
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
sig-release-master-informing
**Which test(s) are failing**:
build-packages-debs
**Since when has it been failing**:
Oct 10 21:03 PDT
**Testgrid link**:
https://k8s-testgrid... | build-packages-debs is consistently failing | https://api.github.com/repos/kubernetes/kubernetes/issues/83888/comments | 6 | 2019-10-14T09:43:29Z | 2019-10-15T10:04:07Z | https://github.com/kubernetes/kubernetes/issues/83888 | 506,546,803 | 83,888 |
[
"kubernetes",
"kubernetes"
] | /sig api-machinery
/kind bug
/cc @sttts
just found this in the published openapi spec from v1.16.1 cluster, sth unhappy in aggregating v2 specs..
```
"io.k8s.apimachinery.pkg.runtime.RawExtension": {
"description": "RawExtension is used to hold extensions in external versions.\n\nTo use this, make ... | Duplicated RawExtension published in openapi v2 spec | https://api.github.com/repos/kubernetes/kubernetes/issues/83887/comments | 1 | 2019-10-14T09:34:53Z | 2019-10-14T10:21:52Z | https://github.com/kubernetes/kubernetes/issues/83887 | 506,542,714 | 83,887 |
[
"kubernetes",
"kubernetes"
] | Hi,
We are experiencing a memory leak in our operator and it seems to be caused by some Timers:

_See here the original issue: https://github.com/elastic/cloud-on-k8s/issues/1984_
After some investigation... | Memory/Timer leak in the work queue | https://api.github.com/repos/kubernetes/kubernetes/issues/83895/comments | 4 | 2019-10-14T08:48:05Z | 2019-10-16T16:35:59Z | https://github.com/kubernetes/kubernetes/issues/83895 | 506,599,031 | 83,895 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
When I delete the pod of csi block volume, it unmount and delete `/var/mnt/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-8efde6e3ee3311e9/dev` directory, but not delete `/var/mnt/kubelet/plugins/kubernetes.io/csi/volumeDevices/pvc-8efde6e3ee3311e9/data/` and the parent directory.
**What you e... | csi block volume not remove data directory when umap volume | https://api.github.com/repos/kubernetes/kubernetes/issues/83885/comments | 2 | 2019-10-14T08:41:10Z | 2019-10-15T09:04:29Z | https://github.com/kubernetes/kubernetes/issues/83885 | 506,517,253 | 83,885 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
Network policy given in "Declare Ne... | Network policy does not work - Minikube | https://api.github.com/repos/kubernetes/kubernetes/issues/83884/comments | 6 | 2019-10-14T06:55:44Z | 2021-06-01T13:26:15Z | https://github.com/kubernetes/kubernetes/issues/83884 | 506,477,828 | 83,884 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
When hpa star... | bug: hpa takes all the metric values from the pods in the same namespaces and with the same labels | https://api.github.com/repos/kubernetes/kubernetes/issues/83878/comments | 11 | 2019-10-14T04:53:50Z | 2023-02-16T03:59:44Z | https://github.com/kubernetes/kubernetes/issues/83878 | 506,446,143 | 83,878 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
CI failed when deprecated metrics. Refer to https://github.com/kubernetes/kubernetes/pull/83836.
The reason is that __a hidden metrics won't be created thus can't be registered to prometheus's registry__.
I guess the other PR failed for the same reason.
#83837 #83838 #83839 #83841
**What you... | Panic happends when deprecating metrics | https://api.github.com/repos/kubernetes/kubernetes/issues/83876/comments | 3 | 2019-10-14T03:17:17Z | 2019-11-11T05:41:42Z | https://github.com/kubernetes/kubernetes/issues/83876 | 506,429,003 | 83,876 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a filter plugin that calls into EvenPodsSpread predicate, example #83460
**Why is this needed**:
Part of #83554
/sig scheduling
/help
/priority important-soon | [migration phase 1] EvenPodsSpread as filter plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83874/comments | 8 | 2019-10-14T02:24:32Z | 2019-10-19T04:54:13Z | https://github.com/kubernetes/kubernetes/issues/83874 | 506,420,093 | 83,874 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a filter plugin that calls into InterPodAffinityPriority predicate, example #83460
**Why is this needed**:
Part of #83554
/sig scheduling
/help
/priority important-soon | [migration phase 1] InterPodAffinityPriority as filter plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83873/comments | 10 | 2019-10-14T02:23:08Z | 2019-10-18T16:23:59Z | https://github.com/kubernetes/kubernetes/issues/83873 | 506,419,850 | 83,873 |
[
"kubernetes",
"kubernetes"
] | ### Flaky Job: pr:pull-kubernetes-e2e-gce-100-performance
Flakes in the past week: **65**
Consistency: **89.80%**
#### Flakiest tests by flake count:
| Test | Flake Count |
| --- | --- |
| Up | 45 |
| Stage | 17 |
| ClusterLoaderV2 | 12 |
#### Previously closed issues for this job flaking:
#81890 #83529 #73884 #672... | pr:pull-kubernetes-e2e-gce-100-performance flaked 65 times in the past week | https://api.github.com/repos/kubernetes/kubernetes/issues/83870/comments | 4 | 2019-10-13T18:37:35Z | 2019-12-16T13:45:58Z | https://github.com/kubernetes/kubernetes/issues/83870 | 506,363,081 | 83,870 |
[
"kubernetes",
"kubernetes"
] | ### Flaky Job: pr:pull-kubernetes-e2e-gce
Flakes in the past week: **73**
Consistency: **88.90%**
#### Flakiest tests by flake count:
| Test | Flake Count |
| --- | --- |
| [k8s.io] Pods should support pod readiness gates [NodeFeature:PodReadinessGate] | 40 |
| [sig-scheduling] PreemptionExecutionPath runs ReplicaSe... | pr:pull-kubernetes-e2e-gce flaked 73 times in the past week | https://api.github.com/repos/kubernetes/kubernetes/issues/83869/comments | 10 | 2019-10-13T18:37:34Z | 2020-01-09T23:09:14Z | https://github.com/kubernetes/kubernetes/issues/83869 | 506,363,075 | 83,869 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**: When many Jobs are pending due to resource restrictions, prefer to schedule Jobs in the order they were created, not just randomly.
**Why is this needed**:
We use the Kubernetes Jobs mechanism to sched... | Schedule jobs by order of creation date, not randomly | https://api.github.com/repos/kubernetes/kubernetes/issues/83868/comments | 6 | 2019-10-13T17:44:33Z | 2020-03-22T23:15:18Z | https://github.com/kubernetes/kubernetes/issues/83868 | 506,356,089 | 83,868 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
`kubectl create deployment` used the default image name in the container spec instead of the deployment name I specified
```
$ kubectl create deployment mark-test --image=nginx --dry-run -o yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app... | kubectl create deployment not using the deployment name in the container spec | https://api.github.com/repos/kubernetes/kubernetes/issues/83851/comments | 8 | 2019-10-13T12:03:47Z | 2020-02-29T00:06:55Z | https://github.com/kubernetes/kubernetes/issues/83851 | 506,316,059 | 83,851 |
[
"kubernetes",
"kubernetes"
] | /platform aws
/kind bug
Hi Team,
When we create a service type loadbalancer with enabled access logs to the S3 buckets without proper s3 permissions/policy, the service fails silently in 'pending' state but a loadbalancer is created in the account.
And when we delete the service the loadbalancer in the acco... | Loadbalancer Service with enabled access-log-s3 | https://api.github.com/repos/kubernetes/kubernetes/issues/83850/comments | 8 | 2019-10-13T09:04:54Z | 2020-03-18T07:26:37Z | https://github.com/kubernetes/kubernetes/issues/83850 | 506,295,303 | 83,850 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a Score that calls into NodAffinity priority, should be added to the existing NodeAffinity plugin, example #83460
**Why is this needed**:
Part of #83554
/sig scheduling
/help
/priority important-soon | [migration phase 1] NodeAffinity as Score plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83848/comments | 4 | 2019-10-13T02:18:06Z | 2019-10-17T15:24:39Z | https://github.com/kubernetes/kubernetes/issues/83848 | 506,263,379 | 83,848 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
`go mod tidy`... | go mod tidy fails in on go1.13 not go1.12 | https://api.github.com/repos/kubernetes/kubernetes/issues/83847/comments | 8 | 2019-10-12T21:34:12Z | 2019-10-13T00:01:54Z | https://github.com/kubernetes/kubernetes/issues/83847 | 506,240,318 | 83,847 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I shrinks ... | PV update validation ignored the capacity storge | https://api.github.com/repos/kubernetes/kubernetes/issues/83845/comments | 7 | 2019-10-12T15:52:49Z | 2020-03-17T01:57:35Z | https://github.com/kubernetes/kubernetes/issues/83845 | 506,203,786 | 83,845 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
By default, u... | PriorityQueue is far from FIFO for same priority Pods | https://api.github.com/repos/kubernetes/kubernetes/issues/83834/comments | 48 | 2019-10-12T10:49:15Z | 2022-04-15T14:23:11Z | https://github.com/kubernetes/kubernetes/issues/83834 | 506,170,524 | 83,834 |
[
"kubernetes",
"kubernetes"
] | ## Overview
The primary concern for graduating ScheduleDaemonSetPods to the stable version could be the overhead to the scheduler and the startup time of daemons. After we graduate this feature, the scheduler would select nodes for all of the DaemonSet pods, which may cause a lot of pods with NodeAffinity to be proc... | Performance concern for the graduation of ScheduleDaemonSetPods | https://api.github.com/repos/kubernetes/kubernetes/issues/83829/comments | 8 | 2019-10-12T08:16:52Z | 2019-10-22T14:59:34Z | https://github.com/kubernetes/kubernetes/issues/83829 | 506,152,647 | 83,829 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Currently (after https://github.com/kubernetes/kubernetes/pull/73700), we use the **Pod last queued time by scheduler** to sort Pod for the same priority:
https://github.com/kubernetes/kubernetes/blob/0599ca2bcfcae7d702f95284f3c2e2c2978c7772/pkg/scheduler/internal/queue/scheduling_queue.go#L717-L72... | Should use Pod creation time instead of its last queued time to sort Pod for the same priority | https://api.github.com/repos/kubernetes/kubernetes/issues/83826/comments | 14 | 2019-10-12T03:57:41Z | 2021-11-08T05:10:05Z | https://github.com/kubernetes/kubernetes/issues/83826 | 506,127,437 | 83,826 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I did a revie... | SharedIndexInformers can miss create notifications | https://api.github.com/repos/kubernetes/kubernetes/issues/83810/comments | 33 | 2019-10-11T22:15:00Z | 2020-01-03T15:20:52Z | https://github.com/kubernetes/kubernetes/issues/83810 | 506,079,431 | 83,810 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
We installed ... | FlexVol not finding plugin on restart | https://api.github.com/repos/kubernetes/kubernetes/issues/83803/comments | 4 | 2019-10-11T20:41:01Z | 2020-01-10T21:17:13Z | https://github.com/kubernetes/kubernetes/issues/83803 | 506,048,575 | 83,803 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
kubectl drain... | kubectl drain can crash if apiserver connection breaks during delete/evict | https://api.github.com/repos/kubernetes/kubernetes/issues/83794/comments | 1 | 2019-10-11T19:23:52Z | 2019-10-23T22:53:08Z | https://github.com/kubernetes/kubernetes/issues/83794 | 506,019,034 | 83,794 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Using Kuberne... | kube-proxy node IP / bind address does not fall back to 127.0.0.1 anymore in iptables mode when node is missing from API | https://api.github.com/repos/kubernetes/kubernetes/issues/83791/comments | 2 | 2019-10-11T17:09:43Z | 2019-10-25T18:15:40Z | https://github.com/kubernetes/kubernetes/issues/83791 | 505,963,896 | 83,791 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be changed**:
Merge `UnreservePlugin` into `ReservePlugin`. Make `ReservePlugin` have `Reserve` and `Unreserve` methods.
**Why is this needed**:
In the current implementation, if one of reserve plugins fails, the... | Merging unreserve plugin into reserve plugin of scheduling framework | https://api.github.com/repos/kubernetes/kubernetes/issues/83788/comments | 10 | 2019-10-11T15:44:12Z | 2020-03-21T04:33:19Z | https://github.com/kubernetes/kubernetes/issues/83788 | 505,926,709 | 83,788 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Our cluster i... | ceph rbd resize fails because wrong provisioner is being used | https://api.github.com/repos/kubernetes/kubernetes/issues/83786/comments | 14 | 2019-10-11T14:51:31Z | 2021-03-20T09:45:54Z | https://github.com/kubernetes/kubernetes/issues/83786 | 505,899,051 | 83,786 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Support dynamically set log level for kube-scheduler, #68780 is blocked on node controller approval, but we can move forward with a scheduler only change.
/sig scheduling | Support dynamically set log level for kube-scheduler | https://api.github.com/repos/kubernetes/kubernetes/issues/83783/comments | 4 | 2019-10-11T14:43:44Z | 2019-10-16T16:34:50Z | https://github.com/kubernetes/kubernetes/issues/83783 | 505,894,784 | 83,783 |
[
"kubernetes",
"kubernetes"
] | Cleanup deprecated scheduler metrics: https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler/metrics/metrics.go
/sig scheduling
/assign @liu-cong
| Remove deprecated scheduler metrics | https://api.github.com/repos/kubernetes/kubernetes/issues/83782/comments | 13 | 2019-10-11T14:27:22Z | 2020-02-21T15:35:22Z | https://github.com/kubernetes/kubernetes/issues/83782 | 505,885,941 | 83,782 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Using volum... | VolumeMount MountPath does not accept colon character | https://api.github.com/repos/kubernetes/kubernetes/issues/83781/comments | 11 | 2019-10-11T13:59:30Z | 2021-09-29T18:48:04Z | https://github.com/kubernetes/kubernetes/issues/83781 | 505,870,667 | 83,781 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
API server panics handling requests for a CRD with OpenAPI validation with `x-kubernetes-int-or-string`
**What you expected to happen**:
CRD is applied successfully.
**How to reproduce it (as minimally and precisely as possible)**:
kind create cluster --image kindest/node:v1.16.1
then kubec... | x-kubernetes-int-or-string causes panic in apiserver 1.16.1 | https://api.github.com/repos/kubernetes/kubernetes/issues/83778/comments | 7 | 2019-10-11T13:15:38Z | 2020-03-13T13:23:42Z | https://github.com/kubernetes/kubernetes/issues/83778 | 505,846,551 | 83,778 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
With the latest fix #83697 , which aims to resolve the issue of deploying pods with single-numa-node policy, it seems to have resulted in failure to deploy pods if the pod spec does not have resources and limits constraints. This is resulting in Kube-dns and other pods which do not have resource c... | Pods error out with 'Topology Affinity Error' if resources and limits are not mentioned as part of the pod spec. This is after #83492 | https://api.github.com/repos/kubernetes/kubernetes/issues/83775/comments | 12 | 2019-10-11T11:17:41Z | 2019-11-01T11:53:24Z | https://github.com/kubernetes/kubernetes/issues/83775 | 505,792,177 | 83,775 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Make `--validate=true` produce warning when invoked non-interactively, but still fail when invoked from terminal.
**Why is this needed**:
Currently `--validate` flag is by default set to true, and uses server-side openAPI definition to perform that validation. Unfortunately, i... | kubectl validation produce warnings when invoked non-interactively | https://api.github.com/repos/kubernetes/kubernetes/issues/83774/comments | 2 | 2019-10-11T11:13:29Z | 2019-10-23T18:05:54Z | https://github.com/kubernetes/kubernetes/issues/83774 | 505,790,539 | 83,774 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
With Kubernet... | Kubernetes < v1.14 resource deletionTimestamp is updated on each DELETE request | https://api.github.com/repos/kubernetes/kubernetes/issues/83771/comments | 9 | 2019-10-11T10:37:54Z | 2019-10-13T11:01:03Z | https://github.com/kubernetes/kubernetes/issues/83771 | 505,775,063 | 83,771 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a Score plugin that calls into NodePreferAvoidPods priority, example #83601. Score Plugin name should be the same.
**Why is this needed**:
Part of #83554
/sig scheduling
/help
/priority important-soon | [migration phase 1] NodePreferAvoidPods as Score plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83770/comments | 2 | 2019-10-11T10:10:06Z | 2019-10-16T18:37:31Z | https://github.com/kubernetes/kubernetes/issues/83770 | 505,762,358 | 83,770 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a Score plugin that calls into ImageLocality priority, example #83601
**Why is this needed**:
Part of #83554
/sig scheduling
/help
/priority important-soon | [migration phase 1] ImageLocality as Score plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83769/comments | 3 | 2019-10-11T09:51:07Z | 2019-10-13T13:36:36Z | https://github.com/kubernetes/kubernetes/issues/83769 | 505,753,235 | 83,769 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**: ci-kubernetes-e2e-gce-scale-performance #1182340570157158400
**Which test(s) are failing**: ClusterLoaderV2
**Since when has it been failing**: 2019-10-10 (1 run)
**Testgrid l... | Failed test: ci-kubernetes-e2e-gce-scale-performance #1182340570157158400 | https://api.github.com/repos/kubernetes/kubernetes/issues/83768/comments | 6 | 2019-10-11T09:48:19Z | 2019-10-28T12:47:30Z | https://github.com/kubernetes/kubernetes/issues/83768 | 505,751,928 | 83,768 |
[
"kubernetes",
"kubernetes"
] | I have deploy a java application in a pod, I set the memory limit is 8G. But the application use much memory than 8G and call the node down.
| Why the memory limit call the node down | https://api.github.com/repos/kubernetes/kubernetes/issues/83767/comments | 16 | 2019-10-11T09:27:54Z | 2020-03-14T08:54:07Z | https://github.com/kubernetes/kubernetes/issues/83767 | 505,741,956 | 83,767 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I've deployed... | kubectl get -o custom-columns "Unable to decode server response" | https://api.github.com/repos/kubernetes/kubernetes/issues/83765/comments | 2 | 2019-10-11T08:00:31Z | 2019-10-11T08:24:09Z | https://github.com/kubernetes/kubernetes/issues/83765 | 505,699,757 | 83,765 |
[
"kubernetes",
"kubernetes"
] | The publishing bot is broken right now (https://github.com/kubernetes/kubernetes/issues/56876) because of a checksum mismatch while running `go mod download`:
```
verifying github.com/coreos/etcd@v3.3.16+incompatible: checksum mismatch
downloaded: h1:2eX1BjV6Wfvl41/35OBA5Np4BHezdTJzhIxSMYxOArA=
go.sum: h1:h... | checksum mismatch for github.com/coreos/etcd@v3.3.16+incompatible | https://api.github.com/repos/kubernetes/kubernetes/issues/83761/comments | 2 | 2019-10-11T05:58:57Z | 2019-10-11T14:29:52Z | https://github.com/kubernetes/kubernetes/issues/83761 | 505,654,330 | 83,761 |
[
"kubernetes",
"kubernetes"
] | ### Authn is NOT Cheap
Authn is NOT cheap, both x509, ServiceAccount, Webhook and some other authn methods. Especially, before the #80465 merged, we found our API Server do ServiceAccount authn cost more then 5min when it's on heavy load, the logs like this:
```bash
I1010 09:50:37.727558 1 request.go:538]... | Authn is NOT Cheap, Provide a Request Limiter Filter before Authn | https://api.github.com/repos/kubernetes/kubernetes/issues/83745/comments | 19 | 2019-10-10T17:25:17Z | 2020-02-20T04:44:04Z | https://github.com/kubernetes/kubernetes/issues/83745 | 505,407,217 | 83,745 |
[
"kubernetes",
"kubernetes"
] | Failed create pod sandbox.
Error syncing pod
the pods are not able to deploy on the nodes with above error | CNI error and networking plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83742/comments | 7 | 2019-10-10T15:36:29Z | 2020-02-08T22:41:36Z | https://github.com/kubernetes/kubernetes/issues/83742 | 505,351,887 | 83,742 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
sig-windows#flannel-overlay-windows-master
**Which test(s) are failing**:
[sig-api-machinery] AdmissionWebhook [Privileged:ClusterAdmin] should deny crd creation [Conforman... | tests: Windows packet fragmentation issue | https://api.github.com/repos/kubernetes/kubernetes/issues/83739/comments | 6 | 2019-10-10T15:14:07Z | 2020-04-15T21:52:46Z | https://github.com/kubernetes/kubernetes/issues/83739 | 505,338,336 | 83,739 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Now Statefulset PodManagementPolicy [detail](https://github.com/kubernetes/kubernetes/blob/4fb75e2f0d9a36c47edcf65f89bb92f20274ee56/pkg/apis/apps/types.go#L50) only defines the policy creating/deleting pods. I hope we can expand the policy, it also can be the policy for updating po... | Statefulset controller supports to update pods parallelly | https://api.github.com/repos/kubernetes/kubernetes/issues/83733/comments | 6 | 2019-10-10T14:29:08Z | 2019-11-09T20:36:45Z | https://github.com/kubernetes/kubernetes/issues/83733 | 505,309,965 | 83,733 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I was studyin... | k8s.io/client-go/tools/cache/Reflector's paging is duplicated | https://api.github.com/repos/kubernetes/kubernetes/issues/83732/comments | 18 | 2019-10-10T14:27:12Z | 2020-03-10T10:21:42Z | https://github.com/kubernetes/kubernetes/issues/83732 | 505,308,836 | 83,732 |
[
"kubernetes",
"kubernetes"
] | **Background info**:
We're using Kubernetes CronJobs to periodically run commands on a clone of our production apps. These have `restartPolicy: Never` and `startingDeadlineSeconds: 60` set to ensure jobs never start 60 seconds past their original schedule. When we deploy new code to any of our environments, we update ... | Kubernetes CronJob runs very old job after upgrade | https://api.github.com/repos/kubernetes/kubernetes/issues/83728/comments | 7 | 2019-10-10T13:07:26Z | 2020-06-05T20:23:30Z | https://github.com/kubernetes/kubernetes/issues/83728 | 505,259,843 | 83,728 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
For detail, p... | kubelet cannot complete a Pod due to ApiServer "Forbidden: may not be transitioned to non-terminated state" | https://api.github.com/repos/kubernetes/kubernetes/issues/83725/comments | 19 | 2019-10-10T11:50:41Z | 2021-06-25T09:21:18Z | https://github.com/kubernetes/kubernetes/issues/83725 | 505,218,854 | 83,725 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
1.Origin:
+ ... | Distinguish between ' and " about shell script | https://api.github.com/repos/kubernetes/kubernetes/issues/83724/comments | 3 | 2019-10-10T11:40:32Z | 2019-10-10T11:51:38Z | https://github.com/kubernetes/kubernetes/issues/83724 | 505,213,996 | 83,724 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Since https://github.com/kubernetes/kubernetes/pull/63194/files traffic shaping has been supported in the form of annotation. However, there is no way to undo the config, if the annotations are removed for example, then the config would still be there.
My expectation is that if... | Undo traffic shaping config when annotations are removed | https://api.github.com/repos/kubernetes/kubernetes/issues/83723/comments | 11 | 2019-10-10T11:20:06Z | 2020-09-21T17:31:30Z | https://github.com/kubernetes/kubernetes/issues/83723 | 505,204,640 | 83,723 |
[
"kubernetes",
"kubernetes"
] | Hello! I got this error:
```
kubectl delete rook-ceph
error: resource(s) were provided, but no name, label selector, or --all flag specified
```
or:
```
kubectl delete rook-ceph --force
error: resource(s) were provided, but no name, label selector, or --all flag specified
``` | How to force delete namespace? | https://api.github.com/repos/kubernetes/kubernetes/issues/83721/comments | 3 | 2019-10-10T10:03:00Z | 2019-10-10T11:16:53Z | https://github.com/kubernetes/kubernetes/issues/83721 | 505,167,028 | 83,721 |
[
"kubernetes",
"kubernetes"
] | Test Issue | https://api.github.com/repos/kubernetes/kubernetes/issues/83719/comments | 7 | 2019-10-10T09:32:20Z | 2020-03-12T08:06:16Z | https://github.com/kubernetes/kubernetes/issues/83719 | 505,150,425 | 83,719 | |
[
"kubernetes",
"kubernetes"
] | ```
jekins-jnlp-slave-wmbjs 0/4 Terminating 0 0s <none> <none> <none> <none>
jekins-jnlp-slave-tzklf 0/4 Pending 0 0s <none> <none> <none> <none>
jekins-jnlp-slave-tzklf 0/4 Pending 0 0s <... | jekins-jnlp-slave always pending and terminating,why | https://api.github.com/repos/kubernetes/kubernetes/issues/83715/comments | 4 | 2019-10-10T08:21:17Z | 2019-10-11T09:14:31Z | https://github.com/kubernetes/kubernetes/issues/83715 | 505,113,354 | 83,715 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
when opening ... | kubelet creates a new pod when vim opens staticPodPath file | https://api.github.com/repos/kubernetes/kubernetes/issues/83708/comments | 6 | 2019-10-10T06:51:08Z | 2019-10-10T13:10:05Z | https://github.com/kubernetes/kubernetes/issues/83708 | 505,072,802 | 83,708 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Pod container... | Pod container restarted even if Pod restartPolicy=Never | https://api.github.com/repos/kubernetes/kubernetes/issues/83705/comments | 9 | 2019-10-10T06:08:11Z | 2020-02-24T02:11:31Z | https://github.com/kubernetes/kubernetes/issues/83705 | 505,056,439 | 83,705 |
[
"kubernetes",
"kubernetes"
] | # Event
Yesterday, my apiserver always crashed because "the number of
"secrets" sent by kubelet to apiserver" was very large and was not released."
# Enviorment
kubernetes: 1.8
# picture
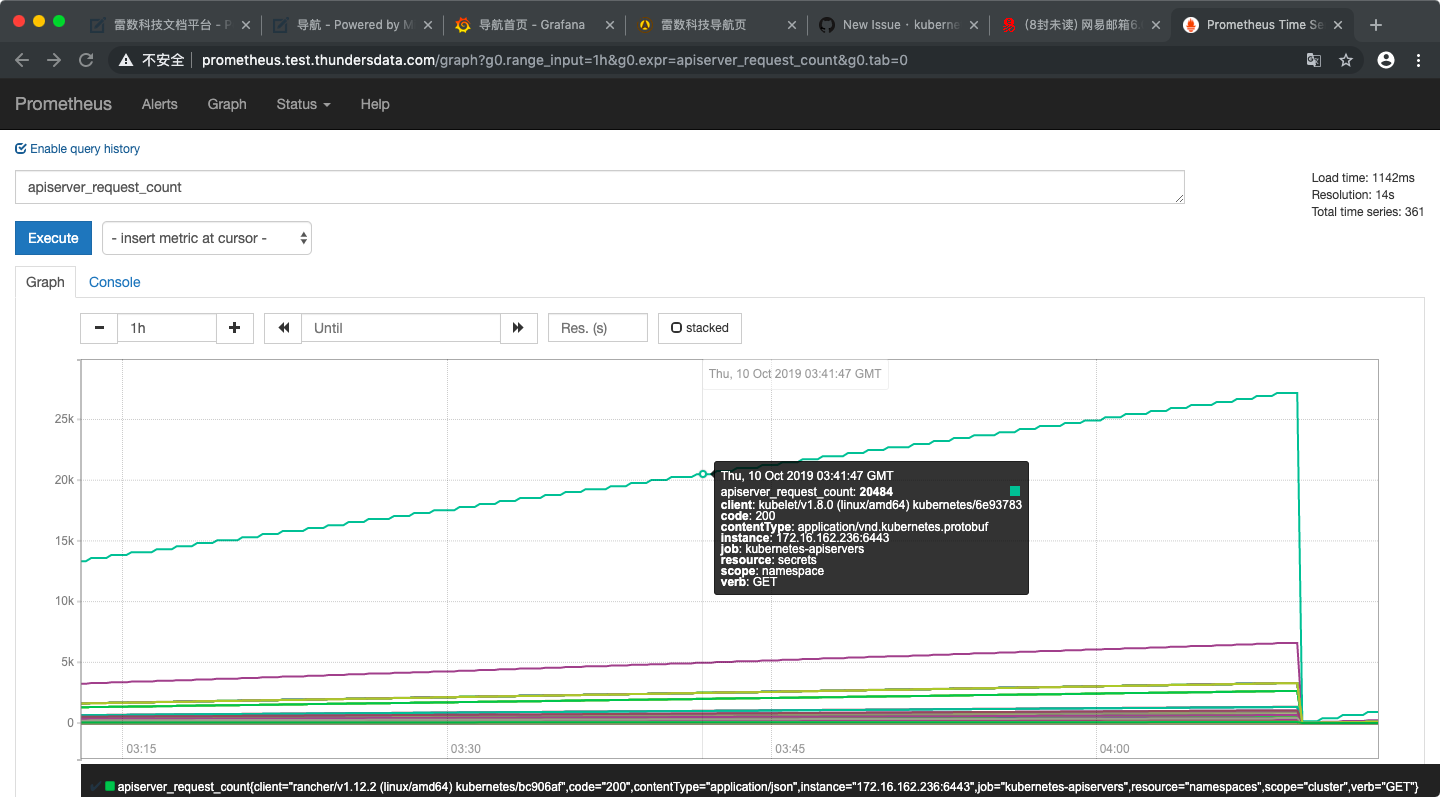
| apiserver_request_count is very big in prometheus | https://api.github.com/repos/kubernetes/kubernetes/issues/83703/comments | 4 | 2019-10-10T04:17:09Z | 2019-10-10T13:18:06Z | https://github.com/kubernetes/kubernetes/issues/83703 | 505,023,024 | 83,703 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Attempted to create a DaemonSets and getting the error:
The DaemonSet "calico-node" is invalid: spec.template.spec.containers[0].securityContext.privileged: Forbidden: disallowed by cluster policy
**What you expected to happen**:
We should be able to create the DaemonSets without this issue... | DaemonSets disallowed by cluster policy | https://api.github.com/repos/kubernetes/kubernetes/issues/83700/comments | 11 | 2019-10-10T02:41:46Z | 2019-10-12T01:28:44Z | https://github.com/kubernetes/kubernetes/issues/83700 | 504,997,974 | 83,700 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
```
Name: ... | HPA scales up when it is expected to scale down. | https://api.github.com/repos/kubernetes/kubernetes/issues/83698/comments | 4 | 2019-10-09T23:19:37Z | 2019-10-23T20:14:30Z | https://github.com/kubernetes/kubernetes/issues/83698 | 504,944,891 | 83,698 |
[
"kubernetes",
"kubernetes"
] |
**What happened**:
I think I'm seeing a problem with the topology manager. I have two numa nodes, 22 cores per node. Kubelet has "--cpu-manager-policy=static --topology-manager-policy=single-numa-node ", and when I try to create a simple pod with 3 cpus and 500Mi of RAM in the guaranteed class it fails. Describ... | topology manager not behaving as expected in 1.16 | https://api.github.com/repos/kubernetes/kubernetes/issues/83695/comments | 6 | 2019-10-09T20:20:05Z | 2019-11-28T11:06:45Z | https://github.com/kubernetes/kubernetes/issues/83695 | 504,871,798 | 83,695 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
**Which test(s) are failing**:
[sig-storage] In-tree Volumes [Driver: local][LocalVolumeType: block] [Testpattern: Pre-provisioned PV (block volmode)] disruptive[Disruptive] Should ... | Failing test: [sig-storage] In-tree Volumes [Driver: local][LocalVolumeType: block] [Testpattern: Pre-provisioned PV (block volmode)] disruptive[Disruptive] Should test that pv used in a pod that is force deleted while the kubelet is down cleans up when the kubelet returns. | https://api.github.com/repos/kubernetes/kubernetes/issues/83693/comments | 4 | 2019-10-09T19:08:30Z | 2019-10-16T16:36:14Z | https://github.com/kubernetes/kubernetes/issues/83693 | 504,837,849 | 83,693 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
MountDevice calls csi.NodeStageVolume and if the call times out the defer func() cleans up the MetaData file. If the call to stage eventually goes through and the mount succeeds, future call to MountDevice will bail out since the directory is already mounted and it will return success without creati... | CSI cleans up MetaData file when MountDevice times out | https://api.github.com/repos/kubernetes/kubernetes/issues/83691/comments | 5 | 2019-10-09T18:21:38Z | 2020-01-09T21:31:09Z | https://github.com/kubernetes/kubernetes/issues/83691 | 504,815,252 | 83,691 |
[
"kubernetes",
"kubernetes"
] | Since this refactor added `SupportedSizeRange`: https://github.com/kubernetes/kubernetes/pull/78306
We seem to have these duplicate fields where `SupportedSizeRange` is used in most places and `MaxSize` is only used in one specific spot.
`MaxSize` is currently only used here:
https://github.com/kubernetes/kubernet... | Storage DriverInfo has redundant fields `MaxSize` and `SupportedSizeRange` | https://api.github.com/repos/kubernetes/kubernetes/issues/83689/comments | 5 | 2019-10-09T17:49:13Z | 2019-10-18T21:08:49Z | https://github.com/kubernetes/kubernetes/issues/83689 | 504,799,295 | 83,689 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
I installed a Pod spec (manifest) with the following CPU resource information:
spec.containers[].resources.requests.cpu: unspecified
spec.containers[].resources.limits.cpu: 500m
k8s created a Pod (or a number of replicas) with the following setting:
spec.containers[].resources.requests.cpu: ... | Why automatic setting for spec.containers[].resources.requests.cpu? | https://api.github.com/repos/kubernetes/kubernetes/issues/83688/comments | 8 | 2019-10-09T17:45:41Z | 2020-03-09T23:10:37Z | https://github.com/kubernetes/kubernetes/issues/83688 | 504,797,616 | 83,688 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Plump through handlers, such as scheduler cache, volume binder among others to NewDefaultRegistry.
**Why is this needed**:
This is needed register factories for Plugins that need to instantiate predicates/priorities.
/sig scheduling
/assign
| [migration phase 1] Make scheduler cache, volume binder and listers available when registering default plugins | https://api.github.com/repos/kubernetes/kubernetes/issues/83687/comments | 3 | 2019-10-09T17:18:34Z | 2019-10-11T02:00:23Z | https://github.com/kubernetes/kubernetes/issues/83687 | 504,784,559 | 83,687 |
[
"kubernetes",
"kubernetes"
] | This issue is a bucket placeholder for collaborating on the "Known Issues" additions for the 1.17 Release Notes. If you know of issues or API changes that are going out in 1.17, please comment here so that we can coordinate incorporating information about these changes in the Release Notes.
/assign @cartyc @evillgen... | 1.17 Release Notes: “Known Issues” | https://api.github.com/repos/kubernetes/kubernetes/issues/83683/comments | 14 | 2019-10-09T15:06:56Z | 2020-02-10T15:30:51Z | https://github.com/kubernetes/kubernetes/issues/83683 | 504,714,059 | 83,683 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
After upgrading from kubelet 1.15 -> 1.16, volumes are no longer relabeled as container_file_t for selinux, causing most pods to fail.
**What you expected to happen**:
**How to reproduce it (as minimally and precisely as possible)**:
* Run a kubernetes cluster on 1.15.[0-3].
* Create a pod ... | SELinux Volumes not relabeled in 1.16, test coverage of volume relabeling is lacking | https://api.github.com/repos/kubernetes/kubernetes/issues/83679/comments | 34 | 2019-10-09T14:21:56Z | 2020-12-10T18:46:49Z | https://github.com/kubernetes/kubernetes/issues/83679 | 504,685,484 | 83,679 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
change grep argument from `ipvs` to `ip_vs` in `lsmod | grep -e ipvs -e nf_conntrack_ipv4` command so it matches correct ipvs modules. This is in `pkg/proxy/ipvs/README.md` file.
**Why is this needed**:
... | kube-proxy README file to list ipvs modules has typo in the command | https://api.github.com/repos/kubernetes/kubernetes/issues/83676/comments | 1 | 2019-10-09T13:47:29Z | 2019-10-22T04:11:54Z | https://github.com/kubernetes/kubernetes/issues/83676 | 504,664,326 | 83,676 |
[
"kubernetes",
"kubernetes"
] | <!--
STOP -- PLEASE READ!
GitHub is not the right place for support requests.
If you're looking for help, check [Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes) and the [troubleshooting guide](https://kubernetes.io/docs/tasks/debug-application-cluster/troubleshooting/).
You can also pos... | Remove permissive-binding to all service accounts in kubernetes cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/83675/comments | 5 | 2019-10-09T13:45:58Z | 2019-10-09T16:25:43Z | https://github.com/kubernetes/kubernetes/issues/83675 | 504,663,361 | 83,675 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
hi,buddies,I ... | Possible Bug: deleted deployment but related pod didn't delete | https://api.github.com/repos/kubernetes/kubernetes/issues/83672/comments | 13 | 2019-10-09T11:54:10Z | 2019-12-20T06:31:49Z | https://github.com/kubernetes/kubernetes/issues/83672 | 504,601,548 | 83,672 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I'm using kub... | How kubelet & apiserver's choose tls-cipher-suites ? | https://api.github.com/repos/kubernetes/kubernetes/issues/83669/comments | 4 | 2019-10-09T09:49:53Z | 2019-10-10T05:24:29Z | https://github.com/kubernetes/kubernetes/issues/83669 | 504,538,455 | 83,669 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Worker nodes ... | Cannot remove disk pressure taint | https://api.github.com/repos/kubernetes/kubernetes/issues/83668/comments | 8 | 2019-10-09T08:57:56Z | 2020-03-10T11:22:40Z | https://github.com/kubernetes/kubernetes/issues/83668 | 504,509,929 | 83,668 |
[
"kubernetes",
"kubernetes"
] | List responses return the most recent avilable `metadata.resourceVersion` for the resource at the time the list response was constructed:
```
curl -s "localhost:8082/api/v1/pods?resourceVersion=0" | jq .metadata
{
"selfLink": "/api/v1/pods",
"resourceVersion": "303"
}
curl -s "localhost:8082/api/v1/pods?reso... | List requests with limit and resourceVersion return incorrect metadata.resourceVersion in response | https://api.github.com/repos/kubernetes/kubernetes/issues/83651/comments | 11 | 2019-10-09T03:09:14Z | 2019-11-28T15:55:36Z | https://github.com/kubernetes/kubernetes/issues/83651 | 504,384,507 | 83,651 |
[
"kubernetes",
"kubernetes"
] | <!--
STOP -- PLEASE READ!
GitHub is not the right place for support requests.
If you're looking for help, check [Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes) and the [troubleshooting guide](https://kubernetes.io/docs/tasks/debug-application-cluster/troubleshooting/).
You can also pos... | Which performance of api-server will be affected by the parameter watch-cache-sizes? | https://api.github.com/repos/kubernetes/kubernetes/issues/83648/comments | 3 | 2019-10-09T02:02:44Z | 2019-10-09T02:27:27Z | https://github.com/kubernetes/kubernetes/issues/83648 | 504,366,864 | 83,648 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Remove the "missed start times" suspension on CronJobs, OR allow this behavior to be customized.
**Why is this needed**:
CronJobs will suspend if 100 start times are missed. There are many ways that this could happen:
* Pods get stuck in Pending/Init
* Containers are crashing... | Remove or allow customization of CronJob missed start times | https://api.github.com/repos/kubernetes/kubernetes/issues/83642/comments | 5 | 2019-10-08T20:40:17Z | 2020-03-08T16:40:34Z | https://github.com/kubernetes/kubernetes/issues/83642 | 504,267,766 | 83,642 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Cache the OpenAPI schema in the `OpenAPISchema` method rather than re-fetching it on every call to this method.
**Why is this needed**:
The API call to retrieve the OpenAPI schema is fairly slow, ... | Cache OpenAPI schema in memory-cached discovery client | https://api.github.com/repos/kubernetes/kubernetes/issues/83639/comments | 7 | 2019-10-08T19:53:48Z | 2020-06-05T00:10:17Z | https://github.com/kubernetes/kubernetes/issues/83639 | 504,245,190 | 83,639 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a filter plugin that calls into CSIMaxVolumeLimitChecker predicate, example #83460
**Why is this needed**:
Part of #83554
/sig scheduling
/help
/priority important-soon | [migration phase 1] CSIMaxVolumeLimitChecker as filter plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83637/comments | 4 | 2019-10-08T19:20:59Z | 2019-10-18T02:50:43Z | https://github.com/kubernetes/kubernetes/issues/83637 | 504,229,955 | 83,637 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
I would like the AWS driver to support un-managed nodes like it does for Azure. See Issue #67984 for details.
**Why is this needed**:
The behavior is that unmanaged nodes just get automatically removed because the AWS cloud controller looks to the AWS API to determine if a ... | Add support for unmanaged nodes for AWS cloud provider | https://api.github.com/repos/kubernetes/kubernetes/issues/83636/comments | 9 | 2019-10-08T19:18:48Z | 2020-03-08T16:40:36Z | https://github.com/kubernetes/kubernetes/issues/83636 | 504,228,861 | 83,636 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a filter plugin that calls into VolumeBindingChecker predicate, example #83460
**Why is this needed**:
Part of #83554
/sig scheduling
/help
/priority important-soon | [migration phase 1] VolumeBindingChecker as filter plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83635/comments | 7 | 2019-10-08T19:14:06Z | 2019-10-11T16:29:53Z | https://github.com/kubernetes/kubernetes/issues/83635 | 504,226,769 | 83,635 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a filter plugin that calls into VolumeZoneChecker predicate, example #83460
**Why is this needed**:
Part of #83554
/sig scheduling
/help
/priority important-soon | [migration phase 1] VolumeZoneChecker as filter plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83634/comments | 4 | 2019-10-08T19:09:11Z | 2019-10-14T01:32:36Z | https://github.com/kubernetes/kubernetes/issues/83634 | 504,224,555 | 83,634 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a filter plugin that calls into PodMatchNodeSelector/NodAffinity predicate, example #83460
**Why is this needed**:
Part of #83554
/sig scheduling
/help
/priority important-soon | [migration phase 1] PodMatchNodeSelector/NodAffinity as filter plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83633/comments | 2 | 2019-10-08T18:50:11Z | 2019-10-12T10:14:38Z | https://github.com/kubernetes/kubernetes/issues/83633 | 504,215,314 | 83,633 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a filter plugin that calls into PodFitsHostPorts predicate, example #83460
**Why is this needed**:
Part of #83554
/sig scheduling
/help
/priority important-soon | [migration phase 1] PodFitsHostPorts as filter plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83632/comments | 2 | 2019-10-08T18:49:02Z | 2019-10-13T18:18:36Z | https://github.com/kubernetes/kubernetes/issues/83632 | 504,214,773 | 83,632 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a filter plugin that calls into NoDiskConflict predicate, example #83460
**Why is this needed**:
Part of #83554
/sig scheduling
/help
/priority important-soon | [migration phase 1] PodFitsHost as filter plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83631/comments | 2 | 2019-10-08T18:48:13Z | 2019-10-11T12:17:41Z | https://github.com/kubernetes/kubernetes/issues/83631 | 504,214,410 | 83,631 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a filter plugin that calls into PodFitsResources predicate, example #83460
**Why is this needed**:
Part of #83554
/sig scheduling
/help
/priority important-soon | [migration phase 1] PodFitsResources as framework plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83630/comments | 2 | 2019-10-08T18:47:28Z | 2019-10-13T10:38:37Z | https://github.com/kubernetes/kubernetes/issues/83630 | 504,214,053 | 83,630 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Add a filter plugin that calls into NoDiskConflict predicate, example #83460
**Why is this needed**:
Part of #83554
/sig scheduling
/help
/priority important-soon | [migration phase 1] NoDiskConflict as filter plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/83629/comments | 2 | 2019-10-08T18:41:58Z | 2019-10-12T04:16:54Z | https://github.com/kubernetes/kubernetes/issues/83629 | 504,211,488 | 83,629 |
[
"kubernetes",
"kubernetes"
] | Currently `PodReadinessGate` requires a two-step update to the Pod for a user provided condition to be set to `True`.
1. The `conditionType` is introduced when creating the pod
1. The Pod `status` is patched to set the condition to `True`.
While the behavior works for the initially intended purpose of this fie... | PodReadinessGate to support conditions defaulting to True | https://api.github.com/repos/kubernetes/kubernetes/issues/83628/comments | 23 | 2019-10-08T18:29:09Z | 2020-09-18T23:28:09Z | https://github.com/kubernetes/kubernetes/issues/83628 | 504,205,369 | 83,628 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
When debugging timeouts related to the stopping of cgroups, the current logs from pod_container_manager_linux.go -> tryKillingCgroupProcesses do not provide any correlation between the PIDs which were killed and the cgroup they belonged to.
```
Oct 02 16:17:25 server atomic-openshift-node[48943... | No way to correlate the killing of unwanted pids to the correspodning cgroup | https://api.github.com/repos/kubernetes/kubernetes/issues/83624/comments | 1 | 2019-10-08T17:49:26Z | 2019-10-09T07:56:03Z | https://github.com/kubernetes/kubernetes/issues/83624 | 504,186,704 | 83,624 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
A pod with a ... | restartPolicy Never does not fail pod if init container fails to pull image | https://api.github.com/repos/kubernetes/kubernetes/issues/83622/comments | 20 | 2019-10-08T17:26:53Z | 2020-08-24T19:39:58Z | https://github.com/kubernetes/kubernetes/issues/83622 | 504,176,469 | 83,622 |
[
"kubernetes",
"kubernetes"
] | **Which jobs are failing**:
pull-kubernetes-e2e-gce
**Which test(s) are failing**:
[sig-network] Services should have session affinity work for NodePort service [LinuxOnly]
[sig-network] Services should be able to switch session affinity for service with type clusterIP [LinuxOnly]
[sig-network] Ser... | session affinity tests flaking, possibly broken due to gradual e2e-gce slowdown? | https://api.github.com/repos/kubernetes/kubernetes/issues/83617/comments | 0 | 2019-10-08T15:30:38Z | 2019-10-28T18:59:01Z | https://github.com/kubernetes/kubernetes/issues/83617 | 504,117,266 | 83,617 |
[
"kubernetes",
"kubernetes"
] | I want to test how the parameter watch-cache-sizes affect api-server. Which performance metrics of api-server should I focus on after I modify watch-cache-sizes. | Which performance of api-server will be affected by the parameter watch-cache-sizes? | https://api.github.com/repos/kubernetes/kubernetes/issues/83613/comments | 1 | 2019-10-08T13:13:17Z | 2019-10-09T02:00:23Z | https://github.com/kubernetes/kubernetes/issues/83613 | 504,036,345 | 83,613 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
My worker node had `nodefs.inodesFree` threshold of 5% and I changed it to 15%. As I had about 10% of free inodes, after restarting `kubelet`, it met its threshold. I expected it to evict Pods one-by-one to clean up, but it evicted all Pods on that node and started cleaning everything. As a result, ... | Kubelet evicts all Pods when config changes to meet eviction threshold | https://api.github.com/repos/kubernetes/kubernetes/issues/83612/comments | 16 | 2019-10-08T09:00:25Z | 2020-03-17T11:06:35Z | https://github.com/kubernetes/kubernetes/issues/83612 | 503,917,867 | 83,612 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
One of our no... | Lots of `du` process are stucked when rotate the containers' logs | https://api.github.com/repos/kubernetes/kubernetes/issues/83608/comments | 9 | 2019-10-08T07:19:30Z | 2020-06-15T05:09:31Z | https://github.com/kubernetes/kubernetes/issues/83608 | 503,872,215 | 83,608 |
[
"kubernetes",
"kubernetes"
] | Kubernetes service is running in default namespace.
Launched pods in default namespace and in other ones likes dev, prod etc.
Cannot access Kubernetes service from the pods.
Getting "No route to host". Please advise. | Getting no route to host when trying to access Kubernetes service from pod | https://api.github.com/repos/kubernetes/kubernetes/issues/83606/comments | 10 | 2019-10-08T05:50:36Z | 2020-04-02T22:22:15Z | https://github.com/kubernetes/kubernetes/issues/83606 | 503,841,712 | 83,606 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
kubectl get cs:
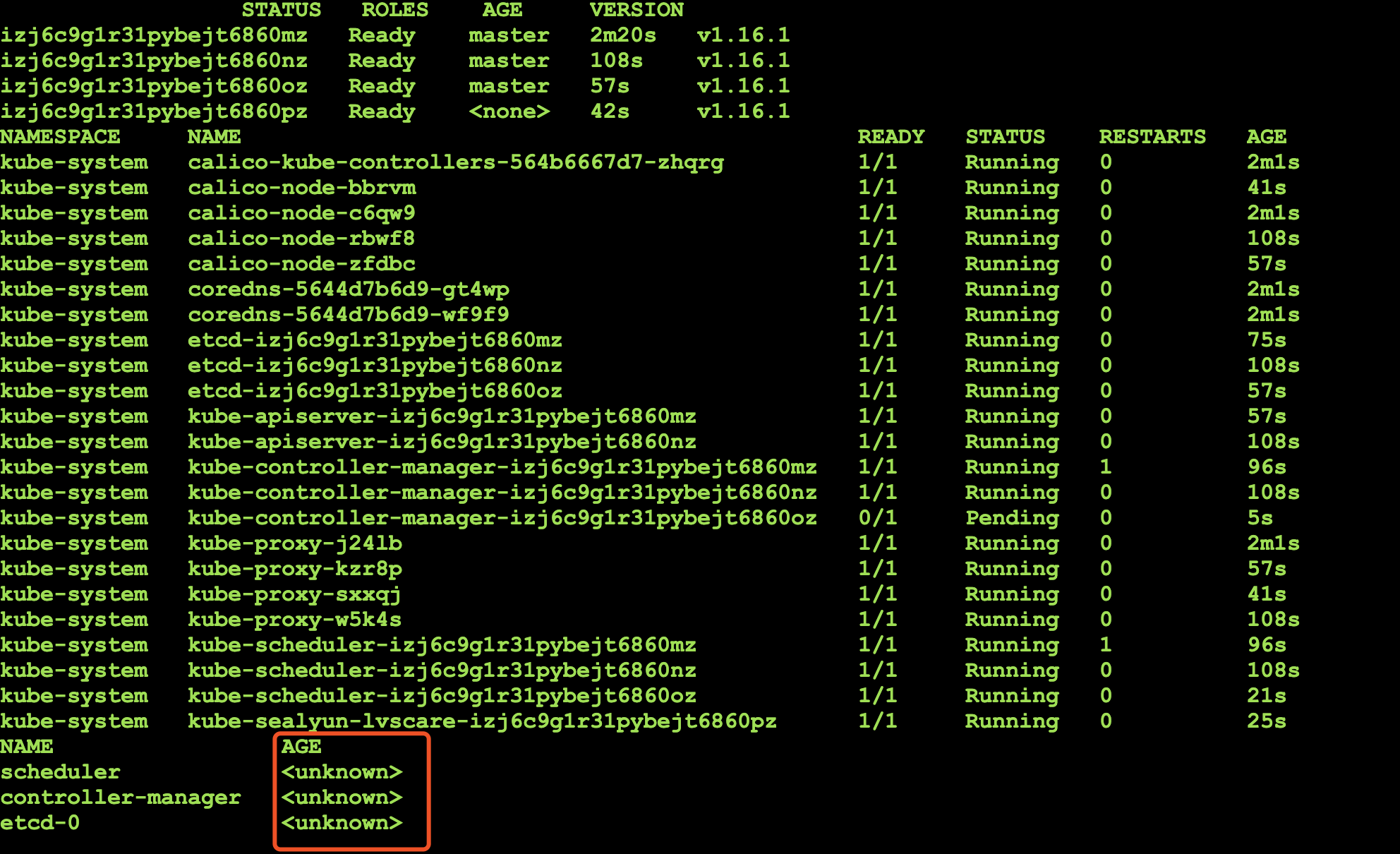
- Kubernetes version (use `kubectl version`):1.16.1
- Cloud provider or hardware configuration:
- OS (e.g: `cat /etc/os-release`):centos7.4
- Kernel (e.g. `uname ... | 1.16 cs age unknown | https://api.github.com/repos/kubernetes/kubernetes/issues/83602/comments | 4 | 2019-10-08T02:31:58Z | 2019-10-08T03:00:25Z | https://github.com/kubernetes/kubernetes/issues/83602 | 503,788,239 | 83,602 |
[
"kubernetes",
"kubernetes"
] | ```
[root@dev7 ~]# kubectl get pvc -n harbor
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-harbor-harbor-redis-0 Bound pvc-c122ef23-5555-4c60-b8be-4e98e4743760 1Gi RWO rook-block ... | increased the pvc from 1G to 2G,but it seams the storage still not enough | https://api.github.com/repos/kubernetes/kubernetes/issues/83600/comments | 8 | 2019-10-08T01:16:16Z | 2019-10-14T00:10:53Z | https://github.com/kubernetes/kubernetes/issues/83600 | 503,770,285 | 83,600 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
ci-kubernetes-kind-e2e-parallel
**Which test(s) are failing**:
BeforeSuite [x]
**Since when has it been failing**: 9/29
**Testgrid link**: https://k8s-testgrid.appspot.com/si... | [Flaky Test] kind-master-parallel (ci-kubernetes-kind-e2e-parallel) | https://api.github.com/repos/kubernetes/kubernetes/issues/83594/comments | 6 | 2019-10-07T22:36:44Z | 2019-11-01T13:38:41Z | https://github.com/kubernetes/kubernetes/issues/83594 | 503,726,880 | 83,594 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which test(s) are failing**:
[sig-storage] In-tree Volumes [Driver: gcepd] [Testpattern: Dynamic PV (ntfs)][sig-windows] volumes should store data
**Since when has it been failing**:
**Testgrid link**:
h... | flaky test for GCE PD e2e test "should store data" | https://api.github.com/repos/kubernetes/kubernetes/issues/83590/comments | 10 | 2019-10-07T21:33:07Z | 2020-09-20T03:54:29Z | https://github.com/kubernetes/kubernetes/issues/83590 | 503,702,586 | 83,590 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Vsphere cloud... | Vsphere cloud provider is reporting link local IP address as node internal/external IP | https://api.github.com/repos/kubernetes/kubernetes/issues/83584/comments | 9 | 2019-10-07T19:25:42Z | 2020-05-08T11:24:32Z | https://github.com/kubernetes/kubernetes/issues/83584 | 503,643,353 | 83,584 |
[
"kubernetes",
"kubernetes"
] | A significant number of the of [InterPodAffinity integration tests](https://github.com/kubernetes/kubernetes/blob/master/test/integration/scheduler/predicates_test.go#L77-L589) are commented out, possibly was done by mistake in the past. I uncommented the tests to see if they pass, but one of them failed.
What we ne... | Uncomment interpod affinity integration tests | https://api.github.com/repos/kubernetes/kubernetes/issues/83581/comments | 6 | 2019-10-07T18:14:27Z | 2019-10-29T08:35:00Z | https://github.com/kubernetes/kubernetes/issues/83581 | 503,609,890 | 83,581 |
[
"kubernetes",
"kubernetes"
] | So that we can set default values different from golang's, however we want to make sure that the change is backward compatible and doesn't break existing CC configurations.
The other reason is that we need to move CC to GA faster so that we can deprecate Policy once the migration is done.
/assign @ravisantoshgudi... | Make all component config parameters nilable | https://api.github.com/repos/kubernetes/kubernetes/issues/83575/comments | 4 | 2019-10-07T16:44:59Z | 2019-11-06T06:32:03Z | https://github.com/kubernetes/kubernetes/issues/83575 | 503,567,817 | 83,575 |
[
"kubernetes",
"kubernetes"
] | The scheduler has evolved at a very fast pace over the past few years, it is important to revisit our unit and integration test coverage of all scheduler features and config combinations.
This is critical now that we are going through a major refactoring of the scheduler core, and so it is a good opportunity to ref... | Improving scheduler tests | https://api.github.com/repos/kubernetes/kubernetes/issues/83574/comments | 5 | 2019-10-07T16:29:50Z | 2020-02-11T17:05:49Z | https://github.com/kubernetes/kubernetes/issues/83574 | 503,560,742 | 83,574 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Given single ... | Allow cross-object `--server-dry-run` to make use of earlier resources in multi-object manifest | https://api.github.com/repos/kubernetes/kubernetes/issues/83562/comments | 17 | 2019-10-07T10:16:57Z | 2020-10-09T05:21:02Z | https://github.com/kubernetes/kubernetes/issues/83562 | 503,358,128 | 83,562 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
An option inside HPA to ignore "Terminating" pods (i.e. pods that have been elected for downscale but are for example waiting for the prestop hook to give permission to k8s to actually stop them) when computing resource usage.
**Why is this needed**:
Let's take an example.
... | Horizontal Pod Autoscaler fooled by terminating pods | https://api.github.com/repos/kubernetes/kubernetes/issues/83561/comments | 20 | 2019-10-07T10:10:18Z | 2024-03-01T12:02:50Z | https://github.com/kubernetes/kubernetes/issues/83561 | 503,354,835 | 83,561 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.