
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.46B | issue_number int64 1 127k |
|---|---|---|---|---|---|---|---|---|---|
[
"MonetDB",
"MonetDB"
] | The database version we are using is 11.43.5 Jan2022 and we are getting this error in many of the tables in Monet DB
when try to select table from the DB we are getting error
sql>select *from "DM_POS_TSV_MRT_P6"."OUTLET_CSL_VISIBILITY";
GDK reported error: BATproject2: does not match always
few often we are facing these kind of issues in many of the DB's In monet with only new verison 11.43.5 jan2022 version
Some times not reproducible the same issue and at the time of loading the data we are getting this error and this is making big issue
can you please provide the solution for the above error
2022-07-18 14:18:02 ERR DB_TSV23_P2_A[40136]: #client1709: BATproject2: !ERROR: does not match always
2022-07-18 14:18:02 ERR DB_TSV23_P2_A[40136]: #client1709: createExceptionInternal: !ERROR: MALException:algebra.projection:GDK reported error: BATproject2: does not match always
| !ERROR: MALException:algebra.projection:GDK reported error: BATproject2: does not match always | https://api.github.com/repos/MonetDB/MonetDB/issues/7315/comments | 2 | 2022-07-18T20:58:44Z | 2022-07-27T15:44:30Z | https://github.com/MonetDB/MonetDB/issues/7315 | 1,308,619,862 | 7,315 |
[
"MonetDB",
"MonetDB"
] | **Is your feature request related to a problem? Please describe.**
The ODBC driver shows the password, which is pretty unsafe if someone watches your screen
**Describe the solution you'd like**
the common dot instead of the password
**Describe alternatives you've considered**
None
**Additional context**
None
| ODBC Driver : please mask/hide password | https://api.github.com/repos/MonetDB/MonetDB/issues/7314/comments | 2 | 2022-07-09T13:16:11Z | 2024-06-27T13:17:44Z | https://github.com/MonetDB/MonetDB/issues/7314 | 1,299,680,725 | 7,314 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
I cannot see the columns of a table in Alteryx. Alteryx uses an ODBC connexion to retrieve the information. On #6800 , Martin suggests that can be linked to SQLColums() function issue.
Here are the ODBC logs if that can help
[SQL.LOG](https://github.com/MonetDB/MonetDB/files/9027104/SQL.LOG)
**To Reproduce**
1/Create ODBC Connection to a monetdb database
2/Open Alteryx, use a data input box and connect to the odbc database configured in 1/
**Expected behavior**
-no error message in logs
-columns appeared in Alteryx
**Screenshots**
**Software versions**
- MonetDB version number : 11.43.9
- odbc driver : 11.43.9.01
- OS and version: Windows 10
- Installed from release package
- Alteryx 2022.1
**Issue labeling **
ODBC driver
**Additional context**
For testing, you can download a version of Alteryx, there is a trial for a few days. Or just contact me, it would be a pleasure.
| ODBC SQLColums() issue with Alteryx | https://api.github.com/repos/MonetDB/MonetDB/issues/7313/comments | 14 | 2022-07-01T08:04:01Z | 2022-08-06T09:29:26Z | https://github.com/MonetDB/MonetDB/issues/7313 | 1,291,060,714 | 7,313 |
[
"MonetDB",
"MonetDB"
] | **Is your feature request related to a problem? Please describe.**
Once you click on ok, the ODBC window closes and you have to open an other sotfware to test the configuration. If it's wrong, we have to reopen the window

**Describe the solution you'd like**
A button to test the configuration
**Describe alternatives you've considered**
None
**Additional context**
None
| Test Button for ODBC Driver | https://api.github.com/repos/MonetDB/MonetDB/issues/7312/comments | 4 | 2022-07-01T05:54:23Z | 2024-08-06T11:18:09Z | https://github.com/MonetDB/MonetDB/issues/7312 | 1,290,944,362 | 7,312 |
[
"MonetDB",
"MonetDB"
] | null | Missing `REGEXP_REPLACE` function. | https://api.github.com/repos/MonetDB/MonetDB/issues/7311/comments | 5 | 2022-06-27T03:55:56Z | 2024-06-27T13:17:42Z | https://github.com/MonetDB/MonetDB/issues/7311 | 1,285,195,290 | 7,311 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
```
ubuntu@ip-172-31-2-193:~$ cat $HOME/.monetdb
name=monetdb
password=monetdb
ubuntu@ip-172-31-2-193:~$ mclient -d voc
.monetdb:1: unknown property: name
user(ubuntu):
```
https://www.monetdb.org/documentation-Jan2022/user-guide/get-started/login-to-monetdb/ | "Getting started" is wrong | https://api.github.com/repos/MonetDB/MonetDB/issues/7310/comments | 1 | 2022-06-27T02:38:50Z | 2022-06-27T09:38:40Z | https://github.com/MonetDB/MonetDB/issues/7310 | 1,285,151,941 | 7,310 |
[
"MonetDB",
"MonetDB"
] | ERROR: type should be string, got "https://www.monetdb.org/easy-setup/ubuntu-debian/\r\n\r\nThe step\r\n```\r\nmonetdb release mydb\r\n```\r\n\r\nprints:\r\n\r\n```\r\nmonetdbd: unknown command: release\r\n```\r\n\r\nFull log:\r\n\r\n```\r\nubuntu@ip-172-31-9-151:~$ echo \"deb https://dev.monetdb.org/downloads/deb/ $(lsb_release -cs) monetdb\" >> /etc/apt/sources.list.d/monetdb.list\r\n-bash: /etc/apt/sources.list.d/monetdb.list: Permission denied\r\nubuntu@ip-172-31-9-151:~$ echo \"deb https://dev.monetdb.org/downloads/deb/ $(lsb_release -cs) monetdb\" | sudo tee /etc/apt/sources.list.d/monetdb.list\r\ndeb https://dev.monetdb.org/downloads/deb/ jammy monetdb\r\nubuntu@ip-172-31-9-151:~$ sudo wget --output-document=/etc/apt/trusted.gpg.d/monetdb.gpg https://www.monetdb.org/downloads/MonetDB-GPG-KEY.gpg\r\n--2022-06-26 02:04:16-- https://www.monetdb.org/downloads/MonetDB-GPG-KEY.gpg\r\nResolving www.monetdb.org (www.monetdb.org)... 192.16.197.137\r\nConnecting to www.monetdb.org (www.monetdb.org)|192.16.197.137|:443... connected.\r\nHTTP request sent, awaiting response... 200 OK\r\nLength: 2032 (2.0K) [application/pgp-signature]\r\nSaving to: ‘/etc/apt/trusted.gpg.d/monetdb.gpg’\r\n\r\n/etc/apt/trusted.gpg.d/monetdb.gpg 100%[==========================================================================================>] 1.98K --.-KB/s in 0s \r\n\r\n2022-06-26 02:04:16 (3.32 GB/s) - ‘/etc/apt/trusted.gpg.d/monetdb.gpg’ saved [2032/2032]\r\n\r\nubuntu@ip-172-31-9-151:~$ sudo apt-get update\r\nHit:1 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy InRelease\r\nGet:2 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-updates InRelease [109 kB]\r\nGet:3 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-backports InRelease [99.8 kB]\r\nGet:4 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy/universe amd64 Packages [14.1 MB]\r\nGet:5 http://security.ubuntu.com/ubuntu jammy-security InRelease [110 kB] \r\nGet:7 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy/universe Translation-en [5652 kB] \r\nGet:6 https://www.monetdb.org/downloads/deb jammy InRelease [61.7 kB] \r\nGet:8 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy/universe amd64 c-n-f Metadata [286 kB]\r\nGet:9 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy/multiverse amd64 Packages [217 kB]\r\nGet:10 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy/multiverse Translation-en [112 kB]\r\nGet:11 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy/multiverse amd64 c-n-f Metadata [8372 B] \r\nGet:12 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-updates/main amd64 Packages [323 kB] \r\nGet:13 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-updates/main Translation-en [78.1 kB] \r\nGet:14 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-updates/main amd64 c-n-f Metadata [5552 B] \r\nGet:15 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-updates/restricted amd64 Packages [194 kB] \r\nGet:16 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-updates/restricted Translation-en [29.5 kB]\r\nGet:17 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-updates/universe amd64 Packages [131 kB] \r\nGet:18 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-updates/universe Translation-en [46.6 kB]\r\nGet:19 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-updates/universe amd64 c-n-f Metadata [2680 B] \r\nGet:20 https://www.monetdb.org/downloads/deb jammy/monetdb amd64 Packages [25.1 kB] \r\nGet:21 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-updates/multiverse amd64 Packages [4192 B] \r\nGet:22 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-updates/multiverse Translation-en [1016 B]\r\nGet:23 http://security.ubuntu.com/ubuntu jammy-security/main amd64 Packages [191 kB] \r\nGet:24 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-updates/multiverse amd64 c-n-f Metadata [232 B]\r\nGet:25 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-backports/main amd64 c-n-f Metadata [112 B]\r\nGet:26 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-backports/restricted amd64 c-n-f Metadata [116 B]\r\nGet:27 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-backports/universe amd64 Packages [4844 B]\r\nGet:28 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-backports/universe Translation-en [7932 B]\r\nGet:29 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-backports/universe amd64 c-n-f Metadata [236 B]\r\nGet:30 http://eu-central-1.ec2.archive.ubuntu.com/ubuntu jammy-backports/multiverse amd64 c-n-f Metadata [116 B]\r\nGet:31 http://security.ubuntu.com/ubuntu jammy-security/main Translation-en [45.9 kB] \r\nGet:32 http://security.ubuntu.com/ubuntu jammy-security/main amd64 c-n-f Metadata [3108 B]\r\nGet:33 http://security.ubuntu.com/ubuntu jammy-security/restricted amd64 Packages [167 kB]\r\nGet:34 http://security.ubuntu.com/ubuntu jammy-security/restricted Translation-en [25.3 kB]\r\nGet:35 http://security.ubuntu.com/ubuntu jammy-security/universe amd64 Packages [78.1 kB]\r\nGet:36 http://security.ubuntu.com/ubuntu jammy-security/universe Translation-en [27.7 kB]\r\nGet:37 http://security.ubuntu.com/ubuntu jammy-security/universe amd64 c-n-f Metadata [1668 B]\r\nGet:38 http://security.ubuntu.com/ubuntu jammy-security/multiverse amd64 Packages [4192 B]\r\nGet:39 http://security.ubuntu.com/ubuntu jammy-security/multiverse Translation-en [900 B]\r\nGet:40 http://security.ubuntu.com/ubuntu jammy-security/multiverse amd64 c-n-f Metadata [228 B]\r\nFetched 22.1 MB in 2s (9461 kB/s) \r\nReading package lists... Done\r\nubuntu@ip-172-31-9-151:~$ sudo apt-get install monetdb5-sql monetdb-client\r\nReading package lists... Done\r\nBuilding dependency tree... Done\r\nReading state information... Done\r\nThe following additional packages will be installed:\r\n libmonetdb-client25 libmonetdb-stream25 libmonetdb25 monetdb5-server\r\nThe following NEW packages will be installed:\r\n libmonetdb-client25 libmonetdb-stream25 libmonetdb25 monetdb-client monetdb5-server monetdb5-sql\r\n0 upgraded, 6 newly installed, 0 to remove and 11 not upgraded.\r\nNeed to get 4237 kB of archives.\r\nAfter this operation, 15.4 MB of additional disk space will be used.\r\nDo you want to continue? [Y/n] \r\nGet:1 https://www.monetdb.org/downloads/deb jammy/monetdb amd64 libmonetdb-stream25 amd64 11.43.15 [116 kB]\r\nGet:2 https://www.monetdb.org/downloads/deb jammy/monetdb amd64 libmonetdb-client25 amd64 11.43.15 [134 kB]\r\nGet:3 https://www.monetdb.org/downloads/deb jammy/monetdb amd64 libmonetdb25 amd64 11.43.15 [1779 kB]\r\nGet:4 https://www.monetdb.org/downloads/deb jammy/monetdb amd64 monetdb-client amd64 11.43.15 [178 kB]\r\nGet:5 https://www.monetdb.org/downloads/deb jammy/monetdb amd64 monetdb5-server amd64 11.43.15 [1821 kB]\r\nGet:6 https://www.monetdb.org/downloads/deb jammy/monetdb amd64 monetdb5-sql amd64 11.43.15 [209 kB]\r\nFetched 4237 kB in 0s (11.9 MB/s) \r\nSelecting previously unselected package libmonetdb-stream25.\r\n(Reading database ... 63612 files and directories currently installed.)\r\nPreparing to unpack .../0-libmonetdb-stream25_11.43.15_amd64.deb ...\r\nUnpacking libmonetdb-stream25 (11.43.15) ...\r\nSelecting previously unselected package libmonetdb-client25.\r\nPreparing to unpack .../1-libmonetdb-client25_11.43.15_amd64.deb ...\r\nUnpacking libmonetdb-client25 (11.43.15) ...\r\nSelecting previously unselected package libmonetdb25.\r\nPreparing to unpack .../2-libmonetdb25_11.43.15_amd64.deb ...\r\nUnpacking libmonetdb25 (11.43.15) ...\r\nSelecting previously unselected package monetdb-client.\r\nPreparing to unpack .../3-monetdb-client_11.43.15_amd64.deb ...\r\nUnpacking monetdb-client (11.43.15) ...\r\nSelecting previously unselected package monetdb5-server.\r\nPreparing to unpack .../4-monetdb5-server_11.43.15_amd64.deb ...\r\nUnpacking monetdb5-server (11.43.15) ...\r\nSelecting previously unselected package monetdb5-sql.\r\nPreparing to unpack .../5-monetdb5-sql_11.43.15_amd64.deb ...\r\nUnpacking monetdb5-sql (11.43.15) ...\r\nSetting up libmonetdb-stream25 (11.43.15) ...\r\nSetting up libmonetdb25 (11.43.15) ...\r\nSetting up libmonetdb-client25 (11.43.15) ...\r\nSetting up monetdb5-server (11.43.15) ...\r\nAdding group `monetdb' (GID 121) ...\r\nDone.\r\nWarning: The home dir /var/lib/monetdb you specified already exists.\r\nAdding system user `monetdb' (UID 114) ...\r\nAdding new user `monetdb' (UID 114) with group `monetdb' ...\r\nThe home directory `/var/lib/monetdb' already exists. Not copying from `/etc/skel'.\r\nadduser: Warning: The home directory `/var/lib/monetdb' does not belong to the user you are currently creating.\r\nSetting up monetdb-client (11.43.15) ...\r\nSetting up monetdb5-sql (11.43.15) ...\r\nProcessing triggers for man-db (2.10.2-1) ...\r\nProcessing triggers for libc-bin (2.35-0ubuntu3) ...\r\nScanning processes... \r\nScanning linux images... \r\n\r\nRunning kernel seems to be up-to-date.\r\n\r\nNo services need to be restarted.\r\n\r\nNo containers need to be restarted.\r\n\r\nNo user sessions are running outdated binaries.\r\n\r\nNo VM guests are running outdated hypervisor (qemu) binaries on this host.\r\nubuntu@ip-172-31-9-151:~$ sudo monetdbd create /var/lib/monetdb\r\nubuntu@ip-172-31-9-151:~$ sudo monetdbd start /var/lib/monetdb\r\nubuntu@ip-172-31-9-151:~$ sudo monetdbd create test\r\nubuntu@ip-172-31-9-151:~$ sudo monetdbd start test\r\nmonetdbd: binding to stream socket port 50000 failed: Address already in use\r\nubuntu@ip-172-31-9-151:~$ sudo monetdbd release test\r\nmonetdbd: unknown command: release\r\nusage: monetdbd command [ command-options ] <dbfarm>\r\n where command is one of:\r\n create, start, stop, get, set, version or help\r\n use the help command to get help for a particular command\r\n The dbfarm to operate on must always be given to\r\n monetdbd explicitly.\r\n```" | Easy setup from the documentation does not work | https://api.github.com/repos/MonetDB/MonetDB/issues/7309/comments | 6 | 2022-06-26T02:09:36Z | 2022-07-13T17:59:19Z | https://github.com/MonetDB/MonetDB/issues/7309 | 1,284,773,265 | 7,309 |
[
"MonetDB",
"MonetDB"
] | The following consecutive gdb statements cause a segmentation fault to occur in `bat_storage.c` on `Jan2022` when built in debug mode.
You can run it as a script by copy pasting the content of the commands into in a file `reproduction-steps.gdb` and then execute
```
sed '/^$/d' reproduction-steps.gdb | gdb mserver5
````
Above commands removes the empty lines from the file and executes the statements in gdb interactively. Empty lines execute the previous commands in interactive mode which can be problematic for the reproduction so therefore they are removed.
Side note: we cannot unfortunately execute the steps as a gdb command file, e.g. `gdb -command reproduction-steps.gdb mserver5` because the `interrrupt` command simply does not work as expected when called from a command file and the combination of break and call as I am using below is considered an error in gdb scripted mode.
```
set pagination off
set non-stop on
shell rm -rf /tmp/devdb
break SQLprelude
run --dbpath=/tmp/devdb
finish
del
# create client 0
p MCinitClient((oid) 0, NULL, NULL)
set $c0 = $0
call $c0->usermodule = userModule()
#Set up the initial state of the database:
# The database consists of a single column table
# This columns consist of the 3 values in the same fysical order as SPECIFIED in VALUES expression
print SQLstatementIntern($c0, "CREATE TABLE foo(i) AS VALUES (10), (20), (30);", "foobar", 1, 0, NULL)
p (MT_Id*) GDKmalloc_internal(sizeof(MT_Id), false)
set $tid = $0
#create client 1 that executes in its own thread
call MT_create_thread($tid, profilerHeartbeat, NULL, MT_THR_DETACHED, "heartbeat")
set $t1 = *$tid
p MCinitClient((oid) 0, NULL, NULL)
set $c1 = $0
call $c1->usermodule = userModule()
thread $t1
interrupt
# client 1 wants to append a value at the end of foo
break log_storage
call SQLstatementIntern($c1, "INSERT INTO foo VALUES (40);", "foobar", 1, 0, NULL)
del
# breaks when client 1 is about to read the segment structure of foo.
#create client 2 that executes in its own thread
call MT_create_thread($tid, profilerHeartbeat, NULL, MT_THR_DETACHED, "heartbeat")
set $t2 = *$tid
p MCinitClient((oid) 0, NULL, NULL)
set $c2 = $0
call $c2->usermodule = userModule()
thread $t2
interrupt
#client 2 concurrently to client 1 wants to delete the original middle value from foo
break split_segment
call SQLstatementIntern($c2, "DELETE FROM foo WHERE i = 20;", "foobar", 1, 0, NULL)
del
# breaks when client 2 is about to modify some pointer in the structure of the segments of foo
watch o->next
continue
del
# we mimic a pointer which is in the process of being written to be set to invalid address 1 (I know: its UD)
p o->next = (segment*) 1
# now back to client 1 which continue executing log_storage
# which has to read the segments of foo which is currently being modified
# and. ...
thread $t1
finish
# poof.
``` | Race condition in MVCC transaction management | https://api.github.com/repos/MonetDB/MonetDB/issues/7308/comments | 2 | 2022-06-23T11:15:17Z | 2024-06-27T13:17:41Z | https://github.com/MonetDB/MonetDB/issues/7308 | 1,282,237,117 | 7,308 |
[
"MonetDB",
"MonetDB"
] |
By default, we used to get the timings after any SQL execution from mclient. In MonetDB-11.43.5, we no longer see that. Do we need to add a parameter or is it being removed from the default?
OLD Version -
---------------------
sql>COPY select * from "tstsql_1" INTO '/nztoexa/di_export/DATA_TO_EXPORT/tstsql_2.dat' using delimiters '|','\n','"' NULL AS '';
10 affected rows (6.822ms) ---->>>> missing in new version mclient
New Version -
----------------------
sql>COPY select * from "tstsql_1" INTO '/nztoexa/di_export/DATA_TO_EXPORT/tstsql_1.dat' using delimiters '|','\n','"' NULL AS '';
sql>
| SQL output time not being displayed by default | https://api.github.com/repos/MonetDB/MonetDB/issues/7307/comments | 1 | 2022-06-20T11:50:37Z | 2022-07-06T07:52:57Z | https://github.com/MonetDB/MonetDB/issues/7307 | 1,276,808,658 | 7,307 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
ODBC Driver assertion failed
**To Reproduce**
command to start odbc client:
```sh
apt install unixodbc
# config MonetDB in $HOME/.odbc.ini
...
isql monetdb -v
```
Input the following statements:
```sql
SELECT avg(42) over (order by row_number() over ());
SELECT 1;
```
It will end up with an assertion failure:
```
+---------------------------------------+
| Connected! |
| |
| sql-statement |
| help [tablename] |
| quit |
| |
+---------------------------------------+
SQL> SELECT avg(42) over (order by row_number() over ())
[37000][MonetDB][ODBC Driver 11.44.0]unexpected end of file
[ISQL]ERROR: Could not SQLPrepare
SQL> SELECT 1
isql: /root/MonetDB/clients/odbc/driver/ODBCStmt.c:194: destroyODBCStmt: Assertion `stmt->Dbc->FirstStmt' failed.
fish: “isql monetdb -v” terminated by signal SIGABRT (Abort)
```
**Expected behavior**
```
+---------------------------------------+
| Connected! |
| |
| sql-statement |
| help [tablename] |
| quit |
| |
+---------------------------------------+
SQL> SELECT avg(42) over (order by row_number() over ())
[37000][MonetDB][ODBC Driver 11.44.0]unexpected end of file
[ISQL]ERROR: Could not SQLPrepare
SQL> SELECT 1
+-----+
| %2 |
+-----+
| 1 |
+-----+
SQLRowCount returns 1
1 rows fetched
```
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Software versions**
- ODBC Driver version number: MonetDB ODBC Driver 11.44.0
- OS and version: Ubuntu 20.04, UnixODBC 2.3.6
- - MonetDB Server version number (I think that the server version doesn't matter): MonetDB Database Server v11.43.13 (hg id: ce33b6b12cd6)
**Issue labeling **
Make liberal use of the labels to characterise the issue topics. e.g. identify severity, version, etc..
| ODBC Driver Assertion `stmt->Dbc->FirstStmt' Failed | https://api.github.com/repos/MonetDB/MonetDB/issues/7306/comments | 8 | 2022-06-19T01:18:36Z | 2024-06-27T13:17:40Z | https://github.com/MonetDB/MonetDB/issues/7306 | 1,275,924,048 | 7,306 |
[
"MonetDB",
"MonetDB"
] | When executing my python UDF in MonetDB on the 8-core machine, no matter using PYTHON or PYTHON_MAP, monetDB only use 1 or at most 2 cores at 100% and is super slow. The integers is just a dummy table for starting app(). The code is as follows:
DROP TABLE integers;
CREATE TABLE integers(i INTEGER);
INSERT INTO integers VALUES (1);
DROP FUNCTION app;
CREATE FUNCTION app() RETURNS STRING LANGUAGE PYTHON_MAP
{
//bootstrap my application which will keep running in the background
return 'OK'
};
SELECT app() from integers;
is there a way to parallelize app() to use all cores?
Thanks! | can we use all the cores for parallel execution of a stand-alone python UDF | https://api.github.com/repos/MonetDB/MonetDB/issues/7305/comments | 1 | 2022-06-16T13:47:59Z | 2022-08-06T09:55:59Z | https://github.com/MonetDB/MonetDB/issues/7305 | 1,273,591,755 | 7,305 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Concurrent creation of remote tables does not return a concurrency conflict error, it runs, but leads to errors.
**To Reproduce**
1) Open 3 databases (db1, db2, db3) with 2 local tables to 2 of them (db1, db2)
2) Concurrently create 2 remote tables to the third database (db3).
The create queries will run, but when selecting a remote table, it connects to the wrong database and fails to find it.
It seems a concurrency issue, however no error is returned during the create remote table queries.
**Software versions**
- MonetDB 11.44.0
- Ubuntu 22.04
| Concurrent creation of remote tables. | https://api.github.com/repos/MonetDB/MonetDB/issues/7304/comments | 6 | 2022-06-15T13:42:33Z | 2024-06-07T12:43:33Z | https://github.com/MonetDB/MonetDB/issues/7304 | 1,272,259,005 | 7,304 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
The performance of multi-column filters is considerably slower than if we were to filter by a single column encoding those multiple values using, for example, a string. I am not sure if MonetDB implements multi-column indexes to solve this.
**To Reproduce**
- Create test data where each row has both unique k1 and k2:
```sql
CREATE TABLE Test (k1 int, k2 int, v int, k1k2 varchar(22));
INSERT INTO Test
SELECT value AS k1, value AS k2, value AS v,
value || '.' || value AS k1k2 -- concatenated k1 and k2
FROM generate_series(1, 10000000);
-- not sure if this index is actually created
CREATE INDEX Test_index on Test (k1, k2);
SELECT *
FROM Test
LIMIT 3;
+------+------+------+------+
| k1 | k2 | v | k1k2 |
+======+======+======+======+
| 1 | 1 | 1 | 1.1 |
| 2 | 2 | 2 | 2.2 |
| 3 | 3 | 3 | 3.3 |
+------+------+------+------+
-- as we can see, both k1 and k2 are unique across all rows
```
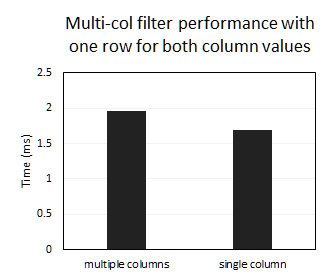
- The performance of filtering using multiple columns and the single encoded column are similar:
```sql
-- multiple columns
SELECT *
FROM Test
WHERE k1 = 5555555 AND k2 = 5555555;
-- single column
SELECT *
FROM Test
WHERE k1k2 = '5555555.5555555';
```
- Create test data with the second example where the last column in the filter is not unique:
```sql
DROP TABLE Test;
CREATE TABLE Test (k1 int, k2 int, v int, k1k2 varchar(22));
INSERT INTO Test
SELECT value AS k1, 1 AS k2, value AS v, -- k2 is 1 for all rows
value || '.' || 1 AS k1k2 -- concatenated k1 and k2
FROM generate_series(1, 10000000);
-- not sure if this index is actually created
CREATE INDEX Test_index ON Test (k1, k2);
SELECT *
FROM Test
LIMIT 3;
+------+------+------+------+
| k1 | k2 | v | k1k2 |
+======+======+======+======+
| 1 | 1 | 1 | 1.1 |
| 2 | 1 | 2 | 2.1 |
| 3 | 1 | 3 | 3.1 |
+------+------+------+------+
```
- The performance of filtering by multiple columns is considerably slower than filtering by the single column:
```sql
-- multiple columns
SELECT *
FROM Test
WHERE k1 = 5555555 AND k2 = 1;
-- single column
SELECT *
FROM Test
WHERE k1k2 = '5555555.5';
```
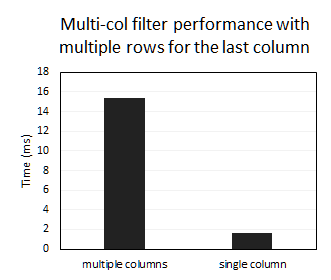
If we instead filter just by `k1`, the performance becomes similar to the first example, which points to the planner executing both filters separately and then combining the results.
**Expected behavior**
The performance of filtering by multiple columns to match the performance of filtering by a single column encoding all values.
**Software versions**
- MonetDB v11.44.0 (hg id: b8bb2db896) (master branch, latest commit)
- Ubuntu 20.04 LTS
- Self-installed and compiled
**Additional context**
MAL plans for both queries in the second example:
```sql
-- multiple columns
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| mal |
+================================================================================================================================================================================+
| function user.main():void; |
| X_1:void := querylog.define("explain select * \nfrom test\nwhere k1 = 5555555 and k2 = 1;":str, "default_pipe":str, 40:int); |
| barrier X_126:bit := language.dataflow(); |
| X_4:int := sql.mvc(); |
| X_8:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k1":str, 0:int); |
| X_15:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k2":str, 0:int); |
| X_20:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int); |
| X_27:bat[:str] := sql.bind(X_4:int, "sys":str, "test":str, "k1k2":str, 0:int); |
| X_34:bat[:lng] := sql.bind_idxbat(X_4:int, "sys":str, "test":str, "test_index":str, 0:int); |
| X_43:lng := mkey.hash(5555555:int); |
| X_46:lng := mkey.rotate_xor_hash(X_43:lng, 22:int, 1:int); |
| C_47:bat[:oid] := algebra.select(X_34:bat[:lng], X_46:lng, X_46:lng, true:bit, true:bit, false:bit); |
| C_52:bat[:oid] := algebra.thetaselect(X_8:bat[:int], C_47:bat[:oid], 5555555:int, "==":str); |
| C_55:bat[:oid] := algebra.thetaselect(X_15:bat[:int], C_52:bat[:oid], 1:int, "==":str); |
| X_56:bat[:int] := algebra.projection(C_55:bat[:oid], X_8:bat[:int]); |
| X_128:void := language.pass(X_8:bat[:int]); |
| X_57:bat[:int] := algebra.projection(C_55:bat[:oid], X_15:bat[:int]); |
| X_129:void := language.pass(X_15:bat[:int]); |
| X_58:bat[:int] := algebra.projection(C_55:bat[:oid], X_20:bat[:int]); |
| X_59:bat[:str] := algebra.projection(C_55:bat[:oid], X_27:bat[:str]); |
| X_130:void := language.pass(C_55:bat[:oid]); |
| X_62:bat[:str] := bat.pack("sys.test":str, "sys.test":str, "sys.test":str, "sys.test":str); |
| X_63:bat[:str] := bat.pack("k1":str, "k2":str, "v":str, "k1k2":str); |
| X_64:bat[:str] := bat.pack("int":str, "int":str, "int":str, "varchar":str); |
| X_65:bat[:int] := bat.pack(32:int, 32:int, 32:int, 22:int); |
| X_66:bat[:int] := bat.pack(0:int, 0:int, 0:int, 0:int); |
| exit X_126:bit; |
| X_61:int := sql.resultSet(X_62:bat[:str], X_63:bat[:str], X_64:bat[:str], X_65:bat[:int], X_66:bat[:int], X_56:bat[:int], X_57:bat[:int], X_58:bat[:int], X_59:bat[:str]); |
| end user.main; |
| # optimizer.inline(0:int, 1:lng) |
| # optimizer.remap(0:int, 1:lng) |
| # optimizer.costModel(1:int, 1:lng) |
| # optimizer.coercions(0:int, 2:lng) |
| # optimizer.aliases(5:int, 4:lng) |
| # optimizer.evaluate(0:int, 4:lng) |
| # optimizer.emptybind(5:int, 5:lng) |
| # optimizer.deadcode(7:int, 4:lng) |
| # optimizer.pushselect(0:int, 7:lng) |
| # optimizer.aliases(5:int, 3:lng) |
| # optimizer.for(0:int, 2:lng) |
| # optimizer.dict(0:int, 2:lng) |
| # optimizer.mitosis() |
| # optimizer.mergetable(0:int, 5:lng) |
| # optimizer.bincopyfrom(0:int, 0:lng) |
| # optimizer.aliases(0:int, 0:lng) |
| # optimizer.constants(2:int, 4:lng) |
| # optimizer.commonTerms(0:int, 3:lng) |
| # optimizer.projectionpath(0:int, 2:lng) |
| # optimizer.deadcode(0:int, 2:lng) |
| # optimizer.matpack(0:int, 1:lng) |
| # optimizer.reorder(1:int, 6:lng) |
| # optimizer.dataflow(1:int, 9:lng) |
| # optimizer.querylog(0:int, 1:lng) |
| # optimizer.multiplex(0:int, 1:lng) |
| # optimizer.generator(0:int, 1:lng) |
| # optimizer.candidates(1:int, 1:lng) |
| # optimizer.deadcode(0:int, 3:lng) |
| # optimizer.postfix(0:int, 2:lng) |
| # optimizer.wlc(0:int, 0:lng) |
| # optimizer.garbageCollector(1:int, 6:lng) |
| # optimizer.profiler(0:int, 1:lng) |
| # optimizer.total(31:int, 119:lng) |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- single column
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| mal |
+================================================================================================================================================================================+
| function user.main():void; |
| X_1:void := querylog.define("explain select *\nfrom test\nwhere k1k2 = \\'5555555.5\\';":str, "default_pipe":str, 28:int); |
| barrier X_105:bit := language.dataflow(); |
| X_4:int := sql.mvc(); |
| C_5:bat[:oid] := sql.tid(X_4:int, "sys":str, "test":str); |
| X_8:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k1":str, 0:int); |
| X_15:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k2":str, 0:int); |
| X_20:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int); |
| X_27:bat[:str] := sql.bind(X_4:int, "sys":str, "test":str, "k1k2":str, 0:int); |
| C_36:bat[:oid] := algebra.thetaselect(X_27:bat[:str], C_5:bat[:oid], "5555555.5":str, "==":str); |
| X_38:bat[:int] := algebra.projection(C_36:bat[:oid], X_8:bat[:int]); |
| X_39:bat[:int] := algebra.projection(C_36:bat[:oid], X_15:bat[:int]); |
| X_40:bat[:int] := algebra.projection(C_36:bat[:oid], X_20:bat[:int]); |
| X_41:bat[:str] := algebra.projection(C_36:bat[:oid], X_27:bat[:str]); |
| X_107:void := language.pass(C_36:bat[:oid]); |
| X_108:void := language.pass(X_27:bat[:str]); |
| X_43:bat[:str] := bat.pack("sys.test":str, "sys.test":str, "sys.test":str, "sys.test":str); |
| X_44:bat[:str] := bat.pack("k1":str, "k2":str, "v":str, "k1k2":str); |
| X_45:bat[:str] := bat.pack("int":str, "int":str, "int":str, "varchar":str); |
| X_46:bat[:int] := bat.pack(32:int, 32:int, 32:int, 22:int); |
| X_47:bat[:int] := bat.pack(0:int, 0:int, 0:int, 0:int); |
| exit X_105:bit; |
| X_42:int := sql.resultSet(X_43:bat[:str], X_44:bat[:str], X_45:bat[:str], X_46:bat[:int], X_47:bat[:int], X_38:bat[:int], X_39:bat[:int], X_40:bat[:int], X_41:bat[:str]); |
| end user.main; |
| # optimizer.inline(0:int, 1:lng) |
| # optimizer.remap(0:int, 1:lng) |
| # optimizer.costModel(1:int, 1:lng) |
| # optimizer.coercions(0:int, 3:lng) |
| # optimizer.aliases(1:int, 4:lng) |
| # optimizer.evaluate(0:int, 3:lng) |
| # optimizer.emptybind(4:int, 6:lng) |
| # optimizer.deadcode(4:int, 4:lng) |
| # optimizer.pushselect(0:int, 7:lng) |
| # optimizer.aliases(4:int, 2:lng) |
| # optimizer.for(0:int, 2:lng) |
| # optimizer.dict(0:int, 2:lng) |
| # optimizer.mitosis() |
| # optimizer.mergetable(0:int, 5:lng) |
| # optimizer.bincopyfrom(0:int, 0:lng) |
| # optimizer.aliases(0:int, 1:lng) |
| # optimizer.constants(0:int, 3:lng) |
| # optimizer.commonTerms(0:int, 3:lng) |
| # optimizer.projectionpath(0:int, 2:lng) |
| # optimizer.deadcode(0:int, 2:lng) |
| # optimizer.matpack(0:int, 0:lng) |
| # optimizer.reorder(1:int, 6:lng) |
| # optimizer.dataflow(1:int, 9:lng) |
| # optimizer.querylog(0:int, 1:lng) |
| # optimizer.multiplex(0:int, 1:lng) |
| # optimizer.generator(0:int, 1:lng) |
| # optimizer.candidates(1:int, 1:lng) |
| # optimizer.deadcode(0:int, 2:lng) |
| # optimizer.postfix(0:int, 3:lng) |
| # optimizer.wlc(0:int, 1:lng) |
| # optimizer.garbageCollector(1:int, 5:lng) |
| # optimizer.profiler(0:int, 0:lng) |
| # optimizer.total(31:int, 114:lng) |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
```
| Improve the performance of multi-column filters | https://api.github.com/repos/MonetDB/MonetDB/issues/7303/comments | 3 | 2022-06-13T14:38:20Z | 2024-06-27T13:17:39Z | https://github.com/MonetDB/MonetDB/issues/7303 | 1,269,545,250 | 7,303 |
[
"MonetDB",
"MonetDB"
] | I am looking to use MonetDB for a time series data by partition the data using a given time interval, for example, by day. The aim in this case is that each partition would contain data of a particular day.
From the [documentation](https://www.monetdb.org/documentation-Jan2022/user-guide/sql-catalog/table-data-partitioning/), I can see that MonetDB provides partitioning as a feature, by I couldn't know how to implement it, I have tried for example: `PARTITION BY DAY`, such is implemented by other systems, by that didn't work.
How could data be partitioned using a fixed time period interval in MonetDB?
Thanks. | MonetDB : Partitioning Data by Time Intervals | https://api.github.com/repos/MonetDB/MonetDB/issues/7302/comments | 1 | 2022-06-12T13:10:30Z | 2022-06-13T10:24:52Z | https://github.com/MonetDB/MonetDB/issues/7302 | 1,268,577,041 | 7,302 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
The query planner sometimes cannot optimize the push-down of filters to the source tables, meaning the subqueries are unnecessarily materialized before the filter is applied, resulting in long execution times and high memory usage. In practice, this means filtering complex views becomes less viable.
**To Reproduce**
- Create test data:
```sql
CREATE TABLE Test (k int, v int);
INSERT INTO Test
SELECT value AS k, value AS v
FROM generate_series(1, 100000000);
```
- The planner is able to optimize the push-down for simple queries. In the plan below, the filter `k = 1231231` is applied to the source tables before the `UNION ALL` is performed:
```sql
SELECT k, v
FROM (
(SELECT k, v
FROM Test)
UNION ALL
(SELECT k, v
FROM Test)
) t
WHERE k = 1231231;
-- clk: 1.574 ms
+------------------------------------------------------------------------------------------+
| rel |
+==========================================================================================+
| union ( |
| | project ( |
| | | select ( |
| | | | table("sys"."test") [ "test"."k" ..., "test"."v" NOT NULL UNIQUE ] COUNT 99999999 |
| | | ) [ ("test"."k" ...) = (int(21) "1231231") ] COUNT 99999999 -- filter k = 1231231 |
| | ) [ "test"."k" ... as "t"."k", "test"."v" NOT NULL UNIQUE as "t"."v" ] COUNT 99999999, |
| | project ( |
| | | select ( |
| | | | table("sys"."test") [ "test"."k" ..., "test"."v" NOT NULL UNIQUE ] COUNT 99999999 |
| | | ) [ ("test"."k" ...) = (int(21) "1231231") ] COUNT 99999999 -- filter k = 1231231 |
| | ) [ "test"."k" ... as "t"."k", "test"."v" NOT NULL UNIQUE as "t"."v" ] COUNT 99999999 |
| ) [ "t"."k" NOT NULL, "t"."v" NOT NULL ] COUNT 199999998 |
...
+------------------------------------------------------------------------------------------+
```
- However, if we add more complexity to the subquery, the planner does not push down the filters, even though it would result in an equivalent plan:
```sql
SELECT k, v
FROM (
SELECT *, rank() OVER (PARTITION BY k ORDER BY v DESC) AS rank
FROM (
(SELECT k, v
FROM Test)
UNION ALL
(SELECT k, v
FROM Test)
) t1
) t2
WHERE rank = 1
AND k = 1231231;
-- clk: 1:15 min
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| rel |
+===============================================================================================================================================================================+
| project ( |
| | select ( |
| | | project ( |
| | | | project ( |
| | | | | union ( |
| | | | | | project ( |
| | | | | | | table("sys"."test") [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000, "test"."v" NOT NULL UNIQUE ] COUNT 99999999 |
| | | | | | ) [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000 as "%1"."k", "test"."v" NOT NULL UNIQUE as "%1"."v" ] COUNT 99999999, |
| | | | | | project ( |
| | | | | | | table("sys"."test") [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000, "test"."v" NOT NULL UNIQUE ] COUNT 99999999 |
| | | | | | ) [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000 as "%2"."k", "test"."v" NOT NULL UNIQUE as "%2"."v" ] COUNT 99999999 |
| | | | | ) [ "%1"."k" NOT NULL as "t1"."k", "%1"."v" NOT NULL as "t1"."v" ] COUNT 199999998 |
| | | | ) [ "t1"."k" NOT NULL, "t1"."v" NOT NULL ] [ "t1"."k" ASC NOT NULL, "t1"."v" NULLS LAST NOT NULL ] COUNT 199999998 |
| | | ) [ "t1"."k" NOT NULL, "t1"."v" NOT NULL, "sys"."rank"("sys"."star"(), "sys"."diff"("t1"."k" NOT NULL), "sys"."diff"("t1"."v" NOT NULL)) as "t2"."rank" ] COUNT 199999998 |
| | ) [ ("t2"."rank") = (int(32) "1"), ("t1"."k" NOT NULL) = (int(21) "1231231") ] COUNT 199999998 -- the k = 1231231 filter is only executed after the materization |
| ) [ "t1"."k" NOT NULL as "t2"."k", "t1"."v" NOT NULL as "t2"."v" ] COUNT 199999998 |
| split_select 0 actions 1 usec |
| push_project_down 3 actions 3 usec |
| merge_projects 0 actions 2 usec |
| push_project_up 2 actions 4 usec |
| split_project 0 actions 1 usec |
| simplify_math 0 actions 1 usec |
| optimize_exps 0 actions 2 usec |
| optimize_select_and_joins_bottomup 0 actions 3 usec |
| project_reduce_casts 0 actions 0 usec |
| optimize_unions_bottomup 0 actions 1 usec |
| optimize_projections 0 actions 2 usec |
| optimize_select_and_joins_topdown 0 actions 2 usec |
| optimize_unions_topdown 0 actions 1 usec |
| dce 0 actions 4 usec |
| push_func_and_select_down 0 actions 1 usec |
| get_statistics 0 actions 102 usec |
| final_optimization_loop 0 actions 2 usec |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
33 tuples
```
- If we push the filter manually, the query executes more than 30000x faster:
```sql
-- manual filter push-down
SELECT k, v
FROM (
SELECT *, rank() OVER (PARTITION BY k ORDER BY v DESC) AS rank
FROM (
(SELECT k, v
FROM Test
WHERE k = 1231231)
UNION ALL
(SELECT k, v
FROM Test
WHERE k = 1231231)
) t1
) t2
WHERE rank = 1;
-- clk: 2.357 ms
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| rel |
+===============================================================================================================================================================================+
| project ( |
| | select ( |
| | | project ( |
| | | | project ( |
| | | | | union ( |
| | | | | | project ( |
| | | | | | | select ( |
| | | | | | | | table("sys"."test") [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000, "test"."v" NOT NULL UNIQUE ] COUNT 99999999 |
| | | | | | | ) [ ("test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000) = (int(21) "1231231") ] COUNT 99999999 |
| | | | | | ) [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000 as "%1"."k", "test"."v" NOT NULL UNIQUE as "%1"."v" ] COUNT 99999999, |
| | | | | | project ( |
| | | | | | | select ( |
| | | | | | | | table("sys"."test") [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000, "test"."v" NOT NULL UNIQUE ] COUNT 99999999 |
| | | | | | | ) [ ("test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000) = (int(21) "1231231") ] COUNT 99999999 |
| | | | | | ) [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000 as "%2"."k", "test"."v" NOT NULL UNIQUE as "%2"."v" ] COUNT 99999999 |
| | | | | ) [ "%1"."k" NOT NULL as "t1"."k", "%1"."v" NOT NULL as "t1"."v" ] COUNT 199999998 |
| | | | ) [ "t1"."k" NOT NULL, "t1"."v" NOT NULL ] [ "t1"."k" ASC NOT NULL, "t1"."v" NULLS LAST NOT NULL ] COUNT 199999998 |
| | | ) [ "t1"."k" NOT NULL, "t1"."v" NOT NULL, "sys"."rank"("sys"."star"(), "sys"."diff"("t1"."k" NOT NULL), "sys"."diff"("t1"."v" NOT NULL)) as "t2"."rank" ] COUNT 199999998 |
| | ) [ ("t2"."rank") = (int(32) "1") ] COUNT 199999998 |
| ) [ "t1"."k" NOT NULL as "t2"."k", "t1"."v" NOT NULL as "t2"."v" ] COUNT 199999998 |
| split_select 0 actions 1 usec |
| push_project_down 3 actions 3 usec |
| merge_projects 0 actions 1 usec |
| push_project_up 2 actions 4 usec |
| split_project 0 actions 1 usec |
| simplify_math 0 actions 1 usec |
| optimize_exps 0 actions 2 usec |
| optimize_select_and_joins_bottomup 0 actions 3 usec |
| project_reduce_casts 0 actions 0 usec |
| optimize_unions_bottomup 0 actions 2 usec |
| optimize_projections 0 actions 1 usec |
| optimize_select_and_joins_topdown 0 actions 2 usec |
| optimize_unions_topdown 0 actions 1 usec |
| dce 0 actions 6 usec |
| push_func_and_select_down 0 actions 0 usec |
| get_statistics 0 actions 78 usec |
| final_optimization_loop 0 actions 1 usec |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
37 tuples
```
- PostgreSQL, on the other hand, is able to optimize the query:
```sql
EXPLAIN ANALYZE
SELECT k, v
FROM (
SELECT *, rank() OVER (PARTITION BY k ORDER BY v DESC) AS rank
FROM (
(SELECT k, v
FROM Test)
UNION ALL
(SELECT k, v
FROM Test)
) t1
) t2
WHERE rank = 1
AND k = 1231231
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
Subquery Scan on t2 (cost=...) (actual time=0.031..0.034 rows=2 loops=1)
Filter: (t2.rank = 1)
-> WindowAgg (cost=...) (actual time=0.030..0.032 rows=2 loops=1)
-> Sort (cost=...) (actual time=0.024..0.024 rows=2 loops=1)
Sort Key: test.v DESC
Sort Method: quicksort Memory: 25kB
-> Append (cost=...) (actual time=0.016..0.020 rows=2 loops=1)
-> Index Scan using test_k_idx on test (cost=...) (actual time=0.016..0.016 rows=1 loops=1)
Index Cond: (k = 1231231)
-> Index Scan using test_k_idx on test test_1 (cost=...) (actual time=0.002..0.002 rows=1 loops=1)
Index Cond: (k = 1231231)
Planning Time: 0.104 ms
Execution Time: 0.055 ms
(13 rows)
```
- Another example:
```sql
SELECT k, v
FROM Test
WHERE (k, v) IN (
-- the planner could push the filter to this query aswell, but it doesn't
SELECT k, max(v)
FROM Test
GROUP BY k
)
AND k = 1231231;
-- clk: 2.544 sec
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| rel |
+===============================================================================================================================================================================================================+
| project ( |
| | semijoin ( |
| | | select ( |
| | | | table("sys"."test") [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000, "test"."v" NOT NULL UNIQUE ] COUNT 99999999 |
| | | ) [ ("test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000) = (int(21) "1231231") ] COUNT 99999999, |
| | | project ( |
| | | | group by ( |
| | | | | table("sys"."test") [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000, "test"."v" NOT NULL UNIQUE ] COUNT 99999999 |
| | | | ) [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000 ] [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000, "sys"."max" no nil ("test"."v" NOT NULL UNIQUE) NOT NULL as "%2"."%2" ] COUNT 99999999 |
| | | ) [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000 as "%7"."%7", "%2"."%2" NOT NULL as "%10"."%10" ] COUNT 99999999 |
| | ) [ ("test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000) any = ("%7"."%7" NOT NULL UNIQUE NUNIQUES 99999999.000000), ("test"."v" NOT NULL UNIQUE) any = ("%10"."%10" NOT NULL) ] COUNT 99999999 |
| ) [ "test"."k" NOT NULL UNIQUE NUNIQUES 99999999.000000, "test"."v" NOT NULL UNIQUE ] COUNT 99999999 |
| split_select 0 actions 1 usec |
| push_project_down 0 actions 0 usec |
| merge_projects 0 actions 1 usec |
| push_project_up 0 actions 0 usec |
| split_project 0 actions 1 usec |
| remove_redundant_join 0 actions 0 usec |
| simplify_math 0 actions 1 usec |
| optimize_exps 0 actions 1 usec |
| optimize_select_and_joins_bottomup 0 actions 2 usec |
| project_reduce_casts 0 actions 0 usec |
| optimize_projections 0 actions 3 usec |
| optimize_joins 0 actions 1 usec |
| optimize_semi_and_anti 0 actions 0 usec |
| optimize_select_and_joins_topdown 0 actions 6 usec |
| dce 0 actions 4 usec |
| push_func_and_select_down 0 actions 1 usec |
| get_statistics 0 actions 32 usec |
| final_optimization_loop 0 actions 0 usec |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
30 tuples
-- PostgreSQL is also able to optimize this one
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
Nested Loop Semi Join (...) (actual time=0.047..0.048 rows=1 loops=1)
Join Filter: (test.v = (max(test_1.v)))
-> Index Scan using test_k_idx on test (...) (actual time=0.031..0.031 rows=1 loops=1)
Index Cond: (k = 1231231)
-> GroupAggregate (...) (actual time=0.013..0.013 rows=1 loops=1)
Group Key: test_1.k
-> Index Scan using test_k_idx on test test_1 (...) (actual time=0.004..0.006 rows=1 loops=1)
Index Cond: (k = 1231231)
Planning Time: 3.834 ms
Execution Time: 0.094 ms
(10 rows)
```
**Expected behavior**
The planner being able to push-down the filter to the source tables if it results in an equivalent plan.
**Software versions**
- MonetDB 5 server v11.44.0 (hg id: 7e070d188d) (master branch; most recent commit)
- Ubuntu 20.04 LTS
- Self-installed and compiled | Query planner unable to optimize filter push-down | https://api.github.com/repos/MonetDB/MonetDB/issues/7301/comments | 5 | 2022-06-09T18:09:45Z | 2024-06-27T13:17:37Z | https://github.com/MonetDB/MonetDB/issues/7301 | 1,266,488,093 | 7,301 |
[
"MonetDB",
"MonetDB"
] | **Is your feature request related to a problem? Please describe.**
MonetDB does not yet support all standard SQL DATE and TIMESTAMP functions.
We miss SQL functions:
- DAYNAME(date or timestamp) returns VARCHAR
- MONTHNAME(date or timestamp) returns VARCHAR
- TIMESTAMPADD(unit, interval, timestamp) returns TIMESTAMP
- TIMESTAMPDIFF(unit, timestamp, timestamp) returns INTERVAL
See also: https://www.monetdb.org/hg/MonetDB/file/tip/clients/odbc/driver/SQLGetInfo.c#l1048
**Describe the solution you'd like**
Implement these 4 scalar date-time functions to be more SQL compliant.
**Describe alternatives you've considered**
Building your own UDFs
Instead of DAYNAME() we support: dayofweek(dt_or_ts) function which returns a day of week number between 1 and 7. With a case statement the respective day name (in English) could be returned by the UDF.
Instead of MONTHNAME() we support: "month"(dt_or_ts) function which returns a month number between 1 and 12. With a case statement the respective month name (in English) could be returned by the UDF.
Instead of TIMESTAMPADD() we support: several sys.sql_add(dt_or_ts, interval) functions.
Instead of TIMESTAMPDIFF() we support: several sys.sql_sub(dt_or_ts, dt_or_ts) functions.
See: https://www.monetdb.org/documentation-Jan2022/user-guide/sql-functions/date-time-functions/
**Additional context**
See also:
https://www.w3schools.com/sql/func_mysql_dayname.asp
https://www.ibm.com/docs/en/db2/11.5?topic=functions-dayname
https://www.w3schools.com/sql/func_mysql_monthname.asp
https://www.ibm.com/docs/en/db2/11.5?topic=functions-monthname
https://www.w3resource.com/mysql/date-and-time-functions/mysql-timestampadd-function.php
https://www.w3resource.com/mysql/date-and-time-functions/mysql-timestampdiff-function.php
https://www.ibm.com/docs/en/db2/11.5?topic=functions-timestampdiff
| Implement missing standard SQL DATE and TIMESTAMP functions | https://api.github.com/repos/MonetDB/MonetDB/issues/7300/comments | 1 | 2022-06-09T17:25:19Z | 2024-06-27T13:17:36Z | https://github.com/MonetDB/MonetDB/issues/7300 | 1,266,443,087 | 7,300 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
sql>select * from sys.tables where name='AS_XQL_LOG_INFO_29042022_RPM';
+-------------+------------------------------+-----------+-------+------+--------+---------------+--------+-----------+
| id | name | schema_id | query | type | system | commit_action | access | temporary |
+=============+==============================+===========+=======+======+========+===============+========+===========+
| -1059856705 | AS_XQL_LOG_INFO_29042022_RPM | 6422 | null | 0 | false | 0 | 0 | 0 |
+-------------+------------------------------+-----------+-------+------+--------+---------------+--------+-----------+
**To Reproduce**
We don't have a specific way to reproduce it, yet if we check the sys.tables the ID shows a negative number.
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**

**Software versions**
- MonetDB-11.43.13 - Even in older version
- CentOS 7
- Compiled
**Issue labeling **
Make liberal use of the labels to characterise the issue topics. e.g. identify severity, version, etc..
**Additional context**
Add any other context about the problem here.
| table corrupt and shows negative id, how can we remove them? | https://api.github.com/repos/MonetDB/MonetDB/issues/7299/comments | 5 | 2022-06-03T04:22:26Z | 2024-08-09T16:12:03Z | https://github.com/MonetDB/MonetDB/issues/7299 | 1,259,394,328 | 7,299 |
[
"MonetDB",
"MonetDB"
] | Assume that we have file `bogus.sql` with the following content:
```sql
select foo.
```
executing this script with the following command
```bash
mclient bogus.sql
```
causes `mclient` to silently exit without any result or error output and `mserver5` becomes non-responsive.
Happens on Jan2022.
| Irresponsive database server after reading incomplete SQL script. | https://api.github.com/repos/MonetDB/MonetDB/issues/7298/comments | 0 | 2022-06-02T08:02:28Z | 2024-06-27T13:17:35Z | https://github.com/MonetDB/MonetDB/issues/7298 | 1,257,836,492 | 7,298 |
[
"MonetDB",
"MonetDB"
] | Let say we have monthly data whose records are chronologically determined by a string field that represents year/month combination like: '1995-03'. As a partial date it would be nice to parse such values as complete `DATE` values by filling in a reasonable default for the missing date fields. However on MonetDB Januari 2022 we get the following behavior:
```
$ mclient -s "select str_to_date('1995-04', '%Y-%m');"
+------------+
| %2 |
+============+
| 1995-04-30 |
+------------+
1 tuple
$ mclient -s "select str_to_date('1995-02', '%Y-%m');"
bad date '1995-02'
$ mclient -s "select str_to_date('1995-01', '%Y-%m');"
+------------+
| %2 |
+============+
| 1995-01-30 |
+------------+
1 tuple
```
And I have seen cases where all of the above queries fail or that the day field value is different then `30`.
On Postgres all of the equivalent examples work:
```
$ psql -c "select to_date('1995-04', 'YYYY-MM');"
to_date
------------
1995-04-01
(1 row)
$ psql -c "select to_date('1995-02', 'YYYY-MM');"
to_date
------------
1995-02-01
(1 row)
$ psql -c "select to_date('1995-01', 'YYYY-MM');"
to_date
------------
1995-01-01
(1 row)
``` | Parsing partial dates behaves unpredictable | https://api.github.com/repos/MonetDB/MonetDB/issues/7297/comments | 5 | 2022-05-30T09:32:09Z | 2024-06-27T13:17:34Z | https://github.com/MonetDB/MonetDB/issues/7297 | 1,252,459,745 | 7,297 |
[
"MonetDB",
"MonetDB"
] | While playing around with [Apache Superset](https://superset.apache.org/) on top of MonetDB, I have noticed that Superset expects its database back-ends to be able to _**implicitly**_ cast any string that is formatted according to a valid standardized timestamp as a `DATE`.
However MonetDB does not seem to support this. The following script runs fine in postgresql, but gives errors on monetdb Januari 2022.
```sql
START TRANSACTION;
CREATE TABLE foo (d DATE);
INSERT INTO FOO VALUES (DATE '2022-05-23 00:00:00.000000'), (DATE '2022-05-30 00:00:00.000000'); -- works in MonetDB
INSERT INTO FOO VALUES ('2022-05-23'), ('2022-05-30'); -- works in MonetDB
INSERT INTO FOO VALUES ('2022-05-23 00:00:00.000000'), ('2022-05-30 00:00:00.000000'); -- breaks in MonetDB
ROLLBACK;
``` | Implictly cast a timestamp string to DATE when appropriate | https://api.github.com/repos/MonetDB/MonetDB/issues/7296/comments | 3 | 2022-05-30T08:59:38Z | 2024-06-27T13:17:33Z | https://github.com/MonetDB/MonetDB/issues/7296 | 1,252,417,714 | 7,296 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
With FIPS enabled, mclient throws error:
rmd_dgst.c(73): OpenSSL internal error, assertation failed: Digest RIPEMD160 forbidden in FIPS mode!
Aborted (core dumped)
**Software versions**
- MonetDB 11.33.3 (Apr2019)
- CentOS 7
- self-installed and compiled
- Libraries:
openssl: OpenSSl 1.0.2k-fips 26 Jan 2017
| mclient aborted w/ FIPS | https://api.github.com/repos/MonetDB/MonetDB/issues/7295/comments | 2 | 2022-05-29T13:07:33Z | 2022-05-31T09:06:49Z | https://github.com/MonetDB/MonetDB/issues/7295 | 1,251,884,651 | 7,295 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Queries using an ambiguous identifier do not fail accordingly. The ambiguity is beween an actual column and an alias.
**To Reproduce**
This query:
```
create table s(a int, w int);
create table t(x int, y int);
SELECT t.x as a, s.w as b
FROM s, t
GROUP by a, b;
```
fails with:
```
SELECT: cannot use non GROUP BY column 't.x' in query results without an aggregate function
```
The intention was to group on `t.x` (aliased as `a`)
At first sight, `t.x` seems grouped. The problem is that its alias clashes with `s.a`. So I think MonetDB is silently grouping on `s.a`, hence the complaint that `t.x` is not grouped. Indeed, the query works by replacing the group-by clause with `GROUP by t.x, b`.
This second query also "works" silently, while it should fail:
```
create table s(a int, w int);
create table t(x int, y int);
SELECT t.x as a, s.w as b
FROM s, t
where a = 0;
```
Again, `a` is totally ambiguous, but MonetDB chooses one instance silently (we can't even guess which one in this case).
**Expected behavior**
Both queries should fail with an "ambiguous identifier" error
**Software versions**
- MonetDB 11.43.14
- OS and version: Rocky Linux 8.5
- self-installed and compiled
| Ambiguous identifier not detected | https://api.github.com/repos/MonetDB/MonetDB/issues/7294/comments | 7 | 2022-05-25T12:18:13Z | 2024-06-07T11:43:52Z | https://github.com/MonetDB/MonetDB/issues/7294 | 1,248,011,719 | 7,294 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Running multiple queries from different clients involving Numpy UDFs hangs (it seems that creates too many servers)
**To Reproduce**
Define the following function
CREATE OR REPLACE FUNCTION bug_test(total_population INTEGER)
RETURNS INTEGER
LANGUAGE PYTHON
{
sum_ = 0
for p in total_population:
sum_ += p
return sum_
};
and run the query `select bug_test(col1) from atable;` with a table containing 10K integer rows, from multiple clients in parallel (we tested with 12 and 24)
**Expected behavior**
All the queries return the result
**Software versions**
- MonetDB version 11.44.0
- OS and version: [e.g. Ubuntu 20.04]
- Self-installed and compiled
| Parallel execution of Numpy UDFs hangs | https://api.github.com/repos/MonetDB/MonetDB/issues/7293/comments | 3 | 2022-05-20T18:04:32Z | 2023-09-13T14:45:38Z | https://github.com/MonetDB/MonetDB/issues/7293 | 1,243,467,614 | 7,293 |
[
"MonetDB",
"MonetDB"
] | Currently in MonetDBe, SQL statements prepended with `EXPLAIN,` `PLAN` and other MonetDB specific keywords are not supported. Even though we can fall back to the embedded mapi server to run such statements, it would be clean and nice to have these statements working in MonetDBe out of the box since they are part of our SQL dialect.
| Make EXPLAIN, PLAN, etc. work in MonetDBe | https://api.github.com/repos/MonetDB/MonetDB/issues/7292/comments | 0 | 2022-05-16T15:13:37Z | 2024-06-27T13:17:32Z | https://github.com/MonetDB/MonetDB/issues/7292 | 1,237,311,320 | 7,292 |
[
"MonetDB",
"MonetDB"
] | I am loading a sizeable csv file (300GB) into a tables using COPY INTO statement. After a long waiting time, I am getting an `"unexpected end of file"` exception and the table if empty after that. Heres's my query:
`COPY d1 FROM '/home/d1_data/d1.csv'
`
And my csv data file:
```
2019-02-01T00:00:10,st0,0.839071,0.179288,0.585304,0.679371,0.492911,0.056175,0.498442,0.938126,0.668068,0.929086,0.081897,0.843644,0.974037,0.159324,0.142218,0.140207,0.625254,0.425917,0.771387,0.096174,0.120735,0.725770,0.139911,0.310633,0.382543,0.896953,0.445951,0.119868,0.424562,0.181185,0.379519,0.105958,0.845021,0.533097,0.723558,0.944910,0.036968,0.112205,0.799767,0.728473,0.968308,0.111421,0.905472,0.980631,0.865119,0.293025,0.973192,0.408123,0.272021,0.125133,0.763793,0.819480,0.600016,0.178615,0.777532,0.081147,0.652687,0.458067,0.767267,0.711449,0.957630,0.115871,0.569370,0.517578,0.093003,0.682874,0.679829,0.485540,0.926170,0.080369,0.570393,0.484541,0.568747,0.626574,0.117149,0.715187,0.655418,0.276893,0.841691,0.173985,0.805234,0.241210,0.858166,0.021120,0.224665,0.238334,0.864353,0.103404,0.868038,0.992483,0.624129,0.755107,0.620674,0.763600,0.199850,0.396798,0.612075,0.515486,0.961466,0.434988
2019-02-01T00:00:20,st0,0.322934,0.755268,0.061692,0.212437,0.231739,0.826009,0.402892,0.546866,0.748315,0.428897,0.634761,0.384299,0.192479,0.391302,0.920955,0.526497,0.150713,0.338057,0.933859,0.137499,0.875741,0.228530,0.297205,0.266878,0.288009,0.060985,0.882594,0.490286,0.870628,0.317989,0.476885,0.132587,0.459073,0.457800,0.380606,0.978631,0.687570,0.353860,0.224363,0.931935,0.272906,0.443753,0.908269,0.173270,0.567581,0.705271,0.659782,0.530196,0.615158,0.107020,0.337759,0.287402,0.113100,0.750601,0.380647,0.338062,0.470644,0.560054,0.916784,0.102615,0.653475,0.234832,0.241591,0.092253,0.984721,0.061122,0.418502,0.268967,0.170532,0.623880,0.505132,0.659034,0.752930,0.888594,0.871888,0.676820,0.938585,0.050625,0.063221,0.559219,0.451311,0.844238,0.915815,0.935894,0.918915,0.271461,0.099396,0.661230,0.405390,0.608056,0.919490,0.483303,0.240281,0.329818,0.181569,0.511471,0.432861,0.463347,0.560382,0.855283
2019-02-01T00:00:30,st0,0.692054,0.538778,0.764992,0.656943,0.006166,0.610429,0.479586,0.639454,0.107885,0.338176,0.535457,0.871265,0.291767,0.955159,0.271295,0.421824,0.772407,0.531340,0.419594,0.776071,0.452270,0.281994,0.479907,0.745093,0.627713,0.774344,0.699013,0.587567,0.878019,0.153955,0.986209,0.704153,0.783832,0.704486,0.200587,0.630304,0.235955,0.429266,0.752330,0.484207,0.394956,0.518921,0.688756,0.720469,0.056679,0.160093,0.502845,0.915870,0.359901,0.744948,0.005774,0.194809,0.180417,0.100580,0.428749,0.621978,0.782535,0.834345,0.960411,0.703126,0.681373,0.894144,0.943699,0.037323,0.294162,0.047351,0.940178,0.396505,0.243780,0.410479,0.257793,0.581372,0.235662,0.441054,0.536284,0.588570,0.946028,0.466676,0.124679,0.803133,0.713820,0.810444,0.810953,0.259700,0.450738,0.995637,0.339662,0.132606,0.189827,0.208749,0.430025,0.843661,0.706039,0.650623,0.797073,0.719763,0.055521,0.852340,0.396091,0.429506
```
Any idea on why is this exception happening? | MonetDB COPY INTO table "unexpected end of file" | https://api.github.com/repos/MonetDB/MonetDB/issues/7291/comments | 3 | 2022-05-12T15:32:07Z | 2022-05-16T12:31:58Z | https://github.com/MonetDB/MonetDB/issues/7291 | 1,234,162,804 | 7,291 |
[
"MonetDB",
"MonetDB"
] | Monet backup validation - we need to know if there is any backup utility inbuilt in monet as we are taking DB level backup using rsync and we have no option to validate if the backup is successful or not.
And also please update us to take backup and validate the backup.
**Software versions**
- MonetDB version number - Jan 2022 monetdb 11.43.5
| Monet Backup validation | https://api.github.com/repos/MonetDB/MonetDB/issues/7290/comments | 1 | 2022-05-03T19:51:18Z | 2022-07-06T08:22:05Z | https://github.com/MonetDB/MonetDB/issues/7290 | 1,224,550,703 | 7,290 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Python UDFs don't accept scalar date parameters
**To Reproduce**
This function expects a `date` parameter and simply returns the python type of the parameter passed:
```
CREATE OR REPLACE FUNCTION test_date(d1 date) RETURNS string
LANGUAGE PYTHON {
return(f"d1: {str(type(d1))}")
};
```
It fails when a scalar date is passed:
```
sql>select test_date(curdate());
Unsupported scalar type 13.
```
It succeeds when a column of dates is passed:
```
sql>select test_date(d) from (values (curdate()),(curdate())) as t(d);
+-----------------------------+
| %4 |
+=============================+
| d1: <class 'numpy.ndarray'> |
+-----------------------------+
1 tuple
```
Type `int`, for comparison, works as expected in both cases.
**Software versions**
- MonetDB version number 11.43.14
- OS and version: Fedora 35
- self-installed and compiled
| Python UDF: Unsupported scalar type 13 | https://api.github.com/repos/MonetDB/MonetDB/issues/7289/comments | 8 | 2022-04-27T18:29:49Z | 2023-10-28T09:48:23Z | https://github.com/MonetDB/MonetDB/issues/7289 | 1,217,733,727 | 7,289 |
[
"MonetDB",
"MonetDB"
] | Maybe you could create an sql command that internally performs all the steps in a single step?
Something like MySql "CHANGE COLUMN", or "ALTER TABLE... ALTER COLUMN colname > new datatype"
According Monetdb docs:
"Change of the data type of a column is not supported.
Instead use command sequence:
ALTER TABLE tbl ADD COLUMN new_column _new_data_type_;
UPDATE tbl SET new_column = CONVERT(old_column, _new_data_type_);
ALTER TABLE tbl DROP COLUMN old_column RESTRICT;
ALTER TABLE tbl RENAME COLUMN new_column TO old_column"
In same way, it would be very useful to may able alter/change the column position/ordinal in the table
Regards. | Change/Alter column data type in a single command | https://api.github.com/repos/MonetDB/MonetDB/issues/7288/comments | 0 | 2022-04-21T14:27:04Z | 2024-06-27T13:17:30Z | https://github.com/MonetDB/MonetDB/issues/7288 | 1,211,123,911 | 7,288 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
when try to update the existing DB to new version we are getting below error.
error details:
mapi_usock=/monet_data01/DBFARM_TSVR_P2_A_BT/DB_TSVR_JR_P2_A/.mapi.sock --set monet_vault_key=/monet_data01/DBFARM_TSVR_P2_A_BT/DB_TSVR_JR_P2_A/.vaultkey --set gdk_nr_threads=128 --set max_clients=2048 --set sql_optimizer=sequential_pipe
2022-04-19 07:38:25 ERR DB_TSVR_JR_P2_A[298637]: #main thread: BBPcheckbats: !ERROR: BBPcheckbats: cannot stat file /monet_data01/DBFARM_TSVR_P2_A_BT/DB_TSVR_JR_P2_A/bat/01/46/14637.tail (expected size 1953432): No such file or directory
**To Reproduce**
upgrade from the version MonetDB-11.31.13 to MonetDB-11.37.11 we are getting error.
**Software versions**
- MonetDB version number [a milestone label]
MonetDB-11.37.11
- OS and version: [e.g. Ubuntu 18.04]
- Linux lnx1538.ch3.qa.i.com 3.10.0-957.27.2.el7.x86_64 #1 SMP Mon Jul 29 17:46:05 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
- Installed from release package or self-installed and compiled
- Self installed and complied
| Unable to upgrade from MonetDB-MonetDB-11.31.13 to MonetDB-11.37.11 | https://api.github.com/repos/MonetDB/MonetDB/issues/7287/comments | 3 | 2022-04-19T13:03:38Z | 2022-07-06T08:25:51Z | https://github.com/MonetDB/MonetDB/issues/7287 | 1,208,343,402 | 7,287 |
[
"MonetDB",
"MonetDB"
] | **Is your feature request related to a problem? Please describe.**
I would like to know if the DataCell functionality still exists in MonetDB. In the documentation, it was mentioned this feature is disabled. Can we still use MonetDB as a streaming DB?
**Describe the solution you'd like**
Enable DataCell or feature to have MonetDB as streaming DB.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
| Is DataCell (Streaming) functionality is disabled? Will i be able to use MonetDB as a streaming DB? | https://api.github.com/repos/MonetDB/MonetDB/issues/7286/comments | 4 | 2022-04-19T03:08:49Z | 2022-04-20T16:56:49Z | https://github.com/MonetDB/MonetDB/issues/7286 | 1,207,659,249 | 7,286 |
[
"MonetDB",
"MonetDB"
] | `**Describe` the bug**
Me and my team are working on C-UDFs in MonetDB and we encountered the following bug for aggregate UDFs:
While aggr_group.data has correct values, aggr_group.count is not equal to the number of groups, as the documentation claims (" aggr_group.count counts not the number of elements of aggr_group.data, but the number of groups."). This causes a lot of problems when we use aggregate UDFs without the group-by column on the SELECT statement.
Lets take the following query as an example:
```
SELECT jit_sum(p_size) FROM ssbm10_part GROUP BY p_mfgr;
```
ssbm10_part has 800000 rows and GROUP BY p_mfgr outputs 5 groups.
jit_sum is the aggregate function you have on the documentation page (https://www.monetdb.org/documentation-Jan2022/dev-guide/sql-extensions/c-udf-blog/).
```
CREATE AGGREGATE jit_sum(input INTEGER)
RETURNS BIGINT
LANGUAGE C {
// initialize one aggregate per group
result->initialize(result, aggr_group.count);
// zero initialize the sums
memset(result->data, 0, result->count * sizeof(result->null_value));
// gather the sums for each of the groups
for(size_t i = 0; i < input.count; i++) {
result->data[aggr_group.data[i]] += input.data[i];
}
};
```
This query should output 5 tuples, but outputs 800000 instead.
If, however, the query is re-written as follows:
SELECT p_mfgr, jit_sum(p_size) FROM ssbm10_part GROUP BY p_mfgr;
the results are correct.
In order to debug this I printed aggr_group.count value and in both cases it is equal to the number of rows of the input column (800000), NOT the number of groups (5).
After digging on capi I found out that there is a temporary random-name generated .c file generated which is basically the UDF function to be compiled. When I opened this file I saw the following function definition:
```
char* jit_sum(void** __inputs, void** __outputs, malloc_function_ptr malloc, free_function_ptr free) {
struct cudf_data_struct_int input = *((struct cudf_data_struct_int*)__inputs[0]);
struct cudf_data_struct_oid aggr_group = *((struct cudf_data_struct_oid*)__inputs[1]);
struct cudf_data_struct_oid arg4 = *((struct cudf_data_struct_oid*)__inputs[2]);
struct cudf_data_struct_bte arg5 = *((struct cudf_data_struct_bte*)__inputs[3]);
struct cudf_data_struct_lng* result = ((struct cudf_data_struct_lng*)__outputs[0]);
// initialize one aggregate per group
result->initialize(result, aggr_group.count);
// zero initialize the sums
memset(result->data, 0, result->count * sizeof(result->null_value));
// gather the sums for each of the groups
for (size_t i = 0; i < input.count; i++) {
result->data[aggr_group.data[i]] += input.data[i];
}
}
```
"input" is the input column,
"aggr_group" is the column which contains information about tuples and their groups.
"result" is the output column.
But what are "arg4" and "arg5" generated for since they are never used?
On capi.c I printed the count (BATcount) of arg4 and it turns out that it was 5, which the number of groups returned from GROUP BY p_mfgr!
I come into conclusion that arg4 and arg5 should not be generated as inputs because they are never used in the UDF and aggr_group.count should be equal to arg4.count.
**Software versions**
- MonetDB 5 server 11.44.0 (hg id: 151fed075b61) (64-bit, 128-bit integers).
- Ubuntu 18.04.
- Self-installed and compiled.
( cmake -DCMAKE_BUILD_TYPE=Debug -DCMAKE_INSTALL_PREFIX=/install_dir/ ../
cmake --build . --target install )
| C-UDFs: aggr_group.count has wrong value (number of input rows instead of number of groups). | https://api.github.com/repos/MonetDB/MonetDB/issues/7285/comments | 0 | 2022-04-11T14:33:13Z | 2024-06-27T13:17:29Z | https://github.com/MonetDB/MonetDB/issues/7285 | 1,200,066,248 | 7,285 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
The source file testing/README needs a rewrite as our testing tools has been changed and improved considerably. So the information in this README file is quite out of date.
**Expected behavior**
Up-to-date, correct and useful information on the testing tools and how to use them.
There is no need to describe all the options of Mtest.py, as that can be retrieved via Mtest.py --help
**Software versions**
source file repositories of branches: Jan2022, default
| contents of file testing/README is out-of-date and needs a rewrite | https://api.github.com/repos/MonetDB/MonetDB/issues/7284/comments | 0 | 2022-04-07T17:24:00Z | 2024-06-27T13:17:28Z | https://github.com/MonetDB/MonetDB/issues/7284 | 1,196,350,802 | 7,284 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Currently some web information presented as tables do not show a 1px border around the cells. It would greatly enhance the readability of the tabular information if a small grey cell border is shown (like on the old website).
For instance the tabular documentation on supported scalar functions, procedures, sql-catalog, ... would need borders:
**To Reproduce**
See webpages:
https://www.monetdb.org/documentation-Jan2022/user-guide/sql-functions/mathematics-functions/
https://www.monetdb.org/documentation-Jan2022/user-guide/sql-functions/string-functions/
https://www.monetdb.org/documentation-Jan2022/user-guide/sql-functions/logical-functions/
https://www.monetdb.org/documentation-Jan2022/user-guide/sql-functions/comparison-functions/
etc.
https://www.monetdb.org/documentation-Jan2022/admin-guide/monitoring/session-procedures/
https://www.monetdb.org/documentation-Jan2022/admin-guide/monitoring/system-procedures/
etc.
https://www.monetdb.org/documentation-Jan2022/user-guide/sql-catalog/schema-table-columns/
https://www.monetdb.org/documentation-Jan2022/user-guide/sql-catalog/functions-arguments-types/
etc.
versus the original webpages with borders:
http://web.archive.org/web/20210412214522/https://www.monetdb.org/Documentation/SQLReference/FunctionsAndOperators/MathematicalFunctionsOperators
http://web.archive.org/web/20210513030115/https://monetdb.org/Documentation/SQLReference/SystemProcedures
The old ones are much easier to read and understand, due to the visual assistance of the borders around the cells of the tables.
**Expected behavior**
Show black/grey borders (1px) around every cell of tabular presented information.
Also the header (top row) with the field names, should have a different background than the information rows.
**Software versions**
www.monetdb.org website pages
**Additional context**
Other RDBMS documentation websites also use borders around cells of tabular presented information.
See for instance:
https://dev.mysql.com/doc/refman/8.0/en/built-in-function-reference.html
https://www.postgresql.org/docs/current/functions-math.html
https://mariadb.com/kb/en/function-and-operator-reference/
| webdocumentation: Add borders to cells for information presented as table for improved readability | https://api.github.com/repos/MonetDB/MonetDB/issues/7283/comments | 2 | 2022-04-07T17:09:35Z | 2024-06-27T13:17:27Z | https://github.com/MonetDB/MonetDB/issues/7283 | 1,196,337,022 | 7,283 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
When a database contains multiple user tables with the same table name but in different schemas, the call sys.dump_table_data(); command fails to complete.
**To Reproduce**
```
create table sys.t7282 ("nr" INTEGER PRIMARY KEY, "val1" INTEGER);
insert into sys.t7282 values (1, 23), (2, 45), (3, 67);
select * from sys.t7282;
create schema test;
create table test.t7282 ("mk" VARCHAR(3) PRIMARY KEY, "val2" INTEGER);
insert into test.t7282 values ('a', 23), ('b', 45);
select * from test.t7282;
delete from dump_statements;
call sys.dump_table_data();
-- Error: SELECT: identifier 'mk' unknown
select * from dump_statements;
-- no rows
-- remove one of the tables with the same name
drop table sys.t7282;
call sys.dump_table_data();
-- now it works as there are no 2 tables with the same name anymore
select * from dump_statements;
-- cleanup
drop table test.t7282;
drop schema test;
```
**Expected behavior**
It should be possible to dump table data of multiple user tables with the same table name but in different schemas.
**Software versions**
- MonetDB 5 server v11.43.13 (Jan2022-SP2), but is also reproducable on Jul2021.
- Windows
- Installed from release installer
**Additional context**
I have already analysed the cause and created the corrected versions of
- sys.dump_table_data(STRING, STRING),
- sys.dump_table_data() and
- sys.dump_database(BOOLEAN);
```
DROP FUNCTION sys.dump_database(BOOLEAN);
DROP PROCEDURE sys.dump_table_data();
DROP PROCEDURE sys.dump_table_data(STRING, STRING);
CREATE PROCEDURE sys.dump_table_data(sch STRING, tbl STRING)
BEGIN
DECLARE tid INT;
SET tid = (SELECT MIN(t.id) FROM sys.tables t, sys.schemas s WHERE t.name = tbl AND t.schema_id = s.id AND s.name = sch);
IF tid IS NOT NULL THEN
DECLARE k INT;
DECLARE m INT;
SET k = (SELECT MIN(c.id) FROM sys.columns c WHERE c.table_id = tid);
SET m = (SELECT MAX(c.id) FROM sys.columns c WHERE c.table_id = tid);
IF k IS NOT NULL AND m IS NOT NULL THEN
DECLARE cname STRING;
DECLARE ctype STRING;
SET cname = (SELECT c.name FROM sys.columns c WHERE c.id = k);
SET ctype = (SELECT c.type FROM sys.columns c WHERE c.id = k);
DECLARE COPY_INTO_STMT STRING;
DECLARE _cnt INT;
SET _cnt = (SELECT count FROM sys.storage(sch, tbl, cname));
IF _cnt > 0 THEN
SET COPY_INTO_STMT = 'COPY ' || _cnt || ' RECORDS INTO ' || sys.FQN(sch, tbl) || '(' || sys.DQ(cname);
DECLARE SELECT_DATA_STMT STRING;
SET SELECT_DATA_STMT = 'SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), ' || sys.prepare_esc(cname, ctype);
WHILE (k < m) DO
SET k = (SELECT MIN(c.id) FROM sys.columns c WHERE c.table_id = tid AND c.id > k);
SET cname = (SELECT c.name FROM sys.columns c WHERE c.id = k);
SET ctype = (SELECT c.type FROM sys.columns c WHERE c.id = k);
SET COPY_INTO_STMT = (COPY_INTO_STMT || ', ' || sys.DQ(cname));
SET SELECT_DATA_STMT = (SELECT_DATA_STMT || '|| ''|'' || ' || sys.prepare_esc(cname, ctype));
END WHILE;
SET COPY_INTO_STMT = (COPY_INTO_STMT || ') FROM STDIN USING DELIMITERS ''|'',E''\\n'',''"'';');
SET SELECT_DATA_STMT = (SELECT_DATA_STMT || ' FROM ' || sys.FQN(sch, tbl));
INSERT INTO sys.dump_statements VALUES ((SELECT COUNT(*) FROM sys.dump_statements) + 1, COPY_INTO_STMT);
CALL sys.EVAL('INSERT INTO sys.dump_statements ' || SELECT_DATA_STMT || ';');
END IF;
END IF;
END IF;
END;
CREATE PROCEDURE sys.dump_table_data()
BEGIN
DECLARE i INT;
SET i = (SELECT MIN(t.id) FROM sys.tables t, sys.table_types ts WHERE t.type = ts.table_type_id AND ts.table_type_name = 'TABLE' AND NOT t.system);
IF i IS NOT NULL THEN
DECLARE M INT;
SET M = (SELECT MAX(t.id) FROM sys.tables t, sys.table_types ts WHERE t.type = ts.table_type_id AND ts.table_type_name = 'TABLE' AND NOT t.system);
DECLARE sch STRING;
DECLARE tbl STRING;
WHILE i IS NOT NULL AND i <= M DO
set sch = (SELECT s.name FROM sys.tables t, sys.schemas s WHERE s.id = t.schema_id AND t.id = i);
set tbl = (SELECT t.name FROM sys.tables t, sys.schemas s WHERE s.id = t.schema_id AND t.id = i);
CALL sys.dump_table_data(sch, tbl);
SET i = (SELECT MIN(t.id) FROM sys.tables t, sys.table_types ts WHERE t.type = ts.table_type_id AND ts.table_type_name = 'TABLE' AND NOT t.system AND t.id > i);
END WHILE;
END IF;
END;
CREATE FUNCTION sys.dump_database(describe BOOLEAN) RETURNS TABLE(o int, stmt STRING)
BEGIN
SET SCHEMA sys;
TRUNCATE sys.dump_statements;
INSERT INTO sys.dump_statements VALUES (1, 'START TRANSACTION;');
INSERT INTO sys.dump_statements VALUES (2, 'SET SCHEMA "sys";');
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_create_roles;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_create_users;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_create_schemas;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_user_defined_types;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_add_schemas_to_users;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_grant_user_privileges;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_sequences;
--functions and table-likes can be interdependent. They should be inserted in the order of their catalogue id.
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(ORDER BY stmts.o), stmts.s
FROM (
SELECT f.o, f.stmt FROM sys.dump_functions f
UNION
SELECT t.o, t.stmt FROM sys.dump_tables t
) AS stmts(o, s);
-- dump table data before adding constraints and fixing sequences
IF NOT DESCRIBE THEN
CALL sys.dump_table_data();
END IF;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_start_sequences;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_column_defaults;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_table_constraint_type;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_indices;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_foreign_keys;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_partition_tables;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_triggers;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_comments;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_table_grants;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_column_grants;
INSERT INTO sys.dump_statements SELECT (SELECT COUNT(*) FROM sys.dump_statements) + RANK() OVER(), stmt FROM sys.dump_function_grants;
--TODO Improve performance of dump_table_data.
--TODO loaders, procedures, window and filter sys.functions.
--TODO look into order dependent group_concat
INSERT INTO sys.dump_statements VALUES ((SELECT COUNT(*) FROM sys.dump_statements) + 1, 'COMMIT;');
RETURN sys.dump_statements;
END;
```
| call sys.dump_table_data(); fails | https://api.github.com/repos/MonetDB/MonetDB/issues/7282/comments | 0 | 2022-04-06T22:56:46Z | 2024-06-27T13:17:26Z | https://github.com/MonetDB/MonetDB/issues/7282 | 1,195,277,081 | 7,282 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Starting from Oct2020, the UDFs that one could define by simply putting a script in `/lib/monetdb5/createdb` must be defined at compile time.
That is rather inconvenient. But even more inconvenient is that they automatically become _system functions_.
I do see the logic: functions defined at compile time are assumed to be vital for the system, therefore should be protected.
I think the assumption here is too strict though.
It should be: functions defined at compile time _in the `sys` schema_ are assumed to be vital for the system, therefore should be protected.
UDFs created in _user schemas_ should not be assumed to be vital for the system. It would be rather odd if they were.
The problem with that is that those UDFs are typically crucial for an application (not for MonetDB!) - that's why they should be available in every database as soon as it is created, but they should remain upgradable.
As it is now, an application cannot upgrade those UDFs ever again, because they are marked as system functions. The only way is to destroy and recreate the database.
**To Reproduce**
1. A SQL script defines:
-- a `myschema` schema
-- a UDF in that schema
2. The SQL script is included my a `CMakeList.txt` file.
3. Compile and create a new db
4. Move to `myschema` and verify that the UDF is there
5. Try to `CREATE OR REPLACE` it.
That fails because the UDF is a system table (though not in the `sys` schema)
**Expected behavior**
Only functions defined in schema `sys` should ever become system functions.
The same goes for tables, btw.
**Software versions**
- MonetDB version number 11.43.12
- OS and version: Fedora 35
- self-installed and compiled
| UDFs defined at compile time in a user schema should not become system functions | https://api.github.com/repos/MonetDB/MonetDB/issues/7281/comments | 1 | 2022-04-06T09:05:03Z | 2023-03-01T10:31:48Z | https://github.com/MonetDB/MonetDB/issues/7281 | 1,194,303,502 | 7,281 |
[
"MonetDB",
"MonetDB"
] | Page https://www.monetdb.org/documentation-Jan2022/admin-guide/system-resources/autoloading-scripts/ is outdated since Oct2020 release.
I actually wish it this documentation were still valid. I liked that autoloading mechanism much better.
| Outdated documentation about autoloading scripts | https://api.github.com/repos/MonetDB/MonetDB/issues/7280/comments | 2 | 2022-04-06T08:40:03Z | 2024-06-27T13:17:25Z | https://github.com/MonetDB/MonetDB/issues/7280 | 1,194,273,287 | 7,280 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug** / **To Reproduce**
Imagine the following table:
Table: T
Field: num of type numeric (double);
Field: text of type text (clob). This field, despite being of the text type, has a number stored.
The following SQL works:
select sum(text) from T
The following SQL works:
select sum(text)-sum(text) from T
The following SQL works in version 11.33.3 but does not work in version 11.43.9:
select sum(num)-sum(text) from T
If I spell out a cast it works on both versions.
select sum(num)-sum(cast(text as float)) from T
Looking at it coldly I can understand that I might actually need to apply the conversion but this opens up a few questions:
Why do the first and second SQLs work? If it's correct the third one doesn't work, the others shouldn't work either.
Why did it work before and now it doesn't? This is going to be quite problematic as users update MonetDB.
If this is not allowed, then the MonetDB needs to return an appropriate message. The error currently returned is actually triggered on a subsequent operation and not on the aggregation. This is because of the type of data returned by this aggregation.
From what I've noticed, the sum(text) expression is returning a strange data type: sec_interval. And with that, it doesn't find a suitable subtraction operation.
**Expected behavior**
Or it prohibits the use of sum with text field and returns a proper error message;
Or allow this usage, but adjust the data type returned by this aggregation;
**Screenshots**
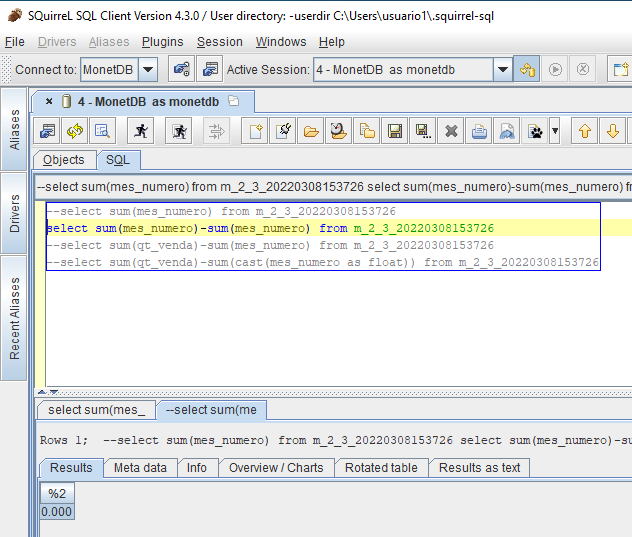
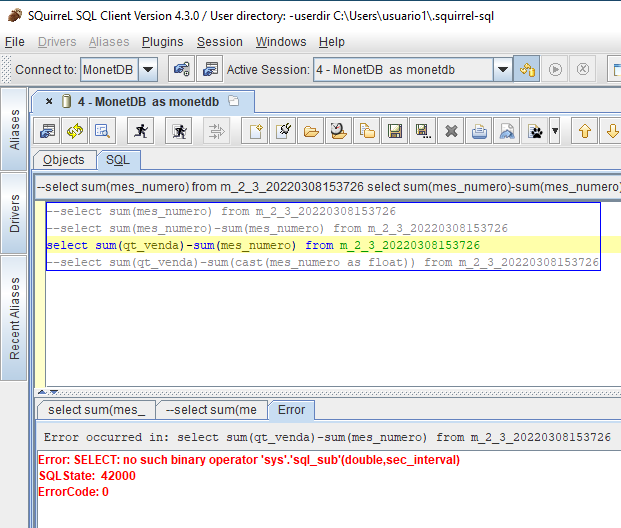
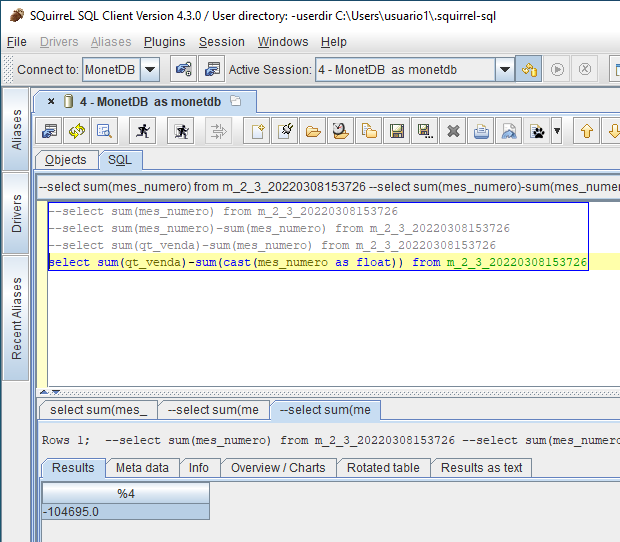
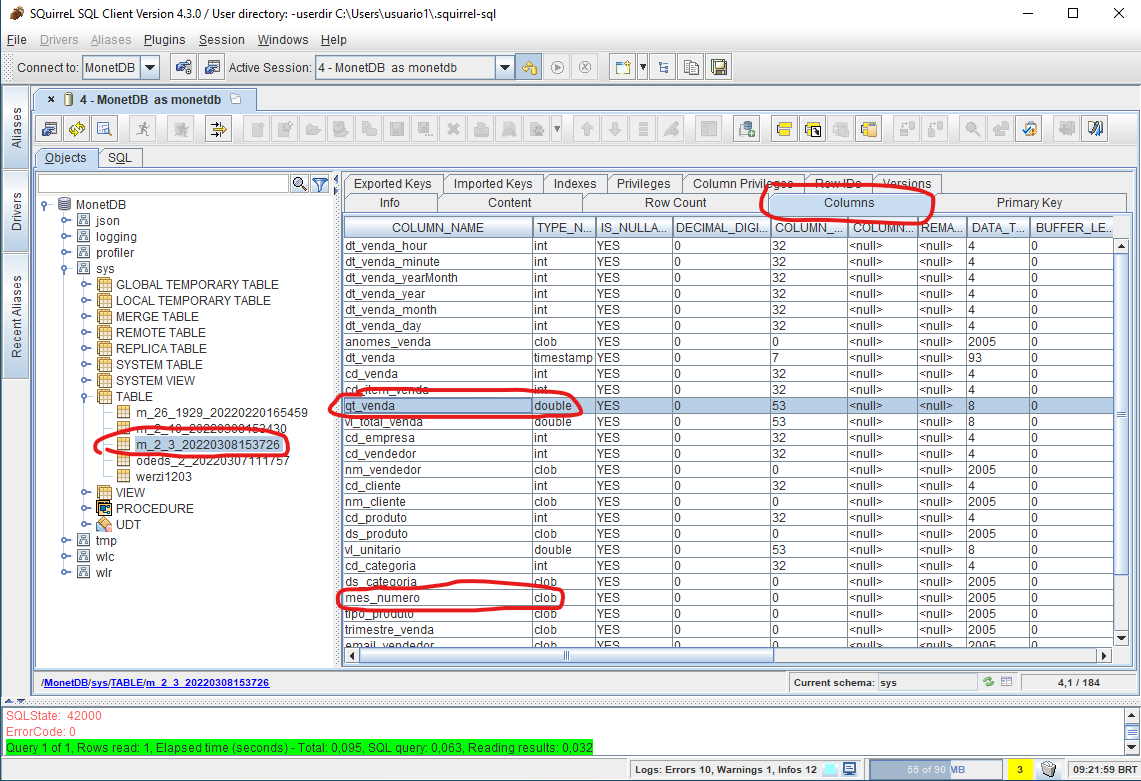
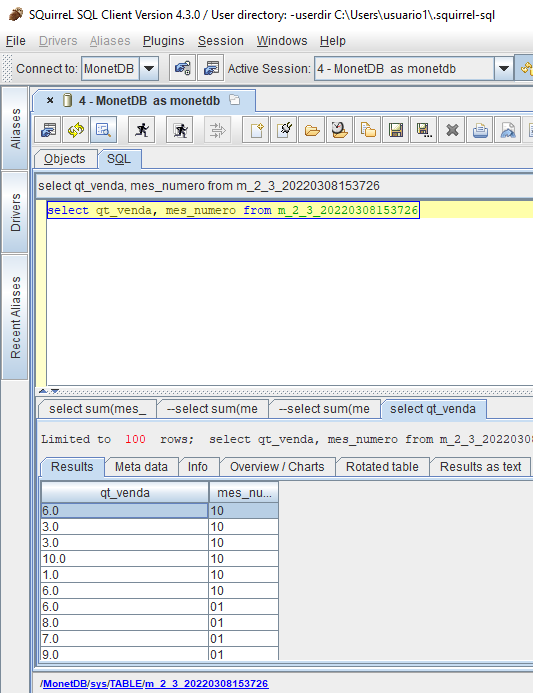
**Software versions**
MonetDB version number: 11.43.9
OS and version: Windows 10
Installed from release package or self-installed and compiled: release package | Possibly inappropriate/incoherent behavior | https://api.github.com/repos/MonetDB/MonetDB/issues/7279/comments | 6 | 2022-03-30T12:24:39Z | 2022-03-31T13:26:11Z | https://github.com/MonetDB/MonetDB/issues/7279 | 1,186,381,691 | 7,279 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
There is a BUG when there is more than one field/filter in the having clause.
**To Reproduce**
To reproduce the problem, simply execute an SQL similar to the one shown in the example below:
select
tablefield1
from
tabletest1
group by
tablefield1
having
count(tablefield2) > 1
and count(tablefield) > 1 -- The error occurs in this second filter. If you remove this second filter, then it works correctly.
**Expected behavior**
Execute the query correctly.
**Screenshots**
This is the error that occurs:
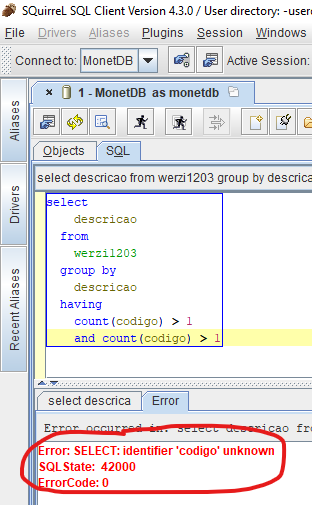
And if I remove the second filter, then it works correctly:

**Software versions**
MonetDB version number: 11.43.9
OS and version: Windows 10
Installed from release package or self-installed and compiled: release package | BUG when there is more than one field/filter in the having clause | https://api.github.com/repos/MonetDB/MonetDB/issues/7278/comments | 0 | 2022-03-29T20:17:27Z | 2024-06-27T13:17:24Z | https://github.com/MonetDB/MonetDB/issues/7278 | 1,185,365,455 | 7,278 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
I've been using MonetDB for about a month now, and the databases I create keep becoming inaccessible. I've reported 2 out of the 10+ of these occurrences in #7268 and #7262.
With them happening so frequently I'm starting to think that I am the issue.
Here is my set up:
I'm on MacOS (ARM architecture) and I've installed monetdb via homebrew.
I have a 1 TB external drive using the APFS storage format connected via USB-C that I put the database on using the following commands:
```
monetdbd create /path/to/external_drive/dbfarm
monetdbd start /path/to/external_drive/dbfarm
monetdb create db
monetdb release db
```
I then log onto the database via the mclient program to perform operations on the database.
```
mclient -u monetdb -d db
```
When I am done using the database, need to disconnect the external drive, or put my computer to sleep with the external drive connected to it, I close all client connections to the database by exiting all mclient interfaces I have open.
Then I run the following commands:
```
monetdb stop db
monetdbd stop /path/to/external_drive/dbfarm
```
When I need to get back to the database I run the following:
```
monetdbd start /path/to/external_drive/dbfarm
monetdb start db
```
Sometimes I get lucky and the database starts with no problems. However, many times I run into the system hanging as described in #7268 and #7262. In one of the issues @sjoerdmullender asked https://github.com/MonetDB/MonetDB/issues/7268#issuecomment-1065298682:
> Do you have a large write-ahead log (WAL)? Try `du` on the `sql_logs` subdirectory of the database. My guess is, you do. And that is why startup takes long. Just let it finish.
I check for this when the database doesn't start up normally. None of these databases have any large write-ahead log files that justify the system not starting the databases under 10 minutes. (I assume a MonetDB database that is holding 60 GB of data shouldn't take longer than 10 minutes to start up. Please let me know if I am incorrect.)
My list of questions are:
- Am I starting and stopping my databases correctly?
- Is there an issue with me hosting the database on an external drive?
- What debugging tools (besides sending logs) can I use to help identify the issue?
I assume the issue isn't going to magically disappear, and I'd love to help solve it. (Especially if the issue is me. Lolz.)
I've been blown away with the performance of MonetDB on huge datasets, and I'd love to keep using the product. This issue is the only one that I've had with MonetDB, and unfortunately, it is severe.
Thank you for your time and help.
**To Reproduce**
I've described the procedure I follow when the issue occurs. It appears to happen at random.
**Expected behavior**
Not being "locked" out of the database when restarting it is the expected behavior.
**Software versions**
- MonetDB version number: MonetDB Database Server Toolkit v11.43.9 (Jan2022-SP1)
- OS and version: MacOS 12.3 (ARM)
- Installed from: Homebrew | Databases consistently become inaccessible | https://api.github.com/repos/MonetDB/MonetDB/issues/7277/comments | 1 | 2022-03-25T15:47:53Z | 2022-08-12T15:16:49Z | https://github.com/MonetDB/MonetDB/issues/7277 | 1,180,955,136 | 7,277 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Unable to run `select count(distinct col_1, col_2) from a_table;` without throwing the error `SELECT: no such binary operator 'count'(tinyint,char)`. Even though `select distinct col_1, col_2 from a_table;` can be successfully ran.
**To Reproduce**
```
create table a_table as
select *
from ( values(0,'cero'),
(1,'uno'),
(2,'dos'),
(3,'tres'),
(4,'cuatro'),
(5,'cinco'),
(6,'seis'),
(7,'siete'),
(8,'ocho'),
(9,'nueve'),
(10,'diez'),
(10,'diez'),
(10,'diez'),
(10,'diez'),
(10,'diez'),
(10,'once')) as nr_es(nr, nm);
select * from a_table;
select distinct nr from a_table;
select distinct nm from a_table;
select distinct nr, nm from a_table;
select count(*) from a_table;
select count(distinct nr) from a_table;
select count(distinct nm) from a_table;
select count(distinct nr, nm) from a_table; -- This throws the error.
drop table a_table;
```
**Expected behavior**
When I run `select count(distinct nr, nm) from a_table;` I expect it to return 12. The tuple number result as the non-count query.
**Software versions**
- MonetDB version number: MonetDB Database Server Toolkit v11.43.9 (Jan2022-SP1)
- OS and version: MacOS 12
- Installed from: Homebrew
| Unable to run count() on two distinct columns | https://api.github.com/repos/MonetDB/MonetDB/issues/7276/comments | 2 | 2022-03-22T21:53:11Z | 2022-03-23T17:11:37Z | https://github.com/MonetDB/MonetDB/issues/7276 | 1,177,346,504 | 7,276 |
[
"MonetDB",
"MonetDB"
] | **Is your feature request related to a problem? Please describe.**
I find myself frequently referencing the MonetDB documentation. It would be nice to do so without having to use a browser.
**Describe the solution you'd like**
MonetDB documentation in PDF format would be excellent.
I've searched the website, but haven't found an area to download the documentation. I apologize if I missed the link while searching the website.
Thank you for your hard work on this project. | MonetDB documentation in PDF format | https://api.github.com/repos/MonetDB/MonetDB/issues/7275/comments | 2 | 2022-03-22T21:00:21Z | 2024-06-28T10:04:41Z | https://github.com/MonetDB/MonetDB/issues/7275 | 1,177,299,580 | 7,275 |
[
"MonetDB",
"MonetDB"
] | On latest 'geo-update' branch (hg id: f73972d12bf5) given a table
```
CREATE TABLE "sys"."test" (
"id" INTEGER,
"g" GEOMETRY
);
```
the query
```
create table test2 as
select id, st_collect(g) as g
from test
where false
group by id;
```
causes a crash to mserver5 | Aggregate function ST_Collect crashes mserver5 | https://api.github.com/repos/MonetDB/MonetDB/issues/7274/comments | 4 | 2022-03-22T14:30:12Z | 2024-06-27T13:17:22Z | https://github.com/MonetDB/MonetDB/issues/7274 | 1,176,875,819 | 7,274 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
When executing concurrent reads and writes, particularly if the read query is large, the client returns the following error: `GDK reported error: BATproject2: does not match always\nBATproject2: does not match always`
This only seems to happen when the writes are updates or deletes.
Here is the log output:
```log
DFLOWworker1018: BATproject2: !ERROR: does not match always
DFLOWworker1018: BATproject2: !ERROR: does not match always
DFLOWworker1018: createExceptionInternal: !ERROR: SQLException:sql.bind:GDK reported error: BATproject2: does not match always
DFLOWworker1018: createExceptionInternal: !ERROR: !ERROR: BATproject2: does not match always
```
**To Reproduce**
The following [gist](https://gist.github.com/nuno-faria/d6ffb69cacca87e397ca779c53189813) can be used to reproduce the error. In it, there are two clients, one executes writes over a simple table (k int, v int), while the other executes the query below:
```sql
SELECT k, sum(v)
FROM Test
GROUP BY k
ORDER BY sum(v) DESC
```
**Software versions**
- MonetDB master branch (most recent commit)
- Ubuntu 20.04 LTS
- Self-installed and compiled | Concurrent reads and writes causes "BATproject2: does not match always" error | https://api.github.com/repos/MonetDB/MonetDB/issues/7273/comments | 3 | 2022-03-21T18:33:53Z | 2024-06-27T13:17:21Z | https://github.com/MonetDB/MonetDB/issues/7273 | 1,175,785,141 | 7,273 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
A simple SQL UDF involving function `epoch_ms` translates to a MAL loop.
**To Reproduce**
The following baseline works as expected:
```
start transaction;
create table t(d date);
insert into t values (curdate());
insert into t values (curdate());
CREATE OR REPLACE FUNCTION test(d1 date, d2 date) RETURNS decimal
BEGIN
return epoch_ms(d1 - d2);
END;
explain select test(d, curdate()) from t;
| X_66:bat[:lng] := batmtime.diff(X_11:bat[:date], "2022-03-20":date, nil:BAT);
| X_67:bat[:lng] := batmtime.epoch_ms(X_66:bat[:lng]);
```
The following (only `* 1000` was added) translates to a MAL loop:
```
CREATE OR REPLACE FUNCTION test(d1 date, d2 date) RETURNS decimal
BEGIN
return epoch_ms(d1 - d2) * 1000;
END;
explain select test(d, curdate()) from t;
| X_77:bat[:lng] := bat.new(nil:lng, X_11:bat[:date]);
| barrier (X_80:oid, X_81:date) := iterator.new(X_11:bat[:date]);
| X_83:lng := sql.f_23(X_81:date, "2022-03-20":date);
| X_77:bat[:lng] := bat.append(X_77:bat[:lng], X_83:lng);
| redo (X_80:oid, X_81:date) := iterator.next(X_11:bat[:date]);
| exit (X_80:oid, X_81:date);
```
The same happens leaving the same body as the original, but returning an `int`:
```
CREATE OR REPLACE FUNCTION test(d1 date, d2 date) RETURNS int
BEGIN
return epoch_ms(d1 - d2);
END;
```
**Expected behavior**
All these variations should translate to a sequence of bulk operators.
This is 11.39:
```
| X_61:bat[:lng] := batmtime.diff(X_11:bat[:date], "2022-03-20":date);
| X_62:bat[:lng] := batmtime.epoch_ms(X_61:bat[:lng]);
| X_63:bat[:int] := batcalc.int(X_62:bat[:lng]);
| X_66:bat[:lng] := batcalc.*(X_63:bat[:int], 1000:sht, nil:BAT);
```
I am not sure if this happens with different functions as well - I didn't find any.
My guess: because this function was changed in 11.43, some signatures may have slipped away.
**Software versions**
- MonetDB version number 11.43.10
- OS and version: Fedora 35
- self-installed and compiled
| Missed rewrite to bulk operators in simple SQL UDF | https://api.github.com/repos/MonetDB/MonetDB/issues/7272/comments | 5 | 2022-03-20T12:07:40Z | 2024-07-10T12:02:57Z | https://github.com/MonetDB/MonetDB/issues/7272 | 1,174,526,171 | 7,272 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Function `epoch_ms` is supposed to return the number of milliseconds since the UNIX epoch 1970-01-01 00:00:00 UTC.
At first sight, it would seem to return seconds instead.
However, the issue seems to be in the result type
**To Reproduce**
The result is 1 (should be 1000).
However, the explain shows that the function computes the correct result (1000), but then it is converted to `decimal`
```
sql>select epoch_ms(interval '1' second);
+----------------------+
| %2 |
+======================+
| 1.000 |
+----------------------+
1 tuple
sql>explain select epoch_ms(interval '1' second);
+-------------------------------------------------------------------------------------------------------------------------+
| mal |
+=========================================================================================================================+
| function user.main():void; |
| X_1:void := querylog.define("explain select epoch_ms(interval \\'1\\' second);":str, "sequential_pipe":str, 7:int); |
| X_11:int := sql.resultSet(".%2":str, "%2":str, "decimal":str, 18:int, 3:int, 10:int, 1000:lng); |
| end user.main; |
```
**Expected behavior**
This is from 11.39:
```
sql>select epoch_ms(interval '1' second);
+------+
| %2 |
+======+
| 1000 |
+------+
1 tuple
sql>explain select epoch_ms(interval '1' second);
+-------------------------------------------------------------------------------------------------------------------------+
| mal |
+=========================================================================================================================+
| function user.main():void; |
| X_1:void := querylog.define("explain select epoch_ms(interval \\'1\\' second);":str, "sequential_pipe":str, 7:int); |
| sql.resultSet(".%2":str, "%2":str, "bigint":str, 64:int, 0:int, 7:int, 1000:lng); |
| end user.main; |
```
**Software versions**
- MonetDB version number 11.43.10
- OS and version: Fedora 35
- self-installed and compiled
| epoch_ms returns seconds | https://api.github.com/repos/MonetDB/MonetDB/issues/7271/comments | 3 | 2022-03-19T19:09:17Z | 2022-03-23T13:51:14Z | https://github.com/MonetDB/MonetDB/issues/7271 | 1,174,334,533 | 7,271 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
When combining the results of two simple queries with a UNION/UNION ALL, if the underlying tables have many records, the execution time is several times higher than the sum of the response time of the individual queries.
The cause is mostly likely the result of the large MAL plan generated, which appears to continuously repeat the same pattern
**To Reproduce**
- Create a test table with a single row:
```sql
CREATE TABLE Test (k int, v int);
INSERT INTO Test VALUES (1, 1);
```
- Check that both the simple queries and the UNION ALL have normal execution times and plans:
```sql
-- \t clock
SELECT * FROM Test WHERE k = 1;
clk: 1.217 ms
PLAN SELECT * FROM Test WHERE k = 1;
+----------------------------------------------------+
| rel |
+====================================================+
| project ( |
| | select ( |
| | | table("sys"."test") [ "test"."k", "test"."v" ] |
| | ) [ ("test"."k") = (int(32) "1") ] |
| ) [ "test"."k", "test"."v" ] |
+----------------------------------------------------+
EXPLAIN SELECT * FROM Test WHERE k = 1;
+----------------------------------------------------------------------------------------------+
| mal |
+==============================================================================================+
| function user.main():void; |
| X_1:void := querylog.define("explain select * from test where k = 1;":str, "default_pipe |
: ":str, 20:int); :
| barrier X_85:bit := language.dataflow(); |
| X_4:int := sql.mvc(); |
| C_5:bat[:oid] := sql.tid(X_4:int, "sys":str, "test":str); |
| X_8:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int); |
| X_15:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int); |
| C_22:bat[:oid] := algebra.thetaselect(X_8:bat[:int], C_5:bat[:oid], 1:int, "==":str); |
| X_24:bat[:int] := algebra.projection(C_22:bat[:oid], X_8:bat[:int]); |
| X_87:void := language.pass(X_8:bat[:int]); |
| X_25:bat[:int] := algebra.projection(C_22:bat[:oid], X_15:bat[:int]); |
| X_88:void := language.pass(C_22:bat[:oid]); |
| X_27:bat[:str] := bat.pack("sys.test":str, "sys.test":str); |
| X_28:bat[:str] := bat.pack("k":str, "v":str); |
| X_29:bat[:str] := bat.pack("int":str, "int":str); |
| X_30:bat[:int] := bat.pack(32:int, 32:int); |
| X_31:bat[:int] := bat.pack(0:int, 0:int); |
| exit X_85:bit; |
| X_26:int := sql.resultSet(X_27:bat[:str], X_28:bat[:str], X_29:bat[:str], X_30:bat[:int] |
: , X_31:bat[:int], X_24:bat[:int], X_25:bat[:int]); :
| end user.main; |
| # optimizer.inline(0:int, 2:lng) |
| # optimizer.remap(0:int, 1:lng) |
| # optimizer.costModel(1:int, 2:lng) |
| # optimizer.coercions(0:int, 1:lng) |
| # optimizer.aliases(1:int, 3:lng) |
| # optimizer.evaluate(0:int, 3:lng) |
| # optimizer.emptybind(2:int, 3:lng) |
| # optimizer.deadcode(2:int, 4:lng) |
| # optimizer.pushselect(0:int, 6:lng) |
| # optimizer.aliases(2:int, 2:lng) |
| # optimizer.for(0:int, 2:lng) |
| # optimizer.dict(0:int, 2:lng) |
| # optimizer.mitosis() |
| # optimizer.mergetable(0:int, 4:lng) |
| # optimizer.bincopyfrom(0:int, 0:lng) |
| # optimizer.aliases(0:int, 0:lng) |
| # optimizer.constants(0:int, 3:lng) |
| # optimizer.commonTerms(0:int, 3:lng) |
| # optimizer.projectionpath(0:int, 2:lng) |
| # optimizer.deadcode(0:int, 2:lng) |
| # optimizer.matpack(0:int, 0:lng) |
| # optimizer.reorder(1:int, 5:lng) |
| # optimizer.dataflow(1:int, 9:lng) |
| # optimizer.querylog(0:int, 1:lng) |
| # optimizer.multiplex(0:int, 1:lng) |
| # optimizer.generator(0:int, 2:lng) |
| # optimizer.candidates(1:int, 0:lng) |
| # optimizer.deadcode(0:int, 3:lng) |
| # optimizer.postfix(0:int, 2:lng) |
| # optimizer.wlc(0:int, 1:lng) |
| # optimizer.garbageCollector(1:int, 4:lng) |
| # optimizer.profiler(0:int, 1:lng) |
| # optimizer.total(31:int, 106:lng) |
+----------------------------------------------------------------------------------------------+
-- UNION ALL ---
(SELECT * FROM Test WHERE k = 1)
UNION ALL
(SELECT * FROM Test WHERE k = 1);
clk: 1.671 ms
PLAN (SELECT * FROM Test WHERE k = 1)
UNION ALL
(SELECT * FROM Test WHERE k = 1);
+---------------------------------------------------------+
| rel |
+=========================================================+
| union ( |
| | project ( |
| | | select ( |
| | | | table("sys"."test") [ "test"."k", "test"."v" ] |
| | | ) [ ("test"."k") = (int(32) "1") ] |
| | ) [ "test"."k" as "%1"."k", "test"."v" as "%1"."v" ], |
| | project ( |
| | | select ( |
| | | | table("sys"."test") [ "test"."k", "test"."v" ] |
| | | ) [ ("test"."k") = (int(32) "1") ] |
| | ) [ "test"."k" as "%2"."k", "test"."v" as "%2"."v" ] |
| ) [ "%1"."k" as "%5"."k", "%1"."v" as "%5"."v" ] |
+---------------------------------------------------------+
EXPLAIN (SELECT * FROM Test WHERE k = 1)
UNION ALL
(SELECT * FROM Test WHERE k = 1);
+----------------------------------------------------------------------------------------------+
| mal |
+==============================================================================================+
| function user.main():void; |
| X_1:void := querylog.define("explain (select * from test where k = 1) union all(select * |
: from test where k = 1);":str, "default_pipe":str, 37:int); :
| barrier X_115:bit := language.dataflow(); |
| X_4:int := sql.mvc(); |
| C_5:bat[:oid] := sql.tid(X_4:int, "sys":str, "test":str); |
| X_8:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int); |
| X_15:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int); |
| C_22:bat[:oid] := algebra.thetaselect(X_8:bat[:int], C_5:bat[:oid], 1:int, "==":str); |
| X_24:bat[:int] := algebra.projection(C_22:bat[:oid], X_8:bat[:int]); |
| X_117:void := language.pass(X_8:bat[:int]); |
| X_25:bat[:int] := algebra.projection(C_22:bat[:oid], X_15:bat[:int]); |
| X_118:void := language.pass(C_22:bat[:oid]); |
| X_29:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int); |
| X_36:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int); |
| C_43:bat[:oid] := algebra.thetaselect(X_29:bat[:int], C_5:bat[:oid], 1:int, "==":str); |
| X_119:void := language.pass(C_5:bat[:oid]); |
| X_45:bat[:int] := algebra.projection(C_43:bat[:oid], X_29:bat[:int]); |
| X_120:void := language.pass(X_29:bat[:int]); |
| X_46:bat[:int] := algebra.projection(C_43:bat[:oid], X_36:bat[:int]); |
| X_121:void := language.pass(C_43:bat[:oid]); |
| X_47:bat[:int] := bat.new(nil:int); |
| X_49:bat[:int] := bat.append(X_47:bat[:int], X_24:bat[:int], true:bit); |
| X_51:bat[:int] := bat.append(X_49:bat[:int], X_45:bat[:int], true:bit); |
| X_52:bat[:int] := bat.new(nil:int); |
| X_53:bat[:int] := bat.append(X_52:bat[:int], X_25:bat[:int], true:bit); |
| X_54:bat[:int] := bat.append(X_53:bat[:int], X_46:bat[:int], true:bit); |
| X_56:bat[:str] := bat.pack(".%5":str, ".%5":str); |
| X_57:bat[:str] := bat.pack("k":str, "v":str); |
| X_58:bat[:str] := bat.pack("int":str, "int":str); |
| X_59:bat[:int] := bat.pack(32:int, 32:int); |
| X_60:bat[:int] := bat.pack(0:int, 0:int); |
| exit X_115:bit; |
| X_55:int := sql.resultSet(X_56:bat[:str], X_57:bat[:str], X_58:bat[:str], X_59:bat[:int] |
: , X_60:bat[:int], X_51:bat[:int], X_54:bat[:int]); :
| end user.main; |
| # optimizer.inline(0:int, 1:lng) |
| # optimizer.remap(0:int, 1:lng) |
| # optimizer.costModel(1:int, 2:lng) |
| # optimizer.coercions(0:int, 2:lng) |
| # optimizer.aliases(2:int, 5:lng) |
| # optimizer.evaluate(0:int, 3:lng) |
| # optimizer.emptybind(4:int, 6:lng) |
| # optimizer.deadcode(4:int, 5:lng) |
| # optimizer.pushselect(0:int, 8:lng) |
| # optimizer.aliases(4:int, 3:lng) |
| # optimizer.for(0:int, 2:lng) |
| # optimizer.dict(0:int, 3:lng) |
| # optimizer.mitosis(0:int, 6:lng) |
| # optimizer.mergetable(0:int, 6:lng) |
| # optimizer.bincopyfrom(0:int, 1:lng) |
| # optimizer.aliases(0:int, 0:lng) |
| # optimizer.constants(4:int, 4:lng) |
| # optimizer.commonTerms(1:int, 9:lng) |
| # optimizer.projectionpath(0:int, 2:lng) |
| # optimizer.deadcode(1:int, 4:lng) |
| # optimizer.matpack(0:int, 0:lng) |
| # optimizer.reorder(1:int, 4:lng) |
| # optimizer.dataflow(1:int, 10:lng) |
| # optimizer.querylog(0:int, 1:lng) |
| # optimizer.multiplex(0:int, 1:lng) |
| # optimizer.generator(0:int, 2:lng) |
| # optimizer.candidates(1:int, 1:lng) |
| # optimizer.deadcode(0:int, 2:lng) |
| # optimizer.postfix(0:int, 3:lng) |
| # optimizer.wlc(0:int, 1:lng) |
| # optimizer.garbageCollector(1:int, 7:lng) |
| # optimizer.profiler(0:int, 0:lng) |
| # optimizer.total(32:int, 139:lng) |
+----------------------------------------------------------------------------------------------+
67 tuples
```
- Add more data (all with `k != 1`, so that the queries above return the same data):
```sql
INSERT INTO Test
SELECT (rand() % 10000) + 2, (rand() % 10000) + 2 FROM generate_series(2, 100000000);
```
- Repeat the test above and check that the UNION ALL query has a higher response time and considerably larger MAL plan (full MAL plan [here](https://gist.github.com/nuno-faria/5216f279bf9aa48d360d70cbc9f7a22c)):
```sql
SELECT * FROM Test WHERE k = 1;
clk: 1.159 ms
PLAN SELECT * FROM Test WHERE k = 1;
-- same plan
EXPLAIN SELECT * FROM Test WHERE k = 1;
-- same mal
-- UNION ALL ---
(SELECT * FROM Test WHERE k = 1)
UNION ALL
(SELECT * FROM Test WHERE k = 1);
clk: 41.535 ms -- 18x higher than the two individual queries combined
PLAN (SELECT * FROM Test WHERE k = 1)
UNION ALL
(SELECT * FROM Test WHERE k = 1);
-- same plan
-- larger MAL
EXPLAIN (SELECT * FROM Test WHERE k = 1)
UNION ALL
(SELECT * FROM Test WHERE k = 1);
+---------------------------------------------------------------------------------------------------------------------------------------------------------------+
| mal |
+===============================================================================================================================================================+
| function user.main():void; |
| X_1:void := querylog.define("explain (select * from test where k = 1) \n union all\n (select * from test where k = 1);":str, "default_pipe":str, 37:int); |
| barrier X_1219:bit := language.dataflow(); |
| X_4:int := sql.mvc(); |
| C_113:bat[:oid] := sql.tid(X_4:int, "sys":str, "test":str, 0:int, 48:int); |
| X_211:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int, 0:int, 48:int); |
| X_313:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int, 0:int, 48:int); |
| C_721:bat[:oid] := algebra.thetaselect(X_211:bat[:int], C_113:bat[:oid], 1:int, "==":str); |
| X_769:bat[:int] := algebra.projection(C_721:bat[:oid], X_211:bat[:int]); |
| X_1221:void := language.pass(X_211:bat[:int]); |
| X_817:bat[:int] := algebra.projection(C_721:bat[:oid], X_313:bat[:int]); |
| X_1222:void := language.pass(C_721:bat[:oid]); |
| X_517:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int, 0:int, 48:int); |
| X_619:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int, 0:int, 48:int); |
| C_865:bat[:oid] := algebra.thetaselect(X_517:bat[:int], C_113:bat[:oid], 1:int, "==":str); |
| X_1223:void := language.pass(C_113:bat[:oid]); |
| X_913:bat[:int] := algebra.projection(C_865:bat[:oid], X_517:bat[:int]); |
| X_1224:void := language.pass(X_517:bat[:int]); |
| X_961:bat[:int] := algebra.projection(C_865:bat[:oid], X_619:bat[:int]); |
| X_1225:void := language.pass(C_865:bat[:oid]); |
| X_47:bat[:int] := bat.new(nil:int); |
| X_1020:bat[:int] := mat.packIncrement(X_769:bat[:int], 48:int); |
| X_1068:bat[:int] := mat.packIncrement(X_913:bat[:int], 48:int); |
| X_52:bat[:int] := bat.new(nil:int); |
| X_1117:bat[:int] := mat.packIncrement(X_817:bat[:int], 48:int); |
| X_1166:bat[:int] := mat.packIncrement(X_961:bat[:int], 48:int); |
| X_56:bat[:str] := bat.pack(".%5":str, ".%5":str); |
| X_57:bat[:str] := bat.pack("k":str, "v":str); |
| X_58:bat[:str] := bat.pack("int":str, "int":str); |
| X_59:bat[:int] := bat.pack(32:int, 32:int); |
| X_60:bat[:int] := bat.pack(0:int, 0:int); |
| C_114:bat[:oid] := sql.tid(X_4:int, "sys":str, "test":str, 1:int, 48:int); |
| X_213:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int, 1:int, 48:int); |
| X_315:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int, 1:int, 48:int); |
| C_722:bat[:oid] := algebra.thetaselect(X_213:bat[:int], C_114:bat[:oid], 1:int, "==":str); |
| X_770:bat[:int] := algebra.projection(C_722:bat[:oid], X_213:bat[:int]); |
| X_1226:void := language.pass(X_213:bat[:int]); |
| X_818:bat[:int] := algebra.projection(C_722:bat[:oid], X_315:bat[:int]); |
| X_1227:void := language.pass(C_722:bat[:oid]); |
| X_519:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int, 1:int, 48:int); |
| X_621:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int, 1:int, 48:int); |
| C_866:bat[:oid] := algebra.thetaselect(X_519:bat[:int], C_114:bat[:oid], 1:int, "==":str); |
| X_1228:void := language.pass(C_114:bat[:oid]); |
| X_914:bat[:int] := algebra.projection(C_866:bat[:oid], X_519:bat[:int]); |
| X_1229:void := language.pass(X_519:bat[:int]); |
| X_962:bat[:int] := algebra.projection(C_866:bat[:oid], X_621:bat[:int]); |
| X_1230:void := language.pass(C_866:bat[:oid]); |
| X_1021:bat[:int] := mat.packIncrement(X_1020:bat[:int], X_770:bat[:int]); |
| X_1070:bat[:int] := mat.packIncrement(X_1068:bat[:int], X_914:bat[:int]); |
| X_1119:bat[:int] := mat.packIncrement(X_1117:bat[:int], X_818:bat[:int]); |
| X_1168:bat[:int] := mat.packIncrement(X_1166:bat[:int], X_962:bat[:int]); |
| C_115:bat[:oid] := sql.tid(X_4:int, "sys":str, "test":str, 2:int, 48:int); |
| X_216:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int, 2:int, 48:int); |
| X_318:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int, 2:int, 48:int); |
| C_723:bat[:oid] := algebra.thetaselect(X_216:bat[:int], C_115:bat[:oid], 1:int, "==":str); |
| X_771:bat[:int] := algebra.projection(C_723:bat[:oid], X_216:bat[:int]); |
| X_1231:void := language.pass(X_216:bat[:int]); |
| X_819:bat[:int] := algebra.projection(C_723:bat[:oid], X_318:bat[:int]); |
| X_1232:void := language.pass(C_723:bat[:oid]); |
| X_522:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int, 2:int, 48:int); |
| X_624:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int, 2:int, 48:int); |
| C_867:bat[:oid] := algebra.thetaselect(X_522:bat[:int], C_115:bat[:oid], 1:int, "==":str); |
| X_1233:void := language.pass(C_115:bat[:oid]); |
| X_915:bat[:int] := algebra.projection(C_867:bat[:oid], X_522:bat[:int]); |
| X_1234:void := language.pass(X_522:bat[:int]); |
| X_963:bat[:int] := algebra.projection(C_867:bat[:oid], X_624:bat[:int]); |
| X_1235:void := language.pass(C_867:bat[:oid]); |
| X_1022:bat[:int] := mat.packIncrement(X_1021:bat[:int], X_771:bat[:int]); |
| X_1071:bat[:int] := mat.packIncrement(X_1070:bat[:int], X_915:bat[:int]); |
| X_1120:bat[:int] := mat.packIncrement(X_1119:bat[:int], X_819:bat[:int]); |
| X_1169:bat[:int] := mat.packIncrement(X_1168:bat[:int], X_963:bat[:int]); |
| C_117:bat[:oid] := sql.tid(X_4:int, "sys":str, "test":str, 3:int, 48:int); |
| X_218:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int, 3:int, 48:int); |
| X_320:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int, 3:int, 48:int); |
| C_724:bat[:oid] := algebra.thetaselect(X_218:bat[:int], C_117:bat[:oid], 1:int, "==":str); |
| X_772:bat[:int] := algebra.projection(C_724:bat[:oid], X_218:bat[:int]); |
| X_1236:void := language.pass(X_218:bat[:int]); |
| X_820:bat[:int] := algebra.projection(C_724:bat[:oid], X_320:bat[:int]); |
| X_1237:void := language.pass(C_724:bat[:oid]); |
| X_524:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int, 3:int, 48:int); |
| X_626:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int, 3:int, 48:int); |
| C_868:bat[:oid] := algebra.thetaselect(X_524:bat[:int], C_117:bat[:oid], 1:int, "==":str); |
| X_1238:void := language.pass(C_117:bat[:oid]); |
| X_916:bat[:int] := algebra.projection(C_868:bat[:oid], X_524:bat[:int]); |
| X_1239:void := language.pass(X_524:bat[:int]); |
| X_964:bat[:int] := algebra.projection(C_868:bat[:oid], X_626:bat[:int]); |
| X_1240:void := language.pass(C_868:bat[:oid]); |
| X_1023:bat[:int] := mat.packIncrement(X_1022:bat[:int], X_772:bat[:int]); |
| X_1072:bat[:int] := mat.packIncrement(X_1071:bat[:int], X_916:bat[:int]); |
| X_1121:bat[:int] := mat.packIncrement(X_1120:bat[:int], X_820:bat[:int]); |
| X_1170:bat[:int] := mat.packIncrement(X_1169:bat[:int], X_964:bat[:int]); |
| C_118:bat[:oid] := sql.tid(X_4:int, "sys":str, "test":str, 4:int, 48:int); |
| X_220:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int, 4:int, 48:int); |
| X_322:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int, 4:int, 48:int); |
| C_725:bat[:oid] := algebra.thetaselect(X_220:bat[:int], C_118:bat[:oid], 1:int, "==":str); |
| X_773:bat[:int] := algebra.projection(C_725:bat[:oid], X_220:bat[:int]); |
| X_1241:void := language.pass(X_220:bat[:int]); |
| X_821:bat[:int] := algebra.projection(C_725:bat[:oid], X_322:bat[:int]); |
| X_1242:void := language.pass(C_725:bat[:oid]); |
| X_526:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int, 4:int, 48:int); |
| X_628:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int, 4:int, 48:int); |
| C_869:bat[:oid] := algebra.thetaselect(X_526:bat[:int], C_118:bat[:oid], 1:int, "==":str); |
| X_1243:void := language.pass(C_118:bat[:oid]); |
...
| X_1066:bat[:int] := mat.packIncrement(X_1065:bat[:int], X_815:bat[:int]); |
| X_1115:bat[:int] := mat.packIncrement(X_1114:bat[:int], X_959:bat[:int]); |
| X_1164:bat[:int] := mat.packIncrement(X_1163:bat[:int], X_863:bat[:int]); |
| X_1213:bat[:int] := mat.packIncrement(X_1212:bat[:int], X_1007:bat[:int]); |
| C_209:bat[:oid] := sql.tid(X_4:int, "sys":str, "test":str, 47:int, 48:int); |
| X_311:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int, 47:int, 48:int); |
| X_413:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int, 47:int, 48:int); |
| C_768:bat[:oid] := algebra.thetaselect(X_311:bat[:int], C_209:bat[:oid], 1:int, "==":str); |
| X_816:bat[:int] := algebra.projection(C_768:bat[:oid], X_311:bat[:int]); |
| X_1456:void := language.pass(X_311:bat[:int]); |
| X_864:bat[:int] := algebra.projection(C_768:bat[:oid], X_413:bat[:int]); |
| X_1457:void := language.pass(C_768:bat[:oid]); |
| X_617:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "k":str, 0:int, 47:int, 48:int); |
| X_719:bat[:int] := sql.bind(X_4:int, "sys":str, "test":str, "v":str, 0:int, 47:int, 48:int); |
| C_912:bat[:oid] := algebra.thetaselect(X_617:bat[:int], C_209:bat[:oid], 1:int, "==":str); |
| X_1458:void := language.pass(C_209:bat[:oid]); |
| X_960:bat[:int] := algebra.projection(C_912:bat[:oid], X_617:bat[:int]); |
| X_1459:void := language.pass(X_617:bat[:int]); |
| X_1008:bat[:int] := algebra.projection(C_912:bat[:oid], X_719:bat[:int]); |
| X_1460:void := language.pass(C_912:bat[:oid]); |
| X_24:bat[:int] := mat.packIncrement(X_1066:bat[:int], X_816:bat[:int]); |
| X_49:bat[:int] := bat.append(X_47:bat[:int], X_24:bat[:int], true:bit); |
| X_45:bat[:int] := mat.packIncrement(X_1115:bat[:int], X_960:bat[:int]); |
| X_51:bat[:int] := bat.append(X_49:bat[:int], X_45:bat[:int], true:bit); |
| X_25:bat[:int] := mat.packIncrement(X_1164:bat[:int], X_864:bat[:int]); |
| X_53:bat[:int] := bat.append(X_52:bat[:int], X_25:bat[:int], true:bit); |
| X_46:bat[:int] := mat.packIncrement(X_1213:bat[:int], X_1008:bat[:int]); |
| X_54:bat[:int] := bat.append(X_53:bat[:int], X_46:bat[:int], true:bit); |
| exit X_1219:bit; |
| X_55:int := sql.resultSet(X_56:bat[:str], X_57:bat[:str], X_58:bat[:str], X_59:bat[:int], X_60:bat[:int], X_51:bat[:int], X_54:bat[:int]); |
| end user.main; |
| # optimizer.inline(0:int, 1:lng) |
| # optimizer.remap(0:int, 2:lng) |
| # optimizer.costModel(1:int, 1:lng) |
| # optimizer.coercions(0:int, 2:lng) |
| # optimizer.aliases(2:int, 4:lng) |
| # optimizer.evaluate(0:int, 4:lng) |
| # optimizer.emptybind(4:int, 6:lng) |
| # optimizer.deadcode(4:int, 5:lng) |
| # optimizer.pushselect(0:int, 8:lng) |
| # optimizer.aliases(4:int, 3:lng) |
| # optimizer.for(0:int, 2:lng) |
| # optimizer.dict(0:int, 2:lng) |
| # optimizer.mitosis(48:int, 97:lng) |
| # optimizer.mergetable(6:int, 162:lng) |
| # optimizer.bincopyfrom(0:int, 1:lng) |
| # optimizer.aliases(0:int, 1:lng) |
| # optimizer.constants(67:int, 33:lng) |
| # optimizer.commonTerms(48:int, 95:lng) |
| # optimizer.projectionpath(0:int, 22:lng) |
| # optimizer.deadcode(48:int, 37:lng) |
| # optimizer.matpack(4:int, 48:lng) |
| # optimizer.reorder(1:int, 56:lng) |
| # optimizer.dataflow(1:int, 109:lng) |
| # optimizer.querylog(0:int, 1:lng) |
| # optimizer.multiplex(0:int, 3:lng) |
| # optimizer.generator(0:int, 3:lng) |
| # optimizer.candidates(1:int, 3:lng) |
| # optimizer.deadcode(0:int, 30:lng) |
| # optimizer.postfix(0:int, 27:lng) |
| # optimizer.wlc(0:int, 1:lng) |
| # optimizer.garbageCollector(1:int, 129:lng) |
| # optimizer.profiler(0:int, 0:lng) |
| # optimizer.total(32:int, 938:lng) |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------+
1011 tuples -- 15x larger than the previous one
```
**Expected behavior**
UNION ALL's response time should be similar to the sum of running the queries individually.
**Software versions**
- MonetDB master branch (most recent commit)
- Ubuntu 20.04 LTS
- Self-installed and compiled
| UNION/UNION ALL generates unreasonable large MAL plan for simple queries, degrading performance | https://api.github.com/repos/MonetDB/MonetDB/issues/7270/comments | 2 | 2022-03-16T14:48:54Z | 2024-06-27T13:17:19Z | https://github.com/MonetDB/MonetDB/issues/7270 | 1,171,128,342 | 7,270 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
When operating a daily query, since this moring the database crashes on it, reporting the following merovingian error.
2022-03-15 10:01:32 MSG merovingian[16291]: target connection is on local UNIX domain socket, passing on filedescriptor instead of proxying
2022-03-15 10:01:37 ERR htm[551514]: mserver5: /home/skinkie/MonetDB/gdk/gdk_bat.c:247: COLnew_intern: Assertion `cap <= BUN_MAX' failed.
2022-03-15 10:01:41 MSG merovingian[16291]: database 'htm' (-1) has crashed with signal SIGABRT (dumped core)
**To Reproduce**
On my local installation I can reproduce this error by executing a query, that did not have any issues in the past years. But my expectation is that this also implies to have a database of similar size, over thousand tables.
**Expected behavior**
The query executes.
**Software versions**
- MonetDB 5 server 11.42.0 (hg id: d8bce54d40) (64-bit, 128-bit integers)
- OS and version: 5.16.10-arch1-1
**Additional context**
Access to the offending query and database are obviously available on request. I am sure that a clean database resolves this issue, but I may have hit a way interesting enough to investigate. | COLnew_intern: Assertion `cap <= BUN_MAX' failed. | https://api.github.com/repos/MonetDB/MonetDB/issues/7269/comments | 8 | 2022-03-15T09:11:03Z | 2022-03-18T10:37:35Z | https://github.com/MonetDB/MonetDB/issues/7269 | 1,169,385,326 | 7,269 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
I attempted to start up a database I have been working on, and it is failing to start up. I get the following error when I try:
```
$ monetdb start maapl
starting database 'maapl'... FAILED
start: starting 'maapl' failed: unknown or impossible state: 4
```
The merovingian.log file spits out the following when it try to start the database:
```
2022-03-10 19:43:28 MSG control[2892]: (local): served status list
2022-03-10 19:43:28 ERR control[2892]: (local): failed to fork mserver: unknown or impossible state: 4
```
**To Reproduce**
No clue what I did to break it. It would be nice to know how to fix it though.
The last line in the merovingian.log file before it stopped working is:
```
2022-03-10 09:49:07 ERR merovingian[1539]: strange, trying to kill process 0 to stop database 'maapl' which seems to be served by process -1 instead
```
I am happy to send logs if needed.
**Expected behavior**
I expect my database to be accessible whenever I try to start it.
**Software versions**
- MonetDB version number [a milestone label]: MonetDB Database Server Toolkit v11.43.9 (Jan2022-SP1)
- OS and version: Mac OS 12 (M1)
- Installed from release package or self-installed and compiled: Homebrew | Database Inaccessible - "Unknown or impossible state: 4" Error | https://api.github.com/repos/MonetDB/MonetDB/issues/7268/comments | 4 | 2022-03-11T02:56:56Z | 2023-10-28T09:50:52Z | https://github.com/MonetDB/MonetDB/issues/7268 | 1,165,941,424 | 7,268 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Deleting `n` rows from a table and then updating the rest, leaves `n` of the remaining rows not updated.
**To Reproduce**
I have shared the reproduction privately.
**Expected behavior**
All the remaining rows should be updated.
**Software versions**
- MonetDB Jan2022-SP1 installed on Fedora 35 using the release packages and changeset `64c356e13d86` (the current tip of Jan2022) compiled on Arch Linux.
| Update after delete does not update some rows | https://api.github.com/repos/MonetDB/MonetDB/issues/7267/comments | 1 | 2022-03-10T15:19:36Z | 2024-06-27T13:17:18Z | https://github.com/MonetDB/MonetDB/issues/7267 | 1,165,362,371 | 7,267 |
[
"MonetDB",
"MonetDB"
] | **Is your feature request related to a problem? Please describe.**
I'm importing data that has both empty and 'NA' strings that I would like to import as null. To my current understanding adding more than one string to the NULL AS clause throws a syntax error.
I've tried,
```
NULL AS '' AND 'NA'
-- and
NULL AS ''
NULL AS 'NA'
```
both giving me syntax errors.
**Describe the solution you'd like**
It would be nice to have some syntax that allows multiple strings to be read in as null. Such as:
```
NULL AS '' AND 'NA'
```
I'm not too concerned about the format. Just the feature would be nice. If I've missed some documentation that explains how this behavior is possible, please let me know.
If this possible, then having documentation about NULL AS clause explaining how this can be done would be great.
Thank you for your time and hard work on this product. | Select multiple character strings for NULL AS clause | https://api.github.com/repos/MonetDB/MonetDB/issues/7266/comments | 1 | 2022-03-08T18:20:43Z | 2024-06-27T13:17:17Z | https://github.com/MonetDB/MonetDB/issues/7266 | 1,162,977,531 | 7,266 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
COPY INTO command is not reading in full fixed width delimited file.
I have a fixed width delimited file:
```
$ head lar_1994.rawdata
199400000000011111000941NA NANA NA 582400580 1
199400000000011111000921NA NANA NA 552100320 2
199400000000011111000881NA NANA NA 552100280 3
199400000000011111001141NA NANA NA 582400350 4
199400000000011111000851NA NANA NA 481400280 5
199400000000011111001151NA NANA NA 552100640 6
199400000000011111000881NA NANA NA 551200340 7
199400000000011111000931NA NANA NA 582400320 8
199400000000011111000881NA NANA NA 582400260 9
199400000000011111000571NA NANA NA 581400400 10
```
```
$ tail lar_1994.rawdata
1994990000046271320006738960120990009.0258140070019 350
1994990000046271310030548960120990030.00581401910 351
1994990000046271110012238960120990057.025824007101 352
1994990000046271310020748960120990059.07551202320 353
1994990000046271110004168960120990059.11551200281 354
1994990000046271310012868960120990069.03582400521 355
1994990000046271110011868960120990070.04582400731 356
1994990000046271310011668960120990074.02581400651 357
1994990000046271310011668960120990074.02551200381 358
1994990000046271310011668960120990074.02581401201 359
```
That has 12,215,807 records in it.
```
$ wc -l lar_1994.rawdata
12215807 lar_1994.rawdata
```
When I run the following code:
```
CREATE TABLE IF NOT EXISTS lar_1994 (
"year" text,
respondent_id text,
agency_code text,
loan_type text,
loan_purpose text,
occupancy_type text,
loan_amount_000s text,
action_taken text,
msa_md_of_property text,
state_code text,
county_code text,
census_tract_number text,
applicant_race_1 text,
co_applicant_race_1 text,
applicant_sex text,
co_applicant_sex text,
applicant_income_000s text,
purchaser_type text,
denial_reason_1 text,
denial_reason_2 text,
denial_reason_3 text,
edit_status text,
sequence_number text
);
COPY INTO lar_1994 (
"year",
respondent_id,
agency_code,
loan_type,
loan_purpose,
occupancy_type,
loan_amount_000s,
action_taken,
msa_md_of_property,
state_code,
county_code,
census_tract_number,
applicant_race_1,
co_applicant_race_1,
applicant_sex,
co_applicant_sex,
applicant_income_000s,
purchaser_type,
denial_reason_1,
denial_reason_2,
denial_reason_3,
edit_status,
sequence_number)
FROM '/path/to/lar_1994.rawdata' ON CLIENT
FWF(
4,
10,
1,
1,
1,
1,
5,
1,
4,
2,
3,
7,
1,
1,
1,
1,
4,
1,
1,
1,
1,
1,
7
);
```
Only 17,189 records are put into the table.
```
sql>CREATE TABLE IF NOT EXISTS lar_1994 (
more>"year" text,
more>respondent_id text,
more>agency_code text,
more>loan_type text,
more>loan_purpose text,
more>occupancy_type text,
more>loan_amount_000s text,
more>action_taken text,
more>msa_md_of_property text,
more>state_code text,
more>county_code text,
more>census_tract_number text,
more>applicant_race_1 text,
more>co_applicant_race_1 text,
more>applicant_sex text,
more>co_applicant_sex text,
more>applicant_income_000s text,
more>purchaser_type text,
more>denial_reason_1 text,
more>denial_reason_2 text,
more>denial_reason_3 text,
more>edit_status text,
more>sequence_number text
more>);
operation successful
sql>COPY INTO lar_1994 (
more>"year",
more>respondent_id,
more>agency_code,
more>loan_type,
more>loan_purpose,
more>occupancy_type,
more>loan_amount_000s,
more>action_taken,
more>msa_md_of_property,
more>state_code,
more>county_code,
more>census_tract_number,
more>applicant_race_1,
more>co_applicant_race_1,
more>applicant_sex,
more>co_applicant_sex,
more>applicant_income_000s,
more>purchaser_type,
more>denial_reason_1,
more>denial_reason_2,
more>denial_reason_3,
more>edit_status,
more>sequence_number)
more>FROM '/path/to/lar_1994.rawdata' ON CLIENT
more>FWF(
more>4,
more>10,
more>1,
more>1,
more>1,
more>1,
more>5,
more>1,
more>4,
more>2,
more>3,
more>7,
more>1,
more>1,
more>1,
more>1,
more>4,
more>1,
more>1,
more>1,
more>1,
more>1,
more>7
more>);
17189 affected rows
```
The file has been cleaned and there are no null bytes or non utf-8 compliant characters.
**To Reproduce**
I uploaded the file [here](https://drive.google.com/uc?id=1FwpI8o4XiW-VG63avlvkeS4iXzwDYGsc&export=download). Please let me know if I am trying to import the data incorrectly, or if there is something else I must do to make it read in the full file.
**Expected behavior**
I expect all records to be read into the file, or for a message to explain why not all records were read in with a description on how to do so.
**Software versions**
- MonetDB version number [a milestone label]: MonetDB Database Server Toolkit v11.43.9 (Jan2022-SP1)
- OS and version: MacOS 12 (M1 processor)
- Installed from release package or self-installed and compiled: Homebrew
| COPY INTO Not Reading in all records of fixed width delimited file | https://api.github.com/repos/MonetDB/MonetDB/issues/7265/comments | 3 | 2022-03-07T20:34:44Z | 2024-08-05T11:28:40Z | https://github.com/MonetDB/MonetDB/issues/7265 | 1,161,895,068 | 7,265 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
The value of a sequence is not logged between sessions, causing it to reset to the initial one.
The exception is when, in addition to updating the sequence, another operation - which logs to the WAL - is executed (e.g. an insert).
**To Reproduce**
- Create a sequence and update its value:
```sql
CREATE SEQUENCE test_sequence AS bigint start with 1;
SELECT next_value_for('sys', 'test_sequence');
SELECT next_value_for('sys', 'test_sequence');
SELECT next_value_for('sys', 'test_sequence');
+------+
| %2 |
+======+
| 3 |
+------+
```
- Restart the server
- Update the sequence value and check that it reset to the initial one:
```sql
SELECT next_value_for('sys', 'test_sequence');
+------+
| %2 |
+======+
| 1 |
+------+
```
- Check that the sequence is persisted when another operation is performed:
```sql
CREATE TABLE Test (k int);
SELECT next_value_for('sys', 'test_sequence');
SELECT next_value_for('sys', 'test_sequence');
SELECT next_value_for('sys', 'test_sequence');
+------+
| %2 |
+======+
| 3 |
+------+
INSERT INTO Test VALUES (1);
1 affected row, last generated key: 3
-- restart the server
SELECT next_value_for('sys', 'test_sequence');
+------+
| %2 |
+======+
| 4 |
+------+
```
**Expected behavior**
The sequence is committed to the WAL on its own.
**Software versions**
- MonetDB master branch (most recent commit)
- Ubuntu 20.04 LTS
- Self-installed and compiled
| Sequence value is not durable between server restarts | https://api.github.com/repos/MonetDB/MonetDB/issues/7264/comments | 1 | 2022-03-07T17:17:46Z | 2022-03-11T07:51:23Z | https://github.com/MonetDB/MonetDB/issues/7264 | 1,161,699,870 | 7,264 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
The PRIMARY KEY constraint is ignored when the server restarts, allowing multiples rows with the same key.
**To Reproduce**
- Create a table with primary key
```sql
CREATE TABLE Test (k int PRIMARY KEY, v int);
\d Test
CREATE TABLE "sys"."test" (
"k" INTEGER NOT NULL,
"v" INTEGER,
CONSTRAINT "test_k_pkey" PRIMARY KEY ("k")
);
```
- Check that the PRIMARY KEY constraint is respected:
```sql
INSERT INTO Test VALUES(1, 1);
1 affected row
INSERT INTO Test VALUES(1, 1);
INSERT INTO: PRIMARY KEY constraint 'test.test_k_pkey' violated
```
- Restart the server
- Check that the PRIMARY KEY constraint is ignored:
```sql
\d Test
CREATE TABLE "sys"."test" (
"k" INTEGER NOT NULL,
"v" INTEGER,
CONSTRAINT "test_k_pkey" PRIMARY KEY ("k") -- still here
);
INSERT INTO Test VALUES(1, 1);
1 affected row
INSERT INTO Test VALUES(1, 1);
1 affected row
INSERT INTO Test VALUES(1, 1);
1 affected row
SELECT * FROM Test;
+------+------+
| k | v |
+======+======+
| 1 | 1 |
| 1 | 1 |
| 1 | 1 |
| 1 | 1 |
+------+------+
```
**Software versions**
- MonetDB master branch (most recent commit)
- Ubuntu 20.04 LTS
- Self-installed and compiled
| PRIMARY KEY constraint is not persistent through server restarts | https://api.github.com/repos/MonetDB/MonetDB/issues/7263/comments | 1 | 2022-03-07T13:06:53Z | 2024-06-27T13:17:15Z | https://github.com/MonetDB/MonetDB/issues/7263 | 1,161,394,928 | 7,263 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
I was performing the following operation on a large table:
```
UPDATE table SET column = replace(column, '.', '');
```
Then the database was taking an extremely long time to complete the operation (far longer than it should have), and I couldn't connect another client to the database. To free up my CPU (which was being maxed out by mserver5) I had to send a SIGKILL to the process. Now, whenever I start the database:
```
monetdb start database
```
mserver5 just maxes out my CPU, and the message:
```
starting database 'database'...
```
just stays on my terminal. If I kill that command, mserver5 continues to max out my CPU usage. If I restart the server, I can't connect to the database by running the `mclient -d database` command.
These were the last lines of the mdbtrace.log file before the issues started happening:
```
2022-03-04 13:01:55 M_ERROR MAL_SERVER client1 monetdb5/mal/mal_exception.c:104 createExceptionInternal SQLException:sql.resultSet:45000!Result set construction failed: stream Server write: socket write: Broken pipe
2022-03-04 13:13:45 M_ERROR MAL_SERVER client4 monetdb5/mal/mal_exception.c:104 createExceptionInternal SQLException:sql.resultSet:45000!Result set construction failed: stream Server write: socket write: Broken pipe
```
When I start the server again this appears in the merovingian.log file (note that there isn't any output after the mserver5 command):
```
2022-03-05 13:32:42 MSG control[1522]: (local): served status list
2022-03-05 13:32:42 MSG merovingian[1522]: database 'maapl_project' has crashed after start on 2022-03-05 13:16:54, attempting restart, up min/avg/max: 26m/1h/3h, crash average: 1.00 1.00 0.60 (22-4=18)
2022-03-05 13:32:43 MSG maapl_project[1790]: arguments: /opt/homebrew/Cellar/monetdb/11.43.9/bin/mserver5 --dbpath=/Volumes/external_drive/monetdb_test/maapl_project --set merovingian_uri=mapi:monetdb://A-Computer.local:50000/maapl_project --set mapi_listenaddr=none --set mapi_usock=/Volumes/external_drive/monetdb_test/maapl_project/.mapi.sock --set monet_vault_key=/Volumes/external_drive/monetdb_test/maapl_project/.vaultkey --set gdk_nr_threads=8 --set max_clients=64 --set sql_optimizer=default_pipe
```
And mserver5 starts to max out my CPU. I can't connect to the database in any way (msqldump also doesn't work). The only way to shut down the server is by sending a SIGKILL to the process. I can send the database into maintenance mode, but it is inaccessible even then. Even from the DBA (monetdb) account.
What more information would help with addressing the bug? I can send the log files if necessary. Thank you for this product. I'm excited to keep using it. (It is a bit unfortunate that I am locked out of my data though.)
**To Reproduce**
I have no idea how the error happened. I ran the command `UPDATE table SET column = replace(column, '.', '');` on another test database I made, but it didn't cause any issues.
**Expected behavior**
The server doesn't have any issues and I'm not locked out of using it.
**Software versions**
- MonetDB version number [a milestone label]: MonetDB 5 server v11.43.9 (Jan2022-SP1)
- OS and version: Mac OS (ARM/M1)
- Installed from release package or self-installed and compiled: Obtained from Homebrew. | Database Inaccessible | https://api.github.com/repos/MonetDB/MonetDB/issues/7262/comments | 9 | 2022-03-05T20:54:29Z | 2024-06-07T11:57:42Z | https://github.com/MonetDB/MonetDB/issues/7262 | 1,160,444,077 | 7,262 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Certain error message for CREATE TABLE query is not descriptive and doesn't explain the actual error.
**To Reproduce**
Run the following in an mclient sql shell.
```
create table some_table (
TransId bigint,
AssessorParcelNumber varchar(50),
APNIndicatorStndCode varchar(1),
TaxIDNumber varchar(50),
TaxIDIndicatorStndCode varchar(1),
UnformattedAssessorParcelNumber varchar(50),
AlternateParcelNumber varchar(50),
HawaiiCondoCPRCode varchar(4),
PropertyHouseNumber varchar(13),
PropertyHouseNumberExt varchar(10),
PropertyStreetPreDirectional varchar(2),
PropertyStreetName varchar(50),
PropertyStreetSuffix varchar(6),
PropertyStreetPostDirectional varchar(2),
PropertyBuildingNumber varchar(45),
PropertyFullStreetAddress varchar(80),
PropertyCity varchar(45),
PropertyState varchar(2),
PropertyZip varchar(15),
PropertyZip4 varchar(4),
OriginalPropertyFullStreetAddress varchar(100),
OriginalPropertyAddressLastline varchar(100),
PropertyAddressStndCode varchar(1),
LegalLot varchar(100),
LegalOtherLot varchar(100),
LegalLotCode varchar(2),
LegalBlock varchar(50),
LegalSubdivisionName varchar(200),
LegalCondoProjectPUDDevName varchar(100),
LegalBuildingNumber varchar(45),
LegalUnit varchar(100),
LegalSection varchar(100),
LegalPhase varchar(50),
LegalTract varchar(50),
LegalDistrict varchar(45),
LegalMunicipality varchar(50),
LegalCity varchar(50),
LegalTownship varchar(50),
LegalSTRSection varchar(100),
LegalSTRTownship varchar(15),
LegalSTRRange varchar(15),
LegalSTRMeridian varchar(35),
LegalSecTwnRngMer varchar(165),
LegalRecordersMapReference varchar(100),
LegalDescription varchar(2000),
LegalLotSize varchar(14),
PropertySequenceNumber int,
PropertyAddressMatchcode varchar(1),
PropertyAddressUnitDesignator varchar(10),
PropertyAddressUnitNumber varchar(25),
PropertyAddressCarrierRoute varchar(4),
PropertyAddressGeoCodeMatchCode varchar(1),
PropertyAddressLatitude varchar(15),
PropertyAddressLongitude varchar(15),
PropertyAddressCensusTractAndBlock varchar(16),
PropertyAddressConfidenceScore tinyint,
PropertyAddressCBSACode int,
PropertyAddressCBSADivisionCode int,
PropertyAddressMatchType int,
PropertyAddressDPV varchar(1),
PropertyGeocodeQualityCode varchar(50),
PropertyAddressQualityCode varchar(10),
FIPS varchar(5),
LoadID bigint,
ImportParcelID bigint,
BKFSPID int,
AssessmentRecordMatchFlag tinyint,
BatchID int,
);
```
Produces the following error text in the mclient shell.
`syntax error in: "create table junk_db (
transid bigint,
assessorparcelnumber varchar(50),
apnindi"`
**Expected behavior**
The actual error is that there is a `,` after the final item in the create statement when there shouldn't be.
**Screenshots**
<img width="1264" alt="Screen Shot 2022-03-04 at 8 58 30 AM" src="https://user-images.githubusercontent.com/22198719/156796941-4b47ff72-a26a-43ce-8483-ab944cfa3097.png">
**Software versions**
- MonetDB version number: MonetDB Database Server Toolkit v11.43.9 (Jan2022-SP1)
- OS and version: Mac OS Monterey
- Installed from release package.
| Misleading error message | https://api.github.com/repos/MonetDB/MonetDB/issues/7261/comments | 2 | 2022-03-04T16:03:28Z | 2024-06-27T13:17:14Z | https://github.com/MonetDB/MonetDB/issues/7261 | 1,159,800,529 | 7,261 |
[
"MonetDB",
"MonetDB"
] | 
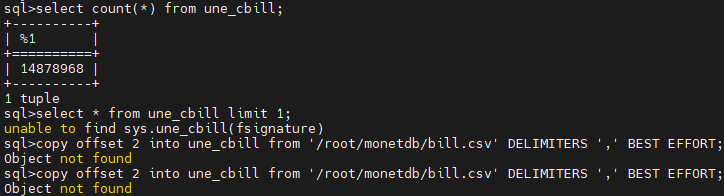


Check whether the virtual memory cannot be released
Check whether there are commands that can be restored | Object not found | https://api.github.com/repos/MonetDB/MonetDB/issues/7260/comments | 6 | 2022-03-02T03:07:04Z | 2023-10-28T09:58:38Z | https://github.com/MonetDB/MonetDB/issues/7260 | 1,156,277,903 | 7,260 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Some queries generate an empty execution MAL. This causes the query to silently fail - when performing a select - or return `Incorrect MAL plan encountered` - when preparing a statement. Some modifications to the query (such as replacing the `OR` with `AND`) make it work.
The error only appears to happen with commit aeddf4146a61311ff7bdecfb6942e56185982634 and above.
**To Reproduce**
- Create a simple table:
```sql
CREATE TABLE Test (x int);
```
- Check that the query execution returns nothing (not zero tuples, actually does not return any output):
```sql
-- this is just a minimal example I extracted from the real query
SELECT *
FROM Test
WHERE x IN (SELECT x FROM Test)
AND (x IN (SELECT x FROM Test)
OR (x IN (SELECT x FROM Test)))
```
- Check that the `PREPARE` returns the "Incorrect MAL plan encountered" error message:
```sql
PREPARE
SELECT *
FROM Test
WHERE x IN (SELECT x FROM Test)
AND (x IN (SELECT x FROM Test)
OR (x IN (SELECT x FROM Test)))
>Internal error while compiling statement: MALException:garbageCollector:42000!Error in optimizer garbageCollector: MALException:optimizer.garbagecollector:42000!Incorrect MAL plan encountered
```
**Software versions**
- MonetDB master branch (most recent commit)
- Ubuntu 20.04 LTS
- Self-installed and compiled
**Additional context**
- MAL plan (empty):
```sql
+--------------------------------------------------------------------------------------------+
| mal |
+============================================================================================+
| function user.main():void; |
| X_1:void := querylog.define("explain select *\nfrom test\nwhere x in (select x from te |
: st)\n and (x in (select x from test)\n or (x in (select x from test)))\n;":str, "default_p :
: ipe":str, 101:int); :
| end user.main; |
| # optimizer.inline(0:int, 6:lng) |
| # optimizer.remap(4:int, 12:lng) |
| # optimizer.costModel(1:int, 4:lng) |
| # optimizer.coercions(0:int, 2:lng) |
| # optimizer.aliases(5:int, 6:lng) |
| # optimizer.evaluate(0:int, 6:lng) |
| # optimizer.emptybind(16:int, 12:lng) |
| # optimizer.deadcode(94:int, 9:lng) |
| # optimizer.pushselect(0:int, 5:lng) |
| # optimizer.aliases(0:int, 0:lng) |
| # optimizer.for(0:int, 1:lng) |
| # optimizer.dict(0:int, 2:lng) |
| # optimizer.mitosis(0:int, 1:lng) |
| # optimizer.mergetable(0:int, 8:lng) |
| # optimizer.bincopyfrom(0:int, 0:lng) |
| # optimizer.aliases(0:int, 1:lng) |
| # optimizer.constants(0:int, 2:lng) |
| # optimizer.commonTerms(0:int, 1:lng) |
| # optimizer.projectionpath(0:int, 0:lng) |
| # optimizer.deadcode(0:int, 2:lng) |
| # optimizer.matpack(0:int, 0:lng) |
| # optimizer.reorder(1:int, 3:lng) |
| # optimizer.dataflow(0:int, 3:lng) |
| # optimizer.querylog(0:int, 1:lng) |
| # optimizer.multiplex(0:int, 1:lng) |
| # optimizer.generator(0:int, 1:lng) |
| # optimizer.candidates(1:int, 0:lng) |
| # optimizer.deadcode(0:int, 2:lng) |
| # optimizer.postfix(0:int, 1:lng) |
| # optimizer.wlc(0:int, 1:lng) |
| # optimizer.garbageCollector(1:int, 2:lng) |
| # optimizer.profiler(0:int, 0:lng) |
| # optimizer.total(32:int, 151:lng) |
+--------------------------------------------------------------------------------------------+
```
- SQL plan (this one seems ok):
```sql
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| rel |
+========================================================================================================================================================================================================================================================+
| project ( |
| | select ( |
| | | group by ( |
| | | | left outer join ( |
| | | | | project ( |
| | | | | | group by ( |
| | | | | | | left outer join ( |
| | | | | | | | project ( |
| | | | | | | | | semijoin ( |
| | | | | | | | | | table("sys"."test") [ "test"."x" ], |
| | | | | | | | | | project ( |
| | | | | | | | | | | table("sys"."test") [ "test"."x" ] |
| | | | | | | | | | ) [ "test"."x" as "%16"."%16" ] |
| | | | | | | | | ) [ ("test"."x") any = ("%16"."%16") ] |
| | | | | | | | ) [ "test"."x", "sys"."identity"("test"."x") NOT NULL UNIQUE HASHCOL as "%17"."%17" ], |
| | | | | | | | project ( |
| | | | | | | | | table("sys"."test") [ "test"."x" ] |
| | | | | | | | ) [ "test"."x" as "%10"."%10", "sys"."identity"("%10"."%10") NOT NULL UNIQUE HASHCOL as "%20"."%20" ] |
| | | | | | | ) [ ] |
| | | | | | ) [ "%17"."%17" NOT NULL UNIQUE HASHCOL ] [ "sys"."anyequal"("test"."x", "%10"."%10", "%20"."%20" NOT NULL UNIQUE HASHCOL ) as "%21"."%21", "test"."x", "%17"."%17" NOT NULL UNIQUE HASHCOL ] |
| | | | | ) [ "%21"."%21", "test"."x", "%17"."%17" NOT NULL UNIQUE HASHCOL , "sys"."identity"("%21"."%21") NOT NULL UNIQUE HASHCOL as "%22"."%22" ], |
| | | | | project ( |
| | | | | | table("sys"."test") [ "test"."x" ] |
| | | | | ) [ "test"."x" as "%13"."%13", "sys"."identity"("%13"."%13") NOT NULL UNIQUE HASHCOL as "%23"."%23" ] |
| | | | ) [ ] |
| | | ) [ "%22"."%22" NOT NULL UNIQUE HASHCOL ] [ "sys"."anyequal"("test"."x", "%13"."%13", "%23"."%23" NOT NULL UNIQUE HASHCOL ) as "%24"."%24", "%21"."%21", "test"."x", "%17"."%17" NOT NULL UNIQUE HASHCOL , "%22"."%22" NOT NULL UNIQUE HASHCOL ] |
| | ) [ (("%11"."%11") = (boolean(1) "true")) or (("%14"."%14") = (boolean(1) "true")) ] |
| ) [ "test"."x" ] |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
```
- Logs when executing the `PREPARE`:
```log
createExceptionInternal: !ERROR: MALException:optimizer.garbagecollector:42000!Incorrect MAL plan encountered
createExceptionInternal: !ERROR: MALException:garbageCollector:42000!Error in optimizer garbageCollector: MALException:optimizer.garbagecollector:42000!Incorrect MAL plan encountered
createExceptionInternal: !ERROR: MALException:garbageCollector:42000!Error in optimizer garbageCollector: MALException:optimizer.garbagecollector:42000!Incorrect MAL plan encountered
createExceptionInternal: !ERROR: ParseException:SQLparser:42000!Internal error while compiling statement: MALException:garbageCollector:42000!Error in optimizer garbageCollector: MALException:optimizer.garbagecollector:42000!Incorrect MAL plan encountered
createExceptionInternal: !ERROR: MALException:cache.remove:42000!internal error, symbol missing
```
| Query generates empty MAL | https://api.github.com/repos/MonetDB/MonetDB/issues/7259/comments | 2 | 2022-02-28T19:15:48Z | 2022-03-01T12:44:16Z | https://github.com/MonetDB/MonetDB/issues/7259 | 1,154,454,560 | 7,259 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
I have a field of type double and I want to convert its content to text.
But, the result of the conversion seems incorrect to me (it's coming with scientific notation).
**To Reproduce**
Just trying to convert the content of a field of type double to text.
I think for scientific notation to show up, the content must have a zero at the end (as can be seen in screenshot below).
**Expected behavior**
Convert the contents of the double field to text only (no scientific notation).
**Screenshots**
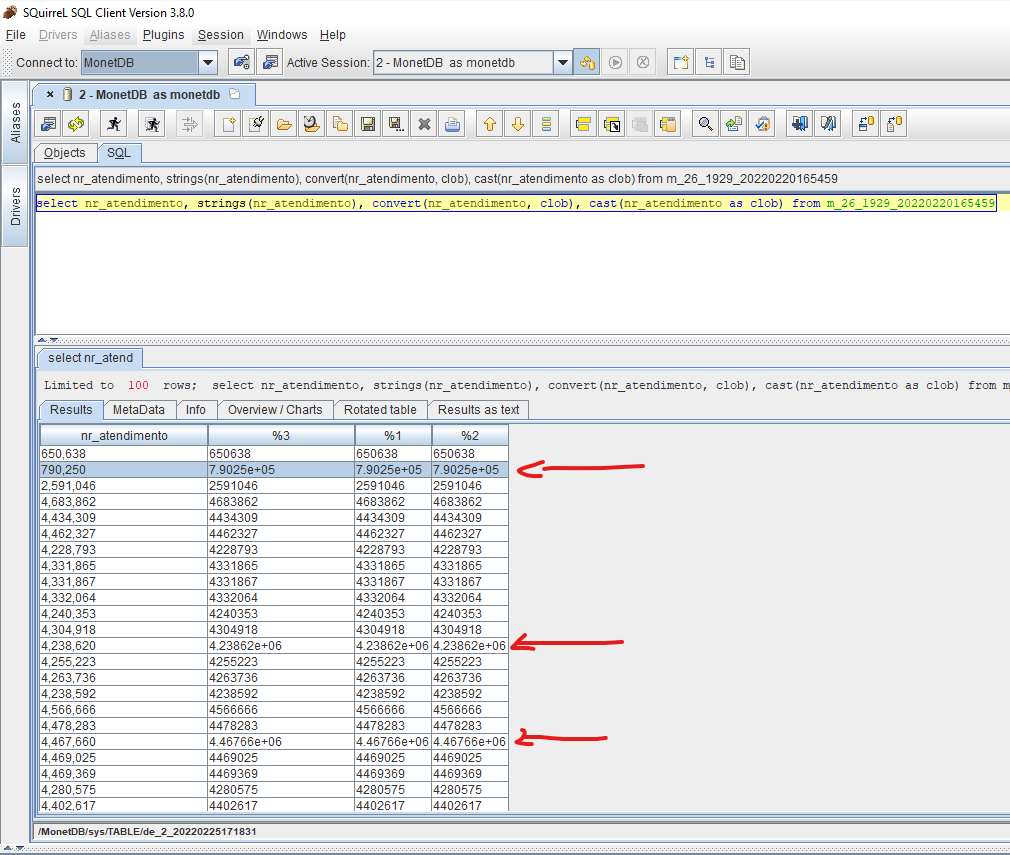
**Software versions**
- MonetDB version number: 11.43.9
- OS and version: Windows 10
- Installed from release package or self-installed and compiled: release package | Number to text conversion is incorrect (it's coming with scientific notation) | https://api.github.com/repos/MonetDB/MonetDB/issues/7258/comments | 8 | 2022-02-28T12:55:44Z | 2022-04-20T16:44:17Z | https://github.com/MonetDB/MonetDB/issues/7258 | 1,154,058,355 | 7,258 |
[
"MonetDB",
"MonetDB"
] | **Is your feature request related to a problem?
We created a user with SHA512 Hash key encrypted password, While to trying to connect the same using mclient its not taking the has password and getting invalid credentials. Please help on how the encrypted password feature works in monet.
**Describe the solution you'd like**
I need to get info about how to connect to database user using encrypted password and how the password encryption works.
| Encrypted Password Request | https://api.github.com/repos/MonetDB/MonetDB/issues/7257/comments | 2 | 2022-02-24T15:31:27Z | 2024-07-10T12:26:42Z | https://github.com/MonetDB/MonetDB/issues/7257 | 1,149,430,179 | 7,257 |
[
"MonetDB",
"MonetDB"
] | I want to evaluate queries runtime in MonetDB. What I have been doing so far is using the --performance flag, the running the query and considering the reported clk value.
sql:0.053 opt:8.887 run:15.779 clk:27.059 ms
I am interested in evaluating the impact of results transmission and printing time. I have used the option that I have found on this [question](https://stackoverflow.com/a/50346106/6120602). So inside `mclient` I am disabling the result output by setting `\f trash` to ignore the results when measuring only then prepending [`trace`](https://www.monetdb.org/Documentation/Manuals/SQLreference/Trace) to your query and you get your results like this:
The first of the two lines shows you the server timings, the second one the overall timing including passing the results back to the client. However, both the result values are significantly higher than the original runtime:
sql>\f trash
sql>trace select count(*) from categories;
sql:0.086 opt:10.932 run:64.368 clk:92.800 ms
sql:0.086 opt:0.000 run:0.000 clk:451.572 ms
My guess is that the second values are higher because they are also measuring the trace command runtime which is an additional work. The question is still, how could I evaluate the query runtime in MonetDB with vs without passing and outputting the results? | Query runtime evaluation (passing vs not passing results) | https://api.github.com/repos/MonetDB/MonetDB/issues/7256/comments | 1 | 2022-02-23T20:29:33Z | 2022-02-24T21:33:13Z | https://github.com/MonetDB/MonetDB/issues/7256 | 1,148,544,795 | 7,256 |
[
"MonetDB",
"MonetDB"
] | ## Describe the bug
The following phenomenon occurs when using a merge table composed of a remote table.
If the `WHERE` clause is configured using the `COALESCE` function in the SQL `SELECT` clause, the memory of the server where the merge table is located is rapidly occupied.
When query 1 below is executed, the memory increases rapidly and then comes down again as shown in Figures 1-3.
The Merge table `store.DATA_20210428_151721_190` has 113,670,794 rows
#### Query 1
``` sql
select idx,
'*' as category,
COALESCE(CAST(op_unique_carrier AS TEXT),'[Null]') as colorby,
op_unique_carrier as op_unique_carrier_colorby ,
COALESCE(fl_date, cast('1970-01-01 00:00:00.000' as timestamp)) as xvalue,
COALESCE(dep_delay, 0.0) as yvalue
from store.DATA_20210428_151721_190
where 1=1
and COALESCE(dep_delay,50) >= 10
and COALESCE(dep_delay,50) < 1700
```
[Figure 1- Before SQL Execution]
[Figure 2- SQL Execution: Memory Increase]
[Figure 3-After SQL execution: memory reduction]
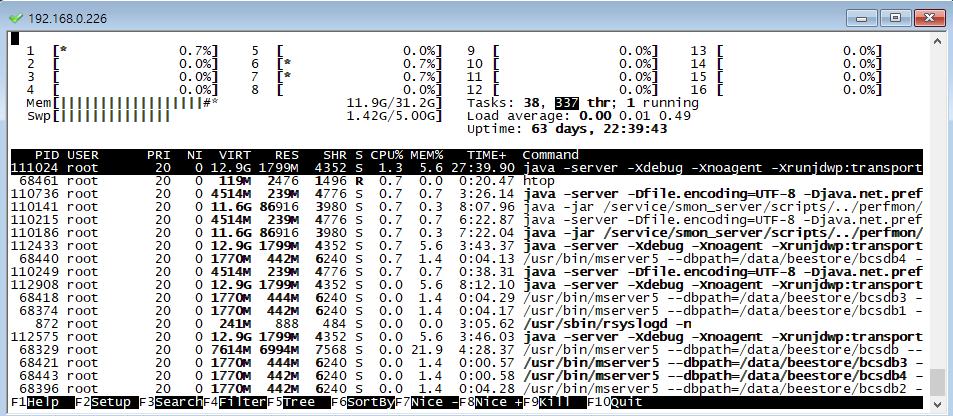
When query 1 is executed simultaneously with different `WHERE` conditions, the server hangs due to insufficient memory as shown in Figure 4, and the MonetDB server must be restarted for the service to return to normal. However, under the same load conditions, there is no problem in the older version of MonetDB, 11.41.5 (Jul2021) As Figure 5.
In case of simultaneous load conditions, the comparison data of the two servers is attached. (They are different servers, but the memory requirements are the same.)
[Figure 4 : MonetDB 11.43.9]
<img src="https://user-images.githubusercontent.com/81399392/155061166-db478fd3-95ff-4cb9-a598-647975455824.png">
[Figure 5 : MonetDB 11.41.5]
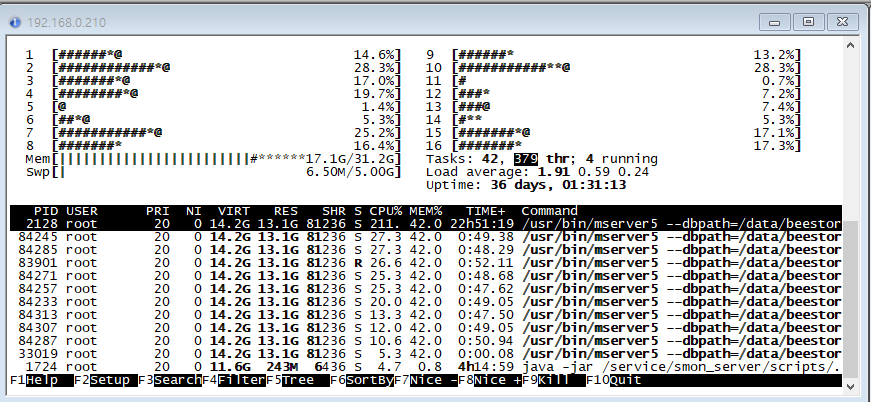
If `COALESCE` is removed from query 1 and executed as in query 2, the above phenomenon does not occur.
##### Query 2
``` sql
select idx,
'*' as category,
COALESCE(CAST(op_unique_carrier AS TEXT),'[Null]') as colorby,
op_unique_carrier as op_unique_carrier_colorby ,
COALESCE(fl_date, cast('1970-01-01 00:00:00.000' as timestamp)) as xvalue,
COALESCE(dep_delay, 0.0) as yvalue
from store.DATA_20210428_151721_190
where 1=1
and dep_delay >= 10
and dep_delay < 1700
```
## Reproduction
By using the `WHERE` conditional clause containing the `COALESCE` function on the merge table consisting of a remote table containing more than 100 million data
``` sql
select idx,
'*' as category,
COALESCE(CAST(op_unique_carrier AS TEXT),'[Null]') as colorby,
op_unique_carrier as op_unique_carrier_colorby ,
COALESCE(fl_date, cast('1970-01-01 00:00:00.000' as timestamp)) as xvalue,
COALESCE(dep_delay, 0.0) as yvalue
from store.DATA_20210428_151721_190
where 1=1
and COALESCE(dep_delay,50) >= 10
and COALESCE(dep_delay,50) < 1700
```
## Expected behavior
There should be no memory growth as in MonetDB 11.41.5 (Jul2021).
## Screenshots
All attached to the text.
## Software versions
- MonetDB version number : MonetDB 5 server 11.43.9 (Jan2022-SP1)
``` bash
[root@beestore ~]# mserver5 --version
MonetDB 5 server 11.43.9 (Jan2022-SP1) (64-bit, 128-bit integers)
Copyright (c) 1993 - July 2008 CWI
Copyright (c) August 2008 - 2022 MonetDB B.V., all rights reserved
Visit https://www.monetdb.org/ for further information
Found 31.2 GiB available memory, 16 available cpu cores
Libraries:
libpcre: 8.32 2012-11-30
libxml2: 2.9.1
Compiled by: mockbuild@14f3eb203288488dbd3f167a3ec87b16 (x86_64-pc-linux-gnu)
Compilation: /usr/bin/cc -O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -specs =/usr/lib/rpm/redhat/redhat-hardened-cc1 -m64 -mtune=generic
Linking: /usr/bin/ld
```
## OS and version
CentOS Linux release 7.4.1708 (Core)
## Installation from release package or self-installed and compiled
Installed from release package
## Issue labeling
Memory Issue | [Memory Issue] Memory increases rapidly when use COALESCE on where clause | https://api.github.com/repos/MonetDB/MonetDB/issues/7255/comments | 3 | 2022-02-22T04:09:19Z | 2024-07-10T12:31:07Z | https://github.com/MonetDB/MonetDB/issues/7255 | 1,146,431,256 | 7,255 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Committing a transaction that has removed a considerable amount of rows takes longer than reasonable.
**To Reproduce**
```
set optimizer='sequential_pipe';
start transaction;
-- a table with 100M random integers, with about 10M unique values
CREATE TABLE x AS
SELECT rand() % (10 * 1000 * 1000) as a1
FROM sys.generate_series(1, (100 * 1000 * 1000));
-- without this delete (about 10%), the commit takes less than 1s
-- with the delete, the commit takes forever (I had to kill the server after waiting longer than 30 minutes)
-- DELETE FROM x
-- WHERE a1 in (SELECT rand() % (10 * 1000 * 1000) FROM sys.generate_series(1, (1000 * 1000)));
commit;
```
**Software versions**
- MonetDB version number 11.43.10
- OS and version: Fedora 35
- self-installed and compiled
| Commit with deletions is very slow | https://api.github.com/repos/MonetDB/MonetDB/issues/7254/comments | 2 | 2022-02-18T18:26:08Z | 2024-06-27T13:17:11Z | https://github.com/MonetDB/MonetDB/issues/7254 | 1,143,544,531 | 7,254 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
An `INSERT INTO <table> SELECT ..` statement that takes less than 1 second in 11.39 takes about 45 minutes in 11.43.
I could not yet make a reproducible script for the issue. I see it happening regularly on a production ETL.
The query is
```
INSERT INTO relations SELECT * FROM newlinks;
```
where:
```
sql> \d newlinks
CREATE VIEW newlinks AS
SELECT contract as subject, (SELECT id FROM dict WHERE idstr = 'supplier') as predicate, partner as object, CAST(1 as DOUBLE) as prob
FROM contract_partner;
sql>\d relations
CREATE TABLE "spinque"."relations" (
"subject" INTEGER,
"predicate" INTEGER,
"object" INTEGER,
"prob" DOUBLE
);
ALTER TABLE "spinque"."relations" ALTER COLUMN "prob" SET DEFAULT 1.000000;
sql>\d contract_partner
CREATE TABLE "spinque"."contract_partner" (
"cotract" INTEGER,
"partner" INTEGER,
);
```
What `gdb` says:
```
#0 HASHgetlink (i=143692107, h=0x7ffa800aec30) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/gdk/gdk_hash.h:137
#1 HASHdelete_locked (b=b@entry=0x7ffab8150100, p=p@entry=85696165, v=v@entry=0x7ff831007a94) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/gdk/gdk_hash.c:1314
#2 0x00007ffadd4ab8a9 in BATappend_or_update (b=b@entry=0x7ffab8150100, p=p@entry=0x7ffa8fe18cb0, positions=0x7ffa35d40ee8, positions@entry=0x0, n=n@entry=0x7ffa8fe1b050, mayappend=mayappend@entry=true, autoincr=<optimized out>, autoincr@entry=false, force=true) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/gdk/gdk_batop.c:1556
#3 0x00007ffadd4ae0ab in BATupdate (b=b@entry=0x7ffab8150100, p=p@entry=0x7ffa8fe18cb0, n=n@entry=0x7ffa8fe1b050, force=force@entry=true) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/gdk/gdk_batop.c:1622
#4 0x00007ffacee6230c in delta_append_bat (tr=tr@entry=0x7ffaa0213630, batp=batp@entry=0x7ffac47ac6a8, id=<optimized out>, offset=<optimized out>, offset@entry=0, offsets=offsets@entry=0x7ffa8fe18cb0, i=i@entry=0x7ffa8fe1b050, storage_type=0x0) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/sql/storage/bat/bat_storage.c:2074
#5 0x00007ffacee651f1 in append_col_execute (cnt=134430, tt=5, storage_type=<optimized out>, incoming_data=0x7ffa8fe1b050, offsets=0x7ffa8fe18cb0, offset=0, id=<optimized out>, delta=0x7ffac47ac6a8, tr=0x7ffaa0213630) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/sql/storage/bat/bat_storage.c:2183
#6 append_col_execute (storage_type=<optimized out>, tt=5, cnt=134430, incoming_data=0x7ffa8fe1b050, offsets=0x7ffa8fe18cb0, offset=0, id=<optimized out>, delta=0x7ffac47ac6a8, tr=0x7ffaa0213630) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/sql/storage/bat/bat_storage.c:2174
#7 append_col (tr=0x7ffaa0213630, c=0x7ffab814ffd0, offset=0, offsets=0x7ffa8fe18cb0, data=0x7ffa8fe1b050, cnt=134430, tpe=5) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/sql/storage/bat/bat_storage.c:2212
#8 0x00007ffaced80645 in mvc_append_wrap (cntxt=<optimized out>, mb=<optimized out>, stk=<optimized out>, pci=<optimized out>) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/sql/backends/monet5/sql.c:1784
#9 0x00007ffadd8f9ba3 in runMALsequence (cntxt=cntxt@entry=0x13a1dd0, mb=mb@entry=0x7ffaa0150090, startpc=startpc@entry=1, stoppc=stoppc@entry=0, stk=stk@entry=0x7ffa93a1ac30, env=env@entry=0x0, pcicaller=0x0) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/monetdb5/mal/mal_interpreter.c:656
#10 0x00007ffadd8fb59b in runMAL (cntxt=cntxt@entry=0x13a1dd0, mb=mb@entry=0x7ffaa0150090, mbcaller=mbcaller@entry=0x0, env=env@entry=0x0) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/monetdb5/mal/mal_interpreter.c:335
#11 0x00007ffaced8d85b in SQLrun (c=c@entry=0x13a1dd0, m=m@entry=0x7ffaa015c4f0) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/sql/backends/monet5/sql_execute.c:246
#12 0x00007ffaced8e79b in SQLengineIntern (c=0x13a1dd0, be=0x7ffaa0213730) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/sql/backends/monet5/sql_execute.c:699
#13 0x00007ffadd90b297 in runPhase (phase=4, c=0x13a1dd0) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/monetdb5/mal/mal_scenario.c:451
#14 runPhase (phase=4, c=0x13a1dd0) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/monetdb5/mal/mal_scenario.c:446
#15 runScenarioBody (once=<optimized out>, c=<optimized out>) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/monetdb5/mal/mal_scenario.c:477
#16 runScenario (c=c@entry=0x13a1dd0, once=once@entry=0) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/monetdb5/mal/mal_scenario.c:508
#17 0x00007ffadd90b7e2 in MSserveClient (c=c@entry=0x13a1dd0) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/monetdb5/mal/mal_session.c:531
#18 0x00007ffadd90bea7 in MSscheduleClient (command=command@entry=0x7ffaa010a5b0 "", challenge=challenge@entry=0x7ffac47acd83 "L7BcGu7iGu9", fin=0x7ffac80063e0, fout=fout@entry=0x7ffac8003de0, protocol=protocol@entry=PROTOCOL_9, blocksize=blocksize@entry=8190) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/monetdb5/mal/mal_session.c:388
#19 0x00007ffadd98c8ae in doChallenge (data=<optimized out>) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/monetdb5/modules/mal/mal_mapi.c:220
#20 0x00007ffadd4f98aa in THRstarter (a=0x7ffac80062c0) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/gdk/gdk_utils.c:1638
#21 0x00007ffadd539229 in thread_starter (arg=0x7ffac800c130) at /opt/monetdb/SpinqueMonetDB-11.43.202202171906/gdk/gdk_system.c:833
#22 0x00007ffadcedfa87 in start_thread (arg=<optimized out>) at pthread_create.c:435
#23 0x00007ffadcf638d4 in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:100
```
This is `b`:
```
(gdb) p *b
$2 = {hseqbase = 0, creator_tid = 65, batCacheid = 439, batCopiedtodisk = true, batDirtyflushed = false, batDirtydesc = false, batTransient = false, batRestricted = 1 '\001', batRole = PERSISTENT, unused = 0, batSharecnt = 0, batInserted = 221697766, batCount = 221697766, batCapacity = 232488960, T = {
id = 0x7ffadd6d3aa3 "t", width = 4, type = 6 '\006', shift = 2 '\002', varsized = false, key = false, nonil = true, nil = false, sorted = false, revsorted = false, nokey = {0, 0}, nosorted = 0, norevsorted = 0, minpos = 9223372036854775807, maxpos = 9223372036854775807, unique_est = 30862161,
seq = 9223372036854775808, heap = 0x7ffab81502d0, baseoff = 0, vheap = 0x0, hash = 0x7ffa800aec30, imprints = 0x0, orderidx = 0x0, strimps = 0x0, props = 0x0}, theaplock = {lock = {__data = {__lock = 0, __count = 0, __owner = 0, __nusers = 0, __kind = 0, __spins = 0, __elision = 0, __list = {__prev = 0x0,
__next = 0x0}}, __size = '\000' <repeats 39 times>, __align = 0}, name = "heaplock439", '\000' <repeats 20 times>}, thashlock = {lock = {__data = {__readers = 3, __writers = 0, __wrphase_futex = 1, __writers_futex = 1, __pad3 = 0, __pad4 = 0, __cur_writer = 6208, __shared = 0, __rwelision = 0 '\000',
__pad1 = "\000\000\000\000\000\000", __pad2 = 0, __flags = 0}, __size = "\003\000\000\000\000\000\000\000\001\000\000\000\001", '\000' <repeats 11 times>, "@\030", '\000' <repeats 29 times>, __align = 3}, name = "hashlock439", '\000' <repeats 20 times>}, batIdxLock = {lock = {__data = {__lock = 0,
__count = 0, __owner = 0, __nusers = 0, __kind = 0, __spins = 0, __elision = 0, __list = {__prev = 0x0, __next = 0x0}}, __size = '\000' <repeats 39 times>, __align = 0}, name = "BATlock439", '\000' <repeats 21 times>}}
```
This is `n`:
```
(gdb) p *n
$4 = {hseqbase = 0, creator_tid = 38450, batCacheid = 515, batCopiedtodisk = false, batDirtyflushed = false, batDirtydesc = true, batTransient = true, batRestricted = 1 '\001', batRole = TRANSIENT, unused = 0, batSharecnt = 0, batInserted = 0, batCount = 134430, batCapacity = 134656, T = {id = 0x7ffadd6d3aa3 "t",
width = 4, type = 6 '\006', shift = 2 '\002', varsized = false, key = false, nonil = true, nil = false, sorted = true, revsorted = false, nokey = {0, 0}, nosorted = 0, norevsorted = 0, minpos = 9223372036854775807, maxpos = 9223372036854775807, unique_est = 0, seq = 9223372036854775808, heap = 0x7ffa8fe55fa0,
baseoff = 0, vheap = 0x0, hash = 0x0, imprints = 0x0, orderidx = 0x0, strimps = 0x0, props = 0x0}, theaplock = {lock = {__data = {__lock = 0, __count = 0, __owner = 0, __nusers = 0, __kind = 0, __spins = 0, __elision = 0, __list = {__prev = 0x0, __next = 0x0}}, __size = '\000' <repeats 39 times>, __align = 0},
name = "heaplock515", '\000' <repeats 20 times>}, thashlock = {lock = {__data = {__readers = 0, __writers = 0, __wrphase_futex = 0, __writers_futex = 0, __pad3 = 0, __pad4 = 0, __cur_writer = 0, __shared = 0, __rwelision = 0 '\000', __pad1 = "\000\000\000\000\000\000", __pad2 = 0, __flags = 0},
__size = '\000' <repeats 55 times>, __align = 0}, name = "hashlock515", '\000' <repeats 20 times>}, batIdxLock = {lock = {__data = {__lock = 0, __count = 0, __owner = 0, __nusers = 0, __kind = 0, __spins = 0, __elision = 0, __list = {__prev = 0x0, __next = 0x0}}, __size = '\000' <repeats 39 times>,
__align = 0}, name = "BATlock515", '\000' <repeats 21 times>}}
```
This is `p`:
```
(gdb) p *p
$5 = {hseqbase = 0, creator_tid = 38450, batCacheid = 520, batCopiedtodisk = false, batDirtyflushed = false, batDirtydesc = true, batTransient = true, batRestricted = 1 '\001', batRole = TRANSIENT, unused = 0, batSharecnt = 0, batInserted = 0, batCount = 134430, batCapacity = 134656, T = {id = 0x7ffadd6d3aa3 "t",
width = 8, type = 7 '\a', shift = 3 '\003', varsized = false, key = true, nonil = true, nil = false, sorted = true, revsorted = false, nokey = {0, 0}, nosorted = 0, norevsorted = 0, minpos = 9223372036854775807, maxpos = 9223372036854775807, unique_est = 0, seq = 9223372036854775808, heap = 0x7ffa8fe4ff60,
baseoff = 0, vheap = 0x0, hash = 0x0, imprints = 0x0, orderidx = 0x0, strimps = 0x0, props = 0x0}, theaplock = {lock = {__data = {__lock = 0, __count = 0, __owner = 0, __nusers = 0, __kind = 0, __spins = 0, __elision = 0, __list = {__prev = 0x0, __next = 0x0}}, __size = '\000' <repeats 39 times>, __align = 0},
name = "heaplock520", '\000' <repeats 20 times>}, thashlock = {lock = {__data = {__readers = 0, __writers = 0, __wrphase_futex = 0, __writers_futex = 0, __pad3 = 0, __pad4 = 0, __cur_writer = 0, __shared = 0, __rwelision = 0 '\000', __pad1 = "\000\000\000\000\000\000", __pad2 = 0, __flags = 0},
__size = '\000' <repeats 55 times>, __align = 0}, name = "hashlock520", '\000' <repeats 20 times>}, batIdxLock = {lock = {__data = {__lock = 0, __count = 0, __owner = 0, __nusers = 0, __kind = 0, __spins = 0, __elision = 0, __list = {__prev = 0x0, __next = 0x0}}, __size = '\000' <repeats 39 times>,
__align = 0}, name = "BATlock520", '\000' <repeats 21 times>}}
```
It seems that the time is spent appending the new values one by one, calling `HASHdelete_locked()` and `HASHinsert_locked()` every time.
I don't really understand why this operation doesn't just result in a simple `BATappend()`.
What in the original query should trigger a row-at-a-time update?
**Software versions**
- MonetDB version number 11.43.10
- OS and version: Fedora 35
- self-installed and compiled
| Extremely slow INSERT INTO <table> SELECT | https://api.github.com/repos/MonetDB/MonetDB/issues/7253/comments | 36 | 2022-02-18T13:12:12Z | 2024-06-27T13:17:10Z | https://github.com/MonetDB/MonetDB/issues/7253 | 1,143,041,319 | 7,253 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
I would like to run some complex algorithms on DNA sequence data in MonetDB using the embedded Python.
It is a dynamic programming algorithm implemented in Python, lets call it dp().
The inputs are two strings and some integer parameters in a table form (multiple rows), and the output is a table (2 strings and an integer in each row).
I inserted 50 strings in table A (~100 chars).
My main function would consist of two steps:
- Step 1: sample 10 strings from A, run the dp() on each pair, and store some subresults in another table (usually results in couple hundred records)
- Step 2: use a modified version of dp() on all the records from A using the subresults from Step 1.
If I run only Step 1 multiple times it works fine. If I run only Step 2 multiple times it works fine.
If I run Step 1 and Step 2 sequentually after starting the server it works fine.
But if I want to run Step 1, Step 2 in a loop (for measuring time etc) then I get errors:
- Python error: the input parameters are not defined (although the exact same code ran without error before).
```
#2022-02-15 17:26:50: client1: createExceptionInternal: !ERROR: MALException:pyapi3.eval:PY000!Python exception
#2022-02-15 17:26:50: client1: createExceptionInternal: !ERROR: > 6. x, y = s1, s2
#2022-02-15 17:26:50: client1: createExceptionInternal: !ERROR: name 's1' is not defined
```
And the function looks like dp(s1, s2, ...)
- Segmentation fault: mserver5 stops, with gdb the cause (see github repo for full backtrace):
```
Thread 30 "mserver5" received signal SIGSEGV, Segmentation fault.
[Switching to Thread 0x7fffe3483700 (LWP 28220)]
0x00007ffff1d6d763 in PyAPIeval (cntxt=0x5555555dfc70, mb=0x7fffc4068180, stk=0x7fffc40f2170, pci=0x7fffc40b1060, grouped=false, mapped=false) at /home/<...>/MonetDB-11.43.9/sql/backends/monet5/UDF/pyapi3/pyapi3.c:226
226 varres = sqlfun ? sqlfun->varres : 0;
```
**To Reproduce**
In this repository you can find the scripts to reproduce the problem (dp() is the Needleman-Wunsch algorithm): https://github.com/liptakpanna/monetdb_reproduce
**Software versions**
MonetDB version build from source: 11.43.9
Running on Ubuntu 20.04.
Python version: 3.8.10.
**Additional context**
I tried to debug my code, but it is suspicious that the exact same code runs fine for the first time, but not for the second time.
I even removed the random sampling and fixed the rows it chooses.
Could it be some kind of memory issue? The server had 4GB RAM available (but I also tried it with 12GB on Windows).
Should it be possible to run relatively complex Python algorithms inside MonetDB?
Thanks in advance! | Segmentation fault on second run | https://api.github.com/repos/MonetDB/MonetDB/issues/7252/comments | 2 | 2022-02-17T14:02:36Z | 2024-06-27T13:17:09Z | https://github.com/MonetDB/MonetDB/issues/7252 | 1,141,378,885 | 7,252 |
[
"MonetDB",
"MonetDB"
] | When importing a SQL file, the `\>` & `\<` can be mixed up, resulting in the immediate overwriting of the file.
Mclient should ask if the user wants to overwrite the file.
Example, using the VOC example:
` \> /full/path/to/voc_dump.sql` overwrites the file, instead of reading it. | ask before overwrite | https://api.github.com/repos/MonetDB/MonetDB/issues/7251/comments | 1 | 2022-02-17T12:31:11Z | 2024-06-28T10:05:02Z | https://github.com/MonetDB/MonetDB/issues/7251 | 1,141,278,727 | 7,251 |
[
"MonetDB",
"MonetDB"
] | `type_digits` is always `0` for `type=geometry` columns. I'm not sure what implications this might have but let's try to be consistent | type_digits attribute of sys.columns is wrong for geometry type columns | https://api.github.com/repos/MonetDB/MonetDB/issues/7250/comments | 1 | 2022-02-16T17:30:05Z | 2024-06-27T13:17:07Z | https://github.com/MonetDB/MonetDB/issues/7250 | 1,140,346,498 | 7,250 |
[
"MonetDB",
"MonetDB"
] | I want to aggregate the average and the weighted average of the same column and have them side-by-side in the results. However, this is giving me the following exception: `ERROR = !SELECT: no such aggregate 'sql_div'` and now `"!syntax error, unexpected IDENT in: "select"`. I reckon this is due to the way I am extracting the seconds from the data.
I tried to adapt the query from the [documentation](https://www.monetdb.org/documentation-Jan2022/user-guide/sql-functions/date-time-functions/) but I had no luck.
```
QUERY = SELECT
id_station,
avg(pH) as mean,
sum(
pH *
(60 - extract("second"(timetz '2019-06-01 17:00','%Y/%m/%d %H:%M') - interval '1' hour))
) / (60 * 61 / 2) as weighted_mean
FROM
datapoints
WHERE
-- Last 60 periods
time > timestamptz '2019-06-01 17:00'
GROUP BY
id_station;
ERROR = !syntax error, unexpected IDENT in: "select
! id_station,
! avg(ph) as mean,
! sum(
! ph *
! (60 - extract"
CODE = 42000
``` | "!ERROR = !SELECT: no such aggregate 'sql_div'" for time operations | https://api.github.com/repos/MonetDB/MonetDB/issues/7249/comments | 2 | 2022-02-10T22:47:03Z | 2022-02-11T08:45:03Z | https://github.com/MonetDB/MonetDB/issues/7249 | 1,131,162,456 | 7,249 |
[
"MonetDB",
"MonetDB"
] | I want to aggregate the average and the standard deviation of the same column and have them side-by-side in the results. However, this is giving me the following exception: `Cannot use non GROUP BY column 'id_station' in query results without an aggregate function`. The aggregations work fine separately but when joined in a same select statement this exception persists.
I found a similar previous https://github.com/MonetDB/MonetDB/issues/6624 that's marked as resolved but I couldn't find my solution there.
```
sql>SELECT
id_station,
avg(pH) as mean
FROM
datapoints;
MAPI = (monetdb) /tmp/.s.monetdb.54320
ERROR = !Cannot use non GROUP BY column 'id_station' in query results without an aggregate function
CODE = 42000
``` | "Cannot use non GROUP BY column 'id_station' in query results without an aggregate function" when using an aggregate function is used with an attribute selection | https://api.github.com/repos/MonetDB/MonetDB/issues/7248/comments | 1 | 2022-02-10T21:55:03Z | 2022-02-10T22:22:03Z | https://github.com/MonetDB/MonetDB/issues/7248 | 1,131,066,117 | 7,248 |
[
"MonetDB",
"MonetDB"
] | I want to aggregate the average and the standard deviation of the same column and have them side-by-side in the results. However, this is giving me the following exception: `!SELECT: cannot use non GROUP BY column 'ph' in query results without an aggregate function`. The aggregations work fine separately but when joined in a same select statement this exception persists.
I found a similar previous [issue](https://github.com/MonetDB/MonetDB/issues/6624) that's marked as resolved but I couldn't find my solution there.
> sql>SELECT
> avg(pH) ,
> stddev(pH)
> FROM
> datapoints;
> MAPI = (monetdb) /tmp/.s.monetdb.54320
> ERROR = !SELECT: cannot use non GROUP BY column 'ph' in query results without an aggregate function
> CODE = 42000
| "Cannot use non GROUP BY column in query results without an aggregate function" when using two aggregate functions side-by-side | https://api.github.com/repos/MonetDB/MonetDB/issues/7247/comments | 2 | 2022-02-10T15:04:17Z | 2022-02-10T21:01:24Z | https://github.com/MonetDB/MonetDB/issues/7247 | 1,130,248,874 | 7,247 |
[
"MonetDB",
"MonetDB"
] | I am trying to perform upsampling on time series data. This is supposed to guarantee to have one value each a given period of time. For example a value each minute, so if there's a lag in the data the query would fill it with some gap filling strategy (interpolation, last value, zero, null, etc.).
I found some reference to interpolation in a [previous release](https://www.monetdb.org/documentation-Jan2022/admin-guide/release-notes/mar2018/) but it wasn't very concrete. Is there a possibility to interpolate time series on MonetDB?
| Time Series Interpolation | https://api.github.com/repos/MonetDB/MonetDB/issues/7246/comments | 4 | 2022-02-09T21:20:09Z | 2022-08-18T17:28:25Z | https://github.com/MonetDB/MonetDB/issues/7246 | 1,129,032,423 | 7,246 |
[
"MonetDB",
"MonetDB"
] | (I'm having a lot of fun with Monet, by the way! Seems like a great project)
**Describe the bug**
I found that one table I was I recreating repeatedly with identical data, via a cronjob, was sometimes populated and sometimes empty when I opened it back up. No errors are printed, and all scripts finish smoothly.
My conclusion is: the tables randomly appear empty to connections opened in a new process from the one that imported the table, but always return data when queried from the same process, even if the connection is closed and reopened.
See expected behavior section for some statistics.
**To Reproduce**
Reproducible via attached scripts.
There are 3 data files involved here, and I'm not sure how/if they are interacting to cause this. (It took me ~4 hours to shrink my real-world issue down to something simpler and to find a small subset of input data that would reproduce it, but I give up on determining the exact cause) I bet you all have some better debugging tools than I do!
- Unpack the `.tar.gz` file
- Run `bash create_data.sh`. This will download 1 CSV with `curl` and generate 2 other trivial files with `python` and `echo`. (Total data ~100MB and ~700k rows). Of particular interest is the fake `query_profiling.csv`, which has 7 records
- Then run `bash loop.sh | tee loop_output.txt`. This imports the 3 tables, and counts the rows in `query_profiling` 2 different ways, 100 times. It's about 5 seconds per loop.
**Expected behavior**
After running `loop.py`, I saw these results (`loop_output_stats.txt` in the tar, produced from `loop_output_example.txt`):
```
100 Row count from 'plain' python: 7
78 Row count from subprocess: 0
22 Row count from subprocess: 7
```
I expected: all 100 runs find 7 rows via both methods
Actual: only 22 of 100 "subprocess" runs find 7 rows, while 100 of 100 "plain python" runs find 7 rows
**Software versions**
- monetdbe 0.11 from pip
- both Ubuntu 20.04 and a derivative of 21.10
**Issue labeling **
**Additional context**
In my experiments, I believe there are 2 things that can each work around this, but I'm not sure why, and I don't have hard data on it yet.
1) closing and reopening the connection after line 24 in `make_tables.py`. That's surprsing though, since there is a `conn.close()` on the last line.
2) as mentioned above, not starting a new process, but that's not really an option in practice
[monetdbe_random_import_fail.tar.gz](https://github.com/MonetDB/MonetDB/files/8029615/monetdbe_random_import_fail.tar.gz)
| monetdbe silently importing 0 rows, at random | https://api.github.com/repos/MonetDB/MonetDB/issues/7245/comments | 1 | 2022-02-09T05:13:04Z | 2024-07-19T08:37:53Z | https://github.com/MonetDB/MonetDB/issues/7245 | 1,128,063,234 | 7,245 |
[
"MonetDB",
"MonetDB"
] | Our app and system is running in C# on .Net Core, we would like to use the embedded version of MonetDB i.e. MonetDB\e. Essentially we would like to use MonetDB\e as an alternative to SQLite.
Any thoughts on how this could be accomplished?
| Using MonetDb\e in C# | https://api.github.com/repos/MonetDB/MonetDB/issues/7244/comments | 1 | 2022-02-07T13:39:19Z | 2024-06-28T10:06:14Z | https://github.com/MonetDB/MonetDB/issues/7244 | 1,126,010,656 | 7,244 |
[
"MonetDB",
"MonetDB"
] | According to the [string function docs](https://www.monetdb.org/documentation-Jan2022/user-guide/sql-functions/string-functions/), the `difference` function:
> converts two strings s1 and s2 to their soundex codes and reports the number of matching code positions. Since soundex codes have four characters, the result ranges from zero to four, with zero being no match and four being an exact match
I think this should say "reports the number of differing code positions", and "zero being an exact match and four being no match"
```
-- 0 is exact match
SELECT soundex('bare') s1, soundex('bear') s2, difference('bare', 'bear') d
s1 | s2 | d
-- | -- | --
B600 | B600 | 0
```
Since this was my first time exploring soundex, I also found the example `difference('MonetDB', 'DB3')` (result=4) a tad confusing. I thought: "these strings have some similarity, why is the score at an extreme?". Maybe `difference('frowned', 'around')` (result=1) better shows the usefulness of soundex. | documentation for soundex difference is backwards | https://api.github.com/repos/MonetDB/MonetDB/issues/7243/comments | 1 | 2022-02-05T15:59:17Z | 2024-06-27T13:17:04Z | https://github.com/MonetDB/MonetDB/issues/7243 | 1,124,963,927 | 7,243 |
[
"MonetDB",
"MonetDB"
] | I was revisiting table partitioning, got mixed up briefly, and took notes on the confusion.
### Incomplete syntax?
In https://www.monetdb.org/documentation-Jan2022/user-guide/sql-manual/data-definition/merge-tables/, I think the syntax explanation for `ALTER TABLE ... ADD TABLE` is missing the `AS PARTITION` part. Should it be the following?
```
ALTER TABLE [ IF EXISTS ] [ schema_name . ] merge_table_name
ADD TABLE [ schema_name . ] table_name
[ AS PARTITION partition_spec ]
```
### Link to examples for partitioning
Might I suggest that the [merge table](https://www.monetdb.org/documentation-Jan2022/user-guide/sql-manual/data-definition/merge-tables/) docs page links to the nice [updatable merge tables](https://www.monetdb.org/documentation-Jan2022/user-guide/blog-archive/update-mergetables/) blog post, since the former has no examples and the latter has many? Maybe just something like "for examples, see this blog post". I later saw there are other links leading there in the "SQL Summary" section, but when moving through "Data Definition", I spent much time trying to make sense of the (probably incomplete) syntax in issue 1.
### Merge statement content on merge tables page
In https://www.monetdb.org/documentation-Jan2022/user-guide/sql-manual/data-definition/merge-tables/, there is general information and also syntax explanations for `MERGE INTO`. I assume this is meant for https://www.monetdb.org/documentation-Jan2022/user-guide/sql-manual/data-manipulation/merge-statement/ instead.
Perhaps it could read "Merge/partitioned tables have no relationship with the `MERGE INTO` command. For info on `MERGE INTO`, see this link"
### Wrong link, link consistency, and preferred sources
This one is a little twisty and maybe not super useful, but I'll submit it anyways. In https://www.monetdb.org/documentation-Jan2022/user-guide/sql-summary/, you could review these:
- text `CREATE MERGE TABLE` leads to [merge statement docs](https://www.monetdb.org/documentation-Jan2022/user-guide/sql-manual/data-manipulation/merge-statement/) (wrong topic)
- text `ALTER TABLE ADD TABLE`, leads to [alter statement docs](https://www.monetdb.org/documentation-Jan2022/user-guide/sql-manual/data-definition/alter-statement/) (see next bullet)
- text `ALTER TABLE ADD TABLE`, leads to [merge table docs](https://www.monetdb.org/documentation-Jan2022/user-guide/sql-manual/data-definition/merge-tables/) (see previous bullet)
For bullets 2 &3, it's a question of what's preferred, but there's a 3rd option of linking to the `ALTER TABLE ADD TABLE` [section within the same page](https://www.monetdb.org/documentation-Jan2022/user-guide/sql-summary/#alter-table-add-table). At least currently, given issue 1, this within-the-page option is the only one leading the user to the full syntax they need.
| documentation issues for "merge table" and "merge into" | https://api.github.com/repos/MonetDB/MonetDB/issues/7242/comments | 1 | 2022-02-04T19:54:58Z | 2024-06-27T13:17:02Z | https://github.com/MonetDB/MonetDB/issues/7242 | 1,124,564,889 | 7,242 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Replacing a view by a query on the view itself crashes the server.
**To Reproduce**
CREATE TABLE IF NOT EXISTS t7240 (val INTEGER);
INSERT INTO t7240(val) VALUES (1), (2), (3);
SELECT * FROM t7240;
CREATE OR REPLACE VIEW v7240 AS (SELECT * FROM t7240);
SELECT * FROM v7240;
-- replace the view now with a query on itself
CREATE OR REPLACE VIEW v7240 AS (SELECT * FROM v7240);
-- now the server is killed
SELECT * FROM v7240;
DROP VIEW v7240;
DROP TABLE t7240;
**Expected behavior**
No crash of the server.
Expected SQL parser Error msg instead (e.g. cannot replace view t7240 with a query including the view itself)
**Software versions**
- MonetDB 5 server v11.43.5 (Jan2022)
- OS and version: Compiled for amd64-pc-windows-msvc/32bit
- self-installed
| Replacing a view by a query on the view itself crashes the server. | https://api.github.com/repos/MonetDB/MonetDB/issues/7241/comments | 0 | 2022-02-04T15:57:44Z | 2024-06-27T13:17:01Z | https://github.com/MonetDB/MonetDB/issues/7241 | 1,124,357,047 | 7,241 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
I'm not sure if this is intended to work in embedded Monet, but the "history" tables [here](https://www.monetdb.org/documentation-Jan2022/user-guide/sql-catalog/querylog-calls-history-queue/) don't seem to be populating.
Also, a section heading on that page has a typo: "queyrlog_history", if it impacts documentation search results
Tangential: it also hits the known issue where certain types don't play well with Python, so a `select *` will fail with `KeyError: 6`, even if there are no rows to show. At least in `querylog_history`, the `id` field seems to cause this issue. That's a little harder to work through than when doing a `sum` or something where you know which expression is the cause.
**To Reproduce**
```python
import monetdbe
conn = monetdbe.connect("test.db")
conn.cursor().execute("CREATE TABLE IF NOT EXISTS foo (a TEXT, b TEXT)")
conn.commit()
print("Getting history rows")
# No rows
print("History DF:", conn.cursor().execute("SELECT * FROM sys.querylog_history").fetchdf(), "\n")
print("Getting calls rows")
# "select *" will cause an error, but start,stop are fine
print("Calls DF:", conn.cursor().execute("SELECT start, stop, arguments FROM sys.querylog_calls").fetchdf(), "\n")
print("Getting catalog rows")
# letting the KeyError happen now
print("Catalog DF:", conn.cursor().execute("SELECT * FROM sys.querylog_catalog").fetchdf(), "\n")
```
For me, the output is:
```
Getting history rows
History DF: Empty DataFrame
Columns: [id, owner, defined, query, pipe, plan, mal, optimize, start, stop, arguments, tuples, run, ship, cpu, io]
Index: []
Getting calls rows
Calls DF: Empty DataFrame
Columns: [start, stop, arguments]
Index: []
Getting catalog rows
Traceback (most recent call last):
File "/home/dcromartie/dev/try-monet/history_example.py", line 17, in <module>
print("Catalog DF:", conn.cursor().execute("SELECT * FROM sys.querylog_catalog").fetchdf(), "\n")
File "/home/dcromartie/virtualenvs/trymonet/lib/python3.9/site-packages/monetdbe/cursors.py", line 155, in execute
return self._execute_monetdbe(operation, parameters)
File "/home/dcromartie/virtualenvs/trymonet/lib/python3.9/site-packages/monetdbe/cursors.py", line 143, in _execute_monetdbe
self._set_description()
File "/home/dcromartie/virtualenvs/trymonet/lib/python3.9/site-packages/monetdbe/cursors.py", line 51, in _set_description
self.description = self.connection.get_description()
File "/home/dcromartie/virtualenvs/trymonet/lib/python3.9/site-packages/monetdbe/connection.py", line 143, in get_description
descriptions = list(zip(name, type_code, display_size, internal_size, precision, scale, null_ok))
File "/home/dcromartie/virtualenvs/trymonet/lib/python3.9/site-packages/monetdbe/connection.py", line 137, in <genexpr>
type_code = (monet_c_type_map[rcol.type].sql_type for rcol in columns)
KeyError: 6
```
**Expected behavior**
1 or more rows returned
**Software versions**
- `monetdbe` version `0.11` installed from pypi
**Issue labeling **
Sorry, I'm not sure if I can add my own labels or not. Let me know if I'm missing the feature. This is low urgency, and I'm completely playing around.
| querylog_* tables in MonetDBe | https://api.github.com/repos/MonetDB/MonetDB/issues/7240/comments | 2 | 2022-02-04T15:46:59Z | 2022-02-10T19:01:31Z | https://github.com/MonetDB/MonetDB/issues/7240 | 1,124,346,067 | 7,240 |
[
"MonetDB",
"MonetDB"
] | I was unable to find any documentation on lateral joins in the main Monet docs site. Is there any? Is it a fully-endorsed feature the team wants to publicize? There was a mention of fixing a crash related to lateral joins in the release notes, so I started looking.
I found some example on a [mailing list](https://www.monetdb.org/pipermail/users-list/2018-June/010259.html), but it took a while to find, once I tried another search engine. It was only one example, so I'm not sure if there are additional ways to use lateral joins. (Small point: this mailing list example wasn't directly usable in embedded Monet, since `generate_series` is broken). I did get something working after ~20 minutes.
I don't have any urgent need for these joins, and I'm more just playing around and taking mental inventory of what is supported by Monet vs Postgres, which I am most familiar with.
Thanks for all your help lately!
| Documention for lateral joins | https://api.github.com/repos/MonetDB/MonetDB/issues/7239/comments | 0 | 2022-02-04T15:19:37Z | 2024-06-27T13:17:00Z | https://github.com/MonetDB/MonetDB/issues/7239 | 1,124,317,454 | 7,239 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Select query with system function "index"(name, true) produces a GDK error:
createExceptionInternal: !ERROR: MALException:algebra.projection:GDK reported error: project1_bte: does not match always
Select query with system function "index"(name, false) triggers an assertion failure:
gdk/gdk_bat.c:2537: BATassertProps: Assertion `strcmp(b->theap->filename, filename) == 0' failed.
**To Reproduce**
compile mserver5 from Jan2022 branch and start it.
start mclient and run queries:
select name, "index"(name, true) nm_idx from sys.schemas order by nm_idx;
select name, "index"(name, false) nm_idx from sys.schemas order by nm_idx;
**Expected behavior**
+----------+--------+
| name | nm_idx |
+======+======+
| sys | 4 |
| tmp | 12 |
| json | 20 |
| profiler | 32 |
| wlc | 48 |
| wlr | 56 |
| logging | 64 |
+----------+--------+
**Software versions**
- MonetDB version number: MonetDB 5 server v11.43.8 (hg id: 0768335463bb)
- OS and version: Fedora 35
- self-compiled with assertions enabled
| query with system function: "index"(varchar, boolean) fails with GDK error or assertion failure. | https://api.github.com/repos/MonetDB/MonetDB/issues/7238/comments | 2 | 2022-02-03T18:47:41Z | 2024-06-27T13:16:59Z | https://github.com/MonetDB/MonetDB/issues/7238 | 1,123,436,898 | 7,238 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
When performing a SELECT with concurrent writes, there is a rare chance that the SELECT returns corrupt data.
This was detected in the following use case:
1. A client acquires a timestamp (`current_ts`) that will be used to retrieve data from a table `Test`;
2. It uses `current_ts` to get the data with the maximum `ts` such that `ts <= current_ts`, grouping by id. For instance, in the following example, considering that `current_ts = 7`, it would return rows 3 and 4.
| # | id | val | ts |
|---|----|-----|----|
| 1 | u1 | 100 | 0 |
| 2 | u1 | 60 | 5 |
| 3 | u1 | 52 | 6 |
| 4 | u2 | 100 | 0 |
| 5 | u2 | 73 | 10 |
To achieve that, the following query is used:
```sql
SELECT id, val, ts
FROM test
WHERE (id, ts) IN (
SELECT id, max(t.ts)
FROM test t
WHERE t.ts <= current_ts
GROUP BY id
)
```
Since the table is always pre-populated with `ts = 0` and new inserts use existing ids, the query should always return the same number of rows.
3. The client then selects a random item and inserts a new row with a different `val` and the next `current_ts`.
The problem is that sometimes the query in step 2 does not return all rows. In addition, some of the rows are corrupted (e.g. `id` being set to an empty string). This is a small example where the query returned 898 rows instead of 4000:
| id | val | ts |
|------|-------|----|
| '' | 100.0 | 0 |
| u770 | 100.0 | 0 |
| '' | 100.0 | 0 |
| u771 | 100.0 | 0 |
However, immediately executing the same query with the same `current_ts` in the same connection now returns the correct data.
**To Reproduce**
[This gist](https://gist.github.com/nuno-faria/5bb15a84bc93f5d2b745445d4d7b76cc) contains the code to (hopefully) reproduce this error.
The method `Test.execute` contains the relevant code. In case the error occurs, it prints `ERROR` to the terminal and logs the data retrieved, as well as the result of retrying that query, in the file `error.txt`. I also leave [here](https://gist.github.com/nuno-faria/47538bbb87602e6e3e27b092a156a22c) a real example of a `error.txt` file:
Unfortunally, I am not able to narrow the problem down more than this.
**Expected behavior**
Always return the same number of rows with the correct values.
**Software versions**
- MonetDB v11.43.6 Jan22 branch (most recent commit)
- Ubuntu 20.04 LTS
- unixODBC 2.3.6, MonetDB ODBC driver installed from source, just like the server
- Self-installed and compiled
**Additional context**
Seems to never happen without concurrent inserts. Additionally, there are no error messages in the logs. | SELECT with concurrent writes sometimes returns corrupt data | https://api.github.com/repos/MonetDB/MonetDB/issues/7237/comments | 3 | 2022-02-02T20:07:12Z | 2024-06-27T13:16:58Z | https://github.com/MonetDB/MonetDB/issues/7237 | 1,122,337,836 | 7,237 |
[
"MonetDB",
"MonetDB"
] | The following functions from the geom module have broken implementations, wrong arguments or are not conformant with the OGC standard.
| SQL Func | MAL Sig | C Impl | Problem/Description |
| :---: | :---: | :---: | :---: |
| Has_Z ||| Non-conformant and unknown arguments |
| Has_M ||| Non-conformant and unknown arguments |
| get_type ||| Non-conformant/weird implementation |
||| mbrFromString | no SQL exp/calls mbrFROMSTR |
||| mbrFromMBR | no SQL exp/not used |
|| calc.wkb || no SQL exp |
|| calc.wkb | wkbFromWKB | no SQL exp |
|| calc.wkb | geom_2_geom | no SQL exp |
||| mbrFROMSTR | Parsing WKT should not allowed given current impl. | | Geom broken/non-conformant functions | https://api.github.com/repos/MonetDB/MonetDB/issues/7236/comments | 0 | 2022-02-02T15:15:08Z | 2024-06-27T13:16:57Z | https://github.com/MonetDB/MonetDB/issues/7236 | 1,122,051,143 | 7,236 |
[
"MonetDB",
"MonetDB"
] | I noticed this on the [serial types docs page](https://www.monetdb.org/documentation-Jan2022/user-guide/sql-manual/data-types/serial-types/), but maybe it exists in additional places. I am pretty confused, as it doesn't seem pervasive.
I typed "AUTO INCREMENT" into a table creation statement, and Monet complained about my syntax. Eventually I copy-pasted the example from the docs, and saw that there is an underscore that is invisible to the eyes, but is in the source HTML. If it's just about font-color, it seems to be a very exact match, so that's interesting. This is happening in both the syntax explanation block, and at `CREATE TABLE test_serial`
Possibly related to browser (Firefox 96 on Ubuntu)
Screenshot below
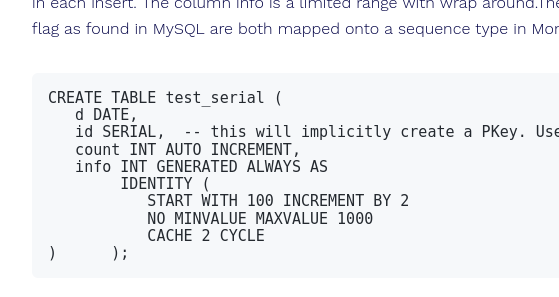
| "hidden" underscores in docs | https://api.github.com/repos/MonetDB/MonetDB/issues/7235/comments | 5 | 2022-01-31T14:39:17Z | 2024-06-27T13:16:56Z | https://github.com/MonetDB/MonetDB/issues/7235 | 1,119,515,774 | 7,235 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
1) `sys.reverse` example in [string function docs](https://www.monetdb.org/documentation-Jan2022/user-guide/sql-functions/string-functions/) does not succeed
2) `not_like` example in [comparison function docs](https://www.monetdb.org/documentation-Jan2022/user-guide/sql-functions/comparison-functions/) does not succeed
(Also, while I am here, I'm not sure the `like` patterns like `'_B%'` in the docs would qualify as "pcre", as stated. That is, wouldn't that fail in `perl` or `grep -P`?)
**To Reproduce**
- `SELECT sys.reverse('MonetDB')` gives `SELECT: no such unary operator 'sys'.'reverse'(char)`
- `SELECT not_like('a', '%a%')` gives `SELECT: no such binary operator 'not_like'(char,char)`
**Expected behavior**
No error
**Software versions**
- monetdbe (embedded) version 0.11
| sys.reverse and not_like: no such operator error | https://api.github.com/repos/MonetDB/MonetDB/issues/7234/comments | 5 | 2022-01-31T14:10:46Z | 2022-02-03T19:32:28Z | https://github.com/MonetDB/MonetDB/issues/7234 | 1,119,477,755 | 7,234 |
[
"MonetDB",
"MonetDB"
] | Referring to [this page](https://www.monetdb.org/documentation-Jan2022/user-guide/sql-functions/string-functions/)
The example calls for the `space` and `splitpart` functions seem to have had some accident. They currently say just `select 's'` and `splitpart('a`
| missing/mangled text in space/splitpart function docs | https://api.github.com/repos/MonetDB/MonetDB/issues/7233/comments | 1 | 2022-01-31T13:51:07Z | 2024-06-27T13:16:55Z | https://github.com/MonetDB/MonetDB/issues/7233 | 1,119,455,689 | 7,233 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
MonetDB recently added the option to perform transactional non-conflicting inserts concurrently. However, if the field being inserted is defined as `NOT NULL`, one of the inserts fails. This also causes non-transactional inserts to conflict when the inserts contain multiple rows (e.g. `INSERT INTO Test VALUES (1), (2), ...`).
**To Reproduce**
- Create a test table with a `NOT NULL` field:
```sql
CREATE TABLE Test (k int NOT NULL);
```
- Perform two concurrent transactions:
```sql
-- T1
BEGIN TRANSACTION;
INSERT INTO Test VALUES (1);
COMMIT;
-- T2
BEGIN TRANSACTION;
INSERT INTO Test VALUES (2);
COMMIT;
-- last to commit is aborted
```
- If the table is instead created without the `NOT NULL` (`CREATE TABLE Test (k int)`), both inserts succeed.
**Expected behavior**
Both inserts to succeed.
**Software versions**
- MonetDB v11.43.6 Jan22
- Ubuntu 20.04 LTS
- Self-installed and compiled | False conflicts when inserting in a not null field | https://api.github.com/repos/MonetDB/MonetDB/issues/7232/comments | 0 | 2022-01-28T12:50:20Z | 2024-06-27T13:16:54Z | https://github.com/MonetDB/MonetDB/issues/7232 | 1,117,368,335 | 7,232 |
[
"MonetDB",
"MonetDB"
] | The documentation at https://www.monetdb.org/documentation-Jul2021/user-guide/sql-programming/function-definitions/ shows an example for defining an `MS_ROUND`function. When trying to follow these examples to create my own function, there was some friction, since it seems to be interpreted as the `TRUNCATE` that empties tables, and fails. I see a `truncate` for strings, and I guess you can put quotes around it to avoid this syntax issue, but I don't see one for numbers.
Changing to the predefined `ms_trunc` might be the fix?
(Smaller point: After that, users will get the error: `CREATE OR REPLACE FUNCTION: not allowed to replace system function ms_round;`. This is better; I think most users would work around that, probably just altering the name. But you all might have a better example sitting around that works on the first attempt )
To reproduce, `SELECT truncate(100.24535, 2);` gives: `syntax error, unexpected TRUNCATE in: "prepare select truncate" `
I have only run this in monetdbe (embedded)
Thank you! | docs for "function definitions" page / no "truncate" function | https://api.github.com/repos/MonetDB/MonetDB/issues/7231/comments | 1 | 2022-01-28T00:43:56Z | 2024-06-27T13:16:53Z | https://github.com/MonetDB/MonetDB/issues/7231 | 1,116,881,848 | 7,231 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
When preparing a statement of inserts with selects, the prepare fails when the parameters have different types.
**To Reproduce**
- Create the test table and add some data:
```sql
CREATE TABLE Test (c1 int not null, c2 varchar(255) not null, c3 int not null);
INSERT INTO Test VALUES (1, 'asd', 1);
```
- Create a prepared statement of a insert with select:
```sql
PREPARE INSERT INTO Test
SELECT c1, ?, ?
FROM Test;
-- or PREPARE INSERT INTO Test (c1, c2, c3) SELECT ...
> Internal error while compiling statement: TypeException:user.p0_0[16]:'algebra.select' undefined in: X_15:any := algebra.select(X_14:bat[:int], X_16:str, X_16:str, true:bit, true:bit, false:bit);
```
**Additional notes**
- If both parameters have the same type, the prepare works correctly. E.g.:
```sql
CREATE TABLE Test (c1 int not null, c2 varchar(255) not null, c3 varchar(255) null);
INSERT INTO Test VALUES (1, 'asd', 'asd');
PREPARE INSERT INTO Test
SELECT c1, ?, ?
FROM Test;
> execute prepared statement using: EXEC 0(...)
+---------+--------+-------+--------+-------+--------+
| type | digits | scale | schema | table | column |
+=========+========+=======+========+=======+========+
| varchar | 255 | 0 | null | null | null |
| varchar | 255 | 0 | null | null | null |
+---------+--------+-------+--------+-------+--------+
```
- The error also does not occur when all the columns are custom parameters, i.e.:
```sql
PREPARE INSERT INTO Test
SELECT ?, ?, ?
FROM Test;
> execute prepared statement using: EXEC 0(...)
+---------+--------+-------+--------+-------+--------+
| type | digits | scale | schema | table | column |
+=========+========+=======+========+=======+========+
| int | 32 | 0 | null | null | null |
| varchar | 255 | 0 | null | null | null |
| int | 32 | 0 | null | null | null |
+---------+--------+-------+--------+-------+--------+
```
- The error also does not occur when we remove the `not null` from the table definition. However, the types are not correct:
```sql
CREATE TABLE Test (c1 int, c2 varchar(255), c3 int);
INSERT INTO Test VALUES (1, 'asd', 1);
PREPARE INSERT INTO Test
SELECT c1, ?, ?
FROM Test;
> execute prepared statement using: EXEC 0(...)
+------+--------+-------+--------+-------+--------+
| type | digits | scale | schema | table | column |
+======+========+=======+========+=======+========+
| int | 32 | 0 | null | null | null | -- should be varchar
| int | 32 | 0 | null | null | null |
+------+--------+-------+--------+-------+--------+
```
And if we try to use the prepared statement:
```sql
-- trying to pass a string to c2
EXEC 0('asd', 1);
> conversion of string 'asd' to type int failed.
-- or trying to pass an integer to c2
EXEC 0(1, 1);
> Append failed
```
**Software versions**
- MonetDB v11.43.0 (Jan22 branch)
- Ubuntu 20.04
- Self-installed and compiled
| Prepared statement of INSERT with SELECT fails when types difer | https://api.github.com/repos/MonetDB/MonetDB/issues/7230/comments | 2 | 2022-01-26T16:13:28Z | 2024-06-27T13:16:52Z | https://github.com/MonetDB/MonetDB/issues/7230 | 1,115,201,160 | 7,230 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
Jan2022 Docker Image has wrong db version 11.41.13 (Jul2021-SP2)
**To Reproduce**
docker run -d --rm --name testdb monetdb/monetdb:Jan2022
docker exec -it testdb monetdb version
results in:
MonetDB Database Server Toolkit v11.41.13 (Jul2021-SP2)
**Expected behavior**
MonetDB Database Server Toolkit v11.43.5 (Jan2022)
**Software versions**
- MonetDB version number Jan2022
- Installed from release docker image
**Issue labeling**
Docker Image
Jan2022
Severe | Jan2022 Docker Image has wrong version | https://api.github.com/repos/MonetDB/MonetDB/issues/7229/comments | 1 | 2022-01-24T13:33:15Z | 2022-01-24T15:25:19Z | https://github.com/MonetDB/MonetDB/issues/7229 | 1,112,656,797 | 7,229 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
A wrong transaction conflict is detected when a simple script is executed while another session has simply opened a transaction (without doing anything else)
**To Reproduce**
On an empty database:
**Session 1:**
```
START TRANSACTION;
```
**Session 2:**
```
START TRANSACTION;
CREATE TABLE a(s string, i int, b1 bigint);
COMMIT;
START TRANSACTION;
ALTER TABLE a ADD UNIQUE (s, b1);
COMMIT;
START TRANSACTION;
CREATE TABLE b(i int);
UPDATE a SET i = 1;
DROP TABLE b;
COMMIT;
```
This produces:
```
COMMIT: transaction is aborted because of concurrency conflicts, will ROLLBACK instead
```
**Expected behavior**
No concurrency conflicts
**Software versions**
- MonetDB v11.41.13 (Jul2021-SP2)
- OS and version: Fedora 35
- Installed from release package
| COMMIT: transaction is aborted because of concurrency conflicts, will ROLLBACK instead | https://api.github.com/repos/MonetDB/MonetDB/issues/7228/comments | 10 | 2022-01-21T16:15:27Z | 2024-06-27T13:16:51Z | https://github.com/MonetDB/MonetDB/issues/7228 | 1,110,653,464 | 7,228 |
[
"MonetDB",
"MonetDB"
] | See date calculations below. Is it a bug or a feature?
select cast('2021-03-29' as date) - interval '1' month;
--Result: 2021-03-01
--Expected: 2021-02-28
select cast('2021-05-31' as date) + interval '1' month;
--Result: 2021-07-01
--Expected: 2021-06-30
select cast('2020-03-29' as date) - interval '1' year;
--Result: 2019-03-01
--Expected: 2019-02-28
select cast('2020-02-29' as date) + interval '1' year;
--Result: 2021-03-01
--Expected: 2021-02-28
Affects Version/s
Jul2021
| Date calculations, bug or feature | https://api.github.com/repos/MonetDB/MonetDB/issues/7227/comments | 1 | 2022-01-21T12:43:19Z | 2024-06-27T13:16:50Z | https://github.com/MonetDB/MonetDB/issues/7227 | 1,110,429,486 | 7,227 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
I have uploaded this [covid dataset](https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/owid-covid-data.cs) to a table in monetdbe. I gave the `new_deaths` column an `INT` type, and `new_cases_per_million` a `DOUBLE` type.
These 3 queries work fine:
```
SELECT avg(new_deaths) FROM covid;
SELECT sum(cast(new_deaths AS BIGINT)) FROM covid;
SELECT sum(new_cases_per_million) FROM covid;
```
But this one fails:
```
SELECT sum(new_deaths) FROM covid;
```
The stacktrace is:
```
ERROR: Traceback (most recent call last):
File "/home/dcromartie/dev/try-monet/app.py", line 66, in page_db
result = fetch_initial_rows_df(cursor, query_part)
File "/home/dcromartie/dev/try-monet/app.py", line 30, in fetch_initial_rows_df
results = cursor.execute(query)
File "/home/dcromartie/virtualenvs/trymonet/lib/python3.9/site-packages/monetdbe/cursors.py", line 155, in execute
return self._execute_monetdbe(operation, parameters)
File "/home/dcromartie/virtualenvs/trymonet/lib/python3.9/site-packages/monetdbe/cursors.py", line 143, in _execute_monetdbe
self._set_description()
File "/home/dcromartie/virtualenvs/trymonet/lib/python3.9/site-packages/monetdbe/cursors.py", line 51, in _set_description
self.description = self.connection.get_description()
File "/home/dcromartie/virtualenvs/trymonet/lib/python3.9/site-packages/monetdbe/connection.py", line 143, in get_description
descriptions = list(zip(name, type_code, display_size, internal_size, precision, scale, null_ok))
File "/home/dcromartie/virtualenvs/trymonet/lib/python3.9/site-packages/monetdbe/connection.py", line 137, in <genexpr>
type_code = (monet_c_type_map[rcol.type].sql_type for rcol in columns)
KeyError: 5
```
Then I found this triggers the same `KeyError: 5`:
```
SELECT columnsize + heapsize FROM sys.storage;
```
**To Reproduce**
```
import monetdbe
conn = monetdbe.connect("bug.db")
conn.cursor().execute("SELECT columnsize + heapsize FROM sys.storage")
```
**Expected behavior**
No error, or a clearer error message
**Software versions**
- monetdbe==0.11
- Ubuntu 21.10
- Installed via pip
| simple select/sum giving vague error in monetdbe | https://api.github.com/repos/MonetDB/MonetDB/issues/7226/comments | 3 | 2022-01-18T19:50:59Z | 2024-06-27T13:16:49Z | https://github.com/MonetDB/MonetDB/issues/7226 | 1,107,302,989 | 7,226 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
When an append goes over the initial capacity and the BAT needs to be extended, invalid memory access occurs.
**To Reproduce**
Take this minimal UDF, which simply creates a BAT with a number of strings:
```
str
bat_HeapExtendTest(bat *r) {
BAT *bn = NULL;
char buf[20];
BUN initial_capacity = 0; // This actually creates a BAT with initial capacity = 256
BUN count = 257; // Just one over the initial capacity, will trigger a BATextend()
if ((bn = COLnew(0, TYPE_str, initial_capacity, TRANSIENT)) == NULL) goto fail;
for (BUN i = 1; i <= count; i++) {
sprintf(buf, "String " BUNFMT, i);
if (bunfastapp(bn, buf) != GDK_SUCCEED) goto fail;
}
BBPkeepref(*r = bn->batCacheid);
return MAL_SUCCEED;
fail:
if (bn)
BBPreclaim(bn);
throw(MAL, "heapExtendTest", GDK_EXCEPTION);
}
```
And map it to SQL:
```
command("sys", "heapExtendTest", bat_HeapExtendTest, false, "", args(1, 1, batarg("", str))),
```
```
CREATE OR REPLACE FUNCTION heapExtendTest() RETURNS TABLE(s string) EXTERNAL NAME sys."heapExtendTest";
```
Finally call it:
```
select * from heapExtendTest();
```
This produces undefined behaviour (mostly SIGSEGV), and when compiled in DEBUG mode:
```
<path>/src/gdk/gdk_utils.c:1987: GDKfree: Assertion `((char *) s)[i] == '\xBD'' failed.
```
On a different UDF, which boils down to the same issue, I got the same assertion, but really during the `GDKrealloc()` that is triggered by `HEAPextend()`. Both cases are symptoms of invalid memory access.
**IMPORTANT**. This UDF works fine when `initial_capacity >= count`, i.e. if the BAT capacity doesn't need to be extended. I suppose this was not caught before because most internal functions do know the required result capacity in advance.
**Expected behavior**
A table with strings from `String 1` to `String 257`.
**Software versions**
- MonetDB version number 1.41.14 (hg id: e465e28319)
- OS and version: Fedora 35
- self-installed and compiled
| Invalid memory access when extending a BAT during appends | https://api.github.com/repos/MonetDB/MonetDB/issues/7225/comments | 2 | 2022-01-16T11:20:34Z | 2024-06-27T13:16:49Z | https://github.com/MonetDB/MonetDB/issues/7225 | 1,105,024,715 | 7,225 |
[
"MonetDB",
"MonetDB"
] | In monetdbe (embedded), none of the examples in this documentation succeed for me: https://www.monetdb.org/documentation-Jul2021/user-guide/sql-functions/generator-functions/
The first example gives: `SELECT: no such table returning function 'generate_series'(tinyint, tinyint)`
I saw something online that suggested maybe I need to try: `SELECT generate_series...`, but that gives `SELECT: no such binary operator 'generate_series'(tinyint,tinyint)`
I'm using monetdbe version `0.11`, the latest from Pypi, if I'm not mistaken
Thanks! | No generator functions working in monetdbe? | https://api.github.com/repos/MonetDB/MonetDB/issues/7224/comments | 1 | 2022-01-15T15:37:58Z | 2022-01-17T08:02:39Z | https://github.com/MonetDB/MonetDB/issues/7224 | 1,104,757,088 | 7,224 |
[
"MonetDB",
"MonetDB"
] | I request a package on termux GitHub, and installed it successfully.
then I followed the steps in https://cloud.tencent.com/developer/article/1054833
and failed at the step of $ monetdb start my-first-db
see
https://github.com/termux/termux-packages/issues/8520 | failed to start monetdb database on Android termux | https://api.github.com/repos/MonetDB/MonetDB/issues/7223/comments | 2 | 2022-01-14T22:27:56Z | 2022-01-15T10:40:09Z | https://github.com/MonetDB/MonetDB/issues/7223 | 1,104,176,508 | 7,223 |
[
"MonetDB",
"MonetDB"
] | We were hoping you could provide us (or point us to) a way to improve the performance of concurrent, non-conflicting inserts.
Right now, we think that write performance is being bottlenecked by the sequential commit to the WAL. To test this theory, we executed a [simple benchmark](https://gist.github.com/nuno-faria/304f61c42eb100951e959f1db0a61a46) that compared the insert performance with the WAL in disk (NVMe) and in ramdisk (Google Cloud instance, 32 cores & 32 GB RAM; MonetDB branch Jan22 used). Additionally, we considered a different number of inserts per transaction (1 with autocommit=on, 5 and 10 with autocommit=off):
<img width="733" alt="image" src="https://user-images.githubusercontent.com/26089290/149510540-aada8e75-80f0-4af3-bd3e-8f076c9b4a23.png">
Even though we used an NVMe, the write performance in disk stagnates after 4 threads, unlike with ramdisk. So 1) this is a problem with the storage.
Furthermore, the throughput in disk increases when each transaction inserts more data, so 2) this is a problem with the commit.
For comparison, PostgreSQL single insert/tx achieves up to 35k inserts/s (or 15x higher than MonetDB) and linearly scales to 32 threads.
To see if we could remove the bottleneck, we commented out the `commit` lock in the commit function `sql_trans_commit`, as presented in this [file](https://gist.github.com/nuno-faria/90f62a6969a54b8b59ea8b0e01cd33a9), obtaining the following results:
<img width="373" alt="image" src="https://user-images.githubusercontent.com/26089290/149509728-b42af01d-c87d-441c-9841-d1c3bd1e43af.png">
Without the `commit` lock, the write performance now scales up to 16 threads in disk. In addition, the table correctly displayed all data inserted, while the recently committed data is still in the WAL. However, when the flush from the WAL to the store occurs, sometimes most of the data disappears and the database crashes with the following message:
```log
2022-01-13 11:39:07 ERR testdb[23397]: !FATAL: write-ahead logging failure
2022-01-13 11:39:10 MSG merovingian[23228]: database 'testdb' (-1) has exited with exit status 1
```
We also notice that before the crash, a new log file appears while the other is still there.
Other times, the data is flushed correctly to the store, without any crash.
We believe there could be a way here to prevent the crash without compromising write performance, since our workload only requires non-conflicting inserts (e.g., READ UNCOMMITTED isolation would suffice). However, we lack the necessary knowledge about the MonetDB internals. | Improve the performance of concurrent, non-conflicting INSERTS | https://api.github.com/repos/MonetDB/MonetDB/issues/7222/comments | 3 | 2022-01-14T12:06:42Z | 2022-04-15T19:33:06Z | https://github.com/MonetDB/MonetDB/issues/7222 | 1,103,544,556 | 7,222 |
[
"MonetDB",
"MonetDB"
] |
I have problem to compile and run the data generater.
>We run the tpcds benchmark every day and query 72 is not the slowest, still runs at a reasonable speed. Can you show the traces?
_Originally posted by @PedroTadim in https://github.com/MonetDB/MonetDB/issues/7219#issuecomment-1010848129_ | could you supply the tpcds benchmark datasets of scale 10G gz file? | https://api.github.com/repos/MonetDB/MonetDB/issues/7221/comments | 5 | 2022-01-13T13:54:19Z | 2024-06-07T11:58:03Z | https://github.com/MonetDB/MonetDB/issues/7221 | 1,101,775,667 | 7,221 |
[
"MonetDB",
"MonetDB"
] | I found the GitHub is newer.
for example, the newest release at GitHub is
https://github.com/MonetDB/MonetDB/releases/tag/Jan2022_release
but the newest of monetdb.org is
https://www.monetdb.org/downloads/Windows/Jul2021-SP2/ | what is the different between the release of GitHub and monetdb.org? | https://api.github.com/repos/MonetDB/MonetDB/issues/7220/comments | 2 | 2022-01-13T11:58:08Z | 2022-01-13T13:03:08Z | https://github.com/MonetDB/MonetDB/issues/7220 | 1,101,611,830 | 7,220 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
it run in 54 s. the scale is 1GB.
**To Reproduce**
I copied the sql from
https://codeload.github.com/cwida/tpcds-result-reproduction/zip/refs/heads/master
extract to d:/tpcds/app
and copied the data from
https://github.com/Altinity/tpc-ds/tree/master/data
extract to d:/tpcds/data
the file customer_001.dat need to be converted to utf8
I wrote the import command in following
```
copy into call_center from 'd:/tpcds/data/call_center_001.dat' delimiters '|' NULL AS '';
copy into catalog_page from 'd:/tpcds/data/catalog_page_001.dat' delimiters '|' NULL AS '';
copy into catalog_returns from 'd:/tpcds/data/catalog_returns_001.dat' delimiters '|' NULL AS '';
copy into catalog_sales from 'd:/tpcds/data/catalog_sales_001.dat' delimiters '|' NULL AS '';
copy into customer from 'd:/tpcds/data/customer_001.dat' delimiters '|' NULL AS '';
copy into customer_address from 'd:/tpcds/data/customer_address_001.dat' delimiters '|' NULL AS '';
copy into customer_demographics from 'd:/tpcds/data/customer_demographics_001.dat' delimiters '|' NULL AS '';
copy into date_dim from 'd:/tpcds/data/date_dim_001.dat' delimiters '|' NULL AS '';
copy into dbgen_version from 'd:/tpcds/data/dbgen_version_001.dat' delimiters '|' NULL AS '';
copy into household_demographics from 'd:/tpcds/data/household_demographics_001.dat' delimiters '|' NULL AS '';
copy into income_band from 'd:/tpcds/data/income_band_001.dat' delimiters '|' NULL AS '';
copy into inventory from 'd:/tpcds/data/inventory_001.dat' delimiters '|' NULL AS '';
copy into item from 'd:/tpcds/data/item_001.dat' delimiters '|' NULL AS '';
copy into promotion from 'd:/tpcds/data/promotion_001.dat' delimiters '|' NULL AS '';
copy into reason from 'd:/tpcds/data/reason_001.dat' delimiters '|' NULL AS '';
copy into ship_mode from 'd:/tpcds/data/ship_mode_001.dat' delimiters '|' NULL AS '';
copy into store from 'd:/tpcds/data/store_001.dat' delimiters '|' NULL AS '';
copy into store_returns from 'd:/tpcds/data/store_returns_001.dat' delimiters '|' NULL AS '';
copy into store_sales from 'd:/tpcds/data/store_sales_001.dat' delimiters '|' NULL AS '';
copy into time_dim from 'd:/tpcds/data/time_dim_001.dat' delimiters '|' NULL AS '';
copy into warehouse from 'd:/tpcds/data/warehouse_001.dat' delimiters '|' NULL AS '';
copy into web_page from 'd:/tpcds/data/web_page_001.dat' delimiters '|' NULL AS '';
copy into web_returns from 'd:/tpcds/data/web_returns_001.dat' delimiters '|' NULL AS '';
copy into web_sales from 'd:/tpcds/data/web_sales_001.dat' delimiters '|' NULL AS '';
copy into web_site from 'd:/tpcds/data/web_site_001.dat' delimiters '|' NULL AS '';
```
then run 72.txt(I modify the `+5` to `+ INTERVAL '5' DAY`)
```
SELECT i_item_desc,
w_warehouse_name,
d1.d_week_seq,
sum(CASE
WHEN p_promo_sk IS NULL THEN 1
ELSE 0
END) no_promo,
sum(CASE
WHEN p_promo_sk IS NOT NULL THEN 1
ELSE 0
END) promo,
count(*) total_cnt
FROM catalog_sales
JOIN inventory ON (cs_item_sk = inv_item_sk)
JOIN warehouse ON (w_warehouse_sk=inv_warehouse_sk)
JOIN item ON (i_item_sk = cs_item_sk)
JOIN customer_demographics ON (cs_bill_cdemo_sk = cd_demo_sk)
JOIN household_demographics ON (cs_bill_hdemo_sk = hd_demo_sk)
JOIN date_dim d1 ON (cs_sold_date_sk = d1.d_date_sk)
JOIN date_dim d2 ON (inv_date_sk = d2.d_date_sk)
JOIN date_dim d3 ON (cs_ship_date_sk = d3.d_date_sk)
LEFT OUTER JOIN promotion ON (cs_promo_sk=p_promo_sk)
LEFT OUTER JOIN catalog_returns ON (cr_item_sk = cs_item_sk
AND cr_order_number = cs_order_number)
WHERE d1.d_week_seq = d2.d_week_seq
AND inv_quantity_on_hand < cs_quantity
AND d3.d_date > d1.d_date + INTERVAL '5' DAY -- SQL Server: DATEADD(day, 5, d1.d_date)
AND hd_buy_potential = '>10000'
AND d1.d_year = 1999
AND cd_marital_status = 'D'
GROUP BY i_item_desc,
w_warehouse_name,
d1.d_week_seq
ORDER BY total_cnt DESC,
i_item_desc,
w_warehouse_name,
d1.d_week_seq
LIMIT 100;
```
It stoped after the above output.
**Expected behavior**
run in less than 1 second.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Software versions**
- MonetDB version number [a milestone label]
- OS and version: [e.g. Ubuntu 18.04]
- Installed from release package or self-installed and compiled
**Issue labeling **
Make liberal use of the labels to characterise the issue topics. e.g. identify severity, version, etc..
**Additional context**
Add any other context about the problem here.
| tpcds query no.72 very slow | https://api.github.com/repos/MonetDB/MonetDB/issues/7219/comments | 4 | 2022-01-12T09:28:47Z | 2023-10-28T10:00:33Z | https://github.com/MonetDB/MonetDB/issues/7219 | 1,100,096,331 | 7,219 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
tpch query 14 raise overflow error
```
sql>--14
sql>SELECT
more> 100.00 * SUM(CASE
more> WHEN P_TYPE LIKE 'PROMO%'
more> THEN L_EXTENDEDPRICE * (1 - L_DISCOUNT)
more> ELSE 0
more> END) / SUM(L_EXTENDEDPRICE * (1 - L_DISCOUNT)) AS PROMO_REVENUE
more>FROM
more> LINEITEM,
more> PART
more>WHERE
more> L_PARTKEY = P_PARTKEY
more> AND L_SHIPDATE >= DATE '1994-05-01'
more> AND L_SHIPDATE < DATE '1994-05-01' + INTERVAL '1' MONTH
more>LIMIT 100;
overflow in conversion to DECIMAL(18,10).
sql:0.000 opt:0.000 run:0.000 clk:506.265 ms
```
**To Reproduce**
```
Welcome to mclient, the MonetDB/SQL interactive terminal (Jul2021-SP2)
Database: MonetDB v11.41.13 (Jul2021-SP2), 'demo'
FOLLOW US on https://twitter.com/MonetDB or https://github.com/MonetDB/MonetDB
Type \q to quit, \? for a list of available commands
auto commit mode: on
sql>\< d:/tpch/dss.ddl
sql>\t performance
sql>copy into nation from 'e:/10/nation.tbl.gz' delimiters '|';
25 affected rows
sql:0.000 opt:1.000 run:55.003 clk:58.248 ms
sql>copy into customer from 'e:/10/customer.tbl.gz' delimiters '|';
1500000 affected rows
sql:0.000 opt:0.000 run:5725.328 clk:7701.261 ms
sql>copy into lineitem from 'e:/10/lineitem.tbl.gz' delimiters '|';
59986052 affected rows
sql:0.000 opt:0.000 run:382197.861 clk:418752.104 ms
sql>copy into part from 'e:/10/part.tbl.gz' delimiters '|';
2000000 affected rows
sql:0.000 opt:0.000 run:4449.254 clk:5170.089 ms
sql>copy into partsupp from 'e:/10/partsupp.tbl.gz' delimiters '|';
8000000 affected rows
sql:0.000 opt:0.000 run:119288.823 clk:123990.386 ms
sql>copy into orders from 'e:/10/orders.tbl.gz' delimiters '|';
15000000 affected rows
sql:0.000 opt:0.000 run:86004.920 clk:92107.641 ms
sql>copy into region from 'e:/10/region.tbl.gz' delimiters '|';
5 affected rows
sql>copy into supplier from 'e:/10/supplier.tbl.gz' delimiters '|';
100000 affected rows
sql:0.000 opt:1.001 run:364.020 clk:448.498 ms
sql>
--14
SELECT
100.00 * SUM(CASE
WHEN P_TYPE LIKE 'PROMO%'
THEN L_EXTENDEDPRICE * (1 - L_DISCOUNT)
ELSE 0
END) / SUM(L_EXTENDEDPRICE * (1 - L_DISCOUNT)) AS PROMO_REVENUE
FROM
LINEITEM,
PART
WHERE
L_PARTKEY = P_PARTKEY
AND L_SHIPDATE >= DATE '1994-05-01'
AND L_SHIPDATE < DATE '1994-05-01' + INTERVAL '1' MONTH
LIMIT 100;
```
**Expected behavior**
A result such as
16.123557247777
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Software versions**
- MonetDB version number [a milestone label]
- OS and version: [e.g. Ubuntu 18.04]
- Installed from release package or self-installed and compiled
**Issue labeling **
Make liberal use of the labels to characterise the issue topics. e.g. identify severity, version, etc..
**Additional context**
Add any other context about the problem here.
| tpch query 14 raise overflow error | https://api.github.com/repos/MonetDB/MonetDB/issues/7218/comments | 8 | 2022-01-10T03:02:08Z | 2024-06-07T11:58:39Z | https://github.com/MonetDB/MonetDB/issues/7218 | 1,097,404,446 | 7,218 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
This happens about 1 in 10 times I use a script that uses
`
COPY {n} OFFSET 2 RECORDS INTO "sys"."{table}" FROM '{absPath}' {using_delimitors}
`
to do a big (10M+ records) import.
when this happens my Ubuntu 18.04 server goes into a strange state; `ps -auwx` shows some processes hand then hangs completely. ctrl-c doesn't work. `service monetdbd stop` brings the system back to a normal state.
**To Reproduce**
I cannot reproduce it. When i happens and I restart the server to import the same data it works ok.
**Software versions**
- MonetDB Database Server Toolkit v11.41.5 (Jul2021)
- Ubuntu 18.04]
- Installed from release package
| monetdb sometimes hangs during copy from /abs/path | https://api.github.com/repos/MonetDB/MonetDB/issues/7217/comments | 1 | 2022-01-08T19:27:45Z | 2022-01-10T12:46:36Z | https://github.com/MonetDB/MonetDB/issues/7217 | 1,097,016,645 | 7,217 |
[
"MonetDB",
"MonetDB"
] | **Describe the bug**
I have multiple perl scripts running every night, one after the other, that each updating their own tables. The scripts use transactional updates. For some reason one of the scripts brings monetdb into a state where from that point on all scripts fail with a _Update failed due to conflict with another transaction_.
**To Reproduce**
I have not been able to narrow down the problem yet. The problem may have started with a full disk.
**Expected behavior**
I would expect that if one script fails, that session is aborted (and rolled back), but following sessions would be unaffected. Is that a misconception?
**Screenshots**
```
$ mclient
Welcome to mclient, the MonetDB/SQL interactive terminal (Jul2021)
Database: MonetDB v11.41.5 (Jul2021), 'mapi:monetdb://monet1:50000/mapfilter'
FOLLOW US on https://twitter.com/MonetDB or https://github.com/MonetDB/MonetDB
Type \q to quit, \? for a list of available commands
auto commit mode: on
sql>drop table x;
Transaction conflict while dropping table sys.x
```
**Software versions**
- MonetDB Database Server Toolkit v11.41.5 (Jul2021)
- Ubuntu 18.04]
- Installed from release package
| Update failed due to conflict with another transaction | https://api.github.com/repos/MonetDB/MonetDB/issues/7216/comments | 2 | 2022-01-08T19:27:40Z | 2022-02-10T18:45:58Z | https://github.com/MonetDB/MonetDB/issues/7216 | 1,097,016,622 | 7,216 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.