
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.46B | issue_number int64 1 127k |
|---|---|---|---|---|---|---|---|---|---|
[
"hwchase17",
"langchain"
] | can you tell me how to use local llm to replace the openai model,thanks, i can not find related codes | replace openai | https://api.github.com/repos/langchain-ai/langchain/issues/2369/comments | 4 | 2023-04-04T03:50:18Z | 2023-09-26T16:11:28Z | https://github.com/langchain-ai/langchain/issues/2369 | 1,653,125,585 | 2,369 |
[
"hwchase17",
"langchain"
] | Token usage calculation is not working for ChatOpenAI.
# How to reproduce
```python3
from langchain.callbacks import get_openai_callback
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(model_name="gpt-3.5-tu... | Token usage calculation is not working for ChatOpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/2359/comments | 15 | 2023-04-03T22:36:12Z | 2023-11-16T07:16:05Z | https://github.com/langchain-ai/langchain/issues/2359 | 1,652,866,109 | 2,359 |
[
"hwchase17",
"langchain"
] | This is because the SQLDatabase class does not have view support. | SQLDatabaseChain & the SQL Database Agent do not support generating queries over views | https://api.github.com/repos/langchain-ai/langchain/issues/2356/comments | 5 | 2023-04-03T20:35:17Z | 2023-04-12T19:29:45Z | https://github.com/langchain-ai/langchain/issues/2356 | 1,652,736,092 | 2,356 |
[
"hwchase17",
"langchain"
] | I haven't found a method for it in the class but I assumed it can look similar to `from_existing_index`
```
@classmethod
def from_existing_collection(
cls,
collection_name: str,
embedding: Embeddings,
text_key: str = "text",
namespace: Optional[str] = None,
) ->... | [Pinecone] How to use collection to query against instead of an index? | https://api.github.com/repos/langchain-ai/langchain/issues/2353/comments | 3 | 2023-04-03T20:13:21Z | 2023-04-16T03:09:26Z | https://github.com/langchain-ai/langchain/issues/2353 | 1,652,709,721 | 2,353 |
[
"hwchase17",
"langchain"
] | steps to reproduce are fairly simple:
```python
Python 3.10.10 (main, Mar 5 2023, 22:26:53) [GCC 12.2.1 20230201] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from langchain.document_loaders import YoutubeLoader
>>> loader = YoutubeLoader("https://www.youtube.com/watch?... | Broken Youtube Transcript loader | https://api.github.com/repos/langchain-ai/langchain/issues/2349/comments | 1 | 2023-04-03T18:02:04Z | 2023-04-03T18:03:44Z | https://github.com/langchain-ai/langchain/issues/2349 | 1,652,520,952 | 2,349 |
[
"hwchase17",
"langchain"
] | Hi,
I have been trying to use flan-u2l for my usecase using sequential chains. However, I am getting following token limit error even though FLAN-U2L has receptive of 2048 token size according to paper:
```ValueError: Error raised by inference API: Input validation error: `inputs` must have less than 1000 tokens. Giv... | Token Size Limit Issue While calling FLAN-U2L using Langchain! | https://api.github.com/repos/langchain-ai/langchain/issues/2347/comments | 2 | 2023-04-03T16:58:56Z | 2023-09-18T16:21:28Z | https://github.com/langchain-ai/langchain/issues/2347 | 1,652,435,441 | 2,347 |
[
"hwchase17",
"langchain"
] | Can check here: https://replit.com/@OlegAzava/LangChainChatSave
```python
Traceback (most recent call last):
File "main.py", line 15, in <module>
chat_prompt.save('./test.json')
File "/home/runner/LangChainChatSave/venv/lib/python3.10/site-packages/langchain/prompts/chat.py", line 187, in save
raise... | Cannot save multi message chat prompt | https://api.github.com/repos/langchain-ai/langchain/issues/2341/comments | 2 | 2023-04-03T14:58:23Z | 2023-09-18T16:21:33Z | https://github.com/langchain-ai/langchain/issues/2341 | 1,652,240,892 | 2,341 |
[
"hwchase17",
"langchain"
] | Hi, I think it's currently impossible to pass a user parameter - this is helpful for complying with abuse monitoring guidelines of both Azure OpenAI and OpenAI.
I would like to request this feature if not roadmapped.
Thanks! | OpenAI / Azure OpenAI missing optional user parameter | https://api.github.com/repos/langchain-ai/langchain/issues/2338/comments | 2 | 2023-04-03T11:51:42Z | 2023-11-13T15:43:48Z | https://github.com/langchain-ai/langchain/issues/2338 | 1,651,912,299 | 2,338 |
[
"hwchase17",
"langchain"
] | Hi,
I have been using Langchain for my usecase with ChatGPT and I would like to know the expected pricing for my prompts + outputs that I generate. Is there any way we can calculate pricing for it using lang-chain?
Is there any way we can get the total token used during the request similar to when using the OpenAI ... | How to calculate pricing for ChatGPT API using Sequential Chaining ? | https://api.github.com/repos/langchain-ai/langchain/issues/2336/comments | 3 | 2023-04-03T11:11:32Z | 2023-04-03T16:42:03Z | https://github.com/langchain-ai/langchain/issues/2336 | 1,651,856,598 | 2,336 |
[
"hwchase17",
"langchain"
] | ```
$ poetry install
Installing dependencies from lock file
Warning: poetry.lock is not consistent with pyproject.toml. You may be getting improper dependencies. Run `poetry lock [--no-update]` to fix it.
```
```
$ poetry update
Updating dependencies
Resolving dependencies... (76.9s)
Writing lock file
... | poetry.lock is not consistent with pyproject.toml | https://api.github.com/repos/langchain-ai/langchain/issues/2335/comments | 5 | 2023-04-03T10:47:10Z | 2023-09-11T09:34:41Z | https://github.com/langchain-ai/langchain/issues/2335 | 1,651,815,456 | 2,335 |
[
"hwchase17",
"langchain"
] | ```
Request:
- GET https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains%5Cpath%5Cchain.json
Available matches:
- GET https://raw.githubusercontent.com/hwchase17/langchain-hub/v0.3/chains/path/chain.json URL does not match
.venv\lib\site-packages\responses\__init__.py:1032: ConnectionEr... | Unit tests were not executed properly locally on a Windows system | https://api.github.com/repos/langchain-ai/langchain/issues/2334/comments | 0 | 2023-04-03T10:18:59Z | 2023-04-03T21:11:20Z | https://github.com/langchain-ai/langchain/issues/2334 | 1,651,775,118 | 2,334 |
[
"hwchase17",
"langchain"
] | this is my code for hooking up an LLM to answer questions over a database(remote pg).

but find error:
. Please reduce your prompt; or completion length. | https://api.github.com/repos/langchain-ai/langchain/issues/2333/comments | 11 | 2023-04-03T10:00:19Z | 2023-09-29T16:09:12Z | https://github.com/langchain-ai/langchain/issues/2333 | 1,651,740,115 | 2,333 |
[
"hwchase17",
"langchain"
] | The following code snippet doesn't work as I expect:
# Query
rds = Redis.from_existing_index(embeddings, redis_url="redis://localhost:6379", index_name='iname')
query = "something to search"
retriever = rds.as_retriever(search_type="similarity_limit", k=2, score_threshold=0.6)
results = retri... | Redis "as_retriever": k and score_threshold parameters are lost | https://api.github.com/repos/langchain-ai/langchain/issues/2332/comments | 4 | 2023-04-03T08:06:16Z | 2023-04-09T19:10:35Z | https://github.com/langchain-ai/langchain/issues/2332 | 1,651,556,380 | 2,332 |
[
"hwchase17",
"langchain"
] | I am getting errors with lanchain latest version.

| Can't generate DDL for NullType() | https://api.github.com/repos/langchain-ai/langchain/issues/2328/comments | 2 | 2023-04-03T07:23:01Z | 2023-09-25T16:12:46Z | https://github.com/langchain-ai/langchain/issues/2328 | 1,651,493,057 | 2,328 |
[
"hwchase17",
"langchain"
] | Hi there,
I've been trying out question answering with docs loaded into a VectorDB. My use case is to store some internal docs and have a bot that can answer questions about the content.
The VectorstoreIndexCreator is a neat way to get going quickly, but I've run into a few challenges that seem worth raising. Hopef... | VectorstoreIndexCreator questions/suggestions | https://api.github.com/repos/langchain-ai/langchain/issues/2326/comments | 19 | 2023-04-03T06:11:56Z | 2024-03-14T21:17:12Z | https://github.com/langchain-ai/langchain/issues/2326 | 1,651,405,859 | 2,326 |
[
"hwchase17",
"langchain"
] | When building the docker image by using the command "docker build -t langchain .", it will generate the error:
docker build -t langchain .
[+] Building 2.7s (8/12)
=> [internal] load build definition from Dockerfile 0.0s
=> => t... | Error in Dockerfile | https://api.github.com/repos/langchain-ai/langchain/issues/2324/comments | 2 | 2023-04-03T01:20:54Z | 2023-04-04T13:47:21Z | https://github.com/langchain-ai/langchain/issues/2324 | 1,651,175,971 | 2,324 |
[
"hwchase17",
"langchain"
] | When running the code shown below I ended up with what seemed like an endless agent loop. I stopped the code and repeated the code, but the error did not repeat. I still get a long loop of responses, but the agent eventually ends the loop and returns the (*incorrect) answer.
 in a Jupyter notebook, running locally, I'm having the following error:
```
!pip install google-search-results
```
```
Requirement already satisfied: langchain in /opt/homebrew/lib/python3.11/site-packages (0.0.129)
Requirement already satisfied: huggingface_h... | SerpAPIWrapper() fails when run from a Jupyter notebook | https://api.github.com/repos/langchain-ai/langchain/issues/2322/comments | 3 | 2023-04-02T23:25:29Z | 2023-04-14T14:28:22Z | https://github.com/langchain-ai/langchain/issues/2322 | 1,651,132,568 | 2,322 |
[
"hwchase17",
"langchain"
] | Claude have been there for a while and now is free through Slack (https://www.anthropic.com/index/claude-now-in-slack). Is it good time to integrate it into Langchain? BTW, it is a little bit surprise no one had a proposal for this before. | Claude integration | https://api.github.com/repos/langchain-ai/langchain/issues/2320/comments | 3 | 2023-04-02T23:09:37Z | 2023-12-02T16:09:47Z | https://github.com/langchain-ai/langchain/issues/2320 | 1,651,128,224 | 2,320 |
[
"hwchase17",
"langchain"
] | Is there a plan to implement Reflexion in Langchain as a separate agent (or maybe an add-on to existing agents)?
https://arxiv.org/abs/2303.11366
Sample implementation: https://github.com/GammaTauAI/reflexion-human-eval/blob/main/reflexion.py | Implementation of Reflexion in Langchain | https://api.github.com/repos/langchain-ai/langchain/issues/2316/comments | 14 | 2023-04-02T21:59:11Z | 2024-07-06T18:51:06Z | https://github.com/langchain-ai/langchain/issues/2316 | 1,651,108,611 | 2,316 |
[
"hwchase17",
"langchain"
] | Probably use this
https://huggingface.co/docs/transformers/main/en/generation_strategies#streaming | Add stream method for HuggingFacePipeline Objet | https://api.github.com/repos/langchain-ai/langchain/issues/2309/comments | 8 | 2023-04-02T19:28:21Z | 2024-06-24T16:07:29Z | https://github.com/langchain-ai/langchain/issues/2309 | 1,651,065,839 | 2,309 |
[
"hwchase17",
"langchain"
] | Hi,
I'm following the [Chat index examples](https://python.langchain.com/en/latest/modules/chains/index_examples/chat_vector_db.html) and was surprised that the history is not a Memory object but just an array. However, it is possible to pass a memory object to the constructor, if
1. I also set memory_key to 'c... | ConversationalRetrievalChain + Memory | https://api.github.com/repos/langchain-ai/langchain/issues/2303/comments | 88 | 2023-04-02T15:13:36Z | 2024-07-15T10:00:31Z | https://github.com/langchain-ai/langchain/issues/2303 | 1,650,985,481 | 2,303 |
[
"hwchase17",
"langchain"
] | Hello, I'm trying to go through the Tracing Walkthrough (https://python.langchain.com/en/latest/tracing/agent_with_tracing.html). Where do I find my LANGCHAIN_API_KEY?
Thanks! | where to find LANGCHAIN_API_KEY? | https://api.github.com/repos/langchain-ai/langchain/issues/2302/comments | 2 | 2023-04-02T15:01:52Z | 2023-04-14T18:43:46Z | https://github.com/langchain-ai/langchain/issues/2302 | 1,650,981,278 | 2,302 |
[
"hwchase17",
"langchain"
] |
I'm trying to build an agent to execute some shell and python code locally as follows
```from langchain.agents import initialize_agent,load_tools
from langchain import OpenAI, LLMBashChain
llm = OpenAI(temperature=0)
llm_bash_chain = LLMBashChain(llm=llm, verbose=True)
print(llm_bash_chain.prompt)
tools ... | Simulate sandbox execution of bash code or python code. | https://api.github.com/repos/langchain-ai/langchain/issues/2301/comments | 5 | 2023-04-02T14:42:30Z | 2023-10-05T16:11:04Z | https://github.com/langchain-ai/langchain/issues/2301 | 1,650,974,035 | 2,301 |
[
"hwchase17",
"langchain"
] | I'm trying to build Chat bot with ConversationalRetrievalChain, and got this error when trying to use "refine" chain type
```
File "/Users/chris/.pyenv/versions/3.10.10/lib/python3.10/site-packages/langchain/chains/question_answering/__init__.py", line 218, in load_qa_chain
return loader_mapping[chain_type](
... | chain_type "refine" error with ChatOpenAI in ConversationalRetrievalChain | https://api.github.com/repos/langchain-ai/langchain/issues/2296/comments | 7 | 2023-04-02T10:53:26Z | 2023-11-01T16:07:55Z | https://github.com/langchain-ai/langchain/issues/2296 | 1,650,900,292 | 2,296 |
[
"hwchase17",
"langchain"
] | if i create a llm by `llm=OpenAI()`, how can i set params `organization, api_base` and so on like in package `openai`? many thanks. | how can I config angchain.llms.OpenAI like openai | https://api.github.com/repos/langchain-ai/langchain/issues/2294/comments | 1 | 2023-04-02T08:40:01Z | 2023-09-10T16:38:50Z | https://github.com/langchain-ai/langchain/issues/2294 | 1,650,862,077 | 2,294 |
[
"hwchase17",
"langchain"
] | This code not work
`llm = ChatOpenAI(temperature=0)`
It seems that Temperature has not been added to the **kwargs of the request In ChatOpenAI
And this code is working fine
`llm = ChatOpenAI(model_kwargs={'temperature': 0})` | temperature not work in ChatOpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/2292/comments | 3 | 2023-04-02T07:40:03Z | 2023-06-27T09:08:11Z | https://github.com/langchain-ai/langchain/issues/2292 | 1,650,846,478 | 2,292 |
[
"hwchase17",
"langchain"
] | 1) In chains with multiple sub-chains, Is there a way to pass the initial input as an argument to all subsequent chains?
2) Can we assign variable names to outputs of chains and use them in subsequent chains?
I am trying to get additional information from an article using preprocess_chain. I would like to send the ... | In chains with multiple sub-chains, Is there a way to pass the initial input as an argument to all subsequent chains? | https://api.github.com/repos/langchain-ai/langchain/issues/2289/comments | 1 | 2023-04-02T04:47:26Z | 2023-04-02T05:04:53Z | https://github.com/langchain-ai/langchain/issues/2289 | 1,650,804,547 | 2,289 |
[
"hwchase17",
"langchain"
] | I'm trying to replicate the Zapier agent example [here](https://python.langchain.com/en/latest/modules/agents/tools/examples/zapier.html?highlight=zapier), but the agent doesn't find the right tools even though I've created the relevant Zapier NLA actions in my account.
When I run:
`agent.run("Summarize the last em... | Agent not loading tools from ZapierToolkit | https://api.github.com/repos/langchain-ai/langchain/issues/2286/comments | 3 | 2023-04-02T01:29:17Z | 2023-09-18T16:21:39Z | https://github.com/langchain-ai/langchain/issues/2286 | 1,650,766,257 | 2,286 |
[
"hwchase17",
"langchain"
] | Sorry if this is a dumb question:
Why is the ZeroShotAgent called "zero-shot-react-description" instead of "zero-shot-mrkl-description" or something like that? It is implemented to follow the MRKL design, not the reAct design. I am misunderstanding something?
Here is the code:
```
AGENT_TO_CLASS = {
"z... | ReAct vs MRKL | https://api.github.com/repos/langchain-ai/langchain/issues/2284/comments | 5 | 2023-04-01T22:44:51Z | 2023-09-29T16:09:21Z | https://github.com/langchain-ai/langchain/issues/2284 | 1,650,698,780 | 2,284 |
[
"hwchase17",
"langchain"
] | LLM response is parsed with `RegexParser `with the pattern `"(.*?)\nScore: (.*)"` which is not reliable. In some instances the `Score `is missing or present without newline `"\n"`
This leads to
`ValueError: Could not parse output: ....`
Update:
`"Answer:"` in some cases is missing too
| RegexParser pattern "(.*?)\nScore: (.*)" is not reliable | https://api.github.com/repos/langchain-ai/langchain/issues/2282/comments | 2 | 2023-04-01T20:46:38Z | 2023-08-25T16:16:06Z | https://github.com/langchain-ai/langchain/issues/2282 | 1,650,648,539 | 2,282 |
[
"hwchase17",
"langchain"
] | I am getting some issues while trying to connect from langchain to databricks via sqlalchemy.
It works fine when I connect directly via sqlalchemy.
I think the issue is in the below lines
https://github.com/hwchase17/langchain/blob/09f94642543b23d7c9db81aa15ef54a1b6e13840/langchain/sql_database.py#L32-L33
the ... | Kindly add support for databricks-sql-connector (databricks library) via sqlalchemy in langchain | https://api.github.com/repos/langchain-ai/langchain/issues/2277/comments | 2 | 2023-04-01T18:45:35Z | 2023-08-11T16:31:54Z | https://github.com/langchain-ai/langchain/issues/2277 | 1,650,597,393 | 2,277 |
[
"hwchase17",
"langchain"
] | I'm trying to create a conversation agent essentially defined like this:
```python
tools = load_tools([]) # "wikipedia"])
llm = ChatOpenAI(model_name=MODEL, verbose=True)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent = initialize_agent(tools, llm,
agent="chat-c... | Exception when Conversation Agent doesn't receive json output | https://api.github.com/repos/langchain-ai/langchain/issues/2276/comments | 7 | 2023-04-01T18:43:07Z | 2023-10-16T16:09:00Z | https://github.com/langchain-ai/langchain/issues/2276 | 1,650,596,807 | 2,276 |
[
"hwchase17",
"langchain"
] | It appears that MongoDB Atlas Search supports Vector Search via the `kNNBeta` operator:
- https://github.com/esteininger/vector-search/blob/master/foundations/atlas-vector-search/Atlas_Vector_Search_Demonstration.ipynb
- https://www.mongodb.com/docs/atlas/atlas-search/knn-beta/
Is there anyone else that is worki... | MongoDB Atlas Search Support | https://api.github.com/repos/langchain-ai/langchain/issues/2274/comments | 9 | 2023-04-01T17:15:15Z | 2023-09-27T16:10:39Z | https://github.com/langchain-ai/langchain/issues/2274 | 1,650,567,180 | 2,274 |
[
"hwchase17",
"langchain"
] | I got this error in 0.0.127 and 0.0.128 version, and worked fine in previous versions. I'm using ConversationalRetrievalChain with PGVector.
```
PG_CONNECTION_STRING = PGVector.connection_string_from_db_params(
driver=os.environ.get("PGVECTOR_DRIVER", "psycopg2"),
host=os.environ.get("PGVECTOR_HOST", "loc... | VectorStoreRetriever does not support async in 0.0.128 | https://api.github.com/repos/langchain-ai/langchain/issues/2268/comments | 4 | 2023-04-01T09:48:31Z | 2023-09-29T16:09:26Z | https://github.com/langchain-ai/langchain/issues/2268 | 1,650,390,352 | 2,268 |
[
"hwchase17",
"langchain"
] | **Any comments would be appreciated.**
When an import statement is executed inside a function or object creation in Python, a new module object is created every time the function or object is called or instantiated, respectively.
We have multiple imports like that in many classes in a code base:
```python
cl... | avoiding unnecessary imports in Python classes and functions using sys.modules | https://api.github.com/repos/langchain-ai/langchain/issues/2266/comments | 1 | 2023-04-01T08:36:52Z | 2023-08-25T16:13:15Z | https://github.com/langchain-ai/langchain/issues/2266 | 1,650,366,622 | 2,266 |
[
"hwchase17",
"langchain"
] | how can I use `TextSplitter` for `GPTSimpleVectorIndex` to split document by such “\n” or/and other? | how to use TextSplitter for GPTSimpleVectorIndex | https://api.github.com/repos/langchain-ai/langchain/issues/2265/comments | 2 | 2023-04-01T08:35:09Z | 2023-04-02T08:00:59Z | https://github.com/langchain-ai/langchain/issues/2265 | 1,650,366,217 | 2,265 |
[
"hwchase17",
"langchain"
] | Does anyone have an example of how to use `condense_question_prompt` and `qa_prompt` with `ConversationalRetrievalChain`? I have some information which I want to always be included in the context of a user's question (e.g. 'You are a bot whose name is Bob'), but this context information is seemingly lost when I ask a q... | Prompt engineering for ConversationalRetrievalChain | https://api.github.com/repos/langchain-ai/langchain/issues/2264/comments | 4 | 2023-04-01T08:10:59Z | 2024-01-19T04:04:35Z | https://github.com/langchain-ai/langchain/issues/2264 | 1,650,359,937 | 2,264 |
[
"hwchase17",
"langchain"
] | For GPT-4, image inputs are still in [limited alpha](https://openai.com/research/gpt-4#:~:text=image%20inputs%20are%20still%20in%20limited%20alpha).
For GPT-3.5, it would be great to see LangChain use the MM-ReAct agent.
- Repo: [github.com/microsoft/MM-REACT](https://github.com/microsoft/MM-REACT)
- Website: [... | MM-ReAct (Multimodal Reasoning and Action) | https://api.github.com/repos/langchain-ai/langchain/issues/2262/comments | 7 | 2023-04-01T05:52:16Z | 2024-01-25T14:13:54Z | https://github.com/langchain-ai/langchain/issues/2262 | 1,650,313,544 | 2,262 |
[
"hwchase17",
"langchain"
] | This could improve the model's/langchain's awareness of the structured context surrounding an external source in its conversational memory.
The conversational memory document store can act as a buffer for all external sources.
Original: https://github.com/hwchase17/langchain/issues/709#issuecomment-1492828239
| Structured conversational memory: store query result (e.g. url response + metadata) directly into document store | https://api.github.com/repos/langchain-ai/langchain/issues/2261/comments | 1 | 2023-04-01T05:25:31Z | 2023-08-25T16:13:20Z | https://github.com/langchain-ai/langchain/issues/2261 | 1,650,306,640 | 2,261 |
[
"hwchase17",
"langchain"
] | Real-time search-based planning has been shown to enhance the performance of AI agents:
1. AlphaGo, MuZero (planning in games)
2. Libratus, Pluribus (planning in Poker)
3. Behavioural forecasting in self-driving (e.g. Waymo VectorNet)
The basic principle is that given some target objective, an agent (in this case... | Add module for real-time search to improve engagement and intent satisfaction | https://api.github.com/repos/langchain-ai/langchain/issues/2259/comments | 1 | 2023-04-01T04:49:22Z | 2023-08-25T16:13:25Z | https://github.com/langchain-ai/langchain/issues/2259 | 1,650,293,522 | 2,259 |
[
"hwchase17",
"langchain"
] | I think we could increase the integration of local models with some of the introspection tools, so that e.g.
1. one could visualize/collect metrics on a large collection of search-augmented conversations with keywords extracted by a local model.
2. others...? | Introspection/Tracing: Use local models as a way to extract useful characterizations of data (input, intermediate, output) without external API call | https://api.github.com/repos/langchain-ai/langchain/issues/2258/comments | 1 | 2023-04-01T04:14:06Z | 2023-08-25T16:13:31Z | https://github.com/langchain-ai/langchain/issues/2258 | 1,650,285,248 | 2,258 |
[
"hwchase17",
"langchain"
] | There are 2 ways to overcome context window limit:
1. Store the outputs of old conversations back into the document store (similar to external memory), utilizing an external index (e.g. inverse document index) to query the documents
2. Hierarchically compress a summary of conversation history, feeding it into future ... | discussion: Combining strategies to overcome context-window limit | https://api.github.com/repos/langchain-ai/langchain/issues/2257/comments | 2 | 2023-04-01T03:57:18Z | 2023-09-10T16:39:01Z | https://github.com/langchain-ai/langchain/issues/2257 | 1,650,278,293 | 2,257 |
[
"hwchase17",
"langchain"
] | Memory doesn't seem to be supported when using the 'sources' chains. It appears to have issues writing multiple output keys.
Is there a work around to this?
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)... | Memory not supported with sources chain? | https://api.github.com/repos/langchain-ai/langchain/issues/2256/comments | 28 | 2023-04-01T03:50:19Z | 2024-03-01T18:47:16Z | https://github.com/langchain-ai/langchain/issues/2256 | 1,650,276,231 | 2,256 |
[
"hwchase17",
"langchain"
] | I write my code according to `docs/modules/chains/index_examples/vector_db_qa.ipynb`, but the following error happened:
```console
Using embedded DuckDB without persistence: data will be transient
Traceback (most recent call last):
File "/home/todo/intership/GPTtrace/try.py", line 76, in <module>
qa.run(quer... | Number of requested results 4 cannot be greater than number of elements in index 2 | https://api.github.com/repos/langchain-ai/langchain/issues/2255/comments | 10 | 2023-04-01T03:18:44Z | 2023-11-03T14:15:32Z | https://github.com/langchain-ai/langchain/issues/2255 | 1,650,268,985 | 2,255 |
[
"hwchase17",
"langchain"
] | Please ask: how many rows
> Entering new AgentExecutor chain...
Thought: I need to find the number of rows in the dataframe
**Action: python_repl_ast**
Action Input: len(df)
Observation: 45
Thought:I have the number of rows
Final Answer: 45
> Finished chain.
45
Please ask: does fg-40f support local ... | Toolkits - Pandas Dataframe Agent failed to call "python_repl_ast" consistently | https://api.github.com/repos/langchain-ai/langchain/issues/2252/comments | 21 | 2023-04-01T01:14:39Z | 2024-06-21T16:56:26Z | https://github.com/langchain-ai/langchain/issues/2252 | 1,650,226,595 | 2,252 |
[
"hwchase17",
"langchain"
] | The following code produces the "too many requests" error. Using a different host does not fix it.
```py
name="Execute Query Tool"
description="Useful for executing a query against a search engine. Returns the results of the query."
search = SearxSearchWrapper(searx_host="https://www.gruble.de")
def func (quer... | SearxSearchWrapper: ('Searx API returned an error: ', 'Too Many Requests') | https://api.github.com/repos/langchain-ai/langchain/issues/2251/comments | 3 | 2023-04-01T00:37:48Z | 2023-08-11T16:31:55Z | https://github.com/langchain-ai/langchain/issues/2251 | 1,650,208,796 | 2,251 |
[
"hwchase17",
"langchain"
] | Issue:
Python tool uses exec and eval instead of subprocess.
Description:
This leaves the chain open to an attack vector where malicious code can be injected and blindly executed.
Solution:
Commands should be sanitized and then passed to subprocess instead.
Note:
This issue applies to any command ... | Python tool uses exec and eval instead of subprocess | https://api.github.com/repos/langchain-ai/langchain/issues/2249/comments | 1 | 2023-03-31T22:52:56Z | 2023-09-12T21:30:13Z | https://github.com/langchain-ai/langchain/issues/2249 | 1,650,139,503 | 2,249 |
[
"hwchase17",
"langchain"
] | I am getting `UnicodeDecodeError`s from BeautifulSoup (the offending character is 0x9d - right double quotation mark). I am using Python 3.10 x64 on Windows 10 21H2.
The solution I would propose is to add the ability to pass some kwargs to the BSHTMLLoader constructor so we can specify the encoding to pass to `open(... | `UnicodeDecodeError` when using `BSHTMLLoader` on Windows | https://api.github.com/repos/langchain-ai/langchain/issues/2247/comments | 0 | 2023-03-31T21:13:09Z | 2023-04-03T17:17:47Z | https://github.com/langchain-ai/langchain/issues/2247 | 1,650,046,790 | 2,247 |
[
"hwchase17",
"langchain"
] | In the docs, in https://python.langchain.com/en/latest/modules/models/llms/integrations/promptlayer_openai.html there is a hyperlink to the PromptLayer dashboard that links to "https://ww.promptlayer.com", which is incorrect. | Wrong PromptLayer Dashboard hyperlink | https://api.github.com/repos/langchain-ai/langchain/issues/2245/comments | 2 | 2023-03-31T20:33:41Z | 2023-03-31T22:21:36Z | https://github.com/langchain-ai/langchain/issues/2245 | 1,649,993,009 | 2,245 |
[
"hwchase17",
"langchain"
] | When using the `conversational_chat` agent, an issue occurs when the LLM returns a markdown result that has a code block included. My use case is an agent that reads from an internal database using an agent to get information that will be used to build a block of code. The agent correctly uses the tools, but fails to r... | Issues with conversational_chat and LLM chains responding with a multi-line markdown code block | https://api.github.com/repos/langchain-ai/langchain/issues/2241/comments | 4 | 2023-03-31T18:32:25Z | 2023-12-02T16:09:52Z | https://github.com/langchain-ai/langchain/issues/2241 | 1,649,835,002 | 2,241 |
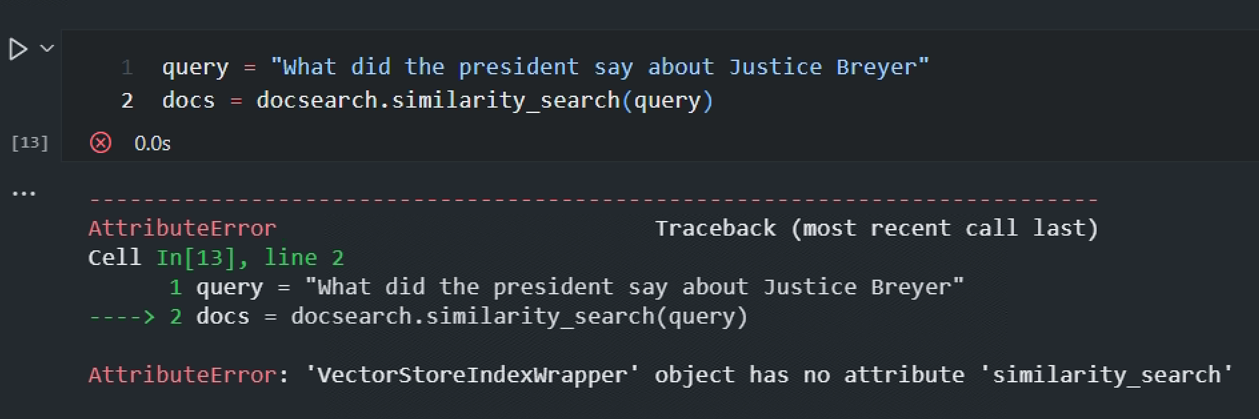
[
"hwchase17",
"langchain"
] | When running `docs/modules/chains/index_examples/question_answering.ipynb`, the following error occurs:
I didn't change the code, just ran the file directly. | 'VectorStoreIndexWrapper' object has no attribute 'similarity_search' | https://api.github.com/repos/langchain-ai/langchain/issues/2235/comments | 2 | 2023-03-31T16:37:22Z | 2023-04-01T01:13:57Z | https://github.com/langchain-ai/langchain/issues/2235 | 1,649,683,980 | 2,235 |
[
"hwchase17",
"langchain"
] | It would be good to allow more parameters to the `BingSearchWrapper`, so that for example the internet search can be limited to a single domain. See [Getting results from a specific site
](https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/filter-answers#getting-results-from-a-specific-site).
[Advan... | [Bing Search] allow additional parameters like site restriction | https://api.github.com/repos/langchain-ai/langchain/issues/2229/comments | 1 | 2023-03-31T14:31:32Z | 2023-09-10T16:39:06Z | https://github.com/langchain-ai/langchain/issues/2229 | 1,649,464,362 | 2,229 |
[
"hwchase17",
"langchain"
] | It would be great to see LangChain wrap around Vicuna, a chat assistant fine-tuned from LLaMA on user-shared conversations.
Vicuna-13B is an open-source chatbot trained using user-shared conversations collected from [ShareGPT](https://sharegpt.com/). The chatbot has been evaluated using GPT-4. It has achieved more t... | Vicuna (Fine-tuned LLaMa) | https://api.github.com/repos/langchain-ai/langchain/issues/2228/comments | 30 | 2023-03-31T13:27:32Z | 2023-10-13T12:08:05Z | https://github.com/langchain-ai/langchain/issues/2228 | 1,649,357,823 | 2,228 |
[
"hwchase17",
"langchain"
] | Hello!
I would like to propose adding BaseCallbackHandler, AsyncCallbackHandler, and AsyncCallbackManager to the exports of langchain.callbacks. Doing so would enable developers to create custom CallbackHandlers and run their own code for each of the steps handled by the BaseCallbackHandler, as well as their async c... | Add BaseCallbackHandler, AsyncCallbackHandler and AsyncCallbackManager to exports of langchain.callbacks | https://api.github.com/repos/langchain-ai/langchain/issues/2227/comments | 3 | 2023-03-31T12:54:40Z | 2023-09-25T10:18:43Z | https://github.com/langchain-ai/langchain/issues/2227 | 1,649,307,593 | 2,227 |
[
"hwchase17",
"langchain"
] | Hello!
I've noticed that when creating a custom CallbackHandler in LangChain, there is currently no method for dealing with the Observation step. Specifically, in the agent.py file, the Agent and AgentExecutor class does not call any on_agent_observation function, and this function is not present in the BaseCallback... | Add on_agent_observation method to BaseCallbackHandler for custom observation logic | https://api.github.com/repos/langchain-ai/langchain/issues/2226/comments | 2 | 2023-03-31T12:46:23Z | 2023-09-25T16:13:17Z | https://github.com/langchain-ai/langchain/issues/2226 | 1,649,296,178 | 2,226 |
[
"hwchase17",
"langchain"
] | We are using Chroma for storing the records in vector form. When searching the query, the return documents do not give accurate results.
c1 = Chroma('langchain', embedding, persist_directory)
qa = ChatVectorDBChain(vectorstore=c1, combine_docs_chain=doc_chain, question_generator=question_generator,top_k_docs_for_c... | similarity Search Issue | https://api.github.com/repos/langchain-ai/langchain/issues/2225/comments | 4 | 2023-03-31T11:19:55Z | 2023-09-18T16:21:43Z | https://github.com/langchain-ai/langchain/issues/2225 | 1,649,180,957 | 2,225 |
[
"hwchase17",
"langchain"
] | I am trying to create a chatbot using your documentation from here:
https://python.langchain.com/en/latest/modules/agents/agent_executors/examples/chatgpt_clone.html
However, in order to reduce costs, instead of using ChatGPT I want to use a HuggingFace Model.
I tried to use a conversational model, but I got an er... | Chatbot using HuggingFace model, not working | https://api.github.com/repos/langchain-ai/langchain/issues/2224/comments | 6 | 2023-03-31T09:26:50Z | 2023-09-27T16:10:49Z | https://github.com/langchain-ai/langchain/issues/2224 | 1,649,020,314 | 2,224 |
[
"hwchase17",
"langchain"
] | **Any comments would be appreciated.**
The issue is that the json module is unable to serialize the Document object, which is a custom class that inherits from BaseModel. The error message specifically says that the Document object is not JSON serializable, meaning it cannot be converted into a JSON string. This is ... | TypeError: Object of type Document is not JSON serializable | https://api.github.com/repos/langchain-ai/langchain/issues/2222/comments | 15 | 2023-03-31T08:51:41Z | 2024-05-14T15:23:19Z | https://github.com/langchain-ai/langchain/issues/2222 | 1,648,966,589 | 2,222 |
[
"hwchase17",
"langchain"
] | Provided I have given a system prompt, I wanted to use gpt-4 as the llm for my agents. I read around, but it only seems like gpt-3 davinci and nothing beyond it is an option.
Can gpt-3.5-turbo or gpt-4 be included as a llm option for agents? | Is it possible to use gpt-3.5-turbo or gpt-4 as the LLM model for agents? | https://api.github.com/repos/langchain-ai/langchain/issues/2220/comments | 7 | 2023-03-31T07:45:45Z | 2023-10-18T16:09:33Z | https://github.com/langchain-ai/langchain/issues/2220 | 1,648,853,042 | 2,220 |
[
"hwchase17",
"langchain"
] | PGVector works fine for me when coupled with OpenAIEmbeddings. However, when I try to use HuggingFaceEmbeddings, I get the following error: `StatementError: (builtins.ValueError) expected 1536 dimensions, not 768`
Example code:
```python
from langchain.vectorstores.pgvector import PGVector
from langchain.text_spl... | PGVector does not work with HuggingFaceEmbeddings | https://api.github.com/repos/langchain-ai/langchain/issues/2219/comments | 18 | 2023-03-31T07:34:07Z | 2024-08-10T16:06:41Z | https://github.com/langchain-ai/langchain/issues/2219 | 1,648,834,828 | 2,219 |
[
"hwchase17",
"langchain"
] | I'm using this code:
```
aiplugin_tool = AIPluginTool.from_plugin_url("https://xxxx/plugin/.well-known/ai-plugin.json")
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
llm = ChatOpenAI(temperature=0)
extra_info_tool = make_vector_tool("{}/{}".format(os.getcwd(), "extra_in... | Sometimes requests tools connect to a wrong URL while using AIPluginTool. | https://api.github.com/repos/langchain-ai/langchain/issues/2218/comments | 4 | 2023-03-31T06:08:18Z | 2023-09-26T16:12:09Z | https://github.com/langchain-ai/langchain/issues/2218 | 1,648,730,777 | 2,218 |
[
"hwchase17",
"langchain"
] | > Entering new AgentExecutor chain...
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha]
Action Input: Wolfram Alpha 222+222
Observation: the action to take, should be one of [Time, TODO List, Python Execute, Wolfram Alpha] is not a v... | Failed to decide which tool to use. | https://api.github.com/repos/langchain-ai/langchain/issues/2217/comments | 3 | 2023-03-31T05:26:32Z | 2023-09-25T16:13:33Z | https://github.com/langchain-ai/langchain/issues/2217 | 1,648,693,829 | 2,217 |
[
"hwchase17",
"langchain"
] | While using the LangChain package to create a Vectorstore index, I encountered an AttributeError in the chroma.py file. The traceback indicates that the 'LocalAPI' object does not have the attribute 'get_or_create_collection'. This issue occurred when trying to create an index using the following code:
`index = Vect... | AttributeError in Chroma: 'LocalAPI' object has no attribute 'get_or_create_collection' | https://api.github.com/repos/langchain-ai/langchain/issues/2213/comments | 4 | 2023-03-31T03:41:39Z | 2023-09-25T16:13:38Z | https://github.com/langchain-ai/langchain/issues/2213 | 1,648,617,710 | 2,213 |
[
"hwchase17",
"langchain"
] | hi, I want to include json data in the template, the code and error is as follows, please help me to solve it.
```python
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
from langchain.chains import ConversationChain
from langchain.prompts.chat import SystemMessagePromp... | error when there are quotation marks in prompt template string | https://api.github.com/repos/langchain-ai/langchain/issues/2212/comments | 3 | 2023-03-31T03:21:33Z | 2023-12-06T11:53:08Z | https://github.com/langchain-ai/langchain/issues/2212 | 1,648,605,512 | 2,212 |
[
"hwchase17",
"langchain"
] | ## Concept
It would be useful if Agents had the ability to fact check their own work using a different LLM in an adversarial manner to "second guess" their assumptions and potentially provide feedback before allowing the final "answer" to surface to the end user.
For example, if a chain completes and an Agent is ... | Implement "Adversarial fact checking" functionality | https://api.github.com/repos/langchain-ai/langchain/issues/2211/comments | 3 | 2023-03-31T02:15:24Z | 2023-09-26T16:12:14Z | https://github.com/langchain-ai/langchain/issues/2211 | 1,648,559,252 | 2,211 |
[
"hwchase17",
"langchain"
] | null | Plugin chat gpt | https://api.github.com/repos/langchain-ai/langchain/issues/2208/comments | 2 | 2023-03-31T00:58:01Z | 2023-09-10T16:39:12Z | https://github.com/langchain-ai/langchain/issues/2208 | 1,648,510,025 | 2,208 |
[
"hwchase17",
"langchain"
] | Greetings. Followed the tutorial and got pretty far, so I know langchain works on the environment (below). However, the following error below appeared out of nowhere. Tried restarting the environment and still getting the same error. Tried pip uninstalling langchain and reinstalling but still outputting the same error.... | cannot import name 'PromptTemplate' from partially initialized module 'langchain' (most likely due to a circular import) | https://api.github.com/repos/langchain-ai/langchain/issues/2206/comments | 0 | 2023-03-30T23:03:17Z | 2023-03-30T23:19:52Z | https://github.com/langchain-ai/langchain/issues/2206 | 1,648,435,963 | 2,206 |
[
"hwchase17",
"langchain"
] | I am using langchain in CoLab and have come across this ChromaDB/VectorStore problem a few times, mostly recently with the code below. The piece of text I am importing is only a few hundred characters. I found this issue on the ChromaDB repository: https://github.com/chroma-core/chroma/issues/225, which is the same or ... | ChromaDB/VectorStore Problem: "NotEnoughElementsException: Number of requested results 4 cannot be greater than number of elements in index 1" | https://api.github.com/repos/langchain-ai/langchain/issues/2205/comments | 7 | 2023-03-30T22:36:23Z | 2023-09-26T16:12:18Z | https://github.com/langchain-ai/langchain/issues/2205 | 1,648,415,099 | 2,205 |
[
"hwchase17",
"langchain"
] | WARNING:langchain.llms.openai:Retrying langchain.llms.openai.completion_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
**Does anyone has a solution for this error ??**
| Rate limit error when using davinci model | https://api.github.com/repos/langchain-ai/langchain/issues/2204/comments | 6 | 2023-03-30T21:11:48Z | 2023-03-31T20:16:02Z | https://github.com/langchain-ai/langchain/issues/2204 | 1,648,328,520 | 2,204 |
[
"hwchase17",
"langchain"
] | I want to know if I am use this example to upload a text which exceeds 4097 tokens, it will definitely report an error because which passed the text_splitter takes 4000 as a block default, and then takes the first three segments. This way, the token passed into the model must be greater than 4097, even if the chain_ t... | summarization | https://api.github.com/repos/langchain-ai/langchain/issues/2192/comments | 2 | 2023-03-30T11:58:21Z | 2023-09-18T16:21:48Z | https://github.com/langchain-ai/langchain/issues/2192 | 1,647,474,312 | 2,192 |
[
"hwchase17",
"langchain"
] | Hi,
I want to use a model deployment from Azure for embeddings (I use version 0.0.123 of langchain). Like this:
```python
AzureOpenAI(
deployment_name="<my deployment name>",
model_name="text-embedding-ada-002",
...
)
```
But I get 'The API deployment for this resource does not exist.' in the respo... | AzureOpenAI wrong engine name | https://api.github.com/repos/langchain-ai/langchain/issues/2190/comments | 1 | 2023-03-30T11:51:06Z | 2023-09-10T16:39:21Z | https://github.com/langchain-ai/langchain/issues/2190 | 1,647,464,242 | 2,190 |
[
"hwchase17",
"langchain"
] | Hi, I read the docs and examples then tried to make a chatbot and a qustion answering bot over docs. I wonder is there any way to combine there two function together?
From my point of view, I mean basically it's chatbot which uses memory module to carry on conversation with users. If the user asking a question, then... | Is there any way to combine chatbot and question answering over docs? | https://api.github.com/repos/langchain-ai/langchain/issues/2185/comments | 10 | 2023-03-30T09:14:50Z | 2023-10-26T00:23:23Z | https://github.com/langchain-ai/langchain/issues/2185 | 1,647,226,241 | 2,185 |
[
"hwchase17",
"langchain"
] | Does API Chain support post method? How we can call post external api with llm? Appreciate any information, thanks. | Question: Does API Chain support post method? | https://api.github.com/repos/langchain-ai/langchain/issues/2184/comments | 12 | 2023-03-30T08:55:19Z | 2024-05-07T14:47:12Z | https://github.com/langchain-ai/langchain/issues/2184 | 1,647,194,820 | 2,184 |
[
"hwchase17",
"langchain"
] | I'm wondering if we can use langchain without llm from openai. I've tried replace openai with "bloom-7b1" and "flan-t5-xl" and used agent from langchain according to visual chatgpt [https://github.com/microsoft/visual-chatgpt](url).
Here is my demo:
```
class Text2Image:
def __init__(self, device):
... | Using langchain without openai api? | https://api.github.com/repos/langchain-ai/langchain/issues/2182/comments | 13 | 2023-03-30T08:07:21Z | 2023-12-30T16:09:14Z | https://github.com/langchain-ai/langchain/issues/2182 | 1,647,123,616 | 2,182 |
[
"hwchase17",
"langchain"
] | I am having a hard time understanding how I can add documents to an **existing** Redis Index.
This is what I do: first I try to instantiate `rds` from an existing Redis instance:
```
rds = Redis.from_existing_index(
embedding=openAIEmbeddings,
redis_url="redis://localhost:6379",
index_name='tech... | Redis: add to existing Index | https://api.github.com/repos/langchain-ai/langchain/issues/2181/comments | 12 | 2023-03-30T07:42:53Z | 2023-09-28T16:09:57Z | https://github.com/langchain-ai/langchain/issues/2181 | 1,647,085,810 | 2,181 |
[
"hwchase17",
"langchain"
] | I believe by default the model used in it is text-davinci-003 , how can i change that model to text-ada-001,
basically i want to create a question and answer bot in which i provide the model with text file input (txt file)
i based on that i want the bot the answer the question i ask it , based on only text file th... | Not able to Change model in Text Loader and VectorStoreIndexCreator | https://api.github.com/repos/langchain-ai/langchain/issues/2175/comments | 1 | 2023-03-30T04:52:26Z | 2023-09-18T16:21:54Z | https://github.com/langchain-ai/langchain/issues/2175 | 1,646,909,112 | 2,175 |
[
"hwchase17",
"langchain"
] | NOTE: fixed in #2238 PR.
I'm running `tests/unit_tests` on the Windows platform and several tests related to `bash` failed.
>test_llm_bash/
test_simple_question
and
>test_bash/
test_pwd_command
test_incorrect_command
test_incorrect_command_return_err_output
test_create_directory_and_file... | failed tests on Windows platform | https://api.github.com/repos/langchain-ai/langchain/issues/2174/comments | 3 | 2023-03-30T03:43:17Z | 2023-04-03T15:58:28Z | https://github.com/langchain-ai/langchain/issues/2174 | 1,646,855,969 | 2,174 |
[
"hwchase17",
"langchain"
] | I am trying to use the FAISS class to initialize an index using pre-computed embeddings, but it seems that the method is not being recognized. However, I found the function in both the [source code](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/faiss.py#L348) and documentation. Details in sc... | [BUG] FAISS.from_embeddings doesn't seem to exist | https://api.github.com/repos/langchain-ai/langchain/issues/2165/comments | 2 | 2023-03-29T21:20:49Z | 2023-09-10T16:39:31Z | https://github.com/langchain-ai/langchain/issues/2165 | 1,646,550,037 | 2,165 |
[
"hwchase17",
"langchain"
] |
I am facing this issue when trying to import the following.
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain.memory import ConversationBufferMemory
from langchain.memory.chat_memory import ChatMessageHistory
from langchain.memory.chat_message_histo... | Error while importing RedisChatMessageHistory | https://api.github.com/repos/langchain-ai/langchain/issues/2163/comments | 2 | 2023-03-29T21:04:55Z | 2023-09-10T16:39:37Z | https://github.com/langchain-ai/langchain/issues/2163 | 1,646,528,525 | 2,163 |
[
"hwchase17",
"langchain"
] | Hi, I am accessing the confluence API to retrieve Pages from a specific Space and process them. I am trying to embed them into Redis, see: `embed_document_splits`.
On the surface it seems to work but the index size in Redis only grows until 57 keys, then stops growing while the code happily runs.
So why is the i... | Storing Embeddings to Redis does not grow its index proportionally | https://api.github.com/repos/langchain-ai/langchain/issues/2162/comments | 2 | 2023-03-29T20:53:39Z | 2023-09-10T16:39:41Z | https://github.com/langchain-ai/langchain/issues/2162 | 1,646,514,182 | 2,162 |
[
"hwchase17",
"langchain"
] | What is the default Openai model used in the langchain agents create_csv_agent and how about if someone want to change the model to GPT4 .... how to do this... Thank you | create_csv_agent in agents | https://api.github.com/repos/langchain-ai/langchain/issues/2159/comments | 5 | 2023-03-29T19:28:16Z | 2023-05-01T15:29:07Z | https://github.com/langchain-ai/langchain/issues/2159 | 1,646,390,568 | 2,159 |
[
"hwchase17",
"langchain"
] | Hi
Like you have supported SQLDatabaseChain to return directly the query results without going back to LLM, can you do the same for SQLAgent as well , right now the data is always sent. and setting return_direct in tools will not help as it will return early if there are multiple tries in agent flow | SQLAgent direct return | https://api.github.com/repos/langchain-ai/langchain/issues/2158/comments | 1 | 2023-03-29T18:45:20Z | 2023-08-25T16:13:52Z | https://github.com/langchain-ai/langchain/issues/2158 | 1,646,334,900 | 2,158 |
[
"hwchase17",
"langchain"
] | https://docs.abyssworld.xyz/abyss-world-whitepaper/roadmap-and-development-milestones/milestones
This is an example of a three-level subdirectory.
However, the Gitbook loader can only traverse up to two levels.
I suspect that this issue lies with the Gitbook loader itself.
If this problem does indeed exist, I am... | Gitbook loader can't traverse more than 2 level of subdirectory | https://api.github.com/repos/langchain-ai/langchain/issues/2156/comments | 1 | 2023-03-29T18:30:19Z | 2023-08-25T16:13:56Z | https://github.com/langchain-ai/langchain/issues/2156 | 1,646,315,806 | 2,156 |
[
"hwchase17",
"langchain"
] | I am trying to `query` a `VectorstoreIndexCreator()` with a hugging face LLM and am running a validation error -- I would love to put up a PR/fix this myself, but I'm at a loss for what I need to do so any guidance and I'd be happy to try to put up a fix.
The validation error is below...
```
ValidationError: 1 v... | Cannot initialize LLMChain with HuggingFace LLM when querying VectorstoreIndexCreator() | https://api.github.com/repos/langchain-ai/langchain/issues/2154/comments | 1 | 2023-03-29T17:03:24Z | 2023-09-10T16:39:46Z | https://github.com/langchain-ai/langchain/issues/2154 | 1,646,196,792 | 2,154 |
[
"hwchase17",
"langchain"
] | Many customers has their knowledge base sitting on either in SharePoint , OneDrive and Documentum. Can we have a new document loader for all these? | New Document loader request for Sharepoint , OneDrive and Documentum | https://api.github.com/repos/langchain-ai/langchain/issues/2153/comments | 17 | 2023-03-29T16:36:16Z | 2024-04-27T14:07:57Z | https://github.com/langchain-ai/langchain/issues/2153 | 1,646,158,055 | 2,153 |
[
"hwchase17",
"langchain"
] | ## Bug description
Hello! I've been using the SQL agent for some time now and I've noticed that it burns tokens unnecessarily in certain cases, leading to slower LLM responses and hitting token limits. This happens usually when the user's question requires information from more than one table.
Unlike `SQLDatabase... | bug(sql_agent): Optimise token usage for user questions which require information from more than one table | https://api.github.com/repos/langchain-ai/langchain/issues/2150/comments | 4 | 2023-03-29T15:31:13Z | 2023-12-08T16:08:35Z | https://github.com/langchain-ai/langchain/issues/2150 | 1,646,058,913 | 2,150 |
[
"hwchase17",
"langchain"
] | Hi,
I keep getting the below warning every time the chain finishes.
`WARNING:root:Failed to persist run: HTTPConnectionPool(host='localhost', port=8000): Max retries exceeded with url: /chain-runs (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x000001B8E0B5D0D0>: Failed to establish ... | Max retries exceeded with url: /chain-runs | https://api.github.com/repos/langchain-ai/langchain/issues/2145/comments | 12 | 2023-03-29T12:56:09Z | 2024-04-02T13:32:04Z | https://github.com/langchain-ai/langchain/issues/2145 | 1,645,755,617 | 2,145 |
[
"hwchase17",
"langchain"
] | I have set up a docker-compose stack with ghcr.io/chroma-core/chroma:0.3.14 (chroma_server) and clickhouse/clickhouse-server:22.9-alpine (click house) almost just like the chroma compose example in their rep. Just the port differs. I have also setup: CHROMA_API_IMPL, CHROMA_SERVER_HOST, CHROMA_SERVER_HTTP_PORT at the ... | Setting chromadb client-server results in "Remote end closed connection without response" | https://api.github.com/repos/langchain-ai/langchain/issues/2144/comments | 12 | 2023-03-29T11:53:11Z | 2023-09-27T16:11:11Z | https://github.com/langchain-ai/langchain/issues/2144 | 1,645,644,133 | 2,144 |
[
"hwchase17",
"langchain"
] | The contrast used for the documentation on this UI (https://python.langchain.com/en/latest/getting_started/getting_started.html), makes the docs hard to read. Can this be improved? I can take a stab if pointed towards the UI code. | Docs UI | https://api.github.com/repos/langchain-ai/langchain/issues/2143/comments | 9 | 2023-03-29T11:36:24Z | 2023-09-27T16:11:14Z | https://github.com/langchain-ai/langchain/issues/2143 | 1,645,618,664 | 2,143 |
[
"hwchase17",
"langchain"
] | I have a question about ChatGPTPluginRetriever and VectorStore Retriever. I wanner use Enterprise Private Data with chatGPT, several weeks ago, there is no OpenAI chatGPT Plugin, I intend to use LangChain Vector Store implenment this function, but I have not finish this job, chatgpt plugin come true, I have read [chatg... | what's difference between ChatGPTPluginRetriever and VectorStore Retriever | https://api.github.com/repos/langchain-ai/langchain/issues/2142/comments | 1 | 2023-03-29T11:20:31Z | 2023-09-18T16:21:59Z | https://github.com/langchain-ai/langchain/issues/2142 | 1,645,590,007 | 2,142 |
[
"hwchase17",
"langchain"
] | I am testing out the newly released support for ChatGPT plugins with langchain. Below I am doing a sample test with Wolfram Alpha but it throws the below error
"openai.error.InvalidRequestError: This model's maximum context length is 4097 tokens. However, your messages resulted in 127344 tokens. Please reduce the l... | Model's maximum context length error with ChatGPT plugins | https://api.github.com/repos/langchain-ai/langchain/issues/2140/comments | 5 | 2023-03-29T10:07:05Z | 2023-09-18T16:22:04Z | https://github.com/langchain-ai/langchain/issues/2140 | 1,645,459,755 | 2,140 |
[
"hwchase17",
"langchain"
] | My aim is to chat with a vector index, so I tried to port code to the new retrieval abstraction. In addition, I pass arguments to the pinecone vector store eg to filter by metadata or specify the collection/ namespace needed. However, I only get the chain to work if I specify `vectordbkwargs` twice, once in the retriev... | Unnecessary need to pass vectordbkwargs multiple times in new retrieval class? | https://api.github.com/repos/langchain-ai/langchain/issues/2139/comments | 2 | 2023-03-29T08:11:36Z | 2023-09-18T16:22:10Z | https://github.com/langchain-ai/langchain/issues/2139 | 1,645,257,394 | 2,139 |
[
"hwchase17",
"langchain"
] | hello,can you share the ways how to use other llm not the openAI,thanks | llms | https://api.github.com/repos/langchain-ai/langchain/issues/2138/comments | 5 | 2023-03-29T08:07:07Z | 2023-09-26T16:12:49Z | https://github.com/langchain-ai/langchain/issues/2138 | 1,645,250,309 | 2,138 |
[
"hwchase17",
"langchain"
] | Hey all,
I'm trying to make a bot that can use the math and search functions while still using tools. What I have so far is this:
```
from langchain import OpenAI, LLMMathChain, SerpAPIWrapper
from langchain.agents import initialize_agent, Tool
from langchain.chat_models import ChatOpenAI
from langchain.chains... | Creating conversational bots with memory, agents, and tools | https://api.github.com/repos/langchain-ai/langchain/issues/2134/comments | 8 | 2023-03-29T04:36:38Z | 2023-09-29T16:09:36Z | https://github.com/langchain-ai/langchain/issues/2134 | 1,645,018,466 | 2,134 |
[
"hwchase17",
"langchain"
] | I want to migrate from `VectorDBQAWithSourcesChain` to `RetrievalQAWithSourcesChain`. The sample code use Qdrant vector store, it work fine with VectorDBQAWithSourcesChain.
When I run the code with RetrievalQAWithSourcesChain changes, it prompt me the following error:
```
openai.error.InvalidRequestError: This mod... | RetrievalQAWithSourcesChain causing openai.error.InvalidRequestError: This model's maximum context length is 4097 tokens | https://api.github.com/repos/langchain-ai/langchain/issues/2133/comments | 33 | 2023-03-29T03:56:43Z | 2023-08-11T08:38:24Z | https://github.com/langchain-ai/langchain/issues/2133 | 1,644,990,510 | 2,133 |
[
"hwchase17",
"langchain"
] | Firs time attempting to use this project on an M2 Max Apple laptop, using the example code in the guide
```python
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
self.openai_llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "ll... | Unable to run 'Getting Started' example with due to numpy error | https://api.github.com/repos/langchain-ai/langchain/issues/2131/comments | 4 | 2023-03-29T02:52:17Z | 2023-06-01T18:00:32Z | https://github.com/langchain-ai/langchain/issues/2131 | 1,644,947,002 | 2,131 |
[
"hwchase17",
"langchain"
] | It would be great to see a JavaScript/TypeScript REPL as a LangChain tool.
Consider [ts-node](https://typestrong.org/ts-node/) which is a TypeScript execution and REPL for Node.js, with source map and native ESM support. It provides a command-line interface (CLI) for running TS files directly, without the need for c... | JS/TS REPL | https://api.github.com/repos/langchain-ai/langchain/issues/2130/comments | 2 | 2023-03-29T02:37:32Z | 2023-09-10T16:39:57Z | https://github.com/langchain-ai/langchain/issues/2130 | 1,644,937,384 | 2,130 |
[
"hwchase17",
"langchain"
] | I get an error when I try to follow the introduction page:
```
from langchain.llms import OpenAI
import os
from langchain.chains import LLMChain
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.prompts import PromptTemplate
os.environ["OPENAI_API_KEY"] = "...
... | error in intro docs | https://api.github.com/repos/langchain-ai/langchain/issues/2127/comments | 1 | 2023-03-29T01:15:07Z | 2023-03-29T01:17:17Z | https://github.com/langchain-ai/langchain/issues/2127 | 1,644,880,832 | 2,127 |
[
"hwchase17",
"langchain"
] | Is there any way to retrieve the "standalone question" generated during the summarization process of the `ConversationalRetrievalChain`? I was able to print it for debugging [here in base.py](https://github.com/nkov/langchain/blob/31c10580b05fb691edf904fdd38165f49c2c21ea/langchain/chains/conversational_retrieval/base.p... | Retrieving the standalone question from ConversationalRetrievalChain | https://api.github.com/repos/langchain-ai/langchain/issues/2125/comments | 4 | 2023-03-29T00:06:50Z | 2024-02-09T03:48:32Z | https://github.com/langchain-ai/langchain/issues/2125 | 1,644,833,146 | 2,125 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.