
repo_id
stringlengths 15
89
| file_path
stringlengths 27
180
| content
stringlengths 1
2.23M
| __index_level_0__
int64 0
0
|
|---|---|---|---|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/data_collator.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# データ照合者
データ照合器は、データセット要素のリストを入力として使用してバッチを形成するオブジェクトです。これらの要素は、
`train_dataset` または `eval_dataset` の要素と同じ型。
バッチを構築できるようにするために、データ照合者は何らかの処理 (パディングなど) を適用する場合があります。そのうちのいくつかは(
[`DataCollatorForLanguageModeling`]) ランダムなデータ拡張 (ランダム マスキングなど) も適用します
形成されたバッチ上で。
使用例は、[サンプル スクリプト](../examples) または [サンプル ノートブック](../notebooks) にあります。
## Default data collator
[[autodoc]] data.data_collator.default_data_collator
## DefaultDataCollator
[[autodoc]] data.data_collator.DefaultDataCollator
## DataCollatorWithPadding
[[autodoc]] data.data_collator.DataCollatorWithPadding
## DataCollatorForTokenClassification
[[autodoc]] data.data_collator.DataCollatorForTokenClassification
## DataCollatorForSeq2Seq
[[autodoc]] data.data_collator.DataCollatorForSeq2Seq
## DataCollatorForLanguageModeling
[[autodoc]] data.data_collator.DataCollatorForLanguageModeling
- numpy_mask_tokens
- tf_mask_tokens
- torch_mask_tokens
## DataCollatorForWholeWordMask
[[autodoc]] data.data_collator.DataCollatorForWholeWordMask
- numpy_mask_tokens
- tf_mask_tokens
- torch_mask_tokens
## DataCollatorForPermutationLanguageModeling
[[autodoc]] data.data_collator.DataCollatorForPermutationLanguageModeling
- numpy_mask_tokens
- tf_mask_tokens
- torch_mask_tokens
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/processors.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Processors
Transformers ライブラリでは、プロセッサは 2 つの異なる意味を持ちます。
- [Wav2Vec2](../model_doc/wav2vec2) などのマルチモーダル モデルの入力を前処理するオブジェクト (音声とテキスト)
または [CLIP](../model_doc/clip) (テキストとビジョン)
- 古いバージョンのライブラリで GLUE または SQUAD のデータを前処理するために使用されていたオブジェクトは非推奨になりました。
## Multi-modal processors
マルチモーダル モデルでは、オブジェクトが複数のモダリティ (テキスト、
視覚と音声)。これは、2 つ以上の処理オブジェクトをグループ化するプロセッサーと呼ばれるオブジェクトによって処理されます。
トークナイザー (テキスト モダリティ用)、画像プロセッサー (視覚用)、特徴抽出器 (オーディオ用) など。
これらのプロセッサは、保存およびロード機能を実装する次の基本クラスを継承します。
[[autodoc]] ProcessorMixin
## Deprecated processors
すべてのプロセッサは、同じアーキテクチャに従っています。
[`~data.processors.utils.DataProcessor`]。プロセッサは次のリストを返します。
[`~data.processors.utils.InputExample`]。これら
[`~data.processors.utils.InputExample`] は次のように変換できます。
[`~data.processors.utils.Input features`] をモデルにフィードします。
[[autodoc]] data.processors.utils.DataProcessor
[[autodoc]] data.processors.utils.InputExample
[[autodoc]] data.processors.utils.InputFeatures
## GLUE
[一般言語理解評価 (GLUE)](https://gluebenchmark.com/) は、
既存の NLU タスクの多様なセットにわたるモデルのパフォーマンス。紙と同時発売された [GLUE: A
自然言語理解のためのマルチタスクベンチマークおよび分析プラットフォーム](https://openreview.net/pdf?id=rJ4km2R5t7)
このライブラリは、MRPC、MNLI、MNLI (不一致)、CoLA、SST2、STSB、
QQP、QNLI、RTE、WNLI。
それらのプロセッサは次のとおりです。
- [`~data.processors.utils.MrpcProcessor`]
- [`~data.processors.utils.MnliProcessor`]
- [`~data.processors.utils.MnliMismatchedProcessor`]
- [`~data.processors.utils.Sst2Processor`]
- [`~data.processors.utils.StsbProcessor`]
- [`~data.processors.utils.QqpProcessor`]
- [`~data.processors.utils.QnliProcessor`]
- [`~data.processors.utils.RteProcessor`]
- [`~data.processors.utils.WnliProcessor`]
さらに、次のメソッドを使用して、データ ファイルから値をロードし、それらをリストに変換することができます。
[`~data.processors.utils.InputExample`]。
[[autodoc]] data.processors.glue.glue_convert_examples_to_features
## XNLI
[クロスリンガル NLI コーパス (XNLI)](https://www.nyu.edu/projects/bowman/xnli/) は、
言語を超えたテキスト表現の品質。 XNLI は、[*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/) に基づくクラウドソースのデータセットです。テキストのペアには、15 個のテキスト含意アノテーションがラベル付けされています。
さまざまな言語 (英語などの高リソース言語とスワヒリ語などの低リソース言語の両方を含む)。
論文 [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053) と同時にリリースされました。
このライブラリは、XNLI データをロードするプロセッサをホストします。
- [`~data.processors.utils.XnliProcessor`]
テストセットにはゴールドラベルが付いているため、評価はテストセットで行われますのでご了承ください。
これらのプロセッサを使用する例は、[run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) スクリプトに示されています。
## SQuAD
[The Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) は、次のベンチマークです。
質問応答に関するモデルのパフォーマンスを評価します。 v1.1 と v2.0 の 2 つのバージョンが利用可能です。最初のバージョン
(v1.1) は、論文 [SQuAD: 100,000+ question for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250) とともにリリースされました。 2 番目のバージョン (v2.0) は、論文 [Know What You Don't と同時にリリースされました。
知っておくべき: SQuAD の答えられない質問](https://arxiv.org/abs/1806.03822)。
このライブラリは、次の 2 つのバージョンのそれぞれのプロセッサをホストします。
### Processors
それらのプロセッサは次のとおりです。
- [`~data.processors.utils.SquadV1Processor`]
- [`~data.processors.utils.SquadV2Processor`]
どちらも抽象クラス [`~data.processors.utils.SquadProcessor`] を継承しています。
[[autodoc]] data.processors.squad.SquadProcessor
- all
さらに、次のメソッドを使用して、SQuAD の例を次の形式に変換できます。
モデルの入力として使用できる [`~data.processors.utils.SquadFeatures`]。
[[autodoc]] data.processors.squad.squad_convert_examples_to_features
これらのプロセッサと前述の方法は、データを含むファイルだけでなく、
*tensorflow_datasets* パッケージ。以下に例を示します。
### Example usage
以下にプロセッサを使用した例と、データ ファイルを使用した変換方法を示します。
```python
# Loading a V2 processor
processor = SquadV2Processor()
examples = processor.get_dev_examples(squad_v2_data_dir)
# Loading a V1 processor
processor = SquadV1Processor()
examples = processor.get_dev_examples(squad_v1_data_dir)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
*tensorflow_datasets* の使用は、データ ファイルを使用するのと同じくらい簡単です。
```python
# tensorflow_datasets only handle Squad V1.
tfds_examples = tfds.load("squad")
examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
これらのプロセッサを使用する別の例は、[run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) スクリプトに示されています。
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/callback.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# コールバック数
コールバックは、PyTorch のトレーニング ループの動作をカスタマイズできるオブジェクトです。
トレーニング ループを検査できる [`Trainer`] (この機能は TensorFlow にはまだ実装されていません)
状態を確認し (進捗レポート、TensorBoard または他の ML プラットフォームへのログ記録など)、決定を下します (初期段階など)。
停止中)。
コールバックは、返される [`TrainerControl`] オブジェクトを除けば、「読み取り専用」のコード部分です。
トレーニング ループ内では何も変更できません。トレーニング ループの変更が必要なカスタマイズの場合は、次のことを行う必要があります。
[`Trainer`] をサブクラス化し、必要なメソッドをオーバーライドします (例については、[trainer](trainer) を参照してください)。
デフォルトでは、`TrainingArguments.report_to` は `"all"` に設定されているため、[`Trainer`] は次のコールバックを使用します。
- [`DefaultFlowCallback`] は、ログ記録、保存、評価のデフォルトの動作を処理します。
- [`PrinterCallback`] または [`ProgressCallback`] で進行状況を表示し、
ログ (最初のログは、[`TrainingArguments`] を通じて tqdm を非アクティブ化する場合に使用され、そうでない場合に使用されます)
2番目です)。
- [`~integrations.TensorBoardCallback`] (PyTorch >= 1.4 を介して) tensorboard にアクセスできる場合
またはテンソルボードX)。
- [`~integrations.WandbCallback`] [wandb](https://www.wandb.com/) がインストールされている場合。
- [`~integrations.CometCallback`] [comet_ml](https://www.comet.ml/site/) がインストールされている場合。
- [mlflow](https://www.mlflow.org/) がインストールされている場合は [`~integrations.MLflowCallback`]。
- [`~integrations.NeptuneCallback`] [neptune](https://neptune.ai/) がインストールされている場合。
- [`~integrations.AzureMLCallback`] [azureml-sdk](https://pypi.org/project/azureml-sdk/) の場合
インストールされています。
- [`~integrations.CodeCarbonCallback`] [codecarbon](https://pypi.org/project/codecarbon/) の場合
インストールされています。
- [`~integrations.ClearMLCallback`] [clearml](https://github.com/allegroai/clearml) がインストールされている場合。
- [`~integrations.DagsHubCallback`] [dagshub](https://dagshub.com/) がインストールされている場合。
- [`~integrations.FlyteCallback`] [flyte](https://flyte.org/) がインストールされている場合。
- [`~integrations.DVCLiveCallback`] [dvclive](https://www.dvc.org/doc/dvclive) がインストールされている場合。
パッケージがインストールされているが、付随する統合を使用したくない場合は、`TrainingArguments.report_to` を、使用したい統合のみのリストに変更できます (例: `["azure_ml", "wandb"]`) 。
コールバックを実装するメインクラスは [`TrainerCallback`] です。それは、
[`TrainingArguments`] は [`Trainer`] をインスタンス化するために使用され、それにアクセスできます。
[`TrainerState`] を介してトレーナーの内部状態を取得し、トレーニング ループ上でいくつかのアクションを実行できます。
[`TrainerControl`]。
## 利用可能なコールバック
ライブラリで利用可能な [`TrainerCallback`] のリストは次のとおりです。
[[autodoc]] integrations.CometCallback
- setup
[[autodoc]] DefaultFlowCallback
[[autodoc]] PrinterCallback
[[autodoc]] ProgressCallback
[[autodoc]] EarlyStoppingCallback
[[autodoc]] integrations.TensorBoardCallback
[[autodoc]] integrations.WandbCallback
- setup
[[autodoc]] integrations.MLflowCallback
- setup
[[autodoc]] integrations.AzureMLCallback
[[autodoc]] integrations.CodeCarbonCallback
[[autodoc]] integrations.NeptuneCallback
[[autodoc]] integrations.ClearMLCallback
[[autodoc]] integrations.DagsHubCallback
[[autodoc]] integrations.FlyteCallback
[[autodoc]] integrations.DVCLiveCallback
- setup
## TrainerCallback
[[autodoc]] TrainerCallback
以下は、カスタム コールバックを PyTorch [`Trainer`] に登録する方法の例です。
```python
class MyCallback(TrainerCallback):
"A callback that prints a message at the beginning of training"
def on_train_begin(self, args, state, control, **kwargs):
print("Starting training")
trainer = Trainer(
model,
args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
callbacks=[MyCallback], # We can either pass the callback class this way or an instance of it (MyCallback())
)
```
コールバックを登録する別の方法は、次のように `trainer.add_callback()` を呼び出すことです。
```python
trainer = Trainer(...)
trainer.add_callback(MyCallback)
# Alternatively, we can pass an instance of the callback class
trainer.add_callback(MyCallback())
```
## TrainerState
[[autodoc]] TrainerState
## TrainerControl
[[autodoc]] TrainerControl
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/output.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Model outputs
すべてのモデルには、[`~utils.ModelOutput`] のサブクラスのインスタンスである出力があります。それらは
モデルによって返されるすべての情報を含むデータ構造ですが、タプルまたは
辞書。
これがどのようになるかを例で見てみましょう。
```python
from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
outputs = model(**inputs, labels=labels)
```
`outputs`オブジェクトは[`~modeling_outputs.SequenceClassifierOutput`]である。
これは、オプションで `loss`、`logits`、オプションで `hidden_states`、オプションで `attentions` 属性を持つことを意味します。
オプションの `attentions` 属性を持つことを意味する。ここでは、`labels`を渡したので`loss`があるが、`hidden_states`と`attentions`はない。
`output_hidden_states=True`や`output_attentions=True`を渡していないので、`hidden_states`と`attentions`はない。
`output_attentions=True`を渡さなかったからだ。
<Tip>
`output_hidden_states=True`を渡すと、`outputs.hidden_states[-1]`が `outputs.last_hidden_states` と正確に一致することを期待するかもしれない。
しかし、必ずしもそうなるとは限りません。モデルによっては、最後に隠された状態が返されたときに、正規化やその後の処理を適用するものもあります。
</Tip>
通常と同じように各属性にアクセスできます。その属性がモデルから返されなかった場合は、
は `None`を取得します。ここで、たとえば`outputs.loss`はモデルによって計算された損失であり、`outputs.attentions`は
`None`。
`outputs`オブジェクトをタプルとして考える場合、`None`値を持たない属性のみが考慮されます。
たとえば、ここには 2 つの要素、`loss`、次に`logits`があります。
```python
outputs[:2]
```
たとえば、タプル `(outputs.loss, Outputs.logits)` を返します。
`outputs`オブジェクトを辞書として考慮する場合、「None」を持たない属性のみが考慮されます。
価値観。たとえば、ここには`loss` と `logits`という 2 つのキーがあります。
ここでは、複数のモデル タイプで使用される汎用モデルの出力を文書化します。具体的な出力タイプは次のとおりです。
対応するモデルのページに記載されています。
## ModelOutput
[[autodoc]] utils.ModelOutput
- to_tuple
## BaseModelOutput
[[autodoc]] modeling_outputs.BaseModelOutput
## BaseModelOutputWithPooling
[[autodoc]] modeling_outputs.BaseModelOutputWithPooling
## BaseModelOutputWithCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithCrossAttentions
## BaseModelOutputWithPoolingAndCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
## BaseModelOutputWithPast
[[autodoc]] modeling_outputs.BaseModelOutputWithPast
## BaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
## Seq2SeqModelOutput
[[autodoc]] modeling_outputs.Seq2SeqModelOutput
## CausalLMOutput
[[autodoc]] modeling_outputs.CausalLMOutput
## CausalLMOutputWithCrossAttentions
[[autodoc]] modeling_outputs.CausalLMOutputWithCrossAttentions
## CausalLMOutputWithPast
[[autodoc]] modeling_outputs.CausalLMOutputWithPast
## MaskedLMOutput
[[autodoc]] modeling_outputs.MaskedLMOutput
## Seq2SeqLMOutput
[[autodoc]] modeling_outputs.Seq2SeqLMOutput
## NextSentencePredictorOutput
[[autodoc]] modeling_outputs.NextSentencePredictorOutput
## SequenceClassifierOutput
[[autodoc]] modeling_outputs.SequenceClassifierOutput
## Seq2SeqSequenceClassifierOutput
[[autodoc]] modeling_outputs.Seq2SeqSequenceClassifierOutput
## MultipleChoiceModelOutput
[[autodoc]] modeling_outputs.MultipleChoiceModelOutput
## TokenClassifierOutput
[[autodoc]] modeling_outputs.TokenClassifierOutput
## QuestionAnsweringModelOutput
[[autodoc]] modeling_outputs.QuestionAnsweringModelOutput
## Seq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
## Seq2SeqSpectrogramOutput
[[autodoc]] modeling_outputs.Seq2SeqSpectrogramOutput
## SemanticSegmenterOutput
[[autodoc]] modeling_outputs.SemanticSegmenterOutput
## ImageClassifierOutput
[[autodoc]] modeling_outputs.ImageClassifierOutput
## ImageClassifierOutputWithNoAttention
[[autodoc]] modeling_outputs.ImageClassifierOutputWithNoAttention
## DepthEstimatorOutput
[[autodoc]] modeling_outputs.DepthEstimatorOutput
## Wav2Vec2BaseModelOutput
[[autodoc]] modeling_outputs.Wav2Vec2BaseModelOutput
## XVectorOutput
[[autodoc]] modeling_outputs.XVectorOutput
## Seq2SeqTSModelOutput
[[autodoc]] modeling_outputs.Seq2SeqTSModelOutput
## Seq2SeqTSPredictionOutput
[[autodoc]] modeling_outputs.Seq2SeqTSPredictionOutput
## SampleTSPredictionOutput
[[autodoc]] modeling_outputs.SampleTSPredictionOutput
## TFBaseModelOutput
[[autodoc]] modeling_tf_outputs.TFBaseModelOutput
## TFBaseModelOutputWithPooling
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPooling
## TFBaseModelOutputWithPoolingAndCrossAttentions
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions
## TFBaseModelOutputWithPast
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPast
## TFBaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions
## TFSeq2SeqModelOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqModelOutput
## TFCausalLMOutput
[[autodoc]] modeling_tf_outputs.TFCausalLMOutput
## TFCausalLMOutputWithCrossAttentions
[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions
## TFCausalLMOutputWithPast
[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithPast
## TFMaskedLMOutput
[[autodoc]] modeling_tf_outputs.TFMaskedLMOutput
## TFSeq2SeqLMOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqLMOutput
## TFNextSentencePredictorOutput
[[autodoc]] modeling_tf_outputs.TFNextSentencePredictorOutput
## TFSequenceClassifierOutput
[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutput
## TFSeq2SeqSequenceClassifierOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput
## TFMultipleChoiceModelOutput
[[autodoc]] modeling_tf_outputs.TFMultipleChoiceModelOutput
## TFTokenClassifierOutput
[[autodoc]] modeling_tf_outputs.TFTokenClassifierOutput
## TFQuestionAnsweringModelOutput
[[autodoc]] modeling_tf_outputs.TFQuestionAnsweringModelOutput
## TFSeq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput
## FlaxBaseModelOutput
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutput
## FlaxBaseModelOutputWithPast
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPast
## FlaxBaseModelOutputWithPooling
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPooling
## FlaxBaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions
## FlaxSeq2SeqModelOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqModelOutput
## FlaxCausalLMOutputWithCrossAttentions
[[autodoc]] modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions
## FlaxMaskedLMOutput
[[autodoc]] modeling_flax_outputs.FlaxMaskedLMOutput
## FlaxSeq2SeqLMOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqLMOutput
## FlaxNextSentencePredictorOutput
[[autodoc]] modeling_flax_outputs.FlaxNextSentencePredictorOutput
## FlaxSequenceClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxSequenceClassifierOutput
## FlaxSeq2SeqSequenceClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqSequenceClassifierOutput
## FlaxMultipleChoiceModelOutput
[[autodoc]] modeling_flax_outputs.FlaxMultipleChoiceModelOutput
## FlaxTokenClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxTokenClassifierOutput
## FlaxQuestionAnsweringModelOutput
[[autodoc]] modeling_flax_outputs.FlaxQuestionAnsweringModelOutput
## FlaxSeq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqQuestionAnsweringModelOutput
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/tokenizer.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Tokenizer
トークナイザーは、モデルの入力の準備を担当します。ライブラリには、すべてのモデルのトークナイザーが含まれています。ほとんど
トークナイザーの一部は、完全な Python 実装と、
Rust ライブラリ [🤗 Tokenizers](https://github.com/huggingface/tokenizers)。 「高速」実装では次のことが可能になります。
1. 特にバッチトークン化を行う場合の大幅なスピードアップと
2. 元の文字列 (文字と単語) とトークン空間の間でマッピングする追加のメソッド (例:
特定の文字を含むトークンのインデックス、または特定のトークンに対応する文字の範囲)。
基本クラス [`PreTrainedTokenizer`] および [`PreTrainedTokenizerFast`]
モデル入力の文字列入力をエンコードし (以下を参照)、Python をインスタンス化/保存するための一般的なメソッドを実装します。
ローカル ファイルまたはディレクトリ、またはライブラリによって提供される事前トレーニング済みトークナイザーからの「高速」トークナイザー
(HuggingFace の AWS S3 リポジトリからダウンロード)。二人とも頼りにしているのは、
共通メソッドを含む [`~tokenization_utils_base.PreTrainedTokenizerBase`]
[`~tokenization_utils_base.SpecialTokensMixin`]。
したがって、[`PreTrainedTokenizer`] と [`PreTrainedTokenizerFast`] はメインを実装します。
すべてのトークナイザーを使用するためのメソッド:
- トークン化 (文字列をサブワード トークン文字列に分割)、トークン文字列を ID に変換したり、その逆の変換を行ったりします。
エンコード/デコード (つまり、トークン化と整数への変換)。
- 基礎となる構造 (BPE、SentencePiece...) から独立した方法で、語彙に新しいトークンを追加します。
- 特別なトークン (マスク、文の始まりなど) の管理: トークンの追加、属性への割り当て。
トークナイザーにより、簡単にアクセスでき、トークン化中に分割されないようにすることができます。
[`BatchEncoding`] は、
[`~tokenization_utils_base.PreTrainedTokenizerBase`] のエンコード メソッド (`__call__`、
`encode_plus` および `batch_encode_plus`) であり、Python 辞書から派生しています。トークナイザーが純粋な Python の場合
tokenizer の場合、このクラスは標準の Python 辞書と同じように動作し、によって計算されたさまざまなモデル入力を保持します。
これらのメソッド (`input_ids`、`attention_mask`...)。トークナイザーが「高速」トークナイザーである場合 (つまり、
HuggingFace [トークナイザー ライブラリ](https://github.com/huggingface/tokenizers))、このクラスはさらに提供します
元の文字列 (文字と単語) と
トークンスペース (例: 指定された文字または対応する文字の範囲を構成するトークンのインデックスの取得)
与えられたトークンに)。
## PreTrainedTokenizer
[[autodoc]] PreTrainedTokenizer
- __call__
- apply_chat_template
- batch_decode
- decode
- encode
- push_to_hub
- all
## PreTrainedTokenizerFast
[`PreTrainedTokenizerFast`] は [tokenizers](https://huggingface.co/docs/tokenizers) ライブラリに依存します。 🤗 トークナイザー ライブラリから取得したトークナイザーは、
🤗 トランスに非常に簡単にロードされます。これがどのように行われるかを理解するには、[🤗 tokenizers からの tokenizers を使用する](../fast_tokenizers) ページを参照してください。
[[autodoc]] PreTrainedTokenizerFast
- __call__
- apply_chat_template
- batch_decode
- decode
- encode
- push_to_hub
- all
## BatchEncoding
[[autodoc]] BatchEncoding
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/model.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Models
ベースクラスである [`PreTrainedModel`]、[`TFPreTrainedModel`]、[`FlaxPreTrainedModel`] は、モデルの読み込みと保存に関する共通のメソッドを実装しており、これはローカルのファイルやディレクトリから、またはライブラリが提供する事前学習モデル構成(HuggingFaceのAWS S3リポジトリからダウンロード)からモデルを読み込むために使用できます。
[`PreTrainedModel`] と [`TFPreTrainedModel`] は、次の共通のメソッドも実装しています:
- 語彙に新しいトークンが追加された場合に、入力トークン埋め込みのリサイズを行う
- モデルのアテンションヘッドを刈り込む
各モデルに共通するその他のメソッドは、[`~modeling_utils.ModuleUtilsMixin`](PyTorchモデル用)および[`~modeling_tf_utils.TFModuleUtilsMixin`](TensorFlowモデル用)で定義されており、テキスト生成の場合、[`~generation.GenerationMixin`](PyTorchモデル用)、[`~generation.TFGenerationMixin`](TensorFlowモデル用)、および[`~generation.FlaxGenerationMixin`](Flax/JAXモデル用)もあります。
## PreTrainedModel
[[autodoc]] PreTrainedModel
- push_to_hub
- all
<a id='from_pretrained-torch-dtype'></a>
### 大規模モデルの読み込み
Transformers 4.20.0では、[`~PreTrainedModel.from_pretrained`] メソッドが再設計され、[Accelerate](https://huggingface.co/docs/accelerate/big_modeling) を使用して大規模モデルを扱うことが可能になりました。これには Accelerate >= 0.9.0 と PyTorch >= 1.9.0 が必要です。以前の方法でフルモデルを作成し、その後事前学習の重みを読み込む代わりに(これにはメモリ内のモデルサイズが2倍必要で、ランダムに初期化されたモデル用と重み用の2つが必要でした)、モデルを空の外殻として作成し、事前学習の重みが読み込まれるときにパラメーターを実体化するオプションが追加されました。
このオプションは `low_cpu_mem_usage=True` で有効にできます。モデルはまず空の重みを持つメタデバイス上に作成され、その後状態辞書が内部に読み込まれます(シャードされたチェックポイントの場合、シャードごとに読み込まれます)。この方法で使用される最大RAMは、モデルの完全なサイズだけです。
```py
from transformers import AutoModelForSeq2SeqLM
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", low_cpu_mem_usage=True)
```
さらに、モデルが完全にRAMに収まらない場合(現時点では推論のみ有効)、異なるデバイスにモデルを直接配置できます。`device_map="auto"` を使用すると、Accelerateは各レイヤーをどのデバイスに配置するかを決定し、最速のデバイス(GPU)を最大限に活用し、残りの部分をCPU、あるいはGPU RAMが不足している場合はハードドライブにオフロードします。モデルが複数のデバイスに分割されていても、通常どおり実行されます。
`device_map` を渡す際、`low_cpu_mem_usage` は自動的に `True` に設定されるため、それを指定する必要はありません。
```py
from transformers import AutoModelForSeq2SeqLM
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", device_map="auto")
```
モデルがデバイス間でどのように分割されたかは、その `hf_device_map` 属性を見ることで確認できます:
```py
t0pp.hf_device_map
```
```python out
{'shared': 0,
'decoder.embed_tokens': 0,
'encoder': 0,
'decoder.block.0': 0,
'decoder.block.1': 1,
'decoder.block.2': 1,
'decoder.block.3': 1,
'decoder.block.4': 1,
'decoder.block.5': 1,
'decoder.block.6': 1,
'decoder.block.7': 1,
'decoder.block.8': 1,
'decoder.block.9': 1,
'decoder.block.10': 1,
'decoder.block.11': 1,
'decoder.block.12': 1,
'decoder.block.13': 1,
'decoder.block.14': 1,
'decoder.block.15': 1,
'decoder.block.16': 1,
'decoder.block.17': 1,
'decoder.block.18': 1,
'decoder.block.19': 1,
'decoder.block.20': 1,
'decoder.block.21': 1,
'decoder.block.22': 'cpu',
'decoder.block.23': 'cpu',
'decoder.final_layer_norm': 'cpu',
'decoder.dropout': 'cpu',
'lm_head': 'cpu'}
```
同じフォーマットに従って、独自のデバイスマップを作成することもできます(レイヤー名からデバイスへの辞書です)。モデルのすべてのパラメータを指定されたデバイスにマップする必要がありますが、1つのレイヤーが完全に同じデバイスにある場合、そのレイヤーのサブモジュールのすべてがどこに行くかの詳細を示す必要はありません。例えば、次のデバイスマップはT0ppに適しています(GPUメモリがある場合):
```python
device_map = {"shared": 0, "encoder": 0, "decoder": 1, "lm_head": 1}
```
モデルのメモリへの影響を最小限に抑えるもう 1 つの方法は、低精度の dtype (`torch.float16` など) でモデルをインスタンス化するか、以下で説明する直接量子化手法を使用することです。
### Model Instantiation dtype
Pytorch では、モデルは通常 `torch.float32` 形式でインスタンス化されます。これは、しようとすると問題になる可能性があります
重みが fp16 にあるモデルをロードすると、2 倍のメモリが必要になるためです。この制限を克服するには、次のことができます。
`torch_dtype` 引数を使用して、目的の `dtype` を明示的に渡します。
```python
model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype=torch.float16)
```
または、モデルを常に最適なメモリ パターンでロードしたい場合は、特別な値 `"auto"` を使用できます。
そして、`dtype` はモデルの重みから自動的に導出されます。
```python
model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype="auto")
```
スクラッチからインスタンス化されたモデルには、どの `dtype` を使用するかを指示することもできます。
```python
config = T5Config.from_pretrained("t5")
model = AutoModel.from_config(config)
```
Pytorch の設計により、この機能は浮動小数点 dtype でのみ使用できます。
## ModuleUtilsMixin
[[autodoc]] modeling_utils.ModuleUtilsMixin
## TFPreTrainedModel
[[autodoc]] TFPreTrainedModel
- push_to_hub
- all
## TFModelUtilsMixin
[[autodoc]] modeling_tf_utils.TFModelUtilsMixin
## FlaxPreTrainedModel
[[autodoc]] FlaxPreTrainedModel
- push_to_hub
- all
## Pushing to the Hub
[[autodoc]] utils.PushToHubMixin
## Sharded checkpoints
[[autodoc]] modeling_utils.load_sharded_checkpoint
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/configuration.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 構成
基本クラス [`PretrainedConfig`] は、設定をロード/保存するための一般的なメソッドを実装します。
ローカル ファイルまたはディレクトリから、またはライブラリ (ダウンロードされた) によって提供される事前トレーニング済みモデル構成から
HuggingFace の AWS S3 リポジトリから)。
各派生構成クラスはモデル固有の属性を実装します。すべての構成クラスに存在する共通の属性は次のとおりです。
`hidden_size`、`num_attention_heads`、および `num_hidden_layers`。テキスト モデルはさらに以下を実装します。
`vocab_size`。
## PretrainedConfig
[[autodoc]] PretrainedConfig
- push_to_hub
- all
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/keras_callbacks.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Keras callbacks
Keras を使用して Transformers モデルをトレーニングする場合、一般的な処理を自動化するために使用できるライブラリ固有のコールバックがいくつかあります。
タスク:
## KerasMetricCallback
[[autodoc]] KerasMetricCallback
## PushToHubCallback
[[autodoc]] PushToHubCallback
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/logging.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Logging
🤗 Transformersには、ライブラリの詳細度を簡単に設定できる中央集中型のロギングシステムがあります。
現在、ライブラリのデフォルトの詳細度は「WARNING」です。
詳細度を変更するには、直接設定メソッドの1つを使用するだけです。例えば、詳細度をINFOレベルに変更する方法は以下の通りです。
```python
import transformers
transformers.logging.set_verbosity_info()
```
環境変数 `TRANSFORMERS_VERBOSITY` を使用して、デフォルトの冗長性をオーバーライドすることもできます。設定できます
`debug`、`info`、`warning`、`error`、`critical` のいずれかに変更します。例えば:
```bash
TRANSFORMERS_VERBOSITY=error ./myprogram.py
```
さらに、一部の「警告」は環境変数を設定することで無効にできます。
`TRANSFORMERS_NO_ADVISORY_WARNINGS` を *1* などの true 値に設定します。これにより、次を使用してログに記録される警告が無効になります。
[`logger.warning_advice`]。例えば:
```bash
TRANSFORMERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
```
以下は、独自のモジュールまたはスクリプトでライブラリと同じロガーを使用する方法の例です。
```python
from transformers.utils import logging
logging.set_verbosity_info()
logger = logging.get_logger("transformers")
logger.info("INFO")
logger.warning("WARN")
```
このロギング モジュールのすべてのメソッドは以下に文書化されています。主なメソッドは次のとおりです。
[`logging.get_verbosity`] ロガーの現在の冗長レベルを取得します。
[`logging.set_verbosity`] を使用して、冗長性を選択したレベルに設定します。順番に(少ないものから)
冗長から最も冗長まで)、それらのレベル (括弧内は対応する int 値) は次のとおりです。
- `transformers.logging.CRITICAL` または `transformers.logging.FATAL` (int 値、50): 最も多いもののみをレポートします。
重大なエラー。
- `transformers.logging.ERROR` (int 値、40): エラーのみを報告します。
- `transformers.logging.WARNING` または `transformers.logging.WARN` (int 値、30): エラーと
警告。これはライブラリで使用されるデフォルトのレベルです。
- `transformers.logging.INFO` (int 値、20): エラー、警告、および基本情報をレポートします。
- `transformers.logging.DEBUG` (int 値、10): すべての情報をレポートします。
デフォルトでは、モデルのダウンロード中に「tqdm」進行状況バーが表示されます。 [`logging.disable_progress_bar`] および [`logging.enable_progress_bar`] を使用して、この動作を抑制または抑制解除できます。
## `logging` vs `warnings`
Python には、よく組み合わせて使用される 2 つのロギング システムがあります。上で説明した `logging` と `warnings` です。
これにより、特定のバケット内の警告をさらに分類できます (例: 機能またはパスの`FutureWarning`)
これはすでに非推奨になっており、`DeprecationWarning`は今後の非推奨を示します。
両方とも`transformers`ライブラリで使用します。 `logging`の`captureWarning`メソッドを活用して適応させて、
これらの警告メッセージは、上記の冗長設定ツールによって管理されます。
それはライブラリの開発者にとって何を意味しますか?次のヒューリスティックを尊重する必要があります。
- `warnings`は、ライブラリおよび`transformers`に依存するライブラリの開発者に優先されるべきです。
- `logging`は、日常のプロジェクトでライブラリを使用するライブラリのエンドユーザーに使用する必要があります。
以下の`captureWarnings`メソッドのリファレンスを参照してください。
[[autodoc]] logging.captureWarnings
## Base setters
[[autodoc]] logging.set_verbosity_error
[[autodoc]] logging.set_verbosity_warning
[[autodoc]] logging.set_verbosity_info
[[autodoc]] logging.set_verbosity_debug
## Other functions
[[autodoc]] logging.get_verbosity
[[autodoc]] logging.set_verbosity
[[autodoc]] logging.get_logger
[[autodoc]] logging.enable_default_handler
[[autodoc]] logging.disable_default_handler
[[autodoc]] logging.enable_explicit_format
[[autodoc]] logging.reset_format
[[autodoc]] logging.enable_progress_bar
[[autodoc]] logging.disable_progress_bar
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/modeling_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# カスタムレイヤーとユーティリティ
このページには、ライブラリで使用されるすべてのカスタム レイヤーと、モデリングに提供されるユーティリティ関数がリストされます。
これらのほとんどは、ライブラリ内のモデルのコードを研究する場合にのみ役に立ちます。
## Pytorch custom modules
[[autodoc]] pytorch_utils.Conv1D
[[autodoc]] modeling_utils.PoolerStartLogits
- forward
[[autodoc]] modeling_utils.PoolerEndLogits
- forward
[[autodoc]] modeling_utils.PoolerAnswerClass
- forward
[[autodoc]] modeling_utils.SquadHeadOutput
[[autodoc]] modeling_utils.SQuADHead
- forward
[[autodoc]] modeling_utils.SequenceSummary
- forward
## PyTorch Helper Functions
[[autodoc]] pytorch_utils.apply_chunking_to_forward
[[autodoc]] pytorch_utils.find_pruneable_heads_and_indices
[[autodoc]] pytorch_utils.prune_layer
[[autodoc]] pytorch_utils.prune_conv1d_layer
[[autodoc]] pytorch_utils.prune_linear_layer
## TensorFlow custom layers
[[autodoc]] modeling_tf_utils.TFConv1D
[[autodoc]] modeling_tf_utils.TFSequenceSummary
## TensorFlow loss functions
[[autodoc]] modeling_tf_utils.TFCausalLanguageModelingLoss
[[autodoc]] modeling_tf_utils.TFMaskedLanguageModelingLoss
[[autodoc]] modeling_tf_utils.TFMultipleChoiceLoss
[[autodoc]] modeling_tf_utils.TFQuestionAnsweringLoss
[[autodoc]] modeling_tf_utils.TFSequenceClassificationLoss
[[autodoc]] modeling_tf_utils.TFTokenClassificationLoss
## TensorFlow Helper Functions
[[autodoc]] modeling_tf_utils.get_initializer
[[autodoc]] modeling_tf_utils.keras_serializable
[[autodoc]] modeling_tf_utils.shape_list
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/trainer_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# トレーナー用ユーティリティ
このページには、[`Trainer`] で使用されるすべてのユーティリティ関数がリストされています。
これらのほとんどは、ライブラリ内のトレーナーのコードを学習する場合にのみ役に立ちます。
## Utilities
[[autodoc]] EvalPrediction
[[autodoc]] IntervalStrategy
[[autodoc]] enable_full_determinism
[[autodoc]] set_seed
[[autodoc]] torch_distributed_zero_first
## Callbacks internals
[[autodoc]] trainer_callback.CallbackHandler
## Distributed Evaluation
[[autodoc]] trainer_pt_utils.DistributedTensorGatherer
## Distributed Evaluation
[[autodoc]] HfArgumentParser
## Debug Utilities
[[autodoc]] debug_utils.DebugUnderflowOverflow
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/audio_utils.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# `FeatureExtractor` 用のユーティリティ
このページには、*短時間フーリエ変換* や *ログ メル スペクトログラム* などの一般的なアルゴリズムを使用して生のオーディオから特別な特徴を計算するために、オーディオ [`FeatureExtractor`] で使用できるすべてのユーティリティ関数がリストされています。
これらのほとんどは、ライブラリ内のオーディオ プロセッサのコードを学習する場合にのみ役に立ちます。
## オーディオ変換
[[autodoc]] audio_utils.hertz_to_mel
[[autodoc]] audio_utils.mel_to_hertz
[[autodoc]] audio_utils.mel_filter_bank
[[autodoc]] audio_utils.optimal_fft_length
[[autodoc]] audio_utils.window_function
[[autodoc]] audio_utils.spectrogram
[[autodoc]] audio_utils.power_to_db
[[autodoc]] audio_utils.amplitude_to_db
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/generation_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 発電用ユーティリティ
このページには、[`~generation.GenerationMixin.generate`] で使用されるすべてのユーティリティ関数がリストされています。
[`~generation.GenerationMixin.greedy_search`],
[`~generation.GenerationMixin.contrastive_search`],
[`~generation.GenerationMixin.sample`],
[`~generation.GenerationMixin.beam_search`],
[`~generation.GenerationMixin.beam_sample`],
[`~generation.GenerationMixin.group_beam_search`]、および
[`~generation.GenerationMixin.constrained_beam_search`]。
これらのほとんどは、ライブラリ内の生成メソッドのコードを学習する場合にのみ役に立ちます。
## 出力を生成する
[`~generation.GenerationMixin.generate`] の出力は、次のサブクラスのインスタンスです。
[`~utils.ModelOutput`]。この出力は、返されたすべての情報を含むデータ構造です。
[`~generation.GenerationMixin.generate`] によって作成されますが、タプルまたは辞書としても使用できます。
以下に例を示します。
```python
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
inputs = tokenizer("Hello, my dog is cute and ", return_tensors="pt")
generation_output = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
```
`generation_output` オブジェクトは、できる限り [`~generation.GreedySearchDecoderOnlyOutput`] です。
以下のそのクラスのドキュメントを参照してください。これは、次の属性があることを意味します。
- `sequences`: 生成されたトークンのシーケンス
- `scores` (オプション): 各生成ステップの言語モデリング ヘッドの予測スコア
- `hidden_states` (オプション): 生成ステップごとのモデルの隠れた状態
- `attentions` (オプション): 生成ステップごとのモデルのアテンションの重み
ここでは、`output_scores=True`を渡したので `scores` がありますが、`hidden_states` はありません。
`attentions` は、`output_hidden_states=True`または`output_attentions=True`を渡さなかったためです。
通常と同じように各属性にアクセスできます。その属性がモデルから返されなかった場合は、
は「なし」を取得します。ここで、たとえば`generation_output.scores`は、生成されたすべての予測スコアです。
言語モデリングのヘッドであり、`generation_output.attentions`は`None`です。
`generation_output` オブジェクトをタプルとして使用する場合、`None` 値を持たない属性のみが保持されます。
たとえば、ここには 2 つの要素、`loss`、次に`logits`があります。
```python
generation_output[:2]
```
たとえば、タプル `(generation_output.sequences,generation_output.scores)` を返します。
`generation_output` オブジェクトを辞書として使用する場合、`None` を持たない属性のみが保持されます。
ここでは、たとえば、`sequences`と`scores`という 2 つのキーがあります。
ここではすべての出力タイプを文書化します。
### PyTorch
[[autodoc]] generation.GreedySearchEncoderDecoderOutput
[[autodoc]] generation.GreedySearchDecoderOnlyOutput
[[autodoc]] generation.SampleEncoderDecoderOutput
[[autodoc]] generation.SampleDecoderOnlyOutput
[[autodoc]] generation.BeamSearchEncoderDecoderOutput
[[autodoc]] generation.BeamSearchDecoderOnlyOutput
[[autodoc]] generation.BeamSampleEncoderDecoderOutput
[[autodoc]] generation.BeamSampleDecoderOnlyOutput
[[autodoc]] generation.ContrastiveSearchEncoderDecoderOutput
[[autodoc]] generation.ContrastiveSearchDecoderOnlyOutput
### TensorFlow
[[autodoc]] generation.TFGreedySearchEncoderDecoderOutput
[[autodoc]] generation.TFGreedySearchDecoderOnlyOutput
[[autodoc]] generation.TFSampleEncoderDecoderOutput
[[autodoc]] generation.TFSampleDecoderOnlyOutput
[[autodoc]] generation.TFBeamSearchEncoderDecoderOutput
[[autodoc]] generation.TFBeamSearchDecoderOnlyOutput
[[autodoc]] generation.TFBeamSampleEncoderDecoderOutput
[[autodoc]] generation.TFBeamSampleDecoderOnlyOutput
[[autodoc]] generation.TFContrastiveSearchEncoderDecoderOutput
[[autodoc]] generation.TFContrastiveSearchDecoderOnlyOutput
### FLAX
[[autodoc]] generation.FlaxSampleOutput
[[autodoc]] generation.FlaxGreedySearchOutput
[[autodoc]] generation.FlaxBeamSearchOutput
## LogitsProcessor
[`LogitsProcessor`] を使用して、言語モデルのヘッドの予測スコアを変更できます。
世代。
### PyTorch
[[autodoc]] AlternatingCodebooksLogitsProcessor
- __call__
[[autodoc]] ClassifierFreeGuidanceLogitsProcessor
- __call__
[[autodoc]] EncoderNoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] EncoderRepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] EpsilonLogitsWarper
- __call__
[[autodoc]] EtaLogitsWarper
- __call__
[[autodoc]] ExponentialDecayLengthPenalty
- __call__
[[autodoc]] ForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] ForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] ForceTokensLogitsProcessor
- __call__
[[autodoc]] HammingDiversityLogitsProcessor
- __call__
[[autodoc]] InfNanRemoveLogitsProcessor
- __call__
[[autodoc]] LogitNormalization
- __call__
[[autodoc]] LogitsProcessor
- __call__
[[autodoc]] LogitsProcessorList
- __call__
[[autodoc]] LogitsWarper
- __call__
[[autodoc]] MinLengthLogitsProcessor
- __call__
[[autodoc]] MinNewTokensLengthLogitsProcessor
- __call__
[[autodoc]] NoBadWordsLogitsProcessor
- __call__
[[autodoc]] NoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] PrefixConstrainedLogitsProcessor
- __call__
[[autodoc]] RepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] SequenceBiasLogitsProcessor
- __call__
[[autodoc]] SuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] SuppressTokensLogitsProcessor
- __call__
[[autodoc]] TemperatureLogitsWarper
- __call__
[[autodoc]] TopKLogitsWarper
- __call__
[[autodoc]] TopPLogitsWarper
- __call__
[[autodoc]] TypicalLogitsWarper
- __call__
[[autodoc]] UnbatchedClassifierFreeGuidanceLogitsProcessor
- __call__
[[autodoc]] WhisperTimeStampLogitsProcessor
- __call__
### TensorFlow
[[autodoc]] TFForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] TFForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] TFForceTokensLogitsProcessor
- __call__
[[autodoc]] TFLogitsProcessor
- __call__
[[autodoc]] TFLogitsProcessorList
- __call__
[[autodoc]] TFLogitsWarper
- __call__
[[autodoc]] TFMinLengthLogitsProcessor
- __call__
[[autodoc]] TFNoBadWordsLogitsProcessor
- __call__
[[autodoc]] TFNoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] TFRepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] TFSuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] TFSuppressTokensLogitsProcessor
- __call__
[[autodoc]] TFTemperatureLogitsWarper
- __call__
[[autodoc]] TFTopKLogitsWarper
- __call__
[[autodoc]] TFTopPLogitsWarper
- __call__
### FLAX
[[autodoc]] FlaxForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] FlaxForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] FlaxForceTokensLogitsProcessor
- __call__
[[autodoc]] FlaxLogitsProcessor
- __call__
[[autodoc]] FlaxLogitsProcessorList
- __call__
[[autodoc]] FlaxLogitsWarper
- __call__
[[autodoc]] FlaxMinLengthLogitsProcessor
- __call__
[[autodoc]] FlaxSuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] FlaxSuppressTokensLogitsProcessor
- __call__
[[autodoc]] FlaxTemperatureLogitsWarper
- __call__
[[autodoc]] FlaxTopKLogitsWarper
- __call__
[[autodoc]] FlaxTopPLogitsWarper
- __call__
[[autodoc]] FlaxWhisperTimeStampLogitsProcessor
- __call__
## StoppingCriteria
[`StoppingCriteria`] を使用して、(EOS トークン以外の) 生成を停止するタイミングを変更できます。これは PyTorch 実装でのみ利用可能であることに注意してください。
[[autodoc]] StoppingCriteria
- __call__
[[autodoc]] StoppingCriteriaList
- __call__
[[autodoc]] MaxLengthCriteria
- __call__
[[autodoc]] MaxTimeCriteria
- __call__
## Constraints
[`Constraint`] を使用すると、生成時に出力に特定のトークンまたはシーケンスが含まれるように強制できます。これは PyTorch 実装でのみ利用可能であることに注意してください。
[[autodoc]] Constraint
[[autodoc]] PhrasalConstraint
[[autodoc]] DisjunctiveConstraint
[[autodoc]] ConstraintListState
## BeamSearch
[[autodoc]] BeamScorer
- process
- finalize
[[autodoc]] BeamSearchScorer
- process
- finalize
[[autodoc]] ConstrainedBeamSearchScorer
- process
- finalize
## Utilities
[[autodoc]] top_k_top_p_filtering
[[autodoc]] tf_top_k_top_p_filtering
## Streamers
[[autodoc]] TextStreamer
[[autodoc]] TextIteratorStreamer
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/image_processing_utils.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 画像プロセッサ用ユーティリティ
このページには、画像プロセッサーで使用されるすべてのユーティリティー関数がリストされています。主に機能的なものです。
画像を処理するために使用される変換。
これらのほとんどは、ライブラリ内の画像プロセッサのコードを学習する場合にのみ役に立ちます。
## Image Transformations
[[autodoc]] image_transforms.center_crop
[[autodoc]] image_transforms.center_to_corners_format
[[autodoc]] image_transforms.corners_to_center_format
[[autodoc]] image_transforms.id_to_rgb
[[autodoc]] image_transforms.normalize
[[autodoc]] image_transforms.pad
[[autodoc]] image_transforms.rgb_to_id
[[autodoc]] image_transforms.rescale
[[autodoc]] image_transforms.resize
[[autodoc]] image_transforms.to_pil_image
## ImageProcessingMixin
[[autodoc]] image_processing_utils.ImageProcessingMixin
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/pipelines_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# パイプライン用のユーティリティ
このページには、ライブラリがパイプラインに提供するすべてのユーティリティ関数がリストされます。
これらのほとんどは、ライブラリ内のモデルのコードを研究する場合にのみ役に立ちます。
## Argument handling
[[autodoc]] pipelines.ArgumentHandler
[[autodoc]] pipelines.ZeroShotClassificationArgumentHandler
[[autodoc]] pipelines.QuestionAnsweringArgumentHandler
## Data format
[[autodoc]] pipelines.PipelineDataFormat
[[autodoc]] pipelines.CsvPipelineDataFormat
[[autodoc]] pipelines.JsonPipelineDataFormat
[[autodoc]] pipelines.PipedPipelineDataFormat
## Utilities
[[autodoc]] pipelines.PipelineException
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/tokenization_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Utilities for Tokenizers
このページには、トークナイザーによって使用されるすべてのユーティリティ関数 (主にクラス) がリストされます。
[`~tokenization_utils_base.PreTrainedTokenizerBase`] 間の共通メソッドを実装します。
[`PreTrainedTokenizer`] と [`PreTrainedTokenizerFast`] およびミックスイン
[`~tokenization_utils_base.SpecialTokensMixin`]。
これらのほとんどは、ライブラリ内のトークナイザーのコードを学習する場合にのみ役に立ちます。
## PreTrainedTokenizerBase
[[autodoc]] tokenization_utils_base.PreTrainedTokenizerBase
- __call__
- all
## SpecialTokensMixin
[[autodoc]] tokenization_utils_base.SpecialTokensMixin
## Enums and namedtuples
[[autodoc]] tokenization_utils_base.TruncationStrategy
[[autodoc]] tokenization_utils_base.CharSpan
[[autodoc]] tokenization_utils_base.TokenSpan
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/time_series_utils.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 時系列ユーティリティ
このページには、時系列ベースのモデルに使用できるすべてのユーティリティ関数とクラスがリストされます。
これらのほとんどは、時系列モデルのコードを研究している場合、または分散出力クラスのコレクションに追加したい場合にのみ役立ちます。
## Distributional Output
[[autodoc]] time_series_utils.NormalOutput
[[autodoc]] time_series_utils.StudentTOutput
[[autodoc]] time_series_utils.NegativeBinomialOutput
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/file_utils.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 一般的なユーティリティ
このページには、ファイル `utils.py` にある Transformers の一般的なユーティリティ関数がすべてリストされています。
これらのほとんどは、ライブラリで一般的なコードを学習する場合にのみ役に立ちます。
## 列挙型と名前付きタプル
[[autodoc]] utils.ExplicitEnum
[[autodoc]] utils.PaddingStrategy
[[autodoc]] utils.TensorType
## 特別なデコレーター
[[autodoc]] utils.add_start_docstrings
[[autodoc]] utils.add_start_docstrings_to_model_forward
[[autodoc]] utils.add_end_docstrings
[[autodoc]] utils.add_code_sample_docstrings
[[autodoc]] utils.replace_return_docstrings
## 特殊なプロパティ
[[autodoc]] utils.cached_property
## その他のユーティリティ
[[autodoc]] utils._LazyModule
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/bert-generation.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BertGeneration
## Overview
BertGeneration モデルは、次を使用してシーケンス間のタスクに利用できる BERT モデルです。
[シーケンス生成のための事前トレーニング済みチェックポイントの活用](https://arxiv.org/abs/1907.12461) で提案されている [`EncoderDecoderModel`]
タスク、Sascha Rothe、Sishi Nagayan、Aliaksei Severyn 著。
論文の要約は次のとおりです。
*大規模なニューラル モデルの教師なし事前トレーニングは、最近、自然言語処理に革命をもたらしました。による
NLP 実践者は、公開されたチェックポイントからウォームスタートして、複数の項目で最先端の技術を推進してきました。
コンピューティング時間を大幅に節約しながらベンチマークを実行します。これまでのところ、主に自然言語に焦点を当ててきました。
タスクを理解する。この論文では、シーケンス生成のための事前トレーニングされたチェックポイントの有効性を実証します。私たちは
公開されている事前トレーニング済み BERT と互換性のある Transformer ベースのシーケンス間モデルを開発しました。
GPT-2 および RoBERTa チェックポイントを使用し、モデルの初期化の有用性について広範な実証研究を実施しました。
エンコーダとデコーダ、これらのチェックポイント。私たちのモデルは、機械翻訳に関する新しい最先端の結果をもたらします。
テキストの要約、文の分割、および文の融合。*
## Usage examples and tips
- モデルを [`EncoderDecoderModel`] と組み合わせて使用して、2 つの事前トレーニングされたモデルを活用できます。
後続の微調整のための BERT チェックポイント。
```python
>>> # leverage checkpoints for Bert2Bert model...
>>> # use BERT's cls token as BOS token and sep token as EOS token
>>> encoder = BertGenerationEncoder.from_pretrained("bert-large-uncased", bos_token_id=101, eos_token_id=102)
>>> # add cross attention layers and use BERT's cls token as BOS token and sep token as EOS token
>>> decoder = BertGenerationDecoder.from_pretrained(
... "bert-large-uncased", add_cross_attention=True, is_decoder=True, bos_token_id=101, eos_token_id=102
... )
>>> bert2bert = EncoderDecoderModel(encoder=encoder, decoder=decoder)
>>> # create tokenizer...
>>> tokenizer = BertTokenizer.from_pretrained("bert-large-uncased")
>>> input_ids = tokenizer(
... "This is a long article to summarize", add_special_tokens=False, return_tensors="pt"
... ).input_ids
>>> labels = tokenizer("This is a short summary", return_tensors="pt").input_ids
>>> # train...
>>> loss = bert2bert(input_ids=input_ids, decoder_input_ids=labels, labels=labels).loss
>>> loss.backward()
```
- 事前トレーニングされた [`EncoderDecoderModel`] もモデル ハブで直接利用できます。
```python
>>> # instantiate sentence fusion model
>>> sentence_fuser = EncoderDecoderModel.from_pretrained("google/roberta2roberta_L-24_discofuse")
>>> tokenizer = AutoTokenizer.from_pretrained("google/roberta2roberta_L-24_discofuse")
>>> input_ids = tokenizer(
... "This is the first sentence. This is the second sentence.", add_special_tokens=False, return_tensors="pt"
... ).input_ids
>>> outputs = sentence_fuser.generate(input_ids)
>>> print(tokenizer.decode(outputs[0]))
```
チップ:
- [`BertGenerationEncoder`] と [`BertGenerationDecoder`] は、
[`EncoderDecoder`] と組み合わせます。
- 要約、文の分割、文の融合、および翻訳の場合、入力に特別なトークンは必要ありません。
したがって、入力の末尾に EOS トークンを追加しないでください。
このモデルは、[patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。元のコードは次のとおりです
[ここ](https://tfhub.dev/s?module-type=text-generation&subtype=module,placeholder) があります。
## BertGenerationConfig
[[autodoc]] BertGenerationConfig
## BertGenerationTokenizer
[[autodoc]] BertGenerationTokenizer
- save_vocabulary
## BertGenerationEncoder
[[autodoc]] BertGenerationEncoder
- forward
## BertGenerationDecoder
[[autodoc]] BertGenerationDecoder
- forward
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/albert.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ALBERT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=albert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-albert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/albert-base-v2">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## 概要
ALBERTモデルは、「[ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942)」という論文でZhenzhong Lan、Mingda Chen、Sebastian Goodman、Kevin Gimpel、Piyush Sharma、Radu Soricutによって提案されました。BERTのメモリ消費を減らしトレーニングを高速化するためのパラメータ削減技術を2つ示しています:
- 埋め込み行列を2つの小さな行列に分割する。
- グループ間で分割された繰り返し層を使用する。
論文の要旨は以下の通りです:
*自然言語表現の事前学習時にモデルのサイズを増やすと、下流タスクのパフォーマンスが向上することがしばしばあります。しかし、ある時点でさらなるモデルの増大は、GPU/TPUのメモリ制限、長い訓練時間、予期せぬモデルの劣化といった問題のために困難になります。これらの問題に対処するために、我々はBERTのメモリ消費を低減し、訓練速度を高めるための2つのパラメータ削減技術を提案します。包括的な実証的証拠は、我々の提案方法が元のBERTに比べてはるかによくスケールするモデルを生み出すことを示しています。また、文間の一貫性をモデリングに焦点を当てた自己教師あり損失を使用し、複数の文が含まれる下流タスクに一貫して助けとなることを示します。その結果、我々の最良のモデルは、BERT-largeに比べてパラメータが少ないにもかかわらず、GLUE、RACE、SQuADベンチマークで新たな最先端の結果を確立します。*
このモデルは[lysandre](https://huggingface.co/lysandre)により提供されました。このモデルのjaxバージョンは[kamalkraj](https://huggingface.co/kamalkraj)により提供されました。オリジナルのコードは[こちら](https://github.com/google-research/ALBERT)で見ることができます。
## 使用上のヒント
- ALBERTは絶対位置埋め込みを使用するモデルなので、通常、入力を左側ではなく右側にパディングすることが推奨されます。
- ALBERTは繰り返し層を使用するためメモリ使用量は小さくなりますが、同じ数の(繰り返し)層を反復しなければならないため、隠れ層の数が同じであればBERTのようなアーキテクチャと同様の計算コストがかかります。
- 埋め込みサイズEは隠れサイズHと異なりますが、これは埋め込みが文脈に依存しない(一つの埋め込みベクトルが一つのトークンを表す)のに対し、隠れ状態は文脈に依存する(1つの隠れ状態がトークン系列を表す)ため、H >> Eとすることがより論理的です。また、埋め込み行列のサイズはV x Eと大きいです(Vは語彙サイズ)。E < Hであれば、パラメータは少なくなります。
- 層はパラメータを共有するグループに分割されています(メモリ節約のため)。次文予測(NSP: Next Sentence Prediction)は文の順序予測に置き換えられます:入力では、2つの文AとB(それらは連続している)があり、Aに続いてBを与えるか、Bに続いてAを与えます。モデルはそれらが入れ替わっているかどうかを予測する必要があります。
## 参考資料
- [テキスト分類タスクガイド](../tasks/sequence_classification)
- [トークン分類タスクガイド](../tasks/token_classification)
- [質問応答タスクガイド](../tasks/question_answering)
- [マスクされた言語モデルタスクガイド](../tasks/masked_language_modeling)
- [多肢選択タスクガイド](../tasks/multiple_choice)
## AlbertConfig
[[autodoc]] AlbertConfig
## AlbertTokenizer
[[autodoc]] AlbertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## AlbertTokenizerFast
[[autodoc]] AlbertTokenizerFast
## Albert specific outputs
[[autodoc]] models.albert.modeling_albert.AlbertForPreTrainingOutput
[[autodoc]] models.albert.modeling_tf_albert.TFAlbertForPreTrainingOutput
<frameworkcontent>
<pt>
## AlbertModel
[[autodoc]] AlbertModel
- forward
## AlbertForPreTraining
[[autodoc]] AlbertForPreTraining
- forward
## AlbertForMaskedLM
[[autodoc]] AlbertForMaskedLM
- forward
## AlbertForSequenceClassification
[[autodoc]] AlbertForSequenceClassification
- forward
## AlbertForMultipleChoice
[[autodoc]] AlbertForMultipleChoice
## AlbertForTokenClassification
[[autodoc]] AlbertForTokenClassification
- forward
## AlbertForQuestionAnswering
[[autodoc]] AlbertForQuestionAnswering
- forward
</pt>
<tf>
## TFAlbertModel
[[autodoc]] TFAlbertModel
- call
## TFAlbertForPreTraining
[[autodoc]] TFAlbertForPreTraining
- call
## TFAlbertForMaskedLM
[[autodoc]] TFAlbertForMaskedLM
- call
## TFAlbertForSequenceClassification
[[autodoc]] TFAlbertForSequenceClassification
- call
## TFAlbertForMultipleChoice
[[autodoc]] TFAlbertForMultipleChoice
- call
## TFAlbertForTokenClassification
[[autodoc]] TFAlbertForTokenClassification
- call
## TFAlbertForQuestionAnswering
[[autodoc]] TFAlbertForQuestionAnswering
- call
</tf>
<jax>
## FlaxAlbertModel
[[autodoc]] FlaxAlbertModel
- __call__
## FlaxAlbertForPreTraining
[[autodoc]] FlaxAlbertForPreTraining
- __call__
## FlaxAlbertForMaskedLM
[[autodoc]] FlaxAlbertForMaskedLM
- __call__
## FlaxAlbertForSequenceClassification
[[autodoc]] FlaxAlbertForSequenceClassification
- __call__
## FlaxAlbertForMultipleChoice
[[autodoc]] FlaxAlbertForMultipleChoice
- __call__
## FlaxAlbertForTokenClassification
[[autodoc]] FlaxAlbertForTokenClassification
- __call__
## FlaxAlbertForQuestionAnswering
[[autodoc]] FlaxAlbertForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/bart.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BART
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=bart">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-bart-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/bart-large-mnli">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
**免責事項:** 何か奇妙なものを見つけた場合は、[Github 問題](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) を提出し、割り当ててください。
@patrickvonplaten
## Overview
Bart モデルは、[BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation、
翻訳と理解](https://arxiv.org/abs/1910.13461) Mike Lewis、Yinhan Liu、Naman Goyal、Marjan 著
ガズビニネジャド、アブデルラフマン・モハメド、オメル・レヴィ、ベス・ストヤノフ、ルーク・ゼトルモイヤー、2019年10月29日。
要約によると、
- Bart は、双方向エンコーダ (BERT など) を備えた標準の seq2seq/機械翻訳アーキテクチャを使用します。
左から右へのデコーダ (GPT など)。
- 事前トレーニング タスクには、元の文の順序をランダムにシャッフルし、新しい埋め込みスキームが含まれます。
ここで、テキストの範囲は単一のマスク トークンに置き換えられます。
- BART は、テキスト生成用に微調整した場合に特に効果的ですが、理解タスクにも適しています。それ
RoBERTa のパフォーマンスを GLUE および SQuAD の同等のトレーニング リソースと同等にし、新たな成果を達成します。
さまざまな抽象的な対話、質問応答、要約タスクに関する最先端の結果が得られ、成果が得られます。
ルージュは最大6枚まで。
チップ:
- BART は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
左。
- エンコーダーとデコーダーを備えたシーケンスツーシーケンス モデル。エンコーダには破損したバージョンのトークンが供給され、デコーダには元のトークンが供給されます(ただし、通常のトランスフォーマー デコーダと同様に、将来のワードを隠すためのマスクがあります)。次の変換の構成は、エンコーダーの事前トレーニング タスクに適用されます。
* ランダムなトークンをマスクします (BERT と同様)
* ランダムなトークンを削除します
* k 個のトークンのスパンを 1 つのマスク トークンでマスクします (0 トークンのスパンはマスク トークンの挿入です)
* 文を並べ替えます
* ドキュメントを回転して特定のトークンから開始するようにします
このモデルは [sshleifer](https://huggingface.co/sshleifer) によって提供されました。著者のコードは [ここ](https://github.com/pytorch/fairseq/tree/master/examples/bart) にあります。
### Examples
- シーケンス間タスク用の BART およびその他のモデルを微調整するための例とスクリプトは、次の場所にあります。
[examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md)。
- Hugging Face `datasets` を使用して [`BartForConditionalGeneration`] をトレーニングする方法の例
オブジェクトは、この [フォーラム ディスカッション](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904) で見つけることができます。
- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://arxiv.org/abs/2010.13002) で説明されています。
## Implementation Notes
- Bart はシーケンスの分類に `token_type_ids` を使用しません。 [`BartTokenizer`] を使用するか、
[`~BartTokenizer.encode`] を使用して適切に分割します。
- [`BartModel`] のフォワードパスは、渡されなかった場合、`decoder_input_ids` を作成します。
これは、他のモデリング API とは異なります。この機能の一般的な使用例は、マスクの塗りつぶしです。
- モデルの予測は、次の場合に元の実装と同一になるように意図されています。
`forced_bos_token_id=0`。ただし、これは、渡す文字列が次の場合にのみ機能します。
[`fairseq.encode`] はスペースで始まります。
- [`~generation.GenerationMixin.generate`] は、次のような条件付き生成タスクに使用する必要があります。
要約については、その docstring の例を参照してください。
- *facebook/bart-large-cnn* 重みをロードするモデルには `mask_token_id` がないか、実行できません。
マスクを埋めるタスク。
## Mask Filling
`facebook/bart-base` および `facebook/bart-large` チェックポイントを使用して、マルチトークン マスクを埋めることができます。
```python
from transformers import BartForConditionalGeneration, BartTokenizer
model = BartForConditionalGeneration.from_pretrained("facebook/bart-large", forced_bos_token_id=0)
tok = BartTokenizer.from_pretrained("facebook/bart-large")
example_english_phrase = "UN Chief Says There Is No <mask> in Syria"
batch = tok(example_english_phrase, return_tensors="pt")
generated_ids = model.generate(batch["input_ids"])
assert tok.batch_decode(generated_ids, skip_special_tokens=True) == [
"UN Chief Says There Is No Plan to Stop Chemical Weapons in Syria"
]
```
## Resources
BART を始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
<PipelineTag pipeline="summarization"/>
- に関するブログ投稿 [分散トレーニング: 🤗 Transformers と Amazon SageMaker を使用した要約のための BART/T5 のトレーニング](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq)。
- 方法に関するノートブック [blurr を使用して fastai で要約するために BART を微調整する](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb). 🌎 🌎
- 方法に関するノートブック [トレーナー クラスを使用して 2 つの言語で要約するために BART を微調整する](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb)。 🌎
- [`BartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)。
- [`TFBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)。
- [`FlaxBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization) でサポートされています。
- [要約](https://huggingface.co/course/chapter7/5?fw=pt#summarization) 🤗 ハグフェイスコースの章。
- [要約タスクガイド](../tasks/summarization.md)
<PipelineTag pipeline="fill-mask"/>
- [`BartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) でサポートされており、 [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)。
- [`TFBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)。
- [`FlaxBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) および [ノートブック]( https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb)。
- [マスクされた言語モデリング](https://huggingface.co/course/chapter7/3?fw=pt) 🤗 顔ハグ コースの章。
- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
<PipelineTag pipeline="translation"/>
- [ヒンディー語から英語への翻訳に Seq2SeqTrainer を使用して mBART を微調整する]方法に関するノート (https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb)。 🌎
- [`BartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)。
- [`TFBartForConditionalGeneration`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/translation) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)。
- [翻訳タスクガイド](../tasks/translation)
以下も参照してください。
- [テキスト分類タスクガイド](../tasks/sequence_classification)
- [質問回答タスク ガイド](../tasks/question_answering)
- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
- [抽出されたチェックポイント](https://huggingface.co/models?search=distilbart) は、この [論文](https://arxiv.org/abs/2010.13002) で説明されています。
## BartConfig
[[autodoc]] BartConfig
- all
## BartTokenizer
[[autodoc]] BartTokenizer
- all
## BartTokenizerFast
[[autodoc]] BartTokenizerFast
- all
## BartModel
[[autodoc]] BartModel
- forward
## BartForConditionalGeneration
[[autodoc]] BartForConditionalGeneration
- forward
## BartForSequenceClassification
[[autodoc]] BartForSequenceClassification
- forward
## BartForQuestionAnswering
[[autodoc]] BartForQuestionAnswering
- forward
## BartForCausalLM
[[autodoc]] BartForCausalLM
- forward
## TFBartModel
[[autodoc]] TFBartModel
- call
## TFBartForConditionalGeneration
[[autodoc]] TFBartForConditionalGeneration
- call
## TFBartForSequenceClassification
[[autodoc]] TFBartForSequenceClassification
- call
## FlaxBartModel
[[autodoc]] FlaxBartModel
- __call__
- encode
- decode
## FlaxBartForConditionalGeneration
[[autodoc]] FlaxBartForConditionalGeneration
- __call__
- encode
- decode
## FlaxBartForSequenceClassification
[[autodoc]] FlaxBartForSequenceClassification
- __call__
- encode
- decode
## FlaxBartForQuestionAnswering
[[autodoc]] FlaxBartForQuestionAnswering
- __call__
- encode
- decode
## FlaxBartForCausalLM
[[autodoc]] FlaxBartForCausalLM
- __call__
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/biogpt.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BioGPT
## Overview
BioGPT モデルは、[BioGPT: 生物医学テキストの生成とマイニングのための生成事前トレーニング済みトランスフォーマー](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo、Liai Sun、Yingce Xia、 Tao Qin、Sheng Zhang、Hoifung Poon、Tie-Yan Liu。 BioGPT は、生物医学テキストの生成とマイニングのための、ドメイン固有の生成事前トレーニング済み Transformer 言語モデルです。 BioGPT は、Transformer 言語モデルのバックボーンに従い、1,500 万の PubMed 抄録で最初から事前トレーニングされています。
論文の要約は次のとおりです。
*事前トレーニング済み言語モデルは、一般的な自然言語領域での大きな成功に触発されて、生物医学領域でますます注目を集めています。一般言語ドメインの事前トレーニング済み言語モデルの 2 つの主なブランチ、つまり BERT (およびそのバリアント) と GPT (およびそのバリアント) のうち、1 つ目は BioBERT や PubMedBERT などの生物医学ドメインで広く研究されています。これらはさまざまな下流の生物医学的タスクで大きな成功を収めていますが、生成能力の欠如により応用範囲が制限されています。この論文では、大規模な生物医学文献で事前トレーニングされたドメイン固有の生成 Transformer 言語モデルである BioGPT を提案します。私たちは 6 つの生物医学的自然言語処理タスクで BioGPT を評価し、ほとんどのタスクで私たちのモデルが以前のモデルよりも優れていることを実証しました。特に、BC5CDR、KD-DTI、DDI のエンドツーエンド関係抽出タスクではそれぞれ 44.98%、38.42%、40.76% の F1 スコアを獲得し、PubMedQA では 78.2% の精度を獲得し、新記録を樹立しました。テキスト生成に関する私たちのケーススタディは、生物医学文献における BioGPT の利点をさらに実証し、生物医学用語の流暢な説明を生成します。*
## Usage tips
- BioGPT は絶対位置埋め込みを備えたモデルであるため、通常は入力を左側ではなく右側にパディングすることをお勧めします。
- BioGPT は因果言語モデリング (CLM) 目的でトレーニングされているため、シーケンス内の次のトークンを予測するのに強力です。 run_generation.py サンプル スクリプトで確認できるように、この機能を利用すると、BioGPT は構文的に一貫したテキストを生成できます。
- モデルは、以前に計算されたキーと値のアテンション ペアである`past_key_values`(PyTorch の場合) を入力として受け取ることができます。この (past_key_values または past) 値を使用すると、モデルがテキスト生成のコンテキストで事前に計算された値を再計算できなくなります。 PyTorch の使用法の詳細については、BioGptForCausalLM.forward() メソッドの past_key_values 引数を参照してください。
このモデルは、[kamalkraj](https://huggingface.co/kamalkraj) によって提供されました。元のコードは [ここ](https://github.com/microsoft/BioGPT) にあります。
## Documentation resources
- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
## BioGptConfig
[[autodoc]] BioGptConfig
## BioGptTokenizer
[[autodoc]] BioGptTokenizer
- save_vocabulary
## BioGptModel
[[autodoc]] BioGptModel
- forward
## BioGptForCausalLM
[[autodoc]] BioGptForCausalLM
- forward
## BioGptForTokenClassification
[[autodoc]] BioGptForTokenClassification
- forward
## BioGptForSequenceClassification
[[autodoc]] BioGptForSequenceClassification
- forward
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/blenderbot.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Blenderbot
**免責事項:** 何か奇妙なものを見つけた場合は、 [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title) を報告してください。
## Overview
Blender チャットボット モデルは、[オープンドメイン チャットボットを構築するためのレシピ](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
論文の要旨は次のとおりです。
*オープンドメインのチャットボットの構築は、機械学習研究にとって難しい分野です。これまでの研究では次のことが示されていますが、
ニューラル モデルをパラメーターの数とトレーニング対象のデータのサイズでスケーリングすると、結果が向上します。
高性能のチャットボットには他の要素も重要であることを示します。良い会話には多くのことが必要です
会話の専門家がシームレスに融合するスキル: 魅力的な話のポイントを提供し、話を聞く
一貫した態度を維持しながら、知識、共感、個性を適切に表現する
ペルソナ。適切なトレーニング データと選択が与えられた場合、大規模モデルがこれらのスキルを学習できることを示します。
世代戦略。 90M、2.7B、9.4B パラメーター モデルを使用してこれらのレシピのバリアントを構築し、モデルを作成します。
コードは公開されています。人間による評価では、当社の最良のモデルが既存のアプローチよりも優れていることがマルチターンで示されています
魅力と人間性の測定という観点からの対話。次に、分析によってこの作業の限界について説明します。
弊社機種の故障事例*
チップ:
- Blenderbot は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
左。
このモデルは [sshleifer](https://huggingface.co/sshleifer) によって提供されました。著者のコードは [ここ](https://github.com/facebookresearch/ParlAI) にあります。
## Implementation Notes
- Blenderbot は、標準の [seq2seq モデル トランスフォーマー](https://arxiv.org/pdf/1706.03762.pdf) ベースのアーキテクチャを使用します。
- 利用可能なチェックポイントは、[モデル ハブ](https://huggingface.co/models?search=blenderbot) で見つけることができます。
- これは *デフォルト* Blenderbot モデル クラスです。ただし、次のような小さなチェックポイントもいくつかあります。
`facebook/blenderbot_small_90M` はアーキテクチャが異なるため、一緒に使用する必要があります。
[BlenderbotSmall](ブレンダーボット小)。
## Usage
モデルの使用例を次に示します。
```python
>>> from transformers import BlenderbotTokenizer, BlenderbotForConditionalGeneration
>>> mname = "facebook/blenderbot-400M-distill"
>>> model = BlenderbotForConditionalGeneration.from_pretrained(mname)
>>> tokenizer = BlenderbotTokenizer.from_pretrained(mname)
>>> UTTERANCE = "My friends are cool but they eat too many carbs."
>>> inputs = tokenizer([UTTERANCE], return_tensors="pt")
>>> reply_ids = model.generate(**inputs)
>>> print(tokenizer.batch_decode(reply_ids))
["<s> That's unfortunate. Are they trying to lose weight or are they just trying to be healthier?</s>"]
```
## Documentation resources
- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
- [翻訳タスクガイド](../tasks/translation)
- [要約タスクガイド](../tasks/summarization)
## BlenderbotConfig
[[autodoc]] BlenderbotConfig
## BlenderbotTokenizer
[[autodoc]] BlenderbotTokenizer
- build_inputs_with_special_tokens
## BlenderbotTokenizerFast
[[autodoc]] BlenderbotTokenizerFast
- build_inputs_with_special_tokens
## BlenderbotModel
*forward* および *generate* の引数については、`transformers.BartModel`を参照してください。
[[autodoc]] BlenderbotModel
- forward
## BlenderbotForConditionalGeneration
*forward* と *generate* の引数については、[`~transformers.BartForConditionalGeneration`] を参照してください。
[[autodoc]] BlenderbotForConditionalGeneration
- forward
## BlenderbotForCausalLM
[[autodoc]] BlenderbotForCausalLM
- forward
## TFBlenderbotModel
[[autodoc]] TFBlenderbotModel
- call
## TFBlenderbotForConditionalGeneration
[[autodoc]] TFBlenderbotForConditionalGeneration
- call
## FlaxBlenderbotModel
[[autodoc]] FlaxBlenderbotModel
- __call__
- encode
- decode
## FlaxBlenderbotForConditionalGeneration
[[autodoc]] FlaxBlenderbotForConditionalGeneration
- __call__
- encode
- decode
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/bigbird_pegasus.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BigBirdPegasus
## Overview
BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) で提案されました。
ザヒール、マンジルとグルガネシュ、グルとダベイ、クマール・アヴィナヴァとエインズリー、ジョシュアとアルベルティ、クリスとオンタノン、
サンティアゴとファム、フィリップとラブラ、アニルードとワン、キーファンとヤン、リーなど。 BigBird は注目度が低い
BERT などの Transformer ベースのモデルをさらに長いシーケンスに拡張する、Transformer ベースのモデル。まばらに加えて
アテンションと同様に、BigBird は入力シーケンスにランダム アテンションだけでなくグローバル アテンションも適用します。理論的には、
まばらで全体的でランダムな注意を適用すると、完全な注意に近づくことが示されていますが、
長いシーケンスでは計算効率が大幅に向上します。より長いコンテキストを処理できる機能の結果として、
BigBird は、質問応答や
BERT または RoBERTa と比較した要約。
論文の要約は次のとおりです。
*BERT などのトランスフォーマーベースのモデルは、NLP で最も成功した深層学習モデルの 1 つです。
残念ながら、それらの中核的な制限の 1 つは、シーケンスに対する二次依存性 (主にメモリに関する) です。
完全な注意メカニズムによる長さです。これを解決するために、BigBird は、まばらな注意メカニズムを提案します。
この二次依存関係を線形に削減します。 BigBird がシーケンス関数の汎用近似器であることを示します。
チューリングは完全であるため、二次完全注意モデルのこれらの特性が保存されます。途中、私たちの
理論分析により、O(1) 個のグローバル トークン (CLS など) を持つ利点の一部が明らかになり、
スパース注意メカニズムの一部としてのシーケンス。提案されたスパース アテンションは、次の長さのシーケンスを処理できます。
同様のハードウェアを使用して以前に可能であったものの 8 倍。より長いコンテキストを処理できる機能の結果として、
BigBird は、質問応答や要約などのさまざまな NLP タスクのパフォーマンスを大幅に向上させます。私達も
ゲノミクスデータへの新しいアプリケーションを提案します。*
## Usage tips
- BigBird の注意がどのように機能するかについての詳細な説明については、[このブログ投稿](https://huggingface.co/blog/big-bird) を参照してください。
- BigBird には、**original_full** と **block_sparse** の 2 つの実装が付属しています。シーケンス長が 1024 未満の場合、次を使用します。
**block_sparse** を使用してもメリットがないため、**original_full** を使用することをお勧めします。
- コードは現在、3 ブロックと 2 グローバル ブロックのウィンドウ サイズを使用しています。
- シーケンスの長さはブロック サイズで割り切れる必要があります。
- 現在の実装では **ITC** のみがサポートされています。
- 現在の実装では **num_random_blocks = 0** はサポートされていません。
- BigBirdPegasus は [PegasusTokenizer](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pegasus/tokenization_pegasus.py) を使用します。
- BigBird は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
左。
元のコードは [こちら](https://github.com/google-research/bigbird) にあります。
## ドキュメント リソース
- [テキスト分類タスクガイド](../tasks/sequence_classification)
- [質問回答タスク ガイド](../tasks/question_answering)
- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
- [翻訳タスクガイド](../tasks/translation)
- [要約タスクガイド](../tasks/summarization)
## BigBirdPegasusConfig
[[autodoc]] BigBirdPegasusConfig
- all
## BigBirdPegasusModel
[[autodoc]] BigBirdPegasusModel
- forward
## BigBirdPegasusForConditionalGeneration
[[autodoc]] BigBirdPegasusForConditionalGeneration
- forward
## BigBirdPegasusForSequenceClassification
[[autodoc]] BigBirdPegasusForSequenceClassification
- forward
## BigBirdPegasusForQuestionAnswering
[[autodoc]] BigBirdPegasusForQuestionAnswering
- forward
## BigBirdPegasusForCausalLM
[[autodoc]] BigBirdPegasusForCausalLM
- forward
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/audio-spectrogram-transformer.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Audio Spectrogram Transformer
## 概要
Audio Spectrogram Transformerモデルは、[AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778)という論文でYuan Gong、Yu-An Chung、James Glassによって提案されました。これは、音声を画像(スペクトログラム)に変換することで、音声に[Vision Transformer](vit)を適用します。このモデルは音声分類において最先端の結果を得ています。
論文の要旨は以下の通りです:
*過去10年間で、畳み込みニューラルネットワーク(CNN)は、音声スペクトログラムから対応するラベルへの直接的なマッピングを学習することを目指す、エンドツーエンドの音声分類モデルの主要な構成要素として広く採用されてきました。長距離のグローバルなコンテキストをより良く捉えるため、最近の傾向として、CNNの上にセルフアテンション機構を追加し、CNN-アテンションハイブリッドモデルを形成することがあります。しかし、CNNへの依存が必要かどうか、そして純粋にアテンションに基づくニューラルネットワークだけで音声分類において良いパフォーマンスを得ることができるかどうかは明らかではありません。本論文では、これらの問いに答えるため、音声分類用では最初の畳み込みなしで純粋にアテンションベースのモデルであるAudio Spectrogram Transformer(AST)を紹介します。我々はASTを様々なオーディオ分類ベンチマークで評価し、AudioSetで0.485 mAP、ESC-50で95.6%の正解率、Speech Commands V2で98.1%の正解率という新たな最先端の結果を達成しました。*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/audio_spectogram_transformer_architecture.png"
alt="drawing" width="600"/>
<small> Audio Spectrogram Transformerのアーキテクチャ。<a href="https://arxiv.org/abs/2104.01778">元論文</a>より抜粋。</small>
このモデルは[nielsr](https://huggingface.co/nielsr)より提供されました。
オリジナルのコードは[こちら](https://github.com/YuanGongND/ast)で見ることができます。
## 使用上のヒント
- 独自のデータセットでAudio Spectrogram Transformer(AST)をファインチューニングする場合、入力の正規化(入力の平均を0、標準偏差を0.5にすること)処理することが推奨されます。[`ASTFeatureExtractor`]はこれを処理します。デフォルトではAudioSetの平均と標準偏差を使用していることに注意してください。著者が下流のデータセットの統計をどのように計算しているかは、[`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py)で確認することができます。
- ASTは低い学習率が必要であり 著者は[PSLA論文](https://arxiv.org/abs/2102.01243)で提案されたCNNモデルに比べて10倍小さい学習率を使用しています)、素早く収束するため、タスクに適した学習率と学習率スケジューラーを探すことをお勧めします。
## 参考資料
Audio Spectrogram Transformerの使用を開始するのに役立つ公式のHugging Faceおよびコミュニティ(🌎で示されている)の参考資料の一覧です。
<PipelineTag pipeline="audio-classification"/>
- ASTを用いた音声分類の推論を説明するノートブックは[こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/AST)で見ることができます。
- [`ASTForAudioClassification`]は、この[例示スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification)と[ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)によってサポートされています。
- こちらも参照:[音声分類タスク](../tasks/audio_classification)。
ここに参考資料を提出したい場合は、気兼ねなくPull Requestを開いてください。私たちはそれをレビューいたします!参考資料は、既存のものを複製するのではなく、何か新しいことを示すことが理想的です。
## ASTConfig
[[autodoc]] ASTConfig
## ASTFeatureExtractor
[[autodoc]] ASTFeatureExtractor
- __call__
## ASTModel
[[autodoc]] ASTModel
- forward
## ASTForAudioClassification
[[autodoc]] ASTForAudioClassification
- forward
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/altclip.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# AltCLIP
## 概要
AltCLIPモデルは、「[AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679v2)」という論文でZhongzhi Chen、Guang Liu、Bo-Wen Zhang、Fulong Ye、Qinghong Yang、Ledell Wuによって提案されました。AltCLIP(CLIPの言語エンコーダーの代替)は、様々な画像-テキストペアおよびテキスト-テキストペアでトレーニングされたニューラルネットワークです。CLIPのテキストエンコーダーを事前学習済みの多言語テキストエンコーダーXLM-Rに置き換えることで、ほぼ全てのタスクでCLIPに非常に近い性能を得られ、オリジナルのCLIPの能力を多言語理解などに拡張しました。
論文の要旨は以下の通りです:
*この研究では、強力なバイリンガルマルチモーダル表現モデルを訓練するための概念的に単純で効果的な方法を提案します。OpenAIによってリリースされたマルチモーダル表現モデルCLIPから開始し、そのテキストエンコーダを事前学習済みの多言語テキストエンコーダXLM-Rに交換し、教師学習と対照学習からなる2段階のトレーニングスキーマを用いて言語と画像の表現を整合させました。幅広いタスクの評価を通じて、我々の方法を検証します。ImageNet-CN、Flicker30k-CN、COCO-CNを含む多くのタスクで新たな最先端の性能を達成しました。さらに、ほぼすべてのタスクでCLIPに非常に近い性能を得ており、これはCLIPのテキストエンコーダを変更するだけで、多言語理解などの拡張を実現できることを示唆しています。*
このモデルは[jongjyh](https://huggingface.co/jongjyh)により提供されました。
## 使用上のヒントと使用例
AltCLIPの使用方法はCLIPに非常に似ています。CLIPとの違いはテキストエンコーダーにあります。私たちはカジュアルアテンションではなく双方向アテンションを使用し、XLM-Rの[CLS]トークンをテキスト埋め込みを表すものとして取ることに留意してください。
AltCLIPはマルチモーダルな視覚言語モデルです。これは画像とテキストの類似度や、ゼロショット画像分類に使用できます。AltCLIPはViTのようなTransformerを使用して視覚的特徴を、双方向言語モデルを使用してテキスト特徴を取得します。テキストと視覚の両方の特徴は、同一の次元を持つ潜在空間に射影されます。射影された画像とテキスト特徴間のドット積が類似度スコアとして使用されます。
Transformerエンコーダーに画像を与えるには、各画像を固定サイズの重複しないパッチの系列に分割し、それらを線形に埋め込みます。画像全体を表現するための[CLS]トークンが追加されます。著者は絶対位置埋め込みも追加し、結果として得られるベクトルの系列を標準的なTransformerエンコーダーに供給します。[`CLIPImageProcessor`]を使用して、モデルのために画像のサイズ変更(または拡大縮小)と正規化を行うことができます。
[`AltCLIPProcessor`]は、テキストのエンコードと画像の前処理を両方行うために、[`CLIPImageProcessor`]と[`XLMRobertaTokenizer`]を単一のインスタンスにラップします。以下の例は、[`AltCLIPProcessor`]と[`AltCLIPModel`]を使用して画像-テキスト類似スコアを取得する方法を示しています。
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AltCLIPModel, AltCLIPProcessor
>>> model = AltCLIPModel.from_pretrained("BAAI/AltCLIP")
>>> processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
>>> outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
<Tip>
このモデルは`CLIPModel`をベースにしており、オリジナルの[CLIP](clip)と同じように使用してください。
</Tip>
## AltCLIPConfig
[[autodoc]] AltCLIPConfig
- from_text_vision_configs
## AltCLIPTextConfig
[[autodoc]] AltCLIPTextConfig
## AltCLIPVisionConfig
[[autodoc]] AltCLIPVisionConfig
## AltCLIPProcessor
[[autodoc]] AltCLIPProcessor
## AltCLIPModel
[[autodoc]] AltCLIPModel
- forward
- get_text_features
- get_image_features
## AltCLIPTextModel
[[autodoc]] AltCLIPTextModel
- forward
## AltCLIPVisionModel
[[autodoc]] AltCLIPVisionModel
- forward
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/bartpho.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BARTpho
## Overview
BARTpho モデルは、Nguyen Luong Tran、Duong Minh Le、Dat Quoc Nguyen によって [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnam](https://arxiv.org/abs/2109.09701) で提案されました。
論文の要約は次のとおりです。
*BARTpho には、BARTpho_word と BARTpho_syllable の 2 つのバージョンがあり、初の公開された大規模な単一言語です。
ベトナム語用に事前トレーニングされたシーケンスツーシーケンス モデル。当社の BARTpho は「大規模な」アーキテクチャと事前トレーニングを使用します
シーケンス間ノイズ除去モデル BART のスキームなので、生成 NLP タスクに特に適しています。実験
ベトナム語テキスト要約の下流タスクでは、自動評価と人間による評価の両方で、BARTpho が
強力なベースライン mBART を上回り、最先端の性能を向上させます。将来を容易にするためにBARTphoをリリースします
生成的なベトナム語 NLP タスクの研究と応用。*
このモデルは [dqnguyen](https://huggingface.co/dqnguyen) によって提供されました。元のコードは [こちら](https://github.com/VinAIResearch/BARTpho) にあります。
## Usage example
```python
>>> import torch
>>> from transformers import AutoModel, AutoTokenizer
>>> bartpho = AutoModel.from_pretrained("vinai/bartpho-syllable")
>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bartpho-syllable")
>>> line = "Chúng tôi là những nghiên cứu viên."
>>> input_ids = tokenizer(line, return_tensors="pt")
>>> with torch.no_grad():
... features = bartpho(**input_ids) # Models outputs are now tuples
>>> # With TensorFlow 2.0+:
>>> from transformers import TFAutoModel
>>> bartpho = TFAutoModel.from_pretrained("vinai/bartpho-syllable")
>>> input_ids = tokenizer(line, return_tensors="tf")
>>> features = bartpho(**input_ids)
```
## Usage tips
- mBARTに続いて、BARTphoはBARTの「大規模な」アーキテクチャを使用し、その上に追加の層正規化層を備えています。
エンコーダとデコーダの両方。したがって、[BART のドキュメント](bart) の使用例は、使用に適応する場合に使用されます。
BARTpho を使用する場合は、BART に特化したクラスを mBART に特化した対応するクラスに置き換えることによって調整する必要があります。
例えば:
```python
>>> from transformers import MBartForConditionalGeneration
>>> bartpho = MBartForConditionalGeneration.from_pretrained("vinai/bartpho-syllable")
>>> TXT = "Chúng tôi là <mask> nghiên cứu viên."
>>> input_ids = tokenizer([TXT], return_tensors="pt")["input_ids"]
>>> logits = bartpho(input_ids).logits
>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
>>> probs = logits[0, masked_index].softmax(dim=0)
>>> values, predictions = probs.topk(5)
>>> print(tokenizer.decode(predictions).split())
```
- この実装はトークン化のみを目的としています。`monolingual_vocab_file`はベトナム語に特化した型で構成されています
多言語 XLM-RoBERTa から利用できる事前トレーニング済み SentencePiece モデル`vocab_file`から抽出されます。
他の言語 (サブワードにこの事前トレーニング済み多言語 SentencePiece モデル`vocab_file`を使用する場合)
セグメンテーションにより、独自の言語に特化した`monolingual_vocab_file`を使用して BartphoTokenizer を再利用できます。
## BartphoTokenizer
[[autodoc]] BartphoTokenizer
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/barthez.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BARThez
## Overview
BARThez モデルは、Moussa Kamal Eddine、Antoine J.-P によって [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) で提案されました。ティクシエ、ミカリス・ヴァジルジャンニス、10月23日、
2020年。
論文の要約:
*帰納的転移学習は、自己教師あり学習によって可能になり、自然言語処理全体を実行します。
(NLP) 分野は、BERT や BART などのモデルにより、無数の自然言語に新たな最先端技術を確立し、嵐を巻き起こしています。
タスクを理解すること。いくつかの注目すべき例外はありますが、利用可能なモデルと研究のほとんどは、
英語を対象に実施されました。この作品では、フランス語用の最初の BART モデルである BARTez を紹介します。
(我々の知る限りに)。 BARThez は、過去の研究から得た非常に大規模な単一言語フランス語コーパスで事前トレーニングされました
BART の摂動スキームに合わせて調整しました。既存の BERT ベースのフランス語モデルとは異なり、
CamemBERT と FlauBERT、BARThez は、エンコーダだけでなく、
そのデコーダは事前トレーニングされています。 FLUE ベンチマークからの識別タスクに加えて、BARThez を新しい評価に基づいて評価します。
この論文とともにリリースする要約データセット、OrangeSum。また、すでに行われている事前トレーニングも継続します。
BARTHez のコーパス上で多言語 BART を事前訓練し、結果として得られるモデル (mBARTHez と呼ぶ) が次のことを示します。
バニラの BARThez を大幅に強化し、CamemBERT や FlauBERT と同等かそれを上回ります。*
このモデルは [moussakam](https://huggingface.co/moussakam) によって寄稿されました。著者のコードは[ここ](https://github.com/moussaKam/BARThez)にあります。
<Tip>
BARThez の実装は、トークン化を除いて BART と同じです。詳細については、[BART ドキュメント](bart) を参照してください。
構成クラスとそのパラメータ。 BARThez 固有のトークナイザーについては以下に記載されています。
</Tip>
### Resources
- BARThez は、BART と同様の方法でシーケンス間のタスクを微調整できます。以下を確認してください。
[examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md)。
## BarthezTokenizer
[[autodoc]] BarthezTokenizer
## BarthezTokenizerFast
[[autodoc]] BarthezTokenizerFast
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/big_bird.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BigBird
## Overview
BigBird モデルは、[Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) で提案されました。
ザヒール、マンジルとグルガネシュ、グルとダベイ、クマール・アヴィナヴァとエインズリー、ジョシュアとアルベルティ、クリスとオンタノン、
サンティアゴとファム、フィリップとラブラ、アニルードとワン、キーファンとヤン、リーなど。 BigBird は注目度が低い
BERT などの Transformer ベースのモデルをさらに長いシーケンスに拡張する、Transformer ベースのモデル。まばらに加えて
アテンションと同様に、BigBird は入力シーケンスにランダム アテンションだけでなくグローバル アテンションも適用します。理論的には、
まばらで全体的でランダムな注意を適用すると、完全な注意に近づくことが示されていますが、
長いシーケンスでは計算効率が大幅に向上します。より長いコンテキストを処理できる機能の結果として、
BigBird は、質問応答や
BERT または RoBERTa と比較した要約。
論文の要約は次のとおりです。
*BERT などのトランスフォーマーベースのモデルは、NLP で最も成功した深層学習モデルの 1 つです。
残念ながら、それらの中核的な制限の 1 つは、シーケンスに対する二次依存性 (主にメモリに関する) です。
完全な注意メカニズムによる長さです。これを解決するために、BigBird は、まばらな注意メカニズムを提案します。
この二次依存関係を線形に削減します。 BigBird がシーケンス関数の汎用近似器であることを示します。
チューリングは完全であるため、二次完全注意モデルのこれらの特性が保存されます。途中、私たちの
理論分析により、O(1) 個のグローバル トークン (CLS など) を持つ利点の一部が明らかになり、
スパース注意メカニズムの一部としてのシーケンス。提案されたスパース アテンションは、次の長さのシーケンスを処理できます。
同様のハードウェアを使用して以前に可能であったものの 8 倍。より長いコンテキストを処理できる機能の結果として、
BigBird は、質問応答や要約などのさまざまな NLP タスクのパフォーマンスを大幅に向上させます。私達も
ゲノミクスデータへの新しいアプリケーションを提案します。*
チップ:
- BigBird の注意がどのように機能するかについての詳細な説明については、[このブログ投稿](https://huggingface.co/blog/big-bird) を参照してください。
- BigBird には、**original_full** と **block_sparse** の 2 つの実装が付属しています。シーケンス長が 1024 未満の場合、次を使用します。
**block_sparse** を使用してもメリットがないため、**original_full** を使用することをお勧めします。
- コードは現在、3 ブロックと 2 グローバル ブロックのウィンドウ サイズを使用しています。
- シーケンスの長さはブロック サイズで割り切れる必要があります。
- 現在の実装では **ITC** のみがサポートされています。
- 現在の実装では **num_random_blocks = 0** はサポートされていません
- BigBird は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
左。
このモデルは、[vasudevgupta](https://huggingface.co/vasudevgupta) によって提供されました。元のコードが見つかる
[こちら](https://github.com/google-research/bigbird)。
## ドキュメント リソース
- [テキスト分類タスクガイド](../tasks/sequence_classification)
- [トークン分類タスクガイド](../tasks/token_classification)
- [質問回答タスク ガイド](../tasks/question_answering)
- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
- [多肢選択タスク ガイド](../tasks/multiple_choice)
## BigBirdConfig
[[autodoc]] BigBirdConfig
## BigBirdTokenizer
[[autodoc]] BigBirdTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## BigBirdTokenizerFast
[[autodoc]] BigBirdTokenizerFast
## BigBird specific outputs
[[autodoc]] models.big_bird.modeling_big_bird.BigBirdForPreTrainingOutput
<frameworkcontent>
<pt>
## BigBirdModel
[[autodoc]] BigBirdModel
- forward
## BigBirdForPreTraining
[[autodoc]] BigBirdForPreTraining
- forward
## BigBirdForCausalLM
[[autodoc]] BigBirdForCausalLM
- forward
## BigBirdForMaskedLM
[[autodoc]] BigBirdForMaskedLM
- forward
## BigBirdForSequenceClassification
[[autodoc]] BigBirdForSequenceClassification
- forward
## BigBirdForMultipleChoice
[[autodoc]] BigBirdForMultipleChoice
- forward
## BigBirdForTokenClassification
[[autodoc]] BigBirdForTokenClassification
- forward
## BigBirdForQuestionAnswering
[[autodoc]] BigBirdForQuestionAnswering
- forward
</pt>
<jax>
## FlaxBigBirdModel
[[autodoc]] FlaxBigBirdModel
- __call__
## FlaxBigBirdForPreTraining
[[autodoc]] FlaxBigBirdForPreTraining
- __call__
## FlaxBigBirdForCausalLM
[[autodoc]] FlaxBigBirdForCausalLM
- __call__
## FlaxBigBirdForMaskedLM
[[autodoc]] FlaxBigBirdForMaskedLM
- __call__
## FlaxBigBirdForSequenceClassification
[[autodoc]] FlaxBigBirdForSequenceClassification
- __call__
## FlaxBigBirdForMultipleChoice
[[autodoc]] FlaxBigBirdForMultipleChoice
- __call__
## FlaxBigBirdForTokenClassification
[[autodoc]] FlaxBigBirdForTokenClassification
- __call__
## FlaxBigBirdForQuestionAnswering
[[autodoc]] FlaxBigBirdForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/bit.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Big Transfer (BiT)
## Overview
BiT モデルは、Alexander Kolesnikov、Lucas Beyer、Xiaohua Zhai、Joan Puigcerver、Jessica Yung、Sylvain Gelly によって [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) で提案されました。ニール・ホールズビー。
BiT は、[ResNet](resnet) のようなアーキテクチャ (具体的には ResNetv2) の事前トレーニングをスケールアップするための簡単なレシピです。この方法により、転移学習が大幅に改善されます。
論文の要約は次のとおりです。
*事前トレーニングされた表現の転送により、サンプル効率が向上し、視覚用のディープ ニューラル ネットワークをトレーニングする際のハイパーパラメーター調整が簡素化されます。大規模な教師ありデータセットでの事前トレーニングと、ターゲット タスクでのモデルの微調整のパラダイムを再検討します。私たちは事前トレーニングをスケールアップし、Big Transfer (BiT) と呼ぶシンプルなレシピを提案します。いくつかの慎重に選択されたコンポーネントを組み合わせ、シンプルなヒューリスティックを使用して転送することにより、20 を超えるデータセットで優れたパフォーマンスを実現します。 BiT は、クラスごとに 1 つのサンプルから合計 100 万のサンプルまで、驚くほど広範囲のデータ領域にわたって良好にパフォーマンスを発揮します。 BiT は、ILSVRC-2012 で 87.5%、CIFAR-10 で 99.4%、19 タスクの Visual Task Adaptation Benchmark (VTAB) で 76.3% のトップ 1 精度を達成しました。小規模なデータセットでは、BiT は ILSVRC-2012 (クラスあたり 10 例) で 76.8%、CIFAR-10 (クラスあたり 10 例) で 97.0% を達成しました。高い転写性能を実現する主要成分を詳細に分析※。
## Usage tips
- BiT モデルは、アーキテクチャの点で ResNetv2 と同等ですが、次の点が異なります: 1) すべてのバッチ正規化層が [グループ正規化](https://arxiv.org/abs/1803.08494) に置き換えられます。
2) [重みの標準化](https://arxiv.org/abs/1903.10520) は畳み込み層に使用されます。著者らは、両方の組み合わせが大きなバッチサイズでのトレーニングに役立ち、重要な効果があることを示しています。
転移学習への影響。
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
元のコードは [こちら](https://github.com/google-research/big_transfer) にあります。
## Resources
BiT を始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
<PipelineTag pipeline="image-classification"/>
- [`BitForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
- 参照: [画像分類タスク ガイド](../tasks/image_classification)
ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
## BitConfig
[[autodoc]] BitConfig
## BitImageProcessor
[[autodoc]] BitImageProcessor
- preprocess
## BitModel
[[autodoc]] BitModel
- forward
## BitForImageClassification
[[autodoc]] BitForImageClassification
- forward
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/bertweet.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BERTweet
## Overview
BERTweet モデルは、Dat Quoc Nguyen、Thanh Vu によって [BERTweet: A pre-trained language model for English Tweets](https://www.aclweb.org/anthology/2020.emnlp-demos.2.pdf) で提案されました。アン・トゥアン・グエンさん。
論文の要約は次のとおりです。
*私たちは、英語ツイート用に初めて公開された大規模な事前トレーニング済み言語モデルである BERTweet を紹介します。私たちのBERTweetは、
BERT ベースと同じアーキテクチャ (Devlin et al., 2019) は、RoBERTa 事前トレーニング手順 (Liu et al.) を使用してトレーニングされます。
al.、2019)。実験では、BERTweet が強力なベースラインである RoBERTa ベースおよび XLM-R ベースを上回るパフォーマンスを示すことが示されています (Conneau et al.,
2020)、3 つのツイート NLP タスクにおいて、以前の最先端モデルよりも優れたパフォーマンス結果が得られました。
品詞タグ付け、固有表現認識およびテキスト分類。*
## Usage example
```python
>>> import torch
>>> from transformers import AutoModel, AutoTokenizer
>>> bertweet = AutoModel.from_pretrained("vinai/bertweet-base")
>>> # For transformers v4.x+:
>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base", use_fast=False)
>>> # For transformers v3.x:
>>> # tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base")
>>> # INPUT TWEET IS ALREADY NORMALIZED!
>>> line = "SC has first two presumptive cases of coronavirus , DHEC confirms HTTPURL via @USER :cry:"
>>> input_ids = torch.tensor([tokenizer.encode(line)])
>>> with torch.no_grad():
... features = bertweet(input_ids) # Models outputs are now tuples
>>> # With TensorFlow 2.0+:
>>> # from transformers import TFAutoModel
>>> # bertweet = TFAutoModel.from_pretrained("vinai/bertweet-base")
```
<Tip>
この実装は、トークン化方法を除いて BERT と同じです。詳細については、[BERT ドキュメント](bert) を参照してください。
API リファレンス情報。
</Tip>
このモデルは [dqnguyen](https://huggingface.co/dqnguyen) によって提供されました。元のコードは [ここ](https://github.com/VinAIResearch/BERTweet) にあります。
## BertweetTokenizer
[[autodoc]] BertweetTokenizer
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/blenderbot-small.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Blenderbot Small
[`BlenderbotSmallModel`] と
[`BlenderbotSmallForConditionalGeneration`] はチェックポイントと組み合わせてのみ使用されます
[facebook/blenderbot-90M](https://huggingface.co/facebook/blenderbot-90M)。より大規模な Blenderbot チェックポイントは、
代わりに [`BlenderbotModel`] とともに使用してください。
[`BlenderbotForConditionalGeneration`]
## Overview
Blender チャットボット モデルは、[オープンドメイン チャットボットを構築するためのレシピ](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller、Emily Dinan、Naman Goyal、Da Ju、Mary Williamson、yinghan Liu、で提案されました。
ジン・シュー、マイル・オット、カート・シャスター、エリック・M・スミス、Y-ラン・ブーロー、ジェイソン・ウェストン、2020年4月30日。
論文の要旨は次のとおりです。
*オープンドメインのチャットボットの構築は、機械学習研究にとって難しい分野です。これまでの研究では次のことが示されていますが、
ニューラル モデルをパラメーターの数とトレーニング対象のデータのサイズでスケーリングすると、結果が向上します。
高性能のチャットボットには他の要素も重要であることを示します。良い会話には多くのことが必要です
会話の専門家がシームレスに融合するスキル: 魅力的な話のポイントを提供し、話を聞く
一貫した態度を維持しながら、知識、共感、個性を適切に表現する
ペルソナ。適切なトレーニング データと選択が与えられた場合、大規模モデルがこれらのスキルを学習できることを示します。
世代戦略。 90M、2.7B、9.4B パラメーター モデルを使用してこれらのレシピのバリアントを構築し、モデルを作成します。
コードは公開されています。人間による評価では、当社の最良のモデルが既存のアプローチよりも優れていることがマルチターンで示されています
魅力と人間性の測定という観点からの対話。次に、分析によってこの作業の限界について説明します。
弊社機種の故障事例*
チップ:
- Blenderbot Small は絶対位置埋め込みを備えたモデルなので、通常は入力を右側にパディングすることをお勧めします。
左。
このモデルは、[patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。著者のコードは次のとおりです
[ここ](https://github.com/facebookresearch/ParlAI) をご覧ください。
## Documentation resources
- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
- [翻訳タスクガイド](../tasks/translation)
- [要約タスクガイド](../tasks/summarization)
## BlenderbotSmallConfig
[[autodoc]] BlenderbotSmallConfig
## BlenderbotSmallTokenizer
[[autodoc]] BlenderbotSmallTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## BlenderbotSmallTokenizerFast
[[autodoc]] BlenderbotSmallTokenizerFast
## BlenderbotSmallModel
[[autodoc]] BlenderbotSmallModel
- forward
## BlenderbotSmallForConditionalGeneration
[[autodoc]] BlenderbotSmallForConditionalGeneration
- forward
## BlenderbotSmallForCausalLM
[[autodoc]] BlenderbotSmallForCausalLM
- forward
## TFBlenderbotSmallModel
[[autodoc]] TFBlenderbotSmallModel
- call
## TFBlenderbotSmallForConditionalGeneration
[[autodoc]] TFBlenderbotSmallForConditionalGeneration
- call
## FlaxBlenderbotSmallModel
[[autodoc]] FlaxBlenderbotSmallModel
- __call__
- encode
- decode
## FlaxBlenderbotForConditionalGeneration
[[autodoc]] FlaxBlenderbotSmallForConditionalGeneration
- __call__
- encode
- decode
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/bert-japanese.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BertJapanese
## Overview
BERT モデルは日本語テキストでトレーニングされました。
2 つの異なるトークン化方法を備えたモデルがあります。
- MeCab と WordPiece を使用してトークン化します。これには、[MeCab](https://taku910.github.io/mecab/) のラッパーである [fugashi](https://github.com/polm/fugashi) という追加の依存関係が必要です。
- 文字にトークン化します。
*MecabTokenizer* を使用するには、`pip installTransformers["ja"]` (または、インストールする場合は `pip install -e .["ja"]`) する必要があります。
ソースから)依存関係をインストールします。
[cl-tohakuリポジトリの詳細](https://github.com/cl-tohaku/bert-japanese)を参照してください。
MeCab および WordPiece トークン化でモデルを使用する例:
```python
>>> import torch
>>> from transformers import AutoModel, AutoTokenizer
>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese")
>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese")
>>> ## Input Japanese Text
>>> line = "吾輩は猫である。"
>>> inputs = tokenizer(line, return_tensors="pt")
>>> print(tokenizer.decode(inputs["input_ids"][0]))
[CLS] 吾輩 は 猫 で ある 。 [SEP]
>>> outputs = bertjapanese(**inputs)
```
文字トークン化を使用したモデルの使用例:
```python
>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese-char")
>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-char")
>>> ## Input Japanese Text
>>> line = "吾輩は猫である。"
>>> inputs = tokenizer(line, return_tensors="pt")
>>> print(tokenizer.decode(inputs["input_ids"][0]))
[CLS] 吾 輩 は 猫 で あ る 。 [SEP]
>>> outputs = bertjapanese(**inputs)
```
<Tip>
- この実装はトークン化方法を除いて BERT と同じです。その他の使用例については、[BERT のドキュメント](bert) を参照してください。
</Tip>
このモデルは[cl-tohaku](https://huggingface.co/cl-tohaku)から提供されました。
## BertJapaneseTokenizer
[[autodoc]] BertJapaneseTokenizer
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/bert.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BERT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=bert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-bert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/bert-base-uncased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
BERT モデルは、Jacob Devlin、Ming-Wei Chang、Kenton Lee、Kristina Toutanova によって [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) で提案されました。それは
マスクされた言語モデリング目標と次の文の組み合わせを使用して事前トレーニングされた双方向トランスフォーマー
Toronto Book Corpus と Wikipedia からなる大規模なコーパスでの予測。
論文の要約は次のとおりです。
*BERT と呼ばれる新しい言語表現モデルを導入します。これは Bidirectional Encoder Representations の略です
トランスフォーマーより。最近の言語表現モデルとは異なり、BERT は深い双方向性を事前にトレーニングするように設計されています。
すべてのレイヤーの左と右の両方のコンテキストを共同で条件付けすることにより、ラベルのないテキストから表現します。結果として、
事前トレーニングされた BERT モデルは、出力層を 1 つ追加するだけで微調整して、最先端のモデルを作成できます。
実質的なタスク固有のものを必要とせず、質問応答や言語推論などの幅広いタスクに対応
アーキテクチャの変更。*
*BERT は概念的にはシンプルですが、経験的に強力です。 11 の自然な要素に関する新しい最先端の結果が得られます。
言語処理タスク(GLUE スコアを 80.5% に押し上げる(7.7% ポイントの絶対改善)、MultiNLI を含む)
精度は 86.7% (絶対値 4.6% 向上)、SQuAD v1.1 質問応答テスト F1 は 93.2 (絶対値 1.5 ポイント)
改善) および SQuAD v2.0 テスト F1 から 83.1 (5.1 ポイントの絶対改善)。*
## Usage tips
- BERT は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
左。
- BERT は、マスク言語モデリング (MLM) および次の文予測 (NSP) の目標を使用してトレーニングされました。それは
マスクされたトークンの予測や NLU では一般に効率的ですが、テキスト生成には最適ではありません。
- ランダム マスキングを使用して入力を破壊します。より正確には、事前トレーニング中に、トークンの指定された割合 (通常は 15%) が次によってマスクされます。
* 確率0.8の特別なマスクトークン
* 確率 0.1 でマスクされたトークンとは異なるランダムなトークン
* 確率 0.1 の同じトークン
- モデルは元の文を予測する必要がありますが、2 番目の目的があります。入力は 2 つの文 A と B (間に分離トークンあり) です。確率 50% では、文はコーパス内で連続していますが、残りの 50% では関連性がありません。モデルは、文が連続しているかどうかを予測する必要があります。
このモデルは [thomwolf](https://huggingface.co/thomwolf) によって提供されました。元のコードは [こちら](https://github.com/google-research/bert) にあります。
## Resources
BERT を始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
<PipelineTag pipeline="text-classification"/>
- に関するブログ投稿 [別の言語での BERT テキスト分類](https://www.philschmid.de/bert-text-classification-in-a-different-language)。
- [マルチラベル テキスト分類のための BERT (およびその友人) の微調整](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/BERT/Fine_tuning_BERT_(and_friends)_for_multi_label_text_classification.ipynb) のノートブック.
- 方法に関するノートブック [PyTorch を使用したマルチラベル分類のための BERT の微調整](https://colab.research.google.com/github/abhmishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)。
- 方法に関するノートブック [要約のために BERT を使用して EncoderDecoder モデルをウォームスタートする](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)。
- [`BertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)。
- [`TFBertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)。
- [`FlaxBertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb)。
- [テキスト分類タスクガイド](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification"/>
- [Hugging Face Transformers with Keras: Fine-tune a non-English BERT for Named Entity Recognition](https://www.philschmid.de/huggingface-transformers-keras-tf) の使用方法に関するブログ投稿。
- 各単語の最初の単語部分のみを使用した [固有表現認識のための BERT の微調整](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/Custom_Named_Entity_Recognition_with_BERT_only_first_wordpiece.ipynb) のノートブックトークン化中の単語ラベル内。単語のラベルをすべての単語部分に伝播するには、代わりにノートブックのこの [バージョン](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/BERT/Custom_Named_Entity_Recognition_with_BERT.ipynb) を参照してください。
- [`BertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)。
- [`TFBertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)。
- [`FlaxBertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification) によってサポートされています。
- [トークン分類](https://huggingface.co/course/chapter7/2?fw=pt) 🤗 ハグフェイスコースの章。
- [トークン分類タスクガイド](../tasks/token_classification)
<PipelineTag pipeline="fill-mask"/>
- [`BertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) でサポートされており、 [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)。
- [`TFBertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/lang-modeling#run_mlmpy) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)。
- [`FlaxBertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) および [ノートブック]( https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb)。
- [マスクされた言語モデリング](https://huggingface.co/course/chapter7/3?fw=pt) 🤗 顔ハグ コースの章。
- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
<PipelineTag pipeline="question-answering"/>
- [`BertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)。
- [`TFBertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)。
- [`FlaxBertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering) でサポートされています。
- [質問回答](https://huggingface.co/course/chapter7/7?fw=pt) 🤗 ハグフェイスコースの章。
- [質問回答タスク ガイド](../tasks/question_answering)
**複数の選択肢**
- [`BertForMultipleChoice`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)。
- [`TFBertForMultipleChoice`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)。
- [多肢選択タスク ガイド](../tasks/multiple_choice)
⚡️ **推論**
- 方法に関するブログ投稿 [Hugging Face Transformers と AWS Inferentia を使用して BERT 推論を高速化する](https://huggingface.co/blog/bert-inferentia-sagemaker)。
- 方法に関するブログ投稿 [GPU 上の DeepSpeed-Inference を使用して BERT 推論を高速化する](https://www.philschmid.de/bert-deepspeed-inference)。
⚙️ **事前トレーニング**
- [Hugging Face Transformers と Habana Gaudi を使用した BERT の事前トレーニング] に関するブログ投稿 (https://www.philschmid.de/pre-training-bert-habana)。
🚀 **デプロイ**
- 方法に関するブログ投稿 [ハグフェイス最適化でトランスフォーマーを ONNX に変換する](https://www.philschmid.de/convert-transformers-to-onnx)。
- 方法に関するブログ投稿 [AWS 上の Habana Gaudi を使用したハグ顔トランスフォーマーのための深層学習環境のセットアップ](https://www.philschmid.de/getting-started-habana-gaudi#conclusion)。
- に関するブログ投稿 [Hugging Face Transformers、Amazon SageMaker、および Terraform モジュールを使用した自動スケーリング BERT](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker-advanced)。
- に関するブログ投稿 [HuggingFace、AWS Lambda、Docker を使用したサーバーレス BERT](https://www.philschmid.de/serverless-bert-with-huggingface-aws-lambda-docker)。
- に関するブログ投稿 [Amazon SageMaker と Training Compiler を使用した Hugging Face Transformers BERT 微調整](https://www.philschmid.de/huggingface-amazon-sagemaker-training-compiler)。
- に関するブログ投稿 [Transformers と Amazon SageMaker を使用した BERT のタスク固有の知識の蒸留](https://www.philschmid.de/knowledge-distillation-bert-transformers)
## BertConfig
[[autodoc]] BertConfig
- all
## BertTokenizer
[[autodoc]] BertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
<frameworkcontent>
<pt>
## BertTokenizerFast
[[autodoc]] BertTokenizerFast
</pt>
<tf>
## TFBertTokenizer
[[autodoc]] TFBertTokenizer
</tf>
</frameworkcontent>
## Bert specific outputs
[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
[[autodoc]] models.bert.modeling_tf_bert.TFBertForPreTrainingOutput
[[autodoc]] models.bert.modeling_flax_bert.FlaxBertForPreTrainingOutput
<frameworkcontent>
<pt>
## BertModel
[[autodoc]] BertModel
- forward
## BertForPreTraining
[[autodoc]] BertForPreTraining
- forward
## BertLMHeadModel
[[autodoc]] BertLMHeadModel
- forward
## BertForMaskedLM
[[autodoc]] BertForMaskedLM
- forward
## BertForNextSentencePrediction
[[autodoc]] BertForNextSentencePrediction
- forward
## BertForSequenceClassification
[[autodoc]] BertForSequenceClassification
- forward
## BertForMultipleChoice
[[autodoc]] BertForMultipleChoice
- forward
## BertForTokenClassification
[[autodoc]] BertForTokenClassification
- forward
## BertForQuestionAnswering
[[autodoc]] BertForQuestionAnswering
- forward
</pt>
<tf>
## TFBertModel
[[autodoc]] TFBertModel
- call
## TFBertForPreTraining
[[autodoc]] TFBertForPreTraining
- call
## TFBertModelLMHeadModel
[[autodoc]] TFBertLMHeadModel
- call
## TFBertForMaskedLM
[[autodoc]] TFBertForMaskedLM
- call
## TFBertForNextSentencePrediction
[[autodoc]] TFBertForNextSentencePrediction
- call
## TFBertForSequenceClassification
[[autodoc]] TFBertForSequenceClassification
- call
## TFBertForMultipleChoice
[[autodoc]] TFBertForMultipleChoice
- call
## TFBertForTokenClassification
[[autodoc]] TFBertForTokenClassification
- call
## TFBertForQuestionAnswering
[[autodoc]] TFBertForQuestionAnswering
- call
</tf>
<jax>
## FlaxBertModel
[[autodoc]] FlaxBertModel
- __call__
## FlaxBertForPreTraining
[[autodoc]] FlaxBertForPreTraining
- __call__
## FlaxBertForCausalLM
[[autodoc]] FlaxBertForCausalLM
- __call__
## FlaxBertForMaskedLM
[[autodoc]] FlaxBertForMaskedLM
- __call__
## FlaxBertForNextSentencePrediction
[[autodoc]] FlaxBertForNextSentencePrediction
- __call__
## FlaxBertForSequenceClassification
[[autodoc]] FlaxBertForSequenceClassification
- __call__
## FlaxBertForMultipleChoice
[[autodoc]] FlaxBertForMultipleChoice
- __call__
## FlaxBertForTokenClassification
[[autodoc]] FlaxBertForTokenClassification
- __call__
## FlaxBertForQuestionAnswering
[[autodoc]] FlaxBertForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/autoformer.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Autoformer
## 概要
Autoformerモデルは、「[Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008)」という論文でHaixu Wu、Jiehui Xu、Jianmin Wang、Mingsheng Longによって提案されました。
このモデルは、予測プロセス中にトレンドと季節性成分を逐次的に分解できる深層分解アーキテクチャとしてTransformerを増強します。
論文の要旨は以下の通りです:
*例えば異常気象の早期警告や長期的なエネルギー消費計画といった実応用において、予測時間を延長することは重要な要求です。本論文では、時系列の長期予測問題を研究しています。以前のTransformerベースのモデルは、長距離依存関係を発見するために様々なセルフアテンション機構を採用しています。しかし、長期未来の複雑な時間的パターンによってモデルが信頼できる依存関係を見つけることを妨げられます。また、Transformerは、長い系列の効率化のためにポイントワイズなセルフアテンションのスパースバージョンを採用する必要があり、情報利用のボトルネックとなります。Transformerを超えて、我々は自己相関機構を持つ新しい分解アーキテクチャとしてAutoformerを設計しました。系列分解の事前処理の慣行を破り、それを深層モデルの基本的な内部ブロックとして革新します。この設計は、複雑な時系列に対するAutoformerの進行的な分解能力を強化します。さらに、確率過程理論に触発されて、系列の周期性に基づいた自己相関機構を設計し、サブ系列レベルでの依存関係の発見と表現の集約を行います。自己相関は効率と精度の両方でセルフアテンションを上回ります。長期予測において、Autoformerは、エネルギー、交通、経済、気象、疾病の5つの実用的な応用をカバーする6つのベンチマークで38%の相対的な改善をもたらし、最先端の精度を達成します。*
このモデルは[elisim](https://huggingface.co/elisim)と[kashif](https://huggingface.co/kashif)より提供されました。
オリジナルのコードは[こちら](https://github.com/thuml/Autoformer)で見ることができます。
## 参考資料
Autoformerの使用を開始するのに役立つ公式のHugging Faceおよびコミュニティ(🌎で示されている)の参考資料の一覧です。ここに参考資料を提出したい場合は、気兼ねなくPull Requestを開いてください。私たちはそれをレビューいたします!参考資料は、既存のものを複製するのではなく、何か新しいことを示すことが理想的です。
- HuggingFaceブログでAutoformerに関するブログ記事をチェックしてください:[はい、Transformersは時系列予測に効果的です(+ Autoformer)](https://huggingface.co/blog/autoformer)
## AutoformerConfig
[[autodoc]] AutoformerConfig
## AutoformerModel
[[autodoc]] AutoformerModel
- forward
## AutoformerForPrediction
[[autodoc]] AutoformerForPrediction
- forward
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/bark.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Bark
## Overview
Bark は、[suno-ai/bark](https://github.com/suno-ai/bark) で Suno AI によって提案されたトランスフォーマーベースのテキスト読み上げモデルです。
Bark は 4 つの主要なモデルで構成されています。
- [`BarkSemanticModel`] ('テキスト'モデルとも呼ばれる): トークン化されたテキストを入力として受け取り、テキストの意味を捉えるセマンティック テキスト トークンを予測する因果的自己回帰変換モデル。
- [`BarkCoarseModel`] ('粗い音響' モデルとも呼ばれる): [`BarkSemanticModel`] モデルの結果を入力として受け取る因果的自己回帰変換器。 EnCodec に必要な最初の 2 つのオーディオ コードブックを予測することを目的としています。
- [`BarkFineModel`] ('微細音響' モデル)、今回は非因果的オートエンコーダー トランスフォーマーで、以前のコードブック埋め込みの合計に基づいて最後のコードブックを繰り返し予測します。
- [`EncodecModel`] からすべてのコードブック チャネルを予測したので、Bark はそれを使用して出力オーディオ配列をデコードします。
最初の 3 つのモジュールはそれぞれ、特定の事前定義された音声に従って出力サウンドを調整するための条件付きスピーカー埋め込みをサポートできることに注意してください。
### Optimizing Bark
Bark は、コードを数行追加するだけで最適化でき、**メモリ フットプリントが大幅に削減**され、**推論が高速化**されます。
#### Using half-precision
モデルを半精度でロードするだけで、推論を高速化し、メモリ使用量を 50% 削減できます。
```python
from transformers import BarkModel
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
```
#### Using 🤗 Better Transformer
Better Transformer は、内部でカーネル融合を実行する 🤗 最適な機能です。パフォーマンスを低下させることなく、速度を 20% ~ 30% 向上させることができます。モデルを 🤗 Better Transformer にエクスポートするのに必要なコードは 1 行だけです。
```python
model = model.to_bettertransformer()
```
この機能を使用する前に 🤗 Optimum をインストールする必要があることに注意してください。 [インストール方法はこちら](https://huggingface.co/docs/optimum/installation)
#### Using CPU offload
前述したように、Bark は 4 つのサブモデルで構成されており、オーディオ生成中に順番に呼び出されます。言い換えれば、1 つのサブモデルが使用されている間、他のサブモデルはアイドル状態になります。
CUDA デバイスを使用している場合、メモリ フットプリントの 80% 削減による恩恵を受ける簡単な解決策は、アイドル状態の GPU のサブモデルをオフロードすることです。この操作は CPU オフロードと呼ばれます。 1行のコードで使用できます。
```python
model.enable_cpu_offload()
```
この機能を使用する前に、🤗 Accelerate をインストールする必要があることに注意してください。 [インストール方法はこちら](https://huggingface.co/docs/accelerate/basic_tutorials/install)
#### Combining optimization techniques
最適化手法を組み合わせて、CPU オフロード、半精度、🤗 Better Transformer をすべて一度に使用できます。
```python
from transformers import BarkModel
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
# load in fp16
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
# convert to bettertransformer
model = BetterTransformer.transform(model, keep_original_model=False)
# enable CPU offload
model.enable_cpu_offload()
```
推論最適化手法の詳細については、[こちら](https://huggingface.co/docs/transformers/perf_infer_gpu_one) をご覧ください。
### Tips
Suno は、多くの言語で音声プリセットのライブラリを提供しています [こちら](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c)。
これらのプリセットは、ハブ [こちら](https://huggingface.co/suno/bark-small/tree/main/speaker_embeddings) または [こちら](https://huggingface.co/suno/bark/tree/main/speaker_embeddings)。
```python
>>> from transformers import AutoProcessor, BarkModel
>>> processor = AutoProcessor.from_pretrained("suno/bark")
>>> model = BarkModel.from_pretrained("suno/bark")
>>> voice_preset = "v2/en_speaker_6"
>>> inputs = processor("Hello, my dog is cute", voice_preset=voice_preset)
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
Bark は、非常にリアルな **多言語** 音声だけでなく、音楽、背景ノイズ、単純な効果音などの他の音声も生成できます。
```python
>>> # Multilingual speech - simplified Chinese
>>> inputs = processor("惊人的!我会说中文")
>>> # Multilingual speech - French - let's use a voice_preset as well
>>> inputs = processor("Incroyable! Je peux générer du son.", voice_preset="fr_speaker_5")
>>> # Bark can also generate music. You can help it out by adding music notes around your lyrics.
>>> inputs = processor("♪ Hello, my dog is cute ♪")
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
このモデルは、笑う、ため息、泣くなどの**非言語コミュニケーション**を生成することもできます。
```python
>>> # Adding non-speech cues to the input text
>>> inputs = processor("Hello uh ... [clears throat], my dog is cute [laughter]")
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
オーディオを保存するには、モデル設定と scipy ユーティリティからサンプル レートを取得するだけです。
```python
>>> from scipy.io.wavfile import write as write_wav
>>> # save audio to disk, but first take the sample rate from the model config
>>> sample_rate = model.generation_config.sample_rate
>>> write_wav("bark_generation.wav", sample_rate, audio_array)
```
このモデルは、[Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe) および [Sanchit Gandhi (sanchit-gandhi)](https://github.com/sanchit-gandhi) によって提供されました。
元のコードは [ここ](https://github.com/suno-ai/bark) にあります。
## BarkConfig
[[autodoc]] BarkConfig
- all
## BarkProcessor
[[autodoc]] BarkProcessor
- all
- __call__
## BarkModel
[[autodoc]] BarkModel
- generate
- enable_cpu_offload
## BarkSemanticModel
[[autodoc]] BarkSemanticModel
- forward
## BarkCoarseModel
[[autodoc]] BarkCoarseModel
- forward
## BarkFineModel
[[autodoc]] BarkFineModel
- forward
## BarkCausalModel
[[autodoc]] BarkCausalModel
- forward
## BarkCoarseConfig
[[autodoc]] BarkCoarseConfig
- all
## BarkFineConfig
[[autodoc]] BarkFineConfig
- all
## BarkSemanticConfig
[[autodoc]] BarkSemanticConfig
- all
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/beit.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BEiT
## Overview
BEiT モデルは、[BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) で提案されました。
ハンボ・バオ、リー・ドン、フル・ウェイ。 BERT に触発された BEiT は、自己教師ありの事前トレーニングを作成した最初の論文です。
ビジョン トランスフォーマー (ViT) は、教師付き事前トレーニングよりも優れたパフォーマンスを発揮します。クラスを予測するためにモデルを事前トレーニングするのではなく
([オリジナルの ViT 論文](https://arxiv.org/abs/2010.11929) で行われたように) 画像の BEiT モデルは、次のように事前トレーニングされています。
マスクされた OpenAI の [DALL-E モデル](https://arxiv.org/abs/2102.12092) のコードブックからビジュアル トークンを予測します
パッチ。
論文の要約は次のとおりです。
*自己教師あり視覚表現モデル BEiT (Bidirectional Encoderpresentation) を導入します。
イメージトランスフォーマーより。自然言語処理分野で開発されたBERTに倣い、マスク画像を提案します。
ビジョントランスフォーマーを事前にトレーニングするためのモデリングタスク。具体的には、事前トレーニングでは各画像に 2 つのビューがあります。
パッチ (16x16 ピクセルなど)、およびビジュアル トークン (つまり、個別のトークン)。まず、元の画像を「トークン化」して、
ビジュアルトークン。次に、いくつかの画像パッチをランダムにマスクし、それらをバックボーンの Transformer に供給します。事前トレーニング
目的は、破損したイメージ パッチに基づいて元のビジュアル トークンを回復することです。 BEiTの事前トレーニング後、
事前トレーニングされたエンコーダーにタスク レイヤーを追加することで、ダウンストリーム タスクのモデル パラメーターを直接微調整します。
画像分類とセマンティックセグメンテーションに関する実験結果は、私たちのモデルが競争力のある結果を達成することを示しています
以前の事前トレーニング方法を使用して。たとえば、基本サイズの BEiT は、ImageNet-1K で 83.2% のトップ 1 精度を達成します。
同じ設定でゼロからの DeiT トレーニング (81.8%) を大幅に上回りました。また、大型BEiTは
86.3% は ImageNet-1K のみを使用しており、ImageNet-22K での教師付き事前トレーニングを使用した ViT-L (85.2%) を上回っています。*
## Usage tips
- BEiT モデルは通常のビジョン トランスフォーマーですが、教師ありではなく自己教師ありの方法で事前トレーニングされています。彼らは
ImageNet-1K および CIFAR-100 で微調整すると、[オリジナル モデル (ViT)](vit) と [データ効率の高いイメージ トランスフォーマー (DeiT)](deit) の両方を上回るパフォーマンスを発揮します。推論に関するデモノートブックもチェックできます。
カスタム データの微調整は [こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (置き換えるだけで済みます)
[`BeitImageProcessor`] による [`ViTFeatureExtractor`] と
[`ViTForImageClassification`] by [`BeitForImageClassification`])。
- DALL-E の画像トークナイザーと BEiT を組み合わせる方法を紹介するデモ ノートブックも利用可能です。
マスクされた画像モデリングを実行します。 [ここ](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BEiT) で見つけることができます。
- BEiT モデルは各画像が同じサイズ (解像度) であることを期待しているため、次のように使用できます。
[`BeitImageProcessor`] を使用して、モデルの画像のサイズを変更 (または再スケール) し、正規化します。
- 事前トレーニングまたは微調整中に使用されるパッチ解像度と画像解像度の両方が名前に反映されます。
各チェックポイント。たとえば、`microsoft/beit-base-patch16-224`は、パッチ付きの基本サイズのアーキテクチャを指します。
解像度は 16x16、微調整解像度は 224x224 です。すべてのチェックポイントは [ハブ](https://huggingface.co/models?search=microsoft/beit) で見つけることができます。
- 利用可能なチェックポイントは、(1) [ImageNet-22k](http://www.image-net.org/) で事前トレーニングされています (
1,400 万の画像と 22,000 のクラス) のみ、(2) ImageNet-22k でも微調整、または (3) [ImageNet-1k](http://www.image-net.org/challenges/LSVRC)でも微調整/2012/) (ILSVRC 2012 とも呼ばれ、130 万件のコレクション)
画像と 1,000 クラス)。
- BEiT は、T5 モデルからインスピレーションを得た相対位置埋め込みを使用します。事前トレーニング中に、著者は次のことを共有しました。
いくつかの自己注意層間の相対的な位置の偏り。微調整中、各レイヤーの相対位置
バイアスは、事前トレーニング後に取得された共有相対位置バイアスで初期化されます。ご希望の場合は、
モデルを最初から事前トレーニングするには、`use_relative_position_bias` または
追加するには、[`BeitConfig`] の `use_relative_position_bias` 属性を `True` に設定します。
位置の埋め込み。
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/beit_architecture.jpg"
alt="drawing" width="600"/>
<small> BEiT の事前トレーニング。 <a href="https://arxiv.org/abs/2106.08254">元の論文から抜粋。</a> </small>
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。このモデルの JAX/FLAX バージョンは、
[kamalkraj](https://huggingface.co/kamalkraj) による投稿。元のコードは [ここ](https://github.com/microsoft/unilm/tree/master/beit) にあります。
## Resources
BEiT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
<PipelineTag pipeline="image-classification"/>
- [`BeitForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
- 参照: [画像分類タスク ガイド](../tasks/image_classification)
**セマンティック セグメンテーション**
- [セマンティック セグメンテーション タスク ガイド](../tasks/semantic_segmentation)
ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
## BEiT specific outputs
[[autodoc]] models.beit.modeling_beit.BeitModelOutputWithPooling
[[autodoc]] models.beit.modeling_flax_beit.FlaxBeitModelOutputWithPooling
## BeitConfig
[[autodoc]] BeitConfig
## BeitFeatureExtractor
[[autodoc]] BeitFeatureExtractor
- __call__
- post_process_semantic_segmentation
## BeitImageProcessor
[[autodoc]] BeitImageProcessor
- preprocess
- post_process_semantic_segmentation
## BeitModel
[[autodoc]] BeitModel
- forward
## BeitForMaskedImageModeling
[[autodoc]] BeitForMaskedImageModeling
- forward
## BeitForImageClassification
[[autodoc]] BeitForImageClassification
- forward
## BeitForSemanticSegmentation
[[autodoc]] BeitForSemanticSegmentation
- forward
## FlaxBeitModel
[[autodoc]] FlaxBeitModel
- __call__
## FlaxBeitForMaskedImageModeling
[[autodoc]] FlaxBeitForMaskedImageModeling
- __call__
## FlaxBeitForImageClassification
[[autodoc]] FlaxBeitForImageClassification
- __call__
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/align.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ALIGN
## 概要
ALIGNモデルは、「[Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918)」という論文でChao Jia、Yinfei Yang、Ye Xia、Yi-Ting Chen、Zarana Parekh、Hieu Pham、Quoc V. Le、Yunhsuan Sung、Zhen Li、Tom Duerigによって提案されました。ALIGNはマルチモーダルな視覚言語モデルです。これは画像とテキストの類似度や、ゼロショット画像分類に使用できます。ALIGNは[EfficientNet](efficientnet)を視覚エンコーダーとして、[BERT](bert)をテキストエンコーダーとして搭載したデュアルエンコーダー構造を特徴とし、対照学習によって視覚とテキストの表現を整合させることを学びます。それまでの研究とは異なり、ALIGNは巨大でノイジーなデータセットを活用し、コーパスのスケールを利用して単純な方法ながら最先端の表現を達成できることを示しています。
論文の要旨は以下の通りです:
*事前学習された表現は、多くの自然言語処理(NLP)および知覚タスクにとって重要になっています。NLPにおける表現学習は、人間のアノテーションのない生のテキストでの学習へと移行していますが、視覚および視覚言語の表現は依然として精巧な学習データセットに大きく依存しており、これは高価であったり専門知識を必要としたりします。視覚アプリケーションの場合、ImageNetやOpenImagesのような明示的なクラスラベルを持つデータセットを使用して学習されることがほとんどです。視覚言語の場合、Conceptual Captions、MSCOCO、CLIPなどの人気のあるデータセットはすべて、それぞれ無視できないデータ収集(およびクリーニング)プロセスを含みます。このコストのかかるキュレーションプロセスはデータセットのサイズを制限し、訓練されたモデルのスケーリングを妨げます。本論文では、Conceptual Captionsデータセットの高価なフィルタリングや後処理ステップなしで得られた、10億を超える画像alt-textペアのノイズの多いデータセットを活用します。シンプルなデュアルエンコーダーアーキテクチャは、対照損失を使用して画像とテキストペアの視覚的および言語的表現を整合させることを学習します。我々は、コーパスの規模がそのノイズを補い、このような単純な学習スキームでも最先端の表現につながることを示します。我々の視覚表現は、ImageNetやVTABなどの分類タスクへの転移において強力な性能を発揮します。整合した視覚的および言語的表現は、ゼロショット画像分類を可能にし、また、より洗練されたクロスアテンションモデルと比較しても、Flickr30KおよびMSCOCO画像テキスト検索ベンチマークにおいて新たな最先端の結果を達成します。また、これらの表現は、複雑なテキストおよびテキスト+画像のクエリを用いたクロスモーダル検索を可能にします。*
このモデルは[Alara Dirik](https://huggingface.co/adirik)により提供されました。
オリジナルのコードは公開されておらず、この実装は元論文に基づいたKakao Brainの実装をベースにしています。
## 使用例
ALIGNはEfficientNetを使用して視覚的特徴を、BERTを使用してテキスト特徴を取得します。テキストと視覚の両方の特徴は、同一の次元を持つ潜在空間に射影されます。射影された画像とテキスト特徴間のドット積が類似度スコアとして使用されます。
[`AlignProcessor`]は、テキストのエンコードと画像の前処理を両方行うために、[`EfficientNetImageProcessor`]と[`BertTokenizer`]を単一のインスタンスにラップします。以下の例は、[`AlignProcessor`]と[`AlignModel`]を使用して画像-テキスト類似度スコアを取得する方法を示しています。
```python
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
candidate_labels = ["an image of a cat", "an image of a dog"]
inputs = processor(text=candidate_labels, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
```
## 参考資料
ALIGNの使用を開始するのに役立つ公式のHugging Faceとコミュニティ(🌎で示されている)の参考資料の一覧です。
- [ALIGNとCOYO-700Mデータセット](https://huggingface.co/blog/vit-align)に関するブログ投稿。
- ゼロショット画像分類[デモ](https://huggingface.co/spaces/adirik/ALIGN-zero-shot-image-classification)。
- `kakaobrain/align-base` モデルの[モデルカード](https://huggingface.co/kakaobrain/align-base)。
ここに参考資料を提出したい場合は、気兼ねなくPull Requestを開いてください。私たちはそれをレビューいたします!参考資料は、既存のものを複製するのではなく、何か新しいことを示すことが理想的です。
## AlignConfig
[[autodoc]] AlignConfig
- from_text_vision_configs
## AlignTextConfig
[[autodoc]] AlignTextConfig
## AlignVisionConfig
[[autodoc]] AlignVisionConfig
## AlignProcessor
[[autodoc]] AlignProcessor
## AlignModel
[[autodoc]] AlignModel
- forward
- get_text_features
- get_image_features
## AlignTextModel
[[autodoc]] AlignTextModel
- forward
## AlignVisionModel
[[autodoc]] AlignVisionModel
- forward
| 0
|
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/model_doc/auto.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Auto Classes
多くの場合、`from_pretrained()`メソッドに与えられた事前学習済みモデルの名前やパスから、使用したいアーキテクチャを推測することができます。自動クラスはこの仕事をあなたに代わって行うためにここにありますので、事前学習済みの重み/設定/語彙への名前/パスを与えると自動的に関連するモデルを取得できます。
[`AutoConfig`]、[`AutoModel`]、[`AutoTokenizer`]のいずれかをインスタンス化すると、関連するアーキテクチャのクラスが直接作成されます。例えば、
```python
model = AutoModel.from_pretrained("bert-base-cased")
```
これは[`BertModel`]のインスタンスであるモデルを作成します。
各タスクごと、そして各バックエンド(PyTorch、TensorFlow、またはFlax)ごとに`AutoModel`のクラスが存在します。
## 自動クラスの拡張
それぞれの自動クラスには、カスタムクラスで拡張するためのメソッドがあります。例えば、`NewModel`というモデルのカスタムクラスを定義した場合、`NewModelConfig`を確保しておけばこのようにして自動クラスに追加することができます:
```python
from transformers import AutoConfig, AutoModel
AutoConfig.register("new-model", NewModelConfig)
AutoModel.register(NewModelConfig, NewModel)
```
その後、通常どおりauto classesを使用することができるようになります!
<Tip warning={true}>
あなたの`NewModelConfig`が[`~transformers.PretrainedConfig`]のサブクラスである場合、その`model_type`属性がコンフィグを登録するときに使用するキー(ここでは`"new-model"`)と同じに設定されていることを確認してください。
同様に、あなたの`NewModel`が[`PreTrainedModel`]のサブクラスである場合、その`config_class`属性がモデルを登録する際に使用するクラス(ここでは`NewModelConfig`)と同じに設定されていることを確認してください。
</Tip>
## AutoConfig
[[autodoc]] AutoConfig
## AutoTokenizer
[[autodoc]] AutoTokenizer
## AutoFeatureExtractor
[[autodoc]] AutoFeatureExtractor
## AutoImageProcessor
[[autodoc]] AutoImageProcessor
## AutoProcessor
[[autodoc]] AutoProcessor
## Generic model classes
以下の自動クラスは、特定のヘッドを持たないベースモデルクラスをインスタンス化するために利用可能です。
### AutoModel
[[autodoc]] AutoModel
### TFAutoModel
[[autodoc]] TFAutoModel
### FlaxAutoModel
[[autodoc]] FlaxAutoModel
## Generic pretraining classes
以下の自動クラスは、事前学習ヘッドを持つモデルをインスタンス化するために利用可能です。
### AutoModelForPreTraining
[[autodoc]] AutoModelForPreTraining
### TFAutoModelForPreTraining
[[autodoc]] TFAutoModelForPreTraining
### FlaxAutoModelForPreTraining
[[autodoc]] FlaxAutoModelForPreTraining
## Natural Language Processing
以下の自動クラスは、次の自然言語処理タスクに利用可能です。
### AutoModelForCausalLM
[[autodoc]] AutoModelForCausalLM
### TFAutoModelForCausalLM
[[autodoc]] TFAutoModelForCausalLM
### FlaxAutoModelForCausalLM
[[autodoc]] FlaxAutoModelForCausalLM
### AutoModelForMaskedLM
[[autodoc]] AutoModelForMaskedLM
### TFAutoModelForMaskedLM
[[autodoc]] TFAutoModelForMaskedLM
### FlaxAutoModelForMaskedLM
[[autodoc]] FlaxAutoModelForMaskedLM
### AutoModelForMaskGeneration
[[autodoc]] AutoModelForMaskGeneration
### TFAutoModelForMaskGeneration
[[autodoc]] TFAutoModelForMaskGeneration
### AutoModelForSeq2SeqLM
[[autodoc]] AutoModelForSeq2SeqLM
### TFAutoModelForSeq2SeqLM
[[autodoc]] TFAutoModelForSeq2SeqLM
### FlaxAutoModelForSeq2SeqLM
[[autodoc]] FlaxAutoModelForSeq2SeqLM
### AutoModelForSequenceClassification
[[autodoc]] AutoModelForSequenceClassification
### TFAutoModelForSequenceClassification
[[autodoc]] TFAutoModelForSequenceClassification
### FlaxAutoModelForSequenceClassification
[[autodoc]] FlaxAutoModelForSequenceClassification
### AutoModelForMultipleChoice
[[autodoc]] AutoModelForMultipleChoice
### TFAutoModelForMultipleChoice
[[autodoc]] TFAutoModelForMultipleChoice
### FlaxAutoModelForMultipleChoice
[[autodoc]] FlaxAutoModelForMultipleChoice
### AutoModelForNextSentencePrediction
[[autodoc]] AutoModelForNextSentencePrediction
### TFAutoModelForNextSentencePrediction
[[autodoc]] TFAutoModelForNextSentencePrediction
### FlaxAutoModelForNextSentencePrediction
[[autodoc]] FlaxAutoModelForNextSentencePrediction
### AutoModelForTokenClassification
[[autodoc]] AutoModelForTokenClassification
### TFAutoModelForTokenClassification
[[autodoc]] TFAutoModelForTokenClassification
### FlaxAutoModelForTokenClassification
[[autodoc]] FlaxAutoModelForTokenClassification
### AutoModelForQuestionAnswering
[[autodoc]] AutoModelForQuestionAnswering
### TFAutoModelForQuestionAnswering
[[autodoc]] TFAutoModelForQuestionAnswering
### FlaxAutoModelForQuestionAnswering
[[autodoc]] FlaxAutoModelForQuestionAnswering
### AutoModelForTextEncoding
[[autodoc]] AutoModelForTextEncoding
### TFAutoModelForTextEncoding
[[autodoc]] TFAutoModelForTextEncoding
## Computer vision
以下の自動クラスは、次のコンピュータービジョンタスクに利用可能です。
### AutoModelForDepthEstimation
[[autodoc]] AutoModelForDepthEstimation
### AutoModelForImageClassification
[[autodoc]] AutoModelForImageClassification
### TFAutoModelForImageClassification
[[autodoc]] TFAutoModelForImageClassification
### FlaxAutoModelForImageClassification
[[autodoc]] FlaxAutoModelForImageClassification
### AutoModelForVideoClassification
[[autodoc]] AutoModelForVideoClassification
### AutoModelForMaskedImageModeling
[[autodoc]] AutoModelForMaskedImageModeling
### TFAutoModelForMaskedImageModeling
[[autodoc]] TFAutoModelForMaskedImageModeling
### AutoModelForObjectDetection
[[autodoc]] AutoModelForObjectDetection
### AutoModelForImageSegmentation
[[autodoc]] AutoModelForImageSegmentation
### AutoModelForImageToImage
[[autodoc]] AutoModelForImageToImage
### AutoModelForSemanticSegmentation
[[autodoc]] AutoModelForSemanticSegmentation
### TFAutoModelForSemanticSegmentation
[[autodoc]] TFAutoModelForSemanticSegmentation
### AutoModelForInstanceSegmentation
[[autodoc]] AutoModelForInstanceSegmentation
### AutoModelForUniversalSegmentation
[[autodoc]] AutoModelForUniversalSegmentation
### AutoModelForZeroShotImageClassification
[[autodoc]] AutoModelForZeroShotImageClassification
### TFAutoModelForZeroShotImageClassification
[[autodoc]] TFAutoModelForZeroShotImageClassification
### AutoModelForZeroShotObjectDetection
[[autodoc]] AutoModelForZeroShotObjectDetection
## Audio
以下の自動クラスは、次の音声タスクに利用可能です。
### AutoModelForAudioClassification
[[autodoc]] AutoModelForAudioClassification
### AutoModelForAudioFrameClassification
[[autodoc]] TFAutoModelForAudioClassification
### TFAutoModelForAudioFrameClassification
[[autodoc]] AutoModelForAudioFrameClassification
### AutoModelForCTC
[[autodoc]] AutoModelForCTC
### AutoModelForSpeechSeq2Seq
[[autodoc]] AutoModelForSpeechSeq2Seq
### TFAutoModelForSpeechSeq2Seq
[[autodoc]] TFAutoModelForSpeechSeq2Seq
### FlaxAutoModelForSpeechSeq2Seq
[[autodoc]] FlaxAutoModelForSpeechSeq2Seq
### AutoModelForAudioXVector
[[autodoc]] AutoModelForAudioXVector
### AutoModelForTextToSpectrogram
[[autodoc]] AutoModelForTextToSpectrogram
### AutoModelForTextToWaveform
[[autodoc]] AutoModelForTextToWaveform
## Multimodal
以下の自動クラスは、次のマルチモーダルタスクに利用可能です。
### AutoModelForTableQuestionAnswering
[[autodoc]] AutoModelForTableQuestionAnswering
### TFAutoModelForTableQuestionAnswering
[[autodoc]] TFAutoModelForTableQuestionAnswering
### AutoModelForDocumentQuestionAnswering
[[autodoc]] AutoModelForDocumentQuestionAnswering
### TFAutoModelForDocumentQuestionAnswering
[[autodoc]] TFAutoModelForDocumentQuestionAnswering
### AutoModelForVisualQuestionAnswering
[[autodoc]] AutoModelForVisualQuestionAnswering
### AutoModelForVision2Seq
[[autodoc]] AutoModelForVision2Seq
### TFAutoModelForVision2Seq
[[autodoc]] TFAutoModelForVision2Seq
### FlaxAutoModelForVision2Seq
[[autodoc]] FlaxAutoModelForVision2Seq
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/tr/_toctree.yml
|
- sections:
- local: index
title: 🤗 Transformers
title: Get started
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/tr/index.md
|
<!--Telif Hakkı 2020 The HuggingFace Ekibi. Tüm hakları saklıdır.
Apache Lisansı, Sürüm 2.0 (Lisans); bu dosyayı yürürlükteki yasalara uygun bir şekilde kullanabilirsiniz. Lisansın bir kopyasını aşağıdaki adresten alabilirsiniz.
http://www.apache.org/licenses/LICENSE-2.0
Lisansa tabi olmayan durumlarda veya yazılı anlaşma olmadıkça, Lisans kapsamında dağıtılan yazılım, herhangi bir türde (açık veya zımni) garanti veya koşul olmaksızın, "OLDUĞU GİBİ" ESASINA GÖRE dağıtılır. Lisans hükümleri, özel belirli dil kullanımı, yetkileri ve kısıtlamaları belirler.
⚠️ Bu dosya Markdown biçimindedir, ancak belge oluşturucumuz için özgü sözdizimleri içerir (MDX gibi) ve muhtemelen Markdown görüntüleyicinizde düzgün bir şekilde görüntülenmeyebilir.
-->
# 🤗 Transformers
[PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/) ve [JAX](https://jax.readthedocs.io/en/latest/) için son teknoloji makine öğrenimi.
🤗 Transformers, güncel önceden eğitilmiş (pretrained) modelleri indirmenizi ve eğitmenizi kolaylaştıran API'ler ve araçlar sunar. Önceden eğitilmiş modeller kullanarak, hesaplama maliyetlerinizi ve karbon ayak izinizi azaltabilir, ve sıfırdan bir modeli eğitmek için gereken zaman ve kaynaklardan tasarruf edebilirsiniz. Bu modeller farklı modalitelerde ortak görevleri destekler. Örneğin:
📝 **Doğal Dil İşleme**: metin sınıflandırma, adlandırılmış varlık tanıma, soru cevaplama, dil modelleme, özetleme, çeviri, çoktan seçmeli ve metin oluşturma.<br>
🖼️ **Bilgisayarlı Görü**: görüntü sınıflandırma, nesne tespiti ve bölümleme (segmentation).<br>
🗣️ **Ses**: otomatik konuşma tanıma ve ses sınıflandırma.<br>
🐙 **Çoklu Model**: tablo soru cevaplama, optik karakter tanıma, taranmış belgelerden bilgi çıkarma, video sınıflandırma ve görsel soru cevaplama.
🤗 Transformers, PyTorch, TensorFlow ve JAX arasında çerçeve (framework) uyumluluğu sağlar. Bu, bir modelin yaşam döngüsünün her aşamasında farklı bir çerçeve kullanma esnekliği sunar; bir çerçevede üç satır kodla bir modeli eğitebilir ve başka bir çerçevede tahminleme için kullanabilirsiniz. Modeller ayrıca üretim ortamlarında kullanılmak üzere ONNX ve TorchScript gibi bir formata aktarılabilir.
Büyüyen topluluğa [Hub](https://huggingface.co/models), [Forum](https://discuss.huggingface.co/) veya [Discord](https://discord.com/invite/JfAtkvEtRb) üzerinden katılabilirsiniz!
## Hugging Face ekibinden özel destek arıyorsanız
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Uzman Hızlandırma Programı" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
## İçindekiler
Dokümantasyon, beş bölüme ayrılmıştır:
- **BAŞLARKEN**, kütüphanenin hızlı bir turunu ve çalışmaya başlamak için kurulum talimatlarını sağlar.
- **ÖĞRETİCİLER**, başlangıç yapmak için harika bir yerdir. Bu bölüm, kütüphane kullanmaya başlamak için ihtiyacınız olan temel becerileri kazanmanıza yardımcı olacaktır.
- **NASIL YAPILIR KILAVUZLARI**, önceden eğitilmiş bir modele dil modellemesi için ince ayar (fine-tuning) yapmak veya özel bir model yazmak, ve paylaşmak gibi belirli bir hedefe nasıl ulaşılacağını gösterir.
- **KAVRAMSAL REHBERLER**, modellerin, görevlerin ve 🤗 Transformers tasarım felsefesinin temel kavramları ve fikirleri hakkında daha fazla tartışma ve açıklama sunar.
- **API** tüm sınıfları (class) ve fonksiyonları (functions) açıklar:
- **ANA SINIFLAR**, yapılandırma, model, tokenizer ve pipeline gibi en önemli sınıfları (classes) ayrıntılandırır.
- **MODELLER**, kütüphanede kullanılan her modelle ilgili sınıfları ve fonksiyonları detaylı olarak inceler.
- **DAHİLİ YARDIMCILAR**, kullanılan yardımcı sınıfları ve fonksiyonları detaylı olarak inceler.
## Desteklenen Modeller ve Çerçeveler
Aşağıdaki tablo, her bir model için kütüphanede yer alan mevcut desteği temsil etmektedir. Her bir model için bir Python tokenizer'ına ("slow" olarak adlandırılır) sahip olup olmadıkları, 🤗 Tokenizers kütüphanesi tarafından desteklenen hızlı bir tokenizer'a sahip olup olmadıkları, Jax (Flax aracılığıyla), PyTorch ve/veya TensorFlow'da destek olup olmadıklarını göstermektedir.
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
| Model | PyTorch support | TensorFlow support | Flax Support |
|:------------------------------------------------------------------------:|:---------------:|:------------------:|:------------:|
| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ❌ |
| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ❌ | ❌ |
| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
| [DiNAT](model_doc/dinat) | ✅ | ❌ | ❌ |
| [DINOv2](model_doc/dinov2) | ✅ | ❌ | ❌ |
| [DistilBERT](model_doc/distilbert) | ✅ | ✅ | ✅ |
| [DiT](model_doc/dit) | ✅ | ❌ | ✅ |
| [DonutSwin](model_doc/donut) | ✅ | ❌ | ❌ |
| [DPR](model_doc/dpr) | ✅ | ✅ | ❌ |
| [DPT](model_doc/dpt) | ✅ | ❌ | ❌ |
| [EfficientFormer](model_doc/efficientformer) | ✅ | ✅ | ❌ |
| [EfficientNet](model_doc/efficientnet) | ✅ | ❌ | ❌ |
| [ELECTRA](model_doc/electra) | ✅ | ✅ | ✅ |
| [EnCodec](model_doc/encodec) | ✅ | ❌ | ❌ |
| [Encoder decoder](model_doc/encoder-decoder) | ✅ | ✅ | ✅ |
| [ERNIE](model_doc/ernie) | ✅ | ❌ | ❌ |
| [ErnieM](model_doc/ernie_m) | ✅ | ❌ | ❌ |
| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
| [FLAVA](model_doc/flava) | ✅ | ❌ | ❌ |
| [FNet](model_doc/fnet) | ✅ | ❌ | ❌ |
| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
| [Fuyu](model_doc/fuyu) | ✅ | ❌ | ❌ |
| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
| [IDEFICS](model_doc/idefics) | ✅ | ❌ | ❌ |
| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
| [LED](model_doc/led) | ✅ | ✅ | ❌ |
| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
| [LLaMA](model_doc/llama) | ✅ | ❌ | ❌ |
| [Llama2](model_doc/llama2) | ✅ | ❌ | ❌ |
| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
| [Mistral](model_doc/mistral) | ✅ | ❌ | ❌ |
| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
| [OWLv2](model_doc/owlv2) | ✅ | ❌ | ❌ |
| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
| [SeamlessM4T](model_doc/seamless_m4t) | ✅ | ❌ | ❌ |
| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
| [SwiftFormer](model_doc/swiftformer) | ✅ | ❌ | ❌ |
| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
| [Vision Encoder decoder](model_doc/vision-encoder-decoder) | ✅ | ✅ | ✅ |
| [VisionTextDualEncoder](model_doc/vision-text-dual-encoder) | ✅ | ✅ | ✅ |
| [VisualBERT](model_doc/visual_bert) | ✅ | ❌ | ❌ |
| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
| [ViTMatte](model_doc/vitmatte) | ✅ | ❌ | ❌ |
| [ViTMSN](model_doc/vit_msn) | ✅ | ❌ | ❌ |
| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
<!-- End table-->
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/hi/pipeline_tutorial.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# अनुमान के लिए पाइपलाइन
[`pipeline`] किसी भी भाषा, कंप्यूटर दृष्टि, भाषण और मल्टीमॉडल कार्यों पर अनुमान लगाने के लिए [Hub] (https://huggingface.co/models) से किसी भी मॉडल का उपयोग करना आसान बनाता है। भले ही आपके पास किसी विशिष्ट तौर-तरीके का अनुभव न हो या आप मॉडलों के पीछे अंतर्निहित कोड से परिचित न हों, फिर भी आप [`pipeline`] के अनुमान के लिए उनका उपयोग कर सकते हैं! यह ट्यूटोरियल आपको ये सिखाएगा:
* अनुमान के लिए [`pipeline`] का उपयोग करें।
* एक विशिष्ट टोकननाइज़र या मॉडल का उपयोग करें।
* ऑडियो, विज़न और मल्टीमॉडल कार्यों के लिए [`pipeline`] का उपयोग करें।
<Tip>
समर्थित कार्यों और उपलब्ध मापदंडों की पूरी सूची के लिए [`pipeline`] दस्तावेज़ पर एक नज़र डालें।
</Tip>
## पाइपलाइन का उपयोग
जबकि प्रत्येक कार्य में एक संबद्ध [`pipeline`] होता है, सामान्य [`pipeline`] अमूर्त का उपयोग करना आसान होता है जिसमें शामिल होता है
सभी कार्य-विशिष्ट पाइपलाइनें। [`pipeline`] स्वचालित रूप से एक डिफ़ॉल्ट मॉडल और सक्षम प्रीप्रोसेसिंग क्लास लोड करता है
आपके कार्य के लिए अनुमान का. आइए स्वचालित वाक् पहचान (एएसआर) के लिए [`pipeline`] का उपयोग करने का उदाहरण लें, या
वाक्-से-पाठ.
1. एक [`pipeline`] बनाकर प्रारंभ करें और अनुमान कार्य निर्दिष्ट करें:
```py
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition")
```
2. अपना इनपुट [`pipeline`] पर भेजें। वाक् पहचान के मामले में, यह एक ऑडियो इनपुट फ़ाइल है:
```py
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}
```
क्या वह परिणाम नहीं जो आपके मन में था? कुछ [सबसे अधिक डाउनलोड किए गए स्वचालित वाक् पहचान मॉडल](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=trending) देखें
यह देखने के लिए हब पर जाएं कि क्या आपको बेहतर ट्रांस्क्रिप्शन मिल सकता है।
आइए OpenAI से [व्हिस्पर लार्ज-v2](https://huggingface.co/openai/whisper-large) मॉडल आज़माएं। व्हिस्पर जारी किया गया
Wav2Vec2 की तुलना में 2 साल बाद, और लगभग 10 गुना अधिक डेटा पर प्रशिक्षित किया गया था। इस प्रकार, यह अधिकांश डाउनस्ट्रीम पर Wav2Vec2 को मात देता है
बेंचमार्क. इसमें विराम चिह्न और आवरण की भविष्यवाणी करने का अतिरिक्त लाभ भी है, जिनमें से कोई भी संभव नहीं है
Wav2Vec2.
आइए इसे यहां आज़माकर देखें कि यह कैसा प्रदर्शन करता है:
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
```
अब यह परिणाम अधिक सटीक दिखता है! Wav2Vec2 बनाम व्हिस्पर पर गहन तुलना के लिए, [ऑडियो ट्रांसफॉर्मर्स कोर्स] (https://huggingface.co/learn/audio-course/chapter5/asr_models) देखें।
हम वास्तव में आपको विभिन्न भाषाओं में मॉडल, आपके क्षेत्र में विशेषीकृत मॉडल और बहुत कुछ के लिए हब की जांच करने के लिए प्रोत्साहित करते हैं।
आप हब पर सीधे अपने ब्राउज़र से मॉडल परिणामों की जांच और तुलना कर सकते हैं कि यह फिट बैठता है या नहीं
अन्य मामलों की तुलना में कोने के मामलों को बेहतर ढंग से संभालता है।
और यदि आपको अपने उपयोग के मामले के लिए कोई मॉडल नहीं मिलता है, तो आप हमेशा अपना खुद का [प्रशिक्षण](training) शुरू कर सकते हैं!
यदि आपके पास कई इनपुट हैं, तो आप अपने इनपुट को एक सूची के रूप में पास कर सकते हैं:
```py
transcriber(
[
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)
```
पाइपलाइनें प्रयोग के लिए बहुत अच्छी हैं क्योंकि एक मॉडल से दूसरे मॉडल पर स्विच करना मामूली काम है; हालाँकि, प्रयोग की तुलना में बड़े कार्यभार के लिए उन्हें अनुकूलित करने के कुछ तरीके हैं। संपूर्ण डेटासेट पर पुनरावृत्ति करने या वेबसर्वर में पाइपलाइनों का उपयोग करने के बारे में निम्नलिखित मार्गदर्शिकाएँ देखें:
दस्तावेज़ों में से:
* [डेटासेट पर पाइपलाइनों का उपयोग करना](#using-pipelines-on-a-dataset)
* [वेबसर्वर के लिए पाइपलाइनों का उपयोग करना](./pipeline_webserver)
## प्राचल
[`pipeline`] कई मापदंडों का समर्थन करता है; कुछ कार्य विशिष्ट हैं, और कुछ सभी पाइपलाइनों के लिए सामान्य हैं।
सामान्य तौर पर, आप अपनी इच्छानुसार कहीं भी पैरामीटर निर्दिष्ट कर सकते हैं:
```py
transcriber = pipeline(model="openai/whisper-large-v2", my_parameter=1)
out = transcriber(...) # This will use `my_parameter=1`.
out = transcriber(..., my_parameter=2) # This will override and use `my_parameter=2`.
out = transcriber(...) # This will go back to using `my_parameter=1`.
```
आइए 3 महत्वपूर्ण बातों पर गौर करें:
### उपकरण
यदि आप `device=0` का उपयोग करते हैं, तो पाइपलाइन स्वचालित रूप से मॉडल को निर्दिष्ट डिवाइस पर डाल देती है।
यह इस पर ध्यान दिए बिना काम करेगा कि आप PyTorch या Tensorflow का उपयोग कर रहे हैं या नहीं।
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0)
```
यदि मॉडल एकल GPU के लिए बहुत बड़ा है और आप PyTorch का उपयोग कर रहे हैं, तो आप `device_map="auto"` को स्वचालित रूप से सेट कर सकते हैं
निर्धारित करें कि मॉडल वज़न को कैसे लोड और संग्रहीत किया जाए। `device_map` तर्क का उपयोग करने के लिए 🤗 [Accelerate] (https://huggingface.co/docs/accelerate) की आवश्यकता होती है
पैकेट:
```bash
pip install --upgrade accelerate
```
निम्नलिखित कोड स्वचालित रूप से सभी डिवाइसों में मॉडल भार को लोड और संग्रहीत करता है:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")
```
ध्यान दें कि यदि `device_map='auto'` पारित हो गया है, तो अपनी `pipeline` को चालू करते समय `device=device` तर्क जोड़ने की कोई आवश्यकता नहीं है क्योंकि आपको कुछ अप्रत्याशित व्यवहार का सामना करना पड़ सकता है!
### बैच का आकार
डिफ़ॉल्ट रूप से, पाइपलाइनें [यहां] (https://huggingface.co/docs/transformers/main_classes/pipelines#pipeline-batching) विस्तार से बताए गए कारणों के लिए बैच अनुमान नहीं लगाएंगी। इसका कारण यह है कि बैचिंग आवश्यक रूप से तेज़ नहीं है, और वास्तव में कुछ मामलों में काफी धीमी हो सकती है।
लेकिन अगर यह आपके उपयोग के मामले में काम करता है, तो आप इसका उपयोग कर सकते हैं:
```py
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
texts = transcriber(audio_filenames)
```
यह प्रदान की गई 4 ऑडियो फाइलों पर पाइपलाइन चलाता है, लेकिन यह उन्हें 2 के बैच में पास करेगा
आपसे किसी और कोड की आवश्यकता के बिना मॉडल (जो एक जीपीयू पर है, जहां बैचिंग से मदद मिलने की अधिक संभावना है) पर जाएं।
आउटपुट हमेशा उसी से मेल खाना चाहिए जो आपको बैचिंग के बिना प्राप्त हुआ होगा। इसका उद्देश्य केवल पाइपलाइन से अधिक गति प्राप्त करने में आपकी सहायता करना है।
पाइपलाइनें बैचिंग की कुछ जटिलताओं को भी कम कर सकती हैं क्योंकि, कुछ पाइपलाइनों के लिए, एक एकल आइटम (जैसे एक लंबी ऑडियो फ़ाइल) को एक मॉडल द्वारा संसाधित करने के लिए कई भागों में विभाजित करने की आवश्यकता होती है। पाइपलाइन आपके लिए यह [*chunk batching*](./main_classes/pipelines#pipeline-chunk-batching) करती है।
### कार्य विशिष्ट प्राचल
सभी कार्य कार्य विशिष्ट प्राचल प्रदान करते हैं जो आपको अपना काम पूरा करने में मदद करने के लिए अतिरिक्त लचीलेपन और विकल्पों की अनुमति देते हैं।
उदाहरण के लिए, [`transformers.AutomaticSpeechRecognitionPipeline.__call__`] विधि में एक `return_timestamps` प्राचल है जो वीडियो उपशीर्षक के लिए आशाजनक लगता है:
```py
>>> transcriber = pipeline(model="openai/whisper-large-v2", return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}
```
जैसा कि आप देख सकते हैं, मॉडल ने पाठ का अनुमान लगाया और **when** विभिन्न वाक्यों का उच्चारण किया गया तो आउटपुट भी दिया।
प्रत्येक कार्य के लिए कई प्राचल उपलब्ध हैं, इसलिए यह देखने के लिए कि आप किसके साथ छेड़छाड़ कर सकते हैं, प्रत्येक कार्य का API संदर्भ देखें!
उदाहरण के लिए, [`~transformers.AutomaticSpeechRecognitionPipeline`] में एक `chunk_length_s` प्राचल है जो सहायक है
वास्तव में लंबी ऑडियो फ़ाइलों पर काम करने के लिए (उदाहरण के लिए, संपूर्ण फिल्मों या घंटे-लंबे वीडियो को उपशीर्षक देना) जो आमतौर पर एक मॉडल होता है
अपने आप संभाल नहीं सकता:
```python
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30, return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/sanchit-gandhi/librispeech_long/resolve/main/audio.wav")
{'text': " Chapter 16. I might have told you of the beginning of this liaison in a few lines, but I wanted you to see every step by which we came. I, too, agree to whatever Marguerite wished, Marguerite to be unable to live apart from me. It was the day after the evening...
```
यदि आपको कोई ऐसा पैरामीटर नहीं मिल रहा है जो वास्तव में आपकी मदद करेगा, तो बेझिझक [अनुरोध करें](https://github.com/huggingface/transformers/issues/new?assignees=&labels=feature&template=feature-request.yml)!
## डेटासेट पर पाइपलाइनों का उपयोग करना
पाइपलाइन बड़े डेटासेट पर भी अनुमान चला सकती है। ऐसा करने का सबसे आसान तरीका हम एक पुनरावर्तक का उपयोग करने की सलाह देते हैं:
```py
def data():
for i in range(1000):
yield f"My example {i}"
pipe = pipeline(model="gpt2", device=0)
generated_characters = 0
for out in pipe(data()):
generated_characters += len(out[0]["generated_text"])
```
पुनरावर्तक `data()` प्रत्येक परिणाम और पाइपलाइन स्वचालित रूप से उत्पन्न करता है
पहचानता है कि इनपुट पुनरावर्तनीय है और डेटा प्राप्त करना शुरू कर देगा
यह इसे GPU पर प्रोसेस करना जारी रखता है (यह हुड के तहत [DataLoader](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) का उपयोग करता है)।
यह महत्वपूर्ण है क्योंकि आपको संपूर्ण डेटासेट के लिए मेमोरी आवंटित करने की आवश्यकता नहीं है
और आप जितनी जल्दी हो सके GPU को फीड कर सकते हैं।
चूंकि बैचिंग से चीज़ें तेज़ हो सकती हैं, इसलिए यहां `batch_size` प्राचल को ट्यून करने का प्रयास करना उपयोगी हो सकता है।
किसी डेटासेट पर पुनरावृति करने का सबसे सरल तरीका बस एक को 🤗 [Dataset](https://github.com/huggingface/datasets/) से लोड करना है:
```py
# KeyDataset is a util that will just output the item we're interested in.
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)
```
## वेबसर्वर के लिए पाइपलाइनों का उपयोग करना
<Tip>
एक अनुमान इंजन बनाना एक जटिल विषय है जो अपने आप में उपयुक्त है
पृष्ठ।
</Tip>
[Link](./pipeline_webserver)
## विज़न पाइपलाइन
दृष्टि कार्यों के लिए [`pipeline`] का उपयोग करना व्यावहारिक रूप से समान है।
अपना कार्य निर्दिष्ट करें और अपनी छवि क्लासिफायरियर को भेजें। छवि एक लिंक, एक स्थानीय पथ या बेस64-एन्कोडेड छवि हो सकती है। उदाहरण के लिए, बिल्ली की कौन सी प्रजाति नीचे दिखाई गई है?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
```
## पाठ पाइपलाइन
NLP कार्यों के लिए [`pipeline`] का उपयोग करना व्यावहारिक रूप से समान है।
```py
>>> from transformers import pipeline
>>> # This model is a `zero-shot-classification` model.
>>> # It will classify text, except you are free to choose any label you might imagine
>>> classifier = pipeline(model="facebook/bart-large-mnli")
>>> classifier(
... "I have a problem with my iphone that needs to be resolved asap!!",
... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
... )
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}
```
## बहुविध पाइपलाइन
[`pipeline`] एक से अधिक तौर-तरीकों का समर्थन करती है। उदाहरण के लिए, एक दृश्य प्रश्न उत्तर (VQA) कार्य पाठ और छवि को जोड़ता है। अपनी पसंद के किसी भी छवि लिंक और छवि के बारे में कोई प्रश्न पूछने के लिए स्वतंत्र महसूस करें। छवि एक URL या छवि का स्थानीय पथ हो सकती है।
उदाहरण के लिए, यदि आप इस [invoice image](https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png) का उपयोग करते हैं:
```py
>>> from transformers import pipeline
>>> vqa = pipeline(model="impira/layoutlm-document-qa")
>>> vqa(
... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
... question="What is the invoice number?",
... )
[{'score': 0.42515, 'answer': 'us-001', 'start': 16, 'end': 16}]
```
<Tip>
ऊपर दिए गए उदाहरण को चलाने के लिए आपको 🤗 ट्रांसफॉर्मर के अलावा [`pytesseract`](https://pypi.org/project/pytesseract/) इंस्टॉल करना होगा:
```bash
sudo apt install -y tesseract-ocr
pip install pytesseract
```
</Tip>
## 🤗 `त्वरण` के साथ बड़े मॉडलों पर `pipeline` का उपयोग करना:
आप 🤗 `accelerate` का उपयोग करके बड़े मॉडलों पर आसानी से `pipeline` चला सकते हैं! पहले सुनिश्चित करें कि आपने `accelerate` को `pip install accelerate` के साथ इंस्टॉल किया है।
सबसे पहले `device_map='auto'` का उपयोग करके अपना मॉडल लोड करें! हम अपने उदाहरण के लिए `facebook/opt-1.3b` का उपयोग करेंगे।
```py
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
यदि आप `bitsandbytes` इंस्टॉल करते हैं और `load_in_8bit=True` तर्क जोड़ते हैं तो आप 8-बिट लोडेड मॉडल भी पास कर सकते हैं
```py
# pip install accelerate bitsandbytes
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
ध्यान दें कि आप चेकपॉइंट को किसी भी हगिंग फेस मॉडल से बदल सकते हैं जो BLOOM जैसे बड़े मॉडल लोडिंग का समर्थन करता है!
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/hi/_toctree.yml
|
- sections:
- local: pipeline_tutorial
title: पाइपलाइनों के साथ अनुमान चलाएँ
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/te/_toctree.yml
|
- sections:
- local: index
title: 🤗 Transformers
- local: quicktour
title: త్వరిత పర్యటన
title: ప్రారంభించడానికి
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/te/index.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
[పైటోర్చ్](https://pytorch.org/), [టెన్సర్ఫ్లో](https://www.tensorflow.org/), మరియు [జాక్స్](https://jax.readthedocs.io/en/latest/) కోసం స్థితి-కలాన యంత్ర అభ్యాసం.
🤗 ట్రాన్స్ఫార్మర్స్ అభివృద్ధిస్తున్నది API మరియు ఉపకరణాలు, పూర్వ-చేతన మోడల్లను సులభంగా డౌన్లోడ్ మరియు శిక్షణ చేయడానికి అవసరమైన సమయం, వనరులు, మరియు వస్తువులను నుంచి మోడల్ను శీర్షికం నుంచి ప్రశిక్షించడం వరకు దేవాయనం చేస్తుంది. ఈ మోడల్లు విభిన్న మోడాలిటీలలో సాధారణ పనులకు మద్దతు చేస్తాయి, వంటివి:
📝 **ప్రాకృతిక భాష ప్రక్రియ**: వచన వర్గీకరణ, పేరుల యొక్క యెంటిటీ గుర్తువు, ప్రశ్న సంవాద, భాషా రచన, సంక్షేపణ, అనువాదం, అనేక ప్రకారాలు, మరియు వచన సృష్టి.<br>
🖼️ **కంప్యూటర్ విషయం**: చిత్రం వర్గీకరణ, వస్త్రం గుర్తువు, మరియు విభజన.<br>
🗣️ **ఆడియో**: స్వయంచలన ప్రసంగాన్ని గుర్తుచేసేందుకు, ఆడియో వర్గీకరణ.<br>
🐙 **బహుమూలిక**: పట్టి ప్రశ్న సంవాద, ఆప్టికల్ సిఫర్ గుర్తువు, డాక్యుమెంట్లు స్క్యాన్ చేసినంతగా సమాచార పొందడం, వీడియో వర్గీకరణ, మరియు దృశ్య ప్రశ్న సంవాద.
🤗 ట్రాన్స్ఫార్మర్స్ పైన మద్దతు చేస్తుంది పైన తొలగించడానికి పైన పైన పైన ప్రోగ్రామ్లో మోడల్ను శిక్షించండి, మరియు అన్ని ప్రాథమిక యొక్కడా ఇన్ఫరెన్స్ కోసం లోడ్ చేయండి. మో
డల్లు కూడా ప్రొడక్షన్ వాతావరణాలలో వాడుకోవడానికి ONNX మరియు TorchScript వంటి ఆకృతులకు ఎగుమతి చేయవచ్చు.
ఈరువులకు [హబ్](https://huggingface.co/models), [ఫోరం](https://discuss.huggingface.co/), లేదా [డిస్కార్డ్](https://discord.com/invite/JfAtkvEtRb) లో ఈ పెద్ద సముదాయంలో చేరండి!
## మీరు హగ్గింగ్ ఫేస్ టీమ్ నుండి అనుకూల మద్దతు కోసం చూస్తున్నట్లయితే
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
## విషయాలు
డాక్యుమెంటేషన్ ఐదు విభాగాలుగా నిర్వహించబడింది:
- **ప్రారంభించండి** లైబ్రరీ యొక్క శీఘ్ర పర్యటన మరియు రన్నింగ్ కోసం ఇన్స్టాలేషన్ సూచనలను అందిస్తుంది.
- **ట్యుటోరియల్స్** మీరు అనుభవశూన్యుడు అయితే ప్రారంభించడానికి గొప్ప ప్రదేశం. మీరు లైబ్రరీని ఉపయోగించడం ప్రారంభించడానికి అవసరమైన ప్రాథమిక నైపుణ్యాలను పొందడానికి ఈ విభాగం మీకు సహాయం చేస్తుంది.
- **హౌ-టు-గైడ్లు** లాంగ్వేజ్ మోడలింగ్ కోసం ప్రిట్రైన్డ్ మోడల్ని ఫైన్ట్యూన్ చేయడం లేదా కస్టమ్ మోడల్ను ఎలా వ్రాయాలి మరియు షేర్ చేయాలి వంటి నిర్దిష్ట లక్ష్యాన్ని ఎలా సాధించాలో మీకు చూపుతాయి.
- **కాన్సెప్చువల్ గైడ్స్** మోడల్లు, టాస్క్లు మరియు 🤗 ట్రాన్స్ఫార్మర్ల డిజైన్ ఫిలాసఫీ వెనుక ఉన్న అంతర్లీన భావనలు మరియు ఆలోచనల గురించి మరింత చర్చ మరియు వివరణను అందిస్తుంది.
- **API** అన్ని తరగతులు మరియు విధులను వివరిస్తుంది:
- **ప్రధాన తరగతులు** కాన్ఫిగరేషన్, మోడల్, టోకెనైజర్ మరియు పైప్లైన్ వంటి అత్యంత ముఖ్యమైన తరగతులను వివరిస్తుంది.
- **మోడల్స్** లైబ్రరీలో అమలు చేయబడిన ప్రతి మోడల్కు సంబంధించిన తరగతులు మరియు విధులను వివరిస్తుంది.
- **అంతర్గత సహాయకులు** అంతర్గతంగా ఉపయోగించే యుటిలిటీ క్లాస్లు మరియు ఫంక్షన్ల వివరాలు.
## మద్దతు ఉన్న నమూనాలు మరియు ఫ్రేమ్వర్క్లు
దిగువన ఉన్న పట్టిక ఆ ప్రతి మోడల్కు పైథాన్ కలిగి ఉన్నా లైబ్రరీలో ప్రస్తుత మద్దతును సూచిస్తుంది
టోకెనైజర్ ("నెమ్మదిగా" అని పిలుస్తారు). Jax (ద్వారా
ఫ్లాక్స్), పైటార్చ్ మరియు/లేదా టెన్సర్ఫ్లో.
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
| Model | PyTorch support | TensorFlow support | Flax Support |
|:------------------------------------------------------------------------:|:---------------:|:------------------:|:------------:|
| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ❌ |
| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ❌ | ❌ |
| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
| [DiNAT](model_doc/dinat) | ✅ | ❌ | ❌ |
| [DINOv2](model_doc/dinov2) | ✅ | ❌ | ❌ |
| [DistilBERT](model_doc/distilbert) | ✅ | ✅ | ✅ |
| [DiT](model_doc/dit) | ✅ | ❌ | ✅ |
| [DonutSwin](model_doc/donut) | ✅ | ❌ | ❌ |
| [DPR](model_doc/dpr) | ✅ | ✅ | ❌ |
| [DPT](model_doc/dpt) | ✅ | ❌ | ❌ |
| [EfficientFormer](model_doc/efficientformer) | ✅ | ✅ | ❌ |
| [EfficientNet](model_doc/efficientnet) | ✅ | ❌ | ❌ |
| [ELECTRA](model_doc/electra) | ✅ | ✅ | ✅ |
| [EnCodec](model_doc/encodec) | ✅ | ❌ | ❌ |
| [Encoder decoder](model_doc/encoder-decoder) | ✅ | ✅ | ✅ |
| [ERNIE](model_doc/ernie) | ✅ | ❌ | ❌ |
| [ErnieM](model_doc/ernie_m) | ✅ | ❌ | ❌ |
| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
| [FLAVA](model_doc/flava) | ✅ | ❌ | ❌ |
| [FNet](model_doc/fnet) | ✅ | ❌ | ❌ |
| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
| [IDEFICS](model_doc/idefics) | ✅ | ❌ | ❌ |
| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
| [LED](model_doc/led) | ✅ | ✅ | ❌ |
| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
| [LLaMA](model_doc/llama) | ✅ | ❌ | ❌ |
| [Llama2](model_doc/llama2) | ✅ | ❌ | ❌ |
| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
| [Mistral](model_doc/mistral) | ✅ | ❌ | ❌ |
| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
| [SwiftFormer](model_doc/swiftformer) | ✅ | ❌ | ❌ |
| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
| [Vision Encoder decoder](model_doc/vision-encoder-decoder) | ✅ | ✅ | ✅ |
| [VisionTextDualEncoder](model_doc/vision-text-dual-encoder) | ✅ | ✅ | ✅ |
| [VisualBERT](model_doc/visual_bert) | ✅ | ❌ | ❌ |
| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
| [ViTMatte](model_doc/vitmatte) | ✅ | ❌ | ❌ |
| [ViTMSN](model_doc/vit_msn) | ✅ | ❌ | ❌ |
| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
<!-- End table-->
| 0
|
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/te/quicktour.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# శీఘ్ర పర్యటన
[[ఓపెన్-ఇన్-కోలాబ్]]
🤗 ట్రాన్స్ఫార్మర్లతో లేచి పరుగెత్తండి! మీరు డెవలపర్ అయినా లేదా రోజువారీ వినియోగదారు అయినా, ఈ శీఘ్ర పర్యటన మీకు ప్రారంభించడానికి సహాయం చేస్తుంది మరియు [`pipeline`] అనుమితి కోసం ఎలా ఉపయోగించాలో మీకు చూపుతుంది, [AutoClass](./model_doc/auto) తో ప్రీట్రైన్డ్ మోడల్ మరియు ప్రిప్రాసెసర్/ ఆటో, మరియు PyTorch లేదా TensorFlowతో మోడల్కు త్వరగా శిక్షణ ఇవ్వండి. మీరు ఒక అనుభవశూన్యుడు అయితే, ఇక్కడ పరిచయం చేయబడిన భావనల గురించి మరింత లోతైన వివరణల కోసం మా ట్యుటోరియల్స్ లేదా [course](https://huggingface.co/course/chapter1/1)ని తనిఖీ చేయమని మేము సిఫార్సు చేస్తున్నాము.
మీరు ప్రారంభించడానికి ముందు, మీరు అవసరమైన అన్ని లైబ్రరీలను ఇన్స్టాల్ చేశారని నిర్ధారించుకోండి:
```bash
!pip install transformers datasets
```
మీరు మీ ప్రాధాన్య యంత్ర అభ్యాస ఫ్రేమ్వర్క్ను కూడా ఇన్స్టాల్ చేయాలి:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
## పైప్లైన్
<Youtube id="tiZFewofSLM"/>
[`pipeline`] అనుమితి కోసం ముందుగా శిక్షణ పొందిన నమూనాను ఉపయోగించడానికి సులభమైన మరియు వేగవంతమైన మార్గం. మీరు వివిధ పద్ధతులలో అనేక పనుల కోసం [`pipeline`] వెలుపల ఉపయోగించవచ్చు, వాటిలో కొన్ని క్రింది పట్టికలో చూపబడ్డాయి:
<Tip>
అందుబాటులో ఉన్న పనుల పూర్తి జాబితా కోసం, [పైప్లైన్ API సూచన](./main_classes/pipelines)ని తనిఖీ చేయండి.
</Tip>
Here is the translation in Telugu:
| **పని** | **వివరణ** | **మోడాలిటీ** | **పైప్లైన్ ఐడెంటిఫైయర్** |
|------------------------------|--------------------------------------------------------------------------------------------------------|-----------------|------------------------------------------|
| వచన వర్గీకరణు | కొన్ని వచనాల అంతా ఒక లేబుల్ను కొడి | NLP | pipeline(task=“sentiment-analysis”) |
| వచన సృష్టి | ప్రమ్పుటం కలిగినంత వచనం సృష్టించండి | NLP | pipeline(task=“text-generation”) |
| సంక్షేపణ | వచనం లేదా పత్రం కొరకు సంక్షేపణ తయారుచేసండి | NLP | pipeline(task=“summarization”) |
| చిత్రం వర్గీకరణు | చిత్రంలో ఒక లేబుల్ను కొడి | కంప్యూటర్ విషయం | pipeline(task=“image-classification”) |
| చిత్రం విభజన | ఒక చిత్రంలో ప్రతి వ్యక్తిగత పిక్సల్ను ఒక లేబుల్గా నమోదు చేయండి (సెమాంటిక్, పానొప్టిక్, మరియు ఇన్స్టన్స్ విభజనలను మద్దతు చేస్తుంది) | కంప్యూటర్ విషయం | pipeline(task=“image-segmentation”) |
| వస్త్రం గుర్తువు | ఒక చిత్రంలో పదాల యొక్క బౌండింగ్ బాక్స్లను మరియు వస్త్రాల వర్గాలను అంచనా చేయండి | కంప్యూటర్ విషయం | pipeline(task=“object-detection”) |
| ఆడియో గుర్తువు | కొన్ని ఆడియో డేటానికి ఒక లేబుల్ను కొడి | ఆడియో | pipeline(task=“audio-classification”) |
| స్వయంచలన ప్రసంగ గుర్తువు | ప్రసంగాన్ని వచనంగా వర్ణించండి | ఆడియో | pipeline(task=“automatic-speech-recognition”) |
| దృశ్య ప్రశ్న సంవాదం | వచనం మరియు ప్రశ్నను నమోదు చేసిన చిత్రంతో ప్రశ్నకు సమాధానం ఇవ్వండి | బహుమూలిక | pipeline(task=“vqa”) |
| పత్రం ప్రశ్న సంవాదం | ప్రశ్నను పత్రం లేదా డాక్యుమెంట్తో సమాధానం ఇవ్వండి | బహుమూలిక | pipeline(task="document-question-answering") |
| చిత్రం వ్రాసాయింగ్ | కొన్ని చిత్రానికి పిటియార్లను సృష్టించండి | బహుమూలిక | pipeline(task="image-to-text") |
[`pipeline`] యొక్క ఉదాహరణను సృష్టించడం ద్వారా మరియు మీరు దానిని ఉపయోగించాలనుకుంటున్న పనిని పేర్కొనడం ద్వారా ప్రారంభించండి. ఈ గైడ్లో, మీరు సెంటిమెంట్ విశ్లేషణ కోసం [`pipeline`]ని ఉదాహరణగా ఉపయోగిస్తారు:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis")
```
సెంటిమెంట్ విశ్లేషణ కోసం [`pipeline`] డిఫాల్ట్ [ప్రీట్రైన్డ్ మోడల్](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) మరియు టోకెనైజర్ని డౌన్లోడ్ చేస్తుంది మరియు కాష్ చేస్తుంది. ఇప్పుడు మీరు మీ లక్ష్య వచనంలో `classifier`ని ఉపయోగించవచ్చు:
```py
>>> classifier("We are very happy to show you the 🤗 Transformers library.")
[{'label': 'POSITIVE', 'score': 0.9998}]
```
మీరు ఒకటి కంటే ఎక్కువ ఇన్పుట్లను కలిగి ఉంటే, నిఘంటువుల జాబితాను అందించడానికి మీ ఇన్పుట్లను జాబితాగా [`pipeline`]కి పంపండి:
```py
>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
>>> for result in results:
... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
label: POSITIVE, with score: 0.9998
label: NEGATIVE, with score: 0.5309
```
[`pipeline`] మీకు నచ్చిన ఏదైనా పని కోసం మొత్తం డేటాసెట్ను కూడా పునరావృతం చేయగలదు. ఈ ఉదాహరణ కోసం, స్వయంచాలక ప్రసంగ గుర్తింపును మన పనిగా ఎంచుకుందాం:
```py
>>> import torch
>>> from transformers import pipeline
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
```
మీరు మళ్లీ మళ్లీ చెప్పాలనుకుంటున్న ఆడియో డేటాసెట్ను లోడ్ చేయండి (మరిన్ని వివరాల కోసం 🤗 డేటాసెట్లు [త్వరిత ప్రారంభం](https://huggingface.co/docs/datasets/quickstart#audio) చూడండి. ఉదాహరణకు, [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) డేటాసెట్ను లోడ్ చేయండి:
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
```
డేటాసెట్ యొక్క నమూనా రేటు నమూనాతో సరిపోలుతుందని మీరు నిర్ధారించుకోవాలి
రేటు [`facebook/wav2vec2-base-960h`](https://huggingface.co/facebook/wav2vec2-base-960h) దీనిపై శిక్షణ పొందింది:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
```
`"ఆడియో"` కాలమ్కి కాల్ చేస్తున్నప్పుడు ఆడియో ఫైల్లు స్వయంచాలకంగా లోడ్ చేయబడతాయి మరియు మళ్లీ నమూనా చేయబడతాయి.
మొదటి 4 నమూనాల నుండి ముడి వేవ్ఫార్మ్ శ్రేణులను సంగ్రహించి, పైప్లైన్కు జాబితాగా పాస్ చేయండి:
```py
>>> result = speech_recognizer(dataset[:4]["audio"])
>>> print([d["text"] for d in result])
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HELL T WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AN I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I FURN A JOINA COUT']
```
ఇన్పుట్లు పెద్దగా ఉన్న పెద్ద డేటాసెట్ల కోసం (స్పీచ్ లేదా విజన్ వంటివి), మెమరీలోని అన్ని ఇన్పుట్లను లోడ్ చేయడానికి మీరు జాబితాకు బదులుగా జెనరేటర్ను పాస్ చేయాలనుకుంటున్నారు. మరింత సమాచారం కోసం [పైప్లైన్ API సూచన](./main_classes/pipelines)ని చూడండి.
### పైప్లైన్లో మరొక మోడల్ మరియు టోకెనైజర్ని ఉపయోగించండి
[`pipeline`] [Hub](https://huggingface.co/models) నుండి ఏదైనా మోడల్ను కలిగి ఉంటుంది, దీని వలన ఇతర వినియోగ-కేసుల కోసం [`pipeline`]ని సులభంగా స్వీకరించవచ్చు. ఉదాహరణకు, మీరు ఫ్రెంచ్ టెక్స్ట్ను హ్యాండిల్ చేయగల మోడల్ కావాలనుకుంటే, తగిన మోడల్ కోసం ఫిల్టర్ చేయడానికి హబ్లోని ట్యాగ్లను ఉపయోగించండి. అగ్ర ఫిల్టర్ చేసిన ఫలితం మీరు ఫ్రెంచ్ టెక్స్ట్ కోసం ఉపయోగించగల సెంటిమెంట్ విశ్లేషణ కోసం ఫైన్ట్యూన్ చేయబడిన బహుభాషా [BERT మోడల్](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment)ని అందిస్తుంది:
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
ముందుగా శిక్షణ పొందిన మోడల్ను లోడ్ చేయడానికి [`AutoModelForSequenceClassification`] మరియు [`AutoTokenizer`]ని ఉపయోగించండి మరియు దాని అనుబంధిత టోకెనైజర్ (తదుపరి విభాగంలో `AutoClass`పై మరిన్ని):
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
ముందుగా శిక్షణ పొందిన మోడల్ను లోడ్ చేయడానికి [`TFAutoModelForSequenceClassification`] మరియు [`AutoTokenizer`]ని ఉపయోగించండి మరియు దాని అనుబంధిత టోకెనైజర్ (తదుపరి విభాగంలో `TFAutoClass`పై మరిన్ని):
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
[`pipeline`]లో మోడల్ మరియు టోకెనైజర్ను పేర్కొనండి మరియు ఇప్పుడు మీరు ఫ్రెంచ్ టెక్స్ట్పై `క్లాసిఫైయర్`ని వర్తింపజేయవచ్చు:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
మీరు మీ వినియోగ-కేస్ కోసం మోడల్ను కనుగొనలేకపోతే, మీరు మీ డేటాపై ముందుగా శిక్షణ పొందిన మోడల్ను చక్కగా మార్చాలి. ఎలాగో తెలుసుకోవడానికి మా [ఫైన్ట్యూనింగ్ ట్యుటోరియల్](./training)ని చూడండి. చివరగా, మీరు మీ ప్రీట్రైన్డ్ మోడల్ని ఫైన్ట్యూన్ చేసిన తర్వాత, దయచేసి అందరి కోసం మెషిన్ లెర్నింగ్ని డెమోక్రటైజ్ చేయడానికి హబ్లోని సంఘంతో మోడల్ను [షేరింగ్](./model_sharing) పరిగణించండి! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
హుడ్ కింద, మీరు పైన ఉపయోగించిన [`pipeline`]కి శక్తిని అందించడానికి [`AutoModelForSequenceClassification`] మరియు [`AutoTokenizer`] తరగతులు కలిసి పని చేస్తాయి. ఒక [AutoClass](./model_doc/auto) అనేది ముందుగా శిక్షణ పొందిన మోడల్ యొక్క ఆర్కిటెక్చర్ను దాని పేరు లేదా మార్గం నుండి స్వయంచాలకంగా తిరిగి పొందే సత్వరమార్గం. మీరు మీ టాస్క్ కోసం తగిన `ఆటోక్లాస్`ని మాత్రమే ఎంచుకోవాలి మరియు ఇది అనుబంధిత ప్రీప్రాసెసింగ్ క్లాస్.
మునుపటి విభాగం నుండి ఉదాహరణకి తిరిగి వెళ్లి, [`pipeline`] ఫలితాలను ప్రతిబింబించడానికి మీరు `ఆటోక్లాస్`ని ఎలా ఉపయోగించవచ్చో చూద్దాం.
### AutoTokenizer
ఒక మోడల్కు ఇన్పుట్లుగా సంఖ్యల శ్రేణిలో వచనాన్ని ప్రీప్రాసెసింగ్ చేయడానికి టోకెనైజర్ బాధ్యత వహిస్తుంది. పదాన్ని ఎలా విభజించాలి మరియు ఏ స్థాయిలో పదాలను విభజించాలి ([tokenizer సారాంశం](./tokenizer_summary)లో టోకనైజేషన్ గురించి మరింత తెలుసుకోండి) సహా టోకనైజేషన్ ప్రక్రియను నియంత్రించే అనేక నియమాలు ఉన్నాయి. గుర్తుంచుకోవలసిన ముఖ్యమైన విషయం ఏమిటంటే, మీరు మోడల్కు ముందే శిక్షణ పొందిన అదే టోకనైజేషన్ నియమాలను ఉపయోగిస్తున్నారని నిర్ధారించుకోవడానికి మీరు అదే మోడల్ పేరుతో టోకెనైజర్ను తక్షణం చేయాలి.
[`AutoTokenizer`]తో టోకెనైజర్ను లోడ్ చేయండి:
```py
>>> from transformers import AutoTokenizer
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
మీ వచనాన్ని టోకెనైజర్కు పంపండి:
```py
>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
>>> print(encoding)
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
టోకెనైజర్ వీటిని కలిగి ఉన్న నిఘంటువుని అందిస్తుంది:
* [input_ids](./glossary#input-ids): మీ టోకెన్ల సంఖ్యాపరమైన ప్రాతినిధ్యం.
* [అటెన్షన్_మాస్క్](./glossary#attention-mask): ఏ టోకెన్లకు హాజరు కావాలో సూచిస్తుంది.
ఒక టోకెనైజర్ ఇన్పుట్ల జాబితాను కూడా ఆమోదించగలదు మరియు ఏకరీతి పొడవుతో బ్యాచ్ను తిరిగి ఇవ్వడానికి టెక్స్ట్ను ప్యాడ్ చేసి కత్తిరించవచ్చు:
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
<Tip>
టోకనైజేషన్ గురించి మరిన్ని వివరాల కోసం [ప్రీప్రాసెస్](./preprocessing) ట్యుటోరియల్ని చూడండి మరియు ఇమేజ్, ఆడియో మరియు మల్టీమోడల్ ఇన్పుట్లను ప్రీప్రాసెస్ చేయడానికి [`AutoImageProcessor`], [`AutoFeatureExtractor`] మరియు [`AutoProcessor`] ఎలా ఉపయోగించాలి.
</Tip>
### AutoModel
<frameworkcontent>
<pt>
🤗 ట్రాన్స్ఫార్మర్లు ప్రీట్రైన్డ్ ఇన్స్టాన్స్లను లోడ్ చేయడానికి సులభమైన మరియు ఏకీకృత మార్గాన్ని అందిస్తాయి. దీని అర్థం మీరు [`AutoTokenizer`]ని లోడ్ చేసినట్లుగా [`AutoModel`]ని లోడ్ చేయవచ్చు. టాస్క్ కోసం సరైన [`AutoModel`]ని ఎంచుకోవడం మాత్రమే తేడా. టెక్స్ట్ (లేదా సీక్వెన్స్) వర్గీకరణ కోసం, మీరు [`AutoModelForSequenceClassification`]ని లోడ్ చేయాలి:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
[`AutoModel`] క్లాస్ ద్వారా సపోర్ట్ చేసే టాస్క్ల కోసం [టాస్క్ సారాంశం](./task_summary)ని చూడండి.
</Tip>
ఇప్పుడు మీ ప్రీప్రాసెస్ చేయబడిన బ్యాచ్ ఇన్పుట్లను నేరుగా మోడల్కి పంపండి. మీరు `**`ని జోడించడం ద్వారా నిఘంటువుని అన్ప్యాక్ చేయాలి:
```py
>>> pt_outputs = pt_model(**pt_batch)
```
మోడల్ తుది యాక్టివేషన్లను `logits` లక్షణంలో అవుట్పుట్ చేస్తుంది. సంభావ్యతలను తిరిగి పొందడానికి సాఫ్ట్మాక్స్ ఫంక్షన్ను `logits` కు వర్తింపజేయండి:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 ట్రాన్స్ఫార్మర్లు ప్రీట్రైన్డ్ ఇన్స్టాన్స్లను లోడ్ చేయడానికి సులభమైన మరియు ఏకీకృత మార్గాన్ని అందిస్తాయి. మీరు [`AutoTokenizer`]ని లోడ్ చేసినట్లుగా మీరు [`TFAutoModel`]ని లోడ్ చేయవచ్చని దీని అర్థం. టాస్క్ కోసం సరైన [`TFAutoModel`]ని ఎంచుకోవడం మాత్రమే తేడా. టెక్స్ట్ (లేదా సీక్వెన్స్) వర్గీకరణ కోసం, మీరు [`TFAutoModelForSequenceClassification`]ని లోడ్ చేయాలి:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
[`AutoModel`] క్లాస్ ద్వారా సపోర్ట్ చేసే టాస్క్ల కోసం [టాస్క్ సారాంశం](./task_summary)ని చూడండి.
</Tip>
ఇప్పుడు మీ ప్రీప్రాసెస్ చేయబడిన బ్యాచ్ ఇన్పుట్లను నేరుగా మోడల్కి పంపండి. మీరు టెన్సర్లను ఇలా పాస్ చేయవచ్చు:
```py
>>> tf_outputs = tf_model(tf_batch)
```
మోడల్ తుది యాక్టివేషన్లను `logits` లక్షణంలో అవుట్పుట్ చేస్తుంది. సంభావ్యతలను తిరిగి పొందడానికి సాఫ్ట్మాక్స్ ఫంక్షన్ను `logits`కు వర్తింపజేయండి:
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
అన్ని 🤗 ట్రాన్స్ఫార్మర్స్ మోడల్లు (PyTorch లేదా TensorFlow) తుది యాక్టివేషన్కు *ముందు* టెన్సర్లను అవుట్పుట్ చేస్తాయి
ఫంక్షన్ (softmax వంటిది) ఎందుకంటే చివరి యాక్టివేషన్ ఫంక్షన్ తరచుగా నష్టంతో కలిసిపోతుంది. మోడల్ అవుట్పుట్లు ప్రత్యేక డేటాక్లాస్లు కాబట్టి వాటి లక్షణాలు IDEలో స్వయంచాలకంగా పూర్తి చేయబడతాయి. మోడల్ అవుట్పుట్లు టుపుల్ లేదా డిక్షనరీ లాగా ప్రవర్తిస్తాయి (మీరు పూర్ణాంకం, స్లైస్ లేదా స్ట్రింగ్తో ఇండెక్స్ చేయవచ్చు) ఈ సందర్భంలో, ఏదీ లేని గుణాలు విస్మరించబడతాయి.
</Tip>
### మోడల్ను సేవ్ చేయండి
<frameworkcontent>
<pt>
మీ మోడల్ చక్కగా ట్యూన్ చేయబడిన తర్వాత, మీరు దానిని [`PreTrainedModel.save_pretrained`]ని ఉపయోగించి దాని టోకెనైజర్తో సేవ్ చేయవచ్చు:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
మీరు మోడల్ని మళ్లీ ఉపయోగించడానికి సిద్ధంగా ఉన్నప్పుడు, దాన్ని [`PreTrainedModel.from_pretrained`]తో రీలోడ్ చేయండి:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
మీ మోడల్ చక్కగా ట్యూన్ చేయబడిన తర్వాత, మీరు దానిని [`TFPreTrainedModel.save_pretrained`]ని ఉపయోగించి దాని టోకెనైజర్తో సేవ్ చేయవచ్చు:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
మీరు మోడల్ని మళ్లీ ఉపయోగించడానికి సిద్ధంగా ఉన్నప్పుడు, దాన్ని [`TFPreTrainedModel.from_pretrained`]తో రీలోడ్ చేయండి:
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
ఒక ప్రత్యేకించి అద్భుతమైన 🤗 ట్రాన్స్ఫార్మర్స్ ఫీచర్ మోడల్ను సేవ్ చేయగల సామర్థ్యం మరియు దానిని PyTorch లేదా TensorFlow మోడల్గా రీలోడ్ చేయగలదు. `from_pt` లేదా `from_tf` పరామితి మోడల్ను ఒక ఫ్రేమ్వర్క్ నుండి మరొక ఫ్రేమ్వర్క్కి మార్చగలదు:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent>
## కస్టమ్ మోడల్ బిల్డ్స్
మోడల్ ఎలా నిర్మించబడుతుందో మార్చడానికి మీరు మోడల్ కాన్ఫిగరేషన్ క్లాస్ని సవరించవచ్చు. దాచిన లేయర్లు లేదా అటెన్షన్ హెడ్ల సంఖ్య వంటి మోడల్ లక్షణాలను కాన్ఫిగరేషన్ నిర్దేశిస్తుంది. మీరు కస్టమ్ కాన్ఫిగరేషన్ క్లాస్ నుండి మోడల్ను ప్రారంభించినప్పుడు మీరు మొదటి నుండి ప్రారంభిస్తారు. మోడల్ అట్రిబ్యూట్లు యాదృచ్ఛికంగా ప్రారంభించబడ్డాయి మరియు అర్థవంతమైన ఫలితాలను పొందడానికి మీరు మోడల్ను ఉపయోగించే ముందు దానికి శిక్షణ ఇవ్వాలి.
[`AutoConfig`]ని దిగుమతి చేయడం ద్వారా ప్రారంభించండి, ఆపై మీరు సవరించాలనుకుంటున్న ప్రీట్రైన్డ్ మోడల్ను లోడ్ చేయండి. [`AutoConfig.from_pretrained`]లో, మీరు అటెన్షన్ హెడ్ల సంఖ్య వంటి మీరు మార్చాలనుకుంటున్న లక్షణాన్ని పేర్కొనవచ్చు:
```py
>>> from transformers import AutoConfig
>>> my_config = AutoConfig.from_pretrained("distilbert-base-uncased", n_heads=12)
```
<frameworkcontent>
<pt>
[`AutoModel.from_config`]తో మీ అనుకూల కాన్ఫిగరేషన్ నుండి మోడల్ను సృష్టించండి:
```py
>>> from transformers import AutoModel
>>> my_model = AutoModel.from_config(my_config)
```
</pt>
<tf>
[`TFAutoModel.from_config`]తో మీ అనుకూల కాన్ఫిగరేషన్ నుండి మోడల్ను సృష్టించండి:
```py
>>> from transformers import TFAutoModel
>>> my_model = TFAutoModel.from_config(my_config)
```
</tf>
</frameworkcontent>
అనుకూల కాన్ఫిగరేషన్లను రూపొందించడం గురించి మరింత సమాచారం కోసం [కస్టమ్ ఆర్కిటెక్చర్ని సృష్టించండి](./create_a_model) గైడ్ను చూడండి.
## శిక్షకుడు - పైటార్చ్ ఆప్టిమైజ్ చేసిన శిక్షణ లూప్
అన్ని మోడల్లు ప్రామాణికమైన [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) కాబట్టి మీరు వాటిని ఏదైనా సాధారణ శిక్షణ లూప్లో ఉపయోగించవచ్చు. మీరు మీ స్వంత శిక్షణ లూప్ను వ్రాయగలిగినప్పటికీ, 🤗 ట్రాన్స్ఫార్మర్లు PyTorch కోసం [`ట్రైనర్`] తరగతిని అందజేస్తాయి, ఇందులో ప్రాథమిక శిక్షణ లూప్ ఉంటుంది మరియు పంపిణీ చేయబడిన శిక్షణ, మిశ్రమ ఖచ్చితత్వం మరియు మరిన్ని వంటి ఫీచర్ల కోసం అదనపు కార్యాచరణను జోడిస్తుంది.
మీ విధిని బట్టి, మీరు సాధారణంగా కింది పారామితులను [`ట్రైనర్`]కి పంపుతారు:
1. మీరు [`PreTrainedModel`] లేదా [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)తో ప్రారంభిస్తారు:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. [`TrainingArguments`] మీరు నేర్చుకునే రేటు, బ్యాచ్ పరిమాణం మరియు శిక్షణ పొందవలసిన యుగాల సంఖ్య వంటి మార్చగల మోడల్ హైపర్పారామీటర్లను కలిగి ఉంది. మీరు ఎలాంటి శిక్షణా వాదనలను పేర్కొనకుంటే డిఫాల్ట్ విలువలు ఉపయోగించబడతాయి:
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(
... output_dir="path/to/save/folder/",
... learning_rate=2e-5,
... per_device_train_batch_size=8,
... per_device_eval_batch_size=8,
... num_train_epochs=2,
... )
```
3. టోకెనైజర్, ఇమేజ్ ప్రాసెసర్, ఫీచర్ ఎక్స్ట్రాక్టర్ లేదా ప్రాసెసర్ వంటి ప్రీప్రాసెసింగ్ క్లాస్ని లోడ్ చేయండి:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
4. డేటాసెట్ను లోడ్ చేయండి:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
```
5. డేటాసెట్ను టోకనైజ్ చేయడానికి ఒక ఫంక్షన్ను సృష్టించండి:
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"])
```
ఆపై దానిని [`~datasets.Dataset.map`]తో మొత్తం డేటాసెట్లో వర్తింపజేయండి:
```py
>>> dataset = dataset.map(tokenize_dataset, batched=True)
```
6. మీ డేటాసెట్ నుండి ఉదాహరణల సమూహాన్ని సృష్టించడానికి [`DataCollatorWithPadding`]:
```py
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
ఇప్పుడు ఈ తరగతులన్నింటినీ [`Trainer`]లో సేకరించండి:
```py
>>> from transformers import Trainer
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
మీరు సిద్ధంగా ఉన్నప్పుడు, శిక్షణను ప్రారంభించడానికి [`~Trainer.train`]కి కాల్ చేయండి:
```py
>>> trainer.train() # doctest: +SKIP
```
<Tip>
సీక్వెన్స్-టు-సీక్వెన్స్ మోడల్ని ఉపయోగించే - అనువాదం లేదా సారాంశం వంటి పనుల కోసం, బదులుగా [`Seq2SeqTrainer`] మరియు [`Seq2SeqTrainingArguments`] తరగతులను ఉపయోగించండి.
</Tip>
మీరు [`Trainer`] లోపల ఉన్న పద్ధతులను ఉపవర్గీకరించడం ద్వారా శిక్షణ లూప్ ప్రవర్తనను అనుకూలీకరించవచ్చు. ఇది లాస్ ఫంక్షన్, ఆప్టిమైజర్ మరియు షెడ్యూలర్ వంటి లక్షణాలను అనుకూలీకరించడానికి మిమ్మల్ని అనుమతిస్తుంది. ఉపవర్గీకరించబడే పద్ధతుల కోసం [`Trainer`] సూచనను పరిశీలించండి.
శిక్షణ లూప్ను అనుకూలీకరించడానికి మరొక మార్గం [కాల్బ్యాక్లు](./main_classes/callbacks). మీరు ఇతర లైబ్రరీలతో అనుసంధానం చేయడానికి కాల్బ్యాక్లను ఉపయోగించవచ్చు మరియు పురోగతిపై నివేదించడానికి శిక్షణ లూప్ను తనిఖీ చేయవచ్చు లేదా శిక్షణను ముందుగానే ఆపవచ్చు. శిక్షణ లూప్లోనే కాల్బ్యాక్లు దేనినీ సవరించవు. లాస్ ఫంక్షన్ వంటివాటిని అనుకూలీకరించడానికి, మీరు బదులుగా [`Trainer`]ని ఉపవర్గం చేయాలి.
## TensorFlowతో శిక్షణ పొందండి
అన్ని మోడల్లు ప్రామాణికమైన [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) కాబట్టి వాటిని [Keras]తో TensorFlowలో శిక్షణ పొందవచ్చు(https: //keras.io/) API. 🤗 ట్రాన్స్ఫార్మర్లు మీ డేటాసెట్ని సులభంగా `tf.data.Dataset`గా లోడ్ చేయడానికి [`~TFPreTrainedModel.prepare_tf_dataset`] పద్ధతిని అందజేస్తుంది కాబట్టి మీరు వెంటనే Keras' [`compile`](https://keras.io /api/models/model_training_apis/#compile-method) మరియు [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) పద్ధతులు.
1. మీరు [`TFPreTrainedModel`] లేదా [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)తో ప్రారంభిస్తారు:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. టోకెనైజర్, ఇమేజ్ ప్రాసెసర్, ఫీచర్ ఎక్స్ట్రాక్టర్ లేదా ప్రాసెసర్ వంటి ప్రీప్రాసెసింగ్ క్లాస్ని లోడ్ చేయండి:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
3. డేటాసెట్ను టోకనైజ్ చేయడానికి ఒక ఫంక్షన్ను సృష్టించండి:
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"]) # doctest: +SKIP
```
4. [`~datasets.Dataset.map`]తో మొత్తం డేటాసెట్పై టోకెనైజర్ని వర్తింపజేయి, ఆపై డేటాసెట్ మరియు టోకెనైజర్ను [`~TFPreTrainedModel.prepare_tf_dataset`]కి పంపండి. మీరు కావాలనుకుంటే బ్యాచ్ పరిమాణాన్ని కూడా మార్చవచ్చు మరియు డేటాసెట్ను ఇక్కడ షఫుల్ చేయవచ్చు:
```py
>>> dataset = dataset.map(tokenize_dataset) # doctest: +SKIP
>>> tf_dataset = model.prepare_tf_dataset(
... dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer
... ) # doctest: +SKIP
```
5. మీరు సిద్ధంగా ఉన్నప్పుడు, శిక్షణను ప్రారంభించడానికి మీరు `కంపైల్` మరియు `ఫిట్`కి కాల్ చేయవచ్చు. ట్రాన్స్ఫార్మర్స్ మోడల్స్ అన్నీ డిఫాల్ట్ టాస్క్-సంబంధిత లాస్ ఫంక్షన్ని కలిగి ఉన్నాయని గుర్తుంచుకోండి, కాబట్టి మీరు కోరుకునే వరకు మీరు ఒకదానిని పేర్కొనవలసిన అవసరం లేదు:
```py
>>> from tensorflow.keras.optimizers import Adam
>>> model.compile(optimizer=Adam(3e-5)) # No loss argument!
>>> model.fit(tf_dataset) # doctest: +SKIP
```
## తరవాత ఏంటి?
ఇప్పుడు మీరు 🤗 ట్రాన్స్ఫార్మర్స్ త్వరిత పర్యటనను పూర్తి చేసారు, మా గైడ్లను తనిఖీ చేయండి మరియు అనుకూల మోడల్ను వ్రాయడం, టాస్క్ కోసం మోడల్ను చక్కగా తీర్చిదిద్దడం మరియు స్క్రిప్ట్తో మోడల్కు శిక్షణ ఇవ్వడం వంటి మరింత నిర్దిష్టమైన పనులను ఎలా చేయాలో తెలుసుకోండి. 🤗 ట్రాన్స్ఫార్మర్స్ కోర్ కాన్సెప్ట్ల గురించి మరింత తెలుసుకోవడానికి మీకు ఆసక్తి ఉంటే, ఒక కప్పు కాఫీ తాగి, మా కాన్సెప్టువల్ గైడ్లను చూడండి!
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_repo.py
|
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utility that performs several consistency checks on the repo. This includes:
- checking all models are properly defined in the __init__ of models/
- checking all models are in the main __init__
- checking all models are properly tested
- checking all object in the main __init__ are documented
- checking all models are in at least one auto class
- checking all the auto mapping are properly defined (no typos, importable)
- checking the list of deprecated models is up to date
Use from the root of the repo with (as used in `make repo-consistency`):
```bash
python utils/check_repo.py
```
It has no auto-fix mode.
"""
import inspect
import os
import re
import sys
import types
import warnings
from collections import OrderedDict
from difflib import get_close_matches
from pathlib import Path
from typing import List, Tuple
from transformers import is_flax_available, is_tf_available, is_torch_available
from transformers.models.auto import get_values
from transformers.models.auto.configuration_auto import CONFIG_MAPPING_NAMES
from transformers.models.auto.feature_extraction_auto import FEATURE_EXTRACTOR_MAPPING_NAMES
from transformers.models.auto.image_processing_auto import IMAGE_PROCESSOR_MAPPING_NAMES
from transformers.models.auto.processing_auto import PROCESSOR_MAPPING_NAMES
from transformers.models.auto.tokenization_auto import TOKENIZER_MAPPING_NAMES
from transformers.utils import ENV_VARS_TRUE_VALUES, direct_transformers_import
# All paths are set with the intent you should run this script from the root of the repo with the command
# python utils/check_repo.py
PATH_TO_TRANSFORMERS = "src/transformers"
PATH_TO_TESTS = "tests"
PATH_TO_DOC = "docs/source/en"
# Update this list with models that are supposed to be private.
PRIVATE_MODELS = [
"AltRobertaModel",
"DPRSpanPredictor",
"LongT5Stack",
"RealmBertModel",
"T5Stack",
"MT5Stack",
"UMT5Stack",
"Pop2PianoStack",
"SwitchTransformersStack",
"TFDPRSpanPredictor",
"MaskFormerSwinModel",
"MaskFormerSwinPreTrainedModel",
"BridgeTowerTextModel",
"BridgeTowerVisionModel",
"Kosmos2TextModel",
"Kosmos2TextForCausalLM",
"Kosmos2VisionModel",
]
# Update this list for models that are not tested with a comment explaining the reason it should not be.
# Being in this list is an exception and should **not** be the rule.
IGNORE_NON_TESTED = PRIVATE_MODELS.copy() + [
# models to ignore for not tested
"FuyuForCausalLM", # Not tested fort now
"InstructBlipQFormerModel", # Building part of bigger (tested) model.
"UMT5EncoderModel", # Building part of bigger (tested) model.
"Blip2QFormerModel", # Building part of bigger (tested) model.
"ErnieMForInformationExtraction",
"GraphormerDecoderHead", # Building part of bigger (tested) model.
"JukeboxVQVAE", # Building part of bigger (tested) model.
"JukeboxPrior", # Building part of bigger (tested) model.
"DecisionTransformerGPT2Model", # Building part of bigger (tested) model.
"SegformerDecodeHead", # Building part of bigger (tested) model.
"MgpstrModel", # Building part of bigger (tested) model.
"BertLMHeadModel", # Needs to be setup as decoder.
"MegatronBertLMHeadModel", # Building part of bigger (tested) model.
"RealmBertModel", # Building part of bigger (tested) model.
"RealmReader", # Not regular model.
"RealmScorer", # Not regular model.
"RealmForOpenQA", # Not regular model.
"ReformerForMaskedLM", # Needs to be setup as decoder.
"TFElectraMainLayer", # Building part of bigger (tested) model (should it be a TFPreTrainedModel ?)
"TFRobertaForMultipleChoice", # TODO: fix
"TFRobertaPreLayerNormForMultipleChoice", # TODO: fix
"SeparableConv1D", # Building part of bigger (tested) model.
"FlaxBartForCausalLM", # Building part of bigger (tested) model.
"FlaxBertForCausalLM", # Building part of bigger (tested) model. Tested implicitly through FlaxRobertaForCausalLM.
"OPTDecoderWrapper",
"TFSegformerDecodeHead", # Not a regular model.
"AltRobertaModel", # Building part of bigger (tested) model.
"BlipTextLMHeadModel", # No need to test it as it is tested by BlipTextVision models
"TFBlipTextLMHeadModel", # No need to test it as it is tested by BlipTextVision models
"BridgeTowerTextModel", # No need to test it as it is tested by BridgeTowerModel model.
"BridgeTowerVisionModel", # No need to test it as it is tested by BridgeTowerModel model.
"BarkCausalModel", # Building part of bigger (tested) model.
"BarkModel", # Does not have a forward signature - generation tested with integration tests.
"SeamlessM4TTextToUnitModel", # Building part of bigger (tested) model.
"SeamlessM4TCodeHifiGan", # Building part of bigger (tested) model.
"SeamlessM4TTextToUnitForConditionalGeneration", # Building part of bigger (tested) model.
]
# Update this list with test files that don't have a tester with a `all_model_classes` variable and which don't
# trigger the common tests.
TEST_FILES_WITH_NO_COMMON_TESTS = [
"models/decision_transformer/test_modeling_decision_transformer.py",
"models/camembert/test_modeling_camembert.py",
"models/mt5/test_modeling_flax_mt5.py",
"models/mbart/test_modeling_mbart.py",
"models/mt5/test_modeling_mt5.py",
"models/pegasus/test_modeling_pegasus.py",
"models/camembert/test_modeling_tf_camembert.py",
"models/mt5/test_modeling_tf_mt5.py",
"models/xlm_roberta/test_modeling_tf_xlm_roberta.py",
"models/xlm_roberta/test_modeling_flax_xlm_roberta.py",
"models/xlm_prophetnet/test_modeling_xlm_prophetnet.py",
"models/xlm_roberta/test_modeling_xlm_roberta.py",
"models/vision_text_dual_encoder/test_modeling_vision_text_dual_encoder.py",
"models/vision_text_dual_encoder/test_modeling_tf_vision_text_dual_encoder.py",
"models/vision_text_dual_encoder/test_modeling_flax_vision_text_dual_encoder.py",
"models/decision_transformer/test_modeling_decision_transformer.py",
"models/bark/test_modeling_bark.py",
]
# Update this list for models that are not in any of the auto MODEL_XXX_MAPPING. Being in this list is an exception and
# should **not** be the rule.
IGNORE_NON_AUTO_CONFIGURED = PRIVATE_MODELS.copy() + [
# models to ignore for model xxx mapping
"AlignTextModel",
"AlignVisionModel",
"ClapTextModel",
"ClapTextModelWithProjection",
"ClapAudioModel",
"ClapAudioModelWithProjection",
"Blip2ForConditionalGeneration",
"Blip2QFormerModel",
"Blip2VisionModel",
"ErnieMForInformationExtraction",
"GitVisionModel",
"GraphormerModel",
"GraphormerForGraphClassification",
"BlipForConditionalGeneration",
"BlipForImageTextRetrieval",
"BlipForQuestionAnswering",
"BlipVisionModel",
"BlipTextLMHeadModel",
"BlipTextModel",
"BrosSpadeEEForTokenClassification",
"BrosSpadeELForTokenClassification",
"TFBlipForConditionalGeneration",
"TFBlipForImageTextRetrieval",
"TFBlipForQuestionAnswering",
"TFBlipVisionModel",
"TFBlipTextLMHeadModel",
"TFBlipTextModel",
"Swin2SRForImageSuperResolution",
"BridgeTowerForImageAndTextRetrieval",
"BridgeTowerForMaskedLM",
"BridgeTowerForContrastiveLearning",
"CLIPSegForImageSegmentation",
"CLIPSegVisionModel",
"CLIPSegTextModel",
"EsmForProteinFolding",
"GPTSanJapaneseModel",
"TimeSeriesTransformerForPrediction",
"InformerForPrediction",
"AutoformerForPrediction",
"JukeboxVQVAE",
"JukeboxPrior",
"SamModel",
"DPTForDepthEstimation",
"DecisionTransformerGPT2Model",
"GLPNForDepthEstimation",
"ViltForImagesAndTextClassification",
"ViltForImageAndTextRetrieval",
"ViltForTokenClassification",
"ViltForMaskedLM",
"PerceiverForMultimodalAutoencoding",
"PerceiverForOpticalFlow",
"SegformerDecodeHead",
"TFSegformerDecodeHead",
"FlaxBeitForMaskedImageModeling",
"BeitForMaskedImageModeling",
"ChineseCLIPTextModel",
"ChineseCLIPVisionModel",
"CLIPTextModel",
"CLIPTextModelWithProjection",
"CLIPVisionModel",
"CLIPVisionModelWithProjection",
"ClvpForCausalLM",
"ClvpModel",
"GroupViTTextModel",
"GroupViTVisionModel",
"TFCLIPTextModel",
"TFCLIPVisionModel",
"TFGroupViTTextModel",
"TFGroupViTVisionModel",
"FlaxCLIPTextModel",
"FlaxCLIPTextModelWithProjection",
"FlaxCLIPVisionModel",
"FlaxWav2Vec2ForCTC",
"DetrForSegmentation",
"Pix2StructVisionModel",
"Pix2StructTextModel",
"Pix2StructForConditionalGeneration",
"ConditionalDetrForSegmentation",
"DPRReader",
"FlaubertForQuestionAnswering",
"FlavaImageCodebook",
"FlavaTextModel",
"FlavaImageModel",
"FlavaMultimodalModel",
"GPT2DoubleHeadsModel",
"GPTSw3DoubleHeadsModel",
"InstructBlipVisionModel",
"InstructBlipQFormerModel",
"LayoutLMForQuestionAnswering",
"LukeForMaskedLM",
"LukeForEntityClassification",
"LukeForEntityPairClassification",
"LukeForEntitySpanClassification",
"MgpstrModel",
"OpenAIGPTDoubleHeadsModel",
"OwlViTTextModel",
"OwlViTVisionModel",
"Owlv2TextModel",
"Owlv2VisionModel",
"OwlViTForObjectDetection",
"RagModel",
"RagSequenceForGeneration",
"RagTokenForGeneration",
"RealmEmbedder",
"RealmForOpenQA",
"RealmScorer",
"RealmReader",
"TFDPRReader",
"TFGPT2DoubleHeadsModel",
"TFLayoutLMForQuestionAnswering",
"TFOpenAIGPTDoubleHeadsModel",
"TFRagModel",
"TFRagSequenceForGeneration",
"TFRagTokenForGeneration",
"Wav2Vec2ForCTC",
"HubertForCTC",
"SEWForCTC",
"SEWDForCTC",
"XLMForQuestionAnswering",
"XLNetForQuestionAnswering",
"SeparableConv1D",
"VisualBertForRegionToPhraseAlignment",
"VisualBertForVisualReasoning",
"VisualBertForQuestionAnswering",
"VisualBertForMultipleChoice",
"TFWav2Vec2ForCTC",
"TFHubertForCTC",
"XCLIPVisionModel",
"XCLIPTextModel",
"AltCLIPTextModel",
"AltCLIPVisionModel",
"AltRobertaModel",
"TvltForAudioVisualClassification",
"BarkCausalModel",
"BarkCoarseModel",
"BarkFineModel",
"BarkSemanticModel",
"MusicgenModel",
"MusicgenForConditionalGeneration",
"SpeechT5ForSpeechToSpeech",
"SpeechT5ForTextToSpeech",
"SpeechT5HifiGan",
"VitMatteForImageMatting",
"SeamlessM4TTextToUnitModel",
"SeamlessM4TTextToUnitForConditionalGeneration",
"SeamlessM4TCodeHifiGan",
"SeamlessM4TForSpeechToSpeech", # no auto class for speech-to-speech
"TvpForVideoGrounding",
]
# DO NOT edit this list!
# (The corresponding pytorch objects should never have been in the main `__init__`, but it's too late to remove)
OBJECT_TO_SKIP_IN_MAIN_INIT_CHECK = [
"FlaxBertLayer",
"FlaxBigBirdLayer",
"FlaxRoFormerLayer",
"TFBertLayer",
"TFLxmertEncoder",
"TFLxmertXLayer",
"TFMPNetLayer",
"TFMobileBertLayer",
"TFSegformerLayer",
"TFViTMAELayer",
]
# Update this list for models that have multiple model types for the same model doc.
MODEL_TYPE_TO_DOC_MAPPING = OrderedDict(
[
("data2vec-text", "data2vec"),
("data2vec-audio", "data2vec"),
("data2vec-vision", "data2vec"),
("donut-swin", "donut"),
]
)
# This is to make sure the transformers module imported is the one in the repo.
transformers = direct_transformers_import(PATH_TO_TRANSFORMERS)
def check_missing_backends():
"""
Checks if all backends are installed (otherwise the check of this script is incomplete). Will error in the CI if
that's not the case but only throw a warning for users running this.
"""
missing_backends = []
if not is_torch_available():
missing_backends.append("PyTorch")
if not is_tf_available():
missing_backends.append("TensorFlow")
if not is_flax_available():
missing_backends.append("Flax")
if len(missing_backends) > 0:
missing = ", ".join(missing_backends)
if os.getenv("TRANSFORMERS_IS_CI", "").upper() in ENV_VARS_TRUE_VALUES:
raise Exception(
"Full repo consistency checks require all backends to be installed (with `pip install -e .[dev]` in the "
f"Transformers repo, the following are missing: {missing}."
)
else:
warnings.warn(
"Full repo consistency checks require all backends to be installed (with `pip install -e .[dev]` in the "
f"Transformers repo, the following are missing: {missing}. While it's probably fine as long as you "
"didn't make any change in one of those backends modeling files, you should probably execute the "
"command above to be on the safe side."
)
def check_model_list():
"""
Checks the model listed as subfolders of `models` match the models available in `transformers.models`.
"""
# Get the models from the directory structure of `src/transformers/models/`
models_dir = os.path.join(PATH_TO_TRANSFORMERS, "models")
_models = []
for model in os.listdir(models_dir):
if model == "deprecated":
continue
model_dir = os.path.join(models_dir, model)
if os.path.isdir(model_dir) and "__init__.py" in os.listdir(model_dir):
_models.append(model)
# Get the models in the submodule `transformers.models`
models = [model for model in dir(transformers.models) if not model.startswith("__")]
missing_models = sorted(set(_models).difference(models))
if missing_models:
raise Exception(
f"The following models should be included in {models_dir}/__init__.py: {','.join(missing_models)}."
)
# If some modeling modules should be ignored for all checks, they should be added in the nested list
# _ignore_modules of this function.
def get_model_modules() -> List[str]:
"""Get all the model modules inside the transformers library (except deprecated models)."""
_ignore_modules = [
"modeling_auto",
"modeling_encoder_decoder",
"modeling_marian",
"modeling_mmbt",
"modeling_outputs",
"modeling_retribert",
"modeling_utils",
"modeling_flax_auto",
"modeling_flax_encoder_decoder",
"modeling_flax_utils",
"modeling_speech_encoder_decoder",
"modeling_flax_speech_encoder_decoder",
"modeling_flax_vision_encoder_decoder",
"modeling_timm_backbone",
"modeling_tf_auto",
"modeling_tf_encoder_decoder",
"modeling_tf_outputs",
"modeling_tf_pytorch_utils",
"modeling_tf_utils",
"modeling_tf_vision_encoder_decoder",
"modeling_vision_encoder_decoder",
]
modules = []
for model in dir(transformers.models):
# There are some magic dunder attributes in the dir, we ignore them
if model == "deprecated" or model.startswith("__"):
continue
model_module = getattr(transformers.models, model)
for submodule in dir(model_module):
if submodule.startswith("modeling") and submodule not in _ignore_modules:
modeling_module = getattr(model_module, submodule)
if inspect.ismodule(modeling_module):
modules.append(modeling_module)
return modules
def get_models(module: types.ModuleType, include_pretrained: bool = False) -> List[Tuple[str, type]]:
"""
Get the objects in a module that are models.
Args:
module (`types.ModuleType`):
The module from which we are extracting models.
include_pretrained (`bool`, *optional*, defaults to `False`):
Whether or not to include the `PreTrainedModel` subclass (like `BertPreTrainedModel`) or not.
Returns:
List[Tuple[str, type]]: List of models as tuples (class name, actual class).
"""
models = []
model_classes = (transformers.PreTrainedModel, transformers.TFPreTrainedModel, transformers.FlaxPreTrainedModel)
for attr_name in dir(module):
if not include_pretrained and ("Pretrained" in attr_name or "PreTrained" in attr_name):
continue
attr = getattr(module, attr_name)
if isinstance(attr, type) and issubclass(attr, model_classes) and attr.__module__ == module.__name__:
models.append((attr_name, attr))
return models
def is_building_block(model: str) -> bool:
"""
Returns `True` if a model is a building block part of a bigger model.
"""
if model.endswith("Wrapper"):
return True
if model.endswith("Encoder"):
return True
if model.endswith("Decoder"):
return True
if model.endswith("Prenet"):
return True
def is_a_private_model(model: str) -> bool:
"""Returns `True` if the model should not be in the main init."""
if model in PRIVATE_MODELS:
return True
return is_building_block(model)
def check_models_are_in_init():
"""Checks all models defined in the library are in the main init."""
models_not_in_init = []
dir_transformers = dir(transformers)
for module in get_model_modules():
models_not_in_init += [
model[0] for model in get_models(module, include_pretrained=True) if model[0] not in dir_transformers
]
# Remove private models
models_not_in_init = [model for model in models_not_in_init if not is_a_private_model(model)]
if len(models_not_in_init) > 0:
raise Exception(f"The following models should be in the main init: {','.join(models_not_in_init)}.")
# If some test_modeling files should be ignored when checking models are all tested, they should be added in the
# nested list _ignore_files of this function.
def get_model_test_files() -> List[str]:
"""
Get the model test files.
Returns:
`List[str]`: The list of test files. The returned files will NOT contain the `tests` (i.e. `PATH_TO_TESTS`
defined in this script). They will be considered as paths relative to `tests`. A caller has to use
`os.path.join(PATH_TO_TESTS, ...)` to access the files.
"""
_ignore_files = [
"test_modeling_common",
"test_modeling_encoder_decoder",
"test_modeling_flax_encoder_decoder",
"test_modeling_flax_speech_encoder_decoder",
"test_modeling_marian",
"test_modeling_tf_common",
"test_modeling_tf_encoder_decoder",
]
test_files = []
model_test_root = os.path.join(PATH_TO_TESTS, "models")
model_test_dirs = []
for x in os.listdir(model_test_root):
x = os.path.join(model_test_root, x)
if os.path.isdir(x):
model_test_dirs.append(x)
for target_dir in [PATH_TO_TESTS] + model_test_dirs:
for file_or_dir in os.listdir(target_dir):
path = os.path.join(target_dir, file_or_dir)
if os.path.isfile(path):
filename = os.path.split(path)[-1]
if "test_modeling" in filename and os.path.splitext(filename)[0] not in _ignore_files:
file = os.path.join(*path.split(os.sep)[1:])
test_files.append(file)
return test_files
# This is a bit hacky but I didn't find a way to import the test_file as a module and read inside the tester class
# for the all_model_classes variable.
def find_tested_models(test_file: str) -> List[str]:
"""
Parse the content of test_file to detect what's in `all_model_classes`. This detects the models that inherit from
the common test class.
Args:
test_file (`str`): The path to the test file to check
Returns:
`List[str]`: The list of models tested in that file.
"""
with open(os.path.join(PATH_TO_TESTS, test_file), "r", encoding="utf-8", newline="\n") as f:
content = f.read()
all_models = re.findall(r"all_model_classes\s+=\s+\(\s*\(([^\)]*)\)", content)
# Check with one less parenthesis as well
all_models += re.findall(r"all_model_classes\s+=\s+\(([^\)]*)\)", content)
if len(all_models) > 0:
model_tested = []
for entry in all_models:
for line in entry.split(","):
name = line.strip()
if len(name) > 0:
model_tested.append(name)
return model_tested
def should_be_tested(model_name: str) -> bool:
"""
Whether or not a model should be tested.
"""
if model_name in IGNORE_NON_TESTED:
return False
return not is_building_block(model_name)
def check_models_are_tested(module: types.ModuleType, test_file: str) -> List[str]:
"""Check models defined in a module are all tested in a given file.
Args:
module (`types.ModuleType`): The module in which we get the models.
test_file (`str`): The path to the file where the module is tested.
Returns:
`List[str]`: The list of error messages corresponding to models not tested.
"""
# XxxPreTrainedModel are not tested
defined_models = get_models(module)
tested_models = find_tested_models(test_file)
if tested_models is None:
if test_file.replace(os.path.sep, "/") in TEST_FILES_WITH_NO_COMMON_TESTS:
return
return [
f"{test_file} should define `all_model_classes` to apply common tests to the models it tests. "
+ "If this intentional, add the test filename to `TEST_FILES_WITH_NO_COMMON_TESTS` in the file "
+ "`utils/check_repo.py`."
]
failures = []
for model_name, _ in defined_models:
if model_name not in tested_models and should_be_tested(model_name):
failures.append(
f"{model_name} is defined in {module.__name__} but is not tested in "
+ f"{os.path.join(PATH_TO_TESTS, test_file)}. Add it to the all_model_classes in that file."
+ "If common tests should not applied to that model, add its name to `IGNORE_NON_TESTED`"
+ "in the file `utils/check_repo.py`."
)
return failures
def check_all_models_are_tested():
"""Check all models are properly tested."""
modules = get_model_modules()
test_files = get_model_test_files()
failures = []
for module in modules:
# Matches a module to its test file.
test_file = [file for file in test_files if f"test_{module.__name__.split('.')[-1]}.py" in file]
if len(test_file) == 0:
failures.append(f"{module.__name__} does not have its corresponding test file {test_file}.")
elif len(test_file) > 1:
failures.append(f"{module.__name__} has several test files: {test_file}.")
else:
test_file = test_file[0]
new_failures = check_models_are_tested(module, test_file)
if new_failures is not None:
failures += new_failures
if len(failures) > 0:
raise Exception(f"There were {len(failures)} failures:\n" + "\n".join(failures))
def get_all_auto_configured_models() -> List[str]:
"""Return the list of all models in at least one auto class."""
result = set() # To avoid duplicates we concatenate all model classes in a set.
if is_torch_available():
for attr_name in dir(transformers.models.auto.modeling_auto):
if attr_name.startswith("MODEL_") and attr_name.endswith("MAPPING_NAMES"):
result = result | set(get_values(getattr(transformers.models.auto.modeling_auto, attr_name)))
if is_tf_available():
for attr_name in dir(transformers.models.auto.modeling_tf_auto):
if attr_name.startswith("TF_MODEL_") and attr_name.endswith("MAPPING_NAMES"):
result = result | set(get_values(getattr(transformers.models.auto.modeling_tf_auto, attr_name)))
if is_flax_available():
for attr_name in dir(transformers.models.auto.modeling_flax_auto):
if attr_name.startswith("FLAX_MODEL_") and attr_name.endswith("MAPPING_NAMES"):
result = result | set(get_values(getattr(transformers.models.auto.modeling_flax_auto, attr_name)))
return list(result)
def ignore_unautoclassed(model_name: str) -> bool:
"""Rules to determine if a model should be in an auto class."""
# Special white list
if model_name in IGNORE_NON_AUTO_CONFIGURED:
return True
# Encoder and Decoder should be ignored
if "Encoder" in model_name or "Decoder" in model_name:
return True
return False
def check_models_are_auto_configured(module: types.ModuleType, all_auto_models: List[str]) -> List[str]:
"""
Check models defined in module are each in an auto class.
Args:
module (`types.ModuleType`):
The module in which we get the models.
all_auto_models (`List[str]`):
The list of all models in an auto class (as obtained with `get_all_auto_configured_models()`).
Returns:
`List[str]`: The list of error messages corresponding to models not tested.
"""
defined_models = get_models(module)
failures = []
for model_name, _ in defined_models:
if model_name not in all_auto_models and not ignore_unautoclassed(model_name):
failures.append(
f"{model_name} is defined in {module.__name__} but is not present in any of the auto mapping. "
"If that is intended behavior, add its name to `IGNORE_NON_AUTO_CONFIGURED` in the file "
"`utils/check_repo.py`."
)
return failures
def check_all_models_are_auto_configured():
"""Check all models are each in an auto class."""
# This is where we need to check we have all backends or the check is incomplete.
check_missing_backends()
modules = get_model_modules()
all_auto_models = get_all_auto_configured_models()
failures = []
for module in modules:
new_failures = check_models_are_auto_configured(module, all_auto_models)
if new_failures is not None:
failures += new_failures
if len(failures) > 0:
raise Exception(f"There were {len(failures)} failures:\n" + "\n".join(failures))
def check_all_auto_object_names_being_defined():
"""Check all names defined in auto (name) mappings exist in the library."""
# This is where we need to check we have all backends or the check is incomplete.
check_missing_backends()
failures = []
mappings_to_check = {
"TOKENIZER_MAPPING_NAMES": TOKENIZER_MAPPING_NAMES,
"IMAGE_PROCESSOR_MAPPING_NAMES": IMAGE_PROCESSOR_MAPPING_NAMES,
"FEATURE_EXTRACTOR_MAPPING_NAMES": FEATURE_EXTRACTOR_MAPPING_NAMES,
"PROCESSOR_MAPPING_NAMES": PROCESSOR_MAPPING_NAMES,
}
# Each auto modeling files contains multiple mappings. Let's get them in a dynamic way.
for module_name in ["modeling_auto", "modeling_tf_auto", "modeling_flax_auto"]:
module = getattr(transformers.models.auto, module_name, None)
if module is None:
continue
# all mappings in a single auto modeling file
mapping_names = [x for x in dir(module) if x.endswith("_MAPPING_NAMES")]
mappings_to_check.update({name: getattr(module, name) for name in mapping_names})
for name, mapping in mappings_to_check.items():
for _, class_names in mapping.items():
if not isinstance(class_names, tuple):
class_names = (class_names,)
for class_name in class_names:
if class_name is None:
continue
# dummy object is accepted
if not hasattr(transformers, class_name):
# If the class name is in a model name mapping, let's not check if there is a definition in any modeling
# module, if it's a private model defined in this file.
if name.endswith("MODEL_MAPPING_NAMES") and is_a_private_model(class_name):
continue
failures.append(
f"`{class_name}` appears in the mapping `{name}` but it is not defined in the library."
)
if len(failures) > 0:
raise Exception(f"There were {len(failures)} failures:\n" + "\n".join(failures))
def check_all_auto_mapping_names_in_config_mapping_names():
"""Check all keys defined in auto mappings (mappings of names) appear in `CONFIG_MAPPING_NAMES`."""
# This is where we need to check we have all backends or the check is incomplete.
check_missing_backends()
failures = []
# `TOKENIZER_PROCESSOR_MAPPING_NAMES` and `AutoTokenizer` is special, and don't need to follow the rule.
mappings_to_check = {
"IMAGE_PROCESSOR_MAPPING_NAMES": IMAGE_PROCESSOR_MAPPING_NAMES,
"FEATURE_EXTRACTOR_MAPPING_NAMES": FEATURE_EXTRACTOR_MAPPING_NAMES,
"PROCESSOR_MAPPING_NAMES": PROCESSOR_MAPPING_NAMES,
}
# Each auto modeling files contains multiple mappings. Let's get them in a dynamic way.
for module_name in ["modeling_auto", "modeling_tf_auto", "modeling_flax_auto"]:
module = getattr(transformers.models.auto, module_name, None)
if module is None:
continue
# all mappings in a single auto modeling file
mapping_names = [x for x in dir(module) if x.endswith("_MAPPING_NAMES")]
mappings_to_check.update({name: getattr(module, name) for name in mapping_names})
for name, mapping in mappings_to_check.items():
for model_type in mapping:
if model_type not in CONFIG_MAPPING_NAMES:
failures.append(
f"`{model_type}` appears in the mapping `{name}` but it is not defined in the keys of "
"`CONFIG_MAPPING_NAMES`."
)
if len(failures) > 0:
raise Exception(f"There were {len(failures)} failures:\n" + "\n".join(failures))
def check_all_auto_mappings_importable():
"""Check all auto mappings can be imported."""
# This is where we need to check we have all backends or the check is incomplete.
check_missing_backends()
failures = []
mappings_to_check = {}
# Each auto modeling files contains multiple mappings. Let's get them in a dynamic way.
for module_name in ["modeling_auto", "modeling_tf_auto", "modeling_flax_auto"]:
module = getattr(transformers.models.auto, module_name, None)
if module is None:
continue
# all mappings in a single auto modeling file
mapping_names = [x for x in dir(module) if x.endswith("_MAPPING_NAMES")]
mappings_to_check.update({name: getattr(module, name) for name in mapping_names})
for name in mappings_to_check:
name = name.replace("_MAPPING_NAMES", "_MAPPING")
if not hasattr(transformers, name):
failures.append(f"`{name}`")
if len(failures) > 0:
raise Exception(f"There were {len(failures)} failures:\n" + "\n".join(failures))
def check_objects_being_equally_in_main_init():
"""
Check if a (TensorFlow or Flax) object is in the main __init__ iif its counterpart in PyTorch is.
"""
attrs = dir(transformers)
failures = []
for attr in attrs:
obj = getattr(transformers, attr)
if not hasattr(obj, "__module__") or "models.deprecated" in obj.__module__:
continue
module_path = obj.__module__
module_name = module_path.split(".")[-1]
module_dir = ".".join(module_path.split(".")[:-1])
if (
module_name.startswith("modeling_")
and not module_name.startswith("modeling_tf_")
and not module_name.startswith("modeling_flax_")
):
parent_module = sys.modules[module_dir]
frameworks = []
if is_tf_available():
frameworks.append("TF")
if is_flax_available():
frameworks.append("Flax")
for framework in frameworks:
other_module_path = module_path.replace("modeling_", f"modeling_{framework.lower()}_")
if os.path.isfile("src/" + other_module_path.replace(".", "/") + ".py"):
other_module_name = module_name.replace("modeling_", f"modeling_{framework.lower()}_")
other_module = getattr(parent_module, other_module_name)
if hasattr(other_module, f"{framework}{attr}"):
if not hasattr(transformers, f"{framework}{attr}"):
if f"{framework}{attr}" not in OBJECT_TO_SKIP_IN_MAIN_INIT_CHECK:
failures.append(f"{framework}{attr}")
if hasattr(other_module, f"{framework}_{attr}"):
if not hasattr(transformers, f"{framework}_{attr}"):
if f"{framework}_{attr}" not in OBJECT_TO_SKIP_IN_MAIN_INIT_CHECK:
failures.append(f"{framework}_{attr}")
if len(failures) > 0:
raise Exception(f"There were {len(failures)} failures:\n" + "\n".join(failures))
_re_decorator = re.compile(r"^\s*@(\S+)\s+$")
def check_decorator_order(filename: str) -> List[int]:
"""
Check that in a given test file, the slow decorator is always last.
Args:
filename (`str`): The path to a test file to check.
Returns:
`List[int]`: The list of failures as a list of indices where there are problems.
"""
with open(filename, "r", encoding="utf-8", newline="\n") as f:
lines = f.readlines()
decorator_before = None
errors = []
for i, line in enumerate(lines):
search = _re_decorator.search(line)
if search is not None:
decorator_name = search.groups()[0]
if decorator_before is not None and decorator_name.startswith("parameterized"):
errors.append(i)
decorator_before = decorator_name
elif decorator_before is not None:
decorator_before = None
return errors
def check_all_decorator_order():
"""Check that in all test files, the slow decorator is always last."""
errors = []
for fname in os.listdir(PATH_TO_TESTS):
if fname.endswith(".py"):
filename = os.path.join(PATH_TO_TESTS, fname)
new_errors = check_decorator_order(filename)
errors += [f"- {filename}, line {i}" for i in new_errors]
if len(errors) > 0:
msg = "\n".join(errors)
raise ValueError(
"The parameterized decorator (and its variants) should always be first, but this is not the case in the"
f" following files:\n{msg}"
)
def find_all_documented_objects() -> List[str]:
"""
Parse the content of all doc files to detect which classes and functions it documents.
Returns:
`List[str]`: The list of all object names being documented.
"""
documented_obj = []
for doc_file in Path(PATH_TO_DOC).glob("**/*.rst"):
with open(doc_file, "r", encoding="utf-8", newline="\n") as f:
content = f.read()
raw_doc_objs = re.findall(r"(?:autoclass|autofunction):: transformers.(\S+)\s+", content)
documented_obj += [obj.split(".")[-1] for obj in raw_doc_objs]
for doc_file in Path(PATH_TO_DOC).glob("**/*.md"):
with open(doc_file, "r", encoding="utf-8", newline="\n") as f:
content = f.read()
raw_doc_objs = re.findall(r"\[\[autodoc\]\]\s+(\S+)\s+", content)
documented_obj += [obj.split(".")[-1] for obj in raw_doc_objs]
return documented_obj
# One good reason for not being documented is to be deprecated. Put in this list deprecated objects.
DEPRECATED_OBJECTS = [
"AutoModelWithLMHead",
"BartPretrainedModel",
"DataCollator",
"DataCollatorForSOP",
"GlueDataset",
"GlueDataTrainingArguments",
"LineByLineTextDataset",
"LineByLineWithRefDataset",
"LineByLineWithSOPTextDataset",
"PretrainedBartModel",
"PretrainedFSMTModel",
"SingleSentenceClassificationProcessor",
"SquadDataTrainingArguments",
"SquadDataset",
"SquadExample",
"SquadFeatures",
"SquadV1Processor",
"SquadV2Processor",
"TFAutoModelWithLMHead",
"TFBartPretrainedModel",
"TextDataset",
"TextDatasetForNextSentencePrediction",
"Wav2Vec2ForMaskedLM",
"Wav2Vec2Tokenizer",
"glue_compute_metrics",
"glue_convert_examples_to_features",
"glue_output_modes",
"glue_processors",
"glue_tasks_num_labels",
"squad_convert_examples_to_features",
"xnli_compute_metrics",
"xnli_output_modes",
"xnli_processors",
"xnli_tasks_num_labels",
"TFTrainer",
"TFTrainingArguments",
]
# Exceptionally, some objects should not be documented after all rules passed.
# ONLY PUT SOMETHING IN THIS LIST AS A LAST RESORT!
UNDOCUMENTED_OBJECTS = [
"AddedToken", # This is a tokenizers class.
"BasicTokenizer", # Internal, should never have been in the main init.
"CharacterTokenizer", # Internal, should never have been in the main init.
"DPRPretrainedReader", # Like an Encoder.
"DummyObject", # Just picked by mistake sometimes.
"MecabTokenizer", # Internal, should never have been in the main init.
"ModelCard", # Internal type.
"SqueezeBertModule", # Internal building block (should have been called SqueezeBertLayer)
"TFDPRPretrainedReader", # Like an Encoder.
"TransfoXLCorpus", # Internal type.
"WordpieceTokenizer", # Internal, should never have been in the main init.
"absl", # External module
"add_end_docstrings", # Internal, should never have been in the main init.
"add_start_docstrings", # Internal, should never have been in the main init.
"convert_tf_weight_name_to_pt_weight_name", # Internal used to convert model weights
"logger", # Internal logger
"logging", # External module
"requires_backends", # Internal function
"AltRobertaModel", # Internal module
]
# This list should be empty. Objects in it should get their own doc page.
SHOULD_HAVE_THEIR_OWN_PAGE = [
# Benchmarks
"PyTorchBenchmark",
"PyTorchBenchmarkArguments",
"TensorFlowBenchmark",
"TensorFlowBenchmarkArguments",
"AutoBackbone",
"BeitBackbone",
"BitBackbone",
"ConvNextBackbone",
"ConvNextV2Backbone",
"DinatBackbone",
"Dinov2Backbone",
"FocalNetBackbone",
"MaskFormerSwinBackbone",
"MaskFormerSwinConfig",
"MaskFormerSwinModel",
"NatBackbone",
"ResNetBackbone",
"SwinBackbone",
"TimmBackbone",
"TimmBackboneConfig",
"VitDetBackbone",
]
def ignore_undocumented(name: str) -> bool:
"""Rules to determine if `name` should be undocumented (returns `True` if it should not be documented)."""
# NOT DOCUMENTED ON PURPOSE.
# Constants uppercase are not documented.
if name.isupper():
return True
# PreTrainedModels / Encoders / Decoders / Layers / Embeddings / Attention are not documented.
if (
name.endswith("PreTrainedModel")
or name.endswith("Decoder")
or name.endswith("Encoder")
or name.endswith("Layer")
or name.endswith("Embeddings")
or name.endswith("Attention")
):
return True
# Submodules are not documented.
if os.path.isdir(os.path.join(PATH_TO_TRANSFORMERS, name)) or os.path.isfile(
os.path.join(PATH_TO_TRANSFORMERS, f"{name}.py")
):
return True
# All load functions are not documented.
if name.startswith("load_tf") or name.startswith("load_pytorch"):
return True
# is_xxx_available functions are not documented.
if name.startswith("is_") and name.endswith("_available"):
return True
# Deprecated objects are not documented.
if name in DEPRECATED_OBJECTS or name in UNDOCUMENTED_OBJECTS:
return True
# MMBT model does not really work.
if name.startswith("MMBT"):
return True
if name in SHOULD_HAVE_THEIR_OWN_PAGE:
return True
return False
def check_all_objects_are_documented():
"""Check all models are properly documented."""
documented_objs = find_all_documented_objects()
modules = transformers._modules
objects = [c for c in dir(transformers) if c not in modules and not c.startswith("_")]
undocumented_objs = [c for c in objects if c not in documented_objs and not ignore_undocumented(c)]
if len(undocumented_objs) > 0:
raise Exception(
"The following objects are in the public init so should be documented:\n - "
+ "\n - ".join(undocumented_objs)
)
check_docstrings_are_in_md()
check_model_type_doc_match()
def check_model_type_doc_match():
"""Check all doc pages have a corresponding model type."""
model_doc_folder = Path(PATH_TO_DOC) / "model_doc"
model_docs = [m.stem for m in model_doc_folder.glob("*.md")]
model_types = list(transformers.models.auto.configuration_auto.MODEL_NAMES_MAPPING.keys())
model_types = [MODEL_TYPE_TO_DOC_MAPPING[m] if m in MODEL_TYPE_TO_DOC_MAPPING else m for m in model_types]
errors = []
for m in model_docs:
if m not in model_types and m != "auto":
close_matches = get_close_matches(m, model_types)
error_message = f"{m} is not a proper model identifier."
if len(close_matches) > 0:
close_matches = "/".join(close_matches)
error_message += f" Did you mean {close_matches}?"
errors.append(error_message)
if len(errors) > 0:
raise ValueError(
"Some model doc pages do not match any existing model type:\n"
+ "\n".join(errors)
+ "\nYou can add any missing model type to the `MODEL_NAMES_MAPPING` constant in "
"models/auto/configuration_auto.py."
)
# Re pattern to catch :obj:`xx`, :class:`xx`, :func:`xx` or :meth:`xx`.
_re_rst_special_words = re.compile(r":(?:obj|func|class|meth):`([^`]+)`")
# Re pattern to catch things between double backquotes.
_re_double_backquotes = re.compile(r"(^|[^`])``([^`]+)``([^`]|$)")
# Re pattern to catch example introduction.
_re_rst_example = re.compile(r"^\s*Example.*::\s*$", flags=re.MULTILINE)
def is_rst_docstring(docstring: str) -> True:
"""
Returns `True` if `docstring` is written in rst.
"""
if _re_rst_special_words.search(docstring) is not None:
return True
if _re_double_backquotes.search(docstring) is not None:
return True
if _re_rst_example.search(docstring) is not None:
return True
return False
def check_docstrings_are_in_md():
"""Check all docstrings are written in md and nor rst."""
files_with_rst = []
for file in Path(PATH_TO_TRANSFORMERS).glob("**/*.py"):
with open(file, encoding="utf-8") as f:
code = f.read()
docstrings = code.split('"""')
for idx, docstring in enumerate(docstrings):
if idx % 2 == 0 or not is_rst_docstring(docstring):
continue
files_with_rst.append(file)
break
if len(files_with_rst) > 0:
raise ValueError(
"The following files have docstrings written in rst:\n"
+ "\n".join([f"- {f}" for f in files_with_rst])
+ "\nTo fix this run `doc-builder convert path_to_py_file` after installing `doc-builder`\n"
"(`pip install git+https://github.com/huggingface/doc-builder`)"
)
def check_deprecated_constant_is_up_to_date():
"""
Check if the constant `DEPRECATED_MODELS` in `models/auto/configuration_auto.py` is up to date.
"""
deprecated_folder = os.path.join(PATH_TO_TRANSFORMERS, "models", "deprecated")
deprecated_models = [m for m in os.listdir(deprecated_folder) if not m.startswith("_")]
constant_to_check = transformers.models.auto.configuration_auto.DEPRECATED_MODELS
message = []
missing_models = sorted(set(deprecated_models) - set(constant_to_check))
if len(missing_models) != 0:
missing_models = ", ".join(missing_models)
message.append(
"The following models are in the deprecated folder, make sure to add them to `DEPRECATED_MODELS` in "
f"`models/auto/configuration_auto.py`: {missing_models}."
)
extra_models = sorted(set(constant_to_check) - set(deprecated_models))
if len(extra_models) != 0:
extra_models = ", ".join(extra_models)
message.append(
"The following models are in the `DEPRECATED_MODELS` constant but not in the deprecated folder. Either "
f"remove them from the constant or move to the deprecated folder: {extra_models}."
)
if len(message) > 0:
raise Exception("\n".join(message))
def check_repo_quality():
"""Check all models are properly tested and documented."""
print("Checking all models are included.")
check_model_list()
print("Checking all models are public.")
check_models_are_in_init()
print("Checking all models are properly tested.")
check_all_decorator_order()
check_all_models_are_tested()
print("Checking all objects are properly documented.")
check_all_objects_are_documented()
print("Checking all models are in at least one auto class.")
check_all_models_are_auto_configured()
print("Checking all names in auto name mappings are defined.")
check_all_auto_object_names_being_defined()
print("Checking all keys in auto name mappings are defined in `CONFIG_MAPPING_NAMES`.")
check_all_auto_mapping_names_in_config_mapping_names()
print("Checking all auto mappings could be imported.")
check_all_auto_mappings_importable()
print("Checking all objects are equally (across frameworks) in the main __init__.")
check_objects_being_equally_in_main_init()
print("Checking the DEPRECATED_MODELS constant is up to date.")
check_deprecated_constant_is_up_to_date()
if __name__ == "__main__":
check_repo_quality()
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_dummies.py
|
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
This script is responsible for making sure the dummies in utils/dummies_xxx.py are up to date with the main init.
Why dummies? This is to make sure that a user can always import all objects from `transformers`, even if they don't
have the necessary extra libs installed. Those objects will then raise helpful error message whenever the user tries
to access one of their methods.
Usage (from the root of the repo):
Check that the dummy files are up to date (used in `make repo-consistency`):
```bash
python utils/check_dummies.py
```
Update the dummy files if needed (used in `make fix-copies`):
```bash
python utils/check_dummies.py --fix_and_overwrite
```
"""
import argparse
import os
import re
from typing import Dict, List, Optional
# All paths are set with the intent you should run this script from the root of the repo with the command
# python utils/check_dummies.py
PATH_TO_TRANSFORMERS = "src/transformers"
# Matches is_xxx_available()
_re_backend = re.compile(r"is\_([a-z_]*)_available()")
# Matches from xxx import bla
_re_single_line_import = re.compile(r"\s+from\s+\S*\s+import\s+([^\(\s].*)\n")
# Matches if not is_xxx_available()
_re_test_backend = re.compile(r"^\s+if\s+not\s+\(?is\_[a-z_]*\_available\(\)")
# Template for the dummy objects.
DUMMY_CONSTANT = """
{0} = None
"""
DUMMY_CLASS = """
class {0}(metaclass=DummyObject):
_backends = {1}
def __init__(self, *args, **kwargs):
requires_backends(self, {1})
"""
DUMMY_FUNCTION = """
def {0}(*args, **kwargs):
requires_backends({0}, {1})
"""
def find_backend(line: str) -> Optional[str]:
"""
Find one (or multiple) backend in a code line of the init.
Args:
line (`str`): A code line in an init file.
Returns:
Optional[`str`]: If one (or several) backend is found, returns it. In the case of multiple backends (the line
contains `if is_xxx_available() and `is_yyy_available()`) returns all backends joined on `_and_` (so
`xxx_and_yyy` for instance).
"""
if _re_test_backend.search(line) is None:
return None
backends = [b[0] for b in _re_backend.findall(line)]
backends.sort()
return "_and_".join(backends)
def read_init() -> Dict[str, List[str]]:
"""
Read the init and extract backend-specific objects.
Returns:
Dict[str, List[str]]: A dictionary mapping backend name to the list of object names requiring that backend.
"""
with open(os.path.join(PATH_TO_TRANSFORMERS, "__init__.py"), "r", encoding="utf-8", newline="\n") as f:
lines = f.readlines()
# Get to the point we do the actual imports for type checking
line_index = 0
while not lines[line_index].startswith("if TYPE_CHECKING"):
line_index += 1
backend_specific_objects = {}
# Go through the end of the file
while line_index < len(lines):
# If the line is an if is_backend_available, we grab all objects associated.
backend = find_backend(lines[line_index])
if backend is not None:
while not lines[line_index].startswith(" else:"):
line_index += 1
line_index += 1
objects = []
# Until we unindent, add backend objects to the list
while len(lines[line_index]) <= 1 or lines[line_index].startswith(" " * 8):
line = lines[line_index]
single_line_import_search = _re_single_line_import.search(line)
if single_line_import_search is not None:
# Single-line imports
objects.extend(single_line_import_search.groups()[0].split(", "))
elif line.startswith(" " * 12):
# Multiple-line imports (with 3 indent level)
objects.append(line[12:-2])
line_index += 1
backend_specific_objects[backend] = objects
else:
line_index += 1
return backend_specific_objects
def create_dummy_object(name: str, backend_name: str) -> str:
"""
Create the code for a dummy object.
Args:
name (`str`): The name of the object.
backend_name (`str`): The name of the backend required for that object.
Returns:
`str`: The code of the dummy object.
"""
if name.isupper():
return DUMMY_CONSTANT.format(name)
elif name.islower():
return DUMMY_FUNCTION.format(name, backend_name)
else:
return DUMMY_CLASS.format(name, backend_name)
def create_dummy_files(backend_specific_objects: Optional[Dict[str, List[str]]] = None) -> Dict[str, str]:
"""
Create the content of the dummy files.
Args:
backend_specific_objects (`Dict[str, List[str]]`, *optional*):
The mapping backend name to list of backend-specific objects. If not passed, will be obtained by calling
`read_init()`.
Returns:
`Dict[str, str]`: A dictionary mapping backend name to code of the corresponding backend file.
"""
if backend_specific_objects is None:
backend_specific_objects = read_init()
dummy_files = {}
for backend, objects in backend_specific_objects.items():
backend_name = "[" + ", ".join(f'"{b}"' for b in backend.split("_and_")) + "]"
dummy_file = "# This file is autogenerated by the command `make fix-copies`, do not edit.\n"
dummy_file += "from ..utils import DummyObject, requires_backends\n\n"
dummy_file += "\n".join([create_dummy_object(o, backend_name) for o in objects])
dummy_files[backend] = dummy_file
return dummy_files
def check_dummies(overwrite: bool = False):
"""
Check if the dummy files are up to date and maybe `overwrite` with the right content.
Args:
overwrite (`bool`, *optional*, default to `False`):
Whether or not to overwrite the content of the dummy files. Will raise an error if they are not up to date
when `overwrite=False`.
"""
dummy_files = create_dummy_files()
# For special correspondence backend name to shortcut as used in utils/dummy_xxx_objects.py
short_names = {"torch": "pt"}
# Locate actual dummy modules and read their content.
path = os.path.join(PATH_TO_TRANSFORMERS, "utils")
dummy_file_paths = {
backend: os.path.join(path, f"dummy_{short_names.get(backend, backend)}_objects.py")
for backend in dummy_files.keys()
}
actual_dummies = {}
for backend, file_path in dummy_file_paths.items():
if os.path.isfile(file_path):
with open(file_path, "r", encoding="utf-8", newline="\n") as f:
actual_dummies[backend] = f.read()
else:
actual_dummies[backend] = ""
# Compare actual with what they should be.
for backend in dummy_files.keys():
if dummy_files[backend] != actual_dummies[backend]:
if overwrite:
print(
f"Updating transformers.utils.dummy_{short_names.get(backend, backend)}_objects.py as the main "
"__init__ has new objects."
)
with open(dummy_file_paths[backend], "w", encoding="utf-8", newline="\n") as f:
f.write(dummy_files[backend])
else:
raise ValueError(
"The main __init__ has objects that are not present in "
f"transformers.utils.dummy_{short_names.get(backend, backend)}_objects.py. Run `make fix-copies` "
"to fix this."
)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--fix_and_overwrite", action="store_true", help="Whether to fix inconsistencies.")
args = parser.parse_args()
check_dummies(args.fix_and_overwrite)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_config_docstrings.py
|
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import re
from transformers.utils import direct_transformers_import
# All paths are set with the intent you should run this script from the root of the repo with the command
# python utils/check_config_docstrings.py
PATH_TO_TRANSFORMERS = "src/transformers"
# This is to make sure the transformers module imported is the one in the repo.
transformers = direct_transformers_import(PATH_TO_TRANSFORMERS)
CONFIG_MAPPING = transformers.models.auto.configuration_auto.CONFIG_MAPPING
# Regex pattern used to find the checkpoint mentioned in the docstring of `config_class`.
# For example, `[bert-base-uncased](https://huggingface.co/bert-base-uncased)`
_re_checkpoint = re.compile(r"\[(.+?)\]\((https://huggingface\.co/.+?)\)")
CONFIG_CLASSES_TO_IGNORE_FOR_DOCSTRING_CHECKPOINT_CHECK = {
"DecisionTransformerConfig",
"EncoderDecoderConfig",
"MusicgenConfig",
"RagConfig",
"SpeechEncoderDecoderConfig",
"TimmBackboneConfig",
"VisionEncoderDecoderConfig",
"VisionTextDualEncoderConfig",
"LlamaConfig",
}
def get_checkpoint_from_config_class(config_class):
checkpoint = None
# source code of `config_class`
config_source = inspect.getsource(config_class)
checkpoints = _re_checkpoint.findall(config_source)
# Each `checkpoint` is a tuple of a checkpoint name and a checkpoint link.
# For example, `('bert-base-uncased', 'https://huggingface.co/bert-base-uncased')`
for ckpt_name, ckpt_link in checkpoints:
# allow the link to end with `/`
if ckpt_link.endswith("/"):
ckpt_link = ckpt_link[:-1]
# verify the checkpoint name corresponds to the checkpoint link
ckpt_link_from_name = f"https://huggingface.co/{ckpt_name}"
if ckpt_link == ckpt_link_from_name:
checkpoint = ckpt_name
break
return checkpoint
def check_config_docstrings_have_checkpoints():
configs_without_checkpoint = []
for config_class in list(CONFIG_MAPPING.values()):
# Skip deprecated models
if "models.deprecated" in config_class.__module__:
continue
checkpoint = get_checkpoint_from_config_class(config_class)
name = config_class.__name__
if checkpoint is None and name not in CONFIG_CLASSES_TO_IGNORE_FOR_DOCSTRING_CHECKPOINT_CHECK:
configs_without_checkpoint.append(name)
if len(configs_without_checkpoint) > 0:
message = "\n".join(sorted(configs_without_checkpoint))
raise ValueError(
f"The following configurations don't contain any valid checkpoint:\n{message}\n\n"
"The requirement is to include a link pointing to one of the models of this architecture in the "
"docstring of the config classes listed above. The link should have be a markdown format like "
"[myorg/mymodel](https://huggingface.co/myorg/mymodel)."
)
if __name__ == "__main__":
check_config_docstrings_have_checkpoints()
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/extract_warnings.py
|
import argparse
import json
import os
import time
import zipfile
from get_ci_error_statistics import download_artifact, get_artifacts_links
from transformers import logging
logger = logging.get_logger(__name__)
def extract_warnings_from_single_artifact(artifact_path, targets):
"""Extract warnings from a downloaded artifact (in .zip format)"""
selected_warnings = set()
buffer = []
def parse_line(fp):
for line in fp:
if isinstance(line, bytes):
line = line.decode("UTF-8")
if "warnings summary (final)" in line:
continue
# This means we are outside the body of a warning
elif not line.startswith(" "):
# process a single warning and move it to `selected_warnings`.
if len(buffer) > 0:
warning = "\n".join(buffer)
# Only keep the warnings specified in `targets`
if any(f": {x}: " in warning for x in targets):
selected_warnings.add(warning)
buffer.clear()
continue
else:
line = line.strip()
buffer.append(line)
if from_gh:
for filename in os.listdir(artifact_path):
file_path = os.path.join(artifact_path, filename)
if not os.path.isdir(file_path):
# read the file
if filename != "warnings.txt":
continue
with open(file_path) as fp:
parse_line(fp)
else:
try:
with zipfile.ZipFile(artifact_path) as z:
for filename in z.namelist():
if not os.path.isdir(filename):
# read the file
if filename != "warnings.txt":
continue
with z.open(filename) as fp:
parse_line(fp)
except Exception:
logger.warning(
f"{artifact_path} is either an invalid zip file or something else wrong. This file is skipped."
)
return selected_warnings
def extract_warnings(artifact_dir, targets):
"""Extract warnings from all artifact files"""
selected_warnings = set()
paths = [os.path.join(artifact_dir, p) for p in os.listdir(artifact_dir) if (p.endswith(".zip") or from_gh)]
for p in paths:
selected_warnings.update(extract_warnings_from_single_artifact(p, targets))
return selected_warnings
if __name__ == "__main__":
def list_str(values):
return values.split(",")
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument("--workflow_run_id", type=str, required=True, help="A GitHub Actions workflow run id.")
parser.add_argument(
"--output_dir",
type=str,
required=True,
help="Where to store the downloaded artifacts and other result files.",
)
parser.add_argument("--token", default=None, type=str, help="A token that has actions:read permission.")
# optional parameters
parser.add_argument(
"--targets",
default="DeprecationWarning,UserWarning,FutureWarning",
type=list_str,
help="Comma-separated list of target warning(s) which we want to extract.",
)
parser.add_argument(
"--from_gh",
action="store_true",
help="If running from a GitHub action workflow and collecting warnings from its artifacts.",
)
args = parser.parse_args()
from_gh = args.from_gh
if from_gh:
# The artifacts have to be downloaded using `actions/download-artifact@v3`
pass
else:
os.makedirs(args.output_dir, exist_ok=True)
# get download links
artifacts = get_artifacts_links(args.workflow_run_id, token=args.token)
with open(os.path.join(args.output_dir, "artifacts.json"), "w", encoding="UTF-8") as fp:
json.dump(artifacts, fp, ensure_ascii=False, indent=4)
# download artifacts
for idx, (name, url) in enumerate(artifacts.items()):
print(name)
print(url)
print("=" * 80)
download_artifact(name, url, args.output_dir, args.token)
# Be gentle to GitHub
time.sleep(1)
# extract warnings from artifacts
selected_warnings = extract_warnings(args.output_dir, args.targets)
selected_warnings = sorted(selected_warnings)
with open(os.path.join(args.output_dir, "selected_warnings.json"), "w", encoding="UTF-8") as fp:
json.dump(selected_warnings, fp, ensure_ascii=False, indent=4)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/release.py
|
# coding=utf-8
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utility that prepares the repository for releases (or patches) by updating all versions in the relevant places. It
also performs some post-release cleanup, by updating the links in the main README to respective model doc pages (from
main to stable).
To prepare for a release, use from the root of the repo on the release branch with:
```bash
python release.py
```
or use `make pre-release`.
To prepare for a patch release, use from the root of the repo on the release branch with:
```bash
python release.py --patch
```
or use `make pre-patch`.
To do the post-release cleanup, use from the root of the repo on the main branch with:
```bash
python release.py --post_release
```
or use `make post-release`.
"""
import argparse
import os
import re
import packaging.version
# All paths are defined with the intent that this script should be run from the root of the repo.
PATH_TO_EXAMPLES = "examples/"
# This maps a type of file to the pattern to look for when searching where the version is defined, as well as the
# template to follow when replacing it with the new version.
REPLACE_PATTERNS = {
"examples": (re.compile(r'^check_min_version\("[^"]+"\)\s*$', re.MULTILINE), 'check_min_version("VERSION")\n'),
"init": (re.compile(r'^__version__\s+=\s+"([^"]+)"\s*$', re.MULTILINE), '__version__ = "VERSION"\n'),
"setup": (re.compile(r'^(\s*)version\s*=\s*"[^"]+",', re.MULTILINE), r'\1version="VERSION",'),
}
# This maps a type of file to its path in Transformers
REPLACE_FILES = {
"init": "src/transformers/__init__.py",
"setup": "setup.py",
}
README_FILE = "README.md"
def update_version_in_file(fname: str, version: str, file_type: str):
"""
Update the version of Transformers in one file.
Args:
fname (`str`): The path to the file where we want to update the version.
version (`str`): The new version to set in the file.
file_type (`str`): The type of the file (should be a key in `REPLACE_PATTERNS`).
"""
with open(fname, "r", encoding="utf-8", newline="\n") as f:
code = f.read()
re_pattern, replace = REPLACE_PATTERNS[file_type]
replace = replace.replace("VERSION", version)
code = re_pattern.sub(replace, code)
with open(fname, "w", encoding="utf-8", newline="\n") as f:
f.write(code)
def update_version_in_examples(version: str):
"""
Update the version in all examples files.
Args:
version (`str`): The new version to set in the examples.
"""
for folder, directories, fnames in os.walk(PATH_TO_EXAMPLES):
# Removing some of the folders with non-actively maintained examples from the walk
if "research_projects" in directories:
directories.remove("research_projects")
if "legacy" in directories:
directories.remove("legacy")
for fname in fnames:
if fname.endswith(".py"):
update_version_in_file(os.path.join(folder, fname), version, file_type="examples")
def global_version_update(version: str, patch: bool = False):
"""
Update the version in all needed files.
Args:
version (`str`): The new version to set everywhere.
patch (`bool`, *optional*, defaults to `False`): Whether or not this is a patch release.
"""
for pattern, fname in REPLACE_FILES.items():
update_version_in_file(fname, version, pattern)
if not patch:
# We don't update the version in the examples for patch releases.
update_version_in_examples(version)
def clean_main_ref_in_model_list():
"""
Replace the links from main doc to stable doc in the model list of the README.
"""
# If the introduction or the conclusion of the list change, the prompts may need to be updated.
_start_prompt = "🤗 Transformers currently provides the following architectures"
_end_prompt = "1. Want to contribute a new model?"
with open(README_FILE, "r", encoding="utf-8", newline="\n") as f:
lines = f.readlines()
# Find the start of the list.
start_index = 0
while not lines[start_index].startswith(_start_prompt):
start_index += 1
start_index += 1
index = start_index
# Update the lines in the model list.
while not lines[index].startswith(_end_prompt):
if lines[index].startswith("1."):
lines[index] = lines[index].replace(
"https://huggingface.co/docs/transformers/main/model_doc",
"https://huggingface.co/docs/transformers/model_doc",
)
index += 1
with open(README_FILE, "w", encoding="utf-8", newline="\n") as f:
f.writelines(lines)
def get_version() -> packaging.version.Version:
"""
Reads the current version in the main __init__.
"""
with open(REPLACE_FILES["init"], "r") as f:
code = f.read()
default_version = REPLACE_PATTERNS["init"][0].search(code).groups()[0]
return packaging.version.parse(default_version)
def pre_release_work(patch: bool = False):
"""
Do all the necessary pre-release steps:
- figure out the next minor release version and ask confirmation
- update the version eveywhere
- clean-up the model list in the main README
Args:
patch (`bool`, *optional*, defaults to `False`): Whether or not this is a patch release.
"""
# First let's get the default version: base version if we are in dev, bump minor otherwise.
default_version = get_version()
if patch and default_version.is_devrelease:
raise ValueError("Can't create a patch version from the dev branch, checkout a released version!")
if default_version.is_devrelease:
default_version = default_version.base_version
elif patch:
default_version = f"{default_version.major}.{default_version.minor}.{default_version.micro + 1}"
else:
default_version = f"{default_version.major}.{default_version.minor + 1}.0"
# Now let's ask nicely if we have found the right version.
version = input(f"Which version are you releasing? [{default_version}]")
if len(version) == 0:
version = default_version
print(f"Updating version to {version}.")
global_version_update(version, patch=patch)
if not patch:
print("Cleaning main README, don't forget to run `make fix-copies`.")
clean_main_ref_in_model_list()
def post_release_work():
"""
Do all the necesarry post-release steps:
- figure out the next dev version and ask confirmation
- update the version eveywhere
- clean-up the model list in the main README
"""
# First let's get the current version
current_version = get_version()
dev_version = f"{current_version.major}.{current_version.minor + 1}.0.dev0"
current_version = current_version.base_version
# Check with the user we got that right.
version = input(f"Which version are we developing now? [{dev_version}]")
if len(version) == 0:
version = dev_version
print(f"Updating version to {version}.")
global_version_update(version)
print("Cleaning main README, don't forget to run `make fix-copies`.")
clean_main_ref_in_model_list()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--post_release", action="store_true", help="Whether this is pre or post release.")
parser.add_argument("--patch", action="store_true", help="Whether or not this is a patch release.")
args = parser.parse_args()
if not args.post_release:
pre_release_work(patch=args.patch)
elif args.patch:
print("Nothing to do after a patch :-)")
else:
post_release_work()
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_doc_toc.py
|
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
This script is responsible for cleaning the model section of the table of content by removing duplicates and sorting
the entries in alphabetical order.
Usage (from the root of the repo):
Check that the table of content is properly sorted (used in `make quality`):
```bash
python utils/check_doc_toc.py
```
Auto-sort the table of content if it is not properly sorted (used in `make style`):
```bash
python utils/check_doc_toc.py --fix_and_overwrite
```
"""
import argparse
from collections import defaultdict
from typing import List
import yaml
PATH_TO_TOC = "docs/source/en/_toctree.yml"
def clean_model_doc_toc(model_doc: List[dict]) -> List[dict]:
"""
Cleans a section of the table of content of the model documentation (one specific modality) by removing duplicates
and sorting models alphabetically.
Args:
model_doc (`List[dict]`):
The list of dictionaries extracted from the `_toctree.yml` file for this specific modality.
Returns:
`List[dict]`: List of dictionaries like the input, but cleaned up and sorted.
"""
counts = defaultdict(int)
for doc in model_doc:
counts[doc["local"]] += 1
duplicates = [key for key, value in counts.items() if value > 1]
new_doc = []
for duplicate_key in duplicates:
titles = list({doc["title"] for doc in model_doc if doc["local"] == duplicate_key})
if len(titles) > 1:
raise ValueError(
f"{duplicate_key} is present several times in the documentation table of content at "
"`docs/source/en/_toctree.yml` with different *Title* values. Choose one of those and remove the "
"others."
)
# Only add this once
new_doc.append({"local": duplicate_key, "title": titles[0]})
# Add none duplicate-keys
new_doc.extend([doc for doc in model_doc if counts[doc["local"]] == 1])
# Sort
return sorted(new_doc, key=lambda s: s["title"].lower())
def check_model_doc(overwrite: bool = False):
"""
Check that the content of the table of content in `_toctree.yml` is clean (no duplicates and sorted for the model
API doc) and potentially auto-cleans it.
Args:
overwrite (`bool`, *optional*, defaults to `False`):
Whether to just check if the TOC is clean or to auto-clean it (when `overwrite=True`).
"""
with open(PATH_TO_TOC, encoding="utf-8") as f:
content = yaml.safe_load(f.read())
# Get to the API doc
api_idx = 0
while content[api_idx]["title"] != "API":
api_idx += 1
api_doc = content[api_idx]["sections"]
# Then to the model doc
model_idx = 0
while api_doc[model_idx]["title"] != "Models":
model_idx += 1
model_doc = api_doc[model_idx]["sections"]
# Extract the modalities and clean them one by one.
modalities_docs = [(idx, section) for idx, section in enumerate(model_doc) if "sections" in section]
diff = False
for idx, modality_doc in modalities_docs:
old_modality_doc = modality_doc["sections"]
new_modality_doc = clean_model_doc_toc(old_modality_doc)
if old_modality_doc != new_modality_doc:
diff = True
if overwrite:
model_doc[idx]["sections"] = new_modality_doc
if diff:
if overwrite:
api_doc[model_idx]["sections"] = model_doc
content[api_idx]["sections"] = api_doc
with open(PATH_TO_TOC, "w", encoding="utf-8") as f:
f.write(yaml.dump(content, allow_unicode=True))
else:
raise ValueError(
"The model doc part of the table of content is not properly sorted, run `make style` to fix this."
)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--fix_and_overwrite", action="store_true", help="Whether to fix inconsistencies.")
args = parser.parse_args()
check_model_doc(args.fix_and_overwrite)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_doctest_list.py
|
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
This script is responsible for cleaning the list of doctests by making sure the entries all exist and are in
alphabetical order.
Usage (from the root of the repo):
Check that the doctest list is properly sorted and all files exist (used in `make repo-consistency`):
```bash
python utils/check_doctest_list.py
```
Auto-sort the doctest list if it is not properly sorted (used in `make fix-copies`):
```bash
python utils/check_doctest_list.py --fix_and_overwrite
```
"""
import argparse
import os
# All paths are set with the intent you should run this script from the root of the repo with the command
# python utils/check_doctest_list.py
REPO_PATH = "."
DOCTEST_FILE_PATHS = ["not_doctested.txt", "slow_documentation_tests.txt"]
def clean_doctest_list(doctest_file: str, overwrite: bool = False):
"""
Cleans the doctest in a given file.
Args:
doctest_file (`str`):
The path to the doctest file to check or clean.
overwrite (`bool`, *optional*, defaults to `False`):
Whether or not to fix problems. If `False`, will error when the file is not clean.
"""
non_existent_paths = []
all_paths = []
with open(doctest_file, "r", encoding="utf-8") as f:
for line in f:
line = line.strip().split(" ")[0]
path = os.path.join(REPO_PATH, line)
if not (os.path.isfile(path) or os.path.isdir(path)):
non_existent_paths.append(line)
all_paths.append(line)
if len(non_existent_paths) > 0:
non_existent_paths = "\n".join([f"- {f}" for f in non_existent_paths])
raise ValueError(f"`{doctest_file}` contains non-existent paths:\n{non_existent_paths}")
sorted_paths = sorted(all_paths)
if all_paths != sorted_paths:
if not overwrite:
raise ValueError(
f"Files in `{doctest_file}` are not in alphabetical order, run `make fix-copies` to fix "
"this automatically."
)
with open(doctest_file, "w", encoding="utf-8") as f:
f.write("\n".join(sorted_paths) + "\n")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--fix_and_overwrite", action="store_true", help="Whether to fix inconsistencies.")
args = parser.parse_args()
for doctest_file in DOCTEST_FILE_PATHS:
doctest_file = os.path.join(REPO_PATH, "utils", doctest_file)
clean_doctest_list(doctest_file, args.fix_and_overwrite)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/tests_fetcher.py
|
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Welcome to tests_fetcher V2.
This util is designed to fetch tests to run on a PR so that only the tests impacted by the modifications are run, and
when too many models are being impacted, only run the tests of a subset of core models. It works like this.
Stage 1: Identify the modified files. For jobs that run on the main branch, it's just the diff with the last commit.
On a PR, this takes all the files from the branching point to the current commit (so all modifications in a PR, not
just the last commit) but excludes modifications that are on docstrings or comments only.
Stage 2: Extract the tests to run. This is done by looking at the imports in each module and test file: if module A
imports module B, then changing module B impacts module A, so the tests using module A should be run. We thus get the
dependencies of each model and then recursively builds the 'reverse' map of dependencies to get all modules and tests
impacted by a given file. We then only keep the tests (and only the core models tests if there are too many modules).
Caveats:
- This module only filters tests by files (not individual tests) so it's better to have tests for different things
in different files.
- This module assumes inits are just importing things, not really building objects, so it's better to structure
them this way and move objects building in separate submodules.
Usage:
Base use to fetch the tests in a pull request
```bash
python utils/tests_fetcher.py
```
Base use to fetch the tests on a the main branch (with diff from the last commit):
```bash
python utils/tests_fetcher.py --diff_with_last_commit
```
"""
import argparse
import collections
import importlib.util
import json
import os
import re
import tempfile
from contextlib import contextmanager
from pathlib import Path
from typing import Dict, List, Optional, Tuple, Union
from git import Repo
PATH_TO_REPO = Path(__file__).parent.parent.resolve()
PATH_TO_EXAMPLES = PATH_TO_REPO / "examples"
PATH_TO_TRANFORMERS = PATH_TO_REPO / "src/transformers"
PATH_TO_TESTS = PATH_TO_REPO / "tests"
# List here the models to always test.
IMPORTANT_MODELS = [
"auto",
# Most downloaded models
"bert",
"clip",
"t5",
"xlm-roberta",
"gpt2",
"bart",
"mpnet",
"gpt-j",
"wav2vec2",
"deberta-v2",
"layoutlm",
"opt",
"longformer",
"vit",
# Pipeline-specific model (to be sure each pipeline has one model in this list)
"tapas",
"vilt",
"clap",
"detr",
"owlvit",
"dpt",
"videomae",
]
@contextmanager
def checkout_commit(repo: Repo, commit_id: str):
"""
Context manager that checks out a given commit when entered, but gets back to the reference it was at on exit.
Args:
repo (`git.Repo`): A git repository (for instance the Transformers repo).
commit_id (`str`): The commit reference to checkout inside the context manager.
"""
current_head = repo.head.commit if repo.head.is_detached else repo.head.ref
try:
repo.git.checkout(commit_id)
yield
finally:
repo.git.checkout(current_head)
def clean_code(content: str) -> str:
"""
Remove docstrings, empty line or comments from some code (used to detect if a diff is real or only concern
comments or docstings).
Args:
content (`str`): The code to clean
Returns:
`str`: The cleaned code.
"""
# We need to deactivate autoformatting here to write escaped triple quotes (we cannot use real triple quotes or
# this would mess up the result if this function applied to this particular file).
# fmt: off
# Remove docstrings by splitting on triple " then triple ':
splits = content.split('\"\"\"')
content = "".join(splits[::2])
splits = content.split("\'\'\'")
# fmt: on
content = "".join(splits[::2])
# Remove empty lines and comments
lines_to_keep = []
for line in content.split("\n"):
# remove anything that is after a # sign.
line = re.sub("#.*$", "", line)
# remove white lines
if len(line) != 0 and not line.isspace():
lines_to_keep.append(line)
return "\n".join(lines_to_keep)
def keep_doc_examples_only(content: str) -> str:
"""
Remove everything from the code content except the doc examples (used to determined if a diff should trigger doc
tests or not).
Args:
content (`str`): The code to clean
Returns:
`str`: The cleaned code.
"""
# Keep doc examples only by splitting on triple "`"
splits = content.split("```")
# Add leading and trailing "```" so the navigation is easier when compared to the original input `content`
content = "```" + "```".join(splits[1::2]) + "```"
# Remove empty lines and comments
lines_to_keep = []
for line in content.split("\n"):
# remove anything that is after a # sign.
line = re.sub("#.*$", "", line)
# remove white lines
if len(line) != 0 and not line.isspace():
lines_to_keep.append(line)
return "\n".join(lines_to_keep)
def get_all_tests() -> List[str]:
"""
Walks the `tests` folder to return a list of files/subfolders. This is used to split the tests to run when using
paralellism. The split is:
- folders under `tests`: (`tokenization`, `pipelines`, etc) except the subfolder `models` is excluded.
- folders under `tests/models`: `bert`, `gpt2`, etc.
- test files under `tests`: `test_modeling_common.py`, `test_tokenization_common.py`, etc.
"""
# test folders/files directly under `tests` folder
tests = os.listdir(PATH_TO_TESTS)
tests = [f"tests/{f}" for f in tests if "__pycache__" not in f]
tests = sorted([f for f in tests if (PATH_TO_REPO / f).is_dir() or f.startswith("tests/test_")])
# model specific test folders
model_test_folders = os.listdir(PATH_TO_TESTS / "models")
model_test_folders = [f"tests/models/{f}" for f in model_test_folders if "__pycache__" not in f]
model_test_folders = sorted([f for f in model_test_folders if (PATH_TO_REPO / f).is_dir()])
tests.remove("tests/models")
# Sagemaker tests are not meant to be run on the CI.
if "tests/sagemaker" in tests:
tests.remove("tests/sagemaker")
tests = model_test_folders + tests
return tests
def diff_is_docstring_only(repo: Repo, branching_point: str, filename: str) -> bool:
"""
Check if the diff is only in docstrings (or comments and whitespace) in a filename.
Args:
repo (`git.Repo`): A git repository (for instance the Transformers repo).
branching_point (`str`): The commit reference of where to compare for the diff.
filename (`str`): The filename where we want to know if the diff isonly in docstrings/comments.
Returns:
`bool`: Whether the diff is docstring/comments only or not.
"""
folder = Path(repo.working_dir)
with checkout_commit(repo, branching_point):
with open(folder / filename, "r", encoding="utf-8") as f:
old_content = f.read()
with open(folder / filename, "r", encoding="utf-8") as f:
new_content = f.read()
old_content_clean = clean_code(old_content)
new_content_clean = clean_code(new_content)
return old_content_clean == new_content_clean
def diff_contains_doc_examples(repo: Repo, branching_point: str, filename: str) -> bool:
"""
Check if the diff is only in code examples of the doc in a filename.
Args:
repo (`git.Repo`): A git repository (for instance the Transformers repo).
branching_point (`str`): The commit reference of where to compare for the diff.
filename (`str`): The filename where we want to know if the diff is only in codes examples.
Returns:
`bool`: Whether the diff is only in code examples of the doc or not.
"""
folder = Path(repo.working_dir)
with checkout_commit(repo, branching_point):
with open(folder / filename, "r", encoding="utf-8") as f:
old_content = f.read()
with open(folder / filename, "r", encoding="utf-8") as f:
new_content = f.read()
old_content_clean = keep_doc_examples_only(old_content)
new_content_clean = keep_doc_examples_only(new_content)
return old_content_clean != new_content_clean
def get_impacted_files_from_tiny_model_summary(diff_with_last_commit: bool = False) -> List[str]:
"""
Return a list of python modeling files that are impacted by the changes of `tiny_model_summary.json` in between:
- the current head and the main branch if `diff_with_last_commit=False` (default)
- the current head and its parent commit otherwise.
Returns:
`List[str]`: The list of Python modeling files that are impacted by the changes of `tiny_model_summary.json`.
"""
repo = Repo(PATH_TO_REPO)
folder = Path(repo.working_dir)
if not diff_with_last_commit:
print(f"main is at {repo.refs.main.commit}")
print(f"Current head is at {repo.head.commit}")
commits = repo.merge_base(repo.refs.main, repo.head)
for commit in commits:
print(f"Branching commit: {commit}")
else:
print(f"main is at {repo.head.commit}")
commits = repo.head.commit.parents
for commit in commits:
print(f"Parent commit: {commit}")
if not os.path.isfile(folder / "tests/utils/tiny_model_summary.json"):
return []
files = set()
for commit in commits:
with checkout_commit(repo, commit):
with open(folder / "tests/utils/tiny_model_summary.json", "r", encoding="utf-8") as f:
old_content = f.read()
with open(folder / "tests/utils/tiny_model_summary.json", "r", encoding="utf-8") as f:
new_content = f.read()
# get the content as json object
old_content = json.loads(old_content)
new_content = json.loads(new_content)
old_keys = set(old_content.keys())
new_keys = set(new_content.keys())
# get the difference
keys_with_diff = old_keys.symmetric_difference(new_keys)
common_keys = old_keys.intersection(new_keys)
# if both have the same key, check its content
for key in common_keys:
if old_content[key] != new_content[key]:
keys_with_diff.add(key)
# get the model classes
impacted_model_classes = []
for key in keys_with_diff:
if key in new_keys:
impacted_model_classes.extend(new_content[key]["model_classes"])
# get the module where the model classes are defined. We want to use the main `__init__` file, but it requires
# all the framework being installed, which is not ideal for a simple script like test fetcher.
# So we create a temporary and modified main `__init__` and access its `_import_structure`.
with open(folder / "src/transformers/__init__.py") as fp:
lines = fp.readlines()
new_lines = []
# Get all the code related to `_import_structure`
for line in lines:
if line == "_import_structure = {\n":
new_lines.append(line)
elif line == "# Direct imports for type-checking\n":
break
elif len(new_lines) > 0:
# bypass the framework check so we can get all the information even if frameworks are not available
line = re.sub(r"is_.+_available\(\)", "True", line)
line = line.replace("OptionalDependencyNotAvailable", "Exception")
line = line.replace("Exception()", "Exception")
new_lines.append(line)
# create and load the temporary module
with tempfile.TemporaryDirectory() as tmpdirname:
with open(os.path.join(tmpdirname, "temp_init.py"), "w") as fp:
fp.write("".join(new_lines))
spec = importlib.util.spec_from_file_location("temp_init", os.path.join(tmpdirname, "temp_init.py"))
module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(module)
# Finally, get `_import_structure` that we need
import_structure = module._import_structure
# map model classes to their defined module
reversed_structure = {}
for key, values in import_structure.items():
for value in values:
reversed_structure[value] = key
# Get the corresponding modeling file path
for model_class in impacted_model_classes:
module = reversed_structure[model_class]
framework = ""
if model_class.startswith("TF"):
framework = "tf"
elif model_class.startswith("Flax"):
framework = "flax"
fn = (
f"modeling_{module.split('.')[-1]}.py"
if framework == ""
else f"modeling_{framework}_{module.split('.')[-1]}.py"
)
files.add(
f"src.transformers.{module}.{fn}".replace(".", os.path.sep).replace(f"{os.path.sep}py", ".py")
)
return sorted(files)
def get_diff(repo: Repo, base_commit: str, commits: List[str]) -> List[str]:
"""
Get the diff between a base commit and one or several commits.
Args:
repo (`git.Repo`):
A git repository (for instance the Transformers repo).
base_commit (`str`):
The commit reference of where to compare for the diff. This is the current commit, not the branching point!
commits (`List[str]`):
The list of commits with which to compare the repo at `base_commit` (so the branching point).
Returns:
`List[str]`: The list of Python files with a diff (files added, renamed or deleted are always returned, files
modified are returned if the diff in the file is not only in docstrings or comments, see
`diff_is_docstring_only`).
"""
print("\n### DIFF ###\n")
code_diff = []
for commit in commits:
for diff_obj in commit.diff(base_commit):
# We always add new python files
if diff_obj.change_type == "A" and diff_obj.b_path.endswith(".py"):
code_diff.append(diff_obj.b_path)
# We check that deleted python files won't break corresponding tests.
elif diff_obj.change_type == "D" and diff_obj.a_path.endswith(".py"):
code_diff.append(diff_obj.a_path)
# Now for modified files
elif diff_obj.change_type in ["M", "R"] and diff_obj.b_path.endswith(".py"):
# In case of renames, we'll look at the tests using both the old and new name.
if diff_obj.a_path != diff_obj.b_path:
code_diff.extend([diff_obj.a_path, diff_obj.b_path])
else:
# Otherwise, we check modifications are in code and not docstrings.
if diff_is_docstring_only(repo, commit, diff_obj.b_path):
print(f"Ignoring diff in {diff_obj.b_path} as it only concerns docstrings or comments.")
else:
code_diff.append(diff_obj.a_path)
return code_diff
def get_modified_python_files(diff_with_last_commit: bool = False) -> List[str]:
"""
Return a list of python files that have been modified between:
- the current head and the main branch if `diff_with_last_commit=False` (default)
- the current head and its parent commit otherwise.
Returns:
`List[str]`: The list of Python files with a diff (files added, renamed or deleted are always returned, files
modified are returned if the diff in the file is not only in docstrings or comments, see
`diff_is_docstring_only`).
"""
repo = Repo(PATH_TO_REPO)
if not diff_with_last_commit:
print(f"main is at {repo.refs.main.commit}")
print(f"Current head is at {repo.head.commit}")
branching_commits = repo.merge_base(repo.refs.main, repo.head)
for commit in branching_commits:
print(f"Branching commit: {commit}")
return get_diff(repo, repo.head.commit, branching_commits)
else:
print(f"main is at {repo.head.commit}")
parent_commits = repo.head.commit.parents
for commit in parent_commits:
print(f"Parent commit: {commit}")
return get_diff(repo, repo.head.commit, parent_commits)
def get_diff_for_doctesting(repo: Repo, base_commit: str, commits: List[str]) -> List[str]:
"""
Get the diff in doc examples between a base commit and one or several commits.
Args:
repo (`git.Repo`):
A git repository (for instance the Transformers repo).
base_commit (`str`):
The commit reference of where to compare for the diff. This is the current commit, not the branching point!
commits (`List[str]`):
The list of commits with which to compare the repo at `base_commit` (so the branching point).
Returns:
`List[str]`: The list of Python and Markdown files with a diff (files added or renamed are always returned, files
modified are returned if the diff in the file is only in doctest examples).
"""
print("\n### DIFF ###\n")
code_diff = []
for commit in commits:
for diff_obj in commit.diff(base_commit):
# We only consider Python files and doc files.
if not diff_obj.b_path.endswith(".py") and not diff_obj.b_path.endswith(".md"):
continue
# We always add new python/md files
if diff_obj.change_type in ["A"]:
code_diff.append(diff_obj.b_path)
# Now for modified files
elif diff_obj.change_type in ["M", "R"]:
# In case of renames, we'll look at the tests using both the old and new name.
if diff_obj.a_path != diff_obj.b_path:
code_diff.extend([diff_obj.a_path, diff_obj.b_path])
else:
# Otherwise, we check modifications contain some doc example(s).
if diff_contains_doc_examples(repo, commit, diff_obj.b_path):
code_diff.append(diff_obj.a_path)
else:
print(f"Ignoring diff in {diff_obj.b_path} as it doesn't contain any doc example.")
return code_diff
def get_all_doctest_files() -> List[str]:
"""
Return the complete list of python and Markdown files on which we run doctest.
At this moment, we restrict this to only take files from `src/` or `docs/source/en/` that are not in `utils/not_doctested.txt`.
Returns:
`List[str]`: The complete list of Python and Markdown files on which we run doctest.
"""
py_files = [str(x.relative_to(PATH_TO_REPO)) for x in PATH_TO_REPO.glob("**/*.py")]
md_files = [str(x.relative_to(PATH_TO_REPO)) for x in PATH_TO_REPO.glob("**/*.md")]
test_files_to_run = py_files + md_files
# only include files in `src` or `docs/source/en/`
test_files_to_run = [x for x in test_files_to_run if x.startswith(("src/", "docs/source/en/"))]
# not include init files
test_files_to_run = [x for x in test_files_to_run if not x.endswith(("__init__.py",))]
# These are files not doctested yet.
with open("utils/not_doctested.txt") as fp:
not_doctested = {x.split(" ")[0] for x in fp.read().strip().split("\n")}
# So far we don't have 100% coverage for doctest. This line will be removed once we achieve 100%.
test_files_to_run = [x for x in test_files_to_run if x not in not_doctested]
return sorted(test_files_to_run)
def get_new_doctest_files(repo, base_commit, branching_commit) -> List[str]:
"""
Get the list of files that were removed from "utils/not_doctested.txt", between `base_commit` and
`branching_commit`.
Returns:
`List[str]`: List of files that were removed from "utils/not_doctested.txt".
"""
for diff_obj in branching_commit.diff(base_commit):
# Ignores all but the "utils/not_doctested.txt" file.
if diff_obj.a_path != "utils/not_doctested.txt":
continue
# Loads the two versions
folder = Path(repo.working_dir)
with checkout_commit(repo, branching_commit):
with open(folder / "utils/not_doctested.txt", "r", encoding="utf-8") as f:
old_content = f.read()
with open(folder / "utils/not_doctested.txt", "r", encoding="utf-8") as f:
new_content = f.read()
# Compute the removed lines and return them
removed_content = {x.split(" ")[0] for x in old_content.split("\n")} - {
x.split(" ")[0] for x in new_content.split("\n")
}
return sorted(removed_content)
return []
def get_doctest_files(diff_with_last_commit: bool = False) -> List[str]:
"""
Return a list of python and Markdown files where doc example have been modified between:
- the current head and the main branch if `diff_with_last_commit=False` (default)
- the current head and its parent commit otherwise.
Returns:
`List[str]`: The list of Python and Markdown files with a diff (files added or renamed are always returned, files
modified are returned if the diff in the file is only in doctest examples).
"""
repo = Repo(PATH_TO_REPO)
test_files_to_run = [] # noqa
if not diff_with_last_commit:
print(f"main is at {repo.refs.main.commit}")
print(f"Current head is at {repo.head.commit}")
branching_commits = repo.merge_base(repo.refs.main, repo.head)
for commit in branching_commits:
print(f"Branching commit: {commit}")
test_files_to_run = get_diff_for_doctesting(repo, repo.head.commit, branching_commits)
else:
print(f"main is at {repo.head.commit}")
parent_commits = repo.head.commit.parents
for commit in parent_commits:
print(f"Parent commit: {commit}")
test_files_to_run = get_diff_for_doctesting(repo, repo.head.commit, parent_commits)
all_test_files_to_run = get_all_doctest_files()
# Add to the test files to run any removed entry from "utils/not_doctested.txt".
new_test_files = get_new_doctest_files(repo, repo.head.commit, repo.refs.main.commit)
test_files_to_run = list(set(test_files_to_run + new_test_files))
# Do not run slow doctest tests on CircleCI
with open("utils/slow_documentation_tests.txt") as fp:
slow_documentation_tests = set(fp.read().strip().split("\n"))
test_files_to_run = [
x for x in test_files_to_run if x in all_test_files_to_run and x not in slow_documentation_tests
]
# Make sure we did not end up with a test file that was removed
test_files_to_run = [f for f in test_files_to_run if (PATH_TO_REPO / f).exists()]
return sorted(test_files_to_run)
# (:?^|\n) -> Non-catching group for the beginning of the doc or a new line.
# \s*from\s+(\.+\S+)\s+import\s+([^\n]+) -> Line only contains from .xxx import yyy and we catch .xxx and yyy
# (?=\n) -> Look-ahead to a new line. We can't just put \n here or using find_all on this re will only catch every
# other import.
_re_single_line_relative_imports = re.compile(r"(?:^|\n)\s*from\s+(\.+\S+)\s+import\s+([^\n]+)(?=\n)")
# (:?^|\n) -> Non-catching group for the beginning of the doc or a new line.
# \s*from\s+(\.+\S+)\s+import\s+\(([^\)]+)\) -> Line continues with from .xxx import (yyy) and we catch .xxx and yyy
# yyy will take multiple lines otherwise there wouldn't be parenthesis.
_re_multi_line_relative_imports = re.compile(r"(?:^|\n)\s*from\s+(\.+\S+)\s+import\s+\(([^\)]+)\)")
# (:?^|\n) -> Non-catching group for the beginning of the doc or a new line.
# \s*from\s+transformers(\S*)\s+import\s+([^\n]+) -> Line only contains from transformers.xxx import yyy and we catch
# .xxx and yyy
# (?=\n) -> Look-ahead to a new line. We can't just put \n here or using find_all on this re will only catch every
# other import.
_re_single_line_direct_imports = re.compile(r"(?:^|\n)\s*from\s+transformers(\S*)\s+import\s+([^\n]+)(?=\n)")
# (:?^|\n) -> Non-catching group for the beginning of the doc or a new line.
# \s*from\s+transformers(\S*)\s+import\s+\(([^\)]+)\) -> Line continues with from transformers.xxx import (yyy) and we
# catch .xxx and yyy. yyy will take multiple lines otherwise there wouldn't be parenthesis.
_re_multi_line_direct_imports = re.compile(r"(?:^|\n)\s*from\s+transformers(\S*)\s+import\s+\(([^\)]+)\)")
def extract_imports(module_fname: str, cache: Dict[str, List[str]] = None) -> List[str]:
"""
Get the imports a given module makes.
Args:
module_fname (`str`):
The name of the file of the module where we want to look at the imports (given relative to the root of
the repo).
cache (Dictionary `str` to `List[str]`, *optional*):
To speed up this function if it was previously called on `module_fname`, the cache of all previously
computed results.
Returns:
`List[str]`: The list of module filenames imported in the input `module_fname` (a submodule we import from that
is a subfolder will give its init file).
"""
if cache is not None and module_fname in cache:
return cache[module_fname]
with open(PATH_TO_REPO / module_fname, "r", encoding="utf-8") as f:
content = f.read()
# Filter out all docstrings to not get imports in code examples. As before we need to deactivate formatting to
# keep this as escaped quotes and avoid this function failing on this file.
splits = content.split('\"\"\"') # fmt: skip
content = "".join(splits[::2])
module_parts = str(module_fname).split(os.path.sep)
imported_modules = []
# Let's start with relative imports
relative_imports = _re_single_line_relative_imports.findall(content)
relative_imports = [
(mod, imp) for mod, imp in relative_imports if "# tests_ignore" not in imp and imp.strip() != "("
]
multiline_relative_imports = _re_multi_line_relative_imports.findall(content)
relative_imports += [(mod, imp) for mod, imp in multiline_relative_imports if "# tests_ignore" not in imp]
# We need to remove parts of the module name depending on the depth of the relative imports.
for module, imports in relative_imports:
level = 0
while module.startswith("."):
module = module[1:]
level += 1
if len(module) > 0:
dep_parts = module_parts[: len(module_parts) - level] + module.split(".")
else:
dep_parts = module_parts[: len(module_parts) - level]
imported_module = os.path.sep.join(dep_parts)
imported_modules.append((imported_module, [imp.strip() for imp in imports.split(",")]))
# Let's continue with direct imports
direct_imports = _re_single_line_direct_imports.findall(content)
direct_imports = [(mod, imp) for mod, imp in direct_imports if "# tests_ignore" not in imp and imp.strip() != "("]
multiline_direct_imports = _re_multi_line_direct_imports.findall(content)
direct_imports += [(mod, imp) for mod, imp in multiline_direct_imports if "# tests_ignore" not in imp]
# We need to find the relative path of those imports.
for module, imports in direct_imports:
import_parts = module.split(".")[1:] # ignore the name of the repo since we add it below.
dep_parts = ["src", "transformers"] + import_parts
imported_module = os.path.sep.join(dep_parts)
imported_modules.append((imported_module, [imp.strip() for imp in imports.split(",")]))
result = []
# Double check we get proper modules (either a python file or a folder with an init).
for module_file, imports in imported_modules:
if (PATH_TO_REPO / f"{module_file}.py").is_file():
module_file = f"{module_file}.py"
elif (PATH_TO_REPO / module_file).is_dir() and (PATH_TO_REPO / module_file / "__init__.py").is_file():
module_file = os.path.sep.join([module_file, "__init__.py"])
imports = [imp for imp in imports if len(imp) > 0 and re.match("^[A-Za-z0-9_]*$", imp)]
if len(imports) > 0:
result.append((module_file, imports))
if cache is not None:
cache[module_fname] = result
return result
def get_module_dependencies(module_fname: str, cache: Dict[str, List[str]] = None) -> List[str]:
"""
Refines the result of `extract_imports` to remove subfolders and get a proper list of module filenames: if a file
as an import `from utils import Foo, Bar`, with `utils` being a subfolder containing many files, this will traverse
the `utils` init file to check where those dependencies come from: for instance the files utils/foo.py and utils/bar.py.
Warning: This presupposes that all intermediate inits are properly built (with imports from the respective
submodules) and work better if objects are defined in submodules and not the intermediate init (otherwise the
intermediate init is added, and inits usually have a lot of dependencies).
Args:
module_fname (`str`):
The name of the file of the module where we want to look at the imports (given relative to the root of
the repo).
cache (Dictionary `str` to `List[str]`, *optional*):
To speed up this function if it was previously called on `module_fname`, the cache of all previously
computed results.
Returns:
`List[str]`: The list of module filenames imported in the input `module_fname` (with submodule imports refined).
"""
dependencies = []
imported_modules = extract_imports(module_fname, cache=cache)
# The while loop is to recursively traverse all inits we may encounter: we will add things as we go.
while len(imported_modules) > 0:
new_modules = []
for module, imports in imported_modules:
# If we end up in an __init__ we are often not actually importing from this init (except in the case where
# the object is fully defined in the __init__)
if module.endswith("__init__.py"):
# So we get the imports from that init then try to find where our objects come from.
new_imported_modules = extract_imports(module, cache=cache)
for new_module, new_imports in new_imported_modules:
if any(i in new_imports for i in imports):
if new_module not in dependencies:
new_modules.append((new_module, [i for i in new_imports if i in imports]))
imports = [i for i in imports if i not in new_imports]
if len(imports) > 0:
# If there are any objects lefts, they may be a submodule
path_to_module = PATH_TO_REPO / module.replace("__init__.py", "")
dependencies.extend(
[
os.path.join(module.replace("__init__.py", ""), f"{i}.py")
for i in imports
if (path_to_module / f"{i}.py").is_file()
]
)
imports = [i for i in imports if not (path_to_module / f"{i}.py").is_file()]
if len(imports) > 0:
# Then if there are still objects left, they are fully defined in the init, so we keep it as a
# dependency.
dependencies.append(module)
else:
dependencies.append(module)
imported_modules = new_modules
return dependencies
def create_reverse_dependency_tree() -> List[Tuple[str, str]]:
"""
Create a list of all edges (a, b) which mean that modifying a impacts b with a going over all module and test files.
"""
cache = {}
all_modules = list(PATH_TO_TRANFORMERS.glob("**/*.py")) + list(PATH_TO_TESTS.glob("**/*.py"))
all_modules = [str(mod.relative_to(PATH_TO_REPO)) for mod in all_modules]
edges = [(dep, mod) for mod in all_modules for dep in get_module_dependencies(mod, cache=cache)]
return list(set(edges))
def get_tree_starting_at(module: str, edges: List[Tuple[str, str]]) -> List[Union[str, List[str]]]:
"""
Returns the tree starting at a given module following all edges.
Args:
module (`str`): The module that will be the root of the subtree we want.
eges (`List[Tuple[str, str]]`): The list of all edges of the tree.
Returns:
`List[Union[str, List[str]]]`: The tree to print in the following format: [module, [list of edges
starting at module], [list of edges starting at the preceding level], ...]
"""
vertices_seen = [module]
new_edges = [edge for edge in edges if edge[0] == module and edge[1] != module and "__init__.py" not in edge[1]]
tree = [module]
while len(new_edges) > 0:
tree.append(new_edges)
final_vertices = list({edge[1] for edge in new_edges})
vertices_seen.extend(final_vertices)
new_edges = [
edge
for edge in edges
if edge[0] in final_vertices and edge[1] not in vertices_seen and "__init__.py" not in edge[1]
]
return tree
def print_tree_deps_of(module, all_edges=None):
"""
Prints the tree of modules depending on a given module.
Args:
module (`str`): The module that will be the root of the subtree we want.
all_eges (`List[Tuple[str, str]]`, *optional*):
The list of all edges of the tree. Will be set to `create_reverse_dependency_tree()` if not passed.
"""
if all_edges is None:
all_edges = create_reverse_dependency_tree()
tree = get_tree_starting_at(module, all_edges)
# The list of lines is a list of tuples (line_to_be_printed, module)
# Keeping the modules lets us know where to insert each new lines in the list.
lines = [(tree[0], tree[0])]
for index in range(1, len(tree)):
edges = tree[index]
start_edges = {edge[0] for edge in edges}
for start in start_edges:
end_edges = {edge[1] for edge in edges if edge[0] == start}
# We will insert all those edges just after the line showing start.
pos = 0
while lines[pos][1] != start:
pos += 1
lines = lines[: pos + 1] + [(" " * (2 * index) + end, end) for end in end_edges] + lines[pos + 1 :]
for line in lines:
# We don't print the refs that where just here to help build lines.
print(line[0])
def init_test_examples_dependencies() -> Tuple[Dict[str, List[str]], List[str]]:
"""
The test examples do not import from the examples (which are just scripts, not modules) so we need som extra
care initializing the dependency map, which is the goal of this function. It initializes the dependency map for
example files by linking each example to the example test file for the example framework.
Returns:
`Tuple[Dict[str, List[str]], List[str]]`: A tuple with two elements: the initialized dependency map which is a
dict test example file to list of example files potentially tested by that test file, and the list of all
example files (to avoid recomputing it later).
"""
test_example_deps = {}
all_examples = []
for framework in ["flax", "pytorch", "tensorflow"]:
test_files = list((PATH_TO_EXAMPLES / framework).glob("test_*.py"))
all_examples.extend(test_files)
# Remove the files at the root of examples/framework since they are not proper examples (they are eith utils
# or example test files).
examples = [
f for f in (PATH_TO_EXAMPLES / framework).glob("**/*.py") if f.parent != PATH_TO_EXAMPLES / framework
]
all_examples.extend(examples)
for test_file in test_files:
with open(test_file, "r", encoding="utf-8") as f:
content = f.read()
# Map all examples to the test files found in examples/framework.
test_example_deps[str(test_file.relative_to(PATH_TO_REPO))] = [
str(e.relative_to(PATH_TO_REPO)) for e in examples if e.name in content
]
# Also map the test files to themselves.
test_example_deps[str(test_file.relative_to(PATH_TO_REPO))].append(
str(test_file.relative_to(PATH_TO_REPO))
)
return test_example_deps, all_examples
def create_reverse_dependency_map() -> Dict[str, List[str]]:
"""
Create the dependency map from module/test filename to the list of modules/tests that depend on it recursively.
Returns:
`Dict[str, List[str]]`: The reverse dependency map as a dictionary mapping filenames to all the filenames
depending on it recursively. This way the tests impacted by a change in file A are the test files in the list
corresponding to key A in this result.
"""
cache = {}
# Start from the example deps init.
example_deps, examples = init_test_examples_dependencies()
# Add all modules and all tests to all examples
all_modules = list(PATH_TO_TRANFORMERS.glob("**/*.py")) + list(PATH_TO_TESTS.glob("**/*.py")) + examples
all_modules = [str(mod.relative_to(PATH_TO_REPO)) for mod in all_modules]
# Compute the direct dependencies of all modules.
direct_deps = {m: get_module_dependencies(m, cache=cache) for m in all_modules}
direct_deps.update(example_deps)
# This recurses the dependencies
something_changed = True
while something_changed:
something_changed = False
for m in all_modules:
for d in direct_deps[m]:
# We stop recursing at an init (cause we always end up in the main init and we don't want to add all
# files which the main init imports)
if d.endswith("__init__.py"):
continue
if d not in direct_deps:
raise ValueError(f"KeyError:{d}. From {m}")
new_deps = set(direct_deps[d]) - set(direct_deps[m])
if len(new_deps) > 0:
direct_deps[m].extend(list(new_deps))
something_changed = True
# Finally we can build the reverse map.
reverse_map = collections.defaultdict(list)
for m in all_modules:
for d in direct_deps[m]:
reverse_map[d].append(m)
# For inits, we don't do the reverse deps but the direct deps: if modifying an init, we want to make sure we test
# all the modules impacted by that init.
for m in [f for f in all_modules if f.endswith("__init__.py")]:
direct_deps = get_module_dependencies(m, cache=cache)
deps = sum([reverse_map[d] for d in direct_deps if not d.endswith("__init__.py")], direct_deps)
reverse_map[m] = list(set(deps) - {m})
return reverse_map
def create_module_to_test_map(
reverse_map: Dict[str, List[str]] = None, filter_models: bool = False
) -> Dict[str, List[str]]:
"""
Extract the tests from the reverse_dependency_map and potentially filters the model tests.
Args:
reverse_map (`Dict[str, List[str]]`, *optional*):
The reverse dependency map as created by `create_reverse_dependency_map`. Will default to the result of
that function if not provided.
filter_models (`bool`, *optional*, defaults to `False`):
Whether or not to filter model tests to only include core models if a file impacts a lot of models.
Returns:
`Dict[str, List[str]]`: A dictionary that maps each file to the tests to execute if that file was modified.
"""
if reverse_map is None:
reverse_map = create_reverse_dependency_map()
# Utility that tells us if a given file is a test (taking test examples into account)
def is_test(fname):
if fname.startswith("tests"):
return True
if fname.startswith("examples") and fname.split(os.path.sep)[-1].startswith("test"):
return True
return False
# Build the test map
test_map = {module: [f for f in deps if is_test(f)] for module, deps in reverse_map.items()}
if not filter_models:
return test_map
# Now we deal with the filtering if `filter_models` is True.
num_model_tests = len(list(PATH_TO_TESTS.glob("models/*")))
def has_many_models(tests):
# We filter to core models when a given file impacts more than half the model tests.
model_tests = {Path(t).parts[2] for t in tests if t.startswith("tests/models/")}
return len(model_tests) > num_model_tests // 2
def filter_tests(tests):
return [t for t in tests if not t.startswith("tests/models/") or Path(t).parts[2] in IMPORTANT_MODELS]
return {module: (filter_tests(tests) if has_many_models(tests) else tests) for module, tests in test_map.items()}
def check_imports_all_exist():
"""
Isn't used per se by the test fetcher but might be used later as a quality check. Putting this here for now so the
code is not lost. This checks all imports in a given file do exist.
"""
cache = {}
all_modules = list(PATH_TO_TRANFORMERS.glob("**/*.py")) + list(PATH_TO_TESTS.glob("**/*.py"))
all_modules = [str(mod.relative_to(PATH_TO_REPO)) for mod in all_modules]
direct_deps = {m: get_module_dependencies(m, cache=cache) for m in all_modules}
for module, deps in direct_deps.items():
for dep in deps:
if not (PATH_TO_REPO / dep).is_file():
print(f"{module} has dependency on {dep} which does not exist.")
def _print_list(l) -> str:
"""
Pretty print a list of elements with one line per element and a - starting each line.
"""
return "\n".join([f"- {f}" for f in l])
def create_json_map(test_files_to_run: List[str], json_output_file: str):
"""
Creates a map from a list of tests to run to easily split them by category, when running parallelism of slow tests.
Args:
test_files_to_run (`List[str]`): The list of tests to run.
json_output_file (`str`): The path where to store the built json map.
"""
if json_output_file is None:
return
test_map = {}
for test_file in test_files_to_run:
# `test_file` is a path to a test folder/file, starting with `tests/`. For example,
# - `tests/models/bert/test_modeling_bert.py` or `tests/models/bert`
# - `tests/trainer/test_trainer.py` or `tests/trainer`
# - `tests/test_modeling_common.py`
names = test_file.split(os.path.sep)
if names[1] == "models":
# take the part like `models/bert` for modeling tests
key = os.path.sep.join(names[1:3])
elif len(names) > 2 or not test_file.endswith(".py"):
# test folders under `tests` or python files under them
# take the part like tokenization, `pipeline`, etc. for other test categories
key = os.path.sep.join(names[1:2])
else:
# common test files directly under `tests/`
key = "common"
if key not in test_map:
test_map[key] = []
test_map[key].append(test_file)
# sort the keys & values
keys = sorted(test_map.keys())
test_map = {k: " ".join(sorted(test_map[k])) for k in keys}
with open(json_output_file, "w", encoding="UTF-8") as fp:
json.dump(test_map, fp, ensure_ascii=False)
def infer_tests_to_run(
output_file: str,
diff_with_last_commit: bool = False,
filter_models: bool = True,
json_output_file: Optional[str] = None,
):
"""
The main function called by the test fetcher. Determines the tests to run from the diff.
Args:
output_file (`str`):
The path where to store the summary of the test fetcher analysis. Other files will be stored in the same
folder:
- examples_test_list.txt: The list of examples tests to run.
- test_repo_utils.txt: Will indicate if the repo utils tests should be run or not.
- doctest_list.txt: The list of doctests to run.
diff_with_last_commit (`bool`, *optional*, defaults to `False`):
Whether to analyze the diff with the last commit (for use on the main branch after a PR is merged) or with
the branching point from main (for use on each PR).
filter_models (`bool`, *optional*, defaults to `True`):
Whether or not to filter the tests to core models only, when a file modified results in a lot of model
tests.
json_output_file (`str`, *optional*):
The path where to store the json file mapping categories of tests to tests to run (used for parallelism or
the slow tests).
"""
modified_files = get_modified_python_files(diff_with_last_commit=diff_with_last_commit)
print(f"\n### MODIFIED FILES ###\n{_print_list(modified_files)}")
# Create the map that will give us all impacted modules.
reverse_map = create_reverse_dependency_map()
impacted_files = modified_files.copy()
for f in modified_files:
if f in reverse_map:
impacted_files.extend(reverse_map[f])
# Remove duplicates
impacted_files = sorted(set(impacted_files))
print(f"\n### IMPACTED FILES ###\n{_print_list(impacted_files)}")
# Grab the corresponding test files:
if any(x in modified_files for x in ["setup.py", ".circleci/create_circleci_config.py"]):
test_files_to_run = ["tests", "examples"]
repo_utils_launch = True
else:
# All modified tests need to be run.
test_files_to_run = [
f for f in modified_files if f.startswith("tests") and f.split(os.path.sep)[-1].startswith("test")
]
impacted_files = get_impacted_files_from_tiny_model_summary(diff_with_last_commit=diff_with_last_commit)
# Then we grab the corresponding test files.
test_map = create_module_to_test_map(reverse_map=reverse_map, filter_models=filter_models)
for f in modified_files + impacted_files:
if f in test_map:
test_files_to_run.extend(test_map[f])
test_files_to_run = sorted(set(test_files_to_run))
# Remove repo utils tests
test_files_to_run = [f for f in test_files_to_run if not f.split(os.path.sep)[1] == "repo_utils"]
# Remove SageMaker tests
test_files_to_run = [f for f in test_files_to_run if not f.split(os.path.sep)[1] == "sagemaker"]
# Make sure we did not end up with a test file that was removed
test_files_to_run = [f for f in test_files_to_run if (PATH_TO_REPO / f).exists()]
repo_utils_launch = any(f.split(os.path.sep)[0] == "utils" for f in modified_files)
if repo_utils_launch:
repo_util_file = Path(output_file).parent / "test_repo_utils.txt"
with open(repo_util_file, "w", encoding="utf-8") as f:
f.write("tests/repo_utils")
examples_tests_to_run = [f for f in test_files_to_run if f.startswith("examples")]
test_files_to_run = [f for f in test_files_to_run if not f.startswith("examples")]
print(f"\n### TEST TO RUN ###\n{_print_list(test_files_to_run)}")
if len(test_files_to_run) > 0:
with open(output_file, "w", encoding="utf-8") as f:
f.write(" ".join(test_files_to_run))
# Create a map that maps test categories to test files, i.e. `models/bert` -> [...test_modeling_bert.py, ...]
# Get all test directories (and some common test files) under `tests` and `tests/models` if `test_files_to_run`
# contains `tests` (i.e. when `setup.py` is changed).
if "tests" in test_files_to_run:
test_files_to_run = get_all_tests()
create_json_map(test_files_to_run, json_output_file)
print(f"\n### EXAMPLES TEST TO RUN ###\n{_print_list(examples_tests_to_run)}")
if len(examples_tests_to_run) > 0:
# We use `all` in the case `commit_flags["test_all"]` as well as in `create_circleci_config.py` for processing
if examples_tests_to_run == ["examples"]:
examples_tests_to_run = ["all"]
example_file = Path(output_file).parent / "examples_test_list.txt"
with open(example_file, "w", encoding="utf-8") as f:
f.write(" ".join(examples_tests_to_run))
doctest_list = get_doctest_files()
print(f"\n### DOCTEST TO RUN ###\n{_print_list(doctest_list)}")
if len(doctest_list) > 0:
doctest_file = Path(output_file).parent / "doctest_list.txt"
with open(doctest_file, "w", encoding="utf-8") as f:
f.write(" ".join(doctest_list))
def filter_tests(output_file: str, filters: List[str]):
"""
Reads the content of the output file and filters out all the tests in a list of given folders.
Args:
output_file (`str` or `os.PathLike`): The path to the output file of the tests fetcher.
filters (`List[str]`): A list of folders to filter.
"""
if not os.path.isfile(output_file):
print("No test file found.")
return
with open(output_file, "r", encoding="utf-8") as f:
test_files = f.read().split(" ")
if len(test_files) == 0 or test_files == [""]:
print("No tests to filter.")
return
if test_files == ["tests"]:
test_files = [os.path.join("tests", f) for f in os.listdir("tests") if f not in ["__init__.py"] + filters]
else:
test_files = [f for f in test_files if f.split(os.path.sep)[1] not in filters]
with open(output_file, "w", encoding="utf-8") as f:
f.write(" ".join(test_files))
def parse_commit_message(commit_message: str) -> Dict[str, bool]:
"""
Parses the commit message to detect if a command is there to skip, force all or part of the CI.
Args:
commit_message (`str`): The commit message of the current commit.
Returns:
`Dict[str, bool]`: A dictionary of strings to bools with keys the following keys: `"skip"`,
`"test_all_models"` and `"test_all"`.
"""
if commit_message is None:
return {"skip": False, "no_filter": False, "test_all": False}
command_search = re.search(r"\[([^\]]*)\]", commit_message)
if command_search is not None:
command = command_search.groups()[0]
command = command.lower().replace("-", " ").replace("_", " ")
skip = command in ["ci skip", "skip ci", "circleci skip", "skip circleci"]
no_filter = set(command.split(" ")) == {"no", "filter"}
test_all = set(command.split(" ")) == {"test", "all"}
return {"skip": skip, "no_filter": no_filter, "test_all": test_all}
else:
return {"skip": False, "no_filter": False, "test_all": False}
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--output_file", type=str, default="test_list.txt", help="Where to store the list of tests to run"
)
parser.add_argument(
"--json_output_file",
type=str,
default="test_map.json",
help="Where to store the tests to run in a dictionary format mapping test categories to test files",
)
parser.add_argument(
"--diff_with_last_commit",
action="store_true",
help="To fetch the tests between the current commit and the last commit",
)
parser.add_argument(
"--filter_tests",
action="store_true",
help="Will filter the pipeline/repo utils tests outside of the generated list of tests.",
)
parser.add_argument(
"--print_dependencies_of",
type=str,
help="Will only print the tree of modules depending on the file passed.",
default=None,
)
parser.add_argument(
"--commit_message",
type=str,
help="The commit message (which could contain a command to force all tests or skip the CI).",
default=None,
)
args = parser.parse_args()
if args.print_dependencies_of is not None:
print_tree_deps_of(args.print_dependencies_of)
elif args.filter_tests:
filter_tests(args.output_file, ["pipelines", "repo_utils"])
else:
repo = Repo(PATH_TO_REPO)
commit_message = repo.head.commit.message
commit_flags = parse_commit_message(commit_message)
if commit_flags["skip"]:
print("Force-skipping the CI")
quit()
if commit_flags["no_filter"]:
print("Running all tests fetched without filtering.")
if commit_flags["test_all"]:
print("Force-launching all tests")
diff_with_last_commit = args.diff_with_last_commit
if not diff_with_last_commit and not repo.head.is_detached and repo.head.ref == repo.refs.main:
print("main branch detected, fetching tests against last commit.")
diff_with_last_commit = True
if not commit_flags["test_all"]:
try:
infer_tests_to_run(
args.output_file,
diff_with_last_commit=diff_with_last_commit,
json_output_file=args.json_output_file,
filter_models=not commit_flags["no_filter"],
)
filter_tests(args.output_file, ["repo_utils"])
except Exception as e:
print(f"\nError when trying to grab the relevant tests: {e}\n\nRunning all tests.")
commit_flags["test_all"] = True
if commit_flags["test_all"]:
with open(args.output_file, "w", encoding="utf-8") as f:
f.write("tests")
example_file = Path(args.output_file).parent / "examples_test_list.txt"
with open(example_file, "w", encoding="utf-8") as f:
f.write("all")
test_files_to_run = get_all_tests()
create_json_map(test_files_to_run, args.json_output_file)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_tf_ops.py
|
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import json
import os
from tensorflow.core.protobuf.saved_model_pb2 import SavedModel
# All paths are set with the intent you should run this script from the root of the repo with the command
# python utils/check_copies.py
REPO_PATH = "."
# Internal TensorFlow ops that can be safely ignored (mostly specific to a saved model)
INTERNAL_OPS = [
"Assert",
"AssignVariableOp",
"EmptyTensorList",
"MergeV2Checkpoints",
"ReadVariableOp",
"ResourceGather",
"RestoreV2",
"SaveV2",
"ShardedFilename",
"StatefulPartitionedCall",
"StaticRegexFullMatch",
"VarHandleOp",
]
def onnx_compliancy(saved_model_path, strict, opset):
saved_model = SavedModel()
onnx_ops = []
with open(os.path.join(REPO_PATH, "utils", "tf_ops", "onnx.json")) as f:
onnx_opsets = json.load(f)["opsets"]
for i in range(1, opset + 1):
onnx_ops.extend(onnx_opsets[str(i)])
with open(saved_model_path, "rb") as f:
saved_model.ParseFromString(f.read())
model_op_names = set()
# Iterate over every metagraph in case there is more than one (a saved model can contain multiple graphs)
for meta_graph in saved_model.meta_graphs:
# Add operations in the graph definition
model_op_names.update(node.op for node in meta_graph.graph_def.node)
# Go through the functions in the graph definition
for func in meta_graph.graph_def.library.function:
# Add operations in each function
model_op_names.update(node.op for node in func.node_def)
# Convert to list, sorted if you want
model_op_names = sorted(model_op_names)
incompatible_ops = []
for op in model_op_names:
if op not in onnx_ops and op not in INTERNAL_OPS:
incompatible_ops.append(op)
if strict and len(incompatible_ops) > 0:
raise Exception(f"Found the following incompatible ops for the opset {opset}:\n" + incompatible_ops)
elif len(incompatible_ops) > 0:
print(f"Found the following incompatible ops for the opset {opset}:")
print(*incompatible_ops, sep="\n")
else:
print(f"The saved model {saved_model_path} can properly be converted with ONNX.")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--saved_model_path", help="Path of the saved model to check (the .pb file).")
parser.add_argument(
"--opset", default=12, type=int, help="The ONNX opset against which the model has to be tested."
)
parser.add_argument(
"--framework", choices=["onnx"], default="onnx", help="Frameworks against which to test the saved model."
)
parser.add_argument(
"--strict", action="store_true", help="Whether make the checking strict (raise errors) or not (raise warnings)"
)
args = parser.parse_args()
if args.framework == "onnx":
onnx_compliancy(args.saved_model_path, args.strict, args.opset)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_build.py
|
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import importlib
from pathlib import Path
# Test all the extensions added in the setup
FILES_TO_FIND = [
"kernels/rwkv/wkv_cuda.cu",
"kernels/rwkv/wkv_op.cpp",
"kernels/deformable_detr/ms_deform_attn.h",
"kernels/deformable_detr/cuda/ms_deform_im2col_cuda.cuh",
"models/graphormer/algos_graphormer.pyx",
]
def test_custom_files_are_present(transformers_path):
# Test all the extensions added in the setup
for file in FILES_TO_FIND:
if not (transformers_path / file).exists():
return False
return True
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--check_lib", action="store_true", help="Whether to check the build or the actual package.")
args = parser.parse_args()
if args.check_lib:
transformers_module = importlib.import_module("transformers")
transformers_path = Path(transformers_module.__file__).parent
else:
transformers_path = Path.cwd() / "build/lib/transformers"
if not test_custom_files_are_present(transformers_path):
raise ValueError("The built release does not contain the custom files. Fix this before going further!")
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_table.py
|
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utility that checks the big table in the file docs/source/en/index.md and potentially updates it.
Use from the root of the repo with:
```bash
python utils/check_inits.py
```
for a check that will error in case of inconsistencies (used by `make repo-consistency`).
To auto-fix issues run:
```bash
python utils/check_inits.py --fix_and_overwrite
```
which is used by `make fix-copies`.
"""
import argparse
import collections
import os
import re
from typing import List
from transformers.utils import direct_transformers_import
# All paths are set with the intent you should run this script from the root of the repo with the command
# python utils/check_table.py
TRANSFORMERS_PATH = "src/transformers"
PATH_TO_DOCS = "docs/source/en"
REPO_PATH = "."
def _find_text_in_file(filename: str, start_prompt: str, end_prompt: str) -> str:
"""
Find the text in filename between two prompts.
Args:
filename (`str`): The file to search into.
start_prompt (`str`): A string to look for at the start of the content searched.
end_prompt (`str`): A string that will mark the end of the content to look for.
Returns:
`str`: The content between the prompts.
"""
with open(filename, "r", encoding="utf-8", newline="\n") as f:
lines = f.readlines()
# Find the start prompt.
start_index = 0
while not lines[start_index].startswith(start_prompt):
start_index += 1
start_index += 1
# Now go until the end prompt.
end_index = start_index
while not lines[end_index].startswith(end_prompt):
end_index += 1
end_index -= 1
while len(lines[start_index]) <= 1:
start_index += 1
while len(lines[end_index]) <= 1:
end_index -= 1
end_index += 1
return "".join(lines[start_index:end_index]), start_index, end_index, lines
# Regexes that match TF/Flax/PT model names. Add here suffixes that are used to identify models, separated by |
_re_tf_models = re.compile(r"TF(.*)(?:Model|Encoder|Decoder|ForConditionalGeneration)")
_re_flax_models = re.compile(r"Flax(.*)(?:Model|Encoder|Decoder|ForConditionalGeneration)")
# Will match any TF or Flax model too so need to be in an else branch after the two previous regexes.
_re_pt_models = re.compile(r"(.*)(?:Model|Encoder|Decoder|ForConditionalGeneration)")
# This is to make sure the transformers module imported is the one in the repo.
transformers_module = direct_transformers_import(TRANSFORMERS_PATH)
def camel_case_split(identifier: str) -> List[str]:
"""
Split a camel-cased name into words.
Args:
identifier (`str`): The camel-cased name to parse.
Returns:
`List[str]`: The list of words in the identifier (as seprated by capital letters).
Example:
```py
>>> camel_case_split("CamelCasedClass")
["Camel", "Cased", "Class"]
```
"""
# Regex thanks to https://stackoverflow.com/questions/29916065/how-to-do-camelcase-split-in-python
matches = re.finditer(".+?(?:(?<=[a-z])(?=[A-Z])|(?<=[A-Z])(?=[A-Z][a-z])|$)", identifier)
return [m.group(0) for m in matches]
def _center_text(text: str, width: int) -> str:
"""
Utility that will add spaces on the left and right of a text to make it centered for a given width.
Args:
text (`str`): The text to center.
width (`int`): The desired length of the result.
Returns:
`str`: A text of length `width` with the original `text` in the middle.
"""
text_length = 2 if text == "✅" or text == "❌" else len(text)
left_indent = (width - text_length) // 2
right_indent = width - text_length - left_indent
return " " * left_indent + text + " " * right_indent
SPECIAL_MODEL_NAME_LINK_MAPPING = {
"Data2VecAudio": "[Data2VecAudio](model_doc/data2vec)",
"Data2VecText": "[Data2VecText](model_doc/data2vec)",
"Data2VecVision": "[Data2VecVision](model_doc/data2vec)",
"DonutSwin": "[DonutSwin](model_doc/donut)",
}
MODEL_NAMES_WITH_SAME_CONFIG = {
"BARThez": "BART",
"BARTpho": "BART",
"BertJapanese": "BERT",
"BERTweet": "BERT",
"BORT": "BERT",
"ByT5": "T5",
"CPM": "OpenAI GPT-2",
"DePlot": "Pix2Struct",
"DialoGPT": "OpenAI GPT-2",
"DiT": "BEiT",
"FLAN-T5": "T5",
"FLAN-UL2": "T5",
"HerBERT": "BERT",
"LayoutXLM": "LayoutLMv2",
"Llama2": "LLaMA",
"MADLAD-400": "T5",
"MatCha": "Pix2Struct",
"mBART-50": "mBART",
"Megatron-GPT2": "OpenAI GPT-2",
"mLUKE": "LUKE",
"MMS": "Wav2Vec2",
"NLLB": "M2M100",
"PhoBERT": "BERT",
"T5v1.1": "T5",
"TAPEX": "BART",
"UL2": "T5",
"Wav2Vec2Phoneme": "Wav2Vec2",
"XLM-V": "XLM-RoBERTa",
"XLS-R": "Wav2Vec2",
"XLSR-Wav2Vec2": "Wav2Vec2",
}
def get_model_table_from_auto_modules() -> str:
"""
Generates an up-to-date model table from the content of the auto modules.
"""
# Dictionary model names to config.
config_maping_names = transformers_module.models.auto.configuration_auto.CONFIG_MAPPING_NAMES
model_name_to_config = {
name: config_maping_names[code]
for code, name in transformers_module.MODEL_NAMES_MAPPING.items()
if code in config_maping_names
}
model_name_to_prefix = {name: config.replace("Config", "") for name, config in model_name_to_config.items()}
# Dictionaries flagging if each model prefix has a backend in PT/TF/Flax.
pt_models = collections.defaultdict(bool)
tf_models = collections.defaultdict(bool)
flax_models = collections.defaultdict(bool)
# Let's lookup through all transformers object (once).
for attr_name in dir(transformers_module):
lookup_dict = None
if _re_tf_models.match(attr_name) is not None:
lookup_dict = tf_models
attr_name = _re_tf_models.match(attr_name).groups()[0]
elif _re_flax_models.match(attr_name) is not None:
lookup_dict = flax_models
attr_name = _re_flax_models.match(attr_name).groups()[0]
elif _re_pt_models.match(attr_name) is not None:
lookup_dict = pt_models
attr_name = _re_pt_models.match(attr_name).groups()[0]
if lookup_dict is not None:
while len(attr_name) > 0:
if attr_name in model_name_to_prefix.values():
lookup_dict[attr_name] = True
break
# Try again after removing the last word in the name
attr_name = "".join(camel_case_split(attr_name)[:-1])
# Let's build that table!
model_names = list(model_name_to_config.keys()) + list(MODEL_NAMES_WITH_SAME_CONFIG.keys())
# model name to doc link mapping
model_names_mapping = transformers_module.models.auto.configuration_auto.MODEL_NAMES_MAPPING
model_name_to_link_mapping = {value: f"[{value}](model_doc/{key})" for key, value in model_names_mapping.items()}
# update mapping with special model names
model_name_to_link_mapping = {
k: SPECIAL_MODEL_NAME_LINK_MAPPING[k] if k in SPECIAL_MODEL_NAME_LINK_MAPPING else v
for k, v in model_name_to_link_mapping.items()
}
# MaskFormerSwin and TimmBackbone are backbones and so not meant to be loaded and used on their own. Instead, they define architectures which can be loaded using the AutoBackbone API.
names_to_exclude = ["MaskFormerSwin", "TimmBackbone", "Speech2Text2"]
model_names = [name for name in model_names if name not in names_to_exclude]
model_names.sort(key=str.lower)
columns = ["Model", "PyTorch support", "TensorFlow support", "Flax Support"]
# We'll need widths to properly display everything in the center (+2 is to leave one extra space on each side).
widths = [len(c) + 2 for c in columns]
widths[0] = max([len(doc_link) for doc_link in model_name_to_link_mapping.values()]) + 2
# Build the table per se
table = "|" + "|".join([_center_text(c, w) for c, w in zip(columns, widths)]) + "|\n"
# Use ":-----:" format to center-aligned table cell texts
table += "|" + "|".join([":" + "-" * (w - 2) + ":" for w in widths]) + "|\n"
check = {True: "✅", False: "❌"}
for name in model_names:
if name in MODEL_NAMES_WITH_SAME_CONFIG.keys():
prefix = model_name_to_prefix[MODEL_NAMES_WITH_SAME_CONFIG[name]]
else:
prefix = model_name_to_prefix[name]
line = [
model_name_to_link_mapping[name],
check[pt_models[prefix]],
check[tf_models[prefix]],
check[flax_models[prefix]],
]
table += "|" + "|".join([_center_text(l, w) for l, w in zip(line, widths)]) + "|\n"
return table
def check_model_table(overwrite=False):
"""
Check the model table in the index.md is consistent with the state of the lib and potentially fix it.
Args:
overwrite (`bool`, *optional*, defaults to `False`):
Whether or not to overwrite the table when it's not up to date.
"""
current_table, start_index, end_index, lines = _find_text_in_file(
filename=os.path.join(PATH_TO_DOCS, "index.md"),
start_prompt="<!--This table is updated automatically from the auto modules",
end_prompt="<!-- End table-->",
)
new_table = get_model_table_from_auto_modules()
if current_table != new_table:
if overwrite:
with open(os.path.join(PATH_TO_DOCS, "index.md"), "w", encoding="utf-8", newline="\n") as f:
f.writelines(lines[:start_index] + [new_table] + lines[end_index:])
else:
raise ValueError(
"The model table in the `index.md` has not been updated. Run `make fix-copies` to fix this."
)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--fix_and_overwrite", action="store_true", help="Whether to fix inconsistencies.")
args = parser.parse_args()
check_model_table(args.fix_and_overwrite)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/create_dummy_models.py
|
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import collections.abc
import copy
import inspect
import json
import multiprocessing
import os
import shutil
import tempfile
import traceback
from pathlib import Path
from check_config_docstrings import get_checkpoint_from_config_class
from datasets import load_dataset
from get_test_info import get_model_to_tester_mapping, get_tester_classes_for_model
from huggingface_hub import Repository, create_repo, hf_api, upload_folder
from transformers import (
CONFIG_MAPPING,
FEATURE_EXTRACTOR_MAPPING,
IMAGE_PROCESSOR_MAPPING,
PROCESSOR_MAPPING,
TOKENIZER_MAPPING,
AutoTokenizer,
LayoutLMv3TokenizerFast,
PreTrainedTokenizer,
PreTrainedTokenizerFast,
logging,
)
from transformers.feature_extraction_utils import FeatureExtractionMixin
from transformers.file_utils import is_tf_available, is_torch_available
from transformers.image_processing_utils import BaseImageProcessor
from transformers.models.auto.configuration_auto import AutoConfig, model_type_to_module_name
from transformers.models.fsmt import configuration_fsmt
from transformers.processing_utils import ProcessorMixin, transformers_module
from transformers.tokenization_utils_base import PreTrainedTokenizerBase
# make sure tokenizer plays nice with multiprocessing
os.environ["TOKENIZERS_PARALLELISM"] = "false"
logging.set_verbosity_error()
logging.disable_progress_bar()
logger = logging.get_logger(__name__)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
if not is_torch_available():
raise ValueError("Please install PyTorch.")
if not is_tf_available():
raise ValueError("Please install TensorFlow.")
FRAMEWORKS = ["pytorch", "tensorflow"]
INVALID_ARCH = []
TARGET_VOCAB_SIZE = 1024
data = {"training_ds": None, "testing_ds": None}
COMPOSITE_MODELS = {
"EncoderDecoderModel": "EncoderDecoderModel-bert-bert",
"SpeechEncoderDecoderModel": "SpeechEncoderDecoderModel-wav2vec2-bert",
"VisionEncoderDecoderModel": "VisionEncoderDecoderModel-vit-gpt2",
"VisionTextDualEncoderModel": "VisionTextDualEncoderModel-vit-bert",
}
# This list contains the model architectures for which a tiny version could not be created.
# Avoid to add new architectures here - unless we have verified carefully that it's (almost) impossible to create them.
# One such case is: no model tester class is implemented for a model type (like `MT5`) because its architecture is
# identical to another one (`MT5` is based on `T5`), but trained on different datasets or with different techniques.
UNCONVERTIBLE_MODEL_ARCHITECTURES = {
"BertGenerationEncoder",
"BertGenerationDecoder",
"CamembertForSequenceClassification",
"CamembertForMultipleChoice",
"CamembertForMaskedLM",
"CamembertForCausalLM",
"CamembertForTokenClassification",
"CamembertForQuestionAnswering",
"CamembertModel",
"TFCamembertForMultipleChoice",
"TFCamembertForTokenClassification",
"TFCamembertForQuestionAnswering",
"TFCamembertForSequenceClassification",
"TFCamembertForMaskedLM",
"TFCamembertModel",
"TFCamembertForCausalLM",
"DecisionTransformerModel",
"GraphormerModel",
"InformerModel",
"JukeboxModel",
"MarianForCausalLM",
"MaskFormerSwinModel",
"MaskFormerSwinBackbone",
"MT5Model",
"MT5ForConditionalGeneration",
"UMT5ForConditionalGeneration",
"TFMT5ForConditionalGeneration",
"TFMT5Model",
"QDQBertForSequenceClassification",
"QDQBertForMaskedLM",
"QDQBertModel",
"QDQBertForTokenClassification",
"QDQBertLMHeadModel",
"QDQBertForMultipleChoice",
"QDQBertForQuestionAnswering",
"QDQBertForNextSentencePrediction",
"ReformerModelWithLMHead",
"RetriBertModel",
"Speech2Text2ForCausalLM",
"TimeSeriesTransformerModel",
"TrajectoryTransformerModel",
"TrOCRForCausalLM",
"XLMProphetNetForConditionalGeneration",
"XLMProphetNetForCausalLM",
"XLMProphetNetModel",
"XLMRobertaModel",
"XLMRobertaForTokenClassification",
"XLMRobertaForMultipleChoice",
"XLMRobertaForMaskedLM",
"XLMRobertaForCausalLM",
"XLMRobertaForSequenceClassification",
"XLMRobertaForQuestionAnswering",
"TFXLMRobertaForSequenceClassification",
"TFXLMRobertaForMaskedLM",
"TFXLMRobertaForCausalLM",
"TFXLMRobertaForQuestionAnswering",
"TFXLMRobertaModel",
"TFXLMRobertaForMultipleChoice",
"TFXLMRobertaForTokenClassification",
}
def get_processor_types_from_config_class(config_class, allowed_mappings=None):
"""Return a tuple of processors for `config_class`.
We use `tuple` here to include (potentially) both slow & fast tokenizers.
"""
# To make a uniform return type
def _to_tuple(x):
if not isinstance(x, collections.abc.Sequence):
x = (x,)
else:
x = tuple(x)
return x
if allowed_mappings is None:
allowed_mappings = ["processor", "tokenizer", "image_processor", "feature_extractor"]
processor_types = ()
# Check first if a model has `ProcessorMixin`. Otherwise, check if it has tokenizers, and/or an image processor or
# a feature extractor
if config_class in PROCESSOR_MAPPING and "processor" in allowed_mappings:
processor_types = _to_tuple(PROCESSOR_MAPPING[config_class])
else:
if config_class in TOKENIZER_MAPPING and "tokenizer" in allowed_mappings:
processor_types = TOKENIZER_MAPPING[config_class]
if config_class in IMAGE_PROCESSOR_MAPPING and "image_processor" in allowed_mappings:
processor_types += _to_tuple(IMAGE_PROCESSOR_MAPPING[config_class])
elif config_class in FEATURE_EXTRACTOR_MAPPING and "feature_extractor" in allowed_mappings:
processor_types += _to_tuple(FEATURE_EXTRACTOR_MAPPING[config_class])
# Remark: some configurations have no processor at all. For example, generic composite models like
# `EncoderDecoderModel` is used for any (compatible) text models. Also, `DecisionTransformer` doesn't
# require any processor.
# We might get `None` for some tokenizers - remove them here.
processor_types = tuple(p for p in processor_types if p is not None)
return processor_types
def get_architectures_from_config_class(config_class, arch_mappings, models_to_skip=None):
"""Return a tuple of all possible architectures attributed to a configuration class `config_class`.
For example, BertConfig -> [BertModel, BertForMaskedLM, ..., BertForQuestionAnswering].
"""
# A model architecture could appear in several mappings. For example, `BartForConditionalGeneration` is in
# - MODEL_FOR_PRETRAINING_MAPPING_NAMES
# - MODEL_WITH_LM_HEAD_MAPPING_NAMES
# - MODEL_FOR_MASKED_LM_MAPPING_NAMES
# - MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES
# We avoid the duplication.
architectures = set()
if models_to_skip is None:
models_to_skip = []
models_to_skip = UNCONVERTIBLE_MODEL_ARCHITECTURES.union(models_to_skip)
for mapping in arch_mappings:
if config_class in mapping:
models = mapping[config_class]
models = tuple(models) if isinstance(models, collections.abc.Sequence) else (models,)
for model in models:
if model.__name__ not in models_to_skip:
architectures.add(model)
architectures = tuple(architectures)
return architectures
def get_config_class_from_processor_class(processor_class):
"""Get the config class from a processor class.
Some config/model classes use tokenizers/feature_extractors from other models. For example, `GPT-J` uses
`GPT2Tokenizer`. If no checkpoint is found for a config class, or a checkpoint is found without necessary file(s) to
create the processor for `processor_class`, we get the config class that corresponds to `processor_class` and use it
to find a checkpoint in order to create the processor.
"""
processor_prefix = processor_class.__name__
for postfix in ["TokenizerFast", "Tokenizer", "ImageProcessor", "FeatureExtractor", "Processor"]:
processor_prefix = processor_prefix.replace(postfix, "")
# `Wav2Vec2CTCTokenizer` -> `Wav2Vec2Config`
if processor_prefix == "Wav2Vec2CTC":
processor_prefix = "Wav2Vec2"
# Find the new configuration class
new_config_name = f"{processor_prefix}Config"
new_config_class = getattr(transformers_module, new_config_name)
return new_config_class
def build_processor(config_class, processor_class, allow_no_checkpoint=False):
"""Create a processor for `processor_class`.
If a processor is not able to be built with the original arguments, this method tries to change the arguments and
call itself recursively, by inferring a new `config_class` or a new `processor_class` from another one, in order to
find a checkpoint containing the necessary files to build a processor.
The processor is not saved here. Instead, it will be saved in `convert_processors` after further changes in
`convert_processors`. For each model architecture`, a copy will be created and saved along the built model.
"""
# Currently, this solely uses the docstring in the source file of `config_class` to find a checkpoint.
checkpoint = get_checkpoint_from_config_class(config_class)
if checkpoint is None:
# try to get the checkpoint from the config class for `processor_class`.
# This helps cases like `XCLIPConfig` and `VideoMAEFeatureExtractor` to find a checkpoint from `VideoMAEConfig`.
config_class_from_processor_class = get_config_class_from_processor_class(processor_class)
checkpoint = get_checkpoint_from_config_class(config_class_from_processor_class)
processor = None
try:
processor = processor_class.from_pretrained(checkpoint)
except Exception as e:
logger.error(f"{e.__class__.__name__}: {e}")
# Try to get a new processor class from checkpoint. This is helpful for a checkpoint without necessary file to load
# processor while `processor_class` is an Auto class. For example, `sew` has `Wav2Vec2Processor` in
# `PROCESSOR_MAPPING_NAMES`, its `tokenizer_class` is `AutoTokenizer`, and the checkpoint
# `https://huggingface.co/asapp/sew-tiny-100k` has no tokenizer file, but we can get
# `tokenizer_class: Wav2Vec2CTCTokenizer` from the config file. (The new processor class won't be able to load from
# `checkpoint`, but it helps this recursive method to find a way to build a processor).
if (
processor is None
and checkpoint is not None
and issubclass(processor_class, (PreTrainedTokenizerBase, AutoTokenizer))
):
try:
config = AutoConfig.from_pretrained(checkpoint)
except Exception as e:
logger.error(f"{e.__class__.__name__}: {e}")
config = None
if config is not None:
if not isinstance(config, config_class):
raise ValueError(
f"`config` (which is of type {config.__class__.__name__}) should be an instance of `config_class`"
f" ({config_class.__name__})!"
)
tokenizer_class = config.tokenizer_class
new_processor_class = None
if tokenizer_class is not None:
new_processor_class = getattr(transformers_module, tokenizer_class)
if new_processor_class != processor_class:
processor = build_processor(config_class, new_processor_class)
# If `tokenizer_class` is not specified in `config`, let's use `config` to get the process class via auto
# mappings, but only allow the tokenizer mapping being used. This is to make `Wav2Vec2Conformer` build
if processor is None:
new_processor_classes = get_processor_types_from_config_class(
config.__class__, allowed_mappings=["tokenizer"]
)
# Used to avoid infinite recursion between a pair of fast/slow tokenizer types
names = [
x.__name__.replace("Fast", "") for x in [processor_class, new_processor_class] if x is not None
]
new_processor_classes = [
x for x in new_processor_classes if x is not None and x.__name__.replace("Fast", "") not in names
]
if len(new_processor_classes) > 0:
new_processor_class = new_processor_classes[0]
# Let's use fast tokenizer if there is any
for x in new_processor_classes:
if x.__name__.endswith("Fast"):
new_processor_class = x
break
processor = build_processor(config_class, new_processor_class)
if processor is None:
# Try to build each component (tokenizer & feature extractor) of a `ProcessorMixin`.
if issubclass(processor_class, ProcessorMixin):
attrs = {}
for attr_name in processor_class.attributes:
attrs[attr_name] = []
# This could be a tuple (for tokenizers). For example, `CLIPProcessor` has
# - feature_extractor_class = "CLIPFeatureExtractor"
# - tokenizer_class = ("CLIPTokenizer", "CLIPTokenizerFast")
attr_class_names = getattr(processor_class, f"{attr_name}_class")
if not isinstance(attr_class_names, tuple):
attr_class_names = (attr_class_names,)
for name in attr_class_names:
attr_class = getattr(transformers_module, name)
attr = build_processor(config_class, attr_class)
if attr is not None:
attrs[attr_name].append(attr)
# try to build a `ProcessorMixin`, so we can return a single value
if all(len(v) > 0 for v in attrs.values()):
try:
processor = processor_class(**{k: v[0] for k, v in attrs.items()})
except Exception as e:
logger.error(f"{e.__class__.__name__}: {e}")
else:
# `checkpoint` might lack some file(s) to load a processor. For example, `facebook/hubert-base-ls960`
# has no tokenizer file to load `Wav2Vec2CTCTokenizer`. In this case, we try to build a processor
# with the configuration class (for example, `Wav2Vec2Config`) corresponding to `processor_class`.
config_class_from_processor_class = get_config_class_from_processor_class(processor_class)
if config_class_from_processor_class != config_class:
processor = build_processor(config_class_from_processor_class, processor_class)
# Try to create an image processor or a feature extractor without any checkpoint
if (
processor is None
and allow_no_checkpoint
and (issubclass(processor_class, BaseImageProcessor) or issubclass(processor_class, FeatureExtractionMixin))
):
try:
processor = processor_class()
except Exception as e:
logger.error(f"{e.__class__.__name__}: {e}")
# validation
if processor is not None:
if not (isinstance(processor, processor_class) or processor_class.__name__.startswith("Auto")):
raise ValueError(
f"`processor` (which is of type {processor.__class__.__name__}) should be an instance of"
f" {processor_class.__name__} or an Auto class!"
)
return processor
def get_tiny_config(config_class, model_class=None, **model_tester_kwargs):
"""Retrieve a tiny configuration from `config_class` using each model's `ModelTester`.
Args:
config_class: Subclass of `PreTrainedConfig`.
Returns:
An instance of `config_class` with tiny hyperparameters
"""
model_type = config_class.model_type
# For model type like `data2vec-vision` and `donut-swin`, we can't get the config/model file name directly via
# `model_type` as it would be sth. like `configuration_data2vec_vision.py`.
# A simple way is to use `inspect.getsourcefile(config_class)`.
config_source_file = inspect.getsourcefile(config_class)
# The modeling file name without prefix (`modeling_`) and postfix (`.py`)
modeling_name = config_source_file.split(os.path.sep)[-1].replace("configuration_", "").replace(".py", "")
try:
print("Importing", model_type_to_module_name(model_type))
module_name = model_type_to_module_name(model_type)
if not modeling_name.startswith(module_name):
raise ValueError(f"{modeling_name} doesn't start with {module_name}!")
test_file = os.path.join("tests", "models", module_name, f"test_modeling_{modeling_name}.py")
models_to_model_testers = get_model_to_tester_mapping(test_file)
# Find the model tester class
model_tester_class = None
tester_classes = []
if model_class is not None:
tester_classes = get_tester_classes_for_model(test_file, model_class)
else:
for _tester_classes in models_to_model_testers.values():
tester_classes.extend(_tester_classes)
if len(tester_classes) > 0:
# sort with the length of the class names first, then the alphabetical order
# This is to avoid `T5EncoderOnlyModelTest` is used instead of `T5ModelTest`, which has
# `is_encoder_decoder=False` and causes some pipeline tests failing (also failures in `Optimum` CI).
# TODO: More fine grained control of the desired tester class.
model_tester_class = sorted(tester_classes, key=lambda x: (len(x.__name__), x.__name__))[0]
except ModuleNotFoundError:
error = f"Tiny config not created for {model_type} - cannot find the testing module from the model name."
raise ValueError(error)
if model_tester_class is None:
error = f"Tiny config not created for {model_type} - no model tester is found in the testing module."
raise ValueError(error)
# CLIP-like models have `text_model_tester` and `vision_model_tester`, and we need to pass `vocab_size` to
# `text_model_tester` via `text_kwargs`. The same trick is also necessary for `Flava`.
if "vocab_size" in model_tester_kwargs:
if "text_kwargs" in inspect.signature(model_tester_class.__init__).parameters.keys():
vocab_size = model_tester_kwargs.pop("vocab_size")
model_tester_kwargs["text_kwargs"] = {"vocab_size": vocab_size}
# `parent` is an instance of `unittest.TestCase`, but we don't need it here.
model_tester = model_tester_class(parent=None, **model_tester_kwargs)
if hasattr(model_tester, "get_pipeline_config"):
config = model_tester.get_pipeline_config()
elif hasattr(model_tester, "prepare_config_and_inputs"):
# `PoolFormer` has no `get_config` defined. Furthermore, it's better to use `prepare_config_and_inputs` even if
# `get_config` is defined, since there might be some extra changes in `prepare_config_and_inputs`.
config = model_tester.prepare_config_and_inputs()[0]
elif hasattr(model_tester, "get_config"):
config = model_tester.get_config()
else:
error = (
f"Tiny config not created for {model_type} - the model tester {model_tester_class.__name__} lacks"
" necessary method to create config."
)
raise ValueError(error)
# make sure this is long enough (some model tester has `20` for this attr.) to pass `text-generation`
# pipeline tests.
max_positions = []
for key in ["max_position_embeddings", "max_source_positions", "max_target_positions"]:
if getattr(config, key, 0) > 0:
max_positions.append(getattr(config, key))
if getattr(config, "text_config", None) is not None:
if getattr(config.text_config, key, None) is not None:
max_positions.append(getattr(config.text_config, key))
if len(max_positions) > 0:
max_position = max(200, min(max_positions))
for key in ["max_position_embeddings", "max_source_positions", "max_target_positions"]:
if getattr(config, key, 0) > 0:
setattr(config, key, max_position)
if getattr(config, "text_config", None) is not None:
if getattr(config.text_config, key, None) is not None:
setattr(config.text_config, key, max_position)
return config
def convert_tokenizer(tokenizer_fast: PreTrainedTokenizerFast):
new_tokenizer = tokenizer_fast.train_new_from_iterator(
data["training_ds"]["text"], TARGET_VOCAB_SIZE, show_progress=False
)
# Make sure it at least runs
if not isinstance(new_tokenizer, LayoutLMv3TokenizerFast):
new_tokenizer(data["testing_ds"]["text"])
return new_tokenizer
def convert_feature_extractor(feature_extractor, tiny_config):
to_convert = False
kwargs = {}
if hasattr(tiny_config, "image_size"):
kwargs["size"] = tiny_config.image_size
kwargs["crop_size"] = tiny_config.image_size
to_convert = True
elif (
hasattr(tiny_config, "vision_config")
and tiny_config.vision_config is not None
and hasattr(tiny_config.vision_config, "image_size")
):
kwargs["size"] = tiny_config.vision_config.image_size
kwargs["crop_size"] = tiny_config.vision_config.image_size
to_convert = True
# Speech2TextModel specific.
if hasattr(tiny_config, "input_feat_per_channel"):
kwargs["feature_size"] = tiny_config.input_feat_per_channel
kwargs["num_mel_bins"] = tiny_config.input_feat_per_channel
to_convert = True
if to_convert:
feature_extractor = feature_extractor.__class__(**kwargs)
return feature_extractor
def convert_processors(processors, tiny_config, output_folder, result):
"""Change a processor to work with smaller inputs.
For tokenizers, we try to reduce their vocabulary size.
For feature extractor, we use smaller image size or change
other attributes using the values from `tiny_config`. See `convert_feature_extractor`.
This method should not fail: we catch the errors and put them in `result["warnings"]` with descriptive messages.
"""
def _sanity_check(fast_tokenizer, slow_tokenizer, keep_fast_tokenizer=False):
"""Set tokenizer(s) to `None` if the fast/slow tokenizers have different values for `vocab_size` or `length`.
If `keep_fast_tokenizer=True`, the fast tokenizer will be kept.
"""
# sanity check 1: fast and slow tokenizers should be compatible (vocab_size)
if fast_tokenizer is not None and slow_tokenizer is not None:
if fast_tokenizer.vocab_size != slow_tokenizer.vocab_size:
warning_messagae = (
"The fast/slow tokenizers "
f"({fast_tokenizer.__class__.__name__}/{slow_tokenizer.__class__.__name__}) have different "
"vocabulary size: "
f"fast_tokenizer.vocab_size = {fast_tokenizer.vocab_size} and "
f"slow_tokenizer.vocab_size = {slow_tokenizer.vocab_size}."
)
result["warnings"].append(warning_messagae)
if not keep_fast_tokenizer:
fast_tokenizer = None
slow_tokenizer = None
# sanity check 2: fast and slow tokenizers should be compatible (length)
if fast_tokenizer is not None and slow_tokenizer is not None:
if len(fast_tokenizer) != len(slow_tokenizer):
warning_messagae = (
f"The fast/slow tokenizers () have different length: "
f"len(fast_tokenizer) = {len(fast_tokenizer)} and "
f"len(slow_tokenizer) = {len(slow_tokenizer)}."
)
result["warnings"].append(warning_messagae)
if not keep_fast_tokenizer:
fast_tokenizer = None
slow_tokenizer = None
return fast_tokenizer, slow_tokenizer
tokenizers = []
feature_extractors = []
for processor in processors:
if isinstance(processor, PreTrainedTokenizerBase):
if processor.__class__.__name__ not in {x.__class__.__name__ for x in tokenizers}:
tokenizers.append(processor)
elif isinstance(processor, BaseImageProcessor):
if processor.__class__.__name__ not in {x.__class__.__name__ for x in feature_extractors}:
feature_extractors.append(processor)
elif isinstance(processor, FeatureExtractionMixin):
if processor.__class__.__name__ not in {x.__class__.__name__ for x in feature_extractors}:
feature_extractors.append(processor)
elif isinstance(processor, ProcessorMixin):
if hasattr(processor, "tokenizer"):
if processor.tokenizer.__class__.__name__ not in {x.__class__.__name__ for x in tokenizers}:
tokenizers.append(processor.tokenizer)
# Currently, we only have these 2 possibilities
if hasattr(processor, "image_processor"):
if processor.image_processor.__class__.__name__ not in {
x.__class__.__name__ for x in feature_extractors
}:
feature_extractors.append(processor.image_processor)
elif hasattr(processor, "feature_extractor"):
if processor.feature_extractor.__class__.__name__ not in {
x.__class__.__name__ for x in feature_extractors
}:
feature_extractors.append(processor.feature_extractor)
# check the built processors have the unique type
num_types = len({x.__class__.__name__ for x in feature_extractors})
if num_types >= 2:
raise ValueError(f"`feature_extractors` should contain at most 1 type, but it contains {num_types} types!")
num_types = len({x.__class__.__name__.replace("Fast", "") for x in tokenizers})
if num_types >= 2:
raise ValueError(f"`tokenizers` should contain at most 1 tokenizer type, but it contains {num_types} types!")
fast_tokenizer = None
slow_tokenizer = None
for tokenizer in tokenizers:
if isinstance(tokenizer, PreTrainedTokenizerFast):
fast_tokenizer = tokenizer
else:
slow_tokenizer = tokenizer
# If the (original) fast/slow tokenizers don't correspond, keep only the fast tokenizer.
# This doesn't necessarily imply the fast/slow tokenizers in a single Hub repo. has issues.
# It's more of an issue in `build_processor` which tries to get a checkpoint with as much effort as possible.
# For `YosoModel` (which uses `AlbertTokenizer(Fast)`), its real (Hub) checkpoint doesn't contain valid files to
# load the slower tokenizer (`AlbertTokenizer`), and it ends up finding the (canonical) checkpoint of `AlbertModel`,
# which has different vocabulary.
# TODO: Try to improve `build_processor`'s definition and/or usage to avoid the above situation in the first place.
fast_tokenizer, slow_tokenizer = _sanity_check(fast_tokenizer, slow_tokenizer, keep_fast_tokenizer=True)
original_fast_tokenizer, original_slow_tokenizer = fast_tokenizer, slow_tokenizer
if fast_tokenizer:
try:
# Wav2Vec2ForCTC , ByT5Tokenizer etc. all are already small enough and have no fast version that can
# be retrained
if fast_tokenizer.vocab_size > TARGET_VOCAB_SIZE:
fast_tokenizer = convert_tokenizer(fast_tokenizer)
except Exception:
result["warnings"].append(
(
f"Failed to convert the fast tokenizer for {fast_tokenizer.__class__.__name__}.",
traceback.format_exc(),
)
)
# If `fast_tokenizer` exists, `slow_tokenizer` should correspond to it.
if fast_tokenizer:
# Make sure the fast tokenizer can be saved
try:
# We don't save it to `output_folder` at this moment - only at the end of this function.
with tempfile.TemporaryDirectory() as tmpdir:
fast_tokenizer.save_pretrained(tmpdir)
try:
slow_tokenizer = AutoTokenizer.from_pretrained(tmpdir, use_fast=False)
except Exception:
result["warnings"].append(
(
f"Failed to load the slow tokenizer saved from {fast_tokenizer.__class__.__name__}.",
traceback.format_exc(),
)
)
# Let's just keep the fast version
slow_tokenizer = None
except Exception:
result["warnings"].append(
(
f"Failed to save the fast tokenizer for {fast_tokenizer.__class__.__name__}.",
traceback.format_exc(),
)
)
fast_tokenizer = None
# If the (possibly converted) fast/slow tokenizers don't correspond, set them to `None`, and use the original
# tokenizers.
fast_tokenizer, slow_tokenizer = _sanity_check(fast_tokenizer, slow_tokenizer, keep_fast_tokenizer=False)
# If there is any conversion failed, we keep the original tokenizers.
if (original_fast_tokenizer is not None and fast_tokenizer is None) or (
original_slow_tokenizer is not None and slow_tokenizer is None
):
warning_messagae = (
"There are some issues when converting the fast/slow tokenizers. The original tokenizers from the Hub "
" will be used instead."
)
result["warnings"].append(warning_messagae)
# Let's use the original version at the end (`original_fast_tokenizer` and `original_slow_tokenizer`)
fast_tokenizer = original_fast_tokenizer
slow_tokenizer = original_slow_tokenizer
# Make sure the fast tokenizer can be saved
if fast_tokenizer:
# We don't save it to `output_folder` at this moment - only at the end of this function.
with tempfile.TemporaryDirectory() as tmpdir:
try:
fast_tokenizer.save_pretrained(tmpdir)
except Exception:
result["warnings"].append(
(
f"Failed to save the fast tokenizer for {fast_tokenizer.__class__.__name__}.",
traceback.format_exc(),
)
)
fast_tokenizer = None
# Make sure the slow tokenizer can be saved
if slow_tokenizer:
# We don't save it to `output_folder` at this moment - only at the end of this function.
with tempfile.TemporaryDirectory() as tmpdir:
try:
slow_tokenizer.save_pretrained(tmpdir)
except Exception:
result["warnings"].append(
(
f"Failed to save the slow tokenizer for {slow_tokenizer.__class__.__name__}.",
traceback.format_exc(),
)
)
slow_tokenizer = None
# update feature extractors using the tiny config
try:
feature_extractors = [convert_feature_extractor(p, tiny_config) for p in feature_extractors]
except Exception:
result["warnings"].append(
(
"Failed to convert feature extractors.",
traceback.format_exc(),
)
)
feature_extractors = []
if hasattr(tiny_config, "max_position_embeddings") and tiny_config.max_position_embeddings > 0:
if fast_tokenizer is not None:
if fast_tokenizer.__class__.__name__ in [
"RobertaTokenizerFast",
"XLMRobertaTokenizerFast",
"LongformerTokenizerFast",
"MPNetTokenizerFast",
]:
fast_tokenizer.model_max_length = tiny_config.max_position_embeddings - 2
else:
fast_tokenizer.model_max_length = tiny_config.max_position_embeddings
if slow_tokenizer is not None:
if slow_tokenizer.__class__.__name__ in [
"RobertaTokenizer",
"XLMRobertaTokenizer",
"LongformerTokenizer",
"MPNetTokenizer",
]:
slow_tokenizer.model_max_length = tiny_config.max_position_embeddings - 2
else:
slow_tokenizer.model_max_length = tiny_config.max_position_embeddings
processors = [fast_tokenizer, slow_tokenizer] + feature_extractors
processors = [p for p in processors if p is not None]
for p in processors:
p.save_pretrained(output_folder)
return processors
def get_checkpoint_dir(output_dir, model_arch):
"""Get framework-agnostic architecture name. Used to save all PT/TF/Flax models into the same directory."""
arch_name = model_arch.__name__
if arch_name.startswith("TF"):
arch_name = arch_name[2:]
elif arch_name.startswith("Flax"):
arch_name = arch_name[4:]
return os.path.join(output_dir, arch_name)
def build_model(model_arch, tiny_config, output_dir):
"""Create and save a model for `model_arch`.
Also copy the set of processors to each model (under the same model type) output folder.
"""
checkpoint_dir = get_checkpoint_dir(output_dir, model_arch)
processor_output_dir = os.path.join(output_dir, "processors")
# copy the (same set of) processors (for a model type) to the model arch. specific folder
if os.path.isdir(processor_output_dir):
shutil.copytree(processor_output_dir, checkpoint_dir, dirs_exist_ok=True)
tiny_config = copy.deepcopy(tiny_config)
if any(model_arch.__name__.endswith(x) for x in ["ForCausalLM", "LMHeadModel"]):
tiny_config.is_encoder_decoder = False
tiny_config.is_decoder = True
model = model_arch(config=tiny_config)
model.save_pretrained(checkpoint_dir)
model.from_pretrained(checkpoint_dir)
return model
def fill_result_with_error(result, error, trace, models_to_create):
"""Fill `result` with errors for all target model arch if we can't build processor"""
error = (error, trace)
result["error"] = error
for framework in FRAMEWORKS:
if framework in models_to_create:
result[framework] = {}
for model_arch in models_to_create[framework]:
result[framework][model_arch.__name__] = {"model": None, "checkpoint": None, "error": error}
result["processor"] = {p.__class__.__name__: p.__class__.__name__ for p in result["processor"].values()}
def upload_model(model_dir, organization, token):
"""Upload the tiny models"""
arch_name = model_dir.split(os.path.sep)[-1]
repo_name = f"tiny-random-{arch_name}"
repo_id = f"{organization}/{repo_name}"
repo_exist = False
error = None
try:
create_repo(repo_id=repo_id, exist_ok=False, repo_type="model", token=token)
except Exception as e:
error = e
if "You already created" in str(e):
error = None
logger.warning("Remote repository exists and will be cloned.")
repo_exist = True
try:
create_repo(repo_id=repo_id, exist_ok=True, repo_type="model", token=token)
except Exception as e:
error = e
if error is not None:
raise error
with tempfile.TemporaryDirectory() as tmpdir:
repo = Repository(local_dir=tmpdir, clone_from=repo_id, token=token)
repo.git_pull()
shutil.copytree(model_dir, tmpdir, dirs_exist_ok=True)
if repo_exist:
# Open a PR on the existing Hub repo.
hub_pr_url = upload_folder(
folder_path=model_dir,
repo_id=repo_id,
repo_type="model",
commit_message=f"Update tiny models for {arch_name}",
commit_description=f"Upload tiny models for {arch_name}",
create_pr=True,
token=token,
)
logger.warning(f"PR open in {hub_pr_url}.")
# TODO: We need this information?
else:
# Push to Hub repo directly
repo.git_add(auto_lfs_track=True)
repo.git_commit(f"Upload tiny models for {arch_name}")
repo.git_push(blocking=True) # this prints a progress bar with the upload
logger.warning(f"Tiny models {arch_name} pushed to {repo_id}.")
def build_composite_models(config_class, output_dir):
import tempfile
from transformers import (
BertConfig,
BertLMHeadModel,
BertModel,
BertTokenizer,
BertTokenizerFast,
EncoderDecoderModel,
GPT2Config,
GPT2LMHeadModel,
GPT2Tokenizer,
GPT2TokenizerFast,
SpeechEncoderDecoderModel,
TFEncoderDecoderModel,
TFVisionEncoderDecoderModel,
TFVisionTextDualEncoderModel,
VisionEncoderDecoderModel,
VisionTextDualEncoderModel,
ViTConfig,
ViTFeatureExtractor,
ViTModel,
Wav2Vec2Config,
Wav2Vec2Model,
Wav2Vec2Processor,
)
# These will be removed at the end if they are empty
result = {"error": None, "warnings": []}
if config_class.model_type == "encoder-decoder":
encoder_config_class = BertConfig
decoder_config_class = BertConfig
encoder_processor = (BertTokenizerFast, BertTokenizer)
decoder_processor = (BertTokenizerFast, BertTokenizer)
encoder_class = BertModel
decoder_class = BertLMHeadModel
model_class = EncoderDecoderModel
tf_model_class = TFEncoderDecoderModel
elif config_class.model_type == "vision-encoder-decoder":
encoder_config_class = ViTConfig
decoder_config_class = GPT2Config
encoder_processor = (ViTFeatureExtractor,)
decoder_processor = (GPT2TokenizerFast, GPT2Tokenizer)
encoder_class = ViTModel
decoder_class = GPT2LMHeadModel
model_class = VisionEncoderDecoderModel
tf_model_class = TFVisionEncoderDecoderModel
elif config_class.model_type == "speech-encoder-decoder":
encoder_config_class = Wav2Vec2Config
decoder_config_class = BertConfig
encoder_processor = (Wav2Vec2Processor,)
decoder_processor = (BertTokenizerFast, BertTokenizer)
encoder_class = Wav2Vec2Model
decoder_class = BertLMHeadModel
model_class = SpeechEncoderDecoderModel
tf_model_class = None
elif config_class.model_type == "vision-text-dual-encoder":
# Not encoder-decoder, but encoder-encoder. We just keep the same name as above to make code easier
encoder_config_class = ViTConfig
decoder_config_class = BertConfig
encoder_processor = (ViTFeatureExtractor,)
decoder_processor = (BertTokenizerFast, BertTokenizer)
encoder_class = ViTModel
decoder_class = BertModel
model_class = VisionTextDualEncoderModel
tf_model_class = TFVisionTextDualEncoderModel
with tempfile.TemporaryDirectory() as tmpdir:
try:
# build encoder
models_to_create = {"processor": encoder_processor, "pytorch": (encoder_class,), "tensorflow": []}
encoder_output_dir = os.path.join(tmpdir, "encoder")
build(encoder_config_class, models_to_create, encoder_output_dir)
# build decoder
models_to_create = {"processor": decoder_processor, "pytorch": (decoder_class,), "tensorflow": []}
decoder_output_dir = os.path.join(tmpdir, "decoder")
build(decoder_config_class, models_to_create, decoder_output_dir)
# build encoder-decoder
encoder_path = os.path.join(encoder_output_dir, encoder_class.__name__)
decoder_path = os.path.join(decoder_output_dir, decoder_class.__name__)
if config_class.model_type != "vision-text-dual-encoder":
# Specify these explicitly for encoder-decoder like models, but not for `vision-text-dual-encoder` as it
# has no decoder.
decoder_config = decoder_config_class.from_pretrained(decoder_path)
decoder_config.is_decoder = True
decoder_config.add_cross_attention = True
model = model_class.from_encoder_decoder_pretrained(
encoder_path,
decoder_path,
decoder_config=decoder_config,
)
elif config_class.model_type == "vision-text-dual-encoder":
model = model_class.from_vision_text_pretrained(encoder_path, decoder_path)
model_path = os.path.join(
output_dir,
f"{model_class.__name__}-{encoder_config_class.model_type}-{decoder_config_class.model_type}",
)
model.save_pretrained(model_path)
if tf_model_class is not None:
model = tf_model_class.from_pretrained(model_path)
model.save_pretrained(model_path)
# copy the processors
encoder_processor_path = os.path.join(encoder_output_dir, "processors")
decoder_processor_path = os.path.join(decoder_output_dir, "processors")
if os.path.isdir(encoder_processor_path):
shutil.copytree(encoder_processor_path, model_path, dirs_exist_ok=True)
if os.path.isdir(decoder_processor_path):
shutil.copytree(decoder_processor_path, model_path, dirs_exist_ok=True)
# fill `result`
result["processor"] = {x.__name__: x.__name__ for x in encoder_processor + decoder_processor}
result["pytorch"] = {model_class.__name__: {"model": model_class.__name__, "checkpoint": model_path}}
result["tensorflow"] = {}
if tf_model_class is not None:
result["tensorflow"] = {
tf_model_class.__name__: {"model": tf_model_class.__name__, "checkpoint": model_path}
}
except Exception:
result["error"] = (
f"Failed to build models for {config_class.__name__}.",
traceback.format_exc(),
)
if not result["error"]:
del result["error"]
if not result["warnings"]:
del result["warnings"]
return result
def get_token_id_from_tokenizer(token_id_name, tokenizer, original_token_id):
"""Use `tokenizer` to get the values of `bos_token_id`, `eos_token_ids`, etc.
The argument `token_id_name` should be a string ending with `_token_id`, and `original_token_id` should be an
integer that will be return if `tokenizer` has no token corresponding to `token_id_name`.
"""
token_id = original_token_id
if not token_id_name.endswith("_token_id"):
raise ValueError(f"`token_id_name` is {token_id_name}, which doesn't end with `_token_id`!")
token = getattr(tokenizer, token_id_name.replace("_token_id", "_token"), None)
if token is not None:
if isinstance(tokenizer, PreTrainedTokenizerFast):
token_id = tokenizer._convert_token_to_id_with_added_voc(token)
else:
token_id = tokenizer._convert_token_to_id(token)
return token_id
def get_config_overrides(config_class, processors):
# `Bark` configuration is too special. Let's just not handle this for now.
if config_class.__name__ == "BarkConfig":
return {}
config_overrides = {}
# Check if there is any tokenizer (prefer fast version if any)
tokenizer = None
for processor in processors:
if isinstance(processor, PreTrainedTokenizerFast):
tokenizer = processor
break
elif isinstance(processor, PreTrainedTokenizer):
tokenizer = processor
if tokenizer is None:
return config_overrides
# Get some properties of the (already converted) tokenizer (smaller vocab size, special token ids, etc.)
# We use `len(tokenizer)` instead of `tokenizer.vocab_size` to avoid potential issues for tokenizers with non-empty
# `added_tokens_encoder`. One example is the `DebertaV2Tokenizer` where the mask token is the extra token.
vocab_size = len(tokenizer)
# The original checkpoint has length `35998`, but it doesn't have ids `30400` and `30514` but instead `35998` and
# `35999`.
if config_class.__name__ == "GPTSanJapaneseConfig":
vocab_size += 2
config_overrides["vocab_size"] = vocab_size
# Used to create a new model tester with `tokenizer.vocab_size` in order to get the (updated) special token ids.
model_tester_kwargs = {"vocab_size": vocab_size}
# `FSMTModelTester` accepts `src_vocab_size` and `tgt_vocab_size` but not `vocab_size`.
if config_class.__name__ == "FSMTConfig":
del model_tester_kwargs["vocab_size"]
model_tester_kwargs["src_vocab_size"] = tokenizer.src_vocab_size
model_tester_kwargs["tgt_vocab_size"] = tokenizer.tgt_vocab_size
_tiny_config = get_tiny_config(config_class, **model_tester_kwargs)
# handle the possibility of `text_config` inside `_tiny_config` for clip-like models (`owlvit`, `groupvit`, etc.)
if hasattr(_tiny_config, "text_config"):
_tiny_config = _tiny_config.text_config
# Collect values of some special token ids
for attr in dir(_tiny_config):
if attr.endswith("_token_id"):
token_id = getattr(_tiny_config, attr)
if token_id is not None:
# Using the token id values from `tokenizer` instead of from `_tiny_config`.
token_id = get_token_id_from_tokenizer(attr, tokenizer, original_token_id=token_id)
config_overrides[attr] = token_id
if config_class.__name__ == "FSMTConfig":
config_overrides["src_vocab_size"] = tokenizer.src_vocab_size
config_overrides["tgt_vocab_size"] = tokenizer.tgt_vocab_size
# `FSMTConfig` has `DecoderConfig` as `decoder` attribute.
config_overrides["decoder"] = configuration_fsmt.DecoderConfig(
vocab_size=tokenizer.tgt_vocab_size, bos_token_id=config_overrides["eos_token_id"]
)
return config_overrides
def build(config_class, models_to_create, output_dir):
"""Create all models for a certain model type.
Args:
config_class (`PretrainedConfig`):
A subclass of `PretrainedConfig` that is used to determine `models_to_create`.
models_to_create (`dict`):
A dictionary containing the processor/model classes that we want to create the instances. These models are
of the same model type which is associated to `config_class`.
output_dir (`str`):
The directory to save all the checkpoints. Each model architecture will be saved in a subdirectory under
it. Models in different frameworks with the same architecture will be saved in the same subdirectory.
"""
if data["training_ds"] is None or data["testing_ds"] is None:
ds = load_dataset("wikitext", "wikitext-2-raw-v1")
data["training_ds"] = ds["train"]
data["testing_ds"] = ds["test"]
if config_class.model_type in [
"encoder-decoder",
"vision-encoder-decoder",
"speech-encoder-decoder",
"vision-text-dual-encoder",
]:
return build_composite_models(config_class, output_dir)
result = {k: {} for k in models_to_create}
# These will be removed at the end if they are empty
result["error"] = None
result["warnings"] = []
# Build processors
processor_classes = models_to_create["processor"]
if len(processor_classes) == 0:
error = f"No processor class could be found in {config_class.__name__}."
fill_result_with_error(result, error, None, models_to_create)
logger.error(result["error"][0])
return result
for processor_class in processor_classes:
try:
processor = build_processor(config_class, processor_class, allow_no_checkpoint=True)
if processor is not None:
result["processor"][processor_class] = processor
except Exception:
error = f"Failed to build processor for {processor_class.__name__}."
trace = traceback.format_exc()
fill_result_with_error(result, error, trace, models_to_create)
logger.error(result["error"][0])
return result
if len(result["processor"]) == 0:
error = f"No processor could be built for {config_class.__name__}."
fill_result_with_error(result, error, None, models_to_create)
logger.error(result["error"][0])
return result
try:
tiny_config = get_tiny_config(config_class)
except Exception as e:
error = f"Failed to get tiny config for {config_class.__name__}: {e}"
trace = traceback.format_exc()
fill_result_with_error(result, error, trace, models_to_create)
logger.error(result["error"][0])
return result
# Convert the processors (reduce vocabulary size, smaller image size, etc.)
processors = list(result["processor"].values())
processor_output_folder = os.path.join(output_dir, "processors")
try:
processors = convert_processors(processors, tiny_config, processor_output_folder, result)
except Exception:
error = "Failed to convert the processors."
trace = traceback.format_exc()
result["warnings"].append((error, trace))
if len(processors) == 0:
error = f"No processor is returned by `convert_processors` for {config_class.__name__}."
fill_result_with_error(result, error, None, models_to_create)
logger.error(result["error"][0])
return result
try:
config_overrides = get_config_overrides(config_class, processors)
except Exception as e:
error = f"Failure occurs while calling `get_config_overrides`: {e}"
trace = traceback.format_exc()
fill_result_with_error(result, error, trace, models_to_create)
logger.error(result["error"][0])
return result
# Just for us to see this easily in the report
if "vocab_size" in config_overrides:
result["vocab_size"] = config_overrides["vocab_size"]
# Update attributes that `vocab_size` involves
for k, v in config_overrides.items():
if hasattr(tiny_config, k):
setattr(tiny_config, k, v)
# So far, we only have to deal with `text_config`, as `config_overrides` contains text-related attributes only.
# `FuyuConfig` saves data under both FuyuConfig and its `text_config`. This is not good, but let's just update
# every involved fields to avoid potential failure.
if (
hasattr(tiny_config, "text_config")
and tiny_config.text_config is not None
and hasattr(tiny_config.text_config, k)
):
setattr(tiny_config.text_config, k, v)
# If `text_config_dict` exists, we need to update its value here too in order to # make
# `save_pretrained -> from_pretrained` work.
if hasattr(tiny_config, "text_config_dict"):
tiny_config.text_config_dict[k] = v
if result["warnings"]:
logger.warning(result["warnings"][0][0])
# update `result["processor"]`
result["processor"] = {type(p).__name__: p.__class__.__name__ for p in processors}
for pytorch_arch in models_to_create["pytorch"]:
result["pytorch"][pytorch_arch.__name__] = {}
error = None
try:
model = build_model(pytorch_arch, tiny_config, output_dir=output_dir)
except Exception as e:
model = None
error = f"Failed to create the pytorch model for {pytorch_arch}: {e}"
trace = traceback.format_exc()
result["pytorch"][pytorch_arch.__name__]["model"] = model.__class__.__name__ if model is not None else None
result["pytorch"][pytorch_arch.__name__]["checkpoint"] = (
get_checkpoint_dir(output_dir, pytorch_arch) if model is not None else None
)
if error is not None:
result["pytorch"][pytorch_arch.__name__]["error"] = (error, trace)
logger.error(f"{pytorch_arch.__name__}: {error}")
for tensorflow_arch in models_to_create["tensorflow"]:
# Make PT/TF weights compatible
pt_arch_name = tensorflow_arch.__name__[2:] # Remove `TF`
pt_arch = getattr(transformers_module, pt_arch_name)
result["tensorflow"][tensorflow_arch.__name__] = {}
error = None
if pt_arch.__name__ in result["pytorch"] and result["pytorch"][pt_arch.__name__]["checkpoint"] is not None:
ckpt = get_checkpoint_dir(output_dir, pt_arch)
# Use the same weights from PyTorch.
try:
model = tensorflow_arch.from_pretrained(ckpt)
model.save_pretrained(ckpt)
except Exception as e:
# Conversion may fail. Let's not create a model with different weights to avoid confusion (for now).
model = None
error = f"Failed to convert the pytorch model to the tensorflow model for {pt_arch}: {e}"
trace = traceback.format_exc()
else:
try:
model = build_model(tensorflow_arch, tiny_config, output_dir=output_dir)
except Exception as e:
model = None
error = f"Failed to create the tensorflow model for {tensorflow_arch}: {e}"
trace = traceback.format_exc()
result["tensorflow"][tensorflow_arch.__name__]["model"] = (
model.__class__.__name__ if model is not None else None
)
result["tensorflow"][tensorflow_arch.__name__]["checkpoint"] = (
get_checkpoint_dir(output_dir, tensorflow_arch) if model is not None else None
)
if error is not None:
result["tensorflow"][tensorflow_arch.__name__]["error"] = (error, trace)
logger.error(f"{tensorflow_arch.__name__}: {error}")
if not result["error"]:
del result["error"]
if not result["warnings"]:
del result["warnings"]
return result
def build_tiny_model_summary(results, organization=None, token=None):
"""Build a summary: a dictionary of the form
{
model architecture name:
{
"tokenizer_classes": [...],
"processor_classes": [...],
"model_classes": [...],
}
..
}
"""
tiny_model_summary = {}
for config_name in results:
processors = [key for key, value in results[config_name]["processor"].items()]
tokenizer_classes = sorted([x for x in processors if x.endswith("TokenizerFast") or x.endswith("Tokenizer")])
processor_classes = sorted([x for x in processors if x not in tokenizer_classes])
for framework in FRAMEWORKS:
if framework not in results[config_name]:
continue
for arch_name in results[config_name][framework]:
model_classes = [arch_name]
base_arch_name = arch_name[2:] if arch_name.startswith("TF") else arch_name
# tiny model is not created for `arch_name`
if results[config_name][framework][arch_name]["model"] is None:
model_classes = []
if base_arch_name not in tiny_model_summary:
tiny_model_summary[base_arch_name] = {}
tiny_model_summary[base_arch_name].update(
{
"tokenizer_classes": tokenizer_classes,
"processor_classes": processor_classes,
}
)
tiny_model_summary[base_arch_name]["model_classes"] = sorted(
tiny_model_summary[base_arch_name].get("model_classes", []) + model_classes
)
if organization is not None:
repo_name = f"tiny-random-{base_arch_name}"
# composite models' checkpoints have more precise repo. names on the Hub.
if base_arch_name in COMPOSITE_MODELS:
repo_name = f"tiny-random-{COMPOSITE_MODELS[base_arch_name]}"
repo_id = f"{organization}/{repo_name}"
try:
commit_hash = hf_api.repo_info(repo_id, token=token).sha
except Exception:
# The directory is not created, but processor(s) is/are included in `results`.
logger.warning(f"Failed to get information for {repo_id}.\n{traceback.format_exc()}")
del tiny_model_summary[base_arch_name]
continue
tiny_model_summary[base_arch_name]["sha"] = commit_hash
return tiny_model_summary
def build_failed_report(results, include_warning=True):
failed_results = {}
for config_name in results:
if "error" in results[config_name]:
if config_name not in failed_results:
failed_results[config_name] = {}
failed_results[config_name] = {"error": results[config_name]["error"]}
if include_warning and "warnings" in results[config_name]:
if config_name not in failed_results:
failed_results[config_name] = {}
failed_results[config_name]["warnings"] = results[config_name]["warnings"]
for framework in FRAMEWORKS:
if framework not in results[config_name]:
continue
for arch_name in results[config_name][framework]:
if "error" in results[config_name][framework][arch_name]:
if config_name not in failed_results:
failed_results[config_name] = {}
if framework not in failed_results[config_name]:
failed_results[config_name][framework] = {}
if arch_name not in failed_results[config_name][framework]:
failed_results[config_name][framework][arch_name] = {}
error = results[config_name][framework][arch_name]["error"]
failed_results[config_name][framework][arch_name]["error"] = error
return failed_results
def build_simple_report(results):
text = ""
failed_text = ""
for config_name in results:
for framework in FRAMEWORKS:
if framework not in results[config_name]:
continue
for arch_name in results[config_name][framework]:
if "error" in results[config_name][framework][arch_name]:
result = results[config_name][framework][arch_name]["error"]
failed_text += f"{arch_name}: {result[0]}\n"
else:
result = ("OK",)
text += f"{arch_name}: {result[0]}\n"
return text, failed_text
def update_tiny_model_summary_file(report_path):
with open(os.path.join(report_path, "tiny_model_summary.json")) as fp:
new_data = json.load(fp)
with open("tests/utils/tiny_model_summary.json") as fp:
data = json.load(fp)
for key, value in new_data.items():
if key not in data:
data[key] = value
else:
for attr in ["tokenizer_classes", "processor_classes", "model_classes"]:
# we might get duplication here. We will remove them below when creating `updated_data`.
data[key][attr].extend(value[attr])
new_sha = value.get("sha", None)
if new_sha is not None:
data[key]["sha"] = new_sha
updated_data = {}
for key in sorted(data.keys()):
updated_data[key] = {}
for attr, value in data[key].items():
# deduplication and sort
updated_data[key][attr] = sorted(set(value)) if attr != "sha" else value
with open(os.path.join(report_path, "updated_tiny_model_summary.json"), "w") as fp:
json.dump(updated_data, fp, indent=4, ensure_ascii=False)
def create_tiny_models(
output_path,
all,
model_types,
models_to_skip,
no_check,
upload,
organization,
token,
num_workers=1,
):
clone_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
if os.getcwd() != clone_path:
raise ValueError(f"This script should be run from the root of the clone of `transformers` {clone_path}")
report_path = os.path.join(output_path, "reports")
os.makedirs(report_path)
_pytorch_arch_mappings = [
x
for x in dir(transformers_module)
if x.startswith("MODEL_") and x.endswith("_MAPPING") and x != "MODEL_NAMES_MAPPING"
]
_tensorflow_arch_mappings = [
x for x in dir(transformers_module) if x.startswith("TF_MODEL_") and x.endswith("_MAPPING")
]
pytorch_arch_mappings = [getattr(transformers_module, x) for x in _pytorch_arch_mappings]
tensorflow_arch_mappings = [getattr(transformers_module, x) for x in _tensorflow_arch_mappings]
config_classes = CONFIG_MAPPING.values()
if not all:
config_classes = [CONFIG_MAPPING[model_type] for model_type in model_types]
# A map from config classes to tuples of processors (tokenizer, feature extractor, processor) classes
processor_type_map = {c: get_processor_types_from_config_class(c) for c in config_classes}
to_create = {}
for c in config_classes:
processors = processor_type_map[c]
models = get_architectures_from_config_class(c, pytorch_arch_mappings, models_to_skip)
tf_models = get_architectures_from_config_class(c, tensorflow_arch_mappings, models_to_skip)
if len(models) + len(tf_models) > 0:
to_create[c] = {"processor": processors, "pytorch": models, "tensorflow": tf_models}
results = {}
if num_workers <= 1:
for c, models_to_create in list(to_create.items()):
print(f"Create models for {c.__name__} ...")
result = build(c, models_to_create, output_dir=os.path.join(output_path, c.model_type))
results[c.__name__] = result
print("=" * 40)
else:
all_build_args = []
for c, models_to_create in list(to_create.items()):
all_build_args.append((c, models_to_create, os.path.join(output_path, c.model_type)))
with multiprocessing.Pool() as pool:
results = pool.starmap(build, all_build_args)
results = {buid_args[0].__name__: result for buid_args, result in zip(all_build_args, results)}
if upload:
if organization is None:
raise ValueError("The argument `organization` could not be `None`. No model is uploaded")
to_upload = []
for model_type in os.listdir(output_path):
# This is the directory containing the reports
if model_type == "reports":
continue
for arch in os.listdir(os.path.join(output_path, model_type)):
if arch == "processors":
continue
to_upload.append(os.path.join(output_path, model_type, arch))
to_upload = sorted(to_upload)
upload_results = {}
if len(to_upload) > 0:
for model_dir in to_upload:
try:
upload_model(model_dir, organization, token)
except Exception as e:
error = f"Failed to upload {model_dir}. {e.__class__.__name__}: {e}"
logger.error(error)
upload_results[model_dir] = error
with open(os.path.join(report_path, "failed_uploads.json"), "w") as fp:
json.dump(upload_results, fp, indent=4)
# Build the tiny model summary file. The `tokenizer_classes` and `processor_classes` could be both empty lists.
# When using the items in this file to update the file `tests/utils/tiny_model_summary.json`, the model
# architectures with `tokenizer_classes` and `processor_classes` being both empty should **NOT** be added to
# `tests/utils/tiny_model_summary.json`.
tiny_model_summary = build_tiny_model_summary(results, organization=organization, token=token)
with open(os.path.join(report_path, "tiny_model_summary.json"), "w") as fp:
json.dump(tiny_model_summary, fp, indent=4)
with open(os.path.join(report_path, "tiny_model_creation_report.json"), "w") as fp:
json.dump(results, fp, indent=4)
# Build the warning/failure report (json format): same format as the complete `results` except this contains only
# warnings or errors.
failed_results = build_failed_report(results)
with open(os.path.join(report_path, "failed_report.json"), "w") as fp:
json.dump(failed_results, fp, indent=4)
simple_report, failed_report = build_simple_report(results)
# The simplified report: a .txt file with each line of format:
# {model architecture name}: {OK or error message}
with open(os.path.join(report_path, "simple_report.txt"), "w") as fp:
fp.write(simple_report)
# The simplified failure report: same above except this only contains line with errors
with open(os.path.join(report_path, "simple_failed_report.txt"), "w") as fp:
fp.write(failed_report)
update_tiny_model_summary_file(report_path=os.path.join(output_path, "reports"))
if __name__ == "__main__":
# This has to be `spawn` to avoid hanging forever!
multiprocessing.set_start_method("spawn")
def list_str(values):
return values.split(",")
parser = argparse.ArgumentParser()
parser.add_argument("--all", action="store_true", help="Will create all tiny models.")
parser.add_argument(
"--no_check",
action="store_true",
help="If set, will not check the validity of architectures. Use with caution.",
)
parser.add_argument(
"-m",
"--model_types",
type=list_str,
help="Comma-separated list of model type(s) from which the tiny models will be created.",
)
parser.add_argument(
"--models_to_skip",
type=list_str,
help=(
"Comma-separated list of model class names(s) from which the tiny models won't be created.\nThis is usually "
"the list of model classes that have their tiny versions already uploaded to the Hub."
),
)
parser.add_argument("--upload", action="store_true", help="If to upload the created tiny models to the Hub.")
parser.add_argument(
"--organization",
default=None,
type=str,
help="The organization on the Hub to which the tiny models will be uploaded.",
)
parser.add_argument(
"--token", default=None, type=str, help="A valid authentication token for HuggingFace Hub with write access."
)
parser.add_argument("output_path", type=Path, help="Path indicating where to store generated model.")
parser.add_argument("--num_workers", default=1, type=int, help="The number of workers to run.")
args = parser.parse_args()
if not args.all and not args.model_types:
raise ValueError("Please provide at least one model type or pass `--all` to export all architectures.")
create_tiny_models(
args.output_path,
args.all,
args.model_types,
args.models_to_skip,
args.no_check,
args.upload,
args.organization,
args.token,
args.num_workers,
)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/add_pipeline_model_mapping_to_test.py
|
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""A script to add and/or update the attribute `pipeline_model_mapping` in model test files.
This script will be (mostly) used in the following 2 situations:
- run within a (scheduled) CI job to:
- check if model test files in the library have updated `pipeline_model_mapping`,
- and/or update test files and (possibly) open a GitHub pull request automatically
- being run by a `transformers` member to quickly check and update some particular test file(s)
This script is **NOT** intended to be run (manually) by community contributors.
"""
import argparse
import glob
import inspect
import os
import re
import unittest
from get_test_info import get_test_classes
from tests.test_pipeline_mixin import pipeline_test_mapping
PIPELINE_TEST_MAPPING = {}
for task, _ in pipeline_test_mapping.items():
PIPELINE_TEST_MAPPING[task] = {"pt": None, "tf": None}
# DO **NOT** add item to this set (unless the reason is approved)
TEST_FILE_TO_IGNORE = {
"tests/models/esm/test_modeling_esmfold.py", # The pipeline test mapping is added to `test_modeling_esm.py`
}
def get_framework(test_class):
"""Infer the framework from the test class `test_class`."""
if "ModelTesterMixin" in [x.__name__ for x in test_class.__bases__]:
return "pt"
elif "TFModelTesterMixin" in [x.__name__ for x in test_class.__bases__]:
return "tf"
elif "FlaxModelTesterMixin" in [x.__name__ for x in test_class.__bases__]:
return "flax"
else:
return None
def get_mapping_for_task(task, framework):
"""Get mappings defined in `XXXPipelineTests` for the task `task`."""
# Use the cached results
if PIPELINE_TEST_MAPPING[task].get(framework, None) is not None:
return PIPELINE_TEST_MAPPING[task][framework]
pipeline_test_class = pipeline_test_mapping[task]["test"]
mapping = None
if framework == "pt":
mapping = getattr(pipeline_test_class, "model_mapping", None)
elif framework == "tf":
mapping = getattr(pipeline_test_class, "tf_model_mapping", None)
if mapping is not None:
mapping = dict(mapping.items())
# cache the results
PIPELINE_TEST_MAPPING[task][framework] = mapping
return mapping
def get_model_for_pipeline_test(test_class, task):
"""Get the model architecture(s) related to the test class `test_class` for a pipeline `task`."""
framework = get_framework(test_class)
if framework is None:
return None
mapping = get_mapping_for_task(task, framework)
if mapping is None:
return None
config_classes = list({model_class.config_class for model_class in test_class.all_model_classes})
if len(config_classes) != 1:
raise ValueError("There should be exactly one configuration class from `test_class.all_model_classes`.")
# This could be a list/tuple of model classes, but it's rare.
model_class = mapping.get(config_classes[0], None)
if isinstance(model_class, (tuple, list)):
model_class = sorted(model_class, key=lambda x: x.__name__)
return model_class
def get_pipeline_model_mapping(test_class):
"""Get `pipeline_model_mapping` for `test_class`."""
mapping = [(task, get_model_for_pipeline_test(test_class, task)) for task in pipeline_test_mapping]
mapping = sorted([(task, model) for task, model in mapping if model is not None], key=lambda x: x[0])
return dict(mapping)
def get_pipeline_model_mapping_string(test_class):
"""Get `pipeline_model_mapping` for `test_class` as a string (to be added to the test file).
This will be a 1-line string. After this is added to a test file, `make style` will format it beautifully.
"""
framework = get_framework(test_class)
if framework == "pt":
framework = "torch"
default_value = "{}"
mapping = get_pipeline_model_mapping(test_class)
if len(mapping) == 0:
return ""
texts = []
for task, model_classes in mapping.items():
if isinstance(model_classes, (tuple, list)):
# A list/tuple of model classes
value = "(" + ", ".join([x.__name__ for x in model_classes]) + ")"
else:
# A single model class
value = model_classes.__name__
texts.append(f'"{task}": {value}')
text = "{" + ", ".join(texts) + "}"
text = f"pipeline_model_mapping = {text} if is_{framework}_available() else {default_value}"
return text
def is_valid_test_class(test_class):
"""Restrict to `XXXModelTesterMixin` and should be a subclass of `unittest.TestCase`."""
base_class_names = {"ModelTesterMixin", "TFModelTesterMixin", "FlaxModelTesterMixin"}
if not issubclass(test_class, unittest.TestCase):
return False
return len(base_class_names.intersection([x.__name__ for x in test_class.__bases__])) > 0
def find_test_class(test_file):
"""Find a test class in `test_file` to which we will add `pipeline_model_mapping`."""
test_classes = [x for x in get_test_classes(test_file) if is_valid_test_class(x)]
target_test_class = None
for test_class in test_classes:
# If a test class has defined `pipeline_model_mapping`, let's take it
if getattr(test_class, "pipeline_model_mapping", None) is not None:
target_test_class = test_class
break
# Take the test class with the shortest name (just a heuristic)
if target_test_class is None and len(test_classes) > 0:
target_test_class = sorted(test_classes, key=lambda x: (len(x.__name__), x.__name__))[0]
return target_test_class
def find_block_ending(lines, start_idx, indent_level):
end_idx = start_idx
for idx, line in enumerate(lines[start_idx:]):
indent = len(line) - len(line.lstrip())
if idx == 0 or indent > indent_level or (indent == indent_level and line.strip() == ")"):
end_idx = start_idx + idx
elif idx > 0 and indent <= indent_level:
# Outside the definition block of `pipeline_model_mapping`
break
return end_idx
def add_pipeline_model_mapping(test_class, overwrite=False):
"""Add `pipeline_model_mapping` to `test_class`."""
if getattr(test_class, "pipeline_model_mapping", None) is not None:
if not overwrite:
return "", -1
line_to_add = get_pipeline_model_mapping_string(test_class)
if len(line_to_add) == 0:
return "", -1
line_to_add = line_to_add + "\n"
# The code defined the class `test_class`
class_lines, class_start_line_no = inspect.getsourcelines(test_class)
# `inspect` gives the code for an object, including decorator(s) if any.
# We (only) need the exact line of the class definition.
for idx, line in enumerate(class_lines):
if line.lstrip().startswith("class "):
class_lines = class_lines[idx:]
class_start_line_no += idx
break
class_end_line_no = class_start_line_no + len(class_lines) - 1
# The index in `class_lines` that starts the definition of `all_model_classes`, `all_generative_model_classes` or
# `pipeline_model_mapping`. This assumes they are defined in such order, and we take the start index of the last
# block that appears in a `test_class`.
start_idx = None
# The indent level of the line at `class_lines[start_idx]` (if defined)
indent_level = 0
# To record if `pipeline_model_mapping` is found in `test_class`.
def_line = None
for idx, line in enumerate(class_lines):
if line.strip().startswith("all_model_classes = "):
indent_level = len(line) - len(line.lstrip())
start_idx = idx
elif line.strip().startswith("all_generative_model_classes = "):
indent_level = len(line) - len(line.lstrip())
start_idx = idx
elif line.strip().startswith("pipeline_model_mapping = "):
indent_level = len(line) - len(line.lstrip())
start_idx = idx
def_line = line
break
if start_idx is None:
return "", -1
# Find the ending index (inclusive) of the above found block.
end_idx = find_block_ending(class_lines, start_idx, indent_level)
# Extract `is_xxx_available()` from existing blocks: some models require specific libraries like `timm` and use
# `is_timm_available()` instead of `is_torch_available()`.
# Keep leading and trailing whitespaces
r = re.compile(r"\s(is_\S+?_available\(\))\s")
for line in class_lines[start_idx : end_idx + 1]:
backend_condition = r.search(line)
if backend_condition is not None:
# replace the leading and trailing whitespaces to the space character " ".
target = " " + backend_condition[0][1:-1] + " "
line_to_add = r.sub(target, line_to_add)
break
if def_line is None:
# `pipeline_model_mapping` is not defined. The target index is set to the ending index (inclusive) of
# `all_model_classes` or `all_generative_model_classes`.
target_idx = end_idx
else:
# `pipeline_model_mapping` is defined. The target index is set to be one **BEFORE** its start index.
target_idx = start_idx - 1
# mark the lines of the currently existing `pipeline_model_mapping` to be removed.
for idx in range(start_idx, end_idx + 1):
# These lines are going to be removed before writing to the test file.
class_lines[idx] = None # noqa
# Make sure the test class is a subclass of `PipelineTesterMixin`.
parent_classes = [x.__name__ for x in test_class.__bases__]
if "PipelineTesterMixin" not in parent_classes:
# Put `PipelineTesterMixin` just before `unittest.TestCase`
_parent_classes = [x for x in parent_classes if x != "TestCase"] + ["PipelineTesterMixin"]
if "TestCase" in parent_classes:
# Here we **assume** the original string is always with `unittest.TestCase`.
_parent_classes.append("unittest.TestCase")
parent_classes = ", ".join(_parent_classes)
for idx, line in enumerate(class_lines):
# Find the ending of the declaration of `test_class`
if line.strip().endswith("):"):
# mark the lines of the declaration of `test_class` to be removed
for _idx in range(idx + 1):
class_lines[_idx] = None # noqa
break
# Add the new, one-line, class declaration for `test_class`
class_lines[0] = f"class {test_class.__name__}({parent_classes}):\n"
# Add indentation
line_to_add = " " * indent_level + line_to_add
# Insert `pipeline_model_mapping` to `class_lines`.
# (The line at `target_idx` should be kept by definition!)
class_lines = class_lines[: target_idx + 1] + [line_to_add] + class_lines[target_idx + 1 :]
# Remove the lines that are marked to be removed
class_lines = [x for x in class_lines if x is not None]
# Move from test class to module (in order to write to the test file)
module_lines = inspect.getsourcelines(inspect.getmodule(test_class))[0]
# Be careful with the 1-off between line numbers and array indices
module_lines = module_lines[: class_start_line_no - 1] + class_lines + module_lines[class_end_line_no:]
code = "".join(module_lines)
moddule_file = inspect.getsourcefile(test_class)
with open(moddule_file, "w", encoding="UTF-8", newline="\n") as fp:
fp.write(code)
return line_to_add
def add_pipeline_model_mapping_to_test_file(test_file, overwrite=False):
"""Add `pipeline_model_mapping` to `test_file`."""
test_class = find_test_class(test_file)
if test_class:
add_pipeline_model_mapping(test_class, overwrite=overwrite)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--test_file", type=str, help="A path to the test file, starting with the repository's `tests` directory."
)
parser.add_argument(
"--all",
action="store_true",
help="If to check and modify all test files.",
)
parser.add_argument(
"--overwrite",
action="store_true",
help="If to overwrite a test class if it has already defined `pipeline_model_mapping`.",
)
args = parser.parse_args()
if not args.all and not args.test_file:
raise ValueError("Please specify either `test_file` or pass `--all` to check/modify all test files.")
elif args.all and args.test_file:
raise ValueError("Only one of `--test_file` and `--all` could be specified.")
test_files = []
if args.test_file:
test_files = [args.test_file]
else:
pattern = os.path.join("tests", "models", "**", "test_modeling_*.py")
for test_file in glob.glob(pattern):
# `Flax` is not concerned at this moment
if not test_file.startswith("test_modeling_flax_"):
test_files.append(test_file)
for test_file in test_files:
if test_file in TEST_FILE_TO_IGNORE:
print(f"[SKIPPED] {test_file} is skipped as it is in `TEST_FILE_TO_IGNORE` in the file {__file__}.")
continue
add_pipeline_model_mapping_to_test_file(test_file, overwrite=args.overwrite)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/print_env.py
|
#!/usr/bin/env python3
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# this script dumps information about the environment
import os
import sys
import transformers
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
print("Python version:", sys.version)
print("transformers version:", transformers.__version__)
try:
import torch
print("Torch version:", torch.__version__)
print("Cuda available:", torch.cuda.is_available())
print("Cuda version:", torch.version.cuda)
print("CuDNN version:", torch.backends.cudnn.version())
print("Number of GPUs available:", torch.cuda.device_count())
print("NCCL version:", torch.cuda.nccl.version())
except ImportError:
print("Torch version:", None)
try:
import deepspeed
print("DeepSpeed version:", deepspeed.__version__)
except ImportError:
print("DeepSpeed version:", None)
try:
import tensorflow as tf
print("TensorFlow version:", tf.__version__)
print("TF GPUs available:", bool(tf.config.list_physical_devices("GPU")))
print("Number of TF GPUs available:", len(tf.config.list_physical_devices("GPU")))
except ImportError:
print("TensorFlow version:", None)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/update_tiny_models.py
|
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""A script running `create_dummy_models.py` with a pre-defined set of arguments.
This file is intended to be used in a CI workflow file without the need of specifying arguments. It creates and uploads
tiny models for all model classes (if their tiny versions are not on the Hub yet), as well as produces an updated
version of `tests/utils/tiny_model_summary.json`. That updated file should be merged into the `main` branch of
`transformers` so the pipeline testing will use the latest created/updated tiny models.
"""
import argparse
import copy
import json
import multiprocessing
import os
import time
from create_dummy_models import COMPOSITE_MODELS, create_tiny_models
from huggingface_hub import ModelFilter, hf_api
import transformers
from transformers import AutoFeatureExtractor, AutoImageProcessor, AutoTokenizer
from transformers.image_processing_utils import BaseImageProcessor
def get_all_model_names():
model_names = set()
# Each auto modeling files contains multiple mappings. Let's get them in a dynamic way.
for module_name in ["modeling_auto", "modeling_tf_auto", "modeling_flax_auto"]:
module = getattr(transformers.models.auto, module_name, None)
if module is None:
continue
# all mappings in a single auto modeling file
mapping_names = [
x
for x in dir(module)
if x.endswith("_MAPPING_NAMES")
and (x.startswith("MODEL_") or x.startswith("TF_MODEL_") or x.startswith("FLAX_MODEL_"))
]
for name in mapping_names:
mapping = getattr(module, name)
if mapping is not None:
for v in mapping.values():
if isinstance(v, (list, tuple)):
model_names.update(v)
elif isinstance(v, str):
model_names.add(v)
return sorted(model_names)
def get_tiny_model_names_from_repo():
# All model names defined in auto mappings
model_names = set(get_all_model_names())
with open("tests/utils/tiny_model_summary.json") as fp:
tiny_model_info = json.load(fp)
tiny_models_names = set()
for model_base_name in tiny_model_info:
tiny_models_names.update(tiny_model_info[model_base_name]["model_classes"])
# Remove a tiny model name if one of its framework implementation hasn't yet a tiny version on the Hub.
not_on_hub = model_names.difference(tiny_models_names)
for model_name in copy.copy(tiny_models_names):
if not model_name.startswith("TF") and f"TF{model_name}" in not_on_hub:
tiny_models_names.remove(model_name)
elif model_name.startswith("TF") and model_name[2:] in not_on_hub:
tiny_models_names.remove(model_name)
return sorted(tiny_models_names)
def get_tiny_model_summary_from_hub(output_path):
special_models = COMPOSITE_MODELS.values()
# All tiny model base names on Hub
model_names = get_all_model_names()
models = hf_api.list_models(
filter=ModelFilter(
author="hf-internal-testing",
)
)
_models = set()
for x in models:
model = x.modelId
org, model = model.split("/")
if not model.startswith("tiny-random-"):
continue
model = model.replace("tiny-random-", "")
if not model[0].isupper():
continue
if model not in model_names and model not in special_models:
continue
_models.add(model)
models = sorted(_models)
# All tiny model names on Hub
summary = {}
for model in models:
repo_id = f"hf-internal-testing/tiny-random-{model}"
model = model.split("-")[0]
try:
repo_info = hf_api.repo_info(repo_id)
content = {
"tokenizer_classes": set(),
"processor_classes": set(),
"model_classes": set(),
"sha": repo_info.sha,
}
except Exception:
continue
try:
time.sleep(1)
tokenizer_fast = AutoTokenizer.from_pretrained(repo_id)
content["tokenizer_classes"].add(tokenizer_fast.__class__.__name__)
except Exception:
pass
try:
time.sleep(1)
tokenizer_slow = AutoTokenizer.from_pretrained(repo_id, use_fast=False)
content["tokenizer_classes"].add(tokenizer_slow.__class__.__name__)
except Exception:
pass
try:
time.sleep(1)
img_p = AutoImageProcessor.from_pretrained(repo_id)
content["processor_classes"].add(img_p.__class__.__name__)
except Exception:
pass
try:
time.sleep(1)
feat_p = AutoFeatureExtractor.from_pretrained(repo_id)
if not isinstance(feat_p, BaseImageProcessor):
content["processor_classes"].add(feat_p.__class__.__name__)
except Exception:
pass
try:
time.sleep(1)
model_class = getattr(transformers, model)
m = model_class.from_pretrained(repo_id)
content["model_classes"].add(m.__class__.__name__)
except Exception:
pass
try:
time.sleep(1)
model_class = getattr(transformers, f"TF{model}")
m = model_class.from_pretrained(repo_id)
content["model_classes"].add(m.__class__.__name__)
except Exception:
pass
content["tokenizer_classes"] = sorted(content["tokenizer_classes"])
content["processor_classes"] = sorted(content["processor_classes"])
content["model_classes"] = sorted(content["model_classes"])
summary[model] = content
with open(os.path.join(output_path, "hub_tiny_model_summary.json"), "w") as fp:
json.dump(summary, fp, ensure_ascii=False, indent=4)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--num_workers", default=1, type=int, help="The number of workers to run.")
args = parser.parse_args()
# This has to be `spawn` to avoid hanging forever!
multiprocessing.set_start_method("spawn")
output_path = "tiny_models"
all = True
model_types = None
models_to_skip = get_tiny_model_names_from_repo()
no_check = True
upload = True
organization = "hf-internal-testing"
create_tiny_models(
output_path,
all,
model_types,
models_to_skip,
no_check,
upload,
organization,
token=os.environ.get("TOKEN", None),
num_workers=args.num_workers,
)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_task_guides.py
|
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utility that checks the list of models in the tips in the task-specific pages of the doc is up to date and potentially
fixes it.
Use from the root of the repo with:
```bash
python utils/check_task_guides.py
```
for a check that will error in case of inconsistencies (used by `make repo-consistency`).
To auto-fix issues run:
```bash
python utils/check_task_guides.py --fix_and_overwrite
```
which is used by `make fix-copies`.
"""
import argparse
import os
from transformers.utils import direct_transformers_import
# All paths are set with the intent you should run this script from the root of the repo with the command
# python utils/check_task_guides.py
TRANSFORMERS_PATH = "src/transformers"
PATH_TO_TASK_GUIDES = "docs/source/en/tasks"
def _find_text_in_file(filename: str, start_prompt: str, end_prompt: str) -> str:
"""
Find the text in filename between two prompts.
Args:
filename (`str`): The file to search into.
start_prompt (`str`): A string to look for at the start of the content searched.
end_prompt (`str`): A string that will mark the end of the content to look for.
Returns:
`str`: The content between the prompts.
"""
with open(filename, "r", encoding="utf-8", newline="\n") as f:
lines = f.readlines()
# Find the start prompt.
start_index = 0
while not lines[start_index].startswith(start_prompt):
start_index += 1
start_index += 1
# Now go until the end prompt.
end_index = start_index
while not lines[end_index].startswith(end_prompt):
end_index += 1
end_index -= 1
while len(lines[start_index]) <= 1:
start_index += 1
while len(lines[end_index]) <= 1:
end_index -= 1
end_index += 1
return "".join(lines[start_index:end_index]), start_index, end_index, lines
# This is to make sure the transformers module imported is the one in the repo.
transformers_module = direct_transformers_import(TRANSFORMERS_PATH)
# Map between a task guide and the corresponding auto class.
TASK_GUIDE_TO_MODELS = {
"asr.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_CTC_MAPPING_NAMES,
"audio_classification.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES,
"language_modeling.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_CAUSAL_LM_MAPPING_NAMES,
"image_classification.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES,
"masked_language_modeling.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_MASKED_LM_MAPPING_NAMES,
"multiple_choice.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_MULTIPLE_CHOICE_MAPPING_NAMES,
"object_detection.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_OBJECT_DETECTION_MAPPING_NAMES,
"question_answering.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES,
"semantic_segmentation.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING_NAMES,
"sequence_classification.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES,
"summarization.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES,
"token_classification.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES,
"translation.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES,
"video_classification.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING_NAMES,
"document_question_answering.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING_NAMES,
"monocular_depth_estimation.md": transformers_module.models.auto.modeling_auto.MODEL_FOR_DEPTH_ESTIMATION_MAPPING_NAMES,
}
# This list contains model types used in some task guides that are not in `CONFIG_MAPPING_NAMES` (therefore not in any
# `MODEL_MAPPING_NAMES` or any `MODEL_FOR_XXX_MAPPING_NAMES`).
SPECIAL_TASK_GUIDE_TO_MODEL_TYPES = {
"summarization.md": ("nllb",),
"translation.md": ("nllb",),
}
def get_model_list_for_task(task_guide: str) -> str:
"""
Return the list of models supporting a given task.
Args:
task_guide (`str`): The name of the task guide to check.
Returns:
`str`: The list of models supporting this task, as links to their respective doc pages separated by commas.
"""
model_maping_names = TASK_GUIDE_TO_MODELS[task_guide]
special_model_types = SPECIAL_TASK_GUIDE_TO_MODEL_TYPES.get(task_guide, set())
model_names = {
code: name
for code, name in transformers_module.MODEL_NAMES_MAPPING.items()
if (code in model_maping_names or code in special_model_types)
}
return ", ".join([f"[{name}](../model_doc/{code})" for code, name in model_names.items()]) + "\n"
def check_model_list_for_task(task_guide: str, overwrite: bool = False):
"""
For a given task guide, checks the model list in the generated tip for consistency with the state of the lib and
updates it if needed.
Args:
task_guide (`str`):
The name of the task guide to check.
overwrite (`bool`, *optional*, defaults to `False`):
Whether or not to overwrite the table when it's not up to date.
"""
current_list, start_index, end_index, lines = _find_text_in_file(
filename=os.path.join(PATH_TO_TASK_GUIDES, task_guide),
start_prompt="<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->",
end_prompt="<!--End of the generated tip-->",
)
new_list = get_model_list_for_task(task_guide)
if current_list != new_list:
if overwrite:
with open(os.path.join(PATH_TO_TASK_GUIDES, task_guide), "w", encoding="utf-8", newline="\n") as f:
f.writelines(lines[:start_index] + [new_list] + lines[end_index:])
else:
raise ValueError(
f"The list of models that can be used in the {task_guide} guide needs an update. Run `make fix-copies`"
" to fix this."
)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--fix_and_overwrite", action="store_true", help="Whether to fix inconsistencies.")
args = parser.parse_args()
for task_guide in TASK_GUIDE_TO_MODELS.keys():
check_model_list_for_task(task_guide, args.fix_and_overwrite)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/not_doctested.txt
|
docs/source/en/_config.py
docs/source/en/accelerate.md
docs/source/en/add_new_model.md
docs/source/en/add_new_pipeline.md
docs/source/en/add_tensorflow_model.md
docs/source/en/attention.md
docs/source/en/benchmarks.md
docs/source/en/bertology.md
docs/source/en/big_models.md
docs/source/en/community.md
docs/source/en/contributing.md
docs/source/en/create_a_model.md
docs/source/en/custom_models.md
docs/source/en/custom_tools.md
docs/source/en/debugging.md
docs/source/en/fast_tokenizers.md
docs/source/en/glossary.md
docs/source/en/hpo_train.md
docs/source/en/index.md
docs/source/en/installation.md
docs/source/en/internal/audio_utils.md
docs/source/en/internal/file_utils.md
docs/source/en/internal/image_processing_utils.md
docs/source/en/internal/modeling_utils.md
docs/source/en/internal/pipelines_utils.md
docs/source/en/internal/time_series_utils.md
docs/source/en/internal/tokenization_utils.md
docs/source/en/internal/trainer_utils.md
docs/source/en/llm_tutorial.md
docs/source/en/main_classes/agent.md
docs/source/en/main_classes/callback.md
docs/source/en/main_classes/configuration.md
docs/source/en/main_classes/data_collator.md
docs/source/en/main_classes/deepspeed.md
docs/source/en/main_classes/feature_extractor.md
docs/source/en/main_classes/image_processor.md
docs/source/en/main_classes/keras_callbacks.md
docs/source/en/main_classes/logging.md
docs/source/en/main_classes/model.md
docs/source/en/main_classes/onnx.md
docs/source/en/main_classes/optimizer_schedules.md
docs/source/en/main_classes/output.md
docs/source/en/main_classes/pipelines.md
docs/source/en/main_classes/processors.md
docs/source/en/main_classes/quantization.md
docs/source/en/main_classes/tokenizer.md
docs/source/en/main_classes/trainer.md
docs/source/en/model_doc/albert.md
docs/source/en/model_doc/align.md
docs/source/en/model_doc/altclip.md
docs/source/en/model_doc/audio-spectrogram-transformer.md
docs/source/en/model_doc/auto.md
docs/source/en/model_doc/autoformer.md
docs/source/en/model_doc/bark.md
docs/source/en/model_doc/bart.md
docs/source/en/model_doc/barthez.md
docs/source/en/model_doc/bartpho.md
docs/source/en/model_doc/beit.md
docs/source/en/model_doc/bert-generation.md
docs/source/en/model_doc/bert-japanese.md
docs/source/en/model_doc/bert.md
docs/source/en/model_doc/bertweet.md
docs/source/en/model_doc/big_bird.md
docs/source/en/model_doc/bigbird_pegasus.md
docs/source/en/model_doc/biogpt.md
docs/source/en/model_doc/bit.md
docs/source/en/model_doc/blenderbot-small.md
docs/source/en/model_doc/blenderbot.md
docs/source/en/model_doc/blip-2.md
docs/source/en/model_doc/blip.md
docs/source/en/model_doc/bloom.md
docs/source/en/model_doc/bort.md
docs/source/en/model_doc/bridgetower.md
docs/source/en/model_doc/camembert.md
docs/source/en/model_doc/canine.md
docs/source/en/model_doc/chinese_clip.md
docs/source/en/model_doc/clap.md
docs/source/en/model_doc/clip.md
docs/source/en/model_doc/clipseg.md
docs/source/en/model_doc/codegen.md
docs/source/en/model_doc/conditional_detr.md
docs/source/en/model_doc/convbert.md
docs/source/en/model_doc/convnext.md
docs/source/en/model_doc/convnextv2.md
docs/source/en/model_doc/cpm.md
docs/source/en/model_doc/cpmant.md
docs/source/en/model_doc/ctrl.md
docs/source/en/model_doc/cvt.md
docs/source/en/model_doc/data2vec.md
docs/source/en/model_doc/deberta-v2.md
docs/source/en/model_doc/deberta.md
docs/source/en/model_doc/decision_transformer.md
docs/source/en/model_doc/deformable_detr.md
docs/source/en/model_doc/deit.md
docs/source/en/model_doc/deplot.md
docs/source/en/model_doc/deta.md
docs/source/en/model_doc/detr.md
docs/source/en/model_doc/dialogpt.md
docs/source/en/model_doc/dinat.md
docs/source/en/model_doc/dinov2.md
docs/source/en/model_doc/distilbert.md
docs/source/en/model_doc/dit.md
docs/source/en/model_doc/dpr.md
docs/source/en/model_doc/dpt.md
docs/source/en/model_doc/efficientformer.md
docs/source/en/model_doc/efficientnet.md
docs/source/en/model_doc/electra.md
docs/source/en/model_doc/encodec.md
docs/source/en/model_doc/ernie.md
docs/source/en/model_doc/ernie_m.md
docs/source/en/model_doc/esm.md
docs/source/en/model_doc/flan-t5.md
docs/source/en/model_doc/flan-ul2.md
docs/source/en/model_doc/flaubert.md
docs/source/en/model_doc/flava.md
docs/source/en/model_doc/fnet.md
docs/source/en/model_doc/focalnet.md
docs/source/en/model_doc/fsmt.md
docs/source/en/model_doc/funnel.md
docs/source/en/model_doc/git.md
docs/source/en/model_doc/glpn.md
docs/source/en/model_doc/gpt-sw3.md
docs/source/en/model_doc/gpt2.md
docs/source/en/model_doc/gpt_bigcode.md
docs/source/en/model_doc/gpt_neo.md
docs/source/en/model_doc/gpt_neox.md
docs/source/en/model_doc/gpt_neox_japanese.md
docs/source/en/model_doc/gptj.md
docs/source/en/model_doc/gptsan-japanese.md
docs/source/en/model_doc/graphormer.md
docs/source/en/model_doc/groupvit.md
docs/source/en/model_doc/herbert.md
docs/source/en/model_doc/hubert.md
docs/source/en/model_doc/ibert.md
docs/source/en/model_doc/idefics.md
docs/source/en/model_doc/imagegpt.md
docs/source/en/model_doc/informer.md
docs/source/en/model_doc/instructblip.md
docs/source/en/model_doc/jukebox.md
docs/source/en/model_doc/layoutlm.md
docs/source/en/model_doc/layoutlmv2.md
docs/source/en/model_doc/layoutlmv3.md
docs/source/en/model_doc/layoutxlm.md
docs/source/en/model_doc/led.md
docs/source/en/model_doc/levit.md
docs/source/en/model_doc/lilt.md
docs/source/en/model_doc/llama.md
docs/source/en/model_doc/llama2.md
docs/source/en/model_doc/longformer.md
docs/source/en/model_doc/longt5.md
docs/source/en/model_doc/luke.md
docs/source/en/model_doc/lxmert.md
docs/source/en/model_doc/m2m_100.md
docs/source/en/model_doc/madlad-400.md
docs/source/en/model_doc/marian.md
docs/source/en/model_doc/mask2former.md
docs/source/en/model_doc/maskformer.md
docs/source/en/model_doc/matcha.md
docs/source/en/model_doc/mbart.md
docs/source/en/model_doc/mctct.md
docs/source/en/model_doc/mega.md
docs/source/en/model_doc/megatron-bert.md
docs/source/en/model_doc/megatron_gpt2.md
docs/source/en/model_doc/mgp-str.md
docs/source/en/model_doc/mistral.md
docs/source/en/model_doc/mluke.md
docs/source/en/model_doc/mms.md
docs/source/en/model_doc/mobilebert.md
docs/source/en/model_doc/mobilenet_v1.md
docs/source/en/model_doc/mobilenet_v2.md
docs/source/en/model_doc/mobilevit.md
docs/source/en/model_doc/mobilevitv2.md
docs/source/en/model_doc/mpnet.md
docs/source/en/model_doc/mpt.md
docs/source/en/model_doc/mra.md
docs/source/en/model_doc/mt5.md
docs/source/en/model_doc/musicgen.md
docs/source/en/model_doc/mvp.md
docs/source/en/model_doc/nat.md
docs/source/en/model_doc/nezha.md
docs/source/en/model_doc/nllb-moe.md
docs/source/en/model_doc/nllb.md
docs/source/en/model_doc/nystromformer.md
docs/source/en/model_doc/oneformer.md
docs/source/en/model_doc/open-llama.md
docs/source/en/model_doc/openai-gpt.md
docs/source/en/model_doc/opt.md
docs/source/en/model_doc/owlvit.md
docs/source/en/model_doc/pegasus.md
docs/source/en/model_doc/pegasus_x.md
docs/source/en/model_doc/perceiver.md
docs/source/en/model_doc/phobert.md
docs/source/en/model_doc/pix2struct.md
docs/source/en/model_doc/plbart.md
docs/source/en/model_doc/poolformer.md
docs/source/en/model_doc/pop2piano.md
docs/source/en/model_doc/prophetnet.md
docs/source/en/model_doc/pvt.md
docs/source/en/model_doc/qdqbert.md
docs/source/en/model_doc/rag.md
docs/source/en/model_doc/realm.md
docs/source/en/model_doc/reformer.md
docs/source/en/model_doc/regnet.md
docs/source/en/model_doc/rembert.md
docs/source/en/model_doc/resnet.md
docs/source/en/model_doc/retribert.md
docs/source/en/model_doc/roberta-prelayernorm.md
docs/source/en/model_doc/roberta.md
docs/source/en/model_doc/roc_bert.md
docs/source/en/model_doc/roformer.md
docs/source/en/model_doc/rwkv.md
docs/source/en/model_doc/sam.md
docs/source/en/model_doc/segformer.md
docs/source/en/model_doc/sew-d.md
docs/source/en/model_doc/sew.md
docs/source/en/model_doc/speech-encoder-decoder.md
docs/source/en/model_doc/speech_to_text_2.md
docs/source/en/model_doc/speecht5.md
docs/source/en/model_doc/splinter.md
docs/source/en/model_doc/squeezebert.md
docs/source/en/model_doc/swiftformer.md
docs/source/en/model_doc/swin.md
docs/source/en/model_doc/swin2sr.md
docs/source/en/model_doc/swinv2.md
docs/source/en/model_doc/table-transformer.md
docs/source/en/model_doc/tapas.md
docs/source/en/model_doc/time_series_transformer.md
docs/source/en/model_doc/timesformer.md
docs/source/en/model_doc/trajectory_transformer.md
docs/source/en/model_doc/transfo-xl.md
docs/source/en/model_doc/trocr.md
docs/source/en/model_doc/tvlt.md
docs/source/en/model_doc/ul2.md
docs/source/en/model_doc/umt5.md
docs/source/en/model_doc/unispeech-sat.md
docs/source/en/model_doc/unispeech.md
docs/source/en/model_doc/upernet.md
docs/source/en/model_doc/van.md
docs/source/en/model_doc/videomae.md
docs/source/en/model_doc/vilt.md
docs/source/en/model_doc/vision-encoder-decoder.md
docs/source/en/model_doc/vision-text-dual-encoder.md
docs/source/en/model_doc/visual_bert.md
docs/source/en/model_doc/vit.md
docs/source/en/model_doc/vit_hybrid.md
docs/source/en/model_doc/vit_mae.md
docs/source/en/model_doc/vit_msn.md
docs/source/en/model_doc/vivit.md
docs/source/en/model_doc/wav2vec2-conformer.md
docs/source/en/model_doc/wav2vec2.md
docs/source/en/model_doc/wav2vec2_phoneme.md
docs/source/en/model_doc/wavlm.md
docs/source/en/model_doc/whisper.md
docs/source/en/model_doc/xclip.md
docs/source/en/model_doc/xglm.md
docs/source/en/model_doc/xlm-prophetnet.md
docs/source/en/model_doc/xlm-roberta-xl.md
docs/source/en/model_doc/xlm-roberta.md
docs/source/en/model_doc/xlm-v.md
docs/source/en/model_doc/xlm.md
docs/source/en/model_doc/xlnet.md
docs/source/en/model_doc/xls_r.md
docs/source/en/model_doc/xlsr_wav2vec2.md
docs/source/en/model_doc/xmod.md
docs/source/en/model_doc/yolos.md
docs/source/en/model_doc/yoso.md
docs/source/en/model_memory_anatomy.md
docs/source/en/model_sharing.md
docs/source/en/model_summary.md
docs/source/en/multilingual.md
docs/source/en/notebooks.md
docs/source/en/pad_truncation.md
docs/source/en/peft.md
docs/source/en/perf_hardware.md
docs/source/en/perf_infer_cpu.md
docs/source/en/perf_infer_gpu_one.md
docs/source/en/perf_torch_compile.md
docs/source/en/perf_train_cpu.md
docs/source/en/perf_train_cpu_many.md
docs/source/en/perf_train_gpu_many.md
docs/source/en/perf_train_gpu_one.md
docs/source/en/perf_train_special.md
docs/source/en/perf_train_tpu.md
docs/source/en/perf_train_tpu_tf.md
docs/source/en/performance.md
docs/source/en/perplexity.md
docs/source/en/philosophy.md
docs/source/en/pipeline_webserver.md
docs/source/en/pr_checks.md
docs/source/en/preprocessing.md
docs/source/en/run_scripts.md
docs/source/en/sagemaker.md
docs/source/en/serialization.md
docs/source/en/tasks/asr.md
docs/source/en/tasks/audio_classification.md
docs/source/en/tasks/document_question_answering.md
docs/source/en/tasks/idefics.md # causes other tests to fail
docs/source/en/tasks/image_captioning.md
docs/source/en/tasks/image_classification.md
docs/source/en/tasks/language_modeling.md
docs/source/en/tasks/masked_language_modeling.md
docs/source/en/tasks/monocular_depth_estimation.md
docs/source/en/tasks/multiple_choice.md
docs/source/en/tasks/object_detection.md
docs/source/en/tasks/question_answering.md
docs/source/en/tasks/semantic_segmentation.md
docs/source/en/tasks/sequence_classification.md
docs/source/en/tasks/summarization.md
docs/source/en/tasks/text-to-speech.md
docs/source/en/tasks/token_classification.md
docs/source/en/tasks/translation.md
docs/source/en/tasks/video_classification.md
docs/source/en/tasks/visual_question_answering.md
docs/source/en/tasks/zero_shot_image_classification.md
docs/source/en/tasks/zero_shot_object_detection.md
docs/source/en/tasks_explained.md
docs/source/en/tf_xla.md
docs/source/en/tflite.md
docs/source/en/tokenizer_summary.md
docs/source/en/torchscript.md
docs/source/en/training.md
docs/source/en/transformers_agents.md
docs/source/en/troubleshooting.md
src/transformers/activations.py
src/transformers/activations_tf.py
src/transformers/audio_utils.py
src/transformers/benchmark/benchmark.py
src/transformers/benchmark/benchmark_args.py
src/transformers/benchmark/benchmark_args_tf.py
src/transformers/benchmark/benchmark_args_utils.py
src/transformers/benchmark/benchmark_tf.py
src/transformers/benchmark/benchmark_utils.py
src/transformers/commands/add_new_model.py
src/transformers/commands/add_new_model_like.py
src/transformers/commands/convert.py
src/transformers/commands/download.py
src/transformers/commands/env.py
src/transformers/commands/lfs.py
src/transformers/commands/pt_to_tf.py
src/transformers/commands/run.py
src/transformers/commands/serving.py
src/transformers/commands/train.py
src/transformers/commands/transformers_cli.py
src/transformers/commands/user.py
src/transformers/configuration_utils.py
src/transformers/convert_graph_to_onnx.py
src/transformers/convert_pytorch_checkpoint_to_tf2.py
src/transformers/convert_slow_tokenizer.py
src/transformers/convert_slow_tokenizers_checkpoints_to_fast.py
src/transformers/convert_tf_hub_seq_to_seq_bert_to_pytorch.py
src/transformers/data/data_collator.py
src/transformers/data/datasets/glue.py
src/transformers/data/datasets/language_modeling.py
src/transformers/data/datasets/squad.py
src/transformers/data/metrics/squad_metrics.py
src/transformers/data/processors/glue.py
src/transformers/data/processors/squad.py
src/transformers/data/processors/utils.py
src/transformers/data/processors/xnli.py
src/transformers/debug_utils.py
src/transformers/deepspeed.py
src/transformers/dependency_versions_check.py
src/transformers/dependency_versions_table.py
src/transformers/dynamic_module_utils.py
src/transformers/feature_extraction_sequence_utils.py
src/transformers/feature_extraction_utils.py
src/transformers/file_utils.py
src/transformers/hf_argparser.py
src/transformers/hyperparameter_search.py
src/transformers/image_processing_utils.py
src/transformers/image_transforms.py
src/transformers/image_utils.py
src/transformers/integrations/bitsandbytes.py
src/transformers/integrations/deepspeed.py
src/transformers/integrations/integration_utils.py
src/transformers/integrations/peft.py
src/transformers/keras_callbacks.py
src/transformers/modelcard.py
src/transformers/modeling_flax_outputs.py
src/transformers/modeling_flax_pytorch_utils.py
src/transformers/modeling_flax_utils.py
src/transformers/modeling_outputs.py
src/transformers/modeling_tf_outputs.py
src/transformers/modeling_tf_pytorch_utils.py
src/transformers/modeling_tf_utils.py
src/transformers/modeling_utils.py
src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py
src/transformers/models/albert/modeling_flax_albert.py
src/transformers/models/align/configuration_align.py
src/transformers/models/align/convert_align_tf_to_hf.py
src/transformers/models/align/modeling_align.py
src/transformers/models/altclip/configuration_altclip.py
src/transformers/models/altclip/modeling_altclip.py
src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py
src/transformers/models/audio_spectrogram_transformer/convert_audio_spectrogram_transformer_original_to_pytorch.py
src/transformers/models/auto/auto_factory.py
src/transformers/models/auto/configuration_auto.py
src/transformers/models/auto/modeling_auto.py
src/transformers/models/auto/modeling_flax_auto.py
src/transformers/models/auto/modeling_tf_auto.py
src/transformers/models/autoformer/configuration_autoformer.py
src/transformers/models/autoformer/modeling_autoformer.py
src/transformers/models/bark/convert_suno_to_hf.py
src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/bart/modeling_flax_bart.py
src/transformers/models/bart/modeling_tf_bart.py
src/transformers/models/beit/convert_beit_unilm_to_pytorch.py
src/transformers/models/beit/modeling_flax_beit.py
src/transformers/models/bert/convert_bert_original_tf2_checkpoint_to_pytorch.py
src/transformers/models/bert/convert_bert_original_tf_checkpoint_to_pytorch.py
src/transformers/models/bert/convert_bert_pytorch_checkpoint_to_original_tf.py
src/transformers/models/bert/convert_bert_token_dropping_original_tf2_checkpoint_to_pytorch.py
src/transformers/models/bert/modeling_flax_bert.py
src/transformers/models/bert_generation/modeling_bert_generation.py
src/transformers/models/big_bird/convert_bigbird_original_tf_checkpoint_to_pytorch.py
src/transformers/models/big_bird/modeling_flax_big_bird.py
src/transformers/models/bigbird_pegasus/convert_bigbird_pegasus_tf_to_pytorch.py
src/transformers/models/biogpt/configuration_biogpt.py
src/transformers/models/biogpt/convert_biogpt_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/biogpt/modeling_biogpt.py
src/transformers/models/bit/configuration_bit.py
src/transformers/models/bit/convert_bit_to_pytorch.py
src/transformers/models/bit/modeling_bit.py
src/transformers/models/blenderbot/convert_blenderbot_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/blenderbot/modeling_flax_blenderbot.py
src/transformers/models/blenderbot/modeling_tf_blenderbot.py
src/transformers/models/blenderbot_small/modeling_flax_blenderbot_small.py
src/transformers/models/blenderbot_small/modeling_tf_blenderbot_small.py
src/transformers/models/blip/configuration_blip.py
src/transformers/models/blip/convert_blip_original_pytorch_to_hf.py
src/transformers/models/blip/modeling_blip_text.py
src/transformers/models/blip/modeling_tf_blip_text.py
src/transformers/models/blip_2/configuration_blip_2.py
src/transformers/models/blip_2/convert_blip_2_original_to_pytorch.py
src/transformers/models/blip_2/modeling_blip_2.py # causes other tests to fail
src/transformers/models/bloom/convert_bloom_original_checkpoint_to_pytorch.py
src/transformers/models/bloom/modeling_bloom.py
src/transformers/models/bloom/modeling_flax_bloom.py
src/transformers/models/bridgetower/configuration_bridgetower.py
src/transformers/models/bridgetower/modeling_bridgetower.py
src/transformers/models/bros/convert_bros_to_pytorch.py
src/transformers/models/byt5/convert_byt5_original_tf_checkpoint_to_pytorch.py
src/transformers/models/camembert/modeling_camembert.py
src/transformers/models/camembert/modeling_tf_camembert.py
src/transformers/models/canine/convert_canine_original_tf_checkpoint_to_pytorch.py
src/transformers/models/chinese_clip/configuration_chinese_clip.py
src/transformers/models/chinese_clip/convert_chinese_clip_original_pytorch_to_hf.py
src/transformers/models/chinese_clip/modeling_chinese_clip.py
src/transformers/models/clap/convert_clap_original_pytorch_to_hf.py
src/transformers/models/clip/convert_clip_original_pytorch_to_hf.py
src/transformers/models/clip/modeling_clip.py
src/transformers/models/clip/modeling_flax_clip.py
src/transformers/models/clip/modeling_tf_clip.py
src/transformers/models/clipseg/configuration_clipseg.py
src/transformers/models/clipseg/convert_clipseg_original_pytorch_to_hf.py
src/transformers/models/codegen/modeling_codegen.py
src/transformers/models/conditional_detr/convert_conditional_detr_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/convbert/convert_convbert_original_tf1_checkpoint_to_pytorch_and_tf2.py
src/transformers/models/convbert/modeling_convbert.py
src/transformers/models/convbert/modeling_tf_convbert.py
src/transformers/models/convnext/convert_convnext_to_pytorch.py
src/transformers/models/convnext/modeling_tf_convnext.py
src/transformers/models/convnextv2/configuration_convnextv2.py
src/transformers/models/convnextv2/convert_convnextv2_to_pytorch.py
src/transformers/models/convnextv2/modeling_convnextv2.py
src/transformers/models/cpmant/configuration_cpmant.py
src/transformers/models/cpmant/modeling_cpmant.py
src/transformers/models/cpmant/tokenization_cpmant.py
src/transformers/models/ctrl/modeling_tf_ctrl.py
src/transformers/models/cvt/convert_cvt_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/cvt/modeling_tf_cvt.py
src/transformers/models/data2vec/convert_data2vec_audio_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/data2vec/convert_data2vec_text_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/data2vec/convert_data2vec_vision_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/data2vec/modeling_data2vec_text.py
src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
src/transformers/models/deberta/modeling_tf_deberta.py
src/transformers/models/deberta_v2/modeling_tf_deberta_v2.py
src/transformers/models/decision_transformer/modeling_decision_transformer.py
src/transformers/models/deformable_detr/convert_deformable_detr_to_pytorch.py
src/transformers/models/deformable_detr/load_custom.py
src/transformers/models/deit/convert_deit_timm_to_pytorch.py
src/transformers/models/deprecated/bort/convert_bort_original_gluonnlp_checkpoint_to_pytorch.py
src/transformers/models/deprecated/mctct/configuration_mctct.py
src/transformers/models/deprecated/mctct/feature_extraction_mctct.py
src/transformers/models/deprecated/mctct/modeling_mctct.py
src/transformers/models/deprecated/mctct/processing_mctct.py
src/transformers/models/deprecated/mmbt/configuration_mmbt.py
src/transformers/models/deprecated/mmbt/modeling_mmbt.py
src/transformers/models/deprecated/open_llama/configuration_open_llama.py
src/transformers/models/deprecated/open_llama/modeling_open_llama.py
src/transformers/models/deprecated/retribert/configuration_retribert.py
src/transformers/models/deprecated/retribert/modeling_retribert.py
src/transformers/models/deprecated/retribert/tokenization_retribert.py
src/transformers/models/deprecated/retribert/tokenization_retribert_fast.py
src/transformers/models/deprecated/tapex/tokenization_tapex.py
src/transformers/models/deprecated/trajectory_transformer/configuration_trajectory_transformer.py
src/transformers/models/deprecated/trajectory_transformer/convert_trajectory_transformer_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/deprecated/trajectory_transformer/modeling_trajectory_transformer.py
src/transformers/models/deprecated/transfo_xl/convert_transfo_xl_original_tf_checkpoint_to_pytorch.py
src/transformers/models/deprecated/transfo_xl/modeling_tf_transfo_xl.py
src/transformers/models/deprecated/transfo_xl/modeling_tf_transfo_xl_utilities.py
src/transformers/models/deprecated/transfo_xl/modeling_transfo_xl.py
src/transformers/models/deprecated/transfo_xl/modeling_transfo_xl_utilities.py
src/transformers/models/deprecated/van/configuration_van.py
src/transformers/models/deprecated/van/convert_van_to_pytorch.py
src/transformers/models/deprecated/van/modeling_van.py
src/transformers/models/deta/convert_deta_resnet_to_pytorch.py
src/transformers/models/deta/convert_deta_swin_to_pytorch.py
src/transformers/models/detr/convert_detr_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/detr/convert_detr_to_pytorch.py
src/transformers/models/dialogpt/convert_dialogpt_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/dinov2/configuration_dinov2.py
src/transformers/models/dinov2/convert_dinov2_to_hf.py
src/transformers/models/dinov2/modeling_dinov2.py
src/transformers/models/distilbert/modeling_distilbert.py
src/transformers/models/distilbert/modeling_flax_distilbert.py
src/transformers/models/distilbert/modeling_tf_distilbert.py
src/transformers/models/dit/convert_dit_unilm_to_pytorch.py
src/transformers/models/donut/configuration_donut_swin.py
src/transformers/models/donut/convert_donut_to_pytorch.py
src/transformers/models/donut/modeling_donut_swin.py
src/transformers/models/dpr/convert_dpr_original_checkpoint_to_pytorch.py
src/transformers/models/dpr/modeling_dpr.py
src/transformers/models/dpr/modeling_tf_dpr.py
src/transformers/models/dpt/configuration_dpt.py
src/transformers/models/dpt/convert_dpt_hybrid_to_pytorch.py
src/transformers/models/dpt/convert_dpt_to_pytorch.py
src/transformers/models/efficientformer/configuration_efficientformer.py
src/transformers/models/efficientformer/convert_efficientformer_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/efficientformer/modeling_efficientformer.py
src/transformers/models/efficientnet/configuration_efficientnet.py
src/transformers/models/efficientnet/convert_efficientnet_to_pytorch.py
src/transformers/models/efficientnet/modeling_efficientnet.py
src/transformers/models/electra/convert_electra_original_tf_checkpoint_to_pytorch.py
src/transformers/models/electra/modeling_flax_electra.py
src/transformers/models/encodec/configuration_encodec.py
src/transformers/models/encodec/convert_encodec_checkpoint_to_pytorch.py
src/transformers/models/encoder_decoder/modeling_encoder_decoder.py
src/transformers/models/encoder_decoder/modeling_flax_encoder_decoder.py
src/transformers/models/encoder_decoder/modeling_tf_encoder_decoder.py
src/transformers/models/ernie/modeling_ernie.py
src/transformers/models/esm/configuration_esm.py
src/transformers/models/esm/convert_esm.py
src/transformers/models/esm/modeling_esm.py
src/transformers/models/esm/modeling_esmfold.py
src/transformers/models/esm/modeling_tf_esm.py
src/transformers/models/esm/openfold_utils/chunk_utils.py
src/transformers/models/esm/openfold_utils/data_transforms.py
src/transformers/models/esm/openfold_utils/feats.py
src/transformers/models/esm/openfold_utils/loss.py
src/transformers/models/esm/openfold_utils/protein.py
src/transformers/models/esm/openfold_utils/residue_constants.py
src/transformers/models/esm/openfold_utils/rigid_utils.py
src/transformers/models/esm/openfold_utils/tensor_utils.py
src/transformers/models/falcon/configuration_falcon.py
src/transformers/models/falcon/modeling_falcon.py
src/transformers/models/flaubert/configuration_flaubert.py
src/transformers/models/flaubert/modeling_flaubert.py
src/transformers/models/flaubert/modeling_tf_flaubert.py
src/transformers/models/flava/convert_dalle_to_flava_codebook.py
src/transformers/models/flava/convert_flava_original_pytorch_to_hf.py
src/transformers/models/flava/modeling_flava.py
src/transformers/models/fnet/convert_fnet_original_flax_checkpoint_to_pytorch.py
src/transformers/models/fnet/modeling_fnet.py
src/transformers/models/focalnet/configuration_focalnet.py
src/transformers/models/focalnet/convert_focalnet_to_hf_format.py
src/transformers/models/focalnet/modeling_focalnet.py
src/transformers/models/fsmt/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/fsmt/modeling_fsmt.py
src/transformers/models/funnel/configuration_funnel.py
src/transformers/models/funnel/convert_funnel_original_tf_checkpoint_to_pytorch.py
src/transformers/models/funnel/modeling_funnel.py
src/transformers/models/funnel/modeling_tf_funnel.py
src/transformers/models/fuyu/convert_fuyu_model_weights_to_hf.py
src/transformers/models/git/configuration_git.py
src/transformers/models/git/convert_git_to_pytorch.py
src/transformers/models/glpn/configuration_glpn.py
src/transformers/models/glpn/convert_glpn_to_pytorch.py
src/transformers/models/gpt2/CONVERSION.md
src/transformers/models/gpt2/convert_gpt2_original_tf_checkpoint_to_pytorch.py
src/transformers/models/gpt2/modeling_flax_gpt2.py
src/transformers/models/gpt2/modeling_tf_gpt2.py
src/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py
src/transformers/models/gpt_bigcode/modeling_gpt_bigcode.py
src/transformers/models/gpt_neo/convert_gpt_neo_mesh_tf_to_pytorch.py
src/transformers/models/gpt_neo/modeling_flax_gpt_neo.py
src/transformers/models/gpt_neo/modeling_gpt_neo.py
src/transformers/models/gpt_neox/modeling_gpt_neox.py
src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py
src/transformers/models/gpt_sw3/convert_megatron_to_pytorch.py
src/transformers/models/gptj/configuration_gptj.py
src/transformers/models/gptj/modeling_flax_gptj.py
src/transformers/models/gptj/modeling_tf_gptj.py
src/transformers/models/gptsan_japanese/configuration_gptsan_japanese.py
src/transformers/models/gptsan_japanese/convert_gptsan_tf_checkpoint_to_pytorch.py
src/transformers/models/gptsan_japanese/modeling_gptsan_japanese.py
src/transformers/models/graphormer/collating_graphormer.py
src/transformers/models/graphormer/configuration_graphormer.py
src/transformers/models/graphormer/modeling_graphormer.py
src/transformers/models/groupvit/configuration_groupvit.py
src/transformers/models/groupvit/convert_groupvit_nvlab_to_hf.py
src/transformers/models/hubert/configuration_hubert.py
src/transformers/models/hubert/convert_distilhubert_original_s3prl_checkpoint_to_pytorch.py
src/transformers/models/hubert/convert_hubert_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/hubert/convert_hubert_original_s3prl_checkpoint_to_pytorch.py
src/transformers/models/hubert/modeling_tf_hubert.py
src/transformers/models/ibert/configuration_ibert.py
src/transformers/models/ibert/modeling_ibert.py
src/transformers/models/ibert/quant_modules.py
src/transformers/models/idefics/configuration_idefics.py
src/transformers/models/idefics/image_processing_idefics.py
src/transformers/models/idefics/modeling_idefics.py
src/transformers/models/idefics/perceiver.py
src/transformers/models/idefics/processing_idefics.py
src/transformers/models/idefics/vision.py
src/transformers/models/imagegpt/convert_imagegpt_original_tf2_to_pytorch.py
src/transformers/models/informer/configuration_informer.py
src/transformers/models/informer/modeling_informer.py
src/transformers/models/instructblip/configuration_instructblip.py
src/transformers/models/instructblip/convert_instructblip_original_to_pytorch.py
src/transformers/models/instructblip/modeling_instructblip.py
src/transformers/models/instructblip/processing_instructblip.py
src/transformers/models/jukebox/configuration_jukebox.py
src/transformers/models/jukebox/convert_jukebox.py
src/transformers/models/jukebox/modeling_jukebox.py
src/transformers/models/kosmos2/convert_kosmos2_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/led/configuration_led.py
src/transformers/models/led/modeling_led.py
src/transformers/models/led/modeling_tf_led.py
src/transformers/models/levit/convert_levit_timm_to_pytorch.py
src/transformers/models/levit/modeling_levit.py
src/transformers/models/lilt/configuration_lilt.py
src/transformers/models/llama/configuration_llama.py
src/transformers/models/llama/convert_llama_weights_to_hf.py
src/transformers/models/llama/modeling_llama.py
src/transformers/models/longformer/configuration_longformer.py
src/transformers/models/longformer/convert_longformer_original_pytorch_lightning_to_pytorch.py
src/transformers/models/longt5/configuration_longt5.py
src/transformers/models/longt5/convert_longt5x_checkpoint_to_flax.py
src/transformers/models/longt5/modeling_flax_longt5.py
src/transformers/models/luke/configuration_luke.py
src/transformers/models/luke/convert_luke_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/luke/modeling_luke.py
src/transformers/models/lxmert/configuration_lxmert.py
src/transformers/models/lxmert/convert_lxmert_original_tf_checkpoint_to_pytorch.py
src/transformers/models/lxmert/modeling_lxmert.py
src/transformers/models/lxmert/modeling_tf_lxmert.py
src/transformers/models/m2m_100/convert_m2m100_original_checkpoint_to_pytorch.py
src/transformers/models/m2m_100/modeling_m2m_100.py
src/transformers/models/marian/configuration_marian.py
src/transformers/models/marian/convert_marian_tatoeba_to_pytorch.py
src/transformers/models/marian/convert_marian_to_pytorch.py
src/transformers/models/marian/modeling_flax_marian.py
src/transformers/models/marian/modeling_tf_marian.py
src/transformers/models/markuplm/configuration_markuplm.py
src/transformers/models/markuplm/feature_extraction_markuplm.py
src/transformers/models/mask2former/convert_mask2former_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/maskformer/configuration_maskformer_swin.py
src/transformers/models/maskformer/convert_maskformer_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/maskformer/convert_maskformer_resnet_to_pytorch.py
src/transformers/models/maskformer/convert_maskformer_swin_to_pytorch.py
src/transformers/models/maskformer/modeling_maskformer_swin.py
src/transformers/models/mbart/convert_mbart_original_checkpoint_to_pytorch.py
src/transformers/models/mbart/modeling_flax_mbart.py
src/transformers/models/mega/configuration_mega.py
src/transformers/models/mega/convert_mega_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/mega/modeling_mega.py
src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
src/transformers/models/megatron_bert/modeling_megatron_bert.py
src/transformers/models/megatron_gpt2/checkpoint_reshaping_and_interoperability.py
src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
src/transformers/models/mgp_str/configuration_mgp_str.py
src/transformers/models/mgp_str/modeling_mgp_str.py
src/transformers/models/mistral/configuration_mistral.py
src/transformers/models/mistral/modeling_mistral.py
src/transformers/models/mluke/convert_mluke_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/mobilebert/convert_mobilebert_original_tf_checkpoint_to_pytorch.py
src/transformers/models/mobilenet_v1/configuration_mobilenet_v1.py
src/transformers/models/mobilenet_v1/convert_original_tf_checkpoint_to_pytorch.py
src/transformers/models/mobilenet_v2/configuration_mobilenet_v2.py
src/transformers/models/mobilenet_v2/convert_original_tf_checkpoint_to_pytorch.py
src/transformers/models/mobilevit/configuration_mobilevit.py
src/transformers/models/mobilevit/convert_mlcvnets_to_pytorch.py
src/transformers/models/mobilevitv2/convert_mlcvnets_to_pytorch.py
src/transformers/models/mpnet/configuration_mpnet.py
src/transformers/models/mpnet/modeling_mpnet.py
src/transformers/models/mpnet/modeling_tf_mpnet.py
src/transformers/models/mpt/configuration_mpt.py
src/transformers/models/mpt/modeling_mpt.py
src/transformers/models/mra/configuration_mra.py
src/transformers/models/mra/convert_mra_pytorch_to_pytorch.py
src/transformers/models/mra/modeling_mra.py
src/transformers/models/mt5/configuration_mt5.py
src/transformers/models/mt5/modeling_flax_mt5.py
src/transformers/models/mt5/modeling_mt5.py
src/transformers/models/mt5/modeling_tf_mt5.py
src/transformers/models/musicgen/convert_musicgen_transformers.py
src/transformers/models/mvp/modeling_mvp.py
src/transformers/models/nezha/modeling_nezha.py
src/transformers/models/nllb_moe/configuration_nllb_moe.py
src/transformers/models/nllb_moe/convert_nllb_moe_sharded_original_checkpoint_to_pytorch.py
src/transformers/models/nllb_moe/modeling_nllb_moe.py
src/transformers/models/nougat/convert_nougat_to_hf.py
src/transformers/models/nystromformer/configuration_nystromformer.py
src/transformers/models/nystromformer/convert_nystromformer_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/nystromformer/modeling_nystromformer.py
src/transformers/models/oneformer/convert_to_hf_oneformer.py
src/transformers/models/openai/convert_openai_original_tf_checkpoint_to_pytorch.py
src/transformers/models/openai/modeling_openai.py
src/transformers/models/openai/modeling_tf_openai.py
src/transformers/models/opt/convert_opt_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/opt/modeling_flax_opt.py
src/transformers/models/owlvit/configuration_owlvit.py
src/transformers/models/owlvit/convert_owlvit_original_flax_to_hf.py
src/transformers/models/pegasus/convert_pegasus_tf_to_pytorch.py
src/transformers/models/pegasus/modeling_flax_pegasus.py
src/transformers/models/pegasus/modeling_tf_pegasus.py
src/transformers/models/pegasus_x/modeling_pegasus_x.py
src/transformers/models/perceiver/configuration_perceiver.py
src/transformers/models/perceiver/convert_perceiver_haiku_to_pytorch.py
src/transformers/models/persimmon/convert_persimmon_weights_to_hf.py
src/transformers/models/persimmon/modeling_persimmon.py
src/transformers/models/pix2struct/configuration_pix2struct.py
src/transformers/models/pix2struct/convert_pix2struct_original_pytorch_to_hf.py
src/transformers/models/pix2struct/image_processing_pix2struct.py
src/transformers/models/pix2struct/processing_pix2struct.py
src/transformers/models/plbart/convert_plbart_original_checkpoint_to_torch.py
src/transformers/models/poolformer/convert_poolformer_original_to_pytorch.py
src/transformers/models/pop2piano/convert_pop2piano_weights_to_hf.py
src/transformers/models/pop2piano/feature_extraction_pop2piano.py
src/transformers/models/pop2piano/processing_pop2piano.py
src/transformers/models/pop2piano/tokenization_pop2piano.py
src/transformers/models/prophetnet/configuration_prophetnet.py
src/transformers/models/prophetnet/convert_prophetnet_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/prophetnet/modeling_prophetnet.py
src/transformers/models/pvt/configuration_pvt.py
src/transformers/models/pvt/convert_pvt_to_pytorch.py
src/transformers/models/pvt/image_processing_pvt.py
src/transformers/models/pvt/modeling_pvt.py
src/transformers/models/qdqbert/configuration_qdqbert.py
src/transformers/models/qdqbert/modeling_qdqbert.py
src/transformers/models/rag/configuration_rag.py
src/transformers/models/rag/modeling_rag.py
src/transformers/models/rag/modeling_tf_rag.py
src/transformers/models/rag/retrieval_rag.py
src/transformers/models/realm/modeling_realm.py
src/transformers/models/realm/retrieval_realm.py
src/transformers/models/reformer/convert_reformer_trax_checkpoint_to_pytorch.py
src/transformers/models/regnet/configuration_regnet.py
src/transformers/models/regnet/convert_regnet_seer_10b_to_pytorch.py
src/transformers/models/regnet/convert_regnet_to_pytorch.py
src/transformers/models/regnet/modeling_flax_regnet.py
src/transformers/models/rembert/configuration_rembert.py
src/transformers/models/rembert/convert_rembert_tf_checkpoint_to_pytorch.py
src/transformers/models/rembert/modeling_rembert.py
src/transformers/models/rembert/modeling_tf_rembert.py
src/transformers/models/resnet/convert_resnet_to_pytorch.py
src/transformers/models/resnet/modeling_flax_resnet.py
src/transformers/models/roberta/convert_roberta_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/roberta/modeling_flax_roberta.py
src/transformers/models/roberta_prelayernorm/convert_roberta_prelayernorm_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/roberta_prelayernorm/modeling_flax_roberta_prelayernorm.py
src/transformers/models/roc_bert/configuration_roc_bert.py
src/transformers/models/roformer/convert_roformer_original_tf_checkpoint_to_pytorch.py
src/transformers/models/roformer/modeling_flax_roformer.py
src/transformers/models/roformer/modeling_roformer.py
src/transformers/models/roformer/modeling_tf_roformer.py
src/transformers/models/rwkv/configuration_rwkv.py
src/transformers/models/rwkv/convert_rwkv_checkpoint_to_hf.py
src/transformers/models/rwkv/modeling_rwkv.py
src/transformers/models/sam/configuration_sam.py
src/transformers/models/sam/convert_sam_original_to_hf_format.py
src/transformers/models/sam/image_processing_sam.py
src/transformers/models/sam/modeling_sam.py
src/transformers/models/sam/modeling_tf_sam.py
src/transformers/models/sam/processing_sam.py
src/transformers/models/seamless_m4t/convert_fairseq2_to_hf.py
src/transformers/models/segformer/configuration_segformer.py
src/transformers/models/segformer/convert_segformer_original_to_pytorch.py
src/transformers/models/sew/convert_sew_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/sew_d/convert_sew_d_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/speech_encoder_decoder/configuration_speech_encoder_decoder.py
src/transformers/models/speech_encoder_decoder/convert_mbart_wav2vec2_seq2seq_original_to_pytorch.py
src/transformers/models/speech_encoder_decoder/convert_speech_to_text_wav2vec2_seq2seq_original_to_pytorch.py
src/transformers/models/speech_encoder_decoder/modeling_flax_speech_encoder_decoder.py
src/transformers/models/speech_to_text/convert_s2t_fairseq_to_tfms.py
src/transformers/models/speech_to_text/modeling_tf_speech_to_text.py
src/transformers/models/speecht5/configuration_speecht5.py
src/transformers/models/speecht5/convert_hifigan.py
src/transformers/models/speecht5/convert_speecht5_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/speecht5/number_normalizer.py
src/transformers/models/splinter/configuration_splinter.py
src/transformers/models/splinter/modeling_splinter.py
src/transformers/models/squeezebert/modeling_squeezebert.py
src/transformers/models/swiftformer/configuration_swiftformer.py
src/transformers/models/swiftformer/convert_swiftformer_original_to_hf.py
src/transformers/models/swiftformer/modeling_swiftformer.py
src/transformers/models/swin/convert_swin_simmim_to_pytorch.py
src/transformers/models/swin/convert_swin_timm_to_pytorch.py
src/transformers/models/swin/modeling_tf_swin.py
src/transformers/models/swin2sr/configuration_swin2sr.py
src/transformers/models/swin2sr/convert_swin2sr_original_to_pytorch.py
src/transformers/models/swinv2/convert_swinv2_timm_to_pytorch.py
src/transformers/models/swinv2/modeling_swinv2.py
src/transformers/models/switch_transformers/configuration_switch_transformers.py
src/transformers/models/switch_transformers/convert_big_switch.py
src/transformers/models/switch_transformers/convert_switch_transformers_original_flax_checkpoint_to_pytorch.py
src/transformers/models/switch_transformers/modeling_switch_transformers.py
src/transformers/models/t5/configuration_t5.py
src/transformers/models/t5/convert_t5_original_tf_checkpoint_to_pytorch.py
src/transformers/models/t5/convert_t5x_checkpoint_to_flax.py
src/transformers/models/t5/convert_t5x_checkpoint_to_pytorch.py
src/transformers/models/t5/modeling_flax_t5.py
src/transformers/models/t5/modeling_t5.py
src/transformers/models/t5/modeling_tf_t5.py
src/transformers/models/table_transformer/configuration_table_transformer.py
src/transformers/models/table_transformer/convert_table_transformer_to_hf.py
src/transformers/models/table_transformer/convert_table_transformer_to_hf_no_timm.py
src/transformers/models/tapas/configuration_tapas.py
src/transformers/models/tapas/convert_tapas_original_tf_checkpoint_to_pytorch.py
src/transformers/models/tapas/modeling_tapas.py
src/transformers/models/tapas/modeling_tf_tapas.py
src/transformers/models/timesformer/convert_timesformer_to_pytorch.py
src/transformers/models/timm_backbone/configuration_timm_backbone.py
src/transformers/models/timm_backbone/modeling_timm_backbone.py
src/transformers/models/trocr/convert_trocr_unilm_to_pytorch.py
src/transformers/models/tvlt/configuration_tvlt.py
src/transformers/models/tvlt/modeling_tvlt.py
src/transformers/models/umt5/configuration_umt5.py
src/transformers/models/umt5/convert_umt5_checkpoint_to_pytorch.py
src/transformers/models/umt5/modeling_umt5.py
src/transformers/models/unispeech/convert_unispeech_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/unispeech_sat/configuration_unispeech_sat.py
src/transformers/models/unispeech_sat/convert_unispeech_original_s3prl_checkpoint_to_pytorch.py
src/transformers/models/unispeech_sat/convert_unispeech_sat_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/upernet/configuration_upernet.py
src/transformers/models/upernet/convert_convnext_upernet_to_pytorch.py
src/transformers/models/upernet/convert_swin_upernet_to_pytorch.py
src/transformers/models/videomae/configuration_videomae.py
src/transformers/models/videomae/convert_videomae_to_pytorch.py
src/transformers/models/vilt/configuration_vilt.py
src/transformers/models/vilt/convert_vilt_original_to_pytorch.py
src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py
src/transformers/models/vision_encoder_decoder/modeling_tf_vision_encoder_decoder.py
src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py
src/transformers/models/vision_text_dual_encoder/modeling_vision_text_dual_encoder.py
src/transformers/models/visual_bert/convert_visual_bert_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/visual_bert/modeling_visual_bert.py
src/transformers/models/vit/convert_dino_to_pytorch.py
src/transformers/models/vit/convert_vit_timm_to_pytorch.py
src/transformers/models/vit/modeling_flax_vit.py
src/transformers/models/vit_hybrid/configuration_vit_hybrid.py
src/transformers/models/vit_hybrid/convert_vit_hybrid_timm_to_pytorch.py
src/transformers/models/vit_hybrid/modeling_vit_hybrid.py
src/transformers/models/vit_mae/convert_vit_mae_to_pytorch.py
src/transformers/models/vit_mae/modeling_tf_vit_mae.py
src/transformers/models/vit_msn/configuration_vit_msn.py
src/transformers/models/vit_msn/convert_msn_to_pytorch.py
src/transformers/models/vivit/configuration_vivit.py
src/transformers/models/vivit/convert_vivit_flax_to_pytorch.py
src/transformers/models/vivit/image_processing_vivit.py
src/transformers/models/vivit/modeling_vivit.py
src/transformers/models/wav2vec2/convert_wav2vec2_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/wav2vec2/convert_wav2vec2_original_s3prl_checkpoint_to_pytorch.py
src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py
src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
src/transformers/models/wav2vec2_conformer/convert_wav2vec2_conformer_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/wavlm/convert_wavlm_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/wavlm/convert_wavlm_original_s3prl_checkpoint_to_pytorch.py
src/transformers/models/whisper/convert_openai_to_hf.py
src/transformers/models/whisper/english_normalizer.py
src/transformers/models/whisper/modeling_flax_whisper.py
src/transformers/models/x_clip/configuration_x_clip.py
src/transformers/models/x_clip/convert_x_clip_original_pytorch_to_hf.py
src/transformers/models/xglm/configuration_xglm.py
src/transformers/models/xglm/convert_xglm_original_ckpt_to_trfms.py
src/transformers/models/xglm/modeling_flax_xglm.py
src/transformers/models/xglm/modeling_tf_xglm.py
src/transformers/models/xglm/modeling_xglm.py
src/transformers/models/xlm/convert_xlm_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/xlm/modeling_tf_xlm.py
src/transformers/models/xlm/modeling_xlm.py
src/transformers/models/xlm_prophetnet/configuration_xlm_prophetnet.py
src/transformers/models/xlm_prophetnet/modeling_xlm_prophetnet.py
src/transformers/models/xlm_roberta/modeling_flax_xlm_roberta.py
src/transformers/models/xlm_roberta/modeling_tf_xlm_roberta.py
src/transformers/models/xlm_roberta/modeling_xlm_roberta.py
src/transformers/models/xlm_roberta_xl/convert_xlm_roberta_xl_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
src/transformers/models/xlnet/convert_xlnet_original_tf_checkpoint_to_pytorch.py
src/transformers/models/xlnet/modeling_tf_xlnet.py
src/transformers/models/xlnet/modeling_xlnet.py
src/transformers/models/xmod/convert_xmod_original_pytorch_checkpoint_to_pytorch.py
src/transformers/models/yolos/convert_yolos_to_pytorch.py
src/transformers/models/yoso/convert_yoso_pytorch_to_pytorch.py
src/transformers/models/yoso/modeling_yoso.py
src/transformers/onnx/__main__.py
src/transformers/onnx/config.py
src/transformers/onnx/convert.py
src/transformers/onnx/features.py
src/transformers/onnx/utils.py
src/transformers/optimization.py
src/transformers/optimization_tf.py
src/transformers/pipelines/audio_classification.py
src/transformers/pipelines/audio_utils.py
src/transformers/pipelines/automatic_speech_recognition.py
src/transformers/pipelines/base.py
src/transformers/pipelines/conversational.py
src/transformers/pipelines/depth_estimation.py
src/transformers/pipelines/document_question_answering.py
src/transformers/pipelines/feature_extraction.py
src/transformers/pipelines/fill_mask.py
src/transformers/pipelines/image_classification.py
src/transformers/pipelines/image_segmentation.py
src/transformers/pipelines/image_to_text.py
src/transformers/pipelines/mask_generation.py
src/transformers/pipelines/object_detection.py
src/transformers/pipelines/pt_utils.py
src/transformers/pipelines/question_answering.py
src/transformers/pipelines/table_question_answering.py
src/transformers/pipelines/text_classification.py
src/transformers/pipelines/token_classification.py
src/transformers/pipelines/video_classification.py
src/transformers/pipelines/visual_question_answering.py
src/transformers/pipelines/zero_shot_audio_classification.py
src/transformers/pipelines/zero_shot_classification.py
src/transformers/pipelines/zero_shot_image_classification.py
src/transformers/pipelines/zero_shot_object_detection.py
src/transformers/processing_utils.py
src/transformers/pytorch_utils.py
src/transformers/sagemaker/trainer_sm.py
src/transformers/sagemaker/training_args_sm.py
src/transformers/testing_utils.py
src/transformers/tf_utils.py
src/transformers/time_series_utils.py
src/transformers/tokenization_utils.py
src/transformers/tokenization_utils_base.py
src/transformers/tokenization_utils_fast.py
src/transformers/tools/agent_types.py
src/transformers/tools/agents.py
src/transformers/tools/base.py
src/transformers/tools/document_question_answering.py
src/transformers/tools/evaluate_agent.py
src/transformers/tools/image_captioning.py
src/transformers/tools/image_question_answering.py
src/transformers/tools/image_segmentation.py
src/transformers/tools/prompts.py
src/transformers/tools/python_interpreter.py
src/transformers/tools/speech_to_text.py
src/transformers/tools/text_classification.py
src/transformers/tools/text_question_answering.py
src/transformers/tools/text_summarization.py
src/transformers/tools/text_to_speech.py
src/transformers/tools/translation.py
src/transformers/trainer.py
src/transformers/trainer_callback.py
src/transformers/trainer_pt_utils.py
src/transformers/trainer_seq2seq.py
src/transformers/trainer_tf.py
src/transformers/trainer_utils.py
src/transformers/training_args.py
src/transformers/training_args_seq2seq.py
src/transformers/training_args_tf.py
src/transformers/utils/backbone_utils.py
src/transformers/utils/bitsandbytes.py
src/transformers/utils/constants.py
src/transformers/utils/doc.py
src/transformers/utils/dummy_detectron2_objects.py
src/transformers/utils/dummy_essentia_and_librosa_and_pretty_midi_and_scipy_and_torch_objects.py
src/transformers/utils/dummy_flax_objects.py
src/transformers/utils/dummy_keras_nlp_objects.py
src/transformers/utils/dummy_music_objects.py
src/transformers/utils/dummy_pt_objects.py
src/transformers/utils/dummy_sentencepiece_and_tokenizers_objects.py
src/transformers/utils/dummy_sentencepiece_objects.py
src/transformers/utils/dummy_speech_objects.py
src/transformers/utils/dummy_tensorflow_text_objects.py
src/transformers/utils/dummy_tf_objects.py
src/transformers/utils/dummy_tokenizers_objects.py
src/transformers/utils/dummy_vision_objects.py
src/transformers/utils/fx.py
src/transformers/utils/generic.py
src/transformers/utils/hp_naming.py
src/transformers/utils/hub.py
src/transformers/utils/import_utils.py
src/transformers/utils/logging.py
src/transformers/utils/model_parallel_utils.py
src/transformers/utils/notebook.py
src/transformers/utils/peft_utils.py
src/transformers/utils/quantization_config.py
src/transformers/utils/sentencepiece_model_pb2.py
src/transformers/utils/sentencepiece_model_pb2_new.py
src/transformers/utils/versions.py
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/past_ci_versions.py
|
import argparse
import os
past_versions_testing = {
"pytorch": {
"1.13": {
"torch": "1.13.1",
"torchvision": "0.14.1",
"torchaudio": "0.13.1",
"python": 3.9,
"cuda": "cu116",
"install": (
"python3 -m pip install --no-cache-dir -U torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1"
" --extra-index-url https://download.pytorch.org/whl/cu116"
),
"base_image": "nvidia/cuda:11.6.2-cudnn8-devel-ubuntu20.04",
},
"1.12": {
"torch": "1.12.1",
"torchvision": "0.13.1",
"torchaudio": "0.12.1",
"python": 3.9,
"cuda": "cu113",
"install": (
"python3 -m pip install --no-cache-dir -U torch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1"
" --extra-index-url https://download.pytorch.org/whl/cu113"
),
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"1.11": {
"torch": "1.11.0",
"torchvision": "0.12.0",
"torchaudio": "0.11.0",
"python": 3.9,
"cuda": "cu113",
"install": (
"python3 -m pip install --no-cache-dir -U torch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0"
" --extra-index-url https://download.pytorch.org/whl/cu113"
),
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"1.10": {
"torch": "1.10.2",
"torchvision": "0.11.3",
"torchaudio": "0.10.2",
"python": 3.9,
"cuda": "cu113",
"install": (
"python3 -m pip install --no-cache-dir -U torch==1.10.2 torchvision==0.11.3 torchaudio==0.10.2"
" --extra-index-url https://download.pytorch.org/whl/cu113"
),
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
# torchaudio < 0.10 has no CUDA-enabled binary distributions
"1.9": {
"torch": "1.9.1",
"torchvision": "0.10.1",
"torchaudio": "0.9.1",
"python": 3.9,
"cuda": "cu111",
"install": (
"python3 -m pip install --no-cache-dir -U torch==1.9.1 torchvision==0.10.1 torchaudio==0.9.1"
" --extra-index-url https://download.pytorch.org/whl/cu111"
),
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
},
"tensorflow": {
"2.11": {
"tensorflow": "2.11.1",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.11.1",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"2.10": {
"tensorflow": "2.10.1",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.10.1",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"2.9": {
"tensorflow": "2.9.3",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.9.3",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"2.8": {
"tensorflow": "2.8.2",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.8.2",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"2.7": {
"tensorflow": "2.7.3",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.7.3",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"2.6": {
"tensorflow": "2.6.5",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.6.5",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
"2.5": {
"tensorflow": "2.5.3",
"install": "python3 -m pip install --no-cache-dir -U tensorflow==2.5.3",
"base_image": "nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04",
},
},
}
if __name__ == "__main__":
parser = argparse.ArgumentParser("Choose the framework and version to install")
parser.add_argument(
"--framework", help="The framework to install. Should be `torch` or `tensorflow`", type=str, required=True
)
parser.add_argument("--version", help="The version of the framework to install.", type=str, required=True)
args = parser.parse_args()
info = past_versions_testing[args.framework][args.version]
os.system(f'echo "export INSTALL_CMD=\'{info["install"]}\'" >> ~/.profile')
print(f'echo "export INSTALL_CMD=\'{info["install"]}\'" >> ~/.profile')
cuda = ""
if args.framework == "pytorch":
cuda = info["cuda"]
os.system(f"echo \"export CUDA='{cuda}'\" >> ~/.profile")
print(f"echo \"export CUDA='{cuda}'\" >> ~/.profile")
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/slow_documentation_tests.txt
|
docs/source/en/generation_strategies.md
docs/source/en/model_doc/ctrl.md
docs/source/en/model_doc/kosmos-2.md
docs/source/en/model_doc/seamless_m4t.md
docs/source/en/task_summary.md
docs/source/en/tasks/prompting.md
src/transformers/models/blip_2/modeling_blip_2.py
src/transformers/models/ctrl/modeling_ctrl.py
src/transformers/models/fuyu/modeling_fuyu.py
src/transformers/models/kosmos2/modeling_kosmos2.py
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_inits.py
|
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utility that checks the custom inits of Transformers are well-defined: Transformers uses init files that delay the
import of an object to when it's actually needed. This is to avoid the main init importing all models, which would
make the line `import transformers` very slow when the user has all optional dependencies installed. The inits with
delayed imports have two halves: one definining a dictionary `_import_structure` which maps modules to the name of the
objects in each module, and one in `TYPE_CHECKING` which looks like a normal init for type-checkers. The goal of this
script is to check the objects defined in both halves are the same.
This also checks the main init properly references all submodules, even if it doesn't import anything from them: every
submodule should be defined as a key of `_import_structure`, with an empty list as value potentially, or the submodule
won't be importable.
Use from the root of the repo with:
```bash
python utils/check_inits.py
```
for a check that will error in case of inconsistencies (used by `make repo-consistency`).
There is no auto-fix possible here sadly :-(
"""
import collections
import os
import re
from pathlib import Path
from typing import Dict, List, Optional, Tuple
# Path is set with the intent you should run this script from the root of the repo.
PATH_TO_TRANSFORMERS = "src/transformers"
# Matches is_xxx_available()
_re_backend = re.compile(r"is\_([a-z_]*)_available()")
# Catches a one-line _import_struct = {xxx}
_re_one_line_import_struct = re.compile(r"^_import_structure\s+=\s+\{([^\}]+)\}")
# Catches a line with a key-values pattern: "bla": ["foo", "bar"]
_re_import_struct_key_value = re.compile(r'\s+"\S*":\s+\[([^\]]*)\]')
# Catches a line if not is_foo_available
_re_test_backend = re.compile(r"^\s*if\s+not\s+is\_[a-z_]*\_available\(\)")
# Catches a line _import_struct["bla"].append("foo")
_re_import_struct_add_one = re.compile(r'^\s*_import_structure\["\S*"\]\.append\("(\S*)"\)')
# Catches a line _import_struct["bla"].extend(["foo", "bar"]) or _import_struct["bla"] = ["foo", "bar"]
_re_import_struct_add_many = re.compile(r"^\s*_import_structure\[\S*\](?:\.extend\(|\s*=\s+)\[([^\]]*)\]")
# Catches a line with an object between quotes and a comma: "MyModel",
_re_quote_object = re.compile(r'^\s+"([^"]+)",')
# Catches a line with objects between brackets only: ["foo", "bar"],
_re_between_brackets = re.compile(r"^\s+\[([^\]]+)\]")
# Catches a line with from foo import bar, bla, boo
_re_import = re.compile(r"\s+from\s+\S*\s+import\s+([^\(\s].*)\n")
# Catches a line with try:
_re_try = re.compile(r"^\s*try:")
# Catches a line with else:
_re_else = re.compile(r"^\s*else:")
def find_backend(line: str) -> Optional[str]:
"""
Find one (or multiple) backend in a code line of the init.
Args:
line (`str`): A code line of the main init.
Returns:
Optional[`str`]: If one (or several) backend is found, returns it. In the case of multiple backends (the line
contains `if is_xxx_available() and `is_yyy_available()`) returns all backends joined on `_and_` (so
`xxx_and_yyy` for instance).
"""
if _re_test_backend.search(line) is None:
return None
backends = [b[0] for b in _re_backend.findall(line)]
backends.sort()
return "_and_".join(backends)
def parse_init(init_file) -> Optional[Tuple[Dict[str, List[str]], Dict[str, List[str]]]]:
"""
Read an init_file and parse (per backend) the `_import_structure` objects defined and the `TYPE_CHECKING` objects
defined.
Args:
init_file (`str`): Path to the init file to inspect.
Returns:
`Optional[Tuple[Dict[str, List[str]], Dict[str, List[str]]]]`: A tuple of two dictionaries mapping backends to list of
imported objects, one for the `_import_structure` part of the init and one for the `TYPE_CHECKING` part of the
init. Returns `None` if the init is not a custom init.
"""
with open(init_file, "r", encoding="utf-8", newline="\n") as f:
lines = f.readlines()
# Get the to `_import_structure` definition.
line_index = 0
while line_index < len(lines) and not lines[line_index].startswith("_import_structure = {"):
line_index += 1
# If this is a traditional init, just return.
if line_index >= len(lines):
return None
# First grab the objects without a specific backend in _import_structure
objects = []
while not lines[line_index].startswith("if TYPE_CHECKING") and find_backend(lines[line_index]) is None:
line = lines[line_index]
# If we have everything on a single line, let's deal with it.
if _re_one_line_import_struct.search(line):
content = _re_one_line_import_struct.search(line).groups()[0]
imports = re.findall(r"\[([^\]]+)\]", content)
for imp in imports:
objects.extend([obj[1:-1] for obj in imp.split(", ")])
line_index += 1
continue
single_line_import_search = _re_import_struct_key_value.search(line)
if single_line_import_search is not None:
imports = [obj[1:-1] for obj in single_line_import_search.groups()[0].split(", ") if len(obj) > 0]
objects.extend(imports)
elif line.startswith(" " * 8 + '"'):
objects.append(line[9:-3])
line_index += 1
# Those are stored with the key "none".
import_dict_objects = {"none": objects}
# Let's continue with backend-specific objects in _import_structure
while not lines[line_index].startswith("if TYPE_CHECKING"):
# If the line is an if not is_backend_available, we grab all objects associated.
backend = find_backend(lines[line_index])
# Check if the backend declaration is inside a try block:
if _re_try.search(lines[line_index - 1]) is None:
backend = None
if backend is not None:
line_index += 1
# Scroll until we hit the else block of try-except-else
while _re_else.search(lines[line_index]) is None:
line_index += 1
line_index += 1
objects = []
# Until we unindent, add backend objects to the list
while len(lines[line_index]) <= 1 or lines[line_index].startswith(" " * 4):
line = lines[line_index]
if _re_import_struct_add_one.search(line) is not None:
objects.append(_re_import_struct_add_one.search(line).groups()[0])
elif _re_import_struct_add_many.search(line) is not None:
imports = _re_import_struct_add_many.search(line).groups()[0].split(", ")
imports = [obj[1:-1] for obj in imports if len(obj) > 0]
objects.extend(imports)
elif _re_between_brackets.search(line) is not None:
imports = _re_between_brackets.search(line).groups()[0].split(", ")
imports = [obj[1:-1] for obj in imports if len(obj) > 0]
objects.extend(imports)
elif _re_quote_object.search(line) is not None:
objects.append(_re_quote_object.search(line).groups()[0])
elif line.startswith(" " * 8 + '"'):
objects.append(line[9:-3])
elif line.startswith(" " * 12 + '"'):
objects.append(line[13:-3])
line_index += 1
import_dict_objects[backend] = objects
else:
line_index += 1
# At this stage we are in the TYPE_CHECKING part, first grab the objects without a specific backend
objects = []
while (
line_index < len(lines)
and find_backend(lines[line_index]) is None
and not lines[line_index].startswith("else")
):
line = lines[line_index]
single_line_import_search = _re_import.search(line)
if single_line_import_search is not None:
objects.extend(single_line_import_search.groups()[0].split(", "))
elif line.startswith(" " * 8):
objects.append(line[8:-2])
line_index += 1
type_hint_objects = {"none": objects}
# Let's continue with backend-specific objects
while line_index < len(lines):
# If the line is an if is_backend_available, we grab all objects associated.
backend = find_backend(lines[line_index])
# Check if the backend declaration is inside a try block:
if _re_try.search(lines[line_index - 1]) is None:
backend = None
if backend is not None:
line_index += 1
# Scroll until we hit the else block of try-except-else
while _re_else.search(lines[line_index]) is None:
line_index += 1
line_index += 1
objects = []
# Until we unindent, add backend objects to the list
while len(lines[line_index]) <= 1 or lines[line_index].startswith(" " * 8):
line = lines[line_index]
single_line_import_search = _re_import.search(line)
if single_line_import_search is not None:
objects.extend(single_line_import_search.groups()[0].split(", "))
elif line.startswith(" " * 12):
objects.append(line[12:-2])
line_index += 1
type_hint_objects[backend] = objects
else:
line_index += 1
return import_dict_objects, type_hint_objects
def analyze_results(import_dict_objects: Dict[str, List[str]], type_hint_objects: Dict[str, List[str]]) -> List[str]:
"""
Analyze the differences between _import_structure objects and TYPE_CHECKING objects found in an init.
Args:
import_dict_objects (`Dict[str, List[str]]`):
A dictionary mapping backend names (`"none"` for the objects independent of any specific backend) to
list of imported objects.
type_hint_objects (`Dict[str, List[str]]`):
A dictionary mapping backend names (`"none"` for the objects independent of any specific backend) to
list of imported objects.
Returns:
`List[str]`: The list of errors corresponding to mismatches.
"""
def find_duplicates(seq):
return [k for k, v in collections.Counter(seq).items() if v > 1]
# If one backend is missing from the other part of the init, error early.
if list(import_dict_objects.keys()) != list(type_hint_objects.keys()):
return ["Both sides of the init do not have the same backends!"]
errors = []
# Find all errors.
for key in import_dict_objects.keys():
# Duplicate imports in any half.
duplicate_imports = find_duplicates(import_dict_objects[key])
if duplicate_imports:
errors.append(f"Duplicate _import_structure definitions for: {duplicate_imports}")
duplicate_type_hints = find_duplicates(type_hint_objects[key])
if duplicate_type_hints:
errors.append(f"Duplicate TYPE_CHECKING objects for: {duplicate_type_hints}")
# Missing imports in either part of the init.
if sorted(set(import_dict_objects[key])) != sorted(set(type_hint_objects[key])):
name = "base imports" if key == "none" else f"{key} backend"
errors.append(f"Differences for {name}:")
for a in type_hint_objects[key]:
if a not in import_dict_objects[key]:
errors.append(f" {a} in TYPE_HINT but not in _import_structure.")
for a in import_dict_objects[key]:
if a not in type_hint_objects[key]:
errors.append(f" {a} in _import_structure but not in TYPE_HINT.")
return errors
def check_all_inits():
"""
Check all inits in the transformers repo and raise an error if at least one does not define the same objects in
both halves.
"""
failures = []
for root, _, files in os.walk(PATH_TO_TRANSFORMERS):
if "__init__.py" in files:
fname = os.path.join(root, "__init__.py")
objects = parse_init(fname)
if objects is not None:
errors = analyze_results(*objects)
if len(errors) > 0:
errors[0] = f"Problem in {fname}, both halves do not define the same objects.\n{errors[0]}"
failures.append("\n".join(errors))
if len(failures) > 0:
raise ValueError("\n\n".join(failures))
def get_transformers_submodules() -> List[str]:
"""
Returns the list of Transformers submodules.
"""
submodules = []
for path, directories, files in os.walk(PATH_TO_TRANSFORMERS):
for folder in directories:
# Ignore private modules
if folder.startswith("_"):
directories.remove(folder)
continue
# Ignore leftovers from branches (empty folders apart from pycache)
if len(list((Path(path) / folder).glob("*.py"))) == 0:
continue
short_path = str((Path(path) / folder).relative_to(PATH_TO_TRANSFORMERS))
submodule = short_path.replace(os.path.sep, ".")
submodules.append(submodule)
for fname in files:
if fname == "__init__.py":
continue
short_path = str((Path(path) / fname).relative_to(PATH_TO_TRANSFORMERS))
submodule = short_path.replace(".py", "").replace(os.path.sep, ".")
if len(submodule.split(".")) == 1:
submodules.append(submodule)
return submodules
IGNORE_SUBMODULES = [
"convert_pytorch_checkpoint_to_tf2",
"modeling_flax_pytorch_utils",
"models.esm.openfold_utils",
"modeling_attn_mask_utils",
]
def check_submodules():
"""
Check all submodules of Transformers are properly registered in the main init. Error otherwise.
"""
# This is to make sure the transformers module imported is the one in the repo.
from transformers.utils import direct_transformers_import
transformers = direct_transformers_import(PATH_TO_TRANSFORMERS)
import_structure_keys = set(transformers._import_structure.keys())
# This contains all the base keys of the _import_structure object defined in the init, but if the user is missing
# some optional dependencies, they may not have all of them. Thus we read the init to read all additions and
# (potentiall re-) add them.
with open(os.path.join(PATH_TO_TRANSFORMERS, "__init__.py"), "r") as f:
init_content = f.read()
import_structure_keys.update(set(re.findall(r"import_structure\[\"([^\"]*)\"\]", init_content)))
module_not_registered = [
module
for module in get_transformers_submodules()
if module not in IGNORE_SUBMODULES and module not in import_structure_keys
]
if len(module_not_registered) > 0:
list_of_modules = "\n".join(f"- {module}" for module in module_not_registered)
raise ValueError(
"The following submodules are not properly registed in the main init of Transformers:\n"
f"{list_of_modules}\n"
"Make sure they appear somewhere in the keys of `_import_structure` with an empty list as value."
)
if __name__ == "__main__":
check_all_inits()
check_submodules()
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/get_github_job_time.py
|
import argparse
import math
import traceback
import dateutil.parser as date_parser
import requests
def extract_time_from_single_job(job):
"""Extract time info from a single job in a GitHub Actions workflow run"""
job_info = {}
start = job["started_at"]
end = job["completed_at"]
start_datetime = date_parser.parse(start)
end_datetime = date_parser.parse(end)
duration_in_min = round((end_datetime - start_datetime).total_seconds() / 60.0)
job_info["started_at"] = start
job_info["completed_at"] = end
job_info["duration"] = duration_in_min
return job_info
def get_job_time(workflow_run_id, token=None):
"""Extract time info for all jobs in a GitHub Actions workflow run"""
headers = None
if token is not None:
headers = {"Accept": "application/vnd.github+json", "Authorization": f"Bearer {token}"}
url = f"https://api.github.com/repos/huggingface/transformers/actions/runs/{workflow_run_id}/jobs?per_page=100"
result = requests.get(url, headers=headers).json()
job_time = {}
try:
job_time.update({job["name"]: extract_time_from_single_job(job) for job in result["jobs"]})
pages_to_iterate_over = math.ceil((result["total_count"] - 100) / 100)
for i in range(pages_to_iterate_over):
result = requests.get(url + f"&page={i + 2}", headers=headers).json()
job_time.update({job["name"]: extract_time_from_single_job(job) for job in result["jobs"]})
return job_time
except Exception:
print(f"Unknown error, could not fetch links:\n{traceback.format_exc()}")
return {}
if __name__ == "__main__":
r"""
Example:
python get_github_job_time.py --workflow_run_id 2945609517
"""
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument("--workflow_run_id", type=str, required=True, help="A GitHub Actions workflow run id.")
args = parser.parse_args()
job_time = get_job_time(args.workflow_run_id)
job_time = dict(sorted(job_time.items(), key=lambda item: item[1]["duration"], reverse=True))
for k, v in job_time.items():
print(f'{k}: {v["duration"]}')
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_model_tester.py
|
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import glob
import os
from get_test_info import get_tester_classes
if __name__ == "__main__":
failures = []
pattern = os.path.join("tests", "models", "**", "test_modeling_*.py")
test_files = glob.glob(pattern)
# TODO: deal with TF/Flax too
test_files = [
x for x in test_files if not (x.startswith("test_modeling_tf_") or x.startswith("test_modeling_flax_"))
]
for test_file in test_files:
tester_classes = get_tester_classes(test_file)
for tester_class in tester_classes:
# A few tester classes don't have `parent` parameter in `__init__`.
# TODO: deal this better
try:
tester = tester_class(parent=None)
except Exception:
continue
if hasattr(tester, "get_config"):
config = tester.get_config()
for k, v in config.to_dict().items():
if isinstance(v, int):
target = None
if k in ["vocab_size"]:
target = 100
elif k in ["max_position_embeddings"]:
target = 128
elif k in ["hidden_size", "d_model"]:
target = 40
elif k == ["num_layers", "num_hidden_layers", "num_encoder_layers", "num_decoder_layers"]:
target = 5
if target is not None and v > target:
failures.append(
f"{tester_class.__name__} will produce a `config` of type `{config.__class__.__name__}`"
f' with config["{k}"] = {v} which is too large for testing! Set its value to be smaller'
f" than {target}."
)
if len(failures) > 0:
raise Exception(f"There were {len(failures)} failures:\n" + "\n".join(failures))
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_copies.py
|
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utility that checks whether the copies defined in the library match the original or not. This includes:
- All code commented with `# Copied from` comments,
- The list of models in the main README.md matches the ones in the localized READMEs,
- Files that are registered as full copies of one another in the `FULL_COPIES` constant of this script.
This also checks the list of models in the README is complete (has all models) and add a line to complete if there is
a model missing.
Use from the root of the repo with:
```bash
python utils/check_copies.py
```
for a check that will error in case of inconsistencies (used by `make repo-consistency`) or
```bash
python utils/check_copies.py --fix_and_overwrite
```
for a check that will fix all inconsistencies automatically (used by `make fix-copies`).
"""
import argparse
import glob
import os
import re
import subprocess
from typing import List, Optional, Tuple
from transformers.utils import direct_transformers_import
# All paths are set with the intent you should run this script from the root of the repo with the command
# python utils/check_copies.py
TRANSFORMERS_PATH = "src/transformers"
MODEL_TEST_PATH = "tests/models"
PATH_TO_DOCS = "docs/source/en"
REPO_PATH = "."
# Mapping for files that are full copies of others (keys are copies, values the file to keep them up to data with)
FULL_COPIES = {
"examples/tensorflow/question-answering/utils_qa.py": "examples/pytorch/question-answering/utils_qa.py",
"examples/flax/question-answering/utils_qa.py": "examples/pytorch/question-answering/utils_qa.py",
}
LOCALIZED_READMES = {
# If the introduction or the conclusion of the list change, the prompts may need to be updated.
"README.md": {
"start_prompt": "🤗 Transformers currently provides the following architectures",
"end_prompt": "1. Want to contribute a new model?",
"format_model_list": (
"**[{title}]({model_link})** (from {paper_affiliations}) released with the paper {paper_title_link} by"
" {paper_authors}.{supplements}"
),
},
"README_zh-hans.md": {
"start_prompt": "🤗 Transformers 目前支持如下的架构",
"end_prompt": "1. 想要贡献新的模型?",
"format_model_list": (
"**[{title}]({model_link})** (来自 {paper_affiliations}) 伴随论文 {paper_title_link} 由 {paper_authors}"
" 发布。{supplements}"
),
},
"README_zh-hant.md": {
"start_prompt": "🤗 Transformers 目前支援以下的架構",
"end_prompt": "1. 想要貢獻新的模型?",
"format_model_list": (
"**[{title}]({model_link})** (from {paper_affiliations}) released with the paper {paper_title_link} by"
" {paper_authors}.{supplements}"
),
},
"README_ko.md": {
"start_prompt": "🤗 Transformers는 다음 모델들을 제공합니다",
"end_prompt": "1. 새로운 모델을 올리고 싶나요?",
"format_model_list": (
"**[{title}]({model_link})** ({paper_affiliations} 에서 제공)은 {paper_authors}.{supplements}의"
" {paper_title_link}논문과 함께 발표했습니다."
),
},
"README_es.md": {
"start_prompt": "🤗 Transformers actualmente proporciona las siguientes arquitecturas",
"end_prompt": "1. ¿Quieres aportar un nuevo modelo?",
"format_model_list": (
"**[{title}]({model_link})** (from {paper_affiliations}) released with the paper {paper_title_link} by"
" {paper_authors}.{supplements}"
),
},
"README_ja.md": {
"start_prompt": "🤗Transformersは現在、以下のアーキテクチャを提供しています",
"end_prompt": "1. 新しいモデルを投稿したいですか?",
"format_model_list": (
"**[{title}]({model_link})** ({paper_affiliations} から) {paper_authors}.{supplements} から公開された研究論文"
" {paper_title_link}"
),
},
"README_hd.md": {
"start_prompt": "🤗 ट्रांसफॉर्मर वर्तमान में निम्नलिखित आर्किटेक्चर का समर्थन करते हैं",
"end_prompt": "1. एक नए मॉडल में योगदान देना चाहते हैं?",
"format_model_list": (
"**[{title}]({model_link})** ({paper_affiliations} से) {paper_authors}.{supplements} द्वारा"
"अनुसंधान पत्र {paper_title_link} के साथ जारी किया गया"
),
},
}
# This is to make sure the transformers module imported is the one in the repo.
transformers_module = direct_transformers_import(TRANSFORMERS_PATH)
def _should_continue(line: str, indent: str) -> bool:
# Helper function. Returns `True` if `line` is empty, starts with the `indent` or is the end parenthesis of a
# function definition
return line.startswith(indent) or len(line.strip()) == 0 or re.search(r"^\s*\)(\s*->.*:|:)\s*$", line) is not None
def find_code_in_transformers(object_name: str, base_path: str = None) -> str:
"""
Find and return the source code of an object.
Args:
object_name (`str`):
The name of the object we want the source code of.
base_path (`str`, *optional*):
The path to the base folder where files are checked. If not set, it will be set to `TRANSFORMERS_PATH`.
Returns:
`str`: The source code of the object.
"""
parts = object_name.split(".")
i = 0
# We can't set this as the default value in the argument, otherwise `CopyCheckTester` will fail, as it uses a
# patched temp directory.
if base_path is None:
base_path = TRANSFORMERS_PATH
# Detail: the `Copied from` statement is originally designed to work with the last part of `TRANSFORMERS_PATH`,
# (which is `transformers`). The same should be applied for `MODEL_TEST_PATH`. However, its last part is `models`
# (to only check and search in it) which is a bit confusing. So we keep the copied statement staring with
# `tests.models.` and change it to `tests` here.
if base_path == MODEL_TEST_PATH:
base_path = "tests"
# First let's find the module where our object lives.
module = parts[i]
while i < len(parts) and not os.path.isfile(os.path.join(base_path, f"{module}.py")):
i += 1
if i < len(parts):
module = os.path.join(module, parts[i])
if i >= len(parts):
raise ValueError(
f"`object_name` should begin with the name of a module of transformers but got {object_name}."
)
with open(os.path.join(base_path, f"{module}.py"), "r", encoding="utf-8", newline="\n") as f:
lines = f.readlines()
# Now let's find the class / func in the code!
indent = ""
line_index = 0
for name in parts[i + 1 :]:
while (
line_index < len(lines) and re.search(rf"^{indent}(class|def)\s+{name}(\(|\:)", lines[line_index]) is None
):
line_index += 1
indent += " "
line_index += 1
if line_index >= len(lines):
raise ValueError(f" {object_name} does not match any function or class in {module}.")
# We found the beginning of the class / func, now let's find the end (when the indent diminishes).
start_index = line_index - 1
while line_index < len(lines) and _should_continue(lines[line_index], indent):
line_index += 1
# Clean up empty lines at the end (if any).
while len(lines[line_index - 1]) <= 1:
line_index -= 1
code_lines = lines[start_index:line_index]
return "".join(code_lines)
_re_copy_warning = re.compile(r"^(\s*)#\s*Copied from\s+transformers\.(\S+\.\S+)\s*($|\S.*$)")
_re_copy_warning_for_test_file = re.compile(r"^(\s*)#\s*Copied from\s+tests\.(\S+\.\S+)\s*($|\S.*$)")
_re_replace_pattern = re.compile(r"^\s*(\S+)->(\S+)(\s+.*|$)")
_re_fill_pattern = re.compile(r"<FILL\s+[^>]*>")
def get_indent(code: str) -> str:
"""
Find the indent in the first non empty line in a code sample.
Args:
code (`str`): The code to inspect.
Returns:
`str`: The indent looked at (as string).
"""
lines = code.split("\n")
idx = 0
while idx < len(lines) and len(lines[idx]) == 0:
idx += 1
if idx < len(lines):
return re.search(r"^(\s*)\S", lines[idx]).groups()[0]
return ""
def run_ruff(code):
command = ["ruff", "format", "-", "--config", "pyproject.toml", "--silent"]
process = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, stdin=subprocess.PIPE)
stdout, _ = process.communicate(input=code.encode())
return stdout.decode()
def stylify(code: str) -> str:
"""
Applies the ruff part of our `make style` command to some code. This formats the code using `ruff format`.
As `ruff` does not provide a python api this cannot be done on the fly.
Args:
code (`str`): The code to format.
Returns:
`str`: The formatted code.
"""
has_indent = len(get_indent(code)) > 0
if has_indent:
code = f"class Bla:\n{code}"
formatted_code = run_ruff(code)
return formatted_code[len("class Bla:\n") :] if has_indent else formatted_code
def check_codes_match(observed_code: str, theoretical_code: str) -> Optional[int]:
"""
Checks if two version of a code match with the exception of the class/function name.
Args:
observed_code (`str`): The code found.
theoretical_code (`str`): The code to match.
Returns:
`Optional[int]`: The index of the first line where there is a difference (if any) and `None` if the codes
match.
"""
observed_code_header = observed_code.split("\n")[0]
theoretical_code_header = theoretical_code.split("\n")[0]
# Catch the function/class name: it is expected that those do not match.
_re_class_match = re.compile(r"class\s+([^\(:]+)(?:\(|:)")
_re_func_match = re.compile(r"def\s+([^\(]+)\(")
for re_pattern in [_re_class_match, _re_func_match]:
if re_pattern.match(observed_code_header) is not None:
observed_obj_name = re_pattern.search(observed_code_header).groups()[0]
theoretical_name = re_pattern.search(theoretical_code_header).groups()[0]
theoretical_code_header = theoretical_code_header.replace(theoretical_name, observed_obj_name)
# Find the first diff. Line 0 is special since we need to compare with the function/class names ignored.
diff_index = 0
if theoretical_code_header != observed_code_header:
return 0
diff_index = 1
for observed_line, theoretical_line in zip(observed_code.split("\n")[1:], theoretical_code.split("\n")[1:]):
if observed_line != theoretical_line:
return diff_index
diff_index += 1
def is_copy_consistent(filename: str, overwrite: bool = False) -> Optional[List[Tuple[str, int]]]:
"""
Check if the code commented as a copy in a file matches the original.
Args:
filename (`str`):
The name of the file to check.
overwrite (`bool`, *optional*, defaults to `False`):
Whether or not to overwrite the copies when they don't match.
Returns:
`Optional[List[Tuple[str, int]]]`: If `overwrite=False`, returns the list of differences as tuples `(str, int)`
with the name of the object having a diff and the line number where theere is the first diff.
"""
with open(filename, "r", encoding="utf-8", newline="\n") as f:
lines = f.readlines()
diffs = []
line_index = 0
# Not a for loop cause `lines` is going to change (if `overwrite=True`).
while line_index < len(lines):
search_re = _re_copy_warning
if filename.startswith("tests"):
search_re = _re_copy_warning_for_test_file
search = search_re.search(lines[line_index])
if search is None:
line_index += 1
continue
# There is some copied code here, let's retrieve the original.
indent, object_name, replace_pattern = search.groups()
base_path = TRANSFORMERS_PATH if not filename.startswith("tests") else MODEL_TEST_PATH
theoretical_code = find_code_in_transformers(object_name, base_path=base_path)
theoretical_indent = get_indent(theoretical_code)
start_index = line_index + 1 if indent == theoretical_indent else line_index
line_index = start_index + 1
subcode = "\n".join(theoretical_code.split("\n")[1:])
indent = get_indent(subcode)
# Loop to check the observed code, stop when indentation diminishes or if we see a End copy comment.
should_continue = True
while line_index < len(lines) and should_continue:
line_index += 1
if line_index >= len(lines):
break
line = lines[line_index]
# There is a special pattern `# End copy` to stop early. It's not documented cause it shouldn't really be
# used.
should_continue = _should_continue(line, indent) and re.search(f"^{indent}# End copy", line) is None
# Clean up empty lines at the end (if any).
while len(lines[line_index - 1]) <= 1:
line_index -= 1
observed_code_lines = lines[start_index:line_index]
observed_code = "".join(observed_code_lines)
# Before comparing, use the `replace_pattern` on the original code.
if len(replace_pattern) > 0:
patterns = replace_pattern.replace("with", "").split(",")
patterns = [_re_replace_pattern.search(p) for p in patterns]
for pattern in patterns:
if pattern is None:
continue
obj1, obj2, option = pattern.groups()
theoretical_code = re.sub(obj1, obj2, theoretical_code)
if option.strip() == "all-casing":
theoretical_code = re.sub(obj1.lower(), obj2.lower(), theoretical_code)
theoretical_code = re.sub(obj1.upper(), obj2.upper(), theoretical_code)
theoretical_code = stylify(theoretical_code)
# Test for a diff and act accordingly.
diff_index = check_codes_match(observed_code, theoretical_code)
if diff_index is not None:
diffs.append([object_name, diff_index + start_index + 1])
if overwrite:
lines = lines[:start_index] + [theoretical_code] + lines[line_index:]
line_index = start_index + 1
if overwrite and len(diffs) > 0:
# Warn the user a file has been modified.
print(f"Detected changes, rewriting {filename}.")
with open(filename, "w", encoding="utf-8", newline="\n") as f:
f.writelines(lines)
return diffs
def check_copies(overwrite: bool = False):
"""
Check every file is copy-consistent with the original. Also check the model list in the main README and other
READMEs are consistent.
Args:
overwrite (`bool`, *optional*, defaults to `False`):
Whether or not to overwrite the copies when they don't match.
"""
all_files = glob.glob(os.path.join(TRANSFORMERS_PATH, "**/*.py"), recursive=True)
all_test_files = glob.glob(os.path.join(MODEL_TEST_PATH, "**/*.py"), recursive=True)
all_files = list(all_files) + list(all_test_files)
diffs = []
for filename in all_files:
new_diffs = is_copy_consistent(filename, overwrite)
diffs += [f"- {filename}: copy does not match {d[0]} at line {d[1]}" for d in new_diffs]
if not overwrite and len(diffs) > 0:
diff = "\n".join(diffs)
raise Exception(
"Found the following copy inconsistencies:\n"
+ diff
+ "\nRun `make fix-copies` or `python utils/check_copies.py --fix_and_overwrite` to fix them."
)
check_model_list_copy(overwrite=overwrite)
def check_full_copies(overwrite: bool = False):
"""
Check the files that are full copies of others (as indicated in `FULL_COPIES`) are copy-consistent.
Args:
overwrite (`bool`, *optional*, defaults to `False`):
Whether or not to overwrite the copies when they don't match.
"""
diffs = []
for target, source in FULL_COPIES.items():
with open(source, "r", encoding="utf-8") as f:
source_code = f.read()
with open(target, "r", encoding="utf-8") as f:
target_code = f.read()
if source_code != target_code:
if overwrite:
with open(target, "w", encoding="utf-8") as f:
print(f"Replacing the content of {target} by the one of {source}.")
f.write(source_code)
else:
diffs.append(f"- {target}: copy does not match {source}.")
if not overwrite and len(diffs) > 0:
diff = "\n".join(diffs)
raise Exception(
"Found the following copy inconsistencies:\n"
+ diff
+ "\nRun `make fix-copies` or `python utils/check_copies.py --fix_and_overwrite` to fix them."
)
def get_model_list(filename: str, start_prompt: str, end_prompt: str) -> str:
"""
Extracts the model list from a README.
Args:
filename (`str`): The name of the README file to check.
start_prompt (`str`): The string to look for that introduces the model list.
end_prompt (`str`): The string to look for that ends the model list.
Returns:
`str`: The model list.
"""
with open(os.path.join(REPO_PATH, filename), "r", encoding="utf-8", newline="\n") as f:
lines = f.readlines()
# Find the start of the list.
start_index = 0
while not lines[start_index].startswith(start_prompt):
start_index += 1
start_index += 1
result = []
current_line = ""
end_index = start_index
# Keep going until the end of the list.
while not lines[end_index].startswith(end_prompt):
if lines[end_index].startswith("1."):
if len(current_line) > 1:
result.append(current_line)
current_line = lines[end_index]
elif len(lines[end_index]) > 1:
current_line = f"{current_line[:-1]} {lines[end_index].lstrip()}"
end_index += 1
if len(current_line) > 1:
result.append(current_line)
return "".join(result)
def convert_to_localized_md(model_list: str, localized_model_list: str, format_str: str) -> Tuple[bool, str]:
"""
Compare the model list from the main README to the one in a localized README.
Args:
model_list (`str`): The model list in the main README.
localized_model_list (`str`): The model list in one of the localized README.
format_str (`str`):
The template for a model entry in the localized README (look at the `format_model_list` in the entries of
`LOCALIZED_READMES` for examples).
Returns:
`Tuple[bool, str]`: A tuple where the first value indicates if the READMEs match or not, and the second value
is the correct localized README.
"""
def _rep(match):
title, model_link, paper_affiliations, paper_title_link, paper_authors, supplements = match.groups()
return format_str.format(
title=title,
model_link=model_link,
paper_affiliations=paper_affiliations,
paper_title_link=paper_title_link,
paper_authors=paper_authors,
supplements=" " + supplements.strip() if len(supplements) != 0 else "",
)
# This regex captures metadata from an English model description, including model title, model link,
# affiliations of the paper, title of the paper, authors of the paper, and supplemental data (see DistilBERT for
# example).
_re_capture_meta = re.compile(
r"\*\*\[([^\]]*)\]\(([^\)]*)\)\*\* \(from ([^)]*)\)[^\[]*([^\)]*\)).*?by (.*?[A-Za-z\*]{2,}?)\. (.*)$"
)
# This regex is used to synchronize link.
_re_capture_title_link = re.compile(r"\*\*\[([^\]]*)\]\(([^\)]*)\)\*\*")
if len(localized_model_list) == 0:
localized_model_index = {}
else:
try:
localized_model_index = {
re.search(r"\*\*\[([^\]]*)", line).groups()[0]: line
for line in localized_model_list.strip().split("\n")
}
except AttributeError:
raise AttributeError("A model name in localized READMEs cannot be recognized.")
model_keys = [re.search(r"\*\*\[([^\]]*)", line).groups()[0] for line in model_list.strip().split("\n")]
# We exclude keys in localized README not in the main one.
readmes_match = not any(k not in model_keys for k in localized_model_index)
localized_model_index = {k: v for k, v in localized_model_index.items() if k in model_keys}
for model in model_list.strip().split("\n"):
title, model_link = _re_capture_title_link.search(model).groups()
if title not in localized_model_index:
readmes_match = False
# Add an anchor white space behind a model description string for regex.
# If metadata cannot be captured, the English version will be directly copied.
localized_model_index[title] = _re_capture_meta.sub(_rep, model + " ")
elif _re_fill_pattern.search(localized_model_index[title]) is not None:
update = _re_capture_meta.sub(_rep, model + " ")
if update != localized_model_index[title]:
readmes_match = False
localized_model_index[title] = update
else:
# Synchronize link
localized_model_index[title] = _re_capture_title_link.sub(
f"**[{title}]({model_link})**", localized_model_index[title], count=1
)
sorted_index = sorted(localized_model_index.items(), key=lambda x: x[0].lower())
return readmes_match, "\n".join((x[1] for x in sorted_index)) + "\n"
def _find_text_in_file(filename: str, start_prompt: str, end_prompt: str) -> Tuple[str, int, int, List[str]]:
"""
Find the text in a file between two prompts.
Args:
filename (`str`): The name of the file to look into.
start_prompt (`str`): The string to look for that introduces the content looked for.
end_prompt (`str`): The string to look for that ends the content looked for.
Returns:
Tuple[str, int, int, List[str]]: The content between the two prompts, the index of the start line in the
original file, the index of the end line in the original file and the list of lines of that file.
"""
with open(filename, "r", encoding="utf-8", newline="\n") as f:
lines = f.readlines()
# Find the start prompt.
start_index = 0
while not lines[start_index].startswith(start_prompt):
start_index += 1
start_index += 1
end_index = start_index
while not lines[end_index].startswith(end_prompt):
end_index += 1
end_index -= 1
while len(lines[start_index]) <= 1:
start_index += 1
while len(lines[end_index]) <= 1:
end_index -= 1
end_index += 1
return "".join(lines[start_index:end_index]), start_index, end_index, lines
def check_model_list_copy(overwrite: bool = False):
"""
Check the model lists in the README is consistent with the ones in the other READMES and also with `index.nmd`.
Args:
overwrite (`bool`, *optional*, defaults to `False`):
Whether or not to overwrite the copies when they don't match.
"""
# Fix potential doc links in the README
with open(os.path.join(REPO_PATH, "README.md"), "r", encoding="utf-8", newline="\n") as f:
readme = f.read()
new_readme = readme.replace("https://huggingface.co/transformers", "https://huggingface.co/docs/transformers")
new_readme = new_readme.replace(
"https://huggingface.co/docs/main/transformers", "https://huggingface.co/docs/transformers/main"
)
if new_readme != readme:
if overwrite:
with open(os.path.join(REPO_PATH, "README.md"), "w", encoding="utf-8", newline="\n") as f:
f.write(new_readme)
else:
raise ValueError(
"The main README contains wrong links to the documentation of Transformers. Run `make fix-copies` to "
"automatically fix them."
)
md_list = get_model_list(
filename="README.md",
start_prompt=LOCALIZED_READMES["README.md"]["start_prompt"],
end_prompt=LOCALIZED_READMES["README.md"]["end_prompt"],
)
# Build the converted Markdown.
converted_md_lists = []
for filename, value in LOCALIZED_READMES.items():
_start_prompt = value["start_prompt"]
_end_prompt = value["end_prompt"]
_format_model_list = value["format_model_list"]
localized_md_list = get_model_list(filename, _start_prompt, _end_prompt)
readmes_match, converted_md_list = convert_to_localized_md(md_list, localized_md_list, _format_model_list)
converted_md_lists.append((filename, readmes_match, converted_md_list, _start_prompt, _end_prompt))
# Compare the converted Markdowns
for converted_md_list in converted_md_lists:
filename, readmes_match, converted_md, _start_prompt, _end_prompt = converted_md_list
if filename == "README.md":
continue
if overwrite:
_, start_index, end_index, lines = _find_text_in_file(
filename=os.path.join(REPO_PATH, filename), start_prompt=_start_prompt, end_prompt=_end_prompt
)
with open(os.path.join(REPO_PATH, filename), "w", encoding="utf-8", newline="\n") as f:
f.writelines(lines[:start_index] + [converted_md] + lines[end_index:])
elif not readmes_match:
raise ValueError(
f"The model list in the README changed and the list in `{filename}` has not been updated. Run "
"`make fix-copies` to fix this."
)
# Map a model name with the name it has in the README for the check_readme check
SPECIAL_MODEL_NAMES = {
"Bert Generation": "BERT For Sequence Generation",
"BigBird": "BigBird-RoBERTa",
"Data2VecAudio": "Data2Vec",
"Data2VecText": "Data2Vec",
"Data2VecVision": "Data2Vec",
"DonutSwin": "Swin Transformer",
"Marian": "MarianMT",
"MaskFormerSwin": "Swin Transformer",
"OpenAI GPT-2": "GPT-2",
"OpenAI GPT": "GPT",
"Perceiver": "Perceiver IO",
"SAM": "Segment Anything",
"ViT": "Vision Transformer (ViT)",
}
# Update this list with the models that shouldn't be in the README. This only concerns modular models or those who do
# not have an associated paper.
MODELS_NOT_IN_README = [
"BertJapanese",
"Encoder decoder",
"FairSeq Machine-Translation",
"HerBERT",
"RetriBERT",
"Speech Encoder decoder",
"Speech2Text",
"Speech2Text2",
"TimmBackbone",
"Vision Encoder decoder",
"VisionTextDualEncoder",
]
# Template for new entries to add in the main README when we have missing models.
README_TEMPLATE = (
"1. **[{model_name}](https://huggingface.co/docs/main/transformers/model_doc/{model_type})** (from "
"<FILL INSTITUTION>) released with the paper [<FILL PAPER TITLE>](<FILL ARKIV LINK>) by <FILL AUTHORS>."
)
def check_readme(overwrite: bool = False):
"""
Check if the main README contains all the models in the library or not.
Args:
overwrite (`bool`, *optional*, defaults to `False`):
Whether or not to add an entry for the missing models using `README_TEMPLATE`.
"""
info = LOCALIZED_READMES["README.md"]
models, start_index, end_index, lines = _find_text_in_file(
os.path.join(REPO_PATH, "README.md"),
info["start_prompt"],
info["end_prompt"],
)
models_in_readme = [re.search(r"\*\*\[([^\]]*)", line).groups()[0] for line in models.strip().split("\n")]
model_names_mapping = transformers_module.models.auto.configuration_auto.MODEL_NAMES_MAPPING
absents = [
(key, name)
for key, name in model_names_mapping.items()
if SPECIAL_MODEL_NAMES.get(name, name) not in models_in_readme
]
# Remove exceptions
absents = [(key, name) for key, name in absents if name not in MODELS_NOT_IN_README]
if len(absents) > 0 and not overwrite:
print(absents)
raise ValueError(
"The main README doesn't contain all models, run `make fix-copies` to fill it with the missing model(s)"
" then complete the generated entries.\nIf the model is not supposed to be in the main README, add it to"
" the list `MODELS_NOT_IN_README` in utils/check_copies.py.\nIf it has a different name in the repo than"
" in the README, map the correspondence in `SPECIAL_MODEL_NAMES` in utils/check_copies.py."
)
new_models = [README_TEMPLATE.format(model_name=name, model_type=key) for key, name in absents]
all_models = models.strip().split("\n") + new_models
all_models = sorted(all_models, key=lambda x: re.search(r"\*\*\[([^\]]*)", x).groups()[0].lower())
all_models = "\n".join(all_models) + "\n"
if all_models != models:
if overwrite:
print("Fixing the main README.")
with open(os.path.join(REPO_PATH, "README.md"), "w", encoding="utf-8", newline="\n") as f:
f.writelines(lines[:start_index] + [all_models] + lines[end_index:])
else:
raise ValueError("The main README model list is not properly sorted. Run `make fix-copies` to fix this.")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--fix_and_overwrite", action="store_true", help="Whether to fix inconsistencies.")
args = parser.parse_args()
check_readme(args.fix_and_overwrite)
check_copies(args.fix_and_overwrite)
check_full_copies(args.fix_and_overwrite)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/get_previous_daily_ci.py
|
import os
import zipfile
import requests
from get_ci_error_statistics import download_artifact, get_artifacts_links
def get_daily_ci_runs(token, num_runs=7):
"""Get the workflow runs of the scheduled (daily) CI.
This only selects the runs triggered by the `schedule` event on the `main` branch.
"""
headers = None
if token is not None:
headers = {"Accept": "application/vnd.github+json", "Authorization": f"Bearer {token}"}
# The id of a workflow (not of a workflow run)
workflow_id = "636036"
url = f"https://api.github.com/repos/huggingface/transformers/actions/workflows/{workflow_id}/runs"
# On `main` branch + event being `schedule` + not returning PRs + only `num_runs` results
url += f"?branch=main&event=schedule&exclude_pull_requests=true&per_page={num_runs}"
result = requests.get(url, headers=headers).json()
return result["workflow_runs"]
def get_last_daily_ci_runs(token):
"""Get the last completed workflow run id of the scheduled (daily) CI."""
workflow_runs = get_daily_ci_runs(token)
workflow_run_id = None
for workflow_run in workflow_runs:
if workflow_run["status"] == "completed":
workflow_run_id = workflow_run["id"]
break
return workflow_run_id
def get_last_daily_ci_artifacts(artifact_names, output_dir, token):
"""Get the artifacts of last completed workflow run id of the scheduled (daily) CI."""
workflow_run_id = get_last_daily_ci_runs(token)
if workflow_run_id is not None:
artifacts_links = get_artifacts_links(worflow_run_id=workflow_run_id, token=token)
for artifact_name in artifact_names:
if artifact_name in artifacts_links:
artifact_url = artifacts_links[artifact_name]
download_artifact(
artifact_name=artifact_name, artifact_url=artifact_url, output_dir=output_dir, token=token
)
def get_last_daily_ci_reports(artifact_names, output_dir, token):
"""Get the artifacts' content of the last completed workflow run id of the scheduled (daily) CI."""
get_last_daily_ci_artifacts(artifact_names, output_dir, token)
results = {}
for artifact_name in artifact_names:
artifact_zip_path = os.path.join(output_dir, f"{artifact_name}.zip")
if os.path.isfile(artifact_zip_path):
results[artifact_name] = {}
with zipfile.ZipFile(artifact_zip_path) as z:
for filename in z.namelist():
if not os.path.isdir(filename):
# read the file
with z.open(filename) as f:
results[artifact_name][filename] = f.read().decode("UTF-8")
return results
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_docstrings.py
|
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utility that checks all docstrings of public objects have an argument section matching their signature.
Use from the root of the repo with:
```bash
python utils/check_docstrings.py
```
for a check that will error in case of inconsistencies (used by `make repo-consistency`).
To auto-fix issues run:
```bash
python utils/check_docstrings.py --fix_and_overwrite
```
which is used by `make fix-copies` (note that this fills what it cans, you might have to manually fill information
like argument descriptions).
"""
import argparse
import ast
import enum
import inspect
import operator as op
import re
from pathlib import Path
from typing import Any, Optional, Tuple, Union
from check_repo import ignore_undocumented
from transformers.utils import direct_transformers_import
PATH_TO_TRANSFORMERS = Path("src").resolve() / "transformers"
# This is to make sure the transformers module imported is the one in the repo.
transformers = direct_transformers_import(PATH_TO_TRANSFORMERS)
OPTIONAL_KEYWORD = "*optional*"
# Re pattern that catches args blocks in docstrings (with all variation around the name supported).
_re_args = re.compile(r"^\s*(Args?|Arguments?|Attributes?|Params?|Parameters?):\s*$")
# Re pattern that parses the start of an arg block: catches <name> (<description>) in those lines.
_re_parse_arg = re.compile(r"^(\s*)(\S+)\s+\((.+)\)(?:\:|$)")
# Re pattern that parses the end of a description of an arg (catches the default in *optional*, defaults to xxx).
_re_parse_description = re.compile(r"\*optional\*, defaults to (.*)$")
# This is a temporary list of objects to ignore while we progressively fix them. Do not add anything here, fix the
# docstrings instead. If formatting should be ignored for the docstring, you can put a comment # no-format on the
# line before the docstring.
OBJECTS_TO_IGNORE = [
# Deprecated
"InputExample",
"InputFeatures",
# Signature is *args/**kwargs
# "PretrainedConfig", #ignored but could be fixed
# "GenerationConfig", #ignored but could be fixed
"TFSequenceSummary",
"TFBertTokenizer",
"TFGPT2Tokenizer",
# Missing arguments in the docstring
"ASTFeatureExtractor",
"AlbertModel",
"AlbertTokenizerFast",
"AlignTextModel",
"AlignVisionConfig",
"AudioClassificationPipeline",
"AutoformerConfig",
"AutomaticSpeechRecognitionPipeline",
"AzureOpenAiAgent",
"BarkCoarseConfig",
"BarkConfig",
"BarkFineConfig",
"BarkSemanticConfig",
"BartConfig",
"BartTokenizerFast",
"BarthezTokenizerFast",
"BeitModel",
"BertConfig",
"BertJapaneseTokenizer",
"BertModel",
"BertTokenizerFast",
"BigBirdConfig",
"BigBirdForQuestionAnswering",
"BigBirdModel",
"BigBirdPegasusConfig",
"BigBirdTokenizerFast",
"BitImageProcessor",
"BlenderbotConfig",
"BlenderbotSmallConfig",
"BlenderbotSmallTokenizerFast",
"BlenderbotTokenizerFast",
"Blip2QFormerConfig",
"Blip2VisionConfig",
"BlipTextConfig",
"BlipVisionConfig",
"BloomConfig",
"BloomTokenizerFast",
"BridgeTowerTextConfig",
"BridgeTowerVisionConfig",
"BrosModel",
"CamembertConfig",
"CamembertModel",
"CamembertTokenizerFast",
"CanineModel",
"CanineTokenizer",
"ChineseCLIPTextModel",
"ClapTextConfig",
"ConditionalDetrConfig",
"ConditionalDetrImageProcessor",
"ConvBertConfig",
"ConvBertTokenizerFast",
"ConvNextConfig",
"ConvNextV2Config",
"ConversationalPipeline",
"CpmAntTokenizer",
"CvtConfig",
"CvtModel",
"DeiTImageProcessor",
"DPRReaderTokenizer",
"DPRReaderTokenizerFast",
"DPTModel",
"Data2VecAudioConfig",
"Data2VecTextConfig",
"Data2VecTextModel",
"Data2VecVisionModel",
"DataCollatorForLanguageModeling",
"DebertaConfig",
"DebertaV2Config",
"DebertaV2Tokenizer",
"DebertaV2TokenizerFast",
"DecisionTransformerConfig",
"DeformableDetrConfig",
"DeformableDetrImageProcessor",
"DeiTModel",
"DepthEstimationPipeline",
"DetaConfig",
"DetaImageProcessor",
"DetrConfig",
"DetrImageProcessor",
"DinatModel",
"DistilBertConfig",
"DistilBertTokenizerFast",
"DocumentQuestionAnsweringPipeline",
"DonutSwinModel",
"EarlyStoppingCallback",
"EfficientFormerConfig",
"EfficientFormerImageProcessor",
"EfficientNetConfig",
"ElectraConfig",
"ElectraTokenizerFast",
"EncoderDecoderModel",
"EncoderRepetitionPenaltyLogitsProcessor",
"ErnieConfig",
"ErnieMConfig",
"ErnieMModel",
"ErnieModel",
"ErnieMTokenizer",
"EsmConfig",
"EsmModel",
"FlaxAlbertForMaskedLM",
"FlaxAlbertForMultipleChoice",
"FlaxAlbertForPreTraining",
"FlaxAlbertForQuestionAnswering",
"FlaxAlbertForSequenceClassification",
"FlaxAlbertForTokenClassification",
"FlaxAlbertModel",
"FlaxBartForCausalLM",
"FlaxBartForConditionalGeneration",
"FlaxBartForQuestionAnswering",
"FlaxBartForSequenceClassification",
"FlaxBartModel",
"FlaxBeitForImageClassification",
"FlaxBeitForMaskedImageModeling",
"FlaxBeitModel",
"FlaxBertForCausalLM",
"FlaxBertForMaskedLM",
"FlaxBertForMultipleChoice",
"FlaxBertForNextSentencePrediction",
"FlaxBertForPreTraining",
"FlaxBertForQuestionAnswering",
"FlaxBertForSequenceClassification",
"FlaxBertForTokenClassification",
"FlaxBertModel",
"FlaxBigBirdForCausalLM",
"FlaxBigBirdForMaskedLM",
"FlaxBigBirdForMultipleChoice",
"FlaxBigBirdForPreTraining",
"FlaxBigBirdForQuestionAnswering",
"FlaxBigBirdForSequenceClassification",
"FlaxBigBirdForTokenClassification",
"FlaxBigBirdModel",
"FlaxBlenderbotForConditionalGeneration",
"FlaxBlenderbotModel",
"FlaxBlenderbotSmallForConditionalGeneration",
"FlaxBlenderbotSmallModel",
"FlaxBloomForCausalLM",
"FlaxBloomModel",
"FlaxCLIPModel",
"FlaxDistilBertForMaskedLM",
"FlaxDistilBertForMultipleChoice",
"FlaxDistilBertForQuestionAnswering",
"FlaxDistilBertForSequenceClassification",
"FlaxDistilBertForTokenClassification",
"FlaxDistilBertModel",
"FlaxElectraForCausalLM",
"FlaxElectraForMaskedLM",
"FlaxElectraForMultipleChoice",
"FlaxElectraForPreTraining",
"FlaxElectraForQuestionAnswering",
"FlaxElectraForSequenceClassification",
"FlaxElectraForTokenClassification",
"FlaxElectraModel",
"FlaxEncoderDecoderModel",
"FlaxGPT2LMHeadModel",
"FlaxGPT2Model",
"FlaxGPTJForCausalLM",
"FlaxGPTJModel",
"FlaxGPTNeoForCausalLM",
"FlaxGPTNeoModel",
"FlaxMBartForConditionalGeneration",
"FlaxMBartForQuestionAnswering",
"FlaxMBartForSequenceClassification",
"FlaxMBartModel",
"FlaxMarianMTModel",
"FlaxMarianModel",
"FlaxOPTForCausalLM",
"FlaxPegasusForConditionalGeneration",
"FlaxPegasusModel",
"FlaxRegNetForImageClassification",
"FlaxRegNetModel",
"FlaxResNetForImageClassification",
"FlaxResNetModel",
"FlaxRoFormerForMaskedLM",
"FlaxRoFormerForMultipleChoice",
"FlaxRoFormerForQuestionAnswering",
"FlaxRoFormerForSequenceClassification",
"FlaxRoFormerForTokenClassification",
"FlaxRoFormerModel",
"FlaxRobertaForCausalLM",
"FlaxRobertaForMaskedLM",
"FlaxRobertaForMultipleChoice",
"FlaxRobertaForQuestionAnswering",
"FlaxRobertaForSequenceClassification",
"FlaxRobertaForTokenClassification",
"FlaxRobertaModel",
"FlaxRobertaPreLayerNormForCausalLM",
"FlaxRobertaPreLayerNormForMaskedLM",
"FlaxRobertaPreLayerNormForMultipleChoice",
"FlaxRobertaPreLayerNormForQuestionAnswering",
"FlaxRobertaPreLayerNormForSequenceClassification",
"FlaxRobertaPreLayerNormForTokenClassification",
"FlaxRobertaPreLayerNormModel",
"FlaxSpeechEncoderDecoderModel",
"FlaxViTForImageClassification",
"FlaxViTModel",
"FlaxVisionEncoderDecoderModel",
"FlaxVisionTextDualEncoderModel",
"FlaxWav2Vec2ForCTC",
"FlaxWav2Vec2ForPreTraining",
"FlaxWav2Vec2Model",
"FlaxWhisperForAudioClassification",
"FlaxWhisperForConditionalGeneration",
"FlaxWhisperModel",
"FlaxWhisperTimeStampLogitsProcessor",
"FlaxXGLMForCausalLM",
"FlaxXGLMModel",
"FlaxXLMRobertaForCausalLM",
"FlaxXLMRobertaForMaskedLM",
"FlaxXLMRobertaForMultipleChoice",
"FlaxXLMRobertaForQuestionAnswering",
"FlaxXLMRobertaForSequenceClassification",
"FlaxXLMRobertaForTokenClassification",
"FlaxXLMRobertaModel",
"FNetConfig",
"FNetModel",
"FNetTokenizerFast",
"FSMTConfig",
"FeatureExtractionPipeline",
"FillMaskPipeline",
"FlaubertConfig",
"FlavaConfig",
"FlavaForPreTraining",
"FlavaImageModel",
"FlavaImageProcessor",
"FlavaMultimodalModel",
"FlavaTextConfig",
"FlavaTextModel",
"FocalNetModel",
"FunnelTokenizerFast",
"GPTBigCodeConfig",
"GPTJConfig",
"GPTNeoXConfig",
"GPTNeoXJapaneseConfig",
"GPTNeoXTokenizerFast",
"GPTSanJapaneseConfig",
"GitConfig",
"GitVisionConfig",
"GraphormerConfig",
"GroupViTTextConfig",
"GroupViTVisionConfig",
"HerbertTokenizerFast",
"HubertConfig",
"HubertForCTC",
"IBertConfig",
"IBertModel",
"IdeficsConfig",
"IdeficsProcessor",
"ImageClassificationPipeline",
"ImageGPTConfig",
"ImageSegmentationPipeline",
"ImageToImagePipeline",
"ImageToTextPipeline",
"InformerConfig",
"InstructBlipQFormerConfig",
"JukeboxPriorConfig",
"JukeboxTokenizer",
"LEDConfig",
"LEDTokenizerFast",
"LayoutLMForQuestionAnswering",
"LayoutLMTokenizerFast",
"LayoutLMv2Config",
"LayoutLMv2ForQuestionAnswering",
"LayoutLMv2TokenizerFast",
"LayoutLMv3Config",
"LayoutLMv3ImageProcessor",
"LayoutLMv3TokenizerFast",
"LayoutXLMTokenizerFast",
"LevitConfig",
"LiltConfig",
"LiltModel",
"LongT5Config",
"LongformerConfig",
"LongformerModel",
"LongformerTokenizerFast",
"LukeModel",
"LukeTokenizer",
"LxmertTokenizerFast",
"M2M100Config",
"M2M100Tokenizer",
"MarkupLMProcessor",
"MaskGenerationPipeline",
"MBart50TokenizerFast",
"MBartConfig",
"MCTCTFeatureExtractor",
"MPNetConfig",
"MPNetModel",
"MPNetTokenizerFast",
"MT5Config",
"MT5TokenizerFast",
"MarianConfig",
"MarianTokenizer",
"MarkupLMConfig",
"MarkupLMModel",
"MarkupLMTokenizer",
"MarkupLMTokenizerFast",
"Mask2FormerConfig",
"MaskFormerConfig",
"MaxTimeCriteria",
"MegaConfig",
"MegaModel",
"MegatronBertConfig",
"MegatronBertForPreTraining",
"MegatronBertModel",
"MobileBertConfig",
"MobileBertModel",
"MobileBertTokenizerFast",
"MobileNetV1ImageProcessor",
"MobileNetV1Model",
"MobileNetV2ImageProcessor",
"MobileNetV2Model",
"MobileViTModel",
"MobileViTV2Model",
"MLukeTokenizer",
"MraConfig",
"MusicgenDecoderConfig",
"MusicgenForConditionalGeneration",
"MvpConfig",
"MvpTokenizerFast",
"MT5Tokenizer",
"NatModel",
"NerPipeline",
"NezhaConfig",
"NezhaModel",
"NllbMoeConfig",
"NllbTokenizer",
"NllbTokenizerFast",
"NystromformerConfig",
"OPTConfig",
"ObjectDetectionPipeline",
"OneFormerProcessor",
"OpenAIGPTTokenizerFast",
"OpenLlamaConfig",
"PLBartConfig",
"PegasusConfig",
"PegasusTokenizer",
"PegasusTokenizerFast",
"PegasusXConfig",
"PerceiverImageProcessor",
"PerceiverModel",
"PerceiverTokenizer",
"PersimmonConfig",
"Pipeline",
"Pix2StructConfig",
"Pix2StructTextConfig",
"PLBartTokenizer",
"Pop2PianoConfig",
"PreTrainedTokenizer",
"PreTrainedTokenizerBase",
"PreTrainedTokenizerFast",
"PrefixConstrainedLogitsProcessor",
"ProphetNetConfig",
"QDQBertConfig",
"QDQBertModel",
"QuestionAnsweringPipeline",
"RagConfig",
"RagModel",
"RagRetriever",
"RagSequenceForGeneration",
"RagTokenForGeneration",
"RealmConfig",
"RealmForOpenQA",
"RealmScorer",
"RealmTokenizerFast",
"ReformerConfig",
"ReformerTokenizerFast",
"RegNetConfig",
"RemBertConfig",
"RemBertModel",
"RemBertTokenizer",
"RemBertTokenizerFast",
"RepetitionPenaltyLogitsProcessor",
"RetriBertConfig",
"RetriBertTokenizerFast",
"RoCBertConfig",
"RoCBertModel",
"RoCBertTokenizer",
"RoFormerConfig",
"RobertaConfig",
"RobertaModel",
"RobertaPreLayerNormConfig",
"RobertaPreLayerNormModel",
"RobertaTokenizerFast",
"SEWConfig",
"SEWDConfig",
"SEWDForCTC",
"SEWForCTC",
"SamConfig",
"SamPromptEncoderConfig",
"SeamlessM4TConfig", # use of unconventional markdown
"Seq2SeqTrainingArguments",
"SpecialTokensMixin",
"Speech2Text2Config",
"Speech2Text2Tokenizer",
"Speech2TextTokenizer",
"SpeechEncoderDecoderModel",
"SpeechT5Config",
"SpeechT5Model",
"SplinterConfig",
"SplinterTokenizerFast",
"SqueezeBertTokenizerFast",
"SummarizationPipeline",
"Swin2SRImageProcessor",
"Swinv2Model",
"SwitchTransformersConfig",
"T5Config",
"T5Tokenizer",
"T5TokenizerFast",
"TableQuestionAnsweringPipeline",
"TableTransformerConfig",
"TapasConfig",
"TapasModel",
"TapasTokenizer",
"Text2TextGenerationPipeline",
"TextClassificationPipeline",
"TextGenerationPipeline",
"TFAlbertForMaskedLM",
"TFAlbertForMultipleChoice",
"TFAlbertForPreTraining",
"TFAlbertForQuestionAnswering",
"TFAlbertForSequenceClassification",
"TFAlbertForTokenClassification",
"TFAlbertModel",
"TFBartForConditionalGeneration",
"TFBartForSequenceClassification",
"TFBartModel",
"TFBertForMaskedLM",
"TFBertForMultipleChoice",
"TFBertForNextSentencePrediction",
"TFBertForPreTraining",
"TFBertForQuestionAnswering",
"TFBertForSequenceClassification",
"TFBertForTokenClassification",
"TFBertModel",
"TFBlenderbotForConditionalGeneration",
"TFBlenderbotModel",
"TFBlenderbotSmallForConditionalGeneration",
"TFBlenderbotSmallModel",
"TFBlipForConditionalGeneration",
"TFBlipForImageTextRetrieval",
"TFBlipForQuestionAnswering",
"TFCLIPModel",
"TFCTRLForSequenceClassification",
"TFCTRLLMHeadModel",
"TFCTRLModel",
"TFCamembertForCausalLM",
"TFCamembertForMaskedLM",
"TFCamembertForMultipleChoice",
"TFCamembertForQuestionAnswering",
"TFCamembertForSequenceClassification",
"TFCamembertForTokenClassification",
"TFCamembertModel",
"TFConvBertForMaskedLM",
"TFConvBertForMultipleChoice",
"TFConvBertForQuestionAnswering",
"TFConvBertForSequenceClassification",
"TFConvBertForTokenClassification",
"TFConvBertModel",
"TFConvNextForImageClassification",
"TFConvNextModel",
"TFConvNextV2Model", # Parsing issue. Equivalent to PT ConvNextV2Model, see PR #25558
"TFConvNextV2ForImageClassification",
"TFCvtForImageClassification",
"TFCvtModel",
"TFDPRReader",
"TFData2VecVisionForImageClassification",
"TFData2VecVisionForSemanticSegmentation",
"TFData2VecVisionModel",
"TFDebertaForMaskedLM",
"TFDebertaForQuestionAnswering",
"TFDebertaForSequenceClassification",
"TFDebertaForTokenClassification",
"TFDebertaModel",
"TFDebertaV2ForMaskedLM",
"TFDebertaV2ForMultipleChoice",
"TFDebertaV2ForQuestionAnswering",
"TFDebertaV2ForSequenceClassification",
"TFDebertaV2ForTokenClassification",
"TFDebertaV2Model",
"TFDeiTForImageClassification",
"TFDeiTForImageClassificationWithTeacher",
"TFDeiTForMaskedImageModeling",
"TFDeiTModel",
"TFDistilBertForMaskedLM",
"TFDistilBertForMultipleChoice",
"TFDistilBertForQuestionAnswering",
"TFDistilBertForSequenceClassification",
"TFDistilBertForTokenClassification",
"TFDistilBertModel",
"TFEfficientFormerForImageClassification",
"TFEfficientFormerForImageClassificationWithTeacher",
"TFEfficientFormerModel",
"TFElectraForMaskedLM",
"TFElectraForMultipleChoice",
"TFElectraForPreTraining",
"TFElectraForQuestionAnswering",
"TFElectraForSequenceClassification",
"TFElectraForTokenClassification",
"TFElectraModel",
"TFEncoderDecoderModel",
"TFEsmForMaskedLM",
"TFEsmForSequenceClassification",
"TFEsmForTokenClassification",
"TFEsmModel",
"TFFlaubertForMultipleChoice",
"TFFlaubertForQuestionAnsweringSimple",
"TFFlaubertForSequenceClassification",
"TFFlaubertForTokenClassification",
"TFFlaubertModel",
"TFFlaubertWithLMHeadModel",
"TFFunnelBaseModel",
"TFFunnelForMaskedLM",
"TFFunnelForMultipleChoice",
"TFFunnelForPreTraining",
"TFFunnelForQuestionAnswering",
"TFFunnelForSequenceClassification",
"TFFunnelForTokenClassification",
"TFFunnelModel",
"TFGPT2DoubleHeadsModel",
"TFGPT2ForSequenceClassification",
"TFGPT2LMHeadModel",
"TFGPT2Model",
"TFGPTJForCausalLM",
"TFGPTJForQuestionAnswering",
"TFGPTJForSequenceClassification",
"TFGPTJModel",
"TFGroupViTModel",
"TFHubertForCTC",
"TFHubertModel",
"TFLEDForConditionalGeneration",
"TFLEDModel",
"TFLayoutLMForMaskedLM",
"TFLayoutLMForQuestionAnswering",
"TFLayoutLMForSequenceClassification",
"TFLayoutLMForTokenClassification",
"TFLayoutLMModel",
"TFLayoutLMv3ForQuestionAnswering",
"TFLayoutLMv3ForSequenceClassification",
"TFLayoutLMv3ForTokenClassification",
"TFLayoutLMv3Model",
"TFLongformerForMaskedLM",
"TFLongformerForMultipleChoice",
"TFLongformerForQuestionAnswering",
"TFLongformerForSequenceClassification",
"TFLongformerForTokenClassification",
"TFLongformerModel",
"TFLxmertForPreTraining",
"TFLxmertModel",
"TFMBartForConditionalGeneration",
"TFMBartModel",
"TFMPNetForMaskedLM",
"TFMPNetForMultipleChoice",
"TFMPNetForQuestionAnswering",
"TFMPNetForSequenceClassification",
"TFMPNetForTokenClassification",
"TFMPNetModel",
"TFMarianMTModel",
"TFMarianModel",
"TFMobileBertForMaskedLM",
"TFMobileBertForMultipleChoice",
"TFMobileBertForNextSentencePrediction",
"TFMobileBertForPreTraining",
"TFMobileBertForQuestionAnswering",
"TFMobileBertForSequenceClassification",
"TFMobileBertForTokenClassification",
"TFMobileBertModel",
"TFMobileViTForImageClassification",
"TFMobileViTForSemanticSegmentation",
"TFMobileViTModel",
"TFOPTForCausalLM",
"TFOPTModel",
"TFOpenAIGPTDoubleHeadsModel",
"TFOpenAIGPTForSequenceClassification",
"TFOpenAIGPTLMHeadModel",
"TFOpenAIGPTModel",
"TFPegasusForConditionalGeneration",
"TFPegasusModel",
"TFRagModel",
"TFRagSequenceForGeneration",
"TFRagTokenForGeneration",
"TFRemBertForCausalLM",
"TFRemBertForMaskedLM",
"TFRemBertForMultipleChoice",
"TFRemBertForQuestionAnswering",
"TFRemBertForSequenceClassification",
"TFRemBertForTokenClassification",
"TFRemBertModel",
"TFRepetitionPenaltyLogitsProcessor",
"TFResNetForImageClassification",
"TFResNetModel",
"TFRoFormerForCausalLM",
"TFRoFormerForMaskedLM",
"TFRoFormerForMultipleChoice",
"TFRoFormerForQuestionAnswering",
"TFRoFormerForSequenceClassification",
"TFRoFormerForTokenClassification",
"TFRoFormerModel",
"TFRobertaForMaskedLM",
"TFRobertaForMultipleChoice",
"TFRobertaForQuestionAnswering",
"TFRobertaForSequenceClassification",
"TFRobertaForTokenClassification",
"TFRobertaModel",
"TFRobertaPreLayerNormForMaskedLM",
"TFRobertaPreLayerNormForMultipleChoice",
"TFRobertaPreLayerNormForQuestionAnswering",
"TFRobertaPreLayerNormForSequenceClassification",
"TFRobertaPreLayerNormForTokenClassification",
"TFRobertaPreLayerNormModel",
"TFSamModel",
"TFSegformerForImageClassification",
"TFSegformerForSemanticSegmentation",
"TFSegformerModel",
"TFSpeech2TextForConditionalGeneration",
"TFSpeech2TextModel",
"TFSwinForImageClassification",
"TFSwinForMaskedImageModeling",
"TFSwinModel",
"TFT5EncoderModel",
"TFT5ForConditionalGeneration",
"TFT5Model",
"TFTapasForMaskedLM",
"TFTapasForQuestionAnswering",
"TFTapasForSequenceClassification",
"TFTapasModel",
"TFTransfoXLForSequenceClassification",
"TFTransfoXLLMHeadModel",
"TFTransfoXLModel",
"TFViTForImageClassification",
"TFViTMAEForPreTraining",
"TFViTMAEModel",
"TFViTModel",
"TFVisionEncoderDecoderModel",
"TFVisionTextDualEncoderModel",
"TFWav2Vec2ForCTC",
"TFWav2Vec2Model",
"TFWhisperForConditionalGeneration",
"TFWhisperModel",
"TFXGLMForCausalLM",
"TFXGLMModel",
"TFXLMForMultipleChoice",
"TFXLMForQuestionAnsweringSimple",
"TFXLMForSequenceClassification",
"TFXLMForTokenClassification",
"TFXLMModel",
"TFXLMRobertaForCausalLM",
"TFXLMRobertaForMaskedLM",
"TFXLMRobertaForMultipleChoice",
"TFXLMRobertaForQuestionAnswering",
"TFXLMRobertaForSequenceClassification",
"TFXLMRobertaForTokenClassification",
"TFXLMRobertaModel",
"TFXLMWithLMHeadModel",
"TFXLNetForMultipleChoice",
"TFXLNetForQuestionAnsweringSimple",
"TFXLNetForSequenceClassification",
"TFXLNetForTokenClassification",
"TFXLNetLMHeadModel",
"TFXLNetModel",
"TimeSeriesTransformerConfig",
"TokenClassificationPipeline",
"TrOCRConfig",
"TrainerState",
"TrainingArguments",
"TrajectoryTransformerConfig",
"TranslationPipeline",
"TvltImageProcessor",
"UMT5Config",
"UperNetConfig",
"UperNetForSemanticSegmentation",
"ViTHybridImageProcessor",
"ViTHybridModel",
"ViTMSNModel",
"ViTModel",
"VideoClassificationPipeline",
"ViltConfig",
"ViltForImagesAndTextClassification",
"ViltModel",
"VisionEncoderDecoderModel",
"VisionTextDualEncoderModel",
"VisualBertConfig",
"VisualBertModel",
"VisualQuestionAnsweringPipeline",
"VitMatteForImageMatting",
"VitsTokenizer",
"VivitModel",
"Wav2Vec2CTCTokenizer",
"Wav2Vec2Config",
"Wav2Vec2ConformerConfig",
"Wav2Vec2ConformerForCTC",
"Wav2Vec2FeatureExtractor",
"Wav2Vec2PhonemeCTCTokenizer",
"WavLMConfig",
"WavLMForCTC",
"WhisperConfig",
"WhisperFeatureExtractor",
"WhisperForAudioClassification",
"XCLIPTextConfig",
"XCLIPVisionConfig",
"XGLMConfig",
"XGLMModel",
"XGLMTokenizerFast",
"XLMConfig",
"XLMProphetNetConfig",
"XLMRobertaConfig",
"XLMRobertaModel",
"XLMRobertaTokenizerFast",
"XLMRobertaXLConfig",
"XLMRobertaXLModel",
"XLNetConfig",
"XLNetTokenizerFast",
"XmodConfig",
"XmodModel",
"YolosImageProcessor",
"YolosModel",
"YosoConfig",
"ZeroShotAudioClassificationPipeline",
"ZeroShotClassificationPipeline",
"ZeroShotImageClassificationPipeline",
"ZeroShotObjectDetectionPipeline",
]
# Supported math operations when interpreting the value of defaults.
MATH_OPERATORS = {
ast.Add: op.add,
ast.Sub: op.sub,
ast.Mult: op.mul,
ast.Div: op.truediv,
ast.Pow: op.pow,
ast.BitXor: op.xor,
ast.USub: op.neg,
}
def find_indent(line: str) -> int:
"""
Returns the number of spaces that start a line indent.
"""
search = re.search(r"^(\s*)(?:\S|$)", line)
if search is None:
return 0
return len(search.groups()[0])
def stringify_default(default: Any) -> str:
"""
Returns the string representation of a default value, as used in docstring: numbers are left as is, all other
objects are in backtiks.
Args:
default (`Any`): The default value to process
Returns:
`str`: The string representation of that default.
"""
if isinstance(default, bool):
# We need to test for bool first as a bool passes isinstance(xxx, (int, float))
return f"`{default}`"
elif isinstance(default, enum.Enum):
# We need to test for enum first as an enum with int values will pass isinstance(xxx, (int, float))
return f"`{str(default)}`"
elif isinstance(default, int):
return str(default)
elif isinstance(default, float):
result = str(default)
return str(round(default, 2)) if len(result) > 6 else result
elif isinstance(default, str):
return str(default) if default.isnumeric() else f'`"{default}"`'
elif isinstance(default, type):
return f"`{default.__name__}`"
else:
return f"`{default}`"
def eval_math_expression(expression: str) -> Optional[Union[float, int]]:
# Mainly taken from the excellent https://stackoverflow.com/a/9558001
"""
Evaluate (safely) a mathematial expression and returns its value.
Args:
expression (`str`): The expression to evaluate.
Returns:
`Optional[Union[float, int]]`: Returns `None` if the evaluation fails in any way and the value computed
otherwise.
Example:
```py
>>> eval_expr('2^6')
4
>>> eval_expr('2**6')
64
>>> eval_expr('1 + 2*3**(4^5) / (6 + -7)')
-5.0
```
"""
try:
return eval_node(ast.parse(expression, mode="eval").body)
except TypeError:
return
def eval_node(node):
if isinstance(node, ast.Num): # <number>
return node.n
elif isinstance(node, ast.BinOp): # <left> <operator> <right>
return MATH_OPERATORS[type(node.op)](eval_node(node.left), eval_node(node.right))
elif isinstance(node, ast.UnaryOp): # <operator> <operand> e.g., -1
return MATH_OPERATORS[type(node.op)](eval_node(node.operand))
else:
raise TypeError(node)
def replace_default_in_arg_description(description: str, default: Any) -> str:
"""
Catches the default value in the description of an argument inside a docstring and replaces it by the value passed.
Args:
description (`str`): The description of an argument in a docstring to process.
default (`Any`): The default value that whould be in the docstring of that argument.
Returns:
`str`: The description updated with the new default value.
"""
# Lots of docstrings have `optional` or **opational** instead of *optional* so we do this fix here.
description = description.replace("`optional`", OPTIONAL_KEYWORD)
description = description.replace("**optional**", OPTIONAL_KEYWORD)
if default is inspect._empty:
# No default, make sure the description doesn't have any either
idx = description.find(OPTIONAL_KEYWORD)
if idx != -1:
description = description[:idx].rstrip()
if description.endswith(","):
description = description[:-1].rstrip()
elif default is None:
# Default None are not written, we just set `*optional*`. If there is default that is not None specified in the
# description, we do not erase it (as sometimes we set the default to `None` because the default is a mutable
# object).
idx = description.find(OPTIONAL_KEYWORD)
if idx == -1:
description = f"{description}, {OPTIONAL_KEYWORD}"
elif re.search(r"defaults to `?None`?", description) is not None:
len_optional = len(OPTIONAL_KEYWORD)
description = description[: idx + len_optional]
else:
str_default = None
# For numbers we may have a default that is given by a math operation (1/255 is really popular). We don't
# want to replace those by their actual values.
if isinstance(default, (int, float)) and re.search("defaults to `?(.*?)(?:`|$)", description) is not None:
# Grab the default and evaluate it.
current_default = re.search("defaults to `?(.*?)(?:`|$)", description).groups()[0]
if default == eval_math_expression(current_default):
try:
# If it can be directly converted to the type of the default, it's a simple value
str_default = str(type(default)(current_default))
except Exception:
# Otherwise there is a math operator so we add a code block.
str_default = f"`{current_default}`"
if str_default is None:
str_default = stringify_default(default)
# Make sure default match
if OPTIONAL_KEYWORD not in description:
description = f"{description}, {OPTIONAL_KEYWORD}, defaults to {str_default}"
elif _re_parse_description.search(description) is None:
idx = description.find(OPTIONAL_KEYWORD)
len_optional = len(OPTIONAL_KEYWORD)
description = f"{description[:idx + len_optional]}, defaults to {str_default}"
else:
description = _re_parse_description.sub(rf"*optional*, defaults to {str_default}", description)
return description
def get_default_description(arg: inspect.Parameter) -> str:
"""
Builds a default description for a parameter that was not documented.
Args:
arg (`inspect.Parameter`): The argument in the signature to generate a description for.
Returns:
`str`: The description.
"""
if arg.annotation is inspect._empty:
arg_type = "<fill_type>"
elif hasattr(arg.annotation, "__name__"):
arg_type = arg.annotation.__name__
else:
arg_type = str(arg.annotation)
if arg.default is inspect._empty:
return f"`{arg_type}`"
elif arg.default is None:
return f"`{arg_type}`, {OPTIONAL_KEYWORD}"
else:
str_default = stringify_default(arg.default)
return f"`{arg_type}`, {OPTIONAL_KEYWORD}, defaults to {str_default}"
def find_source_file(obj: Any) -> Path:
"""
Finds the source file of an object.
Args:
obj (`Any`): The object whose source file we are looking for.
Returns:
`Path`: The source file.
"""
module = obj.__module__
obj_file = PATH_TO_TRANSFORMERS
for part in module.split(".")[1:]:
obj_file = obj_file / part
return obj_file.with_suffix(".py")
def match_docstring_with_signature(obj: Any) -> Optional[Tuple[str, str]]:
"""
Matches the docstring of an object with its signature.
Args:
obj (`Any`): The object to process.
Returns:
`Optional[Tuple[str, str]]`: Returns `None` if there is no docstring or no parameters documented in the
docstring, otherwise returns a tuple of two strings: the current documentation of the arguments in the
docstring and the one matched with the signature.
"""
if len(getattr(obj, "__doc__", "")) == 0:
# Nothing to do, there is no docstring.
return
# Read the docstring in the source code to see if there is a special command to ignore this object.
try:
source, _ = inspect.getsourcelines(obj)
except OSError:
source = []
idx = 0
while idx < len(source) and '"""' not in source[idx]:
idx += 1
ignore_order = False
if idx < len(source):
line_before_docstring = source[idx - 1]
if re.search(r"^\s*#\s*no-format\s*$", line_before_docstring):
# This object is ignored
return
elif re.search(r"^\s*#\s*ignore-order\s*$", line_before_docstring):
ignore_order = True
# Read the signature
signature = inspect.signature(obj).parameters
obj_doc_lines = obj.__doc__.split("\n")
# Get to the line where we start documenting arguments
idx = 0
while idx < len(obj_doc_lines) and _re_args.search(obj_doc_lines[idx]) is None:
idx += 1
if idx == len(obj_doc_lines):
# Nothing to do, no parameters are documented.
return
indent = find_indent(obj_doc_lines[idx])
arguments = {}
current_arg = None
idx += 1
start_idx = idx
# Keep going until the arg section is finished (nonempty line at the same indent level) or the end of the docstring.
while idx < len(obj_doc_lines) and (
len(obj_doc_lines[idx].strip()) == 0 or find_indent(obj_doc_lines[idx]) > indent
):
if find_indent(obj_doc_lines[idx]) == indent + 4:
# New argument -> let's generate the proper doc for it
re_search_arg = _re_parse_arg.search(obj_doc_lines[idx])
if re_search_arg is not None:
_, name, description = re_search_arg.groups()
current_arg = name
if name in signature:
default = signature[name].default
if signature[name].kind is inspect._ParameterKind.VAR_KEYWORD:
default = None
new_description = replace_default_in_arg_description(description, default)
else:
new_description = description
init_doc = _re_parse_arg.sub(rf"\1\2 ({new_description}):", obj_doc_lines[idx])
arguments[current_arg] = [init_doc]
elif current_arg is not None:
arguments[current_arg].append(obj_doc_lines[idx])
idx += 1
# We went too far by one (perhaps more if there are a lot of new lines)
idx -= 1
while len(obj_doc_lines[idx].strip()) == 0:
arguments[current_arg] = arguments[current_arg][:-1]
idx -= 1
# And we went too far by one again.
idx += 1
old_doc_arg = "\n".join(obj_doc_lines[start_idx:idx])
old_arguments = list(arguments.keys())
arguments = {name: "\n".join(doc) for name, doc in arguments.items()}
# Add missing arguments with a template
for name in set(signature.keys()) - set(arguments.keys()):
arg = signature[name]
# We ignore private arguments or *args/**kwargs (unless they are documented by the user)
if name.startswith("_") or arg.kind in [
inspect._ParameterKind.VAR_KEYWORD,
inspect._ParameterKind.VAR_POSITIONAL,
]:
arguments[name] = ""
else:
arg_desc = get_default_description(arg)
arguments[name] = " " * (indent + 4) + f"{name} ({arg_desc}): <fill_docstring>"
# Arguments are sorted by the order in the signature unless a special comment is put.
if ignore_order:
new_param_docs = [arguments[name] for name in old_arguments if name in signature]
missing = set(signature.keys()) - set(old_arguments)
new_param_docs.extend([arguments[name] for name in missing if len(arguments[name]) > 0])
else:
new_param_docs = [arguments[name] for name in signature.keys() if len(arguments[name]) > 0]
new_doc_arg = "\n".join(new_param_docs)
return old_doc_arg, new_doc_arg
def fix_docstring(obj: Any, old_doc_args: str, new_doc_args: str):
"""
Fixes the docstring of an object by replacing its arguments documentaiton by the one matched with the signature.
Args:
obj (`Any`):
The object whose dostring we are fixing.
old_doc_args (`str`):
The current documentation of the parameters of `obj` in the docstring (as returned by
`match_docstring_with_signature`).
new_doc_args (`str`):
The documentation of the parameters of `obj` matched with its signature (as returned by
`match_docstring_with_signature`).
"""
# Read the docstring in the source code and make sure we have the right part of the docstring
source, line_number = inspect.getsourcelines(obj)
# Get to the line where we start documenting arguments
idx = 0
while idx < len(source) and _re_args.search(source[idx]) is None:
idx += 1
if idx == len(source):
# Args are not defined in the docstring of this object
return
# Get to the line where we stop documenting arguments
indent = find_indent(source[idx])
idx += 1
start_idx = idx
while idx < len(source) and (len(source[idx].strip()) == 0 or find_indent(source[idx]) > indent):
idx += 1
idx -= 1
while len(source[idx].strip()) == 0:
idx -= 1
idx += 1
if "".join(source[start_idx:idx])[:-1] != old_doc_args:
# Args are not fully defined in the docstring of this object
return
obj_file = find_source_file(obj)
with open(obj_file, "r", encoding="utf-8") as f:
content = f.read()
# Replace content
lines = content.split("\n")
lines = lines[: line_number + start_idx - 1] + [new_doc_args] + lines[line_number + idx - 1 :]
print(f"Fixing the docstring of {obj.__name__} in {obj_file}.")
with open(obj_file, "w", encoding="utf-8") as f:
f.write("\n".join(lines))
def check_docstrings(overwrite: bool = False):
"""
Check docstrings of all public objects that are callables and are documented.
Args:
overwrite (`bool`, *optional*, defaults to `False`):
Whether to fix inconsistencies or not.
"""
failures = []
hard_failures = []
to_clean = []
for name in dir(transformers):
# Skip objects that are private or not documented.
if name.startswith("_") or ignore_undocumented(name) or name in OBJECTS_TO_IGNORE:
continue
obj = getattr(transformers, name)
if not callable(obj) or not isinstance(obj, type) or getattr(obj, "__doc__", None) is None:
continue
# Check docstring
try:
result = match_docstring_with_signature(obj)
if result is not None:
old_doc, new_doc = result
else:
old_doc, new_doc = None, None
except Exception as e:
print(e)
hard_failures.append(name)
continue
if old_doc != new_doc:
if overwrite:
fix_docstring(obj, old_doc, new_doc)
else:
failures.append(name)
elif not overwrite and new_doc is not None and ("<fill_type>" in new_doc or "<fill_docstring>" in new_doc):
to_clean.append(name)
# Deal with errors
error_message = ""
if len(hard_failures) > 0:
error_message += (
"The argument part of the docstrings of the following objects could not be processed, check they are "
"properly formatted."
)
error_message += "\n" + "\n".join([f"- {name}" for name in hard_failures])
if len(failures) > 0:
error_message += (
"The following objects docstrings do not match their signature. Run `make fix-copies` to fix this."
)
error_message += "\n" + "\n".join([f"- {name}" for name in failures])
if len(to_clean) > 0:
error_message += (
"The following objects docstrings contain templates you need to fix: search for `<fill_type>` or "
"`<fill_docstring>`."
)
error_message += "\n" + "\n".join([f"- {name}" for name in to_clean])
if len(error_message) > 0:
error_message = "There was at least one problem when checking docstrings of public objects.\n" + error_message
raise ValueError(error_message)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--fix_and_overwrite", action="store_true", help="Whether to fix inconsistencies.")
args = parser.parse_args()
check_docstrings(overwrite=args.fix_and_overwrite)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/custom_init_isort.py
|
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utility that sorts the imports in the custom inits of Transformers. Transformers uses init files that delay the
import of an object to when it's actually needed. This is to avoid the main init importing all models, which would
make the line `import transformers` very slow when the user has all optional dependencies installed. The inits with
delayed imports have two halves: one definining a dictionary `_import_structure` which maps modules to the name of the
objects in each module, and one in `TYPE_CHECKING` which looks like a normal init for type-checkers. `isort` or `ruff`
properly sort the second half which looks like traditionl imports, the goal of this script is to sort the first half.
Use from the root of the repo with:
```bash
python utils/custom_init_isort.py
```
which will auto-sort the imports (used in `make style`).
For a check only (as used in `make quality`) run:
```bash
python utils/custom_init_isort.py --check_only
```
"""
import argparse
import os
import re
from typing import Any, Callable, List, Optional
# Path is defined with the intent you should run this script from the root of the repo.
PATH_TO_TRANSFORMERS = "src/transformers"
# Pattern that looks at the indentation in a line.
_re_indent = re.compile(r"^(\s*)\S")
# Pattern that matches `"key":" and puts `key` in group 0.
_re_direct_key = re.compile(r'^\s*"([^"]+)":')
# Pattern that matches `_import_structure["key"]` and puts `key` in group 0.
_re_indirect_key = re.compile(r'^\s*_import_structure\["([^"]+)"\]')
# Pattern that matches `"key",` and puts `key` in group 0.
_re_strip_line = re.compile(r'^\s*"([^"]+)",\s*$')
# Pattern that matches any `[stuff]` and puts `stuff` in group 0.
_re_bracket_content = re.compile(r"\[([^\]]+)\]")
def get_indent(line: str) -> str:
"""Returns the indent in given line (as string)."""
search = _re_indent.search(line)
return "" if search is None else search.groups()[0]
def split_code_in_indented_blocks(
code: str, indent_level: str = "", start_prompt: Optional[str] = None, end_prompt: Optional[str] = None
) -> List[str]:
"""
Split some code into its indented blocks, starting at a given level.
Args:
code (`str`): The code to split.
indent_level (`str`): The indent level (as string) to use for identifying the blocks to split.
start_prompt (`str`, *optional*): If provided, only starts splitting at the line where this text is.
end_prompt (`str`, *optional*): If provided, stops splitting at a line where this text is.
Warning:
The text before `start_prompt` or after `end_prompt` (if provided) is not ignored, just not split. The input `code`
can thus be retrieved by joining the result.
Returns:
`List[str]`: The list of blocks.
"""
# Let's split the code into lines and move to start_index.
index = 0
lines = code.split("\n")
if start_prompt is not None:
while not lines[index].startswith(start_prompt):
index += 1
blocks = ["\n".join(lines[:index])]
else:
blocks = []
# This variable contains the block treated at a given time.
current_block = [lines[index]]
index += 1
# We split into blocks until we get to the `end_prompt` (or the end of the file).
while index < len(lines) and (end_prompt is None or not lines[index].startswith(end_prompt)):
# We have a non-empty line with the proper indent -> start of a new block
if len(lines[index]) > 0 and get_indent(lines[index]) == indent_level:
# Store the current block in the result and rest. There are two cases: the line is part of the block (like
# a closing parenthesis) or not.
if len(current_block) > 0 and get_indent(current_block[-1]).startswith(indent_level + " "):
# Line is part of the current block
current_block.append(lines[index])
blocks.append("\n".join(current_block))
if index < len(lines) - 1:
current_block = [lines[index + 1]]
index += 1
else:
current_block = []
else:
# Line is not part of the current block
blocks.append("\n".join(current_block))
current_block = [lines[index]]
else:
# Just add the line to the current block
current_block.append(lines[index])
index += 1
# Adds current block if it's nonempty.
if len(current_block) > 0:
blocks.append("\n".join(current_block))
# Add final block after end_prompt if provided.
if end_prompt is not None and index < len(lines):
blocks.append("\n".join(lines[index:]))
return blocks
def ignore_underscore_and_lowercase(key: Callable[[Any], str]) -> Callable[[Any], str]:
"""
Wraps a key function (as used in a sort) to lowercase and ignore underscores.
"""
def _inner(x):
return key(x).lower().replace("_", "")
return _inner
def sort_objects(objects: List[Any], key: Optional[Callable[[Any], str]] = None) -> List[Any]:
"""
Sort a list of objects following the rules of isort (all uppercased first, camel-cased second and lower-cased
last).
Args:
objects (`List[Any]`):
The list of objects to sort.
key (`Callable[[Any], str]`, *optional*):
A function taking an object as input and returning a string, used to sort them by alphabetical order.
If not provided, will default to noop (so a `key` must be provided if the `objects` are not of type string).
Returns:
`List[Any]`: The sorted list with the same elements as in the inputs
"""
# If no key is provided, we use a noop.
def noop(x):
return x
if key is None:
key = noop
# Constants are all uppercase, they go first.
constants = [obj for obj in objects if key(obj).isupper()]
# Classes are not all uppercase but start with a capital, they go second.
classes = [obj for obj in objects if key(obj)[0].isupper() and not key(obj).isupper()]
# Functions begin with a lowercase, they go last.
functions = [obj for obj in objects if not key(obj)[0].isupper()]
# Then we sort each group.
key1 = ignore_underscore_and_lowercase(key)
return sorted(constants, key=key1) + sorted(classes, key=key1) + sorted(functions, key=key1)
def sort_objects_in_import(import_statement: str) -> str:
"""
Sorts the imports in a single import statement.
Args:
import_statement (`str`): The import statement in which to sort the imports.
Returns:
`str`: The same as the input, but with objects properly sorted.
"""
# This inner function sort imports between [ ].
def _replace(match):
imports = match.groups()[0]
# If there is one import only, nothing to do.
if "," not in imports:
return f"[{imports}]"
keys = [part.strip().replace('"', "") for part in imports.split(",")]
# We will have a final empty element if the line finished with a comma.
if len(keys[-1]) == 0:
keys = keys[:-1]
return "[" + ", ".join([f'"{k}"' for k in sort_objects(keys)]) + "]"
lines = import_statement.split("\n")
if len(lines) > 3:
# Here we have to sort internal imports that are on several lines (one per name):
# key: [
# "object1",
# "object2",
# ...
# ]
# We may have to ignore one or two lines on each side.
idx = 2 if lines[1].strip() == "[" else 1
keys_to_sort = [(i, _re_strip_line.search(line).groups()[0]) for i, line in enumerate(lines[idx:-idx])]
sorted_indices = sort_objects(keys_to_sort, key=lambda x: x[1])
sorted_lines = [lines[x[0] + idx] for x in sorted_indices]
return "\n".join(lines[:idx] + sorted_lines + lines[-idx:])
elif len(lines) == 3:
# Here we have to sort internal imports that are on one separate line:
# key: [
# "object1", "object2", ...
# ]
if _re_bracket_content.search(lines[1]) is not None:
lines[1] = _re_bracket_content.sub(_replace, lines[1])
else:
keys = [part.strip().replace('"', "") for part in lines[1].split(",")]
# We will have a final empty element if the line finished with a comma.
if len(keys[-1]) == 0:
keys = keys[:-1]
lines[1] = get_indent(lines[1]) + ", ".join([f'"{k}"' for k in sort_objects(keys)])
return "\n".join(lines)
else:
# Finally we have to deal with imports fitting on one line
import_statement = _re_bracket_content.sub(_replace, import_statement)
return import_statement
def sort_imports(file: str, check_only: bool = True):
"""
Sort the imports defined in the `_import_structure` of a given init.
Args:
file (`str`): The path to the init to check/fix.
check_only (`bool`, *optional*, defaults to `True`): Whether or not to just check (and not auto-fix) the init.
"""
with open(file, encoding="utf-8") as f:
code = f.read()
# If the file is not a custom init, there is nothing to do.
if "_import_structure" not in code:
return
# Blocks of indent level 0
main_blocks = split_code_in_indented_blocks(
code, start_prompt="_import_structure = {", end_prompt="if TYPE_CHECKING:"
)
# We ignore block 0 (everything untils start_prompt) and the last block (everything after end_prompt).
for block_idx in range(1, len(main_blocks) - 1):
# Check if the block contains some `_import_structure`s thingy to sort.
block = main_blocks[block_idx]
block_lines = block.split("\n")
# Get to the start of the imports.
line_idx = 0
while line_idx < len(block_lines) and "_import_structure" not in block_lines[line_idx]:
# Skip dummy import blocks
if "import dummy" in block_lines[line_idx]:
line_idx = len(block_lines)
else:
line_idx += 1
if line_idx >= len(block_lines):
continue
# Ignore beginning and last line: they don't contain anything.
internal_block_code = "\n".join(block_lines[line_idx:-1])
indent = get_indent(block_lines[1])
# Slit the internal block into blocks of indent level 1.
internal_blocks = split_code_in_indented_blocks(internal_block_code, indent_level=indent)
# We have two categories of import key: list or _import_structure[key].append/extend
pattern = _re_direct_key if "_import_structure = {" in block_lines[0] else _re_indirect_key
# Grab the keys, but there is a trap: some lines are empty or just comments.
keys = [(pattern.search(b).groups()[0] if pattern.search(b) is not None else None) for b in internal_blocks]
# We only sort the lines with a key.
keys_to_sort = [(i, key) for i, key in enumerate(keys) if key is not None]
sorted_indices = [x[0] for x in sorted(keys_to_sort, key=lambda x: x[1])]
# We reorder the blocks by leaving empty lines/comments as they were and reorder the rest.
count = 0
reorderded_blocks = []
for i in range(len(internal_blocks)):
if keys[i] is None:
reorderded_blocks.append(internal_blocks[i])
else:
block = sort_objects_in_import(internal_blocks[sorted_indices[count]])
reorderded_blocks.append(block)
count += 1
# And we put our main block back together with its first and last line.
main_blocks[block_idx] = "\n".join(block_lines[:line_idx] + reorderded_blocks + [block_lines[-1]])
if code != "\n".join(main_blocks):
if check_only:
return True
else:
print(f"Overwriting {file}.")
with open(file, "w", encoding="utf-8") as f:
f.write("\n".join(main_blocks))
def sort_imports_in_all_inits(check_only=True):
"""
Sort the imports defined in the `_import_structure` of all inits in the repo.
Args:
check_only (`bool`, *optional*, defaults to `True`): Whether or not to just check (and not auto-fix) the init.
"""
failures = []
for root, _, files in os.walk(PATH_TO_TRANSFORMERS):
if "__init__.py" in files:
result = sort_imports(os.path.join(root, "__init__.py"), check_only=check_only)
if result:
failures = [os.path.join(root, "__init__.py")]
if len(failures) > 0:
raise ValueError(f"Would overwrite {len(failures)} files, run `make style`.")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--check_only", action="store_true", help="Whether to only check or fix style.")
args = parser.parse_args()
sort_imports_in_all_inits(check_only=args.check_only)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_self_hosted_runner.py
|
import argparse
import json
import subprocess
def get_runner_status(target_runners, token):
offline_runners = []
cmd = (
f'curl -H "Accept: application/vnd.github+json" -H "Authorization: Bearer {token}"'
" https://api.github.com/repos/huggingface/transformers/actions/runners"
)
output = subprocess.run(cmd, shell=True, stdout=subprocess.PIPE)
o = output.stdout.decode("utf-8")
status = json.loads(o)
runners = status["runners"]
for runner in runners:
if runner["name"] in target_runners:
if runner["status"] == "offline":
offline_runners.append(runner)
# save the result so we can report them on Slack
with open("offline_runners.txt", "w") as fp:
fp.write(json.dumps(offline_runners))
if len(offline_runners) > 0:
failed = "\n".join([x["name"] for x in offline_runners])
raise ValueError(f"The following runners are offline:\n{failed}")
if __name__ == "__main__":
def list_str(values):
return values.split(",")
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--target_runners",
default=None,
type=list_str,
required=True,
help="Comma-separated list of runners to check status.",
)
parser.add_argument(
"--token", default=None, type=str, required=True, help="A token that has actions:read permission."
)
args = parser.parse_args()
get_runner_status(args.target_runners, args.token)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/sort_auto_mappings.py
|
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utility that sorts the names in the auto mappings defines in the auto modules in alphabetical order.
Use from the root of the repo with:
```bash
python utils/sort_auto_mappings.py
```
to auto-fix all the auto mappings (used in `make style`).
To only check if the mappings are properly sorted (as used in `make quality`), do:
```bash
python utils/sort_auto_mappings.py --check_only
```
"""
import argparse
import os
import re
from typing import Optional
# Path are set with the intent you should run this script from the root of the repo.
PATH_TO_AUTO_MODULE = "src/transformers/models/auto"
# re pattern that matches mapping introductions:
# SUPER_MODEL_MAPPING_NAMES = OrderedDict or SUPER_MODEL_MAPPING = OrderedDict
_re_intro_mapping = re.compile(r"[A-Z_]+_MAPPING(\s+|_[A-Z_]+\s+)=\s+OrderedDict")
# re pattern that matches identifiers in mappings
_re_identifier = re.compile(r'\s*\(\s*"(\S[^"]+)"')
def sort_auto_mapping(fname: str, overwrite: bool = False) -> Optional[bool]:
"""
Sort all auto mappings in a file.
Args:
fname (`str`): The name of the file where we want to sort auto-mappings.
overwrite (`bool`, *optional*, defaults to `False`): Whether or not to fix and overwrite the file.
Returns:
`Optional[bool]`: Returns `None` if `overwrite=True`. Otherwise returns `True` if the file has an auto-mapping
improperly sorted, `False` if the file is okay.
"""
with open(fname, "r", encoding="utf-8") as f:
content = f.read()
lines = content.split("\n")
new_lines = []
line_idx = 0
while line_idx < len(lines):
if _re_intro_mapping.search(lines[line_idx]) is not None:
# Start of a new mapping!
indent = len(re.search(r"^(\s*)\S", lines[line_idx]).groups()[0]) + 8
while not lines[line_idx].startswith(" " * indent + "("):
new_lines.append(lines[line_idx])
line_idx += 1
blocks = []
while lines[line_idx].strip() != "]":
# Blocks either fit in one line or not
if lines[line_idx].strip() == "(":
start_idx = line_idx
while not lines[line_idx].startswith(" " * indent + ")"):
line_idx += 1
blocks.append("\n".join(lines[start_idx : line_idx + 1]))
else:
blocks.append(lines[line_idx])
line_idx += 1
# Sort blocks by their identifiers
blocks = sorted(blocks, key=lambda x: _re_identifier.search(x).groups()[0])
new_lines += blocks
else:
new_lines.append(lines[line_idx])
line_idx += 1
if overwrite:
with open(fname, "w", encoding="utf-8") as f:
f.write("\n".join(new_lines))
else:
return "\n".join(new_lines) != content
def sort_all_auto_mappings(overwrite: bool = False):
"""
Sort all auto mappings in the library.
Args:
overwrite (`bool`, *optional*, defaults to `False`): Whether or not to fix and overwrite the file.
"""
fnames = [os.path.join(PATH_TO_AUTO_MODULE, f) for f in os.listdir(PATH_TO_AUTO_MODULE) if f.endswith(".py")]
diffs = [sort_auto_mapping(fname, overwrite=overwrite) for fname in fnames]
if not overwrite and any(diffs):
failures = [f for f, d in zip(fnames, diffs) if d]
raise ValueError(
f"The following files have auto mappings that need sorting: {', '.join(failures)}. Run `make style` to fix"
" this."
)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--check_only", action="store_true", help="Whether to only check or fix style.")
args = parser.parse_args()
sort_all_auto_mappings(not args.check_only)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/get_ci_error_statistics.py
|
import argparse
import json
import math
import os
import time
import traceback
import zipfile
from collections import Counter
import requests
def get_job_links(workflow_run_id, token=None):
"""Extract job names and their job links in a GitHub Actions workflow run"""
headers = None
if token is not None:
headers = {"Accept": "application/vnd.github+json", "Authorization": f"Bearer {token}"}
url = f"https://api.github.com/repos/huggingface/transformers/actions/runs/{workflow_run_id}/jobs?per_page=100"
result = requests.get(url, headers=headers).json()
job_links = {}
try:
job_links.update({job["name"]: job["html_url"] for job in result["jobs"]})
pages_to_iterate_over = math.ceil((result["total_count"] - 100) / 100)
for i in range(pages_to_iterate_over):
result = requests.get(url + f"&page={i + 2}", headers=headers).json()
job_links.update({job["name"]: job["html_url"] for job in result["jobs"]})
return job_links
except Exception:
print(f"Unknown error, could not fetch links:\n{traceback.format_exc()}")
return {}
def get_artifacts_links(worflow_run_id, token=None):
"""Get all artifact links from a workflow run"""
headers = None
if token is not None:
headers = {"Accept": "application/vnd.github+json", "Authorization": f"Bearer {token}"}
url = f"https://api.github.com/repos/huggingface/transformers/actions/runs/{worflow_run_id}/artifacts?per_page=100"
result = requests.get(url, headers=headers).json()
artifacts = {}
try:
artifacts.update({artifact["name"]: artifact["archive_download_url"] for artifact in result["artifacts"]})
pages_to_iterate_over = math.ceil((result["total_count"] - 100) / 100)
for i in range(pages_to_iterate_over):
result = requests.get(url + f"&page={i + 2}", headers=headers).json()
artifacts.update({artifact["name"]: artifact["archive_download_url"] for artifact in result["artifacts"]})
return artifacts
except Exception:
print(f"Unknown error, could not fetch links:\n{traceback.format_exc()}")
return {}
def download_artifact(artifact_name, artifact_url, output_dir, token):
"""Download a GitHub Action artifact from a URL.
The URL is of the form `https://api.github.com/repos/huggingface/transformers/actions/artifacts/{ARTIFACT_ID}/zip`,
but it can't be used to download directly. We need to get a redirect URL first.
See https://docs.github.com/en/rest/actions/artifacts#download-an-artifact
"""
headers = None
if token is not None:
headers = {"Accept": "application/vnd.github+json", "Authorization": f"Bearer {token}"}
result = requests.get(artifact_url, headers=headers, allow_redirects=False)
download_url = result.headers["Location"]
response = requests.get(download_url, allow_redirects=True)
file_path = os.path.join(output_dir, f"{artifact_name}.zip")
with open(file_path, "wb") as fp:
fp.write(response.content)
def get_errors_from_single_artifact(artifact_zip_path, job_links=None):
"""Extract errors from a downloaded artifact (in .zip format)"""
errors = []
failed_tests = []
job_name = None
with zipfile.ZipFile(artifact_zip_path) as z:
for filename in z.namelist():
if not os.path.isdir(filename):
# read the file
if filename in ["failures_line.txt", "summary_short.txt", "job_name.txt"]:
with z.open(filename) as f:
for line in f:
line = line.decode("UTF-8").strip()
if filename == "failures_line.txt":
try:
# `error_line` is the place where `error` occurs
error_line = line[: line.index(": ")]
error = line[line.index(": ") + len(": ") :]
errors.append([error_line, error])
except Exception:
# skip un-related lines
pass
elif filename == "summary_short.txt" and line.startswith("FAILED "):
# `test` is the test method that failed
test = line[len("FAILED ") :]
failed_tests.append(test)
elif filename == "job_name.txt":
job_name = line
if len(errors) != len(failed_tests):
raise ValueError(
f"`errors` and `failed_tests` should have the same number of elements. Got {len(errors)} for `errors` "
f"and {len(failed_tests)} for `failed_tests` instead. The test reports in {artifact_zip_path} have some"
" problem."
)
job_link = None
if job_name and job_links:
job_link = job_links.get(job_name, None)
# A list with elements of the form (line of error, error, failed test)
result = [x + [y] + [job_link] for x, y in zip(errors, failed_tests)]
return result
def get_all_errors(artifact_dir, job_links=None):
"""Extract errors from all artifact files"""
errors = []
paths = [os.path.join(artifact_dir, p) for p in os.listdir(artifact_dir) if p.endswith(".zip")]
for p in paths:
errors.extend(get_errors_from_single_artifact(p, job_links=job_links))
return errors
def reduce_by_error(logs, error_filter=None):
"""count each error"""
counter = Counter()
counter.update([x[1] for x in logs])
counts = counter.most_common()
r = {}
for error, count in counts:
if error_filter is None or error not in error_filter:
r[error] = {"count": count, "failed_tests": [(x[2], x[0]) for x in logs if x[1] == error]}
r = dict(sorted(r.items(), key=lambda item: item[1]["count"], reverse=True))
return r
def get_model(test):
"""Get the model name from a test method"""
test = test.split("::")[0]
if test.startswith("tests/models/"):
test = test.split("/")[2]
else:
test = None
return test
def reduce_by_model(logs, error_filter=None):
"""count each error per model"""
logs = [(x[0], x[1], get_model(x[2])) for x in logs]
logs = [x for x in logs if x[2] is not None]
tests = {x[2] for x in logs}
r = {}
for test in tests:
counter = Counter()
# count by errors in `test`
counter.update([x[1] for x in logs if x[2] == test])
counts = counter.most_common()
error_counts = {error: count for error, count in counts if (error_filter is None or error not in error_filter)}
n_errors = sum(error_counts.values())
if n_errors > 0:
r[test] = {"count": n_errors, "errors": error_counts}
r = dict(sorted(r.items(), key=lambda item: item[1]["count"], reverse=True))
return r
def make_github_table(reduced_by_error):
header = "| no. | error | status |"
sep = "|-:|:-|:-|"
lines = [header, sep]
for error in reduced_by_error:
count = reduced_by_error[error]["count"]
line = f"| {count} | {error[:100]} | |"
lines.append(line)
return "\n".join(lines)
def make_github_table_per_model(reduced_by_model):
header = "| model | no. of errors | major error | count |"
sep = "|-:|-:|-:|-:|"
lines = [header, sep]
for model in reduced_by_model:
count = reduced_by_model[model]["count"]
error, _count = list(reduced_by_model[model]["errors"].items())[0]
line = f"| {model} | {count} | {error[:60]} | {_count} |"
lines.append(line)
return "\n".join(lines)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument("--workflow_run_id", type=str, required=True, help="A GitHub Actions workflow run id.")
parser.add_argument(
"--output_dir",
type=str,
required=True,
help="Where to store the downloaded artifacts and other result files.",
)
parser.add_argument("--token", default=None, type=str, help="A token that has actions:read permission.")
args = parser.parse_args()
os.makedirs(args.output_dir, exist_ok=True)
_job_links = get_job_links(args.workflow_run_id, token=args.token)
job_links = {}
# To deal with `workflow_call` event, where a job name is the combination of the job names in the caller and callee.
# For example, `PyTorch 1.11 / Model tests (models/albert, single-gpu)`.
if _job_links:
for k, v in _job_links.items():
# This is how GitHub actions combine job names.
if " / " in k:
index = k.find(" / ")
k = k[index + len(" / ") :]
job_links[k] = v
with open(os.path.join(args.output_dir, "job_links.json"), "w", encoding="UTF-8") as fp:
json.dump(job_links, fp, ensure_ascii=False, indent=4)
artifacts = get_artifacts_links(args.workflow_run_id, token=args.token)
with open(os.path.join(args.output_dir, "artifacts.json"), "w", encoding="UTF-8") as fp:
json.dump(artifacts, fp, ensure_ascii=False, indent=4)
for idx, (name, url) in enumerate(artifacts.items()):
download_artifact(name, url, args.output_dir, args.token)
# Be gentle to GitHub
time.sleep(1)
errors = get_all_errors(args.output_dir, job_links=job_links)
# `e[1]` is the error
counter = Counter()
counter.update([e[1] for e in errors])
# print the top 30 most common test errors
most_common = counter.most_common(30)
for item in most_common:
print(item)
with open(os.path.join(args.output_dir, "errors.json"), "w", encoding="UTF-8") as fp:
json.dump(errors, fp, ensure_ascii=False, indent=4)
reduced_by_error = reduce_by_error(errors)
reduced_by_model = reduce_by_model(errors)
s1 = make_github_table(reduced_by_error)
s2 = make_github_table_per_model(reduced_by_model)
with open(os.path.join(args.output_dir, "reduced_by_error.txt"), "w", encoding="UTF-8") as fp:
fp.write(s1)
with open(os.path.join(args.output_dir, "reduced_by_model.txt"), "w", encoding="UTF-8") as fp:
fp.write(s2)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/notification_service_doc_tests.py
|
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import collections
import json
import math
import os
import re
import time
from fnmatch import fnmatch
from typing import Dict, List
import requests
from slack_sdk import WebClient
client = WebClient(token=os.environ["CI_SLACK_BOT_TOKEN"])
def handle_test_results(test_results):
expressions = test_results.split(" ")
failed = 0
success = 0
# When the output is short enough, the output is surrounded by = signs: "== OUTPUT =="
# When it is too long, those signs are not present.
time_spent = expressions[-2] if "=" in expressions[-1] else expressions[-1]
for i, expression in enumerate(expressions):
if "failed" in expression:
failed += int(expressions[i - 1])
if "passed" in expression:
success += int(expressions[i - 1])
return failed, success, time_spent
def extract_first_line_failure(failures_short_lines):
failures = {}
file = None
in_error = False
for line in failures_short_lines.split("\n"):
if re.search(r"_ \[doctest\]", line):
in_error = True
file = line.split(" ")[2]
elif in_error and not line.split(" ")[0].isdigit():
failures[file] = line
in_error = False
return failures
class Message:
def __init__(self, title: str, doc_test_results: Dict):
self.title = title
self._time_spent = doc_test_results["time_spent"].split(",")[0]
self.n_success = doc_test_results["success"]
self.n_failures = doc_test_results["failures"]
self.n_tests = self.n_success + self.n_failures
# Failures and success of the modeling tests
self.doc_test_results = doc_test_results
@property
def time(self) -> str:
time_spent = [self._time_spent]
total_secs = 0
for time in time_spent:
time_parts = time.split(":")
# Time can be formatted as xx:xx:xx, as .xx, or as x.xx if the time spent was less than a minute.
if len(time_parts) == 1:
time_parts = [0, 0, time_parts[0]]
hours, minutes, seconds = int(time_parts[0]), int(time_parts[1]), float(time_parts[2])
total_secs += hours * 3600 + minutes * 60 + seconds
hours, minutes, seconds = total_secs // 3600, (total_secs % 3600) // 60, total_secs % 60
return f"{int(hours)}h{int(minutes)}m{int(seconds)}s"
@property
def header(self) -> Dict:
return {"type": "header", "text": {"type": "plain_text", "text": self.title}}
@property
def no_failures(self) -> Dict:
return {
"type": "section",
"text": {
"type": "plain_text",
"text": f"🌞 There were no failures: all {self.n_tests} tests passed. The suite ran in {self.time}.",
"emoji": True,
},
"accessory": {
"type": "button",
"text": {"type": "plain_text", "text": "Check Action results", "emoji": True},
"url": f"https://github.com/huggingface/transformers/actions/runs/{os.environ['GITHUB_RUN_ID']}",
},
}
@property
def failures(self) -> Dict:
return {
"type": "section",
"text": {
"type": "plain_text",
"text": (
f"There were {self.n_failures} failures, out of {self.n_tests} tests.\nThe suite ran in"
f" {self.time}."
),
"emoji": True,
},
"accessory": {
"type": "button",
"text": {"type": "plain_text", "text": "Check Action results", "emoji": True},
"url": f"https://github.com/huggingface/transformers/actions/runs/{os.environ['GITHUB_RUN_ID']}",
},
}
@property
def category_failures(self) -> List[Dict]:
failure_blocks = []
MAX_ERROR_TEXT = 3000 - len("The following examples had failures:\n\n\n\n") - len("[Truncated]\n")
line_length = 40
category_failures = {k: v["failed"] for k, v in doc_test_results.items() if isinstance(v, dict)}
def single_category_failures(category, failures):
text = ""
if len(failures) == 0:
return ""
text += f"*{category} failures*:".ljust(line_length // 2).rjust(line_length // 2) + "\n"
for idx, failure in enumerate(failures):
new_text = text + f"`{failure}`\n"
if len(new_text) > MAX_ERROR_TEXT:
text = text + "[Truncated]\n"
break
text = new_text
return text
for category, failures in category_failures.items():
report = single_category_failures(category, failures)
if len(report) == 0:
continue
block = {
"type": "section",
"text": {
"type": "mrkdwn",
"text": f"The following examples had failures:\n\n\n{report}\n",
},
}
failure_blocks.append(block)
return failure_blocks
@property
def payload(self) -> str:
blocks = [self.header]
if self.n_failures > 0:
blocks.append(self.failures)
if self.n_failures > 0:
blocks.extend(self.category_failures)
if self.n_failures == 0:
blocks.append(self.no_failures)
return json.dumps(blocks)
@staticmethod
def error_out():
payload = [
{
"type": "section",
"text": {
"type": "plain_text",
"text": "There was an issue running the tests.",
},
"accessory": {
"type": "button",
"text": {"type": "plain_text", "text": "Check Action results", "emoji": True},
"url": f"https://github.com/huggingface/transformers/actions/runs/{os.environ['GITHUB_RUN_ID']}",
},
}
]
print("Sending the following payload")
print(json.dumps({"blocks": json.loads(payload)}))
client.chat_postMessage(
channel=os.environ["CI_SLACK_CHANNEL_ID_DAILY"],
text="There was an issue running the tests.",
blocks=payload,
)
def post(self):
print("Sending the following payload")
print(json.dumps({"blocks": json.loads(self.payload)}))
text = f"{self.n_failures} failures out of {self.n_tests} tests," if self.n_failures else "All tests passed."
self.thread_ts = client.chat_postMessage(
channel=os.environ["CI_SLACK_CHANNEL_ID_DAILY"],
blocks=self.payload,
text=text,
)
def get_reply_blocks(self, job_name, job_link, failures, text):
# `text` must be less than 3001 characters in Slack SDK
# keep some room for adding "[Truncated]" when necessary
MAX_ERROR_TEXT = 3000 - len("[Truncated]")
failure_text = ""
for key, value in failures.items():
new_text = failure_text + f"*{key}*\n_{value}_\n\n"
if len(new_text) > MAX_ERROR_TEXT:
# `failure_text` here has length <= 3000
failure_text = failure_text + "[Truncated]"
break
# `failure_text` here has length <= MAX_ERROR_TEXT
failure_text = new_text
title = job_name
content = {"type": "section", "text": {"type": "mrkdwn", "text": text}}
if job_link is not None:
content["accessory"] = {
"type": "button",
"text": {"type": "plain_text", "text": "GitHub Action job", "emoji": True},
"url": job_link,
}
return [
{"type": "header", "text": {"type": "plain_text", "text": title.upper(), "emoji": True}},
content,
{"type": "section", "text": {"type": "mrkdwn", "text": failure_text}},
]
def post_reply(self):
if self.thread_ts is None:
raise ValueError("Can only post reply if a post has been made.")
job_link = self.doc_test_results.pop("job_link")
self.doc_test_results.pop("failures")
self.doc_test_results.pop("success")
self.doc_test_results.pop("time_spent")
sorted_dict = sorted(self.doc_test_results.items(), key=lambda t: t[0])
for job, job_result in sorted_dict:
if len(job_result["failures"]):
text = f"*Num failures* :{len(job_result['failed'])} \n"
failures = job_result["failures"]
blocks = self.get_reply_blocks(job, job_link, failures, text=text)
print("Sending the following reply")
print(json.dumps({"blocks": blocks}))
client.chat_postMessage(
channel=os.environ["CI_SLACK_CHANNEL_ID_DAILY"],
text=f"Results for {job}",
blocks=blocks,
thread_ts=self.thread_ts["ts"],
)
time.sleep(1)
def get_job_links():
run_id = os.environ["GITHUB_RUN_ID"]
url = f"https://api.github.com/repos/huggingface/transformers/actions/runs/{run_id}/jobs?per_page=100"
result = requests.get(url).json()
jobs = {}
try:
jobs.update({job["name"]: job["html_url"] for job in result["jobs"]})
pages_to_iterate_over = math.ceil((result["total_count"] - 100) / 100)
for i in range(pages_to_iterate_over):
result = requests.get(url + f"&page={i + 2}").json()
jobs.update({job["name"]: job["html_url"] for job in result["jobs"]})
return jobs
except Exception as e:
print("Unknown error, could not fetch links.", e)
return {}
def retrieve_artifact(name: str):
_artifact = {}
if os.path.exists(name):
files = os.listdir(name)
for file in files:
try:
with open(os.path.join(name, file), encoding="utf-8") as f:
_artifact[file.split(".")[0]] = f.read()
except UnicodeDecodeError as e:
raise ValueError(f"Could not open {os.path.join(name, file)}.") from e
return _artifact
def retrieve_available_artifacts():
class Artifact:
def __init__(self, name: str):
self.name = name
self.paths = []
def __str__(self):
return self.name
def add_path(self, path: str):
self.paths.append({"name": self.name, "path": path})
_available_artifacts: Dict[str, Artifact] = {}
directories = filter(os.path.isdir, os.listdir())
for directory in directories:
artifact_name = directory
if artifact_name not in _available_artifacts:
_available_artifacts[artifact_name] = Artifact(artifact_name)
_available_artifacts[artifact_name].add_path(directory)
return _available_artifacts
if __name__ == "__main__":
github_actions_job_links = get_job_links()
available_artifacts = retrieve_available_artifacts()
docs = collections.OrderedDict(
[
("*.py", "API Examples"),
("*.md", "MD Examples"),
]
)
# This dict will contain all the information relative to each doc test category:
# - failed: list of failed tests
# - failures: dict in the format 'test': 'error_message'
doc_test_results = {
v: {
"failed": [],
"failures": {},
}
for v in docs.values()
}
# Link to the GitHub Action job
doc_test_results["job_link"] = github_actions_job_links.get("run_doctests")
artifact_path = available_artifacts["doc_tests_gpu_test_reports"].paths[0]
artifact = retrieve_artifact(artifact_path["name"])
if "stats" in artifact:
failed, success, time_spent = handle_test_results(artifact["stats"])
doc_test_results["failures"] = failed
doc_test_results["success"] = success
doc_test_results["time_spent"] = time_spent[1:-1] + ", "
all_failures = extract_first_line_failure(artifact["failures_short"])
for line in artifact["summary_short"].split("\n"):
if re.search("FAILED", line):
line = line.replace("FAILED ", "")
line = line.split()[0].replace("\n", "")
if "::" in line:
file_path, test = line.split("::")
else:
file_path, test = line, line
for file_regex in docs.keys():
if fnmatch(file_path, file_regex):
category = docs[file_regex]
doc_test_results[category]["failed"].append(test)
failure = all_failures[test] if test in all_failures else "N/A"
doc_test_results[category]["failures"][test] = failure
break
message = Message("🤗 Results of the doc tests.", doc_test_results)
message.post()
message.post_reply()
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/download_glue_data.py
|
""" Script for downloading all GLUE data.
Original source: https://gist.github.com/W4ngatang/60c2bdb54d156a41194446737ce03e2e
Note: for legal reasons, we are unable to host MRPC.
You can either use the version hosted by the SentEval team, which is already tokenized,
or you can download the original data from (https://download.microsoft.com/download/D/4/6/D46FF87A-F6B9-4252-AA8B-3604ED519838/MSRParaphraseCorpus.msi) and extract the data from it manually.
For Windows users, you can run the .msi file. For Mac and Linux users, consider an external library such as 'cabextract' (see below for an example).
You should then rename and place specific files in a folder (see below for an example).
mkdir MRPC
cabextract MSRParaphraseCorpus.msi -d MRPC
cat MRPC/_2DEC3DBE877E4DB192D17C0256E90F1D | tr -d $'\r' > MRPC/msr_paraphrase_train.txt
cat MRPC/_D7B391F9EAFF4B1B8BCE8F21B20B1B61 | tr -d $'\r' > MRPC/msr_paraphrase_test.txt
rm MRPC/_*
rm MSRParaphraseCorpus.msi
1/30/19: It looks like SentEval is no longer hosting their extracted and tokenized MRPC data, so you'll need to download the data from the original source for now.
2/11/19: It looks like SentEval actually *is* hosting the extracted data. Hooray!
"""
import argparse
import os
import sys
import urllib.request
import zipfile
TASKS = ["CoLA", "SST", "MRPC", "QQP", "STS", "MNLI", "SNLI", "QNLI", "RTE", "WNLI", "diagnostic"]
TASK2PATH = {
"CoLA": "https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FCoLA.zip?alt=media&token=46d5e637-3411-4188-bc44-5809b5bfb5f4",
"SST": "https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FSST-2.zip?alt=media&token=aabc5f6b-e466-44a2-b9b4-cf6337f84ac8",
"MRPC": "https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2Fmrpc_dev_ids.tsv?alt=media&token=ec5c0836-31d5-48f4-b431-7480817f1adc",
"QQP": "https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FQQP.zip?alt=media&token=700c6acf-160d-4d89-81d1-de4191d02cb5",
"STS": "https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FSTS-B.zip?alt=media&token=bddb94a7-8706-4e0d-a694-1109e12273b5",
"MNLI": "https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FMNLI.zip?alt=media&token=50329ea1-e339-40e2-809c-10c40afff3ce",
"SNLI": "https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FSNLI.zip?alt=media&token=4afcfbb2-ff0c-4b2d-a09a-dbf07926f4df",
"QNLI": "https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FQNLIv2.zip?alt=media&token=6fdcf570-0fc5-4631-8456-9505272d1601",
"RTE": "https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FRTE.zip?alt=media&token=5efa7e85-a0bb-4f19-8ea2-9e1840f077fb",
"WNLI": "https://firebasestorage.googleapis.com/v0/b/mtl-sentence-representations.appspot.com/o/data%2FWNLI.zip?alt=media&token=068ad0a0-ded7-4bd7-99a5-5e00222e0faf",
"diagnostic": "https://storage.googleapis.com/mtl-sentence-representations.appspot.com/tsvsWithoutLabels%2FAX.tsv?GoogleAccessId=firebase-adminsdk-0khhl@mtl-sentence-representations.iam.gserviceaccount.com&Expires=2498860800&Signature=DuQ2CSPt2Yfre0C%2BiISrVYrIFaZH1Lc7hBVZDD4ZyR7fZYOMNOUGpi8QxBmTNOrNPjR3z1cggo7WXFfrgECP6FBJSsURv8Ybrue8Ypt%2FTPxbuJ0Xc2FhDi%2BarnecCBFO77RSbfuz%2Bs95hRrYhTnByqu3U%2FYZPaj3tZt5QdfpH2IUROY8LiBXoXS46LE%2FgOQc%2FKN%2BA9SoscRDYsnxHfG0IjXGwHN%2Bf88q6hOmAxeNPx6moDulUF6XMUAaXCSFU%2BnRO2RDL9CapWxj%2BDl7syNyHhB7987hZ80B%2FwFkQ3MEs8auvt5XW1%2Bd4aCU7ytgM69r8JDCwibfhZxpaa4gd50QXQ%3D%3D",
}
MRPC_TRAIN = "https://dl.fbaipublicfiles.com/senteval/senteval_data/msr_paraphrase_train.txt"
MRPC_TEST = "https://dl.fbaipublicfiles.com/senteval/senteval_data/msr_paraphrase_test.txt"
def download_and_extract(task, data_dir):
print(f"Downloading and extracting {task}...")
data_file = f"{task}.zip"
urllib.request.urlretrieve(TASK2PATH[task], data_file)
with zipfile.ZipFile(data_file) as zip_ref:
zip_ref.extractall(data_dir)
os.remove(data_file)
print("\tCompleted!")
def format_mrpc(data_dir, path_to_data):
print("Processing MRPC...")
mrpc_dir = os.path.join(data_dir, "MRPC")
if not os.path.isdir(mrpc_dir):
os.mkdir(mrpc_dir)
if path_to_data:
mrpc_train_file = os.path.join(path_to_data, "msr_paraphrase_train.txt")
mrpc_test_file = os.path.join(path_to_data, "msr_paraphrase_test.txt")
else:
print("Local MRPC data not specified, downloading data from %s" % MRPC_TRAIN)
mrpc_train_file = os.path.join(mrpc_dir, "msr_paraphrase_train.txt")
mrpc_test_file = os.path.join(mrpc_dir, "msr_paraphrase_test.txt")
urllib.request.urlretrieve(MRPC_TRAIN, mrpc_train_file)
urllib.request.urlretrieve(MRPC_TEST, mrpc_test_file)
if not os.path.isfile(mrpc_train_file):
raise ValueError(f"Train data not found at {mrpc_train_file}")
if not os.path.isfile(mrpc_test_file):
raise ValueError(f"Test data not found at {mrpc_test_file}")
urllib.request.urlretrieve(TASK2PATH["MRPC"], os.path.join(mrpc_dir, "dev_ids.tsv"))
dev_ids = []
with open(os.path.join(mrpc_dir, "dev_ids.tsv"), encoding="utf8") as ids_fh:
for row in ids_fh:
dev_ids.append(row.strip().split("\t"))
with open(mrpc_train_file, encoding="utf8") as data_fh, open(
os.path.join(mrpc_dir, "train.tsv"), "w", encoding="utf8"
) as train_fh, open(os.path.join(mrpc_dir, "dev.tsv"), "w", encoding="utf8") as dev_fh:
header = data_fh.readline()
train_fh.write(header)
dev_fh.write(header)
for row in data_fh:
label, id1, id2, s1, s2 = row.strip().split("\t")
if [id1, id2] in dev_ids:
dev_fh.write("%s\t%s\t%s\t%s\t%s\n" % (label, id1, id2, s1, s2))
else:
train_fh.write("%s\t%s\t%s\t%s\t%s\n" % (label, id1, id2, s1, s2))
with open(mrpc_test_file, encoding="utf8") as data_fh, open(
os.path.join(mrpc_dir, "test.tsv"), "w", encoding="utf8"
) as test_fh:
header = data_fh.readline()
test_fh.write("index\t#1 ID\t#2 ID\t#1 String\t#2 String\n")
for idx, row in enumerate(data_fh):
label, id1, id2, s1, s2 = row.strip().split("\t")
test_fh.write("%d\t%s\t%s\t%s\t%s\n" % (idx, id1, id2, s1, s2))
print("\tCompleted!")
def download_diagnostic(data_dir):
print("Downloading and extracting diagnostic...")
if not os.path.isdir(os.path.join(data_dir, "diagnostic")):
os.mkdir(os.path.join(data_dir, "diagnostic"))
data_file = os.path.join(data_dir, "diagnostic", "diagnostic.tsv")
urllib.request.urlretrieve(TASK2PATH["diagnostic"], data_file)
print("\tCompleted!")
return
def get_tasks(task_names):
task_names = task_names.split(",")
if "all" in task_names:
tasks = TASKS
else:
tasks = []
for task_name in task_names:
if task_name not in TASKS:
raise ValueError(f"Task {task_name} not found!")
tasks.append(task_name)
return tasks
def main(arguments):
parser = argparse.ArgumentParser()
parser.add_argument("--data_dir", help="directory to save data to", type=str, default="glue_data")
parser.add_argument(
"--tasks", help="tasks to download data for as a comma separated string", type=str, default="all"
)
parser.add_argument(
"--path_to_mrpc",
help="path to directory containing extracted MRPC data, msr_paraphrase_train.txt and msr_paraphrase_text.txt",
type=str,
default="",
)
args = parser.parse_args(arguments)
if not os.path.isdir(args.data_dir):
os.mkdir(args.data_dir)
tasks = get_tasks(args.tasks)
for task in tasks:
if task == "MRPC":
format_mrpc(args.data_dir, args.path_to_mrpc)
elif task == "diagnostic":
download_diagnostic(args.data_dir)
else:
download_and_extract(task, args.data_dir)
if __name__ == "__main__":
sys.exit(main(sys.argv[1:]))
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/get_modified_files.py
|
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# this script reports modified .py files under the desired list of top-level sub-dirs passed as a list of arguments, e.g.:
# python ./utils/get_modified_files.py utils src tests examples
#
# it uses git to find the forking point and which files were modified - i.e. files not under git won't be considered
# since the output of this script is fed into Makefile commands it doesn't print a newline after the results
import re
import subprocess
import sys
fork_point_sha = subprocess.check_output("git merge-base main HEAD".split()).decode("utf-8")
modified_files = (
subprocess.check_output(f"git diff --diff-filter=d --name-only {fork_point_sha}".split()).decode("utf-8").split()
)
joined_dirs = "|".join(sys.argv[1:])
regex = re.compile(rf"^({joined_dirs}).*?\.py$")
relevant_modified_files = [x for x in modified_files if regex.match(x)]
print(" ".join(relevant_modified_files), end="")
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/get_test_info.py
|
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import importlib
import os
import sys
# This is required to make the module import works (when the python process is running from the root of the repo)
sys.path.append(".")
r"""
The argument `test_file` in this file refers to a model test file. This should be a string of the from
`tests/models/*/test_modeling_*.py`.
"""
def get_module_path(test_file):
"""Return the module path of a model test file."""
components = test_file.split(os.path.sep)
if components[0:2] != ["tests", "models"]:
raise ValueError(
"`test_file` should start with `tests/models/` (with `/` being the OS specific path separator). Got "
f"{test_file} instead."
)
test_fn = components[-1]
if not test_fn.endswith("py"):
raise ValueError(f"`test_file` should be a python file. Got {test_fn} instead.")
if not test_fn.startswith("test_modeling_"):
raise ValueError(
f"`test_file` should point to a file name of the form `test_modeling_*.py`. Got {test_fn} instead."
)
components = components[:-1] + [test_fn.replace(".py", "")]
test_module_path = ".".join(components)
return test_module_path
def get_test_module(test_file):
"""Get the module of a model test file."""
test_module_path = get_module_path(test_file)
test_module = importlib.import_module(test_module_path)
return test_module
def get_tester_classes(test_file):
"""Get all classes in a model test file whose names ends with `ModelTester`."""
tester_classes = []
test_module = get_test_module(test_file)
for attr in dir(test_module):
if attr.endswith("ModelTester"):
tester_classes.append(getattr(test_module, attr))
# sort with class names
return sorted(tester_classes, key=lambda x: x.__name__)
def get_test_classes(test_file):
"""Get all [test] classes in a model test file with attribute `all_model_classes` that are non-empty.
These are usually the (model) test classes containing the (non-slow) tests to run and are subclasses of one of the
classes `ModelTesterMixin`, `TFModelTesterMixin` or `FlaxModelTesterMixin`, as well as a subclass of
`unittest.TestCase`. Exceptions include `RagTestMixin` (and its subclasses).
"""
test_classes = []
test_module = get_test_module(test_file)
for attr in dir(test_module):
attr_value = getattr(test_module, attr)
# (TF/Flax)ModelTesterMixin is also an attribute in specific model test module. Let's exclude them by checking
# `all_model_classes` is not empty (which also excludes other special classes).
model_classes = getattr(attr_value, "all_model_classes", [])
if len(model_classes) > 0:
test_classes.append(attr_value)
# sort with class names
return sorted(test_classes, key=lambda x: x.__name__)
def get_model_classes(test_file):
"""Get all model classes that appear in `all_model_classes` attributes in a model test file."""
test_classes = get_test_classes(test_file)
model_classes = set()
for test_class in test_classes:
model_classes.update(test_class.all_model_classes)
# sort with class names
return sorted(model_classes, key=lambda x: x.__name__)
def get_model_tester_from_test_class(test_class):
"""Get the model tester class of a model test class."""
test = test_class()
if hasattr(test, "setUp"):
test.setUp()
model_tester = None
if hasattr(test, "model_tester"):
# `(TF/Flax)ModelTesterMixin` has this attribute default to `None`. Let's skip this case.
if test.model_tester is not None:
model_tester = test.model_tester.__class__
return model_tester
def get_test_classes_for_model(test_file, model_class):
"""Get all [test] classes in `test_file` that have `model_class` in their `all_model_classes`."""
test_classes = get_test_classes(test_file)
target_test_classes = []
for test_class in test_classes:
if model_class in test_class.all_model_classes:
target_test_classes.append(test_class)
# sort with class names
return sorted(target_test_classes, key=lambda x: x.__name__)
def get_tester_classes_for_model(test_file, model_class):
"""Get all model tester classes in `test_file` that are associated to `model_class`."""
test_classes = get_test_classes_for_model(test_file, model_class)
tester_classes = []
for test_class in test_classes:
tester_class = get_model_tester_from_test_class(test_class)
if tester_class is not None:
tester_classes.append(tester_class)
# sort with class names
return sorted(tester_classes, key=lambda x: x.__name__)
def get_test_to_tester_mapping(test_file):
"""Get a mapping from [test] classes to model tester classes in `test_file`.
This uses `get_test_classes` which may return classes that are NOT subclasses of `unittest.TestCase`.
"""
test_classes = get_test_classes(test_file)
test_tester_mapping = {test_class: get_model_tester_from_test_class(test_class) for test_class in test_classes}
return test_tester_mapping
def get_model_to_test_mapping(test_file):
"""Get a mapping from model classes to test classes in `test_file`."""
model_classes = get_model_classes(test_file)
model_test_mapping = {
model_class: get_test_classes_for_model(test_file, model_class) for model_class in model_classes
}
return model_test_mapping
def get_model_to_tester_mapping(test_file):
"""Get a mapping from model classes to model tester classes in `test_file`."""
model_classes = get_model_classes(test_file)
model_to_tester_mapping = {
model_class: get_tester_classes_for_model(test_file, model_class) for model_class in model_classes
}
return model_to_tester_mapping
def to_json(o):
"""Make the information succinct and easy to read.
Avoid the full class representation like `<class 'transformers.models.bert.modeling_bert.BertForMaskedLM'>` when
displaying the results. Instead, we use class name (`BertForMaskedLM`) for the readability.
"""
if isinstance(o, str):
return o
elif isinstance(o, type):
return o.__name__
elif isinstance(o, (list, tuple)):
return [to_json(x) for x in o]
elif isinstance(o, dict):
return {to_json(k): to_json(v) for k, v in o.items()}
else:
return o
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/notification_service.py
|
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import ast
import collections
import functools
import json
import operator
import os
import re
import sys
import time
from typing import Dict, List, Optional, Union
import requests
from get_ci_error_statistics import get_job_links
from get_previous_daily_ci import get_last_daily_ci_reports
from slack_sdk import WebClient
client = WebClient(token=os.environ["CI_SLACK_BOT_TOKEN"])
NON_MODEL_TEST_MODULES = [
"benchmark",
"deepspeed",
"extended",
"fixtures",
"generation",
"onnx",
"optimization",
"pipelines",
"sagemaker",
"trainer",
"utils",
]
def handle_test_results(test_results):
expressions = test_results.split(" ")
failed = 0
success = 0
# When the output is short enough, the output is surrounded by = signs: "== OUTPUT =="
# When it is too long, those signs are not present.
time_spent = expressions[-2] if "=" in expressions[-1] else expressions[-1]
for i, expression in enumerate(expressions):
if "failed" in expression:
failed += int(expressions[i - 1])
if "passed" in expression:
success += int(expressions[i - 1])
return failed, success, time_spent
def handle_stacktraces(test_results):
# These files should follow the following architecture:
# === FAILURES ===
# <path>:<line>: Error ...
# <path>:<line>: Error ...
# <empty line>
total_stacktraces = test_results.split("\n")[1:-1]
stacktraces = []
for stacktrace in total_stacktraces:
try:
line = stacktrace[: stacktrace.index(" ")].split(":")[-2]
error_message = stacktrace[stacktrace.index(" ") :]
stacktraces.append(f"(line {line}) {error_message}")
except Exception:
stacktraces.append("Cannot retrieve error message.")
return stacktraces
def dicts_to_sum(objects: Union[Dict[str, Dict], List[dict]]):
if isinstance(objects, dict):
lists = objects.values()
else:
lists = objects
# Convert each dictionary to counter
counters = map(collections.Counter, lists)
# Sum all the counters
return functools.reduce(operator.add, counters)
class Message:
def __init__(
self, title: str, ci_title: str, model_results: Dict, additional_results: Dict, selected_warnings: List = None
):
self.title = title
self.ci_title = ci_title
# Failures and success of the modeling tests
self.n_model_success = sum(r["success"] for r in model_results.values())
self.n_model_single_gpu_failures = sum(dicts_to_sum(r["failed"])["single"] for r in model_results.values())
self.n_model_multi_gpu_failures = sum(dicts_to_sum(r["failed"])["multi"] for r in model_results.values())
# Some suites do not have a distinction between single and multi GPU.
self.n_model_unknown_failures = sum(dicts_to_sum(r["failed"])["unclassified"] for r in model_results.values())
self.n_model_failures = (
self.n_model_single_gpu_failures + self.n_model_multi_gpu_failures + self.n_model_unknown_failures
)
# Failures and success of the additional tests
self.n_additional_success = sum(r["success"] for r in additional_results.values())
all_additional_failures = dicts_to_sum([r["failed"] for r in additional_results.values()])
self.n_additional_single_gpu_failures = all_additional_failures["single"]
self.n_additional_multi_gpu_failures = all_additional_failures["multi"]
self.n_additional_unknown_gpu_failures = all_additional_failures["unclassified"]
self.n_additional_failures = (
self.n_additional_single_gpu_failures
+ self.n_additional_multi_gpu_failures
+ self.n_additional_unknown_gpu_failures
)
# Results
self.n_failures = self.n_model_failures + self.n_additional_failures
self.n_success = self.n_model_success + self.n_additional_success
self.n_tests = self.n_failures + self.n_success
self.model_results = model_results
self.additional_results = additional_results
self.thread_ts = None
if selected_warnings is None:
selected_warnings = []
self.selected_warnings = selected_warnings
@property
def time(self) -> str:
all_results = [*self.model_results.values(), *self.additional_results.values()]
time_spent = [r["time_spent"].split(", ")[0] for r in all_results if len(r["time_spent"])]
total_secs = 0
for time in time_spent:
time_parts = time.split(":")
# Time can be formatted as xx:xx:xx, as .xx, or as x.xx if the time spent was less than a minute.
if len(time_parts) == 1:
time_parts = [0, 0, time_parts[0]]
hours, minutes, seconds = int(time_parts[0]), int(time_parts[1]), float(time_parts[2])
total_secs += hours * 3600 + minutes * 60 + seconds
hours, minutes, seconds = total_secs // 3600, (total_secs % 3600) // 60, total_secs % 60
return f"{int(hours)}h{int(minutes)}m{int(seconds)}s"
@property
def header(self) -> Dict:
return {"type": "header", "text": {"type": "plain_text", "text": self.title}}
@property
def ci_title_section(self) -> Dict:
return {"type": "section", "text": {"type": "mrkdwn", "text": self.ci_title}}
@property
def no_failures(self) -> Dict:
return {
"type": "section",
"text": {
"type": "plain_text",
"text": f"🌞 There were no failures: all {self.n_tests} tests passed. The suite ran in {self.time}.",
"emoji": True,
},
"accessory": {
"type": "button",
"text": {"type": "plain_text", "text": "Check Action results", "emoji": True},
"url": f"https://github.com/huggingface/transformers/actions/runs/{os.environ['GITHUB_RUN_ID']}",
},
}
@property
def failures(self) -> Dict:
return {
"type": "section",
"text": {
"type": "plain_text",
"text": (
f"There were {self.n_failures} failures, out of {self.n_tests} tests.\n"
f"Number of model failures: {self.n_model_failures}.\n"
f"The suite ran in {self.time}."
),
"emoji": True,
},
"accessory": {
"type": "button",
"text": {"type": "plain_text", "text": "Check Action results", "emoji": True},
"url": f"https://github.com/huggingface/transformers/actions/runs/{os.environ['GITHUB_RUN_ID']}",
},
}
@property
def warnings(self) -> Dict:
# If something goes wrong, let's avoid the CI report failing to be sent.
button_text = "Check warnings (Link not found)"
# Use the workflow run link
job_link = f"https://github.com/huggingface/transformers/actions/runs/{os.environ['GITHUB_RUN_ID']}"
if "Extract warnings in CI artifacts" in github_actions_job_links:
button_text = "Check warnings"
# Use the actual job link
job_link = f"{github_actions_job_links['Extract warnings in CI artifacts']}"
huggingface_hub_warnings = [x for x in self.selected_warnings if "huggingface_hub" in x]
text = f"There are {len(self.selected_warnings)} warnings being selected."
text += f"\n{len(huggingface_hub_warnings)} of them are from `huggingface_hub`."
return {
"type": "section",
"text": {
"type": "plain_text",
"text": text,
"emoji": True,
},
"accessory": {
"type": "button",
"text": {"type": "plain_text", "text": button_text, "emoji": True},
"url": job_link,
},
}
@staticmethod
def get_device_report(report, rjust=6):
if "single" in report and "multi" in report:
return f"{str(report['single']).rjust(rjust)} | {str(report['multi']).rjust(rjust)} | "
elif "single" in report:
return f"{str(report['single']).rjust(rjust)} | {'0'.rjust(rjust)} | "
elif "multi" in report:
return f"{'0'.rjust(rjust)} | {str(report['multi']).rjust(rjust)} | "
@property
def category_failures(self) -> Dict:
model_failures = [v["failed"] for v in self.model_results.values()]
category_failures = {}
for model_failure in model_failures:
for key, value in model_failure.items():
if key not in category_failures:
category_failures[key] = dict(value)
else:
category_failures[key]["unclassified"] += value["unclassified"]
category_failures[key]["single"] += value["single"]
category_failures[key]["multi"] += value["multi"]
individual_reports = []
for key, value in category_failures.items():
device_report = self.get_device_report(value)
if sum(value.values()):
if device_report:
individual_reports.append(f"{device_report}{key}")
else:
individual_reports.append(key)
header = "Single | Multi | Category\n"
category_failures_report = prepare_reports(
title="The following modeling categories had failures", header=header, reports=individual_reports
)
return {"type": "section", "text": {"type": "mrkdwn", "text": category_failures_report}}
def compute_diff_for_failure_reports(self, curr_failure_report, prev_failure_report): # noqa
# Remove the leading and training parts that don't contain failure count information.
model_failures = curr_failure_report.split("\n")[3:-2]
prev_model_failures = prev_failure_report.split("\n")[3:-2]
entries_changed = set(model_failures).difference(prev_model_failures)
prev_map = {}
for f in prev_model_failures:
items = [x.strip() for x in f.split("| ")]
prev_map[items[-1]] = [int(x) for x in items[:-1]]
curr_map = {}
for f in entries_changed:
items = [x.strip() for x in f.split("| ")]
curr_map[items[-1]] = [int(x) for x in items[:-1]]
diff_map = {}
for k, v in curr_map.items():
if k not in prev_map:
diff_map[k] = v
else:
diff = [x - y for x, y in zip(v, prev_map[k])]
if max(diff) > 0:
diff_map[k] = diff
entries_changed = []
for model_name, diff_values in diff_map.items():
diff = [str(x) for x in diff_values]
diff = [f"+{x}" if (x != "0" and not x.startswith("-")) else x for x in diff]
diff = [x.rjust(9) for x in diff]
device_report = " | ".join(diff) + " | "
report = f"{device_report}{model_name}"
entries_changed.append(report)
entries_changed = sorted(entries_changed, key=lambda s: s.split("| ")[-1])
return entries_changed
@property
def model_failures(self) -> List[Dict]:
# Obtain per-model failures
def per_model_sum(model_category_dict):
return dicts_to_sum(model_category_dict["failed"].values())
failures = {}
non_model_failures = {
k: per_model_sum(v) for k, v in self.model_results.items() if sum(per_model_sum(v).values())
}
for k, v in self.model_results.items():
if k in NON_MODEL_TEST_MODULES:
pass
if sum(per_model_sum(v).values()):
dict_failed = dict(v["failed"])
pytorch_specific_failures = dict_failed.pop("PyTorch")
tensorflow_specific_failures = dict_failed.pop("TensorFlow")
other_failures = dicts_to_sum(dict_failed.values())
failures[k] = {
"PyTorch": pytorch_specific_failures,
"TensorFlow": tensorflow_specific_failures,
"other": other_failures,
}
model_reports = []
other_module_reports = []
for key, value in non_model_failures.items():
if key in NON_MODEL_TEST_MODULES:
device_report = self.get_device_report(value)
if sum(value.values()):
if device_report:
report = f"{device_report}{key}"
else:
report = key
other_module_reports.append(report)
for key, value in failures.items():
device_report_values = [
value["PyTorch"]["single"],
value["PyTorch"]["multi"],
value["TensorFlow"]["single"],
value["TensorFlow"]["multi"],
sum(value["other"].values()),
]
if sum(device_report_values):
device_report = " | ".join([str(x).rjust(9) for x in device_report_values]) + " | "
report = f"{device_report}{key}"
model_reports.append(report)
# (Possibly truncated) reports for the current workflow run - to be sent to Slack channels
model_header = "Single PT | Multi PT | Single TF | Multi TF | Other | Category\n"
sorted_model_reports = sorted(model_reports, key=lambda s: s.split("| ")[-1])
model_failures_report = prepare_reports(
title="These following model modules had failures", header=model_header, reports=sorted_model_reports
)
module_header = "Single | Multi | Category\n"
sorted_module_reports = sorted(other_module_reports, key=lambda s: s.split("| ")[-1])
module_failures_report = prepare_reports(
title="The following non-model modules had failures", header=module_header, reports=sorted_module_reports
)
# To be sent to Slack channels
model_failure_sections = [
{"type": "section", "text": {"type": "mrkdwn", "text": model_failures_report}},
{"type": "section", "text": {"type": "mrkdwn", "text": module_failures_report}},
]
# Save the complete (i.e. no truncation) failure tables (of the current workflow run)
# (to be uploaded as artifacts)
if not os.path.isdir(os.path.join(os.getcwd(), "test_failure_tables")):
os.makedirs(os.path.join(os.getcwd(), "test_failure_tables"))
model_failures_report = prepare_reports(
title="These following model modules had failures",
header=model_header,
reports=sorted_model_reports,
to_truncate=False,
)
file_path = os.path.join(os.getcwd(), "test_failure_tables/model_failures_report.txt")
with open(file_path, "w", encoding="UTF-8") as fp:
fp.write(model_failures_report)
module_failures_report = prepare_reports(
title="The following non-model modules had failures",
header=module_header,
reports=sorted_module_reports,
to_truncate=False,
)
file_path = os.path.join(os.getcwd(), "test_failure_tables/module_failures_report.txt")
with open(file_path, "w", encoding="UTF-8") as fp:
fp.write(module_failures_report)
target_workflow = "huggingface/transformers/.github/workflows/self-scheduled.yml@refs/heads/main"
if os.environ.get("CI_WORKFLOW_REF") == target_workflow:
# Get the last previously completed CI's failure tables
artifact_names = ["test_failure_tables"]
output_dir = os.path.join(os.getcwd(), "previous_reports")
os.makedirs(output_dir, exist_ok=True)
prev_tables = get_last_daily_ci_reports(
artifact_names=artifact_names, output_dir=output_dir, token=os.environ["ACCESS_REPO_INFO_TOKEN"]
)
# if the last run produces artifact named `test_failure_tables`
if (
"test_failure_tables" in prev_tables
and "model_failures_report.txt" in prev_tables["test_failure_tables"]
):
# Compute the difference of the previous/current (model failure) table
prev_model_failures = prev_tables["test_failure_tables"]["model_failures_report.txt"]
entries_changed = self.compute_diff_for_failure_reports(model_failures_report, prev_model_failures)
if len(entries_changed) > 0:
# Save the complete difference
diff_report = prepare_reports(
title="Changed model modules failures",
header=model_header,
reports=entries_changed,
to_truncate=False,
)
file_path = os.path.join(os.getcwd(), "test_failure_tables/changed_model_failures_report.txt")
with open(file_path, "w", encoding="UTF-8") as fp:
fp.write(diff_report)
# To be sent to Slack channels
diff_report = prepare_reports(
title="*Changed model modules failures*",
header=model_header,
reports=entries_changed,
)
model_failure_sections.append(
{"type": "section", "text": {"type": "mrkdwn", "text": diff_report}},
)
return model_failure_sections
@property
def additional_failures(self) -> Dict:
failures = {k: v["failed"] for k, v in self.additional_results.items()}
errors = {k: v["error"] for k, v in self.additional_results.items()}
individual_reports = []
for key, value in failures.items():
device_report = self.get_device_report(value)
if sum(value.values()) or errors[key]:
report = f"{key}"
if errors[key]:
report = f"[Errored out] {report}"
if device_report:
report = f"{device_report}{report}"
individual_reports.append(report)
header = "Single | Multi | Category\n"
failures_report = prepare_reports(
title="The following non-modeling tests had failures", header=header, reports=individual_reports
)
return {"type": "section", "text": {"type": "mrkdwn", "text": failures_report}}
@property
def payload(self) -> str:
blocks = [self.header]
if self.ci_title:
blocks.append(self.ci_title_section)
if self.n_model_failures > 0 or self.n_additional_failures > 0:
blocks.append(self.failures)
if self.n_model_failures > 0:
blocks.append(self.category_failures)
for block in self.model_failures:
if block["text"]["text"]:
blocks.append(block)
if self.n_additional_failures > 0:
blocks.append(self.additional_failures)
if self.n_model_failures == 0 and self.n_additional_failures == 0:
blocks.append(self.no_failures)
if len(self.selected_warnings) > 0:
blocks.append(self.warnings)
return json.dumps(blocks)
@staticmethod
def error_out(title, ci_title="", runner_not_available=False, runner_failed=False, setup_failed=False):
blocks = []
title_block = {"type": "header", "text": {"type": "plain_text", "text": title}}
blocks.append(title_block)
if ci_title:
ci_title_block = {"type": "section", "text": {"type": "mrkdwn", "text": ci_title}}
blocks.append(ci_title_block)
offline_runners = []
if runner_not_available:
text = "💔 CI runners are not available! Tests are not run. 😭"
result = os.environ.get("OFFLINE_RUNNERS")
if result is not None:
offline_runners = json.loads(result)
elif runner_failed:
text = "💔 CI runners have problems! Tests are not run. 😭"
elif setup_failed:
text = "💔 Setup job failed. Tests are not run. 😭"
else:
text = "💔 There was an issue running the tests. 😭"
error_block_1 = {
"type": "header",
"text": {
"type": "plain_text",
"text": text,
},
}
text = ""
if len(offline_runners) > 0:
text = "\n • " + "\n • ".join(offline_runners)
text = f"The following runners are offline:\n{text}\n\n"
text += "🙏 Let's fix it ASAP! 🙏"
error_block_2 = {
"type": "section",
"text": {
"type": "plain_text",
"text": text,
},
"accessory": {
"type": "button",
"text": {"type": "plain_text", "text": "Check Action results", "emoji": True},
"url": f"https://github.com/huggingface/transformers/actions/runs/{os.environ['GITHUB_RUN_ID']}",
},
}
blocks.extend([error_block_1, error_block_2])
payload = json.dumps(blocks)
print("Sending the following payload")
print(json.dumps({"blocks": blocks}))
client.chat_postMessage(
channel=os.environ["CI_SLACK_REPORT_CHANNEL_ID"],
text=text,
blocks=payload,
)
def post(self):
payload = self.payload
print("Sending the following payload")
print(json.dumps({"blocks": json.loads(payload)}))
text = f"{self.n_failures} failures out of {self.n_tests} tests," if self.n_failures else "All tests passed."
self.thread_ts = client.chat_postMessage(
channel=os.environ["CI_SLACK_REPORT_CHANNEL_ID"],
blocks=payload,
text=text,
)
def get_reply_blocks(self, job_name, job_result, failures, device, text):
"""
failures: A list with elements of the form {"line": full test name, "trace": error trace}
"""
# `text` must be less than 3001 characters in Slack SDK
# keep some room for adding "[Truncated]" when necessary
MAX_ERROR_TEXT = 3000 - len("[Truncated]")
failure_text = ""
for idx, error in enumerate(failures):
new_text = failure_text + f'*{error["line"]}*\n_{error["trace"]}_\n\n'
if len(new_text) > MAX_ERROR_TEXT:
# `failure_text` here has length <= 3000
failure_text = failure_text + "[Truncated]"
break
# `failure_text` here has length <= MAX_ERROR_TEXT
failure_text = new_text
title = job_name
if device is not None:
title += f" ({device}-gpu)"
content = {"type": "section", "text": {"type": "mrkdwn", "text": text}}
# TODO: Make sure we always have a valid job link (or at least a way not to break the report sending)
# Currently we get the device from a job's artifact name.
# If a device is found, the job name should contain the device type, for example, `XXX (single-gpu)`.
# This could be done by adding `machine_type` in a job's `strategy`.
# (If `job_result["job_link"][device]` is `None`, we get an error: `... [ERROR] must provide a string ...`)
if job_result["job_link"] is not None and job_result["job_link"][device] is not None:
content["accessory"] = {
"type": "button",
"text": {"type": "plain_text", "text": "GitHub Action job", "emoji": True},
"url": job_result["job_link"][device],
}
return [
{"type": "header", "text": {"type": "plain_text", "text": title.upper(), "emoji": True}},
content,
{"type": "section", "text": {"type": "mrkdwn", "text": failure_text}},
]
def post_reply(self):
if self.thread_ts is None:
raise ValueError("Can only post reply if a post has been made.")
sorted_dict = sorted(self.model_results.items(), key=lambda t: t[0])
for job, job_result in sorted_dict:
if len(job_result["failures"]):
for device, failures in job_result["failures"].items():
text = "\n".join(
sorted([f"*{k}*: {v[device]}" for k, v in job_result["failed"].items() if v[device]])
)
blocks = self.get_reply_blocks(job, job_result, failures, device, text=text)
print("Sending the following reply")
print(json.dumps({"blocks": blocks}))
client.chat_postMessage(
channel=os.environ["CI_SLACK_REPORT_CHANNEL_ID"],
text=f"Results for {job}",
blocks=blocks,
thread_ts=self.thread_ts["ts"],
)
time.sleep(1)
for job, job_result in self.additional_results.items():
if len(job_result["failures"]):
for device, failures in job_result["failures"].items():
blocks = self.get_reply_blocks(
job,
job_result,
failures,
device,
text=f'Number of failures: {job_result["failed"][device]}',
)
print("Sending the following reply")
print(json.dumps({"blocks": blocks}))
client.chat_postMessage(
channel=os.environ["CI_SLACK_REPORT_CHANNEL_ID"],
text=f"Results for {job}",
blocks=blocks,
thread_ts=self.thread_ts["ts"],
)
time.sleep(1)
def retrieve_artifact(artifact_path: str, gpu: Optional[str]):
if gpu not in [None, "single", "multi"]:
raise ValueError(f"Invalid GPU for artifact. Passed GPU: `{gpu}`.")
_artifact = {}
if os.path.exists(artifact_path):
files = os.listdir(artifact_path)
for file in files:
try:
with open(os.path.join(artifact_path, file)) as f:
_artifact[file.split(".")[0]] = f.read()
except UnicodeDecodeError as e:
raise ValueError(f"Could not open {os.path.join(artifact_path, file)}.") from e
return _artifact
def retrieve_available_artifacts():
class Artifact:
def __init__(self, name: str, single_gpu: bool = False, multi_gpu: bool = False):
self.name = name
self.single_gpu = single_gpu
self.multi_gpu = multi_gpu
self.paths = []
def __str__(self):
return self.name
def add_path(self, path: str, gpu: str = None):
self.paths.append({"name": self.name, "path": path, "gpu": gpu})
_available_artifacts: Dict[str, Artifact] = {}
directories = filter(os.path.isdir, os.listdir())
for directory in directories:
artifact_name = directory
name_parts = artifact_name.split("_postfix_")
if len(name_parts) > 1:
artifact_name = name_parts[0]
if artifact_name.startswith("single-gpu"):
artifact_name = artifact_name[len("single-gpu") + 1 :]
if artifact_name in _available_artifacts:
_available_artifacts[artifact_name].single_gpu = True
else:
_available_artifacts[artifact_name] = Artifact(artifact_name, single_gpu=True)
_available_artifacts[artifact_name].add_path(directory, gpu="single")
elif artifact_name.startswith("multi-gpu"):
artifact_name = artifact_name[len("multi-gpu") + 1 :]
if artifact_name in _available_artifacts:
_available_artifacts[artifact_name].multi_gpu = True
else:
_available_artifacts[artifact_name] = Artifact(artifact_name, multi_gpu=True)
_available_artifacts[artifact_name].add_path(directory, gpu="multi")
else:
if artifact_name not in _available_artifacts:
_available_artifacts[artifact_name] = Artifact(artifact_name)
_available_artifacts[artifact_name].add_path(directory)
return _available_artifacts
def prepare_reports(title, header, reports, to_truncate=True):
report = ""
MAX_ERROR_TEXT = 3000 - len("[Truncated]")
if not to_truncate:
MAX_ERROR_TEXT = float("inf")
if len(reports) > 0:
# `text` must be less than 3001 characters in Slack SDK
# keep some room for adding "[Truncated]" when necessary
for idx in range(len(reports)):
_report = header + "\n".join(reports[: idx + 1])
new_report = f"{title}:\n```\n{_report}\n```\n"
if len(new_report) > MAX_ERROR_TEXT:
# `report` here has length <= 3000
report = report + "[Truncated]"
break
report = new_report
return report
if __name__ == "__main__":
# runner_status = os.environ.get("RUNNER_STATUS")
# runner_env_status = os.environ.get("RUNNER_ENV_STATUS")
setup_status = os.environ.get("SETUP_STATUS")
# runner_not_available = True if runner_status is not None and runner_status != "success" else False
# runner_failed = True if runner_env_status is not None and runner_env_status != "success" else False
# Let's keep the lines regardig runners' status (we might be able to use them again in the future)
runner_not_available = False
runner_failed = False
setup_failed = True if setup_status is not None and setup_status != "success" else False
org = "huggingface"
repo = "transformers"
repository_full_name = f"{org}/{repo}"
# This env. variable is set in workflow file (under the job `send_results`).
ci_event = os.environ["CI_EVENT"]
# To find the PR number in a commit title, for example, `Add AwesomeFormer model (#99999)`
pr_number_re = re.compile(r"\(#(\d+)\)$")
title = f"🤗 Results of the {ci_event} tests."
# Add Commit/PR title with a link for push CI
# (check the title in 2 env. variables - depending on the CI is triggered via `push` or `workflow_run` event)
ci_title_push = os.environ.get("CI_TITLE_PUSH")
ci_title_workflow_run = os.environ.get("CI_TITLE_WORKFLOW_RUN")
ci_title = ci_title_push if ci_title_push else ci_title_workflow_run
ci_sha = os.environ.get("CI_SHA")
ci_url = None
if ci_sha:
ci_url = f"https://github.com/{repository_full_name}/commit/{ci_sha}"
if ci_title is not None:
if ci_url is None:
raise ValueError(
"When a title is found (`ci_title`), it means a `push` event or a `workflow_run` even (triggered by "
"another `push` event), and the commit SHA has to be provided in order to create the URL to the "
"commit page."
)
ci_title = ci_title.strip().split("\n")[0].strip()
# Retrieve the PR title and author login to complete the report
commit_number = ci_url.split("/")[-1]
ci_detail_url = f"https://api.github.com/repos/{repository_full_name}/commits/{commit_number}"
ci_details = requests.get(ci_detail_url).json()
ci_author = ci_details["author"]["login"]
merged_by = None
# Find the PR number (if any) and change the url to the actual PR page.
numbers = pr_number_re.findall(ci_title)
if len(numbers) > 0:
pr_number = numbers[0]
ci_detail_url = f"https://api.github.com/repos/{repository_full_name}/pulls/{pr_number}"
ci_details = requests.get(ci_detail_url).json()
ci_author = ci_details["user"]["login"]
ci_url = f"https://github.com/{repository_full_name}/pull/{pr_number}"
merged_by = ci_details["merged_by"]["login"]
if merged_by is None:
ci_title = f"<{ci_url}|{ci_title}>\nAuthor: {ci_author}"
else:
ci_title = f"<{ci_url}|{ci_title}>\nAuthor: {ci_author} | Merged by: {merged_by}"
elif ci_sha:
ci_title = f"<{ci_url}|commit: {ci_sha}>"
else:
ci_title = ""
if runner_not_available or runner_failed or setup_failed:
Message.error_out(title, ci_title, runner_not_available, runner_failed, setup_failed)
exit(0)
arguments = sys.argv[1:][0]
try:
models = ast.literal_eval(arguments)
# Need to change from elements like `models/bert` to `models_bert` (the ones used as artifact names).
models = [x.replace("models/", "models_") for x in models]
except SyntaxError:
Message.error_out(title, ci_title)
raise ValueError("Errored out.")
github_actions_job_links = get_job_links(
workflow_run_id=os.environ["GITHUB_RUN_ID"], token=os.environ["ACCESS_REPO_INFO_TOKEN"]
)
available_artifacts = retrieve_available_artifacts()
modeling_categories = [
"PyTorch",
"TensorFlow",
"Flax",
"Tokenizers",
"Pipelines",
"Trainer",
"ONNX",
"Auto",
"Unclassified",
]
# This dict will contain all the information relative to each model:
# - Failures: the total, as well as the number of failures per-category defined above
# - Success: total
# - Time spent: as a comma-separated list of elapsed time
# - Failures: as a line-break separated list of errors
model_results = {
model: {
"failed": {m: {"unclassified": 0, "single": 0, "multi": 0} for m in modeling_categories},
"success": 0,
"time_spent": "",
"failures": {},
"job_link": {},
}
for model in models
if f"run_all_tests_gpu_{model}_test_reports" in available_artifacts
}
unclassified_model_failures = []
# This prefix is used to get job links below. For past CI, we use `workflow_call`, which changes the job names from
# `Model tests (...)` to `PyTorch 1.5 / Model tests (...)` for example.
job_name_prefix = ""
if ci_event.startswith("Past CI - "):
framework, version = ci_event.replace("Past CI - ", "").split("-")
framework = "PyTorch" if framework == "pytorch" else "TensorFlow"
job_name_prefix = f"{framework} {version}"
elif ci_event.startswith("Nightly CI"):
job_name_prefix = "Nightly CI"
elif ci_event.startswith("Push CI (AMD) - "):
flavor = ci_event.replace("Push CI (AMD) - ", "")
job_name_prefix = f"AMD {flavor}"
for model in model_results.keys():
for artifact_path in available_artifacts[f"run_all_tests_gpu_{model}_test_reports"].paths:
artifact = retrieve_artifact(artifact_path["path"], artifact_path["gpu"])
if "stats" in artifact:
# Link to the GitHub Action job
# The job names use `matrix.folder` which contain things like `models/bert` instead of `models_bert`
job_name = f"Model tests ({model.replace('models_', 'models/')}, {artifact_path['gpu']}-gpu)"
if job_name_prefix:
job_name = f"{job_name_prefix} / {job_name}"
model_results[model]["job_link"][artifact_path["gpu"]] = github_actions_job_links.get(job_name)
failed, success, time_spent = handle_test_results(artifact["stats"])
model_results[model]["success"] += success
model_results[model]["time_spent"] += time_spent[1:-1] + ", "
stacktraces = handle_stacktraces(artifact["failures_line"])
for line in artifact["summary_short"].split("\n"):
if line.startswith("FAILED "):
line = line[len("FAILED ") :]
line = line.split()[0].replace("\n", "")
if artifact_path["gpu"] not in model_results[model]["failures"]:
model_results[model]["failures"][artifact_path["gpu"]] = []
model_results[model]["failures"][artifact_path["gpu"]].append(
{"line": line, "trace": stacktraces.pop(0)}
)
if re.search("test_modeling_tf_", line):
model_results[model]["failed"]["TensorFlow"][artifact_path["gpu"]] += 1
elif re.search("test_modeling_flax_", line):
model_results[model]["failed"]["Flax"][artifact_path["gpu"]] += 1
elif re.search("test_modeling", line):
model_results[model]["failed"]["PyTorch"][artifact_path["gpu"]] += 1
elif re.search("test_tokenization", line):
model_results[model]["failed"]["Tokenizers"][artifact_path["gpu"]] += 1
elif re.search("test_pipelines", line):
model_results[model]["failed"]["Pipelines"][artifact_path["gpu"]] += 1
elif re.search("test_trainer", line):
model_results[model]["failed"]["Trainer"][artifact_path["gpu"]] += 1
elif re.search("onnx", line):
model_results[model]["failed"]["ONNX"][artifact_path["gpu"]] += 1
elif re.search("auto", line):
model_results[model]["failed"]["Auto"][artifact_path["gpu"]] += 1
else:
model_results[model]["failed"]["Unclassified"][artifact_path["gpu"]] += 1
unclassified_model_failures.append(line)
# Additional runs
additional_files = {
"Examples directory": "run_examples_gpu",
"PyTorch pipelines": "run_tests_torch_pipeline_gpu",
"TensorFlow pipelines": "run_tests_tf_pipeline_gpu",
"Torch CUDA extension tests": "run_tests_torch_cuda_extensions_gpu_test_reports",
}
if ci_event in ["push", "Nightly CI"] or ci_event.startswith("Past CI"):
del additional_files["Examples directory"]
del additional_files["PyTorch pipelines"]
del additional_files["TensorFlow pipelines"]
elif ci_event.startswith("Scheduled CI (AMD)"):
del additional_files["TensorFlow pipelines"]
del additional_files["Torch CUDA extension tests"]
elif ci_event.startswith("Push CI (AMD)"):
additional_files = {}
additional_results = {
key: {
"failed": {"unclassified": 0, "single": 0, "multi": 0},
"success": 0,
"time_spent": "",
"error": False,
"failures": {},
"job_link": {},
}
for key in additional_files.keys()
}
for key in additional_results.keys():
# If a whole suite of test fails, the artifact isn't available.
if additional_files[key] not in available_artifacts:
additional_results[key]["error"] = True
continue
for artifact_path in available_artifacts[additional_files[key]].paths:
# Link to the GitHub Action job
job_name = key
if artifact_path["gpu"] is not None:
job_name = f"{key} ({artifact_path['gpu']}-gpu)"
if job_name_prefix:
job_name = f"{job_name_prefix} / {job_name}"
additional_results[key]["job_link"][artifact_path["gpu"]] = github_actions_job_links.get(job_name)
artifact = retrieve_artifact(artifact_path["path"], artifact_path["gpu"])
stacktraces = handle_stacktraces(artifact["failures_line"])
failed, success, time_spent = handle_test_results(artifact["stats"])
additional_results[key]["failed"][artifact_path["gpu"] or "unclassified"] += failed
additional_results[key]["success"] += success
additional_results[key]["time_spent"] += time_spent[1:-1] + ", "
if len(artifact["errors"]):
additional_results[key]["error"] = True
if failed:
for line in artifact["summary_short"].split("\n"):
if line.startswith("FAILED "):
line = line[len("FAILED ") :]
line = line.split()[0].replace("\n", "")
if artifact_path["gpu"] not in additional_results[key]["failures"]:
additional_results[key]["failures"][artifact_path["gpu"]] = []
additional_results[key]["failures"][artifact_path["gpu"]].append(
{"line": line, "trace": stacktraces.pop(0)}
)
selected_warnings = []
if "warnings_in_ci" in available_artifacts:
directory = available_artifacts["warnings_in_ci"].paths[0]["path"]
with open(os.path.join(directory, "selected_warnings.json")) as fp:
selected_warnings = json.load(fp)
message = Message(title, ci_title, model_results, additional_results, selected_warnings=selected_warnings)
# send report only if there is any failure (for push CI)
if message.n_failures or (ci_event != "push" and not ci_event.startswith("Push CI (AMD)")):
message.post()
message.post_reply()
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/update_metadata.py
|
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utility that updates the metadata of the Transformers library in the repository `huggingface/transformers-metadata`.
Usage for an update (as used by the GitHub action `update_metadata`):
```bash
python utils/update_metadata.py --token <token> --commit_sha <commit_sha>
```
Usage to check all pipelines are properly defined in the constant `PIPELINE_TAGS_AND_AUTO_MODELS` of this script, so
that new pipelines are properly added as metadata (as used in `make repo-consistency`):
```bash
python utils/update_metadata.py --check-only
```
"""
import argparse
import collections
import os
import re
import tempfile
from typing import Dict, List, Tuple
import pandas as pd
from datasets import Dataset
from huggingface_hub import hf_hub_download, upload_folder
from transformers.utils import direct_transformers_import
# All paths are set with the intent you should run this script from the root of the repo with the command
# python utils/update_metadata.py
TRANSFORMERS_PATH = "src/transformers"
# This is to make sure the transformers module imported is the one in the repo.
transformers_module = direct_transformers_import(TRANSFORMERS_PATH)
# Regexes that match TF/Flax/PT model names.
_re_tf_models = re.compile(r"TF(.*)(?:Model|Encoder|Decoder|ForConditionalGeneration)")
_re_flax_models = re.compile(r"Flax(.*)(?:Model|Encoder|Decoder|ForConditionalGeneration)")
# Will match any TF or Flax model too so need to be in an else branch afterthe two previous regexes.
_re_pt_models = re.compile(r"(.*)(?:Model|Encoder|Decoder|ForConditionalGeneration)")
# Fill this with tuples (pipeline_tag, model_mapping, auto_model)
PIPELINE_TAGS_AND_AUTO_MODELS = [
("pretraining", "MODEL_FOR_PRETRAINING_MAPPING_NAMES", "AutoModelForPreTraining"),
("feature-extraction", "MODEL_MAPPING_NAMES", "AutoModel"),
("audio-classification", "MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES", "AutoModelForAudioClassification"),
("text-generation", "MODEL_FOR_CAUSAL_LM_MAPPING_NAMES", "AutoModelForCausalLM"),
("automatic-speech-recognition", "MODEL_FOR_CTC_MAPPING_NAMES", "AutoModelForCTC"),
("image-classification", "MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES", "AutoModelForImageClassification"),
("image-segmentation", "MODEL_FOR_IMAGE_SEGMENTATION_MAPPING_NAMES", "AutoModelForImageSegmentation"),
("image-to-image", "MODEL_FOR_IMAGE_TO_IMAGE_MAPPING_NAMES", "AutoModelForImageToImage"),
("fill-mask", "MODEL_FOR_MASKED_LM_MAPPING_NAMES", "AutoModelForMaskedLM"),
("object-detection", "MODEL_FOR_OBJECT_DETECTION_MAPPING_NAMES", "AutoModelForObjectDetection"),
(
"zero-shot-object-detection",
"MODEL_FOR_ZERO_SHOT_OBJECT_DETECTION_MAPPING_NAMES",
"AutoModelForZeroShotObjectDetection",
),
("question-answering", "MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES", "AutoModelForQuestionAnswering"),
("text2text-generation", "MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES", "AutoModelForSeq2SeqLM"),
("text-classification", "MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES", "AutoModelForSequenceClassification"),
("automatic-speech-recognition", "MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES", "AutoModelForSpeechSeq2Seq"),
(
"table-question-answering",
"MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING_NAMES",
"AutoModelForTableQuestionAnswering",
),
("token-classification", "MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES", "AutoModelForTokenClassification"),
("multiple-choice", "MODEL_FOR_MULTIPLE_CHOICE_MAPPING_NAMES", "AutoModelForMultipleChoice"),
(
"next-sentence-prediction",
"MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING_NAMES",
"AutoModelForNextSentencePrediction",
),
(
"audio-frame-classification",
"MODEL_FOR_AUDIO_FRAME_CLASSIFICATION_MAPPING_NAMES",
"AutoModelForAudioFrameClassification",
),
("audio-xvector", "MODEL_FOR_AUDIO_XVECTOR_MAPPING_NAMES", "AutoModelForAudioXVector"),
(
"document-question-answering",
"MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING_NAMES",
"AutoModelForDocumentQuestionAnswering",
),
(
"visual-question-answering",
"MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING_NAMES",
"AutoModelForVisualQuestionAnswering",
),
("image-to-text", "MODEL_FOR_FOR_VISION_2_SEQ_MAPPING_NAMES", "AutoModelForVision2Seq"),
(
"zero-shot-image-classification",
"MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING_NAMES",
"AutoModelForZeroShotImageClassification",
),
("depth-estimation", "MODEL_FOR_DEPTH_ESTIMATION_MAPPING_NAMES", "AutoModelForDepthEstimation"),
("video-classification", "MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING_NAMES", "AutoModelForVideoClassification"),
("mask-generation", "MODEL_FOR_MASK_GENERATION_MAPPING_NAMES", "AutoModelForMaskGeneration"),
("text-to-audio", "MODEL_FOR_TEXT_TO_SPECTROGRAM_MAPPING_NAMES", "AutoModelForTextToSpectrogram"),
("text-to-audio", "MODEL_FOR_TEXT_TO_WAVEFORM_MAPPING_NAMES", "AutoModelForTextToWaveform"),
]
def camel_case_split(identifier: str) -> List[str]:
"""
Split a camel-cased name into words.
Args:
identifier (`str`): The camel-cased name to parse.
Returns:
`List[str]`: The list of words in the identifier (as seprated by capital letters).
Example:
```py
>>> camel_case_split("CamelCasedClass")
["Camel", "Cased", "Class"]
```
"""
# Regex thanks to https://stackoverflow.com/questions/29916065/how-to-do-camelcase-split-in-python
matches = re.finditer(".+?(?:(?<=[a-z])(?=[A-Z])|(?<=[A-Z])(?=[A-Z][a-z])|$)", identifier)
return [m.group(0) for m in matches]
def get_frameworks_table() -> pd.DataFrame:
"""
Generates a dataframe containing the supported auto classes for each model type, using the content of the auto
modules.
"""
# Dictionary model names to config.
config_maping_names = transformers_module.models.auto.configuration_auto.CONFIG_MAPPING_NAMES
model_prefix_to_model_type = {
config.replace("Config", ""): model_type for model_type, config in config_maping_names.items()
}
# Dictionaries flagging if each model prefix has a backend in PT/TF/Flax.
pt_models = collections.defaultdict(bool)
tf_models = collections.defaultdict(bool)
flax_models = collections.defaultdict(bool)
# Let's lookup through all transformers object (once) and find if models are supported by a given backend.
for attr_name in dir(transformers_module):
lookup_dict = None
if _re_tf_models.match(attr_name) is not None:
lookup_dict = tf_models
attr_name = _re_tf_models.match(attr_name).groups()[0]
elif _re_flax_models.match(attr_name) is not None:
lookup_dict = flax_models
attr_name = _re_flax_models.match(attr_name).groups()[0]
elif _re_pt_models.match(attr_name) is not None:
lookup_dict = pt_models
attr_name = _re_pt_models.match(attr_name).groups()[0]
if lookup_dict is not None:
while len(attr_name) > 0:
if attr_name in model_prefix_to_model_type:
lookup_dict[model_prefix_to_model_type[attr_name]] = True
break
# Try again after removing the last word in the name
attr_name = "".join(camel_case_split(attr_name)[:-1])
all_models = set(list(pt_models.keys()) + list(tf_models.keys()) + list(flax_models.keys()))
all_models = list(all_models)
all_models.sort()
data = {"model_type": all_models}
data["pytorch"] = [pt_models[t] for t in all_models]
data["tensorflow"] = [tf_models[t] for t in all_models]
data["flax"] = [flax_models[t] for t in all_models]
# Now let's find the right processing class for each model. In order we check if there is a Processor, then a
# Tokenizer, then a FeatureExtractor, then an ImageProcessor
processors = {}
for t in all_models:
if t in transformers_module.models.auto.processing_auto.PROCESSOR_MAPPING_NAMES:
processors[t] = "AutoProcessor"
elif t in transformers_module.models.auto.tokenization_auto.TOKENIZER_MAPPING_NAMES:
processors[t] = "AutoTokenizer"
elif t in transformers_module.models.auto.image_processing_auto.IMAGE_PROCESSOR_MAPPING_NAMES:
processors[t] = "AutoImageProcessor"
elif t in transformers_module.models.auto.feature_extraction_auto.FEATURE_EXTRACTOR_MAPPING_NAMES:
processors[t] = "AutoFeatureExtractor"
else:
# Default to AutoTokenizer if a model has nothing, for backward compatibility.
processors[t] = "AutoTokenizer"
data["processor"] = [processors[t] for t in all_models]
return pd.DataFrame(data)
def update_pipeline_and_auto_class_table(table: Dict[str, Tuple[str, str]]) -> Dict[str, Tuple[str, str]]:
"""
Update the table maping models to pipelines and auto classes without removing old keys if they don't exist anymore.
Args:
table (`Dict[str, Tuple[str, str]]`):
The existing table mapping model names to a tuple containing the pipeline tag and the auto-class name with
which they should be used.
Returns:
`Dict[str, Tuple[str, str]]`: The updated table in the same format.
"""
auto_modules = [
transformers_module.models.auto.modeling_auto,
transformers_module.models.auto.modeling_tf_auto,
transformers_module.models.auto.modeling_flax_auto,
]
for pipeline_tag, model_mapping, auto_class in PIPELINE_TAGS_AND_AUTO_MODELS:
model_mappings = [model_mapping, f"TF_{model_mapping}", f"FLAX_{model_mapping}"]
auto_classes = [auto_class, f"TF_{auto_class}", f"Flax_{auto_class}"]
# Loop through all three frameworks
for module, cls, mapping in zip(auto_modules, auto_classes, model_mappings):
# The type of pipeline may not exist in this framework
if not hasattr(module, mapping):
continue
# First extract all model_names
model_names = []
for name in getattr(module, mapping).values():
if isinstance(name, str):
model_names.append(name)
else:
model_names.extend(list(name))
# Add pipeline tag and auto model class for those models
table.update({model_name: (pipeline_tag, cls) for model_name in model_names})
return table
def update_metadata(token: str, commit_sha: str):
"""
Update the metadata for the Transformers repo in `huggingface/transformers-metadata`.
Args:
token (`str`): A valid token giving write access to `huggingface/transformers-metadata`.
commit_sha (`str`): The commit SHA on Transformers corresponding to this update.
"""
frameworks_table = get_frameworks_table()
frameworks_dataset = Dataset.from_pandas(frameworks_table)
resolved_tags_file = hf_hub_download(
"huggingface/transformers-metadata", "pipeline_tags.json", repo_type="dataset", token=token
)
tags_dataset = Dataset.from_json(resolved_tags_file)
table = {
tags_dataset[i]["model_class"]: (tags_dataset[i]["pipeline_tag"], tags_dataset[i]["auto_class"])
for i in range(len(tags_dataset))
}
table = update_pipeline_and_auto_class_table(table)
# Sort the model classes to avoid some nondeterministic updates to create false update commits.
model_classes = sorted(table.keys())
tags_table = pd.DataFrame(
{
"model_class": model_classes,
"pipeline_tag": [table[m][0] for m in model_classes],
"auto_class": [table[m][1] for m in model_classes],
}
)
tags_dataset = Dataset.from_pandas(tags_table)
with tempfile.TemporaryDirectory() as tmp_dir:
frameworks_dataset.to_json(os.path.join(tmp_dir, "frameworks.json"))
tags_dataset.to_json(os.path.join(tmp_dir, "pipeline_tags.json"))
if commit_sha is not None:
commit_message = (
f"Update with commit {commit_sha}\n\nSee: "
f"https://github.com/huggingface/transformers/commit/{commit_sha}"
)
else:
commit_message = "Update"
upload_folder(
repo_id="huggingface/transformers-metadata",
folder_path=tmp_dir,
repo_type="dataset",
token=token,
commit_message=commit_message,
)
def check_pipeline_tags():
"""
Check all pipeline tags are properly defined in the `PIPELINE_TAGS_AND_AUTO_MODELS` constant of this script.
"""
in_table = {tag: cls for tag, _, cls in PIPELINE_TAGS_AND_AUTO_MODELS}
pipeline_tasks = transformers_module.pipelines.SUPPORTED_TASKS
missing = []
for key in pipeline_tasks:
if key not in in_table:
model = pipeline_tasks[key]["pt"]
if isinstance(model, (list, tuple)):
model = model[0]
model = model.__name__
if model not in in_table.values():
missing.append(key)
if len(missing) > 0:
msg = ", ".join(missing)
raise ValueError(
"The following pipeline tags are not present in the `PIPELINE_TAGS_AND_AUTO_MODELS` constant inside "
f"`utils/update_metadata.py`: {msg}. Please add them!"
)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--token", type=str, help="The token to use to push to the transformers-metadata dataset.")
parser.add_argument("--commit_sha", type=str, help="The sha of the commit going with this update.")
parser.add_argument("--check-only", action="store_true", help="Activate to just check all pipelines are present.")
args = parser.parse_args()
if args.check_only:
check_pipeline_tags()
else:
update_metadata(args.token, args.commit_sha)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/utils/check_config_attributes.py
|
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import os
import re
from transformers.configuration_utils import PretrainedConfig
from transformers.utils import direct_transformers_import
# All paths are set with the intent you should run this script from the root of the repo with the command
# python utils/check_config_docstrings.py
PATH_TO_TRANSFORMERS = "src/transformers"
# This is to make sure the transformers module imported is the one in the repo.
transformers = direct_transformers_import(PATH_TO_TRANSFORMERS)
CONFIG_MAPPING = transformers.models.auto.configuration_auto.CONFIG_MAPPING
SPECIAL_CASES_TO_ALLOW = {
# used to compute the property `self.chunk_length`
"EncodecConfig": ["overlap"],
# used as `self.bert_model = BertModel(config, ...)`
"DPRConfig": True,
"FuyuConfig": True,
# not used in modeling files, but it's an important information
"FSMTConfig": ["langs"],
# used internally in the configuration class file
"GPTNeoConfig": ["attention_types"],
# used internally in the configuration class file
"EsmConfig": ["is_folding_model"],
# used during training (despite we don't have training script for these models yet)
"Mask2FormerConfig": ["ignore_value"],
# `ignore_value` used during training (despite we don't have training script for these models yet)
# `norm` used in conversion script (despite not using in the modeling file)
"OneFormerConfig": ["ignore_value", "norm"],
# used during preprocessing and collation, see `collating_graphormer.py`
"GraphormerConfig": ["spatial_pos_max"],
# used internally in the configuration class file
"T5Config": ["feed_forward_proj"],
# used internally in the configuration class file
# `tokenizer_class` get default value `T5Tokenizer` intentionally
"MT5Config": ["feed_forward_proj", "tokenizer_class"],
"UMT5Config": ["feed_forward_proj", "tokenizer_class"],
# used internally in the configuration class file
"LongT5Config": ["feed_forward_proj"],
# used internally in the configuration class file
"Pop2PianoConfig": ["feed_forward_proj"],
# used internally in the configuration class file
"SwitchTransformersConfig": ["feed_forward_proj"],
# having default values other than `1e-5` - we can't fix them without breaking
"BioGptConfig": ["layer_norm_eps"],
# having default values other than `1e-5` - we can't fix them without breaking
"GLPNConfig": ["layer_norm_eps"],
# having default values other than `1e-5` - we can't fix them without breaking
"SegformerConfig": ["layer_norm_eps"],
# having default values other than `1e-5` - we can't fix them without breaking
"CvtConfig": ["layer_norm_eps"],
# having default values other than `1e-5` - we can't fix them without breaking
"PerceiverConfig": ["layer_norm_eps"],
# used internally to calculate the feature size
"InformerConfig": ["num_static_real_features", "num_time_features"],
# used internally to calculate the feature size
"TimeSeriesTransformerConfig": ["num_static_real_features", "num_time_features"],
# used internally to calculate the feature size
"AutoformerConfig": ["num_static_real_features", "num_time_features"],
# used internally to calculate `mlp_dim`
"SamVisionConfig": ["mlp_ratio"],
# For (head) training, but so far not implemented
"ClapAudioConfig": ["num_classes"],
# Not used, but providing useful information to users
"SpeechT5HifiGanConfig": ["sampling_rate"],
# Actually used in the config or generation config, in that case necessary for the sub-components generation
"SeamlessM4TConfig": [
"max_new_tokens",
"t2u_max_new_tokens",
"t2u_decoder_attention_heads",
"t2u_decoder_ffn_dim",
"t2u_decoder_layers",
"t2u_encoder_attention_heads",
"t2u_encoder_ffn_dim",
"t2u_encoder_layers",
"t2u_max_position_embeddings",
],
}
# TODO (ydshieh): Check the failing cases, try to fix them or move some cases to the above block once we are sure
SPECIAL_CASES_TO_ALLOW.update(
{
"CLIPSegConfig": True,
"DeformableDetrConfig": True,
"DetaConfig": True,
"DinatConfig": True,
"DonutSwinConfig": True,
"EfficientFormerConfig": True,
"FSMTConfig": True,
"JukeboxConfig": True,
"LayoutLMv2Config": True,
"MaskFormerSwinConfig": True,
"MT5Config": True,
# For backward compatibility with trust remote code models
"MptConfig": True,
"MptAttentionConfig": True,
"NatConfig": True,
"OneFormerConfig": True,
"PerceiverConfig": True,
"RagConfig": True,
"SpeechT5Config": True,
"SwinConfig": True,
"Swin2SRConfig": True,
"Swinv2Config": True,
"SwitchTransformersConfig": True,
"TableTransformerConfig": True,
"TapasConfig": True,
"UniSpeechConfig": True,
"UniSpeechSatConfig": True,
"WavLMConfig": True,
"WhisperConfig": True,
# TODO: @Arthur (for `alignment_head` and `alignment_layer`)
"JukeboxPriorConfig": True,
# TODO: @Younes (for `is_decoder`)
"Pix2StructTextConfig": True,
"IdeficsConfig": True,
"IdeficsVisionConfig": True,
"IdeficsPerceiverConfig": True,
}
)
def check_attribute_being_used(config_class, attributes, default_value, source_strings):
"""Check if any name in `attributes` is used in one of the strings in `source_strings`
Args:
config_class (`type`):
The configuration class for which the arguments in its `__init__` will be checked.
attributes (`List[str]`):
The name of an argument (or attribute) and its variant names if any.
default_value (`Any`):
A default value for the attribute in `attributes` assigned in the `__init__` of `config_class`.
source_strings (`List[str]`):
The python source code strings in the same modeling directory where `config_class` is defined. The file
containing the definition of `config_class` should be excluded.
"""
attribute_used = False
for attribute in attributes:
for modeling_source in source_strings:
# check if we can find `config.xxx`, `getattr(config, "xxx", ...)` or `getattr(self.config, "xxx", ...)`
if (
f"config.{attribute}" in modeling_source
or f'getattr(config, "{attribute}"' in modeling_source
or f'getattr(self.config, "{attribute}"' in modeling_source
):
attribute_used = True
# Deal with multi-line cases
elif (
re.search(
rf'getattr[ \t\v\n\r\f]*\([ \t\v\n\r\f]*(self\.)?config,[ \t\v\n\r\f]*"{attribute}"',
modeling_source,
)
is not None
):
attribute_used = True
# `SequenceSummary` is called with `SequenceSummary(config)`
elif attribute in [
"summary_type",
"summary_use_proj",
"summary_activation",
"summary_last_dropout",
"summary_proj_to_labels",
"summary_first_dropout",
]:
if "SequenceSummary" in modeling_source:
attribute_used = True
if attribute_used:
break
if attribute_used:
break
# common and important attributes, even if they do not always appear in the modeling files
attributes_to_allow = [
"bos_index",
"eos_index",
"pad_index",
"unk_index",
"mask_index",
"image_size",
"use_cache",
"out_features",
"out_indices",
"sampling_rate",
]
attributes_used_in_generation = ["encoder_no_repeat_ngram_size"]
# Special cases to be allowed
case_allowed = True
if not attribute_used:
case_allowed = False
for attribute in attributes:
# Allow if the default value in the configuration class is different from the one in `PretrainedConfig`
if attribute in ["is_encoder_decoder"] and default_value is True:
case_allowed = True
elif attribute in ["tie_word_embeddings"] and default_value is False:
case_allowed = True
# Allow cases without checking the default value in the configuration class
elif attribute in attributes_to_allow + attributes_used_in_generation:
case_allowed = True
elif attribute.endswith("_token_id"):
case_allowed = True
# configuration class specific cases
if not case_allowed:
allowed_cases = SPECIAL_CASES_TO_ALLOW.get(config_class.__name__, [])
case_allowed = allowed_cases is True or attribute in allowed_cases
return attribute_used or case_allowed
def check_config_attributes_being_used(config_class):
"""Check the arguments in `__init__` of `config_class` are used in the modeling files in the same directory
Args:
config_class (`type`):
The configuration class for which the arguments in its `__init__` will be checked.
"""
# Get the parameters in `__init__` of the configuration class, and the default values if any
signature = dict(inspect.signature(config_class.__init__).parameters)
parameter_names = [x for x in list(signature.keys()) if x not in ["self", "kwargs"]]
parameter_defaults = [signature[param].default for param in parameter_names]
# If `attribute_map` exists, an attribute can have different names to be used in the modeling files, and as long
# as one variant is used, the test should pass
reversed_attribute_map = {}
if len(config_class.attribute_map) > 0:
reversed_attribute_map = {v: k for k, v in config_class.attribute_map.items()}
# Get the path to modeling source files
config_source_file = inspect.getsourcefile(config_class)
model_dir = os.path.dirname(config_source_file)
# Let's check against all frameworks: as long as one framework uses an attribute, we are good.
modeling_paths = [os.path.join(model_dir, fn) for fn in os.listdir(model_dir) if fn.startswith("modeling_")]
# Get the source code strings
modeling_sources = []
for path in modeling_paths:
if os.path.isfile(path):
with open(path, encoding="utf8") as fp:
modeling_sources.append(fp.read())
unused_attributes = []
for config_param, default_value in zip(parameter_names, parameter_defaults):
# `attributes` here is all the variant names for `config_param`
attributes = [config_param]
# some configuration classes have non-empty `attribute_map`, and both names could be used in the
# corresponding modeling files. As long as one of them appears, it is fine.
if config_param in reversed_attribute_map:
attributes.append(reversed_attribute_map[config_param])
if not check_attribute_being_used(config_class, attributes, default_value, modeling_sources):
unused_attributes.append(attributes[0])
return sorted(unused_attributes)
def check_config_attributes():
"""Check the arguments in `__init__` of all configuration classes are used in python files"""
configs_with_unused_attributes = {}
for _config_class in list(CONFIG_MAPPING.values()):
# Skip deprecated models
if "models.deprecated" in _config_class.__module__:
continue
# Some config classes are not in `CONFIG_MAPPING` (e.g. `CLIPVisionConfig`, `Blip2VisionConfig`, etc.)
config_classes_in_module = [
cls
for name, cls in inspect.getmembers(
inspect.getmodule(_config_class),
lambda x: inspect.isclass(x)
and issubclass(x, PretrainedConfig)
and inspect.getmodule(x) == inspect.getmodule(_config_class),
)
]
for config_class in config_classes_in_module:
unused_attributes = check_config_attributes_being_used(config_class)
if len(unused_attributes) > 0:
configs_with_unused_attributes[config_class.__name__] = unused_attributes
if len(configs_with_unused_attributes) > 0:
error = "The following configuration classes contain unused attributes in the corresponding modeling files:\n"
for name, attributes in configs_with_unused_attributes.items():
error += f"{name}: {attributes}\n"
raise ValueError(error)
if __name__ == "__main__":
check_config_attributes()
| 0
|
hf_public_repos/transformers/utils
|
hf_public_repos/transformers/utils/test_module/custom_tokenization.py
|
from transformers import BertTokenizer
class CustomTokenizer(BertTokenizer):
pass
| 0
|
hf_public_repos/transformers/utils
|
hf_public_repos/transformers/utils/test_module/custom_feature_extraction.py
|
from transformers import Wav2Vec2FeatureExtractor
class CustomFeatureExtractor(Wav2Vec2FeatureExtractor):
pass
| 0
|
hf_public_repos/transformers/utils
|
hf_public_repos/transformers/utils/test_module/custom_processing.py
|
from transformers import ProcessorMixin
class CustomProcessor(ProcessorMixin):
feature_extractor_class = "AutoFeatureExtractor"
tokenizer_class = "AutoTokenizer"
| 0
|
hf_public_repos/transformers/utils
|
hf_public_repos/transformers/utils/test_module/custom_tokenization_fast.py
|
from transformers import BertTokenizerFast
from .custom_tokenization import CustomTokenizer
class CustomTokenizerFast(BertTokenizerFast):
slow_tokenizer_class = CustomTokenizer
pass
| 0
|
hf_public_repos/transformers/utils
|
hf_public_repos/transformers/utils/test_module/custom_modeling.py
|
import torch
from transformers import PreTrainedModel
from .custom_configuration import CustomConfig, NoSuperInitConfig
class CustomModel(PreTrainedModel):
config_class = CustomConfig
def __init__(self, config):
super().__init__(config)
self.linear = torch.nn.Linear(config.hidden_size, config.hidden_size)
def forward(self, x):
return self.linear(x)
def _init_weights(self, module):
pass
class NoSuperInitModel(PreTrainedModel):
config_class = NoSuperInitConfig
def __init__(self, config):
super().__init__(config)
self.linear = torch.nn.Linear(config.attribute, config.attribute)
def forward(self, x):
return self.linear(x)
def _init_weights(self, module):
pass
| 0
|
hf_public_repos/transformers/utils
|
hf_public_repos/transformers/utils/test_module/custom_configuration.py
|
from transformers import PretrainedConfig
class CustomConfig(PretrainedConfig):
model_type = "custom"
def __init__(self, attribute=1, **kwargs):
self.attribute = attribute
super().__init__(**kwargs)
class NoSuperInitConfig(PretrainedConfig):
model_type = "custom"
def __init__(self, attribute=1, **kwargs):
self.attribute = attribute
| 0
|
hf_public_repos/transformers/utils
|
hf_public_repos/transformers/utils/test_module/custom_image_processing.py
|
from transformers import CLIPImageProcessor
class CustomImageProcessor(CLIPImageProcessor):
pass
| 0
|
hf_public_repos/transformers/utils
|
hf_public_repos/transformers/utils/test_module/custom_pipeline.py
|
import numpy as np
from transformers import Pipeline
def softmax(outputs):
maxes = np.max(outputs, axis=-1, keepdims=True)
shifted_exp = np.exp(outputs - maxes)
return shifted_exp / shifted_exp.sum(axis=-1, keepdims=True)
class PairClassificationPipeline(Pipeline):
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "second_text" in kwargs:
preprocess_kwargs["second_text"] = kwargs["second_text"]
return preprocess_kwargs, {}, {}
def preprocess(self, text, second_text=None):
return self.tokenizer(text, text_pair=second_text, return_tensors=self.framework)
def _forward(self, model_inputs):
return self.model(**model_inputs)
def postprocess(self, model_outputs):
logits = model_outputs.logits[0].numpy()
probabilities = softmax(logits)
best_class = np.argmax(probabilities)
label = self.model.config.id2label[best_class]
score = probabilities[best_class].item()
logits = logits.tolist()
return {"label": label, "score": score, "logits": logits}
| 0
|
hf_public_repos/transformers/utils
|
hf_public_repos/transformers/utils/tf_ops/onnx.json
|
{
"opsets": {
"1": [
"Abs",
"Add",
"AddV2",
"ArgMax",
"ArgMin",
"AvgPool",
"AvgPool3D",
"BatchMatMul",
"BatchMatMulV2",
"BatchToSpaceND",
"BiasAdd",
"BiasAddV1",
"Cast",
"Ceil",
"CheckNumerics",
"ComplexAbs",
"Concat",
"ConcatV2",
"Const",
"ConstV2",
"Conv1D",
"Conv2D",
"Conv2DBackpropInput",
"Conv3D",
"Conv3DBackpropInputV2",
"DepthToSpace",
"DepthwiseConv2d",
"DepthwiseConv2dNative",
"Div",
"Dropout",
"Elu",
"Equal",
"Erf",
"Exp",
"ExpandDims",
"Flatten",
"Floor",
"Gather",
"GatherNd",
"GatherV2",
"Greater",
"Identity",
"IdentityN",
"If",
"LRN",
"LSTMBlockCell",
"LeakyRelu",
"Less",
"Log",
"LogSoftmax",
"LogicalAnd",
"LogicalNot",
"LogicalOr",
"LookupTableSizeV2",
"MatMul",
"Max",
"MaxPool",
"MaxPool3D",
"MaxPoolV2",
"Maximum",
"Mean",
"Min",
"Minimum",
"MirrorPad",
"Mul",
"Neg",
"NoOp",
"NotEqual",
"OneHot",
"Pack",
"Pad",
"PadV2",
"Placeholder",
"PlaceholderV2",
"PlaceholderWithDefault",
"Pow",
"Prod",
"RFFT",
"RandomNormal",
"RandomNormalLike",
"RandomUniform",
"RandomUniformLike",
"RealDiv",
"Reciprocal",
"Relu",
"Relu6",
"Reshape",
"Rsqrt",
"Selu",
"Shape",
"Sigmoid",
"Sign",
"Size",
"Slice",
"Softmax",
"Softplus",
"Softsign",
"SpaceToBatchND",
"SpaceToDepth",
"Split",
"SplitV",
"Sqrt",
"Square",
"SquaredDifference",
"Squeeze",
"StatelessIf",
"StopGradient",
"StridedSlice",
"StringJoin",
"Sub",
"Sum",
"Tanh",
"Tile",
"TopKV2",
"Transpose",
"TruncateDiv",
"Unpack",
"ZerosLike"
],
"2": [],
"3": [],
"4": [],
"5": [],
"6": [
"AddN",
"All",
"Any",
"FloorDiv",
"FusedBatchNorm",
"FusedBatchNormV2",
"FusedBatchNormV3"
],
"7": [
"Acos",
"Asin",
"Atan",
"Cos",
"Fill",
"FloorMod",
"GreaterEqual",
"LessEqual",
"Loop",
"MatrixBandPart",
"Multinomial",
"Range",
"ResizeBilinear",
"ResizeNearestNeighbor",
"Scan",
"Select",
"SelectV2",
"Sin",
"SoftmaxCrossEntropyWithLogits",
"SparseSoftmaxCrossEntropyWithLogits",
"StatelessWhile",
"Tan",
"TensorListFromTensor",
"TensorListGetItem",
"TensorListLength",
"TensorListReserve",
"TensorListResize",
"TensorListSetItem",
"TensorListStack",
"While"
],
"8": [
"BroadcastTo",
"ClipByValue",
"FIFOQueueV2",
"HashTableV2",
"IteratorGetNext",
"IteratorV2",
"LookupTableFindV2",
"MaxPoolWithArgmax",
"QueueDequeueManyV2",
"QueueDequeueUpToV2",
"QueueDequeueV2",
"ReverseSequence"
],
"9": [
"SegmentMax",
"SegmentMean",
"SegmentMin",
"SegmentProd",
"SegmentSum",
"Sinh",
"SparseSegmentMean",
"SparseSegmentMeanWithNumSegments",
"SparseSegmentSqrtN",
"SparseSegmentSqrtNWithNumSegments",
"SparseSegmentSum",
"SparseSegmentSumWithNumSegments",
"UnsortedSegmentMax",
"UnsortedSegmentMin",
"UnsortedSegmentProd",
"UnsortedSegmentSum",
"Where"
],
"10": [
"CropAndResize",
"CudnnRNN",
"DynamicStitch",
"FakeQuantWithMinMaxArgs",
"IsFinite",
"IsInf",
"NonMaxSuppressionV2",
"NonMaxSuppressionV3",
"NonMaxSuppressionV4",
"NonMaxSuppressionV5",
"ParallelDynamicStitch",
"ReverseV2",
"Roll"
],
"11": [
"Bincount",
"Cumsum",
"InvertPermutation",
"LeftShift",
"MatrixDeterminant",
"MatrixDiagPart",
"MatrixDiagPartV2",
"MatrixDiagPartV3",
"RaggedRange",
"RightShift",
"Round",
"ScatterNd",
"SparseFillEmptyRows",
"SparseReshape",
"SparseToDense",
"TensorScatterUpdate",
"Unique"
],
"12": [
"Einsum",
"MatrixDiag",
"MatrixDiagV2",
"MatrixDiagV3",
"MatrixSetDiagV3",
"SquaredDistance"
],
"13": []
}
}
| 0
|
hf_public_repos/transformers/templates
|
hf_public_repos/transformers/templates/adding_a_new_example_script/README.md
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# How to add a new example script in 🤗 Transformers
This folder provide a template for adding a new example script implementing a training or inference task with the
models in the 🤗 Transformers library. To use it, you will need to install cookiecutter:
```
pip install cookiecutter
```
or refer to the installation page of the [cookiecutter documentation](https://cookiecutter.readthedocs.io/).
You can then run the following command inside the `examples` folder of the transformers repo:
```
cookiecutter ../templates/adding_a_new_example_script/
```
and answer the questions asked, which will generate a new folder where you will find a pre-filled template for your
example following the best practices we recommend for them.
Adjust the way the data is preprocessed, the model is loaded or the Trainer is instantiated then when you're happy, add
a `README.md` in the folder (or complete the existing one if you added a script to an existing folder) telling a user
how to run your script.
Make a PR to the 🤗 Transformers repo. Don't forget to tweet about your new example with a carbon screenshot of how to
run it and tag @huggingface!
| 0
|
hf_public_repos/transformers/templates
|
hf_public_repos/transformers/templates/adding_a_new_example_script/cookiecutter.json
|
{
"example_name": "text classification",
"directory_name": "{{cookiecutter.example_name|lower|replace(' ', '-')}}",
"example_shortcut": "{{cookiecutter.directory_name}}",
"model_class": "AutoModel",
"authors": "The HuggingFace Team",
"can_train_from_scratch": ["True", "False"],
"with_trainer": ["True", "False"]
}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_example_script
|
hf_public_repos/transformers/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning a 🤗 Transformers model on {{cookiecutter.example_name}}.
"""
# You can also adapt this script on your own {{cookiecutter.example_name}} task. Pointers for this are left as comments.
{%- if cookiecutter.with_trainer == "True" %}
import logging
import math
import os
import sys
from dataclasses import dataclass, field
from typing import Optional, List
import datasets
import torch
from datasets import load_dataset
import transformers
from transformers import (
CONFIG_MAPPING,
MODEL_MAPPING,
AutoConfig,
{{cookiecutter.model_class}},
AutoTokenizer,
DataCollatorWithPadding,
HfArgumentParser,
Trainer,
TrainingArguments,
default_data_collator,
set_seed,
)
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import send_example_telemetry
logger = logging.getLogger(__name__)
{%- if cookiecutter.can_train_from_scratch == "True" %}
# You should update this to your particular problem to have better documentation of `model_type`
MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
model_name_or_path: Optional[str] = field(
default=None,
metadata={
"help": "The model checkpoint for weights initialization. "
"Don't set if you want to train a model from scratch."
},
)
model_type: Optional[str] = field(
default=None,
metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"}
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
{%- elif cookiecutter.can_train_from_scratch == "False" %}
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"}
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
trust_remote_code: bool = field(
default=False,
metadata={
"help": (
"Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
"should only be set to `True` for repositories you trust and in which you have read the code, as it will "
"execute code present on the Hub on your local machine."
)
},
)
{% endif %}
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
)
test_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input test data file to predict the label on (a text file)."},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
},
)
max_predict_samples: Optional[int] = field(
default=None,
metadata={
"help": "For debugging purposes or quicker training, truncate the number of prediction examples to this "
"value if set."
},
)
def __post_init__(self):
if (
self.dataset_name is None
and self.train_file is None
and self.validation_file is None
and self.test_file is None
):
raise ValueError("Need either a dataset name or a training/validation/test file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
if self.test_file is not None:
extension = self.test_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`test_file` should be a csv, a json or a txt file."
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_{{cookiecutter.example_shortcut}}", model_args, data_args)
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# Set seed before initializing model.
set_seed(training_args.seed)
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
if data_args.test_file is not None:
data_files["test"] = data_args.test_file
extension = data_args.test_file.split(".")[-1]
if extension == "txt":
extension = "text"
raw_datasets = load_dataset(extension, data_files=data_files)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
{%- if cookiecutter.can_train_from_scratch == "True" %}
config_kwargs = {
"cache_dir": model_args.cache_dir,
"revision": model_args.model_revision,
"token": model_args.token,
"trust_remote_code": model_args.trust_remote_code,
}
if model_args.config_name:
config = AutoConfig.from_pretrained(model_args.config_name, **config_kwargs)
elif model_args.model_name_or_path:
config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
else:
config = CONFIG_MAPPING[model_args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
tokenizer_kwargs = {
"cache_dir": model_args.cache_dir,
"use_fast": model_args.use_fast_tokenizer,
"revision": model_args.model_revision,
"token": model_args.token,
"trust_remote_code": model_args.trust_remote_code,
}
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
elif model_args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script. "
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if model_args.model_name_or_path:
model = {{cookiecutter.model_class}}.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
else:
logger.info("Training new model from scratch")
model = {{cookiecutter.model_class}}.from_config(config)
model.resize_token_embeddings(len(tokenizer))
{%- elif cookiecutter.can_train_from_scratch == "False" %}
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
# num_labels=num_labels, Uncomment if you have a certain number of labels
finetuning_task=data_args.task_name,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
model = AutoModelForSequenceClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
{% endif %}
# Preprocessing the datasets.
# First we tokenize all the texts.
if training_args.do_train:
column_names = raw_datasets["train"].column_names
elif training_args.do_eval:
column_names = raw_datasets["validation"].column_names
elif training_args.do_predict:
column_names = raw_datasets["test"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
def tokenize_function(examples):
return tokenizer(examples[text_column_name], padding="max_length", truncation=True)
if training_args.do_train:
if "train" not in raw_datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = raw_datasets["train"]
if data_args.max_train_samples is not None:
# Select Sample from Dataset
train_dataset = train_dataset.select(range(data_args.max_train_samples))
# tokenize train dataset in batch
with training_args.main_process_first(desc="train dataset map tokenization"):
train_dataset = train_dataset.map(
tokenize_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=[text_column_name],
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_eval:
if "validation" not in raw_datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = raw_datasets["validation"]
# Selecting samples from dataset
if data_args.max_eval_samples is not None:
eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
# tokenize validation dataset
with training_args.main_process_first(desc="validation dataset map tokenization"):
eval_dataset = eval_dataset.map(
tokenize_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=[text_column_name],
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_predict:
if "test" not in raw_datasets:
raise ValueError("--do_predict requires a test dataset")
predict_dataset = raw_datasets["test"]
# Selecting samples from dataset
if data_args.max_predict_samples is not None:
predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
# tokenize predict dataset
with training_args.main_process_first(desc="prediction dataset map tokenization"):
predict_dataset = predict_dataset.map(
tokenize_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=[text_column_name],
load_from_cache_file=not data_args.overwrite_cache,
)
# Data collator
data_collator=default_data_collator if not training_args.fp16 else DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8)
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
)
# Training
if training_args.do_train:
{%- if cookiecutter.can_train_from_scratch == "False" %}
if last_checkpoint is not None:
checkpoint = last_checkpoint
elif os.path.isdir(model_args.model_name_or_path):
checkpoint = model_args.model_name_or_path
else:
checkpoint = None
{%- elif cookiecutter.can_train_from_scratch == "True" %}
if last_checkpoint is not None:
checkpoint = last_checkpoint
elif model_args.model_name_or_path is not None and os.path.isdir(model_args.model_name_or_path):
checkpoint = model_args.model_name_or_path
else:
checkpoint = None
{% endif %}
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model() # Saves the tokenizer too for easy upload
metrics = train_result.metrics
max_train_samples = (
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
)
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
# Prediction
if training_args.do_predict:
logger.info("*** Predict ***")
predictions, labels, metrics = trainer.predict(predict_dataset)
max_predict_samples = data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
trainer.log_metrics("predict", metrics)
trainer.save_metrics("predict", metrics)
# write custom code for saving predictions according to task
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
{%- elif cookiecutter.with_trainer == "False" %}
import argparse
import logging
import math
import os
import random
import datasets
from datasets import load_dataset, load_metric
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
import transformers
from accelerate import Accelerator
from transformers import (
CONFIG_MAPPING,
MODEL_MAPPING,
AdamW,
AutoConfig,
{{cookiecutter.model_class}},
AutoTokenizer,
DataCollatorWithPadding,
PretrainedConfig,
SchedulerType,
default_data_collator,
get_scheduler,
set_seed,
)
from transformers.utils import send_example_telemetry
logger = logging.getLogger(__name__)
{%- if cookiecutter.can_train_from_scratch == "True" %}
# You should update this to your particular problem to have better documentation of `model_type`
MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
{% endif %}
def parse_args():
parser = argparse.ArgumentParser(description="Finetune a transformers model on a text classification task")
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help="The name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help= "The configuration name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--train_file", type=str, default=None, help="A csv or a json file containing the training data."
)
parser.add_argument(
"--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
)
parser.add_argument(
"--max_length",
type=int,
default=128,
help=(
"The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
" sequences shorter will be padded if `--pad_to_max_lengh` is passed."
),
)
parser.add_argument(
"--pad_to_max_length",
action="store_true",
help="If passed, pad all samples to `max_length`. Otherwise, dynamic padding is used.",
)
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to pretrained model or model identifier from huggingface.co/models.",
required=True,
)
parser.add_argument(
"--config_name",
type=str,
default=None,
help="Pretrained config name or path if not the same as model_name",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--use_slow_tokenizer",
action="store_true",
help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
)
parser.add_argument(
"--per_device_train_batch_size",
type=int,
default=8,
help="Batch size (per device) for the training dataloader.",
)
parser.add_argument(
"--per_device_eval_batch_size",
type=int,
default=8,
help="Batch size (per device) for the evaluation dataloader.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-5,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--lr_scheduler_type",
type=SchedulerType,
default="linear",
help="The scheduler type to use.",
choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
)
parser.add_argument(
"--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
{%- if cookiecutter.can_train_from_scratch == "True" %}
parser.add_argument(
"--model_type",
type=str,
default=None,
help="Model type to use if training from scratch.",
choices=MODEL_TYPES,
)
{% endif %}
args = parser.parse_args()
# Sanity checks
if args.task_name is None and args.train_file is None and args.validation_file is None:
raise ValueError("Need either a task name or a training/validation file.")
else:
if args.train_file is not None:
extension = args.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if args.validation_file is not None:
extension = args.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
return args
def main():
args = parse_args()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_{{cookiecutter.example_shortcut}", args)
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
accelerator = Accelerator()
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state)
# Setup logging, we only want one process per machine to log things on the screen.
# accelerator.is_local_main_process is only True for one process per machine.
logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(args.dataset_name, args.dataset_config_name)
else:
data_files = {}
if args.train_file is not None:
data_files["train"] = args.train_file
if args.validation_file is not None:
data_files["validation"] = args.validation_file
extension = args.train_file.split(".")[-1]
raw_datasets = load_dataset(extension, data_files=data_files)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Load pretrained model and tokenizer
#
# In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
{%- if cookiecutter.can_train_from_scratch == "True" %}
if model_args.config_name:
config = AutoConfig.from_pretrained(args.model_name_or_path)
elif model_args.model_name_or_path:
config = AutoConfig.from_pretrained(args.model_name_or_path)
else:
config = CONFIG_MAPPING[args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, use_fast=not args.use_slow_tokenizer)
elif model_args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, use_fast=not args.use_slow_tokenizer)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script. "
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if model_args.model_name_or_path:
model = {{cookiecutter.model_class}}.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
)
else:
logger.info("Training new model from scratch")
model = {{cookiecutter.model_class}}.from_config(config)
model.resize_token_embeddings(len(tokenizer))
{%- elif cookiecutter.can_train_from_scratch == "False" %}
config = AutoConfig.from_pretrained(
args.config_name if model_args.config_name else args.model_name_or_path,
# num_labels=num_labels, Uncomment if you have a certain number of labels
finetuning_task=data_args.task_name,
)
tokenizer = AutoTokenizer.from_pretrained(
args.tokenizer_name if model_args.tokenizer_name else args.model_name_or_path,
use_fast=not args.use_slow_tokenizer,
)
model = AutoModelForSequenceClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
)
{% endif %}
# Preprocessing the datasets.
# First we tokenize all the texts.
column_names = raw_datasets["train"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
padding = "max_length" if args.pad_to_max_length else False
def tokenize_function(examples):
result = tokenizer(examples[text_column_name], padding=padding, max_length=args.max_length, truncation=True)
if "label" in examples:
result["labels"] = examples["label"]
return result
processed_datasets = raw_datasets.map(
preprocess_function, batched=True, remove_columns=raw_datasets["train"].column_names
)
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["validation"]
# Log a few random samples from the training set:
for index in random.sample(range(len(train_dataset)), 3):
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
# DataLoaders creation:
if args.pad_to_max_length:
# If padding was already done ot max length, we use the default data collator that will just convert everything
# to tensors.
data_collator = default_data_collator
else:
# Otherwise, `DataCollatorWithPadding` will apply dynamic padding for us (by padding to the maximum length of
# the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
# of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=(8 if accelerator.use_fp16 else None))
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
# Optimizer
# Split weights in two groups, one with weight decay and the other not.
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
# Prepare everything with our `accelerator`.
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)
# Note -> the training dataloader needs to be prepared before we grab his length below (cause its length will be
# shorter in multiprocess)
# Scheduler and math around the number of training steps.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
else:
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps,
num_training_steps=args.max_train_steps,
)
# TODO Get the proper metric function
# metric = load_metric(xxx)
# Train!
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
completed_steps = 0
for epoch in range(args.num_train_epochs):
model.train()
for step, batch in enumerate(train_dataloader):
outputs = model(**batch)
loss = outputs.loss
loss = loss / args.gradient_accumulation_steps
accelerator.backward(loss)
if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
completed_steps += 1
if completed_steps >= args.max_train_steps:
break
model.eval()
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
metric.add_batch(
predictions=accelerator.gather(predictions),
references=accelerator.gather(batch["labels"]),
)
eval_metric = metric.compute()
logger.info(f"epoch {epoch}: {eval_metric}")
if args.output_dir is not None:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(args.output_dir, save_function=accelerator.save)
if __name__ == "__main__":
main()
{% endif %}
| 0
|
hf_public_repos/transformers/templates
|
hf_public_repos/transformers/templates/adding_a_new_model/README.md
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Adding a new model
This folder contains templates to generate new models that fit the current API and pass all tests. It generates
models in both PyTorch, TensorFlow, and Flax and completes the `__init__.py` and auto-modeling files, and creates the
documentation. Their use is described in the [next section](#cookiecutter-templates).
There is also a CLI tool to generate a new model like an existing one called `transformers-cli add-new-model-like`.
Jump to the [Add new model like section](#add-new-model-like-command) to learn how to use it.
## Cookiecutter Templates
Using the `cookiecutter` utility requires to have all the `dev` dependencies installed. Let's first clone the
repository and install it in our environment:
```shell script
git clone https://github.com/huggingface/transformers
cd transformers
pip install -e ".[dev]"
```
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
(PyTorch, TensorFlow and/or Flax) then do:
```bash
pip install -e ".[quality]"
```
Once the installation is done, you can use the CLI command `add-new-model` to generate your models:
```shell script
transformers-cli add-new-model
```
This should launch the `cookiecutter` package which should prompt you to fill in the configuration.
The `modelname` should be cased according to the plain text casing, i.e., BERT, RoBERTa, DeBERTa.
```
modelname [<ModelNAME>]:
uppercase_modelname [<MODEL_NAME>]:
lowercase_modelname [<model_name>]:
camelcase_modelname [<ModelName>]:
```
Fill in the `authors` with your team members:
```
authors [The HuggingFace Team]:
```
The checkpoint identifier is the checkpoint that will be used in the examples across the files. Put the name you wish,
as it will appear on the modelhub. Do not forget to include the organisation.
```
checkpoint_identifier [organisation/<model_name>-base-cased]:
```
The tokenizer should either be based on BERT if it behaves exactly like the BERT tokenizer, or a standalone otherwise.
```
Select tokenizer_type:
1 - Based on BERT
2 - Standalone
Choose from 1, 2 [1]:
```
<!---
Choose if your model is an encoder-decoder, or an encoder-only architecture.
If your model is an encoder-only architecture, the generated architecture will be based on the BERT model.
If your model is an encoder-decoder architecture, the generated architecture will be based on the BART model. You can,
of course, edit the files once the generation is complete.
```
Select is_encoder_decoder_model:
1 - True
2 - False
Choose from 1, 2 [1]:
```
-->
Once the command has finished, you should have a total of 7 new files spread across the repository:
```
docs/source/model_doc/<model_name>.md
src/transformers/models/<model_name>/configuration_<model_name>.py
src/transformers/models/<model_name>/modeling_<model_name>.py
src/transformers/models/<model_name>/modeling_tf_<model_name>.py
src/transformers/models/<model_name>/tokenization_<model_name>.py
tests/test_modeling_<model_name>.py
tests/test_modeling_tf_<model_name>.py
```
You can run the tests to ensure that they all pass:
```
python -m pytest ./tests/test_*<model_name>*.py
```
Feel free to modify each file to mimic the behavior of your model.
⚠ You should be careful about the classes preceded by the following line:️
```python
# Copied from transformers.[...]
```
This line ensures that the copy does not diverge from the source. If it *should* diverge, because the implementation
is different, this line needs to be deleted. If you don't delete this line and run `make fix-copies`,
your changes will be overwritten.
Once you have edited the files to fit your architecture, simply re-run the tests (and edit them if a change
is needed!) afterwards to make sure everything works as expected.
Once the files are generated and you are happy with your changes, here's a checklist to ensure that your contribution
will be merged quickly:
- You should run the `make fixup` utility to fix the style of the files and to ensure the code quality meets the
library's standards.
- You should complete the documentation file (`docs/source/model_doc/<model_name>.rst`) so that your model may be
usable.
## Add new model like command
Using the `transformers-cli add-new-model-like` command requires to have all the `dev` dependencies installed. Let's
first clone the repository and install it in our environment:
```shell script
git clone https://github.com/huggingface/transformers
cd transformers
pip install -e ".[dev]"
```
Depending on your OS, and since the number of optional dependencies of Transformers is growing, you might get a
failure with this command. If that's the case make sure to install the Deep Learning framework you are working with
(PyTorch, TensorFlow and/or Flax) then do:
```bash
pip install -e ".[quality]"
```
Once the installation is done, you can use the CLI command `add-new-model-like` to generate your models:
```shell script
transformers-cli add-new-model-like
```
This will start a small questionnaire you have to fill.
```
What identifier would you like to use for the model type of this model?
```
You will have to input the model type of the model you want to clone. The model type can be found in several places:
- inside the configuration of any checkpoint of that model
- the name of the documentation page of that model
For instance the doc page of `BigBirdPegasus` is `https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus`
so its model type is `"bigbird_pegasus"`.
If you make a typo, the command will suggest you the closest model types it can find.
Once this is done, the questionnaire will ask you for the new model name and its various casings:
```
What is the name for your new model?
What identifier would you like to use for the model type of this model?
What name would you like to use for the module of this model?
What prefix (camel-cased) would you like to use for the model classes of this model?
What prefix (upper-cased) would you like to use for the constants relative to this model?
```
From your answer to the first question, defaults will be determined for all others. The first name should be written
as you want your model be named in the doc, with no special casing (like RoBERTa) and from there, you can either stick
with the defaults or change the cased versions.
Next will be the name of the config class to use for this model:
```
What will be the name of the config class for this model?
```
Then, you will be asked for a checkpoint identifier:
```
Please give a checkpoint identifier (on the model Hub) for this new model.
```
This is the checkpoint that will be used in the examples across the files and the integration tests. Put the name you
wish, as it will appear on the Model Hub. Do not forget to include the organisation.
Then you will have to say whether your model re-uses the same processing classes as the model you're cloning:
```
Will your new model use the same processing class as Xxx (XxxTokenizer/XxxFeatureExtractor/XxxImageProcessor)
```
Answer yes if you have no intentions to make any change to the class used for preprocessing. It can use different
files (for instance you can reuse the `BertTokenizer` with a new vocab file).
If you answer no, you will have to give the name of the classes
for the new tokenizer/image processor/feature extractor/processor (depending on the model you're cloning).
Next the questionnaire will ask
```
Should we add # Copied from statements when creating the new modeling file?
```
This is the intenal mechanism used in the library to make sure code copied from various modeling files stay consistent.
If you plan to completely rewrite the modeling file, you should answer no, whereas if you just want to tweak one part
of the model, you should answer yes.
Lastly, the questionnaire will inquire about frameworks:
```
Should we add a version of your new model in all the frameworks implemented by Old Model (xxx)?
```
If you answer yes, the new model will have files for all the frameworks implemented by the model you're cloning.
Otherwise, you will get a new question to select the frameworks you want.
Once the command has finished, you will see a new subfolder in the `src/transformers/models/` folder, with the
necessary files (configuration and modeling files for all frameworks requested, and maybe the processing files,
depending on your choices).
You will also see a doc file and tests for your new models. First you should run
```
make style
make fix-copies
```
and then you can start tweaking your model. You should:
- fill the doc file at `docs/source/model_doc/model_name.md`
- tweak the configuration and modeling files to your need
Once you're done, you can run the tests to ensure that they all pass:
```
python -m pytest ./tests/test_*<model_name>*.py
```
⚠ You should be careful about the classes preceded by the following line:️
```python
# Copied from transformers.[...]
```
This line ensures that the copy does not diverge from the source. If it *should* diverge, because the implementation
is different, this line needs to be deleted. If you don't delete this line and run `make fix-copies`,
your changes will be overwritten.
Once you have edited the files to fit your architecture, simply re-run the tests (and edit them if a change
is needed!) afterwards to make sure everything works as expected.
Once the files are generated and you are happy with your changes, here's a checklist to ensure that your contribution
will be merged quickly:
- You should run the `make fixup` utility to fix the style of the files and to ensure the code quality meets the
library's standards.
- You should add your model to the main README then run `make fix-copies`.
| 0
|
hf_public_repos/transformers/templates
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter.json
|
{
"modelname": "BrandNewBERT",
"uppercase_modelname": "BRAND_NEW_BERT",
"lowercase_modelname": "brand_new_bert",
"camelcase_modelname": "BrandNewBert",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "brand-new-bert-base-cased",
"tokenizer_type": ["Based on BERT", "Based on BART", "Standalone"],
"generate_tensorflow_pytorch_and_flax": [
"PyTorch, TensorFlow and Flax",
"PyTorch & TensorFlow",
"PyTorch & Flax",
"TensorFlow & Flax",
"PyTorch",
"TensorFlow",
"Flax"
],
"is_encoder_decoder_model": ["True", "False"]
}
| 0
|
hf_public_repos/transformers/templates
|
hf_public_repos/transformers/templates/adding_a_new_model/ADD_NEW_MODEL_PROPOSAL_TEMPLATE.md
|
**TEMPLATE**
=====================================
*search & replace the following keywords, e.g.:*
`:%s/\[name of model\]/brand_new_bert/g`
-[lowercase name of model] # e.g. brand_new_bert
-[camelcase name of model] # e.g. BrandNewBert
-[name of mentor] # e.g. [Peter](https://github.com/peter)
-[link to original repo]
-[start date]
-[end date]
How to add [camelcase name of model] to 🤗 Transformers?
=====================================
Mentor: [name of mentor]
Begin: [start date]
Estimated End: [end date]
Adding a new model is often difficult and requires an in-depth knowledge
of the 🤗 Transformers library and ideally also of the model's original
repository. At Hugging Face, we are trying to empower the community more
and more to add models independently.
The following sections explain in detail how to add [camelcase name of model]
to Transformers. You will work closely with [name of mentor] to
integrate [camelcase name of model] into Transformers. By doing so, you will both gain a
theoretical and deep practical understanding of [camelcase name of model].
But more importantly, you will have made a major
open-source contribution to Transformers. Along the way, you will:
- get insights into open-source best practices
- understand the design principles of one of the most popular NLP
libraries
- learn how to do efficiently test large NLP models
- learn how to integrate Python utilities like `black`, `ruff`,
`make fix-copies` into a library to always ensure clean and readable
code
To start, let's try to get a general overview of the Transformers
library.
General overview of 🤗 Transformers
----------------------------------
First, you should get a general overview of 🤗 Transformers. Transformers
is a very opinionated library, so there is a chance that
you don't agree with some of the library's philosophies or design
choices. From our experience, however, we found that the fundamental
design choices and philosophies of the library are crucial to
efficiently scale Transformers while keeping maintenance costs at a
reasonable level.
A good first starting point to better understand the library is to read
the [documentation of our philosophy](https://huggingface.co/transformers/philosophy.html).
As a result of our way of working, there are some choices that we try to apply to all models:
- Composition is generally favored over abstraction
- Duplicating code is not always bad if it strongly improves the
readability or accessibility of a model
- Model files are as self-contained as possible so that when you read
the code of a specific model, you ideally only have to look into the
respective `modeling_....py` file.
In our opinion, the library's code is not just a means to provide a
product, *e.g.*, the ability to use BERT for inference, but also as the
very product that we want to improve. Hence, when adding a model, the
user is not only the person that will use your model, but also everybody
that will read, try to understand, and possibly tweak your code.
With this in mind, let's go a bit deeper into the general library
design.
### Overview of models
To successfully add a model, it is important to understand the
interaction between your model and its config,
`PreTrainedModel`, and `PretrainedConfig`. For
exemplary purposes, we will call the PyTorch model to be added to 🤗 Transformers
`BrandNewBert`.
Let's take a look:
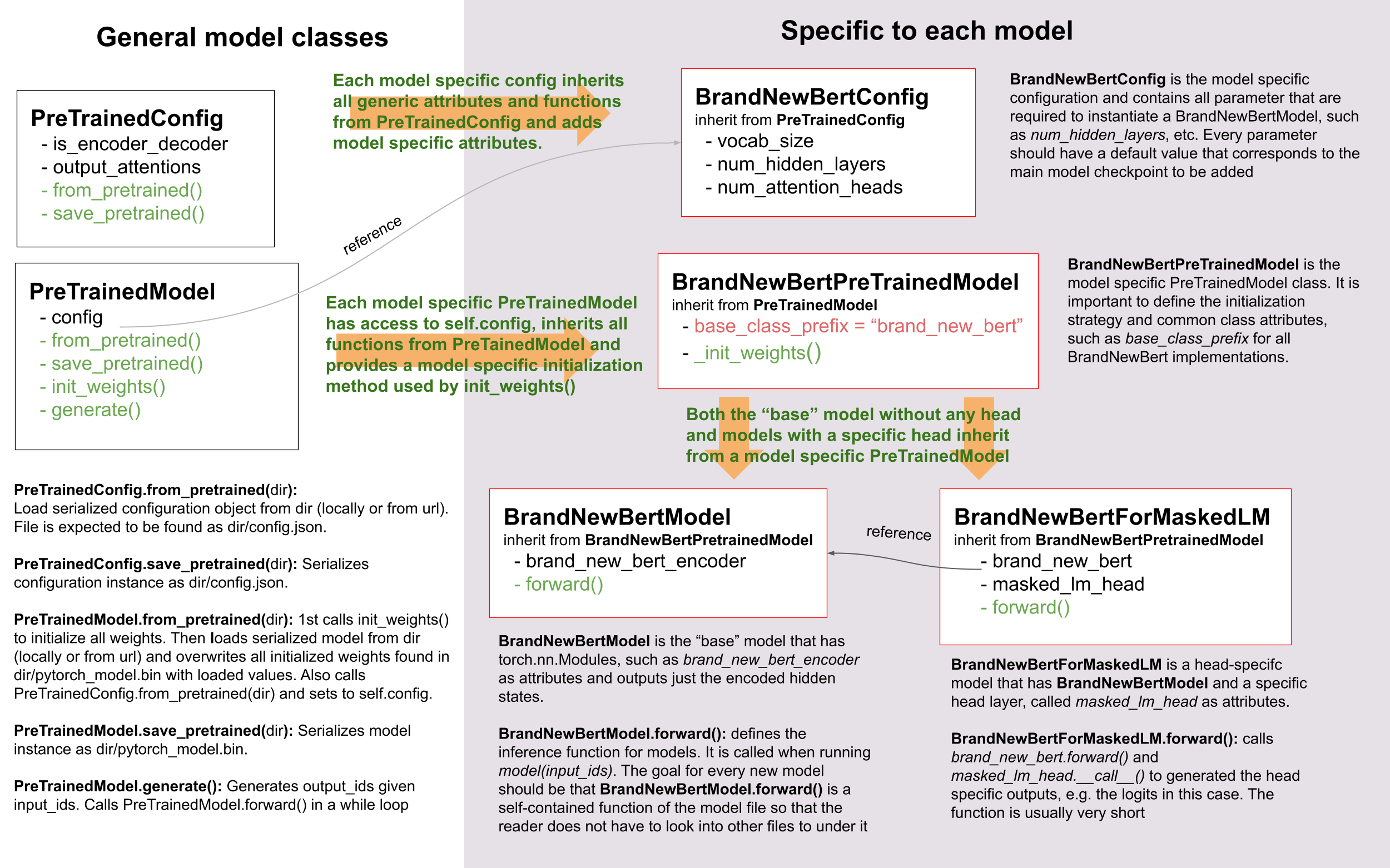
As you can see, we do make use of inheritance in 🤗 Transformers, but we
keep the level of abstraction to an absolute minimum. There are never
more than two levels of abstraction for any model in the library.
`BrandNewBertModel` inherits from
`BrandNewBertPreTrainedModel` which in
turn inherits from `PreTrainedModel` and that's it.
As a general rule, we want to make sure
that a new model only depends on `PreTrainedModel`. The
important functionalities that are automatically provided to every new
model are
`PreTrainedModel.from_pretrained` and `PreTrainedModel.save_pretrained`, which are
used for serialization and deserialization. All
of the other important functionalities, such as
`BrandNewBertModel.forward` should be
completely defined in the new `modeling_brand_new_bert.py` module. Next,
we want to make sure that a model with a specific head layer, such as
`BrandNewBertForMaskedLM` does not inherit
from `BrandNewBertModel`, but rather uses
`BrandNewBertModel` as a component that
can be called in its forward pass to keep the level of abstraction low.
Every new model requires a configuration class, called
`BrandNewBertConfig`. This configuration
is always stored as an attribute in
`PreTrainedModel`, and
thus can be accessed via the `config` attribute for all classes
inheriting from `BrandNewBertPreTrainedModel`
```python
# assuming that `brand_new_bert` belongs to the organization `brandy`
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
Similar to the model, the configuration inherits basic serialization and
deserialization functionalities from
`PretrainedConfig`. Note
that the configuration and the model are always serialized into two
different formats - the model to a `pytorch_model.bin` file
and the configuration to a `config.json` file. Calling
`PreTrainedModel.save_pretrained` will automatically call
`PretrainedConfig.save_pretrained`, so that both model and configuration are saved.
### Overview of tokenizers
Not quite ready yet :-( This section will be added soon!
Step-by-step recipe to add a model to 🤗 Transformers
----------------------------------------------------
Everyone has different preferences of how to port a model so it can be
very helpful for you to take a look at summaries of how other
contributors ported models to Hugging Face. Here is a list of community
blog posts on how to port a model:
1. [Porting GPT2
Model](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28)
by [Thomas](https://huggingface.co/thomwolf)
2. [Porting WMT19 MT Model](https://huggingface.co/blog/porting-fsmt)
by [Stas](https://huggingface.co/stas)
From experience, we can tell you that the most important things to keep
in mind when adding a model are:
- Don't reinvent the wheel! Most parts of the code you will add for
the new 🤗 Transformers model already exist somewhere in 🤗
Transformers. Take some time to find similar, already existing
models and tokenizers you can copy from.
[grep](https://www.gnu.org/software/grep/) and
[rg](https://github.com/BurntSushi/ripgrep) are your friends. Note
that it might very well happen that your model's tokenizer is based
on one model implementation, and your model's modeling code on
another one. *E.g.*, FSMT's modeling code is based on BART, while
FSMT's tokenizer code is based on XLM.
- It's more of an engineering challenge than a scientific challenge.
You should spend more time on creating an efficient debugging
environment than trying to understand all theoretical aspects of the
model in the paper.
- Ask for help when you're stuck! Models are the core component of 🤗
Transformers so we, at Hugging Face, are more than happy to help
you at every step to add your model. Don't hesitate to ask if you
notice you are not making progress.
In the following, we try to give you a general recipe that we found most
useful when porting a model to 🤗 Transformers.
The following list is a summary of everything that has to be done to add
a model and can be used by you as a To-Do List:
1. [ ] (Optional) Understood theoretical aspects
2. [ ] Prepared transformers dev environment
3. [ ] Set up debugging environment of the original repository
4. [ ] Created script that successfully runs forward pass using
original repository and checkpoint
5. [ ] Successfully opened a PR and added the model skeleton to Transformers
6. [ ] Successfully converted original checkpoint to Transformers
checkpoint
7. [ ] Successfully ran forward pass in Transformers that gives
identical output to original checkpoint
8. [ ] Finished model tests in Transformers
9. [ ] Successfully added Tokenizer in Transformers
10. [ ] Run end-to-end integration tests
11. [ ] Finished docs
12. [ ] Uploaded model weights to the hub
13. [ ] Submitted the pull request for review
14. [ ] (Optional) Added a demo notebook
To begin with, we usually recommend to start by getting a good
theoretical understanding of `[camelcase name of model]`. However, if you prefer to
understand the theoretical aspects of the model *on-the-job*, then it is
totally fine to directly dive into the `[camelcase name of model]`'s code-base. This
option might suit you better, if your engineering skills are better than
your theoretical skill, if you have trouble understanding
`[camelcase name of model]`'s paper, or if you just enjoy programming much more than
reading scientific papers.
### 1. (Optional) Theoretical aspects of [camelcase name of model]
You should take some time to read *[camelcase name of model]'s* paper, if such
descriptive work exists. There might be large sections of the paper that
are difficult to understand. If this is the case, this is fine - don't
worry! The goal is not to get a deep theoretical understanding of the
paper, but to extract the necessary information required to effectively
re-implement the model in 🤗 Transformers. That being said, you don't
have to spend too much time on the theoretical aspects, but rather focus
on the practical ones, namely:
- What type of model is *[camelcase name of model]*? BERT-like encoder-only
model? GPT2-like decoder-only model? BART-like encoder-decoder
model? Look at the `model_summary` if
you're not familiar with the differences between those.
- What are the applications of *[camelcase name of model]*? Text
classification? Text generation? Seq2Seq tasks, *e.g.,*
summarization?
- What is the novel feature of the model making it different from
BERT/GPT-2/BART?
- Which of the already existing [🤗 Transformers
models](https://huggingface.co/transformers/#contents) is most
similar to *[camelcase name of model]*?
- What type of tokenizer is used? A sentencepiece tokenizer? Word
piece tokenizer? Is it the same tokenizer as used for BERT or BART?
After you feel like you have gotten a good overview of the architecture
of the model, you might want to write to [name of mentor] with any
questions you might have. This might include questions regarding the
model's architecture, its attention layer, etc. We will be more than
happy to help you.
#### Additional resources
Before diving into the code, here are some additional resources that might be worth taking a look at:
- [link 1]
- [link 2]
- [link 3]
- ...
#### Make sure you've understood the fundamental aspects of [camelcase name of model]
Alright, now you should be ready to take a closer look into the actual code of [camelcase name of model].
You should have understood the following aspects of [camelcase name of model] by now:
- [characteristic 1 of [camelcase name of model]]
- [characteristic 2 of [camelcase name of model]]
- ...
If any of the mentioned aspects above are **not** clear to you, now is a great time to talk to [name of mentor].
### 2. Next prepare your environment
1. Fork the [repository](https://github.com/huggingface/transformers)
by clicking on the 'Fork' button on the repository's page. This
creates a copy of the code under your GitHub user account.
2. Clone your `transformers` fork to your local disk, and add the base
repository as a remote:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Set up a development environment, for instance by running the
following command:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
and return to the parent directory
```bash
cd ..
```
4. We recommend adding the PyTorch version of *[camelcase name of model]* to
Transformers. To install PyTorch, please follow the instructions [here](https://pytorch.org/get-started/locally/).
**Note:** You don't need to have CUDA installed. Making the new model
work on CPU is sufficient.
5. To port *[camelcase name of model]*, you will also need access to its
original repository:
```bash
git clone [link to original repo].git
cd [lowercase name of model]
pip install -e .
```
Now you have set up a development environment to port *[camelcase name of model]*
to 🤗 Transformers.
### Run a pretrained checkpoint using the original repository
**3. Set up debugging environment**
At first, you will work on the original *[camelcase name of model]* repository.
Often, the original implementation is very "researchy". Meaning that
documentation might be lacking and the code can be difficult to
understand. But this should be exactly your motivation to reimplement
*[camelcase name of model]*. At Hugging Face, one of our main goals is to *make
people stand on the shoulders of giants* which translates here very well
into taking a working model and rewriting it to make it as **accessible,
user-friendly, and beautiful** as possible. This is the number-one
motivation to re-implement models into 🤗 Transformers - trying to make
complex new NLP technology accessible to **everybody**.
You should start thereby by diving into the [original repository]([link to original repo]).
Successfully running the official pretrained model in the original
repository is often **the most difficult** step. From our experience, it
is very important to spend some time getting familiar with the original
code-base. You need to figure out the following:
- Where to find the pretrained weights?
- How to load the pretrained weights into the corresponding model?
- How to run the tokenizer independently from the model?
- Trace one forward pass so that you know which classes and functions
are required for a simple forward pass. Usually, you only have to
reimplement those functions.
- Be able to locate the important components of the model: Where is
the model's class? Are there model sub-classes, *e.g.*,
EncoderModel, DecoderModel? Where is the self-attention layer? Are
there multiple different attention layers, *e.g.*, *self-attention*,
*cross-attention*...?
- How can you debug the model in the original environment of the repo?
Do you have to add `print` statements, can you work with
an interactive debugger like [ipdb](https://pypi.org/project/ipdb/), or should you use
an efficient IDE to debug the model, like PyCharm?
It is very important that before you start the porting process, that you
can **efficiently** debug code in the original repository! Also,
remember that you are working with an open-source library, so do not
hesitate to open an issue, or even a pull request in the original
repository. The maintainers of this repository are most likely very
happy about someone looking into their code!
At this point, it is really up to you which debugging environment and
strategy you prefer to use to debug the original model. We strongly
advise against setting up a costly GPU environment, but simply work on a
CPU both when starting to dive into the original repository and also
when starting to write the 🤗 Transformers implementation of the model.
Only at the very end, when the model has already been successfully
ported to 🤗 Transformers, one should verify that the model also works as
expected on GPU.
In general, there are two possible debugging environments for running
the original model
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- Local python scripts.
Jupyter notebooks have the advantage that they allow for cell-by-cell
execution which can be helpful to better split logical components from
one another and to have faster debugging cycles as intermediate results
can be stored. Also, notebooks are often easier to share with other
contributors, which might be very helpful if you want to ask the Hugging
Face team for help. If you are familiar with Jupyter notebooks, we
strongly recommend you to work with them.
The obvious disadvantage of Jupyter notebooks is that if you are not
used to working with them you will have to spend some time adjusting to
the new programming environment and that you might not be able to use
your known debugging tools anymore, like `ipdb`.
**4. Successfully run forward pass**
For each code-base, a good first step is always to load a **small**
pretrained checkpoint and to be able to reproduce a single forward pass
using a dummy integer vector of input IDs as an input. Such a script
could look like this (in pseudocode):
```python
model = [camelcase name of model]Model.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
```
Next, regarding the debugging strategy, there are generally a few from
which to choose from:
- Decompose the original model into many small testable components and
run a forward pass on each of those for verification
- Decompose the original model only into the original *tokenizer* and
the original *model*, run a forward pass on those, and use
intermediate print statements or breakpoints for verification
Again, it is up to you which strategy to choose. Often, one or the other
is advantageous depending on the original code base.
If the original code-base allows you to decompose the model into smaller
sub-components, *e.g.*, if the original code-base can easily be run in
eager mode, it is usually worth the effort to do so. There are some
important advantages to taking the more difficult road in the beginning:
- at a later stage when comparing the original model to the Hugging
Face implementation, you can verify automatically for each component
individually that the corresponding component of the 🤗 Transformers
implementation matches instead of relying on visual comparison via
print statements
- it can give you some rope to decompose the big problem of porting a
model into smaller problems of just porting individual components
and thus structure your work better
- separating the model into logical meaningful components will help
you to get a better overview of the model's design and thus to
better understand the model
- at a later stage those component-by-component tests help you to
ensure that no regression occurs as you continue changing your code
[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed)
integration checks for ELECTRA gives a nice example of how this can be
done.
However, if the original code-base is very complex or only allows
intermediate components to be run in a compiled mode, it might be too
time-consuming or even impossible to separate the model into smaller
testable sub-components. A good example is [T5's
MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow)
library which is very complex and does not offer a simple way to
decompose the model into its sub-components. For such libraries, one
often relies on verifying print statements.
No matter which strategy you choose, the recommended procedure is often
the same in that you should start to debug the starting layers first and
the ending layers last.
It is recommended that you retrieve the output, either by print
statements or sub-component functions, of the following layers in the
following order:
1. Retrieve the input IDs passed to the model
2. Retrieve the word embeddings
3. Retrieve the input of the first Transformer layer
4. Retrieve the output of the first Transformer layer
5. Retrieve the output of the following n - 1 Transformer layers
6. Retrieve the output of the whole [camelcase name of model] Model
Input IDs should thereby consists of an array of integers, *e.g.*,
`input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
The outputs of the following layers often consist of multi-dimensional
float arrays and can look like this:
```bash
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
We expect that every model added to 🤗 Transformers passes a couple of
integration tests, meaning that the original model and the reimplemented
version in 🤗 Transformers have to give the exact same output up to a
precision of 0.001! Since it is normal that the exact same model written
in different libraries can give a slightly different output depending on
the library framework, we accept an error tolerance of 1e-3 (0.001). It
is not enough if the model gives nearly the same output, they have to be
the almost identical. Therefore, you will certainly compare the
intermediate outputs of the 🤗 Transformers version multiple times
against the intermediate outputs of the original implementation of
*[camelcase name of model]* in which case an **efficient** debugging environment
of the original repository is absolutely important. Here is some advice
to make your debugging environment as efficient as possible.
- Find the best way of debugging intermediate results. Is the original
repository written in PyTorch? Then you should probably take the
time to write a longer script that decomposes the original model
into smaller sub-components to retrieve intermediate values. Is the
original repository written in Tensorflow 1? Then you might have to
rely on TensorFlow print operations like
[tf.print](https://www.tensorflow.org/api_docs/python/tf/print) to
output intermediate values. Is the original repository written in
Jax? Then make sure that the model is **not jitted** when running
the forward pass, *e.g.*, check-out [this
link](https://github.com/google/jax/issues/196).
- Use the smallest pretrained checkpoint you can find. The smaller the
checkpoint, the faster your debug cycle becomes. It is not efficient
if your pretrained model is so big that your forward pass takes more
than 10 seconds. In case only very large checkpoints are available,
it might make more sense to create a dummy model in the new
environment with randomly initialized weights and save those weights
for comparison with the 🤗 Transformers version of your model
- Make sure you are using the easiest way of calling a forward pass in
the original repository. Ideally, you want to find the function in
the original repository that **only** calls a single forward pass,
*i.e.* that is often called `predict`, `evaluate`, `forward` or
`__call__`. You don't want to debug a function that calls `forward`
multiple times, *e.g.*, to generate text, like
`autoregressive_sample`, `generate`.
- Try to separate the tokenization from the model's
forward pass. If the original repository shows
examples where you have to input a string, then try to find out
where in the forward call the string input is changed to input ids
and start from this point. This might mean that you have to possibly
write a small script yourself or change the original code so that
you can directly input the ids instead of an input string.
- Make sure that the model in your debugging setup is **not** in
training mode, which often causes the model to yield random outputs
due to multiple dropout layers in the model. Make sure that the
forward pass in your debugging environment is **deterministic** so
that the dropout layers are not used. Or use
`transformers.utils.set_seed` if the old and new
implementations are in the same framework.
#### More details on how to create a debugging environment for [camelcase name of model]
[TODO FILL: Here the mentor should add very specific information on what the student should do]
[to set up an efficient environment for the special requirements of this model]
### Port [camelcase name of model] to 🤗 Transformers
Next, you can finally start adding new code to 🤗 Transformers. Go into
the clone of your 🤗 Transformers' fork:
cd transformers
In the special case that you are adding a model whose architecture
exactly matches the model architecture of an existing model you only
have to add a conversion script as described in [this
section](#write-a-conversion-script). In this case, you can just re-use
the whole model architecture of the already existing model.
Otherwise, let's start generating a new model with the amazing
Cookiecutter!
**Use the Cookiecutter to automatically generate the model's code**
To begin with head over to the [🤗 Transformers
templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
to make use of our `cookiecutter` implementation to automatically
generate all the relevant files for your model. Again, we recommend only
adding the PyTorch version of the model at first. Make sure you follow
the instructions of the `README.md` on the [🤗 Transformers
templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
carefully.
**Open a Pull Request on the main huggingface/transformers repo**
Before starting to adapt the automatically generated code, now is the
time to open a "Work in progress (WIP)" pull request, *e.g.*, "\[WIP\]
Add *[camelcase name of model]*", in 🤗 Transformers so that you and the Hugging
Face team can work side-by-side on integrating the model into 🤗
Transformers.
You should do the following:
1. Create a branch with a descriptive name from your main branch
```
git checkout -b add_[lowercase name of model]
```
2. Commit the automatically generated code:
```
git add .
git commit
```
3. Fetch and rebase to current main
```
git fetch upstream
git rebase upstream/main
```
4. Push the changes to your account using:
```
git push -u origin a-descriptive-name-for-my-changes
```
5. Once you are satisfied, go to the webpage of your fork on GitHub.
Click on "Pull request". Make sure to add the GitHub handle of
[name of mentor] as a reviewer, so that the Hugging
Face team gets notified for future changes.
6. Change the PR into a draft by clicking on "Convert to draft" on the
right of the GitHub pull request web page.
In the following, whenever you have done some progress, don't forget to
commit your work and push it to your account so that it shows in the
pull request. Additionally, you should make sure to update your work
with the current main from time to time by doing:
git fetch upstream
git merge upstream/main
In general, all questions you might have regarding the model or your
implementation should be asked in your PR and discussed/solved in the
PR. This way, [name of mentor] will always be notified when you are
committing new code or if you have a question. It is often very helpful
to point [name of mentor] to your added code so that the Hugging
Face team can efficiently understand your problem or question.
To do so, you can go to the "Files changed" tab where you see all of
your changes, go to a line regarding which you want to ask a question,
and click on the "+" symbol to add a comment. Whenever a question or
problem has been solved, you can click on the "Resolve" button of the
created comment.
In the same way, [name of mentor] will open comments when reviewing
your code. We recommend asking most questions on GitHub on your PR. For
some very general questions that are not very useful for the public,
feel free to ping [name of mentor] by Slack or email.
**5. Adapt the generated models code for [camelcase name of model]**
At first, we will focus only on the model itself and not care about the
tokenizer. All the relevant code should be found in the generated files
`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py` and
`src/transformers/models/[lowercase name of model]/configuration_[lowercase name of model].py`.
Now you can finally start coding :). The generated code in
`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py` will
either have the same architecture as BERT if it's an encoder-only model
or BART if it's an encoder-decoder model. At this point, you should
remind yourself what you've learned in the beginning about the
theoretical aspects of the model: *How is the model different from BERT
or BART?*\". Implement those changes which often means to change the
*self-attention* layer, the order of the normalization layer, etc...
Again, it is often useful to look at the similar architecture of already
existing models in Transformers to get a better feeling of how your
model should be implemented.
**Note** that at this point, you don't have to be very sure that your
code is fully correct or clean. Rather, it is advised to add a first
*unclean*, copy-pasted version of the original code to
`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py`
until you feel like all the necessary code is added. From our
experience, it is much more efficient to quickly add a first version of
the required code and improve/correct the code iteratively with the
conversion script as described in the next section. The only thing that
has to work at this point is that you can instantiate the 🤗 Transformers
implementation of *[camelcase name of model]*, *i.e.* the following command
should work:
```python
from transformers import [camelcase name of model]Model, [camelcase name of model]Config
model = [camelcase name of model]Model([camelcase name of model]Config())
```
The above command will create a model according to the default
parameters as defined in `[camelcase name of model]Config()` with random weights,
thus making sure that the `init()` methods of all components works.
[TODO FILL: Here the mentor should add very specific information on what exactly has to be changed for this model]
[...]
[...]
**6. Write a conversion script**
Next, you should write a conversion script that lets you convert the
checkpoint you used to debug *[camelcase name of model]* in the original
repository to a checkpoint compatible with your just created 🤗
Transformers implementation of *[camelcase name of model]*. It is not advised to
write the conversion script from scratch, but rather to look through
already existing conversion scripts in 🤗 Transformers for one that has
been used to convert a similar model that was written in the same
framework as *[camelcase name of model]*. Usually, it is enough to copy an
already existing conversion script and slightly adapt it for your use
case. Don't hesitate to ask [name of mentor] to point you to a
similar already existing conversion script for your model.
- If you are porting a model from TensorFlow to PyTorch, a good
starting point might be BERT's conversion script
[here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
- If you are porting a model from PyTorch to PyTorch, a good starting
point might be BART's conversion script
[here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
In the following, we'll quickly explain how PyTorch models store layer
weights and define layer names. In PyTorch, the name of a layer is
defined by the name of the class attribute you give the layer. Let's
define a dummy model in PyTorch, called `SimpleModel` as follows:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
Now we can create an instance of this model definition which will fill
all weights: `dense`, `intermediate`, `layer_norm` with random weights.
We can print the model to see its architecture
```python
model = SimpleModel()
print(model)
```
This will print out the following:
```bash
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
We can see that the layer names are defined by the name of the class
attribute in PyTorch. You can print out the weight values of a specific
layer:
```python
print(model.dense.weight.data)
```
to see that the weights were randomly initialized
```bash
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
In the conversion script, you should fill those randomly initialized
weights with the exact weights of the corresponding layer in the
checkpoint. *E.g.*,
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
While doing so, you must verify that each randomly initialized weight of
your PyTorch model and its corresponding pretrained checkpoint weight
exactly match in both **shape and name**. To do so, it is **necessary**
to add assert statements for the shape and print out the names of the
checkpoints weights. *E.g.*, you should add statements like:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
Besides, you should also print out the names of both weights to make
sure they match, *e.g.*,
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
If either the shape or the name doesn't match, you probably assigned
the wrong checkpoint weight to a randomly initialized layer of the 🤗
Transformers implementation.
An incorrect shape is most likely due to an incorrect setting of the
config parameters in `[camelcase name of model]Config()` that do not exactly match
those that were used for the checkpoint you want to convert. However, it
could also be that PyTorch's implementation of a layer requires the
weight to be transposed beforehand.
Finally, you should also check that **all** required weights are
initialized and print out all checkpoint weights that were not used for
initialization to make sure the model is correctly converted. It is
completely normal, that the conversion trials fail with either a wrong
shape statement or wrong name assignment. This is most likely because
either you used incorrect parameters in `[camelcase name of model]Config()`, have a
wrong architecture in the 🤗 Transformers implementation, you have a bug
in the `init()` functions of one of the components of the 🤗 Transformers
implementation or you need to transpose one of the checkpoint weights.
This step should be iterated with the previous step until all weights of
the checkpoint are correctly loaded in the Transformers model. Having
correctly loaded the checkpoint into the 🤗 Transformers implementation,
you can then save the model under a folder of your choice
`/path/to/converted/checkpoint/folder` that should then contain both a
`pytorch_model.bin` file and a `config.json` file:
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
[TODO FILL: Here the mentor should add very specific information on what exactly has to be done for the conversion of this model]
[...]
[...]
**7. Implement the forward pass**
Having managed to correctly load the pretrained weights into the 🤗
Transformers implementation, you should now make sure that the forward
pass is correctly implemented. In [Get familiar with the original
repository](#34-run-a-pretrained-checkpoint-using-the-original-repository),
you have already created a script that runs a forward pass of the model
using the original repository. Now you should write an analogous script
using the 🤗 Transformers implementation instead of the original one. It
should look as follows:
[TODO FILL: Here the model name might have to be adapted, *e.g.*, maybe [camelcase name of model]ForConditionalGeneration instead of [camelcase name of model]Model]
```python
model = [camelcase name of model]Model.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
It is very likely that the 🤗 Transformers implementation and the
original model implementation don't give the exact same output the very
first time or that the forward pass throws an error. Don't be
disappointed - it's expected! First, you should make sure that the
forward pass doesn't throw any errors. It often happens that the wrong
dimensions are used leading to a `"Dimensionality mismatch"`
error or that the wrong data type object is used, *e.g.*, `torch.long`
instead of `torch.float32`. Don't hesitate to ask [name of mentor]
for help, if you don't manage to solve certain errors.
The final part to make sure the 🤗 Transformers implementation works
correctly is to ensure that the outputs are equivalent to a precision of
`1e-3`. First, you should ensure that the output shapes are identical,
*i.e.* `outputs.shape` should yield the same value for the script of the
🤗 Transformers implementation and the original implementation. Next, you
should make sure that the output values are identical as well. This one
of the most difficult parts of adding a new model. Common mistakes why
the outputs are not identical are:
- Some layers were not added, *i.e.* an activation layer
was not added, or the residual connection was forgotten
- The word embedding matrix was not tied
- The wrong positional embeddings are used because the original
implementation uses on offset
- Dropout is applied during the forward pass. To fix this make sure
`model.training is False` and that no dropout layer is
falsely activated during the forward pass, *i.e.* pass
`self.training` to [PyTorch's functional
dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
The best way to fix the problem is usually to look at the forward pass
of the original implementation and the 🤗 Transformers implementation
side-by-side and check if there are any differences. Ideally, you should
debug/print out intermediate outputs of both implementations of the
forward pass to find the exact position in the network where the 🤗
Transformers implementation shows a different output than the original
implementation. First, make sure that the hard-coded `input_ids` in both
scripts are identical. Next, verify that the outputs of the first
transformation of the `input_ids` (usually the word embeddings) are
identical. And then work your way up to the very last layer of the
network. At some point, you will notice a difference between the two
implementations, which should point you to the bug in the 🤗 Transformers
implementation. From our experience, a simple and efficient way is to
add many print statements in both the original implementation and 🤗
Transformers implementation, at the same positions in the network
respectively, and to successively remove print statements showing the
same values for intermediate presentions.
When you're confident that both implementations yield the same output,
verifying the outputs with
`torch.allclose(original_output, output, atol=1e-3)`, you're done with
the most difficult part! Congratulations - the work left to be done
should be a cakewalk 😊.
**8. Adding all necessary model tests**
At this point, you have successfully added a new model. However, it is
very much possible that the model does not yet fully comply with the
required design. To make sure, the implementation is fully compatible
with 🤗 Transformers, all common tests should pass. The Cookiecutter
should have automatically added a test file for your model, probably
under the same `tests/test_modeling_[lowercase name of model].py`. Run this test
file to verify that all common tests pass:
```python
pytest tests/test_modeling_[lowercase name of model].py
```
[TODO FILL: Here the mentor should add very specific information on what tests are likely to fail after having implemented the model
, e.g. given the model, it might be very likely that `test_attention_output` fails]
[...]
[...]
Having fixed all common tests, it is now crucial to ensure that all the
nice work you have done is well tested, so that
- a) The community can easily understand your work by looking at
specific tests of *[camelcase name of model]*
- b) Future changes to your model will not break any important
feature of the model.
At first, integration tests should be added. Those integration tests
essentially do the same as the debugging scripts you used earlier to
implement the model to 🤗 Transformers. A template of those model tests
is already added by the Cookiecutter, called
`[camelcase name of model]ModelIntegrationTests` and only has to be filled out by
you. To ensure that those tests are passing, run
```python
RUN_SLOW=1 pytest -sv tests/test_modeling_[lowercase name of model].py::[camelcase name of model]ModelIntegrationTests
```
**Note:** In case you are using Windows, you should replace `RUN_SLOW=1` with `SET RUN_SLOW=1`
Second, all features that are special to *[camelcase name of model]* should be
tested additionally in a separate test under
`[camelcase name of model]ModelTester`/`[camelcase name of model]ModelTest`. This part is often
forgotten but is extremely useful in two ways:
- It helps to transfer the knowledge you have acquired during the
model addition to the community by showing how the special features
of *[camelcase name of model]* should work.
- Future contributors can quickly test changes to the model by running
those special tests.
[TODO FILL: Here the mentor should add very specific information on what special features of the model should be tested additionally]
[...]
[...]
**9. Implement the tokenizer**
Next, we should add the tokenizer of *[camelcase name of model]*. Usually, the
tokenizer is equivalent or very similar to an already existing tokenizer
of 🤗 Transformers.
[TODO FILL: Here the mentor should add a comment whether a new tokenizer is required or if this is not the case which existing tokenizer closest resembles
[camelcase name of model]'s tokenizer and how the tokenizer should be implemented]
[...]
[...]
It is very important to find/extract the original tokenizer file and to
manage to load this file into the 🤗 Transformers' implementation of the
tokenizer.
For [camelcase name of model], the tokenizer files can be found here:
- [To be filled out by mentor]
and having implemented the 🤗 Transformers' version of the tokenizer can be loaded as follows:
[To be filled out by mentor]
To ensure that the tokenizer works correctly, it is recommended to first
create a script in the original repository that inputs a string and
returns the `input_ids`. It could look similar to this (in pseudo-code):
```bash
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = [camelcase name of model]Model.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
You might have to take a deeper look again into the original repository
to find the correct tokenizer function or you might even have to do
changes to your clone of the original repository to only output the
`input_ids`. Having written a functional tokenization script that uses
the original repository, an analogous script for 🤗 Transformers should
be created. It should look similar to this:
```python
from transformers import [camelcase name of model]Tokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = [camelcase name of model]Tokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
```
When both `input_ids` yield the same values, as a final step a tokenizer
test file should also be added.
[TODO FILL: Here mentor should point the student to test files of similar tokenizers]
Analogous to the modeling test files of *[camelcase name of model]*, the
tokenization test files of *[camelcase name of model]* should contain a couple of
hard-coded integration tests.
[TODO FILL: Here mentor should again point to an existing similar test of another model that the student can copy & adapt]
**10. Run End-to-end integration tests**
Having added the tokenizer, you should also add a couple of end-to-end
integration tests using both the model and the tokenizer to
`tests/test_modeling_[lowercase name of model].py` in 🤗 Transformers. Such a test
should show on a meaningful text-to-text sample that the 🤗 Transformers
implementation works as expected. A meaningful text-to-text sample can
include *e.g.* a source-to-target-translation pair, an
article-to-summary pair, a question-to-answer pair, etc... If none of
the ported checkpoints has been fine-tuned on a downstream task it is
enough to simply rely on the model tests. In a final step to ensure that
the model is fully functional, it is advised that you also run all tests
on GPU. It can happen that you forgot to add some `.to(self.device)`
statements to internal tensors of the model, which in such a test would
show in an error. In case you have no access to a GPU, the Hugging Face
team can take care of running those tests for you.
**11. Add Docstring**
Now, all the necessary functionality for *[camelcase name of model]* is added -
you're almost done! The only thing left to add is a nice docstring and
a doc page. The Cookiecutter should have added a template file called
`docs/source/model_doc/[lowercase name of model].rst` that you should fill out.
Users of your model will usually first look at this page before using
your model. Hence, the documentation must be understandable and concise.
It is very useful for the community to add some *Tips* to show how the
model should be used. Don't hesitate to ping [name of mentor]
regarding the docstrings.
Next, make sure that the docstring added to
`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py` is
correct and included all necessary inputs and outputs. It is always to
good to remind oneself that documentation should be treated at least as
carefully as the code in 🤗 Transformers since the documentation is
usually the first contact point of the community with the model.
**Code refactor**
Great, now you have added all the necessary code for *[camelcase name of model]*.
At this point, you should correct some potential incorrect code style by
running:
```bash
make style
```
and verify that your coding style passes the quality check:
```bash
make quality
```
There are a couple of other very strict design tests in 🤗 Transformers
that might still be failing, which shows up in the tests of your pull
request. This is often because of some missing information in the
docstring or some incorrect naming. [name of mentor] will surely
help you if you're stuck here.
Lastly, it is always a good idea to refactor one's code after having
ensured that the code works correctly. With all tests passing, now it's
a good time to go over the added code again and do some refactoring.
You have now finished the coding part, congratulation! 🎉 You are
Awesome! 😎
**12. Upload the models to the model hub**
In this final part, you should convert and upload all checkpoints to the
model hub and add a model card for each uploaded model checkpoint. You
should work alongside [name of mentor] here to decide on a fitting
name for each checkpoint and to get the required access rights to be
able to upload the model under the author's organization of
*[camelcase name of model]*.
It is worth spending some time to create fitting model cards for each
checkpoint. The model cards should highlight the specific
characteristics of this particular checkpoint, *e.g.*, On which dataset
was the checkpoint pretrained/fine-tuned on? On what down-stream task
should the model be used? And also include some code on how to correctly
use the model.
**13. (Optional) Add notebook**
It is very helpful to add a notebook that showcases in-detail how
*[camelcase name of model]* can be used for inference and/or fine-tuned on a
downstream task. This is not mandatory to merge your PR, but very useful
for the community.
**14. Submit your finished PR**
You're done programming now and can move to the last step, which is
getting your PR merged into main. Usually, [name of mentor]
should have helped you already at this point, but it is worth taking
some time to give your finished PR a nice description and eventually add
comments to your code, if you want to point out certain design choices
to your reviewer.
### Share your work!!
Now, it's time to get some credit from the community for your work!
Having completed a model addition is a major contribution to
Transformers and the whole NLP community. Your code and the ported
pre-trained models will certainly be used by hundreds and possibly even
thousands of developers and researchers. You should be proud of your
work and share your achievement with the community.
**You have made another model that is super easy to access for everyone
in the community! 🤯**
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/test_modeling_flax_{{cookiecutter.lowercase_modelname}}.py
|
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
{% if cookiecutter.is_encoder_decoder_model == "False" %}
import unittest
from transformers import is_flax_available, {{cookiecutter.camelcase_modelname}}Config
from transformers.testing_utils import require_flax, slow
from ...test_configuration_common import ConfigTester
from ...test_modeling_flax_common import FlaxModelTesterMixin, ids_tensor
if is_flax_available():
import numpy as np
from transformers import (
Flax{{cookiecutter.camelcase_modelname}}ForCausalLM,
Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM,
Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification,
Flax{{cookiecutter.camelcase_modelname}}Model,
)
class Flax{{cookiecutter.camelcase_modelname}}ModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_input_mask=True,
use_token_type_ids=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = 13
self.seq_length = 7
self.is_training = True
self.use_input_mask = True
self.use_token_type_ids = True
self.use_labels = True
self.vocab_size = 99
self.hidden_size = 32
self.num_hidden_layers = 5
self.num_attention_heads = 4
self.intermediate_size = 37
self.hidden_act = "gelu"
self.hidden_dropout_prob = 0.1
self.attention_probs_dropout_prob = 0.1
self.max_position_embeddings = 512
self.type_vocab_size = 16
self.type_sequence_label_size = 2
self.initializer_range = 0.02
self.num_labels = 3
self.num_choices = 4
self.scope = None
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = {{cookiecutter.camelcase_modelname}}Config(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
initializer_range=self.initializer_range,
return_dict=True,
)
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
def create_and_check_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = Flax{{cookiecutter.camelcase_modelname}}Model(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
inputs = [input_ids, input_mask]
result = model(*inputs)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_lm_head(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.is_decoder = True
model = Flax{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
prediction_scores = model(**inputs)["logits"]
self.parent.assertListEqual(
list(prediction_scores.shape), [self.batch_size, self.seq_length, self.vocab_size]
)
def create_and_check_for_masked_lm(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(**inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_for_sequence_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(**inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_for_multiple_choice(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_choices = self.num_choices
model = Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice(config=config)
multiple_choice_inputs_ids = np.tile(np.expand_dims(input_ids, 1), (1, self.num_choices, 1))
multiple_choice_input_mask = np.tile(np.expand_dims(input_mask, 1), (1, self.num_choices, 1))
multiple_choice_token_type_ids = np.tile(np.expand_dims(token_type_ids, 1), (1, self.num_choices, 1))
inputs = {
"input_ids": multiple_choice_inputs_ids,
"attention_mask": multiple_choice_input_mask,
"token_type_ids": multiple_choice_token_type_ids,
}
result = model(**inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
def create_and_check_for_token_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(**inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_for_question_answering(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(**inputs)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_flax
class Flax{{cookiecutter.camelcase_modelname}}ModelTest(FlaxModelTesterMixin, unittest.TestCase):
all_model_classes = (
(
Flax{{cookiecutter.camelcase_modelname}}Model,
Flax{{cookiecutter.camelcase_modelname}}ForCausalLM,
Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification,
Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
)
if is_flax_available()
else ()
)
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = Flax{{cookiecutter.camelcase_modelname}}ModelTester(self)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
def test_for_causal_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_lm_head(*config_and_inputs)
def test_for_multiple_choice(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
def test_for_question_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
def test_for_sequence_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
def test_for_token_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
model = Flax{{cookiecutter.camelcase_modelname}}Model.from_pretrained("{{cookiecutter.checkpoint_identifier}}")
self.assertIsNotNone(model)
def _assert_tensors_equal(a, b, atol=1e-12, prefix=""):
"""If tensors not close, or a and b arent both tensors, raise a nice Assertion error."""
if a is None and b is None:
return True
try:
if _assert_tensors_equal(a, b, atol=atol):
return True
raise
except Exception:
if len(prefix) > 0:
prefix = f"{prefix}: "
raise AssertionError(f"{prefix}{a} != {b}")
@require_flax
class Flax{{cookiecutter.camelcase_modelname}}ModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_masked_lm(self):
model = Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM.from_pretrained("{{cookiecutter.checkpoint_identifier}}")
input_ids = np.array([[0, 1, 2, 3, 4, 5]])
output = model(input_ids)[0]
# TODO Replace vocab size
vocab_size = 32000
expected_shape = [1, 6, vocab_size]
self.assertEqual(output.shape, expected_shape)
print(output[:, :3, :3])
# TODO Replace values below with what was printed above.
expected_slice = np.array(
[
[
[-0.05243197, -0.04498899, 0.05512108],
[-0.07444685, -0.01064632, 0.04352357],
[-0.05020351, 0.05530146, 0.00700043],
]
]
)
_assert_tensors_equal(output[:, :3, :3], expected_slice, atol=1e-4)
{% else %}
import unittest
from transformers import (
is_flax_available,
{{cookiecutter.camelcase_modelname}}Config,
{{cookiecutter.camelcase_modelname}}Tokenizer,
)
from transformers.testing_utils import require_sentencepiece, require_flax, require_tokenizers, slow
from ...test_configuration_common import ConfigTester
from ...test_modeling_flax_common import FlaxModelTesterMixin, ids_tensor
if is_flax_available():
import numpy as np
import jax.numpy as jnp
from transformers import (
Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}Model,
)
@require_flax
class Flax{{cookiecutter.camelcase_modelname}}ModelTester:
config_cls = {{cookiecutter.camelcase_modelname}}Config
config_updates = {}
hidden_act = "gelu"
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_labels=False,
vocab_size=99,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
intermediate_size=37,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=20,
eos_token_id=2,
pad_token_id=1,
bos_token_id=0,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.bos_token_id = bos_token_id
def prepare_config_and_inputs_for_common(self):
input_ids = ids_tensor([self.batch_size, self.seq_length - 1], self.vocab_size).clip(3, self.vocab_size)
eos_tensor = np.expand_dims(np.array([self.eos_token_id] * self.batch_size), 1)
input_ids = np.concatenate([input_ids, eos_tensor], axis=1)
decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
config = self.config_cls(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
encoder_layers=self.num_hidden_layers,
decoder_layers=self.num_hidden_layers,
encoder_attention_heads=self.num_attention_heads,
decoder_attention_heads=self.num_attention_heads,
encoder_ffn_dim=self.intermediate_size,
decoder_ffn_dim=self.intermediate_size,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
eos_token_ids=[2],
bos_token_id=self.bos_token_id,
pad_token_id=self.pad_token_id,
decoder_start_token_id=self.pad_token_id,
**self.config_updates,
)
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(config, input_ids, decoder_input_ids)
return config, inputs_dict
def check_use_cache_forward(self, model_class_name, config, inputs_dict):
max_decoder_length = 20
model = model_class_name(config)
encoder_outputs = model.encode(inputs_dict["input_ids"])
decoder_input_ids, decoder_attention_mask = (
inputs_dict["decoder_input_ids"],
inputs_dict["decoder_attention_mask"],
)
past_key_values = model.init_cache(decoder_input_ids.shape[0], max_decoder_length, encoder_outputs)
decoder_attention_mask = jnp.ones((decoder_input_ids.shape[0], max_decoder_length), dtype="i4")
decoder_position_ids = jnp.broadcast_to(
jnp.arange(decoder_input_ids.shape[-1] - 1)[None, :],
(decoder_input_ids.shape[0], decoder_input_ids.shape[-1] - 1),
)
outputs_cache = model.decode(
decoder_input_ids[:, :-1],
encoder_outputs,
decoder_attention_mask=decoder_attention_mask,
past_key_values=past_key_values,
decoder_position_ids=decoder_position_ids,
)
decoder_position_ids = jnp.array(decoder_input_ids.shape[0] * [[decoder_input_ids.shape[-1] - 1]], dtype="i4")
outputs_cache_next = model.decode(
decoder_input_ids[:, -1:],
encoder_outputs,
decoder_attention_mask=decoder_attention_mask,
past_key_values=outputs_cache.past_key_values,
decoder_position_ids=decoder_position_ids,
)
outputs = model.decode(decoder_input_ids, encoder_outputs)
diff = np.max(np.abs((outputs_cache_next[0][:, -1, :5] - outputs[0][:, -1, :5])))
self.parent.assertTrue(diff < 1e-3, msg=f"Max diff is {diff}")
def check_use_cache_forward_with_attn_mask(self, model_class_name, config, inputs_dict):
max_decoder_length = 20
model = model_class_name(config)
encoder_outputs = model.encode(inputs_dict["input_ids"])
decoder_input_ids, decoder_attention_mask = (
inputs_dict["decoder_input_ids"],
inputs_dict["decoder_attention_mask"],
)
decoder_attention_mask_cache = jnp.concatenate(
[
decoder_attention_mask,
jnp.zeros((decoder_attention_mask.shape[0], max_decoder_length - decoder_attention_mask.shape[1])),
],
axis=-1,
)
past_key_values = model.init_cache(decoder_input_ids.shape[0], max_decoder_length, encoder_outputs)
decoder_position_ids = jnp.broadcast_to(
jnp.arange(decoder_input_ids.shape[-1] - 1)[None, :],
(decoder_input_ids.shape[0], decoder_input_ids.shape[-1] - 1),
)
outputs_cache = model.decode(
decoder_input_ids[:, :-1],
encoder_outputs,
decoder_attention_mask=decoder_attention_mask_cache,
past_key_values=past_key_values,
decoder_position_ids=decoder_position_ids,
)
decoder_position_ids = jnp.array(decoder_input_ids.shape[0] * [[decoder_input_ids.shape[-1] - 1]], dtype="i4")
outputs_cache_next = model.decode(
decoder_input_ids[:, -1:],
encoder_outputs,
past_key_values=outputs_cache.past_key_values,
decoder_attention_mask=decoder_attention_mask_cache,
decoder_position_ids=decoder_position_ids,
)
outputs = model.decode(decoder_input_ids, encoder_outputs, decoder_attention_mask=decoder_attention_mask)
diff = np.max(np.abs((outputs_cache_next[0][:, -1, :5] - outputs[0][:, -1, :5])))
self.parent.assertTrue(diff < 1e-3, msg=f"Max diff is {diff}")
def prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(
config,
input_ids,
decoder_input_ids,
attention_mask=None,
decoder_attention_mask=None,
):
if attention_mask is None:
attention_mask = np.not_equal(input_ids, config.pad_token_id).astype(np.int8)
if decoder_attention_mask is None:
decoder_attention_mask = np.concatenate([np.ones(decoder_input_ids[:, :1].shape, dtype=np.int8), np.not_equal(decoder_input_ids[:, 1:], config.pad_token_id).astype(np.int8)], axis=-1)
return {
"input_ids": input_ids,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": decoder_attention_mask,
}
@require_flax
class Flax{{cookiecutter.camelcase_modelname}}ModelTest(FlaxModelTesterMixin, unittest.TestCase):
all_model_classes = (
(
Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}Model,
) if is_flax_available()
else ()
)
all_generative_model_classes = (Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,) if is_flax_available() else ()
is_encoder_decoder = True
test_pruning = False
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = Flax{{cookiecutter.camelcase_modelname}}ModelTester(self)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config)
def test_config(self):
self.config_tester.run_common_tests()
def test_use_cache_forward(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
self.model_tester.check_use_cache_forward(model_class, config, inputs_dict)
def test_use_cache_forward_with_attn_mask(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
self.model_tester.check_use_cache_forward_with_attn_mask(model_class, config, inputs_dict)
def _assert_tensors_equal(a, b, atol=1e-12, prefix=""):
"""If tensors not close, or a and b arent both tensors, raise a nice Assertion error."""
if a is None and b is None:
return True
try:
if _assert_tensors_equal(a, b, atol=atol):
return True
raise
except Exception:
if len(prefix) > 0:
prefix = f"{prefix}: "
raise AssertionError(f"{prefix}{a} != {b}")
def _long_tensor(tok_lst):
return np.array(tok_lst, dtype=np.int32)
TOLERANCE = 1e-4
@slow
@require_sentencepiece
@require_tokenizers
@require_flax
class Flax{{cookiecutter.camelcase_modelname}}ModelIntegrationTest(unittest.TestCase):
def test_inference_no_head(self):
model = Flax{{cookiecutter.camelcase_modelname}}Model.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
# change to intended input here
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(model.config, input_ids, decoder_input_ids)
output = model(**inputs_dict)[0]
expected_shape = (1, 11, 1024)
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = np.array(
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]],
)
_assert_tensors_equal(output[:, :3, :3], expected_slice, atol=TOLERANCE)
def test_inference_with_head(self):
model = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
# change to intended input here
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(model.config, input_ids, decoder_input_ids)
output = model(**inputs_dict)[0]
expected_shape = (1, 11, 1024)
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = np.array(
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]],
)
_assert_tensors_equal(output[:, :3, :3], expected_slice, atol=TOLERANCE)
def test_seq_to_seq_generation(self):
hf = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
tok = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
batch_input = [
# string 1,
# string 2,
# string 3,
# string 4,
]
# The below article tests that we don't add any hypotheses outside of the top n_beams
dct = tok.batch_encode_plus(
batch_input,
max_length=512,
padding="max_length",
truncation_strategy="only_first",
truncation=True,
return_tensors="np",
)
hypotheses_batch = hf.generate(
input_ids=dct["input_ids"],
attention_mask=dct["attention_mask"],
num_beams=2,
)
EXPECTED = [
# here expected 1,
# here expected 2,
# here expected 3,
# here expected 4,
]
generated = tok.batch_decode(
hypotheses_batch.tolist(), clean_up_tokenization_spaces=True, skip_special_tokens=True
)
assert generated == EXPECTED
{%- endif %}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/to_replace_{{cookiecutter.lowercase_modelname}}.py
|
## Copyright 2022 The HuggingFace Team. All rights reserved.
##
## Licensed under the Apache License, Version 2.0 (the "License");
## you may not use this file except in compliance with the License.
## You may obtain a copy of the License at
##
## http://www.apache.org/licenses/LICENSE-2.0
##
## Unless required by applicable law or agreed to in writing, software
## distributed under the License is distributed on an "AS IS" BASIS,
## WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
## See the License for the specific language governing permissions and
## limitations under the License.
## This file is made so that specific statements may be copied inside existing files. This is useful to copy
## import statements in __init__.py, or to complete model lists in the AUTO files.
##
## It is to be used as such:
## Put '# To replace in: "FILE_PATH"' in order to indicate the contents will be copied in the file at path FILE_PATH
## Put '# Below: "STATEMENT"' in order to copy the contents below **the first occurence** of that line in the file at FILE_PATH
## Put '# Replace with:' followed by the lines containing the content to define the content
## End a statement with '# End.'. If starting a new statement without redefining the FILE_PATH, it will continue pasting
## content in that file.
##
## Put '## COMMENT' to comment on the file.
# To replace in: "src/transformers/__init__.py"
# Below: " # PyTorch models structure" if generating PyTorch
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
"{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"{{cookiecutter.camelcase_modelname}}ForCausalLM",
"{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"{{cookiecutter.camelcase_modelname}}Layer",
"{{cookiecutter.camelcase_modelname}}Model",
"{{cookiecutter.camelcase_modelname}}PreTrainedModel",
"load_tf_weights_in_{{cookiecutter.lowercase_modelname}}",
]
)
{% else %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
"{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"{{cookiecutter.camelcase_modelname}}ForCausalLM",
"{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"{{cookiecutter.camelcase_modelname}}Model",
"{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
)
{% endif -%}
# End.
# Below: " # TensorFlow models structure" if generating TensorFlow
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
"TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"TF{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"TF{{cookiecutter.camelcase_modelname}}ForCausalLM",
"TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"TF{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"TF{{cookiecutter.camelcase_modelname}}Layer",
"TF{{cookiecutter.camelcase_modelname}}Model",
"TF{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
)
{% else %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
"TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"TF{{cookiecutter.camelcase_modelname}}Model",
"TF{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
)
{% endif -%}
# End.
# Below: " # Flax models structure" if generating Flax
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
"Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"Flax{{cookiecutter.camelcase_modelname}}ForCausalLM",
"Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"Flax{{cookiecutter.camelcase_modelname}}Layer",
"Flax{{cookiecutter.camelcase_modelname}}Model",
"Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
)
{% else %}
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].extend(
[
"Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"Flax{{cookiecutter.camelcase_modelname}}Model",
"Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
)
{% endif -%}
# End.
# Below: " # Fast tokenizers structure"
# Replace with:
_import_structure["models.{{cookiecutter.lowercase_modelname}}"].append("{{cookiecutter.camelcase_modelname}}TokenizerFast")
# End.
# Below: " # Models"
# Replace with:
"models.{{cookiecutter.lowercase_modelname}}": ["{{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP", "{{cookiecutter.camelcase_modelname}}Config", "{{cookiecutter.camelcase_modelname}}Tokenizer"],
# End.
# To replace in: "src/transformers/__init__.py"
# Below: " # PyTorch model imports" if generating PyTorch
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
from .models.{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
{{cookiecutter.camelcase_modelname}}ForMaskedLM,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}ForTokenClassification,
{{cookiecutter.camelcase_modelname}}Layer,
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}PreTrainedModel,
load_tf_weights_in_{{cookiecutter.lowercase_modelname}},
)
{% else %}
from .models.{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif -%}
# End.
# Below: " # TensorFlow model imports" if generating TensorFlow
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
from .models.{{cookiecutter.lowercase_modelname}} import (
TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
TF{{cookiecutter.camelcase_modelname}}ForMaskedLM,
TF{{cookiecutter.camelcase_modelname}}ForCausalLM,
TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
TF{{cookiecutter.camelcase_modelname}}ForTokenClassification,
TF{{cookiecutter.camelcase_modelname}}Layer,
TF{{cookiecutter.camelcase_modelname}}Model,
TF{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% else %}
from .models.{{cookiecutter.lowercase_modelname}} import (
TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
TF{{cookiecutter.camelcase_modelname}}Model,
TF{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif -%}
# End.
# Below: " # Flax model imports" if generating Flax
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" %}
from .models.{{cookiecutter.lowercase_modelname}} import (
Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM,
Flax{{cookiecutter.camelcase_modelname}}ForCausalLM,
Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification,
Flax{{cookiecutter.camelcase_modelname}}Layer,
Flax{{cookiecutter.camelcase_modelname}}Model,
Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% else %}
from .models.{{cookiecutter.lowercase_modelname}} import (
Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}Model,
Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif -%}
# End.
# Below: " # Fast tokenizers imports"
# Replace with:
from .models.{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}TokenizerFast
# End.
# Below: " from .models.albert import ALBERT_PRETRAINED_CONFIG_ARCHIVE_MAP, AlbertConfig"
# Replace with:
from .models.{{cookiecutter.lowercase_modelname}} import {{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP, {{cookiecutter.camelcase_modelname}}Config, {{cookiecutter.camelcase_modelname}}Tokenizer
# End.
# To replace in: "src/transformers/models/__init__.py"
# Below: "from . import ("
# Replace with:
{{cookiecutter.lowercase_modelname}},
# End.
# To replace in: "src/transformers/models/auto/configuration_auto.py"
# Below: "# Add configs here"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}Config"),
# End.
# Below: "# Add archive maps here"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP"),
# End.
# Below: "# Add full (and cased) model names here"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}"),
# End.
# To replace in: "src/transformers/models/auto/modeling_auto.py" if generating PyTorch
# Below: "# Base model mapping"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}Model"),
# End.
# Below: "# Model with LM heads mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForMaskedLM"),
{% else %}
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForConditionalGeneration"),
{% endif -%}
# End.
# Below: "# Model for Causal LM mapping"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForCausalLM"),
# End.
# Below: "# Model for Masked LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForMaskedLM"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Sequence Classification mapping"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForSequenceClassification"),
# End.
# Below: "# Model for Question Answering mapping"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForQuestionAnswering"),
# End.
# Below: "# Model for Token Classification mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForTokenClassification"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Multiple Choice mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForMultipleChoice"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Seq2Seq Causal LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else %}
("{{cookiecutter.lowercase_modelname}}", "{{cookiecutter.camelcase_modelname}}ForConditionalGeneration"),
{% endif -%}
# End.
# To replace in: "src/transformers/models/auto/modeling_tf_auto.py" if generating TensorFlow
# Below: "# Base model mapping"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}Model"),
# End.
# Below: "# Model with LM heads mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForMaskedLM"),
{% else %}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration"),
{% endif -%}
# End.
# Below: "# Model for Causal LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForCausalLM"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Masked LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForMaskedLM"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Sequence Classification mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Question Answering mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Token Classification mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForTokenClassification"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Multiple Choice mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Seq2Seq Causal LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else %}
("{{cookiecutter.lowercase_modelname}}", "TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration"),
{% endif -%}
# End.
# To replace in: "src/transformers/models/auto/modeling_flax_auto.py" if generating Flax
# Below: "# Base model mapping"
# Replace with:
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}Model"),
# End.
# Below: "# Model for Masked LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM"),
{% else %}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration"),
{% endif -%}
# End.
# Below: "# Model for Causal LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForCausalLM"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Masked LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Sequence Classification mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification"),
{% else %}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification"),
{% endif -%}
# End.
# Below: "# Model for Question Answering mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering"),
{% else %}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering"),
{% endif -%}
# End.
# Below: "# Model for Token Classification mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Multiple Choice mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice"),
{% else -%}
{% endif -%}
# End.
# Below: "# Model for Seq2Seq Causal LM mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else %}
("{{cookiecutter.lowercase_modelname}}", "Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration"),
{% endif -%}
# End.
# To replace in: "utils/check_repo.py" if generating PyTorch
# Below: "models to ignore for model xxx mapping"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else -%}
"{{cookiecutter.camelcase_modelname}}Encoder",
"{{cookiecutter.camelcase_modelname}}Decoder",
"{{cookiecutter.camelcase_modelname}}DecoderWrapper",
{% endif -%}
# End.
# Below: "models to ignore for not tested"
# Replace with:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else -%}
"{{cookiecutter.camelcase_modelname}}Encoder", # Building part of bigger (tested) model.
"{{cookiecutter.camelcase_modelname}}Decoder", # Building part of bigger (tested) model.
"{{cookiecutter.camelcase_modelname}}DecoderWrapper", # Building part of bigger (tested) model.
{% endif -%}
# End.
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/configuration_{{cookiecutter.lowercase_modelname}}.py
|
# coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" {{cookiecutter.modelname}} model configuration """
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
{{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP = {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/config.json",
# See all {{cookiecutter.modelname}} models at https://huggingface.co/models?filter={{cookiecutter.lowercase_modelname}}
}
class {{cookiecutter.camelcase_modelname}}Config(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`~{{cookiecutter.camelcase_modelname}}Model`].
It is used to instantiate an {{cookiecutter.modelname}} model according to the specified arguments, defining the model
architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of
the {{cookiecutter.modelname}} [{{cookiecutter.checkpoint_identifier}}](https://huggingface.co/{{cookiecutter.checkpoint_identifier}}) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used
to control the model outputs. Read the documentation from [`PretrainedConfig`]
for more information.
Args:
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
vocab_size (`int`, *optional*, defaults to 30522):
Vocabulary size of the {{cookiecutter.modelname}} model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`~{{cookiecutter.camelcase_modelname}}Model`] or
[`~TF{{cookiecutter.camelcase_modelname}}Model`].
hidden_size (`int`, *optional*, defaults to 768):
Dimension of the encoder layers and the pooler layer.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimension of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler.
If string, `"gelu"`, `"relu"`, `"selu"` and `"gelu_new"` are supported.
hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
The dropout ratio for the attention probabilities.
max_position_embeddings (`int`, *optional*, defaults to 512):
The maximum sequence length that this model might ever be used with.
Typically set this to something large just in case (e.g., 512 or 1024 or 2048).
type_vocab_size (`int`, *optional*, defaults to 2):
The vocabulary size of the `token_type_ids` passed when calling [`~{{cookiecutter.camelcase_modelname}}Model`] or
[`~TF{{cookiecutter.camelcase_modelname}}Model`].
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
The epsilon used by the layer normalization layers.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
{% else -%}
vocab_size (`int`, *optional*, defaults to 50265):
Vocabulary size of the {{cookiecutter.modelname}} model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`~{{cookiecutter.camelcase_modelname}}Model`] or
[`~TF{{cookiecutter.camelcase_modelname}}Model`].
d_model (`int`, *optional*, defaults to 1024):
Dimension of the layers and the pooler layer.
encoder_layers (`int`, *optional*, defaults to 12):
Number of encoder layers.
decoder_layers (`int`, *optional*, defaults to 12):
Number of decoder layers.
encoder_attention_heads (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer encoder.
decoder_attention_heads (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer decoder.
decoder_ffn_dim (`int`, *optional*, defaults to 4096):
Dimension of the "intermediate" (often named feed-forward) layer in decoder.
encoder_ffn_dim (`int`, *optional*, defaults to 4096):
Dimension of the "intermediate" (often named feed-forward) layer in decoder.
activation_function (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string,
`"gelu"`, `"relu"`, `"silu"` and `"gelu_new"` are supported.
dropout (`float`, *optional*, defaults to 0.1):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
activation_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for activations inside the fully connected layer.
classifier_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for classifier.
max_position_embeddings (`int`, *optional*, defaults to 1024):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
init_std (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
encoder_layerdrop (`float`, *optional*, defaults to 0.0):
The LayerDrop probability for the encoder. See the [LayerDrop paper](see
https://arxiv.org/abs/1909.11556) for more details.
decoder_layerdrop (`float`, *optional*, defaults to 0.0):
The LayerDrop probability for the decoder. See the [LayerDrop paper](see
https://arxiv.org/abs/1909.11556) for more details.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models).
{% endif -%}
Example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Model, {{cookiecutter.camelcase_modelname}}Config
>>> # Initializing a {{cookiecutter.modelname}} {{cookiecutter.checkpoint_identifier}} style configuration
>>> configuration = {{cookiecutter.camelcase_modelname}}Config()
>>> # Initializing a model from the {{cookiecutter.checkpoint_identifier}} style configuration
>>> model = {{cookiecutter.camelcase_modelname}}Model(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```
"""
model_type = "{{cookiecutter.lowercase_modelname}}"
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else -%}
keys_to_ignore_at_inference = ["past_key_values"]
{% endif -%}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
{%- else %}
attribute_map = {
"num_attention_heads": "encoder_attention_heads",
"hidden_size": "d_model"
}
{%- endif %}
def __init__(
self,
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
vocab_size=30522,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=2,
initializer_range=0.02,
layer_norm_eps=1e-12,
use_cache=True,
{% else -%}
vocab_size=50265,
max_position_embeddings=1024,
encoder_layers=12,
encoder_ffn_dim=4096,
encoder_attention_heads=16,
decoder_layers=12,
decoder_ffn_dim=4096,
decoder_attention_heads=16,
encoder_layerdrop=0.0,
decoder_layerdrop=0.0,
use_cache=True,
is_encoder_decoder=True,
activation_function="gelu",
d_model=1024,
dropout=0.1,
attention_dropout=0.0,
activation_dropout=0.0,
init_std=0.02,
decoder_start_token_id=2,
classifier_dropout=0.0,
scale_embedding=False,
{% endif -%}
pad_token_id=1,
bos_token_id=0,
eos_token_id=2,
**kwargs
):
self.vocab_size = vocab_size
self.max_position_embeddings = max_position_embeddings
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.initializer_range = initializer_range
self.type_vocab_size = type_vocab_size
self.layer_norm_eps = layer_norm_eps
self.use_cache = use_cache
{% else -%}
self.d_model = d_model
self.encoder_ffn_dim = encoder_ffn_dim
self.encoder_layers = encoder_layers
self.encoder_attention_heads = encoder_attention_heads
self.decoder_ffn_dim = decoder_ffn_dim
self.decoder_layers = decoder_layers
self.decoder_attention_heads = decoder_attention_heads
self.dropout = dropout
self.attention_dropout = attention_dropout
self.activation_dropout = activation_dropout
self.activation_function = activation_function
self.init_std = init_std
self.encoder_layerdrop = encoder_layerdrop
self.decoder_layerdrop = decoder_layerdrop
self.classifier_dropout = classifier_dropout
self.use_cache = use_cache
self.num_hidden_layers = encoder_layers
self.scale_embedding = scale_embedding # scale factor will be sqrt(d_model) if True
{% endif -%}
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
{% else -%}
is_encoder_decoder=is_encoder_decoder,
decoder_start_token_id=decoder_start_token_id,
{% endif -%}
**kwargs
)
| 0
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.