
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91
values | source stringclasses 1
value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
score:2
In my case this is occur bcoz of i declared
<form> inside another
<form/> tag.
score:5
You can portal a form like this:
import Portal from '@material-ui/core/Portal'; const FooComponent = (props) => { const portalRef = useRef(null); return <> <form> First form <div ref={portalRef} /> </form> <Portal container={portalRef.current}> <form>Another form here</form> </Portal> </>; }
In the example above I use the react material-ui Portal component. But you can try to implement it with React Portals as well
score:24
I faced this issue when using
ant design table and turns out its not ant design which throws the warning. It's the web standards description
"Every form must be enclosed within a FORM element. There can be several forms in a single document, but the FORM element can't be nested."
So, there should not be a form tag inside a form tag.
To solve the issue (in our case), remove the
Form tag inside the DynamicFieldSet "return" and replace with a
div tag
Hope it helps :)
Source: stackoverflow.com
Related Query
- React: how to use child FormItem components without getting Warning: validateDOMNesting: <form> cannot appear as a descendant of <form>
- How to use async await in React components without useEffect
- How does react components use data without passing as props
- How to use React without unsafe inline JavaScript/CSS code?
- How to get values from child components in React
- How do I make components in React Native without using JSX?
- How to use SCSS variables into my React components
- How to style child components in React with CSS Modules
- How to use react j s components in react native app?
- How will React 0.14's Stateless Components offer performance improvements without shouldComponentUpdate?
- How can I dispatch from child components in React Redux?
- How to handle click events on child components in React.js, is there a React "way"?
- How to create custom React Native components with child nodes
- How to use redux-toolkit createSlice with React class components
- How to use jinja2 server side rendering alongside react without violating inline-script CSP
- How to use Media Queries inside a React Styled Components Keyframe?
- How to deal with React Native animated.timing in same child components
- How to use react components from other files
- how to import data in react from a js file to use in components
- React Typescript how send props and use it in child component
- How can I use React Material UI's transition components to animate adding an item to a list?
- How I can render react components without jsx format?
- How to update (re-render) the child components in React when the parent's state change?
- How to style child components in react styled-components
- How to use this.refs for a list of child components
- How does React re-use child components / keep the state of child components when re-rendering the parent component?
- How to traverse all React components including DOM components without TestUtils.findAllInRenderedTree?
- how to use curly brackets without it being an expression in react
- How to use this.props in React Styled Components
- How to use client.query without JSX components in Apollo Client?
More Query from same tag
- Enforce prop should be either of two functional components
- add a plugin from a library in tailwind
- Delete from array React
- passing function between a parent component and child component problem
- Why componentWillMount should not be used?
- Redux mapDispatch ToProps. What data should i pass as an argument?
- How to use Media Queries inside a React Styled Components Keyframe?
- how can I pass a useState props using TypeScript to a child component
- State is not upating in renderer() component
- useState with an argument in it's array is breaking a setInterval and makes it glitchy and erratic
- Updating Multiple Documents In Mongoose With Different Values Each -- Express Js
- Working with the same ReactJS form component on the same page
- next.js swr I do not want to execute it only at the time of initial drawing
- How to add header to axios.create in react/redux app
- How to show a message after Redux dispatch
- How to communicate between React components which do not share a parent?
- React Antd table rendering before data is populated
- React-UseState hook-> state update does not re-render the page immediately
- How can I use create-react-app with Spring Boot?
- I have an object. I need to print its name as <option> on an <selector> but return another variable
- Server side rendering with loadable components not working
- Trying to return a promise from an action creator dispatched from mapDispatchToProps
- Legend not displaying on Line or Bar chart - React-Chartjs-2
- TypeScript is not recognizing reducer, shows type as any on hover
- module import work with react in dev but not in build
- Can't get the cookies from golang server inside the react js project
- the props change when the state change
- React semantic ui table.row set row active onclick
- React and express
- React.js, Displaying Two Svg Images Next To Each Other With Space In Between | https://www.appsloveworld.com/reactjs/100/12/react-how-to-use-child-formitem-components-without-getting-warning-validatedomn | CC-MAIN-2022-40 | refinedweb | 851 | 50.57 |
Rails 5.1 loves Javascript
Ruby/Rails developers have had a controversial relationship with Javascript for the past years. True or false, Javascript was accused of being the holdback for web; we all know that this is not true anymore. The language has improved significantly over the past few years; partly due to advent of ES6.
Furthermore, the rivalry between Rails and Javascript doesn’t exist anymore. If you want to create ambitious web applications the only option is Javascript! Basically, there is no other choice.
This makes it possible for the two ecosystems to thrive next to each other. Javascript is great for frontend work; also it could be an option for backend implementation; however some people prefer to write their backend in other languages. For that, Ruby/Rails could be a great choice.
Apparently that hate relationship is improving now with onset of Rails 5.1. The first beta version of 5.1 is out and it comes with out of the box support for Webpack/React/Angular/Vue.js. Surprise!
Rails 5.1 is a huge step in the right direction. It includes
webpacker gem which lets us to use Webpack to manage app-like JavaScript modules in Rails.
Webpacker makes it easy to use the JavaScript preprocessor and bundler Webpack to manage application-like JavaScript in Rails.
The nice thing about webpacker is that it coexists with asset pipeline, as the purpose is to use it for app-like Javascript (served from
app/javascript/packs directory), not images, css or even Javascript snippets. These will continue to be served from
app/assets directory. More details on this later.
Let’s see how we can harness the power of Rails 5.1 to create a Rails/React app. Note that Rails 5.1 is a beta version; so let’s not rely on it for production.
First thing to do is to install Rails 5.1. Let’s create a
Gemfile with the following content:
source ''
ruby '2.2.5'
gem 'rails', github: 'rails/rails'
This makes sure that we are pulling the most recent version of rails from master branch on github (at this moment it’s Rails 5.1.0beta1).
Then we just need to run
bundle install to install Rails.
Voila!
Now that we have Rails 5.1 installed, we can run the following to create a React friendly Rails app:
rails new myapp --webpack=react
When this command succeeds we have a new folder named myapp in the current directory. We need to
cd into it and run
bundle install to install all dependencies. The next necessary step is to install javascript dependencies via yarn or npm. If we settle on yarn for this, we just need to run
yarn, this will install our Javascript dependencies.
Note: to use webpacker with angular and Vue create your new app as following:
rails new myapp --webpack=angular #webpacker with angular
rails new myapp --webpack=vue #webpacker with Vue.js
At this point, Rails has created a javascript friendly app for us. If you look under
app/javascript you see a new folder named
packs with two files in it (application.js and hello_react.js). This packs folder is a new thing added in Rails 5.1.
app/javascript
└── packs
├── application.js
└── hello_react.js1 directory, 2 files
Everything under
packs directory is automatically compiled by Webpack. The best practice is to place actual application logic in a relevant structure within
app/javascript and only use these pack files to reference that code so it’ll be compiled. Let’s have a look at
hello_react.js:
import React from 'react'
import ReactDOM from 'react-dom'class Hello extends React.Component {
render() {
return <div>Hello {this.props.name}!</div>
}
}document.addEventListener("DOMContentLoaded", e => {
ReactDOM.render(<Hello name="React" />, document.body.appendChild(document.createElement('div')))
})
It’s a react component! Rails has generated us a sample react component that we can render in a view whenever we want. We can even write
jsx in it. What could be better!?
This react component only renders
Hello React but we can make complex components if we need to.
The next step is to render our component using Rails. Let’s create a Rails controller:
bundle exec rails g controller Pages index
This command created a
PagesController with an index method in it. It also creates us a view template at
app/views/pages/index.html.erb. To render our React component, we just need to replace the content of the file with:
<%= javascript_pack_tag 'hello_react' %>
This tells Rails to embed our React component in this view.
We have everything ready now. We just need to run our rails server in one terminal and run our webpack-dev-server in another one; but before that let’s add a small tweak to our
config/environments/development.rb to enable javascript_pack_tag to load assets from webpack-dev-server:
config.x.webpacker[:dev_server_host] = ""
We are ready to run our servers now. In one terminal, run
bundle exec rails server to start Rails server and in the other one run:
./bin/webpack-dev-server --host 127.0.0.1
If you open your browser and navigate to you should see
Hello React on your screen.
Note: you may face
No data received ERR_EMPTY_RESPONSE error when running your server. Have a look at this issue for solutions.
Dissecting Webpacker
According to the docs:
Webpacker ships with three binstubs:
./bin/webpack,
./bin/webpack-watcherand
./bin/webpack-dev-server. They're thin wrappers around the standard webpack.js executable, just to ensure that the right configuration file is loaded.
./bin/webpack-dev-server will launch a Webpack Dev Server listening on serving our pack files. It will recompile the files as we make changes. We set
config.x.webpacker[:dev_server_host] in our
development.rb to tell Webpacker to load our packs from the Webpack Dev Server. This setup allows us to leverage advanced Webpack features, such as Hot Module Replacement. If we want to enable Hot Module Loading we just need to send a
--hot option to webpack-dev-server binstub when running it:
./bin/webpack-dev-server --hot --host 127.0.0.1
Webpacker provides us with a default set of configuration for development and production environments. If you look under
config/webpack you see:
config/webpack
├── development.js
├── production.js
└── shared.js0 directories, 3 files
Feel free to change them according to your needs but in most basic cases the default configs are good enough.
Linking to Sprockets’ assets
Lots of times we need to load normal assets that are served using asset pipeline. To do so, we just need to add
.erb extension to our javascript file, then we can use Sprockets’ asset helpers to load the asset:
// app/javascript/my_pack/example.js.erb
<% helpers = ActionController::Base.helpers %>
var catImagePath = "<%= helpers.image_path('kitten.png') %>";
According to the docs, this has been enabled by the
rails-erb-loader loader rule in
config/webpack/shared.js.
Deploying to Heroku
The first step to deploy our app on Heroku is to add a
Procfile with following content:
web: bundle exec puma -p $PORT
After that we just need to create a new heroku app and add respective buildpacks for node and ruby:
heroku create
heroku buildpacks:add --index 1 heroku/nodejs
heroku buildpacks:add --index 2 heroku/ruby
After that we can push our app to heroku with:
git push heroku master
Done!
You can find the full source code for this example here.
Resources: | https://daqo.medium.com/rails-5-1-loves-javascript-a1d84d5318b?readmore=1&source=user_profile---------6---------------------------- | CC-MAIN-2021-39 | refinedweb | 1,246 | 58.08 |
Jaime Rodriguez On Windows Store apps, Windows Phone, HTML and XAML.
As usual, raw, unedited, useful info from the Microsoft’s internal WPF discussions lists.
Answer: You must use call the EnableModelessKeyboardInterop method for keyboard to work.
Answer: That's right - we do a number of things to sync with rendering. Time only "changes" at the start of a render pass, which is scheduled differently based on a number of factors (Desktop Window Manager present and enabled? Monitor refresh rate, desired framerate for animations, etc), and then too the time chosen is actually "in the future" a bit because we're trying to produce a set of changes that will be correct when they hit the screen. To do this, we estimate the future presentation time for a given UI thread's render pass. My guess is that this is what they're seeing in this case
Answer:Blend’s behaviors are an attached property, but publicly they are not exposed as a DP- you can do attached properties that are not DP’s by having just the static GetProperty/SetProperty.We use this syntax to keep the behavior syntax smaller- by not using a real DP here we were able to default the collection to having a value and remove 2 lines of XAML. If this were a real DP then you’d have to add the collection to the XAML as well:
<Button>
<i:Interaction.Behaviors>
<i:BehaviorCollection>
<s:SimpleBehavior/>
</i:BehaviorCollection>
</i:Interaction.Behaviors>
</Button>
In addition behaviors cannot be used inside of styles; the core issue is that we intentionally made behaviors not sharable- you can’t apply the same behavior to multiple elements. The reason is that if you use the WPF animation API as an example that it adds a ton of complexity to make the types sharable and it really detracts from the level of simplicity that we were looking for in Behaviors.
In WPF, everything applied through a style is shared across each element that it’s applied to. To get around this in early prototypes I used a trick with Freezables and the CoerceValueCallback to clone the behaviors every time they’re applied to an element and are already applied to something else, but none of this is present in SL and it can lead to some unexpected runtime behavior.
Answer:We don’t have any automatic selection logic. You can iterate over all of the frames and find the one you want based upon each frame’s properties. You should be able to get them all from a frame by doing frame.Decoder.Frames. Alternatively, you can just do BitmapDecoder.Create and read the frames that way rather than indirectly through BitmapFrame.Create.Note: pre-Win7 WIC does not support Vista’s PNG icon frames. If you hit a PNG frame you will get an exception on Vista and XP.
1. Is there a way to get WPF to listen to these changes given that WPF does not appear to subscribe to change events via PropertyDescriptor.AddValueChanged? It appears that WPF will bind to the properties offered through the type descriptor, but WPF does not monitor that type descriptor for value changes. It does appear to listen to INotifyPropertyChanged events, but this is not that useful if we are extending and object with custom properties.
2. Is there a way to have WPF bypass ICustomTypeDescriptor.GetProperties() when setting up a binding? In this case, custom types may hide the thing we actually want to bind to, so it would be useful to force WPF not to use the custom descriptor during binding.
Answer:1. WPF will listen to ValueChanged if the object doesn’t implement INotifyPropertyChanged. If both are available we only listen to INPC, to avoid duplicate notifications. There are objects that expose both – chiefly ADO.Net’s DataRowView – so it’s a real issue. If you have appropriate access, you can get the object to raise the PropertyChanged event with a property name for your custom property. But if it’s not your object (and its OnPropertyChanged method is private), you’re out of luck.
2. No. We actually call TypeDescriptor.GetProperties(item), which in turn calls ICTD.GetProperties, so it’s out of our hands. Usually people want the custom descriptor to override the native one; we don’t have any way to ask for the other way around. (I’m curious what your scenario is, though. This is the first time someone’s asked for this.)
Subject: Binding to dictionary with multiple indexers If I add a second indexer to a collection class, it will no longer bind to WPF FrameworkElement such that its index path can be referenced. The following works fine on regular collection, But I add a second indexer, or if the collection is keyed, the binding no longer works:
Path=[0].
Answer: Your two indexers have different signatures, probably something like
public object this[int index] { …}
public object this[string s] {…}
The property path is declared in XAML, where everything is a string. So when you say “Path=[0]”, WPF has to decide whether you mean the first indexer with argument (int)0, or the second indexer with argument (string)”0”. There’s nothing in the XAML to indicate which one you mean, so I think we choose the line of least resistance and pick the second indexer – it requires no type conversion.
At any rate, you can provide the missing guidance by saying
Path=[(sys:Int32)0]
assuming you’ve previously declared
xmlns:sys=”clr-namespace:System;assembly=mscorlib”
This says what you think it does: “use the indexer that takes an int argument”.
Subject: SketchFlow transitions between screens? Is it possible to create transitions between screens in SketchFlow?
Answer: It should be doing this by default. The default transition is a fade, if you right-click a navigation connection in the map, there are a few more to choose from “Transition Styles”.
Subject: RE: How to improve the text rendering of your .NET 4.0 WPF Applications
Answer: Important caveat: Do not use TextFormattingMode=”Display” on text that is going to be scaled by a RenderTransform (or scaled in any way other than by changing the font size). It will end up blurry.
Some more recommendations:
Subject: RE: Partner's question about WPF-Image convert & Flash support
Answer:
There are external EMF->XAML converters:
Indeed, WPF does not provide any native flash rendering. I doubt we ever will. Some options: 1) Host a web browser. Yes this is HWND interop code, so there are some compromises: the infamous airspace issues being the most prominent.
2) For display only, you might look at a DirectShow filter, like:
Subject: Property increment value i nBlend If you expose a numeric property on a type and it is available in the property window you can change the value by dragging the cursor up, down, left and right. Is there a way to tell Blend what the incremental value should be?
Yes, you need to supply a design-time assembly that uses the NumberIncrementsAttribute.
public sealed class NumberIncrementsAttribute : Attribute, IIndexableAttribute
Name:
Microsoft.Windows.Design.PropertyEditing.NumberIncrementsAttribute
Assembly:
Microsoft.Windows.Design.Interaction, Version=4.0.0.0
Subject: pack: registration?
I forget, how do you open a pack: URI? I tried using WebRequest.Create, but that gave me an error saying that pack: wasn’t registered… Then I tried using PackUriHelper to cause it’s static cctor to run, to try and get the prefix registered… PackWebRequest isn’t constructable (from what I can see)…
[Multiple interesting data points]
#1 System.Windows.Application has a static ctor where ResourceContainer package is added to PreloadedPackages so that downstream PackWebRequestFactory can find it. So you need to be running in the context of an Avalon application to get this.
#2 If you use PackUriHelper class, the “pack:” prefix gets registered with the System.Uri class and this helps in performing the correct parsing and construction of System.Uri objects for pack Uris.
The other registration is of the pack: scheme with WebRequest so that you can use WebRequest.Create method to return the PackWebRequest object. This can be done in your code. PackWebRequestFactory does not register it. You could use PackWebRequestFactory directly to get the PackWebRequest too –
PackWebRequest request = (PackWebRequest)((IWebRequestCreate)new PackWebRequestFactory()).Create(packUri);
Subject: RichTextBox viewable area
Is there any way to get the viewable area in a RichTextBox?
Answer:
TextPointer upperLeftCorner = rtb.GetPositionFromPoint(new Point(0, 0), true /* snapToText */); TextPointer lowerRightCorner = rtb.GetPositionFromPoint(new Point(rtb.ActualWidth, rtb.ActualHeight), true /* snapToText */);
You could refine this to get a tighter fit by looking at RichTextBox.ViewportWidth/ViewportHeight, to omit space for surrounding chrome like the possibly visible ScollViewer or Border. But for optimizing a property set on the viewable area first, including a small amount of extra content around the viewport is probably fine.
Subject: ValidatesOnDataErrors not working on bindings inside an ItemsControl.
I noticed that ValidatesOnDataErrors is not working on bindings inside an ItemsControl.ItemTemplate. I confirmed this problem has been fixed in Framework 4.0 but our target is 3.5.
the workaround is to use the “long” form of ValidatesOnDataErrors:
<Binding.ValidationRules>
<DataErrorValidationRule/>
</Binding.ValidationRules>
Happy coding!! | http://blogs.msdn.com/b/jaimer/archive/2009/11.aspx | CC-MAIN-2013-20 | refinedweb | 1,534 | 55.24 |
The Serial Programming Guide for POSIX Operating Systems will teach you how to successfully, efficiently, and portably program the serial ports on your UNIX® workstation or PC. Each chapter provides programming examples that use the POSIX (Portable Standard for UNIX) terminal control functions and should work with very few modifications under IRIX®, HP-UX, SunOS®, Solaris®, Digital UNIX®, Linux®, and most other UNIX operating systems. The biggest difference between operating systems that you will find is the filenames used for serial port device and lock files.
This guide is organized into the following chapters and appendices:
This chapter introduces serial communications, RS-232 and other standards that are used on most computers as well as how to access a serial port from a C program.
Computers transfer information (data) one or more bits at a time. Serial refers to the transfer of data one bit at a time. Serial communications include most network devices, keyboards, mice, MODEMs, and terminals.
When doing serial communications each word (i.e. byte or character) of data you send or receive is sent one bit at a time. Each bit is either on or off. The terms you'll hear sometimes are mark for the on state and space for the off state.
The speed of the serial data is most often expressed as bits-per-second ("bps") or baudot rate ("baud"). This just represents the number of ones and zeroes that can be sent in one second. Back at the dawn of the computer age, 300 baud was considered fast, but today computers can handle RS-232 speeds as high as 430,800 baud! When the baud rate exceeds 1,000, you'll usually see the rate shown in kilo baud, or kbps (e.g. 9.6k, 19.2k, etc). For rates above 1,000,000 that rate is shown in megabaud, or Mbps (e.g. 1.5Mbps).
When referring to serial devices or ports, they are either labeled as Data Communications Equipment ("DCE") or Data Terminal Equipment ("DTE"). The difference between these is simple - every signal pair, like transmit and receive, is swapped. When connecting two DTE or two DCE interfaces together, a serial null-MODEM cable or adapter is used that swaps the signal pairs.
RS-232 is a standard electrical interface for serial communications defined by the Electronic Industries Association ("EIA"). RS-232 actually comes in 3 different flavors (A, B, and C) with each one defining a different voltage range for the on and off levels. The most commonly used variety is RS-232C, which defines a mark (on) bit as a voltage between -3V and -12V and a space (off) bit as a voltage between +3V and +12V. The RS-232C specification says these signals can go about 25 feet (8m) before they become unusable. You can usually send signals a bit farther than this as long as the baud is low enough.
Besides wires for incoming and outgoing data, there are others that provide timing, status, and handshaking:
Two standards for serial interfaces you may also see are RS-422 and RS-574. RS-422 uses lower voltages and differential signals to allow cable lengths up to about 1000ft (300m). RS-574 defines the 9-pin PC serial connector and voltages.
The RS-232 standard defines some 18 different signals for serial communications. Of these, only six are generally available in the UNIX environment.
Technically the logic ground is not a signal, but without it none of the other signals will operate. Basically, the logic ground acts as a reference voltage so that the electronics know which voltages are positive or negative.
The TXD signal carries data transmitted from your workstation to the computer or device on the other end (like a MODEM). A mark voltage is interpreted as a value of 1, while a space voltage is interpreted as a value of 0.
The RXD signal carries data transmitted from the computer or device on the other end to your workstation. Like TXD, mark and space voltages are interpreted as 1 and 0, respectively.
The DCD signal is received from the computer or device on the other end of your serial cable. A space voltage on this signal line indicates that the computer or device is currently connected or on line. DCD is not always used or available.
The DTR signal is generated by your workstation and tells the computer or device on the other end that you are ready (a space voltage) or not-ready (a mark voltage). DTR is usually enabled automatically whenever you open the serial interface on the workstation.
The CTS signal is received from the other end of the serial cable. A space voltage indicates that is alright to send more serial data from your workstation.
CTS is usually used to regulate the flow of serial data from your workstation to the other end.
The RTS signal is set to the space voltage by your workstation to indicate that more data is ready to be sent.
Like CTS, RTS helps to regulate the flow of data between your workstation and the computer or device on the other end of the serial cable. Most workstations leave this signal set to the space voltage all the time.
For the computer to understand the serial data coming into it, it needs some way to determine where one character ends and the next begins. This guide deals exclusively with asynchronous serial data.
In asynchronous mode the serial data line stays in the mark (1) state until a character is transmitted. A start bit preceeds each character and is followed immediately by each bit in the character, an optional parity bit, and one or more stop bits. The start bit is always a space (0) and tells the computer that new serial data is available. Data can be sent or received at any time, thus the name asynchronous.
Figure 1 - Asynchronous Data Transmission
The optional parity bit is a simple sum of the data bits indicating whether or not the data contains an even or odd number of 1 bits. With even parity, the parity bit is 0 if there is an even number of 1's in the character. With odd parity, the parity bit is 0 if there is an odd number of 1's in the data. You may also hear the terms space parity, mark parity, and no parity. Space parity means that the parity bit is always 0, while mark parity means the bit is always 1. No parity means that no parity bit is present or transmitted.
The remaining bits are called stop bits. There can be 1, 1.5, or 2 stop bits between characters and they always have a value of 1. Stop bits traditionally were used to give the computer time to process the previous character, but now only serve to synchronize the receiving computer to the incoming characters.
Asynchronous data formats are usually expressed as "8N1", "7E1", and so forth. These stand for "8 data bits, no parity, 1 stop bit" and "7 data bits, even parity, 1 stop bit" respectively.
Full duplex means that the computer can send and receive data simultaneously - there are two separate data channels (one coming in, one going out).
Half duplex means that the computer cannot send or receive data at the same time. Usually this means there is only a single data channel to talk over. This does not mean that any of the RS-232 signals are not used. Rather, it usually means that the communications link uses some standard other than RS-232 that does not support full duplex operation.
It is often necessary to regulate the flow of data when transferring data between two serial interfaces. This can be due to limitations in an intermediate serial communications link, one of the serial interfaces, or some storage media. Two methods are commonly used for asynchronous data.
The first method is often called "software" flow control and uses special characters to start (XON or DC1, 021 octal) or stop (XOFF or DC3, 023 octal) the flow of data. These characters are defined in the American Standard Code for Information Interchange ("ASCII"). While these codes are useful when transferring textual information, they cannot be used when transferring other types of information without special programming.
The second method is called "hardware" flow control and uses the RS-232 CTS and RTS signals instead of special characters. The receiver sets CTS to the space voltage when it is ready to receive more data and to the mark voltage when it is not ready. Likewise, the sender sets RTS to the space voltage when it is ready to send more data. Because hardware flow control uses a separate set of signals, it is much faster than software flow control which needs to send or receive multiple bits of information to do the same thing. CTS/RTS flow control is not supported by all hardware or operating systems.
Normally a receive or transmit data signal stays at the mark voltage until a new character is transferred. If the signal is dropped to the space voltage for a long period of time, usually 1/4 to 1/2 second, then a break condition is said to exist.
A break is sometimes used to reset a communications line or change the operating mode of communications hardware like a MODEM. Chapter 3, Talking to MODEMs covers these applications in more depth.
Unlike asynchronous data, synchronous data appears as a constant stream of bits. To read the data on the line, the computer must provide or receive a common bit clock so that both the sender and receiver are synchronized.
Even with this synchronization, the computer must mark the beginning of the data somehow. The most common way of doing this is to use a data packet protocol like Serial Data Link Control ("SDLC") or High-Speed Data Link Control ("HDLC").
Each protocol defines certain bit sequences to represent the beginning and end of a data packet. Each also defines a bit sequence that is used when there is no data. These bit sequences allow the computer see the beginning of a data packet.
Because synchronous protocols do not use per-character synchronization bits they typically provide at least a 25% improvement in performance over asynchronous communications and are suitable for remote networking and configurations with more than two serial interfaces.
Despite the speed advantages of synchronous communications, most RS-232 hardware does not support it due to the extra hardware and software required.
Like all devices, UNIX provides access to serial ports via device files. To access a serial port you simply open the corresponding device file.
Each serial port on a UNIX system has one or more device files (files in the /dev directory) associated with it:
Since a serial port is a file, the open(2) function is used to access it. The one hitch with UNIX is that device files are usually not accessable by normal users. Workarounds include changing the access permissions to the file(s) in question, running your program as the super-user (root), or making your program set-userid so that it runs as the owner of the device file.
For now we'll assume that the file is accessable by all users. The
code to open serial port 1 on an
sgi® workstation running
IRIX is:
Listing 1 - Opening a serial port.
f1", O_RDWR | O_NOCTTY | O_NDELAY); if (fd == -1) { /* * Could not open the port. */ perror("open_port: Unable to open /dev/ttyf1 - "); } else fcntl(fd, F_SETFL, 0); return (fd); }
Other systems would require the corresponding device file name, but otherwise the code is the same.
You'll notice that when we opened the device file we used two other flags along with the read+write mode:
fd = open("/dev/ttyf1", O_RDWR | O_NOCTTY | O_NDELAY);
The O_NOCTTY flag tells UNIX that this program doesn't want to be the "controlling terminal" for that port. If you don't specify this then any input (such as keyboard abort signals and so forth) will affect your process. Programs like getty(1M/8) use this feature when starting the login process, but normally a user program does not want this behavior.
The O_NDELAY flag tells UNIX that this program doesn't care what state the DCD signal line is in - whether the other end of the port is up and running. If you do not specify this flag, your process will be put to sleep until the DCD signal line is the space voltage.
Writing data to the port is easy - just use the write(2) system call to send data it:
n = write(fd, "ATZ\r", 4); if (n < 0) fputs("write() of 4 bytes failed!\n", stderr);
The write function returns the number of bytes sent or -1 if an error occurred. Usually the only error you'll run into is EIO when a MODEM or data link drops the Data Carrier Detect (DCD) line. This condition will persist until you close the port.
Reading data from a port is a little trickier. When you operate the port in raw data mode, each read(2) system call will return however many characters are actually available in the serial input buffers. If no characters are available, the call will block (wait) until characters come in, an interval timer expires, or an error occurs. The read function can be made to return immediately by doing the following:
fcntl(fd, F_SETFL, FNDELAY);
The FNDELAY option causes the read function to return 0 if no characters are available on the port. To restore normal (blocking) behavior, call fcntl() without the FNDELAY option:
fcntl(fd, F_SETFL, 0);
This is also used after opening a serial port with the O_NDELAY option.
To close the serial port, just use the close system call:
close(fd);
Closing a serial port will also usually set the DTR signal low which causes most MODEMs to hang up.
This chapter discusses how to configure a serial port from C using the POSIX termios interface.(3) and tcsetattr(3). These get and set terminal attributes, respectively; you provide a pointer to a termios structure that contains all of the serial options available: baud rate constants (CBAUD, B9600, etc.) are used for older interfaces that lack the c_ispeed and c_ospeed members. See the next section for information on the POSIX functions used to set the baud rate.
Never initialize the c_cflag (or any other flag) member directly; you should always use the bitwise AND, OR, and NOT operators to set or clear bits in the members. Different operating system versions (and even patches) can and do use the bits differently, so using the bitwise operators will prevent you from clobbering a bit flag that is needed in a newer serial driver.
The baud rate is stored in different places depending on the operating system. Older interfaces store the baud rate in the c_cflag member using one of the baud rate constants in table 4, while newer implementations provide the c_ispeed and c_ospeed members that contain the actual baud rate value.
The cfsetospeed(3) and cfsetispeed(3) functions are provided to set the baud rate in the termios structure regardless of the underlying operating system interface. Typically you'd use the following code to set the baud rate:
Listing 2 - Settingflag |= (CLOCAL | CREAD); /* * Set the new options for the port... */ tcsetattr(fd, TCSANOW, &options);
The tcgetattr(3) function fills the termios structure you provide with the current serial port configuration. After we set the baud rates and enable local mode and serial data receipt, we select the new configuration using tcsetattr(3). The TCSANOW constant specifies that all changes should occur immediately without waiting for output data to finish sending or input data to finish receiving. There are other constants to wait for input and output to finish or to flush the input and output buffers.
Most systems do not support different input and output speeds, so be sure to set both to the same value for maximum portability.
Unlike the baud rate, there is no convienience function to set the character size. Instead you must do a little bitmasking to set things up. The character size is specified in bits:
options.c_cflag &= ~CSIZE; /* Mask the character size bits */ options.c_cflag |= CS8; /* Select 8 data bits */
Like the character size you must manually set the parity enable and parity type bits. UNIX serial drivers support even, odd, and no parity bit generation. Space parity can be simulated with clever coding.
options.c_cflag &= ~PARENB options.c_cflag &= ~CSTOPB options.c_cflag &= ~CSIZE; options.c_cflag |= CS8;
options.c_cflag |= PARENB options.c_cflag &= ~PARODD options.c_cflag &= ~CSTOPB options.c_cflag &= ~CSIZE; options.c_cflag |= CS7;
options.c_cflag |= PARENB options.c_cflag |= PARODD options.c_cflag &= ~CSTOPB options.c_cflag &= ~CSIZE; options.c_cflag |= CS7;
options.c_cflag &= ~PARENB options.c_cflag &= ~CSTOPB options.c_cflag &= ~CSIZE; options.c_cflag |= CS8;
Some versions of UNIX support hardware flow control using the CTS (Clear To Send) and RTS (Request To Send) signal lines. If the CNEW_RTSCTS or CRTSCTS constants are defined on your system then hardware flow control is probably supported. Do the following to enable hardware flow control:
options.c_cflag |= CNEW_RTSCTS; /* Also called CRTSCTS */
Similarly, to disable hardware flow control:
options.c_cflag &= ~CNEW_RTSCTS;
The local modes member c_lflag controls how input characters are managed by the serial driver. In general you will configure the c_lflag member for canonical or raw input.flag |= (ICANON | ECHO | ECHOE);
Raw input is unprocessed. Input characters are passed through exactly as they are received, when they are received. Generally you'll deselect the ICANON, ECHO, ECHOE, and ISIG options when using raw input:
options.c_lflag &= ~(ICANON | ECHO | ECHOE | ISIG);
Never enable input echo (ECHO, ECHOE) when sending commands to a MODEM or other computer that is echoing characters, as you will generate a feedback loop between the two serial interfaces!
The input modes member c_iflag controls any input processing that is done to characters received on the port. Like the c_cflag field, the final value stored in c_iflag is the bitwise OR of the desired options.
You should enable input parity checking when you have enabled parity in the c_cflag member (PARENB). The revelant constants for input parity checking are INPCK, IGNPAR, PARMRK , and ISTRIP. Generally you will select INPCK and ISTRIP to enable checking and stripping of the parity bit:
options.c_iflag |= (INPCK | ISTRIP); (000 octal) is sent to your program before every character with a parity error. Otherwise, a DEL (177 octal) and NUL character is sent along with the bad character.
Software flow control is enabled using the IXON, IXOFF , and IXANY constants:
options.c_iflag |= (IXON | IXOFF | IXANY);
To disable software flow control simply mask those bits:
options.c_iflag &= ~(IXON | IXOFF | IXANY);
The XON (start data) and XOFF (stop data) characters are defined in the c_cc array described below.
The c_oflag member contains output filtering options. Like the input modes, you can select processed or raw data output.
Processed output is selected by setting the OPOST option in the c_oflag member:
options.c_oflag |= OPOST;
Of all the different options, you will only probably use the ONLCR option which maps newlines into CR-LF pairs. The rest of the output options are primarily historic and date back to the time when line printers and terminals could not keep up with the serial data stream!
Raw output is selected by resetting the OPOST option in the c_oflag member:
options.c_oflag &= ~OPOST;
When the OPOST option is disabled, all other option bits in c_oflag are ignored.
The c_cc character array contains control character definitions as well as timeout parameters. Constants are defined for every element of this array.
The VSTART and VSTOP elements of the c_cc array contain the characters used for software flow control. Normally they should be set to DC1 (021 octal) and DC3 (023 octal) which represent the ASCII standard XON and XOFF characters.
UNIX serial interface drivers provide the ability to specify character and packet timeouts. Two elements of the c_cc array are used for timeouts: VMIN and VTIME. Timeouts are ignored in canonical input mode or when the NDELAY option is set on the file via open or fcntl.
VMIN specifies the minimum number of characters to read. If it is set to 0, then the VTIME value specifies the time to wait for every character read. Note that this does not mean that a read call for N bytes will wait for N characters to come in. Rather, the timeout will apply to the first character and the read call will return the number of characters immediately available (up to the number you request).. This method allows you to tell the serial driver you need exactly N bytes and any read call will return 0 or N bytes. However, the timeout only applies to the first character read, so if for some reason the driver misses one character inside the N byte packet then the read call could block forever waiting for additional input characters.
VTIME specifies the amount of time to wait for incoming characters in tenths of seconds. If VTIME is set to 0 (the default), reads will block (wait) indefinitely unless the NDELAY option is set on the port with open or fcntl.
This chapter covers the basics of dialup telephone Modulator/Demodulator (MODEM) communications. Examples are provided for MODEMs that use the defacto standard "AT" command set.
MODEMs are devices that modulate serial data into frequencies that can be transferred over an analog data link such as a telephone line or cable TV connection. A standard telephone MODEM converts serial data into tones that can be passed over the phone lines; because of the speed and complexity of the conversion these tones sound more like loud screeching if you listen to them.
Telephone MODEMs are available today that can transfer data across a telephone line at nearly 53,000 bits per second, or 53kbps. In addition, most MODEMs use data compression technology that can increase the bit rate to well over 100kbps on some types of data.
The first step in communicating with a MODEM is to open and configure the port for raw input:
Listing 3 - Configuring the port for raw input.
int fd; struct termios options; /* open the port */ fd = open("/dev/ttyf1", O_RDWR | O_NOCTTY | O_NDELAY););
Next you need to establish communications with the MODEM. The best way to do this is by sending the "AT" command to the MODEM. This also allows smart MODEMs to detect the baud you are using. When the MODEM is connected correctly and powered on it will respond with the response "OK".
Listing 4 - Initializing the MODEM.\r", 3) < 3)); }
Most MODEMs support the "AT" command set, so called because each command starts with the "AT" characters. Each command is sent with the "AT" characters starting in the first column followed by the specific command and a carriage return (CR, 015 octal). After processing the command the MODEM will reply with one of several textual messages depending on the command.
The ATD command dials the specified number. In addition to numbers and dashes you can specify tone ("T") or pulse ("P") dialing, pause for one second (","), and wait for a dialtone ("W"):
ATDT 555-1212 ATDT 18008008008W1234,1,1234 ATD T555-1212WP1234
The MODEM will reply with one of the following messages:
NO DIALTONE BUSY NO CARRIER CONNECT CONNECT baud
The ATH command causes the MODEM to hang up. Since the MODEM must be in "command" mode you probably won't use it during a normal phone call.
Most MODEMs will also hang up if DTR is dropped; you can do this by setting the baud to 0 for at least 1 second. Dropping DTR also returns the MODEM to command mode.
After a successful hang up the MODEM will reply with "NO CARRIER". If the MODEM is still connected the "CONNECT" or "CONNECT baud" message will be sent.
First and foremost, don't forget to disable input echoing. Input echoing will cause a feedback loop between the MODEM and computer.
Second, when sending MODEM commands you must terminate them with a carriage return (CR) and not a newline (NL). The C character constant for CR is "\r".
Finally, when dealing with a MODEM make sure you use a baud that the MODEM supports. While many MODEMs do auto-baud detection, some have limits (19.2kbps is common) that you must observe.
This chapter covers advanced serial programming techniques using the ioctl(2) and select(2) system calls.
In Chapter 2, Configuring the Serial Port we used the tcgetattr and tcsetattr functions to configure the serial port. Under UNIX these functions use the ioctl(2) system call to do their magic.
The ioctl system call takes three arguments:
int ioctl(int fd, int request, ...);
The fd argument specifies the serial port file descriptor.
The request argument is a constant defined in the
<termios.h> header file and is typically one of the following:
The
TIOCMGET ioctl gets the current "MODEM"
status bits, which consist of all of the RS-232 signal lines except
RXD and TXD:
To get the status bits, call ioctl with a pointer to an integer to hold the bits:
Listing 5 - Getting the MODEM status bits.
#include <unistd.h> #include <termios.h> int fd; int status; ioctl(fd, TIOCMGET, &status);
The
TIOCMSET ioctl sets the "MODEM" status bits
defined above. To drop the DTR signal you can do:
Listing 6 - Dropping DTR with the TIOCMSET ioctl.
#include <unistd.h> #include <termios.h> int fd; int status; ioctl(fd, TIOCMGET, &status); status &= ~TIOCM_DTR; ioctl(fd, TIOCMSET, status);
The bits that can be set depend on the operating system, driver, and modes in use. Consult your operating system documentation for more information.
The
FIONREAD ioctl gets the number of bytes in
the serial port input buffer. As with
TIOCMGET you pass in
a pointer to an integer to hold the number of bytes:
Listing 7 - Getting the number of bytes in the input buffer.
#include <unistd.h> #include <termios.h> int fd; int bytes; ioctl(fd, FIONREAD, &bytes);
This can be useful when polling a serial port for data, as your program can determine the number of bytes in the input buffer before attempting a read.
While simple applications can poll or wait on data coming from the serial port, most applications are not simple and need to handle input from multiple sources.
UNIX provides this capability through the select(2) system call. This system call allows your program to check for input, output, or error conditions on one or more file descriptors. The file descriptors can point to serial ports, regular files, other devices, pipes, or sockets. You can poll to check for pending input, wait for input indefinitely, or timeout after a specific amount of time, making the select system call extremely flexible.
Most GUI Toolkits provide an interface to select; we will discuss the X Intrinsics ("Xt") library later in this chapter.
The select system call accepts 5 arguments:
int select(int max_fd, fd_set *input, fd_set *output, fd_set *error, struct timeval *timeout);
The max_fd argument specifies the highest numbered file
descriptor in the input, output, and error sets.
The input, output, and error arguments specify
sets of file descriptors for pending input, output, or error
conditions; specify
NULL to disable monitoring for the
corresponding condition. These sets are initialized using three macros:
FD_ZERO(fd_set); FD_SET(fd, fd_set); FD_CLR(fd, fd_set);
The FD_ZERO macro clears the set entirely. The FD_SET and FD_CLR macros add and remove a file descriptor from the set, respectively.
The timeout argument specifies a timeout value which consists
of seconds (timeout.tv_sec) and microseconds (timeout.tv_usec
). To poll one or more file descriptors, set the seconds and
microseconds to zero. To wait indefinitely specify
NULL
for the timeout pointer.
The select system call returns the number of file descriptors that have a pending condition, or -1 if there was an error.
Suppose we are reading data from a serial port and a socket. We want to check for input from either file descriptor, but want to notify the user if no data is seen within 10 seconds. To do this we'll need to use the select system call:
Listing 8 - Using SELECT to process input from more than one source.
#include <unistd.h> #include <sys/types.h> #include <sys/time.h> #include <sys/select.h> int n; int socket; int fd; int max_fd; fd_set input; struct timeval timeout; /* Initialize the input set */ FD_ZERO(input); FD_SET(fd, input); FD_SET(socket, input); max_fd = (socket > fd ? socket : fd) + 1; /* Initialize the timeout structure */ timeout.tv_sec = 10; timeout.tv_usec = 0; /* Do the select */ n = select(max_fd, NULL, NULL, ; /* See if there was an error */ if (n 0) perror("select failed"); else if (n == 0) puts("TIMEOUT"); else { /* We have input */ if (FD_ISSET(fd, input)) process_fd(); if (FD_ISSET(socket, input)) process_socket(); }
You'll notice that we first check the return value of the select system call. Values of 0 and -1 yield the appropriate warning and error messages. Values greater than 0 mean that we have data pending on one or more file descriptors.
To determine which file descriptor(s) have pending input, we use the FD_ISSET macro to test the input set for each file descriptor. If the file descriptor flag is set then the condition exists (input pending in this case) and we need to do something.
The X Intrinsics library provides an interface to the select system call via the XtAppAddInput(3x) and XtAppRemoveInput(3x) functions:
int XtAppAddInput(XtAppContext context, int fd, int mask, XtInputProc proc, XtPointer data); void XtAppRemoveInput(XtAppContext context, int input);
The select system call is used internally to implement timeouts, work procedures, and check for input from the X server. These functions can be used with any Xt-based toolkit including Xaw, Lesstif, and Motif.
The proc argument to XtAppAddInput specifies the function to call when the selected condition (e.g. input available) exists on the file descriptor. In the previous example you could specify the process_fd or process_socket functions.
Because Xt limits your access to the select system call, you'll need to implement timeouts through another mechanism, probably via XtAppAddTimeout(3x).
This appendix provides pinout information for many of the common serial ports you will find.
RS-232 comes in three flavors (A, B, C) and uses a 25-pin D-Sub connector:
Figure 2 - RS-232 Connector
RS-422 also uses a 25-pin D-Sub connector, but with differential signals:
Figure 3 - RS-422 Connector
The RS-574 interface is used exclusively by PC manufacturers and uses a 9-pin male D-Sub connector:
Figure 4 - RS-574 Connector
Older SGI equipment uses a 9-pin female D-Sub connector. Unlike RS-574, the SGI pinouts nearly match those of RS-232:
Figure 5 - SGI 9-Pin Connector
The SGI Indigo, Indigo2, and Indy workstations use the Apple 8-pin MiniDIN connector for their serial ports:
Figure 6 - SGI 8-Pin Connector
This chapter lists the ASCII control codes and their names. | https://www.cmrr.umn.edu/~strupp/serial.html | CC-MAIN-2019-51 | refinedweb | 5,166 | 62.07 |
Play a multimedia file in J2ME Program (Audio/Video) using MMAPI
By: Vikram Goyal Printer Friendly Format.
//A Simple MMAPI MIDlet
import javax.microedition.midlet.MIDlet;
import javax.microedition.media.Manager;
import javax.microedition.media.Player;
public class SimplePlayer extends MIDlet {
public void startApp() {
try {
Player player =
Manager.createPlayer(getClass().getResourceAsStream("/media/audio/chapter3/baby.wav"),"audio/x-wav");
player.start();
} catch(Exception e) {
e.printStackTrace();
}
}
public void pauseApp() {
}
public void destroyApp(boolean unconditional) {
}
}
To keep things simple at this stage, the media file is played by creating an InputStream on a wav file, which is embedded in the MIDlet’s JAR. This media file is kept in the folder media/audio/chapter3 and is called baby.wav (which is the sound of a baby crying).
Of course, you don’t need to play an audio file only. You can substitute the wav file with a video file, provided the emulator supports the format of the video file. The video will not show anywhere, because this listing doesn’t provide a mechanism to show the video. You can substitute the wav file for a midi, tone, or any other supported audio format. The point is that playing multimedia files using the MMAPI is as simple as creating a Player instance using the Manager class and calling method start() on. when iam trying to executing above program i am ge
View Tutorial By: BHAGYALAXMI at 2008-10-11 06:45:57
2. pls send simple to hard j2me coding
View Tutorial By: Seenu at 2008-10-29 15:19:03
3. java.lang.IllegalArgumentException means usually t
View Tutorial By: Seink at 2008-11-12 11:03:00
4. me too got the same problem....
but m sure
View Tutorial By: HEHE at 2008-11-19 01:49:04
5. me too got the same problem....
but m sure
View Tutorial By: HEHE at 2008-11-19 01:50:15
6. I am not found a J2ME file for playing a audio pla
View Tutorial By: S.M. ASHIQUER RAHMAN at 2008-11-22 22:33:43
7. I want to say, that you have to give complete code
View Tutorial By: Jasvir Yadav at 2009-09-05 07:23:15
8. You are totally learning yourself
The code
View Tutorial By: Narayan at 2009-09-14 03:28:35
9. very good helped me a lot
View Tutorial By: Swaran at 2009-12-30 09:51:36
10. I agree with BHAGYALAXMI. I faced the same problem
View Tutorial By: Alok at 2010-01-10 12:03:37
11. Even i got d same error. can u plz tell me where t
View Tutorial By: Priya at 2011-03-14 12:16:54
12. java.lang.IllegalArgumentException
at java
View Tutorial By: gopal at 2011-03-21 00:45:51
13. I run the code . It's good.
View Tutorial By: Golam Rabbi at 2011-07-12 07:06:00
14. @All
You need to first keep your .w
View Tutorial By: Nithya at 2011-08-31 02:27:48
15. What exactly is d directry for d folder Media?? It
View Tutorial By: Oraclematrix at 2012-01-15 21:40:54
16. javax.microedition.media.MediaException: Malformed
View Tutorial By: adi at 2012-04-01 11:51:17
17. Put *.wav at where store java file and nnsert thes
View Tutorial By: BAE at 2012-09-18 12:26:55
18. one have to store .wav file in res folder of your
View Tutorial By: swetha at 2013-06-14 06:47:57
19. public void playSound(String filename) {
View Tutorial By: Rowan at 2014-07-17 10:26:02 | https://www.java-samples.com/showtutorial.php?tutorialid=830 | CC-MAIN-2020-05 | refinedweb | 611 | 67.96 |
On Thu, Aug 5, 2010 at 2:49 AM, Ivan Lazar Miljenovic <ivan.miljenovic at gmail.com> wrote: > As part of an attempt at resolving the FGL vs inductive-graphs naming > mess, one solution that Edward Kmett and I thrashed out will involve > utilising a new top-level module namespace of Graph.* instead of using > Data.Graph.* as currently found in FGL. However, Don Stewart > recommended that I ask of the collective wisdom that is the libraries > mailing list before moving ahead with this proposal. > > The three main reasons for such a new top-level namespace are: > > * Avoid module clashes (ala mtl and monads-{fd,tf}): for my > still-vapourware graph classes library I would have to use > Data.Graph.Classes or some such due to Data.Graph being used by the > containers library; the new library Thomas Bereknyei are working on > can then use Graph.Inductive to avoid clashing with FGL's > Data.Graph.Inductive. > > * Reduce the length of module names: this reason might not mean as > much and the net benefit would be minimal, but something like > Graph.Inductive.Algorithms.Directed is a bit nicer than > Data.Graph.Inductive.Algorithms.Directed > > * Not all graph-related modules are necessarily strictly about > data-types, etc. (and I can't find any distinction about what defines > the Data.* namespace anyway); e.g. my graphviz library currently uses > Data.GraphViz.*, though it should arguably go under Graphics.* instead > (it's currently under Data.* because that's how I found it when I took > over maintainership). > > So, am I able to start using Graph as a new top-level namespace? The > end goal is that eventually all graph-related libraries will use this > namespace (whereas currently most such libraries use Data.Graph.*, > graphviz being the notable exception). Personally, I dislike this proposal. Yes, there are an awful lot of modules a well-developed graph ecosystem will have. But this is true of lists, or arrays, or any other extremely common and useful abstraction. (Should we have a toplevel Monad.* namespace because there are so ridiculously many monad libraries and transformers and whatnot?) Clashes are more an argument for merging and improving libraries, or at least maintainers coordinating with each other. -- gwern | http://www.haskell.org/pipermail/libraries/2010-August/014033.html | CC-MAIN-2014-15 | refinedweb | 368 | 59.4 |
How do you use existing (but not basic) Qml types (for example Rectangle, Buttons, etc.) as properties for custom C++ - defined types?
- mahlersand
Seems like a stupid question, but I have not found anything about this. There is a page in the documentation that shows how to use custom types as properties for C++ - defined types, but what do I do if I want, for example, a Rectangle as a background for an Item?
- p3c0 Moderators
Hi @mahlersand
If I understood you correctly, you cant use
Rectangle,
Buttonsdirectly inside C++ defined types as they don't have a public C++ API's. if you are using
QQuickPaintedItemthen you can draw your own rectangle using various
QPaintermethods.
- mahlersand
@p3c0 Yes, it's just that i wanted to avoid that, as i wanted the
Rectangleto be accessible and modifiable from within the QML code. That is currently only (theoretically) possible through the private classes
#include <QtQuick/5.5.0/QtQuick/private/qquickrectangle_p.h>, but it is not really working.
- p3c0 Moderators
@mahlersand Using private classes is not recommended as its implementation may change from version to version. The best would be to use
QQuickPaintedItemand create your own custom types. | https://forum.qt.io/topic/58994/how-do-you-use-existing-but-not-basic-qml-types-for-example-rectangle-buttons-etc-as-properties-for-custom-c-defined-types/1 | CC-MAIN-2018-09 | refinedweb | 197 | 54.22 |
import "golang.org/x/text/internal/gen"
Package gen contains common code for the various code generation tools in the text repository. Its usage ensures consistency between tools.
This package defines command line flags that are common to most generation tools. The flags allow for specifying specific Unicode and CLDR versions in the public Unicode data repository ().
A local Unicode data mirror can be set through the flag -local or the environment variable UNICODE_DIR. The former takes precedence. The local directory should follow the same structure as the public repository.
IANA data can also optionally be mirrored by putting it in the iana directory rooted at the top of the local mirror. Beware, though, that IANA data is not versioned. So it is up to the developer to use the right version.
UnicodeVersion reports the requested CLDR version.
Init performs common initialization for a gen command. It parses the flags and sets up the standard logging parameters.
IsLocal reports whether data files are available locally.
func Open(urlRoot, subdir, path string) io.ReadCloser
Open opens subdir/path if a local directory is specified and the file exists, where subdir is a directory relative to the local root, or fetches it from urlRoot/path otherwise. It will call log.Fatal if there are any errors.
func OpenCLDRCoreZip() io.ReadCloser
OpenCLDRCoreZip opens the CLDR core zip file. It will call log.Fatal if there are any errors.
func OpenIANAFile(path string) io.ReadCloser
OpenIANAFile opens the requested IANA file. The file is specified relative to the IANA root, which is typically either or the iana directory in the local mirror. It will call log.Fatal if there are any errors.
func OpenUCDFile(file string) io.ReadCloser
OpenUCDFile opens the requested UCD file. The file is specified relative to the public Unicode root directory. It will call log.Fatal if there are any errors.
func OpenUnicodeFile(category, version, file string) io.ReadCloser
OpenUnicodeFile opens the requested file of the requested category from the root of the Unicode data archive. The file is specified relative to the public Unicode root directory. If version is "", it will use the default Unicode version. It will call log.Fatal if there are any errors.
Repackage rewrites a Go file from belonging to package main to belonging to the given package.
UnicodeVersion reports the requested Unicode version.
WriteCLDRVersion writes a constant for the CLDR version from which the tables are generated.
WriteGo prepends a standard file comment and package statement to the given bytes, applies gofmt, and writes them to w.
WriteGoFile prepends a standard file comment and package statement to the given bytes, applies gofmt, and writes them to a file with the given name. It will call log.Fatal if there are any errors.
WriteUnicodeVersion writes a constant for the Unicode version from which the tables are generated.
type CodeWriter struct { Size int Hash hash.Hash32 // content hash // contains filtered or unexported fields }
CodeWriter is a utility for writing structured code. It computes the content hash and size of written content. It ensures there are newlines between written code blocks.
func NewCodeWriter() *CodeWriter
NewCodeWriter returns a new CodeWriter.
func (w *CodeWriter) Write(p []byte) (n int, err error)
func (w *CodeWriter) WriteArray(x interface{})
WriteArray writes an array value.
func (w *CodeWriter) WriteComment(comment string, args ...interface{})
WriteComment writes a comment block. All line starts are prefixed with "//". Initial empty lines are gobbled. The indentation for the first line is stripped from consecutive lines.
func (w *CodeWriter) WriteConst(name string, x interface{})
WriteConst writes a constant of the given name and value.
WriteGo appends the buffer with the total size of all created structures and writes it as a Go file to the the given writer with the given package name.
func (w *CodeWriter) WriteGoFile(filename, pkg string)
WriteGoFile appends the buffer with the total size of all created structures and writes it as a Go file to the the given file with the given package name.
func (w *CodeWriter) WriteSlice(x interface{})
WriteSlice writes a slice value.
func (w *CodeWriter) WriteString(s string)
WriteString writes a string literal.
func (w *CodeWriter) WriteType(x interface{}) string
WriteType writes a definition of the type of the given value and returns the type name.
func (w *CodeWriter) WriteVar(name string, x interface{})
WriteVar writes a variable of the given name and value.
Package gen imports 21 packages (graph) and is imported by 2 packages. Updated 2017-08-15. Refresh now. Tools for package owners. | http://godoc.org/golang.org/x/text/internal/gen | CC-MAIN-2017-34 | refinedweb | 746 | 60.51 |
interactive_add_button_layout 1.0.0
Custom Layout with interactive add button to impove your UI and UX .
Interactive Add button layout #
Custom Layout with interactive add button to impove your UI and UX .
inspired from Oleg Frolov.
Usage #
Import the Package #
add this dependencies to your app
dependencies: interactive_add_button_layout: ^0.1.0
Use the Package #
add this import statement
import 'package:interactive_add_button_layout/interactive_add_button_layout.dart';
The layout need to be the root layout of your widget (screen)
and Now to use it, add this code to your widget :
return Scaffold( ... body: AddButtonLayout( parameters )
The layout has 6 parameters which are :
child: you know what is that xD, in case you don't it's the child of the layout which mean that the layout is his parent .
row: a List of Widgets to be diplayed in a row for the Row layout .
column: a List of Widgets to be diplayed in a column for the Column layout .
onPressed: the function to be called when the user click the add button .
color: the color of the layout (color of the background), by default it's
Color(0xff2A1546).
btnColor: the color of the add button
the
row and
column and
child are required !
Example : #
you can find a demo app in
./example
Gif #
Contribution #
Feel free to contribute, to report a bug or to suggest a feature, Thank you :) | https://pub.dev/packages/interactive_add_button_layout | CC-MAIN-2020-34 | refinedweb | 225 | 55.95 |
Share code: Serving files over HTTP
- Webmaster4o
Note: This has been done before, but there were a few improvements I wanted to make to what had been done before.
This script is an editor action, called "Serve Files." It has three improvements over existing implementations:
- Serve every file from the directory of your script at its filename
- Serve a zip of the entire directory in which your script is contained at
/. This is useful for copying a lot of files to a computer at once
- Printing your local IP to the console, to make it easier to see where you should go on your computer
It will also clean up the zip it creates after you stop the server.
Here's the script:
import os import shutil import socket import urllib.parse import dialogs import editor import flask # SETUP # Resolve local IP by connecting to Google's DNS server s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) s.connect(("8.8.8.8", 80)) localip = s.getsockname()[0] s.close() # Initialize Flask app = flask.Flask(__name__) # Calculate path details directory, filename = os.path.split(editor.get_path()) dirpath, dirname = os.path.split(directory.rstrip("/")) zippath = os.path.abspath("./{}.zip".format(dirname)) # Make an archive shutil.make_archive(dirname, "zip", dirpath, dirname) # Configure server routings @app.route("/") def index(): """Serve a zip of it all from the root""" return flask.send_file(zippath) @app.route("/<path:path>") def serve_file(path): """Serve individual files from elsewhere""" return flask.send_from_directory(directory, path) # Run the app print("Running at {}".format(localip)) app.run(host="0.0.0.0", port=80) # After it finishes os.remove(zippath)
- Webmaster4o
I think Flask tries to get the
Content-Typecorrect, but I'm not sure if there's a header for forcing download. I'll look into it. 👍 | https://forum.omz-software.com/topic/3326/share-code-serving-files-over-http | CC-MAIN-2017-26 | refinedweb | 296 | 58.69 |
In this tutorial, we will learn about the well built relationship between pointers and arrays in C/C++ programming. Pointers are variables that are used to store the address of a variable/function and even arrays that are blocks holding sequential data. We can operate an array using pointers in a very interesting and useful manner.
Before moving ahead make sure to go through the following introductory reading about pointers:
Pointers with arrays
When we declare any array, we have to specify its data type and size. For example, an integer array named ‘array’ of size 5 will be declared as follows:
int array[5];
This means that we have indeed created 5 integer variables named array[0], array[1], array[2], array[3] and array[4]. These five integers will be stored in the memory as a block of five consecutive integers. The figure below shows the horizontal memory for example purposes.
For example, we are showing that array[0] is stored at 100, array[1] will be 4 bytes ahead of array[0] at 104 because integer variables need 4 bytes of memory. Thus, array[2] will be at address 108, array[3] will be at address112 and array[4] will be at address 114. . The overall size of the array will be 20 bytes(5×4) and these 20 bytes will form one consecutive block as shown in the section of the memory in which the array is stored.
Similarly, we can also show the memory horizontally from left to right as well. We will increase the address while moving from left to right. Additionally, the array[5] has the following values: {10,11,12,13,14}.
The following table shows the addresses and values for each index.
Note: The address locations are just for example purposes and do not depict exact locations.
Important: The array elements are stored in contiguous memory locations, each element occupying four bytes, since it is an integer array.
Now for observational purposes let use the horizontal representation of the memory. This time we will show the memory a little bit more extended to the right so that we can accommodate more variables. Let’s say we have an integer variable ‘x’ and its value is set to ‘100’. For example, x is located at address 200. Now if we have a pointer to integer ‘ptr’. In ‘ptr’ we want to store the address of ‘x’. This will be accomplished through the lines of code given below.
int x = 100; int *ptr; ptr = &x;
You can also view it in the horizontal memory segment as shown below:
Now if we print ptr as an output then the value in ptr would be equal to 200. You can use the following statement to print the value of ‘ptr.’ This is the address of the variable ‘x’.
printf("\n%d",ptr);
If we deference ptr and print the value stored in this location then the value will be equal to 100. You can use the following statement to print the value. Use an asterisk sign in front of the pointer variable to access the value of the variable it points to.
printf("\n%d",*ptr);
Additionally, we also know that we can increment/decrement a pointer variable by a constant. So we can do something like this:
ptr=ptr+1; printf(ptr);
This will take us to the address of the next integer. As integers take up 4 bytes of memory so now the next index will be at 204. If we want to print ‘ptr’ then the output should be 204.
If we try to dereference ‘ptr’, and try to print *ptr then we do not know the value at this address. We can not say what will be printed. We know that ‘x’ is at address 200 but do not know the value of the variable at the next address (204) location.
Assigning an array to a pointer
However, this can be known when working with arrays and pointers. For this integer array (array[5]), also shown in the figure located at address 100. We will now declare a pointer to an integer called ‘ptr.’ Next, we will store the address of the first element of the array in this pointer. This will be achieved by putting an ampersand operator(&) in front of array[0]. Then printing ‘ptr’ will give us the output 100.
int array[5]={10,11,12,13,14}; int *ptr; ptr = &array[0]; printf("\n%d",ptr);
Printing *ptr will give 10 in the output.
printf("\n%d",*ptr);
If I want to print (ptr+1) then the address would be 204 and if i try to dereference (p+1) and try to print this value then it will be ’11.’
printf("\n%d",ptr+1); printf("\n%d",*(ptr+1));
Similarly, if we wanted to access the third element of the array we could print (ptr+2).
Thus, using pointer arithmetic makes sense in the case of arrays, as we know the value in the adjacent location.
Accessing the address of the first element of an array
One more property of the array is that by just using the name of the array we can access the address of the first element of the array. Then ‘array’ gives us the pointer to the first element in the array.
For example:
ptr =array;
In fact we do not even need to take this address in another pointer variable. If we simply print ‘array’ then this gives us nothing but the address of the first element of the array which is 100 in our case.
int array[5]={10,11,12,13,14}; int *ptr; ptr = array; printf("\n%d",array);
Assigning an array to a pointer is equal to assigning the memory address of the first value in the array to the pointer
How to get the memory address and value of an array element?
- To obtain the value of the first element of the array we will have to deference ‘array’ as shown below. This will give us the value of the first element of the array which is 10 in our case.
printf("\n%d",*array);
- If we want to print (array+1) then this will give us the address of the second element in the array i.e.104 and *(a+1) will give us the value of the second element of the array i.e. ’11’ in our case.
printf("\n%d",array+1); printf("\n%d",*(array+1));
For an element in the array at index ‘i’, we can retrieve the address of this particular element in the memory using either &array[i] or (array+i). These two will give us the address of array[i].
The value of array[i] can be retrieved using either array[i] or *(array+i). This is an important concept. Both statements are equivalent.
- The address of the first element in the array can also be called the base address. Simply using the variable name e.g. ‘array’ gives us the base address of the array.
Let us look at some example C codes to further understand the concepts of pointers with arrays.
Subscript notation vs Pointers. Which one to choose when accessing values?
As you noticed, we used two different methods to locate the memory addresses of the elements of the array as well as accessing the value of the elements. We used both subscript notation and pointers to access the values of elements. Although we obtained the same result in either case but using one of them has a slightly higher advantage over the other, depending upon the way you want to access the elements.
- If you want to access elements in an array in a particular fixed order e.g. from beginning to end or using some other logic, then using pointers is clearly a better option. Moreover, using pointers to access elements in arrays is more faster than using subscript notation.
- However, if there is no fixed logic being used to access the elements then it is very easy to use the subscript notation instead of working with pointers. It is simpler and easier to program.
Example Codes for pointers with arrays
In our first example program, we have an integer array called ‘num’. If we simply print ‘num’ then it should give us the address of the first element in the array. We can also obtain the address of the first element in the array by using the ampersand operator in front of num[0]. Printing num[0] will print the first element in the array. Moreover, we can also access the first element in the array by using an asterisk operator in front of the variable name ‘num.’
#include <stdio.h> int main(){ int num[]={1,2,3,4,5,6}; printf("Address of first element: %d\n",num); printf("Address of first element: %d\n",&num[0]); printf("Value of first element: %d\n",num[0]); printf("Value of first element: %d\n",*num); }
Code Output
Now let’s see the code output. After the compilation of the above code, you will get the following output.
As you can see the first two lines are the same. They are giving us the address of the first element in the array. The second two lines are also same and give us the value of the first element of the array. In our case, it is ‘1’.
- To find the address of the first element, we can either use name of array e.g. num or &num[0].
- To find the value of the first element we can either use num[0] or *num.
Using loop() to access all elements’ locations and values
In fact, if we run a loop() like this for 0 to index 6 then we can print addresses of the elements at index i as &A[i] or (A+i). Similarly, we can print the value of the ith element as A[i] or *(A+i). The following code does that.
#include <stdio.h> int main(){ int num[]={1,2,3,4,5,6}; int i; for (i=0;i<6;i++){ printf("Address: %d\n",&num[i]); printf("Address: %d\n",num+i); printf("Value: %d\n",num[i]); printf("Value: %d\n",*(num+i)); printf("\n"); } }
Code output
Now let’s see the code output. After the compilation of the above code, you will get the following output.
Acessing Array Elements through a Pointer
Notice, the address printed for a particular index are same and the value at that index is also the same. Also, note that as the array ‘num’ is of integer data type that takes 4 bytes of memory per variable hence the addresses of consecutive elements differ by 4.
Using the variable name ‘num’ returns a pointer to the base address or the address of the first element. We can equate the variable ‘num’ against some pointer variable ‘ptr.’
int *ptr = num;
However, we can not increment/decrement the value of the array num like num = num+1; or num = num-1; This will give compilation error. However, we can increment the pointer like ptr = ptr + 1; once we assign num to some pointer variable but incrementing/decrementing ‘num’ itself would be invalid.
int *ptr =num; ptr++;
This was an introduction to how arrays are stored in memory, how addresses can be manipulated, and how we can access the values using pointers.
#include <stdio.h> int main(){ int num[]={1,2,3,4,5,6}; int *ptr = num; for (int i=0;i<6;i++){ printf("Address of num[i]: %d",ptr); printf(" Value of num[i]: %d",*ptr); printf("\n"); ptr++; }
Address of num[i]: 424745984 Value of num[i]: 1 Address of num[i]: 424745988 Value of num[i]: 2 Address of num[i]: 424745992 Value of num[i]: 3 Address of num[i]: 424745996 Value of num[i]: 4 Address of num[i]: 424746000 Value of num[i]: 5 Address of num[i]: 424746004 Value of num[i]: 6
You may like to read other pointer tutorials:
- Pointer Arithmetic, Pointer Size, and Pointer Type in C and C++
- Double Pointers or Pointers to Pointers in C/C++
- Pointers as Function Arguments or call by reference in C
- Function Pointers in C/C++ and Function Callbacks
- How to find the Size of structure without sizeof() Operator?
- Dynamic Memory Allocation through Double Pointer and Function without returning address
- C Program to change Endianness of data and bytes swapping example using Pointers
- How to find an array size without using sizeof() and through Pointers Subtraction | https://csgeekshub.com/c-programming/pointers-and-arrays-in-c/ | CC-MAIN-2021-49 | refinedweb | 2,103 | 61.06 |
LinuxQuestions.org
(
/questions/
)
-
Programming
(
)
- -
compile error srgp library in C
(
)
csst0136
10-23-2005 02:48 PM
compile error srgp library in C
i compile the program:
#include <stdio.h>
#include "srgp.h"
int main()
{
SRGP_begin("hw", 500, 300, 1, TRUE);
SRGP_end();
return 1;
}
and i get
/tmp/cc4ddcut.o(text+0x27):In function 'main':
:undefined reference to 'SRGP_begin'
/tmp/cc4ddcut.o(text+0x2f):In function 'main':
:undefined reference to 'SRGP_end'
collect 2:ld returned 1 exit status
Hko
10-24-2005 11:25 AM
You didn't link the lib that contains
SRGP_begin and SRGP_end on the compiler command line.
Or you didn't mention srgp.
c
after the -o option on the compiler command line.
csst0136
10-24-2005 11:43 AM
how do i link the libraries?there is a file libsrgp.a which contains files with extension .o.I have put libsrgp.a into /usr/lib
i compile the program like :
gcc name_program.c
i dont use -o
deiussum
10-24-2005 12:18 PM
To link libraries, you add -l<libraryname> to your comand line. Library name is the name of a library that is usually in the form lib<libraryname>.so (or .a). So in your case, try using -lsrgp. You may also have to include -static to link static libraries (which is what a .a is), but I don't remember for sure.
csst0136
10-24-2005 03:04 PM
i linked -lsrgp and i get more errors like the others
/tmp/****.o
undefined reference ****
deiussum
10-24-2005 03:13 PM
That's probably because srgp relies on additional libraries. Without seeing exact errors, we can't tell you what additional libraries you need to link, but one trick you can use to find out is to use grep.
For instance, say it is complaining about an undefined reference to xxxxxxx.
Type the following to see if there is a .so file in /usr/lib that has that function.
grep "xxxxxxx" /usr/lib/*.so
(Note: This sometimes find files that rely on that function as well, so it doesn't necessarily mean that the function is exported from all the .so files it finds...)
Now, assuming it found a reference xxxxxxx in libyyyyy.so, you could then try adding -lyyyyy.
Edit: You may also have to look in other library directories such as /usr/X11R6/lib. If you find a library you need in any directory that is not part of the standard library search path, you can add it to the search path by adding -L/path/to/library to your command line. Using my previous example, if you found that /usr/X11R6/lib/libyyyyy.so had what you needed you would add:
-L/usr/X11R6/lib -lyyyyy
paulsm4
10-24-2005 04:07 PM
Hi -
As I mentioned in a separate post: please e-mail me the link where you downloaded your version of srgp, and I'll try test building it myself and let you know what I find.
There's every chance it's a simple syntax error in your "makefile", or something not configured correctly in your environment.
On the other hand, it's also possible that this library isn't even intended for Linux, and it might be more trouble that it's worth trying to get it to compile and link.
Please let me know.
Your .. PSM
csst0136
10-24-2005 04:17 PM
i run command grep and i found some libraries like
libKXL.so
libMagick.so
libplot.so
libgdraw.so
etc..
i linked just one of them for example libplot and i didnt get errors but when i run it with ./a.out i got
SRGP:Color table too full to share
A solution is to have the SRGP application request
0 planes in the 4th parameter to SRGP_begin.
For now, the application will have its own
color table rather than try to share.
SRGP FATAL ERROR:
X SERVER ERROR:
(examining the core will be usefull only if using X in synchronous mode):
Badmatch (invalid parameter attributes)
I AM ABOUT TO INVENTIONALLY CRASH SO YOU CAN LOOK
AT THE ACTIVATION STACK USING A DEBUGGER
If your application is an SRGP application ,please remember:
if the error message above says
that you sent a bad argument to a certain function,
you should run your program with tracing ON in order
to see exactly what you sent
If you already had tracing enabled,remember to look in
'SRGPlogfile' for the tracing messages
Aborted.
deiussum
10-24-2005 04:22 PM
He posted the location in his other duplicate thread as,.
I took a quick look myself, and the examples makefile there also links in -lX11. My guess is that though this is an old library, it should work in Linux.
So, try add ing -L/usr/X11R6/lib -lX1ll.
If it still doesn't work, post the exact undefined references and/or try to find the appropriate library with grep.
Give a man a fish, he eats for a day. Teach a man to fish, he eats for a lifetime...
deiussum
10-24-2005 04:31 PM
Ok, looks like you got it to compile while I was posting my last response. You can find the SRGP docs at.
It says this about that fourth parameter of SRGP_begin:
Quote:
The fourth parameter is meaningful only on a display supporting color. It specifies how many planes of the color table should be reserved for SRGP's use; i.e., it places an upper bound on the number of colors that may be displayed simultaneously in the SRGP window. (The upper bound is colors, where is the number of planes.) The fourth parameter is ignored when the program is run on a bilevel display.
If the program is being run on a color display, and you send the special value "0" as the fourth parameter, SRGP will take over the entire color table, giving your application color support as rich as the hardware can offer. (After initializing SRGP, you can inquire the "canvas depth" to determine how many planes are available.) The disadvantage: it will be impossible for the user to simultaneously see the SRGP window's proper coloring and the other clients' windows' proper coloring. Thus, you should request "0" planes only when your application truly needs full control of the color table.
Are you running this from X? I might try passing 0 there to see what happens. Passing 1 sounds like you are requesting only 1 color. It does say it ignores it on a "bilevel display," but I'm not exactly sure what it means by that. I don't think I've ever heard that term used before, but my guess would be it means some sort of GUI system like X11...
paulsm4
10-24-2005 05:05 PM
Thank you very much, deiussum.
I'm exiting stage left for now. The main points that I found (posted in csst0136's other thread) are:
1. srgp.tar.Z extracts nicely into its own subdirectory. You don't need to copy anything into other
places (and certainly not into /usr/lib).
2. You can build the examples with the syntax:
make PROG=xxx (e.g. "make PROG=testpaint", from the "SRGP_DISTRIB/examples" subdirectory)
3. Before you do this, however, you must rebuild "libsrgp.a" (it does not appear to be a Linux/ELF archive)
4. You must add "-I../include", "-L../lib" (both in the sample Makefile) and "-L/usr/X11R6/lib" (SRGP pre-dates X11R6).
5. After you do all this, you can successfully build an SRGP app under Linux/X11R6.
I was not, however, able to successfully run it. For starters, it defaults to some assumptions about colormaps which don't appear to be true for contemporary X11 servers. Changing the 4th parameter from "3" to "0" didn't help. It's unclear what - if any - further problems csst0136 might run into if he were to debug the colormap problem.
'Hope that helps ... at least a little!
PS:
Any recommendations on a good API for "Learning Graphics 101 under Linux"? My top vote would be for Java (which has very good 2D and 3D APIs), but I'm very curious about SDL.
Do you have any recommendations, deiussum?
deiussum
10-24-2005 05:18 PM
Good findings, paulsm. I'm not at home right now so I can't mess with this srgp API at all myself.
Personally, I like OpenGL since most of the graphics I do is 3D based. (You can do 2D stuff too in the form of textured quads, but if you're looking for a typical 2D API it's probably not what you want.) With OpenGL, however, you still need a windowing API of some sort as it leaves window creation/events/etc. up to someone else. SDL is pretty good for creating a simple OpenGL window, but you can use pretty much any windowing API if you know what you are doing.
csst0136
10-25-2005 08:24 AM
thanx a lot for helping me you already help me a lot especially to paulsm4 and deiussum
the problem has solved to run the examples.i just change the depth color from 16 bit to 8 bit from YAST.SRGP runs only for 8 bit.But the strange thing is that when i run the program it opens
a new window which is the place where i draw what the program does but everything becomes black.I can see just the bounds of the windows,the minimize and close button at top right of the window and the mouse cursor with white color.If i click out of the window then all becomes with color(very fine) but when i click into the window again it becomes all black again and what i draw is with white color.
paulsm4
10-25-2005 09:36 PM
Hi -
I suspect the problem with the "weird colors" is a combination of:
1. The library assumes an excessively low color resolution (you had to go into YaST2 and set the X server to 8-bit/256 color mode?)
... and ..
2. The library is using private (instead of shared) colors.
Again, this was all common practice 10 years ago ... but technology has changed.
I'm afraid I don't have time to go poking around SRGP myself to see if I can make it a little more "Linux-circa-2005-friendly". You're certainly welcome to try; I'd definitely encourage to you to post any questions to LQ.
I couldn't find any good, short web articles on Xlib colormaps that didn't have a lot of extraneous stuff but, if you're feeling ambitious, here are some links that'll tell you everything you need to know ... and then some!
... and ...
'Hope that helps .. PSM
All times are GMT -5. The time now is
05:14 PM
. | http://www.linuxquestions.org/questions/programming-9/compile-error-srgp-library-in-c-376104-print/ | CC-MAIN-2016-26 | refinedweb | 1,819 | 72.97 |
Assumptions
Before we dive in, I'm going to be making a few assumptions about you as a reader:
- You are very comfortable with programming in a C-syntax-style language (I will be using C# with XNA).
- You have programmed some sort of tree-like data structure in the past, such as a binary search tree and are familiar with recursion and its strengths and pitfalls.
- You know how to do collision detection with bounding rectangles, bounding spheres, and bounding frustums.
- You have a good grasp of common data structures (arrays, lists, etc) and understand Big-O notation (you can also learn about Big-O in this GDnet article).
- You have a development environment project which contains spatial objects which need collision tests.
Setting the stage
Let's suppose that we are building a very large game world which can contain thousands of physical objects of various types, shapes and sizes, some of which must collide with each other. Each frame we need to find out which objects are intersecting with each other and have some way to handle that intersection. How do we do it without killing performance?
Brute force collision detection
The simplest method is to just compare each object against every other object in the world. Typically, you can do this with two for loops. The code would look something like this:
foreach(gameObject myObject in ObjList) { foreach(gameObject otherObject in ObjList) { if(myObject == otherObject) continue; //avoid self collision check if(myObject.CollidesWith(otherObject)) { //code to handle the collision } } }
Conceptually, this is what we're doing in our picture:
Each red line is an expensive CPU test for intersection. Naturally, you should feel horrified by this code because it is going to run in O(N^2) time. If you have 10,000 objects, then you're going to be doing 100,000,000 collision checks (hundred million). I don't care how fast your CPU is or how well you've tuned your math code, this code would reduce your computer to a sluggish crawl. If you're running your game at 60 frames per second, you're looking at 60 * 100 million calculations per second! It's nuts. It's insane. It's crazy. Let's not do this if we can avoid it, at least not with a large set of objects. This would only be acceptable if we're only checking, say, 10 items against each other (100 checks is palatable). If you know in advance that your game is only going to have a very small number of objects (ie, asteriods), you can probably get away with using this brute force method for collision detection and ignore octrees altogether. If/when you start noticing performance problems due to too many collision checks per frame, consider some simple targeted optimizations:
1. How much computation does your current collision routine take? Do you have a square root hidden away in there (ie, a distance check)? Are you doing a granular collision check (pixel vs pixel, triangle vs triangle, etc)? One common technique is to perform a rough, coarse check for collision before testing for a granular collision check. You can give your objects an enclosing bounding rectangle or bounding sphere and test for intersection with these before testing against a granular check which may involve a lot more math and computation time.
2. Can you get away with calculating fewer collision checks? If your game runs at 60 frames per second, could you skip a few frames? If you know certain objects behave deterministically, can you "solve" for when they will collide ahead of time (ie, pool ball vs. side of pool table). Can you reduce the number of objects which need to be checked for collisions? A technique for this would be to separate objects into several lists. One list could be your "stationary" objects list. They never have to test for collision against each other. The other list could be your "moving" objects, which need to be tested against all other moving objects and against all stationary objects. This could reduce the number of necessary collision tests to reach an acceptable performance level.
3. Can you get away with removing some object collision tests when performance becomes an issue? For example, a smoke particle could interact with a surface object and follow its contours to create a nice aesthetic effect, but it wouldn't break game play if you hit a predefined limit for collision checks and decided to stop ignoring smoke particles for collision. Ignoring essential game object movement would certainly break game play though (ei, player bullets stop intersecting with monsters). So, perhaps maintaining a priority list of collision checks to compute would help. First you handle the high priority collision tests, and if you're not at your threshold, you can handle lower priority collision tests. When the threshold is reached, you dump the rest of the items in the priority list or defer them for testing at a later time.
4. Can you use a faster but still simplistic method for collision detection to get away from a O(N^2) runtime? If you eliminate the objects you've already checked for collisions against, you can reduce the runtime to O(N(N+1)/2), which is much faster and still easy to implement. (technically, it's still O(N^2))
In terms of software engineering, you may end up spending more time than it's worth fine-tuning a bad algorithm & data structure choice to squeeze out a few more ounces of performance. The cost vs. benefit ratio becomes increasingly unfavorable and it becomes time to choose a better data structure to handle collision detection. Spatial partioning algorithms are the proverbial nuke to solving the runtime problem for collision detection. At a small upfront cost to performance, they'll reduce your collision detection tests to logarithmic runtime. The upfront costs of development time and CPU overhead are easily outweighed by the scalability benefits and performance gains.
Conceptual background on spatial partioning
Let's take a step back and look at spatial partitioning and trees in general before diving into Octrees. If we don't understand the conceptual idea, we have no hope of implementing it by sweating over code.
Looking at the brute force implementation above, we're essentially taking every object in the game and comparing their positions against all other objects in the game to see if any are touching. All of these objects are contained spatially within our game world. Well, if we create an enclosing box around our game world and figure out which objects are contained within this enclosing box, then we've got a region of space with a list of contained objects within it. In this case, it would contain every object in the game. We can notice that if we have an object on one corner of the world and another object way on the other side, we don't really need to, or want to, calculate a collision check against them every frame. It'd be a waste of precious CPU time. So, let's try something interesting! If we divide our world exactly in half, we can create three seperate lists of objects. The first list of objects, List A, contains all objects on the left half of the world. The second list, List B, contains objects on the right half of the world. Some objects may touch the dividing line such that they're on each side of the line, so we'll create a third list, List C, for these objects.
We can notice that with each subdivision, we're spatially reducing the world in half and collecting a list of objects in that resulting half. We can elegantly create a binary search tree to contain these lists. Conceptually, this tree should look something like so:
In terms of pseudo code, the tree data structure would look something like this:
public class BinaryTree { //This is a list of all of the objects contained within this node of the tree private List<GameObject> m_objectList; //These are pointers to the left and right child nodes in the tree private BinaryTree m_left, m_right; //This is a pointer to the parent object (for upward tree traversal). private BinaryTree m_parent; }
We know that all objects in List A will never intersect with any objects in List B, so we can almost eliminate half of the number of collision checks. We've still got the objects in List C which could touch objects in either list A or B, so we'll have to check all objects in List C against all objects in Lists A, B & C. If we continue to sub-divide the world into smaller and smaller parts, we can further reduce the number of necessary collision checks by half each time.
This is the general idea behind spatial partitioning. There are many ways to subdivide a world into a tree-like data structure (BSP trees, Quad Trees, K-D trees, OctTrees, etc). Now, by default, we're just assuming that the best division is a cut in half, right down the middle, since we're assuming that all of our objects will be somewhat uniformally distributed throughout the world. It's not a bad assumption to make, but some spatial division algorithms may decide to make a cut such that each side has an equal amount of objects (a weighted cut) so that the resulting tree is more balanced. However, what happens if all of these objects move around? In order to maintain a near even division, you'd have to either shift the splitting plane or completely rebuild the tree each frame. It'd be a bit of a mess with a lot of complexity. So, for my implementation of a spatial partioning tree I decided to cut right down the middle every time. As a result, some trees may end up being a bit more sparse than others, but that's okay -- it doesn't cost much.
To subdivide or not to subdivide? That is the question.
Let's assume that we have a somewhat sparse region with only a few objects. We could continue subdividing our space until we've found the smallest possible enclosing area for that object. But is that really necessary? Let's remember that the whole reason we're creating a tree is to reduce the number of collision checks we need to perform each frame -- not to create a perfectly enclosing region of space for every object. Here are the rules I use for deciding whether to subdivide or not:
- If we create a subdivision which only contains one object, we can stop subdividing even though we could keep dividing further. This rule will become an important part of the criteria for what defines a "leaf node" in our octree.
- The other important criteria is to set a minimum size for a region. If you have an extremely small object which is nanometers in size (or, god forbid, you have a bug and forgot to initialize an object size!), you're going to keep subdividing to the point where you potentially overflow your call stack. For my own implementation, I defined the smallest containing region to be a 1x1x1 cube. Any objects in this teeny cube will just have to be run with the O(N^2) brute force collision test (I don't anticipate many objects anyways!).
- If a containing region doesn't contain any objects, we shouldn't try to include it in the tree.
If the quad tree subdivision and data structure makes sense, then an octree should be pretty straight forward as well. We're just adding a third dimension, using bounding cubes instead of bounding squares, and have eight possible child nodes instead of four. Some of you might wonder what should happen if you have a game world with non-cubic dimensions, say 200x300x400. You can still use an octree with cubic dimensions -- some child nodes will just end up empty if the game world doesn't have anything there. Obviously, you'll want to set the dimensions of your octree to at least the largest dimension of your game world.
Octree Construction
So, as you've read, an octree is a special type of subdividing tree commonly used for objects in 3D space (or anything with 3 dimensions). Our enclosing region is going to be a three dimensionsal rectangle (commonly a cube). We will then apply our subdivision logic above, and cut our enclosing region into eight smaller rectangles. If a game object completely fits within one of these subdivided regions, we'll push it down the tree into that node's containing region. We'll then recursively continue subdividing each resulting region until one of our breaking conditions is met. At the end, we should expect to have a nice tree-like data structure.
In terms of our Octree class data structure, I decided to do the following for each tree:
- Each node has a bounding region which defines the enclosing region
- Each node has a reference to the parent node
- Contains an array of eight child nodes (use arrays for code simplicity and cache performance)
- Contains a list of objects contained within the current enclosing region
- I use a byte-sized bitmask for figuring out which child nodes are actively being used (the optimization benefits at the cost of additional complexity is somewhat debatable)
- I use a few static variables to indicate the state of the tree
public class OctTree { BoundingBox m_region; List<Physical> m_objects; /// <summary> /// These are items which we're waiting to insert into the data structure. /// We want to accrue as many objects in here as possible before we inject them into the tree. This is slightly more cache friendly. /// </summary> static Queue<Physical> m_pendingInsertion = new Queue<Physical>(); /// <summary> /// These are all of the possible child octants for this node in the tree. /// </summary> OctTree[] m_childNode = new OctTree[8]; /// <summary> /// This is a bitmask indicating which child nodes are actively being used. /// It adds slightly more complexity, but is faster for performance since there is only one comparison instead of 8. /// </summary> byte m_activeNodes = 0; /// <summary> /// The minumum size for enclosing region is a 1x1x1 cube. /// </summary> const int MIN_SIZE = 1; /// <summary> /// this is how many frames we'll wait before deleting an empty tree branch. Note that this is not a constant. The maximum lifespan doubles /// every time a node is reused, until it hits a hard coded constant of 64 /// </summary> int m_maxLifespan = 8; // int m_curLife = -1; //this is a countdown time showing how much time we have left to live /// <summary> /// A reference to the parent node is nice to have when we're trying to do a tree update. /// </summary> OctTree _parent; static bool m_treeReady = false; //the tree has a few objects which need to be inserted before it is complete static bool m_treeBuilt = false; //there is no pre-existing tree yet. }
Initializing the enclosing region
The first step in building an octree is to define the enclosing region for the entire tree. This will be the bounding box for the root node of the tree which initially contains all objects in the game world. Before we go about initializing this bounding volume, we have a few design decisions we need to make:
1. What should happen if an object moves outside of the bounding volume of the root node? Do we want to resize the entire octree so that all objects are enclosed? If we do, we'll have to completely rebuild the octree from scratch. If we don't, we'll need to have some way to either handle out of bounds objects, or ensure that objects never go out of bounds.
2. How do we want to create the enclosing region for our octree? Do we want to use a preset dimension, such as a 200x400x200 (X,Y,Z) rectangle? Or do we want to use a cubic dimension which is a power of 2? What should be the smallest allowable enclosing region which cannot be subdivided?
Personally, I decided that I would use a cubic enclosing region with dimensions which are a power of 2, and sufficiently large to completely enclose my world. The smallest allowable cube is a 1x1x1 unit region. With this, I know that I can always cleanly subdivide my world and get integer numbers (even though the Vector3 uses floats). I also decided that my enclosing region would enclose the entire game world, so if an object leaves this region, it should be quietly destroyed. At the smallest octant, I will have to run a brute force collision check against all other objects, but I don't realistically expect more than 3 objects to occupy that small of an area at a time, so the performance costs of O(N^2) are completely acceptable.
So, I normally just initialize my octree with a constructor which takes a region size and a list of items to insert into the tree. I feel it's barely worth showing this part of the code since it's so elementary, but I'll include it for completeness. Here are my constructors:
/*Note: we want to avoid allocating memory for as long as possible since there can be lots of nodes.*/ /// <summary> /// Creates an oct tree which encloses the given region and contains the provided objects. /// </summary> /// <param name="region">The bounding region for the oct tree.</param> /// <param name="objList">The list of objects contained within the bounding region</param> private OctTree(BoundingBox region, List<Physical> objList) { m_region = region; m_objects = objList; m_curLife = -1; } public OctTree() { m_objects = new List<Physical>(); m_region = new BoundingBox(Vector3.Zero, Vector3.Zero); m_curLife = -1; } /// <summary> /// Creates an octTree with a suggestion for the bounding region containing the items. /// </summary> /// <param name="region">The suggested dimensions for the bounding region. /// Note: if items are outside this region, the region will be automatically resized.</param> public OctTree(BoundingBox region) { m_region = region; m_objects = new List<Physical>(); m_curLife = -1; }
Building an initial octree
I'm a big fan of lazy initialization. I try to avoid allocating memory or doing work until I absolutely have to. In the case of my octree, I avoid building the data structure as long as possible. We'll accept a user's request to insert an object into the data structure, but we don't actually have to build the tree until someone runs a query against it. What does this do for us? Well, let's assume that the process of constructing and traversing our tree is somewhat computationally expensive. If a user wants to give us 1,000 objects to insert into the tree, does it make sense to recompute every subsequent enclosing area a thousand times? Or, can we save some time and do a bulk blast? I created a "pending" queue of items and a few flags to indicate the build state of the tree. All of the inserted items get put into the pending queue and when a query is made, those pending requests get flushed and injected into the tree. This is especially handy during a game loading sequence since you'll most likely be inserting thousands of objects at once. After the game world has been loaded, the number of objects injected into the tree is orders of magnitude fewer.
My lazy initialization routine is contained within my UpdateTree() method. It checks to see if the tree has been built, and builds the data structure if it doesn't exist and has pending objects.
/// <summary> /// Processes all pending insertions by inserting them into the tree. /// </summary> /// <remarks>Consider deprecating this?</remarks> private void UpdateTree() //complete & tested { if (!m_treeBuilt) { while (m_pendingInsertion.Count != 0) m_objects.Add(m_pendingInsertion.Dequeue()); BuildTree(); } else { while (m_pendingInsertion.Count != 0) Insert(m_pendingInsertion.Dequeue()); } m_treeReady = true; }
As for building the tree itself, this can be done recursively. So for each recurisive iteration, I start off with a list of objects contained within the bounding region. I check my termination rules, and if we pass, we create eight subdivided bounding areas which are perfectly contained within our enclosed region. Then, I go through every object in my given list and test to see if any of them will fit perfectly within any of my octants. If they do fit, I insert them into a corresponding list for that octant. At the very end, I check the counts on my corresponding octant lists and create new octrees and attach them to our current node, and mark my bitmask to indicate that those child octants are actively being used. All of the left over objects have been pushed down to us from our parent, but can't be pushed down to any children, so logically, this must be the smallest octant which can contain the object.
/// <summary> /// Naively builds an oct tree from scratch. /// </summary> private void BuildTree() //complete & tested { //terminate the recursion if we're a leaf node if (m_objects.Count <= 1) return; Vector3 dimensions = m_region.Max - m_region.Min; if (dimensions == Vector3.Zero) { FindEnclosingCube(); dimensions = m_region.Max - m_region.Min; } //Check to see if the dimensions of the box are greater than the minimum dimensions if (dimensions.X <= MIN_SIZE && dimensions.Y <= MIN_SIZE && dimensions.Z <= MIN_SIZE) { return; } Vector3 half = dimensions / 2.0f; Vector3 center = m_region.Min + half; //Create subdivided regions for each octant BoundingBox[] octant = new BoundingBox[8]; octant[0] = new BoundingBox(m_region.Min, center); octant[1] = new BoundingBox(new Vector3(center.X, m_region.Min.Y, m_region.Min.Z), new Vector3(m_region.Max.X, center.Y, center.Z)); octant[2] = new BoundingBox(new Vector3(center.X, m_region.Min.Y, center.Z), new Vector3(m_region.Max.X, center.Y, m_region.Max.Z)); octant[3] = new BoundingBox(new Vector3(m_region.Min.X, m_region.Min.Y, center.Z), new Vector3(center.X, center.Y, m_region.Max.Z)); octant[4] = new BoundingBox(new Vector3(m_region.Min.X, center.Y, m_region.Min.Z), new Vector3(center.X, m_region.Max.Y, center.Z)); octant[5] = new BoundingBox(new Vector3(center.X, center.Y, m_region.Min.Z), new Vector3(m_region.Max.X, m_region.Max.Y, center.Z)); octant[6] = new BoundingBox(center, m_region.Max); octant[7] = new BoundingBox(new Vector3(m_region.Min.X, center.Y, center.Z), new Vector3(center.X, m_region.Max.Y, m_region.Max.Z)); //This will contain all of our objects which fit within each respective octant. List<Physical>[] octList = new List<Physical>[8]; for (int i = 0; i < 8; i++) octList[i] = new List<Physical>(); //this list contains all of the objects which got moved down the tree and can be delisted from this node. List<Physical> delist = new List<Physical>(); foreach (Physical obj in m_objects) { if (obj.BoundingBox.Min != obj.BoundingBox.Max) { for (int a = 0; a < 8; a++) { if (octant[a].Contains(obj.BoundingBox) == ContainmentType.Contains) { octList[a].Add(obj); delist.Add(obj); break; } } } else if (obj.BoundingSphere.Radius != 0) { for (int a = 0; a < 8; a++) { if (octant[a].Contains(obj.BoundingSphere) == ContainmentType.Contains) { octList[a].Add(obj); delist.Add(obj); break; } } } } //delist every moved object from this node. foreach (Physical obj in delist) m_objects.Remove(obj); //Create child nodes where there are items contained in the bounding region for (int a = 0; a < 8; a++) { if (octList[a].Count != 0) { m_childNode[a] = CreateNode(octant[a], octList[a]); m_activeNodes |= (byte)(1 << a); m_childNode[a].BuildTree(); } } m_treeBuilt = true; m_treeReady = true; } private OctTree CreateNode(BoundingBox region, List<Physical> objList) //complete & tested { if (objList.Count == 0) return null; OctTree ret = new OctTree(region, objList); ret._parent = this; return ret; } private OctTree CreateNode(BoundingBox region, Physical Item) { List<Physical> objList = new List<Physical>(1); //sacrifice potential CPU time for a smaller memory footprint objList.Add(Item); OctTree ret = new OctTree(region, objList); ret._parent = this; return ret; }
Updating a tree
Let's imagine that our tree has a lot of moving objects in it. If any object moves, there is a good chance that the object has moved outside of its enclosing octant. How do we handle changes in object position while maintaining the integrity of our tree structure?
Technique 1: Keep it super simple, trash & rebuild everything.
Some implementations of an Octree will completely rebuild the entire tree every frame and discard the old one. This is super simple and it works, and if this is all you need, then prefer the simple technique. The general concensus is that the upfront CPU cost of rebuilding the tree every frame is much cheaper than running a brute force collision check, and programmer time is too valuable to be spent on an unnecessary optimization.
For those of us who like challenges and to over-engineer things, the "trash & rebuild" technique comes with a few small problems:
- You're constantly allocating and deallocating memory each time you rebuild your tree. Allocating new memory comes with a small cost. If possible, you want to minimize the amount of memory being allocated and reallocated over time by reusing memory you've already got.
- Most of the tree is unchanging, so it's a waste of CPU time to rebuild the same branches over and over again.
Technique 2: Keep the existing tree, update the changed branches
I noticed that most branches of a tree don't need to be updated. They just contain stationary objects. Wouldn't it be nice if, instead of rebuilding the entire tree every frame, we just updated the parts of the tree which needed an update? This technique keeps the existing tree and updates only the branches which had an object which moved. It's a bit more complex to implement, but it's a lot more fun too, so let's really get into that!
During my first attempt at this, I mistakenly thought that an object in a child node could only go up or down one traversal of the tree. This is wrong. If an object in a child node reaches the edge of that node, and that edge also happens to be an edge for the enclosing parent node, then that object needs to be inserted above its parent, and possibly up even further. So, the bottom line is that we don't know how far up an object needs to be pushed up the tree. Just as well, an object can move such that it can be neatly enclosed in a child node, or that child's child node. We don't know how far down the tree we can go. Fortunately since we include a reference to each node's parent, we can easily solve this problem recursively with minimal computation!
The general idea behind the update algorithm is to first let all objects in the tree update themselves. Some may move or change in size. We want to get a list of every object which moved, so the object update method should return to us a boolean value indicating if its bounding area changed. Once we've got a list of all of our moved objects, we want to start at our current node and try to traverse up the tree until we find a node which completely encloses the moved object (most of the time, the current node still encloses the object). If the object isn't completely enclosed by the current node, we keep moving it up to its next parent node. In the worst case, our root node will be guaranteed to contain the object. After we've moved our object as far up the tree as possible, we'll try to move it as far down the tree as we can. Most of the time, if we moved the object up, we won't be able to move it back down. But, if the object moved so that a child node of the current node could contain it, we have the chance to push it back down the tree. It's important to be able to move objects down the tree as well, or else all moving objects would eventually migrate to the top and we'd start getting some performance problems during collision detection routines.
Branch Removal
In some cases, an object will move out of a node and that node will no longer have any objects contained within it, nor have any children which contain objects. If this happens, we have an empty branch and we need to mark it as such and prune this dead branch off the tree. There is an interesting question hiding here: When do you want to prune the dead branches off a tree? Allocating new memory costs time, so if we're just going to reuse this same region in a few cycles, why not keep it around for a bit? How long can we keep it around before it becomes more expensive to maintain the dead branch? I decided to give each of my nodes a count down timer which activates when the branch is dead. If an object moves into this nodes octant while the death timer is active, I double the lifespan and reset the death timer. This ensures that octants which are frequently used are hot and stick around, and nodes which are infrequently used are removed before they start to cost more than they're worth. A practical example of this usefulness would be apparent when you have a machine gun shooting a stream of bullets. Those bullets follow in close succession of each other, so it'd be a shame to immediately delete a node as soon as the first bullet leaves it, only to recreate it a fraction of a second later as the second bullet re-enters it. And if there's a lot of bullets, we can probably keep these octants around for a little while. If a child branch is empty and hasn't been used in a while, it's safe to prune it out of our tree.
Anyways, let's look at the code which does all of this magic. First up, we have the Update() method. This is a method which is recursively called on all child trees. It moves all objects around, does some house keeping work for the data structure, and then moves each moved object into its correct node (parent or child).
public void Update(GameTime gameTime) { if (m_treeBuilt == true) { //Start a count down death timer for any leaf nodes which don't have objects or children. //when the timer reaches zero, we delete the leaf. If the node is reused before death, we double its lifespan. //this gives us a "frequency" usage score and lets us avoid allocating and deallocating memory unnecessarily if (m_objects.Count == 0) { if (HasChildren == false) { if (m_curLife == -1) m_curLife = m_maxLifespan; else if (m_curLife > 0) { m_curLife--; } } } else { if (m_curLife != -1) { if(m_maxLifespan <= 64) m_maxLifespan *= 2; m_curLife = -1; } } List<Physical> movedObjects = new List<Physical>(m_objects.Count); //go through and update every object in the current tree node foreach (Physical gameObj in m_objects) { //we should figure out if an object actually moved so that we know whether we need to update this node in the tree. if (gameObj.Update(gameTime)) { movedObjects.Add(gameObj); } } //prune any dead objects from the tree. int listSize = m_objects.Count; for (int a = 0; a < listSize; a++) { if (!m_objects[a].Alive) { if (movedObjects.Contains(m_objects[a])) movedObjects.Remove(m_objects[a]); m_objects.RemoveAt(a--); listSize--; } } //recursively update any child nodes. for( int flags = m_activeNodes, index = 0; flags > 0; flags >>=1, index++) if ((flags & 1) == 1) m_childNode[index].Update(gameTime); //If an object moved, we can insert it into the parent and that will insert it into the correct tree node. //note that we have to do this last so that we don't accidentally update the same object more than once per frame. foreach (Physical movedObj in movedObjects) { OctTree current = this; //figure out how far up the tree we need to go to reinsert our moved object //we are either using a bounding rect or a bounding sphere //try to move the object into an enclosing parent node until we've got full containment if (movedObj.BoundingBox.Max != movedObj.BoundingBox.Min) { while (current.m_region.Contains(movedObj.BoundingBox) != ContainmentType.Contains) if (current._parent != null) current = current._parent; else break; //prevent infinite loops when we go out of bounds of the root node region } else { while (current.m_region.Contains(movedObj.BoundingSphere) != ContainmentType.Contains)//we must be using a bounding sphere, so check for its containment. if (current._parent != null) current = current._parent; else break; } //now, remove the object from the current node and insert it into the current containing node. m_objects.Remove(movedObj); current.Insert(movedObj); //this will try to insert the object as deep into the tree as we can go. } //prune out any dead branches in the tree for (int flags = m_activeNodes, index = 0; flags > 0; flags >>= 1, index++) if ((flags & 1) == 1 && m_childNode[index].m_curLife == 0) { m_childNode[index] = null; m_activeNodes ^= (byte)(1 << index); //remove the node from the active nodes flag list } //now that all objects have moved and they've been placed into their correct nodes in the octree, we can look for collisions. if (IsRoot == true) { //This will recursively gather up all collisions and create a list of them. //this is simply a matter of comparing all objects in the current root node with all objects in all child nodes. //note: we can assume that every collision will only be between objects which have moved. //note 2: An explosion can be centered on a point but grow in size over time. In this case, you'll have to override the update method for the explosion. List<IntersectionRecord> irList = GetIntersection(new List<Physical>()); foreach (IntersectionRecord ir in irList) { if (ir.PhysicalObject != null) ir.PhysicalObject.HandleIntersection(ir); if (ir.OtherPhysicalObject != null) ir.OtherPhysicalObject.HandleIntersection(ir); } } } else { } }
Note that we call an Insert() method for moved objects. The insertion of objects into the tree is very similar to the method used to build the initial tree. Insert() will try to push objects as far down the tree as possible. Notice that I also try to avoid creating new bounding areas if I can use an existing one from a child node.
/// <summary> /// A tree has already been created, so we're going to try to insert an item into the tree without rebuilding the whole thing /// </summary> /// <typeparam name="T">A physical object</typeparam> /// <param name="Item">The physical object to insert into the tree</param> private void Insert<T>(T Item) where T : Physical { /*make sure we're not inserting an object any deeper into the tree than we have to. -if the current node is an empty leaf node, just insert and leave it.*/ if (m_objects.Count <= 1 && m_activeNodes == 0) { m_objects.Add(Item); return; } Vector3 dimensions = m_region.Max - m_region.Min; //Check to see if the dimensions of the box are greater than the minimum dimensions if (dimensions.X <= MIN_SIZE && dimensions.Y <= MIN_SIZE && dimensions.Z <= MIN_SIZE) { m_objects.Add(Item); return; } Vector3 half = dimensions / 2.0f; Vector3 center = m_region.Min + half; //Find or create subdivided regions for each octant in the current region BoundingBox[] childOctant = new BoundingBox[8]; childOctant[0] = (m_childNode[0] != null) ? m_childNode[0].m_region : new BoundingBox(m_region.Min, center); childOctant[1] = (m_childNode[1] != null) ? m_childNode[1].m_region : new BoundingBox(new Vector3(center.X, m_region.Min.Y, m_region.Min.Z), new Vector3(m_region.Max.X, center.Y, center.Z)); childOctant[2] = (m_childNode[2] != null) ? m_childNode[2].m_region : new BoundingBox(new Vector3(center.X, m_region.Min.Y, center.Z), new Vector3(m_region.Max.X, center.Y, m_region.Max.Z)); childOctant[3] = (m_childNode[3] != null) ? m_childNode[3].m_region : new BoundingBox(new Vector3(m_region.Min.X, m_region.Min.Y, center.Z), new Vector3(center.X, center.Y, m_region.Max.Z)); childOctant[4] = (m_childNode[4] != null) ? m_childNode[4].m_region : new BoundingBox(new Vector3(m_region.Min.X, center.Y, m_region.Min.Z), new Vector3(center.X, m_region.Max.Y, center.Z)); childOctant[5] = (m_childNode[5] != null) ? m_childNode[5].m_region : new BoundingBox(new Vector3(center.X, center.Y, m_region.Min.Z), new Vector3(m_region.Max.X, m_region.Max.Y, center.Z)); childOctant[6] = (m_childNode[6] != null) ? m_childNode[6].m_region : new BoundingBox(center, m_region.Max); childOctant[7] = (m_childNode[7] != null) ? m_childNode[7].m_region : new BoundingBox(new Vector3(m_region.Min.X, center.Y, center.Z), new Vector3(center.X, m_region.Max.Y, m_region.Max.Z)); //First, is the item completely contained within the root bounding box? //note2: I shouldn't actually have to compensate for this. If an object is out of our predefined bounds, then we have a problem/error. // Wrong. Our initial bounding box for the terrain is constricting its height to the highest peak. Flying units will be above that. // Fix: I resized the enclosing box to 256x256x256. This should be sufficient. if (Item.BoundingBox.Max != Item.BoundingBox.Min && m_region.Contains(Item.BoundingBox) == ContainmentType.Contains) { bool found = false; //we will try to place the object into a child node. If we can't fit it in a child node, then we insert it into the current node object list. for(int a=0;a<8;a++) { //is the object fully contained within a quadrant? if (childOctant[a].Contains(Item.BoundingBox) == if (Item.BoundingSphere.Radius != 0 && m_region.Contains(Item.BoundingSphere) == ContainmentType.Contains) { bool found = false; //we will try to place the object into a child node. If we can't fit it in a child node, then we insert it into the current node object list. for (int a = 0; a < 8; a++) { //is the object contained within a child quadrant? if (childOctant[a].Contains(Item.BoundingSphere) == { //either the item lies outside of the enclosed bounding box or it is intersecting it. Either way, we need to rebuild //the entire tree by enlarging the containing bounding box //BoundingBox enclosingArea = FindBox(); BuildTree(); } }
Collision Detection
Finally, our octree has been built and everything is as it should be. How do we perform collision detection against it?
First, let's list out the different ways we want to look for collisions:
- Frustum intersections. We may have a frustum which intersects with a region of the world. We only want the objects which intersect with the given frustum. This is particularly useful for culling regions outside of the camera view space, and for figuring out what objects are within a mouse selection area.
- Ray intersections. We may want to shoot a directional ray from any given point and want to know either the nearest intersecting object, or get a list of all objects which intersect that ray (like a rail gun). This is very useful for mouse picking. If the user clicks on the screen, we want to draw a ray into the world and figure out what they clicked on.
- Bounding Box intersections. We want to know which objects in the world are intersecting a given bounding box. This is most useful for "box" shaped game objects (houses, cars, etc).
- Bounding Sphere Intersections. We want to know which objects are intersecting with a given bounding sphere. Most objects will probably be using a bounding sphere for coarse collision detection since the mathematics is computationally the least expensive and somewhat easy.
The main idea behind recursive collision detection processing for an octree is that you start at the root/current node and test for intersection with all objects in that node against the intersector. Then, you do a bounding box intersection test against all active child nodes with the intersector. If a child node fails this intersection test, you can completely ignore the rest of that child's tree. If a child node passes the intersection test, you recursively traverse down the tree and repeat. Each node should pass a list of intersection records up to its caller, which appends those intersections to its own list of intersections. When the recursion finishes, the original caller will get a list of every intersection for the given intersector. The beauty of this is that it takes very little code to implement and performance is very fast.
In a lot of these collisions, we're probably going to be getting a lot of results. We're also going to want to have some way of responding to each collision, depending on what objects are colliding. For example, a player hero should pick up a floating bonus item (quad damage!), but a rocket shouldn't explode if it hits said bonus item. I created a new class to contain information about each intersection. This class contains references to the intersecting objects, the point of intersection, the normal at the point of intersection, etc. These intersection records become quite useful when you pass them to an object and tell them to handle it. For completeness and clarity, here is my intersection record class:
public class IntersectionRecord { Vector3 m_position; /// <summary> /// This is the exact point in 3D space which has an intersection. /// </summary> public Vector3 Position { get { return m_position; } } Vector3 m_normal; /// <summary> /// This is the normal of the surface at the point of intersection /// </summary> public Vector3 Normal { get { return m_normal; } } Ray m_ray; /// <summary> /// This is the ray which caused the intersection /// </summary> public Ray Ray { get { return m_ray; } } Physical m_intersectedObject1; /// <summary> /// This is the object which is being intersected /// </summary> public Physical PhysicalObject { get { return m_intersectedObject1; } set { m_intersectedObject1 = value; } } Physical m_intersectedObject2; /// <summary> /// This is the other object being intersected (may be null, as in the case of a ray-object intersection) /// </summary> public Physical OtherPhysicalObject { get { return m_intersectedObject2; } set { m_intersectedObject2 = value; } } /// <summary> /// this is a reference to the current node within the octree for where the collision occurred. In some cases, the collision handler /// will want to be able to spawn new objects and insert them into the tree. This node is a good starting place for inserting these objects /// since it is a very near approximation to where we want to be in the tree. /// </summary> OctTree m_treeNode; /// <summary> /// check the object identities between the two intersection records. If they match in either order, we have a duplicate. /// </summary> /// <param name="otherRecord">the other record to compare against</param> /// <returns>true if the records are an intersection for the same pair of objects, false otherwise.</returns> public override bool Equals(object otherRecord) { IntersectionRecord o = (IntersectionRecord)otherRecord; // //return (m_intersectedObject1 != null && m_intersectedObject2 != null && m_intersectedObject1.ID == m_intersectedObject2.ID); if (otherRecord == null) return false; if (o.m_intersectedObject1.ID == m_intersectedObject1.ID && o.m_intersectedObject2.ID == m_intersectedObject2.ID) return true; if (o.m_intersectedObject1.ID == m_intersectedObject2.ID && o.m_intersectedObject2.ID == m_intersectedObject1.ID) return true; return false; } double m_distance; /// <summary> /// This is the distance from the ray to the intersection point. /// You'll usually want to use the nearest collision point if you get multiple intersections. /// </summary> public double Distance { get { return m_distance; } } private bool m_hasHit = false; public bool HasHit { get { return m_hasHit; } } public IntersectionRecord() { m_position = Vector3.Zero; m_normal = Vector3.Zero; m_ray = new Ray(); m_distance = float.MaxValue; m_intersectedObject1 = null; } public IntersectionRecord(Vector3 hitPos, Vector3 hitNormal, Ray ray, double distance) { m_position = hitPos; m_normal = hitNormal; m_ray = ray; m_distance = distance; //m_hitObject = hitGeom; m_hasHit = true; } /// <summary> /// Creates a new intersection record indicating whether there was a hit or not and the object which was hit. /// </summary> /// <param name="hitObject">Optional: The object which was hit. Defaults to null.</param> public IntersectionRecord(Physical hitObject = null) { m_hasHit = hitObject != null; m_intersectedObject1 = hitObject; m_position = Vector3.Zero; m_normal = Vector3.Zero; m_ray = new Ray(); m_distance = 0.0f; } }
Intersection with a Bounding Frustum
/// <summary> /// Gives you a list of all intersection records which intersect or are contained within the given frustum area /// </summary> /// <param name="frustum">The containing frustum to check for intersection/containment with</param> /// <returns>A list of intersection records with collisions</returns> private List<IntersectionRecord> GetIntersection(BoundingFrustum frustum, Physical.PhysicalType type = Physical.PhysicalType.ALL) { if (m_objects.Count == 0 && HasChildren == false) //terminator for any recursion return null; List<IntersectionRecord> ret = new List<IntersectionRecord>(); //test each object in the list for intersection foreach (Physical obj in m_objects) { //skip any objects which don't meet our type criteria if ((int)((int)type & (int)obj.Type) == 0) continue; //test for intersection IntersectionRecord ir = obj.Intersects(frustum); if (ir != null) ret.Add(ir); } //test each object in the list for intersection for (int a = 0; a < 8; a++) { if (m_childNode[a] != null && (frustum.Contains(m_childNode[a].m_region) == ContainmentType.Intersects || frustum.Contains(m_childNode[a].m_region) == ContainmentType.Contains)) { List<IntersectionRecord> hitList = m_childNode[a].GetIntersection(frustum); if (hitList != null) { foreach (IntersectionRecord ir in hitList) ret.Add(ir); } } } return ret; }
The bounding frustum intersection list can be used to only render objects which are visible to the current camera view. I use a scene database to figure out how to render all objects in the game world. Here is a snippet of code from my rendering function which uses the bounding frustum of the active camera:
/// <summary> /// This renders every active object in the scene database /// </summary> /// <param name="gameTime"></param> public int Render() { int triangles = 0; //Renders all visible objects by iterating through the oct tree recursively and testing for intersection //with the current camera view frustum foreach (IntersectionRecord ir in m_octTree.AllIntersections(m_cameras[m_activeCamera].Frustum)) { ir.PhysicalObject.SetDirectionalLight(m_globalLight[0].Direction, m_globalLight[0].Color); ir.PhysicalObject.View = m_cameras[m_activeCamera].View; ir.PhysicalObject.Projection = m_cameras[m_activeCamera].Projection; ir.PhysicalObject.UpdateLOD(m_cameras[m_activeCamera]); triangles += ir.PhysicalObject.Render(m_cameras[m_activeCamera]); } return triangles; }
Intersection with a Ray
/// <summary> /// Gives you a list of intersection records for all objects which intersect with the given ray /// </summary> /// <param name="intersectRay">The ray to intersect objects against</param> /// <returns>A list of all intersections</returns> private List<IntersectionRecord> GetIntersection(Ray intersectRay, Physical.PhysicalType type = Physical.PhysicalType.ALL) { if (m_objects.Count == 0 && HasChildren == false) //terminator for any recursion return null; List<IntersectionRecord> ret = new List<IntersectionRecord>(); //the ray is intersecting this region, so we have to check for intersection with all of our contained objects and child regions. //test each object in the list for intersection foreach (Physical obj in m_objects) { //skip any objects which don't meet our type criteria if ((int)((int)type & (int)obj.Type) == 0) continue; if (obj.BoundingBox.Intersects(intersectRay) != null) { IntersectionRecord ir = obj.Intersects(intersectRay); if (ir.HasHit) ret.Add(ir); } } // test each child octant for intersection for (int a = 0; a < 8; a++) { if (m_childNode[a] != null && m_childNode[a].m_region.Intersects(intersectRay) != null) { List<IntersectionRecord> hits = m_childNode[a].GetIntersection(intersectRay, type); if (hits != null) { foreach (IntersectionRecord ir in hits) ret.Add(ir); } } } return ret; }
Intersection with a list of objects
This is a particularly useful recursive method for determining if a list of objects in the current node intersect with any objects in any child nodes (See: Update() method for usage). It's the method which will be used most frequently, so it's good to get this right and efficient. What we want to do is start at the root node of the tree. We compare all objects in the current node against all other objects in the current node for collision. We gather up any of those collisions as intersection records, and insert them into a list. We then pass our list of tested objects down to our child nodes. The child nodes will then test their objects against themselves, then against the objects we passed down to them. The child nodes will capture any collisions in a list, and return that list to its parent. The parent then takes the collision list recieved from its child nodes and appends it to its own list of collisions, finally returning it to its caller.
If you count out the number of collision tests in the illustration above, you can see that we conducted 29 hit tests and recieved 4 hits. This is much better than [11*11 = 121] hit tests.
private List<IntersectionRecord> GetIntersection(List<Physical> parentObjs, Physical.PhysicalType type = Physical.PhysicalType.ALL) { List<IntersectionRecord> intersections = new List<IntersectionRecord>(); //assume all parent objects have already been processed for collisions against each other. //check all parent objects against all objects in our local node foreach (Physical pObj in parentObjs) { foreach (Physical lObj in m_objects) { //We let the two objects check for collision against each other. They can figure out how to do the coarse and granular checks. //all we're concerned about is whether or not a collision actually happened. IntersectionRecord ir = pObj.Intersects(lObj); if (ir != null) { intersections.Add(ir); } } } //now, check all our local objects against all other local objects in the node if (m_objects.Count > 1) { #region self-congratulation /* * This is a rather brilliant section of code. Normally, you'd just have two foreach loops, like so: * foreach(Physical lObj1 in m_objects) * { * foreach(Physical lObj2 in m_objects) * { * //intersection check code * } * } * * The problem is that this runs in O(N*N) time and that we're checking for collisions with objects which have already been checked. * Imagine you have a set of four items: {1,2,3,4} * You'd first check: {1} vs {1,2,3,4} * Next, you'd check {2} vs {1,2,3,4} * but we already checked {1} vs {2}, so it's a waste to check {2} vs. {1}. What if we could skip this check by removing {1}? * We'd have a total of 4+3+2+1 collision checks, which equates to O(N(N+1)/2) time. If N is 10, we are already doing half as many collision checks as necessary. * Now, we can't just remove an item at the end of the 2nd for loop since that would break the iterator in the first foreach loop, so we'd have to use a * regular for(int i=0;i<size;i++) style loop for the first loop and reduce size each iteration. This works...but look at the for loop: we're allocating memory for * two additional variables: i and size. What if we could figure out some way to eliminate those variables? * So, who says that we have to start from the front of a list? We can start from the back end and still get the same end results. With this in mind, * we can completely get rid of a for loop and use a while loop which has a conditional on the capacity of a temporary list being greater than 0. * since we can poll the list capacity for free, we can use the capacity as an indexer into the list items. Now we don't have to increment an indexer either! * The result is below. */ #endregion List<Physical> tmp = new List<Physical>(m_objects.Count); tmp.AddRange(m_objects); while (tmp.Count > 0) { foreach (Physical lObj2 in tmp) { if (tmp[tmp.Count - 1] == lObj2 || (tmp[tmp.Count - 1].IsStatic && lObj2.IsStatic)) continue; IntersectionRecord ir = tmp[tmp.Count - 1].Intersects(lObj2); if (ir != null) intersections.Add(ir); } //remove this object from the temp list so that we can run in O(N(N+1)/2) time instead of O(N*N) tmp.RemoveAt(tmp.Count-1); } } //now, merge our local objects list with the parent objects list, then pass it down to all children. foreach (Physical lObj in m_objects) if (lObj.IsStatic == false) parentObjs.Add(lObj); //parentObjs.AddRange(m_objects); //each child node will give us a list of intersection records, which we then merge with our own intersection records. for (int flags = m_activeNodes, index = 0; flags > 0; flags >>= 1, index++) if ((flags & 1) == 1) intersections.AddRange(m_childNode[index].GetIntersection(parentObjs, type)); return intersections; }
Screenshot Demos
This is a view of the game world from a distance showing the outlines for each bounding volume for the octree.
This view shows a bunch of successive projectiles moving through the game world with the frequently-used nodes being preserved instead of deleted.
Complete Code Sample
I've attached a complete code sample of the octree class, the intersection record class, and my generic physical object class. I don't guarantee that they're all bug free since it's all a work in progress and hasn't been rigorously tested yet.
About the Author(s)
I am currently an independent game developer working on my first game. I have a four year degree in computer science & software engineering, and a minor in philosophy. My philosophical instinct is saying, "don't judge my correctness based on my credentials, but upon rigorous testing of my given claims."
License
Public Domain
Im not a fan of quadtree or octree, but must admit that article its one of the best...
Only one comment? Really? Man, this tutorial is amazing! I plan on implementing something similar into my game engine in the near future and I'm sure I will be able to do it using this tutorial only!
Thank you very much for this amazing work <3
Wow! Unbelievable, this article is so detailed, thank you professor.
Very interesting article, thanks for the explanations!
However, the code would need to be reviewed a little bit, with blocks of codes being put in separate methods, GetIntersection being coded once for all as generic for any kind of intersection checks (with common logic of type check and children intersection tests) - except maybe for the last one (list of objects), where you could also avoid to use a separate tmp list of Physical, and just keep the index of the last object to treat in m_objects instead.
Yeah, I found some bugs in my code later on and fixed them. I think the in-place update may have been overly complicating things and adding additional potential sources for errors. I recommend using my code implementation as a good starting point / reference instead of blindly just copy/pasting it. I'm sure someone smarter than I could design it much better, but this was my second iteration
Great article and super useful code. I have one question. In the FindEnclosingCube() method, there is this:
Did you intend for that to be the highest significant bit of highX, or the largest power of 2 that contains highX? I assume it was the highest that contains the number, so I replaced it with:
I probably broke the whole thing... Haven't put it into action yet.
Here is the code you're referencing:
What's going on here?
I'm trying to create a cube which encloses every single object in the game world. A perfect cube has sides which are all of the same length. We could have a cube with side lengths of 1000 which perfectly encloses every object. However, 1000 is a number which doesn't divide by two very cleanly. In my octree, I decided that the smallest a quadrant should be is 1x1x1. I wouldn't get much more of a performance gain by going smaller.
So, if my enclosing cube is 1000x1000x1000, I can't get a nice 1x1x1 cube by successively dividing by two:
1000 / 2 = 500
500 / 2 = 250
250 / 2 = 125
125 / 2 = 62.5
62.5 / 2 = 31.25
31.25 / 2 = 15.625
(etc)
However, if we increase the size of our enclosing cube to be a power of 2, we can easily divide by 2 each time to get clean numbers, all the way down to a 1x1x1 cube. If we have our enclosing cube of 1000x1000x1000, then the nearest cube with a power of 2 we want would be 1024x1024x1024. So, the function you're asking about should take any number and return the power of 2 value which is closest to the given number. ie, 63 would result in 64, 65 would result in 128, etc.
In the Insert() method, shouldn't there be a "break;" when an item has been inserted? (talking about the for(int a=0;a<8;a++) loop) | http://www.gamedev.net/page/resources/_/technical/game-programming/introduction-to-octrees-r3529?forceDownload=1&_k=880ea6a14ea49e853634fbdc5015a024 | CC-MAIN-2016-50 | refinedweb | 9,239 | 54.32 |
While Java is the default programming language for Android, it isn’t always the best method for making apps, specifically games. Many engines used to make Android games use the Android Native Development Kit (NDK), because the NDK allows developers to write code in C/C++ that compiles to native code. This means that NDK games/apps can squeeze more performance out of devices. Here is your guide on how to use the Android NDK.
What is the Android NDK?
The Android Native Development Kit allows developers to get the most performance out of devices, this can be beneficial for game engines like Unity or Unreal Engine. Because the source code is compiled directly into machine code for the CPU (and not into an intermediate language, as with Java) then developers are able to get the best performance. It is also possible to use other developers’ libraries or your own if there is something that you absolutely need to use.
How it works
The “ndk-build” script is the heart of the Android NDK and it is responsible for automatically going through your project and determining what to build. The script is also responsible for generating binaries and copying those binaries to your app’s project path.
You have the ability to use the “native” keyword to tell the compiler that the implementation is native. An example is
public native int numbers(int x, int y);. More info on the ABI can be found here.
Everything works under an interface known as the Java Native Interface (JNI), this is how the Java and C/C++ components talk to each other. More information on the JNI can be found here.
If you are going to build using the ndk build script, you will need to create two files: Android.mk and Application.mk. The Android.mk needs to go in your jni folder and defines the module plus its name, the build flags (which libraries link to), and what source files need to be compiled. Application.mk also goes in the jni directory. It describes the native modules that your app requires.
How to install and use
Installing the Android NDK is as easy as going to Preferences>Android SDK>Android NDK on OS X, and File>Settings>Android SDK>SDK Tools>NDK on Windows. Once installed, you will need to do a little more tweaking to get your app ready for NDK use. We will be starting with a new application as an example. You will need Android Studio 2.2 or higher to continue, make sure you have the latest version before you get started. Create a new project and select “Basic Activity” when prompted. Click the play button to run the app to make sure it works. Once everything is set up, let’s get everything ready for native development:
Go to preferences, or settings, depending on your operating system and click Build Tools>Gradle and select “Use default gradle wrapper (recommended)” if it is not already selected.
Find the latest experimental gradle plugin from here and note the version. Open your project’s, not module’s, build.gradle and replace
classpath 'com.android.tools.build:gradle:2.1.0' with
classpath 'com.android.tools.build:gradle-experimental:version number'
This will replace the stable version of Gradle with an experimental version with Android NDK support.
Go to your module’s build.gradle and replace the old code with this:
apply plugin: 'com.android.model.application'model { android { compileSdkVersion 23 buildToolsVersion "23.0.3" defaultConfig { applicationId "com.example.abutt.aandk" minSdkVersion.apiLevel 22 targetSdkVersion.apiLevel 23 versionCode 1 versionName "1.0" } buildTypes { release { minifyEnabled false proguardFiles.add(file('proguard-android.txt')) } } ndk { moduleName "hello-android-jni" } } } // others below this line: no change
Run the app and make sure everything is working and that the app acts like it did before. Under the “buildTypes” block in the build.gradle for the module add:
ndk { moduleName "hello-android-jni" }
In your app’s MainActivity.java, add this to the end of the program:
// new code static { System.loadLibrary("hello-android-jni"); } public native String getMsgFromJni(); // new code done } // class MainActivity
Run the program and make sure everything is still working as it should. Next up is to make the C/C++ file, you should notice that the getMsgFromJni() function is red, hover your mouse over the function until a red lightbulb pops up. Click the lightbulb and click the first option creating a function.
The C/C++ file will be under a new folder called “jni.” Open this file and paste this into the file:
#include <jni.h>JNIEXPORT jstring JNICALL
Java_com_example_abutt_aandk_MainActivity_getMsgFromJni(JNIEnv *env, jobject instance) {// TODO
return (*env)->NewStringUTF(env, "Hello From Jni! This was done in C!");
}
Make sure to change “com_example_abutt_aandk” to your app’s name. This file is read by the getMsgFromJni() function to display “Hello From Jni! This was done C!”
Go back to your app’s MainActivity and add this to the end of the OnCreate() method:
((TextView) findViewById(R.id.jni_msgView)).setText(getMsgFromJni());
That’s it! Your app should run correctly and be utilizing the Android NDK! Now this isn’t a real-world example on how the NDK would be used. A more-real world example would be developing for OpenGL and Vulkan natively or using an engine like Unity or Unreal Engine that has the NDK built in.
Wrap Up
The Android NDK has some very specific uses and probably shouldn’t be used in everyday development. But the NDK has given engine creators a great way to optimize their products for Android, enabling great graphical capabilities while using fewer resources. Making a simple application using the Android NDK is not too difficult and with some practice native OpenGL is a real possibility. Do you use the Android NDK for development? Let us know in the comments below! | https://www.androidauthority.com/android-ndk-everything-need-know-677642/ | CC-MAIN-2018-39 | refinedweb | 977 | 57.37 |
How to fix DynamoDB timeouts in Serverless apps
In this post we are going to look at how to debug DynamoDB timeouts in Serverless apps. This is a fairly specific issue related to Node.js Lambda functions calling DynamoDB. But we recently had to work through this issue. Hopefully sharing our experience ends up being helpful to other folks.
Let’s start by looking at the issue itself.
The issue
We noticed that a certain percentage of our Node.js Lambda function calls were timing out. We used AWS X-Ray to trace the calls and found that the DynamoDB call seemed to be taking abnormally long. However there were no specific types of calls that were timing out. We observed timeouts across BatchGet, Get, Query, and Update calls.
Roughly 0.00002% of all our DynamoDB calls were timing out. We confirmed with Mike Apted that this is a farily normal timeout rate for DynamoDB calls.
Thus, the next step was to figure out how to handle these timeouts so that our users weren’t being adversely affected by them.
There are two common ways DynamoDB calls might timeout.
1. HTTP connections are timing out
The first reason DynamoDB calls are taking long is because the HTTP requests that the AWS SDK is making to DynamoDB is timing out.
The AWS Node.js SDK has 2 settings:
HTTP Connect Timeout
This sets the socket to timeout after failing to establish a connection with the server after a set amount of milliseconds. This timeout has no effect once a socket connection has been established.
HTTP Timeout
Sets the socket to timeout after a set amount of inactivity on the socket. Defaults to two minutes.
On the other hand, for Lambda and API Gateway:
- API Gateway has a maximum timeout setting of 29 sec.
- Hence, Lambda should have a timeout of lesser than 29 sec.
And it only makes sense that DynamoDB’s connection timeout is set to be lesser than that of Lambda. In fact, we want to keep it short. If DynamoDB times out, we want it to fail quickly and retry again. We want the DynamoDB calls to timeout before Lambda and API Gateway timeout. However, that is not what happens by default. As we talked about the issue above, our Lambda functions were timing out because the DynamoDB calls were taking too long.
So the first thing we need to do is to change the connection timeout for our DynamoDB client.
In our Lambda function, change the timeout by using the following:
import AWS from 'aws-sdk'; const dynamoDb = new AWS.DynamoDB.DocumentClient({ httpOptions: { timeout: 5000 } });
2. Retries are taking long
Sometimes a DynamoDB call might fail. However, the response usually specifies if the error can be retried. By default, the AWS Node.js SDK client auto-retries such errors. It uses an exponential backoff strategy while retrying. For calls to most AWS services, the client auto-retries up to 3 times. It waits 100 ms before the first retry, 200 ms before the second, and 400 ms before the third attempt.
However for calls to DynamoDB, the client auto-retries up to 10 times. Starting with 50 ms for the first retry, then 100 ms, 200 ms, 400 ms all the way to 25600 ms for the last retry. The worst case scenario here is that a failed DynamoDB call takes over 50 sec before responding to your Lambda function. Given that API Gateway will timeout by 29 sec, you won’t get to find out if the DynamoDB call timed out or errored out.
Hence, to be able to debug the issue, we need to reduce the retry count for our DynamoDB client. It needs to completely fail before our Lambda (or API Gateway) times out.
To reduce the number of retries do the following:
import AWS from 'aws-sdk'; const dynamoDb = new AWS.DynamoDB.DocumentClient({ maxRetries: 3 });
Now you should be able to figure out why your DynamoDB calls were failing in the first place.
Summary
Hopefully this post gives you a good idea on how to work with the DynamoDB timeouts that you are seeing in your Serverless app. A special thanks to Mike Apted, Adriano Raiano, and Carl Nordenfelt for helping us track down the issue.
Do your Serverless deployments take too long? Incremental deploys in Seed can speed it up 100x!Learn More | https://seed.run/blog/how-to-fix-dynamodb-timeouts-in-serverless-application.html | CC-MAIN-2022-27 | refinedweb | 731 | 74.29 |
Consider a normal decimal number, such as 5623. We intuitively understand that these digits mean (5 * 1000) + (6 * 100) + (2 * 10) + (3 * 1). Because there are 10 decimal numbers, the value of each subsequent digit to the left increases by a factor of 10.
Binary numbers work the same way, except because there are only 2 binary digits ).
The following table counts to 15 in decimal and binary:
Converting binary to decimal
In the following examples, we assume that we’re dealing with unsigned integers.
Consider the 8 bit (1 byte) binary number 0101 1110. Binary represented in binary just like positive unsigned numbers (with the sign bit set to 0).
Negative signed numbers are represented in binary as the bitwise inverse of the positive number, plus 1.
Converting integers to binary two’s complement
For example, here’s how we represent -5.
Why types matter
Consider the binary value 1011 0100. What value does this represent? You’d probably say 180, and if this were a?
In case the section title didn’t give it away, this is where types come into play. The type of the variable determines both how a variable’s value is encoded into binary, and decoded back into a value. So if the variable type was an unsigned integer, it would know that 1011 0100 was standard binary, and should be printed as 180. If the variable was a signed integer, it would know that 1011 0100 was encoded using two’s complement (now guaranteed as of C+ time
Question #1
Show Solution
The answer is 77.
Question #2.
Question #3
We already know that 93 is 0101 1101 from the previous answer.
For two’s complement, we invert the bits: 1010 0010
And add 1: 1010 0011
Question #4
Working right to left:
1010 0010 = (0 * 1) + (1 * 2) + (0 * 4) + (0 * 8) + (0 * 16) + (1 * 32) + (0 * 64) + (1 * 128) = 2 + 32 + 128 = 162.
The answer is 162.
Question #5
Since we’re told this number is in two’s complement, we can “undo” the two’s complement by inverting the bits and adding 1.
First, start with our binary number: 1010 0010
Flip the bits: 0101 1101
Add 1: 0101 1110
Convert to decimal: 64 + 16 + 8 + 4 + 2 = 94
Remember that this is a two’s complement #, and the original left bit was negative: -94
The answer is -94
Question #6
Write a program that asks the user to input a number between 0 and 255. Print this number as an 8-bit binary number (of the form #### ####). Don’t use any bitwise operators. Don’t use std::bitset.
std::bitset
Show Hint
Solution:
Actually, I think the solution above is too complicated. Should have done this instead (since we can't use std::bitset):
i've done question 6 this way.
Minor things to fix:
1. You don't need argc and argv in this code
2. On line 9, just do
std::cout << num % 2;
#include <iostream>
int substractInt(char bitStatus, int number, int pow)
{
if (bitStatus == '1')
number = number - pow;
return number;
}
char divideInt(int number, int pow)
{
char binNum{};
(number >= pow) ? binNum = '1' : binNum = '0';
return binNum;
}
int askUser()
{
int number{};
std::cout << "enter a number between 0 - 225: ";
std::cin >> number;
return number;
}
int main()
{
int number{ askUser() };
const int eb_128{ 128 };
char iTb7{ divideInt(number, eb_128) };
number = { substractInt(iTb7, number, eb_128) };
const int eb_64{ 64 };
char iTb6{ divideInt(number, eb_64) };
number = { substractInt(iTb6, number, eb_64) };
const int eb_32{ 32 };
char iTb5{ divideInt(number, eb_32) };
number = { substractInt(iTb5, number, eb_32) };
const int eb_16{ 16 };
char iTb4{ divideInt(number, eb_16) };
number = { substractInt(iTb4, number, eb_16) };
const int eb_8{ 8 };
char iTb3{ divideInt(number, eb_8) };
number = { substractInt(iTb3, number, eb_8) };
const int eb_4{ 4 };
char iTb2{ divideInt(number, eb_4) };
number = { substractInt(iTb2, number, eb_4) };
const int eb_2{ 2 };
char iTb1{ divideInt(number, eb_2) };
number = { substractInt(iTb1, number, eb_2) };
const int eb_1{ 1 };
char iTb0{ divideInt(number, eb_1) };
number = { substractInt(iTb0, number, eb_1) };
std::cout << iTb7 << iTb6 << iTb5 << iTb4 << '\'' << iTb3 << iTb2 << iTb1 << iTb0;
return 0;
}
Loved reading this chapter, very glad I did!
Of course, loops make it easier but they are not covered yet. Respecting that fact, the following program works.
You don't need the else statement in the checkBit function because it will return anyway if the if statement executes. You can change it to:
I think this one is really easy.
I think you aren't allowed to use bit operators.
Here's another way to convert a positive number n (represented in binary two's complement) to -n.
1. Looking at n's binary representation, go from right to left, until you find a 1.
2. Flip all bits to the left of that 1.
Example:
0010 1100 (decimal: 44) -the first rightmost bit is at position 2 (starting count from 0)
1101 0100 (decimal: -44) -after flipping all bits to the left of the rightmost bit
I'm not sure if this is an efficient way but it's shorter and outputs the correct result.
"Consider the decimal number 148 again. What’s the largest power of 2 that’s smaller than 148? 128, so we’ll start there.
Is 148 >= 128? Yes, so the 128 bit must be 1. 148 - 128 = 20, which means we need to find bits worth 20 more."
doesn't this mean its always 1 ?
because we are looking for a number that is smaller than the DECIMAL number
so the LEFT operand will always be greater than or equal to the RIGHT operand ?
The leftmost digit will always be 1 in this method (which is fine, it's analogous to how we write normal decimal numbers, where the leftmost digit is never 0).
I used method one for question 6, and got the following:
This seems to be a lot more straightforward than the provided response. Is it worse somehow?
Your solution is a better solution for computers, whereas the methods outlined in the article above are better for hand calculation. People generally find hand-calculation of modulus difficult.
If I were going to write this in production code, I'd just use std::bitset.
Ah that makes sense. Thanks!
Good question Chayim and I was wondering the same thing myself. But it is the same for decimal numbers too. Say you want to convert a decimal number, say 937, to a decimal number (yeah I know it, already is one but bear with me). Apply the algorithm. Divide 937 by 10 and you get 93 remainder 7. The 7 goes in the units column. etc... Each time you divide the original number by the base (10 in this case, 2 in the example) you are really just determining the value to put in each column starting from the least significant. Consider the first division - What doesn't fit in the 10's column (or 2nd column) is the remainder and that gets put in the units. And so on...
1. Wow, method 1 for converting decimal to binary is super easy, barely an inconvenience. I'd say it's easier than converting binary to decimal, as long as you have a piece of paper handy.
2. About question #6:
My program is similar to yours, except function @printAndDecrementBit() takes the exponent (instead of the power) as the second argument. I stole your function from 5.3 — Modulus and Exponentiation ...
... and used it inside @printAndDecrementBit(). Is it legal to steal code like this?
What has the remainders of half the number from backwards make up the binary number?
The remainders themselves make up the binary number. When you divide by 2, you can either have a 1 for a remainder or 0. So for remainder of 1 you put 1 into the binary number and for no remainder you put 0.
You did not answer my question, I know that the remainder makes up the binary but my question is why and why is it reversed.
Name (required)
Website
Save my name, email, and website in this browser for the next time I comment. | https://www.learncpp.com/cpp-tutorial/converting-between-binary-and-decimal/ | CC-MAIN-2021-17 | refinedweb | 1,348 | 62.78 |
I noticed that for a rank 1 array with 3 elements numpy returns (3,) for the shape. I know that this tuple represents the size of the array along each dimension, but why isn't it (3,1)?
import numpy as np
a = np.array([1, 2, 3]) # Create a rank 1 array
print a.shape # Prints "(3,)"
b = np.array([[1,2,3],[4,5,6]]) # Create a rank 2 array
print b.shape # Prints "(2, 3)"
In a nutshell, it's because it's one-dimensional array (hence the one-element shape tuple). Perhaps the following will help clear things up:
>>> np.array([1, 2, 3]).shape (3,) >>> np.array([[1, 2, 3]]).shape (1, 3) >>> np.array([[1], [2], [3]]).shape (3, 1)
We can even go three dimensions (and higher):
>>> np.array([[[1]], [[2]], [[3]]]).shape (3, 1, 1) | https://codedump.io/share/5xZTaTMq4cz8/1/for-a-nparray1-2-3-why-is-the-shape-3-instead-of-31 | CC-MAIN-2017-09 | refinedweb | 143 | 89.65 |
servlet compilation error.
I use Apache Tomcat4.1,j2sdk1.4.2_08 on windows XP.
I am able to do the foll ,
1.See the Apache Tomcat/4.1.31 homepage and execute the examples of that.
2.Compile all other java files.
3.execute simple JSP examples like date display etc.
but unable to compile servlets.
I set the path and classpath in Environment Variables(XP).
path=C:\Sun\AppServer\bin;C:\j2sdk1.4.2_08\bin;C:\program files\apache group\tomcat4.1\Common\lib\Servlet.jar
CLASSPATH=.;C:\Sun\AppServer\bin;C:\j2sdk1.4.2_08\bin;C:\program files\apache group\tomcat4.1\Common\lib\Servlet.jar
but still I get
javax.servlet does not exist.
I am sure that am missing some simple step,please help me out
Try just putting servlet.jar (watch case) on your classpath.
Also, I know that, with at least some versions of Windows, you need to wrap your classpath/path env variables with quotes if there are spaces in the directory names.
I have done the mentioned changes, but still the problem persists even after restart,
Now my path and classpath are,
CLASSPATH="C:\Program Files\Apache Group\Tomcat 4.1\common\lib\servlet.jar"
path=C:\Sun\AppServer\bin;C:\j2sdk1.4.2_08\bin;
The path on which servlet.jar resides ac copied from its properties is,
C:\Program Files\Apache Group\Tomcat 4.1\common\lib\servlet.jar
Please help
Thanks for your reply and time.<br />Windows 2000,j2sdk1.4.2_08
javac -classpath "C:\Program Files\Apache Group\Tomcat 4.1\common\lib\servlet.jar" <yourServlet>.java
Alco-Haul: We move spirits.
Demented Deliberations of a Dilettante
Rancher
(Plus, of course, major open source Java toolkits ship with build.xml files included.)
Bill
javac -classpath "C:\Program Files\Apache Group\Tomcat 4.1\common\lib\servlet.jar" <yourServlet>.java
I have tried and it doesnt help.But the example servlets in Tomcat seem to work fine.I am damn sure am missing something very silly but could not figure out.PLEASE HELP
Thanks for your reply and time.<br />Windows 2000,j2sdk1.4.2_08
I have tried and it doesnt help. But the example servlets in Tomcat seem to work fine. I am damn sure am missing something very silly but could not figure out.
Wait.
What doesn't work?
Are you trying to compile or run a servlet?
The classpath has nothing to do with running servlets.
Tomcat ignores your classpath.
You DO need servlet-api.jar on your class path to compile your servlet.
What are you trying to do that isn't working?
Do I have to download a Servlet-api.jar file from somewhere apart from the
normal installation of tomcat..??
Sorry for getting confused between running and compiling and also confusing you.
Thanks for your reply and time.<br />Windows 2000,j2sdk1.4.2_08
What errors are you getting when you try to compile your servlet with that classpath?
[<B>] CLASSPATH= .;"C:\Program Files\Apache Group\Tomcat 4.1\common\lib\servlet.jar" [</B>]
if you refer to the reply to Ben Souther .My classpath does have servlet.jar file.I havent change my settings yet.Only change I have made to it after that is to add a . to include currentdirectory.
The link you gave does give info abt Configuring Tomcat and deploying
webapplication.Am not able to relate it to servlet compilation.My tomcat
is working fine and even samples are working fine.
Thanks for your reply and time.<br />Windows 2000,j2sdk1.4.2_08
Here's one way to triple check your classpath.
1.) From the command line, type:
echo %CLASSPATH% > MYCP.txt
2.) Open MYCP.txt with notepad and copy the part of the classpath
that points to the common/lib directory.
3.) Open Explorer and paste the path into the address field.
Explorer should be pointing to the directory with the jars.
You should see servlet.jar in there.
I have a doubt with the sample am code am testing with,
please hav a");
}
}
I am using javac helloworld.java to compile
Thanks for your reply and time.<br />Windows 2000,j2sdk1.4.2_08
PS: It's always a good idea to stick to Java naming conventions.
Classnames should start with an upper case letter (Helloworld.java).
helloworld.java:2 : p ackage javax.servlet does not exist
import javax.servlet.*;
helloworld.java:3 : p ackage javax.servlet.http.*; does not exist
import javax.servlet.http.*;
etc...
Even the javap javax.servlet.http.HTTPServlet; does not work
ERROR:could not find javax.servlet.http.HTTPServlet;
I have tried unistalling and reinstalling TOMCAT but still doesnt work.
please suggest any other server to learn servlets..
[ July 24, 2005: Message edited by: yash Vi ]
Thanks for your reply and time.<br />Windows 2000,j2sdk1.4.2_08
Originally posted by yash Vi:
: and p together has given a smiley .. please replace the smiley with
: p while reading
You can edit your post - use the icon that looks like a paper and pencil. Put a space in to prevent the smiley. Or select the box right at the bottom of the input form (Scroll down and check "Disable smilies in this post").
Ask a Meaningful Question and HowToAskQuestionsOnJavaRanch
Getting someone to think and try something out is much more useful than just telling them the answer.
directory of the jar files..Is there anything else to be done apart from classpath....
Thanks for your reply and time.<br />Windows 2000,j2sdk1.4.2_08
Your class path is
[<B>] CLASSPATH= .;"C:\Program Files\Apache Group\Tomcat 4.1\common\lib\servlet.jar" [</B>]
But no
servlet-api.jar in your classpath. Change from servlet.jar to servlet-api.jar in your classpath.
your classpath should be like this
I hope, now it will work.
bye for now
sat
Download it from here.
---------------------<br />SCJP(1.4)With 95%<br /> <br />Do it Right and Forget it!
In Tomcat4 it was servlet.jar
In Tomcat5 the split it into servlet-api.jar and jsp-api.jar
Try moving it into a directory that doesn't contain spaces in it.
ie copy it to C:\java\servlet.jar, add that to your classpath and try compiling again
| https://coderanch.com/t/360793/java/servlet-compilation-error | CC-MAIN-2017-09 | refinedweb | 1,040 | 71.92 |
Terminality
A Sublime Text 3 Plugin for Sublime Text's Internal Console
Details
Installs
- Total 50K
- Win 24K
- OS X 13K
- Linux 13K
Readme
- Source
- raw.githubusercontent.com
Terminality
A Sublime Text 3 Plugin for Sublime Text's Internal Console
What is Terminality
Terminality is a plugin to allows Sublime Text to be used as Terminal. This included input and output from/to Sublime Text's buffer. Although Terminality can run many commands, it is not gurranteed that it can be used for all commands.
The command is language-based. Current version support the following languages…
- C
- Compile and Run
- C++
- Compile and Run
- Lua
- Run
- Python
- Run as Python 2 (
pythoncommand)
- Run as Python 3 (
python3command)
- Rust (thanks to @divinites)
- Run
- Ruby
- Run
- Swift (OS X only)
- Run
Is that it? No, Terminality allows you to add your own commands to be used inside Sublime Text. Please see the section belows for more informations.
How to use it?
Just pressing
Ctrl+Key+R and the menu will show up, let's you select which command to run.
If you want to pass arguments to command (depends on how each command use the arguments), pressing
Ctrl+Key+Shift+R instead. This will let's you select the command first, then ask you for arguments input.
Key is
Alt in Windows, Linux,
Cmd in OS X
Note! This key binding is conflicted with SFTP. You might have to override it yourself.
Settings
Terminality is using a very complex settings system in which you can control how settings affect the whole Sublime Text or each project you want.
As you might already know, you can override default settings by set the desire settings inside user's settings file (can be access via
Preferences > Packages Settings > Terminality > Settings - User).
But if you want to override the settings for particular project, you can add the
terminality dictionary to the .sublime-project file. Under this dictionary, it works like a user's settings file but for that project instead.
To summarize, Terminality will look for any settings in your project settings file first, then user's settings file, and finally, the default package settings.
How Terminality can helps my current workflow?
Good question! You might think Terminality is just a plugin that showing a list of commands which you already know how to use it. Sure, that what it is under the hood but Terminality does not stop there. Here are the list of somethings that Terminality can do for you…
- Run tests on your project
- Exclusively build and run your project without affecting another project
- Dynamically run Sublime Text's commands based on your project or current file
- One keystroke project deployment
- And much more…
How can I created my own command to be used with Terminality?
You can create your own command to be used with Terminality by override the commands in which using only
execution_units key in the settings.
Or if you want to create and share some of your Terminality commands, use the Collections (See Collections section belows).
In v0.3.7 or earlier, you must set it in
additional_execution_unitsinstead.
In v0.3.8 or later,
additional_execution_unitsis deprecated and will be removed in v0.4.0
// Settings file { // ... Your other settings ... "execution_units": { // ... See Language Scopes section belows ... }, // ... Your other settings ... }
Language Scopes
Terminality use Sublime Text's syntax language scope in which you can look it up at the status bar when pressing
Ctrl+Alt+Shift+P (Windows and Linux) and
Ctrl+Shift+P (OSX).
Language Scope section is a dictionary contains commands which will available for specified language scope.
The key of the language scope is simply a scope name you want to specified. If you want the command to be available to all language just simply use the
* as a language scope.
You cannot override the default language scope. However, you can remove the default commands for that language scope by set the value to non-dictionary type (such as
0).
"<Language Scope>": { // ... See Commands section belows ... }
Commands
Command section is a dictionary contains informations about how to run the command.
The key of the command is simply a command name you want to use as a command reference (this will also be used as command name if you did not specified the
name key).
You can override the command by use the exactly same command reference name of the command you want to override (included default one). And you can also remove the commands by set the value to non-dictionary type (such as
0).
Each key is optional (exceptions in the Limitations/Rules section belows) and has the following meaning…
name[macros string] A name of the command (which showing in the menu).
description[macros string] A description of the command (which show as subtitle in the menu).
order[string] A string which used for sorting menus
location[macros string] A location path to run the command
required[list] A list of macro name (without $) that have to be set before run the command (if any of the macro is not set, command will not run).
arguments[string] A text to show when ask for arguments input.
command[macros string] A macros string define the command that will be run.
window_command[macros string] A macros string define the Sublime Text's window command (included any plugin you installed) that will be run.
view_command[macros string] A macros string define the Sublime Text's view command (command in which only run within a view) that will be run.
args[dict] A dictionary that will be passed to
window_commandor
view_command. Each macro inside the dictionary's value will be parsed recursively.
platforms[list] A list of supported platforms. In
<os>-<arch>,
<os>or
<arch>format (
osand
archare from Sublime Text's
sublime.platform()and
sublime.arch()command).
no_echo[bool] Specify whether input will be echo (
false) or not (
true).
read_only[bool] Specify whether running view can receives input from user (
false) or not (
true).
close_on_exit[bool] Specify whether running view will be closed when command is terminated (
true) or not (
false).
macros[dict] A dictionary contains custom macro definitions. See Custom Macros section belows.
"<Command Reference>": { "name": "<Command Reference>", "description": "<Command Name> command", "order": "<Command Name>" "location": "$working", "required": [], "arguments": "Arguments", // You can use only one of "command", "window_command" or "view_command" "command": "<No default value>", "window_command": "<No default value>", "view_command": "<No default value>", // "args" will only use with "window_command" and "view_command" "args": {}, "platforms": [<No default value>], "no_echo": false, "read_only": false, "close_on_exit": false, "macros": {} }
Limitations/Rules
- Every macro name (except inside
required) should have
$prefix.
- Each action must contains only one of
command,
window_commandand
view_command(other can be omitted)
location,
no_echo,
read_onlyand
close_on_exitonly works with
commandonly
argsonly works with
window_commandor
view_commandonly
See example inside Terminality's user settings file (and also in Terminality's .sublime-project file itself!).
Predefined Macros
file: Path to current working file
file_relative: Relative path of
file
file_name: Name of
file
working: This will use
working_projectbut if not found it will use
projectand if still not found it will use
parent
working_relative: Relative path of
working
working_name: Name of
working
working_project: Project folder contains current working file
working_project_relative: Relative path of
working_project
working_project_name: Name of
working_project
project: First project folder
project_relative: Relative path of
project
project_name: Name of
project
parent: Parent folder contains current working file
parent_relative: Relative path of
parent
parent_name: Name of
parent
packages_path: Path to Sublime Text's packages folder
raw_selection: Raw text of last selection
selection: Striped text of last selection
arguments: A text which passed via arguments input
sep: Path separator (
/or
\depends on your operating system)
$:
$symbol
Custom Macros
You can create your own macro to be used with custom command by adding each macro to
macros section in your execution unit (See Commands aboves). Each macro is a key-value pairs in which key indicated macro name (
a-zA-Z0-9_ without prefixed
$) and value is a list of any combination of the following values…
"String and/or $macro"This will be a parsed string (which must not contains self-recursion) if previous value is not found
["Start:End"]This will substring the previous value (if any) from
startto
end
["RegEx Pattern", <Optional Capture Group>]This will return a specified group (or default match if not specified) from previous value matching
["String and/or $macro", "Start:End"]This will substring the specified string/macro from
startto
endif previous value is not found
["String and/or $macro", "RegEx Pattern", <Optional Capture Group>]This will return a specified group (or default match if not specified) from specified string/macro matching if previous value is not found
Substring works just like Python's substring. You can omitted
start or
end as you like.
Macro works as a sequence, if current macro is not found it will look at the next macro.
Example:
"CustomMacro": [ "$file_name", // Get the file name from predefined macro [":-4"], // Remove the last 4 characters (if value is found) ["$file", "\\w+"], // Get the result from parsing "$file" with RegEx if previous value is not found "" // If nothing can be used, use empty string ]
Collections
Implemented in v0.3.8 and later
Collections is a package contains Terminality commands which can be install by place in the
User directory.
The structure of Collections file is simply a JSON file with .terminality-collections extension. Inside the file contains the following format…
{ "execution_units": { // ... See Language Scopes section aboves ... } }
Please note that Collections is not a settings file (although it contains the same key name). Any other key will be ignored completely. | https://packagecontrol.io/packages/Terminality | CC-MAIN-2019-47 | refinedweb | 1,588 | 50.57 |
Program Arcade GamesWith Python And Pygame
Chapter 15: Searching
Searching is an important and very common operation that computers do all the time. Searches are used every time someone does a ctrl-f for “find”, when a user uses “type-to” to quickly select an item, or when a web server pulls information about a customer to present a customized web page with the customer's order.
There are a lot of ways to search for data. Google has based an entire multi-billion dollar company on this fact. This chapter introduces the two simplest methods for searching, the linear search and the binary search.
15.1 Reading From a File
Before discussing how to search we need to learn how to read data from a file. Reading in a data set from a file is way more fun than typing it in by hand each time.
Let's say we need to create a program that will allow us to quickly
find the name of a super-villain. To start with, our program needs a database
of super-villains.
To download this data set, download and save this file:
These are random names generated by the nine.frenchboys.net website, although last I checked they no longer have a super-villain generator.
Save this file and remember which directory you saved it to.
In the same directory as super_villains.txt, create, save, and run the following python program:
file = open("super_villains.txt") for line in file: print(line)
There is only one new command in this code open. Because it is a built-in function like print, there is no need for an import. Full details on this function can be found in the Python documentation but at this point the documentation for that command is so technical it might not even be worth looking at.
The above program has two problems with it, but it provides a simple example of reading in a file. Line 1 opens a file and gets it ready to be read. The name of the file is in between the quotes. The new variable file is an object that represents the file being read. Line 3 shows how a normal for loop may be used to read through a file line by line. Think of file as a list of lines, and the new variable line will be set to each of those lines as the program runs through the loop.
Try running the program. One of the problems with the it is that the text is printed double-spaced. The reason for this is that each line pulled out of the file and stored in the variable line includes the carriage return as part of the string. Remember the carriage return and line feed introduced back in Chapter 1? The print statement adds yet another carriage return and the result is double-spaced output.
The second problem is that the file is opened, but not closed. This problem isn't as obvious as the double-spacing issue, but it is important. The Windows operating system can only open so many files at once. A file can normally only be opened by one program at a time. Leaving a file open will limit what other programs can do with the file and take up system resources. It is necessary to close the file to let Windows know the program is no longer working with that file. In this case it is not too important because once any program is done running, the Windows will automatically close any files left open. But since it is a bad habit to program like that, let's update the code:
file = open("super_villains.txt") for line in file: line = line.strip() print(line) file.close()
The listing above works better. It has two new additions. On line 4 is a call to the strip method built into every String class. This function returns a new string without the trailing spaces and carriage returns of the original string. The method does not alter the original string but instead creates a new one. This line of code would not work:
line.strip()
If the programmer wants the original variable to reference the new string, she must assign it to the new returned string as shown on line 4.
The second addition is on line 7. This closes the file so that the operating system doesn't have to go around later and clean up open files after the program ends.
15.2 Reading Into an Array
It is useful to read in the contents of a file to an array so that the program can do processing on it later. This can easily be done in python with the following code:
# Read in a file from disk and put it in an array. file = open("super_villains.txt") name_list = [] for line in file: line = line.strip() name_list.append(line) file.close()
This combines the new pattern of how to read a file, along with the previously learned pattern of how to create an empty array and append to it as new data comes in, which was shown back in Chapter 7. To verify the file was read into the array correctly a programmer could print the length of the array:
print( "There were",len(name_list),"names in the file.")
Or the programmer could bring the entire contents of the array:
for name in name_list: print(name)
Go ahead and make sure you can read in the file before continuing on to the different searches.
15.3 Linear Search
If a program has a set of data in an array, how can it go about finding where a specific element is? This can be done one of two ways. The first method is to use a linear search. This starts at the first element, and keeps comparing elements until it finds the desired element (or runs out of elements.)
15.3.1 Linear Search Algorithm
# --- Linear search key = "Morgiana the Shrew" i = 0 while i < len(name_list) and name_list[i] != key: i += 1 if i < len(name_list): print( "The name is at position", i) else: print( "The name was not in the list." )
The linear search is rather simple. Line 4 sets up an increment variable that will keep track of exactly where in the list the program needs to check next. The first element that needs to be checked is zero, so i is set to zero.
The next line is a bit more complex. The computer needs to keep looping until one of two things happens. It finds the element, or it runs out of elements. The first comparison sees if the current element we are checking is less than the length of the list. If so, we can keep looping. The second comparison sees if the current element in the name list is equal to the name we are searching for.
This check to see if the program has run out of elements must occur first. Otherwise the program will check against a non-existent element which will cause an error.
Line 6 simply moves to the next element if the conditions to keep searching are met in line 5.
At the end of the loop, the program checks to see if the end of the list was reached on line 8. Remember, a list of n elements is numbered 0 to n-1. Therefore if i is equal to the length of the list, the end has been reached. If it is less, we found the element.
15.4 Variations On The Linear Search
Variations on the linear search can be used to create several common algorithms. For example, say we had a list of aliens. We might want to check this group of aliens to see if one of the aliens is green. Or are all the aliens green? Which aliens are green?
To begin with, we'd need to define our alien:
class Alien: """ Class that defines an alien""" def __init__(self, color, weight): """ Constructor. Set name and color""" self.color = color self.weight = weight
Then we'd need to create a function to check and see if it has the property that we are looking for. In this case, is it green? We'll assume the color is a text string, and we'll convert it to upper case to eliminate case-sensitivity.
def has_property(my_alien): """ Check to see if an item has a property. In this case, is the alien green? """ if my_alien.color.upper() == "GREEN": return True else: return False
15.4.1 Does At Least One Item Have a Property?
Is at least one alien green? We can check. The basic algorithm behind this check:
def check_if_one_item_has_property_v1(my_list): """ Return true if at least one item has a property. """ i = 0 while i < len(my_list) and not has_property(my_list[i]): i += 1 if i < len(my_list): # Found an item with the property return True else: # There is no item with the property return False
This could also be done with a for loop. In this case, the loop will exit early by using a return once the item has been found. The code is shorter, but not every programmer would prefer it. Some programmers feel that loops should not be prematurely ended with a return or break statement. It all goes to personal preference, or the personal preference of the person that is footing the bill.
def check_if_one_item_has_property_v2(my_list): """ Return true if at least one item has a property. Works the same as v1, but less code. """ for item in my_list: if has_property(item): return True return False
15.4.2 Do All Items Have a Property?
Are all aliens green? This code is very similar to the prior example. Spot the difference and see if you can figure out the reason behind the change.
def check_if_all_items_have_property(my_list): """ Return true if at ALL items have a property. """ for item in my_list: if not has_property(item): return False return True
15.4.3 Create a List With All Items Matching a Property
What if you wanted a list of aliens that are green? This is a combination of our prior code, and the code to append items to a list that we learned about back in Chapter 7.
def get_matching_items(list): """ Build a brand new list that holds all the items that match our property. """ matching_list = [] for item in list: if has_property(item): matching_list.append(item) return matching_list
How would you run all these in a test? The code above can be combined with this code to run:
alien_list = [] alien_list.append(Alien("Green", 42)) alien_list.append(Alien("Red", 40)) alien_list.append(Alien("Blue", 41)) alien_list.append(Alien("Purple", 40)) result = check_if_one_item_has_property_v1(alien_list) print("Result of test check_if_one_item_has_property_v1:", result) result = check_if_one_item_has_property_v2(alien_list) print("Result of test check_if_one_item_has_property_v2:", result) result = check_if_all_items_have_property(alien_list) print("Result of test check_if_all_items_have_property:", result) result = get_matching_items(alien_list) print("Number of items returned from test get_matching_items:", len(result))
For a full working example see:
programarcadegames.com/python_examples/show_file.php?file=property_check_examples.py
These common algorithms can be used as part of a solution to a larger problem, such as find all the addresses in a list of customers that aren't valid.
15.5 Binary Search
A faster way to search a list is possible with the binary search. The process of a binary search can be described by using the classic number guessing game “guess a number between 1 and 100” as an example. To make it easier to understand the process, let's modify the game to be “guess a number between 1 and 128.” The number range is inclusive, meaning both 1 and 128 are possibilities.
If a person were to use the linear search as a method to guess the secret number, the game would be rather long and boring.
Guess a number 1 to 128: 1 Too low. Guess a number 1 to 128: 2 Too low. Guess a number 1 to 128: 3 Too low. .... Guess a number 1 to 128: 93 Too low. Guess a number 1 to 128: 94 Correct!
Most people will use a binary search to find the number. Here is an example of playing the game using a binary search:
Guess a number 1 to 128: 64 Too low. Guess a number 1 to 128: 96 Too high. Guess a number 1 to 128: 80 Too low. Guess a number 1 to 128: 88 Too low. Guess a number 1 to 128: 92 Too low. Guess a number 1 to 128: 94 Correct!
Each time through the rounds of the number guessing game, the guesser is able to eliminate one half of the problem space by getting a “high” or “low” as a result of the guess.
In a binary search, it is necessary to track an upper and a lower bound of the list that the answer can be in. The computer or number-guessing human picks the midpoint of those elements. Revisiting the example:
A lower bound of 1, upper bound of 128, mid point of $\dfrac{1+128}{2} = 64.5$.
Guess a number 1 to 128: 64 Too low.
A lower bound of 65, upper bound of 128, mid point of $\dfrac{65+128}{2} = 96.5$.
Guess a number 1 to 128: 96 Too high.
A lower bound of 65, upper bound of 95, mid point of $\dfrac{65+95}{2} = 80$.
Guess a number 1 to 128: 80 Too low.
A lower bound of 81, upper bound of 95, mid point of $\dfrac{81+95}{2} = 88$.
Guess a number 1 to 128: 88 Too low.
A lower bound of 89, upper bound of 95, mid point of $\dfrac{89+95}{2} = 92$.
Guess a number 1 to 128: 92 Too low.
A lower bound of 93, upper bound of 95, mid point of $\dfrac{93+95}{2} = 94$.
Guess a number 1 to 128: 94 Correct!
A binary search requires significantly fewer guesses. Worst case, it can guess a number between 1 and 128 in 7 guesses. One more guess raises the limit to 256. 9 guesses can get a number between 1 and 512. With just 32 guesses, a person can get a number between 1 and 4.2 billion.
To figure out how large the list can be given a certain number of guesses, the
formula works out like $n=x^{g}$ where $n$ is the size of the list and $g$ is the
number of guesses. For example:
$2^7=128$ (7 guesses can handle 128 different numbers)
$2^8=256$
$2^9=512$
$2^{32}=4,294,967,296$
If you have the problem size, we can figure out the number of guesses using
the log function. Specifically, log base 2. If you don't
specify a base, most people will assume you mean the natural log with a base of
$e \approx 2.71828$ which is not what we want. For example, using log base 2 to
find how many guesses:
$log_2 128 = 7$
$log_2 65,536 = 16$
Enough math! Where is the code? The code to do a binary search is more complex than a linear search:
# --- Binary search key = "Morgiana the Shrew" lower_bound = 0 upper_bound = len(name_list)-1 found = False # Loop until we find the item, or our upper/lower bounds meet while lower_bound <= upper_bound and not found: # Find the middle position middle_pos = (lower_bound + upper_bound) // 2 # Figure out if we: # move up the lower bound, or # move down the upper bound, or # we found what we are looking for if name_list[middle_pos] < key: lower_bound = middle_pos + 1 elif name_list[middle_pos] > key: upper_bound = middle_pos - 1 else: found = True if found: print( "The name is at position", middle_pos) else: print( "The name was not in the list." )
Since lists start at element zero, line 3 sets the lower bound to zero. Line 4 sets the upper bound to the length of the list minus one. So for a list of 100 elements the lower bound will be 0 and the upper bound 99.
The Boolean variable on line 5 will be used to let the while loop know that the element has been found.
Line 8 checks to see if the element has been found or if we've run out of elements. If we've run out of elements the lower bound will end up equaling the upper bound.
Line 11 finds the middle position. It is possible to get a middle position of something like 64.5. It isn't possible to look up position 64.5. (Although J.K. Rowling was rather clever in enough coming up with Platform $9\frac{3}{4}$, that doesn't work here.) The best way of handling this is to use the // operator first introduced way back in Chapter 5. This is similar to the / operator, but will only return integer results. For example, 11 // 2 would give 5 as an answer, rather than 5.5.
Starting at line 17 the program checks to see if the guess is high, low, or correct. If the guess is low, the lower bound is moved up to just past the guess. If the guess is too high, the upper bound is moved just below the guess. If the answer has been found, found is set to True ending the search.
With the a list of 100 elements, a person can reasonably guess that on average with the linear search, a program will have to check 50 of them before finding the element. With the binary search, on average you'll still need to do about seven guesses. In an advanced algorithms course you can find the exact formula. For this course, just assume average and worst cases are the same.
15.6 Review
15.6.1 Multiple Choice Quiz
15.6.2 Short Answer Worksheet | http://programarcadegames.com/index.php?chapter=searching&lang=fi | CC-MAIN-2020-24 | refinedweb | 2,972 | 81.63 |
#include "mex.h" void mexFunction(int nlhs, mxArray *plhs[], int nrhs, const mxArray *prhs[]);
mexFunction(nlhs, plhs, nrhs, prhs) integer*4 nlhs, nrhs mwPointer plhs(*), prhs(*)
The number of expected output mxArrays
Array of pointers to the expected output mxArrays
The number of input mxArrays
Array of pointers to the input mxArrays. These mxArrays are read only and should not be modified by your MEX-file. Changing the data in these mxArrays may produce undesired side effects.
mexFunction is not a routine you call. Rather, mexFunction is the name of a function in C (subroutine in Fortran) that you must write in every MEX-file. When you invoke a MEX-function, MATLAB software finds and loads the corresponding MEX-file of the same name. MATLAB then searches for a symbol named mexFunction within the MEX-file. If it finds one, it calls the MEX-function using the address of the mexFunction symbol. If MATLAB cannot find a routine named mexFunction inside the MEX-file, it issues an error message.
When you invoke a MEX-file, MATLAB automatically seeds nlhs, plhs, nrhs, and prhs with the caller's information. In the syntax of the MATLAB language, functions have the general form:
[a,b,c,...] = fun(d,e,f,...)
where the ... denotes more items of the same format. The a,b,c... are left-hand side arguments, and the d,e,f... are right-hand side arguments. The arguments nlhs and nrhs contain the number of left-hand side and right-hand side arguments, respectively, with which the MEX-function is called. prhs is an array of mxArray pointers whose length is nrhs. plhs is an array whose length is nlhs, where your function must set pointers for the returned left-hand side mxArrays.
See mexfunction.c in the mex subdirectory of the examples directory.
Get MATLAB trial software
Includes the most popular MATLAB recorded presentations with Q&A sessions led by MATLAB experts. | http://www.mathworks.com/access/helpdesk/help/techdoc/apiref/mexfunction.html | crawl-002 | refinedweb | 322 | 55.84 |
Web scraping and REST API calls on App Engine with Jsoup and groovy-wslite
Posted on 27 July, 2016 (3 years ago)
After my Twitter sentiment article, those past couple of days, I've been playing again with the Cloud Natural Language API. This time, I wanted to make a little demo analyzing the text of speeches and remarks published by the press office of the White House. It's interesting to see how speeches alternate negative and positive sequences, to reinforce the argument being exposed.
As usual, for my cloud demos, my weapons of choice for rapid development are Apache Groovy, with Glide & Gaelyk on Google App Engine! But for this demo, I needed two things:
- a way to scrape the content of the speeches & remarks from the White House press office
- a library for easily making REST calls to the Natural Language API
In both cases, we need to issue calls through the internet, and there are some limitations on App Engine with regards to such outbound networking. But if you use the plain Java HTTP / URL networking classes, you are fine. And under the hood, it's using App Engine's own URL Fetch service.
For interacting with the REST API, groovy-wslight came to my rescue, although I could have used the Java SDK like in my previous article.
Let's look at Jsoup and scraping first. In my controller fetching the content, I did something along those lines (you can run this script in the Groovy console):
@Grab('org.jsoup:jsoup:1.9.2')
import org.jsoup.*
def url = ''
def doc = Jsoup.connect(url)
.userAgent('Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0')
.get()
println doc.select('.forall-body .field-item p').collect { it.text() }.join('\n\n')
Now I'm gonna make a call with groovy-wslight to the NL API:
@Grab('com.github.groovy-wslite:groovy-wslite:1.1.3')
import wslite.rest.*
def apiKey = 'MY_TOP_SECRET_API_KEY'
def client = new RESTClient('')
def result = client.post(path: 'documents:annotateText', query: [key: apiKey]) {
type ContentType.JSON
json document: [
type : 'PLAIN_TEXT',
content: text
], features: [
extractSyntax : true,
extractEntities : true,
extractDocumentSentiment: true
]
}
// returns a list of parsed sentences
println result.json.sentences.text.content
// prints the overall sentiment of the speech
println result.json.documentSentiment.polarity
Groovy-wslight nicely handles XML and JSON payloads: you can use Groovy maps for the input value, which will be marshalled to JSON transparently, and the GPath notation to easily access the resulting JSON object returned by this API.
It was very quick and straightforward to use Jsoup and groovy-wslight for my web scraping and REST handling needs, and it was a breeze to integrate them in my App Engine application. In a follow-up article, I'll tell you a bit more about the sentiment analysis of the sentences of the speeches, so please stay tuned for the next installment! | https://glaforge.appspot.com/article/web-scraping-and-rest-api-calls-on-app-engine-with-jsoup-and-groovy-wslite | CC-MAIN-2019-51 | refinedweb | 489 | 61.87 |
VTK/Wrapping C++11 Code
The purpose of this page is to track the status of C++11 support in the VTK wrappers.
Most VTK code follows the C++03 standard, and the oldest supported compiler is (I believe) Visual Studio .NET 2003. However, all VTK code is also compatible with C++11, and in fact VTK uses some features of C99 that were incorporated into C++11. Users of VTK have already begun moving their own code to C++11.
The following is a list of various new C++11 features to be supported. I will be adding these features to my WrapVTK project before moving them into VTK proper.
Current status:
- C++11 changes merged into master on 22 Nov 2013. Released in VTK 6.1.
- C++14 changes merged into master on 4 Nov 2015. Released in VTK 7.0.
Contents
- 1 Closing angle brackets
- 2 Rvalue references
- 3 The constexpr keyword
- 4 New static_assert()
- 5 Keyword decltype()
- 6 Method declaration with trailing return type
- 7 Trailers final and override
- 8 Trailer noexcept()
- 9 Function bodies default, delete
- 10 Auto variable type
- 11 New literal nullptr
- 12 New string literal types
- 13 New char types
- 14 New string types
- 15 User-defined literal suffixes
- 16 New enum classes
- 17 The thread_local storage specifier
- 18 Explicit conversion operators
- 19 Creating type aliases with "using"
- 20 Variadic templates
- 21 Attributes
- 22 Keyword alignof()
- 23 C99 features
- 24 Extern Templates
- 25 Lamdas
- 26 Variadic macros
- 27 New initializer syntax
- 28 Universal character names
- 29 Inline namespaces
- 30 C++14 parsing
- 31 C++17
Closing angle brackets
Support code like std::vector<std::vector<int>> without requiring spaces between > and >.
Done.
Rvalue references
Use of "&&" to indicate an rvalue reference. As long as it is only used in assignment operators and copy constructors, I don't think the wrappers have to worry about the semantics, they just have to parse it. Are there bits available to represent it? It requires a modifier for "ref", and "const ref" already exists, so just as we use the CONST qualifier bit for "const &", we can have an "RVALUE" qualifier bit for "&&".
Done.
The constexpr keyword
Initially, this keyword can be ignored (until proper constant expression parsing is implemented).
Done.
New static_assert()
Uses of static_assert() can easily be removed by the lexer, though removing it in the parser is possible, too, with a little extra work.
Done.
Keyword decltype()
This provides the type of the expression in the parentheses. I can defer the type deduction (for templates, the type deduction will have to be deferred anyway). Deducing the type will require a complete constant_expression parser, which I don't have yet. I will probably implement the constant_expression parser as its own recursive descent parser, rather than implement it as part of the main yacc parser.
Done.
Method declaration with trailing return type
This is just a new function trailer, it will be easy to implement once decltype() is implemented.
template<class Lhs, class Rhs> auto add(const Lhs &lhs, const Rhs &rhs) -> decltype(lhs+rhs) {return lhs + rhs;}
Done.
Trailers final and override
These are trivial to implement because the wrappers can ignore the semantics. Though it might be useful for the wrappers to honor "final". Note: Unlike "throw" and "const", these are not keywords. They should be parsed as identifiers.
Note that "final" can be used in a class definition immediately after the class_id to declare that the class cannot be subclassed.
Done.
Trailer noexcept()
This goes along with the throw() trailer that already exists:
noexcept noexcept ( constant_expression )
Done.
Function bodies default, delete
Similar in syntax to the "= 0" body for pure virtual methods. In C++11, any method that the compiler can auto-generate (default constructor, copy constructor, destructor, assignment operator) can have its body replaced by "= default;" or "= delete;". The wrappers must honor these settings when it auto-generates these methods.
Done.
Auto variable type
For variables declared with "auto", the type will have to be deduced, in much the same way as is done with macro constants.
Done.
New literal nullptr
May require a new keyword, and a type constant for nullptr_t.
Done.
New string literal types
Prefixes "R", "u8", "u", "U". Plus, the prefix "L" is not implemented yet.
Done. Caveat: raw strings supported everywhere except for in preprocessor directives.
New char types
These are char16_t, char32_t, and also the pre-C++11 type wchar_t. Are these primitive types, or are they typdefs to a unique type, similar to nullptr_t? Or typedefs to a non-unique type, like size_t? I believe that wchar_t, at least, is required to be a primitive type. Unlike wchar_t and char, we at least know that char16_t and char32_t are unsigned. Also, in the C++11 standard (though not necessarily in pre-standard compilers) they are primitive types.
Done.
New string types
The C++11 library defines std::u16string and std::u32string. The wrapper parser recognizes std::string as a special type, but this should not be extended to u16string and u32string. They should not be special-cased within the parser code itself, it should be up to the wrapper back-ends like vtkWrapPython to recognize them and wrap them.
Not done, deferred.
User-defined literal suffixes
Tokenization of literals will have to be extended, and the new operator"" will have to be added. Capturing the literals as strings will be easy, but when I implement a constant_expression parser, these will have to be parsed whenever they are declared with constexpr.
Done.
New enum classes
Tricky, but they can still be considered to be enums. I'll have to add a type member to EnumInfo. The grammar will also have to allow for forward declaration of enums.
Done.
The thread_local storage specifier
This should be parsed and handled similar to static.
Done.
Explicit conversion operators
Implement "explicit" specifier for conversion operators. This is already parsed, so it is just a matter of setting the IsExplicit flag when the specifier is present.
Done.
Creating type aliases with "using"
using FunctionType = void (*)(double); template <typename Second> using TypedefName = SomeType<OtherType, Second, 5>;
Done.
Variadic templates
This will involve three pieces:
- parsing the template parameters
- parsing the pack expansions
- and, if variadic templates are ever to be wrapped, instantiation
Done.
Attributes
Attributes of the form [[name]], [[name(x,y)]], and alignas(type) will have to be parsed. A set of attributes can be defined for wrapping hints at some point in the future, but until then attributes can be ignored. If the attributes are hard to parse, then token sequence "[[" can be defined as a new token (allowing for space between the left brackets).
Done. Caveat: attributes are simply ignored, unless they start with vtk::
Keyword alignof()
Operator alignof(type), e.g. alignof(int). It will have to be handled similarly to sizeof(), i.e. not at all until constant expression parsing is implemented.
Done.
C99 features
Specifiers _Alignas(), _Generic(), _Thread_local, _Noreturn.
Qualifer _Atomic.
Done.
Extern Templates
New "extern template" template declaration.
Done.
Lamdas
Lambda will not appear as part of class definitions, so they can be ignored.
Nothing to be done.
Variadic macros
If "..." ends a macro parameter list, then in the body of the macro __VA_ARGS__ should expand to the portion of the argument list that corresponds to the ellipsis.
Done, plus gcc and MSVC extensions.
New initializer syntax
C++11 has a new initializer list syntax:
int x {}; // default initialization (initializes "int" to zero) int x { 2 }; // equivalent to "int x = 2;" int x[3] { 1, 2, 3 }; // equivalent to "int x[3] = { 1, 2, 3 };" mystruct myval { "hello", "there" }; // equivalent to "mystruct myval = { "hello", "there" };" myclass myinstance { 1.0, 2.0 }; // equivalent to "myclass myinstance(1.0, 2.0);" std::vector<int> vec { 10, 11, 12 }; // a completely new form of initialization
Done.
Universal character names
Non-ascii characters can be specified, in strings and identifiers, via these codes, where x is a hexadecimal digit:
\uxxxx \Uxxxxxxxx
Done. It's easy to handle these in strings, because they can be copied verbatim. Their use in identifiers is tricky, because the wrappers must be able to compare identifiers. So, when they appear within identifiers, they should be converted to the utf-8 encoding of the codepoint.
Inline namespaces
The "namespace" keyword can be preceded by "inline".
Not done yet.
C++14 parsing
C++14 brings far fewer changes than C++11.
Template variable declarations
This should parse cleanly, with or without the "constexpr".
template<class T> constexpr T pi = 3.14159;
Done.
Template template declarations with typename
This should parse cleanly. In C++11 and earlier, it won't parse unless the final "typename" is replaced with "class'.
template<template<typename> typename X> struct D;
Done.
Binary literals
0b11100110 0b00011001
Done.
Apostrophe in numeric literals
1'000'000 0b0100'0001 1.345'234'543e10
Done.
C++17
"u8" prefix for character literals
For character literals, u8 means the character is unicode and fits in "char" (i.e. 8 bits). Hence, it is only useful for latin1 characters.
Done.
Parameter pack fold expressions
Parameter pack folding can take the following syntax:
- ( pack op ... )
- ( ... op pack )
- ( pack op ... op init )
- ( init op ... op pack )
Nothing to be done. These are used for evaluation, rather than declaration, so they require no changes to our parser.
Hexadecimal float literals
These are of the same form as decimal float literals, except:
- They start with 0x
- The significand is in hexadecimal
- The exponent is marked with "p" or "P"
- The exponent is mandatory (note that the exponent is still in decimal!)
0xa.bp5 0x.bp-1 0xa.p3 0x1p-2
Not done yet. | https://itk.org/Wiki/VTK/Wrapping_C%2B%2B11_Code | CC-MAIN-2020-40 | refinedweb | 1,602 | 55.44 |
<<
methinksMembers
Content count215
Joined
Last visited
Community Reputation222 Neutral
About methinks
- RankMember
methinks posted a topic in General and Gameplay ProgrammingI'm trying to learn how to write plugins (OSX Yosemite). Everything compiles and runs properly, the shared object is loaded, but function in the shared object doesn't execute. All the files remain in the same directory. The host application, compiled as follows: g++ -ldl -o Host Host.cpp // Host.cpp #include <iostream> #include <dlfcn.h> using namespace std; int main(int argc, char* argv[]) { void * plugin = dlopen("Plugin.mod", RTLD_NOW); if(plugin == nullptr) { cout << "Error opening file" << endl; } else { cout << "File open, attempting to access function" << endl; dlerror(); dlsym(plugin, "run"); // This is where the line "Plugin Running" should be printed to the console char * errMsg = dlerror(); if(errMsg) { cout << "Unable to access function" << endl; } else { cout << "Success: " << endl; } dlclose(plugin); } } The plugin that gets called g++ -fPIC -c Plugin.cpp g++ -shared -o Plugin.mod Plugin.o // Plugin.cpp #include <iostream> using namespace std; extern "C" void run() { cout << "Plugin running" << endl; } and the output: File open, attempting to access function Success: Is this a problem with the code, or the compilation?
methinks replied to methinks's topic in General and Gameplay ProgrammingThanks for the feedback. I'll look into instanceof, it looks like it will do what I need for the type, though I'll still face the same problem for other pieces of data (Such as UUID). To be honest, I don't know quite yet, the id will probably be used as keys in a HashMap, but I haven't gotten that far yet. Partly I'm just trying to understand the language itself.()
methinks posted a topic in General and Gameplay ProgrammingI'm coming from C++, trying to learn Java. The issue is that Java doesn't allow overriding of static functions. In this case, I would like each class that inherits from a parent (let's call it the Item class) to have an identifier that get by calling getId(). class Item { abstract String getId(); } class ItemA extends Item { String getId() { return "ITEM_A"; } } The thing is that I want to be able to call getId without having to instantiate the class, so that I can do something like this: void foo(Item i) { if(i.getId() == ItemA.getId()) { //Do Something } } Java doesn't allow abstract static functions, so I'm left with defining non-abstract static functions. As a result, the above function doesn't work, because i.getId() returns the Parent object's id, not that of the child object. Are there any ways around this, or what would be a better way of dealing with it?
methinks replied to Juliean's topic in General and Gameplay ProgrammingIt doesn't look like a namespace issue, because they are showing the same namespace (a::A::A) Could it be that the project is trying to compile the same class multiple times? (Do you have an include guard in the header?)
methinks replied to methinks's topic in General and Gameplay ProgrammingOk, so a more generic version of the question: what is the best way to share the data between different classes that are completely un-related?
methinks posted a topic in General and Gameplay ProgrammingI want to add a central data manager to my project, so that different classes can share data. It will also act as a map to avoid doubling up on resources. [attachment=15516:layout1.png]: [attachment=15517:layout2.png] Oh yeah, I'm doing this in C++, but the concepts should apply to most languages
methinks replied to KaiserJohan's topic in General and Gameplay ProgrammingThe mesh is the data describing the points that make up the object (This includes faces and edges). This is just one small part of the model. "Model" is a generic term. It means any data related to drawing a 3d item onto the screen. Exactly what data this includes depends on the program or file format. In some case it might just be the mesh, although usually it also includes some of the following: Material - the colours, shading models, and other things that determine how to apply lights and rendering Textures - the images that are mapped onto the mesh UV - co-ordinates that determine how textures are applied to the mesh vertex groups - used to break the model into smaller chunks for special purposes bones / armatures - used to link parts of the mesh to specific parts of animations animations - how the mesh moves ... the list goes on, depending on what you're trying to do with the mesh.
methinks replied to Sik_the_hedgehog's topic in 2D and 3D ArtThe difference is what actually gets saved. The 3ds file only saves the model data itself (geometry, materials, etc) while the blender file contains structures explaining the data as well (the so-called DNA structure) that guarantees both forward and backward compatibility. Add to this the workspace setup (tool settings, layouts, preferences, etc), the blender file actually contains far more data. (To be very specific, the blender file is a direct dump of the internal data structure, while the 3ds is an optimized format to store only very specific data)
OpenGL
methinks posted a topic in Graphics and GPU ProgrammingI know that in directx, the 3d stereo works by shifting the camera and rendering two different images. I was wondering if there is any way to write directly to the buffer, to display different textures to each eye. This would be useful for having 3d background images, or in my case, writing a 3d image viewer. I know this can be done in opengl by accessing the quad buffer, but I haven't been able to find any documentation for directx. If it helps any, I'm working with nvidia cards. Thanks
methinks replied to methinks's topic in General and Gameplay ProgrammingThanks for the reply. Just a couple of questions/comments. How is your example different from the second example I gave, where the model does the processing. Quote:Original post by Antheus I don't see all that much use between following such designs too strictly in non-CRUD applications. Each of such frameworks ends up with some fatal flaw which requires horrible hacks to work around. Thanks for the input. Right now, I'm just trying to understand the design, to see if it'll do what I need. Quote:Original post by Antheus Paint application works on Image. Just about every OS provides all the required functionality out of box, from drawing, editing to input handling. There is not much need for abstractions. Same applies to many other problems. MVC makes only sense if building some well-tiered framework where certain functionality may deliberately not be available. The paint application was just an example, but even so, I'd like to keep some separation, to make it easier to port between platforms.
methinks posted a topic in General and Gameplay ProgrammingI'm trying to understand the MVC pattern, and I'm having difficulty figuring out where data processing takes place. Let's say I was building a paint program using MVC, which would be the better way to go? the user draws a line the line is sent to the controller the controller processes the line, turning it into an image the line image is sent to the model, which adds it to the existing image data the controller tells the view to update the view gets and displays the updated image data or the user draws a line the line is sent to the controller the controller sends the line data to the model the model processes the line, and adds it to the existing image data the controller tells the view to update the view gets and displays the updated image data Thanks
methinks posted a topic in General and Gameplay ProgrammingI'm getting the following warning when I compile my program: ld: warning: directory '/Users/alex/Library/Frameworks' following -F not found Does anybody know what causes this error, and ideally how to fix it? I'm pretty sure that it started after I updated xCode via the automatic update (xCode 3.2.2). Normally I wouldn't worry about it too much, but I'm having a problem rendering in opengl (via SDL), and I want to make sure that it's not because of some linking error. Thank you
methinks replied to methinks's topic in General and Gameplay Programmingnot exactly a clean solution, but it seems to work... thanks!
methinks posted a topic in General and Gameplay ProgrammingThis is probably just some stupid mistake, but I can't find it... I'm trying to use a static variable in a class, but it keeps giving me a link error. main program #include <iostream> #include "foo.h" int main (int argc, char* argv[]) { foo a; a.set(10); std::cout<<a.get()<<std::endl; return 0; } foo.h #ifndef FOO_H #define FOO_H #include <iostream> #include <string> class foo { public: void set(int); int get(); private: static int value; }; #endif //FOO_H foo.cpp #include "foo.h" void foo::set(int in) { value = in; } int foo::get() { return value; } The output: "foo::value", referenced from: foo::set(int) in foo.o foo::get() in foo.o ld: symbol(s) not found collect2: ld returned 1 exit status Using gcc4.2.1 on osx Thanks
methinks posted a topic in General and Gameplay ProgrammingI ran into a small problem after I upgraded to xCode 3.1 Whenever I create a new project, it automatically appends the path where I want to put it with the project's name. For example, if I project path is: /myProject/src xCode will create it in /myProject/src/myProject In the last version of xCode, I could manually change it before the project was actually created, but now it doesn't give me that chance anymore. Does anybody know if I can change that behavior, or at least how to re-set the path? Thanks | https://www.gamedev.net/profile/57410-methinks/?tab=reputation | CC-MAIN-2017-30 | refinedweb | 1,673 | 58.52 |
Asked by:
The name 'InitializeControl' does not exist in the current context
Hi all ,
i am having visual studio 2012 sp1.
I am getting build error ( The name 'InitializeControl' does not exist in the current context )
when i removed all lines that uses the resources , the solution build successfully.
any idea how to solve this ?!
Thanks Mohd Al-Bakri
- Moved by Ego JiangMicrosoft contingent staff Friday, December 21, 2012 6:01 AM it is a sharepoint issue (From:MSBuild)
Question
All replies
Hi Al,
What project did you create and what language did you use?
I found a blog talking about this issue which you can refer to:
Best regards,
Ego [MSFT]
MSDN Community Support | Feedback to us
Develop and promote your apps in Windows Store
Please remember to mark the replies as answers if they help and unmark them if they provide no help.
Hi,
Based on your project is SharePoint 2010 project, found a solution and its worked for me for only 1 day i dont know what is wrong with the VS. so i think the issue with my environment
replace all the resources you have by the following format
Text='<%$ Resources:[TMS.UI,]TM_AddNewTask_lblTaskTitle %>'
note the spaces between ($ R) and (e %),, and note also the [ ,].
its worked , the day after that it did not , i had rebooted the server. i back to the same error.
I switch to VS 2010 SP1. i already spent 2 days.
please any one verify if the above worked for him.
Thanks Mohd Al-Bakri
I am using VS2012,and work on SharePoint2013 Visual WebPart. So it dosn't work. :(
Hi TecTeng,
Please post your question in SP 2013 forum. This is SP 2010 forum and i am going to delete your post now.
- hey man , sorry i forgot to tell you after you use you need to make sure that the resource key already exist in the resource file that attache do the solution , then copy past it to the iis App_GlobalResources file , then also copy it to the 14 resources in your case will be 15. then build the solution.
Thanks Mohd Al-Bakri
Hi Mohd Al-Bakri,
>please any one verify if the above worked for him.
Is this solution worked for you? If yes then please close your thread by marking an answer which helped you. since this thread is started by you so you need verify whether it works for you or not.
in standard way, when you try to add UserControl to some SP2013 web part by drag-n-drop method it register reference for that user control, and it looks like this:
<%@ Register Src="~/_controltemplates/15/MySolution.ProjectTitle/PropagateDesign.ascx" TagPrefix="ucc" TagName="SomeUserControlName" %>
and it's not working.
In order to make it work, you just need to change way of registering references for that user control like SharePoint does, and in my case it looks like this:
<%@ Register TagPrefix="ucc" Namespace="MySolution.ProjectTitle.ControlTemplates.MySolution.ProjectTitle" Assembly="MySolution.ProjectTitle, Version=1.0.0.0, Culture=neutral, PublicKeyToken=de6ba60f3bca4edd" %>
last part of references (Assembly) you can find in web.config file of your SP application
with this kind of registration you will be able to have one registration line and to list all UserControls from that namespace
COOL SOLUTION => enjoy
Not sure if anyone is still having this issue, I resolved mine by "tricking" VS.net into doing a clean build of file.ascx.g.cs
I had a similar issue - mine happened in VS2012 for SP2010 when I manually deleted obj, pkg, etc... folders... Looks like the code behind doesn't generate successfully, so I had to change
<%@ Control Language="C#" AutoEventWireup="true" CodeBehind="file.ascx.cs" Inherits="project.webpartnamespace.class" %>
to
<%@ Control Language="C#" AutoEventWireup="true" CodeBehind="file.ascx.cs" Inherits="project.webpartnamespace" %>
then rebuild - to get a single error that class already defined, and then back to:
<%@ Control Language="C#" AutoEventWireup="true" CodeBehind="file.ascx.cs" Inherits="project.webpartnamespace.class" %>
Armine Bell
- The common issue seems to be the ascx.g.vb (or cs) file doesn't get generated if the connection to the SharePoint environment wasn't successful. Double check the Site Url under project properties, make sure it's accurate, then right click on your VisualWebPart1.ascx (or whatever name you have) and choose "Run Custom Tool". I know that there are many causes to this issue, but from my work in SharePoint 2010 and 2013 this tends to be a more common fix than some of the others. Hope you find your solution!
- Proposed as answer by zvgould191 Wednesday, April 16, 2014 10:18 PM
The issue is related to the ascx.g.vb and happened to me as I had changed the URL of the site after creating the project. This sometimes automatically deletes the file and doesn't generate it back even if you open/close Visual studio numerous times.
Rightclick on the "ascx.vb" (OR CS) file and select "Run Custom Tool" to regenerate the file to fix it. | http://social.msdn.microsoft.com/Forums/vstudio/en-US/42844122-dd66-4219-8d87-53adab077338/the-name-initializecontrol-does-not-exist-in-the-current-context?forum=sharepointdevelopmentprevious | CC-MAIN-2014-35 | refinedweb | 835 | 62.48 |
Opened 12 months ago
Last modified 5 weeks ago
#10929 new enhancement
"Edit Paste"
Description
It's sometimes useful to be able to edit a paste -- either its title or its contents. The TracPastePlugin doesn't currently provide this feature.
It would probably make sense to have a separate PASTEBIN_EDIT permission for this, and perhaps (inspired in part by trac:ticket:10909#comment:18) an even finer-grained PASTEBIN_EDIT_OWN permission so that a configuration could allow paste authors to edit their own pastes but no others.
Attachments (0)
Change History (3)
comment:1 follow-up: ↓ 2 Changed 12 months ago by ejucovy
comment:2 in reply to: ↑ 1 Changed 12 months ago by rjollos
[...] But then it becomes a little unclear what the TracPastePlugin would actually be providing.
Yeah, I guess it would sort of just be a front-end that adds a few more capabilities that you don't have when creating wiki pages, such as the ability to specify a title through a create pastes page. t:TracObjectModelProposal ties in here to I suppose.
For now, I'm fine with adding a PASTEBIN_EDIT permission, though I don't know when I'll have time to work on it.
comment:3 Changed 5 weeks ago by roland kohn
i'd like to upvote that one.
currently seems unhandy to have to delete and re-add a paste if something needs to be changed. we wouldn't really need a version history, edit_own permission or anything too complicated
On the other hand, making pastes editable might raise broader questions. Should editable pastes have visible version history? If so, perhaps pastes should actually be implemented and stored in the wiki engine, or (as gist.github does) with a web frontend to a version control backend. But then it becomes a little unclear what the TracPastePlugin would actually be providing.
In the long term, this might actually be a use case for trac:wiki:TracDev/Proposals/WikiNamespaces -- if that feature ever gets into core, I could imagine the TracPastePlugin sort of evolving into a wiki namespace/backend configuration with a custom UI on top of it. | http://trac-hacks.org/ticket/10929 | CC-MAIN-2014-10 | refinedweb | 354 | 50.67 |
The story of the evolution of Chess will take us back to 6 AD. Chess is believed to be derived from the Indian game Chaturanga sometime before the 7th century. 9 AD chess traveled to Europe through the Byzantine transmission.
The next big change in chess was around 1485 when the game of modern chess became popular and has almost the same. The modern chess soon popularised as Chess of the Mad Queen. From the recent statistics around 600 million, active players are around the globe. And still, many passive players to be counted including me.
My grandfather was a very vigorous chess player and was always my opponent. He was a man of strategies and mystical moves. But due to his age-related problems and Parkinson's disease, he's not able to make a good move and he was retarding from the game. Then I thought of my newly bought Lego Mindstorms EV3 robotics kit and I thought of making a virtual hand for my grandpa. I searched for any chess playing robots with EV3 and I found Charlie. Unfortunately, it was not made up of EV3 kit and also I lacked many parts to build that. So I decided to build a robot of my own. So I started to think of another method. And I found it.Hypothetical Design
Nowadays almost all the chess boards include a metal sheet and all the pieces have a small magnet in them to avoid the fall of pieces due to external perturbations. I was interested in exploiting that feature of chess boards. So I designed a customized chessboard of my own. And I can use a magnet to move the pieces over the chessboard flawlessly.
XY Plotter
The hypothesis includes an XY plotter that can designate any position in the chessboard using an (x, y) co-ordinate. In a chessboard, the cells are designated using X co-ordinates using alphabets (A, B, C, D, E, F, G, H) and Y co-ordinates using numbers (1, 2, 3, 4, 5, 6, 7, 8). So the combination of this XY co-ordinates can uniquely identify a cell in a chessboard.
Magnet
A magnet is connected to the XY plotter which is activated only when needed to displace a piece from one position to another and is kept deactivated after movement.
Movements
We are designating the cell A1 as the origin. All other moves are based on the distance from the origin. We have four types of available moves,
1. Diagonal Move
2. Vertical Move
3. Horizontal Move
4. Offset Move
Let's try to simulate a move from C1 to D3
1. Magnet is moved to C1 using a diagonal move from A1
2. The magnet is turned on and the piece is moved to the corner of the cell C1 using Offset move.
3. The piece is moved vertically along the line as shown
4. The piece is then moved horizontally along the line as shown
5. Now the piece is in the corner of the target D3 cell. The piece is taken back to the center using OffsetNull move.
6. Now the piece is in the target position. The magnet is turned off and is taken back to A1 using a diagonal move.Building Instructions
The full build instructions can be seen in the Github repo. The final build will be look like this.
The connections from the ev3 brick to the motors are:
X axis Motor - Port B
Y axis Motor - Port D
Z axis Motor - Port A
We are only using one Lego mindstrorms ev3 31313 kit for building the whole project, so we have only 2 Large motors and one medium motor for the entire movements. Actually Gear Racks are very helpful in making this mechanism easier, unfortunately this kit doesn't contain the Gear Racks.
So I made three ideologies to move in X, Y and Z axis which you can seen in the below images. These are the key concepts in the brick building.
Here I used two gears for making precise movement in the X-Direction.
The Y-axis motor is centralized, having both sides axles fitted on tyres. Why we moving like that is ? because we have only one motor for each axis.
According to the rotations of the medium motor, the magnet will move upwards or downwards. The magnet(Neodymium) is attached on the brick with the double sided sticker. In the next step, let's build the case for this lego robot.Building the Case
Here I actually made a customized chess board and case for the Caissa. 40x40 cm acrylic sheet is cutoff and a sticker of chess board is pasted on it. I made a larger chess board and will choose smaller magnetic chess pieces for smooth movement.
This was supported by the square pillars(Aluminium) having a bush attached on it's top.
These pillars should have at least, minimum length of chess robot. The whole things are attached in the plywood(Base). For restricting the Y-axis motion in 1D you can use the wooden strips(optional).
The case Building is over. Let's have a look on the software section.SoftwareAlexa Skill
Do the preliminary set up by doing the following steps. The setup guide is given here
- Install ev3dev for programming your EV3 Brick
- Install Visual Studio Code for editing code
- Install Alexa Gadgets Python Softwareit describes how it is done. Amazon ID and Alexa Gadget Secret should be noted up because it uniquely identifies our gadget. The following figure shows how a gadget interacts with an Echo device, and where the Alexa Gadgets interfaces fit in.
Schematics
caissa folder, you will see an INI file and a Python file. Open up the
caissa.
-. (screenshots are given for reference)
Select bluetooth devices or pair a new device “Caissa”. The name you give your Skill will also be the way you open the Skill. For example, “Alexa, open Caissa”,
caissa
MoveIntent with slots for
IniY, which maps to a predefined
AMAZON.NUMBER integer value. The combination of the intent and slots will allow us to write code that reacts to:
“Alexa, movefrom C3 to C4”
caisaa
caissa,
Move chessmania”. chess mania"
return handlerInput.responseBuilder
.speak(out)
.reprompt("Awaiting commands")
.getResponse();
MoveIntentHandler
This handler is invoked when you say, “Alexa, tell caissato movefrom C3 to C4”, or other similar supported utterance. When the skill is invoked using this utterance, the following code gets the values from the
IniX,
IniY,
FinX,
Finy slots to construct a command that will be sent to the EV3 Brick to make EV3RSTORM move.
let Inix = Alexa.getSlotValue(handlerInput.requestEnvelope, 'IniX');
let Iniy = Alexa.getSlotValue(handlerInput.requestEnvelope, 'IniY');
Iniy = Math.max(1, Math.min(8, parseInt(Iniy)));
let Finx = Alexa.getSlotValue(handlerInput.requestEnvelope, 'FinX');
let Finy= Alexa.getSlotValue(handlerInput.requestEnvelope, 'FinY');
Finy = Math.max(1, Math.min(8, parseInt(Finy)));
Once all the parameters are available, a
control custom directive is constructed to send to the
MindstormsGadget. This custom directive is then parsed on the EV3 Brick using code we’ll review later.
let directive = Util.build(endpointId, NAMESPACE, NAME_CONTROL,
{
type: 'move',
inix: Inix,
iniy: Iniy,
finx: Finx,
finy: Finy
});
return handlerInput.responseBuilder
.speak(`Moving `)
.addDirective(directive)
.withShouldEndSession(false)
.getResponse();
Now it is the time chessmania”, build the python code.Python Code
Python is the working end that receives a directive (command) from the Alexa skill, elucidates the positions and building corresponding Lego instructions and hence performing visible movements.
Here I discuss all the functions that we need to customize for the flawless working of our chess player.
1. on_custom_mindstorms_gadget_control(self, directive)
It is the function that is invoked when a custom directive is sent from Alexa to Lego Mindstorms.
def on_custom_mindstorms_gadget_control(self, directive):
"""
Handles the Custom.Mindstorms.Gadget control directive.
:param directive: the custom directive with the matching namespace and name
"""
try:
payload = json.loads(directive.payload.decode("utf-8"))
control_type = payload["type"]
if control_type == "move":
self._Move(payload["inix"],int(payload["iniy"]),payload["finx"],int(payload["finy"]))
except KeyError:
print("Missing expected parameters: {}".format(directive), file=sys.stderr)
It decodes the directive and decides the type of intent. It also decodes the slot values provided inside the directive. In our case if the type is 'move' then it invokes _Move() function else it returns an error.
2. ReadLetter(self, x)
For the easiness of movements, we want to convert the letter denoting the X coordinate to a number ranging from 1 to 8.
def ReadLetter(self,x):
x=x[0]
x=x.upper()
return ord(x) - 64
The ReadLetter(x) function takes input x (changes it to upper case) and then converts it into ASCII. After that from the ASCII value, 64 is reduced. In effect, it produces numbers from 1 to 8 for letters from A to H.
3. MoveDiagonal(self, xsteps:int, ysteps:int)
This function produces a diagonal movement combining horizontal and vertical movements. xsteps is the distance that to be moved in the X direction and ysteps is the distance that to be moved in the Y direction.
def MoveDiagonal(self,xsteps:int,ysteps:int):
self.XM.on_for_rotations(SpeedPercent(20),xsteps)
self.YM.on_for_rotations(SpeedPercent(10),-ysteps*0.3)
It is used only when the magnet is in a low position, else it may affect nearby pieces. It is used to move from origin to initial position and then to move back from the final position to the origin.
4. Offset(self)
It is the function used for the square correction. The piece that is at the center of the cell is taken to the corner of the cell.
def Offset(self):
self.XM.on_for_rotations(SpeedPercent(20),0.5)
self.YM.on_for_rotations(SpeedPercent(10),-0.15)
It is done so, because all the succeeding movements are along the borderlines, not to disturb any other pieces in the neighboring cells.
5. OffsetNull(self)
It is the function that nullifies the Offset() movement. After the horizontal and vertical moves, the piece will in the corner of the cell. To take back the piece to the center the OffsetNull() function is used.
def OffsetNull(self):
self.XM.on_for_rotations(SpeedPercent(20),-0.7)
self.YM.on_for_rotations(SpeedPercent(10),0.2)
6. MoveHorizontal(self, xsteps)
It is the function that produces a horizontal movement.
def MoveHorizontal(self,xsteps):
self.XM.on_for_rotations(SpeedPercent(20),xsteps)
The expected parameter is xsteps. It produces a horizontal movement corresponding to the value of xsteps.
7. MoveVertical(self, ysteps)
It is the function that produces a vertical movement.
def MoveVertical(self,ysteps):
self.YM.on_for_rotations(SpeedPercent(10),-ysteps*0.3)
The expected parameter is ysteps. It produces a vertical movement corresponding to the value of ysteps
8. MagOn(self)
In our case, we have connected our magnet to the medium motor which moves upward and downward. MagOn() is the function that turns the magnet upward, in effect which turns the magnet on.
def MagOn(self):
self.ZM.on_for_rotations(SpeedPercent(30),-3)
9. MagOff(self)
MagOff() is the function that turns the magnet downward, in effect which turns the magnet off.
def MagOff(self):
self.ZM.on_for_rotations(SpeedPercent(30),3)
10. _Move(self, inix:str, iniy:int, finx:str, finy:int, is_blocking=False)
It is the function that performs a complete movement. All the above functions (except the first one) are invoked accordingly.
def _Move(self,inix:str,iniy:int,finx:str,finy:int,is_blocking=False):
"""
Handles Move commands from the directive.
"""
print("Move command: ({})".format(inix), file=sys.stderr)
print("Move command: ({})".format(iniy), file=sys.stderr)
print("Move command: ({})".format(finx), file=sys.stderr)
print("Move command: ({})".format(finy), file=sys.stderr)
#Move from base position to the piece to be moved
xsteps = int(self.ReadLetter(inix)-1)
ysteps = int(int(iniy)-1)
if (xsteps==0 and ysteps==0):
print()
else:
self.MoveDiagonal(xsteps,ysteps)
#Turn Magnet Upwards
self.MagOn()
#Counting Steps
xsteps = int(self.ReadLetter(finx)-self.ReadLetter(inix))
ysteps = int(int(finy)-int(iniy))
if xsteps==0:
self.MoveVertical(ysteps)
elif ysteps==0:
self.MoveHorizontal(xsteps)
else:
#Square Correction
self.Offset()
#X Movement
self.MoveHorizontal(xsteps)
#Y Movement
self.MoveVertical(ysteps)
#Square Correction
self.OffsetNull()
#Turn Magnet downwards
self.MagOff()
#Return to origin
xsteps = int(self.ReadLetter(finx)-1)
ysteps = int(int(finy)-1)
self.MoveDiagonal(-xsteps,-ysteps)
print()
It uses the value of initial and final positions. First of all, it moves from 'A1' to the initial position. Then it turns the magnet on. Then performs an Offset movement for nonlinear movements. Then it produces horizontal and vertical movements and then an OffsetNull() move. After placing the piece in the target cell, it turns off the magnet and comes back to the initial position.Calibration
Note: When calibrating the chess pieces, we need to take care of the poles of chess piece and the magnet on medium motor, should be of opposite poles(North-south or vice versa).
Even though we have built Caissa and given it properly working code there are many chances of misbehaviors. The rotation of the corresponding motor that can move 1 cell in the X direction is xwidth and that in the Y direction is ywidth, those should be perfectly measured. Calibration is the key for the perfect working of caissa. You can adjust Offset() and OffsetNull() functions for the proper working.Demo Video
Here is some movements of Caïssa.
In this video, It is partially automated. It can also be fully automated.
I think that, this is a project which is having creative and engaging experiences that showcase the use of voice interaction with the lego mindstrorms.31313. | https://www.hackster.io/coderscafe/caissa-38becd | CC-MAIN-2021-17 | refinedweb | 2,262 | 58.89 |
.xib files in Xamarin.Mac
This article covers working with .xib files created in Xcode's Interface Builder to create and maintain user interfaces for a Xamarin.Mac application.
Note
The preferred way to create a user interface for a Xamarin.Mac app is with storyboards. This documentation has been left in place for historical reasons and for working with older Xamarin.Mac projects. For more information, please see our Introduction to Storyboards documentation.
Overview
When working with C# and .NET in a Xamarin.Mac application, you have access to the same user interface elements and tools that a developer working in Objective-C and Xcode does. Because Xamarin.Mac integrates directly with Xcode, you can use Xcode's Interface Builder to create and maintain your user interfaces (or optionally create them directly in C# code).
A .xib file is used by macOS to define elements of your application's user interface (such as Menus, Windows, Views, Labels, Text Fields) that are created and maintained graphically in Xcode's Interface Builder.
In this article, we'll cover the basics of working with .xib files in a Xamarin.Mac application. It is highly suggested that you work through the Hello, Mac article first, as it covers key concepts and techniques that we'll be using in this article.
You may want to take a look at the Exposing C# classes / methods to Objective-C section of the Xamarin.Mac Internals document as well, it explains the
Register and
Export attributes used to wire up your C# classes to Objective-C objects and UI elements.
Introduction to Xcode and Interface Builder
As part of Xcode, Apple has created a tool called Interface Builder, which allows you to create your User Interface visually in a designer. Xamarin.Mac integrates fluently with Interface Builder, allowing you to create your UI with the same tools that Objective-C users do.
Components of Xcode
When you open a .xib file in Xcode from Visual Studio for Mac, it opens with a Project Navigator on the left, the Interface Hierarchy and Interface Editor in the middle, and a Properties & Utilities section on the right:
Let's take a look at what each of these Xcode sections does and how you will use them to create the interface for your Xamarin.Mac application.
Project navigation
When you open a .xib file for editing in Xcode, Visual Studio for Mac creates an Xcode project file in the background to communicate changes between itself and Xcode. Later, when you switch back to Visual Studio for Mac from Xcode, any changes made to this project are synchronized with your Xamarin.Mac project by Visual Studio for Mac.
The Project Navigation section allows you to navigate between all of the files that make up this shim Xcode project. Typically, you will only be interested in the .xib files in this list such as MainMenu.xib and MainWindow.xib.
Interface hierarchy
The Interface Hierarchy section allows you to easily access several key properties of the User Interface such as its Placeholders and main Window. You can also use this section to access the individual elements (views) that make up your user interface and the adjust the way that they are nested by dragging them around within the hierarchy.
Interface editor
The Interface Editor section provides the surface on which you graphically layout your User Interface. You'll drag elements from the Library section of the Properties & Utilities section to create your design. As you add user interface elements (views) to the design surface, they will be added to the Interface Hierarchy section in the order that they appear in the Interface Editor.
Properties & utilities
The Properties & Utilities section is divided into two main sections that we will be working with, Properties (also called Inspectors) and the Library:
Initially this section is almost empty, however if you select an element in the Interface Editor or Interface Hierarchy, the Properties section will be populated with information about the given element and properties that you can adjust.
Within the Properties section, there are 8 different Inspector Tabs, as shown in the following illustration:.
In the Library section, you can find controls and objects to place into the designer to graphically build your user interface:
Now that you are familiar with the Xcode IDE and Interface Builder, let’s look at using it to create a user interface.
Creating and maintaining windows in Xcode
The preferred method for creating a Xamarin.Mac app's User Interface is with Storyboards (please see our Introduction to Storyboards documentation for more information) and, as a result, any new project started in Xamarin.Mac will use Storyboards by default.
To switch to using a .xib based UI, do the following:
Open Visual Studio for Mac and start a new Xamarin.Mac project.
In the Solution Pad, right-click on the project and select Add > New File...
Select Mac > Windows Controller:
Enter
MainWindowfor the name and click the New button:
Right-click on the project again and select Add > New File...
Select Mac > Main Menu:
Leave the name as
MainMenuand click the New button.
In the Solution Pad select the Main.storyboard file, right-click and select Remove:
In the Remove Dialog Box, click the Delete button:
In the Solution Pad, double-click the Info.plist file to open it for editing.
MainMenufrom the Main Interface dropdown:
In the Solution Pad, double-click the MainMenu.xib file to open it for editing in Xcode's Interface Builder.
In the Library Inspector, type
objectin the search field then drag a new Object onto the design surface:
In the Identity Inspector, enter
AppDelegatefor the Class:
Select File's Owner from the Interface Hierarchy, switch to the Connection Inspector and drag a line from the delegate to the
AppDelegateObject just added to the project:
Save the changes and return to Visual Studio for Mac.
With all these changes in place, edit the AppDelegate.cs file and make it look like the following:
using AppKit; using Foundation; namespace MacXib { [Register ("AppDelegate")] public class AppDelegate : NSApplicationDelegate { public MainWindowController mainWindowController { get; set; } public AppDelegate () { } public override void DidFinishLaunching (NSNotification notification) { // Insert code here to initialize your application mainWindowController = new MainWindowController (); mainWindowController.Window.MakeKeyAndOrderFront (this); } public override void WillTerminate (NSNotification notification) { // Insert code here to tear down your application } } }
Now the app's Main Window is defined in a .xib file automatically included in the project when adding a Window Controller. To edit your windows design, in the Solution Pad, double click the MainWindow.xib file:
This will open the window design in Xcode's Interface Builder:
Standard window workflow
For any window that you create and work with in your Xamarin.Mac application, the process is basically the same:
- For new windows that are not the default added automatically to your project, add a new window definition to the project.
- Double-click the .xib file to open the window design for editing in Xcode's Interface Builder.
- Set any required window properties in the Attribute Inspector and the Size Inspector.
- Drag in the controls required to build your interface and configure them in the Attribute Inspector.
- Use the Size Inspector to handle the resizing for your UI elements.
- Expose the window's UI elements to C# code via outlets and actions.
- Save your changes and switch back to Visual Studio for Mac to sync with Xcode.
Designing a window layout
The process for laying out a User Interface in Interface builder is basically the same for every element that you add:
- Find the desired control in the Library Inspector and drag it into the Interface Editor and position it.
- Set any required window properties in the Attribute Inspector.
- Use the Size Inspector to handle the resizing for your UI elements.
- If you are using a custom class, set it in the Identity Inspector.
- Expose the UI elements to C# code via outlets and actions.
- Save your changes and switch back to Visual Studio for Mac to sync with Xcode.
For Example:
In Xcode, drag a Push Button from the Library Section:
Drop the button onto the Window:
With the label still selected in the Interface Editor, switch to the Size Inspector:
In the Autosizing Box click the Dim Red Bracket at the right and the Dim Red Horizontal Arrow in the center:
This ensures that the label will stretch to grow and shrink as the window is resized in the running application. The Red Brackets and the top and left of the Autosizing Box box tell the label to be stuck to its given X and Y locations.
Save your changes to the User Interface
As you were resizing and moving controls around, you should have noticed that Interface Builder gives you helpful snap hints that are based on OS X Human Interface Guidelines. These guidelines will help you create high quality applications that will have a familiar look and feel for Mac users.
If you look in the Interface Hierarchy section, notice how the layout and hierarchy of the elements that make up our user Interface are shown:
From here you can select items to edit or drag to reorder UI elements if needed. For example, if a UI element was being covered by another element, you could drag it to the bottom of the list to make it the top-most item on the window.
For more information on working with Windows in a Xamarin.Mac application, please see our Windows documentation.
Exposing UI elements to C# code
Once you have finished laying out the look and feel of your user interface in Interface Builder, you'll need to expose elements of the UI so that they can be accessed from C# code. To do this, you'll be using actions and outlets. Visual Studio for Mac to sync.
A WindowController.cs file will be added to your project in the Solution Pad in Visual Studio for Mac:
Reopen the Storyboard in Xcode's Interface Builder.
The WindowController.h file will be available for use:, outlets and actions are added directly in code via Control-dragging. More specifically, this means that. Visual Studio for Mac created a file called MainWindow.h as part of the shim Xcode project it generated to use the Interface Builder:
This stub .h file mirrors the MainWindow.designer.cs that is automatically added to a Xamarin.Mac project when a new
NSWindow is created. This file will be used to synchronize the changes made by Interface Builder and is where we will create your outlets and actions so that UI elements are exposed to C# code.
Adding an outlet
With a basic understanding of what outlets and actions are, let's look at creating an outlet to expose a UI element to MainWindowController.m file in the Code Editor, which is incorrect. If you remember from our discussion on what outlets and actions are above, we need to have the MainWindow.h selected.
At the top of the Code Editor click on the Automatic Link and select the MainWindow.h file:
Xcode should now have the correct file selected:
The last step was very important! If you don't have the correct file selected, you won't be able to create outlets and actions or they will be exposed to the wrong class in C#!
In the Interface Editor, hold down the Control key on the keyboard and click-drag the label we created above onto the code editor just below the
@interface MainWindow : NSWindow { }code:
A dialog box will be displayed. Leave the Connection set to outlet and enter
ClickedLabelfor the Name:
Click the Connect button to create the outlet:
Save the changes to the file.
Adding an action
Next, let's look at creating an action to expose a user interaction with UI element to your C# code.
Do the following:
Make sure we are still in the Assistant Editor and the MainWindow.h file is visible in the Code Editor.
In the Interface Editor, hold down the Control key on the keyboard and click-drag the button we created above onto the code editor just below the
@property (assign) IBOutlet NSTextField *ClickedLabel;code:
Change the Connection type to action:
Enter
ClickedButtonas the Name:
Click the Connect button to create action:
Save the changes to the file.
With your User Interface wired-up and exposed to C# code, switch back to Visual Studio for Mac and let it synchronize the changes from Xcode and Interface Builder.
Writing the code
With your User Interface created and its UI elements exposed to code via outlets and actions, you are ready to write the code to bring your program to life. For example, open the MainWindow.cs file for editing by double-clicking it in the Solution Pad:
And add the following code to the
MainWindow class to work with the sample outlet that you created above:
private int numberOfTimesClicked = 0; ... public override void AwakeFromNib () { base.AwakeFromNib (); // Set the initial value for the label ClickedLabel.StringValue = "Button has not been clicked yet."; }
Note that the
NSLabel is accessed in C# by the direct name that you assigned it in Xcode when you created its outlet in Xcode, in this case, it's called
ClickedLabel. You can access any method or property of the exposed object the same way you would any normal C# class.
Important
You need to use
AwakeFromNib, instead of another method such as
Initialize, because
AwakeFromNib is called after the OS has loaded and instantiated the User Interface from the .xib file. If you tried to access the label control before the .xib file has been fully loaded and instantiated, you’d get a
NullReferenceException error because the label control would not be created yet.
Next, add the following partial class to the
MainWindow class:
partial void ClickedButton (Foundation.NSObject sender) { // Update counter and label ClickedLabel.StringValue = string.Format("The button has been clicked {0} time{1}.",++numberOfTimesClicked, (numberOfTimesClicked < 2) ? "" : "s"); }
This code attaches to the action that you created in Xcode and Interface Builder and will be called any time the user clicks the button.
Some UI elements automatically have built in actions, for example, items in the default Menu Bar such as the Open... menu item (
openDocument:). In the Solution Pad, double-click the AppDelegate.cs file to open it for editing and add the following code below the
DidFinishLaunching method:
[Export ("openDocument:")] void OpenDialog (NSObject sender) { var dlg = NSOpenPanel.OpenPanel; dlg.CanChooseFiles = false; dlg.CanChooseDirectories = true; if (dlg.RunModal () == 1) { var alert = new NSAlert () { AlertStyle = NSAlertStyle.Informational, InformativeText = "At this point we should do something with the folder that the user just selected in the Open File Dialog box...", MessageText = "Folder Selected" }; alert.RunModal (); } }
The key line here is
[Export ("openDocument:")], it tells
NSMenu that the AppDelegate has a method
void OpenDialog (NSObject sender) that responds to the
openDocument: action.
For more information on working with Menus, please see our Menus documentation.
Synchronizing changes with Xcode
When you switch back to Visual Studio for Mac from Xcode, any changes that you have made in Xcode will automatically be synchronized with your Xamarin.Mac project.
If you select the MainWindow.designer.cs in the Solution Pad you'll be able to see how our outlet and action have been wired up in our C# code:
Notice how the two definitions in the MainWindow.designer.cs file:
[Outlet] AppKit.NSTextField ClickedLabel { get; set; } [Action ("ClickedButton:")] partial void ClickedButton (Foundation.NSObject sender);
Line up with the definitions in the MainWindow.h file in Xcode:
@property (assign) IBOutlet NSTextField *ClickedLabel; - (IBAction)ClickedButton:(id)sender;
As you can see, Visual Studio for Mac listens for changes to the .h file, and then automatically synchronizes those changes in the respective .designer.cs file to expose them to your application. You may also notice that MainWindow.designer.cs is a partial class, so that Visual Studio for Mac doesn't have to modify MainWindow.cs which would overwrite any changes that we have made to the class.
You normally will never need to open the MainWindow.
Adding a new window to a project
Aside from the main document window, a Xamarin.Mac application might need to display other types of windows to the user, such as Preferences or Inspector Panels. When adding a new Window to your project you should always use the Cocoa Window with Controller option, as this makes the process of loading the Window from the .xib file easier.
To add a new window, do the following:
In the Solution Pad, right-click on the project and select Add > New File...
In the New File dialog box, select Xamarin.Mac > Cocoa Window with Controller:
Enter
PreferencesWindowfor the Name and click the New button.
Double-click the PreferencesWindow.xib file to open it for editing in Interface Builder:
Design your interface:
Save your changes and return to Visual Studio for Mac to sync with Xcode.
Add the following code to AppDelegate.cs to display your new window:
[Export("applicationPreferences:")] void ShowPreferences (NSObject sender) { var preferences = new PreferencesWindowController (); preferences.Window.MakeKeyAndOrderFront (this); }
The
var preferences = new PreferencesWindowController (); line creates a new instance of the Window Controller that loads the Window from the .xib file and inflates it. The
preferences.Window.MakeKeyAndOrderFront (this); line displays the new Window to the user.
If you run the code and select the Preferences... from the Application Menu, the window will be displayed:
For more information on working with Windows in a Xamarin.Mac application, please see our Windows documentation.
Adding a new view to a project
There are times when it is easier to break your Window's design down into several, more manageable .xib files. For example, like switching out the contents of the main Window when selecting a Toolbar item in a Preferences Window or swapping out content in response to a Source List selection.
When adding a new View to your project you should always use the Cocoa View with Controller option, as this makes the process of loading the View from the .xib file easier.
To add a new view, do the following:
In the Solution Pad, right-click on the project and select Add > New File...
In the New File dialog box, select Xamarin.Mac > Cocoa View with Controller:
Enter
SubviewTablefor the Name and click the New button.
Double-click the SubviewTable.xib file to open it for editing in Interface Builder and Design the User Interface:
Wire up any required actions and outlets.
Save your changes and return to Visual Studio for Mac to sync with Xcode.
Next edit the SubviewTable.cs and add the following code to the AwakeFromNib file to populate the new View when it is loaded:
public override void AwakeFromNib () { base.AwakeFromNib (); // Create the Product Table Data Source and populate it var DataSource = new ProductTableDataSource (); DataSource.Products.Add (new Product ("Xamarin.iOS", "Allows you to develop native iOS Applications in C#")); DataSource.Products.Add (new Product ("Xamarin.Android", "Allows you to develop native Android Applications in C#")); DataSource.Products.Add (new Product ("Xamarin.Mac", "Allows you to develop Mac native Applications in C#")); DataSource.Sort ("Title", true); // Populate the Product Table ProductTable.DataSource = DataSource; ProductTable.Delegate = new ProductTableDelegate (DataSource); // Auto select the first row ProductTable.SelectRow (0, false); }
Add an enum to the project to track which view is currently being display. For example, SubviewType.cs:
public enum SubviewType { None, TableView, OutlineView, ImageView }
Edit the .xib file of the window that will be consuming the View and displaying it. Add a Custom View that will act as the container for the View once it is loaded into memory by C# code and expose it to an outlet called
ViewContainer:
Save your changes and return to Visual Studio for Mac to sync with Xcode.
Next, edit the .cs file of the Window that will be displaying the new view (for example, MainWindow.cs) and add the following code:
private SubviewType ViewType = SubviewType.None; private NSViewController SubviewController = null; private NSView Subview = null; ... private void DisplaySubview(NSViewController controller, SubviewType type) { // Is this view already displayed? if (ViewType == type) return; // Is there a view already being displayed? if (Subview != null) { // Yes, remove it from the view Subview.RemoveFromSuperview (); // Release memory Subview = null; SubviewController = null; } // Save values ViewType = type; SubviewController = controller; Subview = controller.View; // Define frame and display Subview.Frame = new CGRect (0, 0, ViewContainer.Frame.Width, ViewContainer.Frame.Height); ViewContainer.AddSubview (Subview); }
When we need to show a new View loaded from a .xib file in the Window's Container (the Custom View added above), this code handles removing any existing view and swapping it out for the new one. It looks to see it you already have a view displayed, if so it removes it from the screen. Next it takes the view that has been passed in (as loaded from a View Controller) resizes it to fit in the Content Area and adds it to the content for display.
To display a new view, use the following code:
DisplaySubview(new SubviewTableController(), SubviewType.TableView);
This creates a new instance of the View Controller for the new view to be displayed, sets its type (as specified by the enum added to the project) and uses the
DisplaySubview method added to the Window's class to actually display the view. For example:
For more information on working with Windows in a Xamarin.Mac application, please see our Windows and Dialogs documentation.
Summary
This article has taken a detailed look at working with .xib files in a Xamarin.Mac application. We saw the different types and uses of .xib files to create your application's User Interface, how to create and maintain .xib files in Xcode's Interface Builder and how to work with .xib files in C# code. | https://docs.microsoft.com/en-us/xamarin/mac/app-fundamentals/xib | CC-MAIN-2018-30 | refinedweb | 3,617 | 54.83 |
Jdbc Driver - JDBC
Type 3. * Native-protocol, pure Java driver, also called Type 4.For JDBC...JDBC Driver Types Type of JDBC Driver four..Type 1(JDBC-ODBC Driver)Type 2(java native driver)Type 3Type 4 Type of JDBC
JDBC Driver and Its Types
JDBC Driver and Its Types
...-Protocol Driver
The JDBC type 3 driver, also known as the network-protocol... Connectivity (JDBC) driver types. Driver types are used to categorize the technology
used
java- jdbc with type 4 driver
java- jdbc with type 4 driver My program code is-----
import... : Invalid Oracle URL Specified
Please tell me its solution..
Thanks..
... and Register the JDBC driver:***
DriverManager.registerDriver(new
no driver - JDBC
());
System.exit(1);
}
/* Type 2 driver url */
//String url = "jdbc:db2:r_m";
String url = "jdbc:db2://localhost:50000/r_m...
{
try
{
//Loads Type 2 Driver
Class.forName
fastest type of JDBC driver
fastest type of JDBC driver What is the fastest type of JDBC driver
Driver
Driver can u send type4 jdbc driver class name and url for microsoft sql server 2008
Fastest type of JDBC Driver
Fastest type of JDBC Driver hello,
What is the fastest type of JDBC driver?
hii,
Type 4 is the fastest JDBC driver
JDBC Driver - JDBC
JDBC Driver What are the diffrent types of JDBC driver
MySQL Driver for JDBC - JDBC
MySQL Driver for JDBC Sir, I have started reading your JDBC tutorial...... Example."); Connection conn = null; String url = "jdbc:mysql://localhost:3306 Hi,Please download the driver from
JDBC driver is the fastest one
JDBC driver is the fastest one Which type of JDBC driver is the fastest one
JDBC - JDBC
! Hello,There are four types of JDBC drivers. There are mainly four type of JDBC drivers available. They are:Type 1 : JDBC-ODBC Bridge Driver A JDBC-ODBC... on each client machine that uses this type of driver. Hence, this kind of driver
jdbc driver
jdbc driver hello,
can we create a own jdbc driver? how can we create
Driver Manager Class
of managing the different types of JDBC database driver running on an application... the driver with the DriverManager class.
3. getConnection(String url...;
The JDBC Driver Manager
The JDBC Driver
main(String[]args){
try{
Connection con = null;
String url = "jdbc:mysql://localhost:3306/";
String db = "test";
String driver...){
System.out.println(e);
}
}
}
3)Now to retrieve this image use its image_id
Set properties for a JDBC driver
Set properties for a JDBC driver How do I set properties for a JDBC driver and where are the properties stored
Product Components of JDBC
. The JDBC Driver Manager.
3. The JDBC Test Suite.
4. The JDBC-ODBC Bridge...;
3. The JDBC Test Suite.
The function of JDBC driver test... as JDBC type 1 driver is a database driver that utilize the ODBC driver
jdbc - JDBC
management so i need how i can connect the pgm to database by using jdbc...? if u replyed its very useful for me... Hi,
Please read JDBC tutorial...:
Class.forName(driver).newInstance();
conn = DriverManager.getConnection(url
choosing best jdbc connection - JDBC
and
It is the fastest JDBC driver.
Type 1 and Type 3 drivers will be slower than Type 2 drivers... is the best type of Jdbc
JDBC Net pure Java Driver
A native... in details to visit...
JDBC
con = null;
String url = "jdbc:mysql://localhost:3306/";
String db...JDBC save a data in the database I need a code to save a data... between java and mysql using JDBC and saves the data into the database.
import
JDBC
!");
Connection con = null;
String url = "jdbc:mysql://localhost:3306/";
String db...{
Class.forName(driver);
con = DriverManager.getConnection(url+db,"root","root");
try...JDBC code to save a data in the database I need a code to save
jdbc
driver = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql://localhost:3306/test...(driver);
return DriverManager.getConnection(url, username, password...jdbc i had written jdbc connection in method and i need to get
How To Use Database Driver
to interact with database. In JDBC there are four types Database
driver
Type 1: JDBC-ODBC Bridge driver
Type 2: Native-API/partly Java driver
Type 3: AllJava/Net-protocol driver
Type 4: All Java/Native-protocol driver
Each
JDBC CONNECTIVITY - JDBC
of JDBC drivers. Each driver has to be register with this class.
getConnection...- This is the class where Type 1 Driver is implemented.
For more information, visit...JDBC CONNECTIVITY String jclass="sun.jdbc.odbc.JdbcOdbcDriver
JDBC
JDBC We are using the same piece of code (irrespective of type of driver we are using) for getting the connection. On what basis you decide which type of driver you are using
JDBC Database URLs
:
JDBC Database URL
specify a JDBC driver name
Connection to a database..., database name or instance etc.
URL'S EXAMPLE :
JDBC ODBC Bridge driver...=your_password
Oracle JDBC Driver(TYPE 4) :
JDBC Training, Learn JDBC yourself
Architecture, JDBC
Driver and Its Types, JDBC
Versions From First To Latest... driver types - Learn JDBC
Driver types
JDBC 4.0... database driver
Database connection url
Opening and closing the connection
ResultSetMetaData - JDBC
!");
Connection con = null;
String url = "jdbc:mysql://localhost:3306...{
Class.forName(driver);
con = DriverManager.getConnection(url+db, user, pass... in Database!");
Connection con = null;
String url = "jdbc:mysql
JDBC Components
Java applications to a JDBC driver. DriverManager is the very
important part of the JDBC architecture.
3. JDBC Test
Suite
The JDBC driver
test suite helps JDBC... platform, it includes the Java Standard Edition.
2. JDBC Driver
Manager
The JDBC
No suitable driver found for jdbc:mysql://localhost:3306/TEST
No suitable driver found for jdbc:mysql://localhost:3306/TEST hii,
I have wrietten web project using jsp and hibernate but its not working.
ava.sql.SQLException: No suitable driver found for jdbc:mysql://localhost:3306/TEST
jdbc mysqll - JDBC
";
String url = "jdbc:mysql://192.168.10.211:3306/";
String dbName = "amar...jdbc mysqll import java.sql.*;
public class AllTableName{
public...("com.mysql.jdbc.Driver");
Connection con=DriverManager.getConnection("jdbc:mysql
jdbc mysql - JDBC
(String[] args) {
String driver = "com.mysql.jdbc.Driver";
String url = "jdbc...{
Class.forName(driver);
Connection con=DriverManager.getConnection(url+dbName,userName...jdbc mysql import java.sql.*;
public class AllTableName
type 4 drivers - JDBC
type 4 drivers Hi!
What is the syntax for Type - 4 drivers. give me any sample code.
Thanks in advance.. Hi Friend,
Please visit the following link:
jdbc
executes according to the default isolation level of the underluing odbc driver... and no exclusive locks are honored.
3) TRANSACTIONREADCOMMITTED: A transaction
JDB What is the difference b/w jdbc driver and jdbc driver manager... use their product we need a supporter, ie Driver
Each driver should supply a class that implements the Driver interface.
When a Driver class is loaded
Database drivers - JDBC
as:
* JDBC-ODBC bridge plus ODBC driver, also called Type 1.
* Native-API, partly Java driver, also called Type 2.
* JDBC-Net, pure Java driver, also called Type 3.
* Native-protocol, pure Java driver
conn = null;
String url = "jdbc:mysql://localhost:3306/";
String dbName = "jdbctutorial";
String driver = "com.mysql.jdbc.Driver";
String...(driver).newInstance();
conn = DriverManager.getConnection(url+dbName
Frameworks and example source for writing a JDBC driver.
Frameworks and example source for writing a JDBC driver. Where can I find info, frameworks and example source for writing a JDBC driver
jdbc - JDBC
.");
Connection conn = null;
String url = "jdbc:mysql://localhost:3306/";
String dbName = "jdbctutorial";
String driver = "com.mysql.jdbc.Driver... {
Class.forName(driver).newInstance();
conn
Introduction to the JDBC
driver types. These are:
Type 1: JDBC-ODBC
Bridge Driver
The first type of JDBC driver is JDBC-ODBC...;
Type 3: JDBC-Net
Pure Java Driver
jdbc - JDBC
= null;
String url = "jdbc:mysql://localhost:3306/";
String db...{
Class.forName(driver);
con = DriverManager.getConnection(url+db,"root","root... in JSP to create a table.
2)how desc can be written in JDBC concepts
JDBC - JDBC
database table!");
Connection con = null;
String url = "jdbc:mysql... is
Connection con=DriverManager.getConnection(url,username,password... implementing class. Hi friend,
Example of JDBC Connection with Statement
A Brief Introduction to JDBC
.
JDBC Driver Types
There are 4 types of JDBC drivers available.
Type 1: JDBC... to invoke JDBC driver. The type 2 drivers are specific to particular database... offers better performance then JDBC-ODBC bridge driver. The type 2 driver uses
jdbc - JDBC
");
3) Connect to database:***********
a) If you are using oracle oci driver... driver,you have to use:
Connection conn = DriverManager.getConnection ("jdbc...jdbc kindly give the example program for connecting oracle dase
jdbc - JDBC
conn = null;
String url = "jdbc:mysql://localhost:3306/";
String dbName = "databasename";
String driver = "com.mysql.jdbc.Driver";
String...(driver).newInstance();
conn = DriverManager.getConnection(url+dbName
;
String url = "jdbc:mysql://192.168.10.211:3306/amar";
String driver... Example!");
Connection con = null;
String url = "jdbc:mysql://localhost...{
Class.forName(driver);
con = DriverManager.getConnection(url, user, pass
.");
Connection con = null;
String url = "jdbc:mysql://192.168.10.211... {
Class.forName(driver).newInstance();
con = DriverManager.getConnection(url...creating jdbc sql statements I had written the following program
Redirect the log used by DriverManager and JDBC driver
Redirect the log used by DriverManager and JDBC driver How can I get or redirect the log used by DriverManager and JDBC drivers
unable to retrive the data from mysql using servlet using jdbc driver
Connection con = null;
String url = "jdbc:mysql://localhost:3306/";
String dbName = "rapax";
String driver = "com.mysql.jdbc.Driver";
String...unable to retrive the data from mysql using servlet using jdbc driver
Which JDBC Type Using - Java Beginners
Which JDBC Type Using As there are 4 types of JDBC driver.
I wanted to know:
How would one come to know that which jdbc type any web application... friend,
Read for more information.
jdbc
what are different type of locks what are different type of locks
Types of locks in JDBC:
Row and Key Locks:: It is useful when... accesses most of the tables of a table. These are of two types:
a) Shared lock:
One
Driver and Its Types |
JDBC Versions From First To Latest ... of java.sql Package |
Driver Manager JDBC |
Data
Source JDBC... Next |
JDBC
Mysql Connection Url |
JDBC Insert
Statement |
JDBC Insert
JDBC-SERVLET
=DriverManager.getConnection("jdbc:odbc:{Microsoft Access Driver(*.mdb...
jdbc:odbc:{Microsoft Access Driver(*.mdb)}
First set the datasoruce name... that datasource name in url like
jdbc:odbc:msdsn
i tried the program
Installing the Driver and Configuring the CLASSPATH
Installing the Driver and Configuring the CLASSPATH What is the procedure to Installing the Driver and Configuring the CLASSPATH mysql jdbc connector? the jar file
JDBC Architecture
database or during connectivity.
JDBC Driver's Type
JDBC Driver can be broadly categorized into 4 categories--
JDBC-ODBC BRIDGE DRIVER(TYPE 1) .... Types of JDBC Drivers
JDBC API
JDBC programming interface
error - JDBC
conn = null;
String url = "jdbc:oracle:thin:@localhost:1521:xe";
String dbName = "jdbctutorial";
String driver = "oracle.jdbc.driver.OracleDriver...error i wrote the program using dbms type 4 driver.it is comipled
Java JDBC
Java JDBC What is the fastest type of JDBC driver
jdbc - JDBC
jdbc Hi,
Could you please tell me ,How can we connect to Sql server through JDBC.
Which driver i need to download.
Thank You Hi Friend,
Please visit the following code:
JDBC - JDBC
JDBC JDBC driver class not found:com.mysql.jdbc.Driver.....
Am... path.
For read more information on JDBC visit to :
Thanks 4 Features, JDBC 4.0 Features
, SQL XML data type etc.
Here are some features of jdbc 4.0
1. Auto loading...
.style1 {
margin-left: 40px;
}
JDBC 4 Features
In this section we are discussing about the new features of JDBC 4.0.
Jdbc 4.0 ships with Java SE 6
java - JDBC
";
String driverName = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql...();
}
}
----------------------------------------------------
in this program using jdbc driver, if you...java how to store and retrive images from oracle 10g using jdbc
First Step towards JDBC!
four JDBC driver types. These are:
Type 1: JDBC-ODBC
Bridge Driver
The first type of JDBC dirver is JDBC-ODBC...
commands to DBMS-specific native calls.
Type 3: JDBC-Net
Pure
jdbc - JDBC
drivers for concurrent access?
Question: Is the JDBC-ODBC Bridge multi-threaded?
Answer: No. The JDBC-ODBC Bridge does not support concurrent access from different threads. The JDBC-ODBC Bridge uses synchronized methods
type4driver - JDBC
type4driver i want create connectivity of my java program to the ms acces with the help of type 4 driver but we are not able to connect the connection ...becuz i don,t have jar file for ms acces so give me url and also the jar
java - JDBC
User DSN tab
3. Add a user DSN
4. Select Microsoft Access Driver(*.mdb)
5...{
String url="jdbc:odbc:access";
File file=new File("c:\\barbie.jpg...("sun.jdbc.odbc.JdbcOdbcDriver");
Connection con = DriverManager.getConnection("jdbc:odbc
jdbc-oracle - JDBC
jdbc-oracle Hi!
sub: image insertion in oracle:
I inserted the image in oracle database using java through jdbc-odbc bridge driver... tablename; it displays the following:
" COLUMN OR ATTRIBUTE TYPE CANNOT
jdbc - JDBC
jdbc please help me i am getting jV.sql.exception: data source name and no default driver specified while inserting the image to the database with oracle 11g
jsp - JDBC
;<%Connection con = null; String<input type
jdbc - JDBC
= null;
String url = "jdbc:mysql://localhost:3306/";
String dbName... * from subfac");
while (rs10.next())
{
if(t.equals(rs10.getString(3...='"+rs10.getSring(3)+"'");
st1.executeUpdate("drop table "+subfac
jdbc - JDBC
Deletion Example");
Connection con = null;
String url = "jdbc:mysql://localhost...jdbc jdbc
Expert:Ramakrishna
Statement st1=con.createStatement...(rs10.getString(3)))
{
String sub=rs10.getString(1);
String fac=rs10.getString(2
Ask Questions?
If you are facing any programming issue, such as compilation errors or not able to find the code you are looking for.
Ask your questions, our development team will try to give answers to your questions. | http://www.roseindia.net/tutorialhelp/comment/28193 | CC-MAIN-2013-20 | refinedweb | 2,303 | 51.24 |
Karlijn Willems9,961 Points
Trying to create an array of arrays... Stuck on the error: Object reference not set to an instance of an object
I don't know if I'm getting any closer with these loops. I don't really understand how to add any content (an integer) in a cell of the table.
Also I am getting the error: Bummer! Object reference not set to an instance of an object. It is not referring to a codeline and I don't get what it is pointing to so I'm stuck here...
I appreciate any help! :)
namespace Treehouse.CodeChallenges { public static class MathHelpers { public static int[][] BuildMultiplicationTable(int maxFactor) { int[][] table = new int[maxFactor][]; for (int rowIndex = 0; rowIndex < table[rowIndex].Length; rowIndex++) { table[rowIndex] = new int[maxFactor +1]; for (int colIndex = 0; colIndex < table[rowIndex].Length; colIndex++) { int cell = rowIndex * colIndex; table[rowIndex][colIndex] = cell; } } return table; } } }
3 Answers
Steven Parker181,132 Points
When you initialize your individual rows, you correctly set the size to one more than the highest factor. But you didn't do that for the outer table.
Also, in the outer (rowIndex) loop, you use the length of individual rows in the conditional clause instead of the length of the table itself.
Karlijn Willems9,961 Points
Thank you! I think I changed it with all the corrections you gave me. I also checked the code on jagged arrays in c# 7 in a Nutshell... but still getting the same error. This is my code now:
public static class MathHelpers { public static int[][] BuildMultiplicationTable(int maxFactor) { int[][] jaggedArray = new int[maxFactor + 1][];
for (int i = 0; i < jaggedArray.Length; i++) { jaggedArray[i] = new int[maxFactor + 1]; for (int j = 0; j < jaggedArray[maxFactor].Length; j++) { jaggedArray[i][j] = i * j; } } return jaggedArray; }
}
update: sorry it only recognizes part of the code as code...
Karlijn Willems9,961 Points
Thnx for the the explanation on the code formatting :)
Your right, it works! I was playing around with the variablenames a bit too much I guess... Thanks again!
Steven Parker181,132 Points
Steven Parker181,132 Points
To make your code look like what the "Get Help" button did, use the instructions for code formatting in the Markdown Cheatsheet pop-up below the "Add an Answer" area.
Or watch this video on code formatting.
Not counting variable names, t appears you made an additional change that wasn't one of the suggestions. Now the inner loop is using "maxFactor" in the limit condition instead of "rowIndex" (now "i"). That row won't be established until the last iteration of the outer loop. | https://teamtreehouse.com/community/trying-to-create-an-array-of-arrays-stuck-on-the-error-object-reference-not-set-to-an-instance-of-an-object | CC-MAIN-2020-10 | refinedweb | 435 | 64.3 |
Hi,
I have problems with upgrading to the newest Vuforia plugin for Unity in Windows 10. If I install the Vuforia plugin using the Unity installer, an older, 7.x version gets installed. That works all right, however, the Asset Store samples (in particular the Vuforia Hololens sample project) require Vuforia 8. However, once I install the latest version (8.0.10), Unity will no longer recognize that Vuforia is installed. There is no "Vuforia" submenu under "GameObject" or "Help", and the Vuforia namespace is not visible either.
After some research I found out that the Vuforia plugin gets installed to /Path_To_Editor/Editor_Version/Editor/Data/PlaybackEngines/VuforiaSupport/. I could verify that the version 8.0 installer works, because that directory gets completely replaced during installation. Replacing that directory with the previous version (7.x), after restarting Unity, Vuforia gets detected again (albeit as expected, as version 7.x). For some reason the contents from the 8.0 version won't be detected.
I have the same problem with Unity 2018.2.14 and 2018.3.3. Any ideas what's happening here?
Thank you!
Hello,
The version of Vuforia in a given version of the Unity Editor is static. For example, Unity Editor 2018.3.3 is released with Vuforia 7.2. If Vuforia updates the SDK to 7.5, the version of Vuforia in the Unity Editor 2018.3.3 is not updated to 7.5.
To upgrade the version of Vuforia embedded in the Unity Editor, please follow these steps:
If you have any previously installed Vuforia samples, you'll also want to download the updated versions of those from the Asset Store.
Thanks,
Vuforia Engine Support | https://developer.vuforia.com/forum/unity/problems-installation-vuforia-8-unity?sort=2 | CC-MAIN-2020-50 | refinedweb | 279 | 52.76 |
/* Generic support for remote debugging interfaces. Copyright 1993, 1994, 1995, 1996, 1998, actually contains two distinct logical "packages". They are packaged together in this one file because they are typically used together. The first package is an addition to the serial package. The addition provides reading and writing with debugging output and timeouts based on user settable variables. These routines are intended to support serial port based remote backends. These functions are prefixed with sr_. The second package is a collection of more or less generic functions for use by remote backends. They support user settable variables for debugging, retries, and the like. Todo: * a pass through mode a la kermit or telnet. * autobaud. * ask remote to change his baud rate. */ #include <ctype.h> #include "defs.h" #include "gdb_string.h" #include "gdbcmd.h" #include "target.h" #include "serial.h" #include "gdbcore.h" /* for exec_bfd */ #include "inferior.h" /* for generic_mourn_inferior */ #include "remote-utils.h" #include "regcache.h" void _initialize_sr_support (void); struct _sr_settings sr_settings = { 4, /* timeout: remote-hms.c had 2 remote-bug.c had "with a timeout of 2, we time out waiting for the prompt after an s-record dump." remote.c had (2): This was 5 seconds, which is a long time to sit and wait. Unless this is going though some terminal server or multiplexer or other form of hairy serial connection, I would think 2 seconds would be plenty. */ 10, /* retries */ NULL, /* device */ NULL, /* descriptor */ }; struct gr_settings *gr_settings = NULL; static void usage (char *, char *); static void sr_com (char *, int); static void usage (char *proto, char *junk) { if (junk != NULL) fprintf_unfiltered (gdb_stderr, "Unrecognized arguments: `%s'.\n", junk); error (_("Usage: target %s [DEVICE [SPEED [DEBUG]]]\n\ where DEVICE is the name of a device or HOST:PORT"), proto); return; } #define CHECKDONE(p, q) \ { \ if (q == p) \ { \ if (*p == '\0') \ return; \ else \ usage(proto, p); \ } \ } void sr_scan_args (char *proto, char *args) { int n; char *p, *q; /* if no args, then nothing to do. */ if (args == NULL || *args == '\0') return; /* scan off white space. */ for (p = args; isspace (*p); ++p);; /* find end of device name. */ for (q = p; *q != '\0' && !isspace (*q); ++q);; /* check for missing or empty device name. */ CHECKDONE (p, q); sr_set_device (savestring (p, q - p)); /* look for baud rate. */ n = strtol (q, &p, 10); /* check for missing or empty baud rate. */ CHECKDONE (p, q); baud_rate = n; /* look for debug value. */ n = strtol (p, &q, 10); /* check for missing or empty debug value. */ CHECKDONE (p, q); sr_set_debug (n); /* scan off remaining white space. */ for (p = q; isspace (*p); ++p);; /* if not end of string, then there's unrecognized junk. */ if (*p != '\0') usage (proto, p); return; } void gr_generic_checkin (void) { sr_write_cr (""); gr_expect_prompt (); } void gr_open (char *args, int from_tty, struct gr_settings *gr) { target_preopen (from_tty); sr_scan_args (gr->ops->to_shortname, args); unpush_target (gr->ops); gr_settings = gr; if (sr_get_desc () != NULL) gr_close (0); /* If no args are specified, then we use the device specified by a previous command or "set remotedevice". But if there is no device, better stop now, not dump core. */ if (sr_get_device () == NULL) usage (gr->ops->to_shortname, NULL); sr_set_desc (serial_open (sr_get_device ())); if (!sr_get_desc ()) perror_with_name ((char *) sr_get_device ()); if (baud_rate != -1) { if (serial_setbaudrate (sr_get_desc (), baud_rate) != 0) { serial_close (sr_get_desc ()); perror_with_name (sr_get_device ()); } } serial_raw (sr_get_desc ()); /* If there is something sitting in the buffer we might take it as a response to a command, which would be bad. */ serial_flush_input (sr_get_desc ()); /* default retries */ if (sr_get_retries () == 0) sr_set_retries (1); /* default clear breakpoint function */ if (gr_settings->clear_all_breakpoints == NULL) gr_settings->clear_all_breakpoints = remove_breakpoints; if (from_tty) { printf_filtered ("Remote debugging using `%s'", sr_get_device ()); if (baud_rate != -1) printf_filtered (" at baud rate of %d", baud_rate); printf_filtered ("\n"); } push_target (gr->ops); gr_checkin (); gr_clear_all_breakpoints (); return; } /* Read a character from the remote system masking it down to 7 bits and doing all the fancy timeout stuff. */ int sr_readchar (void) { int buf; buf = serial_readchar (sr_get_desc (), sr_get_timeout ()); if (buf == SERIAL_TIMEOUT) error (_("Timeout reading from remote system.")); if (sr_get_debug () > 0) printf_unfiltered ("%c", buf); return buf & 0x7f; } int sr_pollchar (void) { int buf; buf = serial_readchar (sr_get_desc (), 0); if (buf == SERIAL_TIMEOUT) buf = 0; if (sr_get_debug () > 0) { if (buf) printf_unfiltered ("%c", buf); else printf_unfiltered ("<empty character poll>"); } return buf & 0x7f; } /* Keep discarding input from the remote system, until STRING is found. Let the user break out immediately. */ void sr_expect (char *string) { char *p = string; immediate_quit++; while (1) { if (sr_readchar () == *p) { p++; if (*p == '\0') { immediate_quit--; return; } } else p = string; } } void sr_write (char *a, int l) { int i; if (serial_write (sr_get_desc (), a, l) != 0) perror_with_name (_("sr_write: Error writing to remote")); if (sr_get_debug () > 0) for (i = 0; i < l; i++) printf_unfiltered ("%c", a[i]); return; } void sr_write_cr (char *s) { sr_write (s, strlen (s)); sr_write ("\r", 1); return; } int sr_timed_read (char *buf, int n) { int i; char c; i = 0; while (i < n) { c = sr_readchar (); if (c == 0) return i; buf[i] = c; i++; } return i; } /* Get a hex digit from the remote system & return its value. If ignore_space is nonzero, ignore spaces (not newline, tab, etc). */ int sr_get_hex_digit (int ignore_space) { int ch; while (1) { ch = sr_readchar (); if (ch >= '0' && ch <= '9') return ch - '0'; else if (ch >= 'A' && ch <= 'F') return ch - 'A' + 10; else if (ch >= 'a' && ch <= 'f') return ch - 'a' + 10; else if (ch != ' ' || !ignore_space) { gr_expect_prompt (); error (_("Invalid hex digit from remote system.")); } } } /* Get a byte from the remote and put it in *BYT. Accept any number leading spaces. */ void sr_get_hex_byte (char *byt) { int val; val = sr_get_hex_digit (1) << 4; val |= sr_get_hex_digit (0); *byt = val; } /* Read a 32-bit hex word from the remote, preceded by a space */ long sr_get_hex_word (void) { long val; int j; val = 0; for (j = 0; j < 8; j++) val = (val << 4) + sr_get_hex_digit (j == 0); return val; } /* Put a command string, in args, out to the remote. The remote is assumed to be in raw mode, all writing/reading done through desc. Ouput from the remote is placed on the users terminal until the prompt from the remote is seen. FIXME: Can't handle commands that take input. */ static void sr_com (char *args, int fromtty) { sr_check_open (); if (!args) return; /* Clear all input so only command relative output is displayed */ sr_write_cr (args); sr_write ("\030", 1); registers_changed (); gr_expect_prompt (); } void gr_close (int quitting) { gr_clear_all_breakpoints (); if (sr_is_open ()) { serial_close (sr_get_desc ()); sr_set_desc (NULL); } return; } /* gr_detach() takes a program previously attached to and detaches it. We better not have left any breakpoints in the program or it'll die when it hits one. Close the open connection to the remote debugger. Use this when you want to detach and do something else with your gdb. */ void gr_detach (char *args, int from_tty) { if (args) error (_("Argument given to \"detach\" when remotely debugging.")); if (sr_is_open ()) gr_clear_all_breakpoints (); pop_target (); if (from_tty) puts_filtered ("Ending remote debugging.\n"); return; } void gr_files_info (struct target_ops *ops) { #ifdef __GO32__ printf_filtered ("\tAttached to DOS asynctsr\n"); #else printf_filtered ("\tAttached to %s", sr_get_device ()); if (baud_rate != -1) printf_filtered ("at %d baud", baud_rate); printf_filtered ("\n"); #endif if (exec_bfd) { printf_filtered ("\tand running program %s\n", bfd_get_filename (exec_bfd)); } printf_filtered ("\tusing the %s protocol.\n", ops->to_shortname); } void gr_mourn (void) { gr_clear_all_breakpoints (); unpush_target (gr_get_ops ()); generic_mourn_inferior (); } void gr_kill (void) { return; } /* This is called not only when we first attach, but also when the user types "run" after having attached. */ void gr_create_inferior (char *execfile, char *args, char **env) { int entry_pt; if (args && *args) error (_("Can't pass arguments to remote process.")); if (execfile == 0 || exec_bfd == 0) error (_("No executable file specified")); entry_pt = (int) bfd_get_start_address (exec_bfd); sr_check_open (); gr_kill (); gr_clear_all_breakpoints (); init_wait_for_inferior (); gr_checkin (); insert_breakpoints (); /* Needed to get correct instruction in cache */ proceed (entry_pt, -1, 0); } /* Given a null terminated list of strings LIST, read the input until we find one of them. Return the index of the string found or -1 on error. '?' means match any single character. Note that with the algorithm we use, the initial character of the string cannot recur in the string, or we will not find some cases of the string in the input. If PASSTHROUGH is non-zero, then pass non-matching data on. */ int gr_multi_scan (char *list[], int passthrough) { char *swallowed = NULL; /* holding area */ char *swallowed_p = swallowed; /* Current position in swallowed. */ int ch; int ch_handled; int i; int string_count; int max_length; char **plist; /* Look through the strings. Count them. Find the largest one so we can allocate a holding area. */ for (max_length = string_count = i = 0; list[i] != NULL; ++i, ++string_count) { int length = strlen (list[i]); if (length > max_length) max_length = length; } /* if we have no strings, then something is wrong. */ if (string_count == 0) return (-1); /* otherwise, we will need a holding area big enough to hold almost two copies of our largest string. */ swallowed_p = swallowed = alloca (max_length << 1); /* and a list of pointers to current scan points. */ plist = (char **) alloca (string_count * sizeof (*plist)); /* and initialize */ for (i = 0; i < string_count; ++i) plist[i] = list[i]; for (ch = sr_readchar (); /* loop forever */ ; ch = sr_readchar ()) { QUIT; /* Let user quit and leave process running */ ch_handled = 0; for (i = 0; i < string_count; ++i) { if (ch == *plist[i] || *plist[i] == '?') { ++plist[i]; if (*plist[i] == '\0') return (i); if (!ch_handled) *swallowed_p++ = ch; ch_handled = 1; } else plist[i] = list[i]; } if (!ch_handled) { char *p; /* Print out any characters which have been swallowed. */ if (passthrough) { for (p = swallowed; p < swallowed_p; ++p) fputc_unfiltered (*p, gdb_stdout); fputc_unfiltered (ch, gdb_stdout); } swallowed_p = swallowed; } } #if 0 /* Never reached. */ return (-1); #endif } /* Get ready to modify the registers array. On machines which store individual registers, this doesn't need to do anything. On machines which store all the registers in one fell swoop, this makes sure that registers contains all the registers from the program being debugged. */ void gr_prepare_to_store (void) { /* Do nothing, since we assume we can store individual regs */ } void _initialize_sr_support (void) { /* FIXME-now: if target is open... */ add_setshow_filename_cmd ("remotedevice", no_class, &sr_settings.device, _("\ Set device for remote serial I/O."), _("\ Show device for remote serial I/O."), _("\ This device is used as the serial port when debugging using remote targets."), NULL, NULL, /* FIXME: i18n: */ &setlist, &showlist); add_com ("remote", class_obscure, sr_com, _("Send a command to the remote monitor.")); } | http://opensource.apple.com/source/gdb/gdb-1344/src/gdb/remote-utils.c | CC-MAIN-2014-15 | refinedweb | 1,639 | 63.7 |
18 March 2009 11:48 [Source: ICIS news]
MUNICH (ICIS news)--Wacker Chemie plans to invest €800m ($1.04bn) in 2009, with the "vast majority" going towards its polysilicon business, president and CEO Rudolf Staudigl said on Wednesday.
"We see absolutely no sign of slowdown in demand for polysilicon from our customers," Staudigl said at the company's annual press conference.
"We definitely expect our polysilicon business to remain attractive over the next few years and that's why we are continuing to expand capacity," he added.
Wacker plans to boost its polysilicon capacity from 15,000 tonnes/year today to 35,500 tonnes/year by the end of 2011, said Staudigl.
Major expansions include its Polysilicon Stage 8 project in ?xml:namespace>
The Stage 8 project in Burghausen is being expanded from its original target of 7,000 tonnes, to 10,000 tonnes at an additional cost of €100m, while the Stage 9 Nunchritz facility will cost about €760m.
"Eighty percent of our production yield has already been sold for several years ahead, including output from Stage 8. Some of our supply contracts run until 2018," said Staudigl.
Wacker, which released its annual and fourth quarter results earlier on Wednesday, spent a record €916m in capital investments in 2008. Despite the heavy expenditures, the company has a net cash position of €30m and access to €500m in credit facilities.
Wacker Polysilicon sales jumped 81% to €828m for the full year, while earnings before interest, tax, depreciation and amortisation (EBITDA) rose 132% to €422m.
Overall Wacker sales rose 14% to €4.3bn and EBITDA climbed 5% to 1.06bn.
( | http://www.icis.com/Articles/2009/03/18/9201034/wacker-to-invest-800m-in-2009-will-boost-polysilicon-ceo.html | CC-MAIN-2015-11 | refinedweb | 269 | 61.46 |
Below a how-to of getting started with Java.
You need to download these three things:
1) Java Development Kit (JDK for short):
Oracle.com
(JDK 6 Update 21)
Click Download, select Platform (e.g. Windows), click the link below to download Java SE Development Kit 6u21.
2) Elipse Helios, the compiler of Java code (the syntax coloured, checks for possible errors, etc.):
Eclipse.org
On the right, there is a section of links named Download Links, you need to select your own platform-specific version of the program.
3) Java learning materials, such as Introduction to Programming Using Java, the fifth edition: Math.hws.edu
Also available online: Math.hws.edu
There are a few things to know about Java if you are an experienced programmer (C++/C/C#, etc.).
One of the most important things, the main public file class must be exactly the SAME as the file name, unlike C# and C++ where it doesn't make any difference which class holds the main function, so e.g.:
import javax.swing.JOptionPane; public class simple { public static void main (String[] args) { JOptionPane.showMessageDialog(null, "Hello Somebody!"); } }
The main public class is simple, and the Java file name is simple.java
Otherwise (without it or differently named) you may get compiling errors. One can always be on the lookout for other differences between Java and other curly-bracket programming languages, for example the concept of inheritance in Java.
Regarding Introduction to Programming Using Java, if you are an experienced programmer, you can skip most of the book and concentrate on the graphics, the chapters 6 (Introduction to GUI Programming) and 12 (titled Advanced GUI Programming). | http://www.moddb.com/groups/curly-bracket-programming-realm/tutorials/java-eclipse-ide | CC-MAIN-2016-40 | refinedweb | 277 | 55.13 |
Guards and Hooks
Guards and Hooks… what are they? For what reason we should use them? Is there any articles/examples to see them in action? I've tried to find it, but didn't understand at all.
Comments are currently closed for this discussion. You can start a new one.
Keyboard shortcuts
Generic
Comment Form
You can use
Command ⌘ instead of
Control ^ on Mac
Support Staff 1 Posted by Ondina D.F. on 21 Jan, 2013 04:10 PM
Hi Seth,
You’re right, there are no examples (yet) showing how to use guards and hooks.
For now, you could take a look at the readme files and the tests on github to get a general idea about guards and hooks:......
Guards......
Hooks......
I haven’t used guards and hooks until now. A really silly example here:
In context config:
In plain text: if View’s name is Bender, draw a rectangle before running Mediator’s initialize().
The guard checks if a certain condition has been met (view.name =="Bender")
I created a guard inside the Mediator, but any class with an approve() method can be used to check against different conditions.
_viewProcessorMap.map(HookedView).toNoProcess().withHooks(HookedMediator).withGuards(IsViewVisible);
IsViewVisible could have an aprove() method like this:
public function approve():Boolean
{ return (view.visible); }
HTH
Ondina
P.S. Adding Shaun as a guard to approve my example or to talk about more complex scenarios ;-)
discussionProcessorMap.map(MySillyExample).toNoProcess().withGuards(ShaunSmith);
2 Posted by Seth Gilmer on 22 Jan, 2013 07:41 AM
Thank you, Ondina.
It was really helpful. Now I see basic idea.
Support Staff 3 Posted by Ondina D.F. on 22 Jan, 2013 10:00 AM
Seth, you’re welcome!!
I’m closing this discussion for now, but please don’t hesitate to ask more questions in another thread or to re-open this, if need be.
Ondina
Ondina D.F. closed this discussion on 22 Jan, 2013 10:00 AM. | http://robotlegs.tenderapp.com/discussions/robotlegs-2/752-guards-and-hooks | CC-MAIN-2019-13 | refinedweb | 326 | 67.55 |
Current Version:
Linux Kernel - 3.80
Synopsis
#include <time.h> size_t strftime(char *s, size_t max, const char *format, const struct tm *tm);
Description name of the day of the week according to the current locale.
- %A
- The full name of the day of the aq%aq
Note that the return value 0 does not necessarily indicate an error. For example, in many locales %p yields an empty string. An empty format string will likewise yield an empty string.
Environment
Conforming To
In SUSv2, the %S specifier allowed a range of 00 to 61, to allow for the theoretical possibility of a minute that included a double leap second (there never has been such a minute).
Notes
ISO 8601 week dates
Glibc notes.
Example
"%a, %d %b %Y %T %z"
RFC 822-compliant date format (with an English locale for %a and %b)
"%a, %d %b %y %T %z"
Example program); }
Colophon GNU texinfo documentation on glibc date/time functions. Modified Sat Jul 24 18:03:44 1993 by Rik Faith (faith@cs.unc.edu) Applied fix by Wolfgang Franke, aeb, 961011 Corrected return value, aeb, 970307 Added Single UNIX Spec conversions and %z, aeb/esr, 990329. 2005-11-22 mtk, added Glibc Notes covering optional 'flag' and 'width' components of conversion specifications. | https://community.spiceworks.com/linux/man/3/strftime | CC-MAIN-2018-51 | refinedweb | 213 | 63.09 |
Hi, Please see my post titled "The whole story" "Martin P. Hellwig" <martin.hellwig at dcuktec.org> wrote in message news:QoKdnQZ7zfEFW2jUnZ2dnUVZ8jqdnZ2d at bt.com... > Carbon Man wrote: >> I have a program that is generated from a generic process. It's job is to >> check to see whether records (replicated from another system) exist in a >> local table, and if it doesn't, to add them. > <cut> > To answer the topic question, it would be limited to the memory your > platform can allocate and I guess that the most critical part would be if > you run out of memory for handling the namespace references. > > However my magic 8 ball whispers to me that the provided solution tries to > be smarter than the given problem requires, which is not a good thing. If > so and if possible, please provide a more detailed explanation of the > actual problem you want to solve instead of the problem you currently have > with the provided solution. > > -- > MPH > | https://mail.python.org/pipermail/python-list/2009-April/535036.html | CC-MAIN-2016-30 | refinedweb | 162 | 60.14 |
Avoiding Data Corruption with Rails' Active Record Validations
Rendered to the browser, the support form looks like this:
Figure 1: The customer support form
Finally, implementing the submit method in its simplest form can be done in just a few lines:
def submit @question = Question.new(params[:question]) if @question.save flash[:notice] = "Your question has been successfully sent to customer service. Would you like to submit another question?" render :action => "index" end end
Although the support form is now functional, with no controls in place for validating input, chances are your support team will soon be greeted with support requests replete with blank names and messages, invalid email addresses, and incorrect phone numbers. The result? Angry customers! However, you can use Active Record's validation features to avoid such problems altogether.
Active Record's Validation Methods
Rails' Active Record validation features go a long way towards automating some of the most commonplace validation tasks, such as checking for the presence of a data field, determining string length, ensuring uniqueness, and even validating a string according to rules as defined by a regular expression. Setting the desired validation rules is as simple as modifying the model, as you'll soon see.
Validating Presence
Logically, you want to make sure the user completes the name, phone number, email address, and message fields. To do so, use the validates_presence_of method. To make sure these fields are not blank, modify the Question model so it looks like this:
class Question < ActiveRecord::Base validates_presence_of :name, :message=>"can't be blank!" validates_presence_of :email, :message=>"can't be blank!" validates_presence_of :phone, :message=>"can't be blank!" validates_presence_of :message, :message=>"can't be blank!" end
Next, you'll modify the submit method to display the form anew should errors occur:
def submit @question = Question.new(params[:question]) if @question.save flash[:notice] = "Your question has been successfully sent to customer service. Would you like to submit another question?" render :action => "index" else render :action => "index" end end
Finally, to display the error messages should a field not be completed, add the following line to the top of the form view (/support/index.rhtml):
<%= error_messages_for("question") %>
Go ahead and submit the form, but this time not completing any of the fields, and you'll be greeted with a response as shown in the following screenshot, followed by presentation of the form anew:
Figure 2: The result generated by the form.
By following a similar process, you can take advantage of Rails' other validation methods to impose further constraints upon your user input! I'll introduce a few others below.
Page 2 of 3
| http://www.developer.com/db/article.php/10920_3710466_2/Avoiding-Data-Corruption-with-Rails-Active-Record-Validations.htm | CC-MAIN-2014-52 | refinedweb | 435 | 53.51 |
Sometime ago there was an article in C++ Report on the subject of writing your own operator=(). Despite the considerable efforts of the author there were still faults in his proposals. The reason that I mention that is that I expect there to be some flaws in this article as well. Please find them and send them in. That way we will all be wiser. Indeed I will be most disappointed if none of you have anything to add to this article. The biggest reward I get for writing for publication is the amount I learn from my mistakes.
Obviously I like to be right and it gives me a warm feeling when others adopt some idea of mine (particularly if they are more expert than I am) but the profit comes from learning something new.
The first decision that any class designer has to make with regard to operator=() is what semantics are appropriate to the type in question. The following possibilities spring to mind:
Unique Objects - a bit like Java's objects
Pure value types - no inheritance anticipated.
Polymorphic types
With potential ordering across subtypes
Without ordering between subtypes.
Let me tackle these in ascending order of difficulty.
This one is very easy. Check the following code:
class Unique { public: bool operator==(Unique const volatile &) const volatile throw(); // rest of interfaces }; inline bool Unique::operator == (Unique const volatile & rhs) const volatile throw() { return (this == &rhs) ? true : false; }
The idea here is that the meaning of identity is that they are the same object. At first sight you may wonder if such a strong definition of identity has any utility. If there were no possibility of aliasing (referencing) the answer would be 'no' but with objects being passed around by reference there may be times when you want to determine if two references to instances of a Unique actually refer to the same instance.
As I was writing this an errant thought crossed my mind, objects that possess this characteristic (identity means the same object) are inherently unordered when it comes to various Standard Library features that handle collections of objects. Yet, some STL features require an ordering. I wonder if this would be good enough?
inline int Unique::compare (Unique const volatile & rhs) const volatile throw() { return (*this == rhs) ? 0 : 1; } inline bool Unique::operator < (Unique const volatile & rhs) const volatile throw( { return compare(rhs) ? true : false; }
I think that needs rather more thought than I currently have time for (the copy date for this issue of Overload was seven days ago :-( ) so it is a chance for you to do the thinking and share the results with the rest of us.
The only problem with operator==() in this case is ensuring that the prototype is correct. There is no problem with derived types because two identifiers can only refer to the same address if the objects are the same (and therefore have the same dynamic type as well). This means that there would seem to be no problem with making operator==() a member function. The only caveat is that you might have problems if you elected to provide some other meaning for operator==() when applied to objects of different derived types. However, I would suggest that any design that supported such a bizarre concept would belong in a fantasy nightmare world.
So how about the inclusion of volatile? The simple question is 'Why not?' There can be a hidden cost to gratuitous usage of volatile (it disables many potential optimisations) but in the instances above the objects are never accessed and so making the implementation as broad as possible should not incur a cost.
A similar argument supports the addition of a throw() exception specification. All the functions above are leaf functions or functions forwarding to leaf functions. If an exception gets raised inside this code you have a serious problem.
Again, I think these functions are simple enough to justify inlining, but perhaps you disagree. If so please share your reasons.
This is not quite as simple as it may seem. We have to ask ourselves what it might mean if someone compared an instance of a derived type with an instance of our type. Of course you have not prepared your pure value type for derivation, but that does not mean that someone will not do it one day. What do you want to do in such a case? There seem to be two choices:
Compare the base subobject of the instances
Check that you are not comparing derived instances
class PureValue { public: int compare(PureValue const &) const; // rest of interfaces }; inline bool operator == (PureValue lhs, PureValue rhs) { return lhs.compare(rhs) ? false : true; }
Note the differences between this and the unique object case. I have removed the use of volatile because I can no longer get that for free (if I need a volatile case I will need to provide that as a separate function. Actually this seems unlikely.)
When deciding on the low-level design of PureValue you will need to decide whether you are going to pass it around by value or by reference. Only the class designer can know which is better suited to the type being implemented. Of course the way C++ works makes this purely a decision for the class designer. You may think that pass by (const) reference will normally be the way to go but I think this is less obvious than sometimes imagined. Even with the const qualification pass by reference inhibits many desirable optimisations and in the case of multi-threaded code pass by reference has some bad implications. Suppose that some other thread has access to that variable (as a class designer you do not know this will not happen) even though you passed by const & the object might be changed by another thread. Much safer to pass by value and write a copy constructor that locks the instance during copying. (This is another entry point for the thoughtful reader to contribute an article).
Once I decide that I will pass the right-hand operand by value, symmetry suggests that I should handle the left-hand operand the same way. That more or less requires a non-member operator==(). However note that there is no cause for using friend. The compare() member function seems a much better way to go. It is useful for other things as well. Exactly how you implement PureValue::compare() will depend on the details of PureValue. However I think the const & parameter is probably correct this time. The other parameter (this) is being passed as a pointer and you have no choice. If you intend calling PureValue::compare() direct from code that needs to be thread safe you will need to take suitable action at the call site.
What about inlining operator==()? Well why do you think I chose not to? And what happened to the exception specifications? I didn't just get lazy. Think about it.
Suppose that we want to prevent comparisons between base instances and derived instances and we want to 'force' derived classes to do their own work. Now we need a utility to detect breaches of this design constraint. Ideally we would like to detect this problem at compile time. To be honest, I cannot think of any way to do that (cue for another contribution☺). However, the following will manage it at runtime:
class NoDerive { public: bool notDerived() const; int compare(NoDerive const &) const; // rest of interfaces }; bool NoDerive::notDerived() const { return typeid(*this) == typeid(NoDerive); } int NoDerive::compare (NoDerive const & rhs) const { if (!(notDerived() && rhs.notDerived())) throw IllegalComparison(); // normal code } bool operator== (NoDerive const & lhs, NoDerive const & rhs) { return lhs.compare(rhs) ? false : true; }
The NoDerive::notDerived() member function relies on being able to determine the dynamic type of the instance. For this reason all parameters must be passed by (const) reference or as pointers. If it matters this means that the normal code in NoDerive::compare() will need to lock the parameters while they are being accessed. It might be worth considering starting the code by copying the parameters to local variables. By the way you should not get into the habit of thinking that multi-threaded code will be run on a single processor. There are many things that would be safe under such a condition that become disastrous when using multiple processors (something that will become increasingly common in future years).
Again we must consider what we want. Think about Chess pieces. These are a fairly good example of a simple polymorphic type (actually we have an interesting complication because pawns can promote, but we will leave that for another article in a different context). Each Chess piece has its own properties. Some of those are fixed by its fundamental type (legal moves, colour etc) other things vary during a game (position, value to the player - captured pieces have no value, rooks on open files have enhanced value - etc.) Because each side has pairs of rooks, knights etc. we can reasonable ask two questions:
Are two pieces the same type?
Do they belong to the same side?
The second question does not seem to lend itself to the identity operator as well as the first. My sense is that the second question should be relegated to a member function. Or even to comparing the return value of a member function Colour::whatColour().
Let us look at a draft for a base class for a hierarchy of Chess pieces.
class ChessPiece { public: enum Colour {unknown, black, white}; Colour whatColour(); bool sameType(ChessPiece const &)const; int compare(ChessPiece const &)const; virtual ~ChessPiece() = 0; virtual void move(); private: Colour col; Position pos; };
This is far from a complete design, but it will do for a start. Note that functions such as compare must be in the base class, whereas functions such as move() must be implemented in the relevant derived class (Pawn, King etc) Oddly, in this case we probably would not use compare() to provide an implementation of operator ==(). This will meet our needs perfectly well:
bool operator == (ChessPiece const & lhs, ChessPiece const & rhs) { return lhs.sameType(rhs); }
and the implementation of ChessPiece::sameType() could be something such as:
bool ChessPiece::sameType (ChessPiece const & rhs)const { return typeid(*this) == typeid(rhs); }
While Chess pieces are a good simple example of a flat hierarchy many other hierarchies have considerable depth. The first issue we must face is that if we are to avoid comparing things of different derived types we must provide base class functionality. An ABC with only an interface is not good enough. Using ABC's as equivalent to Java interfaces is fine but we can do more with ours and sometimes that works to our advantage.
As I am running a bit short of time I am simply going to offer you the sample code at the end of this article which I wrote for a discussion in comp.lang.c++. Note that the following code is simply to illustrate a principle. But, feel free to rip it to shreds. The unusual returns in compareInstances simply allow some simple test of concept code.
For testing purposes identity has been treated as 'same object'. In real code do something else.
This design detects attempts to compare derived objects for which no class specific comparison has been provided Unfortunately this is at run time. Any ideas as how to move that forward to compile or link time would be gratefully received.
I would also like to hear of any ideas as to how to force all derived classes to implement a particular function. Pure virtuals are not strong enough as the requirement is satisfied as soon as a derived class provides an implementation. What I want is a way to require diagnosis of the use of any derived class that does not provide its own implementation of a pure virtual in the base class. I considered using a virtual base class on the grounds that it is the most derived class that constructs it, but a few moments of thought convinced me that that would not work. Anyone got any ideas?
#include <iostream> #include <typeinfo> //introduce namespace std using std::typeid; using std::cout; class Base { virtual int compareInstances (Base const & rhs)const { if(typeid(Base) != typeid(*this)) return 99; return (&rhs == this)? 0 : 3; } public: bool sametypes(Base const & rhs) const { return (typeid(*this) == typeid(rhs)) ?true :false; } int compare(Base const & rhs) const { return sametypes(rhs) ?compareInstances(rhs) :2; } virtual ~Base(){}; }; class Derived: public Base { int compareInstances (Base const & rhs)const { if(typeid(Derived)!= typeid(*this)) return 99; return (&rhs == this)? 0 : 4; } }; class MoreDerived : public Derived { // class in which no compareInstances // has been provided }; // wrap the compare member function to // create operator == bool operator == (Base const & lhs, Base const & rhs) { int value = lhs.compare(rhs); if (value == 99) throw "Sliced comparison"; return value ? false : true; } // small test harness int main( void ) { try{ Base b1, b2; Derived d1, d2; cout << (b1==b1) << endl; cout << (d1==d1) << endl; cout << (b1==b2) << endl; cout << (d1==d2) << endl; cout << (b1==d2) << endl; cout << (d1==b2) << endl; MoreDerived md1, md2; cout << (md1==md2) << endl; } catch ( char const * message) { cout << message << endl; } return 0; }
And a final thought, I wonder if a protected template member function in the base class might work. No because it falls foul of the same problem, how can we force its call in the most derived class? | https://accu.org/index.php/journals/577 | CC-MAIN-2018-30 | refinedweb | 2,238 | 61.56 |
Action bar (ActionBar) was introduced from API level 11. In this post I will explain how to create actionbar tab navigation using fragments. The final result is shown below where user can move between tabs.
Creating Android Action bar (ActionBar) with tab navigation
The first step is getting the actionbar reference and add the tab to it:
@Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); ActionBar bar = getActionBar(); bar.setNavigationMode(ActionBar.NAVIGATION_MODE_TABS); for (int i=1; i <= 3; i++) { Tab tab = bar.newTab(); tab.setText("Tab " + i); tab.setTabListener(this); bar.addTab(tab); } }
Notice that first of all we don’t use any “main” layout. Second at line 3 we get the reference to the action bar simply using the method getActionBar. At line 4 we set the navigation mode in our case NAVIGATION_MODE_TABS. There three different navigation type supported:
- Navigation mode list
- Navigation mode standard
- Navigation mode tabs
After these steps we have to create our tabs and add it to the action bar. In our example we create three different tabs. What we want is when user touches one of the tab the UI content changes. To achieve it we need two things:
- Fragment that fills the UI when user changes the tab according to the tab selected
- A listener that gets notification when user interacts with the tabs
Tab Fragment
In our example, fragment will be very simple, it just shows a text in the middle of the screen. The layout looks like:
<?xml version="1.0" encoding="utf-8"?> <RelativeLayout xmlns: <TextView android: </RelativeLayout>
While the fragment source code is very simple:
public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); Bundle data = getArguments(); index = data.getInt("idx"); } @Override public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState) { View v = inflater.inflate(R.layout.fragment, null); TextView tv = (TextView) v.findViewById(R.id.msg); tv.setText("Fragment " + (index + 1)); return v; }
Just notice that we pass the fragment index using arguments bundle (line 2,3).Now we have our fragment we have simply to implement the listener.
Tab listener
We can make our Activity implements the listener so that when user selects a tab we show the relative fragment.
public class MainActivity extends Activity implements TabListener { List<Fragment> fragList = new ArrayList<Fragment>(); Fragment f = null; // Thx to Andre Krause for his support! TabFragment tf = null; @Override public void onTabSelected(Tab tab, FragmentTransaction ft) { // Fragment f = null; // TabFragment tf = null; if (fragList.size() > tab.getPosition()) fragList.get(tab.getPosition()); if (f == null) { tf = new TabFragment(); Bundle data = new Bundle(); data.putInt("idx", tab.getPosition()); tf.setArguments(data); fragList.add(tf); } else tf = (TabFragment) f; ft.replace(android.R.id.content, tf); } @Override public void onTabUnselected(Tab tab, FragmentTransaction ft) { if (fragList.size() > tab.getPosition()) { ft.remove(fragList.get(tab.getPosition())); } } }
TabListener has several methods we have to override. The most important is onTabSelected that is called when user selects a tab. In this method first we check if we have our fragment in the fragment list (line 9-10), if so we reuse it and show the fragment (see line 20). If not, we create our fragment line (12-18) and add it to our fragment list. At the end (line 22), we simply replace the UI content (android.R.id.content) with the right fragment. The result is shown below:
Source code available @github
Android Actionbar Drop Down navigation
As per the design guidelines (), you should really enable swiping between the action bar tabs by using a ViewPager. There's a good tutorial in the training section which explains how to do it:
Can you explain?
Whats the class of the object fragList refers to?
I've edited the source code so it is more clear. Anyway fraglist is defined as
List fragList = new ArrayList();
Thx for your comment
im getting an error:
"The method remove(Fragment) in the type FragmentTransaction is not applicable for the arguments (Fragment)"
this error is at lines:
ft.replace(android.R.id.content, tf);
ft.remove(fragList.get(tab.getPosition()));
Also what data type is "index"
I've added the full source code at github. Look at the link in the post. You can download all the source code. Thx
The source code still gives the error, what's the solution?
hey if i want to add a swipe gesture to switch between different tabs how would i do that??
what is "fragList.get(tab.getPosition());" in line 10 use for?
and "f" in line is always null, so u always create a new TabFragment and not reuse like u say
i change the code to "f =fragList.get(tab.getPosition());" in line 10
but it will be an error because fragList position not always same to tab position
example when u click tab 3 first when the app loaded
Is there any way to easily implement swiping between these tabs?
Apologies, I'm an android noob, just trying to work it out.
Also, how do I define each of these fragments, so that I can have different content in each? I understand right now it is a loop to generate example fragments.
Thanks!
you can use ViewPager from android support v4 too do that, i really know if Tab can do that or not
for different content each Fragment, just create some class that extends Fragment, each class can have a different view and content
*i dont really know
Very useful! Working. Thanks
Hello, thank you for this, but I now have a problem:
I don't know how I can stay on the selected Tab when I come back (by a back button) after I started another activity in this view? You understand what I want? I get on the third tab, click on something, a new activity starts, and I want to come back an the third tab by a button. The best would be that the tabbar still stay there so I also could select from this the other tabs.
Hello Fransceo,
Thank you for the tutorial. I wanted to ask how we can go from tab 1 to tab 2 by clicking on a button on tab1 layout.?
Thanks,
Sushant
hey?
Why does it make the navigation tab displayed as spinner on smaller screen? can we avoid it? Thanks
I want to remove the action bar or add tabs on top of action bar. I don’t want to see the application name and icon on it and remove the space . how can I do it? | http://www.survivingwithandroid.com/2013/06/android-action-bar-with-tab.html | CC-MAIN-2016-26 | refinedweb | 1,081 | 64.3 |
PHP Cloud Development on Red Hat's OpenShift PaaS
OpenShift is Red Hat's Cloud Computing Platform as a Service (PaaS) offering. For PHP cloud development, OpenShift offers an application platform in the cloud where you can build, test, deploy, and run your applications. Also, OpenShift enables you to use a great variety of the latest and greatest technology Quickstarts that allow you to boot your favorite platform on OpenShift almost instantaneously.
All you need to do to begin PHP cloud development on OpenShift is take three simple steps: Sign up and create an account on OpenShift, find the QuickStart for your favorite platform and follow the instructions on the Quickstart page (usually in the README.md file), and host that platform on OpenShift. Your favorite platform is available on OpenShift, and you can start on your project!
What you can do on cloud?
- Host and run your own blog on your own server using Wordpress Quickstart.
- Set up your own e-commerce site for your burgeoning business using Magento e-commerce Quickstart.
- Developing your own web application using web.py framework Quickstart.
Note: All the PHP application types are available on the official Openshift get started page.
Note: OpenShift Quickstarts can be found on GitHub under the 'OpenShift' account.
Create an OpenShift Account
Creating an OpenShift account is a very simple task: just follow the new account link and sign up with your email address and a password. After signing into your OpenShift account, you should see something like in the below figure:
Figure 1 - OpenShift account management console
After creating the OpenShift account, you will receive a confirmation email, where you will find the next five steps. I list them here, just to point out how easy you can create a cloud application:
1. Go to the OpenShift Web Management Console
2. Choose an Instant Application like Wordpress or an Application Type like JBoss
3. Name your Application and Namespace
4. Click on your URL
5. Congratulations, you're in the cloud!
In the management Console of your OpenShift account, you need to set up the namespace under which your applications will be grouped under. You also have the option to set the namespace later, when creating applications, but I prefer to do this at this point. The namespace set for my incoming application is OctaviaExamples. As you can read in the next figure, the namespace is unique and it is contained in the public URL as a suffix: OctaviaExamples.rhcloud.com.
Figure 2 - Setting up a namespace for your group of applications
Install OpenShift RHC Client Tool
"The OpenShift Client tool, known as rhc, is built and packaged using the Ruby programming language. OpenShift integrates with the Git version control system to provide powerful, decentralized version control for your application source code."
1) To install OpenShift Client tools you need to download Git for Windows. Download it and then run the installer. After the installation is completed, to verify that Git is correctly configured, go in the corresponding folder, where this application was installed and run the Git Bash executable, and run the $ git -- version command. If everything worked fine you should see something like the below figure:
Figure 3 - Verifying installation for Git
2) To install OpenShift Client tools you also need to download RubyInstaller 2.0.0. Download it and then run the installer.
Note: While running the setup you need to select the "Add Ruby executables to your PATH" check box so you can run Ruby from the command line. After the installation is completed, to verify that Ruby is correctly configured, go in the corresponding folder, where this application was installed and run the ruby -e 'puts "welcome"' command. If everything worked fine you should see something like figure below:
Figure 4 - Verifying installation for Ruby
3) After the Ruby and Git are successfully installed, use the RubyGems package manager (included in Ruby) to install the OpenShift client tools. Run the gem install rhc command and you should get something like the figure below:
Figure 5 - Install RubyGems package
Page 1 of<< | https://www.developer.com/lang/php/php-cloud-development-on-red-hats-openshift-paas.html | CC-MAIN-2019-04 | refinedweb | 679 | 61.06 |
Iterative JSON parser with a standard Python iterator interface
Project description_c: a C extension using YAJL 2.x. This is the fastest, but might require a compiler and the YAJL development files to be present when installing this package. Binary wheel distributions exist for major platforms/architectures to spare users from having to compile the package.
- yajl2_cffi: wrapper around YAJL 2.x using CFFI.
-
You can import a specific backend and use it in the same way as the top level library:
import ijson.backends.yajl2_cffi as ijson for item in ijson.items(...): # ...
Importing the top level library as import ijson uses the pure Python backend.
Acknowledgements
ijson was originally developed and actively maintained until 2016 by Ivan Sagalaev. In 2019 he handed over the maintenance of the project and the PyPI ownership..
Project details
Release history Release notifications
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages. | https://pypi.org/project/ijson/2.4/ | CC-MAIN-2019-30 | refinedweb | 160 | 50.02 |
FAQ: Technical
From Mono
Mono Platforms
What operating systems does Mono run on?
Mono runs on Linux, UNIX and Windows systems. For a more detailed list, see the Supported Platforms page.
Is Mono Binary Compatible with Windows?
Yes, Mono is binary compatible with Windows. Which means that you can run binaries produced by .NET compilers from Microsoft and other vendors.
When porting your applications, you should make sure that you test its functionality as differences in the underlying operating system and differences in the VM implementations (bugs, missing features) might affect your application.
Mono does not have every .NET 1.1 API implemented (see the Mono release notes for Mono 1.0) and when executing a binary from Windows that consumes an unimplemented API you might get an obscure message about tokens not being found.
In these cases it is useful to compile your application with Mono's C# compiler just to ensure that you are consuming APIs that are supported.
This is not a perfect solution, as some APIs in Mono throw NotImplementedExceptions in certain cases, so you still should test your application with Mono.
Are there any reasons to build on Mono instead of using Visual Studio and copying the binaries?
In general, you can continue to use Visual Studio to write your code if you feel comfortable doing so.
Using Linux to develop will encourage you to test your software on Linux more frequently and if you have the chance, it will also help you to "dogfood" your own product.
Jonathan Pryor adds:
The benefit is that you can more easily know which APIs exist vs. which do not. In general, if an API doesn't exist within Mono, we try NOT to provide the method within the assembly (with a default version throwing NotImplemetedException()), so that you can use a mcs/gmcs compile to determine if all the APIs you use actually exist.
This isn't always possible, so there are several instances where a NotImplementedException is thrown, but when a NIE can be avoided by omitting the member, the member is omitted.
The alternative is to build under .NET and run under Mono, which leaves you (more) at the mercy of NotImplementedException's or MissingMememberException. A decent regression test platform should find these issues, so this might not be an actual problem.
Can I run Mono applications without using 'mono program.exe'?
Yes, this is possible on Linux systems, to do this, use something like:
if [ ! -e /proc/sys/fs/binfmt_misc/register ]; then /sbin/modprobe binfmt_misc mount -t binfmt_misc none /proc/sys/fs/binfmt_misc fi if [ -e /proc/sys/fs/binfmt_misc/register ]; then echo ':CLR:M::MZ::/usr/bin/mono:' > /proc/sys/fs/binfmt_misc/register else echo "No binfmt_misc support" exit 1 fi
This practice is discouraged as it is not portable.
It is better to follow the pattern described in the Application Deployment Guidelines and use a wrapper script to invoke Mono. That has several advantages (portability, ability to write relocatable applications, avoiding pollution of bin directories and allowing for flags and options to be passed to Mono).
If you create software with MonoDevelop and you have selected "Unix Integration", the scripts will be generated by default.
What architectures does Mono support?
See our Supported Platforms page.
Can Mono run on Windows 9x, or ME editions?
Mono requires Unicode versions of Win32 APIs to run, and only a handful of the "W" functions is supported under Win9x. There is Microsoft Layer for Unicode that provides implementation of these APIs on 9x systems.
Unfortunately it uses linker trick for delayed load that is not supported by ld, so some sort of adapter is necessary. You will need MSLU and one of the following libs to link Mono to unicows.dll or alternatively search the net for "libunicows".
No changes to the Mono source code are required, the only thing is to make sure that linker will resolve imports to adapter library instead of Win32 libs. This is achieved by inserting -lunimono before -lkerner32/user32 in the linker's specs file.
Why support Windows, when you can run the real thing?
There are various reasons:
- Supporting Windows helps us identify the portable portions of Mono from the non-portable versions of it, helping Mono become more portable in the future.
- It assists us since we can isolate problems in Mono by partitioning the problem (is it a runtime issue, or an OS issue?).
- About half the contributors to Mono are Windows developers. They have many different reasons for contributing to the effort, and we find it very important to let those developers run the runtime on Windows without forcing them to use a new operating system.
- Mono does not heavily modify the windows registry, update system DLLs, install DLLs to the Windows/System32 path.
- It helps Windows-based developers to test their code under Mono before they deploy into Linux.
- Mono and applications that embed Mono can be deployed without an installer (you can "xcopy" deploy your application and the required Mono files without installing the .NET runtime).
A reader comments:
In other words, I knew Mono would not cause any legacy enterprise applications to stop working - and it hasn't. However, our CIO is against it because of the changes that would be made to Windows 2000, such as, affecting security.
Another user comments:
By the way, the Mono libraries, including corlib, needed to support the application total 14MB so fit easily on even the smallest memory sticks.
How to detect the execution platform ?
The.
This means that in order to detect properly code running on Unix platforms you must check both values (4 and 128). This ensure that the detection code will work as expected when executed on Mono CLR 1.x runtime and with both Mono and Microsoft CLR 2.x runtimes.
using System; class Program { static void Main () { int p = (int) Environment.OSVersion.Platform; if ((p == 4) || (p == 128)) { Console.WriteLine ("Running on Unix"); } else { Console.WriteLine ("NOT running on Unix"); } } }
How can I tell where the Mono runtime is installed (Windows OS)?
While it can be argued that there are no totally reliable methods for detecting the presence of a Mono installation in a Windows environment, the following shows one way which detection may be achieved:
Firstly, look for the version string stored in a certain registry key.
$version = HKLM_LOCAL_MACHINE\Software\Novell\Mono\DefaultCLR
Then, using this version string, check the registry again for the path prefix, $monoprefix:
$monoprefix = HKLM_LOCAL_MACHINE\Software\Novell\Mono\$version\SdkInstallRoot
(optional) You might wish to then check this by detecting whether or not $mono-prefix\bin\mono.exe exists.
If one of the steps above failed, Mono may not be properly installed or the version may be too old.
Adapted from Robert Jordan's explanation, link to email held at the mono-list archive ()
How can I detect if am running in Mono?
Having code that depends on the underlying runtime is considered to be bad coding style, but sometimes such code is necessary to work around runtime bugs. The supported way of detecting Mono is:
using System; class Program { static void Main () { Type t = Type.GetType ("Mono.Runtime"); if (t != null) Console.WriteLine ("You are running with the Mono VM"); else Console.WriteLine ("You are running something else"); } }
Any other hack, such as checking the underlying type of System.Int32 or of other corlib types, is doomed to fail in the future.
Does Mono run on Fedora Core 5
Mono will run on FC5 as long as you turn off SELinux. Otherwise, some applications may experience errors.
Some people have reported compilation problems as well, but there are no details at this point, make sure you turn off SELinux if you want to use Mono
Updated as of May 8th.
Does Mono run on very small systems
The current default minimal mono install requires less than 4 MB of disk space and 4 MB of memory (plus disk and memory required by the operating system and programs running on mono). Mono plus basic Gtk# support requires less than 8 MB of disk space. To reduce further the footprint of Mono, see the Small footprint page.
Compatibility
Can Mono run applications developed with the Microsoft.NET framework?
Yes, Mono can run applications developed with the Microsoft .NET Framework on UNIX. There are a few caveats to keep in mind: Mono has not been completed yet, so a few API calls might be missing; And in some cases the Mono behavior might be incorrect.
Mono today ships with support for the .NET 1.1 API for the supported namespaces; Support for the 2.0 API is not complete.
I am using Visual Studio 2005, will Mono run my code?
Visual Studio 2005 produces code that targets the .NET 2.x API. This means that most code will work until you hit an API that has not been implemented in Mono.
This will appear as a TypeLoadException when you try to use a method or a property from one of the assemblies.
To make Visual Studio produce 1.1-based applications see this blog post here ().
Will missing API entry points be implemented?
Yes, the goal of Mono is to implement precisely the .NET Framework API (as well as compile-time selectable subsets, for those interested in a lighter version of Mono).
If the behavior of an API call is different, will you fix it?
Yes, we will. But we will need your assistance for this. If you find a bug in the Mono implementation, please fill a bug report in. Do not assume we know about the problem, we might not, and using the bug tracking system helps us organize the development process.
Can I develop my applications on Windows, and deploy on a supported Mono platform (like Linux)?
Yes, you can. As of today, Mono is not 100% finished, so it is sometimes useful to compile the code with Mono, to find out if your application depends on unimplemented functionality.
Will applications run out the box with Mono?
Sometimes they will. But sometimes a .NET application might invoke Win32 API calls, or assume certain patterns that are not correct for cross-platform applications.
You can find which native methods an assembly is using by using monodis like this:
$ monodis --implmap file.exe
The above command will list all of the invocations that the application has.
Must I have mono to create or run Gtk# applications in Windows?
No. Currently you can use the Gtk-Sharp Installer for .NET Framework which when coupled with the Microsoft .NET Framework, will allow you to build .NET applications that use Gtk# as their graphical user interface.
What is a 100% .NET application?
A '100% .NET application' is one that only uses the APIs defined under the System namespace and does not use P/Invoke. These applications would in theory run unmodified on Windows, Linux, HP-UX, Solaris, MacOS X and others. Note that this requirement also holds for all assemblies used by the application. If one of them is Windows-specific, then the entire program is not a 100% .NET application. Furthermore, a 100% .NET application must not contain non-standard data streams in the assembly. For example, Visual Studio .NET will insert a #- stream into assemblies built under the "Debug" target. This stream contains debugging information for use by Visual Studio .NET; however, this stream can not be interpreted by Mono (unless you're willing to donate support). Thus, it is recommended that all Visual Studio .NET-compiled code be compiled under the Release target before it is executed under Mono.
Can I execute my Visual Studio .NET program (Visual Basic .NET, Visual C#, Managed Extensions for C++, C++/CLI, etc.) under Mono?
Yes, with some reservations.
The .NET program must either be a 100% .NET application, or (somehow) have all dependent assemblies available on all desired platforms. (How to do so is outside the bounds of this FAQ).
Mono must also have an implementation for the .NET assemblies used. For example the System.EnterpriseServices namespace is part of .NET, but it has not been implemented in Mono. Thus, any applications using this namespace will not run under Mono.
With regards to languages, C# applications tend to be most portable. Visual Basic .NET applications are portable, but Mono's Microsoft.VisualBasic.dll implementation is incomplete. It is recommended to either avoid using this assembly in your own code, only use the portions that Mono has implemented, or to help implement the missing features. Additionally, you can set 'Option Strict On', which eliminates the implicit calls to the unimplemented Microsoft.VisualBasic.CompilerServices.ObjectType class. (Thanks to Jörg Rosenkranz.)
Managed Extensions for C++ and C++/CLi are least likely to operate under Mono. Mono does not support mixed mode assemblies (that is, assemblies containing both managed and unmanaged code, which Managed C++ can produce). You need a fully-managed assembly to run under Mono, and getting the Visual C++ .NET compiler to generate such an executable can be difficult. You need to use only the .NET-framework assemblies, not the C libraries (you can't use printf(3) for example.), and you need to use the linker options /nodefaultlib /entry:main mscoree.lib in addition to the /clr compiler flag. You can still use certain compiler intrinsic functions (such as memcpy(3)) and the STL.
You should also see Converting Managed Extensions for C++ Projects from Mixed Mode to Pure Intermediate Language () at MSDN. Finally, you can use PEVERIFY.EXE from the .NET SDK to determine if the assembly is fully managed.
Thanks to Serge Chaban for the linker flags to use.
C++/CLI meanwhile needs to use the /clr:pure or /clr:safe compiler flag to avoid the use of mixed-mode assemblies.
Does Mono have a Global Assembly Cache (GAC)?
Yes, Mono has a Global Assembly Cache.
It operates in a similar way to the .NET Global Assembly Cache, but has a few extensions, see the Assemblies and the GAC article for details.
What about serialization compatibility? Can I serialize an object in Mono and deserialize it in MS.NET or vice versa?
The serialization format implemented in Mono is fully compatible with that of MS.NET. However, having a compatible format is not enough. In order to successfully exchange serialized objects, the corresponding classes need to have the same internal structure (that is, the same public and private fields) in both sides.
If you are serializing your own classes, there is no problem, since you have control over the assemblies and classes being used for serialization.
However, if you are serializing objects from the framework, serialization compatibility is not guaranteed, since the internal structure of those objects may be different. This compatibility is not even guaranteed between different MS.NET versions or Mono versions.
Our policy is to do our best to make the framework classes compatible between Mono and MS.NET, however sometimes this is not possible because the internal implementation is too different. Notice also that when we change a class to make it compatible with MS.NET, we lose compatibility with older versions of Mono.
In summary, if you are designing an application that will run in different environments and platforms which are not under your control, and which need to share serialized objects (either using remoting, plain files, or whatever), you must be careful with what objects you share, and avoid objects from the framework when possible.
(Notice that this only applies to serializers based on the System.Runtime.Serialization framework, and does not apply to the XmlSerializer).
Can I use Mono to build applications for the Compact Framework?
Binaries produced by Mono do not contain the same public key expected by the compact framework. The compact framework will refuse to load applications that have been compiled with this key.
JB Evain produced a patcher that can be used to modify binaries produced by Mono to run on the Compact Framework, you can find it here ().
Patches binaries will be loaded in the Compact Framework, but if your assembly consumes features that are not present on it, your software will crash.
How can I map a Windows P/Invoke Library into a Unix library?
See the Config page, and in particular the <dllmap> and <dllentry> directives.
Development Tools
Does Mono have a debugger?
Yes, see our Debugger page for more information.
Also look at the Guide:Debugger for a tutorial and reference guide to the Mono debugger.
Debugger Tutorial
See the Guide:Debugger for a debugger tutorial and reference guide.
What Platforms does the Debugger Support?
Currently the Mono Debugger only supports Linux on x86 and x86-64 platforms.
How can I debug my programs?
You must have the Mono Debugger installed (mdb), and compile your code with debugging information, this is done by passing the -debug flag to the compiler:
$ mcs -debug sample.cs $ mdb sample.exe (mdb) run
Mono-aware compilers generate debugging information in a file with the extension .mdb.
Can I convert Microsoft PDB files to Mono MDB files?
You can convert PDB files to MDB files using a program written by Robert Jordan, see his emails on the subject here () and here ().
Does Mono have a profiler?
Mono has a built-in profiler which can be activated by running Mono with the --profile argument. The profiler can be further tuned, see the manual page for mono (mono(1)) for more details. Most of the time you want to use the statistical profiler (which has a very low performance overhead):
/path/to/mono --profile=default:stat program.exe
If you have binutils installed (the addr2line program specifically), you'll get detailed profiling info also on unmanaged code.
In addition it is possible to create custom profilers using Mono's profiling interface. For a list of existing profilers for Mono see our Performance Tips page.
Does Mono have a memory profiler?
Mono has several memory profilers: a built-in one (see manual page), HeapShot for information about the Mono live memory usage, HeapBuddy for memory allocation patterns and OprofileWithAnonJitData using OProfile to profile JITed code.
See the Profile page for more information.
Does Mono have Code Coverage Tools?
Mono has a bundled code coverage tool that you can use with your applications. Use the "coverage" profiler, like this:
$ mono --profile=cov demo.exe
See the Code Coverage page for more information.
Does Mono have some kind of tracing facility?
The Mono runtime has a built-in tracing facility to trace the method execution and it reports parameters passed, values returned and exceptions thrown. This is enabled with the --trace flag to the Mono runtime.
The tracing facility has a simple syntax for limiting the scope of traces, see the mono manual page for more details on this facility.
How can I debug problems with my DllImports?
You can export the following environment variables to turn on DllImport logging, it is useful when tracking down the source of a problem when loading a library:
MONO_LOG_LEVEL="debug" MONO_LOG_MASK="dll" mono program.exe
Web Services
How is Mono related to Web Services?
Mono is only related to Web Services in that it will implement the same set of classes that have been authored in the .NET Framework to simplify and streamline the process of building Web Services.
But most importantly, Mono is an Open Source implementation of the .NET Framework.
Can I author Web Services with Mono?
You will be able to write Web Services on .NET that run on Mono and vice-versa.
If Mono implements the SDK classes, will I be able to write and execute .NET Web Services with it?
Yes. When the project is finished, you will be able to use the same technologies that are available through the .NET Framework SDK on Windows to write Web Services.
What about Soup? Can I use Soup without Mono?
Soup is a library for GNOME applications to create SOAP servers and SOAP clients, and can be used without Mono. You can browse the source code for soup using GNOME's Bonsai ().
Can I use CORBA?
Yes. The CLI contains enough information about a class that exposing it to other RPC systems (like CORBA) is really simple, and does not even require support from an object.
Remoting.CORBA () is a CORBA implementation that is gaining momentum. Building an implementation of the Bonobo interfaces once this is ready should be relatively simple.
There are other CORBA implementations for .NET available as well.
Can I serialize my objects to other things other than XML?
Yes. We support runtime/binary serialization as well as XML serialization. You also write your own serialization providers.
Will Mono use ORBit?
There are a few advantages in using ORBit, like reusing existing code and leveraging all the work done on it. Michael Meeks has posted a few reasons (), as well as some ideas () that could be used to reuse ORBit.
Most users are likely to choose a native .NET solution, like Remoting.CORBA ()
MonoDoc
What is MonoDoc?
MonoDoc is a graphical documentation browser for the Mono documentation: class libraries, tutorials and manual pages. Currently, monodoc has a GUI front-end written in Gtk# and a Web front-end using ASP.NET
The contents of Monodoc today are visible on the web here ()
More information about the Mono documentation can be found on the Documentation page.
Development Tools and Issues
Will it be possible to use the CLI features without using byte codes or the JIT?
Yes. The CLI engine will be made available as a shared library. The garbage collection engine, the threading abstraction, the object system, the dynamic type code system and the JIT are available for C developers to integrate with their applications if they wish to do so.
Will you have new development tools?
With any luck, Free Software enthusiasts will contribute tools to improve the developer environment. These tools could be developed initially using the Microsoft implementation of the CLI and then executed later with Mono. We are recommending people to use and contribute to existing projects like SharpDevelop, Anjuta and Eclipse.
What kind of rules make the Common Intermediate Language useful for JITers?
The main rule is that the stack in the CLI is not a general purpose stack. You are not allowed to use it for other purposes than computing values and passing arguments to functions or return values. At any given call or return instruction, the types on the stack have to be the same independently of the flow of execution of your code.
Is it true that the CIL is ideal for JITing and not efficient for interpreters?
The CIL is better suited to be JITed than JVM byte codes, but you can interpret them as trivially as you can interpret JVM byte codes.
Isn't it a little bit confusing to have the name of "XSP" (the same as in the Apache Project) for the ASP.NET support in Mono?
. In Mono, xsp is just the name of the C# code generator for ASP.NET pages. In the Apache Project, it is a term for the "eXtensible Server Pages" technology so as they are very different things, they don't conflict.
Are there any plan to develop an aspx server for Mono?
. The XSP reference server is available and you can also use mod_mono with Apache.
Is there any way I can develop the class libraries using Linux yet?
Yes. Mono has been self hosting since May 2002.
Is there any way I can install a known working copy of mono in /usr, and an experimental copy somewhere else, and have both copies use their own libraries?
Yes. Just use two installation prefixes.
How should I write tests or a tests suite?
If you do a test suite for C#, you might want to keep it independent of the Mono C# compiler, so that other compiler implementations can later use it.
Would it be too terrible to have another corlib signed as mscorlib?
We rename corlib to mscorlib also when saving the PE files, in fact, the runtime can execute program created by mono just fine.
It is not worth doing the above for individual files. The C# compiler is so fast that usually the cost of compiling a few hundred source files is smaller than the cost of creating the separate dll files.
Also the final results will be an assembly that references all of the other .dll files, it wont be a single unit.
If you want to merge the assemblies, you could try the prototype "merge" tool that is part of Cecil.
Is there any plans for implementing remoting in the near future?
The remoting infrastructure is in place. We have implementations of the TcpChannel, HttpChannel and the Soap and Binary Formatters. They are compatible with .NET.
However, some classes from the library may have a different binary representation, because they may have a different internal data structure, so for example you won't be able to exchange a Hashtable object between Mono and MS.NET. It should not be a problem if you are using primitive types, arrays or your own classes. If you have problems, please post a test case.
My C code uses the __stdcall which is not available on Linux, how can I make the code portable Windows/UNIX across platforms?Replace the __stdcall attribute with the STDCALL macro, and include this in your C code for newer gcc versions:
#ifndef STDCALL #define STDCALL __attribute__((stdcall)) #endif
I want to be able to execute Mono binaries, without having to use the "mono" command. How can I do this?
From Carlos Perelló:
I think that the best solution is the binfmt feature with the wrapper that exists with Debian packages at:
If you want use it with Big endian machines, you should apply a patch ()
It works really good and lets you use wine also, it reads the .exe file headers and check if it's a .net executable.
This way you just execute: ./my-cool-mono-application.exe and it works without the need of any wrapper.
I see funny characters when I run programs, what is the problem?
(From Peter Williams and Gonzalo Paniagua):This is Red Hat 9 (probably) using UTF8 on its console; the bytes are the UTF8 endianness markers. You can do:
LC_ALL=C mono myexe.exe
And they wont show up.Alternatively, you can do:
$ echo -e "\033%G"
to enable UTF-8 on the console.
How does Unicode interact with Mono?
These are a few bits that you might want to know when dealing with Unicode strings in Mono and Unix:
- Mono compilers will default to the current language encoding as their native encoding. If your LANG environment variable contains the terminator UTF-8 (for example mine is LANG=en_US.UTF-8) it will process its input files as UTF-8
- You can control the encoding used by the compilers using the -codepage: command line option, for the special case of utf-8, you can use: -codepage:utf8 to inform the compiler that your sources are in UTF-8, for more codepages, see the manual page for the compiler.
- CIL executables generated by the Mono compilers store everything in UTF-16 encodings.
- If you are dealing with ASP.NET that invokes the compiler automatically for you, you can control the encoding used by specifying this on the web config file. See the reference for [[Config_system.web_globalization|web/globalization] for details.
The above takes care of converting the input you provide to Mono compilers and runtimes into Unicode. Another issue is how these characters get rendered into the screen.
For console output Mono will use the encoding specified in your LANG environment variable to display the Unicode strings that the program has. If your LANG variable does not allow for the full range of Unicode strings to be displayed (for example, LANG=en alone) then only the subset supported by that specific character set can be displayed.
How do I build mono/mcs on Windows from Mono's Subversion repository?
See the article Building Mono on Windows () by Kevin Shockey with help from Paco.
I just made a change in my code and am getting Segfaults, what is it?
Segfaults are typically the result of a stack overflow, these are caused by recursive invocations of a method, and these happen frequently with OO code, as developers forget to call the "base" method, for example:
class Child : Parent { public override GetNumber () { return GetNumber () + 1; } }
When the developer really wanted:
class Child : Parent { public override GetNumber () { return base.GetNumber () + 1; } }
Although Mono has support for turning these into a StackOverflowException, the code that does this introduces an instability into the Garbage Collector, so it is no longer being turned on by default.
What are the issues with FileSystemWatcher?
The Mono implementation of FileSystemWatcher has a number of backends, the most optimal one, the one with fewer dependencies is the inotify-backend (available in Mono 1.1.17 and newer versions).
With this backend the kernel provides Mono with updates on any changes to files on the file system but it requires an inotify-enabled kernel, which only newer Linux distributions ship.
In older Linux systems, you must have installed FAM or Gamin (it will work with either one). You might need the -devel packets installed.
For the *BSD family, there's a Kqueue based implementation that will be used when detected at runtime.
If none of the above work, Mono falls back to polling the directories for changes, which far from optimal.
Am using Mono with FakeRoot an my application hangs, what can I do?
Try this:
mkdir /tmp/fakeroot-wapi MONO_SHARED_DIR=/tmp/fakeroot-wapi fakeroot ...
Otherwise mono would try to write to /root/.wapi/ because fakeroot doesn't fake the pwent functions that Mono is using to obtain the home directory.
Mono and ASP.NET
See FAQ: ASP.NET ()
Mono and ADO.NET
What is the status of ADO.NET support?. Could I start migrating applications from MS.NET to Mono?
The ADO.NET support is fairly complete and there are many database providers available.
In developing the data architecture for the application are there and objects I should stay away from in order to insure the smoothest possible transition (minimum code rewrite) to Mono's ADO.NET implementation? (For example, strongly typed datasets versus untyped datasets, etc...)
We are implementing all the classes in Microsoft .NET's System.Data, so you can be sure that things will work the same in Mono as with the Microsoft implementation. There is strongly typed dataset support in Mono now.
Can you connect to a Sybase database using Mono?
Yes. use Mono.Data.SybaseClient. First of all you have to create a SybaseConnection, and then, from it, use it as any other IDbConnection-based class. See here () for more info.
Has the MySQL Connector/Net replaced ByteFX.Data
Yes it has. MySQL Connector/Net is made by MySQL AB and are the best people who would know how to access their databases. The author of ByteFX.Data no longer develops ByteFX.Data because he is employed by MySQL AB now. See here () for more info.
How do I connect to a SQLite database?
Use Mono.Data.SqliteClient. Make sure you are using at least Mono 1.1.4 since SQL Lite provider does not work in the Mono 1.0.x releases and prior. Use a connection string like "URI=file:SqliteTest.db" if you are using SQL Lite version 2.x or use "version=3,URI=file:SqliteTest.db" if using SQL Lite version 3.x. See SQLite for more info.
What provider do I use to connect to PostgreSQL?
You would use Npgsql which is included with Mono. It is also included with the Win32 installer for PostgreSQL 8.0 which runs natively on Windows. See here () for more info.
Do you have any plans to implement ObjectSpaces?
No. Note that Microsoft dropped ObjectSpaces for .NET Framework 2.0.
Mono and EnterpriseServices
The following document link to the status of EnterpriseServices in Mono:
Mono and Java
Why don't you use Java?
After all, there are many languages that target the Java VM.
You can get very good tools for doing Java development on free systems right now. Red Hat () has contributed a GCC () front-end for Java () that can take Java sources or Java byte codes and generate native executables; Transvirtual implemented Kaffe () a JIT engine for Java; Intel also has a Java VM called ORP ().
The JVM is not designed to be a general purpose virtual machine. The Common Intermediate Language (CIL), on the other hand, is designed to be a target for a wide variety of programming languages, and has a set of rules designed to be optimal for JITers.
Could Java target the CLI?
Yes, Java could target the CLI, Microsoft's J# compiler does that. The IKVM () project builds a Java runtime that works on top of .NET and on top of Mono. IKVM is essentially a JIT compiler that translates from JVM bytecodes into CIL instructions, and then lets the native JIT engine take over.
Is it possible to write a JVM byte code to CIL converter?
Yes, this is what IKVM () does.
Could mono become a hybrid CIL/java platform?
This can be obtained easily with IKVM.
Do you plan to implement a Javascript compiler?
Yes. The beginnings of the JScript compiler can be found on SVN. Cesar coordinates this effort.
Can Mono or .NET share system classes (loaded from mscore.dll and other libs) or will it behave like Sun's Java VM?
What you can do with mono is to load different applications in their own application domain: this is a feature of the CLR that allows sandboxing applications inside a single process space. This is usually exploited to compartmentalize different parts of the same app, but it can also be effectively used to reduce the startup and memory overhead. Using different appdomains the runtime representation of types and methods is shared across applications.
Mono and the Enterprise Application Blocks
The Enteprise Application Blocks license that Microsoft has chosen explicitly prevents developers from using it on non-Windows platforms (see the [ license wording, section 10).
There are a few alternatives available on Mono.
What can I used instead of the Data Access Application Block?
You can use the Mono Provider Factory which is a standard component of all Mono installations.
Extending Mono
Would you allow other classes other than those in the specification?
Yes. The Microsoft class collection is very big, but it is by no means complete. For more information on extending Mono, see our ideas page.
Do you plan to Embrace and Extend .NET?
Embracing a good technology is good. Extending technologies in incompatible ways is bad for the users, so we do not plan on making incompatible changes to the technologies.).
Do you plan on exploring, changing other parts?
The Mono team at Novell is currently focused on improving Mono's performance, platform support, coverage, quality and features, so we are likely going to be busy doing those things.
But Mono has already been used as a foundation for trying out new ideas for the C# language (there are three or four compilers derived from Mono's C# compiler) and a number of innovative ideas (like continuations for the VM) have been implemented as research prototypes on top of Mono.
We need to explore in a case-by-case basis which of these ideas can be integrated into Mono, we are certainly open to the idea of getting some of these ideas merged into Mono, but in addition to the standard considerations for any contributed code we have to take into account things like whether we can maintain it effectively, whether it makes too many changes to Mono, whether it is a clean and mainteinable implementation.
So in short: we are open to the idea of deviating from .NET for research purposes and when the idea is good, but we will incorporate based on a case-by-case study of the proposal.
Is there any way I can develop the class libraries using Linux yet?
Yes. Mono has been self hosting since March 2002.
Is there any way I can install a known working copy of mono in /usr, and an experimental copy somewhere else, and have both copies use their own libraries?
Yes. Just use two installation prefixes.
I have a great library that I want to contribute, will you take it?
The first step for a library to be integrated into Mono is for the library to be licensed under the terms of the MIT X11 license.
These days we recommend that third-party libraries are maintained independently of the core of the Mono class libraries and that they are shipped independently with their own release schedule.
The problem with bundling libraries with Mono is that they have a higher requirement for backwards-compatibility, so any breakage in the API requires us to ship a new version of the library and keep the old version around. Maintaining too many libraries can be cumbersome after a while.
We recommend that the libraries are given a chance to evolve, and have their API mature before they are installed in the GAC, which is the first step towards being considered for inclusion with Mono. To learn more about this read our Application Deployment Guidelines.
There is another downside that library developers face when bundling libraries with Mono: their release schedule ends tied to Mono, which might be too slow for a rapidly evolving library. This also imposes extra work if you try to match our release and development schedules.
A better practice is to keep the library on its own schedule, release it on its own schedule and ensure that packages are available for most distributions.
Portability
Will Mono only work on Linux?
Currently, we are doing our work on Linux-based systems and Windows. We do not expect many Linux-isms in the code, so it should be easy to port Mono to other UNIX variants.
What about Mono on non Linux-based systems?
Our main intention at Novell is to be able to develop GNOME applications with Mono, but if you are interested in providing a port of the Winforms classes to other platforms (frame buffer or MacOS X for example), we would gladly integrate them, as long they are under an open source license.
What operating systems/CPUs do you support?
Mono currently runs on Linux, Windows, Solaris, FreeBSD, HP-UX and MacOS X. The Just-In-Time engine (JIT) is available on x86 and PowerPC, Sparc and S390 processors and can generate code and optimizations tailored for a particular CPU. Interpreters exist for the Itanium, HP-PA, StrongARM CPUs.
Does Mono run on Windows?
Yes. You can get pre-compiled binaries from
What is WAPI?
WAPI stands for Windows API.
For portability reasons, Mono uses Win32 APIs for I/O and related operations (semaphores, process creation, etc). You can find the Unix versions of these Win32 APIs in mono/mono/io-layer.
So on Windows, Mono directly uses Win32, while on Unix Mono uses Win32 APIs implemented in the io-layer.
This was necessary because many of the System.IO, etc. APIs have "Win32-isms" which prevent direct Unix implementation.
Part of the wapi implementation is per-user shared-data, stored in =~/.wapi=. This holds process IDs of mono processes, file share information (so opening a file opened for exclusive read can be denied), and other assorted information.
Deleting this shared data can have bad effects on mono applications. :-)
Does Mono run on Linux?
Yes. You can get pre-compiled binaries from
Will I require Cygwin to run mono?
No. Cygwin is only required to build Mono..
Will Mono depend on GNOME?
It will depend only if you are using a particular assembly (for example, for doing Gtk# based GUI applications). If you are just interested in Mono for implementing a 'Hello World Enterprise P2P Web Service', you will not need any GNOME components.
Do you plan to port Rhino to C#?
. Eto Demerzal has started a Rhino port to C#.
Has anyone succeeded in building a Mac version of the C# environment. If so can you explain how?
Yes, Mono works on Linux/PPC and MacOS X (10.2 and 10.3)
Reusing Existing Code
What projects will you reuse or build upon?
We want to get Mono in the hands of programmers soon. We are interested in reusing existing open source software.
Will I be able to use Microsoft SQL Server 2000 or will I need to switch to a specific Open Source Database. Will I need to recode?
There is no need to rewrite your code as long as you keep using Microsoft SQL Server. If you want to use an open source database, you might need to make changes to your code.
What do I need to watch out for when programming in VB.NET so that I'm sure to be able to run those apps on Linux?
Not making any P/Invoke or DLL calls should and not using anything in the Microsoft namespaces should suffice. Also do not use any Methods/Classes marked as "This type/method supports the .NET Framework infrastructure and is not intended to be used directly from your code." even if you know what these classes/methods do.
Will built-in reporting be supported for crystal reports?
Crystal Reports are proprietary. Someone may try to emulate the behavior, but no-one has yet volunteered.
What about writing to the registry? As I understand it, Linux does not have a counterpart to the registry. Should I avoid relying on that feature?
Try to avoid it. Although there would be a emulation for registry in Mono too. GNOME does have a registry like mechanism for configuration. But Even if gnome has a configuration system similar to the registry, the keys will not be equal, so you will probably end up having to do some runtime detection, and depending on this load an assembly that has your platform-specific hacks.
System.Data.SqlClient with FreeTDS, will you port parts of these to C# and use them?
This has been done. System.Data.SqlClient is a fully managed provider for Microsoft SQL Server 7, 2000, and 2005 databases written in 100% C#. It used FreeTDS and jTDS as resources.
Operating System Questions
Can I use signal handlers with Mono?
In general, you should not use signal handlers with Mono. Signal handlers behave like new threads and execute within the context of the thread that receives the signal which makes them very error prone.
If you still need to use a signal handler here are some guidelines for how to do this, but keep in mind that this is an unsupported use of the runtime and that you might very well be facing bugs on your own.
You should keep in mind that all you can do in a signal handler is set a static variable, anything else will randomly corrupt the state of your application.
But to set the variable, you need need to ensure that the signal handler is JITed before the signal is actually delivered. You must ensure at startup that your application will call the signal handler to ensure that the code has been JITed in advance, and only then set the signal handler to point to it.
A sample program that uses signal handlers in this way is mono-service you can browse the source code here ().
How to open a link in the user's browser?
See the Howto_OpenBrowser
Mono and GCC
Will you support running C code on the Mono VM?
C is going to be supported through the GCC CIL project that is underway, this code is now hosted on the GCC CVS repository.
Also, invoking existing C code from Mono is possible by using P/Invoke, the Platform Invocation services.
Will you support running C++, Managed C++, C++ CLI code on the Mono VM?
For more details see our C++ page.
I have a C++ library that I would like to call from Mono, what can I do?
There are a few possible approaches:
- Use a code generator such as SWIG that parses the C++ code and generates C wrapper functions and C# code which DllImports the C wrappers.
Pro: This permits use of C++ code from C# Con: Not terribly elegant; Extra layer of C code may impact performance.
- There was work on a WHIRL-to-IL compiler, which would compile C (and probably C++) into CIL which Mono could execute.
Long term solutions that require a lot of work might be possible:
- Modify GCC's to produce CIL.
What is the WHIRL-to-IL tion for using C++ with Mono?
We are no longer considering WHIRL as an intermediate IR for supporting C and C++, instead its now possible to use GCC 4.0 internal representation to generate CIL code.
What about Managed C++?
Once a full translator for GCC exists, we are interested in looking at expanding the GCC frontends to include extensions for Managed C++.
Are you working on a GCC front-end to C#?
We are not working on a GCC front-end for C#.
What about making a front-end to GCC that takes CIL images and generates native code?
There is no active work on this area, but Mono already provides pre-compilation services (Ahead-of-Time compilation).
Mono and the Basic Language
Does Mono implement the Basic language?
An implementation of the VB.NET language is now available, to find out more about the current state of the compiler see the page on Basic.
What about VB6
Mono does not have current plans to implement VB6 at this point.
The major value of VB6 is reportedly its deep integration with COM-based controls which would not be available on Unix, and it seems to be generally accepted that the major value of VB6 is the availability of third party controls.
An effort to implement a full stack would probably require a COM-stack to be implemented and a way of running existing controls. A task that is outside the scope of Mono.
What about VBScript and VBA?
Those languages are simpler to implement due to the restricted dependency on external COM objects, but there are no plans at this point to implement them by the Mono team.
Performance
How fast is Mono?
We can not predict the future, but a conservative estimate is that it would be at least 'as fast as other JIT engines'.
In general, it is hard to answer the question rating from zero to ten as on a typical application there are many elements involved:
- the quality of the generated code, this being a metric of the code generator and the optimizations implemented on it. You can read about some optimizations in Mono on the Runtime page.
- The maturity of the class libraries used by the application. Mono's tuning of class libraries has been done in an as-needed basis, and not every class is at the same level of maturity.
- The host operating system: I/O benchmarks are dominated by the operating system specifics (file system performance, file system synchronization guarantees, micro kernel or not and so on).
- Mono's GC is a conservative collector, while Java and Microsoft's .NET are copying/tracing collectors, so many benchmarks will go in one direction or the other depending on the task being performed.
- On Web applications and database applications, the configuration and tuning of the web server will play a dominant role, while Mono's performance these days is no longer on the critical path.
The best thing to do is to test your application in Mono and identify if the performance of your application is good enough in Mono.
We are currently working on a Compacting GC that will assist in some of the limitations described above.
Can you compare Mono performance with other languages/platforms?
The folks at the Language Shootout () compare Mono's performance with other platforms.
Do you track Mono's performance improvements?
See our Performance Testing page for more details on the tests that we are tracking on performance.
What kind of framework does Mono have for new optimizations?
Mono's JIT engine has been recently re-architected, and it provides many new features, and layers suitable for optimization. It is relatively easy to add new optimizations to Mono.
Read the Runtime page for more details.
Are you working on improving Mono performance?
Optimization and performance are things that we keep in mind during the development of our software. We routinely implement code, profile it and tune it. This is an ongoing process in all of Mono.
How can I improve the performance of my application?
We have a number of recommendations in our Performance Tips page covering some common practices to improve the performance of your application.
Are there any advantages in the CIL byte code over Java bytecode?
The CIL has some advantages over the Java byte code: The existence of structs in addition to classes helps a lot the performance and minimizes the memory footprint of applications.
Generics in the CLI world are first-class citizens, they are not just a strong-typing addition to the language. The generic specifications are embedded into the instruction stream, the JIT uses this information to JIT a unique instances of a method that is optimized for the type arguments.
The CIL is really an intermediate representation and there are a number of restrictions on how you can emit CIL code that simplify creating better JIT engines.
For example, on the CIL, the stack is not really an abstraction available for the code generator to use at will. Rather, it is a way of creating a postfix representation of the parsed tree. At any given call point or return point, the contents of the stack are expected to contain the same object types independently of how the instruction was reached.
Mono and Portable.NET
What are the differences between Mono and Portable.NET?
Most of Mono is being written using C#, with only a few parts written in C (The JIT engine, the runtime, the interfaces to the garbage collection system).
It is easier to describe what is unique about Mono:
- An advanced native-code compilation engine: Both just-in-time compilation (JIT) and pre-compilation of CIL bytecodes into native code are supported.
-. SSA-based partial redunancy elimination.
- A self-hosting C# compiler written in C#, which is clean, easy to maintain.
- Mono has a complete C# 1.0 implementation and has been stress tested a lot more than Portable.NET's compiler.
- Generics support and complete C# 2.0 support.
- A multi-platform runtime engine: both a JIT engine and an interpreter exist. The JIT engine runs currently on x86, PowerPC, S390, S390x, Sparc, x86-64, Itanium and ARM systems, while the interpreter works on x86, SPARC, ARM, s390, PowerPC, HP-PA and Alpha systems.
- The JIT engine is written using a portable instruction selector which not only generates good code but is also the foundation to re-target the JIT engine to other systems.
- Full support for remoting in the runtime.
-.
- Our class libraries are licensed under the terms of the MIT X11 license which is a very liberal license as opposed to the GNU GPL with exceptions, this means that Mono can be used in places where the GPL with exceptions is not permissible.
- Mono has a complete Web Services stack: we implement ASP.NET web servers and web clients as well as implementing the Remoting-based SOAP infrastructure.
- Remoting implementation: Mono has a complete remoting infrastructure that is used in our own codebase to provide added functionality and performance to our ASP.NET engine and more.
- Mono's C# compiler flags more errors and warnings on invalid C# code.
- Mono's C# compiler is a CLS consumer and producer, which means that it will enforce during development the CLS rules.
- Mono's C# compiler has strong error handling and has closer adherence to the specification with support for definite assignment (required to generate verifiable IL code).
- Mono's C# compiler is written in C# which is easier for new developers to come in and improve, fix and tune. The Mono C# compiler in C# is faster than their C-based compiler.
- Mono has a complete Reflection and Reflection.Emit: these are important for advanced applications, compilers and dynamic code generation (Applications like IKVM and IronPython depend on this feature for example).
- Mono has a complete managed XML stack: XML, XPath, XML Serializer, XML Schema handling are fully functional, feature complete and tuned for performance. In addition to the Microsoft API, mono ships with the Mono.Xml.Ext library that contains an XQuery/XPath2 implementations.
- Mono has a complete cryptography stack: we implement the 1.0 and 1.1 APIs as well as using our fully managed stack to implement the SSL/TLS transports.
- Extensive database support: Mono ships with database provides for Firebird, IBM DB2, Oracle, Sybase, Microsoft SQL Server, SQLite, MySQL, PostgreSQL, Ole DB and ODBC.
- A more complete System.Drawing implementation, based on Cairo.
- Mono includes LDAP support.
- Mono has a larger community of active developers. Full time developer from companies (Novell and Mainsoft) as well as volunteers from the community.
In general, Mono is more mature and complete since it has been used to develop itself, which is a big motivator for stability and correctness, while Portable.NET remains pretty much an untested platform.
I hear Mono keeps changing the P/Invoke API, why?
We are just fixing our implementation to be compatible with the Microsoft implementation. In other words, the Mono P/Invoke API is more complete when compared to the Portable.NET version, hence various pieces of software that depend on this extended functionality fail to work properly with Portable.NET.
Common Problems
I have a multi-threaded application, and I keep getting timeouts, what is happening?
For a complete explanation of the problem, see our article: ThreadPool Deadlocks
MONO_EXTERNAL_ENCODINGS
When I run an application, I get the following error message:
** Message: Bad encoding for '????' Consider using MONO_EXTERNAL_ENCODINGS
This problem arises when you have files in your file system that Mono can not convert into Unicode. Mono uses the UTF-8 encoding for the filenames stored in your file system by default, because it is the universally accepted standard.
The problem typically arises when you transfer files that were stored on a system that used a different encoding. This might happen if you copy a backup from an older system that encoded filename is latin-1 encoding and your current system uses UTF-8 (Example: the old system probably had LANG set to "en_US" and the new system uses "en_US.UTF-8).
It is highly recommended that you fix the encoding of your filenames on your file system using a tool like convmv, a perl utility that lets you rename files from one encoding to another.
Alternatively, you can set the MONO_EXTERNAL_ENCODINGS variable, but this is not recommended. To use this set the MONO_EXTERNAL_ENCODINGS variable to a comma separated list of encodings that the Mono runtime should try to use when guessing the values encoded in a filename.
See the manual page for details on how Mono uses this variable.
The values allowed are those returned by "iconv --list".
This is a sample:
$ export MONO_EXTERNAL_ENCODINGS="utf8:latin1"
Notice that in older versions of Mono, the error message had a typo, and said "MONO_EXTERNAL_ENCODING" instead of "MONO_EXTERNAL_ENCODINGS"
The problem with using MONO_EXTERNAL_ENCODINGS is that even if Mono will be able to parse your filenames, Mono will still store the filenames internall as Unicode. If you try to move, overwrite or do any other manipulation in the file Mono will transform the filename from Unicode to your native encoding and it might fail to find the file.
ICMP Ping throws an exception
I used Mono to create a small C# console application that uses the ICMP class from to ping a host.
ICMP ping = new ICMP(); ping.Open(); TimeSpan span = ping.Send("192.168.1.1", new TimeSpan(0,0,5));
Unfortunately there is an exception.
Unhandled Exception: System.Net.Sockets.SocketException: Access denied in <0x000b8> System.Net.Sockets.Socket:.ctor (AddressFamily family, SocketType type, ProtocolType proto) in [0x00004] (at cPing.cs:41) ICMP:Open () in [0x00007] (at Main.cs:14) MainClass:Main (System.String[] args
The same code works fine when run in Visual Studio 2005 Professional or Mono on Windows. It does not work on Linux because you must run as root in order send ICMP packets. The /bin/ping program runs on Linux with the setuid bit. To ping from a Mono program you may either P/Invoke /bin/ping or setuid root your Mono program (after undertaking a thorough security audit of the runtime, the class libraries and any third party libraries that are linked, of course).
How can I configure Web.config and an ASPX file to turn the trace on?
<configuration> <system.web> <trace enabled="false" requestLimit="10" pageOutput="true" traceMode="SortByTime" localOnly="false" /> ...
I never used pageOutput="true". If it doesn't work you may set it to "false" and get the trace from Trace.axd.
SelectSingleNode and SelectNodes ignore the default namespace I set in XmlNamespaceManager and thus do not return the expected nodes
(It is also likely to happen that you do not pass the XmlNamespaceManager argument to SelectNodes and SelectSingleNode, though in such cases you will soon notice since it will cause an error saying that you need it.)
You can't use the default namespace in XPath (see | section 2.3 () of the XPath specification for details). Thus code like below won't work:
XmlNamespaceManager nm = new XmlNamespaceManager (nameTable); nm.AddNamespace ("", ""); return node.SelectSingleNode ("/html/body/form", nm);
You need to set non-empty prefix to the namespace you want to map e.g.:
XmlNamespaceManager nm = new XmlNamespaceManager (nameTable); nm.AddNamespace ("h", ""); return node.SelectSingleNode ("/h:html/h:body/h:form", nm);
Note that you don't have to change the prefixes in queried documents. They have nothing to do with the registered prefixes in the argument XmlNamespaceManager.
_wapi_shm_semaphores_init problems
If you get an error message like this:
** (process:2473): CRITICAL **: _wapi_shm_semaphores_init: semget error: No space left on device. Try deleting some semaphores with ipcs and ipcrm
It means that you have run out of semaphores.
Mono keeps a file in ~/.wapi tracking the semaphore usage and will clean it up on shutdown. But if Mono fails to shutdown properly (abnormal program termination) or if you delete the file that Mono uses to track this information, semaphores might leak.
This typically happens when Mono has not had a chance to cleanup (abnormal program termination, or if you have instructed Mono to use a different location for semaphores, using a chroot environment and then wiping it out).
You can use: ipcs -s to list all the semaphores, and you must manually remove them (using ipcrm). These semaphores typically look like this:
$ ipcs -s ------ Semaphore Arrays -------- key semid owner perms nsems ... 0x4d036b25 156139526 username 600 8 ... $
To delete use:
ipcrm -s NNNN
Where NNNN is the number of the semaphore.
How can I execute assemblies from shared folders in Windows?
Open up a SDK command prompt and execute the following command:
caspol -q -machine -addgroup 1 -url* FullTrust -name "Z Drive"
Replace Z: with the drive (or path) where you have your shared folders.
To enable 1.1 assemblies you need to open a SDK 1.1 command prompt and to enable 2.0 assemblies you need to open a SDK 2.0 command prompt.
For more information see this:
Credits
The FAQ contains material contributed by Miguel de Icaza, Jaime Anguiano, Lluis Sánchez, Niel Bornstein. | http://www.mono-project.com/FAQ:_Technical | crawl-001 | refinedweb | 9,979 | 65.12 |
2018-09-14 15:07:19 8 Comments
Kindly check my code of reversing the array, I can't find the error. It is showing the same array before and after the function call which I don't know why?
#include <iostream> using namespace std; void reverseArray(int *arr, int size) { int *Copy_arr = new int[size]; int temp; for (int i = 0; i < size; i++) { Copy_arr[i] = arr[i]; } for (int i = 0; i < size; i++) { temp = arr[i]; arr[i] = arr[(size - 1) - i]; arr[(size - 1) - i] = temp; } cout << "Array before function call was: "; for (int i = 0; i < size; i++) { cout << Copy_arr[i] << " "; } cout << endl << "Array after function call is: "; for (int i = 0; i < size; i++) { cout << arr[i] << " "; } cout << endl; } void main() { int size; cout << "Enter size of array\n"; cin >> size; int *p = new int[size]; cout << "Enter the elements of array\n"; for (int i = 0; i < size; i++) { cin >> p[i]; } reverseArray(p, size); }
Related Questions
Sponsored Content
10 Answered Questions
[SOLVED] Why is reading lines from stdin much slower in C++ than Python?
- 2012-02-21 02:17:50
- JJC
- 199625 View
- 1499 Score
- 10 Answer
- Tags: python c++ benchmarking iostream getline
25 Answered Questions
[SOLVED] Easiest way to convert int to string in C++
- 2011-04-08 04:19:41
- Nemo
- 2188443 View
- 1231 Score
- 25 Answer
- Tags: c++ string int type-conversion
11 Answered Questions
[SOLVED] How can I profile C++ code running on Linux?
22 Answered Questions
[SOLVED] Why do we need virtual functions in C++?
- 2010-03-06 07:10:35
- Jake Wilson
- 443746 View
- 988 Score
- 22 Answer
- Tags: c++ virtual-functions
21 Answered Questions
[SOLVED] What is the "-->" operator in C++?
- 2009-10-29 06:57:45
- GManNickG
- 630495 View
- 7853 Score
- 21 Answer
- Tags: c++ operators code-formatting standards-compliance
13 Answered Questions
[SOLVED] What is the effect of extern "C" in C++?
- 2009-06-25 02:10:07
- Litherum
- 577006 View
- 1246 Score
- 13 Answer
- Tags: c++ c linkage name-mangling extern-c
1 Answered Questions
[SOLVED] The Definitive C++ Book Guide and List
33 Answered Questions
[SOLVED] What are the differences between a pointer variable and a reference variable in C++?
21 Answered Questions
[SOLVED] Why is it faster to process a sorted array than an unsorted array?
- 2012-06-27 13:51:36
- GManNickG
- 1240752 View
- 21873 Score
- 21 Answer
- Tags: java c++ performance optimization branch-prediction
6 Answered Questions
[SOLVED] C++11 introduced a standardized memory model. What does it mean? And how is it going to affect C++ programming?
- 2011-06-11 23:30:14
- Nawaz
- 166032 View
- 1577 Score
- 6 Answer
- Tags: c++ multithreading c++11 language-lawyer memory-model
@Yves Daoust 2018-09-14 15:32:33
You can use the following solution to reverse an array in C++:
@Yves Daoust 2018-09-14 15:33:06
Why the downvote ?
@Jean-Baptiste Yunès 2018-09-14 15:35:05
May be lack of explanation? (I'm not the downvoter)
@Jean-Baptiste Yunès 2018-09-14 15:55:46
Worst? No explanation on why OP's code is wrong, and then why yours is correct => downvote
@Abdullrahman Salim 2018-09-14 15:34:23
the problem is that you are not using a buffer to reverse with, so they way it is now is that half of of the reversing loop does what you want and the other half sets everything back. in a way it reverses the reversed array.
as @Jarod42 and @kiran Biradar pointed out that there are better ways of doing this using functions from the standard library, but I assume you want to doing it without the library.
here is a simple fix, replace arr with Copy_arr
@user463035818 2018-09-14 15:43:13
you "fixed" the problem, but you still do twice as much as needed
@Abdullrahman Salim 2018-09-14 15:47:26
How so? in terms of performance?, he made the Copy_arr anyway so it isn't really that big of a deal
@Jarod42 2018-09-14 15:48:49
for (int i = 0; i != size; ++i) { arr[i] = Copy_arr[size - 1 - i]; }would be enough.
@user463035818 2018-09-14 15:49:19
if you dont use
Copy_arrthen half of the loop is sufficient, i'd say this is a clear opportunity for saving some work
@Abdullrahman Salim 2018-09-14 15:49:58
I see, but I wanted him to see the error in HIS code so he can understand it and not give him completely new code
@user463035818 2018-09-14 15:51:31
yeah well not saying that this is not an answer, just that it isnt the best way to do it. Look at Jarods answer, he is using a minor modification of OPs code (even less different from OPs than yours ;)
@Abdullrahman Salim 2018-09-14 15:53:24
Well I changed one variable twice in the whole code (so like 2 words), I wouldn't say I'm that different from OP. but you are right.
@user463035818 2018-09-14 15:54:09
btw "the problem is that you are not using a buffer to reverse with" is something to be really critized, doing something in-place is usually prefered if possible and not "a problem" as you state
@Abdullrahman Salim 2018-09-14 15:58:58
Forgive me for not understanding, but you mean like the way I tried to explain it, or like using the word "problem"?
@user463035818 2018-09-14 16:20:27
yes probably just the wording. I would agree with "The problem is caused by ....", sorry for nitpicking ;)
@Jarod42 2018-09-14 15:09:03
in
You reverse the array twice.
arr[0]and
arr[size - 1]are swapped for
i == 0AND for
i == size - 1.
It should be
Or even simpler
@Slava 2018-09-14 15:23:49
Whole function should be
std::reverse( arr, arr + size );Anyway you should point to multiple memory leaks in the OP program.
@Jarod42 2018-09-14 15:30:12
@Slava: For unrelated errors, I tend to use comments for that, and those comments are already present. | https://tutel.me/c/programming/questions/52334718/reversing+the+array+in+c | CC-MAIN-2018-39 | refinedweb | 1,024 | 60.58 |
Here's a C program to display only the negative elements of the array using for loops and IF conditions.
# include <stdio.h> # include <conio.h> void main() { int a[20], i, n ; clrscr() ; printf("Enter the limit : ") ; scanf("%d", &n) ; printf("\nEnter the elements :\n\n") ; for(i = 0 ; i < n ; i++) scanf("%d", &a[i]) ; printf("\nThe negative elements are :\n\n") ; for(i = 0 ; i < n ; i++) { if(a[i] < 0) printf("%d\t", a[i]) ; } getch() ; }
Output of above program is
Enter the limit : 5
Enter the elements :
10 -20 30 -40 -50
The negative elements are :
-20 -40 -50 negative values in that array. For this we have another for loop which runs from 0 to n - 1 (one less than the limit specified by the user) and using an IF condition we check whether the value inside the array at a particular index is less than 0 i.e. negative and if the IF condition becomes true than we print that value otherwise we continue with next values until the loop is terminated.
Also look at: With little modification we can make this program to check for positive elements of an array. Here, look at this version of above program. Program to Display Positive Elements of the Array.
6. Hi There,
Program to Display Negative Elements of the Array in C | C Programbeing,
Preethi
Greetings Mate,
Brilliant article, glad I slogged through the #topic it seems that a whole lot of the details really come back to from my past project.
why is saying c programming is a based on java?
Very useful article, if I run into challenges along the way, I will share them here.
Obrigado, | http://cprogramming.language-tutorial.com/2012/01/program-to-display-negative-elements-of.html | CC-MAIN-2021-10 | refinedweb | 284 | 55.58 |
I have a complex data structure that I'm trying to process.
Explanation of the data structure: I have a dictionary of classes. The key is a name. The value is a class reference. The class contains two lists of dictionaries.
Here's a simple example of my data structure:
import scipy.stats class employee_salaries(object): def __init__(self,management, players, disparity): self.management = management self.players = players self.disparity = disparity # the coach's salary was 12 his 1st year and 11 his 2nd year mgmt1 = [{'Coach':12, 'Owner':15, 'Team Manager': 13}, {'Coach':11, 'Owner':14, 'Team Manager':15}] plyrs1 = [{'Point Guard': 14, 'Power Forward':16,},{'Point Guard':16, 'Power Forward':18}] NBA = {} mgmt2 = [{'Coach':10, 'Owner':12}, {'Coach':13,'Owner':15}] plyrs2 = [{'Point Guard':17, 'Power Forward':14}, {'Point Guard': 22, 'Power Forward':16}] NBA['cavs'] = employee_salaries(mgmt1,plyrs1,0) NBA['celtics'] = employee_salaries(mgmt2,plyrs2,0)
Let's say I wanted to determine the disparity between the Point Guard's salary and the Owner's salary over these two years.
for key, value in NBA.iteritems(): x1=[]; x2=[] num = len(NBA[key].players) for i in range(0,num): x1.append(NBA[key].players[i]['Point Guard']) x2.append(NBA[key].management[i]['Owner']) tau, p_value = scipy.stats.kendalltau(x1, x2) NBA[key].disparity = tau print NBA['cavs'].disparity
Keep in mind this is not my real data. In my actual data structure, there are over 150 keys. And there are more elements in the list of dictionaries. When I run the code above on my real data, I get a runtime error.
RuntimeError: maximum recursion depth exceeded in cmp error.
How can I change the code above so that it doesn't give me a maximum recursion depth error? I want to do this type of comparison and be able to save the value. | http://www.howtobuildsoftware.com/index.php/how-do/bOx/python-list-dictionary-recursion-python-runtimeerror-maximum-recursion-depth-exceeded-in-cmp | CC-MAIN-2018-05 | refinedweb | 307 | 61.22 |
* Not really everything.
Imports Are Required**
In the AS2 days, you could get around having to write an
import statement by simply using the fully-qualified class name within the class body (such as
flash.display.Sprite as opposed to just
Sprite). While you are welcome to use the fully-qualified class name as you write your code,
import statements for each class are required in AS3.
So there's not a whole lot of need to write fully-qualified class names, unless you happen to use two classes that share the same short name within the same class — perhaps if you are using Flash's
Camera class along with a 3D library's
Camera class.
** Unless the Class is in the Same Package
The exception to the previous rule is if the class you are using and the class you are writing are both in the same package. All classes in a package are implicitly available to each other, without an
import statement.
It's still not a bad idea to write the
import statement anyway, because:
Import Statements Are Self-Documenting Code
By listing all of your imports, you create a sort of manifest of what other classes your class relies on in order to do its job. It may seem like a trivial thing, but this information can actually be quite useful. Consider the following class***:
package com.activetuts { import com.activetuts.SuperTrace; import com.activetuts.ActiveTween; public class QuickTip { public function QuickTip { var tracer:SuperTrace = new SuperTrace(); tracer.log("Quick Tip"); var tween:ActiveTween = new ActiveTween(); tween.go(); } } }
*** Hopefully it's obvious that this class is illustrative, not functional.
If you then use this
QuickTip class, Flash will automatically make sure that the
SuperTrace and
ActiveTween classes are also compiled into the resulting SWF, because you used
QuickTip, and
QuickTip requires these classes.
Simple enough, but now consider more realistic classes which use dozens of other classes. If you need to know which classes are in use, a quick look at the
import section can give you a decent idea. It's not exhaustive, and it's a little misleading even, but you'll be hard-pressed to find someone who thinks that self-documenting code is a bad thing.
flash Classes Need Importing, But Are Not Compiled
There is a common misconception around the idea that using lots of classes necessarily means the file size of your SWF will increase. Normally, that's true. But any class that starts with
flash is one provided by the Flash Player, and will not have any effect on the size of your SWF. The byte code for, say,
Sprite is contained in the Flash Player, and you're simply registering the fact that you will use a Sprite, not bundling that byte code into your SWF. This is kind of the point of having the Flash Player.
I don't expect you to believe me on this. I expect you to be slightly incredulous, and demand proof. I welcome you to prove this to yourself, by following these steps:
- Create a new FLA and associated document class.
In the document class, write the minimum you need to actually define it as a document class:
package { import flash.display.Sprite; public class Document extends Sprite { public function Document() { } } }
- Open up the Publish Settings by pressing Option-Shift-F12 / Alt-Shift-F12 (or by choosing File > Publish Settings...).
- Click on the "Flash" tab.
- In the "Advanced" section, check the "Generate size report" option.
- Also, in the "SWF Settings" section, check the "Export SWC" option, an uncheck the "Include XMP metadata" option (this last option removes a bunch of metadata from the SWF that inflates the size of the SWF and also make a mess of the size report we'll be looking at).
- Press Control/Command-Enter to Test the Movie.
- Press Control/Command-B to open up the Bandwidth Profiler (also available under View > Bandwidth Profiler while viewing the SWF)
- Notice the number of bytes this SWF is (mine is currently 354, your mileage may vary, but it'll be in that ballpark). Be sure to note the bytes, and not the Kilobytes. Remember this number.
- Close the SWF.
Edit your document class to use a bunch of
flashclasses. For example:
package { import flash.display.*; import flash.media.*; import flash.net.*; import flash.text.*; public class Document extends MovieClip { public function Document() { var l:Loader = new Loader(); l.load(new URLRequest("someasset.swf")); var tf:TextField = new TextField(); var format:TextFormat = new TextFormat("Verdana"); format.align = TextFormatAlign.CENTER; tf.defaultTextFormat = format; var v:Video = new Video(); var s:Sound = new Sound(); var channel:SoundChannel = s.play(); } } }
We're using quite a few classes, which themselves incorporate even more classes. All of these classes, though, are
flashclasses.
- Test the Movie again. The Bandwidth Profiler should still be open from last time; if not, open it again.
- Note the size of the SWF: I'm reporting 596 bytes with the above code, an increase of 242 bytes. That's not a lot considering that I'm using
MovieClip(which extends a whole bunch of other classes),
Loader,
URLRequest,
TextField,
TextFormat,
TextFormatAlign,
Video,
Sound, and
SoundChannel. That's a lot of functionality for 242 bytes.
In the Output panel, you'll see something like the following (if you used the above code verbatim, you'll also see sound and load errors, but those aren't important):
flash-test.swf Movie Report ---------------------------- Frame # Frame Bytes Total Bytes Scene ------- ----------- ----------- ----- 1 598 598 Scene 1 (AS 3.0 Classes Export Frame) Scene Shape Bytes Text Bytes ActionScript Bytes ------- ----------- ---------- ------------------ Scene 1 0 0 546 ActionScript Bytes Location ------------------ -------- 546 Scene 1:Frame 1:Document
This test should illustrate that, even though we have used many Flash-provided classes, the resulting size of our SWF is comparatively small. The proof comes with the size report, though, in which we see no entries for any of the built-in classes. We see our
Document class but no other classes, and that one class is responsible for all ActionScript bytes.
If this is not enough proof for you, feel free to expand on the experiment. You could add even more Flash-provided classes, while measuring the increase in the size of the SWF as still be just a matter of bytes. You could incorporate classes of your own, and make sure they appear in the list of classes, and also affect the size of the SWF in a more obvious way. For example, I created this simple
Test class:
package { public class Test { public function Test() { trace("TEST"); } } }
Including this single, 7-line class, which uses no other classes itself, bumped my test SWF to 717 bytes, an increase of 121 bytes. This increase is half of the increase we saw when adding all of those
flash classes; the byte-to-functionality ratio should indicate that the
flash classes are not compiled into your SWF.
Note, too, that you'll see an additional entry in the size report for the extra class; something like this:
flash-test.swf Movie Report ---------------------------- Frame # Frame Bytes Total Bytes Scene ------- ----------- ----------- ----- 1 719 719 Scene 1 (AS 3.0 Classes Export Frame) Scene Shape Bytes Text Bytes ActionScript Bytes ------- ----------- ---------- ------------------ Scene 1 0 0 673 ActionScript Bytes Location ------------------ -------- 179 Scene 1:Frame 1:Test 494 Scene 1:Frame 1:Document
The moral of the story: feel free to use as many
flash classes as you want****. They will not affect the size of your SWF (although the code that uses those classes will, of course)
**** Keep in mind that components and Flex classes are not provided by the Flash Player. These classes appear to be integrated, but if the package does not start with
flash, then it's not provided by the Player.
Wildcard Imports are Not Inefficient
I'm sorry for the double-negative*****, but this is another common misconception that I'd like to clear up.
First, a quick definition. A wildcard import is one that looks like this:
import flash.display.*;
This makes available all classes within the
flash.display package. This is shorthand compared to (for example):
import flash.display.Bitmap; import flash.display.BitmapData; import flash.display.BlendMode; import flash.display.Graphics; import flash.display.Sprite;
Now, the misconception. When I say, "this makes available all classes," I do NOT mean that every class in that package is automatically compiled into your SWF. I mean that any class in that package is available to you in short-name form as you write the class. So in the preceding example, I would be free to write this:
var sp:Sprite = new Sprite; var g:Graphics = sp.graphics; g.beginFill(0); g.drawRect(0, 0, 100, 100); sp.blendMode = BlendMode.MULTIPLY;
That code uses Sprite, Graphics, and BlendMode, all of which are in the flash.display package, and all of which need imported. Either approach has the same result. Feel free to use wild card imports.
Again, a simple experiment for those who require proof. For this experiment, we need non-
flash classes. You will need to have external classes available, either ones you've written, or something like Papervision3D or TweenMax. I won't get into downloading and installing these packages, but for the purposes of my sample code I'll be using a simple package of four classes created for this purpose. You can find them, along with test files, in the download package, in the "wildcard-import" folder. The classes are in the
library package.
- Create a new FLA, and associated document class.
- In your code, import a single class. For example:
import library.One.
- And be sure to use it, such as with
var o:One = new One();
- Test the Movie (press Command-Return / Control-Enter, or go to Control > Test Movie).
- Open the Bandwidth Profiler with the SWF running (press Command-B / Control-B or go to View > Bandwidth Profiler)
- Note the size of the SWF (again, in bytes, not Kilobytes).
- Close the SWF
- Edit your document class so that the import uses a wild card instead. For example:
import library.*;
- Test the Movie again.
- Note the size of the SWF. It should be identical as last time.
- You can also enable the size report (don't forget to turn on the SWC option and turn off the XMP option) to see which classes are getting compiled.
This should indicate that even though it sort of looks like we're importing everything from the package, we're really only compiling the classes we actually use.
***** No, I'm not
An Import Statement Alone Will Not Compile the Class
That is, in this following hypothetical example:
package { import SuperTrace; import ActiveTween; public class QuickTip { public function QuickTip() { } } }
The
SuperTrace and
ActiveTween classes are imported. But they are never used within the class. The Flash compiler is usually smart enough to figure this out, and determine that those two classes need not be compiled for the
QuickTip class.
Of course, if another class does use the
SuperTrace class, then it will be compiled. The point is that the compiler is pretty good at not including unneeded classes in your SWF.
You can prove this by setting up a test similar to the previous tests: compare both the byte size and the size reports of two SWFs that are identical except for the usage of an imported class. You can see such an example by comparing the "import-without-use" and "import-with-use" projects included in the source zip.
If, for some reason, you need to ensure that the
SuperTrace and
ActiveTween classes compile, even if you're not using them in this class, you can force that by simply referencing them in the body of the class. For example:
package com.activetuts { import com.activetuts.SuperTrace; import com.activetuts.ActiveTween; public class QuickTip { public function QuickTip { SuperTrace; ActiveTween; } } }
That's enough to get the compiler to see these as needed classes, even though the lines don't do much when the code is<< | https://code.tutsplus.com/tutorials/everything-you-could-possibly-want-to-know-about-import-statements--active-8118 | CC-MAIN-2021-04 | refinedweb | 2,004 | 63.09 |
Groovy Gains Big Sky Sponsorship and aboutGroovy Portal
- |
-
-
-
-
-
-
Read later
Reading List
"Jochen will be able to focus his efforts exclusively on Groovy development now which will help ensure that Groovy 1.0 is released the end of 2006 and future enhancements in Groovy will be addressed at an accelerated rate", commented Jay Zimmerman, President of Big Sky Technology and creator/director of the No Fluff Just Stuff Java Symposium Series. When asked why Big Sky Technology has stepped up to fund this initiative in the Groovy space, Zimmerman commented: "The NFJS Symposium series has always been a big advocate of the open source community from its inception in 2002. Over the last five years we have seen the pain points in the Java space from our conversations with NFJS attendees which for the most part are corporate developers. With Groovy we have decided to take a more activist role by directly supporting ongoing Groovy development as we see great benefits to the Java development community namely addressing unit testing, streamlining XML usage, better ORM support, and being able to take advantage of Groovy's dynamic language features like closures.
Zimmerman also noted that the NFJS will be offering a full Groovy track at events in 2007.
Also on the Groovy front the portal aboutGroovy.com was announced this month:
aboutGroovy.com -- your source for news about the programming language Groovy. In the days and weeks to come, aboutGroovy.com will bring you the best of news, tutorials, and rich media from across the Internet. Welcome aboard!
aboutGroovy is a partnership between Big Sky Technologies and Scott Davis, Editor and Chief and author of such titles as JBoss at Work and Pragmatic GIS.InfoQ sat down with Zimmerman and Theodorou to discuss the announcements. First Zimmerman was asked why now for a full Groovy track and the support of development:
So many reasons.....Theodorou was then asked what was on his list to improve in Groovy now that it is his full time focus:
One, Groovy 1.0 will be out 1st week of January and ready for prime time use.
Two, Groovy gets rid of a lot of the verbosity found in straight Java code. Scott Hickey said it best, . "
Three, Java developers can become productive in a very short amount of time with Groovy due to the familiar syntax and on a practical level, developers can inject Groovy code into their for applications immediately without having to fight the internal political battle with upper technical management regarding the merits of another language and the accompanying learning curve which goes with it.
Improvement of the documentation - Not all methods are documented and there is a need for writing a document about the internal dos and don'ts, structures and goals, ideas and implementation technics. I started with that a while back ... but it should be more than just a paragraph =).
Make it a real JSR - That means writing a spec and a test test compatibility kit (tck).
Build system - The current build requires maven 1.0.2 (exact version) so we are thinking about migrating to Gant, our upcoming Groovy based build tool.
Performance - 1.0 had many internal changes allowing a better way to improve the performance in following releases. One such improvement is to have new MetaClasses for special types like Maps, Closures, instances of GroovyObject... we will experiment with code generation during runtime here to get performance to the maximum level.
Java5 language support - enums and annotations are high on our list, because more and more tools out there do need them.
Finally, Zimmerman was asked how the AboutGroovy.com portal come into being:
We wanted to see a central place for all Groovy/Grails related content (articles, presentations, interviews, book downloads and Groovy/Grails discussions to occur). In addition, I wanted the portal to be built with Grails to showcase the technology. To accomplish this task, Big Sky Technology partnered with Scott Davis and Davisworld Consulting. Phase 1 is now out and available for use. We have many new features to be added to the site over the next three months, so stay tuned!
Rate this Article
- Editor Review
- Chief Editor Action
Hello stranger!You need to Register an InfoQ account or Login or login to post comments. But there's so much more behind being registered.
Get the most out of the InfoQ experience.
Tell us what you think
Groovy
by
Rick Hightower
After 1.0 is done, please focus on updating the Eclipse plugin. I predict no widespread adoption of Groovy until the IDE support is as good as what we have for Java (where possible). (jroller.com/page/RickHigh?entry=predictions_for...)
See this issue jira.codehaus.org/browse/GROOVY-1422 which still seems to be unresolved.
See what the poster has to to say....
"The lack of code completion in the Groovy source code editor is a huge problem. Not only does it speed up input, but allows one to explore unfamiliar APIs. This last fact alone makes it easier to code in Java, even though the code can never be as terse and and elegant as the equivalent Groovy code. Code completion for Java based libraries alone would be a huge boost in productivity. Completion hints for dynamic Groovy types would be an added bonus."
It seems from the comments that this issue may be fixed, but when I tried it recently... not so much.
Has anyone tried the NetBeans support for Groovy? Is it any good? The Eclipse support is not so great!
This has to be a top priority to support Groovy on the most popular IDE.
Re: Groovy
by
Scott Hickey
ways in the last 9 months. There isn't code completion
for Java classes yet but work is being done there.
There is some basic code completion already there.
Even without that, the plugin is still very usable for
real world project work. My project team has been
using it for about since last May. There is step
debugging available, color syntax highlighting, and
hyperlinks to the Groovy source from the console. It
also supports mixing Grovy and Java source is the same
project (it still requires keeping the build order for
the classes in mind).
The developers on the plugin understand that code
completion and code browsing are the two most
important features for the plugin. They are also the
most complicated.
The code completion in place today will recognize
variables and methods defined in the same groovy
module. In the subversion trunk, there was some recent
work done to add Groovy DGM to the code completion
list.
I have used Eclipse for a large Groovy project and have some experience creating an environment that allows real world work to get
done. Some of it has included using ant from Eclipse
to do things like regression testing and code coverage
with Cobertura.
I have tried NetBeans (last January - March) and didn't have good luck getting the debugging working with Groovy - although I was able to use JSwat (which is now build using NetBeans) with good success.
Re: Groovy
by
Rick Hightower
RE: Even without that, the plugin is still very usable for real world project work.
This is debateable. Yes some people will use Groovy even without good IDE support. I don't debate this. But, (with all due respect) there are people who like to drink their own yellow snow cone. I was talking about widespread adoption of Groovy not edge cases on the fringes of the bell shaped curve or people using it in production. (BTW I am not accusing you of drinking your own piss yellow snow cone it is just an example of a thing that won't be widespread).
I wrote this post because I am one of those people who are waiting for the Groovy plugin to improve. I'd love to start using Groovy, but not without code completion. ;o)
The code completion I am interested in the most is for Java classes so if I import a Java class.
import com.arcmind.utils.MyClass;
I can do this.
myobj = new MyClass();
myobj.|
And get code completion where the | is. This is what I am waiting for....
(Okay... And annotations and enums would be nice too, but the biggest hold up for me is code completion.)
When this comes out.... I will start using Groovy.
IDE Support
by
Matt Giacomini
Thanks to Big Sky!
by
Daniel Serodio
Congrats to Big Sky and Theodorou !
Now only if we could get some sponsoring for the Eclipse plugin... :-)
Re: IDE Support
by
Cyril Gambis | https://www.infoq.com/news/2006/12/groovy-sponsorship | CC-MAIN-2017-34 | refinedweb | 1,433 | 64.41 |
Objective
In this article, we will see how to work with LINQ to SharePoint. I have tried to address all the common errors we encounter when first time we start using LINQ against SharePoint.
We will see ,
1. How to insert an item in SharePoint list using SPLinq
2. How to update an item in SharePoint list using SPLinq
3. How to delete an item in SharePoint list using SPLinq
4. How to fetch items from SharePoint list using SPLinq.
Advantage
1. SPLinq supports visual studio intellisense
2. SPLinq provides strong typecasting and data typing
3. SPLinq works without CAML query.
4. Using SPLinq , existing knowledge of LINQ could be apply to SharePoint development .
5. SPLinq provides completely language dependent development of SharePoint
6. Multiple list item insertion and deletion can be performed very easily with one syntax.
7. Join operation can be performed very easily on the related list
Using CAML when performing operation against SharePoint list was biggest challenge. CAML does not provide developer friendly syntaxes. SPLinq helps us to get rid of CAML.
SPLinq can be used with
1. Managed application , like windows or console or WPF
2. With SharePoint client object models.
3. With SharePoint webparts.
4. With SPGridView.
Challenge
The main challenge working with SPLInq is creation of entity class on command prompt. SPMetal creates a partial Entity class to apply Linq against that.
Assumption,
Step1
Open the command prompt and change directory to
C:\Program Files\Common Files\Microsoft Shared\Web Server Extensions\14\BIN
Type command CD C:\Program Files\Common Files\Microsoft Shared\Web Server Extensions\14\BIN
Step2
This would be the namespace under which class of the list will get created. In my case name of the namespace would be nwind.
3. /code:Product.cs
This is the file name of the generated class. Since we are giving name Product for the file then class generated will be ProductDataContext
Step3
Open visual studio and create a new project of type console. Right click on the Project and select Properties
Click on the Build tab and change Platform Target to Any CPU.
Click on the Application tab and change the Target framework type to .Net Framework 3.5
Step4
The class we created in Step2 will by default get saved in the same folder with SPMetal.exe. So to see where the class got created we need to navigate to folder
C:\Program Files\Common Files\Microsoft Shared\Web Server Extensions\14\BIN
Add.
Step5
Add the namespace
Nwind is the name of the namespace of the class we created in Step2.
Now console application project is ready for the CRUD operation on SharePoint 2010 list using SPLinq
Fetch the items from list using SPLinq
Code for fetching list items
ProductDataContext context = new ProductDataContext("<a href=""></a>"); var result = from r in context.Test1_Product select r; foreach (var r in result) { Console.WriteLine(r.ProductId + ":" + r.ProductName + ":" + r.ProductPrice); } Console.ReadKey(true);
Output
Insert to SharePoint list using SPLinq
1. Create the instance of Data Context
2. Get the entity list where item would get inserted
3. Create instance of List item to be inserted
4. Call the InsertOnsubmit on the instance of Entity list.
5. Call sumitchange on the context
Code for inserting a list item
ProductDataContext context = new ProductDataContext("<a href=""></a>"); EntityList<Test1_ProductItem> products = context.GetList<Test1_ProductItem>("Test1_Product"); Test1_ProductItem itemToInsert = new Test1_ProductItem() { ProductId = "9", ProductName = "Soccer Ball", ProductPrice = 600 }; products.InsertOnSubmit(itemToInsert); context.SubmitChanges();
Update a Particular list item in SharePoint list
1. Create instance of Data Context
2. Fetch the list item to be updated using SPLInq
3. Modify the list item property wished to be updated. I am updating Product name to Dhananjay of Product Id 1
4. Call the submit change on the context
Code for updating a list item
ProductDataContext context = new ProductDataContext("<a href=""></a>"); var itemToUpdate = (from r in context.Test1_Product where r.ProductId == "1" select r).First(); itemToUpdate.ProductName = "Dhananjay"; context.SubmitChanges();
Delete a Particular item from the list
1. Create the instance of Data Context
2. Get the entity list where item would get inserted
3. Fetch the list item to be deleted using SPLInq
4. Call deleteonsubmit to delete a particular item from SharePoint list
5. Call the submit change on the context
Code for deleting a list item
ProductDataContext context = new ProductDataContext("<a href=""></a>"); EntityList<Test1_ProductItem> products = context.GetList<Test1_ProductItem>("Test1_Product"); var itemToDelete = (from r in context.Test1_Product where r.ProductId == "1" select r).First(); products.DeleteOnSubmit(itemToDelete); context.SubmitChanges(); | https://debugmode.net/2010/11/10/linq-to-sharepoint-crud-operation-on-sharepoint-2010-list-using-splinq/ | CC-MAIN-2022-40 | refinedweb | 753 | 59.6 |
CGLCreateContext()
Can share be the context we are creating? Should it be? Why do we need to share name space with a context?
Quote:CGLError CGLCreateContext(CGLPixelFormatObj pix, CGLContextObj share, CGLContextObj *ctx);
If not NULL, the context with which to share display lists and an OpenGL texture name space.
Can share be the context we are creating? Should it be? Why do we need to share name space with a context?
You would never pass the context you're currently creating, it has to be another context. If you wanted your new context to share textures and display lists with a context you have already created, you would pass the other context's address in the 'share' parameter.
The best example for this, I think, is to have a fullScreen context and a windowed conext with a shared namespace. You can then switch back and forth from fullscreen to windowed mode easily that way, without having to reload anything.
HTH
HTH | http://idevgames.com/forums/thread-6604-post-13091.html | CC-MAIN-2013-20 | refinedweb | 161 | 73.88 |
why does the same request keep hitting my server even though I didn't call the endpoint
I have a question to something I tried to resolve but it seems to keep happening. I have a simple server endpoint
/example and I call that endpoint from a curl
123.45.678.901/example and the server runs a function and returns something to me and then I
res.end(), but I noticed that after a while the endpoint is hit again even though I didn't call it and I can see on the terminal where the server is open one of my console.logs appears. This is the code
const express = require ("express"); const app = express(); const port = 80; //middleware function const authenticateUser = (req,res,next) => { console.log("header w/ access_token sent in:", req.header("token")) request.get({ url: [url here were I authenticate the token they sent me] }, function optionalCallback(err, httpResponse, body){ if (err) { res.send("Authentication failed, please check your access_token"); res.end(); } console.log("Authentication has been cleared"); next() }) } //here I tell express to use my middleware always app.use(authenticateUser); app.get("/example", (req,res) =>{ console.log("in /example endpoint"); (some function being called here that returns something to the client) res.end(); }) app.listen(port, () => console.log(`App is listening on port ${port}`));
this is what I see when the ghost call is made to the server, I know I didn't call the endpoint because if I had the
undefined I see there would show a token I pass in through Headers in the cURL:.
- Purpose of a SSL/TLS certificate
I have been reading about ssl/tls and certificates recently to enable https for one of our websites.
As far as my current understanding goes, a ssl/tls certificate verifies that we as client are connected to the correct site or not. For that the signature inside of the certificate is used to verify whether the certificate is legitimate or not. And finally to establish a secure connection algorithms like ECDHE (Elliptic curve Diffie–Hellman) are used.
My question is if I want to connect to a website say, "" and I key in "" into my browser address bar, I am guaranteed that I will be connected to the correct website. So what is the purpose of having a SSL/TLS certificate installed on a web server when I know that I am keying in the proper address.
Am I missing something in my understanding of how https works?
Also ECDHE algorithm does not rely on any information like public key from the certificate to establish a secure connection.
- Spring Boot Application with HTTPS on AWS Fargate
I have a Spring Boot Application running on AWS Fargate in a ECS Cluster + ALB on the following flow:
ALB (443/HTTPS) -> Spring Boot Application (8080:HTTP)
So, I want to enable HTTP/2 in my application, but to do this, I need my application to run on HTTPS (TLS/SSL).
How can I configure a certificate on AWS Fargate, once my domain is attached in ALB and not directly on my task/container?
- Angular 2+ local proxy doesn't cache images
There is angular application launched with "ng serve --ssl=true --port 3000 --proxy-config proxy.conf.json". And proxy.conf.json:
{ "/app/img/*": { "target": "", "secure": false, "changeOrigin": true } }
When get icon directly from browser: <img [src]="''"> it's cached and in chrome network I see 'Served from disc cache'. Request from chrome network:
Response Headers: HTTP/1.1 200 OK Accept-Ranges: bytes Content-Type: image/png Date: Thu, 02 Jul 2020 12:28:09 GMT Last-Modified: Thu, 02 Jul 2020 02:46:08 GMT Server: Apache/2.4 Content-Length: 2775 Connection: keep-alive Request Headers: GET /app/img/some-icon.png HTTP/1.1 Host: some.url
but when call through the proxy: <img [src]="'/app/img/some-icon.png'"> it doesn't.
Response Headers: HTTP/1.1 200 OK X-Powered-By: Express Access-Control-Allow-Origin: * accept-ranges: bytes content-type: image/png date: Thu, 02 Jul 2020 12:33:07 GMT last-modified: Thu, 02 Jul 2020 02:46:08 GMT server: Apache/2.4 content-length: 2775 connection: Close Request Headers: GET /app/img/some-icon.png HTTP/1.1 Host: localhost:3000
Why it cached at all in first case, if there are no any cache related headers? Why it is not cached with proxy?
- Setting up litecoin server
I have set up a litecoin server and wanted to connect to node on my network. However i am not able to do this. When i query the server about the number of block it returns 0. How should litecoin.conf file look like? I saw few example files on github but it didn't help me. I also want to connect to this server through my electrum wallet.
My current litecoin.conf file:
addnode=12.3.45.67:1234 connect=12.3.45.67:1234 rpcuser=user rpcpassword=password rpcallowip=ip_of_machine_with_electrum_wallet(?) txindex=1 paytxfee=0.00500000 blocknotify=/home/user/.litecoin/block.sh %s server=1
the node data:
host=12.3.45.67 rpcport=1234 rpcuser=user rpcpassword=password
thanks in advance for any help
- How can I set `Content-Disposition : attachment` header in azure blob storage?
I want this header to be there on every file served from azure blob storage. Their documentation says it can be set, but they dont explain how. Even the support engineers at Microsoft are not aware of this. Can someone help me this. Screenshots would be great .
I am using paperclip gem to handle the file creation with azure-sdk
- Referencing A C sharp file in a Node Server.js project
I am beginning node.js development using Visual Studio Community 2019.
I currently have a server.js file with the following code:
var http = require('http'); http.createServer(function (req, res) { res.writeHead(200, {'Content-Type': 'text/plain'}); res.end('Hello World from Port: ' + res.connection.localPort); }).listen(1337);
I also have a C sharp Class like so:
public class Class1 { public Class1() { string mystr = "Text to be displayed"; } }
How can I reference mystr into the server file so that I can use the variable, e.g display it on the page.
- Laravel: Load an API Resource key only if the given resource instance is the top level
I have a Term model who has a "parent" relationship that points to another term in the
termstable. I load these relationships recursively, and return a
Termresource. The resource references the taxonomy the term is related to.
class Term extends JsonResource { public function toArray($request) { return [ 'parent' => $this->whenLoaded('parent', function() { return Term::make($this->parent); }, $this-parent_id), 'taxonomy' => $this->whenLoaded('taxonomy', function() { return Taxonomy::make($this->taxonomy); }, $this->taxonomy_id); ]; } }
The issue is that the
taxonomykey appears on every parent term all the way up the tree:
{ "id": 48, "name": "Freestone Hills", "slug": "freestone-hills", "parent": { "id": 47, "name": "Sanoma Coast", "slug": "sanoma-coast", "parent": { "id": 47, "name": "California", "slug": "california", "taxonomy": 8 // or here }, "taxonomy": 8 // but not here }, "taxonomy": 8 // I want this here }
All parent terms will always belong to the same taxonomy so it's pointless to include the key anywhere except the root element.
Is there any way to say "only show this key if we are at the top level"? I'd rather not duplicate the information for the taxonomy, especially when there's an entire object for the taxonomy when I actually do load in that relationship.
- Downloading API xlsx response in Jenkins Job
I have a jenkins job that sends a POST request to an API. This API sends back a response that is an excel file. How do I download this response as an artifact in Jenkins ?
- Status code 304 brakes the site on hard refresh with ctrl + f5 on laravel 7
I am using the middleware for caching everything in my app with Php redis.
The problem is with the status code on the cache and some headers. When I check the site with cached files all works as expected, I have tried moving from page to page and using
F5key to refresh pages. All worked to the point where I try to use
Ctrl + F5then I get an error 500.
If I change the status 304 to 200 in the following line
$response = response($cache['content'], 304);then everything works fine again.
Also, the application caches everything in the client browser too.
Here is my middleware code:
<?php namespace App\Http\Middleware; use Cache; use Closure; use RedisManager; class CacheResponse { /** * Handle an incoming request. * * @param \Illuminate\Http\Request $request * @param \Closure $next * @return mixed */ public function handle($request, Closure $next, $ttl=1440) { if(auth()->user() != null || $request->isMethod('post')) { return $next($request); } $params = $request->query(); unset($params['_method']); ksort($params); $key = md5(url()->current()); if(Cache::has($key)){ $cache = Cache::get($key); $response = response($cache['content'], 304); $response->header('Last-Modified', $cache['last_modified']); $response->header('X-Proxy-Cache', 'HIT'); } else { $response = $next($request); if(!empty($response->content())) Cache::put($key,['last_modified' => $response->headers->get('last-modified'), 'content' => $response->content()],$ttl); $response->header('Last-Modified', $response->headers->get('last-modified')); $response->header('X-Proxy-Cache', 'MISS'); } return $response; } }
Any ideas about what could be wrong with all this?
My App is on laravel 7 | https://quabr.com/58848086/why-does-the-same-request-keep-hitting-my-server-even-though-i-didnt-call-the-e | CC-MAIN-2020-29 | refinedweb | 1,555 | 55.34 |
CherryPy is a minimalistic, pythonic and object oriented web framework.
Web Frameworks normally allow developers to develop web applications without getting their hands dirty with low level details such as HTTP protocols and threading concepts.
CherryPy is a battle-tested framework that has existed in the industry for more than a decade.
However, it’s very modern and allows us build applications the way you would build any Object Oriented application in Python.
This makes it very attractive especially for those people coming from system or more general-purpose languages like C++, Java and Python.
The code written in CherryPy is one of the cleanest and attractive you’ll ever see. Python is always a language considered to be for artists due to its beauty, and certainly CherryPy more than fits that profile.
CherryPy is considered minimalistic in that it wraps the HTTP protocol and does not otherwise offer much more than what is defined in the RFC 7231. However, this makes it very extensible and also easy to grasp. Extensible can be done via packages.
We are Building a Vibrant YouTube Community
We have a fast rising YouTube Channel of friends. So far we’ve accumulated almost 3 million agreggate views and more than 10,000 subscribers as of the time of writing this. Here’s the Channel: ProgrammingWizards TV.
Please go ahead subscribe(free obviously) as well. If you have a question or a comment you can post there instead of in this site.People are suggesting us tutorials to do there so you can too.
Features
- CherryPy allows us write web applications in Object Oriented manner.
- CherryPy includes a reliable HTTP/1.1 compliant, WSGI thread-pooled web server. This makes it a viable production ready web server just like it is a web framework.
By being HTTP/1.1 compliant, this makes cherryPy take advantage of latest features HTTP features that allow construction of practical information systems.
HTTP as you know stands for HyperText Transfer Protocol, and is an application-level protocol for distributed, collaborative and hypermedia information systems.
HTTP has been powering the web for almost 3 decades since the inception of World Wide Web by Sir Tim Berners Lee.
- Thirdly CherryPy is easy to run on multiple HTTP servers via different ports at once.
- CherryPy is enhanced with powerful built-in tools for caching, data encoding,sessions, authentication, static content etcetra.
- CherryPy can run on Python 2.7+,3.1+, PyPy, Jython and even Android via the SL4A.
- CherryPy is open source and is distributed under the BSD license.
CherryPy website is here.
Object Relational Mappers
The following are some of the Object Relational Mappers that can be used with CherryPy.
- SQLAchemy – an ORM for python applications.
- SQLObject – an ORM that provides an object interface to a database.
- Storm – the ORM made by Canonical Ltd, who are makers of Ubuntu.
Templating Languages
The following are some of the templating languages that can be used with CherryPy:
- Jinja – General purpose tempating language.
- Mako – Template language written in Python.
- Cheetah – Open source template engine.
- CherryTemplate – a templating language for CherryPy.
- Genshi – XML templating language.
Hello World
Here’s a simple Hello World in CherryPy.
import cherrypy class MrHello(object): def index(self): return "Mr Hello says: `Hello World!`" index.exposed = True cherrypy.quickstart(MrHello())
This will start the CherryPy server at a port probably
8080e.g
ENGINE Serving on
Pount that URL browser and you’ll see a message like this:
RESULT
Mr Hello says: `Hello World!`
Best Regards. | https://camposha.info/cherrypy-introduction/ | CC-MAIN-2020-16 | refinedweb | 583 | 58.69 |
You can subscribe to this list here.
Showing
1
results of 1
The branch "master" has been updated in SBCL:
via 0cd4731bb43b3f79d33e85300407031f808763f0 (commit)
from ba008a77f32b2ef30e8492757afb8b54731c76cf (commit)
- Log -----------------------------------------------------------------
commit 0cd4731bb43b3f79d33e85300407031f808763f0
Author: Alastair Bridgewater <nyef@...>
Date: Mon Dec 30 17:37:04 2013 -0500.
---
NEWS | 4 ++++
src/runtime/gencgc.c | 13 ++++++++++++-
2 files changed, 16 insertions(+), 1 deletions(-)
diff --git a/NEWS b/NEWS
index 75355ee..5977d64 100644
--- a/NEWS
+++ b/NEWS
@@ -14,6 +14,10 @@ changes relative to sbcl-1.1.14:
* enhancement: sb-ext:save-lisp-and-die on Windows now accepts
:application-type argument, which can be :console or :gui. :gui allows
having GUI applications without an automatically appearing console window.
+ * enhancement: reduced conservativism on GENCGC platforms:
+ conservative roots that point to unboxed pages must be tagged
+ pointers to the start of a valid-looking object, not merely point
+ to within the allocated part of the page, in order to pin the page.
* bug fix: Windows applications without the console window no longer misbehave.
(patch by Wilfredo Velazquez, lp#1256034).
* bug fix: modular arithmetic optimizations do not stumble on dead branches
diff --git a/src/runtime/gencgc.c b/src/runtime/gencgc.c
index 5d218b1..77ec797 100644
--- a/src/runtime/gencgc.c
+++ b/src/runtime/gencgc.c
@@ -201,7 +201,18 @@ static inline boolean page_boxed_p(page_index_t page) {
}
static inline boolean code_page_p(page_index_t page) {
- return (page_table[page].allocated & CODE_PAGE_FLAG);
+ /* This is used by the conservative pinning logic to determine if
+ * a page can contain code objects. Ideally, we'd be able to
+ * check the page allocation flag to see if it is CODE_PAGE_FLAG,
+ * but this turns out not to be reliable (in fact, badly
+ * unreliable) at the moment. On the upside, all code objects are
+ * boxed objects, so we can simply re-use the boxed_page_p() logic
+ * for a tighter result than merely "is this page allocated". */
+#if 0
+ return (page_table[page].allocated & CODE_PAGE_FLAG) == CODE_PAGE_FLAG;
+#else
+ return page_boxed_p(page);
+#endif
}
static inline boolean page_boxed_no_region_p(page_index_t page) {
-----------------------------------------------------------------------
hooks/post-receive
--
SBCL | http://sourceforge.net/p/sbcl/mailman/sbcl-commits/?viewmonth=201312&viewday=30&style=flat | CC-MAIN-2014-52 | refinedweb | 329 | 57.47 |
Sets a trap within a guest.
#include <zircon/syscalls.h> zx_status_t zx_guest_set_trap(zx_handle_t handle, uint32_t kind, zx_vaddr_t addr, size_t size, zx_handle_t port_handle, uint64_t key);
zx_guest_set_trap() sets a trap within a guest, which generates a packet when there is an access by a VCPU within the address range defined by addr and size, within the address space defined by kind.
kind may be either ZX_GUEST_TRAP_BELL, ZX_GUEST_TRAP_MEM, or ZX_GUEST_TRAP_IO. If ZX_GUEST_TRAP_BELL or ZX_GUEST_TRAP_MEM is specified, then addr and size must both be page-aligned. ZX_GUEST_TRAP_BELL is an asynchronous trap, and both ZX_GUEST_TRAP_MEM and ZX_GUEST_TRAP_IO are synchronous traps.
Packets for synchronous traps will be delivered through
zx_vcpu_resume() and packets for asynchronous traps will be delivered through port_handle.
port_handle must be ZX_HANDLE_INVALID for synchronous traps. For asynchronous traps port_handle must be valid and a packet for the trap will be delivered through port_handle each time the trap is triggered. A fixed number of packets are pre-allocated per trap. If all the packets are exhausted, execution of the VCPU that caused the trap will be paused. When at least one packet is dequeued, execution of the VCPU will resume. To dequeue a packet from port_handle, use
zx_port_wait(). Multiple threads may use
zx_port_wait() to dequeue packets, enabling the use of a thread pool to handle traps.
key is used to set the key field within
zx_port_packet_t, and can be used to distinguish between packets for different traps.
ZX_GUEST_TRAP_BELL is a type of trap that defines a door-bell. If there is an access to the memory region specified by the trap, then a packet is generated that does not fetch the instruction associated with the access. The packet will then be delivered asynchronously via port_handle.
To identify what kind of trap generated a packet, use ZX_PKT_TYPE_GUEST_MEM, ZX_PKT_TYPE_GUEST_IO, ZX_PKT_TYPE_GUEST_BELL, and ZX_PKT_TYPE_GUEST_VCPU. ZX_PKT_TYPE_GUEST_VCPU is a special packet, not caused by a trap, that indicates that the guest requested to start an additional VCPU.
handle must be of type ZX_OBJ_TYPE_GUEST and have ZX_RIGHT_WRITE.
port_handle must be of type ZX_OBJ_TYPE_PORT and have ZX_RIGHT_WRITE.
zx_guest_set_trap() returns ZX_OK on success. On failure, an error value is returned.
ZX_ERR_ACCESS_DENIED handle or port_handle do not have the ZX_RIGHT_WRITE right.
ZX_ERR_ALREADY_EXISTS A trap with the same kind and addr already exists.
ZX_ERR_BAD_HANDLE handle or port_handle are invalid handles.
ZX_ERR_INVALID_ARGS kind is not a valid address space, addr or size do not meet the requirements of kind, size is 0, or ZX_GUEST_TRAP_MEM was specified with a port_handle.
ZX_ERR_NO_MEMORY Failure due to lack of memory. There is no good way for userspace to handle this (unlikely) error. In a future build this error will no longer occur.
ZX_ERR_OUT_OF_RANGE The region specified by addr and size is outside of of the valid bounds of the address space kind.
ZX_ERR_WRONG_TYPE handle is not a handle to a guest, or port_handle is not a handle to a port.
ZX_GUEST_TRAP_BELL shares the same address space as ZX_GUEST_TRAP_MEM.
On x86-64, if kind is ZX_GUEST_TRAP_BELL or ZX_GUEST_TRAP_MEM and addr is the address of the local APIC, then size must be equivalent to the size of a page. This is due to a special page being mapped when a trap is requested at the address of the local APIC. This allows us to take advantage of hardware acceleration when available.
zx_guest_create()
zx_port_create()
zx_port_wait()
zx_vcpu_create()
zx_vcpu_interrupt()
zx_vcpu_read_state()
zx_vcpu_resume()
zx_vcpu_write_state() | https://fuchsia.googlesource.com/fuchsia/+/refs/heads/main/docs/reference/syscalls/guest_set_trap.md | CC-MAIN-2021-31 | refinedweb | 546 | 65.12 |
enterprise Java applications. loading discovery mechanism (that causes loading issues), using
static wiring (see the SLF4J site for more info). To use slf4j, make sure
you use:
slf4j-api-XXX.jar,
jcl104-overslf4j-XXX.jar
and
slf4j-log4j-XXX.jar (where XXX stands for the slf4j version).
The last jar provides the static wiring between slf4j and log4j - if another implementation
is desired (such as jdk14), then a different jar is required (for the jdk14 that would be
slf4j-jdk14-XXX.jar) - see the official SLF4J site for more information. uses the SpringSource Enterprise Bundle Repository for its dependencies, which you might find useful. Additionally, for artifacts that have not yet made it into SpringSource Repository, Spring DM provides a small, temporary (Amazon S3) Maven repository (link | browser-friendly link) for its internal usage..
Remove the official OSGi jars (osgi.jar or osgi-r4-core.jar) from the classpath and use only the actual OSGi platform (Equinox/Knopflerfish/Felix) jars. The former provides only the public classes without an actual implementation and thus cannot be used during runtime, only during the compilation stage..
Eclipse PDE uses Equinox OSGi platform underneath which (like other OSGi platforms) caches the bundles between re-runs. When
the cache is not properly updated, one can encounter strange behaviour (such as the new services/code being picked up)
or errors ranging from class versioning to linkage. Consider doing a complete clean build or, in case of Eclipse,
creating a new workspace or deleting the bundle folder (depends on each project settings but most users should find it at:
[workspace_dir]\.metadata\.plugins\org.eclipse.pde.core\OSGi\org.eclipse.osgi\bundles).
In Spring DM 1.1 M2, the proxy infrastructure has been refined to avoid type leaks, the usage of dynamic imports or exposure of class loader chain delegation. If you encounter class visibility problems during the upgrade then it's likely you have missing imports which were previously resolved as a side effect of Spring DM proxy weaving process.
To deal with dynamics, Spring DM creates proxies around the imported services. The proxies are classes (generated at runtime), different
from the target but able to intercept the calls made to it. Since a proxy is different then its target, comparing objects against it can
yield different results then when the comparison is done against the target. In most scenarios this is not a problem but there might be
corner cases where this contract matters. Since 1.1, Spring DM importer proxies implement
InfrastructureProxy
interface (from Spring framework) which allow access to the raw target.
Make sure the Spring DM collections are injected into object of compatible types (for example
list into
java.util.List or
java.util.Collection). If the types are not compatible,
the container will have to perform
type conversion,
transforming the Spring DM managed collection into a 'normal' one, unaware of the OSGi dynamics.
Since Spring 2.5.6, the symbolic names of the artifacts have changed slightly. Spring DM aligned its symbolic names as well with the
new patter since 1.2.0 M2.).
To fix this problem, change the reference to the old symbolic name (usually inside the fragments manifests or LDAP filters) to the new one.
Since 2.3.0, Knopflerfish changed the way it does bootpath delegation which causes classes to be loaded from inside and outside OSGi. Set
the system property
org.knopflerfish.framework.strictbootclassloading to
true before starting up the Knopflerfish
platform to prevent this from happening. See Knopflerfish 2.3.x release notes for more information. | https://docs.spring.io/osgi/docs/current/reference/html/spring-osgi-faq.html | CC-MAIN-2017-43 | refinedweb | 590 | 56.25 |
table of contents
NAME¶
getgrouplist - get list of groups to which a user belongs
SYNOPSIS¶
#include <grp.h>
int getgrouplist(const char *user, gid_t
group,
gid_t *groups, int *ngroups);
getgrouplist():
Since glibc 2.19:
_DEFAULT_SOURCE
Glibc 2.19 and earlier:
_BSD_SOURCE
DESCRIPTION¶¶¶
This function is present since glibc 2.2.4.
ATTRIBUTES¶
For an explanation of the terms used in this section, see attributes(7).
CONFORMING TO¶
This function is nonstandard; it appears on most BSDs.
BUGS¶
In glibc versions before 2.3.3, the implementation of this function contains a buffer-overrun bug: it returns the complete list of groups for user in the array groups, even when the number of groups exceeds *ngroups.
EXAMPLES¶
The program below displays the group list for the user named in its first command-line argument. The second command-line argument specifies¶
#include <stdio.h> #include <stdlib.h> #include <grp.h> #include <pwd.h> int main(int argc, char *argv[]) {
int ngroups;
struct passwd *pw;
struct group *gr;
if (argc != 3) {
fprintf(stderr, "Usage: %s <user> <ngroups>\n", argv[0]);
exit(EXIT_FAILURE);
}
ngroups = atoi(argv[2]);
gid_t *groups = malloc(sizeof(*groups) * ngroups); (int j = 0; j < ngroups; j++) {
printf("%d", groups[j]);
gr = getgrgid(groups[j]);
if (gr != NULL)
printf(" (%s)", gr->gr_name);
printf("\n");
}
exit(EXIT_SUCCESS); }
SEE ALSO¶
getgroups(2), setgroups(2), getgrent(3), group_member(3), group(5), passwd(5)
COLOPHON¶
This page is part of release 5.10 of the Linux man-pages project. A description of the project, information about reporting bugs, and the latest version of this page, can be found at. | https://manpages.debian.org/testing/manpages-dev/getgrouplist.3.en.html | CC-MAIN-2021-49 | refinedweb | 263 | 58.89 |
0
(Before I ask my question, I have tried looking through google and the site already, and didn't find anything relevant to what my problem was. All I was finding was more complex than my current level.)
Anyway, my problem is that I'm getting an "expression must have (pointer-to-) function type error" in my code. I'm confused because I have never seen this type of error before.
Here's what I have so far. (I have pointed out where I have the error in the code.)
#include <iostream> #include <string> #include <iomanip> #include <fstream> #include <cmath> using namespace std; const int MONTHS_PER_YEAR = 12; // Hard coding Number of Months in a Year void PrintGreeting(); // Function Prototype for PrintGreeting() int main () { float purchasePrice; // Declaring Purchase Price float amountDown; // Declaring Amount Down float annualInterestRate; // Declaring Annual Interest Rate int years; // Declaring Number of Years ifstream din; // Declaring Input File Variable ofstream dout; // Declaring Output File Variable float monthlyInterest; // Declaring Monthly Interest float monthlyPayment; // Declaring Monthly Payment PrintGreeting(); // Calls PrintGreeting din.open("vette.in"); // finding vette.in dout.open("vette.out"); // creating vette.out din >> purchasePrice >> amountDown >> annualInterestRate >> years; // inputting the values from an input file monthlyInterest = annualInterestRate / MONTHS_PER_YEAR; // finding the Monthly Interest monthlyPayment = monthlyInterest(purchasePrice - amountDown); // attempting to find the first part of the equation to find the Monthly Payment. This is the part of the code where I'm getting the error. return 0; } // ======================================================================= void PrintGreeting () { /* Purpose: Prints a nicely formatted greeting to the screen. Pre: None. Post: Greeting has been printed to the screen. */ cout << "\n\n\n\n\n"; cout << "Welcome to the EZ Speeeder \n"; cout << "This program is a Monthly Payment Calculator. \n"; cout << "Fall 2012 - Programmed by Zachary Daniels. \n"; cout << "\n\n\n\n\n"; }
The values from the input file are as follows:
The Purchase Price is 105670.00
The Amount Down is 12345
The Annual Interest Rate is 5.7
And the Number of Years is 4.
Can anybody help me figure out why it's giving me this error? | https://www.daniweb.com/programming/software-development/threads/438333/expression-must-have-pointer-to-function-type | CC-MAIN-2018-43 | refinedweb | 340 | 54.73 |
i have a given picture and have to create a picture that is twice as wide as the given picture. For each pixel (x, y) in the original picture, the pixels (2 * x, y) and (2 * x + 1, y) in the new picture should be set to the same color as it.
i am not allowed to use any other module( like PIL)
so i have to create a picture that is twice width
plz help me out here
here is what i have so far
import media
def widen(new_pic):
height = media.get_height(pic)
width = media.get_width(pic)
new_pic = media.create_picture( width * 2, height)
new_height = media.get_height(new_pic)
new_width = media.get_width(new_pic)
for y in range(0, new_height):
for x in range(0, new_width):
from_p = media.get_pixels(pic)
to_p = media.get_pixels(new_pic, 2 * x + 1, y)
media.set_color(to_p, media.get_color(from_p))
return new_pic
im not sure that i have used range function right but i dont really know how to use pixel pix to make same color | https://www.daniweb.com/programming/software-development/threads/410516/new-to-python-help-with-image | CC-MAIN-2016-50 | refinedweb | 169 | 74.69 |
OOPhoto - Embrace Failure Or Optimize My Domain?
The latest OOPhoto application can be experienced here.
The latest OOPhoto code can be seen here.
After putting some code and a lot of thought out there about OOPhoto, my latest attempt at learning object oriented programming in ColdFusion, it seems that I have reached a bit of a cross roads. Do I push forward with the intent to learn strict object oriented principles? Or, do I accept the fact that ColdFusion is not the best language for pure object orientation and put CF-optimized code in place?
If I decide to try using more pure object oriented principles such as using collections of objects over queries and favoring composed objects over foreign keys, I know that my solution will not be scalable; ColdFusion simply is not there yet in terms of object instantiation speed. However, going down that road may have several benefits. For starters, I strongly feel that understanding the core principles of solution is good. Once we understand the way something works we can see how to optimize it to fit our needs. Also, if I know that this path will eventually fail, it will help free my mind from the fear of failure and perhaps allow me to make mental leaps that I would not have been able to make previously.
On the other hand, if I know that pure object orientation is a path to failure, should I just skip that and move straight into ColdFusion-optimized object orientation? After all, that's where I'm going to end up eventually. Does it seems silly to invest time learning principles that cannot be directly applied to my domain.
This is a tough decision to make and, I think it forces the even more important question:
Is the ultimate goal here to learn object oriented programming? Or is it to learn how to build the best ColdFusion applications that I can?
No doubt, when I kicked off this series, learning Object Oriented Programming, or OOP, was my primary goal; however, it was my primary goal because I believed that it would allow me to write better code. So really, although my superficial goal was learning OOP, my underlying goal was learning how to build better ColdFusion applications.
Now that I more clearly see my true goal, it seems obvious that the best choice is to move forward with ColdFusion-optimized object orientation. I will put aside my dreams of learning pure OOP and embrace the fact that better applications can be written using an object oriented "influence."
Perhaps you should move forward with the project using another language.
@Christopher,
I think that would add way more overhead to the project than would be worth it. I don't much feel like learning a whole other language just learn more about object orientation. project is to write the best CF code, then probably you should optimize. But if the goal is to /learn/ to write better CF code, then you should continue on the OO path.
Do you *know* your OO solution won't be scalable? And even if you know it as fact, can you write it out anyway and then try to find another OO solution that *will be* scalable?
If we all keep refusing to use all the objects we want we're going to be like the angry monkeys:
A few monkeys were put in a room with a stepladder and a banana that could only be reached if the monkeys used the stepladder. However, when a monkey would climb upon the stepladder, all the monkeys would be doused with water. Then new monkeys were introduced and when they tried to use the stepladder, the other monkeys would get angry and beat him up. Eventually, the room contained none who had been doused with water, but the monkeys who had been beat up for using the stepladder were still refusing to allow new monkeys to get the banana.
We'll all be refusing to write better code even if CF is capable and we'll never know why - it's some throwback to an ancient tradition.
@Sammy,
Hmm. I have to be honest that I am really torn on this. Part of me really wants to heed your advice and move forward with more of a pure OOP stand point. After all, I have never done that and it would be nice to try it. If nothing else, I really like the idea of feeling the "pain points" of a solution before I realize why other solutions are better.
I suppose the decision has not been made yet....
Part of me really wants to be the monkey that gets that dang banana!
The punishment should fit the crime.
Often, when we complain about the performance penalties of writing pure OO in ColdFusion, we talk about scalability issues and with overhead.
Honestly, and no offense intended, your photo viewer application will NEVER run into scalability problems. You aren't trying to supplant Flickr, right?
You wanted a simple application that you could practice OO on. By and large, instances of this application won't see any heavy load. Optimization for milliseconds really doesn't seem like the end goal here.
So go for the pure OO app. Along the way, you'll learn a lot about what works and what doesn't work. You'll get to try certain techniques that will be awesome and some that will be pure crap. Regardless of how it turns out, you probably won't miss the wasted milliseconds....
Dan Wilson
Ben, be careful with this slippery slope:
"my underlying goal was learning how to build better ColdFusion applications."
You're implying that pure OO code yields "better CF applications" which is not necessarily true. Use the right hammer for the job.
Also, I think it is a bad idea to go forward with pure OO knowing it is the wrong path. Pretty is, is pretty does, and if there is a better way to skin the cat that will yield better results, that should always take precedence in my mind.
Maybe I missed the part where you defined what "better" means. This whole thing, although well intentioned, is going to be difficult for you. Here is why:
1. You are working alone. Imagine doing the same project, but with a team of 50 spread around the world. You don't know the names of these people much less how their code works. Now think about development maintenance of the project. You HAVE to have things loosely coupled. You need to be able to upgrade components and not worry about the rest of the app falling apart. You need to be able to have TESTS for your objects that don't depend on other objects. OOP in general helps for different parts of the application not have to worry about other parts.
2. Your project isn't that big. Imagine a project that IS flickr. It needs MASSIVE scalability. Not you need to optimize six ways from Sunday. OOP helps you compartmentalize your thinking. Maybe one process needs to be put on a different server or cluster. Maybe you need priority queuing. Think of all the hassles of massive scalability. OOP helps you by making objects more portable and making code more separable.
3. You weren't raised on OOP. Ask someone with a one handed tennis backhand to use two. Or vice versa. It's just not how they were taught. They will resist you. Every post in this series, you can see the same theme, "I am trying this stupid two handed backhand but it's stupid and wrong and I should just give up and do my one handed. I hit better that way anyway. Is the point to learn two handed backhand or to play better tennis?"
Here is my advice.
1. Decide if you will ever work on a team of more than 15 people. If not, I wouldn't worry about it so much. Treat this like a fun exploration and NOT something so serious.
2. Stop worrying about it. Learning is good for learning sake. Maybe this series helps Adobe to build particular improvements. Document your findings, but stop fretting. It is not unlike your "women" whining. ;)
Ok, with that said, it has been fun watching you publicly struggle. I bet alot of people benefit from knowing that even a strong programmer like you struggles too.
This is such a small project really, why not go for the pure OO, then optimize. Doing both would yield maximum benefit. could write something that runs faster using what I already know. But it is becoming much easier for me to optimize and maintain the pieces of the project now.
Struggling through the challenges and failures seems worth it to me.
@All,
Your points are well taken. I will move forward with the pure OOP style (or at least as pure as I can figure out). Something in my gut tells me that this is the best learning experience even if I assume that something like the IBO patterns will eventually be a hugely useful tool.
Plus, with a pure OO model, I think I need less "tricks" to get things to work. We'll see.
@Glen,
I done whine..... that much :)
Ben,
I have to chime in here also and thank for you doing this development out in the open as you have. I feel your pain. I have been attacking (learning) OO Coldfusion for the last few months and have made very little progress ( in between supporting my normal procedurally coded applications ), although I have learned a lot from the various people that post frequently on these topics. I am constantly reminded of a quote from Ursula LeGuin's EarthSea books: "Infinite are the arguments of mages."
I find some reassurance in that I am not struggling alone, and I wish you the best of luck with your difficult decision. :-) I'll be watching, hoping to get inspiration from your trials.
-Andy Lynch
@Andy,
Thanks for the support. I really hope to come out of this journey knowing some good stuff. If nothing else, it has been awesome to get such great advice from the big thinkers.
One thing to remember about scalability here - none of the "big" sites (flickr, facebook, linked-in, etc.) scale because they are particularly well written from an OO perspective. They scale because of caching (especially) and other optimizations, most of which are not reducible to how OO their apps are.
Keep going pure OO!
....
Keep going towards pure OOP, make it your bitch.
I heartily agree with the advice most everyone is giving here. Plough ahead with learning the principles of OO, and worry about performance and such later. In any paradigm, whether OO, functional, or declarative, there are ways to optimize if necessary.
But to be honest, I think that a lot of the difficulties Ben is facing comes from the comical way ColdFusion implemented object-oriented programming.
Instantiation takes forever. The difference between classes and objects (or between static and instance members) is far from obvious. The package / namespace system forces all sorts of workarounds. And how what the heck is a pseudo-constructor, anyway? (Yes, that was rhetorical.)
Throw into the mix CF's typical loose typing and the ability to attach functions to objects JavaScript-style, and you have something that bears only a passing resemblance to OO as we have learned to use it in other languages.
Is there a support group out there for Java developers who think that OO in CF rather awkward, ungainly, and uncomfortable? I know I'm not the only one! :) | http://www.bennadel.com/blog/1304-oophoto-embrace-failure-or-optimize-my-domain.htm | CC-MAIN-2014-52 | refinedweb | 1,952 | 73.27 |
In this following entry I am going to walk you through how to write a User Defined Table Function ( UDTF ) in C . A User Define Function ( UDF ) allows a database user to extend the capability of their DB2 installation by writing custom functions which can then be used in queries . If the value returned by a UDF is a table, they are User Defined Table Function.
As a step one we have to come up with a code for the Table Function. I also thought of picking up an example from TPC-DS. Query 96 in TPC-DS is as follows
The above query computes the sales count in a specific store for a given 30 minute time window. So we have to join store_sales to time_dim table to be able to achieve this. Lets take a look at how to rewrite that query with a UDTF . Before we do that let us understand the time_dim table.
The following is the definition of time_dim table
If we count the number of entries in this table we notice that there are 86400 which corresponds to the number of seconds in a day. So if we took a look at this table we can find that the t_time_sk value changes from 0 to 86399. So the above query would be equivalent to a table function which generates a sequence of integers starting at 30600 for a total of 1800 values. Let us define a UDTF generate_times(BIGINT,BIGINT) that will take two values
and then return a table of integers. Lets define the function as follows.
The above command defines a UDTF in the catalogs . It defines among other things
Note that the external name has two parts seperated by ! . The first part gives the binary that contains the function. The binary should be available under 'function' folder under the instance root. For eg. If your instance root is /home/user1/sqllib/ then the binary should be copied under /home/user1/sqllib/function folder.
So far so good. Except we need to implement the function that would then allow us to invoke it in the query. Lets have a look at the implementation.
#include "sqludf.h"
Lets look at the code in a little detail. The first thing you need to do is to be include the header file sqludf.h. This file would be located under the 'include' folder under your instance root.
All the arguments to the function are all pointers to the input values to the function. We have three arguments, two input arguments , one to hold the starting value of time, the second to hold the number of iterations and the third to hold the output. In our case these are
Corresponding to each of these you would require an indicator to indicate to your code if any of these are Null. The type of SQLUDF_BIGINT and SQLUDF_SMALLINT are defined in sqludf.h
You can use the macro SQLUDF_NOTNULL to check if they are null. Ideally the input indicators should be check for validity before processing. Since I wanted to keep the example code very minimal , I have skipped this step in the code above.
#define SQLUDF_NOTNULL(nullptr) (*nullptr >= 0)
A table function is treated just like a Table. You can open the table, fetch rows from the table and close the table. You have to preserve the state of the computation between successive fetch. So the way to do it would be to make use of the routine infrastructure provided scratch pad. It is a 100 byte scratch pad provided to you to keep some state between fetch. If additional memory is allocated , care should be taken to free them upon closing the table function or upon error.
Upon entering the body of the function we initialize a pointer to the scratch area . Then we enter the processing step where we determine the call type . Upon opening or closing the table function we initialize the counter to the value pointed by start. With each fetch you copy the current counter value to the output variable , increment the counter value and check for the terminating condition. If we reached the terminating condition we set the SQLUDF_STATE to "02000" which indicates an end of table. Other values for SQLUDF_STATE are
Now we are ready to compile the program and copy the program to ~/sqllib/function folder. The program can be compiled and linked as follows
gcc -m64 -fpic -I$DB2PATH/include -c $tpcds.c -D_REENTRANT
Now we have all the pieces ready to rewrite the query above.
The results should be same ! | https://www.ibm.com/developerworks/community/blogs/roycecil/?lang=en | CC-MAIN-2016-36 | refinedweb | 763 | 72.26 |
I'm trying to understand the advantages of currying over partial applications in Scala. Please consider the following code:
def sum(f: Int => Int) = (a: Int, b: Int) => f(a) + f(b)
def sum2(f: Int => Int, a: Int, b: Int): Int = f(a) + f(b)
def sum3(f: Int => Int)(a: Int, b: Int): Int = f(a) + f(b)
val ho = sum({identity})
val partial = sum2({ identity }, _, _)
val currying = sum3({ identity })
val a = currying(2, 2)
val b = partial(2, 2)
val c = ho(2, 2)
Currying is mostly used if the second parameter section is a function or a by name parameter. This has two advantages. First, the function argument can then look like a code block enclosed in braces. E.g.
using(new File(name)) { f => ... }
This reads better than the uncurried alternative:
using(new File(name), f => { ... })
Second, and more importantly, type inference can usually figure out the function's parameter type, so it does not have to be given at the call site.
For instance, if I define a
max function over lists like this:
def max[T](xs: List[T])(compare: (T, T) => Boolean)
I can call it like this:
max(List(1, -3, 43, 0)) ((x, y) => x < y)
or even shorter:
max(List(1, -3, 43, 0)) (_ < _)
If I defined
max as an uncurried function, this would not work, I'd have to call it like this:
max(List(1, -3, 43, 0), (x: Int, y: Int) => x < y)
If the last parameter is not a function or by-name parameter, I would not advise currying. Scala's
_ notatation is amost as lightweight, more flexible, and IMO clearer. | https://codedump.io/share/aTeVYVoCiOqt/1/usefulness-as-in-practical-applications-of-currying-vs-partial-application-in-scala | CC-MAIN-2017-26 | refinedweb | 281 | 60.58 |
Home > Products >
acetic acid Suppliers
Home > Products >
acetic acid Suppliers
> Compare Suppliers
Company List
Product List
< Back to list items
Page:1/5
Germany
We are glad to introduce our firm to you as one of the
leading and largest exporters of both glacial acetic acid
99.5%) and (refind naphthalene ...
China (mainland)
Shenzhen Yuhuaxing Printing Products Co., Ltd. is an
industrial enterprise specializing in manufacturing various
types of labels and tags. We ma...
Adhesive Products of Wealth China Co., Ltd. establish the
branches and offices in most cities of China to expand our
market and improve our afte...
Hongnai Chemical company is based in China for chemical
materials, and specializes in manufactureing, supplying and
exporting the basis chemical...
Our company is one of the large chemical manufacturers in
China, which specializes in manufacturing, supplying and
selling the basis chemical ra...
We are a manufacturer involved in import and export
business throughout the world. We have long experience in
international trade. We invite you......
Tianjin Xinyuan Chemical Co.,Ltd. is the largest
manufacturer of perchloric acid in china even in Asia.
established in 1995,which has now de...
We are a group of company based in Hong Kong since 1973
with offices in China, India, Singapore, US & Central
America. Our main area of activity...
It is is China-Canada joint venture Company, which is a
modern enterprise focus on scientific research and
marketing, It?s the partner of Vancou...
Tianjin Jinlaifu Chemical Co., Ltd. founded in early
1999, is a large chemical raw aterials manufacturer and
provider. we have convenient traffi...
Lianyungang Dongyuan Food CO.,LTD. was established in June
2002 by a team who has experience of more than 20 years in
this field. We apply ourse...
We are one of the suppliers of Chemicals , which
specializes in Chemical Dyestuff and Pigment.
Our factory could finish production and delive...
Jiaxing Jlight Chemicals Co., Ltd.
we have established wide cooperation with renowned domestic
and overseas research institutes and universities...
Hebei Rihao Chemical Co.,Ltd, lies in Shijiazhuang
Hebei,China, with 10 years history, is one of the leading
industrial chemicals manufacturer a...
Shijiazhuang aimeite chemical CO.,LTD committed in
supplying inorganic/organic chemicals, pigments and
dyestuffs in China. It lies in Shijiazhua...
Wuzhou Boda (Tianjin) International Trade Co., Ltd. is
Joint-stock? company which is specialized in chemical
products research, development, man...
Tianjin Shunfan Shunda Chemicals Import and Export Co. Ltd
is a trading company, specializing in exporting
inorganic/organic chemicals, pigments...
Shandong Golden Spring Chemical & Industry Co., Ltd. is a
part of Shandong Golden Spring Group Co., Limited., which
was established in early 200...
SINOCHEM MONGOLIA ALLIANCE
At present our business range:the basic inorganic and
organic which are used in Paint & Coating Industry,Rubber
Industry, Water Treatment Indust...
We are a leading manufacturer and exporter which has been
handling various chemicals
We are keen to establish business relationship with trade
...
We are Tianjin Wanfengyuan Chemical Co., Ltd, especially
dealing with the chemical products, and have been in this
line for many years. Our prod...
We are a wholly owned subsidiary company of HeBei Long Kun
Industrial Group,which is specilizing in chemical materials
import and export trading...
XT Chemical Co.,Ltd is a professional manufacturer and
exporter in the field of chemical products. Our main
products are Caustic soda,Sodium tri...
Shijiazhuang Bingqing Chemical Co., Ltd. is located in
Xinhua District, Shijiazhuang City, China. Our company is
one of the biggest specialized ...
Show:
20
30
40
Showing 1 - 30 items
Supplier Name
Year Established
Business Certification
A.I.L. Eurochem Corp.
Shenzhen Yuhuaxing Printing Products Co., Ltd.
Adhesive Products of Wealth China Co., Ltd.
Hongnai Chemical Co.,Ltd.
Hebei Dechuang Chemicals Imp. & Exp. Co., Ltd.
Shijiazhuang Pengjia Co., Ltd.
SHIJIAZHUANG LATEEN CHEMICAL CO.,LTD
Hebei D. C. Chem Co., Ltd.
Tianjin Xinyuan Chemical Company
Hebei Yonghui Chemicals Imp. & Exp. Co., Ltd.
Chemical Export Co.
Shijiazhuang Lateen Co., Ltd.
Vikudha Overseas Corp Ltd.
zhengzhou Asia Pacific Chemicals Co.,Ltd
Tianin Jinlaifu Chemical Co.,Ltd
lianyungang dongyuan food co.,ltd.
Hebei Jinlun Chemicals Co., Ltd.
Jiaxing Jlight Chemicals Co., Ltd.
Hebei Rihao Chemical Co., Ltd.
shijiazhuang aimeite chemical Co.,Ltd
Wuzhou Boda (Tianjin) International Trade Co., Ltd.
Tianjin Chenfeng Chemicals Import and Export Co., Ltd/Tianjin Chenfeng chemicals import&export co.,Ltd
Shandong Golden Spring Group Co.,Ltd./Shandong Golden Spring Chemical & Industry Co.,Ltd
Sinochem Mongolia Alliance Exp&Imp Tianjin Branch
Qingdao aoyate chemical co.,ltd
guozhong chemical limited company
Tianjin WFY Chemical Co., Ltd
Xingtai Tianen Chemical Product Imp.&Exp.Co.,Ltd
XT Chemical Co. Ltd
Shijiazhuang Bingqing Chemical Co., Ltd.
1
2
3
4
5 | https://www.ttnet.net/hot-search/suppliers-acetic-acid.html | CC-MAIN-2021-04 | refinedweb | 768 | 53.88 |
On 11/09/2012 08:39 AM, Gene Czarcinski wrote: > On 11/09/2012 07:36 AM, Guido Günther wrote: >> On Thu, Nov 08, 2012 at 04:13:41PM -0500, Gene Czarcinski wrote: >>> >This patch changes how parameters are passed to dnsmasq. Instead of >>> >being on the command line, the parameters are put into a file (one >>> >parameter per line) and a commandline --conf-file= specifies the >>> >location of the file. The file is located in the same directory as >>> >the leases file. >> It'd be great if the commit message would state_why_ this is useful. >> Cheers, > Much as it pains me to admit it but you have a valid point. I have > been working on this for some time and the usefulness of this is > "obvious" to me. While one of the first objectives was to remove the > command line clutter by moving the dnsmasq parameters into a > conf-file, it is with some planned (by me) future > additions/enhancements where it becomes more important. > > 1. Specify a second conf-file which will initially be allocated as a > zero-length file. This file will not be deleted when the network is > destroyed. The purpose here is to be able to add log-queries and/or > log-dhcp parameters to turn on dnsmasq logging. This can produce a > log of clutter in syslog so it should be used onlt when necessary. > But, when it it needed, it can be the only way to figure out what is > happening. I thought that we had determined this wouldn't work, because dnsmasq has its capabilities/privileges dropped as soon as it does the initial read of its config, and so it can't re-read its config files? Even if that isn't the case and dnsmasq *is* able to reread this config file, we can't allow that until we have a "network tainting" system in place similar to what we currently have for domains. This is needed to make it plainly clear that a configuration is operating "outside the box" and therefore all troubleshooting assumptions are invalid (this is what happens to a domain when, for example, a direct qemu-monitor command is sent to the domain, a "generic ethernet" device with a script file is attached, or an arbitrary commandline option is added to the qemu commandline). As a matter of fact, I think the more proper method of implementing this is to, as we've done in qemu, introduce a special dnsmasq namespace to the network xml, and allow specifying arbitrary command args via xml in that namespace. This way all of the config is still available in a single location, so there's never a question during debugging of whether or not extra command args were given to dnsmasq. > > 2. A previous patch I submitted which was accepted involved adding the > local=/<domain-name>/ parameter. With this parameter, dnsmasq will > not forward queries for the domain it handles. However, currently it > will forward reverse lookup queries for it subnetwork. The fix is to > add more local=/<ip4>.in-addr-arpa/ for IPv6 and > local=/<ip6>.ip6.arpa/. And "<ip6>.ip6.arpa" expands into a forty > four character string. > > I also find it a lot easier to look and and understand a conf-file > than looking at the the command line. It's the above reasons that are most compelling to me. > > In addition, the rest of the string of submitted updates all assume > this this one is applied. > > And lastly, from what I have observed, configuration files are > preferred to command line parameters. Well, we do call qemu with a big hairy long commandline... :-) | https://www.redhat.com/archives/libvir-list/2012-November/msg00558.html | CC-MAIN-2015-27 | refinedweb | 607 | 59.33 |
Hello,
I am halfway through an app using Code Warrior for Palm and cannot get a new function to appear.
I only have nine functions in the particular segment.
The function is:
static Boolean StrToDouble(Char* dist, double newdist);
I did have the function appearing at first but could not proceed due to a link error so I inserted the 'static' and it worked. I was trying to alter the return value when all reference to the function disappeared and now the program will not compile while the function is there. If I comment it out it will compile. I am at a loss as to why a function cannot be active. I have defined it under processes.
The color of the function indicates it is inactive and it does not appear in the drop down list. Also I get a stupid error claiming every line of the program is a syntax error.
Regards, Bazza
While this list is for CodeWarrior, it is also for Freescale devices. I'm sure there are much more appropriate forums dedicated to palm, but sorry I dont know Palm or their forums.
Anyway, I shortly asked Google for "Palm strToDouble" and some hits did show up. strToDouble is a library function used on Palm, please check the documentation of the libraries you are using.
Note that the function is strToDouble" not "StrToDouble" as in your initial mail (but I'm not 100% that he palm linker is case sensitive. I would hope so, but ANSI-C does not guarantee this).
Also name collisions tend to generate strange error messages, unfortunately you did not copy the ones you got, so its hard to say if they were actually a mystery or just what to expect for your error setup.
Anyway, the first thing to do when you get some error you really do not expect is to check the preprocessor output. Then look how your strToDouble code looks like and search in it for other declarations of strToDouble. Usually the name collision can be easily spotted this way (actually not sure for your case as you may have a link time name collision only).
Also you found the cure: use another name (or in C++, use a namespace).
Daniel | https://community.nxp.com/thread/18426 | CC-MAIN-2019-18 | refinedweb | 374 | 69.62 |
A Response To PHP- The Wrong Way.
In general, PHP - The Wrong Way delivers three positive fundamental messages: keep things as simple as possible, don’t use/apply tools dogmatically, and write secure software by default. This is generally good advice, except PHP — The Wrong Way expresses much of its advice through a series of gross mischaracterizations of the PHP community, the nature of frameworks, standards, and PHP itself.
To set the tone, the article starts off with a hyperbolic hero image depicting literally nobody in the PHP community. I am a long-time, active member of the Reddit PHP community, and follow “the Laravel clique” on Twitter. I’ve yet to come across someone who behaves like that.
Following that image, we come to the second mischaracterization, aimed directly at and the book Modern PHP.
It’s unclear who “these people” are as the author never actually provides names or even examples of these propagations. It’s a nebulous complaint as abstract as the very abstractions lamented by the author further into the article.
This website has been created in an attempt to present a pragmatic view on PHP programming. A view dictated by experience and practical consequence rather than popular trends, theory, or academic dogma.
Given what has been stated thus far, I’m not so sure that this statement is sincere, as it already has the aroma of rant spiced with a dash of ad hominem. But the real issue here is how the author has implied that only the contents in PHP — The Wrong Way reflect a pragmatic, experienced, and practical view, and that its counterpart is nothing more than “popular trends, theory, or academic dogma”.
That said, let’s continue on to the meat of the document.
The wrong way: Religious following of rules and guidelines.
In all fairness, this is one of the most salient points of the whole article. Every construct in programming is a tool. Use the right tool for the right job and you’ll see the benefits. Use the wrong tool for the wrong job, and you won’t. Unfortunately, the rest of the article doesn’t really seem to follow this tempered approach to tool evaluation.
The wrong way: Always use a framework on top of PHP.
To arrive at the above conclusion, the author puts forth a series of irrational arguments and statements.
This trend has not emerged and become popular because it in any way improve the result of the developing process, or because it is the right thing to do from a technology and architectural point of view. This trend has become popular because some of the developers of frameworks has managed to sweep away the masses with their polemic against programming from the ground up with stanzas like “Don’t re-invent the wheel!” and “Don’t do it yourself, others are more skillful than you”.
Interesting accusation. Would love to see some evidence to back up the claim of the motivations of the framework developers. What’s even more interesting though, is you don’t see quotes like “Don’t re-invent the wheel!” and “Don’t do it yourself, others are more skillful than you” coming from the framework developers, you see them from a broad spectrum of non-framework developers in the community (one of the many mischaracterizations present in this article).
And the point these developers are making is simple: building stabled, tested, secure software is time consuming. Unless you’re learning, there’s little value to be had from building a clone of a battle tested thing that already exists.
Regardless, let’s talk about the idea of building things from scratch as a viable alternative to using a framework.
Naturally, which approach is best depends on the nature of the problem. Given the purpose of a web framework like Laravel or Symfony is to build websites and web applications, and given PHP’s raison d’être is building websites and web applications, we’ll go ahead and assume that web development is indeed the context in which the author is lamenting the using of web frameworks.
When building a website or web application, you tend to run into the same basic problems over and over again: you want pretty URLs, you don’t want to repeat the bootstraping of the same configuration for every view/endpoint of your app, you need some kind of input validation, and if you’re rendering HTML, some kind of very terse output escaping. You’ll also likely need a way to establish and manage sessions, protect all POST requests with CSRF tokens, manage cookies, and many other common problems inherent to web development.
In solving those problems in any reasonably maintainable, readable, and understandable way (e.g. not wet spaghetti), it is *inevitable* that you will end up writing your own abstractions to make things re-usable and organized. If you build enough web applications / websites, you find that you’re not only repeating yourself within a single project, but across projects. Being the “experienced, pragmatic, and practical” programmer that you are, you decide to extract those abstractions out into re-usable bits of code that are project agnostic — a.k.a. libraries. But after you’ve developed those libraries, you realize that you’re always importing the same sets of them over and over again, always setting up the same basic project structure over and over again, and wiring things together the same way over and over again. So you start writing a boilerplate backbone to save yourself some time — a thing that describes what libraries to include, and a basic, logical structure to get you started with. Sounds an awful lot like a framework: an opinionated assembly of libraries and boilerplate. So now you’re effectively doing three things: maintaining a set of libraries, a framework of those libraries for the types of projects you work on, and the actual projects themselves.
To go with a more accurate usage of the author’s carpenter analogy, imagine if you were asked to build a table, but before you build the table, you grew a forest, milled the rough lumber, and also built the table saw with which to mill that lumber. If you’re a better carpenter than you are a machinist or arborist, you just wind up with an unsafe, half-baked table saw and shitty trees, and it’s taken you a really long time to even get started on that table. If you are a first-class machinist and arborist, then you already know exactly how much work goes into growing a forest and building a high quality table saw, and realize it’s a ridiculous amount of effort when all you want to do is build a god damned table.
Thus an “experienced, pragmatic, and practical” carpenter would tell you to just buy pre-made, high quality tools and materials, and focus on getting the job done. I wonder if an “experienced, pragmatic, and practical” programmer might have similar advice when it comes to writing software…
The take-away here is that the author seems to have an odd perception of the purpose of a framework — it’s not a bag of random abstractions designed to trick you out of writing things from scratch yourself, it’s a tool meant to save considerable amounts of time. That’s its purpose — to save time. When used correctly, it will.
Continuing on…
Many of todays programmers completely ignore the fundamental principles of sound programming
Citation needed.
and they spend huge amount of time fantasying new layers of complexity in order to appear more clever, more cool, and more acceptable by whomever they regard as their peers.
These people seems to be infatuated by the though of having other people follow their “way of doing things”, becoming some kind of PHP community leaders, and having other people use their latest “hip” Open Source tools, that they forget to make sure that the advice they are giving is sound and solid
There we go with the mischaracterizations again. I can’t speak for anyone else, but I sure as hell don’t sit around my computer deliberately thinking of ways to make my code more complicated so that I can feel cooler than or superior to someone else. The only fantasizing going on here is coming from the author.
A framework is not just a collection of reusable code, you cannot simply take a piece of code from the framework and integrate it into your own project.
Patently false. Maybe at some point in the future I’ll take the time to post example repositories of how you can use just a tiny fraction of a monolithic framework in an existing project external to that framework. It would be silly to do it (which makes the author’s point rather moot, by the way), but you absolutely could.
A framework is a system that helps you build software, but at the same time it forces you to work within the limitations and restrictions of the framework itself. The framework itself has lot of interdependent functionality. One piece cannot work without the other
We’ll see this “limitations and restrictions” theme come up later, but it is a concept central to the author’s bias against frameworks (I say bias because the overall negativity, selective quoting, and lack of balance in the language surrounding the discussion of frameworks in the article highlights this bias quite strongly). The author does not actually enumerate these limitations and restrictions, just presumes they are there and then rests their argument against frameworks on that presumption.
In reality, at worst, a framework simply won’t provide a feature that meets your needs. “I need my web application to have an artificial intelligence”. Great, sounds like you’ll have to write one yourself, but the use of a framework certainly isn’t going to inhibit this effort..
The author fails to make a critical separation of two concepts: a standard library for working with the HTTP request/response cycle (which PHP has built in by default, but Python and Ruby don’t have as much support for in their standard libraries), and actual application architecture/abstraction around common web patterns. Django and Rails solve both problems for their respective languages, but PHP by default only solves the first problem, and does not have the same sufficient abstractions for common web patterns that Django and Rails developers enjoy. Hence why the PHP ecosystem also has frameworks. In other words, you can’t as easily do in plain PHP what you can in Django in Rails. They offer what the PHP standard library offers, and then some. Plain PHP and Django and Rails are categorically not equivalent.
As such PHP was, and still is, a framework in and of itself
By the author’s own definition of a framework, this is a dubious claim. PHP is a collection of libraries, but it makes precisely zero assumptions about how those should be used. Regardless, the point that’s implied is absurd. Because PHP itself is a “framework”, we don’t need higher level frameworks?
When you use a framework in PHP you add a layer of abstraction on top of yet another layer of abstraction, one that was already in place for you to use to begin with
The author simply takes it as a given that higher levels of abstraction are bad, and again, rests their argument on this assumption. You can do everything PHP does in C, but you use PHP because it makes those things easier. Similarly, you can do everything Laravel or Symfony do yourself, but Laravel and Symfony make those things easier. They offer an abstraction level designed to simplify very common patterns of web development which have emerged over the last several years, just as PHP offered a level of abstraction to simplify the problems Rasmus was facing in the early days of the web.
The added layer of abstraction that the framework provides may simply serve to organize your code into a pre-fixed set of patterns, or it may add even more complexity by intertwining hundreds or even thousands of classes and methods into a nightmare of dependencies…
The “nightmare of dependencies” part of that quote is particularly interesting. When I’m using Eloquent and want to save some changes to a user object, I just do this:
$user->email = ‘foo@bar.com’;
$user->save();
I’m not really seeing the nightmare of dependencies there. In fact, that’s the whole point of a framework — a tool that insulates me from that nightmare of dependencies that I would have to require and include myself if I wanted similar functionality. To work with data as PHP objects in my application, I don’t need to know a shred of the architecture that makes `$user->save();` possible. I just use it. And it just works. It’s not like I opened a closet and some avalanche of code buried me alive. So the author is effectively creating a straw man to support their argument. It’s simply not a reality that you have to deal with a “nightmare of dependencies” when you work with a framework (unless of course you have FUD about PSR standards, and don’t have Composer or an autoloader that makes code importing a breeze…)
…either way you’re adding layers of complexity to your code that isn’t needed!
This is the remainder of the above quote, which is quite telling: either way. In other words, frameworks are never needed because the code they add is too complex and is never needed?
The poor construction of the argument notwithstanding, the complaint about “layers of complexity” is unfounded. You are not directly exposed to the underlying complexity. In fact, you are only exposed to the public simplicity, just like you are with PHP and C.
Don’t believe me? Here’s the source for `strtotime()`:
There’s a whole bunch of underlying complexity there which you are never exposed to. Instead, you only have to worry about calling `strtotime()` with the right argument. The complexity that makes `strtotime()` possible is literally none of your concern. If PHP itself is a framework as the author claims it to be, it’s interesting how they don’t consider the underlying complexity of C to be a problem when using PHP, but God forbid Laravel makes it easy to validate a form, and internally uses some dependencies to do so…
The more abstraction you use, the less efficient the interface becomes and the more error prone the application becomes. The higher abstraction, the more detail and efficiency, is lost.
Wat? The entire purpose of abstraction is to simplify the interface for working with or invoking complex behavior. What the author describes is the opposite of reality. The grain of truth the author may be looking for here is inappropriately applied abstraction causes unwanted fragility and can lead to a poor API, but they did not make such a distinction, only a blanket statement that all abstraction is bad.
Understand this clearly: The ideal number of lines of code in any project is as few as possible!
I’m just going to give the author the benefit of the doubt here and chalk this statement up to lazy writing, rather than poor reasoning. Instead, I’ll address what I assume is their intent: simpler is better. Yes, that’s true. Which is why using frameworks and libraries that simplify common, repetitive tasks, is a good thing…
Some companies began listening to the hype about PHP frameworks and they started their next projects using one of these popular general purpose frameworks only to end up in a disaster. They not only discovered.
Wait, what? What companies? Author provides precisely zero examples to back up this claim. Regardless, the reasoning doesn’t track. The nature of a general purpose framework is to get out of the way, to NOT make assumptions that would interfere with the specific requirements of different projects. But in fact, the “general purpose frameworks” the author is alluding to are anything but: they are web frameworks (Remember? We talked about this already). People who have to build websites and web applications, have web development problems to solve: CSRF protection, input validation, etc etc (we covered this). Thus web frameworks help solve those specific, but common problems. Once you get past the common low-level stuff that those frameworks help you with, they make no meaningful assumptions about the types of application you will build with them. You can build everything from a simple CRUD gaming community with forums, tournaments and leaderboards, to a pure JSON API to power an insurance company’s claims system, to a Facebook or Twitter clone, to an e-commerce site that sells unwanted fried chicken. If a company finds that the “general purpose” framework they’ve chosen prohibits them from achieving their specific goals, then only one of two conclusions can be drawn: the framework is terrible and therefore not the right tool for the job, or the company is full of incompetent programmers. Since the popular frameworks the author is alluding to are not terrible, and most companies aren’t full of incompetent programmers, I’m inclined to believe the author is inventing problems out of thin air.
There is one point the author makes that has a smidgen of merit: scalability. It’s no secret that frameworks like Laravel, Symfony, and Zend are heavy, and tie up more system resources than say, a simple bare-bones script. However, I will let Anthony Ferrara explain the fallacy of prioritizing hardware costs over human costs, as he does a better job than I could. So while you should strive for performant code, and indeed a framework can be a hindrance to that quest, rolling your own custom-tailored internal framework/libraries doesn’t give you that performance for free. It costs time and money.
My company deliberately sheds our home-grown abstractions/libraries whenever a suitable 3rd party library or framework upgrade can replace them. It’s cheaper and easier for us to delegate that work to the framework/library maintainer than it is for us to try and maintain something on our own, even if our own version is slightly more optimal for our needs. Moreover, the standardization on an external tool makes it FAR easier for new developers to get up to speed, because we can hire for skills and experience that a developer can already have.
The business case for rolling your own framework/libraries manifests only in a thin set of circumstances where performance or uncommon needs are ultimately paramount. But as Anthony Ferrara pointed out, you probably don’t have the scalability issues you think you do, so optimize for fleshware, not hardware.
On to design patterns…
The wrong way: Thinking of patterns when solving problems.
As stated, the above is not necessarily bad per se. But once again, the supporting arguments that led to such a conclusion are…. off..
It’s unclear what the author’s line of reasoning here is. All of these different paradigms have their own design patterns. Functional programming has monads and currying, for example. Yet the author seems to be arguing against the use of design patterns as if they somehow only pertain to OO, and thus preclude other programming paradigms. This is simply not true.
Regardless, the conclusion drawn is at least sound: don’t apply design patterns for the sake of applying design patterns. Like anything else, they’re a tool. Use them appropriately or suffer the consequences.
The wrong way: Always use object-oriented programming.
The author gets back into referencing PHP’s different paradigms, and at this point it’s worth calling out a fallacy in thinking they’re equally viable.
For starters, I’m not sure what “reflective” programming is. It’s not a paradigm by any classical sense. Reflection is something you can do in PHP, but it’s not a paradigm for managing state and behavior.
PHP’s support for functional programming is quite poor, as poor as JavaScript’s support for object-oriented programming is. Functions are not first class, and the lack of implicit closure makes working with lambas very cumbersome. You will have a harder time writing functional code in PHP than you will object-oriented code in PHP.
Regarding procedural/imperative programming (procedural is just a form of imperative programming, and for the purposes of this argument, I will just refer to procedural as the paradigm) it is fundamentally harder to write complex software using purely procedural code, than OO or purely functional code. It’s a mix of global and semi-global state management, and function definitions without any of the advantages of encapsulation or polymorphism provided by functional or OO programming, or the advantages of a nominally typed object system to express complex objects and behaviors as named “bundles”.
It’s “simpler” in so far as you are working only with basic language constructs and primitives, rather than a potentially very complicated matrix of named objects, but it’s more complex because you have to work harder to maintain clear separations of concerns, and hide information from unwanted changes/mutations, or behavior from inappropriate access. This is fine for very simple projects, but anything complex benefits strongly from the extra structure that OO provides.
require 'some/lib/file.php';
require 'another/lib/file.php';
require 'something/else.php';
$foo;
bar(...);
Where did `$foo` come from? How many times was it mutated before you got access to it? Which file supplied it? Which files mutated it? What about `bar()`? You might dig into one of those files, only to see that they too require their own files, and now you have a rabbit hole to explore. An IDE will only tell you some of what you need to know, but this very typical procedural code is much harder to grok than equally typical, modern OO PHP:
use Acme\User;
$user = new User('Bob', 34);
$user->sayName();
$user->haveBirthday();
$user->getAge(); // 35
Where did `User` come from? the `Acme\User` class. Where is that? In the defined PSR-4 root folder, under `Acme/User.php`. Very clear 1–1 mapping of classes and files. Where did `$user` come from? From the instantiation, silly. It’s not global, it didn’t just appear out of thin air from some nested sequence of required files. Where are `sayName`, `haveBirthday`, and `getAge` defined? Obviously right in the `User` class, which you know the location of. Just open it and see them. Devil’s advocate: those methods could be located anywhere along a very deep inheritance hierarchy. But that’s why you shouldn’t write very deep inheritance hierarchies…
The kicker is that even simple OO usage doesn’t really cost anything. The tradeoff line where OO is too complex is incredibly small. FizzBuzz doesn’t benefit from OO, but representing a data structure as a named object instead of an associative array has immediate benefits. You are 100% in control of how much complexity you build into your OO design. OO itself does not inherently make something more complex, as this author naively states:
The fact is that so-called object-oriented programming as such often inflict a heavy burden of unneeded complexity!
You can just as easily over-complicate procedural programming or functional programming by adding unnecessary abstraction layers. OO doesn’t have a monopoly on over-complication.
Today one of the main strengths of PHP is it’s!
The author’s final point would be made more clear if they gave some real examples, specifically ones that show the link between consistent use of OOP and reduced creativity and efficiency.
Now, onto the FIG…
The wrong way: Following the PHP-FIG beyond the PSR-1 and PSR-2.
This is the least thoughtful section of the article. The entire first half of this section is just an ad hominem against FIG, trying to construct a boogeyman, and going so far as to say shit like this…
They do this by classifying the work of the PHP-FIG as “Modern PHP” in their books, on their websites, blog-posts, forums, etc., and by classifying other ways as backwards.
…without any examples or evidence.
Unrelated ad hominem aside, there are several arguments made in this section which don’t track:
One of the problems with the PHP-FIG is that even though many frameworks and Open Source projects has adopted several of their standards, these standards mainly deal with problems from a “framework perspective”...
Given the author has summarized anything beyond PSR-1 and PSR-2 (which are code style and formatting guidelines) as bad, and references PSR-0 and PSR-4 later on, let’s assume PSR-0/4 are included in the reference to “several of their standards”. Given that, this makes not a shred of sense. PSR-0/4 describe a standard by which code may be imported. In fact, it effectively describes a standard that makes code importing in PHP as seamless and simple as it is in Java, C#, and many other languages. Without PSR-0/4, this is what you have to do to use a class:
require 'some/path/to/myclass.php';
$instance = new myclass;
Except without standards, this is fraught with peril. The path could work in some places, but not in others since it’s relative, meaning libraries don’t have a standard way of determining where a file is located in the project structure. Different libraries and frameworks and users can require code in different places, and it’s not at all clear when or where a file may have been included in a request lifecycle, thus allowing the possibility of usage to come before inclusion, and a fatal runtime error to result. `require` could be called several times during the request lifecycle, eating unnecessary memory. It’s not guaranteed that `require_once` will be used everywhere there is a dependency on `myclass`. The class name could be completely different from the filename. Could be `my_class`, `MyClass`, `My_Class`. The file could even have more than one class in it. You can’t know how to use the contents of the file you’ve imported just by virtue of importing it. You HAVE to open the file and inspect it to see what’s going on. Even worse, that file might have dependencies it doesn’t `require` itself, and it expected those dependencies to have been loaded by something earlier in the request. So you have to just execute the request to see if it blows up. If it does, gotta dig into that required file to see what hidden dependencies it has. (None of this is FUD by the way; I used to live and breathe these very problems. It was a dark time.)
PSR-0/4 corrects this issue by describing conventions which allow PHP’s autoloader to work in a consistent way. Developers are all on the same page about where code physically lives in the project structure, and how to import that code where it’s needed. Importing always happens lazily at usage time (e.g. when `new` or a static call is made), and only has to happen once. Moreover, since the autoloaded path is derived from the namespace of the class, and the name itself, it simultaneously enforces namespaces (avoids collisions) AND consistency of the class name. When writing object-oriented code in PHP, this simplicity and standardized consistency eliminates entire classes of bugs and manifestations of complexity.
But the biggest advantage of all is that it has allowed two awesome things to happen: it’s allowed libraries to be consumed quickly and easily, dramatically increasing the re-usability of libraries that solve common problems, and it’s allowed Composer to be a thing. No more downloading a zip file that might contain some arbitrary file structure, manually extracting those files out into the right folder structure, and dealing with that one asshole who distributed his library as a .rar instead of .zip. And then if that library had dependencies, you had to hope the author included the right versions of those dependencies for you, and then you had to find a way to avoid collisions with different versions of that same file.
With Composer, it’s like any other sane language with a package manager: you simply type a command into your terminal, and it handles all of that installation process for you automatically. It puts the code in a consistent location, all dependencies are recursively found, and that code now just works.
composer require some/library
$foo = new Some\Library\Class;
Done. Simple. Easy. Painless.
Yet the author claims all of this library interoperability that PSR-0/4 allowed to flourish, is only a framework thing? I think not.
Ok, what about PSR-3? That describes a logger interface. What’s the advantage? If project A and project B both need a logger, and are written to accept the PSR-3 standard, guess what? They can use the exact same logger. It’s guaranteed to work in both. No adapting or re-implementing needs to be done. Frameworks have nothing to do with it. If you agree with the PSR-3 logger interface, then use it. If you don’t, then don’t (but don’t complain when you no longer want to maintain your home-grown logger and proprietary API and then can’t swap it out for a 3rd-party maintained, well-tested implementation).
… which renders them pretty unusable in many real-life industry situations
Such as? Not sure how being able to easily and quickly import new libraries, or adhere to a contract that lets you hot swap different implementations of a library, is “unusable in many real-life industry standards”. Once again, examples would go a long way.
If those supposed “real-life industry standards” are rooted in the old manual process I described above, it seems to me those standards are quite inferior to the new standards (hence why FIG exists, and “Modern PHP” and were written), which save time and reduce complexity. If legacy standards are prohibiting a company from adopting new standards, then that’s some technical debt they will have to deal with, but for the author to imply that you should flat out avoid PSR-0/4/3/n because they are not compatible with antiquated or half-baked proprietary standards, is preposterous..
As you can tell, I’m not really one to be dismissive (as per the length of this article), but the absurdity of this statement speaks for itself. It’s a non sequitur — applying PSR-0/4 (an agenda by framework fanatics) is incompatible with the goals of writing “efficient, secure, and cost-effective” software??
This is like saying the color blue is bad because it smells like the 21st of Jupiter.
I should hope so, that’s the entire purpose of adopting those standards after all…
Many industries demand highly scalable, run-time critical, and cost effective software that simply cannot be developed using these standards of the PHP-FIG.
Again with the non sequitur. PSR-0/4 have nothing to do with ability or inability to write highly scalable, run-time critical, and cost effective software. It’s like saying you can’t cook potatoes if it’s raining out.
Examples of these supposed problems would go a long way in reinforcing the arguments the author is making.
The wrong way: Not developing secure software by default.
One of the few redeeming qualities of this article. [Oh but wait…]
At least PHP — The Right Way takes the time to provide concrete examples of how and what you should do, rather than un-actionable nebulous rantings about what you shouldn’t. | https://medium.com/@jon.lemaitre/a-response-to-php-the-wrong-way-fe7bb253e295 | CC-MAIN-2017-22 | refinedweb | 5,320 | 59.33 |
Use the Node, Luke!
Items in the SCons build tree are represented as Nodes, not only plain file names. In the case of an output into your VariantDir, the node will remember the output path (such as build/file.o) as well as the original source input path (file.o) and for both of these, it also knows the absolute path. These properties are something you'll always want to see when debugging.
print n.abspath
print n.srcnode().abspath
See the section File and Directory Nodes for specific property documentation.
Use the Emitters, Leia!
SCons is a little obsessive and really likes to keep track of everything. It likes to know what files come in and what will fall out. With this information, it can make sure everything is properly rebuilt on any change and it can nicely clean your directory with the -c switch.
If you need to call some external command, it's a good idea to provide this information to SCons so that it knows what will happen. In my build, I need to generate header files for JNI classes using javah. The built-in tool doesn't really work for me because it needs Java compilation first so I ended up writing my own.
The file and class names in Java are tightly coupled, you can pretty much just do
file = clsname.replace('.', '/') + '.java'
to find the source file for a class. I'm using this fact to make my emitter. I take great care to have the correct .java files listed as the source for the Builder. Having only the directory just doesn't cut it, I have to Glob() in subdirs too. To have a good idea of what's happening, I first debug-print my source and target nodes in the emitter:
The emitted target node doesn't need to have an absolute path or contain the VariantDir name, that should be handled by SCons. Just imagine you are building in the same directory and return a relative path.
def emit_javah(target, source, env):
print 'emit source', [x.abspath for x in source]
print 'emit target orig', [x.abspath for x in target]
The emitted target node doesn't need to have an absolute path or contain the VariantDir name, that should be handled by SCons. Just imagine you are building in the same directory and return a relative path. | https://blog.rplasil.name/2015/06/correct-scons-variantdir-and-emitters.html | CC-MAIN-2018-26 | refinedweb | 398 | 74.19 |
Manning's Countdown to 2014
. Use discount code crdotd14 all month for 50% off every deal.
A friendly place for programming greenhorns!
Big Moose Saloon
Search
|
Java FAQ
|
Recent Topics
Register / Login
JavaRanch
»
Java Forums
»
Frameworks
»
Spring
Author
How to pass an object between MVC controllers?
Nathan Russell
Ranch Hand
Joined: Aug 18, 2004
Posts: 75
posted
Aug 15, 2010 14:12:49
0
Hi,
A bit of a newbie question I'm afraid, which I wonder if anyone can help with.
I'm a complete newbie to Spring, and am tring to get to grips with Spring MVC. I've been reading 'Expert Spring MVC and Web Flow', but to be honest its serving to confuse more than educate
I've put together the basic airline flight booking app in Chapter 4. Whilst its a bit better than a HelloWorld app, it still leaves me with unanswered questions, so I'm trying to put together something a bit more substantial.
The app I want to put together is a simple home insurance quote application. I have my domain classes already defined as a series of POJOs, and I want to present 3 screens - About You, About Your Home and Your Quote where fields on the screens are properties of the various POJO classes.
My main domain class is Quote which has properties of type Proposer, Property, CoverOptions, Premium. Proposer has properties to describe the policy proposer, Property describes the property to insure, etc.
As I see it at the moment I need 3 SimpleFormController controllers - one for each of the screens; and that I need to create a new Quote object and pass it between screens as the controller progressively populates more of the properties within. And that I also need to ensure that if a new session starts midway through the process - perhaps on the About Your Property controller - this is detected and they are sent back to the beginning where a new Quote object can be created for them.
My current thoughts are that I actually need 4 controllers - Init, About You, About Your Property and Your Quote; and the Quote object will be stored within the http session. In the constructor of About You, About Your Property and Your Quote I need to get the Quote object from the session. If it does not exist I need to issue a redirect: prefix to the Init controller whose contrstructor will create and store in the session a new Quote object and then issue a redirect: to the About You controller.
But this does not sound very 'DI' - especially the creation of the Quote object.
Any pointers to help clear up my understanding would be very much appreciated;
Cheers
Nathan
Mark Secrist
Ranch Hand
Joined: Jul 01, 2003
Posts: 89
posted
Aug 19, 2010 11:59:39
0
There are pretty much two approaches that don't necessarily require separate controllers
1. Use annotation driven controller to define methods to handle the submit from each page (I presume you're using Spring 2.5 or higher)
2. Look at WebFlow to do this work, which you've already discovered to be more difficult to master
I'm more familiar with the former approach. The trick will be that your domain object (or command object) will need to be defined as a session attribute. Have a look at the reference doc at:
Also, if you have access to the Spring Recipies book by Gary Mak, he covers the basics of how this works in one of his chapters. Also, you might check out another forum post at
Nathan Russell
Ranch Hand
Joined: Aug 18, 2004
Posts: 75
posted
Aug 20, 2010 08:27:22
0
Thanks for your reply Mark.
I've just got to the chapters in the book to do with Web Flow and was initially thinking 'yes, this is what I need'. However, having had a play I've decided its probably not what I need on the grounds that a) the book is outdated and b) it looks flippin' complicated !
OK, so going back to your original suggestion (using annotation driven controllers to define methods to handle the submit from each page), could you elaborate a little on that please? The book doesn't describe using annotations in controllers
(and yes, I am using Spring 2.5 or higher - 2.5.6 SEC02 to be precise
)
Roughly how would you go about setting up a project like mine? (3 pages where an object is passed between the pages and progressively populated with the data from each page). I'm imagining something like this:
web.xml
<>*.htm</url-pattern> </servlet-mapping> </web-app>
spring-servlet.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" ""> <beans> <bean name="/AboutYou.htm" class="mypackage.AboutYouController"> </bean> <bean name="/AboutYourProperty.htm" class="mypackage.AboutYourPropertyController"> </bean> <bean name="/YourQuote.htm" class="mypackage.YourQuoteController"> </bean> <bean id="viewResolver" class="org.springframework.web.servlet.view.InternalResourceViewResolver"> <property name="prefix" value="/WEB-INF/views/jsp/" /> <property name="suffix" value=".jsp" /> </bean> </beans>
But I cant picture how I would instantiate my Quote object once and pass it into each controller??
I'm also a bit confused with some of the terminology (which probably explains why I'm finding this so hard!) Is my POJO (my Quote object) my domain object? or my command object? or a bean? And where do services fit into this? - I imagine that I need to write some business logic methods somewhere, at a minimum I would need a doQuoteCalculation() (but extending the app into something more useful I would need doPostcodeLookup(), soSaveQuote() etc etc)
Any pointers you can offer would be very very much appreciated;
Best regards
Nathan
Mark Secrist
Ranch Hand
Joined: Jul 01, 2003
Posts: 89
posted
Aug 20, 2010 10:17:33
0
Hi Nathan,
You've asked a lot of really good questions. Let me start with the architecture question first.
You have a lot of flexibility in how you architect a solution using the Spring MVC approach. A lot depends on the complexity. You might decide to compose a service layer that handles aggregating multiple calls to several DAO objects, which would be responsible for fetching your domain objects. If the service functionality isn't that complex, then it may just make sense to roll that into the controller and have it act as your service layer. The service layer should NOT just be a pass through proxy for calls to the DAO. Methods on the service layer should be more granular and provide cohesive business functionality. A good way to approach this is to roughly sketch the page flow from the user perspective on paper or a whiteboard and then simply begin to work it through to the back end in terms of what data you'll need. As you begin to look at required interactions, you may also begin to see logical groupings of functionality that may make a logical service layer. The controller would then simply be responsible for collecting data from the web page, validating and then calling the correct service functionality to perform the next steps.
Ok, in terms of the controller the Spring annotation way. I suspect you may indeed be getting tripped up by terminology. The term 'command object' comes from the old AbstractFormController/SimpleFormControler and from a broader
pattern
for doign MVC (I think Struts also uses this term). Another term that is used is 'form backing object'. This object can be a POJO and it could be a domain/model object and could even have persistence annotations (ala JPA or Hibernate). From here, I think your question is about the origin of this object and that has a lot to do with your approach to this series of pages. I assume from what you've said already that a user (me for example) would come to some starting page (/AboutYou.htm?) and begin filling out information over a series of pages. The implication is that there is a starting page, which will usually be accessed via a GET request. Usually this first invocation is where the command object is initialized. As an aside, if I was doing something similar with a specific instance (i.e. editing a product entry, which implies a product id as the key), I might pass in the product id as part of the initial GET request but initialization would probably result in a populated object (likely from a data store of some kind).
From there, the user would progress from one page to the next through a series of submits (which are POST requests). You would handle the submit for each page by doing whatever you needed to do (i.e. validating, performing calculations, etc) to set up for the next page. I found the POST -> redirect -> GET approach to work pretty well. The POST handles the binding of the data from the form to the command object. From there, I process the result and redirect to a GET request (same controller) where I prepare for the next page before returning the view to render the next form page. What makes this work is that the command object is a session object that is simply kept available to all invocations to the controller. This is made easier by the annotation based approach as there aren't the same restrictions as with the SimpleFormController.
Based on what you've posted, a controller to do all this might look like the following
@Controller @SessionAttributes("quote") // The name of the object I'll be storing, which must be consistently used everywhere else public class QuoteController { /* * This is pretty much all there is to initialization. You can make this more complex as needed but the key is that at some * point a Quote instance gets initialized to a known starting state. Usually it's the first page of the sequence. */ @RequestMapping( * ... do something with each item * </c::forEach> */ @ModelAttribute("referenceList1") List<String> getRefList1() { // build the list and return it } }
I hope this helps.
Nathan Russell
Ranch Hand
Joined: Aug 18, 2004
Posts: 75
posted
Aug 20, 2010 14:46:26
0
Mark,
Thank you so so much for this - I most definately owe you a beer for this
Its all coming together very nicely.
One further question though (hopefully it'll be my last!) - when a new session comes along and issues a GET to /AboutYourProperty.htm (ie. tries to start in the middle of the process) Spring throws 'org.springframework.web.HttpSessionRequiredException: Session attribute 'quote' required - not found in session'
Looking at the method this makes sense:
@RequestMapping(value="/AboutYourProperty.htm", method=RequestMethod.GET) public String initYourProperty(@ModelAttribute("quote") QuoteRequestType quote, Model model ) { model.addAttribute("quote", quote); return "AboutYourProperty"; }
But is there a way of catching this nicely. My initial thought was that I'd do something like this:
@RequestMapping(value="/AboutYourProperty.htm", method=RequestMethod.GET) public String initYourProperty(@ModelAttribute("quote") QuoteRequestType quote, Model model ) { if (quote == null) { return "redirect:/AboutYou.htm"; } model.addAttribute("quote", quote); return "AboutYourProperty"; }
But I think the exception is thrown before the method even runs.
Any ideas?
Cheers
Nathan
Mark Secrist
Ranch Hand
Joined: Jul 01, 2003
Posts: 89
posted
Aug 20, 2010 15:34:30
0
This session issue can definately cause problems for sure. If you were using Spring 3.0+, there's a nifty @ExceptionHandler annotation you could add to a method that could do the work for you. As it is, you'll need to configure an exception resolver in the bean file for SimpleMappingExceptionResolver. One thought I had was that you could simply redirect back to a known good starting point. The one issue with the SimpleMappingExceptionResolver is that it mapps to a view (i.e.
JSP
). What you really want is to direct this kind of exception to a path (like your starting path). That would allow you to perform initialization via the controller before directing back to the starting view. This is where the @ExceptionHandler annotation is nice.
However, a few options come to mind. You could have a look at the classes and interfaces associated with the Spring Exception handler and write your own. Petty much all you would need to do is extend SimpleMappingExceptionResolver and override the doResolveException method. You'd still configure it in the bean file, but it allows you to do initialization if you want before directing to the configured view. Another solution would possibly be to create error definitions in the web.xml file that would map to the appropriate URI.
Nathan Russell
Ranch Hand
Joined: Aug 18, 2004
Posts: 75
posted
Aug 23, 2010 13:39:38
0
As before, thanks for your help Mark.
I wrote an implementation of org.springframework.web.servlet.HandlerExceptionResolver and in the method
public ModelAndView resolveException(HttpServletRequest request, HttpServletResponse response, Object o, Exception e)
I wrote
if (e.getClass().equals(HttpSessionRequiredException.class)) { return new ModelAndView("redirect:/AboutYou.htm"); }
The redirect does exactly what I need - Perfect
Thanks once again,
Nathan
Don't get me started about those stupid
light bulbs
.
subject: How to pass an object between MVC controllers?
Similar Threads
Head First Servlets & JSP book - Reader Question
MVC & Swing - How model classes work together ?
Database connection in servlet
Relationship between Model (in MVC) and DAO
Submitting form data as JSON with JQuery
All times are in JavaRanch time: GMT-6 in summer, GMT-7 in winter
JForum
|
Paul Wheaton | http://www.coderanch.com/t/506713/Spring/pass-object-MVC-controllers | CC-MAIN-2013-48 | refinedweb | 2,238 | 61.06 |
To create Web applications, you need access to an installation of Microsoft's Internet Information Server (IIS) running on a server that must have the .NET Framework installed. Visual Studio will create the files you need and upload them directly to the server when you create the Web application (usually in the IIS Web root directory named wwwroot ).
To avoid cluttering the Web root directory, you can create IIS virtual directories in which to store your Web applications. To support virtual directories, right-click a folder in the Windows Explorer and select Web Sharing.
To create a Web application, make sure IIS is running and, in the IDE, select the File, New, Project menu item to open the New Project dialog box you see in Figure 8.1. This time, select the ASP.NET Web Application icon in the Templates box, as you see in the figure. Enter the URL of your Web server in the Location box or browse to it by clicking the Browse button. If you're developing your Web applications with an installation of IIS on the same machine as Visual Studio, as in this example, the URL will be . To create a Web application named ch08_01, we enter this location in the Location box: .
To open a Web application that you've already created, use the File, Open, Project From Web menu item (not the File, Open, Project menu item). The IDE will ask for the URL of the server to use, and then will open the Open Project dialog box.
By default, a new Web form is automatically added to the new Web application, and that Web application opens in the IDE, as you see in Figure 8.2.
You can see the new Web form, WebForm1 , in the middle of Figure 8.2. What you're looking at is the visual representation of the Web form's file, WebForm1.aspx. Web forms like WebForm1 are based on the System.Web.UI.Page class , as you can see in the beginning of the actual code for WebForm1.aspx:
namespace ch08_01 { /// <summary> /// Summary description for WebForm1. /// </summary> public class WebForm1 : System.Web.UI.Page { . . .
The text in the Web form you see in Figure 8.2 indicates that the Web form is in grid layout mode , which means you can position controls where you want them in the Web form, just as you can in a Windows form.
You can set the Web form's layout yourself using the pageLayout property. Besides the grid layout mode, the other option is flow layout . Flow layout is the layout for controls that browsers usually use. With flow layout, the controls you add to a Web form "flow," much like the words in a word processor's page, changing position when the page changes size. To place your controls where you want them, use grid layout.
Now that you have the Web form open in the C# IDE, you can customize it much as you'd customize a Windows form. For example, you can set the Web form's background color using the properties window. This time, however, use the bgColor property, which corresponds in Web pages to the BackColor property of Windows forms. At design time, the properties window will display the HTML properties of the Web form you can work with. (In the IDE, HTML properties begin with a lowercase initial letter, such as bgColor and link .) You can set the foreground color (that is, the default color of text) used in Web forms and HTML pages with the text property, mirroring the attribute of the same name in HTML pages.
You can also set the text in the browser's title bar when the Web form is being displayed using the title property. And as in other Web pages, you can set the background image used in Web forms and HTML pages, using the background property. You can set this property to the URL of an image at runtime. Or, at design time, you can browse to an image file to assign to this property.
The Web form itself, WebForm1.aspx, is where the actual HTML that browsers will open is stored. You can see that HTML directly if you click the HTML button at the bottom of the Web form designer ( next to the Design button), as you see in Figure 8.3.
This is the HTML that a Web browser will see, and you can edit this HTML directly, as we'll do later in this chapter. Note the ASP directives in this document, which begin here with <%@ and <asp: . These ASP.NET directives will be executed by IIS, which will create HTML from them, and that's what is sent to the browser.
Let's add some Web server controls to this Web application. Click the Design button in the IDE to get back to the visual representation of the Web form, select the Web Forms tab in the toolbox, and then drag a button and a text box to the Web form. Give the button the caption Click Me using the properties window as you would in Windows applications. This adds a new System.Web.UI.WebControls.Button object and a new System.Web.UI.WebControls.TextBox object to WebForm1.aspx:
namespace ch08_01 { /// <summary> /// Summary description for WebForm1. /// </summary> public class WebForm1 : System.Web.UI.Page { protected System.Web.UI.WebControls.Button Button1; protected System.Web.UI.WebControls.TextBox TextBox1; . . .
As you've done in Windows applications, double-click the button to open its Click event handler in the "code-behind" file, WebForm1.aspx.cs, which is where your C# code for the Web application goes:
private void Button1_Click(object sender, System.EventArgs e) { }
Except for the fact that Button1 is capitalized hereall Web server names begin with an initial capitalthis is exactly what you'd see in a Windows application. Add this code to display a message, "Web Applications!" , in the text box:
private void Button1_Click(object sender, System.EventArgs e) { TextBox1.Text = "Web Applications!"; }
Now run this new application just as you would any Windows application, by selecting the Debug, Start menu item. This makes Visual Studio upload your code to the Web server and launches Internet Explorer to display your Web application, as you see in Figure 8.4. When you click the Click Me button, the message "Web Applications!" appears in the text box, as you see in Figure 8.4.
Coding this application was remarkably like coding a Windows application. But there are still significant differences, as we'll see in the next section. | https://flylib.com/books/en/1.254.1.92/1/ | CC-MAIN-2022-05 | refinedweb | 1,098 | 64 |
facebook.com/ georgiatoday
Issue IIs ssu ue no: 810/10
• JANUARY 19 - 21, 2016
• PUBLIS PUBLISHED TWICE WEEKLY
FOCUS ON CHANGING THE SYSTEM
New Prime Minister Giorgi Kvirikashvili discusses gambling reformation for social welfare
PAGE 2
PRICE: GEL 2.50
In this week’s issue... US Ambassador: Georgia Needs Energy Diversification PAGE 2
Georgia’s PM Meets Businessmen, Promises ‘Interesting’ Offers PAGE 3
Men are rational, women are adaptive? ISET PAGE 4
Georgia to Introduce Estonian Model of Corporate Income Tax BY TAMAR SVANIDZE
T
he Head of the Georgian Government has announced that the State is actively working to establish in Georgia a tax system similar to the Estonian corporate income tax model. The Prime Minister of Georgia, Giorgi Kvirikashvili, revealed that consultations about this issue are ongoing with representatives of the International Monetary Fund and the majority of the Georgian Parliament.
“The Government has begun work regarding tax liberalization. This means corporate income taxation only in the case of profit sharing. Earnings will be created within the company and will be taxed only if considered as distributed dividend. If companies reinvest their income they will be free from tax. This will help to attract potential investment resources existing on the local market,” Kvirikashvili stated. Estonia’s current system of corporate earnings taxation is a unique system which shifts the momentum of corporate taxation from the moment of earning the profit to the moment of its distribution.
Giorgi Kvirikashvili Discusses Infrastructural Projects with Governors PAGE 5
Changes in Composition of Board of Directors of JSC PASHA Bank Georgia PAGE 6
Mexico’s Healthcare Reform GALT & TAGGART PAGE 7 Prepared for Georgia Today Business by
Markets Asof15ͲJanͲ2016
STOCKS
w/w
m/m
BONDS
Price
w/w
m/m
GBP16.95
Ͳ5,8%
Ͳ9,1%
GEOROG05/17
100.31(YTM6.61%)
Ͳ0,4%
Ͳ0,6%
GBP1.65
+1,9%
Ͳ0,9%
GEORG04/21
102.93(YTM6.21%)
Ͳ0,6%
Ͳ2,3%
TBCBank(TBCBLI)
US$9
Ͳ17,4%
Ͳ7,0%
GRAIL07/22
100.88(YTM7.58%)
Ͳ0,7%
Ͳ2,2%
GEBGG07/17
103.06(YTM5.53%)
Ͳ0,4%
Ͳ0,8%
COMMODITIES
Price
w/w
m/m
28,94
Ͳ13,7%
Ͳ24,7%
1088,88
Ͳ1,4%
+2,6%
BankofGeorgia(BGEOLN) GHG(GHGLN)
CrudeOil,Brent(US$/bbl) GoldSpot(US$/OZ)
INDICES
Price
Price
w/w
GEL/USD
2,4250
+0,4%
+1,5%
GEL/EUR
CURRENCIES
2,6198
Ͳ0,6%
+0,4%
m/m
Price
w/w
m/m
GEL/GBP
3,4573
Ͳ1,4%
Ͳ3,9%
FTSE100
5804,10
Ͳ1,8%
Ͳ3,6%
GEL/CHF
2,4227
Ͳ0,3%
+0,6%
FTSE250
16160,60
Ͳ3,4%
Ͳ4,9%
GEL/RUB
0,0312
Ͳ3,4%
DAX DOWJONES NASDAQ
Ͳ8,5%
9545,27
Ͳ3,1%
Ͳ8,7%
GEL/TRY
0,7960
Ͳ0,7%
Ͳ1,2%
15988,08
Ͳ2,2%
Ͳ8,8%
GEL/AZN
1,5225
+3,6%
Ͳ33,3%
4488,42
Ͳ3,3%
Ͳ10,1%
GEL/AMD
0,0050
Ͳ
+2,0%
97,08
Ͳ7,6%
Ͳ12,2%
GEL/UAH
0,0994
Ͳ4,3%
Ͳ0,5%
709,19
Ͳ4,2%
Ͳ9,0%
EUR/USD
0,9163
+0,1%
+0,2%
SP500
1880,33
Ͳ2,2%
Ͳ8,0%
GBP/USD
0,7015
+1,8%
+5,5%
MICEX
1608,36
MSCIFM
MSCIEMEE MSCIEM
Ͳ8,0%
Ͳ7,7%
CHF/USD
1,0012
+0,6%
+1,0%
2153,53
Ͳ4,5%
Ͳ5,9%
RUB/USD
77,7049
+4,0%
+11,1%
GTIndex(GEL)
885,86
Ͳ
Ͳ
TRY/USD
3,0470
+0,9%
+2,8%
GTIndex(USD)
721,35
Ͳ0,3%
Ͳ1,0%
AZN/USD
1,5704
+0,2%
+50,1%
2
BUSINESS
GEORGIA TODAY
JANUARY 19 - 21, 2016
Government Turns its Attention to Online Casinos BY EKA KARSAULIDZE
T
he Parliament of Georgia once again raised the issue of the dangerous impact of online casinos and the question of their closure. This time the initiative belongs to new Prime Minister of Georgia, Giorgi Kvirikashvili. At present there are no specific details about future regulations, but the government intends to study the issue in detail. According to PM Kvirikashvili, the absence of any regulations for the online casino business has
resulted in serious negative consequences for the population of Georgia. The authorities plan to thoroughly explore the online casinos market in the near future and then begin to work out the necessary regulations. The PM claimed that if the regulations are not entirely effective, the government would consider more stringent measures. However, it is unknown whether, by this, PM Kvirikashvili was referring to the possibility of their complete shut down or not. “I want to figure out what options we have and how far it’s possible to implement them in Georgia. If it’s physically impossible, then we’ll think about more stringent measures,” he said. “By all means we must prevent further destructive impact on
Online casinos are used by around 85% of all players in the gambling industry, 70% of which are minors
citizens by the online casino market.” Despite the fact that gambling in general is recognized as one of the most pernicious and intractable addictions, the PM highlighted that future regulations will concern only online casinos. “In this issue we separate offline casinos. New regulations will not touch them, as their existence is important for the tourism and hospitality industry,” noted Kvirikashvili. The main reason for the creation of the regulations named the easy availability for juveniles to online games and casinos. According to some reports, the number of people using online casinos in Georgia is increasing by the year. They are used by around 85% of all players in the gambling indus-
try, 70% of which are minors. The majority of the population of Georgia actively supports the Prime Minister’s proposal, which indicates that there are serious problems in this area. On the other hand, if the closure of the online casinos becomes a reality, it will be considered by some as a hard interference in business by the Government. However, the main task of the Government to look after the welfare of its citizens will most likely be the saving grace in such an argument. The initiative to restrict access to online casinos was first sounded at the beginning of 2015, though at the time the Government did not support it, arguing that gambling makes a significant contribution to the budget.
Saburtalo to Be Freed from Traffic Jams BY EKA KARSAULIDZE
S
aburtalo district in Tbilisi is considered by many as a place where traffic jams occur most often. To solve this problem, five options for the improvement of onsite traffic have been presented to Tbilisi City Hall. To date the government has tended to focus more on traffic regulation and street infra-
Five options for the improvement of on-site traffic have been presented to Tbilisi City Hall by Germany Company ‘A+ S Consult GmbH Forschung und Entwicklung’
structure improvements than large-scale construction. The restriction of vehicles, not only in Saburtalo but in other districts of the capital, need to be a part of the unified traffic Master Plan of Georgia. “To study the most challenging aspects of transportation in Tbilisi, we chose a foreign company which has been engaged in the field for many years,” said Vice-Mayor of Tbilisi, Lasha Abashidze. “We intend to make future decisions based on the information and recommendations they presented to us.” Germany Company ‘A+ S Consult GmbH Forschung und Entwicklung’ studied in detail the traffic flow in the Saakadze Square and 26 May Square areas, as well as along Pekini, Kandelaki and others surrounding streets. Following this, they presented the State with five alternative ways to solve the problem which includes better regulation of traffic, as well as large-scale infrastructure projects. According to the company’s research, Saburtalo exceeds the allowable capacity of flow, as a result of which it experiences reduced speed of movement, traffic jams, noise and polluted air. “We have proposed five options,” said Christian
Boettger, Head of Transport Department of ‘A+S Consult GmbH Forschung und Entwicklung’ Company. “It is essential to solve the major problems with the establishment of new traffic lights at various points in the studied areas. In addition, to solve the problem of traffic jams in Tbilisi overall, the government should create new pedestrianized areas. We have presented our vision of problems and a number of solutions and now it is up to the heads of the capital to decide which version is more suitable for them.” Tbilisi City Hall had already announced that they are leaning towards one version which includes the establishment of new ‘smart’ traffic lights, safety islands, public transport development and he introduction of a number of other systems for traffic regulation. “I was satisfied that the studies paid attention to the large area opposite the Holiday Inn Hotel on 26 May Square,” said Shalva Ogbaidze, member of the City Council. “In the past there were suggestions to install a tunnel there, but I’m pleased to see that this option has now been excluded and this area will simply be released to movement in other ways.” Government officials, representatives of NGOs and experts point out that it was important for the State to abandon large-scale infrastructure projects in favor of traffic regulation, the changing of traffic flow and even the limitation of that flow in some areas – options suggested by foreign experts. Moreover, co-director of Georgia’s traffic Master Plan, Merab Bolkvadze, highlighted that although the work on the Plan is at an early stage of development, they fully support such a system and believe that it is possible to solve problems on the roads with the correct regulations.
US Ambassador: Georgia Needs Energy Diversification BY ZVIAD ADZINBAIA
U
S Ambassador to Georgia, Ian C. Kelly, told reporters that Georgia should not become dependent on one source of energy alone. The Ambassador says Georgia needs to take care of its energy diversification. “We have expressed our concern over the fact that Georgia should not become dependent on one source of energy and should maintain diversification,” Kelly was quoted as saying. According to the Ambassador, he is satisfied with the explanations of the Georgian government. “I think Georgia does have a short-term energy need and it should talk to all potential energy suppliers,”
the Ambassador said, adding that the government must be transparent about its energy policy. When asked how normal it is for Georgia to have relations with Gazprom, as its territories are occupied by Russia, the Ambassador replied, “The Georgian government can well realize the existent challenges.” A public protest was held on Saturday near the governmental administration building to rail against the ‘hidden negotiations’ of the government with Russia’s energy giant Gazprom. The protesters accused the government of working against the state and national interests of Georgia.
BUSINESS
GEORGIA TODAY JANUARY 19 - 21, 2016
3
Georgia’s PM Meets Businessmen, Promises “Interesting” Offers BY TAMAR SVANIDZE
G
eorgia’s Prime Minister, Giorgi Kvirikashvili, has met with representatives of the Business Association. It was his first meeting with the Business Association members as Head of
the Georgian Government. Before the meeting, the President of Associations of Banks, Zurab Gvasalia, told reporters that to thank you for what you are doing for our country,” he said. The PM also expressed his interest in learning of the strategy and longterm plans of the Business Association. “I want each of you to feel that you are important in the decisionmaking process,” Kvirikashvili added.
Georgia-Germany Relations Discussed at MFA BY ZVIAD ADZINBAIA
G
Minister Janelidze underlined the need to make maximum use of economic co-operation potential
eorgian Foreign Minister Mikheil Janelidze met the Ambassador Extraordinary and Plenipotentiary of the Federal Republic of Germany to Georgia, Bettina Cadenbach. The Minister is said to have positively assessed the existing close partnership between Georgia and Germany in the political, trade and economic, cultural
and other spheres. Minister Janelidze also underlined the need to make maximum use of economic co-operation potential, which means increased interest of the German business communities in Georgia and a greater volume of German investments in the country. “In this context, Minister Janelidze welcomed the efforts of the German Federal Government to promote the intensification of economic relations, and underlined the need to share Germany’s experience in certain spheres,” the MFA stated. Ambassador Cadenbach once again
expressed the readiness of the German Government to facilitate the further enhancement of bilateral co-operation with Georgia, particularly in the economic sector. “The Ambassador once again reaffirmed Germany’s strong support for the reforms carried out by the Government of Georgia as well as for Georgia’s European integration and territorial integrity,” the MFA said. The talks also included the celebration of the Germany-Georgia Friendship Year in 2017 and Georgia’s participation as Guest of Honor in the Frankfurt Book Fair 2018.
4
BUSINESS
GEORGIA TODAY
JANUARY 19 - 21,.
Men are Rational, Women are Adaptive?
Insights From Georgia’s Consumer Confidence Index
BY YAROSLAVA BABYCH
F
or over three and a half years, the ISET Policy Institute has been tracing the trends in the Georgian consumer sentiments. Every month a team of callers dial randomly generated telephone numbers to interview around 330 people from all over Georgia. The interviewer first asks the basic questions about the respondent’s age, level of education, place of residence, and then follows up with questions about the current financial situation of the household and the person’s expectations about the future economic situation in the country. The answers form the basis of CCI the Consumer Confidence Index. The CCI is a very important indicator for economists. Very low consumer sentiment, for example, means that people
10 Galaktion Street
are likely to spend less, thus depressing the overall economy. Few people realize that behind a single CCI number there is a great deal of useful and sometimes surprising information. The CCI data can be used to informally test some important economic theories. For instance, the theories of rational and adaptive expectations. Here I must disappoint the readers – the terms “rational” and “adaptive” in economics don’t mean the same thing as in our everyday language. Rational has nothing to do with being sensible or logical, and adaptive doesn’t mean that someone is easily adjusting to change. Without digging deep into theory, let’s just say that in trying to predict the future, people with rational expectations are using all the relevant information available to them at the time. What this means, is that people will not be always right about the future, but on average and over time people’s predictions will be right.
So says the rational expectations theory. What about adaptive expectations? People with adaptive expectations form their predictions of the future based on the information about the past. To put it simply, if it has been raining for the last 10 days, you will expect a rainy day tomorrow as well. So what can we say about the expectations of the Georgian consumers? The CCI index can offer some interesting insights. First, let’s look at the correlation between the CCI expectations index (which asks questions about what people expect from the economy in the next 12 months) and the actual average GDP growth 12 months into the future. We can observe that the overall correlation is not very strong (the correlation coefficient is 0.36. This is on the low side. Consider that a coefficient of 1 means perfect correlation, while 0 means no correlation at all). This, however, is not true for every group of people. For men, for example, the expectations about the future and the actual future growth seem to be more strongly correlated (correlation coeffi-
*indicates significance of the coefficient on 10% level; CC =1 indicates perfect positive correlation between two variables; CC = -1 indicates perfectly negative correlation between two variables; CC = 0 indicates no correlation between two variables.
Tel: (995 32) 2 45 08 08 E-mail: info@peoplescafe.ge
cient 0.55). For women, this correlation is almost non-existent. For insights on adaptive expectations, we correlate the CCI expectations index with the actual GDP growth in that month. A strong correlation could imply that people are using the current month’s economic situation to predict what will will happen in the future. The correlation seems to be rather strong for almost all groups, but the strongest correlation we observe in women over 35 years old - the coefficient value is 0.64. (Interestingly, women younger than 35 demonstrate the lowest correlation coefficients in both categories). Does this prove that Georgian men conform to rational expectations hypothesis, while Georgian women to the adaptive expectations? Not really. The simple correlations are by no means a formal test, much less the proof of the rational and adaptive expectations hypotheses. Nevertheless, the results, and especially the differences between the samples of men and women are interesting, don’t you think?
BUSINESS
GEORGIA TODAY JANUARY 19 - 21, 2016
5
Georgian Glass to Be Exported To Italy BY ANA AKHALAIA
T
hirteen
The JSC “Mina” Ksani Glass Factory, 2014.
Giorgi Kvirikashvili Discusses Infrastructural Projects with Governors BY ANA AKHALAIA
P
rime Minister of Georgia, Giorgi Kvirikashvili, and the governors met at a working meeting held in the Government Administration to discuss problems within the regions and current and planned infrastructure projects. As the Government Administration revealed, highlighted topics at the meeting were the investment potential of each region, regional development prospects, and ways of attracting investments to provide for the country’s economic development. The discussions also focused on the needs of the
PM Kvirikashvili said that the government’s goal is to provide safe drinking water for all families and significant
steps should be carried out in this direction. He also emphasized the importance of looking after the country’s youth and
NEW YEAR SALES!
577 22 02 20 577 23 02 30
FROM 800$ sales@redco.ge
regional populations, including gasification, roads and drinking water network rehabilitation projects.
the need for youth involvement in the country’s development processes. At the Administration meeting, the PM heard the opinions and suggestions of the governors about the future plans and working format, as well as about the necessary strengthening of communication with the many branches of government. The meeting was attended by the Minister of Economy and Sustainable Development, Minister of Energy, Minister of Environment and Natural Resources, Minister of Regional Development and Infrastructure, Secretary of Economic Council, Head of Government Administration and the Head of the Department for Relations with Regions and Local Self-Government Units.
FULLY RENOVATED FLATS IN BAKURIANI!
OPEN YOUR DOORS!
6
BUSINESS
GEORGIA TODAY
JANUARY 19 - 21, 2016
Partnership Fund Discussing Construction of Energy Efficient Block Factory BY ANA AKHALAIA
P
lans com-
pleted sig-
nificantly reduce the utility costs for heating and cooling,” Cholokashvili said. The project investment is worth USD 13.5 million. The project is currently under discussion and negotiations are ongoing between the partners.
Handcrafted Georgian natural wines and tapas style food 6, Erekle II str (old town) 0322 93 21 21
Every Wednesday 20% off on special Georgian artisan wine!
Georgian Tapas Menu at g.Vino 0322 93 21 21 fb: g.vinotbilisi
6, Erekle II str (old town)
Changes in Georgian ‘Livo’ Natural Juices Composition of Presented at Berlin Exhibition Board of Directors of JSC PASHA Bank Georgia BY ANA AKHALAIA
G
eorgian natural juices company ‘Livo’ is taking part in the Grüne Woche international exhibition in Berlin. Grüne Woche (International Green Week) was opened on 16 January. With the support of the Ministry of Agriculture, various Georgian companies are presenting their products, includng wine, Chacha (Georgian pomace brandy), beer, lemonades, juices, tea, churchkhela, jam, and more, at the exhibition. Also on show at the exhibition are classic examples of traditional Georgian cuisine with dishes like Khachapuri, Chvishtari, and Phkhali. To compliment the tasty offerings, Georgian ensemble Shvidkatsa will perform polyphonic folk songs for the guests.
P
ASHA Bank Georgia is pleased to announce the appointment of Mr. Chingiz Abdullayev as Member of the Board of Directors and Chief Financial Officer of the Board of Directors as of January 13th, 2016. He is in charge of supervising Financial Management, Treasury as well as Administration and Procurement Departments. Chingiz Abdullayev the Financial Management Department. He became a Member of the Board of Directors on January 13th, 2016. The Board of Directors of JSC PASHA Bank Georgia consists of three Executive Directors, involved in day-to-day management of the Bank. Its current composition is as follows: Chairman of the Board of Directors: Shahin Mammadov
International Green Week (IGW) is taking place for the 81st time in 2016; a one-of-a-kind international exhibition for the food, agricultural and horticultural industries. Producers from all over
FOR RENT
Member of the Board of Directors: George (Goga) Japaridze Member of the Board of Directors: Chingiz Abdullayev PASHA Bank is a Baku-based financial institution operating in Azerbaijan, Georgia and Turkey, providing a full range of corporate and investment banking services to large and medium-sized enterprises.
Apartment in Vake (behind the Vake Swimming Pool) in an ecologically clean environment with beautiful views. The 120 sq. m. duplex apartment on the th 10 floor, newly renovated, with a new kitchen, fireplace, balconies.
Price: 900 USD Tel: 577521020 Tekla (English); 597000109 Dato (Georgian)
the world come to IGW to test market food and luxury items and reinforce their brand image. The opening of the exhibition was attended by the Georgian Minister of Agriculture, Otar Danelia, the Ambassador Extraordinary and Plenipotentiary of Germany, Lado Chanturia, and the Georgian delegation. ‘Livo’ was founded by the Sales Management Company in 2013. Their natural juices are produced in their ‘Citro’ factory in Adjara. The juices are made from local citrus and raw fruit by direct squeezing, which preserves the aromatic taste and the healthy qualities of the juice. According to Quality Lab laboratory, ‘Livo’ juices do not contain any genetically modified organisms. ‘Livo’ lemon juice was awarded a gold medal at the World Food Ukraine international exhibition in Kiev in 2014. The company’s juices are also sold in Russia and Estonia.
BUSINESS
GEORGIA TODAY JANUARY 19 - 21, 2016
7.
Mexico’s Healthcare Reform FOR GEORGIA TODAY BY DAVID NINIKELASHVILI
S
ectoror-
g deter-
mined, respec-
tively)..
8
BUSINESS
GEORGIA TODAY
JANUARY 19 - 21, 2016
Diaspora Money Transfers Down by USD 360 Million BY ANA AKHALAIA
M
oney transfers from abroad in 2015, compared to 2014, decreased by USD 360 million, (25%) and amounted USD 1 billion 80 million. According to eugeorgia.info, the biggest share of transfers (40%), due to the numerous diaspora there, came first and foremost from Russia, where trans-
fers decreased by USD 277 million (39%) last year compared to 2014 amounting to USD 433 million. It should be noted that, in recent years, the share of remittances from Russia has shown a tendency of decline. In 2014 it accounted for half of all transfers. Greece is in second place in remittances, from where the Georgian diaspora transferred just USD 118 million, USD 87 million less than 2014, last year due to the financial crisis. In third place is Italy, from where money
transfers reduced by USD 12 million and amounted to USD 109 million. However, transfers from the US have increased by USD 18 million, amounting to USD 100 million; by USD 4 million from Turkey (USD 69 million); by USD 9 million from Israel (USD 33 million) due to the visa facilitation; and by USD 2 million from Germany (USD 27 million). Remittances from Spain have decreased by almost USD 2 million (USD 27 million), and by USD 10 million from Ukraine (USD 21 million).
ProCredit Bank Offers Best Interest Earnings, +1% for Deposits in GEL
G
ood news for ProCredit Bank customers in 2016: a higher interest rate paid on term deposit accounts in GEL. In order to make it more attractive to save in the local currency, the top interest rate earned by private clients on term deposit accounts is now 12%; or you can make regular payments into a savings
plan account and earn 11.5% interest. ProCredit Bank is also offering the top
interest rate of 12% on child deposit accounts. The increased interest on these accounts gives you an incentive to save as your deposit will earn more interest and grow faster. Open a deposit account in local currency and earn an extra 1% from ProCredit Bank! The German bank for your savings!
BUSINESS
GEORGIA TODAY JANUARY 19 - 21, 2016
Hotel Intourist Palace - For Those Who Know and Appreciate the Best! BY MERI TALIASHVILI
H
otel Intourist Palace is located in the heart of Batumi city, on the Black Sea coast, just in front of the wellloved evergreen boulevard and only 100 meters away from the beach. In its 76 years of existence, more than one million foreign travelers, businessmen, politicians, diplomats, artists and athletes have visited Intourist Palace. If you want to feel the splendor and luxury of the hotel, visit one of Georgia’s most wonderful resort cities, Batumi. Georgia Today met General Manager of Hotel Intourist Palace, Mrs. Tugce Turk Ayag, to speak about this fabulous hotel.
MRS. TUGCE, THE HOTEL INTOURIST PALACE HAS A VERY LONG AND INTERESTING HISTORY. WHEN AND HOW WAS IT FOUNDED? The 5-storey Hotel Intourist Palace was constructed in 1939 by famous Soviet period architect Alexey Shchusev. Where the Hotel now stands was once the unique St. Alexander Nevsky state cathedral which belonged to the world’s most famous houses of worship for its architectural significance and rare beauty. It is known that the church was founded on September 25th in 1888 and Russian Emperor Alexander III and his family were present at the ceremony. The cathedral was a functioning building from the beginning of the 19th century to 1936, when it was destroyed by Soviet atheists. The foundation of the cathedral became the basis of a new building, Hotel Intourist. The Hotel was chosen as a meeting place for the three allied heads of government, but at the last moment the meeting place was transferred to Yalta. During the hotel’s 70-year existence it has undergone a major overhaul and was redesigned twice in 1979-1980 and 2005-2006. The hotel’s distinctive feature is its original semicircular facade with the view of boulevard and alley which leads to the main colonnades of Batumi boulevard.
WHAT DISTINGUISHES HOTEL INTOURIST PALACE FROM OTHER EXISTING HOTELS IN BATUMI? Hotel Intourist Palace is a top-class hotel and an ideal choice for guests of good taste. Here, one will relax in an elegant and luxurious atmosphere. Additionally, you will be provided with the most modern amenities, sports and fitness center. The hotel’s classic rooms are furnished with wooden furniture. All rooms are equipped with air conditioning, a mini bar, a safe, a TV and free internet. The Hotel has an indoor and outdoor pool, sauna, restaurant, terrace, night club and casino. I cannot say that other hotels have less service, but the fact that we are an international brand already means an advantage.
competition, the amount of work has not decreased but is in fact unusually high. So, the demand for the Intourist Palace is high, which is an incentive for all of us.
IN YOUR OPINION, WHY SHOULD A VACATIONER CHOOSE HOTEL INTOURIST? Because each visitor receives special attention and high quality service. This approach to our guests makes our hotel a postcard of Batumi. That is why the majority of tourists in Batumi express their satisfaction with Hotel Intourist service the most. Visitors say this: “Intourist is still Intourist.” Our goal is to offer comfort, luxury and elegance. The hotel has 145 rooms. In addition to the standard rooms, we have the highest standard improved design and luxury categories- premieres and presidential apartments. In order for you to spend a pleasant evening or more, our hotel offers a wide choice of restaurants and bars. Restaurant ‘Tbilisi’ offers delicious dishes in a pleasing and high-class environment. Banquets, parties, weddings and other celebrations can also be organized; in cafe-bar ‘Bakuriani’ you will find a beautiful, comfortable atmosphere and live music. If you want to feel the rhythm and energy of life, then you can visit our night club. We provide two conference halls for any kind of conference and meetings, as ideal for private negotiations as for large meetings.
MRS. TUGCE, SOME MONTHS AGO HOTEL INTOURIST PALACE MOVED TO METRO HOLDING MANAGEMENT. WHAT INNOVATIONS WILL THIS CHANGE BRING?
THE SUCCESS OF ANY COMPANY OR ORGANIZATION DEPENDS ON THE SERVICE. WHAT DO YOU DO TO IMPROVE THE QUALITY OF SERVICE YOU OFFER?
We have gradually rehabilitated and renovated the hotel inventory, the rooms and the hotel’s restaurants. As I mentioned above, highly skilled trainers are retraining our staff. We are preparing a new menu and for the summer season we will offer new services to our guests, both half board and full board packages, as well as a variety of tours. Our great attention is paid to charity: we make a modest contribution to the development of sports and the arts in Adjara. We look forward to welcoming you to come and see for yourself the wonders Intourist Palace can offer you.
Our service is different. Here, trainers take care of our personnel’s professional skills, teaching them with international standards, not local. It is very important to us that the competition has increased. Several top hotels have already opened in Adjara. Intourist Palace welcomes competition if it will be based on the right principles. Our Hotel by meaning works for the business segment. We have absolutely everything a person could possibly need for valuable and comfortable relaxation. Despite high
24-hour room service; 24-hour banking service; Currency Exchange; Cable TV; Minibar; Restaurant Tbilisi; Winter Garden “Bakuriani”; Georgian Wine House; Bar on Swimming Pool; Swedish Breakfast; Catering; Conference and banquet halls; Fitness Center; Beauty Salon; Sauna; Hamam – Turkish Bath; Jacuzzi; Spa Center; Indoor and Outdoor Pools; Transportation Services; Wireless high-speed internet; Night Club “Discorium”; 24-hour Casino.
9
10
BUSINESS
GEORGIA TODAY
JANUARY 19 - 21, 2016
Georgia Takes Part in New York Times Travel Show BY ANA AKHALAIA
T
he Georgian National Tourism Administration (GNTA), under the Mini s t r y o f E c o n o m y, recently took part in the New York Times Travel Show. Several
Georgian companies were also represented at North America’s largest fair-exhibition. The international exhibition in New York was attended by more than 280 tourism professionals from 150 countries. More than 500 companies were represented at the Show. Along with the exhibition, Head of the National Tourism Administration,
Government to Decriminalize Economic Crimes SOURCE: GEORGIANJOURNAL.GE
T
hegovernmentplans to decriminalize economic crimes. This is one of the reforms planned by the executive branch of the government for economic development. The issue was considered at a meeting between representatives of the business sector and Prime Minister Giorgi Kvirikashvili. “You define our country’s economic development. That is why we want to discuss the government’s major trends with you. We have identified four main areas. One of them is the creation of jobs
Giorgi Chogovadze, met with the heads of the world’s tourism companies and associations, a number of whom expressed an interest in the Georgian tourism market. The United States is an important tourism market for Georgia. According to statistics 31,143 tourists visited Georgia from the US in 2015. This was a 10% increase compared to 2014.
ICANN Approves ‘.გე’ Web Addresses SOURCE: GEORGIANJOURNAL.GE
and economic development. In this regard, we have to carry out tax reforms. Decriminalization of economic crimes is also very important in order to prevent imprisonments,” said the PM. He added that his economic team is working to promote the development of start-up businesses and to create a funding mechanism.
T
hrough the decision of the Internet Corporation for Assigned Names and Numbers (ICANN), Georgia has officially been given the right to write web addresses in Georgian by means of the modern alphabet (Mkhedruli), allowing for local web addresses to end with ‘.გე’ (.ge). The “.ge” domains coordinator, IT Development Center will hold a press-conference at 14:00 on January 20 in Tbilisi Marriot at which the procedures carried out by Georgia before the privilege was granted will be presented. The Internet Corporation for Assigned Names and Numbers (ICANN) is a US based non-profit organization, created in 1998, that is responsible for coordinating the maintenance and methodologies of databases, with unique identifiers, related to the namespaces of the Internet in order to ensure the network’s stable and secure operation.
BUSINESS
GEORGIA TODAY JANUARY 19 - 21, 2016
11
Georgia May be Added to Germany’s Safe Countries List
Foreign Minister: European Integration Part of National Identity BY ZVIAD ADZINBAIA
G
eorgian Foreign Minister Mikheil Janelidze received representatives of the diplomatic corps accredited in Georgia and spoke about the importance of Georgia’s integration with the European Union. “It is not just a core foreign policy priority of Georgia, but it has become a part of our national identity because of the sense of belonging to the European system of values,” the Minister said of the integration process. According to the Minister, the Georgian people believe that secure, stable and democratic development of the country can only be assured within the European and Trans-Atlantic area. The MFA says special attention was paid to the restoration of Georgia’s territorial integrity as the main challenge facing the Georgian Government, and, in this context, the importance of Georgia’s constructive participation in the Geneva International Discussions. The Minister also spoke about the need of confidence-building and engagement of the international community in the process of reconciliation with Abkhazians and Ossetians. During the meeting, Minister Janelidze highlighted the successes achieved in the course of 2015, including the Association Agreement signed with the EU, which involves the Deep and Comprehensive Free Trade Agreement (DCFTA), the European Commission’s positive assessment of the Visa Liberalization
Action Plan of Georgia in its final progress report, and the NATO-Georgia Joint Training and Evaluation Center, all a significant step forward. He went on to identify economic diplomacy as one of the Ministry’s top priorities. He emphasized that Georgia has the potential of being turned into a hub linking Europe with growing East Asian markets. In this context the Minister spoke about the importance of the revi-
I
n order to decrease migrant flow to Germany, a local government in Bavaria has requested that the federal Government expand its so-called ‘safe countries’ list. Georgian news agency Interpressnews released this information based on news from German publication Süddeutsche Zeitung. The initiative means that those arriv-
ing in Germany from Georgia will be refused asylum as Georgia is now considered to be a safe country. According to the article, a country where there is no political persecution is assessed as safe. According to Bavaria’s Interior Minister, Joachim Herrman, the list will assist the Government to make decisions over asylum-seekers faster. He added that Armenia, Moldova, Ukraine, India, Mali, Mongolia, Algeria, Gambia and Bangladesh should also be on the list.
It is not just a core foreign policy priority of Georgia, but it has become a part of our national identity because of the sense of belonging to the European system of values
PUBLISHER & GM
George Sharashidze COMMERCIAL DEPARTMENT
Commercial Director: Iva Merabishvili Marketing Manager: Mako Burduli
GEORGIA TODAY
talization of the historic ‘Silk Road’. The Silk Road Forum held in Tbilisi in 2015 served this very goal, contributing to the deepening of cooperation of the Silk Road countries in the fields of transport, communication, infrastructure, trade, energy and industry.
BY TAMAR SVANIDZE. 19 - 21, 2016 | https://issuu.com/georgiatodaynewspaper/docs/19.01.2016_issue810 | CC-MAIN-2020-29 | refinedweb | 5,975 | 50.06 |
On Wed, Apr 11, 2018 at 02:16:23PM -0500, Eric W. Biederman wrote: > Christian Brauner <christian.brau...@canonical.com> writes: > > > On Wed, Apr 11, 2018 at 01:37:18PM -0500, Eric W. Biederman wrote: > >> Christian Brauner <christian.brau...@canonical.com> writes: > >> > >> > On Wed, Apr 11, 2018 at 11:40:14AM -0500, Eric W. Biederman wrote: > >> >> Christian Brauner <christian.brau...@canonical.com> writes: > >> >> > Yeah, agreed. > >> >> > But I think the patch is not complete. To guarantee that no > >> >> > non-initial > >> >> > user namespace actually receives uevents we need to: > >> >> > 1. only sent uevents to uevent sockets that are located in network > >> >> > namespaces that are owned by init_user_ns > >> >> > 2. filter uevents that are sent to sockets in mc_list that have > >> >> > opened a > >> >> > uevent socket that is owned by init_user_ns *from* a > >> >> > non-init_user_ns > >> >> > > >> >> > We account for 1. by only recording uevent sockets in the global > >> >> > uevent > >> >> > socket list who are owned by init_user_ns. > >> >> > But to account for 2. we need to filter by the user namespace who owns > >> >> > the socket in mc_list. So in addition to that we also need to slightly > >> >> > change the filter logic in kobj_bcast_filter() I think: > >> >> > > >> >> > diff --git a/lib/kobject_uevent.c b/lib/kobject_uevent.c > >> >> > index 22a2c1a98b8f..064d7d29ace5 100644 > >> >> > --- a/lib/kobject_uevent.c > >> >> > +++ b/lib/kobject_uevent.c > >> >> > @@ -251,7 +251,8 @@ static int kobj_bcast_filter(struct sock *dsk, > >> >> > struct sk_buff *skb, void *data) > >> >> > return sock_ns != ns; > >> >> > } > >> >> > > >> >> > - return 0; > >> >> > + /* Check if socket was opened from non-initial user namespace. > >> >> > */ > >> >> > + return sk_user_ns(dsk) != &init_user_ns; > >> >> > } > >> >> > #endif > >> >> > > >> >> > > >> >> > But correct me if I'm wrong. > >> >> > >> >> You are worrying about NETLINK_LISTEN_ALL_NSID sockets. That has > >> >> permissions and an explicit opt-in to receiving packets from multiple > >> >> network namespaces. > >> > > >> > I don't think that's what I'm talking about unless that is somehow the > >> > default for NETLINK_KOBJECT_UEVENT sockets. What I'm worried about is > >> > doing > >> > > >> > unshare -U --map-root > >> > > >> > then opening a NETLINK_KOBJECT_UEVENT socket and starting to listen to > >> > uevents. Imho, this should not be possible because I'm in a > >> > non-init_user_ns. But currently I'm able to - even with the patch to > >> > come - since the uevent socket in the kernel was created when init_net > >> > was created and hence is *owned* by the init_user_ns which means it is > >> > in the list of uevent sockets. Here's a demo of what I mean: > >> > > >> > > >> > >> Why do you care about this case? > > > > It's not so much that I care about this case since any workload that > > wants to run a separate udevd will have to unshare the network namespace > > and the user namespace for it to make complete sense. > > What I do care about is that the two of us are absolutely in the clear > > about what semantics we are going to expose to userspace and it seems > > that we were talking past each other wrt to this "corner case". > > For userspace, it needs to be very clear that the intention is to filter > > by *owning user namespace of the network namespace a given task resides > > in* and not by user namespace of the task per se. This is what this > > corner case basically shows, I think. > > If this is just a clarification of semantics then yes this is a > productive question. I almost agree with your definition above. > > I would make the definition very simple. Uevents will not be broadcast > via netlink in a network namespace where net->user_ns != &init_user_ns, > with the exception of uevents for network devices in that network > namespace.
Advertising
Well, for the sake of posterity :) I should add that I'd prefer we'd add what I suggested above: - return 0; + /* Check if socket was opened from non-initial user namespace. */ + return sk_user_ns(dsk) != &init_user_ns; } to slam the door shut once and for all for all non-init_user_ns namespaces because it *seems* like the cleanest solution: uevents are owned by init_user_ns; period. Because it is the only user namespace that can do anything interesting with them *by default*. But what we have now right now with my upcoming patch is at least sufficient and safe. Christian > > The existing filtering by the sending uid and verifying that it is uid 0 > gives a little more room to filter if we want (as udev & friends will > ignore the uevent), but I don't see the point. > > Eric | https://www.mail-archive.com/netdev@vger.kernel.org/msg228449.html | CC-MAIN-2018-17 | refinedweb | 703 | 72.36 |
> > Tuc at T-B-O-H.NET wrote: > > I'd like to upgrade my sendmail version in advance of > > upgrading to the next release of the OS. I was wondering if I > > ..................... > > I don't want to build out of ports because it is set up not to > > override the base install. > > I ran into the same problem years ago, with sendmail from ports > installing into the /usr/local path, and creating two different versions > on the same system, and generally making a Big Mess of itself. > What I was afraid of. And I'll admit there is a bunch of "ASSUME" factor here. When I get on a machine running a certain OS, I have certain expectations of whats "base" install, and what "other" has been installed. If I want sendmail, I'd go to /etc/mail . If it was /usr/local/etc/mail, I'd probably sit there for a few edits of the sendmail.cf in there or something until I realized .. "OH, on THIS machine its in /usr/local/etc/mail". I hate wasting time. :) > > But from some posts here a couple months ago, and reading the Makefile, > I ~THINK~ it [the port] is now set up to replace the stock sendmail and > install into the regular system paths. > > I'm only like 90% on this, but hopefully someone else will confirm: I > think the port will do what you want. > From the Makefile :
.if exists(${DESTDIR}/etc/mail/mailer.conf) && ${PREFIX} == "/usr" pre-everything:: @${ECHO_CMD} "#" @${ECHO_CMD} "# You can't override the base sendmail this way." @${ECHO_CMD} "# your version FreeBSD use mailwrapper." @${ECHO_CMD} "#" @${ECHO_CMD} "# Please install with normal PREFIX" @${ECHO_CMD} "# and activate the port version with" @${ECHO_CMD} "# cd ${PORTSDIR}/mail/sendmail && make mailer.conf" @${ECHO_CMD} "#" @${FALSE} .endif So atleast for /usr/ports/mail/sendmail, the answer is "No". (Unless, I'm reading it wrong, then its either "YES", or "DEFINITE MAYBE".) Tuc _______________________________________________ freebsd-questions@freebsd.org mailing list To unsubscribe, send any mail to "[EMAIL PROTECTED]" | https://www.mail-archive.com/freebsd-questions@freebsd.org/msg177657.html | CC-MAIN-2018-39 | refinedweb | 331 | 75.91 |
Google Sheets is an awesome product by Google which allows you to keep track of data in spreadsheet format. Even though you may be using Sheets regularly, you might not know that it can also be used as a database for your app! In this article, I will teach you how you can do that. Let's begin!
Let's take the example of a Feedback Form on a website. As a first step, create a sheet, giving it an appropriate name. In the first row, add the headers for your sheet. For our Feedback Form, let's consider "Name, Email ID & Feedback" will be the required entries.
Now, taking the URL of the Sheet:, take the Sheet id from it.
The Sheet id is the part after d/, in the above link, it's
1Z5dAPskMy0iC7Tm95c00tC5p366JqiNht9NmWz-hDqQ
Next, go to to create an API for Google Sheets. Use this Sheet ID & give a name to your API.
Afterward, you'll see your API URL like this.
o add data to the Google Sheet, simply POST data to this URL, passing in the
tabId ( name of
subsheet ) as a parameter.
By default, the
tabId of the sheet will be
Sheet1 if you don't edit it yourself. So, considering the below form.
Here is a complete code example in React
import React, { useState } from "react"; export default function Contact() { const [formData, setFormData] = useState({}); const [message, setMessage] = useState(""); const handleInput = e => { const copyFormData = { ...formData }; copyFormData[e.target.name] = e.target.value; setFormData(copyFormData); }; const sendData = async e => { e.preventDefault(); const {name, email, message} = formData try { const response = await fetch( "<your_google_sheet_nocodeapi_endpoiint>?tabId=Feedback", { method: "post", body: JSON.stringify([[name, email, message]]), headers: { "Content-Type": "application/json" } } ); const json = await response.json(); console.log("Success:", JSON.stringify(json)); setMessage("Success"); } catch (error) { console.error("Error:", error); setMessage("Error"); } }; return ( <div className="App"> <form className="input-form" id="contact" name="contact" required onSubmit={sendData} > <input name="name" type="text" placeholder="Name" required onChange={handleInput} /> <input name="email" type="email" placeholder="Email" required onChange={handleInput} /> <textarea name="message" placeholder="Message" onChange={handleInput} /> <input name="submit" type="submit" value="Send" /> {message} </form> </div> ); }
Now, when you submit some data through the form, it will appear in your Google Sheet!
Working with tabId
In your API, the tabId is passed in as a query parameter. According to the tabId, the data can be pushed to a different sub-sheet. Here, let's create
- A Feedback Form
- A Contact Form, and
- A Newsletter Form,
all sending data to different subsheets.
Codesandbox Link:
The data in the above sandbox is added to this Google Sheet :
That's it! Congrats! Check out the rest of our APIs in the marketplace to try something new! Read some more use-cases to get inspiration!
Originally published at nocodeapi.com
Discussion (8)
When i add too much data in react form, then once it's looking good but after that the data is not append in columns A it's append on, where last data finish. What's the reason for it please. I want, my data always show in first column.
Have you set header key values into your google sheet before adding your form values?
No,
Sounds cool! Can we make the google sheet private and still post the content?
Yes, you can do that.
Wow! Thanks for the reply!
Dear friend
i created list box value and radio value in react form when submit button data not sent google sheet.
please tutorial me
good friend
Why my multi select form data is not shown in gsheet please? Else everything is working only array data is not displayed. | https://dev.to/mddanishyusuf/integrate-google-sheets-with-your-feedback-form-21lc | CC-MAIN-2021-17 | refinedweb | 606 | 57.16 |
# Locks in PostgreSQL: 1. Relation-level locks
The previous two series of articles covered [isolation and multiversion concurrency control](https://habr.com/en/company/postgrespro/blog/467437/) and [logging](https://habr.com/en/company/postgrespro/blog/491730/).
In this series, we will discuss **locks**.
This series will consist of four articles:
1. Relation-level locks (this article).
2. [Row-level locks](https://habr.com/en/company/postgrespro/blog/503008/).
3. [Locks on other objects and predicate locks](https://habr.com/en/company/postgrespro/blog/504498/).
4. [Locks in RAM](https://habr.com/en/company/postgrespro/blog/507036/).
The material of all the articles is based on training courses on administration that Pavel [pluzanov](https://habr.com/ru/users/pluzanov/) and I are creating (mostly [in Russian](https://postgrespro.ru/education/courses), although one course is available [in English](https://postgrespro.com/education/courses)), but does not repeat them verbatim and is intended for careful reading and self-experimenting.
> Many thanks to Elena Indrupskaya for the translation of these articles into English.
>
>

General information on locks
============================
PostgreSQL has a wide variety of techniques that serve to lock something (or are at least called so). Therefore, I will first explain in the most general terms why locks are needed at all, what kinds of them are available and how they differ from one another. Then we will figure out what of this variety is used in PostgreSQL and only after that we will start discussing different kinds of locks in detail.
Locking is used to order concurrent access to shared resources.
By concurrent access, simultaneous access of several processes is meant. These processes themselves can run either in parallel (if the hardware permits) or sequentially in a time-sharing mode — it makes no difference.
Without concurrency, no locking is needed (for example: the shared buffer cache requires locking, while a local one does not).
Before accessing a resource, a process must *acquire* the lock associated with this resource. So this is a matter of certain discipline: everything works fine while processes conform to established rules of access to a shared resource. If a DBMS controls locking, it maintains order on its own; but if an application sets locks, the responsibility falls on it.
At a low level, a lock is an area in the shared memory with some indication of whether the lock is released or acquired (and maybe some additional information): the process number, acquisition time and so forth).
> Note that this area in the shared memory itself is a resource that allows concurrent access. If we descend yet to a lower level, we will see that to regulate access, OS provides specialized synchronization primitives (such as semaphores or mutexes). Their purpose is to ensure that code accessing a shared resource is used only in one process. At the lowest level, these primitives are implemented through atomic processor instructions (such as `test-and-set` or `compare-and-swap`).
>
>
When a resource is no longer needed to a process, the latter *releases* the lock so that other processes can use it.
Certainly, sometimes a lock cannot be acquired: the resource can be already in use by someone else. Then the process either stands in a wait queue (if the locking technique permits this) or repeats an attempt to acquire the lock some time later. Anyway, the process has to be idle in a wait for the resource to be free.
> Sometimes, other, non-blocking, strategies can be used. For example: [multiversion concurrency control](https://habr.com/en/company/postgrespro/blog/467437/) in certain cases, allows several processes to work simultaneously with different versions of data without blocking one another.
>
>
In general, by the resource to be protected we mean anything that we can unambiguously identify and associate the lock address with it.
For example: a DBMS object such as a data page (identified by the filename and location inside the file), table (OID in the system catalog), or table row (the page and offset inside it) can be a resource. A memory structure such as a hash table, buffer and so forth (identified by a previously assigned number) can also be a resource. Sometimes it is even convenient to use abstract resources, which have no physical meaning (identified just by a unique number).
Many factors affect the efficiency of locking, of which we give prominence to two.
* The **granularity** is critical when the resources are organized in a hierarchy.
For example: a table consists of pages, which contain table rows. All these objects can be resources. If processes are interested only in a few rows, but a lock is acquired at the table level, other processes will be unable to simultaneously work with different rows. Therefore, the higher the granularity, the better for enabling parallelization.
But this causes increase of the number of locks (for which the information needs to be stored in memory). In this case, *escalation* of locks can be applied: when the number of low-level high-granularity locks exceeds a certain limit, they are replaced with one higher-level lock.
* Locks can be acquired in various **modes**.
The names of the modes can be any; what really matters is the matrix of their compatibility with each other. The mode that is incompatible with any mode (including itself) is usually called *exclusive*. If modes are compatible, several processes can acquire a lock simultaneously; modes like these are called *shared*. In general, the more modes compatible with each other can be distinguished, the more opportunities for concurrency occur.
By the duration, locks can be divided into long and short.
* **Long** locks are acquired for a potentially long time (usually up to the end of the transaction) and most often relate to such resources as tables (relations) and rows. As a rule, PostgreSQL controls these locks automatically, but a user, however, has certain control over this process.
A large number of modes is typical of long locks to enable as many simultaneous data operations as possible. Usually an extensive infrastructure (for example: support of wait queues and detection of deadlocks) and monitoring tools are available for such locks since the maintenance cost of all these convenient features is anyway incomparably less than the cost of operations over data being protected.
* **Short** locks are acquired for a short time (from a few processor instructions to fractions of seconds) and usually relate to data structures in the shared memory. PostgreSQL controls such locks in a fully automatic fashion — you only need to be aware of their existence.
The minimum of modes (exclusive and shared) and a simple infrastructure are typical of short locks. Sometimes there can even be no monitoring tools.
PostgreSQL uses different kinds of locks.
**Object-level locks** pertain to long, «heavy-weight» locking. Relations and other objects are resources here. If in this article you come across the word «lock» or «locking» without clarification, it means just this, «normal» locking.
Among long locks, **row-level locks** stand out separately. They are implemented differently from other long locks because they are potentially huge in number (imagine an update of a million of rows in one transaction). We will discuss these locks in the next article.
The third article of the series will cover the remaining object-level locks, as well as **predicate locks** (since the information on all these locks is uniformly stored in RAM).
Short locks comprise various **locks on RAM structures**. We will discuss them in the last article of the series.
Object-level locks
==================
So, we are starting with object-level locks. By an object here we primarily mean *relations*, that is, tables, indexes, sequences and materialized views, but also some other entities. These locks are normally used to protect objects against simultaneous changes or against use when the object is being changed, but also for other needs.
The wording is vague, isn't it? Exactly so, since locks in this group are used for various purposes. The only thing that unites them is how they are organized.
Organization
------------
Object locks are stored in the shared memory of the server. The number of them is limited by the product of two parameter values: *max\_locks\_per\_transaction* × *max\_connections*.
The pool of locks is one for all transactions, that is, a transaction can acquire more locks than *max\_locks\_per\_transaction*: the only important thing is that the total number of locks in the system does not exceed the number specified. The pool is created at startup, so to change any of the two above parameters a server restart is required.
You can see all the locks in the `pg_locks` view.
If a resource is already locked in an incompatible mode, the transaction that tries to acquire the lock is queued to wait until the lock is released. Waiting transactions do not consume processor resources: backend processes involved «fall asleep» and are waked up by the OS when the resource gets free.
When to continue the work, one transaction needs a resource that is in use by another transaction, while the second one needs a resource that is in use by the first, a *deadlock* occurs. In general, a deadlock of more than two transactions can arise. In such a case, the wait will last infinitely, therefore, PostgreSQL detects such situations automatically and aborts one of the transactions to enable the others continue. (We will discuss deadlocks in detail in the next article.)
Object types
------------
The following is a list of lock types (or, if you like, object types) that we will deal with in this and next articles. The names are provided according to the `locktype` column of the `pg_locks` view.
* **relation**
Locks on relations.
* **transactionid** и **virtualxid**
Locks on the transaction ID (actual or virtual). Each transaction itself holds an exclusive lock on its own ID, therefore, such locks are convenient to use when we need to wait until completion of another transaction.
* **tuple**
Locks on a tuple. Used in some instances to prioritize several transactions waiting for a lock on the same row.
We will put off a talk on other types of locks until the third article of this series. All of them are acquired either in the exclusive or in the share/exclusive mode.
* **extend**
Used when adding pages to a file of some relation.
* **object**
Locks on objects different from relations (databases, schemas, subscriptions and so forth).
* **page**
Locks on a page — used infrequently and only by certain types of indexes.
* **advisory**
Advisory locks — a user has them acquired manually.
Relation-level locks
====================
In order not to fall out of context, in a figure like this, I will mark those types of locks that will be discussed further.
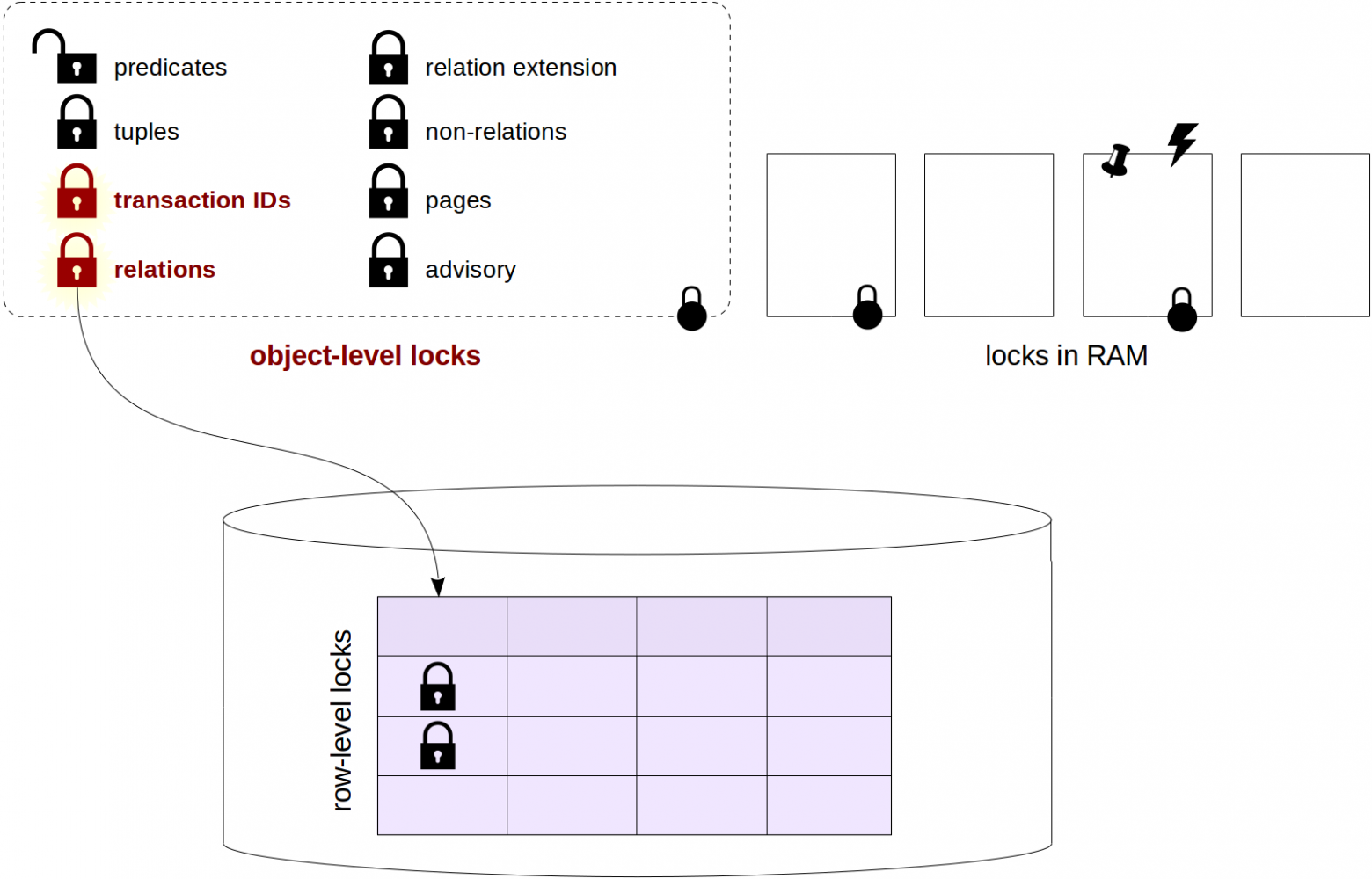
Modes
-----
Unless a relation-level lock is the most important among locks, it is mostly rich in modes for sure. As many as 8 different modes are defined for it. That many are needed to enable simultaneous execution of the maximum possible number of commands related to one table.
There is no point in committing these modes to your memory or trying to get an insight into their names; what is really important is to have near at hand the [matrix](https://postgrespro.com/docs/postgresql/10/explicit-locking#LOCKING-TABLES) that shows which locks conflict each other. For convenience, it is provided here along with examples of commands that require the corresponding levels of locking:
| Locking mode | AS | RS | RE | SUE | S | SRE | E | AE | Example of SQL commands |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Access Share | | | | | | | | X | SELECT |
| Row Share | | | | | | | X | X | SELECT FOR UPDATE/SHARE |
| Row Exclusive | | | | | X | X | X | X | INSERT, UPDATE, DELETE |
| Share Update Exclusive | | | | X | X | X | X | X | VACUUM, ALTER TABLE\*, СREATE INDEX CONCURRENTLY |
| Share | | | X | X | | X | X | X | CREATE INDEX |
| Share Row Exclusive | | | X | X | X | X | X | X | CREATE TRIGGER, ALTER TABLE\* |
| Exclusive | | X | X | X | X | X | X | X | REFRESH MAT. VIEW CONCURRENTLY |
| Access Exclusive | X | X | X | X | X | X | X | X | DROP, TRUNCATE, VACUUM FULL, LOCK TABLE, ALTER TABLE\*, REFRESH MAT. VIEW |
A few comments:
* First 4 modes allow concurrent changes of the table data, while the next 4 do not.
* The first mode (Access Share) is the weakest, it is compatible with any other but the last (Access Exclusive). This last mode is exclusive, it is incompatible with any other.
* The ALTER TABLE command has many flavors, and different flavors require different-level locks. Therefore, this command occurs in different rows of the matrix and is marked with an asterisk.
To illustrate
-------------
Let's consider an example. What happens if we execute the CREATE INDEX command?
We learn from the documentation that this command acquires a Share lock. From the matrix, we learn that the command is compatible with itself (that is, several indexes can be created simultaneously) and with read commands. So, SELECT command will continue working, while UPDATE, DELETE and INSERT will be blocked.
And vice versa: non-completed transactions that change table data will block execution of the CREATE INDEX command. It's for this reason that the CREATE INDEX CONCURRENTLY flavor of the command is available. Its execution takes longer (and it can even fail with an error), but it allows concurrent data updates.
You can make sure of this in practice. For experiments we will use the table of «bank» accounts, which is familiar to us since the [first series](https://habr.com/en/company/postgrespro/blog/467437/) and in which will store the account number and amount.
```
=> CREATE TABLE accounts(
acc_no integer PRIMARY KEY,
amount numeric
);
=> INSERT INTO accounts
VALUES (1,1000.00), (2,2000.00), (3,3000.00);
```
In the second session, we'll start a transaction. We will need the process ID of the backend process.
```
| => SELECT pg_backend_pid();
```
```
| pg_backend_pid
| ----------------
| 4746
| (1 row)
```
What locks does the transaction that just started hold? Looking into `pg_locks`:
```
=> SELECT locktype, relation::REGCLASS, virtualxid AS virtxid, transactionid AS xid, mode, granted
FROM pg_locks WHERE pid = 4746;
```
```
locktype | relation | virtxid | xid | mode | granted
------------+----------+---------+-----+---------------+---------
virtualxid | | 5/15 | | ExclusiveLock | t
(1 row)
```
As I said before, a transaction always holds an Exclusive lock on its own ID, which is virtual in this case. This process has no other locks.
Now let's update a table row. How will the situation change?
```
| => UPDATE accounts SET amount = amount + 100 WHERE acc_no = 1;
```
```
=> \g
```
```
locktype | relation | virtxid | xid | mode | granted
---------------+---------------+---------+--------+------------------+---------
relation | accounts_pkey | | | RowExclusiveLock | t
relation | accounts | | | RowExclusiveLock | t
virtualxid | | 5/15 | | ExclusiveLock | t
transactionid | | | 529404 | ExclusiveLock | t
(4 rows)
```
Locks on the table being changed and on the index (created for the primary key) being used by the UPDATE command appeared. Both locks acquired are Row Exclusive. Besides, an exclusive lock on the actual transaction ID was added (the ID appeared as soon as the transaction started changing data).
Now we'll try to create an index on the table in yet another session.
```
|| => SELECT pg_backend_pid();
```
```
|| pg_backend_pid
|| ----------------
|| 4782
|| (1 row)
```
```
|| => CREATE INDEX ON accounts(acc_no);
```
The command «hangs» waiting for the resource to be free. What lock in particular does it try to acquire? Let's figure this out:
```
=> SELECT locktype, relation::REGCLASS, virtualxid AS virtxid, transactionid AS xid, mode, granted
FROM pg_locks WHERE pid = 4782;
```
```
locktype | relation | virtxid | xid | mode | granted
------------+----------+---------+-----+---------------+---------
virtualxid | | 6/15 | | ExclusiveLock | t
relation | accounts | | | ShareLock | f
(2 rows)
```
It's clear now that the transaction tries to acquire a Share lock on the table, but cannot (`granted = f`).
In order to find the process ID (pid) of the locking process, and in general, several pids, it is convenient to use the function that appeared in version 9.6 (before that, the conclusions had to be made by carefully examining all the contents of `pg_locks`):
```
=> SELECT pg_blocking_pids(4782);
```
```
pg_blocking_pids
------------------
{4746}
(1 row)
```
And then, to understand the situation, we can get information on the sessions to which the pids found pertain:
```
=> SELECT * FROM pg_stat_activity
WHERE pid = ANY(pg_blocking_pids(4782)) \gx
```
```
-[ RECORD 1 ]----+------------------------------------------------------------
datid | 16386
datname | test
pid | 4746
usesysid | 16384
usename | student
application_name | psql
client_addr |
client_hostname |
client_port | -1
backend_start | 2019-08-07 15:02:53.811842+03
xact_start | 2019-08-07 15:02:54.090672+03
query_start | 2019-08-07 15:02:54.10621+03
state_change | 2019-08-07 15:02:54.106965+03
wait_event_type | Client
wait_event | ClientRead
state | idle in transaction
backend_xid | 529404
backend_xmin |
query | UPDATE accounts SET amount = amount + 100 WHERE acc_no = 1;
backend_type | client backend
```
When the transaction is completed, the locks are released and index is created.
```
| => COMMIT;
```
```
| COMMIT
```
```
|| CREATE INDEX
```
Join the queue!..
-----------------
To better understand what occurrence of an incompatible lock entails, let's see what will happen if we execute the VACUUM FULL command during system operation.
Let SELECT be the first command executed on the above table. It acquires a weakest-level, Access Share, lock. To control the time of releasing the lock, we execute this command inside the transaction — the lock won't be released until the transaction completes. Actually several commands can read (and update) a table, and execution of some queries can take pretty long.
```
=> BEGIN;
=> SELECT * FROM accounts;
```
```
acc_no | amount
--------+---------
2 | 2000.00
3 | 3000.00
1 | 1100.00
(3 rows)
```
```
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for
FROM pg_locks WHERE relation = 'accounts'::regclass;
```
```
locktype | mode | granted | pid | wait_for
----------+-----------------+---------+------+----------
relation | AccessShareLock | t | 4710 | {}
(1 row)
```
Then the administrator executes the VACUUM FULL command, which requires a lock that has the Access Exclusive level and that is inconsistent with everything, even with Access Share. (The LOCK TABLE command requires the same lock.) And the transaction is queued.
```
| => BEGIN;
| => LOCK TABLE accounts; -- the same lock mode as for VACUUM FULL
```
```
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for
FROM pg_locks WHERE relation = 'accounts'::regclass;
```
```
locktype | mode | granted | pid | wait_for
----------+---------------------+---------+------+----------
relation | AccessShareLock | t | 4710 | {}
relation | AccessExclusiveLock | f | 4746 | {4710}
(2 rows)
```
But the application continues to issue queries, and so the SELECT command also occurs in the system. Hypothetically, it could «make it through» while VACUUM FULL is waiting, but no — it honestly stands in a queue for VACUUM FULL.
```
|| => SELECT * FROM accounts;
```
```
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for
FROM pg_locks WHERE relation = 'accounts'::regclass;
```
```
locktype | mode | granted | pid | wait_for
----------+---------------------+---------+------+----------
relation | AccessShareLock | t | 4710 | {}
relation | AccessExclusiveLock | f | 4746 | {4710}
relation | AccessShareLock | f | 4782 | {4746}
(3 rows)
```
When the first transaction with the SELECT command completes and releases the lock, the VACUUM FULL command (which we simulated by the LOCK TABLE command) starts.
```
=> COMMIT;
```
```
COMMIT
```
```
| LOCK TABLE
```
```
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for
FROM pg_locks WHERE relation = 'accounts'::regclass;
```
```
locktype | mode | granted | pid | wait_for
----------+---------------------+---------+------+----------
relation | AccessExclusiveLock | t | 4746 | {}
relation | AccessShareLock | f | 4782 | {4746}
(2 rows)
```
And it's only after VACUUM FULL completes and releases the lock, all the queued commands (SELECT in this example) will be able to acquire appropriate locks (Access Share) and execute.
```
| => COMMIT;
```
```
| COMMIT
```
```
|| acc_no | amount
|| --------+---------
|| 2 | 2000.00
|| 3 | 3000.00
|| 1 | 1100.00
|| (3 rows)
```
So, an improperly executed command can paralyze work of the system for the time interval that is way longer than it takes to execute the command itself.
Monitoring tools
================
It's beyond doubt that locks are needed for correct work, but they can cause undesirable waits. These waits can be tracked in order to figure out their root cause and eliminate it whenever possible (for example: by changing the algorithm of the application).
We are already acquainted with one way to do this: when a long lock occurs, we can query the `pg_locks` view, look at locked and locking transactions (using the `pg_blocking_pids` function) and interpret the data using `pg_stat_activity`.
Another way is to turn the *log\_lock\_waits* parameter on. In this case, information will get into the server message log if a transaction waited longer than *deadlock\_timeout* (although the parameter is used for deadlocks, normal waits are meant here).
Let's try.
```
=> ALTER SYSTEM SET log_lock_waits = on;
=> SELECT pg_reload_conf();
```
The default value of the *deadlock\_timeout* parameter is one second:
```
=> SHOW deadlock_timeout;
```
```
deadlock_timeout
------------------
1s
(1 row)
```
Let's reproduce a lock.
```
=> BEGIN;
=> UPDATE accounts SET amount = amount - 100.00 WHERE acc_no = 1;
```
```
UPDATE 1
```
```
| => BEGIN;
| => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
```
The second UPDATE command is waiting for the lock. Let's wait for a second and complete the first transaction.
```
=> SELECT pg_sleep(1);
=> COMMIT;
```
```
COMMIT
```
Now the second transaction can be completed.
```
| UPDATE 1
```
```
| => COMMIT;
```
```
| COMMIT
```
And all the important information was logged:
```
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
```
```
2019-08-07 15:26:30.827 MSK [5898] student@test LOG: process 5898 still waiting for ShareLock on transaction 529427 after 1000.186 ms
2019-08-07 15:26:30.827 MSK [5898] student@test DETAIL: Process holding the lock: 5862. Wait queue: 5898.
2019-08-07 15:26:30.827 MSK [5898] student@test CONTEXT: while updating tuple (0,4) in relation "accounts"
2019-08-07 15:26:30.827 MSK [5898] student@test STATEMENT: UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
```
```
2019-08-07 15:26:30.836 MSK [5898] student@test LOG: process 5898 acquired ShareLock on transaction 529427 after 1009.536 ms
2019-08-07 15:26:30.836 MSK [5898] student@test CONTEXT: while updating tuple (0,4) in relation "accounts"
2019-08-07 15:26:30.836 MSK [5898] student@test STATEMENT: UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
```
[Read on](https://habr.com/en/company/postgrespro/blog/503008/). | https://habr.com/ru/post/500714/ | null | null | 3,581 | 53.92 |
The objective of this post is to explain how to control a LED through WiFi, using the ESP8266.
Introduction
The objective of this post is to explain how to control a LED wirelessly through WiFi, with the ESP8266 acting as a web server.
Most of the code used here will be based on previous tutorials, so only a brief explanation will be done. In the related posts section bellow, I will leave links for all the relevant related posts.
If you are using a development board such as the NodeMCU, you can use the built in LED to test the code presented in this tutorial without the needed for additional hardware. If your development board doesn’t have a controllable LED, you can check this previous post on how to control a LED with the ESP8266.
The setup code
Most of the relevant code will be similar to the one of this previous post where we explained how to set a simple HTTP web server with the ESP8266.
So, we start by including the libraries needed to connect the ESP8266 to a WiFi network and to set the HTTP server.
#include <ESP8266WiFi.h>
#include <ESP8266WebServer.h>
Next, we declare a global object variable from the ESP8266WebServer class. This class will have the methods needed to set the HTTP server.
ESP8266WebServer server(80);
We passed 80 for the constructor, which indicates that the server will be listening on port 80.
We will also declare a global variable to specify the LED pin and another for its state (on or off).
int ledPin = 16;
bool ledState = LOW;
There is no problem in initializing a Boolean variable with LOW because it will correspond to “0” [1]. Also, I’m using GPIO 16 because, on the NodeMCU (one of the most used ESP boards), it corresponds to the board’s LED pin.
We need to specify that the pin will be an output pin. We do this in the setup function.
pinMode(ledPin, OUTPUT);
Also in the setup function, we will specify the URLs where our server will be listening to incoming HTTP requests. We will define 3 URLs, one for each operation on the LED: turn on, turn off and toggle.
server.on(“/on”, turnOn); //Associate the handler function to the path
server.on(“/off”, turnOff); //Associate the handler function to the path
server.on(“/toggle”, toggle); //Associate the handler function to the path
The first argument of the on method specifies the path where the server should listen, and the second argument specifies the name of the handling function that will be executed by the ESP8266 when a request to the corresponding path is received. We will specify those functions latter.
Bellow is the complete setup function. We start by connecting to the WiFi network, doing some prints to the serial port indicating if the connection was successful and we declare the paths of our HTTP server. We finalize the setup of our server by calling the begin method on the server object.
void setup() {
pinMode(ledPin, OUTPUT);
Serial.begin(115200);
WiFi.begin(“YourNetworkName”, “YourPassword”); //Connect to the WiFi network
while (WiFi.status() != WL_CONNECTED) { //Wait for connection
delay(500);
Serial.println(“Waiting to connect…”);
}
Serial.print(“IP address: “);
Serial.println(WiFi.localIP()); //Print the local IP
server.on(“/on”, turnOn); //Associate the handler function to the path
server.on(“/off”, turnOff); //Associate the handler function to the path
server.on(“/toggle”, toggle); //Associate the handler function to the path
server.begin(); //Start the server
Serial.println(“Server listening”);
}
To handle the actual incoming of HTTP requests, we need to call the handleClient method on the server object, on the main loop function.
void loop() {
server.handleClient();
}
The handling functions
For the turnOn handler function, we will start by setting the ledState variable to HIGH, since we want to turn on the LED.
ledState = HIGH;
We then write the state of the LED with the digitalWrite function.
digitalWrite(ledPin, ledState);
In the last line of code of the handler function, we will just send the HTTP response, so the client knows the action was performed. If we remember the previous post, the first argument of the function is the HTTP response code, the second the type of content of the response, and the third the actual response.
server.send(200, “text/plain”, “LED on”);
You can check the full handling function bellow.
void turnOn(){
ledState = HIGH;
digitalWrite(ledPin, ledState);
server.send(200, “text/plain”, “LED on”);
}
The handler for the turnOff URL is exactly the same, except for the fact that we will set the ledState variable to LOW.
void turnOff(){
ledState = LOW;
digitalWrite(ledPin, ledState);
server.send(200, “text/plain”, “LED off”);
}
The toggling handling function is also similar, except that we apply the NOT operator to the ledState variable and assign it to itself.
void toggle(){
ledState = !ledState;
digitalWrite(ledPin, ledState);
server.send(200, “text/plain”, “LED toggled”);
}
Important: When directly copying the code from the blog, a stray error may occur when trying to compile it on Arduino. In my case, this occurs because the editor assumes the wrong type of quotes. The easiest way to fix this, given the number of existing quotes, is to do a find and replace and put the correct quotes.
Testing the code
To test the code, we simply copy the IP that gets printed on the serial console and use it in a web browser in the format seen bellow.
For the on path, we should get the result shown in figure 1. Note that you will probably have a different IP, depending on which was assigned to the ESP on your network.
Figure 1 – LED on URL.
For the off path, we can see the expected output in figure 2.
Figure 2 – LED off URL.
Finally, the result for the toggle path is shown in figure 3.
Figure 3 – LED toggle URL..
Final notes
As we saw in this post, associating hardware functionality to a URL of the ESP8266 web server is very easy. Although we used 3 different endpoints, we could have only used one and allow the client to pass the state of the LED in the query parameters, for example.
When associating functionality to the handling functions, we need to consider that we should not leave the client waiting for a response for a long time, which may cause a timeout. If we need to perform an operation that takes some time, it’s always an option to consider doing it asynchronously.
Although this simple example may seem a little bit useless in the real world IoT, if we change the LED for a relay (the code is exactly the same, just a little bit of extra hardware), we can start controlling high power devices, such as lamps or heaters.
Related posts
- ESP8266: Blinking a LED
- ESP8266: Setting a simple HTTP webserver
- ESP8266: Connecting to a WiFi Network
- ESP8266: uploading code from Arduino IDE
- ESP8266 Webserver: Getting query parameters
References
[1]
[2]
Technical details
ESP8266 libraries: v2.3.0
Pingback: ESP8266 Webserver: Accessing the body of a HTTP request | techtutorialsx | https://techtutorialsx.com/2016/11/19/esp8266-webserver-controlling-a-led-through-wifi/ | CC-MAIN-2017-26 | refinedweb | 1,181 | 62.88 |
selabel_lookup_best_match - Man Page
obtain a best match SELinux security context — Only supported on file backend.
Synopsis
#include <selinux/selinux.h>
#include <selinux/label.h>
int selabel_lookup_best_match(struct selabel_handle *hnd, char **context,
const char *key,
const char **links,
int type);
int selabel_lookup_best_match_raw(struct selabel_handle *hnd, char **context,
const char *key,
const char **links,
int type);
Description
selabel_lookup_best_match() performs a best match lookup operation on the handle hnd, returning the result in the memory pointed to by context, which must be freed by the caller using freecon(3). The key parameter is a file path to check for best match using zero or more link (aliases) parameters. The order of precedence for best match is:
- An exact match for the real path (key) or
- An exact match for any of the links (aliases), or
- The longest fixed prefix match.
The type parameter is an optional file mode argument that should be set to the mode bits of the file, as determined by lstat(2). mode may be zero, however full matching may not occur.
selabel_lookup_best_match_raw() behaves identically to selabel_lookup_best_match() but does not perform context translation..
Notes
Example usage - When a service creates a device node, it may also create one or more symlinks to the device node. These symlinks may be the only stable name for the device, e.g. if the partition is dynamically assigned. The file label backend supports this by looking up the "best match" for a device node based on its real path (key) and any links to it (aliases). The order of precedence for best match is described above.
See Also
selabel_open(3), selabel_stats(3), selinux_set_callback(3), selinux(8), lstat(2), selabel_file(5)
Referenced By
The man page selabel_lookup_best_match_raw(3) is an alias of selabel_lookup_best_match(3). | https://www.mankier.com/3/selabel_lookup_best_match | CC-MAIN-2021-21 | refinedweb | 289 | 53.1 |
This is the mail archive of the docbook@lists.oasis-open.org mailing list for the DocBook project.
At 21:39 2003 05 20 +0200, Tobias Reif wrote: >Paul Grosso wrote: > > >>There may be no processing expections, but somewhere we have to >>say what this attribute is expected to represent: the namespace >>name. Given that the name ("namespace") is unclear, I'd like it >>recorded that the value of this attribute is expected to be a >>namespace name. > > >What's a "namespace name"? The term is officially defined at/by paul >I'd use nothing but a URI/URL when representing, naming, or otherwise representing an XML namespace. --------------------------------------------------------------------- To unsubscribe, e-mail: docbook-unsubscribe@lists.oasis-open.org For additional commands, e-mail: docbook-help@lists.oasis-open.org | https://www.sourceware.org/ml/docbook/2003-05/msg00145.html | CC-MAIN-2019-13 | refinedweb | 129 | 57.87 |
LINQ Interview Questions
LINQ is an abbreviated form of Language -integrated Quer. It is an innovation which is used to bridge the gap between two platforms, namely Visual Studio 2008 and the .NET framework. There is a number of LINQ queries that are used to retrieve data from the data sources. In this, blog, we are providing a collection of LINQ interview questions that will help you in cracking interviews. Traditionally, the queries against data can be expressed in the form of simple strings without supporting IntelliSense. Likewise, users can use the coding patterns for the purpose of transforming data in XML documents, ADO.NET datasets, .NET collections, SQL databases and another format for which LINQ provider is available.
We are providing a vast collection of LINQ interview questions, which will help you in achieving success factors.
Advantages of LINQ
- Unified data access (Single syntax to learn)
- Strongly typed (During completion automatically catch errors)
- IntelliSense (Prompt attributes and syntax)
- Bind-able result sets
- Allows debugging through the .NET debugger
- Type checking at compile time
Disadvantages of LINQ
- Not suitable to write complex queries like SQL
- It does not support SQL features such as cached execution
- Performance degraded if the query is incorrect
- In order to incorporate changes in query, you need to recompile and redeploy it
The LINQ interview questions that most probably asked during the interview are providing in this blog that will help you in order to achieve the desired goals.
Most Frequently Asked LINQ Interview Questions And Answers With Examples:
- What is LINQ and why it is used?
- What is the difference between Linq and lambda expression?
- What are the types of LINQ?
- What is the difference between SQL and LINQ?
- Explain Query and Sequence operators in LINQ?
- What is the difference between the Take and Skip clause in LINQ?
- What is Action in LINQ?
- What is an Anonymous function in LINQ?
- How LINQ is beneficial than stored procedures?
- What is PLINQ and how it is different from LINQ?
- What is Select() and SelectMany() in LINQ?
- What is deferred execution in Linq?
- What is the difference between SkipWhile() and Skip() methods in LINQ?
- What are compiled queries in LINQ?
- How to retrieve a single row with LINQ?
- What are the difference between Conversion Operator ToDictionary and IEnumerable of LINQ?
- What is the difference between Single() and First() extension methods in LINQ?
- What is the difference between N-layer and N-tier architecture in LINQ?
- What are entity classes in LINQ?
- Explain expression trees in LINQ?
- What are Quantifier Operations in LINQ?
LINQ is an abbreviated form of Language Integrated Query, which is a part of the language used to used provide seamless and consistent access to a number of data sources such as XML and databases. LINQ is categorized into three varieties namely LINQ (C#), LINQ providers (LINQ to SQL, LINQ to XML and LINQ to Objects), and data sources (collections, SQL and XML)
LINQ is used to make the code readable and compact and it is used to query different types of data sources. likewise, it is familiar language, required less coding, readable code, compile-time safety, IntelliSense support and shaping up of data support.
Following are the difference between LINQ expression and LAMBDA expression
1. LINQ expression- In order to extend the functionality a query capabilities LINQ expression to the language syntax of C# and Visual Basic.
2. Lambda expression- It is a function that is used to create expressions in the form of a tree. With the help of lambda expression, users can write local functions that can be passed as a return value of function calls
LINQ is of five types namely-
- LINQ to objects
- LINQ to dataset
- LINQ to XML (XLINQ)
- LINQ to entities
- LINQ to SQL (DLINQ)
Following is the difference between SQL and LINQ queries-
1. SQL- The main return type of local variable that holds query in SQL is IQueryable. Moreover, it is a Structured Query Language used for the manipulation of data.
2. LINQ- The main return type of local variable that holds query in LINQ is IEnumerable. Moreover, it translates the query into equivalent SQL queries and sends them for processing to the server.
The query is an expression which is used to recover data from a variety of data sources and query can be expressed in specialized languages.
Three types of actions can be performed on LINQ query namely
- Get data source
- Create Query
- Execution of Query
LINQ does not support sequence operators but it is having the following qualities-
- Take lambda expression with an index parameter
- Depend on the properties of sequential rows
- Depend on the CLR implementation
Following are the difference between TAKE and SKIP clause
1. Take clause- Take clause in LINQ is used to return a specific number of elements.
2. Skip clause- Skip clause is used to skip the specified number of elements in the query and return rest all of the present elements.
Action in LINQ is a delegate type that is used to declare delegate variables without any need to define a custom type. The Action types that represent delegate without return value are the Action types in the System namespace
LINQ is beneficial than stored procedure due to-
- Debugging
- Type safety
- Deployment
PLINQ stands for Parallel LINQ which is a query execution engine that drives and manages their operations on the top of the managed environment of .NET. | https://www.bestinterviewquestion.com/linq-interview-questions | CC-MAIN-2019-47 | refinedweb | 900 | 61.06 |
DataModelSelection not updatedAndreas Franke Apr 10, 2007 9:06 AM
Hi,
have a table and use row selection with DataModelSelection. If the whole table is loaded all is perfect. But when I use searchpattern like in booking example(ajax) to reduce tablesize DataModelSelection not updated. For example all times the first row from whole table is selected while this row no longer exist in reduced table.
public abstract class AbstractListBean<T extends BaseEntity>implements Serializable { protected String searchString; @PersistenceContext protected EntityManager em; @DataModelSelection private T selectedEntity; }
@Stateful @Scope(ScopeType.CONVERSATION) @Name("specialreleaselist") @SuppressWarnings("unchecked") public class SpecialreleaseListBean extends AbstractListBean<SpecialRelease> implements SpecialreleaseList { /** * */ private static final long serialVersionUID = 1L; @In FacesMessages facesMessages; @DataModel protected List<SpecialRelease> sprTablelist; @Factory("sprTablelist") public void find(){ sprTablelist = loadList(); } @Factory(value="specialreleasepattern", scope=ScopeType.EVENT) public String getSearchPattern(){ return searchString==null ? "%" : '%' + searchString.toLowerCase().replace('*', '%') + '%'; } protected List<SpecialRelease> loadList() { List readFromDB = null; readFromDB = readFromDB("select s from SpecialRelease s where lower(s.description) like #{specialreleasepattern}"); return readFromDB; } }
What is the right way updating DataModelSelection?
Thanks
Andi
1. Re: DataModelSelection not updatedAndreas Franke Apr 11, 2007 3:57 AM (in response to Andreas Franke)
Helllo,
no idea why the selected datamodel not updated? Only the sequence from whole table are existent in reduced table.
Thanks
Andi
2. Re: DataModelSelection not updatedPete Muir Apr 11, 2007 8:08 AM (in response to Andreas Franke)
Try using page parameters or the seam el enhancement instead
3. Re: DataModelSelection not updatedAndreas Franke Apr 12, 2007 8:57 AM (in response to Andreas Franke)
Hi Pete,
I don't know what you mean. Neither page parameters nor el enhancement should be used for my problem.
First time I load a table with all entries. When I select a row, the correspondending entity is displayed on the bottom of the page.
Then I use search to reduce the table with this one
<a:region <h:inputText <a:support </h:inputText> </a:region><!-- End searchRegion -->
A few entries are display now, but when I select on of these (i.e. the first one) the displayed entity is this one from whole table of the first load.
Why DataModelSelection not updated on search result table? There should be a possibility to refresh the DataModelSelection!
Have no idea to solve this with el or page parameters
Thanks
4. Re: DataModelSelection not updatedPete Muir Apr 12, 2007 9:19 AM (in response to Andreas Franke)
Actually, imo, page parameters (or the el enhancement) are the best way to do an entity selection from a table - the @DataModel/@DataModelSelection stuff I don't use anymore.
Take a look at the booking example for how to do it with EL enhancement, or at a seam-gen'd app or the reference manual for how to use page parameters.
5. Re: DataModelSelection not updatedAndreas Franke Apr 13, 2007 10:25 AM (in response to Andreas Franke)
Hi Pete,
thank you for your suggestion. I use now el enhancement and it works.
Bye
Andi
6. Re: DataModelSelection not updatedAndy Gibson Apr 14, 2007 1:02 AM (in response to Andreas Franke)
What is this El Enhancement that you speak of?
When you say page parameters, I assume you mean passing the Id of the object to be edited from the search page to the edit page as a parameter of the URL..i.e. editperson.xhtml?PersonId=123 ?
I've been thinking about the issue of moving objects from page to page recently, and I realized that Seam gives you multiple ways of doing it.
I'm trying to find a way where we can be consistent that won't trip us up down the line. Since the different methods are all easy give or take a few lines of code, page parameters offers the advantage of bookmarkable URLs.
What might be nice to see is some kind of VERY simple crud app that is in pure seam (as opposed to the framework stuff) that includes the different methods of passing objects, or at least indicates some kind of best practices. However, I know how busy you guys are.
7. Re: DataModelSelection not updatedAndreas Franke Apr 14, 2007 1:39 AM (in response to Andreas Franke)
You can find on Seam docs what el enhancement is.
Look at
page parameters are also descriped there
8. Re: DataModelSelection not updatedAndy Gibson Apr 14, 2007 8:06 PM (in response to Andreas Franke)
Ah, OK, thats the EL enhancement, I had seen it, just didn't realize that was what it was called.
My only problem with the el enhancements is using it in pages.xml since in order to refer to it as an outcome, you need to include the whole expression, including the variable name i.e.
HotelBooking.selectHotel(hot)
which means if you change the iterator variable name in the jsf page you break your navigation. I think I'll stick with the parameters, especially since it gives you bookmarkable links. | https://developer.jboss.org/thread/135408 | CC-MAIN-2018-13 | refinedweb | 821 | 53.41 |
The Text Access API provides a means to allow text that is stored in alternative formats to work with ICU services. ICU normally operates on text that is stored in UTF-16 format, in (UChar *) arrays for the C APIs or as type UnicodeString for C++ APIs.
ICU Text Access allows other formats, such as UTF-8 or non-contiguous UTF-16 strings, to be placed in a UText wrapper and then passed to ICU services.
There are three general classes of usage for UText:
Application Level Use. This is the simplest usage - applications would use one of the utext_open() functions on their input text, and pass the resulting UText to the desired ICU service.
Second is usage in ICU Services, such as break iteration, that will need to operate on input presented to them as a UText. These implementations will need to use the iteration and related UText functions to gain access to the actual text.
The third class of UText users are "text providers." These are the UText implementations for the various text storage formats. An application or system with a unique text storage format can implement a set of UText provider functions for that format, which will then allow ICU services to operate on that format.
Iterating over text
Here is sample code for a forward iteration over the contents of a UText
UChar32 c; UText *ut = whatever(); for (c=utext_next32From(ut, 0); c>=0; c=utext_next32(ut)) { // do whatever with the codepoint c here. }
And here is similar code to iterate in the reverse direction, from the end of the text towards the beginning.
UChar32 c; UText *ut = whatever(); int textLength = utext_nativeLength(ut); for (c=utext_previous32From(ut, textLength); c>=0; c=utext_previous32(ut)) { // do whatever with the codepoint c here. }
Characters and Indexing
Indexing into text by UText functions is nearly always in terms of the native indexing of the underlying text storage. The storage format could be UTF-8 or UTF-32, for example. When coding to the UText access API, no assumptions can be made regarding the size of characters, or how far an index may move when iterating between characters.
All indices supplied to UText functions are pinned to the length of the text. An out-of-bounds index is not considered to be an error, but is adjusted to be in the range 0 <= index <= length of input text.
When an index position is returned from a UText function, it will be a native index to the underlying text. In the case of multi-unit characters, it will always refer to the first position of the character, never to the interior. This is essentially the same thing as saying that a returned index will always point to a boundary between characters.
When a native index is supplied to a UText function, all indices that refer to any part of a multi-unit character representation are considered to be equivalent. In the case of multi-unit characters, an incoming index will be logically normalized to refer to the start of the character.
It is possible to test whether a native index is on a code point boundary by doing a utext_setNativeIndex() followed by a utext_getNativeIndex(). If the index is returned unchanged, it was on a code point boundary. If an adjusted index is returned, the original index referred to the interior of a character.
Conventions for calling UText functions
Most UText access functions have as their first parameter a (UText *) pointer, which specifies the UText to be used. Unless otherwise noted, the pointer must refer to a valid, open UText. Attempting to use a closed UText or passing a NULL pointer is a programming error and will produce undefined results or NULL pointer exceptions.
The UText_Open family of functions can either open an existing (closed) UText, or heap allocate a new UText. Here is sample code for creating a stack-allocated UText.
char *s = whatever(); // A utf-8 string U_ErrorCode status = U_ZERO_ERROR; UText ut = UTEXT_INITIALIZER; utext_openUTF8(ut, s, -1, &status); if (U_FAILURE(status)) { // error handling } else { // work with the UText }
Any existing UText passed to an open function _must_ have been initialized, either by the UTEXT_INITIALIZER, or by having been originally heap-allocated by an open function. Passing NULL will cause the open function to heap-allocate and fully initialize a new UText.
Definition in file utext.h.
#include "unicode/utypes.h"
#include "unicode/uchar.h"
Go to the source code of this file. | http://icu.sourcearchive.com/documentation/4.4.1-5/utext_8h.html | CC-MAIN-2018-13 | refinedweb | 741 | 51.48 |
I'm converting a project from MonoMac to Xamarin.Mac but I cannot add the Xamarin.Mac assembly to my "References" - it never appears in the list of assemblies available. If I manually edit the csproj file and add
<Reference Include="Xamarin.Mac" />
The build fails with
...etc.../Helpers.cs(7,7): Error CS0246: The type or namespace name 'Foundation' could not be found (are you missing a using directive or an assembly reference?) (CS0246) (Livedrive.Mac)
Yet I can see that it has been installed:
$ ls /Library/Frameworks/Xamarin.Mac.framework/Versions/Current/lib/reference/full
OpenTK.dll OpenTK.pdb Xamarin.Mac.dll Xamarin.Mac.pdb
I'm using VS4Mac 8.7.6 (build 2) that was d/l'ed today.
What am I missing?
Answers
Sorry, I should add that I'm using the original csproj file that used to reference "MonoMac". I deleted the reference to MonoMac but it won't let me add "Xamarin.Mac". But if I create a new project, it auto-adds Xamarin.Mac for me with no issues. Yet the older csproj cannot seem to find it. | https://forums.xamarin.com/discussion/comment/421468/ | CC-MAIN-2020-45 | refinedweb | 185 | 52.87 |
rpn_target_assign¶
paddle.fluid.layers.
rpn_target_assign(bbox_pred, cls_logits, anchor_box, anchor_var, gt_boxes, is_crowd, im_info, rpn_batch_size_per_im=256, rpn_straddle_thresh=0.0, rpn_fg_fraction=0.5, rpn_positive_overlap=0.7, rpn_negative_overlap=0.3, use_random=True)[source]
Target Assign Layer for region proposal network (RPN) in Faster-RCNN detection.
This layer can be, for given the Intersection-over-Union (IoU) overlap between anchors and ground truth boxes, to assign classification and regression targets to each each anchor, these target labels are used for train RPN. The classification targets is a binary class label (of being an object or not). Following the paper of Faster-RCNN, the positive labels are two kinds of anchors: (i) the anchor/anchors with the highest IoU overlap with a ground-truth box, or (ii) an anchor that has an IoU overlap higher than rpn_positive_overlap(0.7) with any ground-truth box. Note that a single ground-truth box may assign positive labels to multiple anchors. A non-positive anchor is when its IoU ratio is lower than rpn_negative_overlap (0.3) for all ground-truth boxes. Anchors that are neither positive nor negative do not contribute to the training objective. The regression targets are the encoded ground-truth boxes associated with the positive anchors.
- Parameters
bbox_pred (Variable) – A 3-D Tensor with shape [N, M, 4] represents the predicted locations of M bounding bboxes. N is the batch size, and each bounding box has four coordinate values and the layout is [xmin, ymin, xmax, ymax]. The data type can be float32 or float64.
cls_logits (Variable) – A 3-D Tensor with shape [N, M, 1] represents the predicted confidence predictions. N is the batch size, 1 is the frontground and background sigmoid, M is number of bounding boxes. The data type can be float32 or float64.
anchor_box (Variable) – A 2-D Tensor with shape [M, 4] holds M boxes, each box is represented as [xmin, ymin, xmax, ymax], [xmin, ymin] is the left top coordinate of the anchor box, if the input is image feature map, they are close to the origin of the coordinate system. [xmax, ymax] is the right bottom coordinate of the anchor box. The data type can be float32 or float64.
anchor_var (Variable) – A 2-D Tensor with shape [M,4] holds expanded variances of anchors. The data type can be float32 or float64.
gt_boxes (Variable) – The ground-truth bounding boxes (bboxes) are a 2D LoDTensor with shape [Ng, 4], Ng is the total number of ground-truth bboxes of mini-batch input. The data type can be float32 or float64.
is_crowd (Variable) – A 1-D LoDTensor which indicates groud-truth is crowd. The data type must be int32.
im_info (Variable) – A 2-D LoDTensor with shape [N, 3]. N is the batch size,
is the height, width and scale. (3) –
rpn_batch_size_per_im (int) – Total number of RPN examples per image. The data type must be int32.
rpn_straddle_thresh (float) – Remove RPN anchors that go outside the image by straddle_thresh pixels. The data type must be float32.
rpn_fg_fraction (float) – Target fraction of RoI minibatch that is labeled foreground (i.e. class > 0), 0-th class is background. The data type must be float32.
rpn_positive_overlap (float) – Minimum overlap required between an anchor and ground-truth box for the (anchor, gt box) pair to be a positive example. The data type must be float32.
rpn_negative_overlap (float) – Maximum overlap allowed between an anchor and ground-truth box for the (anchor, gt box) pair to be a negative examples. The data type must be float32.
- Returns
A tuple(predicted_scores, predicted_location, target_label, target_bbox, bbox_inside_weight) is returned. The predicted_scores and predicted_location is the predicted result of the RPN. The target_label and target_bbox is the ground truth, respectively. The predicted_location is a 2D Tensor with shape [F, 4], and the shape of target_bbox is same as the shape of the predicted_location, F is the number of the foreground anchors. The predicted_scores is a 2D Tensor with shape [F + B, 1], and the shape of target_label is same as the shape of the predicted_scores, B is the number of the background anchors, the F and B is depends on the input of this operator. Bbox_inside_weight represents whether the predicted loc is fake_fg or not and the shape is [F, 4].
- Return type
tuple
Examples
import paddle.fluid as fluid bbox_pred = fluid.data(name='bbox_pred', shape=[None, 4], dtype='float32') cls_logits = fluid.data(name='cls_logits', shape=[None, 1], dtype='float32') anchor_box = fluid.data(name='anchor_box', shape=[None, 4], dtype='float32') anchor_var = fluid.data(name='anchor_var', shape=[None, 4], dtype='float32') gt_boxes = fluid.data(name='gt_boxes', shape=[None, 4], dtype='float32') is_crowd = fluid.data(name='is_crowd', shape=[None], dtype='float32') im_info = fluid.data(name='im_infoss', shape=[None, 3], dtype='float32') loc, score, loc_target, score_target, inside_weight = fluid.layers.rpn_target_assign( bbox_pred, cls_logits, anchor_box, anchor_var, gt_boxes, is_crowd, im_info) | https://www.paddlepaddle.org.cn/documentation/docs/en/api/layers/rpn_target_assign.html | CC-MAIN-2020-16 | refinedweb | 792 | 58.38 |
K from both a data science standpoint and personal experience. As I indicated below I am an editor and an administrator on the English Wikipedia with about 20,000 edits under my belt. Some of the information and experience I have will be less helpful for data scientists on this particular challenge, but the beauty of Wikipedia is all data is available. Everything, should you want it.
Many of these suggestions will be remedial or duplicative for veteran data miners. However you can always benefit from local knowledge. You can make a comment here or on my wikipedia talk page if you need some more information.
But enough of that, on to my suggestions for folks looking to win the challenge!
General model:
- Zeros are very important. Depending on time in the dataset and tenure of the account, zeros may comprise 30-50% of the editors after a certain number of months. Modeling zeros differently than a small number of edits will be important.
- Zeros at different tenures. Many accounts probably follow a Poisson or ZIP, but early drop-offs (not quite at 1 edit but maybe 2-3) are very different. As are very late stage dropoffs. In those cases (>1 year tenure) you will probably find different predictors of retirement, namely social networks. Imagine an editor who registers an account and makes ~40 edits over the span of a month. They have passed the technical hurdles for contribution (syntax, registration, autoconfirmation, etc.) but haven’t necessarily established a social network. Given the reduced dataset for the contest, you may have to determine this by number of edits made to (user) talk pages.
- Time matters. Account characteristics are very different based on how/why/when they came to wikipedia. Many editors to wikipedia showed up not because of the (edit) button but because they read about wikipedia in the popular press.
Editors
- Look at edit type. Does the edit remove content (just in bytes) or add it? Is the edit an exact reversion to a previous state? Reversion is a variable in the dataset (probably determined by comparing hashes)
- Look at edit persistence. Do the edits of a given editor tend to stick around or be reverted/trimmed over time? There are multiple implications to persistence, so don’t assume “good” edits are always kept and “bad” edits reverted.
- User page. Do those editors have a user page? You can determine this by checking how many contributions to the User namespace an account ID has associated with it. There is a strong social norm against editing other users’ pages, so an account that has multiple edits to a single User page is likely editing their own page.
- Look at the activity on their User Talk page. What kind of messages are they getting? Do they respond (by adding bytes) or removing the message (strict reversion)? Again, the restrictions on dataset preclude perfect matching between accounts and user pages, but a User Talk page most edited by a given account ID is likely to be their talk page.
- Advanced permissions probably don’t matter. Only a vanishingly small percentage of editors are administrators. Permissions like ACC are also rare. Rollback might be interesting to look at, but it didn’t exist for about half of the sample.
Articles
- Which articles or article topics the editor edits matter, but perhaps not as much as some other characteristics. Again, difficult to determine completely with anonymized data but you can see how article edits are clustered together.
- Look for different kinds of edits. Small edits with “minor” marked on their edit summary indicate “wikignoming”, a very different editing style from someone who creates or expands articles. The dataset does not seem to include the “minor” edit bit, but you can take a guess by looking at the deltas.
- Imagine that editors have not one focus but a space of focus along the dimensionality of categorization. Maybe the space is all connected–an editor might be interested in statistics, mechanics, econometrics, and signal processing. Or maybe they are not connected–an editor interested in Phong shading, Pixar, and Jersey Shore. Again, your guess will have to come from editor clustering, but it will be better than nothing.
- When looking at groupings of articles you may discover that some articles are more conducive to new editors than others. You might also note that some articles (holding level of protection constant) are more likely to attract attention from new editors. What is also happening is reception and attention are endogenous to editor behavior. For most subjects a single editor is atomistic, but new editors may find receptive topic areas more readily.
- Pay less attention to the “quality” scores for articles. Most of the actual quality review is for “Good” or “Featured” articles and only ~0.5% of articles are good or featured. Pay much more attention to the edit rate and (if you can do it) some measure of traffic. Edits are roughly proportional to traffic under two conditions: there must not be an “edit war” ongoing and the article must remain at a given level of “protection”. Inserting either of those two conditions makes edit rate a very noisy measure of traffic.
Statistics
- You can lean on past work on Wikipedia itself, both from editors and academics.
- Even small sample studies may give some hints. Look at this small study done on editors whose first edits to the encyclopedia are new... | https://www.r-bloggers.com/wikipedia-for-kaggle-participants/ | CC-MAIN-2017-09 | refinedweb | 906 | 56.35 |
#include <OW_Exec.hpp>
#include <OW_Exec.hpp>
Collaboration diagram for OW_NAMESPACE::PopenStreams:
Definition at line 57 of file OW_Exec.hpp.
Definition at line 344 of file OW_Exec.cpp.
Definition at line 349 of file OW_Exec.cpp.
Definition at line 418 of file OW_Exec.cpp.
Set a pipe to the process's stderr.
Definition at line 378 of file OW_Exec.cpp.
References m_impl.
Get a read-only pipe to the process's stderr.
Definition at line 373 of file OW_Exec.cpp.
Get additional pipes that may be connected to the process.
Definition at line 383 of file OW_Exec.cpp.
Same as getExitStatus(0, 10*1000, 10*1000);.
Definition at line 403 of file OW_Exec.cpp.
Waits for the process to terminate and returns its exit status.
Takes increasingly severe measures to ensure that the process dies -- the following steps are taken in order until termination is detected:
1. If wait_initial > 0, waits wait_initial seconds for the process to die on its own.
2. If wait_close > 0, closes the input and output pipes and then waits wait_close seconds for the process to die.
3. If wait_term > 0, sends process a SIGTERM signal and waits wait_term seconds for it to die.
4. Sends the process a SIGKILL signal.
In steps 1-3 the function returns as soon as termination is detected. After calling this function the object is basically useless, except that if the function is called again it will return the same exit status without going through the above steps.
Note to maintainers: it is important that if wait_close == 0 then the pipes are NOT closed.
Wait times are no larger than 4294967 seconds.
Definition at line 408 of file OW_Exec.cpp.
References m_impl.
Referenced by OW_NAMESPACE::runHelper().
Set a pipe to the process's stdin.
Definition at line 358 of file OW_Exec.cpp.
Get a write-only pipe to the process's stdin.
Definition at line 353 of file OW_Exec.cpp.
Referenced by OW_NAMESPACE::runHelper(), and OW_NAMESPACE::Exec::safePopen().
Definition at line 423 of file OW_Exec.cpp.
Set a pipe to the process's stdout.
Definition at line 368 of file OW_Exec.cpp.
Get a read-only pipe to the process's stdout.
Definition at line 363 of file OW_Exec.cpp.
Set the process's pid.
Definition at line 398 of file OW_Exec.cpp.
Get the process's pid.
If the process's exit status has already been read by calling getExitStatus(), then this will return -1
Definition at line 393 of file OW_Exec.cpp.
Set additional pipes that may be connected to the process.
Definition at line 388 of file OW_Exec.cpp.
Sets the process's exit status.
This function is used by Exec::gatherOutput()
Definition at line 413 of file OW_Exec.cpp.
[friend]
Definition at line 430 of file OW_Exec.cpp.
[private]
Definition at line 154 of file OW_Exec.hpp.
Referenced by err(), extraPipes(), getExitStatus(), in(), operator=(), OW_NAMESPACE::operator==(), out(), pid(), setExtraPipes(), and setProcessStatus(). | http://openwbem.org/openwbem-docs/html/class_o_w___n_a_m_e_s_p_a_c_e_1_1_popen_streams.html | CC-MAIN-2018-05 | refinedweb | 484 | 61.83 |
This document covers add-on writing for Anki 2.1.x. For instructions on writing add-ons for Anki 2.0.x, please see
Anki is written in a user-friendly language called Python. If you’re not familiar with Python, please read the Python tutorial before proceeding with the rest of this document.
Because Python is a dynamic language, add-ons are extremely powerful in Anki - not only can they extend the program, but they can also modify arbitrary aspects of it, such as altering the way scheduling works, modifying the UI, and so on.
No special development environment is required to develop add-ons. All you need is a text editor. If you’re on Windows or a Mac, please use the packaged version of Anki that’s provided on the website, as there are no instructions available for building it from scratch on those platforms.
While you can write plugins in a simple text editor like notepad, you may want to look into an editor that can provide syntax highlighting (colouring of the code) to make things easier.
Anki is comprised of two parts:
anki contains all the "backend" code - opening collections, fetching and answering cards, and so on. It is used by Anki’s GUI, and can also be included in command line programs to access Anki decks without the GUI.
aqt contains the UI part of Anki. Anki’s UI is built upon PyQt, Python bindings for the cross-platform GUI toolkit Qt. PyQt follows Qt’s API very closely, so the documentation can be very useful when you want to know how to use a particular GUI component.
When Anki starts up, it checks for modules in the add-ons folder, and runs each one it finds. When add-ons are run, they typically modify existing code or add new menu items to provide a new feature.
This document contains some hints to get you started, but it is not a comprehensive guide. To actually write an add-on, you will need to familiarize yourself with Anki’s source code, and the source code of other add-ons that do similiar things to what you are trying to accomplish.
Because of our limited resources, no official support is available for add-on writing. If you have any questions, you will either need to find the answers yourself in the source code, or post your questions on the community-supported add-on forum.
You can also use the add-on forum to request someone write an add-on for you. You may need to offer some money before anyone becomes interested in helping you.
You can access the top level add-ons folder by going to the Tools>Add-ons menu item in the main Anki window. Click on the View Files button, and a folder will pop up. If you had no add-ons installed, the top level add-ons folder will be shown. If you had an add-on selected, the add-on’s module folder will be shown, and you will need to go up one level.
The add-ons folder is named "addons21", corresponding to Anki 2.1. If you have an "addons" folder, it is because you have previously used Anki 2.0.x.
Each add-on uses one folder inside the add-on folder. Anki looks for a file called __init__.py file inside the folder, eg:
addons21/my_addon/__init__.py
If __init__.py does not exist, Anki will ignore the folder.
When choosing a folder name, it is recommended to stick to a-z and 0-9 characters to avoid problems with Python’s module system.
While you can use whatever folder name you wish for folders you create yourself, when you download an add-on from AnkiWeb, Anki will use the item’s ID as the folder name, such as:
addons21/48927303923/__init__.py
Anki will also place a meta.json file in the folder, which keeps track of the original add-on name, when it was downloaded, and whether it’s enabled or not.
You should not store user data in the add-on folder, as it’s deleted when the user upgrades an add-on.
Add the following to my_first_addon/__init__.py in your add-ons folder:
#)
Restart Anki, and you should find a test item in the tools menu. Running it will display a dialog with the card count.
If you make a mistake when entering in the plugin, Anki will show an error message on startup indicating where the problem is.
All operations on a collection file are accessed via mw.col. Some basic examples of what you can do follow. Please note that you should put these in testFunction() as above. You can’t run them directly in an add-on, as add-ons are initialized during Anki startup, before any collection or profile has been loaded.
Get a due card:
card = mw.col.sched.getCard() if not card: # current deck is finished
Answer the card:
mw.col.sched.answerCard(card, ease)
Edit a note (append " new" to the end of each field):
note = card.note() for (name, value) in note.items(): note[name] = value + " new" note.flush()
Get card IDs for notes with tag x:
ids = mw.col.findCards("tag:x")
Get question and answer for each of those ids:
for id in ids: card = mw.col.getCard(id) question = card.q() answer = card.a()
Reset the scheduler after any DB changes. Note that we call reset() on the main window, since the GUI has to be updated as well:
mw.reset()
Import a text file into the collection
from anki.importing import TextImporter file = u"/path/to/text.txt" # select deck did = mw.col.decks.id("ImportDeck") mw.col.decks.select(did) # anki defaults to the last note type used in the selected deck m = mw.col.models.byName("Basic") deck = mw.col.decks.get(did) deck['mid'] = m['id'] mw.col.decks.save(deck) # and puts cards in the last deck used by the note type m['did'] = did # import into the collection ti = TextImporter(mw.col, file) ti.initMapping() ti.run()
Almost every GUI operation has an associated function in anki, so any of the operations that Anki makes available can also be called in an add-on.
If you want to access the collection outside of the GUI, you can do so with the following code:
from anki import Collection col = Collection("/path/to/collection.anki2")
If you make any modifications to the collection outside of Anki, you must make sure to call col.close() when you’re done, or those changes will be lost.
When you need to perform operations that are not already supported by anki, you can access the database directly. Anki collections are stored in SQLite files. Please see the SQLite documentation for more information.
Anki’s DB object supports the following functions:
execute() allows you to perform an insert or update operation. Use named arguments with ?. eg:
mw.col.db.execute("update cards set ivl = ? where id = ?", newIvl, cardId)
executemany() allows you to perform bulk update or insert operations. For large updates, this is much faster than calling execute() for each data point. eg:
data = [[newIvl1, cardId1], [newIvl2, cardId2]] mw.col.db.executemany(same_sql_as_above, data)
scalar() returns a single item:
showInfo("card count: %d" % mw.col.db.scalar("select count() from cards"))
list() returns a list of the first column in each row, eg [1, 2, 3]:
ids = mw.col.db.list("select id from cards limit 3")
all() returns a list of rows, where each row is a list:
ids_and_ivl = mw.col.db.all("select id, ivl from cards")
execute() can also be used to iterate over a result set without building an intermediate list. eg:
for id, ivl in mw.col.db.execute("select id, ivl from cards limit 3"): showInfo("card id %d has ivl %d" % (id, ivl))
Add-ons should never modify the schema of existing tables, as that may break future versions of Anki.
If you need to store addon-specific data, consider using Anki’s configuration support.
If you need the data to sync across devices, small options can be stored within mw.col.conf. Please don’t store large amounts of data there, as it’s sent on every sync.
Hooks have been added to a few parts of the code to make writing add-ons easier. There are two types: hooks take some arguments and return no value, and filters take a value and return it (perhaps modified).
A simple example of the former is in the leech handling. When the scheduler (anki/sched.py) discovers a leech, it calls:
runHook("leech", card)
If you wished to perform a special operation when a leech was discovered, such as moving the card to a "Difficult" deck, you could do it with the following code:
from anki.hooks import addHook from aqt import mw def onLeech(card): # can modify without .flush(), as scheduler will do it for us card.did = mw.col.decks.id("Difficult") # if the card was in a cram deck, we have to put back the original due # time and original deck card.odid = 0 if card.odue: card.due = card.odue card.odue = 0 addHook("leech", onLeech)
An example of a filter is in aqt/editor.py. The editor calls the "editFocusLost" filter each time a field loses focus, so that add-ons can apply changes to the note:
if runFilter( "editFocusLost", False, self.note, self.currentField): # something updated the note; schedule reload def onUpdate(): self.loadNote() self.checkValid() self.mw.progress.timer(100, onUpdate, False)
Each filter in this example accepts three arguments: a modified flag, the note, and the current field. If a filter makes no changes it returns the modified flag the same as it received it; if it makes a change it returns True. In this way, if any single add-on makes a change, the UI will reload the note to show updates.
The Japanese Support add-on uses this hook to automatically generate one field from another. A slightly simplified version is presented below:
def onFocusLost(flag, n, fidx): from aqt import mw # japanese model? if "japanese" not in n.model()['name'].lower(): return flag # have src and dst fields? for c, name in enumerate(mw.col.models.fieldNames(n.model())): for f in srcFields: if name == f: src = f srcIdx = c for f in dstFields: if name == f: dst = f if not src or not dst: return flag # dst field already filled? if n[dst]: return flag # event coming from src field? if fidx != srcIdx: return flag # grab source text srcTxt = mw.col.media.strip(n[src]) if not srcTxt: return flag # update field try: n[dst] = mecab.reading(srcTxt) except Exception, e: mecab = None raise return True addHook('editFocusLost', onFocusLost)
The first argument of a filter is the argument that should be returned. In the focus lost filter this is a flag, but in other cases it may be some other object. For example, in anki/collection.py, _renderQA() calls the "mungeQA" filter which contains the generated HTML for the front and back of cards. latex.py uses this filter to convert text in LaTeX tags into images.
In Anki 2.1, a hook was added for adding buttons to the editor. It can be used like so:
from aqt.utils import showInfo from anki.hooks import addHook # cross out the currently selected text def onStrike(editor): editor.web.eval("wrap('<del>', '</del>');") def addMyButton(buttons, editor): editor._links['strike'] = onStrike return buttons + [editor._addButton( "iconname", # "/full/path/to/icon.png", "strike", # link name "tooltip")] addHook("setupEditorButtons", addMyButton)
If you want to modify a function that doesn’t already have a hook, it’s possible to overwrite that function with a custom version instead. This is sometimes referred to as monkey patching.
In aqt/editor.py there is a function setupButtons() which creates the buttons like bold, italics and so on that you see in the editor. Let’s imagine you want to add another button in your add-on.
The simplest way is to copy and paste the function from the Anki source code, add your text to the bottom, and then overwrite the original, like so:
from aqt.editor import Editor def mySetupButtons(self): <copy & pasted code from original> <custom add-on code> Editor.setupButtons = mySetupButtons
This approach is fragile however, as if the original code is updated in a future version of Anki, you would also have to update your add-on. A better approach would be to save the original, and call it in our custom version:
from aqt.editor import Editor def mySetupButtons(self): origSetupButtons(self) <custom add-on code> origSetupButtons = Editor.setupButtons Editor.setupButtons = mySetupButtons
Because this is a common operation, Anki provides a function called wrap() which makes this a little more convenient. A real example:
from anki.hooks import wrap from aqt.editor import Editor from aqt.utils import showInfo def buttonPressed(self): showInfo("pressed " + `self`) def mySetupButtons(self): # - size=False tells Anki not to use a small button # - the lambda is necessary to pass the editor instance to the # callback, as we're passing in a function rather than a bound # method self._addButton("mybutton", lambda s=self: buttonPressed(self), text="PressMe", size=False) Editor.setupButtons = wrap(Editor.setupButtons, mySetupButtons)
By default, wrap() runs your custom code after the original code. You can pass a third argument, "before", to reverse this. If you need to run code both before and after the original version, you can do so like so:
from anki.hooks import wrap from aqt.editor import Editor def mySetupButtons(self, _old): <before code> ret = _old(self) <after code> return ret Editor.setupButtons = wrap(Editor.setupButtons, mySetupButtons, "around")
If you need to modify the middle of a function rather than run code before or after it, there may a good argument for adding a hook to that function in the original code. In these situations, please post on the support site and ask for a hook to be added.
As mentioned in the overview, the Qt documentation is invaluable for learning how to display different GUI widgets.
One particular thing to bear in mind is that objects are garbage collected in Python, so if you do something like:
def myfunc(): widget = QWidget() widget.show()
…then the widget will disappear as soon as the function exits. To prevent this, assign top level widgets to an existing object, like:
def myfunc(): mw.myWidget = widget = QWidget() widget.show()
This is often not required when you create a Qt object and give it an existing object as the parent, as the parent will keep a reference to the object.
Anki ships with only the standard modules necessary to run the program - a full copy of Python is not included. For that reason, if you need to use a standard module that is not included with Anki, you’ll need to bundle it with your add-on.
This only works with pure Python modules - modules that require C extensions such as numpy are much more difficult to package, as you would need to compile them for each of the operating systems Anki supports. If you’re doing something sophisticated, it would be easier to get your users to install a standalone copy of Python instead.
If you include a config.json file with a JSON dictionary in it, Anki will allow users to edit it from the add-on manager.
A simple example: in config.json:
{"myvar": 5}
In config.md:
This is documentation for this add-on's configuration, in *markdown* format.
In your add-on’s code:
from aqt import mw config = mw.addonManager.getConfig(__name__) print("var is", config['myvar'])
When updating your add-on, you can make changes to config.json. Any newly added keys will be merged with the existing configuration.
If you change the value of existing keys in config.json, users who have customized their configuration will continue to see the old values unless they use the "restore defaults" button.
If you need to programmatically modify the config, you can save your changes with:
mw.addonManager.writeConfig(__name__, config)
Add-ons that manage options in their own GUI can have that GUI displayed when the config button is clicked:
mw.addonManager.setConfigAction(__name__, myOptionsFunc)
Avoid key names starting with an underscore - they are reserved for future use by Anki.
When your add-on needs configuration data other than simple keys and values, it can use a special folder called user_files in the root of your add-on’s folder. Any files placed in this folder will be preserved when the add-on is upgraded. All other files in the add-on folder are removed on upgrade.
To ensure the user_files folder is created for the user, you can put a README.txt or similar file inside it before zipping up your add-on.
When Anki upgrades an add-on, it will ignore any files in the .zip that already exist in the user_files folder.
(coming in 2.1.0beta16)
Anki provides a hook to modify the question and answer HTML before it is displayed in the review screen, preview dialog, and card layout screen. This can be useful for adding Javascript to the card.
An example:
from anki.hooks import addHook def prepare(html, card, context): return html + """ <script> document.body.style.background = "blue"; </script>""" addHook('prepareQA', prepare)
The hook takes three arguments: the HTML of the question or answer, the current card object (so you can limit your add-on to specific note types for example), and a string representing the context the hook is running in.
Make sure you return the modified HTML.
Context is one of: "reviewQuestion", "reviewAnswer", "clayoutQuestion", "clayoutAnswer", "previewQuestion" or "previewAnswer".
Because Anki fades the previous text out before revealing the new text, Javascript hooks are required to perform actions like scrolling at the correct time. You can use them like so:
from anki.hooks import addHook def prepare(html, card, context): return html + """ <script> onUpdateHook.push(function () { window.scrollTo(0, 2000); }) </script>""" addHook('prepareQA', prepare)
onUpdateHook fires after the new card has been placed in the DOM, but before it is shown.
onShownHook fires after the card has faded in.
The hooks are reset each time the question or answer is shown.
If your code throws an exception, it will be caught by Anki’s standard exception handler (which catches anything written to stderr). If you need to print information for debugging purposes, you can use aqt.utils.showInfo, or write it to stderr with sys.stderr.write("text\n").
Anki also includes a REPL. From within the program, press the shortcut key and a window will open up. You can enter expressions or statements into the top area, and then press ctrl+return/command+return to evaluate them. An example session follows:
>>> mw <no output> >>> print(mw) <aqt.main.AnkiQt object at 0x10c0ddc20> >>> invalidName Traceback (most recent call last): File "/Users/dae/Lib/anki/qt/aqt/main.py", line 933, in onDebugRet exec text File "<string>", line 1, in <module> NameError: name 'invalidName' is not defined >>> a = [a for a in dir(mw.form) if a.startswith("action")] ... print(a) ... print() ... pp(a) ['actionAbout', 'actionCheckMediaDatabase', ...] ['actionAbout', 'actionCheckMediaDatabase', 'actionDocumentation', 'actionDonate', ...] >>> pp(mw.reviewer.card) <anki.cards.Card object at 0x112181150> >>> pp(card()) # shortcut for mw.reviewer.card.__dict__ {'_note': <anki.notes.Note object at 0x11221da90>, '_qa': [...] 'col': <anki.collection._Collection object at 0x1122415d0>, 'data': u'', 'did': 1, 'due': -1, 'factor': 2350, 'flags': 0, 'id': 1307820012852L, [...] } >>> pp(bcard()) # shortcut for selected card in browser <as above>
Note that you need to explicitly print an expression in order to see what it evaluates to. Anki exports pp() (pretty print) in the scope to make it easier to quickly dump the details of objects, and the shortcut ctrl+shift+return will wrap the current text in the upper area with pp() and execute the result.
If you’re on Linux or are running Anki from source, it’s also possible to debug your script with pdb. Place the following line somewhere in your code, and when Anki reaches that point it will kick into the debugger in the terminal:
from aqt.qt import debug; debug()
Alternatively you can export DEBUG=1 in your shell and it will kick into the debugger on an uncaught exception.
Anki’s source code is available at. The colllection object is defined in anki’s collection.py. Other useful files to check out are cards.py, notes.py, sched.py, models.py and decks.py.
It can also be helpful to look in the aqt source to see how it’s calling anki for a particular operation, or to learn more about the GUI.
Much of the GUI is defined in designer files. You can use the Qt Designer program to open the .ui files and browse the GUI in a convenient way.
And finally, it can also be extremely helpful to browse other add-ons to see how they accomplish something.
AnkiWeb expects a .zip file of the contents of an add-on module, without the folder name. For example, if you have a module like the following:
addons21/myaddon/__init__.py addons21/myaddon/my.data
Then the zip file contents should be:
__init__.py my.data
If you include the folder name in the zip like the following, AnkiWeb will not accept the zip file:
myaddon/__init__.py myaddon/my.data
You can give the .zip file any name.
Python automatically creates __pycache__ folders when your add-on is run. Please make sure you delete these prior to creating the zip file, as AnkiWeb can not accept .zip files that contain __pycache__ folders.
You can upload a .zip you’ve created to
Anki 2.1 requires Python 3.6 or later. After installing Python 3 on your machine, you can use the 2to3 tool to automatically convert your existing scripts to Python 3 code on a folder by folder basis, like:
2to3-3.6 --output-dir=aqt3 -W -n aqt mv aqt aqt-old mv aqt3 aqt
Most simple code can be converted automatically, but there may be parts of the code that you need to manually modify.
The syntax for connecting signals and slots has changed in PyQt5. Recent PyQt4 versions support the new syntax as well, so the same syntax can be used for both Anki 2.0 and 2.1 add-ons.
More info is available at
One add-on author reported that the following tool was useful to automatically convert the code:
The Qt modules are in PyQt5 instead of PyQt4. You can do a conditional import, but an easier way is to import from aqt.qt - eg
from aqt.qt import *
That will import all the Qt objects like QDialog without having to specify the Qt version.
Each add-on is now stored in its own folder. If your add-on was previously called demo.py, you’ll need to create a demo folder with an __init__.py file.
If you don’t care about 2.0 compatibility, you can just rename demo.py to demo/__init__.py.
If you plan to support 2.0 with the same file, you can copy your original file into the folder (demo.py → demo/demo.py), and then import it relatively by adding the following to demo/__init__.py:
from . import demo
The folder needs to be zipped up when uploading to AnkiWeb. For more info, please see sharing add-ons.
When an add-on is upgraded, all files in the add-on folder are deleted. The only exception is the special user_files folder. If your add-on requires more than simple key/value configuration, make sure you store the associated files in the user_files folder, or it will be lost on upgrade.
Most Python 3 code will run on Python 2 as well, so it is possible to update your add-ons in such a way that they run on both Anki 2.0 and 2.1. Whether this is worth it depends on the changes you need to make.
Most add-ons that affect the scheduler should require only minor changes to work on 2.1. Add-ons that alter the behaviour of the reviewer, browser or editor may require more work.
The most difficult part is the change from the unsupported QtWebKit to QtWebEngine. If you do any non-trivial work with webviews, some work will be required to port your code to Anki 2.1, and you may find it difficult to support both Anki versions in the one codebase.
If you find your add-on runs without modification, or requires only minor changes, you may find it easiest to add some if statements to your code and upload the same file for both 2.0.x and 2.1.x.
If your add-on requires more significant changes, you may find it easier to stop providing updates for 2.0.x, or to maintain separate files for the two Anki versions.
Qt 5 has dropped WebKit in favour of the Chromium-based WebEngine, so Anki’s webviews are now using WebEngine. Of note:
You can now debug the webviews using an external Chrome instance, by setting the env var QTWEBENGINE_REMOTE_DEBUGGING to 8080 prior to starting Anki, then surfing to localhost:8080 in Chrome.
WebEngine uses a different method of communicating back to Python. AnkiWebView() is a wrapper for webviews which provides a pycmd(str) function in Javascript which will call the ankiwebview’s onBridgeCmd(str) method. Various parts of Anki’s UI like reviewer.py and deckbrowser.py have had to be modified to use this.
Javascript is evaluated asynchronously, so if you need the result of a JS expression you can use ankiwebview’s evalWithCallback().
As a result of this asynchronous behaviour, editor.saveNow() now requires a callback. If your add-on performs actions in the browser, you likely need to call editor.saveNow() first and then run the rest of your code in the callback. Calls to .onSearch() will need to be changed to .search()/.onSearchActivated() as well. See the browser’s .deleteNotes() for an example.
Various operations that were supported by WebKit like setScrollPosition() now need to be implemented in javascript.
Page actions like mw.web.triggerPageAction(QWebEnginePage.Copy) are also asynchronous, and need to be rewritten to use javascript or a delay.
WebEngine doesn’t provide a keyPressEvent() like WebKit did, so the code that catches shortcuts not attached to a menu or button has had to be changed. setStateShortcuts() fires a hook that can be used to adjust the shortcuts for a given state.
Many small 2.0 add-ons relied on users editing the sourcecode to customize them. This is no longer a good idea in 2.1, because changes made by the user will be overwritten when they check for and download updates. 2.1 provides a configuration system to work around this. If you need to continue supporting 2.0 as well, you could use code like the following:
if getattr(mw.addonsManager, "getConfig", None): config = mw.addonManager.getConfig(__name__) else: config = dict(optionA=123, optionB=456) | https://apps.ankiweb.net/docs/addons.html | CC-MAIN-2018-43 | refinedweb | 4,531 | 57.67 |
I am very new to C++ and have written only basic algorithms. In school we use turbo c++ compiler but now i have to attend a workshop for which I need to be able to use a gnu compiler and I do not know how to change my programs for it. I tried to google it but was not very successful. There are few things i want to know in particular:
- if I can't use <conio.h>, what do i do if I want to use a function like clrscr()?
- what is namespace?(i read about this but didn't understand it:()
- If i want to use void main() instead of int main(), if i can't use getch(), then what do i do?
- Is the syntax for structures in turbo c++ and a gcc based compiler the same?
- If i am using int main(), is it not necessary to end it with return 0?
- Out of the following list, which are the header files that i can use in a gcc based compiler:
iostream.h
stdio.h
stdlib.h
ctype.h
time.h
string.h
iomanip.h
math.h
matrix.h
process.h
and in which of them should i drop out the .h?which of them can i use wtih a little modification?
- should it be <math>,<ctype>,<time> or <cmath>,<cctype><ctime>?
what is the difference?
please respond asap...it's sort of urgent | https://www.daniweb.com/programming/software-development/threads/252858/ditching-turbo-c-and-using-gcc | CC-MAIN-2021-17 | refinedweb | 238 | 83.15 |
> lwip-1.3.0.rar > raw.c
/** * @file * Implementation of raw protocol PCBs for low-level handling of * different types of protocols besides (or overriding) those * already available in lwIP. * */ /* *_RAW /* don't build if not configured for use in lwipopts.h */ #include "lwip/def.h" #include "lwip/memp.h" #include "lwip/inet.h" #include "lwip/ip_addr.h" #include "lwip/netif.h" #include "lwip/raw.h" #include "lwip/stats.h" #include "lwip/snmp.h" #include "arch/perf.h" #include /** The list of RAW PCBs */ static struct raw_pcb *raw_pcbs; /** * Determine if in incoming IP packet is covered by a RAW PCB * and if so, pass it to a user-provided receive callback function. * * Given an incoming IP datagram (as a chain of pbufs) this function * finds a corresponding RAW PCB and calls the corresponding receive * callback function. * * @param p pbuf to be demultiplexed to a RAW PCB. * @param inp network interface on which the datagram was received. * @return - 1 if the packet has been eaten by a RAW PCB receive * callback function. The caller MAY NOT not reference the * packet any longer, and MAY NOT call pbuf_free(). * @return - 0 if packet is not eaten (pbuf is still referenced by the * caller). * */ u8_t raw_input(struct pbuf *p, struct netif *inp) { struct raw_pcb *pcb, *prev; struct ip_hdr *iphdr; s16_t proto; u8_t eaten = 0; LWIP_UNUSED_ARG(inp); iphdr = p->payload; proto = IPH_PROTO(iphdr); prev = NULL; pcb = raw_pcbs; /* loop through all raw pcbs until the packet is eaten by one */ /* this allows multiple pcbs to match against the packet by design */ while ((eaten == 0) && (pcb != NULL)) { if (pcb->protocol == proto) { /* receive callback function available? */ if (pcb->recv != NULL) { /* the receive callback function did not eat the packet? */ if (pcb->recv(pcb->recv_arg, pcb, p, &(iphdr->src)) != 0) { /* receive function ate the packet */ p = NULL; eaten = 1; if (prev != NULL) { /* move the pcb to the front of raw_pcbs so that is found faster next time */ prev->next = pcb->next; pcb->next = raw_pcbs; raw_pcbs = pcb; } } } /* no receive callback function was set for this raw PCB */ /* drop the packet */ } prev = pcb; pcb = pcb->next; } return eaten; } /** * Bind a RAW PCB. * * @param pcb RAW PCB to be bound with a local address ipaddr. * @param ipaddr local IP address to bind with. Use IP_ADDR_ANY to * bind to all local interfaces. * * @return lwIP error code. * - ERR_OK. Successful. No error occured. * - ERR_USE. The specified IP address is already bound to by * another RAW PCB. * * @see raw_disconnect() */ err_t raw_bind(struct raw_pcb *pcb, struct ip_addr *ipaddr) { ip_addr_set(&pcb->local_ip, ipaddr); return ERR_OK; } /** * Connect an RAW PCB. This function is required by upper layers * of lwip. Using the raw api you could use raw_sendto() instead * * This will associate the RAW PCB with the remote address. * * @param pcb RAW PCB to be connected with remote address ipaddr and port. * @param ipaddr remote IP address to connect with. * * @return lwIP error code * * @see raw_disconnect() and raw_sendto() */ err_t raw_connect(struct raw_pcb *pcb, struct ip_addr *ipaddr) { ip_addr_set(&pcb->remote_ip, ipaddr); return ERR_OK; } /** * Set the callback function for received packets that match the * raw PCB's protocol and binding. * * The callback function MUST either * - eat the packet by calling pbuf_free() and returning non-zero. The * packet will not be passed to other raw PCBs or other protocol layers. * - not free the packet, and return zero. The packet will be matched * against further PCBs and/or forwarded to another protocol layers. * * @return non-zero if the packet was free()d, zero if the packet remains * available for others. */ void raw_recv(struct raw_pcb *pcb, u8_t (* recv)(void *arg, struct raw_pcb *upcb, struct pbuf *p, struct ip_addr *addr), void *recv_arg) { /* remember recv() callback and user data */ pcb->recv = recv; pcb->recv_arg = recv_arg; } /** * Send the raw IP packet to the given address. Note that actually you cannot * modify the IP headers (this is inconsistent with the receive callback where * you actually get the IP headers), you can only specify the IP payload here. * It requires some more changes in lwIP. (there will be a raw_send() function * then.) * * @param pcb the raw pcb which to send * @param p the IP payload to send * @param ipaddr the destination address of the IP packet * */ err_t raw_sendto(struct raw_pcb *pcb, struct pbuf *p, struct ip_addr *ipaddr) { err_t err; struct netif *netif; struct ip_addr *src_ip; struct pbuf *q; /* q will be sent down the stack */ LWIP_DEBUGF(RAW_DEBUG | LWIP_DBG_TRACE | 3, ("raw_sendto\n")); /* not enough space to add an IP header to first pbuf in given p chain? */ if (pbuf_header(p, IP_HLEN)) { /* allocate header in new pbuf */ q = pbuf_alloc(PBUF_IP, 0, PBUF_RAM); /* new header pbuf could not be allocated? */ if (q == NULL) { LWIP_DEBUGF(RAW_DEBUG | LWIP_DBG_TRACE | 2, ("raw_sendto: could not allocate header\n")); return ERR_MEM; } /* chain header q in front of given pbuf p */ pbuf_chain(q, p); /* { first pbuf q points to header pbuf } */ LWIP_DEBUGF(RAW_DEBUG, ("raw_sendto: added header pbuf %p before given pbuf %p\n", (void *)q, (void *)p)); } else { /* first pbuf q equals given pbuf */ q = p; if(pbuf_header(q, -IP_HLEN)) { LWIP_ASSERT("Can't restore header we just removed!", 0); return ERR_MEM; } } if ((netif = ip_route(ipaddr)) == NULL) { LWIP_DEBUGF(RAW_DEBUG | 1, ("raw_sendto: No route to 0x%"X32_F"\n", ipaddr->addr)); /* free any temporary header pbuf allocated by pbuf_header() */ if (q != p) { pbuf_free(q); } return ERR_RTE; } if (ip_addr_isany(&pcb->local_ip)) { /* use outgoing network interface IP address as source address */ src_ip = &(netif->ip_addr); } else { /* use RAW PCB local IP address as source address */ src_ip = &(pcb->local_ip); } #if LWIP_NETIF_HWADDRHINT netif->addr_hint = &(pcb->addr_hint); #endif /* LWIP_NETIF_HWADDRHINT*/ err = ip_output_if (q, src_ip, ipaddr, pcb->ttl, pcb->tos, pcb->protocol, netif); #if LWIP_NETIF_HWADDRHINT netif->addr_hint = NULL; #endif /* LWIP_NETIF_HWADDRHINT*/ /* did we chain a header earlier? */ if (q != p) { /* free the header */ pbuf_free(q); } return err; } /** * Send the raw IP packet to the address given by raw_connect() * * @param pcb the raw pcb which to send * @param p the IP payload to send * */ err_t raw_send(struct raw_pcb *pcb, struct pbuf *p) { return raw_sendto(pcb, p, &pcb->remote_ip); } /** * Remove an RAW PCB. * * @param pcb RAW PCB to be removed. The PCB is removed from the list of * RAW PCB's and the data structure is freed from memory. * * @see raw_new() */ void raw_remove(struct raw_pcb *pcb) { struct raw_pcb *pcb2; /* pcb to be removed is first in list? */ if (raw_pcbs == pcb) { /* make list start at 2nd pcb */ raw_pcbs = raw_pcbs->next; /* pcb not 1st in list */ } else { for(pcb2 = raw_pcbs; pcb2 != NULL; pcb2 = pcb2->next) { /* find pcb in raw_pcbs list */ if (pcb2->next != NULL && pcb2->next == pcb) { /* remove pcb from list */ pcb2->next = pcb->next; } } } memp_free(MEMP_RAW_PCB, pcb); } /** * Create a RAW PCB. * * @return The RAW PCB which was created. NULL if the PCB data structure * could not be allocated. * * @param proto the protocol number of the IPs payload (e.g. IP_PROTO_ICMP) * * @see raw_remove() */ struct raw_pcb * raw_new(u8_t proto) { struct raw_pcb *pcb; LWIP_DEBUGF(RAW_DEBUG | LWIP_DBG_TRACE | 3, ("raw_new\n")); pcb = memp_malloc(MEMP_RAW_PCB); /* could allocate RAW PCB? */ if (pcb != NULL) { /* initialize PCB to all zeroes */ memset(pcb, 0, sizeof(struct raw_pcb)); pcb->protocol = proto; pcb->ttl = RAW_TTL; pcb->next = raw_pcbs; raw_pcbs = pcb; } return pcb; } #endif /* LWIP_RAW */ | http://read.pudn.com/downloads119/sourcecode/internet/tcp_ip/507869/lwip-1.3.0/src/core/raw.c__.htm | crawl-002 | refinedweb | 1,157 | 62.78 |
The Question is:
How can I generate a weeknumber?
Is this by using the lexical function f$time or f$cvtime?
The Answer is :
By week number, the OpenVMS Wizard will assume you mean the week within
the year, and specifically a value between 1 and 52 inclusive. As there
are various accepted definitions for a week number, there is no single
DCL lexical function or argument that can retrieve the desired.
Given that there are only 52 weeks in a year, and given that DCL is not
particularly suited for date arithmetic, and given that computers are
fast, the simplest way to is to count the week.
For example, assuming that week 1 starts on 1-Jan and week 2 starts on
8-Jan (etc...), this procedure uses combination times to count backwards
in multiples of 7 to find the first day not in the current year, at the
same time as counting up weeks.
$ day=F$CVTIME(p1,"ABSOLUTE","DATE")
$ weeknum=0
$ offset=0
$ year=F$CVTIME(day,,"YEAR")
$ loop:
$ weeknum=weeknum+1
$ offset=offset+7
$ IF F$CVTIME("''day'-''offset'-0",,"YEAR").EQS.Year THEN GOTO loop
$ WRITE SYS$OUTPUT weeknum
$ EXIT
Minor variations can be made to this procedure to accomodate other
definitions for week number.
Remember that in the worst case, the above procedure will loop for 53
iterations, so unless your code is highly performance sensitive, it
shouldn't be a problem. If your code is performance sensitive, please
create and code an algorthm using a compiled language.
Within a compiled language, you can generate the weeknumber for any
given date. For example, you can generate the week number for any
given date using the strftime() C Run-time library function, and
specifically the %W directive. This will give you a week number in
the range [00,53], where Monday is the first day of the week. For
the purposes of this C example, all days in the year preceding the
first Monday are considered to be in week 0.
For example, for current date:
$ run x
$ Monday May 06 2002 is in week number 18
$
x.c
---
#include <time.h>
#include <stdio.h>
main() {
char s[80];
time_t t = time(NULL);
struct tm *tms = localtime(&t);
strftime(s, sizeof(s), "%A %B %d %Y is in week number %W", tms);
puts(s);
} | http://h71000.www7.hp.com/wizard/wiz_7635.html | CC-MAIN-2013-48 | refinedweb | 389 | 61.26 |
Have:
Hi All
We are sorry but wont be able to publish the job interview question today. We hope to publish it later on this week.
Sorry about that
Amit
Have you ever tried to create a DataTemplate for a Generic Class? During last week I had to battle this issue and it is allot more complicated then it sounds. As far as I can tell Creating DataTemplates for Generic classes is impossible. There is some kind of workaround but it is not all that good. OK lets get down to business. This is the class we are trying to template
1: public class GenericClass<T>
2: {
3: private T m_Val;
4:
5: public T Val
6: {
7: get { return m_Val; }
8: set { m_Val = value; }
9: }
10: }:
A:
We pay for user submitted tutorials and articles that we publish. Anyone can send in a contributionLearn More | http://www.dev102.com/2008/07/ | crawl-002 | refinedweb | 146 | 72.05 |
public class Solution { ListNode top; /** @param head The linked list's head. Note that the head is guaranteed to be not null, so it contains at least one node. */ public Solution(ListNode head) { this.top = head; } /** Returns a random node's value. */ public int getRandom() { ListNode n = this.top; int size = size(top); int i = 1; Random rand = new Random(); int stop = rand.nextInt(size); int ans = 0; while(n != null && i < stop){ ans = n.val; i++; n = n.next; } return ans; } public int size(ListNode head){ int count = 0; ListNode n = head; while(n != null){ count++; n = n.next; } return count; } }
It gets the right answer when I click "Run Code" sometimes but I thought that was the point of it being random. | https://discuss.leetcode.com/topic/59336/am-i-doing-something-wrong-here | CC-MAIN-2017-51 | refinedweb | 124 | 87.52 |
08 February 2010 02:03 [Source: ICIS news]
GRAPEVINE, Texas (ICIS news)--Representatives of the US biodiesel industry will meet at the 2010 National Biodiesel Conference & Expo to survey the wreckage of the year before and plot a course forward.
On the eve of the conference kick-off, with renewable fuel businessmen and advocates watching ?xml:namespace>
After a year of flat-lined sales, bankruptcies and other near-death business scenarios, biodiesel sellers were optimistic that last week's news that the US Environmental Protection Agency (EPA) would mandate 1bn gal/year of the renewable fuel be blended into the US fuel supply would invigorate most - if not all - producers.
"That's 1bn gal of biodiesel that will eventually have to hit the market," said one trader nursing a drink. "Still, there's nearly 3bn gal of capacity in the
The financial upheaval of last year may have culled some of that capacity from the market. For the most part, 2009 was a year biodiesel refiners would like to forget. Production plunged after Europe slapped prohibitive levies on
When things looked as if they could not get much worse, Congress delayed extending the $1/gal blending credit the government had been offering refiners for years. Without that subsidy, biodiesel suppliers could not compete with traditional diesel prices. More refineries halted production and some were forced to lay off employees. Many of the 171 refiners who went into 2009 did not come out.
At the Energy Information Administration (EIA), the numbers tell the story - production during the first 10 months of 2009 was 414m gal, down more than a third from the 656m gal produced during the same period of 2008.
Attendance at this year's biodiesel conference is expected to be down. Many of those who survived the fiscal calamities of 2009 will most likely prefer to stay home and lick their wounds than fly to
But after all of last year's pain, this year should hold some gain for the survivors, sources said. Now that the EPA rolled out its renewable fuels mandate, there was some talk that biofuel sellers will no longer need an extension of the $1/gal blending credit that expired in December, a trader said.
Joe Jobe, president of the National Biodiesel Board (NBB) had described 2009 as a “hold-on-for-dear-life year” for the industry, which had 171 refiners going into last January.
Jobe remained optimistic: “The good news is that 2010 could be a year of tremendous recovery for us,” he said.
The biodiesel conference runs from 7-10 February.
To discuss issues facing the chemical industry go to ICIS news | http://www.icis.com/Articles/2010/02/08/9332445/us-biodiesel-industry-hopes-to-leave-wreckage-of-2009.html | CC-MAIN-2015-18 | refinedweb | 441 | 56.18 |
While.
What is Plotly?
Plotly Python is an open-source library built on top of plotly.js which allows users to create professional quality, interactive, web-based or standalone visualizations or applications.
Visualizations can be displayed in Jupyter notebooks, standalone HTML files, or integrated into web-applications via the Dash framework.
Over 40 unique charts and limitless customization options exist across statistical, financial, geographic, scientific, and 3-D plot types.
Getting Started
I’ve decided to pull an ice hockey dataset from Kaggle to use as my example.
I loaded the dataset into pandas and did a subset of the data just for the year 2018, which can be seen as below:
Let’s say we’re interested in seeing a distribution of points by player. For this dataset, a histogram would be a great starting point. To create a histogram in Plotly, you first create a Figure, telling Plotly what data to use:
import plotly.graph_objects as gofig = go.Figure(data=[go.Histogram(x=hockeydf_2018['PTS'])])fig.show()
We import the plotly.graph_objects library as go and use it to create a new Figure — which by naming convention we will call fig.
We pass in the data parameter (which is also known as the Trace) to tell Plotly what we want to plot, as well as what type of plot.
So here we see a histogram displaying the distribution of points per player. Very easy to create, but also very basic. Plotly uses a default Layout definition when it generates the plot, but what if we want to customize it further?
How about we change the number of bins that we sort the data into?
fig = go.Figure(data=[go.Histogram(
x=hockeydf_2018['PTS'],
xbins=dict(start=0,
end=120,
size=5))
])fig.show()
You can start to see how you can easily add elements to a graph to customize it further.
It’s common to use whitespace within the plot definitions to make your code easier to read — and easier to edit later on.
Now, what if we also wanted to add some labels and a title to our histogram?
fig = go.Figure(data=[go.Histogram(
x=hockeydf_2018['PTS'],
xbins=dict(start=0,
end=120,
size=5))
])fig.update_layout(
title_text='2018 NHL Points by Player',
xaxis_title_text='Value',
yaxis_title_text='Count',
)fig.show()
This time, we used the fig.update_layout function to directly add titles to our graph. The updated graph can be seen below:
What about adding additional data (traces) to our plot? It could be interesting to see how the distribution of points varies over time.
I have gone ahead and made two other dataframes which contain players point information for 2000, and 1980.
Point totals likely won’t change too drastically from one year to the next, but if we look at a longer time interval we may see some more interesting trends emerge.
To add these to our plot, you would use the fig.add_trace function. We also need to make a small change to our layout to overlay the histograms and adjust the trace opacity for better visibility:
fig = go.Figure(data=[go.Histogram(
x=hockeydf_2018['PTS'],
name='2018',
xbins=dict(start=0,
end=120,
size=5))
])fig.add_trace(go.Histogram(x=hockeydf_2000['PTS'], name='2000'))
fig.add_trace(go.Histogram(x=hockeydf_1980['PTS'], name='1980'))fig.update_layout(
title_text='NHL Points by Player - 1980, 2000, 2018',
xaxis_title_text='Value',
yaxis_title_text='Count',
barmode='overlay'
)
fig.update_traces(opacity=0.4)fig.show()
It’s as easy as adding options to update_layout, update_traces, or adding data with add_trace.
Our plot now looks like this:
You can quickly see some interesting trends coming out of our comparisons now!
The 1980’s seemed to have a lot more dominant players who were scoring on the high side of the points spectrum, while more recent years we see that the distribution is moved much more to the left, with more players scoring fewer points.
How about rather than overlaying, do a side-by-side comparison?
Using the subplots library:
import plotly.graph_objects as go
from plotly.subplots import make_subplotsfig = make_subplots(rows=1, cols=3,
subplot_titles=('2018', '2000', '1980')
)trace1 = go.Histogram(x=hockeydf_2018['PTS'])
trace2 = go.Histogram(x=hockeydf_2000['PTS'])
trace3 = go.Histogram(x=hockeydf_1980['PTS'])fig.append_trace(trace1, 1, 1)
fig.append_trace(trace2, 1, 2)
fig.append_trace(trace3, 1, 3)fig.update_layout(showlegend=False)fig.show()
Here, we create 3 datasets (traces) which we then append onto fig (the plot).
When we append, we have to choose which row, column position to place the trace in.
In the above code, we created a 1 row, 3 column subplot, so when we append traces we use the (row, column) designation — (1,1), (1,2), (1,3).
Our subplot histogram now looks like:
Pretty cool!
There is an endless amount of customization we can apply — from fonts, bar colors, line/grid styling, to adding annotations and interactive widgets to our plots.
I hope this shows just have easy it is to get start with Plotly, and stay tuned for more guides on some more advanced topics soon. | https://medium.com/swlh/plotly-python-an-introduction-8cd8e41bb53e?source=post_internal_links---------7---------------------------- | CC-MAIN-2021-25 | refinedweb | 843 | 57.47 |
You are given a stair with
n steps,and you are currently at
th stair. From each point in the stair, you can climb either 1 stair or you can climb 2 stairs. You need to output the number of ways in which you can reach step
0
n
.
Example Test Cases
Sample Test Case 1
Input grid:
2
Expected Output:
2
Explanation: You can climb till step
2 in the following ways:
- 1 step + 1 step
- 2 step
Sample Test Case 2
Input grid:
3
Expected Output:
3
Explanation: You can climb three steps in the following ways:
- 1 step + 1 step + 1 step
- 1 step + 2 steps /li>
- 2 steps + 1 step
Solution
We can easily solve this problem using recursion. To reach
th step, the last step will either be taken from
n
n - 2 step or from
n - 1 step. Therefore, the no of ways for reaching
th step is sum of no of ways of reaching
n
n -2 step + the number of ways of reaching
n - 1 step.
Therefore, if we model the above solution in the form of a recursive equation, it would look like this:
f(n) = f(n - 1) + f(n-2)
The above equation is the recursive equation for fibonacci numbers which we can compute very easily as shown in the below code:
Implementation
#include <bits/stdc++.h> using namespace std; int climbStairs(int n) { if (n == 0) return 0; if (n == 1) return 1; if (n == 2) return 2; int t1 = 1, t2 = 2, t3 = 3; int i = 3; while (i < n) { t1 = t2; t2 = t3; t3 = t1 + t2; i++; } return t3; } int main() { int n = 5; cout << "No of ways to climb " << n << " stairs is " << climbStairs(n) << "\n"; } | https://prepfortech.in/interview-topics/dynamic-programming/climbing-stairs | CC-MAIN-2021-17 | refinedweb | 290 | 61.23 |
Japanese often use proverbs in daily life. They come from Chinese, Japanese, and
western sources. Some come from fables, superstitions, or poems, others are simply
bits of common wisdom. Many Japanese people grew up playing the card game “Iroha-garuta,”
where each card has a proverb on it and the player must quickly snatch the card
when its pair is read.
Enjoy these excerpts from “Japanese Proverbs”
A job before breakfast (asameshi).
The phrase “asameshi mae” is generally used by itself. The usual word for “breakfast”
is “asagohan.” Such expressions as “it's child's play” and “that's a cinch” are
the equivalents.
Meeting is the beginning of parting.
This is a saying of Buddhist origin. When we meet, we must part. “To meet, to know,
to love—and then to part, is the sad tale of many a human heart.” —Coleridge.
A paper lantern matched with a temple bell.
A huge bronze bell hangs from the beam of the belfry of a Japanese Buddhist temple.
Paper lanterns are also often seen hanging. In other words, a paper lantern resembles
a temple bell in the sense that they both can be seen hanging. But that is about
the only point of similarity between them. In all other points the one can hardly
bear comparison with the other. Hence, the proverb is often used as a metaphor for
an unequal match, especially for a morganatic marriage, that is, a marriage between
a man of high rank and a woman of lower rank. There is another proverb Tsuri awanu
wa fuen no moto, of which the meaning is: “An ill-matched marriage spells discord.”
A nail (kugi) that sticks out is hammered.
What is implied by this proverb is that there is unwisdom in being too forward,
and wisdom in lying low. Impudence courts disaster. A tall tree catches much wind..
Among blossoms, the cherry; among men, the warrior.
In Japan most cherry trees are grown not so much for their fruit as for their blossoms.
The charm of the cherry blossom, though ephemeral, is too famous to need more than
a mere reminder. Just as it had, and still has, pride of place among the flowers
of this country, so the two-sworded samurai was highly esteemed in feudal Japan
for his character. Hence this parallelism.
Dumplings (dango) rather than blossoms (hana).
From of old it has been, and still is, the custom with the Japanese to go out in
the cherry season to enjoy drinking and eating under the canopy of blossoms. Such
a picnic gives one the impression that eating is the chief object of the pleasure
seekers. This proverb is often quoted when one wants to express preference for utility
to beauty. “Bread is better than the song of birds.” Another proverb of the same
import is: Hana no shita yori, hana no shita. Below the nose (hana) rather than
below the blossoms (hana). Note the play on the word, hana. By “below the nose”
is meant “that which is under the nose; namely, the mouth.”
Charming women who have a smile for everybody are cold-hearted.
By “happo-bijin” is meant a person who is affable to everybody; a person who is
“all things to all men,” as the biblical expression has it. A politician who is
out to be in the good books of members of other parties, as well as of his own,
is also referred to as such.
“Everybody's friend is nobody's friend.”
The word, happo-bijin, literally means “an eight-side belle,” that is to say, a
woman who looks beautiful, no matter from which side she may be looked at. The expression,
happo, “eight sides” is, of course, synonymous with “many sides.” Combined with
a similar expression, shiho, “four sides,” the word, happo, is used adverbially.
Thus by shiho happo ni is meant “every which way.” The word, hattoshin, (lit., eight-head
body), which has come to gain currency in recent years, is often applied to a fair
girl, tall and well-balanced. (Cf. eight-head figure.).
Out of a gourd comes a pony.
The hard-shelled fruit of a plant called bottle gourd are dried, varnished, and
used as bottles for sake, rice wine. Such bottles, as well as the fruit themselves,
are called hyotan in Japanese. This proverb is often quoted when a most unexpected
thing happens, or when a truth comes out of what has been said in jest. “There's
many a true word said in jest.” Another “hyotan” proverb is: Hyotan namazu (It's
like trying to catch a namazu, or catfish, with a gourd). This is an expression
meaning (1) “as slippery as an eel” and (2) vague, non-committal.
Even a sardine's head may become an object of worship through faith.
The pious and credulous may pin their faith even to such a seemingly worthless thing
as a sardine's head, which, in their minds, will work wonders. “Faith moves a mountain.”.
Prayers to a horse's ears.
When a person turns a deaf ear to a piece of good advice, Japanese say that it is
no more effective than are prayers offered to the ears of a horse. Substitute the
word, kaze, (wind) for nembutsu (prayers), and you will have another proverb of
the same import: Uma no mimi ni kaze (Wind in a horse's ears).
As I think it is mine, I find that the snow weighs lightly on my umbrella.
This is a modified form of “Waga yuki to omoeba karoshi kasa no ue” (When I think
it is my snow on my hat, it seems light), a haiku, or 17-syllable verse, by Kikaku,
one of the master hands in this particular branch of literature. Think you are doing
your own job, and you will be sure to find the task you are tackling is interesting. | http://online.jtbusa.com/Historical/Japanese-Proverbs.aspx | CC-MAIN-2017-26 | refinedweb | 980 | 81.73 |
From: Hamish Mackenzie (boost_at_[hidden])
Date: 2002-02-19 13:21:17
On Tue, 2002-02-19 at 10:38, Peter Dimov wrote:
> From: "Hamish Mackenzie" <boost_at_[hidden]>
> > I thought this was solved by Koenig lookup?
> >
> > using std::swap;
> > swap( x, y );
> >
> > Then Koenig lookup will find swap if it is in the namespace that x and y
> > are in will it not?
>
>
>
> In short, yes it will. This is error-prone, though (experts have been known
> to get that wrong) and it doesn't solve the problem within the standard
> library, i.e. std::sort using std::swap (without additional guarantees.)
Ok, I think my proposed swap.hpp in the other post fixes the std::
problem. It is similar to the fix described in the section "Enable
argument-dependent lookup on standard names" except it allows you to
still call it std::swap (rather than std::iter_swap). Unfortunately it
still has all the same problems described which you could argue are due
to the misuse of overloading.
All this talk of typeof and auto, makes me worry that overloading is
going to be used even more in the future simply because it means less
typing (as in pressing of keys) when often it should not be used because
it means less typing (as in type saftey is lost).
I would much rather line an easier way to write the equivalent of the
following prolog code
some_type( TypeValue1 ) :- ...
some_function( some_type( TypeValue1 ), some_type( TypeValue2 ),
ReturnValue ) :- ...
In C++ it is
// Function class
template< typename T1, typname T2 >
class some_function_type;
// Runtime helper
template< typename T1, typname T2 >
typename some_function_type<T1,T2>::return_type some_function(
const T1 & a, const T2 & b )
{
return some_function_type<T1,T2>::execute( a, b );
}
// Define types of type this and may have more
// than one template argument (eg std::vector<T,A> )
template< typename TypeValue1 >
class some_type_type {...};
// Specialize class
template< typename TypeValue1, typname TypeValue2 >
class some_function_type<
some_type_type< TypeValue1 >,
some_type_type< TypeValue2 > >
{
public:
// Compile time version
typedef some_compile_time_expression return_type;
// Runtime version
static return_type execute(
const some_type_type< TypeValue1 > & a,
const some_type_type< TypeValue2 > & b )
{
...
}
};
No wonder people want to use overloading instead of specialization.
Thats not to say we can do without overloading for instance if you want
to define some_function for some_base class and all its derived classes
you need to write
typename some_function_type<some_base, some_base>::return_type
some_function( const some_base & a, const some_base & b )
{
return some_function_type<some_base,some_base>::execute( a, b );
}
You could add do_some_function for overloading by people outside your
namespace but because it returns a value some_function will not be able
to determine the return type for derived classes. Here typeof or auto
would be useful but it still would not fix the fact that three lines of
prolog have become rather a lot of C++.
Hamish Mackenzie
Boost list run by bdawes at acm.org, gregod at cs.rpi.edu, cpdaniel at pacbell.net, john at johnmaddock.co.uk | https://lists.boost.org/Archives/boost/2002/02/25432.php | CC-MAIN-2020-34 | refinedweb | 478 | 50.26 |
I have a function that I wrote recursively in python, it seems to work fine for small inputs, but not the big inputs i need to run it on. The function is basically implementing distributing and FOILing. When I try to run it in on the list a, the python process just gets killed after a while.
Offline
According to kernprof, I've been able to do a little better by changing some of the for loops to list comprehensions, but I still can't expand the a list in the link posted before...
def expand_help(l, r, s): """ Basically what we want to do is walk through a list like l = [(0, 2), (0, 1), (1, 2)] and turn it into something like r = [(-1, [(0, 2)]), (-1, [(0, 1), (1, 2)])], so there are a few different cases. if l[0] is a list then we should expand that, if not then it must be (1, [(0, 2)]) by definition of phi_b_ext. if l[1] is a list, expand that, then if l[2] is a list as well expand it and foil, otherwise multiply each element of l[1] by l[2], similarly, if l[2] is a list, multiply each element of l[2] by l[1], otherwise just multiply l[1] and l[2] """ if type(l[0]) == list: r.extend(expand_help(l[0], [], -1*s)) else: r.append((-1*s, [l[0]])) if type(l[1]) == list: a = expand_help(l[1], [], -1*s) if type(l[2]) == list: b = expand_help(l[2], [], s) t = [(i*p, j+q) for i, j in a for p, q in b] else: t = [(i, j+[l[2]]) for i, j in a] else: if type(l[2]) == list: a = expand_help(l[2], [], s) t = [] for i in a: x, y = i if type(y) == list: y.insert(0, l[1]) t.append((-1*s*x, y)) else: t.append((-1*s*x, [l[1], y])) else: t = [(-1*s, [l[1], l[2]])] r.extend(t) return r
Offline
This appears to be an unusually complex data structure definition and I'm not sure what it is supposed to represent. What's the equivalency between [ (0,2), (0,1), (1,2) ] and [ (-1, [ (0,2) ]), (-1, [ (0,1), (1,2) ]) ] ? What do each of the parts mean?
Offline
There is a (n+1)x(n+1) that looks like this
Ga = [as0, as1, as2] [a1s, a11, a12] [a2s, a21, a22]
We then want to compose a function phi_sk (where k goes between 1 and n-1) with either itself or some other function phi_sk, n times and apply that function to each as* and a*s element. Doing that we get lists like
a = [(1, 0), (2, 1), [(0, 1), (1, 2), (2, 0)]]
The tuples in the list represent the indices into the matrix Ga. By definition of phi_sk, we'll either get a single element (in this case for example phi_s1(a2s) = a1s), or we'll get 3 elements (phi_s1(as1) = -as2 - as1*a12) that will always look like -1*(some element) - (the product of two others). So, I represented the equation -as2 - as1*a12 by the list [(0, 2), (0, 1), (1, 2)].
So, now say we've applied all the phi_sk's to all the as* and a*s elements n times. We'll get back lists like [(1, 0), (2, 1), [(0, 1), (1, 2), (2, 0)]] and even much more complicated ones like this [[(2, 0), (2, 1), (1, 0)], (2, 1), [(1, 0), (1, 2), [(2, 0), (2, 1), (1, 0)]]] What we want do now is build another matrix Phi_L_B where the ij entry are the coffeicients of the ajs terms of the composition of the phi_sk's on a_is. In order to get those coefficients, we need to take a list like [(0, 2), (0, 1), (1, 2)] and associate a sign with each element and figure out the products and sign of the products.
For example looking at this [(1, 0), (2, 1), [(0, 1), (1, 2), (2, 0)]] this represents -a1s - a21*(-as1 - a12*a2s))
if we expand that out we get -a1s + a21*as1 + a21*a12*a2s. Its important to note that the structure we are working over DOES NOT have a commutative multiplication so we cannot change the order. So, I choose to represent the expanded out version in the following way, [(-1, [(1, 0)]), (1, [(2, 1), (0, 1)]), (1, [(2, 1), (1, 2), (2, 0)])] where in a tuple, the first element is the sign, and the second element is a list of elements we multiple together.
TLDR
[.
Offline
[.
That's just too much nesting, both for Python and for mortals. Plus the meaning of each data structure depends heavily on both its contents and context. Only a mathematician would come up with something like this...
Okay, okay, here's what I'm thinking: you have two options. Preferably, you would rewrite your phi_sN functions so that they simplify as they go, and always return a simple (non-recursive) data structure like a list-of-terms; that would probably cost much less than trying to simplify the entire massive expression after the fact.
The other option is to store the whole mess into a tree-like data structure, and simplify it in-place using postorder traversal. Which is not entirely different from what you're doing now, but you need to store it in such a manner that the context doesn't determine what you do with a subexpression (i.e. is this tuple part of a list, or is this list the 2nd member of a tuple, etc.) -- make the data structure more symmetric, and you'll be a good step closer to taming that complexity. It has to be postorder and in-place to keep your memory usage under control.
Actually, if you can modify your existing algorithm to do the simplification in-place (rather than appending to a new data structure) that might help enough to make it work. I'm not really sure that's possible though. In any case, I doubt I'll be much more help.
Offline
I think I have another idea that might work. A generator that returns the most deeply nested element of a list. We expand that, then return the next most deeply nested element. Expand that and so on.
Also, I simplified what expand returns. Its now [(-1, (0, 2)), (-1, (0, 1, 1, 2))] instead of a list of tuples for the second entry in the tuple. Now, when iterating through we just take 2 elements a time instead of 1. I might possibly be able to simplify it more and just have it be a list of tuples. [(-1, 0, 2), (-1, 0, 1, 1, 2)]
Offline
I did not understand neither the purpose nor the data structure completely, but it sounds like something which might better be implemented with map() and numpy's matrix. Did you look into these?
From my experiences you need recursion very very rarely in python.
Offline
So... I did a little more digging, you nerd sniped me for sure. Here's what I came up with for the original problem, but don't get excited until you read the caveats below:
The classes are just containers for variables and terms ("term" being a sequence of variables multiplied together in order, plus a numeric coefficient). I wrote them to ease the complexity of the nesting and to make it easy to print out an expression for debugging. If you need the result in something other than a list-of-terms, it shouldn't be too difficult to write a conversion function. Edit: Custom classes removed; interpret() now returns a sequence of dicts, which represent terms. Closer to the original problem and less extraneous fat.
The interpret() function works on the recursive data structure you defined (e.g. [(1, 0), (2, 1), [(0, 1), (1, 2), (2, 0)]] ) and returns a generator. The generator yields terms, one after the other. Like terms are not combined, because to do so you would have to keep track of all previous terms, which is not possible for obvious reasons. I found that it was surprisingly hard to write this in a way that didn't bleed a lot of memory, but I think it works now; I can write a loop to churn through the generator output and leave it running for some time without the process being killed or locking up my desktop.
However, that brings me to the other caveat: the example input at the end of the code you originally posted? It's really big. Really, really, really big. The expansion contains millions of terms. In the last 10 minutes my computer has generated 32 million terms and I have no way of knowing how close it is to "finished". I imagine the time required to do so could be much, much longer than you could conceivably wait. If my gut instincts are right, rewriting it in C wouldn't help you much; you need to find another approach that doesn't involve enumerating every term in the expression. Perhaps there is some shortcut you can take when generating the expression lists.
To give you an idea of the scale of the problem, the following relatively short input has an expansion 33 terms long:
[(1, 0), [(1, 4), (1, 2), [[(2, 4), (2, 1), (1, 4)], (2, 1), (1, 4)]], [[(4, 0), (4, 1), (1, 0)], [[(4, 2), (4, 1), (1, 2)], (4, 1), (1, 2)], [(2, 0), (2, 1), (1, 0)]]]
The next input I tried, which is about 4 times as long, has an expansion 737 terms long, and the next input, which is about twice as long as that, has an expansion 64,864 terms long and takes a few seconds to calculate. The entire expression is over 3 times longer than the 65k-term expression. There's no rigid correlation between input size and number of terms, which just makes it hard to reason about performance. I tried to figure a way to calculate how big the expansion would be, but then I realized I'm not getting paid for this.
tl;dr -- here's some code that works better for shorter inputs and doesn't lock up for longer ones, but I can't guarantee it will finish churning the test data this millenium. 70 million terms and no end in sight. Hope you didn't need the whole expression at once because that just ain't going to happen.
Last edited by Trent (2013-06-29 00:47:33)
Offline
So, I've spent the past few days playing with the other idea i had, ie starting from deepest nested list first, but I couldn't get the new expand function to pass all the tests.
Taviantor, I need the function to build the Phi_L_B matrix I described in my third post. If you mean more generally what do I need this function for, basically, I'm trying to reimplement the algorithms described in this paper, The guy who wrote that paper wrote a mathematica program to do the computations but only 1 person in our group has mathematica and he said that the program was written for version 5 but the latest version is 9 so he had some trouble getting it to work.
Anyway, it turns out that there is another method described in the paper for generating the Phi_L_B matrix using a "so called" chain rule. I've also been playing with implementing that..
Trent, I'll take a look at your code tomorrow when I am less tired. Also, I gave cython a try on my "optimized" expand function in my second post, but all that happened was that it became faster at expanding small terms, according to the profiling I did.
Offline
Also, I should mention, that as for the example I posted being really big. In terms of the overall picture of the things we are trying to do thats the second non-trivial example. Things are only going to get worse after that.
Offline
Are you absolutely tied to Python? This seems like a task that screams for Scheme or Common Lisp. Two words: tail-call recursion. Python has a recursion limit of 1000 frames.
Offline
Update: I left it to churn overnight and it finished at 567623460 terms. This is the last term:
-1a_3_1*a_1_2*a_2_1*a_1_4*a_4_1*a_1_2*a_2_1*a_1_2*a_2_1*a_1_4*a_4_1*a_1_2*a_2_1*a_1_3*a_3_1*a_1_2*a_2_1*a_1_4*a_4_1*a_1_2*a_2_1*a_1_4*a_4_1*a_1_2*a_2_1*a_1_3*a_3_1*a_1_2*a_2_1*a_1_0
So it's definitely big, but not unmanageable. The main source of slowdown is probably Python, and if you rewrote it in a more appropriate language you might have been able to generate the sequence in considerably less time (but still less than instantaneous -- say, 30 minutes instead of 3 hours). On the other hand, if you're ok with leaving it to crunch numbers overnight, maybe Python's speed isn't a problem here. Still, if you're planning to deal with much bigger expressions, you will soon find yourself leaving it over the weekend, or longer.
Like I said before, it does generate sets of like terms that need to be combined, so you'll need to account for that in the code that makes the matrix Phi_L_B. I haven't read the paper and you didn't explain exactly how that matrix is calculated; I'm assuming the matrix you're going for is much smaller than the entire expression, which is why generators work with you (since you don't need the entire expression at once).
@jakob: I was thinking the same thing when I started, but having finished I'm not sure tail-call optimization can help here. The recursion depth isn't that great -- only around 25 -- and I'm not even sure it's possible to do TC optimization in this case; the logic is just too complex. However, a Lisp would definitely be a more natural choice for this kind of problem.
Offline
pypy and not using recursion, ???, profits!
Evil #archlinux@freenode channel op and general support dude.
. files on github, Screenshots, Random pics and the rest
Offline.
Although it reduces the problem to something that's no longer interesting, it seems apparent to me that you can use this fact to rewrite phi_sk so that every invocation, no matter how deeply nested, always returns a data structure of fixed size. If that's possible, you'd certainly save a lot of time by doing so in the original calculations rather than by calculating a huge tree of lists and then running it through an algorithm to simplify it.
It's also possible I've misunderstood something, so if you have any follow up questions feel free to ask.
Offline
I was feeling bad about the quality of the code in my earlier post, so I went back and made some changes for clarity and documentation. You probably don't need it anymore, but if somebody finds this thread in the future maybe it will be less confusing this way.
Offline
I made a few changes and all appears to be good now. I modified the phi_sk functions to return stuff like [1, [2, 1]] for phi_sk(1, 1, 2) for example or [[-1, [2, 0]], [-1, [2, 1, 1, 0]]] for phi_sk(1, 1, 0) for example, and I modified the function that calls the phi_sk's to simplify as it goes. It appears to be returning the correct results for the example computation done in the paper, and it seems to be able to do computations for the bigger braid we were looking at, but I don't know yet if they are right or not. However, someone was able to get the old mathematica code to run so we will have something to compare to now.
The code is available on github in case anyone is interested. It requires sage to run though. … /braids.py
Offline | https://bbs.archlinux.org/viewtopic.php?pid=1290523 | CC-MAIN-2017-30 | refinedweb | 2,689 | 65.96 |
You need to sign in to do that
Don't have an account?
I am trying to write my first Apex test class. Is there any simple step by step resource as to how to get started? I have a few very small Apex classes that I created in our Sandbox that
compile fine, but now I am ready to move them to production. I have been researching the basics of writing test classes, but it definitely seems a bit overwhelming in terms of where to begin, etc. as an example, If i have an apex class (e2), and I am writing a unit Test class for this class, would the name of the test class be public class e2Test (after the @istest keyword)? when i run a test class through the developer console and choose the test class (e2Test) how does it get associated with the actual class e2??
You would be associating the class with the test class by calling that particular class methods by instantiating the class and calling the methods thereby executing the methods of the classes.
Generally as you mentioned writing test after the classname you are testing makes it clear in case if others are working on that particular class to extend the functionality.
I hope this helped.
Regards,
Anutej
Hey Sara,
Every test class begins with @istest keyword if you want to write the test class for your apex class you need to first check out the associate lookup on the page and create an instance of all those lookups and pass the mandatory value. Next step is check whether it is standard or controller class you have used you need to pass the value according to that. Code coverage must be more than 75%.
Apex code:
public class Invoice_PDF {
public Invoice__c po{get;set;}
public list<Invoice_Line_Item__c> poli{get;set;}
public decimal totQuantity{get;set;}
public decimal totAssessable {get;set;}
public decimal igst18{get;set;}
public decimal total_Amount_with_tax{get;set;}
public Invoice_PDF(ApexPages.StandardController controller)
{
id recid = ApexPages.currentPage().getParameters().get('id');
system.debug(recid);
totQuantity = 0;
totAssessable =0;
igst18=0;
total_Amount_with_tax=0;
po=[SELECT Id, Name, CreatedById, Sales_Order__c, Mode_of_Dispatch__c, Vehicle_No__c, Receiving_Station__c, Payment_Due_on__c, Bill_To__c,
Ship_To__c, PO_Number__c, PO_Date__c, E_Way_Bill_No__c, Date_Time_of_Preparation__c, Date_Time_of_Removal__c, CGST_9__c, SGST_9__c, IGST_18__c,
Total_Invoice_Value__c, Account__c, Cost_Centre__c,Bill_To__r.Name,Bill_To__r.city__c,Bill_To__r.Street__c,Bill_To__r.Country__c,Bill_To__r.State__c,
Ship_To__r.Name,Ship_To__r.city__c,Ship_To__r.Street__c,Ship_To__r.Country__c,Ship_To__r.State__c
FROM Invoice__c WHERE id=:recid];
poli=[SELECT Id,Invoice__c, Sales_Order__c, SO_Line_Item__c, Product_Master__c, Quantity__c, Quantity_in_Kgs__c, UOM__c, Rate__c,
Total_Assessable_Value__c, HSN_Code__c, CGST_9__c, SGST_9__c, IGST_18__c, Product_Description__c, Object_Age__c, WO_Line_Item__c,
Sale_Item_Master__c,Sale_Item_Master__r.name,Sale_Item_Master__r.Length_Mtrs_WB_SD_Coil__c FROM Invoice_Line_Item__c where Invoice__c=:po.id];
}
}
TEST CLASS:
@istest
public class Invoice_PDF_Test
{
public static testmethod void test()
{
insert new Auto_Number__c(Name='IN',Auto_Number__c='1');
Invoice__c inv=new Invoice__c();
inv.Name='123';
insert inv;
PageReference pr = Page.InvoicePDF;
Test.setCurrentPage(pr);
ApexPages.StandardController pp= new ApexPages.StandardController(inv);
pr.getParameters().put('id',String.valueOf(inv.id));
Invoice_PDF ip=new Invoice_PDF(pp);
}
}
Please have a look on below detail.
The test class is used to write the unit test for our code. Here is basic example of test class.
Let me know if you have any doubt.
thank you so much. Yes, this helps quite a bit. Keeps it simple while still clearly explaining the concept. I do have a question related to the types of records in the controller class. I have an apex class that I am using for a visualforce page. The standardcontroller on the VF page is (Project_Budget__c). This is a detail object for the master Object (Project__c). In my Apex Class, I have a constructor for the Project_Budget__c. For the test class, would I need to create a Project Record AND a Project Budget Record? I also have a couple of PageReference Methods. Will I need to create these in my test class as well? Is there an example you might have of how to create a test class instance of a PageReference 'record'? thanks again for all of your assistance! Sara
Thanks, Let me know if you have any doubt.
thanks again so much for your assistance. I am still having trouble getting my first Test Class working. Below is the Apex Class and the Test Class that I am attempting to create. Any input would be very much appreciated.
I found a unit testing trail in trailhead - so I will most definitley complete this as well. | https://developer.salesforce.com/forums/?id=9062I000000QxxuQAC | CC-MAIN-2022-40 | refinedweb | 724 | 56.45 |
Finding build bottlenecks with C++ Build Insights
Kevin
C++ Build Insights offers more than one way to investigate your C++ build times. In this article, we discuss two methods that you can use to identify bottlenecks in your builds: manually by using the vcperf analysis tool, or programmatically with the C++ Build Insights SDK. We present a case study that shows how to use these tools to speed up the Git for Windows open source project. We hope these tutorials will come in handy when analyzing your own builds..
Using the Build Explorer view in WPA
The first thing you’ll want to do when first opening your trace in WPA is to open the Build Explorer view. You can do so by dragging it from the Graph Explorer pane to the Analysis window, as shown below.
The Build Explorer view offers 4 presets that you can select from when navigating your build trace:
- Timelines
- Invocations
- Invocation Properties
- Activity Statistics
Click on the drop-down menu at the top of the view to select the one you need. This step is illustrated below.
In the next 4 sections, we cover each of these presets in turn.
Preset #1: Timelines
The Timelines preset shows how parallel invocations are laid out in time over the course of your build. Each timeline represents a virtual thread on which work happens. An invocation that does work on multiple threads will occupy multiple timelines.
N.B. Accurate parallelism for code generation is only available starting with Visual Studio 2019 version 16.4. In earlier versions, all code generation for a given compiler or linker invocation is placed on one timeline.
When viewing the Timelines preset, hover over a colored bar to see which invocation it corresponds to. The following image shows what happens when hovering over a bar on the 5th timeline.
Preset #2: Invocations
The Invocations preset shows each invocation on its own timeline, regardless of parallelism. It gives a more detailed look into what’s happening within the invocations. With this preset, hovering over a colored bar displays the activity being worked on by an invocation at any point in time. In the example below, we can see that the green bar in Linker 58 corresponds to the whole program analysis activity, a phase of link time code generation. We can also see that the output for Linker 58 was c2.dll.
Preset #3: Invocation Properties
The Invocation Properties preset shows various properties for each invocation in the table at the bottom of the view. Find the invocation you are interested in to see miscellaneous facts about it such as:
- The version of CL or Link that was invoked.
- The working directory.
- Key environment variables such as PATH, or _CL_.
- The full command line, including arguments coming from response (.RSP) files or environment variables.
N.B. Command line or environment variables are sometimes shown in multiple entries if they are too long.
Preset #4: Activity Statistics
The Activity Statistics preset shows aggregated statistics for all build activities tracked by the Build Explorer view. Use it to learn, for example, the total duration of all linker and compiler invocations, or if your build times are dominated by parsing or code generation. Under this preset, the graph section of the view shows when each activity was active, while the table section shows the aggregated duration totals. Drill down on an activity to see all instances of this activity. The graph, table, and drill-down visuals are show in the sequence of images below. View the official C++ Build Insights event table for a description of each activity.
Putting it all together: a bottleneck case study
In this case study, we use a real open source project from GitHub and show you how we found and fixed a bottleneck.
Use these steps if you would like to follow along:
- Clone the Git for Windows GitHub repository.
- Switch to the vs/master branch.
- Open the git\git.sln solution file, starting from the root of the repository.
- Build the x64 Release configuration. This will pull all the package dependencies and do a full build.
- Obtain a trace for a full rebuild of the solution:
- Open an elevated command prompt with vcperf on the PATH.
- Run the following command:
vcperf /start Git
- Rebuild the x64 Release configuration of the git\git.sln solution file in Visual Studio.
- Run the following command:
vcperf /stop Git git.etl. This will save a trace of the build in git.etl.
- Open the trace in WPA.
We use the Timelines preset of the Build Explorer view, and immediately notice a long-running invocation that seems to be a bottleneck at the beginning of the build.
We switch over to the Invocations preset to drill down on that particular invocation. We notice that all files are compiled sequentially. This can be seen by the small teal-colored bars appearing one after the other on the timeline, instead of being stacked one on top of the other.
We look at the Invocation Properties for this invocation, and notice that the command line does not have /MP, the flag that enables parallelism in CL invocations. We also notice from the WorkingDirectory property that the project being built is called libgit.
We enable the /MP flag in the properties page for the libgit projet in Visual Studio.
We capture another full build trace using the steps at the beginning of this section to confirm that we mitigated the issue. The build time was reduced from around 120 seconds to 80 seconds, a 33% improvement.
Identifying bottlenecks using the C++ Build Insights SDK
Most analysis tasks performed manually with vcperf and WPA can also be performed programmatically using the C++ Build Insights SDK. To illustrate this point, we’ve prepared the BottleneckCompileFinder SDK sample. It emits a warning when it finds a bottleneck compiler invocation that doesn’t use the /MP switch. An invocation is considered a bottleneck if no other compiler or linker invocation is ever invoked alongside it.
Let’s repeat the Git for Windows case study from the previous section, but this time by using the BottleneckCompileFinder}/BottleneckCompileFinderfolder, starting from the root of the repository.
- Follow the steps from the Putting it all together: a bottleneck case study section to collect a trace of the Git for Windows solution. Use the /stopnoanalyze command instead of the /stop command when stopping your trace.
- Pass the collected trace as the first argument to the BottleneckCompileFinder executable.
As shown below, BottleneckCompileFinder correctly identifies the libgit project and emits a warning. It also identifies one more: xdiff, though this one has a small duration and doesn’t need to be acted upon.
Going over the sample code
We first filter all start activity, stop activity, and simple events by asking the C++ Build Insights SDK to forward what we need to the OnStartInvocation, OnStopInvocation, and OnCompilerCommandLine functions. The name of the functions has no effect on how the C++ Build Insights SDK will filter the events; only their parameters matter.
AnalysisControl OnStartActivity(const EventStack& eventStack) override { MatchEventStackInMemberFunction(eventStack, this, &BottleneckCompileFinder::OnStartInvocation); return AnalysisControl::CONTINUE; } AnalysisControl OnStopActivity(const EventStack& eventStack) override { MatchEventStackInMemberFunction(eventStack, this, &BottleneckCompileFinder::OnStopInvocation); return AnalysisControl::CONTINUE; } AnalysisControl OnSimpleEvent(const EventStack& eventStack) override { MatchEventStackInMemberFunction(eventStack, this, &BottleneckCompileFinder::OnCompilerCommandLine); return AnalysisControl::CONTINUE; }
Our OnCompilerCommandLine function keeps track of all compiler invocations that don’t use the /MP flag. This information will be used later to emit a warning about these invocations if they are a bottleneck.
void OnCompilerCommandLine(Compiler cl, CommandLine commandLine) { auto it = concurrentInvocations_.find(cl.EventInstanceId()); if (it == concurrentInvocations_.end()) { return; } // Keep track of CL invocations that don't use MP so that we can // warn the user if this invocation is a bottleneck. std::wstring str = commandLine.Value(); if (str.find(L" /MP ") != std::wstring::npos || str.find(L" -MP ") != std::wstring::npos) { it->second.UsesParallelFlag = true; } }
Our OnStartInvocation and OnStopInvocation functions keep track of concurrently running invocations by adding them in a hash map on start, and by removing them on stop. As soon as 2 invocations are active at the same time, we consider all others to no longer be bottlenecks. If a compiler invocation is marked a bottleneck once we reach its stop event, it means there never was another invocation that started while it was running. We warn the user if these invocations do not make use of the /MP flag.
void OnStartInvocation(InvocationGroup group) { // We need to match groups because CL can // start a linker, and a linker can restart // itself. When this happens, the event stack // contains the parent invocations in earlier // positions. // A linker that is spawned by a previous tool is // not considered an invocation that runs in // parallel with the tool that spawned it. if (group.Size() > 1) { return; } // An invocation is speculatively considered a bottleneck // if no other invocations are currently running when it starts. bool isBottleneck = concurrentInvocations_.empty(); // If there is already an invocation running, it is no longer // considered a bottleneck because we are spawning another one // that will run alongside it. Clear its bottleneck flag. if (concurrentInvocations_.size() == 1) { concurrentInvocations_.begin()->second.IsBottleneck = false; } InvocationInfo& info = concurrentInvocations_[ group.Back().EventInstanceId()]; info.IsBottleneck = isBottleneck; } void OnStopInvocation(Invocation invocation) { using namespace std::chrono; auto it = concurrentInvocations_.find(invocation.EventInstanceId()); if (it == concurrentInvocations_.end()) { return; } if (invocation.Type() == Invocation::Type::CL && it->second.IsBottleneck && !it->second.UsesParallelFlag) { std::cout << std::endl << "WARNING: Found a compiler invocation that is a " << "bottleneck but that doesn't use the /MP flag. Consider adding " << "the /MP flag." << std::endl; std::cout << "Information about the invocation:" << std::endl; std::wcout << "Working directory: " << invocation.WorkingDirectory() << std::endl; std::cout << "Duration: " << duration_cast<seconds>(invocation.Duration()).count() << " s" << std::endl; } concurrentInvocations_.erase(invocation.EventInstanceId()); }
Tell us what you think!
We hope the information in this article has helped you understand how you can use the Build Explorer view from vcperf and WPA to diagnose bottlenecks in your builds. We also hope that the provided SDK sample helped you build a mental map of how you can translate manual analyses into automated ones.
Give vcperf a try today by downloading the latest version of Visual Studio 2019, or by cloning the tool directly from the vcperf Github repository. Try out the BottleneckCompileFinder sample from this article by cloning the C++ Build Insights samples repository from GitHub, or refer to the official C++ Build Insights SDK documentation to build your own analysis tools.
Have you found bottlenecks in your builds using vcperf or the C++ Build Insights SDK? Let us know in the comments below, on Twitter (@VisualC), or via email at visualcpp@microsoft.com.
Your way of explaining this topic is really praiseworthy. I would love to take inspiration from your post and write on my blog on this topic. Microsft users will be highly benefited from your information. Keep doing this good writing.
Spotting missing use of /MP can be easy to spot just by looking at the output window during a build.
I’m looking forward to see if this tool can go deeper to find bottlenecks harder / painfully to detect such has template instantiation or (big) headers pulling too much symbols.
Hi Tony,
Thanks for your suggestion. You’ll be happy to know that a post on templates is coming 🙂
As for /MP, I think C++ Build Insights makes it easier to pinpoint which invocations actually need it. It also brings problems like this to your attention without having to intentionally look for them.
Hi Tony,
The template instantiations blog post has been released! 🙂
See here:
Any idea when the the WPA version with this support will come out of preview?
Hi Edward,
The correct WPA version should come out of preview sometime this year. I have been told that it’s scheduled for the end of April, though this might be pushed back due to current world events. If you are not interested in getting the preview, you can clone the vcperf repository from GitHub. There are steps on the README page of the repo which explain how to get the regular WPA to work.
I can’t seem to get this to work. I already had the latest (non-beta) VS 2019 16.5.4, enrolled into the Insider Preview, downloaded the Preview ADK, installed the Windows Performance Tools (unchecking everything else), and collected a trace using vcperf. When I run WPA (v0.10.0) and try to open the trace, it gives me this error in the Diagnostic Console:
Hi e4lam,
I’ve just been told by someone on the WPA team that the current Preview version available for download has problems. I would recommend uninstalling the Preview and installing the regular WPA version available here. Then, you can follow the instructions on the README page of vcperf’s GitHub repo to configure the regular WPA to work with C++ Build Insights.
Sorry for the inconvenience, and thanks for letting us know about this new issue. I will update the instructions in the blog post.
Hi Kevin,
I listened to the episode of cppcast about build insights and vcperf, and got curious to try it out 🙂
However, I just ran into the same problem. It seems to be quite a few steps to follow to build and load the build insights add-in into WPA.
Do you have any estimate when the problems will be fixed in the preview?
Hi Erik,
I’ve just learned that you can obtain a working WPA by downloading the Windows SDK preview rather than the ADK preview. Please download version 19041.1 of the SDK preview, and select only the Windows Performance Toolkit option when installing it. The direct link to the ISO file for this preview is:
Hi again,
I installed WPA 10.0.19041.1 from your link. Now the “missing DLL error” is gone, but I still see no “Diagnostics” panel. Is there any example trace available to just verify the WPA installation?
The tracing seems to work, given this output.
Hi Erik,
Could you please contact me at kevca at microsoft dot com? Thanks!
The 19624 InsiderPreview version of ADK appears to have this issue as well. I installed 19041 and the Graph Explorer then shows up on the left side. Four hours later trying to download/reinstall smaller SDKs…
I ran into an issue where the perfcore_managedinterop.dll / Microsoft.Performance.PerfCore4.ManagedAddIns.ManagedAddInNativeMethods.CreateManagedProxy couldn’t be found as seen in the debug above. So I then used VS / Package Manager w/ a blank project and installed Build Insights. That resolved that issue then ran into where the Microsoft.Performance.NT.Shell.dll was “missing” I wasn’t sure which package it was looking for, and the dll was in the directory w/ wpa.exe so I just uninstalled the insider preview like you said.
I’ll install insider preview version later and let you know if that resolves it. Thanks for the advice to install latest release though! This is the only page google returns searching for the above dll w/ quotes.
Hi Stephen,
Sorry for the inconvenience. As of Visual Studio 16.6 there is now a better way to install the WPA add-in. I would suggest uninstalling all preview or insider versions of the ADK that you have and simply use the latest official version of the ADK. Then, download the latest Visual Studio 2019 and follow the instructions that I have just updated in this blog post to configure WPA. Please let me know if this doesn’t work.
Thanks!
Hey Kevin, I also read your old post ( ), in which it is said that the vcperf also works with VC2017 compiler.
I followed the to build latest vcperf and configure WPA, then after running “vcperf /start” & “vcperf /stop”, no output etl file is generated. Then I found vcperf generates 3 etl files (merged.etl, msvc.etl, system.etl) under C:\Users\WV-SA-LI\AppData\Local\Temp\CppBuildInsights\{xxxxxxxxx-xxxxx-xxxx} folder. Then I tried to open with WPA, and I could not find the “Diagnostics” panel, which seems that no etl contains the C++ Build Insight profiling info?
Btw, I am testing with a windows VM, would that affect?
Any suggestions, thanks a lot!
Hi Sa,
What does vcperf say when you run the stop command? Does it say “Analyzing…” and then exit execution without printing anything else? If so, it might be a crash. If that’s the case, could you please report the problem on Developer Community?
Thanks!
Was it really necessary to create in WPA your own tab? I thing Generic events and an enhanced region file should do the trick? What I find with regions is that you cannot specify a substring in PayLoadIdentifier to create matching regions with no exact counterparts. That way other WPA power users would also have benefitted. Is there some public backlog which WPA features were added in recent builds? I find nowhere information what has changed or improved.
Hi Alois,
We were using the Generic Events table in earlier, unreleased versions of C++ Build Insights, but found that there were performance issues when viewing large build traces. Switching to a custom add-in significantly improved the viewing experience for those traces.
You can find release notes for WPA as part of the ADK release notes available here:
I tried looking at template instantiations in WPA, but I found I was missing a bit of context to really make use of the information
For example, by far the template the compiler spends the most time on in my project is std::conjunction_v. That’s great to know, but I never use that template directly, so tracking down where and why this is getting instantiated so frequently is difficult. I can which files it ends up being instantiated in, but as far as I can see there’s no further detail available. Would it be possible to add the full instantiation stack to these events, so we can see which function/template caused the current template to be instantiated?
Hello jalf,
I would recommend upgrading to the latest VS toolset to get more accurate template events. Earlier events did not distinguish between different specializations for variable templates such as std::conjunction_v, causing them to all be grouped in one entry. VS 16.6 correctly differentiates variable template specializations.
However, VS 16.6 will still not tell you precisely where the instantiations occur beyond the top level cpp file. I also think it would be beneficial to improve these events to give a more precise location. May I suggest you open a feature suggestion on Developer Community in the C++ section for this? It would make it easier for us to track this suggestion for future planning.
Thanks!
Will this work for projects that don’t use the 2019 compiler but are still using Visual Studio 2019? I.e. using the v140 compiler in VS 2019.
Hi Andrew,
Thanks for your question. C++ Build Insights only supports v141 (i.e. the VS 2017 toolset) and above, even when using VS 2019 as the IDE.
Argh so close 🙂
Thanks! | https://devblogs.microsoft.com/cppblog/finding-build-bottlenecks-with-cpp-build-insights/ | CC-MAIN-2020-34 | refinedweb | 3,184 | 55.64 |
When I print a numpy array, I get a truncated representation, but I want the full array.
Is there any way to do this?
Examples:
>>> numpy.arange(10000) array([ 0, 1, 2, ..., 9997, 9998, 9999]) >>> numpy.arange(10000).reshape(250,40) array([[ 0, 1, 2, ..., 37, 38, 39], [ 40, 41, 42, ..., 77, 78, 79], [ 80, 81, 82, ..., 117, 118, 119], ..., [9880, 9881, 9882, ..., 9917, 9918, 9919], [9920, 9921, 9922, ..., 9957, 9958, 9959], [9960, 9961, 9962, ..., 9997, 9998, 9999]])
Use
numpy.set_printoptions:
import sys import numpy numpy.set_printoptions(threshold=sys.maxsize)
import numpy as np np.set_printoptions(threshold=np.inf)
I suggest using
np.inf instead of
np.nan which is suggested by others. They both work for your purpose, but by setting the threshold to "infinity" it is obvious to everybody reading your code what you mean. Having a threshold of "not a number" seems a little vague to me. | https://pythonpedia.com/en/knowledge-base/1987694/how-to-print-the-full-numpy-array--without-truncation- | CC-MAIN-2020-16 | refinedweb | 150 | 81.39 |
Suppose you have a number x between 0 and 1. You want to find a rational approximation for x, but you only want to consider fractions with denominators below a given limit.
For example, suppose x = 1/e = 0.367879… Rational approximations with powers of 10 in the denominator are trivial to find: 3/10, 36/100, 367/1000, etc. But say you’re willing to have a denominator as large as 10. Could you do better than 3/10? Yes, 3/8 = 0.375 is a better approximation. What about denominators no larger than 100? Then 32/87 = 0.36781… is the best choice, much better than 36/100.
How do you find the best approximations? You could do a brute force search. For example, if the maximum denominator size is N, you could try all fractions with denominators less than or equal to N. But there’s a much more efficient algorithm. The algorithm is related to the Farey sequence named after John Farey, though I don’t know whether he invented the algorithm.
The idea is to start with two fractions, a/b = 0/1 and c/d = 1/1. We update either a/b or c/d at each step so that a/b will be the best lower bound of x with denominator no bigger than b, and c/d will be the best upper bound with denominator no bigger than d. At each step we do a sort of binary search by introducing the mediant of the upper and lower bounds. The mediant of a/b and c/d is the fraction (a+c)/(b+d) which always lies between a/b and c/d.
Here is an implementation of the algorithm in Python. The code takes a number x between 0 and 1 and a maximum denominator size N. It returns the numerator and denominator of the best rational approximation to x using denominators no larger than N.
def farey(x, N): a, b = 0, 1 c, d = 1, 1 while (b <= N and d <= N): mediant = float(a+c)/(b+d) if x == mediant: if b + d <= N: return a+c, b+d elif d > b: return c, d else: return a, b elif x > mediant: a, b = a+c, b+d else: c, d = a+c, b+d if (b > N): return c, d else: return a, b
In Python 3.0, the
float statement could be removed since the division operator does floating point division of integers.
Read more about rational approximation in Breastfeeding, the golden ratio, and rational approximation.
Here’s an example of a situation in which you might need rational approximations. Suppose you’re designing an experiment which will randomize subjects between two treatments A and B. You want to randomize in blocks of size no larger than N and you want the probability of assigning treatment A to be p. You could find the best rational approximation a/b to p with denominator b no larger than N and use the denominator as the block size. Each block would be a permutation of a A’s and b–a B’s.
Update: Eugene Wallingford wrote a blog post about implementing the algorithm in Klein, a very restricted language used for teaching compiler writing.
Update: There’s a bug in the code. See discussion below.
20 thoughts on “Best rational approximation”
There is a small bug in the code. The return in the loop allows returning a denominator larger than N. For example farey(.25,3) returns (1,4).
Thanks. I fixed it.
The fix brings up an interesting point. If the mediant is exactly x, but the mediant’s denominator is too big, you need to either return a/b or c/d. Which one do you choose? You can show that the mediant is closer to which ever fraction has the larger denominator.
Hi John,
First, let me take the chance to let you know I love the blog.
I thought I’d mention that Farey addition (calculating the mediant) and the Farey sequence make a few appearances in the highly enjoyable book Indra’s Pearls. In particular, they have a nice visual showing how a mediant and its two parent fractions are vertices of an ideal triangle in the tessellation generated by the modular group (on the upper half plane). It is nice to picture this algorithm in the context of that geometrical picture. Starting with the triangle edge defined by 0/1 and 1/1, you wind your way along edges of the modular tessellation, moving over successively smaller looking triangles as you close in on the number you want to approximate.
A friend used to use a version of this to mischievous ends: he would find an approximation good to two decimal places, and use that on his checks. $138.25 becomes “$138 1/4.” At some point, he met the poor teller who everyone passed his checks on to, and stopped doing it so much. He still uses it every now and again, but only when he knows it will cause humans outside his bank some consternation (eg: mortgage payments).
If you start with (c, d) = (1, 0), the algorithm works for x > 1, too.
The code only return fractions less than x, but a fraction bigger than x could still be better approximation. Example: farey(0.605551,30) gives 3/5, but 17/28 is better approximation.
The reverse of this technique (in binary) is arithmetic compression. Which turns a given rational number into an interval of decimal numbers. This is then repeated with the next rational being inserted into the next interval. This allows the most general (though least efficient) form of compression.
Unfortunately, some work confirmed Ttl’s result and lead me on to discover that the best approximation is found using continued fractions, and I suppose is how this is calculated in Python:
assert Fraction(17, 28) == Fraction('0.605551').limit_denominator(30)
– Paddy.
This reminds me of the Fibonacci version of the golden section search algorithm:
search(x, N):
a,(mediant,b) = 0,fibRange(N) // closest Fibonacci numbers such that mediant < N <= b
while(a!=b):
if x==mediant:
return mediant
if x<mediant:
mediant,b = a+b-mediant,mediant
else:
a,mediant = mediant,3*mediant-(a+b)
return mediant
Of course, that algorithm doesn’t give a denominator (except maybe N).
What you described is a binary search on the Stern-Brocot tree, but your code returns the convergents of the simple continued fraction, both of which are related to (but neither quite corresponds to) the best rational approximation.
You never really described how to turn that binary search into a return value. Your code returns part of the carrier value* of that node tree. In the case of the Stern-Brocot tree, this corresponds to the label of the last node that changed the direction of the search, which in turn corresponds to a convergent of the continued fraction.
It should be noted that simply performing a binary search on the Stern-Brocot tree up to a given bound, is not entirely satisfactory because while going deeper in the tree will always get you closer to your goal, eventually, individual steps can result in worse approximations. (Specifically, after the search changes direction, your approximations get worse until you get halfway to the next direction change)
Now, all convergents are best rational approximation (for a suitably small bound), but not all best approximations (for some bound) are convergents. However, a best approximation might inflate the denominator significantly, but improve the approximation only barely, while by contrast the convergents are the best of the best approximations.
*carrier in the F-(co)algebraic sense.
I tried writing the above algorithm in C++ and can’t get it to work. A very good algorithm for approximating rational numbers is in the book Mathematical Software Tools in C++ by Alain Reverchon.
Here is a translation into C++ with some minor updates. You cannot really determine equality between two floating point numbers, and besides, I need accuracy to some epsilon as well as a maximum size for the numerator. Anyway, here is a C++ offering.
Usage is pretty simple.
Apologies for the loss of indenting above…… And thanks to John for the Python version :)
David: I put <pre> tags around your code and that restored the indenting.
Thanks David W.! I’m going to give it a spin.
John,
This is pretty neat algorithm. One other interesting application is during sampling rate conversion (decimation/interpolation) of signals, especially when input and output rates are constrained by, for example, channel bandwidth, hardware/software interface rates etc. Decimation/interpolation by rational factors are much better for hardware implementation and it is even better if we can find the smallest denominator.
Paddy,
Thanks for the pointer to the fractions module in python. Did not know it existed.
Amal
I think there is a small bug in your code. Your code does not always return the best rational approximation. Try it for x= 0.58496250072 and N=253 for example. Your code returns 31/53 but should return 148/253.
I suggest changing the test in the while-loop to “b+d leq N” and testing after the while-loop whether a/b or c/d is the better approximation.
Do you not think this up about 30 years ago?
sorry for dup,
Here is the correct code
Hi John
Thank you for this algorithm, that was really helpful :). | https://www.johndcook.com/blog/2010/10/20/best-rational-approximation/ | CC-MAIN-2019-51 | refinedweb | 1,584 | 55.24 |
,
Do we have a privilege to download a video of a test run using Rest Api, if yes can you please provide required details.
Thanks,
Anusha
Wonderful integration ! Thanks
Hello. I developed a wrapper for BrowserStack’s API using two methods from this post: get_session_url and get_session_logs. I’d like to publish it on GitHub under MIT license. Can I use them? (attributing the source, of course).
Hi Andre,
You are more than welcome to publish the wrapper on your GitHub.
How to take screenshot of URL which needs authentication?
I want to use BrowserStack Screenshot API.
Hii Dixit,
I think will help you.If not kindly give more description of the issue you are facing.
Hi,
After the test, how to get the screen-shots/video in circleci artifacts
Hi Rao,
You can use your circle.yml file to say which directories need to be placed in the artifacts folder. E.g.: If I store my screenshots in the ./screenshots directory and my logs in the ./logs directory, I would modify the ‘general’ section of my circle.yml to look like the example below
You can also refer the below link to get the screenshots/video in circle CI artifacts
Hey,
It’s great article, but I cant run this, please check bellow:
New Member Registration & Signup – Chess.com
BrowserStack Session url :E
======================================================================
ERROR: test_chess (__main__.SeleniumOnBrowserStack)
An example test: Visit chess.com and click on sign up link
———————————————————————-
Traceback (most recent call last):
File “Test.py”, line 41, 24.976s
FAILED (errors=1)
Hi Adam,
I did a quick check of my code and it worked fine. Can you please check if you have updated the Username and Access_Key in the BrowserStack Library file?
If yes can you please share your code so that I can debug it.
Many thanks for your reply, Please note that the test are running without problem on Browserstack so credentials should be fine. Especially that it works well if I comment those lines:
#print “BrowserStack Session url :”, self.browserstack_obj.get_session_url()
#print “BrowserStack Screenshot url :”, self.browserstack_obj.get_latest_screenshot_url()
Please look at test code bellow:
import unittest, time
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from BrowserStack_Library import BrowserStack_Library
class SeleniumOnBrowserStack(unittest.TestCase):
“Example class written to run Selenium tests on BrowserStack”
def setUp(self):
desired_cap = {‘platform’: ‘Windows’, ‘browserName’: ‘Chrome’, ‘browser_version’: ‘62.0’,
‘browserstack.debug’: ‘true’}
self.driver = webdriver.Remote(command_executor=’:[email protected]:80/wd/hub’,
desired_capabilities=desired_cap)
self.browserstack_obj = BrowserStack_Library()
def test_chess(self):
“An example test: Visit chess.com and click on sign up link”
# Get the Browserstack sesssion url and Screenshot url
print “BrowserStack Session url :”, self.browserstack_obj.get_session_url()
# Go to the URL
self.driver.get(“”)
# Assert that the Home Page has title “Chess.com – Play Chess Online – Free Games”
self.assertIn(“Chess.com – Play Chess Online – Free Games”, self.driver.title)
# Identify the xpath for Play Now button which will take you to the sign up page
elem = self.driver.find_element_by_xpath(“//a[@title=’Play Now’]”)
elem.click()
self.driver.save_screenshot(“test_chess.jpg”)
# Print the title
print self.driver.title
# Get the Browserstack Screenshot url
print “BrowserStack Screenshot url :”, self.browserstack_obj.get_latest_screenshot_url()
def tearDown(self):
self.driver.quit()
if __name__ == ‘__main__’:
unittest.main()
BrowserStack Library code:
“””
Qxf2 BrowserStack library to interact with BrowserStack’s artifacts.
For now, this is useful for:
a) Obtaining the session URL
b) Obtaining URLs of screenshots
“””
import os, requests
class BrowserStack_Library():
“BrowserStack library to interact with BrowserStack artifacts”
def __init__(self,credentials_file=None):
“Constructor for the BrowserStack library”
self.browserstack_url = “”
self.auth = (‘username’, ‘Access_Key’)
def get_build_id(self):
“Get the build ID”
self.build_url = self.browserstack_url + “builds.json”
builds = requests.get(self.build_url, auth=self.auth).json()
build_id = builds[0][‘automation_build’][‘hashed_id’]
return build_id
def get_sessions(self):
“Get a JSON object with all the sessions”
build_id = self.get_build_id()
sessions= requests.get(self.browserstack_url + ‘builds/%s/sessions.json’%build_id, auth=self.auth).json()
return sessions
def get_active_session_id(self):
“Return the session ID of the first active session”
session_id = None
sessions = self.get_sessions()
for session in sessions:
#Get session id of the first session with status = running
if session[‘automation_session’][‘status’]==’running’:
session_id = session[‘automation_session’][‘hashed_id’]
break
return session_id
def get_session_url(self):
“Get the session URL”
build_id = self.get_build_id()
session_id = self.get_active_session_id()
session_url = ‘’%(session_id,session_id)
return session_url
def get_session_logs(self):
“Return the session log in text format”
build_id = self.get_build_id()
session_id = self.get_active_session_id()
session_log = requests.get(self.browserstack_url + ‘builds/%s/sessions/%s/logs’%(build_id,session_id),auth=self.auth).text
return session_log
def get_latest_screenshot_url(self):
“Get the URL of the latest screenshot”
session_log = self.get_session_logs()
#Process the text to locate the URL of the last screenshot
screenshot_request = session_log.split(‘screenshot {}’)[-1]
response_result = screenshot_request.split(‘REQUEST’)[0]
image_url = response_result.split(‘https://’)[-1]
image_url = image_url.split(‘.png’)[0]
screenshot_url = ‘https://’ + image_url + ‘.png’
return screenshot_url
Regards,
Adam
After run it, it returns with this:
FAILED (errors=1)
(venv) C:\development\robot-scripts\aat\demo\Roman_AT>python Test.py
BrowserStack Session url :E
======================================================================
ERROR: test_chess (__main__.SeleniumOnBrowserStack)
An example test: Visit chess.com and click on sign up link
———————————————————————-
Traceback (most recent call last):
File “Test.py”, line 20, 11.705s
FAILED (errors=1)
Okay 🙂 I’ve ran this properly by clicking play instead of command “python Test.py”
But, how to get into the file if I am getting this from printed xml:}
Hi Adam,
I noticed that the BrowserStack Session URL which used to be helpful to get the playback URL seems to be broken, hence you are getting Access Denied message.
The BrowserStack Screenshot url seems to be working fine and you should be able to see the test session screenshot using the url. I will update the BrowserStack Session URL logic shortly.
The issue with video url has been fixed. The code should work fine now
Hi ,
I am using protractor & Jasmine. I want to get the video_url only on a test failure.
Do you have any suggestions.
Thanks
Pinky.
Hi,
Have you taken a look at the BrowserStack JS APIs.
The session object endpoint can be queried to get the video URL in case of a failure.
Hi ,
I looked at it but it doesn’t provide the API for getting a video_url.
I am looking something like a REST api to get the video_url. The ruby code written above looks perfect. But I cannot use it since I use JS .
Any better solution is appreciated.
Thanks
Hi Pinky,
Ya, it doesn’t look like they provide an API for getting video_url. But I see they have some methods to get the session objects, so you may need to end up writing some wrapper around it to get the video_url. In our above Python code also we use session details to get the video_url.
I couldn’t find any other better solutions.
Thanks
Hi Avinash ,
Thank you very much for the response. Also , your python code does exactly what I want to. But I use Javascript and I am not familiar with Python. However will try with the node-browsestack package.
Thanks
Pinky | https://qxf2.com/blog/browserstack-screenshots-video/comment-page-1/ | CC-MAIN-2021-25 | refinedweb | 1,167 | 60.11 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.