
title stringlengths 1 100 | titleSlug stringlengths 3 77 | Java int64 0 1 | Python3 int64 1 1 | content stringlengths 28 44.4k | voteCount int64 0 3.67k | question_content stringlengths 65 5k | question_hints stringclasses 970
values |
|---|---|---|---|---|---|---|---|
📌 Python3 simple solution: Get the mid element from the sorted array | minimum-moves-to-equal-array-elements-ii | 0 | 1 | ```\nclass Solution:\n def minMoves2(self, nums: List[int]) -> int:\n nums.sort()\n mid = nums[len(nums)//2]\n result = 0\n for i in nums:\n result+=abs(mid-i)\n return result\n``` | 6 | Given an integer array `nums` of size `n`, return _the minimum number of moves required to make all array elements equal_.
In one move, you can increment or decrement an element of the array by `1`.
Test cases are designed so that the answer will fit in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[1,2,3... | null |
462: Solution with step by step explanation | minimum-moves-to-equal-array-elements-ii | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Sort the input array nums.\n2. Calculate the median of nums by accessing the middle element of the sorted array. If n is odd, the median is nums[n // 2]. If n is even, the median is the average of nums[n // 2 - 1] and num... | 3 | Given an integer array `nums` of size `n`, return _the minimum number of moves required to make all array elements equal_.
In one move, you can increment or decrement an element of the array by `1`.
Test cases are designed so that the answer will fit in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[1,2,3... | null |
Python easy approach || ✅Beats 92.72% | minimum-moves-to-equal-array-elements-ii | 0 | 1 | ```\nclass Solution:\n def minMoves2(self, nums: List[int]) -> int:\n res = 0\n nums.sort()\n med = nums[len(nums)//2]\n for i in nums:\n res += abs(med-i)\n return res\n```\n**.\n.\n.\n.\n.**\n**Please Up-vote if you find this post helpful : )** | 2 | Given an integer array `nums` of size `n`, return _the minimum number of moves required to make all array elements equal_.
In one move, you can increment or decrement an element of the array by `1`.
Test cases are designed so that the answer will fit in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[1,2,3... | null |
Python || fastest || explanation | minimum-moves-to-equal-array-elements-ii | 0 | 1 | **Upvote if helpful**\n\nIt very basic that we need to sort the array and the elements are to be made equal to onr of the three measures of central tendency mean / median / mode. And we will need to increase values in left to specific value and decrease value at right of array to specific value. This central value is ... | 2 | Given an integer array `nums` of size `n`, return _the minimum number of moves required to make all array elements equal_.
In one move, you can increment or decrement an element of the array by `1`.
Test cases are designed so that the answer will fit in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[1,2,3... | null |
Python Easy Greedy O(1) Space approach | minimum-moves-to-equal-array-elements-ii | 0 | 1 | ```\n#First sort the array\n#then find the mid element\n#then loop through the nums array then see how much operation is need for each element of nums to change it into nums[n]\n#add the count of individual and return (it is the answer)\nclass Solution:\n def minMoves2(self, nums: List[int]) -> int:\n \n ... | 1 | Given an integer array `nums` of size `n`, return _the minimum number of moves required to make all array elements equal_.
In one move, you can increment or decrement an element of the array by `1`.
Test cases are designed so that the answer will fit in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[1,2,3... | null |
Python3 , 2 Line Solution , Median , Easy to Understand | minimum-moves-to-equal-array-elements-ii | 0 | 1 | # Upvote if useful \n```\nfrom statistics import median as m\nclass Solution:\n def minMoves2(self, nums: List[int]) -> int:\n x = int(m(nums))\n return sum([abs(i-x) for i in nums])\n``` | 4 | Given an integer array `nums` of size `n`, return _the minimum number of moves required to make all array elements equal_.
In one move, you can increment or decrement an element of the array by `1`.
Test cases are designed so that the answer will fit in a **32-bit** integer.
**Example 1:**
**Input:** nums = \[1,2,3... | null |
Python solution Beats 100% | island-perimeter | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nMy first thought on how to solve this problem was to iterate through the grid and for each cell with a value of 1, check the surrounding cells to see if they also have a value of 1. If they do, that means they are part of the same island ... | 16 | You are given `row x col` `grid` representing a map where `grid[i][j] = 1` represents land and `grid[i][j] = 0` represents water.
Grid cells are connected **horizontally/vertically** (not diagonally). The `grid` is completely surrounded by water, and there is exactly one island (i.e., one or more connected land cells)... | null |
[python] Straight forward approach - beats 98.69% submissions | island-perimeter | 0 | 1 | Take the following single block as an example\n\nIt has four sides. So perimeter of one block is 4.\n\nNow take a look when two blocks intersect\n. The `grid` is completely surrounded by water, and there is exactly one island (i.e., one or more connected land cells)... | null |
463: Solution with step by step explanation | island-perimeter | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Define a function named "islandPerimeter" that takes in a 2D list of integers called "grid" and returns an integer.\n2. Initialize a variable "perimeter" to 0.\n3. Loop through each cell in the grid using two nested for l... | 6 | You are given `row x col` `grid` representing a map where `grid[i][j] = 1` represents land and `grid[i][j] = 0` represents water.
Grid cells are connected **horizontally/vertically** (not diagonally). The `grid` is completely surrounded by water, and there is exactly one island (i.e., one or more connected land cells)... | null |
Python Easy Solution | Fully Explained ✔ | island-perimeter | 0 | 1 | 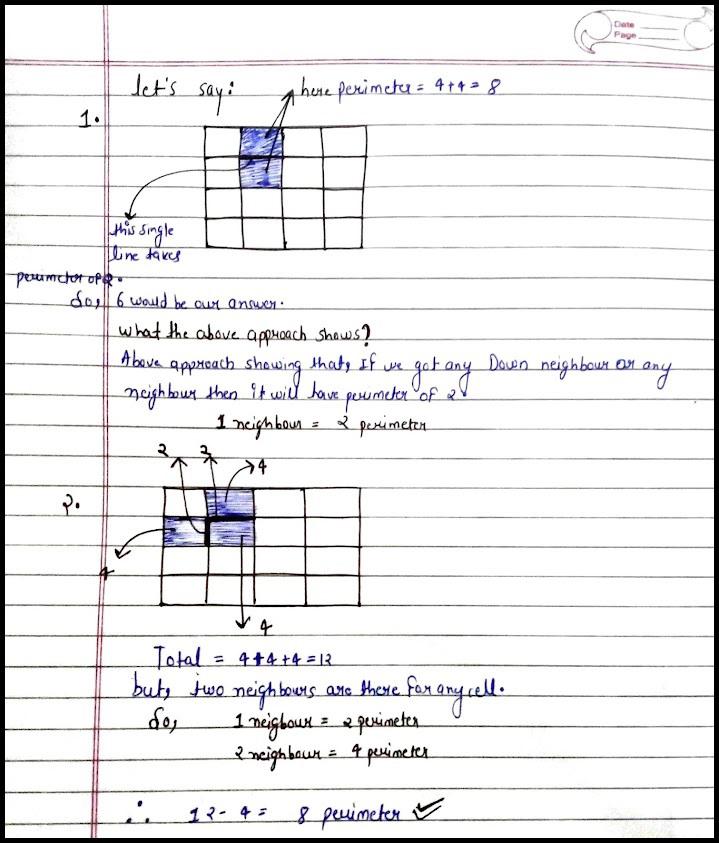\n\n\t# Time: O(mn)\n\tclass Solution:\n\t\t\tdef islandPerimeter(self, grid: List[List[int]]) -> int:\n\t\t\t\tisLands = 0\n\t\t\t\tnghbrs = 0\n\t\t\t\tgrd_len = len(grid)\n\t\t\t\tgrd0_len = len(grid[0])\n\t... | 24 | You are given `row x col` `grid` representing a map where `grid[i][j] = 1` represents land and `grid[i][j] = 0` represents water.
Grid cells are connected **horizontally/vertically** (not diagonally). The `grid` is completely surrounded by water, and there is exactly one island (i.e., one or more connected land cells)... | null |
Easy self explanatory solution - Python | island-perimeter | 0 | 1 | ```python\nclass Solution:\n def islandPerimeter(self, grid: List[List[int]]) -> int: \n return sum(4 - sum(grid[i + dx][j + dy] if i + dx < len(grid) and j + dy < len(grid[0]) else 0 for dx, dy in [(0, 1), (1, 0)]) * 2 for i in range(len(grid)) for j in range(len(grid[0])) if grid[i][j] == 1)\n``` | 1 | You are given `row x col` `grid` representing a map where `grid[i][j] = 1` represents land and `grid[i][j] = 0` represents water.
Grid cells are connected **horizontally/vertically** (not diagonally). The `grid` is completely surrounded by water, and there is exactly one island (i.e., one or more connected land cells)... | null |
Python solution : beats 61.73% : with explanation | island-perimeter | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nwe need to find number of non land tiles(water or boundary)\n# Approach\n<!-- Describe your approach to solving the problem. -->\ntraverse the gienn grid to find a 1 and then check all four directions of the tile and check if there are wa... | 2 | You are given `row x col` `grid` representing a map where `grid[i][j] = 1` represents land and `grid[i][j] = 0` represents water.
Grid cells are connected **horizontally/vertically** (not diagonally). The `grid` is completely surrounded by water, and there is exactly one island (i.e., one or more connected land cells)... | null |
Simple solution with 98% accuracy... | island-perimeter | 0 | 1 | # Intuition\nThe problem statement provides the following information:\n\n The grid represents a map where each cell can be either land (1) or water (0).\n The cells in the grid are connected horizontally or vertically, but not diagonally.\n The grid is completely surrounded by water.\n There is exactly one... | 3 | You are given `row x col` `grid` representing a map where `grid[i][j] = 1` represents land and `grid[i][j] = 0` represents water.
Grid cells are connected **horizontally/vertically** (not diagonally). The `grid` is completely surrounded by water, and there is exactly one island (i.e., one or more connected land cells)... | null |
Solution in Python 3 | island-perimeter | 0 | 1 | ```\nclass Solution:\n def islandPerimeter(self, grid: List[List[int]]) -> int: \n \tM, N, p = len(grid), len(grid[0]), 0\n \tfor m in range(M):\n \t\tfor n in range(N):\n \t\t\tif grid[m][n] == 1:\n \t\t\t\tif m == 0 or grid[m-1][n] == 0: p += 1\n \t\t\t\tif n == 0 or grid[m][n-1] == 0: p += 1... | 40 | You are given `row x col` `grid` representing a map where `grid[i][j] = 1` represents land and `grid[i][j] = 0` represents water.
Grid cells are connected **horizontally/vertically** (not diagonally). The `grid` is completely surrounded by water, and there is exactly one island (i.e., one or more connected land cells)... | null |
✅✅✅ about 98.36% faster python solution | island-perimeter | 0 | 1 | 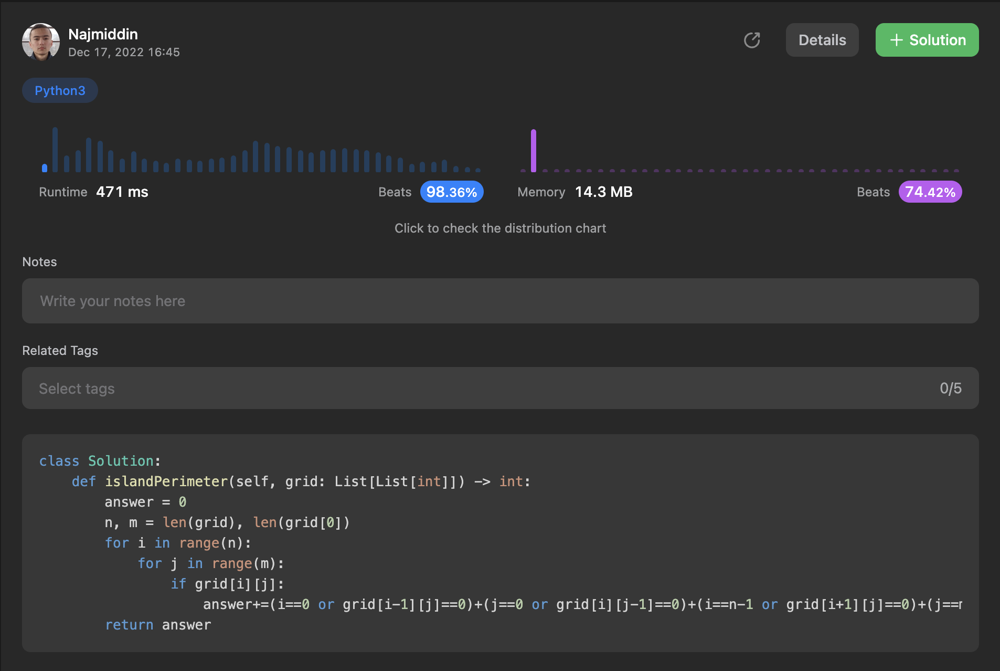\n\n# Code\n```\nclass Solution:\n def islandPerimeter(self, grid: List[List[int]]) -> int:\n answer = 0\n n, m = len(grid), len(grid[0])\n for i in range... | 2 | You are given `row x col` `grid` representing a map where `grid[i][j] = 1` represents land and `grid[i][j] = 0` represents water.
Grid cells are connected **horizontally/vertically** (not diagonally). The `grid` is completely surrounded by water, and there is exactly one island (i.e., one or more connected land cells)... | null |
464: Solution with step by step explanation | can-i-win | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Define the function canIWin which takes in two integers, maxChoosableInteger and desiredTotal, and returns a boolean indicating whether the first player can win the game or not.\n\n2. Check if desiredTotal is less than or... | 5 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
Beats 99% Speed, 99% Memory, mathematical and bitwise approach | can-i-win | 0 | 1 | # Intuition\nI wanted to optimize average runtime even more because even memoized versions were not that great and I felt I solved this \ntoo fast and that there was more to this problem.\n\nSo I made a few additions quickly to the code and now\nit performs much better on typical benchmarks.\n\n> On average, beats over... | 1 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
6 Lines Logical Python Solution | can-i-win | 0 | 1 | # Intuition\nConsider the cases where player A can win and lose\n\n# Approach\n- If the sum of all integers till maxInt is less than the required total then A can\'t win\n- If there exists a number which is greater than or equal to the total then A wins\n- If there exists any move that A can play so that B can\'t win i... | 1 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
4 lines Python with frozenset | can-i-win | 0 | 1 | ```\n def canIWin(self, maxInt: int, total: int) -> bool:\n @functools.lru_cache(None)\n def dp(nums, left):\n return any(left - n <= 0 or not dp(frozenset(nums - {n}), left - n) for n in nums)\n \n return (1 + maxInt) * maxInt // 2 >= total and dp(frozenset(range(1, maxInt + ... | 8 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
Bitmask DP/DFS solution | can-i-win | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
Recursion Python3 | can-i-win | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
MiniMax algo (gametree pruning) Python | can-i-win | 0 | 1 | # Intuition\nSince both players have complete information of game (which numbers have been chosen), play turnwise, minimax algorithm can be used.\n\n# Approach\n[Minimax algo.](https://www.youtube.com/watch?v=rMliVVTlLwY) See previous videos in the playlist for context on game theory.\n\nTraverse game tree, if you are ... | 0 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
Python Bitmask and 1D DP. Beats 70% | can-i-win | 0 | 1 | # Intuition\nUse Bitmask to store whether the numbers are used or not. We can use only 1D dp as the masks for p1 and p2 will never be same. This is because p1 will always have odd number of 1s and p2 will always have even number of 1s.\n\nIf desiredTotal is not achievable at all, that is its greater than 2 ** n or the ... | 0 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
Python: concise dfs with memoization solution. | can-i-win | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
Python | top-down DP with bitmask. 20 lines clean code | can-i-win | 0 | 1 | # Intuition\nJust doing top-down DP to search if any move will make next player lose no matter what move that player to take. \nSo we can just apply top-down dfs to solve this problem\n\n# Approach\nSince we only have at most 20 choosable integers, we can use an integer as a bitmask to record which number has been used... | 0 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
Explained !! | can-i-win | 0 | 1 | ```\nGiven,\nn <= 20\n2 players A and B\nTarget <= 300\n\ninitially total = 0\n\nEach player can choose any value from pool alternatively\ni.e pool = [1 ... n]\n\nAnd increase the total by the picked value\ni.e new total = total + picked value\n\nevery value can be picked only once\n\nAssuming both players A and B play... | 0 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
Python Topdown DP with Bitmasking | can-i-win | 0 | 1 | # Intuition\nUse dp with memo to simulate the game.\n\n# Complexity\n\nAssume m = `maxChoosableInteger`, n = `desiredTotal`. We will have $$n * 2^m$$ combinations for dp.\n\n- Time complexity: $$O(n * 2^m)$$\n- Space complexity: $$O(n * 2^m)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclas... | 0 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
Python3 - Memoization | can-i-win | 0 | 1 | # Intuition\nI didn\'t know how to do this, so I just tried it from the base case and recursed. It required a special test to see if the game were winnable at all, since the recursion is based on the assumption that the other playing forcing a win means you losing (as opposed to a draw)\n\n# Code\n```\nclass Solution:... | 0 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
Python | bitmask | can-i-win | 0 | 1 | # Code\n```\nclass Solution:\n def canIWin(self, maxChoosableInteger: int, desiredTotal: int) -> bool:\n if (1+maxChoosableInteger)*maxChoosableInteger/2<desiredTotal:\n return False\n\n arr = [i for i in range(1, maxChoosableInteger+1)]\n\n @lru_cache(None)\n def dp(total, mas... | 0 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
Python DP Solution | Faster than 91% | Easy to Understand | can-i-win | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\nJust choose one number out of the available list, update the available list and do a DFS from there\n\n# Code\n```python []\nclass Solution:\n def canIWin(self, maxChoosableInteger: int, desiredTotal: int) -> bool:\n candidate = list(range(1... | 0 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
Top-down memo/python simple solution | can-i-win | 0 | 1 | # Intuition\nPlayer 1 can win if and only if Player 2 cannot win\n\n# Approach\nFor each number available, if one of them can lead to player 2\'s loss, then player 1 win\n\n# Complexity\n- Time complexity:\nO(N), N length of available candidate\n\n- Space complexity:\nO(N)\n\n# Code\n```\nclass Solution:\n def canIW... | 0 | In the "100 game " two players take turns adding, to a running total, any integer from `1` to `10`. The player who first causes the running total to **reach or exceed** 100 wins.
What if we change the game so that players **cannot** re-use integers?
For example, two players might take turns drawing from a common pool... | null |
Python 3 || Count The Repetitions || T/M: 34 ms / 13.9 MB 100% / 96% | count-the-repetitions | 0 | 1 | ```\nclass Solution:\n def getMaxRepetitions(self, s1: str, n1: int, s2: str, n2: int) -> int:\n\n rec, track = [0], defaultdict(int) \n ct = start = ptr1 = ptr2 = 0\n\n if not set(s2).issubset(set(s1)): return 0\n\n s1 = \'\'.join(char for char in s1 if char in set(s2))\n \n ... | 3 | We define `str = [s, n]` as the string `str` which consists of the string `s` concatenated `n` times.
* For example, `str == [ "abc ", 3] == "abcabcabc "`.
We define that string `s1` can be obtained from string `s2` if we can remove some characters from `s2` such that it becomes `s1`.
* For example, `s1 = "abc "... | null |
Solution | count-the-repetitions | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int getMaxRepetitions(string s1, int n1, string s2, int n2) {\n vector<int> rapport(102,-1);\n vector<int> rest(102,-1);\n int b=-1;int posRest=0;int rap=0;\n int last=-1;\n rapport[0]=rest[0]=0;\n for(int i=1;i<=s2.size()+1;i++){\n ... | 200 | We define `str = [s, n]` as the string `str` which consists of the string `s` concatenated `n` times.
* For example, `str == [ "abc ", 3] == "abcabcabc "`.
We define that string `s1` can be obtained from string `s2` if we can remove some characters from `s2` such that it becomes `s1`.
* For example, `s1 = "abc "... | null |
java solution | 4ms runtime | with brief explanation | count-the-repetitions | 1 | 1 | # Explanation\n\n. For each repetition of s1, count the number of times we see s2\n. Store the seen count for each repetition of s1\n. Store the index of s2 where we stopped after each repetition of s1\n. For each repetition of s1, check if we\'ve seen this index of s2 before\n. If we have, then we\'ve found a repeatin... | 0 | We define `str = [s, n]` as the string `str` which consists of the string `s` concatenated `n` times.
* For example, `str == [ "abc ", 3] == "abcabcabc "`.
We define that string `s1` can be obtained from string `s2` if we can remove some characters from `s2` such that it becomes `s1`.
* For example, `s1 = "abc "... | null |
Geez. Mad coz bad. /\ | count-the-repetitions | 0 | 1 | \n# Code\n```\nclass Solution:\n def getMaxRepetitions(self, s1: str, n1: int, s2: str, n2: int) -> int:\n if n1 == 0:\n return 0\n\n # Count the number of occurrences of s2 in each repetition of s1\n repeat_count = {} # Map of count2: (count1, next_index)\n count1, count2 = 0... | 0 | We define `str = [s, n]` as the string `str` which consists of the string `s` concatenated `n` times.
* For example, `str == [ "abc ", 3] == "abcabcabc "`.
We define that string `s1` can be obtained from string `s2` if we can remove some characters from `s2` such that it becomes `s1`.
* For example, `s1 = "abc "... | null |
Simple Python solution | count-the-repetitions | 0 | 1 | # Code\n```\nclass Solution:\n def getMaxRepetitions(self, s1: str, n1: int, s2: str, n2: int) -> int:\n l1, l2 = len(s1), len(s2)\n visited = {}\n index = repeat_count = i = 0\n while i < n1:\n print(i)\n for j in range(l1):\n if s1[j] == s2[index]:\n... | 0 | We define `str = [s, n]` as the string `str` which consists of the string `s` concatenated `n` times.
* For example, `str == [ "abc ", 3] == "abcabcabc "`.
We define that string `s1` can be obtained from string `s2` if we can remove some characters from `s2` such that it becomes `s1`.
* For example, `s1 = "abc "... | null |
Python 3 -- Short Simple solution | count-the-repetitions | 0 | 1 | ```\nclass Solution:\n def getMaxRepetitions(self, s1: str, n1: int, s2: str, n2: int) -> int:\n dp = []\n for i in range(len(s2)):\n start = i\n cnt = 0\n for j in range(len(s1)):\n if s1[j] == s2[start]:\n start += 1\n ... | 2 | We define `str = [s, n]` as the string `str` which consists of the string `s` concatenated `n` times.
* For example, `str == [ "abc ", 3] == "abcabcabc "`.
We define that string `s1` can be obtained from string `s2` if we can remove some characters from `s2` such that it becomes `s1`.
* For example, `s1 = "abc "... | null |
O(m*n) Python3 Solution | count-the-repetitions | 0 | 1 | \nIn my code, the first function defined what "contain" is and the second function is to find maximum m.\n\nWe know that, in the best case:\n S1 = s1*n1\n S2 = s2*n2\nWe compute the quotient of lengths of S1 and S2, which is M in the code and M is the best repetition we can get.\nAnd count down from M, return the... | 1 | We define `str = [s, n]` as the string `str` which consists of the string `s` concatenated `n` times.
* For example, `str == [ "abc ", 3] == "abcabcabc "`.
We define that string `s1` can be obtained from string `s2` if we can remove some characters from `s2` such that it becomes `s1`.
* For example, `s1 = "abc "... | null |
[Python3] repeating patterns | count-the-repetitions | 0 | 1 | \n```\nclass Solution:\n def getMaxRepetitions(self, s1: str, n1: int, s2: str, n2: int) -> int:\n cnt = idx = 0 \n count = []\n index = []\n for i in range(n1): \n for ch in s1: \n if ch == s2[idx]: \n idx += 1\n if idx == l... | 0 | We define `str = [s, n]` as the string `str` which consists of the string `s` concatenated `n` times.
* For example, `str == [ "abc ", 3] == "abcabcabc "`.
We define that string `s1` can be obtained from string `s2` if we can remove some characters from `s2` such that it becomes `s1`.
* For example, `s1 = "abc "... | null |
python3 O(|S1|* |S2|) solution, with detailed explanation (beats 100%) | count-the-repetitions | 0 | 1 | 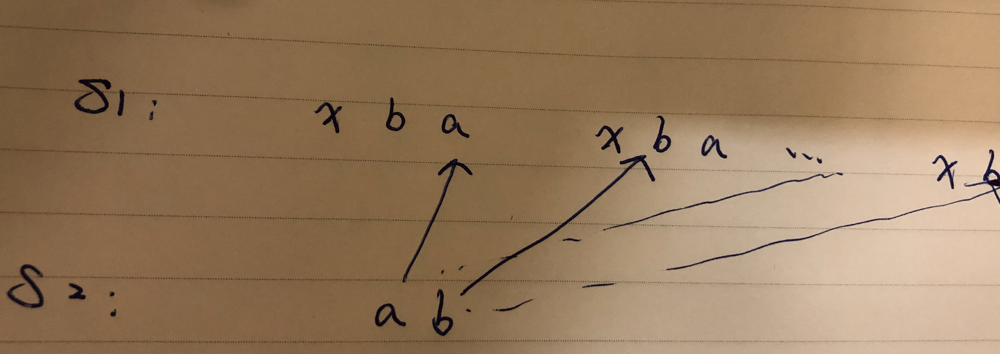\n\n\nThis is a quite tricky solution. It took me a day to understand the [discussion here](httphttps://leetcode.com/problems/count-the-repetitions/discuss/95397/C%2B%2B-0ms-O(str1.length*str2.length)://):\n\nThe basic idea is to detect the repeati... | 0 | We define `str = [s, n]` as the string `str` which consists of the string `s` concatenated `n` times.
* For example, `str == [ "abc ", 3] == "abcabcabc "`.
We define that string `s1` can be obtained from string `s2` if we can remove some characters from `s2` such that it becomes `s1`.
* For example, `s1 = "abc "... | null |
Python3 - 100% Count unique start, length tuples | unique-substrings-in-wraparound-string | 0 | 1 | # Explanation\nIn this problem, a unique substring can be defined as a starting character and length. Also, this is my first 100% ever, so I\'m a little excited :) The proc() method was just so I didn\'t have to copy/paste the same handler code in two places (when I\'m done and when a run is broken)\n\n# Code\n```\... | 1 | We define the string `base` to be the infinite wraparound string of `"abcdefghijklmnopqrstuvwxyz "`, so `base` will look like this:
* `"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd.... "`.
Given a string `s`, return _the number of **unique non-empty substrings** of_ `s` _are present in_ `base`.
**E... | One possible solution might be to consider allocating an array size of 26 for each character in the alphabet. (Credits to @r2ysxu) |
Python solution with explanation | unique-substrings-in-wraparound-string | 0 | 1 | This is basically @fire4fly\'s solution but since there was no explanation I needed some time to figure out what exactly is being done and hopefully i\'ll help someone else with this post.\n\n**Solution**\n\nWe are doing a one pass on the string. On each step we compare if our current and previous character are one aft... | 15 | We define the string `base` to be the infinite wraparound string of `"abcdefghijklmnopqrstuvwxyz "`, so `base` will look like this:
* `"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd.... "`.
Given a string `s`, return _the number of **unique non-empty substrings** of_ `s` _are present in_ `base`.
**E... | One possible solution might be to consider allocating an array size of 26 for each character in the alphabet. (Credits to @r2ysxu) |
467: Solution with step by step explanation | unique-substrings-in-wraparound-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. If s is empty, return 0.\n2. Create an empty dictionary called count to keep track of the maximum length of substring that ends with each character in s.\n3. Initialize curr_count and max_len to 0 and 1 respectively, and ... | 2 | We define the string `base` to be the infinite wraparound string of `"abcdefghijklmnopqrstuvwxyz "`, so `base` will look like this:
* `"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd.... "`.
Given a string `s`, return _the number of **unique non-empty substrings** of_ `s` _are present in_ `base`.
**E... | One possible solution might be to consider allocating an array size of 26 for each character in the alphabet. (Credits to @r2ysxu) |
Python || dynamic programming || dictionaries || faster than 91% | unique-substrings-in-wraparound-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nstoring the largest length of first character of substring in s which is also present in base\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, ... | 0 | We define the string `base` to be the infinite wraparound string of `"abcdefghijklmnopqrstuvwxyz "`, so `base` will look like this:
* `"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd.... "`.
Given a string `s`, return _the number of **unique non-empty substrings** of_ `s` _are present in_ `base`.
**E... | One possible solution might be to consider allocating an array size of 26 for each character in the alphabet. (Credits to @r2ysxu) |
python3 solution for me bp | unique-substrings-in-wraparound-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | We define the string `base` to be the infinite wraparound string of `"abcdefghijklmnopqrstuvwxyz "`, so `base` will look like this:
* `"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd.... "`.
Given a string `s`, return _the number of **unique non-empty substrings** of_ `s` _are present in_ `base`.
**E... | One possible solution might be to consider allocating an array size of 26 for each character in the alphabet. (Credits to @r2ysxu) |
Linear solution | unique-substrings-in-wraparound-string | 0 | 1 | ## Approach \n\nWe have to find continuous or increasing substring where difference between consecutive elements is 1, and record no. of elements appeared before them against each of the elements. If we find a break in the subarray then reset the counter to 1, and then continue in same fashion. When encountered an elem... | 0 | We define the string `base` to be the infinite wraparound string of `"abcdefghijklmnopqrstuvwxyz "`, so `base` will look like this:
* `"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd.... "`.
Given a string `s`, return _the number of **unique non-empty substrings** of_ `s` _are present in_ `base`.
**E... | One possible solution might be to consider allocating an array size of 26 for each character in the alphabet. (Credits to @r2ysxu) |
O(n) time one pass Python Solution | unique-substrings-in-wraparound-string | 0 | 1 | # Complexity\n- Time complexity: $$O(n)$$\n\n- Space complexity: $$O(n)$$\n\n# Code\n```\nclass Solution:\n def findSubstringInWraproundString(self, s: str) -> int:\n s += ","\n res = 0\n dp = [0] * 26\n count = 1\n for i in range(len(s)-1):\n if (s[i]==\'z\' and s[i+1]=... | 0 | We define the string `base` to be the infinite wraparound string of `"abcdefghijklmnopqrstuvwxyz "`, so `base` will look like this:
* `"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd.... "`.
Given a string `s`, return _the number of **unique non-empty substrings** of_ `s` _are present in_ `base`.
**E... | One possible solution might be to consider allocating an array size of 26 for each character in the alphabet. (Credits to @r2ysxu) |
Solution | unique-substrings-in-wraparound-string | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int findSubstringInWraproundString(string s) {\n vector<long long> mxAlpha(26);\n int n = s.length();\n long long ans = 0;\n for(int i=0;i<n;i++)\n {\n int st = i, len=0;\n char ch = s[i];\n while(i<n && s[i]==... | 0 | We define the string `base` to be the infinite wraparound string of `"abcdefghijklmnopqrstuvwxyz "`, so `base` will look like this:
* `"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd.... "`.
Given a string `s`, return _the number of **unique non-empty substrings** of_ `s` _are present in_ `base`.
**E... | One possible solution might be to consider allocating an array size of 26 for each character in the alphabet. (Credits to @r2ysxu) |
Python concise sliding window solution | unique-substrings-in-wraparound-string | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def findSubstringInWraproundString(self, s: str) -> int:\n\n\n left=0\n d=defaultdict(int)\n\n for right,ch in enumerate(s):\n if right==0:\n d[ch]=1\n prev=ch\n continue\n\n if not(ord(ch)-ord(... | 0 | We define the string `base` to be the infinite wraparound string of `"abcdefghijklmnopqrstuvwxyz "`, so `base` will look like this:
* `"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd.... "`.
Given a string `s`, return _the number of **unique non-empty substrings** of_ `s` _are present in_ `base`.
**E... | One possible solution might be to consider allocating an array size of 26 for each character in the alphabet. (Credits to @r2ysxu) |
python DP bottom-up solution | unique-substrings-in-wraparound-string | 0 | 1 | ```\nclass Solution:\n def findSubstringInWraproundString(self, p: str) -> int:\n dp = [1] * len(p)\n res=0\n counter = {\'a\': 0, \'b\': 0, \'c\': 0, \'d\': 0, \'e\': 0, \'f\': 0, \'g\': 0, \'h\': 0, \'i\': 0, \'j\': 0, \'k\': 0, \'l\': 0\n , \'m\': 0, \'n\': 0, \'o\': 0, \'p... | 0 | We define the string `base` to be the infinite wraparound string of `"abcdefghijklmnopqrstuvwxyz "`, so `base` will look like this:
* `"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd.... "`.
Given a string `s`, return _the number of **unique non-empty substrings** of_ `s` _are present in_ `base`.
**E... | One possible solution might be to consider allocating an array size of 26 for each character in the alphabet. (Credits to @r2ysxu) |
Python O(n) | unique-substrings-in-wraparound-string | 0 | 1 | # Intuition\n- We need to check consequtive characters to have sequential values (by module 26).\n- To maintain uniquiness we will be keeping track of longest substrings, that start at given value (first substring character defines the whole substring).\n\n# Approach\nWe can tackle that as a DP problem. \nLet\'s consid... | 0 | We define the string `base` to be the infinite wraparound string of `"abcdefghijklmnopqrstuvwxyz "`, so `base` will look like this:
* `"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd.... "`.
Given a string `s`, return _the number of **unique non-empty substrings** of_ `s` _are present in_ `base`.
**E... | One possible solution might be to consider allocating an array size of 26 for each character in the alphabet. (Credits to @r2ysxu) |
Python (Simple Maths) | unique-substrings-in-wraparound-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | We define the string `base` to be the infinite wraparound string of `"abcdefghijklmnopqrstuvwxyz "`, so `base` will look like this:
* `"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd.... "`.
Given a string `s`, return _the number of **unique non-empty substrings** of_ `s` _are present in_ `base`.
**E... | One possible solution might be to consider allocating an array size of 26 for each character in the alphabet. (Credits to @r2ysxu) |
Python3 DP O(N) time O(1) space | unique-substrings-in-wraparound-string | 0 | 1 | Count the number of substrings ending at a letter. To do so, and to avoid counting duplicates, we only need to find the largest substring ending in the letter. The number of substrings ending at that letter is simply the length of that max substring.\n\ne.g.\nConsider p = abcdzabc\n\n**Consecutive Substrings ending in ... | 1 | We define the string `base` to be the infinite wraparound string of `"abcdefghijklmnopqrstuvwxyz "`, so `base` will look like this:
* `"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd.... "`.
Given a string `s`, return _the number of **unique non-empty substrings** of_ `s` _are present in_ `base`.
**E... | One possible solution might be to consider allocating an array size of 26 for each character in the alphabet. (Credits to @r2ysxu) |
Doubt: Inbuilt function answer not Accepted | validate-ip-address | 0 | 1 | Can anybody tell me why this Solution didn\'t work?\n```\nimport ipaddress\nclass Solution:\n def validIPAddress(self, queryIP: str) -> str:\n try:\n address = ipaddress.ip_address(queryIP)\n if address.version == 4:\n return "IPv4"\n elif address.version == 6:\... | 2 | Given a string `queryIP`, return `"IPv4 "` if IP is a valid IPv4 address, `"IPv6 "` if IP is a valid IPv6 address or `"Neither "` if IP is not a correct IP of any type.
**A valid IPv4** address is an IP in the form `"x1.x2.x3.x4 "` where `0 <= xi <= 255` and `xi` **cannot contain** leading zeros. For example, `"192.16... | null |
Python3 | Beats 100% | Easy to understand | validate-ip-address | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n$$O(n)$$\n\n- Space complexity:\n$$O(1)$$\n\n# Code\n```\nclass Solution:\n def validIPAddress(self, queryIP: str) -> str:\n ... | 1 | Given a string `queryIP`, return `"IPv4 "` if IP is a valid IPv4 address, `"IPv6 "` if IP is a valid IPv6 address or `"Neither "` if IP is not a correct IP of any type.
**A valid IPv4** address is an IP in the form `"x1.x2.x3.x4 "` where `0 <= xi <= 255` and `xi` **cannot contain** leading zeros. For example, `"192.16... | null |
468: Solution with step by step explanation | validate-ip-address | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Define a function that takes in a string IP and returns a string "IPv4", "IPv6" or "Neither" based on whether IP is a valid IPv4 address, a valid IPv6 address, or not a correct IP of any type.\n\n2. Check if "." is in IP.... | 4 | Given a string `queryIP`, return `"IPv4 "` if IP is a valid IPv4 address, `"IPv6 "` if IP is a valid IPv6 address or `"Neither "` if IP is not a correct IP of any type.
**A valid IPv4** address is an IP in the form `"x1.x2.x3.x4 "` where `0 <= xi <= 255` and `xi` **cannot contain** leading zeros. For example, `"192.16... | null |
Check for both cases | validate-ip-address | 0 | 1 | # Intuition\nCheck for both ipv4 and ipv6. Whiever returns true first is the answer.\nIf neither is true then answer is neither\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(1)\n\n# Code\n```\nclass Solution:\n def validIPAd... | 1 | Given a string `queryIP`, return `"IPv4 "` if IP is a valid IPv4 address, `"IPv6 "` if IP is a valid IPv6 address or `"Neither "` if IP is not a correct IP of any type.
**A valid IPv4** address is an IP in the form `"x1.x2.x3.x4 "` where `0 <= xi <= 255` and `xi` **cannot contain** leading zeros. For example, `"192.16... | null |
Easy way, holds any case, brute-force | validate-ip-address | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(N^2)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(... | 1 | Given a string `queryIP`, return `"IPv4 "` if IP is a valid IPv4 address, `"IPv6 "` if IP is a valid IPv6 address or `"Neither "` if IP is not a correct IP of any type.
**A valid IPv4** address is an IP in the form `"x1.x2.x3.x4 "` where `0 <= xi <= 255` and `xi` **cannot contain** leading zeros. For example, `"192.16... | null |
Brute Force Approach | validate-ip-address | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def validIPAddress(self, queryIP: str) -> str:\n \n IPv4 = False\n IPv6 = False\n\n #IPv4\n if \'.\' in queryIP:\n splittedIP = queryIP.split(\'.\')\n if len(splittedIP) != 4:\n IPv4 = False\n else:\... | 0 | Given a string `queryIP`, return `"IPv4 "` if IP is a valid IPv4 address, `"IPv6 "` if IP is a valid IPv6 address or `"Neither "` if IP is not a correct IP of any type.
**A valid IPv4** address is an IP in the form `"x1.x2.x3.x4 "` where `0 <= xi <= 255` and `xi` **cannot contain** leading zeros. For example, `"192.16... | null |
check . : first, then check each parttern | validate-ip-address | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $... | 0 | Given a string `queryIP`, return `"IPv4 "` if IP is a valid IPv4 address, `"IPv6 "` if IP is a valid IPv6 address or `"Neither "` if IP is not a correct IP of any type.
**A valid IPv4** address is an IP in the form `"x1.x2.x3.x4 "` where `0 <= xi <= 255` and `xi` **cannot contain** leading zeros. For example, `"192.16... | null |
💡💡 Neatly coded solution in python3 | validate-ip-address | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nIPv4 - has "." dividers, only numbers until 255 with no leading zeroes (total 4)\nIPv6 - uses ":" to divide, only hexadecimal with no leading zeroes (total 8)\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Com... | 0 | Given a string `queryIP`, return `"IPv4 "` if IP is a valid IPv4 address, `"IPv6 "` if IP is a valid IPv6 address or `"Neither "` if IP is not a correct IP of any type.
**A valid IPv4** address is an IP in the form `"x1.x2.x3.x4 "` where `0 <= xi <= 255` and `xi` **cannot contain** leading zeros. For example, `"192.16... | null |
i hate regexp | validate-ip-address | 0 | 1 | # Code\n```\nimport re\n\nclass Solution:\n def validIPAddress(self, queryIP: str) -> str:\n if queryIP == "":\n return "Neither"\n if \'.\' in queryIP:\n octets = queryIP.split(\'.\')\n if len(octets) != 4:\n return "Neither"\n for octet in oc... | 0 | Given a string `queryIP`, return `"IPv4 "` if IP is a valid IPv4 address, `"IPv6 "` if IP is a valid IPv6 address or `"Neither "` if IP is not a correct IP of any type.
**A valid IPv4** address is an IP in the form `"x1.x2.x3.x4 "` where `0 <= xi <= 255` and `xi` **cannot contain** leading zeros. For example, `"192.16... | null |
Python | validate-ip-address | 0 | 1 | class Solution:\n def validIPAddress(self, queryIP: str) -> str:\n\n def validateIPv4(ip):\n parts = ip.split(\'.\')\n if len(parts) != 4:\n return False\n\n for part in parts:\n if not part.isdigit():\n ... | 0 | Given a string `queryIP`, return `"IPv4 "` if IP is a valid IPv4 address, `"IPv6 "` if IP is a valid IPv6 address or `"Neither "` if IP is not a correct IP of any type.
**A valid IPv4** address is an IP in the form `"x1.x2.x3.x4 "` where `0 <= xi <= 255` and `xi` **cannot contain** leading zeros. For example, `"192.16... | null |
python using regex | validate-ip-address | 0 | 1 | ```\nipv4 = re.compile(r\'^((25[0-5]|(2[0-4]|1\\d|[1-9]|)\\d)\\.?\\b){4}$\')\nipv6 = re.compile(r\'^([0-9a-fA-F]{0,4}:?\\b){8}$\')\n\nclass Solution:\n def validIPAddress(self, queryIP: str) -> str:\n \n if ipv4.fullmatch(queryIP):\n return \'IPv4\'\n elif ipv6.fullmatch(queryIP):\n... | 0 | Given a string `queryIP`, return `"IPv4 "` if IP is a valid IPv4 address, `"IPv6 "` if IP is a valid IPv6 address or `"Neither "` if IP is not a correct IP of any type.
**A valid IPv4** address is an IP in the form `"x1.x2.x3.x4 "` where `0 <= xi <= 255` and `xi` **cannot contain** leading zeros. For example, `"192.16... | null |
[Python3] Good enough | validate-ip-address | 0 | 1 | ``` Python3 []\nclass Solution:\n def validIPAddress(self, queryIP: str) -> str:\n if queryIP.count(\'.\')==3:\n queryIP = queryIP.split(\'.\')\n for x in queryIP:\n if x.startswith(\'0\') and x!=\'0\':\n return \'Neither\'\n elif not x.is... | 0 | Given a string `queryIP`, return `"IPv4 "` if IP is a valid IPv4 address, `"IPv6 "` if IP is a valid IPv6 address or `"Neither "` if IP is not a correct IP of any type.
**A valid IPv4** address is an IP in the form `"x1.x2.x3.x4 "` where `0 <= xi <= 255` and `xi` **cannot contain** leading zeros. For example, `"192.16... | null |
470: Solution with step by step explanation | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Define a function named rand10() that takes no arguments and returns an integer between 1 and 10.\n2. Use a while loop that runs indefinitely until a suitable random number is generated.\n3. Within the loop, use the rand7... | 8 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
470: Solution with step by step explanation | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Define a function named rand10() that takes no arguments and returns an integer between 1 and 10.\n2. Use a while loop that runs indefinitely until a suitable random number is generated.\n3. Within the loop, use the rand7... | 8 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
Python generalised solution for RandM() using RandN() | implement-rand10-using-rand7 | 0 | 1 | **Solution for creating rand10() using rand7()**\n\n```python\n# The rand7() API is already defined for you.\n# def rand7():\n# @return a random integer in the range 1 to 7\n\nclass Solution:\n def rand10(self):\n """\n :rtype: int\n """\n curr = 40\n while curr >= 40:\n ... | 12 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
Python generalised solution for RandM() using RandN() | implement-rand10-using-rand7 | 0 | 1 | **Solution for creating rand10() using rand7()**\n\n```python\n# The rand7() API is already defined for you.\n# def rand7():\n# @return a random integer in the range 1 to 7\n\nclass Solution:\n def rand10(self):\n """\n :rtype: int\n """\n curr = 40\n while curr >= 40:\n ... | 12 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
Simple deterministic solution with 10 calls to rand7 | implement-rand10-using-rand7 | 1 | 1 | # Intuition\nIf could generate a set with `N` items with equal probability, where `N` was divisible by `10`, then we can easily partition the set into `10` equal groups, and then return `1` for the first group, `2` for the second group, etc... \n\n# Approach\nThe approach is simple. Our generator will just call `rand7(... | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
Simple deterministic solution with 10 calls to rand7 | implement-rand10-using-rand7 | 1 | 1 | # Intuition\nIf could generate a set with `N` items with equal probability, where `N` was divisible by `10`, then we can easily partition the set into `10` equal groups, and then return `1` for the first group, `2` for the second group, etc... \n\n# Approach\nThe approach is simple. Our generator will just call `rand7(... | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
Rejecting Sampling | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nI used rejection sampling to get uniform random variables of [1,5]\nand [1,2], that way we can represent 10 different numbers (which i stored in the array arr, see the code)\nprobabilty to get one of [1,2,3,4,5] when rejecting 6 and 7 is ... | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
Rejecting Sampling | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nI used rejection sampling to get uniform random variables of [1,5]\nand [1,2], that way we can represent 10 different numbers (which i stored in the array arr, see the code)\nprobabilty to get one of [1,2,3,4,5] when rejecting 6 and 7 is ... | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
rejection sampling python3 | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
rejection sampling python3 | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
python3 solution | implement-rand10-using-rand7 | 0 | 1 | # Intuition\nUse two `rand7()` to get a two-digit 7-base number $X = Y_1 + 7 Y_2$. The number is at most 49. If the number is greater than 40, regenerate another sample. Conditioning on the condition $X \\le 40$, $X$ is uniformly distributed in $[1, \\cdots, 40]$. So, $\\mod(X, 10)$ is uniformly distributed.\n\n$$P(X \... | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
python3 solution | implement-rand10-using-rand7 | 0 | 1 | # Intuition\nUse two `rand7()` to get a two-digit 7-base number $X = Y_1 + 7 Y_2$. The number is at most 49. If the number is greater than 40, regenerate another sample. Conditioning on the condition $X \\le 40$, $X$ is uniformly distributed in $[1, \\cdots, 40]$. So, $\\mod(X, 10)$ is uniformly distributed.\n\n$$P(X \... | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
Easy python solution with O(1) Time complexity | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n O(1)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# The rand7() API is alread... | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
Easy python solution with O(1) Time complexity | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n O(1)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# The rand7() API is alread... | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
:( | implement-rand10-using-rand7 | 0 | 1 | \n# Code\n```\nclass Solution:\n def rand10(self):\n return sum(rand7() for _ in range(9)) % 10 + 1\n\n``` | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
:( | implement-rand10-using-rand7 | 0 | 1 | \n# Code\n```\nclass Solution:\n def rand10(self):\n return sum(rand7() for _ in range(9)) % 10 + 1\n\n``` | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
Python solution with Detailed explanation | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n* We want to generate a random number between 1 and 10 using the rand7() function, which can only generate numbers between 1 and 7 with equal probability.\n\n* To do t... | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
Python solution with Detailed explanation | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n* We want to generate a random number between 1 and 10 using the rand7() function, which can only generate numbers between 1 and 7 with equal probability.\n\n* To do t... | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
Python3 - [Made Simple] Inefficient but Easy | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
Python3 - [Made Simple] Inefficient but Easy | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
[Python] | Simple | 2 rand7() calls per rand10() | implement-rand10-using-rand7 | 0 | 1 | # Intuition\nWe\'ll pick a random value from the matrix:\n```\n 1 2 3 4 5 6 7 8 9 10\n 2 3 4 5 6 7 8 9 10 1\n 3 4 5 6 7 8 9 10 1 2\ni-> 4 5 6 7 8 9 10 1 2 3\n 5 6 7 8 9 10 1 2 3 4\n 6 7 8 9 10 1 2 3 4 5\n 7 8 9 10 1 2 3 4 5 6\n 8 9 10 1 2 ... | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
[Python] | Simple | 2 rand7() calls per rand10() | implement-rand10-using-rand7 | 0 | 1 | # Intuition\nWe\'ll pick a random value from the matrix:\n```\n 1 2 3 4 5 6 7 8 9 10\n 2 3 4 5 6 7 8 9 10 1\n 3 4 5 6 7 8 9 10 1 2\ni-> 4 5 6 7 8 9 10 1 2 3\n 5 6 7 8 9 10 1 2 3 4\n 6 7 8 9 10 1 2 3 4 5\n 7 8 9 10 1 2 3 4 5 6\n 8 9 10 1 2 ... | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
7 * (rand7() - 1) + rand7() | implement-rand10-using-rand7 | 0 | 1 | ```\nclass Solution:\n def rand10(self):\n """\n :rtype: int\n """\n while True:\n x = 7 * (rand7() - 1) \n y = rand7()\n if x + y <= 10:\n return x+y\n``` | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
7 * (rand7() - 1) + rand7() | implement-rand10-using-rand7 | 0 | 1 | ```\nclass Solution:\n def rand10(self):\n """\n :rtype: int\n """\n while True:\n x = 7 * (rand7() - 1) \n y = rand7()\n if x + y <= 10:\n return x+y\n``` | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
Sample Solution Using Only Addition: | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
Sample Solution Using Only Addition: | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
Simple solution, Python3 | implement-rand10-using-rand7 | 0 | 1 | # Code\n```\n# The rand7() API is already defined for you.\n# def rand7():\n# @return a random integer in the range 1 to 7\n\nclass Solution:\n def rand10(self):\n """\n :rtype: int\n """\n sm = 0\n for _ in range(100):\n sm += rand7()\n res = sm % 10 + 1\n ... | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
Simple solution, Python3 | implement-rand10-using-rand7 | 0 | 1 | # Code\n```\n# The rand7() API is already defined for you.\n# def rand7():\n# @return a random integer in the range 1 to 7\n\nclass Solution:\n def rand10(self):\n """\n :rtype: int\n """\n sm = 0\n for _ in range(100):\n sm += rand7()\n res = sm % 10 + 1\n ... | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
Python3 - Same As Everyone Else's While Loop | implement-rand10-using-rand7 | 0 | 1 | # Approach\nLooks like everyone pretty much did the same thing.\n\n# Code\n```\nclass Solution:\n def rand10(self):\n x = 50\n while x > 47:\n x = rand7() * 7 + rand7()\n return (x - 8) // 4 + 1\n \n \n``` | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
Python3 - Same As Everyone Else's While Loop | implement-rand10-using-rand7 | 0 | 1 | # Approach\nLooks like everyone pretty much did the same thing.\n\n# Code\n```\nclass Solution:\n def rand10(self):\n x = 50\n while x > 47:\n x = rand7() * 7 + rand7()\n return (x - 8) // 4 + 1\n \n \n``` | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
Python easy solution | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n- random first time to get 1-5 to get the bucket since i will split result to [1,2], [3,4] ..., [9,10]\n- assume I get [5,6] =>\nrandom one more time to get the first or last number [1,2,3] = left, [4,5,6] = right\n\n\n# Approach\n<!-- De... | 0 | Given the **API** `rand7()` that generates a uniform random integer in the range `[1, 7]`, write a function `rand10()` that generates a uniform random integer in the range `[1, 10]`. You can only call the API `rand7()`, and you shouldn't call any other API. Please **do not** use a language's built-in random API.
Each ... | null |
Python easy solution | implement-rand10-using-rand7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n- random first time to get 1-5 to get the bucket since i will split result to [1,2], [3,4] ..., [9,10]\n- assume I get [5,6] =>\nrandom one more time to get the first or last number [1,2,3] = left, [4,5,6] = right\n\n\n# Approach\n<!-- De... | 0 | You are given a string `s` of length `n` where `s[i]` is either:
* `'D'` means decreasing, or
* `'I'` means increasing.
A permutation `perm` of `n + 1` integers of all the integers in the range `[0, n]` is called a **valid permutation** if for all valid `i`:
* If `s[i] == 'D'`, then `perm[i] > perm[i + 1]`, an... | null |
Simple Solution without Trie(Python) | concatenated-words | 0 | 1 | \n# Code\n```\ndef solve(string,s):\n for i in range(1,len(string)):\n left,right = string[0:i],string[i:len(string)]\n if left in s:\n if right in s or solve(right,s):\n return True\n return False\nclass Solution:\n def findAllConcatenatedWordsInADict(self, words: List[... | 1 | Given an array of strings `words` (**without duplicates**), return _all the **concatenated words** in the given list of_ `words`.
A **concatenated word** is defined as a string that is comprised entirely of at least two shorter words (not necesssarily distinct) in the given array.
**Example 1:**
**Input:** words = \... | null |
python - trie dfs | concatenated-words | 0 | 1 | \n# Code\n```\nfrom pprint import pprint\nfrom dataclasses import dataclass\n\n@dataclass\nclass Node:\n value: Optional[str]\n children: dict\n\nclass Solution:\n def findAllConcatenatedWordsInADict(self, words: List[str]) -> List[str]:\n root = Node(value=None, children={})\n \n # build ... | 1 | Given an array of strings `words` (**without duplicates**), return _all the **concatenated words** in the given list of_ `words`.
A **concatenated word** is defined as a string that is comprised entirely of at least two shorter words (not necesssarily distinct) in the given array.
**Example 1:**
**Input:** words = \... | null |
Heavily Commented Trie | concatenated-words | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 1 | Given an array of strings `words` (**without duplicates**), return _all the **concatenated words** in the given list of_ `words`.
A **concatenated word** is defined as a string that is comprised entirely of at least two shorter words (not necesssarily distinct) in the given array.
**Example 1:**
**Input:** words = \... | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.