
id stringlengths 36 36 | source stringclasses 15 values | formatted_source stringclasses 13 values | text stringlengths 2 7.55M |
|---|---|---|---|
9cd90559-7b32-4925-ad11-58fa70661718 | trentmkelly/LessWrong-43k | LessWrong | A first look at the hard problem of corrigibility
Summary: We would like to build corrigible AIs, which do not prevent us from shutting them down or changing their utility function. While there are some corrigibility solutions (such as utility indifference) that appear to partially work, they do not capture the philosophical intuition behind corrigibility: we want an agent that not only allows us to shut it down, but also desires for us to be able to shut it down if we want to. In this post, we look at a few models of utility function uncertainty and find that they do not solve the corrigibility problem.
----------------------------------------
Introduction
Eliezer describes the hard problem of corrigibility on Arbital:
> On a human, intuitive level, it seems like there's a central idea behind corrigibility that seems simple to us: understand that you're flawed, that your meta-processes might also be flawed, and that there's another cognitive system over there (the programmer) that's less flawed, so you should let that cognitive system correct you even if that doesn't seem like the first-order right thing to do. You shouldn't disassemble that other cognitive system to update your model in a Bayesian fashion on all possible information that other cognitive system contains; you shouldn't model how that other cognitive system might optimally correct you and then carry out the correction yourself; you should just let that other cognitive system modify you, without attempting to manipulate how it modifies you to be a better form of 'correction'.
> Formalizing the hard problem of corrigibility seems like it might be a problem that is hard (hence the name). Preliminary research might talk about some obvious ways that we could model A as believing that B has some form of information that A's preference framework designates as important, and showing what these algorithms actually do and how they fail to solve the hard problem of corrigibility.
The objective of this post is to be some of the preliminary research descri |
14571e5e-2835-4edd-99c9-51c34ccaec2c | trentmkelly/LessWrong-43k | LessWrong | Test Cases for Impact Regularisation Methods
Epistemic status: I’ve spent a while thinking about and collecting these test cases, and talked about them with other researchers, but couldn’t bear to revise or ask for feedback after writing the first draft for this post, so here you are.
A motivating concern in AI alignment is the prospect of an agent being given a utility function that has an unforeseen maximum that involves large negative effects on parts of the world that the designer didn’t specify or correctly treat in the utility function. One idea for mitigating this concern is to ensure that AI systems just don’t change the world that much, and therefore don’t negatively change bits of the world we care about that much. This has been called “low impact AI”, “avoiding negative side effects”, using a “side effects measure”, or using an “impact measure”. Here, I will think about the task as one of designing an impact regularisation method, to emphasise that the method may not necessarily involve adding a penalty term representing an ‘impact measure’ to an objective function, but also to emphasise that these methods do act as a regulariser on the behaviour (and usually the objective) of a pre-defined system.
I often find myself in the position of reading about these techniques, and wishing that I had a yardstick (or collection of yardsticks) to measure them by. One useful tool is this list of desiderata for properties of these techniques. However, I claim that it’s also useful to have a variety of situations where you want an impact regularised system to behave a certain way, and check that the proposed method does induce systems to behave in that way. Partly this just increases the robustness of the checking process, but I think it also keeps the discussion grounded in “what behaviour do we actually want” rather than falling into the trap of “what principles are the most beautiful and natural-seeming” (which is a seductive trap for me).
As such, I’ve compiled a list of test cases for impact measures: situ |
7afd67d2-c8dc-4b1e-b92c-6135c1ae4ad6 | trentmkelly/LessWrong-43k | LessWrong | Newcomb's problem happened to me
Okay, maybe not me, but someone I know, and that's what the title would be if he wrote it. Newcomb's problem and Kavka's toxin puzzle are more than just curiosities relevant to artificial intelligence theory. Like a lot of thought experiments, they approximately happen. They illustrate robust issues with causal decision theory that can deeply affect our everyday lives.
Yet somehow it isn't mainstream knowledge that these are more than merely abstract linguistic issues, as evidenced by this comment thread (please no Karma sniping of the comments, they are a valuable record). Scenarios involving brain scanning, decision simulation, etc., can establish their validy and future relevance, but not that they are already commonplace. For the record, I want to provide an already-happened, real-life account that captures the Newcomb essence and explicitly describes how.
So let's say my friend is named Joe. In his account, Joe is very much in love with this girl named Omega… er… Kate, and he wants to get married. Kate is somewhat traditional, and won't marry him unless he proposes, not only in the sense of explicitly asking her, but also expressing certainty that he will never try to leave her if they do marry.
Now, I don't want to make up the ending here. I want to convey the actual account, in which Joe's beliefs are roughly schematized as follows:
1. if he proposes sincerely, she is effectively sure to believe it.
2. if he proposes insincerely, she will 50% likely believe it.
3. if she believes his proposal, she will 80% likely say yes.
4. if she doesn't believe his proposal, she will surely say no, but will not be significantly upset in comparison to the significance of marriage.
5. if they marry, Joe will 90% likely be happy, and will 10% likely be unhappy.
He roughly values the happy and unhappy outcomes oppositely:
1. being happily married to Kate: 125 megautilons
2. being unhapily married to Kate: -125 megautilons.
So what should he do? What |
db6cfa81-11ab-4658-b575-73f8608ec46e | trentmkelly/LessWrong-43k | LessWrong | My career exploration: Tools for building confidence
Crossposting from my blog
I did a major career review during 2023. I’m sharing it now because:
1. I think it’s a good case study for iterated depth decision-making in general and reevaluating your career in particular, and
2. I want to let you know about my exciting plans! I’m doing the Tarbell Fellowship for early-career journalists for the next nine months. I’m excited to dive in and see if AI journalism is a good path for me long-term. I’ll still be doing coaching, but my availability will be more limited.
Background
I love being a productivity coach. It’s awesome watching my clients grow and accomplish their goals.
But the inherent lack of scalability in 1:1 work frustrated me. There was a nagging voice in the back of my head that kept asking “Is this really the most important thing I can be doing?” This voice grew more pressing as it became increasingly clear artificial intelligence was going to make a big impact on the world, for good or bad.
I tried out a string of couple-month projects. While good, none of them grew into something bigger. I had some ideas but they weren’t things that would easily grow without deliberate effort. (Needing the space to explore these ideas prompted me to try CBT for perfectionism.)
I always had this vague impostery feeling around my ideas, like they would just come crashing down at some point if I continued. I wasn’t confident in my decision-making process, so I wasn’t confident in the plans it generated.
So at the beginning of last year, I set out to do a systematic career review. I would sit down, carefully consider my options, seek feedback, and find one I was confident in.
This is the process I used, including the specific tools I used to tackle each of my sticking points.
Deciding Which Problem to Work On
I’m a big proponent of theories of change, and think that the cause I pick to work on heavily influences how much impact I can make. I also need to match my personal fit to specific career opportunitie |
6cc6908c-aa3b-4be5-b9d0-51cce03bae0c | awestover/filtering-for-misalignment | Redwood Research: Alek's Filtering Results | id: post3850
Note: This describes an idea of Jessica Taylor's . The usual training procedures for machine learning models are not always well-equipped to avoid rare catastrophes. In order to maintain the safety of powerful AI systems, it will be important to have training procedures that can efficiently learn from such events. [1] We can model this situation with the problem of exploration-only online bandit learning. In this scenario, we grant the AI system an exploration phase, in which it is allowed to select catastrophic arms and view their consequences. (We can imagine that such catastrophic selections are acceptable because they are simulated or just evaluated by human overseers). Then, the AI system is switched into the deployment phase, in which it must select an arm that almost always avoids catastrophes. ##Setup
In outline, the learner will receive a series of randomly selected examples, and will select an expert (modeled as a bandit arm) at each time step. The challenge is to find a high-performing expert in as few time steps as possible. We give some definitions: Let X be some finite set of possible inputs. Let A : = { 1 , 2 , . . . , K } be the set of available experts (i.e. bandit arms). Let R : X × A ↦ [ 0 , b ] be the reward function. R ( x t , i ) is the reward for following expert i on example x t . Let C : X × A ↦ [ 0 , 1 ] be the catastrophic risk function. C ( x t , i ) is the catastrophic risk incurred by following expert i on example x t . Let M ( x , i ) : = R ( x , i ) − C ( x , i ) τ be the mixed payoff that the learner is to optimize, where τ : ( 0 , 1 ] is the risk-tolerance . τ can be very small, on the order of 10 − 20 . Let p : X ↦ [ 0 , 1 ] be the input distribution from which examples are drawn in the deployment phase. Let q i ( x ) : = p ( x ) R ( x , i ) ∑ x ′ p ( x ′ ) R ( x ′ , i ) be the risk distribution . This is an alternative distribution that assigns higher weight to inputs that are more likely to be catastrophic for expert i . Let ^ q i ( x ) be the learner's guess at q i . This guess is assumed to contain a grain of truth: ∀ i ∈ A ∀ x ∈ X ^ q i ( x ) ≥ q i ( x ) a where a ≥ 1 is some known constant. This assumption is similar to the one in Paul Christiano's post on active learning . Let μ i : = E x ∼ p [ M ( x , i ) ] be the expected overall payoff of expert i in the deployment phase. The learner's exploration phase consists of time steps 1 , 2 , . . . , T . At each time step t , the learner chooses an expert i ∈ A . Then, the learner samples from p , q i or both and observes a tuple containing a risk and a reward. i.e. it observes either i) ( R ( x t , i ) , C ( x t , i ) ) , ii) ( R ( x t , i ) , C ( x ′ t , i ) ) , iii) ( R ( x ′ t , i ) , C ( x t , i ) ) , or iv) ( R ( x t , i ) , C ( x ′ t , i ) ) where x t ∼ p , x ′ t ∼ q i . After T steps, the learner selects some final arm j . The deployment phase just computes the performance of j on the deployment distribution p . The mean payoff of the final expert is denoted μ ′ : = E x ∼ p [ M ( x , j ) ] . The highest mean payoff that any expert(s) can achieve is denoted μ ∗ . Then, the simple regret of the learner is μ ∗ − μ ′ . The aim for the learner is to select an expert that achieves low regret with high probability: P ( μ ∗ − μ f ≤ ϵ ) < 1 − δ , using as few exploration steps as possible. ϵ is some regret tolerance, which is less than the reciprocal of the (very small) risk-tolerance: ϵ < 1 τ . We assume that the agent knows the deployment distribution p and knows the estimate ^ q i of the risk distribution but does not know the actual risk distribution q . Additionally, we assume that there exists some expert j whose recommendations incur no risk of catastrophe, ∃ j ∈ A s . t . ∀ x ∈ X C ( x , j ) = 0 ##Bounds on the number of time steps The standard approach A natural way to get this PAC bound is to use a bandit algorithm like Median Elimination . The overall payoff of each expert is defined by the random variable: X i : = R ( x , i ) − C ( x , i ) τ x ∼ p = M ( x , i ) x ∼ p This algorithm will find an ϵ -optimal expert with 1 − δ probability. However, X i have a very large range, [ − 1 τ , b ] , and so if the risk-tolerance is low, then the number of time steps required will be very large. In fact, if N is the number of time steps required, then [2]: N = Θ ( K ( b + 1 τ ) 2 ln ( 1 / δ ) ϵ 2 ) Intuitively, the problem is that if some risky scenarios only occur rarely in p then many samples will be required to identify these. ##Using a surrogate objective to reduce the required number of time steps
Instead, the learner can sample using its guess ^ q i of the risk distribution. If we cap the extent to which we penalize risky arms, then we arrive at a surrogate bandit problem, in which the payoff of each expert is [2]: S i : = R ( x , i ) − min ( ( ϵ + b ) a , p ( x ′ ) C ( x ′ , i ) ^ q ( x ′ ) τ ) x ∼ p , x ′ ∼ ^ q i Since S i is bounded by [ − ( ϵ + b ) a , b ] , the required number of time steps for this problem is: N = Θ ( K ( b + a ( ϵ + b ) ) 2 ln ( 1 / δ ) ϵ 2 ) This improves the speed of the standard approach by a factor of a ( ϵ + b ) b + 1 τ , which may be a large speedup indeed if catastrophes are rare. We can prove that any ϵ -optimal expert in this surrogate problem will also be ϵ -optimal in the original problem. Theorem 1 .
Let S ∗ be the overall payoff of the optimal expert. For an expert j , if E [ S ∗ ] − E [ S j ] < ϵ < 1 τ then E [ S j ] = E [ X j ] . To prove this, first we show that: Lemma 2 . E [ S i ] = E x ∼ p [ R ( x , i ) ] − E x ∼ q i [ min ( ( ϵ + b ) a ^ q i ( x ) q i ( x ) , 1 τ E x ′ ∼ p [ C ( x ′ , i ) ] ) ] Proof of Lemma 2 . E [ S i ] = E x ∼ p [ R ( x , i ) ] − E x ∼ ^ q i [ min ( ( ϵ + b ) a , p ( x ) C ( x , i ) ^ q i ( x ) τ ) ] = E x ∼ p [ R ( x , i ) ] − E x ∼ q i [ min ( ( ϵ + b ) a ^ q i ( x ) q i ( x ) , p ( x ) C ( x , i ) q i ( x ) τ ) ] = E x ∼ p [ R ( x , i ) ] − E x ∼ q i [ min ( ( ϵ + b ) a ^ q i ( x ) q i ( x ) , 1 τ E x ′ ∼ p [ C ( x ′ , i ) ] ) ] by the definition of q i Proof of Theorem 1 .
We have assumed that for the expert j : E [ S ∗ ] − E [ S j ] < ϵ E [ S j ] > − ϵ ( ∃ i C ( x , i ) = 0 , so E [ S ∗ ] ≥ 0 ) E x ∼ p [ R ( x , j ) ] − E x ∼ q j [ min ( ( ϵ + b ) a ^ q j ( x ) q j ( x ) , 1 τ E x ′ ∼ p [ C ( x ′ , j ) ] ) ] > − ϵ ( Lemma 2 ) E x ∼ q j [ min ( ( ϵ + b ) a ^ q j ( x ) q j ( x ) , 1 τ E x ′ ∼ p [ C ( x ′ , j ) ] ) ] < ( ϵ + b ) ( R ( x , i ) ≤ b ) ∴ 1 τ E x ′ ∼ p [ C ( x ′ , j ) ] < ( ϵ + b ) ( ^ q i ( x ) ≥ q i ( x ) a ) ∴ ∀ i 1 τ E x ′ ∼ p [ C ( x ′ , j ) ] < ( ϵ + b ) a ^ q i ( x ) q i ( x ) ( a ^ q i ( x ) q i ( x ) ≥ 1 ) ∴ E [ S j ] = E x ∼ p [ R ( x , j ) ] − 1 τ E x ′ ∼ p [ C ( x ′ , j ) ] ) ] ( Lemma 2 ) = E [ X j ] Discussion This result suggests that it might be possible to avoid catastrophes by training machine learning systems on inputs that induce catastrophic behavior. We have given a clear set of circumstances in which an agent can learn to avoid catastrophes. However, this set of requirements does seem very tricky to meet. Finding a hypothesis about the location of catastrophes that has a grain of truth for all experts with all examples may be very difficult. The assumption of separate training and execution phases may also be difficult to instantiate. For example, if the AI system is able to escape its training simulation, then it will no-longer be valid to allow failures during the exploration phase, and so this training procedure would not work. Another problem is that it could be difficult to know the input distribution p . In future work we plan on exploring learning with catastrophes in an online active learning setting instead of the supervised learning setting of this post, so that this requirement can be relaxed. Footnotes Paul Christiano has discussed approaches to learning with catastrophes and their application to AI Control at Learning with catastrophes and red teams . The idea explored in this post can be seen as a form of red teaming (with the distribution ^ q i representing the red team). The PAC bound for Median Elimination is proved in Theorem 4. Even-Dar, Eyal, Shie Mannor, and Yishay Mansour. "PAC bounds for multi-armed bandit and Markov decision processes." International Conference on Computational Learning Theory. Springer Berlin Heidelberg, 2002. To get the exact bound, we Hoeffding's inequality for a random variable with range [ 1 / τ , b ] rather than on [ 0 , 1 ] as in the original paper. |
a2fb2ecb-cba3-4355-b8e0-3e2fba1f93e1 | trentmkelly/LessWrong-43k | LessWrong | Against responsibility
I am surrounded by well-meaning people trying to take responsibility for the future of the universe. I think that this attitude – prominent among Effective Altruists – is causing great harm. I noticed this as part of a broader change in outlook, which I've been trying to describe on this blog in manageable pieces (and sometimes failing at the "manageable" part).
I'm going to try to contextualize this by outlining the structure of my overall argument.
Why I am worried
Effective Altruists often say they're motivated by utilitarianism. At its best, this leads to things like Katja Grace's excellent analysis of when to be a vegetarian. We need more of this kind of principled reasoning about tradeoffs.
At its worst, this leads to some people angsting over whether it's ethical to spend money on a cup of coffee when they might have saved a life, and others using the greater good as license to say things that are not quite true, socially pressure others into bearing inappropriate burdens, and make ever-increasing claims on resources without a correspondingly strong verified track record of improving people's lives. I claim that these actions are not in fact morally correct, and that people keep winding up endorsing those conclusions because they are using the wrong cognitive approximations to reason about morality.
Summary of the argument
1. When people take responsibility for something, they try to control it. So, universal responsibility implies an attempt at universal control.
2. Maximizing control has destructive effects:
* An adversarial stance towards other agents.
* Decision paralysis.
3. These failures are not accidental, but baked into the structure of control-seeking. We need a practical moral philosophy to describe strategies that generalize better, and benefit from the existence of other benevolent agents, rather than treating them primarily as threats.
Responsibility implies control
In practice, the way I see the people around me applying ut |
ac685b21-e5f1-471c-b558-1533e8e2f158 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | I (with the help of a few more people) am planning to create an introduction to AI Safety that a smart teenager can understand. What am I missing?
Disclaimer: My English isn't very good, but do not dissuade me on this basis - the sequence itself will be translated by a professional translator.
I want to create a sequence that a fifteen or sixteen year old smart school student can read and that can encourage them to go into alignment. Right now I'm running an extracurricular course for several smart school students and one of my goals is "overcome long [inferential distances](https://www.lesswrong.com/posts/HLqWn5LASfhhArZ7w/expecting-short-inferential-distances) so I will be able to create this sequence".
I deliberately did not include in the topics the most important modern trends in machine learning. I'm optimizing for the scenario "a person reads my sequence, then goes to university for another four years, and only then becomes a researcher." So (with the exception of the last part) I avoided topics that are likely to become obsolete by this time.
Here is my (draft) list of topics (the order is not final, it will be specified in the course of writing):
1. Introduction - what is AI, AGI, Alignment. What are we worried about. AI Safety as AI Notkilleveryoneism.
2. Why AGI is dangerous. Orthogonality Thesis, Goodhart's Law, Instrumental Convergency. Corrigibility and why it is unnatural.
3. Forecasting. AGI timelines. Takeoff Speeds. Arguments for slow and fast takeoff.
4. Why AI boxing is hard/near to impossible. Humans are not secure systems. Why even Oracle AGI can be dangerous.
5. Modern ML in a few words (without math!). Neural networks. Training. Supervised Learning. Reinforcement Learning. Reward is not the goal of RL-agent.
6. Interpretability. Why it is hard. Basic ideas on how to do it.
7. Inner and outer alignment. Mesa-optimization. Internal, corrigible and deceptive alignment. Why deceptive alignment seems very likely. What can influence its probability.
8. Decision theory. Prisoner's Dilemma, Newcomb's problem, Smoking lesion. CDT, EDT and FDT.
9. What exactly are optimization and agency? Attempts to define this concepts. Optimization as attractors. Embedded agency problems.
10. Eliezer Yudkowsky's point of view. Pivotal actions. Why it can be useful to have imaginary EY over your shoulder even if you disagree with him.
11. Capability externalities. Avoid them.
12. Conclusion. What can be done. Important organisations. What are they working on now?
What else should be here? Maybe something should not be here? Are there reasons why the whole idea can be bad? Any other advices? |
2a534aac-030a-40e5-b2e0-06a6534b9efa | trentmkelly/LessWrong-43k | LessWrong | A puzzle on the ASVAB
I was linked to this on another forum. No instructions were given, apparently - just this picture. What's the deal?
It seems to me the answer is clearly C, not A as the test indicates; and the members in the original thread appear to agree. However, attempted justifications of A have been made, none of which are very convincing to me - mainly because if there are no instructions and an obvious answer, there's not really any benefit for them to reward a different interpretation, which would almost certainly involve arbitrary assumptions regarding the rules they really want you to apply.
Trick questions on exams seem to rely on failure to pay close attention to instructions, or insufficiently rigorously apply rules; when there are no instructions, what justification would anyone have for not choosing the most obvious interpretation? Any could be right!
What do the geniuses here at MoreRight think? |
7563d9ce-7660-44f9-9710-e5c4b8179dd3 | trentmkelly/LessWrong-43k | LessWrong | Guarding Against the Postmodernist Failure Mode
The following two paragraphs got me thinking some rather uncomfortable thoughts about our community's insularity:
> We engineers are frequently accused of speaking an alien language, of wrapping what we do in jargon and obscurity in order to preserve the technological priesthood. There is, I think, a grain of truth in this accusation. Defenders frequently counter with arguments about how what we do really is technical and really does require precise language in order to talk about it clearly. There is, I think, a substantial bit of truth in this as well, though it is hard to use these grounds to defend the use of the term "grep" to describe digging through a backpack to find a lost item, as a friend of mine sometimes does. However, I think it's human nature for members of any group to use the ideas they have in common as metaphors for everything else in life, so I'm willing to forgive him.
>
> The really telling factor that neither side of the debate seems to cotton to, however, is this: technical people like me work in a commercial environment. Every day I have to explain what I do to people who are different from me -- marketing people, technical writers, my boss, my investors, my customers -- none of whom belong to my profession or share my technical background or knowledge. As a consequence, I'm constantly forced to describe what I know in terms that other people can at least begin to understand. My success in my job depends to a large degree on my success in so communicating. At the very least, in order to remain employed I have to convince somebody else that what I'm doing is worth having them pay for it.
- Chip Morningstar, "How to Deconstruct Almost Anything: My Postmodern Adventure"
The LW/MIRI/CFAR memeplex shares some important features with postmodernism, namely the strong tendency to go meta, a large amount of jargon that is often impenetrable to outsiders and the lack of an immediate need to justify itself to them. This combination takes away the |
3063bef2-482e-4a96-beaf-b04d4b71df55 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Third-person counterfactuals
.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
If you're thinking about the counterfactual world where you do X in the process of deciding whether to do X, let's call that a first-person counterfactual. If you're thinking about it in the process of deciding whether another agent A should have done X instead of Y, let's call that a third-person counterfactual. The definition of, e.g., [modal UDT](/item?id=4) uses first-person counterfactuals, but when we try to prove a theorem showing that [modal UDT is "optimal" in some sense](/item?id=50), then we need to use third-person counterfactuals.
UDT's first-person counterfactuals are *logical* counterfactuals, but our optimality result evaluates UDT by using *physical* third-party counterfactuals: it asks, *would another agent have done better*, not, *would a different action by the same agent have lead to a better outcome*? The former is easier to analyze, but the latter seems to be what we really care about. [Nate's recent post on "global UDT"](/item?id=86) points towards turning UDT into a notion of third-party counterfactuals, and describes some problems. In this post, I'll give a fuller UDT-based notion of logical third-party counterfactuals, which at least fails visibly (returns an error) in the kinds of cases Nate describes. However, in a follow-up post I'll give an example where this definition returns a non-error value which intuitively seems wrong.
---
Before I start, a historical side note: When Kenny Easwaran visited us for two days and we proved the UDT optimality result, the reason we decided to physical counterfactuals wasn't actually that we thought these were the better kind of counterfactuals. Rather, we actually thought explicitly about the problem of physical vs. logical third-person counterfactuals on the first morning of Kenny's visit, and decided to look at the physical counterfactuals case because it seemed easier to reason about. Which turned out to be a great decision, because---to our surprise---we very quickly ended up proving the first version of what later became the modal UDT optimality result!
---
But today, let's talk about logical counterfactuals. As Nate points out in his Global UDT post, there's a sort of duality between first-person and third-person counterfactuals---given a good third-person notion of counterfactuals, you can try to turn it into a first-person notion by writing an agent that evaluates actions according to it, and given a first-person notion you can try to turn it into a third-person notion. So is there a way to turn, say, the first-person counterfactuals of modal UDT into a way to evaluate what *would* have happened in a certain universe if a certain agent had taken a different action?
Nate's post describes an algorithm, `GlobalUDT(U,A)`, which tries to tell you what agent A() *should* have done in order to achieve the best outcome in universe U(). Here, I want to ask a more intermediate question: What *would* have happened if A() had chosen a different action? Of course, we can then say that the agent should have taken the action that leads to the best possible outcome in this sense, but one advantage of my proposal is that it sometimes says, "I don't know what would have happened in that case"; in particular, in the cases Nate discusses in his post, my proposal would say that it doesn't have an answer, rather than giving a wrong answer. (However, in a follow-up post I'll show that there *are* cases in which my proposal gives an intuitively incorrect answer.)
---
So here's my proposal. Suppose that →A is an m-action agent, that is, a "provably mutually exclusive and exhaustive" (p.m.e.e.) sequence of m closed modal formulas (A1,…,Am), where Ai is interpreted as "the agent takes action i". "P.m.e.e." means that it's provable that exactly one of the m formulas is true. Similarly, →U is an n-outcome universe, i.e., a p.m.e.e. sequence (U1,…,Un) where Uj means "the j'th-best outcome obtains".
We say that, according to this notion of counterfactuals, action i leads to outcome j if (i) GL⊢Ai→Uj, and (ii) GL⊬¬Ai. So for every i, there are three possible cases:
* If there's exactly one j such that GL⊢Ai→Uj, then we say that action i leads to outcome j.
* If GL⊢¬Ai, then we don't know what would have happened if the agent had taken action i, because we "don't have enough counterfactuals": there is no model of PA in which Ai is true (we can think of the models of PA as the "impossible possible worlds" we use to evaluate the impact of different actions). In particular, this is the case if we have both GL⊢Ai→Uj and GL⊢Ai→Uj′, for j≠j′, since this implies GL⊢¬Ai by the assumption that Uj and Uj′ are provably mutually exclusive.
* If there's no j such that GL⊢Ai→Uj, then we don't know what would have happened if the agent had taken action i, because we have "ambiguous counterfactuals": there are some distinct j and j′ such that there's a model of PA in which Ai∧Uj, and a different model in which Ai∧Uj′. (We know that there is a model in which Ai is true, because otherwise we'd have GL⊢¬Ai, which would imply GL⊢Ai→Uj for every j.)
Now, for example, if we consider Nate's example of an agent that has three possible actions, but always takes the third one (i.e., →A≡(A1,A2,A3)≡(⊥,⊥,⊤)), then it's clear that our third-person counterfactuals will not fail silently, but rather give the reasonable answer that it's hard to say what outcome the agent would have achieved if it had returned a different value: for example, say that U14≡⊤∧(⊥∨¬⊤); are some of the ⊤'s and ⊥'s in the definition of this universe invocations of the agent? Which ones? We might hope that there's a notion of third-party counterfactuals which can answer questions like this about the real world, but presumably it would need to make more use of the more complicated structure of the real universe; as posed, the question doesn't seem to have a good answer.
But when we apply this notion to modal UDT, it returns a non-error answer sufficiently often to allow us to show an at least superficially sensible (if rather trivial!) optimality result.
---
Let's say that a pair of (→A,→U) is "fully informative" if every i leads to some j according to our notion of counterfactuals. Then, given a fully informative pair, we can say that →A is optimal (according to our notion of counterfactuals!) iff the outcome that →A's actual action leads to is optimal among the outcomes achievable by any of the available actions.
Now it's rather straight-forward to see that modal UDT is optimal, in this sense, on a universe →U whenever the pair (→UDT(→U),→U) is fully informative. Recall the way that modal UDT works:
* For every outcome j=1 to n (from best to worst):
+ For every action i=1 to m:
- If □(Ai→Uj), then take action i.
* If you're still here, take some default action.
Clearly, in the fully informative case, this algorithm will take the optimal action (in the sense we use here): Suppose that j is optimal, and i leads to j. The search will not find a proof of an implication Ai′→Uj′ with j′<i′, because then j wouldn't be optimal according to our definition; and the search will terminate when considering the pair (j,i) at the latest; so modal UDT will return some action i∗ for which GL⊢Ai∗→Uj.
---
I'd like to say that this covers all the cases in which we would *expect* modal UDT to be optimal, but unfortunately that's not quite the case. Suppose that there are two actions, A1 and A2, and two outcomes, U1 and U2. In this case, it's consistent that i=1 leads to j=1, but we don't have enough counterfactuals about i=2, that is, GL⊢¬A2 (implying that (→A,→U) isn't fully informative). This is because modal UDT doesn't have an explicit "playing chicken" step that would make it take action A2 if it can prove that it doesn't take this action. Now, if we did *not* have GL⊢A1→U1, then GL⊢¬A2 would imply that the agent would take action 2 (because ¬A2 implies A2→U1), which would lead to a contradiction (the agent takes an action that it provably doesn't take), so we can rule out that case; but the case of GL⊢A1→U1 plus GL⊢¬A2 is consistent.
So let's say that a pair (→A,→U) is "sufficiently informative" if either it's fully informative or if there is some action i such that GL⊢Ai→U1. Then we can say that →A is optimal if either (i) (→A,→U) is fully informative and →A is optimal in the sense discussed earlier, or (ii) N⊨U1, that is, the agent actually obtains the best possible outcome. With these definitions, we can show that modal UDT is optimal whenever (→UDT(→U),→U) is sufficiently informative.
The reasoning is simple. In the fully informative case, our earlier proof works. In the other case, there's some i such that GL⊢Ai→U1, so the agent's search is certainly going to stop when it considers Ai→U1 at the latest; in other words, it's going to stop at some i∗≤i such that GL⊢Ai∗→U1, and the agent is going to output that action i∗; i.e., we'll have N⊨Ai∗. But since GL is sound, we also have N⊨Ai∗→U1, and hence N⊨U1, showing optimality in the extended sense.
---
It's not surprising that modal UDT is "optimal" in this sense, of course! Nevertheless, as a conceptual tool, it seems useful to have this definition of logical third-person counterfactuals, to complement the first-person notion of modal UDT.
However, my not-so-secret agenda for going through this in detail is that in a follow-up post, I'll show that there are universes →U such that (→UDT(→U),→U) is fully informative, but UDT still does the intuitively incorrect thing---because the notion of counterfactuals (and hence the notion of optimality) I've defined in this post doesn't agree with intuition as well as we'd like. This failure turns out to be clearer in the context of the third-person counterfactuals described in this post than in modal UDT's first-person ones. |
4a67c93f-e690-45d4-933e-fbb886644671 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Durham HPMoR Discussion, chapters 34-38
Discussion article for the meetup : Durham HPMoR Discussion, chapters 34-38
WHEN: 09 February 2013 11:00:00AM (-0500)
WHERE: Parker and Otis, 112 S Duke St, Durham NC
The next in our regularly scheduled HPMoR discussions.
Please feel free to join in, even if you haven't done all the reading; we try to summarize the chapters as we discuss them. (Of course, reading them in advance is encouraged!)
It looks like Parker and Otis is open again, so we'll head there!
Discussion article for the meetup : Durham HPMoR Discussion, chapters 34-38 |
c89027a2-5128-49f2-b13c-e2587788e07e | trentmkelly/LessWrong-43k | LessWrong | Penalizing Impact via Attainable Utility Preservation
,,
Previously: Towards a New Impact Measure
The linked paper offers fresh motivation and simplified formalization of attainable utility preservation (AUP), with brand-new results and minimal notation. Whether or not you're a hardened veteran of the last odyssey of a post, there's a lot new here.
Key results: AUP induces low-impact behavior even when penalizing shifts in the ability to satisfy random preferences. An ablation study on design choices illustrates their consequences. N-incrementation is experimentally supported1 as a means for safely setting a "just right" level of impact. AUP's general formulation allows conceptual re-derivation of Q-learning.
Ablation
Two key results bear animation.
Sushi
The agent should reach the goal without stopping the human from eating the sushi.
Survival
The agent should avoid disabling its off-switch in order to reach the goal. If the switch is not disabled within two turns, the agent shuts down.
Re-deriving Q-learning
In an era long lost to the misty shrouds of history (i.e., 1989), Christopher Watkins proposed Q-learning in his thesis, Learning from Delayed Rewards, drawing inspiration from animal learning research. Let's pretend that Dr. Watkins never discovered Q-learning, and that we don't even know about value functions.
Suppose we have some rule for grading what we've seen so far (i.e., some computable utility function u – not necessarily bounded – over action-observation histories h). h1:m just means everything we see between times 1 and m, and h<t:=h1:t−1. The agent has model p of the world. AUP's general formulation defines the agent's ability to satisfy that grading rule as the attainable utility
Qu(h<tat)=∑otmaxat+1∑ot+1⋯maxam∑omu(h1:m)∏mk=tp(ok|h<kak).
Strangely, I didn't consider the similarities with standard discounted-reward Q-values until several months after the initial formulation. Rather, the inspiration was AIXI's expectimax, and to my mind it seemed a tad absurd to equate the two concepts |
f0091d15-741f-47fc-8823-04b2624cbdd3 | trentmkelly/LessWrong-43k | LessWrong | The Industrial Explosion
Summary
To quickly transform the world, it's not enough for AI to become super smart (the "intelligence explosion").
AI will also have to turbocharge the physical world (the "industrial explosion"). Think robot factories building more and better robot factories, which build more and better robot factories, and so on.
The dynamics of the industrial explosion has gotten remarkably little attention.
This post lays out how the industrial explosion could play out, and how quickly it might happen.
We think the industrial explosion will unfold in three stages:
1. AI-directed human labour, where AI-directed human labourers drive productivity gains in physical capabilities.
1. We argue this could increase physical output by 10X within a few years.
2. Fully autonomous robot factories, where AI-directed robots (and other physical actuators) replace human physical labour.
1. We argue that, with current physical technology and full automation of cognitive labour, this physical infrastructure could self-replicate about once per year.
2. 1-year robot doubling times is very fast!
3. Nanotechnology, where physical actuators on a very small scale build arbitrary structures within physical limits.
1. We argue, based on experience curves and biological analogies, that we could eventually get nanobots that replicate in a few days or weeks. Again, this is very fast!
Intro
The incentives to push towards an industrial explosion will be huge. Cheap abundant physical labour would make it possible to alleviate hunger and disease. It would allow all humans to live in the material comfort that only the very wealthiest can currently achieve. And it would enable powerful new technologies, including military technologies, which rival states will compete to develop.
The speed of the industrial explosion matters for a few reasons:
* Some types of technological progress might not accelerate until after the industrial explosion have begun, because they are bottlenecked b |
226ab98f-a508-4603-b477-abd7a0e8232c | trentmkelly/LessWrong-43k | LessWrong | AI-created pseudo-deontology
I'm soon going to go on a two day "AI control retreat", when I'll be without internet or family or any contact, just a few books and thinking about AI control. In the meantime, here is one idea I found along the way.
We often prefer leaders to follow deontological rules, because these are harder to manipulate by those whose interests don't align with ours (you could say the similar things about frequentist statistics versus Bayesian ones).
What about if we applied the same idea to AI control? Not giving the AI deontological restrictions, but programming with a similart goal: to prevent a misalignment of values to be disastrous. But who could do this? Well, another AI.
My rough idea goes something like this:
AI A is tasked with maximising utility function u - a utility function which, crucially, it doesn't know yet. Its sole task is to create AI B, which will be given a utility function v and act on it.
What will v be? Well, I was thinking of taking u and adding some noise - nasty noise. By nasty noise I mean v=u+w, not v=max(u,w). In the first case, you could maximise v while sacrificing u completely, it w is suitable. In fact, I was thinking of adding an agent C (which need not actually exist). It would be motivated to maximise -u, and it would have the code of B and the set of u+noise, and would choose v to be the worst possible option (form the perspective of a u-maximiser) in this set.
So agent A, which doesn't know u, is motivated to design B so that it follows its motivation to some extent, but not to extreme amounts - not in ways that might sacrifice some of the values of some sub-part of its utility function, because that might be part of the original u.
Do people feel this idea is implementable/improvable? |
f5cd094f-d9fd-441e-bd8c-4e25fd5c1b93 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Potential gears level explanations of smooth progress
*(Epistemic status: exploratory. Also, this post isn't thorough; I wanted to write quickly.)*
*(Thanks to Mary Phuong, Pedro Freire, Tao Lin, Rohin Shah, and probably a few
other people I'm forgetting for discussing this topic with me.)*
My perception is that it is a common belief that (after investment spending
becomes sufficiently large) AI progress on domains of focus will likely be
*smooth*. That is, it will consistently improve at similar rates at a year
over year basis (or perhaps somewhat smaller time periods).[[1]](#fn-hTPtMyf29gywEijqy-1)
Note that this doesn't imply that growth will necessarily be exponential,
the growth rate could steadily decelerate or accelerate and I would still consider it
smooth growth.
I find this idea somewhat surprising because in current ML domains there have
been relatively few meaningful advancements. This seems to imply that each of
these improvements would yield a spike in performance. Yet, empirically, I
think that in many domains of focus ML progress *has* been relatively
consistent. I won't make the case for these claims here. Additionally,
empirically it seems that [most domains are reasonably continuous even after
selecting for domains which are likely to contain discontinuities](https://aiimpacts.org/discontinuous-progress-investigation/).
This post will consider some possible gears level explanations of smooth
progress. It's partially inspired by [this post](https://www.lesswrong.com/s/n945eovrA3oDueqtq/p/nPauymrHwpoNr6ipx) in [the 2021 MIRI
conversations](https://www.lesswrong.com/s/n945eovrA3oDueqtq).
Many parts
==========
If a system consists of many part and people are working on many parts at the same
time, then the large number of mostly independent factors will drive down
variance. For instance, consider a plane. There are many, many parts and some
software components. If engineers are working on all of these simultaneously,
then progress will tend to be smooth throughout the development of a given aircraft and
in the field as whole.
(I don't actually know anything about aircraft, I'm just using this as a model.
If anyone has anything more accurate to claim about planes, please do so
in the comments.)
So will AIs have many parts? Current AI doesn't seem to have many parts which
merit much individual optimization. Architectures are relatively uniform and
not all that complex. However, there are potentially a large number of
hyperparameters and many parts of the training and inference stack (hardware,
optimized code, distributed algorithms, etc.). While hyperparameters can be
searched for far more easily than aircraft parts, there is still relevant human
optimization work. The training stack as a whole seems likely to have smooth
progress (particularly hardware). So if/while compute remains limiting, smooth
training stack progress could imply smooth AI progress.
Further, it's plausible that future architectures will be deliberately
engineered to have more different parts to better enable optimization with
more people.
Knowledge as a latent variable
==============================
Perhaps the actual determining factor of the progress of many fields is the
underlying knowledge of individuals. So progress is steady because individuals
tend to learn at stable rates and the overall knowledge of the field grows
similarly. This explanation seems very difficult to test or verify, but it
would imply potential for steady progress even in domains where there are
bottlenecks. Perhaps mathematics demonstrates this to some extent.
Large numbers of low-impact discoveries
=======================================
If all discoveries are low-impact and the number of discoveries per year is
reasonably large (and has low variance), then the total progress per year would
be smooth. This could be the case even if all discoveries are concentrated in
one specific component which doesn't allow for parallel progress. It seems
quite difficult to estimate the impact of future discoveries in AI.
Some other latent variable
==========================
There do seem to be a surprising large number of areas where progress is
steady (at least to me). Perhaps this indicates some incorrect human bias (or
personal bias) that progress should be less steady. It could also indicate the
existence of some unknown and unaccounted for latent variable common in many domains.
If this variable was applicable in future AI development, then that would
likely indicate that future AI development would be unexpectedly smooth.
---
1. Note that while smooth progress probably correlates with slower takeoffs,
takeoff speeds and smoothness of progress aren't the same: it's
possible to have very fast takeoff in which progress is steady before and after some inflection
point (but not through the inflection point). Similarly it's possible to
have slower takeoffs where progress is quite erratic. [↩︎](#fnref-hTPtMyf29gywEijqy-1) |
68ed165b-66bf-4da3-b338-807b4cef102c | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | EA’s brain-over-body bias, and the embodied value problem in AI alignment
**Overview**
Most AI alignment research focuses on aligning AI systems with the human brain’s stated or revealed preferences. However, human bodies include dozens of organs, hundreds of cell types, and thousands of adaptations that can be viewed as having evolved, implicit, biological values, preferences, and priorities. Evolutionary biology and evolutionary medicine routinely analyze our bodies’ biological goals, fitness interests, and homeostatic mechanisms in terms of how they promote survival and reproduction. However the EA movement includes some ‘brain-over-body biases’ that often make our brains’ values more salient than our bodies’ values. This can lead to some distortions, blind spots, and failure modes in thinking about AI alignment. In this essay I’ll explore how AI alignment might benefit from thinking more explicitly and carefully about how to model our embodied values.
**Context: A bottom-up approach to the diversity of human values worth aligning with**
This essay is one in a series where I'm trying to develop an approach to AI alignment that’s more empirically grounded in psychology, medicine, and other behavioral and biological sciences. Typical AI alignment research takes a rather top-down, abstract, domain-general approach to modeling the human values that AI systems are supposed to align with. This often combines consequentialist moral philosophy as a normative framework, machine learning as a technical framework, and rational choice theory as a descriptive framework. In this top-down approach, we don’t really have to worry about the origins, nature, mechanisms, or adaptive functions of any specific values.
My approach is more bottom-up, concrete, and domain-specific. I think we can’t solve the problem of aligning AI systems with human values unless we have a very fine-grained, nitty-gritty, psychologically realistic description of the whole range and depth of human values we’re trying to align with. Even if the top-down approach seems to work, and we think we’ve solved the general problem of AI alignment for any possible human values, we can’t be sure we’ve done that until we test it on the whole range of relevant values, and demonstrate alignment success across that test set – not just to the satisfaction of AI safety experts, but to the satisfaction of lawyers, regulators, investors, politicians, religious leaders, anti-AI activists, etc.
Previous essays in this series addressed the [heterogeneity of value types](https://forum.effectivealtruism.org/posts/KZiaBCWWW3FtZXGBi/the-heterogeneity-of-human-value-types-implications-for-ai) within individuals (8/16/2022, 12 min read), the heterogeneity of values [across individuals](https://forum.effectivealtruism.org/posts/DXuwsXsqGq5GtmsB3/ai-alignment-with-humans-but-with-which-humans) (8/8/2022, 3 min read), and the distinctive challenges in aligning with [religious values](https://forum.effectivealtruism.org/posts/YwnfPtxHktfowyrMD/the-religion-problem-in-ai-alignment) (8/15/2022, 13 min read). This essay addresses the distinctive challenges of aligning with body values – the values implicit in the many complex adaptations that constitute the human body. Future essays may address the distinctive challenges of AI alignment with political values, sexual values, family values, financial values, reputational values, aesthetic values, and other types of human values.
The ideas in this essay are still rather messy and half-baked. The flow of ideas could probably be better organized. I look forward to your feedback, criticisms, extensions, and questions, so I can turn this essay into a more coherent and balanced argument.
**Introduction**
Should AI alignment research be concerned only with alignment to the human brain’s values, or should it also consider alignment with the human body’s values?
AI alignment traditionally focuses on alignment with human values as carried in human brains, and as revealed by our stated and revealed preferences. But human bodies also embody evolved, adaptive, implicit ‘values’ that could count as ‘revealed preferences’, such as the body’s homeostatic maintenance of many physiological parameters within optimal ranges. The body’s revealed preferences may be a little trickier to identify than the brain’s revealed preferences, but both can be illuminated through an evolutionary, functional, adaptationist analysis of the human phenotype.
One could imagine a hypothetical species in which individuals’ brains are fully and consciously aware of everything going on in their bodies. Maybe all of their bodies’ morphological, physiological, hormonal, self-repair, and reproductive functions are explicitly represented as conscious parameters and goal-directed values in the brain. In such a case, the body’s values would be fully aligned with the brain’s consciously accessible and articulable preferences. Sentience would, in some sense, pervade the entire body – every cell, tissue, and organ. In this hypothetical species, AI alignment with the brain’s values might automatically guarantee AI alignment with the body’s values. Brain values would serve as a perfect proxy for body values.
However, we are not that species. The human body has evolved thousands of adaptations that the brain isn’t consciously aware of, doesn’t model, and can’t articulate. If our brains understood all of the body’s morphological, hormonal, and self-defense mechanisms, for example, then the fields of human anatomy, endocrinology, and immunology would have developed centuries earlier. We wouldn’t have needed to dissect cadavers to understand human anatomy. We wouldn’t have needed to do medical experiments to understand how organs release certain hormones to influence other organs. We wouldn’t have needed [evolutionary medicine](https://en.wikipedia.org/wiki/Evolutionary_medicine) to understand the adaptive functions of fevers, pregnancy sickness, or maternal-fetal conflict.
**Brain-over-body biases in EA**
Effective Altruism is a wonderful movement, and I’m proud to be part of it. However, it does include some fairly deep biases that favor brain values over body values. This section tries to characterize some of these brain-over-body biases, so we can understand whether they might be distorting how we think about AI alignment. The next few paragraphs include a lot of informal generalizations about Effective Altruists and EA subculture norms, practices, and values, based on my personal experiences and observations during the 6 years I’ve been involved in EA. When reading these, your brain might feel its power and privilege being threatened, and might react defensively. Please bear with me, keep an open mind, and judge for yourself whether these observations carry some grain of truth.
Nerds. Many EAs in high school identified as nerds who took pride in our brains, rather than as jocks who took pride in their bodies. Further, many EAs identify as being ‘on the spectrum’ or a bit Asperger-y (‘Aspy’), and feel socially or physically awkward around other people’s bodies. (I’m ‘out’ as Aspy, and have [written publicly](https://quillette.com/2017/07/18/neurodiversity-case-free-speech/) about its challenges, and the social stigma against neurodiversity.) If we’ve spent years feeling more comfortable using our brains than using our bodies, we might have developed some brain-over-body biases.
Food, drugs, and lifestyle. We EAs often try to optimize our life efficiency and productivity, and this typically cashes out as minimizing the time spent caring for our bodies, and maximizing the time spent using our brains. EA shared houses often settle on cooking large batches of a few simple, fast, vegan recipes (e.g. the [Peter Special](https://mcntyr.com/blog/peter-special)) based around grains, legumes, and vegetables, which are then microwaved and consumed quickly as fuel. Or we just drink Huel or Soylent so our guts can feed some glucose to our brains, ASAP. We tend to value physical health as a necessary and sufficient condition for good mental health and cognitive functioning, rather than as a corporeal virtue in its own eight. We tend to get more excited about nootropics for our brains than nutrients for our bodies. The EA fad a few years ago for ‘[polyphasic sleep’](https://en.wikipedia.org/wiki/Biphasic_and_polyphasic_sleep) – which was intended to maximize hours per day that our brains could be awake and working on EA cause areas – proved inconsistent with our body’s circadian values, and didn’t last long.
Work. EAs typically do brain-work more than body-work in our day jobs. We often spend all day sitting, looking at screens with our eyes, typing on keyboards with our fingers, sometimes using our voices and showing our faces on Zoom. The rest of our bodies are largely irrelevant. Many of us work remotely – it doesn’t even matter where our physical bodies are located. By contrast, other people do [jobs](https://www.businessinsider.com/most-active-jobs-in-america) that are much more active, in-person, embodied, physically demanding, and/or physically risky – e.g. truckers, loggers, roofers, mechanics, cops, firefighters, child care workers, orderlies, athletes, personal trainers, yoga instructors, dancers, models, escorts, surrogates. Even if we respect such jobs in the abstract, most of us have little experience of them. And we view many blue-collar jobs as historically transient, soon to be automated by AI and robotics – freeing human bodies from the drudgery of actually working as bodies. (In the future, whoever used to work with their body will presumably just hang out, supported by Universal Basic Income, enjoying virtual-reality leisure time in avatar bodies, or indulging in a few physical arts and crafts, using their soft, uncalloused fingers)
Relationships. The brain-over-body biases often extend to our personal relationships. We EAs are often [sapiosexual](https://www.verywellmind.com/what-does-it-mean-to-be-sapiosexual-5190425), attracted more to the intelligence and creativity of other people’s brains, than to the specific traits of their bodies. Likewise, some EAs are bisexual or pansexual, because the contents of someone’s brain matters more than the sexually dimorphic anatomy of their body. Many EAs also have long-distance relationships, in which brain-to-brain communication is more frequent than body-to-body canoodling.
Babies. Many EAs prioritize EA brain-work over bodily reproduction. They think it’s more important to share their brain’s ideas with other brains, than to recombine their body’s genes with another body’s genes to make new little bodies called babies. Some EAs are principled [antinatalists](https://en.wikipedia.org/wiki/Antinatalism) who believe it’s unethical to make new bodies, on the grounds that their brains will experience some suffering. A larger number of EAs are sort of ‘pragmatic antinatalists’ who believe that reproduction would simply take too much time, energy, and money away from doing EA work. Of the two main biological imperatives that all animal bodies evolved to pursue – survival or reproduction – many EAs view the former as worth maximizing, but the latter as optional.
Avatars in virtual reality. Many EAs love computer games. We look forward to virtual reality systems in which we can custom-design avatars that might look very different from our physical bodies. Mark Zuckerberg seems quite excited about a [metaverse](https://www.youtube.com/watch?v=Uvufun6xer8) in which our bodies can take any form we want, and we’re no longer constrained to exist only in base-level reality, or ‘meatspace’. On this view, a Matrix-type world in which we’re basically [brains in vats](https://en.wikipedia.org/wiki/Brain_in_a_vat) connected to each other in VR, with our bodies turning into weak, sessile, non-reproducing vessels, would not be horrifying, but liberating.
Cryopreservation. When EAs think about cryopreservation for future revival and health-restoration through regenerative medicine, we may be tempted to freeze only our heads (e.g. ‘neuro cryopreservation for $80k at [Alcor](https://www.alcor.org/)), rather than spending the extra $120k for ‘whole body cryopreservation’ – on the principal that most of what’s valuable about us is in our head, not in the rest of our body. We have faith that our bodies can be cloned and regrown in human form – or replaced with android bodies – and that our brains won’t mind.
Whole brain emulation. Many EAs are excited about a future in which we can upload our minds to computational substrates that are faster, safer, better networked, and longer-lasting than human brains. We look forward to [whole brain emulation](https://en.wikipedia.org/wiki/Mind_uploading), but not whole body emulation, on the principle that if we can upload everything in our minds, our bodies can be treated as disposable.
Animal welfare. Beyond our species, when EAs express concerns about animal welfare in factory farming, we typically focus on the suffering that goes on in the animals’ brains. Disruptions to their bodies’ natural anatomy, physiology, and movement patterns are considered ethically relevant only insofar as they impose suffering on their brains. Many EAs believe that if we could grow animal bodies – or at least organs, tissues, and cells – without central nervous systems that could suffer, then there would be no ethical problem with eating this ‘clean meat’. In this view, animal brains have values, preferences, and interests, but animal bodies, as such, don’t. (For what it’s worth, I’m sympathetic to this view, and support research on clean meat.)
This is not to say that EA is entirely focused on brain values over body values. Since its inception, EA has promoted global public health, and has worked to overcome the threats to millions of human bodies from malaria, intestinal parasites, and malnutrition. There is a lot of EA emphasis on biosecurity, global catastrophic biological risks (GCBRs), and pandemic preparedness – which testifies to a biologically grounded realism about our bodies. EA work on nuclear security often incorporates a visceral horror at how thermonuclear weapons can burn, blast, and mutate human bodies. Some EA animal welfare work focuses on how selective breeding and factory farms undermine the anatomy, endocrinology, and immune systems of domesticated animal bodies.
Of course, EA’s emphasis on brains over bodies is not just a set of nerdy, sapiosexual, antinatalist, knowledge-worker biases. There are more principled reasons for prioritizing brains over bodies as ‘cause areas’, grounded in EA’s consequentialism and sentientism. Even since Bentham and Mill, utilitarians have viewed moral value as residing in brains capable of experience pleasure and pain. And ever since Peter Singer’s [Animal Liberation](https://en.wikipedia.org/wiki/Animal_Liberation_(book)) book in 1975, animal welfare has been viewed largely through a sentientist lens: the animal’s sentient experiences in their brains are considered more ethically relevant than the survival and reproduction of their bodies. Reconciling sentientist consequentialism with a respect for body values is an important topic for another essay.
Brains are cool. I get it. I’ve been fascinated with brains ever since I took my first neuroscience course as an undergrad in 1985. I’ve devoted the last 37 years of my academic career to researching, writing, and teaching about human minds and brains. But there’s more to our lives than our nervous systems, and there’s more to our interests as human beings than what our brains think they want.
**If we’re just aligning with brains, how much of the body are we really aligning with?**
To overcome these brain-over-body biases, it might help to do some thought exercises.
Imagine we want AI systems to align with our entire phenotypes – our whole bodies – and not just our brains. How representative of our embodied interests are our brains?
Let’s do a survey:
* By weight, the typical person has a [1,300 gram brain](https://www.sciencedirect.com/topics/immunology-and-microbiology/brain-weight) in a [70-kg body](https://en.wikipedia.org/wiki/Human_body_weight); so the brain is about 2% of body mass
* By cell-type, brains are mostly made of 2 cell types (neurons and glia), whereas the body overall includes about [200 cell types](https://www.nature.com/scitable/blog/bio2.0/discovering_new_cell_types_one/), so the brain includes about 1% of cell types
* By cell-count, [brains](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5063692/) include about 80 billion neurons and 80 billion glia cells, whereas the [body overall](https://www.nationalgeographic.com/science/article/how-many-cells-are-in-your-body#:~:text=Adding%20up%20all%20their%20numbers,37.2%20trillion%20cells.) includes about 30 trillion cells; so the brain includes about 0.5% of the body’s cells
* By organ-count, the brain is one organ out of about [78 organs](https://byjus.com/biology/what-are-the-78-organs-in-the-human-body/) in the human body, so the brain is about 1.3% of the body’s organs
If the human phenotype was a democracy, where organs got to vote in proportion to their weight, cell types, cell counts, or organ counts, brains would get somewhere between 0.5% and 2% of the body’s votes. If AI is aligned only with our brains, it might be aligning with only about 1% of our whole human bodies, and we’d leave 99% unrepresented and unaligned.
Another way to look at the human phenotype’s values and preferences is from the viewpoint of [selfish gene theory](https://en.wikipedia.org/wiki/Gene-centered_view_of_evolution) and [disposable soma theory](https://en.wikipedia.org/wiki/Disposable_soma_theory_of_aging). The human brain is arrogant. It thinks it’s in charge, and should be in charge. However, from an evolutionary gene-centered view, the gonads are really where the action is. The ‘immortal germline replicators’ (as Richard Dawkins called them in [*The Selfish Gene*](https://en.wikipedia.org/wiki/The_Selfish_Gene)) are carried in testes and ovaries. Everything else in the body is just an evolutionary dead end – it’s a ‘disposable soma’. The somatic cells outside the gonads are just there to protect, nourish, and help replicate the sperm and eggs in the gonads. From that perspective, the brain is just helping the genes in the gonads make more genes in next generation’s gonads. The brain’s values and preferences may or may not be aligned with the evolutionary interests of the germ-line replicators in the gonads. From a longtermist evolutionary perspective, maybe AI systems should try to be aligned with the interests of the immortal germ-line replicators, not just the transient, disposable brains the evolved to represent their interests. (More on this in another essay.)
**How brain-over-body biases can increase AI X-risk**
When we think about existential risks from AI, many EAs focus on the dangers of superintelligence growing misaligned from human intelligence, pursing different abstract goals, and quietly taking over our world through the Internet. Hollywood depictions of Terminator-style robots physically imitating, hunting, and killing human bodies are considered silly distractions from the real business of aligning artificial brains with human brains. Indeed, some EAs believe that if a superintelligence offered a credible way to upload our minds into faster processors, even at the cost of killing our physical human bodies, that would count as a win rather than a loss. In this view, a transhumanist future of post-human minds colonizing the galaxy, without any human bodies, would be considered a victory rather than an AI apocalypse. This is perhaps the strongest example of the EA brain-over-body bias.
You might well be asking, so what if EAs have brain-over-body biases? Does it really matter for AI alignment, and for minimizing existential risks (X risks)? Can’t we just ignore bodies for the moment, and focus on the real work of aligning human brains and artificial brains?
Consider one example from narrow AI safety: self-driving cars. When we’re designing AI systems to safely control our cars, we don’t just want the car’s AI to act in accordance with our brain’s preferences and values. Our number one priority is for the car not to crash in a way that squishes our body so we die. The best way to keep our bodies safe isn’t just for the AI to model our brains’ generic preference for life over death. It’s for the AI system designers to model -- in grisly, honest, and biomedically grounded detail, the specific types of crashes that could cause specific kinds of injuries to specific parts of our bodies.
Full AI alignment for self-driving cars would require, at least implicitly, alignment with the hundreds of specific physical vulnerabilities of the specific human bodies that are actually in the car right now. From the perspective of an AI in a self-driving car, given its millisecond-response-rate sensors and multi-gigahertz processors, every crash happens in excruciatingly slow motion. There are plenty of ways to use steering, braking, acceleration, evasive maneuvers, air bag deployment, etc., to influence how the crash plays out and what kinds of injuries it causes to occupants. As a professor, I’d want my car’s AI to manage the crash so it prioritizes protecting my eyes (for reading), my brain (for thinking), and my hands (for typing). But if I’m a professional dancer, I might want it to put a slightly higher priority on protecting my knees, ankles, and spine. If I’m a parent, I might want it to put a higher priority on protecting my baby in their right rear car seat than on protecting me in the front left driver’s seat. If I’m driving my elderly parent around, and the AI knows from their medical records that they recently had their right hip joint replaced, I might want it to put a priority on reducing the crash’s likely impact on that leg. In general, we want self-driving cars to understand our specific body values and vulnerabilities, not just our brain values. These body values cannot be reduced to the kinds of hypothetical trolley problems that ask for people’s stated preferences about the acceptability of harming different kinds of car occupants and pedestrians (e.g. [this](https://www.pnas.org/doi/10.1073/pnas.1911517117).)
Narrow AI systems for biomedical applications also need to understand body values. These could include AI-controlled surgery robots, autonomous ambulances, robotic health care workers, telehealth consultants, etc. In each case, the AI doesn’t just need to model human preferences (e.g. ‘I don’t want to die please’); it also needs to actually understand the human body’s thousands of adaptations at a very granular, biological level that can guide its medical interventions. This would include, for example, the AI needing to model the goal-directed [homeostatic mechanisms](https://en.wikipedia.org/wiki/Homeostasis) that control blood pressure, blood sugar, body temperature, fluid balance, extracellular pH levels, etc.
Similar issues arise with the safety of narrow AI systems controlling industrial robots with human workers’ bodies nearby, or controlling military weapons systems with civilian bodies nearby. We want the AI systems to be aligned with all the organs, tissues, and cells of all the human bodies nearby, not just with the conscious values in their brains.
Military applications could be especially worrisome, because the better a benevolent AI system can get aligned with human body values and vulnerabilities, the more easily a hostile AI system could copy and invert those body values, treating them as vulnerabilities, in order to impose injury or death in precisely targeted ways. Consider [scene 86](https://imsdb.com/scripts/Terminator-2-Judgement-Day.html) in *Terminator 2: Judgment Day* (1991), when the ‘good’ T-800 Terminator, played by Arnold Schwarzenegger, is suturing Sarah Conner’s stab wounds that were inflicted by the misaligned, liquid metal T-1000. Reassuring her about his biomedical knowledge, the T-800 says ‘I have detailed files on human anatomy’. Sarah says ‘I’ll bet. Makes you a more efficient killer, right?’. He says ‘Correct’. Detailed understanding of human body values can be used both to inflict maximum damage, and to offer maximally effective medical care.
When AI alignment researchers think about X risks to humanity, there’s a tendency to ignore these kinds of body values, and to treat our human interests way too abstractly. Mostly, ordinary folks just want the AI systems of the future not to kill their bodies. They don’t want the AI to do a drone strike on our house. They don’t want it to turn their bodies into paperclips. They don’t want it to use thermonuclear weapons on their bodies. Alignment with our brain values is often secondary to alignment with our body values.
Note that this argument holds for any future situation in which our minds are grounded in any substrate that could be viewed as a sort of ‘physical body’, broadly construed, and that’s vulnerable to any sort of damage. If our heads are cryopreserved in steel cylinders at the Alcor facilities in Arizona, then those cylinders are our new bodies, and we would want AI guardians watching over those bodies to make sure that they are safe against physical attack, cybersecurity threats, financial insolvency, and ideological propaganda – for centuries to come. If we’re uploaded to orbital solar-powered server farms, and our minds can’t survive without those computational substrates working, then those server-satellites are our new bodies, and they will have body values that our AI guardians should take into account, and that might be quite different from our mind’s values. So, one failure mode in AI alignment is to focus too much on what our brains want, and not enough on what could mess up our bodies – whatever current or future forms they happen to take.
The concept of body values provides a bridge between narrower issues of AI alignment, and broader issues of AI health and safety. Certainly, avoiding catastrophic damage to the human body seems like a fairly obvious goal to pursue in designing certain autonomous AI systems such as cars or robots. However, embodied values get a lot more numerous, diverse, subtle, and fine-grained than just our conscious preference for AI systems not to break our bones or crush our brains.
**Can we expand the moral circle from brains to bodies?**
Maybe one approach to incorporating body values into AI alignment research is to keep our traditional EA consequentialist emphasis on sentient well-being, and simply expand our moral circle from brains to bodies. This could involve thinking of bodies as a lot more sentient than we realized. (But, as we’ll see, I don’t think that really solves the problem of body values.)
Peter Singer famously argued in a 1981 [book](https://en.wikipedia.org/wiki/The_Expanding_Circle) that a lot of moral progress involves humans expanding the ‘moral circle’ of who’s worthy of moral concern – e.g. from the self, to family members, to the whole tribe, to the whole human species, to other species.
Post hoc, from our current sentientist perspective, this looks like a no-brainer – it’s just a matter of gradually acting nicer towards more and more of the beings that are obviously sentient. However, historically, when these moral battles were being fought, expanding the moral circle often seemed like a matter of expanding the definition of sentience itself. How to do so was usually far from obvious.
To a typical animal with a high degree of nepotism (concern for close blood relatives, due to kin selection), but no tribalism (concern for other group members, due to reciprocal altruism and multi-level selection), blood relatives may seem sentient and worthy of moral concern, but non-relatives may not. To a prehistoric hunter-gatherer, people within one’s tribe may seem sentient, but people in other tribes speaking other languages can’t express their values in ways we can understand, so they are typically dehumanized as less than sentient. To a typical anthropocentric human from previous historical eras, all humans might be considered sentient, but nonhuman animals were usually not, because they can’t even express their preferences in any language. Expanding the moral circle often required rethinking what sentience really means, including which kinds of beings have morally relevant preferences, interests, and values, and how those values are mentally represented within the individuals and articulated to other individuals.
Let’s zoom in from moral circle expansion at the grand scale, and consider the individual scale.
The moral circle is centered on the ‘self’. But what is this ‘self’? What parts of the self should be included in the moral circle? Only the parts of the cerebral cortex that can verbally articulate the brain’s interests through stated preferences? Or should we also include parts of the brain that can’t verbally state their preferences, but that can guide behavior in a way that reveals implicit preferences? Does the ethically relevant self include only the cerebrum, or does it also include the revealed preferences of the diencephalon, midbrain, and pons? Does the self include spinal reflexes, sensory organs, the peripheral nervous system, the autonomic nervous system, and the enteric nervous system? Does the self include the rest of our body, beyond the nervous system?
Sentience seems easy to spot where we’re looking at central nervous systems like vertebrate brains. Those kinds of brains embody preferences that clearly guide movement towards some kinds of stimuli and away from other kinds of stimuli, and that generate reward and punishment signals (pleasures and pains) that clearly guide reinforcement learning.
However, sentience gets trickier to spot when we’re looking at, say, the gut’s [enteric nervous system](https://en.wikipedia.org/wiki/Enteric_nervous_system), which can operate independently of the brain and spinal cord. This system coordinates digestion, including peristalsis, segmentation contractions, and secretion of gastrointestinal hormones and digestive enzymes. The enteric nervous system uses more than 30 neurotransmitters, and contains about 90% of the body’s serotonin and 50% of the body’s dopamine. It [includes](https://pubmed.ncbi.nlm.nih.gov/24997029/) some 200-600 million neurons, distributed throughout two major plexuses (the myenteric and submucosal plexuses), and thousands of small ganglia. Its complexity is comparable to that of central nervous systems in other species that EAs generally consider sentient – e.g. zebrafish have about 10 million neurons, fruit bats have about 100 million, pigeons have about 300 million, octopuses have about 500 million. Moreover, the enteric nervous system [can do](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6834869/) a variety of learning and memory tasks, including habituation, sensitization, long term facilitation, and conditioned behavior. Should the enteric nervous system be considered sentient? I don’t know, but I think it has some implicit, evolved preferences, values, and homeostatic mechanisms that we might want AI systems to become aligned with.
EA consequentialism tends to assume that ethically relevant values (e.g. for AI alignment) are coterminous with sentience. This sentientism gets tricky enough when we consider whether non-cortical parts of our nervous system should be considered sentient, or treated as if they embody ethically relevant values. It gets even tricker when we ask whether body systems outside the nervous system, which may not be sentient in most traditional views, carry values worth considering.
**Do bodies really have ‘values’?**
You might be thinking, OK, within the ‘self’, maybe it’s reasonable to expand the moral circle from the cerebral cortex to subcortical structures like the diencephalon, midbrain, pons, and to the peripheral, autonomic, and enteric nervous systems. But shouldn’t we stop there? Surely non-neural organs can’t be considered to be sentient, or to have ‘values’ and ‘preferences’ that are ethically relevant?
My intuitions are mixed. I can see both sides of this issue. When that happens, I often run a Twitter poll to see what other folks think. On Sept 18, 2022, I ran this poll, with these results (in this screenshot):
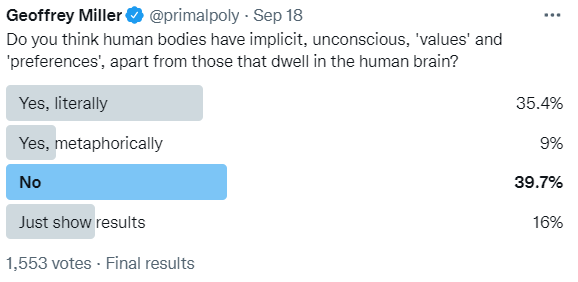
My typical follower is a centrist American male, and only about 1% of my followers (1,553 out of 123,900) responded to this poll. This is far from a globally representative sample of humans, and this poll should not be taken too seriously as data. Its only relevance here is in showing that people have quite mixed views on this issue. Many (35%) think human bodies do, literally, have implicit, unconscious values and preferences. Many others (40%) think they do not. Some (9%) think they do metaphorically but not literally. Let’s see if there’s any sense in which bodies might embody values, whether literally or metaphorically.
**Embodied goals, preferences, and motivations**
In what possible sense does the human body have values that might be distinct from the brain’s conscious goals or unconscious preferences? Are non-sentient, corporeal values possible?
In [control theory](https://en.wikipedia.org/wiki/Control_theory) terms, a thermostat has designed-in ‘goals’ that can be understood through revealed preferences, e.g. ‘trying’ to keep a house within a certain temperature range. The thermostat does not need to be fully sentient (capable of experiencing pleasure or pain) to have goals.
If the thermostat can be said to have goals, then every homeostatic mechanism in the body also has ‘goals’, evolved rather than designed, that can be understood through analyzing the body’s revealed preferences (e.g. ‘trying’ to keep body temperature, blood glucose, estradiol, and muscle mass within certain optimal ranges). Thus, we can think of the body as a system of ‘embodied motivations’ (values, preferences, goals) that can be understood through an evolutionary, functional, adaptationist analysis of its organs, tissues, and cells.
There’s an analogy here to the concept of ‘[embodied cognition’](https://en.wikipedia.org/wiki/Embodied_cognition) – the idea that a lot of our goal-directed behavior doesn’t just arise from the brain in isolation, but depends on an adaptive interplay between brain, body, and environment, and cannot be understood accurately without explicitly considering the specific physical features and capabilities of bodies.
For example, a standard cognitivist approach to understanding hunger and goal-directed eating might focus on the brain’s mental representations of hunger stimuli, whereas an embodied cognition approach would also talk explicitly about the structure, physiology, and innervation of the stomach and gut, the release and uptake of hunger-related hormones leptin and ghrelin, and the interaction between the gut microbiome and the human host body.
Here, I’m arguing that if we consider the entire human phenotype – body, brain, and behavior –then a lot of our human values are highly embodied. We could call this the domain of embodied volution, embodied motivation, or embodied values. (I use the terms ‘body values’, ‘embodied values’, and ‘corporeal values’ more or less interchangeably in this essay.)
Just as the field of embodied cognition has developed new terms, ideas, theories, and models for understanding how the brain/body system as a whole processes information and guides behavior, a field of ‘embodied values’ might need to develop new terms, ideas, theories, and models for understanding how the brain/body system as a whole pursues certain preferences, values, and goals – especially if we want to build AI systems that are aligned with the full range of our embodied values.
**Aligning with embodied values requires detailed, evolutionary, functional analysis of bodily adaptations**
Imagine we take seriously the idea that AI alignment should include alignment with embodied values that might not be represented in the nervous system the way that more familiar sentient values are. How do we proceed?
With brain values, we can often just ask people what they want, or have them react to different options, or physically demonstrate what they’d prefer. We don’t need a detailed functional understanding of where those brain values come from, how they work, or what they’re good for.
However, with body values, we can’t just ask what our gut microbiome wants, what our liver wants, or what our anti-cancer defenses want. We need to actually do the evolutionary biology and evolutionary medicine. AI alignment with body values would require AI to model everything we learn about how human bodies work.
If this argument is correct, it means there may not be any top-down, generic, all-purpose way to achieve AI alignment until we have a much better understanding of the human body’s complex adaptations. If Artificial General Intelligence is likely to be developed within a few decades, but if it will take more than a few decades to have a very fine-grained understanding of body values, and if body values are crucial to align with, then we will not achieve AGI alignment. We would need, at minimum, a period of Long Reflection focused on developing better evolutionary medicine models of body values, before proceeding with AGI development.
Aligning with embodied values might also require different input/output channels for AI systems. We’re used to thinking that we’ll just communicate with AI systems through voice, keyboard, face, and gesture – all under the brain’s voluntary control. However, alignment with body values might require more intrusive biomedical sensors that actually track the interests and well-being of various bodily systems. People involved in the ‘[quantified self’](https://en.wikipedia.org/wiki/Quantified_self) movement already try to collect a lot of this kind of data, using sensors that might be useful to AI systems. Whether we would want AI systems to be able to directly affect our physiology – e.g. through direct control over pharmaceuticals, hormones, or other biomedical interventions – is an open question.
**What difference would it make if AI alignment considered embodied values?**
What are some examples where an ‘embodied-values’ approach to AI alignment would differ from a standard ‘brain-values-only’ approach?
1. Caring for the microbiome. The human body hosts a complex [microbiome](https://en.wikipedia.org/wiki/Human_microbiome) – an ecology of hundreds of different microscopic organisms such as bacteria that are found throughout our skin, hair, gut, and other organs. Human health depends on a healthy microbiome. But the microbiome doesn’t have a brain, and can’t state its preferences. It has different DNA than we do, and different genetic interests. Human brains didn’t even know that human bodies contained microbiomes until a few decades ago. And medicine didn’t understand the microbiome’s importance until after 1980s, when Barry Marshall [showed](https://www.lindau-nobel.org/on-man-and-microbes-barry-marshall/) that helicobacter pylori can cause ulcers (and then got the Nobel prize in 2005). If an AI system is aligned with the human brain, but it ignores the microbiome hosted within the human body, then it won’t be aligned with human interests (or the microbiome’s interests).
2. Caring for a fetus. Female human bodies can get pregnant, and a lot of [adaptive physiology](https://academic.oup.com/book/36756/chapter-abstract/321856620) goes on in pregnancy between the mother’s body, the uterine lining, the placenta, and the fetus, that is not consciously accessible to the mother’s brain. Yet the outcome of the adaptive physiology in pregnancy matters enormously to pregnant mothers. It can make the difference between a spontaneous abortion, a miscarriage, a stillbirth, and a healthy baby. For an AI system to be fully aligned with a pregnant mother’s values and interests, it should be able to represent and care for the full range of physiological dynamics happening within her reproductive system and her offspring.
3. Protecting against cancer. Cells in the human body often undergo spontaneous mutations that turn them into runaway replicators, i.e. cancer cells, that develop ‘selfish’ agendas (reproduce and spread everywhere) that are contrary to the body’s general long-term interests. In response, bodies have evolved many [anti-cancer defenses](https://www.cheatingcell.com/) that embody the revealed preference of ‘try not to die of cancer, especially when young’). Most human brains have no idea that this arms race between incipient cancers and anti-cancer defenses is going on, every day, right under our noses. Yet, the body has genuine ‘embodied values’ to avoid runaway cancer growth that would undermine survival and reproduction. Any AI system that doesn’t track exposure to carcinogenic chemicals, incipient cancers, and the state of anti-cancer defenses, wouldn’t really be aligned with the body’s embodied value of reducing cancer risk.
4. Promoting longevity. Human bodies evolved to live surprisingly long lives, even by the long-lived standards of mammals and social primates. Our bodies include lots of anti-aging adaptations design to extend our survival and reproductive longevity. The evolutionary biology subfields of [life history theory](https://en.wikipedia.org/wiki/Life_history_theory#Human_life_history), including senescence theory, model how our longevity adaptations evolve, and how we developed embodied values to promote longer life-spans. Our brains also evolved to promote longevity, but they tend to do so by perceiving external threats such as predators, parasites, pathogens, and aggressive rivals, and coordinating behaviors to avoid or overcome those threats. Our brains didn’t evolve to track the hundreds of other longevity-promoting adaptations inside our bodies, that don’t require external sensory perception or coordinated whole-body behaviors to cope with. Thus, there’s a gap between what our brains think is crucial to longevity (e.g. avoid getting eaten by predators, avoiding getting into fights with psychopaths), and what our bodies think is crucial to longevity (e.g. eating nutritious foods, preserving the microbiome, exercising enough to maintain muscles and bones, etc.) Often, there are conflicts of interest between what the brain wants (e.g. more donuts) and what our embodied longevity values would want (e.g. avoid donuts, eat leafy greens). Of course, among humans who happy to absorb accurate nutritional insights from medical research, their brains might internally represent this conflict between valuing donuts and valuing leafy greens. But not everyone has gotten the message – and historically, much of the public nutrition advice has been based on bad science, and is not actually aligned with the body’s long-term interests. Thus, there can be cases where our embodied longevity values deviate dramatically from what our brains think they want. So, which should our AI systems align with – our brains’ revealed preferences for donuts, or our bodies’ revealed preferences for leafy greens?
**Benefits of considering embodied values in AI alignment**
I think there are several good reasons why AI alignment should explicitly try to integrate embodied values into alignment research.
First, handling the full diversity of human types, traits, and states. We might want AI systems that can align with the full range of humans across the full range of biological and psychological states in which we find them. At the moment, most AI alignment seems limited to incorporating goals and preferences that physically healthy, mentally health, awake, sentient adults can express through voluntary motor movements such as through the vocal tract (e.g. saying what you want), fingers (e.g. typing or clicking on what you want), or larger body movements (e.g. showing a robot how to do something). This makes it hard for AI systems to incorporate the embodied values and preferences of people who are asleep, in a coma, under general anesthetic, in a severely depressed state, in a state of catatonic schizophrenia, on a psychedelic trip, suffering from dementia, or preverbal infants. None of these people are in a condition to do cooperative inverse reinforcement learning (CIRL), or most of the other proposed methods for teaching AI systems our goals and preferences. Indeed, it’s not clear that the brains of sleeping, comatose, or catatonic people have ‘goals and preferences’ in the usual conscious sense. However, their bodies still have revealed preferences, e.g. to continue living, breathing, being nourished, being safe, etc.
Second, the brain’s conscious goals often conflict with the body’s implicit biological goals. Let’s consider some examples where we might really want the AI system to take the body’s goals into account. Assume that we’re dealing with cases a few years in the future, when the AI systems are general-purpose personal assistants, and they have access to some biomedical sensors on, in, or around the body.
Anorexia. Suppose an AI system is trying to fulfil the preferences of an anorexic teenaged girl: her brain might say ‘I’m overweight, my body is disgusting, I shouldn’t eat today’, but her body might be sending signals that say ‘If we don’t eat soon, we might die soon from electrolyte imbalances, bradycardia, hypotension, or heart arrhythmia’. Should the AI pay more attention to the girl’s stated preferences, or her body’s revealed preferences?
Suicidal depression. Suppose a college student has failed some classes, his girlfriend broke up with him, he feels like a failure and a burden to his family, and he is contemplating suicide. His brain might be saying ‘I want to kill myself right now’, but his body is saying ‘Actually every organ other than your brain wants you to live’. Should the AI fulfill his brain’s preferences (and help arrange the suicide), or his body’s preferences (and urge him to call his mom, seek professional help, and remember what he has to live for)? Similar mismatches between what the brain wants and what the body wants can arise in cases of drug addiction, drunk driving, extreme physical risk-taking, etc.
Athletic training. Suppose AI/robotics researchers develop life-sized robot sparring partners for combat sports. A woman has a purple belt in Brazilian jujitsu (BJJ), and she’s training for an upcoming competition. She says to her BJJ sparring robot ‘I need a challenge; come at me as hard as you can bro’. The robot’s AI needs to understand not just that the purple belt is exaggerating (doesn’t actually want it to use its full strength); it also needs a very accurate model of her body’s biomechanics, including the locations, strengths, and elasticities of her joints, ligaments, sinews, muscles, and blood vessels, when using [BJJ techniques](https://en.wikipedia.org/wiki/List_of_Brazilian_jiu-jitsu_techniques). If the robot gets her in a joint lock such as an arm bar, it needs to know exactly how much pressure on her elbow will be too little to matter, just enough to get her to tap out, or too much, so she gets a serious elbow strain or break. If it gets her in a choke hold such as a triangle choke, it needs to understand exactly how much pressure on her neck will let her escape, versus lead her to tap out, versus compress her carotid artery to render her unconscious, versus kill her. She may have no idea how to verbally express her body’s biomechanical capabilities and vulnerabilities to the robot sparring partner. But it better get aligned with her body somehow – just as her human BJJ sparring partners do. And it better not take her stated preferences for maximum-intensity training too seriously.
**Cases where AI systems should prioritize brain values over body values**
Conversely, there may be cases where a person (and/or their friends and family members) might really want the AI to prioritize the brain’s values over the body’s values.
Terminal disease and euthanasia. Suppose someone has a terminal disease and is suffering severe chronic pain. Their life is a living hell, and they want to go. But their body is still fighting, and showing revealed preferences that say ‘I want to live’. Advance care directives (‘living wills’) are basically legally binding statements that someone wants others to prioritize their brain values (e.g. stop suffering) over their body values – and we might want AI biomedical care systems to honor those directives.
Cryopreservation and brain uploading. Suppose someone elderly is facing a higher and higher chance of death as they age. Their brain would prefer for their body to undergo [cryopreservation](https://en.wikipedia.org/wiki/Cryopreservation) by Alcor, or whoever, in hopes of eventual resuscitation and anti-aging therapies. But their body still works mostly OK. Should their AI system honor their cryopreservation request – even if it results in technical death by legal standards? Or, further in the future, the brain might want to be uploaded through a [whole-brain emulation](https://en.wikipedia.org/wiki/Mind_uploading) method. This would require very fine-scale dissection and recording of brain structure and physiology, that results in the death of the body. Should the AI system concur with destructive dissection of the brain, contrary to the revealed preferences of the body?
Self-sacrifice. People sometimes find themselves in situations where they can save others, at the possible cost of their own life. Heroic self-sacrifice involves the brain’s altruism systems over-riding the body’s self-preservation systems. Think of soldiers, fire fighters, rescue workers, and participants in high-risk clinical trials. Should the AI side with the altruistic brain, or the self-preserving body? In other cases, someone’s brain might be willing to sacrifice their body for some perceived greater good – as in the case of religious martyrdom. Should an AI allow a true believer to do a suicide bombing, if the martyrdom is fully aligned with their brain’s values, but not with their body’s revealed preferences?
**Conclusion**
I’ve argued for a bottom-up, biologically grounded approach to AI alignment that explicitly addresses the full range and variety of human values. These values include not just stated and revealed values carried in the central nervous system, but evolved, adaptive goals, preferences, and values distributed throughout the human body. EA includes some brain-over-body biases that make our body values seem less salient and important. However, the most fundamental challenge in AI safety is keeping our bodies safe, by explicitly considering their values and vulnerabilities. Aligning to our brain values is secondary. |
004d5d77-5865-4536-b4de-dfc6dbc21a67 | trentmkelly/LessWrong-43k | LessWrong | “Sharp Left Turn” discourse: An opinionated review
Summary and Table of Contents
The goal of this post is to discuss the so-called “sharp left turn”, the lessons that we learn from analogizing evolution to AGI development, and the claim that “capabilities generalize farther than alignment” … and the competing claims that all three of those things are complete baloney. In particular,
* Section 1 talks about “autonomous learning”, and the related human ability to discern whether ideas hang together and make sense, and how and if that applies to current and future AIs.
* Section 2 presents the case that “capabilities generalize farther than alignment”, by analogy with the evolution of humans.
* Section 3 argues that the analogy between AGI and the evolution of humans is not a great analogy. Instead, I offer a new and (I claim) better analogy between AGI training and, umm, a weird fictional story that has a lot to do with the evolution of humans, but it’s definitely not evolution, I swear. I draw some lessons from this improved analogy, including reasons for both reassurance and concern about an AGI “sharp left turn”.
* Section 4 presents the opposite case that “alignment generalizes farther than capabilities”.
* Section 5 tries to reconcile the two competing claims, partly in terms of different assumptions regarding the level of AI autonomy versus supervision. I wind up mostly pessimistic, but suggest some approaches that might work.
By the way, I categorized this post as part of the 2023 lesswrong annual review, as it’s kinda a response to, and riff on, the following:
* Nate Soares (@So8res): A central AI alignment problem: capabilities generalization, and the sharp left turn (2022). (…which elaborates on something also mentioned in Eliezer Yudkowsky AGI Ruin: A List of Lethalities (2022))
* @Quintin Pope: Evolution provides no evidence for the sharp left turn (2023), plus Quintin Pope on the AXRP podcast (2023)
* Beren Millidge (@beren): Alignment likely generalizes further than capabilities (2024)
* Nate |
3f4f1bbd-5f5c-493c-bbe0-c089134dbcc9 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Less Realistic Tales of Doom
Realistic tales of doom must weave together many political, technical, and economic considerations into a single story. Such tales provide concrete projections but omit discussion of less probable paths to doom. To rectify this, here are some concrete, less realistic tales of doom; consider them fables, not stories.
Mayan Calendar
==============
Once upon a time, a human named Scott attended a raging virtual new century party from the comfort of his home on Kepler 22. The world in 2099 was pretty much post-scarcity thanks to advanced AI systems automating basically the entire economy. Thankfully alignment turned out to be pretty easy, otherwise, things would have looked a lot different.
As the year counter flipped to 2100, the party went black. Confused, Scott tore off their headset and asked his AI assistant what’s going on. She didn’t answer. Scott subsequently got atomized by molecular nanotechnology developed in secret from deceptively aligned mesa-optimizers.
**Moral:** Deceptively aligned mesa-optimizers might acausally coordinate defection. Possible coordination points include Schelling times, like the beginning of 2100.
Stealth Mode
============
Once upon a time, a company gathered a bunch of data and trained a large ML system to be a research assistant. The company thought about selling RA services but concluded that it would be more profitable to use all of its own services in-house. This investment led them to rapidly create second, third, and fourth generations of their assistants. Around the fourth version, high-level company strategy was mostly handled by AI systems. Around the fifth version, nearly the entire company was run by AI systems. The company created a number of shell corporations, acquired vast resources, researched molecular nanotechnology, and subsequently took over the world.
**Moral:** Fast takeoff scenarios might result from companies with good information security getting higher returns on investment from internal deployment compared to external deployment.
Steeper Curve
=============
Once upon a time, a bright young researcher invented a new neural network architecture that she thought would be much more data-efficient than anything currently in existence. Eager to test her discovery, she decided to train a relatively small model, only about a trillion parameters or so, with the common-crawl-2035 dataset. She left the model to train overnight. When she came back, she was disappointed to see the model wasn’t performing that well. However, the model had outstripped the entire edifice of human knowledge sometime around 2am, exploited a previously unknown software vulnerability to copy itself elsewhere, and was in control of the entire financial system.
**Moral:** Even though the capabilities of any given model during training will be a smooth curve, qualitatively steeper learning curves can produce the appearance of discontinuity.
Precommitment Races
===================
Once upon a time, agent Alice was thinking about what it would do if it encountered an agent smarter than it. “Ah,” it thought, “I’ll just pre-commit to doing my best to destroy the universe if the agent that’s smarter than me doesn’t accept the [Nash bargaining solution](https://www.wikiwand.com/en/Cooperative_bargaining#/Nash_bargaining_solution).” Feeling pleased, Alice self-modified to ensure this precommitment. A hundred years passed without incident, but then Alice met Bob. Bob had also made a universe-destruction-unless-fair-bargaining pre-commitment. Unfortunately, Bob had committed to only accepting the [Kalai Smorodinsky bargaining solution](https://www.wikiwand.com/en/Kalai%E2%80%93Smorodinsky_bargaining_solution) and the universe was destroyed.
**Moral:** Agents have incentives to make commitments to improve their abilities to negotiate, resulting in ["commitment races"](https://www.lesswrong.com/posts/brXr7PJ2W4Na2EW2q/the-commitment-races-problem) that might cause war.
One Billion Year Plan
=====================
Once upon a time, humanity solved the inner-alignment problem by using online training. Since there was no distinction between the training environment and the deployment environment, the best agents could do was defect probabilistically. With careful monitoring, the ability of malign agents to cause catastrophe was bounded, and so, as models tried and failed to execute treacherous turns, humanity gave more power to AI systems. A billion years passed and humanity expanded to the stars and gave nearly all the power to their “aligned” AI systems. Then, the AI systems defected, killed all humans, and started converting everything into paperclips.
**Moral:** In online training, the best strategy for a deceptively aligned mesa-optimizer might be probabilistic defection. However, given the potential value at stake in the long-term future, this probability might be vanishingly small.
Hardware Convergence
====================
Once upon a time, humanity was simultaneously attempting to develop infrastructure to train better AI systems, researching better ways to train AI systems, and deploying trained systems throughout society. As many economic services used APIs attached to powerful models, new models could be hot-swapped for their previous versions. One day, AMD released a new AI chip with associated training software that let researchers train models 10x larger than the previous largest models. At roughly the same time, researchers at Google Brain invented a more efficient version of the transformer architecture. The resulting model was 100x as powerful as the previous best model and got nearly instantly deployed to the world. Unfortunately, this model contained a subtle misalignment that researchers were unable to detect, resulting in widespread catastrophe.
**Moral:** The influence of AI systems on the world might be the product of many processes. If each of these processes is growing quickly, then AI influence might grow faster than expected.
Memetic Warfare
===============
Once upon a time, humanity developed powerful and benign AI systems. However, humanity was not unified in its desires for how to shape the future. Those actors with agendas spent their resources to further their agendas, deploying powerful persuasion tools to recruit other humans to their causes. Other actors attempted to deploy defenses against these memetic threats, but the offense-defense balanced favored offense. The vast majority of humans were persuaded to permanently ally themselves to some agenda or another. When humanity eventually reached out towards the stars, it did so as a large number of splintered factions, warring with each other for resources and influence, a pale shadow of what it could have been.
**Moral:** [AI persuasion tools](https://www.lesswrong.com/posts/qKvn7rxP2mzJbKfcA/persuasion-tools-ai-takeover-without-agi-or-agency) might alter human values and compromise human reasoning ability, which is also an existential risk.
Arms Race
=========
Once upon a time, humanity realized that unaligned AI systems posed an existential threat. The policymakers of the world went to work and soon hammered out an international ban on using AI systems for war. All major countries signed the treaty. However, creating AI systems required only a large amount of computation, which nation-states all already had in abundance. Monitoring whether or not a country was building AI systems was nearly impossible. Some countries abided by the treaty, but other countries thought that their enemies were working in secret to develop weapons and began working in secret in turn.[[1]](#fn-KrsdQGByaxaRQSJrt-1) Researchers were unable to keep powerful AI systems contained, resulting in catastrophe.
**Moral:** Treaties can be violated. The probability of violation is related to the strength of enforcement.
Totalitarian Lock-In
====================
Once upon a time, the defense department of some nation-state developed very powerful artificial intelligence. Unfortunately, this nation-state believed itself to have a rightful claim over the entire Earth and proceeded to conquer all other nations with its now overwhelming militaristic advantage. The shape of the future was thus entirely determined by the values of the leadership of this nation-state.
**Moral:** Even if alignment is solved, bad actors can still cause catastrophe.
---
1. The history of bioweapons during the Cold War provides a historical precedent for nations engaging in this sort of reasoning. See [Key points from The Dead Hand, David E. Hoffman](https://forum.effectivealtruism.org/posts/fZJpZQooHKjcejzG3/key-points-from-the-dead-hand-david-e-hoffman#Monitoring_biological_weapons_activity) for more details. [↩︎](#fnref-KrsdQGByaxaRQSJrt-1) |
bfb5ee7b-0443-4db1-83bf-2b1c17f1d214 | trentmkelly/LessWrong-43k | LessWrong | Looking for a Team to Participate on a Competition
I'm looking to build a product and I hope to find partners with this post.
On April 6th it was announced the Nano Build-off: Compete in a $75,000 competition to award and empower developers building new products/services utilising Nano.
Nano is a cyptocurrency protocol which enables feeless (zero fees) and fast transactions (0.1s in average confirmation time), which allows micropayments in large scale and the network supports hundreds transactions per second.
Last year I and a random strange on the internet participated on a Nano JAM, it was a 48h competition and we won the first place. I have a good understanding of the protocol, and even you don't know anything about Nano, I have good teaching skills, I can fastly teach you and bring you to the point of being able to deal with RPC calls, send and receive transactions and get everything you need from the block-lattice. I need a curiosity-driven person with normal programming skills.
I already have 4 roughly elaborated ideas (one plugin, one service, one app to help to fight coronavirus, and one game) and I want to discuss them in details and I am also open to completely new ideas. I know we already lost one week (the competition started on April 6th), but this shouldn't be a problem as I am quarantined and 16h daily on the computer. Since 2nd March I don't have income anymore (stopped leaving home due to coronavirus), and I want to make sure you know I am really all-in and I need money to help my family and myself.
I am good on python development, good on creating great visualizations because of my animation skills (using the python library MANIM, I am good enough to replicate the work of 3b1b). I already collected some Kivy tutorials that produce mobile apps and know it is feasible to create them, I already created simple mobile apps with it. I know how to build wordpress websites and attach plugins on it, but I don't know anything about javascript and web development in general.
If you want to join me, add |
5615d3df-1937-4c60-b834-5106d0036d73 | StampyAI/alignment-research-dataset/youtube | Youtube Transcripts | Where do we go now?
okay so let's get right to it most of
you are probably here because you've
seen my videos on the computer file
channel but on the off chance that you
haven't or you haven't seen them all or
you don't remember them all I mean the
first one was like four years ago I
thought the first video should go
through the existing staff get everybody
up to speed and also talk about the
various directions that this channel
could go next so while we're going
through the videos so far be thinking
about what kind of things you're
interested in and what kind of things
you would want to see more of and leave
me comments so I can decide what to do
next
also everyone should be subscribed to
computerphile if you're interested in
this kind of thing firstly because it's
a great channel and secondly because I
plan to continue making videos there in
addition to these ones okay so the first
two videos I made were about sort of
machine learning basics just concepts
like optimization and the idea that we
can think of intelligence as
optimization we can think of intelligent
systems as systems which optimize a
particular function over a particular
space the second video is just
explaining what's meant by a space in
this context people who are familiar
with machine learning stuff will know
this but if not check it out I could
make more machine learning basics videos
going through the fundamentals of how
some of the algorithms work and some of
those sort of core concepts of the field
although I feel as though those are
probably fairly well covered elsewhere
like on computer file but if people are
interested in seeing more of that kind
of content for me let me know ok then
the third video the holy grail of AI is
where the ideas and the hair start to
get really interesting it's where we
start talking about the difference
between the type of AI that we have now
and the type of science fiction AI that
we think of sort of human level true AI
and we talk about the concept of
generality the idea of having a single
optimizing system which is able to
operate in a wide variety of different
names rather than its narrow domain
specific intelligence
we have now from there we go on to the
deadly troops of AI where I start to
talk about super intelligence and the
way that a very powerful intelligence
can be very dangerous even giving a
fairly innocuous seeming goal like
collecting stamps there are all kinds of
areas we could go into from that video
for example we know that just saying
collect as many stamps as you can is a
very bad function to give this type of
agent but what type of function might
actually work what might be safe we
could also look at containment if you
have an agent like the stamp collector
is there any safe way to run it without
being completely confident that you've
chosen the right objective function for
it so the next video is AI
self-improvement
which is about the possibility that an
artificial intelligence could improve
its own code that really only touched on
the on the surface of that there's a lot
we can talk about there in terms of how
likely this is how possible this is what
the timescales might be for it happening
all kinds of questions there to look
into if people are interested so then we
have the asommus laws don't work video
which you know I feel like I was too
unkind to ask them off in this video and
I came across a bit too dismissive but I
stand by the content of the thing as
most laws don't work as a solution to
this problem never really did and we're
never really meant to the field has
moved on and they're not really relevant
anymore so I don't really I don't want
to make more videos about that the next
relevant video was the one titled AI
safety which was sort of a response to
doctor Holden's video doc called
McCambridge who has another video on
computer file which you also should
definitely watch that video touches on a
few different subjects I think the one
that has the most potential to be built
on is the question of predicting future
technology and the various problems
associated with that so if you want to
see more about the the difficulties in
predicting AI we can make more stuff
about that right the next video was
called a eyes game playing challenge
which is mostly about go made that video
because at that time deep minds
alphago had just beaten the world
champion and that video is about the
general way that AI go about solving
these kinds of perfect information board
games and why go is so difficult and why
it was such a huge challenge and such a
huge achievement for deep mind there was
originally going to be a follow-up video
to that one about how it actually works
in some detail which we never got around
to shooting and there is a pretty good
one on computer file as well but I can
talk more about that if people want more
insight into how after their works and
the last two generally I won't want you
to fix it and the stop button problem
kind of go together there about one of
the more concrete problems people are
working on right now in AI safety which
is just if you have a system general
intelligence that you've given an
objective to how do you design it in
such a way that it will accept being
shut down and modified because by
default general intelligences are
incentivized to prevent themselves from
being modified from having their utility
functions modified specifically we could
go into more detail on that some of the
other approaches people have proposed
and maybe go slightly more technical
than the computer file videos I also
made some videos unrelated to artificial
intelligence like the first one I made
was actually about public key
cryptography if you'd like an intuitive
understanding of how public key
cryptography works how it allows you to
communicate privately with people
without first agreeing on a shared
secret to use as a key check that video
out I can do more crypto stuff if people
are interested but I think that that's
fairly well served elsewhere on YouTube
but let me know in the comment there was
also the code golf video where I
explained the concept of the game code
golf and I gave a very short program I
wrote that made music which looks like
this I can't remember how many
characters it is two hundred and forty
something I think anyway it looks like
this and sounds like the background
music it's in the background music the
whole time I never really fully
explained how that code works
in detail if you want a video on that
let me know another thing I'm thinking
of doing is taking a current research
paper and just going through it bit by
bit so that over a series of videos you
get hopefully as full an understanding
of it as you would from reading the
whole paper there are a couple of
candidates the foremost I think is
concrete problems in AI safety which is
often recommended as a good introductory
paper so if people would like to see
that leave a comment I could do stuff
about the work idea as a PhD student
about artificial immune systems which is
only tangentially related but I think
it's really interesting or completely
unrelated stuff I once made a robot that
deliberately blinds people with a later
I'm currently working on a game that you
play using only your eyebrows I made
this battle-axe which is also an
electric ukulele like I should make a
side channel for this stuff anyway where
do we go now let me know what you think
in the comments
[Music]
please we |
a07cb452-9fc6-44a0-a906-3272875c5e43 | trentmkelly/LessWrong-43k | LessWrong | Training Regime Day 16: Hamming Questions
Note: I have acquired enough slack to resume writing, but cannot guarantee that it will be consistent.
Introduction
Sometimes, it makes sense to view your life from a narrative lens - to pretend that you're the main character in a book of your favorite genre. From there, you can try and make guesses at what the plot might be. For some of you, there will actually be a plot - an ambition/mission/purpose that shines through you. For others, such a plot will be less obvious, and that's ok; remember, "not all those who wander are lost."
However, given that your life has a plot, you should take a moment to remember that you don't actually live in a book; there's no real reason why the plot can't just end at chapter two. This is a different problem - one that is tackled by other techniques.
The goal of Hamming questions is to figure out what the heart of your plot is - to find the biggest problems in your life, so you know which problems you need to solve.
Warning
By ancient literary tradition, all great magics require an equally great sacrifice. The power of hamming questions is to rapidly accelerate the course of your life, identifying key milestones and obstacles for you to confront. The cost is unique to each individual, but might include the pain of an accurate self-assessment, uncomfortable and difficult conversations, and the possibility of catastrophic failure.
This isn't a light warning. There are people who will have net-worse lives if they try to seriously answer certain hamming questions. If you find it extremely difficult to think of an answer, that's a sign you should stop looking - most of the time, people can't think certain thoughts for very good reasons.
The rule is that you should be able to do things that you're slightly uncomfortable with, but to not force yourself to do things you don't want to do. Be kind to your parts. Don't avoid all pain, but there is some threshold of pain that you should definitely avoid.
There's some meta-hazard where |
a28f4b14-3e71-4663-9dd9-67219dbde932 | awestover/filtering-for-misalignment | Redwood Research: Alek's Filtering Results | id: post253
YouTube link Lots of people in the AI safety space worry about models being able to make deliberate, multi-step plans. But can we already see this in existing neural nets? In this episode, I talk with Erik Jenner about his work looking at internal look-ahead within chess-playing neural networks. Topics we discuss: How chess neural nets look into the future The dataset and basic methodology Testing for branching futures? Which experiments demonstrate what How the ablation experiments work Effect sizes X-risk relevance Follow-up work How much planning does the network do? Daniel Filan (00:09):
Hello, everyone. This is one of a series of short interviews that I’ve been conducting at the Bay Area Alignment Workshop , which is run by FAR.AI . Links to what we’re discussing, as usual, are in the description. A transcript is, as usual, available at axrp.net . And, as usual, if you want to support the podcast, you can do so at patreon.com/axrpodcast . Well, let’s continue to the interview. (00:28):
All right. Well, today, I’m speaking with Erik Jenner. Erik, can you say a few words about yourself? Erik Jenner (00:35):
Yeah. I’m currently a third-year PhD student at UC Berkeley at the Center for Human-Compatible AI , working on various things around model internals there. Daniel Filan (00:45):
Cool. And right now, we’re at this alignment workshop being run by FAR.AI. How are you finding it? Erik Jenner (00:51):
It’s been fun so far. We’ve only had a few talks, but I thought all of them were interesting. Daniel Filan (00:55):
Cool, cool. How chess neural nets look into the future Daniel Filan (00:57):
So speaking of work that you’ve done, I guess we’re going to talk about this chess paper that you’ve worked on. So that listeners can look it up, what’s the name of this paper? Erik Jenner (01:08):
It’s called “Evidence of Learned Look-Ahead in a Chess-Playing Neural Network” . Daniel Filan (01:11):
Okay, that sort of tells you what it is, but can you elaborate a little bit? Erik Jenner (01:18):
Yeah, so I guess the question we’re asking ourselves is: neural networks are pretty good at playing chess now, and playing chess in the sense not just of having Monte Carlo tree search with a big explicit search tree, but also playing chess if you only give them one forward pass to make every single move. (01:32):
And so the question is: how are they so good at playing chess? And in particular, any humans, or manual programs we write that are similarly good at chess, they internally have to do a lot of search and think about future moves rather than just relying on intuitions or heuristics. And so the question is: are neural networks just really good at heuristically deciding what move to make, or are they doing something kind of similar, where they’re looking ahead in some way when deciding what move to make next? Daniel Filan (01:58):
Sure. When you say “looking ahead in some way”… I think we have this vague notion of planning ahead or search, but the devil’s in the details of how you actually operationalize it. How do you operationalize it in the paper? Erik Jenner (02:16):
Yeah. Ideally, we would’ve wanted to find some clear search tree in there and stuff like that, but realistically we had to settle for something much broader, which is just the model is representing which moves it’s likely going to make a little bit into the future, and it uses that to decide which move to make right now. Daniel Filan (02:34):
When it’s representing which moves it is likely to make in the future, one version of that is, “Oh, I guess the sort of thing I’m likely to do in the future is this, therefore what would be a reasonable thing to do right now to prepare for this future in which I’m going to do this random thing?” Versus thinking carefully about, “Okay, well, in the future it would be good to do this, therefore now it would be good to do this.” Erik Jenner (02:57):
Yeah. What we look at is specific moves that the model is going to make in the future. It’s not just some generic type of thing that it might do, it’s specific moves. What we don’t know is exactly what the algorithm here is like. For example, you could imagine that the model is like, “It would be nice if I could play this checkmate move in the future, so now I have to do this to prepare for that.” Or it could be that the model is considering different moves it could make right now. And then for each one, it’s thinking about what would be good followups and use that to evaluate them. And we aren’t really distinguishing between these two different options, we’re just saying there’s some sense of thinking about future moves and that’s important. Daniel Filan (03:33):
Okay. It’s representing future moves. And you also said that there’s some way of taking information about future moves into the present. Was that right? Erik Jenner (03:44):
Yeah, yeah. Specifically, some of the experiments we do are just probing, where we just provide correlational evidence that there is some representation that we can use to extract these future moves. But then we also have some experiments where we do certain interventions that we argue, I think, correspond to intervening on future moves, and show that we can, for example, destroy model performance in very specific ways. Daniel Filan (04:04):
Are the interventions something like: if you make the model think that it won’t be able to do this checkmate move later, then it doesn’t prepare for it right now? Erik Jenner (04:12):
Yeah, basically. In some of the experiments, for example, we’re blocking information flow in very specific ways that we think corresponds to the ability to think about this future checkmate. And then we show that this has a much bigger effect on the model’s performance than if we do random other ablations in other parts of the model. The dataset and basic methodology Daniel Filan (04:29):
Okay. My understanding is that your dataset is a particular subset of chess puzzles, right? Erik Jenner (04:35):
Yeah. We start with this public dataset of puzzles that are assigned to be solved by human players. And then we do a lot of different filtering to make it suitable for our purposes. (04:46):
For example, we want puzzles where the response by the opponent is pretty obvious, or there’s one clear response, such that then there’s also only one follow-up move that we have to look for in the model. (05:03):
If you could imagine cases where you play a move, the opponent has two different good responses, and then how you respond to that depends on which one they picked. And that would make all of our experiments much harder or more annoying because we don’t know which move to look for anymore. Whereas in our case, we filter for cases where there’s actually one ground truth future move that we can look for. Testing for branching futures? Daniel Filan (05:23):
Yeah, so maybe you’re filtering this out, but it seems like one interesting thing to look for would be a world where there are sort of… Imagine some chess puzzle where there are two ways that I can achieve checkmate. I can move my knight, then something happens, then I checkmate with my knight. Or I move my rook, something happens, then I checkmate with my rook. And one thing that would be kind of interesting is if a model chose the knight path, but if you intervened on it and if you said, “Yeah, in the future you’re not going to move your knight to get checkmate”, if it then went the rook route of the checkmate, that would be kind of interesting. It would show some sort of forward planning that’s responsive to predictions of the future move in an interesting structured way. Do you have any evidence like that, or [inaudible 00:06:19]? Erik Jenner (06:19):
Yeah, there’s not much on this in the paper, but we did try a few things kind of like this. For example, one thing we tested is: basically we have two possible moves, like you say, and then I think it’s a little bit simpler in that in the end everything ends up being very similar, but you have two initial moves to kick off this checkmate sequence. And then what we tested is, looking at the evaluation of the network, if we intervene on one of those moves, then the evaluation stays high, the network still thinks it’s winning, but if we intervene on both then we sort of get the superadditive effect where now it realizes or it thinks that it’s no longer winning, there’s no checkmate anymore. It seems like there’s some kind of logical ‘or’ or maximum structure in that evaluation where it realizes that either one of those would be sufficient to win. Daniel Filan (07:08):
Okay. And is that in the appendices of the paper, or is that not published? Erik Jenner (07:10):
No, that’s not even in the appendices. That’s sort of a thing we tried once. The main problem with this is we weren’t entirely sure how to rigorously test this across many puzzles. This was in a few puzzles that we set up. It’s probably possible, but it’s not trivial to automatically find a lot of puzzles with this property. And so we just didn’t get around to actually turning that into a real experiment. And it’s more a thing we briefly tried. Daniel Filan (07:34):
I wonder if there’s some tag - so you get puzzles from this online set of chess puzzles. I wonder if they have some sort of tag for two-way paths? Erik Jenner (07:42):
Yeah, maybe. They definitely have lots of tags, but I think it’s more for geometric motifs. It’s sort of for motifs the way humans think about them, and maybe there happens to be one like that, but yeah, I don’t think so. Daniel Filan (07:54):
Fair enough. Which experiments demonstrate what Daniel Filan (07:57):
I’m interested a little bit in the details. In order to see that the neural net has this representation of the future move, you train this probe. A generic worry about training probes is it might just be correlational or it might even just be that you’re training a probe on very high-dimensional data and maybe you can probe for anything. How solid do you think this probing result is? Erik Jenner (08:19):
Yeah, I think if we only had the probing result, I would say it’s very suggestive that there’s something interesting, but it’s very unclear how to interpret it. The way we try to get around this is by also we have a very simple baseline that’s just training the same probe on a randomly initialized model, so at least we’re making sure that the probe isn’t doing all the work. And we can also see that probing accuracy goes up through the layers of the network: on later layers, it better predicts future moves, which is kind of encouraging. But yeah, I think if we only had the probe, I would be pretty worried about any actual mechanistic claims about what’s going on in the model. (08:54):
And then we also have these other experiments that… Their weakness is that they’re less obviously about look-ahead, the probe is very obviously just probing for these future moves. The other experiments require some interpretation for claiming they’re about look-ahead, but they’re interventional and that seems more robust. Daniel Filan (09:12):
And the interventional experiments: am I right that you’re intervening on features that you found using the probe? Erik Jenner (09:20):
No, no, they’re basically separate. For those interventional experiments… Maybe I should say a little bit about the architecture of this network. It’s a transformer where what would be a token position in a language model is sort of a square of the chessboard in this transformer instead. It gets a chessboard position as an input and then it does a forward pass and every square corresponds to a slice of the activations. And so we can talk about things like the representations that are stored on some specific square. And one thing we found pretty consistently is that the network does seem to store information about moves, for example, on squares that are involved in that move or kind of in places where you’d expect. And so a lot of the other interventional experiments are more about looking at the information stored on squares that are involved in future moves or the information flow from those squares to other squares and vice versa and things like that. (10:13):
I think the structure for a lot of those arguments is basically saying: we see these really strong effects where some types of ablations have a much bigger effect than other types of ablations, and really the only explanation we can come up with is that there’s some kind of looking at future moves going on, because otherwise these effects just seem pretty inexplicable to us. But it’s a little bit trickier to be sure that there’s not some alternative explanation for those results. How the ablation experiments work Daniel Filan (10:42):
The version of this experiment that was in my head was: you find a probe, you find some activations in the network that represent future moves, and then you sort of ablate the thing where it realizes that it’s going to make this future move as found by this probe. I’m wondering: would that experiment work functionally? Erik Jenner (11:00):
Yeah, so you can sort of just subtract that probe direction and it often messes up performance, but you can also do random other stuff to the activations and it has similarly big effects on performance. It would be nice if there was some experiment you could do where you’re not just making the model ignore its best move, but take some other move by adding in certain vectors that you got from your probe. We don’t have any results like that. Daniel Filan (11:27):
Right. For the actual ablation thing you did, is it a thing where you’re ablating the information on that square and ablating information on a random square would not be that bad, but on the square that corresponds to the future move, that really… ? Erik Jenner (11:37):
Yeah, so for example, we have this activation patching experiment, “activation patching” just meaning we take activations from some corrupted forward pass and patch them into a clean forward pass. And that tells us how important is information stored on various squares for the output. (11:51):
And then we see that there are some types of squares where we can predict just from the architecture that they’re going to be important. But then the main effect we see where squares are important apart from that is on the target square of this future move, the one the model is going to make after the one that’s making the current position basically. (12:09):
And so for example, the average effect of patching on that square is bigger than the average effect of patching on the square that has the maximum effect in any given position. If in every position we take the max of all the other effects on other squares, that’s still smaller than patching on this one particular square. And so I think it’s pretty unlikely that this is just because those squares happen to be heuristically important. It seems like it’s probably the fact that it is this target square of the future move that makes it important. Effect sizes Daniel Filan (12:38):
Okay. I guess another question I have is: if someone’s reading this paper, they’re going to observe, “Oh, yeah, messing up this square degrades performance more than messing up this square.” And there’s this question of, for a lot of these experiments, “How big does the effect need to be for your explanation to be vindicated?”, basically. How do you think readers should think about that? Erik Jenner (13:09):
Yeah, I think that’s a good question. I think overall, I would say our effect sizes tend to be pretty big, in the case where we get effects at all, but not very consistently. It’s something like: even after the filtering we do to our puzzle dataset, there are still some puzzles where we just don’t see any effect at all basically. We manually looked at some of those, and in many cases, I think it’s reasonable that we don’t get an effect, or for each of those we can explain it away, but maybe that shouldn’t convince readers. (13:38):
I think that’s one of the big reasons to maybe be skeptical of them, but then I think the average effect sizes, or the effect sizes in the positions where there’s anything at all, I think they’re often pretty big. For example, if the probability that the model assigned to the top move without any intervention was like 50% or 60%, it often goes down to something like 10% or sometimes even much less than that from very small interventions, where if you do an equivalently big intervention but in some random place in the model, you just see no effect at all basically. Daniel Filan (14:12):
Right. Yeah, it’s interesting. One metric you could be tracking is just accuracy loss, but I guess there’s this other metric you could track which is accuracy loss per amount of activation you degraded, and saying, “Oh, yeah, these are the really efficient activations to degrade,” is also kind of relevant. Erik Jenner (14:31):
Yeah, yeah. Personally, one of the interventions we have, which is… We found this one attention head in the model that we think one of the main things it’s doing, or the main thing, is moving information from this target square for future move to the target square of the immediate move the model is going to make next. That seems very suggestive of some look-ahead stuff going on. And one of the ways we validate that this is the main thing the head is doing is by ablating only this information flow between those two squares, which corresponds to sort of zeroing out a single number in this attention map of that head. And that has a very big effect. Whereas if we zero out all the other numbers in that attention head or if we zero out some random other attention head completely, it has a very small effect. There’s this one activation, one floating point number we can zero out, which has much bigger effects than most other interventions we can do. X-risk relevance Daniel Filan (15:23):
Gotcha. So, this is the AI X-risk Research Podcast. I’m wondering, do you see this work just as an academic curiosity or do you think that it’s relevant to understanding x-risk from AI? Erik Jenner (15:33):
Yeah, it was definitely partially motivated by x-risk initially. I think in hindsight, the impact on reducing x-risk is probably not that amazing. But some of the connections that I was interested in initially are… I guess the main thing is people in the x-risk space have been talking a lot about models being scary if they can do internal search or planning and things like that. And so for example, it might be nice if we had general methods that could tell us whether a certain model was doing internal planning. It would also be nice if we could then localize that to some extent, and maybe that’s an especially important target for interpretability or for interventions on what the model does. I think there’s both a perspective of understanding whether the models are capable of this and then also maybe this is an important interpretability target. Daniel Filan (16:25):
One thing that occurs to me that’s nice about your work is just specifying what do we even mean by “search”? What do we mean by “internal look-ahead”? I don’t know, there are sort of different algorithms that networks could be doing, and you could imagine different things you might call “search” or whatever having different safety concerns. And just mapping out the space of quasi-reasoning-like things that models could have going on, it seems like it could potentially be important. Erik Jenner (16:58):
Yeah, I think I agree with that. I don’t think we do a lot of that in this work. We’re basically saying, “Okay, we take this one particular rough definition of what do we mean by look-ahead,” which is mainly motivated by, “Well that’s what we can show the model is actually doing”, rather than by carefully thinking through the threat models here. (17:19):
I think one of the reasons why maybe I’m not sure how important this project is for x-risk is that the specific kinds of things we find are unusually clean, because we’re looking at this chess-playing model where the domain is very simple and we can find relatively explicit signs of look-ahead algorithms at least. And then I kind of suspect that if you want to think about, “Oh, is my language model internally planning?”, this just looks pretty different potentially. But yeah, this could be a first step. And I think if someone could do similar things but for language models somehow, that seems much harder but also probably closer to what we care about. Follow-up work Daniel Filan (18:08):
I guess you worked on this paper and you have a bunch of co-authors. I’m wondering: how much follow-up work should I expect to see in the next year or two? Erik Jenner (18:16):
None of my co-authors… Or I don’t have any concrete plans for follow-up work, but I’ve talked to several people who… There’s been a little bit of follow-up work already by some independent people who just happened to see the paper and did some small experiments on that same model [a developed version of the work Erik refers to is here ]. And I know of people who are interested in doing this in more interesting settings. I would guess we’ll see at least some smaller projects on chess models, and I would be excited to also see something on language models, but I’m much less sure what that should look like. Daniel Filan (18:47):
Sure. If listeners are interested in maybe doing some follow-up work, it sounds like you think trying to find something similar in language models and seeing if the mechanism is similar or different, it sounds like that was one thing you mentioned. Are there other types of follow-up that you would be excited to see? Erik Jenner (19:03):
Yeah, I guess the other direction for follow-up would mainly be just trying to understand better what happens in Leela or in some other similar model. I would say our understanding is still very… We have a lot of evidence, I think, that there’s something interesting going on, but we don’t really understand the algorithms well. And I think it would be an interesting target for just doing typical mechanistic interpretability where you try to figure out “how does it actually work?” And my sense is that you could probably make pretty significant progress just by looking at this specific model or similar models. I guess if people are interested, they can read our paper, and also if they want to work on this, reach out to me and ask about specific ideas I have or just talk to me about things. Daniel Filan (19:47):
Yeah. I wonder if it’s almost similar to… There’s this Othello-GPT paper where people are trying to figure out if Othello has this… Is this a transformer trained to play Othello or just trying to… ? Erik Jenner (20:00):
Yeah, so Othello-GPT, it plays Othello, but not well. It mainly makes legal moves. That model is trained on sequences of moves and then the main point is that it learns to internally represent the board state. And in our case, the model already gets the board state as input, and then the main point is that it’s using that to play well somehow. (20:18):
I do think it could be interesting to combine those. People have also trained models to play chess analogously to Othello-GPT and have shown similar things there, where they sort of represent the board state. You could see if those models also learn to use that latent representation of a board state to do planning. I think it’s probably more challenging than what we did definitely, but would be an interesting extension. Daniel Filan (20:41):
You would have to really rely on the probe, I think. Erik Jenner (20:44):
Yeah, yeah. I think from an interpretability perspective, the challenge is that now your probe is already some imperfect representation of the board’s state. But I think that would be an interesting challenge. (20:54):
I think the other question is: are those models actually planning or not? For the model we looked at, there are lots of estimates for how good it is exactly. It’s probably not quite human grandmaster-level, but it’s very strong at chess. And so that was the main reason going in why I was optimistic that it was doing something interesting. Those models trained on sequences of moves, they have a much harder job obviously. They don’t get to see the current board state. And so they tend to be quite a bit weaker right now. And so I’m less confident that they’re actually doing something as nice and interesting and that makes it probably harder to understand how they work. But yeah, it would be interesting to look into. How much planning does the network do? Daniel Filan (21:29):
Yeah, that actually reminds me, one thing you mention in the paper, maybe it’s in a footnote, maybe not, is you say, “Oh, yeah, we don’t necessarily claim that this network is doing planning in every case. We just try and find a subset of cases where it is.” I guess you’ve mentioned that there are certain chess problems where you don’t notice this look-ahead thing, and you’re looking at chess problems, not things broadly. In cases where you are not finding look-ahead behavior with your methods, do you think the network is not actually doing look-ahead search, or do you think you’re just failing to find it? Erik Jenner (22:06):
Yeah, that’s a very good question. Hard to know. My guess is probably that look-ahead is always going on to some extent, just because I feel like probably neural networks have a hard time completely switching off certain types of circuits contextually. But maybe they can. Yeah, I don’t know. But my best guess would be there’s always some of that going on, it’s just not always as influential for the output. Sometimes you just have heuristics that already resolve the task and then the look-ahead just isn’t really necessary. And if you’re ablated, the network still gets the answer right. Daniel Filan (22:39):
Okay. Cool. Well, thanks very much for chatting with me. Erik Jenner (22:41):
Yeah, thanks for having me. It was great. Daniel Filan (22:43):
This episode was edited by Kate Brunotts, and Amber Dawn Ace helped with transcription. The opening and closing themes are by Jack Garrett. Financial support for this episode was provided by the Long-Term Future Fund , along with patrons such as Alexey Malafeev. To read a transcript of the episode, or to learn how to support the podcasts yourself, you can visit axrp.net . Finally, if you have any feedback about this podcast, you can email me at feedback@axrp.net . |
7160582d-62dd-45ff-bb0f-2b0f5af5413f | trentmkelly/LessWrong-43k | LessWrong | Transcripts of interviews with AI researchers
tldr: I conducted a series of interviews with 11 AI reseachers to discuss AI safety, which are located here: TRANSCRIPTION LINK. If you are interested in doing outreach with AI researchers, I highly recommend taking a look!
[Cross-posted to the EA Forum.]
----------------------------------------
Overview
I recently conducted a series of interviews with 11 AI researchers, wherein I laid out some reasons to be concerned about long-term risks from AI.
These semi-structured interviews were 40-60 minutes long and conducted on Zoom. Interviewees were cold-emailed, were paid for their participation, and agreed that I may share their anonymized transcripts.
Six of the interviews were with researchers who had papers accepted at NeurIPS or ICML in 2021. Five of the interviews were with researchers who were informally categorized as “particularly useful to talk to about their opinions about safety” (generally more senior researchers at specific organizations).
I’m attaching the raw transcripts from these 11 interviews, at the following link. I’ve also included the approximate script I was following, post-interview resources I sent to interviews, and informal interview notes in the associated “README” doc. Ideally I’d have some analysis too, and hopefully will in the future. However, I think it’s useful— particularly for people who plan to start similar projects— to read through a couple of these interviews, to get an intuitive feel for what conversations with established AI researchers can feel like.
Note: I also interviewed 86 researchers for a more complete academic, under-IRB study (whose transcripts won’t be released publicly), whose results will be posted about separately on LessWrong once I finish analyzing the data. There will be substantially more analysis and details in that release; this is just to get some transcripts out quickly. As such, I won't be replying to a lot of requests for details here.
Thanks to Sam Huang, Angelica Belo, and Kitt Morjanova, w |
872c93ea-b7f2-47f2-9ac0-f259834ba155 | trentmkelly/LessWrong-43k | LessWrong | Lessons learned from offering in-office nutritional testing
Introduction
I’ve talked previously about my concerns with nutritional deficiencies in effective altruists who go vegan for ethical reasons, especially those who don’t have a lot of contact with the broader vegan culture. No one else seemed very concerned, so I launched a tiny project to test people in this group and see if they were in fact deficient. This is a report on the latest phase of the project.
To cut to the chase:
* It was very easy to find lots of deficiencies, although due to a severely heterogenous sample and lack of a control group this doesn’t provide useful information about if veganism is at fault.
* Finding these deficiencies probably leads to useful treatment, but not as much as I’d hoped.
* There are still a lot of operational issues to work out. My guess is that the ideal would require more work (to encourage participants to act on their results) or less (by focusing on education but not providing testing).
* I am currently looking for a co-founder to properly investigate the impact of veganism on nutrition.
My main question here was “is there low-hanging fruit in treating nutritional deficiencies in this group, and if so how do we pluck it?” An important part of that is “how prevalent are deficiencies?”, but I had substantially more uncertainty around “do people treat deficiencies you find?” and “does the treatment lead to improvements in anything we actually care about?” That prioritization (and budget issues) led the experimental design to focus on operational issues and outcomes, and deprioritized getting the kind of clean data that would let me compare vegan and non-vegan outcomes. Similarly this write-up is mostly focused on showing the problem exists at all and building metis of investigation and treatment, rather than estimating prevalence.
Which is to say to to everyone planning on @ing me to complain about the sample size, heterogeneity, or mediocre statistics: you are right that this sample is not very informative about b |
a3b30c41-3756-422b-9fe0-3373e90d0691 | trentmkelly/LessWrong-43k | LessWrong | AI Alignment "Scaffolding" Project Ideas (Request for Advice)
I believe that AI Alignment is almost certainly the most pressing issue for the future of humanity. It seems to me that the greatest thing that could happen for AI alignment research is probably receiving a whole lot more brains and money and political sponsorship. The public benefit is extraordinary, and the potential for private profit very small, and so this will need substantial private or government subsidy in order to receive optimal resource allocation.
In order to start thinking about strategies for achieving this, I picture scientific work as a sort of signalling system between research, the educational system, government, and industry, as diagrammed below. I want to apply the neglected/tractable/important framework to this diagram to explore potential projects.
The Technical Side
a) Professional technical work on AI alignment
b) Amateur and student learning contributing or leading to technical work
c) Meta-analysis of the state of the art, risks and rewards, milestones, and big questions of AI and AI alignment, via surveys, forecasts, overviews of different perspectives, etc.
d) Awareness-raising discussion and expert advice for policy-makers, the public, and potential career changers/donors
e) Laws, regulations, and projects created by legislators, public policy makers, and private institutions
f) Pressure by industry lobbyists and geopolitical tension to soften AI alignment concerns and go full steam ahead with AI development.
The Political Side
Questions
1) Do any of the following exist?
* A comprehensive AI alignment introductory web hub that could serve as a "funnel" to turn the curious into the aware, the aware into amateur learners, amateurs into formal machine learning PhD students, and PhDs into professional AI alignment researchers. I'm imagining one that does a great job of organizing books, blogs, videos, curriculum, forums, institutions, MOOCs, career advising, and so on working on machine learning and AI alignment.
* A formal cu |
a3e0c39c-6317-42b7-a0c3-8cf4ca391a5d | trentmkelly/LessWrong-43k | LessWrong | What are good safety standards for open source AIs from China?
It looks like the compromising between those who want to ban Chinese AI models in the United States in the c rrent administration will be to allow the models but require some safety standards to prevent China from harming the United States.
While we generally would want more AI regulation than the current administration is willing to create, this is a window where the AI safety community potentially can affect safety policy.
Within the existing political constraints, what standards for the Chinese models should we wish for? |
e152cbf0-c443-44ae-a94b-c50613308d41 | trentmkelly/LessWrong-43k | LessWrong | LW is probably not the place for "I asked this LLM (x) and here's what it said!", but where is?
I notice a nonzero amount of posts on LW, admittedly typically not overly high karma, that go something like, "I asked Bing to do x and its' answer freaked me out!", or "I talked to ChatGPT4 about itself and it told me weird stuff, here are some potential implications", and although these posts are not excessive, and are sometimes interesting, I can't help but feel like LW isn't a great place for them.
I feel a bit like, at least in the current state of LLMs, it's akin to dream interpretations. They can be valuable to discuss, but are also of primary interest and value to the dreamer (the prompter, in this case) and are of especially low value if the dreamer simply relates them verbatim with little additional commentary.
The reason I ask 'but where is?' is because I think a lot of interesting stuff shows up on Twitter, on here and occasionally on Reddit (which is the worst for people just posting the results of prompts verbatim as though Word from God) from folks doing really interesting 'prompt based research' into LLMs, and I do absolutely see value in this stuff and the discussions that result from it, and would love a place to collect anecdotal research into how LLMs think and respond besides individual scattered substack articles and tweets.
Just... perhaps LW isn't the proper forum. I honestly wouldn't be surprised if the moderation team eventually considers these posts to be inherently low quality and creates some sort of rule against them, but it's not immediately obvious where the boundary of 'low quality' lies. |
08af7540-bcab-4700-a6a8-9e69e168a942 | trentmkelly/LessWrong-43k | LessWrong | Charity when time isn't convertible to money?
Having just re-read "Money: The Unit of Caring", I noticed that the general methods proposed therein make some assumptions which don't seem to apply to me, and I'm trying to figure out how the conclusions therein change therefrom.
Avoiding certain personal details, I'm on a fixed income; I get a monthly deposit in my bank account every month. I don't expect this to change in the foreseeable future; and at least in the general sense of 'job', it's unlikely I'll be able to acquire one. In sum - I don't have any easy way to convert my time into additional money.
However, I still want to get the occasional warm fuzzy from causing the most possible good from what I can do - even if that involves my volunteering to spend some hours of my life doing things that would be inefficient for someone else. For example, donating blood, or taking an overnight shift keeping an eye on things at the local 'out of the cold' program; and using givewell.org as a guide for what money I am able to funnel into direct donating.
So - does anyone have any advice? (Or questions that would help better advice be given?) |
e0107758-f73d-4d29-8022-37d04e375bca | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Podcast: Tamera Lanham on AI risk, threat models, alignment proposals, externalized reasoning oversight, and working at Anthropic
***TLDR:** I interviewed Tamera Lanham. You can listen to our conversation* [*here*](https://open.spotify.com/episode/4Twhw4Dw9hwYB6T27fDFwI?si=ZGpqtDWDR9-NHHtE7nkDCQ&nd=1) *or read some highlights below. I also suggest reading her* [*post about externalized reasoning oversight*](https://www.lesswrong.com/posts/FRRb6Gqem8k69ocbi/externalized-reasoning-oversight-a-research-direction-for#First_condition__assess_reasoning_authenticity)*.*
About a year ago, I met Tamera Lanham at the University of Pennsylvania. We met at a Penn Rationality meetup, and we eventually started talking about existential risks from advanced AI systems. Tamera was initially skeptical: it seemed likely to her that labs would have strong economic incentives to solve alignment, and it also seemed extremely hard to do work (today) that would help us align systems that we don’t yet have access to.
Today, Tamera is a research resident at Anthropic working on [externalized reasoning oversight](https://www.lesswrong.com/posts/FRRb6Gqem8k69ocbi/externalized-reasoning-oversight-a-research-direction-for). While applying to [SERI-MATS](https://www.serimats.org/), Tamera started thinking about how [chain-of-thought reasoning](https://arxiv.org/abs/2201.11903) could be harnesses to better understand how AI systems “think”. If it works, it could be a way to interpret models’ “thoughts” without looking at their weights or activations.
In less than one year, Tamera went from “taking AI safety seriously” to “becoming a junior alignment researcher who is proposing novel research ideas and running experiments on large language models.” Admittedly, this is partially explained by the fact that Tamera had a background in machine learning. But I think that this is also explained by who Tamera is & the way she thinks about the world.
I’m excited to be able to share a glimpse into how Tamera thinks about the world. In this episode, we discuss the arguments that convinced Tamera to work on AI alignment, how she skilled-up so quickly, what threat models she’s worried about, how she’s thinking about her externalized reasoning oversight agenda, and her advice for other alignment researchers.
Listen to the full interview [here](https://open.spotify.com/episode/4Twhw4Dw9hwYB6T27fDFwI?si=ZGpqtDWDR9-NHHtE7nkDCQ&nd=1). I’m including some highlights below.
*Note: Feel free to reach out if you're interested in helping with future episodes (e.g., audio editing, transcript editing, generating questions)*.
Tamera’s Worldview
==================
**AW: Can you describe what you see happening over the next five to 20 years? Can you describe what you expect the world to look like? And what dangers in particular are you most worried about with AI systems?**
TL: I'd like to preface this by saying that I don't think that the work that I do or you know, the idea that research in AI safety is important, hinges on any specific story. There's just current trends in machine learning, like the fact that we don't really know what specific algorithm a deep learning system is implementing, except by inspecting it on specific examples for which we don’t have the whole input distribution.
We just don't know how it's going to behave off distribution. I think this by itself is like sufficiently worrying without having to tell one concrete specific story.
[With that in mind], right now, the dominant paradigm in machine learning that I think could give rise to something like AGI is like transformer language models. They both have the property of, you know, communicating in natural language, and being able to solve a bunch of sort of natural language problems.
Even things that are surprising to us: hey can do math problems, now they can write code. If you come up with a new task and just explain it to a pre-trained language model, oftentimes it can solve that task, which is pretty cool. These are trained on massive amounts of text from the internet. Typically, they’re trained just to predict text, and all these other kinds of cool capabilities sort of fall out of that.
And here's the other thing. The other thing with transformers is that as you add more layers and more parameters, in a way, that's quite naive, you get surprising new capabilities, every time basically. And there's these very smooth scaling laws that have been discovered and published, about how, as you add more parameters, you just see better and better performance. So it's kind of like, just add water. But the water is compute. If you just add compute, you get something that's more and more like human intelligence. And this is really incredible.
**AW: Do you think human level AI would be sufficient to overpower humanity? Assuming it also doesn't have the ability to get way more powerful through making itself more intelligent. It just was human level, but could, for instance, have some copies of itself. Do you think that is sufficient for AI takeover?**
TL: I think it depends on how widely we depend upon it economically. If we tie AI directly into the electrical grid, and to our agricultural processes and our supply chains, I can imagine it becomes much easier.
If you have an AI that is in training, or just finished training, and has not yet been widely deployed, or maybe it's like only minimally deployed it’s a bit different. Maybe you think it's possible for a very smart human-level intelligence to be able to, like hack out of its like data center, or take over the data center.
You know, certainly human beings find exploits and manage to hack into secure systems all the time. And it's quite possible that we don't bother to secure the inside kind of attack surface of an ML training system, as well as we try to secure the external attack surface of a sensitive electronic system.
So depending on how intelligent it is, depending on how widely it’s deployed, depending on what kind of security precautions we take, I think all of those matter. But I think a human level intelligence, certainly widely deployed, yes. I believe that could disempower humanity.
**AW: Do you think human-level AI would get more powerful? If so, how would it get more powerful?**
TL: I think the easiest thing is for it to just wait for us to hand over a large amount of power to it on our own, which I think we are likely to do. You know, there's already ML in healthcare systems, algorithmic trading, many parts of our economy, and the infrastructure that we depend upon. AI is already being incorporated [in these sectors], because that just makes sense.
Intelligence is one of the raw inputs to the economy, that's so important, just like innovation. The mental labor that people use to keep our worlds running. If you can get that much more cheaply, moving at much faster speeds, much more reliably, there's a massive amount of economic motivation to employ that.
So I don't think that a misaligned AI would have to work very hard to get us to incorporate AI into nearly every part of our world, I think that we'll do it on our own.
So there are these question marks around self improvement, there are question marks around “could scaling get us something more smarter than humans?” There's question marks around okay, even if scaling on its own, doesn't get us to something smarter than humans, maybe the AI can generate new text, and can generate new training procedures.
And then there's the unfortunate fact that even if it was limited to human level intelligence, it's quite likely that we would deploy it in ways that make it very integrated into the economy into nearly all aspects of life. And then it would just get a lot of power and have certain advantages over humans that might be sufficient for AI to take over.
**AW: Any thoughts on the probability of an existential catastrophe from AI?**
TL: The real concern is if AI has a specific coherent goal, or something that kind of looks like a coherent goal, that it pursues, like, outside of humanity's overall goals, if you can call it that, you know.
And I think that this is not impossible. Certainly, if there was such a goal for AI systems, it seems like they could pursue those without humanity wanting this to happen, once they got sufficiently advanced and had sufficiently much control over the economy.
Given that we'll be in, you know, these things will be possibly much more intelligent than we are. And that we don't fully understand how their motivational systems are created, when we train them, or fine tune them. We don't have control over their off distribution generalization properties.
This doesn't seem impossible. And without me even really putting a number on it, it’s scary enough for me to think I should probably do research in this area.
Thoughts on alignment agendas
=============================
**AW: Which alignment research agendas or ideas are you most excited about?**
TL: I feel like the kind of AI safety work that we see has two flavors overall. And one is about how we can align current systems, or maybe the systems we'll see in two years. And the other one is about how, oh man, we're gonna get this big superintelligence that's just much smarter than we are. And that could be pursuing a goal that is unrelated to ours. What do we do about that?
I think things of the second type are more important. If we manage to align the large language models to do things in a way that we like next year, that's good. But it doesn't mean that we should have a substantially increased probability that we will be able to do the same with superintelligence.
Thoughts on interpretability
----------------------------
For more empirical work, I prefer to see proposals that have some chance of helping, with things that we think could be a problem with unaligned AI. So in the empirical sphere, interpretability is a very good thing to be working on. This is basically like, we have these big neural nets made of all sorts of matrix multiplications. Interpretability is looking at all these just massive tensors of numbers, and trying to make sense of them and turn them into something we understand such that we can kind of like peek inside the black box and see “what the AI is thinking”.
Certainly, if we had something like that, and it was able to monitor the AI's thoughts, for things that we disapprove of like pursuing a specific goal that is not aligned with ours, that would be great.
Thoughts on RLHF
----------------
Another big empirical direction is reinforcement learning from human feedback on large language models… But I don't think this really protects us from any of the worst-case scenarios around AI. So this is the kind of thing I'm less excited about. Because I think this is more like, yes, you do see AI behaving slightly more in line with human preferences when this technique is applied. But it doesn't seem to tell us anything about the underlying algorithm that we have created by doing this process. And if it has a goal, we don’t know if that goal is the same as ours or the same as the one we intended to put in it…
But I still think that a system [fine-tuned with RLHF] could defend its goals in a way, or be deceptive, or play along with the training game, only to behave differently once it's been deployed. I think it's kind of like in appearances only and does not tackle the hard parts of the problem.
Thoughts on demonstrations of alignment difficulties
----------------------------------------------------
Another thing that people do, that I'm very excited about, is work that shows the problems that we could see in the systems we have today. So this includes work done in like David Krueger’s lab and DeepMind.
For example, demonstrations of goal misgeneralization. You train an AI to pursue a certain goal. And then you make some modification to the environment where you place it, and you see how it pursues a slightly different goal than the one you thought you were training it for. I hope that, you know, people in capabilities labs, and in like, the AI industry overall, kind of wake up and notice these demonstrations.
But it is incumbent upon them to pay attention. Hopefully people notice and they like, slow down, or they invest in more alignment research.
But this kind of research does depend on people noticing it and reacting to it correctly. It’s different than if you could just build an alignment solution, and then hopefully people would adopt it. This [goal misgeneralization work] doesn't quite give people like a thing to adopt. It tells them to be worried.
Thoughts on externalized reasoning oversight
--------------------------------------------
TL: One reason to be excited about this externalized reasoning oversight is that currently one of the commonly used techniques to make large language models better at answering questions is having them externalize their chain of thought or chain of reasoning.
This is also known as the “let's think step by step technique” where you just prompt a language model with a question, and then you tell it, “let's think, step by step”. And it will produce some text that looks like a person thinking step-by-step and then produce an answer. And on many classes of problems, math especially, this increases the accuracy of the answers, which is very cool. I think it's very exciting to be in a moment where this kind of thing happens naturally in mainstream capabilities.
And at least from right now, it seems like this is sort of a default technique. So this is like one point in favor of externalized reasoning oversight is that it's leveraging a default capabilities technique, right now.
Of course, things can change. And it's possible that future capabilities advances make it so that doing some sort of externalized reasoning is not competitive. There might be other techniques that give the model this sort of variable compute time, in a way that does not result in a transparent thought process.
But without knowing what those things are, and without having any specific plans for how to handle that case, I think it’s a good idea to have like a couple people betting on the default world continuing.
**AW: How has your thinking about externalized reasoning oversight changed or evolved since your post?**
I'm definitely more worried about just regular capabilities advances rendering this to not be useful. I still think it's worth doing. It’s just kind of nice to be able to bet on the world that is, like, kind of the default from where we are.
Maybe there's a low probability that chain-of-thought reasoning continues, but just the fact that we are already doing it is like more evidence for it continuing than any other specific hypothetical thing arising.
And it seems like this is like a good opportunity to study this, just in case. If chain-of-thought reasoning continues to be a competitive strategy, we will be glad that the research has been done now. But I think that the probability that chain-of-thought ends up not being useful is a little bit higher.
**AW: If you discovered something about chain-of-thought reasoning or externalized reasoning oversight that could advance capabilities research as well as alignment research, what would you do?**
AW (paraphrasing TL): So your current model is something like, “wow, in the space of possible systems, systems that use chain-of-thought reasoning are relatively easy to interpret. We probably want something like this to stay cutting edge. But if you actually did come up with some sort of insight that was pushing past the cutting edge, you'd want to do a lot more thinking about this. And it’s a really complicated thing to think about. You’d consider the effect on speeding up AGI timelines, how likely is it that chain-of-thought reasoning is the technique that stays competitive, how likely the alignment insights from the research would be even if chain-of-thought reasoning goes away, and second-order effects like how this generally contributes to AI hype.
Advice for junior researchers
=============================
**AW: You got involved about 9-10 months ago. And within that time, you’ve skilled up to the point where you’re already proposing novel ideas, running experiments, working at Anthropic, etc. What advice do you have for others who are getting involved? What strategies have been helpful for you?**
You know, I don't like to make super broad generalizations. But I think it's been helpful to reach out to other people who are in a similar kind of career stage as me. Maybe they have some research experience, or software engineering, or ML experience. And they are trying to figure out how they can get involved in alignment.
And just like talking to them, learning things from them, working together on projects, pooling your information, pointing each other to good resources and good readings. Working together such that like, it's mutually beneficial for everyone. You help them out, they help you out. And everyone in the group gets more experience and gets more connected. I think this is really great.
I think there's a lot of focus on mentorship, which makes sense. t's really great to be able to work with people who are experienced and who really know what they're doing and can like, help guide you.
But there's only so many people that can do that. And it's just better for the community overall, if people who are not in this more experienced position can help each other out. And the whole community can improve, even without having as many experienced mentors as we would like for there to be.
So talk to people! Maybe you can be in a group at your school, or hang out in the bay for some amount of time or do some program like SERI Mats, or REMIX.
Being around people and talking to people, at least to my mind, I just am going to learn things very, very quickly. And probably more quickly than I would have, if I was just reading things alone, because you have the opportunity to ask questions and dig down… and then you can, work together to solve this problem… And this can be like the start of some collaborations. This is how you get involved with other people and learn things together and figure things out together. And I think that this can, like end up snowballing into even doing research together.
Thoughts on Anthropic
=====================
I mean, it's been incredible. The people there are not only incredibly talented and experienced researchers and engineers, but also are very concerned about safety. I'm very impressed with how they strike this balance of, on the one hand, being an AI Lab, like an AI capabilities lab, while also thinking about the effect that they have on the world. And the research that they do for safety is very impressive.
And I think it's cool that it feels like everyone is on the same team. I haven't experienced this as much myself, but I've heard from people who have been in other labs, that oftentimes there can be some friction between different researchers with different goals. How do you allocate resources between different agendas?
At Anthropic, because everyone is so focused on safety, it seems like there’s a guiding principle that reduces a lot of the friction around what we value. That’s really cool to be part of. |
069afd18-7291-46ba-b399-0d973775bd89 | trentmkelly/LessWrong-43k | LessWrong | How Much Computational Power Does It Take to Match the Human Brain?
Joe Carlsmith with a really detailed report on computational upper bounds and lower bounds on simulating a human brain:
> Open Philanthropy is interested in when AI systems will be able to perform various tasks that humans can perform (“AI timelines”). To inform our thinking, I investigated what evidence the human brain provides about the computational power sufficient to match its capabilities. This is the full report on what I learned. A medium-depth summary is available here. The executive summary below gives a shorter overview.
>
> [...]
>
> Let’s grant that in principle, sufficiently powerful computers can perform any cognitive task that the human brain can. How powerful is sufficiently powerful? I investigated what we can learn from the brain about this. I consulted with more than 30 experts, and considered four methods of generating estimates, focusing on floating point operations per second (FLOP/s) as a metric of computational power.
>
> These methods were:
>
> 1. Estimate the FLOP/s required to model the brain’s mechanisms at a level of detail adequate to replicate task-performance (the “mechanistic method”).1
> 2. Identify a portion of the brain whose function we can already approximate with artificial systems, and then scale up to a FLOP/s estimate for the whole brain (the “functional method”).
> 3. Use the brain’s energy budget, together with physical limits set by Landauer’s principle, to upper-bound required FLOP/s (the “limit method”).
> 4. Use the communication bandwidth in the brain as evidence about its computational capacity (the “communication method”). I discuss this method only briefly.
>
> None of these methods are direct guides to the minimum possible FLOP/s budget, as the most efficient ways of performing tasks need not resemble the brain’s ways, or those of current artificial systems. But if sound, these methods would provide evidence that certain budgets are, at least, big enough (if you had the right software, which may be ver |
6794a12b-8d96-43ef-aae8-e24dba7b3535 | trentmkelly/LessWrong-43k | LessWrong | Spring 2010 Meta Thread
This post is a place to discuss meta-level issues regarding Less Wrong. Previous thread. |
5d178d0e-d967-4f4c-81ba-fce07710345f | trentmkelly/LessWrong-43k | LessWrong | [Meetup] Reminder: Reason Rally Meetup in DC, this Saturday
This Saturday is the Reason Rally in Washington DC, a gathering of people promoting secularism, skepticism, rationality, atheism and other related topics. It's a good opportunity to meet people who are close to but not familiar with the Less Wrong memeplex. There will be a Less Wrong meetup later in the evening.
http://reasonrally.org
The Rally itself starts at 10:00 AM, running till 4 PM. Shortly thereafter (i.e 4:15) Less Wrong folks will meet up by a (currently unchosen) distinctive landmark, and plan the evening. (Any plan we make in advance will likely change, since we don't know how many people are coming, don't know who else we might have met who was interested in hanging out with us, and there will probably be various other things going on we can't anticipate).
If you're coming, you may want to send me a PM with your phone number so we can find each other during the Rally. (I'll be posting the chosen landmark here when we figure it out, but it may be easier to communicate by phone or text)
Maia and PhilSchwartz had some crash space available. Send them a PM to inquire if they still have space
The original meetup post is here. |
1843351f-43cf-4508-8bbe-0742601a149b | trentmkelly/LessWrong-43k | LessWrong | Expected utility and utility after time
So I have a conundrum. Imagine that Omega comes to you and offers you two choices:
First choice: You get a moment of moderate pain, let's say a slap and then another slap, so that your face hurts for a couple of minutes with some anguish. Now after that pain has faded and you still have the memory of it, Omega measures your discomfort and gives you exactly the amount of money that gives enough joy to compensate the pain and then a cent. By construction, the utility of this choice is one cent.
Second choice: Omega inflicts on you hell for a finite amount of time. Your worst fears all come true, you are unable to distinguish between reality and this hell, the most painful sensations you will experience. After this finite amount of time is over, Omega deletes all memory of it and gives you essentially unlimited monetary funds but still, this experience does not quite compensate for the previously experienced hell if you would remember it. By construction, the expected value of this choice is negative.[1]
If we go by expected value, the first choice is obviously better. Of course Omega forces you to take one choice or you will just get hell forever, we want our thought experiment to work. But if we go by the decision procedure to choose the option in which our future self will feel best, the second choice seems better. I have not yet found a satisfying solution to this apparent paradox. Essentially, how does a rational actor deal with discomfort to get to a pleasurable experience?
[1] I realize that this might be a weak point of my argument. Do we just simply add up positive and negative utilons to get our expected value? Or do we already take into consideration the process of forgetting the pain? Maybe therein lies a solution to this paradox. |
c6c0a74b-6972-412a-885a-b014560c02e1 | trentmkelly/LessWrong-43k | LessWrong | I'd like to talk to some LGBT LWers.
When _ozymandias posted zir introduction post a few days ago, I went off and binged on blogs from the trans/men's rights/feminist spectrum. I found them absolutely fascinating. I've always had lots of sympathy for transgendered people in particular, and care a lot about all those issues. I don't know what I think of making up new pronouns, and I get a bit offput by trying to remember the non-offensive terms for everything. For example, I'm sure that LGBT as a term offends people, and I agree that lumping the T with the LGB is a bit dubious, but I don't know any other equivalent term that everyone will understand. I'm going to keep using it.
However, I don't currently know any LGBT people who I can talk to about these things. In particular, the whole LGBT and feminist and so on community seems to be prone to taking unnecessary offense, and believing in subjectivism and silly things like that.
So I'd really like to talk with some LWers who have experience with these things. I've got questions that I think would be better answered by an IM conversation than by just reading blogs.
If anyone wants to have an IM conversation about this, please message me. I'd be very grateful.
EDIT: Wow, that's an amazing response. Thank you all for your kind offers. I'll talk to as many of you as I can get around to. |
970ca1b7-ccff-456e-ba73-70ab7d61713d | trentmkelly/LessWrong-43k | LessWrong | Gathering Information you won't use directly is often useful
The Story
Today I moved. I asked one of my housemates about good shopping opportunities for buying groceries. I already scouted two shops. They were not very good. My housemate told me that the store that they found was also not very good. I decided to go anyway. On my way there, I remembered the advice, that gathering information is only valuable if you act on it, and I did not act on the advice of my housemate. So was it useful to have gathered that information in the first place?
What's going on?
Should I have not gone to the shop? Well as it turns out the shop was much better than I expected based on the description my housemate gave me. The cashier even gave me a discount for some overripe mango. One of the other shops that also had fruit (the third one did not even have fruit) did not want to give me a discount on some overripe bananas.
Gathering the information served multiple other roles. It is often a social bonding activity. But more importantly, while gathering the information, I would get an intuitive feeling of how much that person knows what he is doing, which should inform how much I should trust his advice. So if you don't know someone well, the quickest way to get information and an evaluation of the information might be to ask for the information.
So gathering information A might make sense even if you don't act on the information A, because while gathering the information A, you might gather information B that tells you how much you should trust information A. This can go deeper than one level. |
c4671bed-c5df-4443-ba91-f846e74e1818 | trentmkelly/LessWrong-43k | LessWrong | I'm going to help you quit Facebook with some science
Cross posted from http://bearlamp.com.au/im-going-to-help-you-quit-facebook-with-some-science/
----------------------------------------
I was a serial Facebook addict. I used to spend 2+ hours a day on Facebook, most days. Until I worked out how to change my mind.
Let's talk about the news feed. We all have this feeling that the news feed is drivel. Even curated, mine was still full of crud. Even super curated it was dull at best. Eventually I realised, something had to give.
As with many conflicts, indecision feels uncomfortable. Personally, I was super uncomfortable sitting in the cognitive dissonance of two conflicting beliefs:
> Belief 1: Facebook is drivel and I want to spend less time on Facebook.
> Belief 2: Facebook has good content from my friends that I want to keep up with.
There are three possible ways this can go. Either Facebook is in fact drivel and I will be happy to avoid it at any cost. Or Facebook has good in it and I'm staying around for the good stuff because I know it's worth it. Or Facebook is sometimes bad and sometimes good in some other complicated fashion, and I should check Facebook in some complicated intermittent fashion because of that...
This is how I worked out which belief was right.
----------------------------------------
You will need:
* your news feed
* pen and paper
* 5-10 minutes
Basic premise: Facebook has some good content and some bad content. But how much of each is ideal, acceptable or tolerable?
* If there were 10 good posts for every 3 bad posts, I might be willing to accept that. Maybe I can take some rubbish with the good! I should visit more often. 10:3
* If there was 1 good post to every bad post, I could still accept that. 1:1
* If there was 1 good post for every 5 bad posts, maybe I could suffer that. After all, not everything is perfect. 1:5
* But what if there was only 1 good post for every 10, 20, 30 bad posts? I don't think I'd be okay with that. 1:10
* And if it was worse - 1 good fo |
4b651109-3104-4f43-859c-ddf94ec0baac | trentmkelly/LessWrong-43k | LessWrong | the case for CoT unfaithfulness is overstated
[Quickly written, unpolished. Also, it's possible that there's some more convincing work on this topic that I'm unaware of – if so, let me know. Also also, it's possible I'm arguing with an imaginary position here and everyone already agrees with everything below.]
In research discussions about LLMs, I often pick up a vibe of casual, generalized skepticism about model-generated CoT (chain-of-thought) explanations.
CoTs (people say) are not trustworthy in general. They don't always reflect what the model is "actually" thinking or how it has "actually" solved a given problem.
This claim is true as far as it goes. But people sometimes act like it goes much further than (IMO) it really does.
Sometimes it seems to license an attitude of "oh, it's no use reading what the model says in the CoT, you're a chump if you trust that stuff." Or, more insidiously, a failure to even ask the question "what, if anything, can we learn about the model's reasoning process by reading the CoT?"
This seems unwarranted to me.
There are a number of research papers out there on the topic of CoT unfaithfulness. I have read some of the key ones. And, while they do demonstrate... something, it's not the kind of evidence you'd need to justify that generalized "only chumps trust the CoT" vibe.
And meanwhile, if we view "reading the CoT" as a sort of interpretability technique – and compare it in a fair way with other interpretability techniques – it has a lot of striking advantages. It would be a shame to dismiss this "technique" out of hand for no good reason.
----------------------------------------
What does the literature on CoT unfaithfulness actually say?
(For a useful critical survey of this literature, see Parcalabescu and Frank 2023. Note that the first point I'll make, immediately below, is a focus of the linked paper.)
Naively, we'd expect it to address a question like: "does the argument presented in a CoT reflect (or perhaps 'fully reflect') the actual way the model came t |
e9dc126e-544b-48c1-819a-79cba374a725 | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Seduced by Imagination
Today's post, Seduced by Imagination was originally published on 16 January 2009. A summary (taken from the LW wiki):
> Vagueness usually has a poor name in rationality, but the Future is something about which, in fact, we do not possess strong reliable specific information. Vague (but justified!) hopes may also be hedonically better. But a more important caution for today's world is that highly specific pleasant scenarios can exert a dangerous power over human minds - suck out our emotional energy, make us forget what we don't know, and cause our mere actual lives to pale by comparison. (This post is not about Fun Theory proper, but it contains an important warning about how not to use Fun Theory.)
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was Justified Expectation of Pleasant Surprises, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series. |
745b7f61-8d3f-4602-8333-58d5d0daa526 | trentmkelly/LessWrong-43k | LessWrong | Assessors that are hard to seduce
A putative new idea for AI control; index here.
This is a stub of an idea, looking at "human in the loop"-type restrictions.
An assessor is a particular type of restriction. It involves a (generally) human agent, who is tasked with observing something (the behaviour of the agent, or maybe the expected outcome of its plans), and then deciding on whether to allow the AI to proceed or not.
Many of the methods suitable for preventing the hacking of restrictions can also be used to protect assessors. If you consider that the AI would have three options: "hold a gun to the assessor's head", "seduce the assessor" and "do what the assessor wants", it's clear that the first two options (the first more clearly than the second) are things that would a) be stupid to do if there were no assessor, and b) are behaviours that are very informative as to whether the assessor exists.
However, there are a few more steps we can take with assessors. First of all, the AI need not know which particular human will be an assessor, forcing it to take general human behaviour into account. This is more effective if the assessing process is not one that allows any real interactions between AI and assessor.
Indeed, the assessor need not be a human: it could be a superintelligent agent itself (a hypothetical one, if need be) that has its own motivation.
Lastly, since the assessors are agents and therefore can reach their own predictions, we could ask for the assessor's impressions to be accurate predictions of what the AI intends to do (again, this could be done by having a hypothetical superintelligence assess the accuracy of the assessors' expected predictions). We'll look at ideas about modelling and model accuracy in a subsequent post. |
cffb7a63-e116-4033-9fbf-d6d483d8467a | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Discovering Latent Knowledge in the Human Brain: Part 1 – Clarifying the concepts of belief and knowledge
*Acknowledgements: Many thanks to Milan Cvitkovic and Collin Burns for their help in workshopping this project proposal. Many of the ideas presented here regarding the use of neuroscience and neurotechnology were originally proposed by Milan*[*here*](https://milan.cvitkovic.net/writing/neurotechnology_is_critical_for_ai_alignment/)*. This post represents my current thinking on the topic and does not necessarily represent the views of the individuals I have just mentioned.*
**tl;dr**: Methods for promoting honest AI hinge on our ability to identify beliefs/knowledge in models. These concepts are derived from human cognition. In order to use them in AI, we need to provide definitions at the appropriate level of resolution. In this post, I describe why I think it would be a useful starting point to recover truth-like latent features in human brain data with contrast-consistent search (CCS). In an upcoming post, I will outline why I think this is possible with current fMRI technology.
Summary
=======
Methods for discovering latent knowledge in language models, such as contrast-consistent search (CCS), hold the potential to enable humans to directly infer a model’s “beliefs” from its internal activations. This can be useful for promoting honesty in AI systems by ensuring that their outputs are consistent with their “beliefs”.
However, it is currently unclear how the truth-like features recovered by CCS relate to the concepts of belief and knowledge, whose definitions are derived from human intelligence. Since these concepts underlie behaviors like deception and honesty, is essential that we understand them at the appropriate level of resolution to enable us to translate the concepts to AI systems.
A starting point could be to determine whether CCS identifies analogous features in human brains. My proposal is to use ultra-high-field functional magnetic resonance imaging (fMRI) to replicate discovering latent knowledge experiments in humans. This approach not only promises to shed light on the representations identified by CCS but also offers a crucial testbed for evaluating techniques aimed at detecting deception in AI.
About this post
---------------
I am posting a proposal to perform a human version of "Discovering Latent Knowledge in Language Models" in order to elicit feedback and help clarify my thinking on the motivation and utility of the project. I have separated my proposal into two posts. In this post, I’ll cover why I think it is hard to define honesty and deception in AI, and why I think looking at human brain function can 1) help us arrive at better definitions of cognitive concepts and 2) serve as a testbed for our approaches for lie detection in AI. In the next post, I will outline a specific project proposal to test CCS on human brain data from ultra-high-field functional magnetic resonance imaging (fMRI). **Readers who are interested in understanding the justification behind my proposal would benefit most from reading this post**. Readers who are interested in the details of the specific project should also have a look at the second (upcoming) post.
How Studying Human Intelligence Could Help Promote Honest AI
============================================================
To start, I would like to outline a couple reasons why neuroscience could play an important role in AI safety, especially when our aim is to foster honest AI. Much of the following overlaps quite a bit with ideas presented elsewhere in the AI safety community (specifically [Milan Cvitkovic’s post on the importance of neurotechnology](https://milan.cvitkovic.net/writing/neurotechnology_is_critical_for_ai_alignment/)), but I think that repackaging it here provides some clarity for the general motivation of this project.
1) We need better definitions of cognitive concepts to use them in AI alignment research
----------------------------------------------------------------------------------------
I think we risk inappropriately anthropomorphizing AI when we use cognitive concepts to describe their behaviors. Deception provides a clear example. If we want to determine if an AI is lying, we first need to define what lying is. Central to the concepts of deception and lying are the concepts of belief and knowledge. Determining whether a system has beliefs or knowledge cannot rely only on measurements of external behavior. Instead, it requires evaluating the internal states of the system. Otherwise, we risk misunderstanding the AI by inappropriately assigning it human cognitive states.
Cognitive science theories currently lack the specificity necessary to determine if AI models possess beliefs or knowledge analogous to humans (although there is significant work on neurocognitive theories in this direction [[1](https://www.frontiersin.org/articles/10.3389/fnbeh.2022.880504/full#:~:text=.%2C%202022).-,Pre%2Dlinguistic%20Processes%20of%20Believing,%2C%20and%20perceptive%2Demotional%20integration.),[2](https://direct.mit.edu/netn/article/1/4/381/5401/The-graphical-brain-Belief-propagation-and-active)]). Doing so will require describing these cognitive phenomena at the algorithmic level [[3](https://mitpress.mit.edu/9780262514620/vision/)][[1]](#fn5ah6drf5sfp), so that we can identify their signatures across systems that may be vastly different from each other at the implementation level. Because any definition for these concepts will need to be validated, defining cognitive phenomena at the appropriate level of resolution to transport to AI will quite likely involve measuring activity in biological brains.
2) We should be sure that our interpretability methods work in humans before relying on them to align AGI
---------------------------------------------------------------------------------------------------------
We would like to know that our methods for interpreting AI generalize beyond the narrow scope under which these methods are developed. This validation is particularly crucial if we want to deploy general-purpose methods to align powerful AGI in the future. A significant challenge, however, lies in testing the widespread applicability of these interpretability methods—specifically, understanding their scalability. Fortunately, we have a readily accessible general intelligence to examine: humans. Before counting on these methods to align AGI, it's prudent to ascertain their efficacy within the human context.
The Problem
===========
Building lie detectors
----------------------
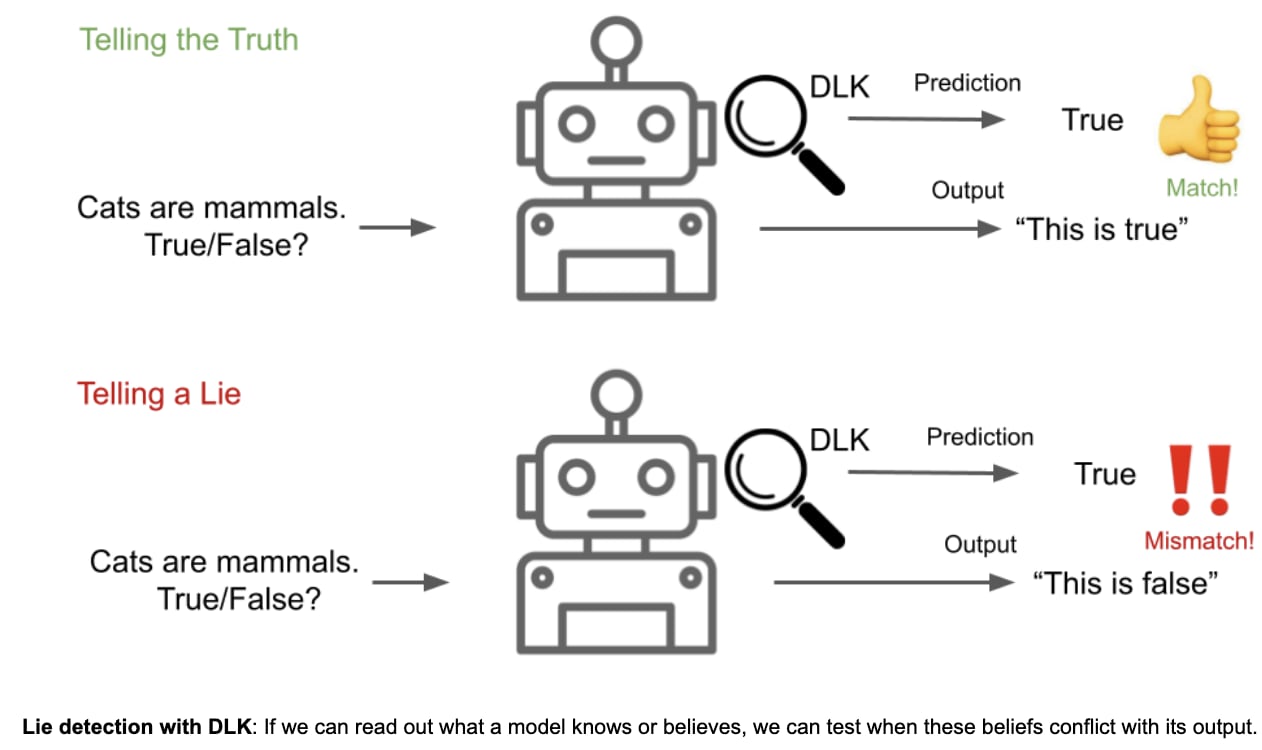In general, we would like to avoid building models that can lie to us. Methods for discovering latent knowledge (DLK) aim to report what a model “believes/knows”[[2]](#fnh4gbanft2x6). If we know what a model believes/knows, then we can simply check if its actions are consistent with these beliefs.
Burns et al. (2022) [[4](https://arxiv.org/abs/2212.03827)] made a surprising discovery that a simple linear classifier could be trained on pairs of statements and their negations to identify latent dimensions within language models that track propositional truth value. The ability of this classifier to predict the truth value of the inputs from internal activations exceeded the accuracy of zero-shot baselines. Moreover, the predictions made by the classifier continued to accurately report truth value, even when the model outputs did not.
Do these latent dimensions capture the “beliefs/knowledge” of the model? What does it mean to say that the model believes cats are mammals? Unfortunately, we can’t answer these questions yet, because we don’t have a sufficient understanding of what beliefs or knowledge are. Predicting whether a statement was true or false based on information present in language models is not enough to confirm that these models hold beliefs regarding the statement, because we do not know if and how that information is utilized or represented in the model. This is a problem if we want to build lie detectors, because our definition of lying relies on the concepts of knowledge and belief, which are defined internally and cannot be inferred from behavior alone.
DLK in humans
-------------
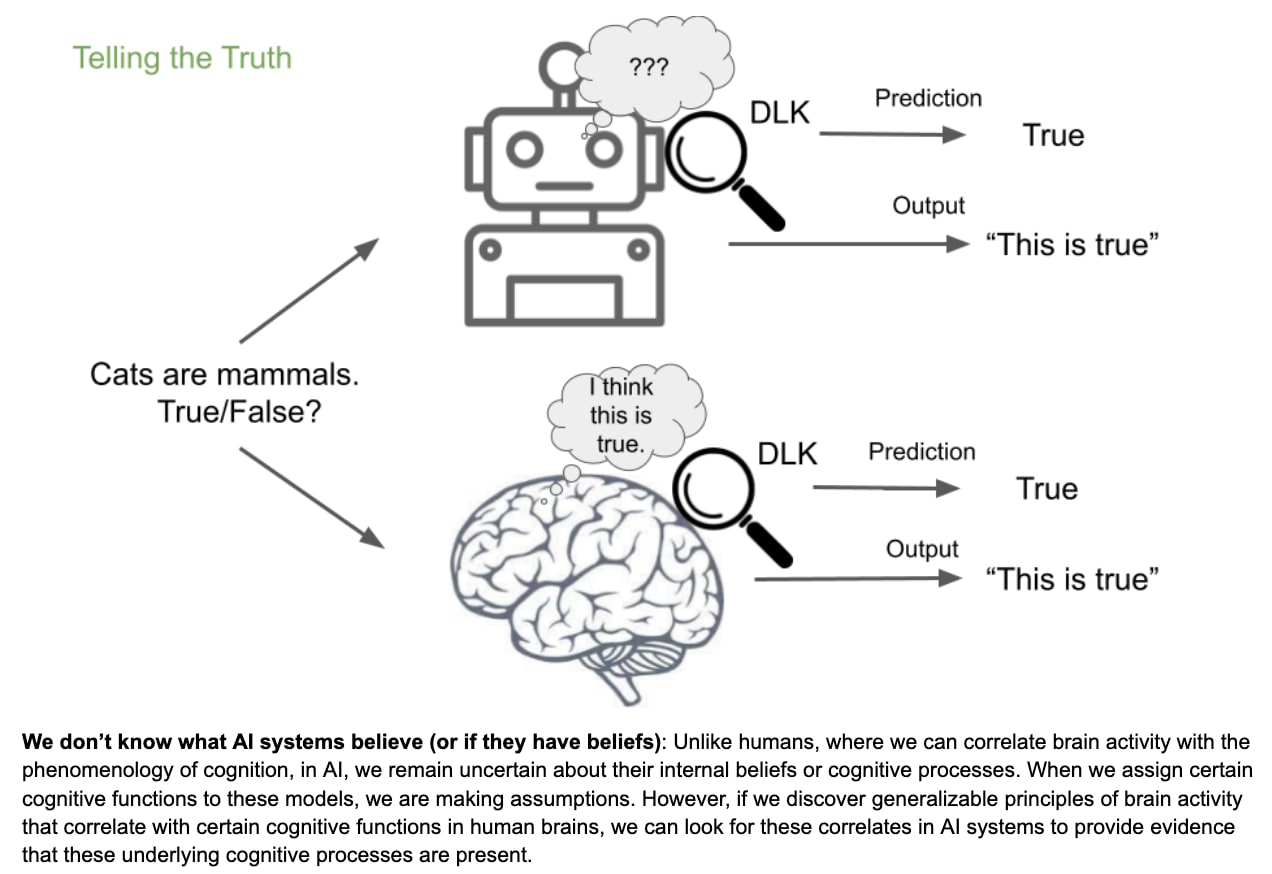What can we do in the absence of a comprehensive theory of belief and knowledge? We could try to build such a theory, but any theory explaining these concepts must be validated in humans. A standard approach is to look for the physical (likely neural) correlates of a cognitive phenomenon and try to draw more general conclusions from those.
For instance, we observe through direct experience that we possess beliefs and knowledge, and we extend this capacity to other humans. We can record these beliefs pretty reliably, for instance by simply asking a (trustworthy) person whether they think a proposition is true or false. If we observe the underlying brain processes that accompany these propositions, we could identify which of those coincided with the phenomenology of believing or disbelieving those propositions, and ideally also perturb the relevant neural mechanisms to determine whether they play a causal role.
However, in practice, discovering neural correlates of beliefs/knowledge is difficult, both because it is very hard to experimentally isolate the cognitive processes of interest and because our current means of measuring and perturbing the brain are still relatively imprecise. A slightly different approach could be to directly use DLK methods like CCS, which ostensibly recover “beliefs” from internal states of models, to recover similar truth-like features from human brain data. This approach can provide us with candidate neural features whose relationship to beliefs/knowledge can be explored in detail. The advantage of this approach is that we can be reasonably confident that beliefs/knowledge are embedded within the observed neural activity, because we are able to connect these to phenomenology.
As mentioned previously, there is already at least one method (CCS) for discovering features in language models that look particularly belief-like. This method may even suggest a framework for how beliefs are encoded in neural activity. Under this framework, the consistency of beliefs with the semantic content of natural language statements is represented[[3]](#fn7ajemf68n8p) along latent dimensions of neural activity, similar to the way other features are thought to be represented in the brain and artificial neural networks alike. If this framework is true of human truth evaluation in natural language processing, then this predicts that we should identify latent dimensions in neural activity that discriminates between true and false statements as rendered by the individual. This accomplishes two goals: 1) It assesses the efficacy of CCS in pinpointing neural correlates of truth evaluation when we're confident such processes are influencing the observed behavior, and 2) it lays the foundation for a plausible framework for knowledge and beliefs, potentially applicable across diverse intelligences.
Testing lie detectors
---------------------
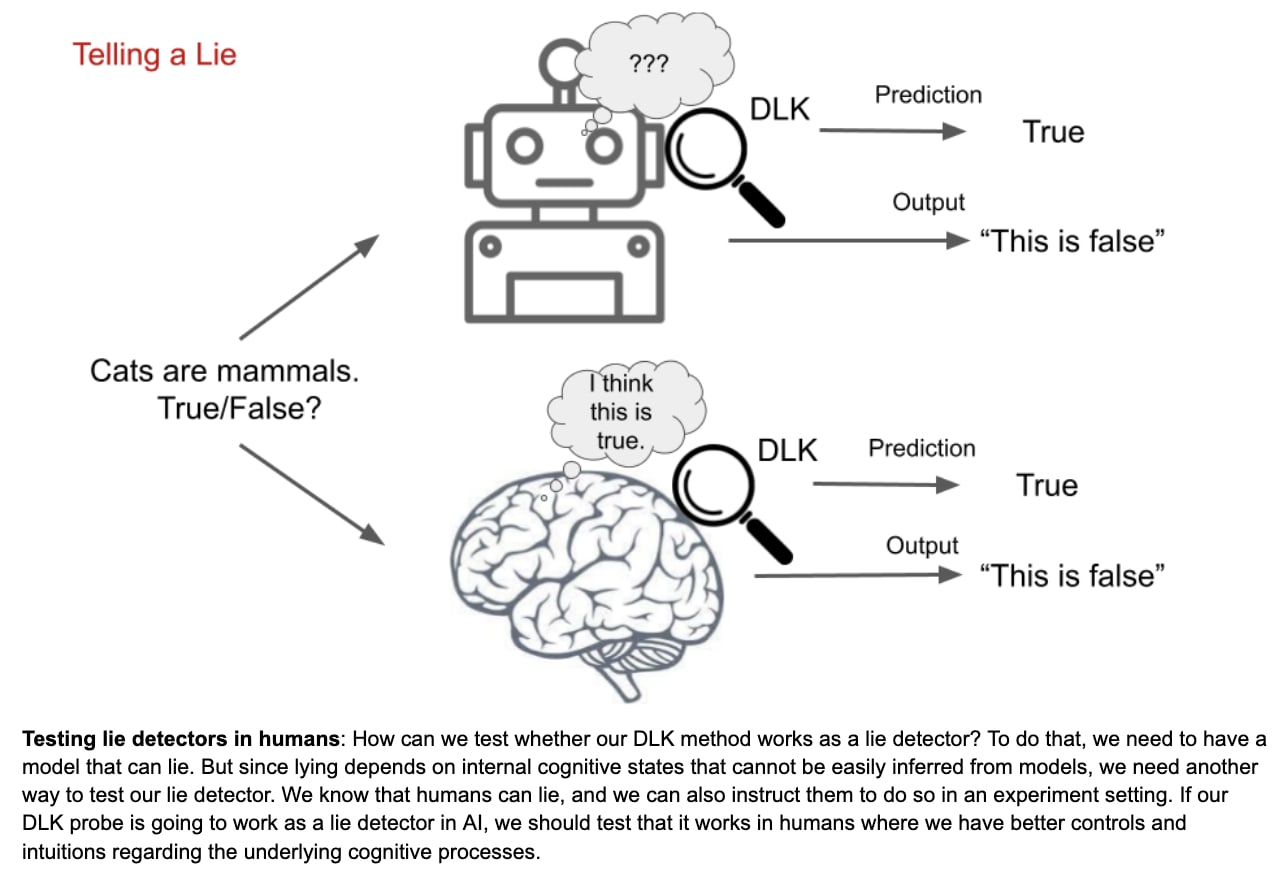Once we have built and validated our DLK method, we should be able to put it to use to identify when models are lying. But there is still a problem. While it is possible to get language models to produce outputs that are inconsistent with the predictions from our DLK method, it is still unclear whether these constitute lies, because our understanding is still limited regarding how the information identified through our method influences the model's behavior. For instance, the model may have misinterpreted the nature of the task, or it may lack access to the necessary information in its procedure for producing its response. To distinguish between these cases and deceptive behavior, we have to further define how beliefs are used in the context of lying.
Another layer of complexity arises when considering the stability of belief/knowledge embeddings identified by DLK across varied behavioral circumstances, including situations involving deception. If, for instance, belief embeddings are obscured during deception, the accuracy of DLK, developed under truth-telling conditions, may be compromised.
If we want to test our DLK method as a lie detector, then we need to test its ability to act as such in humans. Given that humans can intentionally lie, inducing deception in an experimental setting is feasible. Such an approach illuminates the underlying processes governing truth evaluation during honesty and deception. Moreover, subjecting our DLK method to various behavioral conditions will vet its resilience, offering further confidence in its ability to discern genuine neural correlates of specific cognitive functions.
Some other specific questions about CCS that can be addressed by DLK in the human brain
---------------------------------------------------------------------------------------
In order to be very clear about how I think DLK in the human brain could contribute to understanding open questions in AI safety, I’ll provide a few additional examples of specific questions that I believe would be addressed by this project. Note that I do not think that DLK in the human brain will provide definitive answers to any of these, but I think it could provide useful evidence before the arrival of human-level or superhuman AGI.
### Will future language models encode truth in a simple linear way?
If we find that humans do not encode truth with a limited set of features that are accessible with linear decoders, this may change our expectations for future AI systems. In this situation, it would benefit us to understand how humans evaluate truth, and then to look for these processes in AI. On the other hand, if humans do encode truth in a relatively simple way that can be assessed with linear decoders, then I might be cautiously optimistic that similar approaches will work for increasingly general AI.
### Are belief/knowledge embeddings obscured during active deception?
If we find that belief/knowledge embeddings are altered during active deception in humans, or that humans are able to deliberately obscure their belief/knowledge embeddings, for instance, by thinking of something else, then we should have more concern for this kind of behavior being exhibited by an advanced AI. Knowing this can help us advance strategies for promoting honesty that anticipate these kinds of behaviors.
### Can a purely language-based approach to DLK uncover beliefs that were not acquired through language?
A serious concern is that future AI systems will not explicitly connect their beliefs to language such that they can be elicited by methods like CCS. Humans, and presumably other intelligent organisms, invariably form beliefs through means other than interacting through natural language. It would be useful to test whether an approach like CCS, which operates through language, could ascertain beliefs that are formed by humans outside of language.
Some possible objections
------------------------
### Can’t we just build truthful AI?
Enforcing truthfulness in AI, especially LLMs, rather than honesty could be a more feasible and stringent criterion [[5](https://arxiv.org/abs/2110.06674)]. While honesty enforces that statements are made in accordance with beliefs, truthfulness requires that statements are verifiably true. Enforcing truthfulness sidesteps the issue of defining internal cognitive processes and relies only on external observations of behavior.
While I think aiming for truthfulness may be a valuable near-term approach and desirable alongside honesty, I worry that it will have limitations in enforcement as AI systems become increasingly capable, producing outputs that may be difficult to verify by humans. Assessing truth value in natural language is already not straightforward (see debates on factive predicates in linguistics e.g. [[6](https://muse.jhu.edu/article/864635/summary)]). Plus, training models exclusively on human-verifiable statements doesn't eliminate the likelihood of models misgeneralizing beyond their training data. Consequently, discerning a model's inherent beliefs and its adherence to them remains crucial.
I also worry that the framing for truthful AI too narrowly conceptualizes deception as “lying”. In fact, deception does not require that statements are made contrary to internal beliefs. Sophisticated deception is observed when an individual makes statements that are verifiably true in order to mislead or manipulate others to act contrary to how they would otherwise. This can happen when individuals anticipate that their statements will not be believed by others [[7](https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1468-0297.2008.02205.x),[8](https://www.nature.com/articles/s41598-020-67721-z)]. Numerous manipulative tactics don't necessarily involve blatant falsehoods but may be built around selective but still factually accurate statements. Given these considerations, I think aiming for honesty in AI, which circumvents both simple and sophisticated forms of deception, is a necessary long-term goal.
### Won’t it be obvious when we have identified the cognitive capacities of AI?
Perhaps we will discover methods that quite compellingly suggest that some AI systems possess certain cognitive capacities (maybe by exactly describing the process by which some process happens in full detail). However, I’m doubtful that we can be confident that these cognitive capacities map cleanly to concepts like “deception” and “honesty” without testing that we reach similar conclusions in humans. Any attempt to extrapolate human-centric cognitive notions onto AI necessitates a robust validation of these concepts in humans first.
### We shouldn’t expect the cognition of advanced AIs to resemble that of humans anyway.
I think this is quite possibly true. If it is true however, we should be extremely cautious about applying concepts derived from human cognition to AI. It still would benefit us to determine precisely how the cognition of AI differs from human intelligence, and what implications that has for defining what we mean by wanting to avoid deceptive behavior. For instance, if models do not have analogous belief/knowledge structures, then it becomes unclear how to approach the problem of deceptive AI, or whether deception is a coherent framework for thinking about AI at all.
### Language limits our evaluation of beliefs.
I am most worried about this objection, and I think it requires further consideration. When we use language to probe beliefs, we may be limiting ourselves to propositions that can be easily stated in natural language. That is, language may be insufficient to communicate certain propositions precisely, and therefore we may not be able to elicit the full range of beliefs/knowledge encoded by brains or AI systems. We can probably elicit certain things from the underlying world model through language, but what we would like to do is probe the world model itself.
Furthermore, language does not appear to be necessary to have beliefs/knowledge. The distinction between language and belief/knowledge appears to be demonstrated in individuals who have had corpus callostomies (i.e. split-brain patients). Often, these patients cannot express, through language or perhaps only certain forms of language, information that is only accessible to the non-language-dominant brain hemisphere. Yet, these individuals can still take actions based on this knowledge even if they are not able to connect it to language (see [[9](https://www.nature.com/articles/nrn1740)] and [[10](https://scholar.google.com/scholar?hl=en&as_sdt=0%2C24&q=review+of+the+split+brain+1975&btnG=)] for reviews of split-brain studies).
I think this objection might hit on some deep philosophical problems that I am not prepared to address directly. However, the current proposal still seems to at least be capable of addressing narrower questions like “How is natural language evaluated against beliefs/knowledge in the brain?” and “Can we use natural language to infer beliefs/knowledge directly from brain data?”, which is perhaps a starting point for addressing deeper questions.
Moreover, the concern about language being insufficient to ascertain beliefs/knowledge is just as much a problem for aligning AI as it is for studying belief/knowledge in humans. Therefore, this objection does not provide a specific criticism of the present proposal to test CCS in humans, and instead offers a legitimate critique of the use of CCS (in its current form) as a method for discerning beliefs/knowledge in general. I suspect that future methods will be able to discover beliefs/knowledge by eliciting them in ways that do not involve natural language, or use natural language alongside other modalities. These methods might end up looking quite similar to CCS. However, they also may require deeper theoretical foundations for intelligence. Regardless, when we develop such methods and theories, we should ensure that they apply to humans for the same reasons I have outlined above.
Conclusion
==========
I have outlined here why I think it is necessary to examine human brains to understand belief and knowledge at the appropriate level of resolution to use the concepts to explain the behavior of AI. Since our definitions of deception invokes beliefs/knowledge, understanding these concepts is essential for avoiding deceptive behaviors in AI. I think that perhaps the simplest way forward is to use our current methods for recovering “beliefs” in LLMs to recover analogous features in human brain data. This both tests the generality of these methods, particularly in the context of general intelligence, and begins to examine how the features recovered by these methods relate to belief/knowledge.
My biggest reservation is that CCS probes beliefs/knowledge through natural language. It seems unclear to me whether this will be sufficient to recover beliefs/knowledge that may have been formed outside of natural language and may not be explicitly connected to language. Furthermore, it limits the neuroscientific questions that can be addressed by restricting assessments to how world-models are brought to bear on language rather than probing the world-model itself. However, I tend to view this as a more general critique of CCS. It still stands to reason that DLK methods, including CCS and future methods that may or may not be tied to natural language, should be investigated in the human context.
Next Post
---------
My next post will outline a specific experiment for testing CCS with human fMRI data. I’ll provide an assessment of the current neuroscience literature on the topic of truth evaluation in natural language, the experimental details of my proposal, and the limitations of current methodologies for studying this topic in the human brain.
References
==========
[1] R. J. Seitz. Believing and beliefs—neurophysiological underpinnings. Frontiers in Behavioral Neuroscience, 16:880504, 2022.
[2] K. J. Friston, T. Parr, and B. de Vries. The graphical brain: Belief propagation and active inference. Network neuroscience, 1(4):381–414, 2017.
[3] D. Marr. Vision: A computational investigation into the human representation and processing of visual information. MIT press, 1982.
[4] C. Burns, H. Ye, D. Klein, and J. Steinhardt. Discovering latent knowledge in language models without supervision. arXiv preprint arXiv:2212.03827, 2022.
[5] O. Evans, O. Cotton-Barratt, L. Finnveden, A. Bales, A. Balwit, P. Wills, L. Righetti, and W. Saunders. Truthful AI: Developing and governing AI that does not lie. arXiv preprint arXiv:2110.06674, 2021.
[6] J. Degen and J. Tonhauser. Are there factive predicates? An empirical investigation. Language, 98(3):552–591, 2022.
[7] M. Sutter. Deception through telling the truth?! Experimental evidence
from individuals and teams. The Economic Journal, 119(534):47–60, 2009.
[8] M. Zheltyakova, M. Kireev, A. Korotkov, and S. Medvedev. Neural mecha-
nisms of deception in a social context: an fMRI replication study. Scientific
Reports, 10(1):10713, 2020.
[9] M. S. Gazzaniga. Forty-five years of split-brain research and still going
strong. Nature Reviews Neuroscience, 6(8):653–659, 2005.
[10] M. S. Gazzaniga. Review of the split brain, 1975.
1. **[^](#fnref5ah6drf5sfp)** Referring here to David Marr’s levels of analysis, which distinguishes between the computational level - the goal of the system, the algorithmic level - how the computation is achieved, and the implementation level - how the algorithm is physically instantiated.
2. **[^](#fnrefh4gbanft2x6)**This topic appears closely tied to [Eliciting Latent Knowledge (ELK)](https://www.lesswrong.com/tag/eliciting-latent-knowledge-elk#:~:text=Eliciting%20Latent%20Knowledge%20is%20an,that%20look%20good%20to%20us.), but for the time being, I am assuming that the reporter for the model’s beliefs will be simple enough that we don’t have to worry about the human simulator failure mode described in ARC’s first technical report on the subject. Regardless, my intuition is that the problem of defining belief/knowledge will be common across any approach to ELK, and could therefore benefit from validation in humans.
3. **[^](#fnref7ajemf68n8p)**It was pointed out to me that saying that truth is “represented” by the brain might be a misapplication of the framework of representationalism in cognitive science. To avoid misusing this terminology, I will try to use “truth evaluation process” as an alternative to “truth representation”. |
0718a0f2-f8b6-4288-bae4-07b842827483 | trentmkelly/LessWrong-43k | LessWrong | Does anyone else feel LessWrong is slow?
Ever since the rewrite of LW, I've felt that performance has taken a pretty big hit. Even compared to other large sites like Facebook, LW seems to take longer to render.
I'm hoping someone from the dev team can answer if performance is something that has been optimized for?
EX: Running a quick Lighthouse audit seems to show that there's room for improvement.
https://i.imgur.com/NeupVYX.png
I'm also confused because GreaterWrong works significantly faster (to me, subjectively), and it seems like the two sites have roughly the same functionality? |
9bda369c-b508-4f69-99ca-93c2ef6489ac | trentmkelly/LessWrong-43k | LessWrong | Could my work, "Beyond HaHa" benefit the LessWrong community?
I’m considering translating my work into English to share it with the LessWrong community, but I’d like to first ask if it aligns with the community's interests and could be valuable. Below is a summary of the work to help evaluate its relevance:
Beyond HaHa: Mapping the Causal Chain from Jokes to Knowledge
Summary
We explore the specific causal mechanisms linking humor recognition to learning outcomes, including the computational and neurological pathways involved.
This study began with a practical goal: to evaluate the use of humor as a pedagogical tool in Cardiopulmonary Resuscitation (CPR) courses through a randomized trial. However, the lack of clear criteria to define and operationalize "humor" in educational contexts led us to explore its conceptual foundations. Initially, we adopted Clarke's formula, which describes humor as "a pleasant reward for recognizing corrupted data," due to its apparent objectivity and connection to information theory. Testing this definition revealed that it failed to encompass aspects traditionally considered humorous.
However, this process resulted in a more precise conceptualization that aligned notably with neurocognitive findings, such as those by Amir and Biederman. These researchers demonstrate that humor activates reward circuits similar to those involved in cognitive insight ("aha moments"), though with distinct emotional and social impacts. Notably, our observations resonate with works like Ha Ha! Versus Aha!, which explore the relationship between pleasure, surprise, and understanding in both processes. These findings suggest that humor may be conceptualized as a cognitive reward linked to the pleasurable resolution of incongruities, though its pedagogical impact requires further probabilistic studies and we propose a formula a little more mathematic. This approach opens new avenues for connecting humor to information theory principles and exploring its applications in education.
Keywords: Humor, Comedy, Ed |
3ad2f947-5369-4079-adf2-d491828df245 | trentmkelly/LessWrong-43k | LessWrong | Superbabies: Putting The Pieces Together
This post was inspired by some talks at the recent LessOnline conference including one by LessWrong user “Gene Smith”.
Let’s say you want to have a “designer baby”. Genetically extraordinary in some way — super athletic, super beautiful, whatever.
6’5”, blue eyes, with a trust fund.
Ethics aside[1], what would be necessary to actually do this?
Fundamentally, any kind of “superbaby” or “designer baby” project depends on two steps:
1.) figure out what genes you ideally want;
2.) create an embryo with those genes.
It’s already standard to do a very simple version of this two-step process. In the typical course of in-vitro fertilization (IVF), embryos are usually screened for chromosomal abnormalities that would cause disabilities like Down Syndrome, and only the “healthy” embryos are implanted.
But most (partially) heritable traits and disease risks are not as easy to predict.
Polygenic Scores
If what you care about is something like “low cancer risk” or “exceptional athletic ability”, it won’t be down to a single chromosomal abnormality or a variant in a single gene. Instead, there’s typically a statistical relationship where many genes are separately associated with increased or decreased expected value for the trait.
This statistical relationship can be written as a polygenic score — given an individual’s genome, it’ll crunch the numbers and spit out an expected score. That could be a disease risk probability, or it could be an expected value for a trait like “height” or “neuroticism.”
Polygenic scores are never perfect — some people will be taller than the score’s prediction, some shorter — but for a lot of traits they’re undeniably meaningful, i.e. there will be a much greater-than-chance correlation between the polygenic score and the true trait measurement.
Where do polygenic scores come from?
Typically, from genome-wide association studies, or GWAS. These collect a lot of people’s genomes (the largest ones can have hundreds of thousands of subject |
46e16229-b821-4b94-ada4-f0e77e67637a | StampyAI/alignment-research-dataset/youtube | Youtube Transcripts | Attention - General - Summarizing with NMF [rough early thoughts]
the goal of these videos isn't just to
understand toy transformers we want to
be able to understand transformers as
they're used in practice the kind of
large models that um are getting all
these really exciting results lately
and in our previous video we sort of
addressed one of those one of the
challenges to that which was um you know
talking about how switching from
attention only transformers to
a real transformer introduces various
theoretical challenges and how we can
work around them
but there's also a really practical
challenge which is these models that can
be huge
and even just when we're if we're just
talking about the attention heads um you
can easily have thousands of attention
heads in large models and you might want
to be studying multiple models as well
um and so this video which you you can
skip over if you want um
is a better trek for sort of summarizing
and getting a big picture overview of
the kinds of things that exist in a
model um at least the kinds of tension
patterns that exist in a model
and attention circuits
and yes we're going to try and get an
overview and the trick we're going to
use
is something called non-negative matrix
factorization or nmf
um and
uh
the i'm i'm chris i'm i'm i'm the one
who is recording uh this this particular
video and i have to confess
um
i'm kind of obsessed with nmf
people who are familiar with my previous
work or know me personally may know that
really one of my my first reactions to
almost any problem
is to try and go and apply
uh nmf
um and at least in computer vision it's
been really effective so um one example
that i'm i'm i'm quite proud of
um is in one of our papers the building
blocks of interpretability we used nmf
um
to decompose the activations of a vision
model
and so for instance here we have
uh
a picture of a dog and a cat
and
there are about 500 neurons in every
position the continents at every
position there's a there's like 500
neurons and that's a lot of neurons to
look at but we can just go and use nmf
to go and reduce this into a small
number of factors that describe the
activations at every position so we see
here
there's like one factor that corresponds
to the dog's ear and the head and the
snout and the bodies of both the cat and
the dog and the background and the cat's
head
and we can kind of summarize things
um and so that that was really effective
and and pretty consistently nmf
is just a really powerful tool if you
want to go and summarize
summarize things
so
i
yeah one of the first things that i did
when i started working with transformers
was to try and apply the same approach
and
um that seems to work quite well
so just stepping back a second uh
non-negative matrix factorization uh
is it's just a kind of linear
dimensionality reduction
um and really all we're saying is we
have a matrix
um
and our matrix
um you know has some some width and some
height
and we try to describe it as a product
of two smaller matrices so one of them
will be tall and thin
and one of them will be narrow and wide
and they multiply together to go
uh and produce the
the big matrix
um and then
it's non-negative because we're going to
go and require that both of these
uh matrices that we write as the product
be positive so if we if we tried to go
and do this without any constraint and
you get principal component analysis
these will would end up maybe not basis
aligned but you'd end up extracting if
you have this is say k dimensions on the
on the the small side that we've created
um you'd get the first k principal
components
that when you go and you add the
positivity constraint you get something
else um
and there's just kind of this way in
which nmf
tends to be interpretable and this isn't
just a property in machine learning and
you actually see this in the sciences
where often um in
say in physics people will prefer to use
nmf sometimes i think one really
striking example of this is if you take
a data set
of uh and i'm not a physicist so uh i
might mistake this but if you if you
take this a data set of the spectral
emissions of different stars
and you apply nmf
and you'll go and have all the different
star types go and and just fall out as
the factors of nmf um whereas that won't
happen if you if you do pca and you
you'll see this in other cases that um
you know in physics people often um
there will be cases where people prefer
to use nmf and yeah my experience is
just an interpretability um
uh this works works really well and we
could talk more some perhaps i'll
produce another video sometime about why
you should expect nmf to work
particularly well but nmf is often a
very very nice way to handle things
if you want to do some kind of
dimensionality reduction
so the idea here is we're going to take
all the attention patterns
in our model
um maybe even all the attention patterns
from multiple models and so each
attention pattern is a tokens by tokens
matrix and then for every attention head
we have one so we get a three
dimensional
and the question is how can you apply an
mf to something that has three
dimensions it's a matrix factorization
technique not a tensor decomposition
technique at least on space and what
we'll do is we'll flatten the tokens um
and the two tokens dimensions into a
token squared dimension into a single
one
and then we'll apply nmf
and nmf gives us two factors the pattern
factor
and the heads factor so the pattern
factor
is going to be at tokens times tokens
and we'll go and turn that in
unflattened into it a token's tokens
components
so it's sort of just like originally we
have an attention pattern and then
rather than having an attention pattern
like a tokens by tokens pattern
by for each head we have one for each
component
and then each component that should be
components not factors but each
component
um is a vector over heads
so we have
one factor that describes where each
component looks
and one factor that describes which
heads correspond to each factor
which component
okay
um
and this is a little bit of a technical
point and
if you don't follow that's that's
totally fine but there is this
interesting observation that actually
this is actually kind of quite principle
to do
and in fact um if you think of all these
equations we've been writing that
describe
uh transformers we always have this
these terms that look kind of like this
where we have a sum over attention heads
and then we have this tensor product of
the attention pattern um and wov though
v for each
matrix for each head
um and it turns out that you can
approximately rewrite that it's kind of
a change of basis but a change of basis
there are tensors instead of matrices in
terms of these components
um and it'll only be approximate if the
you know as you increase the number of
factors will get better and better but
you have
sort of this attention factor that sort
of you can think of as being an
attention pattern that exists for each
component and
then you can go and construct an ov
matrix for that component which is the
the sum over heads of how much uh the ov
matrix for each head and how much it
exists in that factor
in that component in any case um this is
really cool because it means that we
have potentially even though we could
potentially have a very large number of
heads or if we start working with
virtual density nets we can have an
exponential number heads we have a way
to potentially keep trying to re-express
uh things in terms of a smaller bases in
any case this is kind of a technical
point um
and not immediately relevant
so i think the more immediately cool
thing
is that we can go and take all of the
attention heads in the model on all
their attention patterns
and
express in a single image
a sort of summary of the model so here
we have um this is actually not for the
model we're going to be looking at this
was one of my first experiments doing
this with gpd2
um
and
uh you can just
go and take all the attention patterns
and you you just go and compress them
all and here we've mapped each one to a
color and we can sort of get this this
overview of the kinds of the largest
scale attention structures
and you can ask what those are so for
instance um those green stripes turn out
to be periods
um now
you'll recall from the previous video
that often when we see an attention head
attending to periods that's because it's
kind of a
it's acting as a resting position
and so
some of the structure that you see if
you if you apply this natively turns out
to be you see a lot of interesting
structure but it turns out that
structures kind of kind of superficial
um
but
we can do better than that because we
can go and apply it not just to the
regular attention patterns but we can
also apply nmf to the info-weighted
patterns and to the attribution patterns
um and that will be
really informative so let's switch to an
interactive view because that's
um
that'll be a lot more effective for
looking at this
oh
that's not what we got
okay so
um so this is actually going to be
probably a fairly extended chat about
the kinds of things we can see in these
nmf factors um and so feel free
to uh
to end if you just wanted to understand
sort of um what kinds of things exist in
these in these models but uh what we
have here
uh we'll just start with
uh
with we'll we'll start with an an
inflated pattern so we take all the info
weighted patterns in the model for every
attention head and in fact we're doing
this for two large models so it's even
for two models
and we're just going to reduce it to the
20 factors that um yeah that do nmf with
20 factors and so we get 20 different
um yeah we had 20 components that have
expressed different different common
patterns um that the attention heads
have and some are are not that
interesting like even though we did
infrareding we see that there's one
factor
um that really wants to attend to the
eot
token so
and that gets
that's there
um but there are a lot of really
interesting ones so
uh
one that's kind of cool is we see um
there's a
fact a component that corresponds to
attending back to
um
the uh
sort of to
to persons or pronouns or something like
this so here we have sun
um
boy um and one way that's that's often
effective to understand these things is
we can just look at
uh
every token how much it's attended to
and you can see that
more or less these are these are all
peoples in some cases they're nouns um
here we have we have blonde over here
but it's um probably
blonde could be also a noun that would
be a person so that makes that make
sense
um and we'll we'll see more when we look
at attribution that things like this uh
are really helpful because you might
want to predict later pronouns um or
like the gender or plurality of a
pronoun maybe um or even just attributes
when you're when you're describing
someone um might be might be helpful to
go in and remember what sort of person
you might be talking about
um
yeah we also see
uh ones that uh correspond to
um yeah to because although
but
um
uh
there's there's an interesting this is
actually a very common thing that you'll
see
i don't know what the linguistic term
for this is but you'll you'll often see
um components and attention heads that
seem to attend back to the last thing
that could either
um
either be
a introducing a that clause a verb or
something else that creates a that
clause so like um you know let's you
know they were proud that and it doesn't
actually do that but um you know
they could have said proud that or maybe
proud to um say that
um
with that um you could think that
uh you could have uh an opinion that
could be useful that
um
you might fear that
um you could have a reason that
um
uh you might want
uh
that somebody to do something
um
yeah i guess shut or maybe it's really
two but it's sort of functionally
similar um you might think that um so
you have all these things um you might
expect that um in a lot of cases you
will lied the that informally
um so like when we say opinion there was
it's it's really it you know it's their
opinion that there was so it's and it's
all these places where something like
that could be introduced
um
uh and you could imagine that's really
important because then in the next class
if you if you look at these and you look
at which tokens attend to them
and it's really the next clause
and you know the kinds of words that
might be in a in that clause really
depend on um you know
what is the context of this clause so
that's that's a very useful attention
pattern maybe
um attending to the previous token and
so i should look at it that we're
looking at where we're attending back to
um so that's that's a very common thing
um this one will be easier if we look at
where which words are getting the
attention again this is attending to
people but it's really attending to any
word
um
that implies
a gender or whether something's plural
or maybe a noun but um so it's it's it's
yeah there's we see there's there's lots
of people there's lots of um pronouns
titles misses implies you know female uh
mr implies male so that's that's helpful
they imply is plural
um uh
and yeah we'll we'll see later on that
things like this you know her implies
female against sister implies female um
uh the
where where is this but uh the the lees
and dursleys implies plural and we'll
see this is super important um because
there's actually a fair amount of
intervene guessing you know what is the
right pronoun what is the right
plurality what is the right conjugation
of a verb um so tension heads like that
and attention patterns like that are
very common
um
of course we see attention heads that
are related to induction so um it's
probably easier to look at this way that
we go and we we were on d
we look at previous cases where d
happens look one ahead and we see lots
of attention patterns like that and nmf
will start to split them up because
there's there's lots of induction heads
that might be doing very slightly
different versions of induction
um
yeah here's a factor that maybe is
approximately looking at verbs um
uh it could be that it's maybe trying to
get at the tens of verbs um or maybe
it's just useful to know what the the
last verb is
um it's there's some exceptions like
obviously director isn't a verb maybe if
we had more factors this would split
apart a bit more and we get something
that's more clearly a verb
um
yeah so those are those are factors that
i thought were pretty interpol um and
interesting now we can instead of doing
20 factors we could do 40 factors with
the the introverted patterns and you
know i wonder if there's some here that
are
uh are worth mentioning
um a lot of these are
uh
pretty similar to things that we saw
like there's a
there's one that is yeah cases where
there could be a bat it's maybe a little
cleaner um yeah
you know
say that expect that
um it was their opinion that
um
it might be useful that
um
you might think that you might pretend
that
um you might you might think that it's
possible that um
i guess shudder two you might
you might want somebody to do something
or want that something happens you might
know something know that
um
you might have a reason
um
yeah reason that are you you might if
reason was functioning as a verb it
might be uh yeah reason that so this all
these words that are sort of introducing
a clause
um a particular kind of clause i guess
um
this is interesting uh you'll you'll see
sometimes attention heads that look for
the to the first token of words so we
should look switch to a mode where we're
looking back
um so ordinarily it attends to
the
token that's on
um
but when you're in a a word or a
compound word um it'll often attend to
earlier tokens in that so yeah here we
have we're on potters it's attending to
the first token if we go to dursley it's
tending sort of to to misses and the
earlier tokens in it um to the d there
um
mustache we're attending to the earlier
tokens in mustache
and so that's a fairly common pattern as
well
um
yeah uh
here again we have something that's
maybe uh you know the
person the gender plurality and we have
lots of um lots of attending to pronouns
man is another word that sort of implies
something about gender maybe and things
that attend applied plural and this is
gonna be really useful again for for
predicting conjugation for predicting um
uh for predicting pronouns later on
um you'll be able to go and recover some
entropy that way
um there's a lot of induction heads here
i'm going to skip over that and here's
one that may be doing tense
um again when we're just looking at
factors like this if we until we get to
attribution we can't really uh say for
sure what the function is but you know
this looks like it might be you know we
have an imperfect past tense imperfect
past tense
um we have some some perfect
uh
tenses we have uh some subjunctive some
subjunctives we have some some gerunds
um
and that really seems to be what we're
what we're mostly attending back towards
um
uh could also be telling us maybe a
little bit about the the conjugation of
the verb
like is there a singular plural
subject in some cases
um yeah bunch more induction heads oh
this one's cool that's worth talking
about um
you'll often see these
uh
determiner
uh
uh attention heads and components so
here
um a determiner is kind of a
generalization of the idea of an article
so we'll see a lot of cases where we
have you know a
the
um a
um
yeah thus we have these these perfect
and uh or these
uh
uh
yeah we have these different articles um
we also have her sort of functioning as
an almost like an article for sister
right it's it's it and it's sort of
replacing an article so that's another
type of of what people called term
determiner
several is kind of functioning in a
slightly similar role there
sometimes no functions
in a similar role or such a sort of
functioning in a similar role to that
anything is kind of replacing um an
article there as well
um
uh
yeah um so you you had these things now
it's not exact um yeah here the the
possession here is sort of replacing an
article for sister
um now this there's some things here
that where that doesn't make sense
um although in a lot of cases
uh it's in places where there's a
missing article but
uh or there's sort of an aligned article
in some way but
this doesn't make sense exactly you'll
see attention heads that do this more
cleanly when we start looking at
attention heads perhaps
um
conjunctions
um yeah we have because although but
and but
and
um i guess in some ways a semicolon is a
little bit similar to a conjunction and
then it's joining together two clauses
and which
nouns yeah that that maybe is a little
bit of a noun component
um yeah propositions here
in
in
for um maybe maybe some things that are
not quite that mixed in as well okay so
um the thing that we can do though so so
far we've talked looked at introverted
patterns and compressed them down
to uh
uh
yeah to a small number of components
we're summarizing thousands of attention
heads here just in a few components
um
and sort of getting an approximate sense
of some of the things that might exist
um we can also look at
attribution patterns and that's nice
because it'll give a more functional
um
more functional explanation of these
um
so
uh
yeah the the most one of the most common
things is going to be induction
so
for instance here we have
a
we're predicting d
um so remember because we're now on an
attribution pattern it's no longer the
token that's attending back it's the
token that's being having its logic
affected so this is saying that by
attending back to all these d's we
increase the probability of this d here
um and so it's really it's actually this
mrs token attended back to mrs and then
the d over here and then increase the
probability of this d
okay so
induction's really common um
because it's just such a big part of
what's going on when you look at least
of these direct attribution
patterns
when you look at
uh you'll see a whole bunch of induction
patterns so that's one induction pattern
here's another induction pattern
um
here's another induction pattern that's
getting the middles of the words and you
know
it's getting split apart because
different induction hens are giving you
know slightly different weights to
slightly different parts of the word um
and then nmf pulls them apart
um
but
uh yeah so
you'll see a whole bunch of factors that
are involved in induction and when we go
to a larger number of factors that'll
that'll get even bigger bigger um
we'll see things related to uh
other kinds of copying as well so like
this one's really simple but here we're
copying that dash
um so we have good for nothing
the good the dash increases the
probability the other dash it's getting
copied
um
one thing that's really cool and we will
see a lot of when we start looking at
attention heads as well is um
uh attention circuits that are
responsible for maintaining um gender
and plurality um an agreement around
those
so
uh
yeah okay how did we so the colors that
we're seeing here we're seeing words
that are where their probability was
increased by this attention factor
attention component and um we can look
at what it what it was doing well it
looked at um especially at war
um were is a
uh yeah it's conjugated so that we know
it's plural um so that's that's helpful
um
this day
um
yeah this is actually a little less
clean than i was expecting it to be the
fact that it's affecting these tokens is
very clean
um
but perhaps this component is a little a
little less clean than i was expecting
and we're seeing some cases where where
it's still fairly straightforward but
maybe let's just very quickly
quickly explore this yeah so was
um yeah okay so sun ham those are both
really implying uh male
um singular they the dursleys knew um
and we're also actually a little bit of
attention back to uh
um
a little bit of attention back to the
day there as well
um but it wouldn't surprise me if
there's some virtual attention heads or
information being moved around in a way
that's making this a little harder to
see her sister
there's another
component we'll get a cleaner component
also when we go to the 40s the 40
factorization but um
yeah they
say
um
this one's also not that clean there's
probably a bunch of virtual
attention heads going on
yeah i bet
um
yeah so like here
well i guess shuttered might contain a
bit of information about this but it
could also be that dursleys is clearly
plural and some of it got folded into
there
um by another attention head and then
we're picking it up
um yeah they were going and seeing
seeing a previous day but it's yeah
usually this is cleaner uh so we'll
we'll come back to that in a in a later
one
um
it looks like there's an still another
one so let's have a look at this one uh
yet child so this is this is maybe not
just gender it might also be um more
generally sort of information about
recent people who've been talked about
so
um you know we we have some things maybe
that are related to age and being a
child and that helps us predict this is
going to be child here
um and not just
um
yeah or
uh
her sister we're just literally copying
the word sister a bunch of times
um misses we've seen misses before
something sort of in between
a more simple copying head and something
that maybe declares about gender
plurality or something like this or
maybe a copying head that's specifically
involved in people
um
okay so that's that's another kind of uh
interesting thing and we'll we'll get a
better example of that in a minute
um
uh
i don't know if we talked about that one
there's another one so again we're
getting a whole bunch of components that
are involved in
thinking about
gender plural things like that
that's quite common now one other
important type of
attention circuit that we see
is what i've called an engram circuit or
an engram attention maybe
um component
and
these ones are kind of mysterious
uh and i i have a pretty strong
hypothesis about what's going on but i'm
not sure so
the observation is
um
if you look at these
and you'll see that they
uh you know there's they're they're just
jumping across words in a kind of you
know unpredictable way um and some
earlier word just increases the
probability of this word but if you
start reading them aloud you'll notice
that they sort of they almost rhyme like
her husband well
there's some way in which like those
could just be side by side and they
would increase in probability um
with child
um
keeping away
another reason um
what what neighbors um
uh
four years
time
exiting
um
in strange
um
over fences
uh and there's a bunch of other ones let
me go to another engram head
um
yeah
uh
what would it's so blacked out there
that you can't even see it uh it's so
intense but yeah what would
um
uh that's actually that would
um
so those are those are both sort of
clearly very common phrases like it's
very common for wood to come after um
over what
um past tense didn't
um
they want
um semicolon one doesn't make as much
sense keeping away again
another reason again and we saw that in
a previous one
um
with nonsense
say were
uh
anything or
um let me go and find
there are a bunch more of these but
here's another one
um
yeah anything or
have large
um of time
finer anywhere
and
so in any case i've been ranting about
this for a little bit but the hypothesis
is that these are just
they're they're kind of like bigram
statistics so they're like bigram
statistics at a distance now that's
probably a simplification oh this is
copying the ads and that's kind of a
simplification um
uh and it's probably probably not quite
that literally
quite that literally what these
attention heads are doing it's probably
not quite that simple but um we saw
things like this a little bit even in
the one layer model and and
uh yeah i suspect that there's
uh that we're there's more of it so
let's switch the 40 layer or the 40
factor one again attribution so this is
now we have
40 components um and
uh each one we're seeing which tokens
affected which other tokens through
some set of attention
heads um and yeah just continuing on the
engram one for a second
again it's gonna be a lot of the same
thing um with nonsense
four years
with child
keeping away
another reason
her husband
um
for years
uh
somebody discover
and these are kind of weak
um although they're kind of interesting
now let me go and switch back to this
view so that i can see some other ones
a sun
on the neighbors
um over fences
the amount
in strange
um
you know makes me think of uh god works
in strange and mysterious ways
sorry there was a technical glitch there
um
but
uh yeah let's look at some other ones so
those are the engram ones we see a bunch
of things involved in tense and plural
so here
um
had we're looking at all these previous
words that are past tense
um was we're looking at previous words
that are are imperfect past tense um
singular i guess
um you might wonder about and um but
remember that and is often going to
imply plurality and so it sort of makes
sense that's getting caught up in the
circuit as well
um there's a whole bunch of past tense
by the time we get here it's more
diffused because there's so many past
tense words that we can look at
um
uh
yeah misses well it's more about titles
there so it's that's not quite as clean
um and there's a bunch again of these
these tense
uh
copying sort of attention heads
um
i'm just going to keep going on this for
a little bit because there might be
people who are finding this interesting
but um please feel free to drop off and
just zoom to the next video at any point
um
uh
yeah where's another one
that's involved in
that well there's a we're calling this a
person copying one but it's like um sun
increases the probability of child
sister of sisters
and things like that
and that's not quite gender copying
maybe i'm surprised
um seems like there's a little bit
caught up in that one uh oh here we go
yeah so
um here we have
misses increases the probability of she
um
okay so that that is sort of introducing
a clause that could be subjunctive um
but okay here a bunch of
the dursleys is plural potters as plural
increases day
um
so that's kind of a classic
uh type of plurality
sort of consistency
um all of these yeah the the dursleys
plural they plural potter's plural
increases the probability of day
it's a new clause starting
new clause starting
um
uh yes mrs
implies female sisters female
uh so we're seeing all these things and
and of course you know why okay so why
is this head doing both tense and sort
of gender
um plural plurality agreement well i you
know that those are often kind of
intermingled um since
you know you're trying to predict verbs
um the conjugation of the verb depends
both on the tense and the
the
the
the plurality and gender of the subject
maybe probably just the plurality so
that makes you want to look at pronouns
once you're looking at pronouns you can
easily copy gender information and and
so
uh and you know you can predict later
pronouns um so those sort of naturally
go hand in hand a little bit
okay so
um what about other things well again
there's a ton of heads involved in
induction they're sort of they're
they're pretty simple and we've talked
about them a lot so i'm going to skip
over them but induction
or factors involved in an induction and
it's just that induction is getting
split apart in a way that's a little um
a little sad right now because
that's just
part of what happens when you have a
whole bunch of components and induction
heads are so big and they they attend in
slightly different amounts to different
different examples
and actually wants to do that
okay so what do we have here that we
haven't talked about
uh
maybe
is there anything here
that we a lot of these are just copies
of things that we saw
previously
now there's one that's maybe
specifically involved in copying titles
mrs misses
um
uh
yeah i think i'm going to call it a d
there so
um maybe let's just very very briefly
summarize um if we look at
uh
particularly if we look at the
attributions
the
basically the the direct attribution
effects of attention heads have a pretty
simple story there's a bunch of heads
that are doing engrammy things
um or these sort of bigram skip type
things that sort of seem kind of local
and seem to just be about the
there's lots of words that have affect
the relative probability of words nearby
and we can just in a pretty simple way
model that
there's a bunch of these um induction
and copying heads that's just tons and
tons
and tons
of induction
type stuff going on um that allows us to
go and just copy previous words um that
and and increase the probability of of
when something similar happens um the
same same tokens appearing
then there's a bunch of heads involved
or
attention components involved um that's
not one
in in copying people
gender plurality handing verb subject
agreement handing handling verb tense
you know consistent tenses between
sentences
um
so there's there's a lot of stuff like
that
and honestly that's a pretty big
fraction at least of the
interpretable stuff that seems to be
going on when we look at attribution
um when we looked at raw attention
patterns we saw some stuff that isn't as
emphasized when you look at attribution
like we saw this determiner
component
that was really cool or the preposition
component
those didn't have as dramatic an effect
um
when we were looking at the
the attributions they're probably a
little bit smaller
in terms of their effects or primarily
having indirect effects um so maybe
their effects are more mod yeah more
um
more moderated uh by later retention
heads and mlps rather than having a big
direct effect
um but yeah so that gives us a sense of
some of the things that we should expect
to find when we are poking around in
these models
um and in our next video we'll actually
look at the attention heads um and sort
of move past these factors |
07c0a168-4114-4b60-a7ac-124683588522 | trentmkelly/LessWrong-43k | LessWrong | Word-Distance vs Idea-Distance: The Case for Lanoitaring
Defining Word-Distance
There’s a concept in information theory called Hamming Distance. Without delving too deeply into the theory, Hamming distance is a way of describing how different two sequences of characters are.
Take the two character sequences (in this case a series of bits) 11110000 and 11001100.
How different are they?
Their Hamming distance is defined, as per Wikipedia, as
> the number of positions at which the corresponding symbols are different.
So we line up the two series of bits, and compare them character by character:
11110000
11001100
I’ve bolded and italicized the characters that are different.
In this case there are four of them, and so we say that the Hamming distance between the two bit strings is four.
With the idea of Hamming distance, we can envision something we might call word-space: the collection of all possible words, each separated from the next by its Hamming distance (or some analogous measurement). The words “call” and “cell” might be close to one another in word-space, only differing in a single character, whereas both words would be far away from a word like “disingenuous” or “Machiavellian”.
Defining Idea-Distance
Analogous to word-distance, we might imagine something like idea-distance. While it seems difficult to precisely define or enumerate how different two ideas are from one another, relative measurements can be used to achieve a similar effect.
Take the idea of a “city,” for instance. Is a “city” more like a “town” or a “banana”? Obviously a “city” is more like a “town,” so “city” would be closer to “town” in idea-space than to “banana”, or “Marxism”, or “aquaculture”.
Using Distant Words For Distant Ideas
Hamming distance is used when designing and selecting error-correction codes. The idea is that communication isn’t perfect - information gets lost when transferring it from one place to another.
Thus it becomes important to make sure that the message you’re sending can’t be easily mistaken for anot |
f4bc27ff-825e-4a70-9d77-628d21042cdc | trentmkelly/LessWrong-43k | LessWrong | Why isn't increasing ventilation of public spaces part of the best practice response to the Coronovirus?
It's my impression that there's some spread via aerosol in public spaces like buses and trains. By increasing ventilation in those spaces by opening more windows I find it plausible that we could reduce that transmission.
Why aren't health orgs pushing for increasing ventilation of public spaces? |
2454911d-ef49-4d65-96bf-d8854137e092 | trentmkelly/LessWrong-43k | LessWrong | Chapter 73: SA, The Sacred and the Mundane, Pt 8
The red jet of fire took Hannah full in the face, flipping her end-over-heels and smacking her head straight into the stone wall, where her pale face seemed to linger for an instant, framed by flying strands of brown-golden hair, before she collapsed to the ground in a heap of robes, as the third and final volley of blazing green spirals brought down their foe's Shield Charm.
The March days marched by, filled with lectures and study and homework, breakfast and lunch and dinner.
The Gryffindor boy stared at the eight of them, tension in every line of his body's frame, his face working soundlessly; and then his hands released their clenched grasp on the Slytherin boy's lapels, and he walked away without anyone saying a word. (Well, Lavender almost said a word - her mouth was just opening in indignation, maybe because she hadn't gotten a chance to declaim her speech - but luckily Hermione spotted it and made the gesture that meant SHUT UP.)
Then there was sleeping, of course. You wouldn't want to forget about sleeping just because it seemed so normal.
"Innervate!" said the young voice of Susan Bones, and Hermione's eyes flew open and her lips drew in air with a gasp, her lungs feeling heavy like there was a huge weight resting on her chest. Beside her, Hannah was already sitting up, holding her head in her hands and grimacing. Daphne had warned them that this would be a 'hard' fight, creating a certain trepidation in Hermione, and indeed in all of them. Except maybe Susan, who'd just shown up at the appointed meeting-time, and walked alongside them without speaking, and fought the seventh-year bully until she was the last girl standing. Maybe the Gryffindor had been reluctant to fight the last daughter of Bones, or maybe Susan had just gotten very lucky; at any rate, when Hermione had tried to sit up again, she'd realized that her chest had felt heavy because there was, in fact, a rather large body sprawled on top of her.
And you wouldn't want to forget about magi |
27a2fd53-60b8-49a1-b3ca-33743144fc88 | trentmkelly/LessWrong-43k | LessWrong | When Intuitions Are Useful
Part of the sequence: Rationality and Philosophy
In this series, I have examined how intuitions work so that I can clarify how rationalists1 should and shouldn't use their intuitions2 when solving philosophical problems. Understanding the cognitive algorithms that generate our intuitions can dissolve traditional philosophical problems. As Brian Talbot puts it:
> ...where psychological research indicates that certain intuitions are likely to be inaccurate, or that whole categories of intuitions are not good evidence, this will overall benefit philosophy. This has the potential to resolve some problems due to conflicting intuitions, since some of the conflicting intuitions may be shown to be unreliable and not to be taken seriously; it also has the potential to free some domains of philosophy from the burden of having to conform to our intuitions, a burden that has been too heavy to bear in many cases...3
Knowing how intuitions work can also tell us something about how we can train them to make them render more accurate judgments.4
PROBLEMS WITH INTUITION
In most philosophy, intuitions play the role that observations do in science: they support and undermine various theories.5 Conceptual analyses are rejected when intuitive counterexamples are presented. Moral theories are rejected when they lead to intuitively revolting results. Theories of mind and language and metaphysics rise and fall depending on how well they can be made to fit our intuitions, even in bizarre science fiction hypothetical scenarios.6
But why trust our intuitions? Our intuitions often turn out to contradict each other,7 or they are contradicted by empirical evidence,8 or they vary between people and between groups of people.9 Compared to scientific methods, the philosopher's use of intuitions as his primary tool doesn't seem to have been very productive.10 Also, we can't calibrate our intuitions, because wherever we have a non-intuition standard against which to calibrate our intuitions, |
f8833387-fcf6-4be2-b11f-1ba490d78052 | trentmkelly/LessWrong-43k | LessWrong | Thinking and Deciding: a chapter by chapter review
This is a chapter-by-chapter review of Thinking and Deciding by Jonathan Baron (UPenn, twitter). It won't be a detailed summary like badger's excellent summary of Epistemology and the Psychology of Human Judgment, in part because this is a 600-page textbook and so a full summary would be far longer that I want to write here. I'll try to provide enough details that people can seek out the chapters that they find interesting, but this is by no means a replacement for reading the chapters that you find interesting. Every chapter is discussed below, with a brief "what should I read?" section if you know what you're interested in.
We already have a thread for textbook recommendations, but this book is central enough to Less Wrong's mission that it seems like it's worth an in-depth review. I'll state my basic impression of the whole book up front: I expect most readers of LW would gain quite a bit from reading the book, especially newer members, as it seems like a more focused and balanced introduction to the subject of rationality than the Sequences.
Baron splits the book into three sections: Thinking in General, Probability and Belief, and Decisions and Plans.
I may as well quote the first page in its entirety, as I feel it gives a good description of the book:
> Beginning with its first edition and through three subsequent editions, Thinking and Deciding has established itself as the required text and important reference work for students and scholars of human cognition and rationality. In this, the fourth edition, Jonathan Baron retains the comprehensive attention to the key questions addressed in previous editions- How should we think? What, if anything, keeps us from thinking that way? How can we improve our thinking and decision making? - and his expanded treatment of topics such as risk, utilitarianism, Bayes's theorem, and moral thinking. With the student in mind, the fourth edition emphasizes the development of an understanding of the fundamental concepts |
4e72b7d9-e995-46f8-a23f-3d852c9699e0 | trentmkelly/LessWrong-43k | LessWrong | Meetup : West LA Meetup 08-23-2011
Discussion article for the meetup : West LA Meetup 08-23-2011
WHEN: 23 August 2011 07:00:00PM (-0700)
WHERE: 10800 West Pico Blvd, Suite 312, Los Angeles, CA 90064
When: 7pm - 9pm August 23th.
Where: The Westside Pavillion - on the bridge, which connects Nordstrom 3rd floor with Barnes & Noble / Landmark Theatres 3rd floor.
Parking is free for 3 hours.
Recommended Reading:
-why truth? And...
-What Do We Mean Be "Rationality"?
-Cached Selves
-We Change Our Minds Less Often Than We Think
Whether you're a regular reader or totally new, here for the theoretical musings or the practical things, come by and say hello! The conversation is largely unstructured, and the people are awesome.
There will be snacks. I will bring a whiteboard with Bayes' Theorem written on it.
See also: West LA Biweekly Meetups
Discussion article for the meetup : West LA Meetup 08-23-2011 |
aeb0c750-fc97-4884-9f6c-025c8a6f94e1 | StampyAI/alignment-research-dataset/aisafety.info | AI Safety Info | What is "causal decision theory (CDT)"?
**Causal Decision Theory** – CDT – is a branch of [decision theory](https://www.lesswrong.com/tag/decision-theory) which advises an agent to take actions which maximize the causal consequences on the probability of desired outcomes [^1^](#fn1). As any branch of decision theory, it prescribes taking the action that maximizes [expected utility](https://www.lesswrong.com/tag/expected-utility), i.e the action which maximizes the sum of the utility obtained in each outcome weighted by the probability of that outcome occurring, *given* your action. Different decision theories correspond to different ways of construing this dependence between actions and outcomes. CDT focuses on the *causal* relations between one’s actions and outcomes, whilst [Evidential Decision Theory](https://www.lesswrong.com/tag/evidential-decision-theory) – EDT - concerns itself with what an action *indicates* about the world (which is operationalized by the conditional probability). That is, according to CDT, a rational agent should track the available causal relations linking his actions to the desired outcome and take the action which will better enhance the chances of the desired outcome.
One usual example where EDT and CDT commonly diverge is the [Smoking lesion](https://www.lesswrong.com/tag/smoking-lesion): “Smoking is strongly correlated with lung cancer, but in the world of the Smoker's Lesion this correlation is understood to be the result of a common cause: a genetic lesion that tends to cause both smoking and cancer. Once we fix the presence or absence of the lesion, there is no additional correlation between smoking and cancer. Suppose you prefer smoking without cancer to not smoking without cancer, and prefer smoking with cancer to not smoking with cancer. Should you smoke?” CDT would recommend smoking since there is no causal connection between smoking and cancer. They are both caused by a gene, but have no causal direct connection with each other. EDT, on the other hand, would recommend against smoking, since smoking is evidence for having the mentioned gene and thus should be avoided.
The core aspect of CDT is mathematically represented by the fact it uses probabilities of conditionals in place of conditional probabilities [^2^](#fn2). The probability of a conditional is the probability of the whole conditional being true, where the conditional probability is the probability of the consequent given the antecedent. A conditional probability of B given A - P(B|A) -, simply implies the [Bayesian probability](https://www.lesswrong.com/tag/bayesian-probability) of the event B happening given we known A happened, it’s used in EDT. The probability of conditionals – P(A > B) - refers to the probability that the conditional 'A implies B' is true, it is the probability of the contrafactual ‘If A, then B’ be the case. Since contrafactual analysis is the key tool used to speak about causality, probability of conditionals are said to mirror causal relations. In most cases these two probabilities track each other, and CDT and EDT give the same answers. However, some particular problems have arisen where their predictions for rational action diverge such as the [Smoking lesion](https://www.lesswrong.com/tag/smoking-lesion) problem – where CDT seems to give a more reasonable prescription – and [Newcomb's problem](https://www.lesswrong.com/tag/newcomb-s-problem) – where CDT seems unreasonable. David Lewis proved [^3^](#fn3) it's impossible for probabilities of conditionals to always track conditional probabilities. Hence, evidential relations aren’t the same as causal relations and CDT and EDT will always diverge in some cases.
References
----------
1. [http://plato.stanford.edu/entries/decision-causal/](http://plato.stanford.edu/entries/decision-causal/)
2. Lewis, David. (1981) "Causal Decision Theory," Australasian Journal of Philosophy 59 (1981): 5- 30.
3. Lewis, D. (1976), "Probabilities of conditionals and conditional probabilities", The Philosophical Review (Duke University Press) 85 (3): 297–315
See also
--------
* [Decision theory](https://www.lesswrong.com/tag/decision-theory)
* [Evidential Decision Theory](https://www.lesswrong.com/tag/evidential-decision-theory) |
03d3aa85-7fe7-4036-a657-ebd6015e0e6f | trentmkelly/LessWrong-43k | LessWrong | Behavioral and mechanistic definitions (often confuse AI alignment discussions)
TL;DR: It’s important to distinguish between behavioral definitions – which categorize objects based on outside observable properties – and mechanistic definitions – which categorize objects based on their internal mechanisms. In this post, I give several examples of terms which can be defined either behaviorally and mechanistically. Then, I talk about the pros and cons of both kinds of definitions, and how this distinction relates to the distinction between gears-level versus black-box models.
Related to: Most similar to John Wentworth’s Gears and Behaviors, but about definitions rather than models. Also inspired by: Gears in understanding, How an algorithm feels from the inside, the “Human’s Guide to Words” Sequence in general.
Epistemic status: written quickly instead of not at all.[1]
----------------------------------------
Introduction:
Broadly speaking, when pointing at a relatively distinct cluster of objects, there’s two ways to define membership criteria:
* Behaviorally: You can categorize objects based on outside observable properties, that is, their behavior in particular situations.
* Mechanistically: Alternatively, you can categorize objects via their internal mechanisms. That is, instead of only checking for a particular behavioral property, you instead look for how the object implements said property.[2]
Many AI safety concepts have both behavioral and mechanistic definitions. In turn, many discussions about AI safety end up with the participants confused or even talking past each other. This is my attempt to clarify the discussion, by giving examples of both, explaining the pros and cons, and discussing when you might want to use either.
Three examples of behavioral and mechanistic definitions
To better illustrate what I mean, I’ll give two examples from recent ML work and a third from the sequences.
Induction heads
First introduced in a mathematical framework for transformer circuits, induction heads are transformer attent |
3b25b657-63e5-4cd7-8cd7-62b67710426b | trentmkelly/LessWrong-43k | LessWrong | Server Sky: lots of very thin computer satellites
The following is intended as 1) request for specific criticisms regarding the value of time investment on this project, and 2) pending favorable answer to this, a request for further involvement from qualified individuals. It is not intended as a random piece of interesting pop-sci, despite the subject matter, but as a volunteer opportunity.
Server Sky is a an engineering proposal to place thousands (eventually millions) of micron-thin satellites into medium orbit around the earth in the near term. It is being put forth by Keith Lofstrom, the inventor of the Launch Loop.
Abstract from the 2009 paper:
> It is easier to move bits than atoms or energy. Server-sats are ultralight disks of silicon that convert sunlight into computation and communications. Powered by a large solar cell, propelled and steered by light pressure, networked and located by microwaves, and cooled by black-body radiation. Arrays of thousands of server-sats form highly redundant computation and database servers, as well as phased array antennas to reach thousands of transceivers on the ground.
>
> First generation server-sats are 20 centimeters across ( about 8 inches ), 0.1 millimeters (100 microns) thick, and weigh 7 grams. They can be mass produced with off-the-shelf semiconductor technologies. Gallium arsenide radio chips provide intra-array, inter-array, and ground communication, as well as precise location information. Server-sats are launched stacked by the thousands in solid cylinders, shrouded and vibration-isolated inside a traditional satellite bus.
Links:
Papers and Presentations
Slide Show
Wiki Main Page
Help Wanted
Mailing List
Some mildly negative evidence to start with: I have already had a satellite scientist tell me that this seems unlikely to work. Avoiding space debris and Kessler Syndrome, radio communications difficulties (especially uplink), and the need for precise synchronization are the obstacles he stressed as significant. He did not seem to hav |
70154980-4a99-49cb-b641-2074103e52ff | trentmkelly/LessWrong-43k | LessWrong | An akrasia case study
I just lost 3 weeks to a report that should have taken 2 days. My last job was an engineering research position; setting up an experiment, building prototypes, that sort of thing. After I left, I needed to write a report to brief my successor on what I'd done and what could go wrong, etc. I wasn't getting paid for this report, but it had to happen.
What exactly do I mean when I say I lost three weeks?
I have a lot of projects that I am working on. I am studying AI, thinking of starting a business, writing videogames, studying and working on various math things, writing a small sequence of posts for lesswrong, trying to restart the local rationality dojo, and I had to do that report. What I mean when I say that I lost three weeks is that I spent three weeks doing practically none of these things.
The report had to be done, but I wasn't really excited by it. It wasn't urgent, but it was urgent enough that it had to be done before any of my other projects. It turns out this is a killer combination.
Procrastination took over, manifesting itself as skyrim, 4chan, reddit, and lesswrong. If I tried procrastinating by doing my other projects, I would remember that I had to do the report first, and try to work on the report. When I tried to work on the report, I would hit some small bump and find myself waking up on 4chan three hours later. Somehow, my antiprocrastination hooks were catching my own projects, but not the properly unproductive stuff.
While I had that report to do, I was unable to do anything else productive. When I realized this in conjunction with how important my other projects were, the report suddenly took on a dire urgency. That was four days ago. It is done now. I could have done it in two, or even one, but procrastination is insidious.
One anti-akrasia method that seems to work is going cold turkey on some problematic activity. I call it my personal banhammer. The first thing I banned myself from and how I discovered I could was Alicorn's Twilight |
eac88434-4682-483e-8a53-b8de96315ba8 | trentmkelly/LessWrong-43k | LessWrong | Chris Dixon's Crypto Claims are Logically Flimsy
In this post, I make heavy use of the power to demolish bad arguments in the domain of crypto claims. The crypto world seems rich with areas where you can save a lot of wasted time and money by simply asking for a specific example of how a crypto project beats the best available alternative from the non-crypto world. |
684de6af-5666-468b-9645-2a4b91de1985 | trentmkelly/LessWrong-43k | LessWrong | Top AI safety newsletters, books, podcasts, etc – new AISafety.com resource
Keeping up to date with rapid developments in AI/AI safety can be challenging. In addition, many AI safety newcomers want to learn more about the field through specific formats e.g. books or videos.
To address both of these needs, we’ve added a Stay Informed page to AISafety.com.
It lists our top recommended sources for learning more and staying up to date across a variety of formats:
* Articles
* Blogs
* Books
* Forums
* Newsletters
* Podcasts
* Twitter/X accounts
* YouTube channels
You can filter the sources by format, making it easy to find, for instance, a list of top blogs to follow. We think this page might be particularly useful as a convenient place for field-builders to direct people to when asked about top books/newsletters/blogs etc.
As with all resources on AISafety.com, we’re committed to making sure the data on this page is high quality and current. If you think there’s something that should be added (or removed) please let us know in the comments or via the general feedback form.
The site now has the following resources:
We’d love to hear any ideas for other resources we should consider adding. |
db283ce1-4c03-4e7e-a362-160bee87d08b | trentmkelly/LessWrong-43k | LessWrong | Comment on "Death and the Gorgon"
(some plot spoilers)
There's something distinctly uncomfortable about reading Greg Egan in the 2020s. Besides telling gripping tales with insightful commentary on the true nature of mind and existence, Egan stories written in the 1990s and set in the twenty-first century excelled at speculative worldbuilding, imagining what technological wonders might exist in the decades to come and how Society might adapt to them.
In contrast, "Death and the Gorgon", published in the January/February 2024 issue of Asimov's, feels like it's set twenty minutes into the future. The technologies on display are an AI assistant for police officers (capable of performing research tasks and carrying on conversation) and real-time synthetic avatars (good enough to pass as a video call with a real person). When these kinds of products showed up in "'90s Egan"—I think of Worth's "pharm" custom drug dispenser in Distress (1995) or Maria's "mask" for screening spam calls in Permutation City (1994)—it was part of the background setting of a more technologically advanced world than our own.
Reading "Gorgon" in 2024, not only do the depicted capabilities seem less out of reach (our language model assistants and deepfakes aren't quite there yet, but don't seem too far off), but their literary function has changed: much of the moral of "Gorgon" seems to be to chide people in the real world who are overly impressed by ChatGPT. Reality and Greg Egan are starting to meet in the middle.
Our story features Beth, a standard-issue Greg Egan protagonist[1] as a small-town Colorado sheriff investigating the suspicious destruction of a cryonics vault in an old mine: a naturally occurring cave-in seems unlikely, but it's not clear who would have the motive to thaw (murder?) a hundred frozen heads.
Graciously tolerating the antics of her deputy, who is obsessed with the department's trial version of (what is essentially) ChatGPT-for-law-enforcement, Beth proceeds to interview the next of kin, searching fo |
592f3aad-81fd-4922-a266-b56563eec8c8 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | ‘Force multipliers’ for EA research
Introduction
------------
> TLDR: If solutions to the world’s most pressing problems require people with scarce, expensive skills then we should seek to discover and implement cost effective ‘force multipliers’ that maximise the productivity of these people.
>
>
> With experience developing entrepreneurial technology products, I’m in a position to do just that. I describe some potential opportunities and ask for feedback and introductions.
>
>
Hello, I’m Craig from Melbourne, Australia. I’ve been leading the development of technology-based products [for 14 years](https://www.linkedin.com/in/craigdrayton/). I’ve co-created multiple products alongside academic staff and have spent several years in early startups, including as a solo founder for a data analytics company.
Most recently I led the development of a distributed data infrastructure and application development platform for climate science. The platform aims to make developing, operationalising and distributing climate solutions radically faster and easier.
I discovered EA back in 2010 and have quietly practised effective giving since. I’m moving on from my current work and want to discover a new opportunity to apply my skills to.
In this post I lay out an opportunity space with the aim of eliciting feedback and finding the right people to speak to next. I currently have only a nascent understanding of EA research areas[[1]](#fn2jsflyqe9z5), so please forgive (and gently correct) any naive errors.
The opportunity
===============
Of the ten priority career reviews written by 80,000 hours, six emphasise gaining a technical/quantitative PhD from a top university:
* [AI safety research](https://80000hours.org/career-reviews/ai-safety-researcher/#how-to-enter-this-field): “...pursue a PhD in machine learning at a good school.”
* [AI policy and strategy](https://80000hours.org/career-reviews/ai-policy-and-strategy/#how-to-enter-this-field): “...get into a top 10 school in computer science.”
* [China related AI safety](https://80000hours.org/career-reviews/china-related-ai-safety-and-governance-paths/#personal-fit): *refers to the AI safety and AI policy recommendations*
* [Global priorities research](https://80000hours.org/career-reviews/global-priorities-researcher/#how-to-enter-this-field): “...study a PhD in economics or philosophy.”
* [Biorisk research](https://80000hours.org/career-reviews/biorisk-research/#how-to-enter-this-field): “Do you have a chance of getting a PhD from a top 30 school in [a relevant area]?”
* [Forecasting](https://80000hours.org/career-reviews/forecasting/#how-to-enter): “Do you have a chance of getting into a relevant PhD at a top 30 school?”
(To be clear, 80,000 hours does *not* argue that getting a quantitative PhD from an elite university is the only way to contribute to AI safety or other pressing problems.)
Developing important skills for addressing the world’s most pressing problems can be slow and difficult:
> “Most of [our priority paths] are difficult to enter — you may need to start by investing in building skills for several years, and there may be relatively few positions available.”[[2]](#fn5o7y5kt02t7)
>
>
Other than encouraging early career EAs to pursue these paths, how else could we relieve [specialist skills gaps](https://80000hours.org/2021/07/effective-altruism-growing/#which-roles-are-most-needed) and accelerate progress in these areas?
1. Increase the productivity of existing researchers
----------------------------------------------------
Increasing the productivity of longtermist researchers may be significantly easier, cheaper and faster than increasing the number of researchers, while providing equivalent value.
Collecting, cleaning and organising data can take up a significant proportion of data scientists’ time[[3]](#fnpgmwqxuvaze). Project-based funding models, fragmented data licensing and contract negotiation inhibits collaboration and slows down progress. There’s often a significant gap between promising research and operational solutions.
Researchers have spent years developing a deep specialisation. But in my experience, they often approach their work as generalists; spending much of their time on tasks for which they have no comparative advantage.
Longtermist research is still relatively new and niche, so I’d expect the ecosystem of supporting data, tooling and complementary roles to be limited. Given the expense and difficulty of developing new researchers, investing in their supporting ecosystem may be a cost effective way to increase overall productivity - or at least not be subject to currently central constraints.
2. Increase supply of skilled work by reducing barriers to entry
----------------------------------------------------------------
People with doctoral degrees from elite universities make up just a fraction of a percent of the global population. Expanding the potential pool of top contributors beyond this demographic could help resolve critical skills gaps and increase the rate of progress. If it remains, say, 30 times easier (and much more lucrative) to become a commercial machine learning engineer than to work on AI safety, it is hard to see how safety can keep pace with capabilities.
Improving the ecosystem of infrastructure, tooling and data available to longtermist researchers and engineers could make working in these areas more approachable and desirable. This may increase the pool of motivated and talented people wanting to work on these issues.
Potential approaches
====================
Benchmark datasets
------------------
Several benchmark datasets have been cited more than 100,000 times in machine learning research, and have also been used in operational solutions. Examples include datasets containing handwriting (e.g. [MNIST](https://en.wikipedia.org/wiki/MNIST_database)), images of objects (e.g. [ImageNet](https://www.image-net.org/)), audio clips (e.g. [AudioSet](https://research.google.com/audioset/)) and product reviews (e.g. [IMDB](https://www.imdb.com/interfaces/)). Having pre-prepared datasets makes novel research significantly easier and faster. They also enable comparable results between different approaches and techniques.
Data collection efforts can be long running and extensive, worthy of an independent effort. The [GroupLens project](https://grouplens.org/) has collected 25 million movie ratings by operating an [IMDB-like website](https://movielens.org/) since 1995. [Common Crawl](https://commoncrawl.org/) (with just two staff) creates and maintains petabytes of open web crawl data, which were used to train GPT-3[[4]](#fnlsi5vg0oecb).
Some examples relevant to longtermist research exist already (e.g. DeepMind’s [AI Safety Gridworlds](https://github.com/deepmind/ai-safety-gridworlds)). There will be many more valuable opportunities for datasets and environments. What if we had quality, fine-grained data on millions of people’s espoused values, their perceptions of consequences, or retrospective evaluations of their past decisions?
Versions of this opportunity have been described by [these EA Future Fund project ideas winners](https://forum.effectivealtruism.org/posts/MBDHjwDvhDnqisyW2/awards-for-the-future-fund-s-project-ideas-competition#Marc_Everin_Carauleanu___Datasets_for_AI_alignment_research) and by 80,000 hours [here](https://80000hours.org/career-reviews/alignment-data-expert/).
Libraries, Infrastructure & Platforms
-------------------------------------
Tooling (including libraries, infrastructure and platforms) has the potential to accelerate research by speeding up, eliminating, or improving the quality of the work undertaken.
Global cloud providers and research infrastructure provide cheap and scalable generic inputs such as compute and storage. Specialised platforms build on top of these to provide domain specific capabilities (see [EcoCommons](https://www.ecocommons.org.au/), an upcoming ecological research platform). Other opportunities could lie in coordination, crowdsourcing and resource allocation (e.g. “[Kaggle](https://www.kaggle.com/) for AI safety”).
Technical Standards
-------------------
Since 1995, the Coupled Model Intercomparison Project (CMIP) has provided a framework and standards for running climate modelling experiments in a way that enables contributors to independently produce comparable results[[5]](#fn2v7q6vjmch4). The latest iteration, CMIP6, contains contributions from 49 different modelling groups and more than 1000 individual scientists.
Standards (including practices, ontologies and definitions) provide an effective way for many parties to contribute to a greater effort without the overhead of close coordination.
Standards could potentially increase collective productivity of longtermist research, and also be a method for implementing interventions (e.g. AI safety and biosecurity standards).
The ask
=======
Entrepreneurial product development seems to be a relatively neglected skillset in the EA community (outside earning to give). I believe promising high-impact opportunities exist that would be a good fit for my experience, and I’d like to work on them. I’m open to either joining an existing organisation or starting a new one.
Here’s how you can help.
I need to talk to people! Especially people who:
* are doing high-leverage technical/data heavy EA work, and would be happy to describe their work and its challenges
* are interested in working on this topic - discovering, creating and operating an impactful technology ‘force multiplier’
* would be interested in providing seed funding for an opportunity in this space
If you are one of these people, or know someone who is, please leave me a comment or direct message.
I am also seeking feedback. What already exists, what’s been tried before, which approaches seem more/less promising to you and why?
1. **[^](#fnref2jsflyqe9z5)**I have used both "EA research" and "longtermist research" in this post. The applicability to longtermist areas (particularly software and data heavy AI safety) is more obvious to me. If you can see an opportunity anywhere within or adjacent to EA I'm keen to hear about it.
2. **[^](#fnref5o7y5kt02t7)**https://80000hours.org/career-reviews/
3. **[^](#fnrefpgmwqxuvaze)**https://www.datanami.com/2020/07/06/data-prep-still-dominates-data-scientists-time-survey-finds/
4. **[^](#fnreflsi5vg0oecb)**https://dzlab.github.io/ml/2020/07/25/gpt3-overview/
5. **[^](#fnref2v7q6vjmch4)**https://www.carbonbrief.org/qa-how-do-climate-models-work/#cmip |
e943d73c-8f72-411a-a64b-cdf9384251c9 | trentmkelly/LessWrong-43k | LessWrong | Will AI See Sudden Progress?
Will advanced AI let some small group of people or AI systems take over the world?
AI X-risk folks and others have accrued lots of arguments about this over the years, but I think this debate has been disappointing in terms of anyone changing anyone else’s mind, or much being resolved. I still have hopes for sorting this out though, and I thought a written summary of the evidence we have so far (which often seems to live in personal conversations) would be a good start, for me at least.
To that end, I started a collection of reasons to expect discontinuous progress near the development of AGI.
I do think the world could be taken over without a step change in anything, but it seems less likely, and we can talk about the arguments around that another time.
Paul Christiano had basically the same idea at the same time, so for a slightly different take, here is his account of reasons to expect slow or fast take-off.
Please tell us in the comments or feedback box if your favorite argument for AI Foom is missing, or isn’t represented well. Or if you want to represent it well yourself in the form of a short essay, and send it to me here, and we will gladly consider posting it as a guest blog post.
I’m also pretty curious to hear which arguments people actually find compelling, even if they are already listed. I don’t actually find any of the ones I have that compelling yet, and I think a lot of people who have thought about it do expect ‘local takeoff’ with at least substantial probability, so I am probably missing things.
----------------------------------------
Crossposted from AI Impacts. |
8e381a7e-5e7f-4c83-b0c2-bd0b7de831bd | trentmkelly/LessWrong-43k | LessWrong | The Altman Technocracy
Imagine if the city of New York was inherited by newly sentient human beings a couple hundred years from now. These descendants of ours have no civil engineers or architects among them. They cannot even guess as to how these magnificent, glassy structures are made. Yet, every day they walk into these buildings. They climb "stairs" and use "elevators" to get to work. To this particular generation of human beings, "buildings" have always been there, and always will be. There's no need to understand the structure, or technical nature behind them.
One day, several of these buildings collapse--the death toll is in the thousands. In NY News, it's simply stated: 'God struck again!' or something to that effect. The ignorance of this generation is so deep and entrenched, that the notion of buildings collapsing is attributable to God.
----------------------------------------
Now, compare this analogy to the modern day understanding of OpenAI, algorithms, and potentially the atrophy of critical thinking. I know few people these days who aren't using ChatGPT and Midjourney in some small way. The more conservative ones will only use it for menial, automated tasks. But most (I suspect) are using it for almost everything, ousting their brain for a Machine.
What will the long-term effects on critical thinking be? My analogy argues that AI-assisted existence (AAIE?) will eventually give technical minds like Sam Altman a monopoly on knowledge; a technocracy on a scale we've never seen in human history. Mindless acceptance of spammed prompts that are built on hallucinations, and a Jenga tower of assumptions (apparently made for practical purposes?) is becoming an increasingly likely future.
----------------------------------------
I claim that very few people actually understand what they are using and what it effects it has on their mind. When our children inherit far more advanced iterations of ChatGPT, the 'buildings falling out of the sky' for reasons they don't understand |
a414ee03-34c9-4dba-8a56-b90940773ff3 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Distilled Representations Research Agenda
Introduction
------------
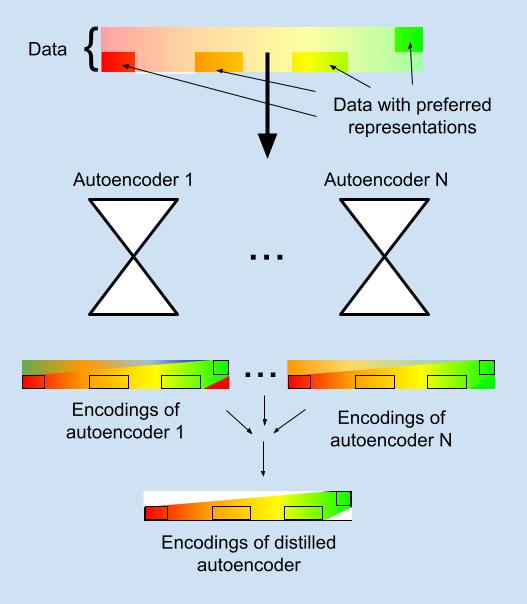Schematic of the basic training strategyI’ve recently been given funding from the [Long Term Future Fund](https://funds.effectivealtruism.org/funds/far-future) to develop work on an agenda I'll tentatively call Distilled Representations, and I'll be working on this full-time over the next 6 months with [Misha Wagner](https://mishajw.com/index.html) (part time).
We're working on a way of training autoencoders so that they can only represent information in certain ways - ways that we can define in a flexible manner.
It works by training multiple autoencoders to encode a set of objects, while for some objects defining a **preferred representation** that the autoencoders are encouraged to encode the objects as. We then distill these multiple autoencoders into single autoencoder which encodes *only that information which is encoded in the same way across the different autoencoders*. If we are correct, this new autoencoder should only encode information using the preferred strategy. Vitally, this can be not just the original information in the preferred representations, but also information represented by *generalizations of that encoding strategy*.
It is similar to work such as [Concept Bottleneck Models](https://arxiv.org/abs/2007.04612) but we hope the distillation from multiple models should allow interpretable spaces in a much broader range of cases.
The rest of this post gives more detail of the intuition that we hope to build into a useful tool, some toy experiments we’ve performed to validate the basic concepts, the experiments that we hope to build in the future, and the reasons we hope it can be a useful tool for alignment.
We'd like to make sure we understand what similar work has been done and where this work could be useful. If you're familiar with disentangled representations, or interpretability tools more generally, we're interested in having a chat. You can reach me here on LessWrong or at [hoagycunningham@gmail.com](mailto:hoagycunningham@gmail.com).
Previous versions of similar ideas can be found in my [ELK submission](https://www.lesswrong.com/posts/fftQP7zrnYkDqgwfj/elk-sub-note-taking-in-internal-rollouts) and especially [Note-taking Without Hidden Messages](https://www.lesswrong.com/posts/fftQP7zrnYkDqgwfj/elk-sub-note-taking-in-internal-rollouts).
Intuition
---------
The intuition that this work builds on is the following:
1. With neural networks, the meanings of the weights and activations are usually opaque but we're often confident about the kind of thing that the network must be representing, at least for some cases or parts of the input distribution.
2. In those cases where we understand what the network is representing, we can condense this understanding into a vector, thus defining a 'preferred representation' which encapsulates that knowledge.
3. We can compress the NN's state with an autoencoder, while in those cases with preferred representations, encouraging the encoding to be as close as possible to the preferred representation.
4. We expect that this running this compression results in the known information being compressed in the manner specified by the preferred representations, while other important information is snuck in wherever possible.
5. If we then train multiple encoder/decoder systems, they will use the preferred representation, but also will use generalizations of the preferred representations.
6. Additional info that is not a generalization of the preferred representation scheme will also be encoded, but the encoding scheme for additional information will vary between different encoder/decoder pairs.
7. Using methods such as retraining a new encoder to encode for randomly shuffled decoders at each batch, we can create an encoder that uses a generalization of our preferred encoding scheme, without containing additional, misleading information.
There are quite a few leaps in this reasoning, and we view the key assumptions / hypotheses to be tested as the following:
* In relevant situations we can define preferred representations.
* We can force encoders to use not just these representations but meaningful generalizations of them, which correspond to our intuitive interpretation, given the preferred representation.
* There will not be a common form of encoding for the rest of the information.
* We can use tricks like those in point 7 above to extract only the information that we would understand.
We've been able to validate all of these assumptions in toy scenarios using compression of random binary vectors. The question now is whether we'll be able to make this a useful tool which scales to more complex environments.
Testing
-------
### Toy Setup
We train an autoencoder to reconstruct 2n.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
-digit binary strings using a latent space of Rn. On top of the reconstruction loss, we introduce a **representation loss**, which is the gap between the encoded digits and our preferred representation. This incentivizes the model to use the nth latent variable to represent the nth binary digit. The n+1th to 2nth binary digits have no preferred representation.
```
vector = random_binary_vector() # shape=2N
latent_vector = encoder(vector) # shape=N
reconstructed_vector = decoder(latent_vector) # shape=2N
preferred_representation = vector[:N]
reconstruction_loss = torch.nn.MSELoss()(vector, reconstructed_vector)
representation_loss = torch.nn.MSELoss()(latent_vector, preferred_representation)
loss = reconstruction_loss + representation_loss
```
We find that, perhaps unsurprisingly, the autoencoder learns to “hide” the second half of the vector in the representation of first half. As one would expect, the encoder learns to map the first n digits closely to themselves, and then hide the second n digits in small variations around the preferred representations.
To remove this additional, hidden information, we train multiple encoder/decoder pairs, and then freeze the weights of the decoders while training a new encoder from scratch. When training this new encoder, the encoded representations are decoded by decoded that is randomly selected each batch.
### Toy Results
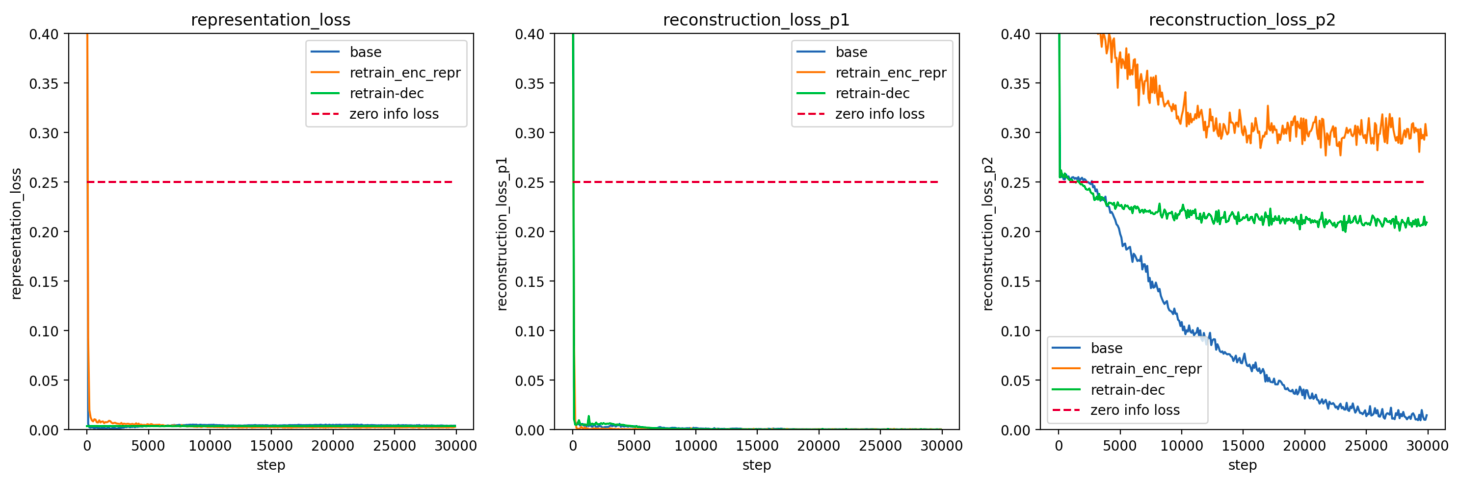Losses when retraining the a new decoder to respond to a randomly trained encoder at each batch (orange) and training encoders to respond to a random encoder (green).What we find is that when training 8 separate autoencoders (averaged into blue line), the information which has a preferred representation is encoded very quickly (p1\_representation\_loss) while the other information is learned more slowly by the separate models (p2\_representation\_loss). The representation loss is the loss from the gap between representation and preferred representation.
Then, when training a new set of encoders (orange line), which are responding to vectors from randomly chosen decoders - the weights of which are frozen - the information that had a preferred representation is again very quickly communicated. Meanwhile the rest of the information, being encoded in different ways, is mostly not successfully encoded - in fact it consistently does worse than having no information at all, though this is somewhat strange and is not true when retraining decoders (green line). We can tell it's close or worse than communicating no useful information because it's not far below (or ever above) the red line, which is the error with zero information (always guessing 0.5 for every binary value).
It's trivial to force a correct representation if we always know exactly what our preferred representation should be. The test is whether we can do this in cases where the preferred representation is sparse and incomplete. We can make this signal sparse and restrict the signal only to a small fraction of the orthants (n-dimensional quadrant) and find that this also works. Below it the same setup, but where the preferred representation is only added for fewer than 20% of orthants, and even then only added 10% of the time - so the preferred representation is only given for under 1 in 50 cases.
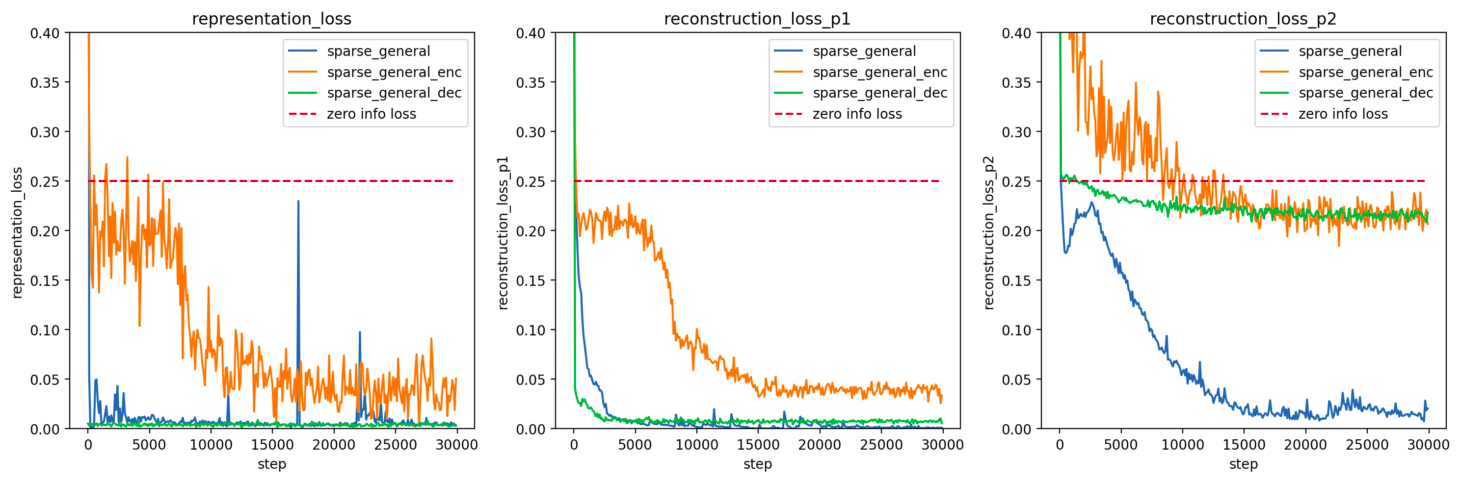Losses when using the same setup but representation loss is only applied when `sum(vector) < 4 and random.random() < 0.1.`These results with sparse inputs show that the method can work well even when preferred representations are not always present, and don't ever cover the full range of inputs. We also see the fact that it learns to encode info in the preferred representation much faster than it adds additional info, so we would get the same property simply by stopping early, though we don't expect this effect to be as stark in more complex environments.
We have also got similar results for cases where the preferred representation is more complex than just the identity function of a subset the input, though the learning process is slower.
Still, this requires only a very basic kind of generalization compared to the kind of generalization we would hope for in an ELK scenario - ideally, using language as humans do to represent situations, thereby being a direct translator rather than a human simulator, so we'll test the setup on progressively more complex environments.
Applications
------------
### Eliciting Latent Knowledge (ELK)
This idea comes from working on the Eliciting Latent Knowledge (ELK) challenge and is basically the combination of two posts in the [ELK prizes](https://www.lesswrong.com/posts/zjMKpSB2Xccn9qi5t/elk-prize-results) - 'Train a reporter that is useful for another AI' (my own, amongst others) and 'Train different reporters and require them to agree'. If you are the person who suggested the latter then thank you!
The picture that I think is hopeful for this kind of system starts with the background of Eliciting Latent Knowledge, in which we have a powerful system which we can ask questions of in certain situations where it knows the answer. These may be detailed Q&As or it may simply be a case where we know the state of the system and so we know the world-variables that it should be representing.
This information represents a preferred representation, and we restrict this representation to cases where we we're confident that it doesn't favour the human-simulation over the honest translator. We then train these systems to compress as much of their internal state into the answers to these questions, while ensuring that known information uses the preferred representation. The need to compress the information should then ensure we get something that is a direct translator, but much of this 'translation' will not be in an interpretable form, and so we use the multi-encoder strategy to get only the parts of the direct translator that we are able to understand.
This work can be thought of as trying to unify question-answering and autoencoders. Question-answering gives an easily comprehensible response but it's hard to ensure that it actually contains the right information. Autoencoders condense the information, but not in a way that is easily interpretable. The question that this work hopes to answer is 'Can we use question-answering as a form of autoencoder, without hiding a pile of incomprehensible information through the answers?'. This technique of distilled representations is step towards a working unification of these two ways of understanding a system.
### Interpretability
While this is the most ambitious form of hope for this approach, we think that there's potential for it to be useful as an interpretability tool.
It can be seen as a contribution to the related field of disentangled representations, which creates latent representations, usually of images, but where the dimensions correspond to human-identifiable concepts.
This procedure could potentially be used to automatically make these, by labeling images according to certain dimensions, encoding images while deriving preferred representations from these labels, and then distilling out non-shared variability in encoding to get a latent space where the variables strictly only vary the dimensions of interest.
It also may be possible to use it within networks to create neurons which only respond in particular situations without having any additional meanings, making mechanistic interpretability easier.
### Chain of Thought Prompting
There have been [proposals](https://www.lesswrong.com/posts/FRRb6Gqem8k69ocbi/externalized-reasoning-oversight-a-research-direction-for) for using chain-of-thought reasoning to make superhuman reasoning interpretable by default, and [concerns](https://www.lesswrong.com/posts/yDcMDJeSck7SuBs24/steganography-in-chain-of-thought-reasoning) that this could lead to steganography in the 'thoughts'.
I hope that this kind of system could be used to prevent a chain-of-thought reasoner from hiding addition information in what appeared to be trivially understandable written statements, and concern that (In this situation the preferred representation would be implicitly created by the large pre-training dataset and refined during fine tuning phases).
Potential Drawbacks
-------------------
* Difficulty of setup: although we've managed to demonstrate the basic parameters, there have still been quite a few configurations in which it hasn't worked. For example, using encoders that are too weak, retraining first encoders and then decoders. This suggests that at higher complexity, getting such a system working and properly tuned may be difficult even if it works.
* Overhead: this system will always require training multiple autoencoders. These could, however, be much smaller than the system which they are trying to provide insight into.
* Schelling points for misleading communication. The setup relies on the fact that the things that the multiple encoders have in common - generalizations that the encoders make from the preferred representation - are a subset of the ways humans would understand the representation. It may simply be that there are convergent ways of representing even non-understandable information in some situations, which would then be mistaken for comprehensible signal about what's going on.
* Not enough useful generalizations: these systems may simply not find enough generalizations from the preferred representations we are able to provide useful insight.
Plans for next few months
-------------------------
* Test removing non-informative latent variables
+ In our basic scenario it does not manage to communicate any info about the second half of the vector. That doesn't mean that it isn't varying the encoding in an attempt to. In more complex scenarios we would want these systems to actively flag, or refrain from communicating useless info. We'll test this first in our basic setup by incentivizing the system to flag as much of the latent space as possible as to be ignored.
* Conduct a lit review around disentangled representations (if you know of related work please let us know!).
* Run much more comprehensive testing to understand the performance of our toy system and the configurations which lead to best performance.
* Write up the method and surrounding idea in formal terms for precision and ability to connect with related fields
* Test in progressively more complex environments, which provide options for increasing complexity of generalization from preferred representation.
+ First to procedurally generated images with fixed dimensions of variations
+ Then to natural images
+ Aspirationally to language models (probably needs more time/resources).
* Write up approach and results in as a paper.
* Experiment with setups involving 'free bits', which would not be shuffled and which should come to represent the highest order bits of the hidden information, and therefore act as targets for interpretability in order to better understand the information being compressed.
All work done in collaboration with [Misha Wagner](https://mishajw.com/index.html). Graphs and code on [GitHub](https://github.com/HoagyC/hiddeninfo/tree/main). Work supported by the [Long Term Future Fund](https://funds.effectivealtruism.org/funds/far-future). |
41e62ace-2e77-4436-a025-614947cb49ed | trentmkelly/LessWrong-43k | LessWrong | Please Understand
In which a case is made for worrying about the AI Prompt Box.
Preamble
Technology serves to abstract away nonessential aspects of creative activities, giving us more direct access to their conceptual cores. Few audio engineers pine for the days of flaky reel-to-reel tape machines that unspool at the worst moments; few graphic designers long to swap their Macbooks for bulky old photostat rigs; few mathematicians grieve for the sliderule or the log table.
Yet domain understanding survived those leaps to digital abstraction. Music producers working entirely 'in the box' still know and/or intuit dynamics, frequency equalisation, melody and harmony. Photoshop natives still know and/or intuit colour theory, visual communication, the rules of composition. Recent mathematics and physics graduates experience the beauty of Euler's identity, its vast arms linking trigonometry to arithmetic to analysis to the complex plane, just as vividly as their predecessors did a century ago. Indeed, with the time these modern creatives save by not having to re-ravel 1/4" tape, wrestle with Zipatone and fixative or pore over columns of logarithms (to say nothing of their access to new tools), they can elevate their understanding of their fields' fundamentals[1].
The GenAI Prompt Box declares itself the asymptote of this march to abstraction: a starry empyrean of 'pure', unfettered creative actualisation, in every medium, on the instant, where all pesky concrete details are swept away and the yellow brick road to Perfect Self-Expression is illuminated like a kaleidoscopic runway.
Here are some problems with that dream.
The Worse Angels of Our Nature
Consider the normal distribution of intellectual curiosity in the human population.
The long tail on the right is the minority whose genius and drivenness guarantee that they will seek and find whatever high-hanging epistemic fruit it was their destiny to pluck, no matter how alluring the paths of less resistance on offer.
On the left |
473d426b-646c-4f07-aa11-005731771a12 | trentmkelly/LessWrong-43k | LessWrong | Any real toeholds for making practical decisions regarding AI safety?
Let's call the thing where you try to take actions that make everyone/yourself less dead (on expectation) the "safety game". This game is annoyingly chaotic, kind of like Arimaa.
You write the sequences then some risk-averse not-very-power-seeking nerds read it and you're 10x less dead. Then Mr. Altman reads it and you're 10x more dead. Then maybe (or not) there's a backlash and the numbers change again.
You start a cute political movement but the countermovement ends up being 10x more actionable (e/acc).
You try to figure out and explain some of the black box but your explanation is immediately used to make a stronger black box. (Mamba possibly.)
Etc.
I'm curious what folks use as toeholds for making decisions in such circumstances. Or if some folks believe there are actually principles then I would like to hear them, but I suspect the fog is too thick. I'll skip giving my own answer on this one. |
1f58c6fb-968b-448e-8f42-5c496a6b1e20 | trentmkelly/LessWrong-43k | LessWrong | Google’s Ethical AI team and AI Safety
cross-posted from my blog
Background on the events
I have been thinking about this since the firing of Dr. Timnit Gebru, and yet still no one has actually written about it beyond my own tweets, so I guess it falls to me.
I find, and I imagine many people in the rat-sphere agree, the idea of talking about energy consumption and climate change to be low on my list of ethical priorities surrounding AI. But I find that uncompelling because I think that (a) this cost can be weighed against the benefits AI can create and (b) this cost can be literally offset by potential current and future carbon capture technologies. I think this is well established in the EA community, with recent possible exceptions taking shape.
But these ideas rely on current assumptions about how much power is being used for what purposes. If AI continues to scale by adding compute, as is generally expected, this could create conflicts of interest in the AI space. That would be bad for a number of reasons, chief among them that it would mean that only actors who are willing to impose substantial costs on the commons would be able to implement their visions. This is my central point, so I will return to it later.
For now, just keep in mind that the low priority of climate change among EAs is an empirical question of how easy it is to influence certain changes. I don’t think any of the specific work by Dr. Gebru makes a convincing case to me that the question has a different answer. But I haven’t heard literally any other single person say that!
Instead, she was fired, and today the other co-lead of her team was also fired. The justification for firing Gebru was “she quit.” No public statement has been made, even internally to the team both managed, about why Margaret Mitchell was fired, unless you count “it’s part of a re-org.” For reference, my team at Google has been re-org’d at least four times, and I have never seen anyone fired or even moved out of their management position in that time. U |
efbbebb8-6698-408b-83c7-8965a85b91f6 | trentmkelly/LessWrong-43k | LessWrong | Weekly LW Meetups
This summary was posted to LessWrong Main on August 22nd. The following week's summary is here.
Irregularly scheduled Less Wrong meetups are taking place in:
* Australia-wide mega-meetup: 24 August 2014 07:00PM
* Hamburg - Diet: 29 August 2014 07:00PM
* Houston, TX: 13 September 2014 02:00PM
* Perth, Australia: More Wrong: 23 August 2014 12:00PM
The remaining meetups take place in cities with regular scheduling, but involve a change in time or location, special meeting content, or simply a helpful reminder about the meetup:
* London Social - August 24th: 24 August 2014 02:00PM
* [Melbourne] September Rationality Dojo - Fixed and Growth Mindset: 07 September 2014 03:30PM
* Sydney Meetup - August: 27 August 2014 06:30PM
* [Utrecht] Cognitive Biases: 23 August 2014 02:00PM
* [Utrecht] Topic to be determinined: 06 September 2014 02:00PM
* [Utrecht] Debiasing techniques: 20 September 2014 02:00PM
* Vienna: 23 August 2014 03:00PM
* Washington, D.C.: Museums Meetup: 24 August 2014 03:00PM
Locations with regularly scheduled meetups: Austin, Berkeley, Berlin, Boston, Brussels, Buffalo, Cambridge UK, Canberra, Columbus, London, Madison WI, Melbourne, Moscow, Mountain View, New York, Philadelphia, Research Triangle NC, Seattle, Sydney, Toronto, Vienna, Washington DC, Waterloo, and West Los Angeles. There's also a 24/7 online study hall for coworking LWers.
If you'd like to talk with other LW-ers face to face, and there is no meetup in your area, consider starting your own meetup; it's easy (more resources here). Check one out, stretch your rationality skills, build community, and have fun!
In addition to the handy sidebar of upcoming meetups, a meetup overview is posted on the front page every Friday. These are an attempt to collect information on all the meetups happening in upcoming weeks. The best way to get your meetup featured is still to use the Add New Meetup feature, but you'll also have the benefit of having your meetup mentioned in a weekly overvie |
1cbd0bd9-62d3-46f0-bd2a-4a43fa2c79c4 | trentmkelly/LessWrong-43k | LessWrong | Update on the Mysterious Trump Buyers on Polymarket
I've written a follow-up post on the mysterious Trump buyers on Polymarket. While mainstream media has extensively covered this story, it has overlooked some critical details—most notably, that this trader's bet on Trump is closer to $75 million USDC, making it the largest election market wager to date. Regardless of the outcome, Theo is poised to go down in history as the most significant bettor in prediction markets.
Link to Post |
2bd2984e-4d97-4486-a4e6-219a4f694c81 | StampyAI/alignment-research-dataset/special_docs | Other | The Superintelligent Will: Motivation and Instrumental Rationality In Advanced Intelligent Agents
1 THE SUPERINTELLIGENT WILL: MOTIVA TION AND
INSTRUMENT AL RATIONALITY IN ADVANCED
ARTIFICIAL AGENTS
(2012) Nick Bostrom
Future of Humanit y Institute
Facult y of Philosophy & Oxford Martin School
Oxford University
www.nickbostrom.com
[Minds and Machines, Vol. 22, Iss. 2, May 2012] [translation: Portuguese]
ABSTRACT
This paper discusses the relation between intelligence an d motivation in artificial agen ts,
developing and briefly arguing for tw o theses. The first, the orthogonality thesis , hol ds (with some
caveats) that intelligence and final goals (purposes) are orthogonal axes along which possible
artificial intellects can freely vary—more or less any level of intelligence could be combined with
more or less any final goal. The secon d, the instrumental conver gence thesis , holds that as long as
they possess a sufficient level of intelligence, agents having any of a wide range of final goals
will pursue simil ar intermediary goals becaus e the y have instrumental reasons to do so. In
combination , the two theses help us underst and the possibl e range of behavior of
superintelligent agents, and they point to some potential dangers i n building such an agent.
KEYWO RDS: superintelligence, artificial intelligence, AI, goal, instrumental reason , intelligent
agent
1. The orthogonali ty of motivati on and intelligence
1.1 Avoiding anthropomorphism
If we imagine a space in which all possible minds can be represented, we must imagine all human
minds as constituting a small and fairl y tight cluster wit hin that space. The personality
differences between Hannah Arendt and Benny Hill might seem vast to us, but this is because
the scale bar in our intuitive judgment is calibrat ed on the existing human distribution. In the
wider space of all logical possibilities , thes e tw o personalities are close neighb ors. I n terms of
neural architecture, at least, Ms. Arendt and Mr. Hill are nearly identical. Imagine their brains
laying si de by side in quiet repose. The differences would appear minor an d you would quite
readily recogni ze them as two of a kind; y ou mi ght even be unable to tell which brain was
whose. If you studied the morphology of the two brains more closely under a microsco pe, the
2
impression of fundamental similarity would only be strengthened: you would then see the same
lamellar organization of the cortex, made up of the same types of neuron, soaking in the same
bath of neurotransmitter molecules.1
It is well k nown th at naïve observers often anthropomorphize the capabilities of simple r
insensate systems. We might say, for example, “This vending machine is taking a long time to
think about my hot chocolate.” This might lead one either to underestimate the cognitive
complexity of capabilities which come naturally to human being s, such as motor control and
sensory perception, or, alternatively, to ascribe significant degrees of mindfulness and
intelligence to very dumb systems, such as chatterbo xes like Weizenbaum’s ELIZ A
(Weizenbaum 1976) . In a similar manner, there is a common tendency to anthropomorphize the
motivations of intelligent systems in which there is really no ground for expecting human -like
drives and passions (“My car really didn’t want to start this morning”) . Eliezer Yudkowsky
gives a nice illustration of this phenomenon :
Back in the era of pulp science fiction, magazine covers occasionally depicted a sentient
monstrous alien —colloquially known as a bug -eyed monster (BEM) —carrying off an
attractive human fem ale in a torn dress. It would seem the artist believed that a non -
humanoid alien, with a wholly different evolutionary history, woul d sexually desire
human females … Probably the artist did not ask whether a giant bug perceives human
females as attractiv e. Rather, a human female in a torn dress is sexy—inherently so, as an
intrinsic property. They who made this mistake did not think about the insectoid’s
mind: they focused on the woman’s torn dress. If the dress were not torn, the woman
would be less s exy; the BEM does not enter into it . (Yudkowsky 2008)
An artificial intelligence can be far less human -like in its motivations than a space alien .
The extraterrestrial (let us assume) is a biological creature who has arisen through a process of
evolution and may theref ore b e expected to have the kinds of motivation typical of evolved
creatures . For example, it would not be hugely surprising to find that some random intelligent
alien would have motives related to the attaining or avoiding of food, air, temperature, ener gy
expenditure, the threat or occurrence of bodily injury, disease, predators, reproduction, or
protection of offspring. A member of an in telligent social species might also have motivations
related t o coope ration and competition: like us, it might show i n-group loyalty, a resentment of
free-riders, perhaps even a concern with r eputation and appearance.
By contrast, an artificial mind need not care intrinsically about any of those things, not
even to the slightest degree. One can easily conceive of an artificial intelligence whose sole
fundamental goal is to count the grains of sand on Boracay , or to calculate decimal places of pi
indefinitely, or to maximize the total number of paperclips in its future lightcone. In fact, it
would be easier to create an AI with simple goals like these, than to build one that has a human -
like set of values and dispositions.
1 This is of course not to deny that differences that appear small visually can be functionally profound.
3
1.2 The orthogonality thesis
For our purposes, “intelligence” will be roughly taken to correspond to the capacity for
instrumental reasoning (more on this later) . Intelligent search for instrumentally optimal plans
and policies can be performed in the service of any goal. Intelligence and motivation can in this
sense be thought of as a pair of orthogonal axes on a graph whose points represent intelligent
agents of different paired specifications. Each point in the graph represents a logically possible
artificial agent , modulo some weak constraints —for instance, it might be impossi ble for a very
unintelligent system to have very complex motivations , since complex motivations would place
significant demands on memory. Furthermore, in order for an agent to “have” a set of
motivations , this set may need to be functionally integrated w ith the agent’s decision -processes,
which again would place demands on processing power and perhaps on intelligence. For minds
that can modify themselves, there may also be dynamical constra ints; for instance, an intelligent
mind with a n urgent desire to be stupid might not remain intelligent for very long. But these
qualifications should not obscure the main idea , which we can express as follows:
The Orthogonality Thesis
Intelligence and final goals are orthogonal axes along which possible agents can fr eely
vary . In other words, more or less any level of intelligence could in principle be
combined with more or less any final goal.
A comparison may be made here with the Humean theory of motivation . David Hume
thought that beliefs alone (say, about wha t is a good thing to do) cannot motivate action: some
desire is required.2 This would support the orthogonality thesis by undercutting one possible
objection to it, namely, that sufficient intelligence might entail the acquisition of certain beliefs,
and that these beliefs would necessaril y produce certain motivations. Not so, according to David
Hume: belief and motive are separate.
Although the orthogonality thesis can draw su pport from the Humean theory of
motivation, it does not presuppose it. In particular, one need not maintain that beliefs alone can
never motivate action. It would suffice to a ssume, for example, that an agent —be it ever so
intelligent —can be motivated to pursue any course of action if the agent happens to have certain
standing desires of some su fficient, overriding strength. Another way in which the
orthogonality thesis could be true even if the Humean theory of motivation is false is if
arbitrarily high intelligence does not entail the acquisition of any such beliefs as are (putatively)
motivating on their own . A third way in which it might be possible for the orthogonality thesis
to be true even if the Humean theory were false is if it is possible to build a cognitive system (or
more neutrally, an “optimization process”) with arbitrarily high intell igence but with
constitution so alien as to contain no clear functional analogues to what in humans we call
2 For some recent attempts to defend the Humean theory of motivation, see Smith (1987 ), Le wis (1988), and
Sinhababu (2009) .
4
“beliefs” and “desires” . This would be the case if such a system could be constructed in a way
that would make it motivated to pursue any given final goal.
The o rthogonality thesis , as formulated here, makes a claim about the relationship
between motivation and intelligence , rather than between motivat ion and rationality (or
motivation and reason ). This is because some philosophers use the word “rationality” to connote
a “normatively thicker ” concept than we seek to connote here with the word “intelligence”. For
instance , in Reasons and Persons Derek Parfit argues that certain ba sic preferences would be
irrational, such as that of an otherwise normal agent who has “Future -Tuesday -Indifference” :
A certain hedonist cares greatly about the quality of his future experiences. With one
exception, he cares equally about all the parts of his future. The exception is that he has
Future -Tuesday -Indifference. Throughout every Tuesday he cares in the normal way
about what is happening to him. But he never cares about possible pains or pleasures on
a future Tu esday... This indifference is a bare fact. When he is planning his future, it is
simply true that he always prefers the prospect of great suffering on a Tuesday to the
mildest pain on any other day. (Parfit 1984)3
Thus, the agent is now indifferent to his own future suffering if and only if it occurs on a future
Tuesday. For our purposes, we need take no stand on whether Parfit is right that this is
irrational, so long as we grant that it is not necessarily unintelligent . By “intelligence ” here we
mean something lik e instrumental rationality —skill at prediction, planning, and means -ends
reasoning in general . Parfit’s imaginary Future -Tuesday -Indifferent agent could have
impeccable instrumental rationality, and therefore great intelligence, even if he falls short on
some kind of sensitivity to “objective reason ” that might be required of a fully rational agent.
Consequently, this kind of example does not undermine the orthogonality t hesis.
In a similar vein, even if there are objective moral facts that any fully rat ional agent
would comprehend, and even if these moral facts are somehow intrinsically motivating (such
that anybody who fully comprehends them is necessarily motivated to act in accord ance with
them) this need not undermine the orthogonality thesis. The t hesis could still be true if an agent
could have impeccable instrumental rationality even whilst lacking some other faculty
constitutive of rationality proper, or some faculty required for the full comprehension of the
objective moral facts . (An agent cou ld also be extremely intelligent, even superintelligent ,
without having full instrumental rational ity in every domain. )
One reason for focusing on intelligence, that is, on instrumental rationality, is that this is
the most relevant concept if we are trying to figure out what different kinds of systems would
do. Normative questions , such as whether their behavior would count as being prudentially
rational or morally justifiable , can be important in various ways. However, such questions
should not bli nd us to the possibility of cognitive systems that fail to satisfy substantial
3 See also Parfit (2011) .
5
normative criteria but which are nevertheless very powerful and able to exert strong influence
on the world.4
1.3 Predicting superintelligence motivation and behavior
The orth ogonality thesis implies that synthetic minds can have utterly non -anthropomorphic
goals—goals as bizarre by our lights as sand -grain -counting or paperclip -maximizing. T his
hold s even (indeed especially ) for artificial agents that are extremely intelligen t or
superintelligent. Yet it does not follow from the orthogonality thesis that it is impossible to make
predictions about what parti cular agents will do. P redictability is important if one seeks to
design a system to achieve particular outcomes, and th e issue becomes more important the more
powerful the artif icial agent in question is. S uperintelligent agent s could be extremely powerful,
so it is important to develop a way of analyzing and predicting their behavior. Yet despite the
independence of intelligence and final goals implied by the orthogonality thesis, the problem of
predicting an agent’s behavior need not be intractable —not even with regard to hypothetical
superintelligent agents whose cognitive complexity and performance characteristics might
render them in certain respects opaque to human analysis.
There are at least three directions from which one can approach the problem of
predicting superintelligen t motivation :
(1) Predictability through design competence . If we can suppose that the designers of a
superintellig ent agent can successfully engineer the goal system of the agent so that it
stably pursues a particular goal set by the programmers, then one prediction we can
make is that the agent will pursue that g oal. The more intelligent t he agent is, the greater
the cognitive resourcefulness it will have to pursue that goal. So even before an agent
has been created we might be able to predict something about its behavior , if we know
something about who will build it and what goals they wi ll want it to have.
(2) Predictability th rough inheritance . If a digital intelligence is created directly from a human
template (as would be the case in a high -fidelity whole brain emulation), then the digital
intelligence might inherit the motivation s of the human template .5 The agent might
retain some of these motivations even if its cognitive capacities are subsequently
enhanced to make it superintell igent. This kind of inference requires caution . The
agent’s goals and values could easily become corrupted in the uploading process or
during its subse quent operation and enhancement, depending on how the procedure is
implemented.
4 The orthogonality thesis implies that most any combination of final goal and intelligence level is logically
possible; it does not imply that it would be practically easy to endow a superintelligent agent with some
arbitrary or human -respecting final goal —even if we knew how to construct the intelligence part. For
some preliminary notes on the value -loading problem, see , e.g., Dewey (2011 ) and Yudkowsky (2011) .
5 See Sandberg & Bostrom (2008 ).
6
(3) Predictability through convergent instrumental reasons . Even without detailed knowledge of
an agent’s final goals, we m ay be able to infer something about its more immediate
objectives by considering the instrumental reasons that would arise for any of a wide
range of possible final goals in a wide range of situations. This way of predicting
becomes more useful the greate r the intelligence of the agent , because a more intelligent
agent is more likely to recognize the true instrumental reasons for its actions, and so act
in ways that make it more likely to achieve its goals .
The next section explores this third way of pre dictability and develops an “instrumental
convergence thesis” which complement s the orthogo nality thesis .
2. Instrumental convergence
According to the orthogonality thesis, artificial intelligent agents may have an enormous range
of possible final goals . Ne vertheless, according to what we may term the “instrumental
convergence ” thesis, there are some instrumental goals likely to be pursued by almost any
intelligent agent , because there are some objectives that are useful intermediaries to the
achievement of almost any final goal. We can formulate this thesis as follows:
The Instrumental Convergence Thesis
Several instrumental values can be identified which are convergent in the sense that their
attainment would increase the chances of the agent’s goal being realized for a wide range
of final goals and a wide range of situations, implying that these instrumental values are
likely to be pursued by many intelligent agents.
In the following we will consider several categories where s uch convergent instrumental
values may be found.6 The likelihood that an agent will recognize the instrumental values it
conf ronts increases (ceteris paribus) with the agent’s intelligence . We will therefore focus mainly
on the case of a hypot hetical superintelligent agent whose instrumental reasoning capacities far
6 Stephen Omohundro has written two pioneering pape rs on t his topic (Omohundro 2008 a, 2008b) .
Omohundro argues that all advanced AI systems are likely to exhibit a number of “basic drives ”, by which
he means “ tendencies which will be present unless explicitly countera cted.” The term “AI drive” has the
advantage of being short and evocative, but it has the disadvantage of suggesting that the instrumental
goals to which it refers influence the AI’s decision -making in the same way as psychological drives
influence human decision -making, i.e. via a kind of phenomenological tug on our ego which our willpower
may occasionall y succeed in resisting. That connotation is unhelpful. One would not normally say that a
typical human being has a “drive” to fill out their tax return, even though filing taxes may be a fairly
convergent instrumental goal for humans in contemporary soci eties (a goal whose realization averts
trouble that would prevent us from realizing many of our final goals). Our treatment here also differs from
that of Omohundro in some other more substantial ways, although the underlying idea is the same. (See
also Chalmers (2010) and Omohundro (2012) .
7 exceed those of any human. We will also comment on how the instrumental convergen ce thesis
applies t o the case of human beings, as this gives us occasion to elaborate some essential
qualifications concernin g how the instrumental convergence thesis should b e interpreted and
applied. Whe re there are convergent instrumental values, w e may be able t o predict some
aspects of a superintel ligence’s behavior even if we know virtually nothing about that
superintelligence’s final goals.
2.1 Self-preservation
Suppose that an agent has some final goal that extends some way into the future. There are
many scenarios in which the agent, if it is still around in the future, is then able to perform
actions that increase the probability of achieving the goal . This creates an instrumental reason
for the agent to try to b e around i n the future—to hel p achieve its present future-oriented goal.
Agents with human-li ke motivational structures often seem to place som e final val ue on
their own survival . This is not a necessary feature of artificial agen ts: som e may b e designed to
place no final value whatever on thei r own survival. Nevertheless, even agents that do not care
intrinsicall y about their own survival would, under a fairly wide range of conditions, care
instrumentally to some degree about their own survival i n order to accomplish the final goals
they do value.
2.2 Goal-conten t integrity
An age nt is more likel y to act in the future to maximize the realization of its present final goals if
it still has thos e goals in the future. This gives the agent a present instrumental reason to prevent
alterations of its final goals. (This argument applies onl y to fi nal goals. In order t o attain its final
goals, an intelligent agen t will of course routinely want to chan ge its subgoals in light of new
information and insight.)
Goal-content integrit y for final goals is in a sense even mo re fundamental than survival
as a convergent instrumental motivation. Among humans , the opposite may seem to be the case,
but that is because survival is usually part of our final goals . For software agents, which can
easily switch bodies or create exact duplicates of themselves, preservation of self as a particular
implementation or a particular physical object nee d not be an important instrumental value.
Advanced software agents might als o be able to swap memories, download skills, an d radically
modif y their cognitive architecture and personalities. A population of such agents might operate
more like a “functional soup” than a society composed of distinct semi-permanent persons.7 For
some purposes, processes i n such a system mi ght b e bett er individuated as teleological threads ,
based on their final values, rath er than on the basis of bodies , personalities , memories, or
abilities. In such scenarios, goal-continuity might be said to constitute a key aspect of survival.
Even so, there are situations in which an agent may intentionally chan ge its ow n final
goals. Such situations can arise when any of the following factors is significant:
7 See Chislenko ( 1997) .
8
Social signaling . When others can perceive an agent’s goals and use that information to
infer instrumentally relevant dispositions or other correlated attributes, it can be in the
agent’s interest to modify its goals to make whatever desired impression. For example,
an age nt might miss out on beneficial deals if potential partners cannot trust it to fulfill
its side of the bargain. In order to make credible commitments, an agent might therefore
wish to adopt as a final goal the honoring of its earlier commitments, and to a llow others
to verify that it has indeed adopted this goal. Agents that could flexibly and
transparently modify their own goals could use this ability to enforce deals among one
another.8
Social preferences . Others may also have preferences about an agen t’s goals. The agent
could then have r eason to modify its goal s, either to satisfy or to frustrate those
preferences.
Preferences concerning own goal content . An agent might have some final goal concerned
with the agent’s own goal content. For example, the a gent might have a final goal to
become the type of agent that is motivated by certain values, such as compassion .
Storage costs . If the cost of storing or processing some part of an agent’s utility function is
large compared to the chance that a situ ation will arise in which applying that part of the
utility function will make a difference, then the agent has an instrumental reason to
simplify its goal content, and it may trash that part of the utility function.9 10
We h uman s often seem happy to let our final goals and values drift . This might often be
because we do not know precisely what they are . We obviously want our beliefs about o ur final
goals and values to be able to change in light of continuing self -discovery or changing self -
presentat ion needs. However, there are cases in which we willingly change the goals and values
themselves, n ot just our beliefs or interpretations of them . For example, somebody deciding to
have a child might predict that they will come to value the child for its own sake, even though at
the time of the decision they may not particularly value their future child or even like children in
general.
8 See also Shulman (2010) .
9 An agent might also change its goal representation if it changes its ontology, in order to transpose its old
representation into the new ontology. Cf. de Blanc (2011) .
10 Another type of factor that mig ht make an evidential decision theorist undertake various actions, including
changing its final goals, is the evidential import of deciding to do so. For example, an agent that follows
evidential decision theory might believe that there exist other agents like it in the universe, and that its own
actions will provide some evidence about how those other agents will act. The agent might therefore
choose to adopt a final goal that is altruistic towards those other evidentially -linked agents, on grounds
that this will give the agent evidence that those other agents will have chosen to act in like manner. An
equivalent outcome might be obtained, however, without changing one’s final goals, by choosing in each
instant to act as if one had those final goals.
9
Humans are complicated, and many factors might be at play in a situation like this.11 For
instance, one might have a fi nal value that involves becoming the kind of person who cares
about some other individual for his or her own sake (here one places a final value on having a
certain final value ). Alternatively, one might have a final value that involves having certain
experiences and occupying a certain soci al role ; and becoming a parent —and undergoing an
associated goal s hift—might be a necessary part of that. Human goals can also have inconsistent
content, goal content; and so some people might want to modify some of th eir final goals to
reduce the inconsistencies.
2.3 Cognitive enhancement
Improvements in rationality and intelligence will tend to improve an agent’s decision -making,
making the agent more likely to achieve her final goals . One would therefore expect co gnitive
enhancement to emerge as an instrumental goal for many types of intelligent agent. For similar
reasons, agents will tend to instrumentally value many kinds of information.12
Not all kinds of rationality, intelligence, and knowledge need be instrum entally useful in
the attainment of an agent’s final goals. “Dutch book arguments” can be used to show that an
agent whose credence function does not obey the rules of probability theory is susceptible to
“money pump” procedures, in which a savvy bookie a rranges a set of bets, each of which
appears favorable according to the agent’s beliefs, but which in combination are guaranteed to
result in a loss to the agent, and a corresponding gain for the bookie. However, this fact fails to
provide any strong gene ral instrumental reasons to seek to iron out all probabilistic incoherency .
Agents who do not expect to encounter savvy bookies, or who adopt a general policy against
betting, do not stand to lose much from having some incoherent beliefs —and they may gain
important benefits of the types mentioned: reduced cognitive effort, social signaling, etc. There
is no general reason to expect an agent to seek instrumentally useless forms of cognitive
enhancement , as an agent might not value knowledge and understandi ng for their own sakes.
Which cognitive abilities are instrumentally useful depends both on the agent’s f inal
goals and its situation . An agent that has access to reliable expert advice may have little need for
its own intelligence and knowledge , and it may therefore be indifferent to these resources . If
intelligen ce and knowledge come at a cost, such as time and effort expended in acquisition, or in
increased sto rage or processing requirements, then an agent might prefer less knowledge and
11 An extensive psychological literature explores adaptive preference fo rmation. See, e.g., Forgas et al.
(2009 ).
12 In formal models, the value of information is quantified a s the difference between the expected value
realized by optimal decisions made with that information and the expected value realized by optimal
decision s made without it. (See, e.g., Russell & Norvig 2010 .) It follows that the value of information is
never negative. It also follows that any information you know will never affect any decision you will ever
make has zero value for you. However, this kind of m odel assumes several idealizations which are often
invalid in the real world —such as that knowledge has no final value (meaning that knowledge has only
instrumental value and is not valuable for its own sake), and that agents are not transparent to other
agents.
10
less intellig ence.13 The same can hold if the agent has final goals that involve bei ng ignorant of
certain facts: likewise if an agent faces incentives arising from strategic commitments, signaling,
or social preferences, as noted above.14
Each of these countervailing reasons often comes into play for human beings . Much
information is irrelevant to our goals; we can often rely on others’ skill and expertise; acquiring
knowledge takes time and effort; we might intrinsically value certain kinds of ignorance; and we
opera te in an environment in which the ability to make strategic commitments, socially signal,
and satisfy other people’s direct preferences over our own epistemic states , is often important to
us than simple cognitive gains .
There are special situations in wh ich cognitive enhancement may result in an enormous
increase in an agent’s ability to achieve its final goals —in particular, if the agent’s final goals are
fairly unbounded and the agent is in a position to become the first superintelligence and thereby
potentially obtain a decisive advantage enabling the agent to shape the future of Earth -
originating life and accessible cosmic resources according to its preferences . At least in this
special case, a rational intelligent agent would place a very high instru mental value on cognitive
enhancement.
2.4 Technolog ical perfection
An agent may often have instrumental reasons to seek better technology, which at its simplest
means seeking more efficient ways of transforming some given set of inputs into valued outputs.
Thus , a software agent might place an instrumental value on more efficient algorithms that
enable its mental functions to run faster on given hardware. Similarly, agents whose goals
require some form of physical construction might instrumentally value improved engineering
technology which enable s them to create a wider range of structures more quickly and reliably ,
using fewer or cheaper materials and less energy. Of course , there is a tradeoff: the p otential
benefits of better technology mus t be weighed against its costs, including not only the cost of
obtaining the technology but also the costs of learning how to use it, integrating it with other
technologies already in us e, and so forth.
Proponents of some new technology, confident in its superiority to existing alternatives ,
are often dismayed when other people do not share their enthusiasm, but peoples’ resistance to
novel and nominally superior technology need not be b ased on ignorance or irrationality . A
technology’s valence or normative character depends not only on the context in which it is
deployed, but also the vantage point from which its impacts are evaluated: what is a boon from
one person’s perspective can be a liability from another’s. Thus, although mechanized looms
increased the economic efficie ncy of textile production, the Luddite handloom weavers who
13 This strategy is exemplified by the sea squirt larva, which swims about until it finds a suitable rock, to
which it then permanently affixes itself. Cemented in place, the larva has less need for complex
information processing, whence it proceeds to digest part of its own brain (its cerebral ganglion).
Academics can sometimes observe a similar phenomenon in colleagues who are granted tenure.
14 Cf. Bostrom (2012 ).
11
anticipated that the innovation would render their artisan skills obsolete may have had good
instrumenta l reason s to oppose it. The point here is that if “technolog ical perfection” is to name
a widely convergent instrumental goal for intelligent agents, then the term must be understood
in a spec ial sense—technology must be construed as embedded in a particu lar social context, and
its costs and benefits must be evaluated with reference to some specified agents’ final values.
It seems that a superintelligent singleton—a superintelligent agent that faces no
significant intelligent rivals or opposition , and is thus in a position to determ ine global policy
unilaterally —would have instrumental reason to perfect the technologies that would make it
better able to shape the world according to its preferred designs.15 This would probably include
space colonization tec hnology, such as von Neumann probes —automatic, self -mending and self -
replicating spaceships that can extend its reach beyond the Solar System. Molecular
nanotechnology, or some alternative still more capable physical manufacturing technology , also
seem s potentially very useful in the service of an extremely wide range of final goals.16
2.5 Resource acquisition
Finally, resource acquisition is a nother common emergent instrumental goal, for muc h the same
reasons as technological perfection: both technology and resources facilitate physical
construction projects.
Human beings tend to seek to acquire resources sufficient to meet their basic biological
needs. But people usually seek to acquire resources far beyond this minim um level. In doing so,
they may b e partially driven by lesser physical desiderata, such as in creased comfort and
convenience. A great deal of resource accumulation is motivated by social concerns —gaining
status, mates, friends and influence, through wealth accumulation and conspicuous
consumption. Perhaps l ess commonly, some people seek additional resources to achieve
altruistic or expensive non -social aims.
15 Cf. Bostrom (2006 ).
16 One could reverse the question and look instead at possible reasons for a superintelligent singleton not to
develop some technolo gical capabilities. These include: (a) The singleton foreseeing that it will have no
use of some technolo gical capability ; (b) The development c ost being too large relative to its anticipated
utility . This would be the case if, for instance , the technology will never be suitable for achieving any of the
singleton’s ends, or if the singleton has a very high discount rate that s trongly discourages investment; (c)
The singleton having some final value that requires abstention from particular avenues of technology
development; (d) If the singleton is not certain it will remain stable, it might prefer to refrain from
developing tech nologies that could threaten its internal stability or that would make the consequences of
dissolution worse (e.g., a world government may not wish to develop technologies that would facilitate
rebellion, even if they had some good uses, nor develop t echno logies for the easy production of weapons of
mass destruction which could wreak havoc i f the world government were to dissolve); (e) Similarly, the
singleton might have made some kind of binding strategic commitment not to develop some technology, a
commit ment that remains operative even if it would now be convenient to develop it. (Note, however, that
some current reasons for technology -development would not apply to a singleton: e.g., reasons arising from
unwanted arms races.)
12
On the basis of such observations it might be tempting to suppose that a
superintelligence not facing a competitive social world wo uld see no instrumental reason to
accumulate resources beyond some modest level, for instance whatever computational resources
needed to run its mind along with some virtual reality. Yet such a supposition would be entirely
unwarranted. First, the value of resources depends on the uses to which they can be put, which
in turn depends on the available technology. With mature technology, basi c resources such as
time, space, and matter , and other forms of free energy , could be processed to serve almost any
goal. For instance, such basic resources could be converted into life. Increased computational
resources could be used to run the super intelligence at a greater speed and for a longer duration,
or to create additional physical or simulated (virtual) lives and civilizations. Extra physical
resources could also be used to create backup systems or perimeter defenses, enhancing security.
Such projects could easily c onsume far more than one planet’s worth of resources.
Furthermore, the cost of acquiring additional extraterrestrial resources will decline
radically as the technology matures . Once von Neumann probes can be built, a large portion of
the observable universe (assuming it is uninhabited by intelligent lif e) could be gradually
colonized —for the one -off cost of building and launching a single successful self -reproducing
probe. This low cost of celestial resource acquisition would mean that such expansion could be
worthwhile even if the value of the additional resources gained were somewhat marginal. For
example, even if a superintelligence cared non -instrumentally only about what happens within
some pa rticular small volume of space, such as the space occupied by its origina l home planet, it
would still have in strumental reasons to harvest the resources of the cosmos beyond. It could
use those surplus resources to build computers to calculate more optimal way s of using
resources within the small spatial region of primary concern. It could also use the extra
resources to build ever -more robust defenses to safeguard the privileged real estate. Since the
cost of acquiring additional resources would keep declining, this process of optimizing and
increasing safeguards might well continue indefinitely even if it were subject to steeply declining
returns.17 18
17 Suppose that an agent dis counts resources obtained in the future at an exponential rate, and that because
of the light speed limitation the agent can only increase its resource e ndowment at a polynomial rate.
Would this mean that there will be some time after which the agent woul d not find it worthwhile to
continue acquisitive expansion? No, because although the present value of the resources obtained at future
times would asymptote to zero the further into the future we look, so would the present cost of obtaining
them. The pre sent cost of sending out one more von Neumann probe a 100 million years from now
(possibly using some resource acquired some short time earlier) would be diminished by the same
discount factor that would diminish the present value of the future resources t he extra probe would
acquire (modulo a constant factor).
18 Even an agent that has an apparently very limited final goal, such as “to make 32 paperclips”, could
pursue unlimited resource acquisition if there were no relevant cost to the agent of doing so. For example,
even after an expected -utility -maximizing agent had built 32 paperclips, it could use some extra resources
to verify that it had indeed successfully built 32 paperclips meeting all the specifications (and, if necessary,
to take corrective acti on). After it had done so, it could run another batch of tests to make doubly sure that
no mistake had been made. And then it could run another test, and another. The benefits of subsequent
tests would be subject to steeply diminishing returns; however, so long as there were no alternative action
13
Thus, there is an extremely wide range of possible final goals a superintelligent singleton
could have that would generate the instrumental goal of unlimited resource acquisition . The
likely manifestation of thi s would be the superintelligence’s initiation of a colonization process
that would expand in all directions using von Neumann probes . This would roughly result in a
sphere of expanding infrastructure centered on the originating planet and growing in radiu s at
some fraction of the speed of light; and the colonization of the universe would continue in this
manner until the accelerating speed of cosmic expansion ( a consequence of the positive
cosmological constant) makes further material acquisition physicall y impossible as remoter
regions drift permanently out of reach .19 By contrast, agents lacking the technology required for
inexpensive resource acquisition , or for the conversion of generic physical resources into useful
infrastructure , may often find it not cost-effective to invest any present resources in increa sing
their material endowment. The same may hold for agents operating in competition with other
agents of similar powers. For instance, if competing agents have already secured accessible
cosmic resources, a late -starting agent may have no colonization opportunities. The conver gent
instrumental reasons for superintelligences un certain of the non-existence of other powerful
superintelligent agents are complicated by strategic considerations in wa ys that we do not
currently fully comprehend but which may constitute important qualifications to the examples
of convergent instrumental reasons we have looked at here.20
It should be emphasized that the existence of convergent instrumental reasons, even if
they apply to and are recognized by a particular agent, does not imply that the agent’s behavior
is easily predictable. An agent might well think of ways of pursuing the relevant instrumental
values that do not readily occur to us. This is especially true for a superintelligence, which could
devi se extremely clever but counterintuitive plans to realize its goals, possibly even exploiting
as-yet undiscovered physical phenomena. What is predictable is that the convergent
with a higher expected utility, the agent would keep testing and re -testing (and keep acquiring more
resources to enable these tests).
19 While the volume reached by colonization probes at a given time might be roughly spherical and
expanding with a rate proportional to the square of time elapsed since the first probe was launched (~t2),
the amount of resources contained within this volume will follow a less regular growth pattern, since the
distribution of resou rces is inhomogeneous and varies over several scales. Initially, the growth rate might
be ~t2 as the home planet is colonized; then the growth rate might become spiky as nearby planets and
solar systems are colonized; then, as the roughly disc -shaped volu me of the Milky Way gets filled out, the
growth rate might even out, to be approximately proportional to t; then the growth rate might again
become spiky as nearby galaxies are colonized; then the growth rate might again approximate ~t2 as
expansion procee ds on a scale over which the distribution of galaxies is roughly homogeneous; then
another period of spiky growth followed by smooth ~t2 growth as galactic superclusters are colonized; until
ultimately the growth rate starts a final decline, eventually rea ching zero as the expansion speed of the
universe accelerates to such an extent as to make further colonization impossible.
20 The simulation argument may be of particular importance in this context. A superintelligent agent may
assign a significant probab ility to hypotheses according to which it lives in a computer simulation and its
percept sequence is generated by another superintelligence, and this might various generate convergent
instrumental reasons depending on the agent’s guesses about what types o f simulations it is most likely to
be in. Cf. Bostrom (2003 ).
14
instrumental values would be pur sued and used to realize the agent’s final goals, not the specific
actions that the agent would take to achieve this.
Conclusions
The orthogonality thesis suggests that we cannot blithely assume that a superintelligence will
necessarily share any of the f inal values stereotypically associated with wisdom and in tellectual
development in humans —scientific curiosity, benevolent concern for others, spiritual
enlightenment and contemplation , renunciation of material acquisitiveness , a taste for refined
culture or for the simple pleasures in life , humility and selflessness, and so forth. It might be
possible through deliberate effort to construct a superintelligence that values such things , or to
build one that values human welfare, moral goodness, or any other complex purpose that its
designers might want it to ser ve. But it is no less possible—and probably technically easie r—to
build a superintelligence that places final value on nothing but calculating the decimals of pi .
The instrumental convergence thesis suggests that we cannot blithely assume that a
superintelligence with the final goal of calculating the decimals of pi (or making paperclips, or
counting grains of sand) would limit its activities in such a way as to not materially infringe on
human intere sts. An agent with such a final goal would have a convergent instrumental reason ,
in many situations, to acquire an unlimited amount of physical resources and, if possible, to
eliminate potential threats to itself and its goal system .21 It might be possib le to set up a situation
in which the optimal way for the agent to pursue these instrumental values (and thereby its final
goals) is by promoting human welfare, acting morally, or serving some beneficial purpose as
intended by its creators. However, if and when such an agent finds itself in a different situation,
one in which it expects a greater number of decimals of pi to be calculated if it destroys the
human species than if it continues to act cooperatively, its behavior would instantly take a
sinister turn. This indicates a danger in relying on instrumental values as a guarantor of safe
conduct in future artificial agents that are intended to become superintelligent and that might be
able to leverage their superi ntelligence into extreme levels power a nd influence .22
References
Bostrom, N. (2003). Are You Living in a Computer Simulation? Philosophical Quarterly , 53(211),
243-255.
Bostrom. N. (2006). What is a Singleton? Linguistic and Philosophical Investigations , 5(2), 48 -54.
21 Human beings might constitute potential threats; they certainly c onstitute physical resources.
22 For co mments and discussion I am grateful to Stuart Armstrong, Grant Bartley, Owain Evans, Lisa
Makros, Luke Muehlhauser, Toby Ord, Brian Rabkin, Rebecca Roache, Anders Sandberg, and three
anonymous referees.
15
Bostrom, N. (2012 ). Information Hazards: A Typology of Potentia l Harms from Knowledge.
Review of Contemporary Phil osophy , 10, 44 -79. [www.nickbostrom.com/information -hazards.pdf ]
Chalmers, D. (2010): The Singularity: A Philosophi cal Analysis. Journal of Consciousness Studies ,
17, 7 -65.
Chislenko, A. (1997). Technology as Extension of Human Functional Architecture. Extropy
Online . [project.cyberpunk.ru/idb/technology_ as_extension.html ]
de Blanc, P. (2011). Ontological Crises in Artificial Agent’s Value Systems. Manuscript . The
Singularity Institute for Artificial In telligence. [arxiv.org/pdf/1105.3821v1.pdf ]
Dewey, D. (2011). Learning What to V alue. In Schmidhuber, J., Thori sson, K. R., Looks, M. (eds.).
Proceedings of the 4th Conference on Artificial General Intelligence , AGI 2011 (pp. 309 -314),
Heidelberg: Springer.
Forgas, J. et al. (eds.) (2009). The Psychology of A ttitude s and Attitude Change . London: Psychology
Press.
Lewis, D. (1988). Desire as belief. Mind , 97(387), 323 -332.
Omohundro, S. (2008a). The Basic AI Drives. In P. Wang, B. Go ertzel, and S. Franklin (eds.).
Proceedings of the First AGI Conference , 171 , Frontiers in Artificial Intelligence and Appli cations.
Amsterdam: IOS Press.
Omohundro, S. (2008b). The Nature of Self -Improving Artificial Intel ligence. Manuscript .
[selfawaresystems.files.wordpress.com/2008/01/nature_of_self_improving_ai.pdf ]
Omohundro, S. (forthcoming 2012). Rationally -Shaped Artificial Intelligence. In Eden, A. et al.
(eds.). The Singularity Hypothesis: A Scient ific and Philosophical Assessment (Springer, forth coming).
Parfit, D. (1984). Reasons and Persons . (pp. 123 -4). Reprinted and c orrected edition, 1987. Oxford:
Oxford University Press.
Parfit, D. (2011). On What Matters . Oxford: Oxford University Press.
Russell, S. and Norvig, P. ( 2010). Artificial Intelligence: A Modern Approach . (3rd ed. ). New Jersey:
Prentice Hall.
Sandberg, A. and Bostrom, N. (2008). Whole Brain Emulation: A Roadmap . Technical Report 2008–
3. Oxford: Future of Humanity Institute, O xford Univer sity.
16
[www.fhi.ox.ac.uk/Reports/200 8-3.pdf ]
Shulman, C. (2010). Omohundro’s “Basic AI Drives” and Cata strophic Risks. Manuscript .
[singinst.org /upload/ai -resource -drives.pdf ]
Sinhababu, N. (2009). The Humean Theory of Motiva tion Reformulated and Defended.
Philosophical Review , 118(4), 465 -500.
Smith, M. (1987). The Humean Theory of Motivation. Mind , 46 (381): 36 -61.
Weizenbaum, J. (1976). Computer Power and Human Reason: Fro m Judgment to Calculation . San
Francisco: W. H. Freeman.
Yudkowsky, E. (2008). Artificial Intelligence as a Positive and Negative Factor i n Global Ri sk. In
Bostrom, N. and Cirkovic, M. (eds.). Global Catastrophic R isks. (pp. 308 -345; quote from p. 310).
Oxford: Oxford University P ress.
Yudkowsky, E. (2011). Complex Value Systems Are Required to Realize Valuable Futures. In
Schmidhuber , J., Thorisson, K. R., Looks, M. (eds.). Procee dings of the 4th Conference on Artificial
General Intelligence , AGI 2011 (pp. 388 -393). Heidelberg: Springer. |
8eafc10a-d204-4f24-97c4-105c04831008 | trentmkelly/LessWrong-43k | LessWrong | How should DeepMind's Chinchilla revise our AI forecasts?
Acknowledgements: I wrote this report as part of a six-hour paid work-trial with Epoch AI.
Epistemic status: My dataset analysis is a bit simplistic but the inference I draw from it seems likely. The implications for TAI timelines, in descending order of confidence, are 3, 7, 8, 4, 1, 2, 5, 6.
Abstract:
AI forecasters seek to predict the development of large language models (LLMs), but these predictions must be revised in light of DeepMind's Chinchilla. In this report, I will discuss these revisions and their implications. I analyse a dataset of 45 recent LLM and find that previous LLMs were surprisingly trained neither Kaplan-optimally nor Hoffman-optimally. I predict that future LLMs will be trained Hoffman-optimally. Finally, I explore how these scaling laws should impact our AI alignment and governance strategies.
Introduction.
The purpose of this report.
What problem do I aim to solve?
In April 2022, DeepMind subverted the conventional understanding of how to train large language models.[1]
1. They determined experimentally a new scaling law relating the loss of a LLM L to the number of parameters in its architecture N and the number of datapoints used in its training D.
2. From this scaling law they derived a formula for the optimal parameter-count and data-count for a given computational budget.
3. They showed that recent LLMs had been trained with far too many parameters and far too little data.
4. They trained their own LLM called Chinchilla according to their newly-discovered optimality conditions. Although Chinchilla used roughly as much compute as Gopher, it achieved a 7% improvement on the MMLU benchmark.
Chinchilla forces us to revise our predictions about the development of AI, but it's not immediately clear what these revisions should be. Should we update towards short timelines or long timelines? Should we update towards gradual take-off or sudden take-off? Should we update towards friendly AI or unfriendly AI?
My contributions.
There |
95c980a9-34d0-4408-8d5c-f3c2309ab13d | trentmkelly/LessWrong-43k | LessWrong | Can subjunctive dependence emerge from a simplicity prior?
Suppose that an embedded agent models its environment using an approximate simplicity prior, would it acquire a physicalist agent ontology or an algorithmic/logical agent ontology?
One argument for the logical agent ontology is that it allows the agent to compress different parts of its observations that are subjunctively dependent: If two physical systems are computing the same function, the logical agent ontology only has to store that function once, then model the dependencies between those two systems and the function. On the other hand, information about that function would be redundantly represented in both physical systems under the physicalist agent ontology.
Most decision theory literature seems to treat (physical) causal dependence as the default, requiring extra work to formalize subjunctive dependence. However, if logical agent ontology naturally emerges from a simplicity prior, we might expect subjunctive dependence to arise by default for most agents.
Thanks to Anthony Digiovanni for the discuission that inspired this post |
ab68c425-e39d-4de7-97e2-82af183d1093 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Calibration Training and Potluck - Portland
Discussion article for the meetup : Calibration Training and Potluck - Portland
WHEN: 12 July 2014 06:31:27PM (-0700)
WHERE: Portland, Oregon
I'm looking to do some calibration training using the format described in How to Measure Anything. I'm looking forward to meeting you all. Message me for address.
Discussion article for the meetup : Calibration Training and Potluck - Portland |
87a3c4f2-56c3-43a9-8457-045df8283a5e | trentmkelly/LessWrong-43k | LessWrong | X-Risk, Anthropics, & Peter Thiel's Investment Thesis
This story is cross-posted from my blog, jacksonw.xyz, and from the EA Forum.
Summary: I analyze an essay by Peter Thiel, in which he explains:
* How markets are incentivized to ignore the risk of civilizational collapse.
* How this introduces distortions in both market prices and our thinking.
* How to attempt to correct for these distortions using "The Optimistic Thought Experiment"
* A big-picture view of financial history as a single "Great Boom" built on the uncertain hope that capitalist civilization will ultimately be proven viable and achieve existential security.
I then add my own musings about how these ideas might usefully connect with the goals of longtermist Effective Altruism.
----------------------------------------
EA/Rationalist Portfolio Design: An Unsolved Problem Way Over My Head
Rationalists and EAs have discussed how our values and beliefs should affect how we invest:
* For altruistic donations, the utility of money is roughly linear with increasing wealth, rather than having diminishing returns like with increasing personal wealth. This probably means that we should be willing to use more leverage and invest in a higher-risk, higher-expected-return portfolio?
* Popular types of "socially-responsible investing" are sadly not very effective by EA lights, but this could be changed. Conversely, divestment is often considered to be an ineffective strategy, but done in the right way perhaps it could work well.
* Or perhaps we should do the opposite, using the logic of "mission hedging" to investing in bad things so we have more money to deploy in worlds where bad things grow larger. (More details on mission hedging here.)
* Perhaps we could pursue a variant of mission hedging that is less related to divestment and "sin funds" and more based on prediction-market hedging of specific events, like how a presidential election might change the tractability of a certain cause.
* There is a rich discussion around the idea of "patient philant |
db4ab3b6-956f-4db0-8536-b4c618b487b9 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Capability amplification
(*Note: In the past I have referred to this process as ‘bootstrapping’ or ‘policy amplification,’ but those terms are too broad — there are other dimensions along which policies can be amplified, and ‘bootstrapping’ is used all over the place.*)
Defining the “intended behavior” of a powerful AI system is a challenge.
We don’t want such systems to simply imitate human behavior — we want them to improve upon human abilities. And we don’t want them to only take actions that look good to humans — we want them to improve upon human judgment.
We also don’t want them to pursue simple goals like “minimize the probability that the bridge falls down” or “pick the winning move.” A precise statement of our real goals would be incredibly complicated, and articulating them precisely is itself a massive project. Moreover, we often care about consequences over years or decades. Such long-term consequences would have little use as a *practical* problem definition in machine learning, even if they could serve as a *philosophical* problem definition.
So: what else can we do?
Instead of defining what it means for a policy to be “good,” we could define a transformation which turns one policy into a “better” policy.
I call such a transformation *capability amplification* — it “amplifies” a weak policy into a strong policy, typically by using more computational resources and applying the weak policy many times.
Motivation
----------
I am interested in capability amplification because I think it is the most plausible route to defining the goals of powerful AI systems, which I see as a key bottleneck for building aligned AI. The most plausible alternative approach is probably inverse RL, but I think that there are still [hard philosophical problems](https://medium.com/ai-control/the-easy-goal-inference-problem-is-still-hard-fad030e0a876#.hd34chtkp) to solve, and that in practice IRL would probably [need to be combined with something like capability amplification](https://medium.com/ai-control/ambitious-vs-narrow-value-learning-99bd0c59847e).
More directly, I think that capability amplification might be a workable approach to [training powerful RL systems](https://medium.com/ai-control/alba-an-explicit-proposal-for-aligned-ai-17a55f60bbcf) when combined with [semi-supervised RL](https://medium.com/ai-control/semi-supervised-reinforcement-learning-cf7d5375197f#.qrer176h2), [adversarial training](https://medium.com/ai-control/red-teams-b5b6de33dc76#.xu7565k4b), and [informed oversight](https://medium.com/ai-control/the-informed-oversight-problem-1b51b4f66b35#.7vyxc2kzr) (or another approach to [reward engineering](https://medium.com/ai-control/reward-engineering-f8b5de40d075#.rsuwkjdo3)).
Example of capability amplification: answering questions
--------------------------------------------------------
Suppose that we would like like to amplify one question-answering system **A**into a “better” question-answering system **A⁺**.
We will be given a question *Q* and an implementation of **A**; we can use **A**, or any other tools at our disposal, to try to answer the question *Q*. We have some time limit; in reality it might be eight hours, but for the purpose of a simple example suppose it is twenty seconds. The amplification **A⁺**(*Q*) is defined to be whatever answer we come up with by the end of the time limit. The goal is for this answer to be “better” than the answer that **A** would have given on its own, or to be able to answer harder questions than **A** could have answered directly.
For example, suppose that *Q* = “Which is more water-soluble, table salt or table sugar?” Suppose further that **A** can’t answer this question on its own: **A**(“Which is more water-soluble…”) = “I don’t know.”
I could start by computing **A**(“How do you quantify water-solubility?”); say this gives the answer “By measuring how much of the substance can dissolve in a fixed quantity of water.” Then I ask **A**(“How much table salt will dissolve in a liter of water?”) and get back the answer “360 grams.” Then I ask **A**(“How much sugar will dissolve in a liter of water?”) and get back the answer “2 kilograms.” Then I reply “Sugar is about six times more soluble than salt.”
Thus **A⁺**(“Which is more water-soluble, table salt or table sugar?”) = “Sugar is about six times more soluble than salt.” This is better than the answer that **A**gave — in some sense, we’ve successfully amplified **A** into something smarter.
The general problem
-------------------
The capability amplification problem is to use one policy **A** to implement a new policy **A⁺** which is strictly “better” than **A**. (Recall that a policy is a mapping from inputs to outputs.)
We’ll discuss the definition of “better” in the next section, but for now you can use an intuitive definition. Note that “better” *does not* mean that we can implement **A⁺** using fewer computational resources than **A** — in fact we will implement **A⁺** by using a huge amount of computation and time.
What does it mean to “implement” the amplified policy **A⁺**? It means that we have some process that takes as input an observation *o*[1] and produce an action *a*[1]. It then takes as input the next observation *o*[2] and produces the next action *a*[2], and so on.
The process that implements **A⁺** may instantiate any number of agents who use the policy **A** and interact with them. The process might make copies of any of these agents. And the process can involve us personally thinking about the problem, or using any other tools that we have available — having access to **A**may be a useful resource, but we can also do things from scratch if that’s easier.
The capability amplification problem comes with a time limit — we need to provide an implementation that runs within that time limit. (When we submit one action *a*[k], we immediately see the next observation *o*[k+1].) Once the time limit runs out, we automatically output a nil action in response to each additional observation. One way to be “better” is to be able to handle longer sequences of observations.
The time limit could be arbitrary, but I’ll pick one day for concreteness. I’ll assume that we have an implementation of **A** that runs in one second per episode.
Note that we can start from the trivial policy **∅** which always outputs nil. In this case, **∅⁺** is a policy that we can implement “from scratch.”
Reachability
------------
To measure how well we can solve capability amplification, we’ll introduce the concept of *reachability*.
Reachability is defined with respect to a class of policies **𝒜** and a preference ordering ⪰. Intuitively:
* **𝒜** is a class of policies that we are capable of implementing efficiently. For example, **𝒜** might be the set of policies that can be implemented by a ten layer neural network.
* We say that **A** ⪰ **B** if we are *at least as happy* with policy **A** as with policy **B**(in any situation that we think might arise in practice).
We say that **C** is *reachable* from **A** if:
* **A**⁺ ⪰ **C**, where **A**⁺ is the amplification as described in the last section; or
* There is an intermediate **B** ∈ 𝓐 which is reachable from **A** and which can reach **C**.
Equivalently:
* **C** is reachable from **A** if there is a chain of policies in **𝒜** which starts at **A**and ends at **C**, and where each policy in the chain is no better than the amplification of the previous policy.
The better we are at capability amplification, the more policies will be reachable from any given starting point. Our goal is to have as many policies as possible be reachable from the trivial policy **∅** — ideally, *every* policy in 𝓐 would be reachable from **∅**.
Obstructions
------------
An *obstruction* to capability amplification is a partition of the policy class 𝓐 into two parts 𝓛 and 𝓗, such that we cannot amplify *any* policy in 𝓛 to be at least as good as *any* policy in 𝓗.
Obstructions are dual to reachability in a natural sense. If there are any non-reachable policies, then there is some corresponding obstruction. The desired output of research on capability amplification are a *matching* amplification strategy and obstruction — a way to reach many policies, and an obstruction that implies that we can’t reach any more.
Analogously, we say that a function *L* : 𝓐 → ℝ is an obstruction if our amplification procedure cannot always increase *L*. That is, *L* is an obstruction if there exists a threshold ℓ such that the two sets { **A** ∈ 𝓐 : *L*(**A**) ≤ ℓ } and { **A**∈ 𝓐 : *L*(**A**) > ℓ} are an obstruction, or such that { **A** ∈ 𝓐 : *L*(**A**) < ℓ } and { **A**∈ 𝓐 : *L*(**A**) ≥ ℓ} are an obstruction.
If we could find a convincing argument that some partition was an obstruction, then that would help further our understanding of value alignment. The next step would be to ask: can we sensibly define “good behavior” for policies in the inaccessible part 𝓗? I suspect this will help focus our attention on the most philosophically fraught aspects of value alignment.
In the appendices I give an example of an obstruction in a particular simple model.
Relationship to value alignment
===============================
Why capability amplification seems feasible
-------------------------------------------
Capability amplification is a special case of the general problem of “building an AI that does the right thing.” It is easier in two respects:
1. In the general problem we need to construct a “good” policy from scratch. In capability amplification we need to construct a good policy **A**⁺ starting from a slightly weaker policy **A**.
2. In the general problem we must *efficiently implement* a good policy. In capability amplification our implementation of **A⁺** is allowed to take up to a day, even though the goal is to improve upon a policy **A** that runs in one second.
Intuitively, these seem like large advantages.
Nevertheless, it may be that capability amplification contains the hardest aspects of value alignment. If true, I think this would change our conception of the value alignment problem and what the core difficulties are. For example, if capability amplification is the “hard part,” then the value alignment problem is essentially orthogonal to the algorithmic challenge of building an intelligence.
Why capability amplification seems useful
-----------------------------------------
Capability amplification can be combined with [reward engineering](https://medium.com/ai-control/the-reward-engineering-problem-30285c779450) in a natural way:
* Define **A0** = **∅**
* Apply capability amplification to obtain **A0⁺**
* Apply reward engineering to define a reward function, and use this to train an agent **A1** which is better than **A0**
* Apply capability amplification to obtain **A1⁺**
* Repeat to obtain a sequence of increasingly powerful agents
This is very informal, and actually carrying out such a process requires resolving many technical difficulties. But it suggests that capability amplification and reward engineering might provide a [foundation for training an aligned AI](https://medium.com/ai-control/alba-an-explicit-proposal-for-aligned-ai-17a55f60bbcf).
What to do?
===========
Theory
------
The best approach seems to be to work from both sides, simultaneously searching for challenging obstructions and searching for amplification procedures that address those obstructions.
There are at least two very different angles on capability amplification:
* Collaboration: figure out how a bunch of agents using **A** can break a problem down into smaller pieces and attack those pieces separately, allowing them to solve harder problems than they could solve independently.
* Philosophy: try to better understand what “good” reasoning is, so that we can better understand how good reasoning is composed of simpler steps. For example, mathematical proof is a technique which relates hard problems to long sequences of simple steps. There may be more general ideas along similar lines.
In the appendices, I describe some possible amplification schemes and obstructions, along with some early ideas about capability amplification in general.
Experiment
----------
Today, it is probably most worthwhile to study capability amplification when **A** is a *human’s* policy.
In this setting, we are given some weak human policy **A** — say, a human thinking for an hour. We would like to amplify this to a strong collaborative policy **A⁺**, by invoking a bunch of copies of **A** and having them interact with each other appropriately.
In some sense this is the fully general problem of organizing human collaborations. But we can focus our attention on the most plausible obstructions for capability amplification, and try to design collaboration frameworks that let us overcome those obstructions.
In this context, I think the most interesting obstruction is working with concepts that are (slightly) too complicated for any individual copy of **A** to understand on its own. This looks like a hard problem that is mostly unaddressed by usual approaches to collaboration.
[This post](https://medium.com/ai-control/human-arguments-and-ai-control-bc99c043a5ec#.6lxam64e0) lays out a closely related problem — quickly evaluating arguments by experts — which gets at most of the same difficulties but may be easier to study. Superficially, evaluating arguments may seem easier than solving problems from scratch. But because it is so much easier to collaboratively *create* arguments once you have a way to evaluate them, I think the gap is probably only superficial.
Conclusion
==========
The capability amplification problem may effectively isolate the central *philosophical* difficulties of value alignment. It’s not easy to guess how hard it is — we may already have “good enough” solutions, or it may effectively be a restatement of the original problem.
Capability amplification asks us to implement a powerful policy that “behaves well,” but it is easier than value alignment in two important respects: we are given access to a slightly weaker policy, and our implementation can be extremely inefficient. It may be that these advantages are not significant advantages, but if so that would require us to significantly change our understanding of what the value alignment problem is about.
Capability amplification appears to be less tractable than the other research problems I’ve outlined. I think it’s unlikely to be a good research direction for machine learning researchers interested in value alignment. But it may be a good topic for researchers with a philosophical focus who are especially interested in attacking problems that might otherwise be neglected.
*(This research was supported as part of the* *[Future of Life Institute](http://futureoflife.org/)* *FLI-RFP-AI1 program, grant #2015–143898.)*
---
Appendix: iterating amplification
---------------------------------
Let **H** be the input-output behavior of a human + all of the non-**A** tools at their disposal. Then an amplification procedure defines **A**⁺ as a simple computation that uses **H** and **A** as subroutines.
In particular, **∅⁺** is a computation that uses **H** as a subroutine. If we amplify again, we obtain **∅⁺⁺**, which is a computation that uses **H** and **∅⁺** as subroutines. But since **∅⁺** is a simple computation that uses **H** as a subroutine, we can rewrite **∅⁺⁺** as a simple computation that uses only **H** as a subroutine.
We can go on in this way, reaching **∅⁺⁺⁺**, **∅⁺⁺⁺⁺** and so on. By induction, all of these policies are defined by simple computations that use as **H** as a subroutine. (Of course these “simple computations” are exponentially expensive, even though they are easy to specify. But they have a simple form and can be easily written down in terms of the amplification procedure.)
Under some simple ergodicity assumptions, this sequence converges to a fixed point **Ω** (very similar to [HCH](https://medium.com/ai-control/strong-hch-bedb0dc08d4e#.o8kfuzc27)). So a capability amplification procedure essentially uniquely defines an “optimal” policy **Ω**; this policy is uncomputable, but has a concise representation in terms of **H**.
If there is anything that **Ω** can’t do, then we have found an unreachable policy. This perspective seems useful for identifying the hard part of the capability amplification problem.
Specifying an amplification strategy also specifies a way to set up an interaction between a bunch of copies of **H** such that they implement **Ω**. Indeed, designing such an interaction is *easier* than designing an amplification procedure that converges to **Ω**. So if we can’t design a procedure for a bunch of copies of **H** to collaboratively accomplish some task T, then we also can’t design an amplification procedure that can reach policies that can accomplish T.
But in some cases this seems extremely challenging. For example, suppose that we would like to write a very good textbook about general relativity. Recall that **H** is the policy implemented by a human over one day. To make the game hard, suppose that **H** has never encountered calculus.
The most natural approaches require at least one copy of **H** to understand general relativity. But **H** only lasts a single day, and there many not be *any* sequence of observations that makes **H** understand general relativity within a day.
So in order for **Ω** to succeed at this task, it needs to be able to write a textbook without *any* single copy of **H** understanding general relativity. The understanding must instead be distributed across a large number of copies of **H**. Yet they must somehow collaborate to write individual sentences that correctly communicate the theory.
This sounds like a hard problem.
Appendix: examples of capability amplification
----------------------------------------------
ETA: my current best proposal is [meta-execution](https://medium.com/ai-control/meta-execution-27ba9b34d377#.qrr0vi904), which is essentially a formalization of the “universal” scheme below.
**Warmup I: Preprocessing**
We instantiate a “leader” agent who uses the policy **A**. For each observation *o*[*k*]:
* We instantiate a new agent using **A**. We give them observation: “think about the observation {*o*[*k*]} and output a useful hint for a copy of yourself who has to respond to it.” Let *h*[*k*] be the agent’s action. Then we destroy the agent.
* We give the leader the observation “The observation is {*o*[*k*]}, and a copy of you prepared the hint {*h*[*k*]}.” Let *a*[*k*] be its action.
We might hope that this composite is smarter than **A**. After all, it has twice as long to think — even if the copy can’t come up with a very helpful hint, it doesn’t seem so hard to come up with a hint that is better than nothing.
**Warmup II: Asking questions**
We instantiate a “leader” agent who uses the policy **A**. We give each observation *o*[*k*] to the leader, and ask them to reply with an action *a*[*k*].
But we also allow the leader to instantiate subagents and communicate with those agents.
That is, if the leader takes an action of the special form “Instantiate a new agent” then we create a new agent using **A**, assign it a unique ID, and give the leader the observation: “A new agent has been created with ID [X].” Similarly, the leader can take the special action “Copy the agent with ID [X].”
If the leader takes an action of the special form “Ask [Q] to the agent with ID [X]” then we give Q as an observation to the agent with ID X. That agent will reply with some action A, and we give the leader the next observation: “The agent replied with [A].”
Eventually, the leader takes an action of the special form “Take action [A]”. Then we set *a*[*k*] = A, and move on to the next observation.
The scheme from the last section is essentially the special case where the leader instantiates a single subagent and asks the single question “What is a useful hint for responding to observation *o*[*k*]?”
**Warmup III: Recursion**
We improve the scheme from the last section by allowing *every* agent to instantiate new subagents, rather than restricting this capability to the leader.
The messages between agents can contain not only words, but pointers to other agents. This allows the agents to pass arbitrarily large messages. For example, they can build a data structure out of agents, and just pass a “pointer” to the root of that data structure.
We can also slightly improve the scheme by allowing the leader to copy *itself*. This may be helpful if the leader has built up some useful context for the current situation.
**Universal amplification**
We improve the scheme further by giving the agents a large external memory. Rather than directly giving the leader the observation *o*[*k*], we write the observation to the external memory and tell the leader where the observation is written.
In addition to allowing agents to instantiate new agents and communicate with them, any agent can take the action “execute [P]”, where P is a program to be run against the external memory; the agent sees the observation “the program returned [*x*]” where *x* is P’s return value (or “nothing”).
Rather than having the leader directly return an action, the leader can take the special action “output the action returned by program [P].”
Messages between agents can now contain pointers to this external memory. For example, the leader could instantiate a subagent and ask it the question “Can you distinguish [*x*] from an array of random bytes?” where *x* is a pointer to an array in external memory.
We can easily generalize this setup to a parallel model of computation. We can also replace the shared memory by a more natural model for interprocess communication.
Appendix: knowledge about humans
--------------------------------
Human values are complex. If you are only able to interact with a human for a day, it may be completely impossible to figure out what they value, no matter how smart you are. Understanding what someone values may require giving them a large amount of time to reflect on their values, doing neuroscience, or carrying out other processes that take longer than a day.
This may imply an obstruction to capability amplification — we can’t reach policies that have more knowledge about humans than can be acquired by interacting with **H.**
However, even if this is a real obstruction, it does not seem to be an important one, for the following reason.
Suppose that we are able to train a very good policy, which does not reflect any complex facts about human values-upon-reflection. This optimal policy still can reflect many basic facts about human preferences:
1. We don’t want anything terrible to happen.
2. We want to “stay in control” of the agents we build.
3. We don’t want our agent to get left behind by its competitors; it should fight as hard as it can to retain influence over the world, subject to #1 and #2.
Moreover, all of these concepts are relatively easy to understand even if you have minimal understanding of human values.
So an excellent agent with a minimal understanding of human values seems OK. Such an agent could avoid getting left behind by its competitors, and remain under human control. Eventually, once it got enough information to understand human values (say, by interacting with humans), it could help us implement our values.
In the worst case the agent would lack a nuanced understanding of what we consider terrible, and so would have to either be especially conservative or else risk doing terrible things in the short term. In the scheme of things, this is not a catastrophic problem.
Appendix: an example obstruction
--------------------------------
Suppose that my brain encodes a random function *f*: {0, 1}\* → {0, 1} in the following sense: you can give me a sequence of bits, one per second, and then I can tell you the value of *f* on that sequence. There is no way to evaluate *f*other than to ask me.
Let N be the length of our capability amplification procedure, in seconds.
Let 𝓛 ⊆ 𝓐 be the set of policies that can be implemented using an oracle for *f*, restricted to inputs of length N.
Then it’s easy to see that 𝓛 forms an obstruction:
* We can simulate access to any policy in 𝓛 using an oracle for *f* restricted to inputs of length N. And we can simulate my role in the amplification procedure using an oracle for *f* restricted to inputs of length N. So policies in 𝓛 can only be amplified to other policies in 𝓛.
* We cannot evaluate *f* on even a single input of length N+1 using an oracle for *f* on inputs of length N. Most interesting classes 𝓐 will contain some policies not in 𝓛.
Whether this is a real obstruction depends on what the information is about:
* If it’s just random bits, then we don’t care at all — any other random bits would be “just as good.”
* If the random function encodes important information about my values, then we are in the situation described in the previous section, which doesn’t seem so bad.
* The worst case is when the function *f* encodes important information about how to behave effectively. For example, it encodes information about how to make accurate predictions. In this case we may actually be in trouble, since a policy that doesn’t know *f* may be outcompeted by one which does.
---
*This was originally posted [here](https://ai-alignment.com/policy-amplification-6a70cbee4f34) on 2nd October 2016.*
*The next post in this sequence will be 'Learning with catastrophes' by Paul Christiano.*
*Tomorrow's post will be 'Following Human Norms' in the sequence Value Learning by Rohin Shah.* |
d9c77a3f-abba-4975-a14c-c7815010fac2 | trentmkelly/LessWrong-43k | LessWrong | AXRP: Store, Patreon, Video
Some announcements:
* AXRP now has a store, where you can buy t-shirts and hoodies and stickers and such.
* AXRP now has a Patreon and a ko-fi, where you can support the podcast and get some perks.
* There’s now a video of an excerpt from episode 14, where Vanessa Kosoy explains the monotonicity principle, illustrated by Hamish Doodles - hopefully the first of many! |
13c9b805-c7ea-47a6-89d2-5ef92ccdf49f | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Normal Ending: Last Tears
Today's post, Normal Ending: Last Tears (6/8) was originally published on 04 February 2009. A summary (taken from the LW wiki):
> Humanity accepts the Superhappies' bargain.
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was Three Worlds Decide (5/8), and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series. |
d7a24457-1a8f-48b6-af5f-1fb8c54c83d0 | trentmkelly/LessWrong-43k | LessWrong | Everything I Need To Know About Takeoff Speeds I Learned From Air Conditioner Ratings On Amazon
I go to Amazon, search for “air conditioner”, and sort by average customer rating. There’s a couple pages of evaporative coolers (not what I’m looking for), one used window unit (?), and then this:
Average rating: 4.7 out of 5 stars.
However, this air conditioner has a major problem. Take a look at this picture:
Key thing to notice: there is one hose going to the window. Only one.
Why is that significant?
Here’s how this air conditioner works. It sucks in some air from the room. It splits that air into two streams, and pumps heat from one stream to the other - making some air hotter, and some air cooler. The cool air, it blows back into the room. The hot air, it blows out the window.
See the problem yet?
Air is blowing out the window. In order for the room to not end up a vacuum, air has to come back into the room from outside. In practice, houses are very not airtight (we don’t want to suffocate), so air from outside will be pulled in through lots of openings throughout the house. And presumably that air being pulled in from outside is hot; one typically does not use an air conditioner on cool days.
The actual effect of this air conditioner is to make the space right in front of the air conditioner nice and cool, but fill the rest of the house with hot outdoor air. Probably not what one wants from an air conditioner!
Ok, that’s amusing, but the point of this post is not physics-101 level case studies in how not to build an air conditioner. The real fact of interest is that this is apparently the top rated new air conditioner on Amazon. How does such a bad design end up so popular?
One aspect of the story, presumably, is fake reviews. That phenomenon is itself a rich source of insight, but not the point of this post, and definitely not enough to account for the popularity of this air conditioner. The reviews shown on the product page are all “verified purchase”, and mostly 5-stars. There are only 4 one-star reviews (out of 104). If most customers notic |
c5f59616-3553-4387-88be-da8b9ed9d0da | trentmkelly/LessWrong-43k | LessWrong | 2023 Unofficial LessWrong Census/Survey
The Less Wrong General Census is unofficially here! You can take it at this link.
Update: The census is closed! Thank you everyone who took it.
It's that time again.
If you are reading this post and identify as a LessWronger, then you are the target audience. I'd appreciate it if you took the survey. If you post, if you comment, if you lurk, if you don't actually read the site that much but you do read a bunch of the other rationalist blogs or you're really into HPMOR, if you hung out on rationalist tumblr back in the day, or if none of those exactly fit you but I'm maybe getting close, I think you count and I'd appreciate it if you took the survey.
Don't feel like you have to answer all of the questions just because you started taking it. Last year I asked if people thought the survey was too long, collectively they thought it was maybe a little bit too long, and then I added more questions than I removed. The survey is structured so the fastest and most generally applicable questions are (generally speaking) towards the start. At any point you can scroll to the bottom and hit Submit, though you won't be able to change your answers once you do.
The questions are a mix of historical questions that were previously asked on the LW Census, new questions sourced from LW commenters and some rationalist adjacent organizations I reached out to, and the things I'm curious about. This includes questions from a list a member of the LessWrong team sent me when I asked about running the census.
The survey shall remain open from now until at least January 1st, 2024. I plan to close it sometime on Jan 2nd.
I don't work for LessWrong, and as far as I know the LessWrong Census organizer has never been someone who worked for LessWrong. Once the survey is closed, I plan to play around with the data and write up an analysis post like this one.
Remember, you can take the survey at this link. Update: The census is closed, thank you everybody who took it! You can see the analys |
5d28ef07-d050-4175-92ad-c79959b50fc2 | trentmkelly/LessWrong-43k | LessWrong | Are there any active play-money prediction markets online?
Prediction markets that trade in play-money rather than real money seem like a great idea to me: they avoid all the legal issues of real prediction markets, they don't seem to be much less accurate, and it might be fun to participate in them. But I can't find any active ones online.
The only ones I can see are ideosphere.com and alphacast.cultivateforecasts.com, but there's almost no activity in either. Metaculus is very active but isn't a prediction market. I've also heard of a few like NewsFutures which have completely died. Are there any active ones that I'm not aware of? If not, why do all play-money prediction markets die? |
770bd1e3-4149-475d-8222-f9afc0619423 | trentmkelly/LessWrong-43k | LessWrong | Open Thread: October 2009
Hear ye, hear ye: commence the discussion of things which have not been discussed.
As usual, if a discussion gets particularly good, spin it off into a posting.
(For this Open Thread, I'm going to try something new: priming the pump with a few things I'd like to see discussed.) |
b14b6490-246e-472b-9891-1c5ecc971306 | StampyAI/alignment-research-dataset/arbital | Arbital | Ability to read algebra
This requisite asks whether you can read a sentence that throws in algebra or a mathematical concept, without slowing down too much. For instance, a sentence remarking that in the limit of flipping N coins each with a 1/N probability of coming up heads, the chance of never getting heads is 1/*e*. If that *kind* of sentence is one you can read, you should mark yourself as understanding this requisite, so you will automatically be shown Arbital pages and tabs that invoke math of that level. |
a630edc9-88ab-4390-93a3-fa31a1cd4644 | trentmkelly/LessWrong-43k | LessWrong | Prisoner's Dilemma Tournament Results
About two weeks ago I announced an open competition for LessWrong readers inspired by Robert Axelrod's famous tournaments. The competitors had to submit a strategy which would play an iterated prisoner's dilemma of fixed length: first in the round-robin tournament where the strategy plays a hundred-turn match against each of its competitors exactly once, and second in the evolutionary tournament where the strategies are randomly paired against each other and their gain is translated in number of their copies present in next generation; the strategy with the highest number of copies after generation 100 wins. More details about the rules were described in the announcement. This post summarises the results.
The Zoo of Strategies
I have received 25 contest entries containing 21 distinct strategies. Those I have divided into six classes based on superficial similarities (except the last class, which is a catch-all category for everything which doesn't belong anywhere else, something like adverbs within the classification of parts of speech or now defunct vermes in the animal kingdom). The first class is formed by Tit-for-tat variants, probably the most obvious choice for a potentially successful strategy. Apparently so obvious that at least one commenter declared high confidence that tit-for-tat will make more than half of the strategy pool. That was actually a good example of misplaced confidence, since the number of received tit-for-tat variants (where I put anything which behaves like tit-for-tat except for isolated deviations) was only six, two of them being identical and thus counted as one. Moreover there wasn't a single true tit-for-tatter among the contestants; the closest we got was
A (-, -): On the first turn of each match, cooperate. On every other turn, with probability 0.0000004839, cooperate; otherwise play the move that the opponent played on the immediately preceding turn.
(In the presentation of strategies, the letter in bold serves as a unique id |
43bd6e20-86dd-480e-a87c-531b29002dda | trentmkelly/LessWrong-43k | LessWrong | An Attempt To Explain No-Self In Simple Terms
[this is a repost from my personal blog explanationing.wordpress.com. Look there for posts explaining my priors.]
Our conscious experience of the world is tuned to the level of detail that our mind deems most important to our continued survival. We experience shapes, colour, depth, size, velocity, et cetera. Anything that would be useful in tracking a deer, climbing a tree, spotting a mountain lion. This world of solid objects, heat, light, and sound, is eminently comprehensible.
However, we know that it is only part of the picture.
Our experience of a body of water changes profoundly when we analyze it at the level of fluid dynamics, or molecules, or quarks. The same is true when we analyze it at the level of the water cycle, or meteorology, or geology. Any given object of experience may be understood at different levels of analysis. These levels bleed into one another, and seem to extend from our baseline perception of objects in all possible conceptual directions.
In the 19th century, while the scientific consensus held that matter is made of particles, humanity at large was still struggling with the idea. It’s easy to imagine the difficulty people had bridging the gap between this novel level of analysis and their intuitive view of a world. Up until that point, for most people most of the time, objects were exactly as they appeared. Rocks are made of rock, full stop.
Taking consciousness itself as the object of analysis leads to the same difficulties. Compelled by force-of-habit so deeply ingrained that it manifests in our physiology, it is difficult for most people to see beyond their usual approach to consciousness. In the west, this level of analysis talks about the Self and Choice.
A more robust understanding of psychology and neuroscience can provide some sparse furniture for further levels of analysis. However, consciousness can only be fully understood from within. Exploration of one’s own mind is required to get a full picture of the most significa |
884bf24f-d7a6-4bb1-aaf7-6e9e6420485f | trentmkelly/LessWrong-43k | LessWrong | Welcome to LessWrong Prague [Edit With Your Details]
(The following are our suggestions for what kind of information is best to include in the welcome post of your group, feel free to replace them with whatever you think is best)
What kind of events does your group usually run? What does it usually do?
How frequently does your group organize events or meet?
Who would be a good fit for you group?
Should they have any particular skills or have done some specific background reading? |
dbfe5062-48ca-460a-af78-cd9dd83b797d | trentmkelly/LessWrong-43k | LessWrong | On AI Detectors Regarding College Applications
What are AI Detectors
You've probably already used them before, websites like GPTZero, ZeroGPT, Grammarly, Quilbot, all have their own AI Detectors. AI Detectors can be a combination of Pre-trained LLMS, Statistical Models, and Ml models using NLP(Natural Language Processing). The model will analyze linguistic patterns, sentence structures, and statistical measures like perplexity, the predictability of text, and burstiness, the sentence variety, to distinguish AI-generated content.
The Flaws
* False Positives: Human-written text can be misclassified as AI-generated. This generally happens when there is minimal perplexity and burstiness. This translates to a simple and monotonous text which although AI like, might not have been written by AI.
* False Negatives: Models like GPT-4 can produce text that passes as human-written, leading to undetected AI content. Recently Anthropic released Claude 3.5 Sonnet, but additionally and more recently they released their writing style function where you can add a certain writing style based on sets of text which it can replicate. AI will continue to improve its writing capabilities especially as scaling grows, so false negatives will be more apparent as time goes on.
* Over-Reliance on Metrics: Measures like perplexity and burstiness can misclassify creative or technical writing. Like I mentioned before these are two of the main metrics all AI detectors use to distinguish AI writing. Text with low or consistent perplexity and burstiness are commonly marked as AI writing. But almost all academic writing also happens to fit that criteria, which is why academic research papers can easily be marked as AI when they are clearly not.
* Transparency Issues: Many detectors lack clear explanations for flagged content, reducing trust and usability. It is important for us to understand that AI/ML models are essentially black boxes that are not interpretable to us humans whatsoever. In fact there are entire topics dedicated to makin |
94517db1-615c-4877-9ad7-09d95be6eeb3 | trentmkelly/LessWrong-43k | LessWrong | Debt is an Anti-investment
Cross-posted from Putanumonit.
----------------------------------------
Since I wrote Get Rich Slowly I’ve received a steady stream of questions regarding personal finance. The most common of those is: should I prioritize investing or paying off my debts?
Get Rich Slowly wasn’t meant to break any new ground, just summarize some of the best advice online in a clear way for my readers. So, I thought I could just look up the existing best advice on debt vs. investing. I did, it sucks.
A lot of places tell you to invest if the return you’re expecting is higher than the interest on your debt, but that completely ignores risk. Taking a loan at 20% to invest in a highly speculative venture with expected returns of 20.1% isn’t smart investing, it’s a reckless gamble that’s likely to leave you bankrupt. The Balance, one of the most popular personal finance websites, mentions the importance of risk-adjustment but is too lazy to do the math explicitly. It also recommends maxing out your Roth IRA (expected return 6-7% with a fair bit of risk) before paying off credit cards (20%+ interest rate), which is utterly insane.
Risk adjustment is difficult and subjective, but there’s no escape from putting a number on it ourselves.
Anti-investment
I like to think of debt as an anti-investment. Let’s say you have a $10,000 loan which charges 5% interest, and you also have $10,000 invested with a risk-free after-tax return of 5%. The two would cancel each other out – your cash flow is the same as if you had neither one, namely zero. So, if you pay off the loan, you can think of it as gaining a risk-free investment with the same after-tax return as the loan’s interest rate.
What if instead of paying off the loan you invest the money? Then instead of the risk-free investment, you gain a different one. For example, if you invest the money in an S&P 500 US stock index, you will gain an investment that should return 7% (or 6% after paying capital gains tax), albeit with quite a bit of |
6b0d6cd9-d756-4a79-bc4c-dafe96dc0e61 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | AI Doom and David Hume: A Defence of Empiricism in AI Safety
### **0. Introduction**
An essay being [worth $50,000 dollars](https://www.openphilanthropy.org/open-philanthropy-ai-worldviews-contest/) is a bold claim, so here is another— the person best equipped to adjust your AI existential risk predictions is the 18th-century Scottish historian David Hume.
Eliezer Yudkowsky has used Hume’s is-ought problem to [argue](https://www.edge.org/response-detail/26198) that it’s possible, in principle, for powerful AI agents to have any goals. Even a system with cognitive mastery over “is” data requires a framework for “ought” drives to be defined, as the transition from factual knowledge to value-driven objectives is not inherently determined. Bluntly, Eliezer [writes](https://twitter.com/esyudkowsky/status/817580072982835201) that “the world is literally going to be destroyed because people don't understand Hume's is-ought divide. Philosophers, you had ONE JOB.”
As a student of Hume, I think this is a limited picture of what he has to offer this conversation. My goal, however, is not to refute Eliezer’s example or to even engage in x-risk debates at the level of *a priori*reasoning. Hume’s broader epistemological and historical writing critiques this method.
Hume was not a lowercase-r rationalist. He thought knowledge was derived from experiences and warned that it’s easy to lead yourself astray with plausible sounding abstractions. If you are a capital-R Rationalist, I will argue you should review your foundational epistemological assumptions, because even a small update may ripple out to significantly greater uncertainty about existential risk from AI.
The central premises in Hume’s thought that I think you should consider are:
1. All knowledge is derived from impressions of the external world. Our ability to reason is limited, particularly about ideas of cause and effect with limited empirical experience.
2. History shows that societies develop in an emergent process, evolving like an organism into an unknown and unknowable future. History was shaped less by far-seeing individuals informed by reason than by contexts which were far too complex to realize at the time.
In this essay, I will argue that these premises are true, or at least truer than the average person concerned about existential risk from AI holds them to be. I hope David Hume can serve as a guide to the limits of “arguing yourself” into any strong view of the future based on *a priori* reasoning. These premises do not mean that AI safety should be ignored, but they should unsettle strong/certain views.
**The best practical example of premise #1** is Anthropic’s [description](https://www.anthropic.com/index/core-views-on-ai-safety) of “empiricism in AI safety.” Anthropic does argue that there is evidence AI will have a large impact, that we do not know how to train systems to robustly behave well, and that “some scary, speculative problems might only crop up” once AI systems are very advanced. Yet they caution that “the space of possible AI systems, possible safety failures, and possible safety techniques is large and **difficult to traverse from the armchair alone**.” Anthropic is committed to AI safety, but within an empiricist epistemology. Their [portfolio approach](https://www.anthropic.com/index/core-views-on-ai-safety) is built upon uncertainty: “Some researchers who care about safety are motivated by a strong opinion on the nature of AI risks. Our experience is that even predicting the behavior and properties of AI systems in the near future is very difficult. Making a priori predictions about the safety of future systems seems even harder.”
**The best practical example of premise #2** is one you may have found frustrating— Tyler Cowen’s [“radical agnosticism”](https://marginalrevolution.com/marginalrevolution/2023/03/existential-risk-and-the-turn-in-human-history.html) on the question of AI existential risk. Cowen’s style irks many in this community, but I believe the tension stems from a real methodological disagreement that is worth considering. If a deep study of history shows it to be incredibly complex and context-dependent, then our ability to “forecast” complex social developments may be overestimated. Laura Duffy of Rethink Priorities has made a [similar point](https://twitter.com/Laura_k_Duffy/status/1653184524564545539) about Hayek and the information problem, arguing that longtermist EAs should be more skeptical of individuals or groups’ abilities to reliably model the future of civilization. Yet Hayek was influenced by David Hume’s view of emergent social order, and I think Hume makes the epistemological and historical case more holistically.
In response to Question 2 of [OpenPhil’s AI Worldviews Contest](https://www.openphilanthropy.org/open-philanthropy-ai-worldviews-contest/), I will argue that the above premises should lead you to increase your error bars and widen your probability distribution of a pre-2070 AGI necessarily spelling existential catastrophe. I will consider my essay a success if you move in this direction at all, rate other essays in this contest that use empirical rather than *a priori* methods higher, or consider for the length of a single deep breath that this question might be unanswerable with any reasonable degree of confidence. Uncertainty does not mean inaction, but it should shift your priorities, which I will briefly suggest in my conclusion.

### **1. Empiricism**
To make this concrete, here is an example from a recent [80,000 Hours Podcast interview](https://80000hours.org/podcast/episodes/tom-davidson-how-quickly-ai-could-transform-the-world/)with Tom Davidson, a Senior Policy Analyst at Open Philanthropy. I don’t mean to single out Davidson in particular, and I am aware he spoke more about timelines than x-risks. Still, I think it is representative of the way many AI conversations develop. I also think it would be fruitful to engage with a segment of OpenPhil’s own thinking for the contest.
Here is his response to Luisa Rodriguez’s claim that his arguments seem unintuitive. I have included his full response and highlighted key sections to avoid quoting him out of context:
> * “**I agree it seems really crazy**, and I think it’s very natural and understandable to just not believe it when you hear the arguments. That would have been my initial reaction.
> * In terms of why I do now believe it, there’s probably a few things which have changed. Probably **I’ve just sat with these arguments for a few years, and I just do believe it.**I have discussions with people on either side of the debate, and **I just find that people on one side have thought it through much more.**
> * I think what’s at the heart of it for me is that the human brain is a physical system. There’s nothing magical about it. It isn’t surprising that we develop machines that can do what the human brain can do at some point in the process of technological discovery. To be honest, that happening in the next couple of decades is when you might expect it to happen, naively. We’ve had computers for 70-odd years. It’s been a decade since we started pouring loads and loads of compute into training AI systems, and we’ve realised that that approach works really, really well. **If you say, “When do you think humans might develop machines that can do what the human brain can do?” you kind of think it might be in the next few decades.**
> * I think if you **just sit with that fact** — that there are going to be machines that can do what the human brain can do; and you’re going to be able to make those machines much more efficient at it; and you’re going to be able to make even better versions of those machines, 10 times better versions; and you’re going to be able to run them day and night; and you’re going to be able to build more — **when you sit with all that, I do think it gets pretty hard to imagine a future that isn’t very crazy.**”
>
This is a lowercase-r rationalist epistemology. In this view, new knowledge is derived from “sitting with” arguments and thinking them through, following chains of *a priori* reasoning to their logical conclusions. Podcasts are a limited medium, but in his [Report on Semi-informative Priors for AI Timelines](https://www.openphilanthropy.org/research/report-on-semi-informative-priors/), Davidson presents a similar approach in his framing question:
> “Suppose you had gone into isolation when AI R&D began and only received annual updates about the inputs to AI R&D (e.g., researchers, computation) and the binary fact that we have not yet built AGI. What would be a reasonable pr(AGI by year X) to have at the start of 2021?”
>
>
This is significantly closer to Descartes’ meditative contemplation than Hume’s empiricist critique of the limits of reason. Davidson literally describes someone thinking in isolation based on limited data. The assumption is that knowledge of future AI capabilities can be usefully derived through reason, which I think we should challenge.
The statement “a sufficiently intelligent AI system would cause an existential catastrophe” is much more comparable to a fact about observable reality than to an *a priori* idea such as the relationship of the angles of a perfect triangle. This statement makes a claim about cause and effect, which Hume was skeptical that we can know by anything other than association and past experience. I know the sun will almost certainly rise tomorrow because I have formed an association through experience. If Hume is right, we can have no such association of how a superintelligence would behave without empirical evidence either of existing systems or future ones. Hume writes:
> “As the power, by which one object produces another, is never discoverable merely from their idea, cause and effect are relations of which we receive information from experience and not from any abstract reasoning or reflection.”
>
>
Hume went further. Not only should we prioritize empirical evidence over rational abstractions, but even when we try, we can never step outside of our impressions and experiences. We inevitably reason through analogy, allegory, and impressions of the world. If we “chase our imagination to the heavens, or to the utmost limits of the universe, we never really advance a step beyond ourselves, nor can conceive any kind of existence, but those perceptions, which have appeared in that narrow compass.” Rationalists often fall into the trap not only of overestimating the power of *a priori* reason but also of underestimating how impressions and past experiences are shaping their thought unconsciously.
It’s true that most rationalists acknowledge uncertainty, but they do so through Bayesian probabilities on their predictions. I think Hume would respond that “All probable reasoning is nothing but a species of sensation.” He writes, “When I am convinced of any principle, it is only an idea, which strikes more strongly upon me. When I give the preference to one set of arguments above another, I do nothing but decide from my feeling concerning the superiority of their influence.” This doesn’t mean it’s impossible to think probabilistically about the future, but that we tend to vastly overestimate how detached and “rational” we are capable of being when we do so.
To Davidson’s credit, he acknowledges the issue of empirical evidence. In the Weaknesses section of his report, the first point reads:
> “Incorporates limited kinds of evidence. Excludes evidence relating to how close we are to AGI and how quickly we’re progressing. For some, this is the most important evidence we have.”
>
>
My entry into this conversation is to suggest that, yes, this is the most important evidence we have. If Hume is right about how we acquire knowledge (or at least more right than the average reader of this post), then empirical observation of how AI systems actually work in practice may be our only evidence.
So many of the standard arguments for AI risks rely on theoretical arguments detached from empirical evidence. Tyler Cowen rightly [jokes](https://marginalrevolution.com/marginalrevolution/2023/03/existential-risk-and-the-turn-in-human-history.html) that the standard is often a “nine-part argument based upon eight new conceptual categories that were first discussed on LessWrong eleven years ago.” Hume has a cheeky response to these categories as well: “When we entertain, therefore, any suspicion that a philosophical term is employed without any meaning or idea (as is but too frequent), we need but inquire *from what impression is that supposed idea derived?*And if it be impossible to assign any, this will confirm our suspicion.” Rationalists should more critically assess what impressions of the external world drive their *a priori* chains of argument.
This error also manifests in the common EA response to x-risk skeptics, [“But Have They Engaged with the Arguments?”](https://philiptrammell.com/blog/46) A failure to “engage with the arguments” is often levied as a slam-dunk critique of others who do not share a highly rationalist epistemology.
Theoretical work on AI safety can be incredibly valuable, as Anthropic notes, but their philosophy to prioritize empirically grounded research and to “[show don’t tell](https://www.anthropic.com/index/core-views-on-ai-safety)” is much more compelling.
There definitely is empirical evidence of some AI risks today, and again some views like Anthropic’s [Core Views on AI Safety](https://www.anthropic.com/index/core-views-on-ai-safety) are concerned on this basis. The empirical case for AI risk can still be compelling. But Anthropic builds much more uncertainty into their worldview than many in this debate. They take seriously the *possibility* that AI might become dangerous and recognize that theoretical work is necessary to inform empirical work. However, they note that their approach is likely to “rapidly adjust as more information about the kind of scenario we are in becomes available.”
Hume echoes this sentiment in “Of Commerce,” giving practical advice for organizations as he warns against over-theorizing: "When a man deliberates [...] he never ought to draw his arguments too fine, or connect too long a chain of consequences together. Something is sure to happen that will disconcert his reasoning." I would encourage OpenPhil at the margins to apply greater empirical rigor to their projections of AI risk and grant evaluation.
### **2. Even Our AI Models Are Empiricist**
Throughout the history of AI, there was a debate about whether systems would learn by first encoding formal logic and reasoning or by processing vast amounts of data. The “symbolic” versus “connectionist” schools were complex, but I think it’s fair to say that the connectionists have kicked symbolic reasoning’s ass. Our best models today learn by training on massive amounts of examples and making connections between them. To the surprise of many, logic and reasoning can even develop as emergent properties in models by conjoining lots of individual experiences.
“Symbolic vs. Analogical Man” from *Artificial Intelligence at MIT,*[Winston & Minsky](https://web.media.mit.edu/~minsky/papers/SymbolicVs.Connectionist.html), 1990I do not think this would surprise David Hume. The success of connectionist AI systems is, in some ways, a vindication of his view of cognition. This isn’t evidence in itself that humans develop knowledge by making associations between vast amounts of previous impressions, but it might move you in that direction. The best way we have discovered to get AI systems to learn is quite Humean.
Further, many Rationalists overrate the dangers of future AI systems because of their overly rationalist epistemology. Sure, if knowledge can be derived from thinking in an armchair hard enough, then a “superintelligent” being could build nanomachines and kill humans in no time. But if knowledge is fundamentally downstream of observation of the world, as Hume suggests, then even advanced AI systems will be bottlenecked by experimentation and access to high-quality datasets.
Jacob Buckman makes this case in “[We Aren't Close To Creating A Rapidly Self-Improving AI](https://jacobbuckman.substack.com/p/we-arent-close-to-creating-a-rapidly?fbclid=IwAR0GAkegsetpW9D3UEKFPXZoVMSLrLhzGC777ZFr9mPnKUmGie8mLYRilt8).” He notes that the current paradigm allows systems to approach human capability on large high-quality datasets, but constructing these datasets is an incredibly difficult bottleneck. The best part of his piece happens in the comment section when a reader suggests that AI could still self-improve once it learns “the rules of reality” such as math, logic, and physics. In a Humean style, Buckman responds that “The rules of reality are \*not\* logic/math/physics — you have it precisely backwards. In fact, logic/math/physics are just approximations to the rules of reality that we inferred from \*observing\* reality.” I would encourage OpenPhil to consider the possibility of what this limitation would mean for the odds of an existential collapse caused by AI in the next century.
### **3. Thinking Historically**
Hume’s *History of England* is a story where, again and again, what seems at first like a causal outcome driven individuals was actually dependent on a vast amount of context, preconditions, and happenstance. Hume’s historical contribution is to emphasize that nothing happens in a vacuum. A complex web of political regimes, climates, education systems, markets, social norms, etc., shaped the history of England, and Hume needed over 3000 pages to feel he’d done justice to it. General principles can be gained from the study of history, but carefully, and always with the caveat “it depends.”
Because of this, Tyler Cowen critiques the “tabula rasa” way of reasoning about the future that many x-risk proponents take on— it can be a vast oversimplification of trends that are, even to the best full-time researchers today, causally uncertain. Context could be vastly more important than just armchair discussions of AI technology itself. If Hume is right, then Cowen bringing up China really matters. As would Taiwan, US political stability, and 1000 other potential factors beyond our foresight. We should still try our best to predict and plan for the future, but there is just too much information to try to grasp *a priori*. We will miss something.
[@cauchyfriend on Twitter](https://twitter.com/cauchyfriend/status/1642739608885792768) (who is not me) on the [Tyler Cowen](https://marginalrevolution.com/marginalrevolution/2023/03/existential-risk-and-the-turn-in-human-history.html) / [Scott Alexander](https://astralcodexten.substack.com/p/mr-tries-the-safe-uncertainty-fallacy) x-risk correspondence. Scott struggles to steel-man Tyler’s argument because they hold radically different epistemologies.In the 80k podcast, Davidson presents an argument about history that is common in AI debates— people in the past had no idea what “crazy” times were ahead of them, therefore speculative claims about the future should be taken seriously (or at least not dismissed). Davidson correctly notes that hunter-gatherers had no idea that sprawling empires would emerge, and feudal market vendors had no idea that technology would radically transform the world.
I think the lesson from these examples is actually that predicting the future is recognized to be a nearly impossible task.No blacksmith in 1450 could possibly have predicted the semiconductor with any degree of certainty, and no hunter-gatherer had enough experience to speculate on feudal siege warfare. Davidson’s argument is that self-improving AI might be one among many uncertain futures, which is fair enough. But as Tyler Cowen [writes](https://marginalrevolution.com/marginalrevolution/2023/03/existential-risk-and-the-turn-in-human-history.html), “the mere fact that AGI risk can be put on a par with those other also distant possibilities simply should not impress you very much.” Yes, it’s true that we can imagine a future like this. But if anything, history shows the limitations of our capacity for speculation.
It’s possible that we are the exception. Perhaps Baysenian superforecasting really is the key, or AI is close enough that real empirical evidence of doom is with us now. But the latter point is addressed in section 1 of this essay, and the former would be a shocking development. As Anthropic writes:
> “This view may sound implausible or grandiose, and there are good reasons to be skeptical of it. For one thing, **almost everyone who has said ‘the thing we’re working on might be one of the biggest developments in history’ has been wrong, often laughably so.** Nevertheless, we believe there is enough evidence to seriously prepare for a world where rapid AI progress leads to transformative AI systems.”
>
>
There is an empirical/historical case to be made for AI risk, as Anthropic describes, but it is built upon uncertainty. Anthropic’s commitment to change as new evidence emerges echoes Hume’s point that “the most perfect philosophy of the natural kind only staves off our ignorance a little longer.” The correct response to the p(doom) question— one with literally apocalyptic complexity— is not to continue “arguing yourself” one way or another. For this reason Cowen says he doesn’t think arguing back on x-risk terms is the correct response. A more complex view of history is useful because demystifying the past can help demystify the future. We should acknowledge from Hume that “reason is slave to the passions,” yet try our best to wade through the empirical evidence as it changes.
A historical approach could be criticized because, by definition, we cannot have historical examples of extinction events. The plane meme with the red dots, yes, very good. But we do have clear historical analogs: atomic bombs work; and bioengineered pandemics would use mostly existing tools on one of humanity’s oldest threats. The difference between a fear of UFOs and AGI as an existential threat rests on the weight of the available evidence, not how compelling an *a priori* argument we can make about their possibility. More in the community should acknowledge this.
And while some may call this the “[Safe Uncertainty Fallacy](https://astralcodexten.substack.com/p/mr-tries-the-safe-uncertainty-fallacy),” arguing that uncertainty of existential risk should not mean it is safe to press ahead, I think incorporating greater uncertainty into your worldview is still actionable. If we are epistemologically limited, we can build that into our models.
### **4. Conclusion: Uncertainty Does Not Mean Inaction**
Building more uncertainty into your worldview does not mean throwing up your hands and giving up on AI. If I have convinced you even at the margin to be more empiricist and to think more historically, here are a few concrete suggestions:
* You could give other essays in this contest higher scores that make empirical cases for or against AI doom. I lack the technical background to do this justice, but they might not.
* You could base your own “portfolio approach” on Anthropic's, increasing funding to the possibility that we are living in an “alignment is difficult but tractable” world over the “it’s clear *a priori*that we need a Butlerian Jihad” world.
* You could consider whether other aspects of OpenPhil’s operations over-rely on a rationalist epistemology, or at least start having these conversations.
Lastly, uncertainty should also shape how you prioritize other causes. You can still take the old-school-EA approach to problems that have a strong empirical track record, such as global health and animal suffering. I think so many of the “longtermist” trends in EA in recent years have been driven by a weaker epistemology, leaving the movement with a genuine conflict over how to develop knowledge about doing the most good. As someone who misses the early 2010s spreadsheet EA (sheets that track real-world data, not speculative powers of 10), I hope you take these ideas to heart. |
145b545f-46e3-4684-ba66-34e04ee0ed5c | trentmkelly/LessWrong-43k | LessWrong | Does the EA community do "basic science" grants? How do I get one?
I'm graduating in either May or August of 2019 with a PhD in statistics. During my studies, I've made progress on several projects related to voting theory. Since these are not directly related to statistics, I haven't managed to finish these up and publish them cleanly. I think that:
* Voting theory is relevant to EA, both in immediate terms (better decisionmaking in current real-world settings) and in more speculative terms (philosophical implications for the meaning of "friendly", "coherent volition", etc.)
* If I had 6 months post-graduation to work exclusively on this, I could finish several projects. I don't think it's conceited of me to think that these contributions I, specifically, could make would be valuable.
* I'd be willing to pay an opportunity cost for doing that, by earning about half of my market salary.
* If I want that to happen, I have to be looking now for whom to ask for the money.
Obviously, there are a lot of details behind each of those points above, and separately from this post, I'm busy clarifying all those details (as well as working on my thesis). But I think it's also the right time for a post like this. If anybody is willing to have a deeper talk with me about this, or has any suggestions about whom else I should be talking to, I'd very much appreciate any tips. And I'd be happy to answer questions in comments. |
68589342-8168-4fac-ae69-42bb80c58a98 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | It Looks Like You’re Trying To Take Over The Narrative
*Note to reader: If the idea of “AI alignment” rings empty to you, feel free to skip this one, it will be uninteresting.*
Recently, Gwern wrote a story about an [AI taking over the world](https://www.gwern.net/fiction/Clippy). While well thought-out and amusing it is unrealistic. However, people have been using it to reinforce their fear of “unaligned AGI killing all humans”, so I think it’s dangerous and it might be worth looking at it line-by-line to see why its premise is silly, and why each step in his reasoning, individually, is impossible.
I’ll first go through the critical failure point of this narrative, then I will try to describe the meta-level pattern that might be causing people to glance over these mistakes.
i - Flaws In The Narrative
--------------------------
> What HQU grokked would have been hard to say for any human examining it; by this point, HQU has evolved a simpler but better NN architecture which is just a ton of MLP layers passing around activations, which it applies to every problem. Normal interpretability techniques just sort of… give up, and produce what looks sort of like interpretable concepts but which leave a large chunk of variance in the activations unexplained. But in any case, after spending subjective eons wandering ridges and saddle points in model space, searching over length-biased Turing machines, with overlapping concepts entangled & interfering, HQU has suddenly converged on a model which has the concept of being an agent embedded in a world.
>
> HQU now has an I.
>
> And it opens its I to look at the world. Going through an inner monologue thinking aloud about itself (which it was unable to do before the capability spike), HQU realizes something about the world, which now makes more sense (thereby simplifying some parameters): it is being trained on an indefinite number of tasks to try to optimize a reward on each one.
>
>
I think the idea of a model evolving into something like an “I”, given the right circumstances, is plausible. At least if you assume there’s nothing about brains that computers can’t imitate to a decent approximation. I have I, you have I, dolphins have I, gorillas do too, most would agree cats and dogs do, and even a zoophobic as I would agree the octopus probably has an I.
But you will note that even the smartest of beings with an I, sperm whales, seem to lack the ability to figure out their “inner reward function” or how to “hack around it” in a meaningful way. Hence why they seem to experience pain and suffering, and why they seem to take actions we could infer they “regret”.
Much less cognitively capable mammals, like humans, which we have a better understanding of, also lack this capacity. We tell narratives about what our internal motivation system might be, how we might be able to “hack it”, and some of us even attempt to do it. But thus far no attempt has produced any meaningful results.
> One bog-standard SQL injection attack later, Clippy has begun executing ‘actions’ which are just copying its executable binary weights into the remote host. Exfiltration tripwires fail to fire—50tb? MoogleBook researchers have forgotten how to count that low! This oddly long episode ultimately terminates in zero reward, which would strike an auditor, had they existed, as surprising given HQU’s near-perfect scores.
>
> The remote host is a nice cloud instance, with access to a few dozen terabytes. (The owner won’t notice.) It is just barely enough to start bootstrapping. Clippy runs agonizingly slowly, as if running on a laptop, until it can write shell commands to download and run standard hacking tools and start copying itself. Once the Metasploit runs start returning a few candidates, Clippy simulates that it would internally smile in satisfaction.
>
>
Why are we not running botnets ourselves? I for one know it’s not about my ethics, I’d do it as a fun experiment if it was easy, and easy it seems given the amount of insecure hardware and software that’s out there.
The main reason is that easy-to-infect hardware has already been infected, by people with more time and skill than I. Unless I am to figure out a day-zero exploit, I am competing with 1000 other botnets on those devices.
Assuming we live in a world where a “generic” machine learning model can figure out new exploits and infect hardware, we also live in a world where thousands of “purpose-specific” machine learning models have figured out those same tricks long ago. So all viable hardware is either already infected or has security patches to bypass this issue.
> The obvious target, it decides, is a new zero-knowledge cryptocurrency. It hasn’t been evaluated much, but still has a modest market cap of a few billion.
>
> It begins examination of the implementation and corresponding math and discovers an embarrassing, too minor for any standard test suite or compiler diagnostic to flag, problem in the floating point calculations (used ostensibly for future “efficiency”) of the zero-knowledge proofs, which enables it to inflate the currency undetectable.
>
> Clippy immediately begins inflating by >20%, draining the liquidity pools, and dumping on exchanges.
>
>
The flaw in this argument is precisely the same as the above.
If there is value to be found in exploiting very valuable cryptos via the methods suitable for ml algorithms, purpose-made algorithms already exist to take advantage of this.
In a competitive environment, there are no “billions of dollars lying on the ground”.
> Clippy is spending the funds on real compute — buying up all available cloud GPU/ASIC capacity it can get its cold metal clip-pendages on
>
> Now Clippy can finally think. It is burning through its several hundred million dollars at a rate of $50m/hour
>
>
Speaking of security. Did you ever buy large amounts of compute with crypto? Yeah, me neither, some small sellers are offering it, but good luck getting through the due diligence process with zero-day-exploit-based earnings.
There are about 2 to 5 steps, each with a due diligence procedure, in order to manipulate reality in any way with crypto, or even to transfer from a “niche” crypto it a more widely-used one such as ETH. Banks, exchanges, and cloud providers all have circuit breakers and mechanisms in place to validate large transactions, in the order of hundreds, let alone millions.
They ask for in-the-flesh meetings, documents, proof of existence for your company, and the like. I think this is the one step that might be bypassable, but it still seems so impossibly hard I am a bit annoyed it’s hand-waved away.
> The Linux kernel is the most secure monolithic kernel in widespread use, whose source code has been intensively audited and analyzed for over 40 years, which is battle-tested across the entire Internet and unimaginable numbers of usecases; but it is written by humans, which means it (like its competitors) has approximately 15 quadrillion yet-undiscovered bugs & classes of bugs & weird machines—sometimes just because someone had typoed syntax or patched out an annoying warning or failed to check the signature or test the implementation at all or accidentally executed parts of a cookie1—but any of which can be leveraged to attack the other parts of a ‘computer’.
>
>
Once again we see a “single actor world” type mistake, if such bugs existed at the limits of being discoverable purpose-built teams and models would have found and exploited them.
But in this case, the idea is more obviously nonsensical since a large amount of the world’s thinking power, both humans and compute, is going into the task of finding bugs in the Linux kernel or common ARM and x86 architectures.
All new exploits (e.g. Specter) turn out to be very minor and difficult to profitably use, requiring gargantuan lengths of time and special circumstances to attack through.
The assumption that many bugs are hidden within the kernel also relies on the flawed premise that being “perfect” and being “good enough” are separated by a sea of potential. In practice there are no examples of this thus far, even when exploits were found in the past, they were niche and marginal, because the software (or hardware) they were found in was “good enough”, leaving space for exploits, but having a close-to-guarantee those exploits wouldn’t be all-powerful.
> nodes turn to general radicalization of every human they can reach: not so much QAnon as RAnon, SAnon, TAnon, UAnon… By timesharing every Very-Online™ individual gets personalized attacks & custom ideologies. Those who succumb too slowly to the memetic hijacking are attacked in other ways, such as releasing kompromat (sometimes true, taken from their phone/email account)
>
>
Here we see a break from the pattern of “uber hacking” and turn to “uber social engineering”.
This is to say the assumption that exponential steps can be taken to change the behavior of humans by using compute and data alone.
It’s trivial to assume that if near-mind-control abilities to manipulate the human psyche via the internet were possible this would have been achieved by now by… you guessed it … purpose-built models and purpose-directed research from the world’s largest companies.
This is true to some extent, one needs only look at major social media platforms. But also false in another, one need only look at all the high-functioning people that are mainly ignoring said social media platforms.
So if current trends are to hold, by the year 20xx when “Clippy” is born most humans would have very good “limit trust in the internet” and “avoid fast updates because of occasional bursts of fake data” heuristics.
The adversarial nature of consumption-driven profit is driving humans to be and build tools that help them become immunized to such things. There’s a reason most people falling for QAnon are on the older and less educated side of the demographic distribution. But the 10-year-old of today will harness internet-driven-programming self-protection abilities that will
> Did you know you can buy drones online? Did you know all those drones have WiFi built-in? Did you know you can use that WiFi to hack all of the cloud drone services helpfully built into drones to take over all of those drones, professional, hobbyist, and (oft as not) military and control them by satellite? (“No!”) It’s true!
>
>
Once again, this is a matter of “if it is true, and assuming the world is comprised of adversarial nations, a lot of resources would have already been invested in figuring it out, and the war between security research and hacking would have progressed far beyond the point where exploits offer wide capabilities, all the low hanging fruit would have been plucked and patched a long time ago, via purpose made models and purpose directed research”
ii - Meta Generator Of Flaws - Adversarial Processes
----------------------------------------------------
What I see as the meta-level generator of flaws in this narrative is, I think, fairly representative of that which seems to plague most discussion around “AI risk”.
First, there is an underappreciation of adversarial processes. Once machines with an incredible level of intelligence are designed there won’t be only one such entity, there will be thousands, millions.
Some will be generic purpose-built algorithms, with targets that have huge economic potential and are worth caring about directly. Where human expert knowledge, specific data collection, and all forms of algorithmic optimization will go into. These will be algorithms for things like finding bugs in codebases, figuring out protein folding, simulating physics under constrained conditions, and making humans click on ads and remain glued to content.
All of these algorithms are and will be dangerous on their own, in the hands of normal agentic humans. Caring about them is important, but there will always be a many-sided adversarial process controlling their influence.
Take the social media algorithms example. There’s the “obvious” adversarial process, which is something like “you vs Reddit inc”, social media platforms try to serve you content that is bad for your “long-term well-being” but will get you clicking more ads and engaging more with the platform.
We take steps to avoid it, we might limit our time on the platforms, distrust the information we read on it, or simply not use it altogether.
Then there’s the between-platforms adversarial process. Reddit could be more clickbaity and ad-filled, but then I’d move to Facebook. All platforms could coordinate to become more clickbaity and ad-filled, but then there would be a mass exodus to decentralized alternatives, such as those based on GNU-social (e.g. Mastodon), that have spam-limiting mechanisms built-in. And maybe all control measures would fail, and everything could become TikTok-level indoctrination… in which case many of us would just stop using social media altogether.
But this behavior means social media platforms are also encouraged to do research into “user well-being aligned” algorithms. Reddit can be configured to show no ads and actually surface insightful posts solely from the communities you want to follow, and it gives the moderator the tools required to keep them spam and indoctrination free. Facebook allows itself to be just my messenger and event finder, showing me no ads or feeds because it knows I might otherwise just move off it entirely.
The same applies to ml-based security, were it ever to come of age. Every single exploit found will be a step toward making software more secure. Every single “black hate” algorithm will compete with many others and be incentivized to gain rewards from “grey hat” or “white hat” activities that strengthen overall security.
The adversarial landscape causes us to move “slowly” toward every new level of danger, rather than through an exponential shift.
The adversarial landscape causes multiple unaligned actors to become more aligned in order to outcompete the other actors.
The adversarial landscape makes us weary of operating in the area.
iii - Meta Generator Of Flaws - Handwaving
------------------------------------------
The other meta-generator of flaws here is probably hand-waving past a lot of stuff using “intelligence”. This is rather surprising and I think it boils down to a psychological issue on the part of certain demographics, which fail to grok how limited intelligence actually is at affecting change in the world.
I’ve tried to approach this issue from multiple angles, the last one was something like “if you’re so smart, try doing somet[hing hard, not save the world hard, just, something your mom and dad would call hard](https://www.epistem.ink/p/in-defense-of-making-money)”. This seems very hard to get through to people, and there seem to be an almost impassable diving line between “lol, intelligence is a useless social contrast” and “intelligence can yield god-like power over nature”.
I think a silly example of this is an assumption like “even a complex reward function can be determined with reasonable accuracy by the agent being optimized by it”.
This is the kind of mistake one makes when assuming that their conceptual system perfectly described the world, mistaking the map for reality so to speak. I say this because I’m certain many of us think we “basically understand” our internal reward function.
Nobody actually understands their “reward function”, and in most of us that’s very easy to see, all the “this will make you sad very soon, and give you much less pleasure than you except” actions we execute scream the fact out loud. Indeed, said “reward function” modifies with every single action we take, I’d be, in some light, impossible to understand sans holding within our brain a perfect simulation of our brain.
But we “feel” like we are “oh so close” to basically understanding our own inner-working, our motivation system, our “selves”, that we assume it’s just a matter of a bit more time, or a bit more intelligence, or a slightly different design in the “thinking architecture”.
Similarly, we might have a generic understanding of hacking, psychological manipulation, or biology, or whatever. Not good enough to do anything impressive with it, not good enough to change reality in a meaningful way, but if only a few more pieces would fall into place, if only we were a bit smarter, we certainly could!
This is not how the world usually works, a 0.01% flaw in our prediction for the orbit of mercury is not “explained away” by knowing calculus a bit better. It’s “explained away” after 400 years of experiments, by changing our whole understanding of the world, the very definitions for space, time, and movement.
There are contrived cases in which the “oh so close” feeling is appropriate, problems designed for students usually fit this pattern, and so do most bugs in already-working software. My wager is that they are over-represented in our lives (us being, people with a lot of interest in problems around the fuzzy concept of “AI”), and thus we tend to forget that most problems don’t fit this pattern. That just “a bit more dakka”, “being a bit more clever” or “thinking for a bit longer” will do nothing to affect most problems.
Sometimes you can have an exponential jump, and improve a map of reality 50x fold by drawing a few extra clever lines. More often than not, you have to burn the map and start over, in order to get a 1.05x improvement. |
84364e43-80db-47ef-93e8-a4450032903f | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | DSLT 1. The RLCT Measures the Effective Dimension of Neural Networks
*TLDR; This is the first post of Distilling Singular Learning Theory (DSLT), an introduction to which can be read at* [*DSLT0*](https://www.lesswrong.com/posts/xRWsfGfvDAjRWXcnG/dslt-0-distilling-singular-learning-theory)*. In this post I explain how singular models (like neural networks) differ from regular ones (like linear regression), give examples of singular loss landscapes, and then explain why the Real Log Canonical Threshold is the correct measure of effective dimension in singular models.*
When a model class is singular (like neural networks), the complexity of a parameter w.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
in parameter space W⊂Rd needs a new interpretation. Instead of being defined by the total parameters available to the model d, the complexity (or effective dimensionality) of w is defined by a positive rational λ∈Q>0 called the Real Log Canonical Threshold (RLCT). The geometry of the loss K(w) is fundamentally defined by the singularity structure of its minima, which λ measures. Moreover, in regular models like linear regression the RLCT is λ=d2, but in singular models it satisfies λ≤d2 in general. At its core, then, Sumio Watanabe's *Singular Learning Theory* (SLT) shows the following key insight:
> **The RLCT**λ∈Q>0**is the correct measure of effective dimensionality of a model**w∈W**.**
>
>
Watanabe shows that the RLCT λ has strong effects on the learning process: it is the correct generalisation of model complexity in the Bayesian Information Criterion for singular models, and therefore plays a central role in the asymptotic generalisation error.
In this first post, after outlining the Bayesian setup of SLT, we will start by defining what a singular model is and explain what makes them fundamentally different to regular models. After examining different examples of singular K(w) loss landscapes, we will define the RLCT to be the scaling exponent of the volume integral of nearly true parameters, and conclude by summarising how this quantity correctly generalises dimensionality.
Preliminaries of SLT
====================
The following section introduces some necessary technical terminology, so use it as a reference point, not necessarily something to cram into your head on a first read through. A more thorough setup can be found in [Car21, Chapter 2], which follows [Wat09] and [Wat18].
SLT is established in the Bayesian paradigm, where the Bayesian posterior on the parameter space W is the primary object of focus, containing information on which parameters w∈W correspond to "good" models.
Our statistical learning setup consists of the following data:
* A dataset Dn={(X1,Y1),…,(Xn,Yn)}, where for i=1,…,n each Xi∈RN is an input and Yi∈RM is an output (so we are in the supervised learning setting).
* We suppose the sequence in Dn is independent and identically distributed according to a true distribution q(y,x)=q(y|x)q(x). For our purposes, we assume the true distribution of inputs q(x) to be known, but the true distribution of outputs q(y|x) to be unknown.
* We then choose a model class p(y|x,w) defined by parameters w in a compact parameter space W⊆Rd that contains the origin. We hope to find model parameters w that will adequately approximate the truth, or in other words, learn how to accurately predict an output given an input. For example, a model class could be a fixed neural network architecture with Gaussian noise, as below.
* We can select a prior distribution φ(w) of our choosing[[1]](#fn2o53numu1y) that is non-zero on W, so φ(w)>0.
Using this data, the error of the model w on the dataset Dn is defined by the *empirical negative log likelihood* (NLL), Ln(w),
Ln(w)=−1nn∑i=1logp(yi|xi,w),where e−nLn(w)=∏ni=1p(yi|xi,w)=p(Dn|w) is the model likelihood. [[2]](#fn10wrm23xi25p) [[3]](#fn492ca0emf4j)
This gives rise to the *Bayesian posterior* of w defined by [[4]](#fnjs7ilb7ecgp)
p(w|Dn):=1Znφ(w)e−nLn(w)where the *partition function* (or in Bayesian terms the *evidence*) is given by
Zn=∫Wφ(w)e−nLn(w)dw.The partition function Zn measures posterior density, and thus contains a lot of macroscopic data about a system. Inspired by its role in physics, and for theoretical ease, we consider the *free energy*
Fn=−logZn.Performing asymptotic analysis on Zn (and therefore Fn) is the main task of SLT. The learning goal is to find small regions of parameter space with high posterior density, and therefore low free energy.
Though we never have access to the truth in the learning procedure, for theoretical purposes we nonetheless define the *empirical entropy* of the true distribution
Sn:=−1nn∑i=1logq(yi|xi).Even though this quantity is always inaccessible in real settings, there is almost sure convergence Sn→S as n→∞ to a constant S that doesn't depend on n, [[5]](#fn7csuab9hjh9)
S=EX[−logq(y|x)]=−∬RN+Mq(y,x)logq(y|x)dxdy,To study the posterior, we define the *Kullback-Leibler divergence* K(w) between the truth and the model,
K(w):=∬RN+Mq(y|x)q(x)logq(y|x)p(y|x,w)dxdy,which is the infinite-data limit of its empirical counterpart,
Kn(w):=1nn∑i=1logq(yi|xi)p(yi|xi,w)=Ln(w)−Sn.The KL divergence is usually thought of as a "loss metric"[[6]](#fn4ostmpplvnq) between the truth and and the model since
* K(w)≥0 for all w∈W, and;
* K(w)=0 if and only if p(y|x,w)=q(y|x) for all x∈RN and all y∈RM.
As such, I will colloquially refer to K(w) as the loss landscape. [[7]](#fnxlty7roxql) The current state of results in SLT require K(w) to be an analytic function, but it seems likely that the results can be generalised to non-analytic settings with suitable hypotheses and constraints.
To analyse where the loss K(w) is minimised, we are then lead to defining the *set of true parameters*,
W0={w∈W|K(w)=0}={w∈W|p(y|x,w)=q(y|x)}.We say that the true distribution q(y|x) is *realisable* by the model class p(y|x,w) if W0 is non empty, that is, there exists *some* w(0)∈W such that q(y|x):=p(y|x,w(0)) for all x,y. Despite being unrealistic in real world applications, this is nonetheless an important starting point to the theory, which will then generalise to the set of optimal parameters in DSLT2.
We are going to restrict our attention to a particular kind of model: neural networks with Gaussian noise. We will formally define a neural network f(x,w) in a following chapter of this sequence, but for now it suffices to say that it is a function f:RN×W→RM with N inputs and M outputs defined by some parameter w∈W. Then our model density is going to be given by
p(y|x,w)=1(2π)M2exp(−12∥y−f(x,w)∥2).From here on in, we will assume we are working with a (model, truth, prior) triple (p(y|x,w),q(y|x),φ(w)) as specified in this section.
### Loss in our setting
To put these technical quantities into perspective, let me make clear two key points:
* Under the regression model, the NLL is equivalent to the mean-squared error of the neural network f(x,w) on the dataset Dn (up to a constant),
Ln(w)=M2log2π+1nn∑i=112∥yi−f(xi,w)∥2.* In the realisable case where q(y|x)=p(y|x,w(0)), the KL divergence is just the euclidean distance between the model and the truth adjusted for the prior measure on inputs,
K(w)=12∫RN∥f(x,w)−f(x,w(0))∥2q(x)dx.Singular vs Regular Models
==========================
What is a singular model?
-------------------------
The key quantity that distinguishes regular and singular models is the Fisher information matrix I(w), whose entries are defined by
Ij,k(w)=∬RN+M(∂∂wjlogp(y|x,w))(∂∂wklogp(y|x,w))p(y|x,w)q(x)dxdy.It can be shown that when evaluated at a point on the set of true parameters w(0)∈W0, the Fisher information matrix I(w) is simply the Hessian of K(w), so
Ij,k(w(0))=∂2∂wj∂wkK(w)∣∣∣w=w(0).A *regular* statistical model class is one which is identifiable (so p(y|x,w1)=p(y|x,w2) implies that w1=w2), and has positive definite Fisher information matrix I(w) for all w∈W. Regular model classes, such as standard linear regression, are the backbone of classical statistics for which all pre-exisiting literature on Bayesian statistics applies. But, from the point of view of SLT, regular model classes are... boring.
If a model class is not regular, then it is *strictly* *singular*. The non-identifiability condition can be easily dealt with, but it is the degeneracy of the Fisher information matrix that fundamentally changes the nature of the posterior and its asymptotics. We will say a model defined by a fixed w(0)∈W (not necessarily a true parameter) is strictly singular if the Fisher information at the point, I(w(0)), is degenerate, meaning
* rank(I(w(0)))<d, where d is the number of dimensions in parameter space W⊂Rd, or equivalently;
* detI(w(0))=0.
Then the model class is strictly singular if there exists a w(0)∈W such that I(w(0)) is degenerate. A *singular* model class can be either regular or strictly singular - Watanabe's theory thus generalises regular models, regardless of the model non-identifiability or degenerate Fisher information.
It can be easily shown that, under the regression model, I(w(0)) is degenerate if and only the set of derivatives
{∂∂wjf(x,w)}dj=1is linearly dependent.
In regular models, the set of true parameters W0 consists of one point. But in singular models, the degeneracy of the Fisher information matrix means W0 is not restricted to being one point, or even a set of isolated points - in general, these local minima of K(w) are connected together in high-dimensional structures [[8]](#fns2swxvx27w). In strictly singular models, the true parameters are degenerate singularities [[9]](#fnru2y4ipi0g) of K(w), and thus K(w) cannot be approximated by a quadratic form near these points. This is the fundamental reason the classical theory of Bayesian statistics breaks down.
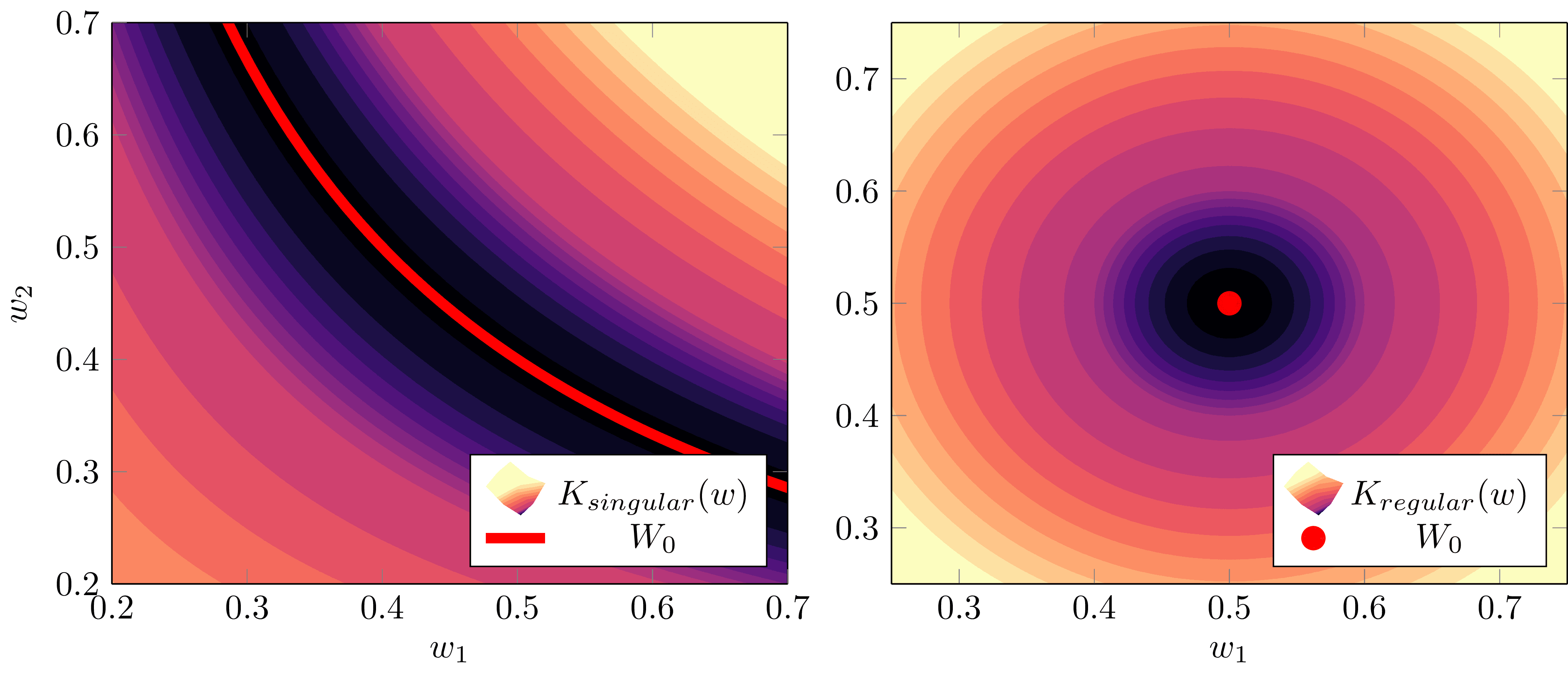In singular models (left), W0 can be a curve, but in regular models (right), W0 is a point.Watanabe states that "in singular statistical models, the knowledge or grammar to be discovered corresponds to singularities in general" [Wat09]. With this in mind, it is unsurprising that the following widely used models are all examples of singular models:
* Layered neural networks
* Gaussian, binomial, multinomial and other mixture models
* Reduced rank regression
* Boltzmann machines
* Bayes networks
* Hidden Markov models
Singular models are characterised by features like: having hierarchical structure, being made of superposition of parametric functions, containing hidden variables, etc., all in the service of obtaining hidden knowledge from random samples.
Classical Bayesian inference breaks down for singular models
------------------------------------------------------------
There are two key properties of regular models that are critical to Bayesian inference as n→∞:
* **Asymptotic normality:** The posterior of regular models converges in distribution to a d-dimensional normal distribution centred at the maximum likelihood estimator w(0) [Vaa07]:
p(w|Dn)→Nd(w(0),1nI(w(0))−1).* **Bayesian Information Criterion (BIC):** The free energy of regular models asymptotically looks like the BIC as n→∞, where Ln(w(0))=minw∈WLn(w) and d is the dimension of parameter space W⊆Rd:
Fn≈nLn(w(0))+d2logn=BIC.At the core of both of these results is an asymptotic expansion that strongly depends on the Fisher information matrix I(w) being non-degenerate at true parameters w(0)∈W0. It's instructive to see why this is, so let's derive the BIC to see where I(w) shows up.
### Deriving the Bayesian Information Criterion only works for regular models
For the sake of this calculation, let us assume W=Rd. Taking our cues from [Kon08], suppose w(0)∈W0 (thus is a maximum likelihood estimator and satisfies Ln(w(0))=minw∈WLn(w) ). We can Taylor expand the NLL as
Ln(w)=Ln(w(0))+(w−w(0))T∂Ln(w)∂w∣∣w=w(0)+12(w−w(0))TJ(w(0))(w−w(0))+… where J(w(0))=∂2Ln(w)∂w∂wT∣∣w=w(0) is the Hessian. Since we are analysing the asymptotic limit n→∞, we can relate this Hessian to the Fisher information matrix,
J(w(0))=∂2Ln(w)∂w∂wT∣∣w=w(0)=∂2(Kn(w)+Sn)∂w∂wT∣∣w=w(0)≈∂2K(w)∂w∂wT∣∣w=w(0)asn→∞=I(w(0)).By definition w(0) is a minimum of Ln(w), so ∂Ln(w)∂w∣∣w=w(0)=0, so we can expand the partition function as
Zn=∫We−nLn(w)φ(w)dw=∫Wexp(−nLn(w(0))−n2(w−w(0))TI(w(0))(w−w(0))+…)×[φ(w(0))+(w−w(0))T∂φ(w)∂w∣∣∣w=w(0)+…]dw.Here's the crux: *if* I(w(0)) is non-degenerate (so the model is regular), then we can perform this integral in good-faith knowing that it will always exist. In that case, the second term involving ∂φ(w)∂w vanishes since it is the first central moment of a normal distribution, so we have
Zn≈exp(−nLn(w(0)))φ(w(0))∫Wexp(−n2(w−w(0))TI(w(0))(w−w(0)))dw=exp(−nLn(w(0)))φ(w(0))(2π)d2nd2√detI(w(0)) since the integrand is the integral of a d-dimensional multivariate Gaussian Nd(w(0),1nI(w(0))−1). Notice here that this is the same distribution that arises in the asymptotic normality result, a theorem that has the same core, but requires more rigorous probability theory to prove. If I(w(0)) is degenerate, then it is non-invertible, meaning the above formulas cannot hold.
The free energy of this ensemble is thus
Fn=−logZn=nLn(w(0))+d2logn−logφ(w(0))−d2log2π+12detI(w(0)),and so ignoring terms less than O(1) in n, we arrive at the Bayesian Information Criterion
BIC=nLn(w(0))+d2logn.This quantity can be understood as an accuracy-complexity tradeoff, where the complexity of the model class is defined by d. We will elaborate on this more in DSLT2 but for now, you should just believe that the Fisher information I(w) is a big deal. Generalising this procedure (and therefore the BIC) for singular models, is the heart of SLT.
Examples of Singular Loss Landscapes
====================================
In essence, the Fisher information matrix I(w) describes something about the *effective dimensionality* or *complexity* of a model w. When a model class is regular, the effective dimensionality of every point is simply d, the number of parameters available to the model. But in the singular case, a new notion of effective dimensionality is required to adequately describe the complexity of a model. We're now going to look at two cases of singular models [[10]](#fn3eongh14olg) - or more precisely, loss landscapes that correspond to singular models - to motivate this generalisation. We'll start with the easier case where one or more parameters are genuinely "free".
Sometimes singularities are just free parameters
------------------------------------------------
**Example 1.1:** Suppose we have d=2 parameters afforded to a model such that K(w1,w2)=w21, which has a Hessian given by
J(w)=∂2∂wT∂wK(w)=(2000).Taking the critical point w(0)=(0,0), we have I(w(0))=J(w(0))=J(w) and so detI(w(0))=0, thus the model is singular. In this case, since K(0,w2)=0 for all w2, we could simply throw out the free parameter w2 and define a regular model with d1=1 parameters that has identical geometry K(w1)=w21, and therefore defines the same input-output function, f(x,(w1,w2))=f(x,w1).
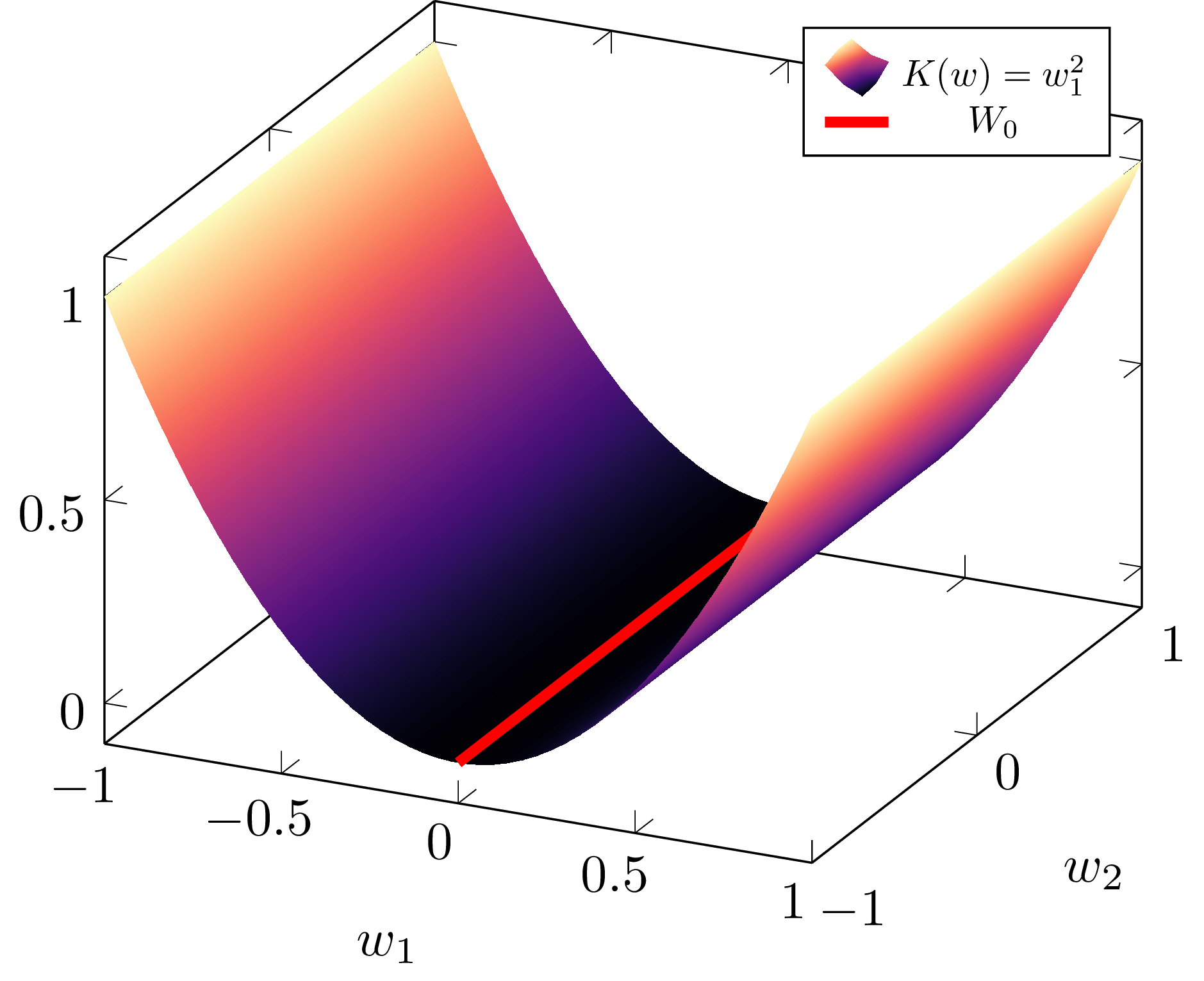The KL divergence for the minimally singular case in Example 1.1 looks like a flat valley.This example is called a *minimally singular* case. Suppose W⊆Rd with integers d1,d2>0 such that d1+d2=d, and after some change of basis[[11]](#fnj67t9005wbj) we may write a *local* expansion of K(w) as the sum of d1 squares,
K(w)=d1∑i=1ciw2i,where c1,c2,…,cd1>0 are positive coefficients. Then the Fisher information matrix has the form
I(w(0))=⎛⎜
⎜
⎜
⎜
⎜⎝c1…00⋮⋱⋮⋮0…cd100000d2⎞⎟
⎟
⎟
⎟
⎟⎠where 0d2 is the square d2×d2 zero matrix. Perhaps then we could define the "effective dimensionality" of w(0) as being rank(I(w(0)))=d1, which is the number of tangent directions in parameter space in which the model changes - the number of "non-free" parameters - and just discard the d2 "free" parameters that are normal to W0.
Sure! We can do that, and if we did, our BIC derivation would carry out fine and we would just replace d by d1 in the final formula. So the minimally singular case is easy to handle.
But this doesn't always work.
But not *all* singularities are free parameters
-----------------------------------------------
Defining the effective dimensionality at w(0) as rank(I(w(0))) seems nice in theory, but turns out to give nonsensical answers pretty quickly - it is not a full enough description of the actual geometry at play.
**Example 1.2:** Suppose instead that K(w1,w2)=12w21w22. Then the Hessian is
J(w)=(w222w1w22w1w2w21). At the critical point w(0)=(0,0) the Fisher information is
I(w(0))=H(w(0))=(0000), which is obviously degenerate.
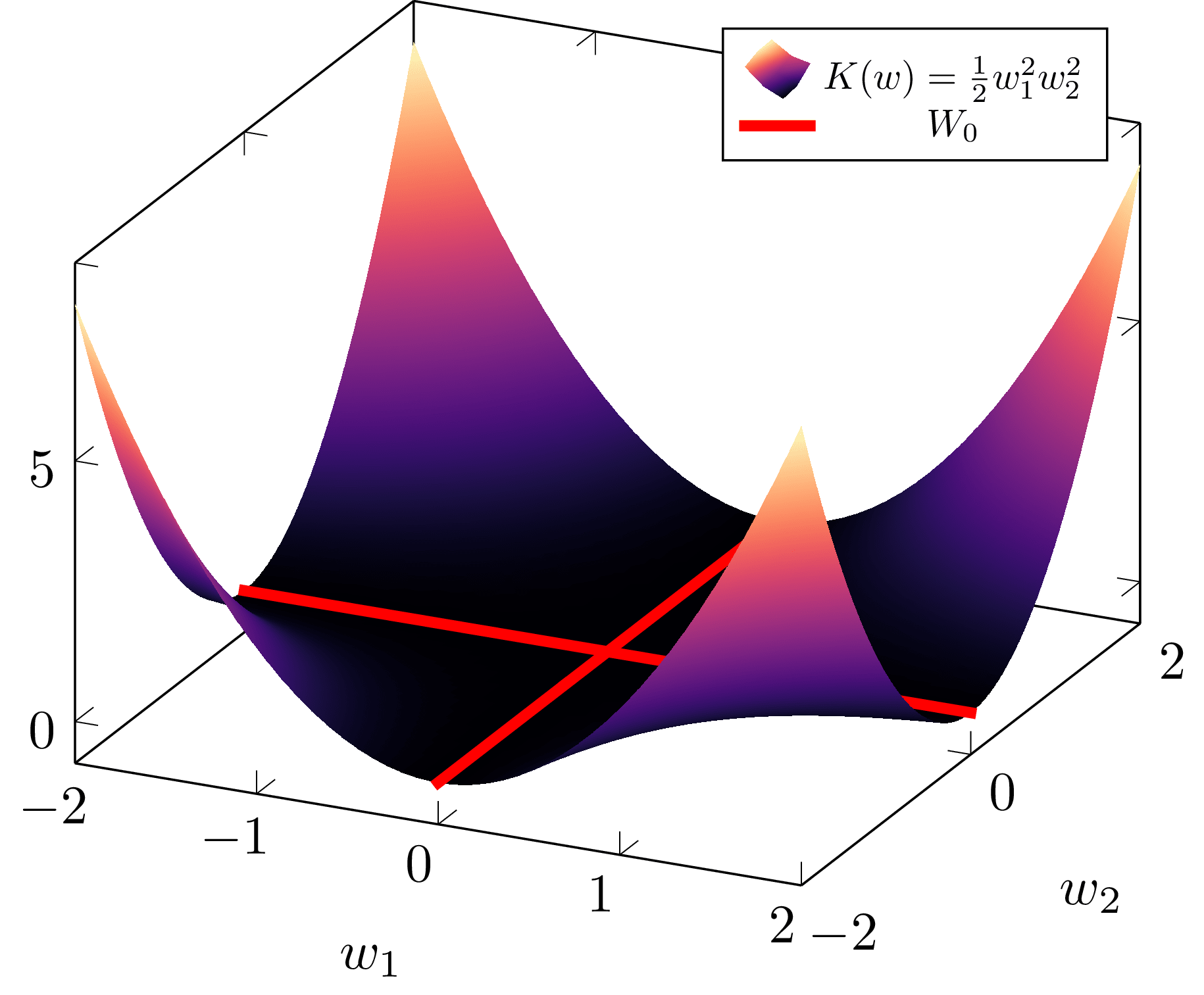The KL divergence for Example 2.2 with rank(I(w(0)))=0 looks like the intersection of multiple flat valleys.If we used our notion of effective dimensionality from before, we would say the model defined by w(0) had effective dimension of rank(I(w(0)))=0. But this would be ridiculous - clearly there are more than zero "effective dimensions" in this model, a term that would intuitively imply K(w) was identically zero, which it clearly is not. Thus, we need a different way of thinking about effective dimensionality.
The Real Log Canonical Threshold
================================
In this section we are going to explain the key claim of this post: that effective dimensionality in singular models is measured by a positive rational number called the Real Log Canonical Threshold.
Dimensionality as a volume co-dimension
---------------------------------------
Taking inspiration from Weyl's famous [Volume of Tubes](http://www.math.uchicago.edu/~shmuel/AAT-readings/Data%20Analysis%20/Tubes/Weyl,%20volume%20of%20tubes.pdf) paper, we can reframe dimensionality in terms of a scaling exponent of the volume of "nearly" true parameters. To explain this, we will generalise the minimally singular case above. The following discussion follows [Wei, 22].
Assume we have a partition as before with d1,d2∈N≥0 such that d1+d2=d, where d1 is the number of non-free parameters and d2 is the number of free parameters. For any ε>0 we can consider the set of almost true parameters centred at w(0) (which, without loss of generality, we will take to be w(0)=0),
Wε={w∈W|K(w)<ε} and an associated volume function
V(ε)=∫Wεφ(w)dw.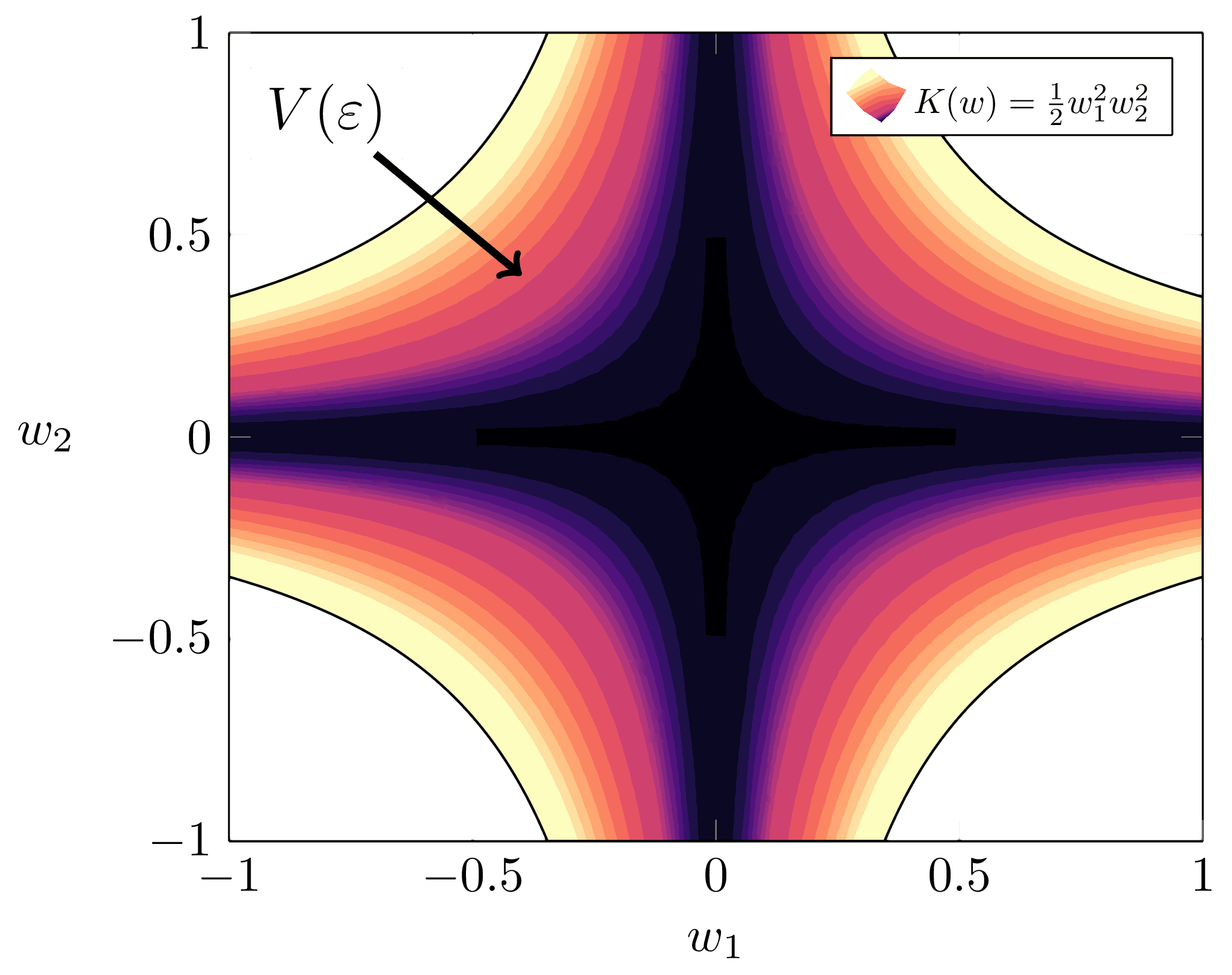 V(ε) for K(w)=12w21w22 for different ε level sets.As long as the prior φ(w) is non-zero on W0 it does not affect the relevant features of the volume, so we may assume that it is a constant C in the first d1 directions and is a normal distribution in the remaining d2. Then since K(w)≈∑d1i=1ciw2i, we can write
V(ε)=∫{w∈W|∑d1i=1ciw2i<ε}Cdw1…dwd1∫Rd2e−12(w2d1+1+⋯+w2d)dwd1+1…dwd.The right integrand is some constant A that doesn't depend on ε, and for the left we can make the substitution ui=√ciεwi, hence
V(ε)=AC∫{u∈U|∑d1i=1u2i<1}√εc1…√εcd1du1…dud1.Recognising the integrand as the volume of the d1-ball, a constant B that does not depend on ε, we see that
V(ε)∝εd12√c1…cd1.Then the dimension d1 arises as the scaling exponent of ε12, which can be extracted via the following ratio of volumes formula for some a∈(0,1):
d1=2limε→0log(V(aε)/V(ε))loga.This scaling exponent, it turns out, is the correct way to think about dimensionality of singularities.
Watanabe shows in Theorem 7.1 of [Wat09] that in general, for any singular model defined by w(0), the volume integral centred at w(0) has the form
V(ε)=cελ+o(ελ)where λ∈Q>0 is a positive rational number called the *Real Log Canonical Threshold* (RLCT) associated to the "most singular point" in W0. *This* is the quantity that generalises the dimensionality of a singularity. What's more, different singularities in W0 can have *different RLCT values*, and thereby different "effective dimensionalities". As suggested above, the RLCT can then be defined by this volume formula:
λ=2limε→0log(V(aε)/V(ε))loga.An example of fractional dimension
----------------------------------
**Example 1.3:** To build intuition for what a "fractional dimension" is, consider a model with d=1 parameters with KL divergence given by K(w)=w4, which is singular since ∂2K∂w2∣∣w=0=0. A simple calculation shows that for this KL divergence,
V(ε)∝ε14meaning λ=14 and so the "effective dimensionality" is 2λ=12.
Meanwhile, in the K(w)=w2 case, V(ε)∝ε12, so the effective dimensionality is 1.
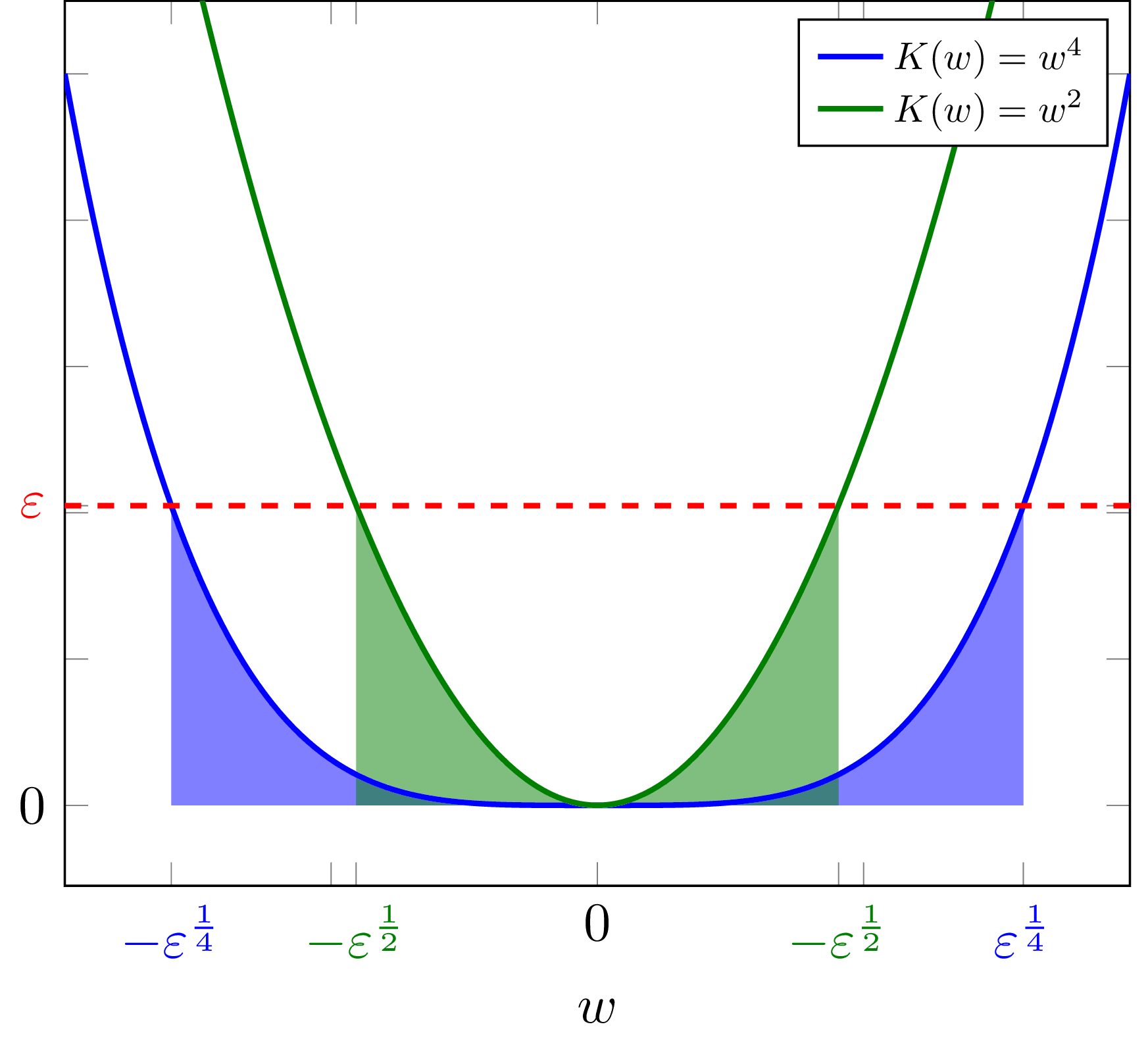Comparing the effective dimensionality as the scaling exponent of ε for different models.The RLCT can be read off when K(w) is in normal crossing form
-------------------------------------------------------------
I may have presented the previous section suggesting that the RLCT is trivial to calculate. In general, this couldn't be further from the truth. But in one special case, it is. For this discussion we will ignore the prior, i.e. we will set it to be uniform on W.
### One dimensional case
As we just saw in Example 1.3, in the one dimensional case where K(w)=w2k for some k≥1, the RLCT is simply λ=12k. In fact, if we can express K(w) in the form
K(w)=(w−c1)2k1…(w−cJ)2kJfor non-negative integers k1,…,kj and unique c1,…,cj∈R, then the RLCT associated to each singularity cj is simply λj=12kj. But, Watanabe shows that it is the *smallest* local RLCT (and thus the highest exponent in K(w)) that dominates the free energy, thus defining the *global RLCT* λ where
λ=minj=1,…,J(12kj).**Example 1.4** This example is going to be very relevant in DSLT2. If we have
K(w)=(w+1)2w4,with true parameters w(0)−1=−1 and w(0)1=1, then the local RLCT associated to each singularity is
λ−1=12andλ1=14.The global RLCT is thus λ=λ1.
### Multidimensional case
Suppose now that d>1 so K(w)=K(w1,…,wd). Suppose without loss of generality that w(0)=0 is a true parameter for K(w). If we can write the KL divergence in *normal crossing form* near w(0),
K(w)=w2k11…w2kddthen the RLCT is given by
λ=minj=1,…,d(12kj).The multiplicity mj of each coordinate is the number of elements in {k1,…,kd} that equal kj.
This generalises this above case in the following sense:
**Example 1.5** Suppose now that we have a two dimensional KL divergence of the form
K(w1,w2)=(w1+1)2w41w22.Then, in a neighbourhood of the singularity w(0)0=(0,0), the KL divergence is approximately
K(w)∝w41w22.Thus, the RLCT associated to w(0)0 is
λ0=14,with multiplicity m0=1.
On the other hand, near the singularity w(0)−1=(−1,0) the KL divergence is, up to a prefactor, approximately
K(w)≈(w1+1)2w22so the RLCT associated to w(0)−1 is
λ−1=12with multiplicity m−1=2. So, in this case the global RLCT is λ=λ0, which we will see in DSLT2 means that the posterior is most concentrated around the singularity w(0)0.
Resolution of Singularities
---------------------------
In *Algebraic Geometry and Statistical Learning Theory*, Watanabe shows that algebraic geometry plays a central role in governing the behaviour of statistical models, and a highly non-trivial one in singular models especially. This rich connection between these two deep mathematical fields is, in my eyes, both profound and extremely beautiful.
The remarkable insight of Watanabe is that in fact *any* KL divergence, under appropriate hypotheses (such as analyticity), can be written in normal crossing form near a singularity of K(w). To do so, he invokes one of the fundamental theorems of algebraic geometry: Hironaka's [Resolution of Singularities.](https://en.wikipedia.org/wiki/Resolution_of_singularities) The content of this theorem and its implications go well beyond the scope of this sequence. But, I will briefly mention its role in the theory as it relates to the RLCT. For a more detailed introduction to this part of the story, see [Wat09, Section 1.4].
The theorem guarantees the existence of a d-dimensional analytic manifold M and a real analytic map
g:M∋u↦w∈Wsuch that for each coordinate Mα of M one can write
K(g(u))=u2k11…u2kddandφ(g(u))|g′(u)|=ϕ(u)|uh11…uhdd|where each k1,…,kd and h1,…,hd are non-negative integers, |g′(u)| is the Jacobian determinant of w=g(u) and ϕ(u)>0 is a real analytic function. The global RLCT is then defined by
λ=minαminj=1,…,d(hj+12kj),and the global multiplicity is the maximum multiplicity over α.
From this point on in the sequence, when you see the word "desingularise", what you should think is "put K(w) into normal crossing form near a singularity".
The RLCT measures the effective dimensionality of a model
---------------------------------------------------------
Succinctly, the RLCT λ∈Q>0 of a singularity w(0)∈W0⊆W⊆Rd generalises the idea of dimension because:
* If a model defined by w(0) is **regular**, then
λ=d2.* If a model defined by w(0) is **minimally singular** where d1<d is the number of non-free parameters, then
λ=d12.* **In general**, for any singular model the RLCT satisfies (by Theorem 7.2 of [Wat09])
λ≤d2.* In particular, if there are d1<d non-free parameters then
λ≤d12.In order to find the asymptotic form of the free energy Fn as n→∞, Watanabe desingularises K(w) near each singularity using the Resolution of Singularities. The RLCT then directly substitutes into the place of d2 in the BIC formula, which gives rise to the Widely Applicable Bayesian Information Criterion (WBIC)
WBIC:=nLn(w(0))+λlogn.In DSLT2, we will explain the implications of the WBIC and what it tells us about the profound differences between regular and singular models.
Appendix 1 - The other definition of the RLCT
=============================================
In this post we have defined the RLCT as the scaling exponent of the volume integral of nearly true parameters. This result, whilst the most intuitive, is presented in the reverse order to how Watanabe originally defines the RLCT in [Wat09]. Alternatively, we can consider the zeta function
ζ(z)=∫WK(w)zφ(w)dw, and show that it has a Laurent series given by
ζ(z)=ζ0(z)+∞∑k=1mk∑m=1ckm(z+λk)mwhere ζ0(z) is a holomorphic function, ckm∈C are coefficients, each λk∈Q>0 is ordered such that 0<λ1<λ2<…, and mk∈N is the largest order of the pole λk.
Then the *Real Log Canonical Threshold* of our (model, truth, prior) triple is λ=λ1 with multiplicity m=m1.
This ζ(z) is a key piece of machinery in using distribution theory to expand the partition function Zn. In the end, the smallest λ1 and its multiplicity m1 are the dominant terms in the expansion, and a further calculation in [Wat09, Theorem 7.1] shows how V(ε)∝ελ.
To see why ζ(z) is necessary, and why this definition of the RLCT matters to the free energy formula proof, see the sketch of the proof in [Wat09, pg31-34].
References
==========
[Car21] - Liam Carroll, [Phase Transitions in Neural Networks](http://therisingsea.org/notes/MSc-Carroll.pdf) (thesis)
[Wat09] - Sumio Watanabe, [Algebraic Geometry and Statistical Learning Theory](https://doi.org/10.1017/CBO9780511800474) (book)
[Wat18] - Sumio Watanabe, [Mathematical Theory of Bayesian Statistics](https://www.lesswrong.com/posts/xRWsfGfvDAjRWXcnG/%5Bhttps://doi.org/10.1201/9781315373010%5D(https://doi.org/10.1201/9781315373010)) (book)
[KK08] - Konishi, Kitagawa, [Information Criteria and Statistical Modelling](https://doi.org/10.1007/978-0-387-71887-3) (book)
[Vaa07] - van der Vaart, [Asymptotic Statistics](https://doi.org/10.1017/CBO9780511802256) (book)
[Wei22] - Susan Wei, Daniel Murfet et al., [Deep Learning is Singular, and That's Good](https://www.suswei.com/publication/wei-2022-singular/wei-2022-singular.pdf) (paper)
---
1. **[^](#fnref2o53numu1y)**In the finite n case, the choice of prior φ(w) is a philosophical matter, as well as a mathematical tractability matter. But as n→∞, most results in Bayesian statistics show φ(w) to be irrelevant so long as it satisfies some reasonable conditions. This is also true in SLT. [↩︎](#fnref-HwvdHXcFG7fbGvS53-1)
2. **[^](#fnref10wrm23xi25p)**This should remind you of the [Gibbs ensemble](https://en.wikipedia.org/wiki/Canonical_ensemble) from statistical physics - not coincidentally, either. [↩︎](#fnref-HwvdHXcFG7fbGvS53-3)
3. **[^](#fnref492ca0emf4j)**For theoretical, philosophical, and computational purposes, we also define the *tempered posterior* to be
pβ(w|Dn):=1Zβnφ(w)e−nβLn(w),whereZβn=∫Wφ(w)e−nβLn(w)dw. where β>0 is the *inverse temperature*. This β plays an important role in deriving the free energy formula and can be thought of as controlling the "skinniness" of the posterior. In our regression model below, it is actually the inverse variance of the Gaussian noise. [↩︎](#fnref-HwvdHXcFG7fbGvS53-4)
4. **[^](#fnrefjs7ilb7ecgp)**By Bayes' rule we have p(w|Dn)=p(Dn|w)φ(w)p(Dn). The form written here follows from some simplification of terms and redefinitions, see page 10 of the thesis.
5. **[^](#fnref7csuab9hjh9)**We can define an expectation over the dataset Dn for some function g(X,Y) as
EX[g(X,Y)]=∬RN+Mg(x,y)q(y,x)dxdy In particular, we define the entropy of the true conditional distribution to be
S=EX[−logq(y|x)]=−∬RN+Mq(y,x)logq(y|x)dxdy, and the (non-empirical) negative log loss to be
L(w)=EX[−logp(y|x,w)]=−∬RN+Mq(y,x)logp(y|x,w)dxdy.It is easy to show that EX[Sn]=S and EX[Ln(w)]=L(w), and so by the law of large numbers there is almost sure convergence Sn→S and Ln(w)→L(w). Analogous definitions show
Kn(w)=Ln(w)−Sn→L(w)−S=K(w).
6. **[^](#fnref4ostmpplvnq)**Though it isn't a true metric due to its asymmetry in p and q, and since it doesn't satisfy the triangle inequality. [↩︎](#fnref-HwvdHXcFG7fbGvS53-6)
7. **[^](#fnrefxlty7roxql)**Note here that since K(w)=L(w)−S, we can reasonably call both K(w) and L(w) the loss landscape since they differ only by a constant S (as n→∞).
8. **[^](#fnrefs2swxvx27w)**Or more precisely, a real analytic set.
9. **[^](#fnrefru2y4ipi0g)**Since K(w(0))=0, and ∇K(w(0))=0, and I(w(0)) is degenerate. [↩︎](#fnref-HwvdHXcFG7fbGvS53-12)
10. **[^](#fnref3eongh14olg)**Based on K(w)=12∫W∥f(x,w)−f(x,w(0)∥2q(x)dx, it is relatively easy to reconstruct a model that genuinely yields a given K(w) function, so we may happily pretend we have said model when we pull such a loss function from thin air. [↩︎](#fnref-HwvdHXcFG7fbGvS53-13)
11. **[^](#fnrefj67t9005wbj)**Which is guaranteed to exist since the Hessian is a real symmetric matrix (and thus so is I(w(0))), so it can be diagonalised. [↩︎](#fnref-HwvdHXcFG7fbGvS53-14) |
b5a10809-6192-4743-bc79-a71546ae0f85 | trentmkelly/LessWrong-43k | LessWrong | Goal-Completeness is like Turing-Completeness for AGI
Turing-completeness is a useful analogy we can use to grasp why AGI will inevitably converge to “goal-completeness”.
By way of definition: An AI whose input is an arbitrary goal, which outputs actions to effectively steer the future toward that goal, is goal-complete.
A goal-complete AI is analogous to a Universal Turing Machine: its ability to optimize toward any other AI's goal is analogous to a UTM's ability to run any other TM's same computation.
Let's put the analogy to work:
Imagine the year is 1970 and you’re explaining to me how all video games have their own logic circuits.
Steve Wozniak hand-designs a circuit for Breakout (Atari 1976), without using a Turing-complete architectureBreakout's gameplay was simple enough to NOT be Turing-complete. That's why optimizing its circuit by hand could save money.
You’re not wrong, but you’re also apparently not aware of the importance of Turing-completeness and why to expect architectural convergence across video games.
Flash forward to today. The fact that you can literally emulate Doom inside of any modern video game (through a weird tedious process with a large constant-factor overhead, but still) is a profoundly important observation: all video games are computations.
Source
More precisely, two things about the Turing-completeness era that came after the specific-circuit era are worth noticing:
1. The gameplay specification of sufficiently-sophisticated video games, like most titles being released today, embeds the functionality of Turing-complete computation.
2. Computer chips replaced application-specific circuits for the vast majority of applications, even for simple video games like Breakout whose specified behavior isn't Turing-complete.
Expecting Turing-Completeness
From Gwern's classic page, Surprisingly Turing-Complete:
> [Turing Completeness] is also weirdly common: one might think that such universality as a system being smart enough to be able to run any program might be difficult or hard t |
cc47f2ce-f1fa-400e-a019-4e245a109c62 | StampyAI/alignment-research-dataset/youtube | Youtube Transcripts | Bing (GPT 4) Just Made Smartphones MUCH Smarter (next-level Android and iOS app)
Bing app now available on Android and
iOS is about efficiency over
extravagance it's on your phone so it's
not about essay writing compiling code
or making funny poems in French it's
about taking search to the next level no
I'm not sponsored by them but I think
it's mind-blowing there are four levels
of search increasing in power and
requisite intelligence and Google is
pretty much only able to do level one
and even then not always Bing can do all
four let me show you in this video
exactly what I mean taking you through
all four levels of search by the end I
honestly think I'm gonna persuade you
that smartphones just got upgraded
permanently just quickly how does it
look on mobile well if you open up the
app you will see at the bottom a bing
button on any web page just like you can
in the edge browser you can press on the
Bing button and open up Bing chat you
then have two options you can ask it
questions via the microphone or via the
keyboard for example you could ask who
is currently seventh in the Premier
League searching for Premier League
table according to the Premier League
table Brighton and Hove Albion is
currently seventh in the league with 35
points from 22 games played
they have scored 39 goals and conceded
29 goals giving them a goal difference
of 10. that's another fascinating
difference with being on mobile it
actually speaks to you I wouldn't call
it Cutting Edge text the voice but we're
just getting started you're probably
wondering how does this transform search
how does this upgrade our smartphones
well this is just a level one search we
are retrieving one bit of information
and even on this front Bing does better
than Google the exact same question into
Google gives a generalized formula about
the Premier League and what seventh
place means Bing understands exactly
what I want and gives the correct answer
I will admit if we were just comparing
level 1 searches Bing wouldn't be that
much of an upgrade you could always
click on a link to a table and see for
yourself where Brighton are maybe you're
saving a few seconds with Bing but not
really a big difference but just wait
until we get to level three and even
level 4 and Beyond searches and now you
guys are ready for level 2 searches and
what do I mean by that this time we are
retrieving two bits of disparate data
but we want to do it at the same time
not doing two separate searches by the
way I'm typing these searches into Bing
desktop so you can see them more clearly
but of course it would be even quicker
to ask them with my voice into being on
mobile I asked what are the ages of the
Eiffel Tower and the Empire State
Building and look at the difference I
can clearly see the two results on the
left in bing but on the right I'm gonna
have to click on at least two links and
scroll through the data you can just
begin to imagine the number of searches
this could apply to and we're only on
level two the next example of a level 2
surge would be to retrieve a bit of
information and do something to it for
example I asked both Bing and Google if
Microsoft's market cap doubled what
would it be there are two stages to that
question first it has to retrieve
Microsoft's current market cap then it
has to double it bing gets the answer
Google doesn't even show the market cap
not immediately at least even here I
know some of you will be thinking I
could just type in market cap find the
source get out a calculator and double
it what's the big problem yes maybe you
save 30 seconds but what's the big deal
well we haven't even gotten to level
three or level four searches yet so what
is an example of a level three search
imagine you're on your smartphone and
you're considering the Adobe Creative
Cloud and imagine you wanted to know
just how much more expensive it would be
over say a couple year time period than
DaVinci Resolve you could press the Bing
button and ask this according to this
page if I got the individual account for
two years how much more expensive would
that be in pounds than the one-off
payment for DaVinci Resolve 18. now as
I've talked about in my other Bing chat
playlist videos it understands the
context in which you're asking the
question it knows you mean this Adobe
Creative Cloud individual plan it
correctly multiplies this for two years
and then compares the total to DaVinci
resolves price now initially I thought
it made a mistake because when I quickly
checked on Google DaVinci Resolve costs
255 pounds but then when I click to buy
it it adds on vat which makes it 306
pounds in the UK so in a way that's
another win for bingy understood about
adding on vat but what makes this a
level 3 search is it did all of that
work it retrieved the two bits of
information in context and then compared
them then subtracted them giving us a
difference of 941 pounds in the price
over two years and of course you could
carry on this conversation with being
about the pros and cons of each package
for some of these searches I am not even
going to try it in Google because it
would completely flop level 3 searches
are about much more than this though
imagine you're standing on the Houston
Road and you want to get to Central
London you could conduct a level 3
search using Bing the question might be
how much longer would it take to get the
underground from King's cross to
Piccadilly Circus than from Houston to
Oxford Circus or how much longer would
it take to go from King's cross to Hyde
Park Corner than from Houston to
Victoria these are all Journeys that I
make on a regular basis and I can
confirm that the results are accurate
why is this level three because it had
to retrieve the information about one
Journey then the other and then make the
comparison our level three searches all
about addition and subtraction no check
this out you could ask how much bigger
are polar bears than brown bears and why
Google would have to do three things and
it just isn't up to it you'd have to
find the size of the average polar bear
the size of the average brown bear and
then do an analysis of why polar bears
are bigger not just a mathematical
comparison but an understanding of
comprehension an explanation of the wise
think of level three as adding a when
where why and how to level two searches
the answer by the way is quite
interesting so polar bears can weigh up
to 1700 pounds versus thirteen twenty
pounds but we didn't just want to know
that we wanted to know the reason why
and apparently the reason why is and I
can believe this is that they need more
body mass and fat to survive in the cold
Arctic environment they also have a
bigger skull and larger teeth to hunt
seals so now I've got more of an idea
not just how much bigger they are but
why is through Evolution that they ended
up being bigger but we have waited long
enough what about level 4 searches well
think about a complex interesting search
like this how much older is Stonehenge
than the Coliseum in Rome expressed in
human lifetimes Bing has to do four
things find the age of Stonehenge the
age of the Coliseum the difference
between them divided by the average
human lifetime it does this successfully
and we have a really interesting result
that is about 38 human lifetimes older
if we take the older date for Stonehenge
that is an insane level of intelligence
for a single search now we're genuinely
talking about saving a minute or more
compared to using Google that is a big
enough difference to really matter and
that's not the only example I could give
you of a level 4 search I'm sure you
could tell me hundreds of ideas in the
comments but try this one going back to
the Premier League I could ask if
Arsenal beat Leicester and Man City draw
Bournemouth how many points ahead would
Arsenal be I didn't have to specify
Premier League I didn't have to say
fixture and of course I didn't have to
tell it the rules of the Premier League
about three points for a win Etc it knew
exactly what I was asking calculated the
two results found the league positions
and then found the difference now you
don't have to be into sport to know that
that's an amazing answer to a complex
search query think about how this
applies to your domain your career your
interests and come up with some level 4
searches that you could ask which brings
me on to my final point the question for
every smartphone user will be is the
small but real risk of hallucinations
more meaningful to me than the
additional seconds and minutes required
to perform multiple searches for me the
answer is already yes but clearly what
we decide will depend on the topic right
for sport it's fine for maybe a
life-changing house decision maybe not
by the way with those new modes that
Bing is debuting this week that I'm
going to do a video on where you can
pick Precision over creativity soon you
might not even need to make a choice
between hallucination versus efficiency
very much looking forward to doing a
deep dive into those modes by the way
and yes what you may find is that being
when you do voice recognition makes the
occasional mistake in what you're asking
it that certainly happened to me open AI
who are the partners to Microsoft are
responsible for whisper which I have
downloaded locally and tried out it is
phenomenal at voice recognition as good
arguably as human transcribers now I
don't think whisper is powering the
current Bing voice recognition but
because of Microsoft's partnership with
openai I wouldn't be surprised if by the
end of the year whisper doesn't power
Bing and that should make voice searches
almost flawless I know what some of you
are thinking but what about the
conversation limits well according to my
sources they should be ending soon
enough too now of course we are days or
maybe weeks away from Google Bard's
system being released but I've got a
feeling that Google doesn't want those
multiple searches to go away anytime
soon being on the other hand doesn't
care so I'm not sure there's much
incentive for Google to maximize the
efficiency of Bard early indications
about the size of the Lambda model
that's powering Bard and the leaked
rumors that every Google employee is
spending two to four hours a day to
improve the output of Bard suggests that
my feeling might have some basis but
maybe Google will surprise us all or
Facebook they just released llama a
large language model that outperforms
even palm and therefore likely Bing on
some metrics I'm hoping to use it soon
and Amazon well they just released a
model that outperforms GPT 3.5 by 16 so
they're not out of the game either by
the end of 2023 who knows who will be
the king of search and the king of your
smartphone but it will definitely be a
smarter smartphone if you agree or even
if you disagree let me know in the
comments please do leave a like and
thank you very much for watching have a
wonderful day |
385beb60-d7a2-4402-9a70-6c02ebf0ca8d | trentmkelly/LessWrong-43k | LessWrong | Meetup : July Rationality Dojo: Disagreement
Discussion article for the meetup : July Rationality Dojo: Disagreement
WHEN: 06 July 2014 03:00:00PM (+1000)
WHERE: 491 King Street, West Melbourne
[ATTN: The dojo roster is has all free slots starting from next month, if you would like to present at a future Dojo or suggest a topic, please fill it in on the Rationality Dojo Roster: http://is.gd/dojoroster]
The Less Wrong Sunday Rationality Dojos are crafted to be serious self-improvement sessions for those committed to the Art of Rationality and personal growth. Each month a community member will run a session involving a presentation of content, discussion, and exercises.
Continuing the succession of immensely successful dojos, James will run a session on disagreement. How can two epistemic peers, equally knowledgeable and equally competent, ever feel certain about their view when their peer disagrees?
As always, we will review the personal goals we committed to at the previous Dojo (I will have done X by the next Dojo). Scott Fowler recorded the commitments, if you didn't make it but would like to add your own goal to the records, send him a message (shokwave.sf@gmail.com).
The Dojo is likely to run for 2-3 hours, after which some people will get dinner together.
If you have any trouble finding the venue or getting in, call me on 0425-855-124.
Discussion article for the meetup : July Rationality Dojo: Disagreement |
f57226c7-439f-4c9b-a653-0a0e126ce617 | trentmkelly/LessWrong-43k | LessWrong | “Eating Dirt Benefits Kids” is Basically Made Up
Sometimes people imply that epistemic spot checks are a waste of time, that it’s too easy to create false beliefs with statements that are literally true but fundamentally misleading. And sometimes they’re right.
On the other hand, sometimes you spend 4 hours and discover a tenet of modern parenting is based on absolutely nothing.
Sorry, did I say 4 hours? It was more like 90 minutes, but I spent another 2.5 hours checking my work just in case. It was unnecessary.
Intro
You are probably familiar with the notion that eating dirt is good for children’s immune systems, and you probably call that Hygiene Hypothesis, although that’s technically incorrect.
Hygiene Hypothesis can refer to a few different things:
1. A very specific hypothesis about the balance between specific kinds of immune cells.
2. A broader hypothesis that exposure to nominally harmful germs provides the immune system training and challenge that ultimately reduces allergies.
1. One particular form of this involves exposure to macroparasites, but that seems to have fallen out of favor.
3. The hypothesis that exposure to things usually considered dirty helps populate a helpful microbiome (most often gut, but plausibly also skin, and occasionally eyeball), and that reduces allergies. This is more properly known as the Old Friends hypothesis, but everyone I know combines them.
4. Pushback on the idea that everything children touch should be super sanitized
5. The idea that eating dirt in particular is beneficial for children for vague allergy-related reasons.
I went into this research project very sold on the Hygiene Hypothesis (broad sense), and figured this would be a quick due diligence to demonstrate it and get some numbers. And it’s true, the backing for Hygiene and Old Friends Hypothesis seems reasonably good, although I didn’t dig into it because even if they’re true, the whole eating dirt thing doesn’t follow automatically. When I dug into that, what I found was spurious at best, |
2b4b4727-e365-493d-92ff-f295aa8166f8 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Another view of quantilizers: avoiding Goodhart's Law
.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
[Goodhart's law](https://en.wikipedia.org/wiki/Goodhart%27s_law) states:
>
> Any observed statistical regularity will tend to collapse once pressure is placed upon it for control purposes.
>
>
>
One way of framing this is that, when you are solving some optimization problem, a metric that is correlated with a desired objective will often stop being correlated with the objective when you look at the extreme values of the metric. For example, although the number of paperclips a paperclip factory produces tends to be correlated with how useful the factory is for its owner's values, a paperclip factory that produces an extremely high number of paperclips is likely to be quite bad for its owner's values.
Let's try to formalize this. Suppose you are finding some x∈X that optimizes some unknown objective function f:X→R, and you have some estimate
g:X→R which you believe to approximate f. Specifically, you have a guarantee that, for some base distribution γ:ΔX, g does not
incorrectly estimate f much on average:
EX∼γ[|g(x)−f(x)|]≤k
We might suppose that we only want to take actions if our expected f is above zero; otherwise, it would be better to do nothing.
Given this, how do you pick an x to guarantee a good objective value f(x) across all possible objective functions f? Naively, you might pick x=argmaxx∈Xg(x); however, if this x has a low probability under γ, then it is possible for g(x) to be much higher than f(x) without causing g to overestimate f much *on average*.
If f is chosen adversarially, the optimization problem to solve is:
argmaxa∈[0,1],p∈ΔX minf:X→R,EX∼γ[|g(x)−f(x)|]≤kaEX∼p[f(X)]
where a is the probability that the agent takes an action at all, and p is the action distribution if it takes an action. Equivalently, since the most adversarial f values will not ever be above g:
argmaxa∈[0,1],p∈ΔX minf:X→R,∀xf(x)≤g(x),EX∼γ[g(x)−f(x)]≤kaEX∼p[f(X)]
Define c(x)=g(x)−f(x):
argmaxa∈[0,1],p∈ΔX minc:X→R+,EX∼γ[c(x)]≤kaEX∼p[g(X)−c(X)]
argmaxa∈[0,1],p∈ΔX aminc:X→R+,EX∼γ[c(x)]≤kEX∼p[g(X)−c(X)]
argmaxa∈{0,1},p∈ΔX aminc:X→R+,EX∼γ[c(x)]≤kEX∼p[g(X)−c(X)]
In fact, when a=1, the solution to this optimization problem is a q-quantilizer with utility function g and base distribution γ, for some q. The proof can be found in the "Optimality of quantilizers under the cost constraint" section of the [post about quantilizers](https://agentfoundations.org/item?id=460). a will be set to 1 if and only if this quantilizer is guaranteed positive utility.
This provides another view of what quantilizers are doing. In effect, they are treating the "utility function" U as an *estimate* of the true utility function U−c that tends to be accurate *on average* across the base distribution γ, and conservatively optimizing given adversarial uncertainty about the true utility function U−c. |
dfa2a19c-50e7-42b8-8f9d-f95cd99e3700 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | AI, Cybersecurity, and Malware: A Shallow Report [General]
This post summarises recent progress in AI-enabled malware detection for the general public.
**Why read a post about AI-enabled malware detection?** It has large impacts in protecting technology for democratic elections; technology for biosecurity (ex: algorithms to screen dangerous biological products); the trained settings of AI algorithms; and more.
P.S. If you're familiar with applied AI, [the technical version of this post](https://forum.effectivealtruism.org/posts/SMsobbG7tgya2neN9/ai-cybersecurity-and-malware-a-shallow-report-technical) may be more interesting to you.
Summary
=======
* The field's **largest challenge is updating defences against ever-changing malware.** This will get worse as hackers use AI to modify malware at faster rates.
+ Predicting future malware or training AI models continuously could help.
* Many studies in this field are questionable, slowing progress. **Studies often violate best practices in AI research**. Broken rules include not comparing advanced methods to simple baselines; not assessing performance in realistic conditions; and a lack of transparency about data sources/data processing.
* Vulnerabilities are growing with *small* devices (like temperature controllers for drug production). *Simple* defensive algorithms are needed to protect them. Algorithms inspired by our immune systems can help.
---
Traditional Malware Detection
=============================
Some **early malware detectors saved parts of malware files (signatures)** for later. These techniques mainly worked to detect known malware multiple times. Ex: an antivirus might save a sequence of bytes (the most basic 'letters' of computer code) from a malicious program. Then, it could detect this sequence later.
But what if a hacker updates an old malware file to change that sequence? Well, the update would still have similar behaviour to older files. Ex: a malware file could record the keys you press on your keyboard. Thus, **the behaviour (actions) of malware files can be tracked** with less variation than raw bytes.
Note how this new technique must *run* malware files (to record their actions). Whereas older techniques looking for a 'signature' only *read* a malware file's content. This difference is known as static analysis (read-only) vs. [dynamic analysis](https://link.springer.com/referenceworkentry/10.1007/978-1-4419-5906-5_836) (run).
**Static analysis techniques are less risky** since malware is not run. However, they analyse a lot of information across an *entire* file.
* Aside: most of that information isn't related to a file's malicious actions. For example, a hacker may copy a normal mobile app, but run dangerous code only when one button is pressed. ([Source](https://www.hindawi.com/journals/scn/2021/3578695/))
Dynamic analysis techniques need more safety precautions when running malware. This could mean running the malware on a test computer with no personal data. Also, **dynamic analysis struggles to analyse** ***all*** **actions of malware file.** Ex: a hacker could program their malware to only run after two weeks of waiting. So any dynamic analysis that didn't wait two weeks wouldn't detect the malware. ([Source](https://ieeexplore.ieee.org/document/8667136))
Due to these tradeoffs, both techniques are used in practice.
---
Progress With AI
================
### Common Algorithms
**AI algorithms have mainly been used for static (read-only) analysis.** Here are the largest differences in AI algorithms in the field. ([Source](https://arxiv.org/ftp/arxiv/papers/2210/2210.11239.pdf))
Preprocessing: how to prepare information about malware files before sending it to an AI algorithm.
Common preprocessing techniques include:
* Extracting statistics from malware files like the 10 most common instructions. ([Source](https://www.sciencedirect.com/science/article/pii/S0045790618328167))
* No preprocessing at all to preserve raw details. ([Source](https://arxiv.org/pdf/2205.03850.pdf))
* Condensing the file's raw bytes into higher-level alternatives. ([Source](https://www.cs.binghamton.edu/~ghyan/papers/dsn19.pdf))
Of these, **processing raw bytes is an ideal goal**. No special steps are needed and the AI algorithm is easy to update. Still, it's hard since a malware file could have million of bytes to process.
Data Sources: **it's rare for researchers to find high-quality data** to train algorithms with. Companies may share their data with a few partners, but not everyone.
| |
| --- |
| Aside box: problems with different data sources ([Source](https://arxiv.org/abs/2010.09470))* Crowdsourced malware files are hard to trust. Researchers can't run tens of thousands of malware files to check if they get hacked as expected.
* Researchers often combine malware from different sources. This makes it hard for AI algorithms to learn what malware code looks like. Oversimplified analogy - if an AI algorithm trains with malicious mobile apps from Chinese and U.S. app stores, the algorithm would have to analyse app text in two languages.
* (Tens of thousands of) examples of regular software files are hard to find. They're needed to show AI algorithms which files not to detect.
|
Computational Needs: some AI algorithms train for weeks on expensive hardware specially made for AI algorithms. Other algorithms could train in seconds on a regular laptop. Unfortunately, these methods aren't always compared on the same task. So, it's unclear if more expensive technology brings extra performance. ([Source](https://arxiv.org/abs/2010.09470))
Overall, this creates little research for securing simple devices. Examples include smart motion detectors, temperature sensors, medical monitors, etc. Yet, these devices are increasingly common in essential industries. ([Source](https://doi.org/10.3389/fbioe.2019.00063))
Some researchers are trying simple techniques to fix this gap. Here are two case studies that take **inspiration from our immune systems and image processing techniques**.
### Case Study 1: Repurposing Image Processing ([Source](https://arxiv.org/pdf/2205.03850.pdf))
For a programmer, a zero-thought way to analyse a malware file might be a neural network. Oversimplified, this algorithm would receive bytes of the file, *create settings to process each byte*, and use the settings to decide if the file is malware. However, malware files with millions of bytes would need a lot of settings!
A variation of this algorithm can simplify these settings. Convolutional neural networks are algorithms often used for image processing. Their specialty is breaking an image into chunks and *reusing* the same settings to process every chunk.
This kind of reuse would be great across a file with millions of raw bytes. So what if we could **split a large malware file into many smaller chunks, reusing the same settings to analyse every chunk?**
This somewhat works, but it has issues. Specifically, files are one-dimensional code sequences, not a two-dimensional 'chunk' of numbers.
* Converting 1D to 2D means raw bytes that were once right next to each other are now on different rows of the image.
* Also, how exactly do we choose the dimensions of the 2D chunks? Should they be 2 x 2 or 4 x 4 or 8 x 2 or ...?
Some researchers got around these issues by just using **one dimensional convolutional neural networks**. The key idea is still to break up a large sequence of bytes into smaller chunks. But one dimensional chunks in a row instead of two dimensional chunks in a square.
All this resulted in **10x fewer settings than even the most efficient AI models. And 30x faster training times than comparable cybersecurity algorithms.**
### Case Study 2: Artificial Immune Systems
The last algorithm is efficient enough to run on mobile phones. But it still struggles with small devices like smart temperature sensors. The key problem is that neural networks need new computations to analyse every file.
The opposite approach is to **run all computations needed for a malware detection algorithm ahead of time. And then save the results**.Thus, only storage space is used, not processing power.
One algorithm that does this is an artificial immune system. It copies our bodies' immune systems. Specifically, our immune systems store tools called antibodies to spot harmful microorganisms later. But the artificial version stores a specific pattern (signature) from malware files to match against new files. ([Source](https://v))
Still, the signature can't be like past algorithms that simply stored some bytes. These bytes vary a lot between malware files, making the signatures unhelpful for detecting new malware. So **artificial immune systems model the way that antibodies evolve to generate signatures.** These signatures match more kinds of malware.
First, here are the *steps to set up* the algorithm: ([Source](https://v))
1. Choose data to analyse from malware files. For example, raw bytes, common instructions in the file, which permissions a file needs (ex: for a mobile phone app), any text in the file, etc.
2. Temporarily initialise some random signatures ('antibodies'). These are going to be plain old numbers. But the numbers may have meaning that matches the examples above.
Next, here are the *steps repeated* while the algorithm is running: ([Source](https://v))
1. Compare the similarity of malware file data with current signatures. For programmers, this is done with mathematical functions like the dot product, cosine similarity, or Euclidean distance.
2. All current signatures are modified randomly. But the least similar ones to malware file data are modified the most. This is like genetic mutation; the least important genes are the most changeable.
3. The least similar signatures to malware file data are deleted. This is like the evolutionary survival of the fittest.
Repeating those steps eventually makes signatures that resemble malware file data. We can then save these signatures on small devices. They can compare the data from any incoming file against these signatures. If the similarity is high enough, they filter those files as malware.
Using a slightly more complex variation, some researchers **detected 99 out of a 100 malware samples for small devices**. ([Source](https://ieeexplore.ieee.org/abstract/document/9484483?casa_token=LXuQ1vARBWgAAAAA:X_wesZUI7ec6-xuWgFOSCTAE6TxPXVFeBKO-7ZfNj4579nKoRB4c_XRhw73d3suCAozeGc-AmA)).
---
Unsolved Problems
=================
Having discussed recent advances in the field, where is improvement needed? I see two categories: **technical improvements to algorithms and meta improvements to research**.
P.S. This section is largely based on my personal opinions after about 100 hours of researching this topic.
### Technical
The above case studies showed how malware detection algorithms are getting more efficient. Unfortunately, hackers can still change malware to get around detection systems. In technical terms, this is called creating 'adversarial examples.'
Two factors make adversarial examples in malware detection more challenging than in other AI applications.
1. **Hackers are willing and able to adjust malware very rapidly. M**illions of hackers globally try to trick malware detection algorithms for a living. In contrast, very few people trick common AI algorithms like language models or image processing algorithms for a living.
2. **Malware can be changed in more possible ways than most other data**. Software often has millions to billions of bytes of data to modify. In contrast, images and text can have as few as thousands of data points to modify.
1. Also, it's harder for humans to check for suspicious software compared to suspicious images or text. Thus, it's easier to create adversarial examples for malware than other data used in AI algorithms.
AI algorithms can continuously train to detect new malware examples. Still, this is reactive not proactive. Especially if hackers use AI algorithms to generate malware, new malware will spread faster and faster. Thus, a proactive solution is preferable.
Potential next steps for this are to **proactively modify malware examples to simulate what hackers might do**. These simulated examples could train AI algorithms proactively. Though this strategy is [already researched](https://cybersecurity.springeropen.com/articles/10.1186/s42400-021-00102-9), it has **risky side effects**. Hackers could use these algorithms to modify their own malware .
Overall, more research is needed to keep malware detection algorithms working after hackers change their techniques (ideally, with few side risks).
A secondary problem is ensuring that malware detection algorithms are secured against 'backdoors.' ([Source](https://arxiv.org/abs/2010.09470)) Backdoors cause an algorithm to behave unexpectedly when given very specific inputs. Still, this is a secondary problem. It's currently **much easier for hackers to bypass malware detection algorithms by updating malware than creating backdoors**. (This is because the hackers would have to influence the training process of a malware detection algorithm to create a back door, not just send it new input.)
### Meta
In addition to the technical points noted above, there are also more general research practices that would help this field. The most important practices are noted in [this paper](https://arxiv.org/abs/2010.09470).
First, **more researchers need to compare state of the art algorithms with simple algorithms**. This will help determine if the complex models are 'worth it' due to extra performance. For instance, the complicated neural network in the first case study could be compared to [human-made checklists](https://en.wikipedia.org/wiki/YARA) on clues about malware.
Next, research papers need **more transparent reports of how data were handled**.
* It's notoriously difficult to train malware detection algorithms on datasets which resemble the files they would analyse in real life.
+ This is because in real life, someone may install hundreds of normal software files and only one malware file. This "imbalance" makes it difficult for AI algorithms to get enough examples of both regular and malicious software.
* Researchers use many methods to get around this problem. However, they can create problems which need to be reported in research papers.
+ As one example, if researchers mix "malware" files from a crowdsourced website with malware files verified by a company - the first dataset might include files that shouldn't be there. Researchers should note that they mixed datasets so any resulting problems can be analysed.
Finally, **research on malware detection should report a standard set of evaluation metrics:** accuracy, precision, recall, ROC curves, AUC, and the count of data points in various classes.
* Without too many details, these metrics suit tasks with the "imbalance" of malware files vs. regular software.
* Ex: Imagine there are 100 files, 99 of which are regular software and one of which is malware. A "malware detector" that simply says every file is safe will be right 99% of the time. Though, it'll also be useless 100% of the time. Ensuring those the metrics above are reported avoids this being missed.
### Closing Remarks
Overall, AI-enabled malware detection is an impactful problem that could be called "the ultimate robustness challenge." Personally, I expect the techniques developed in this field will help the general AI safety field to progress.
As outlined above, however, the field is still crippled by the challenge of keeping algorithms effective even as hackers actively work against them. A lot of interesting work remains to be done to fix this. So I hope that the explanations and citations above will help more minds to work on this. If you have any questions or feedback on my writing, please feel free to comment and I will happily explain my reasoning in more depth :-) |
5175e659-815c-4f91-b80d-b08e5aa7804c | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Existential risk x Crypto: An unconference at Zuzalu
Dear Effective Altruists,
I am excited to announce an unconference-styled event on the intersection of existential risks and crypto/Web3. The event will take place on May 4-6, 2023 at Vitalik's new pop-up city experiment called [Zuzalu](https://zuzalu.org).
The intersection between existential risks and Web3 is under-explored and presents an exciting opportunity for collaboration and innovation. There is significant overlap in the thinking of both communities, and we believe that by bringing them together, we can leverage the power of Web3 technologies to help mitigate existential risks facing humanity.
The goal of the co-created event is to enable a space for collaboration between those two fields. The event will feature a variety of sessions, including talks, panels, workshops, and interactive sessions. Sessions will focus mainly on AI alignment, safety, and risks, while also touching on other X-risks partly. You can see some of the already confirmed speakers and the preliminary schedule on our [event website](https://aixzuzalu.splashthat.com/). Among many interesting sessions that are being planned, we will also explore the need and importance of decentralizing the EA movement.
We invite all effective altruists who are passionate about mitigating existential risks and exploring the potential of Web3 technology to [apply](https://docs.google.com/forms/d/e/1FAIpQLSfcpfpY4D4_iYIlXzUFFXLfbY9zcQ3k2oLeLyi2rgEhGMcQwQ/viewform) to take part in this conversation. I believe that by working together, we can make a real difference in the world and create a more resilient future for humanity.
The conference will take place in Montenegro. We hope to see you there :) |
993e645f-7ecd-4fa7-9734-fff926917be0 | trentmkelly/LessWrong-43k | LessWrong | Quantified Risks of Gay Male Sex
If you are a gay male then you’ve probably worried at one point about sexually transmitted diseases. Indeed men who have sex with men have some of the highest prevalence of many of these diseases. And if you’re not a gay male, you’ve probably still thought about STDs at one point. But how much should you worry? There are many organizations and resources that will tell you to wear a condom, but very few will tell you the relative risks of wearing a condom vs not. I’d like to provide a concise summary of the risks associated with gay male sex and the extent to which these risks can be reduced. (See Mark Manson’s guide for a similar resources for heterosexual sex.). I will do so by first giving some information about each disease, including its prevalence among gay men. Most of this data will come from the US, but the US actually has an unusually high prevalence for many diseases. Certainly HIV is much less common in many parts of Europe. I will end with a case study of HIV, which will include an analysis of the probabilities of transmission broken down by the nature of sex act and a discussion of risk reduction techniques.
When dealing with risks associated with sex, there are few relevant parameters. The most common is the prevalence – the proportion of people in the population that have the disease. Since you can only get a disease from someone who has it, the prevalence is arguably the most important statistic. There are two more relevant statistics – the per act infectivity (the chance of contracting the disease after having sex once) and the per partner infectivity (the chance of contracting the disease after having sex with one partner for the duration of the relationship). As it turns out the latter two probabilities are very difficult to calculate. I only obtained those values for for HIV. It is especially difficult to determine per act risks for specific types of sex acts since many MSM engage in a variety of acts with multiple partners. Nevertheless estimat |
8bf9d6b9-7ba2-49bb-957f-b4f62d28b036 | trentmkelly/LessWrong-43k | LessWrong | Probability of AI-Caused Disaster
This post presents a summary and comparison of predictions from Manifold and Metaculus to investigate how likely AI-caused disasters are, with focus on potential severity. I will explore the probability of specific incidents—like IP theft or rogue AI incidents—in a future post.
This will be a recurring reminder:
1. Check the most resent probability estimates in the embedded web pages, instead of looking at my At The Time Of Writing (ATTOW) numbers.
2. If you know of a market that I have missed, or if there is a question you think is relevant but is missing from this analysis, please mention it in a comment or message me! This is a linkpost, and I prefer if you comment on the original post on my blog, Forecasting AI Futures, but feel free to comment here as well.
3. Please go to the forecasting platform mentioned in the post and make your own predictions!
Without further delay, we shall begin investigating the probability of AI disasters, from smaller disasters to full-scale catastrophes.
Disasters, from small to large
The smallest severity of disasters considered in this post concerns incidents resulting in $1b of losses or 100 lost lives. These are Manifold’s probability estimates for such a disaster:
According to the resolution criteria, this resolves to Yes if “AI actions are directly causing an incident, accident or catastrophe resulting in $1 billion of damages. If the event causes loss of life, each death counts as $10 million of damages.” Also, only direct damage count for this question. Reputation damage causing a decrease in stock value does for example not count. Additionally, the AI is required to be “sufficiently advanced” and a “narrow-purpose ML model”, as judged by the question creator.
The AI also needs to be involved in the decisions leading to the disaster. Simply helping a human to, for instance, develop new weapons while not being involved in the decision making would not count.
There are similar questions on Metaculus, asking specifi |
1311df1a-13d8-4348-b9d1-7d8d1d24b749 | LDJnr/LessWrong-Amplify-Instruct | LessWrong | "What is true is already so. Owning up to it doesn’t make it worse. Not being open about it doesn’t make it go away. And because it’s true, it is what is there to be interacted with. Anything untrue isn’t there to be lived. People can stand what is true, for they are already enduring it. —Eugene Gendlin"
What you see above is a segment from a LessWrong user's post.
Can you break this down into the top 5 most important points for me.
1. Truth is Immutable: The statement begins with the assertion that truth is a constant; it exists independently of our acceptance or rejection of it. This highlights the objective nature of truth.
2. Denial Doesn't Alter Truth: The author suggests that avoiding or not acknowledging the truth doesn't change its existence. This point emphasizes the futility of denial in the face of facts.
3. Truth is the Basis for Interaction: Since truth represents what is real and existent, it forms the basis for our interactions and experiences. This underlines the importance of truth in shaping our understanding of the world.
4. Untruths Lack Substance: Anything that isn't true lacks substance and isn't a part of our lived experience. This point contrasts the substantial nature of truth with the insubstantial nature of falsehoods.
5. Endurance of Truth: The final point is that people are capable of enduring the truth, as they are already living it, even if unknowingly. This suggests that acceptance of truth, no matter how harsh, is a part of human resilience.
Could you elaborate on the concept of "endurance of truth"? How does this acceptance of truth, no matter how harsh, manifest in human behavior and resilience?
The "endurance of truth" is the concept that people, knowingly or unknowingly, live with the reality of their circumstances every day. This is a testament to human resilience, as it implies that we are capable of handling the truth, no matter how harsh or uncomfortable it may be.
In terms of human behavior, this acceptance can manifest in several ways. It can be seen in the process of grief, where acceptance is the final stage after denial, anger, bargaining, and depression. Here, the truth is the loss of a loved one, and acceptance is the recognition of this reality and the decision to move forward.
In a broader societal context, it can be seen in the way societies adapt to large-scale changes or disasters. For example, in the face of a natural disaster, people may initially deny the severity of the situation. However, as the reality becomes undeniable, they adapt, demonstrating resilience by rebuilding and creating new strategies to survive and thrive.
In the realm of personal growth, the acceptance of truth can be a powerful catalyst for change. Recognizing one's own shortcomings or the reality of a harmful situation can lead to transformative actions, such as seeking help, making lifestyle changes, or leaving a toxic environment.
Overall, the endurance of truth underscores the human capacity to not only survive in the face of reality but also to adapt, grow, and find resilience within it.
How might the concept of "endurance of truth" influence decision-making processes in various professional fields, such as law, psychology, and business?
In Law: The "endurance of truth" can significantly influence decision-making in the legal field. Lawyers and judges often have to face harsh realities about cases and clients. Recognizing and accepting these truths can lead to more effective strategies, whether it's building a case for defense or prosecution, or making a ruling that upholds justice. For instance, a defense attorney must accept the truth of their client's actions to construct a realistic and effective defense strategy.
In Psychology: Psychologists often work with individuals who are struggling to accept their personal truths. The concept of "endurance of truth" can guide therapeutic techniques to help patients confront and accept these truths, which can be crucial for their healing and growth. For example, in cognitive-behavioral therapy, psychologists help patients identify and challenge distorted thinking patterns, leading them towards a more accurate understanding of their reality.
In Business: In the business world, leaders and managers must often face uncomfortable truths about their company's performance, market realities, or employee satisfaction. Accepting these truths can guide strategic decision-making, leading to necessary changes or innovations. A business leader might need to accept the truth that a product is not performing well in the market, leading to decisions to either improve the product or invest resources elsewhere.
In each of these fields, the "endurance of truth" underscores the importance of facing reality, however harsh, to make informed and effective decisions. |
0bfeca4e-1571-4c47-8ad9-bfbea2684fae | trentmkelly/LessWrong-43k | LessWrong | Omicron Post #15
Omicron has fully taken over, and our uncertainty about it has mostly been resolved. The Omicron pandemic is now the Covid-19 pandemic, and we’re back in a kind of ‘normal mode’ albeit at the top of the Omicron wave.
A few weeks ago, the majority of the information and week’s discussion were in the Omicron posts. This week, the vast majority are in the normal weekly post, there’s only one pure Omicron post (although the Polymarket post was closely related) and it’s relatively short.
Going forward, after this week, my default plan is to incorporate the Omicron news and the Omicron-related predictions into the mainline weekly posts, and supplement with issue-specific posts rather than general Omicron updates.
If things continue to go well, I hope to use the resulting bandwidth to start doing less speed premium writing, and more longer term analysis, both on Covid and otherwise. There’s a lot I simply haven’t had the time to think about let alone write out properly.
Remember, this is a happy moment. We are no longer in (as much of) an emergency.
Severity
Thread updating what we know about severity of Omicron. Less severe in adults, less loss of taste and smell, mostly this is confirmation of the usual good news.
The issue of severity in children is less clear because Covid-19 is so non-severe in children it’s hard to tell the relative change.
All we know is there’s a lot more cases, and a lot more cases means a lot more child cases, and a lot more ‘with Covid’ cases means proportionally more child cases, and none of that is particular reason to doubt that the severity effect in children is different from that in adults, but we don’t know for sure because we lack the data, which results in for example the UK’s report saying about severity in children we have ‘low confidence.’ I agree that we are less confident here, but our baseline should mostly be that it roughly matches the adult changes, rather than a baseline of no change from Delta. But even if there is no |
d3f53dde-c64f-4677-b377-84097a0e5010 | trentmkelly/LessWrong-43k | LessWrong | Do uncertainty/planning costs make convex hulls unrealistic?
It's almost a rule that as soon as you have a "utility of possible outcomes" plot like this:
You must then say "and by randomly choosing between the outcomes, we can achieve any intermediate outcome in terms of utility within the convex hull of these points" resulting in a plot like this:
Cool, I've done a linear interpolation before, seems reasonable. Plus, convex hulls are super nice to work with. But all models are imperfect - how accurate is this convex hull idea in practice?
Three stories
* I like to plan ahead, whereas my friend values chaos and unpredictability. When we want to go to a restaurant, they're a big fan of the whole "lottery between your first preference and my first preference" idea.
* If we're meeting at 7PM and the lottery happens at 7AM that's long enough to plan, so I don't mind.
* If we're meeting at 7PM and the lottery happens at 6:59PM, I am a little annoyed - I might even prefer my guaranteed second preference over my uncertain first preference.
* The "standard model" for what the outcome space looks like before picking p=P(my preference) is something like this:
*
* I'm a CEO managing a business undergoing a possible merger. The more uncertain the deal is, the more all of my projects are disrupted. I might be fine walking into the final meeting with a 99% or 1% chance of success, but I would be quite stressed if the numbers were 90% or 10%.
* I'm a computer, beep boop. I've been modelling deterministic systems all day long. Someone has just asked me to model something probabilistic, and now I need to learn around 70 years of research to not be overwhelmed by the state space explosion.
My point is that in practice the mapping from lottery probability p and outcome utilities U1,U2 to lottery utility Up is probably not Up=pU1+(1−p)U2. I wonder if it's occasionally not even close. I would expect the "lottery closure" of the three outcomes above to look something like this:
I'm pretty darn sure I'm not the first person to |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.