
url stringlengths 62 66 | repository_url stringclasses 1
value | labels_url stringlengths 76 80 | comments_url stringlengths 71 75 | events_url stringlengths 69 73 | html_url stringlengths 50 56 | id int64 377M 2.15B | node_id stringlengths 18 32 | number int64 1 29.2k | title stringlengths 1 487 | user dict | labels list | state stringclasses 2
values | locked bool 2
classes | assignee dict | assignees list | comments list | created_at int64 1.54k 1.71k | updated_at int64 1.54k 1.71k | closed_at int64 1.54k 1.71k ⌀ | author_association stringclasses 4
values | active_lock_reason stringclasses 2
values | body stringlengths 0 234k ⌀ | reactions dict | timeline_url stringlengths 71 75 | state_reason stringclasses 3
values | draft bool 2
classes | pull_request dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/1810 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1810/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1810/comments | https://api.github.com/repos/huggingface/transformers/issues/1810/events | https://github.com/huggingface/transformers/issues/1810 | 521,782,106 | MDU6SXNzdWU1MjE3ODIxMDY= | 1,810 | NameError: name 'DUMMY_INPUTS' is not defined - From TF to PyTorch | {
"login": "RubensZimbres",
"id": 20270054,
"node_id": "MDQ6VXNlcjIwMjcwMDU0",
"avatar_url": "https://avatars.githubusercontent.com/u/20270054?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RubensZimbres",
"html_url": "https://github.com/RubensZimbres",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [
"Hi! I believe this is a bug that was fixed on master. Could you try and install from source and tell me if it fixes your issue?\r\n\r\nYou can do so with the following command in your python environment:\r\n\r\n```\r\npip install git+https://github.com/huggingface/transformers\r\n```",
"@LysandreJik Thanks for t... | 1,573 | 1,575 | 1,575 | NONE | null | ## 🐛 Bug
I'm using TFBertForSequenceClassification, Tensorflow 2.0.0b0, PyTorch is up-to-date and the code from Hugging Face README.md:
```
import tensorflow as tf
import tensorflow_datasets
from transformers import *
tf.compat.v1.enable_eager_execution()
tokenizer = BertTokenizer.from_pretrained('bert-... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1810/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1810/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1809 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1809/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1809/comments | https://api.github.com/repos/huggingface/transformers/issues/1809/events | https://github.com/huggingface/transformers/issues/1809 | 521,750,456 | MDU6SXNzdWU1MjE3NTA0NTY= | 1,809 | Why do language modeling heads not have activation functions? | {
"login": "langfield",
"id": 35980963,
"node_id": "MDQ6VXNlcjM1OTgwOTYz",
"avatar_url": "https://avatars.githubusercontent.com/u/35980963?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/langfield",
"html_url": "https://github.com/langfield",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"Hi, some Transformers have activation in their heads, for instance, Bert.\r\nSee here: https://github.com/huggingface/transformers/blob/master/transformers/modeling_bert.py#L421\r\n\r\nThis is most likely a design choice with a minor effect for deep transformers as they learn to generate the current or next token ... | 1,573 | 1,573 | 1,573 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
This is more of a question about the transformer architecture in general than anything else. I noticed that, in `modeling_openai.py`, for example, the `self.lm_head()` module is just a linear layer. Why is it sufficient to use a linea... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1809/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1809/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1808 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1808/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1808/comments | https://api.github.com/repos/huggingface/transformers/issues/1808/events | https://github.com/huggingface/transformers/issues/1808 | 521,734,279 | MDU6SXNzdWU1MjE3MzQyNzk= | 1,808 | XLMForSequenceClassification - help with zero-shot cross-lingual classification | {
"login": "rsilveira79",
"id": 11993881,
"node_id": "MDQ6VXNlcjExOTkzODgx",
"avatar_url": "https://avatars.githubusercontent.com/u/11993881?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rsilveira79",
"html_url": "https://github.com/rsilveira79",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"Hi, we've added some details on the multi-modal models here: https://huggingface.co/transformers/multilingual.html\r\nAnd an XNLI example here: https://github.com/huggingface/transformers/tree/master/examples#xnli"
] | 1,573 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
Hi guys
According to XLM description (https://github.com/facebookresearch/XLM?fbclid=IwAR0-ZJpmWmIVfR20fA2KCHgrUU3k0cMUyx2n_V9-9C8g857-nhavrfBnVSI#pretrained-cross-lingual-language-models), we could potentially do XLNI by training in `en` dataset and do inference in other language:
```
XLMs ca... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1808/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1808/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1807 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1807/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1807/comments | https://api.github.com/repos/huggingface/transformers/issues/1807/events | https://github.com/huggingface/transformers/issues/1807 | 521,619,218 | MDU6SXNzdWU1MjE2MTkyMTg= | 1,807 | Whether it belongs to the bug of class trainedtokenizer decode? | {
"login": "yuanxiaosc",
"id": 16183570,
"node_id": "MDQ6VXNlcjE2MTgzNTcw",
"avatar_url": "https://avatars.githubusercontent.com/u/16183570?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yuanxiaosc",
"html_url": "https://github.com/yuanxiaosc",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [
"You're right, this is an error. The PR #1811 aims to fix that issue!",
"It should be fixed now, thanks! Feel free to re-open if the error persists."
] | 1,573 | 1,573 | 1,573 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->


| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1807/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1807/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1806 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1806/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1806/comments | https://api.github.com/repos/huggingface/transformers/issues/1806/events | https://github.com/huggingface/transformers/issues/1806 | 521,590,490 | MDU6SXNzdWU1MjE1OTA0OTA= | 1,806 | Extracting First Hidden States | {
"login": "brytjy",
"id": 46053996,
"node_id": "MDQ6VXNlcjQ2MDUzOTk2",
"avatar_url": "https://avatars.githubusercontent.com/u/46053996?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brytjy",
"html_url": "https://github.com/brytjy",
"followers_url": "https://api.github.com/users/brytjy/fo... | [] | closed | false | null | [] | [] | 1,573 | 1,573 | 1,573 | NONE | null | ## ❓ Questions & Help
For example, right now in order to extract the first hidden states of DistilBert model,
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained('distilbert-base-uncased', **output_hidden_states=True**)
input_ids = torch.tensor(toke... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1806/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1806/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1805 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1805/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1805/comments | https://api.github.com/repos/huggingface/transformers/issues/1805/events | https://github.com/huggingface/transformers/issues/1805 | 521,574,385 | MDU6SXNzdWU1MjE1NzQzODU= | 1,805 | RuntimeError: CUDA error: device-side assert triggered | {
"login": "cswangjiawei",
"id": 33107884,
"node_id": "MDQ6VXNlcjMzMTA3ODg0",
"avatar_url": "https://avatars.githubusercontent.com/u/33107884?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cswangjiawei",
"html_url": "https://github.com/cswangjiawei",
"followers_url": "https://api.github.c... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Are you in a multi-GPU setup ?",
"I did not use multi-GPU setup, I used to `model.cuda()`, it ocuurs \"RuntimeError: CUDA error: device-side assert triggered\", so I changed to `model.cuda(0)`, but the error still occurs.",
"Do you mind showing how you initialize BERT and the code surrounding the error?",
"M... | 1,573 | 1,617 | 1,579 | NONE | null | ## ❓ Questions & Help
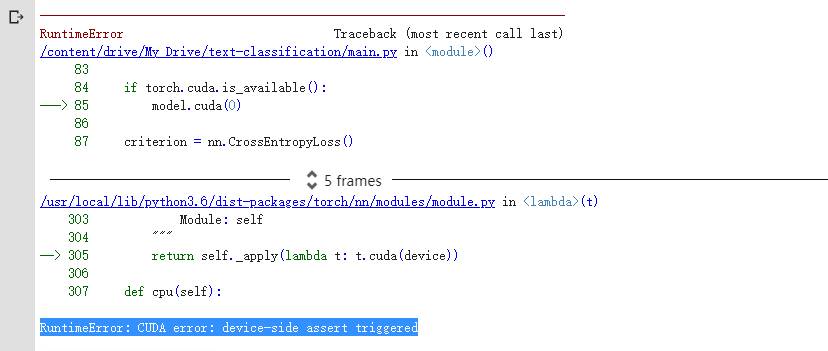. "RuntimeError: CUDA error: device-side assert triggered" occurs. My model is as follows:
```
class TextClassify(nn.Module):
def __init__(self, bert, kernel_size, word_dim, out_di... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1805/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1805/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1804 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1804/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1804/comments | https://api.github.com/repos/huggingface/transformers/issues/1804/events | https://github.com/huggingface/transformers/pull/1804 | 521,481,220 | MDExOlB1bGxSZXF1ZXN0MzM5ODUxNDg5 | 1,804 | fix multi-gpu eval in torch examples | {
"login": "ronakice",
"id": 19197923,
"node_id": "MDQ6VXNlcjE5MTk3OTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/19197923?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ronakice",
"html_url": "https://github.com/ronakice",
"followers_url": "https://api.github.com/users/ron... | [] | closed | false | null | [] | [
"Indeed, good catch, thanks @ronakice "
] | 1,573 | 1,573 | 1,573 | CONTRIBUTOR | null | Although batch_size for eval is updated to include multiple GPUs, DataParallel is missing from the model and hence doesn't use multi-GPUs. This PR allows DataParallel (multi-GPU) model in eval. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1804/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1804/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1804",
"html_url": "https://github.com/huggingface/transformers/pull/1804",
"diff_url": "https://github.com/huggingface/transformers/pull/1804.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1804.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1803 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1803/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1803/comments | https://api.github.com/repos/huggingface/transformers/issues/1803/events | https://github.com/huggingface/transformers/pull/1803 | 521,400,213 | MDExOlB1bGxSZXF1ZXN0MzM5Nzg1Njc2 | 1,803 | fix run_squad.py during fine-tuning xlnet on squad2.0 | {
"login": "importpandas",
"id": 30891974,
"node_id": "MDQ6VXNlcjMwODkxOTc0",
"avatar_url": "https://avatars.githubusercontent.com/u/30891974?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/importpandas",
"html_url": "https://github.com/importpandas",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | [
"This looks good, do you want to add your command and the results you mention in the README of the examples in `examples/README.md`?",
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1803?src=pr&el=h1) Report\n> Merging [#1803](https://codecov.io/gh/huggingface/transformers/pull/1803?src=pr&el=de... | 1,573 | 1,576 | 1,576 | CONTRIBUTOR | null | The following is a piece of code in forward function of xlnet model, which obviously is the key point of training the model on unanswerable questions using cls token representations. But the default value of tensor `is_impossible`(using to indicate whether this example is answerable) is none, and we also hadn't passed... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1803/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1803/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1803",
"html_url": "https://github.com/huggingface/transformers/pull/1803",
"diff_url": "https://github.com/huggingface/transformers/pull/1803.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1803.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1802 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1802/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1802/comments | https://api.github.com/repos/huggingface/transformers/issues/1802/events | https://github.com/huggingface/transformers/issues/1802 | 521,397,577 | MDU6SXNzdWU1MjEzOTc1Nzc= | 1,802 | pip cannot install transformers with python version 3.8.0 | {
"login": "Lyther",
"id": 29906124,
"node_id": "MDQ6VXNlcjI5OTA2MTI0",
"avatar_url": "https://avatars.githubusercontent.com/u/29906124?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Lyther",
"html_url": "https://github.com/Lyther",
"followers_url": "https://api.github.com/users/Lyther/fo... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This looks like an error related to Google SentencePiece and in particular this issue: https://github.com/google/sentencepiece/issues/411",
"https://github.com/google/sentencepiece/issues/411#issuecomment-557596691\r\n\r\n```\r\npip install https://github.com/google/sentencepiece/releases/download/v0.1.84/senten... | 1,573 | 1,589 | 1,589 | NONE | null | ## ❓ Questions & Help
The error message looks like this,
` ERROR: Command errored out with exit status 1:
command: 'c:\users\enderaoe\appdata\local\programs\python\python38-32\python.exe' -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'C:\\Users\\Enderaoe\\AppData\\Local\\Temp\\pip-install-g... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1802/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1802/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1801 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1801/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1801/comments | https://api.github.com/repos/huggingface/transformers/issues/1801/events | https://github.com/huggingface/transformers/issues/1801 | 521,335,428 | MDU6SXNzdWU1MjEzMzU0Mjg= | 1,801 | run_glue.py RuntimeError: module must have its parameters and buffers on device cuda:0 (device_ids[0]) but found one of them on device: cuda:3 | {
"login": "insublee",
"id": 39117829,
"node_id": "MDQ6VXNlcjM5MTE3ODI5",
"avatar_url": "https://avatars.githubusercontent.com/u/39117829?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/insublee",
"html_url": "https://github.com/insublee",
"followers_url": "https://api.github.com/users/ins... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This problem comes out from multiple GPUs usage. The error you have reported says that you have parameters or the buffers of the model in **two different locations**. \r\nSaid this, it's probably related to #1504 issue. Reading comments in the #1504 issue, i saw that @h-sugi suggests 4 days ago to modify the sour... | 1,573 | 1,591 | 1,591 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details) : transformers/examples/run_glue.py
* [ ] my own modified scripts: (give deta... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1801/reactions",
"total_count": 5,
"+1": 5,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1801/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1800 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1800/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1800/comments | https://api.github.com/repos/huggingface/transformers/issues/1800/events | https://github.com/huggingface/transformers/issues/1800 | 521,311,524 | MDU6SXNzdWU1MjEzMTE1MjQ= | 1,800 | Exact and F1 score do not increase when fine-tunes XLM on the SQuAD dataset | {
"login": "ZhengWeiH",
"id": 43492059,
"node_id": "MDQ6VXNlcjQzNDkyMDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/43492059?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZhengWeiH",
"html_url": "https://github.com/ZhengWeiH",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"duplicate #1799 "
] | 1,573 | 1,580 | 1,579 | NONE | null | ## ❓ Questions & Help
I am trying to fine-tune XLM on the SQuAD dataset.
The command is as following:
[CUDA_VISIBLE_DEVICES=0 python run_squad.py --model_type xlm --model_name_or_path xlm-mlm-tlm-xnli15-1024 --do_train --do_eval --train_file $SQUAD_DIR/train-v1.1.json --predict_file $SQUAD_DIR/dev-v1.1.json --per_... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1800/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1800/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1799 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1799/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1799/comments | https://api.github.com/repos/huggingface/transformers/issues/1799/events | https://github.com/huggingface/transformers/issues/1799 | 521,310,381 | MDU6SXNzdWU1MjEzMTAzODE= | 1,799 | Exact and F1 score do not increase when fine-tunes XLM on the SQuAD dataset | {
"login": "ZhengWeiH",
"id": 43492059,
"node_id": "MDQ6VXNlcjQzNDkyMDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/43492059?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZhengWeiH",
"html_url": "https://github.com/ZhengWeiH",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I haven't yet tried XLM for SQUad but I did try to finetune it on a similar (private) dataset. I managed to make it converge however the F1 is much worse than that of BERT (~0.75 vs ~0.80). XLM training seems to be very learning rate sensitive so you may want to tinker with that a bit.",
"Thank you for your answ... | 1,573 | 1,586 | 1,586 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using XLM:
Language I am using the model on English:
The problem arise when using:
[CUDA_VISIBLE_DEVICES=0 python run_squad.py --model_type xlm --model_name_or_path xlm-mlm-tlm-xnli15-1024 --do_train --do_eval --train_file $SQUAD_DIR/train-v1.1... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1799/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1799/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1798 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1798/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1798/comments | https://api.github.com/repos/huggingface/transformers/issues/1798/events | https://github.com/huggingface/transformers/issues/1798 | 521,306,501 | MDU6SXNzdWU1MjEzMDY1MDE= | 1,798 | Add an LSTM and CNN layer on top of BERT embeddings for sentiment analysis task | {
"login": "johnahug",
"id": 57651296,
"node_id": "MDQ6VXNlcjU3NjUxMjk2",
"avatar_url": "https://avatars.githubusercontent.com/u/57651296?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/johnahug",
"html_url": "https://github.com/johnahug",
"followers_url": "https://api.github.com/users/joh... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi @johnahug, I would recommend checking out how the TFBertFor* models work and trying a similar method to add the desired layers via Keras, for example: https://github.com/huggingface/transformers/blob/155c782a2ccd103cf63ad48a2becd7c76a7d2115/transformers/modeling_tf_bert.py#L834\r\n\r\nI might be able to help ou... | 1,573 | 1,580 | 1,579 | NONE | null | I am trying to add an LSTM and a convolutional layer on top of my BERT embeddings using the Transformers package in Tensorflow for a sentiment analysis task. Does someone know how I can go about that? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1798/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1798/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1797 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1797/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1797/comments | https://api.github.com/repos/huggingface/transformers/issues/1797/events | https://github.com/huggingface/transformers/pull/1797 | 521,306,293 | MDExOlB1bGxSZXF1ZXN0MzM5NzA5NDQ3 | 1,797 | TF: model forwards can take an inputs_embeds param | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-... | [] | closed | false | null | [] | [] | 1,573 | 1,573 | 1,573 | MEMBER | null | see https://github.com/huggingface/transformers/pull/1695 (non-TF) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1797/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1797/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1797",
"html_url": "https://github.com/huggingface/transformers/pull/1797",
"diff_url": "https://github.com/huggingface/transformers/pull/1797.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1797.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1796 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1796/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1796/comments | https://api.github.com/repos/huggingface/transformers/issues/1796/events | https://github.com/huggingface/transformers/pull/1796 | 521,277,736 | MDExOlB1bGxSZXF1ZXN0MzM5Njg3MTMw | 1,796 | Fix GPT2LMHeadModel.from_pretrained(from_tf=True) | {
"login": "leogao2",
"id": 54557097,
"node_id": "MDQ6VXNlcjU0NTU3MDk3",
"avatar_url": "https://avatars.githubusercontent.com/u/54557097?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leogao2",
"html_url": "https://github.com/leogao2",
"followers_url": "https://api.github.com/users/leogao... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1796?src=pr&el=h1) Report\n> Merging [#1796](https://codecov.io/gh/huggingface/transformers/pull/1796?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/b5d330d11820f4ac2cc8c909b1a6a77e0cd961e0?src=pr&el=desc) will **d... | 1,573 | 1,583 | 1,583 | CONTRIBUTOR | null | GPT2LMHeadModel.from_pretrained(from_tf=True) doesn't work because pointer points to the GPT2LMHeadModel instance, not the GPT2Model instance.
This bug causes errors like:
'GPT2LMHeadModel' object has no attribute 'h' | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1796/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1796/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1796",
"html_url": "https://github.com/huggingface/transformers/pull/1796",
"diff_url": "https://github.com/huggingface/transformers/pull/1796.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1796.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1795 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1795/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1795/comments | https://api.github.com/repos/huggingface/transformers/issues/1795/events | https://github.com/huggingface/transformers/issues/1795 | 521,267,846 | MDU6SXNzdWU1MjEyNjc4NDY= | 1,795 | RuntimeError: Connection timed out in Single node Multi GPU training | {
"login": "kamalravi",
"id": 9251058,
"node_id": "MDQ6VXNlcjkyNTEwNTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/9251058?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kamalravi",
"html_url": "https://github.com/kamalravi",
"followers_url": "https://api.github.com/users/ka... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"By any chance, did you open the port number you're using?",
"Yes, it is established. What is the master_addr and master_port when submitting a job with single node and multigpu config in GCP?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no fu... | 1,573 | 1,635 | 1,580 | NONE | null | I am trying to pre-train DistilBERT with single node multigpu as given here https://github.com/huggingface/transformers/tree/master/examples/distillation.
I have set the IP address of my gcp instance and port number. I am getting this error. Any solutions?
> File "/opt/conda/lib/python3.6/site-packages/torch/dist... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1795/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1795/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1794 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1794/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1794/comments | https://api.github.com/repos/huggingface/transformers/issues/1794/events | https://github.com/huggingface/transformers/issues/1794 | 521,193,988 | MDU6SXNzdWU1MjExOTM5ODg= | 1,794 | Confused by GPT2DoubleHeadsModel example | {
"login": "weiguowilliam",
"id": 31396452,
"node_id": "MDQ6VXNlcjMxMzk2NDUy",
"avatar_url": "https://avatars.githubusercontent.com/u/31396452?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/weiguowilliam",
"html_url": "https://github.com/weiguowilliam",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [
"For 2: It's next word prediction: https://openai.com/blog/better-language-models/",
"> For 2: It's next word prediction: https://openai.com/blog/better-language-models/\r\n\r\nThank you for your reply. From my perspective, I believe the next word prediction is what the language model does, which means it is the ... | 1,573 | 1,573 | 1,573 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Your library is really helpful. And I have 2 questions about the example of GPT2DoubleHeadsModel.
1.
In source code of model,
> choices = ["Hello, my dog is cute [CLS]", "Hello, my cat is cute [CLS]"]
Here the comment said... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1794/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1794/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1793 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1793/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1793/comments | https://api.github.com/repos/huggingface/transformers/issues/1793/events | https://github.com/huggingface/transformers/issues/1793 | 521,192,076 | MDU6SXNzdWU1MjExOTIwNzY= | 1,793 | MNLI: BERT No Training Progress | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I'm assuming you did multiple runs with ≠ seeds?",
"Yes -- I have tried with multiple different seeds.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> Yes -- I have tried wit... | 1,573 | 1,609 | 1,579 | NONE | null | ## 🐛 Bug
I am using BERT and have successfully set up pipelines for 7/8 GLUE tasks, and I find comparably good accuracy on all of them. However, for MNLI task, training loss does not converge at all. I am correctly using 3 classes with `num_classes`. In fact, I have even tried reduced the scope of MNLI to a 2-class... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1793/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1793/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1792 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1792/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1792/comments | https://api.github.com/repos/huggingface/transformers/issues/1792/events | https://github.com/huggingface/transformers/pull/1792 | 521,064,883 | MDExOlB1bGxSZXF1ZXN0MzM5NTE4MTQ2 | 1,792 | DistilBERT for token classification | {
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"This is great, thanks @stefan-it!",
"This is great, thanks a lot @stefan-it.\r\nI've added your quick benchmark in the readme.",
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1792?src=pr&el=h1) Report\n> Merging [#1792](https://codecov.io/gh/huggingface/transformers/pull/1792?src=pr&el=desc)... | 1,573 | 1,574 | 1,573 | COLLABORATOR | null | Hi,
this PR adds a `DistilBertForTokenClassification` implementation (mainly inspired by the BERT implementation) that allows to perform sequence labeling tasks like NER or PoS tagging.
Additionally, the `run_ner.py` example script was modified to fully support DistilBERT for NER tasks.
I did a small compariso... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1792/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1792/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1792",
"html_url": "https://github.com/huggingface/transformers/pull/1792",
"diff_url": "https://github.com/huggingface/transformers/pull/1792.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1792.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1791 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1791/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1791/comments | https://api.github.com/repos/huggingface/transformers/issues/1791/events | https://github.com/huggingface/transformers/issues/1791 | 520,982,329 | MDU6SXNzdWU1MjA5ODIzMjk= | 1,791 | token indices sequence length is longer than the specified maximum sequence length | {
"login": "cswangjiawei",
"id": 33107884,
"node_id": "MDQ6VXNlcjMzMTA3ODg0",
"avatar_url": "https://avatars.githubusercontent.com/u/33107884?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cswangjiawei",
"html_url": "https://github.com/cswangjiawei",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | [
"This means you're encoding a sequence that is larger than the max sequence the model can handle (which is 512 tokens). This is not an error but a warning; if you pass that sequence to the model it will crash as it cannot handle such a long sequence.\r\n\r\nYou can truncate the sequence: `seq = seq[:512]` or use th... | 1,573 | 1,707 | 1,575 | NONE | null | ## ❓ Questions & Help
When I use Bert, the "token indices sequence length is longer than the specified maximum sequence length for this model (1017 > 512)" occurs. How can I solve this error? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1791/reactions",
"total_count": 54,
"+1": 37,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 17
} | https://api.github.com/repos/huggingface/transformers/issues/1791/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1790 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1790/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1790/comments | https://api.github.com/repos/huggingface/transformers/issues/1790/events | https://github.com/huggingface/transformers/issues/1790 | 520,891,030 | MDU6SXNzdWU1MjA4OTEwMzA= | 1,790 | transformers vs pytorch_pretrained_bert giving different scores for BertForNextSentencePrediction | {
"login": "AjitAntony",
"id": 46282348,
"node_id": "MDQ6VXNlcjQ2MjgyMzQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/46282348?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AjitAntony",
"html_url": "https://github.com/AjitAntony",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [
"Hi, since `pytorch_pretrained_BERT`, many breaking changes have happened, two of which are causing confusion in your snippet:\r\n\r\n- The order of arguments in the forward call has been slightly changed [(v2.0.0)](https://github.com/huggingface/transformers/releases/tag/v2.0.0)\r\n- The models now always return t... | 1,573 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
import torch
from transformers import BertTokenizer, BertModel, BertForMaskedLM,BertForNextSentencePrediction
tokenizer=BertTokenizer.from_pretrained('bert-base-uncased')
BertNSP=BertForNextSentencePrediction.from_pretrained('bert-ba... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1790/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1790/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1789 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1789/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1789/comments | https://api.github.com/repos/huggingface/transformers/issues/1789/events | https://github.com/huggingface/transformers/issues/1789 | 520,872,507 | MDU6SXNzdWU1MjA4NzI1MDc= | 1,789 | BertForMultipleChoice QuickTour issue with weights? | {
"login": "ChrisPalmerNZ",
"id": 11279395,
"node_id": "MDQ6VXNlcjExMjc5Mzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/11279395?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ChrisPalmerNZ",
"html_url": "https://github.com/ChrisPalmerNZ",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [
"The same error occurs to me too. I write a small check code for BertForMultipleChoice and it works as expected (taken from the [documentation](https://github.com/huggingface/transformers/blob/albert/transformers/modeling_bert.py) - rows 945-951). Here the code I wrote.\r\n```\r\ntokenizer = BertTokenizer.from_pret... | 1,573 | 1,573 | 1,573 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (BertForMultipleChoice):
Language I am using the model on (English.):
The problem arise when using:
* [x] the official example scripts:
Arises when running through the last piece of example code found here:
https://github.com/huggingface/transform... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1789/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1789/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1788 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1788/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1788/comments | https://api.github.com/repos/huggingface/transformers/issues/1788/events | https://github.com/huggingface/transformers/issues/1788 | 520,871,682 | MDU6SXNzdWU1MjA4NzE2ODI= | 1,788 | BertForNextSentencePrediction is giving high score for non similar sentences . | {
"login": "AjitAntony",
"id": 46282348,
"node_id": "MDQ6VXNlcjQ2MjgyMzQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/46282348?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AjitAntony",
"html_url": "https://github.com/AjitAntony",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"As explained in #1790, you're passing the `token_type_ids` as the attention mask. Change the model forward pass as such:\r\n\r\n```py\r\nprediction = BertNSP(tokens_tensor, token_type_ids=segments_tensors)\r\n```\r\nYour results will be more accurate:\r\n```py\r\ntensor([[-2.3808, 5.4018]], grad_fn=<AddmmBackward... | 1,573 | 1,643 | 1,588 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
import torch
from transformers import BertTokenizer, BertModel, BertForMaskedLM,BertForNextSentencePrediction
tokenizer=BertTokenizer.from_pretrained('bert-base-uncased')
BertNSP=BertForNextSentencePrediction.from_pretrained('bert-b... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1788/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1788/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1787 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1787/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1787/comments | https://api.github.com/repos/huggingface/transformers/issues/1787/events | https://github.com/huggingface/transformers/issues/1787 | 520,805,250 | MDU6SXNzdWU1MjA4MDUyNTA= | 1,787 | Invalid argument with CTRLModel | {
"login": "ChrisPalmerNZ",
"id": 11279395,
"node_id": "MDQ6VXNlcjExMjc5Mzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/11279395?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ChrisPalmerNZ",
"html_url": "https://github.com/ChrisPalmerNZ",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [
"> ## Bug\r\n> Model I am using (CTRLModel):\r\n> \r\n> Language I am using the model on (English):\r\n> \r\n> The problem arise when using:\r\n> \r\n> * [X ] the official example scripts: (give details)\r\n> \r\n> The tasks I am working on is:\r\n> \r\n> * [X ] the Quick Tour for transformers\r\n> \r\n> ## To Rep... | 1,573 | 1,575 | 1,575 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (CTRLModel):
Language I am using the model on (English):
The problem arise when using:
* [X ] the official example scripts: (give details)
The tasks I am working on is:
* [X ] the Quick Tour for transformers
## To Reproduce
Steps to reprod... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1787/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1787/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1786 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1786/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1786/comments | https://api.github.com/repos/huggingface/transformers/issues/1786/events | https://github.com/huggingface/transformers/issues/1786 | 520,708,585 | MDU6SXNzdWU1MjA3MDg1ODU= | 1,786 | a BertForMaskedLM.from_pretrained error | {
"login": "zhujun5164",
"id": 49580602,
"node_id": "MDQ6VXNlcjQ5NTgwNjAy",
"avatar_url": "https://avatars.githubusercontent.com/u/49580602?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhujun5164",
"html_url": "https://github.com/zhujun5164",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [
"Masked language modeling is an example of autoencoding language modeling , typically mask one or more of words in a sentence and have the model predict those masked words given the other words in sentence. When you changed the vocab size, the number of word to predic from the model also changed.\r\nThis unofficial... | 1,573 | 1,575 | 1,575 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (BertForMaskedLM):
Language I am using the model on (Chinese):
When i want to do a limit vocabulary fine-tune in BerForMaskedLM, the new config/ vocab and model.bin in word_embedding are all been change.
for example:
`config = BertConfig.from_... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1786/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1786/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1785 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1785/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1785/comments | https://api.github.com/repos/huggingface/transformers/issues/1785/events | https://github.com/huggingface/transformers/issues/1785 | 520,678,327 | MDU6SXNzdWU1MjA2NzgzMjc= | 1,785 | "Write with Transformer" source code? | {
"login": "AIsysxd",
"id": 54706002,
"node_id": "MDQ6VXNlcjU0NzA2MDAy",
"avatar_url": "https://avatars.githubusercontent.com/u/54706002?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AIsysxd",
"html_url": "https://github.com/AIsysxd",
"followers_url": "https://api.github.com/users/AIsysx... | [
{
"id": 1565794707,
"node_id": "MDU6TGFiZWwxNTY1Nzk0NzA3",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Write%20With%20Transformer",
"name": "Write With Transformer",
"color": "a84bf4",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"Hello,\r\n\r\nSorry, the web app is not open source right now.",
"Thanks @julien-c . Can you comment on how elastic inference with pytorch models is done?",
"Is there any chance this could be reconsidered? I'd love to use it for experimenting with custom fine-tuned models.",
"Would also love for this for ex... | 1,573 | 1,630 | 1,573 | NONE | null | ## ❓ Questions & Help
Hello, can't find source code of it. May you help, please?
<!-- A clear and concise description of the question. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1785/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1785/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1784 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1784/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1784/comments | https://api.github.com/repos/huggingface/transformers/issues/1784/events | https://github.com/huggingface/transformers/issues/1784 | 520,667,819 | MDU6SXNzdWU1MjA2Njc4MTk= | 1,784 | Unclear documentation for special_tokens_mask | {
"login": "Evpok",
"id": 1656541,
"node_id": "MDQ6VXNlcjE2NTY1NDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1656541?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Evpok",
"html_url": "https://github.com/Evpok",
"followers_url": "https://api.github.com/users/Evpok/follower... | [] | closed | false | null | [] | [
"Indeed, this is a documentation error! Thank you for letting us know!",
"@LysandreJik This was reintroduced in https://github.com/huggingface/transformers/pull/2989 apparently",
"Thanks @Evpok for letting me know, this flew under my radar.",
"My pleasure 😄"
] | 1,573 | 1,589 | 1,573 | CONTRIBUTOR | null | According to [the docs](https://huggingface.co/transformers/main_classes/tokenizer.html#transformers.PreTrainedTokenizer.get_special_tokens_mask), the `special_tokens_mask` returned by e.g. `encode_plus` should have
> 0 for a special token, 1 for a sequence token
Yet when I try
```python
tokenizer = transform... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1784/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1784/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1783 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1783/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1783/comments | https://api.github.com/repos/huggingface/transformers/issues/1783/events | https://github.com/huggingface/transformers/issues/1783 | 520,582,301 | MDU6SXNzdWU1MjA1ODIzMDE= | 1,783 | How to measure similarity of words? | {
"login": "RakshaAg",
"id": 43982672,
"node_id": "MDQ6VXNlcjQzOTgyNjcy",
"avatar_url": "https://avatars.githubusercontent.com/u/43982672?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RakshaAg",
"html_url": "https://github.com/RakshaAg",
"followers_url": "https://api.github.com/users/Rak... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"You should check out BLEU and ROUGE scores. These are often referred to as the precision and recall of NLP.\r\n\r\nYou may be able to craft a pseudo-f1 score out of these as well \r\n`f1 = 2*(bleu*rouge)/(bleu + rouge)`\r\n\r\nI haven't tried this myself yet, but hopefully this helps!\r\n\r\n[https://en.wikipedia.... | 1,573 | 1,579 | 1,579 | NONE | null | I want to know it BERT based contextual embedding can be used to measure similarity of identical words in different contexts.
And, can I estimate a threshold for that.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1783/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1783/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1782 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1782/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1782/comments | https://api.github.com/repos/huggingface/transformers/issues/1782/events | https://github.com/huggingface/transformers/issues/1782 | 520,569,684 | MDU6SXNzdWU1MjA1Njk2ODQ= | 1,782 | model = GPT2LMHeadModel.from_pretrained(args.model_path) try loads in json format | {
"login": "lucasjinreal",
"id": 21303438,
"node_id": "MDQ6VXNlcjIxMzAzNDM4",
"avatar_url": "https://avatars.githubusercontent.com/u/21303438?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lucasjinreal",
"html_url": "https://github.com/lucasjinreal",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | [
"What string was passed under `args.model_path`? Is it a directory or a file name? (It should be a directory)",
"model_path is a model trained with xxx.pth format.\r\n\r\nIs that a directory? contains what?",
"The `model_path` should link to a directory holding the pytorch model and the configuration file assoc... | 1,573 | 1,573 | 1,573 | NONE | null | ## 🐛 Bug
Initial a model in this code:
```
logging.info('loading model from: {}'.format(args.model_path))
model = GPT2LMHeadModel.from_pretrained(args.model_path)
```
It seems inside transforms reading our model in json format which cause error:
```
INFO 11-10 16:18:49 generate.py:167 - loading... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1782/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1782/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1781 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1781/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1781/comments | https://api.github.com/repos/huggingface/transformers/issues/1781/events | https://github.com/huggingface/transformers/issues/1781 | 520,566,004 | MDU6SXNzdWU1MjA1NjYwMDQ= | 1,781 | Dose the file /examples/run_lm_finetuning.py provide a demo to pre-train a BERT | {
"login": "bytekongfrombupt",
"id": 33115565,
"node_id": "MDQ6VXNlcjMzMTE1NTY1",
"avatar_url": "https://avatars.githubusercontent.com/u/33115565?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bytekongfrombupt",
"html_url": "https://github.com/bytekongfrombupt",
"followers_url": "https://... | [] | closed | false | null | [] | [
"Hi, BERT uses the NSP task as well as the MLM task during its pre-training phase. The `run_lm_finetuning.py` script only does MLM so you would need to modify it to pre-train BERT the same way it was done in the paper."
] | 1,573 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi, I'm curious that if the file run_lm_finetuning.py can pre-train a BERT. But if so, why the file named finetuning instead of pre-training? Thanks! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1781/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1781/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1780 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1780/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1780/comments | https://api.github.com/repos/huggingface/transformers/issues/1780/events | https://github.com/huggingface/transformers/issues/1780 | 520,556,363 | MDU6SXNzdWU1MjA1NTYzNjM= | 1,780 | Problems when restoring the pretrain weights for TFbert | {
"login": "BraceLau",
"id": 43031180,
"node_id": "MDQ6VXNlcjQzMDMxMTgw",
"avatar_url": "https://avatars.githubusercontent.com/u/43031180?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BraceLau",
"html_url": "https://github.com/BraceLau",
"followers_url": "https://api.github.com/users/Bra... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, could you provide information about your setup? Which TensorFlow version are you using, which python version, which Transformers version? Thank you.",
"> Hi, could you provide information about your setup? Which TensorFlow version are you using, which python version, which Transformers version? Thank you.\r\... | 1,573 | 1,580 | 1,580 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using Bert:
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [ ] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/S... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1780/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1780/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1779 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1779/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1779/comments | https://api.github.com/repos/huggingface/transformers/issues/1779/events | https://github.com/huggingface/transformers/issues/1779 | 520,555,242 | MDU6SXNzdWU1MjA1NTUyNDI= | 1,779 | Multi GPU dataparallel crash | {
"login": "devroy73",
"id": 12408145,
"node_id": "MDQ6VXNlcjEyNDA4MTQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/12408145?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/devroy73",
"html_url": "https://github.com/devroy73",
"followers_url": "https://api.github.com/users/dev... | [] | closed | false | null | [] | [
"Even I'm facing this issue @LysandreJik @thomwolf can you throw some input on this?\r\nall the input is of the same length still this issue occurs.\r\n@devroy73 meanwhile in data loader you can set drop_last = True",
"Hey @anandhperumal thanks for that it solved my crashing issue. ",
"I tried setting drop_las... | 1,573 | 1,589 | 1,573 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): GPT2
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: run_lm_finetuning
* [ ] my own modified scripts: (give details)
The tasks I am working on ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1779/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1779/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1778 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1778/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1778/comments | https://api.github.com/repos/huggingface/transformers/issues/1778/events | https://github.com/huggingface/transformers/pull/1778 | 520,473,461 | MDExOlB1bGxSZXF1ZXN0MzM5MDU4NTkw | 1,778 | from_pretrained: convert DialoGPT format | {
"login": "yet-another-account",
"id": 10374151,
"node_id": "MDQ6VXNlcjEwMzc0MTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/10374151?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yet-another-account",
"html_url": "https://github.com/yet-another-account",
"followers_url": ... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1778?src=pr&el=h1) Report\n> Merging [#1778](https://codecov.io/gh/huggingface/transformers/pull/1778?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/7a9aae1044aa4699310a8004f631fc0a4bdf1b65?src=pr&el=desc) will **i... | 1,573 | 1,583 | 1,574 | CONTRIBUTOR | null | DialoGPT checkpoints have "lm_head.decoder.weight" instead of "lm_head.weight".
(see: https://www.reddit.com/r/MachineLearning/comments/dt5woy/p_dialogpt_state_of_the_art_conversational_model/f6vmwuy?utm_source=share&utm_medium=web2x) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1778/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1778/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1778",
"html_url": "https://github.com/huggingface/transformers/pull/1778",
"diff_url": "https://github.com/huggingface/transformers/pull/1778.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1778.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1777 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1777/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1777/comments | https://api.github.com/repos/huggingface/transformers/issues/1777/events | https://github.com/huggingface/transformers/issues/1777 | 520,444,971 | MDU6SXNzdWU1MjA0NDQ5NzE= | 1,777 | Could you support albert? | {
"login": "zhu1090093659",
"id": 46916148,
"node_id": "MDQ6VXNlcjQ2OTE2MTQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/46916148?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhu1090093659",
"html_url": "https://github.com/zhu1090093659",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [
"Duplicate of #1649 #1420 #1522 #1564 🤣🤣"
] | 1,573 | 1,573 | 1,573 | NONE | null | ## ❓ Questions & Help
For many students,who haven't large GPU,so they will use small model(eg albert),hence I hope you will support loading albert, Tkanks so much!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1777/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1777/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1776 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1776/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1776/comments | https://api.github.com/repos/huggingface/transformers/issues/1776/events | https://github.com/huggingface/transformers/issues/1776 | 520,378,697 | MDU6SXNzdWU1MjAzNzg2OTc= | 1,776 | Extracting the output layer of HuggingFace GPT2DoubleHeadsModel | {
"login": "h56cho",
"id": 52889259,
"node_id": "MDQ6VXNlcjUyODg5MjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/52889259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h56cho",
"html_url": "https://github.com/h56cho",
"followers_url": "https://api.github.com/users/h56cho/fo... | [] | closed | false | null | [] | [
"Please do not open duplicate issues (#1774)"
] | 1,573 | 1,573 | 1,573 | NONE | null | Hello,
Suppose that I have two GPT2DoubleHeadsModel (let’s call it model A and B).
Is there any way that I can:
1. take the hidden state of a given input at the n-th layer of the model A and feed it directly into the output layer of model B to compute output
AND
2. Take the output obtained from 1. and cal... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1776/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1776/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1775 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1775/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1775/comments | https://api.github.com/repos/huggingface/transformers/issues/1775/events | https://github.com/huggingface/transformers/issues/1775 | 520,169,743 | MDU6SXNzdWU1MjAxNjk3NDM= | 1,775 | pip install transformers not downloading gpt2-xl | {
"login": "samer-noureddine",
"id": 32775563,
"node_id": "MDQ6VXNlcjMyNzc1NTYz",
"avatar_url": "https://avatars.githubusercontent.com/u/32775563?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/samer-noureddine",
"html_url": "https://github.com/samer-noureddine",
"followers_url": "https://... | [] | closed | false | null | [] | [
"We haven't updated the pip version yet, we'll do so in the following weeks. Please install it from source in the meantime:\r\n\r\n```\r\npip install git+https://github.com/huggingface/transformers\r\n```",
"Traceback (most recent call last):\r\n File \"run_pplm.py\", line 936, in <module>\r\n run_pplm_exampl... | 1,573 | 1,630 | 1,573 | NONE | null | Following the release of 1.5 B parameter model, I attempted to upgrade my version using the following command:
pip install transformers --upgrade
The installed library does not have gpt2-xl, and throws this error when I try calling it:
OSError: Model name 'gpt2-xl' was not found in model name list (gpt2, gpt... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1775/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1775/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1774 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1774/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1774/comments | https://api.github.com/repos/huggingface/transformers/issues/1774/events | https://github.com/huggingface/transformers/issues/1774 | 520,106,246 | MDU6SXNzdWU1MjAxMDYyNDY= | 1,774 | For HuggingFace GPT2DoubleHeadsModel, is there a way to directly provide a hidden state for an input? | {
"login": "h56cho",
"id": 52889259,
"node_id": "MDQ6VXNlcjUyODg5MjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/52889259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h56cho",
"html_url": "https://github.com/h56cho",
"followers_url": "https://api.github.com/users/h56cho/fo... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi! You have access to the models' internals so you could definitely rewrite the main loop function to handle such a use-case!\r\n\r\nYou can access the hidden layers as follows:\r\n\r\n```py\r\nblocks = model.transformer.h # this is a list of \"block\"s\r\nblock[0] # contains the MLP/LayerNorm/attention layers\... | 1,573 | 1,579 | 1,579 | NONE | null | Hello,
Say I have two custom trained HuggingFace GPT2DoubleHeadsModels (Model 1 and 2).
I want to take an hidden state of m-th layer of model 1, and use that hidden state as my input for model 2.
Is this possible with HuggingFace GPT2DoubleHeadsModels?
Some coding example would be a great help!
Thank you,
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1774/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1774/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1773 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1773/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1773/comments | https://api.github.com/repos/huggingface/transformers/issues/1773/events | https://github.com/huggingface/transformers/pull/1773 | 520,059,736 | MDExOlB1bGxSZXF1ZXN0MzM4NzEzOTg1 | 1,773 | [WIP] BertAbs summarization | {
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/follower... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1773?src=pr&el=h1) Report\n> Merging [#1773](https://codecov.io/gh/huggingface/transformers/pull/1773?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/0cb163865a4c761c226b151283309eedb2b1ca4d?src=pr&el=desc) will **i... | 1,573 | 1,575 | 1,575 | CONTRIBUTOR | null | This PR builds on the encoder-decoder mechanism to do abstractive summarizaton. Contributions:
- A BeamSearch class that takes any `PreTranedEncoderDecoder` as an input;
- A script `run_summarization.py` that allows to pre-train the model and generate summaries.
Note that to save the checkpoints I had to add a p... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1773/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1773/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1773",
"html_url": "https://github.com/huggingface/transformers/pull/1773",
"diff_url": "https://github.com/huggingface/transformers/pull/1773.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1773.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1772 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1772/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1772/comments | https://api.github.com/repos/huggingface/transformers/issues/1772/events | https://github.com/huggingface/transformers/pull/1772 | 520,047,867 | MDExOlB1bGxSZXF1ZXN0MzM4NzA0MjA0 | 1,772 | Fix run_squad.py | {
"login": "tailorck",
"id": 7613002,
"node_id": "MDQ6VXNlcjc2MTMwMDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/7613002?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tailorck",
"html_url": "https://github.com/tailorck",
"followers_url": "https://api.github.com/users/tailo... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,573 | 1,583 | 1,583 | NONE | null | The `run_squad.py` was looking in the output directory for `config.json` when really it was one level lower in the checkpoint directories. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1772/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1772/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1772",
"html_url": "https://github.com/huggingface/transformers/pull/1772",
"diff_url": "https://github.com/huggingface/transformers/pull/1772.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1772.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1771 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1771/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1771/comments | https://api.github.com/repos/huggingface/transformers/issues/1771/events | https://github.com/huggingface/transformers/issues/1771 | 519,934,080 | MDU6SXNzdWU1MTk5MzQwODA= | 1,771 | Error when Fine-tuning XLM on SQuA | {
"login": "ZhengWeiH",
"id": 43492059,
"node_id": "MDQ6VXNlcjQzNDkyMDU5",
"avatar_url": "https://avatars.githubusercontent.com/u/43492059?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZhengWeiH",
"html_url": "https://github.com/ZhengWeiH",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"> ## Bug\r\n> Model I am using (XLM):\r\n> \r\n> Language I am using the model on (English and Chinese):\r\n> \r\n> The problem arise when using:\r\n> \r\n> [CUDA_VISIBLE_DEVICES=2 python run_squad.py --model_type xlm --model_name_or_path xlm-mlm-tlm-xnli15-1024 --do_train --do_eval --train_file $SQUAD_DIR/Crossl... | 1,573 | 1,579 | 1,579 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (XLM):
Language I am using the model on (English and Chinese):
The problem arise when using:
[CUDA_VISIBLE_DEVICES=2 python run_squad.py --model_type xlm --model_name_or_path xlm-mlm-tlm-xnli15-1024 --do_train --do_eval --train_file $SQ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1771/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1771/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1770 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1770/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1770/comments | https://api.github.com/repos/huggingface/transformers/issues/1770/events | https://github.com/huggingface/transformers/pull/1770 | 519,932,514 | MDExOlB1bGxSZXF1ZXN0MzM4NjA4NzEx | 1,770 | Only init encoder_attention_mask if stack is decoder | {
"login": "rlouf",
"id": 3885044,
"node_id": "MDQ6VXNlcjM4ODUwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3885044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rlouf",
"html_url": "https://github.com/rlouf",
"followers_url": "https://api.github.com/users/rlouf/follower... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1770?src=pr&el=h1) Report\n> Merging [#1770](https://codecov.io/gh/huggingface/transformers/pull/1770?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/1c542df7e554a2014051dd09becf60f157fed524?src=pr&el=desc) will **i... | 1,573 | 1,575 | 1,574 | CONTRIBUTOR | null | We currently initialize `encoder_attention_mask` when it is `None`,
whether the stack is that of an encoder or a decoder. Since this
may lead to bugs that are difficult to tracks down later, I added a condition
that assesses whether the current stack is a decoder. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1770/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1770/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1770",
"html_url": "https://github.com/huggingface/transformers/pull/1770",
"diff_url": "https://github.com/huggingface/transformers/pull/1770.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1770.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1769 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1769/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1769/comments | https://api.github.com/repos/huggingface/transformers/issues/1769/events | https://github.com/huggingface/transformers/issues/1769 | 519,870,890 | MDU6SXNzdWU1MTk4NzA4OTA= | 1,769 | [XLM-R] by Facebook AI Research | {
"login": "TheEdoardo93",
"id": 19664571,
"node_id": "MDQ6VXNlcjE5NjY0NTcx",
"avatar_url": "https://avatars.githubusercontent.com/u/19664571?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TheEdoardo93",
"html_url": "https://github.com/TheEdoardo93",
"followers_url": "https://api.github.c... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"cc @aconneau 😬",
"is there any update in the XLM-R model? ",
"Let me know if you need some-help in porting the xlm-r models to HF.",
"I think that's maybe not the correct way, but I adjusted the `convert_roberta_original_pytorch_checkpoint_to_pytorch.py` script to convert the `fairseq` model into a `transfo... | 1,573 | 1,588 | 1,584 | NONE | null | # 🌟New model addition
## Model description
Yesterday, Facebook has released _open source_ its new NLG model called **XLM-R** (XLM-RoBERTa) on [arXiv](https://arxiv.org/abs/1911.02116). This model uses self-supervised training techniques to achieve state-of-the-art performance in **cross-lingual understanding**, ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1769/reactions",
"total_count": 8,
"+1": 6,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 2,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1769/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1768 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1768/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1768/comments | https://api.github.com/repos/huggingface/transformers/issues/1768/events | https://github.com/huggingface/transformers/issues/1768 | 519,848,586 | MDU6SXNzdWU1MTk4NDg1ODY= | 1,768 | BERT: Uncased vocabulary has 30,552 tokens whereas cased has 28,996 tokens. Why this difference? | {
"login": "culcomp",
"id": 23293114,
"node_id": "MDQ6VXNlcjIzMjkzMTE0",
"avatar_url": "https://avatars.githubusercontent.com/u/23293114?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/culcomp",
"html_url": "https://github.com/culcomp",
"followers_url": "https://api.github.com/users/culcom... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,573 | 1,578 | 1,578 | NONE | null | ## ❓ Questions & Help
I was expecting cased vocabulary to be larger than uncased as it needs to include both tokens with capitalizations and without. But, to the contrary, I found the cased vocabulary to be smaller. May I know reason for this?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1768/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/transformers/issues/1768/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1767 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1767/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1767/comments | https://api.github.com/repos/huggingface/transformers/issues/1767/events | https://github.com/huggingface/transformers/issues/1767 | 519,755,053 | MDU6SXNzdWU1MTk3NTUwNTM= | 1,767 | GPT2 - XL | {
"login": "anandhperumal",
"id": 12907396,
"node_id": "MDQ6VXNlcjEyOTA3Mzk2",
"avatar_url": "https://avatars.githubusercontent.com/u/12907396?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anandhperumal",
"html_url": "https://github.com/anandhperumal",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [
"> ## Bug\r\n> Model I am using (Bert, XLNet....):\r\n> \r\n> Language I am using the model on (English, Chinese....):\r\n> \r\n> The problem arise when using:\r\n> \r\n> * [X ] the official example scripts: (give details)\r\n> * [ ] my own modified scripts: (give details)\r\n> \r\n> The tasks I am working on is:... | 1,573 | 1,573 | 1,573 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....):
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [X ] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an o... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1767/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1767/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1766 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1766/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1766/comments | https://api.github.com/repos/huggingface/transformers/issues/1766/events | https://github.com/huggingface/transformers/pull/1766 | 519,555,080 | MDExOlB1bGxSZXF1ZXN0MzM4Mjc2NDQw | 1,766 | Added additional training utils for run_squad.py | {
"login": "maxmatical",
"id": 8890262,
"node_id": "MDQ6VXNlcjg4OTAyNjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8890262?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maxmatical",
"html_url": "https://github.com/maxmatical",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1766?src=pr&el=h1) Report\n> Merging [#1766](https://codecov.io/gh/huggingface/transformers/pull/1766?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/1c542df7e554a2014051dd09becf60f157fed524?src=pr&el=desc) will **d... | 1,573 | 1,576 | 1,576 | NONE | null | Added different LR schedules and hyperparameters for beta1 and beta2 for AdamW | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1766/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1766/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1766",
"html_url": "https://github.com/huggingface/transformers/pull/1766",
"diff_url": "https://github.com/huggingface/transformers/pull/1766.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1766.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1765 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1765/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1765/comments | https://api.github.com/repos/huggingface/transformers/issues/1765/events | https://github.com/huggingface/transformers/pull/1765 | 519,549,538 | MDExOlB1bGxSZXF1ZXN0MzM4MjcxOTEx | 1,765 | Fix run_bertology.py | {
"login": "adrianbg",
"id": 66751,
"node_id": "MDQ6VXNlcjY2NzUx",
"avatar_url": "https://avatars.githubusercontent.com/u/66751?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adrianbg",
"html_url": "https://github.com/adrianbg",
"followers_url": "https://api.github.com/users/adrianbg/foll... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1765?src=pr&el=h1) Report\n> Merging [#1765](https://codecov.io/gh/huggingface/transformers/pull/1765?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/1c542df7e554a2014051dd09becf60f157fed524?src=pr&el=desc) will **n... | 1,573 | 1,573 | 1,573 | CONTRIBUTOR | null | Make imports and `args.overwrite_cache` match `run_glue.py`. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1765/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1765/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1765",
"html_url": "https://github.com/huggingface/transformers/pull/1765",
"diff_url": "https://github.com/huggingface/transformers/pull/1765.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1765.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1764 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1764/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1764/comments | https://api.github.com/repos/huggingface/transformers/issues/1764/events | https://github.com/huggingface/transformers/pull/1764 | 519,426,650 | MDExOlB1bGxSZXF1ZXN0MzM4MTcxMDE1 | 1,764 | Bug-fix: Roberta Embeddings Not Masked | {
"login": "DomHudson",
"id": 10864294,
"node_id": "MDQ6VXNlcjEwODY0Mjk0",
"avatar_url": "https://avatars.githubusercontent.com/u/10864294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DomHudson",
"html_url": "https://github.com/DomHudson",
"followers_url": "https://api.github.com/users/... | [] | closed | false | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-... | [
{
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.gith... | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1764?src=pr&el=h1) Report\n> Merging [#1764](https://codecov.io/gh/huggingface/transformers/pull/1764?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/a80778f40e4738071b5d01420a0328bb00cdb356?src=pr&el=desc) will **i... | 1,573 | 1,576 | 1,576 | NONE | null | ## Summary
I replace the code that makes the position ids with logic closer to the original fairseq `make_positions` function. It wasn't clear to me what to do in the event that the embeddings are passed in directly through `inputs_embeds` so I resorted to the old methodology and just generating a positional id for al... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1764/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1764/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1764",
"html_url": "https://github.com/huggingface/transformers/pull/1764",
"diff_url": "https://github.com/huggingface/transformers/pull/1764.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1764.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1763 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1763/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1763/comments | https://api.github.com/repos/huggingface/transformers/issues/1763/events | https://github.com/huggingface/transformers/pull/1763 | 519,419,951 | MDExOlB1bGxSZXF1ZXN0MzM4MTY1NTQ3 | 1,763 | Fixed training for TF XLNet | {
"login": "tlkh",
"id": 5409617,
"node_id": "MDQ6VXNlcjU0MDk2MTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5409617?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tlkh",
"html_url": "https://github.com/tlkh",
"followers_url": "https://api.github.com/users/tlkh/followers",
... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1763?src=pr&el=h1) Report\n> Merging [#1763](https://codecov.io/gh/huggingface/transformers/pull/1763?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/d49c43ff789d309e688fb7b252511e9e618e46db?src=pr&el=desc) will **d... | 1,573 | 1,575 | 1,575 | CONTRIBUTOR | null | This PR makes the following changes and fully fixes `model.fit()` training for XLNet. It now works, and was tested with a slightly modified `run_tf_glue.py`, and also tested with XLA, AMP and tf.distribute
- Fix dtype error with `input_mask` and `attention_mask`
- `rel_attn_core()` does not work properly in non-eag... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1763/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1763/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1763",
"html_url": "https://github.com/huggingface/transformers/pull/1763",
"diff_url": "https://github.com/huggingface/transformers/pull/1763.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1763.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1762 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1762/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1762/comments | https://api.github.com/repos/huggingface/transformers/issues/1762/events | https://github.com/huggingface/transformers/issues/1762 | 519,412,002 | MDU6SXNzdWU1MTk0MTIwMDI= | 1,762 | Perplexity for (not-stateful) Transformer - Why is it still fair to compare to RNN? | {
"login": "hoangcuong2011",
"id": 8759715,
"node_id": "MDQ6VXNlcjg3NTk3MTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8759715?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hoangcuong2011",
"html_url": "https://github.com/hoangcuong2011",
"followers_url": "https://api.gith... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,573 | 1,578 | 1,578 | NONE | null | Greetings,
It is clear to me how to compute perplexity for RNNs as RNNs are a stateful model.
In general, given a very long document, I believe we need to: 1. chunk the document into a sequence of chunks, and we compute the cross entropy loss for each of the chunks, before taking the average for all chunks and t... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1762/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1762/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1761 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1761/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1761/comments | https://api.github.com/repos/huggingface/transformers/issues/1761/events | https://github.com/huggingface/transformers/issues/1761 | 519,312,284 | MDU6SXNzdWU1MTkzMTIyODQ= | 1,761 | Roberta Positional Embeddings Not Masked | {
"login": "DomHudson",
"id": 10864294,
"node_id": "MDQ6VXNlcjEwODY0Mjk0",
"avatar_url": "https://avatars.githubusercontent.com/u/10864294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DomHudson",
"html_url": "https://github.com/DomHudson",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-... | [
{
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.gith... | [
"I think you are right. Awesome if you can fix this in a PR.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Closed in #1764"
] | 1,573 | 1,578 | 1,578 | NONE | null | ## Bug
Hi, I think for the RoBERTa model, the positional embeddings are created slightly wrong. In both this library and in `fairseq` the positional embeddings are sequential integers starting from `padding_idx + 1`. However, in `fairseq.utils.make_positions` all indicies of the input that correspond to the padding ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1761/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1761/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1760 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1760/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1760/comments | https://api.github.com/repos/huggingface/transformers/issues/1760/events | https://github.com/huggingface/transformers/issues/1760 | 519,251,526 | MDU6SXNzdWU1MTkyNTE1MjY= | 1,760 | 'RuntimeError: CUDA error' is occured when encoding text with pre-trained model on cuda | {
"login": "jcw521",
"id": 52779032,
"node_id": "MDQ6VXNlcjUyNzc5MDMy",
"avatar_url": "https://avatars.githubusercontent.com/u/52779032?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jcw521",
"html_url": "https://github.com/jcw521",
"followers_url": "https://api.github.com/users/jcw521/fo... | [] | closed | false | null | [] | [
"> ## Bug\r\n> Model I am using (Bert, XLNet....): I am trying to use Bert encoder\r\n> \r\n> Language I am using the model on (English, Chinese....): English\r\n> \r\n> There are two problems when I use BERT for encoding text to vectors\r\n> Here is Error log\r\n> \r\n> First,\r\n> \r\n> ```\r\n> File \"/home/jcw... | 1,573 | 1,573 | 1,573 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): I am trying to use Bert encoder
Language I am using the model on (English, Chinese....): English
There are two problems when I use BERT for encoding text to vectors
Here is Error log
First,
```
File "/home/jcw/VAIRLtext/Text2... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1760/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1760/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1759 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1759/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1759/comments | https://api.github.com/repos/huggingface/transformers/issues/1759/events | https://github.com/huggingface/transformers/issues/1759 | 519,165,735 | MDU6SXNzdWU1MTkxNjU3MzU= | 1,759 | NameError: name 'DUMMY_INPUTS' is not defined | {
"login": "techwithshadab",
"id": 10863620,
"node_id": "MDQ6VXNlcjEwODYzNjIw",
"avatar_url": "https://avatars.githubusercontent.com/u/10863620?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/techwithshadab",
"html_url": "https://github.com/techwithshadab",
"followers_url": "https://api.gi... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"> ## Can someone help me with resolving this error?\r\n> \r\n\r\nWithout any other information, it's very difficult to understand which is the problem with your Jupyter Notebook! **Which is the content of... | 1,573 | 1,579 | 1,579 | NONE | null | ## ❓ Can someone help me with resolving this error?
<!-- A clear and concise description of the question. -->

| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1759/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1759/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1758 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1758/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1758/comments | https://api.github.com/repos/huggingface/transformers/issues/1758/events | https://github.com/huggingface/transformers/issues/1758 | 519,119,817 | MDU6SXNzdWU1MTkxMTk4MTc= | 1,758 | the BertModel have the class "BertForTokenClassification", why XLNetModel don't have the class | {
"login": "zyxdSTU",
"id": 26239665,
"node_id": "MDQ6VXNlcjI2MjM5NjY1",
"avatar_url": "https://avatars.githubusercontent.com/u/26239665?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zyxdSTU",
"html_url": "https://github.com/zyxdSTU",
"followers_url": "https://api.github.com/users/zyxdST... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"By reading the code, I find the BertModel have the class \"BertForTokenClassification\", but XLNetModel\r\ndon't have the class \"XLNetForTokenClassification\". Why? Can someone explain this?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no furt... | 1,573 | 1,578 | 1,578 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1758/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1758/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1757 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1757/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1757/comments | https://api.github.com/repos/huggingface/transformers/issues/1757/events | https://github.com/huggingface/transformers/issues/1757 | 519,101,993 | MDU6SXNzdWU1MTkxMDE5OTM= | 1,757 | Is it possible fine tune XLNet? | {
"login": "tyu0912",
"id": 24836159,
"node_id": "MDQ6VXNlcjI0ODM2MTU5",
"avatar_url": "https://avatars.githubusercontent.com/u/24836159?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tyu0912",
"html_url": "https://github.com/tyu0912",
"followers_url": "https://api.github.com/users/tyu091... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I have tried to fine-tune xlnet on squad1.0 and squad2.0, although it's a few points lower than original results, but it works fine. This #1803 is for fine-tuning on squad2.0, I'm not familiar with other datasets.",
"This issue has been automatically marked as stale because it has not had recent activity. It wil... | 1,573 | 1,579 | 1,579 | NONE | null | ## ❓ Questions & Help
Hello, is there currently a script or recommended process to fine tune XLNet? Currently I am writing my own and using https://mccormickml.com/2019/09/19/XLNet-fine-tuning/ as an inspiration but overall I am still pretty new at this. I managed to get it to run but it seems to be taking forever s... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1757/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1757/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1756 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1756/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1756/comments | https://api.github.com/repos/huggingface/transformers/issues/1756/events | https://github.com/huggingface/transformers/issues/1756 | 519,087,242 | MDU6SXNzdWU1MTkwODcyNDI= | 1,756 | Is it okay to define and use new model by using only a part of full GPT model blocks? Or anyone tried to do so? | {
"login": "duzani",
"id": 30222444,
"node_id": "MDQ6VXNlcjMwMjIyNDQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/30222444?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/duzani",
"html_url": "https://github.com/duzani",
"followers_url": "https://api.github.com/users/duzani/fo... | [] | closed | false | null | [] | [
"### Hi, \r\nAs far as I remember from my experiments with GPT2, the GPT2 blocks will work on its own. What I mean with that is that **the model will produce reasonable outputs, even if you leave out some layers from the original model.** So your idea should work. \r\nWhat I'm not quite sure about is the performanc... | 1,573 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi,
As far as I know, the smallest GPT2 model that comes with pretrained weight has 768 hidden size with 12 transformer blocks.
However, I'm considering to define 'smaller' GPT model with only 1 or 2 transformer blocks and load th... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1756/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1756/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1755 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1755/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1755/comments | https://api.github.com/repos/huggingface/transformers/issues/1755/events | https://github.com/huggingface/transformers/issues/1755 | 519,076,433 | MDU6SXNzdWU1MTkwNzY0MzM= | 1,755 | How to add weighted CrossEntropy loss in sequence classification task? | {
"login": "TinaChen95",
"id": 24587336,
"node_id": "MDQ6VXNlcjI0NTg3MzM2",
"avatar_url": "https://avatars.githubusercontent.com/u/24587336?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TinaChen95",
"html_url": "https://github.com/TinaChen95",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [
"Hi, no specific advice other than computing the loss your-self outside of the model's forward method."
] | 1,573 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I am doing a sequence classification task base on run_ner.py. My dataset is an imbalenced dataset and apperantly 'O' label appears far more than other labels. I'm wondering if it is helpful to use weighted CrossEntropy loss.
If the ans... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1755/reactions",
"total_count": 5,
"+1": 5,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1755/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1754 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1754/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1754/comments | https://api.github.com/repos/huggingface/transformers/issues/1754/events | https://github.com/huggingface/transformers/issues/1754 | 518,884,300 | MDU6SXNzdWU1MTg4ODQzMDA= | 1,754 | Out of Memory Error (OOM) only during evaluation phase of run_lm_finetuning.py and run_glue.py | {
"login": "CMobley7",
"id": 10121829,
"node_id": "MDQ6VXNlcjEwMTIxODI5",
"avatar_url": "https://avatars.githubusercontent.com/u/10121829?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CMobley7",
"html_url": "https://github.com/CMobley7",
"followers_url": "https://api.github.com/users/CMo... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Have you tried the following lines after the call to the `evaluate` function (in the loop over checkpoints)?\r\n\r\n```python\r\ndel model\r\ntorch.cuda.empty_cache()\r\n```\r\n\r\nLet me know if this works.",
"@rlouf, I changed\r\n\r\n```\r\n# Evaluation\r\n results = {}\r\n if args.do_eval and args.local... | 1,573 | 1,584 | 1,584 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): roberta-large
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* the official example scripts: run_lm_finetuning.py and run_glue.py
The tasks I am working on is:
* my own task or d... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1754/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1754/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1753 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1753/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1753/comments | https://api.github.com/repos/huggingface/transformers/issues/1753/events | https://github.com/huggingface/transformers/pull/1753 | 518,865,678 | MDExOlB1bGxSZXF1ZXN0MzM3NzAyOTcz | 1,753 | Added Mish Activation Function | {
"login": "digantamisra98",
"id": 34192716,
"node_id": "MDQ6VXNlcjM0MTkyNzE2",
"avatar_url": "https://avatars.githubusercontent.com/u/34192716?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/digantamisra98",
"html_url": "https://github.com/digantamisra98",
"followers_url": "https://api.gi... | [] | closed | false | null | [] | [
"Ok, why not."
] | 1,573 | 1,574 | 1,574 | CONTRIBUTOR | null | Mish is a new activation function proposed here - https://arxiv.org/abs/1908.08681
It has seen some recent success and has been adopted in SpaCy, Thic, TensorFlow Addons and FastAI-dev.
All benchmarks recorded till now (including against ReLU, Swish and GELU) is present in the repository - https://github.com/diganta... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1753/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1753/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1753",
"html_url": "https://github.com/huggingface/transformers/pull/1753",
"diff_url": "https://github.com/huggingface/transformers/pull/1753.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1753.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1752 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1752/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1752/comments | https://api.github.com/repos/huggingface/transformers/issues/1752/events | https://github.com/huggingface/transformers/issues/1752 | 518,788,776 | MDU6SXNzdWU1MTg3ODg3NzY= | 1,752 | Subtokens in BPE in GPT2 | {
"login": "weiguowilliam",
"id": 31396452,
"node_id": "MDQ6VXNlcjMxMzk2NDUy",
"avatar_url": "https://avatars.githubusercontent.com/u/31396452?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/weiguowilliam",
"html_url": "https://github.com/weiguowilliam",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [
"BPE is a data compression algorithm, the result depends on the statistical properties of the corpus of text on which it has been trained.\r\n\r\nYou can start with this article https://leimao.github.io/blog/Byte-Pair-Encoding/ to get more of an intuition of how it works.",
"> BPE is a data compression algorithm,... | 1,573 | 1,573 | 1,573 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hi, I have a question.
For a word represented by more than 1 subtoken in BPE, I wonder what's the principle to divide it into subtokens?
I use GPT2 small version for example. "bookshelf" is divided into "books","he" and "if".(in... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1752/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1752/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1751 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1751/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1751/comments | https://api.github.com/repos/huggingface/transformers/issues/1751/events | https://github.com/huggingface/transformers/issues/1751 | 518,669,764 | MDU6SXNzdWU1MTg2Njk3NjQ= | 1,751 | input token embedding issues | {
"login": "abrhaleitela",
"id": 43967278,
"node_id": "MDQ6VXNlcjQzOTY3Mjc4",
"avatar_url": "https://avatars.githubusercontent.com/u/43967278?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abrhaleitela",
"html_url": "https://github.com/abrhaleitela",
"followers_url": "https://api.github.c... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,573 | 1,578 | 1,578 | NONE | null | 1. During fine-tuning an XLNet, does the word embeddings kept constant (learned from the pre-trained model) or are they initialized randomly but learned contextually during fine-tuning itself?
2. And how would I set my own word embeddings during fine-tuning (XLNetForSequenceClassification)? I have my own token embe... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1751/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1751/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1750 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1750/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1750/comments | https://api.github.com/repos/huggingface/transformers/issues/1750/events | https://github.com/huggingface/transformers/issues/1750 | 518,641,253 | MDU6SXNzdWU1MTg2NDEyNTM= | 1,750 | How to calculate memory requirements of different GPT models? | {
"login": "Henry-E",
"id": 12613144,
"node_id": "MDQ6VXNlcjEyNjEzMTQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12613144?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Henry-E",
"html_url": "https://github.com/Henry-E",
"followers_url": "https://api.github.com/users/Henry-... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Current commercial GPU VRAM sizes are not large enough to process the XL model. You'll need probably around 32-64 GB of RAM in order to finetune successfully. So for now, you'll have to train on a CPU with a lot of memory attached.",
"How did you come to that number though? \r\n\r\nIn Thomas Wolf's medium post o... | 1,573 | 1,579 | 1,579 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
What's the best way to calculate how much GPU ram is needed to finetune a given GPT size? The GPT-xl model is 6.5GB worth of parameters but clearly this isn't the full story when it comes to fine-tuning. I've tried running a batch siz... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1750/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1750/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1749 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1749/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1749/comments | https://api.github.com/repos/huggingface/transformers/issues/1749/events | https://github.com/huggingface/transformers/issues/1749 | 518,594,548 | MDU6SXNzdWU1MTg1OTQ1NDg= | 1,749 | gpt2 generation crashes when using `past` for some output lengths | {
"login": "joelb-git",
"id": 2745742,
"node_id": "MDQ6VXNlcjI3NDU3NDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/2745742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/joelb-git",
"html_url": "https://github.com/joelb-git",
"followers_url": "https://api.github.com/users/jo... | [] | closed | false | null | [] | [
"@joelb-git Can you check the lowest ```length``` at which this occurs? \r\n\r\nAlso, is this an issue that only occurs when ```past``` is used? \r\n\r\nCan you check if same thing happens when running\r\n\r\n```python examples/run_generation.py --prompt \"Who was Jim Henson ? Jim Henson was a\" --model_type gpt2 -... | 1,573 | 1,597 | 1,573 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): gpt2
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
The tasks I am working on is:... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1749/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1749/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1748 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1748/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1748/comments | https://api.github.com/repos/huggingface/transformers/issues/1748/events | https://github.com/huggingface/transformers/issues/1748 | 518,586,555 | MDU6SXNzdWU1MTg1ODY1NTU= | 1,748 | Released OpenAI GPT-2 1.5B model | {
"login": "TheEdoardo93",
"id": 19664571,
"node_id": "MDQ6VXNlcjE5NjY0NTcx",
"avatar_url": "https://avatars.githubusercontent.com/u/19664571?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TheEdoardo93",
"html_url": "https://github.com/TheEdoardo93",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | [
"Hi, GPT-2 XL was added yesterday with commit d7d36181fdefdabadc53adf51bed4a2680f5880a",
"Yes, sorry for opening a new issue! I didn't see this commit. I'll close the issue! Thank you for your time!"
] | 1,573 | 1,573 | 1,573 | NONE | null | ## 🚀 Feature
- [ ] Blog: [https://openai.com/blog/gpt-2-1-5b-release/](url)
- [ ] Code: [https://github.com/openai/gpt-2](url)
- [ ] Dataset: [https://github.com/openai/gpt-2-output-dataset](url)
## Motivation
A bigger model for text generation which is more human than the OpenAI GPT-2 774M parameters
##... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1748/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1748/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1747 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1747/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1747/comments | https://api.github.com/repos/huggingface/transformers/issues/1747/events | https://github.com/huggingface/transformers/issues/1747 | 518,574,007 | MDU6SXNzdWU1MTg1NzQwMDc= | 1,747 | How to use gpt-2-xl with run_generation.py | {
"login": "avianion",
"id": 37309215,
"node_id": "MDQ6VXNlcjM3MzA5MjE1",
"avatar_url": "https://avatars.githubusercontent.com/u/37309215?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avianion",
"html_url": "https://github.com/avianion",
"followers_url": "https://api.github.com/users/avi... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"You're probably using the command:\r\n```\r\npython run_generation.py --model_type=gpt2 --model_name_or_path=gpt2\r\n```\r\n\r\nto use GPT2-XL for generation you would change the last argument to `gpt2-xl`:\r\n```\r\npython run_generation.py --model_type=gpt2 --model_name_or_path=gpt2-xl\r\n```",
"ah. its becaus... | 1,573 | 1,608 | 1,578 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I am currently running the run_generation.py and putting the model as gpt-2, however I am not satisfied with the results frm the small model.
How can I insert the big model instead? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1747/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1747/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1746 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1746/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1746/comments | https://api.github.com/repos/huggingface/transformers/issues/1746/events | https://github.com/huggingface/transformers/pull/1746 | 518,565,179 | MDExOlB1bGxSZXF1ZXN0MzM3NDM3MTc2 | 1,746 | Fixing models inputs_embeds | {
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1746?src=pr&el=h1) Report\n> Merging [#1746](https://codecov.io/gh/huggingface/transformers/pull/1746?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/f88c104d8f79e78a98c8ce6c1f4a78db73142eab?src=pr&el=desc) will **i... | 1,573 | 1,573 | 1,573 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1746/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1746/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1746",
"html_url": "https://github.com/huggingface/transformers/pull/1746",
"diff_url": "https://github.com/huggingface/transformers/pull/1746.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1746.patch",
"merged_at": 1... | |
https://api.github.com/repos/huggingface/transformers/issues/1745 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1745/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1745/comments | https://api.github.com/repos/huggingface/transformers/issues/1745/events | https://github.com/huggingface/transformers/issues/1745 | 518,494,812 | MDU6SXNzdWU1MTg0OTQ4MTI= | 1,745 | How to stop wordpiece-tokenizing in BertTokenizer? | {
"login": "RichardHWD",
"id": 35796793,
"node_id": "MDQ6VXNlcjM1Nzk2Nzkz",
"avatar_url": "https://avatars.githubusercontent.com/u/35796793?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RichardHWD",
"html_url": "https://github.com/RichardHWD",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [
"No, that's how the model works.\r\n\r\nShort of creating your own model (with you own custom tokenizer) there's no way to do what you want to do.",
"Okkkkkk, it is unreasonable ...."
] | 1,573 | 1,573 | 1,573 | NONE | null | Default BertTokenizer may split one word into two parts or three parts, which is harmful to token labeling task because it will make sentence length lager than input length. It is difficult to fuse these parts back to one representation.
So, how to stop this operation in BertTokenizer? Or there are alternative Tokeniz... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1745/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1745/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1744 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1744/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1744/comments | https://api.github.com/repos/huggingface/transformers/issues/1744/events | https://github.com/huggingface/transformers/issues/1744 | 518,489,015 | MDU6SXNzdWU1MTg0ODkwMTU= | 1,744 | F1 socre is zero while loss is about 0.12xx when using run_ner.py to fine tuning bert model | {
"login": "Sunnycheey",
"id": 32103564,
"node_id": "MDQ6VXNlcjMyMTAzNTY0",
"avatar_url": "https://avatars.githubusercontent.com/u/32103564?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sunnycheey",
"html_url": "https://github.com/Sunnycheey",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [
"Hi @Sunnycheey I had the same issue when using my own data and labels. However, I fixed this once I ensured that the training data (train.txt) was in the correct format: WordToken/space/label, newline after every sentence (fullstop). \r\n\r\nWhile O\r\nvisiting O\r\nOtonga B-Sc\r\nprimary I-Sc\r\nhe O\r\nnoticed O... | 1,573 | 1,574 | 1,574 | NONE | null | ## ❓ Questions & Help
I want to use run_ner.py to do the sequence labeling work, and I make a few class of labels(e.g., B-School_name), then I annotate a few data (about 100 annotations for test) from dataset. Finally, I use run_ner.py to do the fine tuning job, but the f1 score and precision are both zero (but the ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1744/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1744/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1743 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1743/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1743/comments | https://api.github.com/repos/huggingface/transformers/issues/1743/events | https://github.com/huggingface/transformers/pull/1743 | 518,363,448 | MDExOlB1bGxSZXF1ZXN0MzM3MjcxMTEw | 1,743 | Unlimited sequence length in Bert for QA | {
"login": "realEmjot",
"id": 43821946,
"node_id": "MDQ6VXNlcjQzODIxOTQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/43821946?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/realEmjot",
"html_url": "https://github.com/realEmjot",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [] | 1,573 | 1,573 | 1,573 | NONE | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1743/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1743/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1743",
"html_url": "https://github.com/huggingface/transformers/pull/1743",
"diff_url": "https://github.com/huggingface/transformers/pull/1743.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1743.patch",
"merged_at": n... | |
https://api.github.com/repos/huggingface/transformers/issues/1742 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1742/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1742/comments | https://api.github.com/repos/huggingface/transformers/issues/1742/events | https://github.com/huggingface/transformers/issues/1742 | 518,262,673 | MDU6SXNzdWU1MTgyNjI2NzM= | 1,742 | Out of Memory (OOM) when repeatedly running large models | {
"login": "josiahdavis",
"id": 6405428,
"node_id": "MDQ6VXNlcjY0MDU0Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/6405428?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/josiahdavis",
"html_url": "https://github.com/josiahdavis",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | [
"This behavior is expected. `pytorch.cuda.empty_cache()` will free the memory that *can* be freed, think of it as a garbage collector.\r\n\r\nI assume the ˋmodelˋ variable contains the pretrained model. Since the variable doesn’t get out of scope, the reference to the object in the memory of the GPU still exists an... | 1,573 | 1,574 | 1,574 | NONE | null | ## ❓ Any advice for freeing up GPU memory after training a large model (e.g., roberta-large)?
### System Info
```
Platform Linux-4.4.0-1096-aws-x86_64-with-debian-stretch-sid
Python 3.6.6 |Anaconda, Inc.| (default, Jun 28 2018, 17:14:51)
[GCC 7.2.0]
PyTorch 1.3.0
AWS EC2 p3.2xlarge (single GPU)
```
My c... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1742/reactions",
"total_count": 8,
"+1": 8,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1742/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1741 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1741/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1741/comments | https://api.github.com/repos/huggingface/transformers/issues/1741/events | https://github.com/huggingface/transformers/pull/1741 | 517,952,165 | MDExOlB1bGxSZXF1ZXN0MzM2OTI0Nzc2 | 1,741 | GPT-2 XL | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [] | 1,572 | 1,578 | 1,572 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1741/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1741/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1741",
"html_url": "https://github.com/huggingface/transformers/pull/1741",
"diff_url": "https://github.com/huggingface/transformers/pull/1741.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1741.patch",
"merged_at": 1... | |
https://api.github.com/repos/huggingface/transformers/issues/1740 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1740/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1740/comments | https://api.github.com/repos/huggingface/transformers/issues/1740/events | https://github.com/huggingface/transformers/pull/1740 | 517,880,719 | MDExOlB1bGxSZXF1ZXN0MzM2ODY1NzU4 | 1,740 | Fix CTRL past | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1740?src=pr&el=h1) Report\n> Merging [#1740](https://codecov.io/gh/huggingface/transformers/pull/1740?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/5afca00b4732f57329824e1538897e791e02e894?src=pr&el=desc) will **i... | 1,572 | 1,574 | 1,574 | MEMBER | null | Fixes the issue with the re-usable past in CTRL. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1740/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1740/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1740",
"html_url": "https://github.com/huggingface/transformers/pull/1740",
"diff_url": "https://github.com/huggingface/transformers/pull/1740.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1740.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1739 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1739/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1739/comments | https://api.github.com/repos/huggingface/transformers/issues/1739/events | https://github.com/huggingface/transformers/pull/1739 | 517,854,914 | MDExOlB1bGxSZXF1ZXN0MzM2ODQ0NjI1 | 1,739 | [WIP] Adding Google T5 model | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1739?src=pr&el=h1) Report\n> Merging [#1739](https://codecov.io/gh/huggingface/transformers/pull/1739?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/7296f1010b6faaf3b1fb409bc5a9ebadcea51973?src=pr&el=desc) will **i... | 1,572 | 1,579 | 1,576 | MEMBER | null | Add Google T5 model:
- paper: "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer" https://arxiv.org/abs/1910.10683
- code: https://github.com/google-research/text-to-text-transfer-transformer
The original model makes heavy use of model and data parallelism to scale the training up ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1739/reactions",
"total_count": 6,
"+1": 6,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1739/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1739",
"html_url": "https://github.com/huggingface/transformers/pull/1739",
"diff_url": "https://github.com/huggingface/transformers/pull/1739.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1739.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1738 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1738/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1738/comments | https://api.github.com/repos/huggingface/transformers/issues/1738/events | https://github.com/huggingface/transformers/issues/1738 | 517,788,562 | MDU6SXNzdWU1MTc3ODg1NjI= | 1,738 | BART | {
"login": "clmnt",
"id": 821155,
"node_id": "MDQ6VXNlcjgyMTE1NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/821155?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/clmnt",
"html_url": "https://github.com/clmnt",
"followers_url": "https://api.github.com/users/clmnt/followers"... | [] | closed | false | null | [] | [
"Duplicate of #1676"
] | 1,572 | 1,581 | 1,572 | MEMBER | null | # 🌟New model addition
## Model description
method for pre-training seq2seq models by de-noising text. BART outperforms previous work on a bunch of generation tasks (summarization/dialogue/QA), while getting similar performance to RoBERTa on SQuAD/GLUE
## Open Source status
* [ ] the model implementation is... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1738/reactions",
"total_count": 4,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1738/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1737 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1737/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1737/comments | https://api.github.com/repos/huggingface/transformers/issues/1737/events | https://github.com/huggingface/transformers/pull/1737 | 517,704,856 | MDExOlB1bGxSZXF1ZXN0MzM2NzIxOTU2 | 1,737 | Documentation: Updating docblocks in optimizers.py | {
"login": "DomHudson",
"id": 10864294,
"node_id": "MDQ6VXNlcjEwODY0Mjk0",
"avatar_url": "https://avatars.githubusercontent.com/u/10864294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DomHudson",
"html_url": "https://github.com/DomHudson",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1737?src=pr&el=h1) Report\n> Merging [#1737](https://codecov.io/gh/huggingface/transformers/pull/1737?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/e99071f10578adb0191288c1f3301e9a758d6200?src=pr&el=desc) will **n... | 1,572 | 1,572 | 1,572 | NONE | null | ## Summary
Updating documentation for the optimizer classes. I explicitly state that the scheduler classes are multiplying the optimizer's learning rate by a changing variable.
## Closes
https://github.com/huggingface/transformers/issues/1712 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1737/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1737/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1737",
"html_url": "https://github.com/huggingface/transformers/pull/1737",
"diff_url": "https://github.com/huggingface/transformers/pull/1737.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1737.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1736 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1736/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1736/comments | https://api.github.com/repos/huggingface/transformers/issues/1736/events | https://github.com/huggingface/transformers/pull/1736 | 517,683,009 | MDExOlB1bGxSZXF1ZXN0MzM2NzA0NDcw | 1,736 | Fix TFXLNet | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1736?src=pr&el=h1) Report\n> Merging [#1736](https://codecov.io/gh/huggingface/transformers/pull/1736?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/ba973342e3315471a9f44e7465cd245d7bcc5ea2?src=pr&el=desc) will **i... | 1,572 | 1,651 | 1,576 | MEMBER | null | PR to fix #1692 (type casting attention mask in TF 2.0 version of XLNet)
cc @mfuntowicz | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1736/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1736/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1736",
"html_url": "https://github.com/huggingface/transformers/pull/1736",
"diff_url": "https://github.com/huggingface/transformers/pull/1736.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1736.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1735 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1735/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1735/comments | https://api.github.com/repos/huggingface/transformers/issues/1735/events | https://github.com/huggingface/transformers/pull/1735 | 517,680,710 | MDExOlB1bGxSZXF1ZXN0MzM2NzAyNjEw | 1,735 | Do not use GPU when importing transformers | {
"login": "ondewo",
"id": 42312363,
"node_id": "MDEyOk9yZ2FuaXphdGlvbjQyMzEyMzYz",
"avatar_url": "https://avatars.githubusercontent.com/u/42312363?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ondewo",
"html_url": "https://github.com/ondewo",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [
"Well this is actually used in other places, in `modeling_tf_pytorch_utils` for instance, and designed to be overriden by model class-specific inputs, for instance in `modeling_xlm` (hence all the CircleCI errors).\r\n\r\nMaybe making this a python property instead of an attribute would solve your issue as well?",
... | 1,572 | 1,575 | 1,575 | NONE | null | This PR addresses the issue #1507 and the main point is to **not** use GPU already at import time of transformers.
This was caused by the use of class variable `dummy_inputs` that initializes TF by using `tf.constant`. This can be prevented simply by makeing `dummy inputs` a local variable since is not used anywhere... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1735/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1735/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1735",
"html_url": "https://github.com/huggingface/transformers/pull/1735",
"diff_url": "https://github.com/huggingface/transformers/pull/1735.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1735.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1734 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1734/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1734/comments | https://api.github.com/repos/huggingface/transformers/issues/1734/events | https://github.com/huggingface/transformers/pull/1734 | 517,621,124 | MDExOlB1bGxSZXF1ZXN0MzM2NjU0MTIz | 1,734 | add progress bar to convert_examples_to_features | {
"login": "orena1",
"id": 8983713,
"node_id": "MDQ6VXNlcjg5ODM3MTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8983713?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/orena1",
"html_url": "https://github.com/orena1",
"followers_url": "https://api.github.com/users/orena1/foll... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1734?src=pr&el=h1) Report\n> Merging [#1734](https://codecov.io/gh/huggingface/transformers/pull/1734?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/d2e2577dd31ab92f21154e5280d64fa0ae90bbb8?src=pr&el=desc) will **i... | 1,572 | 1,572 | 1,572 | CONTRIBUTOR | null | It takes considerate amount of time (~10 min) to parse the examples to features, it is good to have a progress-bar to track this | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1734/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1734/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1734",
"html_url": "https://github.com/huggingface/transformers/pull/1734",
"diff_url": "https://github.com/huggingface/transformers/pull/1734.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1734.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1733 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1733/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1733/comments | https://api.github.com/repos/huggingface/transformers/issues/1733/events | https://github.com/huggingface/transformers/issues/1733 | 517,521,903 | MDU6SXNzdWU1MTc1MjE5MDM= | 1,733 | 🌟New model addition: VL-BERT | {
"login": "Eurus-Holmes",
"id": 34226570,
"node_id": "MDQ6VXNlcjM0MjI2NTcw",
"avatar_url": "https://avatars.githubusercontent.com/u/34226570?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Eurus-Holmes",
"html_url": "https://github.com/Eurus-Holmes",
"followers_url": "https://api.github.c... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"We have released the code for VL-BERT: https://github.com/jackroos/VL-BERT. Thanks for your attention!",
"@jackroos Awesome! Thanks for your work!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your con... | 1,572 | 1,588 | 1,588 | NONE | null | # 🌟New model addition
## Model description
[VL-BERT: PRE-TRAINING OF GENERIC VISUALLINGUISTIC REPRESENTATIONS](https://arxiv.org/pdf/1908.08530.pdf)
> *We introduce a new pre-trainable generic representation for visual-linguistic tasks,
called Visual-Linguistic BERT (VL-BERT for short). VL-BERT adopts the si... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1733/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1733/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1732 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1732/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1732/comments | https://api.github.com/repos/huggingface/transformers/issues/1732/events | https://github.com/huggingface/transformers/issues/1732 | 517,520,850 | MDU6SXNzdWU1MTc1MjA4NTA= | 1,732 | TFBertForSequenceClassification.from_pretrained ERROR | {
"login": "dkicenan",
"id": 21953155,
"node_id": "MDQ6VXNlcjIxOTUzMTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/21953155?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dkicenan",
"html_url": "https://github.com/dkicenan",
"followers_url": "https://api.github.com/users/dki... | [] | closed | false | null | [] | [
"Just give the path to your folder instead of the model so the loading method can also find the configuration files.\r\n\r\nYou can read more [here](https://huggingface.co/transformers/main_classes/model.html#transformers.PreTrainedModel.from_pretrained)",
"@thomwolf Thank you for your help! I can load the pret... | 1,572 | 1,572 | 1,572 | NONE | null | ### code:
model = TFBertForSequenceClassification.from_pretrained('./bert-base-cased-tf_model.h5')
### Error message:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/DATA/disk1/wutianlong/python/miniconda3/lib/python3.6/site-packages/transformers/modeling_tf_utils.py", line 212,... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1732/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1732/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1731 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1731/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1731/comments | https://api.github.com/repos/huggingface/transformers/issues/1731/events | https://github.com/huggingface/transformers/issues/1731 | 517,509,773 | MDU6SXNzdWU1MTc1MDk3NzM= | 1,731 | Threads running on evaluation? | {
"login": "vivekam101",
"id": 5806230,
"node_id": "MDQ6VXNlcjU4MDYyMzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/5806230?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vivekam101",
"html_url": "https://github.com/vivekam101",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | [
"*attaching complete log\r\n[test_log.txt](https://github.com/huggingface/transformers/files/3806959/test_log.txt)\r\n",
"Sorry. guys. logger has been called multiple times hence the issue closing the issue."
] | 1,572 | 1,572 | 1,572 | NONE | null | Hi Transformers :)
Thanks for the wonderful repo. One quick question. I was running examples/test_examples.py and came to see logs printing multiple times while running in cpu. Is there threads spawned ?
snippet from examples/test_examples.py
**
testargs = ["run_squad.py",
"--train_f... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1731/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1731/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1730 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1730/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1730/comments | https://api.github.com/repos/huggingface/transformers/issues/1730/events | https://github.com/huggingface/transformers/issues/1730 | 517,486,844 | MDU6SXNzdWU1MTc0ODY4NDQ= | 1,730 | resize_token_embeddings doesn't work as expected for BertForMaskedLM | {
"login": "praateekmahajan",
"id": 7589415,
"node_id": "MDQ6VXNlcjc1ODk0MTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7589415?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/praateekmahajan",
"html_url": "https://github.com/praateekmahajan",
"followers_url": "https://api.g... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/... | [
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "htt... | [
"Hi! May I know what version are you using? On the current master branch, this is the result:\r\n\r\n```py\r\nimport torch\r\nfrom transformers import BertForMaskedLM\r\n\r\ninput_ids = torch.tensor([[1,2,3,4,5]])\r\nprint(model.bert.embeddings.word_embeddings.num_embeddings) # 119547\r\nprint(model.cls.prediction... | 1,572 | 1,590 | 1,590 | CONTRIBUTOR | null | ## 🐛 Bug
<!-- Important information -->
Model I am using : **BertForMaskedLM**
Language I am using the model on (English, Chinese....): **multilingual**
The problem arise when using:
* [x] the official example scripts: **BertForMaskedLM**
The tasks I am working on is:
* [x] my own task or dataset: **F... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1730/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1730/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1729 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1729/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1729/comments | https://api.github.com/repos/huggingface/transformers/issues/1729/events | https://github.com/huggingface/transformers/issues/1729 | 517,451,643 | MDU6SXNzdWU1MTc0NTE2NDM= | 1,729 | Roberta embeddings comparison | {
"login": "aclifton314",
"id": 53267795,
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aclifton314",
"html_url": "https://github.com/aclifton314",
"followers_url": "https://api.github.com/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Any update on this issue?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> ## ❓ Questions & Help\r\n> **SYSTEM**\r\n> OS: Linux pop-os 5.0.0\r\n> Python version: 3.6.8\r\n> Torc... | 1,572 | 1,581 | 1,581 | NONE | null | ## ❓ Questions & Help
**SYSTEM**
OS: Linux pop-os 5.0.0
Python version: 3.6.8
Torch version: 1.3.0
Transformers version: 2.1.1
I am running this linux VM with the above software versions on a Windows 10 laptop.
I wanted to compare the cosine similarity between elmo and roberta embeddings for two sequences:
``... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1729/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1729/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1728 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1728/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1728/comments | https://api.github.com/repos/huggingface/transformers/issues/1728/events | https://github.com/huggingface/transformers/issues/1728 | 517,418,210 | MDU6SXNzdWU1MTc0MTgyMTA= | 1,728 | glue_convert_examples_to_features not working if no task is provided | {
"login": "oliviernguyenquoc",
"id": 7463783,
"node_id": "MDQ6VXNlcjc0NjM3ODM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7463783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/oliviernguyenquoc",
"html_url": "https://github.com/oliviernguyenquoc",
"followers_url": "https:/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,572 | 1,578 | 1,578 | NONE | null | ## 🐛 Bug
<!-- Important information -->
The problem arise when using:
* [X] my own modified scripts: (give details)
The tasks I am working on is:
* [X] my own task or dataset: (give details)
In these lines:
https://github.com/huggingface/transformers/blob/04c69db399b2ab9e3af872ce46730fbd9f17aec3/transfo... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1728/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1728/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1727 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1727/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1727/comments | https://api.github.com/repos/huggingface/transformers/issues/1727/events | https://github.com/huggingface/transformers/issues/1727 | 517,413,141 | MDU6SXNzdWU1MTc0MTMxNDE= | 1,727 | loss is nan, for training on MNLI dataset | {
"login": "antgr",
"id": 2175768,
"node_id": "MDQ6VXNlcjIxNzU3Njg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2175768?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/antgr",
"html_url": "https://github.com/antgr",
"followers_url": "https://api.github.com/users/antgr/follower... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/... | [
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "htt... | [
"Hi, there seems to be a problem indeed. Do you mind sharing a link to a notebook so that I can see what's wrong?",
"Is it related to the issue you opened 3 days ago #1704?",
"Yes, its is the same, but I though that was my mistake and closed it. I will provide a link to a notebook to see the code. Here it is: h... | 1,572 | 1,586 | 1,586 | NONE | null | ## 🐛 Bug
Model I am using (Bert, XLNet....):
** Bert **
bert_model = TFBertForSequenceClassification.from_pretrained("bert-base-cased")
Language I am using the model on (English, Chinese....):
** English **
The problem arise when using:
https://medium.com/tensorflow/using-tensorflow-2-for-state-of-the-ar... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1727/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1727/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1726 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1726/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1726/comments | https://api.github.com/repos/huggingface/transformers/issues/1726/events | https://github.com/huggingface/transformers/issues/1726 | 517,329,282 | MDU6SXNzdWU1MTczMjkyODI= | 1,726 | Exceeding max sequence length in Roberta | {
"login": "aclifton314",
"id": 53267795,
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aclifton314",
"html_url": "https://github.com/aclifton314",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"Hey, same here with distilgpt2 . Did you solve this?",
"@iedmrc I did not. I'm still waiting response from someone.",
"If your input sequence is too long then it cannot be fed to the model: it will crash as you have seen in your example. \r\n\r\nThere are two ways to handle this: either shorten your sequence b... | 1,572 | 1,575 | 1,575 | NONE | null | ## ❓ Questions & Help
**SYSTEM**
OS: Linux pop-os 5.0.0
Python version: 3.6.8
Torch version: 1.3.0
Transformers version: 2.1.1
I am running this linux VM with the above software versions on a Windows 10 laptop.
<!-- A clear and concise description of the question. -->
I am interested in comparing the embeddin... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1726/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1726/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1725 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1725/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1725/comments | https://api.github.com/repos/huggingface/transformers/issues/1725/events | https://github.com/huggingface/transformers/issues/1725 | 517,276,150 | MDU6SXNzdWU1MTcyNzYxNTA= | 1,725 | GPT2 text generation repeat | {
"login": "aclifton314",
"id": 53267795,
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aclifton314",
"html_url": "https://github.com/aclifton314",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"Adding **temperature** (in brief, _Temperature is a hyperparameter of LSTMs - and neural networks generally - used to control the randomness of predictions by scaling the logits before applying softmax_) could be an interesting way!\r\n\r\nHere is a modified version of your code _with temperature_:\r\n```\r\nimpor... | 1,572 | 1,598 | 1,573 | NONE | null | ## ❓ Questions & Help
**SYSTEM**
OS: Linux pop-os 5.0.0
Python version: 3.6.8
Torch version: 1.3.0
Transformers version: 2.1.1
I am running this linux VM with the above software versions on a Windows 10 laptop.
<!-- A clear and concise description of the question. -->
I am running the following code:
```pyth... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1725/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1725/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1724 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1724/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1724/comments | https://api.github.com/repos/huggingface/transformers/issues/1724/events | https://github.com/huggingface/transformers/pull/1724 | 517,252,071 | MDExOlB1bGxSZXF1ZXN0MzM2MzU3OTAw | 1,724 | Fix encode_plus | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | [
"Looks good to me, this philosophy (only model-inputs and optional non-model-inputs) seems way better to me than the previous one."
] | 1,572 | 1,574 | 1,574 | MEMBER | null | Add options to control more precisely the output of `encode_plus`.
All the outputs that can't be ingested by a model as deactivated by default.
`token_type_ids` can be ingested by most models and if thus activated by default but can be turned off.
Fix #1532 among others | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1724/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1724/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1724",
"html_url": "https://github.com/huggingface/transformers/pull/1724",
"diff_url": "https://github.com/huggingface/transformers/pull/1724.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1724.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1723 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1723/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1723/comments | https://api.github.com/repos/huggingface/transformers/issues/1723/events | https://github.com/huggingface/transformers/pull/1723 | 517,223,228 | MDExOlB1bGxSZXF1ZXN0MzM2MzM0NTU4 | 1,723 | Fix #1623 | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/transformers/pull/1723?src=pr&el=h1) Report\n> Merging [#1723](https://codecov.io/gh/huggingface/transformers/pull/1723?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/transformers/commit/c8f2712199771e313ab8901698b0886e1c1bf39d?src=pr&el=desc) will **i... | 1,572 | 1,578 | 1,572 | MEMBER | null | Make use of the `--cache_dir` argument in all the examples that include it.
cc @VictorSanh (distillation script) @LysandreJik (all the other scripts) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1723/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1723/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1723",
"html_url": "https://github.com/huggingface/transformers/pull/1723",
"diff_url": "https://github.com/huggingface/transformers/pull/1723.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1723.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1722 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1722/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1722/comments | https://api.github.com/repos/huggingface/transformers/issues/1722/events | https://github.com/huggingface/transformers/issues/1722 | 517,212,978 | MDU6SXNzdWU1MTcyMTI5Nzg= | 1,722 | BUG for XLNet: Low GPU usage and High CPU usage, very low running speed! | {
"login": "Weili-NLP",
"id": 25901705,
"node_id": "MDQ6VXNlcjI1OTAxNzA1",
"avatar_url": "https://avatars.githubusercontent.com/u/25901705?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Weili-NLP",
"html_url": "https://github.com/Weili-NLP",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, could you provide a minimal code that reproduces the issue so that we may help debug/check on our side?",
"hey @LysandreJik,\r\n\r\nI think I am experiencing the same/similar issue. Below are the sample code, a screenshot showing the high CPU and low GPU usage, and the `requirements.txt` file.\r\n\r\nIn term... | 1,572 | 1,593 | 1,580 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): XLNet
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1722/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1722/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1721 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1721/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1721/comments | https://api.github.com/repos/huggingface/transformers/issues/1721/events | https://github.com/huggingface/transformers/pull/1721 | 517,092,802 | MDExOlB1bGxSZXF1ZXN0MzM2MjI4NjUz | 1,721 | Add common getter and setter for input_embeddings & output_embeddings | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | [
"Couldn't get `input_embeddings` and `output_embeddings` to work well as python properties with our class inheritance hierarchy for some reason.\r\n\r\nSwitching to simple `get_xxx` and `set_xxx` for now.\r\n\r\nMaybe let's investigate that again in the future if needed.",
"# [Codecov](https://codecov.io/gh/huggi... | 1,572 | 1,578 | 1,572 | MEMBER | null | This PR adds two attributes `input_embeddings` and `output_embeddings` as common properties for all the models.
Simpler to write weights tying.
Also superseed #1598.
cc @rlouf | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1721/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1721/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1721",
"html_url": "https://github.com/huggingface/transformers/pull/1721",
"diff_url": "https://github.com/huggingface/transformers/pull/1721.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1721.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1720 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1720/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1720/comments | https://api.github.com/repos/huggingface/transformers/issues/1720/events | https://github.com/huggingface/transformers/issues/1720 | 517,089,410 | MDU6SXNzdWU1MTcwODk0MTA= | 1,720 | run_generation.py Runtime error | {
"login": "Yondijr",
"id": 42034404,
"node_id": "MDQ6VXNlcjQyMDM0NDA0",
"avatar_url": "https://avatars.githubusercontent.com/u/42034404?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Yondijr",
"html_url": "https://github.com/Yondijr",
"followers_url": "https://api.github.com/users/Yondij... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"### Description\r\nRunning `python run_generation.py \r\n--model_type=gpt2 \r\n--model_name_or_path=gpt2` in my environment works as expected.\r\n\r\nMy suggestions:\r\n- update PyTorch to latest version with `pip install --upgrade torch`\r\n- try to install Transformers' library from branch master, and not use th... | 1,572 | 1,578 | 1,578 | NONE | null | ## ❓ Questions & Help
**Hi everyone,**
I'm currently trying to execute the run_generation example script.
However I can not get it to work. Tried to reinstall and played around with the parameters. However the error I get is always the same:
**I'm running the example from the website:**
_python run_gener... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1720/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1720/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1719 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1719/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1719/comments | https://api.github.com/repos/huggingface/transformers/issues/1719/events | https://github.com/huggingface/transformers/issues/1719 | 517,036,522 | MDU6SXNzdWU1MTcwMzY1MjI= | 1,719 | Can we fine tune GPT2 using multiple inputs? | {
"login": "tyu0912",
"id": 24836159,
"node_id": "MDQ6VXNlcjI0ODM2MTU5",
"avatar_url": "https://avatars.githubusercontent.com/u/24836159?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tyu0912",
"html_url": "https://github.com/tyu0912",
"followers_url": "https://api.github.com/users/tyu091... | [] | closed | false | null | [] | [
"You can merge them in the same document but add a token that indicates it's the beginning and end of each article. This will allow the generator to understand the concept of a document being a group of text and there are many of those groups in your document.\r\n\r\n**Example (assuming one line is one document):**... | 1,572 | 1,573 | 1,573 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
Hello. I don't think this is possible looking at the code, but to make sure is it possible to use multiple input texts to fine tune GPT-2? For example, I have 5 news articles. Do I submit them all in one document or should I separate ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1719/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1719/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1718 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1718/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1718/comments | https://api.github.com/repos/huggingface/transformers/issues/1718/events | https://github.com/huggingface/transformers/issues/1718 | 517,004,526 | MDU6SXNzdWU1MTcwMDQ1MjY= | 1,718 | Hello, how to upload a .ckpt file in TFBertForSequenceClassification? | {
"login": "hecongqing",
"id": 19923817,
"node_id": "MDQ6VXNlcjE5OTIzODE3",
"avatar_url": "https://avatars.githubusercontent.com/u/19923817?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hecongqing",
"html_url": "https://github.com/hecongqing",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"What model is referring to this .ckpt file? If the model is BERT or ALBERT, you can:\r\n- use the `convert_X_original_tf_checkpoint_to_pytorch --tf_checkpoint_path=dir/model.ckpt-xxx`, where _X_ is albert or bert\r\n- load the .pt model into Transformers as usual\r\n\r\n> ## Questions & Help\r\n> I find the TFBer... | 1,572 | 1,584 | 1,584 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I find the TFBertForSequenceClassification only can upload .h5 file | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1718/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1718/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1717 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1717/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1717/comments | https://api.github.com/repos/huggingface/transformers/issues/1717/events | https://github.com/huggingface/transformers/pull/1717 | 517,002,397 | MDExOlB1bGxSZXF1ZXN0MzM2MTU2NDYx | 1,717 | Retaining unknown token behaver consistency in tokenizer for BERT and XLNET | {
"login": "ziliwang",
"id": 13744942,
"node_id": "MDQ6VXNlcjEzNzQ0OTQy",
"avatar_url": "https://avatars.githubusercontent.com/u/13744942?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ziliwang",
"html_url": "https://github.com/ziliwang",
"followers_url": "https://api.github.com/users/zil... | [] | closed | false | null | [] | [
"Hi, thanks for this but this was the expected behavior for the Bert tokenizer."
] | 1,572 | 1,572 | 1,572 | CONTRIBUTOR | null | I found the BERT tokenizer and XLNET tokenizer behave difference.
for example, `"His name is 燚"`
In BERT, it's tokenized as: `['his', 'name', 'is', '[UNK]']`,
but in XLNET, it's tokenized as: `['▁His', '▁name', '▁is', '▁', '燚']`
The difference may adverse to the uniform training frame for BERT and XLNET, and troubl... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1717/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1717/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1717",
"html_url": "https://github.com/huggingface/transformers/pull/1717",
"diff_url": "https://github.com/huggingface/transformers/pull/1717.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1717.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1716 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1716/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1716/comments | https://api.github.com/repos/huggingface/transformers/issues/1716/events | https://github.com/huggingface/transformers/pull/1716 | 516,960,371 | MDExOlB1bGxSZXF1ZXN0MzM2MTIzMzEw | 1,716 | add qa and result | {
"login": "pohanchi",
"id": 34079344,
"node_id": "MDQ6VXNlcjM0MDc5MzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/34079344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pohanchi",
"html_url": "https://github.com/pohanchi",
"followers_url": "https://api.github.com/users/poh... | [] | closed | false | null | [] | [
"this is a template for albert qa(squad). all modification is on the directory \"transformers/new_template \", \"examples/qa_albert/template\" the true tree structure you can refer to https://github.com/pohanchi/huggingface_albert, test squad 1.1 on albert_base and albert_xlarge is very close to the original pa... | 1,572 | 1,575 | 1,575 | NONE | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1716/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1716/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1716",
"html_url": "https://github.com/huggingface/transformers/pull/1716",
"diff_url": "https://github.com/huggingface/transformers/pull/1716.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1716.patch",
"merged_at": n... | |
https://api.github.com/repos/huggingface/transformers/issues/1715 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1715/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1715/comments | https://api.github.com/repos/huggingface/transformers/issues/1715/events | https://github.com/huggingface/transformers/pull/1715 | 516,953,300 | MDExOlB1bGxSZXF1ZXN0MzM2MTE3NjQ3 | 1,715 | Retaining unknown token behaver consistency in tokenizer for BERT and XLNET | {
"login": "ziliwang",
"id": 13744942,
"node_id": "MDQ6VXNlcjEzNzQ0OTQy",
"avatar_url": "https://avatars.githubusercontent.com/u/13744942?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ziliwang",
"html_url": "https://github.com/ziliwang",
"followers_url": "https://api.github.com/users/zil... | [] | closed | false | null | [] | [] | 1,572 | 1,572 | 1,572 | CONTRIBUTOR | null | I found the BERT tokenizer and XLNET tokenizer behave difference.
for example, `"His name is 燚"`
In BERT, it's tokenized as:` ['his', 'name', 'is', '[UNK]'],`
but in XLNET, it's tokenized as:` ['▁His', '▁name', '▁is', '▁', '燚']`
The difference may adverse to the uniform training frame for BERT and XLNET, and troubl... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1715/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1715/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1715",
"html_url": "https://github.com/huggingface/transformers/pull/1715",
"diff_url": "https://github.com/huggingface/transformers/pull/1715.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1715.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1714 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1714/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1714/comments | https://api.github.com/repos/huggingface/transformers/issues/1714/events | https://github.com/huggingface/transformers/issues/1714 | 516,888,508 | MDU6SXNzdWU1MTY4ODg1MDg= | 1,714 | How to train from scratch | {
"login": "anandhperumal",
"id": 12907396,
"node_id": "MDQ6VXNlcjEyOTA3Mzk2",
"avatar_url": "https://avatars.githubusercontent.com/u/12907396?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anandhperumal",
"html_url": "https://github.com/anandhperumal",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [
"If you want to randomly initialize a model simply initialize it via its constructor rather than from the `from_pretrained` method:\r\n\r\n```py\r\nfrom transformers import GPT2Config, GPT2Model\r\n\r\nconfig = GPT2Config() # define your configuration here\r\nmodel = GPT2Model(config) # Initialize your model from... | 1,572 | 1,573 | 1,573 | NONE | null | I would like to train the model from scratch.
How can I drop the trained weight? using the same architecture for Gpt2 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1714/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1714/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1713 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1713/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1713/comments | https://api.github.com/repos/huggingface/transformers/issues/1713/events | https://github.com/huggingface/transformers/issues/1713 | 516,887,054 | MDU6SXNzdWU1MTY4ODcwNTQ= | 1,713 | How to mask lm_labels and compute loss? --- Finetune gpt2: masking the lm_labels with '-1' and padding increase the perplexity a lot! | {
"login": "fabrahman",
"id": 22799593,
"node_id": "MDQ6VXNlcjIyNzk5NTkz",
"avatar_url": "https://avatars.githubusercontent.com/u/22799593?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fabrahman",
"html_url": "https://github.com/fabrahman",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Can any one help regarding this question? I really appreciate that. Is there any example of finetuning and masking the context and padded indices? I am following [this](https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313), but I get a uge perplexity ... | 1,572 | 1,579 | 1,579 | NONE | null | Hi,
I wanted to finetune gpt2 in a seq2seq format. For that I followed the same approach used for convAI2 explained [here](https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313).
I followed two steps and each step highly increase the ppl.
1) first I ma... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1713/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1713/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1712 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1712/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1712/comments | https://api.github.com/repos/huggingface/transformers/issues/1712/events | https://github.com/huggingface/transformers/issues/1712 | 516,886,153 | MDU6SXNzdWU1MTY4ODYxNTM= | 1,712 | Scheduler documentation blocks subtly wrong | {
"login": "DomHudson",
"id": 10864294,
"node_id": "MDQ6VXNlcjEwODY0Mjk0",
"avatar_url": "https://avatars.githubusercontent.com/u/10864294?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DomHudson",
"html_url": "https://github.com/DomHudson",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"Indeed, happy to welcome a PR on that if you want to fix this",
"Closed by https://github.com/huggingface/transformers/pull/1737"
] | 1,572 | 1,572 | 1,572 | NONE | null | ## Summary
Hi, I noticed that in `optimization.py` the way many of the schedulers describe the learning rate is slightly wrong.
For example, `WarmupLinearSchedule` says
```
Linearly increases learning rate from 0 to 1 over `warmup_steps` training steps.
Linearly decreases learning rate from 1. to 0... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1712/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1712/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1711 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1711/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1711/comments | https://api.github.com/repos/huggingface/transformers/issues/1711/events | https://github.com/huggingface/transformers/issues/1711 | 516,880,276 | MDU6SXNzdWU1MTY4ODAyNzY= | 1,711 | transformers module doesn't work with torch compiled on Cuda 10.0? | {
"login": "ehsan-soe",
"id": 12740904,
"node_id": "MDQ6VXNlcjEyNzQwOTA0",
"avatar_url": "https://avatars.githubusercontent.com/u/12740904?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ehsan-soe",
"html_url": "https://github.com/ehsan-soe",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"Solved! closing."
] | 1,572 | 1,572 | 1,572 | NONE | null | Hi,
I have been using this repo for long time and it was working okay. Very recently it gave me ```ModuleNotFoundError: No module named 'transformers'``` error and I had to reinstall it from source.
It seems like during installation my torch version (or the Cuda it is compiled on) got updated.
I reinstall my PyTor... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1711/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1711/timeline | completed | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.