
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
My init-con... | init-container restarted after docker prune image | https://api.github.com/repos/kubernetes/kubernetes/issues/86531/comments | 15 | 2019-12-23T03:05:16Z | 2021-01-06T13:05:08Z | https://github.com/kubernetes/kubernetes/issues/86531 | 541,549,363 | 86,531 |
[
"kubernetes",
"kubernetes"
] | Hi
I tried to connect with a regional cluster using v1 api and ended up with the following error.
error: google.api_core.exceptions.NotFound: 404 Not found: projects/myprojectname/zones/us-central1-a/clusters/myclustername.
Can you guys make an enhancement for regional gke clusters ?
| gcloud container v1 api support for gke regional clusters | https://api.github.com/repos/kubernetes/kubernetes/issues/86528/comments | 8 | 2019-12-23T00:42:37Z | 2020-05-21T03:22:40Z | https://github.com/kubernetes/kubernetes/issues/86528 | 541,522,971 | 86,528 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Server-side dry-run is being promoted from beta to GA in v1.18.
For the server-side dry-run integration in kubectl, we are making a few changes:
- we're extending the `--dry-run` flag to support t... | document server-side dry run is GA | https://api.github.com/repos/kubernetes/kubernetes/issues/86526/comments | 17 | 2019-12-22T21:02:33Z | 2020-03-12T21:05:20Z | https://github.com/kubernetes/kubernetes/issues/86526 | 541,500,634 | 86,526 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Currently, we primarily have documentation for `kubectl diff` in the helptext itself.
`kubectl diff` is being promoted from beta to GA in v1.18.
For `kubectl diff`, we need more documentation on k... | Document kubectl diff command as GA | https://api.github.com/repos/kubernetes/kubernetes/issues/86525/comments | 9 | 2019-12-22T20:47:12Z | 2020-03-23T15:58:12Z | https://github.com/kubernetes/kubernetes/issues/86525 | 541,499,302 | 86,525 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
when create r... | pod.spec.affinity.podAffinity.preferredDuringSchedulingIgnoredDuringExecution.podAffinityTerm Mismatch explain doc | https://api.github.com/repos/kubernetes/kubernetes/issues/86523/comments | 1 | 2019-12-22T12:54:03Z | 2019-12-22T13:09:54Z | https://github.com/kubernetes/kubernetes/issues/86523 | 541,447,310 | 86,523 |
[
"kubernetes",
"kubernetes"
] | <!--
STOP -- PLEASE READ!
GitHub is not the right place for support requests.
If you're looking for help, check [Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes) and the [troubleshooting guide](https://kubernetes.io/docs/tasks/debug-application-cluster/troubleshooting/).
You can also pos... | sessionAffinityConfig did not take affect | https://api.github.com/repos/kubernetes/kubernetes/issues/86522/comments | 5 | 2019-12-22T10:12:19Z | 2020-02-08T16:49:07Z | https://github.com/kubernetes/kubernetes/issues/86522 | 541,432,070 | 86,522 |
[
"kubernetes",
"kubernetes"
] | <!--
STOP -- PLEASE READ!
GitHub is not the right place for support requests.
If you're looking for help, check [Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes) and the [troubleshooting guide](https://kubernetes.io/docs/tasks/debug-application-cluster/troubleshooting/).
You can also pos... | loadBalancerSourceRanges did not take affect | https://api.github.com/repos/kubernetes/kubernetes/issues/86520/comments | 4 | 2019-12-22T09:38:10Z | 2020-04-12T21:44:05Z | https://github.com/kubernetes/kubernetes/issues/86520 | 541,428,848 | 86,520 |
[
"kubernetes",
"kubernetes"
] | <!--
STOP -- PLEASE READ!
GitHub is not the right place for support requests.
If you're looking for help, check [Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes) and the [troubleshooting guide](https://kubernetes.io/docs/tasks/debug-application-cluster/troubleshooting/).
You can also pos... | ipFamily: IPv6 is set but the ip is still ipv4 | https://api.github.com/repos/kubernetes/kubernetes/issues/86518/comments | 9 | 2019-12-22T07:25:55Z | 2020-03-19T23:38:05Z | https://github.com/kubernetes/kubernetes/issues/86518 | 541,418,268 | 86,518 |
[
"kubernetes",
"kubernetes"
] | [Service]
WorkingDirectory=/var/lib/kubelet
ExecStartPre=/bin/mount -o remount,rw '/sys/fs/cgroup'
ExecStartPre=/bin/mkdir -p /sys/fs/cgroup/cpuset/system.slice/kubelet.service
ExecStartPre=/bin/mkdir -p /sys/fs/cgroup/hugetlb/system.slice/kubelet.service
ExecStartPre=/bin/mkdir -p /sys/fs/cgroup/memory/system.sli... | already set--hostname-override but node port service cannot access with set externaltrafficpolicy | https://api.github.com/repos/kubernetes/kubernetes/issues/86517/comments | 5 | 2019-12-22T06:56:19Z | 2020-02-06T22:49:34Z | https://github.com/kubernetes/kubernetes/issues/86517 | 541,416,190 | 86,517 |
[
"kubernetes",
"kubernetes"
] | [root@master01 service]# curl nginx-02.nginx-clusterip-svc-headless.default.svc.cluster.local:80
curl: (6) Could not resolve host: nginx-02.nginx-clusterip-svc-headless.default.svc.cluster.local; Unknown error
[root@master01 service]# curl nginx-clusterip-svc-headless.default.svc.cluster.local:80
<!DOCTYPE html>
<h... | why I cannt access pod with headless service | https://api.github.com/repos/kubernetes/kubernetes/issues/86516/comments | 6 | 2019-12-22T04:51:06Z | 2023-02-08T00:11:32Z | https://github.com/kubernetes/kubernetes/issues/86516 | 541,407,289 | 86,516 |
[
"kubernetes",
"kubernetes"
] | I created a CR "parent" that creates a CR "child". The "child" CR has **two** ownerrefs: "parent" and "uncle" (another CR). The "parent" ownerRef blockOwnerDeletion is true; the "uncle" ownerRef blockOwnerDeletion is unset.
When I delete "parent", "child" is not deleted. We do not seem to honor blockOwnerDeletion... | BlockOwnerDeletion does not block owner deletion | https://api.github.com/repos/kubernetes/kubernetes/issues/86509/comments | 23 | 2019-12-21T16:53:03Z | 2025-03-05T07:57:45Z | https://github.com/kubernetes/kubernetes/issues/86509 | 541,346,977 | 86,509 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
A NodePort se... | Service cannot be accessed via nodeport | https://api.github.com/repos/kubernetes/kubernetes/issues/86507/comments | 35 | 2019-12-21T11:30:58Z | 2024-10-17T08:35:34Z | https://github.com/kubernetes/kubernetes/issues/86507 | 541,316,895 | 86,507 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
When config... | Pod Probes doesn't work if host = 0.0.0.0 | https://api.github.com/repos/kubernetes/kubernetes/issues/86504/comments | 8 | 2019-12-21T10:27:16Z | 2020-01-03T22:20:57Z | https://github.com/kubernetes/kubernetes/issues/86504 | 541,311,291 | 86,504 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
We ran the following, and got the following:
```
$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
aks-nodepool1-35944238-0 320m 8% 15080Mi 54%
aks-nodepool1-35944238-1 355m 9% 28048Mi 101%
aks-nodepool1-359... | kubectl shows node memory >100%? | https://api.github.com/repos/kubernetes/kubernetes/issues/86499/comments | 19 | 2019-12-20T23:51:45Z | 2021-11-05T20:21:35Z | https://github.com/kubernetes/kubernetes/issues/86499 | 541,248,377 | 86,499 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
All the services are asking to be recreated because the service CIDR changed after upgrading from 1.16.3 ro 1.17.0
```
{
"_index": "logstash-2019.12.20",
"_type": "_doc",
"_id": "kG2RJW8BRYpt1XnHuKKz",
"_version": 1,
"_score": null,
"_source": {
"log": "E1220 23:08:20.3909... | Service is not within the service CIDR please recreate | https://api.github.com/repos/kubernetes/kubernetes/issues/86497/comments | 34 | 2019-12-20T23:18:44Z | 2022-08-08T07:57:59Z | https://github.com/kubernetes/kubernetes/issues/86497 | 541,241,398 | 86,497 |
[
"kubernetes",
"kubernetes"
] | Kubernetes resources A) act differently on `apply` and B) have varying degrees of specificity for `apply` response logs. Can we unify these into a more idempotent `apply` behavior, and make sure that logs disambiguate error vs. modification vs. no change? | Idempotent `apply` with clearer logs | https://api.github.com/repos/kubernetes/kubernetes/issues/86494/comments | 5 | 2019-12-20T21:22:51Z | 2020-05-22T00:43:38Z | https://github.com/kubernetes/kubernetes/issues/86494 | 541,205,784 | 86,494 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about flaky tests or jobs (pass or fail with no underlying change in code) in Kubernetes CI -->
**Which jobs are flaking**:
- pull-kubernetes-e2e-gce
**Which test(s) are flaking**:
- [sig-api-machinery] ResourceQuota should verify ResourceQuota with best... | [Flaky Test] [sig-api-machinery] ResourceQuota | https://api.github.com/repos/kubernetes/kubernetes/issues/86491/comments | 6 | 2019-12-20T19:43:33Z | 2020-01-22T00:27:11Z | https://github.com/kubernetes/kubernetes/issues/86491 | 541,168,217 | 86,491 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Users are unable ... | Enable deleting API objects even when storage-level decryption is not working properly | https://api.github.com/repos/kubernetes/kubernetes/issues/86489/comments | 9 | 2019-12-20T18:42:33Z | 2024-03-14T16:05:55Z | https://github.com/kubernetes/kubernetes/issues/86489 | 541,143,426 | 86,489 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Pod not sched... | node affinity Gt/Lt not working with floats | https://api.github.com/repos/kubernetes/kubernetes/issues/86488/comments | 5 | 2019-12-20T18:36:02Z | 2019-12-20T21:02:15Z | https://github.com/kubernetes/kubernetes/issues/86488 | 541,137,605 | 86,488 |
[
"kubernetes",
"kubernetes"
] | **Environment**: Windows Containers on Windows 10, Azure Kubernetes Services Cluster, Azure Cli, Azure Cloud Shell
I'm following [this][1] Microsoft Tutorial to create a Windows Server container on an Azure Kubernetes Service (AKS) cluster using Azure Cli. In the [Run the Application][3] section of this turorial, I ... | Validation error during deployment using YAML config file | https://api.github.com/repos/kubernetes/kubernetes/issues/86486/comments | 7 | 2019-12-20T16:04:25Z | 2019-12-20T18:31:10Z | https://github.com/kubernetes/kubernetes/issues/86486 | 541,068,256 | 86,486 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
I have ReplicationController with 2 replicas. Pods have deafined custom readinessGates condition. Sometimes after readinessGates condition gets changed to True, pod ready condition does not get updated.
**What you expected to happen**:
pod condition type==ready status to be always updated as soo... | Pod ready condition is not always updated after readiness gates condition changes | https://api.github.com/repos/kubernetes/kubernetes/issues/86485/comments | 19 | 2019-12-20T15:33:32Z | 2020-08-16T05:17:27Z | https://github.com/kubernetes/kubernetes/issues/86485 | 541,053,719 | 86,485 |
[
"kubernetes",
"kubernetes"
] | As shown in https://github.com/kubernetes/kubernetes/issues/86483, performance of up-and-running large clusters was fine in 1.17, but upgrade of such cluster has high probability of killing the cluster.
We should add "control plane upgrade" scalability test to release blocking tests.
@kubernetes/sig-scalability-b... | Upgrades of large clusters should be scalability tested | https://api.github.com/repos/kubernetes/kubernetes/issues/86484/comments | 35 | 2019-12-20T14:15:20Z | 2024-04-30T11:31:51Z | https://github.com/kubernetes/kubernetes/issues/86484 | 541,016,339 | 86,484 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/kubernetes/pull/83520 changed the way how reflectors work.
In particular, when we down kube-apiserver, what happens is:
- watches (from kubelets/kube-proxies) are breaking and reconnecting to a different apiserver
- apiserver (when restarting) initializes watch cache at "now"
- given t... | 1.17 & 1.18 clusters are failing during master rolling upgrade | https://api.github.com/repos/kubernetes/kubernetes/issues/86483/comments | 17 | 2019-12-20T14:12:37Z | 2020-02-04T07:09:26Z | https://github.com/kubernetes/kubernetes/issues/86483 | 541,014,966 | 86,483 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Pods on Windows can't communicate with any resources (db, smb, etc) that hosted at the network of on-premise k8s.
**What you expected to happen**:
Pods should have opportunity to communicate with host's network.
**How to reproduce it (as minimally and precisely as possible)**:
1. setup k8s-m... | Windows Containers can't communicate with resources from host's network | https://api.github.com/repos/kubernetes/kubernetes/issues/86482/comments | 16 | 2019-12-20T13:56:24Z | 2020-07-06T20:35:06Z | https://github.com/kubernetes/kubernetes/issues/86482 | 541,007,414 | 86,482 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
The apiserv... | apiserver, controller-manager and scheduler listen on all interfaces (ipv4 and ipv6) when binding to 0.0.0.0 | https://api.github.com/repos/kubernetes/kubernetes/issues/86479/comments | 16 | 2019-12-20T11:55:28Z | 2022-03-11T13:45:03Z | https://github.com/kubernetes/kubernetes/issues/86479 | 540,958,742 | 86,479 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
failedPredicates declared, but woul... | Scheduler: len(failedPredicates) always 0 | https://api.github.com/repos/kubernetes/kubernetes/issues/86475/comments | 6 | 2019-12-20T09:20:04Z | 2019-12-31T02:05:35Z | https://github.com/kubernetes/kubernetes/issues/86475 | 540,882,752 | 86,475 |
[
"kubernetes",
"kubernetes"
] | Hello,
It's my first time trying K8s cluster. The embarrassing thing is when i did the first task, i failed.
Here is the thing.
I followd official documents to create a web deployment.
I can access my pod in my cluster node.
And then i created a service to link my pod. So i got the service IP.
The official do... | My K8s-Cluster cannot access Service-IP(clusterIP) | https://api.github.com/repos/kubernetes/kubernetes/issues/86471/comments | 9 | 2019-12-20T06:58:10Z | 2020-04-06T16:28:50Z | https://github.com/kubernetes/kubernetes/issues/86471 | 540,809,001 | 86,471 |
[
"kubernetes",
"kubernetes"
] | Test 123 | Testing :) | https://api.github.com/repos/kubernetes/kubernetes/issues/86469/comments | 1 | 2019-12-20T05:57:21Z | 2019-12-20T05:57:56Z | https://github.com/kubernetes/kubernetes/issues/86469 | 540,782,384 | 86,469 |
[
"kubernetes",
"kubernetes"
] | <!--
STOP -- PLEASE READ!
GitHub is not the right place for support requests.
If you're looking for help, check [Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes) and the [troubleshooting guide](https://kubernetes.io/docs/tasks/debug-application-cluster/troubleshooting/).
You can also pos... | how to use runtimeclass and runtimeClassName | https://api.github.com/repos/kubernetes/kubernetes/issues/86467/comments | 4 | 2019-12-20T04:52:10Z | 2020-04-12T21:38:26Z | https://github.com/kubernetes/kubernetes/issues/86467 | 540,757,896 | 86,467 |
[
"kubernetes",
"kubernetes"
] | <!--
STOP -- PLEASE READ!
GitHub is not the right place for support requests.
If you're looking for help, check [Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes) and the [troubleshooting guide](https://kubernetes.io/docs/tasks/debug-application-cluster/troubleshooting/).
You can also pos... | I want to use readinessGates ,how can i create a condition | https://api.github.com/repos/kubernetes/kubernetes/issues/86465/comments | 4 | 2019-12-20T04:25:43Z | 2020-04-12T21:35:11Z | https://github.com/kubernetes/kubernetes/issues/86465 | 540,748,199 | 86,465 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
when apply ... | apply can't work, but delete/apply work | https://api.github.com/repos/kubernetes/kubernetes/issues/86463/comments | 8 | 2019-12-20T03:08:34Z | 2019-12-20T03:53:21Z | https://github.com/kubernetes/kubernetes/issues/86463 | 540,720,754 | 86,463 |
[
"kubernetes",
"kubernetes"
] | I just created a new cluster using version 1.17.0 of the kubeadm & kubelet Debian packages (downloaded from https://packages.cloud.google.com/apt), and observed a strange behavior when using `kubectl` version 1.17.0.
**What happened**:
When running `kubectl get -A all` with `kubectl` version 1.17.0, the command han... | "kubectl get -A all" hangs when using kubectl version 1.17.0 | https://api.github.com/repos/kubernetes/kubernetes/issues/86462/comments | 7 | 2019-12-20T03:04:15Z | 2019-12-20T03:50:38Z | https://github.com/kubernetes/kubernetes/issues/86462 | 540,719,155 | 86,462 |
[
"kubernetes",
"kubernetes"
] | <!--
STOP -- PLEASE READ!
GitHub is not the right place for support requests.
If you're looking for help, check [Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes) and the [troubleshooting guide](https://kubernetes.io/docs/tasks/debug-application-cluster/troubleshooting/).
You can also pos... | my kubernetes version is 1.16.2 I cannot use ephemeralcontainers | https://api.github.com/repos/kubernetes/kubernetes/issues/86461/comments | 2 | 2019-12-20T01:58:42Z | 2019-12-20T02:39:06Z | https://github.com/kubernetes/kubernetes/issues/86461 | 540,695,606 | 86,461 |
[
"kubernetes",
"kubernetes"
] | /assign @ahg-g
/sig scheduling
/priority important-soon
This includes moving the metadata logic into PreFilter.
Part of #85822 | Move Pod Affinity predicate logic to its Filter plugin [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86460/comments | 0 | 2019-12-20T01:46:41Z | 2019-12-21T02:28:09Z | https://github.com/kubernetes/kubernetes/issues/86460 | 540,691,075 | 86,460 |
[
"kubernetes",
"kubernetes"
] | Worker node was added to the master and was running a few days back, now getting the following error
[root@samwise ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
bilbo.devemc.commvault.com Ready master 120d v1.16.1
samwise.devemc.commvault.com NotReady <no... | Worker node fails always in Not ready state | https://api.github.com/repos/kubernetes/kubernetes/issues/86451/comments | 9 | 2019-12-19T21:09:09Z | 2020-07-06T01:16:48Z | https://github.com/kubernetes/kubernetes/issues/86451 | 540,567,594 | 86,451 |
[
"kubernetes",
"kubernetes"
] | CSI drivers need some way to get service account tokens for the pods they are provisioning volumes for. These tokens may be used to authenticate to the Kubernetes API (e.g. the [Certificates API](https://github.com/jetstack/cert-manager-csi), or to authenticate to external services like [vault](https://github.com/hashi... | CSI drivers need some way to get service account tokens | https://api.github.com/repos/kubernetes/kubernetes/issues/86448/comments | 20 | 2019-12-19T18:49:23Z | 2020-11-16T19:02:36Z | https://github.com/kubernetes/kubernetes/issues/86448 | 540,495,887 | 86,448 |
[
"kubernetes",
"kubernetes"
] | /sig scheduling
/priority important-soon
See #86446 as an example.
/assign @danielqsj | Move ServiceAntiAffinityPriority to its Score plugin [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86447/comments | 3 | 2019-12-19T16:49:16Z | 2019-12-27T12:05:39Z | https://github.com/kubernetes/kubernetes/issues/86447 | 540,432,304 | 86,447 |
[
"kubernetes",
"kubernetes"
] | /sig scheduling
/priority important-soon
See #86399 as an example.
There are two parts to this:
PR 1: move RequestedToCapacityRatio plugins/requestedtocapacityratio/requested_to_capacity_ratio.go to plugins/noderesources/requested_to_capacity_ratio.go
PR 2: move resource_allocation.go to plugins/noderesou... | Move resource-based priority functions to their Score plugins [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86445/comments | 2 | 2019-12-19T16:04:38Z | 2019-12-31T17:37:41Z | https://github.com/kubernetes/kubernetes/issues/86445 | 540,407,415 | 86,445 |
[
"kubernetes",
"kubernetes"
] | /sig scheduling
/priority important-soon
See #86399 as an example.
Part of #85822
/assign @tanjunchen | Move VolumeZone predicate to its Filter plugin [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86444/comments | 2 | 2019-12-19T15:47:42Z | 2019-12-26T18:23:39Z | https://github.com/kubernetes/kubernetes/issues/86444 | 540,396,779 | 86,444 |
[
"kubernetes",
"kubernetes"
] | /sig scheduling
/priority important-soon
See #86399 as an example.
Part of #85822
/assign @angao | Move NoDiskConflict predicate to its Filter plugin [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86443/comments | 2 | 2019-12-19T15:46:37Z | 2019-12-25T23:27:39Z | https://github.com/kubernetes/kubernetes/issues/86443 | 540,396,098 | 86,443 |
[
"kubernetes",
"kubernetes"
] | /sig scheduling
/priority important-soon
We need to move the unit tests as well.
See #86399 as an example.
Part of #85822
/assign @zouyee | Move volumebinding predicate to its filter plugin [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86442/comments | 3 | 2019-12-19T15:40:31Z | 2019-12-25T12:34:24Z | https://github.com/kubernetes/kubernetes/issues/86442 | 540,392,077 | 86,442 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
kube version: Server Version: version... | Error creating load balancer in AWS | https://api.github.com/repos/kubernetes/kubernetes/issues/86441/comments | 9 | 2019-12-19T14:49:50Z | 2022-11-03T11:35:18Z | https://github.com/kubernetes/kubernetes/issues/86441 | 540,359,644 | 86,441 |
[
"kubernetes",
"kubernetes"
] | /assign @Huang-Wei
/sig scheduling
/priority important-soon
This includes moving the metadata logic into PostFilter.
Part of #85822 | Move Pod Spread priority logic to its Score plugin [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86440/comments | 0 | 2019-12-19T14:47:42Z | 2019-12-29T07:47:39Z | https://github.com/kubernetes/kubernetes/issues/86440 | 540,358,466 | 86,440 |
[
"kubernetes",
"kubernetes"
] | /sig scheduling
/priority important-soon
See #86399 as an example.
Part of #85822
This will require a PostFilter Plugin to pre-compute the list of tolerations with effect TaintEffectPreferNoSchedule.
/assign @SataQiu | Move Taint and toleration priority to its Score plugin [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86439/comments | 0 | 2019-12-19T14:43:06Z | 2019-12-24T19:43:30Z | https://github.com/kubernetes/kubernetes/issues/86439 | 540,355,796 | 86,439 |
[
"kubernetes",
"kubernetes"
] | /sig scheduling
/priority important-soon
See #86399 as an example.
Part of #85822
This shouldn't need a PostFilter Plugin.
/assign @danielqsj | Move NodeLabelPriority to its Score and Filter plugin [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86437/comments | 1 | 2019-12-19T14:37:57Z | 2019-12-19T23:37:22Z | https://github.com/kubernetes/kubernetes/issues/86437 | 540,352,904 | 86,437 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
It seems that Jobs that get terminated due to exceeding the active deadline seconds get a wrong duration reported via `kubectl`.
This the `kubectl get jobs` for the affected Jobs:
```
$ kubectl get jobs -l app=material-girl
NAME ... | Kubectl reporting wrong duration for jobs aborted due to exceeding deadline | https://api.github.com/repos/kubernetes/kubernetes/issues/86436/comments | 10 | 2019-12-19T14:31:24Z | 2020-11-10T17:55:37Z | https://github.com/kubernetes/kubernetes/issues/86436 | 540,349,209 | 86,436 |
[
"kubernetes",
"kubernetes"
] | /sig scheduling
/priority important-soon
SelectorSpread priority is now called from a plugin named DefaultPodTopologySpread. We need to move the logic to run in the plugin and remove SelectorSpread priority completely.
See #86399 as an example.
Part of #85822
This needs PostFilter Plugin to store the pod s... | Move SelectorSpread priority logic to its Score plugin [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86435/comments | 5 | 2019-12-19T14:30:44Z | 2020-01-09T05:29:46Z | https://github.com/kubernetes/kubernetes/issues/86435 | 540,348,834 | 86,435 |
[
"kubernetes",
"kubernetes"
] | It happens during the "delete" phase in the load test.
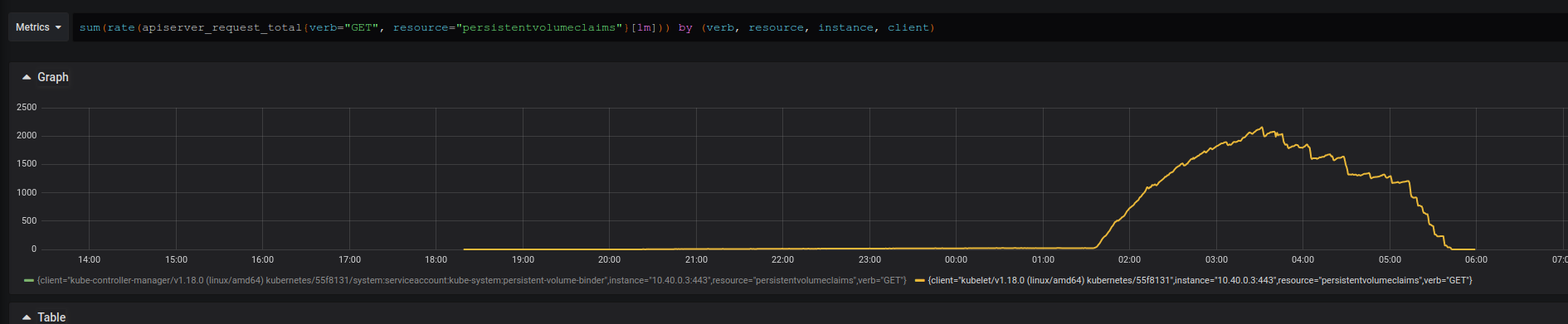
In perf-dash we can see that in total there are ~20M requests like that during the load test.
 are failing**:
Setting up the cluster
**Since when has it been failing**:
long time
**Testgrid link**:
https://k8s-testgrid.appspot.com/sig-scalability-node#node-containerd-throughput
**Reason for failure**:
ht... | [Failing Test] node-containerd-throughput failing | https://api.github.com/repos/kubernetes/kubernetes/issues/86429/comments | 9 | 2019-12-19T11:57:00Z | 2019-12-31T13:25:25Z | https://github.com/kubernetes/kubernetes/issues/86429 | 540,268,878 | 86,429 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are failing**:
ci-kubernetes-e2e-gce-scale-correctness
**Which test(s) are failing**:
- [sig-storage] In-tree Volumes [Driver: gluster] [Testpattern: Inline-volume (default fs)] volumes should allow exec of files on the volume
- [sig-storage] CSI mock volume CSI Volume expansion should expand volume ... | [Failing Test] gce-master-scale-correctness - sig-storage tests | https://api.github.com/repos/kubernetes/kubernetes/issues/86427/comments | 4 | 2019-12-19T11:24:28Z | 2019-12-20T09:22:03Z | https://github.com/kubernetes/kubernetes/issues/86427 | 540,253,143 | 86,427 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
One of presubmits failed in https://github.com/kubernetes/kubernetes/issues/85879 job, but PR was still merged, which caused all kubemark tests to start failing #86423
Last status:
**14 of 15 checks passed**
**tide** Not mergeable. Retesting: pull-kubernetes-kubemark-e2e-gce-big [Details](htt... | Presubmit failed but did not stop the merge | https://api.github.com/repos/kubernetes/kubernetes/issues/86426/comments | 10 | 2019-12-19T10:14:59Z | 2019-12-31T10:05:04Z | https://github.com/kubernetes/kubernetes/issues/86426 | 540,214,323 | 86,426 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/prometheus is this link gone?<!--
STOP -- PLEASE READ!
GitHub is not the right place for support requests.
If you're looking for help, check [Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes) and the [troubleshooting guide](... | https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/prometheus is this link gone? | https://api.github.com/repos/kubernetes/kubernetes/issues/86424/comments | 4 | 2019-12-19T09:45:39Z | 2019-12-20T01:32:47Z | https://github.com/kubernetes/kubernetes/issues/86424 | 540,197,467 | 86,424 |
[
"kubernetes",
"kubernetes"
] | See https://k8s-testgrid.appspot.com/sig-scalability-kubemark#kubemark-100
E.g. failure, the error seems to be:
```
W1219 07:34:39.336] error: error parsing /go/src/k8s.io/kubernetes/kubernetes/test/kubemark/resources/addons/heapster.json: json: line 14: invalid character ':' after object key:value pair
```
... | All CI kubemark tests are failing | https://api.github.com/repos/kubernetes/kubernetes/issues/86423/comments | 2 | 2019-12-19T09:27:30Z | 2019-12-19T18:12:23Z | https://github.com/kubernetes/kubernetes/issues/86423 | 540,186,520 | 86,423 |
[
"kubernetes",
"kubernetes"
] | The apiserver can work communicating using IPv4 with etcd and using IPv6 with the kubelet and the other kubernetes components. I've seen this behaviour on:
https://github.com/kubernetes/kubernetes/pull/85745
https://github.com/kubernetes/kubernetes/pull/86389
This setup works, but I really don't know what are th... | APIserver communicates mixing IPv4 and IPv6 for different components | https://api.github.com/repos/kubernetes/kubernetes/issues/86422/comments | 10 | 2019-12-19T08:36:28Z | 2020-01-09T11:53:49Z | https://github.com/kubernetes/kubernetes/issues/86422 | 540,160,393 | 86,422 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I have been u... | Network cannot be disconnected after kube-proxy switching to ipvs mode | https://api.github.com/repos/kubernetes/kubernetes/issues/86421/comments | 3 | 2019-12-19T08:02:24Z | 2019-12-25T06:32:49Z | https://github.com/kubernetes/kubernetes/issues/86421 | 540,145,884 | 86,421 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
In https://github.com/kubernetes/kubernetes/blob/661a08daf6acb99374401b68639d82e8b3509f04/pkg/kubelet/qos/policy.go#L34 Kubernetes sets OOM score adjustment for Docker but not for containerd.
Set containerd oom score adj to -999.
**Why is this needed**:
In an OOM situation co... | Set containerd oom score adj to -999 | https://api.github.com/repos/kubernetes/kubernetes/issues/86420/comments | 9 | 2019-12-19T07:27:03Z | 2020-06-19T16:53:52Z | https://github.com/kubernetes/kubernetes/issues/86420 | 540,130,844 | 86,420 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
`framework.ConformanceIt` in `kubernetes/test/e2e/storage/subpath.go` has "LinuxOnly" tag, and there is the following TODO description.
```
framework.ConformanceIt("should support subpaths with secret pod [LinuxOnly]", func() {
// TODO(claudiub): Remove [LinuxOnly] tag once Containerd be... | Can [Linux Only] tag be removed in "kubernetes/test/e2e/storage/subpath.go"? | https://api.github.com/repos/kubernetes/kubernetes/issues/86419/comments | 3 | 2019-12-19T07:13:09Z | 2020-03-12T07:12:17Z | https://github.com/kubernetes/kubernetes/issues/86419 | 540,124,943 | 86,419 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are flaking**:
pull-kubernetes-e2e-gce
**Which test(s) are flaking**:
- [sig-api-machinery] CustomResourcePublishOpenAPI [Privileged:ClusterAdmin] updates the published spec when one version gets renamed [Conformance]
- [sig-api-machinery] CustomResourcePublishOpenAPI [Privileged:ClusterAdmin] work... | [Flaky test] [sig-api-machinery] CustomResourcePublishOpenAPI flakes | https://api.github.com/repos/kubernetes/kubernetes/issues/86418/comments | 8 | 2019-12-19T07:01:48Z | 2020-01-09T14:18:08Z | https://github.com/kubernetes/kubernetes/issues/86418 | 540,120,267 | 86,418 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
e2e tests deleting namespaces timed out waiting for namespace cleanup. this was the root cause of https://github.com/kubernetes/kubernetes/issues/86181.
I graphed namespace controller lag times:
* from namespace delete to start of processing by the namespace cleanup controller (average 3:36, min... | Namespace controller cannot keep up with e2e namespace deletion rate | https://api.github.com/repos/kubernetes/kubernetes/issues/86417/comments | 4 | 2019-12-19T06:08:58Z | 2020-02-29T18:33:55Z | https://github.com/kubernetes/kubernetes/issues/86417 | 540,100,429 | 86,417 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
In the [code ... | AAD token obtained by kubectl has spn prefix which is incompatible with AAD on-behalf-of flow | https://api.github.com/repos/kubernetes/kubernetes/issues/86410/comments | 6 | 2019-12-19T04:04:13Z | 2019-12-19T20:40:54Z | https://github.com/kubernetes/kubernetes/issues/86410 | 540,062,226 | 86,410 |
[
"kubernetes",
"kubernetes"
] | /sig scheduling
/priority important-soon
See #86399 as an example.
Part of #85822
This shouldn't need a PostFilter Plugin, it is not worth caching the result of metav1.GetControllerOf.
/assign @denkensk | Move NodePreferAvoidPods priority logic to its Score plugin [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86407/comments | 0 | 2019-12-19T02:39:39Z | 2019-12-25T11:51:30Z | https://github.com/kubernetes/kubernetes/issues/86407 | 540,038,935 | 86,407 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
The pod alway... | Pod pending waiting for pvc due to fsck -a /dev/rbd error | https://api.github.com/repos/kubernetes/kubernetes/issues/86406/comments | 12 | 2019-12-19T02:37:21Z | 2020-09-22T11:57:45Z | https://github.com/kubernetes/kubernetes/issues/86406 | 540,038,375 | 86,406 |
[
"kubernetes",
"kubernetes"
] | /sig scheduling
/priority important-soon
See #86399 as an example.
Part of #85822
Note that this shouldn't need a PostFilter. | Move NodeAffinity priority logic to its Score plugin [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86405/comments | 1 | 2019-12-19T02:25:44Z | 2019-12-25T08:01:45Z | https://github.com/kubernetes/kubernetes/issues/86405 | 540,035,154 | 86,405 |
[
"kubernetes",
"kubernetes"
] | /sig scheduling
/priority important-soon
See #86399 as an example.
Part of #85822 | Move ImageLocality priority logic to its Score plugin [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86404/comments | 3 | 2019-12-19T02:16:24Z | 2019-12-23T16:29:33Z | https://github.com/kubernetes/kubernetes/issues/86404 | 540,032,355 | 86,404 |
[
"kubernetes",
"kubernetes"
] | I noticed this file
/var/lib/docker/containers/aa0faf7c7e4cfe30cb33768a1f3462a225267fbdee00c70b23c7d47903bd38d2/aa0faf7c7e4cfe30cb33768a1f3462a225267fbdee00c70b23c7d47903bd38d2-json.log
is 2.3 GB.
It's the kubeapi-server log.
How can I limit this size? From what I've read, the default log size is only 10 MB, bu... | kube-apiserver container log file seems to have no size limit | https://api.github.com/repos/kubernetes/kubernetes/issues/86403/comments | 5 | 2019-12-19T01:58:13Z | 2019-12-19T19:52:15Z | https://github.com/kubernetes/kubernetes/issues/86403 | 540,027,250 | 86,403 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
sort by me... | The result of `kubectl top pods/nodes --sort-by=cpu/memory` command is not as expected. | https://api.github.com/repos/kubernetes/kubernetes/issues/86401/comments | 4 | 2019-12-19T01:51:59Z | 2020-12-13T09:22:04Z | https://github.com/kubernetes/kubernetes/issues/86401 | 540,025,651 | 86,401 |
[
"kubernetes",
"kubernetes"
] | /assign @ahg-g
/sig scheduling
/priority important-soon
This includes moving the metadata logic into PostFilter.
Part of #85822 | Move Pod Affinity priority logic to its Score plugin [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86398/comments | 0 | 2019-12-19T01:18:53Z | 2019-12-19T21:39:57Z | https://github.com/kubernetes/kubernetes/issues/86398 | 540,016,353 | 86,398 |
[
"kubernetes",
"kubernetes"
] |
**What happened**:
I have a test case:
```go
func TestSimple(t *testing.T) {
var fakeKubeconfigData = `apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: UEhPTlkK
server: https://192.168.1.1
name: prod0
contexts:
- context:
cluster: prod0
user: prod0
n... | Codec.Decode panic with client-go v0.17.0 | https://api.github.com/repos/kubernetes/kubernetes/issues/86394/comments | 2 | 2019-12-18T21:11:57Z | 2019-12-19T08:38:30Z | https://github.com/kubernetes/kubernetes/issues/86394 | 539,926,562 | 86,394 |
[
"kubernetes",
"kubernetes"
] | This issue contains a very basic mock test in order to start the conversation about what a good e2e test would look like for this endpoint. The code below is verified to be hitting the intended endpoint, show as per the queries in APIsnoop's live view of the cluster's audit logs.
## Deploy APISnoop
```shell
kube... | Write CoreV1Secret mock test - +3 coverage | https://api.github.com/repos/kubernetes/kubernetes/issues/86393/comments | 4 | 2019-12-18T21:04:47Z | 2020-04-07T20:54:41Z | https://github.com/kubernetes/kubernetes/issues/86393 | 539,923,358 | 86,393 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
I'd like to propose the following changes to `pkg/scheduler/metrics/metrics.go`.
For metrics to be deprecated, should do it in **two phases** in order to maintain some sort of backwards compatibility. This is not mandatory as all scheduler ... | Cleanup/Enhance scheduler metrics | https://api.github.com/repos/kubernetes/kubernetes/issues/86391/comments | 6 | 2019-12-18T20:32:15Z | 2020-04-17T15:34:42Z | https://github.com/kubernetes/kubernetes/issues/86391 | 539,908,599 | 86,391 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
ci-kubernetes-e2e-gce-scale-correctness #1207269747872239616
https://prow.k8s.io/view/gcs/kubernetes-jenkins/logs/ci-kubernetes-e2e-gce-scale-correctness/1207269747... | [Failing Test] gce-master-scale-correctness (ci-kubernetes-e2e-gce-scale-correctness) | https://api.github.com/repos/kubernetes/kubernetes/issues/86390/comments | 9 | 2019-12-18T16:56:14Z | 2020-01-06T15:31:37Z | https://github.com/kubernetes/kubernetes/issues/86390 | 539,802,675 | 86,390 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
kubectl rollout status should provide a mechanism to view logs for all new pods until the pods are marked as healthy (or completed for init containers.)
**Why is this needed**:
When debugging deployments in CI, it's extremely frustrating to figure out what's going wrong. A some... | kubectl rollout status should be able to show new pod logs | https://api.github.com/repos/kubernetes/kubernetes/issues/86388/comments | 8 | 2019-12-18T15:21:04Z | 2020-09-01T01:27:57Z | https://github.com/kubernetes/kubernetes/issues/86388 | 539,747,736 | 86,388 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
We are making a series of enhancements #81719 to scheduler benchmarks. Once we are done, we should update the README.md.
Ref #86160, #85861
**Why is this needed**:
/sig scheduling
cc @notpad ... | Document how to add/modify/run new scheduler benchmark tests | https://api.github.com/repos/kubernetes/kubernetes/issues/86387/comments | 1 | 2019-12-18T15:04:01Z | 2020-03-24T00:10:48Z | https://github.com/kubernetes/kubernetes/issues/86387 | 539,737,464 | 86,387 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Add deltaType to the parameters for workqueue CRUD
**Why is this needed**:
We usually use workqueue to collect events from DeltaFIFO and send the key of them to controller for processing. However, wh... | add deltaType to the parameters for workqueue CRUD | https://api.github.com/repos/kubernetes/kubernetes/issues/86381/comments | 6 | 2019-12-18T11:19:32Z | 2019-12-19T10:41:59Z | https://github.com/kubernetes/kubernetes/issues/86381 | 539,619,155 | 86,381 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about continuously failing tests or jobs in Kubernetes CI -->
**Which jobs are failing**:
kind serial conformance jobs
**Which test(s) are failing**:
The conformance test SchedulerPredicates [Serial] validates that taints-tolerations is respected i... | Failing Test: SchedulerPredicates [Serial] validates that taints-tolerations is respected if matching [Disruptive] [Conformance] | https://api.github.com/repos/kubernetes/kubernetes/issues/86379/comments | 7 | 2019-12-18T09:15:00Z | 2019-12-18T16:23:58Z | https://github.com/kubernetes/kubernetes/issues/86379 | 539,551,532 | 86,379 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Enable extended resources in kubemark by exposing flags such as `enable-extended-resource` or `extended-resources-conf-path`
**Why is this needed**:
Kubernetes is more and more popular in AI. Due to G... | enable extended resources in kubemark | https://api.github.com/repos/kubernetes/kubernetes/issues/86378/comments | 7 | 2019-12-18T08:52:11Z | 2023-09-08T03:03:07Z | https://github.com/kubernetes/kubernetes/issues/86378 | 539,540,505 | 86,378 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Seems even after #81263 (#81214), the pod starvation (head-of-line blocking) can only be **besteffort alleviated**, i.e. cannot be **totally avoided**.
This is even more worse in this case https://gi... | Totally avoid Pod starvation (HOL blocking) or clarify the user expectation on the wiki | https://api.github.com/repos/kubernetes/kubernetes/issues/86373/comments | 83 | 2019-12-18T04:53:35Z | 2022-02-23T14:16:38Z | https://github.com/kubernetes/kubernetes/issues/86373 | 539,450,627 | 86,373 |
[
"kubernetes",
"kubernetes"
] | I build fluentd image refercing from https://github.com/kubernetes/kubernetes/blob/master/cluster/addons/fluentd-elasticsearch/fluentd-es-image/Gemfile, but found that fluentd version is not 1.7.4 like this:
Installing fluentd (1.6.3)
when I config gem 'fluentd', '~>1.7.4' in Gemfile, the build of fluentd image out... | I build fluentd image but not version 1.7.4 | https://api.github.com/repos/kubernetes/kubernetes/issues/86372/comments | 8 | 2019-12-18T03:34:48Z | 2020-05-22T00:43:38Z | https://github.com/kubernetes/kubernetes/issues/86372 | 539,431,292 | 86,372 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about flaky tests or jobs (pass or fail with no underlying change in code) in Kubernetes CI -->
**Which jobs are flaking**:
pull-kubernetes-e2e-gce
**Which test(s) are flaking**:
* [sig-network] Services should have session affinity work for service with... | [Flaky Test] [sig-network] Services should be able to switch session affinity for service with type clusterIP [LinuxOnly] | https://api.github.com/repos/kubernetes/kubernetes/issues/86370/comments | 35 | 2019-12-17T23:53:31Z | 2020-02-25T19:59:07Z | https://github.com/kubernetes/kubernetes/issues/86370 | 539,373,478 | 86,370 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Conformance... | kubectl logs ... --limit-bytes option is ignored for docker legacy logging | https://api.github.com/repos/kubernetes/kubernetes/issues/86367/comments | 5 | 2019-12-17T22:42:05Z | 2020-02-19T04:58:26Z | https://github.com/kubernetes/kubernetes/issues/86367 | 539,350,200 | 86,367 |
[
"kubernetes",
"kubernetes"
] | Kubelet does not call NodeStage after NodeUnstage timed out. When a pod that uses the volume that's being unstaged is created, kubelet calls just NodePublish.
After the NodeUnstage timeout, kubelet cannot be sure if the storage backed is progressing with unstaging the volume and it should make sure that the volume i... | NodeStage is not called after NodeUnstage timeout | https://api.github.com/repos/kubernetes/kubernetes/issues/86360/comments | 10 | 2019-12-17T17:22:05Z | 2020-02-10T14:05:23Z | https://github.com/kubernetes/kubernetes/issues/86360 | 539,205,889 | 86,360 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
In cert-manager, we provide a library [`github.com/jetstack/cert-manager/pkg/acme/webhook`](https://github.com/jetstack/cert-manager/tree/master/pkg/acme/webhook) that wraps `k8s.io/apiserver` to allow users to create their own webhooks that integrate with parts of our own project. This is to faci... | New LIST/WATCH permission requirement for aggregated apiservers & versioning aggregated apiservers | https://api.github.com/repos/kubernetes/kubernetes/issues/86359/comments | 6 | 2019-12-17T17:08:13Z | 2020-02-05T19:48:26Z | https://github.com/kubernetes/kubernetes/issues/86359 | 539,198,876 | 86,359 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are flaking**:
pull-kubernetes-e2e-gce
**Which test(s) are flaking**:
`[Flaky test] [sig-apps] DisruptionController should block an eviction until the PDB is updated to allow it`
**Testgrid link**:
https://testgrid.k8s.io/presubmits-kubernetes-blocking#pull-kubernetes-e2e-gce&include-filter-by-reg... | [Flaky test] [sig-apps] DisruptionController should block an eviction until the PDB is updated to allow it | https://api.github.com/repos/kubernetes/kubernetes/issues/86358/comments | 8 | 2019-12-17T16:32:15Z | 2020-02-23T20:14:46Z | https://github.com/kubernetes/kubernetes/issues/86358 | 539,178,786 | 86,358 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
When API Server is in heavy load or even in extremely bad situation, clients can not set up their watch request normally.
However, our API Server's metrics does not tell us this status, as watch response code is always 200, even watch request caused error "resource version too old" or API Serv... | Add More Metrics for cacher/watcher | https://api.github.com/repos/kubernetes/kubernetes/issues/86356/comments | 9 | 2019-12-17T15:06:38Z | 2020-07-14T11:33:16Z | https://github.com/kubernetes/kubernetes/issues/86356 | 539,125,194 | 86,356 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are flaking**:
pull-kubernetes-e2e-gce
**Which test(s) are flaking**:
* `[sig-cli] Kubectl Port forwarding With a server listening on localhost that expects a client request should support a client that connects, sends DATA, and disconnects`
```
[sig-cli] Kubectl Port forwarding With a server list... | [Flaky test] [sig-cli] Kubectl Port forwarding With a server listening on localhost that expects a client request should support a client that connects, sends DATA, and disconnects | https://api.github.com/repos/kubernetes/kubernetes/issues/86355/comments | 7 | 2019-12-17T13:37:17Z | 2020-05-17T02:00:15Z | https://github.com/kubernetes/kubernetes/issues/86355 | 539,071,056 | 86,355 |
[
"kubernetes",
"kubernetes"
] | Specifically: https://github.com/kubernetes/kubernetes/blob/ec4f3e306446f30e3db9df0a00b83ddcd2cd9941/pkg/scheduler/core/generic_scheduler.go#L573
and remove all references to PredicateFailureReason and PredicateFailureError from generic_scheduler.go.
/assign @Huang-Wei
/sig scheduling
/priority important-soon
... | Use framework.Status instead of PredicateFailureError to report extenders filter status [Migration Phase 2] | https://api.github.com/repos/kubernetes/kubernetes/issues/86353/comments | 0 | 2019-12-17T13:32:10Z | 2019-12-21T16:41:34Z | https://github.com/kubernetes/kubernetes/issues/86353 | 539,068,286 | 86,353 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Field selectors for job status: `active`, `failed`, `succeeded`
**Why is this needed**:
Currently the only supported status selector is `successful` (which appears to match the `succeeded` field). My use case is to delete jobs that have stopped running and failed. I can obt... | Field selectors for job status: active, failed, succeeded | https://api.github.com/repos/kubernetes/kubernetes/issues/86352/comments | 21 | 2019-12-17T13:20:10Z | 2022-12-22T14:21:21Z | https://github.com/kubernetes/kubernetes/issues/86352 | 539,061,619 | 86,352 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Azure data di... | Azure data disk should use same encryption key as os disk | https://api.github.com/repos/kubernetes/kubernetes/issues/86350/comments | 0 | 2019-12-17T13:12:49Z | 2019-12-18T08:58:21Z | https://github.com/kubernetes/kubernetes/issues/86350 | 539,057,804 | 86,350 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Currently when calculating the utilization of resources on pods the usage of all the containers in the pods is summed and then divided by the sum of the requested resources of all containers. The HPA shou... | HPA should consider individual containers when scaling based on resource metrics | https://api.github.com/repos/kubernetes/kubernetes/issues/86349/comments | 8 | 2019-12-17T12:54:59Z | 2021-10-06T14:58:37Z | https://github.com/kubernetes/kubernetes/issues/86349 | 539,049,024 | 86,349 |
[
"kubernetes",
"kubernetes"
] | SchedulingThroughput measurement in scalability tests is flaky in all but one (1.17) release branches.
Probably threshold is set too high, especially for older branches.
http://perf-dash.k8s.io/#/?jobname=gce-100Nodes-1.14&metriccategoryname=Scheduler&metricname=SchedulingThroughput
http://perf-dash.k8s.io/#/?jobn... | Flaky SchedulingThroughput measurement in scalability tests | https://api.github.com/repos/kubernetes/kubernetes/issues/86345/comments | 6 | 2019-12-17T11:06:08Z | 2020-05-15T13:10:39Z | https://github.com/kubernetes/kubernetes/issues/86345 | 538,995,905 | 86,345 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
If I create VolumeSnapshot with pvc that not exists, It created successfully. I can find error message in csi snapshotter driver pod, but I think we can provide more information. I'm using kubernetes v1.15.0 and ceph-csi/rook-ceph latest version.
**Why is this needed**:
User wa... | Need VolumeSnapshot Status | https://api.github.com/repos/kubernetes/kubernetes/issues/86342/comments | 1 | 2019-12-17T08:40:08Z | 2019-12-17T08:48:28Z | https://github.com/kubernetes/kubernetes/issues/86342 | 538,918,040 | 86,342 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
When we checkpoint then stop container by using docker engine, pod status will be marked as Error. But after that, when we restore Container, pod status should back to Running.
**Why is this needed**:
... | Provide a mechanism to support container migration in K8S | https://api.github.com/repos/kubernetes/kubernetes/issues/86341/comments | 4 | 2019-12-17T08:10:43Z | 2019-12-19T05:02:14Z | https://github.com/kubernetes/kubernetes/issues/86341 | 538,905,201 | 86,341 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are flaking**:
pull-kubernetes-verify
**Which test(s) are flaking**:
staticcheck
Sometimes reports methods as unused when they are, in fact, used
**Testgrid link**:
https://testgrid.k8s.io/presubmits-kubernetes-blocking#pull-kubernetes-verify&include-filter-by-regex=staticcheck
https://prow.... | [Flaky test] staticcheck reports used functions as unused | https://api.github.com/repos/kubernetes/kubernetes/issues/86340/comments | 5 | 2019-12-17T07:52:58Z | 2020-04-12T21:36:42Z | https://github.com/kubernetes/kubernetes/issues/86340 | 538,897,846 | 86,340 |
[
"kubernetes",
"kubernetes"
] | Recently we found our pods were OOMKilled, At the same time, sandbox was OOMKilled too.
```
[Sun Dec 15 23:40:19 2019] runhttp invoked oom-killer: gfp_mask=0x14000c0(GFP_KERNEL), nodemask=(null), order=0, oom_score_adj=-998
[Sun Dec 15 23:40:19 2019] runhttp cpuset=27edbc0dd4ec2a3e9a4d8ef8b014eda12e76ff36da95b0a9... | podsandbox(pause) will be OOMKilled for guaranteed Pods | https://api.github.com/repos/kubernetes/kubernetes/issues/86337/comments | 13 | 2019-12-17T05:56:02Z | 2021-11-23T02:11:10Z | https://github.com/kubernetes/kubernetes/issues/86337 | 538,855,041 | 86,337 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are flaking**:
pull-kubernetes-e2e-kind
**Which test(s) are flaking**:
* `[sig-storage] PersistentVolumes-local [Volume type: blockfswithoutformat] Two pods mounting a local volume one after the other should be able to write from pod1 and read from pod2`
**Testgrid link**:
https://testgrid.k8s.io/... | [Flaky test] [sig-storage] PersistentVolumes-local [Volume type: blockfswithoutformat] Two pods mounting a local volume one after the other should be able to write from pod1 and read from pod2 | https://api.github.com/repos/kubernetes/kubernetes/issues/86336/comments | 5 | 2019-12-17T05:48:29Z | 2020-05-15T08:05:39Z | https://github.com/kubernetes/kubernetes/issues/86336 | 538,852,745 | 86,336 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Add a new configuration to AKS cloud provider for the pre-configured load balancers, and then k8s can skip the reconciliation of loadbalancer backend pool
**Why is this needed**:
On AKS with stand loa... | Add a config option to azure cloud provider for the pre-configured loadbalancer | https://api.github.com/repos/kubernetes/kubernetes/issues/86335/comments | 3 | 2019-12-17T05:31:16Z | 2019-12-20T15:35:33Z | https://github.com/kubernetes/kubernetes/issues/86335 | 538,847,660 | 86,335 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are flaking**:
pull-kubernetes-integration
**Which test(s) are flaking**:
TestPreemption
**Testgrid link**:
https://testgrid.k8s.io/presubmits-kubernetes-blocking#pull-kubernetes-integration&include-filter-by-regex=TestPreemption
/sig scheduling | [Flaky test] TestPreemption | https://api.github.com/repos/kubernetes/kubernetes/issues/86334/comments | 6 | 2019-12-17T05:10:07Z | 2020-01-29T19:53:58Z | https://github.com/kubernetes/kubernetes/issues/86334 | 538,836,373 | 86,334 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are flaking**:
pull-kubernetes-e2e-kind
**Which test(s) are flaking**:
* `[sig-apps] Job should run a job to completion when tasks sometimes fail and are not locally restarted`
**Testgrid link**:
https://testgrid.k8s.io/presubmits-kubernetes-nonblocking#pull-kubernetes-e2e-kind&include-filter-by-r... | [Flaky test] [sig-apps] Job should run a job to completion when tasks sometimes fail and are not locally restarted | https://api.github.com/repos/kubernetes/kubernetes/issues/86333/comments | 2 | 2019-12-17T05:07:13Z | 2020-01-11T10:43:37Z | https://github.com/kubernetes/kubernetes/issues/86333 | 538,835,655 | 86,333 |
[
"kubernetes",
"kubernetes"
] | when any nodes in my cluster has 2 CPU , but my requirement needs 4 CPU;
I set 4 CPU in my yaml doc
resource:
limits:
cpu: '4'
but pod is always in pending ;
the version of my k8s is 1.16
are there some special options to meet my requirement ? | resource extend | https://api.github.com/repos/kubernetes/kubernetes/issues/86332/comments | 3 | 2019-12-17T03:39:58Z | 2019-12-17T05:22:43Z | https://github.com/kubernetes/kubernetes/issues/86332 | 538,813,658 | 86,332 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.