
title stringlengths 1 100 | titleSlug stringlengths 3 77 | Java int64 0 1 | Python3 int64 1 1 | content stringlengths 28 44.4k | voteCount int64 0 3.67k | question_content stringlengths 65 5k | question_hints stringclasses 970
values |
|---|---|---|---|---|---|---|---|
Two Pointers | Python | BEATS 99.19% | assign-cookies | 0 | 1 | # Complexity\n- Time complexity:\n - After sorting, O(g).\n \n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findContentChildren(self, g: List[int], s: List[int]) -> int:\n\n g.sort()\n s.sort()\n\n a = len(g) - 1\n b = len(s) - 1\n ... | 2 | Assume you are an awesome parent and want to give your children some cookies. But, you should give each child at most one cookie.
Each child `i` has a greed factor `g[i]`, which is the minimum size of a cookie that the child will be content with; and each cookie `j` has a size `s[j]`. If `s[j] >= g[i]`, we can assign ... | null |
Python Solution Beats 94.98 % | assign-cookies | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | Assume you are an awesome parent and want to give your children some cookies. But, you should give each child at most one cookie.
Each child `i` has a greed factor `g[i]`, which is the minimum size of a cookie that the child will be content with; and each cookie `j` has a size `s[j]`. If `s[j] >= g[i]`, we can assign ... | null |
O(nlogn) python | assign-cookies | 0 | 1 | ```\nclass Solution:\n def findContentChildren(self, g: List[int], s: List[int]) -> int:\n g=sorted(g)\n s=sorted(s)\n i=0\n j=0\n c=0\n while i<len(g) and j<len(s):\n if g[i]<=s[j]:\n c+=1\n i+=1\n j+=1\n return c\n... | 2 | Assume you are an awesome parent and want to give your children some cookies. But, you should give each child at most one cookie.
Each child `i` has a greed factor `g[i]`, which is the minimum size of a cookie that the child will be content with; and each cookie `j` has a size `s[j]`. If `s[j] >= g[i]`, we can assign ... | null |
Python Solution - easy to understand | assign-cookies | 0 | 1 | ```\nclass Solution:\n def findContentChildren(self, g: List[int], s: List[int]) -> int: \n if len(s)==0:\n return 0\n i=0\n j=0\n c=0\n g.sort()\n s.sort()\n while(i!=len(g) and len(s)!=j):\n if g[i]<=s[j]:\n c+=1\n ... | 2 | Assume you are an awesome parent and want to give your children some cookies. But, you should give each child at most one cookie.
Each child `i` has a greed factor `g[i]`, which is the minimum size of a cookie that the child will be content with; and each cookie `j` has a size `s[j]`. If `s[j] >= g[i]`, we can assign ... | null |
LESS MEMORY | BEATS 95% | assign-cookies | 0 | 1 | Filling from the kid with highest requirement to the lowest. Simple Solution.\n# Code\n```\nclass Solution:\n def findContentChildren(self, g: List[int], s: List[int]) -> int:\n count = 0\n g.sort(reverse=True)\n s.sort(reverse=True)\n for i in g:\n for j in s:\n ... | 1 | Assume you are an awesome parent and want to give your children some cookies. But, you should give each child at most one cookie.
Each child `i` has a greed factor `g[i]`, which is the minimum size of a cookie that the child will be content with; and each cookie `j` has a size `s[j]`. If `s[j] >= g[i]`, we can assign ... | null |
assign-cookies | assign-cookies | 0 | 1 | # Code\n```\nclass Solution:\n def findContentChildren(self, g: List[int], s: List[int]) -> int:\n g.sort()\n s.sort()\n l = len(g) - 1\n m = len(s) - 1\n count = 0\n while l>-1 and m>-1:\n if g[l]<=s[m]:\n l-=1\n m-=1\n ... | 0 | Assume you are an awesome parent and want to give your children some cookies. But, you should give each child at most one cookie.
Each child `i` has a greed factor `g[i]`, which is the minimum size of a cookie that the child will be content with; and each cookie `j` has a size `s[j]`. If `s[j] >= g[i]`, we can assign ... | null |
python3 greedy solution | assign-cookies | 0 | 1 | # Code\n```\nclass Solution:\n def findContentChildren(self, g: List[int], s: List[int]) -> int:\n \n # step1: sort the array\n g.sort()\n s.sort()\n\n # create the index\n cookieIndex = len(s) - 1\n\n ret = 0\n # iterate the kids\n for i in range(len(g) - 1... | 0 | Assume you are an awesome parent and want to give your children some cookies. But, you should give each child at most one cookie.
Each child `i` has a greed factor `g[i]`, which is the minimum size of a cookie that the child will be content with; and each cookie `j` has a size `s[j]`. If `s[j] >= g[i]`, we can assign ... | null |
Easy Solution || Stack | 132-pattern | 1 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 8 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
🚀 99.01% || Stack Solution || Commented Code🚀 | 132-pattern | 1 | 1 | # Problem Description\n\nGiven an array of integers, `nums`, of length `n`. A **132 pattern** is a subsequence of three integers, `nums[i]`, `nums[j]`, and `nums[k]`, where `i < j < k` and `nums[i] < nums[k] < nums[j]`.\n\nDetermine whether the given array contains a **132 pattern**. Return **true** if a **132 pattern*... | 64 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
O(n) Solution Using Stack with detailed Explanation Ever - Optimised Solution | 132-pattern | 1 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe intuition behind this code is to find a "132" pattern in the given array nums. A "132" pattern consists of three elements, nums[i], nums[j], and nums[k], where i < j < k and nums[i] < nums[k] < nums[j]. The code aims to efficiently id... | 5 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
✅ 99.35% Stack & Left Approach & Binary Search | 132-pattern | 1 | 1 | # Comprehensive Guide to Solving "132 Pattern": Detecting the Sneaky Subsequence\n\n## Introduction & Problem Statement\n\nHello, fellow code enthusiasts! Today, we\'re diving deep into the realm of number patterns. Specifically, we\'re tackling the "132 Pattern" problem. The task is to determine if there exists a subs... | 116 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
100% runtime and +80% memory in python | 132-pattern | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 1 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
132 PATTERN USING STACK | 132-pattern | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 1 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
Python solution - using monotonic stack | 132-pattern | 0 | 1 | \n# Code\n```\nclass Solution:\n def find132pattern(self, nums: List[int]) -> bool:\n\n\n # this is an example of monotonic stack ds\n # this actually maintains either decreasing or increasing elements in a stack\n # consider last 2 positions if the \n # consider eg :: 1 5 0 3 4\n ... | 1 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
Python3 Solution | 132-pattern | 0 | 1 | \n```\nclass Solution:\n def find132pattern(self, nums: List[int]) -> bool:\n stack=[]\n curMin=nums[0]\n for num in nums:\n while stack and num>=stack[-1][0]:\n stack.pop()\n\n if stack and num>stack[-1][1]:\n return True\n\n stack.... | 1 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
【Video】How we think about a solution - Stack - Python, JavaScript, Java, C++ | 132-pattern | 1 | 1 | Welcome to my post! This post starts with "How we think about a solution". In other words, that is my thought process to solve the question. This post explains how I get to my solution instead of just posting solution codes or out of blue algorithms. I hope it is helpful for someone.\n\n# Intuition\nUsing stack\n\n---\... | 37 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
NOOB CODE : Efficient and easy to understand | 132-pattern | 0 | 1 | \n# Approach\n1. Initialize an empty list `stack` to store potential candidates for the \'3\' in the \'132\' pattern.\n2. Create a list `min_i` of the same length as `nums` to store the minimum value up to the current index. Initialize the first element of `min_i` with the first element of `nums`.\n3. Iterate through `... | 2 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
Python3 short solution 97% | 132-pattern | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
[Python 3] Monotonic decreasing stack (not reversed) | 132-pattern | 0 | 1 | ```\nclass Solution:\n def find132pattern(self, nums: List[int]) -> bool:\n stack, minVal = [], float(\'inf\')\n\n for n in nums:\n while stack and stack[-1][0] <= n:\n stack.pop()\n\n if stack and stack[-1][1] < n:\n return True\n \n ... | 14 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
✅ Python Solution using Stack | 132-pattern | 0 | 1 | ```\nclass Solution:\n def find132pattern(self, nums: List[int]) -> bool:\n if len(nums)<3:\n return False\n \n second_num = -math.inf\n stck = []\n # Try to find nums[i] < second_num < stck[-1]\n for i in range(len(nums) - 1, -1, -1):\n if nums[i] < seco... | 43 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
456: Solution with step by step explanation | 132-pattern | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Create an empty stack and a variable s3 initialized to negative infinity.\n2. Traverse the input array nums from right to left using a loop:\na. If the current element nums[i] is less than s3, return True as the 132 patte... | 7 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
✅💡Beats 100% | ✌️❣️O(n) Easy and Optimised✌️ Solution and Detailed Explanation✌️ | 132-pattern | 1 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe approach for solving the "132 Pattern" problem involves using a stack to keep track of potential \'3\' candidates in the array nums. We also maintain a separate array minLeft to store the minimum element to the left of each element in... | 3 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
python simple effective | 132-pattern | 0 | 1 | ```\n\nclass Solution:\n def find132pattern(self, nums: List[int]) -> bool:\n stack = []\n num = float(\'-inf\')\n for n in nums[::-1]:\n if n < num:\n return True\n while stack and stack[-1] < n:\n num = stack.pop()\n stack.append(n... | 6 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
[Python] Detailed explanation. Stack solution | 132-pattern | 0 | 1 | ```\nclass Solution:\n def find132pattern(self, nums: List[int]) -> bool:\n ## RC ##\n ## APPROACH : STACK ##\n ## LOGIC ##\n ## 1. We Create Minimum Array, till that position => O(n)\n ## 2. We start iterating from reverse of given array.\n ## 3. Remember we are using Stack... | 30 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
Solution of 132 Pattern in Python3 | 132-pattern | 0 | 1 | \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n Here\'s a breakdown of the approach used in this code:\n\n1. Start with the given array of integers nums.\n\n2. Check if the length of nums is less than 3. If it is, return False because a 132 pattern cannot exist with less than 3 elements.\n\n3.... | 0 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
Very Easy 100% (Fully Explained) (Java, C++, Python, JS, C, Python3) | 132-pattern | 1 | 1 | # **Java Solution:**\nRuntime: 2 ms, faster than 98.34% of Java online submissions for 132 Pattern.\n```\nclass Solution {\n public boolean find132pattern(int[] nums) {\n int min = Integer.MIN_VALUE;\n int peak = nums.length;\n for (int i = nums.length - 1; i >= 0; i--) {\n // We find... | 13 | Given an array of `n` integers `nums`, a **132 pattern** is a subsequence of three integers `nums[i]`, `nums[j]` and `nums[k]` such that `i < j < k` and `nums[i] < nums[k] < nums[j]`.
Return `true` _if there is a **132 pattern** in_ `nums`_, otherwise, return_ `false`_._
**Example 1:**
**Input:** nums = \[1,2,3,4\]
... | null |
Solution | circular-array-loop | 1 | 1 | ```C++ []\nclass Solution {\n public:\n bool circularArrayLoop(vector<int>& nums) {\n const int n = nums.size();\n if (n < 2)\n return false;\n auto advance = [&](int i) {\n const int val = (i + nums[i]) % n;\n return i + nums[i] >= 0 ? val : n + val;\n };\n for (int i = 0; i < n; ++i) {\... | 1 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
Simplest sol using visited set | circular-array-loop | 0 | 1 | # Code\n```\nclass Solution:\n def circularArrayLoop(self, nums: List[int]) -> bool:\n n = len(nums)\n if n == 1:\n return False\n\n visited = set()\n for i in range(n):\n if i not in visited:\n cycleset = set()\n while True:\n ... | 2 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
Python: Fast-Slow pointers - O(n) time + O(1) space | circular-array-loop | 0 | 1 | Hello,\n\nHere is my solution.\n\nIntuition:\n* Scan all cells of the list\n* For each cell `i`, \n\t* Use `Fast-Slow Pointers` to check if there is a cycle starting from `i`\n\t* If there is no cycle from cell `i`, mark visited (nums[j] = 0) all cells that belong to the path starting from cell `i`\n\nComplexity Analys... | 26 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
Python 3 | Short Python, Set | Explanation | circular-array-loop | 0 | 1 | ### Explanation\n- Not the most efficient solution, but it\'s one of the cleanest\n- Time: `O(n)`, Space `O(n)`\n- Note: **The starting index can be any index, NOT zero only**\n- Take each unvisited index and start traverse, mark as visited at the meantime\n- If sign changes or cycle at itself, break the loop; otherwis... | 13 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
457: Solution with step by step explanation | circular-array-loop | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Check if the length of the input list is less than 2. If so, return False as there can\'t be any loops with less than 2 elements.\n\n2. Loop through each element in the input list using the enumerate() function to keep tr... | 5 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
Self Understandable Python (explained code + 98% faster) : | circular-array-loop | 0 | 1 | **Bruteforce Approach :**\n```\nclass Solution:\n def circularArrayLoop(self, nums: List[int]) -> bool:\n for i in range(len(nums)):\n seen=set()\n while True:\n if i in seen: # if index already exist in set means, array is circular \n retu... | 4 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
dfs, beats 79%. | circular-array-loop | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nThe difficult part I got was the calculation of the next indice. everything else was easy to think.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity ... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
Easy & Explained Graph Dfs Solution Python3 || Python Solution | circular-array-loop | 0 | 1 | # Intuition and Approach\n<!-- Describe your first thoughts on how to solve this problem. -->\nBasic intuition to tackle this problem is to find if there exists an cycle inside this circle so to do so first we can simply create think of creating it an directed graph in which at index i to the destination which we can g... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
O(n) time/space solution using UFDS | circular-array-loop | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nFirst ignore the condition that all steps must go in the same direction (positive or negative). For each index $i$, we look at the destination index $j$ (i.e. ($j=(i + nums[i]) \\text{ mod } n$). Then $i$ is connected to $j$; we use some ... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
🐍 python; 3 solutions with explanation; O(N); faster than 98% | circular-array-loop | 0 | 1 | # Approach 1\nWe traverse all nodes to find a cycle using slow and fast pointer method. \nWe only stop if\n1) we find cycle and then we check if the size of it is bigger than 1 or not by checking `fast!=helper(fast)`\n2) we run into opposite jumps.\n\nWhile searching to find the cycle, we mark the visited node by `visi... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
Python solution with slow-fast pointer | circular-array-loop | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nWe are trying to find if there is a cycle in the array. The problem can be reduced to finding a cycle in a linked list. This is because each index i points to another index (i+nums[i])%n, just like each node in a linked list points to ano... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
[[ Python ]] O(N) LiNeAr Sp33d Two PaSs StRaTeGy | circular-array-loop | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nWe can start at index 0 and see if we\'re in a "cycle" by iteratively marching through the steps. We keep track of which slots we\'ve visited... \n\nOur cycles need to all be in the same direction. This leaves us with a problem. Take the ... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
Python O(n) time, O(1) space, only few lines of code, without using fast and slow | circular-array-loop | 0 | 1 | # Intuition\nif we are looping and moving only forward (or only backward) for more than the length of the array, this means that we have a cycle. The maximum length of a list that doesn\'t have a cycle doesn\'t exeed n, or else we are going back to some indexes that are previously visited. \n\n\n# Complexity\n- Time co... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
DFS + self loop check | circular-array-loop | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n- turn array to graph\n- graph loop check\n- Every nums[seq[j]] is either all positive or all negative\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
O(n) in time, O(n) complexity | circular-array-loop | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
Linear time complexity O(n), linear space complexity O(n) | circular-array-loop | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
Simple python solution with top runtime | circular-array-loop | 0 | 1 | # Intuition\nThere are types of cycles in the given list nums which the code will analyse cycles to see if there are any closed cycle following the description conditions. \n\n# Approach\nThe approach is go through the cycle in every elements of nums, and save the visited element of nums in a set:\n```\nvisited = set()... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
[Python] DFS like loop; Explained | circular-array-loop | 0 | 1 | Using DFS and topological sort can solve this problem.\n\nIn the below solution, a for loop is used to minimic the dfs behavior that we search as many steps as we can (for loop works because only one option we can select for the next step). If we find an index that is in our current visting path, we can return True as ... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
Python O(N) time and O(1) Space | circular-array-loop | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(N)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
O(n) time, O(1) space solution | circular-array-loop | 0 | 1 | # Intuition\nFor problems with finding cycle like these, more than likely the fast and slow pointer technique can be applied\n\nNotice O(1) space meaning we cant maintain any sort of seen set hence the common technique to satisify the constraint would be to modify the input array in some ways\n\n# Approach\nAt each nod... | 0 | You are playing a game involving a **circular** array of non-zero integers `nums`. Each `nums[i]` denotes the number of indices forward/backward you must move if you are located at index `i`:
* If `nums[i]` is positive, move `nums[i]` steps **forward**, and
* If `nums[i]` is negative, move `nums[i]` steps **backwa... | null |
Python | poor-pigs | 0 | 1 | I typically share detailed explanations, create videos for solving problems and upload them to YouTube. However, I\'m not feeling motivated to do so for today\'s problem, so I\'ll just share the Python code here.\n\nI changed the argument names in the function because I don\'t want to use word of die.\n\n# Code\n```\nc... | 26 | There are `buckets` buckets of liquid, where **exactly one** of the buckets is poisonous. To figure out which one is poisonous, you feed some number of (poor) pigs the liquid to see whether they will die or not. Unfortunately, you only have `minutesToTest` minutes to determine which bucket is poisonous.
You can feed t... | What if you only have one shot? Eg. 4 buckets, 15 mins to die, and 15 mins to test. How many states can we generate with x pigs and T tests? Find minimum x such that (T+1)^x >= N |
C++ log2 1 line | poor-pigs | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nI don\'t like the description.\nChange the variable names to timeTest, timeDetect.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nThe total test time is `timeTest`. It needs time `timeDetect` to detect whether the... | 62 | There are `buckets` buckets of liquid, where **exactly one** of the buckets is poisonous. To figure out which one is poisonous, you feed some number of (poor) pigs the liquid to see whether they will die or not. Unfortunately, you only have `minutesToTest` minutes to determine which bucket is poisonous.
You can feed t... | What if you only have one shot? Eg. 4 buckets, 15 mins to die, and 15 mins to test. How many states can we generate with x pigs and T tests? Find minimum x such that (T+1)^x >= N |
two liner || python || easy math only | poor-pigs | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(1)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $... | 1 | There are `buckets` buckets of liquid, where **exactly one** of the buckets is poisonous. To figure out which one is poisonous, you feed some number of (poor) pigs the liquid to see whether they will die or not. Unfortunately, you only have `minutesToTest` minutes to determine which bucket is poisonous.
You can feed t... | What if you only have one shot? Eg. 4 buckets, 15 mins to die, and 15 mins to test. How many states can we generate with x pigs and T tests? Find minimum x such that (T+1)^x >= N |
🔥 Python || Detailed Explanation ✅ || Faster Than 98% || Easily Understood || Simple || MATH | poor-pigs | 0 | 1 | **Appreciate if you could upvote this solution**\n<br/>\nMethod: `Math`\n\nLet `T` be the number of times to test so `T = minutesToTest / minutesToDie`\n& `p` be the numbers of pigs to test in each round\n& `b` be the maximum number of buckets that can be test.\n\nFirst of all, we need to find out the relatioship betwe... | 36 | There are `buckets` buckets of liquid, where **exactly one** of the buckets is poisonous. To figure out which one is poisonous, you feed some number of (poor) pigs the liquid to see whether they will die or not. Unfortunately, you only have `minutesToTest` minutes to determine which bucket is poisonous.
You can feed t... | What if you only have one shot? Eg. 4 buckets, 15 mins to die, and 15 mins to test. How many states can we generate with x pigs and T tests? Find minimum x such that (T+1)^x >= N |
Easy 0 ms 100% (Fully Explained)(Java, C++, Python, JS, C, Python3) | poor-pigs | 1 | 1 | # **Java Solution:**\nRuntime: 0 ms, faster than 100.00% of Java online submissions for Poor Pigs.\n```\nclass Solution {\n public int poorPigs(int buckets, int minutesToDie, int minutesToTest) {\n // Calculate the max time for a pig to test buckets...\n // Note that, max time will not be (minutesToTes... | 29 | There are `buckets` buckets of liquid, where **exactly one** of the buckets is poisonous. To figure out which one is poisonous, you feed some number of (poor) pigs the liquid to see whether they will die or not. Unfortunately, you only have `minutesToTest` minutes to determine which bucket is poisonous.
You can feed t... | What if you only have one shot? Eg. 4 buckets, 15 mins to die, and 15 mins to test. How many states can we generate with x pigs and T tests? Find minimum x such that (T+1)^x >= N |
Python short and clean. Functional programming. | poor-pigs | 0 | 1 | # Complexity\n- Time complexity: $$O(log_b(n))$$\n\n- Space complexity: $$O(1)$$\n\nwhere,\n`n is number of buckets`,\n`b is minutes_to_test / minutes_to_die`.\n\n# Code\n```python\nclass Solution:\n def poorPigs(self, buckets: int, minutes_to_die: int, minutes_to_test: int) -> int:\n pigs = log(buckets, minu... | 1 | There are `buckets` buckets of liquid, where **exactly one** of the buckets is poisonous. To figure out which one is poisonous, you feed some number of (poor) pigs the liquid to see whether they will die or not. Unfortunately, you only have `minutesToTest` minutes to determine which bucket is poisonous.
You can feed t... | What if you only have one shot? Eg. 4 buckets, 15 mins to die, and 15 mins to test. How many states can we generate with x pigs and T tests? Find minimum x such that (T+1)^x >= N |
[C++/Python/Picture] 1-line greedy solution with N-dimension puzzle cube scan | poor-pigs | 0 | 1 | **Idea:**\nExample 1: What is the minimal number of pigs are needed to test 9 bucteks within 2 rounds:\n1 2 3\n4 5 6\n7 8 9\nAnswer: 2.\nWhy? \nPig 1 scan horizontally row by row and will spot the row contains poinson after 2 round. Assume row i has posion\nPig 2 scan vertically column by column and... | 35 | There are `buckets` buckets of liquid, where **exactly one** of the buckets is poisonous. To figure out which one is poisonous, you feed some number of (poor) pigs the liquid to see whether they will die or not. Unfortunately, you only have `minutesToTest` minutes to determine which bucket is poisonous.
You can feed t... | What if you only have one shot? Eg. 4 buckets, 15 mins to die, and 15 mins to test. How many states can we generate with x pigs and T tests? Find minimum x such that (T+1)^x >= N |
[Python 3] Solution Explained (video + code) | poor-pigs | 0 | 1 | [](https://www.youtube.com/watch?v=_JcO3fqoG2M)\nhttps://www.youtube.com/watch?v=_JcO3fqoG2M\n```\nclass Solution:\n def poorPigs(self, buckets: int, minutesToDie: int, minutesToTest: int) -> int:\n pigs = 0\n \n while (minutesToTest / minutesToDie + 1) ** pigs < buckets:\n pigs += 1\... | 15 | There are `buckets` buckets of liquid, where **exactly one** of the buckets is poisonous. To figure out which one is poisonous, you feed some number of (poor) pigs the liquid to see whether they will die or not. Unfortunately, you only have `minutesToTest` minutes to determine which bucket is poisonous.
You can feed t... | What if you only have one shot? Eg. 4 buckets, 15 mins to die, and 15 mins to test. How many states can we generate with x pigs and T tests? Find minimum x such that (T+1)^x >= N |
✅ 99.42% 2-Approaches - O(n) | repeated-substring-pattern | 1 | 1 | # Problem Understanding\n\nIn the "459. Repeated Substring Pattern" problem, we are given a string `s`. The task is to check if it can be constructed by taking a substring of it and appending multiple copies of the substring together.\n\nFor instance, given the string `s = "abab"`, the output should be `True` as it is ... | 154 | Given a string `s`, check if it can be constructed by taking a substring of it and appending multiple copies of the substring together.
**Example 1:**
**Input:** s = "abab "
**Output:** true
**Explanation:** It is the substring "ab " twice.
**Example 2:**
**Input:** s = "aba "
**Output:** false
**Example 3:**
... | null |
【Video】Ex-Amazon explains a solution with Python, JavaScript, Java and C++ | repeated-substring-pattern | 1 | 1 | I\'m going to show you two ways to solve this quesiton.\n\n# Solution Video\n\n### Please subscribe to my channel from here. I have 245 videos as of August 21th.\n\nhttp://www.youtube.com/channel/UC9RMNwYTL3SXCP6ShLWVFww?sub_confirmation=1\n\nhttps://youtu.be/Fx7dQgDcZXU\n\n---\n\n# Approach1 with O(n^2) time\nThis is ... | 15 | Given a string `s`, check if it can be constructed by taking a substring of it and appending multiple copies of the substring together.
**Example 1:**
**Input:** s = "abab "
**Output:** true
**Explanation:** It is the substring "ab " twice.
**Example 2:**
**Input:** s = "aba "
**Output:** false
**Example 3:**
... | null |
Python/C++/Java/JS/Go by fold-and-find [w/ Simple proof] | repeated-substring-pattern | 1 | 1 | \n\n---\n\n\n\n---\n\n {\n return (s+s).find(s,1)<s.size();\n }\n};\n```\n\n```Python3 []\nclass Solution:\n def repeatedSubstringPattern(self, s: str) -> bool:\n if not s:\n return False \n ss = (s + s)[1:-1]\n re... | 4 | Given a string `s`, check if it can be constructed by taking a substring of it and appending multiple copies of the substring together.
**Example 1:**
**Input:** s = "abab "
**Output:** true
**Explanation:** It is the substring "ab " twice.
**Example 2:**
**Input:** s = "aba "
**Output:** false
**Example 3:**
... | null |
2 Line Python Solution ✔️✔️ || Briefly Explained 👨💻👨💻 | repeated-substring-pattern | 0 | 1 | # Approach\nThis Python code defines a class `Solution` with a method `repeatedSubstringPattern` that checks if a given string `s` can be formed by repeating a substring within itself.\n\nHere\'s a brief explanation of the code:\n\n1. `ss = (s + s)[1:-1]`: This line creates a new string `ss` by concatenating the input ... | 9 | Given a string `s`, check if it can be constructed by taking a substring of it and appending multiple copies of the substring together.
**Example 1:**
**Input:** s = "abab "
**Output:** true
**Explanation:** It is the substring "ab " twice.
**Example 2:**
**Input:** s = "aba "
**Output:** false
**Example 3:**
... | null |
Most optimal solution using KMP (Knuth-Morris-Pratt) algorithm | repeated-substring-pattern | 1 | 1 | \n\n# Approach\nIn this solution, we calculate the Longest Prefix which is also a Suffix (lps) array using the KMP algorithm. The key observation is that if a string can be divided into multiple copies of a substring, the entire string\'s length minus the last value in the lps array gives the length of the repeating su... | 3 | Given a string `s`, check if it can be constructed by taking a substring of it and appending multiple copies of the substring together.
**Example 1:**
**Input:** s = "abab "
**Output:** true
**Explanation:** It is the substring "ab " twice.
**Example 2:**
**Input:** s = "aba "
**Output:** false
**Example 3:**
... | null |
🔥🔥🔥🔥🔥Beats 100% | JS | TS | Java | C++ | C# | C | PHP | Python | python3 | Kotlin | 🔥🔥🔥🔥🔥 | repeated-substring-pattern | 1 | 1 | ---\n\n\n---\n**Approach**\nTo solve this problem, you can use a sliding window approach to check if the string `s` can be constructed by repeating a substring. Here\'s an approach to solve this problem:\... | 8 | Given a string `s`, check if it can be constructed by taking a substring of it and appending multiple copies of the substring together.
**Example 1:**
**Input:** s = "abab "
**Output:** true
**Explanation:** It is the substring "ab " twice.
**Example 2:**
**Input:** s = "aba "
**Output:** false
**Example 3:**
... | null |
▶️ Python3 beats 98.9% with explanation for O(n) | repeated-substring-pattern | 0 | 1 | # Intuition\n\nShould I concat origibal string twice?\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nLet\'s think my string s contains of two substring s1 and s2 that means s = (s1)(s2) and I have to check s1==s2 or not.\n\nAfter concatinating, my new string will look like (s1s2)(s1s2)\n\nnewS ... | 7 | Given a string `s`, check if it can be constructed by taking a substring of it and appending multiple copies of the substring together.
**Example 1:**
**Input:** s = "abab "
**Output:** true
**Explanation:** It is the substring "ab " twice.
**Example 2:**
**Input:** s = "aba "
**Output:** false
**Example 3:**
... | null |
Another solution | repeated-substring-pattern | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 1 | Given a string `s`, check if it can be constructed by taking a substring of it and appending multiple copies of the substring together.
**Example 1:**
**Input:** s = "abab "
**Output:** true
**Explanation:** It is the substring "ab " twice.
**Example 2:**
**Input:** s = "aba "
**Output:** false
**Example 3:**
... | null |
Python3 Solution | repeated-substring-pattern | 0 | 1 | \n```\nclass Solution:\n def repeatedSubstringPattern(self, s: str) -> bool:\n ds=(s+s)[1:-1]\n return s in ds\n``` | 5 | Given a string `s`, check if it can be constructed by taking a substring of it and appending multiple copies of the substring together.
**Example 1:**
**Input:** s = "abab "
**Output:** true
**Explanation:** It is the substring "ab " twice.
**Example 2:**
**Input:** s = "aba "
**Output:** false
**Example 3:**
... | null |
Python 1-liner. | repeated-substring-pattern | 0 | 1 | # Approach\nTL;DR, Similar to [Editorial solution Approach 2](https://leetcode.com/problems/repeated-substring-pattern/editorial/) but shorter.\n\n# Complexity\n- Time complexity: $$O(n)$$\n\n- Space complexity: $$O(n)$$\n\nwhere, `n is length of s`.\n\n# Code\n```python\nclass Solution:\n def repeatedSubstringPatte... | 1 | Given a string `s`, check if it can be constructed by taking a substring of it and appending multiple copies of the substring together.
**Example 1:**
**Input:** s = "abab "
**Output:** true
**Explanation:** It is the substring "ab " twice.
**Example 2:**
**Input:** s = "aba "
**Output:** false
**Example 3:**
... | null |
Python 3 -- One liner -- Beats 98.19% | repeated-substring-pattern | 0 | 1 | ```\nclass Solution:\n def repeatedSubstringPattern(self, s: str) -> bool:\n return s in s[1:] + s[:-1]\n``` | 53 | Given a string `s`, check if it can be constructed by taking a substring of it and appending multiple copies of the substring together.
**Example 1:**
**Input:** s = "abab "
**Output:** true
**Explanation:** It is the substring "ab " twice.
**Example 2:**
**Input:** s = "aba "
**Output:** false
**Example 3:**
... | null |
python3 | OrderedDict and hashmap | lfu-cache | 0 | 1 | The following points help with the breakdown of logic. \n- get and put methods both increment the counter. \n- We need to keep track of frequencies of a key and the value associated with the key. \n- In order to drop the key with least frequency, we to know the minimum freq at all times. \n- Among minimum freq elements... | 1 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
Python Solution: Two Dictionaries | lfu-cache | 0 | 1 | # Approach\n\nTwo dictionaries:\n1. `self.cache` - stores values and frequency count for a key\n2. `self.cache_counts` - ordered dictionary/set of keys for given frequency count\n\n# Code\n```\nclass LFUCache:\n\n def __init__(self, capacity: int):\n self.capacity = capacity\n self.cache = dict() # key... | 1 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
O(1) Time🔥🔥|| Full Explanation✅|| HashTable✅|| C++|| Java|| Python3 | lfu-cache | 1 | 1 | # What is Cache & LFU Cache ?\n1. A cache is a data structure that stores a limited number of items and is used to quickly retrieve items that have been previously accessed.\n2. An LFU cache evicts the least frequently used item when it reaches capacity, as opposed to an LRU (Least Recently Used) cache, which evicts th... | 78 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
Python ordereddict - few lines of code | lfu-cache | 0 | 1 | # My draft\n```text \n0 "LFUCache" [2] null\n1 "put" [1,1] null \n2 "put" [2,2] null \n3 "get" [1] 1\n4 "put" [3,3] null \n5 "get" [2] -1\n6 "get" [3] 3\n7 "put" [4,4] null \n8 "get" [1] -1\n9 "get" [3] 3\n10 ... | 1 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
Python solution using defaultdict and OrderedDict beats 70% time complexity :-) | lfu-cache | 0 | 1 | # Code\n```\nfrom collections import defaultdict\nfrom collections import OrderedDict\nclass Node:\n def __init__(self, key, val ,count):\n self.key = key\n self.val = val\n self.count = count\nclass LFUCache:\n def __init__(self, capacity: int):\n self.capacity = capacity\n sel... | 1 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
Best Solution in Python | lfu-cache | 0 | 1 | \n# Code\n```\nclass ListNode:\n def __init__(self , key , value):\n self.key = key \n self.val = value \n self.freq = 1 \n\nclass LFUCache:\n\n def __init__(self, capacity: int):\n self.capacity = capacity \n self.cache = dict()\n self.usage = collections.defaultdict(col... | 10 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
🚀Easy Solution🚀||🔥Fully Explained🔥|| C++ || Commented | lfu-cache | 1 | 1 | # Consider\uD83D\uDC4D\n```\n Please Upvote If You Find It Helpful.\n```\n# Complexity\nTime Complexity : O(1)\n\nSpace Complexity : O(N)\n# Code\n```\nclass LFUCache {\n int maxSizeCache; // maximum capacity of the cache\n int size; // current number of elements in the cache\n int minFr... | 18 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
Python short and clean. DoublyLinkedList and HashMap. | lfu-cache | 0 | 1 | # Approach\nTLDR; Similar to [Editorial Solution](https://leetcode.com/problems/lfu-cache/solutions/2815229/lfu-cache/) but shorter and cleaner.\n\n# Complexity\n- Time complexity:\n `LFUCache.get`: $$O(1)$$\n `LFUCache.put`: $$O(1)$$\n\n- Space complexity:\n `LFUCache.get`: $$O(1)$$\n `LFUCache.put`: $$O(1... | 5 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
[Python] Hashmap + Doubly Linked List - Daily Challenge Jan., Day 29 | lfu-cache | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nconsider what kind of data structure do we need?\n1. we need to store key & value\n2. we need to know the relation between key & frequency\n3. if exceed capacity, we need to know the minimum frequency and least recently used node and remo... | 5 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
python3 Solution | lfu-cache | 0 | 1 | \n```\nclass ListNode:\n def __init__(self, key, value):\n self.key = key\n self.val = value\n self.freq = 1\n \nclass LFUCache:\n\n def __init__(self, capacity: int):\n self.capacity = capacity\n self.cache = dict() \n self.usage = collections.defaultdict(collecti... | 3 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
460: Solution with step by step explanation | lfu-cache | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Define the Node class with attributes key, val, freq, prev, and next.\n2. Define the DoublyLinkedList class with attributes head and tail, and methods add_node_to_head, remove_node, is_empty, and remove_tail_node.\n3. Ini... | 4 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
[Python] Simple two hash maps; Explained | lfu-cache | 0 | 1 | We only need two hash maps to maintain the LFU cache:\n(1) the first hash map: maps key to (value, count) pair\n(2) the second hash map: maps count to an OrderedDict which maintains key, value pairs\n\nThe get method: we need to check the first hash map, and update the count in it. Based on the new count of the key, we... | 18 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
Python | Doubly Linked List and Hash Map | O(1) Get and Put operations | lfu-cache | 0 | 1 | # Approach\n1. Maintain a hash map for key to node mapping # {key: node}\n2. Maintain another hash map for frequency to DLL mapping # {freq: (head, tail)}\n3. For any get operation, return the value of key from corresponding node and increase the frequency by 1.\n4. For any put operation,\n a) If key value already e... | 1 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
📌📌Python3 || ⚡859 ms, faster than 79.52% of Python3 | lfu-cache | 0 | 1 | ```\nclass LFUCache:\n\n def __init__(self, capacity: int):\n self.capacity = capacity\n self.time = 0\n self.map = {} \n self.freq_time = {} \n self.priority_queue = [] \n self.update = set()\n\n def get(self, key: int) -> int:\n self.time ... | 5 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
[Python] O(1) using DLL and Dictionary | lfu-cache | 0 | 1 | **Approach:**\n\n*Data Structures:*\n1. Frequency Table: A dictionary to store the mapping of different frequency values with values as DLLs storing (key, value) pairs as nodes\n2. Cache Dicitionary: Nodes in the DLL are stored as values for each key pushed into the cache\n\n*Algorithm:*\n* get(key):\n\t* If key is not... | 64 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
Python || Striver's Solution || HashMap + DLL | lfu-cache | 0 | 1 | ```\nclass Node: \n def __init__(self, key, val):\n self.key=key\n self.val=val\n self.prev=None\n self.next=None\n self.cnt=1\n\nclass Doublell:\n def __init__(self):\n self.size=0\n self.head=Node(0,0)\n self.tail=Node(0,0)\n self.head.next=self.... | 2 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
[JAVA/C++/PYTHON] | EXPLAINED IN DETAIL | CONSTANT TIME | TWO HASHMAP'S | lfu-cache | 1 | 1 | # Intuition & Approach\n\nWe need to maintain all the keys, values and frequencies. Without invalidation (removing from the data structure when it reaches capacity), they can be maintained by a HashMap<Integer, Pair<Integer, Integer>>, keyed by the original key and valued by the frequency-value pair.\n\nWith the invali... | 2 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
O(1) - Two HashMap + DoubleLinkedList - Clean up Solution | lfu-cache | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\nTwo HashMap + DoubleLinkedList approach:\n - HashMap to store (key, DoubleNode(key, value, freq, ...)) pairs\n - HashMap to store (freq, DoubleLinkedList for keys with this freq) pairs\n\nAlso, let\'s clean up empty DoubleLinkedLists and removed... | 2 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
Python3 Solution Using Linked LIsts and HashMap | lfu-cache | 0 | 1 | # Approach\n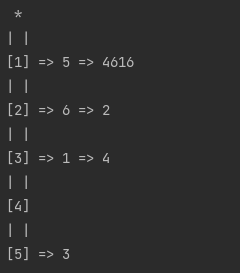\nThis is how it looks like. We have \'nested\' linked lists. One linked list is used for frequency levels holding. Inner one is for holding nodes sorted by updating time. Also we have map for q... | 2 | Design and implement a data structure for a [Least Frequently Used (LFU)](https://en.wikipedia.org/wiki/Least_frequently_used) cache.
Implement the `LFUCache` class:
* `LFUCache(int capacity)` Initializes the object with the `capacity` of the data structure.
* `int get(int key)` Gets the value of the `key` if the... | null |
easy to understand | hamming-distance | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nwe use the bigger number to determine the length of both the binary numbers.\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ ... | 1 | The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return _the **Hamming distance** between them_.
**Example 1:**
**Input:** x = 1, y = 4
**Output:** 2
**Explanation:**
1... | null |
Bitwise XOR and Divide-by-2 Method | hamming-distance | 0 | 1 | # Intuition and Approach\nThe XOR (Exclusive OR) operation in Python can be performed using the `^` operator. The XOR operation returns `True` if exactly one of the operands is `True`, and `False` otherwise. In other words, if the respective bits are different, it returns `1`. \n\nThen the divide-by-2 method is applied... | 1 | The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return _the **Hamming distance** between them_.
**Example 1:**
**Input:** x = 1, y = 4
**Output:** 2
**Explanation:**
1... | null |
Python3 || One lined easy solution | hamming-distance | 0 | 1 | Please do upvote\n# Code\n```\nclass Solution:\n def hammingDistance(self, x: int, y: int) -> int:\n return bin(x^y).count("1")\n``` | 1 | The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return _the **Hamming distance** between them_.
**Example 1:**
**Input:** x = 1, y = 4
**Output:** 2
**Explanation:**
1... | null |
easy python solution | hamming-distance | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 1 | The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return _the **Hamming distance** between them_.
**Example 1:**
**Input:** x = 1, y = 4
**Output:** 2
**Explanation:**
1... | null |
Easy 1 line Python code using bitwise XOR operator | hamming-distance | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 2 | The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return _the **Hamming distance** between them_.
**Example 1:**
**Input:** x = 1, y = 4
**Output:** 2
**Explanation:**
1... | null |
[Python3] Solutions with explanation | hamming-distance | 0 | 1 | One way to compute Hamming distance between **x** and **y** is calculate XOR and count the number of \'1\'s in the binary representation.\n\n```\nclass Solution:\n def hammingDistance(self, x: int, y: int) -> int:\n return bin(x ^ y).count(\'1\')\n```\nAnother way to compute is calculate XOR, then iterate thr... | 1 | The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return _the **Hamming distance** between them_.
**Example 1:**
**Input:** x = 1, y = 4
**Output:** 2
**Explanation:**
1... | null |
461: Solution with step by step explanation | hamming-distance | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize a variable "xor" with the XOR of the given integers "x" and "y".\n2. Initialize a variable "distance" with 0.\n3. While "xor" is not equal to 0, do the following:\na. Bitwise AND "xor" with "xor-1" to unset the... | 5 | The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return _the **Hamming distance** between them_.
**Example 1:**
**Input:** x = 1, y = 4
**Output:** 2
**Explanation:**
1... | null |
just cool one line solution | hamming-distance | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def hammingDistance(self, x: int, y: int) -> int:\n return bin(x^y).count(\'1\')\n``` | 3 | The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return _the **Hamming distance** between them_.
**Example 1:**
**Input:** x = 1, y = 4
**Output:** 2
**Explanation:**
1... | null |
Solution | hamming-distance | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int hammingDistance(int x, int y) {\n return __builtin_popcountll(x^y);\n }\n};\n```\n\n```Python3 []\nclass Solution:\n def hammingDistance(self, x: int, y: int) -> int:\n binx,biny=bin(x).replace(\'0b\',\'0\'),bin(y).replace(\'0b\',\'0\')\n lx,ly=le... | 2 | The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return _the **Hamming distance** between them_.
**Example 1:**
**Input:** x = 1, y = 4
**Output:** 2
**Explanation:**
1... | null |
Easy approach with bit manipulation with explanation | hamming-distance | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n\nThe main idea is to use a XOR operator for these 2 numbers. If 2 bits are the same - we get \'0\' at this position and \'1\' otherwise. So our mission here is to calculate the number of \'1\'s. We can do so by comparing the last bit w... | 3 | The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return _the **Hamming distance** between them_.
**Example 1:**
**Input:** x = 1, y = 4
**Output:** 2
**Explanation:**
1... | null |
Python 1-liner 32ms | hamming-distance | 0 | 1 | ```\ndef hammingDistance(self, x, y):\n return bin(x^y).count(\'1\')\n``` | 9 | The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return _the **Hamming distance** between them_.
**Example 1:**
**Input:** x = 1, y = 4
**Output:** 2
**Explanation:**
1... | null |
Beating 95% Single Line Easy Python Solution | hamming-distance | 0 | 1 | \n\n\n# Code\n```\nclass Solution(object):\n def hammingDistance(self, x, y):\n """\n :type x: int\n :type y: int\n :rtype: int\n """\n return str(bin(x^y)).count... | 3 | The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return _the **Hamming distance** between them_.
**Example 1:**
**Input:** x = 1, y = 4
**Output:** 2
**Explanation:**
1... | null |
Python3 || Two ways, string and bit manipulation (Commented) | hamming-distance | 0 | 1 | Any questions feel free to ask, if the comments helped, leave me a like :)\n```\nclass Solution:\n def hammingDistance(self, x: int, y: int) -> int:\n\n # String solution\n\t\t# TC O(n) SC O(1)\n longer = len(bin(y))-2 \n if x > y: longer = len(bin(x))-2\n\t\t # 2 lines above for padding 0\'s\n ... | 2 | The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return _the **Hamming distance** between them_.
**Example 1:**
**Input:** x = 1, y = 4
**Output:** 2
**Explanation:**
1... | null |
Solution | minimum-moves-to-equal-array-elements-ii | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int minMoves2(vector<int>& nums) {\n int result = 0, length = nums.size();\n sort(nums.begin(), nums.end());\n for (int i = 0; i < length; i++) {\n int median = length / 2;\n result += abs(nums[i] - nums[median]);\n }\n r... | 1 | Given an integer array `nums` of size `n`, return _the minimum number of moves required to make all array elements equal_.
In one move, you can increment or decrement an element of the array by `1`.
Test cases are designed so that the answer will fit in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[1,2,3... | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.