
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | **What happened**:
I'm trying to send a new `Event` to the api server manually creating the event and pushing it with client-go. Setting `EventTime` triggers a validation undocumented nor in api docs nor in struct definition: https://github.com/kubernetes/kubernetes/blob/master/pkg/apis/core/validation/events.go#L122 ... | When creating a new Event, setting EventTime triggers an undocumented validation | https://api.github.com/repos/kubernetes/kubernetes/issues/95913/comments | 4 | 2020-10-27T12:29:03Z | 2020-10-29T14:33:39Z | https://github.com/kubernetes/kubernetes/issues/95913 | 730,407,084 | 95,913 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
I'm using the [aws-ebs-csi-driver](https://github.com/kubernetes-sigs/aws-ebs-csi-driver) for attaching *pre-provisioned* EBS disks to my pods. I've also customized the max attach limit to 1 (for testing purposes) but I intend to use a low value (around 5-8) in production.
The attach limit value is... | When a new node joins the cluster - scheduler doesn't respect CSI volume limit | https://api.github.com/repos/kubernetes/kubernetes/issues/95911/comments | 32 | 2020-10-27T11:42:56Z | 2024-11-16T17:02:02Z | https://github.com/kubernetes/kubernetes/issues/95911 | 730,374,741 | 95,911 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
Before node e2e tests are started, iptables rules are applied. The rules aren't correctly applied for some OSes like, Fedora CoreOS.
**Which test(s) are failing**:
... | node e2e: incorrect iptables settings during starting the tests | https://api.github.com/repos/kubernetes/kubernetes/issues/95905/comments | 3 | 2020-10-27T09:32:13Z | 2020-11-18T06:08:05Z | https://github.com/kubernetes/kubernetes/issues/95905 | 730,275,175 | 95,905 |
[
"kubernetes",
"kubernetes"
] | I have a demand in hpa. for example:
I want to use custom metricName: container_cpu_used_1m with https://github.com/kubernetes-sigs/custom-metrics-apiserver, which mean 1min avage cpu usage of container, to decide scaled up or down?
I can get the value container_cpu_used_1m.
I see a new metric type ContainerRe... | support container based scaling to HPA with custom-metrics server | https://api.github.com/repos/kubernetes/kubernetes/issues/95904/comments | 7 | 2020-10-27T09:27:04Z | 2021-04-12T12:44:14Z | https://github.com/kubernetes/kubernetes/issues/95904 | 730,271,490 | 95,904 |
[
"kubernetes",
"kubernetes"
] | Today the `record.EventRecorder` generates a name for each event generated through it. The problem with the generated name is that it uses the target name + the timestamp, hence there are some situations where there could be 2 events generated with the same name (for more details on our use case, look at https://github... | Add method to record.EventRecorder to define the event name | https://api.github.com/repos/kubernetes/kubernetes/issues/95903/comments | 6 | 2020-10-27T09:17:07Z | 2020-10-29T14:29:42Z | https://github.com/kubernetes/kubernetes/issues/95903 | 730,264,308 | 95,903 |
[
"kubernetes",
"kubernetes"
] | We have a use case where we use the event broadcaster to send test events to kubernetes events and we cannot lose events because they are correlated with other ones. We would love to have a way to disable such event correlator.
Is there a way to make it optional? If not, are you interested in such feature? I can tak... | Make correlator in event broadcaster optional | https://api.github.com/repos/kubernetes/kubernetes/issues/95902/comments | 6 | 2020-10-27T09:16:19Z | 2020-10-29T13:37:01Z | https://github.com/kubernetes/kubernetes/issues/95902 | 730,263,693 | 95,902 |
[
"kubernetes",
"kubernetes"
] | Any failed test has thousands of lines of:
```
W1026 21:42:28.689550 1571093 clientconn.go:1223] grpc: addrConn.createTransport failed to connect to {unix://localhost:68355049939536982930 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing dial unix localhost:68355049939536982930: connect... | test logs FILLED with garbage noise | https://api.github.com/repos/kubernetes/kubernetes/issues/95893/comments | 19 | 2020-10-27T04:49:26Z | 2021-06-15T22:33:36Z | https://github.com/kubernetes/kubernetes/issues/95893 | 730,103,548 | 95,893 |
[
"kubernetes",
"kubernetes"
] | while `kubectl options` advertises that these flags are available but when I try to use it doesn't work, in minikube we have simmilar problem since we use kubectl's templates for grouping the cobra library.
```
$ kubectl options
The following options can be passed to any command:
--log-dir='': If non-e... | klog flags such "log_dir" doesn't do anything on kubectl | https://api.github.com/repos/kubernetes/kubernetes/issues/95891/comments | 3 | 2020-10-27T02:54:53Z | 2020-10-27T02:55:17Z | https://github.com/kubernetes/kubernetes/issues/95891 | 730,057,315 | 95,891 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Move [this testcase](https://github.com/kubernetes/kubernetes/blob/87cc9bca0fcbbdf1b8232c9c71e50023d62667c3/test/e2e/storage/testsuites/volume_expand.go#L153) outside of driver testsuite, perhaps using cs... | Move disallow volume expansion test ouside of storage driver testsuite | https://api.github.com/repos/kubernetes/kubernetes/issues/95888/comments | 16 | 2020-10-27T01:43:28Z | 2024-01-19T06:58:50Z | https://github.com/kubernetes/kubernetes/issues/95888 | 730,029,115 | 95,888 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
kube-scheduler (`v1.18.8`) crashes due to a panic while running `FilterPlugins`:
```
fatal error: concurrent map read and map write
goroutine 2987 [running]:
runtime.throw(0x1c4d8ef, 0x21)
/usr/local/go/src/runtime/panic.go:774 +0x72 fp=0xc0063e5aa8 sp=0xc0063e5a78 pc=0x4313a2
runt... | sched: concurrent map read/write when scheduler plugins write to `CycleState` during the Filter phase | https://api.github.com/repos/kubernetes/kubernetes/issues/95887/comments | 40 | 2020-10-27T01:12:44Z | 2021-05-06T09:49:17Z | https://github.com/kubernetes/kubernetes/issues/95887 | 730,018,276 | 95,887 |
[
"kubernetes",
"kubernetes"
] | **What happened**: `kubectl get pods -o=jsonpath='{range .items[*]}.....{end}'` throws errors if no pods are found in v1.19.3, but returns success with empty response in v1.16.8
**What you expected to happen**: If there are no pods that return, no error should be thrown as the range should evaluate to "no op".
**... | JSONpath support: change in behaviour over versions | https://api.github.com/repos/kubernetes/kubernetes/issues/95882/comments | 4 | 2020-10-26T19:22:47Z | 2020-11-03T09:26:16Z | https://github.com/kubernetes/kubernetes/issues/95882 | 729,840,692 | 95,882 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
In https://github.com/kubernetes/kubernetes/pull/91592 , we found that actually different CNIs apply loopback policys differently.
When you apply a policy to a pod:
- is an ALLOW rule required to access itself over a service IP ?
- is an ALLOW rule required to access itself over locally ?
... | Missing definitions for loopback networkpolicies | https://api.github.com/repos/kubernetes/kubernetes/issues/95879/comments | 10 | 2020-10-26T18:24:46Z | 2021-01-31T14:40:26Z | https://github.com/kubernetes/kubernetes/issues/95879 | 729,803,148 | 95,879 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are failing**:
[node-kubelet-conformance suite](https://testgrid.k8s.io/sig-node-kubelet#node-kubelet-conformance&show-stale-tests=)
**Which test(s) are failing**:
The tests are failing in the `BeforeSuite`.
**Since when has it been failing**:
10/23/2020
**Testgrid link**:
https://test... | Investigate node-kubelet-conformance test failures | https://api.github.com/repos/kubernetes/kubernetes/issues/95877/comments | 28 | 2020-10-26T17:20:27Z | 2020-11-04T19:31:48Z | https://github.com/kubernetes/kubernetes/issues/95877 | 729,757,011 | 95,877 |
[
"kubernetes",
"kubernetes"
] | Instead of relying on the clock:
https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/apiserver/pkg/storage/cacher/time_budget.go#L60
we should do something similar to the golang rate-limitter is doing:
https://github.com/kubernetes/kubernetes/blob/master/vendor/golang.org/x/time/rate/rate.go#L... | timeBudget shouldn't depend on the real clock | https://api.github.com/repos/kubernetes/kubernetes/issues/95875/comments | 19 | 2020-10-26T16:07:49Z | 2021-08-05T08:44:19Z | https://github.com/kubernetes/kubernetes/issues/95875 | 729,698,732 | 95,875 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Container image caching at the control plane level that pushes its cache to new nodes (such as when the cluster scales horizontally) as needed.
**Why is this needed**:
When new nodes are added to a cluster, they don't contain any of the local image caches yet that the other... | Control Plane level Image Caching | https://api.github.com/repos/kubernetes/kubernetes/issues/95862/comments | 8 | 2020-10-26T04:40:00Z | 2021-05-01T02:14:38Z | https://github.com/kubernetes/kubernetes/issues/95862 | 729,228,896 | 95,862 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Separate the upscale and downscale configuration of hpa.
**Why is this needed**:
consider this:
1. we deployed a deployment which replicas is 4, cpu resource request is 2 core, and hpa's cpu targetAverageUtilization is 100.
2. The current service corresponding to the deploym... | Separate the upscale and downscale configuration of hpa | https://api.github.com/repos/kubernetes/kubernetes/issues/95861/comments | 13 | 2020-10-26T04:05:29Z | 2021-04-17T09:36:18Z | https://github.com/kubernetes/kubernetes/issues/95861 | 729,217,368 | 95,861 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Hello everyo... | kubernetes pod-to-pod low bandwidth | https://api.github.com/repos/kubernetes/kubernetes/issues/95860/comments | 19 | 2020-10-26T03:53:30Z | 2021-02-05T20:18:32Z | https://github.com/kubernetes/kubernetes/issues/95860 | 729,213,839 | 95,860 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
We'd like to have an interface for apiserver backend storage, so we can use other KV storage instead of
**Why is this needed**:
We'd like to improve the performance and support DR :)
/sig api-machinery | Replace ETCD with other KV storage | https://api.github.com/repos/kubernetes/kubernetes/issues/95859/comments | 16 | 2020-10-26T02:42:20Z | 2020-10-29T17:26:27Z | https://github.com/kubernetes/kubernetes/issues/95859 | 729,190,940 | 95,859 |
[
"kubernetes",
"kubernetes"
] | HI
my k8s worker node is running on ARM device, and when it joined a cluster, I met the time out issue. do you know what factors may cause the below issue?
Thanks
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz... | error execution phase kubelet-start | https://api.github.com/repos/kubernetes/kubernetes/issues/95857/comments | 3 | 2020-10-25T13:09:03Z | 2020-10-25T17:13:52Z | https://github.com/kubernetes/kubernetes/issues/95857 | 729,017,541 | 95,857 |
[
"kubernetes",
"kubernetes"
] | I have deployed an app and exposed it as a loadbalancer service. I added the resource field in the yaml of the deployment to request for 100m cpu. Defined a HPA to scale the app when the CPU goes above 50%. The app fails to autoscale and the cpu utilization always shows as unknown.kubectl describe hpa gives the followi... | HPA not able to get the CPU metric. | https://api.github.com/repos/kubernetes/kubernetes/issues/95855/comments | 6 | 2020-10-25T09:00:24Z | 2021-03-24T19:28:46Z | https://github.com/kubernetes/kubernetes/issues/95855 | 728,975,111 | 95,855 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
EDIT: I submitted what I think is a better idea to address the same problem here: https://github.com/kubernetes/kubernetes/issues/99009
An image pull policy that is very much like `Always` but with a catch. General flow on a new pod spinning up as follows:
1. Checks for the... | Always-If-Available Image Pull Policy | https://api.github.com/repos/kubernetes/kubernetes/issues/95854/comments | 8 | 2020-10-25T02:25:32Z | 2021-06-25T19:01:25Z | https://github.com/kubernetes/kubernetes/issues/95854 | 728,922,528 | 95,854 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
/sig cloud-provider
/sig storage
... | vSphere (CSI) plugin :Failed to get shared datastores in kubernetes cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/95851/comments | 5 | 2020-10-24T12:03:19Z | 2021-01-18T22:07:15Z | https://github.com/kubernetes/kubernetes/issues/95851 | 728,775,289 | 95,851 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
[~]# kubectl get cs
NAME AGE
controller-manager <unknown>
scheduler <unknown>
etcd-0 <unknown>
etcd-2 <unknown>
etcd-1 <unknown>
[~]# kubectl get cs -o yaml
apiVersion: v1
items:
- apiVersion: v1
conditions:
- m... | kubectl get cs unknown | https://api.github.com/repos/kubernetes/kubernetes/issues/95850/comments | 4 | 2020-10-24T10:36:54Z | 2020-10-24T10:59:28Z | https://github.com/kubernetes/kubernetes/issues/95850 | 728,761,282 | 95,850 |
[
"kubernetes",
"kubernetes"
] | Having the ability to run a job in an exact point in time is a basic requirement for the jobs. | Support year in cronjob (one-off jobs) | https://api.github.com/repos/kubernetes/kubernetes/issues/95846/comments | 6 | 2020-10-24T07:38:45Z | 2020-10-26T19:06:20Z | https://github.com/kubernetes/kubernetes/issues/95846 | 728,729,426 | 95,846 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Using examp... | KubeSchedulerConfiguration documentation example fail | https://api.github.com/repos/kubernetes/kubernetes/issues/95842/comments | 2 | 2020-10-23T21:08:25Z | 2020-10-25T08:53:02Z | https://github.com/kubernetes/kubernetes/issues/95842 | 728,524,798 | 95,842 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
DiagTrack service running in Window... | DiagTrack service running in Windows infra/pause container is consuming non-trival amounts of CPU | https://api.github.com/repos/kubernetes/kubernetes/issues/95840/comments | 6 | 2020-10-23T19:26:08Z | 2020-11-09T18:24:49Z | https://github.com/kubernetes/kubernetes/issues/95840 | 728,468,781 | 95,840 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
I would like a system whereby Service objects can route to multiple backends that do not share labels (and who's labels I do not control).
https://github.com/kubernetes/kubernetes/issues/48528 describes one possible solution, but it was closed by a bot for no reason.
**Why ... | Services can select multiple backends | https://api.github.com/repos/kubernetes/kubernetes/issues/95838/comments | 13 | 2020-10-23T18:57:03Z | 2020-12-05T01:43:25Z | https://github.com/kubernetes/kubernetes/issues/95838 | 728,450,404 | 95,838 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/kubernetes/pull/95531 refactors and moves the scheduler helpers related to `CheckNodeAffinity` to accept a node object instead of a list of labels and fields.
This affects storage code in some places but in operation_generator.go there is a usage that does not have access to a node obje... | Update storage nodeAffinity check to use node object | https://api.github.com/repos/kubernetes/kubernetes/issues/95837/comments | 10 | 2020-10-23T18:55:52Z | 2021-07-06T12:01:54Z | https://github.com/kubernetes/kubernetes/issues/95837 | 728,449,725 | 95,837 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
- `ci-cluster-api-provider-gcp-make-conformance-v1alpha3-k8s-ci-artifacts`
- `periodic-cluster-api-provider-aws-e2e-conformance-v1alpha3-with-k8s-ci-artifacts`
Also... | [Failing Test] Kubectl client Kubectl server-side dry-run should check if kubectl can dry-run update Pods | https://api.github.com/repos/kubernetes/kubernetes/issues/95832/comments | 10 | 2020-10-23T13:35:04Z | 2020-11-13T14:39:46Z | https://github.com/kubernetes/kubernetes/issues/95832 | 728,224,154 | 95,832 |
[
"kubernetes",
"kubernetes"
] | Hello, I am trying to look on how to define a wildcard as host because it is requires to access the application server.
I am getting this error message:
`The host header sent by the client is not allowed`
When I research on the net, it requires to add the wildcard as hostname.
`--webservice-allowed-hostnames=*`
... | How to define wildcard in yaml file | https://api.github.com/repos/kubernetes/kubernetes/issues/95830/comments | 9 | 2020-10-23T12:59:27Z | 2020-12-10T20:37:00Z | https://github.com/kubernetes/kubernetes/issues/95830 | 728,198,381 | 95,830 |
[
"kubernetes",
"kubernetes"
] | I have a 8vcpu/8core box worker node where we are running our nginx pods. nginx pods are limited to use only 2cores max in
YAML definition i.e
request cpu:- 500m
limit cpu:- 2
nginx configuration as below,
worker_process 2
worker_cpu_affinity auto;
nginx is using only 1st 2 CPU00, CPU01 of the nodes wi... | Kubernetes pod using all nodes vCPU | https://api.github.com/repos/kubernetes/kubernetes/issues/95827/comments | 4 | 2020-10-23T12:36:03Z | 2020-10-25T17:14:56Z | https://github.com/kubernetes/kubernetes/issues/95827 | 728,183,199 | 95,827 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
I tried to upgrade from v1.18.9 to v1.19.3, but v1.19.3 didn't work on my cluster:
```
Oct 23 10:39:03 sserver k3s[2828239]: F1023 10:39:03.536403 2828239 kubelet.go:1296] Failed to start ContainerManager failed to get rootfs info: failed to get device for dir "/var/lib/kubelet": could not fin... | k8s v1.19.3 fails to run on btrfs | https://api.github.com/repos/kubernetes/kubernetes/issues/95826/comments | 8 | 2020-10-23T11:08:30Z | 2021-02-23T16:40:23Z | https://github.com/kubernetes/kubernetes/issues/95826 | 728,129,208 | 95,826 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
More than 2... | Podstatus becomes MatchNodeSelector after restart kubelet | https://api.github.com/repos/kubernetes/kubernetes/issues/95822/comments | 6 | 2020-10-23T09:31:47Z | 2021-01-18T08:45:44Z | https://github.com/kubernetes/kubernetes/issues/95822 | 728,065,070 | 95,822 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
The node stat... | The node status queried through kubectl is inconsistent with the status queried through the API | https://api.github.com/repos/kubernetes/kubernetes/issues/95819/comments | 8 | 2020-10-23T08:27:56Z | 2021-03-25T13:46:49Z | https://github.com/kubernetes/kubernetes/issues/95819 | 728,020,663 | 95,819 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
In k8s 1.19... | PSP seccomp needs annotations 'runtime/default' in 1.19.x | https://api.github.com/repos/kubernetes/kubernetes/issues/95817/comments | 8 | 2020-10-23T08:08:56Z | 2021-09-01T20:38:12Z | https://github.com/kubernetes/kubernetes/issues/95817 | 728,008,051 | 95,817 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
The ability to pass an OIDC Authentication token via file or environment variable. e.g.
```
$ kubectl --token-file <(get-token client-id) get pods
```
OR
```
$ KUBE_TOKEN=$(get-token client-id) kubectl get pods
```
**Why is this needed**:
Passing a sensitive str... | Ability to provide OIDC authentication token to kubectl without leaking the token to the process table | https://api.github.com/repos/kubernetes/kubernetes/issues/95815/comments | 8 | 2020-10-23T04:28:39Z | 2021-03-27T20:40:41Z | https://github.com/kubernetes/kubernetes/issues/95815 | 727,903,010 | 95,815 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
I use deployment to create a pod, the pod‘s status turn to running and ready turn to 1 In the first minute, I can use `kubectl exec -it pod-name -- bash` cmd to enter the pod.
But about ten hours later, the pod's ready turn to 0 and status still running. I can not use `kubectl exec -it pod-name --... | Can't enter the pod with error code 126 | https://api.github.com/repos/kubernetes/kubernetes/issues/95814/comments | 4 | 2020-10-23T03:46:27Z | 2021-01-27T08:18:31Z | https://github.com/kubernetes/kubernetes/issues/95814 | 727,868,363 | 95,814 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
I was testing out the pod topology spread functionality in a local `1.19` k8s cluster. I noticed that when I set the constraint to be
```
topologySpreadConstraints:
- maxSkew: 1
topologyKey: <some label that does not match any in the nodes>
whenUnsatisfiable: DoNotSchedule
... | PodTopologySpread schedules pods to nodes without topologySpreadConstraints[*].topologyKey | https://api.github.com/repos/kubernetes/kubernetes/issues/95808/comments | 3 | 2020-10-22T21:16:49Z | 2020-10-23T16:55:58Z | https://github.com/kubernetes/kubernetes/issues/95808 | 727,726,892 | 95,808 |
[
"kubernetes",
"kubernetes"
] | Currently we don't detach volumes from a node if following error occurs:
```
Error checking if volume ("[foobar kubevols/
4a3c-80d6-a507d3a72ec2.vmdk") is already attached to current node ("foobar") Will continue and try detach anyway. err=No VM found
vsphere.go:936] Node "foobar" does not exist, disk [xxx] kubev... | vSphere does not detaches volumes from a node if "VM not found" error | https://api.github.com/repos/kubernetes/kubernetes/issues/95804/comments | 1 | 2020-10-22T18:56:03Z | 2020-11-10T00:09:10Z | https://github.com/kubernetes/kubernetes/issues/95804 | 727,641,954 | 95,804 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
While working with https://github.com/kubernetes/kubernetes/pull/91824/ files gets randomly generated as a result of running unit tests.
Example:
`make test WHAT=./pkg/registry/core/service/storage`
the following files gets randomly generated
`
pkg/scheduler/apis/config/v1beta1/zz_genera... | Randomly genereted files when running unit tests | https://api.github.com/repos/kubernetes/kubernetes/issues/95803/comments | 14 | 2020-10-22T18:25:50Z | 2021-07-12T07:13:05Z | https://github.com/kubernetes/kubernetes/issues/95803 | 727,622,112 | 95,803 |
[
"kubernetes",
"kubernetes"
] | Hi! I was working on our CSI S3 implementation ( https://github.com/IBM/dataset-lifecycle-framework/tree/master/src/csi-s3 ) and have successfully tested it multiple environments of k8s 1.16+ without a problem.
However, in a recent deployment I have been getting some issues about the attacher not being called.
**Sp... | Debug why some /csi.v1.Node methods are not called | https://api.github.com/repos/kubernetes/kubernetes/issues/95796/comments | 6 | 2020-10-22T15:43:42Z | 2021-03-21T18:17:55Z | https://github.com/kubernetes/kubernetes/issues/95796 | 727,507,331 | 95,796 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
`periodic-kubernetes-bazel-build-master`
**Which test(s) are failing**:
Overall
**Since when has it been failing**:
Since ~4PM ET Oct 21
**Testgrid link**:
... | [Failing Test] periodic-kubernetes-bazel-build-master either times out or loses connection | https://api.github.com/repos/kubernetes/kubernetes/issues/95795/comments | 4 | 2020-10-22T15:12:38Z | 2020-10-28T13:36:10Z | https://github.com/kubernetes/kubernetes/issues/95795 | 727,481,307 | 95,795 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
You can crash your K8S with too many pods (more than 50 000).
**What you expected to happen**:
K8S not crash :-)
kube-scheduler need to check taint before put a pod on a Node
**How to reproduce it (as minimally and precisely as possible)**:
If you have some node with taint and other with... | Cron job and tainted node | https://api.github.com/repos/kubernetes/kubernetes/issues/95794/comments | 7 | 2020-10-22T14:26:07Z | 2021-03-21T17:16:55Z | https://github.com/kubernetes/kubernetes/issues/95794 | 727,440,208 | 95,794 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
We've been fa... | Cgroup issue with centOS 8 | https://api.github.com/repos/kubernetes/kubernetes/issues/95792/comments | 6 | 2020-10-22T13:01:55Z | 2021-03-21T17:16:55Z | https://github.com/kubernetes/kubernetes/issues/95792 | 727,368,796 | 95,792 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Deploying the k8s... | Deploying the k8s cluster on the openstack virtual machine Adding service causes the node noready!!! | https://api.github.com/repos/kubernetes/kubernetes/issues/95788/comments | 4 | 2020-10-22T10:17:36Z | 2020-10-22T14:51:56Z | https://github.com/kubernetes/kubernetes/issues/95788 | 727,252,930 | 95,788 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
e2e test for service ExternalIPs
**Why is this needed**:
There is no test covering Service ExternalIPs
## How to test it
Since we can not assume that the e2e binary will have connectivity against the nodes
and that we can add routes to the environment, we are going t... | Add e2e test for Service ExternalIPs | https://api.github.com/repos/kubernetes/kubernetes/issues/95785/comments | 13 | 2020-10-22T08:19:16Z | 2020-12-09T01:28:19Z | https://github.com/kubernetes/kubernetes/issues/95785 | 727,161,271 | 95,785 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
When attempting to kubeadm join a control plane node or worker on a machine with global IPv4 unicast addresses on a loopback address (router to the host w/ BGP Unnumbered), the join fails with the following output:
```
I1009 00:03:38.372308 8018 interface.go:400] Looking for default routes ... | BGP Unnumbered RFC 5549 ResolveBindAddress fails | https://api.github.com/repos/kubernetes/kubernetes/issues/95779/comments | 4 | 2020-10-21T23:55:19Z | 2020-12-09T00:29:36Z | https://github.com/kubernetes/kubernetes/issues/95779 | 726,938,805 | 95,779 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
1. I am cr... | Mounting configmap & EmptyDir failed: MountVolume.SetUp failed for volume... no such file or directory | https://api.github.com/repos/kubernetes/kubernetes/issues/95778/comments | 12 | 2020-10-21T22:14:52Z | 2023-02-12T05:09:23Z | https://github.com/kubernetes/kubernetes/issues/95778 | 726,899,554 | 95,778 |
[
"kubernetes",
"kubernetes"
] | If using waitForFirstConsumer mode, we cannot set Pod spec.nodeName.
Issue https://github.com/openebs/openebs/issues/2915 has detailed explanation.
Should document this behavior in doc.
<!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bu... | waitForFirstConsumer PVCs fail to bind when Pod spec.nodeName is specified | https://api.github.com/repos/kubernetes/kubernetes/issues/95767/comments | 11 | 2020-10-21T17:19:26Z | 2021-05-04T00:34:21Z | https://github.com/kubernetes/kubernetes/issues/95767 | 726,702,494 | 95,767 |
[
"kubernetes",
"kubernetes"
] | Re-posting this issue here from the original issue posted to the metrics server repo.
This is a documentation bug report. For legal compliance purposes within my organization, I am required to know the exact copyright holder of the software we are intending to use. There is no copyright notice in the README or LICEN... | LICENSE file refers to "Licensor" but there is no licensor stated in the LICENSE file or in the README file. #619 | https://api.github.com/repos/kubernetes/kubernetes/issues/95765/comments | 8 | 2020-10-21T15:24:40Z | 2020-10-22T01:41:20Z | https://github.com/kubernetes/kubernetes/issues/95765 | 726,596,269 | 95,765 |
[
"kubernetes",
"kubernetes"
] | Hello there,
I am new to Kubernetes and I am seeking help.
I just deployed a cluster of two nodes, one master and one worker. Apparenty, cluster is working fine, the problem is that pods cannot reach CoreDNS nor Kubernetes Api.
In order to deploy networking I used **flannel** network driver. https://raw.git... | Kubernetes Pod’s cannot reach pods in serviceSubnet | https://api.github.com/repos/kubernetes/kubernetes/issues/95764/comments | 6 | 2020-10-21T13:48:13Z | 2020-10-22T20:40:32Z | https://github.com/kubernetes/kubernetes/issues/95764 | 726,511,414 | 95,764 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
I've configured a hpa with these details:
```
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: api-horizontalautoscaler
namespace: develop
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: api-deployment
minReplic... | HPA not downscaling when memory is under target | https://api.github.com/repos/kubernetes/kubernetes/issues/95762/comments | 8 | 2020-10-21T12:48:10Z | 2021-05-24T10:49:32Z | https://github.com/kubernetes/kubernetes/issues/95762 | 726,448,713 | 95,762 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
```
# kubect... | error: error validating "lxcfs-initializer.yaml": error validating data: ValidationError(Deployment.metadata): unknown field "initializers" in io.k8s.apimachinery.pkg.apis.meta.v1.ObjectMeta; if you choose to ignore these errors, turn validation off with --validate=false | https://api.github.com/repos/kubernetes/kubernetes/issues/95760/comments | 4 | 2020-10-21T11:54:34Z | 2020-10-21T12:28:08Z | https://github.com/kubernetes/kubernetes/issues/95760 | 726,409,555 | 95,760 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
I'd like `kubectl wait` to support multiple wait conditions at once so these are evaluated on the resource with the same ResourceVersion. Like:
```
kubectl wait <resource> --for='condition=Available=True' --for='condition=Progressing=False' --for='condition=Degraded=False
```
... | RFE: Kubectl wait for multiple conditions | https://api.github.com/repos/kubernetes/kubernetes/issues/95759/comments | 29 | 2020-10-21T11:42:29Z | 2025-02-12T17:01:01Z | https://github.com/kubernetes/kubernetes/issues/95759 | 726,401,284 | 95,759 |
[
"kubernetes",
"kubernetes"
] | trying to follow kubernetes tutorial[1]Example: Deploying WordPress and MySQL with Persistent Volumes;
run command 'kubectl apply -f wordpress-deployment.yaml' on google kubernetes using cloudshell;
got this error:**error: error parsing wordpress-deployment.yaml: error converting YAML to JSON: yaml: line 33: could no... | error: error parsing wordpress-deployment.yaml: error converting YAML to JSON: yaml: line 33: could not find expected ':' | https://api.github.com/repos/kubernetes/kubernetes/issues/95754/comments | 5 | 2020-10-21T10:11:16Z | 2020-10-21T18:56:17Z | https://github.com/kubernetes/kubernetes/issues/95754 | 726,337,303 | 95,754 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Set the capping of retrying on the nominated node so that other nodes in the cluster could be chosen for preemption.
**Why is this needed**:
After the pod preemption, a nominated could be set for th... | pod stuck on the nominated node cannot release resource timely | https://api.github.com/repos/kubernetes/kubernetes/issues/95752/comments | 21 | 2020-10-21T09:04:46Z | 2021-01-06T01:47:38Z | https://github.com/kubernetes/kubernetes/issues/95752 | 726,286,360 | 95,752 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**Priorityclass field support edit**:
**some task’s priority is changing by time; Also as platform,we need to support task related to the time period **:
| Priorityclass field support edit | https://api.github.com/repos/kubernetes/kubernetes/issues/95751/comments | 8 | 2020-10-21T08:11:05Z | 2021-03-21T11:10:55Z | https://github.com/kubernetes/kubernetes/issues/95751 | 726,246,493 | 95,751 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
In a cluster with lots pods, the relist step takes too much time, result in node not ready.
Most time spend in updateCache step, which will inspect the pod and get the PodStatus to update the cache serially.
**What you expected to happen**:
PLEG relist should not result in node not ready,... | Kubelet PLEG relist takes too long result in node notready | https://api.github.com/repos/kubernetes/kubernetes/issues/95750/comments | 22 | 2020-10-21T08:02:24Z | 2021-08-08T09:31:27Z | https://github.com/kubernetes/kubernetes/issues/95750 | 726,240,379 | 95,750 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Not able to... | CSS not loading kubernetes.io docs | https://api.github.com/repos/kubernetes/kubernetes/issues/95749/comments | 5 | 2020-10-21T07:52:39Z | 2020-10-22T08:04:01Z | https://github.com/kubernetes/kubernetes/issues/95749 | 726,233,455 | 95,749 |
[
"kubernetes",
"kubernetes"
] | **What happened**: configmap we use for leader election was not deleted even though it's owner is gone
**What you expected to happen**: configmap is deleted
**How to reproduce it (as minimally and precisely as possible)**: idk
**Anything else we need to know?**:
it looks like there is a race-condition / bug i... | ownerReference is not reconciled, leading to abandoned resources | https://api.github.com/repos/kubernetes/kubernetes/issues/95742/comments | 4 | 2020-10-20T21:39:45Z | 2020-11-13T05:57:54Z | https://github.com/kubernetes/kubernetes/issues/95742 | 725,963,624 | 95,742 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
/sig-scheduling
Configurable node affinity constraints to the NodeAffinity plugin args:
```golang
type NodeAffinityArgs struct {
default *v1.NodeAffinity
}
```
These rules are always appended to the ones defined in PodSpecs.
**Why is this needed**:
Some sched... | Add default node affinity constraints to NodeAffinity plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/95738/comments | 21 | 2020-10-20T19:49:10Z | 2020-11-09T23:14:56Z | https://github.com/kubernetes/kubernetes/issues/95738 | 725,894,442 | 95,738 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Windows nodes... | /stats/summary endpoints failing with "Context Deadline Exceeded" on Windows nodes with very high CPU usage | https://api.github.com/repos/kubernetes/kubernetes/issues/95735/comments | 21 | 2020-10-20T18:00:19Z | 2022-01-31T00:32:25Z | https://github.com/kubernetes/kubernetes/issues/95735 | 725,819,948 | 95,735 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
We have a sce... | kubectl exec not working behind c# reverse-proxy on version 1.18 and below. | https://api.github.com/repos/kubernetes/kubernetes/issues/95733/comments | 16 | 2020-10-20T16:13:10Z | 2021-03-13T17:11:52Z | https://github.com/kubernetes/kubernetes/issues/95733 | 725,746,563 | 95,733 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
`periodic-cluster-api-provider-aws-e2e-conformance-v1alpha3-with-k8s-ci-artifacts`
**Which test(s) are failing**:
`Overall`
`conformance tests conformance` (???)
... | [Failing Test] periodic-cluster-api-provider-aws-e2e-conformance-v1alpha3-with-k8s-ci-artifacts | https://api.github.com/repos/kubernetes/kubernetes/issues/95730/comments | 3 | 2020-10-20T14:28:13Z | 2020-10-22T20:49:39Z | https://github.com/kubernetes/kubernetes/issues/95730 | 725,649,152 | 95,730 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
`ci-cluster-api-provider-gcp-make-conformance-v1alpha3-k8s-ci-artifacts`
**Which test(s) are failing**:
Overall
**Since when has it been failing**:
At _least_ O... | [Failing Test] ci-cluster-api-provider-gcp-make-conformance-v1alpha3-k8s-ci-artifacts | https://api.github.com/repos/kubernetes/kubernetes/issues/95729/comments | 6 | 2020-10-20T14:21:15Z | 2020-10-23T13:39:52Z | https://github.com/kubernetes/kubernetes/issues/95729 | 725,642,831 | 95,729 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
When I rest... | The cpu of kubelet is always 100% after containerd.service restart | https://api.github.com/repos/kubernetes/kubernetes/issues/95727/comments | 25 | 2020-10-20T14:05:40Z | 2020-12-23T20:36:01Z | https://github.com/kubernetes/kubernetes/issues/95727 | 725,627,790 | 95,727 |
[
"kubernetes",
"kubernetes"
] | When attempting to list selfsubjectaccessreviews via `get`, I get an error. However, the check via `can-i get` passes (sort of).
```
$ kubectl auth can-i get SelfSubjectAccessReview
Warning: resource 'selfsubjectaccessreviews' is not namespace scoped in group 'authorization.k8s.io'
yes
$ kubectl auth can-i g... | can-i disagrees with usage for SelfSubjectAccessReview | https://api.github.com/repos/kubernetes/kubernetes/issues/95714/comments | 4 | 2020-10-20T01:00:02Z | 2020-10-20T02:27:41Z | https://github.com/kubernetes/kubernetes/issues/95714 | 725,093,126 | 95,714 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Support in Kubernetes to remap/alias dotted DNS names inside the cluster. Either via allowing dotted service names (Or a new property to allow a service to have a dotted name in DNS), some new dedicated r... | Support for split-horizon DNS setups, DNS aliases and/or services with dotted names | https://api.github.com/repos/kubernetes/kubernetes/issues/95712/comments | 27 | 2020-10-19T17:43:16Z | 2024-03-14T16:24:07Z | https://github.com/kubernetes/kubernetes/issues/95712 | 724,840,481 | 95,712 |
[
"kubernetes",
"kubernetes"
] | I got some requirement from users that run serverless workloads, who cares a lot about minimizing the running machines to reduce cost.
They've started to use the `NodeResourcesMostAllocated` Score plugin (just as AutoScaler did) to replace the default `NodeResourcesLeastAllocated` plugin, however, it seems not to be... | scheduler: provide an option to not shuffle internal node index when using percentageOfNodesToScore | https://api.github.com/repos/kubernetes/kubernetes/issues/95709/comments | 21 | 2020-10-19T17:13:32Z | 2021-12-18T21:46:55Z | https://github.com/kubernetes/kubernetes/issues/95709 | 724,809,731 | 95,709 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
The [official... | Fail to find PostFilter extension point | https://api.github.com/repos/kubernetes/kubernetes/issues/95708/comments | 5 | 2020-10-19T16:24:44Z | 2020-10-20T13:33:54Z | https://github.com/kubernetes/kubernetes/issues/95708 | 724,777,481 | 95,708 |
[
"kubernetes",
"kubernetes"
] | Both WindowsGMSA and WindowsRunAsUserName feature gates have been GA since v1.18 and were scheduled to be removed in v1.20.
https://github.com/kubernetes/kubernetes/blob/2046f4212a355a3381da20c4d800283b98e9a081/pkg/features/kube_features.go#L714-L715
/sig windows
/milestone v1.20
/good-first-issue | Remove WindowsGMSA and WindowsRunAsUserName feature gates in 1.20 | https://api.github.com/repos/kubernetes/kubernetes/issues/95707/comments | 25 | 2020-10-19T16:22:30Z | 2021-01-30T09:03:48Z | https://github.com/kubernetes/kubernetes/issues/95707 | 724,775,950 | 95,707 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Upon deactivating IPv6 via kernel sysctl
```
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
```
thus going from
```
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:0... | apiserver bound to 0.0.0.0 fails when applying kernel parameter disable_ipv6 at runtime | https://api.github.com/repos/kubernetes/kubernetes/issues/95706/comments | 11 | 2020-10-19T16:04:56Z | 2021-01-27T16:57:34Z | https://github.com/kubernetes/kubernetes/issues/95706 | 724,762,736 | 95,706 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
build and development support under WSL2 environment, specially for creating a local cluster by local-up-cluster.sh
**Why is this needed**:
for windows users, very neccessary to deploy local kuber... | WSL2: failed to run Kubelet | https://api.github.com/repos/kubernetes/kubernetes/issues/95704/comments | 9 | 2020-10-19T14:18:27Z | 2021-04-06T11:58:45Z | https://github.com/kubernetes/kubernetes/issues/95704 | 724,666,510 | 95,704 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
A deploymen... | Deployment gets restarted with old image tag | https://api.github.com/repos/kubernetes/kubernetes/issues/95703/comments | 16 | 2020-10-19T13:13:54Z | 2020-11-06T14:58:15Z | https://github.com/kubernetes/kubernetes/issues/95703 | 724,598,321 | 95,703 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
I'm getting an issue with kubectl explain <crd> (in my case networkaddonsconfig ) when upgrading from version with `apiextensions.k8s.io/v1beta1` to `apiextensions.k8s.io/v1`, where `DESCRIPTION` is empty even if the updated crd has got the description fields updated.
```
$ kubectl explain example... | upgrades between CRDs are broken - kubectl explain not updated | https://api.github.com/repos/kubernetes/kubernetes/issues/95702/comments | 6 | 2020-10-19T12:59:13Z | 2020-11-03T21:52:27Z | https://github.com/kubernetes/kubernetes/issues/95702 | 724,586,677 | 95,702 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about flaky tests or jobs (pass or fail with no underlying change in code) in Kubernetes CI -->
**Which jobs are flaking**:
* integration-master
**Which test(s) are flaking**:
k8s.io/kubernetes/test/integration/scheduler: TestPostFilterPlugin
**Testg... | [Flaky Test] k8s.io/kubernetes/test/integration/scheduler: TestPostFilterPlugin | https://api.github.com/repos/kubernetes/kubernetes/issues/95700/comments | 3 | 2020-10-19T11:15:34Z | 2020-10-23T19:15:17Z | https://github.com/kubernetes/kubernetes/issues/95700 | 724,515,879 | 95,700 |
[
"kubernetes",
"kubernetes"
] | What should I do if I want to store k/v data to kubernetes etcd? Can you give me a example ? Thank you @floreks | What should I do if I want to store k/v data to kubernetes etcd ? | https://api.github.com/repos/kubernetes/kubernetes/issues/95699/comments | 4 | 2020-10-19T10:11:45Z | 2020-10-19T10:30:58Z | https://github.com/kubernetes/kubernetes/issues/95699 | 724,472,808 | 95,699 |
[
"kubernetes",
"kubernetes"
] | hello,
I created a new ETCD cluster with a backup file from etCD. I am not sure how to modify the Kube-Apiserver - ETCD-Servers,
The official documentation is as follows:
If the access URLs of the restored cluster is changed from the previous cluster, the Kubernetes API server must be reconfigured accordingly. In... | How to modify kube-apiserver - etcd-servers | https://api.github.com/repos/kubernetes/kubernetes/issues/95696/comments | 2 | 2020-10-19T09:23:52Z | 2020-10-19T09:52:20Z | https://github.com/kubernetes/kubernetes/issues/95696 | 724,437,546 | 95,696 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Like described in #28603 I'm searching for a way to temporarily stop a deployment. As far as i understood it should be possible to scale down the pods to 0.
I have done this with the command
`kubectl scale deploy my-application --replicas=0`
The deploment has been scaled down to 0 like expe... | Need a way to temporarily stop a deployment | https://api.github.com/repos/kubernetes/kubernetes/issues/95695/comments | 13 | 2020-10-19T08:20:52Z | 2021-03-21T09:08:55Z | https://github.com/kubernetes/kubernetes/issues/95695 | 724,390,484 | 95,695 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
When creating a service with type `LoadBalancer` on an AWS environment a default TLS negotiation policy is attached.
It's only possible to assign an already predefined policy as part of the service annotations:
```
metadata:
name: my-service
annotations:
... | Add custom TLS policies for AWS ELB | https://api.github.com/repos/kubernetes/kubernetes/issues/95693/comments | 15 | 2020-10-19T07:54:30Z | 2022-03-26T15:58:29Z | https://github.com/kubernetes/kubernetes/issues/95693 | 724,371,315 | 95,693 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Can't shrink ... | Can't shrink by adding label pods when stateless application shrink | https://api.github.com/repos/kubernetes/kubernetes/issues/95688/comments | 4 | 2020-10-19T03:18:36Z | 2020-10-19T11:20:59Z | https://github.com/kubernetes/kubernetes/issues/95688 | 724,225,996 | 95,688 |
[
"kubernetes",
"kubernetes"
] | /sig architecture
/sig node
**What happened**:
The memory limits within my K8s node is not being calculated correctly (see screenshots below)
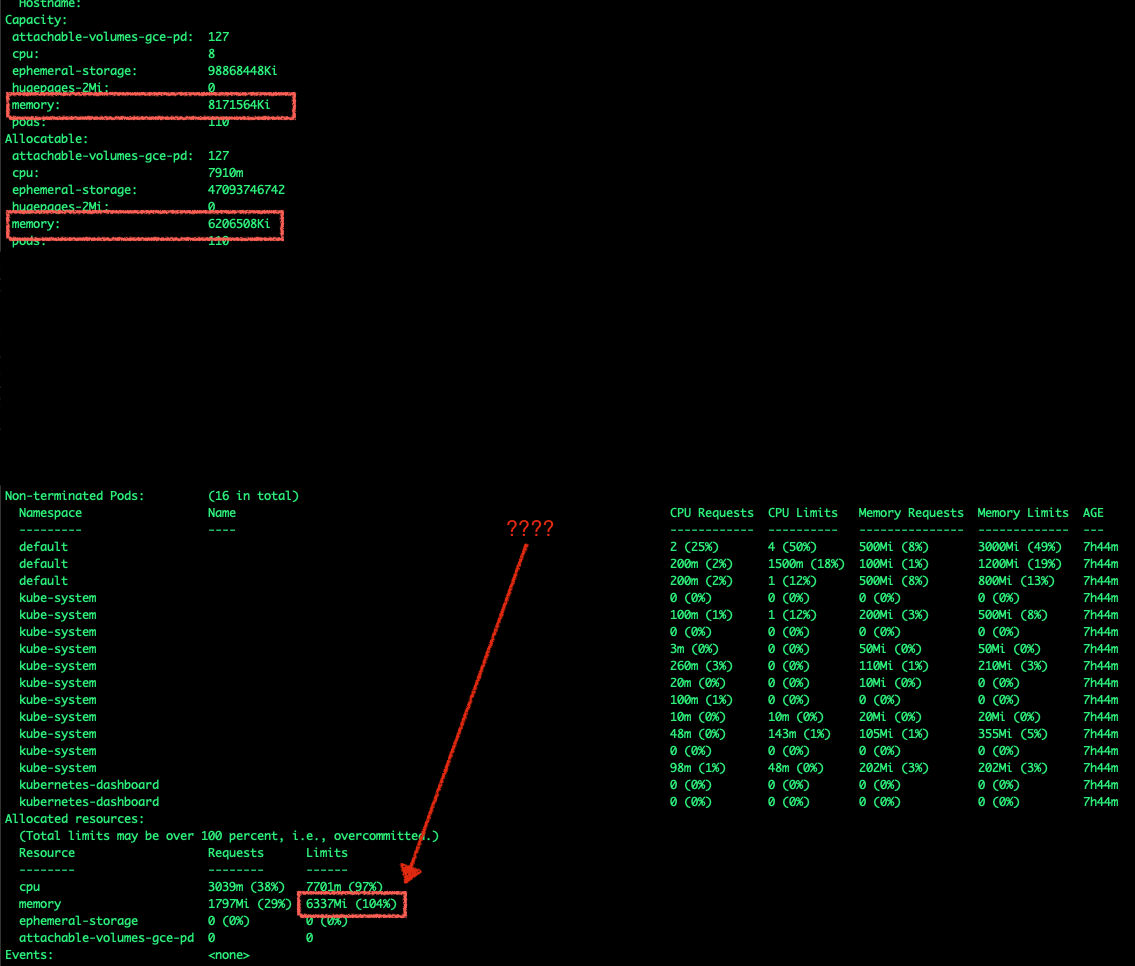
However, when I view them i... | Node resource limits to being calculated correctly | https://api.github.com/repos/kubernetes/kubernetes/issues/95684/comments | 6 | 2020-10-18T22:26:53Z | 2021-03-18T00:50:47Z | https://github.com/kubernetes/kubernetes/issues/95684 | 724,135,122 | 95,684 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Windows Conta... | Windows containers restart in vSphere cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/95682/comments | 10 | 2020-10-18T18:59:11Z | 2020-10-29T07:52:32Z | https://github.com/kubernetes/kubernetes/issues/95682 | 724,074,093 | 95,682 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
api-server ... | apiserver liveness probe failed with status code 500 | https://api.github.com/repos/kubernetes/kubernetes/issues/95681/comments | 7 | 2020-10-18T17:03:01Z | 2022-04-25T09:32:18Z | https://github.com/kubernetes/kubernetes/issues/95681 | 724,051,545 | 95,681 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
When a CRD that uses the scale subresource is created or updated using server-side apply an unexpected error occurs:
```
The WishIHadChosenNoxu "test" is invalid: .spec.cReplicas: Invalid value: 0: .spec.cReplicas accessor error: 3 is of the type float64, expected int64
```
**What you exp... | Validation type error when creating / updating CRDs that use scale subresource | https://api.github.com/repos/kubernetes/kubernetes/issues/95680/comments | 17 | 2020-10-18T15:24:42Z | 2020-10-26T17:25:28Z | https://github.com/kubernetes/kubernetes/issues/95680 | 724,031,088 | 95,680 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about flaky tests or jobs (pass or fail with no underlying change in code) in Kubernetes CI -->
**Which jobs are flaking**:
* Conformance GCE Master
**Which test(s) are flaking**:
Up
**Testgrid link**:
https://testgrid.k8s.io/sig-release-master-block... | [Flaky Test] Conformance GCE Master - failing at Cluster Up step. | https://api.github.com/repos/kubernetes/kubernetes/issues/95677/comments | 4 | 2020-10-18T06:30:38Z | 2020-10-19T17:13:02Z | https://github.com/kubernetes/kubernetes/issues/95677 | 723,939,361 | 95,677 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**: Looking at [this page](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#consuming-extended-resources) it seems that extended resources cannot be overcommitted (requests and li... | Allow extended resources to be overcommitted and contain floating points | https://api.github.com/repos/kubernetes/kubernetes/issues/95673/comments | 10 | 2020-10-17T10:49:43Z | 2021-06-14T14:12:05Z | https://github.com/kubernetes/kubernetes/issues/95673 | 723,730,048 | 95,673 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
sig-netwok jobs running serial tests
**Which test(s) are failing**:
[sig-network] DNS configMap nameserver.*
**Since when has it been failing**:
Seems thi... | [Failing test] DNS ConfigMap * tests are failing | https://api.github.com/repos/kubernetes/kubernetes/issues/95671/comments | 2 | 2020-10-17T09:37:05Z | 2020-10-18T19:10:13Z | https://github.com/kubernetes/kubernetes/issues/95671 | 723,717,617 | 95,671 |
[
"kubernetes",
"kubernetes"
] | Hi,
hopefully I can get some support here - currently trying to deploy k8s cluster via kubespray v2.14.1.
Seems that latest k8s images are not available:
└─ $ ▶ docker image pull gcr.io/google-containers/kube-apiserver:v1.18.9 Error response from daemon: manifest for gcr.io/google-containers/kube-apiserver:v1.18.9... | gcr.io/google-containers/kube-apiserver:v1.18.9 not found | https://api.github.com/repos/kubernetes/kubernetes/issues/95670/comments | 4 | 2020-10-17T08:49:30Z | 2020-10-19T19:25:54Z | https://github.com/kubernetes/kubernetes/issues/95670 | 723,708,811 | 95,670 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
when getting ... | Fix internal loadbalancer configuration failure when truncated FrontendIPConfigName ended with special char | https://api.github.com/repos/kubernetes/kubernetes/issues/95663/comments | 4 | 2020-10-16T21:46:21Z | 2020-10-16T23:56:39Z | https://github.com/kubernetes/kubernetes/issues/95663 | 723,550,165 | 95,663 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**: kubectl create... | kubectl create ingress panics because of missing dry-run flag | https://api.github.com/repos/kubernetes/kubernetes/issues/95658/comments | 1 | 2020-10-16T18:48:05Z | 2020-10-19T14:52:27Z | https://github.com/kubernetes/kubernetes/issues/95658 | 723,451,125 | 95,658 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
When execut... | Invalid indentation level in kubectl describe node output | https://api.github.com/repos/kubernetes/kubernetes/issues/95638/comments | 4 | 2020-10-16T07:35:14Z | 2020-10-18T03:44:40Z | https://github.com/kubernetes/kubernetes/issues/95638 | 722,984,544 | 95,638 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
When kubelet ... | Healthy events will probably not be sent due to the flow limit of pod | https://api.github.com/repos/kubernetes/kubernetes/issues/95637/comments | 8 | 2020-10-16T07:21:37Z | 2021-03-18T04:54:48Z | https://github.com/kubernetes/kubernetes/issues/95637 | 722,976,586 | 95,637 |
[
"kubernetes",
"kubernetes"
] | In https://github.com/kubernetes/kubernetes/issues/95556 we discovered a bug where kube-apiserver metrics were being incorrectly reported (GET vs LIST problem).
In https://github.com/kubernetes/kubernetes/pull/95562 this was addressed together with test exercising that proper metrics are exposed.
However, this test... | More comprehensive test for mapping url paths to metrics labels | https://api.github.com/repos/kubernetes/kubernetes/issues/95636/comments | 7 | 2020-10-16T06:57:16Z | 2020-11-11T01:48:33Z | https://github.com/kubernetes/kubernetes/issues/95636 | 722,961,776 | 95,636 |
[
"kubernetes",
"kubernetes"
] | This might be best written out in a KEP since its a holistic change to the sig-net testing metadata, but could also do it in bite size chunks.
**What would you like to be added**:
ginkgo skip/focus metadata strings or tags which identify:
- service proxy tests,
- kube proxy tests,
for all of the current s... | [service-proxy] and [kube-proxy] tags | https://api.github.com/repos/kubernetes/kubernetes/issues/95633/comments | 9 | 2020-10-16T01:41:35Z | 2021-03-13T21:40:35Z | https://github.com/kubernetes/kubernetes/issues/95633 | 722,796,147 | 95,633 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
I would like to make the `CSIDriver.spec.podInfoOnMount` field mutable.
**Why is this needed**:
Because there are CSI drivers that do not yet support this feature, but will in the near future (lik... | Make CSIDriver.spec.podInfoOnMount mutable | https://api.github.com/repos/kubernetes/kubernetes/issues/95627/comments | 8 | 2020-10-15T23:03:46Z | 2021-04-01T20:36:55Z | https://github.com/kubernetes/kubernetes/issues/95627 | 722,735,607 | 95,627 |
[
"kubernetes",
"kubernetes"
] | CVSS Rating: 4.7 CVSS:3.0/AV:L/AC:H/PR:L/UI:N/S:U/C:H/I:N/A:N (Medium)
In Kubernetes clusters using Ceph RBD as a storage provisioner, with logging level of at least 4, Ceph RBD admin secrets can be written to logs. This occurs in kube-controller-manager's logs during provisioning of Ceph RBD persistent claims.
... | CVE-2020-8566: Ceph RBD adminSecrets exposed in logs when loglevel >= 4 | https://api.github.com/repos/kubernetes/kubernetes/issues/95624/comments | 3 | 2020-10-15T22:07:53Z | 2021-12-02T22:53:56Z | https://github.com/kubernetes/kubernetes/issues/95624 | 722,707,368 | 95,624 |
[
"kubernetes",
"kubernetes"
] | CVSS Rating: 4.7 CVSS:3.0/AV:L/AC:H/PR:L/UI:N/S:U/C:H/I:N/A:N (Medium)
In Kubernetes, if the logging level is to at least 9, authorization and bearer tokens will be written to log files. This can occur both in API server logs and client tool output like `kubectl`.
### Am I vulnerable?
If kube-apiserver is using ... | CVE-2020-8565: Incomplete fix for CVE-2019-11250 allows for token leak in logs when logLevel >= 9 | https://api.github.com/repos/kubernetes/kubernetes/issues/95623/comments | 3 | 2020-10-15T22:05:32Z | 2021-12-02T22:54:04Z | https://github.com/kubernetes/kubernetes/issues/95623 | 722,706,304 | 95,623 |
[
"kubernetes",
"kubernetes"
] | CVSS Rating: 4.7 CVSS:3.0/AV:L/AC:H/PR:L/UI:N/S:U/C:H/I:N/A:N (Medium)
In Kubernetes clusters using a logging level of at least 4, processing a malformed docker config file will result in the contents of the docker config file being leaked, which can include pull secrets or other registry credentials.
### Am I vu... | CVE-2020-8564: Docker config secrets leaked when file is malformed and log level >= 4 | https://api.github.com/repos/kubernetes/kubernetes/issues/95622/comments | 3 | 2020-10-15T22:03:19Z | 2021-12-02T22:54:10Z | https://github.com/kubernetes/kubernetes/issues/95622 | 722,705,294 | 95,622 |
[
"kubernetes",
"kubernetes"
] | CVSS Rating: 5.6 CVSS:3.0/AV:L/AC:H/PR:L/UI:N/S:C/C:H/I:N/A:N (Medium)
In Kubernetes clusters using VSphere as a cloud provider, with a logging level set to 4 or above, VSphere cloud credentials will be leaked in the cloud controller manager's log.
### Am I vulnerable?
If you are using VSphere as a cloud provide... | CVE-2020-8563: Secret leaks in kube-controller-manager when using vSphere provider | https://api.github.com/repos/kubernetes/kubernetes/issues/95621/comments | 3 | 2020-10-15T22:00:44Z | 2021-12-02T22:54:17Z | https://github.com/kubernetes/kubernetes/issues/95621 | 722,704,051 | 95,621 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.