
url stringlengths 62 66 | repository_url stringclasses 1
value | labels_url stringlengths 76 80 | comments_url stringlengths 71 75 | events_url stringlengths 69 73 | html_url stringlengths 50 56 | id int64 377M 2.15B | node_id stringlengths 18 32 | number int64 1 29.2k | title stringlengths 1 487 | user dict | labels list | state stringclasses 2
values | locked bool 2
classes | assignee dict | assignees list | comments list | created_at int64 1.54k 1.71k | updated_at int64 1.54k 1.71k | closed_at int64 1.54k 1.71k ⌀ | author_association stringclasses 4
values | active_lock_reason stringclasses 2
values | body stringlengths 0 234k ⌀ | reactions dict | timeline_url stringlengths 71 75 | state_reason stringclasses 3
values | draft bool 2
classes | pull_request dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/2112 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2112/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2112/comments | https://api.github.com/repos/huggingface/transformers/issues/2112/events | https://github.com/huggingface/transformers/issues/2112 | 535,053,663 | MDU6SXNzdWU1MzUwNTM2NjM= | 2,112 | XLM model masked word prediction Double Language | {
"login": "valdrox",
"id": 13651676,
"node_id": "MDQ6VXNlcjEzNjUxNjc2",
"avatar_url": "https://avatars.githubusercontent.com/u/13651676?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/valdrox",
"html_url": "https://github.com/valdrox",
"followers_url": "https://api.github.com/users/valdro... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I am trying to generate in-context word translations.
For instance, if the target language is french and "well" is the word to translate.
- I walked to the well. -> the translation for "well" should be "puit"
- I am doing well.... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2112/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2112/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2111 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2111/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2111/comments | https://api.github.com/repos/huggingface/transformers/issues/2111/events | https://github.com/huggingface/transformers/issues/2111 | 534,983,409 | MDU6SXNzdWU1MzQ5ODM0MDk= | 2,111 | Could not run run_ner.py based on XLNET model | {
"login": "Vitvicky",
"id": 4017405,
"node_id": "MDQ6VXNlcjQwMTc0MDU=",
"avatar_url": "https://avatars.githubusercontent.com/u/4017405?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Vitvicky",
"html_url": "https://github.com/Vitvicky",
"followers_url": "https://api.github.com/users/Vitvi... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"What is ELnet model? The list of models that can be used for NER are: BERT, RoBERTa, DistilBERT (only for English text) and CamemBERT (only for French text).\r\n\r\n> ## Questions & Help\r\n> Hello everyone, when I try to use ELnet model for the NER task through run_ner.py, it shows the following problem:\r\n> \r... | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
Hello everyone, when I try to use ELnet model for the NER task through run_ner.py, it shows the following problem:
__init__() got an unexpected keyword argument 'do_lower_case'
So is it some problem in the modeling_utils.py? Thanks for someone's response!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2111/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2111/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2110 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2110/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2110/comments | https://api.github.com/repos/huggingface/transformers/issues/2110/events | https://github.com/huggingface/transformers/issues/2110 | 534,914,146 | MDU6SXNzdWU1MzQ5MTQxNDY= | 2,110 | unable to load the downloaded BERT model offline in local machine . could not find config.json and Error no file named ['pytorch_model.bin', 'tf_model.h5', 'model.ckpt.index'] | | {
"login": "AjitAntony",
"id": 46282348,
"node_id": "MDQ6VXNlcjQ2MjgyMzQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/46282348?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AjitAntony",
"html_url": "https://github.com/AjitAntony",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, you're downloading one of the original implementation BERT models, which is in TensorFlow and you are trying to load it into one of our Pytorch models. \r\n\r\nYou can either download one of our checkpoints hosted on our S3 with:\r\n\r\n```py\r\nfrom transformers import BertForMaskedLM\r\n\r\nmodel = BertForMa... | 1,575 | 1,603 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I have downloaded the bert model [from the link in bert github page](https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip) offline but unable to load the model offline .
from transformers import *
model =... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2110/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2110/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2109 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2109/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2109/comments | https://api.github.com/repos/huggingface/transformers/issues/2109/events | https://github.com/huggingface/transformers/issues/2109 | 534,905,762 | MDU6SXNzdWU1MzQ5MDU3NjI= | 2,109 | Error in TFBertForSequenceClassification | {
"login": "emillykkejensen",
"id": 8842355,
"node_id": "MDQ6VXNlcjg4NDIzNTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8842355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/emillykkejensen",
"html_url": "https://github.com/emillykkejensen",
"followers_url": "https://api.g... | [] | closed | false | null | [] | [
"The code line that loads the BERT configuration is surely correct:\r\n```\r\n> config = transformers.BertConfig.from_json_file('./bertlm_model/config.json')\r\n```\r\nBut, for what concern the loading of a fine-tuned BERT model on a custom dataset, I think it's not correct the line you've used. Can you try with th... | 1,575 | 1,576 | 1,576 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): Multi-lingual
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2109/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/transformers/issues/2109/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2108 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2108/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2108/comments | https://api.github.com/repos/huggingface/transformers/issues/2108/events | https://github.com/huggingface/transformers/issues/2108 | 534,837,546 | MDU6SXNzdWU1MzQ4Mzc1NDY= | 2,108 | I am running bert fine tuning with cnnbase model but my project stops at loss.backward() without any prompt in cmd. | {
"login": "FOXaaFOX",
"id": 15794343,
"node_id": "MDQ6VXNlcjE1Nzk0MzQz",
"avatar_url": "https://avatars.githubusercontent.com/u/15794343?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FOXaaFOX",
"html_url": "https://github.com/FOXaaFOX",
"followers_url": "https://api.github.com/users/FOX... | [] | closed | false | null | [] | [
"the step1 logits :\r\nlogits tensor([[ 0.8831, -0.0368, -0.2206, -2.3484, -1.3595]], device='cuda:1',\r\n grad_fn=<AddmmBackward>)\r\nthe step1 loss:\r\ntensor(1.5489, device='cuda:1', grad_fn=NllLossBackward>)\r\nbut why can't loss.backward()?"
] | 1,575 | 1,576 | 1,576 | NONE | null | My aim is to make a five-category text classification
I am running transformers fine tuning bert with `cnnbase` model but my program stops at `loss.backward()` without any prompt in `cmd`.
I debug find that the program stop at the loss.backward line without any error prompt
My program runs successfully in `rn... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2108/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2108/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2107 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2107/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2107/comments | https://api.github.com/repos/huggingface/transformers/issues/2107/events | https://github.com/huggingface/transformers/pull/2107 | 534,829,152 | MDExOlB1bGxSZXF1ZXN0MzUwNjMzNDQ5 | 2,107 | create encoder attention mask from shape of hidden states | {
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/follower... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2107?src=pr&el=h1) Report\n> Merging [#2107](https://codecov.io/gh/huggingface/transformers/pull/2107?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0cb163865a4c761c226b151283309eedb2b1ca4d?src=pr&el=desc) will **i... | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | As noted by @efeiefei (#1770) we currently create masks on the encoder hidden states (when they're not provided) based on the shape of the inputs to the decoder. This is obviously wrong; sequences can be of different lengths. We now create the encoder attention mask based on the `batch_size` and `sequence_length` of th... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2107/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2107/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2107",
"html_url": "https://github.com/huggingface/transformers/pull/2107",
"diff_url": "https://github.com/huggingface/transformers/pull/2107.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2107.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2106 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2106/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2106/comments | https://api.github.com/repos/huggingface/transformers/issues/2106/events | https://github.com/huggingface/transformers/issues/2106 | 534,815,183 | MDU6SXNzdWU1MzQ4MTUxODM= | 2,106 | RobertaTokenizer runs slowly after add _tokens | {
"login": "fatmelon",
"id": 9691826,
"node_id": "MDQ6VXNlcjk2OTE4MjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9691826?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fatmelon",
"html_url": "https://github.com/fatmelon",
"followers_url": "https://api.github.com/users/fatme... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, I've done a short study and I confirm the behavior you see.\r\nI've proposed a simple PR attached that gives interesting results and quite important speed improvement in any case.\r\nTo be discussed!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be close... | 1,575 | 1,582 | 1,582 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi, I use RobertaTokenizer like this:
```python
tokenizer = RobertaTokenizer.from_pretrained(FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case)
tokenizer.add_tokens([x.strip() for x in open('add_tokens.txt').readlines()])
```
... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2106/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2106/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2105 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2105/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2105/comments | https://api.github.com/repos/huggingface/transformers/issues/2105/events | https://github.com/huggingface/transformers/pull/2105 | 534,684,901 | MDExOlB1bGxSZXF1ZXN0MzUwNTE1Mjkx | 2,105 | Some bug in using eval_all_checkpoints | {
"login": "nike00811",
"id": 12585244,
"node_id": "MDQ6VXNlcjEyNTg1MjQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12585244?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nike00811",
"html_url": "https://github.com/nike00811",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2105?src=pr&el=h1) Report\n> Merging [#2105](https://codecov.io/gh/huggingface/transformers/pull/2105?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0cb163865a4c761c226b151283309eedb2b1ca4d?src=pr&el=desc) will **n... | 1,575 | 1,583 | 1,583 | NONE | null | when using --eval_all_checkpoints
checkpoints will find a pytorch_model.bin just under output_dir
when calling evaluate(args, model, tokenizer, prefix=global_step) will get a FileNotFoundError | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2105/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2105/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2105",
"html_url": "https://github.com/huggingface/transformers/pull/2105",
"diff_url": "https://github.com/huggingface/transformers/pull/2105.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2105.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/2104 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2104/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2104/comments | https://api.github.com/repos/huggingface/transformers/issues/2104/events | https://github.com/huggingface/transformers/issues/2104 | 534,663,265 | MDU6SXNzdWU1MzQ2NjMyNjU= | 2,104 | Having trouble reproducing SQuAD 2.0 results using ALBERT v2 models | {
"login": "shuaihuaiyi",
"id": 14048129,
"node_id": "MDQ6VXNlcjE0MDQ4MTI5",
"avatar_url": "https://avatars.githubusercontent.com/u/14048129?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shuaihuaiyi",
"html_url": "https://github.com/shuaihuaiyi",
"followers_url": "https://api.github.com/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"What GPU(s) and hyperparameters are you using?\r\n\r\nSpecifically:\r\n--learning_rate ?\r\n--per_gpu_train_batch_size ?\r\n--gradient_accumulation_steps ?\r\n--warmup_steps ?\r\n\r\nI'm on my third xxlarge-v1 fine-tune, ~23 hours each epoch plus eval on 2x NVIDIA 1080Ti. Results are relatively good, best of all ... | 1,575 | 1,584 | 1,584 | NONE | null | ## ❓ Questions & Help
I tried to finetune ALBERT v2 models on SQuAD 2.0, but sometimes the loss doesn't decrease and performance on dev set is low. The problem may happen when using `albert-large-v2` and `albert-xlarge-v2` in my case. Any suggestions?
. Is there any way to encode the whitespaces as well during tokenization? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2103/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2103/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2102 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2102/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2102/comments | https://api.github.com/repos/huggingface/transformers/issues/2102/events | https://github.com/huggingface/transformers/issues/2102 | 534,619,400 | MDU6SXNzdWU1MzQ2MTk0MDA= | 2,102 | How to pretrain BERT whole word masking (wwm) model? | {
"login": "mralexis1",
"id": 53451708,
"node_id": "MDQ6VXNlcjUzNDUxNzA4",
"avatar_url": "https://avatars.githubusercontent.com/u/53451708?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mralexis1",
"html_url": "https://github.com/mralexis1",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Any ideas on whether this will be included sooner or later?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,584 | 1,584 | NONE | null | ## 🚀 Feature
Code to pretrain BERT whole word masking (wwm) model
## Motivation
WWM offers better performance, but the current codebase doesn't seem to support this feature.
## Additional context
Related i #1352 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2102/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2102/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2101 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2101/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2101/comments | https://api.github.com/repos/huggingface/transformers/issues/2101/events | https://github.com/huggingface/transformers/pull/2101 | 534,617,688 | MDExOlB1bGxSZXF1ZXN0MzUwNDY1OTYx | 2,101 | :bug: #2096 in tokenizer.decode, adds a space after special tokens for string format | {
"login": "mandubian",
"id": 77193,
"node_id": "MDQ6VXNlcjc3MTkz",
"avatar_url": "https://avatars.githubusercontent.com/u/77193?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mandubian",
"html_url": "https://github.com/mandubian",
"followers_url": "https://api.github.com/users/mandubian/... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2101?src=pr&el=h1) Report\n> Merging [#2101](https://codecov.io/gh/huggingface/transformers/pull/2101?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0cb163865a4c761c226b151283309eedb2b1ca4d?src=pr&el=desc) will **d... | 1,575 | 1,576 | 1,576 | NONE | null | This correction is cosmetic to correct the observed formatting issue.
No test was implemented because ideally composition of functions `encode.decode` should in theory return the original sentence. Yet there are some space strip (and lower-casing) in code so it's not certain to return exactly the original sentence wit... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2101/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2101/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2101",
"html_url": "https://github.com/huggingface/transformers/pull/2101",
"diff_url": "https://github.com/huggingface/transformers/pull/2101.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2101.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2100 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2100/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2100/comments | https://api.github.com/repos/huggingface/transformers/issues/2100/events | https://github.com/huggingface/transformers/issues/2100 | 534,613,964 | MDU6SXNzdWU1MzQ2MTM5NjQ= | 2,100 | Unclear how to decode a model's output | {
"login": "George3d6",
"id": 23587658,
"node_id": "MDQ6VXNlcjIzNTg3NjU4",
"avatar_url": "https://avatars.githubusercontent.com/u/23587658?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/George3d6",
"html_url": "https://github.com/George3d6",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"DistilBERT as any BERT is a Transformer encoder so it encodes a sequence of tokens into a vector in the embedding space. It doesn't return a sequence of tokens.\r\n\r\nThe output of the model is `return output # last-layer hidden-state, (all hidden_states), (all attentions)` https://github.com/huggingface/transfor... | 1,575 | 1,706 | 1,575 | NONE | null | ## Unclear how to decode a model's output
Hello, after digging through the docs for about an hour it's still rather unclear to me how one is supposed to decode a model's output.
Using the following code:
```
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2100/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2100/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2099 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2099/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2099/comments | https://api.github.com/repos/huggingface/transformers/issues/2099/events | https://github.com/huggingface/transformers/issues/2099 | 534,548,934 | MDU6SXNzdWU1MzQ1NDg5MzQ= | 2,099 | which special token is used to predict the score in roberta? | {
"login": "tzhxs",
"id": 30310982,
"node_id": "MDQ6VXNlcjMwMzEwOTgy",
"avatar_url": "https://avatars.githubusercontent.com/u/30310982?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tzhxs",
"html_url": "https://github.com/tzhxs",
"followers_url": "https://api.github.com/users/tzhxs/follow... | [] | closed | false | null | [] | [
"Can you give some more information? It's not clear what you mean by \"score\". The special classification token for RoBERTa is `<s>`.",
"Thanks!",
"@tzhxs If that's everything you need, please close this topic.",
"ok"
] | 1,575 | 1,576 | 1,576 | NONE | null | In bert, we use the embedding of <cls> to predict the score, how about the roberta? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2099/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2099/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2098 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2098/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2098/comments | https://api.github.com/repos/huggingface/transformers/issues/2098/events | https://github.com/huggingface/transformers/issues/2098 | 534,515,777 | MDU6SXNzdWU1MzQ1MTU3Nzc= | 2,098 | Understanding output of models and relation to token probability | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | [
"There are different kinds of models.\r\nBut as you talk about MLM, you might be talking about BERT-like models.\r\nBERT is based on a transformer encoder so by definition of transformer, it takes a sequence of tokens (a token is just an encoding of each word into a vocabulary of known size) and returns a sequence ... | 1,575 | 1,576 | 1,576 | COLLABORATOR | null | ## ❓ Questions & Help
So I understand that different models were trained on different objectives. An important one is a masked language modeling objective. I would assume, then, that the model outputs probabilities for each token as the final output. Is that true?
For models that have not been trained on MLM, is ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2098/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2098/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2097 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2097/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2097/comments | https://api.github.com/repos/huggingface/transformers/issues/2097/events | https://github.com/huggingface/transformers/issues/2097 | 534,512,745 | MDU6SXNzdWU1MzQ1MTI3NDU= | 2,097 | about the special tokens | {
"login": "tzhxs",
"id": 30310982,
"node_id": "MDQ6VXNlcjMwMzEwOTgy",
"avatar_url": "https://avatars.githubusercontent.com/u/30310982?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tzhxs",
"html_url": "https://github.com/tzhxs",
"followers_url": "https://api.github.com/users/tzhxs/follow... | [] | closed | false | null | [] | [
"Please close this. It's a duplicated of your other question."
] | 1,575 | 1,576 | 1,576 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
The question about roberta.
I konw that Bert use the embedding of token 'cls' to do predict, but when it comes to roberta, I dont know it clearly. Can you tell me which token's embedding is used to do predict in this project? Is it '<s... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2097/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2097/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2096 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2096/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2096/comments | https://api.github.com/repos/huggingface/transformers/issues/2096/events | https://github.com/huggingface/transformers/issues/2096 | 534,499,441 | MDU6SXNzdWU1MzQ0OTk0NDE= | 2,096 | The added tokens do not work as expected | {
"login": "wenhuchen",
"id": 1457702,
"node_id": "MDQ6VXNlcjE0NTc3MDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1457702?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wenhuchen",
"html_url": "https://github.com/wenhuchen",
"followers_url": "https://api.github.com/users/we... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I think you can keep the issue open, this is a bug that should be fixed.",
"This could be related, I'm on commit d46147294852694d1dc701c72b9053ff2e726265\r\n\r\nIt's strange that the id for \"student\" c... | 1,575 | 1,581 | 1,581 | NONE | null | Here is a minimum example, where we add a special token [ENT]
```
from transformers import BertTokenizer
bert_tokenizer = BertTokenizer.from_pretrained('bert-base-uncased-vocab.txt')
bert_tokenizer.add_tokens(['[ENT]'])
print(len(tokenizer))
x = bert_tokenizer.encode("you are the [ENT] with [ENT] and [ENT]")
... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2096/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2096/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2095 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2095/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2095/comments | https://api.github.com/repos/huggingface/transformers/issues/2095/events | https://github.com/huggingface/transformers/issues/2095 | 534,386,448 | MDU6SXNzdWU1MzQzODY0NDg= | 2,095 | Can't get gradients from TF TransformerXL model forward pass | {
"login": "Morizeyao",
"id": 25135807,
"node_id": "MDQ6VXNlcjI1MTM1ODA3",
"avatar_url": "https://avatars.githubusercontent.com/u/25135807?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Morizeyao",
"html_url": "https://github.com/Morizeyao",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,581 | 1,581 | CONTRIBUTOR | null | ## 🐛 Bug (Actually I'm not very sure if it's a bug or am I doing something wrong)
<!-- Important information -->
- Model I am using : Transformer-XL
- Language I am using the model on (English, Chinese....): Chinese
- The problem arise when using: my own modified scripts
- The tasks I am working on is: ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2095/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2095/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2094 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2094/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2094/comments | https://api.github.com/repos/huggingface/transformers/issues/2094/events | https://github.com/huggingface/transformers/issues/2094 | 534,382,716 | MDU6SXNzdWU1MzQzODI3MTY= | 2,094 | How to save a model as a BertModel | {
"login": "hanmy1021",
"id": 45384357,
"node_id": "MDQ6VXNlcjQ1Mzg0MzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/45384357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hanmy1021",
"html_url": "https://github.com/hanmy1021",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hello! If you try to load your `pytorch_model.bin` directly in `BertForSequenceClassification`, you'll indeed get an error as the model won't know that it is supposed to have three classes. That's what the configuration is for!\r\n\r\nI guess you're doing something similar to this:\r\n\r\n```py\r\nfrom transformer... | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
I first fine-tuned a bert-base-uncased model on SST-2 dataset with run_glue.py. Then i want to use the output pytorch_model.bin to do a further fine-tuning on MNLI dataset. But if i directly use this pytorch_model.bin, an error will occur:
> RuntimeError: Error(s) in loading state_dict for Ber... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2094/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2094/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2093 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2093/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2093/comments | https://api.github.com/repos/huggingface/transformers/issues/2093/events | https://github.com/huggingface/transformers/pull/2093 | 534,375,505 | MDExOlB1bGxSZXF1ZXN0MzUwMjkyNTE1 | 2,093 | Remove pytest dependency. | {
"login": "aaugustin",
"id": 788910,
"node_id": "MDQ6VXNlcjc4ODkxMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/788910?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aaugustin",
"html_url": "https://github.com/aaugustin",
"followers_url": "https://api.github.com/users/aaug... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2093?src=pr&el=h1) Report\n> Merging [#2093](https://codecov.io/gh/huggingface/transformers/pull/2093?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/2670b0d682746e1fe94ab9c7b4d2fd7f4af03193?src=pr&el=desc) will **d... | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | This is a follow-up to PR #2055. This file was added between the moment I wrote #2055 and the moment in was merged. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2093/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2093/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2093",
"html_url": "https://github.com/huggingface/transformers/pull/2093",
"diff_url": "https://github.com/huggingface/transformers/pull/2093.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2093.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2092 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2092/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2092/comments | https://api.github.com/repos/huggingface/transformers/issues/2092/events | https://github.com/huggingface/transformers/issues/2092 | 534,373,784 | MDU6SXNzdWU1MzQzNzM3ODQ= | 2,092 | When I use albertModel, it prints the following repeatedly. | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [] | closed | false | null | [] | [
"I encountered this issue when using apex mixed precision, and I put `amp.initialize` after wrapping the model in `DistributedDataParallel`, and I believe reversing the order to first call `amp.initialize` fixed it",
"I did not use mixed precision.",
"+1, also having this issue for *-v1 and *-v2 models. I'm not... | 1,575 | 1,575 | 1,575 | NONE | null | ```python
0 0
Layer index 0
0 1
Layer index 0
0 2
Layer index 0
0 3
Layer index 0
0 4
Layer index 0
0 5
Layer index 0
0 6
Layer index 0
0 7
Layer index 0
0 8
Layer index 0
0 9
Layer index 0
0 10
Layer index 0
0 11
Layer index 0
0 0
Layer index 0
0 1
Layer index 0
0 2
Layer index 0
0 3... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2092/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2092/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2091 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2091/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2091/comments | https://api.github.com/repos/huggingface/transformers/issues/2091/events | https://github.com/huggingface/transformers/issues/2091 | 534,352,288 | MDU6SXNzdWU1MzQzNTIyODg= | 2,091 | Error msg when running on the colab | {
"login": "liguangzhe",
"id": 43159433,
"node_id": "MDQ6VXNlcjQzMTU5NDMz",
"avatar_url": "https://avatars.githubusercontent.com/u/43159433?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liguangzhe",
"html_url": "https://github.com/liguangzhe",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi! How did you obtain the train-v2.0 and dev-v2.0 files? Did you put the `--version_2_with_negative` flag to specify you're using SQuAD V2?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributio... | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
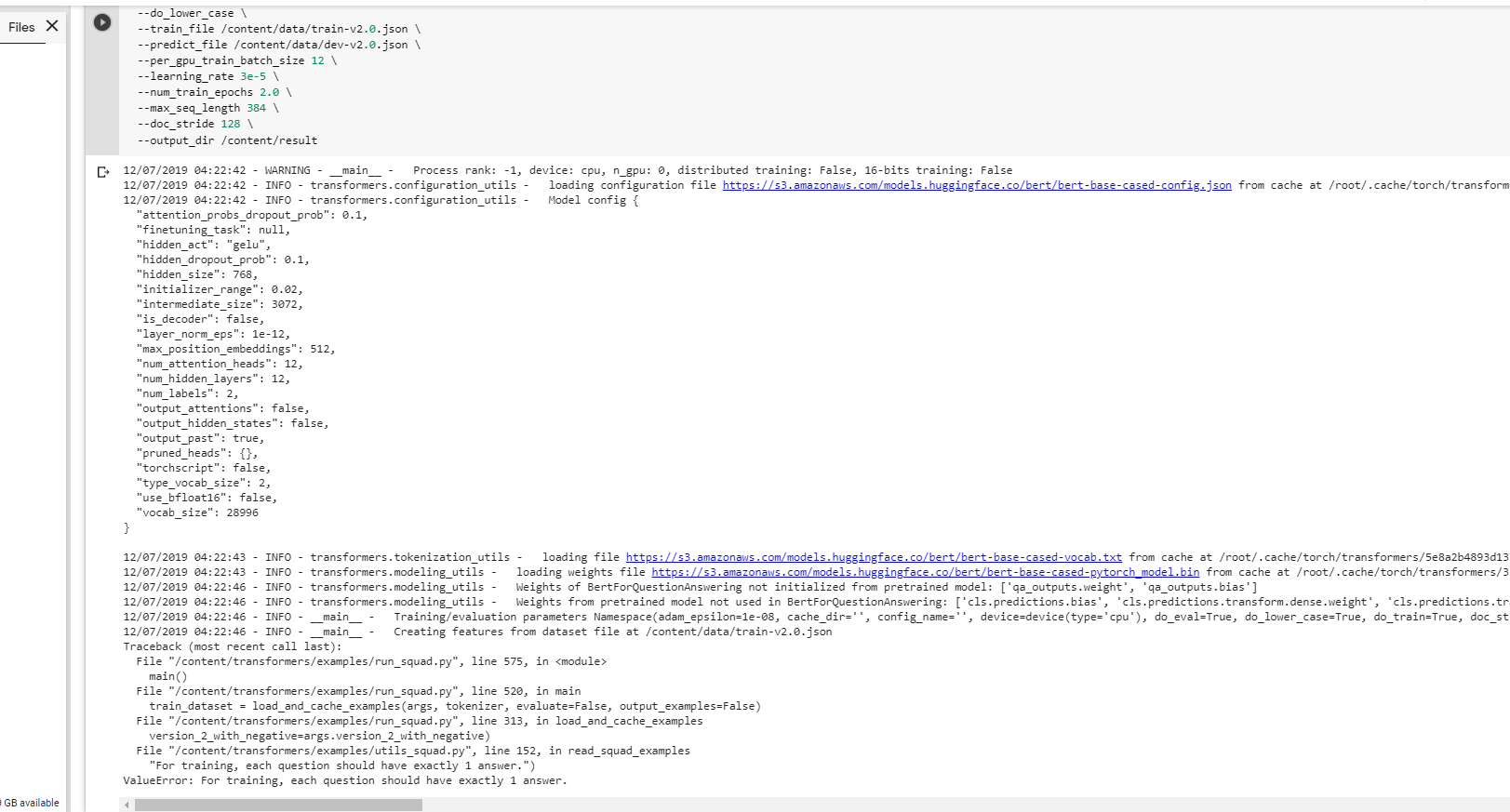
Can anyone tell me where am I wrong or it's not my problem?I cloned whole the files from huggingface. Is it can be fixed? I would appreciate for any suggestion. Thank you. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2091/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2091/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2090 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2090/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2090/comments | https://api.github.com/repos/huggingface/transformers/issues/2090/events | https://github.com/huggingface/transformers/issues/2090 | 534,340,310 | MDU6SXNzdWU1MzQzNDAzMTA= | 2,090 | AssertionError in official example | {
"login": "karajan1001",
"id": 6745454,
"node_id": "MDQ6VXNlcjY3NDU0NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/6745454?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/karajan1001",
"html_url": "https://github.com/karajan1001",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | [
"Dpulicated to #2052 and closed it .\r\n\r\n"
] | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2090/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2090/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2089 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2089/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2089/comments | https://api.github.com/repos/huggingface/transformers/issues/2089/events | https://github.com/huggingface/transformers/issues/2089 | 534,199,221 | MDU6SXNzdWU1MzQxOTkyMjE= | 2,089 | Use run_lm-finetuning on tpu | {
"login": "abdallah197",
"id": 28394606,
"node_id": "MDQ6VXNlcjI4Mzk0NjA2",
"avatar_url": "https://avatars.githubusercontent.com/u/28394606?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abdallah197",
"html_url": "https://github.com/abdallah197",
"followers_url": "https://api.github.com/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hello, the script would need to be adapted to run on TPU to take full advantage of the chips. We're actively working with the Cloud TPU team on scripts for fine-tuning on TPUs, which should be available in the coming weeks.",
"This issue has been automatically marked as stale because it has not had recent activi... | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Is it possible to use the script run_lm-finetuning on TPUs, if not, what do you recommend to fine-tune BERT language model on TPUs using the transformers library | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2089/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2089/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2088 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2088/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2088/comments | https://api.github.com/repos/huggingface/transformers/issues/2088/events | https://github.com/huggingface/transformers/issues/2088 | 534,134,175 | MDU6SXNzdWU1MzQxMzQxNzU= | 2,088 | Help with converting fine-tuned PT model to TF checkpoint | {
"login": "sivakumarch",
"id": 7129326,
"node_id": "MDQ6VXNlcjcxMjkzMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/7129326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sivakumarch",
"html_url": "https://github.com/sivakumarch",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | [
"Hi @thomwolf - any suggestion would be greatly appreciated. \r\n\r\nI am looking forward to hosting one of the fine-tuned model (pytorch) using bert-as-a-service library. However, TF conversion seems to be the way to go, and I'm stuck as the script throws above errors that I am unable to understand. \r\n\r\n",
"... | 1,575 | 1,588 | 1,577 | NONE | null | How do I convert PT model (.bin) to TF checkpoint successfully so that I can start serving using bert-as-a-service?
Below are the steps and errors:
Huggingface v2.2.1, Pytorch 1.2, TF 2.0
1. executed run_lm_finetuning.py to fine-tune an already finetuned model (clinicalBERT) on the target domain dataset. Success... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2088/reactions",
"total_count": 3,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/transformers/issues/2088/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2087 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2087/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2087/comments | https://api.github.com/repos/huggingface/transformers/issues/2087/events | https://github.com/huggingface/transformers/issues/2087 | 534,084,646 | MDU6SXNzdWU1MzQwODQ2NDY= | 2,087 | How can I get similarity matching ? | {
"login": "dimwael",
"id": 32783348,
"node_id": "MDQ6VXNlcjMyNzgzMzQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/32783348?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dimwael",
"html_url": "https://github.com/dimwael",
"followers_url": "https://api.github.com/users/dimwae... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Not sure to understand what you mean by `Using a simple similarity algorithm will always return the most similar even if it is not really correct`. What kind of simple similarity algo are you evoking here? What do you mean those simple algorithms aren't precise enough for your usecase?\r\n\r\nConsidering sentence ... | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
Is there any way that can help me calculate the similarity between 2 questions ? Sometimes the questions is out of the scope of the data set questions. Using a simple similarity algorithm will always return the most similar even if it is not really correct.
It is the same thing as here :
http... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2087/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2087/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2086 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2086/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2086/comments | https://api.github.com/repos/huggingface/transformers/issues/2086/events | https://github.com/huggingface/transformers/issues/2086 | 534,019,055 | MDU6SXNzdWU1MzQwMTkwNTU= | 2,086 | "Only evaluate when single GPU otherwise metrics may not average well" | {
"login": "orenmelamud",
"id": 55256832,
"node_id": "MDQ6VXNlcjU1MjU2ODMy",
"avatar_url": "https://avatars.githubusercontent.com/u/55256832?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/orenmelamud",
"html_url": "https://github.com/orenmelamud",
"followers_url": "https://api.github.com/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I have wondered about this comment as well. I have implemented multi-GPU evaluation and it works perfectly fine. By evaluation I mean that the the work of evaluating is distributed and all results are then gathered to the main GPU (e.g. 0) or CPU which then calculates loss and secondary metrics (f1/pearson). I hav... | 1,575 | 1,582 | 1,581 | NONE | null | Hi,
The script examples/run_lm_finetuning.py skips evaluation on the validation dataset when run in distributed mode on multiple GPUs. The code includes this comment regarding this:
"Only evaluate when single GPU otherwise metrics may not average well"
I'd appreciate it if someone could explain this issue in a f... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2086/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2086/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2085 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2085/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2085/comments | https://api.github.com/repos/huggingface/transformers/issues/2085/events | https://github.com/huggingface/transformers/issues/2085 | 533,999,264 | MDU6SXNzdWU1MzM5OTkyNjQ= | 2,085 | Write With Transformer: PPLM document is stuck | {
"login": "varkarrus",
"id": 38511981,
"node_id": "MDQ6VXNlcjM4NTExOTgx",
"avatar_url": "https://avatars.githubusercontent.com/u/38511981?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/varkarrus",
"html_url": "https://github.com/varkarrus",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"nevermind, it suddenly started working."
] | 1,575 | 1,575 | 1,575 | NONE | null | The Uber PPLM on Write With Transformer does not generate anything, regardless of the parameters. It simply sits there, loading, forever. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2085/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2085/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2084 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2084/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2084/comments | https://api.github.com/repos/huggingface/transformers/issues/2084/events | https://github.com/huggingface/transformers/issues/2084 | 533,988,094 | MDU6SXNzdWU1MzM5ODgwOTQ= | 2,084 | CUDA out of memory for 8x V100 GPU | {
"login": "mittalpatel",
"id": 200955,
"node_id": "MDQ6VXNlcjIwMDk1NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/200955?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mittalpatel",
"html_url": "https://github.com/mittalpatel",
"followers_url": "https://api.github.com/user... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"bert large is bigger than bert base. You're using a batch size of 24 (which is big, especially with 12 gradient accumulation steps). \r\n\r\nReduce your batch size in order for your model + your tensors to fit on the GPU and you won't experience the same error!",
"Right @LysandreJik , reducing the batch size did... | 1,575 | 1,581 | 1,581 | NONE | null | ```
python -m torch.distributed.launch --nproc_per_node=8 run_squad.py \
--model_type bert \
--model_name_or_path bert-base-cased \
--do_train \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train-v1.1.json \
--predict_file $SQUAD_DIR/dev-v1.1.json \
--learning_rate 3e-5... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2084/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2084/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2083 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2083/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2083/comments | https://api.github.com/repos/huggingface/transformers/issues/2083/events | https://github.com/huggingface/transformers/issues/2083 | 533,980,467 | MDU6SXNzdWU1MzM5ODA0Njc= | 2,083 | ALBERT how to obtain the embedding matrix? | {
"login": "alessiocancian",
"id": 18497523,
"node_id": "MDQ6VXNlcjE4NDk3NTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/18497523?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alessiocancian",
"html_url": "https://github.com/alessiocancian",
"followers_url": "https://api.gi... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
Hi, I'm trying to use ALBERT for word embedding with this library.
ALBERT's doc mentioned an embedding size of 128 independently of the model version (base, large, ...) while the hidden_size changes.
I would like to obtain the 128 word (or subword) vectors but the model gives me only the outp... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2083/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2083/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2082 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2082/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2082/comments | https://api.github.com/repos/huggingface/transformers/issues/2082/events | https://github.com/huggingface/transformers/issues/2082 | 533,918,236 | MDU6SXNzdWU1MzM5MTgyMzY= | 2,082 | ImportError: cannot import name 'WarmupLinearSchedule' | {
"login": "Dhanachandra",
"id": 10828657,
"node_id": "MDQ6VXNlcjEwODI4NjU3",
"avatar_url": "https://avatars.githubusercontent.com/u/10828657?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dhanachandra",
"html_url": "https://github.com/Dhanachandra",
"followers_url": "https://api.github.c... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"It is in the [optimization.py](https://github.com/huggingface/transformers/blob/df99f8c5a1c54d64fb013b43107011390c3be0d5/transformers/optimization.py), at line 45. It creates a schedule with a learning rate that decreases linearly after linearly increasing during a warmup period. In order to import it, you have to... | 1,575 | 1,582 | 1,582 | NONE | null | $ pip show transformers
Name: transformers
Version: 2.2.1
Summary: State-of-the-art Natural Language Processing for TensorFlow 2.0 and PyTorch
Home-page: https://github.com/huggingface/transformers
Author: Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Google AI Language Team Authors, Open AI team Auth... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2082/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 2,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2082/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2081 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2081/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2081/comments | https://api.github.com/repos/huggingface/transformers/issues/2081/events | https://github.com/huggingface/transformers/pull/2081 | 533,847,555 | MDExOlB1bGxSZXF1ZXN0MzQ5ODQ3NjUw | 2,081 | handle string with only whitespaces as empty | {
"login": "pglock",
"id": 8183619,
"node_id": "MDQ6VXNlcjgxODM2MTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/8183619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pglock",
"html_url": "https://github.com/pglock",
"followers_url": "https://api.github.com/users/pglock/foll... | [] | closed | false | null | [] | [
"Does this fix the non-deterministic behavior mentioned in #2027 ?",
"Yes, this should return `[]` for every string that only contains whitespace characters. ",
"Ok, great, merging then, thanks!"
] | 1,575 | 1,576 | 1,576 | CONTRIBUTOR | null | #2027 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2081/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2081/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2081",
"html_url": "https://github.com/huggingface/transformers/pull/2081",
"diff_url": "https://github.com/huggingface/transformers/pull/2081.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2081.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2080 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2080/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2080/comments | https://api.github.com/repos/huggingface/transformers/issues/2080/events | https://github.com/huggingface/transformers/issues/2080 | 533,841,300 | MDU6SXNzdWU1MzM4NDEzMDA= | 2,080 | Encoding special tokens | {
"login": "pglock",
"id": 8183619,
"node_id": "MDQ6VXNlcjgxODM2MTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/8183619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pglock",
"html_url": "https://github.com/pglock",
"followers_url": "https://api.github.com/users/pglock/foll... | [] | closed | false | null | [] | [
"I got the same issue for version 2.2.1. ",
"I also meet this issue and you may check out the possible root cause from #2052. \r\n\r\nMy workaround is backoff to 2.1.1 version.\r\n",
"Should have been fixed with https://github.com/huggingface/transformers/pull/2051"
] | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | ## 🐛 Bug
<!-- Important information -->
In version 2.2.1 encoding special tokens changed.
```python
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
tokenizer.decode(tokenizer.encode("[CLS] hello world [SEP]", add_special_tokens=False))
```
output: `'[... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2080/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2080/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2079 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2079/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2079/comments | https://api.github.com/repos/huggingface/transformers/issues/2079/events | https://github.com/huggingface/transformers/issues/2079 | 533,759,604 | MDU6SXNzdWU1MzM3NTk2MDQ= | 2,079 | How to average sub-words embeddings to obtain word embeddings? | {
"login": "speedcell4",
"id": 3585459,
"node_id": "MDQ6VXNlcjM1ODU0NTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3585459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/speedcell4",
"html_url": "https://github.com/speedcell4",
"followers_url": "https://api.github.com/users... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"You may use the word as the input and make the sentence embedding as the word embedding.\r\nfor example, input is \r\n\"puppeteer\"\r\ntokens as\r\n'[CLS]', 'puppet', '##eer', '[SEP]'\r\nand then get embedding of this tokens list output.",
"I have similar usage as well, I did a simple experiment, and observe tha... | 1,575 | 1,650 | 1,586 | NONE | null | Hi~
How to average sub-words embeddings to obtain word embeddings?
I only want word-level embedding instead of sub-word-level, how can I get them?
Is there any tokenizer that provides a method that can output the index/mask of sub-words or something? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2079/reactions",
"total_count": 5,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 5
} | https://api.github.com/repos/huggingface/transformers/issues/2079/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2078 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2078/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2078/comments | https://api.github.com/repos/huggingface/transformers/issues/2078/events | https://github.com/huggingface/transformers/pull/2078 | 533,676,416 | MDExOlB1bGxSZXF1ZXN0MzQ5NzA5MTQ4 | 2,078 | [cli] Uploads: add progress bar | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2078?src=pr&el=h1) Report\n> Merging [#2078](https://codecov.io/gh/huggingface/transformers/pull/2078?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/35ff345fc9df9e777b27903f11fa213e4052595b?src=pr&el=desc) will **i... | 1,575 | 1,575 | 1,575 | MEMBER | null | see https://github.com/huggingface/transformers/pull/2044#discussion_r354057827 for context
There might be a more pythonic way (to do a "simple" method overriding) but I couldn't find it. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2078/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2078/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2078",
"html_url": "https://github.com/huggingface/transformers/pull/2078",
"diff_url": "https://github.com/huggingface/transformers/pull/2078.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2078.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2077 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2077/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2077/comments | https://api.github.com/repos/huggingface/transformers/issues/2077/events | https://github.com/huggingface/transformers/pull/2077 | 533,675,383 | MDExOlB1bGxSZXF1ZXN0MzQ5NzA4MzAx | 2,077 | corrected documentation for past tensor shape for ctrl and gpt2 model | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2077?src=pr&el=h1) Report\n> Merging [#2077](https://codecov.io/gh/huggingface/transformers/pull/2077?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/35ff345fc9df9e777b27903f11fa213e4052595b?src=pr&el=desc) will **n... | 1,575 | 1,576 | 1,575 | MEMBER | null | fix issue #1904 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2077/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2077/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2077",
"html_url": "https://github.com/huggingface/transformers/pull/2077",
"diff_url": "https://github.com/huggingface/transformers/pull/2077.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2077.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2076 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2076/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2076/comments | https://api.github.com/repos/huggingface/transformers/issues/2076/events | https://github.com/huggingface/transformers/issues/2076 | 533,634,909 | MDU6SXNzdWU1MzM2MzQ5MDk= | 2,076 | Text Generation in Hebrew | {
"login": "beneyal",
"id": 3891274,
"node_id": "MDQ6VXNlcjM4OTEyNzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3891274?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/beneyal",
"html_url": "https://github.com/beneyal",
"followers_url": "https://api.github.com/users/beneyal/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,581 | 1,581 | CONTRIBUTOR | null | ## ❓ Questions & Help
Hi all,
I have 30K tweets in Hebrew and I want to create a sort of chatbot that will answer in the style of those tweets, similar to [this](https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313). The only multilingual models that... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2076/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2076/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2075 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2075/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2075/comments | https://api.github.com/repos/huggingface/transformers/issues/2075/events | https://github.com/huggingface/transformers/pull/2075 | 533,580,689 | MDExOlB1bGxSZXF1ZXN0MzQ5NjMwMzE0 | 2,075 | Check link validity | {
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/follower... | [] | closed | false | null | [] | [
"It works so well the CI failed because of a broken link :)",
"Ok great!\r\n\r\nMaybe in the future, we would like to ensure model files can also be loaded without problems but this will suffice for now (and be fast)!\r\n\r\nmerging (when I've converted and added the missing model)",
"Yes it would be great too!... | 1,575 | 1,576 | 1,576 | CONTRIBUTOR | null | We would like to make sure that every download link in the code base works. The best way to do this is to check automatically with the CI; this also prevents us from merging code with broken links.
This PR adds a small script that:
- Lists all source code files
- Extracts links with a regexp
- Performs HEAD req... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2075/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2075/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2075",
"html_url": "https://github.com/huggingface/transformers/pull/2075",
"diff_url": "https://github.com/huggingface/transformers/pull/2075.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2075.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2074 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2074/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2074/comments | https://api.github.com/repos/huggingface/transformers/issues/2074/events | https://github.com/huggingface/transformers/pull/2074 | 533,577,661 | MDExOlB1bGxSZXF1ZXN0MzQ5NjI3Nzc1 | 2,074 | Check the validity of download links | {
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/follower... | [] | closed | false | null | [] | [
"It works so well that the CI failed because of a broken link :)"
] | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | We would like to make sure regularly that every download link in the codebase works. The best way to do this is to check automatically with the CI; this also prevents us from merging code with broken links.
This PR adds a small script that:
- Lists all source code files
- Extract links with a regexp
- Perform HEA... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2074/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2074/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2074",
"html_url": "https://github.com/huggingface/transformers/pull/2074",
"diff_url": "https://github.com/huggingface/transformers/pull/2074.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2074.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/2073 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2073/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2073/comments | https://api.github.com/repos/huggingface/transformers/issues/2073/events | https://github.com/huggingface/transformers/issues/2073 | 533,532,247 | MDU6SXNzdWU1MzM1MzIyNDc= | 2,073 | How to structure text data to finetune distilGPT2 using tf.keras.model.fit()? | {
"login": "brandonbell11",
"id": 51493518,
"node_id": "MDQ6VXNlcjUxNDkzNTE4",
"avatar_url": "https://avatars.githubusercontent.com/u/51493518?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brandonbell11",
"html_url": "https://github.com/brandonbell11",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [] | 1,575 | 1,575 | 1,575 | NONE | null | here is the relevant section of code where I get my text data via a txt file "file_path":
```
examples=[]
with open(file_path, encoding="utf-8") as f:
text = f.read()
tokenized_text = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text))
block_size = 256
for i in range(0, len(tokenized_text)-bloc... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2073/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2073/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2072 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2072/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2072/comments | https://api.github.com/repos/huggingface/transformers/issues/2072/events | https://github.com/huggingface/transformers/issues/2072 | 533,526,741 | MDU6SXNzdWU1MzM1MjY3NDE= | 2,072 | Accessing roberta embeddings | {
"login": "aclifton314",
"id": 53267795,
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aclifton314",
"html_url": "https://github.com/aclifton314",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"Hi, there are several ways to check out the embeddings.\r\n\r\n1 - The easy way is to get the `embeddings` and use it as a `torch.nn.Module` (which it inherits from):\r\n\r\nFor example, this is the output of the embedding layer of the sentence \"Alright, let's do this\", of dimension (batch_size, sequence_length,... | 1,575 | 1,575 | 1,575 | NONE | null | ## Finetune Setup
* Model: roberta-base
* Language: english
* OS: Ubuntu 18.04.3
* Python version: 3.7.3
* PyTorch version: 1.3.1+cpu
* PyTorch Transformers version (or branch): 2.2.0
* Using GPU ? No
* Distributed of parallel setup ? No
* Script inputs:
```
python run_lm_finetuning.py \
--output_dir=$OUTPU... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2072/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2072/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2071 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2071/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2071/comments | https://api.github.com/repos/huggingface/transformers/issues/2071/events | https://github.com/huggingface/transformers/issues/2071 | 533,519,460 | MDU6SXNzdWU1MzM1MTk0NjA= | 2,071 | The generation script could fail when there's a double space in the prompt | {
"login": "cloudygoose",
"id": 1544039,
"node_id": "MDQ6VXNlcjE1NDQwMzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/1544039?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cloudygoose",
"html_url": "https://github.com/cloudygoose",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | [
"Hi! Could you specify the command you used to launch `run_generation` as well as the versions in your environment? Pyton, pytorch, transformers? Thanks.",
"`python scripts_htx/run_generation.py --model_type ctrl --model_name ctrl --repetition 1.2`\r\npython=3.7.3\r\ntorch=1.3.0\r\ntransformers=2.2.1\r\n\r\nBut... | 1,575 | 1,575 | 1,575 | NONE | null | ## 🚀 Feature
Hey, thanks for everything,
The generation script could fail when there's a double space in the prompt, e.g. " I go to"
I know it's not important, but it would be good if the tokenize is ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2071/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2071/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2070 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2070/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2070/comments | https://api.github.com/repos/huggingface/transformers/issues/2070/events | https://github.com/huggingface/transformers/issues/2070 | 533,417,390 | MDU6SXNzdWU1MzM0MTczOTA= | 2,070 | XLMWithLMHeadModel forwarding questions | {
"login": "Y0mingZhang",
"id": 23271442,
"node_id": "MDQ6VXNlcjIzMjcxNDQy",
"avatar_url": "https://avatars.githubusercontent.com/u/23271442?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Y0mingZhang",
"html_url": "https://github.com/Y0mingZhang",
"followers_url": "https://api.github.com/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
1. Why is the labels argument named 'labels' instead of 'masked_lm_labels' like in BertForMaskedLM?
2. When I change labels for masked tokens to -1 as suggested in documentation, I got an error from NLLLoss for label being outside va... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2070/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2070/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2069 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2069/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2069/comments | https://api.github.com/repos/huggingface/transformers/issues/2069/events | https://github.com/huggingface/transformers/pull/2069 | 533,381,577 | MDExOlB1bGxSZXF1ZXN0MzQ5NDY1Njg2 | 2,069 | clean up PT <=> TF conversion | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | [
"Cool!",
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2069?src=pr&el=h1) Report\n> Merging [#2069](https://codecov.io/gh/huggingface/transformers/pull/2069?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ee53de7aac8312140e87d452718e15e3d42e27dd?src=pr&el=des... | 1,575 | 1,651 | 1,575 | MEMBER | null | Cleaning up PT <=> TF conversion method.
cc @VictorSanh | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2069/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2069/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2069",
"html_url": "https://github.com/huggingface/transformers/pull/2069",
"diff_url": "https://github.com/huggingface/transformers/pull/2069.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2069.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2068 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2068/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2068/comments | https://api.github.com/repos/huggingface/transformers/issues/2068/events | https://github.com/huggingface/transformers/pull/2068 | 533,357,788 | MDExOlB1bGxSZXF1ZXN0MzQ5NDQ2MDY3 | 2,068 | Nicer error message when Bert's input is missing batch size | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2068?src=pr&el=h1) Report\n> Merging [#2068](https://codecov.io/gh/huggingface/transformers/pull/2068?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/2d5d86e03779b4b316698438caff0f675ee54abd?src=pr&el=desc) will **i... | 1,575 | 1,668 | 1,575 | MEMBER | null | Currently it fails in the computation of the attention_mask.
Let's fail with a shape error message instead. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2068/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2068/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2068",
"html_url": "https://github.com/huggingface/transformers/pull/2068",
"diff_url": "https://github.com/huggingface/transformers/pull/2068.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2068.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2067 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2067/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2067/comments | https://api.github.com/repos/huggingface/transformers/issues/2067/events | https://github.com/huggingface/transformers/issues/2067 | 533,349,021 | MDU6SXNzdWU1MzMzNDkwMjE= | 2,067 | Save model for tensorflow serving | {
"login": "elixium",
"id": 7610370,
"node_id": "MDQ6VXNlcjc2MTAzNzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/7610370?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/elixium",
"html_url": "https://github.com/elixium",
"followers_url": "https://api.github.com/users/elixium/... | [] | closed | false | null | [] | [
"Did you get the solution to this? @elixium ",
"Hi any update on this? I would like to deploy huggingface Transformers model with Tensorflow Serving too"
] | 1,575 | 1,596 | 1,575 | NONE | null | Hello,
Thanks for the library. I tried your Multi label classification. I trained it with my data. It worked very accurate and fast. Now i want to use this model with tensorflow. I am new on pytorch and i looked some tutorials. As i understand i need to save model then convert to Onnx then to tensorflow. So I tried to... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2067/reactions",
"total_count": 4,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 4
} | https://api.github.com/repos/huggingface/transformers/issues/2067/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2066 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2066/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2066/comments | https://api.github.com/repos/huggingface/transformers/issues/2066/events | https://github.com/huggingface/transformers/issues/2066 | 533,325,866 | MDU6SXNzdWU1MzMzMjU4NjY= | 2,066 | CPU RAM out of memory when detach from GPU | {
"login": "duyduc1110",
"id": 22440962,
"node_id": "MDQ6VXNlcjIyNDQwOTYy",
"avatar_url": "https://avatars.githubusercontent.com/u/22440962?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/duyduc1110",
"html_url": "https://github.com/duyduc1110",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
I am using the following code to get embedding layer from BERT:
```
class BertEmbedding():
def __init__(self, load_model=None, load_config=None, model='bert-base-uncased', max_len=512, batch_size=6):
self.pre_trained_model = model
self.max_len = max_len
self.ba... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2066/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2066/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2065 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2065/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2065/comments | https://api.github.com/repos/huggingface/transformers/issues/2065/events | https://github.com/huggingface/transformers/pull/2065 | 533,322,143 | MDExOlB1bGxSZXF1ZXN0MzQ5NDE3MDY4 | 2,065 | Fixing camembert tokenization | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | [
"Merging now to fix the xlnet test issue on master at the same time.",
"Also cc'ing @louismartin on this.",
"Thanks for fixing that.\r\nThis comes from a problem in fairseq where special tokens are added twice when using SentencePiece.\r\nCross-referencing the fairseq issue: [https://github.com/pytorch/fairseq/... | 1,575 | 1,575 | 1,575 | MEMBER | null | The original fairseq implmentation of Camembert has a bunch of duplicate tokens in the dictionary, in particular there are two `<unk>` tokens but only the index of the first `<unk>` should be used:
```
import torch
camembert = torch.hub.load('pytorch/fairseq', 'camembert.v0')
list(camembert.task.source_dictionary[i... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2065/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2065/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2065",
"html_url": "https://github.com/huggingface/transformers/pull/2065",
"diff_url": "https://github.com/huggingface/transformers/pull/2065.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2065.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2064 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2064/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2064/comments | https://api.github.com/repos/huggingface/transformers/issues/2064/events | https://github.com/huggingface/transformers/issues/2064 | 533,306,946 | MDU6SXNzdWU1MzMzMDY5NDY= | 2,064 | [ Structure of LM vocab trained from scratch ] | {
"login": "simonefrancia",
"id": 7140210,
"node_id": "MDQ6VXNlcjcxNDAyMTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/7140210?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/simonefrancia",
"html_url": "https://github.com/simonefrancia",
"followers_url": "https://api.github.... | [] | closed | false | null | [] | [
"I don't think it is a problem. \r\nYour model will learn the embeddings of the words in your own dictionary.\r\n\r\nActually Nothing will be unchanged if you changed dictionary position as well as you keeped the embedding weight just the same order with your dictionary. ",
"Thanks @karajan1001. \r\nI am not sure... | 1,575 | 1,576 | 1,576 | CONTRIBUTOR | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi,
I am trying to create a BERT LM trained from scratch and I have a question about the tokenizer.
I have a big text corpus and I trained a tokenizer with SentencePiece with 32K as dimension of the vocabulary. Then I applied a tran... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2064/reactions",
"total_count": 3,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2064/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2063 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2063/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2063/comments | https://api.github.com/repos/huggingface/transformers/issues/2063/events | https://github.com/huggingface/transformers/pull/2063 | 533,189,012 | MDExOlB1bGxSZXF1ZXN0MzQ5MzA3Mjk5 | 2,063 | special_tokens_mask value was unused and calculated twice | {
"login": "guillaume-be",
"id": 27071604,
"node_id": "MDQ6VXNlcjI3MDcxNjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/27071604?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guillaume-be",
"html_url": "https://github.com/guillaume-be",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2063?src=pr&el=h1) Report\n> Merging [#2063](https://codecov.io/gh/huggingface/transformers/pull/2063?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/fb0d2f1da102d699c6457fd98be35f89852d08b9?src=pr&el=desc) will **n... | 1,575 | 1,576 | 1,576 | CONTRIBUTOR | null | In the current master, in the `prepare_for_model` method of the `PreTrainedTokenizer` class, the sepcial_tokens_mask is calculated but not used: https://github.com/huggingface/transformers/blob/5bfcd0485ece086ebcbed2d008813037968a9e58/transformers/tokenization_utils.py#L904.
```python
# Handle special_toke... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2063/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2063/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2063",
"html_url": "https://github.com/huggingface/transformers/pull/2063",
"diff_url": "https://github.com/huggingface/transformers/pull/2063.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2063.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2062 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2062/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2062/comments | https://api.github.com/repos/huggingface/transformers/issues/2062/events | https://github.com/huggingface/transformers/issues/2062 | 533,169,793 | MDU6SXNzdWU1MzMxNjk3OTM= | 2,062 | TypeError: argument of type 'PosixPath' is not iterable (in modeling_utils.py) | {
"login": "adiv5",
"id": 22361618,
"node_id": "MDQ6VXNlcjIyMzYxNjE4",
"avatar_url": "https://avatars.githubusercontent.com/u/22361618?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adiv5",
"html_url": "https://github.com/adiv5",
"followers_url": "https://api.github.com/users/adiv5/follow... | [] | closed | false | null | [] | [
"Solved it by typecasting posixpath to string"
] | 1,575 | 1,575 | 1,575 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):BERT
Language I am using the model on (English, Chinese....):English
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2062/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2062/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2061 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2061/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2061/comments | https://api.github.com/repos/huggingface/transformers/issues/2061/events | https://github.com/huggingface/transformers/issues/2061 | 533,140,422 | MDU6SXNzdWU1MzMxNDA0MjI= | 2,061 | BertForSequenceClassification' object has no attribute 'bias | {
"login": "chikubee",
"id": 25073753,
"node_id": "MDQ6VXNlcjI1MDczNzUz",
"avatar_url": "https://avatars.githubusercontent.com/u/25073753?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chikubee",
"html_url": "https://github.com/chikubee",
"followers_url": "https://api.github.com/users/chi... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Can you show us the full error message?",
"Can it be related to #2109 in some way?\r\n\r\n> ## Bug\r\n> Model I am using (Bert, XLNet....):\r\n> \r\n> Language I am using the model on (English, Chinese....):\r\n> \r\n> The problem arise when using:\r\n> \r\n> * [x] the official example scripts: (give details)\... | 1,575 | 1,581 | 1,581 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an of... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2061/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2061/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2060 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2060/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2060/comments | https://api.github.com/repos/huggingface/transformers/issues/2060/events | https://github.com/huggingface/transformers/pull/2060 | 533,127,503 | MDExOlB1bGxSZXF1ZXN0MzQ5MjU2OTk2 | 2,060 | Pr for pplm | {
"login": "mimosavvy",
"id": 4118375,
"node_id": "MDQ6VXNlcjQxMTgzNzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/4118375?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mimosavvy",
"html_url": "https://github.com/mimosavvy",
"followers_url": "https://api.github.com/users/mi... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2060?src=pr&el=h1) Report\n> Merging [#2060](https://codecov.io/gh/huggingface/transformers/pull/2060?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5bfcd0485ece086ebcbed2d008813037968a9e58?src=pr&el=desc) will **n... | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | Updated paper link and better commands to generate samples. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2060/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2060/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2060",
"html_url": "https://github.com/huggingface/transformers/pull/2060",
"diff_url": "https://github.com/huggingface/transformers/pull/2060.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2060.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2059 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2059/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2059/comments | https://api.github.com/repos/huggingface/transformers/issues/2059/events | https://github.com/huggingface/transformers/issues/2059 | 533,068,328 | MDU6SXNzdWU1MzMwNjgzMjg= | 2,059 | How to run a batch of data through BERT model? | {
"login": "yrf1",
"id": 14252783,
"node_id": "MDQ6VXNlcjE0MjUyNzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/14252783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yrf1",
"html_url": "https://github.com/yrf1",
"followers_url": "https://api.github.com/users/yrf1/followers"... | [] | closed | false | null | [] | [
"Did you solve it? I have the same problem as you."
] | 1,575 | 1,585 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I understand how to run **1 data** point of d words through a BERT model, but how can I run **n data** sequence of words through the BERT model?
Nvm solved this issue.
I can just pass sth like a 2xd data that looks like this:
ten... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2059/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2059/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2058 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2058/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2058/comments | https://api.github.com/repos/huggingface/transformers/issues/2058/events | https://github.com/huggingface/transformers/issues/2058 | 533,052,723 | MDU6SXNzdWU1MzMwNTI3MjM= | 2,058 | Automatically allocates memory in GPU, always OOM when create TFALBERT model | {
"login": "guozhiyu",
"id": 20262432,
"node_id": "MDQ6VXNlcjIwMjYyNDMy",
"avatar_url": "https://avatars.githubusercontent.com/u/20262432?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guozhiyu",
"html_url": "https://github.com/guozhiyu",
"followers_url": "https://api.github.com/users/guo... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"What is the batch size you used?",
"The same bug occurs with Python 3.6.9, Transformers 2.2.1 (installed with `pip install transformers`), PyTorch 1.3.1 and TensorFlow 2.0.\r\nStack trace:\r\n```\r\nPython 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31) \r\n[GCC 7.3.0] on linux\r\nType \"help\", \"copyri... | 1,575 | 1,581 | 1,581 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using :ALBERT
Language I am using the model on (English, Chinese....):English
> from transformers import TFAlbertModel
> model2=TFAlbertModel.from_pretrained('albert-base-v1')
Then:
> ---------------------------------------------------------------... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2058/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2058/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2057 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2057/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2057/comments | https://api.github.com/repos/huggingface/transformers/issues/2057/events | https://github.com/huggingface/transformers/issues/2057 | 533,007,147 | MDU6SXNzdWU1MzMwMDcxNDc= | 2,057 | `distilroberta-base` link missing | {
"login": "felicitywang",
"id": 10904994,
"node_id": "MDQ6VXNlcjEwOTA0OTk0",
"avatar_url": "https://avatars.githubusercontent.com/u/10904994?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/felicitywang",
"html_url": "https://github.com/felicitywang",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | [
"It is located under `configuration_roberta.py`, see it [here](https://github.com/huggingface/transformers/blob/1c542df7e554a2014051dd09becf60f157fed524/transformers/configuration_roberta.py#L31) :)",
"Thanks @stefan-it ! Missed the readme part of calling `distilroberta-base` with `RobertaModel` instead of `Disti... | 1,575 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
According to the current master code, link for `distilroberta-base` isn't provided.
https://github.com/huggingface/transformers/blob/1ab8dc44b3d84ed1894f5b6a6fab58fb39298fc7/transformers/configuration_distilbert.py#L28-L33 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2057/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2057/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2056 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2056/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2056/comments | https://api.github.com/repos/huggingface/transformers/issues/2056/events | https://github.com/huggingface/transformers/issues/2056 | 532,998,271 | MDU6SXNzdWU1MzI5OTgyNzE= | 2,056 | cannot import name 'get_linear_schedule_with_warmup' from 'transformers.optimization' | {
"login": "FOXaaFOX",
"id": 15794343,
"node_id": "MDQ6VXNlcjE1Nzk0MzQz",
"avatar_url": "https://avatars.githubusercontent.com/u/15794343?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FOXaaFOX",
"html_url": "https://github.com/FOXaaFOX",
"followers_url": "https://api.github.com/users/FOX... | [] | closed | false | null | [] | [
"This could be related to this issue here: https://github.com/huggingface/transformers/issues/1837 :)",
"I copied the get_linear_schedule_with_warmup function code add to my project in the transformers/optimization.py\r\nand then it worked \r\nThank you for developing such an brilliant library... | 1,575 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
cannot import name 'get_linear_schedule_with_warmup' from 'transformers.optimization'
<!-- A clear and concise description of the question. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2056/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2056/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2055 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2055/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2055/comments | https://api.github.com/repos/huggingface/transformers/issues/2055/events | https://github.com/huggingface/transformers/pull/2055 | 532,924,758 | MDExOlB1bGxSZXF1ZXN0MzQ5MDg0NzI5 | 2,055 | Remove dependency on pytest for running tests | {
"login": "aaugustin",
"id": 788910,
"node_id": "MDQ6VXNlcjc4ODkxMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/788910?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aaugustin",
"html_url": "https://github.com/aaugustin",
"followers_url": "https://api.github.com/users/aaug... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2055?src=pr&el=h1) Report\n> Merging [#2055](https://codecov.io/gh/huggingface/transformers/pull/2055?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/35ff345fc9df9e777b27903f11fa213e4052595b?src=pr&el=desc) will **d... | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2055/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2055/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2055",
"html_url": "https://github.com/huggingface/transformers/pull/2055",
"diff_url": "https://github.com/huggingface/transformers/pull/2055.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2055.patch",
"merged_at": 1... | |
https://api.github.com/repos/huggingface/transformers/issues/2054 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2054/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2054/comments | https://api.github.com/repos/huggingface/transformers/issues/2054/events | https://github.com/huggingface/transformers/issues/2054 | 532,888,320 | MDU6SXNzdWU1MzI4ODgzMjA= | 2,054 | Find dot product of query and key vectors | {
"login": "vr25",
"id": 22553367,
"node_id": "MDQ6VXNlcjIyNTUzMzY3",
"avatar_url": "https://avatars.githubusercontent.com/u/22553367?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vr25",
"html_url": "https://github.com/vr25",
"followers_url": "https://api.github.com/users/vr25/followers"... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I found [this](https://huggingface.co/transformers/_modules/transformers/modeling_bert.html) code which has transpose_for_scores but I am not sure how this can be used with the above code.",
"Yes, the `attentions` outputs of the model are the softmax values.",
"This issue has been automatically marked as stale... | 1,575 | 1,581 | 1,581 | NONE | null | Hi,
I am following [this popular article](http://jalammar.github.io/illustrated-transformer/) to understand the Transformers. Alongside this, I am using [huggingface transformers](https://huggingface.co/transformers/model_doc/bert.html#bertmodel) to get the attention scores.
On running the following code:
`from ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2054/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2054/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2053 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2053/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2053/comments | https://api.github.com/repos/huggingface/transformers/issues/2053/events | https://github.com/huggingface/transformers/issues/2053 | 532,852,026 | MDU6SXNzdWU1MzI4NTIwMjY= | 2,053 | Crosslingual classification with XLM, loss does not converge | {
"login": "DanKing1903",
"id": 32928632,
"node_id": "MDQ6VXNlcjMyOTI4NjMy",
"avatar_url": "https://avatars.githubusercontent.com/u/32928632?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DanKing1903",
"html_url": "https://github.com/DanKing1903",
"followers_url": "https://api.github.com/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I had the same problem with different tasks . I've tried all the XLM pre-training models and got random results. Please let us know if you have solved this problem. I'm trying to figure it out. @DanKing1903 ",
"I was able to reproduce the results of XLM on XNLI.\r\nIt was highly sensitive to hyper parameters.\r\... | 1,575 | 1,587 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I am trying to use the XLM pretrained model `xlm-mlm-tlm-xnli15-1024` for a cross lingual classification task, but I cannot get the loss to converge and the final accuracy is random.
To check this was not an implementation error of ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2053/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2053/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2052 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2052/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2052/comments | https://api.github.com/repos/huggingface/transformers/issues/2052/events | https://github.com/huggingface/transformers/issues/2052 | 532,842,966 | MDU6SXNzdWU1MzI4NDI5NjY= | 2,052 | Missing "do_lower_case" action for special token (e.g. mask_token) | {
"login": "makcedward",
"id": 36614806,
"node_id": "MDQ6VXNlcjM2NjE0ODA2",
"avatar_url": "https://avatars.githubusercontent.com/u/36614806?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/makcedward",
"html_url": "https://github.com/makcedward",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"With Transformers **2.2.0**, it works as expected!\r\n```\r\nPython 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31) \r\n[GCC 7.3.0] on linux\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> import torch\r\n>>> from transformers import BertTokenizer\r\n/home/vidiemme/... | 1,575 | 1,581 | 1,581 | NONE | null | ## 🐛 Bug
Model I am using (Bert, XLNet....): 'bert-base-uncased'
Language I am using the model on (English, Chinese....): English
After upgrading to 2.2.1 version, the BERT tokenizer cannot tokenize special word while it works in 2.1.1 version.
According to [here](https://github.com/huggingface/transformer... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2052/reactions",
"total_count": 6,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/transformers/issues/2052/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2051 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2051/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2051/comments | https://api.github.com/repos/huggingface/transformers/issues/2051/events | https://github.com/huggingface/transformers/pull/2051 | 532,779,656 | MDExOlB1bGxSZXF1ZXN0MzQ4OTY2MzM2 | 2,051 | Fix bug which lowercases special tokens | {
"login": "watkinsm",
"id": 38503580,
"node_id": "MDQ6VXNlcjM4NTAzNTgw",
"avatar_url": "https://avatars.githubusercontent.com/u/38503580?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/watkinsm",
"html_url": "https://github.com/watkinsm",
"followers_url": "https://api.github.com/users/wat... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2051?src=pr&el=h1) Report\n> Merging [#2051](https://codecov.io/gh/huggingface/transformers/pull/2051?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5bfcd0485ece086ebcbed2d008813037968a9e58?src=pr&el=desc) will **i... | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | A previous PR (#1592), which lowercases input and added tokens if `do_lower_case` is set to `True` for a given tokenizer, introduced a bug which lowercases text without considering whether parts of the input are special tokens. The result is that special tokens may not be tokenized properly, e.g. "[CLS]" becomes 4 sepa... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2051/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2051/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2051",
"html_url": "https://github.com/huggingface/transformers/pull/2051",
"diff_url": "https://github.com/huggingface/transformers/pull/2051.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2051.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2050 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2050/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2050/comments | https://api.github.com/repos/huggingface/transformers/issues/2050/events | https://github.com/huggingface/transformers/issues/2050 | 532,692,235 | MDU6SXNzdWU1MzI2OTIyMzU= | 2,050 | [CamemBert] About SentencePiece training | {
"login": "loretoparisi",
"id": 163333,
"node_id": "MDQ6VXNlcjE2MzMzMw==",
"avatar_url": "https://avatars.githubusercontent.com/u/163333?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loretoparisi",
"html_url": "https://github.com/loretoparisi",
"followers_url": "https://api.github.com/u... | [] | closed | false | null | [] | [
"ping author @louismartin :)",
"Hi @loretoparisi, \r\nWe sampled 10**7 lines randomly from the pretraining corpus.\r\nThe size of the vocabulary was chosen to somewhat match the original BERT paper which used a 30k wordpiece vocabulary, so yes it's mostly arbitrary. ",
"@louismartin thanks a lot for the details... | 1,575 | 1,579 | 1,575 | CONTRIBUTOR | null | ## ❓ Questions & Help
According to the paper, SentencePiece uses a vocabulary of size of 32k subword tokens, learned on 107 sentences sampled from the pretraining dataset. How the sampling was performed? The chosen size of the vocabulary (32K subwords token) is related to the pretraining dataset in some way? Or it i... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2050/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2050/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2049 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2049/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2049/comments | https://api.github.com/repos/huggingface/transformers/issues/2049/events | https://github.com/huggingface/transformers/issues/2049 | 532,626,740 | MDU6SXNzdWU1MzI2MjY3NDA= | 2,049 | ModuleNotFoundError: No module named 'git' | {
"login": "wrzzd",
"id": 10881975,
"node_id": "MDQ6VXNlcjEwODgxOTc1",
"avatar_url": "https://avatars.githubusercontent.com/u/10881975?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wrzzd",
"html_url": "https://github.com/wrzzd",
"followers_url": "https://api.github.com/users/wrzzd/follow... | [] | closed | false | null | [] | [
"with referring to that file https://github.com/huggingface/transformers/blob/master/examples/distillation/requirements.txt\r\n\r\nrun:\r\n`pip install -r requirements.txt`",
"> with referring to that file https://github.com/huggingface/transformers/blob/master/examples/distillation/requirements.txt\r\n> \r\n> ru... | 1,575 | 1,577 | 1,577 | NONE | null | ## 🐛 Bug
`
Traceback (most recent call last):
File "train.py", line 32, in <module>
from distiller import Distiller
File "~/transformers/examples/distillation/distiller.py", line 40, in <module>
from utils import logger
File "~/transformers/examples/distillation/utils.py", line 18, in <m... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2049/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2049/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2048 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2048/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2048/comments | https://api.github.com/repos/huggingface/transformers/issues/2048/events | https://github.com/huggingface/transformers/issues/2048 | 532,590,840 | MDU6SXNzdWU1MzI1OTA4NDA= | 2,048 | Changing the number of hidden layers for BERT | {
"login": "paul-you",
"id": 23263212,
"node_id": "MDQ6VXNlcjIzMjYzMjEy",
"avatar_url": "https://avatars.githubusercontent.com/u/23263212?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/paul-you",
"html_url": "https://github.com/paul-you",
"followers_url": "https://api.github.com/users/pau... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi,\r\nThe first ones are loaded and there is currently no simple way to control this.",
"**Is there any evidence than the first layers is the best choice when reducing the number of layers ?**\r\n\r\nFor example in your article about Distil-Bert, you chose to initialize the student by taking the even layers. Wh... | 1,575 | 1,655 | 1,581 | NONE | null | ## ❓ Questions & Help
Hello,
when reducing the number of hidden layers for BERT, say from 12 to 3, which layers are loaded from the pretrained model, the first 3 layers or the last 3 ones? and is there a way to control this?
Thanks in advance
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2048/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2048/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2047 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2047/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2047/comments | https://api.github.com/repos/huggingface/transformers/issues/2047/events | https://github.com/huggingface/transformers/issues/2047 | 532,546,049 | MDU6SXNzdWU1MzI1NDYwNDk= | 2,047 | Tokenization in quickstart guide fails | {
"login": "yenicelik",
"id": 8946130,
"node_id": "MDQ6VXNlcjg5NDYxMzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/8946130?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yenicelik",
"html_url": "https://github.com/yenicelik",
"followers_url": "https://api.github.com/users/ye... | [] | closed | false | null | [] | [
"Oops, that appears to be my fault. Should be a quick fix though, so I'll try to make a PR on it right away. Sorry about that! :grimacing: ",
"Thanks man! :) yeah no worries, thought it may be a good idea to report haha"
] | 1,575 | 1,576 | 1,575 | NONE | null | ## 🐛 Bug
<!-- Important information -->
The same issue as in #226 re-appears in transformers==2.2.1 (it works on 2.1!)
I just encountered the same issue as @dhirajmadan1 with `transformers==2.2.1`. Is this expected somehow?
I am following the quickstart guide: https://huggingface.co/transformers/quickstart... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2047/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2047/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2046 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2046/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2046/comments | https://api.github.com/repos/huggingface/transformers/issues/2046/events | https://github.com/huggingface/transformers/pull/2046 | 532,532,163 | MDExOlB1bGxSZXF1ZXN0MzQ4NzYxMzk2 | 2,046 | Add NER TF2 example. | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2046?src=pr&el=h1) Report\n> Merging [#2046](https://codecov.io/gh/huggingface/transformers/pull/2046?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/7edb51f3a516ca533797fb2bb2f2b7ce86e0df70?src=pr&el=desc) will **i... | 1,575 | 1,578 | 1,575 | CONTRIBUTOR | null | Create a NER example similar to the Pytorch one. It takes the same options, and can be run the same way.
As you asked @julien-c I prefered I did a fresh new PR :) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2046/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2046/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2046",
"html_url": "https://github.com/huggingface/transformers/pull/2046",
"diff_url": "https://github.com/huggingface/transformers/pull/2046.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2046.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2045 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2045/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2045/comments | https://api.github.com/repos/huggingface/transformers/issues/2045/events | https://github.com/huggingface/transformers/pull/2045 | 532,497,609 | MDExOlB1bGxSZXF1ZXN0MzQ4NzMyOTUx | 2,045 | Remove dead code in tests. | {
"login": "aaugustin",
"id": 788910,
"node_id": "MDQ6VXNlcjc4ODkxMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/788910?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aaugustin",
"html_url": "https://github.com/aaugustin",
"followers_url": "https://api.github.com/users/aaug... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2045?src=pr&el=h1) Report\n> Merging [#2045](https://codecov.io/gh/huggingface/transformers/pull/2045?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/7edb51f3a516ca533797fb2bb2f2b7ce86e0df70?src=pr&el=desc) will **i... | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2045/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2045/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2045",
"html_url": "https://github.com/huggingface/transformers/pull/2045",
"diff_url": "https://github.com/huggingface/transformers/pull/2045.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2045.patch",
"merged_at": 1... | |
https://api.github.com/repos/huggingface/transformers/issues/2044 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2044/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2044/comments | https://api.github.com/repos/huggingface/transformers/issues/2044/events | https://github.com/huggingface/transformers/pull/2044 | 532,467,545 | MDExOlB1bGxSZXF1ZXN0MzQ4NzA4MTQ2 | 2,044 | CLI for authenticated file sharing | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-... | [] | closed | false | null | [] | [
"Seen in person with @julien-c, really slick implementation!",
"Can't wait to test it 😊",
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2044?src=pr&el=h1) Report\n> Merging [#2044](https://codecov.io/gh/huggingface/transformers/pull/2044?src=pr&el=desc) into [master](https://codecov.io/gh/hu... | 1,575 | 1,575 | 1,575 | MEMBER | null | ping review @mfuntowicz & @thomwolf
(I'll fix the tests for Python 2 and Python 3.5 tomorrow)
To create an account in `staging` (used by the tests): https://moon-staging.huggingface.co/join
To create an account in `production` (used by the CLI): https://huggingface.co/join | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2044/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2044/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2044",
"html_url": "https://github.com/huggingface/transformers/pull/2044",
"diff_url": "https://github.com/huggingface/transformers/pull/2044.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2044.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2043 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2043/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2043/comments | https://api.github.com/repos/huggingface/transformers/issues/2043/events | https://github.com/huggingface/transformers/issues/2043 | 532,383,935 | MDU6SXNzdWU1MzIzODM5MzU= | 2,043 | Missing xlm-mlm-100-1280 | {
"login": "andompesta",
"id": 6725612,
"node_id": "MDQ6VXNlcjY3MjU2MTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/6725612?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/andompesta",
"html_url": "https://github.com/andompesta",
"followers_url": "https://api.github.com/users... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"It works with **PyTorch**, but not with **TensorFlow**. I'm using Python 3.6.9, Transformers 2.2.1 (installed with `pip install transformers`), PyTorch 1.3.1 and TensorFlow 2.0.0.\r\nWith TensorFlow, the stack trace is the following:\r\n```\r\n> from transformers import TFXLMForSequenceClassification\r\n> model = ... | 1,575 | 1,581 | 1,581 | CONTRIBUTOR | null | ## 🐛 Bug
For some reason I can't download the xlm-mlm-100-1280 model for tensorflow 2.0
Model I am using (Bert, XLNet....): XLM
Language I am using the model on (English, Chinese....): 100 languages
The problem arise when using:
```TFXLMForSequenceClassification.from_pretrained("xlm-mlm-100-1280")```
#... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2043/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2043/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2042 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2042/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2042/comments | https://api.github.com/repos/huggingface/transformers/issues/2042/events | https://github.com/huggingface/transformers/issues/2042 | 532,380,866 | MDU6SXNzdWU1MzIzODA4NjY= | 2,042 | UnboundLocalError: local variable 'extended_attention_mask' referenced before assignment | {
"login": "aclifton314",
"id": 53267795,
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aclifton314",
"html_url": "https://github.com/aclifton314",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"You forgot to add the batch size.\r\nYou can either\r\n- do `input_ids = tokenizer.encode('A sentence to encode with roberta.', add_special_tokens=True, return_tensors='pt')`\r\n- or `input_ids = torch.tensor([tokenizer.encode('A sentence to encode with roberta.')])`\r\n\r\nBut for a specific reason, the current f... | 1,575 | 1,575 | 1,575 | NONE | null | ## Finetuning Setup
* Model: roberta-base
* Language: english
* OS: Ubuntu 18.04.3
* Python version: 3.7.3
* PyTorch version: 1.3.1+cpu
* PyTorch Transformers version (or branch): 2.2.0
* Using GPU ? No
* Distributed of parallel setup ? No
* Script inputs:
```
python run_lm_finetuning.py \
--output_dir=$OUT... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2042/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2042/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2041 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2041/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2041/comments | https://api.github.com/repos/huggingface/transformers/issues/2041/events | https://github.com/huggingface/transformers/issues/2041 | 532,375,160 | MDU6SXNzdWU1MzIzNzUxNjA= | 2,041 | How do I load a pretrained file offline? | {
"login": "zysNLP",
"id": 45376689,
"node_id": "MDQ6VXNlcjQ1Mzc2Njg5",
"avatar_url": "https://avatars.githubusercontent.com/u/45376689?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zysNLP",
"html_url": "https://github.com/zysNLP",
"followers_url": "https://api.github.com/users/zysNLP/fo... | [] | closed | false | null | [] | [
"You can do it, instead of loading `from_pretrained(roberta.large)` like this download the respective `config.json` and `<mode_name>.bin` and save it on your folder then just write \r\n`.from_pretrained('Users/<location>/<your folder name>')` and thats about it.",
"OK, Thank you very much!",
"@shashankMadan-des... | 1,575 | 1,637 | 1,575 | NONE | null | ## ❓ Questions & Help
Hi, when I use "RobertaModel.from_pretrained(roberta.large)" to load model. A progress bar appears to download the pre-training model. I've already downloaded files like "roberta-large-pytorch_model.bin ". How can I stop automatically downloading files to the ".cache" folder and instead specify... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2041/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2041/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2040 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2040/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2040/comments | https://api.github.com/repos/huggingface/transformers/issues/2040/events | https://github.com/huggingface/transformers/issues/2040 | 532,214,948 | MDU6SXNzdWU1MzIyMTQ5NDg= | 2,040 | XLM-R Support | {
"login": "josecannete",
"id": 12201153,
"node_id": "MDQ6VXNlcjEyMjAxMTUz",
"avatar_url": "https://avatars.githubusercontent.com/u/12201153?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/josecannete",
"html_url": "https://github.com/josecannete",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"The latest news about using XLM-R model with Transformers are discussed in #1769 \r\nBriefly, **at the moment it's not possible to use this model with Transformers directly**.\r\n\r\n> ## Questions & Help\r\n> Hello!\r\n> \r\n> Is there a way to use XLM-R (https://github.com/pytorch/fairseq/blob/master/examples/x... | 1,575 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
Hello!
Is there a way to use XLM-R (https://github.com/pytorch/fairseq/blob/master/examples/xlmr/README.md) with the library of transformers? maybe via RoBERTa? can you provide some guidance on this please?
Thank you in advance | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2040/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2040/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2039 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2039/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2039/comments | https://api.github.com/repos/huggingface/transformers/issues/2039/events | https://github.com/huggingface/transformers/issues/2039 | 532,206,287 | MDU6SXNzdWU1MzIyMDYyODc= | 2,039 | Meaning of run_lm_finetuning.py output | {
"login": "aclifton314",
"id": 53267795,
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aclifton314",
"html_url": "https://github.com/aclifton314",
"followers_url": "https://api.github.com/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I have a similar question. When using default settings, does anything change in the tokenizer? Is the tokenizer fine-tuned in anyway (or is any vocabulary added)? In other words, is the vocab.txt of use in any way, when using the default tokenizer? If not, I assume that you only need the `pytorch_model.bin` file a... | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
Is there documentation somewhere about what the various output files that get created when running `run_lm_finetuning.py` are and what the meaning of their contents is? Concretely, what are the files and directories:
```
added_tokens.json
checkpoint-50/
checkpoint-100/
checkpoint-150/ ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2039/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2039/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2038 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2038/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2038/comments | https://api.github.com/repos/huggingface/transformers/issues/2038/events | https://github.com/huggingface/transformers/issues/2038 | 532,169,722 | MDU6SXNzdWU1MzIxNjk3MjI= | 2,038 | run_squad with xlm: Dataparallel has no attribute config. | {
"login": "waalge",
"id": 47293755,
"node_id": "MDQ6VXNlcjQ3MjkzNzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/47293755?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waalge",
"html_url": "https://github.com/waalge",
"followers_url": "https://api.github.com/users/waalge/fo... | [] | closed | false | null | [] | [
"Having exactly same error when updating to transformers v2.2.1, have you fix the bug yet?\r\n\r\n\r\n`12/05/2019 08:57:41 - INFO - __main__ - Saving features into cached file ./datasets/SQuAD/cached_dev_xlnet-base-cased_384\r\n12/05/2019 08:57:53 - INFO - __main__ - ***** Running evaluation *****\r\n12/05/201... | 1,575 | 1,576 | 1,576 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using XLM.
Language I am using the model on English:
The problem arise when using:
* [x] the official example scripts: run_squad.py
## To Reproduce
Steps to reproduce the behavior:
1. Azure VM with 2 GPUs
2. run_squad with XLM
3. Everything fi... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2038/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2038/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2037 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2037/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2037/comments | https://api.github.com/repos/huggingface/transformers/issues/2037/events | https://github.com/huggingface/transformers/issues/2037 | 532,012,007 | MDU6SXNzdWU1MzIwMTIwMDc= | 2,037 | how to select best model in run_glue | {
"login": "TLCFYBJJHYYSND",
"id": 46642887,
"node_id": "MDQ6VXNlcjQ2NjQyODg3",
"avatar_url": "https://avatars.githubusercontent.com/u/46642887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TLCFYBJJHYYSND",
"html_url": "https://github.com/TLCFYBJJHYYSND",
"followers_url": "https://api.gi... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
i'm a green hand and i know it is a rediculous problem.I just saw
` # Saving best-practices: if you use defaults names for the model, you can reload it using from_pretrained()
if args.do_train and (args.local_rank == -1 or tor... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2037/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2037/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2036 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2036/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2036/comments | https://api.github.com/repos/huggingface/transformers/issues/2036/events | https://github.com/huggingface/transformers/issues/2036 | 531,907,761 | MDU6SXNzdWU1MzE5MDc3NjE= | 2,036 | error | {
"login": "rhl2k",
"id": 35575379,
"node_id": "MDQ6VXNlcjM1NTc1Mzc5",
"avatar_url": "https://avatars.githubusercontent.com/u/35575379?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rhl2k",
"html_url": "https://github.com/rhl2k",
"followers_url": "https://api.github.com/users/rhl2k/follow... | [] | closed | false | null | [] | [
"Please, post the command and all the parameters in order to understand deeply your problem. Moreover, please specify your environment (e.g. Python version, PyTorch version, TensorFlow version, Transformers version, OS).\r\n\r\n> ## Questions & Help\r\n> 12/03/2019 09:12:25 - INFO - transformers.modeling_utils - l... | 1,575 | 1,591 | 1,575 | NONE | null | ## ❓ Questions & Help
12/03/2019 09:12:25 - INFO - transformers.modeling_utils - loading weights file model_check_points112/pytorch_model.bin
12/03/2019 09:12:40 - INFO - __main__ - Creating features from dataset file at dev-v1.1.json
Traceback (most recent call last):
File "run_squad.py", line 558, in <mod... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2036/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2036/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2035 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2035/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2035/comments | https://api.github.com/repos/huggingface/transformers/issues/2035/events | https://github.com/huggingface/transformers/issues/2035 | 531,891,504 | MDU6SXNzdWU1MzE4OTE1MDQ= | 2,035 | Doubts on modeling_gpt2.py | {
"login": "shashankMadan-designEsthetics",
"id": 45225143,
"node_id": "MDQ6VXNlcjQ1MjI1MTQz",
"avatar_url": "https://avatars.githubusercontent.com/u/45225143?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shashankMadan-designEsthetics",
"html_url": "https://github.com/shashankMadan-designE... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Can anyone answer it please...",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,582 | 1,582 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi, I've been going through the gpt2 source code and i was tracing out how the self attention and feed forward work basically we have `Block` which is a decoder consisting of other 2 segments `Attention` and `MLP`. I was also reading a ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2035/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2035/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2034 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2034/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2034/comments | https://api.github.com/repos/huggingface/transformers/issues/2034/events | https://github.com/huggingface/transformers/pull/2034 | 531,853,456 | MDExOlB1bGxSZXF1ZXN0MzQ4MjI0Mzkz | 2,034 | Updated examples/README and parser for run_summarization_finetuning | {
"login": "DerekChia",
"id": 1457728,
"node_id": "MDQ6VXNlcjE0NTc3Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/1457728?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DerekChia",
"html_url": "https://github.com/DerekChia",
"followers_url": "https://api.github.com/users/De... | [] | closed | false | null | [] | [
"Let's wait that the summarization script is finalized before merging this."
] | 1,575 | 1,576 | 1,576 | CONTRIBUTOR | null | 1. Updated `examples/README.md` to change default `--model_type` and `--model_name_or_path` to `bert` and `bert_base_cased` because `bert2bert` just won't work
2. Updated `examples/run_summarization_finetuning.py` parser to take in `--do-train` instead of `--do-train=True` for consistency with other examples and `--mo... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2034/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2034/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2034",
"html_url": "https://github.com/huggingface/transformers/pull/2034",
"diff_url": "https://github.com/huggingface/transformers/pull/2034.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2034.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/2033 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2033/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2033/comments | https://api.github.com/repos/huggingface/transformers/issues/2033/events | https://github.com/huggingface/transformers/issues/2033 | 531,777,083 | MDU6SXNzdWU1MzE3NzcwODM= | 2,033 | run_lm_finetuning.py script CLM inputs and labels preparing | {
"login": "AliOsm",
"id": 7662492,
"node_id": "MDQ6VXNlcjc2NjI0OTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/7662492?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AliOsm",
"html_url": "https://github.com/AliOsm",
"followers_url": "https://api.github.com/users/AliOsm/foll... | [] | closed | false | null | [] | [
"Ok, in [modeling_gpt2.py](https://github.com/huggingface/transformers/blob/master/transformers/modeling_gpt2.py) file I found this comment in line `495`:\r\n\r\n```\r\nNote that the labels **are shifted** inside the model, i.e. you can set ``lm_labels = input_ids``\r\n```\r\n\r\nSo, the model takes care of the shi... | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | I'm trying to finetune the GPT-2 on my own dataset, while I'm reading the code in `run_lm_finetuning.py` script, I found a weird thing in line `227`. When the script preparing CLM batch inputs and labels, it gives the model the same `batch` variable as inputs and labels:
```
inputs, labels = mask_tokens(batch, toke... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2033/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/transformers/issues/2033/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2032 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2032/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2032/comments | https://api.github.com/repos/huggingface/transformers/issues/2032/events | https://github.com/huggingface/transformers/issues/2032 | 531,721,228 | MDU6SXNzdWU1MzE3MjEyMjg= | 2,032 | Any workaround to extend the embeddings on TFGPT2DoubleHeadsModel? | {
"login": "alexorona",
"id": 11825654,
"node_id": "MDQ6VXNlcjExODI1NjU0",
"avatar_url": "https://avatars.githubusercontent.com/u/11825654?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alexorona",
"html_url": "https://github.com/alexorona",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [
{
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.gi... | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,581 | 1,581 | CONTRIBUTOR | null | Getting access to Keras' `model.fit()` method makes life so much easier for transfer learning/fine-tuning, but TFGPT2DoubleHeadsModel doesn't currently support extending embeddings, so it really restricts practical applications. You almost always have to add something to the vocabulary / generate special tokens. Does a... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2032/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2032/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2031 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2031/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2031/comments | https://api.github.com/repos/huggingface/transformers/issues/2031/events | https://github.com/huggingface/transformers/issues/2031 | 531,703,735 | MDU6SXNzdWU1MzE3MDM3MzU= | 2,031 | Typo in modeling_albert.py for mask_token | {
"login": "blmoistawinde",
"id": 32953014,
"node_id": "MDQ6VXNlcjMyOTUzMDE0",
"avatar_url": "https://avatars.githubusercontent.com/u/32953014?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/blmoistawinde",
"html_url": "https://github.com/blmoistawinde",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [
"Indeed, good catch, thanks! Fixed on master."
] | 1,575 | 1,575 | 1,575 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Albert
Language I am using the model on (English, Chinese....): English
## To Reproduce
```
tokenizer_class, pretrained_weights = AlbertTokenizer, "albert-base-v1"
tokenizer = tokenizer_class.from_pretrained(pretrained_weights... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2031/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 1,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2031/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2030 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2030/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2030/comments | https://api.github.com/repos/huggingface/transformers/issues/2030/events | https://github.com/huggingface/transformers/issues/2030 | 531,612,289 | MDU6SXNzdWU1MzE2MTIyODk= | 2,030 | cannot import name 'WEIGHTS_NAME' | {
"login": "aclifton314",
"id": 53267795,
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aclifton314",
"html_url": "https://github.com/aclifton314",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"This is **not** a bug! It works as expected.\r\n```\r\n> from transformers import WEIGHTS_NAME\r\n> \r\n```\r\n\r\nI've tried with the latest version of Transformers, installed with `pip install transformers`\r\n\r\nThe variable _WEIGHTS_NAME_ is located in [file_utils.py](https://github.com/huggingface/transforme... | 1,575 | 1,575 | 1,575 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): gpt2
Language I am using the model on (English, Chinese....): english
The problem arise when using:
* [X] the official example scripts: `run_lm_finetuning.py`
* [ ] my own modified scripts: (give details)
## To Reproduce
St... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2030/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2030/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2029 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2029/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2029/comments | https://api.github.com/repos/huggingface/transformers/issues/2029/events | https://github.com/huggingface/transformers/issues/2029 | 531,527,710 | MDU6SXNzdWU1MzE1Mjc3MTA= | 2,029 | gpt-2 generation examples | {
"login": "cloudygoose",
"id": 1544039,
"node_id": "MDQ6VXNlcjE1NDQwMzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/1544039?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cloudygoose",
"html_url": "https://github.com/cloudygoose",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | [
"You can tune the value for **temperature** and **seed**. **Temperature** is a hyper-parameter used to control the randomness of predictions by scaling the logits before applying softmax.\r\n- when temperature is a small value (e.g. 0,2), the GPT-2 model is more confident but also more conservative\r\n- when temper... | 1,575 | 1,598 | 1,575 | NONE | null | ## ❓ Questions & Help
Hi! Thanks for everything, I want to try generation with the gpt-2 model, following:
```
python ./examples/run_generation.py \
--model_type=gpt2 \
--length=20 \
--model_name_or_path=gpt2 \
```
But it does not seem to work very well, for example (Prompt -> Generation):
i go t... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2029/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2029/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2028 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2028/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2028/comments | https://api.github.com/repos/huggingface/transformers/issues/2028/events | https://github.com/huggingface/transformers/issues/2028 | 531,298,315 | MDU6SXNzdWU1MzEyOTgzMTU= | 2,028 | [CamemBERT] Potential error in the docs | {
"login": "manueltonneau",
"id": 29440170,
"node_id": "MDQ6VXNlcjI5NDQwMTcw",
"avatar_url": "https://avatars.githubusercontent.com/u/29440170?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/manueltonneau",
"html_url": "https://github.com/manueltonneau",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [
"RoBERTa and BERT (and CamemBERT) share mostly the same model architecture. Most of the differences lie in:\r\n- the tokenizers\r\n- the pre-training method\r\n\r\ncc @LysandreJik ",
"Cool, thanks for the reply! :) "
] | 1,575 | 1,575 | 1,575 | NONE | null | Thanks for the great work on this repo! As I was going through the details about the available pre-trained models (https://huggingface.co/transformers/v2.2.0/pretrained_models.html), I spotted what I think is an error in the description of camembert-base (12-layer, 768-hidden, 12-heads, 110M parameters; CamemBERT using... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2028/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2028/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2027 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2027/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2027/comments | https://api.github.com/repos/huggingface/transformers/issues/2027/events | https://github.com/huggingface/transformers/issues/2027 | 531,158,878 | MDU6SXNzdWU1MzExNTg4Nzg= | 2,027 | Tokenization differs for different intepreter instances | {
"login": "pglock",
"id": 8183619,
"node_id": "MDQ6VXNlcjgxODM2MTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/8183619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pglock",
"html_url": "https://github.com/pglock",
"followers_url": "https://api.github.com/users/pglock/foll... | [] | closed | false | null | [] | [
"By using **Python 3.6.9**, the results is the following:\r\n\r\n```\r\n> from transformers import BertTokenizer\r\n> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\n> for i in range(5):\r\n print(tokenizer.encode(\" \"))\r\n>>> [101, 100, 102]\r\n[101, 100, 102]\r\n[101, 100, 102]\r\n[101, 100... | 1,575 | 1,576 | 1,576 | CONTRIBUTOR | null | ## 🐛 Bug
<!-- Important information -->
Tokenization of `" "` changes for each python interpreter instance.
## To Reproduce
```python
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
for i in range(5):
print(tokenizer.encode(" "))
```
## Envi... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2027/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2027/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2026 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2026/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2026/comments | https://api.github.com/repos/huggingface/transformers/issues/2026/events | https://github.com/huggingface/transformers/issues/2026 | 531,157,044 | MDU6SXNzdWU1MzExNTcwNDQ= | 2,026 | Does GPT2LMHeadModel need <|startoftext|> and <|endoftext|> tokens? | {
"login": "huntekah",
"id": 15350580,
"node_id": "MDQ6VXNlcjE1MzUwNTgw",
"avatar_url": "https://avatars.githubusercontent.com/u/15350580?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/huntekah",
"html_url": "https://github.com/huntekah",
"followers_url": "https://api.github.com/users/hun... | [] | closed | false | null | [] | [
"Huggingface GPT2's default beggining of sentence token is `<|endoftext|>`, not `<|startoftext|>` as mentioned [here](https://huggingface.co/transformers/model_doc/gpt2.html#gpt2tokenizer). So either just use `<|endoftext|>` or replace tokenizer's default `bos` attribute with `<|startoftext|>`. Or you may add `<|st... | 1,575 | 1,586 | 1,575 | NONE | null | ## ❓ Does GPT2LMHeadModel need <|startoftext|> and <|endoftext|> tokens?
Hey!
I'm using GPT2LMHeadModel to get a good representation of a Language Model - I want to get probabilities for each word. The problem is - the **model predicts probabilities very well for all tokens except for the first one**. The first's... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2026/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2026/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2025 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2025/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2025/comments | https://api.github.com/repos/huggingface/transformers/issues/2025/events | https://github.com/huggingface/transformers/issues/2025 | 531,137,946 | MDU6SXNzdWU1MzExMzc5NDY= | 2,025 | How to convert a tf2 pre-trained model to pytorch model? | {
"login": "tomohideshibata",
"id": 16042472,
"node_id": "MDQ6VXNlcjE2MDQyNDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/16042472?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tomohideshibata",
"html_url": "https://github.com/tomohideshibata",
"followers_url": "https://api... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Have you ever tried [convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/blob/1ab8dc44b3d84ed1894f5b6a6fab58fb39298fc7/transformers/convert_bert_original_tf_checkpoint_to_pytorch.py)?\r\n\r\n> ## Questions & Help\r\n> I have trained a pre-trained model from scratch using... | 1,575 | 1,597 | 1,581 | CONTRIBUTOR | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I have trained a pre-trained model from scratch using a tensorflow 2.0 official script (run_pretraining.py).
https://github.com/tensorflow/models/tree/master/official/nlp/bert
My question is how to convert the pre-trained model to p... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2025/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2025/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2024 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2024/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2024/comments | https://api.github.com/repos/huggingface/transformers/issues/2024/events | https://github.com/huggingface/transformers/issues/2024 | 531,114,591 | MDU6SXNzdWU1MzExMTQ1OTE= | 2,024 | [ALBERT] : ValueError: Layer #1 (named "predictions") expects 11 weight(s), but the saved weights have 10 element(s). | {
"login": "gradient-school",
"id": 43513067,
"node_id": "MDQ6VXNlcjQzNTEzMDY3",
"avatar_url": "https://avatars.githubusercontent.com/u/43513067?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gradient-school",
"html_url": "https://github.com/gradient-school",
"followers_url": "https://api... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/... | [
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "htt... | [
"cc @LysandreJik ",
"It should be fixed now, thanks for raising an issue.",
"Thanks @LysandreJik for your prompt response. The issue mentioned above is resolved but I am getting an error in converting predicted IDs back to token using AlbertTokenizer. Here is the error that I am seeing (pred_index value below i... | 1,575 | 1,582 | 1,582 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): ALBERT
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
import tensorflow as tf
fr... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2024/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2024/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2023 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2023/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2023/comments | https://api.github.com/repos/huggingface/transformers/issues/2023/events | https://github.com/huggingface/transformers/issues/2023 | 531,102,011 | MDU6SXNzdWU1MzExMDIwMTE= | 2,023 | Is it possible to fine-tune models on TPUs using TensorFlow? | {
"login": "SebiSebi",
"id": 9403232,
"node_id": "MDQ6VXNlcjk0MDMyMzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/9403232?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SebiSebi",
"html_url": "https://github.com/SebiSebi",
"followers_url": "https://api.github.com/users/SebiS... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"following, would love to know if this is possible",
"We have some code in the `tpu-experiment` branch, for instance here: https://github.com/huggingface/transformers/tree/tpu-experiments/examples/TPU/tensorflow\r\n\r\nAnd planning to make it clean in the mid-term (not sure that will be before the end of the year... | 1,575 | 1,596 | 1,596 | NONE | null | I have looked at the release notes and found out that:
"Training on TPU using free TPUs provided in the TensorFlow Research Cloud (TFRC) program is possible but requires to implement a custom training loop (not possible with keras.fit at the moment).
We will add an example of such a custom training loop soon." (Not... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2023/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2023/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2022 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2022/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2022/comments | https://api.github.com/repos/huggingface/transformers/issues/2022/events | https://github.com/huggingface/transformers/issues/2022 | 531,065,677 | MDU6SXNzdWU1MzEwNjU2Nzc= | 2,022 | How to convert the ALBERT tfhub model to pytorch model? | {
"login": "jellying",
"id": 8729969,
"node_id": "MDQ6VXNlcjg3Mjk5Njk=",
"avatar_url": "https://avatars.githubusercontent.com/u/8729969?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jellying",
"html_url": "https://github.com/jellying",
"followers_url": "https://api.github.com/users/jelly... | [] | closed | false | null | [] | [
"Hi, if you ran the script `run_pretraining.py` in the original ALBERT repo, you should have put as argument an `--output_dir=dir`. In that directory should be several files, among which `model.ckpt-xxx.index`, `model.ckpt-xxx.meta`, `checkpoint` and `model.ckpt-xxx.data-xxxxx-of-xxxxx`.\r\n\r\nYou can pass this as... | 1,575 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I want to apply ALBERT to other QA datasets. But the first question is how to convert the tf_hub model. I downloaded the tfhub model from the repo "google research". The script ```convert_albert_original_tf_checkpoint_to_pytorch.py``` ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2022/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2022/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2021 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2021/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2021/comments | https://api.github.com/repos/huggingface/transformers/issues/2021/events | https://github.com/huggingface/transformers/issues/2021 | 531,065,347 | MDU6SXNzdWU1MzEwNjUzNDc= | 2,021 | save as tensorflow saved model format and how to inference? | {
"login": "cbqin",
"id": 38031554,
"node_id": "MDQ6VXNlcjM4MDMxNTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/38031554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cbqin",
"html_url": "https://github.com/cbqin",
"followers_url": "https://api.github.com/users/cbqin/follow... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"It's a mix of 2 issues:\r\n- you need to transform your input dict into function args\r\n- you need to expand batch dimension in all tensors\r\n\r\nPlease try:\r\n```\r\ninference_func(**({k: tf.expand_dims(v, axis=0) for k, v in inputs.items()}))\r\n```\r\n",
"This issue has been automatically marked as stale b... | 1,575 | 1,592 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi, l follow the script in readme, train a model and save as tensorflow saved_model format instead of h5 format.
When inferencing, I get some problem, I don't know how to feed the inputs to the model. Here is code.
```python
impor... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2021/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2021/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2020 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2020/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2020/comments | https://api.github.com/repos/huggingface/transformers/issues/2020/events | https://github.com/huggingface/transformers/issues/2020 | 531,034,498 | MDU6SXNzdWU1MzEwMzQ0OTg= | 2,020 | Camenbert length Tokenizer not equal config vocab_size | {
"login": "Keisn1",
"id": 42946489,
"node_id": "MDQ6VXNlcjQyOTQ2NDg5",
"avatar_url": "https://avatars.githubusercontent.com/u/42946489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Keisn1",
"html_url": "https://github.com/Keisn1",
"followers_url": "https://api.github.com/users/Keisn1/fo... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Indeed, upon deeper investigation, it appears that the original fairseq model has a bunch of duplicate tokens in the dictionary:\r\n```\r\nimport torch\r\ncamembert = torch.hub.load('pytorch/fairseq', 'camembert.v0')\r\nlist(camembert.task.source_dictionary[i] for i in range(10))\r\n>>> ['<s>', '<pad>', '</s>', '<... | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi there,
when I load the pretrained Camenbert model and tokenizer via
`model = CamembertForMaskedLM.from_pretrained('camembert-base')
tokenizer = CamembertTokenizer.from_pretrained('camembert-base')`
the length of the tokenize... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2020/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2020/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2019 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2019/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2019/comments | https://api.github.com/repos/huggingface/transformers/issues/2019/events | https://github.com/huggingface/transformers/issues/2019 | 531,027,431 | MDU6SXNzdWU1MzEwMjc0MzE= | 2,019 | [CamemBert] Tokenizer function add_tokens doesn't work | {
"login": "samuel-chp",
"id": 7936511,
"node_id": "MDQ6VXNlcjc5MzY1MTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/7936511?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/samuel-chp",
"html_url": "https://github.com/samuel-chp",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | [
"This method is **not** implemented into the CamemBERT tokenizer, at the moment.\r\n\r\n> ## Questions & Help\r\n> Hi,\r\n> \r\n> I am trying to add new tokens to the CamemBert tokenizer, but when I run the function tokenizer.add_tokens, it doesn't seem to add any token at all :\r\n> \r\n> `from transformers impor... | 1,575 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
Hi,
I am trying to add new tokens to the CamemBert tokenizer, but when I run the function tokenizer.add_tokens, it doesn't seem to add any token at all :
`from transformers import CamembertTokenizer`
`tokenizer = CamembertTokenizer.from_pretrained('camembert-base')`
`tokenizer.add_toke... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2019/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2019/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2018 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2018/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2018/comments | https://api.github.com/repos/huggingface/transformers/issues/2018/events | https://github.com/huggingface/transformers/issues/2018 | 530,969,833 | MDU6SXNzdWU1MzA5Njk4MzM= | 2,018 | FileNotFoundError: [Errno 2] No such file or directory: 'data/dump.txt' | {
"login": "MrLinNing",
"id": 24288811,
"node_id": "MDQ6VXNlcjI0Mjg4ODEx",
"avatar_url": "https://avatars.githubusercontent.com/u/24288811?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MrLinNing",
"html_url": "https://github.com/MrLinNing",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"As stated [here](https://github.com/huggingface/transformers/blob/1ab8dc44b3d84ed1894f5b6a6fab58fb39298fc7/examples/distillation/README.md), the `dump.txt` file is **your training file**. This file will contain one sequence per line (a sequence being composed of one of several coherent sentences).\r\n\r\n> @stefan... | 1,575 | 1,581 | 1,581 | NONE | null |
@stefan-it
Hello, I am new learner in BERT and I want to have a try the excellent work - distilBert.
But the problem happened when I ran the training step, and Could you tell me where can I download the `dump.txt` file ?
Thank you very much!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2018/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2018/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2017 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2017/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2017/comments | https://api.github.com/repos/huggingface/transformers/issues/2017/events | https://github.com/huggingface/transformers/issues/2017 | 530,793,245 | MDU6SXNzdWU1MzA3OTMyNDU= | 2,017 | How to use GPT-2 text generator in spanish | {
"login": "erdos-ml",
"id": 37878638,
"node_id": "MDQ6VXNlcjM3ODc4NjM4",
"avatar_url": "https://avatars.githubusercontent.com/u/37878638?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/erdos-ml",
"html_url": "https://github.com/erdos-ml",
"followers_url": "https://api.github.com/users/erd... | [] | closed | false | null | [] | [
"At the moment, there is **no pre-trained model in Spanish language**. If you want, you can use a **multi-lingual** pre-trained model, such as BERT or XLM. In particular, Transformers offer the following settings of multi-lingual models:\r\n- **bert-base-multilingual-cased** (Masked language modeling + Next sentenc... | 1,575 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I would like to know if there is a way to use the gpt-xl model for text generation in spanish.
The command I use to run the english text generation model is the following:
$ python ./examples/run_generation.py --model_type=gpt... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2017/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2017/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2016 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2016/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2016/comments | https://api.github.com/repos/huggingface/transformers/issues/2016/events | https://github.com/huggingface/transformers/issues/2016 | 530,791,341 | MDU6SXNzdWU1MzA3OTEzNDE= | 2,016 | GPT-2 finetuning with run_lm_finetuning.py script | {
"login": "dkajtoch",
"id": 32985207,
"node_id": "MDQ6VXNlcjMyOTg1MjA3",
"avatar_url": "https://avatars.githubusercontent.com/u/32985207?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dkajtoch",
"html_url": "https://github.com/dkajtoch",
"followers_url": "https://api.github.com/users/dka... | [] | closed | false | null | [] | [
"To me, you have set an extreme `batch_size`. Did you try it with e.g. `per_gpu_train_batch_size=1` and `per_gpu_eval_batch_size=1` ?",
"@iedmrc I finally managed to fine-tune it with `per_gpu_train_batch_size=1` and `gradient_accumulation_steps=32`. Indeed the batch size was the problem but I haven't realized it... | 1,575 | 1,578 | 1,575 | NONE | null | ## ❓ Questions & Help
I tried to finetune gpt-2 model using `run_lm_finetuning.py` script with the following parameters:
```
python run_lm_finetuning.py \
--train_data_file=text8.train \
--output_dir=/content/gpt2 \
--eval_data_file=text8.val \
--model_type=gpt2 \
--model_name_or_path=gpt2 \... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2016/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2016/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2015 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2015/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2015/comments | https://api.github.com/repos/huggingface/transformers/issues/2015/events | https://github.com/huggingface/transformers/issues/2015 | 530,785,803 | MDU6SXNzdWU1MzA3ODU4MDM= | 2,015 | [CamemBERT] Add CamembertForQuestionAnswering | {
"login": "alekseiancheruk",
"id": 32813010,
"node_id": "MDQ6VXNlcjMyODEzMDEw",
"avatar_url": "https://avatars.githubusercontent.com/u/32813010?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alekseiancheruk",
"html_url": "https://github.com/alekseiancheruk",
"followers_url": "https://api... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I wonder if loading as roberta really works for camembert",
"What do you mean with this statement?\r\n\r\n> I wonder if loading as roberta really works for camembert",
"Happy to review a PR for this (should be pretty easy to add!)",
"> \r\n> \r\n> What do you mean with this statement?\r\n> \r\n> > I wonder i... | 1,575 | 1,586 | 1,586 | NONE | null | Firstly, a huge thanks to Hugging Face team for their great work ! As we have now Camembert, it would be nice to use it for question answering using transformers ! You can find SQuAD in French on GitHub so it would be so easy to a lot of people to fine-tune Camembert for this task.
Please consider it in future rele... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2015/reactions",
"total_count": 4,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 4,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2015/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2014 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2014/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2014/comments | https://api.github.com/repos/huggingface/transformers/issues/2014/events | https://github.com/huggingface/transformers/pull/2014 | 530,765,038 | MDExOlB1bGxSZXF1ZXN0MzQ3MzUxMDc1 | 2,014 | Mark tests in TFAutoModelTest as slow. | {
"login": "aaugustin",
"id": 788910,
"node_id": "MDQ6VXNlcjc4ODkxMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/788910?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aaugustin",
"html_url": "https://github.com/aaugustin",
"followers_url": "https://api.github.com/users/aaug... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2014?src=pr&el=h1) Report\n> Merging [#2014](https://codecov.io/gh/huggingface/transformers/pull/2014?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b0ee7c7df3d49a819c4d6cef977214bd91f5c075?src=pr&el=desc) will **d... | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | Each test forces downloading the same 536MB file, which is slow
even with a decent internet connection. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2014/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2014/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2014",
"html_url": "https://github.com/huggingface/transformers/pull/2014",
"diff_url": "https://github.com/huggingface/transformers/pull/2014.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2014.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2013 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2013/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2013/comments | https://api.github.com/repos/huggingface/transformers/issues/2013/events | https://github.com/huggingface/transformers/issues/2013 | 530,759,814 | MDU6SXNzdWU1MzA3NTk4MTQ= | 2,013 | What is the real parameters to weight the triple loss (L_{ce}, L_{mlm}, L_{cos}) in DistilBert? | {
"login": "voidism",
"id": 26344602,
"node_id": "MDQ6VXNlcjI2MzQ0NjAy",
"avatar_url": "https://avatars.githubusercontent.com/u/26344602?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/voidism",
"html_url": "https://github.com/voidism",
"followers_url": "https://api.github.com/users/voidis... | [] | closed | false | null | [] | [
"Hello @voidism,\r\nThank you for your interest!\r\nThe parameters we used for training DistilBERT are the first one you listed: `--alpha_ce 5.0 --alpha_mlm 2.0 --alpha_cos 1.0 --alpha_clm 0.0`.\r\nVictor",
"@VictorSanh Thank you very much!"
] | 1,575 | 1,575 | 1,575 | NONE | null | Hello! Thanks for your great work DistilBert. I want to ask what is the real parameters "alpha" you used in DistilBert to weight the triple loss (L_{ce}, L_{mlm}, L_{cos})?
You did not mention this detail in your NIPS workshop paper (http://arxiv.org/abs/1910.01108). In the [README](https://github.com/huggingface/tr... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2013/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2013/timeline | completed | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.