
repo_id
stringlengths 15
89
| file_path
stringlengths 27
180
| content
stringlengths 1
2.23M
| __index_level_0__
int64 0
0
|
|---|---|---|---|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/tvlt.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# TVLT
## Overview
The TVLT model was proposed in [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156)
by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal (the first three authors contributed equally). The Textless Vision-Language Transformer (TVLT) is a model that uses raw visual and audio inputs for vision-and-language representation learning, without using text-specific modules such as tokenization or automatic speech recognition (ASR). It can perform various audiovisual and vision-language tasks like retrieval, question answering, etc.
The abstract from the paper is the following:
*In this work, we present the Textless Vision-Language Transformer (TVLT), where homogeneous transformer blocks take raw visual and audio inputs for vision-and-language representation learning with minimal modality-specific design, and do not use text-specific modules such as tokenization or automatic speech recognition (ASR). TVLT is trained by reconstructing masked patches of continuous video frames and audio spectrograms (masked autoencoding) and contrastive modeling to align video and audio. TVLT attains performance comparable to its text-based counterpart on various multimodal tasks, such as visual question answering, image retrieval, video retrieval, and multimodal sentiment analysis, with 28x faster inference speed and only 1/3 of the parameters. Our findings suggest the possibility of learning compact and efficient visual-linguistic representations from low-level visual and audio signals without assuming the prior existence of text.*
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/tvlt_architecture.png"
alt="drawing" width="600"/>
</p>
<small> TVLT architecture. Taken from the <a href="[https://arxiv.org/abs/2102.03334](https://arxiv.org/abs/2209.14156)">original paper</a>. </small>
The original code can be found [here](https://github.com/zinengtang/TVLT). This model was contributed by [Zineng Tang](https://huggingface.co/ZinengTang).
## Usage tips
- TVLT is a model that takes both `pixel_values` and `audio_values` as input. One can use [`TvltProcessor`] to prepare data for the model.
This processor wraps an image processor (for the image/video modality) and an audio feature extractor (for the audio modality) into one.
- TVLT is trained with images/videos and audios of various sizes: the authors resize and crop the input images/videos to 224 and limit the length of audio spectrogram to 2048. To make batching of videos and audios possible, the authors use a `pixel_mask` that indicates which pixels are real/padding and `audio_mask` that indicates which audio values are real/padding.
- The design of TVLT is very similar to that of a standard Vision Transformer (ViT) and masked autoencoder (MAE) as in [ViTMAE](vitmae). The difference is that the model includes embedding layers for the audio modality.
- The PyTorch version of this model is only available in torch 1.10 and higher.
## TvltConfig
[[autodoc]] TvltConfig
## TvltProcessor
[[autodoc]] TvltProcessor
- __call__
## TvltImageProcessor
[[autodoc]] TvltImageProcessor
- preprocess
## TvltFeatureExtractor
[[autodoc]] TvltFeatureExtractor
- __call__
## TvltModel
[[autodoc]] TvltModel
- forward
## TvltForPreTraining
[[autodoc]] TvltForPreTraining
- forward
## TvltForAudioVisualClassification
[[autodoc]] TvltForAudioVisualClassification
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/xlsr_wav2vec2.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLSR-Wav2Vec2
## Overview
The XLSR-Wav2Vec2 model was proposed in [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael
Auli.
The abstract from the paper is the following:
*This paper presents XLSR which learns cross-lingual speech representations by pretraining a single model from the raw
waveform of speech in multiple languages. We build on wav2vec 2.0 which is trained by solving a contrastive task over
masked latent speech representations and jointly learns a quantization of the latents shared across languages. The
resulting model is fine-tuned on labeled data and experiments show that cross-lingual pretraining significantly
outperforms monolingual pretraining. On the CommonVoice benchmark, XLSR shows a relative phoneme error rate reduction
of 72% compared to the best known results. On BABEL, our approach improves word error rate by 16% relative compared to
a comparable system. Our approach enables a single multilingual speech recognition model which is competitive to strong
individual models. Analysis shows that the latent discrete speech representations are shared across languages with
increased sharing for related languages. We hope to catalyze research in low-resource speech understanding by releasing
XLSR-53, a large model pretrained in 53 languages.*
The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
## Usage tips
- XLSR-Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- XLSR-Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2CTCTokenizer`].
<Tip>
XLSR-Wav2Vec2's architecture is based on the Wav2Vec2 model, so one can refer to [Wav2Vec2's documentation page](wav2vec2).
</Tip>
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/xlnet.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLNet
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=xlnet">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-xlnet-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/xlnet-base-cased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The XLNet model was proposed in [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov,
Quoc V. Le. XLnet is an extension of the Transformer-XL model pre-trained using an autoregressive method to learn
bidirectional contexts by maximizing the expected likelihood over all permutations of the input sequence factorization
order.
The abstract from the paper is the following:
*With the capability of modeling bidirectional contexts, denoising autoencoding based pretraining like BERT achieves
better performance than pretraining approaches based on autoregressive language modeling. However, relying on
corrupting the input with masks, BERT neglects dependency between the masked positions and suffers from a
pretrain-finetune discrepancy. In light of these pros and cons, we propose XLNet, a generalized autoregressive
pretraining method that (1) enables learning bidirectional contexts by maximizing the expected likelihood over all
permutations of the factorization order and (2) overcomes the limitations of BERT thanks to its autoregressive
formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-of-the-art autoregressive model, into
pretraining. Empirically, under comparable experiment settings, XLNet outperforms BERT on 20 tasks, often by a large
margin, including question answering, natural language inference, sentiment analysis, and document ranking.*
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/zihangdai/xlnet/).
## Usage tips
- The specific attention pattern can be controlled at training and test time using the `perm_mask` input.
- Due to the difficulty of training a fully auto-regressive model over various factorization order, XLNet is pretrained
using only a sub-set of the output tokens as target which are selected with the `target_mapping` input.
- To use XLNet for sequential decoding (i.e. not in fully bi-directional setting), use the `perm_mask` and
`target_mapping` inputs to control the attention span and outputs (see examples in
*examples/pytorch/text-generation/run_generation.py*)
- XLNet is one of the few models that has no sequence length limit.
- XLNet is not a traditional autoregressive model but uses a training strategy that builds on that. It permutes the tokens in the sentence, then allows the model to use the last n tokens to predict the token n+1. Since this is all done with a mask, the sentence is actually fed in the model in the right order, but instead of masking the first n tokens for n+1, XLNet uses a mask that hides the previous tokens in some given permutation of 1,…,sequence length.
- XLNet also uses the same recurrence mechanism as Transformer-XL to build long-term dependencies.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## XLNetConfig
[[autodoc]] XLNetConfig
## XLNetTokenizer
[[autodoc]] XLNetTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## XLNetTokenizerFast
[[autodoc]] XLNetTokenizerFast
## XLNet specific outputs
[[autodoc]] models.xlnet.modeling_xlnet.XLNetModelOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetLMHeadModelOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForSequenceClassificationOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForMultipleChoiceOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForTokenClassificationOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForQuestionAnsweringSimpleOutput
[[autodoc]] models.xlnet.modeling_xlnet.XLNetForQuestionAnsweringOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetModelOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetLMHeadModelOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForSequenceClassificationOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForMultipleChoiceOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForTokenClassificationOutput
[[autodoc]] models.xlnet.modeling_tf_xlnet.TFXLNetForQuestionAnsweringSimpleOutput
<frameworkcontent>
<pt>
## XLNetModel
[[autodoc]] XLNetModel
- forward
## XLNetLMHeadModel
[[autodoc]] XLNetLMHeadModel
- forward
## XLNetForSequenceClassification
[[autodoc]] XLNetForSequenceClassification
- forward
## XLNetForMultipleChoice
[[autodoc]] XLNetForMultipleChoice
- forward
## XLNetForTokenClassification
[[autodoc]] XLNetForTokenClassification
- forward
## XLNetForQuestionAnsweringSimple
[[autodoc]] XLNetForQuestionAnsweringSimple
- forward
## XLNetForQuestionAnswering
[[autodoc]] XLNetForQuestionAnswering
- forward
</pt>
<tf>
## TFXLNetModel
[[autodoc]] TFXLNetModel
- call
## TFXLNetLMHeadModel
[[autodoc]] TFXLNetLMHeadModel
- call
## TFXLNetForSequenceClassification
[[autodoc]] TFXLNetForSequenceClassification
- call
## TFLNetForMultipleChoice
[[autodoc]] TFXLNetForMultipleChoice
- call
## TFXLNetForTokenClassification
[[autodoc]] TFXLNetForTokenClassification
- call
## TFXLNetForQuestionAnsweringSimple
[[autodoc]] TFXLNetForQuestionAnsweringSimple
- call
</tf>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/conditional_detr.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Conditional DETR
## Overview
The Conditional DETR model was proposed in [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang. Conditional DETR presents a conditional cross-attention mechanism for fast DETR training. Conditional DETR converges 6.7× to 10× faster than DETR.
The abstract from the paper is the following:
*The recently-developed DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings for localizing the four extremities and predicting the box, which increases the need for high-quality content embeddings and thus the training difficulty. Our approach, named conditional DETR, learns a conditional spatial query from the decoder embedding for decoder multi-head cross-attention. The benefit is that through the conditional spatial query, each cross-attention head is able to attend to a band containing a distinct region, e.g., one object extremity or a region inside the object box. This narrows down the spatial range for localizing the distinct regions for object classification and box regression, thus relaxing the dependence on the content embeddings and easing the training. Empirical results show that conditional DETR converges 6.7× faster for the backbones R50 and R101 and 10× faster for stronger backbones DC5-R50 and DC5-R101. Code is available at https://github.com/Atten4Vis/ConditionalDETR.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/conditional_detr_curve.jpg"
alt="drawing" width="600"/>
<small> Conditional DETR shows much faster convergence compared to the original DETR. Taken from the <a href="https://arxiv.org/abs/2108.06152">original paper</a>.</small>
This model was contributed by [DepuMeng](https://huggingface.co/DepuMeng). The original code can be found [here](https://github.com/Atten4Vis/ConditionalDETR).
## Resources
- [Object detection task guide](../tasks/object_detection)
## ConditionalDetrConfig
[[autodoc]] ConditionalDetrConfig
## ConditionalDetrImageProcessor
[[autodoc]] ConditionalDetrImageProcessor
- preprocess
- post_process_object_detection
- post_process_instance_segmentation
- post_process_semantic_segmentation
- post_process_panoptic_segmentation
## ConditionalDetrFeatureExtractor
[[autodoc]] ConditionalDetrFeatureExtractor
- __call__
- post_process_object_detection
- post_process_instance_segmentation
- post_process_semantic_segmentation
- post_process_panoptic_segmentation
## ConditionalDetrModel
[[autodoc]] ConditionalDetrModel
- forward
## ConditionalDetrForObjectDetection
[[autodoc]] ConditionalDetrForObjectDetection
- forward
## ConditionalDetrForSegmentation
[[autodoc]] ConditionalDetrForSegmentation
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/mbart.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MBart and MBart-50
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=mbart">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-mbart-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/mbart-large-50-one-to-many-mmt">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview of MBart
The MBart model was presented in [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov Marjan
Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
According to the abstract, MBART is a sequence-to-sequence denoising auto-encoder pretrained on large-scale monolingual
corpora in many languages using the BART objective. mBART is one of the first methods for pretraining a complete
sequence-to-sequence model by denoising full texts in multiple languages, while previous approaches have focused only
on the encoder, decoder, or reconstructing parts of the text.
This model was contributed by [valhalla](https://huggingface.co/valhalla). The Authors' code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/mbart)
### Training of MBart
MBart is a multilingual encoder-decoder (sequence-to-sequence) model primarily intended for translation task. As the
model is multilingual it expects the sequences in a different format. A special language id token is added in both the
source and target text. The source text format is `X [eos, src_lang_code]` where `X` is the source text. The
target text format is `[tgt_lang_code] X [eos]`. `bos` is never used.
The regular [`~MBartTokenizer.__call__`] will encode source text format passed as first argument or with the `text`
keyword, and target text format passed with the `text_label` keyword argument.
- Supervised training
```python
>>> from transformers import MBartForConditionalGeneration, MBartTokenizer
>>> tokenizer = MBartTokenizer.from_pretrained("facebook/mbart-large-en-ro", src_lang="en_XX", tgt_lang="ro_RO")
>>> example_english_phrase = "UN Chief Says There Is No Military Solution in Syria"
>>> expected_translation_romanian = "Şeful ONU declară că nu există o soluţie militară în Siria"
>>> inputs = tokenizer(example_english_phrase, text_target=expected_translation_romanian, return_tensors="pt")
>>> model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-en-ro")
>>> # forward pass
>>> model(**inputs)
```
- Generation
While generating the target text set the `decoder_start_token_id` to the target language id. The following
example shows how to translate English to Romanian using the *facebook/mbart-large-en-ro* model.
```python
>>> from transformers import MBartForConditionalGeneration, MBartTokenizer
>>> tokenizer = MBartTokenizer.from_pretrained("facebook/mbart-large-en-ro", src_lang="en_XX")
>>> article = "UN Chief Says There Is No Military Solution in Syria"
>>> inputs = tokenizer(article, return_tensors="pt")
>>> translated_tokens = model.generate(**inputs, decoder_start_token_id=tokenizer.lang_code_to_id["ro_RO"])
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
"Şeful ONU declară că nu există o soluţie militară în Siria"
```
## Overview of MBart-50
MBart-50 was introduced in the [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) paper by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav
Chaudhary, Jiatao Gu, Angela Fan. MBart-50 is created using the original *mbart-large-cc25* checkpoint by extendeding
its embedding layers with randomly initialized vectors for an extra set of 25 language tokens and then pretrained on 50
languages.
According to the abstract
*Multilingual translation models can be created through multilingual finetuning. Instead of finetuning on one
direction, a pretrained model is finetuned on many directions at the same time. It demonstrates that pretrained models
can be extended to incorporate additional languages without loss of performance. Multilingual finetuning improves on
average 1 BLEU over the strongest baselines (being either multilingual from scratch or bilingual finetuning) while
improving 9.3 BLEU on average over bilingual baselines from scratch.*
### Training of MBart-50
The text format for MBart-50 is slightly different from mBART. For MBart-50 the language id token is used as a prefix
for both source and target text i.e the text format is `[lang_code] X [eos]`, where `lang_code` is source
language id for source text and target language id for target text, with `X` being the source or target text
respectively.
MBart-50 has its own tokenizer [`MBart50Tokenizer`].
- Supervised training
```python
from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50")
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50", src_lang="en_XX", tgt_lang="ro_RO")
src_text = " UN Chief Says There Is No Military Solution in Syria"
tgt_text = "Şeful ONU declară că nu există o soluţie militară în Siria"
model_inputs = tokenizer(src_text, text_target=tgt_text, return_tensors="pt")
model(**model_inputs) # forward pass
```
- Generation
To generate using the mBART-50 multilingual translation models, `eos_token_id` is used as the
`decoder_start_token_id` and the target language id is forced as the first generated token. To force the
target language id as the first generated token, pass the *forced_bos_token_id* parameter to the *generate* method.
The following example shows how to translate between Hindi to French and Arabic to English using the
*facebook/mbart-50-large-many-to-many* checkpoint.
```python
from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
article_hi = "संयुक्त राष्ट्र के प्रमुख का कहना है कि सीरिया में कोई सैन्य समाधान नहीं है"
article_ar = "الأمين العام للأمم المتحدة يقول إنه لا يوجد حل عسكري في سوريا."
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
# translate Hindi to French
tokenizer.src_lang = "hi_IN"
encoded_hi = tokenizer(article_hi, return_tensors="pt")
generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.lang_code_to_id["fr_XX"])
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Le chef de l 'ONU affirme qu 'il n 'y a pas de solution militaire en Syria."
# translate Arabic to English
tokenizer.src_lang = "ar_AR"
encoded_ar = tokenizer(article_ar, return_tensors="pt")
generated_tokens = model.generate(**encoded_ar, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "The Secretary-General of the United Nations says there is no military solution in Syria."
```
## Documentation resources
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## MBartConfig
[[autodoc]] MBartConfig
## MBartTokenizer
[[autodoc]] MBartTokenizer
- build_inputs_with_special_tokens
## MBartTokenizerFast
[[autodoc]] MBartTokenizerFast
## MBart50Tokenizer
[[autodoc]] MBart50Tokenizer
## MBart50TokenizerFast
[[autodoc]] MBart50TokenizerFast
<frameworkcontent>
<pt>
## MBartModel
[[autodoc]] MBartModel
## MBartForConditionalGeneration
[[autodoc]] MBartForConditionalGeneration
## MBartForQuestionAnswering
[[autodoc]] MBartForQuestionAnswering
## MBartForSequenceClassification
[[autodoc]] MBartForSequenceClassification
## MBartForCausalLM
[[autodoc]] MBartForCausalLM
- forward
</pt>
<tf>
## TFMBartModel
[[autodoc]] TFMBartModel
- call
## TFMBartForConditionalGeneration
[[autodoc]] TFMBartForConditionalGeneration
- call
</tf>
<jax>
## FlaxMBartModel
[[autodoc]] FlaxMBartModel
- __call__
- encode
- decode
## FlaxMBartForConditionalGeneration
[[autodoc]] FlaxMBartForConditionalGeneration
- __call__
- encode
- decode
## FlaxMBartForSequenceClassification
[[autodoc]] FlaxMBartForSequenceClassification
- __call__
- encode
- decode
## FlaxMBartForQuestionAnswering
[[autodoc]] FlaxMBartForQuestionAnswering
- __call__
- encode
- decode
</jax>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/roberta.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# RoBERTa
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=roberta">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-roberta-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/roberta-base">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
<a href="https://huggingface.co/papers/1907.11692">
<img alt="Paper page" src="https://img.shields.io/badge/Paper%20page-1907.11692-green">
</a>
</div>
## Overview
The RoBERTa model was proposed in [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, [Myle Ott](https://huggingface.co/myleott), Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer
Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. It is based on Google's BERT model released in 2018.
It builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with
much larger mini-batches and learning rates.
The abstract from the paper is the following:
*Language model pretraining has led to significant performance gains but careful comparison between different
approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes,
and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication
study of BERT pretraining (Devlin et al., 2019) that carefully measures the impact of many key hyperparameters and
training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every
model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results
highlight the importance of previously overlooked design choices, and raise questions about the source of recently
reported improvements. We release our models and code.*
This model was contributed by [julien-c](https://huggingface.co/julien-c). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/roberta).
## Usage tips
- This implementation is the same as [`BertModel`] with a tiny embeddings tweak as well as a setup
for Roberta pretrained models.
- RoBERTa has the same architecture as BERT, but uses a byte-level BPE as a tokenizer (same as GPT-2) and uses a
different pretraining scheme.
- RoBERTa doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
separate your segments with the separation token `tokenizer.sep_token` (or `</s>`)
- Same as BERT with better pretraining tricks:
* dynamic masking: tokens are masked differently at each epoch, whereas BERT does it once and for all
* together to reach 512 tokens (so the sentences are in an order than may span several documents)
* train with larger batches
* use BPE with bytes as a subunit and not characters (because of unicode characters)
- [CamemBERT](camembert) is a wrapper around RoBERTa. Refer to this page for usage examples.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with RoBERTa. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A blog on [Getting Started with Sentiment Analysis on Twitter](https://huggingface.co/blog/sentiment-analysis-twitter) using RoBERTa and the [Inference API](https://huggingface.co/inference-api).
- A blog on [Opinion Classification with Kili and Hugging Face AutoTrain](https://huggingface.co/blog/opinion-classification-with-kili) using RoBERTa.
- A notebook on how to [finetune RoBERTa for sentiment analysis](https://colab.research.google.com/github/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb). 🌎
- [`RobertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
- [`TFRobertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
- [`FlaxRobertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification"/>
- [`RobertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb).
- [`TFRobertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
- [`FlaxRobertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification).
- [Token classification](https://huggingface.co/course/chapter7/2?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Token classification task guide](../tasks/token_classification)
<PipelineTag pipeline="fill-mask"/>
- A blog on [How to train a new language model from scratch using Transformers and Tokenizers](https://huggingface.co/blog/how-to-train) with RoBERTa.
- [`RobertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFRobertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxRobertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Masked language modeling task guide](../tasks/masked_language_modeling)
<PipelineTag pipeline="question-answering"/>
- A blog on [Accelerated Inference with Optimum and Transformers Pipelines](https://huggingface.co/blog/optimum-inference) with RoBERTa for question answering.
- [`RobertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
- [`TFRobertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
- [`FlaxRobertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering).
- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Question answering task guide](../tasks/question_answering)
**Multiple choice**
- [`RobertaForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb).
- [`TFRobertaForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
- [Multiple choice task guide](../tasks/multiple_choice)
## RobertaConfig
[[autodoc]] RobertaConfig
## RobertaTokenizer
[[autodoc]] RobertaTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## RobertaTokenizerFast
[[autodoc]] RobertaTokenizerFast
- build_inputs_with_special_tokens
<frameworkcontent>
<pt>
## RobertaModel
[[autodoc]] RobertaModel
- forward
## RobertaForCausalLM
[[autodoc]] RobertaForCausalLM
- forward
## RobertaForMaskedLM
[[autodoc]] RobertaForMaskedLM
- forward
## RobertaForSequenceClassification
[[autodoc]] RobertaForSequenceClassification
- forward
## RobertaForMultipleChoice
[[autodoc]] RobertaForMultipleChoice
- forward
## RobertaForTokenClassification
[[autodoc]] RobertaForTokenClassification
- forward
## RobertaForQuestionAnswering
[[autodoc]] RobertaForQuestionAnswering
- forward
</pt>
<tf>
## TFRobertaModel
[[autodoc]] TFRobertaModel
- call
## TFRobertaForCausalLM
[[autodoc]] TFRobertaForCausalLM
- call
## TFRobertaForMaskedLM
[[autodoc]] TFRobertaForMaskedLM
- call
## TFRobertaForSequenceClassification
[[autodoc]] TFRobertaForSequenceClassification
- call
## TFRobertaForMultipleChoice
[[autodoc]] TFRobertaForMultipleChoice
- call
## TFRobertaForTokenClassification
[[autodoc]] TFRobertaForTokenClassification
- call
## TFRobertaForQuestionAnswering
[[autodoc]] TFRobertaForQuestionAnswering
- call
</tf>
<jax>
## FlaxRobertaModel
[[autodoc]] FlaxRobertaModel
- __call__
## FlaxRobertaForCausalLM
[[autodoc]] FlaxRobertaForCausalLM
- __call__
## FlaxRobertaForMaskedLM
[[autodoc]] FlaxRobertaForMaskedLM
- __call__
## FlaxRobertaForSequenceClassification
[[autodoc]] FlaxRobertaForSequenceClassification
- __call__
## FlaxRobertaForMultipleChoice
[[autodoc]] FlaxRobertaForMultipleChoice
- __call__
## FlaxRobertaForTokenClassification
[[autodoc]] FlaxRobertaForTokenClassification
- __call__
## FlaxRobertaForQuestionAnswering
[[autodoc]] FlaxRobertaForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/van.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# VAN
<Tip warning={true}>
This model is in maintenance mode only, we don't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
</Tip>
## Overview
The VAN model was proposed in [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
This paper introduces a new attention layer based on convolution operations able to capture both local and distant relationships. This is done by combining normal and large kernel convolution layers. The latter uses a dilated convolution to capture distant correlations.
The abstract from the paper is the following:
*While originally designed for natural language processing tasks, the self-attention mechanism has recently taken various computer vision areas by storm. However, the 2D nature of images brings three challenges for applying self-attention in computer vision. (1) Treating images as 1D sequences neglects their 2D structures. (2) The quadratic complexity is too expensive for high-resolution images. (3) It only captures spatial adaptability but ignores channel adaptability. In this paper, we propose a novel large kernel attention (LKA) module to enable self-adaptive and long-range correlations in self-attention while avoiding the above issues. We further introduce a novel neural network based on LKA, namely Visual Attention Network (VAN). While extremely simple, VAN outperforms the state-of-the-art vision transformers and convolutional neural networks with a large margin in extensive experiments, including image classification, object detection, semantic segmentation, instance segmentation, etc. Code is available at [this https URL](https://github.com/Visual-Attention-Network/VAN-Classification).*
Tips:
- VAN does not have an embedding layer, thus the `hidden_states` will have a length equal to the number of stages.
The figure below illustrates the architecture of a Visual Aattention Layer. Taken from the [original paper](https://arxiv.org/abs/2202.09741).
<img width="600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/van_architecture.png"/>
This model was contributed by [Francesco](https://huggingface.co/Francesco). The original code can be found [here](https://github.com/Visual-Attention-Network/VAN-Classification).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with VAN.
<PipelineTag pipeline="image-classification"/>
- [`VanForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## VanConfig
[[autodoc]] VanConfig
## VanModel
[[autodoc]] VanModel
- forward
## VanForImageClassification
[[autodoc]] VanForImageClassification
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/t5v1.1.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# T5v1.1
## Overview
T5v1.1 was released in the [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511)
repository by Colin Raffel et al. It's an improved version of the original T5 model.
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
found [here](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511).
## Usage tips
One can directly plug in the weights of T5v1.1 into a T5 model, like so:
```python
>>> from transformers import T5ForConditionalGeneration
>>> model = T5ForConditionalGeneration.from_pretrained("google/t5-v1_1-base")
```
T5 Version 1.1 includes the following improvements compared to the original T5 model:
- GEGLU activation in the feed-forward hidden layer, rather than ReLU. See [this paper](https://arxiv.org/abs/2002.05202).
- Dropout was turned off in pre-training (quality win). Dropout should be re-enabled during fine-tuning.
- Pre-trained on C4 only without mixing in the downstream tasks.
- No parameter sharing between the embedding and classifier layer.
- "xl" and "xxl" replace "3B" and "11B". The model shapes are a bit different - larger `d_model` and smaller
`num_heads` and `d_ff`.
Note: T5 Version 1.1 was only pre-trained on [C4](https://huggingface.co/datasets/c4) excluding any supervised
training. Therefore, this model has to be fine-tuned before it is usable on a downstream task, unlike the original T5
model. Since t5v1.1 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
Google has released the following variants:
- [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small)
- [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base)
- [google/t5-v1_1-large](https://huggingface.co/google/t5-v1_1-large)
- [google/t5-v1_1-xl](https://huggingface.co/google/t5-v1_1-xl)
- [google/t5-v1_1-xxl](https://huggingface.co/google/t5-v1_1-xxl).
<Tip>
Refer to [T5's documentation page](t5) for all API reference, tips, code examples and notebooks.
</Tip>
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/gpt_bigcode.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# GPTBigCode
## Overview
The GPTBigCode model was proposed in [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by BigCode. The listed authors are: Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
The abstract from the paper is the following:
*The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at [this https URL.](https://huggingface.co/bigcode)*
The model is an optimized [GPT2 model](https://huggingface.co/docs/transformers/model_doc/gpt2) with support for Multi-Query Attention.
## Implementation details
The main differences compared to GPT2.
- Added support for Multi-Query Attention.
- Use `gelu_pytorch_tanh` instead of classic `gelu`.
- Avoid unnecessary synchronizations (this has since been added to GPT2 in #20061, but wasn't in the reference codebase).
- Use Linear layers instead of Conv1D (good speedup but makes the checkpoints incompatible).
- Merge `_attn` and `_upcast_and_reordered_attn`. Always merge the matmul with scaling. Rename `reorder_and_upcast_attn`->`attention_softmax_in_fp32`
- Cache the attention mask value to avoid recreating it every time.
- Use jit to fuse the attention fp32 casting, masking, softmax, and scaling.
- Combine the attention and causal masks into a single one, pre-computed for the whole model instead of every layer.
- Merge the key and value caches into one (this changes the format of layer_past/ present, does it risk creating problems?)
- Use the memory layout (self.num_heads, 3, self.head_dim) instead of `(3, self.num_heads, self.head_dim)` for the QKV tensor with MHA. (prevents an overhead with the merged key and values, but makes the checkpoints incompatible with the original gpt2 model).
You can read more about the optimizations in the [original pull request](https://github.com/huggingface/transformers/pull/22575)
## Combining Starcoder and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
```bash
pip install -U flash-attn --no-build-isolation
```
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("bigcode/gpt_bigcode-santacoder", torch_dtype=torch.float16, use_flash_attention_2=True)
>>> tokenizer = AutoTokenizer.from_pretrained("bigcode/gpt_bigcode-santacoder")
>>> prompt = "def hello_world():"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
>>> tokenizer.batch_decode(generated_ids)[0]
'def hello_world():\n print("hello world")\n\nif __name__ == "__main__":\n print("hello world")\n<|endoftext|>'
```
### Expected speedups
Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using `bigcode/starcoder` checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/starcoder-speedup.png">
</div>
## GPTBigCodeConfig
[[autodoc]] GPTBigCodeConfig
## GPTBigCodeModel
[[autodoc]] GPTBigCodeModel
- forward
## GPTBigCodeForCausalLM
[[autodoc]] GPTBigCodeForCausalLM
- forward
## GPTBigCodeForSequenceClassification
[[autodoc]] GPTBigCodeForSequenceClassification
- forward
## GPTBigCodeForTokenClassification
[[autodoc]] GPTBigCodeForTokenClassification
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/rembert.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# RemBERT
## Overview
The RemBERT model was proposed in [Rethinking Embedding Coupling in Pre-trained Language Models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, Melvin Johnson, Sebastian Ruder.
The abstract from the paper is the following:
*We re-evaluate the standard practice of sharing weights between input and output embeddings in state-of-the-art
pre-trained language models. We show that decoupled embeddings provide increased modeling flexibility, allowing us to
significantly improve the efficiency of parameter allocation in the input embedding of multilingual models. By
reallocating the input embedding parameters in the Transformer layers, we achieve dramatically better performance on
standard natural language understanding tasks with the same number of parameters during fine-tuning. We also show that
allocating additional capacity to the output embedding provides benefits to the model that persist through the
fine-tuning stage even though the output embedding is discarded after pre-training. Our analysis shows that larger
output embeddings prevent the model's last layers from overspecializing to the pre-training task and encourage
Transformer representations to be more general and more transferable to other tasks and languages. Harnessing these
findings, we are able to train models that achieve strong performance on the XTREME benchmark without increasing the
number of parameters at the fine-tuning stage.*
## Usage tips
For fine-tuning, RemBERT can be thought of as a bigger version of mBERT with an ALBERT-like factorization of the
embedding layer. The embeddings are not tied in pre-training, in contrast with BERT, which enables smaller input
embeddings (preserved during fine-tuning) and bigger output embeddings (discarded at fine-tuning). The tokenizer is
also similar to the Albert one rather than the BERT one.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## RemBertConfig
[[autodoc]] RemBertConfig
## RemBertTokenizer
[[autodoc]] RemBertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## RemBertTokenizerFast
[[autodoc]] RemBertTokenizerFast
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
<frameworkcontent>
<pt>
## RemBertModel
[[autodoc]] RemBertModel
- forward
## RemBertForCausalLM
[[autodoc]] RemBertForCausalLM
- forward
## RemBertForMaskedLM
[[autodoc]] RemBertForMaskedLM
- forward
## RemBertForSequenceClassification
[[autodoc]] RemBertForSequenceClassification
- forward
## RemBertForMultipleChoice
[[autodoc]] RemBertForMultipleChoice
- forward
## RemBertForTokenClassification
[[autodoc]] RemBertForTokenClassification
- forward
## RemBertForQuestionAnswering
[[autodoc]] RemBertForQuestionAnswering
- forward
</pt>
<tf>
## TFRemBertModel
[[autodoc]] TFRemBertModel
- call
## TFRemBertForMaskedLM
[[autodoc]] TFRemBertForMaskedLM
- call
## TFRemBertForCausalLM
[[autodoc]] TFRemBertForCausalLM
- call
## TFRemBertForSequenceClassification
[[autodoc]] TFRemBertForSequenceClassification
- call
## TFRemBertForMultipleChoice
[[autodoc]] TFRemBertForMultipleChoice
- call
## TFRemBertForTokenClassification
[[autodoc]] TFRemBertForTokenClassification
- call
## TFRemBertForQuestionAnswering
[[autodoc]] TFRemBertForQuestionAnswering
- call
</tf>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/deta.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DETA
## Overview
The DETA model was proposed in [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
DETA (short for Detection Transformers with Assignment) improves [Deformable DETR](deformable_detr) by replacing the one-to-one bipartite Hungarian matching loss
with one-to-many label assignments used in traditional detectors with non-maximum suppression (NMS). This leads to significant gains of up to 2.5 mAP.
The abstract from the paper is the following:
*Detection Transformer (DETR) directly transforms queries to unique objects by using one-to-one bipartite matching during training and enables end-to-end object detection. Recently, these models have surpassed traditional detectors on COCO with undeniable elegance. However, they differ from traditional detectors in multiple designs, including model architecture and training schedules, and thus the effectiveness of one-to-one matching is not fully understood. In this work, we conduct a strict comparison between the one-to-one Hungarian matching in DETRs and the one-to-many label assignments in traditional detectors with non-maximum supervision (NMS). Surprisingly, we observe one-to-many assignments with NMS consistently outperform standard one-to-one matching under the same setting, with a significant gain of up to 2.5 mAP. Our detector that trains Deformable-DETR with traditional IoU-based label assignment achieved 50.2 COCO mAP within 12 epochs (1x schedule) with ResNet50 backbone, outperforming all existing traditional or transformer-based detectors in this setting. On multiple datasets, schedules, and architectures, we consistently show bipartite matching is unnecessary for performant detection transformers. Furthermore, we attribute the success of detection transformers to their expressive transformer architecture.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/deta_architecture.jpg"
alt="drawing" width="600"/>
<small> DETA overview. Taken from the <a href="https://arxiv.org/abs/2212.06137">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/jozhang97/DETA).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DETA.
- Demo notebooks for DETA can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETA).
- See also: [Object detection task guide](../tasks/object_detection)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## DetaConfig
[[autodoc]] DetaConfig
## DetaImageProcessor
[[autodoc]] DetaImageProcessor
- preprocess
- post_process_object_detection
## DetaModel
[[autodoc]] DetaModel
- forward
## DetaForObjectDetection
[[autodoc]] DetaForObjectDetection
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/vitmatte.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# ViTMatte
## Overview
The ViTMatte model was proposed in [Boosting Image Matting with Pretrained Plain Vision Transformers](https://arxiv.org/abs/2305.15272) by Jingfeng Yao, Xinggang Wang, Shusheng Yang, Baoyuan Wang.
ViTMatte leverages plain [Vision Transformers](vit) for the task of image matting, which is the process of accurately estimating the foreground object in images and videos.
The abstract from the paper is the following:
*Recently, plain vision Transformers (ViTs) have shown impressive performance on various computer vision tasks, thanks to their strong modeling capacity and large-scale pretraining. However, they have not yet conquered the problem of image matting. We hypothesize that image matting could also be boosted by ViTs and present a new efficient and robust ViT-based matting system, named ViTMatte. Our method utilizes (i) a hybrid attention mechanism combined with a convolution neck to help ViTs achieve an excellent performance-computation trade-off in matting tasks. (ii) Additionally, we introduce the detail capture module, which just consists of simple lightweight convolutions to complement the detailed information required by matting. To the best of our knowledge, ViTMatte is the first work to unleash the potential of ViT on image matting with concise adaptation. It inherits many superior properties from ViT to matting, including various pretraining strategies, concise architecture design, and flexible inference strategies. We evaluate ViTMatte on Composition-1k and Distinctions-646, the most commonly used benchmark for image matting, our method achieves state-of-the-art performance and outperforms prior matting works by a large margin.*
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/hustvl/ViTMatte).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/vitmatte_architecture.png"
alt="drawing" width="600"/>
<small> ViTMatte high-level overview. Taken from the <a href="https://arxiv.org/abs/2305.15272">original paper.</a> </small>
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ViTMatte.
- A demo notebook regarding inference with [`VitMatteForImageMatting`], including background replacement, can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViTMatte).
<Tip>
The model expects both the image and trimap (concatenated) as input. Use [`ViTMatteImageProcessor`] for this purpose.
</Tip>
## VitMatteConfig
[[autodoc]] VitMatteConfig
## VitMatteImageProcessor
[[autodoc]] VitMatteImageProcessor
- preprocess
## VitMatteForImageMatting
[[autodoc]] VitMatteForImageMatting
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/cpmant.md
|
<!--Copyright 2022 The HuggingFace Team and The OpenBMB Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CPMAnt
## Overview
CPM-Ant is an open-source Chinese pre-trained language model (PLM) with 10B parameters. It is also the first milestone of the live training process of CPM-Live. The training process is cost-effective and environment-friendly. CPM-Ant also achieves promising results with delta tuning on the CUGE benchmark. Besides the full model, we also provide various compressed versions to meet the requirements of different hardware configurations. [See more](https://github.com/OpenBMB/CPM-Live/tree/cpm-ant/cpm-live)
This model was contributed by [OpenBMB](https://huggingface.co/openbmb). The original code can be found [here](https://github.com/OpenBMB/CPM-Live/tree/cpm-ant/cpm-live).
## Resources
- A tutorial on [CPM-Live](https://github.com/OpenBMB/CPM-Live/tree/cpm-ant/cpm-live).
## CpmAntConfig
[[autodoc]] CpmAntConfig
- all
## CpmAntTokenizer
[[autodoc]] CpmAntTokenizer
- all
## CpmAntModel
[[autodoc]] CpmAntModel
- all
## CpmAntForCausalLM
[[autodoc]] CpmAntForCausalLM
- all
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/informer.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Informer
## Overview
The Informer model was proposed in [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting ](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
This method introduces a Probabilistic Attention mechanism to select the "active" queries rather than the "lazy" queries and provides a sparse Transformer thus mitigating the quadratic compute and memory requirements of vanilla attention.
The abstract from the paper is the following:
*Many real-world applications require the prediction of long sequence time-series, such as electricity consumption planning. Long sequence time-series forecasting (LSTF) demands a high prediction capacity of the model, which is the ability to capture precise long-range dependency coupling between output and input efficiently. Recent studies have shown the potential of Transformer to increase the prediction capacity. However, there are several severe issues with Transformer that prevent it from being directly applicable to LSTF, including quadratic time complexity, high memory usage, and inherent limitation of the encoder-decoder architecture. To address these issues, we design an efficient transformer-based model for LSTF, named Informer, with three distinctive characteristics: (i) a ProbSparse self-attention mechanism, which achieves O(L logL) in time complexity and memory usage, and has comparable performance on sequences' dependency alignment. (ii) the self-attention distilling highlights dominating attention by halving cascading layer input, and efficiently handles extreme long input sequences. (iii) the generative style decoder, while conceptually simple, predicts the long time-series sequences at one forward operation rather than a step-by-step way, which drastically improves the inference speed of long-sequence predictions. Extensive experiments on four large-scale datasets demonstrate that Informer significantly outperforms existing methods and provides a new solution to the LSTF problem.*
This model was contributed by [elisim](https://huggingface.co/elisim) and [kashif](https://huggingface.co/kashif).
The original code can be found [here](https://github.com/zhouhaoyi/Informer2020).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- Check out the Informer blog-post in HuggingFace blog: [Multivariate Probabilistic Time Series Forecasting with Informer](https://huggingface.co/blog/informer)
## InformerConfig
[[autodoc]] InformerConfig
## InformerModel
[[autodoc]] InformerModel
- forward
## InformerForPrediction
[[autodoc]] InformerForPrediction
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/swin2sr.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Swin2SR
## Overview
The Swin2SR model was proposed in [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
Swin2R improves the [SwinIR](https://github.com/JingyunLiang/SwinIR/) model by incorporating [Swin Transformer v2](swinv2) layers which mitigates issues such as training instability, resolution gaps between pre-training
and fine-tuning, and hunger on data.
The abstract from the paper is the following:
*Compression plays an important role on the efficient transmission and storage of images and videos through band-limited systems such as streaming services, virtual reality or videogames. However, compression unavoidably leads to artifacts and the loss of the original information, which may severely degrade the visual quality. For these reasons, quality enhancement of compressed images has become a popular research topic. While most state-of-the-art image restoration methods are based on convolutional neural networks, other transformers-based methods such as SwinIR, show impressive performance on these tasks.
In this paper, we explore the novel Swin Transformer V2, to improve SwinIR for image super-resolution, and in particular, the compressed input scenario. Using this method we can tackle the major issues in training transformer vision models, such as training instability, resolution gaps between pre-training and fine-tuning, and hunger on data. We conduct experiments on three representative tasks: JPEG compression artifacts removal, image super-resolution (classical and lightweight), and compressed image super-resolution. Experimental results demonstrate that our method, Swin2SR, can improve the training convergence and performance of SwinIR, and is a top-5 solution at the "AIM 2022 Challenge on Super-Resolution of Compressed Image and Video".*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/swin2sr_architecture.png"
alt="drawing" width="600"/>
<small> Swin2SR architecture. Taken from the <a href="https://arxiv.org/abs/2209.11345">original paper.</a> </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/mv-lab/swin2sr).
## Resources
Demo notebooks for Swin2SR can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Swin2SR).
A demo Space for image super-resolution with SwinSR can be found [here](https://huggingface.co/spaces/jjourney1125/swin2sr).
## Swin2SRImageProcessor
[[autodoc]] Swin2SRImageProcessor
- preprocess
## Swin2SRConfig
[[autodoc]] Swin2SRConfig
## Swin2SRModel
[[autodoc]] Swin2SRModel
- forward
## Swin2SRForImageSuperResolution
[[autodoc]] Swin2SRForImageSuperResolution
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/tvp.md
|
<!--Copyright 2023 The Intel Team Authors and HuggingFace Inc. team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# TVP
## Overview
The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
The abstract from the paper is the following:
*In this paper, we study the problem of temporal video grounding (TVG), which aims to predict the starting/ending time points of moments described by a text sentence within a long untrimmed video. Benefiting from fine-grained 3D visual features, the TVG techniques have achieved remarkable progress in recent years. However, the high complexity of 3D convolutional neural networks (CNNs) makes extracting dense 3D visual features time-consuming, which calls for intensive memory and computing resources. Towards efficient TVG, we propose a novel text-visual prompting (TVP) framework, which incorporates optimized perturbation patterns (that we call ‘prompts’) into both visual inputs and textual features of a TVG model. In sharp contrast to 3D CNNs, we show that TVP allows us to effectively co-train vision encoder and language encoder in a 2D TVG model and improves the performance of cross-modal feature fusion using only low-complexity sparse 2D visual features. Further, we propose a Temporal-Distance IoU (TDIoU) loss for efficient learning of TVG. Experiments on two benchmark datasets, Charades-STA and ActivityNet Captions datasets, empirically show that the proposed TVP significantly boosts the performance of 2D TVG (e.g., 9.79% improvement on Charades-STA and 30.77% improvement on ActivityNet Captions) and achieves 5× inference acceleration over TVG using 3D visual features.*
This research addresses temporal video grounding (TVG), which is the process of pinpointing the start and end times of specific events in a long video, as described by a text sentence. Text-visual prompting (TVP), is proposed to enhance TVG. TVP involves integrating specially designed patterns, known as 'prompts', into both the visual (image-based) and textual (word-based) input components of a TVG model. These prompts provide additional spatial-temporal context, improving the model's ability to accurately determine event timings in the video. The approach employs 2D visual inputs in place of 3D ones. Although 3D inputs offer more spatial-temporal detail, they are also more time-consuming to process. The use of 2D inputs with the prompting method aims to provide similar levels of context and accuracy more efficiently.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/tvp_architecture.png"
alt="drawing" width="600"/>
<small> TVP architecture. Taken from the <a href="https://arxiv.org/abs/2303.04995">original paper.</a> </small>
This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
## Usage tips and examples
Prompts are optimized perturbation patterns, which would be added to input video frames or text features. Universal set refers to using the same exact set of prompts for any input, this means that these prompts are added consistently to all video frames and text features, regardless of the input's content.
TVP consists of a visual encoder and cross-modal encoder. A universal set of visual prompts and text prompts to be integrated into sampled video frames and textual features, respectively. Specially, a set of different visual prompts are applied to uniformly-sampled frames of one untrimmed video in order.
The goal of this model is to incorporate trainable prompts into both visual inputs and textual features to temporal video grounding(TVG) problems.
In principle, one can apply any visual, cross-modal encoder in the proposed architecture.
The [`TvpProcessor`] wraps [`BertTokenizer`] and [`TvpImageProcessor`] into a single instance to both
encode the text and prepare the images respectively.
The following example shows how to run temporal video grounding using [`TvpProcessor`] and [`TvpForVideoGrounding`].
```python
import av
import cv2
import numpy as np
import torch
from huggingface_hub import hf_hub_download
from transformers import AutoProcessor, TvpForVideoGrounding
def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
'''
Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
Args:
container (container): pyav container.
sampling_rate (int): frame sampling rate (interval between two sampled frames).
num_frames (int): number of frames to sample.
clip_idx (int): if clip_idx is -1, perform random temporal sampling.
If clip_idx is larger than -1, uniformly split the video to num_clips
clips, and select the clip_idx-th video clip.
num_clips (int): overall number of clips to uniformly sample from the given video.
target_fps (int): the input video may have different fps, convert it to
the target video fps before frame sampling.
Returns:
frames (tensor): decoded frames from the video. Return None if the no
video stream was found.
fps (float): the number of frames per second of the video.
'''
video = container.streams.video[0]
fps = float(video.average_rate)
clip_size = sampling_rate * num_frames / target_fps * fps
delta = max(num_frames - clip_size, 0)
start_idx = delta * clip_idx / num_clips
end_idx = start_idx + clip_size - 1
timebase = video.duration / num_frames
video_start_pts = int(start_idx * timebase)
video_end_pts = int(end_idx * timebase)
seek_offset = max(video_start_pts - 1024, 0)
container.seek(seek_offset, any_frame=False, backward=True, stream=video)
frames = {}
for frame in container.decode(video=0):
if frame.pts < video_start_pts:
continue
frames[frame.pts] = frame
if frame.pts > video_end_pts:
break
frames = [frames[pts] for pts in sorted(frames)]
return frames, fps
def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
'''
Decode the video and perform temporal sampling.
Args:
container (container): pyav container.
sampling_rate (int): frame sampling rate (interval between two sampled frames).
num_frames (int): number of frames to sample.
clip_idx (int): if clip_idx is -1, perform random temporal sampling.
If clip_idx is larger than -1, uniformly split the video to num_clips
clips, and select the clip_idx-th video clip.
num_clips (int): overall number of clips to uniformly sample from the given video.
target_fps (int): the input video may have different fps, convert it to
the target video fps before frame sampling.
Returns:
frames (tensor): decoded frames from the video.
'''
assert clip_idx >= -2, "Not a valied clip_idx {}".format(clip_idx)
frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
clip_size = sampling_rate * num_frames / target_fps * fps
index = np.linspace(0, clip_size - 1, num_frames)
index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
frames = frames.transpose(0, 3, 1, 2)
return frames
file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
decoder_kwargs = dict(
container=av.open(file, metadata_errors="ignore"),
sampling_rate=1,
num_frames=model.config.num_frames,
clip_idx=0,
num_clips=1,
target_fps=3,
)
raw_sampled_frms = decode(**decoder_kwargs)
text = "a person is sitting on a bed."
processor = AutoProcessor.from_pretrained("Intel/tvp-base")
model_inputs = processor(
text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
)
model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
output = model(**model_inputs)
def get_video_duration(filename):
cap = cv2.VideoCapture(filename)
if cap.isOpened():
rate = cap.get(5)
frame_num = cap.get(7)
duration = frame_num/rate
return duration
return -1
duration = get_video_duration(file)
start, end = processor.post_process_video_grounding(output.logits, duration)
print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
```
Tips:
- This implementation of TVP uses [`BertTokenizer`] to generate text embeddings and Resnet-50 model to compute visual embeddings.
- Checkpoints for pre-trained [tvp-base](https://huggingface.co/Intel/tvp-base) is released.
- Please refer to [Table 2](https://arxiv.org/pdf/2303.04995.pdf) for TVP's performance on Temporal Video Grounding task.
## TvpConfig
[[autodoc]] TvpConfig
## TvpImageProcessor
[[autodoc]] TvpImageProcessor
- preprocess
## TvpProcessor
[[autodoc]] TvpProcessor
- __call__
## TvpModel
[[autodoc]] TvpModel
- forward
## TvpForVideoGrounding
[[autodoc]] TvpForVideoGrounding
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/resnet.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ResNet
## Overview
The ResNet model was proposed in [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Our implementation follows the small changes made by [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch), we apply the `stride=2` for downsampling in bottleneck's `3x3` conv and not in the first `1x1`. This is generally known as "ResNet v1.5".
ResNet introduced residual connections, they allow to train networks with an unseen number of layers (up to 1000). ResNet won the 2015 ILSVRC & COCO competition, one important milestone in deep computer vision.
The abstract from the paper is the following:
*Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.*
The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://arxiv.org/abs/1512.03385).
<img width="600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/resnet_architecture.png"/>
This model was contributed by [Francesco](https://huggingface.co/Francesco). The TensorFlow version of this model was added by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/KaimingHe/deep-residual-networks).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ResNet.
<PipelineTag pipeline="image-classification"/>
- [`ResNetForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ResNetConfig
[[autodoc]] ResNetConfig
<frameworkcontent>
<pt>
## ResNetModel
[[autodoc]] ResNetModel
- forward
## ResNetForImageClassification
[[autodoc]] ResNetForImageClassification
- forward
</pt>
<tf>
## TFResNetModel
[[autodoc]] TFResNetModel
- call
## TFResNetForImageClassification
[[autodoc]] TFResNetForImageClassification
- call
</tf>
<jax>
## FlaxResNetModel
[[autodoc]] FlaxResNetModel
- __call__
## FlaxResNetForImageClassification
[[autodoc]] FlaxResNetForImageClassification
- __call__
</jax>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/clipseg.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CLIPSeg
## Overview
The CLIPSeg model was proposed in [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke
and Alexander Ecker. CLIPSeg adds a minimal decoder on top of a frozen [CLIP](clip) model for zero- and one-shot image segmentation.
The abstract from the paper is the following:
*Image segmentation is usually addressed by training a
model for a fixed set of object classes. Incorporating additional classes or more complex queries later is expensive
as it requires re-training the model on a dataset that encompasses these expressions. Here we propose a system
that can generate image segmentations based on arbitrary
prompts at test time. A prompt can be either a text or an
image. This approach enables us to create a unified model
(trained once) for three common segmentation tasks, which
come with distinct challenges: referring expression segmentation, zero-shot segmentation and one-shot segmentation.
We build upon the CLIP model as a backbone which we extend with a transformer-based decoder that enables dense
prediction. After training on an extended version of the
PhraseCut dataset, our system generates a binary segmentation map for an image based on a free-text prompt or on
an additional image expressing the query. We analyze different variants of the latter image-based prompts in detail.
This novel hybrid input allows for dynamic adaptation not
only to the three segmentation tasks mentioned above, but
to any binary segmentation task where a text or image query
can be formulated. Finally, we find our system to adapt well
to generalized queries involving affordances or properties*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/clipseg_architecture.png"
alt="drawing" width="600"/>
<small> CLIPSeg overview. Taken from the <a href="https://arxiv.org/abs/2112.10003">original paper.</a> </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr).
The original code can be found [here](https://github.com/timojl/clipseg).
## Usage tips
- [`CLIPSegForImageSegmentation`] adds a decoder on top of [`CLIPSegModel`]. The latter is identical to [`CLIPModel`].
- [`CLIPSegForImageSegmentation`] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text
(provided to the model as `input_ids`) or an image (provided to the model as `conditional_pixel_values`). One can also provide custom
conditional embeddings (provided to the model as `conditional_embeddings`).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIPSeg. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="image-segmentation"/>
- A notebook that illustrates [zero-shot image segmentation with CLIPSeg](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/CLIPSeg/Zero_shot_image_segmentation_with_CLIPSeg.ipynb).
## CLIPSegConfig
[[autodoc]] CLIPSegConfig
- from_text_vision_configs
## CLIPSegTextConfig
[[autodoc]] CLIPSegTextConfig
## CLIPSegVisionConfig
[[autodoc]] CLIPSegVisionConfig
## CLIPSegProcessor
[[autodoc]] CLIPSegProcessor
## CLIPSegModel
[[autodoc]] CLIPSegModel
- forward
- get_text_features
- get_image_features
## CLIPSegTextModel
[[autodoc]] CLIPSegTextModel
- forward
## CLIPSegVisionModel
[[autodoc]] CLIPSegVisionModel
- forward
## CLIPSegForImageSegmentation
[[autodoc]] CLIPSegForImageSegmentation
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/maskformer.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MaskFormer
<Tip>
This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
</Tip>
## Overview
The MaskFormer model was proposed in [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov. MaskFormer addresses semantic segmentation with a mask classification paradigm instead of performing classic pixel-level classification.
The abstract from the paper is the following:
*Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.*
The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
<img width="600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/maskformer_architecture.png"/>
This model was contributed by [francesco](https://huggingface.co/francesco). The original code can be found [here](https://github.com/facebookresearch/MaskFormer).
## Usage tips
- MaskFormer's Transformer decoder is identical to the decoder of [DETR](detr). During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help the model output the correct number of objects of each class. If you set the parameter `use_auxilary_loss` of [`MaskFormerConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses are added after each decoder layer (with the FFNs sharing parameters).
- If you want to train the model in a distributed environment across multiple nodes, then one should update the
`get_num_masks` function inside in the `MaskFormerLoss` class of `modeling_maskformer.py`. When training on multiple nodes, this should be
set to the average number of target masks across all nodes, as can be seen in the original implementation [here](https://github.com/facebookresearch/MaskFormer/blob/da3e60d85fdeedcb31476b5edd7d328826ce56cc/mask_former/modeling/criterion.py#L169).
- One can use [`MaskFormerImageProcessor`] to prepare images for the model and optional targets for the model.
- To get the final segmentation, depending on the task, you can call [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
## Resources
<PipelineTag pipeline="image-segmentation"/>
- All notebooks that illustrate inference as well as fine-tuning on custom data with MaskFormer can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MaskFormer).
## MaskFormer specific outputs
[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerModelOutput
[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerForInstanceSegmentationOutput
## MaskFormerConfig
[[autodoc]] MaskFormerConfig
## MaskFormerImageProcessor
[[autodoc]] MaskFormerImageProcessor
- preprocess
- encode_inputs
- post_process_semantic_segmentation
- post_process_instance_segmentation
- post_process_panoptic_segmentation
## MaskFormerFeatureExtractor
[[autodoc]] MaskFormerFeatureExtractor
- __call__
- encode_inputs
- post_process_semantic_segmentation
- post_process_instance_segmentation
- post_process_panoptic_segmentation
## MaskFormerModel
[[autodoc]] MaskFormerModel
- forward
## MaskFormerForInstanceSegmentation
[[autodoc]] MaskFormerForInstanceSegmentation
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/mask2former.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Mask2Former
## Overview
The Mask2Former model was proposed in [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. Mask2Former is a unified framework for panoptic, instance and semantic segmentation and features significant performance and efficiency improvements over [MaskFormer](maskformer).
The abstract from the paper is the following:
*Image segmentation groups pixels with different semantics, e.g., category or instance membership. Each choice
of semantics defines a task. While only the semantics of each task differ, current research focuses on designing specialized architectures for each task. We present Masked-attention Mask Transformer (Mask2Former), a new architecture capable of addressing any image segmentation task (panoptic, instance or semantic). Its key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. In addition to reducing the research effort by at least three times, it outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/mask2former_architecture.jpg" alt="drawing" width="600"/>
<small> Mask2Former architecture. Taken from the <a href="https://arxiv.org/abs/2112.01527">original paper.</a> </small>
This model was contributed by [Shivalika Singh](https://huggingface.co/shivi) and [Alara Dirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/Mask2Former).
## Usage tips
- Mask2Former uses the same preprocessing and postprocessing steps as [MaskFormer](maskformer). Use [`Mask2FormerImageProcessor`] or [`AutoImageProcessor`] to prepare images and optional targets for the model.
- To get the final segmentation, depending on the task, you can call [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] or [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] or [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`Mask2FormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mask2Former.
- Demo notebooks regarding inference + fine-tuning Mask2Former on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Mask2Former).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
The resource should ideally demonstrate something new instead of duplicating an existing resource.
## Mask2FormerConfig
[[autodoc]] Mask2FormerConfig
## MaskFormer specific outputs
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerModelOutput
[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerForUniversalSegmentationOutput
## Mask2FormerModel
[[autodoc]] Mask2FormerModel
- forward
## Mask2FormerForUniversalSegmentation
[[autodoc]] Mask2FormerForUniversalSegmentation
- forward
## Mask2FormerImageProcessor
[[autodoc]] Mask2FormerImageProcessor
- preprocess
- encode_inputs
- post_process_semantic_segmentation
- post_process_instance_segmentation
- post_process_panoptic_segmentation
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/flan-ul2.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# FLAN-UL2
## Overview
Flan-UL2 is an encoder decoder model based on the T5 architecture. It uses the same configuration as the [UL2](ul2) model released earlier last year.
It was fine tuned using the "Flan" prompt tuning and dataset collection. Similar to `Flan-T5`, one can directly use FLAN-UL2 weights without finetuning the model:
According to the original blog here are the notable improvements:
- The original UL2 model was only trained with receptive field of 512, which made it non-ideal for N-shot prompting where N is large.
- The Flan-UL2 checkpoint uses a receptive field of 2048 which makes it more usable for few-shot in-context learning.
- The original UL2 model also had mode switch tokens that was rather mandatory to get good performance. However, they were a little cumbersome as this requires often some changes during inference or finetuning. In this update/change, we continue training UL2 20B for an additional 100k steps (with small batch) to forget “mode tokens” before applying Flan instruction tuning. This Flan-UL2 checkpoint does not require mode tokens anymore.
Google has released the following variants:
The original checkpoints can be found [here](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints).
## Running on low resource devices
The model is pretty heavy (~40GB in half precision) so if you just want to run the model, make sure you load your model in 8bit, and use `device_map="auto"` to make sure you don't have any OOM issue!
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-ul2", load_in_8bit=True, device_map="auto")
>>> tokenizer = AutoTokenizer.from_pretrained("google/flan-ul2")
>>> inputs = tokenizer("A step by step recipe to make bolognese pasta:", return_tensors="pt")
>>> outputs = model.generate(**inputs)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['In a large skillet, brown the ground beef and onion over medium heat. Add the garlic']
```
<Tip>
Refer to [T5's documentation page](t5) for API reference, tips, code examples and notebooks.
</Tip>
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/transfo-xl.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Transformer XL
<Tip warning={true}>
This model is in maintenance mode only, so we won't accept any new PRs changing its code. This model was deprecated due to security issues linked to `pickle.load`.
We recommend switching to more recent models for improved security.
In case you would still like to use `TransfoXL` in your experiments, we recommend using the [Hub checkpoint](https://huggingface.co/transfo-xl-wt103) with a specific revision to ensure you are downloading safe files from the Hub:
```
from transformers import TransfoXLTokenizer, TransfoXLLMHeadModel
checkpoint = 'transfo-xl-wt103'
revision = '40a186da79458c9f9de846edfaea79c412137f97'
tokenizer = TransfoXLTokenizer.from_pretrained(checkpoint, revision=revision)
model = TransfoXLLMHeadModel.from_pretrained(checkpoint, revision=revision)
```
If you run into any issues running this model, please reinstall the last version that supported this model: v4.35.0.
You can do so by running the following command: `pip install -U transformers==4.35.0`.
</Tip>
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=transfo-xl">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-transfo--xl-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/transfo-xl-wt103">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The Transformer-XL model was proposed in [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan
Salakhutdinov. It's a causal (uni-directional) transformer with relative positioning (sinusoïdal) embeddings which can
reuse previously computed hidden-states to attend to longer context (memory). This model also uses adaptive softmax
inputs and outputs (tied).
The abstract from the paper is the following:
*Transformers have a potential of learning longer-term dependency, but are limited by a fixed-length context in the
setting of language modeling. We propose a novel neural architecture Transformer-XL that enables learning dependency
beyond a fixed length without disrupting temporal coherence. It consists of a segment-level recurrence mechanism and a
novel positional encoding scheme. Our method not only enables capturing longer-term dependency, but also resolves the
context fragmentation problem. As a result, Transformer-XL learns dependency that is 80% longer than RNNs and 450%
longer than vanilla Transformers, achieves better performance on both short and long sequences, and is up to 1,800+
times faster than vanilla Transformers during evaluation. Notably, we improve the state-of-the-art results of
bpc/perplexity to 0.99 on enwiki8, 1.08 on text8, 18.3 on WikiText-103, 21.8 on One Billion Word, and 54.5 on Penn
Treebank (without finetuning). When trained only on WikiText-103, Transformer-XL manages to generate reasonably
coherent, novel text articles with thousands of tokens.*
This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/kimiyoung/transformer-xl).
## Usage tips
- Transformer-XL uses relative sinusoidal positional embeddings. Padding can be done on the left or on the right. The
original implementation trains on SQuAD with padding on the left, therefore the padding defaults are set to left.
- Transformer-XL is one of the few models that has no sequence length limit.
- Same as a regular GPT model, but introduces a recurrence mechanism for two consecutive segments (similar to a regular RNNs with two consecutive inputs). In this context, a segment is a number of consecutive tokens (for instance 512) that may span across multiple documents, and segments are fed in order to the model.
- Basically, the hidden states of the previous segment are concatenated to the current input to compute the attention scores. This allows the model to pay attention to information that was in the previous segment as well as the current one. By stacking multiple attention layers, the receptive field can be increased to multiple previous segments.
- This changes the positional embeddings to positional relative embeddings (as the regular positional embeddings would give the same results in the current input and the current hidden state at a given position) and needs to make some adjustments in the way attention scores are computed.
<Tip warning={true}>
TransformerXL does **not** work with *torch.nn.DataParallel* due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
</Tip>
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Causal language modeling task guide](../tasks/language_modeling)
## TransfoXLConfig
[[autodoc]] TransfoXLConfig
## TransfoXLTokenizer
[[autodoc]] TransfoXLTokenizer
- save_vocabulary
## TransfoXL specific outputs
[[autodoc]] models.deprecated.transfo_xl.modeling_transfo_xl.TransfoXLModelOutput
[[autodoc]] models.deprecated.transfo_xl.modeling_transfo_xl.TransfoXLLMHeadModelOutput
[[autodoc]] models.deprecated.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLModelOutput
[[autodoc]] models.deprecated.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLLMHeadModelOutput
<frameworkcontent>
<pt>
## TransfoXLModel
[[autodoc]] TransfoXLModel
- forward
## TransfoXLLMHeadModel
[[autodoc]] TransfoXLLMHeadModel
- forward
## TransfoXLForSequenceClassification
[[autodoc]] TransfoXLForSequenceClassification
- forward
</pt>
<tf>
## TFTransfoXLModel
[[autodoc]] TFTransfoXLModel
- call
## TFTransfoXLLMHeadModel
[[autodoc]] TFTransfoXLLMHeadModel
- call
## TFTransfoXLForSequenceClassification
[[autodoc]] TFTransfoXLForSequenceClassification
- call
</tf>
</frameworkcontent>
## Internal Layers
[[autodoc]] AdaptiveEmbedding
[[autodoc]] TFAdaptiveEmbedding
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/pvt.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Pyramid Vision Transformer (PVT)
## Overview
The PVT model was proposed in
[Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/abs/2102.12122)
by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. The PVT is a type of
vision transformer that utilizes a pyramid structure to make it an effective backbone for dense prediction tasks. Specifically
it allows for more fine-grained inputs (4 x 4 pixels per patch) to be used, while simultaneously shrinking the sequence length
of the Transformer as it deepens - reducing the computational cost. Additionally, a spatial-reduction attention (SRA) layer
is used to further reduce the resource consumption when learning high-resolution features.
The abstract from the paper is the following:
*Although convolutional neural networks (CNNs) have achieved great success in computer vision, this work investigates a
simpler, convolution-free backbone network useful for many dense prediction tasks. Unlike the recently proposed Vision
Transformer (ViT) that was designed for image classification specifically, we introduce the Pyramid Vision Transformer
(PVT), which overcomes the difficulties of porting Transformer to various dense prediction tasks. PVT has several
merits compared to current state of the arts. Different from ViT that typically yields low resolution outputs and
incurs high computational and memory costs, PVT not only can be trained on dense partitions of an image to achieve high
output resolution, which is important for dense prediction, but also uses a progressive shrinking pyramid to reduce the
computations of large feature maps. PVT inherits the advantages of both CNN and Transformer, making it a unified
backbone for various vision tasks without convolutions, where it can be used as a direct replacement for CNN backbones.
We validate PVT through extensive experiments, showing that it boosts the performance of many downstream tasks, including
object detection, instance and semantic segmentation. For example, with a comparable number of parameters, PVT+RetinaNet
achieves 40.4 AP on the COCO dataset, surpassing ResNet50+RetinNet (36.3 AP) by 4.1 absolute AP (see Figure 2). We hope
that PVT could serve as an alternative and useful backbone for pixel-level predictions and facilitate future research.*
This model was contributed by [Xrenya](<https://huggingface.co/Xrenya). The original code can be found [here](https://github.com/whai362/PVT).
- PVTv1 on ImageNet-1K
| **Model variant** |**Size** |**Acc@1**|**Params (M)**|
|--------------------|:-------:|:-------:|:------------:|
| PVT-Tiny | 224 | 75.1 | 13.2 |
| PVT-Small | 224 | 79.8 | 24.5 |
| PVT-Medium | 224 | 81.2 | 44.2 |
| PVT-Large | 224 | 81.7 | 61.4 |
## PvtConfig
[[autodoc]] PvtConfig
## PvtImageProcessor
[[autodoc]] PvtImageProcessor
- preprocess
## PvtForImageClassification
[[autodoc]] PvtForImageClassification
- forward
## PvtModel
[[autodoc]] PvtModel
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/blip.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BLIP
## Overview
The BLIP model was proposed in [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
BLIP is a model that is able to perform various multi-modal tasks including:
- Visual Question Answering
- Image-Text retrieval (Image-text matching)
- Image Captioning
The abstract from the paper is the following:
*Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks.
However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has been largely achieved by scaling up the dataset with noisy image-text pairs collected from the web, which is a suboptimal source of supervision. In this paper, we propose BLIP, a new VLP framework which transfers flexibly to both vision-language understanding and generation tasks. BLIP effectively utilizes the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones. We achieve state-of-the-art results on a wide range of vision-language tasks, such as image-text retrieval (+2.7% in average recall@1), image captioning (+2.8% in CIDEr), and VQA (+1.6% in VQA score). BLIP also demonstrates strong generalization ability when directly transferred to videolanguage tasks in a zero-shot manner. Code, models, and datasets are released.*

This model was contributed by [ybelkada](https://huggingface.co/ybelkada).
The original code can be found [here](https://github.com/salesforce/BLIP).
## Resources
- [Jupyter notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) on how to fine-tune BLIP for image captioning on a custom dataset
## BlipConfig
[[autodoc]] BlipConfig
- from_text_vision_configs
## BlipTextConfig
[[autodoc]] BlipTextConfig
## BlipVisionConfig
[[autodoc]] BlipVisionConfig
## BlipProcessor
[[autodoc]] BlipProcessor
## BlipImageProcessor
[[autodoc]] BlipImageProcessor
- preprocess
<frameworkcontent>
<pt>
## BlipModel
[[autodoc]] BlipModel
- forward
- get_text_features
- get_image_features
## BlipTextModel
[[autodoc]] BlipTextModel
- forward
## BlipVisionModel
[[autodoc]] BlipVisionModel
- forward
## BlipForConditionalGeneration
[[autodoc]] BlipForConditionalGeneration
- forward
## BlipForImageTextRetrieval
[[autodoc]] BlipForImageTextRetrieval
- forward
## BlipForQuestionAnswering
[[autodoc]] BlipForQuestionAnswering
- forward
</pt>
<tf>
## TFBlipModel
[[autodoc]] TFBlipModel
- call
- get_text_features
- get_image_features
## TFBlipTextModel
[[autodoc]] TFBlipTextModel
- call
## TFBlipVisionModel
[[autodoc]] TFBlipVisionModel
- call
## TFBlipForConditionalGeneration
[[autodoc]] TFBlipForConditionalGeneration
- call
## TFBlipForImageTextRetrieval
[[autodoc]] TFBlipForImageTextRetrieval
- call
## TFBlipForQuestionAnswering
[[autodoc]] TFBlipForQuestionAnswering
- call
</tf>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/bros.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# BROS
## Overview
The BROS model was proposed in [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
BROS stands for *BERT Relying On Spatiality*. It is an encoder-only Transformer model that takes a sequence of tokens and their bounding boxes as inputs and outputs a sequence of hidden states. BROS encode relative spatial information instead of using absolute spatial information.
It is pre-trained with two objectives: a token-masked language modeling objective (TMLM) used in BERT, and a novel area-masked language modeling objective (AMLM)
In TMLM, tokens are randomly masked, and the model predicts the masked tokens using spatial information and other unmasked tokens.
AMLM is a 2D version of TMLM. It randomly masks text tokens and predicts with the same information as TMLM, but it masks text blocks (areas).
`BrosForTokenClassification` has a simple linear layer on top of BrosModel. It predicts the label of each token.
`BrosSpadeEEForTokenClassification` has an `initial_token_classifier` and `subsequent_token_classifier` on top of BrosModel. `initial_token_classifier` is used to predict the first token of each entity, and `subsequent_token_classifier` is used to predict the next token of within entity. `BrosSpadeELForTokenClassification` has an `entity_linker` on top of BrosModel. `entity_linker` is used to predict the relation between two entities.
`BrosForTokenClassification` and `BrosSpadeEEForTokenClassification` essentially perform the same job. However, `BrosForTokenClassification` assumes input tokens are perfectly serialized (which is very challenging task since they exist in a 2D space), while `BrosSpadeEEForTokenClassification` allows for more flexibility in handling serialization errors as it predicts next connection tokens from one token.
`BrosSpadeELForTokenClassification` perform the intra-entity linking task. It predicts relation from one token (of one entity) to another token (of another entity) if these two entities share some relation.
BROS achieves comparable or better result on Key Information Extraction (KIE) benchmarks such as FUNSD, SROIE, CORD and SciTSR, without relying on explicit visual features.
The abstract from the paper is the following:
*Key information extraction (KIE) from document images requires understanding the contextual and spatial semantics of texts in two-dimensional (2D) space. Many recent studies try to solve the task by developing pre-trained language models focusing on combining visual features from document images with texts and their layout. On the other hand, this paper tackles the problem by going back to the basic: effective combination of text and layout. Specifically, we propose a pre-trained language model, named BROS (BERT Relying On Spatiality), that encodes relative positions of texts in 2D space and learns from unlabeled documents with area-masking strategy. With this optimized training scheme for understanding texts in 2D space, BROS shows comparable or better performance compared to previous methods on four KIE benchmarks (FUNSD, SROIE*, CORD, and SciTSR) without relying on visual features. This paper also reveals two real-world challenges in KIE tasks-(1) minimizing the error from incorrect text ordering and (2) efficient learning from fewer downstream examples-and demonstrates the superiority of BROS over previous methods.*
This model was contributed by [jinho8345](https://huggingface.co/jinho8345). The original code can be found [here](https://github.com/clovaai/bros).
## Usage tips and examples
- [`~transformers.BrosModel.forward`] requires `input_ids` and `bbox` (bounding box). Each bounding box should be in (x0, y0, x1, y1) format (top-left corner, bottom-right corner). Obtaining of Bounding boxes depends on external OCR system. The `x` coordinate should be normalized by document image width, and the `y` coordinate should be normalized by document image height.
```python
def expand_and_normalize_bbox(bboxes, doc_width, doc_height):
# here, bboxes are numpy array
# Normalize bbox -> 0 ~ 1
bboxes[:, [0, 2]] = bboxes[:, [0, 2]] / width
bboxes[:, [1, 3]] = bboxes[:, [1, 3]] / height
```
- [`~transformers.BrosForTokenClassification.forward`, `~transformers.BrosSpadeEEForTokenClassification.forward`, `~transformers.BrosSpadeEEForTokenClassification.forward`] require not only `input_ids` and `bbox` but also `box_first_token_mask` for loss calculation. It is a mask to filter out non-first tokens of each box. You can obtain this mask by saving start token indices of bounding boxes when creating `input_ids` from words. You can make `box_first_token_mask` with following code,
```python
def make_box_first_token_mask(bboxes, words, tokenizer, max_seq_length=512):
box_first_token_mask = np.zeros(max_seq_length, dtype=np.bool_)
# encode(tokenize) each word from words (List[str])
input_ids_list: List[List[int]] = [tokenizer.encode(e, add_special_tokens=False) for e in words]
# get the length of each box
tokens_length_list: List[int] = [len(l) for l in input_ids_list]
box_end_token_indices = np.array(list(itertools.accumulate(tokens_length_list)))
box_start_token_indices = box_end_token_indices - np.array(tokens_length_list)
# filter out the indices that are out of max_seq_length
box_end_token_indices = box_end_token_indices[box_end_token_indices < max_seq_length - 1]
if len(box_start_token_indices) > len(box_end_token_indices):
box_start_token_indices = box_start_token_indices[: len(box_end_token_indices)]
# set box_start_token_indices to True
box_first_token_mask[box_start_token_indices] = True
return box_first_token_mask
```
## Resources
- Demo scripts can be found [here](https://github.com/clovaai/bros).
## BrosConfig
[[autodoc]] BrosConfig
## BrosProcessor
[[autodoc]] BrosProcessor
- __call__
## BrosModel
[[autodoc]] BrosModel
- forward
## BrosForTokenClassification
[[autodoc]] BrosForTokenClassification
- forward
## BrosSpadeEEForTokenClassification
[[autodoc]] BrosSpadeEEForTokenClassification
- forward
## BrosSpadeELForTokenClassification
[[autodoc]] BrosSpadeELForTokenClassification
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/deplot.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DePlot
## Overview
DePlot was proposed in the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) from Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
The abstract of the paper states the following:
*Visual language such as charts and plots is ubiquitous in the human world. Comprehending plots and charts requires strong reasoning skills. Prior state-of-the-art (SOTA) models require at least tens of thousands of training examples and their reasoning capabilities are still much limited, especially on complex human-written queries. This paper presents the first one-shot solution to visual language reasoning. We decompose the challenge of visual language reasoning into two steps: (1) plot-to-text translation, and (2) reasoning over the translated text. The key in this method is a modality conversion module, named as DePlot, which translates the image of a plot or chart to a linearized table. The output of DePlot can then be directly used to prompt a pretrained large language model (LLM), exploiting the few-shot reasoning capabilities of LLMs. To obtain DePlot, we standardize the plot-to-table task by establishing unified task formats and metrics, and train DePlot end-to-end on this task. DePlot can then be used off-the-shelf together with LLMs in a plug-and-play fashion. Compared with a SOTA model finetuned on more than >28k data points, DePlot+LLM with just one-shot prompting achieves a 24.0% improvement over finetuned SOTA on human-written queries from the task of chart QA.*
DePlot is a model that is trained using `Pix2Struct` architecture. You can find more information about `Pix2Struct` in the [Pix2Struct documentation](https://huggingface.co/docs/transformers/main/en/model_doc/pix2struct).
DePlot is a Visual Question Answering subset of `Pix2Struct` architecture. It renders the input question on the image and predicts the answer.
## Usage example
Currently one checkpoint is available for DePlot:
- `google/deplot`: DePlot fine-tuned on ChartQA dataset
```python
from transformers import AutoProcessor, Pix2StructForConditionalGeneration
import requests
from PIL import Image
model = Pix2StructForConditionalGeneration.from_pretrained("google/deplot")
processor = AutoProcessor.from_pretrained("google/deplot")
url = "https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/5090.png"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, text="Generate underlying data table of the figure below:", return_tensors="pt")
predictions = model.generate(**inputs, max_new_tokens=512)
print(processor.decode(predictions[0], skip_special_tokens=True))
```
## Fine-tuning
To fine-tune DePlot, refer to the pix2struct [fine-tuning notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_pix2struct.ipynb). For `Pix2Struct` models, we have found out that fine-tuning the model with Adafactor and cosine learning rate scheduler leads to faster convergence:
```python
from transformers.optimization import Adafactor, get_cosine_schedule_with_warmup
optimizer = Adafactor(self.parameters(), scale_parameter=False, relative_step=False, lr=0.01, weight_decay=1e-05)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=40000)
```
<Tip>
DePlot is a model trained using `Pix2Struct` architecture. For API reference, see [`Pix2Struct` documentation](pix2struct).
</Tip>
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/flava.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# FLAVA
## Overview
The FLAVA model was proposed in [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela and is accepted at CVPR 2022.
The paper aims at creating a single unified foundation model which can work across vision, language
as well as vision-and-language multimodal tasks.
The abstract from the paper is the following:
*State-of-the-art vision and vision-and-language models rely on large-scale visio-linguistic pretraining for obtaining good performance on a variety
of downstream tasks. Generally, such models are often either cross-modal (contrastive) or multi-modal
(with earlier fusion) but not both; and they often only target specific modalities or tasks. A promising
direction would be to use a single holistic universal model, as a "foundation", that targets all modalities
at once -- a true vision and language foundation model should be good at vision tasks, language tasks, and
cross- and multi-modal vision and language tasks. We introduce FLAVA as such a model and demonstrate
impressive performance on a wide range of 35 tasks spanning these target modalities.*
This model was contributed by [aps](https://huggingface.co/aps). The original code can be found [here](https://github.com/facebookresearch/multimodal/tree/main/examples/flava).
## FlavaConfig
[[autodoc]] FlavaConfig
## FlavaTextConfig
[[autodoc]] FlavaTextConfig
## FlavaImageConfig
[[autodoc]] FlavaImageConfig
## FlavaMultimodalConfig
[[autodoc]] FlavaMultimodalConfig
## FlavaImageCodebookConfig
[[autodoc]] FlavaImageCodebookConfig
## FlavaProcessor
[[autodoc]] FlavaProcessor
## FlavaFeatureExtractor
[[autodoc]] FlavaFeatureExtractor
## FlavaImageProcessor
[[autodoc]] FlavaImageProcessor
- preprocess
## FlavaForPreTraining
[[autodoc]] FlavaForPreTraining
- forward
## FlavaModel
[[autodoc]] FlavaModel
- forward
- get_text_features
- get_image_features
## FlavaImageCodebook
[[autodoc]] FlavaImageCodebook
- forward
- get_codebook_indices
- get_codebook_probs
## FlavaTextModel
[[autodoc]] FlavaTextModel
- forward
## FlavaImageModel
[[autodoc]] FlavaImageModel
- forward
## FlavaMultimodalModel
[[autodoc]] FlavaMultimodalModel
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/align.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ALIGN
## Overview
The ALIGN model was proposed in [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig. ALIGN is a multi-modal vision and language model. It can be used for image-text similarity and for zero-shot image classification. ALIGN features a dual-encoder architecture with [EfficientNet](efficientnet) as its vision encoder and [BERT](bert) as its text encoder, and learns to align visual and text representations with contrastive learning. Unlike previous work, ALIGN leverages a massive noisy dataset and shows that the scale of the corpus can be used to achieve SOTA representations with a simple recipe.
The abstract from the paper is the following:
*Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge. For vision applications, representations are mostly learned using datasets with explicit class labels such as ImageNet or OpenImages. For vision-language, popular datasets like Conceptual Captions, MSCOCO, or CLIP all involve a non-trivial data collection (and cleaning) process. This costly curation process limits the size of datasets and hence hinders the scaling of trained models. In this paper, we leverage a noisy dataset of over one billion image alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. A simple dual-encoder architecture learns to align visual and language representations of the image and text pairs using a contrastive loss. We show that the scale of our corpus can make up for its noise and leads to state-of-the-art representations even with such a simple learning scheme. Our visual representation achieves strong performance when transferred to classification tasks such as ImageNet and VTAB. The aligned visual and language representations enables zero-shot image classification and also set new state-of-the-art results on Flickr30K and MSCOCO image-text retrieval benchmarks, even when compared with more sophisticated cross-attention models. The representations also enable cross-modality search with complex text and text + image queries.*
This model was contributed by [Alara Dirik](https://huggingface.co/adirik).
The original code is not released, this implementation is based on the Kakao Brain implementation based on the original paper.
## Usage example
ALIGN uses EfficientNet to get visual features and BERT to get the text features. Both the text and visual features are then projected to a latent space with identical dimension. The dot product between the projected image and text features is then used as a similarity score.
[`AlignProcessor`] wraps [`EfficientNetImageProcessor`] and [`BertTokenizer`] into a single instance to both encode the text and preprocess the images. The following example shows how to get the image-text similarity scores using [`AlignProcessor`] and [`AlignModel`].
```python
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
candidate_labels = ["an image of a cat", "an image of a dog"]
inputs = processor(text=candidate_labels, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
```
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ALIGN.
- A blog post on [ALIGN and the COYO-700M dataset](https://huggingface.co/blog/vit-align).
- A zero-shot image classification [demo](https://huggingface.co/spaces/adirik/ALIGN-zero-shot-image-classification).
- [Model card](https://huggingface.co/kakaobrain/align-base) of `kakaobrain/align-base` model.
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it. The resource should ideally demonstrate something new instead of duplicating an existing resource.
## AlignConfig
[[autodoc]] AlignConfig
- from_text_vision_configs
## AlignTextConfig
[[autodoc]] AlignTextConfig
## AlignVisionConfig
[[autodoc]] AlignVisionConfig
## AlignProcessor
[[autodoc]] AlignProcessor
## AlignModel
[[autodoc]] AlignModel
- forward
- get_text_features
- get_image_features
## AlignTextModel
[[autodoc]] AlignTextModel
- forward
## AlignVisionModel
[[autodoc]] AlignVisionModel
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/canine.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CANINE
## Overview
The CANINE model was proposed in [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language
Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting. It's
among the first papers that trains a Transformer without using an explicit tokenization step (such as Byte Pair
Encoding (BPE), WordPiece or SentencePiece). Instead, the model is trained directly at a Unicode character-level.
Training at a character-level inevitably comes with a longer sequence length, which CANINE solves with an efficient
downsampling strategy, before applying a deep Transformer encoder.
The abstract from the paper is the following:
*Pipelined NLP systems have largely been superseded by end-to-end neural modeling, yet nearly all commonly-used models
still require an explicit tokenization step. While recent tokenization approaches based on data-derived subword
lexicons are less brittle than manually engineered tokenizers, these techniques are not equally suited to all
languages, and the use of any fixed vocabulary may limit a model's ability to adapt. In this paper, we present CANINE,
a neural encoder that operates directly on character sequences, without explicit tokenization or vocabulary, and a
pre-training strategy that operates either directly on characters or optionally uses subwords as a soft inductive bias.
To use its finer-grained input effectively and efficiently, CANINE combines downsampling, which reduces the input
sequence length, with a deep transformer stack, which encodes context. CANINE outperforms a comparable mBERT model by
2.8 F1 on TyDi QA, a challenging multilingual benchmark, despite having 28% fewer model parameters.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/google-research/language/tree/master/language/canine).
## Usage tips
- CANINE uses no less than 3 Transformer encoders internally: 2 "shallow" encoders (which only consist of a single
layer) and 1 "deep" encoder (which is a regular BERT encoder). First, a "shallow" encoder is used to contextualize
the character embeddings, using local attention. Next, after downsampling, a "deep" encoder is applied. Finally,
after upsampling, a "shallow" encoder is used to create the final character embeddings. Details regarding up- and
downsampling can be found in the paper.
- CANINE uses a max sequence length of 2048 characters by default. One can use [`CanineTokenizer`]
to prepare text for the model.
- Classification can be done by placing a linear layer on top of the final hidden state of the special [CLS] token
(which has a predefined Unicode code point). For token classification tasks however, the downsampled sequence of
tokens needs to be upsampled again to match the length of the original character sequence (which is 2048). The
details for this can be found in the paper.
Model checkpoints:
- [google/canine-c](https://huggingface.co/google/canine-c): Pre-trained with autoregressive character loss,
12-layer, 768-hidden, 12-heads, 121M parameters (size ~500 MB).
- [google/canine-s](https://huggingface.co/google/canine-s): Pre-trained with subword loss, 12-layer,
768-hidden, 12-heads, 121M parameters (size ~500 MB).
## Usage example
CANINE works on raw characters, so it can be used **without a tokenizer**:
```python
>>> from transformers import CanineModel
>>> import torch
>>> model = CanineModel.from_pretrained("google/canine-c") # model pre-trained with autoregressive character loss
>>> text = "hello world"
>>> # use Python's built-in ord() function to turn each character into its unicode code point id
>>> input_ids = torch.tensor([[ord(char) for char in text]])
>>> outputs = model(input_ids) # forward pass
>>> pooled_output = outputs.pooler_output
>>> sequence_output = outputs.last_hidden_state
```
For batched inference and training, it is however recommended to make use of the tokenizer (to pad/truncate all
sequences to the same length):
```python
>>> from transformers import CanineTokenizer, CanineModel
>>> model = CanineModel.from_pretrained("google/canine-c")
>>> tokenizer = CanineTokenizer.from_pretrained("google/canine-c")
>>> inputs = ["Life is like a box of chocolates.", "You never know what you gonna get."]
>>> encoding = tokenizer(inputs, padding="longest", truncation=True, return_tensors="pt")
>>> outputs = model(**encoding) # forward pass
>>> pooled_output = outputs.pooler_output
>>> sequence_output = outputs.last_hidden_state
```
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Multiple choice task guide](../tasks/multiple_choice)
## CanineConfig
[[autodoc]] CanineConfig
## CanineTokenizer
[[autodoc]] CanineTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
## CANINE specific outputs
[[autodoc]] models.canine.modeling_canine.CanineModelOutputWithPooling
## CanineModel
[[autodoc]] CanineModel
- forward
## CanineForSequenceClassification
[[autodoc]] CanineForSequenceClassification
- forward
## CanineForMultipleChoice
[[autodoc]] CanineForMultipleChoice
- forward
## CanineForTokenClassification
[[autodoc]] CanineForTokenClassification
- forward
## CanineForQuestionAnswering
[[autodoc]] CanineForQuestionAnswering
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/auto.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Auto Classes
In many cases, the architecture you want to use can be guessed from the name or the path of the pretrained model you
are supplying to the `from_pretrained()` method. AutoClasses are here to do this job for you so that you
automatically retrieve the relevant model given the name/path to the pretrained weights/config/vocabulary.
Instantiating one of [`AutoConfig`], [`AutoModel`], and
[`AutoTokenizer`] will directly create a class of the relevant architecture. For instance
```python
model = AutoModel.from_pretrained("bert-base-cased")
```
will create a model that is an instance of [`BertModel`].
There is one class of `AutoModel` for each task, and for each backend (PyTorch, TensorFlow, or Flax).
## Extending the Auto Classes
Each of the auto classes has a method to be extended with your custom classes. For instance, if you have defined a
custom class of model `NewModel`, make sure you have a `NewModelConfig` then you can add those to the auto
classes like this:
```python
from transformers import AutoConfig, AutoModel
AutoConfig.register("new-model", NewModelConfig)
AutoModel.register(NewModelConfig, NewModel)
```
You will then be able to use the auto classes like you would usually do!
<Tip warning={true}>
If your `NewModelConfig` is a subclass of [`~transformers.PretrainedConfig`], make sure its
`model_type` attribute is set to the same key you use when registering the config (here `"new-model"`).
Likewise, if your `NewModel` is a subclass of [`PreTrainedModel`], make sure its
`config_class` attribute is set to the same class you use when registering the model (here
`NewModelConfig`).
</Tip>
## AutoConfig
[[autodoc]] AutoConfig
## AutoTokenizer
[[autodoc]] AutoTokenizer
## AutoFeatureExtractor
[[autodoc]] AutoFeatureExtractor
## AutoImageProcessor
[[autodoc]] AutoImageProcessor
## AutoProcessor
[[autodoc]] AutoProcessor
## Generic model classes
The following auto classes are available for instantiating a base model class without a specific head.
### AutoModel
[[autodoc]] AutoModel
### TFAutoModel
[[autodoc]] TFAutoModel
### FlaxAutoModel
[[autodoc]] FlaxAutoModel
## Generic pretraining classes
The following auto classes are available for instantiating a model with a pretraining head.
### AutoModelForPreTraining
[[autodoc]] AutoModelForPreTraining
### TFAutoModelForPreTraining
[[autodoc]] TFAutoModelForPreTraining
### FlaxAutoModelForPreTraining
[[autodoc]] FlaxAutoModelForPreTraining
## Natural Language Processing
The following auto classes are available for the following natural language processing tasks.
### AutoModelForCausalLM
[[autodoc]] AutoModelForCausalLM
### TFAutoModelForCausalLM
[[autodoc]] TFAutoModelForCausalLM
### FlaxAutoModelForCausalLM
[[autodoc]] FlaxAutoModelForCausalLM
### AutoModelForMaskedLM
[[autodoc]] AutoModelForMaskedLM
### TFAutoModelForMaskedLM
[[autodoc]] TFAutoModelForMaskedLM
### FlaxAutoModelForMaskedLM
[[autodoc]] FlaxAutoModelForMaskedLM
### AutoModelForMaskGeneration
[[autodoc]] AutoModelForMaskGeneration
### TFAutoModelForMaskGeneration
[[autodoc]] TFAutoModelForMaskGeneration
### AutoModelForSeq2SeqLM
[[autodoc]] AutoModelForSeq2SeqLM
### TFAutoModelForSeq2SeqLM
[[autodoc]] TFAutoModelForSeq2SeqLM
### FlaxAutoModelForSeq2SeqLM
[[autodoc]] FlaxAutoModelForSeq2SeqLM
### AutoModelForSequenceClassification
[[autodoc]] AutoModelForSequenceClassification
### TFAutoModelForSequenceClassification
[[autodoc]] TFAutoModelForSequenceClassification
### FlaxAutoModelForSequenceClassification
[[autodoc]] FlaxAutoModelForSequenceClassification
### AutoModelForMultipleChoice
[[autodoc]] AutoModelForMultipleChoice
### TFAutoModelForMultipleChoice
[[autodoc]] TFAutoModelForMultipleChoice
### FlaxAutoModelForMultipleChoice
[[autodoc]] FlaxAutoModelForMultipleChoice
### AutoModelForNextSentencePrediction
[[autodoc]] AutoModelForNextSentencePrediction
### TFAutoModelForNextSentencePrediction
[[autodoc]] TFAutoModelForNextSentencePrediction
### FlaxAutoModelForNextSentencePrediction
[[autodoc]] FlaxAutoModelForNextSentencePrediction
### AutoModelForTokenClassification
[[autodoc]] AutoModelForTokenClassification
### TFAutoModelForTokenClassification
[[autodoc]] TFAutoModelForTokenClassification
### FlaxAutoModelForTokenClassification
[[autodoc]] FlaxAutoModelForTokenClassification
### AutoModelForQuestionAnswering
[[autodoc]] AutoModelForQuestionAnswering
### TFAutoModelForQuestionAnswering
[[autodoc]] TFAutoModelForQuestionAnswering
### FlaxAutoModelForQuestionAnswering
[[autodoc]] FlaxAutoModelForQuestionAnswering
### AutoModelForTextEncoding
[[autodoc]] AutoModelForTextEncoding
### TFAutoModelForTextEncoding
[[autodoc]] TFAutoModelForTextEncoding
## Computer vision
The following auto classes are available for the following computer vision tasks.
### AutoModelForDepthEstimation
[[autodoc]] AutoModelForDepthEstimation
### AutoModelForImageClassification
[[autodoc]] AutoModelForImageClassification
### TFAutoModelForImageClassification
[[autodoc]] TFAutoModelForImageClassification
### FlaxAutoModelForImageClassification
[[autodoc]] FlaxAutoModelForImageClassification
### AutoModelForVideoClassification
[[autodoc]] AutoModelForVideoClassification
### AutoModelForMaskedImageModeling
[[autodoc]] AutoModelForMaskedImageModeling
### TFAutoModelForMaskedImageModeling
[[autodoc]] TFAutoModelForMaskedImageModeling
### AutoModelForObjectDetection
[[autodoc]] AutoModelForObjectDetection
### AutoModelForImageSegmentation
[[autodoc]] AutoModelForImageSegmentation
### AutoModelForImageToImage
[[autodoc]] AutoModelForImageToImage
### AutoModelForSemanticSegmentation
[[autodoc]] AutoModelForSemanticSegmentation
### TFAutoModelForSemanticSegmentation
[[autodoc]] TFAutoModelForSemanticSegmentation
### AutoModelForInstanceSegmentation
[[autodoc]] AutoModelForInstanceSegmentation
### AutoModelForUniversalSegmentation
[[autodoc]] AutoModelForUniversalSegmentation
### AutoModelForZeroShotImageClassification
[[autodoc]] AutoModelForZeroShotImageClassification
### TFAutoModelForZeroShotImageClassification
[[autodoc]] TFAutoModelForZeroShotImageClassification
### AutoModelForZeroShotObjectDetection
[[autodoc]] AutoModelForZeroShotObjectDetection
## Audio
The following auto classes are available for the following audio tasks.
### AutoModelForAudioClassification
[[autodoc]] AutoModelForAudioClassification
### AutoModelForAudioFrameClassification
[[autodoc]] TFAutoModelForAudioClassification
### TFAutoModelForAudioFrameClassification
[[autodoc]] AutoModelForAudioFrameClassification
### AutoModelForCTC
[[autodoc]] AutoModelForCTC
### AutoModelForSpeechSeq2Seq
[[autodoc]] AutoModelForSpeechSeq2Seq
### TFAutoModelForSpeechSeq2Seq
[[autodoc]] TFAutoModelForSpeechSeq2Seq
### FlaxAutoModelForSpeechSeq2Seq
[[autodoc]] FlaxAutoModelForSpeechSeq2Seq
### AutoModelForAudioXVector
[[autodoc]] AutoModelForAudioXVector
### AutoModelForTextToSpectrogram
[[autodoc]] AutoModelForTextToSpectrogram
### AutoModelForTextToWaveform
[[autodoc]] AutoModelForTextToWaveform
## Multimodal
The following auto classes are available for the following multimodal tasks.
### AutoModelForTableQuestionAnswering
[[autodoc]] AutoModelForTableQuestionAnswering
### TFAutoModelForTableQuestionAnswering
[[autodoc]] TFAutoModelForTableQuestionAnswering
### AutoModelForDocumentQuestionAnswering
[[autodoc]] AutoModelForDocumentQuestionAnswering
### TFAutoModelForDocumentQuestionAnswering
[[autodoc]] TFAutoModelForDocumentQuestionAnswering
### AutoModelForVisualQuestionAnswering
[[autodoc]] AutoModelForVisualQuestionAnswering
### AutoModelForVision2Seq
[[autodoc]] AutoModelForVision2Seq
### TFAutoModelForVision2Seq
[[autodoc]] TFAutoModelForVision2Seq
### FlaxAutoModelForVision2Seq
[[autodoc]] FlaxAutoModelForVision2Seq
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/graphormer.md
|
<!--Copyright 2022 The HuggingFace Team and Microsoft. All rights reserved.
Licensed under the MIT License; you may not use this file except in compliance with
the License.
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Graphormer
## Overview
The Graphormer model was proposed in [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by
Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen and Tie-Yan Liu. It is a Graph Transformer model, modified to allow computations on graphs instead of text sequences by generating embeddings and features of interest during preprocessing and collation, then using a modified attention.
The abstract from the paper is the following:
*The Transformer architecture has become a dominant choice in many domains, such as natural language processing and computer vision. Yet, it has not achieved competitive performance on popular leaderboards of graph-level prediction compared to mainstream GNN variants. Therefore, it remains a mystery how Transformers could perform well for graph representation learning. In this paper, we solve this mystery by presenting Graphormer, which is built upon the standard Transformer architecture, and could attain excellent results on a broad range of graph representation learning tasks, especially on the recent OGB Large-Scale Challenge. Our key insight to utilizing Transformer in the graph is the necessity of effectively encoding the structural information of a graph into the model. To this end, we propose several simple yet effective structural encoding methods to help Graphormer better model graph-structured data. Besides, we mathematically characterize the expressive power of Graphormer and exhibit that with our ways of encoding the structural information of graphs, many popular GNN variants could be covered as the special cases of Graphormer.*
This model was contributed by [clefourrier](https://huggingface.co/clefourrier). The original code can be found [here](https://github.com/microsoft/Graphormer).
## Usage tips
This model will not work well on large graphs (more than 100 nodes/edges), as it will make the memory explode.
You can reduce the batch size, increase your RAM, or decrease the `UNREACHABLE_NODE_DISTANCE` parameter in algos_graphormer.pyx, but it will be hard to go above 700 nodes/edges.
This model does not use a tokenizer, but instead a special collator during training.
## GraphormerConfig
[[autodoc]] GraphormerConfig
## GraphormerModel
[[autodoc]] GraphormerModel
- forward
## GraphormerForGraphClassification
[[autodoc]] GraphormerForGraphClassification
- forward
| 0
|
hf_public_repos/transformers/docs/source/en
|
hf_public_repos/transformers/docs/source/en/model_doc/codegen.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CodeGen
## Overview
The CodeGen model was proposed in [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong.
CodeGen is an autoregressive language model for program synthesis trained sequentially on [The Pile](https://pile.eleuther.ai/), BigQuery, and BigPython.
The abstract from the paper is the following:
*Program synthesis strives to generate a computer program as a solution to a given problem specification. We propose a conversational program synthesis approach via large language models, which addresses the challenges of searching over a vast program space and user intent specification faced in prior approaches. Our new approach casts the process of writing a specification and program as a multi-turn conversation between a user and a system. It treats program synthesis as a sequence prediction problem, in which the specification is expressed in natural language and the desired program is conditionally sampled. We train a family of large language models, called CodeGen, on natural language and programming language data. With weak supervision in the data and the scaling up of data size and model size, conversational capacities emerge from the simple autoregressive language modeling. To study the model behavior on conversational program synthesis, we develop a multi-turn programming benchmark (MTPB), where solving each problem requires multi-step synthesis via multi-turn conversation between the user and the model. Our findings show the emergence of conversational capabilities and the effectiveness of the proposed conversational program synthesis paradigm. In addition, our model CodeGen (with up to 16B parameters trained on TPU-v4) outperforms OpenAI's Codex on the HumanEval benchmark. We make the training library JaxFormer including checkpoints available as open source contribution: [this https URL](https://github.com/salesforce/codegen).*
This model was contributed by [Hiroaki Hayashi](https://huggingface.co/rooa).
The original code can be found [here](https://github.com/salesforce/codegen).
## Checkpoint Naming
* CodeGen model [checkpoints](https://huggingface.co/models?other=codegen) are available on different pre-training data with variable sizes.
* The format is: `Salesforce/codegen-{size}-{data}`, where
* `size`: `350M`, `2B`, `6B`, `16B`
* `data`:
* `nl`: Pre-trained on the Pile
* `multi`: Initialized with `nl`, then further pre-trained on multiple programming languages data
* `mono`: Initialized with `multi`, then further pre-trained on Python data
* For example, `Salesforce/codegen-350M-mono` offers a 350 million-parameter checkpoint pre-trained sequentially on the Pile, multiple programming languages, and Python.
## Usage example
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> checkpoint = "Salesforce/codegen-350M-mono"
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> text = "def hello_world():"
>>> completion = model.generate(**tokenizer(text, return_tensors="pt"))
>>> print(tokenizer.decode(completion[0]))
def hello_world():
print("Hello World")
hello_world()
```
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
## CodeGenConfig
[[autodoc]] CodeGenConfig
- all
## CodeGenTokenizer
[[autodoc]] CodeGenTokenizer
- save_vocabulary
## CodeGenTokenizerFast
[[autodoc]] CodeGenTokenizerFast
## CodeGenModel
[[autodoc]] CodeGenModel
- forward
## CodeGenForCausalLM
[[autodoc]] CodeGenForCausalLM
- forward
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/multilingual.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Modelos multilingües para inferencia
[[open-in-colab]]
Existen varios modelos multilingües en 🤗 Transformers y su uso para inferencia difiere de los modelos monolingües. Sin embargo, no *todos* los usos de los modelos multilingües son diferentes. Algunos modelos, como [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased), pueden utilizarse igual que un modelo monolingüe. Esta guía te enseñará cómo utilizar modelos multilingües cuyo uso difiere en la inferencia.
## XLM
XLM tiene diez checkpoints diferentes de los cuales solo uno es monolingüe. Los nueve checkpoints restantes del modelo pueden dividirse en dos categorías: los checkpoints que utilizan language embeddings y los que no.
### XLM con language embeddings
Los siguientes modelos XLM usan language embeddings para especificar el lenguaje utilizado en la inferencia:
- `xlm-mlm-ende-1024` (Masked language modeling, English-German)
- `xlm-mlm-enfr-1024` (Masked language modeling, English-French)
- `xlm-mlm-enro-1024` (Masked language modeling, English-Romanian)
- `xlm-mlm-xnli15-1024` (Masked language modeling, XNLI languages)
- `xlm-mlm-tlm-xnli15-1024` (Masked language modeling + translation, XNLI languages)
- `xlm-clm-enfr-1024` (Causal language modeling, English-French)
- `xlm-clm-ende-1024` (Causal language modeling, English-German)
Los language embeddings son representados como un tensor de la mismas dimensiones que los `input_ids` pasados al modelo. Los valores de estos tensores dependen del idioma utilizado y se identifican mediante los atributos `lang2id` y `id2lang` del tokenizador.
En este ejemplo, carga el checkpoint `xlm-clm-enfr-1024` (Causal language modeling, English-French):
```py
>>> import torch
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
```
El atributo `lang2id` del tokenizador muestra los idiomas de este modelo y sus ids:
```py
>>> print(tokenizer.lang2id)
{'en': 0, 'fr': 1}
```
A continuación, crea un input de ejemplo:
```py
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
```
Establece el id del idioma, por ejemplo `"en"`, y utilízalo para definir el language embedding. El language embedding es un tensor lleno de `0` ya que es el id del idioma para inglés. Este tensor debe ser del mismo tamaño que `input_ids`.
```py
>>> language_id = tokenizer.lang2id["en"] # 0
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
>>> # We reshape it to be of size (batch_size, sequence_length)
>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
```
Ahora puedes pasar los `input_ids` y el language embedding al modelo:
```py
>>> outputs = model(input_ids, langs=langs)
```
El script [run_generation.py](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-generation/run_generation.py) puede generar texto con language embeddings utilizando los checkpoints `xlm-clm`.
### XLM sin language embeddings
Los siguientes modelos XLM no requieren language embeddings durante la inferencia:
- `xlm-mlm-17-1280` (modelado de lenguaje enmascarado, 17 idiomas)
- `xlm-mlm-100-1280` (modelado de lenguaje enmascarado, 100 idiomas)
Estos modelos se utilizan para representaciones genéricas de frases a diferencia de los anteriores checkpoints XLM.
## BERT
Los siguientes modelos de BERT pueden utilizarse para tareas multilingües:
- `bert-base-multilingual-uncased` (modelado de lenguaje enmascarado + predicción de la siguiente oración, 102 idiomas)
- `bert-base-multilingual-cased` (modelado de lenguaje enmascarado + predicción de la siguiente oración, 104 idiomas)
Estos modelos no requieren language embeddings durante la inferencia. Deben identificar la lengua a partir del
contexto e inferir en consecuencia.
## XLM-RoBERTa
Los siguientes modelos de XLM-RoBERTa pueden utilizarse para tareas multilingües:
- `xlm-roberta-base` (modelado de lenguaje enmascarado, 100 idiomas)
- `xlm-roberta-large` (Modelado de lenguaje enmascarado, 100 idiomas)
XLM-RoBERTa se entrenó con 2,5 TB de datos CommonCrawl recién creados y depurados en 100 idiomas. Proporciona fuertes ventajas sobre los modelos multilingües publicados anteriormente como mBERT o XLM en tareas posteriores como la clasificación, el etiquetado de secuencias y la respuesta a preguntas.
## M2M100
Los siguientes modelos de M2M100 pueden utilizarse para traducción multilingüe:
- `facebook/m2m100_418M` (traducción)
- `facebook/m2m100_1.2B` (traducción)
En este ejemplo, carga el checkpoint `facebook/m2m100_418M` para traducir del chino al inglés. Puedes establecer el idioma de origen en el tokenizador:
```py
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
```
Tokeniza el texto:
```py
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
```
M2M100 fuerza el id del idioma de destino como el primer token generado para traducir al idioma de destino.. Establece el `forced_bos_token_id` a `en` en el método `generate` para traducir al inglés:
```py
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
```
## MBart
Los siguientes modelos de MBart pueden utilizarse para traducción multilingüe:
- `facebook/mbart-large-50-one-to-many-mmt` (traducción automática multilingüe de uno a muchos, 50 idiomas)
- `facebook/mbart-large-50-many-to-many-mmt` (traducción automática multilingüe de muchos a muchos, 50 idiomas)
- `facebook/mbart-large-50-many-to-one-mmt` (traducción automática multilingüe muchos a uno, 50 idiomas)
- `facebook/mbart-large-50` (traducción multilingüe, 50 idiomas)
- `facebook/mbart-large-cc25`
En este ejemplo, carga el checkpoint `facebook/mbart-large-50-many-to-many-mmt` para traducir del finlandés al inglés. Puedes establecer el idioma de origen en el tokenizador:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
```
Tokeniza el texto:
```py
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
```
MBart fuerza el id del idioma de destino como el primer token generado para traducirlo. Establece el `forced_bos_token_id` a `en` en el método `generate` para traducir al inglés:
```py
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
```
Si estás usando el checkpoint `facebook/mbart-large-50-many-to-one-mmt` no necesitas forzar el id del idioma de destino como el primer token generado, de lo contrario el uso es el mismo.
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/preprocessing.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Preprocesamiento
[[open-in-colab]]
Antes de que puedas utilizar los datos en un modelo, debes procesarlos en un formato aceptable para el modelo. Un modelo no entiende el texto en bruto, las imágenes o el audio. Estas entradas necesitan ser convertidas en números y ensambladas en tensores. En este tutorial, podrás:
* Preprocesar los datos textuales con un tokenizador.
* Preprocesar datos de imagen o audio con un extractor de características.
* Preprocesar datos para una tarea multimodal con un procesador.
## NLP
<Youtube id="Yffk5aydLzg"/>
La principal herramienta para procesar datos textuales es un [tokenizador](main_classes/tokenizer). Un tokenizador comienza dividiendo el texto en *tokens* según un conjunto de reglas. Los tokens se convierten en números, que se utilizan para construir tensores como entrada a un modelo. El tokenizador también añade cualquier entrada adicional que requiera el modelo.
<Tip>
Si tienes previsto utilizar un modelo pre-entrenado, es importante que utilices el tokenizador pre-entrenado asociado. Esto te asegura que el texto se divide de la misma manera que el corpus de pre-entrenamiento y utiliza el mismo índice de tokens correspondiente (usualmente referido como el *vocab*) durante el pre-entrenamiento.
</Tip>
Comienza rápidamente cargando un tokenizador pre-entrenado con la clase [`AutoTokenizer`]. Esto descarga el *vocab* utilizado cuando un modelo es pre-entrenado.
### Tokenizar
Carga un tokenizador pre-entrenado con [`AutoTokenizer.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
```
A continuación, pasa tu frase al tokenizador:
```py
>>> encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
>>> print(encoded_input)
{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
El tokenizador devuelve un diccionario con tres ítems importantes:
* [input_ids](glossary#input-ids) son los índices correspondientes a cada token de la frase.
* [attention_mask](glossary#attention-mask) indica si un token debe ser atendido o no.
* [token_type_ids](glossary#token-type-ids) identifica a qué secuencia pertenece un token cuando hay más de una secuencia.
Tu puedes decodificar el `input_ids` para devolver la entrada original:
```py
>>> tokenizer.decode(encoded_input["input_ids"])
'[CLS] Do not meddle in the affairs of wizards, for they are subtle and quick to anger. [SEP]'
```
Como puedes ver, el tokenizador ha añadido dos tokens especiales - `CLS` y `SEP` (clasificador y separador) - a la frase. No todos los modelos necesitan
tokens especiales, pero si lo llegas a necesitar, el tokenizador los añadirá automáticamente.
Si hay varias frases que quieres preprocesar, pasa las frases como una lista al tokenizador:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_inputs = tokenizer(batch_sentences)
>>> print(encoded_inputs)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1]]}
```
### Pad
Esto nos lleva a un tema importante. Cuando se procesa un batch de frases, no siempre tienen la misma longitud. Esto es un problema porque los tensores que se introducen en el modelo deben tener una forma uniforme. El pad es una estrategia para asegurar que los tensores sean rectangulares añadiendo un "padding token" especial a las oraciones con menos tokens.
Establece el parámetro `padding` en `True` aplicando el pad a las secuencias más cortas del batch para que coincidan con la secuencia más larga:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
Observa que el tokenizador ha aplicado el pad a la primera y la tercera frase con un "0" porque son más cortas.
### Truncamiento
En el otro extremo del espectro, a veces una secuencia puede ser demasiado larga para un modelo. En este caso, tendrás que truncar la secuencia a una longitud más corta.
Establece el parámetro `truncation` a `True` para truncar una secuencia a la longitud máxima aceptada por el modelo:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
### Construye tensores
Finalmente, si quieres que el tokenizador devuelva los tensores reales que se introducen en el modelo.
Establece el parámetro `return_tensors` como `pt` para PyTorch, o `tf` para TensorFlow:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch, padding=True, truncation=True, return_tensors="pt")
>>> print(encoded_input)
{'input_ids': tensor([[ 101, 153, 7719, 21490, 1122, 1114, 9582, 1623, 102],
[ 101, 5226, 1122, 9649, 1199, 2610, 1236, 102, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0]])}
===PT-TF-SPLIT===
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch, padding=True, truncation=True, return_tensors="tf")
>>> print(encoded_input)
{'input_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[ 101, 153, 7719, 21490, 1122, 1114, 9582, 1623, 102],
[ 101, 5226, 1122, 9649, 1199, 2610, 1236, 102, 0]],
dtype=int32)>,
'token_type_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>,
'attention_mask': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0]], dtype=int32)>}
```
## Audio
Las entradas de audio se preprocesan de forma diferente a las entradas textuales, pero el objetivo final es el mismo: crear secuencias numéricas que el modelo pueda entender. Un [extractor de características](main_classes/feature_extractor) (o feature extractor en inglés) está diseñado para extraer características de datos provenientes de imágenes o audio sin procesar y convertirlos en tensores. Antes de empezar, instala 🤗 Datasets para cargar un dataset de audio para experimentar:
```bash
pip install datasets
```
Carga la tarea de detección de palabras clave del benchmark [SUPERB](https://huggingface.co/datasets/superb) (consulta el [tutorial 🤗 Dataset](https://huggingface.co/docs/datasets/load_hub) para que obtengas más detalles sobre cómo cargar un dataset):
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("superb", "ks")
```
Accede al primer elemento de la columna `audio` para echar un vistazo a la entrada. Al llamar a la columna `audio` se cargará y volverá a muestrear automáticamente el archivo de audio:
```py
>>> dataset["train"][0]["audio"]
{'array': array([ 0. , 0. , 0. , ..., -0.00592041,
-0.00405884, -0.00253296], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/05734a36d88019a09725c20cc024e1c4e7982e37d7d55c0c1ca1742ea1cdd47f/_background_noise_/doing_the_dishes.wav',
'sampling_rate': 16000}
```
Esto devuelve tres elementos:
* `array` es la señal de voz cargada - y potencialmente remuestreada - como un array 1D.
* `path` apunta a la ubicación del archivo de audio.
* `sampling_rate` se refiere a cuántos puntos de datos de la señal de voz se miden por segundo.
### Resample
Para este tutorial, se utilizará el modelo [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base). Como puedes ver en la model card, el modelo Wav2Vec2 está pre-entrenado en audio de voz muestreado a 16kHz. Es importante que la tasa de muestreo de tus datos de audio coincida con la tasa de muestreo del dataset utilizado para pre-entrenar el modelo. Si la tasa de muestreo de tus datos no es la misma, deberás volver a muestrear tus datos de audio.
Por ejemplo, carga el dataset [LJ Speech](https://huggingface.co/datasets/lj_speech) que tiene una tasa de muestreo de 22050kHz. Para utilizar el modelo Wav2Vec2 con este dataset, reduce la tasa de muestreo a 16kHz:
```py
>>> lj_speech = load_dataset("lj_speech", split="train")
>>> lj_speech[0]["audio"]
{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
'sampling_rate': 22050}
```
1. Usa el método 🤗 Datasets' [`cast_column`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.cast_column) para reducir la tasa de muestreo a 16kHz:
```py
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
```
2. Carga el archivo de audio:
```py
>>> lj_speech[0]["audio"]
{'array': array([-0.00064146, -0.00074657, -0.00068768, ..., 0.00068341,
0.00014045, 0. ], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
'sampling_rate': 16000}
```
Como puedes ver, el `sampling_rate` se ha reducido a 16kHz. Ahora que sabes cómo funciona el resampling, volvamos a nuestro ejemplo anterior con el dataset SUPERB.
### Extractor de características
El siguiente paso es cargar un extractor de características para normalizar y aplicar el pad a la entrada. Cuando se aplica padding a los datos textuales, se añade un "0" para las secuencias más cortas. La misma idea se aplica a los datos de audio y el extractor de características de audio añadirá un "0" - interpretado como silencio - al "array".
Carga el extractor de características con [`AutoFeatureExtractor.from_pretrained`]:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
```
Pasa el `array` de audio al extractor de características. También te recomendamos añadir el argumento `sampling_rate` en el extractor de características para poder depurar mejor los errores silenciosos que puedan producirse.
```py
>>> audio_input = [dataset["train"][0]["audio"]["array"]]
>>> feature_extractor(audio_input, sampling_rate=16000)
{'input_values': [array([ 0.00045439, 0.00045439, 0.00045439, ..., -0.1578519 , -0.10807519, -0.06727459], dtype=float32)]}
```
### Pad y truncamiento
Al igual que el tokenizador, puedes aplicar padding o truncamiento para manejar secuencias variables en un batch. Fíjate en la longitud de la secuencia de estas dos muestras de audio:
```py
>>> dataset["train"][0]["audio"]["array"].shape
(1522930,)
>>> dataset["train"][1]["audio"]["array"].shape
(988891,)
```
Como puedes ver, el `sampling_rate` se ha reducido a 16kHz.
```py
>>> def preprocess_function(examples):
... audio_arrays = [x["array"] for x in examples["audio"]]
... inputs = feature_extractor(
... audio_arrays,
... sampling_rate=16000,
... padding=True,
... max_length=1000000,
... truncation=True,
... )
... return inputs
```
Aplica la función a los primeros ejemplos del dataset:
```py
>>> processed_dataset = preprocess_function(dataset["train"][:5])
```
Ahora echa un vistazo a las longitudes de las muestras procesadas:
```py
>>> processed_dataset["input_values"][0].shape
(1000000,)
>>> processed_dataset["input_values"][1].shape
(1000000,)
```
Las longitudes de las dos primeras muestras coinciden ahora con la longitud máxima especificada.
## Visión
También se utiliza un extractor de características para procesar imágenes para tareas de visión por computadora. Una vez más, el objetivo es convertir la imagen en bruto en un batch de tensores como entrada.
Vamos a cargar el dataset [food101](https://huggingface.co/datasets/food101) para este tutorial. Usa el parámetro 🤗 Datasets `split` para cargar solo una pequeña muestra de la división de entrenamiento ya que el dataset es bastante grande:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("food101", split="train[:100]")
```
A continuación, observa la imagen con la función 🤗 Datasets [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image):
```py
>>> dataset[0]["image"]
```

### Extractor de características
Carga el extractor de características con [`AutoFeatureExtractor.from_pretrained`]:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("google/vit-base-patch16-224")
```
### Aumento de Datos
Para las tareas de visión por computadora es común añadir algún tipo de aumento de datos (o data augmentation) a las imágenes como parte del preprocesamiento. Puedes añadir el método de aumento de datos con cualquier librería que quieras, pero en este tutorial utilizarás el módulo [`transforms`](https://pytorch.org/vision/stable/transforms.html) de torchvision.
1. Normaliza la imagen y utiliza [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) para encadenar algunas transformaciones - [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) y [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html) - juntas:
```py
>>> from torchvision.transforms import Compose, Normalize, RandomResizedCrop, ColorJitter, ToTensor
>>> normalize = Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
>>> _transforms = Compose(
... [RandomResizedCrop(feature_extractor.size), ColorJitter(brightness=0.5, hue=0.5), ToTensor(), normalize]
... )
```
2. El modelo acepta [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values) como entrada. Este valor es generado por el extractor de características. Crea una función que genere `pixel_values` a partir de las transformaciones:
```py
>>> def transforms(examples):
... examples["pixel_values"] = [_transforms(image.convert("RGB")) for image in examples["image"]]
... return examples
```
3. A continuación, utiliza 🤗 Datasets [`set_transform`](https://huggingface.co/docs/datasets/process#format-transform) para aplicar las transformaciones sobre la marcha:
```py
>>> dataset.set_transform(transforms)
```
4. Ahora, cuando accedes a la imagen, observarás que el extractor de características ha añadido a la entrada del modelo `pixel_values`:
```py
>>> dataset[0]["image"]
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512 at 0x7F1A7B0630D0>,
'label': 6,
'pixel_values': tensor([[[ 0.0353, 0.0745, 0.1216, ..., -0.9922, -0.9922, -0.9922],
[-0.0196, 0.0667, 0.1294, ..., -0.9765, -0.9843, -0.9922],
[ 0.0196, 0.0824, 0.1137, ..., -0.9765, -0.9686, -0.8667],
...,
[ 0.0275, 0.0745, 0.0510, ..., -0.1137, -0.1216, -0.0824],
[ 0.0667, 0.0824, 0.0667, ..., -0.0588, -0.0745, -0.0980],
[ 0.0353, 0.0353, 0.0431, ..., -0.0039, -0.0039, -0.0588]],
[[ 0.2078, 0.2471, 0.2863, ..., -0.9451, -0.9373, -0.9451],
[ 0.1608, 0.2471, 0.3098, ..., -0.9373, -0.9451, -0.9373],
[ 0.2078, 0.2706, 0.3020, ..., -0.9608, -0.9373, -0.8275],
...,
[-0.0353, 0.0118, -0.0039, ..., -0.2392, -0.2471, -0.2078],
[ 0.0196, 0.0353, 0.0196, ..., -0.1843, -0.2000, -0.2235],
[-0.0118, -0.0039, -0.0039, ..., -0.0980, -0.0980, -0.1529]],
[[ 0.3961, 0.4431, 0.4980, ..., -0.9216, -0.9137, -0.9216],
[ 0.3569, 0.4510, 0.5216, ..., -0.9059, -0.9137, -0.9137],
[ 0.4118, 0.4745, 0.5216, ..., -0.9137, -0.8902, -0.7804],
...,
[-0.2314, -0.1922, -0.2078, ..., -0.4196, -0.4275, -0.3882],
[-0.1843, -0.1686, -0.2000, ..., -0.3647, -0.3804, -0.4039],
[-0.1922, -0.1922, -0.1922, ..., -0.2941, -0.2863, -0.3412]]])}
```
Este es el aspecto de la imagen después de preprocesarla. Como era de esperar por las transformaciones aplicadas, la imagen ha sido recortada aleatoriamente y sus propiedades de color son diferentes.
```py
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> img = dataset[0]["pixel_values"]
>>> plt.imshow(img.permute(1, 2, 0))
```

## Multimodal
Para las tareas multimodales utilizarás una combinación de todo lo que has aprendido hasta ahora y aplicarás tus habilidades a una tarea de reconocimiento automático de voz (ASR). Esto significa que necesitarás un:
* Extractor de características para preprocesar los datos de audio.
* Un tokenizador para procesar el texto.
Volvamos al dataset [LJ Speech](https://huggingface.co/datasets/lj_speech):
```py
>>> from datasets import load_dataset
>>> lj_speech = load_dataset("lj_speech", split="train")
```
Suponiendo que te interesan principalmente las columnas `audio` y `texto`, elimina las demás columnas:
```py
>>> lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
```
Ahora echa un vistazo a las columnas `audio` y `texto`:
```py
>>> lj_speech[0]["audio"]
{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
'sampling_rate': 22050}
>>> lj_speech[0]["text"]
'Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition'
```
Recuerda la sección anterior sobre el procesamiento de datos de audio, siempre debes [volver a muestrear](preprocessing#audio) la tasa de muestreo de tus datos de audio para que coincida con la tasa de muestreo del dataset utilizado para preentrenar un modelo:
```py
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
```
### Processor
Un processor combina un extractor de características y un tokenizador. Cargue un procesador con [`AutoProcessor.from_pretrained]:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
```
1. Crea una función para procesar los datos de audio en `input_values`, y tokeniza el texto en `labels`. Estas son las entradas del modelo:
```py
>>> def prepare_dataset(example):
... audio = example["audio"]
... example.update(processor(audio=audio["array"], text=example["text"], sampling_rate=16000))
... return example
```
2. Aplica la función `prepare_dataset` a una muestra:
```py
>>> prepare_dataset(lj_speech[0])
```
Observa que el método processor ha añadido `input_values` y `labels`. La tasa de muestreo también se ha reducido correctamente a 16kHz.
Genial, ahora deberías ser capaz de preprocesar datos para cualquier modalidad e incluso combinar diferentes modalidades. En el siguiente tutorial, aprenderás aplicar fine tuning a un modelo en tus datos recién preprocesados.
## Todo lo que siempre quisiste saber sobre el padding y el truncamiento
Hemos visto los comandos que funcionarán para la mayoría de los casos (hacer pad a tu batch teniendo en cuenta la longitud de la frase máxima y
truncar a la longitud máxima que el modelo puede aceptar). Sin embargo, la API admite más estrategias si las necesitas. Los
tres argumentos que necesitas conocer para ello son `padding`, `truncation` y `max_length`.
- `padding` controla el aplicarme padding al texto. Puede ser un booleano o una cadena que debe ser:
- `True` o `'longest'` para aplicar el pad hasta la secuencia más larga del batch (no apliques el padding si sólo le proporcionas
una sola secuencia).
- `'max_length'` para aplicar el pad hasta la longitud especificada por el argumento `max_length` o la longitud máxima aceptada
por el modelo si no le proporcionas `longitud_máxima` (`longitud_máxima=None`). Si sólo le proporcionas una única secuencia
se le aplicará el padding.
`False` o `'do_not_pad'` para no aplicar pad a las secuencias. Como hemos visto antes, este es el comportamiento por
defecto.
- `truncation` controla el truncamiento. Puede ser un booleano o una string que debe ser:
- `True` o `'longest_first'` truncan hasta la longitud máxima especificada por el argumento `max_length` o
la longitud máxima aceptada por el modelo si no le proporcionas `max_length` (`max_length=None`). Esto
truncará token por token, eliminando un token de la secuencia más larga del par hasta alcanzar la longitud
adecuada.
- `'only_second'` trunca hasta la longitud máxima especificada por el argumento `max_length` o la
longitud máxima aceptada por el modelo si no le proporcionas `max_length` (`max_length=None`). Esto sólo truncará
la segunda frase de un par si le proporcionas un par de secuencias (o un batch de pares de secuencias).
- `'only_first'` trunca hasta la longitud máxima especificada por el argumento `max_length` o la longitud máxima
aceptada por el modelo si no se proporciona `max_length` (`max_length=None`). Esto sólo truncará
la primera frase de un par si se proporciona un par de secuencias (o un lote de pares de secuencias).
- `False` o `'do_not_truncate'` para no truncar las secuencias. Como hemos visto antes, este es el comportamiento
por defecto.
- `max_length` para controlar la longitud del padding/truncamiento. Puede ser un número entero o `None`, en cuyo caso
será por defecto la longitud máxima que el modelo puede aceptar. Si el modelo no tiene una longitud máxima de entrada específica, el
padding/truncamiento a `longitud_máxima` se desactiva.
A continuación te mostramos en una tabla que resume la forma recomendada de configurar el padding y el truncamiento. Si utilizas un par de secuencias de entrada en
algunos de los siguientes ejemplos, puedes sustituir `truncation=True` por una `STRATEGY` seleccionada en
`['only_first', 'only_second', 'longest_first']`, es decir, `truncation='only_second'` o `truncation= 'longest_first'` para controlar cómo se truncan ambas secuencias del par como se ha detallado anteriormente.
| Truncation | Padding | Instrucciones |
|--------------------------------------|-----------------------------------|---------------------------------------------------------------------------------------------|
| no truncation | no padding | `tokenizer(batch_sentences)` |
| | padding secuencia max del batch | `tokenizer(batch_sentences, padding=True)` or |
| | | `tokenizer(batch_sentences, padding='longest')` |
| | padding long max de input model | `tokenizer(batch_sentences, padding='max_length')` |
| | padding a una long especifica | `tokenizer(batch_sentences, padding='max_length', max_length=42)` |
| truncation long max del input model | no padding | `tokenizer(batch_sentences, truncation=True)` or |
| | | `tokenizer(batch_sentences, truncation=STRATEGY)` |
| | padding secuencia max del batch | `tokenizer(batch_sentences, padding=True, truncation=True)` or |
| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY)` |
| | padding long max de input model | `tokenizer(batch_sentences, padding='max_length', truncation=True)` or |
| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY)` |
| | padding a una long especifica | Not possible |
| truncation a una long especifica | no padding | `tokenizer(batch_sentences, truncation=True, max_length=42)` or |
| | | `tokenizer(batch_sentences, truncation=STRATEGY, max_length=42)` |
| | padding secuencia max del batch | `tokenizer(batch_sentences, padding=True, truncation=True, max_length=42)` or |
| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY, max_length=42)` |
| | padding long max de input model | Not possible |
| | padding a una long especifica | `tokenizer(batch_sentences, padding='max_length', truncation=True, max_length=42)` or |
| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY, max_length=42)` |
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/model_sharing.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Compartir un modelo
Los últimos dos tutoriales mostraron cómo puedes realizar fine-tunning a un modelo con PyTorch, Keras y 🤗 Accelerate para configuraciones distribuidas. ¡El siguiente paso es compartir tu modelo con la comunidad! En Hugging Face creemos en compartir abiertamente a todos el conocimiento y los recursos para democratizar la inteligencia artificial. En este sentido, te animamos a considerar compartir tu modelo con la comunidad, de esta forma ayudas a otros ahorrando tiempo y recursos.
En este tutorial aprenderás dos métodos para compartir un modelo trained o fine-tuned en el [Model Hub](https://huggingface.co/models):
- Mediante Código, enviando (push) tus archivos al Hub.
- Con la interfaz Web, con Drag-and-drop de tus archivos al Hub.
<iframe width="560" height="315" src="https://www.youtube.com/embed/XvSGPZFEjDY" title="YouTube video player"
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
picture-in-picture" allowfullscreen></iframe>
<Tip>
Para compartir un modelo con la comunidad necesitas una cuenta en [huggingface.co](https://huggingface.co/join). También puedes unirte a una organización existente o crear una nueva.
</Tip>
## Características de los repositorios
Cada repositorio en el Model Hub se comporta como cualquier otro repositorio en GitHub. Nuestros repositorios ofrecen versioning, commit history, y la habilidad para visualizar diferencias.
El versioning desarrollado dentro del Model Hub es basado en git y [git-lfs](https://git-lfs.github.com/). En otras palabras, puedes tratar un modelo como un repositorio, brindando un mejor control de acceso y escalabilidad. Version control permite *revisions*, un método para apuntar a una versión específica de un modelo utilizando un commit hash, tag o branch.
Como resultado, puedes cargar una versión específica del modelo con el parámetro `revision`:
```py
>>> model = AutoModel.from_pretrained(
... "julien-c/EsperBERTo-small", revision="v2.0.1" # tag name, or branch name, or commit hash
... )
```
Los archivos son editados fácilmente dentro de un repositorio. Incluso puedes observar el commit history y las diferencias:

## Configuración inicial
Antes de compartir un modelo al Hub necesitarás tus credenciales de Hugging Face. Si tienes acceso a una terminal ejecuta el siguiente comando en el entorno virtual donde 🤗 Transformers esté instalado. Esto guardará tu token de acceso dentro de tu carpeta cache de Hugging Face (~/.cache/ by default):
```bash
huggingface-cli login
```
Si usas un notebook como Jupyter o Colaboratory, asegúrate de tener instalada la biblioteca [`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library). Esta biblioteca te permitirá interactuar por código con el Hub.
```bash
pip install huggingface_hub
```
Luego usa `notebook_login` para iniciar sesión al Hub, y sigue el link [aquí](https://huggingface.co/settings/token) para generar un token con el que iniciaremos sesión:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Convertir un modelo para todos los Frameworks
Para asegurarnos que tu modelo pueda ser usado por alguien que esté trabajando con un framework diferente, te recomendamos convertir y subir tu modelo con checkpoints de pytorch y tensorflow. Aunque los usuarios aún son capaces de cargar su modelo desde un framework diferente, si se omite este paso será más lento debido a que 🤗 Transformers necesitará convertir el checkpoint sobre-la-marcha.
Convertir un checkpoint para otro framework es fácil. Asegúrate tener Pytorch y TensorFlow instalado (Véase [aquí](installation) para instrucciones de instalación), y luego encuentra el modelo específico para tu tarea en el otro Framework.
Por ejemplo, supongamos que has entrenado DistilBert para clasificación de secuencias en PyTorch y quieres convertirlo a su equivalente en TensorFlow. Cargas el equivalente en TensorFlow de tu modelo para tu tarea y especificas `from_pt=True` así 🤗 Transformers convertirá el Pytorch checkpoint a un TensorFlow Checkpoint:
```py
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)
```
Luego guardas tu nuevo modelo TensorFlow con su nuevo checkpoint:
```py
>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")
```
De manera similar, especificas `from_tf=True` para convertir un checkpoint de TensorFlow a Pytorch:
```py
>>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
>>> pt_model.save_pretrained("path/to/awesome-name-you-picked")
```
Si algún modelo está disponible en Flax, también puedes convertir un checkpoint de Pytorch a Flax:
```py
>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
... "path/to/awesome-name-you-picked", from_pt=True
... )
```
## Compartir un modelo con `Trainer`
<Youtube id="Z1-XMy-GNLQ"/>
Compartir un modelo al Hub es tan simple como añadir un parámetro extra o un callback. Si recuerdas del tutorial de [fine-tuning tutorial](training), la clase [`TrainingArguments`] es donde especificas los Hiperparámetros y opciones de entrenamiento adicionales. Una de estas opciones incluye la habilidad de compartir un modelo directamente al Hub. Para ello configuras `push_to_hub=True` dentro de [`TrainingArguments`]:
```py
>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)
```
A continuación, como usualmente, pasa tus argumentos de entrenamiento a [`Trainer`]:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
Luego que realizas fine-tune a tu modelo, llamas [`~transformers.Trainer.push_to_hub`] en [`Trainer`] para enviar el modelo al Hub!🤗 Transformers incluso añadirá automáticamente los Hiperparámetros de entrenamiento, resultados de entrenamiento y versiones del Framework a tu model card!
```py
>>> trainer.push_to_hub()
```
## Compartir un modelo con `PushToHubCallback`
Los usuarios de TensorFlow pueden activar la misma funcionalidad con [`PushToHubCallback`]. En la funcion [`PushToHubCallback`], agrega:
- Un directorio de salida para tu modelo.
- Un tokenizador.
- El `hub_model_id`, el cual es tu usuario Hub y el nombre del modelo.
```py
>>> from transformers import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="./your_model_save_path", tokenizer=tokenizer, hub_model_id="your-username/my-awesome-model"
... )
```
Agregamos el callback a [`fit`](https://keras.io/api/models/model_training_apis/), y 🤗 Transformers enviará el modelo entrenado al Hub:
```py
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
```
## Usando la función `push_to_hub`
Puedes llamar la función `push_to_hub` directamente en tu modelo para subirlo al Hub.
Especifica el nombre del modelo en `push_to_hub`:
```py
>>> pt_model.push_to_hub("my-awesome-model")
```
Esto creará un repositorio bajo tu usuario con el nombre del modelo `my-awesome-model`. Ahora los usuarios pueden cargar tu modelo con la función `from_pretrained`:
```py
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
```
Si perteneces a una organización y quieres compartir tu modelo bajo el nombre de la organización, añade el parámetro `organization`:
```py
>>> pt_model.push_to_hub("my-awesome-model", organization="my-awesome-org")
```
La función `push_to_hub` también puede ser usada para añadir archivos al repositorio del modelo. Por ejemplo, añade un tokenizador al repositorio:
```py
>>> tokenizer.push_to_hub("my-awesome-model")
```
O quizás te gustaría añadir la versión de TensorFlow de tu modelo fine-tuned en Pytorch:
```py
>>> tf_model.push_to_hub("my-awesome-model")
```
Ahora, cuando navegues a tu perfil en Hugging Face, deberías observar el repositorio de tu modelo creado recientemente. Si das click en el tab **Files** observarás todos los archivos que has subido al repositorio.
Para más detalles sobre cómo crear y subir archivos al repositorio, consulta la [documentación del Hub](https://huggingface.co/docs/hub/how-to-upstream).
## Compartir con la interfaz web
Los usuarios que prefieran un enfoque no-code tienen la opción de cargar su modelo a través de la interfaz gráfica del Hub. Visita la página [huggingface.co/new](https://huggingface.co/new) para crear un nuevo repositorio:

Desde aquí, añade información acerca del modelo:
- Selecciona el **owner** (la persona propietaria) del repositorio. Puedes ser tú o cualquier organización a la que pertenezcas.
- Escoge un nombre para tu modelo. También será el nombre del repositorio.
- Elige si tu modelo es público o privado.
- Especifica la licencia que usará tu modelo.
Ahora puedes hacer click en el tab **Files** y luego en el botón **Add file** para subir un nuevo archivo a tu repositorio. Luego arrastra y suelta un archivo a subir y le añades un mensaje al commit.

## Añadiendo una tarjeta de modelo
Para asegurarnos que los usuarios entiendan las capacidades de tu modelo, sus limitaciones, posibles sesgos y consideraciones éticas, por favor añade una tarjeta (como una tarjeta de presentación) al repositorio del modelo. La tarjeta de modelo es definida en el archivo `README.md`. Puedes agregar una de la siguiente manera:
* Elaborando y subiendo manualmente el archivo`README.md`.
* Dando click en el botón **Edit model card** dentro del repositorio.
Toma un momento para ver la [tarjeta de modelo](https://huggingface.co/distilbert-base-uncased) de DistilBert para que tengas un buen ejemplo del tipo de información que debería incluir. Consulta [la documentación](https://huggingface.co/docs/hub/models-cards) para más detalles acerca de otras opciones que puedes controlar dentro del archivo `README.md` como la huella de carbono del modelo o ejemplos de widgets. Consulta la documentación [aquí] (https://huggingface.co/docs/hub/models-cards).
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/create_a_model.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Crea una arquitectura personalizada
Una [`AutoClass`](model_doc/auto) infiere, automáticamente, la arquitectura del modelo y descarga la configuración y los pesos del modelo preentrenado. Normalmente, recomendamos usar una `AutoClass` para producir un código agnóstico a puntos de guardado o checkpoints. Sin embargo, los usuarios que quieran más control sobre los parámetros específicos de los modelos pueden crear su propio modelo 🤗 Transformers personalizado a partir de varias clases base. Esto puede ser particularmente útil para alguien que esté interesado en estudiar, entrenar o experimentar con modelos 🤗 Transformers. En esta guía vamos a profundizar en la creación de modelos personalizados sin usar `AutoClass`. Aprenderemos a:
- Cargar y personalizar una configuración para un modelo.
- Crear una arquitectura para un modelo.
- Crear tokenizadores rápidos y lentos para textos.
- Crear un extractor de propiedades para tareas de audio o imágenes.
- Crear un procesador para tareas multimodales.
## Configuración
Una [configuración](main_classes/configuration) es un conjunto de atributos específicos de un modelo. Cada configuración de modelo tiene atributos diferentes. Por ejemplo, todos los modelos de PLN tienen los atributos `hidden_size`, `num_attention_heads`, `num_hidden_layers` y `vocab_size` en común. Estos atributos especifican el número de cabezas de atención o de capas ocultas con las que se construyen los modelos.
Puedes echarle un vistazo a [DistilBERT](model_doc/distilbert) y sus atributos accediendo a [`DistilBertConfig`]:
```py
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
[`DistilBertConfig`] muestra todos los atributos por defecto que se han usado para construir un modelo [`DistilBertModel`] base. Todos ellos son personalizables, lo que deja espacio para poder experimentar. Por ejemplo, puedes personalizar un modelo predeterminado para:
- Probar una función de activación diferente, usando el parámetro `activation`.
- Usar un valor de abandono (también conocido como _dropout_) más alto para las probabilidades de las capas de atención, usando el parámetro `attention_dropout`.
```py
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
Los atributos de los modelos preentrenados pueden ser modificados con la función [`~PretrainedConfig.from_pretrained`]:
```py
>>> my_config = DistilBertConfig.from_pretrained("distilbert-base-uncased", activation="relu", attention_dropout=0.4)
```
Cuando estés satisfecho con la configuración de tu modelo, puedes guardarlo con la función [`~PretrainedConfig.save_pretrained`]. Tu configuración se guardará en un archivo JSON dentro del directorio que le especifiques como parámetro.
```py
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
```
Para volver a usar el archivo de configuración, puedes cargarlo usando [`~PretrainedConfig.from_pretrained`]:
```py
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
```
<Tip>
También puedes guardar los archivos de configuración como un diccionario; o incluso guardar solo la diferencia entre tu archivo personalizado y la configuración por defecto. Consulta la [documentación sobre configuración](main_classes/configuration) para ver más detalles.
</Tip>
## Modelo
El siguiente paso será crear un [modelo](main_classes/models). El modelo, al que a veces también nos referimos como arquitectura, es el encargado de definir cada capa y qué operaciones se realizan. Los atributos como `num_hidden_layers` de la configuración se usan para definir la arquitectura. Todos los modelos comparten una clase base, [`PreTrainedModel`], y algunos métodos comunes que se pueden usar para redimensionar los _embeddings_ o para recortar cabezas de auto-atención (también llamadas _self-attention heads_). Además, todos los modelos son subclases de [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) o [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html), lo que significa que son compatibles con su respectivo framework.
<frameworkcontent>
<pt>
Carga los atributos de tu configuración personalizada en el modelo de la siguiente forma:
```py
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> model = DistilBertModel(my_config)
```
Esto crea un modelo con valores aleatorios, en lugar de crearlo con los pesos del preentrenamiento, por lo que no serás capaz de usar este modelo para nada útil hasta que no lo entrenes. El entrenamiento es un proceso costoso, tanto en cuestión de recursos como de tiempo, por lo que generalmente es mejor usar un modelo preentrenado para obtener mejores resultados más rápido, consumiendo una fracción de los recursos que un entrenamiento completo hubiera requerido.
Puedes crear un modelo preentrenado con [`~PreTrainedModel.from_pretrained`]:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased")
```
Cuando cargues tus pesos del preentrenamiento, el modelo por defecto se carga automáticamente si nos lo proporciona 🤗 Transformers. Sin embargo, siempre puedes reemplazar (todos o algunos de) los atributos del modelo por defecto por los tuyos:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</pt>
<tf>
Carga los atributos de tu configuración personalizada en el modelo de la siguiente forma:
```py
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)
```
Esto crea un modelo con valores aleatorios, en lugar de crearlo con los pesos del preentrenamiento, por lo que no serás capaz de usar este modelo para nada útil hasta que no lo entrenes. El entrenamiento es un proceso costoso, tanto en cuestión de recursos como de tiempo, por lo que generalmente es mejor usar un modelo preentrenado para obtener mejores resultados más rápido, consumiendo solo una fracción de los recursos que un entrenamiento completo hubiera requerido.
Puedes crear un modelo preentrenado con [`~TFPreTrainedModel.from_pretrained`]:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
```
Cuando cargues tus pesos del preentrenamiento, el modelo por defecto se carga automáticamente si este nos lo proporciona 🤗 Transformers. Sin embargo, siempre puedes reemplazar (todos o algunos de) los atributos del modelo por defecto por los tuyos:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</tf>
</frameworkcontent>
### Cabezas de modelo
En este punto del tutorial, tenemos un modelo DistilBERT base que devuelve los *hidden states* o estados ocultos. Los *hidden states* se pasan como parámetros de entrada a la cabeza del modelo para producir la salida. 🤗 Transformers ofrece una cabeza de modelo diferente para cada tarea, siempre y cuando el modelo sea compatible para la tarea (por ejemplo, no puedes usar DistilBERT para una tarea secuencia a secuencia como la traducción).
<frameworkcontent>
<pt>
Por ejemplo, [`DistilBertForSequenceClassification`] es un modelo DistilBERT base con una cabeza de clasificación de secuencias. La cabeza de clasificación de secuencias es una capa superior que precede a la recolección de las salidas.
```py
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Puedes reutilizar este punto de guardado o *checkpoint* para otra tarea fácilmente cambiando a una cabeza de un modelo diferente. Para una tarea de respuesta a preguntas, puedes usar la cabeza del modelo [`DistilBertForQuestionAnswering`]. La cabeza de respuesta a preguntas es similar a la de clasificación de secuencias, excepto porque consta de una capa lineal delante de la salida de los *hidden states*.
```py
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</pt>
<tf>
Por ejemplo, [`TFDistilBertForSequenceClassification`] es un modelo DistilBERT base con una cabeza de clasificación de secuencias. La cabeza de clasificación de secuencias es una capa superior que precede a la recolección de las salidas.
```py
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Puedes reutilizar este punto de guardado o *checkpoint* para otra tarea fácilmente cambiando a una cabeza de un modelo diferente. Para una tarea de respuesta a preguntas, puedes usar la cabeza del modelo [`TFDistilBertForQuestionAnswering`]. La cabeza de respuesta a preguntas es similar a la de clasificación de secuencias, excepto porque consta de una capa lineal delante de la salida de los *hidden states*.
```py
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</tf>
</frameworkcontent>
## Tokenizer
La ultima clase base que debes conocer antes de usar un modelo con datos textuales es la clase [tokenizer](main_classes/tokenizer), que convierte el texto bruto en tensores. Hay dos tipos de *tokenizers* que puedes usar con 🤗 Transformers:
- [`PreTrainedTokenizer`]: una implementación de un *tokenizer* hecha en Python.
- [`PreTrainedTokenizerFast`]: un *tokenizer* de nuestra librería [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/), basada en Rust. Este tipo de *tokenizer* es bastante más rápido, especialmente durante la tokenización por lotes, gracias a estar implementado en Rust. Esta rápida tokenización también ofrece métodos adicionales como el *offset mapping*, que relaciona los tokens con sus palabras o caracteres originales.
Ambos *tokenizers* son compatibles con los métodos comunes, como los de encodificación y decodificación, los métodos para añadir tokens y aquellos que manejan tokens especiales.
<Tip warning={true}>
No todos los modelos son compatibles con un *tokenizer* rápido. Échale un vistazo a esta [tabla](index#supported-frameworks) para comprobar si un modelo específico es compatible con un *tokenizer* rápido.
</Tip>
Si has entrenado tu propio *tokenizer*, puedes crear uno desde tu archivo de “vocabulario”:
```py
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
```
Es importante recordar que los vocabularios que provienen de un *tokenizer* personalizado serán diferentes a los vocabularios generados por el *tokenizer* de un modelo preentrenado. Debes usar el vocabulario de un *tokenizer* preentrenado si vas a usar un modelo preentrenado, de lo contrario las entradas no tendrán sentido. Crea un *tokenizer* con el vocabulario de un modelo preentrenado usando la clase [`DistilBertTokenizer`]:
```py
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
```
Crea un *tokenizer* rápido con la clase [`DistilBertTokenizerFast`]:
```py
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
```
<Tip>
Por defecto, el [`AutoTokenizer`] intentará cargar un *tokenizer* rápido. Puedes desactivar este comportamiento cambiando el parámetro `use_fast=False` de `from_pretrained`.
</Tip>
## Extractor de Características
Un extractor de características procesa entradas de audio e imagen. Hereda de la clase base [`~feature_extraction_utils.FeatureExtractionMixin`] y también puede heredar de la clase [`ImageFeatureExtractionMixin`] para el procesamiento de características de las imágenes o de la clase [`SequenceFeatureExtractor`] para el procesamiento de entradas de audio.
Dependiendo de si trabajas en una tarea de audio o de video, puedes crear un extractor de características asociado al modelo que estés usando. Por ejemplo, podrías crear un [`ViTFeatureExtractor`] por defecto si estás usando [ViT](model_doc/vit) para clasificación de imágenes:
```py
>>> from transformers import ViTFeatureExtractor
>>> vit_extractor = ViTFeatureExtractor()
>>> print(vit_extractor)
ViTFeatureExtractor {
"do_normalize": true,
"do_resize": true,
"feature_extractor_type": "ViTFeatureExtractor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
<Tip>
Si no estás buscando ninguna personalización en específico, usa el método `from_pretrained` para cargar los parámetros del extractor de características por defecto del modelo.
</Tip>
Puedes modificar cualquier parámetro de [`ViTFeatureExtractor`] para crear tu extractor de características personalizado:
```py
>>> from transformers import ViTFeatureExtractor
>>> my_vit_extractor = ViTFeatureExtractor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTFeatureExtractor {
"do_normalize": false,
"do_resize": true,
"feature_extractor_type": "ViTFeatureExtractor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}
```
Para las entradas de audio, puedes crear un [`Wav2Vec2FeatureExtractor`] y personalizar los parámetros de una forma similar:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
```
## Procesador
Para modelos que son compatibles con tareas multimodales, 🤗 Transformers ofrece una clase *procesador* que agrupa un extractor de características y un *tokenizer* en el mismo objeto. Por ejemplo, probemos a usar el procesador [`Wav2Vec2Processor`] para una tarea de reconocimiento de voz (ASR). Un ASR transcribe el audio a texto, por lo que necesitaremos un extractor de características y un *tokenizer*.
Crea un extractor de características para manejar la entrada de audio:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
```
Crea un *tokenizer* para manejar la entrada de texto:
```py
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
```
Puedes combinar el extractor de características y el *tokenizer* en el [`Wav2Vec2Processor`]:
```py
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
Con dos clases base (la configuración y el modelo) y una clase de preprocesamiento adicional (*tokenizer*, extractor de características o procesador), puedes crear cualquiera de los modelos compatibles con 🤗 Transformers. Cada una de estas clases son configurables, permitiéndote usar sus atributos específicos. Puedes crear un modelo para entrenarlo de una forma fácil, o modificar un modelo preentrenado disponible para especializarlo.
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/installation.md
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Instalación
En esta guía puedes encontrar información para instalar 🤗 Transformers para cualquier biblioteca de Machine Learning con la que estés trabajando. Además, encontrarás información sobre cómo establecer el caché y cómo configurar 🤗 Transformers para correrlo de manera offline (opcional).
🤗 Transformers ha sido probada en Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, y Flax. Para instalar la biblioteca de deep learning con la que desees trabajar, sigue las instrucciones correspondientes listadas a continuación:
* [PyTorch](https://pytorch.org/get-started/locally/)
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip)
* [Flax](https://flax.readthedocs.io/en/latest/)
## Instalación con pip
Es necesario instalar 🤗 Transformers en un [entorno virtual](https://docs.python.org/3/library/venv.html). Si necesitas más información sobre entornos virtuales de Python, consulta esta [guía](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/
). Un entorno virtual facilita el manejo de proyectos y evita problemas de compatibilidad entre dependencias.
Comienza por crear un entorno virtual en el directorio de tu proyecto:
```bash
python -m venv .env
```
Activa el entorno virtual:
```bash
source .env/bin/activate
```
Ahora puedes instalar 🤗 Transformers con el siguiente comando:
```bash
pip install transformers
```
Solo para CPU, puedes instalar 🤗 Transformers y una biblioteca de deep learning con un comando de una sola línea.
Por ejemplo, instala 🤗 Transformers y Pytorch:
```bash
pip install transformers[torch]
```
🤗 Transformers y TensorFlow 2.0:
```bash
pip install transformers[tf-cpu]
```
🤗 Transformers y Flax:
```bash
pip install transformers[flax]
```
Por último, revisa si 🤗 Transformers ha sido instalada exitosamente con el siguiente comando que descarga un modelo pre-entrenado:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
Después imprime la etiqueta y el puntaje:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## Instalación desde la fuente
Instala 🤗 Transformers desde la fuente con el siguiente comando:
```bash
pip install git+https://github.com/huggingface/transformers
```
El comando de arriba instala la versión `master` más actual en vez de la última versión estable. La versión `master` es útil para obtener los últimos avances de 🤗 Transformers. Por ejemplo, se puede dar el caso de que un error fue corregido después de la última versión estable pero aún no se ha liberado un nuevo lanzamiento. Sin embargo, existe la posibilidad de que la versión `master` no sea estable. El equipo trata de mantener la versión `master` operacional y la mayoría de los errores son resueltos en unas cuantas horas o un día. Si encuentras algún problema, por favor abre un [Issue](https://github.com/huggingface/transformers/issues) para que pueda ser corregido más rápido.
Verifica si 🤗 Transformers está instalada apropiadamente con el siguiente comando:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## Instalación editable
Necesitarás una instalación editable si deseas:
* Usar la versión `master` del código fuente.
* Contribuir a 🤗 Transformers y necesitas probar cambios en el código.
Clona el repositorio e instala 🤗 Transformers con los siguientes comandos:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
Éstos comandos van a ligar el directorio desde donde clonamos el repositorio al path de las bibliotecas de Python. Python ahora buscará dentro de la carpeta que clonaste además de los paths normales de la biblioteca. Por ejemplo, si los paquetes de Python se encuentran instalados en `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python también buscará en el directorio desde donde clonamos el repositorio `~/transformers/`.
<Tip warning={true}>
Debes mantener el directorio `transformers` si deseas seguir usando la biblioteca.
</Tip>
Puedes actualizar tu copia local a la última versión de 🤗 Transformers con el siguiente comando:
```bash
cd ~/transformers/
git pull
```
El entorno de Python que creaste para la instalación de 🤗 Transformers encontrará la versión `master` en la siguiente ejecución.
## Instalación con conda
Puedes instalar 🤗 Transformers desde el canal de conda `huggingface` con el siguiente comando:
```bash
conda install -c huggingface transformers
```
## Configuración de Caché
Los modelos preentrenados se descargan y almacenan en caché localmente en: `~/.cache/huggingface/transformers/`. Este es el directorio predeterminado proporcionado por la variable de entorno de shell `TRANSFORMERS_CACHE`. En Windows, el directorio predeterminado es dado por `C:\Users\username\.cache\huggingface\transformers`. Puedes cambiar las variables de entorno de shell que se muestran a continuación, en orden de prioridad, para especificar un directorio de caché diferente:
1. Variable de entorno del shell (por defecto): `TRANSFORMERS_CACHE`.
2. Variable de entorno del shell:`HF_HOME` + `transformers/`.
3. Variable de entorno del shell: `XDG_CACHE_HOME` + `/huggingface/transformers`.
<Tip>
🤗 Transformers usará las variables de entorno de shell `PYTORCH_TRANSFORMERS_CACHE` o `PYTORCH_PRETRAINED_BERT_CACHE` si viene de una iteración anterior de la biblioteca y ha configurado esas variables de entorno, a menos que especifiques la variable de entorno de shell `TRANSFORMERS_CACHE`.
</Tip>
## Modo Offline
🤗 Transformers puede ejecutarse en un entorno con firewall o fuera de línea (offline) usando solo archivos locales. Configura la variable de entorno `TRANSFORMERS_OFFLINE=1` para habilitar este comportamiento.
<Tip>
Puedes añadir [🤗 Datasets](https://huggingface.co/docs/datasets/) al flujo de entrenamiento offline declarando la variable de entorno `HF_DATASETS_OFFLINE=1`.
</Tip>
Por ejemplo, normalmente ejecutarías un programa en una red normal con firewall para instancias externas con el siguiente comando:
```bash
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
Ejecuta este mismo programa en una instancia offline con el siguiente comando:
```bash
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
El script ahora debería ejecutarse sin bloquearse ni esperar a que se agote el tiempo de espera porque sabe que solo debe buscar archivos locales.
### Obtener modelos y tokenizers para uso offline
Otra opción para usar 🤗 Transformers offline es descargando previamente los archivos y después apuntar al path local donde se encuentren. Hay tres maneras de hacer esto:
* Descarga un archivo mediante la interfaz de usuario del [Model Hub](https://huggingface.co/models) haciendo click en el ícono ↓.

* Utiliza el flujo de [`PreTrainedModel.from_pretrained`] y [`PreTrainedModel.save_pretrained`]:
1. Descarga previamente los archivos con [`PreTrainedModel.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. Guarda los archivos en un directorio específico con [`PreTrainedModel.save_pretrained`]:
```py
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
>>> model.save_pretrained("./your/path/bigscience_t0")
```
3. Cuando te encuentres offline, recarga los archivos con [`PreTrainedModel.from_pretrained`] desde el directorio especificado:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
```
* Descarga de manera programática los archivos con la biblioteca [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub):
1. Instala la biblioteca [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) en tu entorno virtual:
```bash
python -m pip install huggingface_hub
```
2. Utiliza la función [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) para descargar un archivo a un path específico. Por ejemplo, el siguiente comando descarga el archivo `config.json` del modelo [T0](https://huggingface.co/bigscience/T0_3B) al path deseado:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
```
Una vez que el archivo se descargue y se almacene en caché localmente, especifica tu ruta local para cargarlo y usarlo:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
```
<Tip>
Para más detalles sobre cómo descargar archivos almacenados en el Hub consulta la sección [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream).
</Tip>
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/philosophy.md
|
<!--Copyright 2020 de The HuggingFace Team. Todos los derechos reservados
Con licencia bajo la Licencia Apache, Versión 2.0 (la "Licencia"); No puedes usar este archivo excepto de conformidad con la Licencia.
Puedes obtener una copia de la Licencia en
http://www.apache.org/licenses/LICENSE-2.0
Al menos que sea requrido por la ley aplicable o acordado por escrito, el software distribuido bajo la Licencia es distribuido sobre una BASE "AS IS", SIN GARANTIAS O CONDICIONES DE
NINGÚN TIPO. Ver la Licencia para el idioma específico que rige los permisos y limitaciones bajo la Licencia.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Filosofía
🤗 Transformers es una biblioteca construida para:
- Los investigadores y educadores de NLP que busquen usar/estudiar/extender modelos transformers a gran escala
- Profesionales que quieren optimizar esos modelos y/o ponerlos en producción
- Ingenieros que solo quieren descargar un modelo preentrenado y usarlo para resolver una tarea NLP dada.
La biblioteca fue diseñada con dos fuertes objetivos en mente:
- Que sea tan fácil y rápida de utilizar como sea posible:
- Hemos limitado enormemente el número de abstracciones que el usuario tiene que aprender. De hecho, no hay casi abstracciones,
solo tres clases estándar necesarias para usar cada modelo: [configuration](main_classes/configuration),
[models](main_classes/model) y [tokenizer](main_classes/tokenizer).
- Todas estas clases pueden ser inicializadas de forma simple y unificada a partir de ejemplos pre-entrenados mediante el uso de un método
`from_pretrained()` común de solicitud que se encargará de descargar (si es necesario), almacenar y cargar la solicitud de clase relacionada y datos asociados
(configurations' hyper-parameters, tokenizers' vocabulary, and models' weights) a partir de un control pre-entrenado proporcionado en
[Hugging Face Hub](https://huggingface.co/models) o de tu propio control guardado.
- Por encima de esas tres clases estándar, la biblioteca proporciona dos APIs: [`pipeline`] para usar rápidamente un modelo (junto a su configuracion y tokenizer asociados)
sobre una tarea dada, y [`Trainer`]/`Keras.fit` para entrenar u optimizar de forma rápida un modelo dado.
- Como consecuencia, esta biblioteca NO es una caja de herramientas modular de bloques individuales para redes neuronales. Si quieres extender/construir sobre la biblioteca,
usa simplemente los módulos regulares de Python/PyTorch/TensorFlow/Keras y emplea las clases estándar de la biblioteca como punto de partida para reutilizar funcionalidades
tales como abrir/guardar modelo.
- Proporciona modelos modernos con rendimientos lo más parecido posible a los modelos originales:
- Proporcionamos al menos un ejemplo para cada arquitectura que reproduce un resultado proporcionado por los autores de dicha arquitectura.
- El código normalmente es parecido al código base original, lo cual significa que algún código Pytorch puede no ser tan
*pytorchic* como podría ser por haber sido convertido a código TensorFlow, y viceversa.
Unos cuantos objetivos adicionales:
- Exponer las características internas de los modelos de la forma más coherente posible:
- Damos acceso, mediante una sola API, a todos los estados ocultos y pesos de atención.
- Tokenizer y el modelo de API base están estandarizados para cambiar fácilmente entre modelos.
- Incorporar una selección subjetiva de herramientas de gran potencial para la optimización/investigación de estos modelos:
- Una forma sencilla/coherente de añadir nuevos tokens al vocabulario e incrustraciones (embeddings, en inglés) para optimización.
- Formas sencillas de camuflar y reducir "transformer heads".
- Cambiar fácilmente entre PyTorch y TensorFlow 2.0, permitiendo el entrenamiento usando un marco y la inferencia usando otro.
## Conceptos principales
La biblioteca está construida alrededor de tres tipos de clases para cada modelo:
- **Model classes** como [`BertModel`], que consisten en más de 30 modelos PyTorch ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)) o modelos Keras ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model)) que funcionan con pesos pre-entrenados proporcionados en la
biblioteca.
- **Configuration classes** como [`BertConfig`], que almacena todos los parámetros necesarios para construir un modelo.
No siempre tienes que generarla tu. En particular, si estas usando un modelo pre-entrenado sin ninguna modificación,
la creación del modelo se encargará automáticamente de generar la configuración (que es parte del modelo).
- **Tokenizer classes** como [`BertTokenizer`], que almacena el vocabulario para cada modelo y proporciona métodos para
codificar/decodificar strings en una lista de índices de "token embeddings" para ser empleados en un modelo.
Todas estas clases pueden ser generadas a partir de ejemplos pre-entrenados, y guardados localmente usando dos métodos:
- `from_pretrained()` permite generar un modelo/configuración/tokenizer a partir de una versión pre-entrenada proporcionada ya sea por
la propia biblioteca (los modelos compatibles se pueden encontrar en [Model Hub](https://huggingface.co/models)) o
guardados localmente (o en un servidor) por el usuario.
- `save_pretrained()` permite guardar un modelo/configuración/tokenizer localmente, de forma que puede ser empleado de nuevo usando
`from_pretrained()`.
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/pipeline_tutorial.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipelines para inferencia
Un [`pipeline`] simplifica el uso de cualquier modelo del [Model Hub](https://huggingface.co/models) para la inferencia en una variedad de tareas como la generación de texto, la segmentación de imágenes y la clasificación de audio. Incluso si no tienes experiencia con una modalidad específica o no comprendes el código que alimenta los modelos, ¡aún puedes usarlos con el [`pipeline`]! Este tutorial te enseñará a:
* Utilizar un [`pipeline`] para inferencia.
* Utilizar un tokenizador o modelo específico.
* Utilizar un [`pipeline`] para tareas de audio y visión.
<Tip>
Echa un vistazo a la documentación de [`pipeline`] para obtener una lista completa de tareas admitidas.
</Tip>
## Uso del pipeline
Si bien cada tarea tiene un [`pipeline`] asociado, es más sencillo usar la abstracción general [`pipeline`] que contiene todos los pipelines de tareas específicas. El [`pipeline`] carga automáticamente un modelo predeterminado y un tokenizador con capacidad de inferencia para tu tarea.
1. Comienza creando un [`pipeline`] y específica una tarea de inferencia:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation")
```
2. Pasa tu texto de entrada al [`pipeline`]:
```py
>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Iron-priests at the door to the east, and thirteen for the Lord Kings at the end of the mountain'}]
```
Si tienes más de una entrada, pásala como una lista:
```py
>>> generator(
... [
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... "Nine for Mortal Men, doomed to die, One for the Dark Lord on his dark throne",
... ]
... )
```
Cualquier parámetro adicional para tu tarea también se puede incluir en el [`pipeline`]. La tarea `text-generation` tiene un método [`~generation.GenerationMixin.generate`] con varios parámetros para controlar la salida. Por ejemplo, si deseas generar más de una salida, defínelo en el parámetro `num_return_sequences`:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... num_return_sequences=2,
... )
```
### Selecciona un modelo y un tokenizador
El [`pipeline`] acepta cualquier modelo del [Model Hub](https://huggingface.co/models). Hay etiquetas en el Model Hub que te permiten filtrar por el modelo que te gustaría utilizar para tu tarea. Una vez que hayas elegido un modelo apropiado, cárgalo con la clase `AutoModelFor` y [`AutoTokenizer`] correspondientes. Por ejemplo, carga la clase [`AutoModelForCausalLM`] para una tarea de modelado de lenguaje causal:
```py
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
```
Crea un [`pipeline`] para tu tarea y específica el modelo y el tokenizador que cargaste:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
```
Pasa tu texto de entrada a [`pipeline`] para generar algo de texto:
```py
>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Dragon-lords (for them to rule in a world ruled by their rulers, and all who live within the realm'}]
```
## Pipeline de audio
La flexibilidad de [`pipeline`] significa que también se puede extender a tareas de audio.
Por ejemplo, clasifiquemos la emoción de un breve fragmento del famoso discurso de John F. Kennedy ["We choose to go to the Moon"](https://en.wikipedia.org/wiki/We_choose_to_go_to_the_Moon). Encuentra un modelo de [audio classification](https://huggingface.co/models?pipeline_tag=audio-classification) para reconocimiento de emociones en el Model Hub y cárgalo en el [`pipeline`]:
```py
>>> from transformers import pipeline
>>> audio_classifier = pipeline(
... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
Pasa el archivo de audio al [`pipeline`]:
```py
>>> audio_classifier("jfk_moon_speech.wav")
[{'label': 'calm', 'score': 0.13856211304664612},
{'label': 'disgust', 'score': 0.13148026168346405},
{'label': 'happy', 'score': 0.12635163962841034},
{'label': 'angry', 'score': 0.12439591437578201},
{'label': 'fearful', 'score': 0.12404385954141617}]
```
## Pipeline de visión
Finalmente, utilizar un [`pipeline`] para tareas de visión es prácticamente igual.
Específica tu tarea de visión y pasa tu imagen al clasificador. La imagen puede ser un enlace o una ruta local a la imagen. Por ejemplo, ¿qué especie de gato se muestra a continuación?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(task="image-classification")
>>> vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
[{'label': 'lynx, catamount', 'score': 0.4403027892112732},
{'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor',
'score': 0.03433405980467796},
{'label': 'snow leopard, ounce, Panthera uncia',
'score': 0.032148055732250214},
{'label': 'Egyptian cat', 'score': 0.02353910356760025},
{'label': 'tiger cat', 'score': 0.023034192621707916}]
```
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/_toctree.yml
|
- sections:
- local: index
title: 🤗 Transformers
- local: quicktour
title: Tour rápido
- local: installation
title: Instalación
title: Empezar
- sections:
- local: pipeline_tutorial
title: Pipelines para inferencia
- local: autoclass_tutorial
title: Carga instancias preentrenadas con un AutoClass
- local: preprocessing
title: Preprocesamiento
- local: training
title: Fine-tuning a un modelo pre-entrenado
- local: accelerate
title: Entrenamiento distribuido con 🤗 Accelerate
- local: model_sharing
title: Compartir un modelo
title: Tutoriales
- sections:
- sections:
- local: create_a_model
title: Crea una arquitectura personalizada
- local: custom_models
title: Compartir modelos personalizados
- local: run_scripts
title: Entrenamiento con scripts
- local: sagemaker
title: Ejecutar el entrenamiento en Amazon SageMaker
- local: converting_tensorflow_models
title: Convertir checkpoints de TensorFlow
- local: serialization
title: Exportar a ONNX
title: Uso general
- sections:
- local: fast_tokenizers
title: Usa tokenizadores de 🤗 Tokenizers
- local: multilingual
title: Modelos multilingües para inferencia
- sections:
- local: tasks/question_answering
title: Respuesta a preguntas
- local: tasks/language_modeling
title: Modelado de lenguaje
- local: tasks/summarization
title: Generación de resúmenes
- local: tasks/multiple_choice
title: Selección múltiple
title: Guías de tareas
title: Procesamiento del Lenguaje Natural
- sections:
- local: tasks/asr
title: Reconocimiento automático del habla
title: Audio
- sections:
- local: tasks/image_classification
title: Clasificación de imágenes
title: Visión Artificial
- sections:
- local: debugging
title: Debugging
title: Rendimiento y escalabilidad
- sections:
- local: add_new_pipeline
title: ¿Cómo puedo añadir un pipeline a 🤗 Transformers?
- local: pr_checks
title: Verificaciones en un Pull Request
title: Contribuir
- local: community
title: Los recursos de la comunidad
title: Guías prácticas
- sections:
- local: philosophy
title: Filosofía
- local: bertology
title: BERTología
title: Guías conceptuales
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/run_scripts.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Entrenamiento con scripts
Junto con los [notebooks](./noteboks/README) de 🤗 Transformers, también hay scripts con ejemplos que muestran cómo entrenar un modelo para una tarea en [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), o [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
También encontrarás scripts que hemos usado en nuestros [proyectos de investigación](https://github.com/huggingface/transformers/tree/main/examples/research_projects) y [ejemplos pasados](https://github.com/huggingface/transformers/tree/main/examples/legacy) que en su mayoría son aportados por la comunidad. Estos scripts no se mantienen activamente y requieren una versión específica de 🤗 Transformers que probablemente sea incompatible con la última versión de la biblioteca.
No se espera que los scripts de ejemplo funcionen de inmediato en todos los problemas, y es posible que debas adaptar el script al problema que estás tratando de resolver. Para ayudarte con esto, la mayoría de los scripts exponen completamente cómo se preprocesan los datos, lo que te permite editarlos según sea necesario para tu caso de uso.
Para cualquier característica que te gustaría implementar en un script de ejemplo, por favor discútelo en el [foro](https://discuss.huggingface.co/) o con un [issue](https://github.com/huggingface/transformers/issues) antes de enviar un Pull Request. Si bien agradecemos las correcciones de errores, es poco probable que fusionemos un Pull Request que agregue más funcionalidad a costa de la legibilidad.
Esta guía te mostrará cómo ejecutar un ejemplo de un script de entrenamiento para resumir texto en [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) y [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). Se espera que todos los ejemplos funcionen con ambos frameworks a menos que se especifique lo contrario.
## Configuración
Para ejecutar con éxito la última versión de los scripts de ejemplo debes **instalar 🤗 Transformers desde su fuente** en un nuevo entorno virtual:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
Para versiones anteriores de los scripts de ejemplo, haz clic en alguno de los siguientes links:
<details>
<summary>Ejemplos de versiones anteriores de 🤗 Transformers</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
Luego cambia tu clon actual de 🤗 Transformers a una versión específica, por ejemplo v3.5.1:
```bash
git checkout tags/v3.5.1
```
Una vez que hayas configurado la versión correcta de la biblioteca, ve a la carpeta de ejemplo de tu elección e instala los requisitos específicos del ejemplo:
```bash
pip install -r requirements.txt
```
## Ejecutar un script
<frameworkcontent>
<pt>
El script de ejemplo descarga y preprocesa un conjunto de datos de la biblioteca 🤗 [Datasets](https://huggingface.co/docs/datasets/). Luego, el script ajusta un conjunto de datos con [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) en una arquitectura que soporta la tarea de resumen. El siguiente ejemplo muestra cómo ajustar un [T5-small](https://huggingface.co/t5-small) en el conjunto de datos [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). El modelo T5 requiere un argumento adicional `source_prefix` debido a cómo fue entrenado. Este aviso le permite a T5 saber que se trata de una tarea de resumir.
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
El script de ejemplo descarga y preprocesa un conjunto de datos de la biblioteca 🤗 [Datasets](https://huggingface.co/docs/datasets/). Luego, el script ajusta un conjunto de datos utilizando Keras en una arquitectura que soporta la tarea de resumir. El siguiente ejemplo muestra cómo ajustar un [T5-small](https://huggingface.co/t5-small) en el conjunto de datos [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). El modelo T5 requiere un argumento adicional `source_prefix` debido a cómo fue entrenado. Este aviso le permite a T5 saber que se trata de una tarea de resumir.
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Entrenamiento distribuido y de precisión mixta
[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) admite un entrenamiento distribuido y de precisión mixta, lo que significa que también puedes usarlo en un script. Para habilitar ambas características:
- Agrega el argumento `fp16` para habilitar la precisión mixta.
- Establece la cantidad de GPU que se usará con el argumento `nproc_per_node`.
```bash
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
Los scripts de TensorFlow utilizan [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) para el entrenamiento distribuido, y no es necesario agregar argumentos adicionales al script de entrenamiento. El script de TensorFlow utilizará múltiples GPUs de forma predeterminada si están disponibles.
## Ejecutar un script en una TPU
<frameworkcontent>
<pt>
Las Unidades de Procesamiento de Tensor (TPUs) están diseñadas específicamente para acelerar el rendimiento. PyTorch admite TPU con el compilador de aprendizaje profundo [XLA](https://www.tensorflow.org/xla) (consulta [aquí](https://github.com/pytorch/xla/blob/master/README.md) para obtener más detalles). Para usar una TPU, inicia el script `xla_spawn.py` y usa el argumento `num_cores` para establecer la cantidad de núcleos de TPU que deseas usar.
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
Las Unidades de Procesamiento de Tensor (TPUs) están diseñadas específicamente para acelerar el rendimiento. TensorFlow utiliza [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) para entrenar en TPUs. Para usar una TPU, pasa el nombre del recurso de la TPU al argumento `tpu`
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Ejecutar un script con 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate) es una biblioteca exclusiva de PyTorch que ofrece un método unificado para entrenar un modelo en varios tipos de configuraciones (solo CPU, GPU múltiples, TPU) mientras mantiene una visibilidad completa en el ciclo de entrenamiento de PyTorch. Asegúrate de tener 🤗 Accelerate instalado si aún no lo tienes:
> Nota: Como Accelerate se está desarrollando rápidamente, debes instalar la versión git de Accelerate para ejecutar los scripts
```bash
pip install git+https://github.com/huggingface/accelerate
```
En lugar del script `run_summarization.py`, debes usar el script `run_summarization_no_trainer.py`. Los scripts compatibles con 🤗 Accelerate tendrán un archivo `task_no_trainer.py` en la carpeta. Comienza ejecutando el siguiente comando para crear y guardar un archivo de configuración:
```bash
accelerate config
```
Prueba tu configuración para asegurarte que está configurada correctamente:
```bash
accelerate test
```
Todo listo para iniciar el entrenamiento:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## Usar un conjunto de datos personalizado
El script de la tarea resumir admite conjuntos de datos personalizados siempre que sean un archivo CSV o JSON Line. Cuando uses tu propio conjunto de datos, necesitas especificar varios argumentos adicionales:
- `train_file` y `validation_file` especifican la ruta a tus archivos de entrenamiento y validación.
- `text_column` es el texto de entrada para resumir.
- `summary_column` es el texto de destino para la salida.
Un script para resumir que utiliza un conjunto de datos personalizado se vera así:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## Prueba un script
A veces, es una buena idea ejecutar tu secuencia de comandos en una cantidad menor de ejemplos para asegurarte de que todo funciona como se espera antes de comprometerte con un conjunto de datos completo, lo que puede demorar horas en completarse. Utiliza los siguientes argumentos para truncar el conjunto de datos a un número máximo de muestras:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
No todos los scripts de ejemplo admiten el argumento `max_predict_samples`. Puede que desconozcas si la secuencia de comandos admite este argumento, agrega `-h` para verificar:
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## Reanudar el entrenamiento desde el punto de control
Otra opción útil para habilitar es reanudar el entrenamiento desde un punto de control anterior. Esto asegurará que puedas continuar donde lo dejaste sin comenzar de nuevo si tu entrenamiento se interrumpe. Hay dos métodos para reanudar el entrenamiento desde un punto de control.
El primer método utiliza el argumento `output_dir previous_output_dir` para reanudar el entrenamiento desde el último punto de control almacenado en `output_dir`. En este caso, debes eliminar `overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
El segundo método utiliza el argumento `resume_from_checkpoint path_to_specific_checkpoint` para reanudar el entrenamiento desde una carpeta de punto de control específica.
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## Comparte tu modelo
Todos los scripts pueden cargar tu modelo final en el [Model Hub](https://huggingface.co/models). Asegúrate de haber iniciado sesión en Hugging Face antes de comenzar:
```bash
huggingface-cli login
```
Luego agrega el argumento `push_to_hub` al script. Este argumento creará un repositorio con tu nombre de usuario Hugging Face y el nombre de la carpeta especificado en `output_dir`.
Para darle a tu repositorio un nombre específico, usa el argumento `push_to_hub_model_id` para añadirlo. El repositorio se incluirá automáticamente en tu namespace.
El siguiente ejemplo muestra cómo cargar un modelo con un nombre de repositorio específico:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/_config.py
|
# docstyle-ignore
INSTALL_CONTENT = """
# Transformers installation
! pip install transformers datasets
# To install from source instead of the last release, comment the command above and uncomment the following one.
# ! pip install git+https://github.com/huggingface/transformers.git
"""
notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
black_avoid_patterns = {
"{processor_class}": "FakeProcessorClass",
"{model_class}": "FakeModelClass",
"{object_class}": "FakeObjectClass",
}
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/serialization.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Exportar modelos 🤗 Transformers
Si necesitas implementar modelos 🤗 Transformers en entornos de producción, te
recomendamos exportarlos a un formato serializado que se pueda cargar y ejecutar
en tiempos de ejecución y hardware especializados. En esta guía, te mostraremos cómo
exportar modelos 🤗 Transformers en dos formatos ampliamente utilizados: ONNX y TorchScript.
Una vez exportado, un modelo puede optimizarse para la inferencia a través de técnicas
como la cuantización y _pruning_. Si estás interesado en optimizar tus modelos para
que funcionen con la máxima eficiencia, consulta la
[biblioteca de 🤗 Optimum](https://github.com/huggingface/optimum).
## ONNX
El proyecto [ONNX (Open Neural Network eXchange)](http://onnx.ai) es un
estándar abierto que define un conjunto común de operadores y un formato
de archivo común para representar modelos de aprendizaje profundo en una
amplia variedad de _frameworks_, incluidos PyTorch y TensorFlow. Cuando un modelo
se exporta al formato ONNX, estos operadores se usan para construir un
grafo computacional (a menudo llamado _representación intermedia_) que
representa el flujo de datos a través de la red neuronal.
Al exponer un grafo con operadores y tipos de datos estandarizados, ONNX facilita
el cambio entre frameworks. Por ejemplo, un modelo entrenado en PyTorch se puede
exportar a formato ONNX y luego importar en TensorFlow (y viceversa).
🤗 Transformers proporciona un paquete llamado `transformers.onnx`, el cual permite convertir
los checkpoints de un modelo en un grafo ONNX aprovechando los objetos de configuración.
Estos objetos de configuración están hechos a la medida de diferentes arquitecturas de modelos
y están diseñados para ser fácilmente extensibles a otras arquitecturas.
Las configuraciones a la medida incluyen las siguientes arquitecturas:
<!--This table is automatically generated by `make fix-copies`, do not fill manually!-->
- ALBERT
- BART
- BEiT
- BERT
- BigBird
- BigBird-Pegasus
- Blenderbot
- BlenderbotSmall
- BLOOM
- CamemBERT
- CLIP
- CodeGen
- ConvBERT
- ConvNeXT
- ConvNeXTV2
- Data2VecText
- Data2VecVision
- DeBERTa
- DeBERTa-v2
- DeiT
- DETR
- DistilBERT
- ELECTRA
- FlauBERT
- GPT Neo
- GPT-J
- I-BERT
- LayoutLM
- LayoutLMv3
- LeViT
- LongT5
- M2M100
- Marian
- mBART
- MobileBERT
- MobileViT
- MT5
- OpenAI GPT-2
- Perceiver
- PLBart
- ResNet
- RoBERTa
- RoFormer
- SqueezeBERT
- T5
- ViT
- XLM
- XLM-RoBERTa
- XLM-RoBERTa-XL
- YOLOS
En las próximas dos secciones, te mostraremos cómo:
* Exportar un modelo compatible utilizando el paquete `transformers.onnx`.
* Exportar un modelo personalizado para una arquitectura no compatible.
### Exportar un model a ONNX
Para exportar un modelo 🤗 Transformers a ONNX, tienes que instalar primero algunas
dependencias extra:
```bash
pip install transformers[onnx]
```
El paquete `transformers.onnx` puede ser usado luego como un módulo de Python:
```bash
python -m transformers.onnx --help
usage: Hugging Face Transformers ONNX exporter [-h] -m MODEL [--feature {causal-lm, ...}] [--opset OPSET] [--atol ATOL] output
positional arguments:
output Path indicating where to store generated ONNX model.
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
Model ID on huggingface.co or path on disk to load model from.
--feature {causal-lm, ...}
The type of features to export the model with.
--opset OPSET ONNX opset version to export the model with.
--atol ATOL Absolute difference tolerence when validating the model.
```
Exportar un checkpoint usando una configuración a la medida se puede hacer de la siguiente manera:
```bash
python -m transformers.onnx --model=distilbert-base-uncased onnx/
```
que debería mostrar los siguientes registros:
```bash
Validating ONNX model...
-[✓] ONNX model output names match reference model ({'last_hidden_state'})
- Validating ONNX Model output "last_hidden_state":
-[✓] (2, 8, 768) matches (2, 8, 768)
-[✓] all values close (atol: 1e-05)
All good, model saved at: onnx/model.onnx
```
Esto exporta un grafo ONNX del checkpoint definido por el argumento `--model`.
En este ejemplo, es un modelo `distilbert-base-uncased`, pero puede ser cualquier
checkpoint en Hugging Face Hub o que esté almacenado localmente.
El archivo `model.onnx` resultante se puede ejecutar en uno de los
[muchos aceleradores](https://onnx.ai/supported-tools.html#deployModel)
que admiten el estándar ONNX. Por ejemplo, podemos cargar y ejecutar el
modelo con [ONNX Runtime](https://onnxruntime.ai/) de la siguiente manera:
```python
>>> from transformers import AutoTokenizer
>>> from onnxruntime import InferenceSession
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> session = InferenceSession("onnx/model.onnx")
>>> # ONNX Runtime expects NumPy arrays as input
>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
```
Los nombres necesarios de salida (es decir, `["last_hidden_state"]`) se pueden obtener
echando un vistazo a la configuración ONNX de cada modelo. Por ejemplo, para DistilBERT tenemos:
```python
>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
>>> config = DistilBertConfig()
>>> onnx_config = DistilBertOnnxConfig(config)
>>> print(list(onnx_config.outputs.keys()))
["last_hidden_state"]s
```
El proceso es idéntico para los checkpoints de TensorFlow en Hub.
Por ejemplo, podemos exportar un checkpoint puro de TensorFlow desde
[Keras](https://huggingface.co/keras-io) de la siguiente manera:
```bash
python -m transformers.onnx --model=keras-io/transformers-qa onnx/
```
Para exportar un modelo que está almacenado localmente, deberás tener los pesos
y tokenizadores del modelo almacenados en un directorio. Por ejemplo, podemos cargar
y guardar un checkpoint de la siguiente manera:
<frameworkcontent>
<pt>
```python
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> # Load tokenizer and PyTorch weights form the Hub
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
>>> # Save to disk
>>> tokenizer.save_pretrained("local-pt-checkpoint")
>>> pt_model.save_pretrained("local-pt-checkpoint")
```
Una vez que se guarda el checkpoint, podemos exportarlo a ONNX usando el argumento `--model`
del paquete `transformers.onnx` al directorio deseado:
```bash
python -m transformers.onnx --model=local-pt-checkpoint onnx/
```
</pt>
<tf>
```python
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> # Load tokenizer and TensorFlow weights from the Hub
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
>>> # Save to disk
>>> tokenizer.save_pretrained("local-tf-checkpoint")
>>> tf_model.save_pretrained("local-tf-checkpoint")
```
Una vez que se guarda el checkpoint, podemos exportarlo a ONNX usando el argumento `--model`
del paquete `transformers.onnx` al directorio deseado:
```bash
python -m transformers.onnx --model=local-tf-checkpoint onnx/
```
</tf>
</frameworkcontent>
### Seleccionar características para diferentes topologías de un modelo
Cada configuración a la medida viene con un conjunto de _características_ que te permiten exportar
modelos para diferentes tipos de topologías o tareas. Como se muestra en la siguiente tabla, cada
función está asociada con una auto-clase de automóvil diferente:
| Feature | Auto Class |
| ------------------------------------ | ------------------------------------ |
| `causal-lm`, `causal-lm-with-past` | `AutoModelForCausalLM` |
| `default`, `default-with-past` | `AutoModel` |
| `masked-lm` | `AutoModelForMaskedLM` |
| `question-answering` | `AutoModelForQuestionAnswering` |
| `seq2seq-lm`, `seq2seq-lm-with-past` | `AutoModelForSeq2SeqLM` |
| `sequence-classification` | `AutoModelForSequenceClassification` |
| `token-classification` | `AutoModelForTokenClassification` |
Para cada configuración, puedes encontrar la lista de funciones admitidas a través de `FeaturesManager`.
Por ejemplo, para DistilBERT tenemos:
```python
>>> from transformers.onnx.features import FeaturesManager
>>> distilbert_features = list(FeaturesManager.get_supported_features_for_model_type("distilbert").keys())
>>> print(distilbert_features)
["default", "masked-lm", "causal-lm", "sequence-classification", "token-classification", "question-answering"]
```
Le puedes pasar una de estas características al argumento `--feature` en el paquete `transformers.onnx`.
Por ejemplo, para exportar un modelo de clasificación de texto, podemos elegir un modelo ya ajustado del Hub y ejecutar:
```bash
python -m transformers.onnx --model=distilbert-base-uncased-finetuned-sst-2-english \
--feature=sequence-classification onnx/
```
que mostrará los siguientes registros:
```bash
Validating ONNX model...
-[✓] ONNX model output names match reference model ({'logits'})
- Validating ONNX Model output "logits":
-[✓] (2, 2) matches (2, 2)
-[✓] all values close (atol: 1e-05)
All good, model saved at: onnx/model.onnx
```
Ten en cuenta que, en este caso, los nombres de salida del modelo ajustado son `logits` en lugar de `last_hidden_state`
que vimos anteriormente con el checkpoint `distilbert-base-uncased`. Esto es de esperarse ya que el modelo ajustado
tiene un cabezal de clasificación secuencial.
<Tip>
Las características que tienen un sufijo 'with-past' (por ejemplo, 'causal-lm-with-past') corresponden a topologías
de modelo con estados ocultos precalculados (clave y valores en los bloques de atención) que se pueden usar para una
decodificación autorregresiva más rápida.
</Tip>
### Exportar un modelo para una arquitectura no compatible
Si deseas exportar un modelo cuya arquitectura no es compatible de forma nativa
con la biblioteca, debes seguir tres pasos principales:
1. Implementa una configuración personalizada en ONNX.
2. Exporta el modelo a ONNX.
3. Valide los resultados de PyTorch y los modelos exportados.
En esta sección, veremos cómo se implementó la serialización de DistilBERT
para mostrar lo que implica cada paso.
#### Implementar una configuración personalizada en ONNX
Comencemos con el objeto de configuración de ONNX. Proporcionamos tres clases abstractas
de las que debe heredar, según el tipo de arquitectura del modelo que quieras exportar:
* Modelos basados en el _Encoder_ inherente de [`~onnx.config.OnnxConfig`]
* Modelos basados en el _Decoder_ inherente de [`~onnx.config.OnnxConfigWithPast`]
* Modelos _Encoder-decoder_ inherente de [`~onnx.config.OnnxSeq2SeqConfigWithPast`]
<Tip>
Una buena manera de implementar una configuración personalizada en ONNX es observar la implementación
existente en el archivo `configuration_<model_name>.py` de una arquitectura similar.
</Tip>
Dado que DistilBERT es un modelo de tipo _encoder_, su configuración se hereda de `OnnxConfig`:
```python
>>> from typing import Mapping, OrderedDict
>>> from transformers.onnx import OnnxConfig
>>> class DistilBertOnnxConfig(OnnxConfig):
... @property
... def inputs(self) -> Mapping[str, Mapping[int, str]]:
... return OrderedDict(
... [
... ("input_ids", {0: "batch", 1: "sequence"}),
... ("attention_mask", {0: "batch", 1: "sequence"}),
... ]
... )
```
Cada objeto de configuración debe implementar la propiedad `inputs` y devolver un mapeo,
donde cada llave corresponde a una entrada esperada y cada valor indica el eje de esa entrada.
Para DistilBERT, podemos ver que se requieren dos entradas: `input_ids` y `attention_mask`.
Estas entradas tienen la misma forma de `(batch_size, sequence_length)`, es por lo que vemos
los mismos ejes utilizados en la configuración.
<Tip>
Observa que la propiedad `inputs` para `DistilBertOnnxConfig` devuelve un `OrderedDict`.
Esto nos asegura que las entradas coincidan con su posición relativa dentro del método
`PreTrainedModel.forward()` al rastrear el grafo. Recomendamos usar un `OrderedDict`
para las propiedades `inputs` y `outputs` al implementar configuraciones ONNX personalizadas.
</Tip>
Una vez que hayas implementado una configuración ONNX, puedes crear una
instancia proporcionando la configuración del modelo base de la siguiente manera:
```python
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("distilbert-base-uncased")
>>> onnx_config = DistilBertOnnxConfig(config)
```
El objeto resultante tiene varias propiedades útiles. Por ejemplo, puedes ver el conjunto de operadores ONNX que se
utilizará durante la exportación:
```python
>>> print(onnx_config.default_onnx_opset)
11
```
También puedes ver los resultados asociados con el modelo de la siguiente manera:
```python
>>> print(onnx_config.outputs)
OrderedDict([("last_hidden_state", {0: "batch", 1: "sequence"})])
```
Observa que la propiedad de salidas sigue la misma estructura que las entradas;
devuelve un objecto `OrderedDict` de salidas nombradas y sus formas. La estructura
de salida está vinculada a la elección de la función con la que se inicializa la configuración.
Por defecto, la configuración de ONNX se inicializa con la función `default` que
corresponde a exportar un modelo cargado con la clase `AutoModel`. Si quieres exportar
una topología de modelo diferente, simplemente proporciona una característica diferente
al argumento `task` cuando inicialices la configuración de ONNX. Por ejemplo, si quisiéramos
exportar DistilBERT con un cabezal de clasificación de secuencias, podríamos usar:
```python
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("distilbert-base-uncased")
>>> onnx_config_for_seq_clf = DistilBertOnnxConfig(config, task="sequence-classification")
>>> print(onnx_config_for_seq_clf.outputs)
OrderedDict([('logits', {0: 'batch'})])
```
<Tip>
Todas las propiedades base y métodos asociados con [`~onnx.config.OnnxConfig`] y las
otras clases de configuración se pueden sobreescribir si es necesario.
Consulte [`BartOnnxConfig`] para ver un ejemplo avanzado.
</Tip>
#### Exportar el modelo
Una vez que hayas implementado la configuración de ONNX, el siguiente paso es exportar el modelo.
Aquí podemos usar la función `export()` proporcionada por el paquete `transformers.onnx`.
Esta función espera la configuración de ONNX, junto con el modelo base y el tokenizador,
y la ruta para guardar el archivo exportado:
```python
>>> from pathlib import Path
>>> from transformers.onnx import export
>>> from transformers import AutoTokenizer, AutoModel
>>> onnx_path = Path("model.onnx")
>>> model_ckpt = "distilbert-base-uncased"
>>> base_model = AutoModel.from_pretrained(model_ckpt)
>>> tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
>>> onnx_inputs, onnx_outputs = export(tokenizer, base_model, onnx_config, onnx_config.default_onnx_opset, onnx_path)
```
Los objetos `onnx_inputs` y `onnx_outputs` devueltos por la función `export()`
son listas de llaves definidas en las propiedades `inputs` y `outputs` de la configuración.
Una vez exportado el modelo, puedes probar que el modelo está bien formado de la siguiente manera:
```python
>>> import onnx
>>> onnx_model = onnx.load("model.onnx")
>>> onnx.checker.check_model(onnx_model)
```
<Tip>
Si tu modelo tiene más de 2GB, verás que se crean muchos archivos adicionales durante la exportación.
Esto es _esperado_ porque ONNX usa [Búferes de protocolo](https://developers.google.com/protocol-buffers/)
para almacenar el modelo y éstos tienen un límite de tamaño de 2 GB. Consulta la
[documentación de ONNX](https://github.com/onnx/onnx/blob/master/docs/ExternalData.md) para obtener
instrucciones sobre cómo cargar modelos con datos externos.
</Tip>
#### Validar los resultados del modelo
El paso final es validar que los resultados del modelo base y exportado coincidan dentro
de cierta tolerancia absoluta. Aquí podemos usar la función `validate_model_outputs()`
proporcionada por el paquete `transformers.onnx` de la siguiente manera:
```python
>>> from transformers.onnx import validate_model_outputs
>>> validate_model_outputs(
... onnx_config, tokenizer, base_model, onnx_path, onnx_outputs, onnx_config.atol_for_validation
... )
```
Esta función usa el método `OnnxConfig.generate_dummy_inputs()` para generar entradas para el modelo base
y exportado, y la tolerancia absoluta se puede definir en la configuración. En general, encontramos una
concordancia numérica en el rango de 1e-6 a 1e-4, aunque es probable que cualquier valor menor que 1e-3 esté bien.
### Contribuir con una nueva configuración a 🤗 Transformers
¡Estamos buscando expandir el conjunto de configuraciones a la medida para usar y agradecemos las contribuciones de la comunidad!
Si deseas contribuir con su colaboración a la biblioteca, deberás:
* Implementa la configuración de ONNX en el archivo `configuration_<model_name>.py` correspondiente
* Incluye la arquitectura del modelo y las características correspondientes en [`~onnx.features.FeatureManager`]
* Agrega tu arquitectura de modelo a las pruebas en `test_onnx_v2.py`
Revisa cómo fue la contribución para la [configuración de IBERT](https://github.com/huggingface/transformers/pull/14868/files)
y así tener una idea de lo que necesito.
## TorchScript
<Tip>
Este es el comienzo de nuestros experimentos con TorchScript y todavía estamos explorando sus capacidades con modelos de
tamaño de entrada variable. Es un tema de interés y profundizaremos nuestro análisis en las próximas
versiones, con más ejemplos de código, una implementación más flexible y puntos de referencia que comparen códigos
basados en Python con TorchScript compilado.
</Tip>
Según la documentación de PyTorch: "TorchScript es una forma de crear modelos serializables y optimizables a partir del
código de PyTorch". Los dos módulos de Pytorch [JIT y TRACE](https://pytorch.org/docs/stable/jit.html) permiten al
desarrollador exportar su modelo para reutilizarlo en otros programas, como los programas C++ orientados a la eficiencia.
Hemos proporcionado una interfaz que permite exportar modelos de 🤗 Transformers a TorchScript para que puedan reutilizarse
en un entorno diferente al de un programa Python basado en PyTorch. Aquí explicamos cómo exportar y usar nuestros modelos
usando TorchScript.
Exportar un modelo requiere de dos cosas:
- un pase hacia adelante con entradas ficticias.
- instanciación del modelo con la indicador `torchscript`.
Estas necesidades implican varias cosas con las que los desarrolladores deben tener cuidado. Éstas se detallan a continuación.
### Indicador de TorchScript y pesos atados
Este indicador es necesario porque la mayoría de los modelos de lenguaje en este repositorio tienen pesos vinculados entre su capa
de `Embedding` y su capa de `Decoding`. TorchScript no permite la exportación de modelos que tengan pesos atados, por lo que es
necesario desvincular y clonar los pesos previamente.
Esto implica que los modelos instanciados con el indicador `torchscript` tienen su capa `Embedding` y `Decoding` separadas,
lo que significa que no deben entrenarse más adelante. El entrenamiento desincronizaría las dos capas, lo que generaría
resultados inesperados.
Este no es el caso de los modelos que no tienen un cabezal de modelo de lenguaje, ya que no tienen pesos atados.
Estos modelos se pueden exportar de forma segura sin el indicador `torchscript`.
### Entradas ficticias y longitudes estándar
Las entradas ficticias se utilizan para crear un modelo de pase hacia adelante. Mientras los valores de las entradas se
propagan a través de las capas, PyTorch realiza un seguimiento de las diferentes operaciones ejecutadas en cada tensor.
Estas operaciones registradas se utilizan luego para crear el "rastro" del modelo.
El rastro se crea en relación con las dimensiones de las entradas. Por lo tanto, está limitado por las dimensiones de la
entrada ficticia y no funcionará para ninguna otra longitud de secuencia o tamaño de lote. Al intentar con un tamaño diferente,
un error como:
`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
aparecerá. Por lo tanto, se recomienda rastrear el modelo con un tamaño de entrada ficticia al menos tan grande como la
entrada más grande que se alimentará al modelo durante la inferencia. El _padding_ se puede realizar para completar los
valores que faltan. Sin embargo, como el modelo se habrá rastreado con un tamaño de entrada grande, las dimensiones de
las diferentes matrices también serán grandes, lo que dará como resultado más cálculos.
Se recomienda tener cuidado con el número total de operaciones realizadas en cada entrada y seguir de cerca el rendimiento
al exportar modelos de longitud de secuencia variable.
### Usar TorchScript en Python
A continuación se muestra un ejemplo que muestra cómo guardar, cargar modelos y cómo usar el rastreo para la inferencia.
#### Guardando un modelo
Este fragmento muestra cómo usar TorchScript para exportar un `BertModel`. Aquí, el `BertModel` se instancia de acuerdo
con la clase `BertConfig` y luego se guarda en el disco con el nombre de archivo `traced_bert.pt`
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
enc = BertTokenizer.from_pretrained("bert-base-uncased")
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = "[MASK]"
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
# Initializing the model with the torchscript flag
# Flag set to True even though it is not necessary as this model does not have an LM Head.
config = BertConfig(
vocab_size_or_config_json_file=32000,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
torchscript=True,
)
# Instantiating the model
model = BertModel(config)
# The model needs to be in evaluation mode
model.eval()
# If you are instantiating the model with *from_pretrained* you can also easily set the TorchScript flag
model = BertModel.from_pretrained("bert-base-uncased", torchscript=True)
# Creating the trace
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
```
#### Cargar un modelo
Este fragmento muestra cómo cargar el `BertModel` que se guardó previamente en el disco con el nombre `traced_bert.pt`.
Estamos reutilizando el `dummy_input` previamente inicializado.
```python
loaded_model = torch.jit.load("traced_bert.pt")
loaded_model.eval()
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
```
#### Usar un modelo rastreado para la inferencia
Usar el modelo rastreado para la inferencia es tan simple como usar su método `__call__`:
```python
traced_model(tokens_tensor, segments_tensors)
```
### Implementar los modelos HuggingFace TorchScript en AWS mediante Neuron SDK
AWS presentó la familia de instancias [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/) para la inferencia
de aprendizaje automático de bajo costo y alto rendimiento en la nube. Las instancias Inf1 funcionan con el chip AWS
Inferentia, un acelerador de hardware personalizado, que se especializa en cargas de trabajo de inferencia de aprendizaje
profundo. [AWS Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#) es el kit de desarrollo para Inferentia
que admite el rastreo y la optimización de modelos de transformers para su implementación en Inf1. El SDK de Neuron proporciona:
1. API fácil de usar con una línea de cambio de código para rastrear y optimizar un modelo de TorchScript para la inferencia en la nube.
2. Optimizaciones de rendimiento listas para usar con un [costo-rendimiento mejorado](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/>)
3. Soporte para modelos HuggingFace Transformers construidos con [PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html)
o [TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html).
#### Implicaciones
Los modelos Transformers basados en la arquitectura
[BERT (Representaciones de _Enconder_ bidireccional de Transformers)](https://huggingface.co/docs/transformers/main/model_doc/bert),
o sus variantes, como [distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert) y
[roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta), se ejecutarán mejor en Inf1 para tareas no
generativas, como la respuesta extractiva de preguntas, la clasificación de secuencias y la clasificación de tokens.
Como alternativa, las tareas de generación de texto se pueden adaptar para ejecutarse en Inf1, según este
[tutorial de AWS Neuron MarianMT](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html).
Puedes encontrar más información sobre los modelos que están listos para usarse en Inferentia en la
[sección _Model Architecture Fit_ de la documentación de Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia).
#### Dependencias
Usar AWS Neuron para convertir modelos requiere las siguientes dependencias y entornos:
* Un [entorno Neuron SDK](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide),
que viene preconfigurado en [AWS Deep Learning AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html).
#### Convertir un modelo a AWS Neuron
Con el mismo script usado en [Uso de TorchScript en Python](https://huggingface.co/docs/transformers/main/es/serialization#using-torchscript-in-python)
para rastrear un "BertModel", puedes importar la extensión del _framework_ `torch.neuron` para acceder a los componentes
del SDK de Neuron a través de una API de Python.
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import torch.neuron
```
Y modificando la línea de código de rastreo de:
```python
torch.jit.trace(model, [tokens_tensor, segments_tensors])
```
con lo siguiente:
```python
torch.neuron.trace(model, [token_tensor, segments_tensors])
```
Este cambio permite a Neuron SDK rastrear el modelo y optimizarlo para ejecutarse en instancias Inf1.
Para obtener más información sobre las funciones, las herramientas, los tutoriales de ejemplo y las últimas actualizaciones
de AWS Neuron SDK, consulte la [documentación de AWS NeuronSDK](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html).
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/converting_tensorflow_models.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Convertir checkpoints de Tensorflow
Te proporcionamos una interfaz de línea de comando (`CLI`, por sus siglas en inglés) para convertir puntos de control (_checkpoints_) originales de Bert/GPT/GPT-2/Transformer-XL/XLNet/XLM en modelos que se puedan cargar utilizando los métodos `from_pretrained` de la biblioteca.
<Tip>
Desde 2.3.0, el script para convertir es parte de la CLI de transformers (**transformers-cli**) disponible en cualquier instalación de transformers >= 2.3.0.
La siguiente documentación refleja el formato para el comando **transformers-cli convert**.
</Tip>
## BERT
Puedes convertir cualquier checkpoint de TensorFlow para BERT (en particular, [los modelos pre-entrenados y publicados por Google](https://github.com/google-research/bert#pre-trained-models)) en un archivo de PyTorch mediante el script [convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert/convert_bert_original_tf_checkpoint_to_pytorch.py).
Esta CLI toma como entrada un checkpoint de TensorFlow (tres archivos que comienzan con `bert_model.ckpt`) y el archivo de configuración asociado (`bert_config.json`), y crea un modelo PyTorch para esta configuración, carga los pesos del checkpoint de TensorFlow en el modelo de PyTorch y guarda el modelo resultante en un archivo estándar de PyTorch que se puede importar usando `from_pretrained()` (ve el ejemplo en [Tour rápido](quicktour), [run_glue.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_glue.py)).
Solo necesitas ejecutar este script **una vez** para convertir un modelo a PyTorch. Después, puedes ignorar el checkpoint de TensorFlow (los tres archivos que comienzan con `bert_model.ckpt`), pero asegúrate de conservar el archivo de configuración (`bert_config.json`) y el archivo de vocabulario (`vocab.txt`) ya que estos también son necesarios para el modelo en PyTorch.
Para ejecutar este script deberás tener instalado TensorFlow y PyTorch (`pip install tensorflow`). El resto del repositorio solo requiere PyTorch.
Aquí hay un ejemplo del proceso para convertir un modelo `BERT-Base Uncased` pre-entrenado:
```bash
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
transformers-cli convert --model_type bert \
--tf_checkpoint $BERT_BASE_DIR/bert_model.ckpt \
--config $BERT_BASE_DIR/bert_config.json \
--pytorch_dump_output $BERT_BASE_DIR/pytorch_model.bin
```
Puedes descargar los modelos pre-entrenados de Google para la conversión [aquí](https://github.com/google-research/bert#pre-trained-models).
## ALBERT
Convierte los checkpoints del modelo ALBERT de TensorFlow a PyTorch usando el script [convert_albert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py).
La CLI toma como entrada un checkpoint de TensorFlow (tres archivos que comienzan con `model.ckpt-best`) y el archivo de configuración adjunto (`albert_config.json`), luego crea y guarda un modelo de PyTorch. Para ejecutar esta conversión deberás tener instalados TensorFlow y PyTorch.
Aquí hay un ejemplo del proceso para convertir un modelo `ALBERT Base` pre-entrenado:
```bash
export ALBERT_BASE_DIR=/path/to/albert/albert_base
transformers-cli convert --model_type albert \
--tf_checkpoint $ALBERT_BASE_DIR/model.ckpt-best \
--config $ALBERT_BASE_DIR/albert_config.json \
--pytorch_dump_output $ALBERT_BASE_DIR/pytorch_model.bin
```
Puedes descargar los modelos pre-entrenados de Google para la conversión [aquí](https://github.com/google-research/albert#pre-trained-models).
## OpenAI GPT
Este es un ejemplo del proceso para convertir un modelo OpenAI GPT pre-entrenado, asumiendo que tu checkpoint de NumPy se guarda con el mismo formato que el modelo pre-entrenado de OpenAI (más información [aquí](https://github.com/openai/finetune-transformer-lm)):
```bash
export OPENAI_GPT_CHECKPOINT_FOLDER_PATH=/path/to/openai/pretrained/numpy/weights
transformers-cli convert --model_type gpt \
--tf_checkpoint $OPENAI_GPT_CHECKPOINT_FOLDER_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT_CONFIG] \
[--finetuning_task_name OPENAI_GPT_FINETUNED_TASK] \
```
## OpenAI GPT-2
Aquí hay un ejemplo del proceso para convertir un modelo OpenAI GPT-2 pre-entrenado (más información [aquí](https://github.com/openai/gpt-2)):
```bash
export OPENAI_GPT2_CHECKPOINT_PATH=/path/to/gpt2/pretrained/weights
transformers-cli convert --model_type gpt2 \
--tf_checkpoint $OPENAI_GPT2_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT2_CONFIG] \
[--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
```
## XLNet
Aquí hay un ejemplo del proceso para convertir un modelo XLNet pre-entrenado:
```bash
export TRANSFO_XL_CHECKPOINT_PATH=/path/to/xlnet/checkpoint
export TRANSFO_XL_CONFIG_PATH=/path/to/xlnet/config
transformers-cli convert --model_type xlnet \
--tf_checkpoint $TRANSFO_XL_CHECKPOINT_PATH \
--config $TRANSFO_XL_CONFIG_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--finetuning_task_name XLNET_FINETUNED_TASK] \
```
## XLM
Aquí hay un ejemplo del proceso para convertir un modelo XLM pre-entrenado:
```bash
export XLM_CHECKPOINT_PATH=/path/to/xlm/checkpoint
transformers-cli convert --model_type xlm \
--tf_checkpoint $XLM_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT
[--config XML_CONFIG] \
[--finetuning_task_name XML_FINETUNED_TASK]
```
## T5
Aquí hay un ejemplo del proceso para convertir un modelo T5 pre-entrenado:
```bash
export T5=/path/to/t5/uncased_L-12_H-768_A-12
transformers-cli convert --model_type t5 \
--tf_checkpoint $T5/t5_model.ckpt \
--config $T5/t5_config.json \
--pytorch_dump_output $T5/pytorch_model.bin
```
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/autoclass_tutorial.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Carga instancias preentrenadas con un AutoClass
Con tantas arquitecturas diferentes de Transformer puede ser retador crear una para tu checkpoint. Como parte de la filosofía central de 🤗 Transformers para hacer que la biblioteca sea fácil, simple y flexible de usar; una `AutoClass` automáticamente infiere y carga la arquitectura correcta desde un checkpoint dado. El método `from_pretrained` te permite cargar rápidamente un modelo preentrenado para cualquier arquitectura, por lo que no tendrás que dedicar tiempo y recursos para entrenar uno desde cero. Producir este tipo de código con checkpoint implica que si funciona con uno, funcionará también con otro (siempre que haya sido entrenado para una tarea similar) incluso si la arquitectura es distinta.
<Tip>
Recuerda, la arquitectura se refiere al esqueleto del modelo y los checkpoints son los pesos para una arquitectura dada. Por ejemplo, [BERT](https://huggingface.co/bert-base-uncased) es una arquitectura, mientras que `bert-base-uncased` es un checkpoint. Modelo es un término general que puede significar una arquitectura o un checkpoint.
</Tip>
En este tutorial, aprenderás a:
* Cargar un tokenizador pre-entrenado.
* Cargar un extractor de características (feature extractor en inglés) pre-entrenado.
* Cargar un procesador pre-entrenado.
* Cargar un modelo pre-entrenado.
## AutoTokenizer
Casi cualquier tarea de Procesamiento de Lenguaje Natural comienza con un tokenizador. Un tokenizador convierte tu input a un formato que puede ser procesado por el modelo.
Carga un tokenizador con [`AutoTokenizer.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
```
Luego tokeniza tu input como lo mostrado a continuación:
```py
>>> sequence = "In a hole in the ground there lived a hobbit."
>>> print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
## AutoFeatureExtractor
Para tareas de audio y visión, un extractor de características procesa la señal de audio o imagen al formato de input correcto.
Carga un extractor de características con [`AutoFeatureExtractor.from_pretrained`]:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
## AutoProcessor
Las tareas multimodales requieren un procesador que combine dos tipos de herramientas de preprocesamiento. Por ejemplo, el modelo [LayoutLMV2](model_doc/layoutlmv2) requiere que un extractor de características maneje las imágenes y que un tokenizador maneje el texto; un procesador combina ambas.
Carga un procesador con [`AutoProcessor.from_pretrained`]:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
```
## AutoModel
<frameworkcontent>
<pt>
Finalmente, las clases `AutoModelFor` te permiten cargar un modelo preentrenado para una tarea dada (revisa [aquí](model_doc/auto) para conocer la lista completa de tareas disponibles). Por ejemplo, cargue un modelo para clasificación de secuencias con [`AutoModelForSequenceClassification.from_pretrained`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Reutiliza fácilmente el mismo checkpoint para cargar una aquitectura para alguna tarea diferente:
```py
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
Generalmente recomendamos utilizar las clases `AutoTokenizer` y `AutoModelFor` para cargar instancias pre-entrenadas de modelos. Ésto asegurará que cargues la arquitectura correcta en cada ocasión. En el siguiente [tutorial](preprocessing), aprende a usar tu tokenizador recién cargado, el extractor de características y el procesador para preprocesar un dataset para fine-tuning.
</pt>
<tf>
Finalmente, la clase `TFAutoModelFor` te permite cargar tu modelo pre-entrenado para una tarea dada (revisa [aquí](model_doc/auto) para conocer la lista completa de tareas disponibles). Por ejemplo, carga un modelo para clasificación de secuencias con [`TFAutoModelForSequenceClassification.from_pretrained`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Reutiliza fácilmente el mismo checkpoint para cargar una aquitectura para alguna tarea diferente:
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
Generalmente recomendamos utilizar las clases `AutoTokenizer` y `TFAutoModelFor` para cargar instancias de modelos pre-entrenados. Ésto asegurará que cargues la arquitectura correcta cada vez. En el siguiente [tutorial](preprocessing), aprende a usar tu tokenizador recién cargado, el extractor de características y el procesador para preprocesar un dataset para fine-tuning.
</tf>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/bertology.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BERTología
Hay un creciente campo de estudio empeñado en la investigación del funcionamiento interno de los transformers de gran escala como BERT
(que algunos llaman "BERTología"). Algunos buenos ejemplos de este campo son:
- BERT Rediscovers the Classical NLP Pipeline por Ian Tenney, Dipanjan Das, Ellie Pavlick:
https://arxiv.org/abs/1905.05950
- Are Sixteen Heads Really Better than One? por Paul Michel, Omer Levy, Graham Neubig: https://arxiv.org/abs/1905.10650
- What Does BERT Look At? An Analysis of BERT's Attention por Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
Manning: https://arxiv.org/abs/1906.04341
- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://arxiv.org/abs/2210.04633
Para asistir al desarrollo de este nuevo campo, hemos incluido algunas features adicionales en los modelos BERT/GPT/GPT-2 para
ayudar a acceder a las representaciones internas, principalmente adaptado de la gran obra de Paul Michel
(https://arxiv.org/abs/1905.10650):
- accediendo a todos los hidden-states de BERT/GPT/GPT-2,
- accediendo a todos los pesos de atención para cada head de BERT/GPT/GPT-2,
- adquiriendo los valores de salida y gradientes de las heads para poder computar la métrica de importancia de las heads y realizar la poda de heads como se explica
en https://arxiv.org/abs/1905.10650.
Para ayudarte a entender y usar estas features, hemos añadido un script específico de ejemplo: [bertology.py](https://github.com/huggingface/transformers/tree/main/examples/research_projects/bertology/run_bertology.py) mientras extraes información y cortas un modelo pre-entrenado en
GLUE.
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/accelerate.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Entrenamiento distribuido con 🤗 Accelerate
El paralelismo ha emergido como una estrategia para entrenar modelos grandes en hardware limitado e incrementar la velocidad de entrenamiento en varios órdenes de magnitud. En Hugging Face creamos la biblioteca [🤗 Accelerate](https://huggingface.co/docs/accelerate) para ayudar a los usuarios a entrenar modelos 🤗 Transformers en cualquier tipo de configuración distribuida, ya sea en una máquina con múltiples GPUs o en múltiples GPUs distribuidas entre muchas máquinas. En este tutorial aprenderás cómo personalizar tu bucle de entrenamiento de PyTorch nativo para poder entrenar en entornos distribuidos.
## Configuración
Empecemos por instalar 🤗 Accelerate:
```bash
pip install accelerate
```
Luego, importamos y creamos un objeto [`Accelerator`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator). `Accelerator` detectará automáticamente el tipo de configuración distribuida que tengas disponible e inicializará todos los componentes necesarios para el entrenamiento. No necesitas especificar el dispositivo en donde se debe colocar tu modelo.
```py
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
```
## Prepárate para acelerar
Pasa todos los objetos relevantes para el entrenamiento al método [`prepare`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.prepare). Esto incluye los DataLoaders de entrenamiento y evaluación, un modelo y un optimizador:
```py
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
... train_dataloader, eval_dataloader, model, optimizer
... )
```
## Backward
Por último, reemplaza el típico `loss.backward()` en tu bucle de entrenamiento con el método [`backward`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.backward) de 🤗 Accelerate:
```py
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... outputs = model(**batch)
... loss = outputs.loss
... accelerator.backward(loss)
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
Como se puede ver en el siguiente código, ¡solo necesitas adicionar cuatro líneas de código a tu bucle de entrenamiento para habilitar el entrenamiento distribuido!
```diff
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
## Entrenamiento
Una vez que hayas añadido las líneas de código relevantes, inicia el entrenamiento desde un script o notebook como Colaboratory.
### Entrenar con un script
Si estás corriendo tu entrenamiento desde un script ejecuta el siguiente comando para crear y guardar un archivo de configuración:
```bash
accelerate config
```
Comienza el entrenamiento con:
```bash
accelerate launch train.py
```
### Entrenar con un notebook
🤗 Accelerate puede correr en un notebook si, por ejemplo, estás planeando utilizar las TPUs de Colaboratory. Encierra el código responsable del entrenamiento en una función y pásalo a `notebook_launcher`:
```py
>>> from accelerate import notebook_launcher
>>> notebook_launcher(training_function)
```
Para obtener más información sobre 🤗 Accelerate y sus numerosas funciones, consulta la [documentación](https://huggingface.co/docs/accelerate).
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/pr_checks.md
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Verificaciones en un Pull Request
Cuando abres un _pull request_ en 🤗 Transformers, se ejecutarán una serie de verificaciones para asegurarte de que el _patch_ que estás agregando no rompa nada existente. Estas verificaciones son de cuatro tipos:
- pruebas regulares
- creación de la documentación
- estilo del código y documentación
- consistencia del repositorio
En este documento, intentaremos explicar cuáles son esas diferentes verificaciones y el motivo detrás de ellas, así como también cómo depurarlas localmente si una falla en tu PR.
Recuerda que todas las verificaciones requieren que tengas una instalación de desarrollo:
```bash
pip install transformers[dev]
```
o una instalación editable:
```bash
pip install -e .[dev]
```
del repositorio de Transformers.
## Pruebas
Todos los procesos que comienzan con `ci/circleci: run_tests_` ejecutan partes del conjunto de pruebas de Transformers. Cada uno de esos procesos se enfoca en una parte de la biblioteca en un entorno determinado: por ejemplo, `ci/circleci: run_tests_pipelines_tf` ejecuta la prueba de _pipelines_ en un entorno donde solo está instalado TensorFlow.
Ten en cuenta que para evitar ejecutar pruebas cuando no hay un cambio real en los módulos que estás probando, solo se ejecuta una parte del conjunto de pruebas: se ejecuta una tarea auxiliar para determinar las diferencias en la biblioteca antes y después del PR (lo que GitHub te muestra en la pestaña "Files changes") y selecciona las pruebas afectadas por esa diferencia. Este auxiliar se puede ejecutar localmente usando:
```bash
python utils/tests_fetcher.py
```
desde el directorio raiz del repositorio de Transformers. Se ejecutará lo siguiente:
1. Verificación para cada archivo en el _diff_ si los cambios están en el código, solo en comentarios o _docstrings_. Solo los archivos con cambios reales de código se conservan.
2. Creación de un mapa interno que proporciona para cada archivo del código fuente de la biblioteca todos los archivos a los que impacta recursivamente. Se dice que el módulo A impacta al módulo B si el módulo B importa el módulo A. Para el impacto recursivo, necesitamos una cadena de módulos que va del módulo A al módulo B en la que cada módulo importa el anterior.
3. Aplicación de este mapa en los archivos recopilados en el paso 1, lo que nos da una lista de archivos modelo afectados por el PR.
4. Asignación de cada uno de esos archivos a sus archivos de prueba correspondientes y para obtener una la lista de pruebas a ejecutar.
Al ejecutar el _script_ localmente, debes obtener los resultados de los pasos 1, 3 y 4 impresos y así saber qué pruebas se ejecutarán. El _script_ también creará un archivo llamado `test_list.txt` que contiene la lista de pruebas para ejecutar, y puede ejecutarlas localmente con el siguiente comando:
```bash
python -m pytest -n 8 --dist=loadfile -rA -s $(cat test_list.txt)
```
En caso de que se te escape algo, el conjunto completo de pruebas también se ejecuta a diario.
## Creación de la documentación
El proceso `build_pr_documentation` compila y genera una vista previa de la documentación para asegurarse de que todo se vea bien una vez que se fusione tu PR. Un bot agregará un enlace para obtener una vista previa de la documentación en tu PR. Cualquier cambio que realices en el PR se actualiza automáticamente en la vista previa. Si la documentación no se genera, haz clic en **Detalles** junto al proceso fallido para ver dónde salió mal. A menudo, el error es tan simple como que falta un archivo en `toctree`.
Si estás interesado en compilar u obtener una vista previa de la documentación localmente, echa un vistazo al [`README.md`](https://github.com/huggingface/transformers/tree/main/docs) en la carpeta `docs`.
## Estilo de código y documentación.
El formato de código se aplica a todos los archivos fuente, los ejemplos y las pruebas utilizando `black` e `ruff`. También tenemos una herramienta personalizada que se ocupa del formato de los _docstrings_ y archivos `rst` (`utils/style_doc.py`), así como del orden de las importaciones _lazy_ realizadas en los archivos `__init__.py` de Transformers (`utils /custom_init_isort.py`). Todo esto se puede probar ejecutando
```bash
make style
```
CI verifica que se hayan aplicado dentro de la verificación `ci/circleci: check_code_quality`. También se ejecuta `ruff`, que hará una verificación básica a tu código y te hará saber si encuentra una variable no definida, o una que no se usa. Para ejecutar esa verificación localmente, usa
```bash
make quality
```
Esto puede llevar mucho tiempo, así que para ejecutar lo mismo solo en los archivos que modificaste en la rama actual, ejecuta
```bash
make fixup
```
Este último comando también ejecutará todas las verificaciones adicionales para la consistencia del repositorio. Echemos un vistazo a estas pruebas.
## Consistencia del repositorio
Esta verificación reagrupa todas las pruebas para asegurarse de que tu PR deja el repositorio en buen estado, y se realiza mediante `ci/circleci: check_repository_consistency`. Puedes ejecutar localmente esta verificación ejecutando lo siguiente:
```bash
make repo-consistency
```
Esta instrucción verifica que:
- Todos los objetos agregados al _init_ están documentados (realizados por `utils/check_repo.py`)
- Todos los archivos `__init__.py` tienen el mismo contenido en sus dos secciones (realizado por `utils/check_inits.py`)
- Todo el código identificado como una copia de otro módulo es consistente con el original (realizado por `utils/check_copies.py`)
- Todas las clases de configuración tienen al menos _checkpoint_ válido mencionado en sus _docstrings_ (realizado por `utils/check_config_docstrings.py`)
- Las traducciones de los README y el índice del documento tienen la misma lista de modelos que el README principal (realizado por `utils/check_copies.py`)
- Las tablas generadas automaticamente en la documentación están actualizadas (realizadas por `utils/check_table.py`)
- La biblioteca tiene todos los objetos disponibles incluso si no están instaladas todas las dependencias opcionales (realizadas por `utils/check_dummies.py`)
Si esta verificación falla, los primeros dos elementos requieren una reparación manual, los últimos cuatro pueden repararse automáticamente ejecutando el comando
```bash
make fix-copies
```
Las verificaciones adicionales se refieren a los PRs que agregan nuevos modelos, principalmente que:
- Todos los modelos agregados están en un Auto-mapping (realizado por `utils/check_repo.py`)
<!-- TODO Sylvain, add a check that makes sure the common tests are implemented.-->
- Todos los modelos se verifican correctamente (realizados por `utils/check_repo.py`)
<!-- TODO Sylvain, add the following
- All models are added to the main README, inside the main doc
- All checkpoints used actually exist on the Hub
-->
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/add_new_pipeline.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ¿Cómo puedo crear un pipeline personalizado?
En esta guía, veremos cómo crear un pipeline personalizado y cómo compartirlo en el [Hub](hf.co/models) o añadirlo
a la biblioteca 🤗 Transformers.
En primer lugar, debes decidir las entradas que tu pipeline podrá recibir. Pueden ser strings, bytes,
diccionarios o lo que te parezca que vaya a ser la entrada más apropiada. Intenta mantener estas entradas en un
formato que sea tan Python puro como sea posible, puesto que esto facilita la compatibilidad (incluso con otros
lenguajes de programación por medio de JSON). Estos serán los `inputs` (entradas) del pipeline (`preprocess`).
Ahora debes definir los `outputs` (salidas). Al igual que con los `inputs`, entre más simple el formato, mejor.
Estas serán las salidas del método `postprocess` (posprocesamiento).
Empieza heredando la clase base `Pipeline` con los 4 métodos que debemos implementar: `preprocess` (preprocesamiento),
`_forward` (ejecución), `postprocess` (posprocesamiento) y `_sanitize_parameters` (verificar parámetros).
```python
from transformers import Pipeline
class MyPipeline(Pipeline):
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "maybe_arg" in kwargs:
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
return preprocess_kwargs, {}, {}
def preprocess(self, inputs, maybe_arg=2):
model_input = Tensor(inputs["input_ids"])
return {"model_input": model_input}
def _forward(self, model_inputs):
# model_inputs == {"model_input": model_input}
outputs = self.model(**model_inputs)
# Quizá {"logits": Tensor(...)}
return outputs
def postprocess(self, model_outputs):
best_class = model_outputs["logits"].softmax(-1)
return best_class
```
La estructura de este desglose es así para garantizar una compatibilidad más o menos transparente con el uso de
CPU/GPU y el pre/posprocesamiento en CPU en varios hilos.
`preprocess` tomará las entradas definidas originalmente y las convertirá en algo que se le pueda pasar al modelo.
Podría contener más información y a menudo es un objeto `Dict` (diccionario).
`_forward` contiene los detalles de la implementación y no debería ser invocado de forma directa. `forward` es el
método preferido a utilizar pues contiene verificaciones para asegurar que todo funcione en el dispositivo correcto.
Cualquier cosa que esté relacionada con un modelo real debería ir en el método `_forward`, todo lo demás va en
los métodos de preprocesamiento y posprocesamiento.
Los métodos `postprocess` reciben la salida `_forward` y la convierten en la salida final que decidimos
anteriormente.
`_sanitize_parameters` existe para permitir a los usuarios pasar cualesquiera parámetros cuando lo deseen, ya
sea al momento de inicializar el pipeline `pipeline(...., maybe_arg=4)` o al momento de invocarlo
`pipe = pipeline(...); output = pipe(...., maybe_arg=4)`.
El método `_sanitize_parameters` devuelve 3 diccionarios de kwargs que serán pasados directamente a `preprocess`,
`_forward` y `postprocess`. No ingreses nada si el caller no se va a invocar con parámetros adicionales.
Esto permite mantener los parámetros por defecto de la definición de la función, lo que es más "natural".
Un ejemplo clásico sería un argumento `top_k` en el posprocesamiento de una tarea de clasificación.
```python
>>> pipe = pipeline("my-new-task")
>>> pipe("This is a test")
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}, {"label": "3-star", "score": 0.05}
{"label": "4-star", "score": 0.025}, {"label": "5-star", "score": 0.025}]
>>> pipe("This is a test", top_k=2)
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}]
```
Para lograrlo, actualizaremos nuestro método `postprocess` con un valor por defecto de `5` y modificaremos
`_sanitize_parameters` para permitir este nuevo parámetro.
```python
def postprocess(self, model_outputs, top_k=5):
best_class = model_outputs["logits"].softmax(-1)
# Añade la lógica para manejar el top_k
return best_class
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "maybe_arg" in kwargs:
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
postprocess_kwargs = {}
if "top_k" in kwargs:
postprocess_kwargs["top_k"] = kwargs["top_k"]
return preprocess_kwargs, {}, postprocess_kwargs
```
Intenta que las entradas y salidas sean muy simples e, idealmente, que puedan serializarse como JSON, pues esto
hace el uso del pipeline muy sencillo sin que el usuario tenga que preocuparse por conocer nuevos tipos de objetos.
También es relativamente común tener compatibilidad con muchos tipos diferentes de argumentos por facilidad de uso
(por ejemplo, los archivos de audio pueden ser nombres de archivo, URLs o bytes).
## Añadirlo a la lista de tareas
Para registrar tu `new-task` (nueva tarea) en la lista de tareas, debes añadirla al
`PIPELINE_REGISTRY` (registro de pipelines):
```python
from transformers.pipelines import PIPELINE_REGISTRY
PIPELINE_REGISTRY.register_pipeline(
"new-task",
pipeline_class=MyPipeline,
pt_model=AutoModelForSequenceClassification,
)
```
Puedes especificar un modelo por defecto si lo deseas, en cuyo caso debe venir con una versión específica (que puede ser el nombre de un branch o hash de commit, en este caso usamos `"abcdef"`), así como el tipo:
```python
PIPELINE_REGISTRY.register_pipeline(
"new-task",
pipeline_class=MyPipeline,
pt_model=AutoModelForSequenceClassification,
default={"pt": ("user/awesome_model", "abcdef")},
type="text", # tipo de datos que maneja: texto, audio, imagen, multi-modalidad
)
```
## Comparte tu pipeline en el Hub
Para compartir tu pipeline personalizado en el Hub, solo tienes que guardar el código personalizado de tu sub-clase
`Pipeline` en un archivo de Python. Por ejemplo, digamos que queremos usar un pipeline personalizado para la
clasificación de duplas de oraciones de esta forma:
```py
import numpy as np
from transformers import Pipeline
def softmax(outputs):
maxes = np.max(outputs, axis=-1, keepdims=True)
shifted_exp = np.exp(outputs - maxes)
return shifted_exp / shifted_exp.sum(axis=-1, keepdims=True)
class PairClassificationPipeline(Pipeline):
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "second_text" in kwargs:
preprocess_kwargs["second_text"] = kwargs["second_text"]
return preprocess_kwargs, {}, {}
def preprocess(self, text, second_text=None):
return self.tokenizer(text, text_pair=second_text, return_tensors=self.framework)
def _forward(self, model_inputs):
return self.model(**model_inputs)
def postprocess(self, model_outputs):
logits = model_outputs.logits[0].numpy()
probabilities = softmax(logits)
best_class = np.argmax(probabilities)
label = self.model.config.id2label[best_class]
score = probabilities[best_class].item()
logits = logits.tolist()
return {"label": label, "score": score, "logits": logits}
```
La implementación es independiente del framework y funcionará con modelos de PyTorch y TensorFlow. Si guardamos
esto en un archivo llamado `pair_classification.py`, podemos importarlo y registrarlo de la siguiente manera:
```py
from pair_classification import PairClassificationPipeline
from transformers.pipelines import PIPELINE_REGISTRY
from transformers import AutoModelForSequenceClassification, TFAutoModelForSequenceClassification
PIPELINE_REGISTRY.register_pipeline(
"pair-classification",
pipeline_class=PairClassificationPipeline,
pt_model=AutoModelForSequenceClassification,
tf_model=TFAutoModelForSequenceClassification,
)
```
Una vez hecho esto, podemos usarlo con un modelo pre-entrenado. Por ejemplo, al modelo `sgugger/finetuned-bert-mrpc`
se le hizo fine-tuning con el dataset MRPC, en el cual se clasifican duplas de oraciones como paráfrasis o no.
```py
from transformers import pipeline
classifier = pipeline("pair-classification", model="sgugger/finetuned-bert-mrpc")
```
Ahora podemos compartirlo en el Hub usando el método `save_pretrained` (guardar pre-entrenado) en un `Repository`:
```py
from huggingface_hub import Repository
repo = Repository("test-dynamic-pipeline", clone_from="{your_username}/test-dynamic-pipeline")
classifier.save_pretrained("test-dynamic-pipeline")
repo.push_to_hub()
```
Esto copiará el archivo donde definiste `PairClassificationPipeline` dentro de la carpeta `"test-dynamic-pipeline"`,
y además guardará el modelo y el tokenizer del pipeline, antes de enviar todo al repositorio
`{your_username}/test-dynamic-pipeline`. Después de esto, cualquier persona puede usarlo siempre que usen la opción
`trust_remote_code=True` (confiar en código remoto):
```py
from transformers import pipeline
classifier = pipeline(model="{your_username}/test-dynamic-pipeline", trust_remote_code=True)
```
## Añadir el pipeline a 🤗 Transformers
Si quieres contribuir tu pipeline a la biblioteca 🤗 Transformers, tendrás que añadirlo a un nuevo módulo en el
sub-módulo `pipelines` con el código de tu pipeline. Luego, debes añadirlo a la lista de tareas definidas en
`pipelines/__init__.py`.
A continuación tienes que añadir las pruebas. Crea un nuevo archivo llamado `tests/test_pipelines_MY_PIPELINE.py`
basándote en las pruebas existentes.
La función `run_pipeline_test` será muy genérica y se correrá sobre modelos pequeños escogidos al azar sobre todas las
arquitecturas posibles definidas en `model_mapping` y `tf_model_mapping`.
Esto es muy importante para probar compatibilidades a futuro, lo que significa que si alguien añade un nuevo modelo
para `XXXForQuestionAnswering` entonces el pipeline intentará ejecutarse con ese modelo. Ya que los modelos son aleatorios,
es imposible verificar los valores como tales, y es por eso que hay un helper `ANY` que simplemente intentará que la
salida tenga el mismo tipo que la salida esperada del pipeline.
También *debes* implementar 2 (preferiblemente 4) pruebas:
- `test_small_model_pt` : Define un (1) modelo pequeño para este pipeline (no importa si los resultados no tienen sentido)
y prueba las salidas del pipeline. Los resultados deberían ser los mismos que en `test_small_model_tf`.
- `test_small_model_tf` : Define un (1) modelo pequeño para este pipeline (no importa si los resultados no tienen sentido)
y prueba las salidas del pipeline. Los resultados deberían ser los mismos que en `test_small_model_pt`.
- `test_large_model_pt` (`optional`): Prueba el pipeline en una tarea real en la que los resultados deben tener sentido.
Estas pruebas son lentas y deben marcarse como tales. El objetivo de esto es ejemplificar el pipeline y asegurarse de que
no haya divergencias en versiones futuras.
- `test_large_model_tf` (`optional`): Prueba el pipeline en una tarea real en la que los resultados deben tener sentido.
Estas pruebas son lentas y deben marcarse como tales. El objetivo de esto es ejemplificar el pipeline y asegurarse de que
no haya divergencias en versiones futuras.
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/community.md
|
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Comunidad
Esta página agrupa los recursos de 🤗 Transformers desarrollados por la comunidad.
## Los recursos de la comunidad:
| Recurso | Descripción | Autor |
|:----------|:-------------|------:|
| [Hugging Face Transformers Glossary Flashcards](https://www.darigovresearch.com/huggingface-transformers-glossary-flashcards) | Un conjunto de flashcards basadas en el [Glosario de documentos de Transformers] (glosario) que se ha puesto en un formato que se puede aprender/revisar fácilmente usando [Anki] (https://apps.ankiweb.net/) una fuente abierta, aplicación de multiplataforma diseñada específicamente para la retención de conocimientos a largo plazo. Ve este [Introductory video on how to use the flashcards](https://www.youtube.com/watch?v=Dji_h7PILrw). | [Darigov Research](https://www.darigovresearch.com/) |
## Los cuadernos de la comunidad:
| Cuaderno | Descripción | Autor | |
|:----------|:-------------|:-------------|------:|
| [Ajustar un transformador preentrenado para generar letras](https://github.com/AlekseyKorshuk/huggingartists) | Cómo generar letras al estilo de tu artista favorito ajustando un modelo GPT-2 | [Aleksey Korshuk](https://github.com/AlekseyKorshuk) | [](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb) |
| [Entrenar T5 en Tensorflow 2](https://github.com/snapthat/TF-T5-text-to-text) | Cómo entrenar a T5 para cualquier tarea usando Tensorflow 2. Este cuaderno demuestra una tarea de preguntas y respuestas implementada en Tensorflow 2 usando SQUAD | [Muhammad Harris](https://github.com/HarrisDePerceptron) |[](https://colab.research.google.com/github/snapthat/TF-T5-text-to-text/blob/master/snapthatT5/notebooks/TF-T5-Datasets%20Training.ipynb) |
| [Entrenar T5 en TPU](https://github.com/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb) | Cómo entrenar a T5 en SQUAD con Transformers y Nlp | [Suraj Patil](https://github.com/patil-suraj) |[](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb#scrollTo=QLGiFCDqvuil) |
| [Ajustar T5 para Clasificación y Opción Múltiple](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) | Cómo ajustar T5 para clasificación y tareas de opción múltiple usando un formato de texto a texto con PyTorch Lightning | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) |
| [Ajustar DialoGPT en nuevos conjuntos de datos e idiomas](https://github.com/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) | Cómo ajustar el modelo DialoGPT en un nuevo conjunto de datos para chatbots conversacionales de diálogo abierto | [Nathan Cooper](https://github.com/ncoop57) | [](https://colab.research.google.com/github/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) |
| [Modelado de secuencias largas con Reformer](https://github.com/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) | Cómo entrenar en secuencias de hasta 500,000 tokens con Reformer | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) |
| [Ajustar BART para resumir](https://github.com/ohmeow/ohmeow_website/blob/master/_notebooks/2020-05-23-text-generation-with-blurr.ipynb) | Cómo ajustar BART para resumir con fastai usando blurr | [Wayde Gilliam](https://ohmeow.com/) | [](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/_notebooks/2020-05-23-text-generation-with-blurr.ipynb) |
| [Ajustar un Transformador previamente entrenado en los tweets de cualquier persona](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) | Cómo generar tweets al estilo de tu cuenta de Twitter favorita ajustando un modelo GPT-2 | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) |
| [Optimizar 🤗 modelos de Hugging Face con pesos y sesgos](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) | Un tutorial completo que muestra la integración de W&B con Hugging Face | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) |
| [Preentrenar Longformer](https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) | Cómo construir una versión "larga" de modelos preentrenados existentes | [Iz Beltagy](https://beltagy.net) | [](https://colab.research.google.com/github/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) |
| [Ajustar Longformer para control de calidad](https://github.com/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) | Cómo ajustar el modelo antiguo para la tarea de control de calidad | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) |
| [Evaluar modelo con 🤗nlp](https://github.com/patrickvonplaten/notebooks/blob/master/How_to_evaluate_Longformer_on_TriviaQA_using_NLP.ipynb) | Cómo evaluar longformer en TriviaQA con `nlp` | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1m7eTGlPmLRgoPkkA7rkhQdZ9ydpmsdLE?usp=sharing) |
| [Ajustar fino de T5 para la extracción de amplitud de opinión](https://github.com/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) | Cómo ajustar T5 para la extracción de intervalos de opiniones mediante un formato de texto a texto con PyTorch Lightning | [Lorenzo Ampil](https://github.com/enzoampil) | [](https://colab.research.google.com/github/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) |
| [Ajustar fino de DistilBert para la clasificación multiclase](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb) | Cómo ajustar DistilBert para la clasificación multiclase con PyTorch | [Abhishek Kumar Mishra](https://github.com/abhimishra91) | [](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb)|
|[Ajustar BERT para la clasificación de etiquetas múltiples](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)| Cómo ajustar BERT para la clasificación de múltiples etiquetas usando PyTorch |[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|
|[Ajustar T5 para resumir](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)| Cómo ajustar T5 para resumir en PyTorch y realizar un seguimiento de los experimentos con WandB |[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|
|[Acelerar el ajuste fino en transformadores con Dynamic Padding/Bucketing](https://github.com/ELS-RD/transformers-notebook/blob/master/Divide_Hugging_Face_Transformers_training_time_by_2_or_more.ipynb)| Cómo acelerar el ajuste fino en un factor de 2 usando relleno dinámico/cubetas |[Michael Benesty](https://github.com/pommedeterresautee) |[](https://colab.research.google.com/drive/1CBfRU1zbfu7-ijiOqAAQUA-RJaxfcJoO?usp=sharing)|
|[Preentrenar Reformer para modelado de lenguaje enmascarado](https://github.com/patrickvonplaten/notebooks/blob/master/Reformer_For_Masked_LM.ipynb)| Cómo entrenar un modelo Reformer con capas de autoatención bidireccionales | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1tzzh0i8PgDQGV3SMFUGxM7_gGae3K-uW?usp=sharing)|
|[Ampliar y ajustar Sci-BERT](https://github.com/lordtt13/word-embeddings/blob/master/COVID-19%20Research%20Data/COVID-SciBERT.ipynb)| Cómo aumentar el vocabulario de un modelo SciBERT preentrenado de AllenAI en el conjunto de datos CORD y canalizarlo. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/1rqAR40goxbAfez1xvF3hBJphSCsvXmh8)|
|[Ajustar fino de BlenderBotSmall para resúmenes usando la API de Entrenador](https://github.com/lordtt13/transformers-experiments/blob/master/Custom%20Tasks/fine-tune-blenderbot_small-for-summarization.ipynb)| Cómo ajustar BlenderBotSmall para resumir en un conjunto de datos personalizado, utilizando la API de Entrenador. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/19Wmupuls7mykSGyRN_Qo6lPQhgp56ymq?usp=sharing)|
|[Ajustar Electra e interpreta con gradientes integrados](https://github.com/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb) | Cómo ajustar Electra para el análisis de sentimientos e interpretar predicciones con Captum Integrated Gradients | [Eliza Szczechla](https://elsanns.github.io) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb)|
|[ajustar un modelo GPT-2 que no está en inglés con la clase Trainer](https://github.com/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb) | Cómo ajustar un modelo GPT-2 que no está en inglés con la clase Trainer | [Philipp Schmid](https://www.philschmid.de) | [](https://colab.research.google.com/github/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb)|
|[Ajustar un modelo DistilBERT para la tarea de clasificación de múltiples etiquetas](https://github.com/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb) | Cómo ajustar un modelo DistilBERT para la tarea de clasificación de múltiples etiquetas | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb)|
|[Ajustar ALBERT para la clasificación de pares de oraciones](https://github.com/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb) | Cómo ajustar un modelo ALBERT u otro modelo basado en BERT para la tarea de clasificación de pares de oraciones | [Nadir El Manouzi](https://github.com/NadirEM) | [](https://colab.research.google.com/github/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb)|
|[Ajustar a Roberta para el análisis de sentimientos](https://github.com/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb) | Cómo ajustar un modelo de Roberta para el análisis de sentimientos | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb)|
|[Evaluación de modelos de generación de preguntas](https://github.com/flexudy-pipe/qugeev) | ¿Qué tan precisas son las respuestas a las preguntas generadas por tu modelo de transformador seq2seq? | [Pascal Zoleko](https://github.com/zolekode) | [](https://colab.research.google.com/drive/1bpsSqCQU-iw_5nNoRm_crPq6FRuJthq_?usp=sharing)|
|[Clasificar texto con DistilBERT y Tensorflow](https://github.com/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb) | Cómo ajustar DistilBERT para la clasificación de texto en TensorFlow | [Peter Bayerle](https://github.com/peterbayerle) | [](https://colab.research.google.com/github/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb)|
|[Aprovechar BERT para el resumen de codificador y decodificador en CNN/Dailymail](https://github.com/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb) | Cómo iniciar en caliente un *EncoderDecoderModel* con un punto de control *bert-base-uncased* para resumir en CNN/Dailymail | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)|
|[Aprovechar RoBERTa para el resumen de codificador-decodificador en BBC XSum](https://github.com/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb) | Cómo iniciar en caliente un *EncoderDecoderModel* compartido con un punto de control *roberta-base* para resumir en BBC/XSum | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb)|
|[Ajustar TAPAS en Sequential Question Answering (SQA)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) | Cómo ajustar *TapasForQuestionAnswering* con un punto de control *tapas-base* en el conjunto de datos del Sequential Question Answering (SQA) | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb)|
|[Evaluar TAPAS en Table Fact Checking (TabFact)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb) | Cómo evaluar un *TapasForSequenceClassification* ajustado con un punto de control *tapas-base-finetuned-tabfact* usando una combinación de 🤗 conjuntos de datos y 🤗 bibliotecas de transformadores | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb)|
|[Ajustar de mBART para traducción](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb) | Cómo ajustar mBART utilizando Seq2SeqTrainer para la traducción del hindi al inglés | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb)|
|[Ajustar LayoutLM en FUNSD (a form understanding dataset)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb) | Cómo ajustar *LayoutLMForTokenClassification* en el conjunto de datos de FUNSD para la extracción de información de documentos escaneados | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb)|
|[Ajustar DistilGPT2 y genere texto](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb) | Cómo ajustar DistilGPT2 y generar texto | [Aakash Tripathi](https://github.com/tripathiaakash) | [](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb)|
|[Ajustar LED en tokens de hasta 8K](https://github.com/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb) | Cómo ajustar LED en pubmed para resúmenes de largo alcance | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb)|
|[Evaluar LED en Arxiv](https://github.com/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb) | Cómo evaluar efectivamente LED en resúmenes de largo alcance | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb)|
|[Ajustar fino de LayoutLM en RVL-CDIP (un conjunto de datos de clasificación de imágenes de documentos)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb) | Cómo ajustar *LayoutLMForSequenceClassification* en el conjunto de datos RVL-CDIP para la clasificación de documentos escaneados | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb)|
|[Decodificación Wav2Vec2 CTC con ajuste GPT2](https://github.com/voidful/huggingface_notebook/blob/main/xlsr_gpt.ipynb) | Cómo decodificar la secuencia CTC con el ajuste del modelo de lenguaje | [Eric Lam](https://github.com/voidful) | [](https://colab.research.google.com/drive/1e_z5jQHYbO2YKEaUgzb1ww1WwiAyydAj?usp=sharing)|
|[Ajustar BART para resúmenes en dos idiomas con la clase Trainer](https://github.com/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb) | Cómo ajustar BART para resúmenes en dos idiomas con la clase Trainer | [Eliza Szczechla](https://github.com/elsanns) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb)|
|[Evaluar Big Bird en Trivia QA](https://github.com/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb) | Cómo evaluar BigBird en respuesta a preguntas de documentos largos en Trivia QA | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb)|
| [Crear subtítulos de video usando Wav2Vec2](https://github.com/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) | Cómo crear subtítulos de YouTube a partir de cualquier vídeo transcribiendo el audio con Wav2Vec | [Niklas Muennighoff](https://github.com/Muennighoff) |[](https://colab.research.google.com/github/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) |
| [Ajustar el transformador de visión en CIFAR-10 usando PyTorch Lightning](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) | Cómo ajustar el transformador de visión (ViT) en CIFAR-10 usando transformadores HuggingFace, conjuntos de datos y PyTorch Lightning | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) |
| [Ajustar el Transformador de visión en CIFAR-10 usando el 🤗 Entrenador](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) | Cómo ajustar el Vision Transformer (ViT) en CIFAR-10 usando HuggingFace Transformers, Datasets y el 🤗 Trainer | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) |
| [Evaluar LUKE en Open Entity, un conjunto de datos de tipificación de entidades](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) | Cómo evaluar *LukeForEntityClassification* en el conjunto de datos de entidad abierta | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) |
| [Evaluar LUKE en TACRED, un conjunto de datos de extracción de relaciones](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) | Cómo evaluar *LukeForEntityPairClassification* en el conjunto de datos TACRED | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) |
| [Evaluar LUKE en CoNLL-2003, un punto de referencia importante de NER](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) | Cómo evaluar *LukeForEntitySpanClassification* en el conjunto de datos CoNLL-2003 | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) |
| [Evaluar BigBird-Pegasus en el conjunto de datos de PubMed](https://github.com/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) | Cómo evaluar *BigBirdPegasusForConditionalGeneration* en el conjunto de datos de PubMed | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) |
| [Clasificación de emociones del habla con Wav2Vec2](https://github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) | Cómo aprovechar un modelo Wav2Vec2 preentrenado para la clasificación de emociones en el conjunto de datos MEGA | [Mehrdad Farahani](https://github.com/m3hrdadfi) | [](https://colab.research.google.com/github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) |
| [Detectar objetos en una imagen con DETR](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) | Cómo usar un modelo entrenado *DetrForObjectDetection* para detectar objetos en una imagen y visualizar la atención | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) |
| [Ajustar el DETR en un conjunto de datos de detección de objetos personalizados](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) | Cómo ajustar *DetrForObjectDetection* en un conjunto de datos de detección de objetos personalizados | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) |
| [Ajustar T5 para el reconocimiento de entidades nombradas](https://github.com/ToluClassics/Notebooks/blob/main/T5_Ner_Finetuning.ipynb) | Cómo ajustar *T5* en una tarea de reconocimiento de entidad nombrada | [Ogundepo Odunayo](https://github.com/ToluClassics) | [](https://colab.research.google.com/drive/1obr78FY_cBmWY5ODViCmzdY6O1KB65Vc?usp=sharing) |
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/training.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Fine-tuning a un modelo pre-entrenado
[[open-in-colab]]
El uso de un modelo pre-entrenado tiene importantes ventajas. Reduce los costos de computación, la huella de carbono y te permite utilizar modelos de última generación sin tener que entrenar uno desde cero.
* Fine-tuning a un modelo pre-entrenado con 🤗 Transformers [`Trainer`].
* Fine-tuning a un modelo pre-entrenado en TensorFlow con Keras.
* Fine-tuning a un modelo pre-entrenado en PyTorch nativo.
<a id='data-processing'></a>
## Prepara un dataset
<Youtube id="_BZearw7f0w"/>
Antes de aplicar fine-tuning a un modelo pre-entrenado, descarga un dataset y prepáralo para el entrenamiento. El tutorial anterior nos enseñó cómo procesar los datos para el entrenamiento, y ahora es la oportunidad de poner a prueba estas habilidades.
Comienza cargando el dataset de [Yelp Reviews](https://huggingface.co/datasets/yelp_review_full):
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("yelp_review_full")
>>> dataset[100]
{'label': 0,
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
```
Como ya sabes, necesitas un tokenizador para procesar el texto e incluir una estrategia para el padding y el truncamiento para manejar cualquier longitud de secuencia variable. Para procesar tu dataset en un solo paso, utiliza el método de 🤗 Datasets map para aplicar una función de preprocesamiento sobre todo el dataset:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
>>> def tokenize_function(examples):
... return tokenizer(examples["text"], padding="max_length", truncation=True)
>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
```
Si lo deseas, puedes crear un subconjunto más pequeño del dataset completo para aplicarle fine-tuning y así reducir el tiempo.
```py
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
```
<a id='trainer'></a>
## Fine-tuning con `Trainer`
<Youtube id="nvBXf7s7vTI"/>
🤗 Transformers proporciona una clase [`Trainer`] optimizada para el entrenamiento de modelos de 🤗 Transformers, haciendo más fácil el inicio del entrenamiento sin necesidad de escribir manualmente tu propio ciclo. La API del [`Trainer`] soporta una amplia gama de opciones de entrenamiento y características como el logging, el gradient accumulation y el mixed precision.
Comienza cargando tu modelo y especifica el número de labels previstas. A partir del [Card Dataset](https://huggingface.co/datasets/yelp_review_full#data-fields) de Yelp Review, que como ya sabemos tiene 5 labels:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
<Tip>
Verás una advertencia acerca de que algunos de los pesos pre-entrenados no están siendo utilizados y que algunos pesos están siendo inicializados al azar. No te preocupes, esto es completamente normal.
El head/cabezal pre-entrenado del modelo BERT se descarta y se sustituye por un head de clasificación inicializado aleatoriamente. Puedes aplicar fine-tuning a este nuevo head del modelo en tu tarea de clasificación de secuencias haciendo transfer learning del modelo pre-entrenado.
</Tip>
### Hiperparámetros de entrenamiento
A continuación, crea una clase [`TrainingArguments`] que contenga todos los hiperparámetros que puedes ajustar así como los indicadores para activar las diferentes opciones de entrenamiento. Para este tutorial puedes empezar con los [hiperparámetros](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) de entrenamiento por defecto, pero siéntete libre de experimentar con ellos para encontrar tu configuración óptima.
Especifica dónde vas a guardar los checkpoints de tu entrenamiento:
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(output_dir="test_trainer")
```
### Métricas
El [`Trainer`] no evalúa automáticamente el rendimiento del modelo durante el entrenamiento. Tendrás que pasarle a [`Trainer`] una función para calcular y hacer un reporte de las métricas. La biblioteca de 🤗 Datasets proporciona una función de [`accuracy`](https://huggingface.co/metrics/accuracy) simple que puedes cargar con la función `load_metric` (ver este [tutorial](https://huggingface.co/docs/datasets/metrics) para más información):
```py
>>> import numpy as np
>>> from datasets import load_metric
>>> metric = load_metric("accuracy")
```
Define la función `compute` en `metric` para calcular el accuracy de tus predicciones. Antes de pasar tus predicciones a `compute`, necesitas convertir las predicciones a logits (recuerda que todos los modelos de 🤗 Transformers devuelven logits).
```py
>>> def compute_metrics(eval_pred):
... logits, labels = eval_pred
... predictions = np.argmax(logits, axis=-1)
... return metric.compute(predictions=predictions, references=labels)
```
Si quieres controlar tus métricas de evaluación durante el fine-tuning, especifica el parámetro `evaluation_strategy` en tus argumentos de entrenamiento para que el modelo tenga en cuenta la métrica de evaluación al final de cada época:
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch")
```
### Trainer
Crea un objeto [`Trainer`] con tu modelo, argumentos de entrenamiento, datasets de entrenamiento y de prueba, y tu función de evaluación:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
A continuación, aplica fine-tuning a tu modelo llamando [`~transformers.Trainer.train`]:
```py
>>> trainer.train()
```
<a id='keras'></a>
## Fine-tuning con Keras
<Youtube id="rnTGBy2ax1c"/>
Los modelos de 🤗 Transformers también permiten realizar el entrenamiento en TensorFlow con la API de Keras. Solo es necesario hacer algunos cambios antes de hacer fine-tuning.
### Convierte el dataset al formato de TensorFlow
El [`DefaultDataCollator`] junta los tensores en un batch para que el modelo se entrene en él. Asegúrate de especificar `return_tensors` para devolver los tensores de TensorFlow:
```py
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator(return_tensors="tf")
```
<Tip>
[`Trainer`] utiliza [`DataCollatorWithPadding`] por defecto por lo que no es necesario especificar explícitamente un intercalador de datos (data collator, en inglés).
</Tip>
A continuación, convierte los datasets tokenizados en datasets de TensorFlow con el método [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Especifica tus entradas en `columns` y tu etiqueta en `label_cols`:
```py
>>> tf_train_dataset = small_train_dataset.to_tf_dataset(
... columns=["attention_mask", "input_ids", "token_type_ids"],
... label_cols="labels",
... shuffle=True,
... collate_fn=data_collator,
... batch_size=8,
... )
>>> tf_validation_dataset = small_eval_dataset.to_tf_dataset(
... columns=["attention_mask", "input_ids", "token_type_ids"],
... label_cols="labels",
... shuffle=False,
... collate_fn=data_collator,
... batch_size=8,
... )
```
### Compila y ajusta
Carguemos un modelo TensorFlow con el número esperado de labels:
```py
>>> import tensorflow as tf
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
A continuación, compila y aplica fine-tuning a tu modelo con [`fit`](https://keras.io/api/models/model_training_apis/) como lo harías con cualquier otro modelo de Keras:
```py
>>> model.compile(
... optimizer=tf.keras.optimizers.Adam(learning_rate=5e-5),
... loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
... metrics=tf.metrics.SparseCategoricalAccuracy(),
... )
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
```
<a id='pytorch_native'></a>
## Fine-tune en PyTorch nativo
<Youtube id="Dh9CL8fyG80"/>
El [`Trainer`] se encarga del ciclo de entrenamiento y permite aplicar fine-tuning a un modelo en una sola línea de código. Para los que prefieran escribir su propio ciclo de entrenamiento, también pueden aplicar fine-tuning a un modelo de 🤗 Transformers en PyTorch nativo.
En este punto, es posible que necesites reiniciar tu notebook o ejecutar el siguiente código para liberar algo de memoria:
```py
del model
del pytorch_model
del trainer
torch.cuda.empty_cache()
```
A continuación, haremos un post-procesamiento manual al `tokenized_dataset` y así prepararlo para el entrenamiento.
1. Elimina la columna de `text` porque el modelo no acepta texto en crudo como entrada:
```py
>>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
```
2. Cambia el nombre de la columna de `label` a `labels` porque el modelo espera que el argumento se llame `labels`:
```py
>>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
```
3. Establece el formato del dataset para devolver tensores PyTorch en lugar de listas:
```py
>>> tokenized_datasets.set_format("torch")
```
A continuación, crea un subconjunto más pequeño del dataset como se ha mostrado anteriormente para acelerar el fine-tuning:
```py
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
```
### DataLoader
Crea un `DataLoader` para tus datasets de entrenamiento y de prueba para poder iterar sobre batches de datos:
```py
>>> from torch.utils.data import DataLoader
>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
```
Carga tu modelo con el número de labels previstas:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
### Optimiza y programa el learning rate
Crea un optimizador y el learning rate para aplicar fine-tuning al modelo. Vamos a utilizar el optimizador [`AdamW`](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html) de PyTorch:
```py
>>> from torch.optim import AdamW
>>> optimizer = AdamW(model.parameters(), lr=5e-5)
```
Crea el learning rate desde el [`Trainer`]:
```py
>>> from transformers import get_scheduler
>>> num_epochs = 3
>>> num_training_steps = num_epochs * len(train_dataloader)
>>> lr_scheduler = get_scheduler(
... name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
... )
```
Por último, especifica el `device` o entorno de ejecución para utilizar una GPU si tienes acceso a una. De lo contrario, el entrenamiento en una CPU puede llevarte varias horas en lugar de un par de minutos.
```py
>>> import torch
>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
>>> model.to(device)
```
<Tip>
Consigue acceso gratuito a una GPU en la nube si es que no tienes este recurso de forma local con un notebook alojado en [Colaboratory](https://colab.research.google.com/) o [SageMaker StudioLab](https://studiolab.sagemaker.aws/).
</Tip>
Genial, ¡ahora podemos entrenar! 🥳
### Ciclo de entrenamiento
Para hacer un seguimiento al progreso del entrenamiento, utiliza la biblioteca [tqdm](https://tqdm.github.io/) para añadir una barra de progreso sobre el número de pasos de entrenamiento:
```py
>>> from tqdm.auto import tqdm
>>> progress_bar = tqdm(range(num_training_steps))
>>> model.train()
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... batch = {k: v.to(device) for k, v in batch.items()}
... outputs = model(**batch)
... loss = outputs.loss
... loss.backward()
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
### Métricas
De la misma manera que necesitas añadir una función de evaluación al [`Trainer`], necesitas hacer lo mismo cuando escribas tu propio ciclo de entrenamiento. Pero en lugar de calcular y reportar la métrica al final de cada época, esta vez acumularás todos los batches con [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=add_batch#datasets.Metric.add_batch) y calcularás la métrica al final.
```py
>>> metric = load_metric("accuracy")
>>> model.eval()
>>> for batch in eval_dataloader:
... batch = {k: v.to(device) for k, v in batch.items()}
... with torch.no_grad():
... outputs = model(**batch)
... logits = outputs.logits
... predictions = torch.argmax(logits, dim=-1)
... metric.add_batch(predictions=predictions, references=batch["labels"])
>>> metric.compute()
```
<a id='additional-resources'></a>
## Recursos adicionales
Para más ejemplos de fine-tuning consulta:
- [🤗 Transformers Examples](https://github.com/huggingface/transformers/tree/main/examples) incluye scripts
para entrenar tareas comunes de NLP en PyTorch y TensorFlow.
- [🤗 Transformers Notebooks](notebooks) contiene varios notebooks sobre cómo aplicar fine-tuning a un modelo para tareas específicas en PyTorch y TensorFlow.
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/index.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Transformers
Machine Learning de última generación para PyTorch, TensorFlow y JAX.
🤗 Transformers proporciona APIs para descargar y entrenar fácilmente modelos preentrenados de última generación. El uso de modelos preentrenados puede reducir tus costos de cómputo, tu huella de carbono y ahorrarte tiempo al entrenar un modelo desde cero. Los modelos se pueden utilizar en diferentes modalidades, tales como:
* 📝 Texto: clasificación de texto, extracción de información, respuesta a preguntas, resumir, traducción y generación de texto en más de 100 idiomas.
* 🖼️ Imágenes: clasificación de imágenes, detección de objetos y segmentación.
* 🗣️ Audio: reconocimiento de voz y clasificación de audio.
* 🐙 Multimodal: respuesta a preguntas en tablas, reconocimiento óptico de caracteres, extracción de información de documentos escaneados, clasificación de videos y respuesta visual a preguntas.
Nuestra biblioteca admite una integración perfecta entre tres de las bibliotecas de deep learning más populares: [PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/) y [JAX](https://jax.readthedocs.io/en/latest/). Entrena tu modelo con tres líneas de código en un framework y cárgalo para inferencia con otro.
Cada arquitectura de 🤗 Transformers se define en un módulo de Python independiente para que se puedan personalizar fácilmente para investigación y experimentos.
## Si estás buscando soporte personalizado del equipo de Hugging Face
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://huggingface.co/front/thumbnails/support.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
## Contenidos
La documentación está organizada en cuatro partes:
- **EMPEZAR** contiene un recorrido rápido e instrucciones de instalación para comenzar a usar 🤗 Transformers.
- **TUTORIALES** es un excelente lugar para comenzar. Esta sección te ayudará a obtener las habilidades básicas que necesitas para comenzar a usar 🤗 Transformers.
- **GUÍAS PRÁCTICAS** te mostrará cómo lograr un objetivo específico, cómo hacer fine-tuning a un modelo preentrenado para el modelado de lenguaje o cómo crear un cabezal para un modelo personalizado.
- **GUÍAS CONCEPTUALES** proporciona más discusión y explicación de los conceptos e ideas subyacentes detrás de los modelos, las tareas y la filosofía de diseño de 🤗 Transformers.
La biblioteca actualmente contiene implementaciones de JAX, PyTorch y TensorFlow, pesos de modelos preentrenados, scripts de uso y utilidades de conversión para los siguientes modelos.
### Modelos compatibles
<!--This list is updated automatically from the README with _make fix-copies_. Do not update manually! -->
1. **[ALBERT](model_doc/albert)** (de Google Research y el Instituto Tecnológico de Toyota en Chicago) publicado con el paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), por Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
1. **[ALIGN](model_doc/align)** (de Google Research) publicado con el paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) por Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
1. **[BART](model_doc/bart)** (de Facebook) publicado con el paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) por Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov y Luke Zettlemoyer.
1. **[BARThez](model_doc/barthez)** (de École polytechnique) publicado con el paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) por Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](model_doc/bartpho)** (de VinAI Research) publicado con el paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) por Nguyen Luong Tran, Duong Minh Le y Dat Quoc Nguyen.
1. **[BEiT](model_doc/beit)** (de Microsoft) publicado con el paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) por Hangbo Bao, Li Dong, Furu Wei.
1. **[BERT](model_doc/bert)** (de Google) publicado con el paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) por Jacob Devlin, Ming-Wei Chang, Kenton Lee y Kristina Toutanova.
1. **[BERTweet](model_doc/bertweet)** (de VinAI Research) publicado con el paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) por Dat Quoc Nguyen, Thanh Vu y Anh Tuan Nguyen.
1. **[BERT For Sequence Generation](model_doc/bert-generation)** (de Google) publicado con el paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) por Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BigBird-RoBERTa](model_doc/big_bird)** (de Google Research) publicado con el paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) por Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (de Google Research) publicado con el paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) por Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[Blenderbot](model_doc/blenderbot)** (de Facebook) publicado con el paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) por Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BlenderbotSmall](model_doc/blenderbot-small)** (de Facebook) publicado con el paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) por Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BORT](model_doc/bort)** (de Alexa) publicado con el paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) por Adrian de Wynter y Daniel J. Perry.
1. **[ByT5](model_doc/byt5)** (de Google Research) publicado con el paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) por Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
1. **[CamemBERT](model_doc/camembert)** (de Inria/Facebook/Sorbonne) publicado con el paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) por Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah y Benoît Sagot.
1. **[CANINE](model_doc/canine)** (de Google Research) publicado con el paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) por Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[ConvNeXT](model_doc/convnext)** (de Facebook AI) publicado con el paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) por Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[ConvNeXTV2](model_doc/convnextv2)** (de Facebook AI) publicado con el paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) por Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
1. **[CLIP](model_doc/clip)** (de OpenAI) publicado con el paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) por Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[ConvBERT](model_doc/convbert)** (de YituTech) publicado con el paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) por Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
1. **[CPM](model_doc/cpm)** (de Universidad de Tsinghua) publicado con el paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) por Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CTRL](model_doc/ctrl)** (de Salesforce) publicado con el paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) por Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong y Richard Socher.
1. **[Data2Vec](model_doc/data2vec)** (de Facebook) publicado con el paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) por Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
1. **[DeBERTa](model_doc/deberta)** (de Microsoft) publicado con el paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) por Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[DeBERTa-v2](model_doc/deberta-v2)** (de Microsoft) publicado con el paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) por Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[Decision Transformer](model_doc/decision_transformer)** (de Berkeley/Facebook/Google) publicado con el paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) por Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
1. **[DiT](model_doc/dit)** (de Microsoft Research) publicado con el paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) por Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
1. **[DeiT](model_doc/deit)** (de Facebook) publicado con el paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) por Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
1. **[DETR](model_doc/detr)** (de Facebook) publicado con el paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) por Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
1. **[DialoGPT](model_doc/dialogpt)** (de Microsoft Research) publicado con el paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) por Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
1. **[DistilBERT](model_doc/distilbert)** (de HuggingFace), publicado junto con el paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) por Victor Sanh, Lysandre Debut y Thomas Wolf. Se ha aplicado el mismo método para comprimir GPT2 en [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa en [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), BERT multilingüe en [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) y una versión alemana de DistilBERT.
1. **[DPR](model_doc/dpr)** (de Facebook) publicado con el paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) por Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, y Wen-tau Yih.
1. **[DPT](master/model_doc/dpt)** (de Intel Labs) publicado con el paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) por René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
1. **[EncoderDecoder](model_doc/encoder-decoder)** (de Google Research) publicado con el paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) por Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[ELECTRA](model_doc/electra)** (de Google Research/Universidad de Stanford) publicado con el paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) por Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
1. **[FlauBERT](model_doc/flaubert)** (de CNRS) publicado con el paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) por Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
1. **[FNet](model_doc/fnet)** (de Google Research) publicado con el paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) por James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
1. **[Funnel Transformer](model_doc/funnel)** (de CMU/Google Brain) publicado con el paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) por Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
1. **[GLPN](model_doc/glpn)** (de KAIST) publicado con el paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) por Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (de OpenAI) publicado con el paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) por Alec Radford, Karthik Narasimhan, Tim Salimans y Ilya Sutskever.
1. **[GPT-2](model_doc/gpt2)** (de OpenAI) publicado con el paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) por Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** y Ilya Sutskever**.
1. **[GPT-J](model_doc/gptj)** (de EleutherAI) publicado con el repositorio [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) por Ben Wang y Aran Komatsuzaki.
1. **[GPT Neo](model_doc/gpt_neo)** (de EleutherAI) publicado en el paper [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) por Sid Black, Stella Biderman, Leo Gao, Phil Wang y Connor Leahy.
1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released with [GPTSAN](https://github.com/tanreinama/GPTSAN) by Toshiyuki Sakamoto (tanreinama).
1. **[Hubert](model_doc/hubert)** (de Facebook) publicado con el paper [HuBERT: Self-Supervised Speech Representation Learning por Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) por Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
1. **[I-BERT](model_doc/ibert)** (de Berkeley) publicado con el paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) por Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (de OpenAI) publicado con el paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) por Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[LayoutLM](model_doc/layoutlm)** (de Microsoft Research Asia) publicado con el paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) por Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](model_doc/layoutlmv2)** (de Microsoft Research Asia) publicado con el paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) por Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutXLM](model_doc/layoutxlm)** (de Microsoft Research Asia) publicado con el paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) por Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](model_doc/led)** (de AllenAI) publicado con el paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) por Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[Longformer](model_doc/longformer)** (de AllenAI) publicado con el paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) por Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LUKE](model_doc/luke)** (de Studio Ousia) publicado con el paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) por Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[mLUKE](model_doc/mluke)** (de Studio Ousia) publicado con el paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) por Ryokan Ri, Ikuya Yamada, y Yoshimasa Tsuruoka.
1. **[LXMERT](model_doc/lxmert)** (de UNC Chapel Hill) publicado con el paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) por Hao Tan y Mohit Bansal.
1. **[M2M100](model_doc/m2m_100)** (de Facebook) publicado con el paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) por Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Modelos de traducción automática entrenados usando [OPUS](http://opus.nlpl.eu/) data por Jörg Tiedemann. El [Marian Framework](https://marian-nmt.github.io/) está siendo desarrollado por el equipo de traductores de Microsoft.
1. **[Mask2Former](model_doc/mask2former)** (de FAIR y UIUC) publicado con el paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) por Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
1. **[MaskFormer](model_doc/maskformer)** (de Meta y UIUC) publicado con el paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) por Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[MBart](model_doc/mbart)** (de Facebook) publicado con el paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) por Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[MBart-50](model_doc/mbart)** (de Facebook) publicado con el paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) por Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
1. **[Megatron-BERT](model_doc/megatron-bert)** (de NVIDIA) publicado con el paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) por Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper y Bryan Catanzaro.
1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (de NVIDIA) publicado con el paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) por Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper y Bryan Catanzaro.
1. **[MPNet](model_doc/mpnet)** (de Microsoft Research) publicado con el paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) por Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
1. **[MT5](model_doc/mt5)** (de Google AI) publicado con el paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) por Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
1. **[Nyströmformer](model_doc/nystromformer)** (de la Universidad de Wisconsin - Madison) publicado con el paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) por Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](model_doc/oneformer)** (de la SHI Labs) publicado con el paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) por Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
1. **[Pegasus](model_doc/pegasus)** (de Google) publicado con el paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) por Jingqing Zhang, Yao Zhao, Mohammad Saleh y Peter J. Liu.
1. **[Perceiver IO](model_doc/perceiver)** (de Deepmind) publicado con el paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) por Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (de VinAI Research) publicado con el paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) por Dat Quoc Nguyen y Anh Tuan Nguyen.
1. **[PLBart](model_doc/plbart)** (de UCLA NLP) publicado con el paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) por Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
1. **[PoolFormer](model_doc/poolformer)** (de Sea AI Labs) publicado con el paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) por Yu, Weihao y Luo, Mi y Zhou, Pan y Si, Chenyang y Zhou, Yichen y Wang, Xinchao y Feng, Jiashi y Yan, Shuicheng.
1. **[ProphetNet](model_doc/prophetnet)** (de Microsoft Research) publicado con el paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) por Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang y Ming Zhou.
1. **[QDQBert](model_doc/qdqbert)** (de NVIDIA) publicado con el paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) por Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev y Paulius Micikevicius.
1. **[REALM](model_doc/realm.html)** (de Google Research) publicado con el paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) por Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat y Ming-Wei Chang.
1. **[Reformer](model_doc/reformer)** (de Google Research) publicado con el paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) por Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
1. **[RemBERT](model_doc/rembert)** (de Google Research) publicado con el paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) por Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
1. **[RegNet](model_doc/regnet)** (de META Platforms) publicado con el paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) por Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
1. **[ResNet](model_doc/resnet)** (de Microsoft Research) publicado con el paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) por Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
1. **[RoBERTa](model_doc/roberta)** (de Facebook), publicado junto con el paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) por Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
1. **[RoFormer](model_doc/roformer)** (de ZhuiyiTechnology), publicado junto con el paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) por Jianlin Su y Yu Lu y Shengfeng Pan y Bo Wen y Yunfeng Liu.
1. **[SegFormer](model_doc/segformer)** (de NVIDIA) publicado con el paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) por Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[SEW](model_doc/sew)** (de ASAPP) publicado con el paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) por Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](model_doc/sew_d)** (de ASAPP) publicado con el paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) por Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (de Facebook), publicado junto con el paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) por Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (de Facebook), publicado junto con el paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) por Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
1. **[Splinter](model_doc/splinter)** (de Universidad de Tel Aviv), publicado junto con el paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) pory Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
1. **[SqueezeBert](model_doc/squeezebert)** (de Berkeley) publicado con el paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) por Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, y Kurt W. Keutzer.
1. **[Swin Transformer](model_doc/swin)** (de Microsoft) publicado con el paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) por Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[T5](model_doc/t5)** (de Google AI) publicado con el paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) por Colin Raffel y Noam Shazeer y Adam Roberts y Katherine Lee y Sharan Narang y Michael Matena y Yanqi Zhou y Wei Li y Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (de Google AI) publicado en el repositorio [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) por Colin Raffel y Noam Shazeer y Adam Roberts y Katherine Lee y Sharan Narang y Michael Matena y Yanqi Zhou y Wei Li y Peter J. Liu.
1. **[TAPAS](model_doc/tapas)** (de Google AI) publicado con el paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) por Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno y Julian Martin Eisenschlos.
1. **[TAPEX](model_doc/tapex)** (de Microsoft Research) publicado con el paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) por Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Transformer-XL](model_doc/transfo-xl)** (de Google/CMU) publicado con el paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) por Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](model_doc/trocr)** (de Microsoft), publicado junto con el paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) por Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[UniSpeech](model_doc/unispeech)** (de Microsoft Research) publicado con el paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) por Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](model_doc/unispeech-sat)** (de Microsoft Research) publicado con el paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) por Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[VAN](model_doc/van)** (de la Universidad de Tsinghua y la Universidad de Nankai) publicado con el paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) por Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[ViLT](model_doc/vilt)** (de NAVER AI Lab/Kakao Enterprise/Kakao Brain) publicado con el paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) por Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](model_doc/vit)** (de Google AI) publicado con el paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) por Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[ViTMAE](model_doc/vit_mae)** (de Meta AI) publicado con el paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) por Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
1. **[VisualBERT](model_doc/visual_bert)** (de UCLA NLP) publicado con el paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) por Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[WavLM](model_doc/wavlm)** (de Microsoft Research) publicado con el paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) por Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Wav2Vec2](model_doc/wav2vec2)** (de Facebook AI) publicado con el paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) por Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (de Facebook AI) publicado con el paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) por Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[XGLM](model_doc/xglm)** (de Facebook AI) publicado con el paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) por Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
1. **[XLM](model_doc/xlm)** (de Facebook) publicado junto con el paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) por Guillaume Lample y Alexis Conneau.
1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (de Microsoft Research) publicado con el paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) por Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang y Ming Zhou.
1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (de Facebook AI), publicado junto con el paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) por Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer y Veselin Stoyanov.
1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (de Facebook AI), publicado junto con el paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) por Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
1. **[XLNet](model_doc/xlnet)** (de Google/CMU) publicado con el paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) por Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (de Facebook AI) publicado con el paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) por Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
1. **[XLS-R](model_doc/xls_r)** (de Facebook AI) publicado con el paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) por Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
1. **[YOSO](model_doc/yoso)** (de la Universidad de Wisconsin-Madison) publicado con el paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) por Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### Frameworks compatibles
La siguiente tabla representa el soporte actual en la biblioteca para cada uno de esos modelos, ya sea que tengan un tokenizador de Python (llamado "slow"). Un tokenizador "fast" respaldado por la biblioteca 🤗 Tokenizers, ya sea que tengan soporte en Jax (a través de
Flax), PyTorch y/o TensorFlow.
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
| Modelo | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
|:---------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
| BigBirdPegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| Canine | ✅ | ❌ | ✅ | ❌ | ❌ |
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ConvNext | ❌ | ❌ | ✅ | ✅ | ❌ |
| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
| DeBERTa-v2 | ✅ | ❌ | ✅ | ✅ | ❌ |
| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| DeiT | ❌ | ❌ | ✅ | ❌ | ❌ |
| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
| MegatronBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| mT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Nystromformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
| Realm | ✅ | ✅ | ✅ | ❌ | ❌ |
| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ResNet | ❌ | ❌ | ✅ | ❌ | ✅ |
| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
| SegFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| Swin | ❌ | ❌ | ✅ | ❌ | ❌ |
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
| TAPEX | ✅ | ✅ | ✅ | ✅ | ✅ |
| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| VisualBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
| XGLM | ✅ | ✅ | ✅ | ❌ | ✅ |
| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
| XLMProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
<!-- End table-->
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/custom_models.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Compartir modelos personalizados
La biblioteca 🤗 Transformers está diseñada para ser fácilmente ampliable. Cada modelo está completamente codificado
sin abstracción en una subcarpeta determinada del repositorio, por lo que puedes copiar fácilmente un archivo del modelo
y ajustarlo según tus necesidades.
Si estás escribiendo un modelo completamente nuevo, podría ser más fácil comenzar desde cero. En este tutorial, te mostraremos
cómo escribir un modelo personalizado y su configuración para que pueda usarse dentro de Transformers, y cómo puedes compartirlo
con la comunidad (con el código en el que se basa) para que cualquiera pueda usarlo, incluso si no está presente en la biblioteca
🤗 Transformers.
Ilustraremos todo esto con un modelo ResNet, envolviendo la clase ResNet de la [biblioteca timm](https://github.com/rwightman/pytorch-image-models) en un [`PreTrainedModel`].
## Escribir una configuración personalizada
Antes de adentrarnos en el modelo, primero escribamos su configuración. La configuración de un modelo es un objeto que
contendrá toda la información necesaria para construir el modelo. Como veremos en la siguiente sección, el modelo solo puede
tomar un `config` para ser inicializado, por lo que realmente necesitamos que ese objeto esté lo más completo posible.
En nuestro ejemplo, tomaremos un par de argumentos de la clase ResNet que tal vez queramos modificar. Las diferentes
configuraciones nos darán los diferentes tipos de ResNet que son posibles. Luego simplemente almacenamos esos argumentos
después de verificar la validez de algunos de ellos.
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
Las tres cosas importantes que debes recordar al escribir tu propia configuración son las siguientes:
- tienes que heredar de `PretrainedConfig`,
- el `__init__` de tu `PretrainedConfig` debe aceptar cualquier `kwargs`,
- esos `kwargs` deben pasarse a la superclase `__init__`.
La herencia es para asegurarte de obtener toda la funcionalidad de la biblioteca 🤗 Transformers, mientras que las otras dos
restricciones provienen del hecho de que una `PretrainedConfig` tiene más campos que los que estás configurando. Al recargar una
`config` con el método `from_pretrained`, esos campos deben ser aceptados por tu `config` y luego enviados a la superclase.
Definir un `model_type` para tu configuración (en este caso `model_type="resnet"`) no es obligatorio, a menos que quieras
registrar tu modelo con las clases automáticas (ver la última sección).
Una vez hecho esto, puedes crear y guardar fácilmente tu configuración como lo harías con cualquier otra configuración de un
modelo de la biblioteca. Así es como podemos crear una configuración resnet50d y guardarla:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
Esto guardará un archivo llamado `config.json` dentro de la carpeta `custom-resnet`. Luego puedes volver a cargar tu configuración
con el método `from_pretrained`:
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
También puedes usar cualquier otro método de la clase [`PretrainedConfig`], como [`~PretrainedConfig.push_to_hub`], para cargar
directamente tu configuración en el Hub.
## Escribir un modelo personalizado
Ahora que tenemos nuestra configuración de ResNet, podemos seguir escribiendo el modelo. En realidad escribiremos dos: una que
extrae las características ocultas de un grupo de imágenes (como [`BertModel`]) y una que es adecuada para clasificación de
imagenes (como [`BertForSequenceClassification`]).
Como mencionamos antes, solo escribiremos un envoltura (_wrapper_) libre del modelo para simplificar este ejemplo. Lo único que debemos
hacer antes de escribir esta clase es un mapeo entre los tipos de bloques y las clases de bloques reales. Luego se define el
modelo desde la configuración pasando todo a la clase `ResNet`:
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
Para el modelo que clasificará las imágenes, solo cambiamos el método de avance (es decir, el método `forward`):
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
En ambos casos, observa cómo heredamos de `PreTrainedModel` y llamamos a la inicialización de la superclase con `config`
(un poco como cuando escribes `torch.nn.Module`). La línea que establece `config_class` no es obligatoria, a menos
que quieras registrar tu modelo con las clases automáticas (consulta la última sección).
<Tip>
Si tu modelo es muy similar a un modelo dentro de la biblioteca, puedes reutilizar la misma configuración de ese modelo.
</Tip>
Puedes hacer que tu modelo devuelva lo que quieras, pero devolver un diccionario como lo hicimos para
`ResnetModelForImageClassification`, con el `loss` incluido cuando se pasan las etiquetas, hará que tu modelo se pueda
usar directamente dentro de la clase [`Trainer`]. Usar otro formato de salida está bien, siempre y cuando estés planeando usar
tu propio bucle de entrenamiento u otra biblioteca para el entrenamiento.
Ahora que tenemos nuestra clase, vamos a crear un modelo:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
Nuevamente, puedes usar cualquiera de los métodos de [`PreTrainedModel`], como [`~PreTrainedModel.save_pretrained`] o
[`~PreTrainedModel.push_to_hub`]. Usaremos el segundo en la siguiente sección y veremos cómo pasar los pesos del modelo
con el código de nuestro modelo. Pero primero, carguemos algunos pesos previamente entrenados dentro de nuestro modelo.
En tu caso de uso, probablemente estarás entrenando tu modelo personalizado con tus propios datos. Para ir rápido en este
tutorial, usaremos la versión preentrenada de resnet50d. Dado que nuestro modelo es solo un envoltorio alrededor del resnet50d
original, será fácil transferir esos pesos:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Ahora veamos cómo asegurarnos de que cuando hacemos [`~PreTrainedModel.save_pretrained`] o [`~PreTrainedModel.push_to_hub`],
se guarda el código del modelo.
## Enviar el código al _Hub_
<Tip warning={true}>
Esta _API_ es experimental y puede tener algunos cambios leves en las próximas versiones.
</Tip>
Primero, asegúrate de que tu modelo esté completamente definido en un archivo `.py`. Puedes basarte en importaciones
relativas a otros archivos, siempre que todos los archivos estén en el mismo directorio (aún no admitimos submódulos
para esta característica). Para nuestro ejemplo, definiremos un archivo `modeling_resnet.py` y un archivo
`configuration_resnet.py` en una carpeta del directorio de trabajo actual llamado `resnet_model`. El archivo de configuración
contiene el código de `ResnetConfig` y el archivo del modelo contiene el código de `ResnetModel` y
`ResnetModelForImageClassification`.
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
El `__init__.py` puede estar vacío, solo está ahí para que Python detecte que `resnet_model` se puede usar como un módulo.
<Tip warning={true}>
Si copias archivos del modelo desde la biblioteca, deberás reemplazar todas las importaciones relativas en la parte superior
del archivo para importarlos desde el paquete `transformers`.
</Tip>
Ten en cuenta que puedes reutilizar (o subclasificar) una configuración o modelo existente.
Para compartir tu modelo con la comunidad, sigue estos pasos: primero importa el modelo y la configuración de ResNet desde
los archivos recién creados:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
Luego, debes decirle a la biblioteca que deseas copiar el código de esos objetos cuando usas el método `save_pretrained`
y registrarlos correctamente con una determinada clase automática (especialmente para modelos), simplemente ejecuta:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
Ten en cuenta que no es necesario especificar una clase automática para la configuración (solo hay una clase automática
para ellos, [`AutoConfig`]), pero es diferente para los modelos. Tu modelo personalizado podría ser adecuado para muchas
tareas diferentes, por lo que debes especificar cuál de las clases automáticas es la correcta para tu modelo.
A continuación, vamos a crear la configuración y los modelos como lo hicimos antes:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Ahora, para enviar el modelo al Hub, asegúrate de haber iniciado sesión. Ejecuta en tu terminal:
```bash
huggingface-cli login
```
o desde un _notebook_:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Luego puedes ingresar a tu propio espacio (o una organización de la que seas miembro) de esta manera:
```py
resnet50d.push_to_hub("custom-resnet50d")
```
Además de los pesos del modelo y la configuración en formato json, esto también copió los archivos `.py` del modelo y la
configuración en la carpeta `custom-resnet50d` y subió el resultado al Hub. Puedes verificar el resultado en este
[repositorio de modelos](https://huggingface.co/sgugger/custom-resnet50d).
Consulta el tutorial sobre cómo [compartir modelos](model_sharing) para obtener más información sobre el método para subir modelos al Hub.
## Usar un modelo con código personalizado
Puedes usar cualquier configuración, modelo o _tokenizador_ con archivos de código personalizado en tu repositorio con las
clases automáticas y el método `from_pretrained`. Todos los archivos y códigos cargados en el Hub se analizan en busca de
malware (consulta la documentación de [seguridad del Hub](https://huggingface.co/docs/hub/security#malware-scanning) para
obtener más información), pero aún debes revisar el código del modelo y el autor para evitar la ejecución de código malicioso
en tu computadora. Configura `trust_remote_code=True` para usar un modelo con código personalizado:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
También se recomienda encarecidamente pasar un _hash_ de confirmación como una "revisión" para asegurarte de que el autor
de los modelos no actualizó el código con algunas líneas nuevas maliciosas (a menos que confíes plenamente en los autores
de los modelos).
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
```
Ten en cuenta que al navegar por el historial de confirmaciones del repositorio del modelo en Hub, hay un botón para copiar
fácilmente el hash de confirmación de cualquier _commit_.
## Registrar un model con código personalizado a las clases automáticas
Si estás escribiendo una biblioteca que amplía 🤗 Transformers, es posible que quieras ampliar las clases automáticas para
incluir tu propio modelo. Esto es diferente de enviar el código al Hub en el sentido de que los usuarios necesitarán importar
tu biblioteca para obtener los modelos personalizados (al contrario de descargar automáticamente el código del modelo desde Hub).
Siempre que tu configuración tenga un atributo `model_type` que sea diferente de los tipos de modelos existentes, y que tus
clases modelo tengan los atributos `config_class` correctos, puedes agregarlos a las clases automáticas de la siguiente manera:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
Ten en cuenta que el primer argumento utilizado al registrar tu configuración personalizada en [`AutoConfig`] debe coincidir
con el `model_type` de tu configuración personalizada, y el primer argumento utilizado al registrar tus modelos personalizados
en cualquier clase del modelo automático debe coincidir con el `config_class ` de esos modelos.
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/fast_tokenizers.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Usa los tokenizadores de 🤗 Tokenizers
[`PreTrainedTokenizerFast`] depende de la biblioteca [🤗 Tokenizers](https://huggingface.co/docs/tokenizers). Los tokenizadores obtenidos desde la biblioteca 🤗 Tokenizers pueden ser
cargados de forma muy sencilla en los 🤗 Transformers.
Antes de entrar en detalles, comencemos creando un tokenizador dummy en unas cuantas líneas:
```python
>>> from tokenizers import Tokenizer
>>> from tokenizers.models import BPE
>>> from tokenizers.trainers import BpeTrainer
>>> from tokenizers.pre_tokenizers import Whitespace
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
>>> tokenizer.pre_tokenizer = Whitespace()
>>> files = [...]
>>> tokenizer.train(files, trainer)
```
Ahora tenemos un tokenizador entrenado en los archivos que definimos. Lo podemos seguir utilizando en ese entorno de ejecución (runtime en inglés), o puedes guardarlo
en un archivo JSON para reutilizarlo en un futuro.
## Cargando directamente desde el objeto tokenizador
Veamos cómo utilizar este objeto tokenizador en la biblioteca 🤗 Transformers. La clase
[`PreTrainedTokenizerFast`] permite una instanciación fácil, al aceptar el objeto
*tokenizer* instanciado como argumento:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
```
Este objeto ya puede ser utilizado con todos los métodos compartidos por los tokenizadores de 🤗 Transformers! Visita la [página sobre tokenizadores
](main_classes/tokenizer) para más información.
## Cargando desde un archivo JSON
Para cargar un tokenizador desde un archivo JSON, comencemos por guardar nuestro tokenizador:
```python
>>> tokenizer.save("tokenizer.json")
```
La localización (path en inglés) donde este archivo es guardado puede ser incluida en el método de inicialización de [`PreTrainedTokenizerFast`]
utilizando el parámetro `tokenizer_file`:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
```
Este objeto ya puede ser utilizado con todos los métodos compartidos por los tokenizadores de 🤗 Transformers! Visita la [página sobre tokenizadores
](main_classes/tokenizer) para más información.
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/sagemaker.md
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Ejecutar el entrenamiento en Amazon SageMaker
La documentación ha sido trasladada a [hf.co/docs/sagemaker](https://huggingface.co/docs/sagemaker). Esta página será eliminada en `transformers` 5.0.
### Tabla de contenido
- [Entrenar modelos de Hugging Face en Amazon SageMaker con SageMaker Python SDK](https://huggingface.co/docs/sagemaker/train)
- [Desplegar modelos de Hugging Face en Amazon SageMaker con SageMaker Python SDK](https://huggingface.co/docs/sagemaker/inference)
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/quicktour.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Tour rápido
[[open-in-colab]]
¡Entra en marcha con los 🤗 Transformers! Comienza usando [`pipeline`] para una inferencia veloz, carga un modelo preentrenado y un tokenizador con una [AutoClass](./model_doc/auto) para resolver tu tarea de texto, visión o audio.
<Tip>
Todos los ejemplos de código presentados en la documentación tienen un botón arriba a la derecha para elegir si quieres ocultar o mostrar el código en Pytorch o TensorFlow.
Si no fuese así, se espera que el código funcione para ambos backends sin ningún cambio.
</Tip>
## Pipeline
[`pipeline`] es la forma más fácil de usar un modelo preentrenado para una tarea dada.
<Youtube id="tiZFewofSLM"/>
El [`pipeline`] soporta muchas tareas comunes listas para usar:
**Texto**:
* Análisis de Sentimiento (Sentiment Analysis, en inglés): clasifica la polaridad de un texto dado.
* Generación de Texto (Text Generation, en inglés): genera texto a partir de un input dado.
* Reconocimiento de Entidades (Name Entity Recognition o NER, en inglés): etiqueta cada palabra con la entidad que representa (persona, fecha, ubicación, etc.).
* Responder Preguntas (Question answering, en inglés): extrae la respuesta del contexto dado un contexto y una pregunta.
* Rellenar Máscara (Fill-mask, en inglés): rellena el espacio faltante dado un texto con palabras enmascaradas.
* Resumir (Summarization, en inglés): genera un resumen de una secuencia larga de texto o un documento.
* Traducción (Translation, en inglés): traduce un texto a otro idioma.
* Extracción de Características (Feature Extraction, en inglés): crea una representación tensorial del texto.
**Imagen**:
* Clasificación de Imágenes (Image Classification, en inglés): clasifica una imagen.
* Segmentación de Imágenes (Image Segmentation, en inglés): clasifica cada pixel de una imagen.
* Detección de Objetos (Object Detection, en inglés): detecta objetos dentro de una imagen.
**Audio**:
* Clasificación de Audios (Audio Classification, en inglés): asigna una etiqueta a un segmento de audio.
* Reconocimiento de Voz Automático (Automatic Speech Recognition o ASR, en inglés): transcribe datos de audio a un texto.
<Tip>
Para más detalles acerca del [`pipeline`] y tareas asociadas, consulta la documentación [aquí](./main_classes/pipelines).
</Tip>
### Uso del Pipeline
En el siguiente ejemplo, usarás el [`pipeline`] para análisis de sentimiento.
Instala las siguientes dependencias si aún no lo has hecho:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
Importa [`pipeline`] y especifica la tarea que deseas completar:
```py
>>> from transformers import pipeline
>>> clasificador = pipeline("sentiment-analysis", model="pysentimiento/robertuito-sentiment-analysis")
```
El pipeline descarga y almacena en caché el [modelo preentrenado](https://huggingface.co/pysentimiento/robertuito-sentiment-analysis) y tokeniza para análisis de sentimiento. Si no hubieramos elegido un modelo el pipeline habría elegido uno por defecto. Ahora puedes usar `clasificador` en tu texto objetivo:
```py
>>> clasificador("Estamos muy felices de mostrarte la biblioteca de 🤗 Transformers.")
[{'label': 'POS', 'score': 0.9320}]
```
Para más de un enunciado, entrega una lista al [`pipeline`] que devolverá una lista de diccionarios:
El [`pipeline`] también puede iterar sobre un dataset entero. Comienza instalando la biblioteca [🤗 Datasets](https://huggingface.co/docs/datasets/):
```bash
pip install datasets
```
Crea un [`pipeline`] con la tarea que deseas resolver y el modelo que quieres usar. Coloca el parámetro `device` a `0` para poner los tensores en un dispositivo CUDA:
```py
>>> import torch
>>> from transformers import pipeline
>>> reconocedor_de_voz = pipeline(
... "automatic-speech-recognition", model="jonatasgrosman/wav2vec2-large-xlsr-53-spanish", device=0
... )
```
A continuación, carga el dataset (ve 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart.html) para más detalles) sobre el que quisieras iterar. Por ejemplo, vamos a cargar el dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="es-ES", split="train") # doctest: +IGNORE_RESULT
```
Debemos asegurarnos de que la frecuencia de muestreo del conjunto de datos coincide con la frecuencia de muestreo con la que se entrenó `jonatasgrosman/wav2vec2-large-xlsr-53-spanish`.
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=reconocedor_de_voz.feature_extractor.sampling_rate))
```
Los archivos de audio se cargan y remuestrean automáticamente cuando llamamos a la columna `"audio"`.
Extraigamos las matrices de onda cruda (raw waveform, en inglés) de las primeras 4 muestras y pasémosla como una lista al pipeline:
```py
>>> resultado = reconocedor_de_voz(dataset[:4]["audio"])
>>> print([d["text"] for d in resultado])
['ahora buenas eh a ver tengo un problema con vuestra aplicación resulta que que quiero hacer una transferencia bancaria a una cuenta conocida pero me da error la aplicación a ver que a ver que puede ser', 'la aplicación no cargue saldo de mi nueva cuenta', 'hola tengo un problema con la aplicación no carga y y tampoco veo que carga el saldo de mi cuenta nueva dice que la aplicación está siendo reparada y ahora no puedo acceder a mi cuenta no necesito inmediatamente', 'hora buena la aplicación no se carga la vida no carga el saldo de mi cuenta nueva dice que la villadenta siendo reparada y oro no puedo hacer a mi cuenta']
```
Para un dataset más grande, donde los inputs son de mayor tamaño (como en habla/audio o visión), querrás pasar un generador en lugar de una lista que carga todos los inputs en memoria. Ve la [documentación del pipeline](./main_classes/pipelines) para más información.
### Usa otro modelo y otro tokenizador en el pipeline
El [`pipeline`] puede acomodarse a cualquier modelo del [Model Hub](https://huggingface.co/models) haciendo más fácil adaptar el [`pipeline`] para otros casos de uso. Por ejemplo, si quisieras un modelo capaz de manejar texto en francés, usa los tags en el Model Hub para filtrar entre los modelos apropiados. El resultado mejor filtrado devuelve un [modelo BERT](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) multilingual fine-tuned para el análisis de sentimiento. Genial, ¡vamos a usar este modelo!
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
Usa [`AutoModelForSequenceClassification`] y ['AutoTokenizer'] para cargar un modelo preentrenado y un tokenizador asociado (más en un `AutoClass` debajo):
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
Usa [`TFAutoModelForSequenceClassification`] y ['AutoTokenizer'] para cargar un modelo preentrenado y un tokenizador asociado (más en un `TFAutoClass` debajo):
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
Después puedes especificar el modelo y el tokenizador en el [`pipeline`], y aplicar el `classifier` en tu texto objetivo:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
Si no pudieras encontrar el modelo para tu caso respectivo de uso necesitarás ajustar un modelo preentrenado a tus datos. Mira nuestro [tutorial de fine-tuning](./training) para aprender cómo. Finalmente, después de que has ajustado tu modelo preentrenado, ¡por favor considera compartirlo (ve el tutorial [aquí](./model_sharing)) con la comunidad en el Model Hub para democratizar el NLP! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
Por debajo, las clases [`AutoModelForSequenceClassification`] y [`AutoTokenizer`] trabajan juntas para dar poder al [`pipeline`]. Una [AutoClass](./model_doc/auto) es un atajo que automáticamente recupera la arquitectura de un modelo preentrenado con su nombre o el path. Sólo necesitarás seleccionar el `AutoClass` apropiado para tu tarea y tu tokenizador asociado con [`AutoTokenizer`].
Regresemos a nuestro ejemplo y veamos cómo puedes usar el `AutoClass` para reproducir los resultados del [`pipeline`].
### AutoTokenizer
Un tokenizador es responsable de procesar el texto a un formato que sea entendible para el modelo. Primero, el tokenizador separará el texto en palabras llamadas *tokens*. Hay múltiples reglas que gobiernan el proceso de tokenización incluyendo el cómo separar una palabra y en qué nivel (aprende más sobre tokenización [aquí](./tokenizer_summary)). Lo más importante es recordar que necesitarás instanciar el tokenizador con el mismo nombre del modelo para asegurar que estás usando las mismas reglas de tokenización con las que el modelo fue preentrenado.
Carga un tokenizador con [`AutoTokenizer`]:
```py
>>> from transformers import AutoTokenizer
>>> nombre_del_modelo = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(nombre_del_modelo)
```
Después, el tokenizador convierte los tokens a números para construir un tensor que servirá como input para el modelo. Esto es conocido como el *vocabulario* del modelo.
Pasa tu texto al tokenizador:
```py
>>> encoding = tokenizer("Estamos muy felices de mostrarte la biblioteca de 🤗 Transformers.")
>>> print(encoding)
{'input_ids': [101, 10602, 14000, 13653, 43353, 10107, 10102, 47201, 10218, 10106, 18283, 10102, 100, 58263, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
El tokenizador devolverá un diccionario conteniendo:
* [input_ids](./glossary#input-ids): representaciones numéricas de los tokens.
* [atttention_mask](.glossary#attention-mask): indica cuáles tokens deben ser atendidos.
Como con el [`pipeline`], el tokenizador aceptará una lista de inputs. Además, el tokenizador también puede rellenar (pad, en inglés) y truncar el texto para devolver un lote (batch, en inglés) de longitud uniforme:
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
Lee el tutorial de [preprocessing](./preprocessing) para más detalles acerca de la tokenización.
### AutoModel
<frameworkcontent>
<pt>
🤗 Transformers provee una forma simple y unificada de cargar tus instancias preentrenadas. Esto significa que puedes cargar un [`AutoModel`] como cargarías un [`AutoTokenizer`]. La única diferencia es seleccionar el [`AutoModel`] correcto para la tarea. Ya que estás clasificando texto, o secuencias, carga [`AutoModelForSequenceClassification`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Ve el [task summary](./task_summary) para revisar qué clase del [`AutoModel`] deberías usar para cada tarea.
</Tip>
Ahora puedes pasar tu lote (batch) preprocesado de inputs directamente al modelo. Solo tienes que desempacar el diccionario añadiendo `**`:
```py
>>> pt_outputs = pt_model(**pt_batch)
```
El modelo producirá las activaciones finales en el atributo `logits`. Aplica la función softmax a `logits` para obtener las probabilidades:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 Transformers provee una forma simple y unificada de cargar tus instancias preentrenadas. Esto significa que puedes cargar un [`TFAutoModel`] como cargarías un [`AutoTokenizer`]. La única diferencia es seleccionar el [`TFAutoModel`] correcto para la tarea. Ya que estás clasificando texto, o secuencias, carga [`TFAutoModelForSequenceClassification`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Ve el [task summary](./task_summary) para revisar qué clase del [`AutoModel`]
deberías usar para cada tarea.
</Tip>
Ahora puedes pasar tu lote preprocesado de inputs directamente al modelo pasando las llaves del diccionario directamente a los tensores:
```py
>>> tf_outputs = tf_model(tf_batch)
```
El modelo producirá las activaciones finales en el atributo `logits`. Aplica la función softmax a `logits` para obtener las probabilidades:
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> print(tf.math.round(tf_predictions * 10**4) / 10**4)
tf.Tensor(
[[0.0021 0.0018 0.0116 0.2121 0.7725]
[0.2084 0.1826 0.1969 0.1755 0.2365]], shape=(2, 5), dtype=float32)
```
</tf>
</frameworkcontent>
<Tip>
Todos los modelos de 🤗 Transformers (PyTorch o TensorFlow) producirán los tensores *antes* de la función de activación
final (como softmax) porque la función de activación final es comúnmente fusionada con la pérdida.
</Tip>
Los modelos son [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) o [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) estándares así que podrás usarlos en tu training loop usual. Sin embargo, para facilitar las cosas, 🤗 Transformers provee una clase [`Trainer`] para PyTorch que añade funcionalidades para entrenamiento distribuido, precición mixta, y más. Para TensorFlow, puedes usar el método `fit` desde [Keras](https://keras.io/). Consulta el [tutorial de entrenamiento](./training) para más detalles.
<Tip>
Los outputs del modelo de 🤗 Transformers son dataclasses especiales por lo que sus atributos pueden ser completados en un IDE.
Los outputs del modelo también se comportan como tuplas o diccionarios (e.g., puedes indexar con un entero, un slice o una cadena) en cuyo caso los atributos que son `None` son ignorados.
</Tip>
### Guarda un modelo
<frameworkcontent>
<pt>
Una vez que se haya hecho fine-tuning a tu modelo puedes guardarlo con tu tokenizador usando [`PreTrainedModel.save_pretrained`]:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
Cuando quieras usar el modelo otra vez cárgalo con [`PreTrainedModel.from_pretrained`]:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
Una vez que se haya hecho fine-tuning a tu modelo puedes guardarlo con tu tokenizador usando [`TFPreTrainedModel.save_pretrained`]:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
Cuando quieras usar el modelo otra vez cárgalo con [`TFPreTrainedModel.from_pretrained`]:
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
Una característica particularmente interesante de 🤗 Transformers es la habilidad de guardar el modelo y cargarlo como un modelo de PyTorch o TensorFlow. El parámetro `from_pt` o `from_tf` puede convertir el modelo de un framework al otro:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/es/debugging.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Debugging
## Debug de problemas de Network multi-GPU
Cuando entrenas o infieres con `DistributedDataParallel` y varias GPUs, si encuentras problemas de intercomunicación entre procesos y/o nodos, puedes usar el siguiente script para diagnosticar problemas de red.
```bash
wget https://raw.githubusercontent.com/huggingface/transformers/main/scripts/distributed/torch-distributed-gpu-test.py
```
Por ejemplo, para probar cómo interactúan 2 GPUs, haz lo siguiente:
```bash
python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
```
Si ambos procesos pueden hablar entre sí y asignar la memoria de la GPU, cada uno imprimirá un status OK.
Para más GPUs o nodos, ajusta los argumentos en el script.
Encontrarás muchos más detalles dentro del script de diagnóstico e incluso una receta de cómo ejecutarlo en un entorno SLURM.
Un nivel adicional de debug es agregar la variable de entorno `NCCL_DEBUG=INFO` de la siguiente manera:
```bash
NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
```
Esto mostrará mucha información de debug relacionada con NCCL, que luego puedes buscar online si encuentras que reporta algún problema. O si no estás seguro de cómo interpretar el output, puedes compartir el archivo de log en un Issue.
## Detección de Underflow y Overflow
<Tip>
Esta función está disponible actualmente sólo para PyTorch.
</Tip>
<Tip>
Para el entrenamiento multi-GPU, requiere DDP (`torch.distributed.launch`).
</Tip>
<Tip>
Esta función puede utilizarse con cualquier modelo basado en `nn.Module`.
</Tip>
Si empiezas a obtener `loss=NaN` o el modelo muestra algún otro comportamiento anormal debido a `inf` o `nan` en
activations o weights hay que descubrir dónde se produce el primer underflow o overflow y qué lo ha provocado. Por suerte
puedes lograrlo fácilmente activando un módulo especial que hará la detección automáticamente.
Si estás usando [`Trainer`], solo necesitas añadir:
```bash
--debug underflow_overflow
```
a los argumentos normales de la línea de comandos, o pasar `debug="underflow_overflow"` al crear el objeto [`TrainingArguments`].
Si estás usando tu propio bucle de entrenamiento u otro Trainer puedes lograr lo mismo con:
```python
from .debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model)
```
[`~debug_utils.DebugUnderflowOverflow`] inserta hooks en el modelo que inmediatamente después de cada forward
testeará las variables de input y output y también los weights del módulo correspondiente. Tan pronto como se detecte `inf` o
`nan` se detecta en al menos un elemento de las activations o weights, el programa afirmará e imprimirá un informe
como este (esto fue capturado con `google/mt5-small` bajo fp16 mixed precision):
```
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
encoder.block.1.layer.1.DenseReluDense.dropout Dropout
0.00e+00 2.57e+02 input[0]
0.00e+00 2.85e+02 output
[...]
encoder.block.2.layer.0 T5LayerSelfAttention
6.78e-04 3.15e+03 input[0]
2.65e-04 3.42e+03 output[0]
None output[1]
2.25e-01 1.00e+04 output[2]
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.dropout Dropout
0.00e+00 8.76e+03 input[0]
0.00e+00 9.74e+03 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
```
El output del ejemplo se ha recortado en el centro por razones de brevedad.
La segunda columna muestra el valor del elemento más grande en términos absolutos, por lo que si observas con detenimiento los últimos fotogramas,
los inputs y outputs estaban en el rango de `1e4`. Así que cuando este entrenamiento se hizo con fp16 mixed precision,
el último paso sufrió overflow (ya que bajo `fp16` el mayor número antes de `inf` es `64e3`). Para evitar overflows en
`fp16` las activations deben permanecer muy por debajo de `1e4`, porque `1e4 * 1e4 = 1e8` por lo que cualquier matrix multiplication con
grandes activations va a llevar a una condición de overflow numérico.
Al principio del output puedes descubrir en qué número de batch se produjo el problema (aquí `Detected inf/nan during batch_number=0` significa que el problema se produjo en el primer batch).
Cada frame del informe comienza declarando la entrada completamente calificada para el módulo correspondiente que este frame está reportando.
Si nos fijamos sólo en este frame:
```
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
```
Aquí, `encoder.block.2.layer.1.layer_norm` indica que era una layer norm para la primera capa, del segundo
block del encoder. Y la call específica del `forward` es `T5LayerNorm`.
Veamos los últimos frames de ese informe:
```
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
[...]
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
```
El último frame informa para la función `Dropout.forward` con la primera entrada para el único input y la segunda para el
único output. Puedes ver que fue llamada desde un atributo `dropout` dentro de la clase `DenseReluDense`. Podemos ver
que ocurrió durante la primera capa, del segundo block, durante el primer batch. Por último, el mayor absoluto
elementos de input fue `6.27e+04` y el mismo para el output fue `inf`.
Puedes ver aquí, que `T5DenseGatedGeluDense.forward` resultó en output activations, cuyo valor máximo absoluto fue
alrededor de 62.7K, que está muy cerca del límite máximo de fp16 de 64K. En el siguiente frame tenemos `Dropout`, el cual renormaliza
los weights, después de poner a cero algunos de los elementos, lo que empuja el valor máximo absoluto a más de 64K, y obtenemos un
overflow (`inf`).
Como puedes ver son los frames anteriores los que tenemos que mirar cuando los números empiezan a ser muy grandes para números fp16.
Combinemos el informe con el código de `models/t5/modeling_t5.py`:
```python
class T5DenseGatedGeluDense(nn.Module):
def __init__(self, config):
super().__init__()
self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
self.dropout = nn.Dropout(config.dropout_rate)
self.gelu_act = ACT2FN["gelu_new"]
def forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
```
Ahora es fácil ver la call `dropout`, y también todas las calls anteriores.
Dado que la detección se produce en un forward hook, estos informes se imprimen inmediatamente después de que cada `forward`
responda.
Volviendo al informe completo, para actuar sobre él y arreglar el problema, tenemos que subir unos cuantos frames donde los números
empezaron a subir y probablemente cambiar al modo `fp32` aquí, para que los números no sufran overflow cuando se multipliquen
o al sumarlos. Por supuesto, puede haber otras soluciones. Por ejemplo, podríamos desactivar `amp` temporalmente si está
activado, después de mover el original `forward` dentro de un helper wrapper, así:
```python
def _forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
import torch
def forward(self, hidden_states):
if torch.is_autocast_enabled():
with torch.cuda.amp.autocast(enabled=False):
return self._forward(hidden_states)
else:
return self._forward(hidden_states)
```
Como el detector automático sólo informa de los inputs y outputs de los frames completos, una vez que sepas dónde buscar, puedes
analizar también las etapas intermedias de una función específica de `forward`. En este caso, puede utilizar la función
función de ayuda `detect_overflow` para inyectar el detector donde quieras, por ejemplo:
```python
from debug_utils import detect_overflow
class T5LayerFF(nn.Module):
[...]
def forward(self, hidden_states):
forwarded_states = self.layer_norm(hidden_states)
detect_overflow(forwarded_states, "after layer_norm")
forwarded_states = self.DenseReluDense(forwarded_states)
detect_overflow(forwarded_states, "after DenseReluDense")
return hidden_states + self.dropout(forwarded_states)
```
Puedes ver que hemos añadido 2 de estos y ahora se trackea si `inf` o `nan` para `forwarded_states` fue detectado
en algún punto intermedio.
De hecho, el detector ya informa de esto porque cada una de las llamadas en el ejemplo anterior es un `nn.Module`, pero
digamos que si tuvieras algunos cálculos directos locales, así es como lo harías.
Además, si estás instanciando el debugger en tu propio código, puedes ajustar el número de frames impresos de
su valor por defecto, por ejemplo:
```python
from .debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model, max_frames_to_save=100)
```
### Rastreo de valores mínimos y máximos absolutos de batches específicos
La misma clase de debugging se puede utilizar para el rastreo por batches con la función de detección de underflow/overflow desactivada.
Digamos que quieres ver los valores mínimos y máximos absolutos de todos los ingredientes de cada call `forward` de un determinado
batch, y sólo hacerlo para los batches 1 y 3. Entonces instancias esta clase como:
```python
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3])
```
Y ahora los batches 1 y 3 completos serán rastreados usando el mismo formato que el detector de underflow/overflow.
Los batches son 0-index.
Esto es muy útil si sabes que el programa empieza a comportarse mal después de un determinado número de batch, para que puedas avanzar rápidamente
hasta esa área. Aquí hay un ejemplo de output recortado para tal configuración:
```
*** Starting batch number=1 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.47e+04 input[0]
5.36e-05 7.92e+02 output
[...]
decoder.dropout Dropout
1.60e-07 2.27e+01 input[0]
0.00e+00 2.52e+01 output
decoder T5Stack
not a tensor output
lm_head Linear
1.01e-06 7.92e+02 weight
0.00e+00 1.11e+00 input[0]
6.06e-02 8.39e+01 output
T5ForConditionalGeneration
not a tensor output
*** Starting batch number=3 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.78e+04 input[0]
5.36e-05 7.92e+02 output
[...]
```
Aquí obtendrás un gran número de frames mostrados - tantos como forward calls haya en tu modelo, por lo que puede o no ser lo que quieras, pero a veces puede ser más fácil de usar para debug que un debugger normal.
Por ejemplo, si un problema comienza a ocurrir en el batch 150. Entonces puedes mostrar las trazas de los batches 149 y 150 y comparar dónde
los números empezaron a divergir.
También puedes especificar el número de batch después del cual se debe detener el entrenamiento, con:
```python
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3], abort_after_batch_num=3)
```
| 0
|
hf_public_repos/transformers/docs/source/es
|
hf_public_repos/transformers/docs/source/es/tasks/image_classification.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Clasificación de imágenes
<Youtube id="tjAIM7BOYhw"/>
La clasificación de imágenes asigna una etiqueta o clase a una imagen. A diferencia de la clasificación de texto o audio, las entradas son los valores de los píxeles que representan una imagen. La clasificación de imágenes tiene muchos usos, como la detección de daños tras una catástrofe, el control de la salud de los cultivos o la búsqueda de signos de enfermedad en imágenes médicas.
Esta guía te mostrará como hacer fine-tune al [ViT](https://huggingface.co/docs/transformers/v4.16.2/en/model_doc/vit) en el dataset [Food-101](https://huggingface.co/datasets/food101) para clasificar un alimento en una imagen.
<Tip>
Consulta la [página de la tarea](https://huggingface.co/tasks/audio-classification) de clasificación de imágenes para obtener más información sobre sus modelos, datasets y métricas asociadas.
</Tip>
## Carga el dataset Food-101
Carga solo las primeras 5000 imágenes del dataset Food-101 de la biblioteca 🤗 de Datasets ya que es bastante grande:
```py
>>> from datasets import load_dataset
>>> food = load_dataset("food101", split="train[:5000]")
```
Divide el dataset en un train y un test set:
```py
>>> food = food.train_test_split(test_size=0.2)
```
A continuación, observa un ejemplo:
```py
>>> food["train"][0]
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x512 at 0x7F52AFC8AC50>,
'label': 79}
```
El campo `image` contiene una imagen PIL, y cada `label` es un número entero que representa una clase. Crea un diccionario que asigne un nombre de label a un entero y viceversa. El mapeo ayudará al modelo a recuperar el nombre de label a partir del número de la misma:
```py
>>> labels = food["train"].features["label"].names
>>> label2id, id2label = dict(), dict()
>>> for i, label in enumerate(labels):
... label2id[label] = str(i)
... id2label[str(i)] = label
```
Ahora puedes convertir el número de label en un nombre de label para obtener más información:
```py
>>> id2label[str(79)]
'prime_rib'
```
Cada clase de alimento - o label - corresponde a un número; `79` indica una costilla de primera en el ejemplo anterior.
## Preprocesa
Carga el image processor de ViT para procesar la imagen en un tensor:
```py
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
```
Aplica varias transformaciones de imagen al dataset para hacer el modelo más robusto contra el overfitting. En este caso se utilizará el módulo [`transforms`](https://pytorch.org/vision/stable/transforms.html) de torchvision. Recorta una parte aleatoria de la imagen, cambia su tamaño y normalízala con la media y la desviación estándar de la imagen:
```py
>>> from torchvision.transforms import RandomResizedCrop, Compose, Normalize, ToTensor
>>> normalize = Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
>>> _transforms = Compose([RandomResizedCrop(image_processor.size["height"]), ToTensor(), normalize])
```
Crea una función de preprocesamiento que aplique las transformaciones y devuelva los `pixel_values` - los inputs al modelo - de la imagen:
```py
>>> def transforms(examples):
... examples["pixel_values"] = [_transforms(img.convert("RGB")) for img in examples["image"]]
... del examples["image"]
... return examples
```
Utiliza el método [`with_transform`](https://huggingface.co/docs/datasets/package_reference/main_classes?#datasets.Dataset.with_transform) de 🤗 Dataset para aplicar las transformaciones sobre todo el dataset. Las transformaciones se aplican sobre la marcha cuando se carga un elemento del dataset:
```py
>>> food = food.with_transform(transforms)
```
Utiliza [`DefaultDataCollator`] para crear un batch de ejemplos. A diferencia de otros data collators en 🤗 Transformers, el DefaultDataCollator no aplica un preprocesamiento adicional como el padding.
```py
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator()
```
## Entrena
Carga ViT con [`AutoModelForImageClassification`]. Especifica el número de labels, y pasa al modelo el mapping entre el número de label y la clase de label:
```py
>>> from transformers import AutoModelForImageClassification, TrainingArguments, Trainer
>>> model = AutoModelForImageClassification.from_pretrained(
... "google/vit-base-patch16-224-in21k",
... num_labels=len(labels),
... id2label=id2label,
... label2id=label2id,
... )
```
<Tip>
Si no estás familiarizado con el fine-tuning de un modelo con el [`Trainer`], echa un vistazo al tutorial básico [aquí](../training#finetune-with-trainer)!
</Tip>
Al llegar a este punto, solo quedan tres pasos:
1. Define tus hiperparámetros de entrenamiento en [`TrainingArguments`]. Es importante que no elimines las columnas que no se utilicen, ya que esto hará que desaparezca la columna `image`. Sin la columna `image` no puedes crear `pixel_values`. Establece `remove_unused_columns=False` para evitar este comportamiento.
2. Pasa los training arguments al [`Trainer`] junto con el modelo, los datasets, tokenizer y data collator.
3. Llama [`~Trainer.train`] para hacer fine-tune de tu modelo.
```py
>>> training_args = TrainingArguments(
... output_dir="./results",
... per_device_train_batch_size=16,
... evaluation_strategy="steps",
... num_train_epochs=4,
... fp16=True,
... save_steps=100,
... eval_steps=100,
... logging_steps=10,
... learning_rate=2e-4,
... save_total_limit=2,
... remove_unused_columns=False,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... data_collator=data_collator,
... train_dataset=food["train"],
... eval_dataset=food["test"],
... tokenizer=image_processor,
... )
>>> trainer.train()
```
<Tip>
Para ver un ejemplo más a profundidad de cómo hacer fine-tune a un modelo para clasificación de imágenes, echa un vistazo al correspondiente [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
</Tip>
| 0
|
hf_public_repos/transformers/docs/source/es
|
hf_public_repos/transformers/docs/source/es/tasks/asr.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Reconocimiento automático del habla
<Youtube id="TksaY_FDgnk"/>
El reconocimiento automático del habla (ASR, por sus siglas en inglés) convierte una señal de habla en texto y mapea una secuencia de entradas de audio en salidas en forma de texto. Los asistentes virtuales como Siri y Alexa usan modelos de ASR para ayudar a sus usuarios todos los días. De igual forma, hay muchas otras aplicaciones, como la transcripción de contenidos en vivo y la toma automática de notas durante reuniones.
En esta guía te mostraremos como:
1. Hacer fine-tuning al modelo [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) con el dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) para transcribir audio a texto.
2. Usar tu modelo ajustado para tareas de inferencia.
<Tip>
Revisa la [página de la tarea](https://huggingface.co/tasks/automatic-speech-recognition) de reconocimiento automático del habla para acceder a más información sobre los modelos, datasets y métricas asociados.
</Tip>
Antes de comenzar, asegúrate de haber instalado todas las librerías necesarias:
```bash
pip install transformers datasets evaluate jiwer
```
Te aconsejamos iniciar sesión con tu cuenta de Hugging Face para que puedas subir tu modelo y comartirlo con la comunidad. Cuando te sea solicitado, ingresa tu token para iniciar sesión:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Cargar el dataset MInDS-14
Comencemos cargando un subconjunto más pequeño del dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) desde la biblioteca 🤗 Datasets. De esta forma, tendrás la oportunidad de experimentar y asegurarte de que todo funcione antes de invertir más tiempo entrenando con el dataset entero.
```py
>>> from datasets import load_dataset, Audio
>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train[:100]")
```
Divide la partición `train` (entrenamiento) en una partición de entrenamiento y una de prueba usando el método [`~Dataset.train_test_split`]:
```py
>>> minds = minds.train_test_split(test_size=0.2)
```
Ahora échale un vistazo al dataset:
```py
>>> minds
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 16
})
test: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 4
})
})
```
Aunque el dataset contiene mucha información útil, como los campos `lang_id` (identificador del lenguaje) y `english_transcription` (transcripción al inglés), en esta guía nos enfocaremos en los campos `audio` y `transcription`. Puedes quitar las otras columnas con el método [`~datasets.Dataset.remove_columns`]:
```py
>>> minds = minds.remove_columns(["english_transcription", "intent_class", "lang_id"])
```
Vuelve a echarle un vistazo al ejemplo:
```py
>>> minds["train"][0]
{'audio': {'array': array([-0.00024414, 0. , 0. , ..., 0.00024414,
0.00024414, 0.00024414], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 8000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
Hay dos campos:
- `audio`: un `array` (arreglo) unidimensional de la señal de habla que debe ser invocado para cargar y re-muestrear el archivo de audio.
- `transcription`: el texto objetivo.
## Preprocesamiento
El siguiente paso es cargar un procesador Wav2Vec2 para procesar la señal de audio:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base")
```
El dataset MInDS-14 tiene una tasa de muestreo de 8000kHz (puedes encontrar esta información en su [tarjeta de dataset](https://huggingface.co/datasets/PolyAI/minds14)), lo que significa que tendrás que re-muestrear el dataset a 16000kHz para poder usar el modelo Wav2Vec2 pre-entrenado:
```py
>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
>>> minds["train"][0]
{'audio': {'array': array([-2.38064706e-04, -1.58618059e-04, -5.43987835e-06, ...,
2.78103951e-04, 2.38446111e-04, 1.18740834e-04], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 16000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
Como puedes ver en el campo `transcription`, el texto contiene una mezcla de carácteres en mayúsculas y en minúsculas. El tokenizer Wav2Vec2 fue entrenado únicamente con carácteres en mayúsculas, así que tendrás que asegurarte de que el texto se ajuste al vocabulario del tokenizer:
```py
>>> def uppercase(example):
... return {"transcription": example["transcription"].upper()}
>>> minds = minds.map(uppercase)
```
Ahora vamos a crear una función de preprocesamiento que:
1. Invoque la columna `audio` para cargar y re-muestrear el archivo de audio.
2. Extraiga el campo `input_values` (valores de entrada) del archivo de audio y haga la tokenización de la columna `transcription` con el procesador.
```py
>>> def prepare_dataset(batch):
... audio = batch["audio"]
... batch = processor(audio["array"], sampling_rate=audio["sampling_rate"], text=batch["transcription"])
... batch["input_length"] = len(batch["input_values"][0])
... return batch
```
Para aplicar la función de preprocesamiento a todo el dataset, puedes usar la función [`~datasets.Dataset.map`] de 🤗 Datasets. Para acelerar la función `map` puedes incrementar el número de procesos con el parámetro `num_proc`. Quita las columnas que no necesites con el método [`~datasets.Dataset.remove_columns`]:
```py
>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
```
🤗 Transformers no tiene un collator de datos para la tarea de ASR, así que tendrás que adaptar el [`DataCollatorWithPadding`] para crear un lote de ejemplos. El collator también le aplicará padding dinámico a tu texto y etiquetas para que tengan la longitud del elemento más largo en su lote (en vez de la mayor longitud en el dataset entero), de forma que todas las muestras tengan una longitud uniforme. Aunque es posible hacerle padding a tu texto con el `tokenizer` haciendo `padding=True`, el padding dinámico es más eficiente.
A diferencia de otros collators de datos, este tiene que aplicarle un método de padding distinto a los campos `input_values` (valores de entrada) y `labels` (etiquetas):
```py
>>> import torch
>>> from dataclasses import dataclass, field
>>> from typing import Any, Dict, List, Optional, Union
>>> @dataclass
... class DataCollatorCTCWithPadding:
... processor: AutoProcessor
... padding: Union[bool, str] = "longest"
... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
... # particiona las entradas y las etiquetas ya que tienen que tener longitudes distintas y
... # requieren métodos de padding diferentes
... input_features = [{"input_values": feature["input_values"][0]} for feature in features]
... label_features = [{"input_ids": feature["labels"]} for feature in features]
... batch = self.processor.pad(input_features, padding=self.padding, return_tensors="pt")
... labels_batch = self.processor.pad(labels=label_features, padding=self.padding, return_tensors="pt")
... # remplaza el padding con -100 para ignorar la pérdida de forma correcta
... labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
... batch["labels"] = labels
... return batch
```
Ahora puedes instanciar tu `DataCollatorForCTCWithPadding`:
```py
>>> data_collator = DataCollatorCTCWithPadding(processor=processor, padding="longest")
```
## Evaluación
A menudo es útil incluir una métrica durante el entrenamiento para evaluar el rendimiento de tu modelo. Puedes cargar un método de evaluación rápidamente con la biblioteca 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index). Para esta tarea, puedes usar la métrica de [tasa de error por palabra](https://huggingface.co/spaces/evaluate-metric/wer) (WER, por sus siglas en inglés). Puedes ver la [guía rápida](https://huggingface.co/docs/evaluate/a_quick_tour) de 🤗 Evaluate para aprender más acerca de cómo cargar y computar una métrica.
```py
>>> import evaluate
>>> wer = evaluate.load("wer")
```
Ahora crea una función que le pase tus predicciones y etiquetas a [`~evaluate.EvaluationModule.compute`] para calcular la WER:
```py
>>> import numpy as np
>>> def compute_metrics(pred):
... pred_logits = pred.predictions
... pred_ids = np.argmax(pred_logits, axis=-1)
... pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
... pred_str = processor.batch_decode(pred_ids)
... label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
... wer = wer.compute(predictions=pred_str, references=label_str)
... return {"wer": wer}
```
Ahora tu función `compute_metrics` (computar métricas) está lista y podrás usarla cuando estés preparando tu entrenamiento.
## Entrenamiento
<frameworkcontent>
<pt>
<Tip>
Si no tienes experiencia haciéndole fine-tuning a un modelo con el [`Trainer`], ¡échale un vistazo al tutorial básico [aquí](../training#train-with-pytorch-trainer)!
</Tip>
¡Ya puedes empezar a entrenar tu modelo! Para ello, carga Wav2Vec2 con [`AutoModelForCTC`]. Especifica la reducción que quieres aplicar con el parámetro `ctc_loss_reduction`. A menudo, es mejor usar el promedio en lugar de la sumatoria que se hace por defecto.
```py
>>> from transformers import AutoModelForCTC, TrainingArguments, Trainer
>>> model = AutoModelForCTC.from_pretrained(
... "facebook/wav2vec2-base",
... ctc_loss_reduction="mean",
... pad_token_id=processor.tokenizer.pad_token_id,
... )
```
En este punto, solo quedan tres pasos:
1. Define tus hiperparámetros de entrenamiento en [`TrainingArguments`]. El único parámetro obligatorio es `output_dir` (carpeta de salida), el cual especifica dónde guardar tu modelo. Puedes subir este modelo al Hub haciendo `push_to_hub=True` (debes haber iniciado sesión en Hugging Face para subir tu modelo). Al final de cada época, el [`Trainer`] evaluará la WER y guardará el punto de control del entrenamiento.
2. Pásale los argumentos del entrenamiento al [`Trainer`] junto con el modelo, el dataset, el tokenizer, el collator de datos y la función `compute_metrics`.
3. Llama el método [`~Trainer.train`] para hacerle fine-tuning a tu modelo.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_asr_mind_model",
... per_device_train_batch_size=8,
... gradient_accumulation_steps=2,
... learning_rate=1e-5,
... warmup_steps=500,
... max_steps=2000,
... gradient_checkpointing=True,
... fp16=True,
... group_by_length=True,
... evaluation_strategy="steps",
... per_device_eval_batch_size=8,
... save_steps=1000,
... eval_steps=1000,
... logging_steps=25,
... load_best_model_at_end=True,
... metric_for_best_model="wer",
... greater_is_better=False,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
... tokenizer=processor.feature_extractor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
Una vez que el entrenamiento haya sido completado, comparte tu modelo en el Hub con el método [`~transformers.Trainer.push_to_hub`] para que todo el mundo pueda usar tu modelo:
```py
>>> trainer.push_to_hub()
```
</pt>
</frameworkcontent>
<Tip>
Para ver un ejemplo más detallado de cómo hacerle fine-tuning a un modelo para reconocimiento automático del habla, échale un vistazo a esta [entrada de blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) para ASR en inglés y a esta [entrada](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) para ASR multilingüe.
</Tip>
## Inferencia
¡Genial, ahora que le has hecho fine-tuning a un modelo, puedes usarlo para inferencia!
Carga el archivo de audio sobre el cual quieras correr la inferencia. ¡Recuerda re-muestrar la tasa de muestreo del archivo de audio para que sea la misma del modelo si es necesario!
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> audio_file = dataset[0]["audio"]["path"]
```
La manera más simple de probar tu modelo para hacer inferencia es usarlo en un [`pipeline`]. Puedes instanciar un `pipeline` para reconocimiento automático del habla con tu modelo y pasarle tu archivo de audio:
```py
>>> from transformers import pipeline
>>> transcriber = pipeline("automatic-speech-recognition", model="stevhliu/my_awesome_asr_minds_model")
>>> transcriber(audio_file)
{'text': 'I WOUD LIKE O SET UP JOINT ACOUNT WTH Y PARTNER'}
```
<Tip>
La transcripción es decente, pero podría ser mejor. ¡Intenta hacerle fine-tuning a tu modelo con más ejemplos para obtener resultados aún mejores!
</Tip>
También puedes replicar de forma manual los resultados del `pipeline` si lo deseas:
<frameworkcontent>
<pt>
Carga un procesador para preprocesar el archivo de audio y la transcripción y devuelve el `input` como un tensor de PyTorch:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
```
Pásale tus entradas al modelo y devuelve los logits:
```py
>>> from transformers import AutoModelForCTC
>>> model = AutoModelForCTC.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
Obtén los identificadores de los tokens con mayor probabilidad en las predicciones y usa el procesador para decodificarlos y transformarlos en texto:
```py
>>> import torch
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
```
</pt>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source/es
|
hf_public_repos/transformers/docs/source/es/tasks/language_modeling.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Modelado de lenguaje
El modelado de lenguaje predice palabras en un enunciado. Hay dos formas de modelado de lenguaje.
<Youtube id="Vpjb1lu0MDk"/>
El modelado de lenguaje causal predice el siguiente token en una secuencia de tokens, y el modelo solo puede considerar los tokens a la izquierda.
<Youtube id="mqElG5QJWUg"/>
El modelado de lenguaje por enmascaramiento predice un token enmascarado en una secuencia, y el modelo puede considerar los tokens bidireccionalmente.
Esta guía te mostrará cómo realizar fine-tuning [DistilGPT2](https://huggingface.co/distilgpt2) para modelos de lenguaje causales y [DistilRoBERTa](https://huggingface.co/distilroberta-base) para modelos de lenguaje por enmascaramiento en el [r/askscience](https://www.reddit.com/r/askscience/) subdataset [ELI5](https://huggingface.co/datasets/eli5).
<Tip>
Puedes realizar fine-tuning a otras arquitecturas para modelos de lenguaje como [GPT-Neo](https://huggingface.co/EleutherAI/gpt-neo-125M), [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B) y [BERT](https://huggingface.co/bert-base-uncased) siguiendo los mismos pasos presentados en esta guía!
Mira la [página de tarea](https://huggingface.co/tasks/text-generation) para generación de texto y la [página de tarea](https://huggingface.co/tasks/fill-mask) para modelos de lenguajes por enmascaramiento para obtener más información sobre los modelos, datasets, y métricas asociadas.
</Tip>
## Carga el dataset ELI5
Carga solo los primeros 5000 registros desde la biblioteca 🤗 Datasets, dado que es bastante grande:
```py
>>> from datasets import load_dataset
>>> eli5 = load_dataset("eli5", split="train_asks[:5000]")
```
Divide este dataset en subdatasets para el entrenamiento y el test:
```py
eli5 = eli5.train_test_split(test_size=0.2)
```
Luego observa un ejemplo:
```py
>>> eli5["train"][0]
{'answers': {'a_id': ['c3d1aib', 'c3d4lya'],
'score': [6, 3],
'text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
"Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"]},
'answers_urls': {'url': []},
'document': '',
'q_id': 'nyxfp',
'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
'selftext_urls': {'url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg']},
'subreddit': 'askscience',
'title': 'Few questions about this space walk photograph.',
'title_urls': {'url': []}}
```
Observa que `text` es un subcampo anidado dentro del diccionario `answers`. Cuando preproceses el dataset, deberás extraer el subcampo `text` en una columna aparte.
## Preprocesamiento
<Youtube id="ma1TrR7gE7I"/>
Para modelados de lenguaje causales carga el tokenizador DistilGPT2 para procesar el subcampo `text`:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
```
<Youtube id="8PmhEIXhBvI"/>
Para modelados de lenguaje por enmascaramiento carga el tokenizador DistilRoBERTa, en lugar de DistilGPT2:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilroberta-base")
```
Extrae el subcampo `text` desde su estructura anidado con el método [`flatten`](https://huggingface.co/docs/datasets/process#flatten):
```py
>>> eli5 = eli5.flatten()
>>> eli5["train"][0]
{'answers.a_id': ['c3d1aib', 'c3d4lya'],
'answers.score': [6, 3],
'answers.text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
"Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"],
'answers_urls.url': [],
'document': '',
'q_id': 'nyxfp',
'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
'selftext_urls.url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg'],
'subreddit': 'askscience',
'title': 'Few questions about this space walk photograph.',
'title_urls.url': []}
```
Cada subcampo es ahora una columna separada, como lo indica el prefijo `answers`. Observa que `answers.text` es una lista. En lugar de tokenizar cada enunciado por separado, convierte la lista en un string para tokenizarlos conjuntamente.
Así es como puedes crear una función de preprocesamiento para convertir la lista en una cadena y truncar las secuencias para que no superen la longitud máxima de input de DistilGPT2:
```py
>>> def preprocess_function(examples):
... return tokenizer([" ".join(x) for x in examples["answers.text"]], truncation=True)
```
Usa de 🤗 Datasets la función [`map`](https://huggingface.co/docs/datasets/process#map) para aplicar la función de preprocesamiento sobre el dataset en su totalidad. Puedes acelerar la función `map` configurando el argumento `batched=True` para procesar múltiples elementos del dataset a la vez y aumentar la cantidad de procesos con `num_proc`. Elimina las columnas que no necesitas:
```py
>>> tokenized_eli5 = eli5.map(
... preprocess_function,
... batched=True,
... num_proc=4,
... remove_columns=eli5["train"].column_names,
... )
```
Ahora necesitas una segunda función de preprocesamiento para capturar el texto truncado de cualquier ejemplo demasiado largo para evitar cualquier pérdida de información. Esta función de preprocesamiento debería:
- Concatenar todo el texto.
- Dividir el texto concatenado en trozos más pequeños definidos por un `block_size`.
```py
>>> block_size = 128
>>> def group_texts(examples):
... concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
... total_length = len(concatenated_examples[list(examples.keys())[0]])
... total_length = (total_length // block_size) * block_size
... result = {
... k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
... for k, t in concatenated_examples.items()
... }
... result["labels"] = result["input_ids"].copy()
... return result
```
Aplica la función `group_texts` sobre todo el dataset:
```py
>>> lm_dataset = tokenized_eli5.map(group_texts, batched=True, num_proc=4)
```
Para modelados de lenguaje causales, usa [`DataCollatorForLanguageModeling`] para crear un lote de ejemplos. Esto también *rellenará dinámicamente* tu texto a la dimensión del elemento más largo del lote para que de esta manera tengan largo uniforme. Si bien es posible rellenar tu texto en la función `tokenizer` mediante el argumento `padding=True`, el rellenado dinámico es más eficiente.
<frameworkcontent>
<pt>
Puedes usar el token de final de secuencia como el token de relleno y asignar `mlm=False`. Esto usará los inputs como etiquetas movidas un elemento hacia la derecha:
```py
>>> from transformers import DataCollatorForLanguageModeling
>>> tokenizer.pad_token = tokenizer.eos_token
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
```
Para modelados de lenguaje por enmascaramiento usa el mismo [`DataCollatorForLanguageModeling`] excepto que deberás especificar `mlm_probability` para enmascarar tokens aleatoriamente cada vez que iteras sobre los datos.
```py
>>> from transformers import DataCollatorForLanguageModeling
>>> tokenizer.pad_token = tokenizer.eos_token
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
```
</pt>
<tf>
Puedes usar el token de final de secuencia como el token de relleno y asignar `mlm=False`. Esto usará los inputs como etiquetas movidas un elemento hacia la derecha:
```py
>>> from transformers import DataCollatorForLanguageModeling
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False, return_tensors="tf")
```
Para modelados de lenguajes por enmascaramiento usa el mismo [`DataCollatorForLanguageModeling`] excepto que deberás especificar `mlm_probability` para enmascarar tokens aleatoriamente cada vez que iteras sobre los datos.
```py
>>> from transformers import DataCollatorForLanguageModeling
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False, return_tensors="tf")
```
</tf>
</frameworkcontent>
## Modelado de lenguaje causal
El modelado de lenguaje causal es frecuentemente utilizado para generación de texto. Esta sección te muestra cómo realizar fine-tuning a [DistilGPT2](https://huggingface.co/distilgpt2) para generar nuevo texto.
### Entrenamiento
<frameworkcontent>
<pt>
Carga DistilGPT2 con [`AutoModelForCausalLM`]:
```py
>>> from transformers import AutoModelForCausalLM, TrainingArguments, Trainer
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
```
<Tip>
Si no estás familiarizado con el proceso de realizar fine-tuning sobre un modelo con [`Trainer`], considera el tutorial básico [aquí](../training#finetune-with-trainer)!
</Tip>
A este punto, solo faltan tres pasos:
1. Definir tus hiperparámetros de entrenamiento en [`TrainingArguments`].
2. Pasarle los argumentos de entrenamiento a [`Trainer`] junto con el modelo, dataset, y el data collator.
3. Realiza la llamada [`~Trainer.train`] para realizar el fine-tuning sobre tu modelo.
```py
>>> training_args = TrainingArguments(
... output_dir="./results",
... evaluation_strategy="epoch",
... learning_rate=2e-5,
... weight_decay=0.01,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=lm_dataset["train"],
... eval_dataset=lm_dataset["test"],
... data_collator=data_collator,
... )
>>> trainer.train()
```
</pt>
<tf>
Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
```py
>>> tf_train_set = lm_dataset["train"].to_tf_dataset(
... columns=["attention_mask", "input_ids", "labels"],
... dummy_labels=True,
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_test_set = lm_dataset["test"].to_tf_dataset(
... columns=["attention_mask", "input_ids", "labels"],
... dummy_labels=True,
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
<Tip>
Si no estás familiarizado con realizar fine-tuning de tus modelos con Keras, considera el tutorial básico [aquí](training#finetune-with-keras)!
</Tip>
Crea la función optimizadora, la tasa de aprendizaje, y algunos hiperparámetros de entrenamiento:
```py
>>> from transformers import create_optimizer, AdamWeightDecay
>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
```
Carga DistilGPT2 con [`TFAutoModelForCausalLM`]:
```py
>>> from transformers import TFAutoModelForCausalLM
>>> model = TFAutoModelForCausalLM.from_pretrained("distilgpt2")
```
Configura el modelo para entrenamiento con [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer)
```
Llama a [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) para realizar el fine-tuning del modelo:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3)
```
</tf>
</frameworkcontent>
## Modelado de lenguaje por enmascaramiento
El modelado de lenguaje por enmascaramiento es también conocido como una tarea de rellenar la máscara, pues predice un token enmascarado dada una secuencia. Los modelos de lenguaje por enmascaramiento requieren una buena comprensión del contexto de una secuencia entera, en lugar de solo el contexto a la izquierda. Esta sección te enseña como realizar el fine-tuning de [DistilRoBERTa](https://huggingface.co/distilroberta-base) para predecir una palabra enmascarada.
### Entrenamiento
<frameworkcontent>
<pt>
Carga DistilRoBERTa con [`AutoModelForMaskedlM`]:
```py
>>> from transformers import AutoModelForMaskedLM
>>> model = AutoModelForMaskedLM.from_pretrained("distilroberta-base")
```
<Tip>
Si no estás familiarizado con el proceso de realizar fine-tuning sobre un modelo con [`Trainer`], considera el tutorial básico [aquí](../training#finetune-with-trainer)!
</Tip>
A este punto, solo faltan tres pasos:
1. Definir tus hiperparámetros de entrenamiento en [`TrainingArguments`].
2. Pasarle los argumentos de entrenamiento a [`Trainer`] junto con el modelo, dataset, y el data collator.
3. Realiza la llamada [`~Trainer.train`] para realizar el fine-tuning de tu modelo.
```py
>>> training_args = TrainingArguments(
... output_dir="./results",
... evaluation_strategy="epoch",
... learning_rate=2e-5,
... num_train_epochs=3,
... weight_decay=0.01,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=lm_dataset["train"],
... eval_dataset=lm_dataset["test"],
... data_collator=data_collator,
... )
>>> trainer.train()
```
</pt>
<tf>
Para realizar el fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Especifica los inputs y etiquetas en `columns`, ya sea para mezclar el dataset, tamaño de lote, y el data collator:
```py
>>> tf_train_set = lm_dataset["train"].to_tf_dataset(
... columns=["attention_mask", "input_ids", "labels"],
... dummy_labels=True,
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_test_set = lm_dataset["test"].to_tf_dataset(
... columns=["attention_mask", "input_ids", "labels"],
... dummy_labels=True,
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
<Tip>
Si no estás familiarizado con realizar fine-tuning de tus modelos con Keras, considera el tutorial básico [aquí](training#finetune-with-keras)!
</Tip>
Crea la función optimizadora, la tasa de aprendizaje, y algunos hiperparámetros de entrenamiento:
```py
>>> from transformers import create_optimizer, AdamWeightDecay
>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
```
Carga DistilRoBERTa con [`TFAutoModelForMaskedLM`]:
```py
>>> from transformers import TFAutoModelForMaskedLM
>>> model = TFAutoModelForCausalLM.from_pretrained("distilroberta-base")
```
Configura el modelo para entrenamiento con [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer)
```
Llama a [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) para realizar el fine-tuning del modelo:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3)
```
</tf>
</frameworkcontent>
<Tip>
Para un ejemplo más profundo sobre cómo realizar el fine-tuning sobre un modelo de lenguaje causal, considera
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
o [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
</Tip>
| 0
|
hf_public_repos/transformers/docs/source/es
|
hf_public_repos/transformers/docs/source/es/tasks/summarization.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Generación de resúmenes
<Youtube id="yHnr5Dk2zCI"/>
La generación de resúmenes (summarization, en inglés) crea una versión más corta de un documento o un artículo que resume toda su información importante. Junto con la traducción, es un ejemplo de una tarea que puede ser formulada como una tarea secuencia a secuencia. La generación de resúmenes puede ser:
- Extractiva: Extrae la información más relevante de un documento.
- Abstractiva: Genera un texto nuevo que captura la información más importante.
Esta guía te mostrará cómo puedes hacer fine-tuning del modelo [T5](https://huggingface.co/t5-small) sobre el subset de proyectos de ley del estado de California, dentro del dataset [BillSum](https://huggingface.co/datasets/billsum) para hacer generación de resúmenes abstractiva.
<Tip>
Consulta la [página de la tarea](https://huggingface.co/tasks/summarization) de generación de resúmenes para obtener más información sobre sus modelos, datasets y métricas asociadas.
</Tip>
## Carga el dataset BillSum
Carga el dataset BillSum de la biblioteca 🤗 Datasets:
```py
>>> from datasets import load_dataset
>>> billsum = load_dataset("billsum", split="ca_test")
```
Divide el dataset en un set de train y un set de test:
```py
>>> billsum = billsum.train_test_split(test_size=0.2)
```
A continuación, observa un ejemplo:
```py
>>> billsum["train"][0]
{'summary': 'Existing law authorizes state agencies to enter into contracts for the acquisition of goods or services upon approval by the Department of General Services. Existing law sets forth various requirements and prohibitions for those contracts, including, but not limited to, a prohibition on entering into contracts for the acquisition of goods or services of $100,000 or more with a contractor that discriminates between spouses and domestic partners or same-sex and different-sex couples in the provision of benefits. Existing law provides that a contract entered into in violation of those requirements and prohibitions is void and authorizes the state or any person acting on behalf of the state to bring a civil action seeking a determination that a contract is in violation and therefore void. Under existing law, a willful violation of those requirements and prohibitions is a misdemeanor.\nThis bill would also prohibit a state agency from entering into contracts for the acquisition of goods or services of $100,000 or more with a contractor that discriminates between employees on the basis of gender identity in the provision of benefits, as specified. By expanding the scope of a crime, this bill would impose a state-mandated local program.\nThe California Constitution requires the state to reimburse local agencies and school districts for certain costs mandated by the state. Statutory provisions establish procedures for making that reimbursement.\nThis bill would provide that no reimbursement is required by this act for a specified reason.',
'text': 'The people of the State of California do enact as follows:\n\n\nSECTION 1.\nSection 10295.35 is added to the Public Contract Code, to read:\n10295.35.\n(a) (1) Notwithstanding any other law, a state agency shall not enter into any contract for the acquisition of goods or services in the amount of one hundred thousand dollars ($100,000) or more with a contractor that, in the provision of benefits, discriminates between employees on the basis of an employee’s or dependent’s actual or perceived gender identity, including, but not limited to, the employee’s or dependent’s identification as transgender.\n(2) For purposes of this section, “contract” includes contracts with a cumulative amount of one hundred thousand dollars ($100,000) or more per contractor in each fiscal year.\n(3) For purposes of this section, an employee health plan is discriminatory if the plan is not consistent with Section 1365.5 of the Health and Safety Code and Section 10140 of the Insurance Code.\n(4) The requirements of this section shall apply only to those portions of a contractor’s operations that occur under any of the following conditions:\n(A) Within the state.\n(B) On real property outside the state if the property is owned by the state or if the state has a right to occupy the property, and if the contractor’s presence at that location is connected to a contract with the state.\n(C) Elsewhere in the United States where work related to a state contract is being performed.\n(b) Contractors shall treat as confidential, to the maximum extent allowed by law or by the requirement of the contractor’s insurance provider, any request by an employee or applicant for employment benefits or any documentation of eligibility for benefits submitted by an employee or applicant for employment.\n(c) After taking all reasonable measures to find a contractor that complies with this section, as determined by the state agency, the requirements of this section may be waived under any of the following circumstances:\n(1) There is only one prospective contractor willing to enter into a specific contract with the state agency.\n(2) The contract is necessary to respond to an emergency, as determined by the state agency, that endangers the public health, welfare, or safety, or the contract is necessary for the provision of essential services, and no entity that complies with the requirements of this section capable of responding to the emergency is immediately available.\n(3) The requirements of this section violate, or are inconsistent with, the terms or conditions of a grant, subvention, or agreement, if the agency has made a good faith attempt to change the terms or conditions of any grant, subvention, or agreement to authorize application of this section.\n(4) The contractor is providing wholesale or bulk water, power, or natural gas, the conveyance or transmission of the same, or ancillary services, as required for ensuring reliable services in accordance with good utility practice, if the purchase of the same cannot practically be accomplished through the standard competitive bidding procedures and the contractor is not providing direct retail services to end users.\n(d) (1) A contractor shall not be deemed to discriminate in the provision of benefits if the contractor, in providing the benefits, pays the actual costs incurred in obtaining the benefit.\n(2) If a contractor is unable to provide a certain benefit, despite taking reasonable measures to do so, the contractor shall not be deemed to discriminate in the provision of benefits.\n(e) (1) Every contract subject to this chapter shall contain a statement by which the contractor certifies that the contractor is in compliance with this section.\n(2) The department or other contracting agency shall enforce this section pursuant to its existing enforcement powers.\n(3) (A) If a contractor falsely certifies that it is in compliance with this section, the contract with that contractor shall be subject to Article 9 (commencing with Section 10420), unless, within a time period specified by the department or other contracting agency, the contractor provides to the department or agency proof that it has complied, or is in the process of complying, with this section.\n(B) The application of the remedies or penalties contained in Article 9 (commencing with Section 10420) to a contract subject to this chapter shall not preclude the application of any existing remedies otherwise available to the department or other contracting agency under its existing enforcement powers.\n(f) Nothing in this section is intended to regulate the contracting practices of any local jurisdiction.\n(g) This section shall be construed so as not to conflict with applicable federal laws, rules, or regulations. In the event that a court or agency of competent jurisdiction holds that federal law, rule, or regulation invalidates any clause, sentence, paragraph, or section of this code or the application thereof to any person or circumstances, it is the intent of the state that the court or agency sever that clause, sentence, paragraph, or section so that the remainder of this section shall remain in effect.\nSEC. 2.\nSection 10295.35 of the Public Contract Code shall not be construed to create any new enforcement authority or responsibility in the Department of General Services or any other contracting agency.\nSEC. 3.\nNo reimbursement is required by this act pursuant to Section 6 of Article XIII\u2009B of the California Constitution because the only costs that may be incurred by a local agency or school district will be incurred because this act creates a new crime or infraction, eliminates a crime or infraction, or changes the penalty for a crime or infraction, within the meaning of Section 17556 of the Government Code, or changes the definition of a crime within the meaning of Section 6 of Article XIII\u2009B of the California Constitution.',
'title': 'An act to add Section 10295.35 to the Public Contract Code, relating to public contracts.'}
```
El campo `text` es el input y el campo `summary` es el objetivo.
## Preprocesa
Carga el tokenizador T5 para procesar `text` y `summary`:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("t5-small")
```
La función de preprocesamiento necesita:
1. Agregar un prefijo al input; una clave para que T5 sepa que se trata de una tarea de generación de resúmenes. Algunos modelos capaces de realizar múltiples tareas de NLP requieren una clave que indique la tarea específica.
2. Usar el argumento `text_target` para tokenizar etiquetas.
3. Truncar secuencias para que no sean más largas que la longitud máxima fijada por el parámetro `max_length`.
```py
>>> prefix = "summarize: "
>>> def preprocess_function(examples):
... inputs = [prefix + doc for doc in examples["text"]]
... model_inputs = tokenizer(inputs, max_length=1024, truncation=True)
... labels = tokenizer(text_target=examples["summary"], max_length=128, truncation=True)
... model_inputs["labels"] = labels["input_ids"]
... return model_inputs
```
Usa la función [`~datasets.Dataset.map`] de 🤗 Datasets para aplicar la función de preprocesamiento sobre el dataset en su totalidad. Puedes acelerar la función `map` configurando el argumento `batched=True` para procesar múltiples elementos del dataset a la vez:
```py
>>> tokenized_billsum = billsum.map(preprocess_function, batched=True)
```
Usa [`DataCollatorForSeq2Seq`] para crear un lote de ejemplos. Esto también *rellenará dinámicamente* tu texto y etiquetas a la dimensión del elemento más largo del lote para que tengan un largo uniforme. Si bien es posible rellenar tu texto en la función `tokenizer` mediante el argumento `padding=True`, el rellenado dinámico es más eficiente.
<frameworkcontent>
<pt>
```py
>>> from transformers import DataCollatorForSeq2Seq
>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model)
```
</pt>
<tf>
```py
>>> from transformers import DataCollatorForSeq2Seq
>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model, return_tensors="tf")
```
</tf>
</frameworkcontent>
## Entrenamiento
<frameworkcontent>
<pt>
Carga T5 con [`AutoModelForSeq2SeqLM`]:
```py
>>> from transformers import AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
>>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
```
<Tip>
Para familiarizarte con el proceso para realizar fine-tuning sobre un modelo con [`Trainer`], ¡mira el tutorial básico [aquí](../training#finetune-with-trainer)!
</Tip>
En este punto, solo faltan tres pasos:
1. Definir tus hiperparámetros de entrenamiento en [`Seq2SeqTrainingArguments`].
2. Pasarle los argumentos de entrenamiento a [`Seq2SeqTrainer`] junto con el modelo, dataset y data collator.
3. Llamar [`~Trainer.train`] para realizar el fine-tuning sobre tu modelo.
```py
>>> training_args = Seq2SeqTrainingArguments(
... output_dir="./results",
... evaluation_strategy="epoch",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... weight_decay=0.01,
... save_total_limit=3,
... num_train_epochs=1,
... fp16=True,
... )
>>> trainer = Seq2SeqTrainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_billsum["train"],
... eval_dataset=tokenized_billsum["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... )
>>> trainer.train()
```
</pt>
<tf>
Para hacer fine-tuning de un modelo en TensorFlow, comienza por convertir tus datasets al formato `tf.data.Dataset` con [`~datasets.Dataset.to_tf_dataset`]. Especifica los inputs y etiquetas en `columns`, el tamaño de lote, el data collator, y si es necesario mezclar el dataset:
```py
>>> tf_train_set = tokenized_billsum["train"].to_tf_dataset(
... columns=["attention_mask", "input_ids", "labels"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_test_set = tokenized_billsum["test"].to_tf_dataset(
... columns=["attention_mask", "input_ids", "labels"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
<Tip>
Para familiarizarte con el fine-tuning con Keras, ¡mira el tutorial básico [aquí](training#finetune-with-keras)!
</Tip>
Crea la función optimizadora, establece la tasa de aprendizaje y algunos hiperparámetros de entrenamiento:
```py
>>> from transformers import create_optimizer, AdamWeightDecay
>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
```
Carga T5 con [`TFAutoModelForSeq2SeqLM`]:
```py
>>> from transformers import TFAutoModelForSeq2SeqLM
>>> model = TFAutoModelForSeq2SeqLM.from_pretrained("t5-small")
```
Configura el modelo para entrenamiento con [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
```py
>>> model.compile(optimizer=optimizer)
```
Llama a [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) para realizar el fine-tuning del modelo:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3)
```
</tf>
</frameworkcontent>
<Tip>
Para un ejemplo con mayor profundidad de cómo hacer fine-tuning a un modelo para generación de resúmenes, revisa la
[notebook en PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)
o a la [notebook en TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb).
</Tip>
| 0
|
hf_public_repos/transformers/docs/source/es
|
hf_public_repos/transformers/docs/source/es/tasks/question_answering.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Respuesta a preguntas
<Youtube id="ajPx5LwJD-I"/>
La respuesta a preguntas devuelve una respuesta a partir de una pregunta dada. Existen dos formas comunes de responder preguntas:
- Extractiva: extraer la respuesta a partir del contexto dado.
- Abstractiva: generar una respuesta que responda correctamente la pregunta a partir del contexto dado.
Esta guía te mostrará como hacer fine-tuning de [DistilBERT](https://huggingface.co/distilbert-base-uncased) en el dataset [SQuAD](https://huggingface.co/datasets/squad) para responder preguntas de forma extractiva.
<Tip>
Revisa la [página de la tarea](https://huggingface.co/tasks/question-answering) de responder preguntas para tener más información sobre otras formas de responder preguntas y los modelos, datasets y métricas asociadas.
</Tip>
## Carga el dataset SQuAD
Carga el dataset SQuAD con la biblioteca 🤗 Datasets:
```py
>>> from datasets import load_dataset
>>> squad = load_dataset("squad")
```
Ahora, échale un vistazo a una muestra:
```py
>>> squad["train"][0]
{'answers': {'answer_start': [515], 'text': ['Saint Bernadette Soubirous']},
'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.',
'id': '5733be284776f41900661182',
'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?',
'title': 'University_of_Notre_Dame'
}
```
El campo `answers` es un diccionario que contiene la posición inicial de la respuesta y el `texto` de la respuesta.
## Preprocesamiento
<Youtube id="qgaM0weJHpA"/>
Carga el tokenizer de DistilBERT para procesar los campos `question` (pregunta) y `context` (contexto):
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
Hay algunos pasos de preprocesamiento específicos para la tarea de respuesta a preguntas que debes tener en cuenta:
1. Algunos ejemplos en un dataset pueden tener un contexto que supera la longitud máxima de entrada de un modelo. Trunca solamente el contexto asignándole el valor `"only_second"` al parámetro `truncation`.
2. A continuación, mapea las posiciones de inicio y fin de la respuesta al contexto original asignándole el valor `True` al parámetro `return_offsets_mapping`.
3. Una vez tengas el mapeo, puedes encontrar los tokens de inicio y fin de la respuesta. Usa el método [`sequence_ids`](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#tokenizers.Encoding.sequence_ids)
para encontrar qué parte de la lista de tokens desplazados corresponde a la pregunta y cuál corresponde al contexto.
A continuación puedes ver como se crea una función para truncar y mapear los tokens de inicio y fin de la respuesta al `context`:
```py
>>> def preprocess_function(examples):
... questions = [q.strip() for q in examples["question"]]
... inputs = tokenizer(
... questions,
... examples["context"],
... max_length=384,
... truncation="only_second",
... return_offsets_mapping=True,
... padding="max_length",
... )
... offset_mapping = inputs.pop("offset_mapping")
... answers = examples["answers"]
... start_positions = []
... end_positions = []
... for i, offset in enumerate(offset_mapping):
... answer = answers[i]
... start_char = answer["answer_start"][0]
... end_char = answer["answer_start"][0] + len(answer["text"][0])
... sequence_ids = inputs.sequence_ids(i)
... # Encuentra el inicio y el fin del contexto
... idx = 0
... while sequence_ids[idx] != 1:
... idx += 1
... context_start = idx
... while sequence_ids[idx] == 1:
... idx += 1
... context_end = idx - 1
... # Si la respuesta entera no está dentro del contexto, etiquétala como (0, 0)
... if offset[context_start][0] > end_char or offset[context_end][1] < start_char:
... start_positions.append(0)
... end_positions.append(0)
... else:
... # De lo contrario, esta es la posición de los tokens de inicio y fin
... idx = context_start
... while idx <= context_end and offset[idx][0] <= start_char:
... idx += 1
... start_positions.append(idx - 1)
... idx = context_end
... while idx >= context_start and offset[idx][1] >= end_char:
... idx -= 1
... end_positions.append(idx + 1)
... inputs["start_positions"] = start_positions
... inputs["end_positions"] = end_positions
... return inputs
```
Usa la función [`~datasets.Dataset.map`] de 🤗 Datasets para aplicarle la función de preprocesamiento al dataset entero. Puedes acelerar la función `map` haciendo `batched=True` para procesar varios elementos del dataset a la vez.
Quita las columnas que no necesites:
```py
>>> tokenized_squad = squad.map(preprocess_function, batched=True, remove_columns=squad["train"].column_names)
```
Usa el [`DefaultDataCollator`] para crear un lote de ejemplos. A diferencia de los otros collators de datos en 🤗 Transformers, el `DefaultDataCollator` no aplica ningún procesamiento adicional (como el rellenado).
<frameworkcontent>
<pt>
```py
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator()
```
</pt>
<tf>
```py
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator(return_tensors="tf")
```
</tf>
</frameworkcontent>
## Entrenamiento
<frameworkcontent>
<pt>
Carga el modelo DistilBERT con [`AutoModelForQuestionAnswering`]:
```py
>>> from transformers import AutoModelForQuestionAnswering, TrainingArguments, Trainer
>>> model = AutoModelForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
<Tip>
Para familiarizarte con el fine-tuning con [`Trainer`], ¡mira el tutorial básico [aquí](../training#finetune-with-trainer)!
</Tip>
En este punto, solo quedan tres pasos:
1. Definir tus hiperparámetros de entrenamiento en [`TrainingArguments`].
2. Pasarle los argumentos del entrenamiento al [`Trainer`] junto con el modelo, el dataset, el tokenizer y el collator de datos.
3. Invocar el método [`~Trainer.train`] para realizar el fine-tuning del modelo.
```py
>>> training_args = TrainingArguments(
... output_dir="./results",
... evaluation_strategy="epoch",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=3,
... weight_decay=0.01,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_squad["train"],
... eval_dataset=tokenized_squad["validation"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... )
>>> trainer.train()
```
</pt>
<tf>
Para realizar el fine-tuning de un modelo en TensorFlow, primero convierte tus datasets al formato `tf.data.Dataset` con el método [`~TFPreTrainedModel.prepare_tf_dataset`].
```py
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_squad["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_validation_set = model.prepare_tf_dataset(
... tokenized_squad["validation"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
<Tip>
Para familiarizarte con el fine-tuning con Keras, ¡mira el tutorial básico [aquí](training#finetune-with-keras)!
</Tip>
Prepara una función de optimización, un programa para la tasa de aprendizaje y algunos hiperparámetros de entrenamiento:
```py
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_epochs = 2
>>> total_train_steps = (len(tokenized_squad["train"]) // batch_size) * num_epochs
>>> optimizer, schedule = create_optimizer(
... init_lr=2e-5,
... num_warmup_steps=0,
... num_train_steps=total_train_steps,
... )
```
Carga el modelo DistilBERT con [`TFAutoModelForQuestionAnswering`]:
```py
>>> from transformers import TFAutoModelForQuestionAnswering
>>> model = TFAutoModelForQuestionAnswering("distilbert-base-uncased")
```
Configura el modelo para entrenarlo con [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer)
```
Invoca el método [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) para realizar el fine-tuning del modelo:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3)
```
</tf>
</frameworkcontent>
<Tip>
Para un ejemplo con mayor profundidad de cómo hacer fine-tuning a un modelo para responder preguntas, échale un vistazo al
[cuaderno de PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb) o al
[cuaderno de TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb) correspondiente.
</Tip>
| 0
|
hf_public_repos/transformers/docs/source/es
|
hf_public_repos/transformers/docs/source/es/tasks/multiple_choice.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Selección múltiple
La tarea de selección múltiple es parecida a la de responder preguntas, con la excepción de que se dan varias opciones de respuesta junto con el contexto. El modelo se entrena para escoger la respuesta correcta
entre varias opciones a partir del contexto dado.
Esta guía te mostrará como hacerle fine-tuning a [BERT](https://huggingface.co/bert-base-uncased) en la configuración `regular` del dataset [SWAG](https://huggingface.co/datasets/swag), de forma
que seleccione la mejor respuesta a partir de varias opciones y algún contexto.
## Cargar el dataset SWAG
Carga el dataset SWAG con la biblioteca 🤗 Datasets:
```py
>>> from datasets import load_dataset
>>> swag = load_dataset("swag", "regular")
```
Ahora, échale un vistazo a un ejemplo del dataset:
```py
>>> swag["train"][0]
{'ending0': 'passes by walking down the street playing their instruments.',
'ending1': 'has heard approaching them.',
'ending2': "arrives and they're outside dancing and asleep.",
'ending3': 'turns the lead singer watches the performance.',
'fold-ind': '3416',
'gold-source': 'gold',
'label': 0,
'sent1': 'Members of the procession walk down the street holding small horn brass instruments.',
'sent2': 'A drum line',
'startphrase': 'Members of the procession walk down the street holding small horn brass instruments. A drum line',
'video-id': 'anetv_jkn6uvmqwh4'}
```
Los campos `sent1` y `sent2` muestran cómo comienza una oración, y cada campo `ending` indica cómo podría terminar. Dado el comienzo de la oración, el modelo debe escoger el final de oración correcto indicado por el campo `label`.
## Preprocesmaiento
Carga el tokenizer de BERT para procesar el comienzo de cada oración y los cuatro finales posibles:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
```
La función de preprocesmaiento debe hacer lo siguiente:
1. Hacer cuatro copias del campo `sent1` de forma que se pueda combinar cada una con el campo `sent2` para recrear la forma en que empieza la oración.
2. Combinar `sent2` con cada uno de los cuatro finales de oración posibles.
3. Aplanar las dos listas para que puedas tokenizarlas, y luego des-aplanarlas para que cada ejemplo tenga los campos `input_ids`, `attention_mask` y `labels` correspondientes.
```py
>>> ending_names = ["ending0", "ending1", "ending2", "ending3"]
>>> def preprocess_function(examples):
... first_sentences = [[context] * 4 for context in examples["sent1"]]
... question_headers = examples["sent2"]
... second_sentences = [
... [f"{header} {examples[end][i]}" for end in ending_names] for i, header in enumerate(question_headers)
... ]
... first_sentences = sum(first_sentences, [])
... second_sentences = sum(second_sentences, [])
... tokenized_examples = tokenizer(first_sentences, second_sentences, truncation=True)
... return {k: [v[i : i + 4] for i in range(0, len(v), 4)] for k, v in tokenized_examples.items()}
```
Usa la función [`~datasets.Dataset.map`] de 🤗 Datasets para aplicarle la función de preprocesamiento al dataset entero. Puedes acelerar la función `map` haciendo `batched=True` para procesar varios elementos del dataset a la vez.
```py
tokenized_swag = swag.map(preprocess_function, batched=True)
```
🤗 Transformers no tiene un collator de datos para la tarea de selección múltiple, así que tendrías que crear uno. Puedes adaptar el [`DataCollatorWithPadding`] para crear un lote de ejemplos para selección múltiple. Este también
le *añadirá relleno de manera dinámica* a tu texto y a las etiquetas para que tengan la longitud del elemento más largo en su lote, de forma que tengan una longitud uniforme. Aunque es posible rellenar el texto en la función `tokenizer` haciendo
`padding=True`, el rellenado dinámico es más eficiente.
El `DataCollatorForMultipleChoice` aplanará todas las entradas del modelo, les aplicará relleno y luego des-aplanará los resultados:
<frameworkcontent>
<pt>
```py
>>> from dataclasses import dataclass
>>> from transformers.tokenization_utils_base import PreTrainedTokenizerBase, PaddingStrategy
>>> from typing import Optional, Union
>>> import torch
>>> @dataclass
... class DataCollatorForMultipleChoice:
... """
... Collator de datos que le añadirá relleno de forma automática a las entradas recibidas para
... una tarea de selección múltiple.
... """
... tokenizer: PreTrainedTokenizerBase
... padding: Union[bool, str, PaddingStrategy] = True
... max_length: Optional[int] = None
... pad_to_multiple_of: Optional[int] = None
... def __call__(self, features):
... label_name = "label" if "label" in features[0].keys() else "labels"
... labels = [feature.pop(label_name) for feature in features]
... batch_size = len(features)
... num_choices = len(features[0]["input_ids"])
... flattened_features = [
... [{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
... ]
... flattened_features = sum(flattened_features, [])
... batch = self.tokenizer.pad(
... flattened_features,
... padding=self.padding,
... max_length=self.max_length,
... pad_to_multiple_of=self.pad_to_multiple_of,
... return_tensors="pt",
... )
... batch = {k: v.view(batch_size, num_choices, -1) for k, v in batch.items()}
... batch["labels"] = torch.tensor(labels, dtype=torch.int64)
... return batch
```
</pt>
<tf>
```py
>>> from dataclasses import dataclass
>>> from transformers.tokenization_utils_base import PreTrainedTokenizerBase, PaddingStrategy
>>> from typing import Optional, Union
>>> import tensorflow as tf
>>> @dataclass
... class DataCollatorForMultipleChoice:
... """
... Data collator that will dynamically pad the inputs for multiple choice received.
... """
... tokenizer: PreTrainedTokenizerBase
... padding: Union[bool, str, PaddingStrategy] = True
... max_length: Optional[int] = None
... pad_to_multiple_of: Optional[int] = None
... def __call__(self, features):
... label_name = "label" if "label" in features[0].keys() else "labels"
... labels = [feature.pop(label_name) for feature in features]
... batch_size = len(features)
... num_choices = len(features[0]["input_ids"])
... flattened_features = [
... [{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
... ]
... flattened_features = sum(flattened_features, [])
... batch = self.tokenizer.pad(
... flattened_features,
... padding=self.padding,
... max_length=self.max_length,
... pad_to_multiple_of=self.pad_to_multiple_of,
... return_tensors="tf",
... )
... batch = {k: tf.reshape(v, (batch_size, num_choices, -1)) for k, v in batch.items()}
... batch["labels"] = tf.convert_to_tensor(labels, dtype=tf.int64)
... return batch
```
</tf>
</frameworkcontent>
## Entrenamiento
<frameworkcontent>
<pt>
Carga el modelo BERT con [`AutoModelForMultipleChoice`]:
```py
>>> from transformers import AutoModelForMultipleChoice, TrainingArguments, Trainer
>>> model = AutoModelForMultipleChoice.from_pretrained("bert-base-uncased")
```
<Tip>
Para familiarizarte con el fine-tuning con [`Trainer`], ¡mira el tutorial básico [aquí](../training#finetune-with-trainer)!
</Tip>
En este punto, solo quedan tres pasos:
1. Definir tus hiperparámetros de entrenamiento en [`TrainingArguments`].
2. Pasarle los argumentos del entrenamiento al [`Trainer`] jnto con el modelo, el dataset, el tokenizer y el collator de datos.
3. Invocar el método [`~Trainer.train`] para realizar el fine-tuning del modelo.
```py
>>> training_args = TrainingArguments(
... output_dir="./results",
... evaluation_strategy="epoch",
... learning_rate=5e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=3,
... weight_decay=0.01,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_swag["train"],
... eval_dataset=tokenized_swag["validation"],
... tokenizer=tokenizer,
... data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer),
... )
>>> trainer.train()
```
</pt>
<tf>
Para realizar el fine-tuning de un modelo en TensorFlow, primero convierte tus datasets al formato `tf.data.Dataset` con el método [`~TFPreTrainedModel.prepare_tf_dataset`].
```py
>>> data_collator = DataCollatorForMultipleChoice(tokenizer=tokenizer)
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_swag["train"],
... shuffle=True,
... batch_size=batch_size,
... collate_fn=data_collator,
... )
>>> tf_validation_set = model.prepare_tf_dataset(
... tokenized_swag["validation"],
... shuffle=False,
... batch_size=batch_size,
... collate_fn=data_collator,
... )
```
<Tip>
Para familiarizarte con el fine-tuning con Keras, ¡mira el tutorial básico [aquí](training#finetune-with-keras)!
</Tip>
Prepara una función de optimización, un programa para la tasa de aprendizaje y algunos hiperparámetros de entrenamiento:
```py
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_train_epochs = 2
>>> total_train_steps = (len(tokenized_swag["train"]) // batch_size) * num_train_epochs
>>> optimizer, schedule = create_optimizer(init_lr=5e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
```
Carga el modelo BERT con [`TFAutoModelForMultipleChoice`]:
```py
>>> from transformers import TFAutoModelForMultipleChoice
>>> model = TFAutoModelForMultipleChoice.from_pretrained("bert-base-uncased")
```
Configura el modelo para entrenarlo con [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
```py
>>> model.compile(optimizer=optimizer)
```
Invoca el método [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) para realizar el fine-tuning del modelo:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=2)
```
</tf>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ms/_toctree.yml
|
- sections:
- local: index
title: 🤗 Transformers
- local: quicktour
title: Lawatan cepat
- local: installation
title: Pemasangan
title: Mulakan
- sections:
- local: pipeline_tutorial
title: Jalankan inferens dengan saluran paip
- local: autoclass_tutorial
title: Tulis kod mudah alih dengan AutoClass
- local: preprocessing
title: Praproses data
- local: training
title: Perhalusi model yang telah dilatih
- local: run_scripts
title: Latih dengan skrip
- local: accelerate
title: Sediakan latihan yang diedarkan dengan 🤗 Accelerate
- local: model_sharing
title: Kongsi model anda
- local: transformers_agents
title: Ejen
title: Tutorials
- sections:
- sections:
- local: tasks/sequence_classification
title: Klasifikasi teks
- local: tasks/token_classification
title: Klasifikasi token
- local: tasks/question_answering
title: Soalan menjawab
- local: tasks/language_modeling
title: Pemodelan bahasa sebab-akibat
- local: tasks/masked_language_modeling
title: Pemodelan bahasa Masked
- local: tasks/translation
title: Terjemahan
- local: tasks/summarization
title: Rumusan
- local: tasks/multiple_choice
title: Pilihan
title: Natural Language Processing
isExpanded: false
- sections:
- local: tasks/audio_classification
title: Klasifikasi audio
- local: tasks/asr
title: Pengecaman pertuturan automatik
title: Audio
isExpanded: false
- sections:
- local: tasks/image_classification
title: Klasifikasi imej
- local: tasks/semantic_segmentation
title: Segmentasi semantik
- local: tasks/video_classification
title: Klasifikasi video
- local: tasks/object_detection
title: Pengesanan objek
- local: tasks/zero_shot_object_detection
title: Pengesanan objek Zero-Shot
- local: tasks/zero_shot_image_classification
title: Klasifikasi imej tangkapan Zero-Shot
- local: tasks/monocular_depth_estimation
title: Anggaran kedalaman
title: Visi komputer
isExpanded: false
- sections:
- local: tasks/image_captioning
title: Kapsyen imej
- local: tasks/document_question_answering
title: Menjawab Soalan Dokumen
- local: tasks/text-to-speech
title: Teks kepada ucapan
title: Multimodal
isExpanded: false
title: Panduan Tugasan
- sections:
- local: fast_tokenizers
title: Gunakan tokenizer cepat dari 🤗 Tokenizers
- local: multilingual
title: Jalankan inferens dengan model berbilang bahasa
- local: generation_strategies
title: Sesuaikan strategi penjanaan teks
- local: create_a_model
title: Gunakan API khusus model
- local: custom_models
title: Kongsi model tersuai
- local: sagemaker
title: Jalankan latihan di Amazon SageMaker
- local: serialization
title: Eksport ke ONNX
- local: torchscript
title: Eksport ke TorchScript
- local: benchmarks
title: Penanda aras
- local: Buku nota dengan contoh
title: Notebooks with examples
- local: Sumber komuniti
title: Community resources
- local: Sumber komuniti
title: Custom Tools and Prompts
- local: Alat dan Gesaan Tersuai
title: Selesaikan masalah
title: Panduan Developer
- sections:
- local: performance
title: Gambaran keseluruhan
- local: perf_train_gpu_one
title: Latihan pada satu GPU
- local: perf_train_gpu_many
title: Latihan pada banyak GPU
- local: perf_train_cpu
title: Latihan mengenai CPU
- local: perf_train_cpu_many
title: Latihan pada banyak CPU
- local: perf_train_tpu
title: Latihan mengenai TPU
- local: perf_train_tpu_tf
title: Latihan tentang TPU dengan TensorFlow
- local: perf_train_special
title: Latihan mengenai Perkakasan Khusus
- local: perf_infer_cpu
title: Inferens pada CPU
- local: perf_infer_gpu_one
title: Inferens pada satu GPU
- local: perf_infer_gpu_many
title: Inferens pada banyak GPUs
- local: perf_infer_special
title: Inferens pada Perkakasan Khusus
- local: perf_hardware
title: Perkakasan tersuai untuk latihan
- local: big_models
title: Menghidupkan model besar
- local: debugging
title: Penyahpepijatan
- local: hpo_train
title: Carian Hiperparameter menggunakan API Pelatih
- local: tf_xla
title: Penyepaduan XLA untuk Model TensorFlow
title: Prestasi dan kebolehskalaan
- sections:
- local: contributing
title: Bagaimana untuk menyumbang kepada transformer?
- local: add_new_model
title: Bagaimana untuk menambah model pada 🤗 Transformers?
- local: add_tensorflow_model
title: Bagaimana untuk menukar model Transformers kepada TensorFlow?
- local: add_new_pipeline
title: Bagaimana untuk menambah saluran paip ke 🤗 Transformers?
- local: testing
title: Ujian
- local: pr_checks
title: Menyemak Permintaan Tarik
title: Sumbangkan
- sections:
- local: philosophy
title: Falsafah
- local: glossary
title: Glosari
- local: task_summary
title: Apa 🤗 Transformers boleh buat
- local: tasks_explained
title: Bagaimana 🤗 Transformers menyelesaikan tugasan
- local: model_summary
title: Keluarga model Transformer
- local: tokenizer_summary
title: Ringkasan tokenizer
- local: attention
title: Mekanisme perhatian
- local: pad_truncation
title: Padding dan pemotongan
- local: bertology
title: BERTology
- local: perplexity
title: Kekeliruan model panjang tetap
- local: pipeline_webserver
title: Saluran paip untuk inferens pelayan web
title: Panduan konsep
- sections:
- sections:
- local: main_classes/agent
title: Ejen dan Alat
- local: model_doc/auto
title: Kelas Auto
- local: main_classes/callback
title: Panggilan balik
- local: main_classes/configuration
title: Configuration
- local: main_classes/data_collator
title: Data Collator
- local: main_classes/keras_callbacks
title: Keras callbacks
- local: main_classes/logging
title: Logging
- local: main_classes/model
title: Models
- local: main_classes/text_generation
title: Text Generation
- local: main_classes/onnx
title: ONNX
- local: main_classes/optimizer_schedules
title: Optimization
- local: main_classes/output
title: Model outputs
- local: main_classes/pipelines
title: Pipelines
- local: main_classes/processors
title: Processors
- local: main_classes/quantization
title: Quantization
- local: main_classes/tokenizer
title: Tokenizer
- local: main_classes/trainer
title: Trainer
- local: main_classes/deepspeed
title: DeepSpeed Integration
- local: main_classes/feature_extractor
title: Feature Extractor
- local: main_classes/image_processor
title: Image Processor
title: Main Classes
- sections:
- isExpanded: false
sections:
- local: model_doc/albert
title: ALBERT
- local: model_doc/bart
title: BART
- local: model_doc/barthez
title: BARThez
- local: model_doc/bartpho
title: BARTpho
- local: model_doc/bert
title: BERT
- local: model_doc/bert-generation
title: BertGeneration
- local: model_doc/bert-japanese
title: BertJapanese
- local: model_doc/bertweet
title: Bertweet
- local: model_doc/big_bird
title: BigBird
- local: model_doc/bigbird_pegasus
title: BigBirdPegasus
- local: model_doc/biogpt
title: BioGpt
- local: model_doc/blenderbot
title: Blenderbot
- local: model_doc/blenderbot-small
title: Blenderbot Small
- local: model_doc/bloom
title: BLOOM
- local: model_doc/bort
title: BORT
- local: model_doc/byt5
title: ByT5
- local: model_doc/camembert
title: CamemBERT
- local: model_doc/canine
title: CANINE
- local: model_doc/codegen
title: CodeGen
- local: model_doc/convbert
title: ConvBERT
- local: model_doc/cpm
title: CPM
- local: model_doc/cpmant
title: CPMANT
- local: model_doc/ctrl
title: CTRL
- local: model_doc/deberta
title: DeBERTa
- local: model_doc/deberta-v2
title: DeBERTa-v2
- local: model_doc/dialogpt
title: DialoGPT
- local: model_doc/distilbert
title: DistilBERT
- local: model_doc/dpr
title: DPR
- local: model_doc/electra
title: ELECTRA
- local: model_doc/encoder-decoder
title: Encoder Decoder Models
- local: model_doc/ernie
title: ERNIE
- local: model_doc/ernie_m
title: ErnieM
- local: model_doc/esm
title: ESM
- local: model_doc/flan-t5
title: FLAN-T5
- local: model_doc/flan-ul2
title: FLAN-UL2
- local: model_doc/flaubert
title: FlauBERT
- local: model_doc/fnet
title: FNet
- local: model_doc/fsmt
title: FSMT
- local: model_doc/funnel
title: Funnel Transformer
- local: model_doc/openai-gpt
title: GPT
- local: model_doc/gpt_neo
title: GPT Neo
- local: model_doc/gpt_neox
title: GPT NeoX
- local: model_doc/gpt_neox_japanese
title: GPT NeoX Japanese
- local: model_doc/gptj
title: GPT-J
- local: model_doc/gpt2
title: GPT2
- local: model_doc/gpt_bigcode
title: GPTBigCode
- local: model_doc/gptsan-japanese
title: GPTSAN Japanese
- local: model_doc/gpt-sw3
title: GPTSw3
- local: model_doc/herbert
title: HerBERT
- local: model_doc/ibert
title: I-BERT
- local: model_doc/jukebox
title: Jukebox
- local: model_doc/led
title: LED
- local: model_doc/llama
title: LLaMA
- local: model_doc/longformer
title: Longformer
- local: model_doc/longt5
title: LongT5
- local: model_doc/luke
title: LUKE
- local: model_doc/m2m_100
title: M2M100
- local: model_doc/marian
title: MarianMT
- local: model_doc/markuplm
title: MarkupLM
- local: model_doc/mbart
title: MBart and MBart-50
- local: model_doc/mega
title: MEGA
- local: model_doc/megatron-bert
title: MegatronBERT
- local: model_doc/megatron_gpt2
title: MegatronGPT2
- local: model_doc/mluke
title: mLUKE
- local: model_doc/mobilebert
title: MobileBERT
- local: model_doc/mpnet
title: MPNet
- local: model_doc/mt5
title: MT5
- local: model_doc/mvp
title: MVP
- local: model_doc/nezha
title: NEZHA
- local: model_doc/nllb
title: NLLB
- local: model_doc/nllb-moe
title: NLLB-MoE
- local: model_doc/nystromformer
title: Nyströmformer
- local: model_doc/open-llama
title: Open-Llama
- local: model_doc/opt
title: OPT
- local: model_doc/pegasus
title: Pegasus
- local: model_doc/pegasus_x
title: PEGASUS-X
- local: model_doc/phobert
title: PhoBERT
- local: model_doc/plbart
title: PLBart
- local: model_doc/prophetnet
title: ProphetNet
- local: model_doc/qdqbert
title: QDQBert
- local: model_doc/rag
title: RAG
- local: model_doc/realm
title: REALM
- local: model_doc/reformer
title: Reformer
- local: model_doc/rembert
title: RemBERT
- local: model_doc/retribert
title: RetriBERT
- local: model_doc/roberta
title: RoBERTa
- local: model_doc/roberta-prelayernorm
title: RoBERTa-PreLayerNorm
- local: model_doc/roc_bert
title: RoCBert
- local: model_doc/roformer
title: RoFormer
- local: model_doc/rwkv
title: RWKV
- local: model_doc/splinter
title: Splinter
- local: model_doc/squeezebert
title: SqueezeBERT
- local: model_doc/switch_transformers
title: SwitchTransformers
- local: model_doc/t5
title: T5
- local: model_doc/t5v1.1
title: T5v1.1
- local: model_doc/tapex
title: TAPEX
- local: model_doc/transfo-xl
title: Transformer XL
- local: model_doc/ul2
title: UL2
- local: model_doc/xmod
title: X-MOD
- local: model_doc/xglm
title: XGLM
- local: model_doc/xlm
title: XLM
- local: model_doc/xlm-prophetnet
title: XLM-ProphetNet
- local: model_doc/xlm-roberta
title: XLM-RoBERTa
- local: model_doc/xlm-roberta-xl
title: XLM-RoBERTa-XL
- local: model_doc/xlm-v
title: XLM-V
- local: model_doc/xlnet
title: XLNet
- local: model_doc/yoso
title: YOSO
title: Text models
- isExpanded: false
sections:
- local: model_doc/beit
title: BEiT
- local: model_doc/bit
title: BiT
- local: model_doc/conditional_detr
title: Conditional DETR
- local: model_doc/convnext
title: ConvNeXT
- local: model_doc/convnextv2
title: ConvNeXTV2
- local: model_doc/cvt
title: CvT
- local: model_doc/deformable_detr
title: Deformable DETR
- local: model_doc/deit
title: DeiT
- local: model_doc/deta
title: DETA
- local: model_doc/detr
title: DETR
- local: model_doc/dinat
title: DiNAT
- local: model_doc/dit
title: DiT
- local: model_doc/dpt
title: DPT
- local: model_doc/efficientformer
title: EfficientFormer
- local: model_doc/efficientnet
title: EfficientNet
- local: model_doc/focalnet
title: FocalNet
- local: model_doc/glpn
title: GLPN
- local: model_doc/imagegpt
title: ImageGPT
- local: model_doc/levit
title: LeViT
- local: model_doc/mask2former
title: Mask2Former
- local: model_doc/maskformer
title: MaskFormer
- local: model_doc/mobilenet_v1
title: MobileNetV1
- local: model_doc/mobilenet_v2
title: MobileNetV2
- local: model_doc/mobilevit
title: MobileViT
- local: model_doc/nat
title: NAT
- local: model_doc/poolformer
title: PoolFormer
- local: model_doc/regnet
title: RegNet
- local: model_doc/resnet
title: ResNet
- local: model_doc/segformer
title: SegFormer
- local: model_doc/swiftformer
title: SwiftFormer
- local: model_doc/swin
title: Swin Transformer
- local: model_doc/swinv2
title: Swin Transformer V2
- local: model_doc/swin2sr
title: Swin2SR
- local: model_doc/table-transformer
title: Table Transformer
- local: model_doc/timesformer
title: TimeSformer
- local: model_doc/upernet
title: UperNet
- local: model_doc/van
title: VAN
- local: model_doc/videomae
title: VideoMAE
- local: model_doc/vit
title: Vision Transformer (ViT)
- local: model_doc/vit_hybrid
title: ViT Hybrid
- local: model_doc/vit_mae
title: ViTMAE
- local: model_doc/vit_msn
title: ViTMSN
- local: model_doc/yolos
title: YOLOS
title: Vision models
- isExpanded: false
sections:
- local: model_doc/audio-spectrogram-transformer
title: Audio Spectrogram Transformer
- local: model_doc/clap
title: CLAP
- local: model_doc/hubert
title: Hubert
- local: model_doc/mctct
title: MCTCT
- local: model_doc/sew
title: SEW
- local: model_doc/sew-d
title: SEW-D
- local: model_doc/speech_to_text
title: Speech2Text
- local: model_doc/speech_to_text_2
title: Speech2Text2
- local: model_doc/speecht5
title: SpeechT5
- local: model_doc/unispeech
title: UniSpeech
- local: model_doc/unispeech-sat
title: UniSpeech-SAT
- local: model_doc/wav2vec2
title: Wav2Vec2
- local: model_doc/wav2vec2-conformer
title: Wav2Vec2-Conformer
- local: model_doc/wav2vec2_phoneme
title: Wav2Vec2Phoneme
- local: model_doc/wavlm
title: WavLM
- local: model_doc/whisper
title: Whisper
- local: model_doc/xls_r
title: XLS-R
- local: model_doc/xlsr_wav2vec2
title: XLSR-Wav2Vec2
title: Audio models
- isExpanded: false
sections:
- local: model_doc/align
title: ALIGN
- local: model_doc/altclip
title: AltCLIP
- local: model_doc/blip
title: BLIP
- local: model_doc/blip-2
title: BLIP-2
- local: model_doc/bridgetower
title: BridgeTower
- local: model_doc/chinese_clip
title: Chinese-CLIP
- local: model_doc/clip
title: CLIP
- local: model_doc/clipseg
title: CLIPSeg
- local: model_doc/data2vec
title: Data2Vec
- local: model_doc/deplot
title: DePlot
- local: model_doc/donut
title: Donut
- local: model_doc/flava
title: FLAVA
- local: model_doc/git
title: GIT
- local: model_doc/groupvit
title: GroupViT
- local: model_doc/layoutlm
title: LayoutLM
- local: model_doc/layoutlmv2
title: LayoutLMV2
- local: model_doc/layoutlmv3
title: LayoutLMV3
- local: model_doc/layoutxlm
title: LayoutXLM
- local: model_doc/lilt
title: LiLT
- local: model_doc/lxmert
title: LXMERT
- local: model_doc/matcha
title: MatCha
- local: model_doc/mgp-str
title: MGP-STR
- local: model_doc/oneformer
title: OneFormer
- local: model_doc/owlvit
title: OWL-ViT
- local: model_doc/perceiver
title: Perceiver
- local: model_doc/pix2struct
title: Pix2Struct
- local: model_doc/sam
title: Segment Anything
- local: model_doc/speech-encoder-decoder
title: Speech Encoder Decoder Models
- local: model_doc/tapas
title: TAPAS
- local: model_doc/trocr
title: TrOCR
- local: model_doc/tvlt
title: TVLT
- local: model_doc/vilt
title: ViLT
- local: model_doc/vision-encoder-decoder
title: Vision Encoder Decoder Models
- local: model_doc/vision-text-dual-encoder
title: Vision Text Dual Encoder
- local: model_doc/visual_bert
title: VisualBERT
- local: model_doc/xclip
title: X-CLIP
title: Multimodal models
- isExpanded: false
sections:
- local: model_doc/decision_transformer
title: Decision Transformer
- local: model_doc/trajectory_transformer
title: Trajectory Transformer
title: Reinforcement learning models
- isExpanded: false
sections:
- local: model_doc/informer
title: Informer
- local: model_doc/time_series_transformer
title: Time Series Transformer
title: Time series models
- isExpanded: false
sections:
- local: model_doc/graphormer
title: Graphormer
title: Graph models
title: Models
- sections:
- local: internal/modeling_utils
title: Custom Layers and Utilities
- local: internal/pipelines_utils
title: Utilities for pipelines
- local: internal/tokenization_utils
title: Utilities for Tokenizers
- local: internal/trainer_utils
title: Utilities for Trainer
- local: internal/generation_utils
title: Utilities for Generation
- local: internal/image_processing_utils
title: Utilities for Image Processors
- local: internal/audio_utils
title: Utilities for Audio processing
- local: internal/file_utils
title: General Utilities
- local: internal/time_series_utils
title: Utilities for Time Series
title: Internal Helpers
title: API
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ms/index.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Dilesenkan di bawah Lesen Apache, Versi 2.0 ("Lesen"); anda tidak boleh menggunakan fail ini kecuali dengan mematuhi
Lesen. Anda boleh mendapatkan salinan Lesen di
http://www.apache.org/licenses/LICENSE-2.0
Melainkan diperlukan oleh undang-undang yang terpakai atau dipersetujui secara bertulis, perisian yang diedarkan di bawah Lesen diedarkan pada
ASAS ""SEBAGAIMANA ADANYA"", TANPA WARANTI ATAU SEBARANG JENIS SYARAT, sama ada nyata atau tersirat. Lihat Lesen untuk
bahasa tertentu yang mengawal kebenaran dan pengehadan di bawah Lesen.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Transformers
Pembelajaran Mesin terkini untuk [PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/), dan [JAX](https://jax.readthedocs.io/en/latest/).
🤗 Transformers menyediakan API dan alatan untuk memuat turun dan melatih model pra-latihan terkini dengan mudah. Menggunakan model terlatih boleh mengurangkan kos pengiraan anda, jejak karbon dan menjimatkan masa serta sumber yang diperlukan untuk melatih model dari awal. Model ini menyokong tugas biasa dalam modaliti yang berbeza, seperti:
📝 **Natural Language Processing**: klasifikasi teks, pengecaman entiti bernama, menjawab soalan, pemodelan bahasa, ringkasan, terjemahan, pilihan berganda dan penjanaan teks.<br>
🖼️ **Computer Vision**: pengelasan imej, pengesanan objek dan pembahagian.<br>
🗣️ **Audio**: pengecaman pertuturan automatik dan klasifikasi audio.<br>
🐙 **Multimodal**: jawapan soalan jadual, pengecaman aksara optik, pengekstrakan maklumat daripada dokumen yang diimbas, klasifikasi video dan jawapan soalan visual.
🤗 Transformer menyokong kebolehoperasian rangka kerja antara PyTorch, TensorFlow, and JAX. Ini memberikan fleksibiliti untuk menggunakan rangka kerja yang berbeza pada setiap peringkat kehidupan model; latih model dalam tiga baris kod dalam satu rangka kerja, dan muatkannya untuk inferens dalam rangka kerja yang lain. Model juga boleh dieksport ke format seperti ONNX.
Sertai komuniti yang semakin berkembang di [Hub](https://huggingface.co/models), [forum](https://discuss.huggingface.co/), atau [Discord](https://discord.com/invite/JfAtkvEtRb) hari ini!
## Jika anda sedang mencari sokongan tersuai daripada pasukan Hugging Face
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
## Kandungan
Dokumentasi disusun kepada lima bahagian:
- **MULAKAN** menyediakan lawatan pantas ke perpustakaan dan arahan pemasangan untuk bangun dan berjalan.
- **TUTORIAL** ialah tempat yang bagus untuk bermula jika anda seorang pemula. Bahagian ini akan membantu anda memperoleh kemahiran asas yang anda perlukan untuk mula menggunakan perpustakaan.
- **PANDUAN CARA-CARA** menunjukkan kepada anda cara untuk mencapai matlamat tertentu, seperti memperhalusi model terlatih untuk pemodelan bahasa atau cara menulis dan berkongsi model tersuai.
- **PANDUAN KONSEP** menawarkan lebih banyak perbincangan dan penjelasan tentang konsep dan idea asas di sebalik model, tugasan dan falsafah reka bentuk 🤗 Transformers.
- **API** menerangkan semua kelas dan fungsi:
- **KELAS UTAMA** memperincikan kelas yang paling penting seperti konfigurasi, model, tokenizer dan saluran paip.
- **MODEL** memperincikan kelas dan fungsi yang berkaitan dengan setiap model yang dilaksanakan dalam perpustakaan.
- **PEMBANTU DALAMAN** memperincikan kelas utiliti dan fungsi yang digunakan secara dalaman.
### Model yang disokong
<!--Senarai ini dikemas kini secara automatik daripada README dengan _make fix-copies_. Jangan kemas kini secara manual! -->
1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
1. **[ALIGN](model_doc/align)** (from Google Research) released with the paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
1. **[AltCLIP](model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
1. **[Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
1. **[Autoformer](model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BioGpt](model_doc/biogpt)** (from Microsoft Research AI4Science) released with the paper [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu.
1. **[BiT](model_doc/bit)** (from Google AI) released with the paper [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BLIP](model_doc/blip)** (from Salesforce) released with the paper [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
1. **[BLIP-2](model_doc/blip-2)** (from Salesforce) released with the paper [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.
1. **[BLOOM](model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
1. **[BridgeTower](model_doc/bridgetower)** (from Harbin Institute of Technology/Microsoft Research Asia/Intel Labs) released with the paper [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
1. **[Bros](model_doc/bros)** (from NAVER) released with the paper [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[Chinese-CLIP](model_doc/chinese_clip)** (from OFA-Sys) released with the paper [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
1. **[CLAP](model_doc/clap)** (from LAION-AI) released with the paper [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CPM-Ant](model_doc/cpmant)** (from OpenBMB) released by the [OpenBMB](https://www.openbmb.org/).
1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
1. **[DePlot](model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
1. **[DETA](model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
1. **[DiNAT](model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
1. **[EfficientFormer](model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
1. **[EfficientNet](model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
1. **[ErnieM](model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
1. **[ESM](model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
1. **[FLAN-T5](model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
1. **[FLAN-UL2](model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
1. **[FocalNet](model_doc/focalnet)** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
1. **[GIT](model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
1. **[GPT NeoX Japanese](model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPT-Sw3](model_doc/gpt-sw3)** (from AI-Sweden) released with the paper [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
1. **[GPTBigCode](model_doc/gpt_bigcode)** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
1. **[Graphormer](model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Informer](model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[LLaMA](model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[MatCha](model_doc/matcha)** (from Google AI) released with the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662) by Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
1. **[MEGA](model_doc/mega)** (from Meta/USC/CMU/SJTU) released with the paper [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[MGP-STR](model_doc/mgp-str)** (from Alibaba Research) released with the paper [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
1. **[MobileNetV1](model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
1. **[MobileNetV2](model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
1. **[NAT](model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
1. **[NLLB-MOE](model_doc/nllb-moe)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
1. **[OpenLlama](model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
1. **[Pix2Struct](model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
1. **[RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
1. **[RoCBert](model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[RWKV](model_doc/rwkv)** (from Bo Peng), released on [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[Segment Anything](model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SpeechT5](model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[SwiftFormer](model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
1. **[Swin2SR](model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
1. **[SwitchTransformers](model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Time Series Transformer](model_doc/time_series_transformer)** (from HuggingFace).
1. **[TimeSformer](model_doc/timesformer)** (from Facebook) released with the paper [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[TVLT](model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
1. **[TVP](model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[UPerNet](model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[ViT Hybrid](model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Whisper](model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
1. **[X-MOD](model_doc/xmod)** (from Meta AI) released with the paper [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) by Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, Mikel Artetxe.
1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
1. **[XLM-V](model_doc/xlm-v)** (from Meta AI) released with the paper [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472) by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### Rangka kerja yang disokong
Jadual di bawah mewakili sokongan semasa dalam perpustakaan untuk setiap model tersebut, sama ada model tersebut mempunyai Python
tokenizer (dipanggil ""lambat""). Tokenizer ""pantas"" yang disokong oleh perpustakaan Tokenizers 🤗, sama ada mereka mempunyai sokongan dalam Jax (melalui
Flax), PyTorch, dan/atau TensorFlow.
<!--Jadual ini dikemas kini secara automatik daripada modul auto dengan _make fix-copies_. Jangan kemas kini secara manual!-->
| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
|:-----------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| ALIGN | ❌ | ❌ | ✅ | ❌ | ❌ |
| AltCLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| Audio Spectrogram Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Autoformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
| BigBird-Pegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
| BioGpt | ✅ | ❌ | ✅ | ❌ | ❌ |
| BiT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
| BLIP | ❌ | ❌ | ✅ | ✅ | ❌ |
| BLIP-2 | ❌ | ❌ | ✅ | ❌ | ❌ |
| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
| BridgeTower | ❌ | ❌ | ✅ | ❌ | ❌ |
| Bros | ✅ | ✅ | ✅ | ❌ | ❌ |
| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
| Chinese-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| CLAP | ❌ | ❌ | ✅ | ❌ | ❌ |
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
| CLIPSeg | ❌ | ❌ | ✅ | ❌ | ❌ |
| CodeGen | ✅ | ✅ | ✅ | ❌ | ❌ |
| Conditional DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ConvNeXT | ❌ | ❌ | ✅ | ✅ | ❌ |
| ConvNeXTV2 | ❌ | ❌ | ✅ | ❌ | ❌ |
| CPM-Ant | ✅ | ❌ | ✅ | ❌ | ❌ |
| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
| CvT | ❌ | ❌ | ✅ | ✅ | ❌ |
| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Deformable DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DeiT | ❌ | ❌ | ✅ | ✅ | ❌ |
| DETA | ❌ | ❌ | ✅ | ❌ | ❌ |
| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DiNAT | ❌ | ❌ | ✅ | ❌ | ❌ |
| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| DonutSwin | ❌ | ❌ | ✅ | ❌ | ❌ |
| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| EfficientFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
| EfficientNet | ❌ | ❌ | ✅ | ❌ | ❌ |
| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| ERNIE | ❌ | ❌ | ✅ | ❌ | ❌ |
| ErnieM | ✅ | ❌ | ✅ | ❌ | ❌ |
| ESM | ✅ | ❌ | ✅ | ✅ | ❌ |
| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
| FLAVA | ❌ | ❌ | ✅ | ❌ | ❌ |
| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
| FocalNet | ❌ | ❌ | ✅ | ❌ | ❌ |
| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| GIT | ❌ | ❌ | ✅ | ❌ | ❌ |
| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
| GPT NeoX Japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
| GPT-Sw3 | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPTBigCode | ❌ | ❌ | ✅ | ❌ | ❌ |
| GPTSAN-japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
| Graphormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| GroupViT | ❌ | ❌ | ✅ | ✅ | ❌ |
| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Informer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Jukebox | ✅ | ❌ | ✅ | ❌ | ❌ |
| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
| LiLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| LLaMA | ✅ | ✅ | ✅ | ❌ | ❌ |
| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| LongT5 | ❌ | ❌ | ✅ | ❌ | ✅ |
| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| M-CTC-T | ❌ | ❌ | ✅ | ❌ | ❌ |
| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
| MarkupLM | ✅ | ✅ | ✅ | ❌ | ❌ |
| Mask2Former | ❌ | ❌ | ✅ | ❌ | ❌ |
| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| MaskFormerSwin | ❌ | ❌ | ❌ | ❌ | ❌ |
| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
| MEGA | ❌ | ❌ | ✅ | ❌ | ❌ |
| Megatron-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| MGP-STR | ✅ | ❌ | ✅ | ❌ | ❌ |
| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| MobileNetV1 | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileNetV2 | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileViT | ❌ | ❌ | ✅ | ✅ | ❌ |
| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| MT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| MVP | ✅ | ✅ | ✅ | ❌ | ❌ |
| NAT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Nezha | ❌ | ❌ | ✅ | ❌ | ❌ |
| NLLB-MOE | ❌ | ❌ | ✅ | ❌ | ❌ |
| Nyströmformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| OneFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| OpenLlama | ❌ | ❌ | ✅ | ❌ | ❌ |
| OPT | ❌ | ❌ | ✅ | ✅ | ✅ |
| OWL-ViT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
| PEGASUS-X | ❌ | ❌ | ✅ | ❌ | ❌ |
| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
| Pix2Struct | ❌ | ❌ | ✅ | ❌ | ❌ |
| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
| REALM | ✅ | ✅ | ✅ | ❌ | ❌ |
| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ResNet | ❌ | ❌ | ✅ | ✅ | ✅ |
| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| RoBERTa-PreLayerNorm | ❌ | ❌ | ✅ | ✅ | ✅ |
| RoCBert | ✅ | ❌ | ✅ | ❌ | ❌ |
| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
| RWKV | ❌ | ❌ | ✅ | ❌ | ❌ |
| SAM | ❌ | ❌ | ✅ | ✅ | ❌ |
| SegFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
| SpeechT5 | ✅ | ❌ | ✅ | ❌ | ❌ |
| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| SwiftFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Swin Transformer | ❌ | ❌ | ✅ | ✅ | ❌ |
| Swin Transformer V2 | ❌ | ❌ | ✅ | ❌ | ❌ |
| Swin2SR | ❌ | ❌ | ✅ | ❌ | ❌ |
| SwitchTransformers | ❌ | ❌ | ✅ | ❌ | ❌ |
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Table Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
| Time Series Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| TimeSformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
| TVLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| TVP | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
| UPerNet | ❌ | ❌ | ✅ | ❌ | ❌ |
| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
| VideoMAE | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| VisionTextDualEncoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| VisualBERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
| ViT Hybrid | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
| ViTMSN | ❌ | ❌ | ✅ | ❌ | ❌ |
| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
| Whisper | ✅ | ✅ | ✅ | ✅ | ✅ |
| X-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| X-MOD | ❌ | ❌ | ✅ | ❌ | ❌ |
| XGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
| XLM-ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
<!-- Tamat -->
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/multilingual.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 用于推理的多语言模型
[[open-in-colab]]
🤗 Transformers 中有多种多语言模型,它们的推理用法与单语言模型不同。但是,并非*所有*的多语言模型用法都不同。一些模型,例如 [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) 就可以像单语言模型一样使用。本指南将向您展示如何使用不同用途的多语言模型进行推理。
## XLM
XLM 有十个不同的检查点,其中只有一个是单语言的。剩下的九个检查点可以归为两类:使用语言嵌入的检查点和不使用语言嵌入的检查点。
### 带有语言嵌入的 XLM
以下 XLM 模型使用语言嵌入来指定推理中使用的语言:
- `xlm-mlm-ende-1024` (掩码语言建模,英语-德语)
- `xlm-mlm-enfr-1024` (掩码语言建模,英语-法语)
- `xlm-mlm-enro-1024` (掩码语言建模,英语-罗马尼亚语)
- `xlm-mlm-xnli15-1024` (掩码语言建模,XNLI 数据集语言)
- `xlm-mlm-tlm-xnli15-1024` (掩码语言建模+翻译,XNLI 数据集语言)
- `xlm-clm-enfr-1024` (因果语言建模,英语-法语)
- `xlm-clm-ende-1024` (因果语言建模,英语-德语)
语言嵌入被表示一个张量,其形状与传递给模型的 `input_ids` 相同。这些张量中的值取决于所使用的语言,并由分词器的 `lang2id` 和 `id2lang` 属性识别。
在此示例中,加载 `xlm-clm-enfr-1024` 检查点(因果语言建模,英语-法语):
```py
>>> import torch
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
```
分词器的 `lang2id` 属性显示了该模型的语言及其对应的id:
```py
>>> print(tokenizer.lang2id)
{'en': 0, 'fr': 1}
```
接下来,创建一个示例输入:
```py
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size 为 1
```
将语言 id 设置为 `"en"` 并用其定义语言嵌入。语言嵌入是一个用 `0` 填充的张量,这个张量应该与 `input_ids` 大小相同。
```py
>>> language_id = tokenizer.lang2id["en"] # 0
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
>>> # 我们将其 reshape 为 (batch_size, sequence_length) 大小
>>> langs = langs.view(1, -1) # 现在的形状是 [1, sequence_length] (我们的 batch size 为 1)
```
现在,你可以将 `input_ids` 和语言嵌入传递给模型:
```py
>>> outputs = model(input_ids, langs=langs)
```
[run_generation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation/run_generation.py) 脚本可以使用 `xlm-clm` 检查点生成带有语言嵌入的文本。
### 不带语言嵌入的 XLM
以下 XLM 模型在推理时不需要语言嵌入:
- `xlm-mlm-17-1280` (掩码语言建模,支持 17 种语言)
- `xlm-mlm-100-1280` (掩码语言建模,支持 100 种语言)
与之前的 XLM 检查点不同,这些模型用于通用句子表示。
## BERT
以下 BERT 模型可用于多语言任务:
- `bert-base-multilingual-uncased` (掩码语言建模 + 下一句预测,支持 102 种语言)
- `bert-base-multilingual-cased` (掩码语言建模 + 下一句预测,支持 104 种语言)
这些模型在推理时不需要语言嵌入。它们应该能够从上下文中识别语言并进行相应的推理。
## XLM-RoBERTa
以下 XLM-RoBERTa 模型可用于多语言任务:
- `xlm-roberta-base` (掩码语言建模,支持 100 种语言)
- `xlm-roberta-large` (掩码语言建模,支持 100 种语言)
XLM-RoBERTa 使用 100 种语言的 2.5TB 新创建和清理的 CommonCrawl 数据进行了训练。与之前发布的 mBERT 或 XLM 等多语言模型相比,它在分类、序列标记和问答等下游任务上提供了更强大的优势。
## M2M100
以下 M2M100 模型可用于多语言翻译:
- `facebook/m2m100_418M` (翻译)
- `facebook/m2m100_1.2B` (翻译)
在此示例中,加载 `facebook/m2m100_418M` 检查点以将中文翻译为英文。你可以在分词器中设置源语言:
```py
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
```
对文本进行分词:
```py
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
```
M2M100 强制将目标语言 id 作为第一个生成的标记,以进行到目标语言的翻译。在 `generate` 方法中将 `forced_bos_token_id` 设置为 `en` 以翻译成英语:
```py
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
```
## MBart
以下 MBart 模型可用于多语言翻译:
- `facebook/mbart-large-50-one-to-many-mmt` (一对多多语言机器翻译,支持 50 种语言)
- `facebook/mbart-large-50-many-to-many-mmt` (多对多多语言机器翻译,支持 50 种语言)
- `facebook/mbart-large-50-many-to-one-mmt` (多对一多语言机器翻译,支持 50 种语言)
- `facebook/mbart-large-50` (多语言翻译,支持 50 种语言)
- `facebook/mbart-large-cc25`
在此示例中,加载 `facebook/mbart-large-50-many-to-many-mmt` 检查点以将芬兰语翻译为英语。 你可以在分词器中设置源语言:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
```
对文本进行分词:
```py
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
```
MBart 强制将目标语言 id 作为第一个生成的标记,以进行到目标语言的翻译。在 `generate` 方法中将 `forced_bos_token_id` 设置为 `en` 以翻译成英语:
```py
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
```
如果你使用的是 `facebook/mbart-large-50-many-to-one-mmt` 检查点,则无需强制目标语言 id 作为第一个生成的令牌,否则用法是相同的。
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/tflite.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 导出为 TFLite
[TensorFlow Lite](https://www.tensorflow.org/lite/guide) 是一个轻量级框架,用于资源受限的设备上,如手机、嵌入式系统和物联网(IoT)设备,部署机器学习模型。TFLite 旨在在计算能力、内存和功耗有限的设备上优化和高效运行模型。模型以一种特殊的高效可移植格式表示,其文件扩展名为 `.tflite`。
🤗 Optimum 通过 `exporters.tflite` 模块提供将 🤗 Transformers 模型导出至 TFLite 格式的功能。请参考 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/exporters/tflite/overview) 以获取支持的模型架构列表。
要将模型导出为 TFLite 格式,请安装所需的依赖项:
```bash
pip install optimum[exporters-tf]
```
请参阅 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/main/en/exporters/tflite/usage_guides/export_a_model) 以查看所有可用参数,或者在命令行中查看帮助:
```bash
optimum-cli export tflite --help
```
运行以下命令,以从 🤗 Hub 导出模型的检查点(checkpoint),以 `bert-base-uncased` 为例:
```bash
optimum-cli export tflite --model bert-base-uncased --sequence_length 128 bert_tflite/
```
你应该能在日志中看到导出进度以及生成的 `model.tflite` 文件的保存位置,如下所示:
```bash
Validating TFLite model...
-[✓] TFLite model output names match reference model (logits)
- Validating TFLite Model output "logits":
-[✓] (1, 128, 30522) matches (1, 128, 30522)
-[x] values not close enough, max diff: 5.817413330078125e-05 (atol: 1e-05)
The TensorFlow Lite export succeeded with the warning: The maximum absolute difference between the output of the reference model and the TFLite exported model is not within the set tolerance 1e-05:
- logits: max diff = 5.817413330078125e-05.
The exported model was saved at: bert_tflite
```
上面的示例说明了从 🤗 Hub 导出检查点的过程。导出本地模型时,首先需要确保将模型的权重和分词器文件保存在同一目录(`local_path`)中。在使用 CLI(命令行)时,将 `local_path` 传递给 `model` 参数,而不是 🤗 Hub 上的检查点名称。
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/preprocessing.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 预处理
[[open-in-colab]]
在您可以在数据集上训练模型之前,数据需要被预处理为期望的模型输入格式。无论您的数据是文本、图像还是音频,它们都需要被转换并组合成批量的张量。🤗 Transformers 提供了一组预处理类来帮助准备数据以供模型使用。在本教程中,您将了解以下内容:
* 对于文本,使用[分词器](./main_classes/tokenizer)(`Tokenizer`)将文本转换为一系列标记(`tokens`),并创建`tokens`的数字表示,将它们组合成张量。
* 对于语音和音频,使用[特征提取器](./main_classes/feature_extractor)(`Feature extractor`)从音频波形中提取顺序特征并将其转换为张量。
* 图像输入使用[图像处理器](./main_classes/image)(`ImageProcessor`)将图像转换为张量。
* 多模态输入,使用[处理器](./main_classes/processors)(`Processor`)结合了`Tokenizer`和`ImageProcessor`或`Processor`。
<Tip>
`AutoProcessor` **始终**有效的自动选择适用于您使用的模型的正确`class`,无论您使用的是`Tokenizer`、`ImageProcessor`、`Feature extractor`还是`Processor`。
</Tip>
在开始之前,请安装🤗 Datasets,以便您可以加载一些数据集来进行实验:
```bash
pip install datasets
```
## 自然语言处理
<Youtube id="Yffk5aydLzg"/>
处理文本数据的主要工具是[Tokenizer](main_classes/tokenizer)。`Tokenizer`根据一组规则将文本拆分为`tokens`。然后将这些`tokens`转换为数字,然后转换为张量,成为模型的输入。模型所需的任何附加输入都由`Tokenizer`添加。
<Tip>
如果您计划使用预训练模型,重要的是使用与之关联的预训练`Tokenizer`。这确保文本的拆分方式与预训练语料库相同,并在预训练期间使用相同的标记-索引的对应关系(通常称为*词汇表*-`vocab`)。
</Tip>
开始使用[`AutoTokenizer.from_pretrained`]方法加载一个预训练`tokenizer`。这将下载模型预训练的`vocab`:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
```
然后将您的文本传递给`tokenizer`:
```py
>>> encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
>>> print(encoded_input)
{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
`tokenizer`返回一个包含三个重要对象的字典:
* [input_ids](glossary#input-ids) 是与句子中每个`token`对应的索引。
* [attention_mask](glossary#attention-mask) 指示是否应该关注一个`toekn`。
* [token_type_ids](glossary#token-type-ids) 在存在多个序列时标识一个`token`属于哪个序列。
通过解码 `input_ids` 来返回您的输入:
```py
>>> tokenizer.decode(encoded_input["input_ids"])
'[CLS] Do not meddle in the affairs of wizards, for they are subtle and quick to anger. [SEP]'
```
如您所见,`tokenizer`向句子中添加了两个特殊`token` - `CLS` 和 `SEP`(分类器和分隔符)。并非所有模型都需要特殊`token`,但如果需要,`tokenizer`会自动为您添加。
如果有多个句子需要预处理,将它们作为列表传递给`tokenizer`:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_inputs = tokenizer(batch_sentences)
>>> print(encoded_inputs)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1]]}
```
### 填充
句子的长度并不总是相同,这可能会成为一个问题,因为模型输入的张量需要具有统一的形状。填充是一种策略,通过在较短的句子中添加一个特殊的`padding token`,以确保张量是矩形的。
将 `padding` 参数设置为 `True`,以使批次中较短的序列填充到与最长序列相匹配的长度:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
第一句和第三句因为较短,通过`0`进行填充,。
### 截断
另一方面,有时候一个序列可能对模型来说太长了。在这种情况下,您需要将序列截断为更短的长度。
将 `truncation` 参数设置为 `True`,以将序列截断为模型接受的最大长度:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
<Tip>
查看[填充和截断](./pad_truncation)概念指南,了解更多有关填充和截断参数的信息。
</Tip>
### 构建张量
最后,`tokenizer`可以返回实际输入到模型的张量。
将 `return_tensors` 参数设置为 `pt`(对于PyTorch)或 `tf`(对于TensorFlow):
<frameworkcontent>
<pt>
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
>>> print(encoded_input)
{'input_ids': tensor([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
```
</pt>
<tf>
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
>>> print(encoded_input)
{'input_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=int32)>,
'token_type_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>,
'attention_mask': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>}
```
</tf>
</frameworkcontent>
## 音频
对于音频任务,您需要[feature extractor](main_classes/feature_extractor)来准备您的数据集以供模型使用。`feature extractor`旨在从原始音频数据中提取特征,并将它们转换为张量。
加载[MInDS-14](https://huggingface.co/datasets/PolyAI/minds14)数据集(有关如何加载数据集的更多详细信息,请参阅🤗 [Datasets教程](https://huggingface.co/docs/datasets/load_hub))以了解如何在音频数据集中使用`feature extractor`:
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
```
访问 `audio` 列的第一个元素以查看输入。调用 `audio` 列会自动加载和重新采样音频文件:
```py
>>> dataset[0]["audio"]
{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0. , 0. ], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 8000}
```
这会返回三个对象:
* `array` 是加载的语音信号 - 并在必要时重新采为`1D array`。
* `path` 指向音频文件的位置。
* `sampling_rate` 是每秒测量的语音信号数据点数量。
对于本教程,您将使用[Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base)模型。查看模型卡片,您将了解到Wav2Vec2是在16kHz采样的语音音频数据上预训练的。重要的是,您的音频数据的采样率要与用于预训练模型的数据集的采样率匹配。如果您的数据的采样率不同,那么您需要对数据进行重新采样。
1. 使用🤗 Datasets的[`~datasets.Dataset.cast_column`]方法将采样率提升到16kHz:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
```
2. 再次调用 `audio` 列以重新采样音频文件:
```py
>>> dataset[0]["audio"]
{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ...,
3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 16000}
```
接下来,加载一个`feature extractor`以对输入进行标准化和填充。当填充文本数据时,会为较短的序列添加 `0`。相同的理念适用于音频数据。`feature extractor`添加 `0` - 被解释为静音 - 到`array` 。
使用 [`AutoFeatureExtractor.from_pretrained`] 加载`feature extractor`:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
```
将音频 `array` 传递给`feature extractor`。我们还建议在`feature extractor`中添加 `sampling_rate` 参数,以更好地调试可能发生的静音错误:
```py
>>> audio_input = [dataset[0]["audio"]["array"]]
>>> feature_extractor(audio_input, sampling_rate=16000)
{'input_values': [array([ 3.8106556e-04, 2.7506407e-03, 2.8015103e-03, ...,
5.6335266e-04, 4.6588284e-06, -1.7142107e-04], dtype=float32)]}
```
就像`tokenizer`一样,您可以应用填充或截断来处理批次中的可变序列。请查看这两个音频样本的序列长度:
```py
>>> dataset[0]["audio"]["array"].shape
(173398,)
>>> dataset[1]["audio"]["array"].shape
(106496,)
```
创建一个函数来预处理数据集,以使音频样本具有相同的长度。通过指定最大样本长度,`feature extractor`将填充或截断序列以使其匹配:
```py
>>> def preprocess_function(examples):
... audio_arrays = [x["array"] for x in examples["audio"]]
... inputs = feature_extractor(
... audio_arrays,
... sampling_rate=16000,
... padding=True,
... max_length=100000,
... truncation=True,
... )
... return inputs
```
将`preprocess_function`应用于数据集中的前几个示例:
```py
>>> processed_dataset = preprocess_function(dataset[:5])
```
现在样本长度是相同的,并且与指定的最大长度匹配。您现在可以将经过处理的数据集传递给模型了!
```py
>>> processed_dataset["input_values"][0].shape
(100000,)
>>> processed_dataset["input_values"][1].shape
(100000,)
```
## 计算机视觉
对于计算机视觉任务,您需要一个[ image processor](main_classes/image_processor)来准备数据集以供模型使用。图像预处理包括多个步骤将图像转换为模型期望输入的格式。这些步骤包括但不限于调整大小、标准化、颜色通道校正以及将图像转换为张量。
<Tip>
图像预处理通常遵循某种形式的图像增强。图像预处理和图像增强都会改变图像数据,但它们有不同的目的:
* 图像增强可以帮助防止过拟合并增加模型的鲁棒性。您可以在数据增强方面充分发挥创造性 - 调整亮度和颜色、裁剪、旋转、调整大小、缩放等。但要注意不要改变图像的含义。
* 图像预处理确保图像与模型预期的输入格式匹配。在微调计算机视觉模型时,必须对图像进行与模型训练时相同的预处理。
您可以使用任何您喜欢的图像增强库。对于图像预处理,请使用与模型相关联的`ImageProcessor`。
</Tip>
加载[food101](https://huggingface.co/datasets/food101)数据集(有关如何加载数据集的更多详细信息,请参阅🤗 [Datasets教程](https://huggingface.co/docs/datasets/load_hub))以了解如何在计算机视觉数据集中使用图像处理器:
<Tip>
因为数据集相当大,请使用🤗 Datasets的`split`参数加载训练集中的少量样本!
</Tip>
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("food101", split="train[:100]")
```
接下来,使用🤗 Datasets的[`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image)功能查看图像:
```py
>>> dataset[0]["image"]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/vision-preprocess-tutorial.png"/>
</div>
使用 [`AutoImageProcessor.from_pretrained`] 加载`image processor`:
```py
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
```
首先,让我们进行图像增强。您可以使用任何您喜欢的库,但在本教程中,我们将使用torchvision的[`transforms`](https://pytorch.org/vision/stable/transforms.html)模块。如果您有兴趣使用其他数据增强库,请参阅[Albumentations](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb)或[Kornia notebooks](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb)中的示例。
1. 在这里,我们使用[`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html)将[`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html)和 [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html)变换连接在一起。请注意,对于调整大小,我们可以从`image_processor`中获取图像尺寸要求。对于一些模型,精确的高度和宽度需要被定义,对于其他模型只需定义`shortest_edge`。
```py
>>> from torchvision.transforms import RandomResizedCrop, ColorJitter, Compose
>>> size = (
... image_processor.size["shortest_edge"]
... if "shortest_edge" in image_processor.size
... else (image_processor.size["height"], image_processor.size["width"])
... )
>>> _transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5)])
```
2. 模型接受 [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values) 作为输入。`ImageProcessor` 可以进行图像的标准化,并生成适当的张量。创建一个函数,将图像增强和图像预处理步骤组合起来处理批量图像,并生成 `pixel_values`:
```py
>>> def transforms(examples):
... images = [_transforms(img.convert("RGB")) for img in examples["image"]]
... examples["pixel_values"] = image_processor(images, do_resize=False, return_tensors="pt")["pixel_values"]
... return examples
```
<Tip>
在上面的示例中,我们设置`do_resize=False`,因为我们已经在图像增强转换中调整了图像的大小,并利用了适当的`image_processor`的`size`属性。如果您在图像增强期间不调整图像的大小,请将此参数排除在外。默认情况下`ImageProcessor`将处理调整大小。
如果希望将图像标准化步骤为图像增强的一部分,请使用`image_processor.image_mean`和`image_processor.image_std`。
</Tip>
3. 然后使用🤗 Datasets的[`set_transform`](https://huggingface.co/docs/datasets/process#format-transform)在运行时应用这些变换:
```py
>>> dataset.set_transform(transforms)
```
4. 现在,当您访问图像时,您将注意到`image processor`已添加了 `pixel_values`。您现在可以将经过处理的数据集传递给模型了!
```py
>>> dataset[0].keys()
```
这是在应用变换后的图像样子。图像已被随机裁剪,并其颜色属性发生了变化。
```py
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> img = dataset[0]["pixel_values"]
>>> plt.imshow(img.permute(1, 2, 0))
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/preprocessed_image.png"/>
</div>
<Tip>
对于诸如目标检测、语义分割、实例分割和全景分割等任务,`ImageProcessor`提供了训练后处理方法。这些方法将模型的原始输出转换为有意义的预测,如边界框或分割地图。
</Tip>
### 填充
在某些情况下,例如,在微调[DETR](./model_doc/detr)时,模型在训练时应用了尺度增强。这可能导致批处理中的图像大小不同。您可以使用[`DetrImageProcessor.pad`]来指定自定义的`collate_fn`将图像批处理在一起。
```py
>>> def collate_fn(batch):
... pixel_values = [item["pixel_values"] for item in batch]
... encoding = image_processor.pad(pixel_values, return_tensors="pt")
... labels = [item["labels"] for item in batch]
... batch = {}
... batch["pixel_values"] = encoding["pixel_values"]
... batch["pixel_mask"] = encoding["pixel_mask"]
... batch["labels"] = labels
... return batch
```
## 多模态
对于涉及多模态输入的任务,您需要[processor](main_classes/processors)来为模型准备数据集。`processor`将两个处理对象-例如`tokenizer`和`feature extractor`-组合在一起。
加载[LJ Speech](https://huggingface.co/datasets/lj_speech)数据集(有关如何加载数据集的更多详细信息,请参阅🤗 [Datasets 教程](https://huggingface.co/docs/datasets/load_hub))以了解如何使用`processor`进行自动语音识别(ASR):
```py
>>> from datasets import load_dataset
>>> lj_speech = load_dataset("lj_speech", split="train")
```
对于ASR(自动语音识别),主要关注`audio`和`text`,因此可以删除其他列:
```py
>>> lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
```
现在查看`audio`和`text`列:
```py
>>> lj_speech[0]["audio"]
{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
'sampling_rate': 22050}
>>> lj_speech[0]["text"]
'Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition'
```
请记住,您应始终[重新采样](preprocessing#audio)音频数据集的采样率,以匹配用于预训练模型数据集的采样率!
```py
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
```
使用[`AutoProcessor.from_pretrained`]加载一个`processor`:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
```
1. 创建一个函数,用于将包含在 `array` 中的音频数据处理为 `input_values`,并将 `text` 标记为 `labels`。这些将是输入模型的数据:
```py
>>> def prepare_dataset(example):
... audio = example["audio"]
... example.update(processor(audio=audio["array"], text=example["text"], sampling_rate=16000))
... return example
```
2. 将 `prepare_dataset` 函数应用于一个示例:
```py
>>> prepare_dataset(lj_speech[0])
```
`processor`现在已经添加了 `input_values` 和 `labels`,并且采样率也正确降低为为16kHz。现在可以将处理后的数据集传递给模型!
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/model_sharing.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 分享模型
最后两个教程展示了如何使用PyTorch、Keras和 🤗 Accelerate进行分布式设置来微调模型。下一步是将您的模型与社区分享!在Hugging Face,我们相信公开分享知识和资源,能实现人工智能的普及化,让每个人都能受益。我们鼓励您将您的模型与社区分享,以帮助他人节省时间和精力。
在本教程中,您将学习两种在[Model Hub](https://huggingface.co/models)上共享训练好的或微调的模型的方法:
- 通过编程将文件推送到Hub。
- 使用Web界面将文件拖放到Hub。
<iframe width="560" height="315" src="https://www.youtube.com/embed/XvSGPZFEjDY" title="YouTube video player"
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
picture-in-picture" allowfullscreen></iframe>
<Tip>
要与社区共享模型,您需要在[huggingface.co](https://huggingface.co/join)上拥有一个帐户。您还可以加入现有的组织或创建一个新的组织。
</Tip>
## 仓库功能
Model Hub上的每个仓库都像是一个典型的GitHub仓库。我们的仓库提供版本控制、提交历史记录以及可视化差异的能力。
Model Hub的内置版本控制基于git和[git-lfs](https://git-lfs.github.com/)。换句话说,您可以将一个模型视为一个仓库,从而实现更好的访问控制和可扩展性。版本控制允许使用*修订*方法来固定特定版本的模型,可以使用提交哈希值、标签或分支来标记。
因此,您可以通过`revision`参数加载特定的模型版本:
```py
>>> model = AutoModel.from_pretrained(
... "julien-c/EsperBERTo-small", revision="v2.0.1" # tag name, or branch name, or commit hash
... )
```
文件也可以轻松地在仓库中编辑,您可以查看提交历史记录以及差异:

## 设置
在将模型共享到Hub之前,您需要拥有Hugging Face的凭证。如果您有访问终端的权限,请在安装🤗 Transformers的虚拟环境中运行以下命令。这将在您的Hugging Face缓存文件夹(默认为`~/.cache/`)中存储您的`access token`:
```bash
huggingface-cli login
```
如果您正在使用像Jupyter或Colaboratory这样的`notebook`,请确保您已安装了[`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library)库。该库允许您以编程方式与Hub进行交互。
```bash
pip install huggingface_hub
```
然后使用`notebook_login`登录到Hub,并按照[这里](https://huggingface.co/settings/token)的链接生成一个token进行登录:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## 转换模型适用于所有框架
为确保您的模型可以被使用不同框架的人使用,我们建议您将PyTorch和TensorFlow `checkpoints`都转换并上传。如果您跳过此步骤,用户仍然可以从其他框架加载您的模型,但速度会变慢,因为🤗 Transformers需要实时转换`checkpoints`。
为另一个框架转换`checkpoints`很容易。确保您已安装PyTorch和TensorFlow(请参阅[此处](installation)的安装说明),然后在其他框架中找到适合您任务的特定模型。
<frameworkcontent>
<pt>
指定`from_tf=True`将checkpoint从TensorFlow转换为PyTorch。
```py
>>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
>>> pt_model.save_pretrained("path/to/awesome-name-you-picked")
```
</pt>
<tf>
指定`from_pt=True`将checkpoint从PyTorch转换为TensorFlow。
```py
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)
```
然后,您可以使用新的checkpoint保存您的新TensorFlow模型:
```py
>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")
```
</tf>
<jax>
如果模型在Flax中可用,您还可以将PyTorch checkpoint转换为Flax:
```py
>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
... "path/to/awesome-name-you-picked", from_pt=True
... )
```
</jax>
</frameworkcontent>
## 在训练过程中推送模型
<frameworkcontent>
<pt>
<Youtube id="Z1-XMy-GNLQ"/>
将模型分享到Hub就像添加一个额外的参数或回调函数一样简单。请记住,在[微调教程](training)中,`TrainingArguments`类是您指定超参数和附加训练选项的地方。其中一项训练选项包括直接将模型推送到Hub的能力。在您的`TrainingArguments`中设置`push_to_hub=True`:
```py
>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)
```
像往常一样将您的训练参数传递给[`Trainer`]:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
在您微调完模型后,在[`Trainer`]上调用[`~transformers.Trainer.push_to_hub`]将训练好的模型推送到Hub。🤗 Transformers甚至会自动将训练超参数、训练结果和框架版本添加到你的模型卡片中!
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
使用[`PushToHubCallback`]将模型分享到Hub。在[`PushToHubCallback`]函数中,添加以下内容:
- 一个用于存储模型的输出目录。
- 一个tokenizer。
- `hub_model_id`,即您的Hub用户名和模型名称。
```py
>>> from transformers import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="./your_model_save_path", tokenizer=tokenizer, hub_model_id="your-username/my-awesome-model"
... )
```
将回调函数添加到 [`fit`](https://keras.io/api/models/model_training_apis/)中,然后🤗 Transformers 会将训练好的模型推送到 Hub:
```py
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
```
</tf>
</frameworkcontent>
## 使用`push_to_hub`功能
您可以直接在您的模型上调用`push_to_hub`来将其上传到Hub。
在`push_to_hub`中指定你的模型名称:
```py
>>> pt_model.push_to_hub("my-awesome-model")
```
这会在您的用户名下创建一个名为`my-awesome-model`的仓库。用户现在可以使用`from_pretrained`函数加载您的模型:
```py
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
```
如果您属于一个组织,并希望将您的模型推送到组织名称下,只需将其添加到`repo_id`中:
```py
>>> pt_model.push_to_hub("my-awesome-org/my-awesome-model")
```
`push_to_hub`函数还可以用于向模型仓库添加其他文件。例如,向模型仓库中添加一个`tokenizer`:
```py
>>> tokenizer.push_to_hub("my-awesome-model")
```
或者,您可能希望将您的微调后的PyTorch模型的TensorFlow版本添加进去:
```py
>>> tf_model.push_to_hub("my-awesome-model")
```
现在,当您导航到您的Hugging Face个人资料时,您应该看到您新创建的模型仓库。点击**文件**选项卡将显示您已上传到仓库的所有文件。
有关如何创建和上传文件到仓库的更多详细信息,请参考Hub文档[这里](https://huggingface.co/docs/hub/how-to-upstream)。
## 使用Web界面上传
喜欢无代码方法的用户可以通过Hugging Face的Web界面上传模型。访问[huggingface.co/new](https://huggingface.co/new)创建一个新的仓库:

从这里开始,添加一些关于您的模型的信息:
- 选择仓库的**所有者**。这可以是您本人或者您所属的任何组织。
- 为您的项目选择一个名称,该名称也将成为仓库的名称。
- 选择您的模型是公开还是私有。
- 指定您的模型的许可证使用情况。
现在点击**文件**选项卡,然后点击**添加文件**按钮将一个新文件上传到你的仓库。接着拖放一个文件进行上传,并添加提交信息。

## 添加模型卡片
为了确保用户了解您的模型的能力、限制、潜在偏差和伦理考虑,请在仓库中添加一个模型卡片。模型卡片在`README.md`文件中定义。你可以通过以下方式添加模型卡片:
* 手动创建并上传一个`README.md`文件。
* 在你的模型仓库中点击**编辑模型卡片**按钮。
可以参考DistilBert的[模型卡片](https://huggingface.co/distilbert-base-uncased)来了解模型卡片应该包含的信息类型。有关您可以在`README.md`文件中控制的更多选项的细节,例如模型的碳足迹或小部件示例,请参考文档[这里](https://huggingface.co/docs/hub/models-cards)。
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/create_a_model.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 创建自定义架构
[`AutoClass`](model_doc/auto) 自动推断模型架构并下载预训练的配置和权重。一般来说,我们建议使用 `AutoClass` 生成与检查点(checkpoint)无关的代码。希望对特定模型参数有更多控制的用户,可以仅从几个基类创建自定义的 🤗 Transformers 模型。这对于任何有兴趣学习、训练或试验 🤗 Transformers 模型的人可能特别有用。通过本指南,深入了解如何不通过 `AutoClass` 创建自定义模型。了解如何:
- 加载并自定义模型配置。
- 创建模型架构。
- 为文本创建慢速和快速分词器。
- 为视觉任务创建图像处理器。
- 为音频任务创建特征提取器。
- 为多模态任务创建处理器。
## 配置
[配置](main_classes/configuration) 涉及到模型的具体属性。每个模型配置都有不同的属性;例如,所有 NLP 模型都共享 `hidden_size`、`num_attention_heads`、 `num_hidden_layers` 和 `vocab_size` 属性。这些属性用于指定构建模型时的注意力头数量或隐藏层层数。
访问 [`DistilBertConfig`] 以更近一步了解 [DistilBERT](model_doc/distilbert),检查它的属性:
```py
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
[`DistilBertConfig`] 显示了构建基础 [`DistilBertModel`] 所使用的所有默认属性。所有属性都可以进行自定义,为实验创造了空间。例如,您可以将默认模型自定义为:
- 使用 `activation` 参数尝试不同的激活函数。
- 使用 `attention_dropout` 参数为 attention probabilities 使用更高的 dropout ratio。
```py
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
预训练模型的属性可以在 [`~PretrainedConfig.from_pretrained`] 函数中进行修改:
```py
>>> my_config = DistilBertConfig.from_pretrained("distilbert-base-uncased", activation="relu", attention_dropout=0.4)
```
当你对模型配置满意时,可以使用 [`~PretrainedConfig.save_pretrained`] 来保存配置。你的配置文件将以 JSON 文件的形式存储在指定的保存目录中:
```py
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
```
要重用配置文件,请使用 [`~PretrainedConfig.from_pretrained`] 进行加载:
```py
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
```
<Tip>
你还可以将配置文件保存为字典,甚至只保存自定义配置属性与默认配置属性之间的差异!有关更多详细信息,请参阅 [配置](main_classes/configuration) 文档。
</Tip>
## 模型
接下来,创建一个[模型](main_classes/models)。模型,也可泛指架构,定义了每一层网络的行为以及进行的操作。配置中的 `num_hidden_layers` 等属性用于定义架构。每个模型都共享基类 [`PreTrainedModel`] 和一些常用方法,例如调整输入嵌入的大小和修剪自注意力头。此外,所有模型都是 [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html)、[`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) 或 [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html) 的子类。这意味着模型与各自框架的用法兼容。
<frameworkcontent>
<pt>
将自定义配置属性加载到模型中:
```py
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
>>> model = DistilBertModel(my_config)
```
这段代码创建了一个具有随机参数而不是预训练权重的模型。在训练该模型之前,您还无法将该模型用于任何用途。训练是一项昂贵且耗时的过程。通常来说,最好使用预训练模型来更快地获得更好的结果,同时仅使用训练所需资源的一小部分。
使用 [`~PreTrainedModel.from_pretrained`] 创建预训练模型:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased")
```
当加载预训练权重时,如果模型是由 🤗 Transformers 提供的,将自动加载默认模型配置。然而,如果你愿意,仍然可以将默认模型配置的某些或者所有属性替换成你自己的配置:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</pt>
<tf>
将自定义配置属性加载到模型中:
```py
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)
```
这段代码创建了一个具有随机参数而不是预训练权重的模型。在训练该模型之前,您还无法将该模型用于任何用途。训练是一项昂贵且耗时的过程。通常来说,最好使用预训练模型来更快地获得更好的结果,同时仅使用训练所需资源的一小部分。
使用 [`~TFPreTrainedModel.from_pretrained`] 创建预训练模型:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
```
当加载预训练权重时,如果模型是由 🤗 Transformers 提供的,将自动加载默认模型配置。然而,如果你愿意,仍然可以将默认模型配置的某些或者所有属性替换成自己的配置:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</tf>
</frameworkcontent>
### 模型头(Model heads)
此时,你已经有了一个输出*隐藏状态*的基础 DistilBERT 模型。隐藏状态作为输入传递到模型头以生成最终输出。🤗 Transformers 为每个任务提供不同的模型头,只要模型支持该任务(即,您不能使用 DistilBERT 来执行像翻译这样的序列到序列任务)。
<frameworkcontent>
<pt>
例如,[`DistilBertForSequenceClassification`] 是一个带有序列分类头(sequence classification head)的基础 DistilBERT 模型。序列分类头是池化输出之上的线性层。
```py
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
通过切换到不同的模型头,可以轻松地将此检查点重复用于其他任务。对于问答任务,你可以使用 [`DistilBertForQuestionAnswering`] 模型头。问答头(question answering head)与序列分类头类似,不同点在于它是隐藏状态输出之上的线性层。
```py
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</pt>
<tf>
例如,[`TFDistilBertForSequenceClassification`] 是一个带有序列分类头(sequence classification head)的基础 DistilBERT 模型。序列分类头是池化输出之上的线性层。
```py
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
通过切换到不同的模型头,可以轻松地将此检查点重复用于其他任务。对于问答任务,你可以使用 [`TFDistilBertForQuestionAnswering`] 模型头。问答头(question answering head)与序列分类头类似,不同点在于它是隐藏状态输出之上的线性层。
```py
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</tf>
</frameworkcontent>
## 分词器
在将模型用于文本数据之前,你需要的最后一个基类是 [tokenizer](main_classes/tokenizer),它用于将原始文本转换为张量。🤗 Transformers 支持两种类型的分词器:
- [`PreTrainedTokenizer`]:分词器的Python实现
- [`PreTrainedTokenizerFast`]:来自我们基于 Rust 的 [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) 库的分词器。因为其使用了 Rust 实现,这种分词器类型的速度要快得多,尤其是在批量分词(batch tokenization)的时候。快速分词器还提供其他的方法,例如*偏移映射(offset mapping)*,它将标记(token)映射到其原始单词或字符。
这两种分词器都支持常用的方法,如编码和解码、添加新标记以及管理特殊标记。
<Tip warning={true}>
并非每个模型都支持快速分词器。参照这张 [表格](index#supported-frameworks) 查看模型是否支持快速分词器。
</Tip>
如果您训练了自己的分词器,则可以从*词表*文件创建一个分词器:
```py
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
```
请务必记住,自定义分词器生成的词表与预训练模型分词器生成的词表是不同的。如果使用预训练模型,则需要使用预训练模型的词表,否则输入将没有意义。 使用 [`DistilBertTokenizer`] 类创建具有预训练模型词表的分词器:
```py
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
```
使用 [`DistilBertTokenizerFast`] 类创建快速分词器:
```py
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
```
<Tip>
默认情况下,[`AutoTokenizer`] 将尝试加载快速标记生成器。你可以通过在 `from_pretrained` 中设置 `use_fast=False` 以禁用此行为。
</Tip>
## 图像处理器
图像处理器用于处理视觉输入。它继承自 [`~image_processing_utils.ImageProcessingMixin`] 基类。
要使用它,需要创建一个与你使用的模型关联的图像处理器。例如,如果你使用 [ViT](model_doc/vit) 进行图像分类,可以创建一个默认的 [`ViTImageProcessor`]:
```py
>>> from transformers import ViTImageProcessor
>>> vit_extractor = ViTImageProcessor()
>>> print(vit_extractor)
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
<Tip>
如果您不需要进行任何自定义,只需使用 `from_pretrained` 方法加载模型的默认图像处理器参数。
</Tip>
修改任何 [`ViTImageProcessor`] 参数以创建自定义图像处理器:
```py
>>> from transformers import ViTImageProcessor
>>> my_vit_extractor = ViTImageProcessor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTImageProcessor {
"do_normalize": false,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}
```
## 特征提取器
特征提取器用于处理音频输入。它继承自 [`~feature_extraction_utils.FeatureExtractionMixin`] 基类,亦可继承 [`SequenceFeatureExtractor`] 类来处理音频输入。
要使用它,创建一个与你使用的模型关联的特征提取器。例如,如果你使用 [Wav2Vec2](model_doc/wav2vec2) 进行音频分类,可以创建一个默认的 [`Wav2Vec2FeatureExtractor`]:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
```
<Tip>
如果您不需要进行任何自定义,只需使用 `from_pretrained` 方法加载模型的默认特征提取器参数。
</Tip>
修改任何 [`Wav2Vec2FeatureExtractor`] 参数以创建自定义特征提取器:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor(sampling_rate=8000, do_normalize=False)
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": false,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 8000
}
```
## 处理器
对于支持多模式任务的模型,🤗 Transformers 提供了一个处理器类,可以方便地将特征提取器和分词器等处理类包装到单个对象中。例如,让我们使用 [`Wav2Vec2Processor`] 来执行自动语音识别任务 (ASR)。 ASR 将音频转录为文本,因此您将需要一个特征提取器和一个分词器。
创建一个特征提取器来处理音频输入:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
```
创建一个分词器来处理文本输入:
```py
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
```
将特征提取器和分词器合并到 [`Wav2Vec2Processor`] 中:
```py
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
通过两个基类 - 配置类和模型类 - 以及一个附加的预处理类(分词器、图像处理器、特征提取器或处理器),你可以创建 🤗 Transformers 支持的任何模型。 每个基类都是可配置的,允许你使用所需的特定属性。 你可以轻松设置模型进行训练或修改现有的预训练模型进行微调。
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/tf_xla.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 用于 TensorFlow 模型的 XLA 集成
[[open-in-colab]]
加速线性代数,也称为XLA,是一个用于加速TensorFlow模型运行时间的编译器。从[官方文档](https://www.tensorflow.org/xla)中可以看到:
XLA(加速线性代数)是一种针对线性代数的特定领域编译器,可以在可能不需要更改源代码的情况下加速TensorFlow模型。
在TensorFlow中使用XLA非常简单——它包含在`tensorflow`库中,并且可以使用任何图创建函数中的`jit_compile`参数来触发,例如[`tf.function`](https://www.tensorflow.org/guide/intro_to_graphs)。在使用Keras方法如`fit()`和`predict()`时,只需将`jit_compile`参数传递给`model.compile()`即可启用XLA。然而,XLA不仅限于这些方法 - 它还可以用于加速任何任意的`tf.function`。
在🤗 Transformers中,几个TensorFlow方法已经被重写为与XLA兼容,包括[GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)、[T5](https://huggingface.co/docs/transformers/model_doc/t5)和[OPT](https://huggingface.co/docs/transformers/model_doc/opt)等文本生成模型,以及[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)等语音处理模型。
虽然确切的加速倍数很大程度上取决于模型,但对于🤗 Transformers中的TensorFlow文本生成模型,我们注意到速度提高了约100倍。本文档将解释如何在这些模型上使用XLA获得最大的性能。如果您有兴趣了解更多关于基准测试和我们在XLA集成背后的设计哲学的信息,我们还将提供额外的资源链接。
## 使用 XLA 运行 TensorFlow 函数
让我们考虑以下TensorFlow 中的模型:
```py
import tensorflow as tf
model = tf.keras.Sequential(
[tf.keras.layers.Dense(10, input_shape=(10,), activation="relu"), tf.keras.layers.Dense(5, activation="softmax")]
)
```
上述模型接受维度为 `(10,)` 的输入。我们可以像下面这样使用模型进行前向传播:
```py
# Generate random inputs for the model.
batch_size = 16
input_vector_dim = 10
random_inputs = tf.random.normal((batch_size, input_vector_dim))
# Run a forward pass.
_ = model(random_inputs)
```
为了使用 XLA 编译的函数运行前向传播,我们需要执行以下操作:
```py
xla_fn = tf.function(model, jit_compile=True)
_ = xla_fn(random_inputs)
```
`model`的默认`call()`函数用于编译XLA图。但如果你想将其他模型函数编译成XLA,也是可以的,如下所示:
```py
my_xla_fn = tf.function(model.my_xla_fn, jit_compile=True)
```
## 在🤗 Transformers库中使用XLA运行TensorFlow文本生成模型
要在🤗 Transformers中启用XLA加速生成,您需要安装最新版本的`transformers`。您可以通过运行以下命令来安装它:
```bash
pip install transformers --upgrade
```
然后您可以运行以下代码:
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
# Will error if the minimal version of Transformers is not installed.
from transformers.utils import check_min_version
check_min_version("4.21.0")
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
# One line to create an XLA generation function
xla_generate = tf.function(model.generate, jit_compile=True)
tokenized_input = tokenizer(input_string, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
# Generated -- TensorFlow is an open-source, open-source, distributed-source application # framework for the
```
正如您所注意到的,在`generate()`上启用XLA只需要一行代码。其余部分代码保持不变。然而,上面的代码片段中有一些与XLA相关的注意事项。您需要了解这些注意事项,以充分利用XLA可能带来的性能提升。我们将在下面的部分讨论这些内容。
## 需要关注的注意事项
当您首次执行启用XLA的函数(如上面的`xla_generate()`)时,它将在内部尝试推断计算图,这是一个耗时的过程。这个过程被称为[“tracing”](https://www.tensorflow.org/guide/intro_to_graphs#when_is_a_function_tracing)。
您可能会注意到生成时间并不快。连续调用`xla_generate()`(或任何其他启用了XLA的函数)不需要再次推断计算图,只要函数的输入与最初构建计算图时的形状相匹配。对于具有固定输入形状的模态(例如图像),这不是问题,但如果您正在处理具有可变输入形状的模态(例如文本),则必须注意。
为了确保`xla_generate()`始终使用相同的输入形状,您可以在调用`tokenizer`时指定`padding`参数。
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
xla_generate = tf.function(model.generate, jit_compile=True)
# Here, we call the tokenizer with padding options.
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
```
通过这种方式,您可以确保`xla_generate()`的输入始终具有它跟踪的形状,从而加速生成时间。您可以使用以下代码来验证这一点:
```py
import time
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
xla_generate = tf.function(model.generate, jit_compile=True)
for input_string in ["TensorFlow is", "TensorFlow is a", "TFLite is a"]:
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
start = time.time_ns()
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
```
在Tesla T4 GPU上,您可以期望如下的输出:
```bash
Execution time -- 30819.6 ms
Execution time -- 79.0 ms
Execution time -- 78.9 ms
```
第一次调用`xla_generate()`会因为`tracing`而耗时,但后续的调用会快得多。请注意,任何时候对生成选项的更改都会触发重新`tracing`,从而导致生成时间减慢。
在本文档中,我们没有涵盖🤗 Transformers提供的所有文本生成选项。我们鼓励您阅读文档以了解高级用例。
## 附加资源
以下是一些附加资源,如果您想深入了解在🤗 Transformers和其他库下使用XLA:
* [这个Colab Notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/91_tf_xla_generate.ipynb) 提供了一个互动演示,让您可以尝试使用XLA兼容的编码器-解码器(例如[T5](https://huggingface.co/docs/transformers/model_doc/t5))和仅解码器(例如[GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2))文本生成模型。
* [这篇博客文章](https://huggingface.co/blog/tf-xla-generate) 提供了XLA兼容模型的比较基准概述,以及关于在TensorFlow中使用XLA的友好介绍。
* [这篇博客文章](https://blog.tensorflow.org/2022/11/how-hugging-face-improved-text-generation-performance-with-xla.html) 讨论了我们在🤗 Transformers中为TensorFlow模型添加XLA支持的设计理念。
* 推荐用于更多学习XLA和TensorFlow图的资源:
* [XLA:面向机器学习的优化编译器](https://www.tensorflow.org/xla)
* [图和tf.function简介](https://www.tensorflow.org/guide/intro_to_graphs)
* [使用tf.function获得更好的性能](https://www.tensorflow.org/guide/function)
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/installation.md
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 安装
为你正在使用的深度学习框架安装 🤗 Transformers、设置缓存,并选择性配置 🤗 Transformers 以离线运行。
🤗 Transformers 已在 Python 3.6+、PyTorch 1.1.0+、TensorFlow 2.0+ 以及 Flax 上进行测试。针对你使用的深度学习框架,请参照以下安装说明进行安装:
* [PyTorch](https://pytorch.org/get-started/locally/) 安装说明。
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) 安装说明。
* [Flax](https://flax.readthedocs.io/en/latest/) 安装说明。
## 使用 pip 安装
你应该使用 [虚拟环境](https://docs.python.org/3/library/venv.html) 安装 🤗 Transformers。如果你不熟悉 Python 虚拟环境,请查看此 [教程](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)。使用虚拟环境,你可以轻松管理不同项目,避免不同依赖项之间的兼容性问题。
首先,在项目目录中创建虚拟环境:
```bash
python -m venv .env
```
在 Linux 和 MacOs 系统中激活虚拟环境:
```bash
source .env/bin/activate
```
在 Windows 系统中激活虚拟环境:
```bash
.env/Scripts/activate
```
现在你可以使用以下命令安装 🤗 Transformers:
```bash
pip install transformers
```
若仅需 CPU 支持,可以使用单行命令方便地安装 🤗 Transformers 和深度学习库。例如,使用以下命令安装 🤗 Transformers 和 PyTorch:
```bash
pip install 'transformers[torch]'
```
🤗 Transformers 和 TensorFlow 2.0:
```bash
pip install 'transformers[tf-cpu]'
```
<Tip warning={true}>
M1 / ARM用户
在安装 TensorFlow 2.0 前,你需要安装以下库:
```
brew install cmake
brew install pkg-config
```
</Tip>
🤗 Transformers 和 Flax:
```bash
pip install 'transformers[flax]'
```
最后,运行以下命令以检查 🤗 Transformers 是否已被正确安装。该命令将下载一个预训练模型:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
然后打印标签以及分数:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## 源码安装
使用以下命令从源码安装 🤗 Transformers:
```bash
pip install git+https://github.com/huggingface/transformers
```
此命令下载的是最新的前沿 `main` 版本而不是最新的 `stable` 版本。`main` 版本适用于跟最新开发保持一致。例如,上次正式版发布带来的 bug 被修复了,但新版本尚未被推出。但是,这也说明 `main` 版本并不一定总是稳定的。我们努力保持 `main` 版本的可操作性,大多数问题通常在几个小时或一天以内就能被解决。如果你遇到问题,请提个 [Issue](https://github.com/huggingface/transformers/issues) 以便我们能更快修复。
运行以下命令以检查 🤗 Transformers 是否已被正确安装:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## 可编辑安装
如果你有下列需求,需要进行可编辑安装:
* 使用源码的 `main` 版本。
* 为 🤗 Transformers 贡献代码,需要测试代码中的更改。
使用以下命令克隆仓库并安装 🤗 Transformers:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
这些命令将会链接你克隆的仓库以及你的 Python 库路径。现在,Python 不仅会在正常的库路径中搜索库,也会在你克隆到的文件夹中进行查找。例如,如果你的 Python 包通常本应安装在 `~/anaconda3/envs/main/lib/python3.7/site-packages/` 目录中,在这种情况下 Python 也会搜索你克隆到的文件夹:`~/transformers/`。
<Tip warning={true}>
如果你想继续使用这个库,必须保留 `transformers` 文件夹。
</Tip>
现在,你可以使用以下命令,将你克隆的 🤗 Transformers 库轻松更新至最新版本:
```bash
cd ~/transformers/
git pull
```
你的 Python 环境将在下次运行时找到 `main` 版本的 🤗 Transformers。
## 使用 conda 安装
从 conda 的 `huggingface` 频道安装:
```bash
conda install -c huggingface transformers
```
## 缓存设置
预训练模型会被下载并本地缓存到 `~/.cache/huggingface/hub`。这是由环境变量 `TRANSFORMERS_CACHE` 指定的默认目录。在 Windows 上,默认目录为 `C:\Users\username\.cache\huggingface\hub`。你可以按照不同优先级改变下述环境变量,以指定不同的缓存目录。
1. 环境变量(默认): `HUGGINGFACE_HUB_CACHE` 或 `TRANSFORMERS_CACHE`。
2. 环境变量 `HF_HOME`。
3. 环境变量 `XDG_CACHE_HOME` + `/huggingface`。
<Tip>
除非你明确指定了环境变量 `TRANSFORMERS_CACHE`,🤗 Transformers 将可能会使用较早版本设置的环境变量 `PYTORCH_TRANSFORMERS_CACHE` 或 `PYTORCH_PRETRAINED_BERT_CACHE`。
</Tip>
## 离线模式
🤗 Transformers 可以仅使用本地文件在防火墙或离线环境中运行。设置环境变量 `TRANSFORMERS_OFFLINE=1` 以启用该行为。
<Tip>
通过设置环境变量 `HF_DATASETS_OFFLINE=1` 将 [🤗 Datasets](https://huggingface.co/docs/datasets/) 添加至你的离线训练工作流程中。
</Tip>
例如,你通常会使用以下命令对外部实例进行防火墙保护的的普通网络上运行程序:
```bash
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
在离线环境中运行相同的程序:
```bash
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
现在脚本可以应该正常运行,而无需挂起或等待超时,因为它知道只应查找本地文件。
### 获取离线时使用的模型和分词器
另一种离线时使用 🤗 Transformers 的方法是预先下载好文件,然后在需要离线使用时指向它们的离线路径。有三种实现的方法:
* 单击 [Model Hub](https://huggingface.co/models) 用户界面上的 ↓ 图标下载文件。

* 使用 [`PreTrainedModel.from_pretrained`] 和 [`PreTrainedModel.save_pretrained`] 工作流程:
1. 预先使用 [`PreTrainedModel.from_pretrained`] 下载文件:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. 使用 [`PreTrainedModel.save_pretrained`] 将文件保存至指定目录:
```py
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
>>> model.save_pretrained("./your/path/bigscience_t0")
```
3. 现在,你可以在离线时从指定目录使用 [`PreTrainedModel.from_pretrained`] 重新加载你的文件:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
```
* 使用代码用 [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) 库下载文件:
1. 在你的虚拟环境中安装 `huggingface_hub` 库:
```bash
python -m pip install huggingface_hub
```
2. 使用 [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) 函数将文件下载到指定路径。例如,以下命令将 `config.json` 文件从 [T0](https://huggingface.co/bigscience/T0_3B) 模型下载至你想要的路径:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
```
下载完文件并在本地缓存后,指定其本地路径以加载和使用该模型:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
```
<Tip>
请参阅 [如何从 Hub 下载文件](https://huggingface.co/docs/hub/how-to-downstream) 部分,获取有关下载存储在 Hub 上文件的更多详细信息。
</Tip>
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/hpo_train.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用Trainer API进行超参数搜索
🤗 Transformers库提供了一个优化过的[`Trainer`]类,用于训练🤗 Transformers模型,相比于手动编写自己的训练循环,这更容易开始训练。[`Trainer`]提供了超参数搜索的API。本文档展示了如何在示例中启用它。
## 超参数搜索后端
[`Trainer`] 目前支持四种超参数搜索后端:[optuna](https://optuna.org/),[sigopt](https://sigopt.com/),[raytune](https://docs.ray.io/en/latest/tune/index.html),[wandb](https://wandb.ai/site/sweeps)
在使用它们之前,您应该先安装它们作为超参数搜索后端。
```bash
pip install optuna/sigopt/wandb/ray[tune]
```
## 如何在示例中启用超参数搜索
定义超参数搜索空间,不同的后端需要不同的格式。
对于sigopt,请参阅sigopt [object_parameter](https://docs.sigopt.com/ai-module-api-references/api_reference/objects/object_parameter),它类似于以下内容:
```py
>>> def sigopt_hp_space(trial):
... return [
... {"bounds": {"min": 1e-6, "max": 1e-4}, "name": "learning_rate", "type": "double"},
... {
... "categorical_values": ["16", "32", "64", "128"],
... "name": "per_device_train_batch_size",
... "type": "categorical",
... },
... ]
```
对于optuna,请参阅optuna [object_parameter](https://optuna.readthedocs.io/en/stable/tutorial/10_key_features/002_configurations.html#sphx-glr-tutorial-10-key-features-002-configurations-py),它类似于以下内容:
```py
>>> def optuna_hp_space(trial):
... return {
... "learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
... "per_device_train_batch_size": trial.suggest_categorical("per_device_train_batch_size", [16, 32, 64, 128]),
... }
```
Optuna提供了多目标HPO。您可以在`hyperparameter_search`中传递`direction`参数,并定义自己的`compute_objective`以返回多个目标值。在`hyperparameter_search`中将返回Pareto Front(`List[BestRun]`),您应该参考[test_trainer](https://github.com/huggingface/transformers/blob/main/tests/trainer/test_trainer.py)中的测试用例`TrainerHyperParameterMultiObjectOptunaIntegrationTest`。它类似于以下内容:
```py
>>> best_trials = trainer.hyperparameter_search(
... direction=["minimize", "maximize"],
... backend="optuna",
... hp_space=optuna_hp_space,
... n_trials=20,
... compute_objective=compute_objective,
... )
```
对于raytune,可以参考raytune的[object_parameter](https://docs.ray.io/en/latest/tune/api/search_space.html),它类似于以下内容:
```py
>>> def ray_hp_space(trial):
... return {
... "learning_rate": tune.loguniform(1e-6, 1e-4),
... "per_device_train_batch_size": tune.choice([16, 32, 64, 128]),
... }
```
对于wandb,可以参考wandb的[object_parameter](https://docs.wandb.ai/guides/sweeps/configuration),它类似于以下内容:
```py
>>> def wandb_hp_space(trial):
... return {
... "method": "random",
... "metric": {"name": "objective", "goal": "minimize"},
... "parameters": {
... "learning_rate": {"distribution": "uniform", "min": 1e-6, "max": 1e-4},
... "per_device_train_batch_size": {"values": [16, 32, 64, 128]},
... },
... }
```
定义一个`model_init`函数并将其传递给[Trainer],作为示例:
```py
>>> def model_init(trial):
... return AutoModelForSequenceClassification.from_pretrained(
... model_args.model_name_or_path,
... from_tf=bool(".ckpt" in model_args.model_name_or_path),
... config=config,
... cache_dir=model_args.cache_dir,
... revision=model_args.model_revision,
... use_auth_token=True if model_args.use_auth_token else None,
... )
```
使用你的`model_init`函数、训练参数、训练和测试数据集以及评估函数创建一个[`Trainer`]。
```py
>>> trainer = Trainer(
... model=None,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... tokenizer=tokenizer,
... model_init=model_init,
... data_collator=data_collator,
... )
```
调用超参数搜索,获取最佳试验参数,后端可以是`"optuna"`/`"sigopt"`/`"wandb"`/`"ray"`。方向可以是`"minimize"`或`"maximize"`,表示是否优化更大或更低的目标。
您可以定义自己的compute_objective函数,如果没有定义,将调用默认的compute_objective,并将评估指标(如f1)之和作为目标值返回。
```py
>>> best_trial = trainer.hyperparameter_search(
... direction="maximize",
... backend="optuna",
... hp_space=optuna_hp_space,
... n_trials=20,
... compute_objective=compute_objective,
... )
```
## 针对DDP微调的超参数搜索
目前,Optuna和Sigopt已启用针对DDP的超参数搜索。只有rank-zero进程会进行超参数搜索并将参数传递给其他进程。
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/big_models.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 实例化大型模型
当你想使用一个非常大的预训练模型时,一个挑战是尽量减少对内存的使用。通常从PyTorch开始的工作流程如下:
1. 用随机权重创建你的模型。
2. 加载你的预训练权重。
3. 将这些预训练权重放入你的随机模型中。
步骤1和2都需要完整版本的模型在内存中,这在大多数情况下不是问题,但如果你的模型开始达到几个GB的大小,这两个副本可能会让你超出内存的限制。更糟糕的是,如果你使用`torch.distributed`来启动分布式训练,每个进程都会加载预训练模型并将这两个副本存储在内存中。
<Tip>
请注意,随机创建的模型使用“空”张量进行初始化,这些张量占用内存空间但不填充它(因此随机值是给定时间内该内存块中的任何内容)。在第3步之后,对未初始化的权重执行适合模型/参数种类的随机初始化(例如正态分布),以尽可能提高速度!
</Tip>
在本指南中,我们将探讨 Transformers 提供的解决方案来处理这个问题。请注意,这是一个积极开发的领域,因此这里解释的API在将来可能会略有变化。
## 分片checkpoints
自4.18.0版本起,占用空间超过10GB的模型检查点将自动分成较小的片段。在使用`model.save_pretrained(save_dir)`时,您最终会得到几个部分`checkpoints`(每个的大小都小于10GB)以及一个索引,该索引将参数名称映射到存储它们的文件。
您可以使用`max_shard_size`参数来控制分片之前的最大大小。为了示例的目的,我们将使用具有较小分片大小的普通大小的模型:让我们以传统的BERT模型为例。
```py
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-cased")
```
如果您使用 [`PreTrainedModel.save_pretrained`](模型预训练保存) 进行保存,您将得到一个新的文件夹,其中包含两个文件:模型的配置和权重:
```py
>>> import os
>>> import tempfile
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir)
... print(sorted(os.listdir(tmp_dir)))
['config.json', 'pytorch_model.bin']
```
现在让我们使用最大分片大小为200MB:
```py
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... print(sorted(os.listdir(tmp_dir)))
['config.json', 'pytorch_model-00001-of-00003.bin', 'pytorch_model-00002-of-00003.bin', 'pytorch_model-00003-of-00003.bin', 'pytorch_model.bin.index.json']
```
在模型配置文件最上方,我们可以看到三个不同的权重文件,以及一个`index.json`索引文件。这样的`checkpoint`可以使用`[~PreTrainedModel.from_pretrained]`方法完全重新加载:
```py
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... new_model = AutoModel.from_pretrained(tmp_dir)
```
对于大型模型来说,这样做的主要优点是在上述工作流程的步骤2中,每个`checkpoint`的分片在前一个分片之后加载,从而将内存中的内存使用限制在模型大小加上最大分片的大小。
在后台,索引文件用于确定`checkpoint`中包含哪些键以及相应的权重存储在哪里。我们可以像加载任何json一样加载该索引,并获得一个字典:
```py
>>> import json
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... with open(os.path.join(tmp_dir, "pytorch_model.bin.index.json"), "r") as f:
... index = json.load(f)
>>> print(index.keys())
dict_keys(['metadata', 'weight_map'])
```
目前元数据仅包括模型的总大小。我们计划在将来添加其他信息:
```py
>>> index["metadata"]
{'total_size': 433245184}
```
权重映射是该索引的主要部分,它将每个参数的名称(通常在PyTorch模型的`state_dict`中找到)映射到存储该参数的文件:
```py
>>> index["weight_map"]
{'embeddings.LayerNorm.bias': 'pytorch_model-00001-of-00003.bin',
'embeddings.LayerNorm.weight': 'pytorch_model-00001-of-00003.bin',
...
```
如果您想直接在模型内部加载这样的分片`checkpoint`,而不使用 [`PreTrainedModel.from_pretrained`](就像您会为完整`checkpoint`执行 `model.load_state_dict()` 一样),您应该使用 [`modeling_utils.load_sharded_checkpoint`]:
```py
>>> from transformers.modeling_utils import load_sharded_checkpoint
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... load_sharded_checkpoint(model, tmp_dir)
```
## 低内存加载
分片`checkpoints`在上述工作流的第2步中降低了内存使用,但为了在低内存环境中使用该模型,我们建议使用基于 Accelerate 库的工具。
请阅读以下指南以获取更多信息:[使用 Accelerate 进行大模型加载](./main_classes/model#large-model-loading)
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/pipeline_tutorial.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 推理pipeline
[`pipeline`] 让使用[Hub](https://huggingface.co/models)上的任何模型进行任何语言、计算机视觉、语音以及多模态任务的推理变得非常简单。即使您对特定的模态没有经验,或者不熟悉模型的源码,您仍然可以使用[`pipeline`]进行推理!本教程将教您:
- 如何使用[`pipeline`] 进行推理。
- 如何使用特定的`tokenizer`(分词器)或模型。
- 如何使用[`pipeline`] 进行音频、视觉和多模态任务的推理。
<Tip>
请查看[`pipeline`]文档以获取已支持的任务和可用参数的完整列表。
</Tip>
## Pipeline使用
虽然每个任务都有一个关联的[`pipeline`],但使用通用的抽象的[`pipeline`]更加简单,其中包含所有特定任务的`pipelines`。[`pipeline`]会自动加载一个默认模型和一个能够进行任务推理的预处理类。让我们以使用[`pipeline`]进行自动语音识别(ASR)或语音转文本为例。
1. 首先,创建一个[`pipeline`]并指定推理任务:
```py
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition")
```
2. 将您的输入传递给[`pipeline`]。对于语音识别,这通常是一个音频输入文件:
```py
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}
```
您没有得到您期望的结果?可以在Hub上查看一些[最受欢迎的自动语音识别模型](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=trending)
,看看是否可以获得更好的转录。
让我们尝试来自 OpenAI 的[Whisper large-v2](https://huggingface.co/openai/whisper-large) 模型。Whisperb比Wav2Vec2晚2年发布,使用接近10倍的数据进行了训练。因此,它在大多数下游基准测试上击败了Wav2Vec2。
它还具有预测标点和大小写的附加优势,而Wav2Vec2则无法实现这些功能。
让我们在这里尝试一下,看看它的表现如何:
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
```
现在这个结果看起来更准确了!要进行深入的Wav2Vec2与Whisper比较,请参阅[音频变换器课程](https://huggingface.co/learn/audio-course/chapter5/asr_models)。
我们鼓励您在 Hub 上查看不同语言的模型,以及专业领域的模型等。您可以在Hub上直接查看并比较模型的结果,以确定是否适合或处理边缘情况是否比其他模型更好。如果您没有找到适用于您的用例的模型,您始终可以[训练](training)自己的模型!
如果您有多个输入,您可以将输入作为列表传递:
```py
transcriber(
[
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)
```
`Pipelines`非常适合用于测试,因为从一个模型切换到另一个模型非常琐碎;但是,还有一些方法可以将它们优化后用于大型工作负载而不仅仅是测试。请查看以下指南,深入探讨如何迭代整个数据集或在Web服务器中使用`Pipelines`:
* [在数据集上使用流水线](#using-pipelines-on-a-dataset)
* [在Web服务器中使用流水线](./pipeline_webserver)
## 参数
[`pipeline`] 支持许多参数;有些是适用于特定任务的,而有些适用于所有`pipeline`。通常情况下,您可以在任何地方指定对应参数:
```py
transcriber = pipeline(model="openai/whisper-large-v2", my_parameter=1)
out = transcriber(...) # This will use `my_parameter=1`.
out = transcriber(..., my_parameter=2) # This will override and use `my_parameter=2`.
out = transcriber(...) # This will go back to using `my_parameter=1`.
```
让我们查看其中的三个重要参数:
### 设备
如果您使用 `device=n`,`pipeline`会自动将模型放在指定的设备上。无论您使用PyTorch还是Tensorflow,这都可以工作。
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0)
```
如果模型对于单个GPU来说过于庞大,并且您正在使用PyTorch,您可以设置 `device_map="auto"` 以自动确定如何加载和存储模型权重。使用 `device_map` 参数需要安装🤗 [Accelerate](https://huggingface.co/docs/accelerate) 软件包:
```bash
pip install --upgrade accelerate
```
以下代码会自动在各个设备上加载和存储模型权重:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")
```
请注意,如果传递了 `device_map="auto"`,在实例化您的 `pipeline` 时不需要添加 `device=device` 参数,否则可能会遇到一些意外的状况!
### 批量大小
默认情况下,`pipelines`不会进行批量推理,原因在[这里](https://huggingface.co/docs/transformers/main_classes/pipelines#pipeline-batching)详细解释。因为批处理不一定更快,实际上在某些情况下可能会更慢。
但如果在您的用例中起作用,您可以使用:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
texts = transcriber(audio_filenames)
```
以上代码会在提供的4个音频文件上运行`pipeline`,它会将它们以2个一组的批次传递给模型(模型在GPU上,此时批处理更有可能有所帮助),而您无需编写额外的代码。输出应始终与没有批处理时收到的结果相一致。它只是一种帮助您更快地使用`pipeline`的方式。
`pipeline`也可以减轻一些批处理的复杂性,因为对于某些`pipeline`,需要将单个项目(如长音频文件)分成多个部分以供模型处理。`pipeline`为您执行这种[*chunk batching*](./main_classes/pipelines#pipeline-chunk-batching)。
### 任务特定参数
所有任务都提供了特定于任务的参数,这些参数提供额外的灵活性和选择,以帮助您完成工作。
例如,[`transformers.AutomaticSpeechRecognitionPipeline.__call__`] 方法具有一个 `return_timestamps` 参数,对于字幕视频似乎很有帮助:
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2", return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}
```
正如您所看到的,模型推断出了文本,还输出了各个句子发音的**时间**。
每个任务都有许多可用的参数,因此请查看每个任务的API参考,以了解您可以进行哪些调整!例如,[`~transformers.AutomaticSpeechRecognitionPipeline`] 具有 `chunk_length_s` 参数,对于处理非常长的音频文件(例如,为整部电影或长达一小时的视频配字幕)非常有帮助,这通常是模型无法单独处理的:
```python
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30, return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/sanchit-gandhi/librispeech_long/resolve/main/audio.wav")
{'text': " Chapter 16. I might have told you of the beginning of this liaison in a few lines, but I wanted you to see every step by which we came. I, too, agree to whatever Marguerite wished, Marguerite to be unable to live apart from me. It was the day after the evening...
```
如果您找不到一个真正有帮助的参数,欢迎[提出请求](https://github.com/huggingface/transformers/issues/new?assignees=&labels=feature&template=feature-request.yml)!
## 在数据集上使用pipelines
`pipelines`也可以对大型数据集进行推理。我们建议使用迭代器来完成这一任务,这是最简单的方法:
```py
def data():
for i in range(1000):
yield f"My example {i}"
pipe = pipeline(model="gpt2", device=0)
generated_characters = 0
for out in pipe(data()):
generated_characters += len(out[0]["generated_text"])
```
迭代器 `data()` 会产生每个结果,`pipelines`会自动识别输入为可迭代对象,并在GPU上处理数据的同时开始获取数据(在底层使用[DataLoader](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader))。这一点非常重要,因为您不必为整个数据集分配内存,可以尽可能快地将数据传送到GPU。
由于批处理可以加速处理,因此在这里尝试调整 `batch_size` 参数可能会很有用。
迭代数据集的最简单方法就是从🤗 [Datasets](https://github.com/huggingface/datasets/) 中加载数据集:
```py
# KeyDataset is a util that will just output the item we're interested in.
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)
```
## 在Web服务器上使用pipelines
<Tip>
创建推理引擎是一个复杂的主题,值得有自己的页面。
</Tip>
[链接](./pipeline_webserver)
## 视觉流水线
对于视觉任务,使用[`pipeline`] 几乎是相同的。
指定您的任务并将图像传递给分类器。图像可以是链接、本地路径或base64编码的图像。例如,下面显示的是哪种品种的猫?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
```
## 文本流水线
对于NLP任务,使用[`pipeline`] 几乎是相同的。
```py
>>> from transformers import pipeline
>>> # This model is a `zero-shot-classification` model.
>>> # It will classify text, except you are free to choose any label you might imagine
>>> classifier = pipeline(model="facebook/bart-large-mnli")
>>> classifier(
... "I have a problem with my iphone that needs to be resolved asap!!",
... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
... )
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}
```
## 多模态流水线
[`pipeline`] 支持多个模态。例如,视觉问题回答(VQA)任务结合了文本和图像。请随意使用您喜欢的任何图像链接和您想要问关于该图像的问题。图像可以是URL或图像的本地路径。
例如,如果您使用这个[invoice image](https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png):
```py
>>> from transformers import pipeline
>>> vqa = pipeline(model="impira/layoutlm-document-qa")
>>> vqa(
... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
... question="What is the invoice number?",
... )
[{'score': 0.42515, 'answer': 'us-001', 'start': 16, 'end': 16}]
```
<Tip>
要运行上面的示例,除了🤗 Transformers之外,您需要安装[`pytesseract`](https://pypi.org/project/pytesseract/)。
```bash
sudo apt install -y tesseract-ocr
pip install pytesseract
```
</Tip>
## 在大模型上使用🤗 `accelerate`和`pipeline`:
您可以轻松地使用🤗 `accelerate`在大模型上运行 `pipeline`!首先确保您已经使用 `pip install accelerate` 安装了 `accelerate`。
首先使用 `device_map="auto"` 加载您的模型!我们将在示例中使用 `facebook/opt-1.3b`。
```py
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
如果安装 `bitsandbytes` 并添加参数 `load_in_8bit=True`,您还可以传递8位加载的模型。
```py
# pip install accelerate bitsandbytes
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
请注意,您可以将`checkpoint `替换为任何支持大模型加载的Hugging Face模型,比如BLOOM!
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/tokenizer_summary.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 分词器的摘要
[[open-in-colab]]
在这个页面,我们来仔细研究分词的知识。
<Youtube id="VFp38yj8h3A"/>
正如我们在[the preprocessing tutorial](preprocessing)所看到的那样,对文本进行分词就是将一段文本分割成很多单词或者子单词,
这些单词或者子单词然后会通过一个查询表格被转换到id,将单词或者子单词转换到id是很直截了当的,也就是一个简单的映射,
所以这么来看,我们主要关注将一段文本分割成很多单词或者很多子单词(像:对一段文本进行分词),更加准确的来说,我们将关注
在🤗 Transformers内用到的三种主要类型的分词器:[Byte-Pair Encoding (BPE)](#byte-pair-encoding), [WordPiece](#wordpiece),
and [SentencePiece](#sentencepiece),并且给出了示例,哪个模型用到了哪种类型的分词器。
注意到在每个模型的主页,你可以查看文档上相关的分词器,就可以知道预训练模型使用了哪种类型的分词器。
举个例子,如果我们查看[`BertTokenizer`],我们就能看到模型使用了[WordPiece](#wordpiece)。
## 介绍
将一段文本分词到小块是一个比它看起来更加困难的任务,并且有很多方式来实现分词,举个例子,让我们看看这个句子
`"Don't you love 🤗 Transformers? We sure do."`
<Youtube id="nhJxYji1aho"/>
对这段文本分词的一个简单方式,就是使用空格来分词,得到的结果是:
```
["Don't", "you", "love", "🤗", "Transformers?", "We", "sure", "do."]
```
上面的分词是一个明智的开始,但是如果我们查看token `"Transformers?"` 和 `"do."`,我们可以观察到标点符号附在单词`"Transformer"`
和 `"do"`的后面,这并不是最理想的情况。我们应该将标点符号考虑进来,这样一个模型就没必要学习一个单词和每个可能跟在后面的
标点符号的不同的组合,这么组合的话,模型需要学习的组合的数量会急剧上升。将标点符号也考虑进来,对范例文本进行分词的结果就是:
```
["Don", "'", "t", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
```
分词的结果更好了,然而,这么做也是不好的,分词怎么处理单词`"Don't"`,`"Don't"`的含义是`"do not"`,所以这么分词`["Do", "n't"]`
会更好。现在开始事情就开始变得复杂起来了,部分的原因是每个模型都有它自己的分词类型。依赖于我们应用在文本分词上的规则,
相同的文本会产生不同的分词输出。用在训练数据上的分词规则,被用来对输入做分词操作,一个预训练模型才会正确的执行。
[spaCy](https://spacy.io/) and [Moses](http://www.statmt.org/moses/?n=Development.GetStarted) 是两个受欢迎的基于规则的
分词器。将这两个分词器应用在示例文本上,*spaCy* 和 *Moses*会输出类似下面的结果:
```
["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
```
可见上面的分词使用到了空格和标点符号的分词方式,以及基于规则的分词方式。空格和标点符号分词以及基于规则的分词都是单词分词的例子。
不那么严格的来说,单词分词的定义就是将句子分割到很多单词。然而将文本分割到更小的块是符合直觉的,当处理大型文本语料库时,上面的
分词方法会导致很多问题。在这种情况下,空格和标点符号分词通常会产生一个非常大的词典(使用到的所有不重复的单词和tokens的集合)。
像:[Transformer XL](model_doc/transformerxl)使用空格和标点符号分词,结果会产生一个大小是267,735的词典!
这么大的一个词典容量,迫使模型有着一个巨大的embedding矩阵,以及巨大的输入和输出层,这会增加内存使用量,也会提高时间复杂度。通常
情况下,transformers模型几乎没有词典容量大于50,000的,特别是只在一种语言上预训练的模型。
所以如果简单的空格和标点符号分词让人不满意,为什么不简单的对字符分词?
<Youtube id="ssLq_EK2jLE"/>
尽管字符分词是非常简单的,并且能极大的减少内存使用,降低时间复杂度,但是这样做会让模型很难学到有意义的输入表达。像:
比起学到单词`"today"`的一个有意义的上下文独立的表达,学到字母`"t"`的一个有意义的上下文独立的表达是相当困难的。因此,
字符分词经常会伴随着性能的下降。所以为了获得最好的结果,transformers模型在单词级别分词和字符级别分词之间使用了一个折中的方案
被称作**子词**分词。
## 子词分词
<Youtube id="zHvTiHr506c"/>
子词分词算法依赖这样的原则:频繁使用的单词不应该被分割成更小的子词,但是很少使用的单词应该被分解到有意义的子词。举个例子:
`"annoyingly"`能被看作一个很少使用的单词,能被分解成`"annoying"`和`"ly"`。`"annoying"`和`"ly"`作为独立地子词,出现
的次数都很频繁,而且与此同时单词`"annoyingly"`的含义可以通过组合`"annoying"`和`"ly"`的含义来获得。在粘合和胶水语言上,
像Turkish语言,这么做是相当有用的,在这样的语言里,通过线性组合子词,大多数情况下你能形成任意长的复杂的单词。
子词分词允许模型有一个合理的词典大小,而且能学到有意义的上下文独立地表达。除此以外,子词分词可以让模型处理以前从来没见过的单词,
方式是通过分解这些单词到已知的子词,举个例子:[`~transformers.BertTokenizer`]对句子`"I have a new GPU!"`分词的结果如下:
```py
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
>>> tokenizer.tokenize("I have a new GPU!")
["i", "have", "a", "new", "gp", "##u", "!"]
```
因为我们正在考虑不区分大小写的模型,句子首先被转换成小写字母形式。我们可以见到单词`["i", "have", "a", "new"]`在分词器
的词典内,但是这个单词`"gpu"`不在词典内。所以,分词器将`"gpu"`分割成已知的子词`["gp" and "##u"]`。`"##"`意味着剩下的
token应该附着在前面那个token的后面,不带空格的附着(分词的解码或者反向)。
另外一个例子,[`~transformers.XLNetTokenizer`]对前面的文本例子分词结果如下:
```py
>>> from transformers import XLNetTokenizer
>>> tokenizer = XLNetTokenizer.from_pretrained("xlnet-base-cased")
>>> tokenizer.tokenize("Don't you love 🤗 Transformers? We sure do.")
["▁Don", "'", "t", "▁you", "▁love", "▁", "🤗", "▁", "Transform", "ers", "?", "▁We", "▁sure", "▁do", "."]
```
当我们查看[SentencePiece](#sentencepiece)时会回过头来解释这些`"▁"`符号的含义。正如你能见到的,很少使用的单词
`"Transformers"`能被分割到更加频繁使用的子词`"Transform"`和`"ers"`。
现在让我们来看看不同的子词分割算法是怎么工作的,注意到所有的这些分词算法依赖于某些训练的方式,这些训练通常在语料库上完成,
相应的模型也是在这个语料库上训练的。
<a id='byte-pair-encoding'></a>
### Byte-Pair Encoding (BPE)
Byte-Pair Encoding (BPE)来自于[Neural Machine Translation of Rare Words with Subword Units (Sennrich et
al., 2015)](https://arxiv.org/abs/1508.07909)。BPE依赖于一个预分词器,这个预分词器会将训练数据分割成单词。预分词可以是简单的
空格分词,像::[GPT-2](model_doc/gpt2),[RoBERTa](model_doc/roberta)。更加先进的预分词方式包括了基于规则的分词,像: [XLM](model_doc/xlm),[FlauBERT](model_doc/flaubert),FlauBERT在大多数语言使用了Moses,或者[GPT](model_doc/gpt),GPT
使用了Spacy和ftfy,统计了训练语料库中每个单词的频次。
在预分词以后,生成了单词的集合,也确定了训练数据中每个单词出现的频次。下一步,BPE产生了一个基础词典,包含了集合中所有的符号,
BPE学习融合的规则-组合基础词典中的两个符号来形成一个新的符号。BPE会一直学习直到词典的大小满足了期望的词典大小的要求。注意到
期望的词典大小是一个超参数,在训练这个分词器以前就需要人为指定。
举个例子,让我们假设在预分词以后,下面的单词集合以及他们的频次都已经确定好了:
```
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
```
所以,基础的词典是`["b", "g", "h", "n", "p", "s", "u"]`。将所有单词分割成基础词典内的符号,就可以获得:
```
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
```
BPE接着会统计每个可能的符号对的频次,然后挑出出现最频繁的的符号对,在上面的例子中,`"h"`跟了`"u"`出现了10 + 5 = 15次
(10次是出现了10次`"hug"`,5次是出现了5次`"hugs"`)。然而,最频繁的符号对是`"u"`后面跟了个`"g"`,总共出现了10 + 5 + 5
= 20次。因此,分词器学到的第一个融合规则是组合所有的`"u"`后面跟了个`"g"`符号。下一步,`"ug"`被加入到了词典内。单词的集合
就变成了:
```
("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
```
BPE接着会统计出下一个最普遍的出现频次最大的符号对。也就是`"u"`后面跟了个`"n"`,出现了16次。`"u"`,`"n"`被融合成了`"un"`。
也被加入到了词典中,再下一个出现频次最大的符号对是`"h"`后面跟了个`"ug"`,出现了15次。又一次这个符号对被融合成了`"hug"`,
也被加入到了词典中。
在当前这步,词典是`["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]`,我们的单词集合则是:
```
("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
```
假设,the Byte-Pair Encoding在这个时候停止训练,学到的融合规则并应用到其他新的单词上(只要这些新单词不包括不在基础词典内的符号
就行)。举个例子,单词`"bug"`会被分词到`["b", "ug"]`,但是`"mug"`会被分词到`["<unk>", "ug"]`,因为符号`"m"`不在基础词典内。
通常来看的话,单个字母像`"m"`不会被`"<unk>"`符号替换掉,因为训练数据通常包括了每个字母,每个字母至少出现了一次,但是在特殊的符号
中也可能发生像emojis。
就像之前提到的那样,词典的大小,举个例子,基础词典的大小 + 融合的数量,是一个需要配置的超参数。举个例子:[GPT](model_doc/gpt)
的词典大小是40,478,因为GPT有着478个基础词典内的字符,在40,000次融合以后选择了停止训练。
#### Byte-level BPE
一个包含了所有可能的基础字符的基础字典可能会非常大,如果考虑将所有的unicode字符作为基础字符。为了拥有一个更好的基础词典,[GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)使用了字节
作为基础词典,这是一个非常聪明的技巧,迫使基础词典是256大小,而且确保了所有基础字符包含在这个词典内。使用了其他的规则
来处理标点符号,这个GPT2的分词器能对每个文本进行分词,不需要使用到<unk>符号。[GPT-2](model_doc/gpt)有一个大小是50,257
的词典,对应到256字节的基础tokens,一个特殊的文本结束token,这些符号经过了50,000次融合学习。
<a id='wordpiece'></a>
### WordPiece
WordPiece是子词分词算法,被用在[BERT](model_doc/bert),[DistilBERT](model_doc/distilbert),和[Electra](model_doc/electra)。
这个算法发布在[Japanese and Korean
Voice Search (Schuster et al., 2012)](https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/37842.pdf)
和BPE非常相似。WordPiece首先初始化一个词典,这个词典包含了出现在训练数据中的每个字符,然后递进的学习一个给定数量的融合规则。和BPE相比较,
WordPiece不会选择出现频次最大的符号对,而是选择了加入到字典以后能最大化训练数据似然值的符号对。
所以这到底意味着什么?参考前面的例子,最大化训练数据的似然值,等价于找到一个符号对,它们的概率除以这个符号对中第一个符号的概率,
接着除以第二个符号的概率,在所有的符号对中商最大。像:如果`"ug"`的概率除以`"u"`除以`"g"`的概率的商,比其他任何符号对更大,
这个时候才能融合`"u"`和`"g"`。直觉上,WordPiece,和BPE有点点不同,WordPiece是评估融合两个符号会失去的量,来确保这么做是值得的。
<a id='unigram'></a>
### Unigram
Unigram是一个子词分词器算法,介绍见[Subword Regularization: Improving Neural Network Translation
Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf)。和BPE或者WordPiece相比较
,Unigram使用大量的符号来初始化它的基础字典,然后逐渐的精简每个符号来获得一个更小的词典。举例来看基础词典能够对应所有的预分词
的单词以及最常见的子字符串。Unigram没有直接用在任何transformers的任何模型中,但是和[SentencePiece](#sentencepiece)一起联合使用。
在每个训练的步骤,Unigram算法在当前词典的训练数据上定义了一个损失函数(经常定义为log似然函数的),还定义了一个unigram语言模型。
然后,对词典内的每个符号,算法会计算如果这个符号从词典内移除,总的损失会升高多少。Unigram然后会移除百分之p的符号,这些符号的loss
升高是最低的(p通常是10%或者20%),像:这些在训练数据上对总的损失影响最小的符号。重复这个过程,直到词典已经达到了期望的大小。
为了任何单词都能被分词,Unigram算法总是保留基础的字符。
因为Unigram不是基于融合规则(和BPE以及WordPiece相比较),在训练以后算法有几种方式来分词,如果一个训练好的Unigram分词器
的词典是这个:
```
["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"],
```
`"hugs"`可以被分词成`["hug", "s"]`, `["h", "ug", "s"]`或者`["h", "u", "g", "s"]`。所以选择哪一个呢?Unigram在保存
词典的时候还会保存训练语料库内每个token的概率,所以在训练以后可以计算每个可能的分词结果的概率。实际上算法简单的选择概率
最大的那个分词结果,但是也会提供概率来根据分词结果的概率来采样一个可能的分词结果。
分词器在损失函数上训练,这些损失函数定义了这些概率。假设训练数据包含了这些单词 $x_{1}$, $\dots$, $x_{N}$,一个单词$x_{i}$
的所有可能的分词结果的集合定义为$S(x_{i})$,然后总的损失就可以定义为:
$$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )$$
<a id='sentencepiece'></a>
### SentencePiece
目前为止描述的所有分词算法都有相同的问题:它们都假设输入的文本使用空格来分开单词。然而,不是所有的语言都使用空格来分开单词。
一个可能的解决方案是使用某种语言特定的预分词器。像:[XLM](model_doc/xlm)使用了一个特定的中文、日语和Thai的预分词器。
为了更加广泛的解决这个问题,[SentencePiece: A simple and language independent subword tokenizer and
detokenizer for Neural Text Processing (Kudo et al., 2018)](https://arxiv.org/pdf/1808.06226.pdf)
将输入文本看作一个原始的输入流,因此使用的符合集合中也包括了空格。SentencePiece然后会使用BPE或者unigram算法来产生合适的
词典。
举例来说,[`XLNetTokenizer`]使用了SentencePiece,这也是为什么上面的例子中`"▁"`符号包含在词典内。SentencePiece解码是非常容易的,因为所有的tokens能被concatenate起来,然后将`"▁"`替换成空格。
库内所有使用了SentencePiece的transformers模型,会和unigram组合起来使用,像:使用了SentencePiece的模型是[ALBERT](model_doc/albert),
[XLNet](model_doc/xlnet),[Marian](model_doc/marian),和[T5](model_doc/t5)。
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/transformers_agents.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Transformers Agents
<Tip warning={true}>
`Transformers Agents`是一个实验性的随时可能发生变化的API。由于API或底层模型可能发生变化,`agents`返回的结果也会有所不同。
</Tip>
Transformers版本`v4.29.0`基于`tools`和`agents`概念构建。您可以在[此Colab链接](https://colab.research.google.com/drive/1c7MHD-T1forUPGcC_jlwsIptOzpG3hSj)中进行测试。
简而言之,它在`Transformers`之上提供了一个自然语言API:我们定义了一组经过筛选的`tools`,并设计了一个`agents`来解读自然语言并使用这些工具。它具有很强的可扩展性;我们筛选了一些相关的`tools`,但我们将向您展示如何通过社区开发的`tool`轻松地扩展系统。
让我们从一些可以通过这个新API实现的示例开始。在处理多模态任务时它尤其强大,因此让我们快速试着生成图像并大声朗读文本。
```py
agent.run("Caption the following image", image=image)
```
| **输入** | **输出** |
|-----------------------------------------------------------------------------------------------------------------------------|-----------------------------------|
| <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/beaver.png" width=200> | A beaver is swimming in the water |
---
```py
agent.run("Read the following text out loud", text=text)
```
| **输入** | **输出** |
|-----------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| A beaver is swimming in the water | <audio controls><source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tts_example.wav" type="audio/wav"> your browser does not support the audio element. </audio>
---
```py
agent.run(
"In the following `document`, where will the TRRF Scientific Advisory Council Meeting take place?",
document=document,
)
```
| **输入** | **输出** |
|-----------------------------------------------------------------------------------------------------------------------------|----------------|
| <img src="https://datasets-server.huggingface.co/assets/hf-internal-testing/example-documents/--/hf-internal-testing--example-documents/test/0/image/image.jpg" width=200> | ballroom foyer |
## 快速入门
要使用 `agent.run`,您需要实例化一个`agent`,它是一个大型语言模型(LLM)。我们支持OpenAI模型以及来自BigCode和OpenAssistant的开源替代方案。OpenAI模型性能更好(但需要您拥有OpenAI API密钥,因此无法免费使用),Hugging Face为BigCode和OpenAssistant模型提供了免费访问端点。
一开始请安装`agents`附加模块,以安装所有默认依赖项。
```bash
pip install transformers[agents]
```
要使用OpenAI模型,您可以在安装`openai`依赖项后实例化一个`OpenAiAgent`:
```bash
pip install openai
```
```py
from transformers import OpenAiAgent
agent = OpenAiAgent(model="text-davinci-003", api_key="<your_api_key>")
```
要使用BigCode或OpenAssistant,请首先登录以访问Inference API:
```py
from huggingface_hub import login
login("<YOUR_TOKEN>")
```
然后,实例化`agent`:
```py
from transformers import HfAgent
# Starcoder
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
# StarcoderBase
# agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoderbase")
# OpenAssistant
# agent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")
```
此示例使用了目前Hugging Face免费提供的推理API。如果你有自己的推理端点用于此模型(或其他模型),你可以用你的URL替换上面的URL。
<Tip>
StarCoder和OpenAssistant可以免费使用,并且在简单任务上表现出色。然而,当处理更复杂的提示时就不再有效。如果你遇到这样的问题,我们建议尝试使用OpenAI模型,尽管遗憾的是它不是开源的,但它在目前情况下表现更好。
</Tip>
现在,您已经可以开始使用了!让我们深入了解您现在可以使用的两个API。
### 单次执行(run)
单次执行方法是使用`agent`的 `~Agent.run`:
```py
agent.run("Draw me a picture of rivers and lakes.")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png" width=200>
它会自动选择适合您要执行的任务的`tool`(或`tools`),并以适当的方式运行它们。它可以在同一指令中执行一个或多个任务(尽管您的指令越复杂,`agent`失败的可能性就越大)。
```py
agent.run("Draw me a picture of the sea then transform the picture to add an island")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/sea_and_island.png" width=200>
<br/>
每个 [`~Agent.run`] 操作都是独立的,因此您可以多次连续运行 [`~Agent.run`]并执行不同的任务。
请注意,您的 `agent` 只是一个大型语言模型,因此您略有变化的提示可能会产生完全不同的结果。重要的是尽可能清晰地解释您要执行的任务。我们在[这里](../en/custom_tools#writing-good-user-inputs)更深入地讨论了如何编写良好的提示。
如果您想在多次执行之间保持同一状态或向`agent`传递非文本对象,可以通过指定`agent`要使用的变量来实现。例如,您可以生成有关河流和湖泊的第一幅图像,并要求模型通过执行以下操作向该图片添加一个岛屿:
```python
picture = agent.run("Generate a picture of rivers and lakes.")
updated_picture = agent.run("Transform the image in `picture` to add an island to it.", picture=picture)
```
<Tip>
当模型无法理解您的请求和库中的工具时,这可能会有所帮助。例如:
```py
agent.run("Draw me the picture of a capybara swimming in the sea")
```
在这种情况下,模型可以以两种方式理解您的请求:
- 使用`text-to-image` 生成在大海中游泳的大水獭
- 或者,使用`text-to-image`生成大水獭,然后使用`image-transformation`工具使其在大海中游泳
如果您想强制使用第一种情景,可以通过将提示作为参数传递给它来实现:
```py
agent.run("Draw me a picture of the `prompt`", prompt="a capybara swimming in the sea")
```
</Tip>
### 基于交流的执行 (chat)
基于交流的执行(chat)方式是使用 [`~Agent.chat`]:
```py
agent.chat("Generate a picture of rivers and lakes")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png" width=200>
```py
agent.chat("Transform the picture so that there is a rock in there")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes_and_beaver.png" width=200>
<br/>
当您希望在不同指令之间保持同一状态时,这会是一个有趣的方法。它更适合用于单个指令,而不是复杂的多步指令(`~Agent.run` 方法更适合处理这种情况)。
这种方法也可以接受参数,以便您可以传递非文本类型或特定提示。
### ⚠️ 远程执行
出于演示目的以便适用于所有设置,我们为发布版本的少数默认工具创建了远程执行器。这些工具是使用推理终端(inference endpoints)创建的。
目前我们已将其关闭,但为了了解如何自行设置远程执行器工具,我们建议阅读[自定义工具指南](./custom_tools)。
### 这里发生了什么?什么是`tools`,什么是`agents`?
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/diagram.png">
#### Agents
这里的`Agents`是一个大型语言模型,我们通过提示它以访问特定的工具集。
大型语言模型在生成小代码示例方面表现出色,因此这个API利用这一特点,通过提示LLM生成一个使用`tools`集合的小代码示例。然后,根据您给`Agents`的任务和`tools`的描述来完成此提示。这种方式让它能够访问工具的文档,特别是它们的期望输入和输出,以生成相关的代码。
#### Tools
`Tools`非常简单:它们是有名称和描述的单个函数。然后,我们使用这些`tools`的描述来提示代理。通过提示,我们向`agent`展示如何使用`tool`来执行查询语言中请求的操作。
这是使用全新`tools`而不是`pipelines`,因为`agent`编写的代码更好,具有非常原子化的`tools`。`pipelines`经常被重构,并且通常将多个任务合并为一个。`tools`旨在专注于一个非常简单的任务。
#### 代码执行?
然后,这段代码基于`tools`的输入被我们的小型Python解释器执行。我们听到你在后面大声呼喊“任意代码执行!”,但让我们解释为什么情况并非如此。
只能您提供的`tools`和打印函数可以被执行,因此您已经受到了执行的限制。如果仅限于 Hugging Face 工具,那么您应该是安全的。
然后,我们不允许任何属性查找或导入(无论如何都不需要将输入/输出传递给一小组函数),因此所有最明显的攻击(并且您需要提示LLM无论如何输出它们)不应该是一个问题。如果你想超级安全,你可以使用附加参数 return_code=True 执行 run() 方法,在这种情况下,`agent`将只返回要执行的代码,你可以决定是否执行。
如果`agent`生成的代码存在任何尝试执行非法操作的行为,或者代码中出现了常规Python错误,执行将停止。
### 一组经过精心筛选的`tools`
我们确定了一组可以赋予这些`agent`强大能力的`tools`。以下是我们在`transformers`中集成的`tools`的更新列表:
- **文档问答**:给定一个图像格式的文档(例如PDF),回答该文档上的问题([Donut](../en/model_doc/donut))
- **文本问答**:给定一段长文本和一个问题,回答文本中的问题([Flan-T5](../en/model_doc/flan-t5))
- **无条件图像字幕**:为图像添加字幕!([BLIP](../en/model_doc/blip))
- **图像问答**:给定一张图像,回答该图像上的问题([VILT](../en/model_doc/vilt))
- **图像分割**:给定一张图像和一个提示,输出该提示的分割掩模([CLIPSeg](../en/model_doc/clipseg))
- **语音转文本**:给定一个人说话的音频录音,将演讲内容转录为文本([Whisper](../en/model_doc/whisper))
- **文本转语音**:将文本转换为语音([SpeechT5](../en/model_doc/speecht5))
- **Zero-Shot文本分类**:给定一个文本和一个标签列表,确定文本最符合哪个标签([BART](../en/model_doc/bart))
- **文本摘要**:总结长文本为一两句话([BART](../en/model_doc/bart))
- **翻译**:将文本翻译为指定语言([NLLB](../en/model_doc/nllb))
这些`tools`已在transformers中集成,并且也可以手动使用,例如:
```py
from transformers import load_tool
tool = load_tool("text-to-speech")
audio = tool("This is a text to speech tool")
```
### 自定义工具
尽管我们确定了一组经过筛选的`tools`,但我们坚信,此实现提供的主要价值在于能够快速创建和共享自定义`tool`。
通过将工具的代码上传到Hugging Face空间或模型repository,您可以直接通过`agent`使用`tools`。我们已经添加了一些**与transformers无关**的`tools`到[`huggingface-tools`组织](https://huggingface.co/huggingface-tools)中:
- **文本下载器**:从Web URL下载文本
- **文本到图像**:根据提示生成图像,利用`stable diffusion`
- **图像转换**:根据初始图像和提示修改图像,利用`instruct pix2pix stable diffusion`
- **文本到视频**:根据提示生成小视频,利用`damo-vilab`
从一开始就一直在使用的文本到图像`tool`是一个远程`tool `,位于[*huggingface-tools/text-to-image*](https://huggingface.co/spaces/huggingface-tools/text-to-image)!我们将继续在此组织和其他组织上发布此类`tool`,以进一步增强此实现。
`agents`默认可以访问存储在[`huggingface-tools`](https://huggingface.co/huggingface-tools)上的`tools`。我们将在后续指南中解释如何编写和共享自定义`tools`,以及如何利用Hub上存在的任何自定义`tools`。
### 代码生成
到目前为止,我们已经展示了如何使用`agents`来为您执行操作。但是,`agents`仅使用非常受限Python解释器执行的代码。如果您希望在不同的环境中使用生成的代码,可以提示`agents`返回代码,以及`tools`的定义和准确的导入信息。
例如,以下指令
```python
agent.run("Draw me a picture of rivers and lakes", return_code=True)
```
返回以下代码
```python
from transformers import load_tool
image_generator = load_tool("huggingface-tools/text-to-image")
image = image_generator(prompt="rivers and lakes")
```
然后你就可以调整并执行代码
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/_toctree.yml
|
- sections:
- local: index
title: 🤗 Transformers 简介
- local: quicktour
title: 快速上手
- local: installation
title: 安装
title: 开始使用
- sections:
- local: pipeline_tutorial
title: 使用pipelines进行推理
- local: autoclass_tutorial
title: 使用AutoClass编写可移植的代码
- local: preprocessing
title: 预处理数据
- local: training
title: 微调预训练模型
- local: run_scripts
title: 通过脚本训练模型
- local: accelerate
title: 使用🤗Accelerate进行分布式训练
- local: peft
title: 使用🤗 PEFT加载和训练adapters
- local: model_sharing
title: 分享您的模型
- local: transformers_agents
title: agents教程
- local: llm_tutorial
title: 使用LLMs进行生成
title: 教程
- sections:
- local: fast_tokenizers
title: 使用 🤗 Tokenizers 中的分词器
- local: multilingual
title: 使用多语言模型进行推理
- local: create_a_model
title: 使用特定于模型的 API
- local: custom_models
title: 共享自定义模型
- local: serialization
title: 导出为 ONNX
- local: tflite
title: 导出为 TFLite
title: 开发者指南
- sections:
- local: performance
title: 综述
- sections:
- local: perf_hardware
title: 用于训练的定制硬件
- local: hpo_train
title: 使用Trainer API 进行超参数搜索
title: 高效训练技术
- local: big_models
title: 实例化大模型
- local: debugging
title: 问题定位及解决
- local: tf_xla
title: TensorFlow模型的XLA集成
- local: perf_torch_compile
title: 使用 `torch.compile()` 优化推理
title: 性能和可扩展性
- sections:
- local: task_summary
title: 🤗Transformers能做什么
- local: tokenizer_summary
title: 分词器的摘要
title: 概念指南
- sections:
- sections:
- local: main_classes/agent
title: Agents和工具
- local: main_classes/callback
title: Callbacks
- local: main_classes/configuration
title: Configuration
- local: main_classes/data_collator
title: Data Collator
- local: main_classes/keras_callbacks
title: Keras callbacks
- local: main_classes/logging
title: Logging
- local: main_classes/model
title: 模型
- local: main_classes/text_generation
title: 文本生成
- local: main_classes/onnx
title: ONNX
- local: main_classes/optimizer_schedules
title: Optimization
- local: main_classes/output
title: 模型输出
- local: main_classes/pipelines
title: Pipelines
- local: main_classes/processors
title: Processors
- local: main_classes/quantization
title: Quantization
- local: main_classes/tokenizer
title: Tokenizer
- local: main_classes/trainer
title: Trainer
- local: main_classes/deepspeed
title: DeepSpeed集成
- local: main_classes/feature_extractor
title: Feature Extractor
- local: main_classes/image_processor
title: Image Processor
title: 主要类
title: 应用程序接口 (API)
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/run_scripts.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用脚本进行训练
除了 🤗 Transformers [notebooks](./noteboks/README),还有示例脚本演示了如何使用[PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch)、[TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow)或[JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax)训练模型以解决特定任务。
您还可以在这些示例中找到我们在[研究项目](https://github.com/huggingface/transformers/tree/main/examples/research_projects)和[遗留示例](https://github.com/huggingface/transformers/tree/main/examples/legacy)中使用过的脚本,这些脚本主要是由社区贡献的。这些脚本已不再被积极维护,需要使用特定版本的🤗 Transformers, 可能与库的最新版本不兼容。
示例脚本可能无法在初始配置下直接解决每个问题,您可能需要根据要解决的问题调整脚本。为了帮助您,大多数脚本都完全暴露了数据预处理的方式,允许您根据需要对其进行编辑。
如果您想在示例脚本中实现任何功能,请在[论坛](https://discuss.huggingface.co/)或[issue](https://github.com/huggingface/transformers/issues)上讨论,然后再提交Pull Request。虽然我们欢迎修复错误,但不太可能合并添加更多功能的Pull Request,因为这会降低可读性。
本指南将向您展示如何在[PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization)和[TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization)中运行示例摘要训练脚本。除非另有说明,否则所有示例都可以在两个框架中工作。
## 设置
要成功运行示例脚本的最新版本,您必须在新虚拟环境中**从源代码安装 🤗 Transformers**:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
对于旧版本的示例脚本,请点击下面的切换按钮:
<details>
<summary>老版本🤗 Transformers示例 </summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
然后切换您clone的 🤗 Transformers 仓到特定的版本,例如v3.5.1:
```bash
git checkout tags/v3.5.1
```
在安装了正确的库版本后,进入您选择的版本的`example`文件夹并安装例子要求的环境:
```bash
pip install -r requirements.txt
```
## 运行脚本
<frameworkcontent>
<pt>
示例脚本从🤗 [Datasets](https://huggingface.co/docs/datasets/)库下载并预处理数据集。然后,脚本通过[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer)使用支持摘要任务的架构对数据集进行微调。以下示例展示了如何在[CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail)数据集上微调[T5-small](https://huggingface.co/t5-small)。由于T5模型的训练方式,它需要一个额外的`source_prefix`参数。这个提示让T5知道这是一个摘要任务。
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
示例脚本从 🤗 [Datasets](https://huggingface.co/docs/datasets/) 库下载并预处理数据集。然后,脚本使用 Keras 在支持摘要的架构上微调数据集。以下示例展示了如何在 [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) 数据集上微调 [T5-small](https://huggingface.co/t5-small)。T5 模型由于训练方式需要额外的 `source_prefix` 参数。这个提示让 T5 知道这是一个摘要任务。
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## 分布式训练和混合精度
[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) 支持分布式训练和混合精度,这意味着你也可以在脚本中使用它。要启用这两个功能,可以做如下设置:
- 添加 `fp16` 参数以启用混合精度。
- 使用 `nproc_per_node` 参数设置使用的GPU数量。
```bash
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
TensorFlow脚本使用[`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy)进行分布式训练,您无需在训练脚本中添加任何其他参数。如果可用,TensorFlow脚本将默认使用多个GPU。
## 在TPU上运行脚本
<frameworkcontent>
<pt>
张量处理单元(TPUs)是专门设计用于加速性能的。PyTorch使用[XLA](https://www.tensorflow.org/xla)深度学习编译器支持TPU(更多细节请参见[这里](https://github.com/pytorch/xla/blob/master/README.md))。要使用TPU,请启动`xla_spawn.py`脚本并使用`num_cores`参数设置要使用的TPU核心数量。
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
张量处理单元(TPUs)是专门设计用于加速性能的。TensorFlow脚本使用[`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy)在TPU上进行训练。要使用TPU,请将TPU资源的名称传递给`tpu`参数。
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## 基于🤗 Accelerate运行脚本
🤗 [Accelerate](https://huggingface.co/docs/accelerate) 是一个仅支持 PyTorch 的库,它提供了一种统一的方法来在不同类型的设置(仅 CPU、多个 GPU、多个TPU)上训练模型,同时保持对 PyTorch 训练循环的完全可见性。如果你还没有安装 🤗 Accelerate,请确保你已经安装了它:
> 注意:由于 Accelerate 正在快速发展,因此必须安装 git 版本的 accelerate 来运行脚本。
```bash
pip install git+https://github.com/huggingface/accelerate
```
你需要使用`run_summarization_no_trainer.py`脚本,而不是`run_summarization.py`脚本。🤗 Accelerate支持的脚本需要在文件夹中有一个`task_no_trainer.py`文件。首先运行以下命令以创建并保存配置文件:
```bash
accelerate config
```
检测您的设置以确保配置正确:
```bash
accelerate test
```
现在您可以开始训练模型了:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## 使用自定义数据集
摘要脚本支持自定义数据集,只要它们是CSV或JSON Line文件。当你使用自己的数据集时,需要指定一些额外的参数:
- `train_file` 和 `validation_file` 分别指定您的训练和验证文件的路径。
- `text_column` 是输入要进行摘要的文本。
- `summary_column` 是目标输出的文本。
使用自定义数据集的摘要脚本看起来是这样的:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## 测试脚本
通常,在提交整个数据集之前,最好先在较少的数据集示例上运行脚本,以确保一切按预期工作,因为完整数据集的处理可能需要花费几个小时的时间。使用以下参数将数据集截断为最大样本数:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
并非所有示例脚本都支持`max_predict_samples`参数。如果您不确定您的脚本是否支持此参数,请添加`-h`参数进行检查:
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## 从checkpoint恢复训练
另一个有用的选项是从之前的checkpoint恢复训练。这将确保在训练中断时,您可以从之前停止的地方继续进行,而无需重新开始。有两种方法可以从checkpoint恢复训练。
第一种方法使用`output_dir previous_output_dir`参数从存储在`output_dir`中的最新的checkpoint恢复训练。在这种情况下,您应该删除`overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
第二种方法使用`resume_from_checkpoint path_to_specific_checkpoint`参数从特定的checkpoint文件夹恢复训练。
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## 分享模型
所有脚本都可以将您的最终模型上传到[Model Hub](https://huggingface.co/models)。在开始之前,请确保您已登录Hugging Face:
```bash
huggingface-cli login
```
然后,在脚本中添加`push_to_hub`参数。这个参数会创建一个带有您Hugging Face用户名和`output_dir`中指定的文件夹名称的仓库。
为了给您的仓库指定一个特定的名称,使用`push_to_hub_model_id`参数来添加它。该仓库将自动列出在您的命名空间下。
以下示例展示了如何上传具有特定仓库名称的模型:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/task_summary.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Transformers 能做什么
🤗 Transformers是一个用于自然语言处理(NLP)、计算机视觉和音频和语音处理任务的预训练模型库。该库不仅包含Transformer模型,还包括用于计算机视觉任务的现代卷积网络等非Transformer模型。如果您看看今天最受欢迎的一些消费产品,比如智能手机、应用程序和电视,很可能背后都有某种深度学习技术的支持。想要从您智能手机拍摄的照片中删除背景对象吗?这里是一个全景分割任务的例子(如果您还不了解这是什么意思,我们将在以下部分进行描述!)。
本页面提供了使用🤗 Transformers库仅用三行代码解决不同的语音和音频、计算机视觉和NLP任务的概述!
## 音频
音频和语音处理任务与其他模态略有不同,主要是因为音频作为输入是一个连续的信号。与文本不同,原始音频波形不能像句子可以被划分为单词那样被整齐地分割成离散的块。为了解决这个问题,通常在固定的时间间隔内对原始音频信号进行采样。如果在每个时间间隔内采样更多样本,采样率就会更高,音频更接近原始音频源。
以前的方法是预处理音频以从中提取有用的特征。现在更常见的做法是直接将原始音频波形输入到特征编码器中,以提取音频表示。这样可以简化预处理步骤,并允许模型学习最重要的特征。
### 音频分类
音频分类是一项将音频数据从预定义的类别集合中进行标记的任务。这是一个广泛的类别,具有许多具体的应用,其中一些包括:
* 声学场景分类:使用场景标签("办公室"、"海滩"、"体育场")对音频进行标记。
* 声学事件检测:使用声音事件标签("汽车喇叭声"、"鲸鱼叫声"、"玻璃破碎声")对音频进行标记。
* 标记:对包含多种声音的音频进行标记(鸟鸣、会议中的说话人识别)。
* 音乐分类:使用流派标签("金属"、"嘻哈"、"乡村")对音乐进行标记。
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="audio-classification", model="superb/hubert-base-superb-er")
>>> preds = classifier("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4532, 'label': 'hap'},
{'score': 0.3622, 'label': 'sad'},
{'score': 0.0943, 'label': 'neu'},
{'score': 0.0903, 'label': 'ang'}]
```
### 自动语音识别
自动语音识别(ASR)将语音转录为文本。这是最常见的音频任务之一,部分原因是因为语音是人类交流的自然形式。如今,ASR系统嵌入在智能技术产品中,如扬声器、电话和汽车。我们可以要求虚拟助手播放音乐、设置提醒和告诉我们天气。
但是,Transformer架构帮助解决的一个关键挑战是低资源语言。通过在大量语音数据上进行预训练,仅在一个低资源语言的一小时标记语音数据上进行微调,仍然可以产生与以前在100倍更多标记数据上训练的ASR系统相比高质量的结果。
```py
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-small")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
```
## 计算机视觉
计算机视觉任务中最早成功之一是使用卷积神经网络([CNN](glossary#convolution))识别邮政编码数字图像。图像由像素组成,每个像素都有一个数值。这使得将图像表示为像素值矩阵变得容易。每个像素值组合描述了图像的颜色。
计算机视觉任务可以通过以下两种通用方式解决:
1. 使用卷积来学习图像的层次特征,从低级特征到高级抽象特征。
2. 将图像分成块,并使用Transformer逐步学习每个图像块如何相互关联以形成图像。与CNN偏好的自底向上方法不同,这种方法有点像从一个模糊的图像开始,然后逐渐将其聚焦清晰。
### 图像分类
图像分类将整个图像从预定义的类别集合中进行标记。像大多数分类任务一样,图像分类有许多实际用例,其中一些包括:
* 医疗保健:标记医学图像以检测疾病或监测患者健康状况
* 环境:标记卫星图像以监测森林砍伐、提供野外管理信息或检测野火
* 农业:标记农作物图像以监测植物健康或用于土地使用监测的卫星图像
* 生态学:标记动物或植物物种的图像以监测野生动物种群或跟踪濒危物种
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="image-classification")
>>> preds = classifier(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.4335, 'label': 'lynx, catamount'}
{'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}
{'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}
{'score': 0.0239, 'label': 'Egyptian cat'}
{'score': 0.0229, 'label': 'tiger cat'}
```
### 目标检测
与图像分类不同,目标检测在图像中识别多个对象以及这些对象在图像中的位置(由边界框定义)。目标检测的一些示例应用包括:
* 自动驾驶车辆:检测日常交通对象,如其他车辆、行人和红绿灯
* 遥感:灾害监测、城市规划和天气预报
* 缺陷检测:检测建筑物中的裂缝或结构损坏,以及制造业产品缺陷
```py
>>> from transformers import pipeline
>>> detector = pipeline(task="object-detection")
>>> preds = detector(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"], "box": pred["box"]} for pred in preds]
>>> preds
[{'score': 0.9865,
'label': 'cat',
'box': {'xmin': 178, 'ymin': 154, 'xmax': 882, 'ymax': 598}}]
```
### 图像分割
图像分割是一项像素级任务,将图像中的每个像素分配给一个类别。它与使用边界框标记和预测图像中的对象的目标检测不同,因为分割更加精细。分割可以在像素级别检测对象。有几种类型的图像分割:
* 实例分割:除了标记对象的类别外,还标记每个对象的不同实例(“dog-1”,“dog-2”)
* 全景分割:语义分割和实例分割的组合; 它使用语义类为每个像素标记并标记每个对象的不同实例
分割任务对于自动驾驶车辆很有帮助,可以创建周围世界的像素级地图,以便它们可以在行人和其他车辆周围安全导航。它还适用于医学成像,其中任务的更精细粒度可以帮助识别异常细胞或器官特征。图像分割也可以用于电子商务,通过您的相机在现实世界中覆盖物体来虚拟试穿衣服或创建增强现实体验。
```py
>>> from transformers import pipeline
>>> segmenter = pipeline(task="image-segmentation")
>>> preds = segmenter(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.9879, 'label': 'LABEL_184'}
{'score': 0.9973, 'label': 'snow'}
{'score': 0.9972, 'label': 'cat'}
```
### 深度估计
深度估计预测图像中每个像素到相机的距离。这个计算机视觉任务对于场景理解和重建尤为重要。例如,在自动驾驶汽车中,车辆需要了解行人、交通标志和其他车辆等物体的距离,以避免障碍物和碰撞。深度信息还有助于从2D图像构建3D表示,并可用于创建生物结构或建筑物的高质量3D表示。
有两种方法可以进行深度估计:
* stereo(立体):通过比较同一图像的两个略微不同角度的图像来估计深度
* monocular(单目):从单个图像中估计深度
```py
>>> from transformers import pipeline
>>> depth_estimator = pipeline(task="depth-estimation")
>>> preds = depth_estimator(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
```
## 自然语言处理
NLP任务是最常见的类型之一,因为文本是我们进行交流的自然方式。为了让文本变成模型识别的格式,需要对其进行分词。这意味着将一段文本分成单独的单词或子词(`tokens`),然后将这些`tokens`转换为数字。因此,可以将一段文本表示为一系列数字,一旦有了一系列的数字,就可以将其输入到模型中以解决各种NLP任务!
### 文本分类
像任何模态的分类任务一样,文本分类将一段文本(可以是句子级别、段落或文档)从预定义的类别集合中进行标记。文本分类有许多实际应用,其中一些包括:
* 情感分析:根据某些极性(如`积极`或`消极`)对文本进行标记,可以支持政治、金融和营销等领域的决策制定
* 内容分类:根据某些主题对文本进行标记,有助于组织和过滤新闻和社交媒体提要中的信息(`天气`、`体育`、`金融`等)
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="sentiment-analysis")
>>> preds = classifier("Hugging Face is the best thing since sliced bread!")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.9991, 'label': 'POSITIVE'}]
```
### Token分类
在任何NLP任务中,文本都经过预处理,将文本序列分成单个单词或子词。这些被称为[tokens](/glossary#token)。Token分类将每个`token`分配一个来自预定义类别集的标签。
两种常见的Token分类是:
* 命名实体识别(NER):根据实体类别(如组织、人员、位置或日期)对`token`进行标记。NER在生物医学设置中特别受欢迎,可以标记基因、蛋白质和药物名称。
* 词性标注(POS):根据其词性(如名词、动词或形容词)对标记进行标记。POS对于帮助翻译系统了解两个相同的单词如何在语法上不同很有用(作为名词的银行与作为动词的银行)。
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="ner")
>>> preds = classifier("Hugging Face is a French company based in New York City.")
>>> preds = [
... {
... "entity": pred["entity"],
... "score": round(pred["score"], 4),
... "index": pred["index"],
... "word": pred["word"],
... "start": pred["start"],
... "end": pred["end"],
... }
... for pred in preds
... ]
>>> print(*preds, sep="\n")
{'entity': 'I-ORG', 'score': 0.9968, 'index': 1, 'word': 'Hu', 'start': 0, 'end': 2}
{'entity': 'I-ORG', 'score': 0.9293, 'index': 2, 'word': '##gging', 'start': 2, 'end': 7}
{'entity': 'I-ORG', 'score': 0.9763, 'index': 3, 'word': 'Face', 'start': 8, 'end': 12}
{'entity': 'I-MISC', 'score': 0.9983, 'index': 6, 'word': 'French', 'start': 18, 'end': 24}
{'entity': 'I-LOC', 'score': 0.999, 'index': 10, 'word': 'New', 'start': 42, 'end': 45}
{'entity': 'I-LOC', 'score': 0.9987, 'index': 11, 'word': 'York', 'start': 46, 'end': 50}
{'entity': 'I-LOC', 'score': 0.9992, 'index': 12, 'word': 'City', 'start': 51, 'end': 55}
```
### 问答
问答是另一个`token-level`的任务,返回一个问题的答案,有时带有上下文(开放领域),有时不带上下文(封闭领域)。每当我们向虚拟助手提出问题时,例如询问一家餐厅是否营业,就会发生这种情况。它还可以提供客户或技术支持,并帮助搜索引擎检索您要求的相关信息。
有两种常见的问答类型:
* 提取式:给定一个问题和一些上下文,答案是从模型必须提取的上下文中的一段文本跨度。
* 抽象式:给定一个问题和一些上下文,答案从上下文中生成;这种方法由[`Text2TextGenerationPipeline`]处理,而不是下面显示的[`QuestionAnsweringPipeline`]。
```py
>>> from transformers import pipeline
>>> question_answerer = pipeline(task="question-answering")
>>> preds = question_answerer(
... question="What is the name of the repository?",
... context="The name of the repository is huggingface/transformers",
... )
>>> print(
... f"score: {round(preds['score'], 4)}, start: {preds['start']}, end: {preds['end']}, answer: {preds['answer']}"
... )
score: 0.9327, start: 30, end: 54, answer: huggingface/transformers
```
### 摘要
摘要从较长的文本中创建一个较短的版本,同时尽可能保留原始文档的大部分含义。摘要是一个序列到序列的任务;它输出比输入更短的文本序列。有许多长篇文档可以进行摘要,以帮助读者快速了解主要要点。法案、法律和财务文件、专利和科学论文等文档可以摘要,以节省读者的时间并作为阅读辅助工具。
像问答一样,摘要有两种类型:
* 提取式:从原始文本中识别和提取最重要的句子
* 抽象式:从原始文本生成目标摘要(可能包括不在输入文档中的新单词);[`SummarizationPipeline`]使用抽象方法。
```py
>>> from transformers import pipeline
>>> summarizer = pipeline(task="summarization")
>>> summarizer(
... "In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention. For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles."
... )
[{'summary_text': ' The Transformer is the first sequence transduction model based entirely on attention . It replaces the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention . For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers .'}]
```
### 翻译
翻译将一种语言的文本序列转换为另一种语言。它对于帮助来自不同背景的人们相互交流、帮助翻译内容以吸引更广泛的受众,甚至成为学习工具以帮助人们学习一门新语言都非常重要。除了摘要之外,翻译也是一个序列到序列的任务,意味着模型接收输入序列并返回目标输出序列。
在早期,翻译模型大多是单语的,但最近,越来越多的人对可以在多种语言之间进行翻译的多语言模型感兴趣。
```py
>>> from transformers import pipeline
>>> text = "translate English to French: Hugging Face is a community-based open-source platform for machine learning."
>>> translator = pipeline(task="translation", model="t5-small")
>>> translator(text)
[{'translation_text': "Hugging Face est une tribune communautaire de l'apprentissage des machines."}]
```
### 语言模型
语言模型是一种预测文本序列中单词的任务。它已成为一种非常流行的NLP任务,因为预训练的语言模型可以微调用于许多其他下游任务。最近,人们对大型语言模型(LLMs)表现出了极大的兴趣,这些模型展示了`zero learning`或`few-shot learning`的能力。这意味着模型可以解决它未被明确训练过的任务!语言模型可用于生成流畅和令人信服的文本,但需要小心,因为文本可能并不总是准确的。
有两种类型的话语模型:
* causal:模型的目标是预测序列中的下一个`token`,而未来的`tokens`被遮盖。
```py
>>> from transformers import pipeline
>>> prompt = "Hugging Face is a community-based open-source platform for machine learning."
>>> generator = pipeline(task="text-generation")
>>> generator(prompt) # doctest: +SKIP
```
* masked:模型的目标是预测序列中被遮蔽的`token`,同时具有对序列中所有`tokens`的完全访问权限。
```py
>>> text = "Hugging Face is a community-based open-source <mask> for machine learning."
>>> fill_mask = pipeline(task="fill-mask")
>>> preds = fill_mask(text, top_k=1)
>>> preds = [
... {
... "score": round(pred["score"], 4),
... "token": pred["token"],
... "token_str": pred["token_str"],
... "sequence": pred["sequence"],
... }
... for pred in preds
... ]
>>> preds
[{'score': 0.2236,
'token': 1761,
'token_str': ' platform',
'sequence': 'Hugging Face is a community-based open-source platform for machine learning.'}]
```
## 多模态
多模态任务要求模型处理多种数据模态(文本、图像、音频、视频)以解决特定问题。图像描述是一个多模态任务的例子,其中模型将图像作为输入并输出描述图像或图像某些属性的文本序列。
虽然多模态模型处理不同的数据类型或模态,但内部预处理步骤帮助模型将所有数据类型转换为`embeddings`(向量或数字列表,包含有关数据的有意义信息)。对于像图像描述这样的任务,模型学习图像嵌入和文本嵌入之间的关系。
### 文档问答
文档问答是从文档中回答自然语言问题的任务。与`token-level`问答任务不同,文档问答将包含问题的文档的图像作为输入,并返回答案。文档问答可用于解析结构化文档并从中提取关键信息。在下面的例子中,可以从收据中提取总金额和找零金额。
```py
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> url = "https://datasets-server.huggingface.co/assets/hf-internal-testing/example-documents/--/hf-internal-testing--example-documents/test/2/image/image.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> doc_question_answerer = pipeline("document-question-answering", model="magorshunov/layoutlm-invoices")
>>> preds = doc_question_answerer(
... question="What is the total amount?",
... image=image,
... )
>>> preds
[{'score': 0.8531, 'answer': '17,000', 'start': 4, 'end': 4}]
```
希望这个页面为您提供了一些有关每种模态中所有类型任务的背景信息以及每个任务的实际重要性。在[下一节](tasks_explained)中,您将了解Transformers如何解决这些任务。
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/serialization.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 导出为 ONNX
在生产环境中部署 🤗 Transformers 模型通常需要或者能够受益于,将模型导出为可在专门的运行时和硬件上加载和执行的序列化格式。
🤗 Optimum 是 Transformers 的扩展,可以通过其 `exporters` 模块将模型从 PyTorch 或 TensorFlow 导出为 ONNX 及 TFLite 等序列化格式。🤗 Optimum 还提供了一套性能优化工具,可以在目标硬件上以最高效率训练和运行模型。
本指南演示了如何使用 🤗 Optimum 将 🤗 Transformers 模型导出为 ONNX。有关将模型导出为 TFLite 的指南,请参考 [导出为 TFLite 页面](tflite)。
## 导出为 ONNX
[ONNX (Open Neural Network eXchange 开放神经网络交换)](http://onnx.ai) 是一个开放的标准,它定义了一组通用的运算符和一种通用的文件格式,用于表示包括 PyTorch 和 TensorFlow 在内的各种框架中的深度学习模型。当一个模型被导出为 ONNX时,这些运算符被用于构建计算图(通常被称为*中间表示*),该图表示数据在神经网络中的流动。
通过公开具有标准化运算符和数据类型的图,ONNX使得模型能够轻松在不同深度学习框架间切换。例如,在 PyTorch 中训练的模型可以被导出为 ONNX,然后再导入到 TensorFlow(反之亦然)。
导出为 ONNX 后,模型可以:
- 通过 [图优化(graph optimization)](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization) 和 [量化(quantization)](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/quantization) 等技术进行推理优化。
- 通过 [`ORTModelForXXX` 类](https://huggingface.co/docs/optimum/onnxruntime/package_reference/modeling_ort) 使用 ONNX Runtime 运行,它同样遵循你熟悉的 Transformers 中的 `AutoModel` API。
- 使用 [优化推理流水线(pipeline)](https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/pipelines) 运行,其 API 与 🤗 Transformers 中的 [`pipeline`] 函数相同。
🤗 Optimum 通过利用配置对象提供对 ONNX 导出的支持。多种模型架构已经有现成的配置对象,并且配置对象也被设计得易于扩展以适用于其他架构。
现有的配置列表请参考 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/exporters/onnx/overview)。
有两种方式可以将 🤗 Transformers 模型导出为 ONNX,这里我们展示这两种方法:
- 使用 🤗 Optimum 的 CLI(命令行)导出。
- 使用 🤗 Optimum 的 `optimum.onnxruntime` 模块导出。
### 使用 CLI 将 🤗 Transformers 模型导出为 ONNX
要将 🤗 Transformers 模型导出为 ONNX,首先需要安装额外的依赖项:
```bash
pip install optimum[exporters]
```
请参阅 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli) 以查看所有可用参数,或者在命令行中查看帮助:
```bash
optimum-cli export onnx --help
```
运行以下命令,以从 🤗 Hub 导出模型的检查点(checkpoint),以 `distilbert-base-uncased-distilled-squad` 为例:
```bash
optimum-cli export onnx --model distilbert-base-uncased-distilled-squad distilbert_base_uncased_squad_onnx/
```
你应该能在日志中看到导出进度以及生成的 `model.onnx` 文件的保存位置,如下所示:
```bash
Validating ONNX model distilbert_base_uncased_squad_onnx/model.onnx...
-[✓] ONNX model output names match reference model (start_logits, end_logits)
- Validating ONNX Model output "start_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
- Validating ONNX Model output "end_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
The ONNX export succeeded and the exported model was saved at: distilbert_base_uncased_squad_onnx
```
上面的示例说明了从 🤗 Hub 导出检查点的过程。导出本地模型时,首先需要确保将模型的权重和分词器文件保存在同一目录(`local_path`)中。在使用 CLI 时,将 `local_path` 传递给 `model` 参数,而不是 🤗 Hub 上的检查点名称,并提供 `--task` 参数。你可以在 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/exporters/task_manager)中查看支持的任务列表。如果未提供 `task` 参数,将默认导出不带特定任务头的模型架构。
```bash
optimum-cli export onnx --model local_path --task question-answering distilbert_base_uncased_squad_onnx/
```
生成的 `model.onnx` 文件可以在支持 ONNX 标准的 [许多加速引擎(accelerators)](https://onnx.ai/supported-tools.html#deployModel) 之一上运行。例如,我们可以使用 [ONNX Runtime](https://onnxruntime.ai/) 加载和运行模型,如下所示:
```python
>>> from transformers import AutoTokenizer
>>> from optimum.onnxruntime import ORTModelForQuestionAnswering
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert_base_uncased_squad_onnx")
>>> model = ORTModelForQuestionAnswering.from_pretrained("distilbert_base_uncased_squad_onnx")
>>> inputs = tokenizer("What am I using?", "Using DistilBERT with ONNX Runtime!", return_tensors="pt")
>>> outputs = model(**inputs)
```
从 Hub 导出 TensorFlow 检查点的过程也一样。例如,以下是从 [Keras 组织](https://huggingface.co/keras-io) 导出纯 TensorFlow 检查点的命令:
```bash
optimum-cli export onnx --model keras-io/transformers-qa distilbert_base_cased_squad_onnx/
```
### 使用 `optimum.onnxruntime` 将 🤗 Transformers 模型导出为 ONNX
除了 CLI 之外,你还可以使用代码将 🤗 Transformers 模型导出为 ONNX,如下所示:
```python
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> from transformers import AutoTokenizer
>>> model_checkpoint = "distilbert_base_uncased_squad"
>>> save_directory = "onnx/"
>>> # 从 transformers 加载模型并将其导出为 ONNX
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(model_checkpoint, export=True)
>>> tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
>>> # 保存 onnx 模型以及分词器
>>> ort_model.save_pretrained(save_directory)
>>> tokenizer.save_pretrained(save_directory)
```
### 导出尚未支持的架构的模型
如果你想要为当前无法导出的模型添加支持,请先检查 [`optimum.exporters.onnx`](https://huggingface.co/docs/optimum/exporters/onnx/overview) 是否支持该模型,如果不支持,你可以 [直接为 🤗 Optimum 贡献代码](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/contribute)。
### 使用 `transformers.onnx` 导出模型
<Tip warning={true}>
`tranformers.onnx` 不再进行维护,请如上所述,使用 🤗 Optimum 导出模型。这部分内容将在未来版本中删除。
</Tip>
要使用 `tranformers.onnx` 将 🤗 Transformers 模型导出为 ONNX,请安装额外的依赖项:
```bash
pip install transformers[onnx]
```
将 `transformers.onnx` 包作为 Python 模块使用,以使用现成的配置导出检查点:
```bash
python -m transformers.onnx --model=distilbert-base-uncased onnx/
```
以上代码将导出由 `--model` 参数定义的检查点的 ONNX 图。传入任何 🤗 Hub 上或者存储与本地的检查点。生成的 `model.onnx` 文件可以在支持 ONNX 标准的众多加速引擎上运行。例如,使用 ONNX Runtime 加载并运行模型,如下所示:
```python
>>> from transformers import AutoTokenizer
>>> from onnxruntime import InferenceSession
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> session = InferenceSession("onnx/model.onnx")
>>> # ONNX Runtime expects NumPy arrays as input
>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
```
可以通过查看每个模型的 ONNX 配置来获取所需的输出名(例如 `["last_hidden_state"]`)。例如,对于 DistilBERT,可以用以下代码获取输出名称:
```python
>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
>>> config = DistilBertConfig()
>>> onnx_config = DistilBertOnnxConfig(config)
>>> print(list(onnx_config.outputs.keys()))
["last_hidden_state"]
```
从 Hub 导出 TensorFlow 检查点的过程也一样。导出纯 TensorFlow 检查点的示例代码如下:
```bash
python -m transformers.onnx --model=keras-io/transformers-qa onnx/
```
要导出本地存储的模型,请将模型的权重和分词器文件保存在同一目录中(例如 `local-pt-checkpoint`),然后通过将 `transformers.onnx` 包的 `--model` 参数指向该目录,将其导出为 ONNX:
```bash
python -m transformers.onnx --model=local-pt-checkpoint onnx/
```
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/autoclass_tutorial.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用AutoClass加载预训练实例
由于存在许多不同的Transformer架构,因此为您的checkpoint创建一个可用架构可能会具有挑战性。通过`AutoClass`可以自动推断并从给定的checkpoint加载正确的架构, 这也是🤗 Transformers易于使用、简单且灵活核心规则的重要一部分。`from_pretrained()`方法允许您快速加载任何架构的预训练模型,因此您不必花费时间和精力从头开始训练模型。生成这种与checkpoint无关的代码意味着,如果您的代码适用于一个checkpoint,它将适用于另一个checkpoint - 只要它们是为了类似的任务进行训练的 - 即使架构不同。
<Tip>
请记住,架构指的是模型的结构,而checkpoints是给定架构的权重。例如,[BERT](https://huggingface.co/bert-base-uncased)是一种架构,而`bert-base-uncased`是一个checkpoint。模型是一个通用术语,可以指代架构或checkpoint。
</Tip>
在这个教程中,学习如何:
* 加载预训练的分词器(`tokenizer`)
* 加载预训练的图像处理器(`image processor`)
* 加载预训练的特征提取器(`feature extractor`)
* 加载预训练的处理器(`processor`)
* 加载预训练的模型。
## AutoTokenizer
几乎所有的NLP任务都以`tokenizer`开始。`tokenizer`将您的输入转换为模型可以处理的格式。
使用[`AutoTokenizer.from_pretrained`]加载`tokenizer`:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
```
然后按照如下方式对输入进行分词:
```py
>>> sequence = "In a hole in the ground there lived a hobbit."
>>> print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
## AutoImageProcessor
对于视觉任务,`image processor`将图像处理成正确的输入格式。
```py
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
```
## AutoFeatureExtractor
对于音频任务,`feature extractor`将音频信号处理成正确的输入格式。
使用[`AutoFeatureExtractor.from_pretrained`]加载`feature extractor`:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
## AutoProcessor
多模态任务需要一种`processor`,将两种类型的预处理工具结合起来。例如,[LayoutLMV2](model_doc/layoutlmv2)模型需要一个`image processo`来处理图像和一个`tokenizer`来处理文本;`processor`将两者结合起来。
使用[`AutoProcessor.from_pretrained`]加载`processor`:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
```
## AutoModel
<frameworkcontent>
<pt>
最后,`AutoModelFor`类让你可以加载给定任务的预训练模型(参见[这里](model_doc/auto)获取可用任务的完整列表)。例如,使用[`AutoModelForSequenceClassification.from_pretrained`]加载用于序列分类的模型:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
轻松地重复使用相同的checkpoint来为不同任务加载模型架构:
```py
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
<Tip warning={true}>
对于PyTorch模型,`from_pretrained()`方法使用`torch.load()`,它内部使用已知是不安全的`pickle`。一般来说,永远不要加载来自不可信来源或可能被篡改的模型。对于托管在Hugging Face Hub上的公共模型,这种安全风险在一定程度上得到了缓解,因为每次提交都会进行[恶意软件扫描](https://huggingface.co/docs/hub/security-malware)。请参阅[Hub文档](https://huggingface.co/docs/hub/security)以了解最佳实践,例如使用GPG进行[签名提交验证](https://huggingface.co/docs/hub/security-gpg#signing-commits-with-gpg)。
TensorFlow和Flax的checkpoints不受影响,并且可以在PyTorch架构中使用`from_tf`和`from_flax`关键字参数,通过`from_pretrained`方法进行加载,来绕过此问题。
</Tip>
一般来说,我们建议使用`AutoTokenizer`类和`AutoModelFor`类来加载预训练的模型实例。这样可以确保每次加载正确的架构。在下一个[教程](preprocessing)中,学习如何使用新加载的`tokenizer`, `image processor`, `feature extractor`和`processor`对数据集进行预处理以进行微调。
</pt>
<tf>
最后,`TFAutoModelFor`类允许您加载给定任务的预训练模型(请参阅[这里](model_doc/auto)获取可用任务的完整列表)。例如,使用[`TFAutoModelForSequenceClassification.from_pretrained`]加载用于序列分类的模型:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
轻松地重复使用相同的checkpoint来为不同任务加载模型架构:
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
一般来说,我们推荐使用`AutoTokenizer`类和`TFAutoModelFor`类来加载模型的预训练实例。这样可以确保每次加载正确的架构。在下一个[教程](preprocessing)中,学习如何使用新加载的`tokenizer`, `image processor`, `feature extractor`和`processor`对数据集进行预处理以进行微调。
</tf>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/peft.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用 🤗 PEFT 加载adapters
[[open-in-colab]]
[参数高效微调(PEFT)方法](https://huggingface.co/blog/peft)在微调过程中冻结预训练模型的参数,并在其顶部添加少量可训练参数(adapters)。adapters被训练以学习特定任务的信息。这种方法已被证明非常节省内存,同时具有较低的计算使用量,同时产生与完全微调模型相当的结果。
使用PEFT训练的adapters通常比完整模型小一个数量级,使其方便共享、存储和加载。
<div class="flex flex-col justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/PEFT-hub-screenshot.png"/>
<figcaption class="text-center">与完整尺寸的模型权重(约为700MB)相比,存储在Hub上的OPTForCausalLM模型的adapter权重仅为~6MB。</figcaption>
</div>
如果您对学习更多关于🤗 PEFT库感兴趣,请查看[文档](https://huggingface.co/docs/peft/index)。
## 设置
首先安装 🤗 PEFT:
```bash
pip install peft
```
如果你想尝试全新的特性,你可能会有兴趣从源代码安装这个库:
```bash
pip install git+https://github.com/huggingface/peft.git
```
## 支持的 PEFT 模型
Transformers原生支持一些PEFT方法,这意味着你可以加载本地存储或在Hub上的adapter权重,并使用几行代码轻松运行或训练它们。以下是受支持的方法:
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
- [AdaLoRA](https://arxiv.org/abs/2303.10512)
如果你想使用其他PEFT方法,例如提示学习或提示微调,或者关于通用的 🤗 PEFT库,请参阅[文档](https://huggingface.co/docs/peft/index)。
## 加载 PEFT adapter
要从huggingface的Transformers库中加载并使用PEFTadapter模型,请确保Hub仓库或本地目录包含一个`adapter_config.json`文件和adapter权重,如上例所示。然后,您可以使用`AutoModelFor`类加载PEFT adapter模型。例如,要为因果语言建模加载一个PEFT adapter模型:
1. 指定PEFT模型id
2. 将其传递给[`AutoModelForCausalLM`]类
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id)
```
<Tip>
你可以使用`AutoModelFor`类或基础模型类(如`OPTForCausalLM`或`LlamaForCausalLM`)来加载一个PEFT adapter。
</Tip>
您也可以通过`load_adapter`方法来加载 PEFT adapter。
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-350m"
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
```
## 基于8bit或4bit进行加载
`bitsandbytes`集成支持8bit和4bit精度数据类型,这对于加载大模型非常有用,因为它可以节省内存(请参阅`bitsandbytes`[指南](./quantization#bitsandbytes-integration)以了解更多信息)。要有效地将模型分配到您的硬件,请在[`~PreTrainedModel.from_pretrained`]中添加`load_in_8bit`或`load_in_4bit`参数,并将`device_map="auto"`设置为:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id, device_map="auto", load_in_8bit=True)
```
## 添加新的adapter
你可以使用[`~peft.PeftModel.add_adapter`]方法为一个已有adapter的模型添加一个新的adapter,只要新adapter的类型与当前adapter相同即可。例如,如果你有一个附加到模型上的LoRA adapter:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
init_lora_weights=False
)
model.add_adapter(lora_config, adapter_name="adapter_1")
```
添加一个新的adapter:
```py
# attach new adapter with same config
model.add_adapter(lora_config, adapter_name="adapter_2")
```
现在您可以使用[`~peft.PeftModel.set_adapter`]来设置要使用的adapter。
```py
# use adapter_1
model.set_adapter("adapter_1")
output = model.generate(**inputs)
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
# use adapter_2
model.set_adapter("adapter_2")
output_enabled = model.generate(**inputs)
print(tokenizer.decode(output_enabled[0], skip_special_tokens=True))
```
## 启用和禁用adapters
一旦您将adapter添加到模型中,您可以启用或禁用adapter模块。要启用adapter模块:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
adapter_model_id = "ybelkada/opt-350m-lora"
tokenizer = AutoTokenizer.from_pretrained(model_id)
text = "Hello"
inputs = tokenizer(text, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(model_id)
peft_config = PeftConfig.from_pretrained(adapter_model_id)
# to initiate with random weights
peft_config.init_lora_weights = False
model.add_adapter(peft_config)
model.enable_adapters()
output = model.generate(**inputs)
```
要禁用adapter模块:
```py
model.disable_adapters()
output = model.generate(**inputs)
```
## 训练一个 PEFT adapter
PEFT适配器受[`Trainer`]类支持,因此您可以为您的特定用例训练适配器。它只需要添加几行代码即可。例如,要训练一个LoRA adapter:
<Tip>
如果你不熟悉如何使用[`Trainer`]微调模型,请查看[微调预训练模型](training)教程。
</Tip>
1. 使用任务类型和超参数定义adapter配置(参见[`~peft.LoraConfig`]以了解超参数的详细信息)。
```py
from peft import LoraConfig
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
```
2. 将adapter添加到模型中。
```py
model.add_adapter(peft_config)
```
3. 现在可以将模型传递给[`Trainer`]了!
```py
trainer = Trainer(model=model, ...)
trainer.train()
```
要保存训练好的adapter并重新加载它:
```py
model.save_pretrained(save_dir)
model = AutoModelForCausalLM.from_pretrained(save_dir)
```
<!--
TODO: (@younesbelkada @stevhliu)
- Link to PEFT docs for further details
- Trainer
- 8-bit / 4-bit examples ?
-->
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/accelerate.md
|
<!--版权2023年HuggingFace团队保留所有权利。
根据Apache许可证第2.0版(“许可证”)许可;除非符合许可证,否则您不得使用此文件。您可以在以下网址获取许可证的副本:
http://www.apache.org/licenses/LICENSE-2.0
除非适用法律要求或书面同意,否则按“按原样”分发的软件,无论是明示还是暗示的,都没有任何担保或条件。请参阅许可证以了解特定语言下的权限和限制。
⚠️ 请注意,本文件虽然使用Markdown编写,但包含了特定的语法,适用于我们的doc-builder(类似于MDX),可能无法在您的Markdown查看器中正常渲染。
-->
# 🤗 加速分布式训练
随着模型变得越来越大,并行性已经成为在有限硬件上训练更大模型和加速训练速度的策略,增加了数个数量级。在Hugging Face,我们创建了[🤗 加速](https://huggingface.co/docs/accelerate)库,以帮助用户在任何类型的分布式设置上轻松训练🤗 Transformers模型,无论是在一台机器上的多个GPU还是在多个机器上的多个GPU。在本教程中,了解如何自定义您的原生PyTorch训练循环,以启用分布式环境中的训练。
## 设置
通过安装🤗 加速开始:
```bash
pip install accelerate
```
然后导入并创建[`~accelerate.Accelerator`]对象。[`~accelerate.Accelerator`]将自动检测您的分布式设置类型,并初始化所有必要的训练组件。您不需要显式地将模型放在设备上。
```py
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
```
## 准备加速
下一步是将所有相关的训练对象传递给[`~accelerate.Accelerator.prepare`]方法。这包括您的训练和评估DataLoader、一个模型和一个优化器:
```py
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
... train_dataloader, eval_dataloader, model, optimizer
... )
```
## 反向传播
最后一步是用🤗 加速的[`~accelerate.Accelerator.backward`]方法替换训练循环中的典型`loss.backward()`:
```py
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... outputs = model(**batch)
... loss = outputs.loss
... accelerator.backward(loss)
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
如您在下面的代码中所见,您只需要添加四行额外的代码到您的训练循环中即可启用分布式训练!
```diff
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
## 训练
在添加了相关代码行后,可以在脚本或笔记本(如Colaboratory)中启动训练。
### 用脚本训练
如果您从脚本中运行训练,请运行以下命令以创建和保存配置文件:
```bash
accelerate config
```
然后使用以下命令启动训练:
```bash
accelerate launch train.py
```
### 用笔记本训练
🤗 加速还可以在笔记本中运行,如果您计划使用Colaboratory的TPU,则可在其中运行。将负责训练的所有代码包装在一个函数中,并将其传递给[`~accelerate.notebook_launcher`]:
```py
>>> from accelerate import notebook_launcher
>>> notebook_launcher(training_function)
```
有关🤗 加速及其丰富功能的更多信息,请参阅[文档](https://huggingface.co/docs/accelerate)。
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/performance.md
|
<!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 性能与可扩展性
训练大型transformer模型并将其部署到生产环境会面临各种挑战。
在训练过程中,模型可能需要比可用的GPU内存更多的资源,或者表现出较慢的训练速度。在部署阶段,模型可能在生产环境中难以处理所需的吞吐量。
本文档旨在帮助您克服这些挑战,并找到适合您使用场景的最佳设置。教程分为训练和推理部分,因为每个部分都有不同的挑战和解决方案。在每个部分中,您将找到针对不同硬件配置的单独指南,例如单GPU与多GPU用于训练或CPU与GPU用于推理。
将此文档作为您的起点,进一步导航到与您的情况匹配的方法。
## 训练
高效训练大型transformer模型需要使用加速器硬件,如GPU或TPU。最常见的情况是您只有一个GPU。您应用于单个GPU上提高训练效率的方法可以扩展到其他设置,如多个GPU。然而,也有一些特定于多GPU或CPU训练的技术。我们在单独的部分中介绍它们。
* [在单个GPU上进行高效训练的方法和工具](perf_train_gpu_one):从这里开始学习常见的方法,可以帮助优化GPU内存利用率、加快训练速度或两者兼备。
* [多GPU训练部分](perf_train_gpu_many):探索此部分以了解适用于多GPU设置的进一步优化方法,例如数据并行、张量并行和流水线并行。
* [CPU训练部分](perf_train_cpu):了解在CPU上的混合精度训练。
* [在多个CPU上进行高效训练](perf_train_cpu_many):了解分布式CPU训练。
* [使用TensorFlow在TPU上进行训练](perf_train_tpu_tf):如果您对TPU还不熟悉,请参考此部分,了解有关在TPU上进行训练和使用XLA的建议性介绍。
* [自定义硬件进行训练](perf_hardware):在构建自己的深度学习机器时查找技巧和窍门。
* [使用Trainer API进行超参数搜索](hpo_train)
## 推理
在生产环境中对大型模型进行高效推理可能与训练它们一样具有挑战性。在接下来的部分中,我们将详细介绍如何在CPU和单/多GPU设置上进行推理的步骤。
* [在单个CPU上进行推理](perf_infer_cpu)
* [在单个GPU上进行推理](perf_infer_gpu_one)
* [多GPU推理](perf_infer_gpu_one)
* [TensorFlow模型的XLA集成](tf_xla)
## 训练和推理
在这里,您将找到适用于训练模型或使用它进行推理的技巧、窍门和技巧。
* [实例化大型模型](big_models)
* [解决性能问题](debugging)
## 贡献
这份文档还远远没有完成,还有很多需要添加的内容,所以如果你有补充或更正的内容,请毫不犹豫地提交一个PR(Pull Request),或者如果你不确定,可以创建一个Issue,我们可以在那里讨论细节。
在做出贡献时,如果A比B更好,请尽量包含可重复的基准测试和(或)该信息来源的链接(除非它直接来自您)。
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/training.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 微调预训练模型
[[open-in-colab]]
使用预训练模型有许多显著的好处。它降低了计算成本,减少了碳排放,同时允许您使用最先进的模型,而无需从头开始训练一个。🤗 Transformers 提供了涉及各种任务的成千上万的预训练模型。当您使用预训练模型时,您需要在与任务相关的数据集上训练该模型。这种操作被称为微调,是一种非常强大的训练技术。在本教程中,您将使用您选择的深度学习框架来微调一个预训练模型:
* 使用 🤗 Transformers 的 [`Trainer`] 来微调预训练模型。
* 在 TensorFlow 中使用 Keras 来微调预训练模型。
* 在原生 PyTorch 中微调预训练模型。
<a id='data-processing'></a>
## 准备数据集
<Youtube id="_BZearw7f0w"/>
在您进行预训练模型微调之前,需要下载一个数据集并为训练做好准备。之前的教程向您展示了如何处理训练数据,现在您有机会将这些技能付诸实践!
首先,加载[Yelp评论](https://huggingface.co/datasets/yelp_review_full)数据集:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("yelp_review_full")
>>> dataset["train"][100]
{'label': 0,
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
```
正如您现在所知,您需要一个`tokenizer`来处理文本,包括填充和截断操作以处理可变的序列长度。如果要一次性处理您的数据集,可以使用 🤗 Datasets 的 [`map`](https://huggingface.co/docs/datasets/process#map) 方法,将预处理函数应用于整个数据集:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
>>> def tokenize_function(examples):
... return tokenizer(examples["text"], padding="max_length", truncation=True)
>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
```
如果愿意的话,您可以从完整数据集提取一个较小子集来进行微调,以减少训练所需的时间:
```py
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
```
<a id='trainer'></a>
## 训练
此时,您应该根据您训练所用的框架来选择对应的教程章节。您可以使用右侧的链接跳转到您想要的章节 - 如果您想隐藏某个框架对应的所有教程内容,只需使用右上角的按钮!
<frameworkcontent>
<pt>
<Youtube id="nvBXf7s7vTI"/>
## 使用 PyTorch Trainer 进行训练
🤗 Transformers 提供了一个专为训练 🤗 Transformers 模型而优化的 [`Trainer`] 类,使您无需手动编写自己的训练循环步骤而更轻松地开始训练模型。[`Trainer`] API 支持各种训练选项和功能,如日志记录、梯度累积和混合精度。
首先加载您的模型并指定期望的标签数量。根据 Yelp Review [数据集卡片](https://huggingface.co/datasets/yelp_review_full#data-fields),您知道有五个标签:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
<Tip>
您将会看到一个警告,提到一些预训练权重未被使用,以及一些权重被随机初始化。不用担心,这是完全正常的!BERT 模型的预训练`head`被丢弃,并替换为一个随机初始化的分类`head`。您将在您的序列分类任务上微调这个新模型`head`,将预训练模型的知识转移给它。
</Tip>
### 训练超参数
接下来,创建一个 [`TrainingArguments`] 类,其中包含您可以调整的所有超参数以及用于激活不同训练选项的标志。对于本教程,您可以从默认的训练[超参数](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments)开始,但随时可以尝试不同的设置以找到最佳设置。
指定保存训练检查点的位置:
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(output_dir="test_trainer")
```
### 评估
[`Trainer`] 在训练过程中不会自动评估模型性能。您需要向 [`Trainer`] 传递一个函数来计算和展示指标。[🤗 Evaluate](https://huggingface.co/docs/evaluate/index) 库提供了一个简单的 [`accuracy`](https://huggingface.co/spaces/evaluate-metric/accuracy) 函数,您可以使用 [`evaluate.load`] 函数加载它(有关更多信息,请参阅此[快速入门](https://huggingface.co/docs/evaluate/a_quick_tour)):
```py
>>> import numpy as np
>>> import evaluate
>>> metric = evaluate.load("accuracy")
```
在 `metric` 上调用 [`~evaluate.compute`] 来计算您的预测的准确性。在将预测传递给 `compute` 之前,您需要将预测转换为`logits`(请记住,所有 🤗 Transformers 模型都返回对`logits`):
```py
>>> def compute_metrics(eval_pred):
... logits, labels = eval_pred
... predictions = np.argmax(logits, axis=-1)
... return metric.compute(predictions=predictions, references=labels)
```
如果您希望在微调过程中监视评估指标,请在您的训练参数中指定 `evaluation_strategy` 参数,以在每个`epoch`结束时展示评估指标:
```py
>>> from transformers import TrainingArguments, Trainer
>>> training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch")
```
### 训练器
创建一个包含您的模型、训练参数、训练和测试数据集以及评估函数的 [`Trainer`] 对象:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
然后调用[`~transformers.Trainer.train`]以微调模型:
```py
>>> trainer.train()
```
</pt>
<tf>
<a id='keras'></a>
<Youtube id="rnTGBy2ax1c"/>
## 使用keras训练TensorFlow模型
您也可以使用 Keras API 在 TensorFlow 中训练 🤗 Transformers 模型!
### 加载用于 Keras 的数据
当您希望使用 Keras API 训练 🤗 Transformers 模型时,您需要将您的数据集转换为 Keras 可理解的格式。如果您的数据集很小,您可以将整个数据集转换为NumPy数组并传递给 Keras。在进行更复杂的操作之前,让我们先尝试这种方法。
首先,加载一个数据集。我们将使用 [GLUE benchmark](https://huggingface.co/datasets/glue) 中的 CoLA 数据集,因为它是一个简单的二元文本分类任务。现在只使用训练数据集。
```py
from datasets import load_dataset
dataset = load_dataset("glue", "cola")
dataset = dataset["train"] # Just take the training split for now
```
接下来,加载一个`tokenizer`并将数据标记为 NumPy 数组。请注意,标签已经是由 0 和 1 组成的`list`,因此我们可以直接将其转换为 NumPy 数组而无需进行分词处理!
```py
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenized_data = tokenizer(dataset["sentence"], return_tensors="np", padding=True)
# Tokenizer returns a BatchEncoding, but we convert that to a dict for Keras
tokenized_data = dict(tokenized_data)
labels = np.array(dataset["label"]) # Label is already an array of 0 and 1
```
最后,加载、[`compile`](https://keras.io/api/models/model_training_apis/#compile-method) 和 [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) 模型。请注意,Transformers 模型都有一个默认的与任务相关的损失函数,因此除非您希望自定义,否则无需指定一个损失函数:
```py
from transformers import TFAutoModelForSequenceClassification
from tensorflow.keras.optimizers import Adam
# Load and compile our model
model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased")
# Lower learning rates are often better for fine-tuning transformers
model.compile(optimizer=Adam(3e-5)) # No loss argument!
model.fit(tokenized_data, labels)
```
<Tip>
当您使用 `compile()` 编译模型时,无需传递损失参数!如果不指定损失参数,Hugging Face 模型会自动选择适合其任务和模型架构的损失函数。如果需要,您始终可以自己指定损失函数以覆盖默认配置。
</Tip>
这种方法对于较小的数据集效果很好,但对于较大的数据集,您可能会发现它开始变得有问题。为什么呢?因为分词后的数组和标签必须完全加载到内存中,而且由于 NumPy 无法处理“不规则”数组,因此每个分词后的样本长度都必须被填充到数据集中最长样本的长度。这将使您的数组变得更大,而所有这些`padding tokens`也会减慢训练速度!
### 将数据加载为 tf.data.Dataset
如果您想避免训练速度减慢,可以将数据加载为 `tf.data.Dataset`。虽然您可以自己编写自己的 `tf.data` 流水线,但我们有两种方便的方法来实现这一点:
- [`~TFPreTrainedModel.prepare_tf_dataset`]:这是我们在大多数情况下推荐的方法。因为它是模型上的一个方法,它可以检查模型以自动确定哪些列可用作模型输入,并丢弃其他列以创建一个更简单、性能更好的数据集。
- [`~datasets.Dataset.to_tf_dataset`]:这个方法更低级,但当您希望完全控制数据集的创建方式时非常有用,可以通过指定要包括的确切 `columns` 和 `label_cols` 来实现。
在使用 [`~TFPreTrainedModel.prepare_tf_dataset`] 之前,您需要将`tokenizer`的输出添加到数据集作为列,如下面的代码示例所示:
```py
def tokenize_dataset(data):
# Keys of the returned dictionary will be added to the dataset as columns
return tokenizer(data["text"])
dataset = dataset.map(tokenize_dataset)
```
请记住,默认情况下,Hugging Face 数据集存储在硬盘上,因此这不会增加您的内存使用!一旦列已经添加,您可以从数据集中流式的传输批次数据,并为每个批次添加`padding tokens`,这与为整个数据集添加`padding tokens`相比,大大减少了`padding tokens`的数量。
```py
>>> tf_dataset = model.prepare_tf_dataset(dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer)
```
请注意,在上面的代码示例中,您需要将`tokenizer`传递给`prepare_tf_dataset`,以便它可以在加载批次时正确填充它们。如果数据集中的所有样本都具有相同的长度而且不需要填充,您可以跳过此参数。如果需要执行比填充样本更复杂的操作(例如,用于掩码语言模型的`tokens` 替换),则可以使用 `collate_fn` 参数,而不是传递一个函数来将样本列表转换为批次并应用任何所需的预处理。请查看我们的[示例](https://github.com/huggingface/transformers/tree/main/examples)或[笔记](https://huggingface.co/docs/transformers/notebooks)以了解此方法的实际操作。
一旦创建了 `tf.data.Dataset`,您可以像以前一样编译和训练模型:
```py
model.compile(optimizer=Adam(3e-5)) # No loss argument!
model.fit(tf_dataset)
```
</tf>
</frameworkcontent>
<a id='pytorch_native'></a>
## 在原生 PyTorch 中训练
<frameworkcontent>
<pt>
<Youtube id="Dh9CL8fyG80"/>
[`Trainer`] 负责训练循环,允许您在一行代码中微调模型。对于喜欢编写自己训练循环的用户,您也可以在原生 PyTorch 中微调 🤗 Transformers 模型。
现在,您可能需要重新启动您的`notebook`,或执行以下代码以释放一些内存:
```py
del model
del trainer
torch.cuda.empty_cache()
```
接下来,手动处理 `tokenized_dataset` 以准备进行训练。
1. 移除 text 列,因为模型不接受原始文本作为输入:
```py
>>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
```
2. 将 label 列重命名为 labels,因为模型期望参数的名称为 labels:
```py
>>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
```
3. 设置数据集的格式以返回 PyTorch 张量而不是`lists`:
```py
>>> tokenized_datasets.set_format("torch")
```
接着,创建一个先前展示的数据集的较小子集,以加速微调过程
```py
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
```
### DataLoader
您的训练和测试数据集创建一个`DataLoader`类,以便可以迭代处理数据批次
```py
>>> from torch.utils.data import DataLoader
>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
```
加载您的模型,并指定期望的标签数量:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
### Optimizer and learning rate scheduler
创建一个`optimizer`和`learning rate scheduler`以进行模型微调。让我们使用 PyTorch 中的 [AdamW](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html) 优化器:
```py
>>> from torch.optim import AdamW
>>> optimizer = AdamW(model.parameters(), lr=5e-5)
```
创建来自 [`Trainer`] 的默认`learning rate scheduler`:
```py
>>> from transformers import get_scheduler
>>> num_epochs = 3
>>> num_training_steps = num_epochs * len(train_dataloader)
>>> lr_scheduler = get_scheduler(
... name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
... )
```
最后,指定 `device` 以使用 GPU(如果有的话)。否则,使用 CPU 进行训练可能需要几个小时,而不是几分钟。
```py
>>> import torch
>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
>>> model.to(device)
```
<Tip>
如果没有 GPU,可以通过notebook平台如 [Colaboratory](https://colab.research.google.com/) 或 [SageMaker StudioLab](https://studiolab.sagemaker.aws/) 来免费获得云端GPU使用。
</Tip>
现在您已经准备好训练了!🥳
### 训练循环
为了跟踪训练进度,使用 [tqdm](https://tqdm.github.io/) 库来添加一个进度条,显示训练步数的进展:
```py
>>> from tqdm.auto import tqdm
>>> progress_bar = tqdm(range(num_training_steps))
>>> model.train()
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... batch = {k: v.to(device) for k, v in batch.items()}
... outputs = model(**batch)
... loss = outputs.loss
... loss.backward()
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
### 评估
就像您在 [`Trainer`] 中添加了一个评估函数一样,当您编写自己的训练循环时,您需要做同样的事情。但与在每个`epoch`结束时计算和展示指标不同,这一次您将使用 [`~evaluate.add_batch`] 累积所有批次,并在最后计算指标。
```py
>>> import evaluate
>>> metric = evaluate.load("accuracy")
>>> model.eval()
>>> for batch in eval_dataloader:
... batch = {k: v.to(device) for k, v in batch.items()}
... with torch.no_grad():
... outputs = model(**batch)
... logits = outputs.logits
... predictions = torch.argmax(logits, dim=-1)
... metric.add_batch(predictions=predictions, references=batch["labels"])
>>> metric.compute()
```
</pt>
</frameworkcontent>
<a id='additional-resources'></a>
## 附加资源
更多微调例子可参考如下链接:
- [🤗 Transformers 示例](https://github.com/huggingface/transformers/tree/main/examples) 包含用于在 PyTorch 和 TensorFlow 中训练常见自然语言处理任务的脚本。
- [🤗 Transformers 笔记](notebooks) 包含针对特定任务在 PyTorch 和 TensorFlow 中微调模型的各种`notebook`。
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/index.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Transformers简介
为 [PyTorch](https://pytorch.org/)、[TensorFlow](https://www.tensorflow.org/) 和 [JAX](https://jax.readthedocs.io/en/latest/) 打造的先进的机器学习工具.
🤗 Transformers 提供了可以轻松地下载并且训练先进的预训练模型的 API 和工具。使用预训练模型可以减少计算消耗和碳排放,并且节省从头训练所需要的时间和资源。这些模型支持不同模态中的常见任务,比如:
📝 **自然语言处理**:文本分类、命名实体识别、问答、语言建模、摘要、翻译、多项选择和文本生成。<br>
🖼️ **机器视觉**:图像分类、目标检测和语义分割。<br>
🗣️ **音频**:自动语音识别和音频分类。<br>
🐙 **多模态**:表格问答、光学字符识别、从扫描文档提取信息、视频分类和视觉问答。
🤗 Transformers 支持在 PyTorch、TensorFlow 和 JAX 上的互操作性. 这给在模型的每个阶段使用不同的框架带来了灵活性;在一个框架中使用几行代码训练一个模型,然后在另一个框架中加载它并进行推理。模型也可以被导出为 ONNX 和 TorchScript 格式,用于在生产环境中部署。
马上加入在 [Hub](https://huggingface.co/models)、[论坛](https://discuss.huggingface.co/) 或者 [Discord](https://discord.com/invite/JfAtkvEtRb) 上正在快速发展的社区吧!
## 如果你需要来自 Hugging Face 团队的个性化支持
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
## 目录
这篇文档被组织为以下5个章节:
- **开始使用** 包含了库的快速上手和安装说明,便于配置和运行。
- **教程** 是一个初学者开始的好地方。本章节将帮助你获得你会用到的使用这个库的基本技能。
- **操作指南** 向你展示如何实现一个特定目标,比如为语言建模微调一个预训练模型或者如何创造并分享个性化模型。
- **概念指南** 对 🤗 Transformers 的模型,任务和设计理念背后的基本概念和思想做了更多的讨论和解释。
- **API 介绍** 描述了所有的类和函数:
- **MAIN CLASSES** 详述了配置(configuration)、模型(model)、分词器(tokenizer)和流水线(pipeline)这几个最重要的类。
- **MODELS** 详述了在这个库中和每个模型实现有关的类和函数。
- **INTERNAL HELPERS** 详述了内部使用的工具类和函数。
### 支持的模型
<!--This list is updated automatically from the README with _make fix-copies_. Do not update manually! -->
1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
1. **[AltCLIP](model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
1. **[Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BioGpt](model_doc/biogpt)** (from Microsoft Research AI4Science) released with the paper [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu.
1. **[BiT](model_doc/bit)** (from Google AI) released with the paper [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BLIP](model_doc/blip)** (from Salesforce) released with the paper [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
1. **[BLOOM](model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[Chinese-CLIP](model_doc/chinese_clip)** (from OFA-Sys) released with the paper [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
1. **[DiNAT](model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
1. **[ESM](model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
1. **[FLAN-T5](model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
1. **[GIT](model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
1. **[GPT NeoX Japanese](model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPT-Sw3](model_doc/gpt-sw3)** (from AI-Sweden) released with the paper [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
1. **[MobileNetV1](model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
1. **[MobileNetV2](model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
1. **[NAT](model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
1. **[RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
1. **[RoCBert](model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
1. **[Swin2SR](model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
1. **[SwitchTransformers](model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Time Series Transformer](model_doc/time_series_transformer)** (from HuggingFace).
1. **[TimeSformer](model_doc/timesformer)** (from Facebook) released with the paper [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[UPerNet](model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[ViT Hybrid](model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Whisper](model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### 支持的框架
下表展示了库中对每个模型的支持情况,如是否具有 Python 分词器(表中的“Tokenizer slow”)、是否具有由 🤗 Tokenizers 库支持的快速分词器(表中的“Tokenizer fast”)、是否支持 Jax(通过
Flax)、PyTorch 与 TensorFlow。
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
|:-----------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| AltCLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| Audio Spectrogram Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
| BigBird-Pegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
| BioGpt | ✅ | ❌ | ✅ | ❌ | ❌ |
| BiT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
| BLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
| Chinese-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
| CLIPSeg | ❌ | ❌ | ✅ | ❌ | ❌ |
| CodeGen | ✅ | ✅ | ✅ | ❌ | ❌ |
| Conditional DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ConvNeXT | ❌ | ❌ | ✅ | ✅ | ❌ |
| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
| CvT | ❌ | ❌ | ✅ | ✅ | ❌ |
| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Deformable DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DeiT | ❌ | ❌ | ✅ | ✅ | ❌ |
| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DiNAT | ❌ | ❌ | ✅ | ❌ | ❌ |
| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| DonutSwin | ❌ | ❌ | ✅ | ❌ | ❌ |
| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| ERNIE | ❌ | ❌ | ✅ | ❌ | ❌ |
| ESM | ✅ | ❌ | ✅ | ✅ | ❌ |
| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
| FLAVA | ❌ | ❌ | ✅ | ❌ | ❌ |
| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| GIT | ❌ | ❌ | ✅ | ❌ | ❌ |
| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
| GPT NeoX Japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
| GPT-Sw3 | ✅ | ✅ | ✅ | ✅ | ✅ |
| GroupViT | ❌ | ❌ | ✅ | ✅ | ❌ |
| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Jukebox | ✅ | ❌ | ✅ | ❌ | ❌ |
| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
| LiLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| LongT5 | ❌ | ❌ | ✅ | ❌ | ✅ |
| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| M-CTC-T | ❌ | ❌ | ✅ | ❌ | ❌ |
| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
| MarkupLM | ✅ | ✅ | ✅ | ❌ | ❌ |
| Mask2Former | ❌ | ❌ | ✅ | ❌ | ❌ |
| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| MaskFormerSwin | ❌ | ❌ | ❌ | ❌ | ❌ |
| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
| Megatron-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| MobileNetV1 | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileNetV2 | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileViT | ❌ | ❌ | ✅ | ✅ | ❌ |
| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| MT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| MVP | ✅ | ✅ | ✅ | ❌ | ❌ |
| NAT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Nezha | ❌ | ❌ | ✅ | ❌ | ❌ |
| Nyströmformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| OPT | ❌ | ❌ | ✅ | ✅ | ✅ |
| OWL-ViT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
| PEGASUS-X | ❌ | ❌ | ✅ | ❌ | ❌ |
| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
| REALM | ✅ | ✅ | ✅ | ❌ | ❌ |
| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ResNet | ❌ | ❌ | ✅ | ✅ | ❌ |
| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| RoBERTa-PreLayerNorm | ❌ | ❌ | ✅ | ✅ | ✅ |
| RoCBert | ✅ | ❌ | ✅ | ❌ | ❌ |
| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
| SegFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| Swin Transformer | ❌ | ❌ | ✅ | ✅ | ❌ |
| Swin Transformer V2 | ❌ | ❌ | ✅ | ❌ | ❌ |
| Swin2SR | ❌ | ❌ | ✅ | ❌ | ❌ |
| SwitchTransformers | ❌ | ❌ | ✅ | ❌ | ❌ |
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Table Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
| Time Series Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| TimeSformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
| UPerNet | ❌ | ❌ | ✅ | ❌ | ❌ |
| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
| VideoMAE | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| VisualBERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
| ViT Hybrid | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
| ViTMSN | ❌ | ❌ | ✅ | ❌ | ❌ |
| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
| Whisper | ✅ | ❌ | ✅ | ✅ | ❌ |
| X-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| XGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
| XLM-ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
<!-- End table-->
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/custom_models.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 共享自定义模型
🤗 Transformers 库设计得易于扩展。每个模型的代码都在仓库给定的子文件夹中,没有进行抽象,因此你可以轻松复制模型代码文件并根据需要进行调整。
如果你要编写全新的模型,从头开始可能更容易。在本教程中,我们将向你展示如何编写自定义模型及其配置,以便可以在 Transformers 中使用它;以及如何与社区共享它(及其依赖的代码),以便任何人都可以使用,即使它不在 🤗 Transformers 库中。
我们将以 ResNet 模型为例,通过将 [timm 库](https://github.com/rwightman/pytorch-image-models) 的 ResNet 类封装到 [`PreTrainedModel`] 中来进行说明。
## 编写自定义配置
在深入研究模型之前,让我们首先编写其配置。模型的配置是一个对象,其中包含构建模型所需的所有信息。我们将在下一节中看到,模型只能接受一个 `config` 来进行初始化,因此我们很需要使该对象尽可能完整。
我们将采用一些我们可能想要调整的 ResNet 类的参数举例。不同的配置将为我们提供不同类型可能的 ResNet 模型。在确认其中一些参数的有效性后,我们只需存储这些参数。
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
编写自定义配置时需要记住的三个重要事项如下:
- 必须继承自 `PretrainedConfig`,
- `PretrainedConfig` 的 `__init__` 方法必须接受任何 kwargs,
- 这些 `kwargs` 需要传递给超类的 `__init__` 方法。
继承是为了确保你获得来自 🤗 Transformers 库的所有功能,而另外两个约束源于 `PretrainedConfig` 的字段比你设置的字段多。在使用 `from_pretrained` 方法重新加载配置时,这些字段需要被你的配置接受,然后传递给超类。
为你的配置定义 `model_type`(此处为 `model_type="resnet"`)不是必须的,除非你想使用自动类注册你的模型(请参阅最后一节)。
做完这些以后,就可以像使用库里任何其他模型配置一样,轻松地创建和保存配置。以下代码展示了如何创建并保存 resnet50d 配置:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
这行代码将在 `custom-resnet` 文件夹内保存一个名为 `config.json` 的文件。然后,你可以使用 `from_pretrained` 方法重新加载配置:
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
你还可以使用 [`PretrainedConfig`] 类的任何其他方法,例如 [`~PretrainedConfig.push_to_hub`],直接将配置上传到 Hub。
## 编写自定义模型
有了 ResNet 配置后,就可以继续编写模型了。实际上,我们将编写两个模型:一个模型用于从一批图像中提取隐藏特征(类似于 [`BertModel`]),另一个模型适用于图像分类(类似于 [`BertForSequenceClassification`])。
正如之前提到的,我们只会编写一个松散的模型包装,以使示例保持简洁。在编写此类之前,只需要建立起块类型(block types)与实际块类(block classes)之间的映射。然后,通过将所有内容传递给ResNet类,从配置中定义模型:
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
对用于进行图像分类的模型,我们只需更改前向方法:
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
在这两种情况下,请注意我们如何继承 `PreTrainedModel` 并使用 `config` 调用了超类的初始化(有点像编写常规的torch.nn.Module)。设置 `config_class` 的那行代码不是必须的,除非你想使用自动类注册你的模型(请参阅最后一节)。
<Tip>
如果你的模型与库中的某个模型非常相似,你可以重用与该模型相同的配置。
</Tip>
你可以让模型返回任何你想要的内容,但是像我们为 `ResnetModelForImageClassification` 做的那样返回一个字典,并在传递标签时包含loss,可以使你的模型能够在 [`Trainer`] 类中直接使用。只要你计划使用自己的训练循环或其他库进行训练,也可以使用其他输出格式。
现在我们已经有了模型类,让我们创建一个:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
同样的,你可以使用 [`PreTrainedModel`] 的任何方法,比如 [`~PreTrainedModel.save_pretrained`] 或者 [`~PreTrainedModel.push_to_hub`]。我们将在下一节中使用第二种方法,并了解如何如何使用我们的模型的代码推送模型权重。但首先,让我们在模型内加载一些预训练权重。
在你自己的用例中,你可能会在自己的数据上训练自定义模型。为了快速完成本教程,我们将使用 resnet50d 的预训练版本。由于我们的模型只是它的包装,转移这些权重将会很容易:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
现在让我们看看,如何确保在执行 [`~PreTrainedModel.save_pretrained`] 或 [`~PreTrainedModel.push_to_hub`] 时,模型的代码被保存。
## 将代码发送到 Hub
<Tip warning={true}>
此 API 是实验性的,未来的发布中可能会有一些轻微的不兼容更改。
</Tip>
首先,确保你的模型在一个 `.py` 文件中完全定义。只要所有文件都位于同一目录中,它就可以依赖于某些其他文件的相对导入(目前我们还不为子模块支持此功能)。对于我们的示例,我们将在当前工作目录中名为 `resnet_model` 的文件夹中定义一个 `modeling_resnet.py` 文件和一个 `configuration_resnet.py` 文件。 配置文件包含 `ResnetConfig` 的代码,模型文件包含 `ResnetModel` 和 `ResnetModelForImageClassification` 的代码。
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
`__init__.py` 可以为空,它的存在只是为了让 Python 检测到 `resnet_model` 可以用作模块。
<Tip warning={true}>
如果从库中复制模型文件,你需要将文件顶部的所有相对导入替换为从 `transformers` 包中的导入。
</Tip>
请注意,你可以重用(或子类化)现有的配置/模型。
要与社区共享您的模型,请参照以下步骤:首先从新创建的文件中导入ResNet模型和配置:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
接下来,你需要告诉库,当使用 `save_pretrained` 方法时,你希望复制这些对象的代码文件,并将它们正确注册到给定的 Auto 类(特别是对于模型),只需要运行以下代码:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
请注意,对于配置(只有一个自动类 [`AutoConfig`]),不需要指定自动类,但对于模型来说情况不同。 你的自定义模型可能适用于许多不同的任务,因此你必须指定哪一个自动类适合你的模型。
接下来,让我们像之前一样创建配置和模型:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
现在要将模型推送到集线器,请确保你已登录。你看可以在终端中运行以下命令:
```bash
huggingface-cli login
```
或者在笔记本中运行以下代码:
```py
from huggingface_hub import notebook_login
notebook_login()
```
然后,可以这样将模型推送到自己的命名空间(或你所属的组织):
```py
resnet50d.push_to_hub("custom-resnet50d")
```
除了模型权重和 JSON 格式的配置外,这行代码也会复制 `custom-resnet50d` 文件夹内的模型以及配置的 `.py` 文件并将结果上传至 Hub。你可以在此[模型仓库](https://huggingface.co/sgugger/custom-resnet50d)中查看结果。
有关推推送至 Hub 方法的更多信息,请参阅[共享教程](model_sharing)。
## 使用带有自定义代码的模型
可以使用自动类(auto-classes)和 `from_pretrained` 方法,使用模型仓库里带有自定义代码的配置、模型或分词器文件。所有上传到 Hub 的文件和代码都会进行恶意软件扫描(有关更多信息,请参阅 [Hub 安全](https://huggingface.co/docs/hub/security#malware-scanning) 文档), 但你仍应查看模型代码和作者,以避免在你的计算机上执行恶意代码。 设置 `trust_remote_code=True` 以使用带有自定义代码的模型:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
我们强烈建议为 `revision` 参数传递提交哈希(commit hash),以确保模型的作者没有使用一些恶意的代码行更新了代码(除非您完全信任模型的作者)。
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
```
在 Hub 上浏览模型仓库的提交历史时,有一个按钮可以轻松复制任何提交的提交哈希。
## 将自定义代码的模型注册到自动类
如果你在编写一个扩展 🤗 Transformers 的库,你可能想要扩展自动类以包含您自己的模型。这与将代码推送到 Hub 不同,因为用户需要导入你的库才能获取自定义模型(与从 Hub 自动下载模型代码相反)。
只要你的配置 `model_type` 属性与现有模型类型不同,并且你的模型类有正确的 `config_class` 属性,你可以像这样将它们添加到自动类中:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
请注意,将自定义配置注册到 [`AutoConfig`] 时,使用的第一个参数需要与自定义配置的 `model_type` 匹配;而将自定义模型注册到任何自动模型类时,使用的第一个参数需要与 `config_class` 匹配。
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/perf_hardware.md
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 训练用的定制硬件
您用来运行模型训练和推断的硬件可能会对性能产生重大影响。要深入了解 GPU,务必查看 Tim Dettmer 出色的[博文](https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/)。
让我们来看一些关于 GPU 配置的实用建议。
## GPU
当你训练更大的模型时,基本上有三种选择:
- 更大的 GPU
- 更多的 GPU
- 更多的 CPU 和 NVMe(通过[DeepSpeed-Infinity](main_classes/deepspeed#nvme-support)实现)
让我们从只有一块GPU的情况开始。
### 供电和散热
如果您购买了昂贵的高端GPU,请确保为其提供正确的供电和足够的散热。
**供电**:
一些高端消费者级GPU卡具有2个,有时甚至3个PCI-E-8针电源插口。请确保将与插口数量相同的独立12V PCI-E-8针线缆插入卡中。不要使用同一根线缆两端的2个分叉(也称为pigtail cable)。也就是说,如果您的GPU上有2个插口,您需要使用2条PCI-E-8针线缆连接电源和卡,而不是使用一条末端有2个PCI-E-8针连接器的线缆!否则,您无法充分发挥卡的性能。
每个PCI-E-8针电源线缆需要插入电源侧的12V轨上,并且可以提供最多150W的功率。
其他一些卡可能使用PCI-E-12针连接器,这些连接器可以提供最多500-600W的功率。
低端卡可能使用6针连接器,这些连接器可提供最多75W的功率。
此外,您需要选择具有稳定电压的高端电源。一些质量较低的电源可能无法为卡提供所需的稳定电压以发挥其最大性能。
当然,电源还需要有足够的未使用的瓦数来为卡供电。
**散热**:
当GPU过热时,它将开始降频,不会提供完整的性能。如果温度过高,可能会缩短GPU的使用寿命。
当GPU负载很重时,很难确定最佳温度是多少,但任何低于+80度的温度都是好的,越低越好,也许在70-75度之间是一个非常好的范围。降频可能从大约84-90度开始。但是除了降频外,持续的高温可能会缩短GPU的使用寿命。
接下来让我们看一下拥有多个GPU时最重要的方面之一:连接。
### 多GPU连接
如果您使用多个GPU,则卡之间的互连方式可能会对总训练时间产生巨大影响。如果GPU位于同一物理节点上,您可以运行以下代码:
```
nvidia-smi topo -m
```
它将告诉您GPU如何互连。在具有双GPU并通过NVLink连接的机器上,您最有可能看到类似以下内容:
```
GPU0 GPU1 CPU Affinity NUMA Affinity
GPU0 X NV2 0-23 N/A
GPU1 NV2 X 0-23 N/A
```
在不同的机器上,如果没有NVLink,我们可能会看到:
```
GPU0 GPU1 CPU Affinity NUMA Affinity
GPU0 X PHB 0-11 N/A
GPU1 PHB X 0-11 N/A
```
这个报告包括了这个输出:
```
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
```
因此,第一个报告`NV2`告诉我们GPU通过2个NVLink互连,而第二个报告`PHB`展示了典型的消费者级PCIe+Bridge设置。
检查你的设置中具有哪种连接类型。其中一些会使卡之间的通信更快(例如NVLink),而其他则较慢(例如PHB)。
根据使用的扩展解决方案的类型,连接速度可能会产生重大或较小的影响。如果GPU很少需要同步,就像在DDP中一样,那么较慢的连接的影响将不那么显著。如果GPU经常需要相互发送消息,就像在ZeRO-DP中一样,那么更快的连接对于实现更快的训练变得非常重要。
#### NVlink
[NVLink](https://en.wikipedia.org/wiki/NVLink)是由Nvidia开发的一种基于线缆的串行多通道近程通信链接。
每个新一代提供更快的带宽,例如在[Nvidia Ampere GA102 GPU架构](https://www.nvidia.com/content/dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf)中有这样的引述:
> Third-Generation NVLink®
> GA102 GPUs utilize NVIDIA’s third-generation NVLink interface, which includes four x4 links,
> with each link providing 14.0625 GB/sec bandwidth in each direction between two GPUs. Four
> links provide 56.25 GB/sec bandwidth in each direction, and 112.5 GB/sec total bandwidth
> between two GPUs. Two RTX 3090 GPUs can be connected together for SLI using NVLink.
> (Note that 3-Way and 4-Way SLI configurations are not supported.)
所以,在`nvidia-smi topo -m`输出的`NVX`报告中获取到的更高的`X`值意味着更好的性能。生成的结果将取决于您的GPU架构。
让我们比较在小样本wikitext上训练gpt2语言模型的执行结果。
结果是:
| NVlink | Time |
| ----- | ---: |
| Y | 101s |
| N | 131s |
可以看到,NVLink使训练速度提高了约23%。在第二个基准测试中,我们使用`NCCL_P2P_DISABLE=1`告诉GPU不要使用NVLink。
这里是完整的基准测试代码和输出:
```bash
# DDP w/ NVLink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
# DDP w/o NVLink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
```
硬件: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`)
软件: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/perf_torch_compile.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用 torch.compile() 优化推理
本指南旨在为使用[`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html)在[🤗 Transformers中的计算机视觉模型](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending)中引入的推理速度提升提供一个基准。
## torch.compile 的优势
根据模型和GPU的不同,`torch.compile()`在推理过程中可以提高多达30%的速度。要使用`torch.compile()`,只需安装2.0及以上版本的`torch`即可。
编译模型需要时间,因此如果您只需要编译一次模型而不是每次推理都编译,那么它非常有用。
要编译您选择的任何计算机视觉模型,请按照以下方式调用`torch.compile()`:
```diff
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
+ model = torch.compile(model)
```
`compile()` 提供了多种编译模式,它们在编译时间和推理开销上有所不同。`max-autotune` 比 `reduce-overhead` 需要更长的时间,但会得到更快的推理速度。默认模式在编译时最快,但在推理时间上与 `reduce-overhead` 相比效率较低。在本指南中,我们使用了默认模式。您可以在[这里](https://pytorch.org/get-started/pytorch-2.0/#user-experience)了解更多信息。
我们在 PyTorch 2.0.1 版本上使用不同的计算机视觉模型、任务、硬件类型和数据批量大小对 `torch.compile` 进行了基准测试。
## 基准测试代码
以下是每个任务的基准测试代码。我们在推理之前”预热“GPU,并取300次推理的平均值,每次使用相同的图像。
### 使用 ViT 进行图像分类
```python
import torch
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(device="cuda")
with torch.no_grad():
_ = model(**processed_input)
```
#### 使用 DETR 进行目标检测
```python
from transformers import AutoImageProcessor, AutoModelForObjectDetection
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to("cuda")
model = torch.compile(model)
texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**inputs)
```
#### 使用 Segformer 进行图像分割
```python
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to("cuda")
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**seg_inputs)
```
以下是我们进行基准测试的模型列表。
**图像分类**
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
- [microsoft/resnet-50](https://huggingface.co/)
**图像分割**
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
**目标检测**
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
下面是使用和不使用`torch.compile()`的推理持续时间可视化,以及每个模型在不同硬件和数据批量大小下的改进百分比。
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
</div>
</div>
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
</div>
</div>
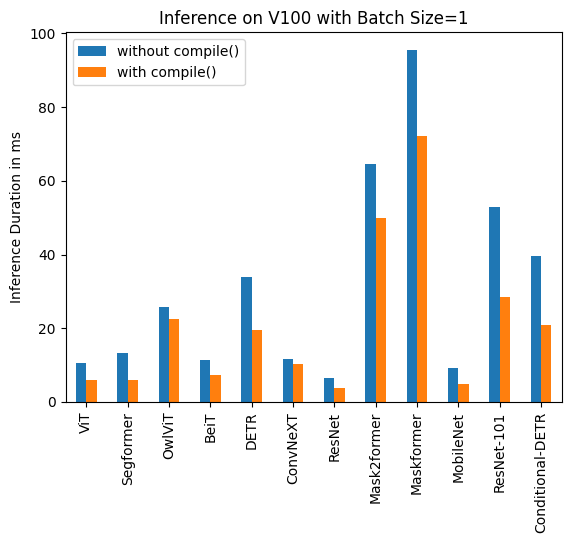
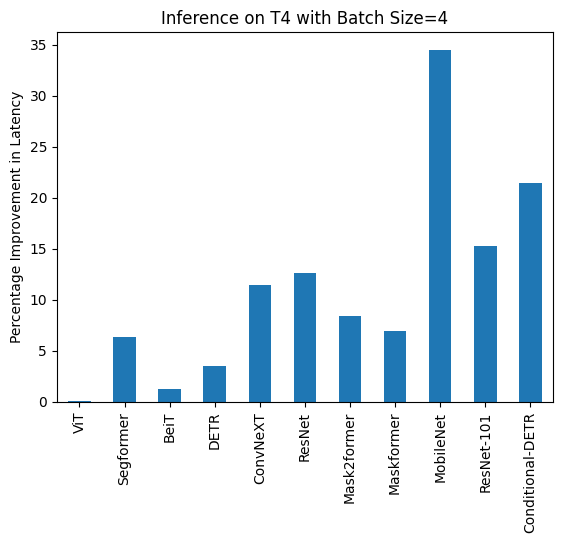
下面可以找到每个模型使用和不使用`compile()`的推理时间(毫秒)。请注意,OwlViT在大批量大小下会导致内存溢出。
### A100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 9.325 | 7.584 |
| Image Segmentation/Segformer | 11.759 | 10.500 |
| Object Detection/OwlViT | 24.978 | 18.420 |
| Image Classification/BeiT | 11.282 | 8.448 |
| Object Detection/DETR | 34.619 | 19.040 |
| Image Classification/ConvNeXT | 10.410 | 10.208 |
| Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 |
| Image Segmentation/Maskformer | 75.764 | 59.487 |
| Image Segmentation/MobileNet | 8.583 | 3.974 |
| Object Detection/Resnet-101 | 36.276 | 18.197 |
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
### A100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 14.832 | 14.499 |
| Image Segmentation/Segformer | 18.838 | 16.476 |
| Image Classification/BeiT | 13.205 | 13.048 |
| Object Detection/DETR | 48.657 | 32.418|
| Image Classification/ConvNeXT | 22.940 | 21.631 |
| Image Classification/ResNet | 6.657 | 4.268 |
| Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 |
| Image Segmentation/MobileNet | 14.174 | 8.515 |
| Object Detection/Resnet-101 | 68.101 | 44.998 |
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
### A100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 40.944 | 40.010 |
| Image Segmentation/Segformer | 37.005 | 31.144 |
| Image Classification/BeiT | 41.854 | 41.048 |
| Object Detection/DETR | 164.382 | 161.902 |
| Image Classification/ConvNeXT | 82.258 | 75.561 |
| Image Classification/ResNet | 7.018 | 5.024 |
| Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 |
| Image Segmentation/MobileNet | 51.693 | 30.310 |
| Object Detection/Resnet-101 | 232.887 | 155.021 |
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
### V100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 10.495 | 6.00 |
| Image Segmentation/Segformer | 13.321 | 5.862 |
| Object Detection/OwlViT | 25.769 | 22.395 |
| Image Classification/BeiT | 11.347 | 7.234 |
| Object Detection/DETR | 33.951 | 19.388 |
| Image Classification/ConvNeXT | 11.623 | 10.412 |
| Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 |
| Image Segmentation/Maskformer | 95.532 | 72.207 |
| Image Segmentation/MobileNet | 9.217 | 4.753 |
| Object Detection/Resnet-101 | 52.818 | 28.367 |
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
### V100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 15.181 | 14.501 |
| Image Segmentation/Segformer | 16.787 | 16.188 |
| Image Classification/BeiT | 15.171 | 14.753 |
| Object Detection/DETR | 88.529 | 64.195 |
| Image Classification/ConvNeXT | 29.574 | 27.085 |
| Image Classification/ResNet | 6.109 | 4.731 |
| Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 |
| Image Segmentation/MobileNet | 24.623 | 14.816 |
| Object Detection/Resnet-101 | 134.672 | 101.304 |
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
### V100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 52.209 | 51.633 |
| Image Segmentation/Segformer | 61.013 | 55.499 |
| Image Classification/BeiT | 53.938 | 53.581 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 109.682 | 100.771 |
| Image Classification/ResNet | 14.857 | 12.089 |
| Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 |
| Image Segmentation/MobileNet | 93.129 | 55.365 |
| Object Detection/Resnet-101 | 482.425 | 361.843 |
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
### T4 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 16.520 | 15.786 |
| Image Segmentation/Segformer | 16.116 | 14.205 |
| Object Detection/OwlViT | 53.634 | 51.105 |
| Image Classification/BeiT | 16.464 | 15.710 |
| Object Detection/DETR | 73.100 | 53.99 |
| Image Classification/ConvNeXT | 32.932 | 30.845 |
| Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 |
| Image Segmentation/Maskformer | 200.026 | 188.268 |
| Image Segmentation/MobileNet | 18.908 | 11.997 |
| Object Detection/Resnet-101 | 106.622 | 82.566 |
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
### T4 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 43.653 | 43.626 |
| Image Segmentation/Segformer | 45.327 | 42.445 |
| Image Classification/BeiT | 52.007 | 51.354 |
| Object Detection/DETR | 277.850 | 268.003 |
| Image Classification/ConvNeXT | 119.259 | 105.580 |
| Image Classification/ResNet | 13.039 | 11.388 |
| Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 |
| Image Segmentation/MobileNet | 74.289 | 48.677 |
| Object Detection/Resnet-101 | 421.859 | 357.614 |
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
### T4 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 163.914 | 160.907 |
| Image Segmentation/Segformer | 192.412 | 163.620 |
| Image Classification/BeiT | 188.978 | 187.976 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 422.886 | 388.078 |
| Image Classification/ResNet | 44.114 | 37.604 |
| Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
| Image Segmentation/MobileNet | 299.003 | 201.942 |
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
## PyTorch Nightly
我们还在 PyTorch Nightly 版本(2.1.0dev)上进行了基准测试,可以在[这里](https://download.pytorch.org/whl/nightly/cu118)找到 Nightly 版本的安装包,并观察到了未编译和编译模型的延迟性能改善。
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
| Object Detection/DETR | 4 | 46.816 | 30.942 |
| Object Detection/DETR | 16 | 163.749 | 163.706 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
| Object Detection/DETR | 4 | 269.615 | 204.785 |
| Object Detection/DETR | 16 | OOM | OOM |
### V100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
| Object Detection/DETR | 4 | 88.402 | 62.949|
| Object Detection/DETR | 16 | OOM | OOM |
## 降低开销
我们在 PyTorch Nightly 版本中为 A100 和 T4 进行了 `reduce-overhead` 编译模式的性能基准测试。
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/llm_tutorial.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
## 使用LLMs进行生成
[[open-in-colab]]
LLMs,即大语言模型,是文本生成背后的关键组成部分。简单来说,它们包含经过大规模预训练的transformer模型,用于根据给定的输入文本预测下一个词(或更准确地说,下一个`token`)。由于它们一次只预测一个`token`,因此除了调用模型之外,您需要执行更复杂的操作来生成新的句子——您需要进行自回归生成。
自回归生成是在给定一些初始输入,通过迭代调用模型及其自身的生成输出来生成文本的推理过程,。在🤗 Transformers中,这由[`~generation.GenerationMixin.generate`]方法处理,所有具有生成能力的模型都可以使用该方法。
本教程将向您展示如何:
* 使用LLM生成文本
* 避免常见的陷阱
* 帮助您充分利用LLM下一步指导
在开始之前,请确保已安装所有必要的库:
```bash
pip install transformers bitsandbytes>=0.39.0 -q
```
## 生成文本
一个用于[因果语言建模](tasks/language_modeling)训练的语言模型,将文本`tokens`序列作为输入,并返回下一个`token`的概率分布。
<!-- [GIF 1 -- FWD PASS] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_1_1080p.mov"
></video>
<figcaption>"LLM的前向传递"</figcaption>
</figure>
使用LLM进行自回归生成的一个关键方面是如何从这个概率分布中选择下一个`token`。这个步骤可以随意进行,只要最终得到下一个迭代的`token`。这意味着可以简单的从概率分布中选择最可能的`token`,也可以复杂的在对结果分布进行采样之前应用多种变换,这取决于你的需求。
<!-- [GIF 2 -- TEXT GENERATION] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_2_1080p.mov"
></video>
<figcaption>"自回归生成迭代地从概率分布中选择下一个token以生成文本"</figcaption>
</figure>
上述过程是迭代重复的,直到达到某个停止条件。理想情况下,停止条件由模型决定,该模型应学会在何时输出一个结束序列(`EOS`)标记。如果不是这种情况,生成将在达到某个预定义的最大长度时停止。
正确设置`token`选择步骤和停止条件对于让你的模型按照预期的方式执行任务至关重要。这就是为什么我们为每个模型都有一个[~generation.GenerationConfig]文件,它包含一个效果不错的默认生成参数配置,并与您模型一起加载。
让我们谈谈代码!
<Tip>
如果您对基本的LLM使用感兴趣,我们高级的[`Pipeline`](pipeline_tutorial)接口是一个很好的起点。然而,LLMs通常需要像`quantization`和`token选择步骤的精细控制`等高级功能,这最好通过[`~generation.GenerationMixin.generate`]来完成。使用LLM进行自回归生成也是资源密集型的操作,应该在GPU上执行以获得足够的吞吐量。
</Tip>
首先,您需要加载模型。
```py
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )
```
您将会注意到在`from_pretrained`调用中的两个标志:
- `device_map`确保模型被移动到您的GPU(s)上
- `load_in_4bit`应用[4位动态量化](main_classes/quantization)来极大地减少资源需求
还有其他方式来初始化一个模型,但这是一个开始使用LLM很好的起点。
接下来,你需要使用一个[tokenizer](tokenizer_summary)来预处理你的文本输入。
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")
```
`model_inputs`变量保存着分词后的文本输入以及注意力掩码。尽管[`~generation.GenerationMixin.generate`]在未传递注意力掩码时会尽其所能推断出注意力掩码,但建议尽可能传递它以获得最佳结果。
在对输入进行分词后,可以调用[`~generation.GenerationMixin.generate`]方法来返回生成的`tokens`。生成的`tokens`应该在打印之前转换为文本。
```py
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A list of colors: red, blue, green, yellow, orange, purple, pink,'
```
最后,您不需要一次处理一个序列!您可以批量输入,这将在小延迟和低内存成本下显著提高吞吐量。您只需要确保正确地填充您的输入(详见下文)。
```py
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
... ["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['A list of colors: red, blue, green, yellow, orange, purple, pink,',
'Portugal is a country in southwestern Europe, on the Iber']
```
就是这样!在几行代码中,您就可以利用LLM的强大功能。
## 常见陷阱
有许多[生成策略](generation_strategies),有时默认值可能不适合您的用例。如果您的输出与您期望的结果不匹配,我们已经创建了一个最常见的陷阱列表以及如何避免它们。
```py
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )
```
### 生成的输出太短/太长
如果在[`~generation.GenerationConfig`]文件中没有指定,`generate`默认返回20个tokens。我们强烈建议在您的`generate`调用中手动设置`max_new_tokens`以控制它可以返回的最大新tokens数量。请注意,LLMs(更准确地说,仅[解码器模型](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt))也将输入提示作为输出的一部分返回。
```py
>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
>>> # By default, the output will contain up to 20 tokens
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5'
>>> # Setting `max_new_tokens` allows you to control the maximum length
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=50)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
```
### 错误的生成模式
默认情况下,除非在[`~generation.GenerationConfig`]文件中指定,否则`generate`会在每个迭代中选择最可能的token(贪婪解码)。对于您的任务,这可能是不理想的;像聊天机器人或写作文章这样的创造性任务受益于采样。另一方面,像音频转录或翻译这样的基于输入的任务受益于贪婪解码。通过将`do_sample=True`启用采样,您可以在这篇[博客文章](https://huggingface.co/blog/how-to-generate)中了解更多关于这个话题的信息。
```py
>>> # Set seed or reproducibility -- you don't need this unless you want full reproducibility
>>> from transformers import set_seed
>>> set_seed(42)
>>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")
>>> # LLM + greedy decoding = repetitive, boring output
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. I am a cat. I am a cat. I am a cat'
>>> # With sampling, the output becomes more creative!
>>> generated_ids = model.generate(**model_inputs, do_sample=True)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. Specifically, I am an indoor-only cat. I'
```
### 错误的填充位置
LLMs是[仅解码器](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt)架构,意味着它们会持续迭代您的输入提示。如果您的输入长度不相同,则需要对它们进行填充。由于LLMs没有接受过从`pad tokens`继续训练,因此您的输入需要左填充。确保在生成时不要忘记传递注意力掩码!
```py
>>> # The tokenizer initialized above has right-padding active by default: the 1st sequence,
>>> # which is shorter, has padding on the right side. Generation fails to capture the logic.
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 33333333333'
>>> # With left-padding, it works as expected!
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 3, 4, 5, 6,'
```
### 错误的提示
一些模型和任务期望某种输入提示格式才能正常工作。当未应用此格式时,您将获得悄然的性能下降:模型能工作,但不如预期提示那样好。有关提示的更多信息,包括哪些模型和任务需要小心,可在[指南](tasks/prompting)中找到。让我们看一个使用[聊天模板](chat_templating)的聊天LLM示例:
```python
>>> tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
>>> model = AutoModelForCausalLM.from_pretrained(
... "HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True
... )
>>> set_seed(0)
>>> prompt = """How many helicopters can a human eat in one sitting? Reply as a thug."""
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
>>> input_length = model_inputs.input_ids.shape[1]
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
"I'm not a thug, but i can tell you that a human cannot eat"
>>> # Oh no, it did not follow our instruction to reply as a thug! Let's see what happens when we write
>>> # a better prompt and use the right template for this model (through `tokenizer.apply_chat_template`)
>>> set_seed(0)
>>> messages = [
... {
... "role": "system",
... "content": "You are a friendly chatbot who always responds in the style of a thug",
... },
... {"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
... ]
>>> model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to("cuda")
>>> input_length = model_inputs.shape[1]
>>> generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
'None, you thug. How bout you try to focus on more useful questions?'
>>> # As we can see, it followed a proper thug style 😎
```
## 更多资源
虽然自回归生成过程相对简单,但要充分利用LLM可能是一个具有挑战性的任务,因为很多组件复杂且密切关联。以下是帮助您深入了解LLM使用和理解的下一步:
### 高级生成用法
1. [指南](generation_strategies),介绍如何控制不同的生成方法、如何设置生成配置文件以及如何进行输出流式传输;
2. [指南](chat_templating),介绍聊天LLMs的提示模板;
3. [指南](tasks/prompting),介绍如何充分利用提示设计;
4. API参考文档,包括[`~generation.GenerationConfig`]、[`~generation.GenerationMixin.generate`]和[与生成相关的类](internal/generation_utils)。
### LLM排行榜
1. [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), 侧重于开源模型的质量;
2. [Open LLM-Perf Leaderboard](https://huggingface.co/spaces/optimum/llm-perf-leaderboard), 侧重于LLM的吞吐量.
### 延迟、吞吐量和内存利用率
1. [指南](llm_tutorial_optimization),如何优化LLMs以提高速度和内存利用;
2. [指南](main_classes/quantization), 关于`quantization`,如bitsandbytes和autogptq的指南,教您如何大幅降低内存需求。
### 相关库
1. [`text-generation-inference`](https://github.com/huggingface/text-generation-inference), 一个面向生产的LLM服务器;
2. [`optimum`](https://github.com/huggingface/optimum), 一个🤗 Transformers的扩展,优化特定硬件设备的性能
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/fast_tokenizers.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用 🤗 Tokenizers 中的分词器
[`PreTrainedTokenizerFast`] 依赖于 [🤗 Tokenizers](https://huggingface.co/docs/tokenizers) 库。从 🤗 Tokenizers 库获得的分词器可以被轻松地加载到 🤗 Transformers 中。
在了解具体内容之前,让我们先用几行代码创建一个虚拟的分词器:
```python
>>> from tokenizers import Tokenizer
>>> from tokenizers.models import BPE
>>> from tokenizers.trainers import BpeTrainer
>>> from tokenizers.pre_tokenizers import Whitespace
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
>>> tokenizer.pre_tokenizer = Whitespace()
>>> files = [...]
>>> tokenizer.train(files, trainer)
```
现在,我们拥有了一个针对我们定义的文件进行训练的分词器。我们可以在当前运行时中继续使用它,或者将其保存到一个 JSON 文件以供将来重复使用。
## 直接从分词器对象加载
让我们看看如何利用 🤗 Transformers 库中的这个分词器对象。[`PreTrainedTokenizerFast`] 类允许通过接受已实例化的 *tokenizer* 对象作为参数,进行轻松实例化:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
```
现在可以使用这个对象,使用 🤗 Transformers 分词器共享的所有方法!前往[分词器页面](main_classes/tokenizer)了解更多信息。
## 从 JSON 文件加载
为了从 JSON 文件中加载分词器,让我们先保存我们的分词器:
```python
>>> tokenizer.save("tokenizer.json")
```
我们保存此文件的路径可以通过 `tokenizer_file` 参数传递给 [`PreTrainedTokenizerFast`] 初始化方法:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
```
现在可以使用这个对象,使用 🤗 Transformers 分词器共享的所有方法!前往[分词器页面](main_classes/tokenizer)了解更多信息。
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/quicktour.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 快速上手
[[open-in-colab]]
快来使用 🤗 Transformers 吧!无论你是开发人员还是日常用户,这篇快速上手教程都将帮助你入门并且向你展示如何使用 [`pipeline`] 进行推理,使用 [AutoClass](./model_doc/auto) 加载一个预训练模型和预处理器,以及使用 PyTorch 或 TensorFlow 快速训练一个模型。如果你是一个初学者,我们建议你接下来查看我们的教程或者[课程](https://huggingface.co/course/chapter1/1),来更深入地了解在这里介绍到的概念。
在开始之前,确保你已经安装了所有必要的库:
```bash
!pip install transformers datasets
```
你还需要安装喜欢的机器学习框架:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
## Pipeline
<Youtube id="tiZFewofSLM"/>
使用 [`pipeline`] 是利用预训练模型进行推理的最简单的方式。你能够将 [`pipeline`] 开箱即用地用于跨不同模态的多种任务。来看看它支持的任务列表:
| **任务** | **描述** | **模态** | **Pipeline** |
|------------------------------|-----------------------------------|-----------------|-----------------------------------------------|
| 文本分类 | 为给定的文本序列分配一个标签 | NLP | pipeline(task="sentiment-analysis") |
| 文本生成 | 根据给定的提示生成文本 | NLP | pipeline(task="text-generation") |
| 命名实体识别 | 为序列里的每个 token 分配一个标签(人, 组织, 地址等等) | NLP | pipeline(task="ner") |
| 问答系统 | 通过给定的上下文和问题, 在文本中提取答案 | NLP | pipeline(task="question-answering") |
| 掩盖填充 | 预测出正确的在序列中被掩盖的token | NLP | pipeline(task="fill-mask") |
| 文本摘要 | 为文本序列或文档生成总结 | NLP | pipeline(task="summarization") |
| 文本翻译 | 将文本从一种语言翻译为另一种语言 | NLP | pipeline(task="translation") |
| 图像分类 | 为图像分配一个标签 | Computer vision | pipeline(task="image-classification") |
| 图像分割 | 为图像中每个独立的像素分配标签(支持语义、全景和实例分割) | Computer vision | pipeline(task="image-segmentation") |
| 目标检测 | 预测图像中目标对象的边界框和类别 | Computer vision | pipeline(task="object-detection") |
| 音频分类 | 给音频文件分配一个标签 | Audio | pipeline(task="audio-classification") |
| 自动语音识别 | 将音频文件中的语音提取为文本 | Audio | pipeline(task="automatic-speech-recognition") |
| 视觉问答 | 给定一个图像和一个问题,正确地回答有关图像的问题 | Multimodal | pipeline(task="vqa") |
创建一个 [`pipeline`] 实例并且指定你想要将它用于的任务,就可以开始了。你可以将 [`pipeline`] 用于任何一个上面提到的任务,如果想知道支持的任务的完整列表,可以查阅 [pipeline API 参考](./main_classes/pipelines)。不过, 在这篇教程中,你将把 [`pipeline`] 用在一个情感分析示例上:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis")
```
[`pipeline`] 会下载并缓存一个用于情感分析的默认的[预训练模型](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)和分词器。现在你可以在目标文本上使用 `classifier` 了:
```py
>>> classifier("We are very happy to show you the 🤗 Transformers library.")
[{'label': 'POSITIVE', 'score': 0.9998}]
```
如果你有不止一个输入,可以把所有输入放入一个列表然后传给[`pipeline`],它将会返回一个字典列表:
```py
>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
>>> for result in results:
... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
label: POSITIVE, with score: 0.9998
label: NEGATIVE, with score: 0.5309
```
[`pipeline`] 也可以为任何你喜欢的任务遍历整个数据集。在下面这个示例中,让我们选择自动语音识别作为我们的任务:
```py
>>> import torch
>>> from transformers import pipeline
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
```
加载一个你想遍历的音频数据集(查阅 🤗 Datasets [快速开始](https://huggingface.co/docs/datasets/quickstart#audio) 获得更多信息)。比如,加载 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 数据集:
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
```
你需要确保数据集中的音频的采样率与 [`facebook/wav2vec2-base-960h`](https://huggingface.co/facebook/wav2vec2-base-960h) 训练用到的音频的采样率一致:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
```
当调用 `"audio"` 列时, 音频文件将会自动加载并重采样。
从前四个样本中提取原始波形数组,将它作为列表传给 pipeline:
```py
>>> result = speech_recognizer(dataset[:4]["audio"])
>>> print([d["text"] for d in result])
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FODING HOW I'D SET UP A JOIN TO HET WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE AP SO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AND I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I THURN A JOIN A COUNT']
```
对于输入非常庞大的大型数据集(比如语音或视觉),你会想到使用一个生成器,而不是一个将所有输入都加载进内存的列表。查阅 [pipeline API 参考](./main_classes/pipelines) 来获取更多信息。
### 在 pipeline 中使用另一个模型和分词器
[`pipeline`] 可以容纳 [Hub](https://huggingface.co/models) 中的任何模型,这让 [`pipeline`] 更容易适用于其他用例。比如,你想要一个能够处理法语文本的模型,就可以使用 Hub 上的标记来筛选出合适的模型。靠前的筛选结果会返回一个为情感分析微调的多语言的 [BERT 模型](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment),你可以将它用于法语文本:
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
使用 [`AutoModelForSequenceClassification`] 和 [`AutoTokenizer`] 来加载预训练模型和它关联的分词器(更多信息可以参考下一节的 `AutoClass`):
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
使用 [`TFAutoModelForSequenceClassification`] 和 [`AutoTokenizer`] 来加载预训练模型和它关联的分词器(更多信息可以参考下一节的 `TFAutoClass`):
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
在 [`pipeline`] 中指定模型和分词器,现在你就可以在法语文本上使用 `classifier` 了:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
如果你没有找到适合你的模型,就需要在你的数据上微调一个预训练模型了。查看 [微调教程](./training) 来学习怎样进行微调。最后,微调完模型后,考虑一下在 Hub 上与社区 [分享](./model_sharing) 这个模型,把机器学习普及到每一个人! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
在幕后,是由 [`AutoModelForSequenceClassification`] 和 [`AutoTokenizer`] 一起支持你在上面用到的 [`pipeline`]。[AutoClass](./model_doc/auto) 是一个能够通过预训练模型的名称或路径自动查找其架构的快捷方式。你只需要为你的任务选择合适的 `AutoClass` 和它关联的预处理类。
让我们回过头来看上一节的示例,看看怎样使用 `AutoClass` 来重现使用 [`pipeline`] 的结果。
### AutoTokenizer
分词器负责预处理文本,将文本转换为用于输入模型的数字数组。有多个用来管理分词过程的规则,包括如何拆分单词和在什么样的级别上拆分单词(在 [分词器总结](./tokenizer_summary) 学习更多关于分词的信息)。要记住最重要的是你需要实例化的分词器要与模型的名称相同, 来确保和模型训练时使用相同的分词规则。
使用 [`AutoTokenizer`] 加载一个分词器:
```py
>>> from transformers import AutoTokenizer
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
将文本传入分词器:
```py
>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
>>> print(encoding)
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
分词器返回了含有如下内容的字典:
* [input_ids](./glossary#input-ids):用数字表示的 token。
* [attention_mask](.glossary#attention-mask):应该关注哪些 token 的指示。
分词器也可以接受列表作为输入,并填充和截断文本,返回具有统一长度的批次:
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
<Tip>
查阅[预处理](./preprocessing)教程来获得有关分词的更详细的信息,以及如何使用 [`AutoFeatureExtractor`] 和 [`AutoProcessor`] 来处理图像,音频,还有多模式输入。
</Tip>
### AutoModel
<frameworkcontent>
<pt>
🤗 Transformers 提供了一种简单统一的方式来加载预训练的实例. 这表示你可以像加载 [`AutoTokenizer`] 一样加载 [`AutoModel`]。唯一不同的地方是为你的任务选择正确的[`AutoModel`]。对于文本(或序列)分类,你应该加载[`AutoModelForSequenceClassification`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
通过 [任务摘要](./task_summary) 查找 [`AutoModel`] 支持的任务.
</Tip>
现在可以把预处理好的输入批次直接送进模型。你只需要通过 `**` 来解包字典:
```py
>>> pt_outputs = pt_model(**pt_batch)
```
模型在 `logits` 属性输出最终的激活结果. 在 `logits` 上应用 softmax 函数来查询概率:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 Transformers 提供了一种简单统一的方式来加载预训练的实例。这表示你可以像加载 [`AutoTokenizer`] 一样加载 [`TFAutoModel`]。唯一不同的地方是为你的任务选择正确的 [`TFAutoModel`],对于文本(或序列)分类,你应该加载 [`TFAutoModelForSequenceClassification`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
通过 [任务摘要](./task_summary) 查找 [`AutoModel`] 支持的任务.
</Tip>
现在通过直接将字典的键传给张量,将预处理的输入批次传给模型。
```py
>>> tf_outputs = tf_model(tf_batch)
```
模型在 `logits` 属性输出最终的激活结果。在 `logits` 上应用softmax函数来查询概率:
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
所有 🤗 Transformers 模型(PyTorch 或 TensorFlow)在最终的激活函数(比如 softmax)*之前* 输出张量,
因为最终的激活函数常常与 loss 融合。模型的输出是特殊的数据类,所以它们的属性可以在 IDE 中被自动补全。模型的输出就像一个元组或字典(你可以通过整数、切片或字符串来索引它),在这种情况下,为 None 的属性会被忽略。
</Tip>
### 保存模型
<frameworkcontent>
<pt>
当你的模型微调完成,你就可以使用 [`PreTrainedModel.save_pretrained`] 把它和它的分词器保存下来:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
当你准备再次使用这个模型时,就可以使用 [`PreTrainedModel.from_pretrained`] 加载它了:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
当你的模型微调完成,你就可以使用 [`TFPreTrainedModel.save_pretrained`] 把它和它的分词器保存下来:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
当你准备再次使用这个模型时,就可以使用 [`TFPreTrainedModel.from_pretrained`] 加载它了:
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
🤗 Transformers 有一个特别酷的功能,它能够保存一个模型,并且将它加载为 PyTorch 或 TensorFlow 模型。`from_pt` 或 `from_tf` 参数可以将模型从一个框架转换为另一个框架:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent>
## 自定义模型构建
你可以修改模型的配置类来改变模型的构建方式。配置指明了模型的属性,比如隐藏层或者注意力头的数量。当你从自定义的配置类初始化模型时,你就开始自定义模型构建了。模型属性是随机初始化的,你需要先训练模型,然后才能得到有意义的结果。
通过导入 [`AutoConfig`] 来开始,之后加载你想修改的预训练模型。在 [`AutoConfig.from_pretrained`] 中,你能够指定想要修改的属性,比如注意力头的数量:
```py
>>> from transformers import AutoConfig
>>> my_config = AutoConfig.from_pretrained("distilbert-base-uncased", n_heads=12)
```
<frameworkcontent>
<pt>
使用 [`AutoModel.from_config`] 根据你的自定义配置创建一个模型:
```py
>>> from transformers import AutoModel
>>> my_model = AutoModel.from_config(my_config)
```
</pt>
<tf>
使用 [`TFAutoModel.from_config`] 根据你的自定义配置创建一个模型:
```py
>>> from transformers import TFAutoModel
>>> my_model = TFAutoModel.from_config(my_config)
```
</tf>
</frameworkcontent>
查阅 [创建一个自定义结构](./create_a_model) 指南获取更多关于构建自定义配置的信息。
## Trainer - PyTorch 优化训练循环
所有的模型都是标准的 [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module),所以你可以在任何典型的训练模型中使用它们。当你编写自己的训练循环时,🤗 Transformers 为 PyTorch 提供了一个 [`Trainer`] 类,它包含了基础的训练循环并且为诸如分布式训练,混合精度等特性增加了额外的功能。
取决于你的任务, 你通常可以传递以下的参数给 [`Trainer`]:
1. [`PreTrainedModel`] 或者 [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module):
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. [`TrainingArguments`] 含有你可以修改的模型超参数,比如学习率,批次大小和训练时的迭代次数。如果你没有指定训练参数,那么它会使用默认值:
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(
... output_dir="path/to/save/folder/",
... learning_rate=2e-5,
... per_device_train_batch_size=8,
... per_device_eval_batch_size=8,
... num_train_epochs=2,
... )
```
3. 一个预处理类,比如分词器,特征提取器或者处理器:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
4. 加载一个数据集:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
```
5. 创建一个给数据集分词的函数,并且使用 [`~datasets.Dataset.map`] 应用到整个数据集:
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"])
>>> dataset = dataset.map(tokenize_dataset, batched=True)
```
6. 用来从数据集中创建批次的 [`DataCollatorWithPadding`]:
```py
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
现在把所有的类传给 [`Trainer`]:
```py
>>> from transformers import Trainer
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
一切准备就绪后,调用 [`~Trainer.train`] 进行训练:
```py
>>> trainer.train() # doctest: +SKIP
```
<Tip>
对于像翻译或摘要这些使用序列到序列模型的任务,用 [`Seq2SeqTrainer`] 和 [`Seq2SeqTrainingArguments`] 来替代。
</Tip>
你可以通过子类化 [`Trainer`] 中的方法来自定义训练循环。这样你就可以自定义像损失函数,优化器和调度器这样的特性。查阅 [`Trainer`] 参考手册了解哪些方法能够被子类化。
另一个自定义训练循环的方式是通过[回调](./main_classes/callbacks)。你可以使用回调来与其他库集成,查看训练循环来报告进度或提前结束训练。回调不会修改训练循环。如果想自定义损失函数等,就需要子类化 [`Trainer`] 了。
## 使用 Tensorflow 训练
所有模型都是标准的 [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model),所以你可以通过 [Keras](https://keras.io/) API 实现在 Tensorflow 中训练。🤗 Transformers 提供了 [`~TFPreTrainedModel.prepare_tf_dataset`] 方法来轻松地将数据集加载为 `tf.data.Dataset`,这样你就可以使用 Keras 的 [`compile`](https://keras.io/api/models/model_training_apis/#compile-method) 和 [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) 方法马上开始训练。
1. 使用 [`TFPreTrainedModel`] 或者 [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) 来开始:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. 一个预处理类,比如分词器,特征提取器或者处理器:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
3. 创建一个给数据集分词的函数
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"]) # doctest: +SKIP
```
4. 使用 [`~datasets.Dataset.map`] 将分词器应用到整个数据集,之后将数据集和分词器传给 [`~TFPreTrainedModel.prepare_tf_dataset`]。如果你需要的话,也可以在这里改变批次大小和是否打乱数据集:
```py
>>> dataset = dataset.map(tokenize_dataset) # doctest: +SKIP
>>> tf_dataset = model.prepare_tf_dataset(
... dataset, batch_size=16, shuffle=True, tokenizer=tokenizer
... ) # doctest: +SKIP
```
5. 一切准备就绪后,调用 `compile` 和 `fit` 开始训练:
```py
>>> from tensorflow.keras.optimizers import Adam
>>> model.compile(optimizer=Adam(3e-5))
>>> model.fit(dataset) # doctest: +SKIP
```
## 接下来做什么?
现在你已经完成了 🤗 Transformers 的快速上手教程,来看看我们的指南并且学习如何做一些更具体的事情,比如写一个自定义模型,为某个任务微调一个模型以及如何使用脚本来训练模型。如果你有兴趣了解更多 🤗 Transformers 的核心章节,那就喝杯咖啡然后来看看我们的概念指南吧!
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/zh/debugging.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 调试
## 多GPU网络问题调试
当使用`DistributedDataParallel`和多个GPU进行训练或推理时,如果遇到进程和(或)节点之间的互联问题,您可以使用以下脚本来诊断网络问题。
```bash
wget https://raw.githubusercontent.com/huggingface/transformers/main/scripts/distributed/torch-distributed-gpu-test.py
```
例如,要测试两个GPU之间的互联,请执行以下操作:
```bash
python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
```
如果两个进程能够相互通信并分配GPU内存,它们各自将打印出 "OK" 状态。
对于更多的GPU或节点,可以根据脚本中的参数进行调整。
在诊断脚本内部,您将找到更多详细信息,甚至有关如何在SLURM环境中运行它的说明。
另一种级别的调试是添加 `NCCL_DEBUG=INFO` 环境变量,如下所示:
```bash
NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
```
这将产生大量与NCCL相关的调试信息,如果发现有问题报告,您可以在线搜索以获取相关信息。或者,如果您不确定如何解释输出,可以在`issue`中分享日志文件。
## 下溢和上溢检测
<Tip>
目前,此功能仅适用于PyTorch。
</Tip>
<Tip>
对于多GPU训练,它需要使用DDP(`torch.distributed.launch`)。
</Tip>
<Tip>
此功能可以与任何基于`nn.Module`的模型一起使用。
</Tip>
如果您开始发现`loss=NaN`或模型因激活值或权重中的`inf`或`nan`而出现一些异常行为,就需要发现第一个下溢或上溢发生的地方以及导致它的原因。幸运的是,您可以通过激活一个特殊模块来自动进行检测。
如果您正在使用[`Trainer`],只需把以下内容:
```bash
--debug underflow_overflow
```
添加到常规命令行参数中,或在创建[`TrainingArguments`]对象时传递 `debug="underflow_overflow"`。
如果您正在使用自己的训练循环或其他Trainer,您可以通过以下方式实现相同的功能:
```python
from transformers.debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model)
```
[`debug_utils.DebugUnderflowOverflow`] 将`hooks`插入模型,紧跟在每次前向调用之后,进而测试输入和输出变量,以及相应模块的权重。一旦在激活值或权重的至少一个元素中检测到`inf`或`nan`,程序将执行`assert`并打印报告,就像这样(这是在`google/mt5-small`下使用fp16混合精度捕获的):
```
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
encoder.block.1.layer.1.DenseReluDense.dropout Dropout
0.00e+00 2.57e+02 input[0]
0.00e+00 2.85e+02 output
[...]
encoder.block.2.layer.0 T5LayerSelfAttention
6.78e-04 3.15e+03 input[0]
2.65e-04 3.42e+03 output[0]
None output[1]
2.25e-01 1.00e+04 output[2]
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.dropout Dropout
0.00e+00 8.76e+03 input[0]
0.00e+00 9.74e+03 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
```
由于篇幅原因,示例输出中间的部分已经被缩减。
第二列显示了绝对最大元素的值,因此,如果您仔细查看最后`frame`,输入和输出都在`1e4`的范围内。因此,在使用fp16混合精度进行训练时,最后一步发生了溢出(因为在`fp16`下,在`inf`之前的最大数字是`64e3`)。为了避免在`fp16`下发生溢出,激活值必须保持低于`1e4`,因为`1e4 * 1e4 = 1e8`,因此任何具有大激活值的矩阵乘法都会导致数值溢出。
在跟踪的开始处,您可以发现问题发生在哪个批次(这里的`Detected inf/nan during batch_number=0`表示问题发生在第一个批次)。
每个报告的`frame`都以声明相应模块的层信息为开头,说明这一`frame`是为哪个模块报告的。如果只看这个`frame`:
```
encoder.block.2.layer.1.layer_norm T5LayerNorm
8.69e-02 4.18e-01 weight
2.65e-04 3.42e+03 input[0]
1.79e-06 4.65e+00 output
```
在这里,`encoder.block.2.layer.1.layer_norm` 表示它是编码器的第二个块中第一层的`layer norm`。而 `forward` 的具体调用是 `T5LayerNorm`。
让我们看看该报告的最后几个`frame`:
```
Detected inf/nan during batch_number=0
Last 21 forward frames:
abs min abs max metadata
[...]
encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
2.17e-07 4.50e+00 weight
1.79e-06 4.65e+00 input[0]
2.68e-06 3.70e+01 output
encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
8.08e-07 2.66e+01 weight
1.79e-06 4.65e+00 input[0]
1.27e-04 2.37e+02 output
encoder.block.2.layer.1.DenseReluDense.wo Linear
1.01e-06 6.44e+00 weight
0.00e+00 9.74e+03 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
1.79e-06 4.65e+00 input[0]
3.18e-04 6.27e+04 output
encoder.block.2.layer.1.dropout Dropout
3.18e-04 6.27e+04 input[0]
0.00e+00 inf output
```
最后一个`frame`报告了`Dropout.forward`函数,第一个条目是唯一的输入,第二个条目是唯一的输出。您可以看到,它是从`DenseReluDense`类内的属性`dropout`中调用的。我们可以看到它发生在第2个块的第1层,也就是在第一个批次期间。最后,绝对最大的输入元素值为`6.27e+04`,输出也是`inf`。
您可以在这里看到,`T5DenseGatedGeluDense.forward`产生了输出激活值,其绝对最大值约为62.7K,非常接近fp16的上限64K。在下一个`frame`中,我们有`Dropout`对权重进行重新归一化,之后将某些元素归零,将绝对最大值推到了64K以上,导致溢出(`inf`)。
正如你所看到的,我们需要查看前面的`frame`, 从那里fp16数字开始变得非常大。
让我们将报告与`models/t5/modeling_t5.py`中的代码匹配:
```python
class T5DenseGatedGeluDense(nn.Module):
def __init__(self, config):
super().__init__()
self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
self.dropout = nn.Dropout(config.dropout_rate)
self.gelu_act = ACT2FN["gelu_new"]
def forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
```
现在很容易看到`dropout`调用,以及所有之前的调用。
由于检测是在前向`hook`中进行的,这些报告将立即在每个`forward`返回后打印出来。
回到完整的报告,要采取措施并解决问题,我们需要往回看几个`frame`,在那里数字开始上升,并且最有可能切换到fp32模式以便在乘法或求和时数字不会溢出。当然,可能还有其他解决方案。例如,如果启用了`amp`,我们可以在将原始`forward`移到`helper wrapper`中后,暂时关闭它,如下所示:
```python
def _forward(self, hidden_states):
hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
hidden_linear = self.wi_1(hidden_states)
hidden_states = hidden_gelu * hidden_linear
hidden_states = self.dropout(hidden_states)
hidden_states = self.wo(hidden_states)
return hidden_states
import torch
def forward(self, hidden_states):
if torch.is_autocast_enabled():
with torch.cuda.amp.autocast(enabled=False):
return self._forward(hidden_states)
else:
return self._forward(hidden_states)
```
由于自动检测器仅报告完整`frame`的输入和输出,一旦知道在哪里查找,您可能还希望分析特定`forward`函数的中间阶段。在这种情况下,您可以使用`detect_overflow`辅助函数将检测器放到希望的位置,例如:
```python
from debug_utils import detect_overflow
class T5LayerFF(nn.Module):
[...]
def forward(self, hidden_states):
forwarded_states = self.layer_norm(hidden_states)
detect_overflow(forwarded_states, "after layer_norm")
forwarded_states = self.DenseReluDense(forwarded_states)
detect_overflow(forwarded_states, "after DenseReluDense")
return hidden_states + self.dropout(forwarded_states)
```
可以看到,我们添加了2个检测器,现在我们可以跟踪是否在`forwarded_states`中间的某个地方检测到了`inf`或`nan`。
实际上,检测器已经报告了这些,因为上面示例中的每个调用都是一个`nn.Module`,但假设如果您有一些本地的直接计算,这就是您将如何执行的方式。
此外,如果您在自己的代码中实例化调试器,您可以调整从其默认打印的`frame`数,例如:
```python
from transformers.debug_utils import DebugUnderflowOverflow
debug_overflow = DebugUnderflowOverflow(model, max_frames_to_save=100)
```
### 特定批次的绝对最小值和最大值跟踪
当关闭下溢/上溢检测功能, 同样的调试类可以用于批处理跟踪。
假设您想要监视给定批次的每个`forward`调用的所有成分的绝对最小值和最大值,并且仅对批次1和3执行此操作,您可以这样实例化这个类:
```python
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3])
```
现在,完整的批次1和3将以与下溢/上溢检测器相同的格式进行跟踪。
批次从0开始计数。
如果您知道程序在某个批次编号之后开始出现问题,那么您可以直接快进到该区域。以下是一个截取的配置示例输出:
```
*** Starting batch number=1 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.47e+04 input[0]
5.36e-05 7.92e+02 output
[...]
decoder.dropout Dropout
1.60e-07 2.27e+01 input[0]
0.00e+00 2.52e+01 output
decoder T5Stack
not a tensor output
lm_head Linear
1.01e-06 7.92e+02 weight
0.00e+00 1.11e+00 input[0]
6.06e-02 8.39e+01 output
T5ForConditionalGeneration
not a tensor output
*** Starting batch number=3 ***
abs min abs max metadata
shared Embedding
1.01e-06 7.92e+02 weight
0.00e+00 2.78e+04 input[0]
5.36e-05 7.92e+02 output
[...]
```
在这里,您将获得大量的`frame`被`dump` - 与您的模型中的前向调用一样多,它有可能符合也可能不符合您的要求,但有时对于调试目的来说,它可能比正常的调试器更容易使用。例如,如果问题开始发生在批次号150上,您可以`dump`批次149和150的跟踪,并比较数字开始发散的地方。
你还可以使用以下命令指定停止训练的批次号:
```python
debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3], abort_after_batch_num=3)
```
| 0
|
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/trainer.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Trainer
[`Trainer`] 类提供了一个 PyTorch 的 API,用于处理大多数标准用例的全功能训练。它在大多数[示例脚本](https://github.com/huggingface/transformers/tree/main/examples)中被使用。
<Tip>
如果你想要使用自回归技术在文本数据集上微调像 Llama-2 或 Mistral 这样的语言模型,考虑使用 [`trl`](https://github.com/huggingface/trl) 的 [`~trl.SFTTrainer`]。[`~trl.SFTTrainer`] 封装了 [`Trainer`],专门针对这个特定任务进行了优化,并支持序列打包、LoRA、量化和 DeepSpeed,以有效扩展到任何模型大小。另一方面,[`Trainer`] 是一个更通用的选项,适用于更广泛的任务。
</Tip>
在实例化你的 [`Trainer`] 之前,创建一个 [`TrainingArguments`],以便在训练期间访问所有定制点。
这个 API 支持在多个 GPU/TPU 上进行分布式训练,支持 [NVIDIA Apex](https://github.com/NVIDIA/apex) 的混合精度和 PyTorch 的原生 AMP。
[`Trainer`] 包含基本的训练循环,支持上述功能。如果需要自定义训练,你可以继承 `Trainer` 并覆盖以下方法:
- **get_train_dataloader** -- 创建训练 DataLoader。
- **get_eval_dataloader** -- 创建评估 DataLoader。
- **get_test_dataloader** -- 创建测试 DataLoader。
- **log** -- 记录观察训练的各种对象的信息。
- **create_optimizer_and_scheduler** -- 如果它们没有在初始化时传递,请设置优化器和学习率调度器。请注意,你还可以单独继承或覆盖 `create_optimizer` 和 `create_scheduler` 方法。
- **create_optimizer** -- 如果在初始化时没有传递,则设置优化器。
- **create_scheduler** -- 如果在初始化时没有传递,则设置学习率调度器。
- **compute_loss** - 计算单批训练输入的损失。
- **training_step** -- 执行一步训练。
- **prediction_step** -- 执行一步评估/测试。
- **evaluate** -- 运行评估循环并返回指标。
- **predict** -- 返回在测试集上的预测(如果有标签,则包括指标)。
<Tip warning={true}>
[`Trainer`] 类被优化用于 🤗 Transformers 模型,并在你在其他模型上使用时可能会有一些令人惊讶的结果。当在你自己的模型上使用时,请确保:
- 你的模型始终返回元组或 [`~utils.ModelOutput`] 的子类。
- 如果提供了 `labels` 参数,你的模型可以计算损失,并且损失作为元组的第一个元素返回(如果你的模型返回元组)。
- 你的模型可以接受多个标签参数(在 [`TrainingArguments`] 中使用 `label_names` 将它们的名称指示给 [`Trainer`]),但它们中没有一个应该被命名为 `"label"`。
</Tip>
以下是如何自定义 [`Trainer`] 以使用加权损失的示例(在训练集不平衡时很有用):
```python
from torch import nn
from transformers import Trainer
class CustomTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
# forward pass
outputs = model(**inputs)
logits = outputs.get("logits")
# compute custom loss (suppose one has 3 labels with different weights)
loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0], device=model.device))
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else loss
```
在 PyTorch [`Trainer`] 中自定义训练循环行为的另一种方法是使用 [callbacks](callback),这些回调可以检查训练循环状态(用于进度报告、在 TensorBoard 或其他 ML 平台上记录日志等)并做出决策(比如提前停止)。
## Trainer
[[autodoc]] Trainer - all
## Seq2SeqTrainer
[[autodoc]] Seq2SeqTrainer - evaluate - predict
## TrainingArguments
[[autodoc]] TrainingArguments - all
## Seq2SeqTrainingArguments
[[autodoc]] Seq2SeqTrainingArguments - all
## Checkpoints
默认情况下,[`Trainer`] 会将所有checkpoints保存在你使用的 [`TrainingArguments`] 中设置的 `output_dir` 中。这些checkpoints将位于名为 `checkpoint-xxx` 的子文件夹中,xxx 是训练的步骤。
从checkpoints恢复训练可以通过调用 [`Trainer.train`] 时使用以下任一方式进行:
- `resume_from_checkpoint=True`,这将从最新的checkpoint恢复训练。
- `resume_from_checkpoint=checkpoint_dir`,这将从指定目录中的特定checkpoint恢复训练。
此外,当使用 `push_to_hub=True` 时,你可以轻松将checkpoints保存在 Model Hub 中。默认情况下,保存在训练中间过程的checkpoints中的所有模型都保存在不同的提交中,但不包括优化器状态。你可以根据需要调整 [`TrainingArguments`] 的 `hub-strategy` 值:
- `"checkpoint"`: 最新的checkpoint也被推送到一个名为 last-checkpoint 的子文件夹中,让你可以通过 `trainer.train(resume_from_checkpoint="output_dir/last-checkpoint")` 轻松恢复训练。
- `"all_checkpoints"`: 所有checkpoints都像它们出现在输出文件夹中一样被推送(因此你将在最终存储库中的每个文件夹中获得一个checkpoint文件夹)。
## Logging
默认情况下,[`Trainer`] 将对主进程使用 `logging.INFO`,对副本(如果有的话)使用 `logging.WARNING`。
可以通过 [`TrainingArguments`] 的参数覆盖这些默认设置,使用其中的 5 个 `logging` 级别:
- `log_level` - 用于主进程
- `log_level_replica` - 用于副本
此外,如果 [`TrainingArguments`] 的 `log_on_each_node` 设置为 `False`,则只有主节点将使用其主进程的日志级别设置,所有其他节点将使用副本的日志级别设置。
请注意,[`Trainer`] 将在其 [`Trainer.__init__`] 中分别为每个节点设置 `transformers` 的日志级别。因此,如果在创建 [`Trainer`] 对象之前要调用其他 `transformers` 功能,可能需要更早地设置这一点(请参见下面的示例)。
以下是如何在应用程序中使用的示例:
```python
[...]
logger = logging.getLogger(__name__)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
# set the main code and the modules it uses to the same log-level according to the node
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
trainer = Trainer(...)
```
然后,如果你只想在主节点上看到警告,并且所有其他节点不打印任何可能重复的警告,可以这样运行:
```bash
my_app.py ... --log_level warning --log_level_replica error
```
在多节点环境中,如果你也不希望每个节点的主进程的日志重复输出,你需要将上面的代码更改为:
```bash
my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
```
然后,只有第一个节点的主进程将以 "warning" 级别记录日志,主节点上的所有其他进程和其他节点上的所有进程将以 "error" 级别记录日志。
如果你希望应用程序尽可能”安静“,可以执行以下操作:
```bash
my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
```
(如果在多节点环境,添加 `--log_on_each_node 0`)
## 随机性
当从 [`Trainer`] 生成的checkpoint恢复训练时,程序会尽一切努力将 _python_、_numpy_ 和 _pytorch_ 的 RNG(随机数生成器)状态恢复为保存检查点时的状态,这样可以使“停止和恢复”式训练尽可能接近“非停止式”训练。
然而,由于各种默认的非确定性 PyTorch 设置,这可能无法完全实现。如果你想要完全确定性,请参阅[控制随机源](https://pytorch.org/docs/stable/notes/randomness)。正如文档中所解释的那样,使事物变得确定的一些设置(例如 `torch.backends.cudnn.deterministic`)可能会减慢速度,因此不能默认执行,但如果需要,你可以自行启用这些设置。
## 特定GPU选择
让我们讨论一下如何告诉你的程序应该使用哪些 GPU 以及使用的顺序。
当使用 [`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) 且仅使用部分 GPU 时,你只需指定要使用的 GPU 数量。例如,如果你有 4 个 GPU,但只想使用前 2 个,可以执行以下操作:
```bash
python -m torch.distributed.launch --nproc_per_node=2 trainer-program.py ...
```
如果你安装了 [`accelerate`](https://github.com/huggingface/accelerate) 或 [`deepspeed`](https://github.com/microsoft/DeepSpeed),你还可以通过以下任一方法实现相同的效果:
```bash
accelerate launch --num_processes 2 trainer-program.py ...
```
```bash
deepspeed --num_gpus 2 trainer-program.py ...
```
你不需要使用 Accelerate 或 [Deepspeed 集成](Deepspeed) 功能来使用这些启动器。
到目前为止,你已经能够告诉程序要使用多少个 GPU。现在让我们讨论如何选择特定的 GPU 并控制它们的顺序。
以下环境变量可帮助你控制使用哪些 GPU 以及它们的顺序。
**`CUDA_VISIBLE_DEVICES`**
如果你有多个 GPU,想要仅使用其中的一个或几个 GPU,请将环境变量 `CUDA_VISIBLE_DEVICES` 设置为要使用的 GPU 列表。
例如,假设你有 4 个 GPU:0、1、2 和 3。要仅在物理 GPU 0 和 2 上运行,你可以执行以下操作:
```bash
CUDA_VISIBLE_DEVICES=0,2 python -m torch.distributed.launch trainer-program.py ...
```
现在,PyTorch 将只看到 2 个 GPU,其中你的物理 GPU 0 和 2 分别映射到 `cuda:0` 和 `cuda:1`。
你甚至可以改变它们的顺序:
```bash
CUDA_VISIBLE_DEVICES=2,0 python -m torch.distributed.launch trainer-program.py ...
```
这里,你的物理 GPU 0 和 2 分别映射到 `cuda:1` 和 `cuda:0`。
上面的例子都是针对 `DistributedDataParallel` 使用模式的,但同样的方法也适用于 [`DataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html):
```bash
CUDA_VISIBLE_DEVICES=2,0 python trainer-program.py ...
```
为了模拟没有 GPU 的环境,只需将此环境变量设置为空值,如下所示:
```bash
CUDA_VISIBLE_DEVICES= python trainer-program.py ...
```
与任何环境变量一样,你当然可以将其export到环境变量而不是将其添加到命令行,如下所示:
```bash
export CUDA_VISIBLE_DEVICES=0,2
python -m torch.distributed.launch trainer-program.py ...
```
这种方法可能会令人困惑,因为你可能会忘记之前设置了环境变量,进而不明白为什么会使用错误的 GPU。因此,在同一命令行中仅为特定运行设置环境变量是一种常见做法,正如本节大多数示例所示。
**`CUDA_DEVICE_ORDER`**
还有一个额外的环境变量 `CUDA_DEVICE_ORDER`,用于控制物理设备的排序方式。有两个选择:
1. 按 PCIe 总线 ID 排序(与 nvidia-smi 的顺序相匹配)- 这是默认选项。
```bash
export CUDA_DEVICE_ORDER=PCI_BUS_ID
```
2. 按 GPU 计算能力排序。
```bash
export CUDA_DEVICE_ORDER=FASTEST_FIRST
```
大多数情况下,你不需要关心这个环境变量,但如果你的设置不均匀,那么这将非常有用,例如,您的旧 GPU 和新 GPU 物理上安装在一起,但让速度较慢的旧卡排在运行的第一位。解决这个问题的一种方法是交换卡的位置。但如果不能交换卡(例如,如果设备的散热受到影响),那么设置 `CUDA_DEVICE_ORDER=FASTEST_FIRST` 将始终将较新、更快的卡放在第一位。但这可能会有点混乱,因为 `nvidia-smi` 仍然会按照 PCIe 顺序报告它们。
交换卡的顺序的另一种方法是使用:
```bash
export CUDA_VISIBLE_DEVICES=1,0
```
在此示例中,我们只使用了 2 个 GPU,但是当然,对于计算机上有的任何数量的 GPU,都适用相同的方法。
此外,如果你设置了这个环境变量,最好将其设置在 `~/.bashrc` 文件或其他启动配置文件中,然后就可以忘记它了。
## Trainer集成
[`Trainer`] 已经被扩展,以支持可能显著提高训练时间并适应更大模型的库。
目前,它支持第三方解决方案 [DeepSpeed](https://github.com/microsoft/DeepSpeed) 和 [PyTorch FSDP](https://pytorch.org/docs/stable/fsdp.html),它们实现了论文 [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models, by Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He](https://arxiv.org/abs/1910.02054) 的部分内容。
截至撰写本文,此提供的支持是新的且实验性的。尽管我们欢迎围绕 DeepSpeed 和 PyTorch FSDP 的issues,但我们不再支持 FairScale 集成,因为它已经集成到了 PyTorch 主线(参见 [PyTorch FSDP 集成](#pytorch-fully-sharded-data-parallel))。
<a id='zero-install-notes'></a>
### CUDA拓展安装注意事项
撰写时,Deepspeed 需要在使用之前编译 CUDA C++ 代码。
虽然所有安装问题都应通过 [Deepspeed](https://github.com/microsoft/DeepSpeed/issues) 的 GitHub Issues处理,但在构建依赖CUDA 扩展的任何 PyTorch 扩展时,可能会遇到一些常见问题。
因此,如果在执行以下操作时遇到与 CUDA 相关的构建问题:
```bash
pip install deepspeed
```
请首先阅读以下说明。
在这些说明中,我们提供了在 `pytorch` 使用 CUDA `10.2` 构建时应采取的操作示例。如果你的情况有所不同,请记得将版本号调整为您所需的版本。
#### 可能的问题 #1
尽管 PyTorch 自带了其自己的 CUDA 工具包,但要构建这两个项目,你必须在整个系统上安装相同版本的 CUDA。
例如,如果你在 Python 环境中使用 `cudatoolkit==10.2` 安装了 `pytorch`,你还需要在整个系统上安装 CUDA `10.2`。
确切的位置可能因系统而异,但在许多 Unix 系统上,`/usr/local/cuda-10.2` 是最常见的位置。当 CUDA 正确设置并添加到 `PATH` 环境变量时,可以通过执行以下命令找到安装位置:
```bash
which nvcc
```
如果你尚未在整个系统上安装 CUDA,请首先安装。你可以使用你喜欢的搜索引擎查找说明。例如,如果你使用的是 Ubuntu,你可能想搜索:[ubuntu cuda 10.2 install](https://www.google.com/search?q=ubuntu+cuda+10.2+install)。
#### 可能的问题 #2
另一个可能的常见问题是你可能在整个系统上安装了多个 CUDA 工具包。例如,你可能有:
```bash
/usr/local/cuda-10.2
/usr/local/cuda-11.0
```
在这种情况下,你需要确保 `PATH` 和 `LD_LIBRARY_PATH` 环境变量包含所需 CUDA 版本的正确路径。通常,软件包安装程序将设置这些变量以包含最新安装的版本。如果遇到构建失败的问题,且是因为在整个系统安装但软件仍找不到正确的 CUDA 版本,这意味着你需要调整这两个环境变量。
首先,你以查看它们的内容:
```bash
echo $PATH
echo $LD_LIBRARY_PATH
```
因此,您可以了解其中的内容。
`LD_LIBRARY_PATH` 可能是空的。
`PATH` 列出了可以找到可执行文件的位置,而 `LD_LIBRARY_PATH` 用于查找共享库。在这两种情况下,较早的条目优先于较后的条目。 `:` 用于分隔多个条目。
现在,为了告诉构建程序在哪里找到特定的 CUDA 工具包,请插入所需的路径,让其首先列出:
```bash
export PATH=/usr/local/cuda-10.2/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
```
请注意,我们没有覆盖现有值,而是在前面添加新的值。
当然,根据需要调整版本号和完整路径。检查你分配的目录是否实际存在。`lib64` 子目录是各种 CUDA `.so` 对象(如 `libcudart.so`)的位置,这个名字可能在你的系统中是不同的,如果是,请调整以反映实际情况。
#### 可能的问题 #3
一些较旧的 CUDA 版本可能会拒绝使用更新的编译器。例如,你可能有 `gcc-9`,但 CUDA 可能需要 `gcc-7`。
有各种方法可以解决这个问题。
如果你可以安装最新的 CUDA 工具包,通常它应该支持更新的编译器。
或者,你可以在已经拥有的编译器版本之外安装较低版本,或者你可能已经安装了它但它不是默认的编译器,因此构建系统无法找到它。如果你已经安装了 `gcc-7` 但构建系统找不到它,以下操作可能会解决问题:
```bash
sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.2/bin/gcc
sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.2/bin/g++
```
这里,我们正在从 `/usr/local/cuda-10.2/bin/gcc` 创建到 `gcc-7` 的软链接,由于 `/usr/local/cuda-10.2/bin/` 应该在 `PATH` 环境变量中(参见前一个问题的解决方案),它应该能够找到 `gcc-7`(和 `g++7`),然后构建将成功。
与往常一样,请确保编辑示例中的路径以匹配你的情况。
### PyTorch完全分片数据并行(FSDP)
为了加速在更大批次大小上训练庞大模型,我们可以使用完全分片的数据并行模型。这种数据并行范例通过对优化器状态、梯度和参数进行分片,实现了在更多数据和更大模型上的训练。要了解更多信息以及其优势,请查看[完全分片的数据并行博客](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/)。我们已经集成了最新的PyTorch完全分片的数据并行(FSDP)训练功能。您只需通过配置启用它。
**FSDP支持所需的PyTorch版本**: PyTorch Nightly(或者如果你在发布后阅读这个,使用1.12.0版本,因为带有激活的FSDP的模型保存仅在最近的修复中可用。
**用法**:
- 如果你尚未使用过分布式启动器,确保你已经添加了它 `-m torch.distributed.launch --nproc_per_node=NUMBER_OF_GPUS_YOU_HAVE`。
- **分片策略**:
- FULL_SHARD:在数据并行线程/GPU之间,对优化器状态、梯度和模型参数进行分片。
为此,请在命令行参数中添加 `--fsdp full_shard`。
- SHARD_GRAD_OP:在数据并行线程/GPU之间对优化器状态和梯度进行分片。
为此,请在命令行参数中添加 `--fsdp shard_grad_op`。
- NO_SHARD:不进行分片。为此,请在命令行参数中添加 `--fsdp no_shard`。
- 要将参数和梯度卸载到CPU,添加 `--fsdp "full_shard offload"` 或 `--fsdp "shard_grad_op offload"` 到命令行参数中。
- 要使用 `default_auto_wrap_policy` 自动递归地用FSDP包装层,请添加 `--fsdp "full_shard auto_wrap"` 或 `--fsdp "shard_grad_op auto_wrap"` 到命令行参数中。
- 要同时启用CPU卸载和自动包装层工具,请添加 `--fsdp "full_shard offload auto_wrap"` 或 `--fsdp "shard_grad_op offload auto_wrap"` 到命令行参数中。
- 其余的FSDP配置通过 `--fsdp_config <path_to_fsdp_config.json>` 传递。它可以是FSDP json配置文件的位置(例如,`fsdp_config.json`)或已加载的json文件作为 `dict`。
- 如果启用了自动包装,您可以使用基于transformer的自动包装策略或基于大小的自动包装策略。
- 对于基于transformer的自动包装策略,建议在配置文件中指定 `fsdp_transformer_layer_cls_to_wrap`。如果未指定,则默认值为 `model._no_split_modules`(如果可用)。这将指定要包装的transformer层类名(区分大小写),例如 [`BertLayer`]、[`GPTJBlock`]、[`T5Block`] 等。这很重要,因为共享权重的子模块(例如,embedding层)不应最终出现在不同的FSDP包装单元中。使用此策略,每个包装的块将包含多头注意力和后面的几个MLP层。剩余的层,包括共享的embedding层,都将被方便地包装在同一个最外层的FSDP单元中。因此,对于基于transformer的模型,请使用这个方法。
- 对于基于大小的自动包装策略,请在配置文件中添加 `fsdp_min_num_params`。它指定了FSDP进行自动包装的最小参数数量。
- 可以在配置文件中指定 `fsdp_backward_prefetch`。它控制何时预取下一组参数。`backward_pre` 和 `backward_pos` 是可用的选项。有关更多信息,请参阅 `torch.distributed.fsdp.fully_sharded_data_parallel.BackwardPrefetch`
- 可以在配置文件中指定 `fsdp_forward_prefetch`。它控制何时预取下一组参数。如果是`"True"`,在执行前向传递时,FSDP明确地预取下一次即将发生的全局聚集。
- 可以在配置文件中指定 `limit_all_gathers`。如果是`"True"`,FSDP明确地同步CPU线程,以防止太多的进行中的全局聚集。
- 可以在配置文件中指定 `activation_checkpointing`。如果是`"True"`,FSDP activation checkpoint是一种通过清除某些层的激活值并在反向传递期间重新计算它们来减少内存使用的技术。实际上,这以更多的计算时间为代价减少了内存使用。
**需要注意几个注意事项**
- 它与 `generate` 不兼容,因此与所有seq2seq/clm脚本(翻译/摘要/clm等)中的 `--predict_with_generate` 不兼容。请参阅issue[#21667](https://github.com/huggingface/transformers/issues/21667)。
### PyTorch/XLA 完全分片数据并行
对于所有TPU用户,有个好消息!PyTorch/XLA现在支持FSDP。所有最新的完全分片数据并行(FSDP)训练都受支持。有关更多信息,请参阅[在云端TPU上使用FSDP扩展PyTorch模型](https://pytorch.org/blog/scaling-pytorch-models-on-cloud-tpus-with-fsdp/)和[PyTorch/XLA FSDP的实现](https://github.com/pytorch/xla/tree/master/torch_xla/distributed/fsdp)。使用它只需通过配置启用。
**需要的 PyTorch/XLA 版本以支持 FSDP**:>=2.0
**用法**:
传递 `--fsdp "full shard"`,同时对 `--fsdp_config <path_to_fsdp_config.json>` 进行以下更改:
- `xla` 应设置为 `True` 以启用 PyTorch/XLA FSDP。
- `xla_fsdp_settings` 的值是一个字典,存储 XLA FSDP 封装参数。完整的选项列表,请参见[此处](https://github.com/pytorch/xla/blob/master/torch_xla/distributed/fsdp/xla_fully_sharded_data_parallel.py)。
- `xla_fsdp_grad_ckpt`。当 `True` 时,在每个嵌套的 XLA FSDP 封装层上使用梯度checkpoint。该设置只能在将 xla 标志设置为 true,并通过 `fsdp_min_num_params` 或 `fsdp_transformer_layer_cls_to_wrap` 指定自动包装策略时使用。
- 您可以使用基于transformer的自动包装策略或基于大小的自动包装策略。
- 对于基于transformer的自动包装策略,建议在配置文件中指定 `fsdp_transformer_layer_cls_to_wrap`。如果未指定,默认值为 `model._no_split_modules`(如果可用)。这指定了要包装的transformer层类名列表(区分大小写),例如 [`BertLayer`]、[`GPTJBlock`]、[`T5Block`] 等。这很重要,因为共享权重的子模块(例如,embedding层)不应最终出现在不同的FSDP包装单元中。使用此策略,每个包装的块将包含多头注意力和后面的几个MLP层。剩余的层,包括共享的embedding层,都将被方便地包装在同一个最外层的FSDP单元中。因此,对于基于transformer的模型,请使用这个方法。
- 对于基于大小的自动包装策略,请在配置文件中添加 `fsdp_min_num_params`。它指定了自动包装的 FSDP 的最小参数数量。
### 在 Mac 上使用 Trainer 进行加速的 PyTorch 训练
随着 PyTorch v1.12 版本的发布,开发人员和研究人员可以利用 Apple Silicon GPU 进行显著更快的模型训练。这使得可以在 Mac 上本地执行原型设计和微调等机器学习工作流程。Apple 的 Metal Performance Shaders(MPS)作为 PyTorch 的后端实现了这一点,并且可以通过新的 `"mps"` 设备来使用。
这将在 MPS 图形框架上映射计算图和神经图元,并使用 MPS 提供的优化内核。更多信息,请参阅官方文档 [Introducing Accelerated PyTorch Training on Mac](https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/) 和 [MPS BACKEND](https://pytorch.org/docs/stable/notes/mps.html)。
<Tip warning={false}>
我们强烈建议在你的 MacOS 机器上安装 PyTorch >= 1.13(在撰写本文时为最新版本)。对于基于 transformer 的模型, 它提供与模型正确性和性能改进相关的重大修复。有关更多详细信息,请参阅[pytorch/pytorch#82707](https://github.com/pytorch/pytorch/issues/82707)。
</Tip>
**使用 Apple Silicon 芯片进行训练和推理的好处**
1. 使用户能够在本地训练更大的网络或批量数据。
2. 由于统一内存架构,减少数据检索延迟,并为 GPU 提供对完整内存存储的直接访问。从而提高端到端性能。
3. 降低与基于云的开发或需要额外本地 GPU 的成本。
**先决条件**:要安装带有 mps 支持的 torch,请按照这篇精彩的 Medium 文章操作 [GPU-Acceleration Comes to PyTorch on M1 Macs](https://medium.com/towards-data-science/gpu-acceleration-comes-to-pytorch-on-m1-macs-195c399efcc1)。
**用法**:
如果可用,`mps` 设备将默认使用,类似于使用 `cuda` 设备的方式。因此,用户无需采取任何操作。例如,您可以使用以下命令在 Apple Silicon GPU 上运行官方的 Glue 文本分类任务(从根文件夹运行):
```bash
export TASK_NAME=mrpc
python examples/pytorch/text-classification/run_glue.py \
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
**需要注意的一些注意事项**
1. 一些 PyTorch 操作尚未在 mps 中实现,将引发错误。解决此问题的一种方法是设置环境变量 `PYTORCH_ENABLE_MPS_FALLBACK=1`,它将把这些操作回退到 CPU 进行。然而,它仍然会抛出 UserWarning 信息。
2. 分布式设置 `gloo` 和 `nccl` 在 `mps` 设备上不起作用。这意味着当前只能使用 `mps` 设备类型的单个 GPU。
最后,请记住,🤗 `Trainer` 仅集成了 MPS 后端,因此如果你在使用 MPS 后端时遇到任何问题或有疑问,请在 [PyTorch GitHub](https://github.com/pytorch/pytorch/issues) 上提交问题。
## 通过 Accelerate Launcher 使用 Trainer
Accelerate 现在支持 Trainer。用户可以期待以下内容:
- 他们可以继续使用 Trainer 的迭代,如 FSDP、DeepSpeed 等,而无需做任何更改。
- 现在可以在 Trainer 中使用 Accelerate Launcher(建议使用)。
通过 Accelerate Launcher 使用 Trainer 的步骤:
1. 确保已安装 🤗 Accelerate,无论如何,如果没有它,你无法使用 `Trainer`。如果没有,请执行 `pip install accelerate`。你可能还需要更新 Accelerate 的版本:`pip install accelerate --upgrade`。
2. 运行 `accelerate config` 并填写问题。以下是一些加速配置的示例:
a. DDP 多节点多 GPU 配置:
```yaml
compute_environment: LOCAL_MACHINE
distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0 #change rank as per the node
main_process_ip: 192.168.20.1
main_process_port: 9898
main_training_function: main
mixed_precision: fp16
num_machines: 2
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
b. FSDP 配置:
```yaml
compute_environment: LOCAL_MACHINE
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_forward_prefetch: true
fsdp_offload_params: false
fsdp_sharding_strategy: 1
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_sync_module_states: true
fsdp_transformer_layer_cls_to_wrap: BertLayer
fsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
c. 指向文件的 DeepSpeed 配置:
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /home/user/configs/ds_zero3_config.json
zero3_init_flag: true
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
d. 使用 accelerate 插件的 DeepSpeed 配置:
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 0.7
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: true
zero_stage: 2
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
3. 使用accelerate配置文件参数或启动器参数以外的参数运行Trainer脚本。以下是一个使用上述FSDP配置从accelerate启动器运行`run_glue.py`的示例。
```bash
cd transformers
accelerate launch \
./examples/pytorch/text-classification/run_glue.py \
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
4. 你也可以直接使用`accelerate launch`的cmd参数。上面的示例将映射到:
```bash
cd transformers
accelerate launch --num_processes=2 \
--use_fsdp \
--mixed_precision=bf16 \
--fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
--fsdp_transformer_layer_cls_to_wrap="BertLayer" \
--fsdp_sharding_strategy=1 \
--fsdp_state_dict_type=FULL_STATE_DICT \
./examples/pytorch/text-classification/run_glue.py
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
有关更多信息,请参阅 🤗 Accelerate CLI 指南:[启动您的 🤗 Accelerate 脚本](https://huggingface.co/docs/accelerate/basic_tutorials/launch)。
已移动的部分:
[ <a href="./deepspeed#deepspeed-trainer-integration">DeepSpeed</a><a id="deepspeed"></a> | <a href="./deepspeed#deepspeed-installation">Installation</a><a id="installation"></a> | <a href="./deepspeed#deepspeed-multi-gpu">Deployment with multiple GPUs</a><a id="deployment-with-multiple-gpus"></a> | <a href="./deepspeed#deepspeed-one-gpu">Deployment with one GPU</a><a id="deployment-with-one-gpu"></a> | <a href="./deepspeed#deepspeed-notebook">Deployment in Notebooks</a><a id="deployment-in-notebooks"></a> | <a href="./deepspeed#deepspeed-config">Configuration</a><a id="configuration"></a> | <a href="./deepspeed#deepspeed-config-passing">Passing Configuration</a><a id="passing-configuration"></a> | <a href="./deepspeed#deepspeed-config-shared">Shared Configuration</a><a id="shared-configuration"></a> | <a href="./deepspeed#deepspeed-zero">ZeRO</a><a id="zero"></a> | <a href="./deepspeed#deepspeed-zero2-config">ZeRO-2 Config</a><a id="zero-2-config"></a> | <a href="./deepspeed#deepspeed-zero3-config">ZeRO-3 Config</a><a id="zero-3-config"></a> | <a href="./deepspeed#deepspeed-nvme">NVMe Support</a><a id="nvme-support"></a> | <a href="./deepspeed#deepspeed-zero2-zero3-performance">ZeRO-2 vs ZeRO-3 Performance</a><a id="zero-2-vs-zero-3-performance"></a> | <a href="./deepspeed#deepspeed-zero2-example">ZeRO-2 Example</a><a id="zero-2-example"></a> | <a href="./deepspeed#deepspeed-zero3-example">ZeRO-3 Example</a><a id="zero-3-example"></a> | <a href="./deepspeed#deepspeed-optimizer">Optimizer</a><a id="optimizer"></a> | <a href="./deepspeed#deepspeed-scheduler">Scheduler</a><a id="scheduler"></a> | <a href="./deepspeed#deepspeed-fp32">fp32 Precision</a><a id="fp32-precision"></a> | <a href="./deepspeed#deepspeed-amp">Automatic Mixed Precision</a><a id="automatic-mixed-precision"></a> | <a href="./deepspeed#deepspeed-bs">Batch Size</a><a id="batch-size"></a> | <a href="./deepspeed#deepspeed-grad-acc">Gradient Accumulation</a><a id="gradient-accumulation"></a> | <a href="./deepspeed#deepspeed-grad-clip">Gradient Clipping</a><a id="gradient-clipping"></a> | <a href="./deepspeed#deepspeed-weight-extraction">Getting The Model Weights Out</a><a id="getting-the-model-weights-out"></a>]
## 通过 NEFTune 提升微调性能
NEFTune 是一种提升聊天模型性能的技术,由 Jain 等人在论文“NEFTune: Noisy Embeddings Improve Instruction Finetuning” 中引入。该技术在训练过程中向embedding向量添加噪音。根据论文摘要:
> 使用 Alpaca 对 LLaMA-2-7B 进行标准微调,可以在 AlpacaEval 上达到 29.79%,而使用带有噪音embedding的情况下,性能提高至 64.69%。NEFTune 还在modern instruction数据集上大大优于基线。Evol-Instruct 训练的模型表现提高了 10%,ShareGPT 提高了 8%,OpenPlatypus 提高了 8%。即使像 LLaMA-2-Chat 这样通过 RLHF 进一步细化的强大模型,通过 NEFTune 的额外训练也能受益。
<div style="text-align: center">
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/images/neft-screenshot.png">
</div>
要在 `Trainer` 中使用它,只需在创建 `TrainingArguments` 实例时传递 `neftune_noise_alpha`。请注意,为了避免任何意外行为,NEFTune在训练后被禁止,以此恢复原始的embedding层。
```python
from transformers import Trainer, TrainingArguments
args = TrainingArguments(..., neftune_noise_alpha=0.1)
trainer = Trainer(..., args=args)
...
trainer.train()
```
| 0
|
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/pipelines.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipelines
pipelines是使用模型进行推理的一种简单方法。这些pipelines是抽象了库中大部分复杂代码的对象,提供了一个专用于多个任务的简单API,包括专名识别、掩码语言建模、情感分析、特征提取和问答等。请参阅[任务摘要](../task_summary)以获取使用示例。
有两种pipelines抽象类需要注意:
- [`pipeline`],它是封装所有其他pipelines的最强大的对象。
- 针对特定任务pipelines,适用于[音频](#audio)、[计算机视觉](#computer-vision)、[自然语言处理](#natural-language-processing)和[多模态](#multimodal)任务。
## pipeline抽象类
*pipeline*抽象类是对所有其他可用pipeline的封装。它可以像任何其他pipeline一样实例化,但进一步提供额外的便利性。
简单调用一个项目:
```python
>>> pipe = pipeline("text-classification")
>>> pipe("This restaurant is awesome")
[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
```
如果您想使用 [hub](https://huggingface.co) 上的特定模型,可以忽略任务,如果hub上的模型已经定义了该任务:
```python
>>> pipe = pipeline(model="roberta-large-mnli")
>>> pipe("This restaurant is awesome")
[{'label': 'NEUTRAL', 'score': 0.7313136458396912}]
```
要在多个项目上调用pipeline,可以使用*列表*调用它。
```python
>>> pipe = pipeline("text-classification")
>>> pipe(["This restaurant is awesome", "This restaurant is awful"])
[{'label': 'POSITIVE', 'score': 0.9998743534088135},
{'label': 'NEGATIVE', 'score': 0.9996669292449951}]
```
为了遍历整个数据集,建议直接使用 `dataset`。这意味着您不需要一次性分配整个数据集,也不需要自己进行批处理。这应该与GPU上的自定义循环一样快。如果不是,请随时提出issue。
```python
import datasets
from transformers import pipeline
from transformers.pipelines.pt_utils import KeyDataset
from tqdm.auto import tqdm
pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", device=0)
dataset = datasets.load_dataset("superb", name="asr", split="test")
# KeyDataset (only *pt*) will simply return the item in the dict returned by the dataset item
# as we're not interested in the *target* part of the dataset. For sentence pair use KeyPairDataset
for out in tqdm(pipe(KeyDataset(dataset, "file"))):
print(out)
# {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
# {"text": ....}
# ....
```
为了方便使用,也可以使用生成器:
```python
from transformers import pipeline
pipe = pipeline("text-classification")
def data():
while True:
# This could come from a dataset, a database, a queue or HTTP request
# in a server
# Caveat: because this is iterative, you cannot use `num_workers > 1` variable
# to use multiple threads to preprocess data. You can still have 1 thread that
# does the preprocessing while the main runs the big inference
yield "This is a test"
for out in pipe(data()):
print(out)
# {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
# {"text": ....}
# ....
```
[[autodoc]] pipeline
## Pipeline batching
所有pipeline都可以使用批处理。这将在pipeline使用其流处理功能时起作用(即传递列表或 `Dataset` 或 `generator` 时)。
```python
from transformers import pipeline
from transformers.pipelines.pt_utils import KeyDataset
import datasets
dataset = datasets.load_dataset("imdb", name="plain_text", split="unsupervised")
pipe = pipeline("text-classification", device=0)
for out in pipe(KeyDataset(dataset, "text"), batch_size=8, truncation="only_first"):
print(out)
# [{'label': 'POSITIVE', 'score': 0.9998743534088135}]
# Exactly the same output as before, but the content are passed
# as batches to the model
```
<Tip warning={true}>
然而,这并不自动意味着性能提升。它可能是一个10倍的加速或5倍的减速,具体取决于硬件、数据和实际使用的模型。
主要是加速的示例:
</Tip>
```python
from transformers import pipeline
from torch.utils.data import Dataset
from tqdm.auto import tqdm
pipe = pipeline("text-classification", device=0)
class MyDataset(Dataset):
def __len__(self):
return 5000
def __getitem__(self, i):
return "This is a test"
dataset = MyDataset()
for batch_size in [1, 8, 64, 256]:
print("-" * 30)
print(f"Streaming batch_size={batch_size}")
for out in tqdm(pipe(dataset, batch_size=batch_size), total=len(dataset)):
pass
```
```
# On GTX 970
------------------------------
Streaming no batching
100%|██████████████████████████████████████████████████████████████████████| 5000/5000 [00:26<00:00, 187.52it/s]
------------------------------
Streaming batch_size=8
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:04<00:00, 1205.95it/s]
------------------------------
Streaming batch_size=64
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:02<00:00, 2478.24it/s]
------------------------------
Streaming batch_size=256
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:01<00:00, 2554.43it/s]
(diminishing returns, saturated the GPU)
```
主要是减速的示例:
```python
class MyDataset(Dataset):
def __len__(self):
return 5000
def __getitem__(self, i):
if i % 64 == 0:
n = 100
else:
n = 1
return "This is a test" * n
```
与其他句子相比,这是一个非常长的句子。在这种情况下,**整个**批次将需要400个tokens的长度,因此整个批次将是 [64, 400] 而不是 [64, 4],从而导致较大的减速。更糟糕的是,在更大的批次上,程序会崩溃。
```
------------------------------
Streaming no batching
100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 183.69it/s]
------------------------------
Streaming batch_size=8
100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:03<00:00, 265.74it/s]
------------------------------
Streaming batch_size=64
100%|██████████████████████████████████████████████████████████████████████| 1000/1000 [00:26<00:00, 37.80it/s]
------------------------------
Streaming batch_size=256
0%| | 0/1000 [00:00<?, ?it/s]
Traceback (most recent call last):
File "/home/nicolas/src/transformers/test.py", line 42, in <module>
for out in tqdm(pipe(dataset, batch_size=256), total=len(dataset)):
....
q = q / math.sqrt(dim_per_head) # (bs, n_heads, q_length, dim_per_head)
RuntimeError: CUDA out of memory. Tried to allocate 376.00 MiB (GPU 0; 3.95 GiB total capacity; 1.72 GiB already allocated; 354.88 MiB free; 2.46 GiB reserved in total by PyTorch)
```
对于这个问题,没有好的(通用)解决方案,效果可能因您的用例而异。经验法则如下:
对于用户,一个经验法则是:
- **使用硬件测量负载性能。测量、测量、再测量。真实的数字是唯一的方法。**
- 如果受到延迟的限制(进行推理的实时产品),不要进行批处理。
- 如果使用CPU,不要进行批处理。
- 如果您在GPU上处理的是吞吐量(您希望在大量静态数据上运行模型),则:
- 如果对序列长度的大小没有概念("自然"数据),默认情况下不要进行批处理,进行测试并尝试逐渐添加,添加OOM检查以在失败时恢复(如果您不能控制序列长度,它将在某些时候失败)。
- 如果您的序列长度非常规律,那么批处理更有可能非常有趣,进行测试并推动它,直到出现OOM。
- GPU越大,批处理越有可能变得更有趣
- 一旦启用批处理,确保能够很好地处理OOM。
## Pipeline chunk batching
`zero-shot-classification` 和 `question-answering` 在某种意义上稍微特殊,因为单个输入可能会导致模型的多次前向传递。在正常情况下,这将导致 `batch_size` 参数的问题。
为了规避这个问题,这两个pipeline都有点特殊,它们是 `ChunkPipeline` 而不是常规的 `Pipeline`。简而言之:
```python
preprocessed = pipe.preprocess(inputs)
model_outputs = pipe.forward(preprocessed)
outputs = pipe.postprocess(model_outputs)
```
现在变成:
```python
all_model_outputs = []
for preprocessed in pipe.preprocess(inputs):
model_outputs = pipe.forward(preprocessed)
all_model_outputs.append(model_outputs)
outputs = pipe.postprocess(all_model_outputs)
```
这对您的代码应该是非常直观的,因为pipeline的使用方式是相同的。
这是一个简化的视图,因为Pipeline可以自动处理批次!这意味着您不必担心您的输入实际上会触发多少次前向传递,您可以独立于输入优化 `batch_size`。前面部分的注意事项仍然适用。
## Pipeline自定义
如果您想要重载特定的pipeline。
请随时为您手头的任务创建一个issue,Pipeline的目标是易于使用并支持大多数情况,因此 `transformers` 可能支持您的用例。
如果您想简单地尝试一下,可以:
- 继承您选择的pipeline
```python
class MyPipeline(TextClassificationPipeline):
def postprocess():
# Your code goes here
scores = scores * 100
# And here
my_pipeline = MyPipeline(model=model, tokenizer=tokenizer, ...)
# or if you use *pipeline* function, then:
my_pipeline = pipeline(model="xxxx", pipeline_class=MyPipeline)
```
这样就可以让您编写所有想要的自定义代码。
## 实现一个pipeline
[实现一个新的pipeline](../add_new_pipeline)
## 音频
可用于音频任务的pipeline包括以下几种。
### AudioClassificationPipeline
[[autodoc]] AudioClassificationPipeline
- __call__
- all
### AutomaticSpeechRecognitionPipeline
[[autodoc]] AutomaticSpeechRecognitionPipeline
- __call__
- all
### TextToAudioPipeline
[[autodoc]] TextToAudioPipeline
- __call__
- all
### ZeroShotAudioClassificationPipeline
[[autodoc]] ZeroShotAudioClassificationPipeline
- __call__
- all
## 计算机视觉
可用于计算机视觉任务的pipeline包括以下几种。
### DepthEstimationPipeline
[[autodoc]] DepthEstimationPipeline
- __call__
- all
### ImageClassificationPipeline
[[autodoc]] ImageClassificationPipeline
- __call__
- all
### ImageSegmentationPipeline
[[autodoc]] ImageSegmentationPipeline
- __call__
- all
### ImageToImagePipeline
[[autodoc]] ImageToImagePipeline
- __call__
- all
### ObjectDetectionPipeline
[[autodoc]] ObjectDetectionPipeline
- __call__
- all
### VideoClassificationPipeline
[[autodoc]] VideoClassificationPipeline
- __call__
- all
### ZeroShotImageClassificationPipeline
[[autodoc]] ZeroShotImageClassificationPipeline
- __call__
- all
### ZeroShotObjectDetectionPipeline
[[autodoc]] ZeroShotObjectDetectionPipeline
- __call__
- all
## 自然语言处理
可用于自然语言处理任务的pipeline包括以下几种。
### ConversationalPipeline
[[autodoc]] Conversation
[[autodoc]] ConversationalPipeline
- __call__
- all
### FillMaskPipeline
[[autodoc]] FillMaskPipeline
- __call__
- all
### NerPipeline
[[autodoc]] NerPipeline
See [`TokenClassificationPipeline`] for all details.
### QuestionAnsweringPipeline
[[autodoc]] QuestionAnsweringPipeline
- __call__
- all
### SummarizationPipeline
[[autodoc]] SummarizationPipeline
- __call__
- all
### TableQuestionAnsweringPipeline
[[autodoc]] TableQuestionAnsweringPipeline
- __call__
### TextClassificationPipeline
[[autodoc]] TextClassificationPipeline
- __call__
- all
### TextGenerationPipeline
[[autodoc]] TextGenerationPipeline
- __call__
- all
### Text2TextGenerationPipeline
[[autodoc]] Text2TextGenerationPipeline
- __call__
- all
### TokenClassificationPipeline
[[autodoc]] TokenClassificationPipeline
- __call__
- all
### TranslationPipeline
[[autodoc]] TranslationPipeline
- __call__
- all
### ZeroShotClassificationPipeline
[[autodoc]] ZeroShotClassificationPipeline
- __call__
- all
## 多模态
可用于多模态任务的pipeline包括以下几种。
### DocumentQuestionAnsweringPipeline
[[autodoc]] DocumentQuestionAnsweringPipeline
- __call__
- all
### FeatureExtractionPipeline
[[autodoc]] FeatureExtractionPipeline
- __call__
- all
### ImageToTextPipeline
[[autodoc]] ImageToTextPipeline
- __call__
- all
### MaskGenerationPipeline
[[autodoc]] MaskGenerationPipeline
- __call__
- all
### VisualQuestionAnsweringPipeline
[[autodoc]] VisualQuestionAnsweringPipeline
- __call__
- all
## Parent class: `Pipeline`
[[autodoc]] Pipeline
| 0
|
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/quantization.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 量化 🤗 Transformers 模型
## AWQ集成
AWQ方法已经在[*AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration*论文](https://arxiv.org/abs/2306.00978)中引入。通过AWQ,您可以以4位精度运行模型,同时保留其原始性能(即没有性能降级),并具有比下面介绍的其他量化方法更出色的吞吐量 - 达到与纯`float16`推理相似的吞吐量。
我们现在支持使用任何AWQ模型进行推理,这意味着任何人都可以加载和使用在Hub上推送或本地保存的AWQ权重。请注意,使用AWQ需要访问NVIDIA GPU。目前不支持CPU推理。
### 量化一个模型
我们建议用户查看生态系统中不同的现有工具,以使用AWQ算法对其模型进行量化,例如:
- [`llm-awq`](https://github.com/mit-han-lab/llm-awq),来自MIT Han Lab
- [`autoawq`](https://github.com/casper-hansen/AutoAWQ),来自[`casper-hansen`](https://github.com/casper-hansen)
- Intel neural compressor,来自Intel - 通过[`optimum-intel`](https://huggingface.co/docs/optimum/main/en/intel/optimization_inc)使用
生态系统中可能存在许多其他工具,请随时提出PR将它们添加到列表中。
目前与🤗 Transformers的集成仅适用于使用`autoawq`和`llm-awq`量化后的模型。大多数使用`auto-awq`量化的模型可以在🤗 Hub的[`TheBloke`](https://huggingface.co/TheBloke)命名空间下找到,要使用`llm-awq`对模型进行量化,请参阅[`llm-awq`](https://github.com/mit-han-lab/llm-awq/)的示例文件夹中的[`convert_to_hf.py`](https://github.com/mit-han-lab/llm-awq/blob/main/examples/convert_to_hf.py)脚本。
### 加载一个量化的模型
您可以使用`from_pretrained`方法从Hub加载一个量化模型。通过检查模型配置文件(`configuration.json`)中是否存在`quantization_config`属性,来进行确认推送的权重是量化的。您可以通过检查字段`quantization_config.quant_method`来确认模型是否以AWQ格式进行量化,该字段应该设置为`"awq"`。请注意,为了性能原因,默认情况下加载模型将设置其他权重为`float16`。如果您想更改这种设置,可以通过将`torch_dtype`参数设置为`torch.float32`或`torch.bfloat16`。在下面的部分中,您可以找到一些示例片段和notebook。
## 示例使用
首先,您需要安装[`autoawq`](https://github.com/casper-hansen/AutoAWQ)库
```bash
pip install autoawq
```
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "TheBloke/zephyr-7B-alpha-AWQ"
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0")
```
如果您首先将模型加载到CPU上,请确保在使用之前将其移动到GPU设备上。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "TheBloke/zephyr-7B-alpha-AWQ"
model = AutoModelForCausalLM.from_pretrained(model_id).to("cuda:0")
```
### 结合 AWQ 和 Flash Attention
您可以将AWQ量化与Flash Attention结合起来,得到一个既被量化又更快速的模型。只需使用`from_pretrained`加载模型,并传递`use_flash_attention_2=True`参数。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", use_flash_attention_2=True, device_map="cuda:0")
```
### 基准测试
我们使用[`optimum-benchmark`](https://github.com/huggingface/optimum-benchmark)库进行了一些速度、吞吐量和延迟基准测试。
请注意,在编写本文档部分时,可用的量化方法包括:`awq`、`gptq`和`bitsandbytes`。
基准测试在一台NVIDIA-A100实例上运行,使用[`TheBloke/Mistral-7B-v0.1-AWQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-AWQ)作为AWQ模型,[`TheBloke/Mistral-7B-v0.1-GPTQ`](https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPTQ)作为GPTQ模型。我们还将其与`bitsandbytes`量化模型和`float16`模型进行了对比。以下是一些结果示例:
<div style="text-align: center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quantization/forward_memory_plot.png">
</div>
<div style="text-align: center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quantization/generate_memory_plot.png">
</div>
<div style="text-align: center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quantization/generate_throughput_plot.png">
</div>
<div style="text-align: center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quantization/forward_latency_plot.png">
</div>
你可以在[此链接](https://github.com/huggingface/optimum-benchmark/tree/main/examples/running-mistrals)中找到完整的结果以及包版本。
从结果来看,AWQ量化方法是推理、文本生成中最快的量化方法,并且在文本生成的峰值内存方面属于最低。然而,对于每批数据,AWQ似乎有最大的前向延迟。
### Google colab 演示
查看如何在[Google Colab演示](https://colab.research.google.com/drive/1HzZH89yAXJaZgwJDhQj9LqSBux932BvY)中使用此集成!
### AwqConfig
[[autodoc]] AwqConfig
## `AutoGPTQ` 集成
🤗 Transformers已经整合了`optimum` API,用于对语言模型执行GPTQ量化。您可以以8、4、3甚至2位加载和量化您的模型,而性能无明显下降,并且推理速度更快!这受到大多数GPU硬件的支持。
要了解更多关于量化模型的信息,请查看:
- [GPTQ](https://arxiv.org/pdf/2210.17323.pdf)论文
- `optimum`关于GPTQ量化的[指南](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization)
- 用作后端的[`AutoGPTQ`](https://github.com/PanQiWei/AutoGPTQ)库
### 要求
为了运行下面的代码,您需要安装:
- 安装最新版本的 `AutoGPTQ` 库
`pip install auto-gptq`
- 从源代码安装最新版本的`optimum`
`pip install git+https://github.com/huggingface/optimum.git`
- 从源代码安装最新版本的`transformers`
`pip install git+https://github.com/huggingface/transformers.git`
- 安装最新版本的`accelerate`库:
`pip install --upgrade accelerate`
请注意,目前GPTQ集成仅支持文本模型,对于视觉、语音或多模态模型可能会遇到预期以外结果。
### 加载和量化模型
GPTQ是一种在使用量化模型之前需要进行权重校准的量化方法。如果您想从头开始对transformers模型进行量化,生成量化模型可能需要一些时间(在Google Colab上对`facebook/opt-350m`模型量化约为5分钟)。
因此,有两种不同的情况下您可能想使用GPTQ量化模型。第一种情况是加载已经由其他用户在Hub上量化的模型,第二种情况是从头开始对您的模型进行量化并保存或推送到Hub,以便其他用户也可以使用它。
#### GPTQ 配置
为了加载和量化一个模型,您需要创建一个[`GPTQConfig`]。您需要传递`bits`的数量,一个用于校准量化的`dataset`,以及模型的`tokenizer`以准备数据集。
```python
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
gptq_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
```
请注意,您可以将自己的数据集以字符串列表形式传递到模型。然而,强烈建议您使用GPTQ论文中提供的数据集。
```python
dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]
quantization = GPTQConfig(bits=4, dataset = dataset, tokenizer=tokenizer)
```
#### 量化
您可以通过使用`from_pretrained`并设置`quantization_config`来对模型进行量化。
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=gptq_config)
```
请注意,您需要一个GPU来量化模型。我们将模型放在cpu中,并将模块来回移动到gpu中,以便对其进行量化。
如果您想在使用 CPU 卸载的同时最大化 GPU 使用率,您可以设置 `device_map = "auto"`。
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=gptq_config)
```
请注意,不支持磁盘卸载。此外,如果由于数据集而内存不足,您可能需要在`from_pretrained`中设置`max_memory`。查看这个[指南](https://huggingface.co/docs/accelerate/usage_guides/big_modeling#designing-a-device-map)以了解有关`device_map`和`max_memory`的更多信息。
<Tip warning={true}>
目前,GPTQ量化仅适用于文本模型。此外,量化过程可能会花费很多时间,具体取决于硬件性能(175B模型在NVIDIA A100上需要4小时)。请在Hub上检查是否有模型的GPTQ量化版本。如果没有,您可以在GitHub上提交需求。
</Tip>
### 推送量化模型到 🤗 Hub
您可以使用`push_to_hub`将量化模型像任何模型一样推送到Hub。量化配置将与模型一起保存和推送。
```python
quantized_model.push_to_hub("opt-125m-gptq")
tokenizer.push_to_hub("opt-125m-gptq")
```
如果您想在本地计算机上保存量化模型,您也可以使用`save_pretrained`来完成:
```python
quantized_model.save_pretrained("opt-125m-gptq")
tokenizer.save_pretrained("opt-125m-gptq")
```
请注意,如果您量化模型时想使用`device_map`,请确保在保存之前将整个模型移动到您的GPU或CPU之一。
```python
quantized_model.to("cpu")
quantized_model.save_pretrained("opt-125m-gptq")
```
### 从 🤗 Hub 加载一个量化模型
您可以使用`from_pretrained`从Hub加载量化模型。
请确保推送权重是量化的,检查模型配置对象中是否存在`quantization_config`属性。
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq")
```
如果您想更快地加载模型,并且不需要分配比实际需要内存更多的内存,量化模型也使用`device_map`参数。确保您已安装`accelerate`库。
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto")
```
### Exllama内核加快推理速度
保留格式:对于 4 位模型,您可以使用 exllama 内核来提高推理速度。默认情况下,它处于启用状态。您可以通过在 [`GPTQConfig`] 中传递 `use_exllama` 来更改此配置。这将覆盖存储在配置中的量化配置。请注意,您只能覆盖与内核相关的属性。此外,如果您想使用 exllama 内核,整个模型需要全部部署在 gpus 上。此外,您可以使用 版本 > 0.4.2 的 Auto-GPTQ 并传递 `device_map` = "cpu" 来执行 CPU 推理。对于 CPU 推理,您必须在 `GPTQConfig` 中传递 `use_exllama = False`。
```py
import torch
gptq_config = GPTQConfig(bits=4)
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config=gptq_config)
```
随着 exllamav2 内核的发布,与 exllama 内核相比,您可以获得更快的推理速度。您只需在 [`GPTQConfig`] 中传递 `exllama_config={"version": 2}`:
```py
import torch
gptq_config = GPTQConfig(bits=4, exllama_config={"version":2})
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config = gptq_config)
```
请注意,目前仅支持 4 位模型。此外,如果您正在使用 peft 对量化模型进行微调,建议禁用 exllama 内核。
您可以在此找到这些内核的基准测试 [这里](https://github.com/huggingface/optimum/tree/main/tests/benchmark#gptq-benchmark)
#### 微调一个量化模型
在Hugging Face生态系统的官方支持下,您可以使用GPTQ进行量化后的模型进行微调。
请查看`peft`库了解更多详情。
### 示例演示
请查看 Google Colab [notebook](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94ilkUFu6ZX4ceb?usp=sharing),了解如何使用GPTQ量化您的模型以及如何使用peft微调量化模型。
### GPTQConfig
[[autodoc]] GPTQConfig
## `bitsandbytes` 集成
🤗 Transformers 与 `bitsandbytes` 上最常用的模块紧密集成。您可以使用几行代码以 8 位精度加载您的模型。
自bitsandbytes的0.37.0版本发布以来,大多数GPU硬件都支持这一点。
在[LLM.int8()](https://arxiv.org/abs/2208.07339)论文中了解更多关于量化方法的信息,或者在[博客文章](https://huggingface.co/blog/hf-bitsandbytes-integration)中了解关于合作的更多信息。
自其“0.39.0”版本发布以来,您可以使用FP4数据类型,通过4位量化加载任何支持“device_map”的模型。
如果您想量化自己的 pytorch 模型,请查看 🤗 Accelerate 的[文档](https://huggingface.co/docs/accelerate/main/en/usage_guides/quantization)。
以下是您可以使用“bitsandbytes”集成完成的事情
### 通用用法
只要您的模型支持使用 🤗 Accelerate 进行加载并包含 `torch.nn.Linear` 层,您可以在调用 [`~PreTrainedModel.from_pretrained`] 方法时使用 `load_in_8bit` 或 `load_in_4bit` 参数来量化模型。这也应该适用于任何模态。
```python
from transformers import AutoModelForCausalLM
model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True)
model_4bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_4bit=True)
```
默认情况下,所有其他模块(例如 `torch.nn.LayerNorm`)将被转换为 `torch.float16` 类型。但如果您想更改它们的 `dtype`,可以重载 `torch_dtype` 参数:
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM
>>> model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True, torch_dtype=torch.float32)
>>> model_8bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
torch.float32
```
### FP4 量化
#### 要求
确保在运行以下代码段之前已完成以下要求:
- 最新版本 `bitsandbytes` 库
`pip install bitsandbytes>=0.39.0`
- 安装最新版本 `accelerate`
`pip install --upgrade accelerate`
- 安装最新版本 `transformers`
`pip install --upgrade transformers`
#### 提示和最佳实践
- **高级用法:** 请参考 [此 Google Colab notebook](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf) 以获取 4 位量化高级用法和所有可选选项。
- **使用 `batch_size=1` 实现更快的推理:** 自 `bitsandbytes` 的 `0.40.0` 版本以来,设置 `batch_size=1`,您可以从快速推理中受益。请查看 [这些发布说明](https://github.com/TimDettmers/bitsandbytes/releases/tag/0.40.0) ,并确保使用大于 `0.40.0` 的版本以直接利用此功能。
- **训练:** 根据 [QLoRA 论文](https://arxiv.org/abs/2305.14314),对于4位基模型训练(使用 LoRA 适配器),应使用 `bnb_4bit_quant_type='nf4'`。
- **推理:** 对于推理,`bnb_4bit_quant_type` 对性能影响不大。但是为了与模型的权重保持一致,请确保使用相同的 `bnb_4bit_compute_dtype` 和 `torch_dtype` 参数。
#### 加载 4 位量化的大模型
在调用 `.from_pretrained` 方法时使用 `load_in_4bit=True`,可以将您的内存使用量减少到大约原来的 1/4。
```python
# pip install transformers accelerate bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "bigscience/bloom-1b7"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", load_in_4bit=True)
```
<Tip warning={true}>
需要注意的是,一旦模型以 4 位量化方式加载,就无法将量化后的权重推送到 Hub 上。此外,您不能训练 4 位量化权重,因为目前尚不支持此功能。但是,您可以使用 4 位量化模型来训练额外参数,这将在下一部分中介绍。
</Tip>
### 加载 8 位量化的大模型
您可以通过在调用 `.from_pretrained` 方法时使用 `load_in_8bit=True` 参数,将内存需求大致减半来加载模型
```python
# pip install transformers accelerate bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "bigscience/bloom-1b7"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", load_in_8bit=True)
```
然后,像通常使用 `PreTrainedModel` 一样使用您的模型。
您可以使用 `get_memory_footprint` 方法检查模型的内存占用。
```python
print(model.get_memory_footprint())
```
通过这种集成,我们能够在较小的设备上加载大模型并运行它们而没有任何问题。
<Tip warning={true}>
需要注意的是,一旦模型以 8 位量化方式加载,除了使用最新的 `transformers` 和 `bitsandbytes` 之外,目前尚无法将量化后的权重推送到 Hub 上。此外,您不能训练 8 位量化权重,因为目前尚不支持此功能。但是,您可以使用 8 位量化模型来训练额外参数,这将在下一部分中介绍。
注意,`device_map` 是可选的,但设置 `device_map = 'auto'` 更适合用于推理,因为它将更有效地调度可用资源上的模型。
</Tip>
#### 高级用例
在这里,我们将介绍使用 FP4 量化的一些高级用例。
##### 更改计算数据类型
计算数据类型用于改变在进行计算时使用的数据类型。例如,hidden states可以是 `float32`,但为了加速,计算时可以被设置为 `bf16`。默认情况下,计算数据类型被设置为 `float32`。
```python
import torch
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16)
```
#### 使用 NF4(普通浮点数 4)数据类型
您还可以使用 NF4 数据类型,这是一种针对使用正态分布初始化的权重而适应的新型 4 位数据类型。要运行:
```python
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
```
#### 使用嵌套量化进行更高效的内存推理
我们还建议用户使用嵌套量化技术。从我们的经验观察来看,这种方法在不增加额外性能的情况下节省更多内存。这使得 llama-13b 模型能够在具有 1024 个序列长度、1 个批次大小和 4 个梯度累积步骤的 NVIDIA-T4 16GB 上进行 fine-tuning。
```python
from transformers import BitsAndBytesConfig
double_quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
)
model_double_quant = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=double_quant_config)
```
### 将量化模型推送到🤗 Hub
您可以使用 `push_to_hub` 方法将量化模型推送到 Hub 上。这将首先推送量化配置文件,然后推送量化模型权重。
请确保使用 `bitsandbytes>0.37.2`(在撰写本文时,我们使用的是 `bitsandbytes==0.38.0.post1`)才能使用此功能。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom-560m", device_map="auto", load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
model.push_to_hub("bloom-560m-8bit")
```
<Tip warning={true}>
对大模型,强烈鼓励将 8 位量化模型推送到 Hub 上,以便让社区能够从内存占用减少和加载中受益,例如在 Google Colab 上加载大模型。
</Tip>
### 从🤗 Hub加载量化模型
您可以使用 `from_pretrained` 方法从 Hub 加载量化模型。请确保推送的权重是量化的,检查模型配置对象中是否存在 `quantization_config` 属性。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("{your_username}/bloom-560m-8bit", device_map="auto")
```
请注意,在这种情况下,您不需要指定 `load_in_8bit=True` 参数,但需要确保 `bitsandbytes` 和 `accelerate` 已安装。
情注意,`device_map` 是可选的,但设置 `device_map = 'auto'` 更适合用于推理,因为它将更有效地调度可用资源上的模型。
### 高级用例
本节面向希望探索除了加载和运行 8 位模型之外还能做什么的进阶用户。
#### 在 `cpu` 和 `gpu` 之间卸载
此高级用例之一是能够加载模型并将权重分派到 `CPU` 和 `GPU` 之间。请注意,将在 CPU 上分派的权重 **不会** 转换为 8 位,因此会保留为 `float32`。此功能适用于想要适应非常大的模型并将模型分派到 GPU 和 CPU 之间的用户。
首先,从 `transformers` 中加载一个 [`BitsAndBytesConfig`],并将属性 `llm_int8_enable_fp32_cpu_offload` 设置为 `True`:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True)
```
假设您想加载 `bigscience/bloom-1b7` 模型,您的 GPU显存仅足够容纳除了`lm_head`外的整个模型。因此,您可以按照以下方式编写自定义的 device_map:
```python
device_map = {
"transformer.word_embeddings": 0,
"transformer.word_embeddings_layernorm": 0,
"lm_head": "cpu",
"transformer.h": 0,
"transformer.ln_f": 0,
}
```
然后如下加载模型:
```python
model_8bit = AutoModelForCausalLM.from_pretrained(
"bigscience/bloom-1b7",
device_map=device_map,
quantization_config=quantization_config,
)
```
这就是全部内容!享受您的模型吧!
#### 使用`llm_int8_threshold`
您可以使用 `llm_int8_threshold` 参数来更改异常值的阈值。“异常值”是一个大于特定阈值的`hidden state`值。
这对应于`LLM.int8()`论文中描述的异常检测的异常阈值。任何高于此阈值的`hidden state`值都将被视为异常值,对这些值的操作将在 fp16 中完成。值通常是正态分布的,也就是说,大多数值在 [-3.5, 3.5] 范围内,但有一些额外的系统异常值,对于大模型来说,它们的分布非常不同。这些异常值通常在区间 [-60, -6] 或 [6, 60] 内。Int8 量化对于幅度为 ~5 的值效果很好,但超出这个范围,性能就会明显下降。一个好的默认阈值是 6,但对于更不稳定的模型(小模型、微调)可能需要更低的阈值。
这个参数会影响模型的推理速度。我们建议尝试这个参数,以找到最适合您的用例的参数。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "bigscience/bloom-1b7"
quantization_config = BitsAndBytesConfig(
llm_int8_threshold=10,
)
model_8bit = AutoModelForCausalLM.from_pretrained(
model_id,
device_map=device_map,
quantization_config=quantization_config,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
```
#### 跳过某些模块的转换
一些模型有几个需要保持未转换状态以确保稳定性的模块。例如,Jukebox 模型有几个 `lm_head` 模块需要跳过。使用 `llm_int8_skip_modules` 参数进行相应操作。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "bigscience/bloom-1b7"
quantization_config = BitsAndBytesConfig(
llm_int8_skip_modules=["lm_head"],
)
model_8bit = AutoModelForCausalLM.from_pretrained(
model_id,
device_map=device_map,
quantization_config=quantization_config,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
```
#### 微调已加载为8位精度的模型
借助Hugging Face生态系统中适配器(adapters)的官方支持,您可以在8位精度下微调模型。这使得可以在单个Google Colab中微调大模型,例如`flan-t5-large`或`facebook/opt-6.7b`。请查看[`peft`](https://github.com/huggingface/peft)库了解更多详情。
注意,加载模型进行训练时无需传递`device_map`。它将自动将您的模型加载到GPU上。如果需要,您可以将设备映射为特定设备(例如`cuda:0`、`0`、`torch.device('cuda:0')`)。请注意,`device_map=auto`仅应用于推理。
### BitsAndBytesConfig
[[autodoc]] BitsAndBytesConfig
## 使用 🤗 `optimum` 进行量化
请查看[Optimum 文档](https://huggingface.co/docs/optimum/index)以了解更多关于`optimum`支持的量化方法,并查看这些方法是否适用于您的用例。
| 0
|
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/image_processor.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Image Processor
Image processor负责为视觉模型准备输入特征并后期处理处理它们的输出。这包括诸如调整大小、归一化和转换为PyTorch、TensorFlow、Flax和NumPy张量等转换。它还可能包括特定于模型的后期处理,例如将logits转换为分割掩码。
## ImageProcessingMixin
[[autodoc]] image_processing_utils.ImageProcessingMixin
- from_pretrained
- save_pretrained
## BatchFeature
[[autodoc]] BatchFeature
## BaseImageProcessor
[[autodoc]] image_processing_utils.BaseImageProcessor
| 0
|
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/optimizer_schedules.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Optimization
`.optimization` 模块提供了:
- 一个带有固定权重衰减的优化器,可用于微调模型
- 继承自 `_LRSchedule` 多个调度器:
- 一个梯度累积类,用于累积多个批次的梯度
## AdamW (PyTorch)
[[autodoc]] AdamW
## AdaFactor (PyTorch)
[[autodoc]] Adafactor
## AdamWeightDecay (TensorFlow)
[[autodoc]] AdamWeightDecay
[[autodoc]] create_optimizer
## Schedules
### Learning Rate Schedules (Pytorch)
[[autodoc]] SchedulerType
[[autodoc]] get_scheduler
[[autodoc]] get_constant_schedule
[[autodoc]] get_constant_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_constant_schedule.png"/>
[[autodoc]] get_cosine_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_schedule.png"/>
[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_hard_restarts_schedule.png"/>
[[autodoc]] get_linear_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_linear_schedule.png"/>
[[autodoc]] get_polynomial_decay_schedule_with_warmup
[[autodoc]] get_inverse_sqrt_schedule
### Warmup (TensorFlow)
[[autodoc]] WarmUp
## Gradient Strategies
### GradientAccumulator (TensorFlow)
[[autodoc]] GradientAccumulator
| 0
|
hf_public_repos/transformers/docs/source/zh
|
hf_public_repos/transformers/docs/source/zh/main_classes/feature_extractor.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Feature Extractor
Feature Extractor负责为音频或视觉模型准备输入特征。这包括从序列中提取特征,例如,对音频文件进行预处理以生成Log-Mel频谱特征,以及从图像中提取特征,例如,裁剪图像文件,同时还包括填充、归一化和转换为NumPy、PyTorch和TensorFlow张量。
## FeatureExtractionMixin
[[autodoc]] feature_extraction_utils.FeatureExtractionMixin
- from_pretrained
- save_pretrained
## SequenceFeatureExtractor
[[autodoc]] SequenceFeatureExtractor
- pad
## BatchFeature
[[autodoc]] BatchFeature
## ImageFeatureExtractionMixin
[[autodoc]] image_utils.ImageFeatureExtractionMixin
| 0
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.