
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.46B | issue_number int64 1 127k |
|---|---|---|---|---|---|---|---|---|---|
[
"hwchase17",
"langchain"
] | I am using the CSV agent to analyze transaction data. I keep getting `ValueError: Could not parse LLM output: ` for the prompts. The agent seems to know what to do.
Any fix for this error?
```
> Entering new AgentExecutor chain...
---------------------------------------------------------------------------
Valu... | CSV Agent: ValueError: Could not parse LLM output: | https://api.github.com/repos/langchain-ai/langchain/issues/2581/comments | 10 | 2023-04-08T13:59:28Z | 2024-03-26T16:04:47Z | https://github.com/langchain-ai/langchain/issues/2581 | 1,659,531,988 | 2,581 |
[
"hwchase17",
"langchain"
] | Following this [guide](https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/googledrive.html), I tried to load my google docs file [doggo wikipedia](https://docs.google.com/document/d/1SJhVh8rQE7gZN_iUnmHC9XF3THRnnxLc/edit?usp=sharing&ouid=107343716482883353356&rtpof=true&sd=true) but I rece... | Document Loaders: GoogleDriveLoader can't load a google docs file. | https://api.github.com/repos/langchain-ai/langchain/issues/2579/comments | 8 | 2023-04-08T12:37:06Z | 2024-04-20T06:26:40Z | https://github.com/langchain-ai/langchain/issues/2579 | 1,659,510,852 | 2,579 |
[
"hwchase17",
"langchain"
] | null | Can you assist \ provide an example how to stream response when using an agent? | https://api.github.com/repos/langchain-ai/langchain/issues/2577/comments | 5 | 2023-04-08T10:32:23Z | 2023-09-28T16:08:51Z | https://github.com/langchain-ai/langchain/issues/2577 | 1,659,480,691 | 2,577 |
[
"hwchase17",
"langchain"
] | Using early_stopping_method with "generate" is not supported with new addition to custom LLM agents.
More specifically:
`agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True, max_execution_time=6, max_iterations=3, early_stopping_method="generate")`
`
Stack trace:
Traceba... | ValueError: Got unsupported early_stopping_method `generate` | https://api.github.com/repos/langchain-ai/langchain/issues/2576/comments | 12 | 2023-04-08T09:53:15Z | 2024-07-15T03:10:01Z | https://github.com/langchain-ai/langchain/issues/2576 | 1,659,468,662 | 2,576 |
[
"hwchase17",
"langchain"
] | How can I create a ConversationChain that uses a PydanticOutputParser for the output?
```py
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
parser = PydanticOutputParser(pydantic_object=Joke)
system_m... | How to use a ConversationChain with PydanticOutputParser | https://api.github.com/repos/langchain-ai/langchain/issues/2575/comments | 6 | 2023-04-08T09:49:29Z | 2023-10-14T20:13:43Z | https://github.com/langchain-ai/langchain/issues/2575 | 1,659,467,745 | 2,575 |
[
"hwchase17",
"langchain"
] |
I want to use qa chain with custom system prompt
```
template = """
You are an AI assis
"""
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
chat_prompt = ChatPromptTemplate.from_messages(
[system_message_prompt])
llm = ChatOpenAI(temperature=0.4, model_name='gpt-3.5-turbo',... | load_qa_with_sources_chain with custom prompt | https://api.github.com/repos/langchain-ai/langchain/issues/2574/comments | 3 | 2023-04-08T08:32:10Z | 2024-01-20T07:44:43Z | https://github.com/langchain-ai/langchain/issues/2574 | 1,659,446,392 | 2,574 |
[
"hwchase17",
"langchain"
] | when I set n >1, it demands I set best_of to that same number...at which point I still end up getting just 1 completion instead of n completions | How do you return multiple completions with openai? | https://api.github.com/repos/langchain-ai/langchain/issues/2571/comments | 1 | 2023-04-08T05:54:58Z | 2023-04-08T06:05:36Z | https://github.com/langchain-ai/langchain/issues/2571 | 1,659,407,187 | 2,571 |
[
"hwchase17",
"langchain"
] | The following custom tool definition triggers an "TypeError: unhashable type: 'Tool'"
@tool
def gender_guesser(query: str) -> str:
"""Useful for when you need to guess a person's gender based on their first name. Pass only the first name as the query, returns the gender."""
d = gender.Detector()
retu... | "Unhashable Type: Tool" when using custom tool | https://api.github.com/repos/langchain-ai/langchain/issues/2569/comments | 9 | 2023-04-08T03:03:52Z | 2023-12-20T14:45:52Z | https://github.com/langchain-ai/langchain/issues/2569 | 1,659,350,654 | 2,569 |
[
"hwchase17",
"langchain"
] | When using the `ConversationalChatAgent`, it sometimes outputs multiple actions in a single response, causing the following error:
```
ValueError: Could not parse LLM output: ...
```
Ideas:
1. Support this behavior so a single `AgentExecutor` run loop can perform multiple actions
2. Adjust prompting strategy ... | ConversationalChatAgent sometimes outputs multiple actions in response | https://api.github.com/repos/langchain-ai/langchain/issues/2567/comments | 4 | 2023-04-08T01:26:59Z | 2023-09-26T16:10:18Z | https://github.com/langchain-ai/langchain/issues/2567 | 1,659,327,099 | 2,567 |
[
"hwchase17",
"langchain"
] | Code:
```
llm = ChatOpenAI(temperature=0, model_name='gpt-4')
tools = load_tools(["serpapi", "llm-math", "python_repl","requests_all","human"], llm=llm)
agent = initialize_agent(tools, llm, agent='zero-shot-react-description', verbose=True)
agent.run("When was eiffel tower built")
```
Output:
> _File [env/li... | Could not parse LLM output when model changed from gpt-3.5-turbo to gpt-4 | https://api.github.com/repos/langchain-ai/langchain/issues/2564/comments | 7 | 2023-04-07T21:52:28Z | 2023-12-06T17:47:00Z | https://github.com/langchain-ai/langchain/issues/2564 | 1,659,237,777 | 2,564 |
[
"hwchase17",
"langchain"
] | Hello! I am attempting to run the snippet of code linked [here](https://github.com/hwchase17/langchain/pull/2201) locally on my
Macbook.
Specifically, I'm attempting to execute the import statement:
```
from langchain.utilities import ApifyWrapper
```
I am running this within a `conda` environment, where the... | Cannot import `ApifyWrapper` | https://api.github.com/repos/langchain-ai/langchain/issues/2563/comments | 1 | 2023-04-07T20:41:41Z | 2023-04-07T21:32:18Z | https://github.com/langchain-ai/langchain/issues/2563 | 1,659,173,947 | 2,563 |
[
"hwchase17",
"langchain"
] | Hi, I am building a chatbot that could answer questions related to some internal data. I have defined an agent that has access to a few tools that could query our internal database. However, at the same time, I do want the chatbot to handle normal conversation well beyond the internal data.
For example, when the use... | Make agent handle normal conversation that are not covered by tools | https://api.github.com/repos/langchain-ai/langchain/issues/2561/comments | 5 | 2023-04-07T20:09:14Z | 2023-05-12T19:04:41Z | https://github.com/langchain-ai/langchain/issues/2561 | 1,659,151,645 | 2,561 |
[
"hwchase17",
"langchain"
] | class BaseLLM, BaseTool, BaseChatModel and Chain have `set_callback_manager` method, I thought it was for setting custom callback_manager, like below. (https://github.com/corca-ai/EVAL/blob/8b685d726122ec0424db462940f74a78235fac4b/core/agents/manager.py#L44-L45)
```python
for tool in tools:
too... | what does set_callback_manager method for? | https://api.github.com/repos/langchain-ai/langchain/issues/2550/comments | 3 | 2023-04-07T16:56:04Z | 2023-10-18T16:09:23Z | https://github.com/langchain-ai/langchain/issues/2550 | 1,659,001,688 | 2,550 |
[
"hwchase17",
"langchain"
] | Below is my code.
The document "sample.pdf" located in my directory folder "data" is of "2000 tokens".
Why it costs me 2000+ tokens everytime i ask a new question.
```
from langchain import OpenAI
from llama_index import GPTSimpleVectorIndex, download_loader,SimpleDirectoryReader,PromptHelper
from llama_in... | Cost getting too high | https://api.github.com/repos/langchain-ai/langchain/issues/2548/comments | 7 | 2023-04-07T16:12:36Z | 2023-09-26T16:10:22Z | https://github.com/langchain-ai/langchain/issues/2548 | 1,658,968,544 | 2,548 |
[
"hwchase17",
"langchain"
] | I'm trying to use an OpenAI client for querying my API according to the [documentation](https://python.langchain.com/en/latest/modules/agents/toolkits/examples/openapi.html), but I obtain an error.
I can confirm that the `OPENAI_API_TYPE`, `OPENAI_API_KEY`, `OPENAI_API_BASE`, `OPENAI_DEPLOYMENT_NAME` and `OPENAI_API... | Error with OpenAPI Agent with `AzureOpenAI` | https://api.github.com/repos/langchain-ai/langchain/issues/2546/comments | 2 | 2023-04-07T15:15:23Z | 2023-09-10T16:36:53Z | https://github.com/langchain-ai/langchain/issues/2546 | 1,658,917,099 | 2,546 |
[
"hwchase17",
"langchain"
] | Plugin code is from [openai](https://github.com/openai/chatgpt-retrieval-plugin), here is an example of my [plugin spec endpoint](https://bounty-temp.marcusweinberger.repl.co/.well-known/ai-plugin.json).
Here is how I am loading the plugin:
```python
from langchain.tools import AIPluginTool, load_tools
tools ... | Loading chatgpt-retrieval-plugin with AIPluginLoader doesn't work | https://api.github.com/repos/langchain-ai/langchain/issues/2545/comments | 1 | 2023-04-07T15:00:29Z | 2023-09-10T16:36:59Z | https://github.com/langchain-ai/langchain/issues/2545 | 1,658,901,259 | 2,545 |
[
"hwchase17",
"langchain"
] | spent an hour to figure this out (great work by the way)
connection to db2 via alchemy
```
db = SQLDatabase.from_uri(
db2_connection_string,
schema='MYSCHEMA',
include_tables=['MY_TABLE_NAME'], # including only one table for illustration
sample_rows_in_table_info=3
)
```
this did not work ... | Lowercased include_tables in SQLDatabase.from_uri | https://api.github.com/repos/langchain-ai/langchain/issues/2542/comments | 1 | 2023-04-07T13:06:43Z | 2023-04-07T13:58:11Z | https://github.com/langchain-ai/langchain/issues/2542 | 1,658,788,229 | 2,542 |
[
"hwchase17",
"langchain"
] | The `__new__` method of `BaseOpenAI` returns a `OpenAIChat` instance if the model name starts with `gpt-3.5-turbo` or `gpt-4`.
https://github.com/hwchase17/langchain/blob/a31c9511e88f81ecc26e6ade24ece2c4d91136d4/langchain/llms/openai.py#L168
However, if you deploy the model in Azure OpenAI Service, the name does n... | Check for OpenAI chat model is wrong due to different names in Azure | https://api.github.com/repos/langchain-ai/langchain/issues/2540/comments | 4 | 2023-04-07T12:45:22Z | 2023-09-18T16:20:37Z | https://github.com/langchain-ai/langchain/issues/2540 | 1,658,768,884 | 2,540 |
[
"hwchase17",
"langchain"
] | Same code with OpenAI works.
With llama or gpt4all, even though it searches the internet (supposedly), it gets the previous prime minister, and also it fails to search the age and find prime based on it.
Is it possible that there is something wrong with the converted model?
 -> requests.Response:
"""GET the URL and return the text."""
return requests.get(url, headers=self.headers, **kwargs)
```
when request some multi language context,need text encoding .
suggest be like:
``` def get(self,... | suggestion: request support UTF-8 encoding contents | https://api.github.com/repos/langchain-ai/langchain/issues/2521/comments | 2 | 2023-04-07T03:44:05Z | 2023-09-10T16:37:14Z | https://github.com/langchain-ai/langchain/issues/2521 | 1,658,320,846 | 2,521 |
[
"hwchase17",
"langchain"
] | I'm wondering if there is a way to use memory in combination with a vector store. For example in a chatbot, for every message, the context of the conversation is the last few hops of the conversation plus some relevant older conversations that are out of the buffer size retrieved from the vector store.
Thanks in adv... | Integrating Memory with Vectorstore | https://api.github.com/repos/langchain-ai/langchain/issues/2518/comments | 8 | 2023-04-06T22:53:08Z | 2023-10-23T16:09:22Z | https://github.com/langchain-ai/langchain/issues/2518 | 1,658,140,870 | 2,518 |
[
"hwchase17",
"langchain"
] | Not sure where to put the partial_variables when using Chat Prompt Templates.
```
chat = ChatOpenAI()
class Colors(BaseModel):
colors: List[str] = Field(description="List of colors")
parser = PydanticOutputParser(pydantic_object=Colors)
format_instructions = parser.get_format_instructions()
promp... | partial_variables and Chat Prompt Templates | https://api.github.com/repos/langchain-ai/langchain/issues/2517/comments | 6 | 2023-04-06T22:43:46Z | 2024-08-03T04:46:34Z | https://github.com/langchain-ai/langchain/issues/2517 | 1,658,134,848 | 2,517 |
[
"hwchase17",
"langchain"
] | The following error appears at the end of the script
```
TypeError: 'NoneType' object is not callable
Exception ignored in: <function PersistentDuckDB.__del__ at 0x7f53e574d4c0>
Traceback (most recent call last):
File ".../.local/lib/python3.9/site-packages/chromadb/db/duckdb.py", line 445, in __del__
Attribu... | ChromaDB error when using HuggingFace Embeddings | https://api.github.com/repos/langchain-ai/langchain/issues/2512/comments | 9 | 2023-04-06T19:21:50Z | 2023-12-22T04:42:48Z | https://github.com/langchain-ai/langchain/issues/2512 | 1,657,927,383 | 2,512 |
[
"hwchase17",
"langchain"
] | Hi,
I have come up with above error: 'root:Could not parse LLM output' when I use ConversationalAgent. However, it is not all the time, but occasionally.
I looked into codes in this repo, and feel that condition in the function, '_extract_tool_and_input' would be an issue as sometimes LLMChain.predict returns out... | ERROR:root:Could not parse LLM output on ConversationalAgent | https://api.github.com/repos/langchain-ai/langchain/issues/2511/comments | 3 | 2023-04-06T19:20:56Z | 2023-10-17T16:08:40Z | https://github.com/langchain-ai/langchain/issues/2511 | 1,657,926,387 | 2,511 |
[
"hwchase17",
"langchain"
] | Following the tutorial for load_qa_with_sources_chain using the example state_of_the_union.txt I encounter interesting situations. Sometimes when I ask a query such as "What did Biden say about Ukraine?" I get a response like this:
"Joe Biden talked about the Ukrainian people's fearlessness, courage, and determinati... | Hallucinating Question about Michael Jackson | https://api.github.com/repos/langchain-ai/langchain/issues/2510/comments | 6 | 2023-04-06T19:11:07Z | 2023-10-15T06:04:51Z | https://github.com/langchain-ai/langchain/issues/2510 | 1,657,916,335 | 2,510 |
[
"hwchase17",
"langchain"
] | Trying to initialize a `ChatOpenAI` is resulting in this error:
```
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(temperature=0)
```
> `openai` has no `ChatCompletion` attribute, this is likely due to an old version of the openai package.
I've upgraded all my packages to latest...
```
p... | `openai` has no `ChatCompletion` attribute | https://api.github.com/repos/langchain-ai/langchain/issues/2505/comments | 7 | 2023-04-06T18:00:51Z | 2023-09-28T16:08:56Z | https://github.com/langchain-ai/langchain/issues/2505 | 1,657,837,119 | 2,505 |
[
"hwchase17",
"langchain"
] | When using the `refine` chain_type of the `load_summarize_chain`, I get some unique output on some longer documents, which might necessitate minor changes to the current prompt.
```
Return original summary.
```
```
The original summary remains appropriate.
```
```
No changes needed to the original summary.
... | Summarize Chain Doesn't Always Return Summary When Using Refine Chain Type | https://api.github.com/repos/langchain-ai/langchain/issues/2504/comments | 10 | 2023-04-06T17:17:27Z | 2023-12-09T16:07:26Z | https://github.com/langchain-ai/langchain/issues/2504 | 1,657,785,547 | 2,504 |
[
"hwchase17",
"langchain"
] | I would like to create a new issue on GitHub regarding the extension of ChatGPTPluginRetriever to support filters for metadata in chatGptRetrievalPlugin. With the ability to extend metadata using chatGptRetrievalPlugin, I believe there will be an increased need to consider filters for metadata as well. In fact, I mysel... | I want to extend ChatGPTPluginRetriever to support filters for chatGptRetrievalPlugin. | https://api.github.com/repos/langchain-ai/langchain/issues/2501/comments | 2 | 2023-04-06T15:49:22Z | 2023-09-10T16:37:19Z | https://github.com/langchain-ai/langchain/issues/2501 | 1,657,669,963 | 2,501 |
[
"hwchase17",
"langchain"
] | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're po... | OpenSearchVectorSearch doesn't permit the user to specify a field name | https://api.github.com/repos/langchain-ai/langchain/issues/2500/comments | 6 | 2023-04-06T15:46:29Z | 2023-04-10T03:04:18Z | https://github.com/langchain-ai/langchain/issues/2500 | 1,657,666,051 | 2,500 |
[
"hwchase17",
"langchain"
] | I am running the following in a Jupyter Notebook:
```
from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
from langchain.python import PythonREPL
from langchain.llms.openai import OpenAI
import os
os.environ["OPENAI_API_KEY"]="sk-xxxxxxxx"
... | 'Agent stopped due to max iterations.' | https://api.github.com/repos/langchain-ai/langchain/issues/2495/comments | 5 | 2023-04-06T14:36:38Z | 2023-09-25T16:11:25Z | https://github.com/langchain-ai/langchain/issues/2495 | 1,657,547,064 | 2,495 |
[
"hwchase17",
"langchain"
] | I have the following code:
```
docsearch = Chroma.from_documents(texts, embeddings,persist_directory=persist_directory)
```
and get the following error:
```
Retrying langchain.embeddings.openai.embed_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: Requests to the Embeddings... | Azure OpenAI Embedding langchain.embeddings.openai.embed_with_retry won't provide any embeddings after retries. | https://api.github.com/repos/langchain-ai/langchain/issues/2493/comments | 33 | 2023-04-06T12:25:58Z | 2024-04-15T16:35:33Z | https://github.com/langchain-ai/langchain/issues/2493 | 1,657,331,728 | 2,493 |
[
"hwchase17",
"langchain"
] |
persist_directory = 'chroma_db_store/index/' or 'chroma_db_store'
docsearch = Chroma(persist_directory=persist_directory, embedding_function=embeddings)
query = "Hey"
docs = docsearch.similarity_search(query)
NoIndexException: Index not found, please create an instance before querying
Folder structure
chrom... | Error while loading saved index in chroma db | https://api.github.com/repos/langchain-ai/langchain/issues/2491/comments | 36 | 2023-04-06T11:52:42Z | 2024-04-18T10:42:12Z | https://github.com/langchain-ai/langchain/issues/2491 | 1,657,278,903 | 2,491 |
[
"hwchase17",
"langchain"
] | `search_index = Chroma(persist_directory='db', embedding_function=OpenAIEmbeddings())`
but trying to do a similarity_search on it, i get this error:
`NoIndexException: Index not found, please create an instance before querying`
folder structure:
db/
- index/
- id_to_uuid_xx.pkl
- index_xx.pkl
... | instantiating Chroma from persist_directory not working: `NoIndexException` | https://api.github.com/repos/langchain-ai/langchain/issues/2490/comments | 2 | 2023-04-06T11:51:58Z | 2023-09-10T16:37:24Z | https://github.com/langchain-ai/langchain/issues/2490 | 1,657,277,903 | 2,490 |
[
"hwchase17",
"langchain"
] | in PromptTemplate i am loading json and it is coming back with below error
Exception has occurred: KeyError and mentioning the key used in json in that case customerNAme | KeyError : While Loading Json Context in Template | https://api.github.com/repos/langchain-ai/langchain/issues/2489/comments | 4 | 2023-04-06T11:44:10Z | 2023-09-25T16:11:30Z | https://github.com/langchain-ai/langchain/issues/2489 | 1,657,267,209 | 2,489 |
[
"hwchase17",
"langchain"
] | Error with the AgentOutputParser() when I follow the notebook "Conversation Agent (for Chat Models)"
`> Entering new AgentExecutor chain...
Traceback (most recent call last):
File "/Users/wzy/opt/anaconda3/envs/py3.8/lib/python3.8/site-packages/langchain/agents/conversational_chat/base.py", line 106, in _extract_t... | ValueError: Could not parse LLM output: on 'chat-conversational-react-description' | https://api.github.com/repos/langchain-ai/langchain/issues/2488/comments | 2 | 2023-04-06T11:17:28Z | 2023-09-26T16:10:32Z | https://github.com/langchain-ai/langchain/issues/2488 | 1,657,228,906 | 2,488 |
[
"hwchase17",
"langchain"
] | My template has a part that is formatted like this:
```
Final:
[{{'instruction': 'What is the INR value of 1 USD?', 'source': 'USD', 'target': 'INR', 'amount': 1}},
{{'instruction': 'Convert 100 USD to EUR.', 'source': 'USD', 'target': 'EUR', 'amount': 100}},
{{'instruction': 'How much is 200 GBP in JP... | KeyError with double curly braces | https://api.github.com/repos/langchain-ai/langchain/issues/2487/comments | 1 | 2023-04-06T11:04:49Z | 2023-04-06T11:19:00Z | https://github.com/langchain-ai/langchain/issues/2487 | 1,657,207,499 | 2,487 |
[
"hwchase17",
"langchain"
] | Traceback (most recent call last):
File "c:\Users\Siddhesh\Desktop\llama.cpp\langchain_test.py", line 10, in <module>
llm = LlamaCpp(model_path="C:\\Users\\Siddhesh\\Desktop\\llama.cpp\\models\\ggml-model-q4_0.bin")
File "pydantic\main.py", line 339, in pydantic.main.BaseModel.__init__
File "pydantic\main... | NameError: Could not load Llama model from path | https://api.github.com/repos/langchain-ai/langchain/issues/2485/comments | 17 | 2023-04-06T10:31:43Z | 2024-03-27T14:56:25Z | https://github.com/langchain-ai/langchain/issues/2485 | 1,657,150,082 | 2,485 |
[
"hwchase17",
"langchain"
] | If index already exists or any doc inside it, I can not update the index or add more docs to it. for example:
docsearch = ElasticVectorSearch.from_texts(texts=texts[0:10], ids=ids[0:10], embedding=embedding, elasticsearch_url=f"http://elastic:{ELASTIC_PASSWORD}@localhost:9200", index_name="test")
Get an error: BadR... | Can not overwrite docs in ElasticVectorSearch as Pinecone do | https://api.github.com/repos/langchain-ai/langchain/issues/2484/comments | 15 | 2023-04-06T10:24:28Z | 2023-09-28T16:09:01Z | https://github.com/langchain-ai/langchain/issues/2484 | 1,657,135,863 | 2,484 |
[
"hwchase17",
"langchain"
] | I am using a Agent and wanted to stream just the final response, do you know if that is supported already? and how to do it? | using a Agent and wanted to stream just the final response | https://api.github.com/repos/langchain-ai/langchain/issues/2483/comments | 28 | 2023-04-06T09:58:04Z | 2024-07-03T10:07:39Z | https://github.com/langchain-ai/langchain/issues/2483 | 1,657,083,533 | 2,483 |
[
"hwchase17",
"langchain"
] | I want to costum a chatmodel, what is necessary like a custom llm's _call() method? | Custom Chat model like llm | https://api.github.com/repos/langchain-ai/langchain/issues/2482/comments | 1 | 2023-04-06T09:47:06Z | 2023-09-10T16:37:29Z | https://github.com/langchain-ai/langchain/issues/2482 | 1,657,060,333 | 2,482 |
[
"hwchase17",
"langchain"
] | I'm trying to save and restore a Langchain Agent with a custom prompt template, and I'm encountering the error `"CustomPromptTemplate" object has no field "_prompt_type"`.
Langchain version: 0.0.132
Source code:
```
import os
os.environ["OPENAI_API_KEY"] = "..."
os.environ["SERPAPI_API_KEY"] = "..."
fr... | Can't save a custom agent: "CustomPromptTemplate" object has no field "_prompt_type" | https://api.github.com/repos/langchain-ai/langchain/issues/2481/comments | 1 | 2023-04-06T08:33:35Z | 2023-09-10T16:37:34Z | https://github.com/langchain-ai/langchain/issues/2481 | 1,656,924,309 | 2,481 |
[
"hwchase17",
"langchain"
] | For example, I want to build an agent with a Q&A tool (wrap the [Q&A with source chain](https://python.langchain.com/en/latest/modules/chains/index_examples/qa_with_sources.html) ) as private knowledge base, together with several other tools to produce the final answer
What's the suggested way to pass the "sources" ... | Passing data from tool to agent | https://api.github.com/repos/langchain-ai/langchain/issues/2478/comments | 2 | 2023-04-06T08:04:52Z | 2023-09-18T16:20:43Z | https://github.com/langchain-ai/langchain/issues/2478 | 1,656,881,285 | 2,478 |
[
"hwchase17",
"langchain"
] | I also tried this for the `csv_agent`. It just gets confused . The default `text-davinci` works in one go.

| support gpt-3.5-turbo model for agent toolkits | https://api.github.com/repos/langchain-ai/langchain/issues/2476/comments | 1 | 2023-04-06T06:25:09Z | 2023-09-10T16:37:44Z | https://github.com/langchain-ai/langchain/issues/2476 | 1,656,743,871 | 2,476 |
[
"hwchase17",
"langchain"
] | Does langchain have Atlassian Confluence support like Llama Hub? | Atlassian Confluence support | https://api.github.com/repos/langchain-ai/langchain/issues/2473/comments | 24 | 2023-04-06T05:29:57Z | 2023-12-13T16:10:48Z | https://github.com/langchain-ai/langchain/issues/2473 | 1,656,690,780 | 2,473 |
[
"hwchase17",
"langchain"
] | `text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) `
If I do this, some text will not be split strictly by default ‘\n\n’ like:
'In state after state, new laws have been passed, not only to suppress the vote, but to subvert entire elections. \n\nWe cannot let this happen. \n\nTonight. I call on ... | how to split documents | https://api.github.com/repos/langchain-ai/langchain/issues/2469/comments | 1 | 2023-04-06T04:24:01Z | 2023-04-25T12:48:06Z | https://github.com/langchain-ai/langchain/issues/2469 | 1,656,641,706 | 2,469 |
[
"hwchase17",
"langchain"
] | Previously, for standard language models setting `batch_size` would control concurrent LLM requests, reducing the risk of timeouts and network issues (https://github.com/hwchase17/langchain/issues/1145).
New chat models don't seem to support this parameter. See the following example:
```python
from langchain.chat_... | Batch Size for Chat Models | https://api.github.com/repos/langchain-ai/langchain/issues/2465/comments | 3 | 2023-04-06T03:45:40Z | 2023-10-16T14:37:35Z | https://github.com/langchain-ai/langchain/issues/2465 | 1,656,615,689 | 2,465 |
[
"hwchase17",
"langchain"
] | Hey!
First things first, I just want to say thanks for this amazing project :)
In MapReduceDocumentsChain class, when you call it asynchronously, i.e. with `acombine_docs`, it still calls the same `self.process_results` method as it does when calling the regular `combine_docs`. I expected, that when you use async,... | Adding async support for reduce step in MapReduceDocumentsChain | https://api.github.com/repos/langchain-ai/langchain/issues/2464/comments | 3 | 2023-04-06T00:24:31Z | 2023-12-06T17:47:15Z | https://github.com/langchain-ai/langchain/issues/2464 | 1,656,491,381 | 2,464 |
[
"hwchase17",
"langchain"
] | When I call
```python
retriever = PineconeHybridSearchRetriever(embeddings=embeddings, index=index, tokenizer=tokenizer)
retriever.get_relevant_documents(query)
```
I'm getting the error:
```
final_result.append(Document(page_content=res["metadata"]["context"]))
KeyError: 'context'
```
What is that ... | KeyError: 'context' when using PineconeHybridSearchRetriever | https://api.github.com/repos/langchain-ai/langchain/issues/2459/comments | 3 | 2023-04-05T20:46:00Z | 2024-05-12T18:19:37Z | https://github.com/langchain-ai/langchain/issues/2459 | 1,656,270,923 | 2,459 |
[
"hwchase17",
"langchain"
] | During an experiment I tryied to load some personal whatsapp conversations into a vectorstore. But loading was failing. Following there's an example of a dataset and code with some half lines working and half failing:
Dataset (whatsapp_chat.txt):
```
19/10/16, 13:24 - Aitor Mira: Buenas Andrea!
19/10/16, 13:24 - ... | WhatsAppChatLoader fails to load 24 hours time format chats | https://api.github.com/repos/langchain-ai/langchain/issues/2457/comments | 1 | 2023-04-05T20:39:23Z | 2023-04-06T16:45:16Z | https://github.com/langchain-ai/langchain/issues/2457 | 1,656,260,004 | 2,457 |
[
"hwchase17",
"langchain"
] | In following the docs for Agent ToolKits, specifically for OpenAPI, I encountered a bug in `reduce_openapi_spec` where the url has `https:` trunc'd off leading to errors when the Agent attempts to make a request.
I'm able to correct it by hardcoding the value for the url in `servers`:
- `api_spec.servers[0]['url'] ... | reduce_openapi_spec removes https: from url | https://api.github.com/repos/langchain-ai/langchain/issues/2456/comments | 5 | 2023-04-05T20:26:58Z | 2023-10-25T20:48:18Z | https://github.com/langchain-ai/langchain/issues/2456 | 1,656,244,370 | 2,456 |
[
"hwchase17",
"langchain"
] | Hi there,
Going through the docs, and it seems there is only SQLAgent available that works for the Postgres/MySQL databases. Is there any support for the Clickhouse database?
| Clickhouse langchain agent? | https://api.github.com/repos/langchain-ai/langchain/issues/2454/comments | 3 | 2023-04-05T20:20:48Z | 2024-03-28T03:37:12Z | https://github.com/langchain-ai/langchain/issues/2454 | 1,656,231,938 | 2,454 |
[
"hwchase17",
"langchain"
] | Currently, tool selection is case sensitive. So if you make a tool "email" and the Agent request the tool "Email" it will say that it is not a valid tool. As there is a lot of variability with agents, we should make it so that the tool selection is case insensitive (with potential additional validation to ensure there ... | Tool selection is case sensitive | https://api.github.com/repos/langchain-ai/langchain/issues/2453/comments | 5 | 2023-04-05T20:12:40Z | 2023-12-11T16:08:38Z | https://github.com/langchain-ai/langchain/issues/2453 | 1,656,223,326 | 2,453 |
[
"hwchase17",
"langchain"
] | Hi! I tried to use pinecon's hybrid search as in this tutorial:
https://python.langchain.com/en/latest/modules/indexes/retrievers/examples/pinecone_hybrid_search.html
The only difference is that I created the indices beforehand, so without this chunk of code:
```python
pinecone.create_index(
name = index_... | Index configuration does not support sparse values | https://api.github.com/repos/langchain-ai/langchain/issues/2451/comments | 2 | 2023-04-05T19:51:05Z | 2023-04-09T19:56:43Z | https://github.com/langchain-ai/langchain/issues/2451 | 1,656,194,417 | 2,451 |
[
"hwchase17",
"langchain"
] | Hello! Are you considering creating a Discord channel? Perhaps one already exists, but I was unable to locate it. | Create discord channel for Langchain | https://api.github.com/repos/langchain-ai/langchain/issues/2448/comments | 3 | 2023-04-05T16:17:28Z | 2023-04-18T02:18:22Z | https://github.com/langchain-ai/langchain/issues/2448 | 1,655,932,782 | 2,448 |
[
"hwchase17",
"langchain"
] | Integrating [RabbitMQ](https://github.com/rabbitmq)'s messaging protocols into LangChain unlocks seamless integration with multiple platforms, including Facebook Messenger, Slack, Microsoft Teams, Twitter, and Zoom. RabbitMQ supports AMQP, STOMP, MQTT, and HTTP [messaging protocols](https://www.rabbitmq.com/protocols.h... | RabbitMQ | https://api.github.com/repos/langchain-ai/langchain/issues/2447/comments | 2 | 2023-04-05T16:14:48Z | 2023-09-25T16:11:50Z | https://github.com/langchain-ai/langchain/issues/2447 | 1,655,929,140 | 2,447 |
[
"hwchase17",
"langchain"
] | I am running a standard LangChain use case of reading a PDF document, generating embeddings using OpenAI, and then saving them to Pinecone index.
```
def read_pdf(file_path):
loader = UnstructuredFileLoader(file_path)
docs = loader.load()
return docs
def create_embeddings(document):
openai_embe... | TypeError: Object of type Document is not JSON serializable | https://api.github.com/repos/langchain-ai/langchain/issues/2446/comments | 6 | 2023-04-05T16:07:37Z | 2023-10-31T16:08:05Z | https://github.com/langchain-ai/langchain/issues/2446 | 1,655,917,246 | 2,446 |
[
"hwchase17",
"langchain"
] | When few documets embedded into vector db everything works fine, with similarity search I can always find the most relevant documents on the top of results. But when it comes to over hundred, searching result will be very confusing, given the same query I could not find any relevant documents. I've tried Chroma, Faiss,... | Similarity search not working well when number of ingested documents is great, say over one hundred. | https://api.github.com/repos/langchain-ai/langchain/issues/2442/comments | 32 | 2023-04-05T14:55:28Z | 2024-05-04T22:03:03Z | https://github.com/langchain-ai/langchain/issues/2442 | 1,655,787,596 | 2,442 |
[
"hwchase17",
"langchain"
] | Hi!
1. Upd: Fixed in https://github.com/hwchase17/langchain/pull/2641
~I've noticed in the `Models -> LLM` [documentation](https://python.langchain.com/en/latest/modules/models/llms/getting_started.html) the following note about `get_num_tokens` function:~
> Notice that by default the tokens are estimated using a ... | docs: get_num_tokens - default tokenizer | https://api.github.com/repos/langchain-ai/langchain/issues/2439/comments | 3 | 2023-04-05T14:26:11Z | 2023-09-18T16:20:53Z | https://github.com/langchain-ai/langchain/issues/2439 | 1,655,733,381 | 2,439 |
[
"hwchase17",
"langchain"
] | I have just started experimenting with OpenAI & Langchain and very new to this field. Is there a way to do country specific searches using the Serper API ? I am in Australia, and the Serper API keep returning US based results. I tried to use the "gl" parameter, but no success
```
from langchain.utilities import Goo... | Country specific searches using the Serper API ? | https://api.github.com/repos/langchain-ai/langchain/issues/2438/comments | 2 | 2023-04-05T14:19:37Z | 2023-09-18T16:20:58Z | https://github.com/langchain-ai/langchain/issues/2438 | 1,655,717,485 | 2,438 |
[
"hwchase17",
"langchain"
] | Are `UnstructuredMarkdownLoader` and `MarkdownTextSplitter` meant to be used together? It seems like the former removes formatting so that the latter can no longer split into sections.
```python
import github
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import... | UnstructuredMarkdownLoader + MarkdownTextSplitter | https://api.github.com/repos/langchain-ai/langchain/issues/2436/comments | 2 | 2023-04-05T13:22:30Z | 2023-09-18T16:21:03Z | https://github.com/langchain-ai/langchain/issues/2436 | 1,655,613,603 | 2,436 |
[
"hwchase17",
"langchain"
] | The value of `qa_prompt` is passed to `load_qa_chain()` as `prompt`, with no option for kwargs.
https://github.com/hwchase17/langchain/blob/4d730a9bbcd384da27e2e7c5a6a6efa5eac55838/langchain/chains/conversational_retrieval/base.py#L164-L168
`_load_map_reduce_chain()` expects multiple prompt templates as kwargs, no... | `ConversationalRetrievalChain.from_llm()` does not work with `chain_type` of `"map_reduce"` | https://api.github.com/repos/langchain-ai/langchain/issues/2435/comments | 3 | 2023-04-05T11:54:22Z | 2023-09-26T16:10:47Z | https://github.com/langchain-ai/langchain/issues/2435 | 1,655,480,306 | 2,435 |
[
"hwchase17",
"langchain"
] | I’m having a few issues with a prompt template using ConversationChain and ConversationEntity Memory.
Currently I’m using a template as follows:
```
template = """Assistant is a large language model based on OpenAI's chatGPT…
The user Assistant is speaking to is a human and their first name is {first_name} and ... | [ConversationEntity Memory Prompt Template] - issues with customisation | https://api.github.com/repos/langchain-ai/langchain/issues/2434/comments | 2 | 2023-04-05T11:33:15Z | 2023-07-23T12:01:01Z | https://github.com/langchain-ai/langchain/issues/2434 | 1,655,448,419 | 2,434 |
[
"hwchase17",
"langchain"
] | I am using version0.0.0132 and i get this error while importing:
ImportError: cannot import name 'PineconeHybridSearchRetriever' from 'langchain.retrievers' | cannot import pineconehybridsearchretriever | https://api.github.com/repos/langchain-ai/langchain/issues/2432/comments | 1 | 2023-04-05T11:05:07Z | 2023-09-10T16:38:09Z | https://github.com/langchain-ai/langchain/issues/2432 | 1,655,408,831 | 2,432 |
[
"hwchase17",
"langchain"
] | So as far as I can't tell, there is no way to return intermediate steps from tools to be combined at the agent level, making them a black box (discounting tracing). For example, an agent using the SQLDatabaseChain can't capture the SQL query used by the SQLChain.
The tool interface is just str -> str, which keeps it... | Tools and return_intermediate_steps | https://api.github.com/repos/langchain-ai/langchain/issues/2431/comments | 3 | 2023-04-05T10:46:10Z | 2023-05-01T22:15:21Z | https://github.com/langchain-ai/langchain/issues/2431 | 1,655,381,372 | 2,431 |
[
"hwchase17",
"langchain"
] | I have a use case in which I want to customize my own chat model; how can I do that?
there is a way to customize [LLM](https://python.langchain.com/en/latest/modules/models/llms/examples/custom_llm.html), but I did not find anything regarding customizing the chat model | How to customize chat model | https://api.github.com/repos/langchain-ai/langchain/issues/2430/comments | 4 | 2023-04-05T09:52:39Z | 2023-09-26T16:10:52Z | https://github.com/langchain-ai/langchain/issues/2430 | 1,655,297,167 | 2,430 |
[
"hwchase17",
"langchain"
] | 👋🏾 I tried using the new Llamacpp LLM and Embedding classes (awesome work!) and I've noticed that any vector store created with it cannot be saved as a pickle as there are cytpe objects containing pointers.
The reason is because the Vector Store has the field `embedding_function` which is the `Callable` to
the ... | Not being able to pickle Llamacpp Embedding | https://api.github.com/repos/langchain-ai/langchain/issues/2429/comments | 3 | 2023-04-05T09:40:10Z | 2023-04-06T17:06:13Z | https://github.com/langchain-ai/langchain/issues/2429 | 1,655,278,934 | 2,429 |
[
"hwchase17",
"langchain"
] | Issue Description:
I'm looking for a way to obtain streaming outputs from the model as a generator, which would enable dynamic chat responses in a front-end application. While this functionality is available in the OpenAI API, I couldn't find a similar option in Langchain.
I'm aware that using `verbose=True` allo... | Title: Request for Streaming Outputs as a Generator for Dynamic Chat Responses | https://api.github.com/repos/langchain-ai/langchain/issues/2428/comments | 30 | 2023-04-05T09:34:44Z | 2023-10-31T22:18:19Z | https://github.com/langchain-ai/langchain/issues/2428 | 1,655,271,271 | 2,428 |
[
"hwchase17",
"langchain"
] | Hi, I want to add memory to agent using create_csv_agent or create_sql_agent as the agent.
I read [this](https://python.langchain.com/en/latest/modules/memory/examples/agent_with_memory.html) to add memory to agent but when doing this:
```
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = c... | create_csv_agent with memory | https://api.github.com/repos/langchain-ai/langchain/issues/2427/comments | 4 | 2023-04-05T08:49:53Z | 2023-11-29T16:11:50Z | https://github.com/langchain-ai/langchain/issues/2427 | 1,655,201,936 | 2,427 |
[
"hwchase17",
"langchain"
] | ## Describe the issue
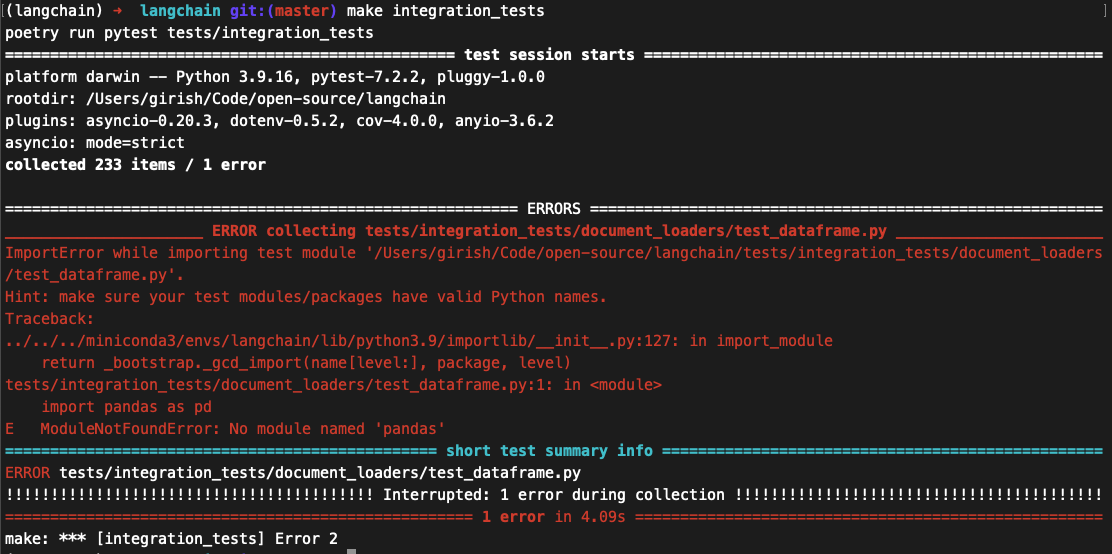
`make integration_tests` failing with the following error.
## How to reproduce it?
1. Install poetry requirements `poetry install -E all`
2. Ru... | Integration tests failing | https://api.github.com/repos/langchain-ai/langchain/issues/2426/comments | 1 | 2023-04-05T08:37:11Z | 2023-04-08T03:43:54Z | https://github.com/langchain-ai/langchain/issues/2426 | 1,655,184,632 | 2,426 |
[
"hwchase17",
"langchain"
] | Hey guys, I'm adding a termination feature, was wondering if langchain supports this? I could not find resources in the docs nor in the code.
Right now I'm doing this:
```
async def cancel_task(task: asyncio.Task[None]) -> None:
try:
task.cancel()
await task
except ... | Premature termination of LLM call | https://api.github.com/repos/langchain-ai/langchain/issues/2425/comments | 1 | 2023-04-05T07:40:09Z | 2023-08-25T16:12:34Z | https://github.com/langchain-ai/langchain/issues/2425 | 1,655,102,889 | 2,425 |
[
"hwchase17",
"langchain"
] | ## Describe the issue
Right now we don't have any template for PR and Issues to provide a structure for their description.
## Expected behaviour
Have a template for PR and Issues.
## What are the benefits of having a template for PR and Issues?
- Provides consistency in the description.
- It saves time ... | Add a template for Issues and PRs | https://api.github.com/repos/langchain-ai/langchain/issues/2424/comments | 1 | 2023-04-05T06:53:49Z | 2023-09-18T16:21:08Z | https://github.com/langchain-ai/langchain/issues/2424 | 1,655,043,999 | 2,424 |
[
"hwchase17",
"langchain"
] | We are trying to integrate langchain in a simple NestJs app, but we are getting this error:
`Error: Package subpath './llms' is not defined by "exports" in /Users/.../node_modules/langchain/package.json
at new NodeError (node:internal/errors:387:5)
at throwExportsNotFound (node:internal/modules/esm/resolve:3... | Error: Package subpath './llms' is not defined by "exports" | https://api.github.com/repos/langchain-ai/langchain/issues/2423/comments | 2 | 2023-04-05T06:42:56Z | 2023-09-18T16:21:13Z | https://github.com/langchain-ai/langchain/issues/2423 | 1,655,031,625 | 2,423 |
[
"hwchase17",
"langchain"
] | I am getting a RateLimit exceed error while using OpenAI and SQL Agent
```
Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
Retrying langchain.llms.openai.comp... | RateLimit Exceeded using OpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/2421/comments | 1 | 2023-04-05T04:51:05Z | 2023-04-05T06:57:38Z | https://github.com/langchain-ai/langchain/issues/2421 | 1,654,932,006 | 2,421 |
[
"hwchase17",
"langchain"
] | null | LLM | https://api.github.com/repos/langchain-ai/langchain/issues/2420/comments | 1 | 2023-04-05T04:36:04Z | 2023-08-25T16:12:40Z | https://github.com/langchain-ai/langchain/issues/2420 | 1,654,921,876 | 2,420 |
[
"hwchase17",
"langchain"
] | I use this HF pipeline and **vicuna** or **alpaca** as a model:
`pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_length=256,
temperature=1.0,
top_p=0.95,
repetition_penalty=1.2
)
llm = HuggingFacePipeline(pipeline=pipe)
from langchain import Promp... | llm_chain generates answers for questions I did not ask | https://api.github.com/repos/langchain-ai/langchain/issues/2418/comments | 6 | 2023-04-05T04:09:58Z | 2023-09-27T16:09:58Z | https://github.com/langchain-ai/langchain/issues/2418 | 1,654,902,702 | 2,418 |
[
"hwchase17",
"langchain"
] | ## Summary
Pretty simple.
There should be a tool that invokes the AWS Lambda function you pass in as a constructor arg.
## Notes
This is a work in progress. I just made this issue to track that it's something being worked on. If you'd like to partner to help me get it up and running, feel free to reach out on... | Tool that invokes AWS Lambda function | https://api.github.com/repos/langchain-ai/langchain/issues/2416/comments | 1 | 2023-04-04T23:16:03Z | 2023-07-01T18:08:22Z | https://github.com/langchain-ai/langchain/issues/2416 | 1,654,697,225 | 2,416 |
[
"hwchase17",
"langchain"
] | Hi all, just wanted to see if there was anyone interested in helping me integrate streaming completion support for the new `LlamaCpp` class.
The base `Llama` class supports streaming at the moment and I purposely designed it to behave almost identically to `openai.Completion.create(..., stream=True)` [see docs](http... | LlamaCpp Streaming Support | https://api.github.com/repos/langchain-ai/langchain/issues/2415/comments | 7 | 2023-04-04T22:54:29Z | 2024-02-01T13:57:43Z | https://github.com/langchain-ai/langchain/issues/2415 | 1,654,680,667 | 2,415 |
[
"hwchase17",
"langchain"
] | When calling `Pinecone.from_texts` without an `index_name` or with a wrong one, it will create a new index (either with the wrong name, or with a uuid as the name). As pinecone is a SaaS only product, that can cause unintended costs to users, and might populate different indexes on each invocation of their code. | If a wrong or none index name is passed into `Pinecone.from_texts` it creates a new index | https://api.github.com/repos/langchain-ai/langchain/issues/2413/comments | 0 | 2023-04-04T22:31:44Z | 2023-04-05T04:24:50Z | https://github.com/langchain-ai/langchain/issues/2413 | 1,654,663,150 | 2,413 |
[
"hwchase17",
"langchain"
] | When I attempt to process an EML messages using the DirectoryLoader i get this error
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x92 in position 19: invalid start byte
from
File ~\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packa... | When Parsing a EML file i get - utf-8' codec can't decode byte 0x92 in position 19: invalid start byte | https://api.github.com/repos/langchain-ai/langchain/issues/2412/comments | 2 | 2023-04-04T21:58:46Z | 2023-04-04T22:45:43Z | https://github.com/langchain-ai/langchain/issues/2412 | 1,654,634,576 | 2,412 |
[
"hwchase17",
"langchain"
] | Hi! After I create an agent using `initialize_agent` , I can call the agent using `agent.run`.
I can see the steps on the terminal e.g.:
```
Thought: Do I need to use a tool? Yes
Action: Index A,
Action Input: ....
```
but in the end, the `run` function returns only a final output (string). How can I get ... | How to know which tool(s) been used on `agent_chain.run`? | https://api.github.com/repos/langchain-ai/langchain/issues/2407/comments | 10 | 2023-04-04T19:32:45Z | 2023-09-28T16:09:11Z | https://github.com/langchain-ai/langchain/issues/2407 | 1,654,459,862 | 2,407 |
[
"hwchase17",
"langchain"
] | I'm attempting to run both demos linked today but am running into issues. I've already migrated my GPT4All model.
When I run the llama.cpp demo all of my CPU cores are pegged at 100% for a minute or so and then it just exits without an error code or output.
When I run the GPT4All demo I get the following error:
... | Unable to run llama.cpp or GPT4All demos | https://api.github.com/repos/langchain-ai/langchain/issues/2404/comments | 23 | 2023-04-04T19:04:58Z | 2023-09-29T16:08:56Z | https://github.com/langchain-ai/langchain/issues/2404 | 1,654,424,489 | 2,404 |
[
"hwchase17",
"langchain"
] | I am working with typescript and I want to use GPT4All. Is it already available? Tried import { GPT4All } from 'langchain/llms'; but with no luck. Can you guys please make this work? | GPT4All + langchain typescript | https://api.github.com/repos/langchain-ai/langchain/issues/2401/comments | 2 | 2023-04-04T18:39:52Z | 2023-04-06T12:27:57Z | https://github.com/langchain-ai/langchain/issues/2401 | 1,654,386,617 | 2,401 |
[
"hwchase17",
"langchain"
] | Add [Raven](https://huggingface.co/BlinkDL/rwkv-4-raven) as a local backend.
| llms: RWKV/Raven backend | https://api.github.com/repos/langchain-ai/langchain/issues/2398/comments | 1 | 2023-04-04T16:31:06Z | 2023-05-30T16:02:34Z | https://github.com/langchain-ai/langchain/issues/2398 | 1,654,207,363 | 2,398 |
[
"hwchase17",
"langchain"
] | Currently, `langchain.sql_database.SQLDatabase` is synchronous-only. This means that the built-in SQLDatabaseTools do not support async usage. SQLAlchemy _does_ [have an async API](https://docs.sqlalchemy.org/en/20/changelog/migration_14.html#asynchronous-io-support-for-core-and-orm) since version 1.4 so it seems lik... | Async SQLDatabase | https://api.github.com/repos/langchain-ai/langchain/issues/2396/comments | 1 | 2023-04-04T16:24:48Z | 2023-09-18T16:21:18Z | https://github.com/langchain-ai/langchain/issues/2396 | 1,654,199,163 | 2,396 |
[
"hwchase17",
"langchain"
] | Hello!
I was following the recent blog post: https://blog.langchain.dev/custom-agents/
Then I noticed something. Sometimes the Agent jump into the conclusion even though the information required to get this conclusion is not available in intermediate steps observations.
Here is the code I used (pretty similar ... | Agent hallucinates the final answer | https://api.github.com/repos/langchain-ai/langchain/issues/2395/comments | 7 | 2023-04-04T14:55:14Z | 2024-02-12T16:19:44Z | https://github.com/langchain-ai/langchain/issues/2395 | 1,654,054,225 | 2,395 |
[
"hwchase17",
"langchain"
] | When loading the converted `ggml-alpaca-7b-q4.bin` model, I met the error:
```
>>> llm = LlamaCpp(model_path="ggml-alpaca-7b-q4.bin")
llama_model_load: loading model from 'ggml-alpaca-7b-q4.bin' - please wait ...
ggml-alpaca-7b-q4.bin: invalid model file (bad magic [got 0x67676d66 want 0x67676a74])
you m... | ggml-alpaca-7b-q4.bin: invalid model file (bad magic [got 0x67676d66 want 0x67676a74]) | https://api.github.com/repos/langchain-ai/langchain/issues/2392/comments | 10 | 2023-04-04T13:58:11Z | 2023-09-29T16:09:01Z | https://github.com/langchain-ai/langchain/issues/2392 | 1,653,950,425 | 2,392 |
[
"hwchase17",
"langchain"
] | Unable to import from `langchain.document_loaders`

`Exception has occurred: ModuleNotFoundError
No module named 'langchain.document_loaders'
File "D:\\repos\gpt\scenarios\chat-with-document\app.py", l... | Unable to import from langchain.document_loaders | https://api.github.com/repos/langchain-ai/langchain/issues/2389/comments | 2 | 2023-04-04T11:19:06Z | 2023-05-09T08:44:46Z | https://github.com/langchain-ai/langchain/issues/2389 | 1,653,689,767 | 2,389 |
[
"hwchase17",
"langchain"
] | I was excited for the new version with Base agent but when installing the pip package it doesn’t seem to be present | PIP package non aligned with version | https://api.github.com/repos/langchain-ai/langchain/issues/2387/comments | 2 | 2023-04-04T10:57:43Z | 2023-09-10T16:38:30Z | https://github.com/langchain-ai/langchain/issues/2387 | 1,653,659,457 | 2,387 |
[
"hwchase17",
"langchain"
] | # Hi
### I'm using elasticsearch as Vectorstores, just a simple call, but it's reporting an error, I've called add_documents beforehand and it's working. But calling similarity_search is giving me an error. Thanks for checking
# Related Environment
* docker >> image elasticsearch:7.17.0
* python >> elasticsearc... | vectorstores error: "search_phase_execution_exceptionm" after using elastic search | https://api.github.com/repos/langchain-ai/langchain/issues/2386/comments | 21 | 2023-04-04T10:53:28Z | 2024-02-21T16:14:07Z | https://github.com/langchain-ai/langchain/issues/2386 | 1,653,653,191 | 2,386 |
[
"hwchase17",
"langchain"
] | ```
MSI@GT62VR MINGW64 ~/dev/gpt/langchain/llm.py
$ python llm.py
> Entering new AgentExecutor chain...
Thought: I need to ask the human a question about what they want to do.
Action:
```
{
"action": "Human",
"action_input": "What do you want to do?"
}
```
What do you want to do?
Find out the... | ValueError: not enough values to unpack | https://api.github.com/repos/langchain-ai/langchain/issues/2385/comments | 5 | 2023-04-04T10:29:37Z | 2023-09-26T16:11:17Z | https://github.com/langchain-ai/langchain/issues/2385 | 1,653,614,477 | 2,385 |
[
"hwchase17",
"langchain"
] | Hi,
How to change the instructions of the agent in lanchain openapi tool kit prompts.py so that the prompts can be according to my own api specs. if i just change the prompts text it doesnt work .
looking forwards | how to format prompts of openapi agent | https://api.github.com/repos/langchain-ai/langchain/issues/2384/comments | 1 | 2023-04-04T10:13:50Z | 2023-08-25T16:12:50Z | https://github.com/langchain-ai/langchain/issues/2384 | 1,653,590,204 | 2,384 |
[
"hwchase17",
"langchain"
] | I was attempting to use `LlamaCppEmbeddings` based on this doc https://python.langchain.com/en/latest/modules/models/text_embedding/examples/llamacpp.html
```python
from langchain.embeddings import LlamaCppEmbeddings
embeddings = LlamaCppEmbeddings(model_path='../llama.cpp/models/7B/ggml-model-q4_0.bin')
outp... | AttributeError: 'Llama' object has no attribute 'embed' | https://api.github.com/repos/langchain-ai/langchain/issues/2381/comments | 1 | 2023-04-04T09:11:08Z | 2023-04-04T09:29:22Z | https://github.com/langchain-ai/langchain/issues/2381 | 1,653,492,495 | 2,381 |
[
"hwchase17",
"langchain"
] | Hi all,
I was running into mypy linting issues when using ```initialize_agent```.
The mypy error says: ```Argument "llm" to "initialize_agent" has incompatible type "ChatOpenAI"; expected "BaseLLM" [arg-type]```
I checked the source code of langchain in my Python directory and the code is as follows:
```pyt... | Types for initialize_agent in Github version does not match release version? | https://api.github.com/repos/langchain-ai/langchain/issues/2380/comments | 1 | 2023-04-04T08:21:19Z | 2023-08-25T16:12:55Z | https://github.com/langchain-ai/langchain/issues/2380 | 1,653,417,836 | 2,380 |
[
"hwchase17",
"langchain"
] |
when I follow the guide of agent part to run the code below:
---------------------------------------------------------------------------
from langchain.agents import load_tools
from langchain.agents import initialize_agent
**from langchain.agents.agent_types import AgentType**
from langchain.llms import OpenAI
... | ModuleNotFoundError: No module named 'langchain.agents.agent_types' | https://api.github.com/repos/langchain-ai/langchain/issues/2379/comments | 12 | 2023-04-04T07:35:42Z | 2023-09-29T16:09:06Z | https://github.com/langchain-ai/langchain/issues/2379 | 1,653,352,080 | 2,379 |
[
"hwchase17",
"langchain"
] | I noticed that when I moved this solution from OpenAI to AzureOpenAI (same model), it produced non-expected results.
After digging into it, discovered that they may be a problem with the way `RetrievalQAWithSourcesChain.from_chain_type` utilizes the LLM specifically with the `map_reduce` chain.
(it does not seem to o... | Bug with "RetrievalQAWithSourcesChain" with AzureOpenAI - works as expected with OpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/2377/comments | 12 | 2023-04-04T06:18:48Z | 2023-09-20T18:08:07Z | https://github.com/langchain-ai/langchain/issues/2377 | 1,653,258,263 | 2,377 |
[
"hwchase17",
"langchain"
] | Currently we provide agents with a predefined list of tools that we would like to place at its disposal before it embarks on its effort to complete the task at hand.
It might be preferable to allow the Agent to query the langchain hub / Huggingface hub repeatedly and traverse the directory of agents / tools until i... | Allow agent to choose its toolset | https://api.github.com/repos/langchain-ai/langchain/issues/2374/comments | 3 | 2023-04-04T04:47:11Z | 2024-06-03T11:04:20Z | https://github.com/langchain-ai/langchain/issues/2374 | 1,653,165,196 | 2,374 |
[
"hwchase17",
"langchain"
] | It might be useful if we could tell an Agent some information about itself before we kick off a chain / agent executor.
For example:
```
You are a helpful AI assistant that lives as a part of the operating system of my unix computer. You have access to the terminal and all the applications which reside on the mac... | Add 'Self information' interface in Agent constructor | https://api.github.com/repos/langchain-ai/langchain/issues/2373/comments | 1 | 2023-04-04T04:41:30Z | 2023-08-25T16:12:59Z | https://github.com/langchain-ai/langchain/issues/2373 | 1,653,161,380 | 2,373 |
[
"hwchase17",
"langchain"
] | There should be a tool type that wraps an Agent so that it can perform some set of operations in the same way that a more typical tool might.
I could imagine that it could even be invoked recursively with such a setup.
If someone is aware of a way to do this which already exists, let me know and we can close thi... | Agent invoker tool | https://api.github.com/repos/langchain-ai/langchain/issues/2372/comments | 1 | 2023-04-04T04:37:40Z | 2023-08-25T16:13:06Z | https://github.com/langchain-ai/langchain/issues/2372 | 1,653,158,852 | 2,372 |
[
"hwchase17",
"langchain"
] | I'm trying to run the `LLMRequestsChain` example from the docs (https://python.langchain.com/en/latest/modules/chains/examples/llm_requests.html) but I am getting this error
```
(.venv) adriangalvan@eth-24s-MBP spec-automation % python3 requests.py
Traceback (most recent call last):
File "/Users/adriangalvan/De... | ImportError: cannot import name 'LLMChain' from partially initialized module 'langchain' | https://api.github.com/repos/langchain-ai/langchain/issues/2371/comments | 1 | 2023-04-04T04:16:41Z | 2023-04-04T04:25:18Z | https://github.com/langchain-ai/langchain/issues/2371 | 1,653,145,087 | 2,371 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.