
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | **Which jobs are failing**:
TestExpectationsOnRecreate unit test, added in https://github.com/kubernetes/kubernetes/pull/91915 along with expectations bugfix during 1.19 and cherry-picked to 1.18/1.17
**Which test(s) are failing**:
`go test -race -count=10 ./pkg/controller/daemon -run TestExpectationsOnRecreat... | Daemonset TestExpectationsOnRecreate fails consistently | https://api.github.com/repos/kubernetes/kubernetes/issues/93604/comments | 9 | 2020-07-31T15:13:16Z | 2020-08-06T16:35:44Z | https://github.com/kubernetes/kubernetes/issues/93604 | 669,918,885 | 93,604 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
```
curl -... | apiserver panic'd on GET /readyz | https://api.github.com/repos/kubernetes/kubernetes/issues/93599/comments | 9 | 2020-07-31T11:25:38Z | 2020-08-05T03:16:57Z | https://github.com/kubernetes/kubernetes/issues/93599 | 669,715,289 | 93,599 |
[
"kubernetes",
"kubernetes"
] |
**What happened**:
I want to use kubeadm to build IPV4/IPv6 dual stack k8s cluster. But node internal IP only shows ipv4. I uses calico network plugin. The pod IP and service can be assgined ipv4 and ipv6. But the pod cannot be accessed over ipv6 addresses.
**What you expected to happen**:
The cluster nodes hav... | DualStack: The node of kubernetes v1.18.2 has only one ipv4 address. Access to pod via ipv6 is not possible | https://api.github.com/repos/kubernetes/kubernetes/issues/93598/comments | 5 | 2020-07-31T10:57:03Z | 2020-08-01T06:39:19Z | https://github.com/kubernetes/kubernetes/issues/93598 | 669,691,945 | 93,598 |
[
"kubernetes",
"kubernetes"
] |
Hello, do you have any suggestions for controller-manager selection optimization and node status update?
--leader-elect-lease-duration=15s
--leader-elect-renew-deadline=10s
--log-dir=/var/log/matrix-diag/Matrix/kube-controller-manager
--logtostderr=false
--node-cidr-mask-size=24
--node-monitor-grace-perio... | controller-manager leader selection optimization | https://api.github.com/repos/kubernetes/kubernetes/issues/93596/comments | 5 | 2020-07-31T08:05:04Z | 2020-12-28T10:41:14Z | https://github.com/kubernetes/kubernetes/issues/93596 | 669,539,836 | 93,596 |
[
"kubernetes",
"kubernetes"
] | /sig area/kubeadm
I installed k8s on a clean ubunut. When I executed the command ``` kubeadm init -v=7 ```, I was confused. my port 6443 was not listening.
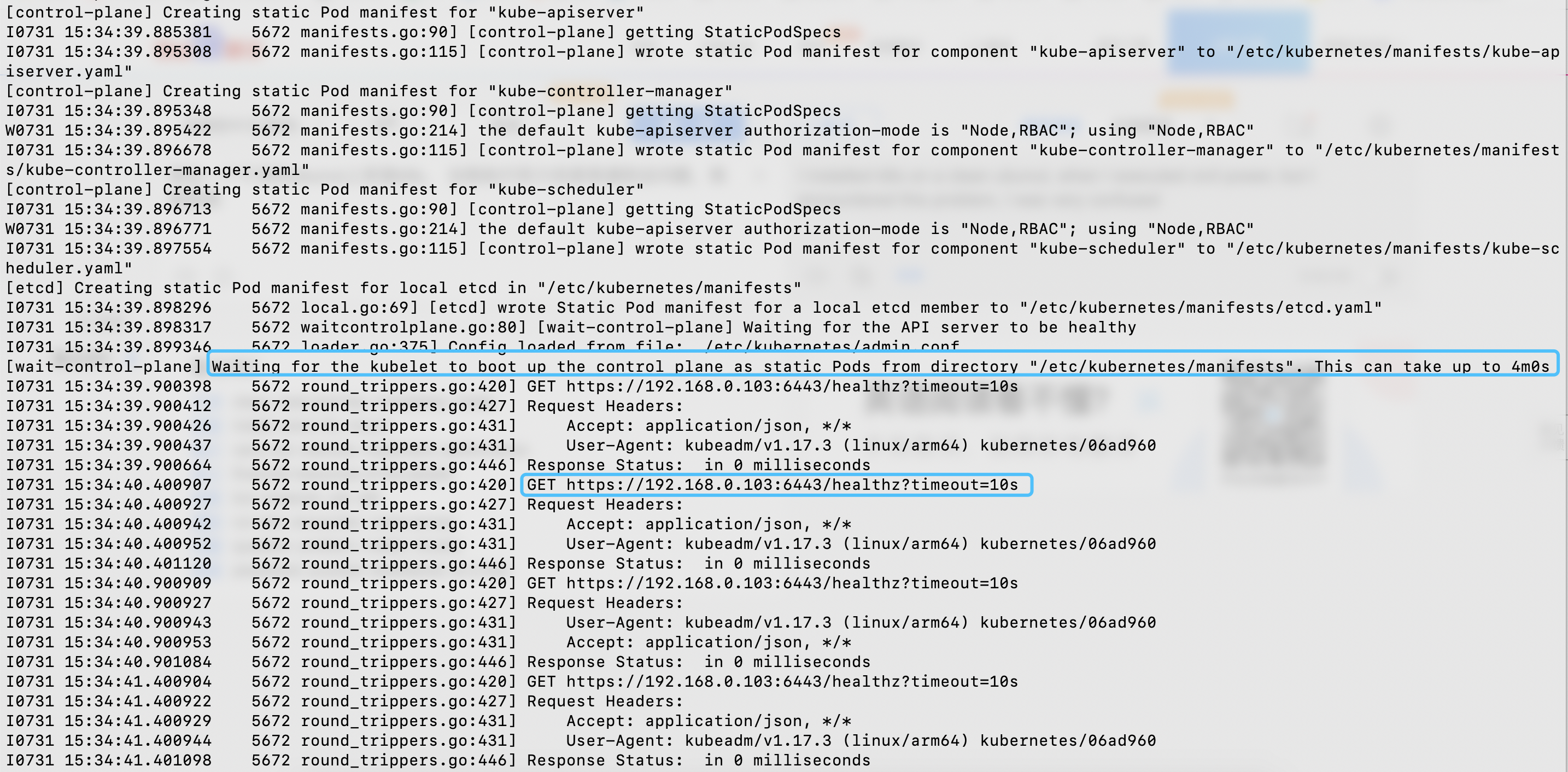
After doing this many times, tell me ```... | kubeadm init stuck at "Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s" | https://api.github.com/repos/kubernetes/kubernetes/issues/93595/comments | 3 | 2020-07-31T07:49:41Z | 2020-07-31T08:02:30Z | https://github.com/kubernetes/kubernetes/issues/93595 | 669,526,754 | 93,595 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a _Reuse_ option to the ReclaimPolicy of PersistentVolumes/StorageClasses.
It should work like the _Retain_ ReclaimPolicy, but instead of keeping the _ClaimRef_ field in a PV after an PVC is deleted it should automatically empty it. So that the PV can automatically be bound to... | Add "Reuse" option to the ReclaimPolicy | https://api.github.com/repos/kubernetes/kubernetes/issues/93594/comments | 7 | 2020-07-31T05:40:21Z | 2021-04-02T08:48:16Z | https://github.com/kubernetes/kubernetes/issues/93594 | 669,434,124 | 93,594 |
[
"kubernetes",
"kubernetes"
] | ```
func listNodes(kubeClient clientset.Interface) (*v1.NodeList, error) {
var nodeList *v1.NodeList
// We must poll because apiserver might not be up. This error causes
// controller manager to restart.
if pollErr := wait.Poll(10*time.Second, apiserverStartupGracePeriod, func() (bool, error) {
var err err... | controller start too slow ,get ListNode must wait 10s | https://api.github.com/repos/kubernetes/kubernetes/issues/93593/comments | 5 | 2020-07-31T03:09:39Z | 2020-12-28T05:36:12Z | https://github.com/kubernetes/kubernetes/issues/93593 | 669,365,401 | 93,593 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Add a new function `Enqueue` to `QueueSort` plugin. `Enqueue` is the first plugin function in a scheduling cycle and is called before a pod is added to `SchedulingQueue`.
```
type QueueSortPlugin in... | Add a new function Enqueue to QueueSort Plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/93591/comments | 38 | 2020-07-31T00:27:12Z | 2022-09-27T19:13:13Z | https://github.com/kubernetes/kubernetes/issues/93591 | 669,300,294 | 93,591 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about flaky tests or jobs (pass or fail with no underlying change in code) in Kubernetes CI -->
**Which jobs are flaking**:
ci-kubernetes-e2e-aks-engine-azure-master-windows-2004
**Which test(s) are flaking**:
the whole test run occasionally is bad
ca... | [Flaky test] [sig-windows] ci-kubernetes-e2e-aks-engine-azure-master-windows-2004 | https://api.github.com/repos/kubernetes/kubernetes/issues/93590/comments | 4 | 2020-07-30T23:10:08Z | 2020-09-22T20:03:48Z | https://github.com/kubernetes/kubernetes/issues/93590 | 669,267,879 | 93,590 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are failing**:
> gce-cos-master-scalability-100 (ci-kubernetes-e2e-gci-gce-scalability)
**Which test(s) are failing**:
>- Extract
>- Overall
**Since when has it been failing**:
> 07-30 11:25 PDT
**Testgrid link**:
> https://testgrid.k8s.io/sig-release-master-blocking#gce-cos-master-scalabilit... | [Failing Test] gce-cos-master-scalability-100 (ci-kubernetes-e2e-gci-gce-scalability) | https://api.github.com/repos/kubernetes/kubernetes/issues/93584/comments | 3 | 2020-07-30T20:05:53Z | 2020-07-31T06:06:49Z | https://github.com/kubernetes/kubernetes/issues/93584 | 669,148,257 | 93,584 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
When testing https://github.com/kubernetes/kubernetes/pull/93475, @ravisantoshgudimetla pointed out that invocation of `generatePodSandboxLinuxConfig` is necessary for the Windows pods to come up: https://github.com/kubernetes/kubernetes/pull/93475/files#r463009694 . Skipping the call to `generatePo... | Investigate removal of call to generatePodSandboxLinuxConfig for Windows kubelet | https://api.github.com/repos/kubernetes/kubernetes/issues/93580/comments | 19 | 2020-07-30T16:42:17Z | 2021-11-12T02:17:17Z | https://github.com/kubernetes/kubernetes/issues/93580 | 668,953,675 | 93,580 |
[
"kubernetes",
"kubernetes"
] | Cronjobs are not running any job on its scheduled times, the jobs runs only when one or more cronjobs are deleted. Is there some cronjob number limit ? Where to get log messages of this problem?
I have exactly the same environment for development and production working perfectly, this only occurs in testing environmen... | Job not running on scheduled time - Kubernetes CronJob | https://api.github.com/repos/kubernetes/kubernetes/issues/93578/comments | 5 | 2020-07-30T16:34:55Z | 2020-09-21T19:19:40Z | https://github.com/kubernetes/kubernetes/issues/93578 | 668,945,803 | 93,578 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
[Newer versions of etcd expose](https://etcd.io/docs/v3.4.0/dev-guide/limit/) `--max-request-bytes` to bypass the default limit of 1.5MB. Currently apis/core validation rejects anything exceeding 1MB. I... | Loosen ConfigMap Max Size Validation | https://api.github.com/repos/kubernetes/kubernetes/issues/93576/comments | 12 | 2020-07-30T16:05:26Z | 2020-12-28T22:53:12Z | https://github.com/kubernetes/kubernetes/issues/93576 | 668,912,547 | 93,576 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
The event `Back-off restarting failed container` should become `Back-off restarting failed container <CONTAINER_NAME>`
**Why is this needed**:
Its hard to tell which container failed, you need to ... | "Back-off restarting failed container": log which container failed | https://api.github.com/repos/kubernetes/kubernetes/issues/93575/comments | 6 | 2020-07-30T15:54:51Z | 2020-12-31T00:45:35Z | https://github.com/kubernetes/kubernetes/issues/93575 | 668,900,266 | 93,575 |
[
"kubernetes",
"kubernetes"
] | make verify WHAT=typecheck-providerless
outputs
> `ERROR(linux/arm): failed to verify: /usr/bin/gopackagesdriver: exit status 1: gopkgsdriver: 6.578579496s for GOROOT=/usr/local/google/home/liggitt/.gvm/gos/go1.15beta1 GOPATH=/usr/local/google/home/liggitt/go/src/k8s.io/kubernetes/_output/local/go GO111MODULE=off... | hack/verify-typecheck-providerless.sh outputs many errors and failure messages but does not fail | https://api.github.com/repos/kubernetes/kubernetes/issues/93574/comments | 5 | 2020-07-30T15:37:58Z | 2020-07-30T19:31:08Z | https://github.com/kubernetes/kubernetes/issues/93574 | 668,879,838 | 93,574 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Deployment of node-local-dns in an ipv6-only cluster fails with the following iptables-related error
~~~
2020/07/30 13:49:00 [INFO] Using Corefile /etc/Corefile
2020/07/30 13:49:00 [INFO] Tearing down
2020/07/30 13:49:00 [INFO] Hit error during teardown - Link not found
2020/07/30 13:49:00 [IN... | node-local-dns fails in ipv6 only cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/93568/comments | 16 | 2020-07-30T13:54:51Z | 2020-12-01T14:48:51Z | https://github.com/kubernetes/kubernetes/issues/93568 | 668,754,064 | 93,568 |
[
"kubernetes",
"kubernetes"
] | /sig scheduling
**What happened**:
I have 3 nodes: 1 master node(with NoSchedule taints) and 2 worker nodes. All of them can be scheduled to run CoreDNS pods(with NoSchedule and CriticalAddonsOnly tolerations). My nodes have two topology keys: zone and hostname. I set two topologySpreadConstraints on these topology... | topologySpreadConstraints cannot spread pods evenly when whenUnsatisfiable is set to ScheduleAnyway | https://api.github.com/repos/kubernetes/kubernetes/issues/93565/comments | 6 | 2020-07-30T10:38:43Z | 2020-08-04T14:24:08Z | https://github.com/kubernetes/kubernetes/issues/93565 | 668,594,657 | 93,565 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
In our cluster volumes fail to be attached giving the error message `Unable to attach or mount volumes: unmounted volumes=[x y z], unattached volumes=[x y z ]: timed out waiting for the condition`
The vo... | Specific message why volume mounts can not be attached | https://api.github.com/repos/kubernetes/kubernetes/issues/93563/comments | 6 | 2020-07-30T10:03:39Z | 2020-12-27T12:19:12Z | https://github.com/kubernetes/kubernetes/issues/93563 | 668,568,932 | 93,563 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are failing**:
`master-blocking` jobs:
- ci-kubernetes-e2e-gce-master-new-gci-kubectl-skew-serial
- ci-kubernetes-gce-conformance-latest
- ci-kubernetes-e2e-gci-gce
- ci-kubernetes-e2e-ubuntu-gce-containerd
- ci-kubernetes-e2e-gci-gce-alpha-features
- ci-kubernetes-e2e-gci-gce-reboot
- ci-kuber... | [SIG Release, SIG Testing] "Extract" phase is failing for multiple jobs using the ci/latest-fast version marker | https://api.github.com/repos/kubernetes/kubernetes/issues/93561/comments | 11 | 2020-07-30T08:38:14Z | 2020-07-31T20:47:40Z | https://github.com/kubernetes/kubernetes/issues/93561 | 668,496,221 | 93,561 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**
We have a Kubernetes cluster ... | Worker node stops sending node status, even if API server is available | https://api.github.com/repos/kubernetes/kubernetes/issues/93560/comments | 5 | 2020-07-30T08:25:49Z | 2020-07-30T17:11:47Z | https://github.com/kubernetes/kubernetes/issues/93560 | 668,486,172 | 93,560 |
[
"kubernetes",
"kubernetes"
] |
**What happened**:
**What you expected to happen**:
**How to reproduce it (as minimally and precisely as possible)**:
$oc create job -f job.yaml
$ oc get job jobname -ojson | jq .status
{
"active": 1,
"failed": 1,
"startTime": "2020-07-30T06:45:37Z"
}
{
"active": 1,
"failed": 2,
"star... | job fails before the `.spec.backoffLimit` | https://api.github.com/repos/kubernetes/kubernetes/issues/93559/comments | 7 | 2020-07-30T07:50:07Z | 2020-08-10T16:35:14Z | https://github.com/kubernetes/kubernetes/issues/93559 | 668,457,993 | 93,559 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
After I use k... | Failed to pull image x509: certificate signed by unknown authority while create deloyment using kubectl apply -f | https://api.github.com/repos/kubernetes/kubernetes/issues/93556/comments | 19 | 2020-07-30T06:16:47Z | 2020-08-20T14:26:46Z | https://github.com/kubernetes/kubernetes/issues/93556 | 668,404,424 | 93,556 |
[
"kubernetes",
"kubernetes"
] | We are using sonobuoy to run conformance test and using the "Conformance" image for running the conformance tests. In order to run selective tests, currently there are two ways ( based on my current understanding) :
1. Use the available test tags like, [NodeConformance] , [Conformance] etc.
2. Use expressions which... | Can we introduce the capabilities of adding custom tags similar to [NodeConformance] , [Conformance] ? | https://api.github.com/repos/kubernetes/kubernetes/issues/93553/comments | 6 | 2020-07-30T03:14:43Z | 2021-01-08T21:13:14Z | https://github.com/kubernetes/kubernetes/issues/93553 | 668,329,204 | 93,553 |
[
"kubernetes",
"kubernetes"
] | ## Motivation
There is no guarantee in which order different event handlers will be
called. If we use different event handlers, it's possible that PV/PVC
assume cache is updated after pods are moved to active queue and
the volume binding plugin may use stale cache.
Example race case:
1. pod go through volu... | Volume Binding PV/PVC Assume Cache should be updated before moving pods to active queue | https://api.github.com/repos/kubernetes/kubernetes/issues/93552/comments | 18 | 2020-07-30T03:02:00Z | 2021-10-05T06:02:20Z | https://github.com/kubernetes/kubernetes/issues/93552 | 668,323,531 | 93,552 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Scheduling plugin "NodeResourcesLeast**Allocatable**" is a score plugin that favors nodes with fewer allocatable resources. Note that this is not the same as NodeResourcesLeast**Allocated**.
**Why is t... | NodeResourcesLeastAllocatable as score plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/93547/comments | 29 | 2020-07-29T20:44:44Z | 2020-10-29T21:27:46Z | https://github.com/kubernetes/kubernetes/issues/93547 | 668,138,651 | 93,547 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
kube-controll... | Error assigning spec.podCIDR to nodes | https://api.github.com/repos/kubernetes/kubernetes/issues/93545/comments | 23 | 2020-07-29T19:51:58Z | 2020-11-05T05:59:04Z | https://github.com/kubernetes/kubernetes/issues/93545 | 668,106,090 | 93,545 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are failing**:
> gce-master-scale-correctness (ci-kubernetes-e2e-gce-scale-correctness)
**Which test(s) are failing**:
> - Overall
> - Test
> - [sig-network] Networking Granular Checks: Services should update nodePort: udp [Slow]
**Since when has it been failing**:
> 07-28 05:01 PDT
**Testgri... | [Failing Test] gce-master-scale-correctness (ci-kubernetes-e2e-gce-scale-correctness) | https://api.github.com/repos/kubernetes/kubernetes/issues/93542/comments | 4 | 2020-07-29T18:07:50Z | 2020-07-30T12:21:56Z | https://github.com/kubernetes/kubernetes/issues/93542 | 668,037,550 | 93,542 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I have 2 no... | podAntiAffinity ignored when rollout restart | https://api.github.com/repos/kubernetes/kubernetes/issues/93538/comments | 7 | 2020-07-29T15:20:16Z | 2020-08-04T16:54:58Z | https://github.com/kubernetes/kubernetes/issues/93538 | 667,929,161 | 93,538 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about flaky tests or jobs (pass or fail with no underlying change in code) in Kubernetes CI -->
**Which jobs are flaking**:
`gci-gce-ingress (ci-kubernetes-e2e-gci-gce-ingress)`
**Which test(s) are flaking**:
`[sig-network] Loadbalancing: L7 GCE [Slo... | [Flaky Test] [sig-network] Loadbalancing: L7 GCE [Slow] [Feature:Ingress] should support multiple TLS certs | https://api.github.com/repos/kubernetes/kubernetes/issues/93536/comments | 8 | 2020-07-29T14:51:10Z | 2020-09-08T20:50:14Z | https://github.com/kubernetes/kubernetes/issues/93536 | 667,907,150 | 93,536 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Clusters bu... | CoreDNS does not tolerate node.cloudprovider.kubernetes.io/uninitialized | https://api.github.com/repos/kubernetes/kubernetes/issues/93533/comments | 20 | 2020-07-29T13:39:28Z | 2020-08-06T11:17:16Z | https://github.com/kubernetes/kubernetes/issues/93533 | 667,853,642 | 93,533 |
[
"kubernetes",
"kubernetes"
] | **Background**:
We recently introduced Guaranteed Pod QOS on jobs running in `k8s-infra-prow-build` GCP project (https://github.com/kubernetes/test-infra/pull/18471). Introducing limits on jobs naturally started causing some failures, one of which was `verify-master` ([testgrid](https://testgrid.k8s.io/sig-release-m... | typecheck uses exorbitant amounts of memory | https://api.github.com/repos/kubernetes/kubernetes/issues/93532/comments | 2 | 2020-07-29T13:21:47Z | 2020-07-31T01:12:14Z | https://github.com/kubernetes/kubernetes/issues/93532 | 667,840,901 | 93,532 |
[
"kubernetes",
"kubernetes"
] | While debugging scalability tests, I discovered that there seem to be some problem with tracing library.
Taking this as an example run:
https://prow.k8s.io/view/gcs/kubernetes-jenkins/logs/ci-kubernetes-e2e-gci-gce-scalability/1287819459200815104
and grepping for all Trace entires, all seem to have start_time wh... | Trace library seem to incorrect print start_time | https://api.github.com/repos/kubernetes/kubernetes/issues/93531/comments | 7 | 2020-07-29T12:09:22Z | 2020-07-31T16:39:11Z | https://github.com/kubernetes/kubernetes/issues/93531 | 667,794,397 | 93,531 |
[
"kubernetes",
"kubernetes"
] | verify-master as a job needs to be broken up in to more specific verification checks
As verify-master runs multiple verification steps it has bucket list smell that results in
- unwieldy log output
- difficulty in assigning ownership of flake or failure
- an overall runtime of[ over an hour](https://testgrid.... | verify-master needs to be broken up | https://api.github.com/repos/kubernetes/kubernetes/issues/93530/comments | 13 | 2020-07-29T11:23:03Z | 2021-07-27T04:47:45Z | https://github.com/kubernetes/kubernetes/issues/93530 | 667,767,458 | 93,530 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
https://k8s-testgrid.appspot.com/sig-network-kind#sig-network-kind,%20IPv6,%20master
**Which test(s) are failing**:
DNS.*
**Anything else we need to know**:
... | DNS sig-network tests failing on IPv6 | https://api.github.com/repos/kubernetes/kubernetes/issues/93527/comments | 5 | 2020-07-29T08:42:11Z | 2020-08-07T21:55:58Z | https://github.com/kubernetes/kubernetes/issues/93527 | 667,662,410 | 93,527 |
[
"kubernetes",
"kubernetes"
] | I'v followed the Kubeflow Deployment with kfctl_k8s_istio official documention(https://www.kubeflow.org/docs/started/k8s/kfctl-k8s-istio/#provisioning-of-persistent-volumes-in-kubernetes) to deploy kubeflow
when I typed `kfctl apply -V -f ${CONFIG_URI}`
there is an error `Segmentation fault`
How can i solve this pr... | k8s Kubeflow Deployment with kfctl_k8s_istio Segmentation fault | https://api.github.com/repos/kubernetes/kubernetes/issues/93526/comments | 5 | 2020-07-29T08:36:56Z | 2020-07-29T12:37:48Z | https://github.com/kubernetes/kubernetes/issues/93526 | 667,658,968 | 93,526 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
The test currently only works on Cloud Providers or environments that set the External IP on nodes, because it is using the framework directly to check the IPs of the pods, using a no-snat-test-proxy to check if the Pods are not using SNAT.
However, this can be simplified, rem... | Failing Test [sig-network] NoSNAT [Feature:NoSNAT] [Slow] Should be able to send traffic between Pods without SNAT | https://api.github.com/repos/kubernetes/kubernetes/issues/93525/comments | 9 | 2020-07-29T08:13:47Z | 2020-08-02T03:21:42Z | https://github.com/kubernetes/kubernetes/issues/93525 | 667,643,847 | 93,525 |
[
"kubernetes",
"kubernetes"
] | I've followed the Kubernetes documentation step by step and Bootstrapping clusters with kubeadm.but when finish install, the kubelet service can not work well. when starting the kubelet service ,there's always the same error occured here:
```
Hairpin mode set to "promiscuous-bridge" but kubenet is not enabled, fall... | kubelet service can not work. exit code=255. | https://api.github.com/repos/kubernetes/kubernetes/issues/93524/comments | 12 | 2020-07-29T06:48:40Z | 2021-01-24T07:09:57Z | https://github.com/kubernetes/kubernetes/issues/93524 | 667,596,949 | 93,524 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
```
State: Waiting
Reason: PodInitializing
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 97m default-scheduler Successfully assigned kube-system/virt-launcher-vmi-cali... | kubevirt virt-launcher pod stuck using multus calico | https://api.github.com/repos/kubernetes/kubernetes/issues/93522/comments | 4 | 2020-07-29T02:37:59Z | 2020-07-29T06:58:25Z | https://github.com/kubernetes/kubernetes/issues/93522 | 667,502,912 | 93,522 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
For each NLB ... | K8s creates too many Security Groups for NLB Health Check | https://api.github.com/repos/kubernetes/kubernetes/issues/93514/comments | 2 | 2020-07-28T23:19:49Z | 2020-08-31T03:32:24Z | https://github.com/kubernetes/kubernetes/issues/93514 | 667,441,243 | 93,514 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
* Deploy minikube
` minikube start --driver=podman --container-runtime=cri-o`
* Deploy kubevirt addon
`minikube addons enable kubevirt`
* kubevirt addon fails to deploy
**What you expected to happen**:
I expect kubevirt addon to deploy correctly
**How to reproduce it (as minimally and pre... | minikube addon kubevirt fails to deploy | https://api.github.com/repos/kubernetes/kubernetes/issues/93513/comments | 11 | 2020-07-28T22:21:25Z | 2022-01-25T02:31:54Z | https://github.com/kubernetes/kubernetes/issues/93513 | 667,419,536 | 93,513 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
The error predicates in https://github.com/kubernetes/apimachinery/blob/master/pkg/api/errors/errors.go (IsNotFound, IsAlreadyExists, etc) don't work if the error that is passed to them has been wrapped using Go 1.13's error wrapping standard.
If we used errors.As (https://golan... | API machinery error predicates don't work with wrapping | https://api.github.com/repos/kubernetes/kubernetes/issues/93512/comments | 2 | 2020-07-28T21:25:43Z | 2020-07-29T14:04:18Z | https://github.com/kubernetes/kubernetes/issues/93512 | 667,389,497 | 93,512 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Based on this issue: https://github.com/kubernetes/kubernetes/issues/93446 I would expect that the API server returns an error if I try to create a Service for an `ipFamily` that has no according `service-cluster-ip-range` instead of silently swallow the mistake and use the default `ipFamily`.
**... | API-Server should validate ipFamily and configured service-cluster-ip-ranges | https://api.github.com/repos/kubernetes/kubernetes/issues/93509/comments | 9 | 2020-07-28T18:37:44Z | 2020-07-29T15:33:32Z | https://github.com/kubernetes/kubernetes/issues/93509 | 667,285,749 | 93,509 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are failing**:
gce-master-scale-correctness
**Which test(s) are failing**:
all - whole test set OOMed
**Since when has it been failing**:
2020-07-28
**Testgrid link**:
https://k8s-testgrid.appspot.com/sig-scalability-gce#gce-master-scale-correctness
**Reason for failure**:
test pod OOMed a... | gce-master-scale-correctness OOMing after test pod limits set | https://api.github.com/repos/kubernetes/kubernetes/issues/93506/comments | 14 | 2020-07-28T14:09:28Z | 2020-11-03T09:41:20Z | https://github.com/kubernetes/kubernetes/issues/93506 | 667,105,433 | 93,506 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
race conditio... | race condition detected during the scheduling with preemption | https://api.github.com/repos/kubernetes/kubernetes/issues/93505/comments | 53 | 2020-07-28T10:46:14Z | 2023-12-03T03:35:33Z | https://github.com/kubernetes/kubernetes/issues/93505 | 666,973,797 | 93,505 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/system-validators/issues/17
please look at this
| Why not support vfs for kubernetes? | https://api.github.com/repos/kubernetes/kubernetes/issues/93504/comments | 5 | 2020-07-28T10:24:24Z | 2020-12-25T12:32:11Z | https://github.com/kubernetes/kubernetes/issues/93504 | 666,960,663 | 93,504 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Move AssumePod Op to ReservePlugins as defaultReserve
Move ForgetPod Op to UnReservePlugins as defaultUnreserve
**Why is this needed**:
make all phases of scheduling can be implemented by plugins in Framework
/assign | Move AssumePod Op to ReservePlugins as defaultReserve | https://api.github.com/repos/kubernetes/kubernetes/issues/93500/comments | 55 | 2020-07-28T08:02:14Z | 2024-10-19T07:20:58Z | https://github.com/kubernetes/kubernetes/issues/93500 | 666,854,607 | 93,500 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are flaking**:
ci-kubernetes-integration-master
**Which test(s) are flaking**:
ci-kubernetes-integration-master
**Testgrid link**:
https://testgrid.k8s.io/sig-release-master-blocking#integration-master&width=5&include-filter-by-regex=TestEndpointSliceMirroring
**Reason for failure**:
`... | [Failing test] TestEndpointSliceMirroring/Service_without_selector | https://api.github.com/repos/kubernetes/kubernetes/issues/93496/comments | 12 | 2020-07-28T03:38:39Z | 2020-08-25T01:44:16Z | https://github.com/kubernetes/kubernetes/issues/93496 | 666,727,827 | 93,496 |
[
"kubernetes",
"kubernetes"
] | I'm fairly new to kubernetes. Using references to install and get everything up and running. Came across Kubernetes Dashboard to manage the cluster.
Steps to reproduce
1. i deployed the dashboard following the below link
https://github.com/kubernetes/dashboard
2. installed dashboard https://github.com/k... | Accessing Dashboard Remotely: ERROR forbidden: User \"system:anonymous\ | https://api.github.com/repos/kubernetes/kubernetes/issues/93494/comments | 9 | 2020-07-28T01:44:37Z | 2020-07-28T14:53:24Z | https://github.com/kubernetes/kubernetes/issues/93494 | 666,689,891 | 93,494 |
[
"kubernetes",
"kubernetes"
] | /sig network
## Versions
**kubeadm version** (use `kubeadm version`):
`
kubeadm version: &version.Info{Major:"1", Minor:"17", GitVersion:"v1.17.5", GitCommit:"e0fccafd69541e3750d460ba0f9743b90336f24f", GitTreeState:"clean", BuildDate:"2020-04-16T11:41:38Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"linux/a... | Incorrect pod IP addresses after kubeadm init /sig network | https://api.github.com/repos/kubernetes/kubernetes/issues/93489/comments | 4 | 2020-07-28T00:09:48Z | 2020-07-29T12:51:48Z | https://github.com/kubernetes/kubernetes/issues/93489 | 666,660,599 | 93,489 |
[
"kubernetes",
"kubernetes"
] | ## What happened
The Kubernetes API `GET /api/v1/nodes` endpoint has a property `items.status.images`, which according to the [documentation](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.18/#nodestatus-v1-core) is a "List of container images on this node".
However, the field only returns at mo... | Nodes with more than 50 images do not return all images in API | https://api.github.com/repos/kubernetes/kubernetes/issues/93488/comments | 8 | 2020-07-27T23:31:36Z | 2022-08-12T08:31:59Z | https://github.com/kubernetes/kubernetes/issues/93488 | 666,647,920 | 93,488 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are flaking**:
* ci-kubernetes-integration-master
* pull-kubernetes-integration
**Which test(s) are flaking**:
Flaking in pre and post-submit:
* TestPostFilterPlugin
* TestReservePluginUnreserve
* TestFilterPlugin
* TestScorePlugin
* TestNodeAffinity
**Testgrid link**:
* https://testgr... | [Flaky Test] integration-master scheduler tests (ci-kubernetes-integration-master) | https://api.github.com/repos/kubernetes/kubernetes/issues/93485/comments | 5 | 2020-07-27T22:03:23Z | 2020-08-02T18:52:40Z | https://github.com/kubernetes/kubernetes/issues/93485 | 666,612,729 | 93,485 |
[
"kubernetes",
"kubernetes"
] | Tracking issue to complete go 1.15.0 bump for 1.19
/milestone v1.19
~~Blocking issues for go 1.15.0:
https://github.com/golang/go/issues?q=is%3Aopen+is%3Aissue+milestone%3AGo1.15+label%3Arelease-blocker~~
~~Changes to go 1.15 since go1.15rc2: https://github.com/golang/go/compare/go1.15rc2...release-branch.go1... | go1.15.0 / k8s 1.19 tracker | https://api.github.com/repos/kubernetes/kubernetes/issues/93484/comments | 5 | 2020-07-27T21:49:38Z | 2020-08-13T20:23:41Z | https://github.com/kubernetes/kubernetes/issues/93484 | 666,606,494 | 93,484 |
[
"kubernetes",
"kubernetes"
] | Looks like this test is never able to succeed because `elasticsearch-logging` service does not exist:
```
I0727 06:43:51.448] Jul 27 06:43:51.447: INFO: Checking the Elasticsearch service exists.
I0727 06:43:51.488] Jul 27 06:43:51.488: INFO: Attempt to check for the existence of the Elasticsearch service failed aft... | ElasticSearch e2e periodic tests are failing due to missing elasticsearch service. | https://api.github.com/repos/kubernetes/kubernetes/issues/93480/comments | 11 | 2020-07-27T20:17:16Z | 2021-04-20T17:24:36Z | https://github.com/kubernetes/kubernetes/issues/93480 | 666,557,979 | 93,480 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I am trying t... | kubernetes doesnt support ":" colon field in volume mount paths | https://api.github.com/repos/kubernetes/kubernetes/issues/93479/comments | 8 | 2020-07-27T20:03:20Z | 2021-09-29T18:47:54Z | https://github.com/kubernetes/kubernetes/issues/93479 | 666,550,250 | 93,479 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Currently if you have a PDB spec like `minAvailable: 1`, and a HPA defining minReplicas=1 and maxReplicas=N, you may end up in a scenario where disruptions get "stuck" if the HPA has scaled to 1. At any point an increase in load could cause the HPA to scale up to 2+, allowing the... | Allow scaling up to meet PDB constraints | https://api.github.com/repos/kubernetes/kubernetes/issues/93476/comments | 83 | 2020-07-27T16:47:55Z | 2025-02-14T02:59:17Z | https://github.com/kubernetes/kubernetes/issues/93476 | 666,436,305 | 93,476 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
When running ... | kubectl --request-timeout (or any other client configuration flag) prevents use of in-cluster configuration | https://api.github.com/repos/kubernetes/kubernetes/issues/93474/comments | 44 | 2020-07-27T15:43:41Z | 2024-07-17T20:08:36Z | https://github.com/kubernetes/kubernetes/issues/93474 | 666,394,240 | 93,474 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
1) I've installed a cluster with kubeadm v1.18.6:
```kubeadm init --v=6 --config=kubeadmin/kubeadm-init.yaml --upload-certs```
```cat kubeadm-init.yaml```
```
---
apiVersion: kubeadm.k8s.io/v1beta1
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: "xxx.xxx.xxx.xxx"
---
apiVersi... | kubectl get cs showing unhealthy statuses for controller-manager and scheduler on v1.18.6 clean install | https://api.github.com/repos/kubernetes/kubernetes/issues/93472/comments | 11 | 2020-07-27T13:49:50Z | 2024-12-24T01:54:44Z | https://github.com/kubernetes/kubernetes/issues/93472 | 666,311,197 | 93,472 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
k8s v1.18.3 k... | k8s v1.18.3 kubectl top node ,cpu sometimes negative | https://api.github.com/repos/kubernetes/kubernetes/issues/93462/comments | 3 | 2020-07-27T05:45:18Z | 2020-10-06T08:02:01Z | https://github.com/kubernetes/kubernetes/issues/93462 | 665,994,212 | 93,462 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
In-cluster traffic for a Service loadbalancer IP with externalTrafficPolicy=Local should be masqueraded and routed to cluster-wide endpoints. A similar patch was added to the iptables proxier in v1.15 in ... | [ipvs] in-cluster traffic for loadbalancer IP with externalTrafficPolicy=Local should use cluster-wide endpoints | https://api.github.com/repos/kubernetes/kubernetes/issues/93456/comments | 24 | 2020-07-27T00:15:22Z | 2023-04-12T18:17:26Z | https://github.com/kubernetes/kubernetes/issues/93456 | 665,888,659 | 93,456 |
[
"kubernetes",
"kubernetes"
] | Hello all,
I have a deployment with k8s v1.18.6 :
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: blue-prod
namespace: blue-prod
labels:
app: blue-prod
spec:
replicas: 3
selector:
matchLabels:
app: blue-prod
template:
metadata:
labels:
app: ... | Deployment Affinity to a specific node | https://api.github.com/repos/kubernetes/kubernetes/issues/93451/comments | 3 | 2020-07-26T10:32:48Z | 2020-07-27T08:36:11Z | https://github.com/kubernetes/kubernetes/issues/93451 | 665,755,116 | 93,451 |
[
"kubernetes",
"kubernetes"
] | when a server is shut down, all watchers terminate, and are now logging that they are going to send a watch cancel request, and that they failed:
```
...
I0726 02:59:40.069592 54198 ???:1] sending watch cancel request for closed watcher{watch-id 11 0 <nil>}
W0726 02:59:40.069628 54198 ???:1] failed to send wat... | excessive watch cancellation logging on server shutdown | https://api.github.com/repos/kubernetes/kubernetes/issues/93450/comments | 4 | 2020-07-26T07:04:14Z | 2020-08-19T18:51:27Z | https://github.com/kubernetes/kubernetes/issues/93450 | 665,723,842 | 93,450 |
[
"kubernetes",
"kubernetes"
] | ```
--- FAIL: TestRecycleSlices (0.01s)
--- PASS: TestRecycleSlices/Empty_slices (0.00s)
--- PASS: TestRecycleSlices/1_to_create_and_1_to_delete (0.00s)
--- PASS: TestRecycleSlices/1_to_create,_update,_and_delete (0.00s)
--- PASS: TestRecycleSlices/2_to_create_and_1_to_delete (0.00s)
--- PASS:... | TestRecycleSlices/1_to_create_and_1_to_delete_for_each_IP_family is flaking | https://api.github.com/repos/kubernetes/kubernetes/issues/93449/comments | 7 | 2020-07-25T21:34:11Z | 2020-07-27T22:15:09Z | https://github.com/kubernetes/kubernetes/issues/93449 | 665,664,536 | 93,449 |
[
"kubernetes",
"kubernetes"
] | **What happened**: Node only have ipv4 address.
**What you expected to happen**: Node should have a single IPv4 block and a single IPv6 block allocated.
**How to reproduce it (as minimally and precisely as possible)**:
1 install k8s by kube-spray (network plugin is calico)
2. modify config according to the web... | DualStack: kubernetes v1.18.5 IPv4/IPv6 dual-stack do not take effect | https://api.github.com/repos/kubernetes/kubernetes/issues/93446/comments | 28 | 2020-07-25T12:58:57Z | 2020-07-29T16:02:19Z | https://github.com/kubernetes/kubernetes/issues/93446 | 665,581,242 | 93,446 |
[
"kubernetes",
"kubernetes"
] | I'm creating an application in C that intermediates and manages scheduled applications (NodeJs) to collect informations into MongoDB.
This makes possible the application's scalability and avoid replicated values.
**Problem**
I think that something comming from k8s is intercepting and modifying the message.
... | TCP socket connection interference on send message | https://api.github.com/repos/kubernetes/kubernetes/issues/93435/comments | 2 | 2020-07-24T20:00:54Z | 2020-07-25T00:46:39Z | https://github.com/kubernetes/kubernetes/issues/93435 | 665,386,851 | 93,435 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Running a `kubectl get` with --all-namespaces in the wrong place consumes one extra argument, resulting in a confusing error.
**What you expected to happen**:
A sane error.
**How to reproduce it (as minimally and precisely as possible)**:
```
$ k get pods
NAME ... | Kubectl parsing of local flags with no args appearing before the command name is broken or at best, confusing | https://api.github.com/repos/kubernetes/kubernetes/issues/93432/comments | 8 | 2020-07-24T18:28:12Z | 2020-10-27T00:06:57Z | https://github.com/kubernetes/kubernetes/issues/93432 | 665,341,494 | 93,432 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
I would like a field that the kubelet can set on it's own node object that indicates the last-requested serving CSR it created. Since the kubelet creates the CSR object, it already has knowledge of whi... | Node: Add field to describe most recent request Serving CSR | https://api.github.com/repos/kubernetes/kubernetes/issues/93428/comments | 7 | 2020-07-24T16:16:37Z | 2020-07-24T17:27:34Z | https://github.com/kubernetes/kubernetes/issues/93428 | 665,273,948 | 93,428 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about flaky tests or jobs (pass or fail with no underlying change in code) in Kubernetes CI -->
**Which jobs are flaking**:
gce-master-scale-correctness
**Which test(s) are flaking**:
[sig-network] Ingress API should support creating Ingress API operations... | [Flaky test] [sig-network] Ingress API should support creating Ingress API operations [Conformance] | https://api.github.com/repos/kubernetes/kubernetes/issues/93424/comments | 4 | 2020-07-24T14:58:14Z | 2020-07-24T21:26:31Z | https://github.com/kubernetes/kubernetes/issues/93424 | 665,226,069 | 93,424 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Created ILB... | GCE ILB does not support modifying svc protocol | https://api.github.com/repos/kubernetes/kubernetes/issues/93422/comments | 6 | 2020-07-24T13:50:24Z | 2020-12-26T08:52:11Z | https://github.com/kubernetes/kubernetes/issues/93422 | 665,182,620 | 93,422 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
In certain azure regions instance metadata is returning location in camel case. This metadata is being propagated to nodes label
https://github.com/kubernetes/kubernetes/blob/539b0a5a0f8c1d96ee6752f2aa5d6d949eb0f513/staging/src/k8s.io/cloud-provider/controllers/node/node_controller.go#L501-L510. ... | Instance metadata region mismatch | https://api.github.com/repos/kubernetes/kubernetes/issues/93421/comments | 7 | 2020-07-24T13:23:27Z | 2020-07-27T19:36:35Z | https://github.com/kubernetes/kubernetes/issues/93421 | 665,166,225 | 93,421 |
[
"kubernetes",
"kubernetes"
] | hi
my k8s version is 1.17.7 (I upgraded directly from 1.14 to 1.17)
but my calico-kube-controllers has a error log.
```
E0724 10:20:22.768850 1 reflector.go:205] github.com/projectcalico/kube-controllers/pkg/controllers/networkpolicy/policy_controller.go:147: Failed to list *v1beta1.NetworkPolicy: the serve... | Old API convert problem[v1beta1.NetworkPolicy to networking.k8s.io/v1beta1] | https://api.github.com/repos/kubernetes/kubernetes/issues/93420/comments | 4 | 2020-07-24T10:44:57Z | 2020-07-24T13:02:55Z | https://github.com/kubernetes/kubernetes/issues/93420 | 665,084,976 | 93,420 |
[
"kubernetes",
"kubernetes"
] | Hello, thanks a lot for advance!
Now I have a kubernaters cluster which runs some pods and services. Then I want to add a standard centos system into my k8s cluster. Is there any normalized method to realize this? Maybe I should copy some binary to the standard centos system, such as kubelet, kube-proxy and kubectl.... | How to add a standard centos system into kubernates cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/93419/comments | 5 | 2020-07-24T10:09:20Z | 2020-12-24T04:00:14Z | https://github.com/kubernetes/kubernetes/issues/93419 | 665,064,966 | 93,419 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
currently we can create a priorityclass with globalvalue: true for the whole cluster, but an evolution would be interesting to have the possibility of also splitting by namespace.
**Why is this neede... | default PriorityClass by namespace | https://api.github.com/repos/kubernetes/kubernetes/issues/93416/comments | 15 | 2020-07-24T09:00:21Z | 2021-01-03T21:12:59Z | https://github.com/kubernetes/kubernetes/issues/93416 | 665,028,262 | 93,416 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Sometimes t... | RBD volume mount timeout when previous mountpoint remove failed | https://api.github.com/repos/kubernetes/kubernetes/issues/93415/comments | 10 | 2020-07-24T08:57:18Z | 2020-12-24T04:00:15Z | https://github.com/kubernetes/kubernetes/issues/93415 | 665,025,821 | 93,415 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Deployed a webhook as a service to a Kubernetes cluster with 2 masters, listening initially on port 8000.
```yaml
apiVersion: v1
kind: Namespace
metadata:
name: webhook
---
kind: Service
apiVersion: v1
metadata:
name: webhook
namespace: webhook
spec:
selector:
app: webhook... | Webhook REST clients cache invalid and possibly not expiring | https://api.github.com/repos/kubernetes/kubernetes/issues/93409/comments | 14 | 2020-07-24T06:41:24Z | 2020-10-15T14:10:25Z | https://github.com/kubernetes/kubernetes/issues/93409 | 664,952,797 | 93,409 |
[
"kubernetes",
"kubernetes"
] | Test Failures are
```
FAIL k8s.io/kubernetes/pkg/kubelet [build failed]
FAIL k8s.io/kubernetes/pkg/kubelet/container [build failed]
FAIL k8s.io/kubernetes/pkg/kubelet/network/dns [build failed]
FAIL k8s.io/kubernetes/pkg/scheduler [build failed]
FAIL k8s.io/kubernetes/vendor/k8s.io/client-go/plugin... | The build failed for some tests while running make test fo GO version go1.15beta1 | https://api.github.com/repos/kubernetes/kubernetes/issues/93407/comments | 4 | 2020-07-24T05:00:59Z | 2020-07-27T04:51:54Z | https://github.com/kubernetes/kubernetes/issues/93407 | 664,916,762 | 93,407 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
look,I have three different CEPHFS file systems in the same Ceph:
```
# ceph fs ls
name: kube-cephfs, metadata pool: cephfs_meta, data pools: [cephfs_data ]
name: node-cephfs, metadata pool: node-ceph... | About creating PVS in Kubernetes using different CEphFS | https://api.github.com/repos/kubernetes/kubernetes/issues/93404/comments | 5 | 2020-07-24T03:00:12Z | 2020-12-21T04:50:11Z | https://github.com/kubernetes/kubernetes/issues/93404 | 664,883,792 | 93,404 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
This issue was originally reported via the Kubernetes HackerOne bug bounty by HackerOne user [lazydog](https://hackerone.com/lazydog) but we have decided that due to the high privileges required, it can be addressed publicly.
A user able to create CRDs could create a malicious CRD such that lis... | Exponential entity expansion allowed by jsonpath function | https://api.github.com/repos/kubernetes/kubernetes/issues/93400/comments | 4 | 2020-07-23T23:11:28Z | 2020-08-02T11:21:41Z | https://github.com/kubernetes/kubernetes/issues/93400 | 664,818,512 | 93,400 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
When creating a deployment (so we can scale up/down), having a container, containing a massive amount of ENV data, results in very destructive behaviour on the entire k8s setup. Including master nodes.
- worker workload increases massively
- etcd database gains a lot of data
- Memory usage of t... | "Self" DOS with large deployment and scaling | https://api.github.com/repos/kubernetes/kubernetes/issues/93399/comments | 14 | 2020-07-23T21:58:21Z | 2021-04-24T19:33:08Z | https://github.com/kubernetes/kubernetes/issues/93399 | 664,790,390 | 93,399 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
https://github.com/kubernetes/kubernetes/issues/93229 indicates that we're missing an e2e test for.
This specific issue is just a tracker to create a new E2E test that demonstrated 93229 .
| E2e Test for multiple services with endpoints | https://api.github.com/repos/kubernetes/kubernetes/issues/93397/comments | 13 | 2020-07-23T21:52:51Z | 2020-09-22T19:23:01Z | https://github.com/kubernetes/kubernetes/issues/93397 | 664,787,964 | 93,397 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Multiple pod IPs are labeled as fc00:2 ::32
**What you expected to happen**:
I expected pod IP to be in 10.244.0.0/16 subnet, as specified during kubeadm init because I am using flannel
**How to reproduce it (as minimally and precisely as possible)**:
`kubeadm init --pod-network-cidr=10.244.... | Pod IP is not in IPv4 format (2 pods on worker node have same IP of fc00:2 ::32) | https://api.github.com/repos/kubernetes/kubernetes/issues/93393/comments | 11 | 2020-07-23T20:39:30Z | 2020-08-04T12:54:06Z | https://github.com/kubernetes/kubernetes/issues/93393 | 664,751,029 | 93,393 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
I ran
`kubectl delete CustomResourceDefinition challenges.acme.cert-manager.io`
Outputs
`customresourcedefinition.apiextensions.k8s.io "challenges.acme.cert-manager.io" deleted`
and then stuck forever.
Exiting using Ctrl+C, and querying again shows that the CRD was not deleted.
*... | kubectl CRD delete hangs | https://api.github.com/repos/kubernetes/kubernetes/issues/93392/comments | 7 | 2020-07-23T19:56:15Z | 2020-08-03T16:01:45Z | https://github.com/kubernetes/kubernetes/issues/93392 | 664,728,473 | 93,392 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Using `k8s.io/cli-runtime/pkg/kustomize` to build with kustomization.yaml that contains inline patch (https://github.com/kubernetes-sigs/kustomize/blob/master/examples/inlinePatch.md) fails with `SliceFromPatches: evalsymlink failure` error.
Here is my simple test code. In the first block, I us... | Inline patch kustomization does not work | https://api.github.com/repos/kubernetes/kubernetes/issues/93391/comments | 3 | 2020-07-23T17:55:08Z | 2020-07-27T22:51:43Z | https://github.com/kubernetes/kubernetes/issues/93391 | 664,662,704 | 93,391 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Create EKS us... | Destroying AWS EKS using Terraform does not delete NLB | https://api.github.com/repos/kubernetes/kubernetes/issues/93390/comments | 13 | 2020-07-23T17:08:12Z | 2023-12-05T08:44:50Z | https://github.com/kubernetes/kubernetes/issues/93390 | 664,636,482 | 93,390 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
when I create... | Error pinging docker registry k8s.gcr.io, but the registry I configured is registry.aliyuncs.com not k8s.gcr.io | https://api.github.com/repos/kubernetes/kubernetes/issues/93386/comments | 7 | 2020-07-23T13:48:21Z | 2020-08-04T10:33:20Z | https://github.com/kubernetes/kubernetes/issues/93386 | 664,488,818 | 93,386 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I lanch a pod... | the pod mount pvc failed due to rbd image xxx is still being used | https://api.github.com/repos/kubernetes/kubernetes/issues/93385/comments | 7 | 2020-07-23T11:12:20Z | 2021-01-25T13:40:02Z | https://github.com/kubernetes/kubernetes/issues/93385 | 664,389,931 | 93,385 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
```
# k get po -owide|grep -w dns
<none>
node-local-dns-cg2nw 0/1 CrashLoopBackOff 4 4m45s 192.168.0.49 master <none> <none>
... | plugin/loop: Loop (192.168.0.49:54616 -> 192.168.0.49:53) detected for zone "in-addr.arpa.", see https://coredns.io/plugins/loop#troubleshooting. Query: "HINFO 8152613472028609709.5116360551987037255.in-addr.arpa." | https://api.github.com/repos/kubernetes/kubernetes/issues/93379/comments | 5 | 2020-07-23T06:36:27Z | 2020-08-10T18:13:21Z | https://github.com/kubernetes/kubernetes/issues/93379 | 664,236,135 | 93,379 |
[
"kubernetes",
"kubernetes"
] |
**Which jobs are failing**:
All jobs in this tab https://k8s-testgrid.appspot.com/sig-network-netd
**Which test(s) are failing**:
**Since when has it been failing**:
07/22 12.00 PDT
**Testgrid link**:
https://k8s-testgrid.appspot.com/sig-network-netd
**Reason for failure**:
U=https://storag... | Jobs https://k8s-testgrid.appspot.com/sig-network-netd | https://api.github.com/repos/kubernetes/kubernetes/issues/93377/comments | 5 | 2020-07-23T06:26:04Z | 2020-07-25T00:10:17Z | https://github.com/kubernetes/kubernetes/issues/93377 | 664,232,291 | 93,377 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Testing API P... | dump_requests lists phantom request for each exempt priority level | https://api.github.com/repos/kubernetes/kubernetes/issues/93376/comments | 2 | 2020-07-23T04:30:36Z | 2020-09-02T17:37:06Z | https://github.com/kubernetes/kubernetes/issues/93376 | 664,195,367 | 93,376 |
[
"kubernetes",
"kubernetes"
] | it looks like the following test jobs have been solidly failing for a couple weeks:
* https://testgrid.k8s.io/google-gce#gci-gce-sd-logging&width=5
* https://testgrid.k8s.io/sig-node-containerd#e2e-gci-sd-logging-k8s-resources&width=5
* https://testgrid.k8s.io/sig-node-containerd#e2e-gci-sd-logging&width=5
if those... | Disable failing sd-logging test jobs until fixed | https://api.github.com/repos/kubernetes/kubernetes/issues/93375/comments | 7 | 2020-07-23T04:18:48Z | 2020-12-20T10:32:10Z | https://github.com/kubernetes/kubernetes/issues/93375 | 664,192,161 | 93,375 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are flaking**:
* ci-kubernetes-kind-e2e-parallel
* pr:pull-kubernetes-e2e-gce
* pr:pull-kubernetes-e2e-gce-ubuntu-containerd
* pr:pull-kubernetes-e2e-gce-ubuntu-containerd
* ci-kubernetes-kind-ipv6-e2e-parallel
**Which test(s) are flaking**:
Second flakiest test in the e2e job according to htt... | [Flaky test] EndpointSlice should create Endpoints and EndpointSlices for Pods matching a Service | https://api.github.com/repos/kubernetes/kubernetes/issues/93374/comments | 26 | 2020-07-23T04:08:37Z | 2020-08-18T17:30:13Z | https://github.com/kubernetes/kubernetes/issues/93374 | 664,189,205 | 93,374 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about flaky tests or jobs (pass or fail with no underlying change in code) in Kubernetes CI -->
**Which jobs are flaking**:
* pull-kubernetes-e2e-gce (5% of runs)
* pull-kubernetes-e2e-kind-ipv6
* pull-kubernetes-e2e-gce-ubuntu-containerd
**Which test... | [Flaky test] Pods should delete a collection of pods | https://api.github.com/repos/kubernetes/kubernetes/issues/93372/comments | 5 | 2020-07-23T03:54:21Z | 2020-07-24T09:08:23Z | https://github.com/kubernetes/kubernetes/issues/93372 | 664,185,196 | 93,372 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
When I have N daemonsets to be deployed on a Node, can I say
DS-N requires "DS-A, DS-B"
Similar to systemd requires/requisite/after ... So DS-N is started only after DS-A & DS-B starts.
**Why i... | Can daemonsets declare dependencies | https://api.github.com/repos/kubernetes/kubernetes/issues/93366/comments | 2 | 2020-07-22T23:07:07Z | 2020-07-23T00:44:52Z | https://github.com/kubernetes/kubernetes/issues/93366 | 664,102,139 | 93,366 |
[
"kubernetes",
"kubernetes"
] | One use-case of `kubectl wait --for=delete` is to wait for a lot of resources that you have just deleted. Unfortunately, this workflow is racy because `kubectl wait --for=delete` will fail when encountering a resource that doesn't exist (yes, it's probably already gone). I suspect we should just consider 404 resources ... | `kubectl wait --for=delete` fails on 404 | https://api.github.com/repos/kubernetes/kubernetes/issues/93365/comments | 6 | 2020-07-22T23:03:01Z | 2020-11-20T05:37:45Z | https://github.com/kubernetes/kubernetes/issues/93365 | 664,100,765 | 93,365 |
[
"kubernetes",
"kubernetes"
] | Currently, `kubectl delete` only allows orphaning (`--cascade=false`) or background cascading (`--cascade=true`, the default). There is no option I know to allow foreground cascading deletion. I propose that we maybe do the same thing we did for `--dry-run`, that is, move from a boolean to an enum by accepting `foregro... | Allow foreground cascading deletion in kubectl | https://api.github.com/repos/kubernetes/kubernetes/issues/93364/comments | 1 | 2020-07-22T23:00:07Z | 2020-09-24T06:58:05Z | https://github.com/kubernetes/kubernetes/issues/93364 | 664,099,763 | 93,364 |
[
"kubernetes",
"kubernetes"
] | Users should be able to know and prevent resources that are being deleted from being applied, since it can be misleading, and racy when they delete and re-apply quickly.
We could offer this through two different user-experience:
1. Create a warning when we detect that the changes are done to a resource that has the... | Detect "kubectl apply" to resources currently being deleted | https://api.github.com/repos/kubernetes/kubernetes/issues/93363/comments | 12 | 2020-07-22T22:55:59Z | 2021-01-11T21:21:36Z | https://github.com/kubernetes/kubernetes/issues/93363 | 664,098,316 | 93,363 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I fetched som... | Terminal commas in APF debug listings | https://api.github.com/repos/kubernetes/kubernetes/issues/93362/comments | 3 | 2020-07-22T22:14:13Z | 2020-07-29T02:26:03Z | https://github.com/kubernetes/kubernetes/issues/93362 | 664,082,277 | 93,362 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I tried fetch... | unexpected results from GET /debug | https://api.github.com/repos/kubernetes/kubernetes/issues/93361/comments | 10 | 2020-07-22T21:27:31Z | 2021-01-04T05:21:01Z | https://github.com/kubernetes/kubernetes/issues/93361 | 664,061,046 | 93,361 |
[
"kubernetes",
"kubernetes"
] | [wait.Until](https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/client-go/tools/watch/until.go#L96-L98) has an outdated code comment that refers to the func `ListWatchUntil`. That function was removed in #90855
```
// Until wraps the watcherClient's watch function with RetryWatcher making sure... | Outdated code comment for ListWatchUntil | https://api.github.com/repos/kubernetes/kubernetes/issues/93360/comments | 8 | 2020-07-22T21:12:42Z | 2021-04-23T11:02:03Z | https://github.com/kubernetes/kubernetes/issues/93360 | 664,053,279 | 93,360 |
[
"kubernetes",
"kubernetes"
] | on kubernetes 1.18 with flowcontrol enabled
when our api-server is under heavy load for a long time it dies because the livenessProbe fails
this is dangerous since it can lead to etcd compaction never running and then etcd falling over
I did not find a way to configure a serviceaccount for livenessProbe except f... | kube-apiserver livenessProbe needs to be excempt from flowcontrol | https://api.github.com/repos/kubernetes/kubernetes/issues/93359/comments | 23 | 2020-07-22T21:05:02Z | 2020-10-22T06:20:31Z | https://github.com/kubernetes/kubernetes/issues/93359 | 664,049,456 | 93,359 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are flaking**:
* pull-kubernetes-e2e-kind-ipv6
* pull-kubernetes-e2e-kind
**Which test(s) are flaking**:
* CSI mock volume ... tests
**Testgrid link**:
* https://testgrid.k8s.io/presubmits-kubernetes-blocking#pull-kubernetes-e2e-kind&include-filter-by-regex=CSI%20mock%20volume&width=5&sort-... | [Flaky test] "PersistentVolumeClaims not all in phase Bound within 5m0s" failing in ~2% of kind presubmits | https://api.github.com/repos/kubernetes/kubernetes/issues/93358/comments | 24 | 2020-07-22T20:55:15Z | 2021-01-08T01:50:37Z | https://github.com/kubernetes/kubernetes/issues/93358 | 664,044,455 | 93,358 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.