
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | **What happened**:
events generated during namespace destroy is inappropriate.
**What you expected to happen**:
appropriate event logs are expected
**How to reproduce it (as minimally and precisely as possible)**:
1) create namespace and initiate pod ( I have supplied ns in pod manifest )
2) watch events.
... | inappropriate event logs during namespace destroy | https://api.github.com/repos/kubernetes/kubernetes/issues/96793/comments | 6 | 2020-11-22T11:50:00Z | 2020-11-24T08:15:49Z | https://github.com/kubernetes/kubernetes/issues/96793 | 748,225,827 | 96,793 |
[
"kubernetes",
"kubernetes"
] | Ran following command:
Command 1 -> kubectl cp infadomain/infadomain-0:/home/Informatica/K8sVolume/**SystemLog** infadomain_K8s
Command 2 -> kubectl cp infadomain/infadomain-0:/home/Informatica/K8sVolume/**SystemLog/** infadomain_K8s
**What you expected to happen**:
Command 1 should copy SystemLog directory.
Com... | kubect copy issue - command does not copy directory but copies directory content | https://api.github.com/repos/kubernetes/kubernetes/issues/96791/comments | 7 | 2020-11-22T07:31:34Z | 2021-04-21T17:10:56Z | https://github.com/kubernetes/kubernetes/issues/96791 | 748,188,355 | 96,791 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
In an kubadm ... | large latency in pod network operations when NodePort services with a lot of ports are created | https://api.github.com/repos/kubernetes/kubernetes/issues/96786/comments | 8 | 2020-11-21T17:22:24Z | 2020-11-27T13:05:09Z | https://github.com/kubernetes/kubernetes/issues/96786 | 748,061,464 | 96,786 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
The following comments stated that `cluster-driver-registrar` sidecar is used to create `CSIDriver` object, but that is already deprecated.
https://github.com/kubernetes/kubernetes/blob/v1.20.0-beta.2/pkg/apis/storage/types.go#L227-L229
**What you expected to happen**:
It should state that `clu... | Description for CSIDriver needs an update | https://api.github.com/repos/kubernetes/kubernetes/issues/96782/comments | 8 | 2020-11-21T14:52:13Z | 2021-04-20T17:00:58Z | https://github.com/kubernetes/kubernetes/issues/96782 | 748,034,131 | 96,782 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
When I regist... | Kubelet return error when device plugin set PreStartRequired option true but container request 0 resource. | https://api.github.com/repos/kubernetes/kubernetes/issues/96779/comments | 2 | 2020-11-21T11:32:10Z | 2021-01-26T01:59:00Z | https://github.com/kubernetes/kubernetes/issues/96779 | 748,001,841 | 96,779 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
`fatal erro... | concurrent map writes in VolumeBinding plugin during Filter | https://api.github.com/repos/kubernetes/kubernetes/issues/96772/comments | 7 | 2020-11-20T23:42:02Z | 2020-11-23T14:51:34Z | https://github.com/kubernetes/kubernetes/issues/96772 | 747,865,305 | 96,772 |
[
"kubernetes",
"kubernetes"
] | Related:
- Part of: https://github.com/kubernetes/k8s.io/issues/1458
- Part of: https://github.com/kubernetes/k8s.io/issues/1522
We should migrate away from the google.com-owned gcr.io/kubernetes-e2e-test-images and instead use the community-owned k8s.gcr.io/e2e-test-images repository.
Affected images are those... | Use k8s.gcr.io/e2e-test-images instead of gcr.io/kubernetes-e2e-test-images for e2e test images | https://api.github.com/repos/kubernetes/kubernetes/issues/96770/comments | 30 | 2020-11-20T21:53:21Z | 2021-11-24T19:20:39Z | https://github.com/kubernetes/kubernetes/issues/96770 | 747,818,025 | 96,770 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Stop using the busybox image and move to something like agnhost
**Why is this needed**:
In non k/k ci clusters, we're hitting docker pull limits on busybox. A possible workaround is to configure mirr... | Move storage e2es off of busybox | https://api.github.com/repos/kubernetes/kubernetes/issues/96769/comments | 8 | 2020-11-20T21:24:43Z | 2021-04-23T11:27:22Z | https://github.com/kubernetes/kubernetes/issues/96769 | 747,803,081 | 96,769 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
I have a pod with:
```
image: gcr.io/k8s-testimages/kettle:latest
imagePullPolicy: Always
```
It will always pull a new image on deploy but this same behavior doesn't seem to happen w... | [Kubectl set image --force] option? | https://api.github.com/repos/kubernetes/kubernetes/issues/96767/comments | 5 | 2020-11-20T20:32:24Z | 2020-11-23T05:57:53Z | https://github.com/kubernetes/kubernetes/issues/96767 | 747,775,994 | 96,767 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Node E2E tests for Kubelet lock contention flags:
- --exit-on-lock-contention
- --lock-file
**Why is this needed**:
These flags are being graduated to KubeletConfiguration on #91877, we should... | Kubelet Lock contention E2E node test | https://api.github.com/repos/kubernetes/kubernetes/issues/96766/comments | 6 | 2020-11-20T20:20:02Z | 2021-04-19T22:55:57Z | https://github.com/kubernetes/kubernetes/issues/96766 | 747,769,388 | 96,766 |
[
"kubernetes",
"kubernetes"
] | Hello Team,
I have a question, could be a dumb one. When both Limits (more than requests) and Requests (less than limits) are specified on a POD. What does scheduler take into consideration for scheduling, is it Requests or limits?
I feel its definitely limits because, that is what the container can use max, if... | When both requests and limits are specified on a POD, What does kubernetes take into consideration to schedule the pod? | https://api.github.com/repos/kubernetes/kubernetes/issues/96765/comments | 3 | 2020-11-20T20:01:01Z | 2020-11-28T05:33:47Z | https://github.com/kubernetes/kubernetes/issues/96765 | 747,759,202 | 96,765 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
kube-controller-manager was unable to update an AWS LoadBalancer's TargetGroup.
**What you expected to happen**:
TargetGroup is updated without error when hosts change.
**How to reproduce it (as minimally and precisely as possible)**:
This has only happened twice so far with only one o... | Unable to update LoadBalancer's TargetGroup: DuplicateTargetGroupName | https://api.github.com/repos/kubernetes/kubernetes/issues/96764/comments | 17 | 2020-11-20T19:22:05Z | 2022-02-08T00:20:37Z | https://github.com/kubernetes/kubernetes/issues/96764 | 747,737,755 | 96,764 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Using the following yaml (which is incorrect), yields an incorrect suggestion to fix.
```
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc-1
spec:
accessModes:
- ReadWriteOnce
resources:
```
```
$ kubectl apply -f mypvc.yaml
The PersistentVolumeClaim "myp... | Incorrect suggestion for missing field | https://api.github.com/repos/kubernetes/kubernetes/issues/96762/comments | 8 | 2020-11-20T18:59:30Z | 2020-11-20T22:17:41Z | https://github.com/kubernetes/kubernetes/issues/96762 | 747,725,425 | 96,762 |
[
"kubernetes",
"kubernetes"
] | `omitempty` doesn't do what we want on a struct, so we always see this stanza in under `status`. To fix this we'd need to fix the places that use it internally, obviously.
Minor, but persistently annoying. I think we can do this with low impact internally but it would change to Go signature and so needs at least a... | ServiceStatus.LoadBalancer should be a pointer | https://api.github.com/repos/kubernetes/kubernetes/issues/96760/comments | 8 | 2020-11-20T17:52:30Z | 2021-08-28T23:45:46Z | https://github.com/kubernetes/kubernetes/issues/96760 | 747,686,159 | 96,760 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Offshoot of h... | Secret volume directories sometimes don't get cleaned up | https://api.github.com/repos/kubernetes/kubernetes/issues/96759/comments | 23 | 2020-11-20T17:35:07Z | 2021-12-11T18:34:45Z | https://github.com/kubernetes/kubernetes/issues/96759 | 747,674,211 | 96,759 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
`ci-cluster-api-provider-gcp-make-conformance-v1alpha3-k8s-ci-artifacts`
**Which test(s) are failing**:
`[sig-auth] ServiceAccounts should mount projected service a... | [Failing Test] [sig-auth] ServiceAccounts should mount projected service account token [Conformance] (ci-cluster-api-provider-gcp-make-conformance-v1alpha3-k8s-ci-artifacts) | https://api.github.com/repos/kubernetes/kubernetes/issues/96757/comments | 4 | 2020-11-20T17:00:02Z | 2020-11-25T15:56:40Z | https://github.com/kubernetes/kubernetes/issues/96757 | 747,645,491 | 96,757 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Running kubectl cp two times isn't idempotent.
````
$ ls -lR test
total 8
-rw-r--r-- 1 steffenrumpf staff 457 21 Feb 2020 test.yml
$ kubectl cp test <somepod>:/tmp/test2
$ kubectl exec <somepod> -- ls -lR /tmp
/tmp:
total 0
drwxr-xr-x 2 app users 29 Nov 20 15:13 test2
/tmp/test2:
t... | Strange behavior of kubectl cp | https://api.github.com/repos/kubernetes/kubernetes/issues/96755/comments | 8 | 2020-11-20T15:25:42Z | 2021-04-25T10:38:08Z | https://github.com/kubernetes/kubernetes/issues/96755 | 747,576,725 | 96,755 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Currently garbage collector is using two api calls per a single object deletion. Given that the performance of controllers is limited by --kube-api-qps flag (set to 100 e.g. in our scalability tests), w... | Increase supported pod deletion rate | https://api.github.com/repos/kubernetes/kubernetes/issues/96752/comments | 27 | 2020-11-20T13:50:20Z | 2022-04-04T07:10:20Z | https://github.com/kubernetes/kubernetes/issues/96752 | 747,506,141 | 96,752 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Pod topology spread constraints are currently only evaluated when scheduling a pod.
The ask is to do that in kube-controller-manager when scaling down a replicaset. The logic would select the failure domain with the highest number of pods when selecting a victim.
The risk is... | Pod Topology Spread constraints should be taken into account on scale down | https://api.github.com/repos/kubernetes/kubernetes/issues/96748/comments | 21 | 2020-11-20T12:11:40Z | 2021-08-20T20:56:45Z | https://github.com/kubernetes/kubernetes/issues/96748 | 747,442,698 | 96,748 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
In a cluster with NPD addon installed and Linux 5.1+ as the kernel OS of the nodes OOMs are not being captured by the NPD.
**What you expected to happen**:
NPD should inform about OOMs by emitting appropriate K8s events.
**How to reproduce it (as minimally and precisely as possible)**:
Creat... | node-problem-detector does not discover OOMs in newer Linux kernels | https://api.github.com/repos/kubernetes/kubernetes/issues/96746/comments | 2 | 2020-11-20T09:49:40Z | 2020-11-21T14:33:34Z | https://github.com/kubernetes/kubernetes/issues/96746 | 747,345,178 | 96,746 |
[
"kubernetes",
"kubernetes"
] |
1) Followed this documentation https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
2) Started the master node using "sudo kubeadm init"
3) Received successful message and "kubeadm join" commands
4) Ran "journalctl -u kubelet" command on master node to see the status of kubelet
... | error failed to read kubelet config file "/var/lib/kubelet/config.yaml", error: open /vනෙවැ 20 10:28:55 master-2 kubelet[5890]: goroutine 1 [running] | https://api.github.com/repos/kubernetes/kubernetes/issues/96741/comments | 5 | 2020-11-20T06:51:28Z | 2020-11-30T20:42:33Z | https://github.com/kubernetes/kubernetes/issues/96741 | 747,225,538 | 96,741 |
[
"kubernetes",
"kubernetes"
] | For pod deletion, currently as long as volume is unpublished (unmount), pod might be deleted right after unmount. It is possible that pod is deleted before volume is unstaged (UnmountDevice). This behavior might cause snapshot test fail especially on Windows where unstage takes longer time.
1. volume is created and ... | Pod should be deleted after volume unstage finished if no other pods using the volume | https://api.github.com/repos/kubernetes/kubernetes/issues/96734/comments | 15 | 2020-11-20T01:49:06Z | 2021-04-24T09:32:18Z | https://github.com/kubernetes/kubernetes/issues/96734 | 747,071,986 | 96,734 |
[
"kubernetes",
"kubernetes"
] | > What happened:
I'm running kubernetes 1.17 and use an autoscaling group that has a mix of OnDemand and spot instances. Some of the spot instances are intermittently put into a `SchedulingDisabled` status, which apparently indicates a node has been cordoned off, but I am certain that nobody has done this:
```
N... | Spot instance worker nodes have status of Ready,SchedulingDisabled | https://api.github.com/repos/kubernetes/kubernetes/issues/96733/comments | 5 | 2020-11-20T01:37:13Z | 2022-06-23T22:44:21Z | https://github.com/kubernetes/kubernetes/issues/96733 | 747,067,758 | 96,733 |
[
"kubernetes",
"kubernetes"
] | One Node in cluster report DiskPressure but the usage of rootfs is 73%, and imagefs (I set docker data root: /data/docker/ instead of the original dir /var/lib/docker/ ) usage is 4%.
when I check kubelet's log, I find kubelet check the dir /var/lib/docker/overlay2/ instead of the correct dir /data/docker/ which mean... | kubelet report wrong DiskPressure | https://api.github.com/repos/kubernetes/kubernetes/issues/96732/comments | 8 | 2020-11-20T01:32:55Z | 2021-06-07T11:30:11Z | https://github.com/kubernetes/kubernetes/issues/96732 | 747,066,259 | 96,732 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
I would like a way to have the readiness probe period more dynamic.
**Why is this needed**:
We have a few use cases were we want extremely aggressive readiness probe times, because pod startup time is critical. In these cases, using an interval over 1s is detrimental. This ... | Dynamic readiness probe period time | https://api.github.com/repos/kubernetes/kubernetes/issues/96731/comments | 35 | 2020-11-20T01:27:00Z | 2021-03-06T19:45:42Z | https://github.com/kubernetes/kubernetes/issues/96731 | 747,064,123 | 96,731 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
The CSIMigration*Complete flags will unregister a particular volume plugin from kube-controller-manager and kubelet. But it requires the CSIMigration* flags to be enabled.
I am proposing we replace the... | Disabling a volume plugin without enabling csi migration | https://api.github.com/repos/kubernetes/kubernetes/issues/96730/comments | 5 | 2020-11-20T00:46:22Z | 2021-01-29T20:59:48Z | https://github.com/kubernetes/kubernetes/issues/96730 | 747,047,816 | 96,730 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
In log messages that log the container id (which is really just kuberuntime_container.go), consistently also log the container name.
**Why is this needed**:
Consider this example:
```
E1117 11:46:0... | log container name alongside id in kuberuntime_container.go | https://api.github.com/repos/kubernetes/kubernetes/issues/96725/comments | 8 | 2020-11-19T22:44:08Z | 2021-04-30T05:06:38Z | https://github.com/kubernetes/kubernetes/issues/96725 | 746,983,551 | 96,725 |
[
"kubernetes",
"kubernetes"
] |
**What happened**:
I can set the Status.LoadBalancer.Ingress in Services that are not Type LoadBalancer
**What you expected to happen**:
The apiserver should reject the Status update
**How to reproduce it (as minimally and precisely as possible)**:
1. kind create cluster
2. wget https://gist.githubuse... | Non LoadBalancer Types can set Status.Loadbalancer.Ingress | https://api.github.com/repos/kubernetes/kubernetes/issues/96724/comments | 3 | 2020-11-19T21:50:49Z | 2020-11-20T17:31:59Z | https://github.com/kubernetes/kubernetes/issues/96724 | 746,951,779 | 96,724 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Right now our... | Snapshot e2es have strict ordering of deleting snapshots before pvcs | https://api.github.com/repos/kubernetes/kubernetes/issues/96719/comments | 7 | 2020-11-19T16:36:54Z | 2021-02-19T01:39:05Z | https://github.com/kubernetes/kubernetes/issues/96719 | 746,741,228 | 96,719 |
[
"kubernetes",
"kubernetes"
] | When we first added SCTP tests, we thought that we weren't going to be able to do actual tests of SCTP network connectivity within kubernetes CI, so we came up with a plan involving a split between tests that involve actual SCTP network connectivity (which require the SCTP kernel module to be available) and tests that ... | Clean up SCTP tests | https://api.github.com/repos/kubernetes/kubernetes/issues/96717/comments | 40 | 2020-11-19T13:34:09Z | 2022-12-14T02:33:36Z | https://github.com/kubernetes/kubernetes/issues/96717 | 746,590,279 | 96,717 |
[
"kubernetes",
"kubernetes"
] | I set up a webhook server in my kubernetes cluster.
This webhook server will check each delete request of resource and decide whether to approve this delete request.
Everything is ok but I always got a nil in req.OldObject.Raw or req.Object.Raw of a delete request.
I don't know why. I need this OldObject.Raw. And... | Object.Raw is nil for a delete request to webhook server | https://api.github.com/repos/kubernetes/kubernetes/issues/96715/comments | 4 | 2020-11-19T13:08:08Z | 2020-11-19T17:06:15Z | https://github.com/kubernetes/kubernetes/issues/96715 | 746,568,805 | 96,715 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
When I add a... | Changes in Pod.spec.containers.ports aren't recognized by API server | https://api.github.com/repos/kubernetes/kubernetes/issues/96714/comments | 16 | 2020-11-19T12:48:32Z | 2021-04-29T18:04:26Z | https://github.com/kubernetes/kubernetes/issues/96714 | 746,554,859 | 96,714 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about flaky tests or jobs (pass or fail with no underlying change in code) in Kubernetes CI -->
**Which jobs are flaking**:
gce-cos-master-default
**Which test(s) are flaking**:
Kubernetes e2e suite.[sig-api-machinery] API priority and fairness should en... | "highqps" not reaching 95% completion threshold on API priority and fairness ... , blocking gce-master-default | https://api.github.com/repos/kubernetes/kubernetes/issues/96710/comments | 15 | 2020-11-19T11:10:58Z | 2020-12-04T22:37:26Z | https://github.com/kubernetes/kubernetes/issues/96710 | 746,480,867 | 96,710 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I have the ... | CRD creation fails with "Forbidden: must not specify anything other than name and generateName" | https://api.github.com/repos/kubernetes/kubernetes/issues/96709/comments | 5 | 2020-11-19T10:51:54Z | 2020-11-20T03:52:49Z | https://github.com/kubernetes/kubernetes/issues/96709 | 746,466,383 | 96,709 |
[
"kubernetes",
"kubernetes"
] | **Client Version**: v1.13.1
**Server Version**: v1.17.9
**Background**:
We were updating config maps using `kubectl apply -f configmap.yaml`. At a point, we started facing issue with `apply` as the size of the metadata was more than the limit. As we understand it, the metadata field keeps previous version of confi... | Inconsistent behaviour when using "kubectl replace" for configmaps | https://api.github.com/repos/kubernetes/kubernetes/issues/96708/comments | 2 | 2020-11-19T08:25:27Z | 2020-11-20T10:55:09Z | https://github.com/kubernetes/kubernetes/issues/96708 | 746,357,534 | 96,708 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
resize Azure ... | resize Azure disk issue when it's in attached state | https://api.github.com/repos/kubernetes/kubernetes/issues/96706/comments | 0 | 2020-11-19T07:45:21Z | 2020-11-20T05:36:51Z | https://github.com/kubernetes/kubernetes/issues/96706 | 746,333,058 | 96,706 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
When I run so... | Failed to create object with non-retriable error | https://api.github.com/repos/kubernetes/kubernetes/issues/96703/comments | 10 | 2020-11-19T07:07:01Z | 2020-11-19T09:18:16Z | https://github.com/kubernetes/kubernetes/issues/96703 | 746,310,239 | 96,703 |
[
"kubernetes",
"kubernetes"
] | Hi Team,
We are getting issue in my kubernetes worker nodes , first all pods are running fine, after one day pods are not running and stuck in init state only, if i describe pod i am getting below error.
**Warning FailedCreatePodContainer 6s (x22 over 4m33s) kubelet unable to ensure pod contai... | Failed to create container, mkdir /sys/fs/cgroup/memory/kubepods/besteffort/pod98211fca-b27e-4316-b1ae-c0d27925aa84: cannot allocate memory | https://api.github.com/repos/kubernetes/kubernetes/issues/96701/comments | 6 | 2020-11-19T06:46:04Z | 2021-09-02T02:37:15Z | https://github.com/kubernetes/kubernetes/issues/96701 | 746,297,689 | 96,701 |
[
"kubernetes",
"kubernetes"
] |
**What happened**:
node is down ,but i find the apiserver pod is running ,and kube-controller-manager,kube-scheduler is also running
**What you expected to happen**:
why ?
**How to reproduce it (as minimally and precisely as possible)**:
1,when is shutdonw m1(master1 node)
[root@m1 ~]#init 0
2,test the n... | node is down ,but apiserver pod is running | https://api.github.com/repos/kubernetes/kubernetes/issues/96700/comments | 13 | 2020-11-19T05:25:14Z | 2021-05-16T18:55:25Z | https://github.com/kubernetes/kubernetes/issues/96700 | 746,259,681 | 96,700 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
````
kubectl explain pod.spec.containers.resources.limits
KIND: Pod
VERSION: v1
FIELD: limits <map[string]string>
DESCRIPTION:
Limits describes the maximum amount of compute resources allowed. More
info:
https://kubernetes.io/docs/concepts/configuration/manage-c... | kubectl explain redirect to a 404 page | https://api.github.com/repos/kubernetes/kubernetes/issues/96697/comments | 9 | 2020-11-19T00:43:25Z | 2021-01-14T15:15:05Z | https://github.com/kubernetes/kubernetes/issues/96697 | 746,151,901 | 96,697 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be modified**:
`k8s.gcr.io/conformance` image to be based on anything other than Docker Hub sourced `debian:stretch-slim`
https://github.com/kubernetes/kubernetes/blob/1c49b4425bf8c5b144e3ce7378b63351364ae8c6/cluste... | Adopt distroless in conformance image | https://api.github.com/repos/kubernetes/kubernetes/issues/96692/comments | 14 | 2020-11-18T21:58:34Z | 2021-06-01T15:00:04Z | https://github.com/kubernetes/kubernetes/issues/96692 | 746,045,015 | 96,692 |
[
"kubernetes",
"kubernetes"
] | This issue is meant as a space for discussing mutating webhooks regarding Server-Side Apply.
Primarily the problem recently reported in https://github.com/kubernetes/kubernetes/issues/96351.
As discovered in the issue it is possible for a mutating admission webhook to change the managedFields in a way that would br... | [Server-Side Apply] Prevent mutating admission controllers from corrupting managedFields | https://api.github.com/repos/kubernetes/kubernetes/issues/96688/comments | 5 | 2020-11-18T19:38:37Z | 2021-03-07T05:15:42Z | https://github.com/kubernetes/kubernetes/issues/96688 | 745,949,204 | 96,688 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
GCP upgraded ... | Please take versioning seriously. 1.16 broke extensions/v1beta configs without any serious warning. | https://api.github.com/repos/kubernetes/kubernetes/issues/96682/comments | 7 | 2020-11-18T18:20:14Z | 2020-11-20T16:19:02Z | https://github.com/kubernetes/kubernetes/issues/96682 | 745,899,066 | 96,682 |
[
"kubernetes",
"kubernetes"
] | This is a long standing issue and we did not manage to come to a conclusion before - https://github.com/kubernetes/kubernetes/pull/72049/files
But previously the problem was changes to umount code was affecting all volume drivers and not just NFS but I think a localized fix to just NFS intree driver is reasonable ... | Use force unmount for nfs if regular unmount fails | https://api.github.com/repos/kubernetes/kubernetes/issues/96678/comments | 5 | 2020-11-18T13:10:28Z | 2020-12-18T20:32:25Z | https://github.com/kubernetes/kubernetes/issues/96678 | 745,646,407 | 96,678 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
given an empty namespace (no pods), if running:
`kubectl wait "pod" --selector app.kubernetes.io/name=myapp --for=delete --timeout=500s`, kubectl errors with the message `error: no matching resources found`.
**What you expected to happen**:
kubectl should exit with status 0, since the condition... | kubectl wait "pod" --for=delete errors out if no matching resources are found | https://api.github.com/repos/kubernetes/kubernetes/issues/96676/comments | 8 | 2020-11-18T12:50:58Z | 2021-05-08T03:29:18Z | https://github.com/kubernetes/kubernetes/issues/96676 | 745,632,702 | 96,676 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
After set --volume-stats-agg-period=0 in kubelet args, the kubelet logs still shows
```
Nov 13 16:59:47 10-31-3-1 kubelet: I1113 16:59:47.852975 2889 fsHandler.go:135] du and find on following dirs took 37m0.97529016s: [ /var/lib/docker/containers/c99cdff4c4840c22c5d12e638cf3fe46672af9bca7164b... | --volume-stats-agg-period=0 cannot disable volume agg feature. | https://api.github.com/repos/kubernetes/kubernetes/issues/96674/comments | 4 | 2020-11-18T12:10:29Z | 2021-01-20T06:17:59Z | https://github.com/kubernetes/kubernetes/issues/96674 | 745,605,578 | 96,674 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
OpenStack Train with StorageClass kubernetes.io/cinder the volume attachment succeeds to the node but the kubelet fails to find the attached volume.
When a pod attempts to use the volume it becomes stuck in state `"ContainerCreating"`. Investigation in OpenStack shows the volume is attached to th... | Cinder volume attachment detection failure in Kubelet | https://api.github.com/repos/kubernetes/kubernetes/issues/96672/comments | 2 | 2020-11-18T11:26:44Z | 2020-12-09T02:35:31Z | https://github.com/kubernetes/kubernetes/issues/96672 | 745,576,720 | 96,672 |
[
"kubernetes",
"kubernetes"
] | When configuring new behaviors section in HPA I faced two scenarios that I think are incorrect.
First one:
stabilizationWindowSeconds set up to 5 minutes for both scale up and scale down
min replica count 2
Application consumes big amount of resources during warm-up
0 minute: current replica count: 2
1 minute: de... | Incorrect behavior on scaling up when using behaviors config on HPA | https://api.github.com/repos/kubernetes/kubernetes/issues/96671/comments | 4 | 2020-11-18T10:57:55Z | 2021-01-05T20:40:00Z | https://github.com/kubernetes/kubernetes/issues/96671 | 745,556,311 | 96,671 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Observing a strange issue in k8s: the pod running in host network namespace getting pod IP address from _vxlan.calico_ interface instead of main _bond0_ host interface.
The _vxlan.calico_ interface from host:
```
# ip ad sh vxlan.calico
96: vxlan.calico: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 197... | Pod with hostNetwork:true reporting podIP from overlay network | https://api.github.com/repos/kubernetes/kubernetes/issues/96670/comments | 14 | 2020-11-18T10:40:29Z | 2021-04-09T22:42:27Z | https://github.com/kubernetes/kubernetes/issues/96670 | 745,542,967 | 96,670 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
livenessP... | livenessProbe failed cannot rebuild conainer | https://api.github.com/repos/kubernetes/kubernetes/issues/96667/comments | 6 | 2020-11-18T09:16:39Z | 2021-04-18T18:48:19Z | https://github.com/kubernetes/kubernetes/issues/96667 | 745,479,692 | 96,667 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Currently the interval between health checks from the kubelet to the container runtime seems to be hardcoded here:
https://github.com/kubernetes/kubernetes/blob/147a120948482e49f93e7d8896f8e32b0418c2d8/... | Allow the configuration of the interval of container runtime healthcheck | https://api.github.com/repos/kubernetes/kubernetes/issues/96664/comments | 8 | 2020-11-18T08:14:57Z | 2021-06-07T20:34:15Z | https://github.com/kubernetes/kubernetes/issues/96664 | 745,437,586 | 96,664 |
[
"kubernetes",
"kubernetes"
] | As I remember, there was a API operation corresponding to `kubectl exec`,
seems like `POST /api/v1/namespaces/{namespace}/pods/{name}/exec`.
But in current API Reference Doc, I cannot find contents about that.
I checked `kubectl exec` command still works fine, but how about API?
That feature has removed in ... | Exec command via API is no longer supported? | https://api.github.com/repos/kubernetes/kubernetes/issues/96663/comments | 7 | 2020-11-18T07:38:23Z | 2021-04-17T09:36:18Z | https://github.com/kubernetes/kubernetes/issues/96663 | 745,415,262 | 96,663 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Run integrati... | [integration test] PVC should create before the PV if it's referenced by PV | https://api.github.com/repos/kubernetes/kubernetes/issues/96658/comments | 2 | 2020-11-18T06:18:17Z | 2020-12-09T02:34:48Z | https://github.com/kubernetes/kubernetes/issues/96658 | 745,367,692 | 96,658 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
running kubeadm.exe join --node-name ip-10-xxx-65-130.ec2.internal is ignored during bootstrapping of a Windows node in AWS.
While using the aws-cloud-controller-manager this node is then rejected from joining the cluster because it is looking for the EC2 hostname rather then the AWS Private DNS ... | kubeadm.exe join --node-name is ignored | https://api.github.com/repos/kubernetes/kubernetes/issues/96654/comments | 3 | 2020-11-17T22:42:29Z | 2020-11-19T16:58:39Z | https://github.com/kubernetes/kubernetes/issues/96654 | 745,141,763 | 96,654 |
[
"kubernetes",
"kubernetes"
] | In recent testings using [scheduler_perf](https://github.com/kubernetes/kubernetes/tree/master/test/integration/scheduler_perf), I encountered the following error which aborts the entire test suite:
```
--- FAIL: BenchmarkPerfScheduling/SchedulingPodAntiAffinity/500Nodes
scheduler_perf_test.go:366: op 2: Error... | [scheduler_perf] Transient API error aborts the scheduler perf test | https://api.github.com/repos/kubernetes/kubernetes/issues/96651/comments | 19 | 2020-11-17T19:55:57Z | 2021-08-25T20:12:57Z | https://github.com/kubernetes/kubernetes/issues/96651 | 745,042,986 | 96,651 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Migrate ownerReferences that refer to deprecated/no-longer-served Kubernetes API versions to current apiVersions
**Why is this needed**:
Objects can be created with ownerReferences pointing at apiVersion/kind combinations which are no longer served and/or have moved API gro... | Add migration of ownerReferences that refer to deprecated/no-longer-served Kubernetes API versions | https://api.github.com/repos/kubernetes/kubernetes/issues/96650/comments | 7 | 2020-11-17T19:52:57Z | 2024-03-26T20:49:42Z | https://github.com/kubernetes/kubernetes/issues/96650 | 745,041,086 | 96,650 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about flaky tests or jobs (pass or fail with no underlying change in code) in Kubernetes CI -->
**Which jobs are flaking**:
pull-kubernetes-bazel-test
**Which test(s) are flaking**:
`TestStartingResourceVersion`
**Reason for failure**:
```
===... | [Flaky test] TestStartingResourceVersion | https://api.github.com/repos/kubernetes/kubernetes/issues/96649/comments | 3 | 2020-11-17T19:32:46Z | 2020-11-20T03:14:51Z | https://github.com/kubernetes/kubernetes/issues/96649 | 745,028,599 | 96,649 |
[
"kubernetes",
"kubernetes"
] | I think we know the most common combos work, but we should verify that apiserver either does something reasonable or refuses to start with a polite error message in the following flag combinations:
| | enablement flag | feature gate | beta api group | alpha api group |
|---|---|---|---|---|
| [ ] | on | on | on | ... | Test APF beta with enablement combos | https://api.github.com/repos/kubernetes/kubernetes/issues/96648/comments | 14 | 2020-11-17T19:17:15Z | 2021-08-07T16:27:26Z | https://github.com/kubernetes/kubernetes/issues/96648 | 745,017,882 | 96,648 |
[
"kubernetes",
"kubernetes"
] | While moving APF to beta (see comments on https://github.com/kubernetes/kubernetes/pull/96527), we discovered that the integration tests commonly present users which are not members of any groups. We had thought that the system enforced membership in either the authenticated or unauthenticated group.
If this is supp... | Verify/enforce user/group invariant | https://api.github.com/repos/kubernetes/kubernetes/issues/96647/comments | 7 | 2020-11-17T19:02:43Z | 2022-01-22T12:17:52Z | https://github.com/kubernetes/kubernetes/issues/96647 | 745,000,985 | 96,647 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
- I create a ... | edit quota silent fail. | https://api.github.com/repos/kubernetes/kubernetes/issues/96645/comments | 8 | 2020-11-17T18:37:20Z | 2021-03-29T03:52:06Z | https://github.com/kubernetes/kubernetes/issues/96645 | 744,984,834 | 96,645 |
[
"kubernetes",
"kubernetes"
] | `timestamp` is defined here but never used. https://github.com/kubernetes/kubernetes/blob/62321af7ab1c8abb44f5d99e7af560b22bd0a7c6/staging/src/k8s.io/client-go/tools/record/event.go#L326
As this is an unexported method it doesn't affect anyone, just a small point of confusion for the reader.
/sig api-machinery
/... | generateEvent timestamp is ignored | https://api.github.com/repos/kubernetes/kubernetes/issues/96642/comments | 3 | 2020-11-17T16:48:29Z | 2020-12-09T02:34:39Z | https://github.com/kubernetes/kubernetes/issues/96642 | 744,905,632 | 96,642 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Pods show "Re... | Deamonset pods.status = "Ready" even though a node is off line | https://api.github.com/repos/kubernetes/kubernetes/issues/96641/comments | 13 | 2020-11-17T16:23:37Z | 2021-05-05T23:51:13Z | https://github.com/kubernetes/kubernetes/issues/96641 | 744,886,004 | 96,641 |
[
"kubernetes",
"kubernetes"
] | As Kubernetes on Windows continues to grow, there is a growing need to be able to define Conformance for clusters containing Windows Nodes.
### Current conformance definition & process
Details: https://github.com/cncf/k8s-conformance
> All vendors are invited to submit conformance testing results for review an... | Towards a definition of Windows Conformance | https://api.github.com/repos/kubernetes/kubernetes/issues/96639/comments | 16 | 2020-11-17T15:33:47Z | 2021-11-08T01:31:56Z | https://github.com/kubernetes/kubernetes/issues/96639 | 744,844,002 | 96,639 |
[
"kubernetes",
"kubernetes"
] | From https://github.com/kubernetes/kubernetes/issues/96038#issuecomment-728928671
**What happened**:
In https://prow.k8s.io/view/gcs/kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-performance/1328563866136743936 one of the nodes (gce-scale-cluster-minion-group-bddx) restarted for some reason (some kernel panic... | kubelet is not able to delete pod with mounted secret/configmap after restart | https://api.github.com/repos/kubernetes/kubernetes/issues/96635/comments | 25 | 2020-11-17T14:20:19Z | 2024-10-03T11:06:24Z | https://github.com/kubernetes/kubernetes/issues/96635 | 744,779,244 | 96,635 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I defined a r... | Missing resource object on pod spec inside a deployment , block the creation of deployment without explicit error. | https://api.github.com/repos/kubernetes/kubernetes/issues/96634/comments | 6 | 2020-11-17T13:06:20Z | 2021-04-16T18:34:12Z | https://github.com/kubernetes/kubernetes/issues/96634 | 744,720,437 | 96,634 |
[
"kubernetes",
"kubernetes"
] | We are facing a problem with cloud disk attachment limits and Kubernetes scheduling.
When running in a cloud provider, normally virtual machines have a limit on how many disks can be attached at the same time.
The `Scheduler` uses the `allocatable` field from the `Node`'s status to check if a pod requiring a volu... | Allow reservation of volumes for each node | https://api.github.com/repos/kubernetes/kubernetes/issues/96633/comments | 6 | 2020-11-17T11:49:36Z | 2021-04-16T13:29:11Z | https://github.com/kubernetes/kubernetes/issues/96633 | 744,665,298 | 96,633 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I have the cu... | Job not failing after backoffLimit is reached | https://api.github.com/repos/kubernetes/kubernetes/issues/96630/comments | 11 | 2020-11-17T10:37:14Z | 2021-04-18T19:48:20Z | https://github.com/kubernetes/kubernetes/issues/96630 | 744,615,444 | 96,630 |
[
"kubernetes",
"kubernetes"
] | <!--
STOP -- PLEASE READ!
GitHub is not the right place for support requests.
If you're looking for help, check the [troubleshooting guide](https://kubernetes.io/docs/tasks/debug-application-cluster/troubleshooting/)
or our [Discussion Forums](https://discuss.kubernetes.io).
You can also post your question o... | Calico is frequently down | https://api.github.com/repos/kubernetes/kubernetes/issues/96625/comments | 9 | 2020-11-17T07:14:55Z | 2020-11-17T16:21:46Z | https://github.com/kubernetes/kubernetes/issues/96625 | 744,478,662 | 96,625 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
We enabled Al... | Enabling AlwaysPullImages admission causes existing Pods cannot be updated | https://api.github.com/repos/kubernetes/kubernetes/issues/96624/comments | 12 | 2020-11-17T05:39:34Z | 2020-12-01T01:53:14Z | https://github.com/kubernetes/kubernetes/issues/96624 | 744,428,383 | 96,624 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
A register method or similar which takes in a registry as an argument, so that restclient metrics can be exposed to other prometheus registries without having to either duplicate the logic, or force the u... | Support registering restclient metrics against non-legacyregistry prometheus registry | https://api.github.com/repos/kubernetes/kubernetes/issues/96621/comments | 10 | 2020-11-16T22:35:46Z | 2021-08-16T23:35:05Z | https://github.com/kubernetes/kubernetes/issues/96621 | 744,247,712 | 96,621 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
During a scal... | Long delay in DetachVolume invocation after the pod is deleted | https://api.github.com/repos/kubernetes/kubernetes/issues/96620/comments | 6 | 2020-11-16T22:14:45Z | 2021-04-16T00:25:11Z | https://github.com/kubernetes/kubernetes/issues/96620 | 744,231,777 | 96,620 |
[
"kubernetes",
"kubernetes"
] | Consider to add one test case which have volumes taken from snapshot attached to the same node as the source volume. It also covers the case that snapshot is taken while volume is still attached to node.
1. create pvc as source volume, and a pod1 which writes data to the volume.
2. after data writing is finished, t... | Add csi snapshot test cases | https://api.github.com/repos/kubernetes/kubernetes/issues/96618/comments | 13 | 2020-11-16T20:53:30Z | 2021-08-14T15:18:10Z | https://github.com/kubernetes/kubernetes/issues/96618 | 744,182,365 | 96,618 |
[
"kubernetes",
"kubernetes"
] | Hello,
We are experiencing an issue with pod probes where they are not ran in sync with the configuration, which let suggests that the `initialDelaySeconds` is not correctly applied (or some other random delay is introduced).
We have a deployment that contains a `livenessProbe` and a `readinessProbe` configured a... | [Probes] Incorrect application of the initialDelaySeconds | https://api.github.com/repos/kubernetes/kubernetes/issues/96614/comments | 37 | 2020-11-16T17:28:30Z | 2025-03-11T19:40:04Z | https://github.com/kubernetes/kubernetes/issues/96614 | 744,024,373 | 96,614 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
ci-kubernetes-kubemark-100-gce-scheduler
**Which test(s) are failing**:
pod-affinity
**Since when has it been failing**:
2020-11-14
**Testgrid link**:
https://k8s... | [Failing Test] ci-kubernetes-kubemark-100-gce-scheduler | https://api.github.com/repos/kubernetes/kubernetes/issues/96612/comments | 6 | 2020-11-16T16:35:12Z | 2021-02-25T13:56:41Z | https://github.com/kubernetes/kubernetes/issues/96612 | 743,980,932 | 96,612 |
[
"kubernetes",
"kubernetes"
] | Environment summary
Provider ACI
https://github.com/virtual-kubelet/azure-aci/tree/master/charts
Version latest
K8s Master Info
1.16.13-gke.401
Helm Chart
Issue Details
I deployed the Virtual-Kubelet in GKE to use the Azure Container Instances. I am able to successfully schedule pods to Azure.
Howeve... | Insufficient cpu - virtual-kubelet - GKE + Azure ACI Provider | https://api.github.com/repos/kubernetes/kubernetes/issues/96592/comments | 7 | 2020-11-15T00:55:46Z | 2020-11-15T16:12:34Z | https://github.com/kubernetes/kubernetes/issues/96592 | 743,153,303 | 96,592 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Make `PodBackoffDuration` configurable.
**Why is this needed**:
The values of `DefaultInitialBackoffDuration` and `DefaultMaxBackoffDuration` are 1s and 10s respectively. The values can be too sm... | Make PodBackoffDuration configurable | https://api.github.com/repos/kubernetes/kubernetes/issues/96590/comments | 4 | 2020-11-14T19:55:34Z | 2020-11-14T22:59:36Z | https://github.com/kubernetes/kubernetes/issues/96590 | 743,068,769 | 96,590 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
After I reb... | Kubelet not coming up after reboot "exit status is 255" | https://api.github.com/repos/kubernetes/kubernetes/issues/96589/comments | 12 | 2020-11-14T17:22:25Z | 2022-02-17T09:13:46Z | https://github.com/kubernetes/kubernetes/issues/96589 | 743,043,455 | 96,589 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
The duration threshold of the trace is hard-code, so it will bring inconvennience to the maintainability of the applications if they want to get more requests in a large cluster. What about to configure the threshold through an environment variables and hard-code the threshold a d... | Add configuration ability for the duration threshold of ApiServer trace | https://api.github.com/repos/kubernetes/kubernetes/issues/96587/comments | 16 | 2020-11-14T12:07:39Z | 2021-05-15T00:37:25Z | https://github.com/kubernetes/kubernetes/issues/96587 | 742,992,117 | 96,587 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Test create method for non-namespaced subresources generate invalid code.
I have the following code generation annotations:
```
// +genclient
// +genclient:nonNamespaced
// +genclient:method=TestMethod,verb=create,subresource=test,input=k8s.io/kubernetes/pkg/apis/autoscaling.Scale,result=k... | Code generator generates invalid fake clients for nonnamespaced subresources create method | https://api.github.com/repos/kubernetes/kubernetes/issues/96585/comments | 3 | 2020-11-14T09:24:34Z | 2020-11-19T21:29:50Z | https://github.com/kubernetes/kubernetes/issues/96585 | 742,967,660 | 96,585 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
The extended scheduler with webhook will retry bind pod forever when the pod is bind successed but the bind request timeout
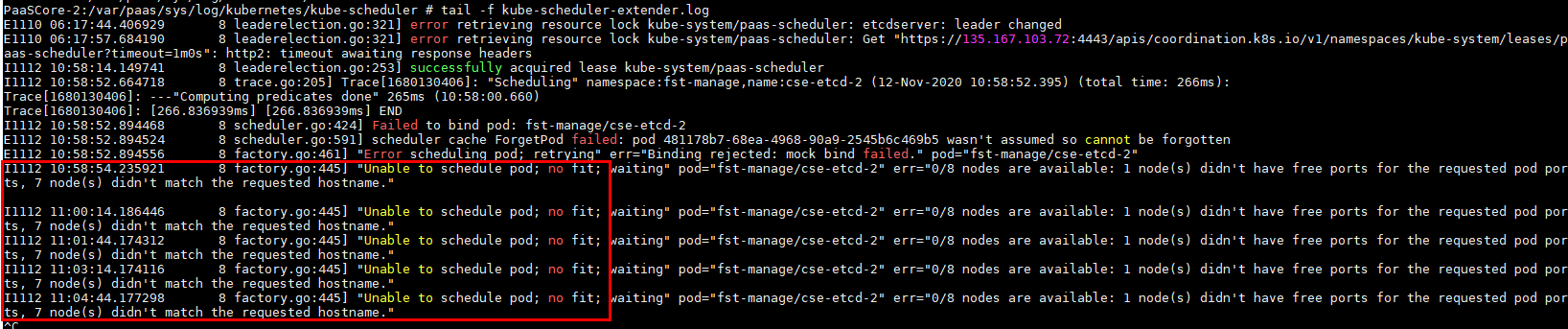
**What you expected to happen**:
Do not perform repeated schedul... | The extended scheduler with webhook will retry bind pod forever when the pod is bind successed but the bind request timeout | https://api.github.com/repos/kubernetes/kubernetes/issues/96579/comments | 7 | 2020-11-14T02:45:19Z | 2021-01-13T11:14:26Z | https://github.com/kubernetes/kubernetes/issues/96579 | 742,907,945 | 96,579 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
`ci-cluster-api-provider-gcp-make-conformance-v1alpha3-k8s-ci-artifacts`
**Which test(s) are failing**:
`[sig-api-machinery] CustomResourcePublishOpenAPI [Privilege... | [Failing Test] [sig-api-machinery] CustomResourcePublishOpenAPI [Privileged:ClusterAdmin] works for CRD preserving unknown fields in an embedded object [Conformance] (ci-cluster-api-provider-gcp-make-conformance-v1alpha3-k8s-ci-artifacts) | https://api.github.com/repos/kubernetes/kubernetes/issues/96577/comments | 19 | 2020-11-14T00:54:09Z | 2020-11-24T21:25:36Z | https://github.com/kubernetes/kubernetes/issues/96577 | 742,881,024 | 96,577 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**: To allow us to select pods and deployments that are using specific nodeSelectors, for example in our use case we are trrying to find pods that we have scheudled to use role=stable (which puts them on stabl... | Add 'nodeSelector' to --field-selector supported query options | https://api.github.com/repos/kubernetes/kubernetes/issues/96569/comments | 20 | 2020-11-13T15:28:31Z | 2022-07-07T20:28:49Z | https://github.com/kubernetes/kubernetes/issues/96569 | 742,536,095 | 96,569 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
`node-kubelet-features-master`
**Which test(s) are failing**:
`[k8s.io] ResourceMetricsAPI [NodeFeature:ResourceMetrics] when querying /resource/metrics should ... | [Failing Test] [sig-node] [k8s.io] ResourceMetricsAPI [NodeFeature:ResourceMetrics] when querying /resource/metrics should report resource usage through the resouce metrics api | https://api.github.com/repos/kubernetes/kubernetes/issues/96568/comments | 1 | 2020-11-13T15:18:38Z | 2020-11-13T20:17:05Z | https://github.com/kubernetes/kubernetes/issues/96568 | 742,528,338 | 96,568 |
[
"kubernetes",
"kubernetes"
] | If you have a kubernetes cluster with log collection enabled and you deploy the following:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: log-fire-hose
labels:
app: log-fire-hose
spec:
replicas: 100
selector:
matchLabels:
app: log-fire-hose
template:
metadata:
... | Implement container log back-pressure mechanism | https://api.github.com/repos/kubernetes/kubernetes/issues/96567/comments | 9 | 2020-11-13T14:43:23Z | 2021-05-01T19:22:37Z | https://github.com/kubernetes/kubernetes/issues/96567 | 742,500,587 | 96,567 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
`ci-kubernetes-e2e-ubuntu-gce`
**Which test(s) are failing**:
`[sig-node] Pods Extended [k8s.io] Pod Container Status should never report success for a pending cont... | [Failing Test] [sig-node] Pods Extended [k8s.io] Pod Container Status should never report success for a pending container (ci-kubernetes-e2e-ubuntu-gce) | https://api.github.com/repos/kubernetes/kubernetes/issues/96565/comments | 31 | 2020-11-13T14:37:07Z | 2021-01-22T00:39:47Z | https://github.com/kubernetes/kubernetes/issues/96565 | 742,496,030 | 96,565 |
[
"kubernetes",
"kubernetes"
] | Is it officially marked as deprecated:
* https://twitter.com/awalterschulze/status/1584553056100057088
* https://github.com/gogo/protobuf
* https://github.com/gogo/protobuf/issues/691#issuecomment-1289137315
* discussion in sig-apimachinery : https://groups.google.com/g/kubernetes-sig-api-machinery/c/tcwFubV9Boo/... | 🐘 Need a replacement for deprecated/unmaintained gogo-protobuf dependency | https://api.github.com/repos/kubernetes/kubernetes/issues/96564/comments | 54 | 2020-11-13T14:28:51Z | 2025-01-18T19:25:04Z | https://github.com/kubernetes/kubernetes/issues/96564 | 742,489,882 | 96,564 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Currently k8s supports `postStart` and `preStop` lifecycle hook, but in my scenario what I need is actually `preStart`.
And l think `PreStart` is very useful in many scenarios, I don’t understand why it ... | PreStart lifecycle hook Required | https://api.github.com/repos/kubernetes/kubernetes/issues/96560/comments | 22 | 2020-11-13T13:09:02Z | 2022-09-15T19:33:07Z | https://github.com/kubernetes/kubernetes/issues/96560 | 742,437,817 | 96,560 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
in my cluster... | after delete statefulset,pod is not delete | https://api.github.com/repos/kubernetes/kubernetes/issues/96557/comments | 8 | 2020-11-13T12:28:32Z | 2020-11-16T11:13:16Z | https://github.com/kubernetes/kubernetes/issues/96557 | 742,415,129 | 96,557 |
[
"kubernetes",
"kubernetes"
] | Without much activity I see that memory increases over time(within 1 week from 50 to 90%) and it clearly affects the latency
I see that buff/cache is growing but I cannot identify what is going wrong; e... | Memory increases over time ( low to none activity on the cluster) | https://api.github.com/repos/kubernetes/kubernetes/issues/96554/comments | 4 | 2020-11-13T10:35:04Z | 2020-11-13T20:58:18Z | https://github.com/kubernetes/kubernetes/issues/96554 | 742,348,866 | 96,554 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Better testing of monotonic time in sample_and_watermark.go
**Why is this needed**:
https://github.com/kubernetes/kubernetes/pull/96530#issuecomment-726343393
@lavalamp
| Want better testing of monotonic time in sample_and_watermark.go | https://api.github.com/repos/kubernetes/kubernetes/issues/96543/comments | 4 | 2020-11-13T00:53:02Z | 2021-02-02T08:14:28Z | https://github.com/kubernetes/kubernetes/issues/96543 | 742,037,935 | 96,543 |
[
"kubernetes",
"kubernetes"
] | Supposing I have 2 sites of a Data-center with different name (DT1 - DT2). I label all my nodes according to the sites (ex: kubectl label node worker-03 topology.myorg.io/datacenter=DT1). After labeling my Nodes I add the following option to the executable of kube-apiserver and kube-scheduler: `--feature-gates=EvenPods... | Pod-Scheduler not respecting constraints imposed by topologySpreadConstraints | https://api.github.com/repos/kubernetes/kubernetes/issues/96542/comments | 6 | 2020-11-12T23:47:39Z | 2020-11-13T02:27:27Z | https://github.com/kubernetes/kubernetes/issues/96542 | 742,011,931 | 96,542 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
We currently run the CSIDriver FSGroupPolicy test a single time; however, if the CSIDriver is not available it's possible that the Pod could be created without applying the fsGroup correctly.
**What you expected to happen**:
This test should run multiple times to ensure that we don't create need... | CSIDriver mock volume FSGroupPolicy needs to run in a loop | https://api.github.com/repos/kubernetes/kubernetes/issues/96540/comments | 12 | 2020-11-12T22:21:29Z | 2021-09-09T14:49:33Z | https://github.com/kubernetes/kubernetes/issues/96540 | 741,970,294 | 96,540 |
[
"kubernetes",
"kubernetes"
] | ref: https://github.com/kubernetes/kubernetes/pull/96527#discussion_r522440243
/sig api-machinery
/kind feature
/cc @lavalamp @MikeSpreitzer
/assign
(I'll do this in a follow-up PR.) | kube-apiserver/options/validation.go: test different combinations of APF runtime config parameters | https://api.github.com/repos/kubernetes/kubernetes/issues/96537/comments | 4 | 2020-11-12T21:45:18Z | 2020-11-24T21:25:43Z | https://github.com/kubernetes/kubernetes/issues/96537 | 741,949,343 | 96,537 |
[
"kubernetes",
"kubernetes"
] | Per the @liggitt comment in this PR https://github.com/kubernetes/kubernetes/pull/95718#issuecomment-725735634 conformance tests will regress because of a newly added Runtime Class GA v1 API is not covered with tests. Full comment:
Full comment:
> Does this have e2e coverage of all verbs on all endpoints of v1 Ru... | Add conformance tests for RuntimeClass v1 API | https://api.github.com/repos/kubernetes/kubernetes/issues/96524/comments | 23 | 2020-11-12T19:05:26Z | 2022-03-24T05:31:41Z | https://github.com/kubernetes/kubernetes/issues/96524 | 741,852,569 | 96,524 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Noticed in https://github.com/kubernetes/kubernetes/pull/95739#discussion_r522249205 , the CSIDriver creation doesn't perform ObjectMeta validation as the other types do.
**What you expected to happen**:
Execute `apivalidation.ValidateObjectMetaUpdate(` when objects are created.
**How to repr... | CSIDriver doesn't perform object metadata validation | https://api.github.com/repos/kubernetes/kubernetes/issues/96521/comments | 3 | 2020-11-12T18:33:13Z | 2020-11-12T18:34:51Z | https://github.com/kubernetes/kubernetes/issues/96521 | 741,830,979 | 96,521 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
See https://g... | CSIDriver object is not validating objectmeta | https://api.github.com/repos/kubernetes/kubernetes/issues/96520/comments | 8 | 2020-11-12T18:32:21Z | 2020-11-13T01:14:22Z | https://github.com/kubernetes/kubernetes/issues/96520 | 741,830,524 | 96,520 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
`ci-kubernetes-e2e-gce-device-plugin-gpu`
**Which test(s) are failing**:
`[sig-scheduling] [Feature:GPUDevicePlugin] run Nvidia GPU Device Plugin tests`
**Since ... | [Failing Test] [sig-scheduling] [Feature:GPUDevicePlugin] run Nvidia GPU Device Plugin tests (ci-kubernetes-e2e-gce-device-plugin-gpu) | https://api.github.com/repos/kubernetes/kubernetes/issues/96519/comments | 14 | 2020-11-12T18:14:44Z | 2020-11-21T00:03:34Z | https://github.com/kubernetes/kubernetes/issues/96519 | 741,819,411 | 96,519 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Trying to con... | Accessing Service VIP from POD fails intermittently on Windows nodes in Overlay network mode | https://api.github.com/repos/kubernetes/kubernetes/issues/96517/comments | 2 | 2020-11-12T17:19:58Z | 2020-11-12T21:17:36Z | https://github.com/kubernetes/kubernetes/issues/96517 | 741,781,673 | 96,517 |
[
"kubernetes",
"kubernetes"
] | The scheduler currently waits for full pod deletion (pod removed from the apiserver) to stop accounting the pod resources to the node. The Kubelet stops accounting for consumed resources on the node once all these conditions are reached:
a) the pod is marked as deleted
b) the pod sync loop observes that deletion
... | Scheduler should consider pod capacity of fully terminated but not deleted pods explicitly | https://api.github.com/repos/kubernetes/kubernetes/issues/96515/comments | 28 | 2020-11-12T16:18:52Z | 2024-03-05T12:41:47Z | https://github.com/kubernetes/kubernetes/issues/96515 | 741,735,324 | 96,515 |
[
"kubernetes",
"kubernetes"
] | Windows analog for #96371
kube-proxy Should fallback to terminating endpoints `iff`:
* externalTrafficPolicy: Local
* traffic is from an external source
* there are no ready and not terminating endpoints on the node
This prevents packet loss in scenarios where a load balancer sends traffic to a node that rec... | windows kube-proxy: fall back to node-local terminating endpoints for external traffic | https://api.github.com/repos/kubernetes/kubernetes/issues/96514/comments | 16 | 2020-11-12T15:47:18Z | 2021-09-15T12:57:33Z | https://github.com/kubernetes/kubernetes/issues/96514 | 741,710,247 | 96,514 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.