
url stringlengths 62 66 | repository_url stringclasses 1
value | labels_url stringlengths 76 80 | comments_url stringlengths 71 75 | events_url stringlengths 69 73 | html_url stringlengths 50 56 | id int64 377M 2.15B | node_id stringlengths 18 32 | number int64 1 29.2k | title stringlengths 1 487 | user dict | labels list | state stringclasses 2
values | locked bool 2
classes | assignee dict | assignees list | comments list | created_at int64 1.54k 1.71k | updated_at int64 1.54k 1.71k | closed_at int64 1.54k 1.71k ⌀ | author_association stringclasses 4
values | active_lock_reason stringclasses 2
values | body stringlengths 0 234k ⌀ | reactions dict | timeline_url stringlengths 71 75 | state_reason stringclasses 3
values | draft bool 2
classes | pull_request dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/2012 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2012/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2012/comments | https://api.github.com/repos/huggingface/transformers/issues/2012/events | https://github.com/huggingface/transformers/issues/2012 | 530,697,350 | MDU6SXNzdWU1MzA2OTczNTA= | 2,012 | How to output the vectors of the last four layers of BERT_Model. | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [] | closed | false | null | [] | [
"TF or pytorch?\r\n\r\nIf what you want is TF, you can check #1936."
] | 1,575 | 1,575 | 1,575 | NONE | null | E.g
output = [the_last_one_layer_output, second_last_layer_output, ...] | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2012/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2012/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2011 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2011/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2011/comments | https://api.github.com/repos/huggingface/transformers/issues/2011/events | https://github.com/huggingface/transformers/pull/2011 | 530,695,368 | MDExOlB1bGxSZXF1ZXN0MzQ3MzA1NTMy | 2,011 | typo fix on the docs as per Pytorch v1.1+ | {
"login": "AdityaSoni19031997",
"id": 22738086,
"node_id": "MDQ6VXNlcjIyNzM4MDg2",
"avatar_url": "https://avatars.githubusercontent.com/u/22738086?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AdityaSoni19031997",
"html_url": "https://github.com/AdityaSoni19031997",
"followers_url": "ht... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2011?src=pr&el=h1) Report\n> Merging [#2011](https://codecov.io/gh/huggingface/transformers/pull/2011?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b0ee7c7df3d49a819c4d6cef977214bd91f5c075?src=pr&el=desc) will **n... | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | https://github.com/huggingface/transformers/issues/2010 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2011/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2011/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2011",
"html_url": "https://github.com/huggingface/transformers/pull/2011",
"diff_url": "https://github.com/huggingface/transformers/pull/2011.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2011.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2010 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2010/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2010/comments | https://api.github.com/repos/huggingface/transformers/issues/2010/events | https://github.com/huggingface/transformers/issues/2010 | 530,694,983 | MDU6SXNzdWU1MzA2OTQ5ODM= | 2,010 | Changing the docs as per Pytorch v1.1+ | {
"login": "AdityaSoni19031997",
"id": 22738086,
"node_id": "MDQ6VXNlcjIyNzM4MDg2",
"avatar_url": "https://avatars.githubusercontent.com/u/22738086?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AdityaSoni19031997",
"html_url": "https://github.com/AdityaSoni19031997",
"followers_url": "ht... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,580 | 1,580 | CONTRIBUTOR | null | ## ❓ Questions & Help
[Docs Link](https://huggingface.co/transformers/migration.html#optimizers-bertadam-openaiadam-are-now-adamw-schedules-are-standard-pytorch-schedules)
```
# From the Docs
### In Transformers, optimizer and schedules are splitted and instantiated like this:
optimizer = AdamW(model.parameter... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2010/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2010/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2009 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2009/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2009/comments | https://api.github.com/repos/huggingface/transformers/issues/2009/events | https://github.com/huggingface/transformers/issues/2009 | 530,675,557 | MDU6SXNzdWU1MzA2NzU1NTc= | 2,009 | Reason for using einsum in xlnet? | {
"login": "SungMinCho",
"id": 8216334,
"node_id": "MDQ6VXNlcjgyMTYzMzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/8216334?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SungMinCho",
"html_url": "https://github.com/SungMinCho",
"followers_url": "https://api.github.com/users... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,580 | 1,580 | NONE | null | ## ❓ Questions & Help
Hello.
This might be a newbie question, so I apologize in advance.
While reading your implementation of xlnet, I ran into several usages of `torch.einsum` function.
example) `k_head_h = torch.einsum('ibh,hnd->ibnd', cat, self.k) `
After studying the definition of einsum, I came to a... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2009/reactions",
"total_count": 6,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/transformers/issues/2009/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2008 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2008/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2008/comments | https://api.github.com/repos/huggingface/transformers/issues/2008/events | https://github.com/huggingface/transformers/issues/2008 | 530,636,971 | MDU6SXNzdWU1MzA2MzY5NzE= | 2,008 | Expand run_lm_finetuning.py to all models | {
"login": "iedmrc",
"id": 13666448,
"node_id": "MDQ6VXNlcjEzNjY2NDQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/13666448?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iedmrc",
"html_url": "https://github.com/iedmrc",
"followers_url": "https://api.github.com/users/iedmrc/fo... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Indeed, here are my 2 cents on that:\r\n- ctrl: easy to add (should work out of the box)\r\n- xlm: should also work out of the box (but need to check if the model is an mlm or a clm model to finetune)\r\n- albert: should work out of the box\r\n- transfo-xl: need to take care of history => a little more work\r\n- x... | 1,575 | 1,604 | 1,604 | CONTRIBUTOR | null | ## 🚀 Feature
[run_lm_finetuning.py](https://github.com/huggingface/transformers/blob/b0ee7c7df3d49a819c4d6cef977214bd91f5c075/examples/run_lm_finetuning.py) is a very useful tool for finetuning many models the library provided. But it doesn't cover all the models. Currently available models are:
- gpt2
- openai... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2008/reactions",
"total_count": 10,
"+1": 10,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2008/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2007 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2007/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2007/comments | https://api.github.com/repos/huggingface/transformers/issues/2007/events | https://github.com/huggingface/transformers/pull/2007 | 530,590,304 | MDExOlB1bGxSZXF1ZXN0MzQ3MjMxODQw | 2,007 | fixed XLNet attention output for both attention streams whenever target_mapping is provided | {
"login": "roskoN",
"id": 8143425,
"node_id": "MDQ6VXNlcjgxNDM0MjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8143425?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/roskoN",
"html_url": "https://github.com/roskoN",
"followers_url": "https://api.github.com/users/roskoN/foll... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2007?src=pr&el=h1) Report\n> Merging [#2007](https://codecov.io/gh/huggingface/transformers/pull/2007?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b0ee7c7df3d49a819c4d6cef977214bd91f5c075?src=pr&el=desc) will **i... | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | XLNet uses two separate attention streams, i.e. there are two separate tensors for representing the model's attention. Both of them need to have their dimensions permuted.
The problem has been described in #1994 . | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2007/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2007/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2007",
"html_url": "https://github.com/huggingface/transformers/pull/2007",
"diff_url": "https://github.com/huggingface/transformers/pull/2007.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2007.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2006 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2006/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2006/comments | https://api.github.com/repos/huggingface/transformers/issues/2006/events | https://github.com/huggingface/transformers/issues/2006 | 530,584,208 | MDU6SXNzdWU1MzA1ODQyMDg= | 2,006 | [ALBERT]: 'AlbertForMaskedLM' object has no attribute 'bias' | {
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"Same issue here. I did slightly different steps, but same result.\r\n\r\n```\r\nmodel = AlbertModel(config=config)\r\nmodel = load_tf_weights_in_albert(model,config,'sample_tf_checkpoint/model.ckpt-100000')\r\n```\r\nThen I get,\r\n\r\n```\r\n------------------------------------------------------------------------... | 1,575 | 1,676 | 1,575 | COLLABORATOR | null | Hi,
I wanted to convert an own trained ALBERT model with the `convert_albert_original_tf_checkpoint_to_pytorch.py` script:
```bash
$ python3 convert_albert_original_tf_checkpoint_to_pytorch.py --tf_checkpoint_path /mnt/albert-base-secrect-language-cased/ --albert_config_file /mnt/albert-base-secrect-language-cas... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2006/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2006/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2005 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2005/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2005/comments | https://api.github.com/repos/huggingface/transformers/issues/2005/events | https://github.com/huggingface/transformers/issues/2005 | 530,564,691 | MDU6SXNzdWU1MzA1NjQ2OTE= | 2,005 | tf.keras.mixed_precision.experimental.Policy | {
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/... | [] | closed | false | null | [] | [
"Sorry, I created this duplicated issue as the previous one. Please delete this one, thank you."
] | 1,575 | 1,575 | 1,575 | COLLABORATOR | null | ## ❓ Questions & Help
I want to use `mixed_precision`, and I found [tf.keras.mixed_precision.experimental.Policy](https://www.tensorflow.org/api_docs/python/tf/keras/mixed_precision/experimental/Policy).
So I put `tf.keras.mixed_precision.experimental.set_policy("mixed_float16")` before `TFBertModel.from_pretrain... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2005/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2005/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2004 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2004/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2004/comments | https://api.github.com/repos/huggingface/transformers/issues/2004/events | https://github.com/huggingface/transformers/issues/2004 | 530,564,118 | MDU6SXNzdWU1MzA1NjQxMTg= | 2,004 | Can we use tf.keras.mixed_precision.experimental.set_policy ? | {
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"For now we need to use:\r\n\r\n```python\r\ntf.config.optimizer.set_experimental_options({\"auto_mixed_precision\": True})\r\n```\r\n\r\nPlease see [example here](https://github.com/huggingface/transformers/blob/master/examples/run_tf_glue.py).",
"Thanks. I tried it during waiting the answer, and it doesn't spee... | 1,575 | 1,580 | 1,580 | COLLABORATOR | null | ## ❓ Questions & Help
I want to use `mixed_precision`, and I found [tf.keras.mixed_precision.experimental.Policy](https://www.tensorflow.org/api_docs/python/tf/keras/mixed_precision/experimental/Policy).
So I put `tf.keras.mixed_precision.experimental.set_policy("mixed_float16")` before `TFBertModel.from_pretrain... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2004/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/2004/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2003 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2003/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2003/comments | https://api.github.com/repos/huggingface/transformers/issues/2003/events | https://github.com/huggingface/transformers/issues/2003 | 530,553,015 | MDU6SXNzdWU1MzA1NTMwMTU= | 2,003 | Where I could find the vocab.json for XLNet | {
"login": "kugwzk",
"id": 15382517,
"node_id": "MDQ6VXNlcjE1MzgyNTE3",
"avatar_url": "https://avatars.githubusercontent.com/u/15382517?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kugwzk",
"html_url": "https://github.com/kugwzk",
"followers_url": "https://api.github.com/users/kugwzk/fo... | [] | closed | false | null | [] | [
"If you want to have `xlnet_config.json`, which is a JSON file which specifies the hyper-parameters of the XLNet model, you can download the .zip file from [here](https://github.com/zihangdai/xlnet/blob/5cd50bc451436e188a8e7fea15358d5a8c916b72/README.md) which contains the pre-trained weights of XLNet model.\r\n\r\... | 1,575 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I notice in tokenizer_xlnet.py there is not the vocab,json only spiece model. So I want to know where I could find the vocab.json? And what I should rename the file ? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2003/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2003/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2002 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2002/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2002/comments | https://api.github.com/repos/huggingface/transformers/issues/2002/events | https://github.com/huggingface/transformers/pull/2002 | 530,512,950 | MDExOlB1bGxSZXF1ZXN0MzQ3MTc4NDY3 | 2,002 | Always use SequentialSampler during evaluation | {
"login": "ethanjperez",
"id": 6402205,
"node_id": "MDQ6VXNlcjY0MDIyMDU=",
"avatar_url": "https://avatars.githubusercontent.com/u/6402205?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ethanjperez",
"html_url": "https://github.com/ethanjperez",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/2002?src=pr&el=h1) Report\n> Merging [#2002](https://codecov.io/gh/huggingface/transformers/pull/2002?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b0ee7c7df3d49a819c4d6cef977214bd91f5c075?src=pr&el=desc) will **n... | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | When evaluating, shouldn't we always use the SequentialSampler instead of DistributedSampler? Evaluation only runs on 1 GPU no matter what, so if you use the DistributedSampler with N GPUs, I think you'll only evaluate on 1/N of the evaluation set. That's at least what I'm finding when I run an older/modified version o... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2002/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2002/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/2002",
"html_url": "https://github.com/huggingface/transformers/pull/2002",
"diff_url": "https://github.com/huggingface/transformers/pull/2002.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/2002.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/2001 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2001/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2001/comments | https://api.github.com/repos/huggingface/transformers/issues/2001/events | https://github.com/huggingface/transformers/issues/2001 | 530,480,780 | MDU6SXNzdWU1MzA0ODA3ODA= | 2,001 | GPT2: how to construct batch for Language Modeling | {
"login": "cbaziotis",
"id": 5629093,
"node_id": "MDQ6VXNlcjU2MjkwOTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/5629093?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cbaziotis",
"html_url": "https://github.com/cbaziotis",
"followers_url": "https://api.github.com/users/cb... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"> I am a little confused about how to prepare input bathces for GPT2LMHeadModel. I want to use GPT2 as an LM. For instance, I want to generate probability distributions over the vocabulary at each timestep, as well as computing the perplexities of sentences. It is important to note that I am working with sentences... | 1,575 | 1,670 | 1,581 | NONE | null | I am a little confused about how to prepare input bathces for GPT2LMHeadModel. I want to use GPT2 as an LM. For instance, I want to generate probability distributions over the vocabulary at each timestep, as well as computing the perplexities of sentences. It is important to note that I am working with sentences and no... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2001/reactions",
"total_count": 28,
"+1": 5,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 23
} | https://api.github.com/repos/huggingface/transformers/issues/2001/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/2000 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/2000/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2000/comments | https://api.github.com/repos/huggingface/transformers/issues/2000/events | https://github.com/huggingface/transformers/issues/2000 | 530,393,842 | MDU6SXNzdWU1MzAzOTM4NDI= | 2,000 | Wrong tokenization in Transformer-XL documentation | {
"login": "DavidNemeskey",
"id": 690386,
"node_id": "MDQ6VXNlcjY5MDM4Ng==",
"avatar_url": "https://avatars.githubusercontent.com/u/690386?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DavidNemeskey",
"html_url": "https://github.com/DavidNemeskey",
"followers_url": "https://api.github.co... | [] | closed | false | null | [] | [
"Indeed, do you want to fix this in a PR?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,582 | 1,582 | CONTRIBUTOR | null | ## 🐛 Bug
This is a documentation-related bug. In the [TransfoXL documentation](https://huggingface.co/transformers/model_doc/transformerxl.html), the tokenization example is wrong. The snippet goes:
```
tokenizer = TransfoXLTokenizer.from_pretrained('transfo-xl-wt103')
...
input_ids = torch.tensor(tokenizer.enc... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/2000/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/2000/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1999 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1999/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1999/comments | https://api.github.com/repos/huggingface/transformers/issues/1999/events | https://github.com/huggingface/transformers/issues/1999 | 530,306,137 | MDU6SXNzdWU1MzAzMDYxMzc= | 1,999 | Training masked language model with Tensorflow | {
"login": "blackcat84",
"id": 25528598,
"node_id": "MDQ6VXNlcjI1NTI4NTk4",
"avatar_url": "https://avatars.githubusercontent.com/u/25528598?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/blackcat84",
"html_url": "https://github.com/blackcat84",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"> I've noticed that in the run_lm_finetuning example the model has an additional argument masked_lm_labels\r\n\r\nYes, I have the same issue here. Did you manage to port the example code to TF?\r\n\r\nIn the torch models the argument is interpreted as follows:\r\n\r\n```\r\n if masked_lm_labels is not None:... | 1,575 | 1,608 | 1,582 | NONE | null | ## ❓ Questions & Help
I'm trying to fine-tune a masked language model starting from bert-base-multilingual-cased with Tensorflow using the PyTorch-based example _examples/run_lm_finetuning_ as starting point. I'd like to take the multilingual model and adapt it to the Italian language.
Unfortunately I'm unable to f... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1999/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1999/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1998 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1998/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1998/comments | https://api.github.com/repos/huggingface/transformers/issues/1998/events | https://github.com/huggingface/transformers/pull/1998 | 530,299,983 | MDExOlB1bGxSZXF1ZXN0MzQ3MDEwMDQ4 | 1,998 | Added Camembert to available models | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1998?src=pr&el=h1) Report\n> Merging [#1998](https://codecov.io/gh/huggingface/transformers/pull/1998?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/1ab8dc44b3d84ed1894f5b6a6fab58fb39298fc7?src=pr&el=desc) will **i... | 1,575 | 1,575 | 1,575 | NONE | null | Added Camembert to the available models in the `run_lm_finetuning.py` example. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1998/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1998/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1998",
"html_url": "https://github.com/huggingface/transformers/pull/1998",
"diff_url": "https://github.com/huggingface/transformers/pull/1998.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1998.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1997 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1997/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1997/comments | https://api.github.com/repos/huggingface/transformers/issues/1997/events | https://github.com/huggingface/transformers/issues/1997 | 530,291,822 | MDU6SXNzdWU1MzAyOTE4MjI= | 1,997 | How to get a spiece.model from customize chinese vocab.txt in Albert xlnet ? | {
"login": "ciel-zhang",
"id": 18700473,
"node_id": "MDQ6VXNlcjE4NzAwNDcz",
"avatar_url": "https://avatars.githubusercontent.com/u/18700473?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ciel-zhang",
"html_url": "https://github.com/ciel-zhang",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Have you taken a look at [sentencepiece](https://github.com/google/sentencepiece)?",
"请问这个问题您解决了吗",
"I have the same problem. Have you solved it?",
"> Have you taken a look at [sentencepiece](https://github.com/google/sentencepiece)?\r\n\r\nI have taken a look at sentencepiece documents, but found nothing to... | 1,575 | 1,590 | 1,590 | NONE | null | ## ❓ Questions & Help
How to get a spiece.model from customize chinese vocab.txt in Albert xlnet ? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1997/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1997/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1996 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1996/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1996/comments | https://api.github.com/repos/huggingface/transformers/issues/1996/events | https://github.com/huggingface/transformers/issues/1996 | 530,284,664 | MDU6SXNzdWU1MzAyODQ2NjQ= | 1,996 | ALBERT is missing from AutoClasses | {
"login": "eladsegal",
"id": 13485709,
"node_id": "MDQ6VXNlcjEzNDg1NzA5",
"avatar_url": "https://avatars.githubusercontent.com/u/13485709?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eladsegal",
"html_url": "https://github.com/eladsegal",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [] | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | Pull request to fix this: https://github.com/huggingface/transformers/pull/1995
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1996/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1996/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1995 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1995/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1995/comments | https://api.github.com/repos/huggingface/transformers/issues/1995/events | https://github.com/huggingface/transformers/pull/1995 | 530,282,755 | MDExOlB1bGxSZXF1ZXN0MzQ2OTk1ODAy | 1,995 | Add ALBERT to AutoClasses | {
"login": "eladsegal",
"id": 13485709,
"node_id": "MDQ6VXNlcjEzNDg1NzA5",
"avatar_url": "https://avatars.githubusercontent.com/u/13485709?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eladsegal",
"html_url": "https://github.com/eladsegal",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1995?src=pr&el=h1) Report\n> Merging [#1995](https://codecov.io/gh/huggingface/transformers/pull/1995?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/1ab8dc44b3d84ed1894f5b6a6fab58fb39298fc7?src=pr&el=desc) will **i... | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | Adds ALBERT to AutoClasses and also fixes some documentation mistakes along the way | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1995/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1995/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1995",
"html_url": "https://github.com/huggingface/transformers/pull/1995",
"diff_url": "https://github.com/huggingface/transformers/pull/1995.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1995.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1994 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1994/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1994/comments | https://api.github.com/repos/huggingface/transformers/issues/1994/events | https://github.com/huggingface/transformers/issues/1994 | 530,276,139 | MDU6SXNzdWU1MzAyNzYxMzk= | 1,994 | XLnet output_attentions=True raises an exception | {
"login": "roskoN",
"id": 8143425,
"node_id": "MDQ6VXNlcjgxNDM0MjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8143425?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/roskoN",
"html_url": "https://github.com/roskoN",
"followers_url": "https://api.github.com/users/roskoN/foll... | [] | closed | false | null | [] | [
"The issue is fixed in #2007 ."
] | 1,575 | 1,575 | 1,575 | CONTRIBUTOR | null | ## 🐛 Bug
I am working on conditional sentences probabilities based on [this code](https://github.com/huggingface/transformers/issues/917#issuecomment-525297746) and whenever `output_attentions=True` and `target_mapping` is provided, there is an exception thrown.
Model I am using (Bert, XLNet....): XLNet ('xlnet... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1994/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1994/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1993 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1993/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1993/comments | https://api.github.com/repos/huggingface/transformers/issues/1993/events | https://github.com/huggingface/transformers/issues/1993 | 530,204,605 | MDU6SXNzdWU1MzAyMDQ2MDU= | 1,993 | Why is the weight of linear layer tied to the input embeddings in OpenAIGPTLMHeadModel? | {
"login": "KaitoHH",
"id": 13927774,
"node_id": "MDQ6VXNlcjEzOTI3Nzc0",
"avatar_url": "https://avatars.githubusercontent.com/u/13927774?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KaitoHH",
"html_url": "https://github.com/KaitoHH",
"followers_url": "https://api.github.com/users/KaitoH... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"The token embedding matrix and the linear layer of the **language modeling head** are indeed tied. The embedding matrix is used to map the vocabulary to vectors of last dimension `hidden_size`. \r\n\r\nThe linear layer is used to do the exact same thing, just the other way around -> mapping the model output of las... | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
Yes the original GPT paper also uses same `W_e` as both token embedding matrix and linear weight, and seems that many succeeding models like GPT-2, XLNet also use the same matrix. In my perspective, the token embedding matrix and the weight in linear layer have nothing related (though they have b... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1993/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1993/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1992 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1992/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1992/comments | https://api.github.com/repos/huggingface/transformers/issues/1992/events | https://github.com/huggingface/transformers/issues/1992 | 530,196,884 | MDU6SXNzdWU1MzAxOTY4ODQ= | 1,992 | Worse F1 on squad2 with finetune+distil distilroberta-base than just finetune | {
"login": "volker42maru",
"id": 51976664,
"node_id": "MDQ6VXNlcjUxOTc2NjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/51976664?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/volker42maru",
"html_url": "https://github.com/volker42maru",
"followers_url": "https://api.github.c... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"cc @VictorSanh ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,580 | 1,580 | NONE | null | Hi there,
I am trying to finetune distilroberta on squad2. First, I simply used the _distilroberta-base_ model and finetuned it on the squad2 dataset using `run_squad.py`, which gave me **74/71 F1/EM**. It's a lot worse than the roberta-base accuracy.
Currently, I am trying to finetune+distil (from roberta-base sq... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1992/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1992/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1991 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1991/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1991/comments | https://api.github.com/repos/huggingface/transformers/issues/1991/events | https://github.com/huggingface/transformers/issues/1991 | 530,191,102 | MDU6SXNzdWU1MzAxOTExMDI= | 1,991 | Facing AttributeError: 'DataParallel' object has no attribute 'resize_token_embeddings' | {
"login": "engrussman",
"id": 43364003,
"node_id": "MDQ6VXNlcjQzMzY0MDAz",
"avatar_url": "https://avatars.githubusercontent.com/u/43364003?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/engrussman",
"html_url": "https://github.com/engrussman",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [
"I've two GPUs install but I've not passed any argument to utilize both GPUs\r\n\r\n\r\n+-----------------------------------------------------------------------------+\r\n| NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 |\r\n|-------------------------------+----------------------+------... | 1,575 | 1,575 | 1,575 | NONE | null | ## 🐛 AttributeError: 'DataParallel' object has no attribute 'resize_token_embeddings'
<!-- Important information -->
I'm facing AttributeError: 'DataParallel' object has no attribute 'resize_token_embeddings' while performing fine-tuning by using run_lm_finetuning.py.
Following are the arguments:
python ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1991/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1991/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1990 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1990/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1990/comments | https://api.github.com/repos/huggingface/transformers/issues/1990/events | https://github.com/huggingface/transformers/issues/1990 | 530,187,794 | MDU6SXNzdWU1MzAxODc3OTQ= | 1,990 | When training QA models, albert-xxlarge-v2 uses much more GPU mem than Bert-large | {
"login": "fatmelon",
"id": 9691826,
"node_id": "MDQ6VXNlcjk2OTE4MjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9691826?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fatmelon",
"html_url": "https://github.com/fatmelon",
"followers_url": "https://api.github.com/users/fatme... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"\r\n\r\n\r\n\r\nThe parameters of Albert XXLarge is much less than that of Bert large, because al... | 1,575 | 1,632 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi,
When I used run_square.py to train QA model, I found that albert-xxlarge-v2 uses much more GPU mem than Bert-large. Specifically, when using Bert large, I can set `Max_sequence_ength = 512`, `bash_size = 12`. But when I ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1990/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1990/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1989 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1989/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1989/comments | https://api.github.com/repos/huggingface/transformers/issues/1989/events | https://github.com/huggingface/transformers/issues/1989 | 530,162,493 | MDU6SXNzdWU1MzAxNjI0OTM= | 1,989 | Will you add XLNet text-generation feature ? | {
"login": "efeiefei",
"id": 8653223,
"node_id": "MDQ6VXNlcjg2NTMyMjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8653223?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/efeiefei",
"html_url": "https://github.com/efeiefei",
"followers_url": "https://api.github.com/users/efeie... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Not in the short term",
"@thomwolf Thanks a lot",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,575 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
There is `run_generation.py` in example now. Do you have a plan to add feature of complete lm_finetune and inference? Just like GPT-2.
Thanks | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1989/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1989/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1988 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1988/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1988/comments | https://api.github.com/repos/huggingface/transformers/issues/1988/events | https://github.com/huggingface/transformers/issues/1988 | 530,117,809 | MDU6SXNzdWU1MzAxMTc4MDk= | 1,988 | Possible error in the HuggingFace Transformers documentation? | {
"login": "h56cho",
"id": 52889259,
"node_id": "MDQ6VXNlcjUyODg5MjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/52889259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h56cho",
"html_url": "https://github.com/h56cho",
"followers_url": "https://api.github.com/users/h56cho/fo... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"The documentation seems correct to me. Have you tried out the example code that's been provided? If you run it and check the resulting `lm_prediction_scores`, you'll see its shape is `torch.Size([1, 2, 7, 50258])`, 2 being the length of `choices`.\r\n\r\nThis comment, and the linked blog post, explains the *Double... | 1,574 | 1,580 | 1,580 | NONE | null | Hello,
According to HuggingFace Transformers documentation website (https://huggingface.co/transformers/model_doc/gpt2.html#gpt2doubleheadsmodel), under the GPT2DoubleHeadsModel, it defines the output lm_prediction_scores as the following:
`lm_prediction_scores: torch.FloatTensor of shape (batch_size, num_choices... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1988/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1988/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1987 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1987/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1987/comments | https://api.github.com/repos/huggingface/transformers/issues/1987/events | https://github.com/huggingface/transformers/pull/1987 | 530,116,651 | MDExOlB1bGxSZXF1ZXN0MzQ2ODY0NDU4 | 1,987 | Saving and resuming | {
"login": "bilal2vec",
"id": 29356759,
"node_id": "MDQ6VXNlcjI5MzU2NzU5",
"avatar_url": "https://avatars.githubusercontent.com/u/29356759?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bilal2vec",
"html_url": "https://github.com/bilal2vec",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1987?src=pr&el=h1) Report\n> Merging [#1987](https://codecov.io/gh/huggingface/transformers/pull/1987?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0cb163865a4c761c226b151283309eedb2b1ca4d?src=pr&el=desc) will **n... | 1,574 | 1,575 | 1,575 | CONTRIBUTOR | null | Here's my basic implementation of the saving and resuming improvements discussed in #1960. So far, I've only modified the `run_lm_finetuning` example, but if my changes are approved I can update the rest of the examples as well.
There are three main changes:
1. The example now saves the optimizer, scheduler, and ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1987/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1987/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1987",
"html_url": "https://github.com/huggingface/transformers/pull/1987",
"diff_url": "https://github.com/huggingface/transformers/pull/1987.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1987.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1986 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1986/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1986/comments | https://api.github.com/repos/huggingface/transformers/issues/1986/events | https://github.com/huggingface/transformers/issues/1986 | 530,106,494 | MDU6SXNzdWU1MzAxMDY0OTQ= | 1,986 | Fine Tuning Bert for Q&A | {
"login": "priteshpatel15",
"id": 7561895,
"node_id": "MDQ6VXNlcjc1NjE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7561895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/priteshpatel15",
"html_url": "https://github.com/priteshpatel15",
"followers_url": "https://api.gith... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"A quick workaround would be appending your data to the SQUAD training dataset and doing the fine-tuning as usual.\r\n",
"Yes thats an approach. I've been reading a bit more about GPT and GPT-2 ... i'm wondering if I could use the generative approach with fine-tuning on a specific task that would help with SQUAD... | 1,574 | 1,592 | 1,580 | NONE | null | This is more of a theoretical question. I would like to use a Bert Model trained on SQUAD 2.0 then train it further on my domain's Q&A dataset.
How would I do that. I've read through the code. As I understand it, I see that the BertforQuestionAnswering would be what I would need to use loaded with a model that is... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1986/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1986/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1985 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1985/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1985/comments | https://api.github.com/repos/huggingface/transformers/issues/1985/events | https://github.com/huggingface/transformers/issues/1985 | 530,093,716 | MDU6SXNzdWU1MzAwOTM3MTY= | 1,985 | run_squad.py for tf | {
"login": "RodSernaPerez",
"id": 37450380,
"node_id": "MDQ6VXNlcjM3NDUwMzgw",
"avatar_url": "https://avatars.githubusercontent.com/u/37450380?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RodSernaPerez",
"html_url": "https://github.com/RodSernaPerez",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [
"Not yet, but it's on the roadmap."
] | 1,574 | 1,575 | 1,575 | NONE | null | Is there any version of the script for fine tunning on Squad using tensorflow? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1985/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1985/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1984 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1984/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1984/comments | https://api.github.com/repos/huggingface/transformers/issues/1984/events | https://github.com/huggingface/transformers/pull/1984 | 530,091,802 | MDExOlB1bGxSZXF1ZXN0MzQ2ODQ1OTI5 | 1,984 | [WIP] Squad refactor | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1984?src=pr&el=h1) Report\n> Merging [#1984](https://codecov.io/gh/huggingface/transformers/pull/1984?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0cb163865a4c761c226b151283309eedb2b1ca4d?src=pr&el=desc) will **d... | 1,574 | 1,576 | 1,575 | MEMBER | null | This PR aims to refactor SQuAD to make it usable with all models with question answering heads, and without having to build the entire tokenization pipeline as it is currently done.
- It is based on processors that manage data, similarly to the GLUE processors. The two new processors are `SquadV1Processor` and `Squa... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1984/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1984/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1984",
"html_url": "https://github.com/huggingface/transformers/pull/1984",
"diff_url": "https://github.com/huggingface/transformers/pull/1984.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1984.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1983 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1983/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1983/comments | https://api.github.com/repos/huggingface/transformers/issues/1983/events | https://github.com/huggingface/transformers/issues/1983 | 530,075,921 | MDU6SXNzdWU1MzAwNzU5MjE= | 1,983 | add special tokens | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [] | closed | false | null | [] | [
"Do you load everything (model, data) on GPU?\r\n\r\n> Hello\r\n> I tried to add special tokens to bert tokenizer via add_special_tokens:\r\n> \r\n> ```\r\n> tokenizer.add_special_tokens({'additional_special_tokens':['SS']})\r\n> ```\r\n> \r\n> But I got CUDA error\r\n> \r\n> ```\r\n> CUDA error: device-side assert... | 1,574 | 1,575 | 1,575 | NONE | null | Hello
I tried to add special tokens to bert tokenizer via add_special_tokens:
```
tokenizer.add_special_tokens({'additional_special_tokens':['SS']})
```
But I got CUDA error
```
CUDA error: device-side assert triggered
```
The code runs without adding additional_special_tokens!
Any idea? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1983/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1983/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1981 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1981/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1981/comments | https://api.github.com/repos/huggingface/transformers/issues/1981/events | https://github.com/huggingface/transformers/issues/1981 | 530,000,684 | MDU6SXNzdWU1MzAwMDA2ODQ= | 1,981 | Transformers for WebNLG tasks | {
"login": "MathewAlexander",
"id": 36654272,
"node_id": "MDQ6VXNlcjM2NjU0Mjcy",
"avatar_url": "https://avatars.githubusercontent.com/u/36654272?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MathewAlexander",
"html_url": "https://github.com/MathewAlexander",
"followers_url": "https://api... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Actually I'm working on this right now. Interested to know as well if anyone else has done it.\r\nMost probably this is possible.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,574 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Can we leverage GPT-2 pre-trained model for WebNLG tasks ?http://webnlg.loria.fr/pages/challenge.html
The WebNLG challenge consists in mapping data to text
similar to what is being done in https://github.com/tyliupku/wiki2bio. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1981/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1981/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1980 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1980/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1980/comments | https://api.github.com/repos/huggingface/transformers/issues/1980/events | https://github.com/huggingface/transformers/pull/1980 | 529,957,107 | MDExOlB1bGxSZXF1ZXN0MzQ2NzM3Njgy | 1,980 | update all tf.shape and tensor.shape to shape_list | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1980?src=pr&el=h1) Report\n> :exclamation: No coverage uploaded for pull request base (`master@49a69d5`). [Click here to learn what that means](https://docs.codecov.io/docs/error-reference#section-missing-base-commit).\n> The diff coverage is `90.69%`... | 1,574 | 1,651 | 1,575 | MEMBER | null | We need to use the special method `shape_list` from `modeling_tf_utils` to be sure we can get TF 2.0 tensor shapes both in eager and non-eager mode.
This PR fixes this for all TF 2.0 models and templates. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1980/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1980/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1980",
"html_url": "https://github.com/huggingface/transformers/pull/1980",
"diff_url": "https://github.com/huggingface/transformers/pull/1980.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1980.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1979 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1979/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1979/comments | https://api.github.com/repos/huggingface/transformers/issues/1979/events | https://github.com/huggingface/transformers/issues/1979 | 529,954,270 | MDU6SXNzdWU1Mjk5NTQyNzA= | 1,979 | AlbertForQuestionAnswering | {
"login": "garkavem",
"id": 33484321,
"node_id": "MDQ6VXNlcjMzNDg0MzIx",
"avatar_url": "https://avatars.githubusercontent.com/u/33484321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/garkavem",
"html_url": "https://github.com/garkavem",
"followers_url": "https://api.github.com/users/gar... | [] | closed | false | null | [] | [
"Hi! The `albert` checkpoints only include the base model (the transformer model), and not the separate heads for each task (classification/question answering/...).\r\n\r\nFor question answering, you would have to first fine-tune the model to this specific task, as the question answering head is initialized randoml... | 1,574 | 1,612 | 1,575 | NONE | null | Hello! Thanks for adding Albert so quickly! I have a problem with Albert answering a simple question from the Huggingface default example:
```
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
model = AlbertForQuestionAnswering.from_pretrained('albert-base-v2')
question, text = "Who was Jim Henson?", "J... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1979/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1979/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1978 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1978/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1978/comments | https://api.github.com/repos/huggingface/transformers/issues/1978/events | https://github.com/huggingface/transformers/issues/1978 | 529,876,561 | MDU6SXNzdWU1Mjk4NzY1NjE= | 1,978 | Modify position_embeddings from pre_trained model | {
"login": "duyduc1110",
"id": 22440962,
"node_id": "MDQ6VXNlcjIyNDQwOTYy",
"avatar_url": "https://avatars.githubusercontent.com/u/22440962?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/duyduc1110",
"html_url": "https://github.com/duyduc1110",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [
"I think you **cannot** change this parameter because doing so you're trying to load weights with (512, 768) shape into an architecture with (1024, 768), and it's not possible.\r\nIf my statement is true (maybe some authors of Transformers can confirm or deny my statement), maybe a way to avoid that end users like ... | 1,574 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
When I load a model like below:
`model1 = BertForSequenceClassification.from_pretrained('bert-base-uncased')`
```
BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Em... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1978/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1978/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1977 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1977/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1977/comments | https://api.github.com/repos/huggingface/transformers/issues/1977/events | https://github.com/huggingface/transformers/issues/1977 | 529,734,085 | MDU6SXNzdWU1Mjk3MzQwODU= | 1,977 | 'convert_tf_checkpoint_to_pytorch.py' file is missing | {
"login": "imayachita",
"id": 3615586,
"node_id": "MDQ6VXNlcjM2MTU1ODY=",
"avatar_url": "https://avatars.githubusercontent.com/u/3615586?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/imayachita",
"html_url": "https://github.com/imayachita",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | [
"_PyTorch-pretrained-BERT_ is a older name of this library; now its name is **Transformers**.\r\nYou can check the latest docs of the library and install it from PyPi with `pip install transformers` (you have to install manually TensorFlow 2.0 and PyTorch as well through `pip install tensorflow==2.0.0` and `pip ins... | 1,574 | 1,575 | 1,575 | NONE | null | Hi all,
I pre-trained BERT base model on my domain-specific corpus using ```https://github.com/google-research/bert``` ```create_pretraining_data.py``` and ```run_pretraining.py```.
Now, I want to use it with this ```pytorch-transformers```. I saw from this page https://devhub.io/repos/huggingface-pytorch-pretrained... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1977/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1977/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1976 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1976/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1976/comments | https://api.github.com/repos/huggingface/transformers/issues/1976/events | https://github.com/huggingface/transformers/pull/1976 | 529,655,087 | MDExOlB1bGxSZXF1ZXN0MzQ2NDkxNjE5 | 1,976 | Merge pull request #1 from huggingface/master | {
"login": "ciel-zhang",
"id": 18700473,
"node_id": "MDQ6VXNlcjE4NzAwNDcz",
"avatar_url": "https://avatars.githubusercontent.com/u/18700473?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ciel-zhang",
"html_url": "https://github.com/ciel-zhang",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1976?src=pr&el=h1) Report\n> Merging [#1976](https://codecov.io/gh/huggingface/transformers/pull/1976?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/96e7ee72380a135bfd07b8fdc2018bcbea65b086?src=pr&el=desc) will **i... | 1,574 | 1,574 | 1,574 | NONE | null | merge | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1976/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1976/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1976",
"html_url": "https://github.com/huggingface/transformers/pull/1976",
"diff_url": "https://github.com/huggingface/transformers/pull/1976.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1976.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1975 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1975/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1975/comments | https://api.github.com/repos/huggingface/transformers/issues/1975/events | https://github.com/huggingface/transformers/issues/1975 | 529,612,630 | MDU6SXNzdWU1Mjk2MTI2MzA= | 1,975 | How can we view different versions of documentation? | {
"login": "drydenb",
"id": 9606974,
"node_id": "MDQ6VXNlcjk2MDY5NzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9606974?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/drydenb",
"html_url": "https://github.com/drydenb",
"followers_url": "https://api.github.com/users/drydenb/... | [] | closed | false | null | [] | [
"We're in the process of building better versioned documentation with easier links to follow, but at the moment the different versions are accessible in the [README](https://github.com/huggingface/transformers#state-of-the-art-natural-language-processing-for-tensorflow-20-and-pytorch), right before the `installatio... | 1,574 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
How can I select a specific version of transformers in the documentation located here: https://huggingface.co/transformers/index.html?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1975/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1975/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1974 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1974/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1974/comments | https://api.github.com/repos/huggingface/transformers/issues/1974/events | https://github.com/huggingface/transformers/issues/1974 | 529,591,822 | MDU6SXNzdWU1Mjk1OTE4MjI= | 1,974 | Albert Hyperparameters for Fine-tuning SQuAD 2.0 | {
"login": "ahotrod",
"id": 44321615,
"node_id": "MDQ6VXNlcjQ0MzIxNjE1",
"avatar_url": "https://avatars.githubusercontent.com/u/44321615?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ahotrod",
"html_url": "https://github.com/ahotrod",
"followers_url": "https://api.github.com/users/ahotro... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Wondering this as well but for GLUE tasks. There don't seem to be a good consensus on hyperparameters such as weight decay and such",
"Results using hyperparameters from my first post above, varying only batch size:\r\n```\r\nalbert_xxlargev1_squad2_512_bs32:\r\n{\r\n \"exact\": 83.67725090541565,\r\n \"f1\": ... | 1,574 | 1,582 | 1,582 | CONTRIBUTOR | null | ## ❓ Questions & Help
I want to fine-tune `albert-xxlarge-v1` on SQuAD 2.0 and am in need of optimal hyperparameters. I did not find any discussion in the Albert original paper regarding suggested fine-tuning hyperparameters, as is provided in the XLNet original paper. I did find the following hard-coded parameter... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1974/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1974/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1973 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1973/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1973/comments | https://api.github.com/repos/huggingface/transformers/issues/1973/events | https://github.com/huggingface/transformers/issues/1973 | 529,583,216 | MDU6SXNzdWU1Mjk1ODMyMTY= | 1,973 | Changes to S3 Roberta / RobertaForSequenceClassification | {
"login": "frankfka",
"id": 31530056,
"node_id": "MDQ6VXNlcjMxNTMwMDU2",
"avatar_url": "https://avatars.githubusercontent.com/u/31530056?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/frankfka",
"html_url": "https://github.com/frankfka",
"followers_url": "https://api.github.com/users/fra... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,574 | 1,580 | 1,580 | NONE | null | Hello,
I'm wondering if there have been any changes in either the pretrained Roberta model or the configuration of RobertaForSequenceClassification within the past month or so. I am initializing it as `RobertaForSequenceClassification.from_pretrained(...)` and running it as demonstrated in `run_glue.py`.
For a cust... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1973/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1973/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1972 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1972/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1972/comments | https://api.github.com/repos/huggingface/transformers/issues/1972/events | https://github.com/huggingface/transformers/issues/1972 | 529,502,784 | MDU6SXNzdWU1Mjk1MDI3ODQ= | 1,972 | How to persist cloud-based transformers | {
"login": "jmwoloso",
"id": 7530947,
"node_id": "MDQ6VXNlcjc1MzA5NDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7530947?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jmwoloso",
"html_url": "https://github.com/jmwoloso",
"followers_url": "https://api.github.com/users/jmwol... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Are you trying to serialize which type of model to .hdf5 file? A pre-trained model such as BertFor* or a custom model trained with Transformers? Are you using GCP or Azure or AWS?\r\n\r\n> ## Questions & Help\r\n> I'm using this repo in the cloud and attempting to persist the model fails as it seems HDF5 and thus... | 1,574 | 1,580 | 1,580 | CONTRIBUTOR | null | ## ❓ Questions & Help
I'm using this repo in the cloud and attempting to persist the model fails as it seems HDF5 and thus h5py doesn't support that paradigm per https://github.com/h5py/h5py/issues/925
What is the recommended method of saving the model in this scenario? Thanks!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1972/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1972/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1971 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1971/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1971/comments | https://api.github.com/repos/huggingface/transformers/issues/1971/events | https://github.com/huggingface/transformers/pull/1971 | 529,466,216 | MDExOlB1bGxSZXF1ZXN0MzQ2MzM4NDc5 | 1,971 | add add_special_tokens=True for input examples | {
"login": "yaolu",
"id": 8982361,
"node_id": "MDQ6VXNlcjg5ODIzNjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/8982361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yaolu",
"html_url": "https://github.com/yaolu",
"followers_url": "https://api.github.com/users/yaolu/follower... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1971?src=pr&el=h1) Report\n> Merging [#1971](https://codecov.io/gh/huggingface/transformers/pull/1971?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5afca00b4732f57329824e1538897e791e02e894?src=pr&el=desc) will **i... | 1,574 | 1,574 | 1,574 | CONTRIBUTOR | null | According to #1957 , in some versions of transformers, add_special_tokens is not set to True by default. In that case, the example code is wrong as input_ids will missing [CLS] and [SEP] tokens. It's better to pass add_special_tokens=True in the example explicitly. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1971/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1971/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1971",
"html_url": "https://github.com/huggingface/transformers/pull/1971",
"diff_url": "https://github.com/huggingface/transformers/pull/1971.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1971.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1970 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1970/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1970/comments | https://api.github.com/repos/huggingface/transformers/issues/1970/events | https://github.com/huggingface/transformers/issues/1970 | 529,445,889 | MDU6SXNzdWU1Mjk0NDU4ODk= | 1,970 | Bert Tensor Dimensions | {
"login": "halidziya",
"id": 9038065,
"node_id": "MDQ6VXNlcjkwMzgwNjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/9038065?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/halidziya",
"html_url": "https://github.com/halidziya",
"followers_url": "https://api.github.com/users/ha... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, thanks for letting us know. Is there any way you could provide a script that reproduces the error in a few lines so that we may see what is wrong on our end?",
"model.predict function fails with output_hidden_states=True in constructor",
"I'm failing to reproduce what you're mentioning with the following s... | 1,574 | 1,581 | 1,581 | NONE | null | ## 🐛 Bug
My code was working on 2.1 it throws an error in 2.2:
transformers\modeling_tf_bert.py:777 call
outputs = self.bert(inputs, **kwargs)
transformers\modeling_tf_bert.py:512 call
attention_mask = tf.fill(input_shape, 1)
tensorflow_core\python\ops\array_ops.py:171 fill
... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1970/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1970/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1969 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1969/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1969/comments | https://api.github.com/repos/huggingface/transformers/issues/1969/events | https://github.com/huggingface/transformers/pull/1969 | 529,445,528 | MDExOlB1bGxSZXF1ZXN0MzQ2MzIxNDY5 | 1,969 | Implemented concurrent encoding and converting of sequences for data binarization | {
"login": "sgraaf",
"id": 8904453,
"node_id": "MDQ6VXNlcjg5MDQ0NTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8904453?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgraaf",
"html_url": "https://github.com/sgraaf",
"followers_url": "https://api.github.com/users/sgraaf/foll... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1969?src=pr&el=h1) Report\n> Merging [#1969](https://codecov.io/gh/huggingface/transformers/pull/1969?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/49108288ba6e6dcfe554d1af98699ae7a1e6f39c?src=pr&el=desc) will **i... | 1,574 | 1,583 | 1,583 | NONE | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1969/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1969/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1969",
"html_url": "https://github.com/huggingface/transformers/pull/1969",
"diff_url": "https://github.com/huggingface/transformers/pull/1969.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1969.patch",
"merged_at": n... | |
https://api.github.com/repos/huggingface/transformers/issues/1968 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1968/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1968/comments | https://api.github.com/repos/huggingface/transformers/issues/1968/events | https://github.com/huggingface/transformers/issues/1968 | 529,387,673 | MDU6SXNzdWU1MjkzODc2NzM= | 1,968 | AlbertPreTrainedModel class is not available in release v2.2.0 | {
"login": "bugface",
"id": 16659741,
"node_id": "MDQ6VXNlcjE2NjU5NzQx",
"avatar_url": "https://avatars.githubusercontent.com/u/16659741?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bugface",
"html_url": "https://github.com/bugface",
"followers_url": "https://api.github.com/users/bugfac... | [] | closed | false | null | [] | [
"Hi, indeed there was a mistake with `TFBertForPretraining` referenced under the ALBERT documentation. This was fixed with 3616209.\r\n\r\nThe `PreTrainedModel` class is not available for ALBERT, which is the same for CTRL, GPT, GPT-2, DistilBERT, CamemBERT, TransformerXL, XLM and XLNet. \r\n\r\nWhy is that class u... | 1,574 | 1,575 | 1,575 | CONTRIBUTOR | null | ## ❓ Questions & Help
In the release v2.2.0, the AlbertForSequenceClassification class inherits the AlbertPreTrainedModel class as "class AlbertForSequenceClassification(AlbertPreTrainedModel)".
However, in the doc, this pre-trained model is not documented. And in the released v2.2.0 transformer, the AlbertPreTr... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1968/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1968/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1967 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1967/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1967/comments | https://api.github.com/repos/huggingface/transformers/issues/1967/events | https://github.com/huggingface/transformers/issues/1967 | 529,346,868 | MDU6SXNzdWU1MjkzNDY4Njg= | 1,967 | Trouble running 'bert-base-multilingual-cased' | {
"login": "jungwhank",
"id": 53588015,
"node_id": "MDQ6VXNlcjUzNTg4MDE1",
"avatar_url": "https://avatars.githubusercontent.com/u/53588015?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jungwhank",
"html_url": "https://github.com/jungwhank",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I think the error was because text is greater than 512 tokens.\r\nI got no error when text is smaller than 512 tokens.",
"Hi! Indeed the models have a maximum input size, which is 512 for BERT. You should have received a warning when tokenizing your sequence, but unfortunately, there isn't much more we can do to... | 1,574 | 1,580 | 1,580 | CONTRIBUTOR | null | ## ❓ Questions & Help
Hi,
I got trouble when I apply Quickstart BERT example to korean news text.
but when I run this code using model 'bert-base-multilingual-cased',
```{.python}
# Predict hidden states features for each layer
with torch.no_grad():
# See the models docstrings for the detail of the in... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1967/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1967/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1966 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1966/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1966/comments | https://api.github.com/repos/huggingface/transformers/issues/1966/events | https://github.com/huggingface/transformers/pull/1966 | 529,243,593 | MDExOlB1bGxSZXF1ZXN0MzQ2MTU1NDM1 | 1,966 | Fix issue: #1962, input shape problem | {
"login": "billpku",
"id": 11024954,
"node_id": "MDQ6VXNlcjExMDI0OTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/11024954?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/billpku",
"html_url": "https://github.com/billpku",
"followers_url": "https://api.github.com/users/billpk... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1966?src=pr&el=h1) Report\n> Merging [#1966](https://codecov.io/gh/huggingface/transformers/pull/1966?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/cc7968227e08858df4a5c618c739e1a3ca050196?src=pr&el=desc) will **d... | 1,574 | 1,574 | 1,574 | CONTRIBUTOR | null | Hi,
To Fix #1962
The input's shape seem to cause error in 2.2.0 version tf_albert_model
Hope that it can help. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1966/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1966/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1966",
"html_url": "https://github.com/huggingface/transformers/pull/1966",
"diff_url": "https://github.com/huggingface/transformers/pull/1966.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1966.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1965 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1965/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1965/comments | https://api.github.com/repos/huggingface/transformers/issues/1965/events | https://github.com/huggingface/transformers/issues/1965 | 529,224,770 | MDU6SXNzdWU1MjkyMjQ3NzA= | 1,965 | XLMForTokenClassification | {
"login": "avacaondata",
"id": 35173563,
"node_id": "MDQ6VXNlcjM1MTczNTYz",
"avatar_url": "https://avatars.githubusercontent.com/u/35173563?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avacaondata",
"html_url": "https://github.com/avacaondata",
"followers_url": "https://api.github.com/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi @alexvaca0 ,\r\n\r\nTry to remove the `d_model` parameter in the constructor. Use `config.emb_dim` (`emb_dim` is specified in the [xlm config](https://s3.amazonaws.com/models.huggingface.co/bert/xlm-mlm-en-2048-config.json)), so this should work:\r\n\r\n```python\r\nself.classifier = nn.Linear(config.emb_dim, c... | 1,574 | 1,580 | 1,580 | NONE | null | # 🌟New model addition
## Model description
As the XLM version for token classification (NER tasks) was not implemented, I followed a similar path as for BertForTokenClassification, and it seems to work. The reason for this is that BERT multilingual works horribly for WikiNER in spanish, achieving only 55% F1 with ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1965/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1965/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1964 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1964/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1964/comments | https://api.github.com/repos/huggingface/transformers/issues/1964/events | https://github.com/huggingface/transformers/issues/1964 | 529,173,514 | MDU6SXNzdWU1MjkxNzM1MTQ= | 1,964 | How to increase model saving checkpoint from 50 to 1000? | {
"login": "snijesh",
"id": 25811390,
"node_id": "MDQ6VXNlcjI1ODExMzkw",
"avatar_url": "https://avatars.githubusercontent.com/u/25811390?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/snijesh",
"html_url": "https://github.com/snijesh",
"followers_url": "https://api.github.com/users/snijes... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"**You haven't to modify the source code in this script**. When you call `run_squad.py` script, you have to pass the `--save_steps` parameter and set its value to 1000 (as you can see [here](https://github.com/huggingface/transformers/blob/master/examples/run_squad.py#L429).) So, the entire command would be somethi... | 1,574 | 1,586 | 1,586 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
When I run the script `run_squad.py` , it creates model check points every 50th iteration. How to increase model saving checkpoint from 50 to 1000. Where should I edit the code ?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1964/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1964/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1963 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1963/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1963/comments | https://api.github.com/repos/huggingface/transformers/issues/1963/events | https://github.com/huggingface/transformers/issues/1963 | 529,149,916 | MDU6SXNzdWU1MjkxNDk5MTY= | 1,963 | Did the underlying pre-trained models change somehow? | {
"login": "jmwoloso",
"id": 7530947,
"node_id": "MDQ6VXNlcjc1MzA5NDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7530947?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jmwoloso",
"html_url": "https://github.com/jmwoloso",
"followers_url": "https://api.github.com/users/jmwol... | [] | closed | false | null | [] | [
"Total user-error here. Made a change to a function that writes the TF Records to storage (the name of one of the features) and didn't propagate that info to the function i wrote that reads the TF Records back in, so it wasn't loading my input masks because it was looking for a key that didn't exist."
] | 1,574 | 1,574 | 1,574 | CONTRIBUTOR | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [X] my own modified scripts: I'm just loading the pre-trained bert-base-unca... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1963/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1963/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1962 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1962/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1962/comments | https://api.github.com/repos/huggingface/transformers/issues/1962/events | https://github.com/huggingface/transformers/issues/1962 | 529,145,886 | MDU6SXNzdWU1MjkxNDU4ODY= | 1,962 | TFBertModel ValueError: Tried to convert 'dims' to a tensor and failed. Error: Cannot convert a partially known TensorShape to a Tensor | {
"login": "roccqqck",
"id": 34628766,
"node_id": "MDQ6VXNlcjM0NjI4NzY2",
"avatar_url": "https://avatars.githubusercontent.com/u/34628766?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/roccqqck",
"html_url": "https://github.com/roccqqck",
"followers_url": "https://api.github.com/users/roc... | [] | closed | false | null | [] | [
"> The code below was fine when transformers 2.1.1\r\n> \r\n> but after I update to transformers 2.2.0\r\n> \r\n> ```\r\n> model = TFBertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=5)\r\n> model.summary()\r\n> \r\n> optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08... | 1,574 | 1,575 | 1,574 | NONE | null | The code below was fine when transformers 2.1.1
but after I update to transformers 2.2.0
```
model = TFBertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=5)
model.summary()
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)
loss = tf.keras.losses.S... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1962/reactions",
"total_count": 5,
"+1": 5,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1962/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1961 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1961/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1961/comments | https://api.github.com/repos/huggingface/transformers/issues/1961/events | https://github.com/huggingface/transformers/issues/1961 | 529,078,435 | MDU6SXNzdWU1MjkwNzg0MzU= | 1,961 | Problems with running 'run_lm_finetuning.py' with bert | {
"login": "bigzhouj",
"id": 29719942,
"node_id": "MDQ6VXNlcjI5NzE5OTQy",
"avatar_url": "https://avatars.githubusercontent.com/u/29719942?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bigzhouj",
"html_url": "https://github.com/bigzhouj",
"followers_url": "https://api.github.com/users/big... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"@LysandreJik do we support this one?",
"We do support BERT in `run_lm_finetuning`, however, we do not support loading BERT checkpoints from the original BERT implementation.\r\n\r\nIf you wish to load a checkpoint that was pre-trained/fine-tuned using the original implementation (which seems to be what you're do... | 1,574 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
My rough modification configuration (local)
root_path = "F://IdeaProjects/transformers"
bert_path = "F://BERT/chinese_L-12_H-768_A-12" (Downloaded from the 'https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1961/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1961/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1960 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1960/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1960/comments | https://api.github.com/repos/huggingface/transformers/issues/1960/events | https://github.com/huggingface/transformers/issues/1960 | 529,069,815 | MDU6SXNzdWU1MjkwNjk4MTU= | 1,960 | Improving model saving and resuming | {
"login": "bilal2vec",
"id": 29356759,
"node_id": "MDQ6VXNlcjI5MzU2NzU5",
"avatar_url": "https://avatars.githubusercontent.com/u/29356759?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bilal2vec",
"html_url": "https://github.com/bilal2vec",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"I think it's very useful this feature because, as you highlight, VMs and other variables could stop the (long) training process.\r\nTechnically, how could you implement this feature? Surrounding all the training code in a `try/except` statement and when it occurs a particular Exception (which one?) you ask the use... | 1,574 | 1,576 | 1,576 | CONTRIBUTOR | null | ## 🚀 Feature
The official transformer examples should make it easier to continue training a model that suddenly stopped (e.g. vm gets preempted in the middle of a training run).
To do this, the examples should be updated to save the `optimizer` and `scheduler` states to the `output_dir` as well as the current ep... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1960/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1960/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1959 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1959/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1959/comments | https://api.github.com/repos/huggingface/transformers/issues/1959/events | https://github.com/huggingface/transformers/pull/1959 | 529,041,623 | MDExOlB1bGxSZXF1ZXN0MzQ1OTkyNjE1 | 1,959 | update Roberta checkpoint conversion | {
"login": "armancohan",
"id": 6425112,
"node_id": "MDQ6VXNlcjY0MjUxMTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/6425112?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/armancohan",
"html_url": "https://github.com/armancohan",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1959?src=pr&el=h1) Report\n> Merging [#1959](https://codecov.io/gh/huggingface/transformers/pull/1959?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5e289f69bc564c94132f77c89a34e5f1dd69a592?src=pr&el=desc) will **n... | 1,574 | 1,576 | 1,576 | CONTRIBUTOR | null | - update to fix fairseq Roberta checkpoint conversion
Fairseq had removed `in_proj_weight` and `in_proj_bias` from the self attention module:
https://github.com/pytorch/fairseq/commit/4c6b689eebe66a53717dacf28cba7a11b6ffa64f
- create save directory if not exist | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1959/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1959/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1959",
"html_url": "https://github.com/huggingface/transformers/pull/1959",
"diff_url": "https://github.com/huggingface/transformers/pull/1959.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1959.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1958 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1958/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1958/comments | https://api.github.com/repos/huggingface/transformers/issues/1958/events | https://github.com/huggingface/transformers/issues/1958 | 529,012,165 | MDU6SXNzdWU1MjkwMTIxNjU= | 1,958 | run_ner.py --do_predict inference mode errors. Right data format? | {
"login": "zampierimatteo91",
"id": 40203129,
"node_id": "MDQ6VXNlcjQwMjAzMTI5",
"avatar_url": "https://avatars.githubusercontent.com/u/40203129?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zampierimatteo91",
"html_url": "https://github.com/zampierimatteo91",
"followers_url": "https://... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Three questions:\r\n- the error occurs at line 522, so at line 507 you've saved the file called `test_results.txt`. Do you see the content of this file and whether is it correct?\r\n- the input file has been formatted as CoNLL-2003?\r\n- **N.B**: moreover, the code block from line 512 to line 525 save to .txt file... | 1,574 | 1,580 | 1,580 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hello again,
I'm here to bother you one more time.
I fine-tuned preloaded BioBERT weights on a custom dataset to run biomedical NER.
Now I want to use the model for inference mode on a 'raw' set of documents. I renamed this set... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1958/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1958/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1957 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1957/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1957/comments | https://api.github.com/repos/huggingface/transformers/issues/1957/events | https://github.com/huggingface/transformers/issues/1957 | 529,007,087 | MDU6SXNzdWU1MjkwMDcwODc= | 1,957 | Do we need to add [CLS] and [SEP] for BertForMaskedLM ? | {
"login": "yaolu",
"id": 8982361,
"node_id": "MDQ6VXNlcjg5ODIzNjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/8982361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yaolu",
"html_url": "https://github.com/yaolu",
"followers_url": "https://api.github.com/users/yaolu/follower... | [] | closed | false | null | [] | [
"like this ? \r\n```\r\ninput_ids = torch.tensor(tokenizer.encode(\"Hello, my dog is cute\", add_special_tokens=True)).unsqueeze(0) # Batch size 1 \r\n```",
"The output **without** `add_special_tokens=True`:\r\n```\r\nimport torch\r\nfrom transformers import BertTokenizer, BertForMaskedLM\r\ntokenizer = BertToke... | 1,574 | 1,574 | 1,574 | CONTRIBUTOR | null | ## ❓ Questions & Help
https://github.com/huggingface/transformers/blob/cc7968227e08858df4a5c618c739e1a3ca050196/transformers/modeling_bert.py#L837-L841
Seems like the example is wrong? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1957/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1957/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1956 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1956/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1956/comments | https://api.github.com/repos/huggingface/transformers/issues/1956/events | https://github.com/huggingface/transformers/issues/1956 | 528,922,526 | MDU6SXNzdWU1Mjg5MjI1MjY= | 1,956 | get_linear_schedule_with_warmup Scheduler | {
"login": "h56cho",
"id": 52889259,
"node_id": "MDQ6VXNlcjUyODg5MjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/52889259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h56cho",
"html_url": "https://github.com/h56cho",
"followers_url": "https://api.github.com/users/h56cho/fo... | [] | closed | false | null | [] | [
"You might be using an old version of the library, try updating it to v2.2.0",
"You're trying to import a method only available in more recent Transformers versions from a (very old) Transformers version called _pytorch-transformers_.\r\n\r\nWith Transformers 2.1.1 (the second recent one) and the new version 2.2.... | 1,574 | 1,574 | 1,574 | NONE | null | Hello,
When I try to execute the line of code below, Python gives me an import error:
```js
from pytorch_transformers import (GPT2Config, GPT2LMHeadModel, GPT2DoubleHeadsModel,
AdamW, get_linear_schedule_with_warmup)
ImportError: cannot import name 'get_linear_schedule_with_... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1956/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1956/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1955 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1955/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1955/comments | https://api.github.com/repos/huggingface/transformers/issues/1955/events | https://github.com/huggingface/transformers/issues/1955 | 528,908,130 | MDU6SXNzdWU1Mjg5MDgxMzA= | 1,955 | run_squad.py crashes during do_eval | {
"login": "Phirefly9",
"id": 16687050,
"node_id": "MDQ6VXNlcjE2Njg3MDUw",
"avatar_url": "https://avatars.githubusercontent.com/u/16687050?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Phirefly9",
"html_url": "https://github.com/Phirefly9",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"same issue",
"I tracked it down further this morning and found the problem, you cannot run do_eval in pytorch distributed mode, do_eval works completely fine when there is no pytorch distributed in the equation. This should probably result in a change to the README\r\n\r\n",
"👍Just ran it, I confirm that do_... | 1,574 | 1,580 | 1,580 | NONE | null | ## 🐛 Bug
When running run_squad.py as provided in the README once training is complete the prediction/evaluation component of the script crashes.
No prediction files are written are written.
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): English
The pro... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1955/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1955/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1954 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1954/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1954/comments | https://api.github.com/repos/huggingface/transformers/issues/1954/events | https://github.com/huggingface/transformers/issues/1954 | 528,893,274 | MDU6SXNzdWU1Mjg4OTMyNzQ= | 1,954 | BertForMultipleChoice | {
"login": "apratim-mishra",
"id": 26097066,
"node_id": "MDQ6VXNlcjI2MDk3MDY2",
"avatar_url": "https://avatars.githubusercontent.com/u/26097066?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/apratim-mishra",
"html_url": "https://github.com/apratim-mishra",
"followers_url": "https://api.gi... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, could you try and test this on a more recent version of the library and let me know if it works?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,574 | 1,580 | 1,580 | NONE | null | ## ❓ Questions & Help
Shape Error when using BrtForMultipleChoice
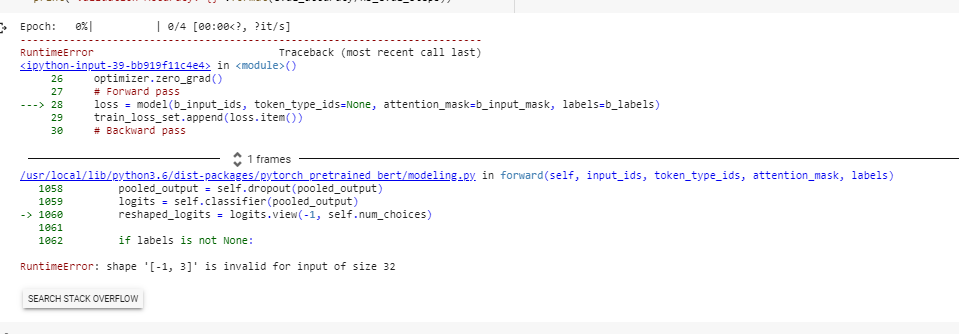
Below is the model i used:
 the second needs the embedding of the whole sequence (shape : [batch_size, hidden_size] ) . ... | 1,574 | 1,586 | 1,586 | NONE | null | ```
model = TFBertModel.from_pretrained('bert-base-chinese')
model.summary()
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1953/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1953/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1952 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1952/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1952/comments | https://api.github.com/repos/huggingface/transformers/issues/1952/events | https://github.com/huggingface/transformers/pull/1952 | 528,801,397 | MDExOlB1bGxSZXF1ZXN0MzQ1Nzk1ODIx | 1,952 | suggest to track repo w/ https rather than ssh | {
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/follower... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1952?src=pr&el=h1) Report\n> Merging [#1952](https://codecov.io/gh/huggingface/transformers/pull/1952?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/8e5d84fcc1a645d3c13b8a2f64fa995637440dad?src=pr&el=desc) will **n... | 1,574 | 1,574 | 1,574 | CONTRIBUTOR | null | cf #1943 we tell users to track the repository via https rather than ssh (as it requires us to enable ssh). | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1952/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1952/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1952",
"html_url": "https://github.com/huggingface/transformers/pull/1952",
"diff_url": "https://github.com/huggingface/transformers/pull/1952.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1952.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1951 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1951/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1951/comments | https://api.github.com/repos/huggingface/transformers/issues/1951/events | https://github.com/huggingface/transformers/issues/1951 | 528,798,243 | MDU6SXNzdWU1Mjg3OTgyNDM= | 1,951 | Benchmark not replicable | {
"login": "Pointy-Hat",
"id": 20556449,
"node_id": "MDQ6VXNlcjIwNTU2NDQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/20556449?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Pointy-Hat",
"html_url": "https://github.com/Pointy-Hat",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hello @Pointy-Hat \r\n\r\nPlease tell us more, as explained [here](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md).",
"Technical data of the cluster used for computation:\r\nSystem: CentOS Linux release 7.5.1804 (Core)\r\nPython: 3.7.4\r\nPytorch: 1.3.1\r\n\r\nCode run:\r\n```\r\npython3... | 1,574 | 1,580 | 1,580 | NONE | null | ## ❓ Questions & Help
Hello. I wanted to test if everything is allright with my downloads and so I ran the code snippet you provided in the section **Fine-tuning Bert model on the MRPC classification task** in the main README file (the only difference being the number of gpus-I use 4). However, my evaluation results a... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1951/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1951/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1950 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1950/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1950/comments | https://api.github.com/repos/huggingface/transformers/issues/1950/events | https://github.com/huggingface/transformers/issues/1950 | 528,740,572 | MDU6SXNzdWU1Mjg3NDA1NzI= | 1,950 | word or sentence embedding from BERT model | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"You can use [`BertModel`](https://huggingface.co/transformers/model_doc/bert.html#transformers.BertModel), it'll return the hidden states for the input sentence.",
"Found it, thanks @bkkaggle . Just for others who are looking for the same information. \r\n\r\nUsing Pytorch:\r\n```\r\ntokenizer = BertTokenizer.fr... | 1,574 | 1,613 | 1,596 | NONE | null | How can I extract embeddings for a sentence or a set of words directly from pre-trained models (Standard BERT)? For example, I am using Spacy for this purpose at the moment where I can do it as follows:
sentence vector:
`sentence_vector = bert_model("This is an apple").vector`
word_vectors:
```
words = bert_mo... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1950/reactions",
"total_count": 24,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 17,
"rocket": 0,
"eyes": 7
} | https://api.github.com/repos/huggingface/transformers/issues/1950/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1949 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1949/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1949/comments | https://api.github.com/repos/huggingface/transformers/issues/1949/events | https://github.com/huggingface/transformers/issues/1949 | 528,651,027 | MDU6SXNzdWU1Mjg2NTEwMjc= | 1,949 | Can i train my own text corpus | {
"login": "shashankMadan-designEsthetics",
"id": 45225143,
"node_id": "MDQ6VXNlcjQ1MjI1MTQz",
"avatar_url": "https://avatars.githubusercontent.com/u/45225143?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shashankMadan-designEsthetics",
"html_url": "https://github.com/shashankMadan-designE... | [] | closed | false | null | [] | [
"You can initialize the weights of your model as the ones of e.g. BERT, and after that you can fine-tune your model with _your own data_ (**transfer learning**). Please see [here](https://github.com/huggingface/transformers/blob/master/examples/run_lm_finetuning.py) for fine-tuning for a particular task.\r\n\r\nHav... | 1,574 | 1,574 | 1,574 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I get the idea of using `from_pretrained` but Can i train my own text corpus and then get the weights? If So how? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1949/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1949/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1948 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1948/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1948/comments | https://api.github.com/repos/huggingface/transformers/issues/1948/events | https://github.com/huggingface/transformers/issues/1948 | 528,633,147 | MDU6SXNzdWU1Mjg2MzMxNDc= | 1,948 | Should I use `attention_mask`? | {
"login": "ShaneTian",
"id": 42370681,
"node_id": "MDQ6VXNlcjQyMzcwNjgx",
"avatar_url": "https://avatars.githubusercontent.com/u/42370681?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ShaneTian",
"html_url": "https://github.com/ShaneTian",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"Hi,\r\n\r\nThe attention mask is useful when there are padding indices on which you do not want to perform attention. You should use it when you're using padding, which should only happen when having a batch size superior to one with different sized sequences in those batches.",
"> Hi,\r\n> \r\n> The attention m... | 1,574 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
#### My Target
1. Transfer sentences to `ids`
2. Padding `ids` when
3. Encode `ids` to vector(`last_hidden_states`)
4. Put this vector to my own downstream model.
#### My code
```py
original_text = "Hello world!"
ids = model.... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1948/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/transformers/issues/1948/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1947 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1947/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1947/comments | https://api.github.com/repos/huggingface/transformers/issues/1947/events | https://github.com/huggingface/transformers/issues/1947 | 528,597,115 | MDU6SXNzdWU1Mjg1OTcxMTU= | 1,947 | Expected object of scalar type Byte but got scalar type Bool for argument #2 'mask' | {
"login": "bigzhouj",
"id": 29719942,
"node_id": "MDQ6VXNlcjI5NzE5OTQy",
"avatar_url": "https://avatars.githubusercontent.com/u/29719942?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bigzhouj",
"html_url": "https://github.com/bigzhouj",
"followers_url": "https://api.github.com/users/big... | [] | closed | false | null | [] | [
"in probability_matrix.masked_fill_(torch.tensor(special_tokens_mask, dtype=torch.bool), value=0.0)",
"Please, describe your environment, post the source code for reproducibility and the error.\r\n\r\n> in probability_matrix.masked_fill_(torch.tensor(special_tokens_mask, dtype=torch.bool), value=0.0)",
"Please ... | 1,574 | 1,574 | 1,574 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
fine tuning bert use wikitext2 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1947/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1947/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1946 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1946/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1946/comments | https://api.github.com/repos/huggingface/transformers/issues/1946/events | https://github.com/huggingface/transformers/pull/1946 | 528,473,972 | MDExOlB1bGxSZXF1ZXN0MzQ1NTI4NjYz | 1,946 | Fixed typo | {
"login": "AveryLiu",
"id": 5574795,
"node_id": "MDQ6VXNlcjU1NzQ3OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/5574795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AveryLiu",
"html_url": "https://github.com/AveryLiu",
"followers_url": "https://api.github.com/users/Avery... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1946?src=pr&el=h1) Report\n> Merging [#1946](https://codecov.io/gh/huggingface/transformers/pull/1946?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5d3b8daad2cc6287d30f03f8a96d0a1f7bc8d0dc?src=pr&el=desc) will **n... | 1,574 | 1,574 | 1,574 | NONE | null | Changed `emove` to `remove` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1946/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1946/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1946",
"html_url": "https://github.com/huggingface/transformers/pull/1946",
"diff_url": "https://github.com/huggingface/transformers/pull/1946.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1946.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1945 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1945/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1945/comments | https://api.github.com/repos/huggingface/transformers/issues/1945/events | https://github.com/huggingface/transformers/issues/1945 | 528,471,135 | MDU6SXNzdWU1Mjg0NzExMzU= | 1,945 | When using the Bert model | {
"login": "bigzhouj",
"id": 29719942,
"node_id": "MDQ6VXNlcjI5NzE5OTQy",
"avatar_url": "https://avatars.githubusercontent.com/u/29719942?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bigzhouj",
"html_url": "https://github.com/bigzhouj",
"followers_url": "https://api.github.com/users/big... | [] | closed | false | null | [] | [
"These two files are **not** in the Transformers library **now**.\r\n\r\n> ## Questions & Help\r\n> pregenerate_training_data.py and finetune_on_pregenerated.py Is it in the project.If so, where?",
"As @TheEdoardo93 says, these files were community maintained and have been removed a few months ago. ",
"so what... | 1,574 | 1,587 | 1,574 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
pregenerate_training_data.py and finetune_on_pregenerated.py Is it in the project.If so, where? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1945/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1945/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1944 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1944/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1944/comments | https://api.github.com/repos/huggingface/transformers/issues/1944/events | https://github.com/huggingface/transformers/pull/1944 | 528,365,031 | MDExOlB1bGxSZXF1ZXN0MzQ1NDQwOTAw | 1,944 | tokenization progress made more sensible via tqdm | {
"login": "iedmrc",
"id": 13666448,
"node_id": "MDQ6VXNlcjEzNjY2NDQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/13666448?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iedmrc",
"html_url": "https://github.com/iedmrc",
"followers_url": "https://api.github.com/users/iedmrc/fo... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1944?src=pr&el=h1) Report\n> Merging [#1944](https://codecov.io/gh/huggingface/transformers/pull/1944?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5d3b8daad2cc6287d30f03f8a96d0a1f7bc8d0dc?src=pr&el=desc) will **i... | 1,574 | 1,583 | 1,583 | CONTRIBUTOR | null | Because tokenization takes a relatively long time, having progress being visualized via tqdm would be nice. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1944/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1944/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1944",
"html_url": "https://github.com/huggingface/transformers/pull/1944",
"diff_url": "https://github.com/huggingface/transformers/pull/1944.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1944.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1943 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1943/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1943/comments | https://api.github.com/repos/huggingface/transformers/issues/1943/events | https://github.com/huggingface/transformers/issues/1943 | 528,356,599 | MDU6SXNzdWU1MjgzNTY1OTk= | 1,943 | git@github.com: Permission denied (publickey) when fetching | {
"login": "iedmrc",
"id": 13666448,
"node_id": "MDQ6VXNlcjEzNjY2NDQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/13666448?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iedmrc",
"html_url": "https://github.com/iedmrc",
"followers_url": "https://api.github.com/users/iedmrc/fo... | [] | closed | false | null | [] | [
"Yeah you can clone using https, it's usually easier (github actually recommends it for simple workflows)\r\n\r\ncc @rlouf ",
"Nice! Then, we might update [this line](https://github.com/huggingface/transformers/blame/5d3b8daad2cc6287d30f03f8a96d0a1f7bc8d0dc/CONTRIBUTING.md#L109) since Github encourages https ins... | 1,574 | 1,574 | 1,574 | CONTRIBUTOR | null | When you wanted to sync forked repository with base, as described [here](https://github.com/huggingface/transformers/blame/aa92a184d2b92faadec975139ad55e2ae749362c/CONTRIBUTING.md#L140)
You get:
```
➜ transformers (master) ✗ git fetch upstream
git@github.com: Permission denied (publickey).
fatal: Could not read... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1943/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1943/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1942 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1942/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1942/comments | https://api.github.com/repos/huggingface/transformers/issues/1942/events | https://github.com/huggingface/transformers/issues/1942 | 528,299,333 | MDU6SXNzdWU1MjgyOTkzMzM= | 1,942 | Wrong paraphrase in the TF2/PyTorch README example. | {
"login": "isaprykin",
"id": 234070,
"node_id": "MDQ6VXNlcjIzNDA3MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/234070?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/isaprykin",
"html_url": "https://github.com/isaprykin",
"followers_url": "https://api.github.com/users/isap... | [] | closed | false | null | [] | [
"Hi, I'm investigating. For now, I confirm the issue that you observe. I've tested on both CPU and GPU and it gives the same result. I've tested with Pytorch and TF models too, same result. Now, let's track the cause!",
"Hi again,\r\nOk I've retrained a Pytorch model using `run_glue.py` on MRPC to check.\r\nThe f... | 1,574 | 1,576 | 1,576 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): TFBertForSequenceClassification
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: https://github.com/huggingface/transformers#quick-tour-tf-20-train... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1942/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1942/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1941 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1941/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1941/comments | https://api.github.com/repos/huggingface/transformers/issues/1941/events | https://github.com/huggingface/transformers/issues/1941 | 528,224,042 | MDU6SXNzdWU1MjgyMjQwNDI= | 1,941 | NER - sciBERT weights not initialized. | {
"login": "zampierimatteo91",
"id": 40203129,
"node_id": "MDQ6VXNlcjQwMjAzMTI5",
"avatar_url": "https://avatars.githubusercontent.com/u/40203129?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zampierimatteo91",
"html_url": "https://github.com/zampierimatteo91",
"followers_url": "https://... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, this means that the script did not find your tokenization file. You're pointing to the folder `../scibert_model` but either that folder does not exist, either it does not contain a `vocab.txt` file which is required by the `BertTokenizer`.",
"Hi LysandreJik,\r\n\r\nMany thanks for your reply.\r\n`vocab.txt` ... | 1,574 | 1,580 | 1,580 | NONE | null | ## ❓ Questions & Help
<!-- Custom weights not initialized when training NER on dataset. -->
Hi all,
first of all thanks for this awesome interface.
Coming to the issue:
I am trying out NER on the Anatem dataset, using Google Colab's GPU.
I imported SciBERT (and BioBERT) models with the solutions provided ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1941/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1941/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1940 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1940/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1940/comments | https://api.github.com/repos/huggingface/transformers/issues/1940/events | https://github.com/huggingface/transformers/pull/1940 | 528,217,548 | MDExOlB1bGxSZXF1ZXN0MzQ1MzIyNTM0 | 1,940 | Add TF2 NER example | {
"login": "jplu",
"id": 959590,
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jplu",
"html_url": "https://github.com/jplu",
"followers_url": "https://api.github.com/users/jplu/followers",
... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1940?src=pr&el=h1) Report\n> Merging [#1940](https://codecov.io/gh/huggingface/transformers/pull/1940?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/88b317739fe56888528c857fc8e90967148a0051?src=pr&el=desc) will **d... | 1,574 | 1,575 | 1,575 | CONTRIBUTOR | null | Hi,
Here my small contribution. I have implemented the TF2 version of the NER example already existing in the repo. I tried to have an implementation as close as possible of the Pytorch version.
Let me know for any needed changes :) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1940/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1940/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1940",
"html_url": "https://github.com/huggingface/transformers/pull/1940",
"diff_url": "https://github.com/huggingface/transformers/pull/1940.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1940.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1939 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1939/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1939/comments | https://api.github.com/repos/huggingface/transformers/issues/1939/events | https://github.com/huggingface/transformers/issues/1939 | 528,215,183 | MDU6SXNzdWU1MjgyMTUxODM= | 1,939 | Abruptly model training was stopped | {
"login": "ellurunaresh",
"id": 10192331,
"node_id": "MDQ6VXNlcjEwMTkyMzMx",
"avatar_url": "https://avatars.githubusercontent.com/u/10192331?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ellurunaresh",
"html_url": "https://github.com/ellurunaresh",
"followers_url": "https://api.github.c... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,574 | 1,580 | 1,580 | NONE | null | I'm fine tuning NER custom dataset using BERT cased model. I'm using script of examples/run_ner.py to fine tune. **In 2nd epoch training was stopped abruptly without displaying any error.**
Epoch: 67%|██████▋ | 2/3 [2:48:41<1:24:21, 5061.32s/it]
Iteration: 98%|█████████▊| 3734/3816 [1:22:30<01:48, 1.32s/it]
... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1939/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1939/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1938 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1938/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1938/comments | https://api.github.com/repos/huggingface/transformers/issues/1938/events | https://github.com/huggingface/transformers/issues/1938 | 528,186,316 | MDU6SXNzdWU1MjgxODYzMTY= | 1,938 | Load output file from fine-tuned bert language model | {
"login": "avinashsai",
"id": 22453634,
"node_id": "MDQ6VXNlcjIyNDUzNjM0",
"avatar_url": "https://avatars.githubusercontent.com/u/22453634?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avinashsai",
"html_url": "https://github.com/avinashsai",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [
"Hmm this script should not output any `.txt` files except `eval_results.txt`. What is inside this output directory except for this file?",
"I didn't provide any evaluation file.\r\nHowever logging info is as follows:\r\n\r\n- Creating features from dataset file at \r\n- Saving features into cached file **bert-ba... | 1,574 | 1,574 | 1,574 | NONE | null | Hi,
I have fine-tuned bert cased language model using **run_lm_finetuning.py**. 'output' is the output file directory and '**bert-base-cased.txt**' is another file created by the model.
1. Does the .txt file mentioned has the output of fine-tuned model??
2. If so, how should I open the file?? I am getting 'UTF-8' ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1938/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1938/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1937 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1937/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1937/comments | https://api.github.com/repos/huggingface/transformers/issues/1937/events | https://github.com/huggingface/transformers/issues/1937 | 528,176,205 | MDU6SXNzdWU1MjgxNzYyMDU= | 1,937 | access to the vocabulary | {
"login": "weiguowilliam",
"id": 31396452,
"node_id": "MDQ6VXNlcjMxMzk2NDUy",
"avatar_url": "https://avatars.githubusercontent.com/u/31396452?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/weiguowilliam",
"html_url": "https://github.com/weiguowilliam",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [
"You can obtain the **50.257 different tokens** with the following code:\r\n```\r\nimport transformers\r\nfrom transformers import GPT2Tokenizer\r\n\r\ntokenizer = GPT2Tokenizer.from_pretrained('gpt2')\r\nvocab = list(tokenizer.encoder.keys())\r\nassert(len(vocab) == tokenizer.vocab_size) # it returns True!\r\n```\... | 1,574 | 1,574 | 1,574 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Is there any way we can get access to the vocabulary in GPT2? Like a list: [subtoken1, subtoken2, ...subtoken 10000...]
Thank you in advance! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1937/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1937/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1936 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1936/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1936/comments | https://api.github.com/repos/huggingface/transformers/issues/1936/events | https://github.com/huggingface/transformers/issues/1936 | 528,056,906 | MDU6SXNzdWU1MjgwNTY5MDY= | 1,936 | how to output specific layer of TFBertForSequenceClassification, or add layer? | {
"login": "roccqqck",
"id": 34628766,
"node_id": "MDQ6VXNlcjM0NjI4NzY2",
"avatar_url": "https://avatars.githubusercontent.com/u/34628766?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/roccqqck",
"html_url": "https://github.com/roccqqck",
"followers_url": "https://api.github.com/users/roc... | [] | closed | false | null | [] | [
"Please, copy and paste the source code in order to reproduce your problem.\r\n\r\n> how to output the last layer of TFBertForSequenceClassification?\r\n> \r\n> I want to output the layer before classifier (Dense)\r\n> \r\n> ```\r\n> Model: \"tf_bert_for_sequence_classification\"\r\n> ______________________________... | 1,574 | 1,582 | 1,574 | NONE | null | how to output the last layer of TFBertForSequenceClassification?
I want to output the layer before classifier (Dense)
```
Model: "tf_bert_for_sequence_classification"
_________________________________________________________________
Layer (type) Output Shape Param #
==========... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1936/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1936/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1935 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1935/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1935/comments | https://api.github.com/repos/huggingface/transformers/issues/1935/events | https://github.com/huggingface/transformers/issues/1935 | 527,932,492 | MDU6SXNzdWU1Mjc5MzI0OTI= | 1,935 | attention_mask added, not multiplied ... is this correct? | {
"login": "fginter",
"id": 644401,
"node_id": "MDQ6VXNlcjY0NDQwMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/644401?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fginter",
"html_url": "https://github.com/fginter",
"followers_url": "https://api.github.com/users/fginter/fo... | [] | closed | false | null | [] | [
"Ping. :) To me this still looks like the code actually fails to apply the attention mask and also the parts of the sequence intended to be masked are accessible. The line is now https://github.com/huggingface/transformers/blob/master/transformers/modeling_bert.py#L237",
"Hi, yes this is correct. Inside the `Bert... | 1,574 | 1,578 | 1,576 | NONE | null | https://github.com/huggingface/transformers/blob/master/transformers/modeling_bert.py#L233
This line adds (+ operator) the attention mask. I wonder whether this is correct, as I would have very much expected the mask to be multiplied. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1935/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 3
} | https://api.github.com/repos/huggingface/transformers/issues/1935/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1934 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1934/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1934/comments | https://api.github.com/repos/huggingface/transformers/issues/1934/events | https://github.com/huggingface/transformers/issues/1934 | 527,920,571 | MDU6SXNzdWU1Mjc5MjA1NzE= | 1,934 | Download model too slow, is there any way | {
"login": "bigzhouj",
"id": 29719942,
"node_id": "MDQ6VXNlcjI5NzE5OTQy",
"avatar_url": "https://avatars.githubusercontent.com/u/29719942?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bigzhouj",
"html_url": "https://github.com/bigzhouj",
"followers_url": "https://api.github.com/users/big... | [] | closed | false | null | [] | [
"If your model download is too slow and fails, you can manually download it from our S3 using your browser, wget or cURL as an alternative method.\r\n\r\nYou can then point to a directory that has both the model weights (xxx-pytorch_model.bin) and the configuration file (xxx-config.json) instead of the checkpoint n... | 1,574 | 1,574 | 1,574 | NONE | null | in run_lm_finetuning.py
transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-pytorch_model.bin not found in cache or force_download set to True, downloading to .... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1934/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1934/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1933 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1933/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1933/comments | https://api.github.com/repos/huggingface/transformers/issues/1933/events | https://github.com/huggingface/transformers/issues/1933 | 527,793,656 | MDU6SXNzdWU1Mjc3OTM2NTY= | 1,933 | Can I use HF XLNet to make a Model that Predicts Backwards? | {
"login": "Fredrum",
"id": 9632594,
"node_id": "MDQ6VXNlcjk2MzI1OTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9632594?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Fredrum",
"html_url": "https://github.com/Fredrum",
"followers_url": "https://api.github.com/users/Fredrum/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,574 | 1,580 | 1,580 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I would like to create a model that lets me generate multi sentence text sequences but backwards, given the tail end of some input text.
Could I do that using the HF XLNet framework?
I am new to this stuff so if this is possible w... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1933/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1933/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1932 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1932/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1932/comments | https://api.github.com/repos/huggingface/transformers/issues/1932/events | https://github.com/huggingface/transformers/issues/1932 | 527,777,463 | MDU6SXNzdWU1Mjc3Nzc0NjM= | 1,932 | Using GPT-2 XL | {
"login": "IrvDelgado",
"id": 28610164,
"node_id": "MDQ6VXNlcjI4NjEwMTY0",
"avatar_url": "https://avatars.githubusercontent.com/u/28610164?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/IrvDelgado",
"html_url": "https://github.com/IrvDelgado",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [
"You don't have to use the PyPi version of this library, but **from the source code** with `pip install git+https://github.com/huggingface/transformers.git`. This is because, at the moment, GPT2 XL version is available only in a dedicated branch called *gpt2-xl* and not in the PyPi version.\r\n\r\nMy environment is... | 1,574 | 1,574 | 1,574 | NONE | null | Hi, Im trying to use the pretrained gpt-xl
but I get the following error:
OSError: Model name 'gpt2-xl' was not found in tokenizers model name list (gpt2, gpt2-medium, gpt2-large, distilgpt2). We assumed 'gpt2-xl' was a path or url to a directory containing vocabulary files named ['vocab.json', 'merges.txt'] but cou... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1932/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1932/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1931 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1931/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1931/comments | https://api.github.com/repos/huggingface/transformers/issues/1931/events | https://github.com/huggingface/transformers/issues/1931 | 527,655,162 | MDU6SXNzdWU1Mjc2NTUxNjI= | 1,931 | Using model output by transformers (v2.0) in older versions (0.4.0 or 1.0.0) | {
"login": "Genius1237",
"id": 15867363,
"node_id": "MDQ6VXNlcjE1ODY3MzYz",
"avatar_url": "https://avatars.githubusercontent.com/u/15867363?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Genius1237",
"html_url": "https://github.com/Genius1237",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Models' architectures should have stayed relatively the same between versions. If you did not get warnings telling you that some layers had not been loaded, then you should be good to go!\r\n\r\nYou could try and compare inferences between two environments which have different versions of the library installed to ... | 1,574 | 1,580 | 1,580 | CONTRIBUTOR | null | ## ❓ Questions & Help
I have a bert model finetuned on in-domain data on the latest version of the package (`2.0`). I would now like to use this in some code that is written with the older version of the package (say `0.4.0` or `1.0.0`). Would this be possible?
I tried pointing the code which imports version `0.4... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1931/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1931/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1930 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1930/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1930/comments | https://api.github.com/repos/huggingface/transformers/issues/1930/events | https://github.com/huggingface/transformers/issues/1930 | 527,637,303 | MDU6SXNzdWU1Mjc2MzczMDM= | 1,930 | BERT bertviz | {
"login": "RuiPChaves",
"id": 33401801,
"node_id": "MDQ6VXNlcjMzNDAxODAx",
"avatar_url": "https://avatars.githubusercontent.com/u/33401801?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RuiPChaves",
"html_url": "https://github.com/RuiPChaves",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [] | 1,574 | 1,574 | 1,574 | NONE | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1930/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1930/timeline | completed | null | null | |
https://api.github.com/repos/huggingface/transformers/issues/1929 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1929/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1929/comments | https://api.github.com/repos/huggingface/transformers/issues/1929/events | https://github.com/huggingface/transformers/issues/1929 | 527,624,336 | MDU6SXNzdWU1Mjc2MjQzMzY= | 1,929 | configuration of the optimizer | {
"login": "antgr",
"id": 2175768,
"node_id": "MDQ6VXNlcjIxNzU3Njg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2175768?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/antgr",
"html_url": "https://github.com/antgr",
"followers_url": "https://api.github.com/users/antgr/follower... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,574 | 1,580 | 1,580 | NONE | null | ## 📚 Migration
<!-- Important information -->
Model I am using (Bert, XLNet....):
Bert
Language I am using the model on (English, Chinese....):
English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
The tasks I am workin... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1929/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1929/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1928 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1928/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1928/comments | https://api.github.com/repos/huggingface/transformers/issues/1928/events | https://github.com/huggingface/transformers/pull/1928 | 527,577,667 | MDExOlB1bGxSZXF1ZXN0MzQ0ODIyNjY1 | 1,928 | Split on punc should receive never_split list | {
"login": "eisenjulian",
"id": 7776575,
"node_id": "MDQ6VXNlcjc3NzY1NzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7776575?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eisenjulian",
"html_url": "https://github.com/eisenjulian",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1928?src=pr&el=h1) Report\n> Merging [#1928](https://codecov.io/gh/huggingface/transformers/pull/1928?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/176cd1ce1b337134425b426207fbe155099c18b4?src=pr&el=desc) will **n... | 1,574 | 1,575 | 1,575 | NONE | null | When tokenizing when a never_split token that contains any punctuation, such as [ or ] they currently get split when they shouldn't be. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1928/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1928/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1928",
"html_url": "https://github.com/huggingface/transformers/pull/1928",
"diff_url": "https://github.com/huggingface/transformers/pull/1928.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1928.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1927 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1927/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1927/comments | https://api.github.com/repos/huggingface/transformers/issues/1927/events | https://github.com/huggingface/transformers/issues/1927 | 527,558,347 | MDU6SXNzdWU1Mjc1NTgzNDc= | 1,927 | Mask probability in run_lm_finetuning.py | {
"login": "leuchine",
"id": 3937040,
"node_id": "MDQ6VXNlcjM5MzcwNDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3937040?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leuchine",
"html_url": "https://github.com/leuchine",
"followers_url": "https://api.github.com/users/leuch... | [] | closed | false | null | [] | [
"The lines:\r\n\r\n```\r\nindices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool() & masked_indices\r\n```\r\nand\r\n```\r\nindices_random = torch.bernoulli(torch.full(labels.shape, 0.5)).bool() & masked_indices & ~indices_replaced\r\n```\r\nmake it that `indices_random` has a 50% chance of being tr... | 1,574 | 1,574 | 1,574 | NONE | null | Hi:
I don't understand why 0.5 is used when replacing masked input tokens with a random word. I think the probability should be 0.1? Or, the positions replaced with [MASK] shall already be stripped out before using 0.5. I think it is a small bug here? Thanks!
# 80% of the time, we replace masked input to... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1927/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1927/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1926 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1926/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1926/comments | https://api.github.com/repos/huggingface/transformers/issues/1926/events | https://github.com/huggingface/transformers/issues/1926 | 527,552,342 | MDU6SXNzdWU1Mjc1NTIzNDI= | 1,926 | How to process ARC dataset with HuggingFace GPT2 | {
"login": "h56cho",
"id": 52889259,
"node_id": "MDQ6VXNlcjUyODg5MjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/52889259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h56cho",
"html_url": "https://github.com/h56cho",
"followers_url": "https://api.github.com/users/h56cho/fo... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,574 | 1,580 | 1,580 | NONE | null | Hello,
I am interested in processing ARC dataset with HuggingFace GPT2.
The ARC dataset (http://nlpprogress.com/english/question_answering.html) is a question answering, which contains 7,787 genuine grade-school level, multiple-choice science questions. The dataset also comes with the full corpus of texts extracted... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1926/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1926/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1925 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1925/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1925/comments | https://api.github.com/repos/huggingface/transformers/issues/1925/events | https://github.com/huggingface/transformers/issues/1925 | 527,529,567 | MDU6SXNzdWU1Mjc1Mjk1Njc= | 1,925 | Need a Restore training mechenisim in run_lm_finetuning.py | {
"login": "chuanmingliu",
"id": 1910024,
"node_id": "MDQ6VXNlcjE5MTAwMjQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1910024?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chuanmingliu",
"html_url": "https://github.com/chuanmingliu",
"followers_url": "https://api.github.com... | [] | closed | false | null | [] | [
"If you want to resume training with the same learning rate, you can save the scheduler and optimizer and reload them when resuming training.\r\n\r\nFor example, you could save the current training state with:\r\n\r\n```python\r\n\r\n# Save the model and tokenizer\r\nmodel.save_pretrained('./checkpoints/')\r\ntoken... | 1,574 | 1,574 | 1,574 | NONE | null | ## 🚀 Feature
<!-- A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist. -->
## Motivation
When training run_lm_finetuning.py for a long time, a restore training feature should be added.
Otherwise, states of sheduler and optimizer are changed ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1925/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1925/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1924 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1924/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1924/comments | https://api.github.com/repos/huggingface/transformers/issues/1924/events | https://github.com/huggingface/transformers/issues/1924 | 527,526,534 | MDU6SXNzdWU1Mjc1MjY1MzQ= | 1,924 | TypeError: convert_examples_to_features() got an unexpected keyword argument 'sequence_a_is_doc' | {
"login": "snijesh",
"id": 25811390,
"node_id": "MDQ6VXNlcjI1ODExMzkw",
"avatar_url": "https://avatars.githubusercontent.com/u/25811390?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/snijesh",
"html_url": "https://github.com/snijesh",
"followers_url": "https://api.github.com/users/snijes... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Please, try to install Transformers library **from source code**, and **not from PyPi**. The former one is the up-to-date version. In fact, if you see in [utils_squad.py](https://github.com/huggingface/transformers/blob/master/examples/utils_squad.py) at row 197, there is a parameter called `sequence_a_is_doc` in ... | 1,574 | 1,580 | 1,580 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert):
Language I am using the model on (English):
The problem arise when using:
```
!python run_squad.py \
--model_type bert \
--model_name_or_path bert-large-uncased \
--do_train \
--do_eval \
--do_lower_case \
--train_file tra... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1924/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1924/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1923 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1923/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1923/comments | https://api.github.com/repos/huggingface/transformers/issues/1923/events | https://github.com/huggingface/transformers/issues/1923 | 527,523,139 | MDU6SXNzdWU1Mjc1MjMxMzk= | 1,923 | Step restarts from step 0 when reload from an existing checkpoint? | {
"login": "chuanmingliu",
"id": 1910024,
"node_id": "MDQ6VXNlcjE5MTAwMjQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1910024?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chuanmingliu",
"html_url": "https://github.com/chuanmingliu",
"followers_url": "https://api.github.com... | [] | closed | false | null | [] | [] | 1,574 | 1,574 | 1,574 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi, everyone
I am totally new to Transformers, it's really a good solution. :-)
Question:
When I reload my program from a break point (existing checkpoint, say checkpoint-30000),
what I expect is that, from Tensorboard, I can ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1923/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1923/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1922 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1922/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1922/comments | https://api.github.com/repos/huggingface/transformers/issues/1922/events | https://github.com/huggingface/transformers/pull/1922 | 527,486,830 | MDExOlB1bGxSZXF1ZXN0MzQ0NzU4NTg5 | 1,922 | update | {
"login": "maxmatical",
"id": 8890262,
"node_id": "MDQ6VXNlcjg4OTAyNjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8890262?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maxmatical",
"html_url": "https://github.com/maxmatical",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1922?src=pr&el=h1) Report\n> Merging [#1922](https://codecov.io/gh/huggingface/transformers/pull/1922?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/26db31e0c09a8b5e1ca7a61c454b159eab9d86be?src=pr&el=desc) will **d... | 1,574 | 1,575 | 1,575 | NONE | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1922/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1922/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1922",
"html_url": "https://github.com/huggingface/transformers/pull/1922",
"diff_url": "https://github.com/huggingface/transformers/pull/1922.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1922.patch",
"merged_at": n... | |
https://api.github.com/repos/huggingface/transformers/issues/1921 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1921/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1921/comments | https://api.github.com/repos/huggingface/transformers/issues/1921/events | https://github.com/huggingface/transformers/issues/1921 | 527,486,174 | MDU6SXNzdWU1Mjc0ODYxNzQ= | 1,921 | FileNotFoundError when running run_squad.py | {
"login": "maxmatical",
"id": 8890262,
"node_id": "MDQ6VXNlcjg4OTAyNjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8890262?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maxmatical",
"html_url": "https://github.com/maxmatical",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | [
"You need to download that json on squad website and put to your local\ndirectory zzz\n\nOn Sat, Nov 23, 2019 at 09:09 Max Tian <notifications@github.com> wrote:\n\n> ❓ Questions & Help\n>\n> I tried fine-tuning BERT on squad on my local computer. The script I ran\n> was\n>\n> python3 ./examples/run_squad.py \\\n>\... | 1,574 | 1,574 | 1,574 | NONE | null | ## ❓ Questions & Help
I tried fine-tuning BERT on squad on my local computer. The script I ran was
```
python3 ./examples/run_squad.py \
--model_type bert \
--model_name_or_path bert-large-uncased-whole-word-masking \
--do_train \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DI... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1921/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1921/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1920 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1920/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1920/comments | https://api.github.com/repos/huggingface/transformers/issues/1920/events | https://github.com/huggingface/transformers/issues/1920 | 527,404,160 | MDU6SXNzdWU1Mjc0MDQxNjA= | 1,920 | CTRLTokenizer not consistent with the fastBPE tokenizer used in Salesforce/CTRL | {
"login": "orenmelamud",
"id": 55256832,
"node_id": "MDQ6VXNlcjU1MjU2ODMy",
"avatar_url": "https://avatars.githubusercontent.com/u/55256832?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/orenmelamud",
"html_url": "https://github.com/orenmelamud",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"Indeed, thanks a lot for the bug report.\r\nThis is fixed on master (by using regex to split instead of white spaces)."
] | 1,574 | 1,575 | 1,575 | NONE | null | ## 🐛 Bug
cc @keskarnitish
<!-- Important information -->
I am using the transformers CTRL re-implementation to fine-tune the original pre-trained model released by Salesforce https://github.com/salesforce/ctrl.
When the input text consists of newline characters, the tokenization of the Transformers tokeniz... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1920/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1920/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1919 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1919/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1919/comments | https://api.github.com/repos/huggingface/transformers/issues/1919/events | https://github.com/huggingface/transformers/pull/1919 | 527,386,971 | MDExOlB1bGxSZXF1ZXN0MzQ0Njc2MDM0 | 1,919 | Fix typo in documentation. toto -> to | {
"login": "CrafterKolyan",
"id": 9883873,
"node_id": "MDQ6VXNlcjk4ODM4NzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9883873?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CrafterKolyan",
"html_url": "https://github.com/CrafterKolyan",
"followers_url": "https://api.github.... | [] | closed | false | null | [] | [
"thank you!"
] | 1,574 | 1,574 | 1,574 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1919/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1919/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1919",
"html_url": "https://github.com/huggingface/transformers/pull/1919",
"diff_url": "https://github.com/huggingface/transformers/pull/1919.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1919.patch",
"merged_at": 1... | |
https://api.github.com/repos/huggingface/transformers/issues/1918 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1918/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1918/comments | https://api.github.com/repos/huggingface/transformers/issues/1918/events | https://github.com/huggingface/transformers/pull/1918 | 527,351,610 | MDExOlB1bGxSZXF1ZXN0MzQ0NjQ2Njk3 | 1,918 | Minor bug fixes on run_ner.py | {
"login": "manansanghi",
"id": 52307004,
"node_id": "MDQ6VXNlcjUyMzA3MDA0",
"avatar_url": "https://avatars.githubusercontent.com/u/52307004?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/manansanghi",
"html_url": "https://github.com/manansanghi",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1918?src=pr&el=h1) Report\n> Merging [#1918](https://codecov.io/gh/huggingface/transformers/pull/1918?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/26db31e0c09a8b5e1ca7a61c454b159eab9d86be?src=pr&el=desc) will **n... | 1,574 | 1,574 | 1,574 | CONTRIBUTOR | null | Adding a dictionary entry outside of initialization requires an '=' instead of ':' | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1918/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1918/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1918",
"html_url": "https://github.com/huggingface/transformers/pull/1918",
"diff_url": "https://github.com/huggingface/transformers/pull/1918.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1918.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1917 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1917/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1917/comments | https://api.github.com/repos/huggingface/transformers/issues/1917/events | https://github.com/huggingface/transformers/issues/1917 | 527,319,982 | MDU6SXNzdWU1MjczMTk5ODI= | 1,917 | run_squad.py not running | {
"login": "maxmatical",
"id": 8890262,
"node_id": "MDQ6VXNlcjg4OTAyNjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8890262?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maxmatical",
"html_url": "https://github.com/maxmatical",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | [] | 1,574 | 1,574 | 1,574 | NONE | null | ## ❓ Questions & Help
When I try to run the script to fine-tune BERT on squad using the code from the examples:
```
python ./examples/run_squad.py \
--model_type bert \
--model_name_or_path bert-large-uncased-whole-word-masking \
--do_train \
--do_eval \
--do_lower_case \
--train_fi... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1917/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1917/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1916 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1916/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1916/comments | https://api.github.com/repos/huggingface/transformers/issues/1916/events | https://github.com/huggingface/transformers/issues/1916 | 527,256,511 | MDU6SXNzdWU1MjcyNTY1MTE= | 1,916 | Truncating GPT2 past | {
"login": "LHolten",
"id": 24637999,
"node_id": "MDQ6VXNlcjI0NjM3OTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/24637999?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LHolten",
"html_url": "https://github.com/LHolten",
"followers_url": "https://api.github.com/users/LHolte... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi! Your usage of `past` seems correct to me. After how many iterations do you feel the need to truncate?",
"I also would like to have an example that works correctly with GPT2. If past is not truncated, the model crashes after it reaches some threshold, which is, I suppose, `model.config.max_position_embeddings... | 1,574 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
I am using code like this to generate text:
```python
while True:
output_token, past = model.forward(output_token, past=past)
output_token = output_token[:, -1, :]
output_token = torch.multinomial(F.softmax(output_token, dim=-1), num_samples=1)
out = to... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1916/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1916/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1915 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1915/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1915/comments | https://api.github.com/repos/huggingface/transformers/issues/1915/events | https://github.com/huggingface/transformers/issues/1915 | 527,222,410 | MDU6SXNzdWU1MjcyMjI0MTA= | 1,915 | Any plan to include BART and T5? | {
"login": "leuchine",
"id": 3937040,
"node_id": "MDQ6VXNlcjM5MzcwNDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3937040?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leuchine",
"html_url": "https://github.com/leuchine",
"followers_url": "https://api.github.com/users/leuch... | [] | closed | false | null | [] | [
"please search for issues beforehand (and fill the template if there's not already a relevant issue)"
] | 1,574 | 1,574 | 1,574 | NONE | null | # 🌟New model addition
## Model description
<!-- Important information -->
## Open Source status
* [ ] the model implementation is available: (give details)
* [ ] the model weights are available: (give details)
* [ ] who are the authors: (mention them)
## Additional context
<!-- Add any other contex... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1915/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1915/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1914 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1914/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1914/comments | https://api.github.com/repos/huggingface/transformers/issues/1914/events | https://github.com/huggingface/transformers/issues/1914 | 527,178,312 | MDU6SXNzdWU1MjcxNzgzMTI= | 1,914 | How to perform common sense reasoning task with GPT-2? | {
"login": "h56cho",
"id": 52889259,
"node_id": "MDQ6VXNlcjUyODg5MjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/52889259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h56cho",
"html_url": "https://github.com/h56cho",
"followers_url": "https://api.github.com/users/h56cho/fo... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,574 | 1,580 | 1,580 | NONE | null | Hello,
I am new to NLP so I have lots of questions.
I am interested in carrying out common sense reasoning task with GPT-2, for example, with Winograd Schema Challenge dataset.
Q1. How should I tokenize the Winograd Schema Challenge dataset to process it with GPT-2 (with the double heads model, for instance)? ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1914/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1914/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1913 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1913/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1913/comments | https://api.github.com/repos/huggingface/transformers/issues/1913/events | https://github.com/huggingface/transformers/issues/1913 | 527,098,833 | MDU6SXNzdWU1MjcwOTg4MzM= | 1,913 | Some Questions about XLNet | {
"login": "qlwang25",
"id": 38132016,
"node_id": "MDQ6VXNlcjM4MTMyMDE2",
"avatar_url": "https://avatars.githubusercontent.com/u/38132016?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/qlwang25",
"html_url": "https://github.com/qlwang25",
"followers_url": "https://api.github.com/users/qlw... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,574 | 1,580 | 1,580 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
1, XLNet is a model with relative position embeddings, so can either pad the inputs on the right or on the left ?
2, If i pad the inputs on the left, the length of input is 100 and the max length is 128, i don't consider the PAD ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1913/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1913/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1912 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1912/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1912/comments | https://api.github.com/repos/huggingface/transformers/issues/1912/events | https://github.com/huggingface/transformers/issues/1912 | 526,977,981 | MDU6SXNzdWU1MjY5Nzc5ODE= | 1,912 | XLNet is getting slower when enabling mems | {
"login": "makcedward",
"id": 36614806,
"node_id": "MDQ6VXNlcjM2NjE0ODA2",
"avatar_url": "https://avatars.githubusercontent.com/u/36614806?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/makcedward",
"html_url": "https://github.com/makcedward",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"When using `past` or `mems` values, you should be careful not to give the model the input ids which have already been computed. We've recently [added a documentation section ](https://huggingface.co/transformers/quickstart.html#using-the-past)detailing the use of `past`, which is similar to the way `mems` should b... | 1,574 | 1,580 | 1,580 | NONE | null | Per API doc, using mems help to reduce inference time. However, I noticed that more time is needed when increasing mem_len. Do I misunderstand the usage of mem_len parameter?
Here is the testing code
```
import time
import torch
from transformers import XLNetTokenizer, XLNetLMHeadModel
tokenizer = XLNetToken... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1912/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1912/timeline | completed | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.