
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.46B | issue_number int64 1 127k |
|---|---|---|---|---|---|---|---|---|---|
[
"langchain-ai",
"langchain"
] | Hi, thanks for developing this great library!
I was using `chain.apredict` inside an async method and just updated to use `OpenAIChat` in `v0.0.98`.\
Now it's giving me error:
```
NotImplementedError: Async generation not implemented for this LLM.
```
The error was generated from this line:
https://github.com/hwchase17/langchain/blob/4b5e850361bd4b47ac739748232d696deac79eaf/langchain/llms/base.py#L337 | OpenAIChat error with async calls | https://api.github.com/repos/langchain-ai/langchain/issues/1372/comments | 5 | 2023-03-01T23:53:04Z | 2023-08-26T18:19:36Z | https://github.com/langchain-ai/langchain/issues/1372 | 1,605,872,338 | 1,372 |
[
"langchain-ai",
"langchain"
] | I'm on v0.0.98 and python3.10, and I'm getting this error when trying to use a `zero-shot-react-description` agent with OpenAIChat:
```
llm = OpenAIChat(temperature=0)
search = GoogleSearchAPIWrapper()
llm_math_chain = LLMMathChain(llm=llm, verbose=True)
tools = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to answer questions about current events"
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
)
]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
result = agent.run("What is OpenAI Foundry?")
```
```
> Entering new AgentExecutor chain...
I'm not sure what OpenAI Foundry is, so I should search for it.
Action: Search
Action Input: "OpenAI Foundry"
Observation: Feb 21, 2023 ... OpenAI has privately announced a new developer product called Foundry, which enables customers to run OpenAI model inference at scale w/ ... 2 days ago ... Conceptually, an industrial foundry is where businesses make the tools that make their physical products. OpenAI's Foundry will be where ... 1 day ago ... LLMs will soon replace lawyers and law enforcement. OpenAI DV could debate a supreme court level lawyer. reply ... Feb 21, 2023 ... OpenAI is reportedly launching a new developer platform, Foundry, that'll let customers run its models on dedicated compute infrastructure. 8 days ago ... Hey everyone, I've heard about this OpenAI's Foundry will let customers buy dedicated compute to run its AI models text-davinci-003 said I ... 2 days ago ... Conceptually, an industrial foundry is where businesses make the tools that make their physical products. OpenAI's Foundry will be where ... 8 days ago ... What Are OpenAI-Foundry Capabilities? · A static allocation of capacity dedicated to the user and providing a predictable environment that can be ... 6 days ago ... Well, well, well, what do we have here? OpenAI has gone and let slip some exciting details about their upcoming service Foundry, ... 6 days ago ... OpenAI is launching a developer platform known as Foundry to allow customers to run large artificial intelligence workloads based on its ... 8 days ago ... If the news posted on Twitter is trustworthy, then OpenAI's Foundry is made for “cutting-edge” customers running larger workloads. Users will be ...
Thought:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/var/folders/hz/pv3vmlvd52769n7ks7h17j1m0000gq/T/ipykernel_36393/1735989655.py in <cell line: 4>()
2 chat_start=time.time()
3 # with get_openai_callback() as cb:
----> 4 result = agent.run("What is OpenAI Foundry?")
5 # tokens = cb.total_tokens
6 end_time=time.time()
/opt/homebrew/lib/python3.10/site-packages/langchain/chains/base.py in run(self, *args, **kwargs)
237 if len(args) != 1:
238 raise ValueError("`run` supports only one positional argument.")
--> 239 return self(args[0])[self.output_keys[0]]
240
241 if kwargs and not args:
/opt/homebrew/lib/python3.10/site-packages/langchain/chains/base.py in __call__(self, inputs, return_only_outputs)
140 except (KeyboardInterrupt, Exception) as e:
141 self.callback_manager.on_chain_error(e, verbose=self.verbose)
--> 142 raise e
143 self.callback_manager.on_chain_end(outputs, verbose=self.verbose)
144 return self.prep_outputs(inputs, outputs, return_only_outputs)
/opt/homebrew/lib/python3.10/site-packages/langchain/chains/base.py in __call__(self, inputs, return_only_outputs)
137 )
138 try:
--> 139 outputs = self._call(inputs)
140 except (KeyboardInterrupt, Exception) as e:
141 self.callback_manager.on_chain_error(e, verbose=self.verbose)
/opt/homebrew/lib/python3.10/site-packages/langchain/agents/agent.py in _call(self, inputs)
501 # We now enter the agent loop (until it returns something).
502 while self._should_continue(iterations):
--> 503 next_step_output = self._take_next_step(
504 name_to_tool_map, color_mapping, inputs, intermediate_steps
505 )
/opt/homebrew/lib/python3.10/site-packages/langchain/agents/agent.py in _take_next_step(self, name_to_tool_map, color_mapping, inputs, intermediate_steps)
404 """
405 # Call the LLM to see what to do.
--> 406 output = self.agent.plan(intermediate_steps, **inputs)
407 # If the tool chosen is the finishing tool, then we end and return.
408 if isinstance(output, AgentFinish):
/opt/homebrew/lib/python3.10/site-packages/langchain/agents/agent.py in plan(self, intermediate_steps, **kwargs)
100 """
101 full_inputs = self.get_full_inputs(intermediate_steps, **kwargs)
--> 102 action = self._get_next_action(full_inputs)
103 if action.tool == self.finish_tool_name:
104 return AgentFinish({"output": action.tool_input}, action.log)
/opt/homebrew/lib/python3.10/site-packages/langchain/agents/agent.py in _get_next_action(self, full_inputs)
62 def _get_next_action(self, full_inputs: Dict[str, str]) -> AgentAction:
63 full_output = self.llm_chain.predict(**full_inputs)
---> 64 parsed_output = self._extract_tool_and_input(full_output)
65 while parsed_output is None:
66 full_output = self._fix_text(full_output)
/opt/homebrew/lib/python3.10/site-packages/langchain/agents/mrkl/base.py in _extract_tool_and_input(self, text)
136
137 def _extract_tool_and_input(self, text: str) -> Optional[Tuple[str, str]]:
--> 138 return get_action_and_input(text)
139
140
/opt/homebrew/lib/python3.10/site-packages/langchain/agents/mrkl/base.py in get_action_and_input(llm_output)
44 match = re.search(regex, llm_output, re.DOTALL)
45 if not match:
---> 46 raise ValueError(f"Could not parse LLM output: `{llm_output}`")
47 action = match.group(1).strip()
48 action_input = match.group(2)
ValueError: Could not parse LLM output: `Based on the search results, OpenAI Foundry is a new developer platform that allows customers to run OpenAI model inference at scale on dedicated compute infrastructure.
Action: None`
``` | Agents can't parse OpenAIChat output | https://api.github.com/repos/langchain-ai/langchain/issues/1371/comments | 7 | 2023-03-01T23:04:05Z | 2023-08-04T02:06:31Z | https://github.com/langchain-ai/langchain/issues/1371 | 1,605,813,256 | 1,371 |
[
"langchain-ai",
"langchain"
] | We probably need to rethink how to define `memory` class that works for agents based on the new chatgpt api. | Memory class for chatgpt api | https://api.github.com/repos/langchain-ai/langchain/issues/1369/comments | 2 | 2023-03-01T20:51:32Z | 2023-09-25T16:17:51Z | https://github.com/langchain-ai/langchain/issues/1369 | 1,605,645,066 | 1,369 |
[
"langchain-ai",
"langchain"
] | Trying to use the new gpt-3.5-turbo model causes an error:
```
llm = OpenAI(model_name="gpt-3.5-turbo")
# ...
llm.run(...)
InvalidRequestError: Invalid URL (POST /v1/completions)
```
I also tried specifying a client but got the same error.
```
import openai
llm = OpenAI(model_name="gpt-3.5-turbo", client=openai.ChatCompletion)
```
Am I missing the trick or does langchain need to have support added specifically for ChatCompletion?
| Trouble using OpenAI ChatCompletion (gpt-3.5-turbo model) | https://api.github.com/repos/langchain-ai/langchain/issues/1368/comments | 13 | 2023-03-01T19:20:09Z | 2023-11-16T16:08:58Z | https://github.com/langchain-ai/langchain/issues/1368 | 1,605,531,358 | 1,368 |
[
"langchain-ai",
"langchain"
] | I'm sure this has been discussed internally, but I wanted to get some feedback and before I started diving into an implementation.
I was working on a custom agent, and noticed there's this pseudo-memory structure that also exists on `agents` with `agent_scratchpad` var needing to exist on the LLMChain and within the prompt. This is a perfect use for memory, as #1293 adds this validation to the base chain. Should also allow us to DRY up some of the validation in the `Agent` class, and leverage different memory types in the future for agents.
My question is - how do people feel about moving `Memory` out of `chains`, and into it's own dir `lanchain.memory`? Additionally, moving all the classes in `langchain.chains.conversation.memory` up?
Are there other parts of the package that use a construct similar to memory that we could extract?
| [Discussion] Abstracting memory from `chain`, using `Memory` with agents | https://api.github.com/repos/langchain-ai/langchain/issues/1366/comments | 0 | 2023-03-01T18:43:11Z | 2023-03-07T18:33:55Z | https://github.com/langchain-ai/langchain/issues/1366 | 1,605,481,412 | 1,366 |
[
"langchain-ai",
"langchain"
] | Has anyone deployed langchain scripts on AWS - Lambda in particular. There is some issue with the way langchain imports numpy that is causing issues. I have tried it with different version and with a docker image as well but get numpy import issues. Locally it works fine. Thanks, Ali | Langchain with AWS Lambda | https://api.github.com/repos/langchain-ai/langchain/issues/1364/comments | 47 | 2023-03-01T15:04:23Z | 2024-06-19T11:42:28Z | https://github.com/langchain-ai/langchain/issues/1364 | 1,605,144,078 | 1,364 |
[
"langchain-ai",
"langchain"
] | Starting a new issue to track [this idea](https://twitter.com/mathisob/status/1630620380707667968?s=20) to provide functionality to translate prompts based on the input language. | Prompt language translations | https://api.github.com/repos/langchain-ai/langchain/issues/1363/comments | 6 | 2023-03-01T14:02:28Z | 2023-09-29T18:55:09Z | https://github.com/langchain-ai/langchain/issues/1363 | 1,605,035,184 | 1,363 |
[
"langchain-ai",
"langchain"
] | Hi, I am reaching out due to several requests from others in the field.
I am the author of TableQA: https://github.com/abhijithneilabraham/tableQA, a tool to query natural language on tabular data. The tool uses a BERT based huggingface model for QA on free text, and uses heuristics to combine it with tabular data to make SQL queries from natural language.
The request from some users was to provide support with LangChain. I was wondering if I should raise an issue to LangChain to merge a feature for tabular data support, with the methodology provided in TableQA as an additional approach?
Regards. | Integration of tabular data querying with LangChain | https://api.github.com/repos/langchain-ai/langchain/issues/1361/comments | 2 | 2023-03-01T10:54:09Z | 2023-09-10T16:43:27Z | https://github.com/langchain-ai/langchain/issues/1361 | 1,604,731,278 | 1,361 |
[
"langchain-ai",
"langchain"
] | ## Description
### Motivation
Using configuration files are great for fast prototyping but given the current state of the framework, it is limited to pre-defined agents, tools and other components. Currently the `load_tools()` function is implemented to load pre-defined tools via tool name.
https://github.com/hwchase17/langchain/blob/fe7dbecfe6f5c4f9ad3237148fb25c91cf5be9f6/langchain/agents/load_tools.py#L179
For custom implementations, I don't suppose we can use the above function to load them.
### Proposed solution
I suggest we create a decorator function for all components which can be initialised via config file. We can take inspiration from the ClassyVision project:
https://github.com/facebookresearch/ClassyVision/blob/74e83dd97afbc9371b336304af09548f5080fa9c/classy_vision/models/__init__.py#L27
Even Pytorch Lightning Flash has a similar concept: https://lightning-flash.readthedocs.io/en/latest/general/registry.html?highlight=registry
### Benefits
Enabling fast prototyping for users in a deep learning research/experimentation fashion can greatly speed up development of applications using LangChain. | Feature Request: Add decorator function to register custom components (agents, tools, etc) | https://api.github.com/repos/langchain-ai/langchain/issues/1360/comments | 1 | 2023-03-01T10:48:12Z | 2023-08-24T16:16:07Z | https://github.com/langchain-ai/langchain/issues/1360 | 1,604,722,715 | 1,360 |
[
"langchain-ai",
"langchain"
] | In addition to completions, the `edit` and `insert` modes of LLMs are also very useful in certain use cases. Specially for combating prompt injection attacks and ensuring certain rules are followed by the LLM while generating output.
Right now, LangChain is closely tied to the completion paradigm. Is there a way we can support these new modes? | Feature request: support Edit and Insert modes for openai/others | https://api.github.com/repos/langchain-ai/langchain/issues/1359/comments | 1 | 2023-03-01T10:30:43Z | 2023-08-24T16:16:13Z | https://github.com/langchain-ai/langchain/issues/1359 | 1,604,697,665 | 1,359 |
[
"langchain-ai",
"langchain"
] | `agent_chain = initialize_agent( tools=tools, llm= HuggingFaceHub(repo_id="google/flan-t5-xl"), agent="conversational-react-description", memory=memory, verbose=False)
agent_chain.run("Hi")`
**throws error. This happens with Bloom as well. Agent only with OpenAI is only working well.**
`_(self, inputs, return_only_outputs)
140 except (KeyboardInterrupt, Exception) as e:
141 self.callback_manager.on_chain_error(e, verbose=self.verbose)
--> 142 raise e
143 self.callback_manager.on_chain_end(outputs, verbose=self.verbose)
...
---> 83 raise ValueError(f"Could not parse LLM output: "{llm_output}")
84 action = match.group(1)
85 action_input = match.group(2)
ValueError: Could not parse LLM output: Assistant, how can I help you today?` | ValueError: Could not parse LLM output: | https://api.github.com/repos/langchain-ai/langchain/issues/1358/comments | 82 | 2023-03-01T08:50:18Z | 2024-06-30T16:02:40Z | https://github.com/langchain-ai/langchain/issues/1358 | 1,604,533,069 | 1,358 |
[
"langchain-ai",
"langchain"
] | I am encountering the following error when trying to import VectorstoreIndexCreator from langchain.indexes:
`ModuleNotFoundError: No module named 'langchain.indexes'` | ModuleNotFoundError: No module named 'langchain.indexes' | https://api.github.com/repos/langchain-ai/langchain/issues/1352/comments | 11 | 2023-03-01T05:37:12Z | 2023-09-29T16:10:12Z | https://github.com/langchain-ai/langchain/issues/1352 | 1,604,280,635 | 1,352 |
[
"langchain-ai",
"langchain"
] | have been very often running into openai.error.InvalidRequestError for getting over 4097 tokens maximum context length. Is there a module/ best practice to manage the context length ?
Quick example I am adding the map reduce summary chain to the URL data loader and its throwing that error:
```
from langchain.document_loaders import UnstructuredURLLoader
urls = [
"https://www.understandingwar.org/backgrounder/russian-offensive-campaign-assessment-february-8-2023",
"https://www.understandingwar.org/backgrounder/russian-offensive-campaign-assessment-february-9-2023"
]
loader = UnstructuredURLLoader(urls=urls)
data = loader.load()
from langchain.chains.summarize import load_summarize_chain
from langchain import OpenAI
import os
os.environ["OPENAI_API_KEY"] = "*"
llm = OpenAI(temperature=0)
chain = load_summarize_chain(llm, chain_type="map_reduce")
print(chain.run(data))
```
Error: `openai.error.InvalidRequestError: This model's maximum context length is 4097 tokens, however you requested 8356 tokens (8100 in your prompt; 256 for the completion). Please reduce your prompt; or completion length.
` | model's maximum context length | https://api.github.com/repos/langchain-ai/langchain/issues/1349/comments | 31 | 2023-03-01T03:22:21Z | 2023-11-15T16:10:23Z | https://github.com/langchain-ai/langchain/issues/1349 | 1,604,163,597 | 1,349 |
[
"langchain-ai",
"langchain"
] | The def get_summarize_call is not returning the output_text. I am getting the response of the intermediate steps but the final output_text is not returned. I see that verbose= true let me see that the petition to the openAI is being made to receive the final output_text but it appears empty in the object values.
`def get_summarize_call(words):
llm = OpenAI(temperature=0, openai_api_key=settings.openai_api_key, )
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=0)
metadata = {"source": "internet", "date": "Friday"}
listText = []
listText .append(Document(page_content=words, metadata=metadata))
texts = text_splitter.split_documents(listText)
prompt_template = """Summarize this conversation in 10 bullet points {text}. Do NOT write sentences that has no sense."""
prompt_template2 = """Choose the more relevant phrases of the following text and summarize them in 10 bullet points: {text}"""
PROMPT = PromptTemplate(
template=prompt_template,
input_variables=["text"]
)
PROMPT2 = PromptTemplate(
template=prompt_template2,
input_variables=["text"]
)
overall_chain = load_summarize_chain(llm,chain_type="map_reduce", map_prompt=PROMPT, combine_prompt=PROMPT2, return_intermediate_steps=True, verbose=True)
values= overall_chain( {"input_documents": texts},return_only_outputs=True)
return values` | load_summarize_chain with return_intermediate_steps=True Does not return output_text. | https://api.github.com/repos/langchain-ai/langchain/issues/1343/comments | 3 | 2023-02-28T18:15:46Z | 2023-08-25T15:17:58Z | https://github.com/langchain-ai/langchain/issues/1343 | 1,603,583,732 | 1,343 |
[
"langchain-ai",
"langchain"
] | While using langchain for pinecone upsert I was frequently running into an error discussed [here](https://community.pinecone.io/t/metadata-size-error/604/11). I found that langchain is including text metadata along with whatever the user sends as metadata [here](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/pinecone.py#:~:text=for%20j%2C,%5D%20%3D%20line). What is the purpose of doing this? It will easily generate metadatas which are over the permissible [limit set by pinecone](https://docs.pinecone.io/docs/limits#metadata:~:text=Max%20metadata%20size%20per%20vector%20is%2010%20KB.) in many cases. | Including text metadata in pinecone upsert. | https://api.github.com/repos/langchain-ai/langchain/issues/1341/comments | 5 | 2023-02-28T15:14:19Z | 2023-09-27T16:13:52Z | https://github.com/langchain-ai/langchain/issues/1341 | 1,603,265,730 | 1,341 |
[
"langchain-ai",
"langchain"
] | I forked & cloned the project to my dev env on MacOS, then ran 'make test', the test case 'test_incorrect_command_return_err_output' from test_bash.py failed with the following output:
<img width="1139" alt="image" src="https://user-images.githubusercontent.com/64731944/221828313-4c3f6284-9fd4-4bb5-b489-8d7e911ada03.png">
I then tried the test in my Linux dev env, the test case passed successfully.
this line of code in the test case:
`output = session.run(["invalid_command"])`
its output on MacOS is:
`/bin/sh: invalid_command: command not found\n`
and on Linux it is
`/bin/sh: 1: invalid_command: not found\n`
The difference is from the underlying "subprocess" library, and as lots of developers use MacOS as their dev env, I think it makes sense to make the test case support both MacOS and Linux, so I would suggest using a regex to do the assertion:
`assert re.match(r'^/bin/sh:.*invalid_command.*not found.*$', output)`
| UT test_bash.py broken on MacOS dev environment | https://api.github.com/repos/langchain-ai/langchain/issues/1339/comments | 0 | 2023-02-28T10:51:39Z | 2023-03-21T16:06:54Z | https://github.com/langchain-ai/langchain/issues/1339 | 1,602,806,273 | 1,339 |
[
"langchain-ai",
"langchain"
] | The LLM discards a lot of information while returning the `LLMResult` and only returns a few keys. Especially in the case of the `OpenAI` LLM, only the total token usage is returned while things like API type, organization ID, response time etc. are all discarded.
These extra keys should be added to the `llm_output` property of the `LLMResult` as an easy fix.
https://github.com/hwchase17/langchain/blob/72ef69d1ba33f052bf3948c1e1d7d6441b14af0a/langchain/schema.py#L46 | Provide more information in the LLMResult | https://api.github.com/repos/langchain-ai/langchain/issues/1337/comments | 1 | 2023-02-28T08:01:30Z | 2023-09-12T21:30:10Z | https://github.com/langchain-ai/langchain/issues/1337 | 1,602,547,100 | 1,337 |
[
"langchain-ai",
"langchain"
] | The OpenAI [embeddings](https://platform.openai.com/docs/api-reference/embeddings/create) API can take a list of string as input. However, in the various stores in `langchain`, we use the following pattern: `[self.embedding_function(text) for text in texts]` to embed a list of documents, e.g. [here](https://github.com/hwchase17/langchain/blob/1aa41b574120fffcb2eee4ddebf023a9807337fb/langchain/vectorstores/qdrant.py#L73) | Leverage Bulk Embeddings APIs where possible | https://api.github.com/repos/langchain-ai/langchain/issues/1335/comments | 2 | 2023-02-28T03:15:46Z | 2023-03-31T16:22:21Z | https://github.com/langchain-ai/langchain/issues/1335 | 1,602,298,983 | 1,335 |
[
"langchain-ai",
"langchain"
] | Langchain Stopped Working in AWS Lambda Function using version 0.0.95,
it works fine in 0.0.94
Specifically it fails to build my AWS Sam Application it gets stuck at [INFO]: Running PythonPipBuilder:ResolveDependencies
switching to 0.0.94 is the solution for now...
| Langchain Stopped Working in AWS Lambda Function using version 0.0.95, it works fine inn 0.0.94 | https://api.github.com/repos/langchain-ai/langchain/issues/1329/comments | 3 | 2023-02-27T20:58:31Z | 2023-09-10T16:43:31Z | https://github.com/langchain-ai/langchain/issues/1329 | 1,601,937,801 | 1,329 |
[
"langchain-ai",
"langchain"
] | Following the example here https://langchain.readthedocs.io/en/latest/modules/indexes/chain_examples/vector_db_qa_with_sources.html,
I'm connecting a weaviate vector store to VectorDBQAWithSourcesChain with chain_type="stuff" and it gives really garbled results, possibly including some defaults that haven't been overwritten.
For example, calling `qa = VectorDBQAWithSourcesChain.from_chain_type(OpenAI(temperature=0), chain_type="stuff", vectorstore=vectorstore_w)` (personal vector store)
gives:
`VectorDBQAWithSourcesChain(memory=None, callback_manager=<langchain.callbacks.shared.SharedCallbackManager object at 0x12c221880>, verbose=False, combine_documents_chain=StuffDocumentsChain(memory=None, callback_manager=<langchain.callbacks.shared.SharedCallbackManager object at 0x12c221880>, verbose=False, input_key='input_documents', output_key='output_text', llm_chain=LLMChain(memory=None, callback_manager=<langchain.callbacks.shared.SharedCallbackManager object at 0x12c221880>, verbose=False, prompt=PromptTemplate(input_variables=['summaries', 'question'], output_parser=None, template='Given the following extracted parts of a long document and a question, create a final answer with references ("SOURCES"). \nIf you don\'t know the answer, just say that you don\'t know. Don\'t try to make up an answer.\nALWAYS return a "SOURCES" part in your answer.\n\nQUESTION: Which state/country\'s law governs the interpretation of the contract?\n=========\nContent: This Agreement is governed by English law and the parties submit to the exclusive jurisdiction of the English courts in relation to any dispute (contractual or non-contractual) concerning this Agreement save that either party may apply to any court for an injunction or other relief to protect its Intellectual Property Rights.\nSource: 28-pl\nContent: No Waiver. Failure or delay in exercising any right or remedy under this Agreement shall not constitute a waiver of such (or any other) right or remedy.\n\n11.7 Severability. The invalidity, illegality or unenforceability of any term (or part of a term) of this Agreement shall not affect the continuation in force of the remainder of the term (if any) and this Agreement.\n\n11.8 No Agency. Except as expressly stated otherwise, nothing in this Agreement shall create an agency, partnership or joint venture of any kind between the parties.\n\n11.9 No Third-Party Beneficiaries.\nSource: 30-pl\nContent: (b) if Google believes, in good faith, that the Distributor has violated or caused Google to violate any Anti-Bribery Laws (as defined in Clause 8.5) or that such a violation is reasonably likely to occur,\nSource: 4-pl\n=========\nFINAL ANSWER: This Agreement is governed by English law.\nSOURCES: 28-pl\n\nQUESTION: What did the president say about Michael Jackson?\n=========\nContent: Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. \n\nLast year COVID-19 kept us apart. This year we are finally together again. \n\nTonight, we meet as Democrats Republicans and Independents. But most importantly as Americans. \n\nWith a duty to one another to the American people to the Constitution. \n\nAnd with an unwavering resolve that freedom will always triumph over tyranny. \n\nSix days ago, Russia’s Vladimir Putin sought to shake the foundations of the free world thinking he could make it bend to his menacing ways. But he badly miscalculated. \n\nHe thought he could roll into Ukraine and the world would roll over. Instead he met a wall of strength he never imagined. \n\nHe met the Ukrainian people. \n\nFrom President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world. \n\nGroups of citizens blocking tanks with their bodies. Everyone from students to retirees teachers turned soldiers defending their homeland.\nSource: 0-pl\nContent: And we won’t stop. \n\nWe have lost so much to COVID-19. Time with one another. And worst of all, so much loss of life. \n\nLet’s use this moment to reset. Let’s stop looking at COVID-19 as a partisan dividing line and see it for what it is: A God-awful disease. \n\nLet’s stop seeing each other as enemies, and start seeing each other for who we really are: Fellow Americans. \n\nWe can’t change how divided we’ve been. But we can change how we move forward—on COVID-19 and other issues we must face together. \n\nI recently visited the New York City Police Department days after the funerals of Officer Wilbert Mora and his partner, Officer Jason Rivera. \n\nThey were responding to a 9-1-1 call when a man shot and killed them with a stolen gun. \n\nOfficer Mora was 27 years old. \n\nOfficer Rivera was 22. \n\nBoth Dominican Americans who’d grown up on the same streets they later chose to patrol as police officers. \n\nI spoke with their families and told them that we are forever in debt for their sacrifice, and we will carry on their mission to restore the trust and safety every community deserves.\nSource: 24-pl\nContent: And a proud Ukrainian people, who have known 30 years of independence, have repeatedly shown that they will not tolerate anyone who tries to take their country backwards. \n\nTo all Americans, I will be honest with you, as I’ve always promised. A Russian dictator, invading a foreign country, has costs around the world. \n\nAnd I’m taking robust action to make sure the pain of our sanctions is targeted at Russia’s economy. And I will use every tool at our disposal to protect American businesses and consumers. \n\nTonight, I can announce that the United States has worked with 30 other countries to release 60 Million barrels of oil from reserves around the world. \n\nAmerica will lead that effort, releasing 30 Million barrels from our own Strategic Petroleum Reserve. And we stand ready to do more if necessary, unified with our allies. \n\nThese steps will help blunt gas prices here at home. And I know the news about what’s happening can seem alarming. \n\nBut I want you to know that we are going to be okay.\nSource: 5-pl\nContent: More support for patients and families. \n\nTo get there, I call on Congress to fund ARPA-H, the Advanced Research Projects Agency for Health. \n\nIt’s based on DARPA—the Defense Department project that led to the Internet, GPS, and so much more. \n\nARPA-H will have a singular purpose—to drive breakthroughs in cancer, Alzheimer’s, diabetes, and more. \n\nA unity agenda for the nation. \n\nWe can do this. \n\nMy fellow Americans—tonight , we have gathered in a sacred space—the citadel of our democracy. \n\nIn this Capitol, generation after generation, Americans have debated great questions amid great strife, and have done great things. \n\nWe have fought for freedom, expanded liberty, defeated totalitarianism and terror. \n\nAnd built the strongest, freest, and most prosperous nation the world has ever known. \n\nNow is the hour. \n\nOur moment of responsibility. \n\nOur test of resolve and conscience, of history itself. \n\nIt is in this moment that our character is formed. Our purpose is found. Our future is forged. \n\nWell I know this nation.\nSource: 34-pl\n=========\nFINAL ANSWER: The president did not mention Michael Jackson.\nSOURCES:\n\nQUESTION: {question}\n=========\n{summaries}\n=========\nFINAL ANSWER:', template_format='f-string', validate_template=True), llm=OpenAI(cache=None, verbose=False, callback_manager=<langchain.callbacks.shared.SharedCallbackManager object at 0x12c221880>, client=<class 'openai.api_resources.completion.Completion'>, model_name='text-davinci-003', temperature=0.0, max_tokens=256, top_p=1, frequency_penalty=0, presence_penalty=0, n=1, best_of=1, model_kwargs={}, openai_api_key=None, batch_size=20, request_timeout=None, logit_bias={}, max_retries=6, streaming=False), output_key='text'), document_prompt=PromptTemplate(input_variables=['page_content', 'source'], output_parser=None, template='Content: {page_content}\nSource: {source}', template_format='f-string', validate_template=True), document_variable_name='summaries'), question_key='question', input_docs_key='docs', answer_key='answer', sources_answer_key='sources', vectorstore=<langchain.vectorstores.weaviate.Weaviate object at 0x12e927c10>, k=4, reduce_k_below_max_tokens=False, max_tokens_limit=3375, search_kwargs={})`
| Issue with VectorDBQAWithSourcesChain and chain_type="stuff" | https://api.github.com/repos/langchain-ai/langchain/issues/1326/comments | 6 | 2023-02-27T19:23:08Z | 2023-09-28T16:12:03Z | https://github.com/langchain-ai/langchain/issues/1326 | 1,601,806,915 | 1,326 |
[
"langchain-ai",
"langchain"
] | Hi in [this Wolfram Alpha demo colab notebook](https://colab.research.google.com/drive/1AAyEdTz-Z6ShKvewbt1ZHUICqak0MiwR?usp=sharing#scrollTo=M4S2HDizS6L2) if you enter
How many ping pong balls fit into a jumbo jet?
… Wolfram Alpha returns "31 million" but the conversational agent decides to choose "that's a lot of ping pong balls".
I'm curious how the agent decides which tool to use and how to improve this so WA is selected in this case.
| How do I coax the "conversational-react-description" agent to use Wolfram Alpha | https://api.github.com/repos/langchain-ai/langchain/issues/1322/comments | 11 | 2023-02-27T11:09:18Z | 2023-11-08T16:10:25Z | https://github.com/langchain-ai/langchain/issues/1322 | 1,600,967,643 | 1,322 |
[
"langchain-ai",
"langchain"
] | Hi @hwchase17, congrats on this fantastic project!
This is Dani, co-founder of [Argilla](https://github.com/argilla-io/argilla). As I mentioned a few weeks ago over Twitter, we and other members of our community are starting to use `langchain` in combination with Argilla. Besides zero/few-shot chains for data labeling and augmentation, I see a lot of potential in using Argilla for storing prompts and generations to monitor and eventually use these data points for fine-tuning LLMs (ranking generations, shifting towards smaller, open-source LLMs, etc.).
As Argilla is designed around the idea of dynamic datasets where you can log and retrieve records continuously, there's already a good fit as a cache layer, but I would like to get your initial thoughts on this to see where and how we could build an integration layer with `langchain`
| Using Argilla as prompt and generations store | https://api.github.com/repos/langchain-ai/langchain/issues/1321/comments | 1 | 2023-02-27T10:26:43Z | 2023-08-24T16:16:23Z | https://github.com/langchain-ai/langchain/issues/1321 | 1,600,898,132 | 1,321 |
[
"langchain-ai",
"langchain"
] | I'm using this for a Q&A bot, utilizing OpenAI and its ada model.
Do you have any tips on generating your own Q&A document? I initially tried ingesting a document that had "Q: how to do X \n A: Do this by doing Y". I then saw it sometimes didn't answer it properly, so I changed the answer to "To do X, you must do Y".
I then noticed that if I slightly reworded the question, but kept the same answer (in case people ask it differently), that it would give that answer on completely unrelated things. So I had to remove all the duplicate answers.
I then noticed it would rarely answer with the "A: " in the reply, so I just got rid of all the questions. But now it won't answer some of the questions, and makes up completely false data, including snippets of various answers. So big hallucinations here too - not sure how to solve hallucinations.
| Using this as a Q&A bot? | https://api.github.com/repos/langchain-ai/langchain/issues/1320/comments | 1 | 2023-02-27T08:25:31Z | 2023-08-24T16:16:28Z | https://github.com/langchain-ai/langchain/issues/1320 | 1,600,709,496 | 1,320 |
[
"langchain-ai",
"langchain"
] | ### Description
the unit test "test_incorrect_command_return_err_output" in test_bash.py expects:
"/bin/sh: 1: invalid_command: not found\n"
while the actual output of being tested BashProcess.run is:
"/bin/sh: invalid_command: command not found\n"
as BashProcess delegates the call to subprocess.run, I think the unit test should adapt to subprocess
### Environment
MacOS 11.4, python 3.11.2
### Steps to reproduce
1. fork and clone the project to the dev machine
2. enter the project directory
3. run 'make test', you will find the assertion error
### Suggestion
Though utilizing regex would make the test robust, as most tests in test_bash.py follow this exactly-matching style, I would suggest changing the assertion's expectation to the output of subprocess.run | UT "test_incorrect_command_return_err_output" in test_bash.py broken | https://api.github.com/repos/langchain-ai/langchain/issues/1319/comments | 1 | 2023-02-27T08:03:45Z | 2023-02-28T07:38:56Z | https://github.com/langchain-ai/langchain/issues/1319 | 1,600,676,512 | 1,319 |
[
"langchain-ai",
"langchain"
] | <img width="1440" alt="Screenshot 2023-02-26 at 8 17 04 PM" src="https://user-images.githubusercontent.com/52064142/221456499-8f60c89d-0e72-45e9-8a20-1483b2a0b62b.png">
When I click in awesome paper it redirects me here https://memprompt.com/ which doesn't open ! | Documentation Link Broken | https://api.github.com/repos/langchain-ai/langchain/issues/1312/comments | 3 | 2023-02-27T02:17:31Z | 2023-09-18T16:24:05Z | https://github.com/langchain-ai/langchain/issues/1312 | 1,600,324,925 | 1,312 |
[
"langchain-ai",
"langchain"
] | It would be great to follow the [rate limits guide](https://platform.openai.com/docs/guides/rate-limits/overview) by OpenAI to ensure that this LLM works as expected no matter what chunk size or chunk overlap.
See related issue: https://github.com/hwchase17/langchain/issues/634 | OpenAI Rate Limits | https://api.github.com/repos/langchain-ai/langchain/issues/1310/comments | 11 | 2023-02-26T20:10:32Z | 2023-12-12T17:03:45Z | https://github.com/langchain-ai/langchain/issues/1310 | 1,600,185,079 | 1,310 |
[
"langchain-ai",
"langchain"
] | <img width="942" alt="image" src="https://user-images.githubusercontent.com/13427145/221388828-8bbe4c56-dcaf-4b78-b32e-3dfa2775b7e7.png">
I used the above to query the index in gpt-index through the langchain agent, but now the result only returns the result str. I hope it can return this structure
<img width="570" alt="image" src="https://user-images.githubusercontent.com/13427145/221388772-b90e720f-7da7-454d-b75a-8a438c763594.png">
Anyone know how to deal with , thanks | How do I get the source of index results | https://api.github.com/repos/langchain-ai/langchain/issues/1301/comments | 8 | 2023-02-26T02:21:23Z | 2024-05-22T16:07:10Z | https://github.com/langchain-ai/langchain/issues/1301 | 1,599,905,275 | 1,301 |
[
"langchain-ai",
"langchain"
] | `ConversationBufferMemory` and the other associated memories all add an extra space in front of AI responses when moving them into the history buffer.
This can be seen in the examples on [this page](https://langchain.readthedocs.io/en/latest/modules/memory/getting_started.html), for instance:
```
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hi there!
AI: Hi there! It's nice to meet you. How can I help you today?
Human: I'm doing well! Just having a conversation with an AI.
AI: That's great! It's always nice to have a conversation with someone new. What would you like to talk about?
Human: Tell me about yourself.
AI:
> Finished ConversationChain chain.
```
In my brief experiments, this sometimes also causes the LLM to copy the double space prefix in future outputs. The `ConversationBufferMemory` then adds a third space, which the LLM can _also_ copy sometimes, leading to four spaces, etc. | ConversationBufferMemory adds an extra space in front of AI responses | https://api.github.com/repos/langchain-ai/langchain/issues/1298/comments | 1 | 2023-02-26T00:56:26Z | 2023-08-24T16:16:33Z | https://github.com/langchain-ai/langchain/issues/1298 | 1,599,889,031 | 1,298 |
[
"langchain-ai",
"langchain"
] | It would be great to see a new LangChain tool for blockchain search engines (or blockchain API providers). There are several blockchain search engine APIs available, including those provided by [Blockchain.com](https://www.blockchain.com/api), [Blockchair](https://blockchair.com/), [Bitquery](https://bitquery.io/), and [Crypto APIs](https://cryptoapis.io/). Jelvix has also compiled a list of the [top 10 best blockchain API providers for developers in 2023](https://jelvix.com/blog/how-to-choose-the-best-blockchain-api-for-your-project). | [Tool Request] Blockchain Search Engine | https://api.github.com/repos/langchain-ai/langchain/issues/1294/comments | 1 | 2023-02-25T18:46:09Z | 2023-09-10T16:43:41Z | https://github.com/langchain-ai/langchain/issues/1294 | 1,599,796,432 | 1,294 |
[
"langchain-ai",
"langchain"
] | I was trying the `SQLDatabaseChain`:
```
db = SQLDatabase.from_uri("sqlite:///../app.db", include_tables=["events"])
llm = OpenAI(temperature=0)
db_chain = SQLDatabaseChain(llm=llm, database=db, verbose=True)
result = db_chain("How many events are there?")
result
```
but was seeing flakey behavior in validity of SQL syntax.
```
OperationalError: (sqlite3.OperationalError) near "SQLQuery": syntax error
[SQL:
SQLQuery: SELECT COUNT(*) FROM events;]
(Background on this error at: https://sqlalche.me/e/14/e3q8)
```
it turns out, upgrading the model fixed the outputs 😲
* thoughts on catching this SQL exception in `SQLDatabaseChain` and throwing a graceful error message?
* more broadly, how do you think about error propagation?
(loving the library overall!! 😄) | Graceful failures with SQL syntax error | https://api.github.com/repos/langchain-ai/langchain/issues/1292/comments | 1 | 2023-02-25T17:35:58Z | 2023-08-24T16:16:43Z | https://github.com/langchain-ai/langchain/issues/1292 | 1,599,777,331 | 1,292 |
[
"langchain-ai",
"langchain"
] | Im having this bug when trying to setup a model within a lambda cloud running SelfHostedHuggingFaceLLM() after the rh.cluster() function.
`
from langchain.llms import SelfHostedPipeline, SelfHostedHuggingFaceLLM
from langchain import PromptTemplate, LLMChain
import runhouse as rh
gpu = rh.cluster(name="rh-a10", instance_type="A10:1").save()
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm = SelfHostedHuggingFaceLLM(model_id="gpt2", hardware=gpu, model_reqs=["pip:./", "transformers", "torch"])
`

I made sure with sky check that the lambda credentials are set, but the error i get within the log is this, which i havent been able to solve.

If i can get any help solving this i would appreciate it. | RuntimeError when setting up self hosted model + runhouse integration | https://api.github.com/repos/langchain-ai/langchain/issues/1290/comments | 2 | 2023-02-25T03:38:32Z | 2023-09-10T16:43:47Z | https://github.com/langchain-ai/langchain/issues/1290 | 1,599,532,047 | 1,290 |
[
"langchain-ai",
"langchain"
] | Please provide tutorials for using other LLM models beside OpenAI. Even though documentation implies it is possible to use other LLM models there is no solid example of that. I would like to download a LLM model and use it with langchain. | Please provide tutorials for using other LLM models beside OpenAI. | https://api.github.com/repos/langchain-ai/langchain/issues/1289/comments | 2 | 2023-02-25T01:04:12Z | 2023-09-18T16:24:10Z | https://github.com/langchain-ai/langchain/issues/1289 | 1,599,462,279 | 1,289 |
[
"langchain-ai",
"langchain"
] | Hi there, loving the library.
I'm running into an issue when trying to run the chromadb example using Python.
It fine upto the following:
`docs = docsearch.similarity_search(query)`
Receiving the following error:
`File "pydantic/main.py", line 342, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for Document
metadata
none is not an allowed value (type=type_error.none.not_allowed)`
I did some debugging and found that the metadatas from the `results` in chromadb in this code bit:
```
docs = [
# TODO: Chroma can do batch querying,
# we shouldn't hard code to the 1st result
Document(page_content=result[0], metadata=result[1])
for result in zip(results["documents"][0], results["metadatas"][0])
]
```
Are all "None" shown as follows:
`.. this.']], 'metadatas': [[None, None, None, None]], 'distances': [[0.3913411498069763, 0.43421220779418945, 0.4523361325263977, 0.45244452357292175]]}`
Running langchain-0.0.94 and have all libraries up to date.
Complete code:
```
with open('state_of_the_union.txt') as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(texts, embeddings)
print('making query')
query = "What did the president say about Ketanji Brown Jackson"
docs = docsearch.similarity_search(query)
print(docs[0].page_content)
```
Any help would be appreciated 👍 | ChromaDB validation error for Document metadata. | https://api.github.com/repos/langchain-ai/langchain/issues/1287/comments | 3 | 2023-02-25T00:07:41Z | 2023-09-18T16:24:15Z | https://github.com/langchain-ai/langchain/issues/1287 | 1,599,426,456 | 1,287 |
[
"langchain-ai",
"langchain"
] | The `load` method of `UnstructuredURLLoader` returns a list of Documents, with a single Document for each url.
```python
def load(self) -> List[Document]:
"""Load file."""
from unstructured.partition.html import partition_html
docs: List[Document] = list()
for url in self.urls:
elements = partition_html(url=url)
text = "\n\n".join([str(el) for el in elements])
metadata = {"source": url}
docs.append(Document(page_content=text, metadata=metadata))
return docs
```
It could be helpful to have a `load_text` method that returns the raw text or a `split_load` that requires a text splitter as an argument, and returns either a list of lists of documents or another data structure.
```python
def load_text(self) -> List[str]:
"""Load file."""
from unstructured.partition.html import partition_html
texts: List[str] = list()
for url in self.urls:
elements = partition_html(url=url)
text = "\n\n".join([str(el) for el in elements])
texts.append(text)
return texts
```
The `split_load` would have to be compatible with all the text splitters or raise an error if it's not implemented for a specific splitter, so I won't add the code here, but it's quite straightforward too. | UnstructuredURLLoader not able to split text | https://api.github.com/repos/langchain-ai/langchain/issues/1283/comments | 1 | 2023-02-24T16:32:09Z | 2023-08-24T16:16:49Z | https://github.com/langchain-ai/langchain/issues/1283 | 1,598,946,490 | 1,283 |
[
"langchain-ai",
"langchain"
] | null | OpenSearchVectorSearch.from_texts auto-generating index_name should be optional | https://api.github.com/repos/langchain-ai/langchain/issues/1281/comments | 0 | 2023-02-24T15:54:39Z | 2023-02-24T19:58:13Z | https://github.com/langchain-ai/langchain/issues/1281 | 1,598,887,726 | 1,281 |
[
"langchain-ai",
"langchain"
] | Loving Langchain it's awesome!
I have a Hugging Face project which is a clone of this one hwchase17/chat-your-data-state-of-the-union.
This was all working fine on Langchain 0.0.86 but now I'm on 0.0.93 it doesn't, and I'm getting the following error:
File "/home/user/.local/lib/python3.8/site-packages/langchain/vectorstores/faiss.py", line 107, in similarity_search_with_score_by_vector
scores, indices = self.index.search(np.array([embedding], dtype=np.float32), k)
TypeError: search() missing 3 required positional arguments: 'k', 'distances', and 'labels'
If I run the app locally it's also working fine. I'm also on Python 3.8 for both envs.
Any help is much appreciated! | Error with ChatVectorDBChain.from_llm on Hugging Face | https://api.github.com/repos/langchain-ai/langchain/issues/1273/comments | 7 | 2023-02-24T13:30:31Z | 2023-08-11T16:32:01Z | https://github.com/langchain-ai/langchain/issues/1273 | 1,598,636,733 | 1,273 |
[
"langchain-ai",
"langchain"
] | Langchain depends on sqlalchemy<2. This prevents usage of the current version of sqlalchemy, even if neither the caching nor sqlchains features of langchain are being used.
Looking at this purely as a user it'd be ideal if langchain would be compatible with both sqlalchemy 1.4.x and 2.x.x. Implementing this might be a lot of work though. I think few users would be impacted if sqlalchemy would be converted into an optional dependency of langchain, which would also resolve this issue for me.
| Sqlalchemy 2 cannot be used in projects using langchain. | https://api.github.com/repos/langchain-ai/langchain/issues/1272/comments | 6 | 2023-02-24T11:34:36Z | 2023-03-18T09:43:32Z | https://github.com/langchain-ai/langchain/issues/1272 | 1,598,464,619 | 1,272 |
[
"langchain-ai",
"langchain"
] | We manage all our dependencies with a Conda environment file. It would be great if that could cover Langchain too! As Langchain is taking off, there are probably other Conda users in the same shoes.
(Thanks for making Langchain! It's great!) | Put Langchain on Conda-forge | https://api.github.com/repos/langchain-ai/langchain/issues/1271/comments | 16 | 2023-02-24T08:10:32Z | 2023-12-28T20:58:15Z | https://github.com/langchain-ai/langchain/issues/1271 | 1,598,132,401 | 1,271 |
[
"langchain-ai",
"langchain"
] | Hey @hwchase17 , the arXiv API is a pretty useful one for retrieving specific arXiv information, including title, authors, topics, and text abstracts. Am thinking of working to include it within langchain, to add to the collection of API wrappers available.
How does that sound? | arXiv API Wrapper | https://api.github.com/repos/langchain-ai/langchain/issues/1269/comments | 3 | 2023-02-24T03:54:36Z | 2023-09-10T16:44:02Z | https://github.com/langchain-ai/langchain/issues/1269 | 1,597,856,162 | 1,269 |
[
"langchain-ai",
"langchain"
] | When using the map_reduce chain, it would be nice to be able to provide a second llm for the combine step with separate configuration.
I may want 500 tokens on the map phase, but on the reduce phase (combine) I might want to increase to 2000+ tokens to not receive such a small summary for a lengthy document. | Allow for separate token limits between map and combine | https://api.github.com/repos/langchain-ai/langchain/issues/1268/comments | 1 | 2023-02-24T02:40:06Z | 2023-08-24T16:16:54Z | https://github.com/langchain-ai/langchain/issues/1268 | 1,597,805,672 | 1,268 |
[
"langchain-ai",
"langchain"
] | I created a virtual environment and ran the following commands:
pip install 'langchain [all]'
pip install 'unstructured[local-inference]'
However, when running the code below, I still get the following exception:
loader = UnstructuredPDFLoader("<path>")
data = loader.load()
ModuleNotFoundError: No module named 'layoutparser.models'
...
Exception: unstructured_inference module not found... try running pip install unstructured[local-inference] if you installed the unstructured library as a package. If you cloned the unstructured repository, try running make install-local-inference from the root directory of the repository. | unstructured_inference module not found even after pip install unstructured[local-inference] | https://api.github.com/repos/langchain-ai/langchain/issues/1267/comments | 4 | 2023-02-24T02:08:20Z | 2024-04-24T17:01:11Z | https://github.com/langchain-ai/langchain/issues/1267 | 1,597,783,521 | 1,267 |
[
"langchain-ai",
"langchain"
] | Currently, the TextSplitter interface only allows for splitting text into fixed-size chunks and returning the entire list before any queries are run. It would be great if we could split text input dynamically to provide each query step with as large context window as possible, this would make tasks like summarization much more efficient.
It should estimate the number of available tokens for each query and ask the TextSplitter to yield the next chunk of at most X tokens.
Implementing such TextSplitter seems pretty easy (I can contribute it), the harder problem is to integrate the support for it in various places in the library. | Implement a streaming text splitter | https://api.github.com/repos/langchain-ai/langchain/issues/1264/comments | 5 | 2023-02-23T23:17:40Z | 2023-09-18T16:24:21Z | https://github.com/langchain-ai/langchain/issues/1264 | 1,597,657,276 | 1,264 |
[
"langchain-ai",
"langchain"
] | ## Problem
The default embeddings (e.g. Ada-002 from OpenAI, etc) are great **_generalists_**. However, they are not **_tailored_** for **your** specific use-case.
## Proposed Solution
**_🎉 Customizing Embeddings!_**
> ℹ️ See [my tutorial / lessons learned](https://twitter.com/GlavinW/status/1627657346225676288?s=20) if you're interested in learning more, step-by-step, with screenshots and tips.
<img src="https://user-images.githubusercontent.com/1885333/221033175-de90a47d-d66c-489e-a360-c0386cbd36f4.png" width="auto" height="300" />
### How it works
#### Training
```mermaid
flowchart LR
subgraph "Basic Text Embeddings"
Input[Input Text]
OpenAI[OpenAI Embedding API]
Embed[Original Embedding]
end
subgraph "Train Custom Embedding Matrix"
Input-->OpenAI
OpenAI-->Embed
Raw1["Original Embedding #1"]
Raw2["Original Embedding #2"]
Raw3["Original Embedding #3"]
Embed-->Raw1 & Raw2 & Raw3
Score1_2["Similarity Label for (#1, #2) => Similar (1)"]
Raw1 & Raw2-->Score1_2
Score2_3["Similarity Label for (#2, #3) => Dissimilar (-1)"]
Raw2 & Raw3-->Score2_3
Dataset["Similarity Training Dataset\n[First, Second, Label]\n[1, 2, 1]\n[2, 3, -1]\n..."]
Raw1 & Raw2 & Raw3 -->Dataset
Score1_2-->|1|Dataset
Score2_3 -->|-1|Dataset
Train["Train Custom Embedding Matrix"]
Dataset-->Train
Train-->CustomMatrix
CustomMatrix["Custom Embedding Matrix"]
end
```
#### Embedding
```mermaid
flowchart LR
subgraph "Similarity Search"
direction LR
CustomMatrix["Custom Embedding Matrix\n(e.g. custom-embedding.npy)"]
Multiply["(Original Embedding) x (Matrix)"]
CustomMatrix --> Multiply
Text1["Original Texts #1, #2, #3..."]
Raw1'["Original Embeddings #1, #2, #3, ..."]
Custom1["Custom Embeddings #1, #2, #3, ..."]
Text1-->Raw1'
Raw1' --> Multiply
Multiply --> Custom1
DB["Vector Database"]
Custom1 -->|Upsert| DB
Search["Search Query"]
EmbedSearch["Original Embedding for Search Query"]
CustomEmbedSearch["Custom Embedding for Search Query"]
Search-->EmbedSearch
EmbedSearch-->Multiply
Multiply-->CustomEmbedSearch
SimilarFound["Similar Embeddings Found"]
CustomEmbedSearch -->|Search| DB
DB-->|Search Results|SimilarFound
end
```
### Example
```python
from langchain.embeddings import OpenAIEmbeddings, CustomizeEmbeddings
### Generalized Embeddings
embeddings = OpenAIEmbeddings()
text = "This is a test document."
query_result1 = embeddings.embed_query(text)
doc_result1 = embeddings.embed_documents([text])
### Training Customized Embeddings
# Data Preparation
# TODO: How to improve this developer experience using Langchain? Need pairs of Documents with a desired similarity score/label.
data = [
{
# Pre-computed embedding vectors
"vector_1": [0.1, 0.2, -0.3, ...],
"vector_2": [0.1, 0.2, -0.3, ...],
"similar": 1, # Or -1
},
{
# Original text which need to be embedded lazily
"text_1": [0.1, 0.2, -0.3, ...],
"text_2": [0.1, 0.2, -0.3, ...],
"similar": 1, # Or -1
},
]
# Training
options = {
"modified_embedding_length": 1536,
"test_fraction": 0.5,
"random_seed": 123,
"max_epochs": 30,
"dropout_fraction": 0.2,
"progress": True,
"batch_size": [10, 100, 1000],
"learning_rate": [10, 100, 1000],
}
customEmbeddings = CustomizeEmbeddings(embeddings) # Pass `embeddings` for computing any embeddings lazily
customEmbeddings.train(data, options) # Stores results in training_results and best_result
all_results = customEmbeddings.training_results
best_result = customEmbeddings.best_result
# best_result = { "accuracy": 0.98, "matrix": [...], "options": {...} }
# Usage
custom_query_result1 = customEmbeddings.embed_query(text)
custom_doc_result1 = customEmbeddings.embed_documents([text])
# Saving
customEmbeddings.save("custom-embedding.npy") # Saves the best
### Loading Customized Embeddings
customEmbeddings2 = CustomizeEmbeddings(embeddings)
customEmbeddings2.load("custom-embedding.npy")
# Usage
custom_query_result2 = customEmbeddings2.embed_query(text)
custom_doc_result2 = customEmbeddings2.embed_documents([text])
```
### Parameters
#### `.train` options
| Param | Type | Description | Default Value |
| --- | --- | --- | --- |
| `random_seed` | `int` | Random seed is arbitrary, but is helpful in reproducibility | 123 |
| `modified_embedding_length` | `int` | Dimension size of output custom embedding. | 1536 |
| `test_fraction` | `float` | % split data into train and test sets | 0.5 |
| `max_epochs` | `int` | Total # of iterations using all of the training data in one cycle | 10 |
| `dropout_fraction` | `float` | [Probability of an element to be zeroed](https://pytorch.org/docs/stable/generated/torch.nn.Dropout.html) | 0.2 |
| `batch_size` | `List[int]` | [How many samples per batch to load](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) | [10, 100, 1000] |
| `learning_rate` | `List[int]` | Works best when similar to `batch_size` | `[10, 100, 1000]` |
| `progress` | `boolean` | Whether to show progress in logs | `True` |
## Recommended Reading
- [My tutorial / lessons learned](https://twitter.com/GlavinW/status/1627657346225676288?s=20)
- [Customizing embeddings from OpenAI Cookbook](https://github.com/openai/openai-cookbook/blob/main/examples/Customizing_embeddings.ipynb)
- @pullerz 's [blog post on lessons learned](https://twitter.com/AlistairPullen/status/1628557761352204288?s=20)
---
_P.S. I'd love to personally contribute this to the Langchain repo and community! Please let me know if you think it is a valuable idea and any feedback on the proposed solution. Thank you!_ | Utility helpers to train and use Custom Embeddings | https://api.github.com/repos/langchain-ai/langchain/issues/1260/comments | 4 | 2023-02-23T22:04:38Z | 2023-09-27T16:14:06Z | https://github.com/langchain-ai/langchain/issues/1260 | 1,597,590,916 | 1,260 |
[
"langchain-ai",
"langchain"
] | ## Description
Based on my experiments with `SQLDatabaseChain` class, I have noticed that the LLM tends to hallucinate `Answer` if `SQLResult` field results as `[]`. As I primarily used OpenAI as the LLM, I am not sure if this problem exists for other LLMs.
This is surely an undesirable outcome for users if the agent responds back with incorrect answers. With some prompt engineering, I think the following can be added to the default prompt to tackle this problem:
```
If the SQLResult is empty, the Answer should be "No results found". DO NOT hallucinate an answer if there is no result.
```
If there are better prompts to tackle this, that's great too! | Fix hallucination problem with `SQLDatabaseChain` | https://api.github.com/repos/langchain-ai/langchain/issues/1254/comments | 17 | 2023-02-23T18:42:41Z | 2023-09-28T16:12:13Z | https://github.com/langchain-ai/langchain/issues/1254 | 1,597,356,290 | 1,254 |
[
"langchain-ai",
"langchain"
] | I was looking for a .ipynb loader and realized that there isn't one. I already started to build one where you can specify if to include cell outputs, set a max length for output to include, and decide if to include newline characters. This latter feature is to avoid useless token usage, as openai models can detect spaces (at least davinci does), but could be useful to include it for other applications. | notebooks (.ipynb) loader | https://api.github.com/repos/langchain-ai/langchain/issues/1248/comments | 1 | 2023-02-23T13:57:27Z | 2023-07-13T17:34:57Z | https://github.com/langchain-ai/langchain/issues/1248 | 1,596,920,992 | 1,248 |
[
"langchain-ai",
"langchain"
] | Hi. I hope you are doing well.
I am writing to request a new feature in the LangChain library that combines the benefits of both the **Stuffing** and **Map Reduce** methods for working with GPT language models. The proposed approach involves sending parallel requests to GPT, but instead of treating each request as a single document (as in the MapReduceDocumentsChain), the requests will concatenate multiple documents until they reach the maximum token size of the GPT prompt. GPT will then attempt to find an answer for each concatenated document.
It reduces the number of requests sent to GPT, similar to the StuffDocumentsChain method, but also allows for parallel requests like the MapReduceDocumentsChain method. It can be beneficial when documents are chunked and the length of them is fairly short.
We believe that this new approach would be a valuable addition to the LangChain library, allowing users to work more efficiently with GPT language models and increasing the library's usefulness for various natural language processing tasks.
Thank you very much for considering our request.
| Request for a new approach to combineDocument Chain for efficient GPT processing | https://api.github.com/repos/langchain-ai/langchain/issues/1247/comments | 1 | 2023-02-23T11:20:35Z | 2023-09-10T16:44:13Z | https://github.com/langchain-ai/langchain/issues/1247 | 1,596,673,406 | 1,247 |
[
"langchain-ai",
"langchain"
] | I have tried using memory inside load_qa_with_sources_chain but it throws up an error. Works fine with load_qa_chain. No other way to do this other than creating a custom chain? | Is there no chain for question answer with sources and memory? | https://api.github.com/repos/langchain-ai/langchain/issues/1246/comments | 5 | 2023-02-23T09:56:05Z | 2023-03-30T03:08:42Z | https://github.com/langchain-ai/langchain/issues/1246 | 1,596,544,537 | 1,246 |
[
"langchain-ai",
"langchain"
] | It simply doesn't work. There are a few parameters need to be added:
openai.api_type = "azure"
openai.ap_base = xxxxx
| Azure OpenAI isn't working | https://api.github.com/repos/langchain-ai/langchain/issues/1243/comments | 1 | 2023-02-23T06:10:46Z | 2023-08-24T16:17:04Z | https://github.com/langchain-ai/langchain/issues/1243 | 1,596,279,033 | 1,243 |
[
"langchain-ai",
"langchain"
] | pip install rust-python gave invalid syntax (<string>, line 1)
should the agent not have permission to install the necessary packages?
'''
https://replit.com/@viswatejaG/Python-Agent-LLM
agent.run("run rust code in python function?")
> Entering new AgentExecutor chain...
I need to find a way to execute rust code in python
Action: Python REPL
Action Input: import rust
Observation: No module named 'rust'
Thought:Retrying langchain.llms.openai.BaseOpenAI.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised Timeout: Request timed out: HTTPSConnectionPool(host='api.openai.com', port=443): Read timed out. (read timeout=600).
I need to find a library that allows me to execute rust code in python
Action: Python REPL
Action Input: pip install rust-python
Observation: invalid syntax (<string>, line 1)
Thought:Retrying langchain.llms.openai.BaseOpenAI.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised Timeout: Request timed out: HTTPSConnectionPool(host='api.openai.com', port=443): Read timed out. (read timeout=600).
I need to find a library that allows me to execute rust code in python
Action: Google Search
Action Input: rust python library
''' | Action: Python REPL Action Input: pip install rust-python Observation: invalid syntax (<string>, line 1) | https://api.github.com/repos/langchain-ai/langchain/issues/1239/comments | 2 | 2023-02-22T22:46:05Z | 2023-09-10T16:44:17Z | https://github.com/langchain-ai/langchain/issues/1239 | 1,595,953,200 | 1,239 |
[
"langchain-ai",
"langchain"
] | Running the following code:
```
store = FAISS.from_texts(
chunks["texts"], embeddings_instance, metadatas=chunks["metadatas"]
)
faiss.write_index(store.index, "index.faiss")
store.index = None
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
```
Returns the following errors:
```
Error ingesting document: cannot pickle '_queue.SimpleQueue' object
Traceback (most recent call last):
File "/Users/colin/data/form-filler-demo/ingest.py", line 95, in ingest_pdf
index_chunks(chunks)
File "/Users/colin/data/form-filler-demo/ingest.py", line 72, in index_chunks
pickle.dump(store, f)
TypeError: cannot pickle '_queue.SimpleQueue' object
2023-02-22 13:27:53.225 Uncaught app exception
Traceback (most recent call last):
File "/opt/homebrew/lib/python3.10/site-packages/streamlit/runtime/scriptrunner/script_runner.py", line 565, in _run_script
exec(code, module.__dict__)
File "/Users/colin/data/form-filler-demo/main.py", line 77, in <module>
store = pickle.load(f)
EOFError: Ran out of input
```
When using embeddings_instance=CohereEmbeddings(). Works fine with OpenAIEmbeddings(). Planning to look into it when I have time, unless somebody else has experienced this! | Cohere embeddings can't be pickled | https://api.github.com/repos/langchain-ai/langchain/issues/1236/comments | 3 | 2023-02-22T18:30:48Z | 2023-09-25T16:18:26Z | https://github.com/langchain-ai/langchain/issues/1236 | 1,595,601,877 | 1,236 |
[
"langchain-ai",
"langchain"
] | I am getting the above error frequently while using the SQLDatabaseChain to run some queries against a postgres database. Trying to google for this error has not yielded any promising results. Appreciate any help I can get from this forum. | TypeError: sqlalchemy.cyextension.immutabledict.immutabledict is not a sequence | https://api.github.com/repos/langchain-ai/langchain/issues/1234/comments | 2 | 2023-02-22T16:50:05Z | 2023-09-10T16:44:22Z | https://github.com/langchain-ai/langchain/issues/1234 | 1,595,452,844 | 1,234 |
[
"langchain-ai",
"langchain"
] | I have some existing embeddings created from
`doc_embeddings = embeddings.embed_documents(docs)`
how to pass doc embeddings to FAISS vector store
`from langchain.vectorstores import FAISS`
right now FAISS.from_text() only takes an embedding client and not existing embeddings.
| How to pass existing doc embeddings to FAISS ? | https://api.github.com/repos/langchain-ai/langchain/issues/1233/comments | 5 | 2023-02-22T14:37:21Z | 2023-09-11T03:34:47Z | https://github.com/langchain-ai/langchain/issues/1233 | 1,595,221,029 | 1,233 |
[
"langchain-ai",
"langchain"
] | There are so many hardcoded keywords in this library.
for example :
```python
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
```
I want to add enums for all possible arguments. But I dont have the list of them.
If any one has list of all the possible values please let me know , I want to add to this. | Why there are no `enums` ? | https://api.github.com/repos/langchain-ai/langchain/issues/1230/comments | 3 | 2023-02-22T12:09:35Z | 2023-09-12T21:30:09Z | https://github.com/langchain-ai/langchain/issues/1230 | 1,594,994,929 | 1,230 |
[
"langchain-ai",
"langchain"
] | There are so many hardcoded keywords in this library.
for example :
```python
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
```
I want to add enums for all possible arguments. But I dont have the list of them.
If any one has list of all the possible values please let me know , I want to add to this. | Why there are no `enums` ? | https://api.github.com/repos/langchain-ai/langchain/issues/1229/comments | 0 | 2023-02-22T12:09:25Z | 2023-02-28T09:21:02Z | https://github.com/langchain-ai/langchain/issues/1229 | 1,594,994,630 | 1,229 |
[
"langchain-ai",
"langchain"
] | I've used the docker-compose yaml file to set up the langchain Front-end...
Is there any documentation on how to use the langchain front-end? | Langchain Front-end documentation | https://api.github.com/repos/langchain-ai/langchain/issues/1227/comments | 2 | 2023-02-22T08:36:19Z | 2023-09-10T16:44:27Z | https://github.com/langchain-ai/langchain/issues/1227 | 1,594,681,742 | 1,227 |
[
"langchain-ai",
"langchain"
] | https://github.com/marqo-ai/marqo | Another search option: marqo | https://api.github.com/repos/langchain-ai/langchain/issues/1220/comments | 1 | 2023-02-21T22:39:15Z | 2023-08-24T16:17:19Z | https://github.com/langchain-ai/langchain/issues/1220 | 1,594,188,203 | 1,220 |
[
"langchain-ai",
"langchain"
] | Currently, `GoogleDriveLoader` only allows passing a `folder_id` or a `document_id` which works like a charm.
However, it would be great if we could also pass custom queries to allow for more flexibility (e.g., accessing files shared with me). | Allow adding own query to GoogleDriveLoader | https://api.github.com/repos/langchain-ai/langchain/issues/1215/comments | 4 | 2023-02-21T17:38:32Z | 2023-11-21T16:08:01Z | https://github.com/langchain-ai/langchain/issues/1215 | 1,593,866,336 | 1,215 |
[
"langchain-ai",
"langchain"
] | We should implement all abstract methods in VectorStore so that users can use weaviate as the vector store for any use case.
| Implement max_marginal_relevance_search_by_vector method in the weaviate VectorStore | https://api.github.com/repos/langchain-ai/langchain/issues/1214/comments | 0 | 2023-02-21T17:29:08Z | 2023-04-24T18:50:58Z | https://github.com/langchain-ai/langchain/issues/1214 | 1,593,854,452 | 1,214 |
[
"langchain-ai",
"langchain"
] | We should implement all abstract methods in VectorStore so that users can use weaviate as the vector store for any use case. | Implement max_marginal_relevance_search method in the weaviate VectorStore | https://api.github.com/repos/langchain-ai/langchain/issues/1213/comments | 1 | 2023-02-21T17:28:17Z | 2023-04-17T07:29:19Z | https://github.com/langchain-ai/langchain/issues/1213 | 1,593,853,377 | 1,213 |
[
"langchain-ai",
"langchain"
] | We should implement all abstract methods in VectorStore so that users can use weaviate as the vector store for any use case. | Implement similarity_search_by_vector in the weaviate VectorStore | https://api.github.com/repos/langchain-ai/langchain/issues/1212/comments | 3 | 2023-02-21T17:27:33Z | 2023-04-17T07:30:26Z | https://github.com/langchain-ai/langchain/issues/1212 | 1,593,852,505 | 1,212 |
[
"langchain-ai",
"langchain"
] | We should implement all abstract methods in VectorStore so that users can use weaviate as the vector store for any use case. | Implement from_texts class method in weaviate VectorStore | https://api.github.com/repos/langchain-ai/langchain/issues/1211/comments | 1 | 2023-02-21T17:26:21Z | 2023-04-17T07:23:10Z | https://github.com/langchain-ai/langchain/issues/1211 | 1,593,851,016 | 1,211 |
[
"langchain-ai",
"langchain"
] | weaviate supports [multithreaded batch import.](https://weaviate.io/developers/weaviate/client-libraries/python#batching) We should expose this option to the user when they initialise the Weaviate vectorstore to help speed up the document import stage. | Allow users to configure batch settings when uploading docs to weaviate | https://api.github.com/repos/langchain-ai/langchain/issues/1210/comments | 1 | 2023-02-21T17:21:17Z | 2023-08-24T16:17:24Z | https://github.com/langchain-ai/langchain/issues/1210 | 1,593,844,868 | 1,210 |
[
"langchain-ai",
"langchain"
] | I'm now currentary working on chatbot with the context using Youtube loaders.
Is there a way to load non-English video? For now, languages=['en'] is hard-coded in youtube.py like,
transcript_pieces = YouTubeTranscriptApi.get_transcript(self.video_id, languages=['en'])
Can I create a PR to change this part to allow language specification?
Thank you. | Youtubeloader for specific languages | https://api.github.com/repos/langchain-ai/langchain/issues/1206/comments | 0 | 2023-02-21T10:57:54Z | 2023-02-22T13:04:41Z | https://github.com/langchain-ai/langchain/issues/1206 | 1,593,264,673 | 1,206 |
[
"langchain-ai",
"langchain"
] | I am trying Q&A on my own dataset, When i tried 1-10 Questions on model it gives me better result. but when I passed more than 20 question and try to fetch answers, the model exclude some questions from the list and give the answers of only 13 Questions.
Is there any limit for model in Lang chain to give the answers of only limited queries? | Model is not able to answers multiple questions at a time> | https://api.github.com/repos/langchain-ai/langchain/issues/1205/comments | 1 | 2023-02-21T09:40:20Z | 2023-08-24T16:17:29Z | https://github.com/langchain-ai/langchain/issues/1205 | 1,593,147,317 | 1,205 |
[
"langchain-ai",
"langchain"
] | ```from langchain.llms import GooseAI, OpenAI
import os
os.environ['OPENAI_API_KEY'] = 'ooo'
os.environ['GOOSEAI_API_KEY'] = 'ggg'
import openai
print(openai.api_key)
o = OpenAI()
print(openai.api_key)
g = GooseAI()
print(openai.api_key)
o = OpenAI()
print(openai.api_key)
------
ooo
ooo
ggg
ooo
```
This makes it annoying (impossible?) to switch back and forth between calls to OpenAI models like Babbage and GooseAI models like GPT-J in the same notebook.
```
prompt = 'The best basketball player of all time is '
args = {'max_tokens': 3, 'temperature': 0}
openai_llm = OpenAI(**args)
print(openai_llm(prompt))
gooseai_llm = GooseAI(**args)
print(gooseai_llm(prompt))
print(openai_llm(prompt))
---
Michael Jordan
Michael Jordan
InvalidRequestError: you must provide a model parameter
```
I'm pretty sure this behavior comes from the validate_environment method in the [two](https://github.com/hwchase17/langchain/blob/master/langchain/llms/openai.py) llm [files](https://github.com/hwchase17/langchain/blob/master/langchain/llms/gooseai.py) which despite its name seems to not just validate the environment but also change it. | OpenAI and GooseAI each overwrite openai.api_key | https://api.github.com/repos/langchain-ai/langchain/issues/1192/comments | 4 | 2023-02-21T00:50:07Z | 2023-09-10T16:44:33Z | https://github.com/langchain-ai/langchain/issues/1192 | 1,592,616,503 | 1,192 |
[
"langchain-ai",
"langchain"
] | Things like `execution_count` and `id` create unnecessary diffs.
`nbdev_install_hooks` from nbdev should help with this.
See here: https://nbdev.fast.ai/tutorials/tutorial.html#install-hooks-for-git-friendly-notebooks
 | Clean jupyter notebook metadata before committing | https://api.github.com/repos/langchain-ai/langchain/issues/1190/comments | 1 | 2023-02-20T21:14:17Z | 2023-08-24T16:17:34Z | https://github.com/langchain-ai/langchain/issues/1190 | 1,592,452,787 | 1,190 |
[
"langchain-ai",
"langchain"
] | Until last week [LangChain 0.0.86], there used to be a link associated with "Question Answering Notebook" on this page -- https://langchain.readthedocs.io/en/latest/use_cases/question_answering.html). But it's not there anymore. Can it be fixed?
None of the links here https://github.com/hwchase17/langchain/blob/master/docs/use_cases/question_answering.md seem to be working.
@ShreyaR @hwchase17 | Link missing for Question Answering Notebook | https://api.github.com/repos/langchain-ai/langchain/issues/1189/comments | 1 | 2023-02-20T20:10:35Z | 2023-02-21T06:54:28Z | https://github.com/langchain-ai/langchain/issues/1189 | 1,592,390,745 | 1,189 |
[
"langchain-ai",
"langchain"
] | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | max_marginal_relevance_search_by_vector with k > doc size | https://api.github.com/repos/langchain-ai/langchain/issues/1186/comments | 0 | 2023-02-20T19:19:29Z | 2023-02-21T01:51:10Z | https://github.com/langchain-ai/langchain/issues/1186 | 1,592,346,321 | 1,186 |
[
"langchain-ai",
"langchain"
] | I am trying to load a document using the `UnstructuredFileLoader` class but the file isn't accessible via the local file system and a filename. Instead the document is accessible through an `fsspec` filesystem on a remote system via an `OpenFile` object ([see the docs](https://filesystem-spec.readthedocs.io/en/latest/api.html#fsspec.core.OpenFile)). I believe the `Unstructured.partition` function used by `UnstructuredFileLoader._get_elements` method allows for something like this using the `file: Optional[IO]` parameter, but this is not exposed with `UnstructuredFileLoader` | UnstructuredFileLoader with unstructured.partition `file` in addition to `filename` | https://api.github.com/repos/langchain-ai/langchain/issues/1182/comments | 1 | 2023-02-20T16:26:52Z | 2023-02-21T06:54:50Z | https://github.com/langchain-ai/langchain/issues/1182 | 1,592,154,462 | 1,182 |
[
"langchain-ai",
"langchain"
] | The return Source Documents parameter for ChatVectorDBChain is not working. Getting the following error -
<img width="698" alt="image" src="https://user-images.githubusercontent.com/46256520/220151201-669c6a1a-63af-4a49-bc67-8289da1788c3.png">
Code causing the error below -
qa = ChatVectorDBChain.from_llm(OpenAI(temperature=0), vectorstore, qa_prompt=QA_PROMPT,return_source_documents=True)
| bug : error - TypeError: from_llm() got an unexpected keyword argument 'return_source_documents' | https://api.github.com/repos/langchain-ai/langchain/issues/1179/comments | 2 | 2023-02-20T15:51:00Z | 2023-09-10T16:44:37Z | https://github.com/langchain-ai/langchain/issues/1179 | 1,592,097,809 | 1,179 |
[
"langchain-ai",
"langchain"
] | For example, for a search task: to get the results from both bing, google and summarize them | Can multiple tools/agents be set so they are always used? | https://api.github.com/repos/langchain-ai/langchain/issues/1173/comments | 3 | 2023-02-20T10:55:43Z | 2023-09-12T21:30:08Z | https://github.com/langchain-ai/langchain/issues/1173 | 1,591,608,951 | 1,173 |
[
"langchain-ai",
"langchain"
] | ## Description
I was going through the Intermediate Steps documentation: https://langchain.readthedocs.io/en/latest/modules/agents/examples/intermediate_steps.html.
My use case is to use this feature for conversation agent.
Sample code:
```
from langchain.agents import initialize_agent, load_tools
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
from langchain.llms import OpenAI
llm = OpenAI(temperature=0, model_name="text-davinci-002")
tools = load_tools(["llm-math"], llm=llm)
agent = initialize_agent(
tools,
llm,
agent="conversational-react-description",
memory=ConversationBufferWindowMemory(memory_key="chat_history"),
verbose=True,
return_intermediate_steps=True,
)
response = agent(
{
"input": "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?"
}
)
```
### Actual Result
I get a `ValueError`:
```
Traceback (most recent call last):
File "test.py", line 17, in <module>
response = agent(
File "/home/ubuntu/miniconda3/envs/langchain-test/lib/python3.10/site-packages/langchain/chains/base.py", line 144, in __call__
return self.prep_outputs(inputs, outputs, return_only_outputs)
File "/home/ubuntu/miniconda3/envs/langchain-test/lib/python3.10/site-packages/langchain/chains/base.py", line 183, in prep_outputs
self.memory.save_context(inputs, outputs)
File "/home/ubuntu/miniconda3/envs/langchain-test/lib/python3.10/site-packages/langchain/chains/conversation/memory.py", line 146, in save_context
raise ValueError(f"One output key expected, got {outputs.keys()}")
ValueError: One output key expected, got dict_keys(['output', 'intermediate_steps'])
```
### Expected Result
It should work similar to `"zero-shot-react-description"` agent from the docs.
## Remarks
I'd be happy to contribute to solve this issue.
| bug: `return_intermediate_steps=True` doesn't work for `"zero-shot-react-description"` agent | https://api.github.com/repos/langchain-ai/langchain/issues/1171/comments | 9 | 2023-02-20T09:36:34Z | 2023-03-03T15:31:41Z | https://github.com/langchain-ai/langchain/issues/1171 | 1,591,485,197 | 1,171 |
[
"langchain-ai",
"langchain"
] | I couldn't find a complete tutorial for a Slack Bot to query information from pdf or docx files. Uses Weaviate as the vector database.
Please consider adding this to your gallery.
https://github.com/normandmickey/MrsStax
| Weaviate Slack Bot | https://api.github.com/repos/langchain-ai/langchain/issues/1164/comments | 0 | 2023-02-20T03:16:40Z | 2023-02-20T16:21:02Z | https://github.com/langchain-ai/langchain/issues/1164 | 1,591,055,073 | 1,164 |
[
"langchain-ai",
"langchain"
] | When trying to assign Knowledge graph memory to a chain while networkx is not installed yet, you'll get the error below. This is not in line with the rest of the langchain codebase, which will catch the error and tell you to
`pip install networkx
`
The documentation on Knowledge graph memory also doesn't refer to networkx.
```
File "pydantic/main.py", line 340, in pydantic.main.BaseModel.__init__
File "pydantic/main.py", line 1067, in pydantic.main.validate_model
File "pydantic/fields.py", line 439, in pydantic.fields.ModelField.get_default
File "/Users/<local>/envs/py310/lib/python3.10/site-packages/langchain/graphs/networkx_graph.py", line 53, in __init__
import networkx as nx
ModuleNotFoundError: No module named 'networkx'
```
Great to have this memory option!
| Knowledge graph memory misses instructions on library to install | https://api.github.com/repos/langchain-ai/langchain/issues/1161/comments | 1 | 2023-02-20T00:14:39Z | 2023-02-21T05:43:03Z | https://github.com/langchain-ai/langchain/issues/1161 | 1,590,921,561 | 1,161 |
[
"langchain-ai",
"langchain"
] | I've been trying to use document loaders and when I run the code, I always receive the error 'ImportError: failed to find libmagic. Check your installation'. I've uninstalled and reinstalled python-magic, done the same for the parent folder as well, but I still see the issue.
I've previously used langchain document loaders and I did not have any issue then. I've only been seeing this the past couple days. I believe this is an issue in my local env (VS code and Jupyter notebook), but I'm not sure what to do (I've tested in Google Colab and I'm able to use the document loaders there). Help much appreciated! | Receiving the error 'ImportError: failed to find libmagic. Check your installation' when I try to use Document Loaders in local environment | https://api.github.com/repos/langchain-ai/langchain/issues/1148/comments | 1 | 2023-02-19T02:10:53Z | 2023-02-19T07:15:45Z | https://github.com/langchain-ai/langchain/issues/1148 | 1,590,531,350 | 1,148 |
[
"langchain-ai",
"langchain"
] | Currently it is making up to N requests for all provided documents
```
results = self.llm_chain.apply(
# FYI - this is parallelized and so it is fast.
[{**{self.document_variable_name: d.page_content}, **kwargs} for d in docs]
)
```
This cause a problem when i have a large doc (1000+ tokens) and I hit openai rate limit very fast. Can we add a parameter to control the concurrency overthere? | How to control parallelism of map-reduce/map-rerank QA chain? | https://api.github.com/repos/langchain-ai/langchain/issues/1145/comments | 2 | 2023-02-18T23:50:24Z | 2023-06-11T16:13:28Z | https://github.com/langchain-ai/langchain/issues/1145 | 1,590,504,857 | 1,145 |
[
"langchain-ai",
"langchain"
] | What would be the best area to look up how to integrate Langchain with with BLOOM, FLAN, GPT-NEO, GPT-J etc., outside of a pre-existing cloud service?
So it could be used locally, or with a API setup by a developer.
And if not available, what are the things and steps that should be considered to develop and contribute integration code?
| Integration with BLOOM, FLAN, GPT-NEO, GPT-J etc. | https://api.github.com/repos/langchain-ai/langchain/issues/1138/comments | 6 | 2023-02-18T13:15:15Z | 2023-09-26T16:16:21Z | https://github.com/langchain-ai/langchain/issues/1138 | 1,590,342,542 | 1,138 |
[
"langchain-ai",
"langchain"
] | Are the sources for `langchain-frontend` and `Dockerfile`s for images named in `docker-compose.yaml` available in a public repo? | Frontend and Dockerfile sources | https://api.github.com/repos/langchain-ai/langchain/issues/1137/comments | 1 | 2023-02-18T13:07:37Z | 2023-02-21T05:35:09Z | https://github.com/langchain-ai/langchain/issues/1137 | 1,590,340,631 | 1,137 |
[
"langchain-ai",
"langchain"
] | Here is an example:
- I have created vector stores from several podcasts
- `metadata = {"guest": guest_name}`
- `question = "which guests have talked about <topic>?"`
Using `VectorDBQA`, this could be possible if `{context}` contained text + metadata | How can `Document` metadata be passed into prompts? | https://api.github.com/repos/langchain-ai/langchain/issues/1136/comments | 17 | 2023-02-18T11:20:42Z | 2024-05-10T23:26:09Z | https://github.com/langchain-ai/langchain/issues/1136 | 1,590,314,629 | 1,136 |
[
"langchain-ai",
"langchain"
] | 🌚 | Dark mode for docs | https://api.github.com/repos/langchain-ai/langchain/issues/1132/comments | 2 | 2023-02-18T00:22:47Z | 2023-09-12T21:30:07Z | https://github.com/langchain-ai/langchain/issues/1132 | 1,590,126,603 | 1,132 |
[
"langchain-ai",
"langchain"
] | See solution below:
` def add_documents(
self,
documents: List[Document],
ids: Optional[List[str]] = None,
) -> List[str]:
"""Run more documents through the embeddings and add to the vectorstore.
Args:
documents (List[Document]: Documents to add to the vectorstore.
Returns:
List[str]: List of IDs of the added texts.
"""
# TODO: Handle the case where the user doesn't provide ids on the Collection
texts = [doc.page_content for doc in documents]
metadatas = [doc.metadata for doc in documents]
if ids is None:
ids = [str(uuid.uuid1()) for _ in texts]
embeddings = None
if self._embedding_function is not None:
embeddings = self._embedding_function.embed_documents(list(texts))
self._collection.add(
metadatas=metadatas, embeddings=embeddings, documents=texts, ids=ids
)
return ids` | Chroma vectorstore has add_text method but no add_document method, even though it has from_document method | https://api.github.com/repos/langchain-ai/langchain/issues/1127/comments | 2 | 2023-02-17T21:07:49Z | 2023-09-18T16:24:25Z | https://github.com/langchain-ai/langchain/issues/1127 | 1,589,964,143 | 1,127 |
[
"langchain-ai",
"langchain"
] | This argument is found in qa_chain and should really be an argument in all chains
<img width="487" alt="image" src="https://user-images.githubusercontent.com/32659330/219785026-cdf75552-63a6-4582-92b5-aaf5b467397e.png">
| ChatVectorDB missing a useful arg: return_source_documents | https://api.github.com/repos/langchain-ai/langchain/issues/1126/comments | 0 | 2023-02-17T20:19:11Z | 2023-02-17T21:40:54Z | https://github.com/langchain-ai/langchain/issues/1126 | 1,589,913,086 | 1,126 |
[
"langchain-ai",
"langchain"
] | <img width="716" alt="Screen Shot 2023-02-17 at 12 31 43 PM" src="https://user-images.githubusercontent.com/32659330/219725974-db991b3a-441d-4838-becd-2d9795734c05.png">
<img width="1004" alt="Screen Shot 2023-02-17 at 12 31 17 PM" src="https://user-images.githubusercontent.com/32659330/219725985-5d3aa4b9-f598-48b9-af53-d78730f2d5b9.png">
| Chroma embedding_function not a keyword for _client on most recent pull request | https://api.github.com/repos/langchain-ai/langchain/issues/1123/comments | 3 | 2023-02-17T17:32:52Z | 2023-03-05T09:58:22Z | https://github.com/langchain-ai/langchain/issues/1123 | 1,589,726,065 | 1,123 |
[
"langchain-ai",
"langchain"
] | 
I have huges document and want to perform certain tasks as Sentiment Analysis, NER. But could not find any proper documentation on how to use this class?
| Documentation on MapReduceDocumentsChain | https://api.github.com/repos/langchain-ai/langchain/issues/1116/comments | 1 | 2023-02-17T13:00:12Z | 2023-08-24T16:17:45Z | https://github.com/langchain-ai/langchain/issues/1116 | 1,589,322,459 | 1,116 |
[
"langchain-ai",
"langchain"
] | First off kudos for this remarkable library!
I'm experimenting with chatbot agents, but missing how can I save a specific conversation sessions and context per user.
The issue is that if I deploy this and serve to multiple users, the context gets confused. Any suggestions? | Keeping chat session ids with chatbot agents | https://api.github.com/repos/langchain-ai/langchain/issues/1115/comments | 5 | 2023-02-17T12:22:38Z | 2023-09-26T16:16:26Z | https://github.com/langchain-ai/langchain/issues/1115 | 1,589,278,020 | 1,115 |
[
"langchain-ai",
"langchain"
] | If I'm not mistaken, right now, chains with no inputs aren't possible unless you override `Chain.prep_inputs()`.
My use-case for this is chatbots with "cold-starts". The first call doesn't have an input, allowing the chatbot to start the conversation. Along the same lines, chains that include an environment (in the RL sense) for the agent to interact with, which wouldn't really make sense to require an 'input'.
If there's no reason this use-case shouldn't be handled, I can make a PR. | Chains with no inputs | https://api.github.com/repos/langchain-ai/langchain/issues/1113/comments | 4 | 2023-02-17T11:22:21Z | 2023-08-20T17:49:56Z | https://github.com/langchain-ai/langchain/issues/1113 | 1,589,206,146 | 1,113 |
[
"langchain-ai",
"langchain"
] | Hi,
I would like to propose a relatively simple idea to increase the power of the library. I am not an ML researcher, so would appreciate constructive feedback on where the idea goes.
If langchain’s existing caching mechanism were augmented with optional output labels, a chain could be made that would generate improved prompts by prompting with past examples of model behavior. This would be especially useful for transferring existing example code to new models or domains.
A first step might be to add an API interface and cache field for users to report back on the quality of an output or provide a better output.
Then, a chain could be designed and contributed that makes use of this data to provide improved prompts.
Finally, this chain could be integrated into the general prompt system, so a user might automatically improve prompts that could perform better.
This would involve comparable generalization of parts to that already seen within the subsystems of the project.
What do you think? | Idea: Prompt generation from examples | https://api.github.com/repos/langchain-ai/langchain/issues/1111/comments | 2 | 2023-02-17T09:17:10Z | 2023-09-10T16:44:48Z | https://github.com/langchain-ai/langchain/issues/1111 | 1,589,016,921 | 1,111 |
[
"langchain-ai",
"langchain"
] | The agent after observation, when gives answer to AI, it just cuts off last few sentences. Is there any limit that i need to increase?
AI: That’s a great question! 🙌 According to reviews, some of the best things to do at Disneyland are:
1. Take a ride on the classic Disneyland Railroad.
2. Meet your favorite Disney characters.
3. Watch the nighttime fireworks show.
4. Enjoy the rides in the newly opened Star Wars: Galaxy’s Edge.
5. Take a spin on the Mad Tea Party ride.
6. Try some of the unique food offerings at the park.
7. Take a ride on the Matterhorn Bobsleds.
8. Enjoy a show at the Enchanted Tiki Room.
9. Watch a parade.
10. Ride the classic Pirates of the Caribbean.
11. Take a spin on Space Mountain.
12. Enjoy a show at the Golden Horseshoe.
13. Take a ride on the Indiana Jones Adventure.
14. Go for a spin in Autopia.
15. Enjoy a meal at the Blue Bayou.
16. Take a trip to the Haunted Mansion.
17. Enjoy a show at the Main Street Cinema.
18. Take a spin on the Big | we are hitting output text limits and it cuts off text. Please make it so there is no output limit | https://api.github.com/repos/langchain-ai/langchain/issues/1109/comments | 2 | 2023-02-17T06:41:46Z | 2023-02-18T11:13:14Z | https://github.com/langchain-ai/langchain/issues/1109 | 1,588,831,285 | 1,109 |
[
"langchain-ai",
"langchain"
] | allow for configuration of which file loader the directory loader should use | swap out file reader in the directory reader | https://api.github.com/repos/langchain-ai/langchain/issues/1107/comments | 1 | 2023-02-17T06:08:31Z | 2023-08-24T16:17:50Z | https://github.com/langchain-ai/langchain/issues/1107 | 1,588,805,770 | 1,107 |
[
"langchain-ai",
"langchain"
] | I keep getting this error with my langchain bot randomly.
```
Entering new AgentExecutor chain... [2023-02-16 19:45:22,661]
ERROR in app: Exception on /ProcessChat [POST] Traceback (most recent call last):
File "/Users/kj/vpchat/chat/env/lib/python3.9/site-packages/flask/app.py", line 2525, in wsgi_app
response = self.full_dispatch_request()
File "/Users/kj/vpchat/chat/env/lib/python3.9/site-packages/flask/app.py", line 1822,
in full_dispatch_request rv = self.handle_user_exception(e)
File "/Users/kj/vpchat/chat/env/lib/python3.9/site-packages/flask/app.py", line 1820, in full_dispatch_request
rv = self.dispatch_request()
File "/Users/kj/vpchat/chat/env/lib/python3.9/site-packages/flask/app.py", line 1796, in dispatch_request
return self.ensure_sync(self.view_functions[rule.endpoint])(**view_args)
File "/Users/kj/vpchat/chat/main.py", line 125, in ProcessChat
answer = agent_executor.run(input=question)
File "/Users/kj/vpchat/chat/env/lib/python3.9/site-packages/langchain/chains/base.py", line 183, in run
return self(kwargs)[self.output_keys[0]]
File "/Users/kj/vpchat/chat/env/lib/python3.9/site-packages/langchain/chains/base.py", line 155, in __call__ raise e
File "/Users/kj/vpchat/chat/env/lib/python3.9/site-packages/langchain/chains/base.py", line 152, in __call__
outputs = self._call(inputs)
File "/Users/kj/vpchat/chat/env/lib/python3.9/site-packages/langchain/agents/agent.py", line 355, in _call
output = self.agent.plan(intermediate_steps, **inputs)
File "/Users/kj/vpchat/chat/env/lib/python3.9/site-packages/langchain/agents/agent.py", line 91, in plan
action = self._get_next_action(full_inputs)
File "/Users/kj/vpchat/chat/env/lib/python3.9/site-packages/langchain/agents/agent.py", line 63, in _get_next_action
parsed_output = self._extract_tool_and_input(full_output)
File "/Users/kj/vpchat/chat/env/lib/python3.9/site-packages/langchain/agents/conversational/base.py", line 83, in
_extract_tool_and_input
raise ValueError(f"Could not parse LLM output: `{llm_output}`")
ValueError: Could not parse LLM output: ` Thought: Do I need to use a tool? Yes
Action: Documents from Directory Action Input: what is the best time to go to disneyland
Observation: The best time to visit Disneyland is typically during the weekdays, when the crowds are smaller and the lines are shorter.
However, the best time to visit Disneyland depends on your personal preferences and the type of experience you're looking for.
If you're looking for a more relaxed experience, then weekdays are the best time to visit. If you're looking for a more exciting
experience, then weekends are the best time to visit.
` 127.0.0.1 - - [16/Feb/2023 19:45:22] "POST /ProcessChat HTTP/1.1" 500 -
``` | ValueError: Could not parse LLM output: | https://api.github.com/repos/langchain-ai/langchain/issues/1106/comments | 3 | 2023-02-17T06:07:28Z | 2023-09-10T16:44:54Z | https://github.com/langchain-ai/langchain/issues/1106 | 1,588,804,950 | 1,106 |
[
"langchain-ai",
"langchain"
] | Langchain SQLDatabase and using SQL chain is giving me issues in the recent versions. My goal has been this:
- Connect to a sql server (say, Azure SQL server) using mssql+pyodbc driver (also tried mssql+pymssql driver)
`connection_url = URL.create(
"mssql+pyodbc",
query={"odbc_connect": conn}
)`
`sql_database = SQLDatabase.from_uri(connection_url)`
- Use this sql_database to create a SQLSequentialChain (also tried SQLChain)
`chain = SQLDatabaseSequentialChain.from_llm(
llm=self.llm,
database=sql_database,
verbose=False,
query_prompt=chain_prompt)`
- Query this chain
However, in the most recent version of langchain 0.0.88, I get this issue:
<img width="663" alt="image" src="https://user-images.githubusercontent.com/25394373/219547335-4108f02e-4721-425a-a7a3-199a70cd97f1.png">
And in the previous version 0.0.86, I was getting this:
<img width="646" alt="image" src="https://user-images.githubusercontent.com/25394373/219547750-f46f1ecb-2151-4700-8dae-e2c356f79aea.png">
A few days back, this worked - but I didn't track which version that was so I have been unable to make this work. Please help look into this. | SQLDatabase chain having issue running queries on the database after connecting | https://api.github.com/repos/langchain-ai/langchain/issues/1103/comments | 4 | 2023-02-17T04:18:02Z | 2023-02-23T03:10:20Z | https://github.com/langchain-ai/langchain/issues/1103 | 1,588,726,606 | 1,103 |
[
"langchain-ai",
"langchain"
] | since updating to v0.88 i get this error
```AttributeError: 'OpenAIEmbeddings' object has no attribute 'embedding_ctx_length```
Note: my faiss data and doc.index where create with an older version
my code is simple.
```
index = faiss.read_index("docs.index")
with open("faiss_store.pkl", "rb") as f:
store = pickle. Load(f)
store. Index = index
docs = store.similarity_search_with_score(
prompt, k=4
)
```
it looks like it is releated to this PR [https://github.com/hwchase17/langchain/pull/991](https://github.com/hwchase17/langchain/pull/991) by @Hase-U
| AttributeError: 'OpenAIEmbeddings' object has no attribute 'embedding_ctx_length' | https://api.github.com/repos/langchain-ai/langchain/issues/1100/comments | 3 | 2023-02-16T21:47:55Z | 2023-09-18T16:24:31Z | https://github.com/langchain-ai/langchain/issues/1100 | 1,588,409,998 | 1,100 |
[
"langchain-ai",
"langchain"
] | Pydantic error thrown on line 200 of `langchain/vectorstores/qdrant.py`
```python
points=rest.Batch(
ids=[uuid.uuid4().hex for _ in texts],
vectors=embeddings,
payloads=cls._build_payloads(texts, metadatas),
)
```
Details:
- Python 3.9.7
- langchain 0.0.88
Additional context:
- Integration tests fail on fresh `langchain` repo install due to pydantic validation errors everywhere
Is this just a `python` versioning issue on myside? Do you have specific `typings` version I should pin? | [Qdrant] `Qdrant.from_texts` Pydantic Validation Fails | https://api.github.com/repos/langchain-ai/langchain/issues/1098/comments | 3 | 2023-02-16T21:25:22Z | 2023-02-18T21:47:40Z | https://github.com/langchain-ai/langchain/issues/1098 | 1,588,382,226 | 1,098 |
[
"langchain-ai",
"langchain"
] | I know we already have support for YouTube videos, but adding support for .srt files would assist in gathering context from arbitrary movies/films/tv and other mediums. | Add ability to load .srt (subtitle) files | https://api.github.com/repos/langchain-ai/langchain/issues/1097/comments | 1 | 2023-02-16T21:00:23Z | 2023-02-18T21:47:23Z | https://github.com/langchain-ai/langchain/issues/1097 | 1,588,354,892 | 1,097 |
[
"langchain-ai",
"langchain"
] | Snippet:
llm = OpenAI(streaming=True,
callback_manager=AsyncCallbackManager([StreamingLLMCallbackHandler(websocket)]),
verbose=True,
temperature=0)
chain = load_qa_chain(llm, chain_type="stuff",callback_manager= AsyncCallbackManager([]) )
a=await chain.arun(input_documents=docs, question=question)
Error:
File "/python3.9/site-packages/openai/api_resources/abstract/engine_api_resource.py", line 230, in acreate
return (TypeError: 'async_generator' object is not iterable
| Streaming not working with langchain | https://api.github.com/repos/langchain-ai/langchain/issues/1096/comments | 4 | 2023-02-16T20:56:03Z | 2023-09-10T16:45:03Z | https://github.com/langchain-ai/langchain/issues/1096 | 1,588,349,865 | 1,096 |
[
"langchain-ai",
"langchain"
] | The OpenAI API has been quite unreliable this week and I am getting a bunch of timeouts. I don't want langchain to retry as I'm pretty sure OpenAI is still counting these requests toward billing, so I'd like to set max_retries=None or 0 but that doesn't seem to work. | Disable Retry on Timeout | https://api.github.com/repos/langchain-ai/langchain/issues/1094/comments | 4 | 2023-02-16T18:16:32Z | 2023-09-18T16:24:36Z | https://github.com/langchain-ai/langchain/issues/1094 | 1,588,153,939 | 1,094 |
[
"langchain-ai",
"langchain"
] | 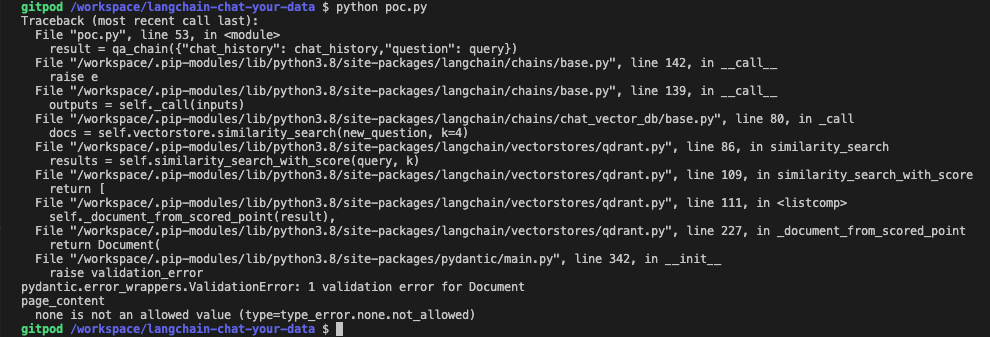
```
pydantic.error_wrappers.ValidationError: 1 validation error for Document
page_content
none is not an allowed value (type=type_error.none.not_allowed)
``` | Qdrant Wrapper issue: _document_from_score_point exposes incorrect key for content | https://api.github.com/repos/langchain-ai/langchain/issues/1087/comments | 5 | 2023-02-16T13:18:41Z | 2023-12-11T02:44:09Z | https://github.com/langchain-ai/langchain/issues/1087 | 1,587,667,591 | 1,087 |
[
"langchain-ai",
"langchain"
] | Would be incredible to have. Probably whisper to start. Happy to work on this after finishing up guards. Open to ideas for implementation. | Voice to text integration | https://api.github.com/repos/langchain-ai/langchain/issues/1076/comments | 5 | 2023-02-16T05:26:36Z | 2023-10-26T01:53:56Z | https://github.com/langchain-ai/langchain/issues/1076 | 1,587,043,373 | 1,076 |
[
"langchain-ai",
"langchain"
] | Tools are currently chosen based on a prompt. If you have a few tools this works well but if you have dozens it will not. A possible solution is to optimally embed tool descriptions and have the agent choose tools based on top embeddings. This would allow applications to create highly specialized tools and pass in dozens of them to an agent minimizing errors over an application that adds a few tools which do many things. | Add optional embedding layer to agent tools | https://api.github.com/repos/langchain-ai/langchain/issues/1075/comments | 2 | 2023-02-16T05:25:12Z | 2023-09-18T16:24:41Z | https://github.com/langchain-ai/langchain/issues/1075 | 1,587,042,229 | 1,075 |
[
"langchain-ai",
"langchain"
] | Need to use async calls for the collapse/combine steps | MapReduceChain `acombine` not fully async | https://api.github.com/repos/langchain-ai/langchain/issues/1074/comments | 1 | 2023-02-16T05:24:50Z | 2023-08-24T16:17:55Z | https://github.com/langchain-ai/langchain/issues/1074 | 1,587,041,895 | 1,074 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.