explore many different components that make up the world of containerization.
So let's get started.
This is a first step in a journey that will take us to running web applications in a DC/OS cluster. DC/OS is an open source project, which has elements of Mesos, primarily written by Mesosphere.
We start at the beginning - the very beginning, starting with building a RESTful Java application that can be run in a cluster.
The cluster is hosted in Microsoft Azure using the Azure Container Service. The code that we write will run on any DC/OS cluster. The virtual machines that are provisioned by the after container service do not contain any proprietary software. It is all 100% open source.
By the end of this post we will have a WAR file. This war file represents a Java application that supports Restful queries.
We will build the restful application first, and then produce a war file. This war file will then be used in another blog post which will demonstrate how to containerize this restful application and scale across a cluster.
Two types of clusters will be supported using the Azure container service. The first cluster will be a Mesosphere cluster, later followed up by a Docker Swarm cluster.
What is amazing about the technologies that we will be talking about is that we can create this restful service, and in a matter of minutes have that restful easily scaling across a cluster of virtually any size.
That's the power of the Azure container service and of a DC/OS cluster.
This solution is built on 100% open source technologies.
Be sure to see part 2 of this post here, where we apskctually run this service in an Azure hosted cluster.
This post will demonstrate
This post assumes nothing about what you have already set up on the development computer. I will be using Windows 10 as my operating system, but the same steps will work across any environment where the Eclipse IDE is supported.
- Step 1 - A demonstration of the final application that we will build
- Step 2 - The tools and technologies that I have installed to make this possible
- Step 3 - Step-by-step instructions and the instructions on how to build out this project
- Step 4 - The creation of a WAR file that represents the completed application to be containerized
Step 1 of 4 - demonstration of the final application that we will build
Let's begin by showing you with a completed application that we will build this post. We will be using Eclipse and you can see that in the image below.
The project is called SimpleRestfulService. You are seeing the completed version. We will run the project by right-mouse clicking in Project Explorer and choosing "Run on Server."
Be sure to see part 2 of this post here, where we actually run this service in an Azure hosted cluster.
Figure 1: Running the Eclipse Project
To call into the restful service, we will type. What we are doing is passing a query parameter of 100 as the course variable. This is the way we pass data into a restful service.
Figure 2: Typing the URL to call the Restful Service
After the call executes, the browser returns the JSON data that relates to course=100. The data is in a text file so a text editor will appear. In my case, my default editor is VIM. Yours could be notepad or something else.
Figure 4: The actual JSON data that is returned in VIM (the editor)
Step 2 of 4 - The tools and technologies that I have installed to make this possible
There are 3 technologies that I have installed to develop the Java Application.
- Eclipse Mars (4.52)
- Purpose: Java IDE to develop solution
- Download:
- Apache Maven
- Purpose: Maven is a build automation tool used primarily for Java projects
- Download:
- Apache Tomcat
- Purpose: The Apache Tomcat ® software is an open source implementation of the Java Servlet, JavaServer Pages, Java Expression Language and Java WebSocket technologies
- Download: I am running version 8 at ## Step 3 of 4 - Step-by-step instructions and the instructions on how to build out this project
Step 3A - File New Project
This step is simply creating a new Eclipse project.
Start by choosing "File/New/Dynamic Web Project." Provide the name you wish to use. I used SimpleRestfulService.
Figure 5: Creating a new Dynamic Web Project
You should see SimpleRestfulService in the Project Explorer.
Figure 6: Eclipse Project Explorer
Step 3B - Convert to Maven project
You now need to convert the project to a Maven project. Do this by right-mouse clicking on the project name and choosing "Configure/Convert to Maven Project."
Figure 7: Converting to a Maven project
Step 3C - Edit pom.xml
Once you convert, a dialog box will show up indicating that a pom.xml file will be created.
POM stands for "Project Object Model". It is an XML representation of a Maven project held in a file named pom.xml. We will use this file to link to external libraries. Paste the following code into your pom.xml file. You will replace all the existing code inside of pom.xml
For the most part, because we wish to use the Jersey Libraries, we will use the pom.xml to include them into our Eclipse/Maven Project.
What is Jersey?.
Figure 8: Converting to a Maven Project
Just click Finish below. You need not modify anything here.
Figure 9: Wizard used to create pom.xml
Figure 10: The generated pom.xml file
This is the code that is generated that you will replace. Replace the contents of pom.xml with the code below.
<project xmlns="" xmlns: <modelVersion>4.0.0</modelVersion> <groupId>SimpleRestfulService</groupId> <artifactId>SimpleRestfulService</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>war</packaging> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>2.3.1</version> <configuration> <source>1.7</source> <target>1.7</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-war-plugin</artifactId> <configuration> <webXml>${project.basedir}/WebContent/WEB-INF/web.xml</webXml> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>asm</groupId> <artifactId>asm</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>com.sun.jersey</groupId> <artifactId>jersey-bundle</artifactId> <version>1.19</version> </dependency> <dependency> <groupId>org.json</groupId> <artifactId>json</artifactId> <version>20140107</version> </dependency> <dependency> <groupId>com.sun.jersey</groupId> <artifactId>jersey-server</artifactId> <version>1.19</version> </dependency> <dependency> <groupId>com.sun.jersey</groupId> <artifactId>jersey-core</artifactId> <version>1.19</version> </dependency> <dependency> <groupId>javax.servlet</groupId> <artifactId>javax.servlet-api</artifactId> <version>3.1.0</version> </dependency> <dependency> <groupId>org.glassfish.jersey.bundles.repackaged</groupId> <artifactId>jersey-guava</artifactId> <version>2.6</version> </dependency> <dependency> <groupId>org.glassfish</groupId> <artifactId>javax.json</artifactId> <version>1.0.4</version> </dependency> </dependencies> </project>
Code: pom.xml
Step 3D - Generate Deployment Descriptor Stub
A deployment descriptor (web.xml) tells the application container how the web app should be configured. This is where you register your servlets and filters, add context parameters, and more.
Figure 11: Generating the Deployment Descriptor file
You will need to add a file called web.xml to the following folder. Be sure to right-mouse click on WB-INF
Figure 12: Targeting the WEB-INF folder
Select "New/Other.."
Figure 13: Adding web.xml to WEB-INF folder
Select "XML File."
Figure 14: Specifying an XML file
Name the file web.xml.
Figure 15: Naming the file web.xml
Paste the following code into web.xml. Notice that the startup web page is Index.html. Let's add this next to our project.
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns: <display-name>SimpleRestfulService</display-name> <welcome-file-list> <welcome-file>Index.html</welcome-file> </welcome-file-list> <servlet> <servlet-name>SimpleRestfulService</servlet-name> <servlet-class>com.sun.jersey.spi.container.servlet.ServletContainer</servlet-class> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>SimpleRestfulService</servlet-name> <url-pattern>/rest/*</url-pattern> </servlet-mapping> </web-app>
Code: web.xml
Figure 16: The final web.xml file
Step 3E - Adding Index.html to the project
Even though this is a simple restful service, we will indicate a simple startup page. Right-mouse click on WebContent and choose "New/HTML File."
Figure 17: Adding an HTML File (Index.html)
Figure 18: Naming the html file (Index.html)
Figure 19: Editing Index.html
Step 3F - Adding the core Java Code for the Restful Service
It is time to now add the main code for our restful service. The two files are;
- AzureCourse.java
- A simple object that represents the data model
- SimpleRestfulService.java
- The main entry point for our restful service. Will return a AzureCourse object formatted as JSON data, as shown in the intro demo.
Right-mouse click on the project name and choose "New/Class."
Figure 20: Adding AzureCourse.java
Enter the details for the new source code file.
- Provide a package name
- com.terkaly
- Specify a source code file name
- AzureCourse.java
Figure 21: Name the source code module AzureCourse.java
Paste in the following code.
package com.terkaly; import javax.xml.bind.annotation.XmlRootElement; @XmlRootElement public class AzureCourse { public AzureCourse() { } public AzureCourse(String courseNumber, String courseTitle) { this.CourseNumber = courseNumber; this.CourseTitle = courseTitle; } // Make sure it is private private String CourseNumber; private String CourseTitle; private String Notes; // Jersey tooling uses getter methods public String getCourseNumber() { return CourseNumber; } public void setCourseNumber(String courseNumber) { CourseNumber = courseNumber; } public String getCourseTitle() { return CourseTitle; } public void setCourseTitle(String courseTitle) { CourseTitle = courseTitle; } public String getNotes() { return this.Notes; } public void setNotes(String notes) { this.Notes = notes; } @Override public String toString() { return "AzureCourse [courseNumber=" + CourseNumber + ", courseTitle=" + CourseTitle + "]"; } }
Code: AzureCourse.java
Repeat process for SimpleRestfulService.java
Right-mouse click on the project name and choose "New/Class."
Figure 22: Adding AzureCourse.java
As before, provide package name and file name.
Figure 23: Name the source code module SimpleRestfulService.java
Paste in the following code.
package com.terkaly; import java.util.ArrayList; import java.util.HashMap; import java.util.Map; import javax.ws.rs.GET; import javax.ws.rs.Path; import javax.ws.rs.Produces; import javax.ws.rs.QueryParam; import javax.ws.rs.core.Response; import org.json.JSONException; @Path("azurecourse") public class SimpleRestfulService { private Map < String, AzureCourse > map = new HashMap < String, AzureCourse > (); public SimpleRestfulService() { AzureCourse azureCourse = new AzureCourse("100", "Building REST in a Container"); azureCourse.setNotes("REST in Mesosphere"); map.put(azureCourse.getCourseNumber(), azureCourse); AzureCourse azureCourse2 = new AzureCourse("101", "Mesosphere and Orchestration"); azureCourse.setNotes("Run your containers"); map.put(azureCourse2.getCourseNumber(), azureCourse2); } // Execute with @GET @Path("query") @Produces("application/json") public ArrayList < AzureCourse > getData(@QueryParam("course") String course) throws JSONException { try { ArrayList < AzureCourse > list = new ArrayList < AzureCourse > (); AzureCourse result = (AzureCourse) map.get(course); list.add(result); return list; } catch (Throwable t) { System.out.println(t.getMessage()); } return null; } }
Code: SimpleRestfulService.java
Step 3G - We are ready to compile
We are code complete at this point. The project is ready to run. Save and close all files.
We need Maven to bring in the dependencies (Jersey, etc) from the pom.xml file. Right-mouse click and choose "Maven/Update Project." You will need to repeat this command again later. Stay tuned for that guidance.
Figure 24: Maven/Update Project
Checking the Build Path
My install had a problem understanding the import statement in my .java file to remedy this problems.
Figure 25: Verifying the Build Path
I went to the “Order and Export” and made all the possible selections. Not all of them were excepted, but this appeared to solve some of the issues oddly enough, I had to re-paste the content for pom.xml. This might’ve been an error that I had done, but re-pasting it seemed to work, along with the changes made to the build path.
Figure 26: Specify The "Order And Export"
Although they did not all stick, I did make the following selections.
Figure 27: Selecting All Available Entries
Run As/Maven Clean, Run As/Maven Install
Eclipse can be a little fickle so I end up running for commands over and over. Those commands are:
- From the menu system
- Project/Clean
- Project/Build
- From Right-Mouse Clicking on Project
- Maven/Update Project
- Run As/Maven Clean
- Run As/Maven Install
Figure 28: Selecting Maven Clean
Ultimately it's the "Run As/Maven Install" that compiles the project so you can run it.
Figure 29: Selecting Maven Install
Step 3H - We are ready to run
Now we are ready to test the finished app.
The process to test the application is the exact same as we demonstrated in step one earlier in this post. You’re going to right-mouse click on the project, and choose “Run As/Run on Server.”
And of course the response is that some JSON data is returned that can be opened in your favorite editor or saved to disk through the browser.
Figure 30: Issuing a Restful Query with HTTP
Step 4 of 4 - The creation of a WAR file that represents the completed application to be containerized
In this final step four of four, we are ready to produce the war file, which can be thought of as a zipped up version of our entire application that can be copied to a Tomcat Web server for execution.
It’s a simple case of right-mouse clicking and selecting “Export/War File."
Figure 31: Exporting the WAR file
Provide a name and destination for the war file
Figure 32: Providing a name for the WAR file
Conclusion
The goal for this post has been achieved – we now have a WAR file that we copied to a Docker-Tomcat image and run it as a container. This means that we will be able to run numerous restful services across our Mesosphere cluster.
In the next post, we will learn how to provision a Mesosphere cluster using the Azure container service, and how to package up and deploy our WAR file across the provisioned cluster.
See | https://blogs.msdn.microsoft.com/allthingscontainer/2016/08/25/building-a-java-based-restful-service-to-run-in-dcos/ | CC-MAIN-2018-05 | refinedweb | 2,376 | 59.3 |
I Keep Getting a Funny Result when i cout<<array[100]/customers(50)*100 the result is some weird number, 11478562 when it should be more like 20 or something in that region
I Keep Getting a Funny Result when i cout<<array[100]/customers(50)*100 the result is some weird number, 11478562 when it should be more like 20 or something in that region
Post some code.
Here Is the Code
Code:#include <iostream> using namespace std; int Another(); int main() { int code; int code_arr[100]; int counter_arr[100]; int customers=0; int i; for(i=0; i<100; ++i) { code_arr[i]=0; counter_arr[i]=0; } while(Another()) { cout<<"Enter Your Zip Code:"; cin>>code; cout<<endl; for(i=0; i<100; ++i) { if(code_arr[i]==code) { counter_arr[i]+=1; cout<<"Added Counter!!"<<endl; ++customers; break; } } if(i>=100) for(i=100; i>0; --i) { if(code_arr[i]==0) { code_arr[i]=code; counter_arr[i]+=1; cout<<"Added Address!!"<<endl; ++customers; break; } } } for(int l=0; l<100; ++l) if(code_arr[l]>0) { cout<<"Zip Code #"<<l+1<<endl <<"Zip Code #"<<code_arr[l]<<endl <<"Number Of Zip Codes from this area : # "<<counter_arr[l]<<endl <<"Total % of total customers : "<<t<<endl<<endl; } cout<<"Total Customers All Up : "<<customers<<endl<<endl; return 0; } int Another() { int response; cout<<endl; cout<<"Would You Like to Process Another Zip Code : "; cin>>response; cout<<endl; return response; }
the last part is the worry, and i forgot to add it!!
here is the problem
Code:<<"Total % of total customers : "<<counter_arr[l]/customers*100<<endl<<endl;
Given that all these variables are int, I would expect you to get 0 as an answer. (Assuming counter_arr[l] < customers, that division will give 0, and 0*100 is 0.)
i see, beginners ignorance, and lack of sleep, thanks for that....
i see i got to use doubles i forgot that principal, maths in c++ is a different thing, you got to be aware of doubles and int etc as well
This causes out-of-bounds access.This causes out-of-bounds access.Code:for(i=100; i>0; --i) { if(code_arr[i]==0)
Because of integer division this should always print 0: smaller / larger = 0 if smaller and larger are integers.Because of integer division this should always print 0: smaller / larger = 0 if smaller and larger are integers.Code:<<"Total % of total customers : "<<counter_arr[l]/customers*100<<endl<<endl;
You can try multiplying by 100 first, or cast customers or counter_arr[l] or both to double to force floating point division.
An easier way to write this kind of program is to use std::map (something like):
Code:map<int, int> zip; do { cout<<"Enter Your Zip Code:"; cin>>code; cout<<endl; ++zip[ code]; //this does the logic of your two for-loops } while (Another()); //print statistics
Last edited by anon; 06-12-2008 at 08:25 AM.
I might be wrong.
Quoted more than 1000 times (I hope).Quoted more than 1000 times (I hope).Thank you, anon. You sure know how to recognize different types of trees from quite a long way away. | https://cboard.cprogramming.com/cplusplus-programming/104059-array-torments.html | CC-MAIN-2017-51 | refinedweb | 518 | 57.1 |
We are about to switch to a new forum software. Until then we have removed the registration on this forum.
Hi everyone, I'm on a project on Android where I have to input some text in Japanese (with google IME keyboard as an example), and as you probably know, I looked a lot for it on forums, and neither controlP5 TextField nor APwidgets work on Processing 3.x... So I was wondering if there was any possibility of creating a "normal" Java TextField in Processing which could normally get IME keyboard characters (I'm not Java skilled enough for that so I hope you'll be able to help me^^) Thanks forward !
Answers
@olivi55=== android has classes (widgets) for that :: textView && EditTextView, with a lot of parameters (scrolling, multilines etc.)...
@akenaton thx I think I'll use that !...but as an example, how could I set this textView or EditTextView location in processing ? And since I'm currently using Ketai library to get the keyboard out, how do they manage together ? (I'm really bad for raw java :/ ) Thx forward !
@olivi55===
not any idea about ketai (i prefer to work with native android); as for the textView see the code below. Of course you can set a lot of other parameters (margin, background color and so on).
@akenaton ...wow thx...i'll try to add thi into my project monday...I'll keep you informed ^^
@akenaton Hi again, I just tried your program...It works well as TextView but when I want to put an EditText, when I tap on it, it loses focus instantly...I found this but since I don't use xml I don't know how to manage it in processing :/
@olivi55=== not sure to understand what you mean.Put your code. Normally when you touch the edit text it opens the soft keyboard input and you can use it. The way for displaying the keyboard can also be customized by code with parameters (SOFT_INPUT_STATE_ALWAYS_VISIBLE and so on)
@akenaton I just tried your code too. It launches on my phone but nothing happens in response to screen touches... ?
@hudson_m4000=== nothing happens because this is a static textView if you want more (keyboard and so on) you must change the textview for an edit text...
@akenaton @hudson_m4000 in fact the program runs, text is here, but when I touch on the EditText, it takes focus, but just after the focus is lost...as it looks it seems the focus is somehow reset in the next run of draw( )...
@olivi55===put the code you are using (mine one transformed with edit ext instance instead of textview)
@akenaton
I just took your code and replaced the TextView as an EditText
@akenaton ok ... I will fiddle around a bit more ! :)
@olivi55== no, it cannot work like this : 1) the parameters for editText and textView are of the same kind but not exactly the same! 2) as you add the textView on the runnable it takes/looses the focus and the keyboard cannot be shown...
simple snippet code::
ok thx ! I'll try to manage it with that... Thx a lot @akenaton for your patience ^^
@akenaton ... sorry something again :/...I managed to change the size of the EditText, but I can't manage to move it..I tried with setMargins, but I get a compiling error :/
@olivi55===you have to understand what happens (hidden by P5!)
So: in order to move it there are different solutions you can try: - most simple:: you add white spaces to the text you enter with setText():: a workaround!!!! - other: you change the params of the parent (fl) adding padding to it (left, top, right, bottom) as integer - other (you have created a relativeLayout for the edit text) so you can add rule to it, which allows you to put the dit text at center, left, right bottom alignment from its parent
try all of them and choose...Remember also that with the getText method you can display the entered text in a classical P5 way text("", int, int); and just before remove the edit text!!!
@akenaton thx again, I'll go on padding fl then !
@akenaton ...still problems -_- sorry :/ ...I can't manage to add a marging to the relative layout :/...isn't there another way to set an exact pixel position of the EditText relatively to its parent ?
@akenaton Line 19 of you latest sample code working with editText, is that valid Processing code? I am getting an error message:
<a href="/two/profile/Override">@Override</a>
Also for anybody running that example, you also need to include:
import android.widget.EditText;
Kf
@kfrager===
this is only a typo when you cut/copy here you have to write only:: @Override, nothing else (erase the other chars)
@akenaton, when posting code w/ annotations, add 1 space between the
@& the annotation in order to work around the forum's code glitch. *-:)
@GoToLoop====
ok && excuse me--- i ll try to remember! :)]
@akenaton hi again ! I'm trying to place my EditText by adding margins but it doesn't change anything :/...any idea on why it doesn't work ? thx forward !
RelativeLayout.LayoutParams params = new RelativeLayout.LayoutParams(RelativeLayout.LayoutParams.WRAP_CONTENT, RelativeLayout.LayoutParams.WRAP_CONTENT); params.setMargins(300,300,300,300); edit.setLayoutParams(params);
Hi @ olivi55 When you add margins, you mean that are you trying to place your editText in your canvas?
Would this work for you:
Kf
@kfrajer OMG thx finally why didn't I try this before thx a lot X)
@akenaton @kfrajer Hi ! me again, and I hope this time is the last time...in my app I have need to make my EditText
.setVisibility(View.GONE)and able to get it back
.setVisibility(View.VISIBLE)after...but when I try it I get this error : android.view.ViewRootImpl$CalledFromWrongThreadException: Only the original thread that created a view hierarchy can touch its views. ...How can I modify this EditText visibility (or just disable it and reenable it after) easily anywhere in my program ? Thx forward again ! ^:)^
@olivi55=== i have not time enough to explain exactly (code) what to do but i think (without seeing what you have written!!!) the solution is to make a runnable and call there .setVisibility()....Android is very threadSensitive!
@akenaton : just perfect thx ! I took back your Runnable syntax from one of your previous posts !...thank you a lot...now I'll now what to do for this error ! It works perfectly now ! | https://forum.processing.org/two/discussion/16539/how-to-manually-create-android-textfield-in-processing | CC-MAIN-2019-18 | refinedweb | 1,073 | 64 |
Welcome to the Parallax Discussion Forums, sign-up to participate.
#include "simpletools.h" #include "fdserial.h" fdserial *xbee; int main() { xbee = fdserial_open(9, 8, 0, 9600); char data; while(1) { data = fdserial_rxChar(xbee); if(data == 'y') high(26); else if(data == 'n') low(26); } }
#include "simpletools.h" #include "fdserial.h" fdserial *xbee; int main() { xbee = fdserial_open(9, 8, 0, 9600); int i; while(1) { i = 1; //The value of i remains the same so I can be sure that this is not the issue in the code not causing LED 26 on the Activity Board light up. if(i == 1) dprint(xbee, "y"); else if(i == 0) dprint(xbee, "n"); print("i= %d\n", i); } }
I was referring to your posts. At each stage you're posting a new thread instead of replying to the original, so the information is scattered across 4 threads. It's hard to help when everything is in multiple places. Just some friendly advice. It helps others to help you if you keep tings in one place while they're all related to the same thing. :cool: | http://forums.parallax.com/discussion/comment/1376188/ | CC-MAIN-2019-09 | refinedweb | 182 | 63.8 |
There's lots of stuff written around dynamic data elsewhere so I won't duplicate it here. I did a little bit of experimentation with it today rather than just watch Mike walk me through it.
My first surprise in springing up dynamic data was this dialog;
It looks like I have to choose between a "Dynamic Data" web site and a "Dynamic Data Entities Web Site".
That seems a bit odd to me. If you look at what the ADO.NET Data Services folks did in terms of being "data neutral" then you get to;
So, there's a pretty nice story around being data source neutral. It makes for a simple demo where you can just take a few CLR types and expose them over REST without having to get into any other data access technology.
It looks like Dynamic Data doesn't have that approach just yet - in fact, you can see that it's heading towards something along those lines when you look at the futures page.
I went down the LINQ to SQL route for a while and the next thing I wondered was whether I could use stored procedures to do the CRUD behind this data access. I suspect not although it might be possible to configure the CUD stored procedures for a particular entity type in LINQ to SQL and have stored procedures invoked for INSERT/UPDATE/DELETE and I gave that a whirl and it does seem to work fine..
The next thing that puzzled me about dynamic data is its choice of putting the metadata into the code. If I build a Dynamic Data site out of my Northwind database then I can get some customisation by doing something like;
public class OrderMetadata
{
[DisplayName("My Region")]
public string RegionDescription { get; set; }
}
[MetadataType(typeof(OrderMetadata))]
public partial class Region
{
}
That is - I add to the partial class Region which was generated for me by LINQ to SQL's code gen. I add to that class purely to add another attribute called MetadataType and that attribute points to another class. In my case, that's OrderMetadata.
Now, this is where things get a little weird for me. As far as I can tell, that other class is purely being used as a container for metadata. That is, it's just a place to store a bunch of attribute values that cannot easily be added to the original Region class itself because there's not really a notion of using a partial class to add attributes to an existing property.
I find this all a bit odd.
For me, I think I'd prefer that the Dynamic Data tooling just generated an XML file that it loaded at runtime and used that to store all metadata that it needed so that you could keep this stuff out of the code. It'd be even nicer if that format could be made to line-up with the XML format that LINQ to SQL already ( optionally and not by default ) uses to keep its object-relational mapping metadata outside of your code. It'd be even nicer still if Dynamic Data gave you a little editor for editing that XML format inside of Visual Studio.
Regardless, you can't always get what you want and, right now, you get this slightly odd (imho) use of classes purely as a means of storing metadata.
Other than that, my experimentations with Dynamic Data weren't anything out of the ordinary :-) Check out the videos here;
if you want an intro. | http://mtaulty.com/CommunityServer/blogs/mike_taultys_blog/archive/2008/09/24/10777.aspx | crawl-002 | refinedweb | 592 | 63.22 |
Overview
Atlassian Sourcetree is a free Git and Mercurial client for Windows.
Atlassian Sourcetree is a free Git and Mercurial client for Mac.
hebtools - Time series analysis tools for wave data
This project has now been migrated to Github
This python package processes raw Datawell Waverider files into a flexible time series. The code allows easier calculation of statistics from the displacement data, more sophisticated masking of improbable data and the ability to deal with larger timeseries than is available from existing software. Similar code is also used to process pressure data from Nortek AWAC sensors details are described below.
The code is organised into one main package named hebtools with four subpackages awac, common, dwr and test
dwr
In the case of a Datawell Waverider buoy the buoy data directory containing year subfolders must be passed to the load method of the parse_raw module which then iterates through the years. To call the module you can use the code below:
from hebtools.dwr import parse_raw parse_raw.load("path_to_buoy_folder") # Parse a specific year parse_raw.load("path_to_buoy_folder","2005") # Parse a specific month parse_raw.load("path_to_buoy_folder","2005","July")
The module then processes the records from the raw files into a pandas DataFrame a good format for doing time series analysis. The main output file is called raw_plus_std and a smaller wave_height_dataframe dataframe is also produced providing details on individual waves extracted from the displacements.
Interrogating these output files in the DataFrame format requires a little knowledge of the pandas data structures and functionality. For example queries and plots inline from a real dataset see this example IPython Notebook An optional year and month parameter can be supplied to process a specific year, month folder. For more details on the approach taken to process the files please see the wiki
Masking and calculation of the standard deviation of displacement values takes place in the error_check module.
The parse_historical module takes a path to a buoy data directory ( organised in year and month subfolders ) and produces a joined DataFrame using the his ( 30 minute ) and hiw files stored in the month folders.
awac
In the awac package there is a parse_wad class that can process a Nortek AWAC wad file. The pressure column can be then be processed in the same way as the Waverider heave displacement without the error correction. The awac_stats.py module which uses an approach similar to wave_concat for calculating time interval based statistics.
parse_wap module takes a Nortek wave parameter file and generates a time indexed pandas Dataframe, with the optional name parameter if the produced DataFrame is intended to be joined to other data.
common
Peak and troughs are detected for the heave/pressure values in the GetExtrema class. In the WaveStats class wave heights and zero crossing periods are calculated, wave heights are calculated from peak to trough. The wave_power module
Testing
The test_dwr module for testing the parse_raw module and WaveStats class, example buoy data is required to test, one of day of anonymised data is provided in the data folder of the test package.
test_awac module tests the parse_wad and parse_wap modules. Short anonymised test data sets for wap and wad files are in the test folder.
Statistic outputs
The dwr/wave_concat module can be run after parse_raw to create a complete dataframe of all wave heights timestamped and sorted temporally for each buoy. The module uses data from the monthly wave_height_dataframe files, statistics are then calculated on the wave sets and then exported as an Excel workbook ( .xlsx file ). This module needs to be passed a path to a buoy data directory, the set size used for statistic calculation are based upon on the duration of the raw files ( usually 30 minutes ).
Statistical terms are calculated (Hrms,Hstd,Hmean where H is the wave heights ) and compared to the standard deviation of the heave displacement ( Hv_std ) to check that the waves conform to accepted statistical distributions.
Plot of output
The plot above compares wave height against the wave height divided by the standard deviation of the displacement signal, any values above 4 are considered to be statistically unrealistic for linear wave theory.
Background
The project was developed with data received from Waverider MKII and MKIII buoys with RFBuoy v2.1.27 producing the raw files. The AWAC was a 1MHz device and Storm v1.14 produced the wad files. The code was developed with the assistance of the Hebridean Marine Energy Futures project.
Some more information on the data acquisition and overall workflow can be found on this poster
Requires:
- Python 2.7 ( developed and tested with 2.7.6 )
- numpy ( developed and tested with 1.6.2 )
- pandas ( minimum 0.12.0 )
- matplotlib ( developed and tested with 1.2.0 )
- openpyxl ( developed and tested with 1.6.1 )
- PyTables ( developed and tested with 3.0.0 )
Almost all of the above requirements can be satisfied with a Python distribution like Anaconda CE.
openpyxl can be installed afterwards by running 'easy_install openpyxl' from the Anaconda scripts directory.
Recommended optional dependencies for speed are numexpr and bottleneck, Windows binaries for these packages are available from Christoph Gohlke's page | https://bitbucket.org/jamesmorrison/hebtools | CC-MAIN-2017-47 | refinedweb | 854 | 52.9 |
This tutorial covers the step to load the MNIST dataset in Python. The MNIST dataset is a large database of handwritten digits. It commonly used for training various image processing systems.
MNIST is short for Modified National Institute of Standards and Technology database.
This dataset is used for training models to recognize handwritten digits. This has an application in scanning for handwritten pin-codes on letters.
MNIST contains a collection of 70,000, 28 x 28 images of handwritten digits from 0 to 9.
Why is MNIST dataset so popular?
MNIST is popular for a multitude of reasons, these are :
- MNSIT dataset is publicly available.
- The data requires little to no processing before using.
- It is a voluminous dataset.
Additionally, this dataset is commonly used in courses on image processing and machine learning.
In this tutorial, we will be learning about the MNIST dataset. We will also look at how to load the MNIST dataset in python.
1. Loading the Dataset in Python
Let’s start by loading the dataset into our python notebook. The easiest way to load the data is through Keras.
from keras.datasets import mnist
MNIST dataset consists of training data and testing data. Each image is stored in 28X28 and the corresponding output is the digit in the image.
We can verify this by looking at the shape of training and testing data.
To load the data into variables use:
(train_X, train_y), (test_X, test_y) = mnist.load_data()
To print the shape of the training and testing vectors use :
print('X_train: ' + str(train_X.shape)) print('Y_train: ' + str(train_y.shape)) print('X_test: ' + str(test_X.shape)) print('Y_test: ' + str(test_y.shape))
We get the following output :
X_train: (60000, 28, 28) Y_train: (60000,) X_test: (10000, 28, 28) Y_test: (10000,)
From this we can conclude the following about MNIST dataset :
- The training set contains 60k images and the testing set contains 10k images.
- The training input vector is of the dimension [60000 X 28 X 28].
- The training output vector is of the dimension [60000 X 1].
- Each individual input vector is of the dimension [28 X 28].
- Each individual output vector is of the dimension [1].
2. Plotting the MNIST Dataset
Let’s try displaying the images in the MNIST dataset. Start by importing Matplotlib.
from matplotlib import pyplot
To plot the data use the following piece of code :
from matplotlib import pyplot for i in range(9): pyplot.subplot(330 + 1 + i) pyplot.imshow(train_X[i], cmap=pyplot.get_cmap('gray')) pyplot.show()
The output comes out as :
Complete Code to Load and Plot MNIST Dataset in Python
The complete code for this tutorial is given below:
from keras.datasets import mnist from matplotlib import pyplot #loading (train_X, train_y), (test_X, test_y) = mnist.load_data() #shape of dataset print('X_train: ' + str(train_X.shape)) print('Y_train: ' + str(train_y.shape)) print('X_test: ' + str(test_X.shape)) print('Y_test: ' + str(test_y.shape)) #plotting from matplotlib import pyplot for i in range(9): pyplot.subplot(330 + 1 + i) pyplot.imshow(train_X[i], cmap=pyplot.get_cmap('gray')) pyplot.show()
What’s next?
Now that you have imported the MNIST dataset, you can use it for image classification.
When it comes to the task of image classification, nothing can beat Convolutional Neural Networks (CNN). CNN contains Convolutional Layers, Pooling Layers, and Flattening Layers.
Let’s see what each of these layers do.
1. Convolution Layer.
Conclusion
This tutorial was about loading MNIST Dataset into python. We explored the MNIST Dataset and discussed briefly about CNN networks that can be used for image classification on MNIST Dataset.
If you’d like to learn further about processing images in Python, read through this tutorial on how to read images in Python using OpenCV. | https://www.askpython.com/python/examples/load-and-plot-mnist-dataset-in-python | CC-MAIN-2021-31 | refinedweb | 612 | 68.36 |
Given a positive integer n. The problem is to check if the number is Fibbinary Number or not. Fibbinary numbers are integers whose binary representation contains no consecutive ones.
Input : 10 Output : Yes Explanation: 1010 is the binary representation of 10 which does not contains any consecutive 1's. Input : 11 Output : No Explanation: 1011 is the binary representation of 11, which contains consecutive 1's.
Approach: If (n & (n >> 1)) == 0, then ‘n’ is a fibbinary number Else not.
// C++ implementation to check whether a number // is fibbinary or not #include <bits/stdc++.h> using namespace std; // function to check whether a number // is fibbinary or not bool isFibbinaryNum(unsigned int n) { // if the number does not contain adjacent ones // then (n & (n >> 1)) operation results to 0 if ((n & (n >> 1)) == 0) return true; // not a fibbinary number return false; } // Driver program to test above int main() { unsigned int n = 10; if (isFibbinaryNum(n)) cout << "Yes"; else cout << "No"; return 0; }
Output:. | http://linksoftvn.com/fibbinary-numbers-no-consecutive-1s-in-binary-o1-approach/ | CC-MAIN-2018-34 | refinedweb | 164 | 51.38 |
No matter how proficient you are, I think, you might still use one of the primary methods of debugging: trace values using
printf,
TRACE,
outputDebugString, etc… and then scan the output while debugging.
Adding information about the line number and the file where the log message comes from is a very efficient method that might save you a lot of time. In this post, I’ll describe one trick that is especially useful in Visual Studio but might also help in other IDE/compilers.
I’ll also show you how modern C++ and C++20 make code nicer.
The Trick
When you’re debugging C++ code, it’s very convenient to output values to console or the output window and scan the log. As simple as:
std::cout << "my val: " << val << '\n';
You can easily enhance this technique by adding LINE and FILE information. That way you’ll see the source of that message. Which might be very handy when you scan lots of logs.
In Visual Studio, there’s a trick that allows you to move quickly from the debug output window to a particular line of code.
All you have to do is to use the following format:
"%s(%d): %s", file, line, message
For example:
myfile.cpp(32) : Hello World
You can now double-click on the line in VS output window, and immediately VS opens myfile at line 32. See below:
.
We’ll implement this code with “standard” C++, then move to modern C++ and finally see what’s coming with C++20.
Standard C++ for Visual Studio & Windows
For VS, first of all, you need to output the message using
OutputDebugString (Win specific function): calls the
MyTrace function that internally calls
OutputDebugString.
Why a macro? It’s for convenience. Otherwise, we would have to pass the line number and the filename manually. File and Line cannot be fetched inside
MyTrace because it would always point to the source code where
MyTrace is implemented – not the code that calls it.
What are
__FILE__ and
__LINE__? In Visual Studio (see msdn), those are predefined macros that can be used in your code. As the name suggest they expand into the filename of the source code and the exact line in a given translation unit. To control the
__FILE__ macro you can use the compiler option
/FC. The option makes filenames longer (full path), or shorter (relative to the solution dir). Please note that
/FC is implied when using Edit and Continue.
Please note that
__FILE__ and
__LINE__ are also specified by the standard, so other compilers should also implement it. See in 19.8 Predefined macro names .
Same goes for
__VA_ARGS__: see 19.3 Macro replacement - cpp.replace); }
But macros are not nice… we have also those C-style
va_start methods… can we use something else instead?
Let’s see what how can we use modern C++ here
Variadic Templates to the Rescue!
MyTrace supports a variable number of arguments… but we’re using
va_start/
va_end technique which scans the arguments at runtime… but how about compile time?
In C++17 we can leverage fold expression and use the following code:
#define MY_TRACE_TMP(...) MyTraceImplTmp(__LINE__, __FILE__, __VA_ARGS__) template <typename ...Args> void MyTraceImplTmp(int line, const char* fileName, Args&& ...args) { std::ostringstream stream; stream << fileName << "(" << line << ") : "; (stream << ... << std::forward<Args>(args)) << '\n'; OutputDebugString(stream.str().c_str()); } // use like: MY_TRACE_TMP("hello world! ", 10, ", ", 42);
The above code takes a variable number of arguments and uses
ostringstream to build a single string. Then the string goes to
OutputDebugString.
This is only a basic implementation, and maybe not perfect. If you want you can experiment with the logging style and arrive with a fully compile-time approach.
There are also other libs that could help here: for example
{fmt} or
pprint - by J. Galowicz.
C++20 and No Macros?
During the last ISO meeting, the committee accepted
std::source_location which is a part of library fundamentals TS v2.
C++ Extensions for Library Fundamentals, Version 2 - 14.1 Class source_location
This new library type is declared as follows:
struct source_location { static constexpr source_location current() noexcept; constexpr source_location() noexcept; constexpr uint_least32_t line() const noexcept; constexpr uint_least32_t column() const noexcept; constexpr const char* file_name() const noexcept; constexpr const char* function_name() const noexcept; };
And here’s a basic example, adapted from cppreference/source_location:
#include <iostream> #include <string_view> #include <experimental/source_location> using namespace std; using namespace std::experimental; void log(const string_view& message, const source_location& location = source_location::current()) { std::cout << "info:" << location.file_name() << ":" << location.line() << " " << location.function_name() << " " << message << '\n'; } int main() { log("Hello world!"); // another log log("super extra!"); }
We can rewrite or log example into
template <typename ...Args> void TraceLoc(const source_location& location, Args&& ...args) { std::ostringstream stream; stream << location.file_name() << "(" << location.line() << ") : "; (stream << ... << std::forward<Args>(args)) << '\n'; std::cout << stream.str(); }
Play with the code @Coliru
(
source_location is not available in VS, so that’s why I used GCC)
Now, rather than using
__FILE__ and
__LINE__ we have a Standard Library object that wraps all the useful information.
Unfortunately, we cannot move that source location argument after variadic args… so we still have to use macros to hide it.
Do you know how to fix it? so we can use a default argument at the end?
Ideally:
template <typename ...Args> void TraceLoc(Args&& ...args, const source_location& location = source_location::current()) { // ... }
But I leave that as an open question.
Summary
In this article, I showed a useful technique that might enhance simple printf-style debugging and logging.
Initially, we took a “standard” code that is mostly C-style and then we tried to update it with modern C++. The first thing was to use variadic template arguments. That way we can scan the input params at compile time, rather than use va_start/va_end C runtime functions. The next step was to look at the future implementation of
source_location a new type that will come in C++20.
With
source_location we could skip using
__FILE__ and
__LINE__ predefined macros, but still, the logging macro (
#define LOG(...)) is helpful as it can hide a default parameter with the location info.
code from the article: @github.
How about your compiler/IDE? Do you use such line/pos functionality as well? Maybe your logging library already contains such improvements? | https://www.bfilipek.com/2019/04/file-pos-log.html | CC-MAIN-2020-40 | refinedweb | 1,040 | 57.57 |
Force-based graph drawing in AS3
This post will be dedicated to drawing graphs in an aesthetically pleasing way. We will use physics "spring" algorithm, and create real-time simulation.
Updates
- you can check out my My tool for drawing graphs in JavaScript!
- there is a 3D version of the flsah graph drawer!
Graphs and their drawing
GraphsA graph is defined by a set of vertices (e. g. ${a, b, c, d}$) and a set of edges, which are the pairs of vertices ($\{ \{ a,b\}, \{b,c\}, \{c,d\}, \{d,a\}\}$). Most of people would draw this graph as a "square", but there are many ways to draw it. Some of them are "nicer" than others.
What is "nicely" drawn graphLet's try to define it. At first, we don't want vertices to be too close to each other. Edges should have more or less equal length and don't cross each other too often. We can define a lot of criterias.
Spring modelIn this model, we add an "antigravity" to each node. Due this, edges won't be too close to each other. We add a spring (an attraction power) between vertices, where is an edge between them. After few iterations (re-counting the power values and re-moving vertices to new positions) we will have a nice looking graph.
I just implemented the algorithm described in this article on Wikipedia.
Vertex class
package { import flash.display.Sprite; import flash.geom.Point; public class Vertex extends Sprite { // speed of vertex public var velocity:Point = new Point(); // force twards other vertices in the network public var net_force:Point = new Point(); public var isDragged:Boolean = false; // I can drag the vertex public function Vertex():void { // I draw a ring into the middle with(graphics) { beginFill(0xFF005E); drawEllipse(-12, -12, 24, 24); endFill(); } } } }
Creating a graph
// set of vertices vertices = new Vector.< Vertex >(n, true); // set of edges in symetric incidence matrix edges = new Vector. < Vector.< Boolean >>(n, true); for(i=0; i < n; i++) edges[i] = new Vector.< Boolean >(n, true); while(e > 0) // add some edges { var a:int = Math.floor(Math.random()*n); var b:int = Math.floor(Math.random()*n); if(a==b || edges[a][b])continue; edges[a][b] = true; edges[b][a] = true; e--; } // creating vertices for(i=0; i < n; i++) { var v:Vertex = new Vertex(); v.x = 200+Math.random()*300; v.y = 100+Math.random()*200; vertices[i] = v; addChild(v); v.addEventListener(MouseEvent.MOUSE_DOWN, drag); v.addEventListener(MouseEvent.MOUSE_UP, sdrag); }
Drawing the modelIn the beginning, we have vertices on random positions. Now we do iterations, in each of them we re-count new position of this vertex towards other vertices and it's edges. We do iterations, until a kinetic energy of the network decreases under some limit. In example below, I don't have any limit, I do iterations "onEnterFrame", so theoretically it never stops. "200" and "0.06" are just constants and you can change them to change repulsion and attraction.
function onEF(e:Event):void { for(i=0; i < n; i++) // loop through vertices { var v:Vertex = vertices[i]; var u:Vertex; v.net_force.x = v.net_force.y = 0; for(j=0; j < n; j++) // loop through other vertices { if(i==j)continue; u = vertices[j]; // squared distance between "u" and "v" in 2D space var rsq:Number = ((v.x-u.x)*(v.x-u.x)+(v.y-u.y)*(v.y-u.y)); // counting the repulsion between two vertices v.net_force.x += 200 * (v.x-u.x) /rsq; v.net_force.y += 200 * (v.y-u.y) /rsq; } for(j=0; j < n; j++) // loop through edges { if(!edges[i][j])continue; u = vertices[j]; // countin the attraction v.net_force.x += 0.06*(u.x - v.x); v.net_force.y += 0.06*(u.y - v.y); } // counting the velocity (with damping 0.85) v.velocity.x = (v.velocity.x + v.net_force.x)*0.85; v.velocity.y = (v.velocity.y + v.net_force.y)*0.85; } for(i=0; i < n; i++) // set new positions { v = vertices[i]; if(v.isDragged){ v.x = mouseX; v.y = mouseY; } else { v.x += v.velocity.x; v.y += v.velocity.y; } } // drawing edges graphics.clear(); graphics.lineStyle(3, 0x333333); for(i=0; i < n; i++) { for(j=0; j < n; j++) { if(!edges[i][j]) continue; graphics.moveTo(vertices[i].x, vertices[i].y); graphics.lineTo(vertices[j].x, vertices[j].y); } } }
You should put a gravity when there are disconnected component.November 30th, 2010
i.e. 4 vertices and 2 edges. in this way they go far away, if you apply a sort of gravity they should stay close together
I think I know what you mean. Just to turn off an antigravity between different components. But then the position of components to each other would be absolutely random, so it will not look very nice. If I add a gravity, they will cover each other, so it will look very strange.December 2nd, 2010
How do you calculate the repulsive and and attractive forces in 3d?December 3rd, 2010
Thanks.
Isaac
It is the same as in 2d. You just add a third coordinate. You can calculate forces in 4d, 5d, 6d … in absolutely the same way.December 3rd, 2010
The variable “rsq” is a squared distance between two vertices in your (probalby euclidean) space. You can find out more on the wikipedia link above.
Thanks. I just did.December 3rd, 2010
Do you have the code avaiable?December 3rd, 2010
No, I want people to do it themselves, it is not so hard. But if you want, I can sell it to you.December 6th, 2010
How much would you charge for that? It’s what I need for a project at my job, and I can’t seem to recreate it!December 8th, 2010
Thanks for thisJanuary 15th, 2011
the code isn’t hard to implement but it’s nice to have a version I can quickly test with reasonable values for the constants
There was one alteration I made with it in the end. For graphs with a single cluster of points and a long tail, the tail edges got really long (it also resulted occasionally in triangles looking like single lines) so I added in an extra force that was given a ‘target edge size’ and applied forces to the vertices to bring them closer to this desired edge side. This gives the graphs a little more body, and stops things from getting stretched too much.January 15th, 2011
Hi, it’s very cool,
Do you have the code avaiable?
Good jobJanuary 31st, 2011
this so cool which program did u use
can I get the code
can you give me your email please ?February 3rd, 2011
increpare could you give me your email please ?February 3rd, 2011
Jime: I used Adobe Flash to create it. You can use any platform and language, which allows you to create some grapihcal output. The algorithm is described above.February 8th, 2011
I am trying to create something similar to this but it would create the vertices and edges with the stroke of the mouse any suggestions? basically this but instead of creating brush strokes it would create a design with the connected line and dot sringsMay 13th, 2011
jackley: What exatly do you need? Drawing some beziér curves from mouse track?May 16th, 2011
hi,
I think Jackley was talking more specifically about this: ; how to render the graph with a distorted picture rather than sticks and modes.
it would mean changing the drawing method, finding “closed” shapes and single lines but it could be nice.
nice blog btw, cool stuffMay 19th, 2011
hi, @ Ivan im planning do to that using Java language do think is it easy ?
any advice can help with that ?
can I use some parts of your code ( above )
ThanksJune 22nd, 2011
Hello Jime, yes you can. It will be very similar in Java as in Flash.June 22nd, 2011
How can I draw Multigraphs with this ? loops and multiple edges!January 22nd, 2012
hi Michel, I have never heard about multigraphs and I am reading about it on wikipedia right now.
You can do it simply by incidence matrix made of integers, which mean number of edges between two vertices. Then draw several different arcs between two vertices, instead of one line.
I was drawing oriented graphs with arcs in my SM Tool (you need Silverlight plugin to see it).January 23rd, 2012
Was thinking about multigraphs too.. would anything change in the calculation of the forces though ? the attraction should be greater when there are more edges between two vertices, shouldn’t it ?February 8th, 2012
I didn’t try it yet, but my novice approach would be just using the number of edges between two vertices as a factor to multiply with. Would that work ? any better ideas ?
[...]. [...]March 19th, 2012
Good implementation. Can you share all project files?March 22nd, 2012
Hi, i’ve been recently implementing such an algorithm but in c# and there the coordinate system is starting in top left corner, y go down positive, and x right positive, and it’s just not working for meJune 19th, 2012
do you have any suggestions that might help me ?
Hello,
The coordinate system in flash is the same. You can also check the JavaScript version.
I have implemented this algorithm in 6 or 7 languages including C#. I am sure you just have some minor mistake – plus instead of minus or something. Look at it again, carefully!June 19th, 2012
How die you implement the extra force to not let the nodes move too far away from each other? Lets say with a given distance to each other?November 25th, 2012
Hi,November 26th, 2012
just add a simple condition – if edge length is out of boundaries, then put it back to boundaries.
But note, that if you set too small bounaries, e.g. you set constant edge length L, many graphs can not be drawn this way.
[...] » Force-based graph drawing in AS3 ツイート (adsbygoogle = window.adsbygoogle || []).push({}); [...]December 20th, 2013
[...] I have found implementation of the Force draw algorithm in AS3 (the web contains JS version too). I will try to convert it to discrete version. But I have [...]January 24th, 2014 | http://blog.ivank.net/force-based-graph-drawing-in-as3.html | CC-MAIN-2015-48 | refinedweb | 1,726 | 75.3 |
Cutter
Two-methods-gem I use a lot for simple debugging & performance measuring purposes.
#inspect method shines when doing reverse engineering, it is especially useful, when it is needed to quickly hack on someone else's code. Also, it is very easy to become 'someone else' for self, when dealing with own code, if it was written very long time ago.
Besides that
#stamper allows doing performance measuments in a handy manner, it can be used to create quick and neat demonstrations of how particular pieces of Ruby code perform.
The one interesting possible usage of
#stamper is performance optimization of templates on Rails View Layer, because it often takes a large load impact (compared to M and C layers) because of Rails lazy-evaluation mechanisms.
Prerequisites
It works on 1.8.7, 1.9.3, JRuby and Rubinius.
Installiation
Include it into Gemfile:
group :development, :test do gem 'cutter' end
Cutter::Inspection
I) #inspect!
Insert
#inspect! method into any of your methods:
def your_method *your_args # ... inspect! {} # curly braces are important - they capture original environment! # or # iii {} as an alias # ... end # your_method(1,"foo",:bar) => # method `your_method' # variables: # your_args: [1, "foo", :bar]
It gives simple but nice trace for inspection: method's name and args that were passed to method.
With
inspect!(:instance) {} we also see instance variables:
def your_method a, b @instance_var = "blip!" inspect!(:instance) {} end # your_method 1, 2 # method: `your_method' # called from class: RSpec::Core::ExampleGroup::Nested_1::Nested_1 # local_variables: # a: 1 # b: 2 # instance_variables: # @instance_var: blip!
With
inspect!(:self) {} we have
self#inspect of class to which method belongs to:
def your_method name, *args # ... inspect!(:self) {} end # your_method(1,2,3,4,5) => # method: `your_method' # called from class: SelfInspectDemo # variables: # name: 1 # args: [2, 3, 4, 5] # block: # self inspection: # #<SelfInspectDemo:0x82be488 @
Option
:caller gives us caller methods chain:
def your_method name, *args # ... inspect!(:caller) {} end # your_method(1,2,3,4,5) => # method: `your_method' # called from class: RSpec::Core::ExampleGroup::Nested_1::Nested_1 # variables: # name: 1 # args: [2, 3, 4, 5] # block: # caller methods: # /home/stanislaw/_work_/gems/cutter/spec/inspection/demo_spec.rb:33:in `your_method' # /home/stanislaw/_work_/gems/cutter/spec/inspection/demo_spec.rb:40:in `block (3 levels) in <top (required)>' # /home/stanislaw/.rvm/gems/ruby-1.9.2-p180@310/gems/rspec-core-2.6.4/lib/rspec/core/example.rb:48:in `instance_eval'
And finally
inspect!(:max) {} produces maximum information: options
:instance,
:self,
:caller are included and Ruby's ordinary
#inspect method is called on every variable.
def your_method *args inspect!(:max) {} end # maximal(1, :two, "three", :four => 5) => # # method: `your_method' (maximal tracing) # called from class: RSpec::Core::ExampleGroup::Nested_1::Nested_1 # local_variables: # args: [1, :two, "three", {:four=>5}] # instance_variables: # @example: #<RSpec::Core::Example:0xa1d378 > # ... # self inspection: # #<RSpec::Core::ExampleGroup::Nested_1::Nested_1:0x9e5f8f4 # ... # caller methods: # /home/stanislaw/work/gems/cutter/spec/inspection/demo_spec.rb:28:in `maximal' # /home/stanislaw/work/gems/cutter/spec/inspection/demo_spec.rb:54:in `block (3 levels) in <top (required)>' # ...
If you want all
#inspect! methods fall silent at once, use
Cutter::Inspection.quiet!
To make them sound again do
Cutter::Inspection.loud!
Three-letters methods
class Object def rrr object = nil raise object.inspect end def ppp object = nil puts object.inspect end def lll object = nil Rails.logger.info object.inspect end if defined? Rails end
#iii
Instead of
#inspect! you can use
#iii - just an alias more convenient for typing.
Finally, you have a group of 4 three-letters methods in your every day debugging workflow.
II) Cutter::Stamper
Acts as
benchmark {} in Rails or
Benchmark.measure {} in common Ruby, but with stamps in any position in block executed.
It is much simpler to write Stamper with Stamps than all these Measure-dos.
Minimal stamper
stamp! method is just an alias for
stamp, use whatever you like:
puts "Minimal stamper" stamper do stamp sleep 0.2 stamp! sleep 0.2 stamp! end
Will produce:
Minimal stamper no name ------- stamp: 0 ms stamp: 200 ms stamp: 400 ms ------- 400ms
Stamper with named stamps
puts "Now with named stamps" Cutter::Stamper.scope :testing_method => "Demonstration of named stamping" do |tm| tm.msg _1: "first piece" tm.msg _2: "second piece" end Cutter::Stamper.scope :inner_scope => "Now internal things" do |i| i.msg first: "I'm the first inner stamp" end stamper :testing_method do |tm| sleep 0.3 tm.stamp! :_1 # The old form of calling #stamp! on yielded scope variable sleep 0.3 stamper :inner_scope do |i| sleep 0.2 i.stamp! :first sleep 0.2 i.stamp! "Stamp with custom text" end tm.stamp! :_2 end
will result in
Now with named stamps Demonstration of named stamping ------------------------------- stamp: 300 ms first piece Now internal things ------------------- stamp: 201 ms I'm the first inner stamp stamp: 401 ms Stamp with custom text ------------------- 401ms stamp: 1001 ms second piece ------------------------------- 1001ms
Stamper with
:capture => true option
Use it to hide the output of piece you are benchmarking.
require 'cutter' N = 100000 result = [] EMB = "String to embed" result << stamper(:capture => true) do N.times do puts "#{EMB}\n" end end result << stamper(:capture => true) do N.times do printf "#{EMB}\n" end end result << stamper(:capture => true) do N.times do print "#{EMB}\n" end end puts result.inspect
Notes
- Both
#inspect! {}and
#stampermethods colorize their output. You can see
lib/cutter/colored_output.rbfile to understand how it is done. I will really appreciate any suggestions of how current color scheme can be improved.
Specs and demos
Clone it
$ git clone $ cd cutter
Specs are just
rake
See demos
rake demo
Contributors
- Stanislaw Pankevich
- Kristian Mandrup | http://www.rubydoc.info/gems/cutter/frames | CC-MAIN-2016-40 | refinedweb | 921 | 59.5 |
A subgraph view on an existing
tf.Graph.
tf.contrib.graph_editor.SubGraphView( inside_ops=(), passthrough_ts=() )
An instance of this class is a subgraph view on an existing
tf.Graph.
"subgraph" means that it can represent part of the whole
tf.Graph.
"view" means that it only provides a passive observation and do not to act
on the
tf.Graph. Note that in this documentation, the term "subgraph" is
often used as substitute to "subgraph view".
A subgraph contains:
- a list of input tensors, accessible via the
inputsproperty.
- a list of output tensors, accessible via the
outputsproperty.
- and the operations in between, accessible via the "ops" property.
An subgraph can be seen as a function F(i0, i1, ...) -> o0, o1, ... It is a function which takes as input some input tensors and returns as output some output tensors. The computation that the function performs is encoded in the operations of the subgraph.
The tensors (input or output) can be of two kinds:
- connected: a connected tensor connects to at least one operation contained in the subgraph. One example is a subgraph representing a single operation and its inputs and outputs: all the input and output tensors of the op are "connected".
- passthrough: a passthrough tensor does not connect to any operation contained in the subgraph. One example is a subgraph representing a single tensor: this tensor is passthrough. By default a passthrough tensor is present both in the input and output tensors of the subgraph. It can however be remapped to only appear as an input (or output) only.
The input and output tensors can be remapped. For instance, some input tensor
can be omitted. For instance, a subgraph representing an operation with two
inputs can be remapped to only take one input. Note that this does not change
at all the underlying
tf.Graph (remember, it is a view). It means that
the other input is being ignored, or is being treated as "given".
The analogy with functions can be extended like this: F(x,y) is the original
function. Remapping the inputs from [x, y] to just [x] means that the subgraph
now represent the function F_y(x) (y is "given").
The output tensors can also be remapped. For instance, some output tensor can
be omitted. Other output tensor can be duplicated as well. As mentioned
before, this does not change at all the underlying
tf.Graph.
The analogy with functions can be extended like this: F(...)->x,y is the
original function. Remapping the outputs from [x, y] to just [y,y] means that
the subgraph now represent the function M(F(...)) where M is the function
M(a,b)->b,b.
It is useful to describe three other kind of tensors:
- internal: an internal tensor is a tensor connecting operations contained in the subgraph. One example in the subgraph representing the two operations A and B connected sequentially: -> A -> B ->. The middle arrow is an internal tensor.
- actual input: an input tensor of the subgraph, regardless of whether it is listed in "inputs" or not (masked-out).
- actual output: an output tensor of the subgraph, regardless of whether it is listed in "outputs" or not (masked-out).
- hidden input: an actual input which has been masked-out using an input remapping. In other word, a hidden input is a non-internal tensor not listed as a input tensor and one of whose consumers belongs to the subgraph.
- hidden output: a actual output which has been masked-out using an output remapping. In other word, a hidden output is a non-internal tensor not listed as an output and one of whose generating operations belongs to the subgraph.
Here are some useful guarantees about an instance of a SubGraphView:
- the input (or output) tensors are not internal.
- the input (or output) tensors are either "connected" or "passthrough".
- the passthrough tensors are not connected to any of the operation of the subgraph.
Note that there is no guarantee that an operation in a subgraph contributes at all to its inputs or outputs. For instance, remapping both the inputs and outputs to empty lists will produce a subgraph which still contains all the original operations. However, the remove_unused_ops function can be used to make a new subgraph view whose operations are connected to at least one of the input or output tensors.
An instance of this class is meant to be a lightweight object which is not modified in-place by the user. Rather, the user can create new modified instances of a given subgraph. In that sense, the class SubGraphView is meant to be used like an immutable python object.
A common problem when using views is that they can get out-of-sync with the
data they observe (in this case, a
tf.Graph). This is up to the user to
ensure that this doesn't happen. To keep on the safe side, it is recommended
that the life time of subgraph views are kept very short. One way to achieve
this is to use subgraphs within a "with make_sgv(...) as sgv:" Python context.
To alleviate the out-of-sync problem, some functions are granted the right to
modified subgraph in place. This is typically the case of graph manipulation
functions which, given some subgraphs as arguments, can modify the underlying
tf.Graph. Since this modification is likely to render the subgraph view
invalid, those functions can modify the argument in place to reflect the
change. For instance, calling the function swap_inputs(svg0, svg1) will modify
svg0 and svg1 in place to reflect the fact that their inputs have now being
swapped.
Methods
consumers
consumers()
Return a Python set of all the consumers of this subgraph view.
A consumer of a subgraph view is a tf.Operation which is a consumer of one of the output tensors and is not in the subgraph.
copy
copy()
Return a copy of itself.
Note that this class is a "view", copying it only create another view and does not copy the underlying part of the tf.Graph.
find_op_by_name
find_op_by_name( op_name )
Return the op named op_name.
input_index
input_index( t )
Find the input index corresponding to the given input tensor t.
is_passthrough
is_passthrough( t )
Check whether a tensor is passthrough.
op
op( op_id )
Get an op by its index.
output_index
output_index( t )
Find the output index corresponding to given output tensor t.
remap
remap( new_input_indices=None, new_output_indices=None )
Remap the inputs and outputs of the subgraph.
Note that this is only modifying the view: the underlying tf.Graph is not affected.
remap_default
remap_default( remove_input_map=True, remove_output_map=True )
Remap the inputs and/or outputs to the default mapping.
remap_inputs
remap_inputs( new_input_indices )
Remap the inputs of the subgraph.
If the inputs of the original subgraph are [t0, t1, t2], remapping to [2,0] will create a new instance whose inputs is [t2, t0].
Note that this is only modifying the view: the underlying
tf.Graph is not
affected.
remap_outputs
remap_outputs( new_output_indices )
Remap the output of the subgraph.
If the output of the original subgraph are [t0, t1, t2], remapping to [1,1,0] will create a new instance whose outputs is [t1, t1, t0].
Note that this is only modifying the view: the underlying tf.Graph is not affected.
remap_outputs_make_unique
remap_outputs_make_unique()
Remap the outputs so that all the tensors appears only once.
remap_outputs_to_consumers
remap_outputs_to_consumers()
Remap the outputs to match the number of consumers.
remove_unused_ops
remove_unused_ops( control_inputs=True )
Remove unused ops.
__bool__
__bool__()
Allows for implicit boolean conversion.
__enter__
__enter__()
Allow Python context to minimize the life time of a subgraph view.
A subgraph view is meant to be a lightweight and transient object. A short lifetime will alleviate the "out-of-sync" issue mentioned earlier. For that reason, a SubGraphView instance can be used within a Python context. For example:
from tensorflow.contrib import graph_editor as ge with ge.make_sgv(...) as sgv: print(sgv)
__exit__
__exit__( exc_type, exc_value, traceback )
__nonzero__
__nonzero__()
Allows for implicit boolean conversion. | https://www.tensorflow.org/versions/r1.15/api_docs/python/tf/contrib/graph_editor/SubGraphView?hl=zh_cn | CC-MAIN-2022-21 | refinedweb | 1,320 | 57.67 |
SimpleBot: Extensible bot for Delta Chat
Project description
SimpleBot
An extensible Delta Chat bot.
Install
To install the latest stable version of SimpleBot run the following command (preferably in a virtual environment):
pip install simplebot
To test unreleased version:
pip install --pre -U -i deltachat pip install
⚠️ NOTE: If Delta Chat Python bindings package is not available for your platform you will need to compile and install the bindings manually, check deltachat documentation for more info.
Quick Start: Running a bot+plugins
(Replace variables
$ADDR and
$PASSWORD with the email and password for the account the bot will use)
Add an account to the bot:
simplebot init "$ADDR" "$PASSWORD"
Install some plugins:
pip install simplebot-echo
Start the bot:
simplebot serve
Plugins
SimpleBot is a base bot that relies on plugins to add functionality, for official plugins check simplebot_plugins
Everyone can publish their own plugins, search in PyPI to discover cool SimpleBot plugins
⚠️ NOTE: Plugins installed as Python packages (for example with
pip) are global to all accounts you register in the bot, to separate plugins per account you need to run each account in its own virtual environment.
Creating per account plugins
If you know how to code in Python, you can quickly create plugins and install them to tweak your bot.
Lets create an "echo bot", create a file named
echo.py and write inside:
import simplebot @simplebot.filter def echo(message, replies): """ Echoes back received message.""" replies.add(text=message.text)
That is it! you have created a plugin that will transform simplebot in an "echo bot" that will echo back any text message you send to it. Now tell simplebot to register your plugin:
simplebot plugin --add ./echo.py
Now you can start the bot and write to it from Delta Chat app to see your new bot in action.
Check the
examples folder to see some examples about how to create plugins.
Note for users
SimpleBot uses Autocrypt end-to-end encryption but note that the operator of the bot service can look into messages that are sent to it.
Credits
SimpleBot is based on deltabot
SimpleBot logo was created by Cuban designer "Dann".
Project details
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages. | https://pypi.org/project/simplebot/1.1.0/ | CC-MAIN-2021-39 | refinedweb | 382 | 56.49 |
The CSS parser currently can process either a string (nsAString, specifically) or a stream (nsIUnicharInputStream). Almost all entry points pass a string. It would simplify the parser slightly, and the scanner considerably, if we always passed a string; this would also facilitate lazy generation of CSS error messages.
Note that the CSSLoader already reads the entire stylesheet from the network before invoking the parser, so there is no loss of parallelism.
Created attachment 423093 [details] [diff] [review]
proposed patch
If we do this, we can also remove the pushback buffer, right? I assume that will happen in followups?
I assume the main drawback here is having to create that contiguous buffer for the string; something we avoided doing before? Have we tried gathering data on how big that buffer tends to be in practice?
(In reply to comment #2)
> If we do this, we can also remove the pushback buffer, right? I assume that
> will happen in followups?
I hadn't thought of that. It would be nice, but the main read buffer is treated as constant, and I don't know if we always push back exactly the characters we just read. I can probably ensure that the scanner does, but the parser uses Pushback() too... Definitely for a followup.
> I assume the main drawback here is having to create that contiguous buffer for
> the string; something we avoided doing before?
You know, I'm not sure we *were* avoiding that before, given that we always wait till OnStreamComplete to start parsing - isn't there a copy in the necko cache at least?
> Have we tried gathering data on how big that buffer tends to be in practice?
That would be an interesting question, yeah. Is that a query you can run on the Google database, cevans? (Size distribution of CSS files.)
> I don't know if we always push back exactly the characters we just read
Hmm. In theory we might not, and more importantly what we read is not what's in the buffer (e.g. a lone '\r' in the buffer). So yeah, something to look into later.
> You know, I'm not sure we *were* avoiding that before, given that we always
> wait till OnStreamComplete to start parsing - isn't there a copy in the necko
> cache at least?
There isn't..
Created attachment 423462 [details] [diff] [review]
patch v1a (rediff, delete a now-unused macro)
CSS_BUFFER_SIZE was used only by code deleted by this patch, so it should go too.
(In reply to comment #4)
>.
Okay, so we had the whole thing in memory but not as one contiguous block and not pre-converted, I get it now.
My *real* goal in wanting the entire sheet in one big buffer is to enable lazy calculation of line numbers for error messages; so I hope this turns out to be an acceptable tradeoff.
I'd still like to see some numbers for the buffer sizes involved, if just from our own Tp run (on try).
I have just pushed my queue to try with a patch on top to report buffer sizes, and will analyze the results tomorrow morning. Here are the sorted results for browser startup + Gmail + LiveJournal.
CSS::ParseSheet: 78 bytes
CSS::ParseSheet: 102 bytes
CSS::ParseSheet: 184 bytes
CSS::ParseSheet: 258 bytes
CSS::ParseSheet: 318 bytes
CSS::ParseSheet: 346 bytes
CSS::ParseSheet: 490 bytes
CSS::ParseSheet: 1226 bytes
CSS::ParseSheet: 1336 bytes
CSS::ParseSheet: 1340 bytes
CSS::ParseSheet: 1522 bytes
CSS::ParseSheet: 1924 bytes
CSS::ParseSheet: 2212 bytes
CSS::ParseSheet: 2552 bytes
CSS::ParseSheet: 2962 bytes
CSS::ParseSheet: 3624 bytes
CSS::ParseSheet: 4636 bytes
CSS::ParseSheet: 4908 bytes
CSS::ParseSheet: 5004 bytes
CSS::ParseSheet: 5086 bytes
CSS::ParseSheet: 5258 bytes
CSS::ParseSheet: 5350 bytes
CSS::ParseSheet: 5706 bytes
CSS::ParseSheet: 5770 bytes
CSS::ParseSheet: 6120 bytes
CSS::ParseSheet: 7982 bytes
CSS::ParseSheet: 8010 bytes
CSS::ParseSheet: 9006 bytes
CSS::ParseSheet: 10216 bytes
CSS::ParseSheet: 10368 bytes
CSS::ParseSheet: 10572 bytes
CSS::ParseSheet: 10654 bytes
CSS::ParseSheet: 10836 bytes
CSS::ParseSheet: 12096 bytes
CSS::ParseSheet: 12148 bytes
CSS::ParseSheet: 12884 bytes
CSS::ParseSheet: 14988 bytes
CSS::ParseSheet: 16516 bytes
CSS::ParseSheet: 21254 bytes
CSS::ParseSheet: 22712 bytes
CSS::ParseSheet: 24270 bytes
CSS::ParseSheet: 30686 bytes
CSS::ParseSheet: 32082 bytes
CSS::ParseSheet: 46172 bytes
CSS::ParseSheet: 50536 bytes
CSS::ParseSheet: 69298 bytes
CSS::ParseSheet: 106626 bytes
CSS::ParseSheet: 106700 bytes
CSS::ParseSheet: 250828 bytes
CSS::ParseSheet: 250828 bytes
It looks like the Opera folks did just the analysis we want here: Their presentation isn't very readable, though - I'll try to make some graphs.
I'm not having any luck getting meaningful graphs out of the MAMA summary tables -- they've been too heavily binned. I did find this graph from another, smaller analysis:
(from )
which is consistent with MAMA's assertion that the average <link>ed stylesheet is about 8000 bytes long and the average inline (<style> or aggregate style="") stylesheet is about 1000 bytes long. More importantly, both data sets agree that the size falls off very fast above the average, although there are some rare huge outliers of all three types (machine-generated HTML with over a megabyte of inline <style> content, for instance)
Created attachment 423561 [details]
Tp4 stylesheet size distribution
Here's a size distribution profile (in bytes of UTF-16) for Tp4's style sheets. For some reason the PNG came out ridiculously huge, you will want to view it at 50% or so.
It's a little hard to tell because I couldn't persuade my plotting program to give me sensible X axis labels, but the majority of sheets are quite small. Here's quantiles:
25% 50% 75% 90%
720 3414 14336 43850
There are, however, outliers to 120,000 bytes.
> machine-generated HTML with over a megabyte of inline <style> content, for
> instance
Wait. For that case we actually have an nsAString that we wrap in a stream. See).
Created attachment 423612 [details] [diff] [review]
v2: avoid a copy for inline style
(In reply to comment #12)
>
>).
That turns out to be quite easy, although I have to bump the nsICSSLoader IID. We are still doing one copy in nsContentUtils::GetNodeTextContent, I think, but I don't think it's practical to avoid that one even when the style element has just one text node child (which should be the norm) because of the way nsTextFragment works. Revised patch attached. There is some more piggyback nsSubstring->nsAString conversion and whitespace cleanup.
Created attachment 423614 [details] [diff] [review]
v2a: avoid a copy for inline style
Of course I remember to prune the header file list in nsStyleLinkingElement.cpp only after posting the patch.
Comment on attachment 423614 [details] [diff] [review]
v2a: avoid a copy for inline style
>diff --git a/layout/style/nsCSSLoader.cpp b/layout/style/nsCSSLoader.cpp
> SheetLoadData(CSSLoaderImpl* aLoader,
>- const nsSubstring& aTitle,
>+ const nsAString& aTitle,
It looks like there are tabs around here for some reason (both before and after
your change). Might be worth it to clean those out (as a followup).
> NS_IMETHOD LoadInlineStyle(nsIContent* aElement,
>- nsIUnicharInputStream* aStream,
>+ const nsAString& aBuffer,
This, on the otherhand, is ending up mis-indented as a result of going from tabs to spaces.
>+++.
I can see doubling chunk sizes until we get to the point that |n| ends up less than |toread| if desired, but I suspect 4KB chunks are as big as we'll typically be able to get our of Read.
>+extern NS_COM nsresult
>+NS_ConsumeStream(nsIUnicharInputStream *aSource, PRUint32 aMaxCount,
>+ nsAString &aBuffer);
Some tabs snuck in here.
(In reply to comment #15)
> It looks like there are tabs around here for some reason (both before and
> after your change). Might be worth it to clean those out (as a followup).
Noted.
> This, on the otherhand, is ending up mis-indented as a result of going from
> tabs to spaces.
Ditto.
> >+++'ll look into it.
>.
The scanner only ever set the low-level error when a stream read failed, so after this change, it is more properly a parser flag. And in the original
patch sequencing, parsers didn't get recycled anymore at this point. This is
what I get for shuffling the queue around so heavily.
In the *current* revision (only on my laptop at this point) this patch is the last of a set of three that, collectively, eliminate the low-level error flag altogether.
> >+++.
I forget who it was, but someone else already tripped over this problem. My current code looks like this:
+NS_ConsumeStream(nsIUnicharInputStream *stream, PRUint32 maxCount,
+ nsAString &result)
+{
+ nsresult rv = NS_OK;
+ result.Truncate();
+
+ // nsIUnicharInputStream does not provide Available(), so allocate
+ // exponentially larger chunks, starting with 8192 bytes. Note
+ // that some implementations will only produce 4096 bytes per call
+ // to Read().
+ PRUint32 chunk = 4096;
+
+ while (maxCount) {
+ if (chunk < PR_UINT32_MAX/2)
+ chunk *= 2;
+
+ // resize result buffer
+ PRUint32 toread = PR_MIN(chunk, maxCount);
+ PRUint32 length = result.Length();
+ result.SetLength(length + toread);
+ if (result.Length() != (length + toread))
+ return NS_ERROR_OUT_OF_MEMORY;
+
+ // repeatedly read until we run out of room
+ while (length < result.Length()) {
+ PRUnichar *buf = result.BeginWriting() + length;
+ PRUint32 n;
+
+ rv = stream->Read(buf, result.Length() - length, &n);
+ if (NS_FAILED(rv) || n == 0)
+ return rv;
+
+ length += n;
+ maxCount -= n;
+ }
+ }
+
+ return rv;
+}
Maybe I can get rid of the inner loop, based on what you say here...
>.
... the idea was to make sure we were reading as much as we possibly could at each go, but we could just as well take advantage of knowing that nsConverterInputStream works in 4096-byte blocks, and that would be simpler code-wise. What do you think?
zw
I think we should assume 4096-byte blocks for now, and as a followup make the unichar input stream hand out a length estimate (which is likely to be bigger than the actual final length, but is the best it can do, in general).
Created attachment 430431 [details] [diff] [review]
v3 part 1: assume infallible malloc
I've revised the "no streams" patch with two new lead-in patches. This is the first. Now that infallible operator new seems to have stuck (finally!) we can throw out all of the out-of-memory checks in the CSS parser. I was considering sending this in ahead of that just because the out-of-memory checks were incomplete and not handled well by higher levels of the parser.
Created attachment 430432 [details] [diff] [review]
v3 part 2: don't use the low-level error to signal namespace lookup failure
GetNamespaceIDForPrefix was abusing the "low-level error" flag to communicate a sticky error indicator to ParseSelectorString. This patch makes it use its own bit for that instead.
Created attachment 430435 [details] [diff] [review]
v3 part 3: don't use streams
And here's the piece that corresponds to the original patch. I fixed NS_ConsumeStream as discussed above, I fixed the indentation (I think) and I threw out the logic changes in ParseColorString for now.
The point of adding part 1 and 2 ahead of this change is simply that this patch can now eliminate the low-level error flag altogether. Many of the parser entry points are now infallible (callers mostly ignore the potential error return already) but I'm leaving the external API as is for now.
Comment on attachment 430431 [details] [diff] [review]
v3 part 1: assume infallible malloc
>+++ b/layout/style/nsCSSParser.cpp
>+ NS_NewCSSStyleRule(&rule, nsnull, declaration);
> *aResult = rule;
Why do you need |rule|? Why not just NS_NewCSSStyleRule directly into aResult?
>@@ -1717,21 +1708,17 @@ CSSParserImpl::GatherMedia(nsMediaList*
>- nsresult rv = aMedia->AppendQuery(query);
AppendQuery doesn't allocate via operator new, so is still fallible.
>@@ -1749,21 +1736,16 @@ CSSParserImpl::ParseMediaQueryExpression
> nsMediaExpression *expr = aQuery->NewExpression();
NewExpression is still fallible.
>@@ -1822,21 +1804,16 @@ CSSParserImpl::ParseMediaQueryExpression
> nsRefPtr<nsCSSValue::Array> a = nsCSSValue::Array::Create(2);
I'm hoping explicit calls to |::operator new| (which is what this is) are infallible? Please check with cjones.
>@@ -1955,20 +1925,17 @@ CSSParserImpl::ParseGroupRule(nsICSSGrou
>- if (!PushGroup(aRule)) {
This happens to be ok, since it uses nsCOMArray, unlike the earlier callsites that use nsTArray... I really dislike that fragility. I would prefer to assume that array grow operations are fallible until all our allocation is infallible. That's assuming that array grow operations really become infallible.
>@@ -2272,20 +2221,16 @@ CSSParserImpl::SkipUntilStack(nsAutoTArr
>- // Just handle out-of-memory by parsing incorrectly. It's
>- // highly unlikely we're dealing with a legitimate style sheet
>- // anyway.
aStack.AppendElement is still fallible.
>@@ -3077,20 +3005,16 @@ CSSParserImpl::ParsePseudoSelector(PRInt
> nsCOMPtr<nsIAtom> pseudo = do_GetAtom(buffer);
I'm not sure I'm happy depending on the exact allocator atom guts use...
>@@ -4881,20 +4784,16 @@ CSSParserImpl::ParseImageRect(nsCSSValue
> nsCSSValueGradientStop* stop = aGradient->mStops.AppendElement();
>- if (!stop) {
AppendElement is fallible.
>@@ -7575,21 +7404,18 @@ CSSParserImpl::ParseFunctionInternals(co
>- if (!aOutput.AppendElement(newValue)) {
That's still fallible.
r- for the array issues above.
Comment on attachment 430432 [details] [diff] [review]
v3 part 2: don't use the low-level error to signal namespace lookup failure
>+++ b/layout/style/nsCSSParser.cpp
CSSParserImpl::ParseSelectorString(const
>+ if (prefixErr)
>+ return NS_ERROR_DOM_NAMESPACE_ERR;
>+ else
No need for else after return.
Comment on attachment 430431 [details] [diff] [review]
v3 part 1: assume infallible malloc
And fr this part 1 patch, it might be good if dbaron OKed it.
Is it possible to do an interdiff from the last thing I reviewed to part 3?
Comment on attachment 430431 [details] [diff] [review]
v3 part 1: assume infallible malloc
I'm gonna push back really **** the r-. I claim that there is no point in doing this patch unless we can remove *all* of the null-checks after memory allocation (since the ultimate point here is to remove mLowLevelError and change most of the parser entry points to return void). I also claim that the existing null-checks do more harm than good, because they conflate a sticky error state (out of memory) with a recoverable error state (syntax error) -- higher layers only see the PR_FALSE return from some parser function, assume a syntax error, and try to recover from that, when we should be bailing out completely. But to do that reliably we'd have to check the low-level error in every parse-failure path, which is a silly thing to implement when we're trying to get rid of oom checks anyway.
I understand why we want the patch. I just think that currently its behavior will be that on OOM we try to scribble somewhere near address 0 (at least; I haven't carefully audited the codepaths that use nsTArray appends here) instead of just dying in a guaranteed safe way. If we could guarantee that there are no null returns from those nsTArrays, then I would be fine with the change. If we decide that such attempts to scribble near 0 (and crash as needed) are ok, then I might be fine with the change too.
Chris, what's the long-term plan for nsTArray? Does it plan to become infallible? Will it offer fallible and infallible grow methods? Something else?
IIRC (from the frame poisoning stuff), all current OSes start up with a fairly large region of address space reserved near 0 (at least a megabyte), but will allow the application to trim that down to one page (4096 bytes) with directed-address allocations. I didn't test whether that area would get used for undirected allocations.
It seems to me that most uses of nsTArray want infallible-resize semantics.
This is reserved in the "can't read" sense, not just "can't write", yes?
(In reply to comment #28)
> This is reserved in the "can't read" sense, not just "can't write", yes?
Yup.
(In reply to comment #24)
> Is it possible to do an interdiff from the last thing I reviewed to part 3?
I'm not sure I understand you here. You want to see part 3 relative to part 2 without part 1? That would take some fixups to compile...
> Yup.
Hmm. In that case I'm probably ok with assuming nsTArray infallible here as long as we don't write to (or read from) memory pointed to by pointer members of the things we'd be allocating that way. Or as long as we can guarantee that nsTArray infallible will land before this ever ships (including in an alpha).
> You want to see part 3 relative to part 2 without part 1?
No, I want to see how part 3 differs from "v2a", and in particular which parts I need to focus on reviewing there and which I have already reviewed...
But if an array grow fails in the current code, and you assume it succeeds, will you end up reading/writing past the end of the array?
(In reply to comment #30)
> > You want to see part 3 relative to part 2 without part 1?
>
> No, I want to see how part 3 differs from "v2a", and in particular which parts
> I need to focus on reviewing there and which I have already reviewed...
interdiff v2a part3 comes out completely wrong - it shows a bunch of things that did *not* change and misses several things that did. I don't know why.
But maybe we should just table part 3 until we decide what to do about part 1, because if I need to back off on part 1, part 3 has to change considerably.
(In reply to comment #31)
> But if an array grow fails in the current code, and you assume it succeeds,
> will you end up reading/writing past the end of the array?
It looks like we will, since nsTArray doesn't invalidate the array if an EnsureCapacity() call fails. Bother.
Created attachment 430667 [details] [diff] [review]
better handling of namespace lookup failure [checkin: comment 33]
I pushed "v3 part 2" by itself, with the requested change from comment 22, and taking out the nsCSSScanner pieces (which would have broken compilation in the absence of part 1).
(In reply to comment #26)
> Chris, what's the long-term plan for nsTArray? Does it plan to become
> infallible? Will it offer fallible and infallible grow methods? Something
> else?
Good question! I don't believe that's been discussed yet. The STL-ification project wants mozilla::Vector with an infallible STL-like API; maybe a solution is to fork nsTArray into infallible mozilla::Vector and fallible mozilla::Fallible(?)Vector.
Comment on attachment 430435 [details] [diff] [review]
v3 part 3: don't use streams
clearing review requests on patches I know will have to be revised before landing.
Created attachment 530171 [details] [diff] [review]
part 0: kill nsIUnicharStreamListener [checkin: comment 58]
Have finally come back around to this bug, & while mucking with ns(I)UnicharStreamLoader, I noticed that nsIUnicharStream*Listener* is only used to define a set of random callbacks from the old HTML parser - not the new one - and there is no user of these callbacks anywhere in the tree.
So I kill it.
Created attachment 530173 [details] [diff] [review]
part 1 (INCOMPLETE): revamp nsIUnicharStreamLoader
This is as far as I've gotten on the actual project here. I rework nsIUnicharStreamLoader so that it produces the entire contents of the decoded stream as a nsString, rather than soaking up the data in a nsPipe which is then fed to an nsConverterInputStream.
Obviously this breaks the build, since it doesn't update css::Loader (the sole user of nsIUnicharStreamLoader, except for a test case). However, before I do any more work I'd like to know if this is barking up the right tree and whether I have understood how to use nsIUnicodeDecoder correctly - the conversion loop (in WriteSegmentFun) was mostly copied from nsConverterInputStream and I'm not sure I got it right.
In general this seems like the right approach, and what we discussed. Was there a specific concern about a particular tree up which you feel you're barking? ;)
I haven't reviewed the details of the OnStartRequest/OnStopRequest/OnDataAvailable changes but two comments:
1) You don't have to guesstimate a 2x expansion (esp. because in the common
cases it's 1x). Use GetMaxLength() on the decoder instead.
2) You should probably check that SetCapacity succeeded.
Other than those, this looks about right at first glance.
Henri, do you have time to look at the unicode conversion code here? You've dealt with unicode decoders most recently, I think.
(In reply to comment #38)
> In general this seems like the right approach, and what we discussed. Was
> there a specific concern about a particular tree up which you feel you're
> barking? ;)
I don't fully understand OnDataAvailable and ReadSegments; it's possible that I did something wrong there, as well as in the use of the UnicodeDecoder. Especially, I'm not sure the mixture of Read and ReadSegments in OnDataAvailable is safe, but there could be other problems.
Ah. Mixing Read and ReadSegments should be ok.
And in particular, nothing jumped out at me as obviously wrong. I didn't check all the arithmetic details, of course....
(In reply to comment #38)
> 1) You don't have to guesstimate a 2x expansion (esp. because in the common
> cases it's 1x). Use GetMaxLength() on the decoder instead.
> 2) You should probably check that SetCapacity succeeded.
The common case (for the sole user, CSS) is ASCII becoming UTF-16, which is a 2x expansion. But I will make these changes.
It's a 2x expansion in number of bytes. But the srcLen is measured in bytes while the dstLen is measured in PRUnichars. And in the common case there are just as many PRUnichars as bytes (or fewer, for UTF-8).
Of course. How silly of me.
Comment on attachment 530171 [details] [diff] [review]
part 0: kill nsIUnicharStreamListener [checkin: comment 58]
Let's get rid this it seems that Google Desktop is now abandoned anyway, so this API isn't supported in the new parser anyway.
(In reply to comment #39)
> Henri, do you have time to look at the unicode conversion code here? You've
> dealt with unicode decoders most recently, I think.
I tried to look at the code carefully, and it seems to me it ends up doing the same thing as the code I assume to be correct:
Aside: I think some day, we should change the decoder interface to suck less by having an interface more like
Created attachment 530385 [details] [diff] [review]
part 0a: whitespace cleanup on style/Loader.cpp [checkin: comment 58]
layout/style/Loader.cpp has a *lot* of trailing whitespace in it. As the next patch makes extensive changes to this file, I thought it might be a good time to get rid of all of that, but obviously this needs to be done separately from changes that need more of a review. :)
Created attachment 530388 [details] [diff] [review]
part 1: revamp nsIUnicharStreamLoader and change css::Loader to use it
This is the meat of the change. I am now fairly confident that the changes in netwerk/ are correct, but it probably deserves a thorough going-over anyway. The changes to css::Loader are *not* correct in at least one regard: the revised handling of synchronous sheet loads triggers a bunch of assertions...
###!!! ASSERTION: Should have an inner whose principal has not yet been set: '!mInner->mPrincipalSet', file /home/zack/src/mozilla/S-mc/layout/style/nsCSSStyleSheet.cpp, line 1136
###!!! ASSERTION: Bad loading table: 'mLoadingDatas.Get(&key, &loadingData) && loadingData == aLoadData', file /home/zack/src/mozilla/S-mc/layout/style/Loader.cpp, line 1632
###!!! ASSERTION: This is unsafe! Fix the caller!: 'Error', file /home/zack/src/mozilla/S-mc/content/events/src/nsEventDispatcher.cpp, line 534
(I'm not sure whether the last one of those is actually this change's fault.) I'm posting this for review anyway because I've not been able to figure out how to do the synchronous load correctly.
One more patch to follow, but it'll be posted to bug 543151.
Comment on attachment 530388 [details] [diff] [review]
part 1: revamp nsIUnicharStreamLoader and change css::Loader to use it
bz is a better reviewer for the loader than I am
One issue I just realiazed for the unichar stream loader. It needs to make the callback in all cases; the new code seems to not do that.
We should probably use a void string to represent the cases we used a null stream for before.
Er, yes. And the synchronous stuff looks broken. Spinning the event loop there is bad; that's why you get the asserts. You should probably just NS_OpenURI as before, take the resulting nsIInputStream, read it into an nsCAutoString (possibly preallocated to the right size) using something like WriteSegmentToCString (copy that from nsBinaryStream.cpp) and then NS_ConvertUTFtoUTF16 to get an nsAString.
Though that will behave differently from what we have now when the input is not actually valid UTF-8. Maybe you want to just factor out the streamloader code that converts a incoming segments to UTF16 and use it both places?
(In reply to comment #52)
> Spinning the event loop there is bad; that's why you get the asserts.
Doesn't a synchronous NS_OpenURI spin the event loop? Not in exactly the same place within the function, but still.
It looks to me like the asserts are all about not setting up the principal quite right.
(In reply to comment #51)
> One issue I just realiazed for the unichar stream loader. It needs to make the
> callback in all cases; the new code seems to not do that.
I thought I set it up so it would (with an empty string, if no data was received).
> Doesn't a synchronous NS_OpenURI spin the event loop?
It depends on the channel implementation. If the channel has an underlying stream it can just hand out (say file://, data:, chrome://, etc, etc), then no.
> It looks to me like the asserts are all about not setting up the principal
> quite right.
The asserts happen because while spinning the event loop for a sync load of URI X you reenter this code with a request for another sync load of URI X and end up getting the same stylesheet object and setting a principal on it a second time. But the key problem is the spinning the event loop and reentering bit.
> I thought I set it up so it would (with an empty string, if no data was
> received).
In nsUnicharStreamLoader::OnStopRequest if DetermineCharset returns error you never call OnStreamComplete. You also don't null out various things and so forth.....
Created attachment 530525 [details] [diff] [review]
part 1 v2: revamp nsIUnicharStreamLoader and change css::Loader to use it
I've got it to the point where it doesn't throw any assertions while loading the UA sheets, but instead it crashes hard inside nsFrame::BoxReflow after spitting out some other assertions:
WARNING: Subdocument container has no content: file /home/zack/src/mozilla/S-mc/layout/base/nsDocumentViewer.cpp, line 2380
###!!! ASSERTION: Must be a box frame!: '!mScrollCornerBox || mScrollCornerBox->IsBoxFrame()', file /home/zack/src/mozilla/S-mc/layout/generic/nsGfxScrollFrame.cpp, line 3328
###!!! ASSERTION: A box layout method was called but InitBoxMetrics was never called: 'metrics', file /home/zack/src/mozilla/S-mc/layout/generic/nsFrame.cpp, line 7199
Program received signal SIGSEGV, Segmentation fault.>)
(gdb) bt
#0>)
at /home/zack/src/mozilla/S-mc/layout/generic/nsFrame.cpp:7108
#1 0x00007ffff52cd727 in nsFrame::DoLayout (this=0x7fffe1c174b8, aState=...)
at /home/zack/src/mozilla/S-mc/layout/generic/nsFrame.cpp:6899
#2 0x00007ffff54b6898 in nsIFrame::Layout (this=0x7fffe1c174b8, aState=...)
at /home/zack/src/mozilla/S-mc/layout/xul/base/src/nsBox.cpp:559
#3 0x00007ffff54bc64a in nsBoxFrame::LayoutChildAt (aState=...,
aBox=0x7fffe1c174b8, aRect=...)
at /home/zack/src/mozilla/S-mc/layout/xul/base/src/nsBoxFrame.cpp:2033
#4 0x00007ffff52e7f7e in LayoutAndInvalidate (aState=...,
aBox=0x7fffe1c174b8, aRect=..., aScrollbarIsBeingHidden=0)
at /home/zack/src/mozilla/S-mc/layout/generic/nsGfxScrollFrame.cpp:3268
#5 0x00007ffff52ec32b in nsGfxScrollFrameInner::LayoutScrollbars (
this=0x7fffe1c171e0, aState=..., aContentArea=..., aOldScrollArea=...)
at /home/zack/src/mozilla/S-mc/layout/generic/nsGfxScrollFrame.cpp:3352
#6 0x00007ffff52f03b5 in nsHTMLScrollFrame::Reflow (this=0x7fffe1c17158,
aPresContext=<value optimized out>, aDesiredSize=..., aReflowState=...,
aStatus=@0x7fffffffc840)
at /home/zack/src/mozilla/S-mc/layout/generic/nsGfxScrollFrame.cpp:916
#7 0x00007ffff52b9046 in nsContainerFrame::ReflowChild (
this=<value optimized out>, aKidFrame=0x7fffe1c17158,
aPresContext=0x7fffe339e800, aDesiredSize=..., aReflowState=..., aX=0,
aY=0, aFlags=0, aStatus=@0x7fffffffc840, aTracker=0x0)
at /home/zack/src/mozilla/S-mc/layout/generic/nsContainerFrame.cpp:959
#8 0x00007ffff5375d6f in ViewportFrame::Reflow (this=0x7fffe331bbc8,
aPresContext=0x7fffe339e800, aDesiredSize=..., aReflowState=...,
aStatus=@0x7fffffffc840)
at /home/zack/src/mozilla/S-mc/layout/generic/nsViewportFrame.cpp:293
#9 0x00007ffff523e981 in PresShell::DoReflow (this=0x7fffe3391c00,
target=0x7fffe331bbc8, aInterruptible=0)
at /home/zack/src/mozilla/S-mc/layout/base/nsPresShell.cpp:7735
this has me pretty well stumped, although I assume it's still an issue with the UA sheet not getting set up correctly. (note: this is without the additional patch in bug 543151.)
xul.css styles scrollcorners as -moz-box. So at a guess, that either didn't load or didn't fully load.
Were there any CSS parse errors before the assertion point? Can you step through what happens when xul.css is parsed?
The way the attached patch calls the streamloader is not quite right, but it only matters in error cases, so I doubt it would cause the issue above...
For what it's worth, it may be worthwhile to break the patch up into pieces to test them independently (e.g. push to try after every patch in the sequence). Specifically:
1) Make the unichar stream loader return a string but then have the CSSLoader
just wrap a StringUnicharInputStream around it and pass that to the CSS
parser.
2) Change the CSS parser API to add an overload for parsing a full sheet from
a string. Convert the non-sync case in CSSLoader to use the new API.
3) Convert inline style parsing to use the new API.
4) Convert the paranoid sink to the new API.
5) Convert sync sheet loads to use the unichar stream loader or something.
6) Remove the old parsing API.
This would incidentally be easier to review too...
Oh, and could we please put the Accept header change in a separate bug?
I checked in patches 0 and 0a:
Update: having broken up the patch a bit, I have everything except sync sheet loads providing strings to the parser, but I also have a weird assertion failure in the leaktests:
localhost.localdomain - - [06/May/2011 12:11:45] "GET /screen.css HTTP/1.1" 200 -
###!!! ASSERTION: unexpected progress values: 'progress <= progressMax', file ../../../../netwerk/protocol/http/nsHttpChannel.cpp, line 4124
It appears that nsHttpChannel's idea of how much of 'screen.css' has been processed (sp. mLogicalOffset) has gotten out of sync with the input stream pump's idea of same. This happens in the patch that changes nsIUnicharStreamLoader, and the affected loads are all CSS, so I deduce that the revised stream loader is handling OnDataAvailable incorrectly, but I don't see how.
Will post updated patch set to this point shortly.
Oh, I'd missed that, sorry. The onDataAvailable contract is that that the callee will read all the data from aInputStream. The last attached patch on this bug will only read at most 4096 bytes, so if more than that is available things won't work right.
That might be the sync sheet issue too, since I bet this ended up reading only the first 4KB of all the chrome stylesheets.
Instead of passing 4096 to ReadSegments there you should pass aCount minus however much you've already read.
(In reply to comment #60)
>
> Instead of passing 4096 to ReadSegments there you should pass aCount minus
> however much you've already read.
Oh, is *that* what that argument means? It sounded like it was a limit on the size of each individual *chunk* passed to the callback function.
(In reply to comment #60)
> Oh, I'd missed that, sorry. The onDataAvailable contract is that that the
> callee will read all the data from aInputStream.
Is that true even if onDataAvailable returns a failure code?
> Oh, is *that* what that argument means?
Yeah, it's the total amount to read. The amount passed to the callback function on each call to the callback is up to the stream.
> Is that true even if onDataAvailable returns a failure code?
No. Only if you return success. Should have been clearer about that.
Thanks for clarifying. I think I've got that part working now, but I ran into a more ... elemental ... problem with using the UnicharStreamLoader for sync loads too: nsFileInputStream doesn't implement ReadSegments.
I am presently testing a patch that implements nsFileInputStream::ReadSegments, but MXR tells me that there are rather a lot of input stream classes that don't implement ReadSegments. I don't really know which of them we could wind up using - either for a sync load or an async one - but I'm wondering if I shouldn't deal with this in nsUnicharStreamLoader, and if so, what the tidiest way to do it would be.
Created attachment 530876 [details] [diff] [review]
v4 part 1
Here we go with the broken-up patch series. This works well enough to pass reftests on my local computer; try is running the full testsuite; there are still some places where I'm not sure the code is right, which I will call out below.
I did the breakup in a different order than the one bz suggested in comment 57 so that I did not have to introduce any new uses of streams. This first patch just adds a new nsCSSParser entry point that parses an entire sheet, but takes a string rather than a stream.
Created attachment 530877 [details] [diff] [review]
v4 part 2
This piece changes nsHTMLParanoidFragmentSink to use the new API and also does some en passant #include-pruning. I'm not sure who the appropriate reviewer is - dbaron, please feel free to bounce it to someone else.
Created attachment 530878 [details] [diff] [review]
v4 part 3
And this part uses the new parser entry point for "normal" use of inline style. Again, please feel free to redirect review to someone more appropriate.
I have high confidence in the patches up to this point.
Created attachment 530879 [details] [diff] [review]
v4 part 4
Rewrite ns(I)UnicharStreamLoader to produce a string rather than a stream, and use it for async (non-chrome, that is) style loads.
Potentially a problem here is what I mentioned in comment 64: the revised streamloader assumes that ReadSegments works, but there are a lot of streams that don't implement it. I don't know what can reasonably be expected of the type of stream we get on the async path.
Created attachment 530880 [details] [diff] [review]
v4 part 5
This piece sends sync stylesheet loads through mostly the same code path as async ones.
Needing careful checking in this piece are the new NS_FeedStreamListener helper function, and the implementation of nsFileInputStream::ReadSegments that I added. Also, is it safe to poke the content charset on a channel, as done here?
Created attachment 530881 [details] [diff] [review]
v4 part 6
This final piece removes no-longer-used stream-taking methods from css::Loader and nsCSSParser. nsCSSScanner can now be cleaned up as well - that will be done in bug 543151.
I am not going to be around much this coming week (travel) and may have very little time for Mozilla hacking after that until mid-August (summer job).
> nsFileInputStream doesn't implement ReadSegments.
Indeed. On purpose. We could deal with it by wrapping in buffered streams as needed (by first testing whether the stream we're given is buffered). This would just happen on the sync load path in the CSSLoader.
> I don't know what can reasonably be expected of the type of stream we get on
> the async path.
They will implement readSegments, as long as the caller is not breaking the API contract. nsIStreamListener.idl documents this.
I'll take a careful look through the patches on Monday. Given the above discussion, I doubt there's much that will need changing, so if you don't have time to address the review comments, if any, just let me know and I'll deal with it. Thanks for working on this!
It might make more sense if bzbarsky reviews the whole patch series here...
No objection from me.
Yeah, that's certainly my plan.
Comment on attachment 530876 [details] [diff] [review]
v4 part 1
Instead of adding and then later removing a second copy of all the guts of ParseSheet, how about we do:
template<typename T>
ParseSheet(T aInput, ....);
for the existing CSSParserImpl code, then have the exact body we have right now and have nsCSSParer::Parse (the old signature) call ParseSheet. Then in the last patch you can remove the templating and just leave the |const nsAString&| version.
r=me with that.
Comment on attachment 530877 [details] [diff] [review]
v4 part 2
r=me
Comment on attachment 530878 [details] [diff] [review]
v4 part 3
Again, I'd prefer a templated version of ParseSheet to a copy-and-remove...
r=me with that.
Comment on attachment 530879 [details] [diff] [review]
v4 part 4
>+++ b/netwerk/base/src/nsUnicharStreamLoader.cpp
>+nsUnicharStreamLoader::Init(nsIUnicharStreamLoaderObserver *aObserver)
>+ mDecoder = nsnull;
>+ mContext = nsnull;
>+ mChannel = nsnull;
Those should all be null already. No need to null them again.
>+ mBuffer.Truncate();
>+ mRawData.Truncate();
Also no need for that.
>+ mRawData.SetCapacity(512);
>+
> return NS_OK;
Here, on the other hand, you should check whether the capacity is actually 512. If it isn't, return NS_ERROR_OUT_OF_MEMORY so this object won't be used.
>+nsUnicharStreamLoader::OnStopRequest(nsIRequest *aRequest,
>+ if (NS_FAILED(rv)) {
>+ // Call the observer but pass it no data.
>+ // XXX Should we pass rv instead of aStatus?
>+ nsAutoString dummy;
>+ mObserver->OnStreamComplete(this, mContext, aStatus, dummy);
Nix dummy and just pass EmptyString() as the last argument.
And yes, I'd say pass rv here. And document this behavior in the idl. That would make this case consistent with the case when we end up with an error from DetermineCharset in OnDataAvailable.
Also, maybe the code should look more like this:
nsresult rv = NS_OK;
if (mRawData.Length() > 0 && NS_SUCCEEDED(aStatus)) {
NS_ABORT_IF_FALSE(mBuffer.Length() == 0,
"should not have both decoded and raw data");
rv = DetermineCharset();
}
and then your code as now, so that if aStatus is a failure we don't try to determine the charset for no reason.
>.
>+++ b/netwerk/base/src/nsUnicharStreamLoader.h
>+ nsCString mRawData;
>+ nsString mBuffer;
Document what those members are for, please.
r=me with the nits
Comment on attachment 530880 [details] [diff] [review]
v4 part 5
Poking the content charset is fine.!
Comment on attachment 530881 [details] [diff] [review]
v4 part 6
r=me, though I expect this will be smaller with the templating approach.
(In reply to comment #75)
> template<typename T>
> ParseSheet(T aInput, ....);
I thought of that but was worried about weird template problems. I'll try it.
> >+nsUnicharStreamLoader::Init(nsIUnicharStreamLoaderObserver *aObserver)
> >+ mDecoder = nsnull;
> >+ mContext = nsnull;
> >+ mChannel = nsnull;
>
> Those should all be null already. No need to null them again.
The old Init method may have been doing that too, I don't remember. Will change.
> >+ mRawData.SetCapacity(512);
> >+
> > return NS_OK;
>
> Here, on the other hand, you should check whether the capacity is actually
> 512. If it isn't, return NS_ERROR_OUT_OF_MEMORY so this object won't be
> used.
I thought string resizing was infallible these days? But ok.
> Nix dummy and just pass EmptyString() as the last argument.
I learned something today!
> And yes, I'd say pass rv here. And document this behavior in the idl. That
> would make this case consistent with the case when we end up with an error
> from DetermineCharset in OnDataAvailable.
Ok.
...
> and then your code as now, so that if aStatus is a failure we don't try to
> determine the charset for no reason.
Ok.
> >.
That was in the old version (as an ASSERTION rather than an ABORT_IF_FALSE); I saw it as enforcing a requirement for the OnDetermineCharset hook to sanitize its output. I don't mind removing it tho.
> >+++ b/netwerk/base/src/nsUnicharStreamLoader.h
> >+ nsCString mRawData;
> >+ nsString mBuffer;
>
> Document what those members are for, please.
Ok.
>!
More handy things I didn't know about! Ok, provided it turns out that I can include the necessary header from layout/style/.
I will try to produce revisions by Sunday.
> I thought string resizing was infallible these days?
Not yet (and possibly not ever).
> That was in the old version (as an ASSERTION rather than an ABORT_IF_FALSE)
I was young and foolish. ;)
> Ok, provided it turns out that I can include the necessary header from
> layout/style/.
You definitely can. Worst case, add an entry to LOCAL_INCLUDEs in layout/style/Makefile.in.
I've made all the requested revisions and pushed the result to try. I have to run now - will upload revised patches later.
Created attachment 532784 [details] [diff] [review]
v5 part 1
The templatized ParseSheet() worked except for a C++ wart. You can't have a template function whose callers pass the argument-with-template-type as a pointer in some cases and a reference in others; if you try, by using bare 'T' as the argument type, C++ will try to pass T by *value* when it should've passed by reference. So I had to change the nsIUnicharInputStream overload to take a reference too. This is a little weird, but it's temporary, so I think we can live with it. I also renamed Parse() to ParseSheet(), even though that overload goes away in part 6, because otherwise templatizing Loader::ParseSheet in part 3 wouldn't work.
Created attachment 532786 [details] [diff] [review]
v5 part 2
No substantive changes in this piece, carrying r=bz forward.
Created attachment 532787 [details] [diff] [review]
v5 part 3
Only substantive change is switching to templatized Loader::ParseSheet.
Created attachment 532791 [details] [diff] [review]
v5 part 4
Changes as requested in comment 78.
Created attachment 532794 [details] [diff] [review]
v5 part 5
Uses nsSyncLoadService::PushSyncStreamToListener as suggested in comment 79. I think I've "fixed [PushSyncStreamToListener] to correctly handle errors from OnStartRequest and OnDataAvailable", too, but I don't know how one would test that.
Created attachment 532795 [details] [diff] [review]
v5 part 6
No substantive changes, carrying r=bz forward (this is indeed a lot smaller, as predicted).
bz: I'd appreciate it if you could take this from here. I'm probably not going to have any hacking time this week (and if I do, I want to spend it on bug 543151) and I definitely won't have time to watch the tree.
Comment on attachment 532784 [details] [diff] [review]
v5 part 1
r=me
Comment on attachment 532787 [details] [diff] [review]
v5 part 3
r=me
Comment on attachment 532791 [details] [diff] [review]
v5 part 4
r=me
Comment on attachment 532794 [details] [diff] [review]
v5 part 5
r=me. Thanks for fixing the sync load service code!
Pushed to cedar:
Zack, are you planning to work on bug 543151, or do you want someone to steal it?
(In reply to comment #94)
>
> Zack, are you planning to work on bug 543151, or do you want someone to
> steal it?
There's a relatively up-to-date patch in there which might even be correct as is; I was going to try to find time tomorrow or Friday to verify that and maybe also break it up for ease of review, but if you'd like to take it over, please be my guest. dbaron hasn't commented on it at all :/
dbaron's on vacation and probably overloaded on reviews. Please toss that patch in my queue too (not instead of), and we'll see whether I can get to him before he does?
Done.
Pushed:
This bug changed the nsIUnicharStreamLoader interface, but the change does not
appear in the "Firefox 6 for developers" page nor the use of the interface is
detected in the add-ons compatibility checker. The effect is that I received a
severe bug report for an add-on I'm maintaining, the day after the release of
Firefox 6; probably, users testing on Aurora and Beta were not enough to detect
the issue earlier, even if the add-on has more than 50K users. Fortunately I was
available to address the issue promptly.
What is the process to track these kind of changes? Is it up to the patch author
to update the documentation? I'm asking firstly because I made an interface
change in another bug and don't want it to be lost, and secondly to understand
if, from now on, I should plan my vacations according to the release calendar :-).
(In reply to Zack Weinberg (:zwol) from comment #100)
>.
Thanks for the pointer, we discussed this on dev-platform and we now have a
procedure :-) It basically consists in adding a new "addon-compat" keyword.
Also, it's welcome to CC Jorge of the Add-ons Team on the bug as well. | https://bugzilla.mozilla.org/show_bug.cgi?id=541496 | CC-MAIN-2016-36 | refinedweb | 7,494 | 62.98 |
Structure that describes a pulse
#include <sys/neutrino.h> struct _pulse { uint16_t type; uint16_t subtype; int8_t code; uint8_t zero[3]; union sigval value; int32_t scoid; };
The _pulse structure describes a pulse, a fixed-size, nonblocking message that carries a small payload (four bytes of data plus a single byte code). The members include:
You can define your own pulses, with a code in the range from _PULSE_CODE_MINAVAIL through _PULSE_CODE_MAXAVAIL.
For more details, see ChannelCreate().
If you define your own pulses, you can decide what information you want to store in this field.
QNX Neutrino
ChannelCreate(), MsgReceive(), MsgReceivePulse(), MsgReceivePulsev(), MsgReceivev(), MsgSendPulse(), sigevent | http://www.qnx.com/developers/docs/6.3.0SP3/neutrino/lib_ref/p/_pulse.html | CC-MAIN-2019-47 | refinedweb | 101 | 55.03 |
Overriding Variables
AS3 makes some strange things possible. Even stranger, it seems to do this without any warning by its compiler: MXMLC. It seems as though one of these strange things is the ability to override the variables of your parent classes.
Normally, a class is considered to hold all the member variables it declares as well as all of those member variables declared by its parent classes. So, the following should result in a conflict:
However, the compiler is just fine with this: no warnings and no errors. This can cause headaches and confusion. Consider the following:
Here, we have assigned different values to name. Which takes precedence? The results of this initial test shed a little light:
But perhaps this is caused simply because Parent initializes first, prints “parent”, then Child initializes and prints “child”. Let’s write a little more code to examine the state of these objects after they’re fully instantiated:
The first two tests should be obvious from the first test. They print:
Then we call printName() on the Parent and Child instances and get:
This would seem to support the order-of-execution explanation of what’s going on. However, it’s not true. One final test blows this theory out of the water. We call childPrintName()
The truth is revealed! We see here that behind the scenes there are really two name fields of a Child object. The private scoping on the variable seems to go one step further than in other languages and actually scope the private variable to only the class declaring it, not simply disallowing access to children. While weird, this actually makes a lot of sense once you know it and explains some issues you may be seeing. The downside is the ease of inadvertently overriding a variable and all the confusion that ensues afterward, at least for those that haven’t read this article. You have, so please explain it to them for me.
#1 by Tim K on September 17th, 2009 · | Quote
private will be unavailabe to ALL other classes even children. If you want a variable to be private AND available to children, then you have to use protected instead of private.
Technically you are not overriding anything, because the name variable (in my mind) doesn’t exist in the child if it’s set to private in the parent. However if you use protected and do not specify that you’d like to override with the override keyword, then you’ll probably get an error.
#2 by jackson on September 17th, 2009 · | Quote
Yep, that was my conclusion too:
This is kind of cool in the sense that you don’t have to worry about your parent classes’ variable names but, as shown above, can also be quite confusing.
Thanks for commenting!
#3 by AlexG on January 28th, 2012 · | Quote
Yeah, private variables are not visible to any other classes, even child classes.
If you do
class Parent
{
protected var name:String; // or public
}
class Child extends Parent
{
protected var name:String;
}
It will give error nr.1152 – conflict in namespaces. | http://jacksondunstan.com/articles/251 | CC-MAIN-2017-39 | refinedweb | 517 | 70.23 |
Memory leak when pickling R rpy2 objects
[Cross posted from]
EDIT: Changed description and example after further digging
I have observed a memory leak when pickling R objects created in python through rpy2. Here is some code that will reproduce the leak (WARNING: Running this might eat up your RAM):
import pickle import tempfile import rpy2.robjects as R def test_R_object_dump(N=1000): """Test creating big R matrices in a loop and dumping them to a temp file""" for i in range(N): print(i, end=", ") with tempfile.TemporaryFile() as f: a = R.r.matrix(1., 5000, 5000) pickle.dump(a, f)
I've observed the leak in Linux (Ubuntu 16.04), Mac OSX seems to not have the issue.
Upon further digging, I believe this might be related to Issue
#321 but on the pickling (rather than unpickling) side of things.
Following a suggestion from lsteve in the joblib issue tracker, I can confirm the memory leak also happens when using python's standard
pickle.dumpinstead of the joblib one.
Rewrote the description and example upon further inspection on the issue.
By similarity with issue
#321I suspect it might be solved by upping the
UNPROTECTargument on
Sexp___getstate__in
sexp.c, but I am not familiar enough with the innards of
rpy2C code to know if this is a reasonable thing to do.
I don't think that this is will fix it in a way you like. The PROTECT / UNPROTECT calls appear balanced as they are; increasing the count in
UNPROTECT()will likely be followed by a segfault shortly after. I am happy to be proven wrong though.
The fact that you report that the problem is not present on OS X suggests that a possible cause would be: - conditional OS X / Linux specific code in rpy2
Thanks for your reply!
If I replace the constructor to create a numpy matrix rather than an R matrix there is no leak, so I don't think python or OS memory management are the issue here. Also, if I replace the python pickle call by an
R.r.saveRDS(with the appropriate changes regarding the file) there is no leak, which makes me believe the pickling mechanism from
rpy2would be the cause.
As I mentioned, I am not very familiar with
rpy2source, any suggestions on what else I can do to help get to the bottom of the issue?
numpyand
rpy2are likely using different strategies to protect their objects from garbage collection (rpy2 is using both Python and R own mechanisms, themselves relying on OS-level primitive. There is a fair chance that rpy2's pickling is partly, or fully, the cause of the problem but the fact that you do not observe the problem on OS X with the exact same code made me consider this an option.
Unfortunately memory management issues in ryp2 are not the funniest problems to tackle (because jumping between Python and R's memory management systems, and because some of the code in rpy2 would likely need a refresh). Try running it using
valgrindand to see if you can find clues. You can also try building/installing rpy2 with debug flags on (they are mentioned in comments in
setup.py).
An other suggestion: did you try calling the garbage collectors at each iteration ?
I did try using the garbage collectors (both of them) to no avail (see the linked original report in the joblib repo when I thought it was a joblib issue). Will try running under
valgrindand see what comes out.
Ran under valgrind, this is what comes out:
I have also checked the ref counting of the object before and after the pickle, but it seems to stay at 1, so I have no idea on what is protecting the stuff from garbage collection.
Incidentally, while diggin' in the source I noticed the
PROTECT-
UNPROTECTcalls in
EmbeddedR_unserializeseem unbalanced (there are two
PROTECTand a call to
UNPROTECT(3)). At the same time, the
rpy2_unserializemethod in
r_utils.chas the opposite problem:
So I am wondering perhaps the fix to issue
#321was applied in the wrong file?
Yes, it looks like there was a mix-up in the fix. Thanks, I'll fix it.
It has no consequence though (the imbalance of one it corrected by the imbalance of the other).
I have reproduced the memory leak in the official
rpy2/rpy2docker container, process just crashes when it exceeds the set memory limit.
I have been browsing through the source trying to find operating system dependant bits, without any success so far. Any pointers on where to look or how to proceed would be appreciated.
Thanks. I have also reproduced it and started investigating. Unfortunately, I have looked where I thought it could happen and did not see anything.
At first sight the leak is not with R objects protected from collection.
The leak seems to disappear if
Sexp___getstate__()not longer returns the Python bytes object
res_stringthat contains the R object serialized. Obviously not suggesting this as fix, as this would make pickling no longer work properly, but this is pointing out where to look. I have to figure out how to proceed.
I think that I got it: this is caused by a combination of rpy2 using Python's pickling protocol slightly incorrectly and the Python C-API being relatively brittle (to Python's credit there is a line of warning in the doc that it is really easy to get things wrong, and surely enough so I did).
If I am correct about the above, a fix should appear any time now.
The bug was definitely non-trivial to fix.
The full fix in present from revision 1561ec889508 in the branch "default", and from revision 41a1821d992b in the branch "version_2.9.x" where it was backported. The next release to have the fix will be rpy2-2.9.1.
I am not planning to backport to rpy2-2.8.x, but anyone wants to submit a pull request I'd review it.
Awesome, thanks a lot for taking care of this! Since this introduces some API change I think it is safer to not backport it to the 2.8 branch.
I'll pull the 2.9.x version and check that our original code which triggered the leak is behaving appropriately.
Thanks again for all your hard work on
rpy2! | https://bitbucket.org/rpy2/rpy2/issues/432/memory-leak-when-pickling-r-rpy2-objects | CC-MAIN-2018-47 | refinedweb | 1,056 | 70.84 |
I'm having some trouble with a program I've tried to make, and was wondering if I could get some help!
So my program is supposed to ask the user how many integers they're entering, allow them to enter the integers, then display the average, max and min values.
Trouble is, the way my code is now, for the average computation, the program is adding up all the entries but the first one. I've tried tweaking in every way I know how, but nothing's working for me.
Here's my code:
import java.util.Scanner; public class integerEntry { public static void main (String [] args) { Scanner keyboard = new Scanner (System.in); { System.out.println ("Please input the number of integers being entered: "); int numberOfEntries = keyboard.nextInt(); System.out.println ("Enter your integers one at at time, followed by the enter key."); double next= keyboard.nextDouble(); double max = 0.0; double min = next; double average = 0.0; double sum = 0.0; for (int Count = 2; Count <= numberOfEntries; Count++) { next= keyboard.nextDouble(); { if (next > max) max = next; else if (next < min) min = next; } sum = sum + next; average = sum / Count; } System.out.println ("The average score is "+average); System.out.println ("The highest score is " +max); System.out.println ("The lowest score is " +min); }}} | http://www.dreamincode.net/forums/topic/156327-using-for-loop-to-compute-maxmin-and-average-problem/ | CC-MAIN-2016-30 | refinedweb | 214 | 60.21 |
Using paintInterface to display applets is powerful, and sometimes even necessary (when you want to display SVG graphics, for example). It is not the only method available to create a Plasmoid, however. Plasma comes with a number of widgets "tailored" for using in Plasmoids. This tutorial will create a very simple "Hello, world!" Plasmoid using this approach.
Set up your applet directory and create a metadata.desktop file as described in the main tutorial.
Here's how our main.py file will look like:
from PyQt4.QtCore import * from PyQt4.QtGui import *.resize(125,125)
def CreateApplet(parent):
return HelloWorldApplet(parent)
Let's take a deeper look at it. As in the main tutorial, we create our class by deriving from plasmascript.Applet. In __init__, we initialize the class. In init() instead, we do all the dirty work of creating the applet and adding the text to it.
First of all, we tell Plasma that this applet has not a way to be configured (self.setHasConfigurationInterface(False)). We then set its aspect ratio mode, which is used with regards of resizing, and we set it to square (Plasma.Square). Then, we start adding a background to the applet, using the SVGs provided normally by the Plasma theme. We do so by creating an instance of Plasma.Svg, which we assign to self.theme, and then we set the SVGs that we will use via self.setImagePath. Written like that, it means that the applet will use the standard "background" SVG provided inside the "widgets" directory of our current Plasma theme. We can also use relative paths or absolute paths to SVGs of our choice, should we need them. The setBackgroundHints sets the Plasmoid's background using the default Plasma background (Plasma.Applet.DefaultBackground), saving us the time and the effort to do it ourselves.
The third and most important step deals with creating a layout. It is a bit special, as compared to the standard QLinearLayout seen in Qt (and PyQt), because it is done inside a QGraphicsView, used by Plasma. We want a simple, linear layout, and so we use a QGraphicsLinearLayout, setting it to be horizontal (Qt.Horizontal).
Then, we create a label, a Plasma.Label to be precise. This is a widget that is Plasma-aware, as we have said, and so makes use of all the goodies provided by Plasma (for example, changing text color if we change Plasma theme). We use then the setText method (analogous to the setText method of a normal QLabel) to set our text ("Hello, world!") to the label, and we add it to the layout. Finally, we resize the applet to 125 x 125 pixels.
Once packaged and installed (see the main tutorial), the Plasmoid will look like this:
This brief tutorial shows how to use Plasma widgets with your applet. Aside Plasma.Label, there are many more widgets you can use.
Notice that at the moment you can exclusively add widgets and create layouts "in the code": this means you can't use an application like Qt Designer to create your applet. | https://techbase.kde.org/index.php?title=Development/Tutorials/Plasma/Python/Using_widgets&oldid=37503 | CC-MAIN-2015-32 | refinedweb | 513 | 66.13 |
Jim Jagielski <jim@jaguNET.com> writes:
> Anyone get a chance to look over and try out the latest patch?
> will lose both and deserve neither"
I still have unanswered questions from the post of the first patch.
Here they are again, hopefully with the now-resolved issues trimmed
out.
Thanks,
Jeff
-----------/-----------
Jim Jagielski <jim@jaguNET.com> writes:
> Comments are welcome... I'd like to commit the patch this week. At
> that point, we port to 2.0, which already has a lot of the
> work done (just need to do the default stuff and handle SingleListen)
which "default stuff" is needed in 2.0?
why is SingleListen needed?
> @@ -433,6 +433,9 @@
> #define JMP_BUF jmp_buf
> #define USE_LONGJMP
> #define USE_FLOCK_SERIALIZED_ACCEPT
> +#define USE_FCNTL_SERIALIZED_ACCEPT
> +#define USE_NONE_SERIALIZED_ACCEPT
> +#define DEFAULT_SERIALIZED_ACCEPT_METHOD flock
> #define SINGLE_LISTEN_UNSERIALIZED_ACCEPT
So what decides when "USE_NONE_SERIALIZED_ACCEPT" is a choice? I'd
think that if you allow it anywhere you'd allow it everywhere, and
that there'd be no need to define anything in ap_config.h.
> ===================================================================
> RCS file: /home/cvs/apache-1.3/src/include/http_main.h,v
> retrieving revision 1.36
> diff -u -r1.36 http_main.h
> --- src/include/http_main.h 2001/01/15 17:04:34 1.36
> +++ src/include/http_main.h 2001/08/20 18:19:42
> @@ -130,6 +130,11 @@
>
> void setup_signal_names(char *prefix);
>
> +/* functions for determination and setting of accept() mutexing */
> +char *default_mutex_method(void);
> +char *init_mutex_method(char *t);
> +char *init_single_listen(int flag);
prefix with "ap_"... yeah, not everything in 1.3 is
namespace-protected, but it is trivial for new functions.
> + return "Request serialized accept method not available";
"Requested", not "Request"
> + return "Request serialized accept method not available";
same as previous comment, but I'd think one of these should never
fail... how about ap_assert() in one of them instead of returning an
error that we shouldn't have logic to check for?
-----------------/--------------
--
Jeff Trawick | trawick@attglobal.net | PGP public key at web site:
Born in Roswell... married an alien... | http://mail-archives.apache.org/mod_mbox/httpd-dev/200108.mbox/%3Cm33d6cl147.fsf@rdu88-250-106.nc.rr.com%3E | CC-MAIN-2014-52 | refinedweb | 322 | 60.11 |
Simple simple `Hello world' java program that prints HelloWorld
Hello World Java
Simple Java Program for beginners... to develop robust applications. Writing a simple Hello World program is stepwise step. This short
example shows how to write first java application and compile
Struts 2 datetimepicker Example
uses the dojo toolkit for creating date
picker. In Struts 2 its very easy...
Struts 2 datetimepicker Example
...;Struts 2 Format Date Example!</title>
<link href="<s
DynaActionform in JAVA - Struts
DynaActionform in JAVA how to use dynaActionFrom?why we use it?give me a demo if possible? Hi Friend,
Please visit the following link:
Hope
very urgent
very urgent **
how to integrate struts1.3
,ejb3,mysql5.0 in jboss server with
myeclipse IDE
Developing Simple Struts Tiles Application
Developing Simple Struts Tiles Application
... will show you how to develop simple Struts Tiles
Application. You will learn how to setup the Struts Tiles and create example
page with it.
What
DynaActionForm
DynaActionForm Q. What is DynaActionForm ? and How you can retrive the value which is set in the JSP Page in case of DynaActionForm
Struts DynaActionForm
Which is the good website for struts 2 tutorials?
Which is the good website for struts 2 tutorials? Hi,
After... for learning Struts 2.
Suggest met the struts 2 tutorials good websites.
Thanks
Hi,
Rose India website is the good
How to design a simple note book
How to design a simple note book
In this example you will learn to make simple note book,
It is a very simple so follow this tutorial.
New File: Create a new file with
appropriate size.
Rectangle Shape
Integrate Struts, Hibernate and Spring
is very good if
you want to learn the process of integrating these technologies... of your changes. This is repetitive
task in the programming, so its is very...
Integrate Struts, Hibernate and Spring
Struts Books
covers everything you need to know about Struts and its supporting technologies...:
The Jakarta Struts Model 2 architecture and its supporting...: you will learn to use Struts very
effectively.John Carnell
Beginners Stuts tutorial.
its essential
features , with a simple lab-oriented practical example... , is a skill that is very much in
demand now. Struts Framework was developed by Craig... that the Struts naming of its classes leaves much to be desired.
(for instance
Simple HTML example
Simple HTML example
In this section we will give you very simple example of a HTML page. After
reading this page you should be able to create simple HTML... pages.
Creating Simple HTML page
Here is simple example of HTML page that displays
Struts 2 Tutorial
2.x is very simple in comparison to
the struts 1.x, few of its... Struts 2 Framework with examples. Struts 2 is very
elegant and flexible front...!!!
Struts 2 Features
It is very extensible as each class of the framework
Simple Editor
Java: Example - Simple Editor
This simple text editor uses a JTextArea with Actions to
implement the menu items. Actions are a good way...
// editor/NutPad.java -- A very simple text editor -- Fred Swartz - 2004-08
Switch Statement example in Java
Switch Statement example in Java
This is very simple Java program for implementing... you an example with complete
java source code for understanding more about
Struts in AJAX - Framework
Framework,if it is possible plz give me one simple example.
Thanks & Regards,
VijayaBabu.M Hi,
Struts 2 provides inbuilt support for Ajax and Dojo. Its very easy to use Ajax in Struts 2 applications.
Please check at http
Struts - Framework
/struts/". Its a very good site to learn struts.
You dont need to be expert... to learn
and can u tell me clearly sir/madam? Hi
Its good...Struts Good day to you Sir/madam,
How can i
Simple FTP upload in Java
Simple FTP upload in Java How to write a program for Simple FTP upload in Java? Any code example of Simple FTP upload in Java will be very helpful for me.
Thanks
Developing Struts Application
time' at that!)to take up a simple and
practical example. Our focus.... This is not JSTL
but Struts Tag Library. We should note the following very carefully...Developing Struts Application
Struts Articles
it.
Struts is a very popular framework for Java Web applications... application. The example also uses Struts Action framework plugins in order... Struts in the WebSphere Portal environment. We created a simple portlet application
Simple Linked Lists
"
The following program is an example of a very simple implementation of
a singly-linked...
52
53
54
55
56
// Purpose: Shows a simple doubly-linked list. Very...
Java Notes: Simple Linked Lists
This shows three programs.
A simple
Spring Bean Example, Spring Bean Creation
:
Spring is simple
Download this example code... Object) in the IoC
container. Here in this tutorial you will see at first a simple...;String mesg = "Spring is simple";
struts - Struts
, please reply my posted question its very urgent
Thanks...struts we are using Struts framework for mobile applications,but we are not using jsps for views instead of jsps we planning to use xhtmls.In str 1 Tutorial and example programs
Struts 1 Tutorials and many example code to learn Struts 1 in detail.
Struts 1...
This lesson is an introduction to the Struts and its architecture...;
- Struts DynaActionForm
In this lesson we will create Struts
JDBC Driver and Its Types
. It is quite small and simple.
This is a very important class. Its...
JDBC Driver and Its Types
.... For example, this is where the driver for the Oracle database may be defined
Struts - Struts
in struts?
please it,s urgent........... session tracking? you mean... that session and delete its value like this...
session.removeAttribute("");
session.invalidate();
Thank you very much for answer Struts is useful in application development? Where to learn Struts?
Thanks
Hi,
Struts is very useful in writing web applications easily and quickly.
Developer can write very extensible and high
XML Syntax Rules
is quite
self-descriptive?
Now let's discuss its syntax-rules which are very
simple...;
The syntax rules for
XML are very simple and strict... that can read and manipulate XML is very
easy. Xml enables an user
Array Relocation Example
Description:
This example demonstrate the Array Relocation where value of any index
can be change.
Code:
import java.util.Arrays;
public class ArrayReallocation {
2 Format Examples
Struts 2 Format Examples are very easy to grasp and you will
learn these concepts...;Struts 2 Format Example!</title>
<link href="<s:url value...
Struts 2 Format Examples
(very urgent) - Design concepts & design patterns
(very urgent) hi friends,
This is my code in html
Linux in Internet
;
Linux is very useful for running Internet. It is now
being very popular due to its specific properties... of Linux have a very
good speed and efficiency.
Generally problem to solve - JSP-Servlet
Simple problem to solve Respected Sir/Madam,
I am... earlier. Its working in a fantastic way. My heartiest solute to Roseindia team. But in that I am facing a very very minute problem. The alert boxes are displayed
Two Element Dividing Number
;
This is very simple java program. In this section we.... If
you are newbie in java programming then you can understand very easy way from this
example.
Description this program
In this program we.2.1 - Struts 2.2.1 Tutorial
support in Struts 2.2.1
Developing Simple Example
Interceptors... and testing the example
Advance Struts Action
Struts Action... Example
Stream Result example
Introduction to XSL Result and its
JSP Simple Examples
:
out> For Simple Calculation and Output
In this example we have used... to access properties
of bean and map values. For example in the EL.... As the elements are increased in an ArrayList, its capacity
also
Drill down in Struts 2.0.14
. For Example, I have many countries list in which drilling down by country gives my its... 2.0.14)I am very new to Struts and your help is much appreciated.
Thanks...Drill down in Struts 2.0.14 Hello Tutor,
I am developing my project Framework
An introduction to the Struts Framework
This article is discussing about the high-class web application development
framework, which is Struts. This article will give you detailed introduction to
the Struts Framework.
Struts
Struts 2 Hello World Example
Struts 2 Hello World Example - Video Tutorial that shows how to create Hello
World example program in Eclipse IDE.
In this video tutorial I will teach you how to develop 'Hello World'
application in Struts 2 framework. We
Web Design books-Page1
;
The web design guide
This site explains in very simple terms how....
There is very little you require to build a website and everything you need.... In historical terms, however, the Internet is still in its infancy and its
Find Your Host Name
the
host name of the local system in a very simple example. Here we are just call... of the local
system in a very simple manner. the complete code of the example is as under.
Here is the Code of the Example :
Hostname.java
Struts 2 zero configuration,Struts 2 zero configuration Example
Struts 2 Zero Configuration
This section discusses Struts 2 zero configuration feature with example. The Struts 2 zero configuration
is another very... Configuration" Struts 2 application uses annotations to
register the actions
Hello - Struts
to going with connect database using oracle10g in struts please write the code and send me its very urgent
only connect to the database code
Hi...://
Thanks
Amardeep
EJB Hello world example
EJB Hello world example
Creating and testing the "Hello World"
Example is the very first... example we are going to show you, how to
create your first hello world example
Struts - Struts
Java Bean tags in struts 2 i need the reference of bean tags in struts 2. Thanks! Hello,Here is example of bean tags in struts 2:http... Tags are used to create forms and its elements. Example can be viewed at http
PHP Getting Started With PHP Tutorial
;
Learn the basics of PHP with this quick and
simple tutorial. Designed for the very beginners.
What is PHP?
It is an open source scripting language which can... to print anything on the screen, so type
either :
Example 1:
<?php
Reply - Struts
Reply Hello Friends,
please write the code in struts and send me I want to display "Welcome to Struts" please send me code its very urgent...
and which file need to be run and compile struts without using database | http://www.roseindia.net/tutorialhelp/comment/2027 | CC-MAIN-2013-48 | refinedweb | 1,739 | 67.55 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.