
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.46B | issue_number int64 1 127k |
|---|---|---|---|---|---|---|---|---|---|
[
"hwchase17",
"langchain"
] | I am trying to follow the [MRKL chat example](https://langchain.readthedocs.io/en/latest/modules/agents/implementations/mrkl_chat.html) but with AzureOpenAI (`text-davinci-003`) and AzureChatOpenAI (`gpt-3.5-turbo`). However, I am running into this error:
```
ValueError: `stop` found in both the input and default par... | ValueError when using Azure and chat-zero-shot-react-description agent | https://api.github.com/repos/langchain-ai/langchain/issues/1852/comments | 3 | 2023-03-21T14:10:21Z | 2023-09-26T16:14:15Z | https://github.com/langchain-ai/langchain/issues/1852 | 1,634,012,102 | 1,852 |
[
"hwchase17",
"langchain"
] | The role attribute in line 616 of openai.py under the llms package of langchain is expected to provide an external modification entry or parameter.
<img width="1146" alt="image" src="https://user-images.githubusercontent.com/29686094/226600002-ba0a89fd-c65a-4d8c-92a0-73e7a44dfdb9.png">
Here are the parameter values... | I would like to provide an entry for role=system | https://api.github.com/repos/langchain-ai/langchain/issues/1848/comments | 4 | 2023-03-21T12:02:49Z | 2023-09-18T16:23:10Z | https://github.com/langchain-ai/langchain/issues/1848 | 1,633,770,590 | 1,848 |
[
"hwchase17",
"langchain"
] | ```python
import os
os.environ["OPENAI_API_KEY"] = "..."
from langchain.agents import Tool, load_tools
from langchain.memory import ConversationBufferMemory
from langchain import OpenAI
from langchain.utilities import GoogleSearchAPIWrapper
from langchain.agents import initialize_agent
tool_names = []
tool_n... | Empty observation when using python_repl | https://api.github.com/repos/langchain-ai/langchain/issues/1846/comments | 2 | 2023-03-21T09:21:58Z | 2023-10-30T16:08:08Z | https://github.com/langchain-ai/langchain/issues/1846 | 1,633,506,456 | 1,846 |
[
"hwchase17",
"langchain"
] |
```
agent = create_csv_agent(llm, 'titanic.csv', verbose=True)
json_agent_executor = create_json_agent(llm, toolkit=json_toolkit, verbose=True)
openapi_agent_executor = create_openapi_agent(
llm=OpenAI(temperature=0),
toolkit=openapi_toolkit,
verbose=True
)
agent_executor = create_sql_agen... | make the `create_python_agent` API more consistency with other same API | https://api.github.com/repos/langchain-ai/langchain/issues/1845/comments | 2 | 2023-03-21T06:44:54Z | 2023-09-10T16:41:13Z | https://github.com/langchain-ai/langchain/issues/1845 | 1,633,317,706 | 1,845 |
[
"hwchase17",
"langchain"
] | Using `VectorDBQAWithSourcesChain` with arun, facing below issue
`ValueError: `run` not supported when there is not exactly one output key. Got ['answer', 'sources'].` | Facing issue when using arun with VectorDBQAWithSourcesChain chain | https://api.github.com/repos/langchain-ai/langchain/issues/1844/comments | 19 | 2023-03-21T05:59:09Z | 2023-10-19T16:09:34Z | https://github.com/langchain-ai/langchain/issues/1844 | 1,633,279,135 | 1,844 |
[
"hwchase17",
"langchain"
] | Hey there, just asking on what the progress is on the "Custom Agent Class" for langchain? 🙂
https://langchain.readthedocs.io/en/latest/modules/agents/examples/custom_agent.html#custom-agent-class | Progress on Custom Agent Class? | https://api.github.com/repos/langchain-ai/langchain/issues/1840/comments | 6 | 2023-03-21T02:06:22Z | 2023-09-28T16:10:58Z | https://github.com/langchain-ai/langchain/issues/1840 | 1,633,115,886 | 1,840 |
[
"hwchase17",
"langchain"
] | I have 3 pdf files in my directory and I "documentized", added metadata, split, embed and store them in pinecone, like this:
```
loader = DirectoryLoader('data/dir', glob="**/*.pdf", loader_cls=UnstructuredPDFLoader)
data = loader.load()
#I added company names explicitly for now
data[0].metadata["company"]="Ap... | How metadata is being used during similarity search and query? | https://api.github.com/repos/langchain-ai/langchain/issues/1838/comments | 10 | 2023-03-21T01:32:20Z | 2024-03-27T12:24:17Z | https://github.com/langchain-ai/langchain/issues/1838 | 1,633,096,854 | 1,838 |
[
"hwchase17",
"langchain"
] | 1. Cannot initialize match chain with ChatOpenAI LLM
llm_math = LLMMathChain(llm=ChatOpenAI(temperature=0))
---------------------------------------------------------------------------
ValidationError Traceback (most recent call last)
Cell In[33], line 1
----> 1 llm_math = LLMMathChai... | LLMMathChain to allow ChatOpenAI as an llm | https://api.github.com/repos/langchain-ai/langchain/issues/1834/comments | 10 | 2023-03-20T23:12:24Z | 2023-04-29T21:57:59Z | https://github.com/langchain-ai/langchain/issues/1834 | 1,633,003,060 | 1,834 |
[
"hwchase17",
"langchain"
] | Hi! I tried implementing the docs from [here](https://langchain.readthedocs.io/en/latest/modules/utils/examples/zapier.html) but am running into this issue – is it due to openAI's API being down?
```
> Entering new AgentExecutor chain...
I need to find the email, summarize it, and send it to slack.
Action: Gmail... | Implementing Zapier example | https://api.github.com/repos/langchain-ai/langchain/issues/1832/comments | 1 | 2023-03-20T22:29:41Z | 2023-09-10T16:41:19Z | https://github.com/langchain-ai/langchain/issues/1832 | 1,632,960,593 | 1,832 |
[
"hwchase17",
"langchain"
] | I tried following [these docs](https://langchain.readthedocs.io/en/latest/modules/utils/examples/zapier.html) to import Zapier integration
```
from langchain.tools.zapier.tool import ZapierNLARunAction
from langchain.utilities.zapier import ZapierNLAWrapper
```
But I'm getting these errors:
`Traceback (most... | Importing Zapier | https://api.github.com/repos/langchain-ai/langchain/issues/1831/comments | 1 | 2023-03-20T21:50:36Z | 2023-03-20T22:28:18Z | https://github.com/langchain-ai/langchain/issues/1831 | 1,632,916,808 | 1,831 |
[
"hwchase17",
"langchain"
] | **Issue:** When trying to read data from some URLs, I get a 403 error during load. I assume this is due to the web-server not allowing all user agents.
**Expected behavior:** It would be great if I could specify a user agent (e.g. standard browsers like Mozilla, maybe also Google bots) for making the URL requests.
... | UnstructuredURLLoader Error 403 | https://api.github.com/repos/langchain-ai/langchain/issues/1829/comments | 9 | 2023-03-20T21:26:40Z | 2023-06-19T00:47:02Z | https://github.com/langchain-ai/langchain/issues/1829 | 1,632,888,908 | 1,829 |
[
"hwchase17",
"langchain"
] | The current documentation https://langchain.readthedocs.io/en/latest/modules/agents/getting_started.html seems to not be up to date with version 0.0.117:
```shell
UserWarning: You are trying to use a chat model. This way of initializing it is no longer supported. Instead, please use: `from langchain.chat_models im... | Documentation not up to date | https://api.github.com/repos/langchain-ai/langchain/issues/1827/comments | 12 | 2023-03-20T18:10:51Z | 2024-02-16T16:10:11Z | https://github.com/langchain-ai/langchain/issues/1827 | 1,632,628,572 | 1,827 |
[
"hwchase17",
"langchain"
] |
I am experiencing an issue with Chroma:
`Chroma.from_texts(texts=chunks, embedding=embeddings, persist_directory=config.PERSIST_DIR, metadatas=None)`
opt/anaconda3/lib/python3.8/site-packages/langchain/vectorstores/chroma.py", line 27, in <listcomp>
(Document(page_content=result[0], metadata=result[1]), re... | Validation error- Metadata should not be empty or None | https://api.github.com/repos/langchain-ai/langchain/issues/1825/comments | 2 | 2023-03-20T17:50:04Z | 2023-09-10T16:41:24Z | https://github.com/langchain-ai/langchain/issues/1825 | 1,632,592,766 | 1,825 |
[
"hwchase17",
"langchain"
] | If I'm reading correctly, this is the function to add_texts to Chroma
```
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
ids: Optional[List[str]] = None,
**kwargs: Any,
) -> List[str]:
"""Run more texts through the embed... | Avoiding recomputation of embeddings with Chroma | https://api.github.com/repos/langchain-ai/langchain/issues/1824/comments | 9 | 2023-03-20T17:48:30Z | 2023-09-28T16:11:03Z | https://github.com/langchain-ai/langchain/issues/1824 | 1,632,590,839 | 1,824 |
[
"hwchase17",
"langchain"
] | Hi,
I would like to contribute to LangChain, need to know if our feature is relevant as part of LangChain.
Would like check with you in private. How we can share our idea?
Moshe | New feature: Contribution | https://api.github.com/repos/langchain-ai/langchain/issues/1823/comments | 1 | 2023-03-20T17:03:16Z | 2023-09-10T16:41:29Z | https://github.com/langchain-ai/langchain/issues/1823 | 1,632,522,870 | 1,823 |
[
"hwchase17",
"langchain"
] | Creating and using AzureChatOpenAI directly works fine, but crashing through ChatVectorDBChain with "ValueError: Should always be something for OpenAI."
Example:
```
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import CharacterText... | Creating and using AzureChatOpenAI directly works fine, but crashing through ChatVectorDBChain with "ValueError: Should always be something for OpenAI." | https://api.github.com/repos/langchain-ai/langchain/issues/1822/comments | 2 | 2023-03-20T16:27:16Z | 2023-03-20T16:47:11Z | https://github.com/langchain-ai/langchain/issues/1822 | 1,632,466,855 | 1,822 |
[
"hwchase17",
"langchain"
] | Hey team,
i have created an API in the below format
`
@app.post("/get_answer")
async def get_answer(user_query):
return vector_db.qa(user_query)
`
And I call this function for 5 user_query, but it only able to process first query other query faces issues from OpenAI. Is calling OpenAI API parallely not al... | async call for question answering | https://api.github.com/repos/langchain-ai/langchain/issues/1816/comments | 1 | 2023-03-20T13:59:50Z | 2023-09-10T16:41:33Z | https://github.com/langchain-ai/langchain/issues/1816 | 1,632,175,081 | 1,816 |
[
"hwchase17",
"langchain"
] | During the tracing of ChatVectorDBChain, even though it shows source_documents but when clicked on Explore, source_documents suddenly becomes [object Object],[object Object].
Here is an example:

and ... | During the tracing of ChatVectorDBChain, even though it shows source_documents but when clicked on Explore, source_documents suddenly becomes [object Object],[object Object] | https://api.github.com/repos/langchain-ai/langchain/issues/1815/comments | 3 | 2023-03-20T10:58:37Z | 2023-09-10T16:41:40Z | https://github.com/langchain-ai/langchain/issues/1815 | 1,631,865,900 | 1,815 |
[
"hwchase17",
"langchain"
] | OpenAI has been fairly unstable with keeping up the load after back to back releases and it tends to fail at some requests.
now If we're embedding a big document in chunks, it tends to fail at some point and Pinecone.from_texts() does not have exception handling, on failure of a chunk whole document that is left is wa... | Need better exception Handling at Pinecone.from_texts() | https://api.github.com/repos/langchain-ai/langchain/issues/1811/comments | 1 | 2023-03-20T05:48:55Z | 2023-09-10T16:41:44Z | https://github.com/langchain-ai/langchain/issues/1811 | 1,631,430,634 | 1,811 |
[
"hwchase17",
"langchain"
] | Error Message:

Usage:
I currently using **AzureChatOpenAI** with below parameters

B... | AzureChatOpenAI failed to accept openai_api_base, throwing error | https://api.github.com/repos/langchain-ai/langchain/issues/1810/comments | 1 | 2023-03-20T05:44:48Z | 2023-09-10T16:41:49Z | https://github.com/langchain-ai/langchain/issues/1810 | 1,631,427,537 | 1,810 |
[
"hwchase17",
"langchain"
] | While I am trying to rebuild chat_pdf based on mayo's example.
I noticed that vector store with pinecone doesn't respond with similar docs when it performs similarity_search function.
I test it against other vector provider like faiss and chroma. In both cases, those all works.
Here is the [code link](https://github... | issue with pinecone similarity_search function | https://api.github.com/repos/langchain-ai/langchain/issues/1809/comments | 2 | 2023-03-20T05:13:20Z | 2023-10-27T16:09:24Z | https://github.com/langchain-ai/langchain/issues/1809 | 1,631,399,350 | 1,809 |
[
"hwchase17",
"langchain"
] | Lots of customers is asking if langchain have a document loader like AWS S3 or GCS for Azure Blob Storage as well. As you know Microsoft is a big partner for OpenAI , so there is a real need to have native document loader for Azure Blob storage as well. We will be very happy to see this feature ASAP. | Document loader for Azure Blob storage | https://api.github.com/repos/langchain-ai/langchain/issues/1805/comments | 3 | 2023-03-20T02:39:16Z | 2023-03-27T15:17:18Z | https://github.com/langchain-ai/langchain/issues/1805 | 1,631,276,872 | 1,805 |
[
"hwchase17",
"langchain"
] | `poetry install -E all` fails with Poetry >=1.4.0 due to upstream incompatibility between `poetry>=1.4.0` and `pydata_sphinx_theme`.
This is a tracking issue. I've already created an issue upstream here: https://github.com/pydata/pydata-sphinx-theme/issues/1253 | Poetry 1.4.0 installation fails | https://api.github.com/repos/langchain-ai/langchain/issues/1801/comments | 2 | 2023-03-19T23:42:55Z | 2023-09-12T21:30:13Z | https://github.com/langchain-ai/langchain/issues/1801 | 1,631,163,256 | 1,801 |
[
"hwchase17",
"langchain"
] | Hi, does anyone know how to override the prompt template of ConversationChain? I am creating a custom prompt template that takes in an additional input variable
```
PROMPT_TEMPLATE = """ {my_info}
{history}
Human: {input}
AI:"""
PROMPT = PromptTemplate(
input_variables=["history", "input", "my_info"], tem... | Error when overriding default prompt template of ConversationChain | https://api.github.com/repos/langchain-ai/langchain/issues/1800/comments | 27 | 2023-03-19T23:33:20Z | 2024-02-08T06:43:47Z | https://github.com/langchain-ai/langchain/issues/1800 | 1,631,160,642 | 1,800 |
[
"hwchase17",
"langchain"
] | `ChatVectorDBChain` with `ChatOpenAI` fails with `Should always be something for OpenAI.`
It appears `_combine_llm_outputs` added to `ChatOpenAI` in v0.0.116 is receiving a `llm_outputs` list containing a `None` value. I think this is related to streaming responses from the OpenAI API.
see https://github.com/hwch... | v0.0.116 ChatVectorDBChain with ChatOpenAI fails with `Should always be something for OpenAI.` | https://api.github.com/repos/langchain-ai/langchain/issues/1799/comments | 2 | 2023-03-19T23:18:24Z | 2023-03-20T14:51:20Z | https://github.com/langchain-ai/langchain/issues/1799 | 1,631,156,471 | 1,799 |
[
"hwchase17",
"langchain"
] | @hwchase17 Thank you for leading work on this repo! It's very clear you've put a lot of love into this project. 🤗 ❤️
My coworker, @3coins, with whom I work daily, is a regular contributor here.
I wanted to offer you a design proposal that I think would be a great addition to LangChain. Here goes:
# Motivation... | [Design Proposal] Standardized interface for LLM provider usage | https://api.github.com/repos/langchain-ai/langchain/issues/1797/comments | 3 | 2023-03-19T22:28:09Z | 2023-09-10T16:41:54Z | https://github.com/langchain-ai/langchain/issues/1797 | 1,631,141,587 | 1,797 |
[
"hwchase17",
"langchain"
] | The current design leaves only two options for initialization `openai-python`:
1. `OPENAI_API_KEY` environment variable
2. pass in `openai_api_key`
LangChain works just fine with the other `openai-python` settings like `openai.api_type`.
Can we make it so it uses `openai.api_key` if it is not `None`?
Happy... | OpenAI base model initialization ignores currently set openi.api_key | https://api.github.com/repos/langchain-ai/langchain/issues/1796/comments | 1 | 2023-03-19T21:45:28Z | 2023-08-24T16:14:16Z | https://github.com/langchain-ai/langchain/issues/1796 | 1,631,129,215 | 1,796 |
[
"hwchase17",
"langchain"
] | I'm using the pipeline for Q&A pipeline on non-english language:
```
pinecone.init(
api_key=PINECONE_API_KEY, # find at app.pinecone.io
environment=PINECONE_API_ENV # next to api key in console
)
index_name = "langchain2"
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
docsearch = Pin... | chain.run threw 403 error | https://api.github.com/repos/langchain-ai/langchain/issues/1795/comments | 6 | 2023-03-19T21:35:50Z | 2023-03-22T20:39:40Z | https://github.com/langchain-ai/langchain/issues/1795 | 1,631,126,760 | 1,795 |
[
"hwchase17",
"langchain"
] | Within the Chroma DB, similarity_search has a default "k" of 4.
However, if there are less than 4 results to return to the query, it will crash instead of returning whatever is available.
```similarity_search(query: str, k: int = 4, filter: Optional[Dict[str, str]] = None, **kwargs: Any) → List[langchain.docstore... | [BUG] Chroma DB - similarity_search - chromadb.errors.NotEnoughElementsException | https://api.github.com/repos/langchain-ai/langchain/issues/1793/comments | 16 | 2023-03-19T21:11:37Z | 2023-09-22T16:05:46Z | https://github.com/langchain-ai/langchain/issues/1793 | 1,631,119,009 | 1,793 |
[
"hwchase17",
"langchain"
] | How to query from an existing index?
I filled up an index in Pinecode using:
```
docsearch = Pinecone.from_texts([t.page_content for t in texts], embeddings, index_name=index_name)
```
Now, I'm creating a separate `.py` file, where I need to use the existing index to query. As I understand I need to use the ... | Query on existing index | https://api.github.com/repos/langchain-ai/langchain/issues/1792/comments | 30 | 2023-03-19T20:55:14Z | 2024-07-06T10:06:53Z | https://github.com/langchain-ai/langchain/issues/1792 | 1,631,113,414 | 1,792 |
[
"hwchase17",
"langchain"
] | # [BUG] OpenMetero prompt token count error
The OpenMetero api returns a json that is large and the GPT-3 api cannot study it to return information
## What and Why?
While running the OpenMetero Lang chain the open metero api returns a large json file that is then sent to the gpt-3 api to understand, which is large... | [BUG] OpenMetero prompt token count error | https://api.github.com/repos/langchain-ai/langchain/issues/1790/comments | 1 | 2023-03-19T18:40:49Z | 2023-08-24T16:14:21Z | https://github.com/langchain-ai/langchain/issues/1790 | 1,631,067,675 | 1,790 |
[
"hwchase17",
"langchain"
] | Is there any chance to add support for selfhost models like ChatGLM or transformer models.
Tried to use runhouse with model “ChatGLM-6B”, but not working. | Add support for selfhost models like ChatGLM or transformer models | https://api.github.com/repos/langchain-ai/langchain/issues/1780/comments | 7 | 2023-03-19T16:33:47Z | 2023-09-19T23:30:45Z | https://github.com/langchain-ai/langchain/issues/1780 | 1,631,012,518 | 1,780 |
[
"hwchase17",
"langchain"
] | https://github.com/hwchase17/langchain/blob/3701b2901e76f2f97239c2152a6a7d01754fb666/langchain/chains/question_answering/map_rerank_prompt.py#L6
This regex is not handling the case where if answer text contains something like: `\n Helpful Score: 100` and the parsing fails even if the score is 100.
It should be s... | Fix regex for map_rerank_prompt.py | https://api.github.com/repos/langchain-ai/langchain/issues/1779/comments | 2 | 2023-03-19T15:26:29Z | 2023-09-10T16:41:59Z | https://github.com/langchain-ai/langchain/issues/1779 | 1,630,987,862 | 1,779 |
[
"hwchase17",
"langchain"
] | It would be great to see LangChain integrate with Standford's Alpaca 7B model, a fine-tuned LlaMa (see https://github.com/hwchase17/langchain/issues/1473).
Standford created an AI able to generate outputs that were largely on par with OpenAI’s `text-davinci-003` and regularly better than GPT-3 — all for a fraction o... | Alpaca (Fine-tuned LLaMA) | https://api.github.com/repos/langchain-ai/langchain/issues/1777/comments | 23 | 2023-03-19T15:16:09Z | 2023-09-22T16:50:52Z | https://github.com/langchain-ai/langchain/issues/1777 | 1,630,984,304 | 1,777 |
[
"hwchase17",
"langchain"
] | This issue may sound silly, I apologize for not being able to find the answer (and for my poor English).
For example, I want my chatbot only use paths from a list I give. I tried to include the following content in suffix:
```py
"""
omit...
You should only use the following file paths:
{path_list}
omit...
"""... | How to use self defined variable in an Agent? | https://api.github.com/repos/langchain-ai/langchain/issues/1774/comments | 5 | 2023-03-19T11:03:28Z | 2023-03-24T23:38:32Z | https://github.com/langchain-ai/langchain/issues/1774 | 1,630,889,769 | 1,774 |
[
"hwchase17",
"langchain"
] | When using the chat application, I encountered an error message stating "openai.error.InvalidRequestError: This model's maximum context length is 4097 tokens" when I asked a question like "Did he mention Stephen Breyer?".
 is still at 1.4.46. | Update poetry lock to allow SQLAlchemy v2 | https://api.github.com/repos/langchain-ai/langchain/issues/1766/comments | 8 | 2023-03-19T01:48:23Z | 2023-04-25T04:10:57Z | https://github.com/langchain-ai/langchain/issues/1766 | 1,630,736,276 | 1,766 |
[
"hwchase17",
"langchain"
] | If I use langchain for question answering on a single document with any LLM, is there a way to also extract the corresponding character offsets (begin and end) of the response in the original document?
Thanks,
Ravi. | Character offsets for the response/Answer | https://api.github.com/repos/langchain-ai/langchain/issues/1763/comments | 1 | 2023-03-18T21:44:36Z | 2023-08-24T16:14:26Z | https://github.com/langchain-ai/langchain/issues/1763 | 1,630,620,637 | 1,763 |
[
"hwchase17",
"langchain"
] | ## Summary
Occurring in [Chat Langchain Demo](https://github.com/hwchase17/chat-langchain) when upgrading from 0.0.105 -> 0.0.106 getting
`ERROR:root:'OpenAIEmbeddings' object has no attribute 'max_retries'`
This occurs AFTER the user sends their first message, instantly receive back the error in the logs. The ... | ERROR:root:'OpenAIEmbeddings' object has no attribute 'max_retries' - VERSION 0.0.106 and up | https://api.github.com/repos/langchain-ai/langchain/issues/1759/comments | 2 | 2023-03-18T18:17:46Z | 2023-09-18T16:23:15Z | https://github.com/langchain-ai/langchain/issues/1759 | 1,630,492,439 | 1,759 |
[
"hwchase17",
"langchain"
] | # Quick summary
Using the `namespace` argument in the function `Pinecone.from_existing_index` has no effect. Indeed, it is passed to `pinecone.Index`, which has no `namespace` argument.
# Steps to reproduce a relevant bug
```
import pinecone
from langchain.docstore.document import Document
from langchain.vector... | namespace argument not taken into account when creating Pinecone index | https://api.github.com/repos/langchain-ai/langchain/issues/1756/comments | 0 | 2023-03-18T12:26:39Z | 2023-03-19T02:55:40Z | https://github.com/langchain-ai/langchain/issues/1756 | 1,630,304,145 | 1,756 |
[
"hwchase17",
"langchain"
] | Currently, the document on [Creating a custom prompt template](https://langchain.readthedocs.io/en/latest/modules/prompts/examples/custom_prompt_template.html) is outdated, as the code in the guide is no longer functional for the following reasons:
1. The document outlines creating a custom prompt template by inheri... | Document for a custom prompt template is outdated. | https://api.github.com/repos/langchain-ai/langchain/issues/1754/comments | 0 | 2023-03-18T10:40:32Z | 2023-03-19T23:51:51Z | https://github.com/langchain-ai/langchain/issues/1754 | 1,630,270,933 | 1,754 |
[
"hwchase17",
"langchain"
] | I tried the code from the documentation here on a Jupyter notebook from VScode : https://langchain.readthedocs.io/en/latest/modules/llms/async_llm.html?highlight=agenerate#async-api-for-llm
It worked but when I replaced:
`from langchain.llms import OpenAI`
with
`
from langchain.chat_models import ChatOpen... | error when using an asynchronous await with ChatGPT | https://api.github.com/repos/langchain-ai/langchain/issues/1751/comments | 6 | 2023-03-18T08:13:50Z | 2023-11-27T21:59:57Z | https://github.com/langchain-ai/langchain/issues/1751 | 1,630,226,364 | 1,751 |
[
"hwchase17",
"langchain"
] | AzureOpenAI seems not work for gpt-3.5-turbo due to this issue | AzureOpenAI gpt-3.5-turbo doesn't support best_of parameter | https://api.github.com/repos/langchain-ai/langchain/issues/1747/comments | 6 | 2023-03-18T00:45:00Z | 2023-09-27T16:12:35Z | https://github.com/langchain-ai/langchain/issues/1747 | 1,630,060,590 | 1,747 |
[
"hwchase17",
"langchain"
] | I'm trying to follow this example [https://langchain.readthedocs.io/en/latest/modules/indexes/chain_examples/chat_vector_db.html?highlight=chatvectordb#chat-vector-db-with-streaming-to-stdout](url)
and I've used PagedPDFSplitter to load a PDF.
This is how I've done it (build_vectorstore returns Chroma.from_documents(... | Getting KeyError: {'context', 'question'} when following Chat Vector DB with streaming example | https://api.github.com/repos/langchain-ai/langchain/issues/1745/comments | 1 | 2023-03-17T22:09:27Z | 2023-09-10T16:42:10Z | https://github.com/langchain-ai/langchain/issues/1745 | 1,629,974,694 | 1,745 |
[
"hwchase17",
"langchain"
] | I have found that the OpenAI embeddings are decent, but suffer when you want specific names or keywords to be included. I've found that the [sparse-dense approach](https://www.pinecone.io/learn/sparse-dense) produces better results, but not supported by the current implementation of the Vectorstore or the chains.
H... | Support for Pinecone Hybrid Search (Sparse-dense embeddings) | https://api.github.com/repos/langchain-ai/langchain/issues/1743/comments | 7 | 2023-03-17T20:02:14Z | 2023-09-25T16:16:15Z | https://github.com/langchain-ai/langchain/issues/1743 | 1,629,872,044 | 1,743 |
[
"hwchase17",
"langchain"
] | It's really useful to move away the prompts etc. from the main codebase. Currently, from the documentation and my own testing, seems that only those chains can be serialized that have OpenAI LLM (only `text-davinci-003`). But, no such support is available for Azure-based OpenAI LLMs (`text-davinci-003` and `gpt-3.5-tur... | Chain Serialization Support with Azure OpenAI LLMs | https://api.github.com/repos/langchain-ai/langchain/issues/1736/comments | 2 | 2023-03-17T12:50:42Z | 2023-10-12T16:11:09Z | https://github.com/langchain-ai/langchain/issues/1736 | 1,629,261,920 | 1,736 |
[
"hwchase17",
"langchain"
] | https://github.com/hwchase17/langchain/blob/276940fd9babf8aec570dd869cc84fbca1c766bf/langchain/vectorstores/milvus.py#L319
I'm using milvus where for my question I'm getting 0 documents and so index out of range error occurs
Error line:
https://github.com/hwchase17/langchain/blob/276940fd9babf8aec570dd869cc84fbc... | list index out of range error if similarity search gives 0 docs | https://api.github.com/repos/langchain-ai/langchain/issues/1733/comments | 7 | 2023-03-17T11:14:48Z | 2023-08-11T05:50:41Z | https://github.com/langchain-ai/langchain/issues/1733 | 1,629,133,888 | 1,733 |
[
"hwchase17",
"langchain"
] | As most scientific papers are released not only as pdf, but also also source code (LaTeX), I propose adding a LaTeX Text Splitter.
I shall split in hierarchical order (e.g. by sections first, then subsections, headings, ...) | LaTeX Text Splitter | https://api.github.com/repos/langchain-ai/langchain/issues/1731/comments | 1 | 2023-03-17T09:51:15Z | 2023-03-18T02:39:19Z | https://github.com/langchain-ai/langchain/issues/1731 | 1,629,015,269 | 1,731 |
[
"hwchase17",
"langchain"
] | Please include ChatGPT Turbo's ChatOpenAI object to be passed as an LLM completion in the Summarizer chain.
_(from langchain.chat_models.openai import ChatOpenAI)_
for the following usage
`summary_chain = load_summarize_chain(llm, chain_type="map_reduce")
summarize_document_chain = AnalyzeDocumentChain(combine_... | Include ChatGPT Turbo model in the Chain (Summarization) | https://api.github.com/repos/langchain-ai/langchain/issues/1730/comments | 5 | 2023-03-17T09:21:12Z | 2023-09-28T16:11:08Z | https://github.com/langchain-ai/langchain/issues/1730 | 1,628,973,092 | 1,730 |
[
"hwchase17",
"langchain"
] | Is there anyway I can use my existing vector store that I already have on pinecone? I don't want to keep generating the embeddings because my documents have a lot of text in them.
I also want to link pinecone and the serpAPI, so that if the answer is not available in pinecone, I can browse the web for answers.
Is th... | Unable to add vector store and SerpAPI to agent | https://api.github.com/repos/langchain-ai/langchain/issues/1729/comments | 1 | 2023-03-17T07:42:56Z | 2023-08-24T16:14:35Z | https://github.com/langchain-ai/langchain/issues/1729 | 1,628,849,552 | 1,729 |
[
"hwchase17",
"langchain"
] | ```
import os, pdb
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter, TokenTextSplitter
from langchain.vectorstores import Milvus
from langchain.document_loaders import TextLoader
from langchain.embeddings import HuggingFaceEmbeddings
from langchai... | Refine Chain Error | https://api.github.com/repos/langchain-ai/langchain/issues/1724/comments | 5 | 2023-03-17T02:43:06Z | 2023-11-01T16:08:05Z | https://github.com/langchain-ai/langchain/issues/1724 | 1,628,593,372 | 1,724 |
[
"hwchase17",
"langchain"
] | the example notebook at https://github.com/hwchase17/langchain/blob/master/docs/modules/agents/agent_toolkits/sql_database.ipynb is broken at the following line.
``` python
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
```
It produces a `KeyError: ... | example sql_database toolkit agent notebook throws "KeyError" in create_sql_agent | https://api.github.com/repos/langchain-ai/langchain/issues/1721/comments | 4 | 2023-03-17T01:16:14Z | 2023-04-12T12:41:52Z | https://github.com/langchain-ai/langchain/issues/1721 | 1,628,532,635 | 1,721 |
[
"hwchase17",
"langchain"
] | https://github.com/hwchase17/langchain/blob/master/langchain/agents/agent_toolkits/sql/toolkit.py#L38
SqlDatabaseToolkit should have custom llm_chain field for QueryCheckerTool. This is causing issues when OpenAI is not available, as the QueryCheckerTool will automatically use OpenAI. | SqlDatabaseToolkit should have custom llm_chain for QueryCheckerTool | https://api.github.com/repos/langchain-ai/langchain/issues/1719/comments | 2 | 2023-03-17T00:12:47Z | 2023-09-18T16:23:20Z | https://github.com/langchain-ai/langchain/issues/1719 | 1,628,492,807 | 1,719 |
[
"hwchase17",
"langchain"
] | I noticed there is no support for stop sequences in the langchain API,
Is this some deliberate choice, or should I make a PR to add support for it? | No stop sequneces supported for OpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/1717/comments | 6 | 2023-03-16T20:05:04Z | 2023-09-28T16:11:13Z | https://github.com/langchain-ai/langchain/issues/1717 | 1,628,182,486 | 1,717 |
[
"hwchase17",
"langchain"
] | Hello, I've noticed that after the latest commit of @MthwRobinson there are two different modules to load Word documents, could they be unified in a single version? Also there are two notebooks that do almost the same thing.
[docx.py](https://github.com/hwchase17/langchain/blob/3c2468452284ee37b8a88a20b864255fa4385b... | Two different document loaders for Microsoft Word files | https://api.github.com/repos/langchain-ai/langchain/issues/1716/comments | 5 | 2023-03-16T18:57:09Z | 2023-05-17T16:18:06Z | https://github.com/langchain-ai/langchain/issues/1716 | 1,628,093,530 | 1,716 |
[
"hwchase17",
"langchain"
] | I was going through [Vectorstore Agent](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/vectorstore.html?highlight=vectorstore%20agent#vectorstore-agent) tutorial and I am facing issues with the `VectorStoreQAWithSourcesTool`.
Looking closely at the code https://github.com/hwchase17/langchai... | bug(QA with Sources): source parsing is not reliable | https://api.github.com/repos/langchain-ai/langchain/issues/1712/comments | 3 | 2023-03-16T15:47:53Z | 2023-03-31T15:41:59Z | https://github.com/langchain-ai/langchain/issues/1712 | 1,627,779,986 | 1,712 |
[
"hwchase17",
"langchain"
] | I have been performing tests on the following dataset (https://www.kaggle.com/datasets/peopledatalabssf/free-7-million-company-dataset) for a couple of days now. Yesterday and earlier agent had no problems with answering questions like:
- "list all companies starting with 'a'"
- "what is the company earliest founde... | performance of CSVAgent dropped significantly | https://api.github.com/repos/langchain-ai/langchain/issues/1710/comments | 1 | 2023-03-16T13:40:36Z | 2023-09-10T16:42:15Z | https://github.com/langchain-ai/langchain/issues/1710 | 1,627,497,863 | 1,710 |
[
"hwchase17",
"langchain"
] | I've just implemented the AsyncCallbackManager and handler, and everything works fine except for the fact I receive this warning
> /usr/local/lib/python3.10/site-packages/langchain/agents/agent.py:456: RuntimeWarning: coroutine 'AsyncCallbackManager.on_agent_action' was never awaited
> self.callback_manager.on_agen... | on_agent_action was never awaited | https://api.github.com/repos/langchain-ai/langchain/issues/1708/comments | 6 | 2023-03-16T11:50:17Z | 2023-03-20T18:33:18Z | https://github.com/langchain-ai/langchain/issues/1708 | 1,627,311,222 | 1,708 |
[
"hwchase17",
"langchain"
] | When using `ConversationSummaryMemory` or `ConversationSummaryBufferMemory`, I sometimes want to see the details of the summarization. I would like to add a parameter for displaying this information.
This feature can be easily added by introducing a `verbose` parameter to the `SummarizerMixin` class and setting its de... | Displaying details of summarization in `ConversationSummaryMemory` and `ConversationSummaryBufferMemory` | https://api.github.com/repos/langchain-ai/langchain/issues/1705/comments | 1 | 2023-03-16T06:55:24Z | 2023-09-10T16:42:20Z | https://github.com/langchain-ai/langchain/issues/1705 | 1,626,834,563 | 1,705 |
[
"hwchase17",
"langchain"
] | Looking at the [tracing](https://langchain.readthedocs.io/en/latest/tracing.html) docs, would be great if I could point the output at my own tracing backend using a portable/open-standard format.
As the tracing features are built out, would be amazing if an output option was just [OLTP using the Python SDK](https://... | Support OpenTelemetry for Tracing | https://api.github.com/repos/langchain-ai/langchain/issues/1704/comments | 2 | 2023-03-16T04:03:41Z | 2023-09-18T16:25:28Z | https://github.com/langchain-ai/langchain/issues/1704 | 1,626,671,239 | 1,704 |
[
"hwchase17",
"langchain"
] | I ask you to test mrkl agent prompt on different LLM. In my experience no LLM other than ones by OpenAI can handle mrkl prompt. I am but one man and make mistakes. I want someone to double check this claim. Bloom came close but it even it can't handle it. They all can't format response up to the standard. Langchain sta... | Testing ZeroShotAgent using different LLM other than OpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/1703/comments | 1 | 2023-03-16T03:51:09Z | 2023-08-24T16:14:46Z | https://github.com/langchain-ai/langchain/issues/1703 | 1,626,660,999 | 1,703 |
[
"hwchase17",
"langchain"
] | Currently it takes 10-15s to get response from OpenAI
I am using example similar to this https://langchain.readthedocs.io/en/latest/modules/agents/examples/agent_vectorstore.html
| Are there any ways to increase response speed? | https://api.github.com/repos/langchain-ai/langchain/issues/1702/comments | 22 | 2023-03-15T21:59:35Z | 2024-05-13T16:07:15Z | https://github.com/langchain-ai/langchain/issues/1702 | 1,626,345,845 | 1,702 |
[
"hwchase17",
"langchain"
] | This won't work, because your class needs runhouse. I would like to use it on my GPU Server so ist should not log in via ssh to it's own:
```
embeddings = SelfHostedEmbeddings(
model_load_fn=get_pipeline,
hardware="cuda",
model_reqs=["./", "torch", "transformers"],
inference_fn=inference_fn
)
... | No local GPU for self hosted embeddings | https://api.github.com/repos/langchain-ai/langchain/issues/1695/comments | 3 | 2023-03-15T16:41:37Z | 2023-10-08T16:08:12Z | https://github.com/langchain-ai/langchain/issues/1695 | 1,625,882,506 | 1,695 |
[
"hwchase17",
"langchain"
] | Sorry if this is a dumb questions but If a have a txt file with sentences separated by newlines how do i split by newlines to generate embeddings for each sentence | Quick question about splitter | https://api.github.com/repos/langchain-ai/langchain/issues/1694/comments | 2 | 2023-03-15T15:31:56Z | 2023-03-15T17:30:11Z | https://github.com/langchain-ai/langchain/issues/1694 | 1,625,759,946 | 1,694 |
[
"hwchase17",
"langchain"
] | I am using this example https://langchain.readthedocs.io/en/latest/modules/chat/examples/agent.html with my data
If I am not using Chat (ChatOpenAI) it works without issue
So probably some issue how you handling output
```
Entering new AgentExecutor chain...
DEBUG:Chroma:time to pre process our knn query: 1.43... | Bug with parsing | https://api.github.com/repos/langchain-ai/langchain/issues/1688/comments | 2 | 2023-03-15T11:32:57Z | 2023-09-10T16:42:25Z | https://github.com/langchain-ai/langchain/issues/1688 | 1,625,343,754 | 1,688 |
[
"hwchase17",
"langchain"
] | With the rise of multi-modal models (GPT-4 announced today), and how popular LangChain is among the research community, we should be ready for new modalities. Ideally, the user should be able to do something like:
```python
vllm = OpenAI(model_name='gpt-4', max_tokens=through_the_roof)
prompt = PromptTemplate(
... | [Feature suggestion] Multi-modal Langchain | https://api.github.com/repos/langchain-ai/langchain/issues/1677/comments | 1 | 2023-03-15T01:40:31Z | 2023-03-17T18:00:16Z | https://github.com/langchain-ai/langchain/issues/1677 | 1,624,571,606 | 1,677 |
[
"hwchase17",
"langchain"
] | I was attempting to split this volume:
https://terrorgum.com/tfox/books/introductionto3dgameprogrammingwithdirectx12.pdf
using
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000
chunk_overlap = 10,
length_function = len,
separators="\n\n"
)
On page ... | RecursiveCharacterTextSplitter.split_text can enter infinite recursive loop | https://api.github.com/repos/langchain-ai/langchain/issues/1663/comments | 7 | 2023-03-14T17:29:33Z | 2023-11-03T16:08:27Z | https://github.com/langchain-ai/langchain/issues/1663 | 1,623,978,467 | 1,663 |
[
"hwchase17",
"langchain"
] | Google has just announced the PaLM API [https://developers.googleblog.com/2023/03/announcing-palm-api-and-makersuite.html](https://developers.googleblog.com/2023/03/announcing-palm-api-and-makersuite.html)!!
| Google Cloud PaLM API integration | https://api.github.com/repos/langchain-ai/langchain/issues/1661/comments | 3 | 2023-03-14T14:38:18Z | 2023-09-28T16:11:18Z | https://github.com/langchain-ai/langchain/issues/1661 | 1,623,618,445 | 1,661 |
[
"hwchase17",
"langchain"
] | Hi. I am trying to generate a customized prompt where I need to escape the curly-braces. Whenever I use curly braces in my prompt, it is being taken as place holders.
So, can you please suggest how to escape the curly braces in the prompts? | How to escape curly-braces "{}" in a customized prompt? | https://api.github.com/repos/langchain-ai/langchain/issues/1660/comments | 9 | 2023-03-14T12:59:42Z | 2024-07-28T09:30:47Z | https://github.com/langchain-ai/langchain/issues/1660 | 1,623,430,725 | 1,660 |
[
"hwchase17",
"langchain"
] | Now Microsoft have released gpt-35-turbo, please can AzureOpenAI be added to chat_models.
Thanks | Add AzureOpenAI for chat_models | https://api.github.com/repos/langchain-ai/langchain/issues/1659/comments | 1 | 2023-03-14T12:03:16Z | 2023-03-20T12:41:19Z | https://github.com/langchain-ai/langchain/issues/1659 | 1,623,336,280 | 1,659 |
[
"hwchase17",
"langchain"
] | I am having trouble using langchain with llama-index (gpt-index). I don't understand what is happening on the langchain side.
When I use OpenAIChat as LLM then sometimes with some user queries I get this error:
```
raise ValueError(f"Could not parse LLM output: `{llm_output}`")
ValueError: Could not parse LLM out... | ValueError: Could not parse LLM output | https://api.github.com/repos/langchain-ai/langchain/issues/1657/comments | 13 | 2023-03-14T09:01:11Z | 2024-01-30T00:52:57Z | https://github.com/langchain-ai/langchain/issues/1657 | 1,623,023,032 | 1,657 |
[
"hwchase17",
"langchain"
] | I am trying to follow the example from this [URL](https://langchain.readthedocs.io/en/latest/modules/indexes/chain_examples/question_answering.html), but I am getting the above error. What might be wrong?
## Environment
OS: Windows 11
Python: 3.9
| AttributeError: 'VectorStoreIndexWrapper' object has no attribute 'similarity_search' | https://api.github.com/repos/langchain-ai/langchain/issues/1655/comments | 5 | 2023-03-14T07:04:19Z | 2023-09-29T16:09:57Z | https://github.com/langchain-ai/langchain/issues/1655 | 1,622,855,759 | 1,655 |
[
"hwchase17",
"langchain"
] | With the newly released ChatOpenAI model, the completion output is being cut off randomly in between
For example I used the below input
Write me an essay on Pune
I got this output
Pune, also known as Poona, is a city located in the western Indian state of Maharashtra. It is the second-largest city in the s... | Output cutoff with ChatOpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/1652/comments | 6 | 2023-03-14T05:37:02Z | 2023-07-07T08:03:54Z | https://github.com/langchain-ai/langchain/issues/1652 | 1,622,767,469 | 1,652 |
[
"hwchase17",
"langchain"
] | SQL Database Agent can't adapt to the turbo model,there is a bug in get_action_and_input function.
this is the code of get_action_and_input for current version:
```python
# file:langchain/agents/mrkl/base.py
def get_action_and_input(llm_output: str) -> Tuple[str, str]:
"""Parse out the action and input from ... | SQL Database Agent can't adapt to the turbo model,there is a bug in get_action_and_input function | https://api.github.com/repos/langchain-ai/langchain/issues/1649/comments | 3 | 2023-03-14T02:42:12Z | 2023-05-12T05:00:41Z | https://github.com/langchain-ai/langchain/issues/1649 | 1,622,625,055 | 1,649 |
[
"hwchase17",
"langchain"
] | The conversational agent at /langchain/agents/conversational/base.py looks to have a regex that isn't good for pulling out multiline Action Inputs, whereas the
The mrkl agent at /langchain/agents/mrkl/base.py has a good regex for pulling out multiline Action Inputs
When I switched the regex FROM the top one at /lan... | conversational/agent has a regex not good for multiline Action Inputs coming from the LLM | https://api.github.com/repos/langchain-ai/langchain/issues/1645/comments | 4 | 2023-03-13T20:58:38Z | 2023-08-20T16:08:47Z | https://github.com/langchain-ai/langchain/issues/1645 | 1,622,249,283 | 1,645 |
[
"hwchase17",
"langchain"
] | Looks like `BaseLLM` supports caching (via `langchain.llm_cache`), but `BaseChatModel` does not. | Add caching support to BaseChatModel | https://api.github.com/repos/langchain-ai/langchain/issues/1644/comments | 9 | 2023-03-13T20:34:16Z | 2023-07-04T10:06:20Z | https://github.com/langchain-ai/langchain/issues/1644 | 1,622,218,946 | 1,644 |
[
"hwchase17",
"langchain"
] | Can the summarization chain be used with ChatGPT's API, `gpt-3.5-turbo`? I have tried the following two code snippets, but they result in this error.
```
openai.error.InvalidRequestError: This model's maximum context length is 4097 tokens. However, your messages resulted in 6063 tokens. Please reduce the length of ... | ChatGPT's API model, gpt-3.5-turbo, doesn't appear to work for summarization tasks | https://api.github.com/repos/langchain-ai/langchain/issues/1643/comments | 11 | 2023-03-13T19:54:13Z | 2023-04-23T08:30:14Z | https://github.com/langchain-ai/langchain/issues/1643 | 1,622,162,962 | 1,643 |
[
"hwchase17",
"langchain"
] | Hey guys,
I'm trying to use langchain because the Tool class is so handy and initialize_agent works well with it, but I am having trouble finding any documentation that allows me to run this self-hosted locally. Everything seems to be remote, but I have a system that I know is capable of what I'm trying to do.
Is... | langchain.llms SelfHostedPipeline and SelfHostedHuggingFaceLLM | https://api.github.com/repos/langchain-ai/langchain/issues/1639/comments | 4 | 2023-03-13T17:11:12Z | 2023-10-14T20:14:17Z | https://github.com/langchain-ai/langchain/issues/1639 | 1,621,910,729 | 1,639 |
[
"hwchase17",
"langchain"
] | https://github.com/hwchase17/langchain/blob/cb646082baa173fdee7f2b1e361be368acef4e7e/langchain/document_loaders/googledrive.py#L120
Suggestion: Include optional param `includeItemsFromAllDrives` when calling `service.files().list()`
Reference: https://stackoverflow.com/questions/65388539/using-python-i-cant-access-... | GoogleDriveLoader not loading docs from Share Drives | https://api.github.com/repos/langchain-ai/langchain/issues/1634/comments | 0 | 2023-03-13T15:03:55Z | 2023-04-08T15:46:57Z | https://github.com/langchain-ai/langchain/issues/1634 | 1,621,682,210 | 1,634 |
[
"hwchase17",
"langchain"
] | Hi, first off, I just want to say that I have been following this from the start, almost, and I see the amazing work you put in. It's an awesome project, well done!
Now that I finally have some time to dive in myself I'm hoping someone can help me bootstrap an idea. I want to chain chatgpt to Codex so that Chat will... | Chaining Chat to Codex | https://api.github.com/repos/langchain-ai/langchain/issues/1631/comments | 3 | 2023-03-13T13:00:10Z | 2023-08-29T18:08:10Z | https://github.com/langchain-ai/langchain/issues/1631 | 1,621,441,455 | 1,631 |
[
"hwchase17",
"langchain"
] | Dataframes (df) are generic containers to store different data-structures and pandas (or CSV) agent help manipulate dfs effectively. But current langchain implementation requires python3.9 to work with pandas agent because of the following invocation:
https://github.com/hwchase17/langchain/blob/6e98ab01e1648924db3bf... | Python3.8 support for pandas agent | https://api.github.com/repos/langchain-ai/langchain/issues/1623/comments | 1 | 2023-03-13T04:01:58Z | 2023-03-15T02:44:00Z | https://github.com/langchain-ai/langchain/issues/1623 | 1,620,711,203 | 1,623 |
[
"hwchase17",
"langchain"
] | Whereas it should be possible to filter by metadata :
- ```langchain.vectorstores.chroma.similarity_search``` takes a ```filter``` input parameter but do not forward it to ```langchain.vectorstores.chroma.similarity_search_with_score```
- ```langchain.vectorstores.chroma.similarity_search_by_vector``` don't take thi... | ChromaDB does not support filtering when using ```similarity_search``` or ```similarity_search_by_vector``` | https://api.github.com/repos/langchain-ai/langchain/issues/1619/comments | 3 | 2023-03-12T23:58:13Z | 2023-09-27T16:13:06Z | https://github.com/langchain-ai/langchain/issues/1619 | 1,620,559,206 | 1,619 |
[
"hwchase17",
"langchain"
] | Hi!
Unstructured has support for providing in-memory text. Would be a great addition as currently, developers have to write and then read from a file if they want to load documents from memory.
Wouldn't mind opening the PR myself but want to make sure its a wanted feature before I get on it. | Allow unstructured loaders to accept in-memory text | https://api.github.com/repos/langchain-ai/langchain/issues/1618/comments | 7 | 2023-03-12T23:09:58Z | 2024-03-18T10:11:03Z | https://github.com/langchain-ai/langchain/issues/1618 | 1,620,546,553 | 1,618 |
[
"hwchase17",
"langchain"
] | The @microsoft team used LangChain to guide [Visual ChatGPT](https://arxiv.org/pdf/2303.04671.pdf).
Here's the architecture of Visual ChatGPT:
<img width="619" alt="screen" src="https://user-images.githubusercontent.com/6625584/230680492-7d737584-c56b-43b2-8240-ed02aaf9ac00.png">
Think of **Prompt Manager** as... | Visual ChatGPT | https://api.github.com/repos/langchain-ai/langchain/issues/1607/comments | 2 | 2023-03-12T02:38:03Z | 2023-09-18T16:23:25Z | https://github.com/langchain-ai/langchain/issues/1607 | 1,620,211,493 | 1,607 |
[
"hwchase17",
"langchain"
] | The new [blog post](https://github.com/huggingface/blog/blob/main/trl-peft.md) for implementing LoRA + RLHF is great. Would appreciate if the example scripts are public!
3 scripts mentioned in the blog posts:
[Script](https://github.com/lvwerra/trl/blob/peft-gpt-neox-20b/examples/sentiment/scripts/gpt-neox-20b_pef... | trl-peft example scripts not visible to public | https://api.github.com/repos/langchain-ai/langchain/issues/1606/comments | 3 | 2023-03-11T22:57:53Z | 2023-09-10T21:07:16Z | https://github.com/langchain-ai/langchain/issues/1606 | 1,620,171,008 | 1,606 |
[
"hwchase17",
"langchain"
] | Wanted to leave some observations similar to the chain of thought *smirk* that was mentioned over here for [JSON agents](https://github.com/hwchase17/langchain/issues/1409).
You can copy this snippet to test for yourself (Mine is in Colab atm)
```
# Install dependencies
!pip install huggingface_hub cohere --quiet... | Observations and Limitations of API Tools | https://api.github.com/repos/langchain-ai/langchain/issues/1603/comments | 2 | 2023-03-11T21:09:46Z | 2023-11-08T11:32:09Z | https://github.com/langchain-ai/langchain/issues/1603 | 1,620,146,572 | 1,603 |
[
"hwchase17",
"langchain"
] | In the current `ConversationBufferWindowMemory`, only the last `k` interactions are kept while the conversation history prior to that is deleted.
A memory similar to this, which keeps all conversation history below `max_token_limit` and deletes conversation history from the beginning when it exceeds the limit, could b... | Idea: A memory similar to ConversationBufferWindowMemory but utilizing token length | https://api.github.com/repos/langchain-ai/langchain/issues/1598/comments | 3 | 2023-03-11T12:05:23Z | 2023-09-10T16:42:36Z | https://github.com/langchain-ai/langchain/issues/1598 | 1,619,983,645 | 1,598 |
[
"hwchase17",
"langchain"
] | I have a use case where I want to be able to create multiple indices of the same set of documents, essentially each index will be built based on some criteria so that I can query from the right set of documents. (I am using FAISS at the moment which does not have great options for filtering within one giant index so th... | Add support for creating index by passing embeddings explicitly | https://api.github.com/repos/langchain-ai/langchain/issues/1597/comments | 1 | 2023-03-11T10:41:51Z | 2023-08-24T16:14:51Z | https://github.com/langchain-ai/langchain/issues/1597 | 1,619,963,356 | 1,597 |
[
"hwchase17",
"langchain"
] | The SemanticSimilarityExampleSelector doesn't behave as expected. The SemanticSimilarityExampleSelector is supposed to select examples based on which examples are most similar to the inputs.
The same issue is found in the [official documentation](https://langchain.readthedocs.io/en/latest/modules/prompts/examples/ex... | bug with SemanticSimilarityExampleSelector | https://api.github.com/repos/langchain-ai/langchain/issues/1596/comments | 2 | 2023-03-11T08:52:10Z | 2023-09-18T16:23:35Z | https://github.com/langchain-ai/langchain/issues/1596 | 1,619,936,437 | 1,596 |
[
"hwchase17",
"langchain"
] | I've been trying things out from the [docs](https://langchain.readthedocs.io/en/latest/modules/memory/getting_started.html) and encountered this error when trying to import the following:
`from langchain.memory import ChatMessageHistory`
ImportError: cannot import name 'AIMessage' from 'langchain.schema'
`from lan... | ImportError: cannot import name 'AIMessage' from 'langchain.schema' | https://api.github.com/repos/langchain-ai/langchain/issues/1595/comments | 3 | 2023-03-11T05:09:26Z | 2023-03-14T15:57:49Z | https://github.com/langchain-ai/langchain/issues/1595 | 1,619,886,185 | 1,595 |
[
"hwchase17",
"langchain"
] | null | Allow encoding such as "encoding='utf8' " to be passed into TextLoader if the file is not the default system encoding. | https://api.github.com/repos/langchain-ai/langchain/issues/1593/comments | 9 | 2023-03-11T00:25:28Z | 2024-05-13T16:07:22Z | https://github.com/langchain-ai/langchain/issues/1593 | 1,619,793,517 | 1,593 |
[
"hwchase17",
"langchain"
] | `add_texts` function takes `texts` which are meant to be added to the OpenSearch vector domain.
These texts are then passed to compute the embeddings using following code,
```
embeddings = [
self.embedding_function.embed_documents(list(text))[0] for text in texts
]
```
which doesn't create expected e... | add_texts function in OpenSearchVectorSearch class doesn't create embeddings as expected | https://api.github.com/repos/langchain-ai/langchain/issues/1592/comments | 2 | 2023-03-11T00:18:18Z | 2023-09-18T16:23:41Z | https://github.com/langchain-ai/langchain/issues/1592 | 1,619,789,882 | 1,592 |
[
"hwchase17",
"langchain"
] | Looks like a similar issue as what OpenAI had when the model was introduced(arguments like best_of, logprobs weren't supported). | AzureOpenAI doesn't work with GPT 3.5 Turbo deployed models | https://api.github.com/repos/langchain-ai/langchain/issues/1591/comments | 18 | 2023-03-11T00:13:29Z | 2023-10-25T16:10:02Z | https://github.com/langchain-ai/langchain/issues/1591 | 1,619,787,442 | 1,591 |
[
"hwchase17",
"langchain"
] | The example in the [documentation](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/json.html) doesn't state how to use them. I have a json [file](https://gist.github.com/Smyja/aaaeb3ef6f2af68c27f0e1ea42bfb52d) that is basically a list of dictionaries, how can i use the tools to access the text ... | How to use JsonListKeysTool and JsonGetValueTool for json agent | https://api.github.com/repos/langchain-ai/langchain/issues/1589/comments | 1 | 2023-03-10T21:06:13Z | 2023-09-10T16:42:51Z | https://github.com/langchain-ai/langchain/issues/1589 | 1,619,623,956 | 1,589 |
[
"hwchase17",
"langchain"
] | version: 0.0.106
OpenAI seems to no longer support max_retries.
https://platform.openai.com/docs/api-reference/completions/create?lang=python
| ERROR:root:'OpenAIEmbeddings' object has no attribute 'max_retries' | https://api.github.com/repos/langchain-ai/langchain/issues/1585/comments | 10 | 2023-03-10T20:12:07Z | 2023-04-14T05:13:51Z | https://github.com/langchain-ai/langchain/issues/1585 | 1,619,559,028 | 1,585 |
[
"hwchase17",
"langchain"
] | I'm wondering if folks have thought about easy ways to upload a file system as a prompt, I know they can exceed the char limit but it'd be very useful for applications like Github Copilot where I'd like to upload my entire codebase and even installed dependencies as background before prompting for specific actions like... | Upload filesystem | https://api.github.com/repos/langchain-ai/langchain/issues/1584/comments | 0 | 2023-03-10T19:44:55Z | 2023-03-10T20:03:33Z | https://github.com/langchain-ai/langchain/issues/1584 | 1,619,529,926 | 1,584 |
[
"hwchase17",
"langchain"
] | It would be nice if we could at least get the final SQL and results from the query like we do for SQLDatabaseChain.
I'll try to put together a pull request. | Allow SQLDatabaseSequentialChain to return some Intermedite steps | https://api.github.com/repos/langchain-ai/langchain/issues/1582/comments | 1 | 2023-03-10T17:11:32Z | 2023-08-24T16:14:57Z | https://github.com/langchain-ai/langchain/issues/1582 | 1,619,320,010 | 1,582 |
[
"hwchase17",
"langchain"
] | There are [rumors](https://twitter.com/transitive_bs/status/1628118163874516992) that GPT-4 (code name DV?) will feature a whopping 32k max context length. It's time to build abstractions for new token lengths.
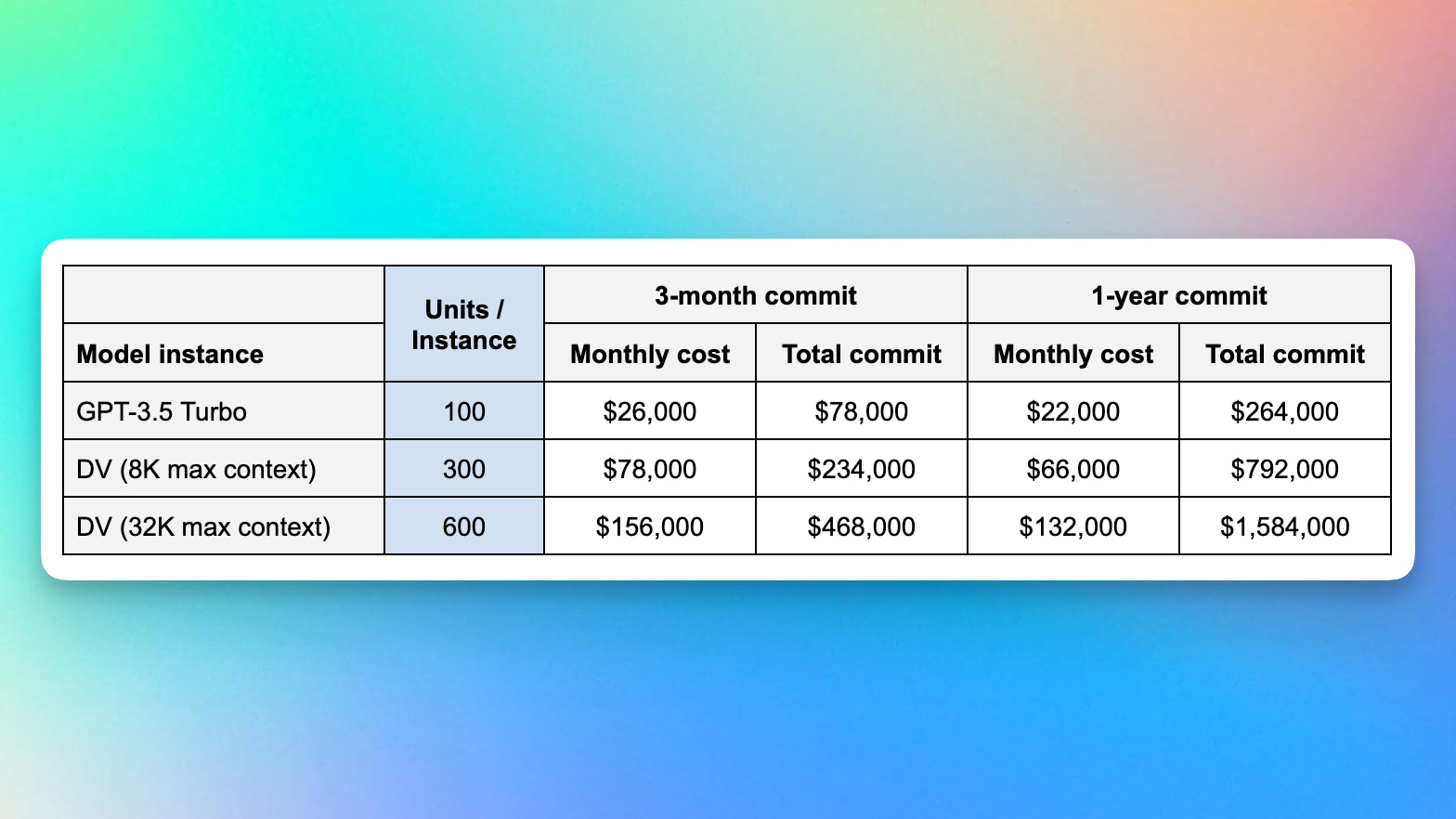 | Token Lengths | https://api.github.com/repos/langchain-ai/langchain/issues/1580/comments | 2 | 2023-03-10T15:10:02Z | 2023-04-07T21:17:39Z | https://github.com/langchain-ai/langchain/issues/1580 | 1,619,135,778 | 1,580 |
[
"hwchase17",
"langchain"
] | SQLAlchemy v2 is out and has important new features.
I suggest relaxing the dependency requirement from `SQLAlchemy = "^1"` to `SQLAlchemy = ">=1.0, <3.0"`
| Missing support for SQLAlchemy v2 | https://api.github.com/repos/langchain-ai/langchain/issues/1578/comments | 2 | 2023-03-10T09:12:13Z | 2023-03-17T04:55:37Z | https://github.com/langchain-ai/langchain/issues/1578 | 1,618,619,296 | 1,578 |
[
"hwchase17",
"langchain"
] | It's currently not possible to pass a custom deployment name as model/deployment names are hard-coded as "text-embedding-ada-002" in variables within the class definition.
In Azure OpenAI, the deployment names can be customized and that doesn't work with OpenAIEmbeddings class.
There is proper Azure support for L... | Missing Azure OpenAI support for "OpenAIEmbeddings" | https://api.github.com/repos/langchain-ai/langchain/issues/1577/comments | 8 | 2023-03-10T09:06:05Z | 2023-09-27T16:13:11Z | https://github.com/langchain-ai/langchain/issues/1577 | 1,618,610,444 | 1,577 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.