
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
I'm currently using version 1.13 of kubenretes. I upgraded to kubeadm 2 weeks ago to install the newly released version 1.15, but it failed because minor version difference was 2 or more.
I know that kubeadm is a GA, but I do not understand ... | Kubeadm upgrade does not upgrade if minor version difference is 2 or more. | https://api.github.com/repos/kubernetes/kubernetes/issues/79704/comments | 4 | 2019-07-03T08:31:52Z | 2019-11-05T01:44:59Z | https://github.com/kubernetes/kubernetes/issues/79704 | 463,616,882 | 79,704 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
I am trying to use build-in cadvisor to monitor the containers. I scrape the metrics from api-server:`http://localhost:8080/api/v1/nodes/minikube/proxy/metrics/cadvisor` and get some metrics like this:
```
container_fs_reads_merged_total{container="nginx",container_name="nginx",d... | cadvisor in kubelet should expose container labels | https://api.github.com/repos/kubernetes/kubernetes/issues/79702/comments | 5 | 2019-07-03T06:59:29Z | 2019-08-22T13:52:44Z | https://github.com/kubernetes/kubernetes/issues/79702 | 463,578,906 | 79,702 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
We have about... | eviction request make a performance spike to etcd | https://api.github.com/repos/kubernetes/kubernetes/issues/79697/comments | 13 | 2019-07-03T05:06:59Z | 2019-08-30T07:33:12Z | https://github.com/kubernetes/kubernetes/issues/79697 | 463,546,569 | 79,697 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**: `status.podIP`... | podIP = "" for hostNetwork pod | https://api.github.com/repos/kubernetes/kubernetes/issues/79693/comments | 2 | 2019-07-03T04:10:16Z | 2019-07-03T23:46:14Z | https://github.com/kubernetes/kubernetes/issues/79693 | 463,534,565 | 79,693 |
[
"kubernetes",
"kubernetes"
] | /kind bug
/sig cli
**What happened**:
When I executed the kubectl get pod command in the k8s cluster, I found that the first execution time was very long, and it was very fast after the second execution. May I ask why? Is there any configuration of apiserver that can solve this problem?
my command is:
kubectl ge... | Kubectl takes a long time to execute | https://api.github.com/repos/kubernetes/kubernetes/issues/79691/comments | 7 | 2019-07-03T03:27:38Z | 2020-01-09T03:31:53Z | https://github.com/kubernetes/kubernetes/issues/79691 | 463,525,700 | 79,691 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
cd $GOPATH/... | agnhost image build failed for ARM arch | https://api.github.com/repos/kubernetes/kubernetes/issues/79689/comments | 5 | 2019-07-03T03:10:04Z | 2019-07-10T06:02:39Z | https://github.com/kubernetes/kubernetes/issues/79689 | 463,521,926 | 79,689 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
**kubectl c... | Invalid options for some kubectl commands should throw error | https://api.github.com/repos/kubernetes/kubernetes/issues/79688/comments | 7 | 2019-07-03T03:08:32Z | 2019-12-04T14:32:53Z | https://github.com/kubernetes/kubernetes/issues/79688 | 463,521,630 | 79,688 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
kubectl versi... | kubectl help for commands with boolean options is misleading | https://api.github.com/repos/kubernetes/kubernetes/issues/79687/comments | 8 | 2019-07-03T02:56:29Z | 2019-11-30T07:52:14Z | https://github.com/kubernetes/kubernetes/issues/79687 | 463,519,156 | 79,687 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
After fixing golint failures under `test/e2e`, we need to put `gomega` for each `Expect()` and `Equal()`.
Then common error checking code has become like:
`gomega.Expect(foo).To(gomega.Equal(bar))`
We can replace this code with `framework.ExpectEqual(foo, bar)` which is more readable and ea... | Use framework.ExpectEqual() for e2e tests | https://api.github.com/repos/kubernetes/kubernetes/issues/79686/comments | 16 | 2019-07-03T02:52:50Z | 2019-08-13T21:16:20Z | https://github.com/kubernetes/kubernetes/issues/79686 | 463,518,401 | 79,686 |
[
"kubernetes",
"kubernetes"
] | There are no commands to regenerate certificates, such as "kubeadm alpha phase certs".only this:
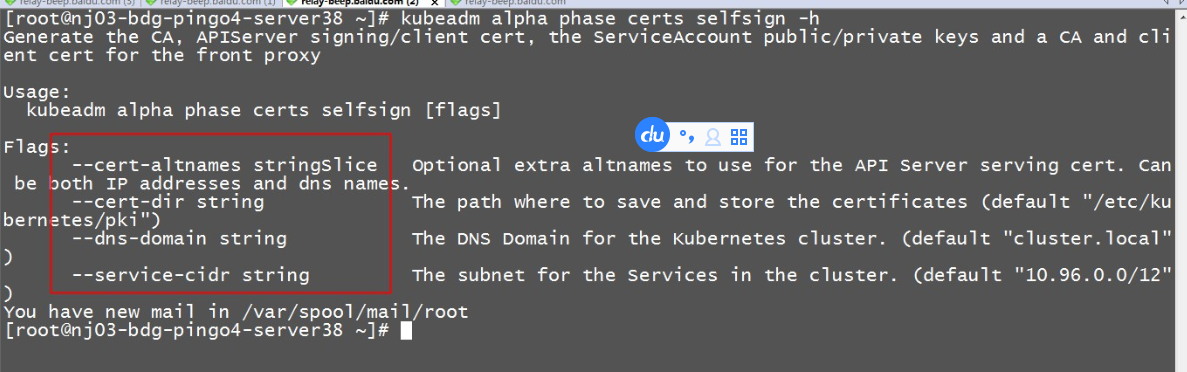
But make a mistake,like this:
[certificates] Generated CA certificate and key.
failure while creating API se... | How to Regenerate Certificate in Version k8s 1.6.2 | https://api.github.com/repos/kubernetes/kubernetes/issues/79684/comments | 5 | 2019-07-03T02:26:11Z | 2019-11-30T04:49:14Z | https://github.com/kubernetes/kubernetes/issues/79684 | 463,512,963 | 79,684 |
[
"kubernetes",
"kubernetes"
] | So I started using namespaces for the first time, and I ran:
```bash
kubectl get pods
```
nothing was showing up...I was really confused, debugging stuff for 30+ minutes..
finally I was like, even tho this is really dumb, maybe they are behind a namespace, so I did:
```bash
kubectl get pods --namespace=min... | Soooo --all-namespaces should be the default | https://api.github.com/repos/kubernetes/kubernetes/issues/79678/comments | 10 | 2019-07-03T00:41:19Z | 2019-07-12T01:55:55Z | https://github.com/kubernetes/kubernetes/issues/79678 | 463,492,591 | 79,678 |
[
"kubernetes",
"kubernetes"
] | This should work as expected:
```bash
kubectl logs --namespace=foo
``` | You should be able to get logs for everything in a namespace | https://api.github.com/repos/kubernetes/kubernetes/issues/79676/comments | 14 | 2019-07-03T00:16:54Z | 2025-02-12T21:59:09Z | https://github.com/kubernetes/kubernetes/issues/79676 | 463,488,030 | 79,676 |
[
"kubernetes",
"kubernetes"
] | ### Flaky Job: pr:pull-kubernetes-integration
Flakes in the past week: **32**
Consistency: **94.90%**
#### Flakiest tests by flake count:
| Test | Flake Count |
| --- | --- |
| k8s.io/kubernetes/vendor/k8s.io/apiextensions-apiserver/test/integration/conversion TestWebhookConverterWithWatchCache | 8 |
| k8s.io/kubern... | pr:pull-kubernetes-integration flaked 32 times in the past week | https://api.github.com/repos/kubernetes/kubernetes/issues/79670/comments | 6 | 2019-07-02T17:06:13Z | 2020-01-15T17:01:54Z | https://github.com/kubernetes/kubernetes/issues/79670 | 463,340,465 | 79,670 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
ci-kubernetes-e2e-kubeadm-kinder-master-on-stable
**Which test(s) are failing**:
task-09-reset
task-10-delete
task-01-add-kubernetes-versions
**Since when has it been failing*... | [Failing Test] Uses kubeadm/kinder to run kubeadm-e2e and e2e tests against a cluster created using kinder's skew-master-on-stable workflow | https://api.github.com/repos/kubernetes/kubernetes/issues/79669/comments | 6 | 2019-07-02T16:44:43Z | 2019-07-05T15:19:53Z | https://github.com/kubernetes/kubernetes/issues/79669 | 463,331,625 | 79,669 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
ci-kubernetes-e2e-kubeadm-kinder-upgrade-stable-master
**Which test(s) are failing**:
task-01-add-kubernetes-versions
task-11-reset
task-12-delete
**Since when has it been fai... | [Failing Test] Uses kubeadm/kinder to run kubeadm-e2e and e2e tests | https://api.github.com/repos/kubernetes/kubernetes/issues/79668/comments | 5 | 2019-07-02T16:39:18Z | 2019-07-05T15:19:03Z | https://github.com/kubernetes/kubernetes/issues/79668 | 463,329,235 | 79,668 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
ci-kubernetes-e2e-gci-gce-serial
**Which test(s) are failing**:
* [sig-cluster-lifecycle] Nodes [Disruptive] Resize [Slow] should be able to add nodes
* [sig-cluster-lifecycle] No... | [Failing Test] Nodes resize test failing in master-blocking | https://api.github.com/repos/kubernetes/kubernetes/issues/79662/comments | 9 | 2019-07-02T16:12:16Z | 2019-08-02T15:36:26Z | https://github.com/kubernetes/kubernetes/issues/79662 | 463,317,268 | 79,662 |
[
"kubernetes",
"kubernetes"
] | Right now, we have e2e test for [volume scheduling limits](https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20190408-volume-scheduling-limits.md) that executes only CSI mock driver with artificial limit of 2 volumes per node.
We need a test with real CSI driver(s).
Proposal:
* Allow indi... | Add e2e test(s) for volume scheduling limits | https://api.github.com/repos/kubernetes/kubernetes/issues/79660/comments | 11 | 2019-07-02T14:31:18Z | 2021-06-24T12:41:53Z | https://github.com/kubernetes/kubernetes/issues/79660 | 463,263,548 | 79,660 |
[
"kubernetes",
"kubernetes"
] | I recently had a node crash on the [vSphere Windows test job](https://k8s-testgrid.appspot.com/sig-windows#cfcr-vsphere-windows-master). The crash dump file points to the symbol `ExfAcquireRundownProtection` from `netio.sys`.
- [WinDbg logs](https://gist.github.com/benmoss/ccf17496a13a4f1e72730b3dd4295480)
- [Crash... | Windows vSphere node crashing from ExfAcquireRundownProtection | https://api.github.com/repos/kubernetes/kubernetes/issues/79658/comments | 11 | 2019-07-02T14:08:20Z | 2022-05-11T05:31:41Z | https://github.com/kubernetes/kubernetes/issues/79658 | 463,250,869 | 79,658 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
There is a duplicate row in the Changelog for v1.12.7
**How to reproduce it (as minimally and precisely as possible)**:
[CHANGELOG-1.12](https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.12.md#changelog-since-v1127) the first and the fourth row are exactly the same.
/sig docs | Duplicate rows in Changelog for v1.12.7 | https://api.github.com/repos/kubernetes/kubernetes/issues/79653/comments | 0 | 2019-07-02T11:44:00Z | 2019-07-08T21:28:27Z | https://github.com/kubernetes/kubernetes/issues/79653 | 463,181,370 | 79,653 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
gce-cos-master-slow
gce-cos-master-alpha-features
gce-cos-master-ingress
gce-cos-master-default
**Which test(s) are failing**:
It fails during the test suite start up
**Since... | Multiple GCE test suites in master-blocking are failing | https://api.github.com/repos/kubernetes/kubernetes/issues/79652/comments | 10 | 2019-07-02T11:41:28Z | 2019-07-05T15:05:51Z | https://github.com/kubernetes/kubernetes/issues/79652 | 463,180,355 | 79,652 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
gce-cos-master-scalability-100
**Which test(s) are failing**:
cluster cannot be created
**Since when has it been failing**:
7/02 01:56 PDT
**Testgrid link**:
https://k8s-te... | [Failing Test] gce-cos-master-scalability-100 cannot download kubernetes.tar.gz (404) | https://api.github.com/repos/kubernetes/kubernetes/issues/79651/comments | 2 | 2019-07-02T11:30:19Z | 2019-07-02T13:18:26Z | https://github.com/kubernetes/kubernetes/issues/79651 | 463,175,490 | 79,651 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I am trying t... | Kubelet does not start static pods on fresh k8s 1.15 install with Ubuntu18 | https://api.github.com/repos/kubernetes/kubernetes/issues/79644/comments | 4 | 2019-07-02T06:57:29Z | 2019-07-02T13:37:14Z | https://github.com/kubernetes/kubernetes/issues/79644 | 463,055,307 | 79,644 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
`CSI Inline volume` is a really valuable feature for users, but there is no resource quota management for it.
A common scenario is:
- There is a storage class, which implemented by csi driver like `k... | Feature request: resource quota management for CSI inline volume | https://api.github.com/repos/kubernetes/kubernetes/issues/79643/comments | 9 | 2019-07-02T06:12:45Z | 2020-06-02T02:14:51Z | https://github.com/kubernetes/kubernetes/issues/79643 | 463,039,369 | 79,643 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Default sched... | Default scheduler crash if scheduler extender filter returns a not found node | https://api.github.com/repos/kubernetes/kubernetes/issues/79640/comments | 1 | 2019-07-02T04:44:30Z | 2019-08-14T09:08:38Z | https://github.com/kubernetes/kubernetes/issues/79640 | 463,017,749 | 79,640 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Allow to scheduler (extender) to update Pod Env: NVIDIA_VISIBLE_DEVICES.
**Why is this needed**:
Currently, it is too tedious and complicated to let scheduler extender or a standalone scheduler to pas... | Allow to scheduler (extender) to update Pod Env: NVIDIA_VISIBLE_DEVICES | https://api.github.com/repos/kubernetes/kubernetes/issues/79635/comments | 7 | 2019-07-02T02:37:01Z | 2019-07-03T02:57:35Z | https://github.com/kubernetes/kubernetes/issues/79635 | 462,990,943 | 79,635 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Kubernetes ... | Kubernetes Service not forwarding to ports other than 80 and 443 | https://api.github.com/repos/kubernetes/kubernetes/issues/79633/comments | 3 | 2019-07-02T01:47:59Z | 2019-07-06T19:52:18Z | https://github.com/kubernetes/kubernetes/issues/79633 | 462,981,101 | 79,633 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
I'm trying to pass a custom policy configuration to the scheduler but some error occurred, the k8s
deployment failed and the kube-scheduler CrashLoopBackOff.
**What you expected to happen**:
Run well
**How to reproduce it (as minimally and precisely as possible)**:
I'm trying the pas... | kube-scheduler in CrashLoopBackoff Error after passing custom scheduling policy | https://api.github.com/repos/kubernetes/kubernetes/issues/79632/comments | 7 | 2019-07-02T01:37:07Z | 2019-12-06T06:11:19Z | https://github.com/kubernetes/kubernetes/issues/79632 | 462,979,028 | 79,632 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
#79076 modifi... | Scheduler: affinity priority function lists nodes from the informer cache instead of scheduler cache | https://api.github.com/repos/kubernetes/kubernetes/issues/79629/comments | 6 | 2019-07-02T00:10:26Z | 2019-07-24T20:50:07Z | https://github.com/kubernetes/kubernetes/issues/79629 | 462,962,350 | 79,629 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Add a lower-level log (2) and/or pod event (info level) whenever the attach detach controller decides to skip processing a volume and let kubelet handle the attaching.
**Why is this needed**:
The typi... | Improve logging when AD controller lets kubelet attach volumes | https://api.github.com/repos/kubernetes/kubernetes/issues/79628/comments | 8 | 2019-07-01T23:44:42Z | 2024-11-03T17:58:38Z | https://github.com/kubernetes/kubernetes/issues/79628 | 462,957,015 | 79,628 |
[
"kubernetes",
"kubernetes"
] | We would like to have drivers that can be used in both ephemeral and non ephemeral modes be supported.
csi-driver-hostpath is an example that can be used in either ephemeral or non ephemeral modes, but only one at a time.
To support both at one time, the driver needs to be aware of which mode its operating on, on... | Support drivers that support both ephemeral and non ephemeral modes | https://api.github.com/repos/kubernetes/kubernetes/issues/79624/comments | 13 | 2019-07-01T22:07:40Z | 2019-08-30T15:46:42Z | https://github.com/kubernetes/kubernetes/issues/79624 | 462,932,323 | 79,624 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
https://testgrid.k8s.io/sig-windows#gce-windows-master
https://testgrid.k8s.io/sig-windows#aks-engine-azure-windows-master
**Which test(s) are failing**:
Proxy version v1 should p... | Test failure: Proxy version v1 should proxy through a service and a pod [Conformance] failing on Windows | https://api.github.com/repos/kubernetes/kubernetes/issues/79622/comments | 4 | 2019-07-01T21:39:44Z | 2019-07-11T21:09:09Z | https://github.com/kubernetes/kubernetes/issues/79622 | 462,923,380 | 79,622 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
I'd like to propose we move `pkg/kubectl/drain` outside of k/k repository. One possible option is to move (or stage) it in `k8s.io/kubectl`.
**Why is this needed**:
Clients that want to drain/cordon n... | Move pkg/kubectl/drain out of k/k repository | https://api.github.com/repos/kubernetes/kubernetes/issues/79616/comments | 25 | 2019-07-01T19:19:09Z | 2020-09-13T05:08:42Z | https://github.com/kubernetes/kubernetes/issues/79616 | 462,869,607 | 79,616 |
[
"kubernetes",
"kubernetes"
] | ** Problem **
Currently we run very job-heavy Kubernetes cluster. That means we have a lot of very small jobs, hence a lot of `Completed` Pods. Problem is, Kubernetes scheduler doesn't seem to take these into account when trying to schedule new pod. As effect, we experience 2 orders of magnitude more pods in one nod... | Allow custom weights for kubernetes scheduler - custom controllers | https://api.github.com/repos/kubernetes/kubernetes/issues/79613/comments | 6 | 2019-07-01T19:11:49Z | 2019-11-29T22:43:15Z | https://github.com/kubernetes/kubernetes/issues/79613 | 462,866,858 | 79,613 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
I was tryin... | Could not simulate an error in discovery/fake/ServerVersion | https://api.github.com/repos/kubernetes/kubernetes/issues/79612/comments | 16 | 2019-07-01T19:09:20Z | 2022-12-19T17:21:46Z | https://github.com/kubernetes/kubernetes/issues/79612 | 462,865,898 | 79,612 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
TestUnreserve... | TestUnreservePlugin is flaky, again | https://api.github.com/repos/kubernetes/kubernetes/issues/79611/comments | 3 | 2019-07-01T18:48:09Z | 2019-07-03T20:52:40Z | https://github.com/kubernetes/kubernetes/issues/79611 | 462,858,016 | 79,611 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Once started, dynamic informers for custom resources are not stopped.
**What you expected to happen**:
After the dynamic informers resynced, they would stop informers belong to no-longer-existing resources.
**How to reproduce it (as minimally and precisely as possible)**:
1. Start a clus... | Dynamic informers do not stop when custom resource definition is removed | https://api.github.com/repos/kubernetes/kubernetes/issues/79610/comments | 40 | 2019-07-01T18:34:31Z | 2025-02-25T23:10:27Z | https://github.com/kubernetes/kubernetes/issues/79610 | 462,852,648 | 79,610 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
We observed lots of 504 response in our monitor system, which get metrics from `apiserver_request_total`. Which mislead us to troubleshooting etcd and webhook performance.
After troubleshooting, we find there are two ways to record 504 in `apiserver_request_total` metric:
1. logical process... | distinguish logical processing timeout and response body write timeout from 504 response | https://api.github.com/repos/kubernetes/kubernetes/issues/79608/comments | 6 | 2019-07-01T16:06:02Z | 2019-11-28T18:15:15Z | https://github.com/kubernetes/kubernetes/issues/79608 | 462,796,378 | 79,608 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
The following YAML
```yaml
---
apiVersion: v1
kind: Service
metadata:
name: cp-schema-registry-external
labels:
app: cp-schema-registry
spec:
type: NodePort
ports:
- name: schema-registry-external
targetPort: 8081
port: 8081
nodePort: 32081
sel... | kubectl wait stucks if YAML declaration contains different resource types | https://api.github.com/repos/kubernetes/kubernetes/issues/79607/comments | 6 | 2019-07-01T16:04:02Z | 2019-11-29T19:40:14Z | https://github.com/kubernetes/kubernetes/issues/79607 | 462,795,454 | 79,607 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
```
kubectl wait -f schema-registry.yaml --for condition=available
```
works for Deployment, but it does not work for StatefulSet
**What you expected to happen**:
Expected that kubectl wait works for StatefulSet
```
kubectl version
Client Version: version.Info{Major:"1", Minor:"13", Git... | kubectl wait works for Deployment, but does not for StatefulSet | https://api.github.com/repos/kubernetes/kubernetes/issues/79606/comments | 63 | 2019-07-01T15:56:03Z | 2025-01-10T14:21:41Z | https://github.com/kubernetes/kubernetes/issues/79606 | 462,791,789 | 79,606 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
I'm trying to install Kubernetes using kubeadm on single node cluster with CPUManager feature-gate set with 'true' and its policy is set to 'static'. But Kubelet process is failed to start and seeing the following error.
```
Jul 1 14:40:59 dl380-006-ECCD-SUT kubelet[55393]: I0701 14:40:59.673... | cpumanager doesn't start kubelet when isolcpus set | https://api.github.com/repos/kubernetes/kubernetes/issues/79603/comments | 7 | 2019-07-01T14:58:35Z | 2019-07-21T14:15:04Z | https://github.com/kubernetes/kubernetes/issues/79603 | 462,762,900 | 79,603 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
I would expect the same security options to be available in Pod securityContext as what are in *both* PodSecurityPolicy and container securityContext. Specifically, adding/removing capabilities and privilege escalation.
**Why is this needed**:
Typing same thing to all cont... | Pod securityContext should support options supported both by PodSecurityPolicy & container securityContext | https://api.github.com/repos/kubernetes/kubernetes/issues/79602/comments | 12 | 2019-07-01T14:44:22Z | 2020-03-07T14:14:36Z | https://github.com/kubernetes/kubernetes/issues/79602 | 462,755,267 | 79,602 |
[
"kubernetes",
"kubernetes"
] | **Rationale**
Device files require user to be in a specific group to access them. Names of these groups are de-facto standardized between distros (if they're present), but the corresponding IDs are not.
ID used inside container needs to match the one on the host for device access to work. Therefore, for access ... | Can't specify correct user / group name for security context | https://api.github.com/repos/kubernetes/kubernetes/issues/79601/comments | 10 | 2019-07-01T14:23:15Z | 2020-02-27T15:48:17Z | https://github.com/kubernetes/kubernetes/issues/79601 | 462,743,948 | 79,601 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
pull-kubernetes-e2e-aks-engine-azure
**Which test(s) are failing**:
`Up`
**Since when has it been failing**:
[2019-05-10 05:20:51 +0000 UTC](https://prow.k8s.io/view/gcs/kubern... | pull-kubernetes-e2e-aks-engine-azure consistently failing | https://api.github.com/repos/kubernetes/kubernetes/issues/79597/comments | 8 | 2019-07-01T11:36:35Z | 2019-08-07T21:55:20Z | https://github.com/kubernetes/kubernetes/issues/79597 | 462,663,966 | 79,597 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
ci-kubernetes-e2e-gce-scale-performance
**Which test(s) are failing**:
load
**Since when has it been failing**:
2019-06-28 however we've observing this behavior earlier as well... | gce-scale-performance fails due to long LIST ReplicationControllers | https://api.github.com/repos/kubernetes/kubernetes/issues/79596/comments | 6 | 2019-07-01T09:45:39Z | 2019-07-25T09:06:07Z | https://github.com/kubernetes/kubernetes/issues/79596 | 462,617,408 | 79,596 |
[
"kubernetes",
"kubernetes"
] | Is there a way to re-scheduling evicted pods in kubernetes to a specific node using custom scheduler?
@kubernetes
| Re-scheduling evicted pods in kubernetes to a specific node using custom scheduler | https://api.github.com/repos/kubernetes/kubernetes/issues/79595/comments | 5 | 2019-07-01T09:41:26Z | 2019-11-29T19:40:15Z | https://github.com/kubernetes/kubernetes/issues/79595 | 462,615,441 | 79,595 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**: The new E2Es are needed to check that the pod satisfying the underlying conditions is scheduled to same nodes in each run.
**Why is this needed**: To validate pod scheduling based on node affinity/node Selector
**Plan for test yaml using Node Selector:**
1. Acquire a node fro... | E2E Proposal: New E2E to ensure pods are scheduled to same nodes always | https://api.github.com/repos/kubernetes/kubernetes/issues/79590/comments | 11 | 2019-07-01T06:59:07Z | 2020-04-09T12:05:46Z | https://github.com/kubernetes/kubernetes/issues/79590 | 462,544,882 | 79,590 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**: As per the comment, https://github.com/kubernetes/kubernetes/pull/77857#issuecomment-503683546
the E2Es for Node Affinity should be modified to use informers sot hat they can be promoted to conformance
**Why is this needed**: To promote node affinity validation E2Es to conform... | Change E2Es for Node Affinity validation to not use events | https://api.github.com/repos/kubernetes/kubernetes/issues/79586/comments | 6 | 2019-07-01T06:02:56Z | 2019-11-28T08:05:11Z | https://github.com/kubernetes/kubernetes/issues/79586 | 462,525,729 | 79,586 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
setup TerminationGracePeriodSeconds on container level
**Why is this needed**:
For some reason, pod may have two containers, container A can handle SIGTERM signal,but it may require seconds to half an h... | container level TerminationGracePeriodSeconds | https://api.github.com/repos/kubernetes/kubernetes/issues/79582/comments | 8 | 2019-07-01T03:38:38Z | 2019-11-28T14:11:10Z | https://github.com/kubernetes/kubernetes/issues/79582 | 462,494,956 | 79,582 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**: Using a pod li... | Draining a node with a pod that uses an AWS NLB does not deregister instances or close the nodeports on said node | https://api.github.com/repos/kubernetes/kubernetes/issues/79581/comments | 7 | 2019-07-01T03:20:22Z | 2020-09-22T18:46:12Z | https://github.com/kubernetes/kubernetes/issues/79581 | 462,491,647 | 79,581 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Useless newline... | Useless newline output | https://api.github.com/repos/kubernetes/kubernetes/issues/79579/comments | 6 | 2019-07-01T01:47:23Z | 2019-07-30T02:14:21Z | https://github.com/kubernetes/kubernetes/issues/79579 | 462,475,180 | 79,579 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
When two or more images on a given node have the same size, their order inside the `node.status.images` field set by the `kubelet` process is not deterministic.
This problem has the side effect of continually triggering controllers which assume this list to be always equal on node updates unles... | kubelet: Images with the same size on a node do not have a stable order | https://api.github.com/repos/kubernetes/kubernetes/issues/79577/comments | 2 | 2019-06-30T23:48:12Z | 2019-08-10T15:59:14Z | https://github.com/kubernetes/kubernetes/issues/79577 | 462,459,874 | 79,577 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Move per test namespace deletion from AfterEach test to AfterSuite.
**Why is this needed**:
We will be creation hundreds to thousands of new e2e tests.
We create a namespace for each one.
After the test, we need to delete them.
This currently extends each test by usually... | Verify namespace deletion during e2e AfterSuite rather than AfterEach test | https://api.github.com/repos/kubernetes/kubernetes/issues/79564/comments | 11 | 2019-06-29T18:58:31Z | 2019-12-16T16:18:57Z | https://github.com/kubernetes/kubernetes/issues/79564 | 462,331,064 | 79,564 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
We have an ... | Kubernetes autoscaler breaks the session affinity | https://api.github.com/repos/kubernetes/kubernetes/issues/79563/comments | 12 | 2019-06-29T15:31:04Z | 2019-12-08T23:15:04Z | https://github.com/kubernetes/kubernetes/issues/79563 | 462,312,862 | 79,563 |
[
"kubernetes",
"kubernetes"
] | Hi Team,
I'm trying to install Kubernetes HA cluster on GCP using GCE. I'm not using GKE for this purpose and trying to use Kubeadm to do the same. However, on my nodes Kubelet keeps failing even after attempting several times.
Below is the error along with details:-
root@kube-master-1:/etc/systemd/system/kube... | Kubelet keeps failing | https://api.github.com/repos/kubernetes/kubernetes/issues/79556/comments | 14 | 2019-06-29T05:51:12Z | 2020-01-03T07:10:16Z | https://github.com/kubernetes/kubernetes/issues/79556 | 462,269,160 | 79,556 |
[
"kubernetes",
"kubernetes"
] | [Critical Pod Annotation](https://github.com/kubernetes/kubernetes/blob/665e76d97623447d13bb3b33b68591a985b49c9d/pkg/features/kube_features.go#L58) is an experimental feature that lets Kubernetes control plane know about a pod being a critical pod by adding a specific annotation to the pod. This was added in 1.5 when K... | Remove Critical Pod Annotation | https://api.github.com/repos/kubernetes/kubernetes/issues/79548/comments | 3 | 2019-06-28T22:59:44Z | 2019-08-15T14:20:35Z | https://github.com/kubernetes/kubernetes/issues/79548 | 462,233,863 | 79,548 |
[
"kubernetes",
"kubernetes"
] | It's a minor gripe, but when I'm trying to find out why my pod fails, I tend to "kubectl logs -f [podname]". A common problem is that it's still initializing and kubectl tells me to go away.
Given that I specified '-f', I'd rather it just hang out in that state and then start piping logs when it's ready, versus me ... | kubectl logs -f should wait when in state PodInitializing | https://api.github.com/repos/kubernetes/kubernetes/issues/79547/comments | 33 | 2019-06-28T22:53:41Z | 2023-01-16T13:10:47Z | https://github.com/kubernetes/kubernetes/issues/79547 | 462,232,794 | 79,547 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
We using go-c... | oidc cache does not work when muliple users and configs for same oidc provider | https://api.github.com/repos/kubernetes/kubernetes/issues/79546/comments | 6 | 2019-06-28T22:47:21Z | 2019-12-12T05:00:33Z | https://github.com/kubernetes/kubernetes/issues/79546 | 462,231,642 | 79,546 |
[
"kubernetes",
"kubernetes"
] | error in update vendor after running `pin-dependancy.sh`
Here is how you can repro on current head:
1- ./hack/pin-dependency.sh k8s.io/utils c55fbcf `ok no errors`
2- hack/update-vendor.sh
```
$ hack/update-vendor.sh
+++ [0628 20:23:24] logfile at /tmp/update-vendor.fFCv/update-vendor.log
+++ [0628 20:23:24... | hack/update-vendor.sh is broken due to incorrect testing of empty array | https://api.github.com/repos/kubernetes/kubernetes/issues/79541/comments | 2 | 2019-06-28T20:43:25Z | 2019-06-29T02:21:38Z | https://github.com/kubernetes/kubernetes/issues/79541 | 462,200,576 | 79,541 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Consider use schedulerCache to replace fields in PluginFactoryArgs
```go
func (c *configFactory) getPluginArgs() (*PluginFactoryArgs, error) {
return &PluginFactoryArgs{
PodLister: ... | Consider use schedulerCache to replace fields in PluginFactoryArgs | https://api.github.com/repos/kubernetes/kubernetes/issues/79538/comments | 1 | 2019-06-28T18:39:29Z | 2019-07-10T23:24:41Z | https://github.com/kubernetes/kubernetes/issues/79538 | 462,161,022 | 79,538 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Starting seeing this error on nodes after upgrading to nodes to 1.13:
```
aws_credentials.go:194] while requesting ECR authorization token RequestError: send request failed
caused by: Post https://api.ecr.us-east-1.amazonaws.com/: dial tcp i/o timeout
remote_runtime.go:96] RunPodSandbox from ... | EKS 1.13 nodes can't communicate with ECR | https://api.github.com/repos/kubernetes/kubernetes/issues/79535/comments | 8 | 2019-06-28T16:49:58Z | 2020-01-03T14:17:16Z | https://github.com/kubernetes/kubernetes/issues/79535 | 462,123,190 | 79,535 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
ci-kubernetes-e2e-gce-new-master-upgrade-master-parallel
**Which test(s) are failing**:
Kubectl client [k8s.io] Kubectl run deployment should create a deployment from an image [Co... | [Failing Test] Kubectl client Conformance test failing | https://api.github.com/repos/kubernetes/kubernetes/issues/79533/comments | 6 | 2019-06-28T16:30:35Z | 2019-08-26T14:06:06Z | https://github.com/kubernetes/kubernetes/issues/79533 | 462,116,059 | 79,533 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
attach/WaitFo... | attach/WaitForAttach timeout value is too small in CSI driver | https://api.github.com/repos/kubernetes/kubernetes/issues/79528/comments | 0 | 2019-06-28T14:47:19Z | 2019-07-03T16:12:59Z | https://github.com/kubernetes/kubernetes/issues/79528 | 462,070,839 | 79,528 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
```Error creating load balancer (will retry): failed to ensure load balancer for service default/test: Only TCP LoadBalancer is supported for AWS ELB```
**What you expected to happen**: kubernetes creating an AWS NLB for UDP
**How to reproduce it (as minimally and precisely as possible)**: Cr... | Support UDP with AWS NLB | https://api.github.com/repos/kubernetes/kubernetes/issues/79523/comments | 54 | 2019-06-28T11:24:38Z | 2020-06-25T04:40:37Z | https://github.com/kubernetes/kubernetes/issues/79523 | 461,988,394 | 79,523 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
When i upgr... | The kubernetes 1.15 kube-proxy report "Unable to find HNS Network specified by cbr0" on windows node | https://api.github.com/repos/kubernetes/kubernetes/issues/79515/comments | 9 | 2019-06-28T08:52:55Z | 2019-09-01T09:41:10Z | https://github.com/kubernetes/kubernetes/issues/79515 | 461,929,368 | 79,515 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
LoadBalance... | LoadBalancer is stuck on pending state when annotation azure-load-balancer-resource-group is set to empty string | https://api.github.com/repos/kubernetes/kubernetes/issues/79513/comments | 1 | 2019-06-28T08:04:08Z | 2019-06-28T17:03:51Z | https://github.com/kubernetes/kubernetes/issues/79513 | 461,910,564 | 79,513 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
It would be very nice if we could log denied ingress/engress traffic when using network policies
**Why is this needed**:
Currently when a network policy rule denies some traffic, that is not log... | logging dropped packets network policies | https://api.github.com/repos/kubernetes/kubernetes/issues/79512/comments | 7 | 2019-06-28T07:50:18Z | 2019-09-04T10:00:34Z | https://github.com/kubernetes/kubernetes/issues/79512 | 461,905,378 | 79,512 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
Refactor the framework integration test with ginkgo to make sure each test run with a separated scheduler.
**Why is this needed**:
> Scheduling framework integration tests rely a lot on shared state, this state is reset in in an ad hoc way that will likely cause flaky tests... | Refactor the scheduling framework integration tests with ginkgo | https://api.github.com/repos/kubernetes/kubernetes/issues/79511/comments | 3 | 2019-06-28T07:44:10Z | 2019-10-06T01:17:54Z | https://github.com/kubernetes/kubernetes/issues/79511 | 461,903,275 | 79,511 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
in my cluster I have a deployment with 5 volumeMounts and 5 volumes :
```
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
generation: 12
labels:
app: istio-ingressgateway
chart: gateways-1.0.4
heritage: Tiller
istio: ingressgateway
release: istio-ingress... | 'kubectl apply' failed when change the number of the volumeMounts | https://api.github.com/repos/kubernetes/kubernetes/issues/79510/comments | 8 | 2019-06-28T07:27:15Z | 2019-07-23T03:19:24Z | https://github.com/kubernetes/kubernetes/issues/79510 | 461,897,482 | 79,510 |
[
"kubernetes",
"kubernetes"
] | We have made some progress on scheduler performance, details are as follows.
**What would you like to be added**:
Improve performance:
- 1. [scheduler: establish node topology info cache](
https://github.com/kubernetes/kubernetes/pull/79360)
- 2. [ Scheduler: reduce iteration and conversion to improve perferman... | Some works about improving scheduler performance | https://api.github.com/repos/kubernetes/kubernetes/issues/79509/comments | 1 | 2019-06-28T07:23:02Z | 2019-07-03T11:38:53Z | https://github.com/kubernetes/kubernetes/issues/79509 | 461,896,075 | 79,509 |
[
"kubernetes",
"kubernetes"
] | I got problem in installing kubectl in Linux Lite v4.4
I added the user 'linuxbrew' first. Then I installed docker by root. The error messages are as follows:
hack/generate-docs.sh
Last 15 lines from /home/linuxbrew/.cache/Homebrew/Logs/kubernetes-cli/03.generate-docs.sh:
!!! [0628 13:31:23] 1: /tmp/kubernet... | 'brew install kubectl' on Linux Lite but failed | https://api.github.com/repos/kubernetes/kubernetes/issues/79503/comments | 4 | 2019-06-28T05:56:32Z | 2019-07-05T10:27:31Z | https://github.com/kubernetes/kubernetes/issues/79503 | 461,869,566 | 79,503 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Got the follo... | hack/update-bazel produces warnings
| https://api.github.com/repos/kubernetes/kubernetes/issues/79499/comments | 13 | 2019-06-28T03:40:46Z | 2020-06-15T21:18:15Z | https://github.com/kubernetes/kubernetes/issues/79499 | 461,840,458 | 79,499 |
[
"kubernetes",
"kubernetes"
] | Within the same namespace, we can create two conflicting LimitRange objects that can block the creation of any pod
**What happened**:
For a given resource, e.g. `memory`, if the `min` specified in the first LimitRange is `greater than` the `max` specified in the second LimitRange, then we would be blocked from cr... | Multiple LimitRange objects can have conflicting values in the same namespace | https://api.github.com/repos/kubernetes/kubernetes/issues/79496/comments | 7 | 2019-06-27T21:57:15Z | 2024-09-12T11:58:22Z | https://github.com/kubernetes/kubernetes/issues/79496 | 461,767,228 | 79,496 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
Approximate... | Sometimes Fails to Restart Pod causing stuck PodInitializing | https://api.github.com/repos/kubernetes/kubernetes/issues/79492/comments | 15 | 2019-06-27T18:50:40Z | 2020-04-28T01:19:27Z | https://github.com/kubernetes/kubernetes/issues/79492 | 461,694,468 | 79,492 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
pull-kubernetes-integration
**Which test(s) are failing**:
k8s.io/kubernetes/test/integration/scheduler
**Since when has it been failing**:
Noticed it midday 27 June 2019
**... | integration flake: pull-kubernetes-integration fails k8s.io/kubernetes/test/integration/scheduler | https://api.github.com/repos/kubernetes/kubernetes/issues/79488/comments | 9 | 2019-06-27T17:37:35Z | 2019-08-17T15:23:07Z | https://github.com/kubernetes/kubernetes/issues/79488 | 461,659,681 | 79,488 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
ci-kubernetes-e2e-gci-gce-serial
**Which test(s) are failing**:
[sig-network] DNS configMap nameserver [IPv4] Forward PTR lookup should forward PTR records lookup to upstream names... | [Failing Test] [sig-network] DNS configMap nameserver failing in master blocking | https://api.github.com/repos/kubernetes/kubernetes/issues/79487/comments | 4 | 2019-06-27T17:36:29Z | 2019-07-01T14:10:05Z | https://github.com/kubernetes/kubernetes/issues/79487 | 461,659,215 | 79,487 |
[
"kubernetes",
"kubernetes"
] | Kubebuilder is becoming the common way to develop operators /controllers for Kubernetes. With the release of various new features of CRD, it seems that new annotations are added to kubebuilder instead of code-generator repo. But one issue with kubebuilder and its controller-runtime and controller-tools repos is that th... | kubebuilder and controller-* libraries should follow k8s release cadence | https://api.github.com/repos/kubernetes/kubernetes/issues/79486/comments | 7 | 2019-06-27T17:32:25Z | 2019-06-27T22:50:38Z | https://github.com/kubernetes/kubernetes/issues/79486 | 461,657,600 | 79,486 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
pull-kubernetes-bazel-build
pull-kubernetes-bazel-test
**Which test(s) are failing**:
N/A
**Since when has it been failing**:
Not sure. Noticed it midday 27 June 2019.
**T... | build flake: pull-kubernetes-bazel-build fails with "UNAVAILABLE: 502:Bad Gateway" | https://api.github.com/repos/kubernetes/kubernetes/issues/79485/comments | 8 | 2019-06-27T17:29:26Z | 2019-10-28T18:04:12Z | https://github.com/kubernetes/kubernetes/issues/79485 | 461,656,455 | 79,485 |
[
"kubernetes",
"kubernetes"
] | Could you please let me know where do we stand with SCTP multi-homing support in K8s?
I am looking at the feasibility analysis of on boarding one of the Telecom NF to my k8s cluster which has SCTP interface to another Telecom NF. And i want to have the SCTP multi-homing feature for high avialability, etc
| @kubernetes/sig-network: Regarding SCTP multi-homing support in Kubernetes | https://api.github.com/repos/kubernetes/kubernetes/issues/79481/comments | 7 | 2019-06-27T16:26:05Z | 2019-11-24T18:41:50Z | https://github.com/kubernetes/kubernetes/issues/79481 | 461,627,478 | 79,481 |
[
"kubernetes",
"kubernetes"
] | Expectation-
We should be able to create PVCs via a storageclass with storagePolicyName defined while using a singed ca cert for secure communications with vCenter.
Bug-
The PVC created with a storageclass with storagePolicyName defined fails with a `x509: certificate signed by unknown authority` error when PVCs ... | Unable to create PVC using a storage class with vSphere storage policy defined (secure connection to vCenter) | https://api.github.com/repos/kubernetes/kubernetes/issues/79809/comments | 22 | 2019-06-27T15:39:10Z | 2019-10-04T16:09:44Z | https://github.com/kubernetes/kubernetes/issues/79809 | 464,348,142 | 79,809 |
[
"kubernetes",
"kubernetes"
] | **What would you like to be added**:
`spec.containers[n].env.valueFrom.environmentVariable`
**Why is this needed**:
In order to reduce application code involved with munging Kubernetes environment variables. | env valueFrom another env var | https://api.github.com/repos/kubernetes/kubernetes/issues/79479/comments | 2 | 2019-06-27T13:58:05Z | 2019-06-28T02:01:10Z | https://github.com/kubernetes/kubernetes/issues/79479 | 461,545,864 | 79,479 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
Scaling a StatefulSet causes SecurityContext reset to default
**What you expected to happen**:
SecurityContext should be preserved upon scaling
**How to reproduce it (as minimally and precisely as possible)**:
deploy a StatefulSet set with
```
securityContext:
sysctls:
... | Stateful set scaling causes SecurityContext loss | https://api.github.com/repos/kubernetes/kubernetes/issues/79478/comments | 8 | 2019-06-27T13:42:14Z | 2020-01-31T16:14:26Z | https://github.com/kubernetes/kubernetes/issues/79478 | 461,537,113 | 79,478 |
[
"kubernetes",
"kubernetes"
] | /kind feature
/sig api-machinery
@sttts @roycaihw @kubernetes/sig-api-machinery-misc
- Multi-types support:
- (https://github.com/kubernetes-client/java/issues/86) Delete calls returns actual objects in the response (e.g. when there's remaining finalizers) while the v2 spec says it's returning a status objec... | [Tracking Issue] Pain points in using OpenAPIv2 schema | https://api.github.com/repos/kubernetes/kubernetes/issues/79472/comments | 9 | 2019-06-27T12:35:53Z | 2020-08-18T12:34:44Z | https://github.com/kubernetes/kubernetes/issues/79472 | 461,503,577 | 79,472 |
[
"kubernetes",
"kubernetes"
] |
**What happened**:
```kubectl taint nodes --selector node-role.kubernetes.io/infra= node-role.kubernetes.io/infra=:NoSchedule --overwrite```
Even if identical taint and effect already exists, it always returns:
```
node/machine04 modified
```
**What you expected to happen**:
return
"node/machine04 not t... | taint --overwrite returns "modified" even when no changes were made | https://api.github.com/repos/kubernetes/kubernetes/issues/79470/comments | 13 | 2019-06-27T11:50:23Z | 2024-03-23T04:58:02Z | https://github.com/kubernetes/kubernetes/issues/79470 | 461,483,670 | 79,470 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
It seems that displaying node taints requires, at the very least, piping into external tools. e.g.
`$ kubectl describe nodes | egrep “Taint|Hostname”`
I've also seen really weird and wonderful comman... | Please add a kubectl extention to display node taints | https://api.github.com/repos/kubernetes/kubernetes/issues/79469/comments | 6 | 2019-06-27T11:48:24Z | 2019-11-24T15:38:48Z | https://github.com/kubernetes/kubernetes/issues/79469 | 461,482,844 | 79,469 |
[
"kubernetes",
"kubernetes"
] | It seems to be consistently failing with:
```
goos: linux
goarch: amd64
pkg: k8s.io/kubernetes/vendor/k8s.io/client-go/rest
BenchmarkCheckRetryClosesBody-8 --- FAIL: BenchmarkCheckRetryClosesBody-8
request_test.go:1451: Unexpected error: Post http://127.0.0.1:36871/api/v1/foo/bar/baz?timeout=1s: context ca... | BenchmarkCheckRetryClosesBody is failing | https://api.github.com/repos/kubernetes/kubernetes/issues/79468/comments | 1 | 2019-06-27T11:43:57Z | 2019-07-03T06:34:29Z | https://github.com/kubernetes/kubernetes/issues/79468 | 461,481,017 | 79,468 |
[
"kubernetes",
"kubernetes"
] | @kubernetes/sig-cluster-lifecycle
Hello,
We are facing the issue of kubenetes node is going down for a few minutes randomly on every alternate days. Node goes in NotReady state. Meanwhile, all pods get restarted. below is the version details.
- Kubernetes version: v1.10.5+coreos.0
- Cloud provider or hardwa... | failed to collect filesystem stats - rootDiskErr: failed to exec du - fork/exec /usr/bin/nice: resource temporarily unavailable | https://api.github.com/repos/kubernetes/kubernetes/issues/79466/comments | 12 | 2019-06-27T10:43:24Z | 2021-12-07T04:04:03Z | https://github.com/kubernetes/kubernetes/issues/79466 | 461,455,849 | 79,466 |
[
"kubernetes",
"kubernetes"
] | I've just finished setting up a test suite with microbenchmarks.
It generally works, but there is a problem with some tests related to open-api that they don't compile, e.g.:
https://storage.googleapis.com/kubernetes-jenkins/logs/ci-benchmark-microbenchmarks/1144171647465426947/artifacts/benchmark-log.txt
```
# k... | Compile errors for some openapi tests in benchmark suite | https://api.github.com/repos/kubernetes/kubernetes/issues/79464/comments | 21 | 2019-06-27T10:00:11Z | 2021-03-28T17:52:40Z | https://github.com/kubernetes/kubernetes/issues/79464 | 461,436,374 | 79,464 |
[
"kubernetes",
"kubernetes"
] | We have one core service HTTP passthrough which originally was working quite well with k8s 1.10 and istio proxy sidecar, but after did the cluster upgrade to 1.11 it is broken:
The core part of the HTTP passthrough is just:
```
function director(r *http.Request) {
r.URL.Scheme = "http"
r.URL.Host = "corr... | k8s 1.10 to 1.11 upgrade breaks one of our core service | https://api.github.com/repos/kubernetes/kubernetes/issues/79461/comments | 5 | 2019-06-27T07:17:50Z | 2019-06-28T19:45:38Z | https://github.com/kubernetes/kubernetes/issues/79461 | 461,359,250 | 79,461 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting reports about failing tests in Kubernetes CI jobs -->
**Which jobs are failing**:
ci-kubernetes-e2e-gce-cos-k8sstable1-serial.
**Which test(s) are failing**:
[sig-network] DNS configMap nameserver [IPv4] Forward PTR lookup should forward PTR records lookup t... | Failing test: [sig-network] DNS configMap nameserver [IPv4] Forward PTR lookup should forward PTR records lookup to upstream nameserver [Slow][Serial] | https://api.github.com/repos/kubernetes/kubernetes/issues/79459/comments | 14 | 2019-06-27T06:16:05Z | 2019-07-11T18:55:01Z | https://github.com/kubernetes/kubernetes/issues/79459 | 461,335,853 | 79,459 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
Does k8s has interface to change glog level without restarting? Sometimes we need upgrade the glog level for debugging and if we restart it, maybe we cannot re-produce bugs.
**What would you like to be added**:
If not have , can k8s add the d... | change glog level without restart | https://api.github.com/repos/kubernetes/kubernetes/issues/79457/comments | 5 | 2019-06-27T04:15:05Z | 2019-06-28T02:38:43Z | https://github.com/kubernetes/kubernetes/issues/79457 | 461,304,188 | 79,457 |
[
"kubernetes",
"kubernetes"
] | I ran:
` $ kubectl config set-context eks1`
I got:
`Context "eks1" created.`
**What would you like to be added**:
I would like set-context to not create a context if it does not exist.
**Why is this needed**:
It is confusing / poorly named api
| `kubectl config set-context` should not create a new context | https://api.github.com/repos/kubernetes/kubernetes/issues/79455/comments | 4 | 2019-06-27T03:04:28Z | 2019-06-28T16:32:58Z | https://github.com/kubernetes/kubernetes/issues/79455 | 461,279,206 | 79,455 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
**kubectl v... | kubectl version command error message is not proper | https://api.github.com/repos/kubernetes/kubernetes/issues/79454/comments | 2 | 2019-06-27T02:53:54Z | 2019-06-28T20:57:42Z | https://github.com/kubernetes/kubernetes/issues/79454 | 461,277,117 | 79,454 |
[
"kubernetes",
"kubernetes"
] | This holds a list of volume expand e2e test related improvements that are not covered in https://github.com/kubernetes/kubernetes/pull/78000
- [ ] Move mounted_volume_resize.go to framework
- [ ] Add actual volume size check for volume expand tests
- [ ] Merge volume expand tests for flex volume to framework (Move... | Umbrella: Imporve volume expand e2e test | https://api.github.com/repos/kubernetes/kubernetes/issues/79445/comments | 5 | 2019-06-26T20:59:55Z | 2019-12-17T00:22:35Z | https://github.com/kubernetes/kubernetes/issues/79445 | 461,178,935 | 79,445 |
[
"kubernetes",
"kubernetes"
] | In some OS configurations, `/etc` is reset upon node reboots. It is conventional to record projects being used in `/etc/projects` and `/etc/projid` to allow actors on the node to avoid project id collisions, so losing information in `/etc` could potentially allow project id collisions to occur.
Currently, [Quotas f... | [Feature:FSQuota] Ensure projects are reflected in /etc on kubelet startup | https://api.github.com/repos/kubernetes/kubernetes/issues/79440/comments | 11 | 2019-06-26T18:25:23Z | 2020-01-28T08:56:40Z | https://github.com/kubernetes/kubernetes/issues/79440 | 461,117,204 | 79,440 |
[
"kubernetes",
"kubernetes"
] | **What happened**:
pv/pvc protection does make a lot of trouble and confusion and receive much of complaint, see
[#77258](https://github.com/kubernetes/kubernetes/issues/77258), [#69697](https://github.com/kubernetes/kubernetes/issues/69697). For much of case besides me, pv/pvc will always stuck in `Terminating ` sta... | How to disable/remove StorageObjectInUseProtection when declaring pv/pvc | https://api.github.com/repos/kubernetes/kubernetes/issues/79437/comments | 12 | 2019-06-26T17:41:48Z | 2019-07-16T13:54:02Z | https://github.com/kubernetes/kubernetes/issues/79437 | 461,099,405 | 79,437 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
InstanceShutd... | InstanceShutdownByProviderID should return true when instance is stopped or terminated in aws | https://api.github.com/repos/kubernetes/kubernetes/issues/79435/comments | 2 | 2019-06-26T16:53:46Z | 2019-08-06T06:11:21Z | https://github.com/kubernetes/kubernetes/issues/79435 | 461,080,170 | 79,435 |
[
"kubernetes",
"kubernetes"
] | I have k8's running on centos machine(local) with 2 worker nodes. I deployed pod with Jenkins running in it with nodeport service( so that we can access through web ). But, when I am accessing from browser it running in offline mode. I cannot install plugins in it
Can please someone help me on this ?
| Jenkins running offline on K8's Worker node | https://api.github.com/repos/kubernetes/kubernetes/issues/79434/comments | 3 | 2019-06-26T16:51:42Z | 2019-07-01T21:58:34Z | https://github.com/kubernetes/kubernetes/issues/79434 | 461,079,341 | 79,434 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
currently the fluentd-elasticsearch cluster addon creates two docker images that are hosted in non-kubernetes controlled repositories and the code to create them is hosted in k/k. either the code should ... | Move fluentd-elasticsearch out of k/k | https://api.github.com/repos/kubernetes/kubernetes/issues/79432/comments | 44 | 2019-06-26T16:34:33Z | 2022-04-14T23:37:20Z | https://github.com/kubernetes/kubernetes/issues/79432 | 461,072,247 | 79,432 |
[
"kubernetes",
"kubernetes"
] | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Refactor the framework integration test to make sure tests start on clean state.
**Why is this needed**:
Scheduling framework integration tests rely a lot on shared state, this state is reset in in an... | Refactor scheduling framework integration tests | https://api.github.com/repos/kubernetes/kubernetes/issues/79427/comments | 2 | 2019-06-26T15:54:57Z | 2019-06-27T01:51:33Z | https://github.com/kubernetes/kubernetes/issues/79427 | 461,054,019 | 79,427 |
[
"kubernetes",
"kubernetes"
] | <!-- Please use this template while reporting a bug and provide as much info as possible. Not doing so may result in your bug not being addressed in a timely manner. Thanks!
If the matter is security related, please disclose it privately via https://kubernetes.io/security/
-->
**What happened**:
When trying... | kubeadm v1.14.2 init failed to pull pause image when using cri and private registry ( seems to pull 2 times ..) | https://api.github.com/repos/kubernetes/kubernetes/issues/79422/comments | 7 | 2019-06-26T14:01:34Z | 2021-02-25T16:21:39Z | https://github.com/kubernetes/kubernetes/issues/79422 | 460,989,803 | 79,422 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.