
repo_id
stringlengths 15
89
| file_path
stringlengths 27
180
| content
stringlengths 1
2.23M
| __index_level_0__
int64 0
0
|
|---|---|---|---|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_{{cookiecutter.lowercase_modelname}}.py
|
# coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch {{cookiecutter.modelname}} model. """
{% if cookiecutter.is_encoder_decoder_model == "False" %}
import math
import os
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from typing import Optional, Tuple, Union
from ...activations import ACT2FN
from ...utils import (
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
from ...modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
CausalLMOutputWithCrossAttentions,
MaskedLMOutput,
MultipleChoiceModelOutput,
QuestionAnsweringModelOutput,
SequenceClassifierOutput,
TokenClassifierOutput,
)
from ...modeling_utils import PreTrainedModel, SequenceSummary
from ...pytorch_utils import (
apply_chunking_to_forward,
find_pruneable_heads_and_indices,
prune_linear_layer,
)
from ...utils import logging
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Config
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST = [
"{{cookiecutter.checkpoint_identifier}}",
# See all {{cookiecutter.modelname}} models at https://huggingface.co/models?filter={{cookiecutter.lowercase_modelname}}
]
def load_tf_weights_in_{{cookiecutter.lowercase_modelname}}(model, config, tf_checkpoint_path):
"""Load tf checkpoints in a pytorch model."""
try:
import re
import numpy as np
import tensorflow as tf
except ImportError:
logger.error(
"Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
"https://www.tensorflow.org/install/ for installation instructions."
)
raise
tf_path = os.path.abspath(tf_checkpoint_path)
logger.info(f"Converting TensorFlow checkpoint from {tf_path}")
# Load weights from TF model
init_vars = tf.train.list_variables(tf_path)
names = []
arrays = []
for name, shape in init_vars:
logger.info(f"Loading TF weight {name} with shape {shape}")
array = tf.train.load_variable(tf_path, name)
names.append(name)
arrays.append(array)
for name, array in zip(names, arrays):
name = name.split("/")
# adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v
# which are not required for using pretrained model
if any(
n in ["adam_v", "adam_m", "AdamWeightDecayOptimizer", "AdamWeightDecayOptimizer_1", "global_step"]
for n in name
):
logger.info(f"Skipping {'/'.join(name)}")
continue
pointer = model
for m_name in name:
if re.fullmatch(r"[A-Za-z]+_\d+", m_name):
scope_names = re.split(r"_(\d+)", m_name)
else:
scope_names = [m_name]
if scope_names[0] == "kernel" or scope_names[0] == "gamma":
pointer = getattr(pointer, "weight")
elif scope_names[0] == "output_bias" or scope_names[0] == "beta":
pointer = getattr(pointer, "bias")
elif scope_names[0] == "output_weights":
pointer = getattr(pointer, "weight")
elif scope_names[0] == "squad":
pointer = getattr(pointer, "classifier")
else:
try:
pointer = getattr(pointer, scope_names[0])
except AttributeError:
logger.info(f"Skipping {'/'.join(name)}")
continue
if len(scope_names) >= 2:
num = int(scope_names[1])
pointer = pointer[num]
if m_name[-11:] == "_embeddings":
pointer = getattr(pointer, "weight")
elif m_name == "kernel":
array = np.transpose(array)
try:
assert (
pointer.shape == array.shape
), f"Pointer shape {pointer.shape} and array shape {array.shape} mismatched"
except AssertionError as e:
e.args += (pointer.shape, array.shape)
raise
logger.info(f"Initialize PyTorch weight {name}")
pointer.data = torch.from_numpy(array)
return model
# Copied from transformers.models.bert.modeling_bert.BertEmbeddings with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}Embeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
self.register_buffer(
"token_type_ids",
torch.zeros(self.position_ids.size(), dtype=torch.long, device=self.position_ids.device),
persistent=False,
)
def forward(
self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
# Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
# when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
# issue #5664
if token_type_ids is None:
if hasattr(self, "token_type_ids"):
buffered_token_type_ids = self.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
# Copied from transformers.models.bert.modeling_bert.BertSelfAttention with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}SelfAttention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads})"
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = position_embedding_type or getattr(config, "position_embedding_type", "absolute")
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
self.is_decoder = config.is_decoder
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
mixed_query_layer = self.query(hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
else:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
seq_length = hidden_states.size()[1]
position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in {{cookiecutter.camelcase_modelname}}Model forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
# Copied from transformers.models.bert.modeling_bert.BertSelfOutput with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}SelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}Attention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
self.self = {{cookiecutter.camelcase_modelname}}SelfAttention(config, position_embedding_type=position_embedding_type)
self.output = {{cookiecutter.camelcase_modelname}}SelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
self_outputs = self.self(
hidden_states,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
# Copied from transformers.models.bert.modeling_bert.BertIntermediate with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}Intermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertOutput with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}Output(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertLayer with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}Layer(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = {{cookiecutter.camelcase_modelname}}Attention(config)
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
assert self.is_decoder, f"{self} should be used as a decoder model if cross attention is added"
self.crossattention = {{cookiecutter.camelcase_modelname}}Attention(config, position_embedding_type="absolute")
self.intermediate = {{cookiecutter.camelcase_modelname}}Intermediate(config)
self.output = {{cookiecutter.camelcase_modelname}}Output(config)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
attention_output = self_attention_outputs[0]
# if decoder, the last output is tuple of self-attn cache
if self.is_decoder:
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
assert hasattr(
self, "crossattention"
), f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers by setting `config.add_cross_attention=True`"
# cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
cross_attn_past_key_value,
output_attentions,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
# add cross-attn cache to positions 3,4 of present_key_value tuple
cross_attn_present_key_value = cross_attention_outputs[-1]
present_key_value = present_key_value + cross_attn_present_key_value
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
)
outputs = (layer_output,) + outputs
# if decoder, return the attn key/values as the last output
if self.is_decoder:
outputs = outputs + (present_key_value,)
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
# Copied from transformers.models.bert.modeling_bert.BertEncoder with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}Encoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.layer = nn.ModuleList([{{cookiecutter.camelcase_modelname}}Layer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=False,
output_hidden_states=False,
return_dict=True,
):
if self.gradient_checkpointing and self.training and use_cache:
logger.warning(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
next_decoder_cache = () if use_cache else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
past_key_value = past_key_values[i] if past_key_values is not None else None
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
layer_module.__call__,
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
else:
layer_outputs = layer_module(
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
# Copied from transformers.models.bert.modeling_bert.BertPredictionHeadTransform with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}PredictionHeadTransform(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
if isinstance(config.hidden_act, str):
self.transform_act_fn = ACT2FN[config.hidden_act]
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertLMPredictionHead with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}LMPredictionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.transform = {{cookiecutter.camelcase_modelname}}PredictionHeadTransform(config)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertOnlyMLMHead with Bert->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}OnlyMLMHead(nn.Module):
def __init__(self, config):
super().__init__()
self.predictions = {{cookiecutter.camelcase_modelname}}LMPredictionHead(config)
def forward(self, sequence_output):
prediction_scores = self.predictions(sequence_output)
return prediction_scores
class {{cookiecutter.camelcase_modelname}}PreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and
a simple interface for downloading and loading pretrained models.
"""
config_class = {{cookiecutter.camelcase_modelname}}Config
load_tf_weights = load_tf_weights_in_{{cookiecutter.lowercase_modelname}}
base_model_prefix = "{{cookiecutter.lowercase_modelname}}"
supports_gradient_checkpointing = True
_keys_to_ignore_on_load_missing = [r"position_ids"]
def _init_weights(self, module):
""" Initialize the weights """
if isinstance(module, nn.Linear):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING = r"""
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general
usage and behavior.
Parameters:
config ([`~{{cookiecutter.camelcase_modelname}}Config`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the configuration.
Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
{{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`{{cookiecutter.camelcase_modelname}}Tokenizer`].
See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings.
Selected in the range `[0, config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert *input_ids* indices into associated vectors
than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The bare {{cookiecutter.modelname}} Model transformer outputting raw hidden-states without any specific head on top.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}Model({{cookiecutter.camelcase_modelname}}PreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well
as a decoder, in which case a layer of cross-attention is added between
the self-attention layers, following the architecture described in [Attention is
all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani,
Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the
`is_decoder` argument of the configuration set to `True`.
To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder`
argument and `add_cross_attention` set to `True`; an
`encoder_hidden_states` is then expected as an input to the forward pass.
"""
def __init__(self, config):
super().__init__(config)
self.config = config
self.embeddings = {{cookiecutter.camelcase_modelname}}Embeddings(config)
self.encoder = {{cookiecutter.camelcase_modelname}}Encoder(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""Prunes heads of the model.
heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
See base class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=BaseModelOutputWithPastAndCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
if the model is configured as a decoder.
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask
is used in the cross-attention if the model is configured as a decoder.
Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`).
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if self.config.is_decoder:
use_cache = use_cache if use_cache is not None else self.config.use_cache
else:
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
batch_size, seq_length = input_shape
device = input_ids.device if input_ids is not None else inputs_embeds.device
# past_key_values_length
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
if attention_mask is None:
attention_mask = torch.ones(((batch_size, seq_length + past_key_values_length)), device=device)
if token_type_ids is None:
if hasattr(self.embeddings, "token_type_ids"):
buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
# If a 2D or 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
)
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
if not return_dict:
return (sequence_output,) + encoder_outputs[1:]
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=sequence_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
@add_start_docstrings("""{{cookiecutter.modelname}} Model with a `language modeling` head on top. """, {{cookiecutter.uppercase_modelname}}_START_DOCSTRING)
class {{cookiecutter.camelcase_modelname}}ForMaskedLM({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
super().__init__(config)
if config.is_decoder:
logger.warning(
"If you want to use `{{cookiecutter.camelcase_modelname}}ForMaskedLM` make sure `config.is_decoder=False` for "
"bi-directional self-attention."
)
self.{{cookiecutter.lowercase_modelname}} = {{cookiecutter.camelcase_modelname}}Model(config)
self.cls = {{cookiecutter.camelcase_modelname}}OnlyMLMHead(config)
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.cls.predictions.decoder
def set_output_embeddings(self, new_embeddings):
self.cls.predictions.decoder = new_embeddings
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MaskedLMOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss.
Indices should be in `[-100, 0, ..., config.vocab_size]` (see `input_ids` docstring)
Tokens with indices set to `-100` are ignored (masked), the loss is only computed for the tokens with labels
in `[0, ..., config.vocab_size]`.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
prediction_scores = self.cls(sequence_output)
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss() # -100 index = padding token
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (prediction_scores,) + outputs[1:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return MaskedLMOutput(
loss=masked_lm_loss,
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
def prepare_inputs_for_generation(self, input_ids, attention_mask=None, **model_kwargs):
input_shape = input_ids.shape
effective_batch_size = input_shape[0]
# add a dummy token
assert self.config.pad_token_id is not None, "The PAD token should be defined for generation"
attention_mask = torch.cat([attention_mask, attention_mask.new_zeros((attention_mask.shape[0], 1))], dim=-1)
dummy_token = torch.full(
(effective_batch_size, 1), self.config.pad_token_id, dtype=torch.long, device=input_ids.device
)
input_ids = torch.cat([input_ids, dummy_token], dim=1)
return {"input_ids": input_ids, "attention_mask": attention_mask}
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a `language modeling` head on top for CLM fine-tuning. """, {{cookiecutter.uppercase_modelname}}_START_DOCSTRING
)
class {{cookiecutter.camelcase_modelname}}ForCausalLM({{cookiecutter.camelcase_modelname}}PreTrainedModel):
_keys_to_ignore_on_load_missing = [r"position_ids", r"predictions.decoder.bias"]
def __init__(self, config):
super().__init__(config)
if not config.is_decoder:
logger.warning("If you want to use `{{cookiecutter.camelcase_modelname}}ForCausalLM` as a standalone, add `is_decoder=True.`")
self.{{cookiecutter.lowercase_modelname}} = {{cookiecutter.camelcase_modelname}}Model(config)
self.cls = {{cookiecutter.camelcase_modelname}}OnlyMLMHead(config)
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.cls.predictions.decoder
def set_output_embeddings(self, new_embeddings):
self.cls.predictions.decoder = new_embeddings
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=CausalLMOutputWithCrossAttentions, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
head_mask=None,
cross_attn_head_mask=None,
past_key_values=None,
labels=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2
tensors of shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional
tensors of shape `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`. The two
additional tensors are only required when the model is used as a decoder in a Sequence to Sequence
model.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the
cross-attention blocks) that can be used (see `past_key_values` input) to speed up sequential
decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
`[-100, 0, ..., config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are
ignored (masked), the loss is only computed for the tokens with labels n `[0, ..., config.vocab_size]`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`).
Returns:
Example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, {{cookiecutter.camelcase_modelname}}ForCausalLM, {{cookiecutter.camelcase_modelname}}Config
>>> import torch
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> config = {{cookiecutter.camelcase_modelname}}Config.from_pretrained("{{cookiecutter.checkpoint_identifier}}")
>>> config.is_decoder = True
>>> model = {{cookiecutter.camelcase_modelname}}ForCausalLM.from_pretrained('{{cookiecutter.checkpoint_identifier}}', config=config)
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> prediction_logits = outputs.logits
```
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
prediction_scores = self.cls(sequence_output)
lm_loss = None
if labels is not None:
# we are doing next-token prediction; shift prediction scores and input ids by one
shifted_prediction_scores = prediction_scores[:, :-1, :].contiguous()
labels = labels[:, 1:].contiguous()
loss_fct = CrossEntropyLoss()
lm_loss = loss_fct(shifted_prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (prediction_scores,) + outputs[1:]
return ((lm_loss,) + output) if lm_loss is not None else output
return CausalLMOutputWithCrossAttentions(
loss=lm_loss,
logits=prediction_scores,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
def prepare_inputs_for_generation(self, input_ids, past_key_values=None, attention_mask=None, **model_kwargs):
input_shape = input_ids.shape
# if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
if attention_mask is None:
attention_mask = input_ids.new_ones(input_shape)
# cut decoder_input_ids if past is used
if past_key_values is not None:
input_ids = input_ids[:, -1:]
return {"input_ids": input_ids, "attention_mask": attention_mask, "past_key_values": past_key_values}
def _reorder_cache(self, past_key_values, beam_idx):
reordered_past = ()
for layer_past in past_key_values:
reordered_past += (tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past[:2]) + layer_past[2:],)
return reordered_past
class {{cookiecutter.camelcase_modelname}}ClassificationHead(nn.Module):
"""Head for sentence-level classification tasks."""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
self.config = config
def forward(self, features, **kwargs):
x = features[:, 0, :] # take <s> token (equiv. to [CLS])
x = self.dropout(x)
x = self.dense(x)
x = ACT2FN[self.config.hidden_act](x)
x = self.dropout(x)
x = self.out_proj(x)
return x
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model transformer with a sequence classification/regression head on top (a linear layer on top of
the pooled output) e.g. for GLUE tasks. """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}ForSequenceClassification({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.{{cookiecutter.lowercase_modelname}} = {{cookiecutter.camelcase_modelname}}Model(config)
self.classifier = {{cookiecutter.camelcase_modelname}}ClassificationHead(config)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=SequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss.
Indices should be in `[0, ..., config.num_labels - 1]`.
If `config.num_labels == 1` a regression loss is computed (Mean-Square loss),
If `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a multiple choice classification head on top (a linear layer on top of
the pooled output and a softmax) e.g. for RocStories/SWAG tasks. """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}ForMultipleChoice({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.{{cookiecutter.lowercase_modelname}} = {{cookiecutter.camelcase_modelname}}Model(config)
self.sequence_summary = SequenceSummary(config)
self.classifier = nn.Linear(config.hidden_size, 1)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MultipleChoiceModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the multiple choice classification loss.
Indices should be in `[0, ..., num_choices-1]` where `num_choices` is the size of the second dimension
of the input tensors. (See `input_ids` above)
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
num_choices = input_ids.shape[1] if input_ids is not None else inputs_embeds.shape[1]
input_ids = input_ids.view(-1, input_ids.size(-1)) if input_ids is not None else None
attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
inputs_embeds = (
inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
if inputs_embeds is not None
else None
)
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
pooled_output = self.sequence_summary(sequence_output)
logits = self.classifier(pooled_output)
reshaped_logits = logits.view(-1, num_choices)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(reshaped_logits, labels)
if not return_dict:
output = (reshaped_logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return MultipleChoiceModelOutput(
loss=loss,
logits=reshaped_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a token classification head on top (a linear layer on top of
the hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks. """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}ForTokenClassification({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.{{cookiecutter.lowercase_modelname}} = {{cookiecutter.camelcase_modelname}}Model(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TokenClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the token classification loss.
Indices should be in `[0, ..., config.num_labels - 1]`.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return TokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layers on top of the hidden-states output to compute `span start logits` and `span end logits`). """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}ForQuestionAnswering({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
super().__init__(config)
config.num_labels = 2
self.num_labels = config.num_labels
self.{{cookiecutter.lowercase_modelname}} = {{cookiecutter.camelcase_modelname}}Model(config)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=QuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
start_positions=None,
end_positions=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`).
Position outside of the sequence are not taken into account for computing the loss.
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`).
Position outside of the sequence are not taken into account for computing the loss.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
total_loss = None
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions = start_positions.clamp(0, ignored_index)
end_positions = end_positions.clamp(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
if not return_dict:
output = (start_logits, end_logits) + outputs[1:]
return ((total_loss,) + output) if total_loss is not None else output
return QuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
{% else %}
import math
import copy
from typing import Optional, Tuple, List, Union
import torch
from torch import nn
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from ...activations import ACT2FN
from ...utils import (
add_code_sample_docstrings,
add_end_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
from ...modeling_attn_mask_utils import _prepare_4d_attention_mask, _prepare_4d_causal_attention_mask
from ...modeling_outputs import (
BaseModelOutput,
BaseModelOutputWithPastAndCrossAttentions,
Seq2SeqLMOutput,
Seq2SeqModelOutput,
Seq2SeqQuestionAnsweringModelOutput,
Seq2SeqSequenceClassifierOutput,
CausalLMOutputWithCrossAttentions
)
from ...modeling_utils import PreTrainedModel
from ...utils import logging
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Config
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST = [
"{{cookiecutter.checkpoint_identifier}}",
# See all {{cookiecutter.modelname}} models at https://huggingface.co/models?filter={{cookiecutter.lowercase_modelname}}
]
def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decoder_start_token_id: int):
"""
Shift input ids one token to the right.
"""
shifted_input_ids = input_ids.new_zeros(input_ids.shape)
shifted_input_ids[:, 1:] = input_ids[:, :-1].clone()
shifted_input_ids[:, 0] = decoder_start_token_id
assert pad_token_id is not None, "self.model.config.pad_token_id has to be defined."
# replace possible -100 values in labels by `pad_token_id`
shifted_input_ids.masked_fill_(shifted_input_ids == -100, pad_token_id)
return shifted_input_ids
class {{cookiecutter.camelcase_modelname}}LearnedPositionalEmbedding(nn.Embedding):
"""
This module learns positional embeddings up to a fixed maximum size.
"""
def __init__(self, num_embeddings: int, embedding_dim: int):
super().__init__(num_embeddings, embedding_dim)
def forward(self, input_ids_shape: torch.Size, past_key_values_length: int = 0):
"""`input_ids_shape` is expected to be [bsz x seqlen]."""
bsz, seq_len = input_ids_shape[:2]
positions = torch.arange(
past_key_values_length, past_key_values_length + seq_len, dtype=torch.long, device=self.weight.device
)
return super().forward(positions)
class {{cookiecutter.camelcase_modelname}}Attention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(
self,
embed_dim: int,
num_heads: int,
dropout: float = 0.0,
is_decoder: bool = False,
bias: bool = True,
):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.head_dim = embed_dim // num_heads
assert (
self.head_dim * num_heads == self.embed_dim
), f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`: {num_heads})."
self.scaling = self.head_dim ** -0.5
self.is_decoder = is_decoder
self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def forward(
self,
hidden_states: torch.Tensor,
key_value_states: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
"""Input shape: Batch x Time x Channel"""
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
bsz, tgt_len, embed_dim = hidden_states.size()
# get query proj
query_states = self.q_proj(hidden_states) * self.scaling
# get key, value proj
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_states = past_key_value[0]
value_states = past_key_value[1]
elif is_cross_attention:
# cross_attentions
key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
elif past_key_value is not None:
# reuse k, v, self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
key_states = torch.cat([past_key_value[0], key_states], dim=2)
value_states = torch.cat([past_key_value[1], value_states], dim=2)
else:
# self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_states, value_states)
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
key_states = key_states.view(*proj_shape)
value_states = value_states.view(*proj_shape)
src_len = key_states.size(1)
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
raise ValueError(
f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is {attn_weights.size()}"
)
if attention_mask is not None:
if attention_mask.size() != (bsz, 1, tgt_len, src_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
)
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
if layer_head_mask is not None:
if layer_head_mask.size() != (self.num_heads,):
raise ValueError(
f"Head mask for a single layer should be of size {(self.num_heads,)}, but is {layer_head_mask.size()}"
)
attn_weights = layer_head_mask.view(1, -1, 1, 1) * attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
if output_attentions:
# this operation is a bit akward, but it's required to
# make sure that attn_weights keeps its gradient.
# In order to do so, attn_weights have to reshaped
# twice and have to be reused in the following
attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
else:
attn_weights_reshaped = None
attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
attn_output = torch.bmm(attn_probs, value_states)
if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is {attn_output.size()}"
)
attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
attn_output = attn_output.transpose(1, 2)
attn_output = attn_output.reshape(bsz, tgt_len, embed_dim)
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights_reshaped, past_key_value
class {{cookiecutter.camelcase_modelname}}EncoderLayer(nn.Module):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config):
super().__init__()
self.embed_dim = config.d_model
self.self_attn = {{cookiecutter.camelcase_modelname}}Attention(
embed_dim=self.embed_dim,
num_heads=config.encoder_attention_heads,
dropout=config.attention_dropout,
)
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
self.activation_dropout = config.activation_dropout
self.fc1 = nn.Linear(self.embed_dim, config.encoder_ffn_dim)
self.fc2 = nn.Linear(config.encoder_ffn_dim, self.embed_dim)
self.final_layer_norm = nn.LayerNorm(self.embed_dim)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: torch.Tensor,
layer_head_mask: torch.Tensor,
output_attentions: bool = False,
):
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape *(batch, seq_len, embed_dim)*
attention_mask (`torch.FloatTensor`): attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
*(config.encoder_attention_heads,)*.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
hidden_states, attn_weights, _ = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
hidden_states = self.fc2(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
if hidden_states.dtype == torch.float16 and (torch.isinf(hidden_states).any() or torch.isnan(hidden_states).any()):
clamp_value = torch.finfo(hidden_states.dtype).max - 1000
hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
return outputs
class {{cookiecutter.camelcase_modelname}}DecoderLayer(nn.Module):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config):
super().__init__()
self.embed_dim = config.d_model
self.self_attn = {{cookiecutter.camelcase_modelname}}Attention(
embed_dim=self.embed_dim,
num_heads=config.decoder_attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
)
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
self.activation_dropout = config.activation_dropout
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.encoder_attn = {{cookiecutter.camelcase_modelname}}Attention(
self.embed_dim,
config.decoder_attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
)
self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.fc1 = nn.Linear(self.embed_dim, config.decoder_ffn_dim)
self.fc2 = nn.Linear(config.decoder_ffn_dim, self.embed_dim)
self.final_layer_norm = nn.LayerNorm(self.embed_dim)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
cross_layer_head_mask: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: Optional[bool] = False,
use_cache: Optional[bool] = True,
):
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape *(batch, seq_len, embed_dim)*
attention_mask (`torch.FloatTensor`): attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
encoder_hidden_states (`torch.FloatTensor`): cross attention input to the layer of shape *(batch, seq_len, embed_dim)*
encoder_attention_mask (`torch.FloatTensor`): encoder attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
*(encoder_attention_heads,)*.
cross_layer_head_mask (`torch.FloatTensor`): mask for cross-attention heads in a given layer of
size *(decoder_attention_heads,)*.
past_key_value (`Tuple(torch.FloatTensor)`): cached past key and value projection states
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
# Self Attention
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
# add present self-attn cache to positions 1,2 of present_key_value tuple
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
past_key_value=self_attn_past_key_value,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
# Cross-Attention Block
cross_attn_present_key_value = None
cross_attn_weights = None
if encoder_hidden_states is not None:
residual = hidden_states
# cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
hidden_states=hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
layer_head_mask=cross_layer_head_mask,
past_key_value=cross_attn_past_key_value,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.encoder_attn_layer_norm(hidden_states)
# add cross-attn to positions 3,4 of present_key_value tuple
present_key_value = present_key_value + cross_attn_present_key_value
# Fully Connected
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
hidden_states = self.fc2(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights, cross_attn_weights)
if use_cache:
outputs += (present_key_value,)
return outputs
# Copied from transformers.models.bart.modeling_bart.BartClassificationHead with Bart->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}ClassificationHead(nn.Module):
"""Head for sentence-level classification tasks."""
def __init__(
self,
input_dim: int,
inner_dim: int,
num_classes: int,
pooler_dropout: float,
):
super().__init__()
self.dense = nn.Linear(input_dim, inner_dim)
self.dropout = nn.Dropout(p=pooler_dropout)
self.out_proj = nn.Linear(inner_dim, num_classes)
def forward(self, hidden_states: torch.Tensor):
hidden_states = self.dropout(hidden_states)
hidden_states = self.dense(hidden_states)
hidden_states = torch.tanh(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.out_proj(hidden_states)
return hidden_states
class {{cookiecutter.camelcase_modelname}}PreTrainedModel(PreTrainedModel):
config_class = {{cookiecutter.camelcase_modelname}}Config
base_model_prefix = "model"
supports_gradient_checkpointing = True
def _init_weights(self, module):
std = self.config.init_std
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=std)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=std)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic
methods the library implements for all its model (such as downloading or saving, resizing the input embeddings,
pruning heads etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)
subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to
general usage and behavior.
Parameters:
config ([`~{{cookiecutter.camelcase_modelname}}Config`]):
Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model
weights.
"""
{{cookiecutter.uppercase_modelname}}_GENERATION_EXAMPLE = r"""
Summarization example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, {{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> model = {{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> ARTICLE_TO_SUMMARIZE = "My friends are cool but they eat too many carbs."
>>> inputs = tokenizer([ARTICLE_TO_SUMMARIZE], max_length=1024, return_tensors='pt')
>>> # Generate Summary
>>> summary_ids = model.generate(inputs['input_ids'], num_beams=4, max_length=5)
>>> print(tokenizer.decode(summary_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False))
```
"""
{{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
decoder_input_ids (`torch.LongTensor` of shape `(batch_size, target_sequence_length)`, *optional*):
Provide for translation and summarization training. By default, the model will create this tensor by
shifting the `input_ids` to the right, following the paper.
decoder_attention_mask (`torch.LongTensor` of shape `(batch_size, target_sequence_length)`, *optional*):
Default behavior: generate a tensor that ignores pad tokens in `decoder_input_ids`. Causal mask will
also be used by default.
If you want to change padding behavior, you should read [`modeling_{{cookiecutter.lowercase_modelname}}._prepare_decoder_attention_mask`] and
modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
information on the default strategy.
head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
decoder_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
encoder_outputs (`tuple(tuple(torch.FloatTensor)`, *optional*):
Tuple consists of (`last_hidden_state`, *optional*: `hidden_states`, *optional*:
`attentions`) `last_hidden_state` of shape `(batch_size, sequence_length, hidden_size)`,
*optional*) is a sequence of hidden-states at the output of the last layer of the encoder. Used in the
cross-attention of the decoder.
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors
of shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of
shape `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`. inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*): Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This is useful if you want more control over how to convert `input_ids` indices into associated
vectors than the model's internal embedding lookup matrix.
decoder_inputs_embeds (`torch.FloatTensor` of shape `(batch_size, target_sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `decoder_input_ids` you can choose to directly pass an embedded
representation. If `past_key_values` is used, optionally only the last `decoder_inputs_embeds`
have to be input (see `past_key_values`). This is useful if you want more control over how to convert
`decoder_input_ids` indices into associated vectors than the model's internal embedding lookup matrix.
If `decoder_input_ids` and `decoder_inputs_embeds` are both unset, `decoder_inputs_embeds`
takes the value of `inputs_embeds`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`).
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
{{cookiecutter.uppercase_modelname}}_STANDALONE_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`ProphetNetTokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
class {{cookiecutter.camelcase_modelname}}Encoder({{cookiecutter.camelcase_modelname}}PreTrainedModel):
"""
Transformer encoder consisting of *config.encoder_layers* self attention layers. Each layer is a
[`{{cookiecutter.camelcase_modelname}}EncoderLayer`].
Args:
config: {{cookiecutter.camelcase_modelname}}Config
embed_tokens (nn.Embedding): output embedding
"""
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, embed_tokens: Optional[nn.Embedding] = None):
super().__init__(config)
self.dropout = config.dropout
self.layerdrop = config.encoder_layerdrop
embed_dim = config.d_model
self.padding_idx = config.pad_token_id
self.max_source_positions = config.max_position_embeddings
self.embed_scale = math.sqrt(embed_dim) if config.scale_embedding else 1.0
if embed_tokens is not None:
self.embed_tokens = embed_tokens
else:
self.embed_tokens = nn.Embedding(config.vocab_size, embed_dim, self.padding_idx)
self.embed_positions = {{cookiecutter.camelcase_modelname}}LearnedPositionalEmbedding(
config.max_position_embeddings,
embed_dim,
)
self.layers = nn.ModuleList([{{cookiecutter.camelcase_modelname}}EncoderLayer(config) for _ in range(config.encoder_layers)])
self.layernorm_embedding = nn.LayerNorm(embed_dim)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
def forward(
self,
input_ids=None,
attention_mask=None,
head_mask=None,
inputs_embeds=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`]
for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded
representation. This is useful if you want more control over how to convert `input_ids` indices
into associated vectors than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# retrieve input_ids and inputs_embeds
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
embed_pos = self.embed_positions(input_shape)
hidden_states = inputs_embeds + embed_pos
hidden_states = self.layernorm_embedding(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
# expand attention_mask
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
attention_mask = _prepare_4d_attention_mask(attention_mask, inputs_embeds.dtype)
encoder_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
# check if head_mask has a correct number of layers specified if desired
if head_mask is not None:
assert head_mask.size()[0] == (
len(self.layers)
), f"The head_mask should be specified for {len(self.layers)} layers, but it is for {head_mask.size()[0]}."
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = torch.randn([])
if self.training and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None)
else:
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
encoder_layer.__call__,
hidden_states,
attention_mask,
(head_mask[idx] if head_mask is not None else None),
output_attentions,
)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
)
class {{cookiecutter.camelcase_modelname}}Decoder({{cookiecutter.camelcase_modelname}}PreTrainedModel):
"""
Transformer decoder consisting of *config.decoder_layers* layers. Each layer is a [`{{cookiecutter.camelcase_modelname}}DecoderLayer`]
Args:
config: {{cookiecutter.camelcase_modelname}}Config
embed_tokens (nn.Embedding): output embedding
"""
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, embed_tokens: Optional[nn.Embedding] = None):
super().__init__(config)
self.dropout = config.dropout
self.layerdrop = config.decoder_layerdrop
self.padding_idx = config.pad_token_id
self.max_target_positions = config.max_position_embeddings
self.embed_scale = math.sqrt(config.d_model) if config.scale_embedding else 1.0
if embed_tokens is not None:
self.embed_tokens = embed_tokens
else:
self.embed_tokens = nn.Embedding(config.vocab_size, config.d_model, self.padding_idx)
self.embed_positions = {{cookiecutter.camelcase_modelname}}LearnedPositionalEmbedding(
config.max_position_embeddings,
config.d_model,
)
self.layers = nn.ModuleList([{{cookiecutter.camelcase_modelname}}DecoderLayer(config) for _ in range(config.decoder_layers)])
self.layernorm_embedding = nn.LayerNorm(config.d_model)
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embed_tokens
def set_input_embeddings(self, value):
self.embed_tokens = value
def forward(
self,
input_ids=None,
attention_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
head_mask=None,
cross_attn_head_mask=None,
past_key_values=None,
inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`]
for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, encoder_sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
of the decoder.
encoder_attention_mask (`torch.LongTensor` of shape `(batch_size, encoder_sequence_length)`, *optional*):
Mask to avoid performing cross-attention on padding tokens indices of encoder input_ids. Mask values
selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2
tensors of shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional
tensors of shape `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the
cross-attention blocks) that can be used (see `past_key_values` input) to speed up sequential
decoding.
If `past_key_values` are used, the user can optionally input only the last
`decoder_input_ids` (those that don't have their past key value states given to this model) of
shape `(batch_size, 1)` instead of all `decoder_input_ids` of shape `(batch_size,
sequence_length)`. inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*): Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This is useful if you want more control over how to convert `input_ids` indices
into associated vectors than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# retrieve input_ids and inputs_embeds
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
# past_key_values_length
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
attention_mask = _prepare_4d_causal_attention_mask(attention_mask, input_shape, inputs_embeds, past_key_values_length)
# expand encoder attention mask
if encoder_hidden_states is not None and encoder_attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
encoder_attention_mask = _prepare_4d_attention_mask(encoder_attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1])
# embed positions
positions = self.embed_positions(input_shape, past_key_values_length)
hidden_states = inputs_embeds + positions
hidden_states = self.layernorm_embedding(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
# decoder layers
if self.gradient_checkpointing and self.training and use_cache:
logger.warning("`use_cache = True` is incompatible with gradient checkpointing`. Setting `use_cache = False`...")
use_cache = False
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
next_decoder_cache = () if use_cache else None
# check if head_mask/cross_attn_head_mask has a correct number of layers specified if desired
for attn_mask, mask_name in zip([head_mask, cross_attn_head_mask], ["head_mask", "cross_attn_head_mask"]):
if attn_mask is not None:
assert attn_mask.size()[0] == (
len(self.layers)
), f"The `{mask_name}` should be specified for {len(self.layers)} layers, but it is for {head_mask.size()[0]}."
for idx, decoder_layer in enumerate(self.layers):
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = torch.randn([])
if self.training and (dropout_probability < self.layerdrop):
continue
past_key_value = past_key_values[idx] if past_key_values is not None else None
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
decoder_layer.__call__,
hidden_states,
attention_mask,
encoder_hidden_states,
encoder_attention_mask,
head_mask[idx] if head_mask is not None else None,
cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None,
None,
output_attentions,
use_cache,
)
else:
layer_outputs = decoder_layer(
hidden_states,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
layer_head_mask=(head_mask[idx] if head_mask is not None else None),
cross_layer_head_mask=(cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None),
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[3 if output_attentions else 1],)
if output_attentions:
all_self_attns += (layer_outputs[1],)
if encoder_hidden_states is not None:
all_cross_attentions += (layer_outputs[2],)
# add hidden states from the last decoder layer
if output_hidden_states:
all_hidden_states += (hidden_states,)
next_cache = next_decoder_cache if use_cache else None
if not return_dict:
return tuple(
v
for v in [hidden_states, next_cache, all_hidden_states, all_self_attns, all_cross_attentions]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_cache,
hidden_states=all_hidden_states,
attentions=all_self_attns,
cross_attentions=all_cross_attentions,
)
@add_start_docstrings(
"The bare {{cookiecutter.modelname}} Model outputting raw hidden-states without any specific head on top.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}Model({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config):
super().__init__(config)
padding_idx, vocab_size = config.pad_token_id, config.vocab_size
self.shared = nn.Embedding(vocab_size, config.d_model, padding_idx)
self.encoder = {{cookiecutter.camelcase_modelname}}Encoder(config, self.shared)
self.decoder = {{cookiecutter.camelcase_modelname}}Decoder(config, self.shared)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.shared
def set_input_embeddings(self, value):
self.shared = value
self.encoder.embed_tokens = self.shared
self.decoder.embed_tokens = self.shared
def get_encoder(self):
return self.encoder
def get_decoder(self):
return self.decoder
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=Seq2SeqModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
encoder_outputs=None,
past_key_values=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if encoder_outputs is None:
encoder_outputs = self.encoder(
input_ids=input_ids,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
# If the user passed a tuple for encoder_outputs, we wrap it in a BaseModelOutput when return_dict=True
elif return_dict and not isinstance(encoder_outputs, BaseModelOutput):
encoder_outputs = BaseModelOutput(
last_hidden_state=encoder_outputs[0],
hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
)
# decoder outputs consists of (dec_features, past_key_value, dec_hidden, dec_attn)
decoder_outputs = self.decoder(
input_ids=decoder_input_ids,
attention_mask=decoder_attention_mask,
encoder_hidden_states=encoder_outputs[0],
encoder_attention_mask=attention_mask,
head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
if not return_dict:
return decoder_outputs + encoder_outputs
return Seq2SeqModelOutput(
last_hidden_state=decoder_outputs.last_hidden_state,
past_key_values=decoder_outputs.past_key_values,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
encoder_hidden_states=encoder_outputs.hidden_states,
encoder_attentions=encoder_outputs.attentions,
)
@add_start_docstrings(
"The {{cookiecutter.modelname}} Model with a language modeling head. Can be used for summarization.", {{cookiecutter.uppercase_modelname}}_START_DOCSTRING
)
class {{cookiecutter.camelcase_modelname}}ForConditionalGeneration({{cookiecutter.camelcase_modelname}}PreTrainedModel):
base_model_prefix = "model"
_keys_to_ignore_on_load_missing = [
r"final_logits_bias",
r"encoder\.version",
r"decoder\.version",
r"lm_head\.weight",
]
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config):
super().__init__(config)
self.model = {{cookiecutter.camelcase_modelname}}Model(config)
self.register_buffer("final_logits_bias", torch.zeros((1, self.model.shared.num_embeddings)))
self.lm_head = nn.Linear(config.d_model, self.model.shared.num_embeddings, bias=False)
# Initialize weights and apply final processing
self.post_init()
def get_encoder(self):
return self.model.get_encoder()
def get_decoder(self):
return self.model.get_decoder()
def resize_token_embeddings(self, new_num_tokens: int) -> nn.Embedding:
new_embeddings = super().resize_token_embeddings(new_num_tokens)
self._resize_final_logits_bias(new_num_tokens)
return new_embeddings
def _resize_final_logits_bias(self, new_num_tokens: int) -> None:
old_num_tokens = self.final_logits_bias.shape[-1]
if new_num_tokens <= old_num_tokens:
new_bias = self.final_logits_bias[:, :new_num_tokens]
else:
extra_bias = torch.zeros((1, new_num_tokens - old_num_tokens), device=self.final_logits_bias.device)
new_bias = torch.cat([self.final_logits_bias, extra_bias], dim=1)
self.register_buffer("final_logits_bias", new_bias)
def get_output_embeddings(self):
return self.lm_head
def set_output_embeddings(self, new_embeddings):
self.lm_head = new_embeddings
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=Seq2SeqLMOutput, config_class=_CONFIG_FOR_DOC)
@add_end_docstrings({{cookiecutter.uppercase_modelname}}_GENERATION_EXAMPLE)
def forward(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
encoder_outputs=None,
past_key_values=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
labels=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should either be in `[0, ..., config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
Returns:
Conditional generation example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, {{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> TXT = "My friends are <mask> but they eat too many carbs."
>>> model = {{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> input_ids = tokenizer([TXT], return_tensors='pt')['input_ids']
>>> logits = model(input_ids).logits
>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
>>> probs = logits[0, masked_index].softmax(dim=0)
>>> values, predictions = probs.topk(5)
>>> tokenizer.decode(predictions).split()
```
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
if use_cache:
logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
use_cache = False
if decoder_input_ids is None and decoder_inputs_embeds is None:
decoder_input_ids = shift_tokens_right(labels, self.config.pad_token_id, self.config.decoder_start_token_id)
outputs = self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
encoder_outputs=encoder_outputs,
decoder_attention_mask=decoder_attention_mask,
head_mask=head_mask,
decoder_head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
lm_logits = self.lm_head(outputs[0]) + self.final_logits_bias
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
masked_lm_loss = loss_fct(lm_logits.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (lm_logits,) + outputs[1:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return Seq2SeqLMOutput(
loss=masked_lm_loss,
logits=lm_logits,
past_key_values=outputs.past_key_values,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
def prepare_inputs_for_generation(
self,
decoder_input_ids,
past_key_values=None,
attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
use_cache=None,
encoder_outputs=None,
**kwargs
):
# cut decoder_input_ids if past is used
if past_key_values is not None:
decoder_input_ids = decoder_input_ids[:, -1:]
return {
"input_ids": None, # encoder_outputs is defined. input_ids not needed
"encoder_outputs": encoder_outputs,
"past_key_values": past_key_values,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"head_mask": head_mask,
"decoder_head_mask": decoder_head_mask,
"cross_attn_head_mask": cross_attn_head_mask,
"use_cache": use_cache, # change this to avoid caching (presumably for debugging)
}
@staticmethod
def _reorder_cache(past_key_values, beam_idx):
reordered_past = ()
for layer_past in past_key_values:
reordered_past += (tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),)
return reordered_past
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} model with a sequence classification/head on top (a linear layer on top of the pooled output) e.g. for GLUE
tasks.
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}ForSequenceClassification({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(config, **kwargs)
self.model = {{cookiecutter.camelcase_modelname}}Model(config)
self.classification_head = {{cookiecutter.camelcase_modelname}}ClassificationHead(
config.d_model,
config.d_model,
config.num_labels,
config.classifier_dropout,
)
self.model._init_weights(self.classification_head.dense)
self.model._init_weights(self.classification_head.out_proj)
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=Seq2SeqSequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
encoder_outputs=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
labels=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ..., config.num_labels - 1]`. If `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
use_cache = False
if input_ids is None and inputs_embeds is not None:
raise NotImplementedError(
f"Passing input embeddings is currently not supported for {self.__class__.__name__}"
)
outputs = self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
encoder_outputs=encoder_outputs,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0] # last hidden state
eos_mask = input_ids.eq(self.config.eos_token_id).to(hidden_states.device)
if len(torch.unique_consecutive(eos_mask.sum(1))) > 1:
raise ValueError("All examples must have the same number of <eos> tokens.")
sentence_representation = hidden_states[eos_mask, :].view(hidden_states.size(0), -1, hidden_states.size(-1))[
:, -1, :
]
logits = self.classification_head(sentence_representation)
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.config.num_labels == 1:
self.config.problem_type = "regression"
elif self.config.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.config.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.config.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return Seq2SeqSequenceClassifierOutput(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.modelname}} Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layer on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class {{cookiecutter.camelcase_modelname}}ForQuestionAnswering({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
super().__init__(config)
config.num_labels = 2
self.num_labels = config.num_labels
self.model = {{cookiecutter.camelcase_modelname}}Model(config)
self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
self.model._init_weights(self.qa_outputs)
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING)
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=Seq2SeqQuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
encoder_outputs=None,
start_positions=None,
end_positions=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (*sequence_length*). Position outside of the sequence
are not taken into account for computing the loss.
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (*sequence_length*). Position outside of the sequence
are not taken into account for computing the loss.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if start_positions is not None and end_positions is not None:
use_cache = False
outputs = self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
encoder_outputs=encoder_outputs,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
total_loss = None
if start_positions is not None and end_positions is not None:
# If we are on multi-GPU, split add a dimension
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions = start_positions.clamp(0, ignored_index)
end_positions = end_positions.clamp(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
if not return_dict:
output = (
start_logits,
end_logits,
) + outputs[1:]
return ((total_loss,) + output) if total_loss is not None else output
return Seq2SeqQuestionAnsweringModelOutput(
loss=total_loss,
start_logits=start_logits,
end_logits=end_logits,
past_key_values=outputs.past_key_values,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
# Copied from transformers.models.bart.modeling_bart.BartDecoderWrapper with Bart->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}DecoderWrapper({{cookiecutter.camelcase_modelname}}PreTrainedModel):
"""
This wrapper class is a helper class to correctly load pretrained checkpoints when the causal language model is
used in combination with the [`EncoderDecoderModel`] framework.
"""
def __init__(self, config):
super().__init__(config)
self.decoder = {{cookiecutter.camelcase_modelname}}Decoder(config)
def forward(self, *args, **kwargs):
return self.decoder(*args, **kwargs)
# Copied from transformers.models.bart.modeling_bart.BartForCausalLM with Bart->{{cookiecutter.camelcase_modelname}}
class {{cookiecutter.camelcase_modelname}}ForCausalLM({{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config):
config = copy.deepcopy(config)
config.is_decoder = True
config.is_encoder_decoder = False
super().__init__(config)
self.model = {{cookiecutter.camelcase_modelname}}DecoderWrapper(config)
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.model.decoder.embed_tokens
def set_input_embeddings(self, value):
self.model.decoder.embed_tokens = value
def get_output_embeddings(self):
return self.lm_head
def set_output_embeddings(self, new_embeddings):
self.lm_head = new_embeddings
def set_decoder(self, decoder):
self.model.decoder = decoder
def get_decoder(self):
return self.model.decoder
@replace_return_docstrings(output_type=CausalLMOutputWithCrossAttentions, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids=None,
attention_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
head_mask=None,
cross_attn_head_mask=None,
past_key_values=None,
inputs_embeds=None,
labels=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`]
for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
if the model is configured as a decoder.
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used
in the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden-states of the attention blocks. Can be used to speed up
decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should either be in `[0, ..., config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are
ignored (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`).
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
Returns:
Example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, {{cookiecutter.camelcase_modelname}}ForCausalLM
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('facebook/bart-large')
>>> model = {{cookiecutter.camelcase_modelname}}ForCausalLM.from_pretrained('facebook/bart-large', add_cross_attention=False)
>>> assert model.config.is_decoder, f"{model.__class__} has to be configured as a decoder."
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
```
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
outputs = self.model.decoder(
input_ids=input_ids,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
head_mask=head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
logits = self.lm_head(outputs[0])
loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (logits,) + outputs[1:]
return (loss,) + output if loss is not None else output
return CausalLMOutputWithCrossAttentions(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
def prepare_inputs_for_generation(self, input_ids, past_key_values=None, attention_mask=None, use_cache=None, **kwargs):
# if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
if attention_mask is None:
attention_mask = input_ids.new_ones(input_ids.shape)
if past_key_values:
input_ids = input_ids[:, -1:]
# first step, decoder_cached_states are empty
return {
"input_ids": input_ids, # encoder_outputs is defined. input_ids not needed
"attention_mask": attention_mask,
"past_key_values": past_key_values,
"use_cache": use_cache,
}
@staticmethod
def _reorder_cache(past_key_values, beam_idx):
reordered_past = ()
for layer_past in past_key_values:
reordered_past += (tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),)
return reordered_past
{% endif -%}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/{{cookiecutter.lowercase_modelname}}.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# {{cookiecutter.modelname}}
## Overview
The {{cookiecutter.modelname}} model was proposed in [<INSERT PAPER NAME HERE>](<INSERT PAPER LINK HERE>) by <INSERT AUTHORS HERE>. <INSERT SHORT SUMMARY HERE>
The abstract from the paper is the following:
*<INSERT PAPER ABSTRACT HERE>*
Tips:
<INSERT TIPS ABOUT MODEL HERE>
This model was contributed by [INSERT YOUR HF USERNAME HERE](<https://huggingface.co/<INSERT YOUR HF USERNAME HERE>). The original code can be found [here](<INSERT LINK TO GITHUB REPO HERE>).
## {{cookiecutter.camelcase_modelname}}Config
[[autodoc]] {{cookiecutter.camelcase_modelname}}Config
## {{cookiecutter.camelcase_modelname}}Tokenizer
[[autodoc]] {{cookiecutter.camelcase_modelname}}Tokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## {{cookiecutter.camelcase_modelname}}TokenizerFast
[[autodoc]] {{cookiecutter.camelcase_modelname}}TokenizerFast
{% if "PyTorch" in cookiecutter.generate_tensorflow_pytorch_and_flax -%}
## {{cookiecutter.camelcase_modelname}}Model
[[autodoc]] {{cookiecutter.camelcase_modelname}}Model
- forward
{% if cookiecutter.is_encoder_decoder_model == "False" %}
## {{cookiecutter.camelcase_modelname}}ForCausalLM
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForCausalLM
- forward
## {{cookiecutter.camelcase_modelname}}ForMaskedLM
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForMaskedLM
- forward
## {{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] transformers.{{cookiecutter.camelcase_modelname}}ForSequenceClassification
- forward
## {{cookiecutter.camelcase_modelname}}ForMultipleChoice
[[autodoc]] transformers.{{cookiecutter.camelcase_modelname}}ForMultipleChoice
- forward
## {{cookiecutter.camelcase_modelname}}ForTokenClassification
[[autodoc]] transformers.{{cookiecutter.camelcase_modelname}}ForTokenClassification
- forward
## {{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- forward
{%- else %}
## {{cookiecutter.camelcase_modelname}}ForConditionalGeneration
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForConditionalGeneration
- forward
## {{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForSequenceClassification
- forward
## {{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- forward
## {{cookiecutter.camelcase_modelname}}ForCausalLM
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForCausalLM
- forward
{% endif -%}
{% endif -%}
{% if "TensorFlow" in cookiecutter.generate_tensorflow_pytorch_and_flax -%}
## TF{{cookiecutter.camelcase_modelname}}Model
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}Model
- call
{% if cookiecutter.is_encoder_decoder_model == "False" %}
## TF{{cookiecutter.camelcase_modelname}}ForMaskedLM
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForMaskedLM
- call
## TF{{cookiecutter.camelcase_modelname}}ForCausalLM
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForCausalLM
- call
## TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification
- call
## TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice
- call
## TF{{cookiecutter.camelcase_modelname}}ForTokenClassification
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForTokenClassification
- call
## TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- call
{%- else %}
## TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
- call
{% endif -%}
{% endif -%}
{% if "Flax" in cookiecutter.generate_tensorflow_pytorch_and_flax -%}
## Flax{{cookiecutter.camelcase_modelname}}Model
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}Model
- call
{% if cookiecutter.is_encoder_decoder_model == "False" %}
## Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM
- call
## Flax{{cookiecutter.camelcase_modelname}}ForCausalLM
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForCausalLM
- call
## Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification
- call
## Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice
- call
## Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification
- call
## Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- call
{%- else %}
## Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification
- call
## Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- call
## Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
- call
{% endif -%}
{% endif -%}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_tf_{{cookiecutter.lowercase_modelname}}.py
|
# coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" TF 2.0 {{cookiecutter.modelname}} model. """
{% if cookiecutter.is_encoder_decoder_model == "False" %}
import math
from typing import Dict, Optional, Tuple, Union
import numpy as np
import tensorflow as tf
from ...activations_tf import get_tf_activation
from ...utils import (
DUMMY_INPUTS,
MULTIPLE_CHOICE_DUMMY_INPUTS,
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
)
from ...modeling_tf_outputs import (
TFBaseModelOutputWithPastAndCrossAttentions,
TFCausalLMOutputWithCrossAttentions,
TFMaskedLMOutput,
TFMultipleChoiceModelOutput,
TFQuestionAnsweringModelOutput,
TFSequenceClassifierOutput,
TFTokenClassifierOutput,
)
from ...modeling_tf_utils import (
TFCausalLanguageModelingLoss,
TFMaskedLanguageModelingLoss,
TFModelInputType,
TFMultipleChoiceLoss,
TFPreTrainedModel,
TFQuestionAnsweringLoss,
TFSequenceClassificationLoss,
TFSequenceSummary,
TFTokenClassificationLoss,
get_initializer,
keras_serializable,
unpack_inputs,
)
from ...tf_utils import check_embeddings_within_bounds, shape_list, stable_softmax
from ...utils import logging
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Config
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST = [
"{{cookiecutter.checkpoint_identifier}}",
# See all {{cookiecutter.modelname}} models at https://huggingface.co/models?filter={{cookiecutter.lowercase_modelname}}
]
# Copied from transformers.models.bert.modeling_tf_bert.TFBertEmbeddings with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}Embeddings(tf.keras.layers.Layer):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.vocab_size = config.vocab_size
self.type_vocab_size = config.type_vocab_size
self.hidden_size = config.hidden_size
self.max_position_embeddings = config.max_position_embeddings
self.initializer_range = config.initializer_range
self.LayerNorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
self.dropout = tf.keras.layers.Dropout(rate=config.hidden_dropout_prob)
def build(self, input_shape: tf.TensorShape):
with tf.name_scope("word_embeddings"):
self.weight = self.add_weight(
name="weight",
shape=[self.vocab_size, self.hidden_size],
initializer=get_initializer(self.initializer_range),
)
with tf.name_scope("token_type_embeddings"):
self.token_type_embeddings = self.add_weight(
name="embeddings",
shape=[self.type_vocab_size, self.hidden_size],
initializer=get_initializer(self.initializer_range),
)
with tf.name_scope("position_embeddings"):
self.position_embeddings = self.add_weight(
name="embeddings",
shape=[self.max_position_embeddings, self.hidden_size],
initializer=get_initializer(self.initializer_range),
)
super().build(input_shape)
def call(
self,
input_ids: tf.Tensor = None,
position_ids: tf.Tensor = None,
token_type_ids: tf.Tensor = None,
inputs_embeds: tf.Tensor = None,
past_key_values_length=0,
training: bool = False,
) -> tf.Tensor:
"""
Applies embedding based on inputs tensor.
Returns:
final_embeddings (`tf.Tensor`): output embedding tensor.
"""
assert not (input_ids is None and inputs_embeds is None)
if input_ids is not None:
check_embeddings_within_bounds(input_ids, self.vocab_size)
inputs_embeds = tf.gather(params=self.weight, indices=input_ids)
input_shape = shape_list(inputs_embeds)[:-1]
if token_type_ids is None:
token_type_ids = tf.fill(dims=input_shape, value=0)
if position_ids is None:
position_ids = tf.expand_dims(
tf.range(start=past_key_values_length, limit=input_shape[1] + past_key_values_length), axis=0
)
position_embeds = tf.gather(params=self.position_embeddings, indices=position_ids)
token_type_embeds = tf.gather(params=self.token_type_embeddings, indices=token_type_ids)
final_embeddings = inputs_embeds + position_embeds + token_type_embeds
final_embeddings = self.LayerNorm(inputs=final_embeddings)
final_embeddings = self.dropout(inputs=final_embeddings, training=training)
return final_embeddings
# Copied from transformers.models.bert.modeling_tf_bert.TFBertSelfAttention with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}SelfAttention(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
if config.hidden_size % config.num_attention_heads != 0:
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number "
f"of attention heads ({config.num_attention_heads})"
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.sqrt_att_head_size = math.sqrt(self.attention_head_size)
self.query = tf.keras.layers.Dense(
units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="query"
)
self.key = tf.keras.layers.Dense(
units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="key"
)
self.value = tf.keras.layers.Dense(
units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="value"
)
self.dropout = tf.keras.layers.Dropout(rate=config.attention_probs_dropout_prob)
self.is_decoder = config.is_decoder
def transpose_for_scores(self, tensor: tf.Tensor, batch_size: int) -> tf.Tensor:
# Reshape from [batch_size, seq_length, all_head_size] to [batch_size, seq_length, num_attention_heads, attention_head_size]
tensor = tf.reshape(tensor=tensor, shape=(batch_size, -1, self.num_attention_heads, self.attention_head_size))
# Transpose the tensor from [batch_size, seq_length, num_attention_heads, attention_head_size] to [batch_size, num_attention_heads, seq_length, attention_head_size]
return tf.transpose(tensor, perm=[0, 2, 1, 3])
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor,
head_mask: tf.Tensor,
encoder_hidden_states: tf.Tensor,
encoder_attention_mask: tf.Tensor,
past_key_value: Tuple[tf.Tensor],
output_attentions: bool,
training: bool = False,
) -> Tuple[tf.Tensor]:
batch_size = shape_list(hidden_states)[0]
mixed_query_layer = self.query(inputs=hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(inputs=encoder_hidden_states), batch_size)
value_layer = self.transpose_for_scores(self.value(inputs=encoder_hidden_states), batch_size)
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(inputs=hidden_states), batch_size)
value_layer = self.transpose_for_scores(self.value(inputs=hidden_states), batch_size)
key_layer = tf.concat([past_key_value[0], key_layer], axis=2)
value_layer = tf.concat([past_key_value[1], value_layer], axis=2)
else:
key_layer = self.transpose_for_scores(self.key(inputs=hidden_states), batch_size)
value_layer = self.transpose_for_scores(self.value(inputs=hidden_states), batch_size)
query_layer = self.transpose_for_scores(mixed_query_layer, batch_size)
if self.is_decoder:
# if cross_attention save Tuple(tf.Tensor, tf.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(tf.Tensor, tf.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
# (batch size, num_heads, seq_len_q, seq_len_k)
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
dk = tf.cast(self.sqrt_att_head_size, dtype=attention_scores.dtype)
attention_scores = tf.divide(attention_scores, dk)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in TF{{cookiecutter.camelcase_modelname}}Model call() function)
attention_scores = tf.add(attention_scores, attention_mask)
# Normalize the attention scores to probabilities.
attention_probs = stable_softmax(logits=attention_scores, axis=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(inputs=attention_probs, training=training)
# Mask heads if we want to
if head_mask is not None:
attention_probs = tf.multiply(attention_probs, head_mask)
attention_output = tf.matmul(attention_probs, value_layer)
attention_output = tf.transpose(attention_output, perm=[0, 2, 1, 3])
# (batch_size, seq_len_q, all_head_size)
attention_output = tf.reshape(tensor=attention_output, shape=(batch_size, -1, self.all_head_size))
outputs = (attention_output, attention_probs) if output_attentions else (attention_output,)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
# Copied from transformers.models.bert.modeling_tf_bert.TFBertSelfOutput with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}SelfOutput(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.dense = tf.keras.layers.Dense(
units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
self.LayerNorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
self.dropout = tf.keras.layers.Dropout(rate=config.hidden_dropout_prob)
def call(self, hidden_states: tf.Tensor, input_tensor: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.dropout(inputs=hidden_states, training=training)
hidden_states = self.LayerNorm(inputs=hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_tf_bert.TFBertAttention with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}Attention(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.self_attention = TF{{cookiecutter.camelcase_modelname}}SelfAttention(config, name="self")
self.dense_output = TF{{cookiecutter.camelcase_modelname}}SelfOutput(config, name="output")
def prune_heads(self, heads):
raise NotImplementedError
def call(
self,
input_tensor: tf.Tensor,
attention_mask: tf.Tensor,
head_mask: tf.Tensor,
encoder_hidden_states: tf.Tensor,
encoder_attention_mask: tf.Tensor,
past_key_value: Tuple[tf.Tensor],
output_attentions: bool,
training: bool = False,
) -> Tuple[tf.Tensor]:
self_outputs = self.self_attention(
hidden_states=input_tensor,
attention_mask=attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_value=past_key_value,
output_attentions=output_attentions,
training=training,
)
attention_output = self.dense_output(
hidden_states=self_outputs[0], input_tensor=input_tensor, training=training
)
# add attentions (possibly with past_key_value) if we output them
outputs = (attention_output,) + self_outputs[1:]
return outputs
# Copied from transformers.models.bert.modeling_tf_bert.TFBertIntermediate with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}Intermediate(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.dense = tf.keras.layers.Dense(
units=config.intermediate_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = get_tf_activation(config.hidden_act)
else:
self.intermediate_act_fn = config.hidden_act
def call(self, hidden_states: tf.Tensor) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_tf_bert.TFBertOutput with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}Output(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.dense = tf.keras.layers.Dense(
units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
self.LayerNorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
self.dropout = tf.keras.layers.Dropout(rate=config.hidden_dropout_prob)
def call(self, hidden_states: tf.Tensor, input_tensor: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.dropout(inputs=hidden_states, training=training)
hidden_states = self.LayerNorm(inputs=hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_tf_bert.TFBertLayer with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}Layer(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.attention = TF{{cookiecutter.camelcase_modelname}}Attention(config, name="attention")
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
if not self.is_decoder:
raise ValueError(f"{self} should be used as a decoder model if cross attention is added")
self.crossattention = TF{{cookiecutter.camelcase_modelname}}Attention(config, name="crossattention")
self.intermediate = TF{{cookiecutter.camelcase_modelname}}Intermediate(config, name="intermediate")
self.bert_output = TF{{cookiecutter.camelcase_modelname}}Output(config, name="output")
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor,
head_mask: tf.Tensor,
encoder_hidden_states: tf.Tensor | None,
encoder_attention_mask: tf.Tensor | None,
past_key_value: Tuple[tf.Tensor] | None,
output_attentions: bool,
training: bool = False,
) -> Tuple[tf.Tensor]:
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
self_attention_outputs = self.attention(
input_tensor=hidden_states,
attention_mask=attention_mask,
head_mask=head_mask,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=self_attn_past_key_value,
output_attentions=output_attentions,
training=training,
)
attention_output = self_attention_outputs[0]
# if decoder, the last output is tuple of self-attn cache
if self.is_decoder:
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
if not hasattr(self, "crossattention"):
raise ValueError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers "
"by setting `config.add_cross_attention=True`"
)
# cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
cross_attention_outputs = self.crossattention(
input_tensor=attention_output,
attention_mask=attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_value=cross_attn_past_key_value,
output_attentions=output_attentions,
training=training,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
# add cross-attn cache to positions 3,4 of present_key_value tuple
cross_attn_present_key_value = cross_attention_outputs[-1]
present_key_value = present_key_value + cross_attn_present_key_value
intermediate_output = self.intermediate(hidden_states=attention_output)
layer_output = self.bert_output(
hidden_states=intermediate_output, input_tensor=attention_output, training=training
)
outputs = (layer_output,) + outputs # add attentions if we output them
# if decoder, return the attn key/values as the last output
if self.is_decoder:
outputs = outputs + (present_key_value,)
return outputs
# Copied from transformers.models.bert.modeling_tf_bert.TFBertEncoder with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}Encoder(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.config = config
self.layer = [TF{{cookiecutter.camelcase_modelname}}Layer(config, name=f"layer_._{i}") for i in range(config.num_hidden_layers)]
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor,
head_mask: tf.Tensor,
encoder_hidden_states: tf.Tensor | None,
encoder_attention_mask: tf.Tensor | None,
past_key_values: Tuple[Tuple[tf.Tensor]] | None,
use_cache: Optional[bool],
output_attentions: bool,
output_hidden_states: bool,
return_dict: bool,
training: bool = False,
) -> Union[TFBaseModelOutputWithPastAndCrossAttentions, Tuple[tf.Tensor]]:
all_hidden_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
next_decoder_cache = () if use_cache else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
past_key_value = past_key_values[i] if past_key_values is not None else None
layer_outputs = layer_module(
hidden_states=hidden_states,
attention_mask=attention_mask,
head_mask=head_mask[i],
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_value=past_key_value,
output_attentions=output_attentions,
training=training,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if self.config.add_cross_attention and encoder_hidden_states is not None:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
# Add last layer
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v for v in [hidden_states, all_hidden_states, all_attentions, all_cross_attentions] if v is not None
)
return TFBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_attentions,
cross_attentions=all_cross_attentions,
)
# Copied from transformers.models.bert.modeling_tf_bert.TFBertPredictionHeadTransform with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}PredictionHeadTransform(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.dense = tf.keras.layers.Dense(
units=config.hidden_size,
kernel_initializer=get_initializer(config.initializer_range),
name="dense",
)
if isinstance(config.hidden_act, str):
self.transform_act_fn = get_tf_activation(config.hidden_act)
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
def call(self, hidden_states: tf.Tensor) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(inputs=hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_tf_bert.TFBertLMPredictionHead with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}LMPredictionHead(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, input_embeddings: tf.keras.layers.Layer, **kwargs):
super().__init__(**kwargs)
self.vocab_size = config.vocab_size
self.hidden_size = config.hidden_size
self.transform = TF{{cookiecutter.camelcase_modelname}}PredictionHeadTransform(config, name="transform")
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.input_embeddings = input_embeddings
def build(self, input_shape: tf.TensorShape):
self.bias = self.add_weight(shape=(self.vocab_size,), initializer="zeros", trainable=True, name="bias")
super().build(input_shape)
def get_output_embeddings(self) -> tf.keras.layers.Layer:
return self.input_embeddings
def set_output_embeddings(self, value: tf.Variable):
self.input_embeddings.weight = value
self.input_embeddings.vocab_size = shape_list(value)[0]
def get_bias(self) -> Dict[str, tf.Variable]:
return {"bias": self.bias}
def set_bias(self, value: tf.Variable):
self.bias = value["bias"]
self.vocab_size = shape_list(value["bias"])[0]
def call(self, hidden_states: tf.Tensor) -> tf.Tensor:
hidden_states = self.transform(hidden_states=hidden_states)
seq_length = shape_list(hidden_states)[1]
hidden_states = tf.reshape(tensor=hidden_states, shape=[-1, self.hidden_size])
hidden_states = tf.matmul(a=hidden_states, b=self.input_embeddings.weight, transpose_b=True)
hidden_states = tf.reshape(tensor=hidden_states, shape=[-1, seq_length, self.vocab_size])
hidden_states = tf.nn.bias_add(value=hidden_states, bias=self.bias)
return hidden_states
# Copied from transformers.models.bert.modeling_tf_bert.TFBertMLMHead with Bert->{{cookiecutter.camelcase_modelname}}
class TF{{cookiecutter.camelcase_modelname}}MLMHead(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, input_embeddings: tf.keras.layers.Layer, **kwargs):
super().__init__(**kwargs)
self.predictions = TF{{cookiecutter.camelcase_modelname}}LMPredictionHead(config, input_embeddings, name="predictions")
def call(self, sequence_output: tf.Tensor) -> tf.Tensor:
prediction_scores = self.predictions(hidden_states=sequence_output)
return prediction_scores
@keras_serializable
class TF{{cookiecutter.camelcase_modelname}}MainLayer(tf.keras.layers.Layer):
config_class = {{cookiecutter.camelcase_modelname}}Config
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, add_pooling_layer: bool = True, **kwargs):
super().__init__(**kwargs)
self.config = config
self.is_decoder = config.is_decoder
self.embeddings = TF{{cookiecutter.camelcase_modelname}}Embeddings(config, name="embeddings")
self.encoder = TF{{cookiecutter.camelcase_modelname}}Encoder(config, name="encoder")
# Copied from transformers.models.bert.modeling_tf_bert.TFBertMainLayer.get_input_embeddings
def get_input_embeddings(self) -> tf.keras.layers.Layer:
return self.embeddings
# Copied from transformers.models.bert.modeling_tf_bert.TFBertMainLayer.set_input_embeddings
def set_input_embeddings(self, value: tf.Variable):
self.embeddings.weight = value
self.embeddings.vocab_size = shape_list(value)[0]
# Copied from transformers.models.bert.modeling_tf_bert.TFBertMainLayer._prune_heads
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
raise NotImplementedError
@unpack_inputs
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
encoder_hidden_states: np.ndarray | tf.Tensor | None = None,
encoder_attention_mask: np.ndarray | tf.Tensor | None = None,
past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: bool = False,
) -> Union[TFBaseModelOutputWithPastAndCrossAttentions, Tuple[tf.Tensor]]:
if not self.config.is_decoder:
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = shape_list(input_ids)
elif inputs_embeds is not None:
input_shape = shape_list(inputs_embeds)[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
batch_size, seq_length = input_shape
if past_key_values is None:
past_key_values_length = 0
past_key_values = [None] * len(self.encoder.layer)
else:
past_key_values_length = shape_list(past_key_values[0][0])[-2]
if attention_mask is None:
attention_mask = tf.fill(dims=(batch_size, seq_length + past_key_values_length), value=1)
if token_type_ids is None:
token_type_ids = tf.fill(dims=input_shape, value=0)
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
training=training,
)
# We create a 3D attention mask from a 2D tensor mask.
# Sizes are [batch_size, 1, 1, to_seq_length]
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
# this attention mask is more simple than the triangular masking of causal attention
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
attention_mask_shape = shape_list(attention_mask)
mask_seq_length = seq_length + past_key_values_length
# Copied from `modeling_tf_t5.py`
# Provided a padding mask of dimensions [batch_size, mask_seq_length]
# - if the model is a decoder, apply a causal mask in addition to the padding mask
# - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, mask_seq_length, mask_seq_length]
if self.is_decoder:
seq_ids = tf.range(mask_seq_length)
causal_mask = tf.less_equal(
tf.tile(seq_ids[None, None, :], (batch_size, mask_seq_length, 1)),
seq_ids[None, :, None],
)
causal_mask = tf.cast(causal_mask, dtype=attention_mask.dtype)
extended_attention_mask = causal_mask * attention_mask[:, None, :]
attention_mask_shape = shape_list(extended_attention_mask)
extended_attention_mask = tf.reshape(
extended_attention_mask, (attention_mask_shape[0], 1, attention_mask_shape[1], attention_mask_shape[2])
)
if past_key_values[0] is not None:
# attention_mask needs to be sliced to the shape `[batch_size, 1, from_seq_length - cached_seq_length, to_seq_length]
extended_attention_mask = extended_attention_mask[:, :, -seq_length:, :]
else:
extended_attention_mask = tf.reshape(
attention_mask, (attention_mask_shape[0], 1, 1, attention_mask_shape[1])
)
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
extended_attention_mask = tf.cast(extended_attention_mask, dtype=embedding_output.dtype)
one_cst = tf.constant(1.0, dtype=embedding_output.dtype)
ten_thousand_cst = tf.constant(-10000.0, dtype=embedding_output.dtype)
extended_attention_mask = tf.multiply(tf.subtract(one_cst, extended_attention_mask), ten_thousand_cst)
# Copied from `modeling_tf_t5.py` with -1e9 -> -10000
if self.is_decoder and encoder_attention_mask is not None:
# If a 2D ou 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, mask_seq_length, mask_seq_length]
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
encoder_attention_mask = tf.cast(
encoder_attention_mask, dtype=extended_attention_mask.dtype
)
num_dims_encoder_attention_mask = len(shape_list(encoder_attention_mask))
if num_dims_encoder_attention_mask == 3:
encoder_extended_attention_mask = encoder_attention_mask[:, None, :, :]
if num_dims_encoder_attention_mask == 2:
encoder_extended_attention_mask = encoder_attention_mask[:, None, None, :]
# T5 has a mask that can compare sequence ids, we can simulate this here with this transposition
# Cf. https://github.com/tensorflow/mesh/blob/8d2465e9bc93129b913b5ccc6a59aa97abd96ec6/mesh_tensorflow/transformer/transformer_layers.py#L270
# encoder_extended_attention_mask = tf.math.equal(encoder_extended_attention_mask,
# tf.transpose(encoder_extended_attention_mask, perm=(-1, -2)))
encoder_extended_attention_mask = (1.0 - encoder_extended_attention_mask) * -10000.0
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
if head_mask is not None:
raise NotImplementedError
else:
head_mask = [None] * self.config.num_hidden_layers
encoder_outputs = self.encoder(
hidden_states=embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = encoder_outputs[0]
if not return_dict:
return (
sequence_output,
) + encoder_outputs[1:]
return TFBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=sequence_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
class TF{{cookiecutter.camelcase_modelname}}PreTrainedModel(TFPreTrainedModel):
"""An abstract class to handle weights initialization and
a simple interface for downloading and loading pretrained models.
"""
config_class = {{cookiecutter.camelcase_modelname}}Config
base_model_prefix = "{{cookiecutter.lowercase_modelname}}"
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING = r"""
This model inherits from [`TFPreTrainedModel`]. Check the superclass documentation for the
generic methods the library implements for all its model (such as downloading or saving, resizing the input
embeddings, pruning heads etc.)
This model is also a [tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model) subclass.
Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general
usage and behavior.
<Tip>
TensorFlow models and layers in `transformers` accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like `model.fit()` things should "just work" for you - just
pass your inputs and labels in any format that `model.fit()` supports! If, however, you want to use the second format outside of Keras methods like `fit()` and `predict()`, such as when creating
your own layers or models with the Keras `Functional` API, there are three possibilities you
can use to gather all the input Tensors in the first positional argument:
- a single Tensor with `input_ids` only and nothing else: `model(input_ids)`
- a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
`model([input_ids, attention_mask])` or `model([input_ids, attention_mask, token_type_ids])`
- a dictionary with one or several input Tensors associated to the input names given in the docstring:
`model({"input_ids": input_ids, "token_type_ids": token_type_ids})`
Note that when creating models and layers with (subclassing)[https://keras.io/guides/making_new_layers_and_models_via_subclassing/]
then you don't need to worry about any of this, as you can just pass inputs like you would to any other Python
function!
</Tip>
Args:
config ([`~{{cookiecutter.camelcase_modelname}}Config`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the configuration.
Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
{{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING = r"""
Args:
input_ids (`np.ndarray`, `tf.Tensor`, `List[tf.Tensor]`, `Dict[str, tf.Tensor]` or `Dict[str, np.ndarray]` and each example must have the shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AutoTokenizer`]. See
[`PreTrainedTokenizer.__call__`] and [`PreTrainedTokenizer.encode`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`np.ndarray` or `tf.Tensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`np.ndarray` or `tf.Tensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
position_ids (`np.ndarray` or `tf.Tensor` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0, config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
head_mask (`np.ndarray` or `tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`np.ndarray` or `tf.Tensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated
vectors than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the
config will be used instead.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail. This argument can be used only in eager mode, in graph mode the value in the config will be
used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This
argument can be used in eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False`):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
@add_start_docstrings(
"The bare {{cookiecutter.modelname}} Model transformer outputing raw hidden-states without any specific head on top.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}Model(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFBaseModelOutputWithPastAndCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
encoder_hidden_states: np.ndarray | tf.Tensor | None = None,
encoder_attention_mask: np.ndarray | tf.Tensor | None = None,
past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
training: Optional[bool] = False,
) -> Union[TFBaseModelOutputWithPastAndCrossAttentions, Tuple[tf.Tensor]]:
r"""
encoder_hidden_states (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`Tuple[Tuple[tf.Tensor]]` of length `config.n_layers`)
contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*, defaults to `True`):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`). Set to `False` during training, `True` during generation
"""
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
return outputs
@add_start_docstrings("""{{cookiecutter.modelname}} Model with a `language modeling` head on top. """, {{cookiecutter.uppercase_modelname}}_START_DOCSTRING)
class TF{{cookiecutter.camelcase_modelname}}ForMaskedLM(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel, TFMaskedLanguageModelingLoss):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
if config.is_decoder:
logger.warning(
"If you want to use `TF{{cookiecutter.camelcase_modelname}}ForMaskedLM` make sure `config.is_decoder=False` for "
"bi-directional self-attention."
)
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
self.mlm = TF{{cookiecutter.camelcase_modelname}}MLMHead(config, input_embeddings=self.{{cookiecutter.lowercase_modelname}}.embeddings, name="mlm___cls")
def get_lm_head(self) -> tf.keras.layers.Layer:
return self.mlm.predictions
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFMaskedLMOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFMaskedLMOutput, Tuple[tf.Tensor]]:
r"""
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ..., config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
"""
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
prediction_scores = self.mlm(sequence_output=sequence_output, training=training)
loss = (
None if labels is None else self.hf_compute_loss(labels=labels, logits=prediction_scores)
)
if not return_dict:
output = (prediction_scores,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TFMaskedLMOutput(
loss=loss,
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a `language modeling` head on top for CLM fine-tuning. """, {{cookiecutter.uppercase_modelname}}_START_DOCSTRING
)
class TF{{cookiecutter.camelcase_modelname}}ForCausalLM(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel, TFCausalLanguageModelingLoss):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
if not config.is_decoder:
logger.warning("If you want to use `TF{{cookiecutter.camelcase_modelname}}ForCausalLM` as a standalone, add `is_decoder=True.`")
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
self.mlm = TF{{cookiecutter.camelcase_modelname}}MLMHead(config, input_embeddings=self.{{cookiecutter.lowercase_modelname}}.embeddings, name="mlm___cls")
def get_lm_head(self) -> tf.keras.layers.Layer:
return self.mlm.predictions
def prepare_inputs_for_generation(self, inputs, past_key_values=None, attention_mask=None, **model_kwargs):
# cut decoder_input_ids if past is used
if past_key_values:
inputs = tf.expand_dims(inputs[:, -1], -1)
return {
"input_ids": inputs,
"attention_mask": attention_mask,
"past_key_values": past_key_values,
"use_cache": model_kwargs["use_cache"],
}
@unpack_inputs
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFCausalLMOutputWithCrossAttentions,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
encoder_hidden_states: np.ndarray | tf.Tensor | None = None,
encoder_attention_mask: np.ndarray | tf.Tensor | None = None,
past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFCausalLMOutputWithCrossAttentions, Tuple[tf.Tensor]]:
r"""
encoder_hidden_states (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`Tuple[Tuple[tf.Tensor]]` of length `config.n_layers`)
contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*, defaults to `True`):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`). Set to `False` during training, `True` during generation
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the cross entropy classification loss. Indices should be in `[0, ..., config.vocab_size - 1]`.
"""
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
logits = self.mlm(sequence_output=sequence_output, training=training)
loss = None
if labels is not None:
# shift labels to the left and cut last logit token
shifted_logits = logits[:, :-1]
labels = labels[:, 1:]
loss = self.hf_compute_loss(labels=labels, logits=shifted_logits)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TFCausalLMOutputWithCrossAttentions(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
class TF{{cookiecutter.camelcase_modelname}}ClassificationHead(tf.keras.layers.Layer):
"""Head for sentence-level classification tasks."""
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.dense = tf.keras.layers.Dense(
units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
self.dropout = tf.keras.layers.Dropout(rate=config.hidden_dropout_prob)
self.out_proj = tf.keras.layers.Dense(
units=config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="out_proj"
)
if isinstance(config.hidden_act, str):
self.classifier_act_fn = get_tf_activation(config.hidden_act)
else:
self.classifier_act_fn = config.hidden_act
def call(self, hidden_states: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_states = hidden_states[:, 0, :] # take <s> token (equiv. to [CLS])
hidden_states = self.dropout(inputs=hidden_states, training=training)
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.classifier_act_fn(hidden_states)
hidden_states = self.dropout(inputs=hidden_states, training=training)
hidden_states = self.out_proj(hidden_states)
return hidden_states
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model transformer with a sequence classification/regression head on top
e.g., for GLUE tasks. """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel, TFSequenceClassificationLoss):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.num_labels = config.num_labels
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
self.classifier = TF{{cookiecutter.camelcase_modelname}}ClassificationHead(config, name="classifier")
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFSequenceClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFSequenceClassifierOutput, Tuple[tf.Tensor]]:
r"""
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ..., config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss),
If `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
logits = self.classifier(hidden_states=outputs[0], training=training)
loss = None if labels is None else self.hf_compute_loss(labels=labels, logits=logits)
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return TFSequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a multiple choice classification head on top (a linear layer on top of
the pooled output and a softmax) e.g. for RocStories/SWAG tasks. """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel, TFMultipleChoiceLoss):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
self.sequence_summary = TFSequenceSummary(
config, config.initializer_range, name="sequence_summary"
)
self.classifier = tf.keras.layers.Dense(
units=1, kernel_initializer=get_initializer(config.initializer_range), name="classifier"
)
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFMultipleChoiceModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFMultipleChoiceModelOutput, Tuple[tf.Tensor]]:
r"""
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size,)`, *optional*):
Labels for computing the multiple choice classification loss. Indices should be in `[0, ..., num_choices]` where `num_choices` is the size of the second dimension of the input tensors. (See
`input_ids` above)
"""
if input_ids is not None:
num_choices = shape_list(input_ids)[1]
seq_length = shape_list(input_ids)[2]
else:
num_choices = shape_list(inputs_embeds)[1]
seq_length = shape_list(inputs_embeds)[2]
flat_input_ids = (
tf.reshape(tensor=input_ids, shape=(-1, seq_length)) if input_ids is not None else None
)
flat_attention_mask = (
tf.reshape(tensor=attention_mask, shape=(-1, seq_length))
if attention_mask is not None
else None
)
flat_token_type_ids = (
tf.reshape(tensor=token_type_ids, shape=(-1, seq_length))
if token_type_ids is not None
else None
)
flat_position_ids = (
tf.reshape(tensor=position_ids, shape=(-1, seq_length))
if position_ids is not None
else None
)
flat_inputs_embeds = (
tf.reshape(
tensor=inputs_embeds, shape=(-1, seq_length, shape_list(inputs_embeds)[3])
)
if inputs_embeds is not None
else None
)
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=flat_input_ids,
attention_mask=flat_attention_mask,
token_type_ids=flat_token_type_ids,
position_ids=flat_position_ids,
head_mask=head_mask,
inputs_embeds=flat_inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
logits = self.sequence_summary(inputs=outputs[0], training=training)
logits = self.classifier(inputs=logits)
reshaped_logits = tf.reshape(tensor=logits, shape=(-1, num_choices))
loss = None if labels is None else self.hf_compute_loss(labels=labels, logits=reshaped_logits)
if not return_dict:
output = (reshaped_logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return TFMultipleChoiceModelOutput(
loss=loss,
logits=reshaped_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a token classification head on top (a linear layer on top of
the hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks. """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}ForTokenClassification(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel, TFTokenClassificationLoss):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.num_labels = config.num_labels
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
self.dropout = tf.keras.layers.Dropout(rate=config.hidden_dropout_prob)
self.classifier = tf.keras.layers.Dense(
units=config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="classifier"
)
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFTokenClassifierOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFTokenClassifierOutput, Tuple[tf.Tensor]]:
r"""
labels (`tf.Tensor` or `np.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
"""
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
sequence_output = self.dropout(inputs=sequence_output, training=training)
logits = self.classifier(inputs=sequence_output)
loss = None if labels is None else self.hf_compute_loss(labels=labels, logits=logits)
if not return_dict:
output = (logits,) + outputs[1:]
return ((loss,) + output) if loss is not None else output
return TFTokenClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""{{cookiecutter.modelname}} Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layer on top of the hidden-states output to compute `span start logits` and `span end logits`). """,
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel, TFQuestionAnsweringLoss):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.num_labels = config.num_labels
self.{{cookiecutter.lowercase_modelname}} = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="{{cookiecutter.lowercase_modelname}}")
self.qa_outputs = tf.keras.layers.Dense(
units=config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="qa_outputs"
)
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFQuestionAnsweringModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: np.ndarray | tf.Tensor | None = None,
token_type_ids: np.ndarray | tf.Tensor | None = None,
position_ids: np.ndarray | tf.Tensor | None = None,
head_mask: np.ndarray | tf.Tensor | None = None,
inputs_embeds: np.ndarray | tf.Tensor | None = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
start_positions: np.ndarray | tf.Tensor | None = None,
end_positions: np.ndarray | tf.Tensor | None = None,
training: Optional[bool] = False,
) -> Union[TFQuestionAnsweringModelOutput, Tuple[tf.Tensor]]:
r"""
start_positions (`tf.Tensor` or `np.ndarray` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the start of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the
sequence are not taken into account for computing the loss.
end_positions (`tf.Tensor` or `np.ndarray` of shape `(batch_size,)`, *optional*):
Labels for position (index) of the end of the labelled span for computing the token classification loss.
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the
sequence are not taken into account for computing the loss.
"""
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = outputs[0]
logits = self.qa_outputs(inputs=sequence_output)
start_logits, end_logits = tf.split(value=logits, num_or_size_splits=2, axis=-1)
start_logits = tf.squeeze(input=start_logits, axis=-1)
end_logits = tf.squeeze(input=end_logits, axis=-1)
loss = None
if start_positions is not None and end_positions is not None:
labels = {"start_position": start_positions}
labels["end_position"] = end_positions
loss = self.hf_compute_loss(labels=labels, logits=(start_logits, end_logits))
if not return_dict:
output = (start_logits, end_logits) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return TFQuestionAnsweringModelOutput(
loss=loss,
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
{% else %}
import random
from typing import Optional, Tuple, Union
import tensorflow as tf
from ...activations_tf import get_tf_activation
from ...utils import (
add_code_sample_docstrings,
add_start_docstrings,
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
from ...modeling_tf_outputs import (
TFBaseModelOutput,
TFBaseModelOutputWithPastAndCrossAttentions,
TFSeq2SeqLMOutput,
TFSeq2SeqModelOutput,
)
# Public API
from ...modeling_tf_utils import (
DUMMY_INPUTS,
TFPreTrainedModel,
keras_serializable,
unpack_inputs,
)
from ...tf_utils import check_embeddings_within_bounds, shape_list, stable_softmax
from ...utils import ContextManagers, logging
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Config
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
_TOKENIZER_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Tokenizer"
LARGE_NEGATIVE = -1e8
# Copied from transformers.models.bart.modeling_tf_bart.shift_tokens_right
def shift_tokens_right(input_ids: tf.Tensor, pad_token_id: int, decoder_start_token_id: int):
pad_token_id = tf.cast(pad_token_id, input_ids.dtype)
decoder_start_token_id = tf.cast(decoder_start_token_id, input_ids.dtype)
start_tokens = tf.fill((shape_list(input_ids)[0], 1), tf.convert_to_tensor(decoder_start_token_id, input_ids.dtype))
shifted_input_ids = tf.concat([start_tokens, input_ids[:, :-1]], -1)
# replace possible -100 values in labels by `pad_token_id`
shifted_input_ids = tf.where(
shifted_input_ids == -100,
tf.fill(shape_list(shifted_input_ids), tf.convert_to_tensor(pad_token_id, input_ids.dtype)),
shifted_input_ids,
)
# "Verify that `labels` has only positive values and -100"
assert_gte0 = tf.debugging.assert_greater_equal(shifted_input_ids, tf.constant(0, dtype=shifted_input_ids.dtype))
# Make sure the assertion op is called by wrapping the result in an identity no-op
with tf.control_dependencies([assert_gte0]):
shifted_input_ids = tf.identity(shifted_input_ids)
return shifted_input_ids
def _make_causal_mask(input_ids_shape: tf.TensorShape, past_key_values_length: int = 0):
"""
Make causal mask used for bi-directional self-attention.
"""
bsz, tgt_len = input_ids_shape
mask = tf.ones((tgt_len, tgt_len)) * LARGE_NEGATIVE
mask_cond = tf.range(shape_list(mask)[-1])
mask = tf.where(mask_cond < tf.reshape(mask_cond + 1, (shape_list(mask)[-1], 1)), 0.0, mask)
if past_key_values_length > 0:
mask = tf.concat([tf.zeros((tgt_len, past_key_values_length)), mask], axis=-1)
return tf.tile(mask[None, None, :, :], (bsz, 1, 1, 1))
def _expand_mask(mask: tf.Tensor, tgt_len: Optional[int] = None):
"""
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
"""
src_len = shape_list(mask)[1]
tgt_len = tgt_len if tgt_len is not None else src_len
one_cst = tf.constant(1.0)
mask = tf.cast(mask, dtype=one_cst.dtype)
expanded_mask = tf.tile(mask[:, None, None, :], (1, 1, tgt_len, 1))
return (one_cst - expanded_mask) * LARGE_NEGATIVE
class TF{{cookiecutter.camelcase_modelname}}LearnedPositionalEmbedding(tf.keras.layers.Embedding):
"""
This module learns positional embeddings up to a fixed maximum size.
"""
def __init__(self, num_embeddings: int, embedding_dim: int, **kwargs):
super().__init__(num_embeddings, embedding_dim, **kwargs)
def call(self, input_shape: tf.TensorShape, past_key_values_length: int = 0):
"""Input is expected to be of size [bsz x seqlen]."""
seq_len = input_shape[1]
position_ids = tf.range(seq_len, delta=1, name="range")
position_ids += past_key_values_length
return super().call(tf.cast(position_ids, dtype=tf.int32))
class TF{{cookiecutter.camelcase_modelname}}Attention(tf.keras.layers.Layer):
"""Multi-headed attention from "Attention Is All You Need"""
def __init__(
self,
embed_dim: int,
num_heads: int,
dropout: float = 0.0,
is_decoder: bool = False,
bias: bool = True,
**kwargs,
):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.num_heads = num_heads
self.dropout = tf.keras.layers.Dropout(dropout)
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
self.scaling = self.head_dim ** -0.5
self.is_decoder = is_decoder
self.k_proj = tf.keras.layers.Dense(embed_dim, use_bias=bias, name="k_proj")
self.q_proj = tf.keras.layers.Dense(embed_dim, use_bias=bias, name="q_proj")
self.v_proj = tf.keras.layers.Dense(embed_dim, use_bias=bias, name="v_proj")
self.out_proj = tf.keras.layers.Dense(embed_dim, use_bias=bias, name="out_proj")
def _shape(self, tensor: tf.Tensor, seq_len: int, bsz: int):
return tf.transpose(tf.reshape(tensor, (bsz, seq_len, self.num_heads, self.head_dim)), (0, 2, 1, 3))
def call(
self,
hidden_states: tf.Tensor,
key_value_states: tf.Tensor | None = None,
past_key_value: Tuple[Tuple[tf.Tensor]] | None = None,
attention_mask: tf.Tensor | None = None,
layer_head_mask: tf.Tensor | None = None,
training=False,
) -> Tuple[tf.Tensor, tf.Tensor | None]:
"""Input shape: Batch x Time x Channel"""
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
bsz, tgt_len, embed_dim = shape_list(hidden_states)
# get query proj
query_states = self.q_proj(hidden_states) * self.scaling
# get key, value proj
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_states = past_key_value[0]
value_states = past_key_value[1]
elif is_cross_attention:
# cross_attentions
key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
elif past_key_value is not None:
# reuse k, v, self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
key_states = tf.concat([past_key_value[0], key_states], axis=2)
value_states = tf.concat([past_key_value[1], value_states], axis=2)
else:
# self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
if self.is_decoder:
# if cross_attention save Tuple(tf.Tensor, tf.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(tf.Tensor, tf.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_states, value_states)
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
query_states = tf.reshape(self._shape(query_states, tgt_len, bsz), proj_shape)
key_states = tf.reshape(key_states, proj_shape)
value_states = tf.reshape(value_states, proj_shape)
src_len = shape_list(key_states)[1]
attn_weights = tf.matmul(query_states, key_states, transpose_b=True)
tf.debugging.assert_equal(
shape_list(attn_weights),
[bsz * self.num_heads, tgt_len, src_len],
message=f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is {shape_list(attn_weights)}",
)
if attention_mask is not None:
tf.debugging.assert_equal(
shape_list(attention_mask),
[bsz, 1, tgt_len, src_len],
message=f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {shape_list(attention_mask)}",
)
attn_weights = tf.reshape(attn_weights, (bsz, self.num_heads, tgt_len, src_len)) + attention_mask
attn_weights = tf.reshape(attn_weights, (bsz * self.num_heads, tgt_len, src_len))
attn_weights = stable_softmax(attn_weights, axis=-1)
if layer_head_mask is not None:
tf.debugging.assert_equal(
shape_list(layer_head_mask),
[self.num_heads],
message=f"Head mask for a single layer should be of size {(self.num_heads)}, but is {shape_list(layer_head_mask)}",
)
attn_weights = tf.reshape(layer_head_mask, (1, -1, 1, 1)) * tf.reshape(
attn_weights, (bsz, self.num_heads, tgt_len, src_len)
)
attn_weights = tf.reshape(attn_weights, (bsz * self.num_heads, tgt_len, src_len))
attn_probs = self.dropout(attn_weights, training=training)
attn_output = tf.matmul(attn_probs, value_states)
tf.debugging.assert_equal(
shape_list(attn_output),
[bsz * self.num_heads, tgt_len, self.head_dim],
message=f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is {shape_list(attn_output)}",
)
attn_output = tf.transpose(
tf.reshape(attn_output, (bsz, self.num_heads, tgt_len, self.head_dim)), (0, 2, 1, 3)
)
attn_output = tf.reshape(attn_output, (bsz, tgt_len, embed_dim))
attn_output = self.out_proj(attn_output)
attn_weights: tf.Tensor = tf.reshape(attn_weights, (bsz, self.num_heads, tgt_len, src_len))
return attn_output, attn_weights, past_key_value
class TF{{cookiecutter.camelcase_modelname}}EncoderLayer(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.embed_dim = config.d_model
self.self_attn = TF{{cookiecutter.camelcase_modelname}}Attention(
self.embed_dim, config.encoder_attention_heads, dropout=config.attention_dropout, name="self_attn"
)
self.self_attn_layer_norm = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="self_attn_layer_norm")
self.dropout = tf.keras.layers.Dropout(config.dropout)
self.activation_fn = get_tf_activation(config.activation_function)
self.activation_dropout = tf.keras.layers.Dropout(config.activation_dropout)
self.fc1 = tf.keras.layers.Dense(config.encoder_ffn_dim, name="fc1")
self.fc2 = tf.keras.layers.Dense(self.embed_dim, name="fc2")
self.final_layer_norm = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="final_layer_norm")
def call(self, hidden_states: tf.Tensor, attention_mask: tf.Tensor, layer_head_mask: tf.Tensor, training=False):
"""
Args:
hidden_states (`tf.Tensor`): input to the layer of shape *(batch, seq_len, embed_dim)*
attention_mask (`tf.Tensor`): attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
layer_head_mask (`tf.Tensor`): mask for attention heads in a given layer of size
*(encoder_attention_heads,)*
"""
residual = hidden_states
hidden_states, self_attn_weights, _ = self.self_attn(
hidden_states=hidden_states, attention_mask=attention_mask, layer_head_mask=layer_head_mask
)
tf.debugging.assert_equal(
shape_list(hidden_states),
shape_list(residual),
message=f"Self attn modified the shape of query {shape_list(residual)} to {shape_list(hidden_states)}",
)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = self.activation_dropout(hidden_states, training=training)
hidden_states = self.fc2(hidden_states)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
return hidden_states, self_attn_weights
class TF{{cookiecutter.camelcase_modelname}}DecoderLayer(tf.keras.layers.Layer):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.embed_dim = config.d_model
self.self_attn = TF{{cookiecutter.camelcase_modelname}}Attention(
embed_dim=self.embed_dim,
num_heads=config.decoder_attention_heads,
dropout=config.attention_dropout,
name="self_attn",
is_decoder=True,
)
self.dropout = tf.keras.layers.Dropout(config.dropout)
self.activation_fn = get_tf_activation(config.activation_function)
self.activation_dropout = tf.keras.layers.Dropout(config.activation_dropout)
self.self_attn_layer_norm = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="self_attn_layer_norm")
self.encoder_attn = TF{{cookiecutter.camelcase_modelname}}Attention(
self.embed_dim,
config.decoder_attention_heads,
dropout=config.attention_dropout,
name="encoder_attn",
is_decoder=True,
)
self.encoder_attn_layer_norm = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="encoder_attn_layer_norm")
self.fc1 = tf.keras.layers.Dense(config.decoder_ffn_dim, name="fc1")
self.fc2 = tf.keras.layers.Dense(self.embed_dim, name="fc2")
self.final_layer_norm = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="final_layer_norm")
def call(
self,
hidden_states,
attention_mask: tf.Tensor | None = None,
encoder_hidden_states: tf.Tensor | None = None,
encoder_attention_mask: tf.Tensor | None = None,
layer_head_mask: tf.Tensor | None = None,
cross_attn_layer_head_mask: tf.Tensor | None = None,
past_key_value: Tuple[tf.Tensor] | None = None,
training=False,
) -> Tuple[tf.Tensor, tf.Tensor, Tuple[Tuple[tf.Tensor]]]:
"""
Args:
hidden_states (`tf.Tensor`): input to the layer of shape *(batch, seq_len, embed_dim)*
attention_mask (`tf.Tensor`): attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
encoder_hidden_states (`tf.Tensor`): cross attention input to the layer of shape *(batch, seq_len, embed_dim)*
encoder_attention_mask (`tf.Tensor`): encoder attention mask of size
*(batch, 1, tgt_len, src_len)* where padding elements are indicated by very large negative values.
layer_head_mask (`tf.Tensor`): mask for attention heads in a given layer of size
*(decoder_attention_heads,)*
cross_attn_layer_head_mask (`tf.Tensor`): mask for heads of the cross-attention module.
*(decoder_attention_heads,)*
past_key_value (`Tuple(tf.Tensor)`): cached past key and value projection states
"""
residual = hidden_states
# Self Attention
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
# add present self-attn cache to positions 1,2 of present_key_value tuple
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
past_key_value=self_attn_past_key_value,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
# Cross-Attention Block
cross_attn_present_key_value = None
cross_attn_weights = None
if encoder_hidden_states is not None:
residual = hidden_states
# cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
hidden_states=hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
layer_head_mask=cross_attn_layer_head_mask,
past_key_value=cross_attn_past_key_value,
)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.encoder_attn_layer_norm(hidden_states)
# add cross-attn to positions 3,4 of present_key_value tuple
present_key_value = present_key_value + cross_attn_present_key_value
# Fully Connected
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = self.activation_dropout(hidden_states, training=training)
hidden_states = self.fc2(hidden_states)
hidden_states = self.dropout(hidden_states, training=training)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
return (
hidden_states,
self_attn_weights,
cross_attn_weights,
present_key_value,
)
class TF{{cookiecutter.camelcase_modelname}}PreTrainedModel(TFPreTrainedModel):
config_class = {{cookiecutter.camelcase_modelname}}Config
base_model_prefix = "model"
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING = r"""
This model inherits from [`TFPreTrainedModel`]. Check the superclass documentation for the
generic methods the library implements for all its model (such as downloading or saving, resizing the input
embeddings, pruning heads etc.)
This model is also a [tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model) subclass. Use
it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage
and behavior.
<Tip>
TensorFlow models and layers in `transformers` accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like `model.fit()` things should "just work" for you - just
pass your inputs and labels in any format that `model.fit()` supports! If, however, you want to use the second format outside of Keras methods like `fit()` and `predict()`, such as when creating
your own layers or models with the Keras `Functional` API, there are three possibilities you
can use to gather all the input Tensors in the first positional argument:
- a single Tensor with `input_ids` only and nothing else: `model(input_ids)`
- a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
`model([input_ids, attention_mask])` or `model([input_ids, attention_mask, token_type_ids])`
- a dictionary with one or several input Tensors associated to the input names given in the docstring:
`model({"input_ids": input_ids, "token_type_ids": token_type_ids})`
Note that when creating models and layers with (subclassing)[https://keras.io/guides/making_new_layers_and_models_via_subclassing/]
then you don't need to worry about any of this, as you can just pass inputs like you would to any other Python
function!
</Tip>
Args:
config ([`~{{cookiecutter.camelcase_modelname}}Config`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~TFPreTrainedModel.from_pretrained`] method to load the
model weights.
"""
{{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING = r"""
Args:
input_ids (`tf.Tensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`tf.Tensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
decoder_input_ids (`tf.Tensor` of shape `(batch_size, target_sequence_length)`, *optional*):
Indices of decoder input sequence tokens in the vocabulary.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
{{cookiecutter.camelcase_modelname}} uses the `eos_token_id` as the starting token for
`decoder_input_ids` generation. If `past_key_values` is used, optionally only the last
`decoder_input_ids` have to be input (see `past_key_values`).
For translation and summarization training, `decoder_input_ids` should be provided. If no
`decoder_input_ids` is provided, the model will create this tensor by shifting the `input_ids` to
the right for denoising pre-training following the paper.
decoder_attention_mask (`tf.Tensor` of shape `(batch_size, target_sequence_length)`, *optional*):
will be made by default and ignore pad tokens. It is not recommended to set this for most use cases.
head_mask (`tf.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
decoder_head_mask (`tf.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
cross_attn_head_mask (`tf.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
encoder_outputs (`tf.FloatTensor`, *optional*):
hidden states at the output of the last layer of the encoder. Used in the cross-attention of the decoder.
of shape `(batch_size, sequence_length, hidden_size)` is a sequence of
past_key_values (`Tuple[Tuple[tf.Tensor]]` of length `config.n_layers`)
contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids`
(those that don't have their past key value states given to this model) of shape `(batch_size, 1)`
instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*, defaults to `True`):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up
decoding (see `past_key_values`). Set to `False` during training, `True` during generation
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the
config will be used instead.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail. This argument can be used only in eager mode, in graph mode the value in the config will be
used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This
argument can be used in eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False`):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
@keras_serializable
class TF{{cookiecutter.camelcase_modelname}}Encoder(tf.keras.layers.Layer):
config_class = {{cookiecutter.camelcase_modelname}}Config
"""
Transformer encoder consisting of *config.encoder_layers* self attention layers. Each layer is a
[`TF{{cookiecutter.camelcase_modelname}}EncoderLayer`].
Args:
config: {{cookiecutter.camelcase_modelname}}Config
"""
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, embed_tokens: Optional[tf.keras.layers.Embedding] = None, **kwargs):
super().__init__(**kwargs)
self.config = config
self.dropout = tf.keras.layers.Dropout(config.dropout)
self.layerdrop = config.encoder_layerdrop
self.padding_idx = config.pad_token_id
self.max_source_positions = config.max_position_embeddings
self.embed_scale = tf.math.sqrt(float(config.d_model)) if config.scale_embedding else 1.0
self.embed_tokens = embed_tokens
self.embed_positions = TF{{cookiecutter.camelcase_modelname}}LearnedPositionalEmbedding(
config.max_position_embeddings,
config.d_model,
name="embed_positions",
)
self.layers = [TF{{cookiecutter.camelcase_modelname}}EncoderLayer(config, name=f"layers.{i}") for i in range(config.encoder_layers)]
self.layernorm_embedding = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="layernorm_embedding")
def get_embed_tokens(self):
return self.embed_tokens
def set_embed_tokens(self, embed_tokens):
self.embed_tokens = embed_tokens
@unpack_inputs
def call(
self,
input_ids=None,
inputs_embeds=None,
attention_mask=None,
head_mask=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
):
"""
Args:
input_ids (`tf.Tensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`]
for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`tf.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, `optional): Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded
representation. This is useful if you want more control over how to convert `input_ids` indices
into associated vectors than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value
in the config will be used instead.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail. This argument can be used only in eager mode, in graph mode the value in the config
will be used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This
argument can be used in eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False`):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = shape_list(input_ids)
elif inputs_embeds is not None:
input_shape = shape_list(inputs_embeds)[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
if inputs_embeds is None:
# if `self.embed_tokens.load_weight_prefix` is set, runs the embedding operation with the correct name
# scope, so that its weights are registered with the desired name for loading/storing. When `tf.name_scope`
# is used with a name ending in `/`, that name replaces the current name scope.
# (embeddings with tf.name_scope: self.embed_tokens.load_weight_prefix/self.embed_tokens.name/embeddings:0)
context = []
if hasattr(self.embed_tokens, "load_weight_prefix"):
context.append(tf.name_scope(self.embed_tokens.load_weight_prefix + "/"))
with ContextManagers(context):
check_embeddings_within_bounds(input_ids, self.embed_tokens.input_dim)
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
embed_pos = self.embed_positions(input_shape)
hidden_states = inputs_embeds + embed_pos
hidden_states = self.layernorm_embedding(hidden_states)
hidden_states = self.dropout(hidden_states, training=training)
# check attention mask and invert
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
attention_mask = _expand_mask(attention_mask)
encoder_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
# check if head_mask has a correct number of layers specified if desired
if head_mask is not None:
tf.debugging.assert_equal(
shape_list(head_mask)[0],
len(self.layers),
message=f"The head_mask should be specified for {len(self.layers)} layers, but it is for {shape_list(head_mask)[0]}.",
)
# encoder layers
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop): # skip the layer
continue
hidden_states, attn = encoder_layer(
hidden_states,
attention_mask,
head_mask[idx] if head_mask is not None else None,
)
if output_attentions:
all_attentions += (attn,)
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
return TFBaseModelOutput(
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
)
@keras_serializable
class TF{{cookiecutter.camelcase_modelname}}Decoder(tf.keras.layers.Layer):
config_class = {{cookiecutter.camelcase_modelname}}Config
"""
Transformer decoder consisting of *config.decoder_layers* layers. Each layer is a [`TF{{cookiecutter.camelcase_modelname}}DecoderLayer`]
Args:
config: {{cookiecutter.camelcase_modelname}}Config
embed_tokens: output embedding
"""
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, embed_tokens: Optional[tf.keras.layers.Embedding] = None, **kwargs):
super().__init__(**kwargs)
self.config = config
self.padding_idx = config.pad_token_id
self.embed_tokens = embed_tokens
self.layerdrop = config.decoder_layerdrop
self.embed_positions = TF{{cookiecutter.camelcase_modelname}}LearnedPositionalEmbedding(
config.max_position_embeddings,
config.d_model,
name="embed_positions",
)
self.embed_scale = tf.math.sqrt(float(config.d_model)) if config.scale_embedding else 1.0
self.layers = [TF{{cookiecutter.camelcase_modelname}}DecoderLayer(config, name=f"layers.{i}") for i in range(config.decoder_layers)]
self.layernorm_embedding = tf.keras.layers.LayerNormalization(epsilon=1e-5, name="layernorm_embedding")
self.dropout = tf.keras.layers.Dropout(config.dropout)
def get_embed_tokens(self):
return self.embed_tokens
def set_embed_tokens(self, embed_tokens):
self.embed_tokens = embed_tokens
@unpack_inputs
def call(
self,
input_ids=None,
inputs_embeds=None,
attention_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
head_mask=None,
cross_attn_head_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
):
r"""
Args:
input_ids (`tf.Tensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
provide it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`]
for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
encoder_hidden_states (`tf.Tensor` of shape `(batch_size, encoder_sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
of the decoder.
encoder_attention_mask (`tf.Tensor` of shape `(batch_size, encoder_sequence_length)`, *optional*):
Mask to avoid performing cross-attention on padding tokens indices of encoder input_ids. Mask values
selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
head_mask (`tf.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
cross_attn_head_mask (`tf.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
past_key_values (`Tuple[Tuple[tf.Tensor]]` of length `config.n_layers` with each tuple having 2 tuples each of which has 2 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden-states of the attention blocks. Can be used to speed up
decoding.
If `past_key_values` are used, the user can optionally input only the last
`decoder_input_ids` (those that don't have their past key value states given to this model) of
shape `(batch_size, 1)` instead of all `decoder_input_ids` of shape `(batch_size,
sequence_length)`.
inputs_embeds (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices
into associated vectors than the model's internal embedding lookup matrix.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value
in the config will be used instead.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail. This argument can be used only in eager mode, in graph mode the value in the config
will be used instead.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This
argument can be used in eager mode, in graph mode the value will always be set to True.
training (`bool`, *optional*, defaults to `False`):
Whether or not to use the model in training mode (some modules like dropout modules have different
behaviors between training and evaluation).
"""
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
elif input_ids is not None:
input_shape = shape_list(input_ids)
elif inputs_embeds is not None:
input_shape = shape_list(inputs_embeds)[:-1]
else:
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
past_key_values_length = (
shape_list(past_key_values[0][0])[2] if past_key_values is not None else 0
)
# embed positions
positions = self.embed_positions(input_shape, past_key_values_length)
if inputs_embeds is None:
# if `self.embed_tokens.load_weight_prefix` is set, runs the embedding operation with the correct name
# scope, so that its weights are registered with the desired name for loading/storing. When `tf.name_scope`
# is used with a name ending in `/`, that name replaces the current name scope.
# (embeddings with tf.name_scope: self.embed_tokens.load_weight_prefix/self.embed_tokens.name/embeddings:0)
context = []
if hasattr(self.embed_tokens, "load_weight_prefix"):
context.append(tf.name_scope(self.embed_tokens.load_weight_prefix + "/"))
with ContextManagers(context):
check_embeddings_within_bounds(input_ids, self.embed_tokens.input_dim)
inputs_embeds = self.embed_tokens(input_ids)
hidden_states = inputs_embeds
attention_mask, combined_attention_mask = self.compute_combined_attns_mask(
input_ids, attention_mask, input_shape, past_key_values_length
)
if encoder_hidden_states is not None and encoder_attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
encoder_attention_mask = _expand_mask(encoder_attention_mask, tgt_len=input_shape[-1])
hidden_states = self.layernorm_embedding(hidden_states + positions)
hidden_states = self.dropout(hidden_states, training=training)
# decoder layers
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
all_cross_attns = () if (output_attentions and encoder_hidden_states is not None) else None
present_key_values = () if use_cache else None
# check if head_mask and cross_attn_head_mask have a correct number of layers specified if desired
for attn_mask_name, attn_mask in [("head_mask", head_mask), ("cross_attn_head_mask", cross_attn_head_mask)]:
if attn_mask is not None:
tf.debugging.assert_equal(
shape_list(attn_mask)[0],
len(self.layers),
message=f"The {attn_mask_name} should be specified for {len(self.layers)} layers, but it is for {shape_list(attn_mask)[0]}.",
)
for idx, decoder_layer in enumerate(self.layers):
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
if output_hidden_states:
all_hidden_states += (hidden_states,)
dropout_probability = random.uniform(0, 1)
if training and (dropout_probability < self.layerdrop):
continue
past_key_value = past_key_values[idx] if past_key_values is not None else None
hidden_states, layer_self_attn, layer_cross_attn, present_key_value = decoder_layer(
hidden_states,
attention_mask=combined_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
layer_head_mask=head_mask[idx] if head_mask is not None else None,
cross_attn_layer_head_mask=cross_attn_head_mask[idx]
if cross_attn_head_mask is not None
else None,
past_key_value=past_key_value,
)
if use_cache:
present_key_values += (present_key_value,)
if output_attentions:
all_self_attns += (layer_self_attn,)
if encoder_hidden_states is not None:
all_cross_attns += (layer_cross_attn,)
if output_hidden_states:
all_hidden_states += (hidden_states,)
if not return_dict:
return hidden_states, present_key_values, all_hidden_states, all_self_attns, all_cross_attns
else:
return TFBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=present_key_values,
hidden_states=all_hidden_states,
attentions=all_self_attns,
cross_attentions=all_cross_attns,
)
@tf.function
def compute_combined_attns_mask(self, input_ids, attention_mask, input_shape, past_key_values_length):
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
combined_attention_mask = None
if input_shape[-1] > 1:
combined_attention_mask = _make_causal_mask(input_shape, past_key_values_length=past_key_values_length)
else:
combined_attention_mask = _expand_mask(
tf.ones((input_shape[0], input_shape[1] + past_key_values_length)), tgt_len=input_shape[-1]
)
if attention_mask is None and input_ids is not None and input_shape[-1] > 1:
attention_mask = tf.cast(
tf.math.not_equal(input_ids, self.config.pad_token_id), input_ids.dtype
)
attention_mask = tf.concat(
[
tf.ones((input_shape[0], past_key_values_length), dtype=attention_mask.dtype),
attention_mask,
],
axis=-1,
)
else:
attention_mask = tf.ones((input_shape[0], input_shape[1] + past_key_values_length))
return attention_mask, combined_attention_mask
@keras_serializable
class TF{{cookiecutter.camelcase_modelname}}MainLayer(tf.keras.layers.Layer):
config_class = {{cookiecutter.camelcase_modelname}}Config
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, **kwargs):
super().__init__(**kwargs)
self.config = config
self.shared = tf.keras.layers.Embedding(
input_dim=config.vocab_size,
output_dim=config.d_model,
embeddings_initializer=tf.keras.initializers.TruncatedNormal(stddev=self.config.init_std),
name="model.shared"
)
# Additional attribute to specify the expected name scope of the layer (for loading/storing weights)
self.shared.load_weight_prefix = "model.shared"
self.encoder = TF{{cookiecutter.camelcase_modelname}}Encoder(config, self.shared, name="encoder")
self.decoder = TF{{cookiecutter.camelcase_modelname}}Decoder(config, self.shared, name="decoder")
def get_input_embeddings(self):
return self.shared
def set_input_embeddings(self, new_embeddings):
self.shared = new_embeddings
self.encoder.embed_tokens = self.shared
self.decoder.embed_tokens = self.shared
@unpack_inputs
def call(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
encoder_outputs: Optional[Union[Tuple, TFBaseModelOutput]] = None,
past_key_values=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
**kwargs
):
if decoder_input_ids is None and decoder_inputs_embeds is None:
use_cache = False
if encoder_outputs is None:
encoder_outputs = self.encoder(
input_ids=input_ids,
attention_mask=attention_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
# If the user passed a tuple for encoder_outputs, we wrap it in a TFBaseModelOutput when return_dict=True
elif return_dict and not isinstance(encoder_outputs, TFBaseModelOutput):
encoder_outputs = TFBaseModelOutput(
last_hidden_state=encoder_outputs[0],
hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
)
# If the user passed a TFBaseModelOutput for encoder_outputs, we wrap it in a tuple when return_dict=False
elif not return_dict and not isinstance(encoder_outputs, tuple):
encoder_outputs = encoder_outputs.to_tuple()
decoder_outputs = self.decoder(
decoder_input_ids,
attention_mask=decoder_attention_mask,
encoder_hidden_states=encoder_outputs[0],
encoder_attention_mask=attention_mask,
head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
if not return_dict:
return decoder_outputs + encoder_outputs
return TFSeq2SeqModelOutput(
last_hidden_state=decoder_outputs.last_hidden_state,
past_key_values=decoder_outputs.past_key_values,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
encoder_hidden_states=encoder_outputs.hidden_states,
encoder_attentions=encoder_outputs.attentions,
)
@add_start_docstrings(
"The bare {{cookiecutter.uppercase_modelname}} Model outputting raw hidden-states without any specific head on top.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}Model(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel):
def __init__(self, config: {{cookiecutter.camelcase_modelname}}Config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.model = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="model")
def get_encoder(self):
return self.model.encoder
def get_decoder(self):
return self.model.decoder
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=TFSeq2SeqModelOutput,
config_class=_CONFIG_FOR_DOC,
)
def call(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
encoder_outputs: Optional[Union[Tuple, TFBaseModelOutput]] = None,
past_key_values=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
training=False,
**kwargs
):
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
head_mask=head_mask,
decoder_head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
encoder_outputs=encoder_outputs,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
return outputs
# Copied from transformers.models.bart.modeling_tf_bart.BiasLayer
class BiasLayer(tf.keras.layers.Layer):
"""
Bias as a layer. It is used for serialization purposes: `tf.keras.Model.save_weights` stores on a per-layer basis,
so all weights have to be registered in a layer.
"""
def __init__(self, shape, initializer, trainable, name, **kwargs):
super().__init__(name=name, **kwargs)
# Note: the name of this variable will NOT be scoped when serialized, i.e. it will not be in the format of
# "outer_layer/inner_layer/.../name:0". Instead, it will be "name:0". For further details, see:
# https://github.com/huggingface/transformers/pull/18833#issuecomment-1233090214
self.bias = self.add_weight(name=name, shape=shape, initializer=initializer, trainable=trainable)
def call(self, x):
return x + self.bias
@add_start_docstrings(
"The {{cookiecutter.uppercase_modelname}} Model with a language modeling head. Can be used for summarization.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration(TF{{cookiecutter.camelcase_modelname}}PreTrainedModel):
_keys_to_ignore_on_load_unexpected = [
r"model.encoder.embed_tokens.weight",
r"model.decoder.embed_tokens.weight",
]
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.model = TF{{cookiecutter.camelcase_modelname}}MainLayer(config, name="model")
self.use_cache = config.use_cache
# final_bias_logits is registered as a buffer in pytorch, so not trainable for the sake of consistency.
self.bias_layer = BiasLayer(
name="final_logits_bias", shape=[1, config.vocab_size], initializer="zeros", trainable=False
)
def get_decoder(self):
return self.model.decoder
def get_encoder(self):
return self.model.encoder
def get_bias(self):
return {"final_logits_bias": self.bias_layer.bias}
def set_bias(self, value):
# Replaces the existing layers containing bias for correct (de)serialization.
vocab_size = value["final_logits_bias"].shape[-1]
self.bias_layer = BiasLayer(
name="final_logits_bias", shape=[1, vocab_size], initializer="zeros", trainable=False
)
self.bias_layer.bias.assign(value["final_logits_bias"])
def get_output_embeddings(self):
return self.get_input_embeddings()
def set_output_embeddings(self, value):
self.set_input_embeddings(value)
@unpack_inputs
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=TFSeq2SeqLMOutput, config_class=_CONFIG_FOR_DOC)
def call(
self,
input_ids=None,
attention_mask=None,
decoder_input_ids=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
encoder_outputs: Optional[TFBaseModelOutput] = None,
past_key_values=None,
inputs_embeds=None,
decoder_inputs_embeds=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
labels=None,
training=False,
):
"""
Returns:
Examples:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> import tensorflow as tf
>>> mname = '{{cookiecutter.checkpoint_identifier}}'
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained(mname)
>>> TXT = "My friends are <mask> but they eat too many carbs."
>>> model = TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained(mname)
>>> batch = tokenizer([TXT], return_tensors='tf')
>>> logits = model(inputs=batch.input_ids).logits
>>> probs = tf.nn.softmax(logits[0])
>>> # probs[5] is associated with the mask token
```"""
if labels is not None:
use_cache = False
if decoder_input_ids is None and decoder_inputs_embeds is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
)
outputs = self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
encoder_outputs=encoder_outputs,
decoder_attention_mask=decoder_attention_mask,
head_mask=head_mask,
decoder_head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training
)
lm_logits = tf.matmul(outputs[0], self.model.shared.weights, transpose_b=True)
lm_logits = self.bias_layer(lm_logits)
masked_lm_loss = None if labels is None else self.hf_compute_loss(labels, lm_logits)
if not return_dict:
output = (lm_logits,) + outputs[1:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return TFSeq2SeqLMOutput(
loss=masked_lm_loss,
logits=lm_logits,
past_key_values=outputs.past_key_values, # index 1 of d outputs
decoder_hidden_states=outputs.decoder_hidden_states, # index 2 of d outputs
decoder_attentions=outputs.decoder_attentions, # index 3 of d outputs
cross_attentions=outputs.cross_attentions, # index 4 of d outputs
encoder_last_hidden_state=outputs.encoder_last_hidden_state, # index 0 of encoder outputs
encoder_hidden_states=outputs.encoder_hidden_states, # 1 of e out
encoder_attentions=outputs.encoder_attentions, # 2 of e out
)
def prepare_inputs_for_generation(
self,
decoder_input_ids,
past_key_values=None,
attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
use_cache=None,
encoder_outputs=None,
**kwargs
):
# cut decoder_input_ids if past is used
if past_key_values is not None:
decoder_input_ids = decoder_input_ids[:, -1:]
return {
"input_ids": None, # needs to be passed to make Keras.layer.__call__ happy
"encoder_outputs": encoder_outputs,
"past_key_values": past_key_values,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"head_mask": head_mask,
"decoder_head_mask": decoder_head_mask,
"cross_attn_head_mask": cross_attn_head_mask,
"use_cache": use_cache, # change this to avoid caching (presumably for debugging)
}
def hf_compute_loss(self, labels, logits):
"""CrossEntropyLoss that ignores pad tokens"""
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True,
reduction=tf.keras.losses.Reduction.NONE,
)
melted_labels = tf.reshape(labels, (-1,))
active_loss = tf.not_equal(melted_labels, self.config.pad_token_id)
reduced_logits = tf.boolean_mask(tf.reshape(logits, (-1, shape_list(logits)[2])), active_loss)
labels = tf.boolean_mask(melted_labels, active_loss)
return loss_fn(labels, reduced_logits)
{% endif -%}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/tokenization_fast_{{cookiecutter.lowercase_modelname}}.py
|
# coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for {{cookiecutter.modelname}}."""
{%- if cookiecutter.tokenizer_type == "Based on BERT" %}
from ...utils import logging
from ..bert.tokenization_bert_fast import BertTokenizerFast
from .tokenization_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Tokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.txt",
}
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"{{cookiecutter.checkpoint_identifier}}": 512,
}
PRETRAINED_INIT_CONFIGURATION = {
"{{cookiecutter.checkpoint_identifier}}": {"do_lower_case": False},
}
class {{cookiecutter.camelcase_modelname}}TokenizerFast(BertTokenizerFast):
r"""
Construct a "fast" {{cookiecutter.modelname}} tokenizer (backed by HuggingFace's *tokenizers* library).
[`~{{cookiecutter.camelcase_modelname}}TokenizerFast`] is identical to [`BertTokenizerFast`] and runs
end-to-end tokenization: punctuation splitting and wordpiece.
Refer to superclass [`BertTokenizerFast`] for usage examples and documentation concerning
parameters.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
slow_tokenizer_class = {{cookiecutter.camelcase_modelname}}Tokenizer
{%- elif cookiecutter.tokenizer_type == "Based on BART" %}
from ...utils import logging
from ..bart.tokenization_bart_fast import BartTokenizerFast
from .tokenization_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Tokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt", "tokenizer_file": "tokenizer.json"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.json",
},
"merges_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/merges.txt",
},
"tokenizer_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/tokenizer.json",
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"{{cookiecutter.checkpoint_identifier}}": 1024,
}
class {{cookiecutter.camelcase_modelname}}TokenizerFast(BartTokenizerFast):
r"""
Construct a "fast" {{cookiecutter.modelname}} tokenizer (backed by HuggingFace's *tokenizers* library).
[`~{{cookiecutter.camelcase_modelname}}TokenizerFast`] is identical to [`BartTokenizerFast`] and runs
end-to-end tokenization: punctuation splitting and wordpiece.
Refer to superclass [`BartTokenizerFast`] for usage examples and documentation concerning
parameters.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = {{cookiecutter.camelcase_modelname}}Tokenizer
{%- elif cookiecutter.tokenizer_type == "Standalone" %}
from typing import List, Optional
from tokenizers import ByteLevelBPETokenizer
from ...tokenization_utils_fast import PreTrainedTokenizerFast
from ...utils import logging
from .tokenization_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Tokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt", "tokenizer_file": "tokenizer.json"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.txt",
},
"tokenizer_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/tokenizer.json",
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"{{cookiecutter.checkpoint_identifier}}": 1024,
}
class {{cookiecutter.camelcase_modelname}}TokenizerFast(PreTrainedTokenizerFast):
"""
Construct a "fast" {{cookiecutter.modelname}} tokenizer (backed by HuggingFace's *tokenizers* library).
Args:
vocab_file (`str`):
Path to the vocabulary file.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
slow_tokenizer_class = {{cookiecutter.camelcase_modelname}}Tokenizer
def __init__(
self,
vocab_file,
merges_file,
unk_token="<|endoftext|>",
bos_token="<|endoftext|>",
eos_token="<|endoftext|>",
add_prefix_space=False,
trim_offsets=True,
**kwargs
):
super().__init__(
ByteLevelBPETokenizer(
vocab_file=vocab_file,
merges_file=merges_file,
add_prefix_space=add_prefix_space,
trim_offsets=trim_offsets,
),
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
**kwargs,
)
self.add_prefix_space = add_prefix_space
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
output = [self.bos_token_id] + token_ids_0 + [self.eos_token_id]
if token_ids_1 is None:
return output
return output + [self.eos_token_id] + token_ids_1 + [self.eos_token_id]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Create a mask from the two sequences passed to be used in a sequence-pair classification task.
{{cookiecutter.modelname}} does not make use of token type ids, therefore a list of zeros is returned.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of zeros.
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep + sep + token_ids_1 + sep) * [0]
{% endif %}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/tokenization_{{cookiecutter.lowercase_modelname}}.py
|
# coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization classes for {{cookiecutter.modelname}}."""
{%- if cookiecutter.tokenizer_type == "Based on BERT" %}
from ...utils import logging
from ..bert.tokenization_bert import BertTokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.txt",
}
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"{{cookiecutter.checkpoint_identifier}}": 512,
}
PRETRAINED_INIT_CONFIGURATION = {
"{{cookiecutter.checkpoint_identifier}}": {"do_lower_case": False},
}
class {{cookiecutter.camelcase_modelname}}Tokenizer(BertTokenizer):
r"""
Construct a {{cookiecutter.modelname}} tokenizer.
[`~{{cookiecutter.camelcase_modelname}}Tokenizer`] is identical to [`BertTokenizer`] and runs end-to-end
tokenization: punctuation splitting and wordpiece.
Refer to superclass [`BertTokenizer`] for usage examples and documentation concerning
parameters.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
{%- elif cookiecutter.tokenizer_type == "Based on BART" %}
from ...utils import logging
from ..bart.tokenization_bart import BartTokenizer
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.json", "merges_file": "merges.txt"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.json",
},
"merges_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/merges.txt",
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"{{cookiecutter.checkpoint_identifier}}": 1024,
}
class {{cookiecutter.camelcase_modelname}}Tokenizer(BartTokenizer):
"""
Construct a {{cookiecutter.modelname}} tokenizer.
[`~{{cookiecutter.camelcase_modelname}}Tokenizer`] is identical to [`BartTokenizer`] and runs end-to-end
tokenization: punctuation splitting and wordpiece.
Refer to superclass [`BartTokenizer`] for usage examples and documentation concerning
parameters.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
{%- elif cookiecutter.tokenizer_type == "Standalone" %}
from typing import List, Optional
from tokenizers import ByteLevelBPETokenizer
from ...tokenization_utils import AddedToken, PreTrainedTokenizer
from ...tokenization_utils_fast import PreTrainedTokenizerFast
from ...utils import logging
logger = logging.get_logger(__name__)
VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"{{cookiecutter.checkpoint_identifier}}": "https://huggingface.co/{{cookiecutter.checkpoint_identifier}}/resolve/main/vocab.txt",
},
}
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
"{{cookiecutter.checkpoint_identifier}}": 1024,
}
class {{cookiecutter.camelcase_modelname}}Tokenizer(PreTrainedTokenizer):
"""
Construct a {{cookiecutter.modelname}} tokenizer. Based on byte-level Byte-Pair-Encoding.
Args:
vocab_file (`str`):
Path to the vocabulary file.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
self,
vocab_file,
unk_token="<|endoftext|>",
bos_token="<|endoftext|>",
eos_token="<|endoftext|>",
**kwargs
):
bos_token = AddedToken(bos_token, lstrip=False, rstrip=False) if isinstance(bos_token, str) else bos_token
eos_token = AddedToken(eos_token, lstrip=False, rstrip=False) if isinstance(eos_token, str) else eos_token
unk_token = AddedToken(unk_token, lstrip=False, rstrip=False) if isinstance(unk_token, str) else unk_token
super().__init__(bos_token=bos_token, eos_token=eos_token, unk_token=unk_token, **kwargs)
""" Initialisation """
@property
def vocab_size(self):
""" Returns vocab size """
def get_vocab(self):
""" Returns vocab as a dict """
def _tokenize(self, text):
""" Returns a tokenized string. """
def _convert_token_to_id(self, token):
""" Converts a token (str) in an id using the vocab. """
def _convert_id_to_token(self, index):
"""Converts an index (integer) in a token (str) using the vocab."""
def convert_tokens_to_string(self, tokens):
""" Converts a sequence of tokens (string) in a single string. """
def save_vocabulary(self, save_directory):
"""
Save the vocabulary and special tokens file to a directory.
Args:
save_directory (`str`):
The directory in which to save the vocabulary.
Returns:
`Tuple(str)`: Paths to the files saved.
"""
def build_inputs_with_special_tokens(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Build model inputs from a sequence or a pair of sequence for sequence classification tasks
by concatenating and adding special tokens.
A {{cookiecutter.modelname}} sequence has the following format:
- single sequence: `<s> X </s>`
- pair of sequences: `<s> A </s></s> B </s>`
Args:
token_ids_0 (`List[int]`):
List of IDs to which the special tokens will be added.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
"""
if token_ids_1 is None:
return [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
cls = [self.cls_token_id]
sep = [self.sep_token_id]
return cls + token_ids_0 + sep + sep + token_ids_1 + sep
def get_special_tokens_mask(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` method.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
return super().get_special_tokens_mask(
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
)
if token_ids_1 is None:
return [1] + ([0] * len(token_ids_0)) + [1]
return [1] + ([0] * len(token_ids_0)) + [1, 1] + ([0] * len(token_ids_1)) + [1]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Create a mask from the two sequences passed to be used in a sequence-pair classification task.
{{cookiecutter.modelname}} does not make use of token type ids, therefore a list of zeros is returned.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of zeros.
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep + sep + token_ids_1 + sep) * [0]
def prepare_for_tokenization(self, text, is_split_into_words=False, **kwargs):
add_prefix_space = kwargs.pop("add_prefix_space", self.add_prefix_space)
if (is_split_into_words or add_prefix_space) and (len(text) > 0 and not text[0].isspace()):
text = " " + text
return (text, kwargs)
class {{cookiecutter.camelcase_modelname}}TokenizerFast(PreTrainedTokenizerFast):
"""
Construct a "fast" {{cookiecutter.modelname}} tokenizer (backed by HuggingFace's *tokenizers* library).
Args:
vocab_file (`str`):
Path to the vocabulary file.
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
self,
vocab_file,
merges_file,
unk_token="<|endoftext|>",
bos_token="<|endoftext|>",
eos_token="<|endoftext|>",
add_prefix_space=False,
trim_offsets=True,
**kwargs
):
super().__init__(
ByteLevelBPETokenizer(
vocab_file=vocab_file,
merges_file=merges_file,
add_prefix_space=add_prefix_space,
trim_offsets=trim_offsets,
),
bos_token=bos_token,
eos_token=eos_token,
unk_token=unk_token,
**kwargs,
)
self.add_prefix_space = add_prefix_space
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
output = [self.bos_token_id] + token_ids_0 + [self.eos_token_id]
if token_ids_1 is None:
return output
return output + [self.eos_token_id] + token_ids_1 + [self.eos_token_id]
def create_token_type_ids_from_sequences(
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
) -> List[int]:
"""
Create a mask from the two sequences passed to be used in a sequence-pair classification task.
{{cookiecutter.modelname}} does not make use of token type ids, therefore a list of zeros is returned.
Args:
token_ids_0 (`List[int]`):
List of IDs.
token_ids_1 (`List[int]`, *optional*):
Optional second list of IDs for sequence pairs.
Returns:
`List[int]`: List of zeros.
"""
sep = [self.sep_token_id]
cls = [self.cls_token_id]
if token_ids_1 is None:
return len(cls + token_ids_0 + sep) * [0]
return len(cls + token_ids_0 + sep + sep + token_ids_1 + sep) * [0]
{% endif %}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/test_modeling_{{cookiecutter.lowercase_modelname}}.py
|
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the PyTorch {{cookiecutter.modelname}} model. """
{% if cookiecutter.is_encoder_decoder_model == "False" -%}
import unittest
from ...test_modeling_common import floats_tensor
from transformers import is_torch_available
from transformers.testing_utils import require_torch, slow, torch_device
from transformers import {{cookiecutter.camelcase_modelname}}Config
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
if is_torch_available():
import torch
from transformers import (
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForMaskedLM,
{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}ForTokenClassification,
{{cookiecutter.camelcase_modelname}}Model,
)
from transformers.models.{{cookiecutter.lowercase_modelname}}.modeling_{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
)
class {{cookiecutter.camelcase_modelname}}ModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_input_mask=True,
use_token_type_ids=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_input_mask = use_input_mask
self.use_token_type_ids = use_token_type_ids
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.num_labels = num_labels
self.num_choices = num_choices
self.scope = scope
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = self.get_config()
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
def get_config(self):
return {{cookiecutter.camelcase_modelname}}Config(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
is_decoder=False,
initializer_range=self.initializer_range,
)
def prepare_config_and_inputs_for_decoder(self):
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = self.prepare_config_and_inputs()
config.is_decoder = True
encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
return (
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
def create_and_check_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = {{cookiecutter.camelcase_modelname}}Model(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
result = model(input_ids, token_type_ids=token_type_ids)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_model_as_decoder(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.add_cross_attention = True
model = {{cookiecutter.camelcase_modelname}}Model(config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
)
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
encoder_hidden_states=encoder_hidden_states,
)
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_for_causal_lm(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
model = {{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_for_masked_lm(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = {{cookiecutter.camelcase_modelname}}ForMaskedLM(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_decoder_model_past_large_inputs(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.is_decoder = True
config.add_cross_attention = True
model = {{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
model.to(torch_device)
model.eval()
# first forward pass
outputs = model(
input_ids,
attention_mask=input_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=True,
)
past_key_values = outputs.past_key_values
# create hypothetical multiple next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
# append to next input_ids and
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
output_from_no_past = model(
next_input_ids,
attention_mask=next_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_hidden_states=True,
)["hidden_states"][0]
output_from_past = model(
next_tokens,
attention_mask=next_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
output_hidden_states=True,
)["hidden_states"][0]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
def create_and_check_for_question_answering(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = {{cookiecutter.camelcase_modelname}}ForQuestionAnswering(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
start_positions=sequence_labels,
end_positions=sequence_labels,
)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def create_and_check_for_sequence_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = {{cookiecutter.camelcase_modelname}}ForSequenceClassification(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_for_token_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = {{cookiecutter.camelcase_modelname}}ForTokenClassification(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_for_multiple_choice(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_choices = self.num_choices
model = {{cookiecutter.camelcase_modelname}}ForMultipleChoice(config=config)
model.to(torch_device)
model.eval()
multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
result = model(
multiple_choice_inputs_ids,
attention_mask=multiple_choice_input_mask,
token_type_ids=multiple_choice_token_type_ids,
labels=choice_labels,
)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_torch
class {{cookiecutter.camelcase_modelname}}ModelTest(ModelTesterMixin, unittest.TestCase):
all_model_classes = (
(
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}ForMaskedLM,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}ForTokenClassification,
)
if is_torch_available()
else ()
)
all_generative_model_classes = ({{cookiecutter.camelcase_modelname}}ForCausalLM,) if is_torch_available() else ()
def setUp(self):
self.model_tester = {{cookiecutter.camelcase_modelname}}ModelTester(self)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_various_embeddings(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
for type in ["absolute", "relative_key", "relative_key_query"]:
config_and_inputs[0].position_embedding_type = type
self.model_tester.create_and_check_model(*config_and_inputs)
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
def test_for_multiple_choice(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
def test_decoder_model_past_with_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
def test_for_question_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
def test_for_sequence_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
def test_for_token_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
def test_model_as_decoder(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_model_as_decoder(*config_and_inputs)
def test_model_as_decoder_with_default_input_mask(self):
# This regression test was failing with PyTorch < 1.3
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
) = self.model_tester.prepare_config_and_inputs_for_decoder()
input_mask = None
self.model_tester.create_and_check_model_as_decoder(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
@slow
def test_model_from_pretrained(self):
for model_name in {{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = {{cookiecutter.camelcase_modelname}}Model.from_pretrained(model_name)
self.assertIsNotNone(model)
@require_torch
class {{cookiecutter.camelcase_modelname}}ModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_masked_lm(self):
model = {{cookiecutter.camelcase_modelname}}ForMaskedLM.from_pretrained("{{cookiecutter.checkpoint_identifier}}")
input_ids = torch.tensor([[0, 1, 2, 3, 4, 5]])
output = model(input_ids)[0]
# TODO Replace vocab size
vocab_size = 32000
expected_shape = torch.Size((1, 6, vocab_size))
self.assertEqual(output.shape, expected_shape)
# TODO Replace values below with what was printed above.
expected_slice = torch.tensor(
[[[-0.0483, 0.1188, -0.0313], [-0.0606, 0.1435, 0.0199], [-0.0235, 0.1519, 0.0175]]]
)
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=1e-4))
{% else -%}
import copy
import tempfile
import unittest
from transformers import is_torch_available
from transformers.utils import cached_property
from transformers.testing_utils import require_sentencepiece, require_tokenizers, require_torch, slow, torch_device
from ...test_configuration_common import ConfigTester
from ...generation.test_utils import GenerationTesterMixin
from ...test_modeling_common import ModelTesterMixin, ids_tensor
if is_torch_available():
import torch
from transformers import (
{{cookiecutter.camelcase_modelname}}Config,
{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}Tokenizer,
)
from transformers.models.{{cookiecutter.lowercase_modelname}}.modeling_{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.camelcase_modelname}}Decoder,
{{cookiecutter.camelcase_modelname}}Encoder,
)
def prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(
config,
input_ids,
decoder_input_ids,
attention_mask=None,
decoder_attention_mask=None,
):
if attention_mask is None:
attention_mask = input_ids.ne(config.pad_token_id)
if decoder_attention_mask is None:
decoder_attention_mask = decoder_input_ids.ne(config.pad_token_id)
return {
"input_ids": input_ids,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": attention_mask,
}
@require_torch
class {{cookiecutter.camelcase_modelname}}ModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_labels=False,
vocab_size=99,
hidden_size=16,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=4,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=20,
eos_token_id=2,
pad_token_id=1,
bos_token_id=0,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.bos_token_id = bos_token_id
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size).clamp(
3,
)
input_ids[:, -1] = self.eos_token_id # Eos Token
decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
config = {{cookiecutter.camelcase_modelname}}Config(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
encoder_layers=self.num_hidden_layers,
decoder_layers=self.num_hidden_layers,
encoder_attention_heads=self.num_attention_heads,
decoder_attention_heads=self.num_attention_heads,
encoder_ffn_dim=self.intermediate_size,
decoder_ffn_dim=self.intermediate_size,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
eos_token_id=self.eos_token_id,
bos_token_id=self.bos_token_id,
pad_token_id=self.pad_token_id,
)
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(config, input_ids, decoder_input_ids)
return config, inputs_dict
def prepare_config_and_inputs_for_common(self):
config, inputs_dict = self.prepare_config_and_inputs()
return config, inputs_dict
def create_and_check_decoder_model_past_large_inputs(self, config, inputs_dict):
model = {{cookiecutter.camelcase_modelname}}Model(config=config).get_decoder().to(torch_device).eval()
input_ids = inputs_dict["input_ids"]
attention_mask = inputs_dict["attention_mask"]
# first forward pass
outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
output, past_key_values = outputs.to_tuple()
# create hypothetical multiple next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = ids_tensor((self.batch_size, 3), 2)
# append to next input_ids and
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
next_attention_mask = torch.cat([attention_mask, next_attn_mask], dim=-1)
output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["last_hidden_state"]
output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)["last_hidden_state"]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-2))
def check_encoder_decoder_model_standalone(self, config, inputs_dict):
model = {{cookiecutter.camelcase_modelname}}Model(config=config).to(torch_device).eval()
outputs = model(**inputs_dict)
encoder_last_hidden_state = outputs.encoder_last_hidden_state
last_hidden_state = outputs.last_hidden_state
with tempfile.TemporaryDirectory() as tmpdirname:
encoder = model.get_encoder()
encoder.save_pretrained(tmpdirname)
encoder = {{cookiecutter.camelcase_modelname}}Encoder.from_pretrained(tmpdirname).to(torch_device)
encoder_last_hidden_state_2 = encoder(inputs_dict["input_ids"], attention_mask=inputs_dict["attention_mask"])[
0
]
self.parent.assertTrue((encoder_last_hidden_state_2 - encoder_last_hidden_state).abs().max().item() < 1e-3)
with tempfile.TemporaryDirectory() as tmpdirname:
decoder = model.get_decoder()
decoder.save_pretrained(tmpdirname)
decoder = {{cookiecutter.camelcase_modelname}}Decoder.from_pretrained(tmpdirname).to(torch_device)
last_hidden_state_2 = decoder(
input_ids=inputs_dict["decoder_input_ids"],
attention_mask=inputs_dict["decoder_attention_mask"],
encoder_hidden_states=encoder_last_hidden_state,
encoder_attention_mask=inputs_dict["attention_mask"],
)[0]
self.parent.assertTrue((last_hidden_state_2 - last_hidden_state).abs().max().item() < 1e-3)
@require_torch
class {{cookiecutter.camelcase_modelname}}ModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
all_model_classes = (
({{cookiecutter.camelcase_modelname}}Model, {{cookiecutter.camelcase_modelname}}ForConditionalGeneration, {{cookiecutter.camelcase_modelname}}ForSequenceClassification, {{cookiecutter.camelcase_modelname}}ForQuestionAnswering)
if is_torch_available()
else ()
)
all_generative_model_classes = ({{cookiecutter.camelcase_modelname}}ForConditionalGeneration,) if is_torch_available() else ()
is_encoder_decoder = True
test_pruning = False
test_head_masking = False
test_missing_keys = False
def setUp(self):
self.model_tester = {{cookiecutter.camelcase_modelname}}ModelTester(self)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config)
def test_config(self):
self.config_tester.run_common_tests()
def test_save_load_strict(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs()
for model_class in self.all_model_classes:
model = model_class(config)
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
self.assertEqual(info["missing_keys"], [])
def test_decoder_model_past_with_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
def test_encoder_decoder_model_standalone(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
self.model_tester.check_encoder_decoder_model_standalone(*config_and_inputs)
# {{cookiecutter.camelcase_modelname}}ForSequenceClassification does not support inputs_embeds
def test_inputs_embeds(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in ({{cookiecutter.camelcase_modelname}}Model, {{cookiecutter.camelcase_modelname}}ForConditionalGeneration, {{cookiecutter.camelcase_modelname}}ForQuestionAnswering):
model = model_class(config)
model.to(torch_device)
model.eval()
inputs = copy.deepcopy(self._prepare_for_class(inputs_dict, model_class))
if not self.is_encoder_decoder:
input_ids = inputs["input_ids"]
del inputs["input_ids"]
else:
encoder_input_ids = inputs["input_ids"]
decoder_input_ids = inputs.get("decoder_input_ids", encoder_input_ids)
del inputs["input_ids"]
inputs.pop("decoder_input_ids", None)
wte = model.get_input_embeddings()
if not self.is_encoder_decoder:
inputs["inputs_embeds"] = wte(input_ids)
else:
inputs["inputs_embeds"] = wte(encoder_input_ids)
inputs["decoder_inputs_embeds"] = wte(decoder_input_ids)
with torch.no_grad():
model(**inputs)[0]
def test_generate_fp16(self):
config, input_dict = self.model_tester.prepare_config_and_inputs()
input_ids = input_dict["input_ids"]
attention_mask = input_ids.ne(1).to(torch_device)
model = {{cookiecutter.camelcase_modelname}}ForConditionalGeneration(config).eval().to(torch_device)
if torch_device == "cuda":
model.half()
model.generate(input_ids, attention_mask=attention_mask)
model.generate(num_beams=4, do_sample=True, early_stopping=False, num_return_sequences=3)
def assert_tensors_close(a, b, atol=1e-12, prefix=""):
"""If tensors have different shapes, different values or a and b are not both tensors, raise a nice Assertion error."""
if a is None and b is None:
return True
try:
if torch.allclose(a, b, atol=atol):
return True
raise
except Exception:
pct_different = (torch.gt((a - b).abs(), atol)).float().mean().item()
if a.numel() > 100:
msg = f"tensor values are {pct_different:.1%} percent different."
else:
msg = f"{a} != {b}"
if prefix:
msg = prefix + ": " + msg
raise AssertionError(msg)
def _long_tensor(tok_lst):
return torch.tensor(tok_lst, dtype=torch.long, device=torch_device)
TOLERANCE = 1e-4
@require_torch
@require_sentencepiece
@require_tokenizers
@slow
class {{cookiecutter.camelcase_modelname}}ModelIntegrationTests(unittest.TestCase):
@cached_property
def default_tokenizer(self):
return {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
def test_inference_no_head(self):
model = {{cookiecutter.camelcase_modelname}}Model.from_pretrained('{{cookiecutter.checkpoint_identifier}}').to(torch_device)
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[2, 0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588]])
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(model.config, input_ids, decoder_input_ids)
with torch.no_grad():
output = model(**inputs_dict)[0]
expected_shape = torch.Size((1, 11, 1024))
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = torch.tensor(
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]], device=torch_device
)
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=TOLERANCE))
def test_inference_head(self):
model = {{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}').to(torch_device)
# change to intended input
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(model.config, input_ids, decoder_input_ids)
with torch.no_grad():
output = model(**inputs_dict)[0]
expected_shape = torch.Size((1, 11, model.config.vocab_size))
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = torch.tensor(
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]], device=torch_device
)
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=TOLERANCE))
def test_seq_to_seq_generation(self):
hf = {{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}').to(torch_device)
tok = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
batch_input = [
# string 1,
# string 2,
# string 3,
# string 4,
]
# The below article tests that we don't add any hypotheses outside of the top n_beams
dct = tok.batch_encode_plus(
batch_input,
max_length=512,
padding="max_length",
truncation_strategy="only_first",
truncation=True,
return_tensors="pt",
)
hypotheses_batch = hf.generate(
input_ids=dct["input_ids"].to(torch_device),
attention_mask=dct["attention_mask"].to(torch_device),
num_beams=2,
)
EXPECTED = [
# here expected 1,
# here expected 2,
# here expected 3,
# here expected 4,
]
generated = tok.batch_decode(
hypotheses_batch.tolist(), clean_up_tokenization_spaces=True, skip_special_tokens=True
)
assert generated == EXPECTED
class {{cookiecutter.camelcase_modelname}}StandaloneDecoderModelTester:
def __init__(
self,
parent,
vocab_size=99,
batch_size=13,
d_model=16,
decoder_seq_length=7,
is_training=True,
is_decoder=True,
use_attention_mask=True,
use_cache=False,
use_labels=True,
decoder_start_token_id=2,
decoder_ffn_dim=32,
decoder_layers=4,
encoder_attention_heads=4,
decoder_attention_heads=4,
max_position_embeddings=30,
is_encoder_decoder=False,
pad_token_id=0,
bos_token_id=1,
eos_token_id=2,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.decoder_seq_length = decoder_seq_length
# For common tests
self.seq_length = self.decoder_seq_length
self.is_training = is_training
self.use_attention_mask = use_attention_mask
self.use_labels = use_labels
self.vocab_size = vocab_size
self.d_model = d_model
self.hidden_size = d_model
self.num_hidden_layers = decoder_layers
self.decoder_layers = decoder_layers
self.decoder_ffn_dim = decoder_ffn_dim
self.encoder_attention_heads = encoder_attention_heads
self.decoder_attention_heads = decoder_attention_heads
self.num_attention_heads = decoder_attention_heads
self.eos_token_id = eos_token_id
self.bos_token_id = bos_token_id
self.pad_token_id = pad_token_id
self.decoder_start_token_id = decoder_start_token_id
self.use_cache = use_cache
self.max_position_embeddings = max_position_embeddings
self.is_encoder_decoder = is_encoder_decoder
self.scope = None
self.decoder_key_length = decoder_seq_length
self.base_model_out_len = 2
self.decoder_attention_idx = 1
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
attention_mask = None
if self.use_attention_mask:
attention_mask = ids_tensor([self.batch_size, self.decoder_seq_length], vocab_size=2)
lm_labels = None
if self.use_labels:
lm_labels = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
config = {{cookiecutter.camelcase_modelname}}Config(
vocab_size=self.vocab_size,
d_model=self.d_model,
decoder_layers=self.decoder_layers,
decoder_ffn_dim=self.decoder_ffn_dim,
encoder_attention_heads=self.encoder_attention_heads,
decoder_attention_heads=self.decoder_attention_heads,
eos_token_id=self.eos_token_id,
bos_token_id=self.bos_token_id,
use_cache=self.use_cache,
pad_token_id=self.pad_token_id,
decoder_start_token_id=self.decoder_start_token_id,
max_position_embeddings=self.max_position_embeddings,
is_encoder_decoder=self.is_encoder_decoder,
)
return (
config,
input_ids,
attention_mask,
lm_labels,
)
def create_and_check_decoder_model_past(
self,
config,
input_ids,
attention_mask,
lm_labels,
):
config.use_cache = True
model = {{cookiecutter.camelcase_modelname}}Decoder(config=config).to(torch_device).eval()
# first forward pass
outputs = model(input_ids, use_cache=True)
outputs_use_cache_conf = model(input_ids)
outputs_no_past = model(input_ids, use_cache=False)
self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
past_key_values = outputs["past_key_values"]
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# append to next input_ids and
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
output_from_no_past = model(next_input_ids)["last_hidden_state"]
output_from_past = model(next_tokens, past_key_values=past_key_values)["last_hidden_state"]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
# test that outputs are equal for slice
assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)
def create_and_check_decoder_model_attention_mask_past(
self,
config,
input_ids,
attention_mask,
lm_labels,
):
model = {{cookiecutter.camelcase_modelname}}Decoder(config=config).to(torch_device).eval()
# create attention mask
attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
half_seq_length = input_ids.shape[-1] // 2
attn_mask[:, half_seq_length:] = 0
# first forward pass
past_key_values = model(input_ids, attention_mask=attn_mask, use_cache=True)["past_key_values"]
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# change a random masked slice from input_ids
random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
# append to next input_ids and attn_mask
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
attn_mask = torch.cat(
[attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
dim=1,
)
# get two different outputs
output_from_no_past = model(next_input_ids)["last_hidden_state"]
output_from_past = model(next_tokens, past_key_values=past_key_values)["last_hidden_state"]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
# test that outputs are equal for slice
assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-2)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
attention_mask,
lm_labels,
) = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"attention_mask": attention_mask,
}
return config, inputs_dict
@require_torch
class {{cookiecutter.camelcase_modelname}}StandaloneDecoderModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
all_model_classes = ({{cookiecutter.camelcase_modelname}}Decoder, {{cookiecutter.camelcase_modelname}}ForCausalLM) if is_torch_available() else ()
all_generative_model_classes = ({{cookiecutter.camelcase_modelname}}ForCausalLM,) if is_torch_available() else ()
test_pruning = False
is_encoder_decoder = False
def setUp(
self,
):
self.model_tester = {{cookiecutter.camelcase_modelname}}StandaloneDecoderModelTester(self, is_training=False)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config)
def test_config(self):
self.config_tester.run_common_tests()
def test_decoder_model_past(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_decoder_model_past(*config_and_inputs)
def test_decoder_model_attn_mask_past(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_decoder_model_attention_mask_past(*config_and_inputs)
def test_retain_grad_hidden_states_attentions(self):
# decoder cannot keep gradients
return
{% endif -%}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/test_modeling_tf_{{cookiecutter.lowercase_modelname}}.py
|
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
{% if cookiecutter.is_encoder_decoder_model == "False" %}
import unittest
from transformers import is_tf_available, {{cookiecutter.camelcase_modelname}}Config
from transformers.testing_utils import require_tf, slow
from ...test_configuration_common import ConfigTester
from ...test_modeling_tf_common import TFModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
if is_tf_available():
import tensorflow as tf
from transformers import (
TF{{cookiecutter.camelcase_modelname}}ForCausalLM,
TF{{cookiecutter.camelcase_modelname}}ForMaskedLM,
TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
TF{{cookiecutter.camelcase_modelname}}ForTokenClassification,
TF{{cookiecutter.camelcase_modelname}}Model,
)
class TF{{cookiecutter.camelcase_modelname}}ModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_input_mask=True,
use_token_type_ids=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = 13
self.seq_length = 7
self.is_training = True
self.use_input_mask = True
self.use_token_type_ids = True
self.use_labels = True
self.vocab_size = 99
self.hidden_size = 32
self.num_hidden_layers = 5
self.num_attention_heads = 4
self.intermediate_size = 37
self.hidden_act = "gelu"
self.hidden_dropout_prob = 0.1
self.attention_probs_dropout_prob = 0.1
self.max_position_embeddings = 512
self.type_vocab_size = 16
self.type_sequence_label_size = 2
self.initializer_range = 0.02
self.num_labels = 3
self.num_choices = 4
self.scope = None
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = {{cookiecutter.camelcase_modelname}}Config(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
initializer_range=self.initializer_range,
return_dict=True,
)
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
def prepare_config_and_inputs_for_decoder(self):
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = self.prepare_config_and_inputs()
config.is_decoder = True
encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
return (
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
def create_and_check_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = TF{{cookiecutter.camelcase_modelname}}Model(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
inputs = [input_ids, input_mask]
result = model(inputs)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_causal_lm_base_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.is_decoder = True
model = TF{{cookiecutter.camelcase_modelname}}Model(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
result = model(inputs)
inputs = [input_ids, input_mask]
result = model(inputs)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_model_as_decoder(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.add_cross_attention = True
model = TF{{cookiecutter.camelcase_modelname}}Model(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
"encoder_hidden_states": encoder_hidden_states,
"encoder_attention_mask": encoder_attention_mask,
}
result = model(inputs)
inputs = [input_ids, input_mask]
result = model(inputs, token_type_ids=token_type_ids, encoder_hidden_states=encoder_hidden_states)
# Also check the case where encoder outputs are not passed
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_causal_lm_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.is_decoder = True
model = TF{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
prediction_scores = model(inputs)["logits"]
self.parent.assertListEqual(
list(prediction_scores.numpy().shape), [self.batch_size, self.seq_length, self.vocab_size]
)
def create_and_check_causal_lm_model_as_decoder(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.add_cross_attention = True
model = TF{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
"encoder_hidden_states": encoder_hidden_states,
"encoder_attention_mask": encoder_attention_mask,
}
result = model(inputs)
inputs = [input_ids, input_mask]
result = model(inputs, token_type_ids=token_type_ids, encoder_hidden_states=encoder_hidden_states)
prediction_scores = result["logits"]
self.parent.assertListEqual(
list(prediction_scores.numpy().shape), [self.batch_size, self.seq_length, self.vocab_size]
)
def create_and_check_causal_lm_model_past(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
):
config.is_decoder = True
model = TF{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
# first forward pass
outputs = model(input_ids, use_cache=True)
outputs_use_cache_conf = model(input_ids)
outputs_no_past = model(input_ids, use_cache=False)
self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
past_key_values = outputs.past_key_values
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# append to next input_ids and attn_mask
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
output_from_no_past = model(next_input_ids, output_hidden_states=True).hidden_states[0]
output_from_past = model(
next_tokens, past_key_values=past_key_values, output_hidden_states=True
).hidden_states[0]
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx]
output_from_past_slice = output_from_past[:, 0, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-6)
def create_and_check_causal_lm_model_past_with_attn_mask(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
):
config.is_decoder = True
model = TF{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
# create attention mask
half_seq_length = self.seq_length // 2
attn_mask_begin = tf.ones((self.batch_size, half_seq_length), dtype=tf.int32)
attn_mask_end = tf.zeros((self.batch_size, self.seq_length - half_seq_length), dtype=tf.int32)
attn_mask = tf.concat([attn_mask_begin, attn_mask_end], axis=1)
# first forward pass
outputs = model(input_ids, attention_mask=attn_mask, use_cache=True)
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
past_key_values = outputs.past_key_values
# change a random masked slice from input_ids
random_seq_idx_to_change = ids_tensor((1,), half_seq_length).numpy() + 1
random_other_next_tokens = ids_tensor((self.batch_size, self.seq_length), config.vocab_size)
vector_condition = tf.range(self.seq_length) == (self.seq_length - random_seq_idx_to_change)
condition = tf.transpose(
tf.broadcast_to(tf.expand_dims(vector_condition, -1), (self.seq_length, self.batch_size))
)
input_ids = tf.where(condition, random_other_next_tokens, input_ids)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
attn_mask = tf.concat(
[attn_mask, tf.ones((attn_mask.shape[0], 1), dtype=tf.int32)],
axis=1,
)
output_from_no_past = model(
next_input_ids,
attention_mask=attn_mask,
output_hidden_states=True,
).hidden_states[0]
output_from_past = model(
next_tokens, past_key_values=past_key_values, attention_mask=attn_mask, output_hidden_states=True
).hidden_states[0]
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx]
output_from_past_slice = output_from_past[:, 0, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-6)
def create_and_check_causal_lm_model_past_large_inputs(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
):
config.is_decoder = True
model = TF{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
input_ids = input_ids[:1, :]
input_mask = input_mask[:1, :]
self.batch_size = 1
# first forward pass
outputs = model(input_ids, attention_mask=input_mask, use_cache=True)
past_key_values = outputs.past_key_values
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = ids_tensor((self.batch_size, 3), 2)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
next_attention_mask = tf.concat([input_mask, next_attn_mask], axis=-1)
output_from_no_past = model(
next_input_ids,
attention_mask=next_attention_mask,
output_hidden_states=True,
).hidden_states[0]
output_from_past = model(
next_tokens,
attention_mask=next_attention_mask,
past_key_values=past_key_values,
output_hidden_states=True,
).hidden_states[0]
self.parent.assertEqual(next_tokens.shape[1], output_from_past.shape[1])
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx]
output_from_past_slice = output_from_past[:, :, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-3)
def create_and_check_decoder_model_past_large_inputs(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.add_cross_attention = True
model = TF{{cookiecutter.camelcase_modelname}}ForCausalLM(config=config)
input_ids = input_ids[:1, :]
input_mask = input_mask[:1, :]
encoder_hidden_states = encoder_hidden_states[:1, :, :]
encoder_attention_mask = encoder_attention_mask[:1, :]
self.batch_size = 1
# first forward pass
outputs = model(
input_ids,
attention_mask=input_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=True,
)
past_key_values = outputs.past_key_values
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = ids_tensor((self.batch_size, 3), 2)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
next_attention_mask = tf.concat([input_mask, next_attn_mask], axis=-1)
output_from_no_past = model(
next_input_ids,
attention_mask=next_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_hidden_states=True,
).hidden_states[0]
output_from_past = model(
next_tokens,
attention_mask=next_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
output_hidden_states=True,
).hidden_states[0]
self.parent.assertEqual(next_tokens.shape[1], output_from_past.shape[1])
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx]
output_from_past_slice = output_from_past[:, :, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-3)
def create_and_check_for_masked_lm(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = TF{{cookiecutter.camelcase_modelname}}ForMaskedLM(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_for_sequence_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_for_multiple_choice(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_choices = self.num_choices
model = TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice(config=config)
multiple_choice_inputs_ids = tf.tile(tf.expand_dims(input_ids, 1), (1, self.num_choices, 1))
multiple_choice_input_mask = tf.tile(tf.expand_dims(input_mask, 1), (1, self.num_choices, 1))
multiple_choice_token_type_ids = tf.tile(tf.expand_dims(token_type_ids, 1), (1, self.num_choices, 1))
inputs = {
"input_ids": multiple_choice_inputs_ids,
"attention_mask": multiple_choice_input_mask,
"token_type_ids": multiple_choice_token_type_ids,
}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
def create_and_check_for_token_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = TF{{cookiecutter.camelcase_modelname}}ForTokenClassification(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_for_question_answering(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
}
result = model(inputs)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_tf
class TF{{cookiecutter.camelcase_modelname}}ModelTest(TFModelTesterMixin, unittest.TestCase):
all_model_classes = (
(
TF{{cookiecutter.camelcase_modelname}}Model,
TF{{cookiecutter.camelcase_modelname}}ForCausalLM,
TF{{cookiecutter.camelcase_modelname}}ForMaskedLM,
TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
TF{{cookiecutter.camelcase_modelname}}ForTokenClassification,
TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
)
if is_tf_available()
else ()
)
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = TF{{cookiecutter.camelcase_modelname}}ModelTester(self)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
"""Test the base model"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
@unittest.skip(reason="Template classes interact badly with this test.")
def test_keras_fit(self):
pass
def test_causal_lm_base_model(self):
"""Test the base model of the causal LM model
is_deocder=True, no cross_attention, no encoder outputs
"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_base_model(*config_and_inputs)
def test_model_as_decoder(self):
"""Test the base model as a decoder (of an encoder-decoder architecture)
is_deocder=True + cross_attention + pass encoder outputs
"""
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_model_as_decoder(*config_and_inputs)
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
def test_for_causal_lm(self):
"""Test the causal LM model"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_model(*config_and_inputs)
def test_causal_lm_model_as_decoder(self):
"""Test the causal LM model as a decoder"""
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_causal_lm_model_as_decoder(*config_and_inputs)
def test_causal_lm_model_past(self):
"""Test causal LM model with `past_key_values`"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_model_past(*config_and_inputs)
def test_causal_lm_model_past_with_attn_mask(self):
"""Test the causal LM model with `past_key_values` and `attention_mask`"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_model_past_with_attn_mask(*config_and_inputs)
def test_causal_lm_model_past_with_large_inputs(self):
"""Test the causal LM model with `past_key_values` and a longer decoder sequence length"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_model_past_large_inputs(*config_and_inputs)
def test_decoder_model_past_with_large_inputs(self):
"""Similar to `test_causal_lm_model_past_with_large_inputs` but with cross-attention"""
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
def test_for_multiple_choice(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
def test_for_question_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
def test_for_sequence_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
def test_for_token_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
model = TF{{cookiecutter.camelcase_modelname}}Model.from_pretrained("{{cookiecutter.checkpoint_identifier}}")
self.assertIsNotNone(model)
@require_tf
class TF{{cookiecutter.camelcase_modelname}}ModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_masked_lm(self):
model = TF{{cookiecutter.camelcase_modelname}}ForMaskedLM.from_pretrained("{{cookiecutter.checkpoint_identifier}}")
input_ids = tf.constant([[0, 1, 2, 3, 4, 5]])
output = model(input_ids)[0]
# TODO Replace vocab size
vocab_size = 32000
expected_shape = [1, 6, vocab_size]
self.assertEqual(output.shape, expected_shape)
print(output[:, :3, :3])
# TODO Replace values below with what was printed above.
expected_slice = tf.constant(
[
[
[-0.05243197, -0.04498899, 0.05512108],
[-0.07444685, -0.01064632, 0.04352357],
[-0.05020351, 0.05530146, 0.00700043],
]
]
)
tf.debugging.assert_near(output[:, :3, :3], expected_slice, atol=1e-4)
{% else %}
import unittest
from transformers import (
is_tf_available,
{{cookiecutter.camelcase_modelname}}Config,
{{cookiecutter.camelcase_modelname}}Tokenizer,
)
from transformers.testing_utils import require_sentencepiece, require_tf, require_tokenizers, slow
from ...test_configuration_common import ConfigTester
from ...test_modeling_tf_common import TFModelTesterMixin, ids_tensor
if is_tf_available():
import tensorflow as tf
from transformers import (
TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
TF{{cookiecutter.camelcase_modelname}}Model,
)
@require_tf
class TF{{cookiecutter.camelcase_modelname}}ModelTester:
config_cls = {{cookiecutter.camelcase_modelname}}Config
config_updates = {}
hidden_act = "gelu"
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_labels=False,
vocab_size=99,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
intermediate_size=37,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=20,
eos_token_id=2,
pad_token_id=1,
bos_token_id=0,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.bos_token_id = bos_token_id
def prepare_config_and_inputs_for_common(self):
input_ids = ids_tensor([self.batch_size, self.seq_length - 1], self.vocab_size)
eos_tensor = tf.expand_dims(tf.constant([self.eos_token_id] * self.batch_size), 1)
input_ids = tf.concat([input_ids, eos_tensor], axis=1)
decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
config = self.config_cls(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
encoder_layers=self.num_hidden_layers,
decoder_layers=self.num_hidden_layers,
encoder_attention_heads=self.num_attention_heads,
decoder_attention_heads=self.num_attention_heads,
encoder_ffn_dim=self.intermediate_size,
decoder_ffn_dim=self.intermediate_size,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
eos_token_ids=[2],
bos_token_id=self.bos_token_id,
pad_token_id=self.pad_token_id,
decoder_start_token_id=self.pad_token_id,
**self.config_updates,
)
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(config, input_ids, decoder_input_ids)
return config, inputs_dict
def check_decoder_model_past_large_inputs(self, config, inputs_dict):
model = TF{{cookiecutter.camelcase_modelname}}Model(config=config).get_decoder()
input_ids = inputs_dict["input_ids"]
input_ids = input_ids[:1, :]
attention_mask = inputs_dict["attention_mask"][:1, :]
self.batch_size = 1
# first forward pass
outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
output, past_key_values = outputs.to_tuple()
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = ids_tensor((self.batch_size, 3), 2)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
next_attention_mask = tf.concat([attention_mask, next_attn_mask], axis=-1)
output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)[0]
output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[0]
self.parent.assertEqual(next_tokens.shape[1], output_from_past.shape[1])
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx]
output_from_past_slice = output_from_past[:, :, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-3)
def prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(
config,
input_ids,
decoder_input_ids,
attention_mask=None,
decoder_attention_mask=None,
):
if attention_mask is None:
attention_mask = tf.cast(tf.math.not_equal(input_ids, config.pad_token_id), tf.int32)
if decoder_attention_mask is None:
decoder_attention_mask = tf.concat([tf.ones(decoder_input_ids[:, :1].shape, dtype=tf.int32), tf.cast(tf.math.not_equal(decoder_input_ids[:, 1:], config.pad_token_id), tf.int32)], axis=-1)
return {
"input_ids": input_ids,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": decoder_attention_mask,
}
@require_tf
class TF{{cookiecutter.camelcase_modelname}}ModelTest(TFModelTesterMixin, unittest.TestCase):
all_model_classes = (TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration, TF{{cookiecutter.camelcase_modelname}}Model) if is_tf_available() else ()
all_generative_model_classes = (TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,) if is_tf_available() else ()
is_encoder_decoder = True
test_pruning = False
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = TF{{cookiecutter.camelcase_modelname}}ModelTester(self)
self.config_tester = ConfigTester(self, config_class={{cookiecutter.camelcase_modelname}}Config)
def test_config(self):
self.config_tester.run_common_tests()
def test_decoder_model_past_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
self.model_tester.check_decoder_model_past_large_inputs(*config_and_inputs)
@unittest.skip(reason="Template classes interact badly with this test.")
def test_keras_fit(self):
pass
def _assert_tensors_equal(a, b, atol=1e-12, prefix=""):
"""If tensors not close, or a and b arent both tensors, raise a nice Assertion error."""
if a is None and b is None:
return True
try:
if tf.debugging.assert_near(a, b, atol=atol):
return True
raise
except Exception:
if len(prefix) > 0:
prefix = f"{prefix}: "
raise AssertionError(f"{prefix}{a} != {b}")
def _long_tensor(tok_lst):
return tf.constant(tok_lst, dtype=tf.int32)
TOLERANCE = 1e-4
@slow
@require_sentencepiece
@require_tokenizers
@require_tf
class TF{{cookiecutter.camelcase_modelname}}ModelIntegrationTest(unittest.TestCase):
def test_inference_no_head(self):
model = TF{{cookiecutter.camelcase_modelname}}Model.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
# change to intended input here
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(model.config, input_ids, decoder_input_ids)
output = model(**inputs_dict)[0]
expected_shape = (1, 11, 1024)
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = tf.Tensor(
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]],
)
tf.debugging.assert_near(output[:, :3, :3], expected_slice, atol=TOLERANCE)
def test_inference_with_head(self):
model = TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
# change to intended input here
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
inputs_dict = prepare_{{cookiecutter.lowercase_modelname}}_inputs_dict(model.config, input_ids, decoder_input_ids)
output = model(**inputs_dict)[0]
expected_shape = (1, 11, 1024)
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = tf.Tensor(
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]],
)
tf.debugging.assert_near(output[:, :3, :3], expected_slice, atol=TOLERANCE)
def test_seq_to_seq_generation(self):
hf = TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
tok = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
batch_input = [
# string 1,
# string 2,
# string 3,
# string 4,
]
# The below article tests that we don't add any hypotheses outside of the top n_beams
dct = tok.batch_encode_plus(
batch_input,
max_length=512,
padding="max_length",
truncation_strategy="only_first",
truncation=True,
return_tensors="tf",
)
hypotheses_batch = hf.generate(
input_ids=dct["input_ids"],
attention_mask=dct["attention_mask"],
num_beams=2,
)
EXPECTED = [
# here expected 1,
# here expected 2,
# here expected 3,
# here expected 4,
]
generated = tok.batch_decode(
hypotheses_batch.tolist(), clean_up_tokenization_spaces=True, skip_special_tokens=True
)
assert generated == EXPECTED
{%- endif %}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/__init__.py
|
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import TYPE_CHECKING
from ...utils import _LazyModule, OptionalDependencyNotAvailable, is_tokenizers_available
{%- if "TensorFlow" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
from ...utils import is_tf_available
{% endif %}
{%- if "PyTorch" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
from ...utils import is_torch_available
{% endif %}
{%- if "Flax" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
from ...utils import is_flax_available
{% endif %}
_import_structure = {
"configuration_{{cookiecutter.lowercase_modelname}}": ["{{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP", "{{cookiecutter.camelcase_modelname}}Config"],
"tokenization_{{cookiecutter.lowercase_modelname}}": ["{{cookiecutter.camelcase_modelname}}Tokenizer"],
}
try:
if not is_tokenizers_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["tokenization_{{cookiecutter.lowercase_modelname}}_fast"] = ["{{cookiecutter.camelcase_modelname}}TokenizerFast"]
{%- if "PyTorch" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_{{cookiecutter.lowercase_modelname}}"] = [
"{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"{{cookiecutter.camelcase_modelname}}ForCausalLM",
"{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"{{cookiecutter.camelcase_modelname}}Layer",
"{{cookiecutter.camelcase_modelname}}Model",
"{{cookiecutter.camelcase_modelname}}PreTrainedModel",
"load_tf_weights_in_{{cookiecutter.lowercase_modelname}}",
]
{% else %}
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_{{cookiecutter.lowercase_modelname}}"] = [
"{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"{{cookiecutter.camelcase_modelname}}ForCausalLM",
"{{cookiecutter.camelcase_modelname}}Model",
"{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
{% endif %}
{% endif %}
{%- if "TensorFlow" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_tf_{{cookiecutter.lowercase_modelname}}"] = [
"TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST",
"TF{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"TF{{cookiecutter.camelcase_modelname}}ForCausalLM",
"TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"TF{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"TF{{cookiecutter.camelcase_modelname}}Layer",
"TF{{cookiecutter.camelcase_modelname}}Model",
"TF{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
{% else %}
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_tf_{{cookiecutter.lowercase_modelname}}"] = [
"TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"TF{{cookiecutter.camelcase_modelname}}Model",
"TF{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
{% endif %}
{% endif %}
{%- if "Flax" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_flax_{{cookiecutter.lowercase_modelname}}"] = [
"Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM",
"Flax{{cookiecutter.camelcase_modelname}}ForCausalLM",
"Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice",
"Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification",
"Flax{{cookiecutter.camelcase_modelname}}Layer",
"Flax{{cookiecutter.camelcase_modelname}}Model",
"Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
{% else %}
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_flax_{{cookiecutter.lowercase_modelname}}"] = [
"Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration",
"Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering",
"Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification",
"Flax{{cookiecutter.camelcase_modelname}}Model",
"Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel",
]
{% endif %}
{% endif %}
if TYPE_CHECKING:
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.uppercase_modelname}}_PRETRAINED_CONFIG_ARCHIVE_MAP, {{cookiecutter.camelcase_modelname}}Config
from .tokenization_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Tokenizer
try:
if not is_tokenizers_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .tokenization_{{cookiecutter.lowercase_modelname}}_fast import {{cookiecutter.camelcase_modelname}}TokenizerFast
{%- if "PyTorch" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
{{cookiecutter.camelcase_modelname}}ForMaskedLM,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}ForTokenClassification,
{{cookiecutter.camelcase_modelname}}Layer,
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}PreTrainedModel,
load_tf_weights_in_{{cookiecutter.lowercase_modelname}},
)
{% else %}
try:
if not is_torch_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_{{cookiecutter.lowercase_modelname}} import (
{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
{{cookiecutter.camelcase_modelname}}ForCausalLM,
{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
{{cookiecutter.camelcase_modelname}}Model,
{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif %}
{% endif %}
{%- if "TensorFlow" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_tf_{{cookiecutter.lowercase_modelname}} import (
TF_{{cookiecutter.uppercase_modelname}}_PRETRAINED_MODEL_ARCHIVE_LIST,
TF{{cookiecutter.camelcase_modelname}}ForMaskedLM,
TF{{cookiecutter.camelcase_modelname}}ForCausalLM,
TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
TF{{cookiecutter.camelcase_modelname}}ForTokenClassification,
TF{{cookiecutter.camelcase_modelname}}Layer,
TF{{cookiecutter.camelcase_modelname}}Model,
TF{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% else %}
try:
if not is_tf_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_tf_{{cookiecutter.lowercase_modelname}} import (
TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
TF{{cookiecutter.camelcase_modelname}}Model,
TF{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif %}
{% endif %}
{%- if "Flax" in cookiecutter.generate_tensorflow_pytorch_and_flax %}
{% if cookiecutter.is_encoder_decoder_model == "False" %}
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_{{cookiecutter.lowercase_modelname}} import (
Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM,
Flax{{cookiecutter.camelcase_modelname}}ForCausalLM,
Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification,
Flax{{cookiecutter.camelcase_modelname}}Layer,
Flax{{cookiecutter.camelcase_modelname}}Model,
Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% else %}
try:
if not is_flax_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_{{cookiecutter.lowercase_modelname}} import (
Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration,
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
Flax{{cookiecutter.camelcase_modelname}}Model,
Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel,
)
{% endif %}
{% endif %}
else:
import sys
sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/modeling_flax_{{cookiecutter.lowercase_modelname}}.py
|
# coding=utf-8
# Copyright 2022 {{cookiecutter.authors}} and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Flax {{cookiecutter.modelname}} model. """
{% if cookiecutter.is_encoder_decoder_model == "False" %}
from typing import Callable, Optional, Tuple
import numpy as np
import flax.linen as nn
import jax
import jax.numpy as jnp
from flax.core.frozen_dict import FrozenDict, unfreeze, freeze
from flax.linen import combine_masks, make_causal_mask
from flax.linen import partitioning as nn_partitioning
from flax.traverse_util import flatten_dict, unflatten_dict
from flax.linen.attention import dot_product_attention_weights
from jax import lax
from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward
from ...modeling_flax_outputs import (
FlaxBaseModelOutputWithPastAndCrossAttentions,
FlaxBaseModelOutputWithPoolingAndCrossAttentions,
FlaxCausalLMOutput,
FlaxCausalLMOutputWithCrossAttentions,
FlaxMaskedLMOutput,
FlaxMultipleChoiceModelOutput,
FlaxQuestionAnsweringModelOutput,
FlaxSequenceClassifierOutput,
FlaxTokenClassifierOutput,
)
from ...modeling_flax_utils import (
ACT2FN,
FlaxPreTrainedModel,
append_call_sample_docstring,
overwrite_call_docstring,
)
from ...utils import logging
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Config
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
_TOKENIZER_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Tokenizer"
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING = r"""
This model inherits from [`FlaxPreTrainedModel`]. Check the superclass documentation for the
generic methods the library implements for all its model (such as downloading, saving and converting weights from
PyTorch models)
This model is also a Flax Linen [flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html) subclass. Use it as a regular Flax linen Module
and refer to the Flax documentation for all matter related to general usage and behavior.
Finally, this model supports inherent JAX features such as:
- [Just-In-Time (JIT) compilation](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
- [Automatic Differentiation](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
- [Vectorization](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
- [Parallelization](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
Parameters:
config ([`~{{cookiecutter.uppercase_modelname}}Config`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~FlaxPreTrainedModel.from_pretrained`] method to load the
model weights.
dtype (`jax.numpy.dtype`, *optional*, defaults to `jax.numpy.float32`):
The data type of the computation. Can be one of `jax.numpy.float32`, `jax.numpy.float16` (on
GPUs) and `jax.numpy.bfloat16` (on TPUs).
This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If
specified all the computation will be performed with the given `dtype`.
**Note that this only specifies the dtype of the computation and does not influence the dtype of model
parameters.**
If you wish to change the dtype of the model parameters, see
[`~FlaxPreTrainedModel.to_fp16`] and [`~FlaxPreTrainedModel.to_bf16`].
"""
{{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING = r"""
Args:
input_ids (`numpy.ndarray` of shape `({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`~{{cookiecutter.uppercase_modelname}}ConfiTokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`numpy.ndarray` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`numpy.ndarray` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
position_ids (`numpy.ndarray` of shape `({0})`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0, config.max_position_embeddings - 1]`.
head_mask (`numpy.ndarray` of shape `({0})`, `optional): Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
remat = nn_partitioning.remat
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertEmbeddings with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Embeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.word_embeddings = nn.Embed(
self.config.vocab_size,
self.config.hidden_size,
embedding_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
)
self.position_embeddings = nn.Embed(
self.config.max_position_embeddings,
self.config.hidden_size,
embedding_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
)
self.token_type_embeddings = nn.Embed(
self.config.type_vocab_size,
self.config.hidden_size,
embedding_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
)
self.LayerNorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
def __call__(self, input_ids, token_type_ids, position_ids, attention_mask, deterministic: bool = True):
# Embed
inputs_embeds = self.word_embeddings(input_ids.astype("i4"))
position_embeds = self.position_embeddings(position_ids.astype("i4"))
token_type_embeddings = self.token_type_embeddings(token_type_ids.astype("i4"))
# Sum all embeddings
hidden_states = inputs_embeds + token_type_embeddings + position_embeds
# Layer Norm
hidden_states = self.LayerNorm(hidden_states)
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
return hidden_states
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertSelfAttention with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}SelfAttention(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
causal: bool = False
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.head_dim = self.config.hidden_size // self.config.num_attention_heads
if self.config.hidden_size % self.config.num_attention_heads != 0:
raise ValueError(
"`config.hidden_size`: {self.config.hidden_size} has to be a multiple of `config.num_attention_heads`\
: {self.config.num_attention_heads}"
)
self.query = nn.Dense(
self.config.hidden_size,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
)
self.key = nn.Dense(
self.config.hidden_size,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
)
self.value = nn.Dense(
self.config.hidden_size,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
)
if self.causal:
self.causal_mask = make_causal_mask(
jnp.ones((1, self.config.max_position_embeddings), dtype="bool"), dtype="bool"
)
def _split_heads(self, hidden_states):
return hidden_states.reshape(hidden_states.shape[:2] + (self.config.num_attention_heads, self.head_dim))
def _merge_heads(self, hidden_states):
return hidden_states.reshape(hidden_states.shape[:2] + (self.config.hidden_size,))
@nn.compact
# Copied from transformers.models.bart.modeling_flax_bart.FlaxBartAttention._concatenate_to_cache
def _concatenate_to_cache(self, key, value, query, attention_mask):
"""
This function takes projected key, value states from a single input token and concatenates the states to cached
states from previous steps. This function is slighly adapted from the official Flax repository:
https://github.com/google/flax/blob/491ce18759622506588784b4fca0e4bf05f8c8cd/flax/linen/attention.py#L252
"""
# detect if we're initializing by absence of existing cache data.
is_initialized = self.has_variable("cache", "cached_key")
cached_key = self.variable("cache", "cached_key", jnp.zeros, key.shape, key.dtype)
cached_value = self.variable("cache", "cached_value", jnp.zeros, value.shape, value.dtype)
cache_index = self.variable("cache", "cache_index", lambda: jnp.array(0, dtype=jnp.int32))
if is_initialized:
*batch_dims, max_length, num_heads, depth_per_head = cached_key.value.shape
# update key, value caches with our new 1d spatial slices
cur_index = cache_index.value
indices = (0,) * len(batch_dims) + (cur_index, 0, 0)
key = lax.dynamic_update_slice(cached_key.value, key, indices)
value = lax.dynamic_update_slice(cached_value.value, value, indices)
cached_key.value = key
cached_value.value = value
num_updated_cache_vectors = query.shape[1]
cache_index.value = cache_index.value + num_updated_cache_vectors
# causal mask for cached decoder self-attention: our single query position should only attend to those key positions that have already been generated and cached, not the remaining zero elements.
pad_mask = jnp.broadcast_to(
jnp.arange(max_length) < cur_index + num_updated_cache_vectors,
tuple(batch_dims) + (1, num_updated_cache_vectors, max_length),
)
attention_mask = combine_masks(pad_mask, attention_mask)
return key, value, attention_mask
def __call__(
self,
hidden_states,
attention_mask,
layer_head_mask,
key_value_states: Optional[jnp.ndarray] = None,
init_cache: bool = False,
deterministic=True,
output_attentions: bool = False,
):
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
batch_size = hidden_states.shape[0]
# get query proj
query_states = self.query(hidden_states)
# get key, value proj
if is_cross_attention:
# cross_attentions
key_states = self.key(key_value_states)
value_states = self.value(key_value_states)
else:
# self_attention
key_states = self.key(hidden_states)
value_states = self.value(hidden_states)
query_states = self._split_heads(query_states)
key_states = self._split_heads(key_states)
value_states = self._split_heads(value_states)
# handle cache prepare causal attention mask
if self.causal:
query_length, key_length = query_states.shape[1], key_states.shape[1]
if self.has_variable("cache", "cached_key"):
mask_shift = self.variables["cache"]["cache_index"]
max_decoder_length = self.variables["cache"]["cached_key"].shape[1]
causal_mask = lax.dynamic_slice(
self.causal_mask, (0, 0, mask_shift, 0), (1, 1, query_length, max_decoder_length)
)
else:
causal_mask = self.causal_mask[:, :, :query_length, :key_length]
causal_mask = jnp.broadcast_to(causal_mask, (batch_size,) + causal_mask.shape[1:])
# combine masks if needed
if attention_mask is not None and self.causal:
attention_mask = jnp.broadcast_to(jnp.expand_dims(attention_mask, axis=(-3, -2)), causal_mask.shape)
attention_mask = combine_masks(attention_mask, causal_mask)
elif self.causal:
attention_mask = causal_mask
elif attention_mask is not None:
attention_mask = jnp.expand_dims(attention_mask, axis=(-3, -2))
# During fast autoregressive decoding, we feed one position at a time,
# and cache the keys and values step by step.
if self.causal and (self.has_variable("cache", "cached_key") or init_cache):
key_states, value_states, attention_mask = self._concatenate_to_cache(
key_states, value_states, query_states, attention_mask
)
# Convert the boolean attention mask to an attention bias.
if attention_mask is not None:
# attention mask in the form of attention bias
attention_bias = lax.select(
attention_mask > 0,
jnp.full(attention_mask.shape, 0.0).astype(self.dtype),
jnp.full(attention_mask.shape, jnp.finfo(self.dtype).min).astype(self.dtype),
)
else:
attention_bias = None
dropout_rng = None
if not deterministic and self.config.attention_probs_dropout_prob > 0.0:
dropout_rng = self.make_rng("dropout")
attn_weights = dot_product_attention_weights(
query_states,
key_states,
bias=attention_bias,
dropout_rng=dropout_rng,
dropout_rate=self.config.attention_probs_dropout_prob,
broadcast_dropout=True,
deterministic=deterministic,
dtype=self.dtype,
precision=None,
)
# Mask heads if we want to
if layer_head_mask is not None:
attn_weights = jnp.einsum("...hqk,h->...hqk", attn_weights, layer_head_mask)
attn_output = jnp.einsum("...hqk,...khd->...qhd", attn_weights, value_states)
attn_output = attn_output.reshape(attn_output.shape[:2] + (-1,))
outputs = (attn_output, attn_weights) if output_attentions else (attn_output,)
return outputs
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertSelfOutput with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}SelfOutput(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.dense = nn.Dense(
self.config.hidden_size,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
dtype=self.dtype,
)
self.LayerNorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
def __call__(self, hidden_states, input_tensor, deterministic: bool = True):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertAttention with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Attention(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
causal: bool = False
dtype: jnp.dtype = jnp.float32
def setup(self):
self.self = Flax{{cookiecutter.camelcase_modelname}}SelfAttention(self.config, dtype=self.dtype)
self.output = Flax{{cookiecutter.camelcase_modelname}}SelfOutput(self.config, dtype=self.dtype)
def __call__(
self,
hidden_states,
attention_mask,
layer_head_mask,
key_value_states=None,
init_cache=False,
deterministic=True,
output_attentions: bool = False,
):
# Attention mask comes in as attention_mask.shape == (*batch_sizes, kv_length)
# FLAX expects: attention_mask.shape == (*batch_sizes, 1, 1, kv_length) such that it is broadcastable
# with attn_weights.shape == (*batch_sizes, num_heads, q_length, kv_length)
attn_outputs = self.self(
hidden_states,
attention_mask,
layer_head_mask=layer_head_mask,
key_value_states=key_value_states,
init_cache=init_cache,
deterministic=deterministic,
output_attentions=output_attentions,
)
attn_output = attn_outputs[0]
hidden_states = self.output(attn_output, hidden_states, deterministic=deterministic)
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_outputs[1],)
return outputs
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertIntermediate with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Intermediate(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.dense = nn.Dense(
self.config.intermediate_size,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
dtype=self.dtype,
)
self.activation = ACT2FN[self.config.hidden_act]
def __call__(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.activation(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertOutput with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Output(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.dense = nn.Dense(
self.config.hidden_size,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
dtype=self.dtype,
)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
self.LayerNorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
def __call__(self, hidden_states, attention_output, deterministic: bool = True):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
hidden_states = self.LayerNorm(hidden_states + attention_output)
return hidden_states
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertLayer with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Layer(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.attention = Flax{{cookiecutter.camelcase_modelname}}Attention(self.config, dtype=self.dtype)
self.intermediate = Flax{{cookiecutter.camelcase_modelname}}Intermediate(self.config, dtype=self.dtype)
self.output = Flax{{cookiecutter.camelcase_modelname}}Output(self.config, dtype=self.dtype)
if self.config.add_cross_attention:
self.crossattention = Flax{{cookiecutter.camelcase_modelname}}Attention(self.config, causal=False, dtype=self.dtype)
def __call__(
self,
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
deterministic: bool = True,
output_attentions: bool = False,
):
# Self Attention
attention_outputs = self.attention(
hidden_states,
attention_mask,
layer_head_mask=layer_head_mask,
init_cache=init_cache,
deterministic=deterministic,
output_attentions=output_attentions,
)
attention_output = attention_outputs[0]
# Cross-Attention Block
if encoder_hidden_states is not None:
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask=encoder_attention_mask,
layer_head_mask=layer_head_mask,
key_value_states=encoder_hidden_states,
deterministic=deterministic,
output_attentions=output_attentions,
)
attention_output = cross_attention_outputs[0]
hidden_states = self.intermediate(attention_output)
hidden_states = self.output(hidden_states, attention_output, deterministic=deterministic)
outputs = (hidden_states,)
if output_attentions:
outputs += (attention_outputs[1],)
if encoder_hidden_states is not None:
outputs += (cross_attention_outputs[1],)
return outputs
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertLayerCollection with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}LayerCollection(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
gradient_checkpointing: bool = False
def setup(self):
if self.gradient_checkpointing:
Flax{{cookiecutter.camelcase_modelname}}CheckpointLayer = remat(Flax{{cookiecutter.camelcase_modelname}}Layer, static_argnums=(5, 6, 7))
self.layers = [
Flax{{cookiecutter.camelcase_modelname}}CheckpointLayer(self.config, name=str(i), dtype=self.dtype)
for i in range(self.config.num_hidden_layers)
]
else:
self.layers = [
Flax{{cookiecutter.camelcase_modelname}}Layer(self.config, name=str(i), dtype=self.dtype) for i in range(self.config.num_hidden_layers)
]
def __call__(
self,
hidden_states,
attention_mask,
head_mask,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
all_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
# Check if head_mask has a correct number of layers specified if desired
if head_mask is not None:
if head_mask.shape[0] != (len(self.layers)):
raise ValueError(
f"The head_mask should be specified for {len(self.layers)} layers, but it is for \
{head_mask.shape[0]}."
)
for i, layer in enumerate(self.layers):
if output_hidden_states:
all_hidden_states += (hidden_states,)
layer_outputs = layer(
hidden_states,
attention_mask,
head_mask[i] if head_mask is not None else None,
encoder_hidden_states,
encoder_attention_mask,
init_cache,
deterministic,
output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions += (layer_outputs[1],)
if encoder_hidden_states is not None:
all_cross_attentions += (layer_outputs[2],)
if output_hidden_states:
all_hidden_states += (hidden_states,)
outputs = (hidden_states,)
if not return_dict:
return tuple(v for v in outputs if v is not None)
return FlaxBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
hidden_states=all_hidden_states,
attentions=all_attentions,
cross_attentions=all_cross_attentions,
)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertEncoder with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Encoder(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
gradient_checkpointing: bool = False
def setup(self):
self.layer = Flax{{cookiecutter.camelcase_modelname}}LayerCollection(self.config, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
def __call__(
self,
hidden_states,
attention_mask,
head_mask,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
return self.layer(
hidden_states,
attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
init_cache=init_cache,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPooler with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Pooler(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.dense = nn.Dense(
self.config.hidden_size,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
dtype=self.dtype,
)
def __call__(self, hidden_states):
cls_hidden_state = hidden_states[:, 0]
cls_hidden_state = self.dense(cls_hidden_state)
return nn.tanh(cls_hidden_state)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPredictionHeadTransform with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}PredictionHeadTransform(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
def setup(self):
self.dense = nn.Dense(self.config.hidden_size, dtype=self.dtype)
self.activation = ACT2FN[self.config.hidden_act]
self.LayerNorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
def __call__(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.activation(hidden_states)
return self.LayerNorm(hidden_states)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertLMPredictionHead with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}LMPredictionHead(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
bias_init: Callable[..., np.ndarray] = jax.nn.initializers.zeros
def setup(self):
self.transform = Flax{{cookiecutter.camelcase_modelname}}PredictionHeadTransform(self.config, dtype=self.dtype)
self.decoder = nn.Dense(self.config.vocab_size, dtype=self.dtype, use_bias=False)
self.bias = self.param("bias", self.bias_init, (self.config.vocab_size,))
def __call__(self, hidden_states, shared_embedding=None):
hidden_states = self.transform(hidden_states)
if shared_embedding is not None:
hidden_states = self.decoder.apply({"params": {"kernel": shared_embedding.T}}, hidden_states)
else:
hidden_states = self.decoder(hidden_states)
hidden_states += self.bias
return hidden_states
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertOnlyMLMHead with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}OnlyMLMHead(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
def setup(self):
self.predictions = Flax{{cookiecutter.camelcase_modelname}}LMPredictionHead(self.config, dtype=self.dtype)
def __call__(self, hidden_states, shared_embedding=None):
hidden_states = self.predictions(hidden_states, shared_embedding=shared_embedding)
return hidden_states
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertOnlyNSPHead with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}OnlyNSPHead(nn.Module):
dtype: jnp.dtype = jnp.float32
def setup(self):
self.seq_relationship = nn.Dense(2, dtype=self.dtype)
def __call__(self, pooled_output):
return self.seq_relationship(pooled_output)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPreTrainingHeads with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}PreTrainingHeads(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
def setup(self):
self.predictions = Flax{{cookiecutter.camelcase_modelname}}LMPredictionHead(self.config, dtype=self.dtype)
self.seq_relationship = nn.Dense(2, dtype=self.dtype)
def __call__(self, hidden_states, pooled_output, shared_embedding=None):
prediction_scores = self.predictions(hidden_states, shared_embedding=shared_embedding)
seq_relationship_score = self.seq_relationship(pooled_output)
return prediction_scores, seq_relationship_score
class Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel(FlaxPreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = {{cookiecutter.camelcase_modelname}}Config
base_model_prefix = "{{cookiecutter.lowercase_modelname}}"
module_class: nn.Module = None
def __init__(
self,
config: {{cookiecutter.camelcase_modelname}}Config,
input_shape: Tuple = (1, 1),
seed: int = 0,
dtype: jnp.dtype = jnp.float32,
_do_init: bool = True,
gradient_checkpointing: bool = False,
**kwargs
):
module = self.module_class(config=config, dtype=dtype, gradient_checkpointing=gradient_checkpointing, **kwargs)
super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype, _do_init=_do_init)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPreTrainedModel.enable_gradient_checkpointing
def enable_gradient_checkpointing(self):
self._module = self.module_class(
config=self.config,
dtype=self.dtype,
gradient_checkpointing=True,
)
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPreTrainedModel.init_weights with Bert->{{cookiecutter.camelcase_modelname}}
def init_weights(self, rng: jax.random.PRNGKey, input_shape: Tuple, params: FrozenDict = None) -> FrozenDict:
# init input tensors
input_ids = jnp.zeros(input_shape, dtype="i4")
token_type_ids = jnp.zeros_like(input_ids)
position_ids = jnp.broadcast_to(jnp.arange(jnp.atleast_2d(input_ids).shape[-1]), input_shape)
attention_mask = jnp.ones_like(input_ids)
head_mask = jnp.ones((self.config.num_hidden_layers, self.config.num_attention_heads))
params_rng, dropout_rng = jax.random.split(rng)
rngs = {"params": params_rng, "dropout": dropout_rng}
if self.config.add_cross_attention:
encoder_hidden_states = jnp.zeros(input_shape + (self.config.hidden_size,))
encoder_attention_mask = attention_mask
module_init_outputs = self.module.init(
rngs,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
return_dict=False,
)
else:
module_init_outputs = self.module.init(
rngs, input_ids, attention_mask, token_type_ids, position_ids, head_mask, return_dict=False
)
random_params = module_init_outputs["params"]
if params is not None:
random_params = flatten_dict(unfreeze(random_params))
params = flatten_dict(unfreeze(params))
for missing_key in self._missing_keys:
params[missing_key] = random_params[missing_key]
self._missing_keys = set()
return freeze(unflatten_dict(params))
else:
return random_params
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPreTrainedModel.init_cache with Bert->{{cookiecutter.camelcase_modelname}}
def init_cache(self, batch_size, max_length):
r"""
Args:
batch_size (`int`):
batch_size used for fast auto-regressive decoding. Defines the batch size of the initialized cache.
max_length (`int`):
maximum possible length for auto-regressive decoding. Defines the sequence length of the initialized
cache.
"""
# init input variables to retrieve cache
input_ids = jnp.ones((batch_size, max_length))
attention_mask = jnp.ones_like(input_ids)
position_ids = jnp.broadcast_to(jnp.arange(jnp.atleast_2d(input_ids).shape[-1]), input_ids.shape)
init_variables = self.module.init(
jax.random.PRNGKey(0), input_ids, attention_mask, position_ids, return_dict=False, init_cache=True
)
return unfreeze(init_variables["cache"])
@add_start_docstrings_to_model_forward({{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertPreTrainedModel.__call__ with Bert->{{cookiecutter.camelcase_modelname}}
def __call__(
self,
input_ids,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
params: dict = None,
dropout_rng: jax.random.PRNGKey = None,
train: bool = False,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
past_key_values: dict = None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
# init input tensors if not passed
if token_type_ids is None:
token_type_ids = jnp.zeros_like(input_ids)
if position_ids is None:
position_ids = jnp.broadcast_to(jnp.arange(jnp.atleast_2d(input_ids).shape[-1]), input_ids.shape)
if attention_mask is None:
attention_mask = jnp.ones_like(input_ids)
if head_mask is None:
head_mask = jnp.ones((self.config.num_hidden_layers, self.config.num_attention_heads))
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
rngs["dropout"] = dropout_rng
inputs = {"params": params or self.params}
if self.config.add_cross_attention:
# if past_key_values are passed then cache is already initialized a private flag init_cache has to be passed
# down to ensure cache is used. It has to be made sure that cache is marked as mutable so that it can be
# changed by FlaxBertAttention module
if past_key_values:
inputs["cache"] = past_key_values
mutable = ["cache"]
else:
mutable = False
outputs = self.module.apply(
inputs,
jnp.array(input_ids, dtype="i4"),
jnp.array(attention_mask, dtype="i4"),
token_type_ids=jnp.array(token_type_ids, dtype="i4"),
position_ids=jnp.array(position_ids, dtype="i4"),
head_mask=jnp.array(head_mask, dtype="i4"),
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
deterministic=not train,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
rngs=rngs,
mutable=mutable,
)
# add updated cache to model output
if past_key_values is not None and return_dict:
outputs, past_key_values = outputs
outputs["past_key_values"] = unfreeze(past_key_values["cache"])
return outputs
elif past_key_values is not None and not return_dict:
outputs, past_key_values = outputs
outputs = outputs[:1] + (unfreeze(past_key_values["cache"]),) + outputs[1:]
else:
outputs = self.module.apply(
inputs,
jnp.array(input_ids, dtype="i4"),
jnp.array(attention_mask, dtype="i4"),
token_type_ids=jnp.array(token_type_ids, dtype="i4"),
position_ids=jnp.array(position_ids, dtype="i4"),
head_mask=jnp.array(head_mask, dtype="i4"),
deterministic=not train,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
rngs=rngs,
)
return outputs
# Copied from transformers.models.bert.modeling_flax_bert.FlaxBertModule with Bert->{{cookiecutter.camelcase_modelname}}
class Flax{{cookiecutter.camelcase_modelname}}Module(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
add_pooling_layer: bool = True
gradient_checkpointing: bool = False
def setup(self):
self.embeddings = Flax{{cookiecutter.camelcase_modelname}}Embeddings(self.config, dtype=self.dtype)
self.encoder = Flax{{cookiecutter.camelcase_modelname}}Encoder(self.config, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
self.pooler = Flax{{cookiecutter.camelcase_modelname}}Pooler(self.config, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids: Optional[jnp.ndarray] = None,
position_ids: Optional[jnp.ndarray] = None,
head_mask: Optional[jnp.ndarray] = None,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# make sure `token_type_ids` is correctly initialized when not passed
if token_type_ids is None:
token_type_ids = jnp.zeros_like(input_ids)
# make sure `position_ids` is correctly initialized when not passed
if position_ids is None:
position_ids = jnp.broadcast_to(jnp.arange(jnp.atleast_2d(input_ids).shape[-1]), input_ids.shape)
hidden_states = self.embeddings(
input_ids, token_type_ids, position_ids, attention_mask, deterministic=deterministic
)
outputs = self.encoder(
hidden_states,
attention_mask,
head_mask=head_mask,
deterministic=deterministic,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
init_cache=init_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
pooled = self.pooler(hidden_states) if self.add_pooling_layer else None
if not return_dict:
# if pooled is None, don't return it
if pooled is None:
return (hidden_states,) + outputs[1:]
return (hidden_states, pooled) + outputs[1:]
return FlaxBaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=hidden_states,
pooler_output=pooled,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
add_start_docstrings(
"The bare {{cookiecutter.camelcase_modelname}} Model transformer outputting raw hidden-states without any specific head on top.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}Model(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}Module
class Flax{{cookiecutter.camelcase_modelname}}ForMaskedLMModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, add_pooling_layer=False, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
self.cls = Flax{{cookiecutter.camelcase_modelname}}OnlyMLMHead(config=self.config, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
if self.config.tie_word_embeddings:
shared_embedding = self.{{cookiecutter.lowercase_modelname}}.variables["params"]["embeddings"]["word_embeddings"]["embedding"]
else:
shared_embedding = None
# Compute the prediction scores
logits = self.cls(hidden_states, shared_embedding=shared_embedding)
if not return_dict:
return (logits,) + outputs[1:]
return FlaxCausalLMOutput(
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings("""{{cookiecutter.camelcase_modelname}} Model with a `language modeling` head on top for MLM training. """, {{cookiecutter.uppercase_modelname}}_START_DOCSTRING)
class Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForMaskedLMModule
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM, _TOKENIZER_FOR_DOC, _CHECKPOINT_FOR_DOC, FlaxMaskedLMOutput, _CONFIG_FOR_DOC
)
class Flax{{cookiecutter.camelcase_modelname}}ForCausalLMModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, add_pooling_layer=False, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
self.cls = Flax{{cookiecutter.camelcase_modelname}}OnlyMLMHead(config=self.config, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
if self.config.tie_word_embeddings:
shared_embedding = self.{{cookiecutter.lowercase_modelname}}.variables["params"]["embeddings"]["word_embeddings"]["embedding"]
else:
shared_embedding = None
# Compute the prediction scores
logits = self.cls(hidden_states, shared_embedding=shared_embedding)
if not return_dict:
return (logits,) + outputs[1:]
return FlaxCausalLMOutput(
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings("""{{cookiecutter.camelcase_modelname}} Model with a `language modeling` head on top for CLM training. """, {{cookiecutter.uppercase_modelname}}_START_DOCSTRING)
class Flax{{cookiecutter.camelcase_modelname}}ForCausalLM(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForCausalLMModule
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForCausalLM, _TOKENIZER_FOR_DOC, _CHECKPOINT_FOR_DOC, FlaxCausalLMOutput, _CONFIG_FOR_DOC
)
class Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassificationModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
self.classifier = nn.Dense(
self.config.num_labels,
dtype=self.dtype,
)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output, deterministic=deterministic)
logits = self.classifier(pooled_output)
if not return_dict:
return (logits,) + outputs[2:]
return FlaxSequenceClassifierOutput(
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled
output) e.g. for GLUE tasks.
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassificationModule
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
_TOKENIZER_FOR_DOC,
_CHECKPOINT_FOR_DOC,
FlaxSequenceClassifierOutput,
_CONFIG_FOR_DOC,
)
class Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoiceModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
self.classifier = nn.Dense(1, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
num_choices = input_ids.shape[1]
input_ids = input_ids.reshape(-1, input_ids.shape[-1]) if input_ids is not None else None
attention_mask = attention_mask.reshape(-1, attention_mask.shape[-1]) if attention_mask is not None else None
token_type_ids = token_type_ids.reshape(-1, token_type_ids.shape[-1]) if token_type_ids is not None else None
position_ids = position_ids.reshape(-1, position_ids.shape[-1]) if position_ids is not None else None
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output, deterministic=deterministic)
logits = self.classifier(pooled_output)
reshaped_logits = logits.reshape(-1, num_choices)
if not return_dict:
return (reshaped_logits,) + outputs[2:]
return FlaxMultipleChoiceModelOutput(
logits=reshaped_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} Model with a multiple choice classification head on top (a linear layer on top of the pooled output and a
softmax) e.g. for RocStories/SWAG tasks.
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoiceModule
overwrite_call_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice, {{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length")
)
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice, _TOKENIZER_FOR_DOC, _CHECKPOINT_FOR_DOC, FlaxMultipleChoiceModelOutput, _CONFIG_FOR_DOC
)
class Flax{{cookiecutter.camelcase_modelname}}ForTokenClassificationModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype, add_pooling_layer=False, gradient_checkpointing=self.gradient_checkpointing)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
self.classifier = nn.Dense(self.config.num_labels, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
logits = self.classifier(hidden_states)
if not return_dict:
return (logits,) + outputs[1:]
return FlaxTokenClassifierOutput(
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
Named-Entity-Recognition (NER) tasks.
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForTokenClassificationModule
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification, _TOKENIZER_FOR_DOC, _CHECKPOINT_FOR_DOC, FlaxTokenClassifierOutput, _CONFIG_FOR_DOC
)
class Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnsweringModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype, add_pooling_layer=False, gradient_checkpointing=self.gradient_checkpointing)
self.qa_outputs = nn.Dense(self.config.num_labels, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
logits = self.qa_outputs(hidden_states)
start_logits, end_logits = logits.split(self.config.num_labels, axis=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
if not return_dict:
return (start_logits, end_logits) + outputs[1:]
return FlaxQuestionAnsweringModelOutput(
start_logits=start_logits,
end_logits=end_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnsweringModule
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
_TOKENIZER_FOR_DOC,
_CHECKPOINT_FOR_DOC,
FlaxQuestionAnsweringModelOutput,
_CONFIG_FOR_DOC,
)
class Flax{{cookiecutter.camelcase_modelname}}ForCausalLMModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
gradient_checkpointing: bool = False
def setup(self):
self.{{cookiecutter.lowercase_modelname}} = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, add_pooling_layer=False, dtype=self.dtype, gradient_checkpointing=self.gradient_checkpointing)
self.cls = Flax{{cookiecutter.camelcase_modelname}}OnlyMLMHead(config=self.config, dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
position_ids,
token_type_ids: Optional[jnp.ndarray] = None,
head_mask: Optional[jnp.ndarray] = None,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# Model
outputs = self.{{cookiecutter.lowercase_modelname}}(
input_ids,
attention_mask,
token_type_ids,
position_ids,
head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
init_cache=init_cache,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
if self.config.tie_word_embeddings:
shared_embedding = self.{{cookiecutter.lowercase_modelname}}.variables["params"]["embeddings"]["word_embeddings"]["embedding"]
else:
shared_embedding = None
# Compute the prediction scores
logits = self.cls(hidden_states, shared_embedding=shared_embedding)
if not return_dict:
return (logits,) + outputs[1:]
return FlaxCausalLMOutputWithCrossAttentions(
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} Model with a language modeling head on top (a linear layer on top of the hidden-states output) e.g for
autoregressive tasks.
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForCausalLM(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForCausalLMModule
def prepare_inputs_for_generation(self, input_ids, max_length, attention_mask: Optional[jax.Array] = None):
# initializing the cache
batch_size, seq_length = input_ids.shape
past_key_values = self.init_cache(batch_size, max_length)
# Note that usually one would have to put 0's in the attention_mask for x > input_ids.shape[-1] and x < cache_length.
# But since the decoder uses a causal mask, those positions are masked anyway.
# Thus, we can create a single static attention_mask here, which is more efficient for compilation
extended_attention_mask = jnp.ones((batch_size, max_length), dtype="i4")
if attention_mask is not None:
position_ids = attention_mask.cumsum(axis=-1) - 1
extended_attention_mask = lax.dynamic_update_slice(extended_attention_mask, attention_mask, (0, 0))
else:
position_ids = jnp.broadcast_to(jnp.arange(seq_length, dtype="i4")[None, :], (batch_size, seq_length))
return {
"past_key_values": past_key_values,
"attention_mask": extended_attention_mask,
"position_ids": position_ids,
}
def update_inputs_for_generation(self, model_outputs, model_kwargs):
model_kwargs["past_key_values"] = model_outputs.past_key_values
model_kwargs["position_ids"] = model_kwargs["position_ids"][:, -1:] + 1
return model_kwargs
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForCausalLM,
_TOKENIZER_FOR_DOC,
_CHECKPOINT_FOR_DOC,
FlaxCausalLMOutputWithCrossAttentions,
_CONFIG_FOR_DOC,
)
{# encoder_decoder #}
{% else %}
import math
import random
from functools import partial
from typing import Callable, Optional, Tuple
import flax.linen as nn
import jax
import jax.numpy as jnp
from flax.core.frozen_dict import FrozenDict, unfreeze, freeze
from flax.linen import combine_masks, make_causal_mask
from flax.linen.attention import dot_product_attention_weights
from flax.traverse_util import flatten_dict, unflatten_dict
from jax import lax
from jax.random import PRNGKey
from ...utils import add_start_docstrings, replace_return_docstrings
from ...modeling_flax_outputs import (
FlaxBaseModelOutput,
FlaxBaseModelOutputWithPastAndCrossAttentions,
FlaxCausalLMOutputWithCrossAttentions,
FlaxSeq2SeqLMOutput,
FlaxSeq2SeqModelOutput,
FlaxSeq2SeqQuestionAnsweringModelOutput,
FlaxSeq2SeqSequenceClassifierOutput,
)
from ...modeling_flax_utils import (
ACT2FN,
FlaxPreTrainedModel,
append_call_sample_docstring,
append_replace_return_docstrings,
overwrite_call_docstring,
)
from ...utils import logging
from .configuration_{{cookiecutter.lowercase_modelname}} import {{cookiecutter.camelcase_modelname}}Config
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "{{cookiecutter.checkpoint_identifier}}"
_CONFIG_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Config"
_TOKENIZER_FOR_DOC = "{{cookiecutter.camelcase_modelname}}Tokenizer"
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING = r"""
This model inherits from [`FlaxPreTrainedModel`]. Check the superclass documentation for the
generic methods the library implements for all its model (such as downloading or saving, resizing the input
embeddings, pruning heads etc.)
This model is also a Flax Linen [flax.nn.Module](https://flax.readthedocs.io/en/latest/_autosummary/flax.nn.module.html) subclass. Use it as a regular Flax
Module and refer to the Flax documentation for all matter related to general usage and behavior.
Finally, this model supports inherent JAX features such as:
- [Just-In-Time (JIT) compilation](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
- [Automatic Differentiation](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
- [Vectorization](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
- [Parallelization](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
Parameters:
config ([`~{{cookiecutter.camelcase_modelname}}Config`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~FlaxPreTrainedModel.from_pretrained`] method to load the
model weights.
dtype (`jax.numpy.dtype`, *optional*, defaults to `jax.numpy.float32`):
The data type of the computation. Can be one of `jax.numpy.float32`, `jax.numpy.float16` (on
GPUs) and `jax.numpy.bfloat16` (on TPUs).
This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If
specified all the computation will be performed with the given `dtype`.
**Note that this only specifies the dtype of the computation and does not influence the dtype of model
parameters.**
If you wish to change the dtype of the model parameters, see
[`~FlaxPreTrainedModel.to_fp16`] and [`~FlaxPreTrainedModel.to_bf16`].
"""
{{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING = r"""
Args:
input_ids (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`jnp.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
decoder_input_ids (`jnp.ndarray` of shape `(batch_size, target_sequence_length)`, *optional*):
Indices of decoder input sequence tokens in the vocabulary.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are decoder input IDs?](../glossary#decoder-input-ids)
For translation and summarization training, `decoder_input_ids` should be provided. If no
`decoder_input_ids` is provided, the model will create this tensor by shifting the `input_ids` to
the right for denoising pre-training following the paper.
decoder_attention_mask (`jnp.ndarray` of shape `(batch_size, target_sequence_length)`, *optional*):
Default behavior: generate a tensor that ignores pad tokens in `decoder_input_ids`. Causal mask will
also be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0, config.max_position_embeddings - 1]`.
decoder_position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each decoder input sequence tokens in the position embeddings. Selected in the
range `[0, config.max_position_embeddings - 1]`.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
{{cookiecutter.uppercase_modelname}}_ENCODE_INPUTS_DOCSTRING = r"""
Args:
input_ids (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`jnp.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0, config.max_position_embeddings - 1]`.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
{{cookiecutter.uppercase_modelname}}_DECODE_INPUTS_DOCSTRING = r"""
Args:
decoder_input_ids (`jnp.ndarray` of shape `(batch_size, target_sequence_length)`):
Indices of decoder input sequence tokens in the vocabulary.
Indices can be obtained using [`~{{cookiecutter.camelcase_modelname}}Tokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for
details.
[What are decoder input IDs?](../glossary#decoder-input-ids)
For translation and summarization training, `decoder_input_ids` should be provided. If no
`decoder_input_ids` is provided, the model will create this tensor by shifting the `input_ids` to
the right for denoising pre-training following the paper.
encoder_outputs (`tuple(tuple(jnp.ndarray)`):
Tuple consists of (`last_hidden_state`, *optional*: `hidden_states`, *optional*:
`attentions`) `last_hidden_state` of shape `(batch_size, sequence_length, hidden_size)`,
*optional*) is a sequence of hidden-states at the output of the last layer of the encoder. Used in the
cross-attention of the decoder.
encoder_attention_mask (`jnp.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
decoder_attention_mask (`jnp.ndarray` of shape `(batch_size, target_sequence_length)`, *optional*):
Default behavior: generate a tensor that ignores pad tokens in `decoder_input_ids`. Causal mask will
also be used by default.
If you want to change padding behavior, you should modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
decoder_position_ids (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each decoder input sequence tokens in the position embeddings. Selected in the
range `[0, config.max_position_embeddings - 1]`.
past_key_values (`Dict[str, np.ndarray]`, *optional*, returned by `init_cache` or when passing previous `past_key_values`):
Dictionary of pre-computed hidden-states (key and values in the attention blocks) that can be used for fast
auto-regressive decoding. Pre-computed key and value hidden-states are of shape *[batch_size, max_length]*.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
def shift_tokens_right(input_ids: jnp.ndarray, pad_token_id: int, decoder_start_token_id: int) -> jnp.ndarray:
"""
Shift input ids one token to the right.
"""
shifted_input_ids = jnp.roll(input_ids, 1, axis=-1)
shifted_input_ids = shifted_input_ids.at[(..., 0)].set(decoder_start_token_id)
# replace possible -100 values in labels by `pad_token_id`
shifted_input_ids = jnp.where(shifted_input_ids == -100, pad_token_id, shifted_input_ids)
return shifted_input_ids
class Flax{{cookiecutter.camelcase_modelname}}Attention(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
embed_dim: int
num_heads: int
dropout: float = 0.0
causal: bool = False
bias: bool = True
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self) -> None:
self.head_dim = self.embed_dim // self.num_heads
assert (
self.head_dim * self.num_heads == self.embed_dim
), f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`: {self.num_heads})."
dense = partial(
nn.Dense,
self.embed_dim,
use_bias=self.bias,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.init_std),
)
self.q_proj, self.k_proj, self.v_proj = dense(), dense(), dense()
self.out_proj = dense()
self.dropout_layer = nn.Dropout(rate=self.dropout)
if self.causal:
self.causal_mask = make_causal_mask(
jnp.ones((1, self.config.max_position_embeddings), dtype="bool"), dtype="bool"
)
def _split_heads(self, hidden_states):
return hidden_states.reshape(hidden_states.shape[:2] + (self.num_heads, self.head_dim))
def _merge_heads(self, hidden_states):
return hidden_states.reshape(hidden_states.shape[:2] + (self.embed_dim,))
@nn.compact
def _concatenate_to_cache(self, key, value, query, attention_mask):
"""
This function takes projected key, value states from a single input token and concatenates the states to cached
states from previous steps. This function is slighly adapted from the official Flax repository:
https://github.com/google/flax/blob/491ce18759622506588784b4fca0e4bf05f8c8cd/flax/linen/attention.py#L252
"""
# detect if we're initializing by absence of existing cache data.
is_initialized = self.has_variable("cache", "cached_key")
cached_key = self.variable("cache", "cached_key", jnp.zeros, key.shape, key.dtype)
cached_value = self.variable("cache", "cached_value", jnp.zeros, value.shape, value.dtype)
cache_index = self.variable("cache", "cache_index", lambda: jnp.array(0, dtype=jnp.int32))
if is_initialized:
*batch_dims, max_length, num_heads, depth_per_head = cached_key.value.shape
# update key, value caches with our new 1d spatial slices
cur_index = cache_index.value
indices = (0,) * len(batch_dims) + (cur_index, 0, 0)
key = lax.dynamic_update_slice(cached_key.value, key, indices)
value = lax.dynamic_update_slice(cached_value.value, value, indices)
cached_key.value = key
cached_value.value = value
num_updated_cache_vectors = query.shape[1]
cache_index.value = cache_index.value + num_updated_cache_vectors
# causal mask for cached decoder self-attention: our single query position should only attend to those key positions that have already been generated and cached, not the remaining zero elements.
pad_mask = jnp.broadcast_to(
jnp.arange(max_length) < cur_index + num_updated_cache_vectors,
tuple(batch_dims) + (1, num_updated_cache_vectors, max_length),
)
attention_mask = combine_masks(pad_mask, attention_mask)
return key, value, attention_mask
def __call__(
self,
hidden_states: jnp.ndarray,
key_value_states: Optional[jnp.ndarray] = None,
attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
deterministic: bool = True,
) -> Tuple[jnp.ndarray]:
"""Input shape: Batch x Time x Channel"""
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
batch_size = hidden_states.shape[0]
# get query proj
query_states = self.q_proj(hidden_states)
# get key, value proj
if is_cross_attention:
# cross_attentions
key_states = self.k_proj(key_value_states)
value_states = self.v_proj(key_value_states)
else:
# self_attention
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
query_states = self._split_heads(query_states)
key_states = self._split_heads(key_states)
value_states = self._split_heads(value_states)
# handle cache prepare causal attention mask
if self.causal:
query_length, key_length = query_states.shape[1], key_states.shape[1]
if self.has_variable("cache", "cached_key"):
mask_shift = self.variables["cache"]["cache_index"]
max_decoder_length = self.variables["cache"]["cached_key"].shape[1]
causal_mask = lax.dynamic_slice(
self.causal_mask, (0, 0, mask_shift, 0), (1, 1, query_length, max_decoder_length)
)
else:
causal_mask = self.causal_mask[:, :, :query_length, :key_length]
causal_mask = jnp.broadcast_to(causal_mask, (batch_size,) + causal_mask.shape[1:])
# combine masks if needed
if attention_mask is not None and self.causal:
attention_mask = jnp.broadcast_to(jnp.expand_dims(attention_mask, axis=(-3, -2)), causal_mask.shape)
attention_mask = combine_masks(attention_mask, causal_mask)
elif self.causal:
attention_mask = causal_mask
elif attention_mask is not None:
attention_mask = jnp.expand_dims(attention_mask, axis=(-3, -2))
# During fast autoregressive decoding, we feed one position at a time,
# and cache the keys and values step by step.
if self.causal and (self.has_variable("cache", "cached_key") or init_cache):
key_states, value_states, attention_mask = self._concatenate_to_cache(
key_states, value_states, query_states, attention_mask
)
# Convert the boolean attention mask to an attention bias.
if attention_mask is not None:
# attention mask in the form of attention bias
attention_bias = lax.select(
attention_mask > 0,
jnp.full(attention_mask.shape, 0.0).astype(self.dtype),
jnp.full(attention_mask.shape, jnp.finfo(self.dtype).min).astype(self.dtype),
)
else:
attention_bias = None
dropout_rng = None
if not deterministic and self.dropout > 0.0:
dropout_rng = self.make_rng("dropout")
attn_weights = dot_product_attention_weights(
query_states,
key_states,
bias=attention_bias,
dropout_rng=dropout_rng,
dropout_rate=self.dropout,
broadcast_dropout=True,
deterministic=deterministic,
dtype=self.dtype,
precision=None,
)
attn_output = jnp.einsum("...hqk,...khd->...qhd", attn_weights, value_states)
attn_output = self._merge_heads(attn_output)
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights
class Flax{{cookiecutter.camelcase_modelname}}EncoderLayer(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
def setup(self) -> None:
self.embed_dim = self.config.d_model
self.self_attn = Flax{{cookiecutter.camelcase_modelname}}Attention(
config=self.config,
embed_dim=self.embed_dim,
num_heads=self.config.encoder_attention_heads,
dropout=self.config.attention_dropout,
dtype=self.dtype
)
self.self_attn_layer_norm = nn.LayerNorm(dtype=self.dtype)
self.dropout_layer = nn.Dropout(rate=self.config.dropout)
self.activation_fn = ACT2FN[self.config.activation_function]
self.activation_dropout_layer = nn.Dropout(rate=self.config.activation_dropout)
self.fc1 = nn.Dense(
self.config.encoder_ffn_dim,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.init_std),
)
self.fc2 = nn.Dense(
self.embed_dim, dtype=self.dtype, kernel_init=jax.nn.initializers.normal(self.config.init_std)
)
self.final_layer_norm = nn.LayerNorm(dtype=self.dtype)
def __call__(
self,
hidden_states: jnp.ndarray,
attention_mask: jnp.ndarray,
output_attentions: bool = True,
deterministic: bool = True,
) -> Tuple[jnp.ndarray]:
residual = hidden_states
hidden_states, attn_weights = self.self_attn(hidden_states=hidden_states, attention_mask=attention_mask)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = self.activation_dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = self.fc2(hidden_states)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
return outputs
class Flax{{cookiecutter.camelcase_modelname}}EncoderLayerCollection(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.layers = [
Flax{{cookiecutter.camelcase_modelname}}EncoderLayer(self.config, name=str(i), dtype=self.dtype) for i in range(self.config.encoder_layers)
]
self.layerdrop = self.config.encoder_layerdrop
def __call__(
self,
hidden_states,
attention_mask,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
all_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
for encoder_layer in self.layers:
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop): # skip the layer
layer_outputs = (None, None)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
output_attentions,
deterministic,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if output_hidden_states:
all_hidden_states += (hidden_states,)
outputs = (hidden_states, all_hidden_states, all_attentions)
if not return_dict:
return tuple(v for v in outputs if v is not None)
return FlaxBaseModelOutput(
last_hidden_state=hidden_states, hidden_states=all_hidden_states, attentions=all_attentions
)
class Flax{{cookiecutter.camelcase_modelname}}DecoderLayer(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
def setup(self) -> None:
self.embed_dim = self.config.d_model
self.self_attn = Flax{{cookiecutter.camelcase_modelname}}Attention(
config=self.config,
embed_dim=self.embed_dim,
num_heads=self.config.decoder_attention_heads,
dropout=self.config.attention_dropout,
causal=True,
dtype=self.dtype,
)
self.dropout_layer = nn.Dropout(rate=self.config.dropout)
self.activation_fn = ACT2FN[self.config.activation_function]
self.activation_dropout_layer = nn.Dropout(rate=self.config.activation_dropout)
self.self_attn_layer_norm = nn.LayerNorm(dtype=self.dtype)
self.encoder_attn = Flax{{cookiecutter.camelcase_modelname}}Attention(
config=self.config,
embed_dim=self.embed_dim,
num_heads=self.config.decoder_attention_heads,
dropout=self.config.attention_dropout,
dtype=self.dtype,
)
self.encoder_attn_layer_norm = nn.LayerNorm(dtype=self.dtype)
self.fc1 = nn.Dense(
self.config.decoder_ffn_dim,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.init_std),
)
self.fc2 = nn.Dense(
self.embed_dim, dtype=self.dtype, kernel_init=jax.nn.initializers.normal(self.config.init_std)
)
self.final_layer_norm = nn.LayerNorm(dtype=self.dtype)
def __call__(
self,
hidden_states: jnp.ndarray,
attention_mask: jnp.ndarray,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
output_attentions: bool = True,
deterministic: bool = True,
) -> Tuple[jnp.ndarray]:
residual = hidden_states
# Self Attention
hidden_states, self_attn_weights = self.self_attn(
hidden_states=hidden_states, attention_mask=attention_mask, init_cache=init_cache
)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
# Cross-Attention Block
cross_attn_weights = None
if encoder_hidden_states is not None:
residual = hidden_states
hidden_states, cross_attn_weights = self.encoder_attn(
hidden_states=hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = residual + hidden_states
hidden_states = self.encoder_attn_layer_norm(hidden_states)
# Fully Connected
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = self.activation_dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = self.fc2(hidden_states)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights, cross_attn_weights)
return outputs
class Flax{{cookiecutter.camelcase_modelname}}DecoderLayerCollection(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.layers = [
Flax{{cookiecutter.camelcase_modelname}}DecoderLayer(self.config, name=str(i), dtype=self.dtype) for i in range(self.config.decoder_layers)
]
self.layerdrop = self.config.decoder_layerdrop
def __call__(
self,
hidden_states,
attention_mask,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
deterministic: bool = True,
init_cache: bool = False,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
# decoder layers
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
for decoder_layer in self.layers:
if output_hidden_states:
all_hidden_states += (hidden_states,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = random.uniform(0, 1)
if not deterministic and (dropout_probability < self.layerdrop):
layer_outputs = (None, None, None)
else:
layer_outputs = decoder_layer(
hidden_states,
attention_mask=attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
init_cache=init_cache,
output_attentions=output_attentions,
deterministic=deterministic,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_self_attns += (layer_outputs[1],)
if encoder_hidden_states is not None:
all_cross_attentions += (layer_outputs[2],)
# add hidden states from the last decoder layer
if output_hidden_states:
all_hidden_states += (hidden_states,)
outputs = [hidden_states, all_hidden_states, all_self_attns, all_cross_attentions]
if not return_dict:
return tuple(v for v in outputs if v is not None)
return FlaxBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
hidden_states=all_hidden_states,
attentions=all_self_attns,
cross_attentions=all_cross_attentions,
)
class Flax{{cookiecutter.camelcase_modelname}}ClassificationHead(nn.Module):
"""Head for sentence-level classification tasks."""
config: {{cookiecutter.camelcase_modelname}}Config
inner_dim: int
num_classes: int
pooler_dropout: float
dtype: jnp.dtype = jnp.float32
def setup(self):
self.dense = nn.Dense(
self.inner_dim, dtype=self.dtype, kernel_init=jax.nn.initializers.normal(self.config.init_std)
)
self.dropout = nn.Dropout(rate=self.pooler_dropout)
self.out_proj = nn.Dense(
self.num_classes,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.init_std),
)
def __call__(self, hidden_states: jnp.ndarray, deterministic: bool):
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
hidden_states = self.dense(hidden_states)
hidden_states = jnp.tanh(hidden_states)
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
hidden_states = self.out_proj(hidden_states)
return hidden_states
class Flax{{cookiecutter.camelcase_modelname}}Encoder(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
embed_tokens: Optional[nn.Embed] = None
def setup(self):
self.dropout_layer = nn.Dropout(rate=self.config.dropout)
embed_dim = self.config.d_model
self.padding_idx = self.config.pad_token_id
self.max_source_positions = self.config.max_position_embeddings
self.embed_scale = math.sqrt(embed_dim) if self.config.scale_embedding else 1.0
if self.embed_tokens is None:
self.embed_tokens = nn.Embed(
self.config.vocab_size,
embed_dim,
embedding_init=jax.nn.initializers.normal(self.config.init_std),
)
# {{cookiecutter.camelcase_modelname}} is set up so that if padding_idx is specified then offset the embedding ids by 2
# and adjust num_embeddings appropriately. Other models don't have this hack
self.offset = 2
self.embed_positions = nn.Embed(
self.config.max_position_embeddings + self.offset,
embed_dim,
embedding_init=jax.nn.initializers.normal(self.config.init_std),
)
self.layers = Flax{{cookiecutter.camelcase_modelname}}EncoderLayerCollection(self.config, self.dtype)
self.layernorm_embedding = nn.LayerNorm(dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
position_ids,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
deterministic: bool = True,
):
input_shape = input_ids.shape
input_ids = input_ids.reshape(-1, input_shape[-1])
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
embed_pos = self.embed_positions(position_ids + self.offset)
hidden_states = inputs_embeds + embed_pos
hidden_states = self.layernorm_embedding(hidden_states)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
outputs = self.layers(
hidden_states,
attention_mask,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
if not return_dict:
return outputs
return FlaxBaseModelOutput(
last_hidden_state=outputs.last_hidden_state,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
class Flax{{cookiecutter.camelcase_modelname}}Decoder(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
embed_tokens: Optional[nn.Embed] = None
def setup(self):
self.dropout_layer = nn.Dropout(rate=self.config.dropout)
embed_dim = self.config.d_model
self.padding_idx = self.config.pad_token_id
self.max_target_positions = self.config.max_position_embeddings
self.embed_scale = math.sqrt(self.config.d_model) if self.config.scale_embedding else 1.0
if self.embed_tokens is None:
self.embed_tokens = nn.Embed(
self.config.vocab_size,
embed_dim,
embedding_init=jax.nn.initializers.normal(self.config.init_std),
)
# {{cookiecutter.camelcase_modelname}} is set up so that if padding_idx is specified then offset the embedding ids by 2
# and adjust num_embeddings appropriately. Other models don't have this hack
self.offset = 2
self.embed_positions = nn.Embed(
self.config.max_position_embeddings + self.offset,
embed_dim,
embedding_init=jax.nn.initializers.normal(self.config.init_std),
)
self.layers = Flax{{cookiecutter.camelcase_modelname}}DecoderLayerCollection(self.config, self.dtype)
self.layernorm_embedding = nn.LayerNorm(dtype=self.dtype)
def __call__(
self,
input_ids,
attention_mask,
position_ids,
encoder_hidden_states: Optional[jnp.ndarray] = None,
encoder_attention_mask: Optional[jnp.ndarray] = None,
init_cache: bool = False,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
deterministic: bool = True,
):
input_shape = input_ids.shape
input_ids = input_ids.reshape(-1, input_shape[-1])
inputs_embeds = self.embed_tokens(input_ids) * self.embed_scale
# embed positions
positions = self.embed_positions(position_ids + self.offset)
hidden_states = inputs_embeds + positions
hidden_states = self.layernorm_embedding(hidden_states)
hidden_states = self.dropout_layer(hidden_states, deterministic=deterministic)
outputs = self.layers(
hidden_states,
attention_mask,
encoder_hidden_states,
encoder_attention_mask,
deterministic=deterministic,
init_cache=init_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
if not return_dict:
return outputs
return FlaxBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=outputs.last_hidden_state,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
class Flax{{cookiecutter.camelcase_modelname}}Module(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.shared = nn.Embed(
self.config.vocab_size,
self.config.d_model,
embedding_init=jax.nn.initializers.normal(self.config.init_std),
)
self.encoder = Flax{{cookiecutter.camelcase_modelname}}Encoder(self.config, dtype=self.dtype, embed_tokens=self.shared)
self.decoder = Flax{{cookiecutter.camelcase_modelname}}Decoder(self.config, dtype=self.dtype, embed_tokens=self.shared)
def _get_encoder_module(self):
return self.encoder
def _get_decoder_module(self):
return self.decoder
def __call__(
self,
input_ids,
attention_mask,
decoder_input_ids,
decoder_attention_mask,
position_ids,
decoder_position_ids,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
deterministic: bool = True,
):
encoder_outputs = self.encoder(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=deterministic,
)
decoder_outputs = self.decoder(
input_ids=decoder_input_ids,
attention_mask=decoder_attention_mask,
position_ids=decoder_position_ids,
encoder_hidden_states=encoder_outputs[0],
encoder_attention_mask=attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=deterministic,
)
if not return_dict:
return decoder_outputs + encoder_outputs
return FlaxSeq2SeqModelOutput(
last_hidden_state=decoder_outputs.last_hidden_state,
decoder_hidden_states=decoder_outputs.hidden_states,
decoder_attentions=decoder_outputs.attentions,
cross_attentions=decoder_outputs.cross_attentions,
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
encoder_hidden_states=encoder_outputs.hidden_states,
encoder_attentions=encoder_outputs.attentions,
)
class Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel(FlaxPreTrainedModel):
config_class = {{cookiecutter.camelcase_modelname}}Config
base_model_prefix: str = "model"
module_class: nn.Module = None
def __init__(
self,
config: {{cookiecutter.camelcase_modelname}}Config,
input_shape: Tuple[int] = (1, 1),
seed: int = 0,
dtype: jnp.dtype = jnp.float32,
_do_init: bool = True,
**kwargs
):
module = self.module_class(config=config, dtype=dtype, **kwargs)
super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype, _do_init=_do_init)
def init_weights(self, rng: jax.random.PRNGKey, input_shape: Tuple, params: FrozenDict = None) -> FrozenDict:
# init input tensors
input_ids = jnp.zeros(input_shape, dtype="i4")
# make sure initialization pass will work for Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassificationModule
input_ids = input_ids.at[(..., -1)].set(self.config.eos_token_id)
attention_mask = jnp.ones_like(input_ids)
decoder_input_ids = input_ids
decoder_attention_mask = jnp.ones_like(input_ids)
batch_size, sequence_length = input_ids.shape
position_ids = jnp.broadcast_to(jnp.arange(sequence_length)[None, :], (batch_size, sequence_length))
decoder_position_ids = jnp.broadcast_to(jnp.arange(sequence_length)[None, :], (batch_size, sequence_length))
params_rng, dropout_rng = jax.random.split(rng)
rngs = {"params": params_rng, "dropout": dropout_rng}
random_params = self.module.init(
rngs,
input_ids,
attention_mask,
decoder_input_ids,
decoder_attention_mask,
position_ids,
decoder_position_ids,
)["params"]
if params is not None:
random_params = flatten_dict(unfreeze(random_params))
params = flatten_dict(unfreeze(params))
for missing_key in self._missing_keys:
params[missing_key] = random_params[missing_key]
self._missing_keys = set()
return freeze(unflatten_dict(params))
else:
return random_params
def init_cache(self, batch_size, max_length, encoder_outputs):
r"""
Args:
batch_size (`int`):
batch_size used for fast auto-regressive decoding. Defines the batch size of the initialized cache.
max_length (`int`):
maximum possible length for auto-regressive decoding. Defines the sequence length of the initialized
cache.
encoder_outputs (`Union[FlaxBaseModelOutput, tuple(tuple(jnp.ndarray)]`):
`encoder_outputs` consists of (`last_hidden_state`, *optional*: `hidden_states`,
*optional*: `attentions`). `last_hidden_state` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) is a sequence of hidden-states at the output of the last layer of the
encoder. Used in the cross-attention of the decoder.
"""
# init input variables to retrieve cache
decoder_input_ids = jnp.ones((batch_size, max_length), dtype="i4")
decoder_attention_mask = jnp.ones_like(decoder_input_ids)
decoder_position_ids = jnp.broadcast_to(
jnp.arange(jnp.atleast_2d(decoder_input_ids).shape[-1]), decoder_input_ids.shape
)
def _decoder_forward(module, decoder_input_ids, decoder_attention_mask, decoder_position_ids, **kwargs):
decoder_module = module._get_decoder_module()
return decoder_module(
decoder_input_ids,
decoder_attention_mask,
decoder_position_ids,
**kwargs,
)
init_variables = self.module.init(
jax.random.PRNGKey(0),
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
decoder_position_ids=decoder_position_ids,
encoder_hidden_states=encoder_outputs[0],
init_cache=True,
method=_decoder_forward, # we only need to call the decoder to init the cache
)
return unfreeze(init_variables["cache"])
@add_start_docstrings({{cookiecutter.uppercase_modelname}}_ENCODE_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=FlaxBaseModelOutput, config_class={{cookiecutter.camelcase_modelname}}Config)
def encode(
self,
input_ids: jnp.ndarray,
attention_mask: Optional[jnp.ndarray] = None,
position_ids: Optional[jnp.ndarray] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
train: bool = False,
params: dict = None,
dropout_rng: PRNGKey = None,
):
r"""
Returns:
Example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> model = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> text = "My friends are cool but they eat too many carbs."
>>> inputs = tokenizer(text, max_length=1024, return_tensors='np')
>>> encoder_outputs = model.encode(**inputs)
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
if attention_mask is None:
attention_mask = jnp.ones_like(input_ids)
if position_ids is None:
batch_size, sequence_length = input_ids.shape
position_ids = jnp.broadcast_to(jnp.arange(sequence_length)[None, :], (batch_size, sequence_length))
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
rngs["dropout"] = dropout_rng
def _encoder_forward(module, input_ids, attention_mask, position_ids, **kwargs):
encode_module = module._get_encoder_module()
return encode_module(input_ids, attention_mask, position_ids, **kwargs)
return self.module.apply(
{"params": params or self.params},
input_ids=jnp.array(input_ids, dtype="i4"),
attention_mask=jnp.array(attention_mask, dtype="i4"),
position_ids=jnp.array(position_ids, dtype="i4"),
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=not train,
rngs=rngs,
method=_encoder_forward,
)
@add_start_docstrings({{cookiecutter.uppercase_modelname}}_DECODE_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=FlaxBaseModelOutputWithPastAndCrossAttentions, config_class={{cookiecutter.camelcase_modelname}}Config)
def decode(
self,
decoder_input_ids,
encoder_outputs,
encoder_attention_mask: Optional[jnp.ndarray] = None,
decoder_attention_mask: Optional[jnp.ndarray] = None,
decoder_position_ids: Optional[jnp.ndarray] = None,
past_key_values: dict = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
train: bool = False,
params: dict = None,
dropout_rng: PRNGKey = None,
):
r"""
Returns:
Example:
```python
>>> import jax.numpy as jnp
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> model = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> text = "My friends are cool but they eat too many carbs."
>>> inputs = tokenizer(text, max_length=1024, return_tensors='np')
>>> encoder_outputs = model.encode(**inputs)
>>> decoder_start_token_id = model.config.decoder_start_token_id
>>> decoder_input_ids = jnp.ones((inputs.input_ids.shape[0], 1), dtype="i4") * decoder_start_token_id
>>> outputs = model.decode(decoder_input_ids, encoder_outputs)
>>> last_decoder_hidden_states = outputs.last_hidden_state
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
encoder_hidden_states = encoder_outputs[0]
if encoder_attention_mask is None:
batch_size, sequence_length = encoder_hidden_states.shape[:2]
encoder_attention_mask = jnp.ones((batch_size, sequence_length))
batch_size, sequence_length = decoder_input_ids.shape
if decoder_attention_mask is None:
decoder_attention_mask = jnp.ones((batch_size, sequence_length))
if decoder_position_ids is None:
if past_key_values is not None:
raise ValueError("Make sure to provide `decoder_position_ids` when passing `past_key_values`.")
decoder_position_ids = jnp.broadcast_to(
jnp.arange(sequence_length)[None, :], (batch_size, sequence_length)
)
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
rngs["dropout"] = dropout_rng
inputs = {"params": params or self.params}
# if past_key_values are passed then cache is already initialized a private flag init_cache has to be
# passed down to ensure cache is used. It has to be made sure that cache is marked as mutable so that
# it can be changed by Flax{{cookiecutter.camelcase_modelname}}Attention module
if past_key_values:
inputs["cache"] = past_key_values
mutable = ["cache"]
else:
mutable = False
def _decoder_forward(module, decoder_input_ids, decoder_attention_mask, decoder_position_ids, **kwargs):
decoder_module = module._get_decoder_module()
return decoder_module(
decoder_input_ids,
decoder_attention_mask,
decoder_position_ids,
**kwargs,
)
outputs = self.module.apply(
inputs,
decoder_input_ids=jnp.array(decoder_input_ids, dtype="i4"),
decoder_attention_mask=jnp.array(decoder_attention_mask, dtype="i4"),
decoder_position_ids=jnp.array(decoder_position_ids, dtype="i4"),
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=jnp.array(encoder_attention_mask, dtype="i4"),
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=not train,
rngs=rngs,
mutable=mutable,
method=_decoder_forward,
)
# add updated cache to model output
if past_key_values is not None and return_dict:
outputs, past = outputs
outputs["past_key_values"] = unfreeze(past["cache"])
return outputs
elif past_key_values is not None and not return_dict:
outputs, past = outputs
outputs = outputs[:1] + (unfreeze(past["cache"]),) + outputs[1:]
return outputs
def __call__(
self,
input_ids: jnp.ndarray,
attention_mask: Optional[jnp.ndarray] = None,
decoder_input_ids: Optional[jnp.ndarray] = None,
decoder_attention_mask: Optional[jnp.ndarray] = None,
position_ids: Optional[jnp.ndarray] = None,
decoder_position_ids: Optional[jnp.ndarray] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
train: bool = False,
params: dict = None,
dropout_rng: PRNGKey = None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
# prepare encoder inputs
if attention_mask is None:
attention_mask = jnp.ones_like(input_ids)
if position_ids is None:
batch_size, sequence_length = input_ids.shape
position_ids = jnp.broadcast_to(jnp.arange(sequence_length)[None, :], (batch_size, sequence_length))
# prepare decoder inputs
if decoder_input_ids is None:
decoder_input_ids = shift_tokens_right(
input_ids, self.config.pad_token_id, decoder_start_token_id=self.config.decoder_start_token_id
)
if decoder_attention_mask is None:
decoder_attention_mask = jnp.ones_like(decoder_input_ids)
if decoder_position_ids is None:
batch_size, sequence_length = decoder_input_ids.shape
decoder_position_ids = jnp.broadcast_to(
jnp.arange(sequence_length)[None, :], (batch_size, sequence_length)
)
# Handle any PRNG if needed
rngs = {"dropout": dropout_rng} if dropout_rng is not None else {}
return self.module.apply(
{"params": params or self.params},
input_ids=jnp.array(input_ids, dtype="i4"),
attention_mask=jnp.array(attention_mask, dtype="i4"),
position_ids=jnp.array(position_ids, dtype="i4"),
decoder_input_ids=jnp.array(decoder_input_ids, dtype="i4"),
decoder_attention_mask=jnp.array(decoder_attention_mask, dtype="i4"),
decoder_position_ids=jnp.array(decoder_position_ids, dtype="i4"),
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=not train,
rngs=rngs,
)
@add_start_docstrings(
"The bare {{cookiecutter.camelcase_modelname}} Model transformer outputting raw hidden-states without any specific head on top.",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}Model(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
module_class = Flax{{cookiecutter.camelcase_modelname}}Module
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}Model, _TOKENIZER_FOR_DOC, _CHECKPOINT_FOR_DOC, FlaxSeq2SeqModelOutput, _CONFIG_FOR_DOC
)
class Flax{{cookiecutter.camelcase_modelname}}ForConditionalGenerationModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
bias_init: Callable[..., jnp.ndarray] = jax.nn.initializers.zeros
def setup(self):
self.model = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype)
self.lm_head = nn.Dense(
self.model.shared.num_embeddings,
use_bias=False,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.init_std),
)
self.final_logits_bias = self.param("final_logits_bias", self.bias_init, (1, self.model.shared.num_embeddings))
def _get_encoder_module(self):
return self.model.encoder
def _get_decoder_module(self):
return self.model.decoder
def __call__(
self,
input_ids,
attention_mask,
decoder_input_ids,
decoder_attention_mask,
position_ids,
decoder_position_ids,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
deterministic: bool = True,
):
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
position_ids=position_ids,
decoder_position_ids=decoder_position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=deterministic,
)
hidden_states = outputs[0]
if self.config.tie_word_embeddings:
shared_embedding = self.model.variables["params"]["shared"]["embedding"]
lm_logits = self.lm_head.apply({"params": {"kernel": shared_embedding.T}}, hidden_states)
else:
lm_logits = self.lm_head(hidden_states)
lm_logits += self.final_logits_bias.astype(self.dtype)
if not return_dict:
output = (lm_logits,) + outputs[1:]
return output
return FlaxSeq2SeqLMOutput(
logits=lm_logits,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
@add_start_docstrings(
"The {{cookiecutter.uppercase_modelname}} Model with a language modeling head. Can be used for summarization.", {{cookiecutter.uppercase_modelname}}_START_DOCSTRING
)
class Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGenerationModule
dtype: jnp.dtype = jnp.float32
@add_start_docstrings({{cookiecutter.uppercase_modelname}}_DECODE_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=FlaxCausalLMOutputWithCrossAttentions, config_class={{cookiecutter.camelcase_modelname}}Config)
def decode(
self,
decoder_input_ids,
encoder_outputs,
encoder_attention_mask: Optional[jnp.ndarray] = None,
decoder_attention_mask: Optional[jnp.ndarray] = None,
decoder_position_ids: Optional[jnp.ndarray] = None,
past_key_values: dict = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
deterministic: bool = True,
params: dict = None,
dropout_rng: PRNGKey = None,
):
r"""
Returns:
Example:
```python
>>> import jax.numpy as jnp
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> model = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> text = "My friends are cool but they eat too many carbs."
>>> inputs = tokenizer(text, max_length=1024, return_tensors='np')
>>> encoder_outputs = model.encode(**inputs)
>>> decoder_start_token_id = model.config.decoder_start_token_id
>>> decoder_input_ids = jnp.ones((inputs.input_ids.shape[0], 1), dtype="i4") * decoder_start_token_id
>>> outputs = model.decode(decoder_input_ids, encoder_outputs)
>>> logits = outputs.logits
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
encoder_hidden_states = encoder_outputs[0]
if encoder_attention_mask is None:
batch_size, sequence_length = encoder_hidden_states.shape[:2]
encoder_attention_mask = jnp.ones((batch_size, sequence_length))
batch_size, sequence_length = decoder_input_ids.shape
if decoder_attention_mask is None:
decoder_attention_mask = jnp.ones((batch_size, sequence_length))
if decoder_position_ids is None:
if past_key_values is not None:
raise ValueError("Make sure to provide `decoder_position_ids` when passing `past_key_values`.")
decoder_position_ids = jnp.broadcast_to(
jnp.arange(sequence_length)[None, :], (batch_size, sequence_length)
)
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
rngs["dropout"] = dropout_rng
inputs = {"params": params or self.params}
# if past_key_values are passed then cache is already initialized a private flag init_cache has to be
# passed down to ensure cache is used. It has to be made sure that cache is marked as mutable so that
# it can be changed by Flax{{cookiecutter.camelcase_modelname}}Attention module
if past_key_values:
inputs["cache"] = past_key_values
mutable = ["cache"]
else:
mutable = False
def _decoder_forward(module, decoder_input_ids, decoder_attention_mask, decoder_position_ids, **kwargs):
decoder_module = module._get_decoder_module()
outputs = decoder_module(
decoder_input_ids,
decoder_attention_mask,
decoder_position_ids,
**kwargs,
)
hidden_states = outputs[0]
if self.config.tie_word_embeddings:
shared_embedding = module.model.variables["params"]["shared"]["embedding"]
lm_logits = module.lm_head.apply({"params": {"kernel": shared_embedding.T}}, hidden_states)
else:
lm_logits = module.lm_head(hidden_states)
lm_logits += module.final_logits_bias.astype(self.dtype)
return lm_logits, outputs
outputs = self.module.apply(
inputs,
decoder_input_ids=jnp.array(decoder_input_ids, dtype="i4"),
decoder_attention_mask=jnp.array(decoder_attention_mask, dtype="i4"),
decoder_position_ids=jnp.array(decoder_position_ids, dtype="i4"),
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=jnp.array(encoder_attention_mask, dtype="i4"),
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=deterministic,
rngs=rngs,
mutable=mutable,
method=_decoder_forward,
)
if past_key_values is None:
lm_logits, decoder_outputs = outputs
else:
(lm_logits, decoder_outputs), past = outputs
if return_dict:
outputs = FlaxCausalLMOutputWithCrossAttentions(
logits=lm_logits,
hidden_states=decoder_outputs.hidden_states,
attentions=decoder_outputs.attentions,
cross_attentions=decoder_outputs.cross_attentions,
)
else:
outputs = (lm_logits,) + decoder_outputs[1:]
# add updated cache to model output
if past_key_values is not None and return_dict:
outputs["past_key_values"] = unfreeze(past["cache"])
return outputs
elif past_key_values is not None and not return_dict:
outputs = outputs[:1] + (unfreeze(past["cache"]),) + outputs[1:]
return outputs
def prepare_inputs_for_generation(
self,
decoder_input_ids,
max_length,
attention_mask: Optional[jax.Array] = None,
decoder_attention_mask: Optional[jax.Array] = None,
encoder_outputs=None,
**kwargs
):
# initializing the cache
batch_size, seq_length = decoder_input_ids.shape
past_key_values = self.init_cache(batch_size, max_length, encoder_outputs)
# Note that usually one would have to put 0's in the attention_mask for x > input_ids.shape[-1] and x < cache_length.
# But since the decoder uses a causal mask, those positions are masked anyways.
# Thus we can create a single static attention_mask here, which is more efficient for compilation
extended_attention_mask = jnp.ones((batch_size, max_length), dtype="i4")
if decoder_attention_mask is not None:
position_ids = decoder_attention_mask.cumsum(axis=-1) - 1
extended_attention_mask = lax.dynamic_update_slice(extended_attention_mask, decoder_attention_mask, (0, 0))
else:
position_ids = jnp.broadcast_to(jnp.arange(seq_length, dtype="i4")[None, :], (batch_size, seq_length))
return {
"past_key_values": past_key_values,
"encoder_outputs": encoder_outputs,
"encoder_attention_mask": attention_mask,
"decoder_attention_mask": extended_attention_mask,
"decoder_position_ids": position_ids,
}
def update_inputs_for_generation(self, model_outputs, model_kwargs):
model_kwargs["past_key_values"] = model_outputs.past_key_values
model_kwargs["decoder_position_ids"] = model_kwargs["decoder_position_ids"][:, -1:] + 1
return model_kwargs
FLAX_{{cookiecutter.uppercase_modelname}}_CONDITIONAL_GENERATION_DOCSTRING = """
Returns:
Summarization example:
```python
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> model = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> ARTICLE_TO_SUMMARIZE = "My friends are cool but they eat too many carbs."
>>> inputs = tokenizer([ARTICLE_TO_SUMMARIZE], max_length=1024, return_tensors='np')
>>> # Generate Summary
>>> summary_ids = model.generate(inputs['input_ids']).sequences
>>> print(tokenizer.batch_decode(summary_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False))
```
Mask filling example:
```python
>>> import jax
>>> from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
>>> model = Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> tokenizer = {{cookiecutter.camelcase_modelname}}Tokenizer.from_pretrained('{{cookiecutter.checkpoint_identifier}}')
>>> TXT = "My friends are <mask> but they eat too many carbs."
>>> input_ids = tokenizer([TXT], return_tensors='np')['input_ids']
>>> logits = model(input_ids).logits
>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
>>> probs = jax.nn.softmax(logits[0, masked_index], axis=0)
>>> values, predictions = jax.lax.top_k(probs, k=1)
>>> tokenizer.decode(predictions).split()
```
"""
overwrite_call_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration, {{cookiecutter.uppercase_modelname}}_INPUTS_DOCSTRING + FLAX_{{cookiecutter.uppercase_modelname}}_CONDITIONAL_GENERATION_DOCSTRING
)
append_replace_return_docstrings(
Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration, output_type=FlaxSeq2SeqLMOutput, config_class=_CONFIG_FOR_DOC
)
class Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassificationModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
num_labels: Optional[int] = None
def setup(self):
self.model = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype)
self.classification_head = Flax{{cookiecutter.camelcase_modelname}}ClassificationHead(
config=self.config,
inner_dim=self.config.d_model,
num_classes=self.num_labels if self.num_labels is not None else self.config.num_labels,
pooler_dropout=self.config.classifier_dropout,
)
def _get_encoder_module(self):
return self.model.encoder
def _get_decoder_module(self):
return self.model.decoder
def __call__(
self,
input_ids,
attention_mask,
decoder_input_ids,
decoder_attention_mask,
position_ids,
decoder_position_ids,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
deterministic: bool = True,
):
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
position_ids=position_ids,
decoder_position_ids=decoder_position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=deterministic,
)
hidden_states = outputs[0] # last hidden state
eos_mask = jnp.where(input_ids == self.config.eos_token_id, 1, 0)
# The first condition is necessary to overcome jax._src.errors.ConcretizationTypeError during JIT compilation
if type(eos_mask) != jax.interpreters.partial_eval.DynamicJaxprTracer:
if len(jnp.unique(eos_mask.sum(1))) > 1:
raise ValueError("All examples must have the same number of <eos> tokens.")
if any(eos_mask.sum(1) == 0):
raise ValueError("There are missing <eos> tokens in input_ids")
# Ensure to keep 1 only for the last <eos> token for each example
eos_mask_noised = eos_mask + jnp.arange(eos_mask.shape[1]) * 1e-6
eos_mask = jnp.where(eos_mask_noised == eos_mask_noised.max(1).reshape(-1, 1), 1, 0)
sentence_representation = jnp.einsum("ijk, ij -> ijk", hidden_states, eos_mask).sum(1)
logits = self.classification_head(sentence_representation, deterministic=deterministic)
if not return_dict:
output = (logits,) + outputs[1:]
return output
return FlaxSeq2SeqSequenceClassifierOutput(
logits=logits,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.camelcase_modelname}} model with a sequence classification/head on top (a linear layer on top of the pooled output) e.g. for GLUE
tasks.
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassificationModule
dtype = jnp.float32
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification,
_TOKENIZER_FOR_DOC,
_CHECKPOINT_FOR_DOC,
FlaxSeq2SeqSequenceClassifierOutput,
_CONFIG_FOR_DOC,
)
class Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnsweringModule(nn.Module):
config: {{cookiecutter.camelcase_modelname}}Config
dtype: jnp.dtype = jnp.float32
num_labels = 2
def setup(self):
self.model = Flax{{cookiecutter.camelcase_modelname}}Module(config=self.config, dtype=self.dtype)
self.qa_outputs = nn.Dense(
self.num_labels, dtype=self.dtype, kernel_init=jax.nn.initializers.normal(self.config.init_std)
)
def _get_encoder_module(self):
return self.model.encoder
def _get_decoder_module(self):
return self.model.decoder
def __call__(
self,
input_ids,
attention_mask,
decoder_input_ids,
decoder_attention_mask,
position_ids,
decoder_position_ids,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
deterministic: bool = True,
):
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
position_ids=position_ids,
decoder_position_ids=decoder_position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
deterministic=deterministic,
)
sequence_output = outputs[0]
logits = self.qa_outputs(sequence_output)
start_logits, end_logits = jnp.split(logits, logits.shape[-1], axis=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
if not return_dict:
output = (start_logits, end_logits) + outputs[1:]
return output
return FlaxSeq2SeqQuestionAnsweringModelOutput(
start_logits=start_logits,
end_logits=end_logits,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
@add_start_docstrings(
"""
{{cookiecutter.uppercase_modelname}} Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layer on top of the hidden-states output to compute `span start logits` and `span end logits`).
""",
{{cookiecutter.uppercase_modelname}}_START_DOCSTRING,
)
class Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering(Flax{{cookiecutter.camelcase_modelname}}PreTrainedModel):
module_class = Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnsweringModule
dtype = jnp.float32
append_call_sample_docstring(
Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering,
_TOKENIZER_FOR_DOC,
_CHECKPOINT_FOR_DOC,
FlaxSeq2SeqQuestionAnsweringModelOutput,
_CONFIG_FOR_DOC,
)
{% endif -%}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/configuration.json
|
{
"modelname": "{{cookiecutter.modelname}}",
"uppercase_modelname": "{{cookiecutter.uppercase_modelname}}",
"lowercase_modelname": "{{cookiecutter.lowercase_modelname}}",
"camelcase_modelname": "{{cookiecutter.camelcase_modelname}}",
"authors": "{{cookiecutter.authors}}",
"checkpoint_identifier": "{{cookiecutter.checkpoint_identifier}}",
"tokenizer_type": "{{cookiecutter.tokenizer_type}}",
"generate_tensorflow_pytorch_and_flax": "{{cookiecutter.generate_tensorflow_pytorch_and_flax}}",
"is_encoder_decoder_model": "{{cookiecutter.is_encoder_decoder_model}}"
}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/tests/encoder-bert-tokenizer.json
|
{
"modelname": "Template",
"uppercase_modelname": "TEMPLATE",
"lowercase_modelname": "template",
"camelcase_modelname": "Template",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "brand-new-bert-base-cased",
"tokenizer_type": "Based on BERT",
"generate_tensorflow_pytorch_and_flax": "PyTorch, TensorFlow and Flax",
"is_encoder_decoder_model": "False"
}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/tests/pt-seq-2-seq-bart-tokenizer.json
|
{
"modelname": "PTNewENCDEC",
"uppercase_modelname": "PT_NEW_ENC_DEC",
"lowercase_modelname": "pt_new_enc_dec_template",
"camelcase_modelname": "PtNewEncDec",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "pt-new-enc-dec-base",
"tokenizer_type": "Based on BART",
"generate_tensorflow_pytorch_and_flax": "PyTorch",
"is_encoder_decoder_model": "True"
}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/tests/tf-seq-2-seq-bart-tokenizer.json
|
{
"modelname": "NewTFENCDEC",
"uppercase_modelname": "NEW_TF_ENC_DEC",
"lowercase_modelname": "new_tf_enc_dec_template",
"camelcase_modelname": "NewTFEncDec",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "new-tf-enc-dec-base_template",
"tokenizer_type": "Based on BART",
"generate_tensorflow_pytorch_and_flax": "TensorFlow",
"is_encoder_decoder_model": "True"
}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/tests/tf-encoder-bert-tokenizer.json
|
{
"modelname": "TemplateTF",
"uppercase_modelname": "TEMPLATE_TF",
"lowercase_modelname": "template_tf",
"camelcase_modelname": "TemplateTf",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "brand-new-bert-base-cased",
"tokenizer_type": "Based on BERT",
"generate_tensorflow_pytorch_and_flax": "TensorFlow",
"is_encoder_decoder_model": "False"
}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/tests/flax-seq-2-seq-bart-tokenizer.json
|
{
"modelname": "FlaxNewENCDEC",
"uppercase_modelname": "FLAX_NEW_ENC_DEC",
"lowercase_modelname": "flax_new_enc_dec_template",
"camelcase_modelname": "FlaxNewEncDec",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "new-flax-enc-dec-base",
"tokenizer_type": "Based on BART",
"generate_tensorflow_pytorch_and_flax": "Flax",
"is_encoder_decoder_model": "True"
}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/tests/pt-encoder-bert-tokenizer.json
|
{
"modelname": "TemplatePT",
"uppercase_modelname": "TEMPLATE_PT",
"lowercase_modelname": "template_pt",
"camelcase_modelname": "TemplatePt",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "brand-new-bert-base-cased",
"tokenizer_type": "Based on BERT",
"generate_tensorflow_pytorch_and_flax": "PyTorch",
"is_encoder_decoder_model": "False"
}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/tests/standalone.json
|
{
"modelname": "TemplateBI",
"uppercase_modelname": "TEMPLATE_BI",
"lowercase_modelname": "template_bi",
"camelcase_modelname": "TemplateBi",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "bi-brand-new-bert-base-cased",
"tokenizer_type": "Standalone",
"generate_tensorflow_pytorch_and_flax": "PyTorch, TensorFlow and Flax",
"is_encoder_decoder_model": "False"
}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/tests/flax-encoder-bert-tokenizer.json
|
{
"modelname": "TemplateFLAX",
"uppercase_modelname": "TEMPLATE_FLAX",
"lowercase_modelname": "template_flax",
"camelcase_modelname": "TemplateFlax",
"authors": "The HuggingFace Team",
"checkpoint_identifier": "brand-new-bert-base-cased",
"tokenizer_type": "Based on BERT",
"generate_tensorflow_pytorch_and_flax": "Flax",
"is_encoder_decoder_model": "False"
}
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/open_model_proposals/README.md
|
Currently the following model proposals are available:
- <s>[BigBird (Google)](./ADD_BIG_BIRD.md)</s>
| 0
|
hf_public_repos/transformers/templates/adding_a_new_model
|
hf_public_repos/transformers/templates/adding_a_new_model/open_model_proposals/ADD_BIG_BIRD.md
|
How to add BigBird to 🤗 Transformers?
=====================================
Mentor: [Patrick](https://github.com/patrickvonplaten)
Begin: 12.02.2020
Estimated End: 19.03.2020
Contributor: [Vasudev](https://github.com/thevasudevgupta)
Adding a new model is often difficult and requires an in-depth knowledge
of the 🤗 Transformers library and ideally also of the model's original
repository. At Hugging Face, we are trying to empower the community more
and more to add models independently.
The following sections explain in detail how to add BigBird
to Transformers. You will work closely with Patrick to
integrate BigBird into Transformers. By doing so, you will both gain a
theoretical and deep practical understanding of BigBird.
But more importantly, you will have made a major
open-source contribution to Transformers. Along the way, you will:
- get insights into open-source best practices
- understand the design principles of one of the most popular NLP
libraries
- learn how to do efficiently test large NLP models
- learn how to integrate Python utilities like `black`, `ruff`,
`make fix-copies` into a library to always ensure clean and readable
code
To start, let's try to get a general overview of the Transformers
library.
General overview of 🤗 Transformers
----------------------------------
First, you should get a general overview of 🤗 Transformers. Transformers
is a very opinionated library, so there is a chance that
you don't agree with some of the library's philosophies or design
choices. From our experience, however, we found that the fundamental
design choices and philosophies of the library are crucial to
efficiently scale Transformers while keeping maintenance costs at a
reasonable level.
A good first starting point to better understand the library is to read
the [documentation of our philosophy](https://huggingface.co/transformers/philosophy.html).
As a result of our way of working, there are some choices that we try to apply to all models:
- Composition is generally favored over abstraction
- Duplicating code is not always bad if it strongly improves the
readability or accessibility of a model
- Model files are as self-contained as possible so that when you read
the code of a specific model, you ideally only have to look into the
respective `modeling_....py` file.
In our opinion, the library's code is not just a means to provide a
product, *e.g.*, the ability to use BERT for inference, but also as the
very product that we want to improve. Hence, when adding a model, the
user is not only the person that will use your model, but also everybody
that will read, try to understand, and possibly tweak your code.
With this in mind, let's go a bit deeper into the general library
design.
### Overview of models
To successfully add a model, it is important to understand the
interaction between your model and its config,
`PreTrainedModel`, and `PretrainedConfig`. For
exemplary purposes, we will call the PyTorch model to be added to 🤗 Transformers
`BrandNewBert`.
Let's take a look:
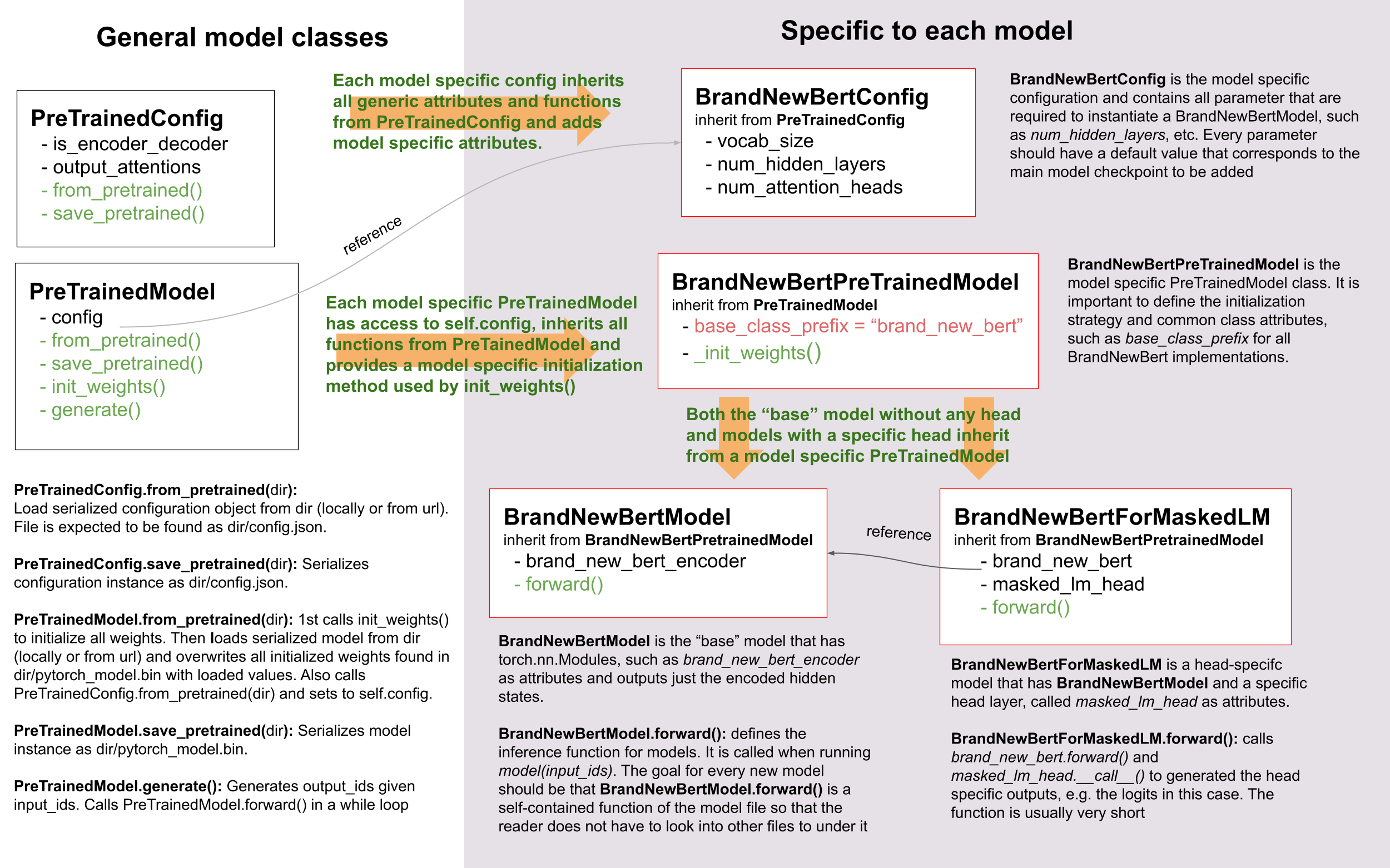
As you can see, we do make use of inheritance in 🤗 Transformers, but we
keep the level of abstraction to an absolute minimum. There are never
more than two levels of abstraction for any model in the library.
`BrandNewBertModel` inherits from
`BrandNewBertPreTrainedModel` which in
turn inherits from `PreTrainedModel` and that's it.
As a general rule, we want to make sure
that a new model only depends on `PreTrainedModel`. The
important functionalities that are automatically provided to every new
model are
`PreTrainedModel.from_pretrained` and `PreTrainedModel.save_pretrained`, which are
used for serialization and deserialization. All
of the other important functionalities, such as
`BrandNewBertModel.forward` should be
completely defined in the new `modeling_brand_new_bert.py` module. Next,
we want to make sure that a model with a specific head layer, such as
`BrandNewBertForMaskedLM` does not inherit
from `BrandNewBertModel`, but rather uses
`BrandNewBertModel` as a component that
can be called in its forward pass to keep the level of abstraction low.
Every new model requires a configuration class, called
`BrandNewBertConfig`. This configuration
is always stored as an attribute in
`PreTrainedModel`, and
thus can be accessed via the `config` attribute for all classes
inheriting from `BrandNewBertPreTrainedModel`
```python
# assuming that `brand_new_bert` belongs to the organization `brandy`
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
Similar to the model, the configuration inherits basic serialization and
deserialization functionalities from
`PretrainedConfig`. Note
that the configuration and the model are always serialized into two
different formats - the model to a `pytorch_model.bin` file
and the configuration to a `config.json` file. Calling
`PreTrainedModel.save_pretrained` will automatically call
`PretrainedConfig.save_pretrained`, so that both model and configuration are saved.
### Overview of tokenizers
Not quite ready yet :-( This section will be added soon!
Step-by-step recipe to add a model to 🤗 Transformers
----------------------------------------------------
Everyone has different preferences of how to port a model so it can be
very helpful for you to take a look at summaries of how other
contributors ported models to Hugging Face. Here is a list of community
blog posts on how to port a model:
1. [Porting GPT2
Model](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28)
by [Thomas](https://huggingface.co/thomwolf)
2. [Porting WMT19 MT Model](https://huggingface.co/blog/porting-fsmt)
by [Stas](https://huggingface.co/stas)
From experience, we can tell you that the most important things to keep
in mind when adding a model are:
- Don't reinvent the wheel! Most parts of the code you will add for
the new 🤗 Transformers model already exist somewhere in 🤗
Transformers. Take some time to find similar, already existing
models and tokenizers you can copy from.
[grep](https://www.gnu.org/software/grep/) and
[rg](https://github.com/BurntSushi/ripgrep) are your friends. Note
that it might very well happen that your model's tokenizer is based
on one model implementation, and your model's modeling code on
another one. *E.g.*, FSMT's modeling code is based on BART, while
FSMT's tokenizer code is based on XLM.
- It's more of an engineering challenge than a scientific challenge.
You should spend more time on creating an efficient debugging
environment than trying to understand all theoretical aspects of the
model in the paper.
- Ask for help when you're stuck! Models are the core component of 🤗
Transformers so we, at Hugging Face, are more than happy to help
you at every step to add your model. Don't hesitate to ask if you
notice you are not making progress.
In the following, we try to give you a general recipe that we found most
useful when porting a model to 🤗 Transformers.
The following list is a summary of everything that has to be done to add
a model and can be used by you as a To-Do List:
1. [ ] (Optional) Understood theoretical aspects
2. [ ] Prepared transformers dev environment
3. [ ] Set up debugging environment of the original repository
4. [ ] Created script that successfully runs forward pass using
original repository and checkpoint
5. [ ] Successfully opened a PR and added the model skeleton to Transformers
6. [ ] Successfully converted original checkpoint to Transformers
checkpoint
7. [ ] Successfully ran forward pass in Transformers that gives
identical output to original checkpoint
8. [ ] Finished model tests in Transformers
9. [ ] Successfully added Tokenizer in Transformers
10. [ ] Run end-to-end integration tests
11. [ ] Finished docs
12. [ ] Uploaded model weights to the hub
13. [ ] Submitted the pull request for review
14. [ ] (Optional) Added a demo notebook
To begin with, we usually recommend to start by getting a good
theoretical understanding of `BigBird`. However, if you prefer to
understand the theoretical aspects of the model *on-the-job*, then it is
totally fine to directly dive into the `BigBird`'s code-base. This
option might suit you better, if your engineering skills are better than
your theoretical skill, if you have trouble understanding
`BigBird`'s paper, or if you just enjoy programming much more than
reading scientific papers.
### 1. (Optional) Theoretical aspects of BigBird
You should take some time to read *BigBird's* paper, if such
descriptive work exists. There might be large sections of the paper that
are difficult to understand. If this is the case, this is fine - don't
worry! The goal is not to get a deep theoretical understanding of the
paper, but to extract the necessary information required to effectively
re-implement the model in 🤗 Transformers. That being said, you don't
have to spend too much time on the theoretical aspects, but rather focus
on the practical ones, namely:
- What type of model is *BigBird*? BERT-like encoder-only
model? GPT2-like decoder-only model? BART-like encoder-decoder
model? Look at the `model_summary` if
you're not familiar with the differences between those.
- What are the applications of *BigBird*? Text
classification? Text generation? Seq2Seq tasks, *e.g.,*
summarization?
- What is the novel feature of the model making it different from
BERT/GPT-2/BART?
- Which of the already existing [🤗 Transformers
models](https://huggingface.co/transformers/#contents) is most
similar to *BigBird*?
- What type of tokenizer is used? A sentencepiece tokenizer? Word
piece tokenizer? Is it the same tokenizer as used for BERT or BART?
After you feel like you have gotten a good overview of the architecture
of the model, you might want to write to Patrick with any
questions you might have. This might include questions regarding the
model's architecture, its attention layer, etc. We will be more than
happy to help you.
#### Additional resources
Before diving into the code, here are some additional resources that might be worth taking a look at:
- [Yannic Kilcher's paper summary](https://www.youtube.com/watch?v=WVPE62Gk3EM&ab_channel=YannicKilcher)
- [Yannic Kilcher's summary of Longformer](https://www.youtube.com/watch?v=_8KNb5iqblE&ab_channel=YannicKilcher) - Longformer and BigBird are **very** similar models. Since Longformer has already been ported to 🤗 Transformers, it is useful to understand the differences between the two models
- [Blog post](https://medium.com/dsc-msit/is-google-bigbird-gonna-be-the-new-leader-in-nlp-domain-8c95cecc30f8) - A relatively superficial blog post about BigBird. Might be a good starting point to understand BigBird
#### Make sure you've understood the fundamental aspects of BigBird
Alright, now you should be ready to take a closer look into the actual code of BigBird.
You should have understood the following aspects of BigBird by now:
- BigBird provides a new attention layer for long-range sequence modelling that can be used
as a drop-in replacement for already existing architectures. This means that every transformer-based model architecture can replace its [Self-attention layer](https://towardsdatascience.com/illustrated-self-attention-2d627e33b20a) with BigBird's self-attention layer.
- BigBird's self-attention layer is composed of three mechanisms: block sparse (local) self-attention, global self-attention, random self-attention
- BigBird's block sparse (local) self-attention is different from Longformer's local self-attention. How so? Why does that matter? => Can be deployed on TPU much easier this way
- BigBird can be implemented for both an encoder-only model **and**
for an encoder-decoder model, which means that we can reuse lots of [code from RoBERTa](https://github.com/huggingface/transformers/blob/main/src/transformers/models/roberta/modeling_roberta.py) and [from PEGASUS](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pegasus/modeling_pegasus.py) at a later stage.
If any of the mentioned aspects above are **not** clear to you, now is a great time to talk to Patrick.
### 2. Next prepare your environment
1. Fork the [repository](https://github.com/huggingface/transformers)
by clicking on the 'Fork' button on the repository's page. This
creates a copy of the code under your GitHub user account.
2. Clone your `transformers` fork to your local disk, and add the base
repository as a remote:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Set up a development environment, for instance by running the
following command:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
and return to the parent directory
```bash
cd ..
```
4. We recommend adding the PyTorch version of *BigBird* to
Transformers. To install PyTorch, please follow the instructions [here](https://pytorch.org/get-started/locally/).
**Note:** You don't need to have CUDA installed. Making the new model
work on CPU is sufficient.
5. To port *BigBird*, you will also need access to its
original repository:
```bash
git clone https://github.com/google-research/bigbird.git
cd big_bird
pip install -e .
```
Now you have set up a development environment to port *BigBird*
to 🤗 Transformers.
### Run a pretrained checkpoint using the original repository
**3. Set up debugging environment**
At first, you will work on the original *BigBird* repository.
Often, the original implementation is very "researchy". Meaning that
documentation might be lacking and the code can be difficult to
understand. But this should be exactly your motivation to reimplement
*BigBird*. At Hugging Face, one of our main goals is to *make
people stand on the shoulders of giants* which translates here very well
into taking a working model and rewriting it to make it as **accessible,
user-friendly, and beautiful** as possible. This is the number-one
motivation to re-implement models into 🤗 Transformers - trying to make
complex new NLP technology accessible to **everybody**.
You should start thereby by diving into the [original repository](https://github.com/google-research/bigbird).
Successfully running the official pretrained model in the original
repository is often **the most difficult** step. From our experience, it
is very important to spend some time getting familiar with the original
code-base. You need to figure out the following:
- Where to find the pretrained weights?
- How to load the pretrained weights into the corresponding model?
- How to run the tokenizer independently from the model?
- Trace one forward pass so that you know which classes and functions
are required for a simple forward pass. Usually, you only have to
reimplement those functions.
- Be able to locate the important components of the model: Where is
the model's class? Are there model sub-classes, *e.g.*,
EncoderModel, DecoderModel? Where is the self-attention layer? Are
there multiple different attention layers, *e.g.*, *self-attention*,
*cross-attention*...?
- How can you debug the model in the original environment of the repo?
Do you have to add `print` statements, can you work with
an interactive debugger like [ipdb](https://pypi.org/project/ipdb/), or should you use
an efficient IDE to debug the model, like PyCharm?
It is very important that before you start the porting process, that you
can **efficiently** debug code in the original repository! Also,
remember that you are working with an open-source library, so do not
hesitate to open an issue, or even a pull request in the original
repository. The maintainers of this repository are most likely very
happy about someone looking into their code!
At this point, it is really up to you which debugging environment and
strategy you prefer to use to debug the original model. We strongly
advise against setting up a costly GPU environment, but simply work on a
CPU both when starting to dive into the original repository and also
when starting to write the 🤗 Transformers implementation of the model.
Only at the very end, when the model has already been successfully
ported to 🤗 Transformers, one should verify that the model also works as
expected on GPU.
In general, there are two possible debugging environments for running
the original model
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- Local python scripts.
Jupyter notebooks have the advantage that they allow for cell-by-cell
execution which can be helpful to better split logical components from
one another and to have faster debugging cycles as intermediate results
can be stored. Also, notebooks are often easier to share with other
contributors, which might be very helpful if you want to ask the Hugging
Face team for help. If you are familiar with Jupyter notebooks, we
strongly recommend you to work with them.
The obvious disadvantage of Jupyter notebooks is that if you are not
used to working with them you will have to spend some time adjusting to
the new programming environment and that you might not be able to use
your known debugging tools anymore, like `ipdb`.
**4. Successfully run forward pass**
For each code-base, a good first step is always to load a **small**
pretrained checkpoint and to be able to reproduce a single forward pass
using a dummy integer vector of input IDs as an input. Such a script
could look something like this:
```python
from bigbird.core import modeling
model = modeling.BertModel(bert_config)
from bigbird.core import utils
params = utils.BigBirdConfig(vocab_size=32000, hidden_size=512,
num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
ckpt_path = 'gs://bigbird-transformer/pretrain/bigbr_base/model.ckpt-0'
ckpt_reader = tf.compat.v1.train.NewCheckpointReader(ckpt_path)
model.set_weights([ckpt_reader.get_tensor(v.name[:-2]) for v in tqdm(model.trainable_weights, position=0)])
input_ids = tf.constant([[31, 51, 99], [15, 5, 0]])
_, pooled_output = model(input_ids=input_ids, token_type_ids=token_type_ids)
...
```
Next, regarding the debugging strategy, there are generally a few from
which to choose from:
- Decompose the original model into many small testable components and
run a forward pass on each of those for verification
- Decompose the original model only into the original *tokenizer* and
the original *model*, run a forward pass on those, and use
intermediate print statements or breakpoints for verification
Again, it is up to you which strategy to choose. Often, one or the other
is advantageous depending on the original code base.
If the original code-base allows you to decompose the model into smaller
sub-components, *e.g.*, if the original code-base can easily be run in
eager mode, it is usually worth the effort to do so. There are some
important advantages to taking the more difficult road in the beginning:
- at a later stage when comparing the original model to the Hugging
Face implementation, you can verify automatically for each component
individually that the corresponding component of the 🤗 Transformers
implementation matches instead of relying on visual comparison via
print statements
- it can give you some rope to decompose the big problem of porting a
model into smaller problems of just porting individual components
and thus structure your work better
- separating the model into logical meaningful components will help
you to get a better overview of the model's design and thus to
better understand the model
- at a later stage those component-by-component tests help you to
ensure that no regression occurs as you continue changing your code
[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed)
integration checks for ELECTRA gives a nice example of how this can be
done.
However, if the original code-base is very complex or only allows
intermediate components to be run in a compiled mode, it might be too
time-consuming or even impossible to separate the model into smaller
testable sub-components. A good example is [T5's
MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow)
library which is very complex and does not offer a simple way to
decompose the model into its sub-components. For such libraries, one
often relies on verifying print statements.
No matter which strategy you choose, the recommended procedure is often
the same in that you should start to debug the starting layers first and
the ending layers last.
It is recommended that you retrieve the output, either by print
statements or sub-component functions, of the following layers in the
following order:
1. Retrieve the input IDs passed to the model
2. Retrieve the word embeddings
3. Retrieve the input of the first Transformer layer
4. Retrieve the output of the first Transformer layer
5. Retrieve the output of the following n - 1 Transformer layers
6. Retrieve the output of the whole BigBird Model
Input IDs should thereby consists of an array of integers, *e.g.*,
`input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
The outputs of the following layers often consist of multi-dimensional
float arrays and can look like this:
```bash
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
We expect that every model added to 🤗 Transformers passes a couple of
integration tests, meaning that the original model and the reimplemented
version in 🤗 Transformers have to give the exact same output up to a
precision of 0.001! Since it is normal that the exact same model written
in different libraries can give a slightly different output depending on
the library framework, we accept an error tolerance of 1e-3 (0.001). It
is not enough if the model gives nearly the same output, they have to be
the almost identical. Therefore, you will certainly compare the
intermediate outputs of the 🤗 Transformers version multiple times
against the intermediate outputs of the original implementation of
*BigBird* in which case an **efficient** debugging environment
of the original repository is absolutely important. Here is some advice
to make your debugging environment as efficient as possible.
- Find the best way of debugging intermediate results. Is the original
repository written in PyTorch? Then you should probably take the
time to write a longer script that decomposes the original model
into smaller sub-components to retrieve intermediate values. Is the
original repository written in Tensorflow 1? Then you might have to
rely on TensorFlow print operations like
[tf.print](https://www.tensorflow.org/api_docs/python/tf/print) to
output intermediate values. Is the original repository written in
Jax? Then make sure that the model is **not jitted** when running
the forward pass, *e.g.*, check-out [this
link](https://github.com/google/jax/issues/196).
- Use the smallest pretrained checkpoint you can find. The smaller the
checkpoint, the faster your debug cycle becomes. It is not efficient
if your pretrained model is so big that your forward pass takes more
than 10 seconds. In case only very large checkpoints are available,
it might make more sense to create a dummy model in the new
environment with randomly initialized weights and save those weights
for comparison with the 🤗 Transformers version of your model
- Make sure you are using the easiest way of calling a forward pass in
the original repository. Ideally, you want to find the function in
the original repository that **only** calls a single forward pass,
*i.e.* that is often called `predict`, `evaluate`, `forward` or
`__call__`. You don't want to debug a function that calls `forward`
multiple times, *e.g.*, to generate text, like
`autoregressive_sample`, `generate`.
- Try to separate the tokenization from the model's
forward pass. If the original repository shows
examples where you have to input a string, then try to find out
where in the forward call the string input is changed to input ids
and start from this point. This might mean that you have to possibly
write a small script yourself or change the original code so that
you can directly input the ids instead of an input string.
- Make sure that the model in your debugging setup is **not** in
training mode, which often causes the model to yield random outputs
due to multiple dropout layers in the model. Make sure that the
forward pass in your debugging environment is **deterministic** so
that the dropout layers are not used. Or use
`transformers.utils.set_seed` if the old and new
implementations are in the same framework.
#### (Important) More details on how to create a debugging environment for BigBird
- BigBird has multiple pretrained checkpoints that should eventually all be ported to
🤗 Transformers. The pretrained checkpoints can be found [here](https://console.cloud.google.com/storage/browser/bigbird-transformer/pretrain;tab=objects?prefix=&forceOnObjectsSortingFiltering=false).
Those checkpoints include both pretrained weights for encoder-only (BERT/RoBERTa) under the folder `bigbr_base` and encoder-decoder (PEGASUS) under the folder `bigbp_large`.
You should start by porting the `bigbr_base` model. The encoder-decoder model
can be ported afterward.
for an encoder-decoder architecture as well as an encoder-only architecture.
- BigBird was written in tf.compat meaning that a mixture of a TensorFlow 1 and
TensorFlow 2 API was used.
- The most important part of the BigBird code-base is [bigbird.bigbird.core](https://github.com/google-research/bigbird/tree/master/bigbird/core) which includes all logic necessary
to implement BigBird.
- The first goal should be to successfully run a forward pass using the RoBERTa checkpoint `bigbr_base/model.ckpt-0.data-00000-of-00001` and `bigbr_base/model.ckpt-0.index`.
### Port BigBird to 🤗 Transformers
Next, you can finally start adding new code to 🤗 Transformers. Go into
the clone of your 🤗 Transformers' fork:
cd transformers
In the special case that you are adding a model whose architecture
exactly matches the model architecture of an existing model you only
have to add a conversion script as described in [this
section](#write-a-conversion-script). In this case, you can just re-use
the whole model architecture of the already existing model.
Otherwise, let's start generating a new model with the amazing
Cookiecutter!
**Use the Cookiecutter to automatically generate the model's code**
To begin with head over to the [🤗 Transformers
templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
to make use of our `cookiecutter` implementation to automatically
generate all the relevant files for your model. Again, we recommend only
adding the PyTorch version of the model at first. Make sure you follow
the instructions of the `README.md` on the [🤗 Transformers
templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
carefully.
Since you will first implement the Encoder-only/RoBERTa-like version of BigBird you should
select the `is_encoder_decoder_model = False` option in the cookiecutter. Also, it is recommended
that you implement the model only in PyTorch in the beginning and select "Standalone" as the
tokenizer type for now.
**Open a Pull Request on the main huggingface/transformers repo**
Before starting to adapt the automatically generated code, now is the
time to open a "Work in progress (WIP)" pull request, *e.g.*, "\[WIP\]
Add *BigBird*", in 🤗 Transformers so that you and the Hugging
Face team can work side-by-side on integrating the model into 🤗
Transformers.
You should do the following:
1. Create a branch with a descriptive name from your main branch
```
git checkout -b add_big_bird
```
2. Commit the automatically generated code:
```
git add .
git commit
```
3. Fetch and rebase to current main
```
git fetch upstream
git rebase upstream/main
```
4. Push the changes to your account using:
```
git push -u origin a-descriptive-name-for-my-changes
```
5. Once you are satisfied, go to the webpage of your fork on GitHub.
Click on "Pull request". Make sure to add the GitHub handle of Patrick
as one reviewer, so that the Hugging Face team gets notified for future changes.
6. Change the PR into a draft by clicking on "Convert to draft" on the
right of the GitHub pull request web page.
In the following, whenever you have done some progress, don't forget to
commit your work and push it to your account so that it shows in the
pull request. Additionally, you should make sure to update your work
with the current main from time to time by doing:
git fetch upstream
git merge upstream/main
In general, all questions you might have regarding the model or your
implementation should be asked in your PR and discussed/solved in the
PR. This way, Patrick will always be notified when you are
committing new code or if you have a question. It is often very helpful
to point Patrick to your added code so that the Hugging
Face team can efficiently understand your problem or question.
To do so, you can go to the "Files changed" tab where you see all of
your changes, go to a line regarding which you want to ask a question,
and click on the "+" symbol to add a comment. Whenever a question or
problem has been solved, you can click on the "Resolve" button of the
created comment.
In the same way, Patrick will open comments when reviewing
your code. We recommend asking most questions on GitHub on your PR. For
some very general questions that are not very useful for the public,
feel free to ping Patrick by Slack or email.
**5. Adapt the generated models code for BigBird**
At first, we will focus only on the model itself and not care about the
tokenizer. All the relevant code should be found in the generated files
`src/transformers/models/big_bird/modeling_big_bird.py` and
`src/transformers/models/big_bird/configuration_big_bird.py`.
Now you can finally start coding :). The generated code in
`src/transformers/models/big_bird/modeling_big_bird.py` will
either have the same architecture as BERT if it's an encoder-only model
or BART if it's an encoder-decoder model. At this point, you should
remind yourself what you've learned in the beginning about the
theoretical aspects of the model: *How is the model different from BERT
or BART?*\". Implement those changes which often means to change the
*self-attention* layer, the order of the normalization layer, etc...
Again, it is often useful to look at the similar architecture of already
existing models in Transformers to get a better feeling of how your
model should be implemented.
**Note** that at this point, you don't have to be very sure that your
code is fully correct or clean. Rather, it is advised to add a first
*unclean*, copy-pasted version of the original code to
`src/transformers/models/big_bird/modeling_big_bird.py`
until you feel like all the necessary code is added. From our
experience, it is much more efficient to quickly add a first version of
the required code and improve/correct the code iteratively with the
conversion script as described in the next section. The only thing that
has to work at this point is that you can instantiate the 🤗 Transformers
implementation of *BigBird*, *i.e.* the following command
should work:
```python
from transformers import BigBirdModel, BigBirdConfig
model = BigBirdModel(BigBirdConfig())
```
The above command will create a model according to the default
parameters as defined in `BigBirdConfig()` with random weights,
thus making sure that the `init()` methods of all components works.
Note that for BigBird you have to change the attention layer. BigBird's attention
layer is quite complex as you can see [here](https://github.com/google-research/bigbird/blob/103a3345f94bf6364749b51189ed93024ca5ef26/bigbird/core/attention.py#L560). Don't
feel discouraged by this! In a first step you should simply make sure that
the layer `BigBirdAttention` has the correct weights as can be found in the
pretrained checkpoints. This means that you have to make sure that in the
`__init__(self, ...)` function of `BigBirdAttention`, all submodules include all
necessary `nn.Module` layers. Only at a later stage do we need to fully rewrite
the complex attention function.
**6. Write a conversion script**
Next, you should write a conversion script that lets you convert the
checkpoint you used to debug *BigBird* in the original
repository to a checkpoint compatible with your just created 🤗
Transformers implementation of *BigBird*. It is not advised to
write the conversion script from scratch, but rather to look through
already existing conversion scripts in 🤗 Transformers for one that has
been used to convert a similar model that was written in the same
framework as *BigBird*. Usually, it is enough to copy an
already existing conversion script and slightly adapt it for your use
case. Don't hesitate to ask Patrick to point you to a
similar already existing conversion script for your model.
- A good starting point to convert the original TF BigBird implementation to the PT Hugging Face implementation is probably BERT's conversion script
[here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
You can copy paste the conversion function into `modeling_big_bird.py` and then adapt it
to your needs.
In the following, we'll quickly explain how PyTorch models store layer
weights and define layer names. In PyTorch, the name of a layer is
defined by the name of the class attribute you give the layer. Let's
define a dummy model in PyTorch, called `SimpleModel` as follows:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
Now we can create an instance of this model definition which will fill
all weights: `dense`, `intermediate`, `layer_norm` with random weights.
We can print the model to see its architecture
```python
model = SimpleModel()
print(model)
```
This will print out the following:
```bash
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
We can see that the layer names are defined by the name of the class
attribute in PyTorch. You can print out the weight values of a specific
layer:
```python
print(model.dense.weight.data)
```
to see that the weights were randomly initialized
```bash
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
In the conversion script, you should fill those randomly initialized
weights with the exact weights of the corresponding layer in the
checkpoint. *E.g.*,
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
While doing so, you must verify that each randomly initialized weight of
your PyTorch model and its corresponding pretrained checkpoint weight
exactly match in both **shape and name**. To do so, it is **necessary**
to add assert statements for the shape and print out the names of the
checkpoints weights. *E.g.*, you should add statements like:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
Besides, you should also print out the names of both weights to make
sure they match, *e.g.*,
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
If either the shape or the name doesn't match, you probably assigned
the wrong checkpoint weight to a randomly initialized layer of the 🤗
Transformers implementation.
An incorrect shape is most likely due to an incorrect setting of the
config parameters in `BigBirdConfig()` that do not exactly match
those that were used for the checkpoint you want to convert. However, it
could also be that PyTorch's implementation of a layer requires the
weight to be transposed beforehand.
Finally, you should also check that **all** required weights are
initialized and print out all checkpoint weights that were not used for
initialization to make sure the model is correctly converted. It is
completely normal, that the conversion trials fail with either a wrong
shape statement or wrong name assignment. This is most likely because
either you used incorrect parameters in `BigBirdConfig()`, have a
wrong architecture in the 🤗 Transformers implementation, you have a bug
in the `init()` functions of one of the components of the 🤗 Transformers
implementation or you need to transpose one of the checkpoint weights.
This step should be iterated with the previous step until all weights of
the checkpoint are correctly loaded in the Transformers model. Having
correctly loaded the checkpoint into the 🤗 Transformers implementation,
you can then save the model under a folder of your choice
`/path/to/converted/checkpoint/folder` that should then contain both a
`pytorch_model.bin` file and a `config.json` file:
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
**7. Implement the forward pass**
Having managed to correctly load the pretrained weights into the 🤗
Transformers implementation, you should now make sure that the forward
pass is correctly implemented. In [Get familiar with the original
repository](#run-a-pretrained-checkpoint-using-the-original-repository),
you have already created a script that runs a forward pass of the model
using the original repository. Now you should write an analogous script
using the 🤗 Transformers implementation instead of the original one. It
should look as follows:
[Here the model name might have to be adapted, *e.g.*, maybe BigBirdForConditionalGeneration instead of BigBirdModel]
```python
model = BigBirdModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
It is very likely that the 🤗 Transformers implementation and the
original model implementation don't give the exact same output the very
first time or that the forward pass throws an error. Don't be
disappointed - it's expected! First, you should make sure that the
forward pass doesn't throw any errors. It often happens that the wrong
dimensions are used leading to a `"Dimensionality mismatch"`
error or that the wrong data type object is used, *e.g.*, `torch.long`
instead of `torch.float32`. Don't hesitate to ask Patrick
for help, if you don't manage to solve certain errors.
The final part to make sure the 🤗 Transformers implementation works
correctly is to ensure that the outputs are equivalent to a precision of
`1e-3`. First, you should ensure that the output shapes are identical,
*i.e.* `outputs.shape` should yield the same value for the script of the
🤗 Transformers implementation and the original implementation. Next, you
should make sure that the output values are identical as well. This one
of the most difficult parts of adding a new model. Common mistakes why
the outputs are not identical are:
- Some layers were not added, *i.e.* an activation layer
was not added, or the residual connection was forgotten
- The word embedding matrix was not tied
- The wrong positional embeddings are used because the original
implementation uses on offset
- Dropout is applied during the forward pass. To fix this make sure
`model.training is False` and that no dropout layer is
falsely activated during the forward pass, *i.e.* pass
`self.training` to [PyTorch's functional
dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
The best way to fix the problem is usually to look at the forward pass
of the original implementation and the 🤗 Transformers implementation
side-by-side and check if there are any differences. Ideally, you should
debug/print out intermediate outputs of both implementations of the
forward pass to find the exact position in the network where the 🤗
Transformers implementation shows a different output than the original
implementation. First, make sure that the hard-coded `input_ids` in both
scripts are identical. Next, verify that the outputs of the first
transformation of the `input_ids` (usually the word embeddings) are
identical. And then work your way up to the very last layer of the
network. At some point, you will notice a difference between the two
implementations, which should point you to the bug in the 🤗 Transformers
implementation. From our experience, a simple and efficient way is to
add many print statements in both the original implementation and 🤗
Transformers implementation, at the same positions in the network
respectively, and to successively remove print statements showing the
same values for intermediate presentions.
When you're confident that both implementations yield the same output,
verifying the outputs with
`torch.allclose(original_output, output, atol=1e-3)`, you're done with
the most difficult part! Congratulations - the work left to be done
should be a cakewalk 😊.
**8. Adding all necessary model tests**
At this point, you have successfully added a new model. However, it is
very much possible that the model does not yet fully comply with the
required design. To make sure, the implementation is fully compatible
with 🤗 Transformers, all common tests should pass. The Cookiecutter
should have automatically added a test file for your model, probably
under the same `tests/test_modeling_big_bird.py`. Run this test
file to verify that all common tests pass:
```python
pytest tests/test_modeling_big_bird.py
```
Having fixed all common tests, it is now crucial to ensure that all the
nice work you have done is well tested, so that
- a) The community can easily understand your work by looking at
specific tests of *BigBird*
- b) Future changes to your model will not break any important
feature of the model.
At first, integration tests should be added. Those integration tests
essentially do the same as the debugging scripts you used earlier to
implement the model to 🤗 Transformers. A template of those model tests
is already added by the Cookiecutter, called
`BigBirdModelIntegrationTests` and only has to be filled out by
you. To ensure that those tests are passing, run
```python
RUN_SLOW=1 pytest -sv tests/test_modeling_big_bird.py::BigBirdModelIntegrationTests
```
**Note**: In case you are using Windows, you should replace `RUN_SLOW=1` with
`SET RUN_SLOW=1`
Second, all features that are special to *BigBird* should be
tested additionally in a separate test under
`BigBirdModelTester`/`BigBirdModelTest`. This part is often
forgotten but is extremely useful in two ways:
- It helps to transfer the knowledge you have acquired during the
model addition to the community by showing how the special features
of *BigBird* should work.
- Future contributors can quickly test changes to the model by running
those special tests.
BigBird has quite a complex attention layer, so it is very important
to add more tests verifying the all parts of BigBird's self-attention layer
works as expected. This means that there should be at least 3 additional tests:
- 1. Verify that the sparse attention works correctly
- 2. Verify that the global attention works correctly
- 3. Verify that the random attention works correctly
**9. Implement the tokenizer**
Next, we should add the tokenizer of *BigBird*. Usually, the
tokenizer is equivalent or very similar to an already existing tokenizer
of 🤗 Transformers.
In the case of BigBird you should be able to just rely on an already existing tokenizer.
If not mistaken, BigBird uses the same tokenizer that was used for `BertGenerationTokenizer`,
which is based on `sentencepiece`. So you should be able to just set the config parameter
`tokenizer_class` to `BertGenerationTokenizer` without having to implement any new tokenizer.
It is very important to find/extract the original tokenizer file and to
manage to load this file into the 🤗 Transformers' implementation of the
tokenizer.
For BigBird, the tokenizer (sentencepiece) files can be found [here](https://github.com/google-research/bigbird/blob/master/bigbird/vocab/gpt2.model), which you should be able to load
as easily as:
```python
from transformers import BertGenerationTokenizer
tokenizer = BertGenerationTokenizer("/path/to/gpt2.model/file")
```
To ensure that the tokenizer works correctly, it is recommended to first
create a script in the original repository that inputs a string and
returns the `input_ids`. It could look similar to this (in pseudo-code):
```bash
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BigBirdModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
You might have to take a deeper look again into the original repository
to find the correct tokenizer function or you might even have to do
changes to your clone of the original repository to only output the
`input_ids`. Having written a functional tokenization script that uses
the original repository, an analogous script for 🤗 Transformers should
be created. It should look similar to this:
```python
from transformers import BertGenerationTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BertGenerationTokenizer.from_pretrained("/path/big/bird/folder")
input_ids = tokenizer(input_str).input_ids
```
When both `input_ids` yield the same values, as a final step a tokenizer
test file should also be added.
Since BigBird is most likely fully based on `BertGenerationTokenizer`,
you should only add a couple of "slow" integration tests. However, in this
case you do **not** need to add any `BigBirdTokenizationTest`.
**10. Run End-to-end integration tests**
Having added the tokenizer, you should also add a couple of end-to-end
integration tests using both the model and the tokenizer to
`tests/test_modeling_big_bird.py` in 🤗 Transformers. Such a test
should show on a meaningful text-to-text sample that the 🤗 Transformers
implementation works as expected. A meaningful text-to-text sample can
include, *e.g.*, a source-to-target-translation pair, an
article-to-summary pair, a question-to-answer pair, etc... If none of
the ported checkpoints has been fine-tuned on a downstream task it is
enough to simply rely on the model tests. In a final step to ensure that
the model is fully functional, it is advised that you also run all tests
on GPU. It can happen that you forgot to add some `.to(self.device)`
statements to internal tensors of the model, which in such a test would
show in an error. In case you have no access to a GPU, the Hugging Face
team can take care of running those tests for you.
**11. Add Docstring**
Now, all the necessary functionality for *BigBird* is added -
you're almost done! The only thing left to add is a nice docstring and
a doc page. The Cookiecutter should have added a template file called
`docs/source/model_doc/big_bird.rst` that you should fill out.
Users of your model will usually first look at this page before using
your model. Hence, the documentation must be understandable and concise.
It is very useful for the community to add some *Tips* to show how the
model should be used. Don't hesitate to ping Patrick
regarding the docstrings.
Next, make sure that the docstring added to
`src/transformers/models/big_bird/modeling_big_bird.py` is
correct and included all necessary inputs and outputs. It is always to
good to remind oneself that documentation should be treated at least as
carefully as the code in 🤗 Transformers since the documentation is
usually the first contact point of the community with the model.
**Code refactor**
Great, now you have added all the necessary code for *BigBird*.
At this point, you should correct some potential incorrect code style by
running:
```bash
make style
```
and verify that your coding style passes the quality check:
```bash
make quality
```
There are a couple of other very strict design tests in 🤗 Transformers
that might still be failing, which shows up in the tests of your pull
request. This is often because of some missing information in the
docstring or some incorrect naming. Patrick will surely
help you if you're stuck here.
Lastly, it is always a good idea to refactor one's code after having
ensured that the code works correctly. With all tests passing, now it's
a good time to go over the added code again and do some refactoring.
You have now finished the coding part, congratulation! 🎉 You are
Awesome! 😎
**12. Upload the models to the model hub**
In this final part, you should convert and upload all checkpoints to the
model hub and add a model card for each uploaded model checkpoint. You
should work alongside Patrick here to decide on a fitting
name for each checkpoint and to get the required access rights to be
able to upload the model under the author's organization of
*BigBird*.
It is worth spending some time to create fitting model cards for each
checkpoint. The model cards should highlight the specific
characteristics of this particular checkpoint, *e.g.*, On which dataset
was the checkpoint pretrained/fine-tuned on? On what down-stream task
should the model be used? And also include some code on how to correctly
use the model.
**13. (Optional) Add notebook**
It is very helpful to add a notebook that showcases in-detail how
*BigBird* can be used for inference and/or fine-tuned on a
downstream task. This is not mandatory to merge your PR, but very useful
for the community.
**14. Submit your finished PR**
You're done programming now and can move to the last step, which is
getting your PR merged into main. Usually, Patrick
should have helped you already at this point, but it is worth taking
some time to give your finished PR a nice description and eventually add
comments to your code, if you want to point out certain design choices
to your reviewer.
### Share your work!!
Now, it's time to get some credit from the community for your work!
Having completed a model addition is a major contribution to
Transformers and the whole NLP community. Your code and the ported
pre-trained models will certainly be used by hundreds and possibly even
thousands of developers and researchers. You should be proud of your
work and share your achievement with the community.
**You have made another model that is super easy to access for everyone
in the community! 🤯**
| 0
|
hf_public_repos/transformers/templates
|
hf_public_repos/transformers/templates/adding_a_missing_tokenization_test/README.md
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
This folder contains a template to add a tokenization test.
## Usage
Using the `cookiecutter` utility requires to have all the `dev` dependencies installed.
Let's first [fork](https://docs.github.com/en/get-started/quickstart/fork-a-repo) the `transformers` repo on github. Once it's done you can clone your fork and install `transformers` in our environment:
```shell script
git clone https://github.com/YOUR-USERNAME/transformers
cd transformers
pip install -e ".[dev]"
```
Once the installation is done, you can generate the template by running the following command. Be careful, the template will be generated inside a new folder in your current working directory.
```shell script
cookiecutter path-to-the folder/adding_a_missing_tokenization_test/
```
You will then have to answer some questions about the tokenizer for which you want to add tests. The `modelname` should be cased according to the plain text casing, i.e., BERT, RoBERTa, DeBERTa.
Once the command has finished, you should have a one new file inside the newly created folder named `test_tokenization_Xxx.py`. At this point the template is finished and you can move it to the sub-folder of the corresponding model in the test folder.
| 0
|
hf_public_repos/transformers/templates
|
hf_public_repos/transformers/templates/adding_a_missing_tokenization_test/cookiecutter.json
|
{
"modelname": "BrandNewBERT",
"uppercase_modelname": "BRAND_NEW_BERT",
"lowercase_modelname": "brand_new_bert",
"camelcase_modelname": "BrandNewBert",
"has_slow_class": ["True", "False"],
"has_fast_class": ["True", "False"],
"slow_tokenizer_use_sentencepiece": ["True", "False"],
"authors": "The HuggingFace Team"
}
| 0
|
hf_public_repos/transformers/templates/adding_a_missing_tokenization_test
|
hf_public_repos/transformers/templates/adding_a_missing_tokenization_test/cookiecutter-template-{{cookiecutter.modelname}}/test_tokenization_{{cookiecutter.lowercase_modelname}}.py
|
# coding=utf-8
# Copyright 2022 {{cookiecutter.authors}}. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the {{cookiecutter.modelname}} tokenizer. """
import unittest
{% if cookiecutter.has_slow_class == "True" and cookiecutter.has_fast_class == "True" -%}
from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, {{cookiecutter.camelcase_modelname}}TokenizerFast
{% elif cookiecutter.has_slow_class == "True" -%}
from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer
{% elif cookiecutter.has_fast_class == "True" -%}
from transformers import {{cookiecutter.camelcase_modelname}}TokenizerFast
{% endif -%}
{% if cookiecutter.has_fast_class == "True" and cookiecutter.slow_tokenizer_use_sentencepiece == "True" -%}
from transformers.testing_utils import require_sentencepiece, require_tokenizers
from ...test_tokenization_common import TokenizerTesterMixin
@require_sentencepiece
@require_tokenizers
{% elif cookiecutter.slow_tokenizer_use_sentencepiece == "True" -%}
from transformers.testing_utils import require_sentencepiece
from ...test_tokenization_common import TokenizerTesterMixin
@require_sentencepiece
{% elif cookiecutter.has_fast_class == "True" -%}
from transformers.testing_utils import require_tokenizers
from ...test_tokenization_common import TokenizerTesterMixin
@require_tokenizers
{% else -%}
from ...test_tokenization_common import TokenizerTesterMixin
{% endif -%}
class {{cookiecutter.camelcase_modelname}}TokenizationTest(TokenizerTesterMixin, unittest.TestCase):
{% if cookiecutter.has_slow_class == "True" -%}
tokenizer_class = {{cookiecutter.camelcase_modelname}}Tokenizer
test_slow_tokenizer = True
{% else -%}
tokenizer_class = None
test_slow_tokenizer = False
{% endif -%}
{% if cookiecutter.has_fast_class == "True" -%}
rust_tokenizer_class = {{cookiecutter.camelcase_modelname}}TokenizerFast
test_rust_tokenizer = True
{% else -%}
rust_tokenizer_class = None
test_rust_tokenizer = False
{% endif -%}
{% if cookiecutter.slow_tokenizer_use_sentencepiece == "True" -%}
test_sentencepiece = True
{% endif -%}
# TODO: Check in `TokenizerTesterMixin` if other attributes need to be changed
def setUp(self):
super().setUp()
raise NotImplementedError(
"Here you have to implement the saving of a toy tokenizer in "
"`self.tmpdirname`."
)
# TODO: add tests with hard-coded target values
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/scripts/check_tokenizers.py
|
from collections import Counter
import datasets
import transformers
from transformers.convert_slow_tokenizer import SLOW_TO_FAST_CONVERTERS
from transformers.utils import logging
logging.set_verbosity_info()
TOKENIZER_CLASSES = {
name: (getattr(transformers, name), getattr(transformers, name + "Fast")) for name in SLOW_TO_FAST_CONVERTERS
}
dataset = datasets.load_dataset("xnli", split="test+validation")
total = 0
perfect = 0
imperfect = 0
wrong = 0
def check_diff(spm_diff, tok_diff, slow, fast):
if spm_diff == list(reversed(tok_diff)):
# AAA -> AA+A vs A+AA case.
return True
elif len(spm_diff) == len(tok_diff) and fast.decode(spm_diff) == fast.decode(tok_diff):
# Second order OK
# Barrich -> Barr + ich vs Bar + rich
return True
spm_reencoded = slow.encode(slow.decode(spm_diff))
tok_reencoded = fast.encode(fast.decode(spm_diff))
if spm_reencoded != spm_diff and spm_reencoded == tok_reencoded:
# Type 3 error.
# Snehagatha ->
# Sne, h, aga, th, a
# Sne, ha, gat, ha
# Encoding the wrong with sp does not even recover what spm gave us
# It fits tokenizer however...
return True
return False
def check_LTR_mark(line, idx, fast):
enc = fast.encode_plus(line)[0]
offsets = enc.offsets
curr, prev = offsets[idx], offsets[idx - 1]
if curr is not None and line[curr[0] : curr[1]] == "\u200f":
return True
if prev is not None and line[prev[0] : prev[1]] == "\u200f":
return True
def check_details(line, spm_ids, tok_ids, slow, fast):
# Encoding can be the same with same result AAA -> A + AA vs AA + A
# We can check that we use at least exactly the same number of tokens.
for i, (spm_id, tok_id) in enumerate(zip(spm_ids, tok_ids)):
if spm_id != tok_id:
break
first = i
for i, (spm_id, tok_id) in enumerate(zip(reversed(spm_ids), reversed(tok_ids))):
if spm_id != tok_id:
break
last = len(spm_ids) - i
spm_diff = spm_ids[first:last]
tok_diff = tok_ids[first:last]
if check_diff(spm_diff, tok_diff, slow, fast):
return True
if check_LTR_mark(line, first, fast):
return True
if last - first > 5:
# We might have twice a single problem, attempt to subdivide the disjointed tokens into smaller problems
spms = Counter(spm_ids[first:last])
toks = Counter(tok_ids[first:last])
removable_tokens = {spm_ for (spm_, si) in spms.items() if toks.get(spm_, 0) == si}
min_width = 3
for i in range(last - first - min_width):
if all(spm_ids[first + i + j] in removable_tokens for j in range(min_width)):
possible_matches = [
k
for k in range(last - first - min_width)
if tok_ids[first + k : first + k + min_width] == spm_ids[first + i : first + i + min_width]
]
for j in possible_matches:
if check_diff(spm_ids[first : first + i], tok_ids[first : first + j], sp, tok) and check_details(
line,
spm_ids[first + i : last],
tok_ids[first + j : last],
slow,
fast,
):
return True
print(f"Spm: {[fast.decode([spm_ids[i]]) for i in range(first, last)]}")
try:
print(f"Tok: {[fast.decode([tok_ids[i]]) for i in range(first, last)]}")
except Exception:
pass
fast.decode(spm_ids[:first])
fast.decode(spm_ids[last:])
wrong = fast.decode(spm_ids[first:last])
print()
print(wrong)
return False
def test_string(slow, fast, text):
global perfect
global imperfect
global wrong
global total
slow_ids = slow.encode(text)
fast_ids = fast.encode(text)
skip_assert = False
total += 1
if slow_ids != fast_ids:
if check_details(text, slow_ids, fast_ids, slow, fast):
skip_assert = True
imperfect += 1
else:
wrong += 1
else:
perfect += 1
if total % 10000 == 0:
print(f"({perfect} / {imperfect} / {wrong} ----- {perfect + imperfect + wrong})")
if skip_assert:
return
assert (
slow_ids == fast_ids
), f"line {text} : \n\n{slow_ids}\n{fast_ids}\n\n{slow.tokenize(text)}\n{fast.tokenize(text)}"
def test_tokenizer(slow, fast):
global batch_total
for i in range(len(dataset)):
# premise, all languages
for text in dataset[i]["premise"].values():
test_string(slow, fast, text)
# hypothesis, all languages
for text in dataset[i]["hypothesis"]["translation"]:
test_string(slow, fast, text)
if __name__ == "__main__":
for name, (slow_class, fast_class) in TOKENIZER_CLASSES.items():
checkpoint_names = list(slow_class.max_model_input_sizes.keys())
for checkpoint in checkpoint_names:
imperfect = 0
perfect = 0
wrong = 0
total = 0
print(f"========================== Checking {name}: {checkpoint} ==========================")
slow = slow_class.from_pretrained(checkpoint, force_download=True)
fast = fast_class.from_pretrained(checkpoint, force_download=True)
test_tokenizer(slow, fast)
print(f"Accuracy {perfect * 100 / total:.2f}")
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/scripts/stale.py
|
# Copyright 2021 The HuggingFace Team, the AllenNLP library authors. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Script to close stale issue. Taken in part from the AllenNLP repository.
https://github.com/allenai/allennlp.
"""
import os
from datetime import datetime as dt
import github.GithubException
from github import Github
LABELS_TO_EXEMPT = [
"good first issue",
"good second issue",
"good difficult issue",
"feature request",
"new model",
"wip",
]
def main():
g = Github(os.environ["GITHUB_TOKEN"])
repo = g.get_repo("huggingface/transformers")
open_issues = repo.get_issues(state="open")
for i, issue in enumerate(open_issues):
print(i, issue)
comments = sorted(list(issue.get_comments()), key=lambda i: i.created_at, reverse=True)
last_comment = comments[0] if len(comments) > 0 else None
if (
last_comment is not None and last_comment.user.login == "github-actions[bot]"
and (dt.utcnow() - issue.updated_at.replace(tzinfo=None)).days > 7
and (dt.utcnow() - issue.created_at.replace(tzinfo=None)).days >= 30
and not any(label.name.lower() in LABELS_TO_EXEMPT for label in issue.get_labels())
):
# print(f"Would close issue {issue.number} since it has been 7 days of inactivity since bot mention.")
try:
issue.edit(state="closed")
except github.GithubException as e:
print("Couldn't close the issue:", repr(e))
elif (
(dt.utcnow() - issue.updated_at.replace(tzinfo=None)).days > 23
and (dt.utcnow() - issue.created_at.replace(tzinfo=None)).days >= 30
and not any(label.name.lower() in LABELS_TO_EXEMPT for label in issue.get_labels())
):
# print(f"Would add stale comment to {issue.number}")
try:
issue.create_comment(
"This issue has been automatically marked as stale because it has not had "
"recent activity. If you think this still needs to be addressed "
"please comment on this thread.\n\nPlease note that issues that do not follow the "
"[contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) "
"are likely to be ignored."
)
except github.GithubException as e:
print("Couldn't create comment:", repr(e))
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/fsmt/gen-card-allenai-wmt16.py
|
#!/usr/bin/env python
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Usage:
# ./gen-card-allenai-wmt16.py
import os
from pathlib import Path
def write_model_card(model_card_dir, src_lang, tgt_lang, model_name):
texts = {
"en": "Machine learning is great, isn't it?",
"ru": "Машинное обучение - это здорово, не так ли?",
"de": "Maschinelles Lernen ist großartig, nicht wahr?",
}
# BLUE scores as follows:
# "pair": [fairseq, transformers]
scores = {
"wmt16-en-de-dist-12-1": [28.3, 27.52],
"wmt16-en-de-dist-6-1": [27.4, 27.11],
"wmt16-en-de-12-1": [26.9, 25.75],
}
pair = f"{src_lang}-{tgt_lang}"
readme = f"""
---
language:
- {src_lang}
- {tgt_lang}
thumbnail:
tags:
- translation
- wmt16
- allenai
license: apache-2.0
datasets:
- wmt16
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of fairseq-based [wmt16 transformer](https://github.com/jungokasai/deep-shallow/) for {src_lang}-{tgt_lang}.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
All 3 models are available:
* [wmt16-en-de-dist-12-1](https://huggingface.co/allenai/wmt16-en-de-dist-12-1)
* [wmt16-en-de-dist-6-1](https://huggingface.co/allenai/wmt16-en-de-dist-6-1)
* [wmt16-en-de-12-1](https://huggingface.co/allenai/wmt16-en-de-12-1)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/{model_name}"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "{texts[src_lang]}"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # {texts[tgt_lang]}
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | fairseq | transformers
-------|---------|----------
{model_name} | {scores[model_name][0]} | {scores[model_name][1]}
The score is slightly below the score reported in the paper, as the researchers don't use `sacrebleu` and measure the score on tokenized outputs. `transformers` score was measured using `sacrebleu` on detokenized outputs.
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR={pair}
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt16 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt16 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/{model_name} $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt16/)
- [test set](http://matrix.statmt.org/test_sets/newstest2016.tgz?1504722372)
### BibTeX entry and citation info
```
@misc{{kasai2020deep,
title={{Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation}},
author={{Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith}},
year={{2020}},
eprint={{2006.10369}},
archivePrefix={{arXiv}},
primaryClass={{cs.CL}}
}}
```
"""
model_card_dir.mkdir(parents=True, exist_ok=True)
path = os.path.join(model_card_dir, "README.md")
print(f"Generating {path}")
with open(path, "w", encoding="utf-8") as f:
f.write(readme)
# make sure we are under the root of the project
repo_dir = Path(__file__).resolve().parent.parent.parent
model_cards_dir = repo_dir / "model_cards"
for model_name in ["wmt16-en-de-dist-12-1", "wmt16-en-de-dist-6-1", "wmt16-en-de-12-1"]:
model_card_dir = model_cards_dir / "allenai" / model_name
write_model_card(model_card_dir, src_lang="en", tgt_lang="de", model_name=model_name)
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/fsmt/tests-to-run.sh
|
#!/usr/bin/env bash
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# these scripts need to be run before any changes to FSMT-related code - it should cover all bases
CUDA_VISIBLE_DEVICES="" RUN_SLOW=1 pytest --disable-warnings tests/test_tokenization_fsmt.py tests/test_configuration_auto.py tests/test_modeling_fsmt.py examples/seq2seq/test_fsmt_bleu_score.py
RUN_SLOW=1 pytest --disable-warnings tests/test_tokenization_fsmt.py tests/test_configuration_auto.py tests/test_modeling_fsmt.py examples/seq2seq/test_fsmt_bleu_score.py
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/fsmt/fsmt-make-super-tiny-model.py
|
#!/usr/bin/env python
# coding: utf-8
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# This script creates a super tiny model that is useful inside tests, when we just want to test that
# the machinery works, without needing to the check the quality of the outcomes.
#
# This version creates a tiny vocab first, and then a tiny model - so the outcome is truly tiny -
# all files ~60KB. As compared to taking a full-size model, reducing to the minimum its layers and
# emb dimensions, but keeping the full vocab + merges files, leading to ~3MB in total for all files.
# The latter is done by `fsmt-make-super-tiny-model.py`.
#
# It will be used then as "stas/tiny-wmt19-en-ru"
import json
import tempfile
from pathlib import Path
from transformers import FSMTConfig, FSMTForConditionalGeneration, FSMTTokenizer
from transformers.models.fsmt.tokenization_fsmt import VOCAB_FILES_NAMES
mname_tiny = "tiny-wmt19-en-ru"
# Build
# borrowed from a test
vocab = [ "l", "o", "w", "e", "r", "s", "t", "i", "d", "n", "w</w>", "r</w>", "t</w>", "lo", "low", "er</w>", "low</w>", "lowest</w>", "newer</w>", "wider</w>", "<unk>", ]
vocab_tokens = dict(zip(vocab, range(len(vocab))))
merges = ["l o 123", "lo w 1456", "e r</w> 1789", ""]
with tempfile.TemporaryDirectory() as tmpdirname:
build_dir = Path(tmpdirname)
src_vocab_file = build_dir / VOCAB_FILES_NAMES["src_vocab_file"]
tgt_vocab_file = build_dir / VOCAB_FILES_NAMES["tgt_vocab_file"]
merges_file = build_dir / VOCAB_FILES_NAMES["merges_file"]
with open(src_vocab_file, "w") as fp: fp.write(json.dumps(vocab_tokens))
with open(tgt_vocab_file, "w") as fp: fp.write(json.dumps(vocab_tokens))
with open(merges_file, "w") as fp : fp.write("\n".join(merges))
tokenizer = FSMTTokenizer(
langs=["en", "ru"],
src_vocab_size = len(vocab),
tgt_vocab_size = len(vocab),
src_vocab_file=src_vocab_file,
tgt_vocab_file=tgt_vocab_file,
merges_file=merges_file,
)
config = FSMTConfig(
langs=['ru', 'en'],
src_vocab_size=1000, tgt_vocab_size=1000,
d_model=4,
encoder_layers=1, decoder_layers=1,
encoder_ffn_dim=4, decoder_ffn_dim=4,
encoder_attention_heads=1, decoder_attention_heads=1,
)
tiny_model = FSMTForConditionalGeneration(config)
print(f"num of params {tiny_model.num_parameters()}")
# Test
batch = tokenizer(["Making tiny model"], return_tensors="pt")
outputs = tiny_model(**batch)
print("test output:", len(outputs.logits[0]))
# Save
tiny_model.half() # makes it smaller
tiny_model.save_pretrained(mname_tiny)
tokenizer.save_pretrained(mname_tiny)
print(f"Generated {mname_tiny}")
# Upload
# transformers-cli upload tiny-wmt19-en-ru
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/fsmt/eval-allenai-wmt19.sh
|
#!/usr/bin/env bash
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# this script evals the following fsmt models
# it covers:
# - allenai/wmt19-de-en-6-6-base
# - allenai/wmt19-de-en-6-6-big
# this script needs to be run from the top level of the transformers repo
if [ ! -d "src/transformers" ]; then
echo "Error: This script needs to be run from the top of the transformers repo"
exit 1
fi
# In these scripts you may have to lower BS if you get CUDA OOM (or increase it if you have a large GPU)
### Normal eval ###
export PAIR=de-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=64
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
MODEL_PATH=allenai/wmt19-de-en-6-6-base
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
MODEL_PATH=allenai/wmt19-de-en-6-6-big
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
### Searching hparams eval ###
export PAIR=de-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=16
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
MODEL_PATH=allenai/wmt19-de-en-6-6-base
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --search="num_beams=5:10:15 length_penalty=0.6:0.7:0.8:0.9:1.0:1.1"
MODEL_PATH=allenai/wmt19-de-en-6-6-big
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --search="num_beams=5:10:15 length_penalty=0.6:0.7:0.8:0.9:1.0:1.1"
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/fsmt/convert-allenai-wmt16.sh
|
#!/usr/bin/env bash
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# this script acquires data and converts it to fsmt model
# it covers:
# - allenai/wmt16-en-de-dist-12-1
# - allenai/wmt16-en-de-dist-6-1
# - allenai/wmt16-en-de-12-1
# this script needs to be run from the top level of the transformers repo
if [ ! -d "src/transformers" ]; then
echo "Error: This script needs to be run from the top of the transformers repo"
exit 1
fi
mkdir data
# get data (run once)
cd data
gdown 'https://drive.google.com/uc?id=1x_G2cjvM1nW5hjAB8-vWxRqtQTlmIaQU'
gdown 'https://drive.google.com/uc?id=1oA2aqZlVNj5FarxBlNXEHpBS4lRetTzU'
gdown 'https://drive.google.com/uc?id=1Wup2D318QYBFPW_NKI1mfP_hXOfmUI9r'
tar -xvzf trans_ende_12-1_0.2.tar.gz
tar -xvzf trans_ende-dist_12-1_0.2.tar.gz
tar -xvzf trans_ende-dist_6-1_0.2.tar.gz
gdown 'https://drive.google.com/uc?id=1mNufoynJ9-Zy1kJh2TA_lHm2squji0i9'
gdown 'https://drive.google.com/uc?id=1iO7um-HWoNoRKDtw27YUSgyeubn9uXqj'
tar -xvzf wmt16.en-de.deep-shallow.dist.tar.gz
tar -xvzf wmt16.en-de.deep-shallow.tar.gz
cp wmt16.en-de.deep-shallow/data-bin/dict.*.txt trans_ende_12-1_0.2
cp wmt16.en-de.deep-shallow.dist/data-bin/dict.*.txt trans_ende-dist_12-1_0.2
cp wmt16.en-de.deep-shallow.dist/data-bin/dict.*.txt trans_ende-dist_6-1_0.2
cp wmt16.en-de.deep-shallow/bpecodes trans_ende_12-1_0.2
cp wmt16.en-de.deep-shallow.dist/bpecodes trans_ende-dist_12-1_0.2
cp wmt16.en-de.deep-shallow.dist/bpecodes trans_ende-dist_6-1_0.2
cd -
# run conversions and uploads
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/trans_ende-dist_12-1_0.2/checkpoint_top5_average.pt --pytorch_dump_folder_path data/wmt16-en-de-dist-12-1
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/trans_ende-dist_6-1_0.2/checkpoint_top5_average.pt --pytorch_dump_folder_path data/wmt16-en-de-dist-6-1
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/trans_ende_12-1_0.2/checkpoint_top5_average.pt --pytorch_dump_folder_path data/wmt16-en-de-12-1
# upload
cd data
transformers-cli upload -y wmt16-en-de-dist-12-1
transformers-cli upload -y wmt16-en-de-dist-6-1
transformers-cli upload -y wmt16-en-de-12-1
cd -
# if updating just small files and not the large models, here is a script to generate the right commands:
perl -le 'for $f (@ARGV) { print qq[transformers-cli upload -y $_/$f --filename $_/$f] for ("wmt16-en-de-dist-12-1", "wmt16-en-de-dist-6-1", "wmt16-en-de-12-1")}' vocab-src.json vocab-tgt.json tokenizer_config.json config.json
# add/remove files as needed
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/fsmt/s3-move.sh
|
# this is the process of uploading the updated models to s3. As I can't upload them directly to the correct orgs, this script shows how this is done
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
1. upload updated models to my account
transformers-cli upload -y wmt19-ru-en
transformers-cli upload -y wmt19-en-ru
transformers-cli upload -y wmt19-de-en
transformers-cli upload -y wmt19-en-de
transformers-cli upload -y wmt19-de-en-6-6-base
transformers-cli upload -y wmt19-de-en-6-6-big
transformers-cli upload -y wmt16-en-de-dist-12-1
transformers-cli upload -y wmt16-en-de-dist-6-1
transformers-cli upload -y wmt16-en-de-12-1
2. ask someone to move them to:
* to facebook: "wmt19-ru-en", "wmt19-en-ru", "wmt19-en-de", "wmt19-de-en"
* to allenai: "wmt16-en-de-dist-12-1", "wmt16-en-de-dist-6-1", "wmt16-en-de-12-1", "wmt19-de-en-6-6-base", "wmt19-de-en-6-6-big"
export b="s3://models.huggingface.co/bert"
stas_to_fb () {
src=$1
shift
aws s3 sync $b/stas/$src $b/facebook/$src $@
}
stas_to_allenai () {
src=$1
shift
aws s3 sync $b/stas/$src $b/allenai/$src $@
}
stas_to_fb wmt19-en-ru
stas_to_fb wmt19-ru-en
stas_to_fb wmt19-en-de
stas_to_fb wmt19-de-en
stas_to_allenai wmt16-en-de-dist-12-1
stas_to_allenai wmt16-en-de-dist-6-1
stas_to_allenai wmt16-en-de-6-1
stas_to_allenai wmt16-en-de-12-1
stas_to_allenai wmt19-de-en-6-6-base
stas_to_allenai wmt19-de-en-6-6-big
3. and then remove all these model files from my account
transformers-cli s3 rm wmt16-en-de-12-1/config.json
transformers-cli s3 rm wmt16-en-de-12-1/merges.txt
transformers-cli s3 rm wmt16-en-de-12-1/pytorch_model.bin
transformers-cli s3 rm wmt16-en-de-12-1/tokenizer_config.json
transformers-cli s3 rm wmt16-en-de-12-1/vocab-src.json
transformers-cli s3 rm wmt16-en-de-12-1/vocab-tgt.json
transformers-cli s3 rm wmt16-en-de-dist-12-1/config.json
transformers-cli s3 rm wmt16-en-de-dist-12-1/merges.txt
transformers-cli s3 rm wmt16-en-de-dist-12-1/pytorch_model.bin
transformers-cli s3 rm wmt16-en-de-dist-12-1/tokenizer_config.json
transformers-cli s3 rm wmt16-en-de-dist-12-1/vocab-src.json
transformers-cli s3 rm wmt16-en-de-dist-12-1/vocab-tgt.json
transformers-cli s3 rm wmt16-en-de-dist-6-1/config.json
transformers-cli s3 rm wmt16-en-de-dist-6-1/merges.txt
transformers-cli s3 rm wmt16-en-de-dist-6-1/pytorch_model.bin
transformers-cli s3 rm wmt16-en-de-dist-6-1/tokenizer_config.json
transformers-cli s3 rm wmt16-en-de-dist-6-1/vocab-src.json
transformers-cli s3 rm wmt16-en-de-dist-6-1/vocab-tgt.json
transformers-cli s3 rm wmt19-de-en-6-6-base/config.json
transformers-cli s3 rm wmt19-de-en-6-6-base/merges.txt
transformers-cli s3 rm wmt19-de-en-6-6-base/pytorch_model.bin
transformers-cli s3 rm wmt19-de-en-6-6-base/tokenizer_config.json
transformers-cli s3 rm wmt19-de-en-6-6-base/vocab-src.json
transformers-cli s3 rm wmt19-de-en-6-6-base/vocab-tgt.json
transformers-cli s3 rm wmt19-de-en-6-6-big/config.json
transformers-cli s3 rm wmt19-de-en-6-6-big/merges.txt
transformers-cli s3 rm wmt19-de-en-6-6-big/pytorch_model.bin
transformers-cli s3 rm wmt19-de-en-6-6-big/tokenizer_config.json
transformers-cli s3 rm wmt19-de-en-6-6-big/vocab-src.json
transformers-cli s3 rm wmt19-de-en-6-6-big/vocab-tgt.json
transformers-cli s3 rm wmt19-de-en/config.json
transformers-cli s3 rm wmt19-de-en/merges.txt
transformers-cli s3 rm wmt19-de-en/pytorch_model.bin
transformers-cli s3 rm wmt19-de-en/tokenizer_config.json
transformers-cli s3 rm wmt19-de-en/vocab-src.json
transformers-cli s3 rm wmt19-de-en/vocab-tgt.json
transformers-cli s3 rm wmt19-en-de/config.json
transformers-cli s3 rm wmt19-en-de/merges.txt
transformers-cli s3 rm wmt19-en-de/pytorch_model.bin
transformers-cli s3 rm wmt19-en-de/tokenizer_config.json
transformers-cli s3 rm wmt19-en-de/vocab-src.json
transformers-cli s3 rm wmt19-en-de/vocab-tgt.json
transformers-cli s3 rm wmt19-en-ru/config.json
transformers-cli s3 rm wmt19-en-ru/merges.txt
transformers-cli s3 rm wmt19-en-ru/pytorch_model.bin
transformers-cli s3 rm wmt19-en-ru/tokenizer_config.json
transformers-cli s3 rm wmt19-en-ru/vocab-src.json
transformers-cli s3 rm wmt19-en-ru/vocab-tgt.json
transformers-cli s3 rm wmt19-ru-en/config.json
transformers-cli s3 rm wmt19-ru-en/merges.txt
transformers-cli s3 rm wmt19-ru-en/pytorch_model.bin
transformers-cli s3 rm wmt19-ru-en/tokenizer_config.json
transformers-cli s3 rm wmt19-ru-en/vocab-src.json
transformers-cli s3 rm wmt19-ru-en/vocab-tgt.json
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/fsmt/eval-allenai-wmt16.sh
|
#!/usr/bin/env bash
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# this script evals the following fsmt models
# it covers:
# - allenai/wmt16-en-de-dist-12-1
# - allenai/wmt16-en-de-dist-6-1
# - allenai/wmt16-en-de-12-1
# this script needs to be run from the top level of the transformers repo
if [ ! -d "src/transformers" ]; then
echo "Error: This script needs to be run from the top of the transformers repo"
exit 1
fi
# In these scripts you may have to lower BS if you get CUDA OOM (or increase it if you have a large GPU)
### Normal eval ###
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=64
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
MODEL_PATH=allenai/wmt16-en-de-dist-12-1
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
MODEL_PATH=allenai/wmt16-en-de-dist-6-1
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
MODEL_PATH=allenai/wmt16-en-de-12-1
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
### Searching hparams eval ###
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=32
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
MODEL_PATH=allenai/wmt16-en-de-dist-12-1
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --search="num_beams=5:10:15 length_penalty=0.6:0.7:0.8:0.9:1.0:1.1"
MODEL_PATH=allenai/wmt16-en-de-dist-6-1
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --search="num_beams=5:10:15 length_penalty=0.6:0.7:0.8:0.9:1.0:1.1"
MODEL_PATH=allenai/wmt16-en-de-12-1
echo $PAIR $MODEL_PATH
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py $MODEL_PATH $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --search="num_beams=5:10:15 length_penalty=0.6:0.7:0.8:0.9:1.0:1.1"
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/fsmt/convert-allenai-wmt19.sh
|
#!/usr/bin/env bash
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# this script acquires data and converts it to fsmt model
# it covers:
# - allenai/wmt19-de-en-6-6-base
# - allenai/wmt19-de-en-6-6-big
# this script needs to be run from the top level of the transformers repo
if [ ! -d "src/transformers" ]; then
echo "Error: This script needs to be run from the top of the transformers repo"
exit 1
fi
mkdir data
# get data (run once)
cd data
gdown 'https://drive.google.com/uc?id=1j6z9fYdlUyOYsh7KJoumRlr1yHczxR5T'
gdown 'https://drive.google.com/uc?id=1yT7ZjqfvUYOBXvMjeY8uGRHQFWoSo8Q5'
gdown 'https://drive.google.com/uc?id=15gAzHeRUCs-QV8vHeTReMPEh1j8excNE'
tar -xvzf wmt19.de-en.tar.gz
tar -xvzf wmt19_deen_base_dr0.1_1.tar.gz
tar -xvzf wmt19_deen_big_dr0.1_2.tar.gz
cp wmt19.de-en/data-bin/dict.*.txt wmt19_deen_base_dr0.1_1
cp wmt19.de-en/data-bin/dict.*.txt wmt19_deen_big_dr0.1_2
cd -
# run conversions and uploads
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/wmt19_deen_base_dr0.1_1/checkpoint_last3_avg.pt --pytorch_dump_folder_path data/wmt19-de-en-6-6-base
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/wmt19_deen_big_dr0.1_2/checkpoint_last3_avg.pt --pytorch_dump_folder_path data/wmt19-de-en-6-6-big
# upload
cd data
transformers-cli upload -y wmt19-de-en-6-6-base
transformers-cli upload -y wmt19-de-en-6-6-big
cd -
# if updating just small files and not the large models, here is a script to generate the right commands:
perl -le 'for $f (@ARGV) { print qq[transformers-cli upload -y $_/$f --filename $_/$f] for ("wmt19-de-en-6-6-base", "wmt19-de-en-6-6-big")}' vocab-src.json vocab-tgt.json tokenizer_config.json config.json
# add/remove files as needed
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/fsmt/eval-facebook-wmt19.sh
|
#!/usr/bin/env bash
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# this script evals the following fsmt models
# it covers:
# - facebook/wmt19-ru-en
# - facebook/wmt19-en-ru
# - facebook/wmt19-de-en
# - facebook/wmt19-en-de
# this script needs to be run from the top level of the transformers repo
if [ ! -d "src/transformers" ]; then
echo "Error: This script needs to be run from the top of the transformers repo"
exit 1
fi
# In these scripts you may have to lower BS if you get CUDA OOM (or increase it if you have a large GPU)
### a short estimate version for quick testing ###
export PAIR=en-ru
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=8
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src | head -10 > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref | head -10 > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
### Normal eval ###
# ru-en
export PAIR=ru-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=50
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
# (target BLEU: 41.3 http://matrix.statmt.org/matrix/output/1907?run_id=6937)
# en-ru
export PAIR=en-ru
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=50
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
# (target BLEU: 36.4 http://matrix.statmt.org/matrix/output/1914?score_id=37605)
# en-de
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
# (target BLEU: 43.1 http://matrix.statmt.org/matrix/output/1909?run_id=6862)
# de-en
export PAIR=de-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=50
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
# (target BLEU: 42.3 http://matrix.statmt.org/matrix/output/1902?run_id=6750)
### Searching hparams eval ###
# en-ru
export PAIR=ru-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=32
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
CUDA_VISIBLE_DEVICES="0" PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --search="num_beams=5 length_penalty=0.6:0.7:0.8:0.9:1.0:1.1"
# en-ru
export PAIR=en-ru
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=16
mkdir -p $DATA_DIR
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
CUDA_VISIBLE_DEVICES="0" PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --search="num_beams=5:8:11:15 length_penalty=0.6:0.7:0.8:0.9:1.0:1.1 early_stopping=true:false"
# en-de
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=16
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
CUDA_VISIBLE_DEVICES="1" PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --search="num_beams=5:8:11:15 length_penalty=0.6:0.7:0.8:0.9:1.0:1.1 early_stopping=true:false"
# de-en
export PAIR=de-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=16
mkdir -p $DATA_DIR
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
CUDA_VISIBLE_DEVICES="1" PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --search="num_beams=5:8:11:15 length_penalty=0.6:0.7:0.8:0.9:1.0:1.1 early_stopping=true:false"
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/fsmt/fsmt-make-tiny-model.py
|
#!/usr/bin/env python
# coding: utf-8
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# This script creates a super tiny model that is useful inside tests, when we just want to test that
# the machinery works, without needing to the check the quality of the outcomes.
#
# This version creates a tiny model through reduction of a normal pre-trained model, but keeping the
# full vocab, merges file, and thus also resulting in a larger model due to a large vocab size.
# This gives ~3MB in total for all files.
#
# If you want a 50 times smaller than this see `fsmt-make-super-tiny-model.py`, which is slightly more complicated
#
#
# It will be used then as "stas/tiny-wmt19-en-de"
# Build
from transformers import FSMTConfig, FSMTForConditionalGeneration, FSMTTokenizer
mname = "facebook/wmt19-en-de"
tokenizer = FSMTTokenizer.from_pretrained(mname)
# get the correct vocab sizes, etc. from the master model
config = FSMTConfig.from_pretrained(mname)
config.update({
"d_model": 4,
"encoder_layers": 1, "decoder_layers": 1,
"encoder_ffn_dim": 4, "decoder_ffn_dim": 4,
"encoder_attention_heads": 1, "decoder_attention_heads": 1})
tiny_model = FSMTForConditionalGeneration(config)
print(f"num of params {tiny_model.num_parameters()}")
# Test
batch = tokenizer(["Making tiny model"], return_tensors="pt")
outputs = tiny_model(**batch)
print("test output:", len(outputs.logits[0]))
# Save
mname_tiny = "tiny-wmt19-en-de"
tiny_model.half() # makes it smaller
tiny_model.save_pretrained(mname_tiny)
tokenizer.save_pretrained(mname_tiny)
print(f"Generated {mname_tiny}")
# Upload
# transformers-cli upload tiny-wmt19-en-de
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/fsmt/gen-card-facebook-wmt19.py
|
#!/usr/bin/env python
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Usage:
# ./gen-card-facebook-wmt19.py
import os
from pathlib import Path
def write_model_card(model_card_dir, src_lang, tgt_lang):
texts = {
"en": "Machine learning is great, isn't it?",
"ru": "Машинное обучение - это здорово, не так ли?",
"de": "Maschinelles Lernen ist großartig, oder?",
}
# BLUE scores as follows:
# "pair": [fairseq, transformers]
scores = {
"ru-en": ["[41.3](http://matrix.statmt.org/matrix/output/1907?run_id=6937)", "39.20"],
"en-ru": ["[36.4](http://matrix.statmt.org/matrix/output/1914?run_id=6724)", "33.47"],
"en-de": ["[43.1](http://matrix.statmt.org/matrix/output/1909?run_id=6862)", "42.83"],
"de-en": ["[42.3](http://matrix.statmt.org/matrix/output/1902?run_id=6750)", "41.35"],
}
pair = f"{src_lang}-{tgt_lang}"
readme = f"""
---
language:
- {src_lang}
- {tgt_lang}
thumbnail:
tags:
- translation
- wmt19
- facebook
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of [fairseq wmt19 transformer](https://github.com/pytorch/fairseq/blob/master/examples/wmt19/README.md) for {src_lang}-{tgt_lang}.
For more details, please see, [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616).
The abbreviation FSMT stands for FairSeqMachineTranslation
All four models are available:
* [wmt19-en-ru](https://huggingface.co/facebook/wmt19-en-ru)
* [wmt19-ru-en](https://huggingface.co/facebook/wmt19-ru-en)
* [wmt19-en-de](https://huggingface.co/facebook/wmt19-en-de)
* [wmt19-de-en](https://huggingface.co/facebook/wmt19-de-en)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "facebook/wmt19-{src_lang}-{tgt_lang}"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "{texts[src_lang]}"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # {texts[tgt_lang]}
```
#### Limitations and bias
- The original (and this ported model) doesn't seem to handle well inputs with repeated sub-phrases, [content gets truncated](https://discuss.huggingface.co/t/issues-with-translating-inputs-containing-repeated-phrases/981)
## Training data
Pretrained weights were left identical to the original model released by fairseq. For more details, please, see the [paper](https://arxiv.org/abs/1907.06616).
## Eval results
pair | fairseq | transformers
-------|---------|----------
{pair} | {scores[pair][0]} | {scores[pair][1]}
The score is slightly below the score reported by `fairseq`, since `transformers`` currently doesn't support:
- model ensemble, therefore the best performing checkpoint was ported (``model4.pt``).
- re-ranking
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR={pair}
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=15
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
note: fairseq reports using a beam of 50, so you should get a slightly higher score if re-run with `--num_beams 50`.
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```bibtex
@inproceedings{{...,
year={{2020}},
title={{Facebook FAIR's WMT19 News Translation Task Submission}},
author={{Ng, Nathan and Yee, Kyra and Baevski, Alexei and Ott, Myle and Auli, Michael and Edunov, Sergey}},
booktitle={{Proc. of WMT}},
}}
```
## TODO
- port model ensemble (fairseq uses 4 model checkpoints)
"""
os.makedirs(model_card_dir, exist_ok=True)
path = os.path.join(model_card_dir, "README.md")
print(f"Generating {path}")
with open(path, "w", encoding="utf-8") as f:
f.write(readme)
# make sure we are under the root of the project
repo_dir = Path(__file__).resolve().parent.parent.parent
model_cards_dir = repo_dir / "model_cards"
for model_name in ["wmt19-ru-en", "wmt19-en-ru", "wmt19-en-de", "wmt19-de-en"]:
base, src_lang, tgt_lang = model_name.split("-")
model_card_dir = model_cards_dir / "facebook" / model_name
write_model_card(model_card_dir, src_lang=src_lang, tgt_lang=tgt_lang)
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/fsmt/convert-facebook-wmt19.sh
|
#!/usr/bin/env bash
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# this script acquires data and converts it to fsmt model
# it covers:
# - facebook/wmt19-ru-en
# - facebook/wmt19-en-ru
# - facebook/wmt19-de-en
# - facebook/wmt19-en-de
# this script needs to be run from the top level of the transformers repo
if [ ! -d "src/transformers" ]; then
echo "Error: This script needs to be run from the top of the transformers repo"
exit 1
fi
mkdir data
# get data (run once)
cd data
wget https://dl.fbaipublicfiles.com/fairseq/models/wmt19.en-de.joined-dict.ensemble.tar.gz
wget https://dl.fbaipublicfiles.com/fairseq/models/wmt19.de-en.joined-dict.ensemble.tar.gz
wget https://dl.fbaipublicfiles.com/fairseq/models/wmt19.en-ru.ensemble.tar.gz
wget https://dl.fbaipublicfiles.com/fairseq/models/wmt19.ru-en.ensemble.tar.gz
tar -xvzf wmt19.en-de.joined-dict.ensemble.tar.gz
tar -xvzf wmt19.de-en.joined-dict.ensemble.tar.gz
tar -xvzf wmt19.en-ru.ensemble.tar.gz
tar -xvzf wmt19.ru-en.ensemble.tar.gz
cd -
# run conversions and uploads
export PAIR=ru-en
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/wmt19.$PAIR.ensemble/model4.pt --pytorch_dump_folder_path data/wmt19-$PAIR
export PAIR=en-ru
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/wmt19.$PAIR.ensemble/model4.pt --pytorch_dump_folder_path data/wmt19-$PAIR
export PAIR=de-en
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/wmt19.$PAIR.joined-dict.ensemble/model4.pt --pytorch_dump_folder_path data/wmt19-$PAIR
export PAIR=en-de
PYTHONPATH="src" python src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py --fsmt_checkpoint_path data/wmt19.$PAIR.joined-dict.ensemble/model4.pt --pytorch_dump_folder_path data/wmt19-$PAIR
# upload
cd data
transformers-cli upload -y wmt19-ru-en
transformers-cli upload -y wmt19-en-ru
transformers-cli upload -y wmt19-de-en
transformers-cli upload -y wmt19-en-de
cd -
# if updating just small files and not the large models, here is a script to generate the right commands:
perl -le 'for $f (@ARGV) { print qq[transformers-cli upload -y $_/$f --filename $_/$f] for map { "wmt19-$_" } ("en-ru", "ru-en", "de-en", "en-de")}' vocab-src.json vocab-tgt.json tokenizer_config.json config.json
# add/remove files as needed
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/fsmt/gen-card-allenai-wmt19.py
|
#!/usr/bin/env python
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Usage:
# ./gen-card-allenai-wmt19.py
import os
from pathlib import Path
def write_model_card(model_card_dir, src_lang, tgt_lang, model_name):
texts = {
"en": "Machine learning is great, isn't it?",
"ru": "Машинное обучение - это здорово, не так ли?",
"de": "Maschinelles Lernen ist großartig, nicht wahr?",
}
# BLUE scores as follows:
# "pair": [fairseq, transformers]
scores = {
"wmt19-de-en-6-6-base": [0, 38.37],
"wmt19-de-en-6-6-big": [0, 39.90],
}
pair = f"{src_lang}-{tgt_lang}"
readme = f"""
---
language:
- {src_lang}
- {tgt_lang}
thumbnail:
tags:
- translation
- wmt19
- allenai
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of fairseq-based [wmt19 transformer](https://github.com/jungokasai/deep-shallow/) for {src_lang}-{tgt_lang}.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
2 models are available:
* [wmt19-de-en-6-6-big](https://huggingface.co/allenai/wmt19-de-en-6-6-big)
* [wmt19-de-en-6-6-base](https://huggingface.co/allenai/wmt19-de-en-6-6-base)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/{model_name}"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "{texts[src_lang]}"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # {texts[tgt_lang]}
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | transformers
-------|---------
{model_name} | {scores[model_name][1]}
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR={pair}
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/{model_name} $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```
@misc{{kasai2020deep,
title={{Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation}},
author={{Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith}},
year={{2020}},
eprint={{2006.10369}},
archivePrefix={{arXiv}},
primaryClass={{cs.CL}}
}}
```
"""
model_card_dir.mkdir(parents=True, exist_ok=True)
path = os.path.join(model_card_dir, "README.md")
print(f"Generating {path}")
with open(path, "w", encoding="utf-8") as f:
f.write(readme)
# make sure we are under the root of the project
repo_dir = Path(__file__).resolve().parent.parent.parent
model_cards_dir = repo_dir / "model_cards"
for model_name in ["wmt19-de-en-6-6-base", "wmt19-de-en-6-6-big"]:
model_card_dir = model_cards_dir / "allenai" / model_name
write_model_card(model_card_dir, src_lang="de", tgt_lang="en", model_name=model_name)
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/benchmark/trainer-benchmark.py
|
#!/usr/bin/env python
# HF Trainer benchmarking tool
#
# This tool can be used to run and compare multiple dimensions of the HF Trainers args.
#
# It then prints a report once in github format with all the information that needs to be shared
# with others and second time in a console-friendly format, so it's easier to use for tuning things up.
#
# The main idea is:
#
# ./trainer-benchmark.py --base-cmd '<cmd args that don't change>' \
# --variations '--tf32 0|--tf32 1' '--fp16 0|--fp16 1|--bf16 1' \
# --target-metric-key train_samples_per_second
#
# The variations can be any command line argument that you want to compare and not just dtype as in
# the example.
#
# --variations allows you to compare variations in multiple dimensions.
#
# as the first dimention has 2 options and the second 3 in our example, this will run the trainer 6
# times adding one of:
#
# 1. --tf32 0 --fp16 0
# 2. --tf32 0 --fp16 1
# 3. --tf32 0 --bf16 1
# 4. --tf32 1 --fp16 0
# 5. --tf32 1 --fp16 1
# 6. --tf32 1 --bf16 1
#
# and print the results. This is just a cartesian product - and more than 2 dimensions can be used.
#
# If you want to rely on defaults, this:
# --variations '--tf32 0|--tf32 1' '--fp16 0|--fp16 1|--bf16 1'
# is identical to this:
# --variations '--tf32 0|--tf32 1' '|--fp16|--bf16'
#
# the leading empty variation in the 2nd dimension is a valid variation.
#
# So here we get the following 6 variations:
#
# 1. --tf32 0
# 2. --tf32 0 --fp16
# 3. --tf32 0 --bf16
# 4. --tf32 1
# 5. --tf32 1 --fp16
# 6. --tf32 1 --bf16
#
# In this particular case we don't know what the default tf32 setting is as it's normally
# pytorch-version dependent). That's why it's best to do an explicit setting of each variation:
# `--tf32 0|--tf32 1`
#
# Here is a full example of a train:
#
# CUDA_VISIBLE_DEVICES=0 python ./scripts/benchmark/trainer-benchmark.py \
# --base-cmd \
# ' examples/pytorch/translation/run_translation.py --model_name_or_path t5-small \
# --output_dir output_dir --do_train --label_smoothing 0.1 --logging_strategy no \
# --save_strategy no --per_device_train_batch_size 32 --max_source_length 512 \
# --max_target_length 512 --num_train_epochs 1 --overwrite_output_dir \
# --source_lang en --target_lang ro --dataset_name wmt16 --dataset_config "ro-en" \
# --source_prefix "translate English to Romanian: " --warmup_steps 50 \
# --max_train_samples 20000 --dataloader_num_workers 2 ' \
# --target-metric-key train_samples_per_second --repeat-times 1 --variations \
# '|--fp16|--bf16' '--tf32 0|--tf32 1' --report-metric-keys train_loss \
# --repeat-times 1 --base-variation '--tf32 0'
#
# and here is a possible output:
#
#
# | Variation | Train | Diff | Train |
# | | samples | % | loss |
# | | per | | |
# | | second | | |
# |:----------------|----------:|-------:|--------:|
# | --tf32 0 | 285.11 | 0 | 2.51 |
# | --tf32 1 | 342.09 | 20 | 2.51 |
# | --fp16 --tf32 0 | 423.49 | 49 | 2.51 |
# | --fp16 --tf32 1 | 423.13 | 48 | 2.51 |
# | --bf16 --tf32 0 | 416.80 | 46 | 2.52 |
# | --bf16 --tf32 1 | 415.87 | 46 | 2.52 |
#
#
# So you can quickly compare the different outcomes.
#
# Typically running each experiment once is enough, but if the environment is unstable you can
# re-run each multiple times, e.g., 3 using --repeat-times 3 and it will report the averaged results.
#
# By default it'll use the lowest result as the base line to use as 100% and then compare the rest to
# it as can be seen from the table above, but you can also specify which combination is the one to use as
# the baseline, e.g., to change to another entry use: --base-variation '--tf32 1 --fp16 0'
#
# --target-metric-key is there to tell the program which metrics to compare - the different metric keys are
# inside output_dir/all_results.json. e.g., to measure eval performance instead of train use:
# --target-metric-key eval_samples_per_second
# but of course you will need to adjust the --base-cmd value in the example to perform evaluation as
# well (as currently it doesn't)
#
import argparse
import datetime
import io
import itertools
import json
import math
import os
import platform
import re
import shlex
import subprocess
import sys
from pathlib import Path
from statistics import fmean
import pandas as pd
import torch
from tqdm import tqdm
import transformers
nan = float("nan")
class Tee:
"""
A helper class to tee print's output into a file.
Usage:
sys.stdout = Tee(filename)
"""
def __init__(self, filename):
self.stdout = sys.stdout
self.file = open(filename, "a")
def __getattr__(self, attr):
return getattr(self.stdout, attr)
def write(self, msg):
self.stdout.write(msg)
# strip tqdm codes
self.file.write(re.sub(r"^.*\r", "", msg, 0, re.M))
def get_original_command(max_width=80, full_python_path=False):
"""
Return the original command line string that can be replayed nicely and wrapped for 80 char width.
Args:
max_width (`int`, `optional`, defaults to 80):
The width to wrap for.
full_python_path (`bool`, `optional`, defaults to `False`):
Whether to replicate the full path or just the last segment (i.e. `python`).
"""
cmd = []
# deal with critical env vars
env_keys = ["CUDA_VISIBLE_DEVICES"]
for key in env_keys:
val = os.environ.get(key, None)
if val is not None:
cmd.append(f"{key}={val}")
# python executable (not always needed if the script is executable)
python = sys.executable if full_python_path else sys.executable.split("/")[-1]
cmd.append(python)
# now the normal args
cmd += list(map(shlex.quote, sys.argv))
# split up into up to MAX_WIDTH lines with shell multi-line escapes
lines = []
current_line = ""
while len(cmd) > 0:
current_line += f"{cmd.pop(0)} "
if len(cmd) == 0 or len(current_line) + len(cmd[0]) + 1 > max_width - 1:
lines.append(current_line)
current_line = ""
return "\\\n".join(lines)
def get_base_command(args, output_dir):
# unwrap multi-line input
args.base_cmd = re.sub(r"[\\\n]+", " ", args.base_cmd)
# remove --output_dir if any and set our own
args.base_cmd = re.sub("--output_dir\s+[^\s]+", "", args.base_cmd)
args.base_cmd += f" --output_dir {output_dir}"
# ensure we have --overwrite_output_dir
args.base_cmd = re.sub("--overwrite_output_dir\s+", "", args.base_cmd)
args.base_cmd += " --overwrite_output_dir"
return [sys.executable] + shlex.split(args.base_cmd)
def process_run_single(id, cmd, variation, output_dir, target_metric_key, metric_keys, verbose):
# Enable to debug everything but the run itself, to do it fast and see the progress.
# This is useful for debugging the output formatting quickly - we can remove it later once
# everybody is happy with the output
if 0:
import random
from time import sleep
sleep(0)
return dict(
{k: random.uniform(0, 100) for k in metric_keys},
**{target_metric_key: random.choice([nan, 10.31, 100.2, 55.6666, 222.22222222])},
)
result = subprocess.run(cmd, capture_output=True, text=True)
if verbose:
print("STDOUT", result.stdout)
print("STDERR", result.stderr)
# save the streams
prefix = variation.replace(" ", "-")
with open(Path(output_dir) / f"log.{prefix}.stdout.txt", "w") as f:
f.write(result.stdout)
with open(Path(output_dir) / f"log.{prefix}.stderr.txt", "w") as f:
f.write(result.stderr)
if result.returncode != 0:
if verbose:
print("failed")
return {target_metric_key: nan}
with io.open(f"{output_dir}/all_results.json", "r", encoding="utf-8") as f:
metrics = json.load(f)
# filter out just the keys we want
return {k: v for k, v in metrics.items() if k in metric_keys}
def process_run(
id,
cmd,
variation_key,
variation,
longest_variation_len,
target_metric_key,
report_metric_keys,
repeat_times,
output_dir,
verbose,
):
results = []
metrics = []
preamble = f"{id}: {variation:<{longest_variation_len}}"
outcome = f"{preamble}: "
metric_keys = set(report_metric_keys + [target_metric_key])
for i in tqdm(range(repeat_times), desc=preamble, leave=False):
single_run_metrics = process_run_single(
id, cmd, variation, output_dir, target_metric_key, metric_keys, verbose
)
result = single_run_metrics[target_metric_key]
if not math.isnan(result):
metrics.append(single_run_metrics)
results.append(result)
outcome += "✓"
else:
outcome += "✘"
outcome = f"\33[2K\r{outcome}"
if len(metrics) > 0:
mean_metrics = {k: fmean([x[k] for x in metrics]) for k in metrics[0].keys()}
mean_target = round(mean_metrics[target_metric_key], 2)
results_str = f"{outcome} {mean_target}"
if len(metrics) > 1:
results_str += f" {tuple(round(x, 2) for x in results)}"
print(results_str)
mean_metrics[variation_key] = variation
return mean_metrics
else:
print(outcome)
return {variation_key: variation, target_metric_key: nan}
def get_versions():
properties = torch.cuda.get_device_properties(torch.device("cuda"))
return f"""
Datetime : {datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
Software:
transformers: {transformers.__version__}
torch : {torch.__version__}
cuda : {torch.version.cuda}
python : {platform.python_version()}
Hardware:
{torch.cuda.device_count()} GPUs : {properties.name}, {properties.total_memory/2**30:0.2f}GB
"""
def process_results(results, target_metric_key, report_metric_keys, base_variation, output_dir):
df = pd.DataFrame(results)
variation_key = "variation"
diff_key = "diff_%"
sentinel_value = nan
if base_variation is not None and len(df[df[variation_key] == base_variation]):
# this may still return nan
sentinel_value = df.loc[df[variation_key] == base_variation][target_metric_key].item()
if math.isnan(sentinel_value):
# as a fallback, use the minimal value as the sentinel
sentinel_value = df.loc[df[target_metric_key] != nan][target_metric_key].min()
# create diff column if possible
if not math.isnan(sentinel_value):
df[diff_key] = df.apply(
lambda r: round(100 * (r[target_metric_key] - sentinel_value) / sentinel_value)
if not math.isnan(r[target_metric_key])
else 0,
axis="columns",
)
# re-order columns
cols = [variation_key, target_metric_key, diff_key, *report_metric_keys]
df = df.reindex(cols, axis="columns") # reorder cols
# capitalize
df = df.rename(str.capitalize, axis="columns")
# make the cols as narrow as possible
df_github = df.rename(lambda c: c.replace("_", "<br>"), axis="columns")
df_console = df.rename(lambda c: c.replace("_", "\n"), axis="columns")
report = ["", "Copy between the cut-here-lines and paste as is to github or a forum"]
report += ["----------8<-----------------8<--------"]
report += ["*** Results:", df_github.to_markdown(index=False, floatfmt=".2f")]
report += ["```"]
report += ["*** Setup:", get_versions()]
report += ["*** The benchmark command line was:", get_original_command()]
report += ["```"]
report += ["----------8<-----------------8<--------"]
report += ["*** Results (console):", df_console.to_markdown(index=False, floatfmt=".2f")]
print("\n\n".join(report))
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"--base-cmd",
default=None,
type=str,
required=True,
help="Base cmd",
)
parser.add_argument(
"--variations",
default=None,
type=str,
nargs="+",
required=True,
help="Multi-dimensional variations, example: '|--fp16|--bf16' '|--tf32'",
)
parser.add_argument(
"--base-variation",
default=None,
type=str,
help="Baseline variation to compare to. if None the minimal target value will be used to compare against",
)
parser.add_argument(
"--target-metric-key",
default=None,
type=str,
required=True,
help="Target metric key in output_dir/all_results.json, e.g., train_samples_per_second",
)
parser.add_argument(
"--report-metric-keys",
default="",
type=str,
help="Report metric keys - other metric keys from output_dir/all_results.json to report, e.g., train_loss. Use a single argument e.g., 'train_loss train_samples",
)
parser.add_argument(
"--repeat-times",
default=1,
type=int,
help="How many times to re-run each variation - an average will be reported",
)
parser.add_argument(
"--output_dir",
default="output_benchmark",
type=str,
help="The output directory where all the benchmark reports will go to and additionally this directory will be used to override --output_dir in the script that is being benchmarked",
)
parser.add_argument(
"--verbose",
default=False,
action="store_true",
help="Whether to show the outputs of each run or just the benchmark progress",
)
args = parser.parse_args()
output_dir = args.output_dir
Path(output_dir).mkdir(exist_ok=True)
base_cmd = get_base_command(args, output_dir)
# split each dimension into its --foo variations
dims = [list(map(str.strip, re.split(r"\|", x))) for x in args.variations]
# build a cartesian product of dimensions and convert those back into cmd-line arg strings,
# while stripping white space for inputs that were empty
variations = list(map(str.strip, map(" ".join, itertools.product(*dims))))
longest_variation_len = max(len(x) for x in variations)
# split wanted keys
report_metric_keys = args.report_metric_keys.split()
# capture prints into a log file for convenience
report_fn = f"benchmark-report-{datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}.txt"
print(f"\nNote: each run's output is also logged under {output_dir}/log.*.std*.txt")
print(f"and this script's output is also piped into {report_fn}")
sys.stdout = Tee(report_fn)
print(f"\n*** Running {len(variations)} benchmarks:")
print(f"Base command: {' '.join(base_cmd)}")
variation_key = "variation"
results = []
for id, variation in enumerate(tqdm(variations, desc="Total completion: ", leave=False)):
cmd = base_cmd + variation.split()
results.append(
process_run(
id + 1,
cmd,
variation_key,
variation,
longest_variation_len,
args.target_metric_key,
report_metric_keys,
args.repeat_times,
output_dir,
args.verbose,
)
)
process_results(results, args.target_metric_key, report_metric_keys, args.base_variation, output_dir)
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/distributed/torch-distributed-gpu-test.py
|
#!/usr/bin/env python
#
# This a `torch.distributed` diagnostics script that checks that all GPUs in the cluster (one or
# many nodes) can talk to each other via nccl and allocate gpu memory.
#
# To run first adjust the number of processes and nodes:
#
# python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
#
# You may need to add --master_addr $MASTER_ADDR --master_port $MASTER_PORT if using a custom addr:port
#
# You can also use the rdzv API: --rdzv_endpoint $MASTER_ADDR:$MASTER_PORT --rdzv_backend c10d
#
# use torch.distributed.launch instead of torch.distributed.run for torch < 1.9
#
# If you get a hanging in `barrier` calls you have some network issues, you may try to debug this with:
#
# NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
#
# which should tell you what's going on behind the scenes.
#
#
# This script can be run via `srun` in the SLURM environment as well. Here is a SLURM script that
# runs on 2 nodes of 4 gpus per node:
#
# #SBATCH --job-name=test-nodes # name
# #SBATCH --nodes=2 # nodes
# #SBATCH --ntasks-per-node=1 # crucial - only 1 task per dist per node!
# #SBATCH --cpus-per-task=10 # number of cores per tasks
# #SBATCH --gres=gpu:4 # number of gpus
# #SBATCH --time 0:05:00 # maximum execution time (HH:MM:SS)
# #SBATCH --output=%x-%j.out # output file name
#
# GPUS_PER_NODE=4
# MASTER_ADDR=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
# MASTER_PORT=6000
#
# srun --jobid $SLURM_JOBID bash -c 'python -m torch.distributed.run \
# --nproc_per_node $GPUS_PER_NODE --nnodes $SLURM_NNODES --node_rank $SLURM_PROCID \
# --master_addr $MASTER_ADDR --master_port $MASTER_PORT \
# torch-distributed-gpu-test.py'
#
import fcntl
import os
import socket
import torch
import torch.distributed as dist
def printflock(*msgs):
"""solves multi-process interleaved print problem"""
with open(__file__, "r") as fh:
fcntl.flock(fh, fcntl.LOCK_EX)
try:
print(*msgs)
finally:
fcntl.flock(fh, fcntl.LOCK_UN)
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
hostname = socket.gethostname()
gpu = f"[{hostname}-{local_rank}]"
try:
# test distributed
dist.init_process_group("nccl")
dist.all_reduce(torch.ones(1).to(device), op=dist.ReduceOp.SUM)
dist.barrier()
# test cuda is available and can allocate memory
torch.cuda.is_available()
torch.ones(1).cuda(local_rank)
# global rank
rank = dist.get_rank()
world_size = dist.get_world_size()
printflock(f"{gpu} is OK (global rank: {rank}/{world_size})")
dist.barrier()
if rank == 0:
printflock(f"pt={torch.__version__}, cuda={torch.version.cuda}, nccl={torch.cuda.nccl.version()}")
except Exception:
printflock(f"{gpu} is broken")
raise
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/pegasus/build_test_sample_spm_no_bos.py
|
#!/usr/bin/env python
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# this script builds a small sample spm file tests/fixtures/test_sentencepiece_no_bos.model, with features needed by pegasus
# 1. pip install sentencepiece
#
# 2. wget https://raw.githubusercontent.com/google/sentencepiece/master/data/botchan.txt
# 3. build
import sentencepiece as spm
# pegasus:
# 1. no bos
# 2. eos_id is 1
# 3. unk_id is 2
# build a sample spm file accordingly
spm.SentencePieceTrainer.train('--input=botchan.txt --model_prefix=test_sentencepiece_no_bos --bos_id=-1 --unk_id=2 --eos_id=1 --vocab_size=1000')
# 4. now update the fixture
# mv test_sentencepiece_no_bos.model ../../tests/fixtures/
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/tatoeba/README.md
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
Setup transformers following instructions in README.md, (I would fork first).
```bash
git clone git@github.com:huggingface/transformers.git
cd transformers
pip install -e .
pip install pandas GitPython wget
```
Get required metadata
```
curl https://cdn-datasets.huggingface.co/language_codes/language-codes-3b2.csv > language-codes-3b2.csv
curl https://cdn-datasets.huggingface.co/language_codes/iso-639-3.csv > iso-639-3.csv
```
Install Tatoeba-Challenge repo inside transformers
```bash
git clone git@github.com:Helsinki-NLP/Tatoeba-Challenge.git
```
To convert a few models, call the conversion script from command line:
```bash
python src/transformers/models/marian/convert_marian_tatoeba_to_pytorch.py --models heb-eng eng-heb --save_dir converted
```
To convert lots of models you can pass your list of Tatoeba model names to `resolver.convert_models` in a python client or script.
```python
from transformers.convert_marian_tatoeba_to_pytorch import TatoebaConverter
resolver = TatoebaConverter(save_dir='converted')
resolver.convert_models(['heb-eng', 'eng-heb'])
```
### Upload converted models
Since version v3.5.0, the model sharing workflow is switched to git-based system . Refer to [model sharing doc](https://huggingface.co/transformers/main/model_sharing.html#model-sharing-and-uploading) for more details.
To upload all converted models,
1. Install [git-lfs](https://git-lfs.github.com/).
2. Login to `huggingface-cli`
```bash
huggingface-cli login
```
3. Run the `upload_models` script
```bash
./scripts/tatoeba/upload_models.sh
```
### Modifications
- To change naming logic, change the code near `os.rename`. The model card creation code may also need to change.
- To change model card content, you must modify `TatoebaCodeResolver.write_model_card`
| 0
|
hf_public_repos/transformers/scripts
|
hf_public_repos/transformers/scripts/tatoeba/upload_models.sh
|
#!/bin/bash
for FILE in converted/*; do
model_name=`basename $FILE`
huggingface-cli repo create $model_name -y
git clone https://huggingface.co/Helsinki-NLP/$model_name
mv $FILE/* $model_name/
cd $model_name
git add . && git commit -m "initial commit"
git push
cd ..
done
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/.circleci/TROUBLESHOOT.md
|
# Troubleshooting
This is a document explaining how to deal with various issues on Circle-CI. The entries may include actually solutions or pointers to Issues that cover those.
## Circle CI
* pytest worker runs out of resident RAM and gets killed by `cgroups`: https://github.com/huggingface/transformers/issues/11408
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/.circleci/create_circleci_config.py
|
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import copy
import os
import random
from dataclasses import dataclass
from typing import Any, Dict, List, Optional
import yaml
COMMON_ENV_VARIABLES = {
"OMP_NUM_THREADS": 1,
"TRANSFORMERS_IS_CI": True,
"PYTEST_TIMEOUT": 120,
"RUN_PIPELINE_TESTS": False,
"RUN_PT_TF_CROSS_TESTS": False,
"RUN_PT_FLAX_CROSS_TESTS": False,
}
# Disable the use of {"s": None} as the output is way too long, causing the navigation on CircleCI impractical
COMMON_PYTEST_OPTIONS = {"max-worker-restart": 0, "dist": "loadfile"}
DEFAULT_DOCKER_IMAGE = [{"image": "cimg/python:3.8.12"}]
class EmptyJob:
job_name = "empty"
def to_dict(self):
return {
"working_directory": "~/transformers",
"docker": copy.deepcopy(DEFAULT_DOCKER_IMAGE),
"steps":["checkout"],
}
@dataclass
class CircleCIJob:
name: str
additional_env: Dict[str, Any] = None
cache_name: str = None
cache_version: str = "0.7"
docker_image: List[Dict[str, str]] = None
install_steps: List[str] = None
marker: Optional[str] = None
parallelism: Optional[int] = 1
pytest_num_workers: int = 8
pytest_options: Dict[str, Any] = None
resource_class: Optional[str] = "xlarge"
tests_to_run: Optional[List[str]] = None
working_directory: str = "~/transformers"
# This should be only used for doctest job!
command_timeout: Optional[int] = None
def __post_init__(self):
# Deal with defaults for mutable attributes.
if self.additional_env is None:
self.additional_env = {}
if self.cache_name is None:
self.cache_name = self.name
if self.docker_image is None:
# Let's avoid changing the default list and make a copy.
self.docker_image = copy.deepcopy(DEFAULT_DOCKER_IMAGE)
if self.install_steps is None:
self.install_steps = []
if self.pytest_options is None:
self.pytest_options = {}
if isinstance(self.tests_to_run, str):
self.tests_to_run = [self.tests_to_run]
if self.parallelism is None:
self.parallelism = 1
def to_dict(self):
env = COMMON_ENV_VARIABLES.copy()
env.update(self.additional_env)
cache_branch_prefix = os.environ.get("CIRCLE_BRANCH", "pull")
if cache_branch_prefix != "main":
cache_branch_prefix = "pull"
job = {
"working_directory": self.working_directory,
"docker": self.docker_image,
"environment": env,
}
if self.resource_class is not None:
job["resource_class"] = self.resource_class
if self.parallelism is not None:
job["parallelism"] = self.parallelism
steps = [
"checkout",
{"attach_workspace": {"at": "~/transformers/test_preparation"}},
{
"restore_cache": {
"keys": [
# check the fully-matched cache first
f"v{self.cache_version}-{self.cache_name}-{cache_branch_prefix}-pip-" + '{{ checksum "setup.py" }}',
# try the partially-matched cache from `main`
f"v{self.cache_version}-{self.cache_name}-main-pip-",
# try the general partially-matched cache
f"v{self.cache_version}-{self.cache_name}-{cache_branch_prefix}-pip-",
]
}
},
{
"restore_cache": {
"keys": [
f"v{self.cache_version}-{self.cache_name}-{cache_branch_prefix}-site-packages-" + '{{ checksum "setup.py" }}',
f"v{self.cache_version}-{self.cache_name}-main-site-packages-",
f"v{self.cache_version}-{self.cache_name}-{cache_branch_prefix}-site-packages-",
]
}
},
]
steps.extend([{"run": l} for l in self.install_steps])
steps.extend([{"run": 'pip install "fsspec>=2023.5.0,<2023.10.0"'}])
steps.extend([{"run": "pip install pytest-subtests"}])
steps.append(
{
"save_cache": {
"key": f"v{self.cache_version}-{self.cache_name}-{cache_branch_prefix}-pip-" + '{{ checksum "setup.py" }}',
"paths": ["~/.cache/pip"],
}
}
)
steps.append(
{
"save_cache": {
"key": f"v{self.cache_version}-{self.cache_name}-{cache_branch_prefix}-site-packages-" + '{{ checksum "setup.py" }}',
"paths": ["~/.pyenv/versions/"],
}
}
)
steps.append({"run": {"name": "Show installed libraries and their versions", "command": "pip freeze | tee installed.txt"}})
steps.append({"store_artifacts": {"path": "~/transformers/installed.txt"}})
all_options = {**COMMON_PYTEST_OPTIONS, **self.pytest_options}
pytest_flags = [f"--{key}={value}" if (value is not None or key in ["doctest-modules"]) else f"-{key}" for key, value in all_options.items()]
pytest_flags.append(
f"--make-reports={self.name}" if "examples" in self.name else f"--make-reports=tests_{self.name}"
)
steps.append({"run": {"name": "Create `test-results` directory", "command": "mkdir test-results"}})
test_command = ""
if self.command_timeout:
test_command = f"timeout {self.command_timeout} "
test_command += f"python -m pytest --junitxml=test-results/junit.xml -n {self.pytest_num_workers} " + " ".join(pytest_flags)
if self.parallelism == 1:
if self.tests_to_run is None:
test_command += " << pipeline.parameters.tests_to_run >>"
else:
test_command += " " + " ".join(self.tests_to_run)
else:
# We need explicit list instead of `pipeline.parameters.tests_to_run` (only available at job runtime)
tests = self.tests_to_run
if tests is None:
folder = os.environ["test_preparation_dir"]
test_file = os.path.join(folder, "filtered_test_list.txt")
if os.path.exists(test_file):
with open(test_file) as f:
tests = f.read().split(" ")
# expand the test list
if tests == ["tests"]:
tests = [os.path.join("tests", x) for x in os.listdir("tests")]
expanded_tests = []
for test in tests:
if test.endswith(".py"):
expanded_tests.append(test)
elif test == "tests/models":
expanded_tests.extend([os.path.join(test, x) for x in os.listdir(test)])
elif test == "tests/pipelines":
expanded_tests.extend([os.path.join(test, x) for x in os.listdir(test)])
else:
expanded_tests.append(test)
# Avoid long tests always being collected together
random.shuffle(expanded_tests)
tests = " ".join(expanded_tests)
# Each executor to run ~10 tests
n_executors = max(len(tests) // 10, 1)
# Avoid empty test list on some executor(s) or launching too many executors
if n_executors > self.parallelism:
n_executors = self.parallelism
job["parallelism"] = n_executors
# Need to be newline separated for the command `circleci tests split` below
command = f'echo {tests} | tr " " "\\n" >> tests.txt'
steps.append({"run": {"name": "Get tests", "command": command}})
command = 'TESTS=$(circleci tests split tests.txt) && echo $TESTS > splitted_tests.txt'
steps.append({"run": {"name": "Split tests", "command": command}})
steps.append({"store_artifacts": {"path": "~/transformers/tests.txt"}})
steps.append({"store_artifacts": {"path": "~/transformers/splitted_tests.txt"}})
test_command = ""
if self.timeout:
test_command = f"timeout {self.timeout} "
test_command += f"python -m pytest -n {self.pytest_num_workers} " + " ".join(pytest_flags)
test_command += " $(cat splitted_tests.txt)"
if self.marker is not None:
test_command += f" -m {self.marker}"
if self.name == "pr_documentation_tests":
# can't use ` | tee tee tests_output.txt` as usual
test_command += " > tests_output.txt"
# Save the return code, so we can check if it is timeout in the next step.
test_command += '; touch "$?".txt'
# Never fail the test step for the doctest job. We will check the results in the next step, and fail that
# step instead if the actual test failures are found. This is to avoid the timeout being reported as test
# failure.
test_command = f"({test_command}) || true"
else:
test_command += " || true"
steps.append({"run": {"name": "Run tests", "command": test_command}})
# Deal with errors
check_test_command = f'if [ -s reports/{self.job_name}/errors.txt ]; '
check_test_command += 'then echo "Some tests errored out!"; echo ""; '
check_test_command += f'cat reports/{self.job_name}/errors.txt; '
check_test_command += 'echo ""; echo ""; '
py_command = f'import os; fp = open("reports/{self.job_name}/summary_short.txt"); failed = os.linesep.join([x for x in fp.read().split(os.linesep) if x.startswith("ERROR ")]); fp.close(); fp = open("summary_short.txt", "w"); fp.write(failed); fp.close()'
check_test_command += f"$(python3 -c '{py_command}'); "
check_test_command += 'cat summary_short.txt; echo ""; exit -1; '
# Deeal with failed tests
check_test_command += f'elif [ -s reports/{self.job_name}/failures_short.txt ]; '
check_test_command += 'then echo "Some tests failed!"; echo ""; '
check_test_command += f'cat reports/{self.job_name}/failures_short.txt; '
check_test_command += 'echo ""; echo ""; '
py_command = f'import os; fp = open("reports/{self.job_name}/summary_short.txt"); failed = os.linesep.join([x for x in fp.read().split(os.linesep) if x.startswith("FAILED ")]); fp.close(); fp = open("summary_short.txt", "w"); fp.write(failed); fp.close()'
check_test_command += f"$(python3 -c '{py_command}'); "
check_test_command += 'cat summary_short.txt; echo ""; exit -1; '
check_test_command += f'elif [ -s reports/{self.job_name}/stats.txt ]; then echo "All tests pass!"; '
# return code `124` means the previous (pytest run) step is timeout
if self.name == "pr_documentation_tests":
check_test_command += 'elif [ -f 124.txt ]; then echo "doctest timeout!"; '
check_test_command += 'else echo "other fatal error"; echo ""; exit -1; fi;'
steps.append({"run": {"name": "Check test results", "command": check_test_command}})
steps.append({"store_test_results": {"path": "test-results"}})
steps.append({"store_artifacts": {"path": "~/transformers/tests_output.txt"}})
steps.append({"store_artifacts": {"path": "~/transformers/reports"}})
job["steps"] = steps
return job
@property
def job_name(self):
return self.name if "examples" in self.name else f"tests_{self.name}"
# JOBS
torch_and_tf_job = CircleCIJob(
"torch_and_tf",
additional_env={"RUN_PT_TF_CROSS_TESTS": True},
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng git-lfs cmake",
"git lfs install",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[sklearn,tf-cpu,torch,testing,sentencepiece,torch-speech,vision]",
"pip install -U --upgrade-strategy eager tensorflow_probability",
"pip install -U --upgrade-strategy eager -e git+https://github.com/huggingface/accelerate@main#egg=accelerate",
],
marker="is_pt_tf_cross_test",
pytest_options={"rA": None, "durations": 0},
)
torch_and_flax_job = CircleCIJob(
"torch_and_flax",
additional_env={"RUN_PT_FLAX_CROSS_TESTS": True},
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng",
"pip install -U --upgrade-strategy eager --upgrade pip",
"pip install -U --upgrade-strategy eager .[sklearn,flax,torch,testing,sentencepiece,torch-speech,vision]",
"pip install -U --upgrade-strategy eager -e git+https://github.com/huggingface/accelerate@main#egg=accelerate",
],
marker="is_pt_flax_cross_test",
pytest_options={"rA": None, "durations": 0},
)
torch_job = CircleCIJob(
"torch",
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng time",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[sklearn,torch,testing,sentencepiece,torch-speech,vision,timm]",
"pip install -U --upgrade-strategy eager -e git+https://github.com/huggingface/accelerate@main#egg=accelerate",
],
parallelism=1,
pytest_num_workers=6,
)
tf_job = CircleCIJob(
"tf",
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng cmake",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[sklearn,tf-cpu,testing,sentencepiece,tf-speech,vision]",
"pip install -U --upgrade-strategy eager tensorflow_probability",
],
parallelism=1,
)
flax_job = CircleCIJob(
"flax",
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[flax,testing,sentencepiece,flax-speech,vision]",
],
parallelism=1,
)
pipelines_torch_job = CircleCIJob(
"pipelines_torch",
additional_env={"RUN_PIPELINE_TESTS": True},
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[sklearn,torch,testing,sentencepiece,torch-speech,vision,timm,video]",
],
marker="is_pipeline_test",
pytest_num_workers=6,
)
pipelines_tf_job = CircleCIJob(
"pipelines_tf",
additional_env={"RUN_PIPELINE_TESTS": True},
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y cmake",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[sklearn,tf-cpu,testing,sentencepiece,vision]",
"pip install -U --upgrade-strategy eager tensorflow_probability",
],
marker="is_pipeline_test",
)
custom_tokenizers_job = CircleCIJob(
"custom_tokenizers",
additional_env={"RUN_CUSTOM_TOKENIZERS": True},
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y cmake",
{
"name": "install jumanpp",
"command":
"wget https://github.com/ku-nlp/jumanpp/releases/download/v2.0.0-rc3/jumanpp-2.0.0-rc3.tar.xz\n"
"tar xvf jumanpp-2.0.0-rc3.tar.xz\n"
"mkdir jumanpp-2.0.0-rc3/bld\n"
"cd jumanpp-2.0.0-rc3/bld\n"
"sudo cmake .. -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=/usr/local\n"
"sudo make install\n",
},
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[ja,testing,sentencepiece,jieba,spacy,ftfy,rjieba]",
"python -m unidic download",
],
parallelism=None,
resource_class=None,
tests_to_run=[
"./tests/models/bert_japanese/test_tokenization_bert_japanese.py",
"./tests/models/openai/test_tokenization_openai.py",
"./tests/models/clip/test_tokenization_clip.py",
],
)
examples_torch_job = CircleCIJob(
"examples_torch",
additional_env={"OMP_NUM_THREADS": 8},
cache_name="torch_examples",
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[sklearn,torch,sentencepiece,testing,torch-speech]",
"pip install -U --upgrade-strategy eager -r examples/pytorch/_tests_requirements.txt",
"pip install -U --upgrade-strategy eager -e git+https://github.com/huggingface/accelerate@main#egg=accelerate",
],
pytest_num_workers=1,
)
examples_tensorflow_job = CircleCIJob(
"examples_tensorflow",
cache_name="tensorflow_examples",
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y cmake",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[sklearn,tensorflow,sentencepiece,testing]",
"pip install -U --upgrade-strategy eager -r examples/tensorflow/_tests_requirements.txt",
],
)
examples_flax_job = CircleCIJob(
"examples_flax",
cache_name="flax_examples",
install_steps=[
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[flax,testing,sentencepiece]",
"pip install -U --upgrade-strategy eager -r examples/flax/_tests_requirements.txt",
],
)
hub_job = CircleCIJob(
"hub",
additional_env={"HUGGINGFACE_CO_STAGING": True},
install_steps=[
"sudo apt-get -y update && sudo apt-get install git-lfs",
'git config --global user.email "ci@dummy.com"',
'git config --global user.name "ci"',
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[torch,sentencepiece,testing,vision]",
],
marker="is_staging_test",
pytest_num_workers=1,
)
onnx_job = CircleCIJob(
"onnx",
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y cmake",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[torch,tf,testing,sentencepiece,onnxruntime,vision,rjieba]",
],
pytest_options={"k onnx": None},
pytest_num_workers=1,
)
exotic_models_job = CircleCIJob(
"exotic_models",
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[torch,testing,vision]",
"pip install -U --upgrade-strategy eager torchvision",
"pip install -U --upgrade-strategy eager scipy",
"pip install -U --upgrade-strategy eager 'git+https://github.com/facebookresearch/detectron2.git'",
"sudo apt install tesseract-ocr",
"pip install -U --upgrade-strategy eager pytesseract",
"pip install -U --upgrade-strategy eager natten",
"pip install -U --upgrade-strategy eager python-Levenshtein",
"pip install -U --upgrade-strategy eager opencv-python",
"pip install -U --upgrade-strategy eager nltk",
],
tests_to_run=[
"tests/models/*layoutlmv*",
"tests/models/*nat",
"tests/models/deta",
"tests/models/nougat",
],
pytest_num_workers=1,
pytest_options={"durations": 100},
)
repo_utils_job = CircleCIJob(
"repo_utils",
install_steps=[
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager .[quality,testing,torch]",
],
parallelism=None,
pytest_num_workers=1,
resource_class="large",
tests_to_run="tests/repo_utils",
)
# We also include a `dummy.py` file in the files to be doc-tested to prevent edge case failure. Otherwise, the pytest
# hangs forever during test collection while showing `collecting 0 items / 21 errors`. (To see this, we have to remove
# the bash output redirection.)
py_command = 'from utils.tests_fetcher import get_doctest_files; to_test = get_doctest_files() + ["dummy.py"]; to_test = " ".join(to_test); print(to_test)'
py_command = f"$(python3 -c '{py_command}')"
command = f'echo "{py_command}" > pr_documentation_tests_temp.txt'
doc_test_job = CircleCIJob(
"pr_documentation_tests",
additional_env={"TRANSFORMERS_VERBOSITY": "error", "DATASETS_VERBOSITY": "error", "SKIP_CUDA_DOCTEST": "1"},
install_steps=[
"sudo apt-get -y update && sudo apt-get install -y libsndfile1-dev espeak-ng time ffmpeg",
"pip install --upgrade --upgrade-strategy eager pip",
"pip install -U --upgrade-strategy eager -e .[dev]",
"pip install -U --upgrade-strategy eager -e git+https://github.com/huggingface/accelerate@main#egg=accelerate",
"pip install --upgrade --upgrade-strategy eager pytest pytest-sugar",
"pip install -U --upgrade-strategy eager natten",
"find -name __pycache__ -delete",
"find . -name \*.pyc -delete",
# Add an empty file to keep the test step running correctly even no file is selected to be tested.
"touch dummy.py",
{
"name": "Get files to test",
"command": command,
},
{
"name": "Show information in `Get files to test`",
"command":
"cat pr_documentation_tests_temp.txt"
},
{
"name": "Get the last line in `pr_documentation_tests.txt`",
"command":
"tail -n1 pr_documentation_tests_temp.txt | tee pr_documentation_tests.txt"
},
],
tests_to_run="$(cat pr_documentation_tests.txt)", # noqa
pytest_options={"-doctest-modules": None, "doctest-glob": "*.md", "dist": "loadfile", "rvsA": None},
command_timeout=1200, # test cannot run longer than 1200 seconds
pytest_num_workers=1,
)
REGULAR_TESTS = [
torch_and_tf_job,
torch_and_flax_job,
torch_job,
tf_job,
flax_job,
custom_tokenizers_job,
hub_job,
onnx_job,
exotic_models_job,
]
EXAMPLES_TESTS = [
examples_torch_job,
examples_tensorflow_job,
examples_flax_job,
]
PIPELINE_TESTS = [
pipelines_torch_job,
pipelines_tf_job,
]
REPO_UTIL_TESTS = [repo_utils_job]
DOC_TESTS = [doc_test_job]
def create_circleci_config(folder=None):
if folder is None:
folder = os.getcwd()
# Used in CircleCIJob.to_dict() to expand the test list (for using parallelism)
os.environ["test_preparation_dir"] = folder
jobs = []
all_test_file = os.path.join(folder, "test_list.txt")
if os.path.exists(all_test_file):
with open(all_test_file) as f:
all_test_list = f.read()
else:
all_test_list = []
if len(all_test_list) > 0:
jobs.extend(PIPELINE_TESTS)
test_file = os.path.join(folder, "filtered_test_list.txt")
if os.path.exists(test_file):
with open(test_file) as f:
test_list = f.read()
else:
test_list = []
if len(test_list) > 0:
jobs.extend(REGULAR_TESTS)
extended_tests_to_run = set(test_list.split())
# Extend the test files for cross test jobs
for job in jobs:
if job.job_name in ["tests_torch_and_tf", "tests_torch_and_flax"]:
for test_path in copy.copy(extended_tests_to_run):
dir_path, fn = os.path.split(test_path)
if fn.startswith("test_modeling_tf_"):
fn = fn.replace("test_modeling_tf_", "test_modeling_")
elif fn.startswith("test_modeling_flax_"):
fn = fn.replace("test_modeling_flax_", "test_modeling_")
else:
if job.job_name == "test_torch_and_tf":
fn = fn.replace("test_modeling_", "test_modeling_tf_")
elif job.job_name == "test_torch_and_flax":
fn = fn.replace("test_modeling_", "test_modeling_flax_")
new_test_file = str(os.path.join(dir_path, fn))
if os.path.isfile(new_test_file):
if new_test_file not in extended_tests_to_run:
extended_tests_to_run.add(new_test_file)
extended_tests_to_run = sorted(extended_tests_to_run)
for job in jobs:
if job.job_name in ["tests_torch_and_tf", "tests_torch_and_flax"]:
job.tests_to_run = extended_tests_to_run
fn = "filtered_test_list_cross_tests.txt"
f_path = os.path.join(folder, fn)
with open(f_path, "w") as fp:
fp.write(" ".join(extended_tests_to_run))
example_file = os.path.join(folder, "examples_test_list.txt")
if os.path.exists(example_file) and os.path.getsize(example_file) > 0:
with open(example_file, "r", encoding="utf-8") as f:
example_tests = f.read()
for job in EXAMPLES_TESTS:
framework = job.name.replace("examples_", "").replace("torch", "pytorch")
if example_tests == "all":
job.tests_to_run = [f"examples/{framework}"]
else:
job.tests_to_run = [f for f in example_tests.split(" ") if f.startswith(f"examples/{framework}")]
if len(job.tests_to_run) > 0:
jobs.append(job)
doctest_file = os.path.join(folder, "doctest_list.txt")
if os.path.exists(doctest_file):
with open(doctest_file) as f:
doctest_list = f.read()
else:
doctest_list = []
if len(doctest_list) > 0:
jobs.extend(DOC_TESTS)
repo_util_file = os.path.join(folder, "test_repo_utils.txt")
if os.path.exists(repo_util_file) and os.path.getsize(repo_util_file) > 0:
jobs.extend(REPO_UTIL_TESTS)
if len(jobs) == 0:
jobs = [EmptyJob()]
config = {"version": "2.1"}
config["parameters"] = {
# Only used to accept the parameters from the trigger
"nightly": {"type": "boolean", "default": False},
"tests_to_run": {"type": "string", "default": test_list},
}
config["jobs"] = {j.job_name: j.to_dict() for j in jobs}
config["workflows"] = {"version": 2, "run_tests": {"jobs": [j.job_name for j in jobs]}}
with open(os.path.join(folder, "generated_config.yml"), "w") as f:
f.write(yaml.dump(config, indent=2, width=1000000, sort_keys=False))
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--fetcher_folder", type=str, default=None, help="Only test that all tests and modules are accounted for."
)
args = parser.parse_args()
create_circleci_config(args.fetcher_folder)
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/.circleci/config.yml
|
version: 2.1
setup: true
orbs:
continuation: circleci/continuation@0.1.0
parameters:
nightly:
type: boolean
default: false
jobs:
# Ensure running with CircleCI/huggingface
check_circleci_user:
docker:
- image: cimg/python:3.8.12
parallelism: 1
steps:
- run: echo $CIRCLE_PROJECT_USERNAME
- run: |
if [ "$CIRCLE_PROJECT_USERNAME" = "huggingface" ]; then
exit 0
else
echo "The CI is running under $CIRCLE_PROJECT_USERNAME personal account. Please follow https://support.circleci.com/hc/en-us/articles/360008097173-Troubleshooting-why-pull-requests-are-not-triggering-jobs-on-my-organization- to fix it."; exit -1
fi
# Fetch the tests to run
fetch_tests:
working_directory: ~/transformers
docker:
- image: cimg/python:3.8.12
parallelism: 1
steps:
- checkout
- run: pip install --upgrade --upgrade-strategy eager pip
- run: pip install -U --upgrade-strategy eager GitPython
- run: pip install -U --upgrade-strategy eager .
- run: mkdir -p test_preparation
- run: python utils/tests_fetcher.py | tee tests_fetched_summary.txt
- store_artifacts:
path: ~/transformers/tests_fetched_summary.txt
- run: |
if [ -f test_list.txt ]; then
cp test_list.txt test_preparation/test_list.txt
else
touch test_preparation/test_list.txt
fi
- run: |
if [ -f examples_test_list.txt ]; then
mv examples_test_list.txt test_preparation/examples_test_list.txt
else
touch test_preparation/examples_test_list.txt
fi
- run: |
if [ -f filtered_test_list_cross_tests.txt ]; then
mv filtered_test_list_cross_tests.txt test_preparation/filtered_test_list_cross_tests.txt
else
touch test_preparation/filtered_test_list_cross_tests.txt
fi
- run: |
if [ -f doctest_list.txt ]; then
cp doctest_list.txt test_preparation/doctest_list.txt
else
touch test_preparation/doctest_list.txt
fi
- run: |
if [ -f test_repo_utils.txt ]; then
mv test_repo_utils.txt test_preparation/test_repo_utils.txt
else
touch test_preparation/test_repo_utils.txt
fi
- run: python utils/tests_fetcher.py --filter_tests
- run: |
if [ -f test_list.txt ]; then
mv test_list.txt test_preparation/filtered_test_list.txt
else
touch test_preparation/filtered_test_list.txt
fi
- store_artifacts:
path: test_preparation/test_list.txt
- store_artifacts:
path: test_preparation/doctest_list.txt
- store_artifacts:
path: ~/transformers/test_preparation/filtered_test_list.txt
- store_artifacts:
path: test_preparation/examples_test_list.txt
- run: python .circleci/create_circleci_config.py --fetcher_folder test_preparation
- run: |
if [ ! -s test_preparation/generated_config.yml ]; then
echo "No tests to run, exiting early!"
circleci-agent step halt
fi
- run: cp test_preparation/generated_config.yml test_preparation/generated_config.txt
- store_artifacts:
path: test_preparation/generated_config.txt
- store_artifacts:
path: test_preparation/filtered_test_list_cross_tests.txt
- continuation/continue:
configuration_path: test_preparation/generated_config.yml
# To run all tests for the nightly build
fetch_all_tests:
working_directory: ~/transformers
docker:
- image: cimg/python:3.8.12
parallelism: 1
steps:
- checkout
- run: pip install --upgrade --upgrade-strategy eager pip
- run: pip install -U --upgrade-strategy eager GitPython
- run: pip install -U --upgrade-strategy eager .
- run: |
mkdir test_preparation
echo -n "tests" > test_preparation/test_list.txt
echo -n "all" > test_preparation/examples_test_list.txt
echo -n "tests/repo_utils" > test_preparation/test_repo_utils.txt
- run: |
echo -n "tests" > test_list.txt
python utils/tests_fetcher.py --filter_tests
mv test_list.txt test_preparation/filtered_test_list.txt
- run: python .circleci/create_circleci_config.py --fetcher_folder test_preparation
- run: cp test_preparation/generated_config.yml test_preparation/generated_config.txt
- store_artifacts:
path: test_preparation/generated_config.txt
- continuation/continue:
configuration_path: test_preparation/generated_config.yml
check_code_quality:
working_directory: ~/transformers
docker:
- image: cimg/python:3.8.12
resource_class: large
environment:
TRANSFORMERS_IS_CI: yes
PYTEST_TIMEOUT: 120
parallelism: 1
steps:
- checkout
- restore_cache:
keys:
- v0.7-code_quality-pip-{{ checksum "setup.py" }}
- v0.7-code-quality-pip
- restore_cache:
keys:
- v0.7-code_quality-site-packages-{{ checksum "setup.py" }}
- v0.7-code-quality-site-packages
- run: pip install --upgrade --upgrade-strategy eager pip
- run: pip install -U --upgrade-strategy eager .[all,quality]
- save_cache:
key: v0.7-code_quality-pip-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- save_cache:
key: v0.7-code_quality-site-packages-{{ checksum "setup.py" }}
paths:
- '~/.pyenv/versions/'
- run:
name: Show installed libraries and their versions
command: pip freeze | tee installed.txt
- store_artifacts:
path: ~/transformers/installed.txt
- run: ruff check examples tests src utils
- run: ruff format tests src utils --check
- run: python utils/custom_init_isort.py --check_only
- run: python utils/sort_auto_mappings.py --check_only
- run: python utils/check_doc_toc.py
check_repository_consistency:
working_directory: ~/transformers
docker:
- image: cimg/python:3.8.12
resource_class: large
environment:
TRANSFORMERS_IS_CI: yes
PYTEST_TIMEOUT: 120
parallelism: 1
steps:
- checkout
- restore_cache:
keys:
- v0.7-repository_consistency-pip-{{ checksum "setup.py" }}
- v0.7-repository_consistency-pip
- restore_cache:
keys:
- v0.7-repository_consistency-site-packages-{{ checksum "setup.py" }}
- v0.7-repository_consistency-site-packages
- run: pip install --upgrade --upgrade-strategy eager pip
- run: pip install -U --upgrade-strategy eager .[all,quality]
- save_cache:
key: v0.7-repository_consistency-pip-{{ checksum "setup.py" }}
paths:
- '~/.cache/pip'
- save_cache:
key: v0.7-repository_consistency-site-packages-{{ checksum "setup.py" }}
paths:
- '~/.pyenv/versions/'
- run:
name: Show installed libraries and their versions
command: pip freeze | tee installed.txt
- store_artifacts:
path: ~/transformers/installed.txt
- run: python utils/check_copies.py
- run: python utils/check_table.py
- run: python utils/check_dummies.py
- run: python utils/check_repo.py
- run: python utils/check_inits.py
- run: python utils/check_config_docstrings.py
- run: python utils/check_config_attributes.py
- run: python utils/check_doctest_list.py
- run: make deps_table_check_updated
- run: python utils/update_metadata.py --check-only
- run: python utils/check_task_guides.py
- run: python utils/check_docstrings.py
workflows:
version: 2
setup_and_quality:
when:
not: <<pipeline.parameters.nightly>>
jobs:
- check_circleci_user
- check_code_quality
- check_repository_consistency
- fetch_tests
nightly:
when: <<pipeline.parameters.nightly>>
jobs:
- check_circleci_user
- check_code_quality
- check_repository_consistency
- fetch_all_tests
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile
|
# https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-22-12.html#rel-22-12
FROM nvcr.io/nvidia/pytorch:22.12-py3
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
ARG PYTORCH='2.1.0'
# Example: `cu102`, `cu113`, etc.
ARG CUDA='cu118'
RUN apt -y update
RUN apt install -y libaio-dev
RUN python3 -m pip install --no-cache-dir --upgrade pip
ARG REF=main
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
RUN python3 -m pip uninstall -y torch torchvision torchaudio
# Install latest release PyTorch
# (PyTorch must be installed before pre-compiling any DeepSpeed c++/cuda ops.)
# (https://www.deepspeed.ai/tutorials/advanced-install/#pre-install-deepspeed-ops)
RUN python3 -m pip install --no-cache-dir -U torch==$PYTORCH torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/$CUDA
RUN python3 -m pip install --no-cache-dir ./transformers[deepspeed-testing]
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/accelerate@main#egg=accelerate
# Uninstall `transformer-engine` shipped with the base image
RUN python3 -m pip uninstall -y transformer-engine
# Uninstall `torch-tensorrt` shipped with the base image
RUN python3 -m pip uninstall -y torch-tensorrt
# recompile apex
RUN python3 -m pip uninstall -y apex
RUN git clone https://github.com/NVIDIA/apex
# `MAX_JOBS=1` disables parallel building to avoid cpu memory OOM when building image on GitHub Action (standard) runners
# TODO: check if there is alternative way to install latest apex
# RUN cd apex && MAX_JOBS=1 python3 -m pip install --global-option="--cpp_ext" --global-option="--cuda_ext" --no-cache -v --disable-pip-version-check .
# Pre-build **latest** DeepSpeed, so it would be ready for testing (otherwise, the 1st deepspeed test will timeout)
RUN python3 -m pip uninstall -y deepspeed
# This has to be run (again) inside the GPU VMs running the tests.
# The installation works here, but some tests fail, if we don't pre-build deepspeed again in the VMs running the tests.
# TODO: Find out why test fail.
RUN DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 DS_BUILD_UTILS=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check 2>&1
# When installing in editable mode, `transformers` is not recognized as a package.
# this line must be added in order for python to be aware of transformers.
RUN cd transformers && python3 setup.py develop
# The base image ships with `pydantic==1.8.2` which is not working - i.e. the next command fails
RUN python3 -m pip install -U --no-cache-dir "pydantic<2"
RUN python3 -c "from deepspeed.launcher.runner import main"
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-gpu/Dockerfile
|
FROM nvidia/cuda:10.2-cudnn7-devel-ubuntu18.04
LABEL maintainer="Hugging Face"
LABEL repository="transformers"
RUN apt update && \
apt install -y bash \
build-essential \
git \
curl \
ca-certificates \
python3 \
python3-pip && \
rm -rf /var/lib/apt/lists
RUN python3 -m pip install --no-cache-dir --upgrade pip && \
python3 -m pip install --no-cache-dir \
jupyter \
tensorflow \
torch
RUN git clone https://github.com/NVIDIA/apex
RUN cd apex && \
python3 setup.py install && \
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
WORKDIR /workspace
COPY . transformers/
RUN cd transformers/ && \
python3 -m pip install --no-cache-dir .
CMD ["/bin/bash"]
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-doc-builder/Dockerfile
|
FROM python:3.8
LABEL maintainer="Hugging Face"
RUN apt update
RUN git clone https://github.com/huggingface/transformers
RUN python3 -m pip install --no-cache-dir --upgrade pip && python3 -m pip install --no-cache-dir git+https://github.com/huggingface/doc-builder ./transformers[dev]
RUN apt-get -y update && apt-get install -y libsndfile1-dev && apt install -y tesseract-ocr
# Torch needs to be installed before deepspeed
RUN python3 -m pip install --no-cache-dir ./transformers[deepspeed]
RUN python3 -m pip install --no-cache-dir torchvision git+https://github.com/facebookresearch/detectron2.git pytesseract
RUN python3 -m pip install -U "itsdangerous<2.1.0"
# Test if the image could successfully build the doc. before publishing the image
RUN doc-builder build transformers transformers/docs/source/en --build_dir doc-build-dev --notebook_dir notebooks/transformers_doc --clean
RUN rm -rf doc-build-dev
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-past-gpu/Dockerfile
|
ARG BASE_DOCKER_IMAGE
FROM $BASE_DOCKER_IMAGE
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
# Use login shell to read variables from `~/.profile` (to pass dynamic created variables between RUN commands)
SHELL ["sh", "-lc"]
RUN apt update
RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg git-lfs libaio-dev
RUN git lfs install
RUN python3 -m pip install --no-cache-dir --upgrade pip
ARG REF=main
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
RUN python3 -m pip install --no-cache-dir -e ./transformers[dev,onnxruntime]
# When installing in editable mode, `transformers` is not recognized as a package.
# this line must be added in order for python to be aware of transformers.
RUN cd transformers && python3 setup.py develop
ARG FRAMEWORK
ARG VERSION
# Control `setuptools` version to avoid some issues
RUN [ "$VERSION" != "1.10" ] && python3 -m pip install -U setuptools || python3 -m pip install -U "setuptools<=59.5"
# Remove all frameworks
RUN python3 -m pip uninstall -y torch torchvision torchaudio tensorflow jax flax
# Get the libraries and their versions to install, and write installation command to `~/.profile`.
RUN python3 ./transformers/utils/past_ci_versions.py --framework $FRAMEWORK --version $VERSION
# Install the target framework
RUN echo "INSTALL_CMD = $INSTALL_CMD"
RUN $INSTALL_CMD
RUN [ "$FRAMEWORK" != "pytorch" ] && echo "`deepspeed-testing` installation is skipped" || python3 -m pip install --no-cache-dir ./transformers[deepspeed-testing]
# Remove `accelerate`: it requires `torch`, and this causes import issues for TF-only testing
# We will install `accelerate@main` in Past CI workflow file
RUN python3 -m pip uninstall -y accelerate
# Uninstall `torch-tensorrt` and `apex` shipped with the base image
RUN python3 -m pip uninstall -y torch-tensorrt apex
# Pre-build **nightly** release of DeepSpeed, so it would be ready for testing (otherwise, the 1st deepspeed test will timeout)
RUN python3 -m pip uninstall -y deepspeed
# This has to be run inside the GPU VMs running the tests. (So far, it fails here due to GPU checks during compilation.)
# Issue: https://github.com/microsoft/DeepSpeed/issues/2010
# RUN git clone https://github.com/microsoft/DeepSpeed && cd DeepSpeed && rm -rf build && \
# DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 DS_BUILD_UTILS=1 python3 -m pip install . --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check 2>&1
RUN python3 -m pip install -U "itsdangerous<2.1.0"
# When installing in editable mode, `transformers` is not recognized as a package.
# this line must be added in order for python to be aware of transformers.
RUN cd transformers && python3 setup.py develop
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-pytorch-deepspeed-nightly-gpu/Dockerfile
|
# https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-22-12.html#rel-22-12
FROM nvcr.io/nvidia/pytorch:22.12-py3
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
# Example: `cu102`, `cu113`, etc.
ARG CUDA='cu118'
RUN apt -y update
RUN apt install -y libaio-dev
RUN python3 -m pip install --no-cache-dir --upgrade pip
ARG REF=main
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
RUN python3 -m pip uninstall -y torch torchvision torchaudio
# Install **nightly** release PyTorch (flag `--pre`)
# (PyTorch must be installed before pre-compiling any DeepSpeed c++/cuda ops.)
# (https://www.deepspeed.ai/tutorials/advanced-install/#pre-install-deepspeed-ops)
RUN python3 -m pip install --no-cache-dir -U --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/$CUDA
RUN python3 -m pip install --no-cache-dir ./transformers[deepspeed-testing]
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/accelerate@main#egg=accelerate
# Uninstall `transformer-engine` shipped with the base image
RUN python3 -m pip uninstall -y transformer-engine
# Uninstall `torch-tensorrt` and `apex` shipped with the base image
RUN python3 -m pip uninstall -y torch-tensorrt apex
# Pre-build **nightly** release of DeepSpeed, so it would be ready for testing (otherwise, the 1st deepspeed test will timeout)
RUN python3 -m pip uninstall -y deepspeed
# This has to be run inside the GPU VMs running the tests. (So far, it fails here due to GPU checks during compilation.)
# Issue: https://github.com/microsoft/DeepSpeed/issues/2010
# RUN git clone https://github.com/microsoft/DeepSpeed && cd DeepSpeed && rm -rf build && \
# DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 DS_BUILD_UTILS=1 python3 -m pip install . --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check 2>&1
## For `torchdynamo` tests
## (see https://github.com/huggingface/transformers/pull/17765)
#RUN git clone https://github.com/pytorch/functorch
#RUN python3 -m pip install --no-cache-dir ./functorch[aot]
#RUN cd functorch && python3 setup.py develop
#
#RUN git clone https://github.com/pytorch/torchdynamo
#RUN python3 -m pip install -r ./torchdynamo/requirements.txt
#RUN cd torchdynamo && python3 setup.py develop
#
## install TensorRT
#RUN python3 -m pip install --no-cache-dir -U nvidia-pyindex
#RUN python3 -m pip install --no-cache-dir -U nvidia-tensorrt==8.2.4.2
#
## install torch_tensorrt (fx path)
#RUN git clone https://github.com/pytorch/TensorRT.git
#RUN cd TensorRT/py && python3 setup.py install --fx-only
# When installing in editable mode, `transformers` is not recognized as a package.
# this line must be added in order for python to be aware of transformers.
RUN cd transformers && python3 setup.py develop
# Disable for now as deepspeed is not installed above. To be enabled once the issue is fixed.
# RUN python3 -c "from deepspeed.launcher.runner import main"
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-pytorch-tpu/docker-entrypoint.sh
|
#!/bin/bash
source ~/.bashrc
echo "running docker-entrypoint.sh"
conda activate container
echo $KUBE_GOOGLE_CLOUD_TPU_ENDPOINTS
echo "printed TPU info"
export XRT_TPU_CONFIG="tpu_worker;0;${KUBE_GOOGLE_CLOUD_TPU_ENDPOINTS:7}"
exec "$@"#!/bin/bash
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-pytorch-tpu/Dockerfile
|
FROM google/cloud-sdk:slim
# Build args.
ARG GITHUB_REF=refs/heads/main
# TODO: This Dockerfile installs pytorch/xla 3.6 wheels. There are also 3.7
# wheels available; see below.
ENV PYTHON_VERSION=3.6
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
cmake \
git \
curl \
ca-certificates
# Install conda and python.
# NOTE new Conda does not forward the exit status... https://github.com/conda/conda/issues/8385
RUN curl -o ~/miniconda.sh https://repo.anaconda.com/miniconda/Miniconda3-4.7.12-Linux-x86_64.sh && \
chmod +x ~/miniconda.sh && \
~/miniconda.sh -b && \
rm ~/miniconda.sh
ENV PATH=/root/miniconda3/bin:$PATH
RUN conda create -y --name container python=$PYTHON_VERSION
# Run the rest of commands within the new conda env.
# Use absolute path to appease Codefactor.
SHELL ["/root/miniconda3/bin/conda", "run", "-n", "container", "/bin/bash", "-c"]
RUN conda install -y python=$PYTHON_VERSION mkl
RUN pip uninstall -y torch && \
# Python 3.7 wheels are available. Replace cp36-cp36m with cp37-cp37m
gsutil cp 'gs://tpu-pytorch/wheels/torch-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' . && \
gsutil cp 'gs://tpu-pytorch/wheels/torch_xla-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' . && \
gsutil cp 'gs://tpu-pytorch/wheels/torchvision-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' . && \
pip install 'torch-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
pip install 'torch_xla-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
pip install 'torchvision-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
rm 'torch-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
rm 'torch_xla-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
rm 'torchvision-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
apt-get install -y libomp5
ENV LD_LIBRARY_PATH=root/miniconda3/envs/container/lib
# Install huggingface/transformers at the current PR, plus dependencies.
RUN git clone https://github.com/huggingface/transformers.git && \
cd transformers && \
git fetch origin $GITHUB_REF:CI && \
git checkout CI && \
cd .. && \
pip install ./transformers && \
pip install -r ./transformers/examples/pytorch/_test_requirements.txt && \
pip install pytest
RUN python -c "import torch_xla; print(torch_xla.__version__)"
RUN python -c "import transformers as trf; print(trf.__version__)"
RUN conda init bash
COPY docker-entrypoint.sh /usr/local/bin/
RUN chmod +x /usr/local/bin/docker-entrypoint.sh
ENTRYPOINT ["/usr/local/bin/docker-entrypoint.sh"]
CMD ["bash"]
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-pytorch-tpu/bert-base-cased.jsonnet
|
local base = import 'templates/base.libsonnet';
local tpus = import 'templates/tpus.libsonnet';
local utils = import "templates/utils.libsonnet";
local volumes = import "templates/volumes.libsonnet";
local bertBaseCased = base.BaseTest {
frameworkPrefix: "hf",
modelName: "bert-base-cased",
mode: "example",
configMaps: [],
timeout: 3600, # 1 hour, in seconds
image: std.extVar('image'),
imageTag: std.extVar('image-tag'),
tpuSettings+: {
softwareVersion: "pytorch-nightly",
},
accelerator: tpus.v3_8,
volumeMap+: {
datasets: volumes.PersistentVolumeSpec {
name: "huggingface-cluster-disk",
mountPath: "/datasets",
},
},
command: utils.scriptCommand(
|||
python -m pytest -s transformers/examples/pytorch/test_xla_examples.py -v
test_exit_code=$?
echo "\nFinished running commands.\n"
test $test_exit_code -eq 0
|||
),
};
bertBaseCased.oneshotJob
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-pytorch-tpu/dataset.yaml
|
apiVersion: v1
kind: PersistentVolume
metadata:
name: huggingface-cluster-disk
spec:
storageClassName: ""
capacity:
storage: 500Gi
accessModes:
- ReadOnlyMany
claimRef:
namespace: default
name: huggingface-cluster-disk-claim
gcePersistentDisk:
pdName: huggingface-cluster-disk
fsType: ext4
readOnly: true
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: huggingface-cluster-disk-claim
spec:
# Specify "" as the storageClassName so it matches the PersistentVolume's StorageClass.
# A nil storageClassName value uses the default StorageClass. For details, see
# https://kubernetes.io/docs/concepts/storage/persistent-volumes/#class-1
storageClassName: ""
accessModes:
- ReadOnlyMany
resources:
requests:
storage: 1Ki
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-pytorch-cpu/Dockerfile
|
FROM ubuntu:18.04
LABEL maintainer="Hugging Face"
LABEL repository="transformers"
RUN apt update && \
apt install -y bash \
build-essential \
git \
curl \
ca-certificates \
python3 \
python3-pip && \
rm -rf /var/lib/apt/lists
RUN python3 -m pip install --no-cache-dir --upgrade pip && \
python3 -m pip install --no-cache-dir \
jupyter \
torch
WORKDIR /workspace
COPY . transformers/
RUN cd transformers/ && \
python3 -m pip install --no-cache-dir .
CMD ["/bin/bash"]
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-all-latest-gpu/Dockerfile
|
FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu20.04
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
# Use login shell to read variables from `~/.profile` (to pass dynamic created variables between RUN commands)
SHELL ["sh", "-lc"]
# The following `ARG` are mainly used to specify the versions explicitly & directly in this docker file, and not meant
# to be used as arguments for docker build (so far).
ARG PYTORCH='2.1.0'
# (not always a valid torch version)
ARG INTEL_TORCH_EXT='2.1.0'
# Example: `cu102`, `cu113`, etc.
ARG CUDA='cu118'
RUN apt update
RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg git-lfs
RUN git lfs install
RUN python3 -m pip install --no-cache-dir --upgrade pip
ARG REF=main
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
# TODO: Handle these in a python utility script
RUN [ ${#PYTORCH} -gt 0 -a "$PYTORCH" != "pre" ] && VERSION='torch=='$PYTORCH'.*' || VERSION='torch'; echo "export VERSION='$VERSION'" >> ~/.profile
RUN echo torch=$VERSION
# `torchvision` and `torchaudio` should be installed along with `torch`, especially for nightly build.
# Currently, let's just use their latest releases (when `torch` is installed with a release version)
# TODO: We might need to specify proper versions that work with a specific torch version (especially for past CI).
RUN [ "$PYTORCH" != "pre" ] && python3 -m pip install --no-cache-dir -U $VERSION torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/$CUDA || python3 -m pip install --no-cache-dir -U --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/$CUDA
RUN python3 -m pip install --no-cache-dir -U tensorflow==2.13 protobuf==3.20.3 tensorflow_text tensorflow_probability
RUN python3 -m pip install --no-cache-dir -e ./transformers[dev,onnxruntime]
RUN python3 -m pip uninstall -y flax jax
RUN python3 -m pip install --no-cache-dir intel_extension_for_pytorch==$INTEL_TORCH_EXT -f https://developer.intel.com/ipex-whl-stable-cpu
RUN python3 -m pip install --no-cache-dir git+https://github.com/facebookresearch/detectron2.git pytesseract
RUN python3 -m pip install -U "itsdangerous<2.1.0"
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/accelerate@main#egg=accelerate
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/peft@main#egg=peft
# Add bitsandbytes for mixed int8 testing
RUN python3 -m pip install --no-cache-dir bitsandbytes
# Add auto-gptq for gtpq quantization testing
RUN python3 -m pip install --no-cache-dir auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
# Add einops for additional model testing
RUN python3 -m pip install --no-cache-dir einops
# Add autoawq for quantization testing
RUN python3 -m pip install --no-cache-dir https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp38-cp38-linux_x86_64.whl
# For bettertransformer + gptq
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/optimum@main#egg=optimum
# For video model testing
RUN python3 -m pip install --no-cache-dir decord av==9.2.0
# For `dinat` model
RUN python3 -m pip install --no-cache-dir natten -f https://shi-labs.com/natten/wheels/$CUDA/
# For `nougat` tokenizer
RUN python3 -m pip install --no-cache-dir python-Levenshtein
# When installing in editable mode, `transformers` is not recognized as a package.
# this line must be added in order for python to be aware of transformers.
RUN cd transformers && python3 setup.py develop
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-tensorflow-gpu/Dockerfile
|
FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu20.04
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
RUN apt update
RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg
RUN python3 -m pip install --no-cache-dir --upgrade pip
ARG REF=main
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-tensorflow,testing]
# If set to nothing, will install the latest version
ARG TENSORFLOW='2.13'
RUN [ ${#TENSORFLOW} -gt 0 ] && VERSION='tensorflow=='$TENSORFLOW'.*' || VERSION='tensorflow'; python3 -m pip install --no-cache-dir -U $VERSION
RUN python3 -m pip uninstall -y torch flax
RUN python3 -m pip install -U "itsdangerous<2.1.0"
RUN python3 -m pip install --no-cache-dir -U tensorflow_probability
# When installing in editable mode, `transformers` is not recognized as a package.
# this line must be added in order for python to be aware of transformers.
RUN cd transformers && python3 setup.py develop
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-tensorflow-cpu/Dockerfile
|
FROM ubuntu:18.04
LABEL maintainer="Hugging Face"
LABEL repository="transformers"
RUN apt update && \
apt install -y bash \
build-essential \
git \
curl \
ca-certificates \
python3 \
python3-pip && \
rm -rf /var/lib/apt/lists
RUN python3 -m pip install --no-cache-dir --upgrade pip && \
python3 -m pip install --no-cache-dir \
mkl \
tensorflow-cpu
WORKDIR /workspace
COPY . transformers/
RUN cd transformers/ && \
python3 -m pip install --no-cache-dir .
CMD ["/bin/bash"]
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-cpu/Dockerfile
|
FROM ubuntu:18.04
LABEL maintainer="Hugging Face"
LABEL repository="transformers"
RUN apt update && \
apt install -y bash \
build-essential \
git \
curl \
ca-certificates \
python3 \
python3-pip && \
rm -rf /var/lib/apt/lists
RUN python3 -m pip install --no-cache-dir --upgrade pip && \
python3 -m pip install --no-cache-dir \
jupyter \
tensorflow-cpu \
torch
WORKDIR /workspace
COPY . transformers/
RUN cd transformers/ && \
python3 -m pip install --no-cache-dir .
CMD ["/bin/bash"]
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-pytorch-amd-gpu/Dockerfile
|
FROM rocm/dev-ubuntu-20.04:5.6
# rocm/pytorch has no version with 2.1.0
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
ARG PYTORCH='2.1.0'
ARG TORCH_VISION='0.16.0'
ARG TORCH_AUDIO='2.1.0'
ARG ROCM='5.6'
RUN apt update && \
apt install -y --no-install-recommends git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-dev python3-pip ffmpeg && \
apt clean && \
rm -rf /var/lib/apt/lists/*
RUN python3 -m pip install --no-cache-dir --upgrade pip
RUN python3 -m pip install torch==$PYTORCH torchvision==$TORCH_VISION torchaudio==$TORCH_AUDIO --index-url https://download.pytorch.org/whl/rocm$ROCM
RUN python3 -m pip install --no-cache-dir --upgrade pip setuptools ninja git+https://github.com/facebookresearch/detectron2.git pytesseract "itsdangerous<2.1.0"
ARG REF=main
WORKDIR /
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-torch,testing,video]
RUN python3 -m pip uninstall -y tensorflow flax
# When installing in editable mode, `transformers` is not recognized as a package.
# this line must be added in order for python to be aware of transformers.
RUN cd transformers && python3 setup.py develop
| 0
|
hf_public_repos/transformers/docker
|
hf_public_repos/transformers/docker/transformers-pytorch-gpu/Dockerfile
|
FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu20.04
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
RUN apt update
RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg
RUN python3 -m pip install --no-cache-dir --upgrade pip
ARG REF=main
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
# If set to nothing, will install the latest version
ARG PYTORCH='2.1.0'
ARG TORCH_VISION=''
ARG TORCH_AUDIO=''
# Example: `cu102`, `cu113`, etc.
ARG CUDA='cu118'
RUN [ ${#PYTORCH} -gt 0 ] && VERSION='torch=='$PYTORCH'.*' || VERSION='torch'; python3 -m pip install --no-cache-dir -U $VERSION --extra-index-url https://download.pytorch.org/whl/$CUDA
RUN [ ${#TORCH_VISION} -gt 0 ] && VERSION='torchvision=='TORCH_VISION'.*' || VERSION='torchvision'; python3 -m pip install --no-cache-dir -U $VERSION --extra-index-url https://download.pytorch.org/whl/$CUDA
RUN [ ${#TORCH_AUDIO} -gt 0 ] && VERSION='torchaudio=='TORCH_AUDIO'.*' || VERSION='torchaudio'; python3 -m pip install --no-cache-dir -U $VERSION --extra-index-url https://download.pytorch.org/whl/$CUDA
RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-torch,testing,video]
RUN python3 -m pip uninstall -y tensorflow flax
RUN python3 -m pip install --no-cache-dir git+https://github.com/facebookresearch/detectron2.git pytesseract
RUN python3 -m pip install -U "itsdangerous<2.1.0"
# When installing in editable mode, `transformers` is not recognized as a package.
# this line must be added in order for python to be aware of transformers.
RUN cd transformers && python3 setup.py develop
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/examples/README.md
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Examples
We host a wide range of example scripts for multiple learning frameworks. Simply choose your favorite: [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch) or [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
We also have some [research projects](https://github.com/huggingface/transformers/tree/main/examples/research_projects), as well as some [legacy examples](https://github.com/huggingface/transformers/tree/main/examples/legacy). Note that unlike the main examples these are not actively maintained, and may require specific older versions of dependencies in order to run.
While we strive to present as many use cases as possible, the example scripts are just that - examples. It is expected that they won't work out-of-the-box on your specific problem and that you will be required to change a few lines of code to adapt them to your needs. To help you with that, most of the examples fully expose the preprocessing of the data, allowing you to tweak and edit them as required.
Please discuss on the [forum](https://discuss.huggingface.co/) or in an [issue](https://github.com/huggingface/transformers/issues) a feature you would like to implement in an example before submitting a PR; we welcome bug fixes, but since we want to keep the examples as simple as possible it's unlikely that we will merge a pull request adding more functionality at the cost of readability.
## Important note
**Important**
To make sure you can successfully run the latest versions of the example scripts, you have to **install the library from source** and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
Then cd in the example folder of your choice and run
```bash
pip install -r requirements.txt
```
To browse the examples corresponding to released versions of 🤗 Transformers, click on the line below and then on your desired version of the library:
<details>
<summary>Examples for older versions of 🤗 Transformers</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.21.0/examples">v4.21.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.20.1/examples">v4.20.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.19.4/examples">v4.19.4</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.18.0/examples">v4.18.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.17.0/examples">v4.17.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.16.2/examples">v4.16.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.15.0/examples">v4.15.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.14.1/examples">v4.14.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.13.0/examples">v4.13.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.12.5/examples">v4.12.5</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.11.3/examples">v4.11.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.10.3/examples">v4.10.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.9.2/examples">v4.9.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.8.2/examples">v4.8.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.7.0/examples">v4.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.6.1/examples">v4.6.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
Alternatively, you can switch your cloned 🤗 Transformers to a specific version (for instance with v3.5.1) with
```bash
git checkout tags/v3.5.1
```
and run the example command as usual afterward.
## Running the Examples on Remote Hardware with Auto-Setup
[run_on_remote.py](./run_on_remote.py) is a script that launches any example on remote self-hosted hardware,
with automatic hardware and environment setup. It uses [Runhouse](https://github.com/run-house/runhouse) to launch
on self-hosted hardware (e.g. in your own cloud account or on-premise cluster) but there are other options
for running remotely as well. You can easily customize the example used, command line arguments, dependencies,
and type of compute hardware, and then run the script to automatically launch the example.
You can refer to
[hardware setup](https://runhouse-docs.readthedocs-hosted.com/en/latest/api/python/cluster.html#hardware-setup)
for more information about hardware and dependency setup with Runhouse, or this
[Colab tutorial](https://colab.research.google.com/drive/1sh_aNQzJX5BKAdNeXthTNGxKz7sM9VPc) for a more in-depth
walkthrough.
You can run the script with the following commands:
```bash
# First install runhouse:
pip install runhouse
# For an on-demand V100 with whichever cloud provider you have configured:
python run_on_remote.py \
--example pytorch/text-generation/run_generation.py \
--model_type=gpt2 \
--model_name_or_path=gpt2 \
--prompt "I am a language model and"
# For byo (bring your own) cluster:
python run_on_remote.py --host <cluster_ip> --user <ssh_user> --key_path <ssh_key_path> \
--example <example> <args>
# For on-demand instances
python run_on_remote.py --instance <instance> --provider <provider> \
--example <example> <args>
```
You can also adapt the script to your own needs.
| 0
|
hf_public_repos/transformers
|
hf_public_repos/transformers/examples/run_on_remote.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import shlex
import runhouse as rh
if __name__ == "__main__":
# Refer to https://runhouse-docs.readthedocs-hosted.com/en/latest/api/python/cluster.html#hardware-setup for cloud access
# setup instructions, if using on-demand hardware
# If user passes --user <user> --host <host> --key_path <key_path> <example> <args>, fill them in as BYO cluster
# If user passes --instance <instance> --provider <provider> <example> <args>, fill them in as on-demand cluster
# Throw an error if user passes both BYO and on-demand cluster args
# Otherwise, use default values
parser = argparse.ArgumentParser()
parser.add_argument("--user", type=str, default="ubuntu")
parser.add_argument("--host", type=str, default="localhost")
parser.add_argument("--key_path", type=str, default=None)
parser.add_argument("--instance", type=str, default="V100:1")
parser.add_argument("--provider", type=str, default="cheapest")
parser.add_argument("--use_spot", type=bool, default=False)
parser.add_argument("--example", type=str, default="pytorch/text-generation/run_generation.py")
args, unknown = parser.parse_known_args()
if args.host != "localhost":
if args.instance != "V100:1" or args.provider != "cheapest":
raise ValueError("Cannot specify both BYO and on-demand cluster args")
cluster = rh.cluster(
name="rh-cluster", ips=[args.host], ssh_creds={"ssh_user": args.user, "ssh_private_key": args.key_path}
)
else:
cluster = rh.cluster(
name="rh-cluster", instance_type=args.instance, provider=args.provider, use_spot=args.use_spot
)
example_dir = args.example.rsplit("/", 1)[0]
# Set up remote environment
cluster.install_packages(["pip:./"]) # Installs transformers from local source
# Note transformers is copied into the home directory on the remote machine, so we can install from there
cluster.run([f"pip install -r transformers/examples/{example_dir}/requirements.txt"])
cluster.run(["pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu117"])
# Run example. You can bypass the CLI wrapper and paste your own code here.
cluster.run([f'python transformers/examples/{args.example} {" ".join(shlex.quote(arg) for arg in unknown)}'])
# Alternatively, we can just import and run a training function (especially if there's no wrapper CLI):
# from my_script... import train
# reqs = ['pip:./', 'torch', 'datasets', 'accelerate', 'evaluate', 'tqdm', 'scipy', 'scikit-learn', 'tensorboard']
# launch_train_gpu = rh.function(fn=train,
# system=gpu,
# reqs=reqs,
# name='train_bert_glue')
#
# We can pass in arguments just like we would to a function:
# launch_train_gpu(num_epochs = 3, lr = 2e-5, seed = 42, batch_size = 16
# stream_logs=True)
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/legacy/run_language_modeling.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for language modeling on a text file (GPT, GPT-2, CTRL, BERT, RoBERTa, XLNet).
GPT, GPT-2 and CTRL are fine-tuned using a causal language modeling (CLM) loss. BERT and RoBERTa are fine-tuned
using a masked language modeling (MLM) loss. XLNet is fine-tuned using a permutation language modeling (PLM) loss.
"""
import logging
import math
import os
from dataclasses import dataclass, field
from glob import glob
from typing import Optional
from torch.utils.data import ConcatDataset
import transformers
from transformers import (
CONFIG_MAPPING,
MODEL_WITH_LM_HEAD_MAPPING,
AutoConfig,
AutoModelWithLMHead,
AutoTokenizer,
DataCollatorForLanguageModeling,
DataCollatorForPermutationLanguageModeling,
DataCollatorForWholeWordMask,
HfArgumentParser,
LineByLineTextDataset,
LineByLineWithRefDataset,
PreTrainedTokenizer,
TextDataset,
Trainer,
TrainingArguments,
set_seed,
)
from transformers.trainer_utils import is_main_process
logger = logging.getLogger(__name__)
MODEL_CONFIG_CLASSES = list(MODEL_WITH_LM_HEAD_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
model_name_or_path: Optional[str] = field(
default=None,
metadata={
"help": (
"The model checkpoint for weights initialization. Leave None if you want to train a model from"
" scratch."
)
},
)
model_type: Optional[str] = field(
default=None,
metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
train_data_file: Optional[str] = field(
default=None, metadata={"help": "The input training data file (a text file)."}
)
train_data_files: Optional[str] = field(
default=None,
metadata={
"help": (
"The input training data files (multiple files in glob format). "
"Very often splitting large files to smaller files can prevent tokenizer going out of memory"
)
},
)
eval_data_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
)
train_ref_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input train ref data file for whole word mask in Chinese."},
)
eval_ref_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input eval ref data file for whole word mask in Chinese."},
)
line_by_line: bool = field(
default=False,
metadata={"help": "Whether distinct lines of text in the dataset are to be handled as distinct sequences."},
)
mlm: bool = field(
default=False, metadata={"help": "Train with masked-language modeling loss instead of language modeling."}
)
whole_word_mask: bool = field(default=False, metadata={"help": "Whether ot not to use whole word mask."})
mlm_probability: float = field(
default=0.15, metadata={"help": "Ratio of tokens to mask for masked language modeling loss"}
)
plm_probability: float = field(
default=1 / 6,
metadata={
"help": (
"Ratio of length of a span of masked tokens to surrounding context length for permutation language"
" modeling."
)
},
)
max_span_length: int = field(
default=5, metadata={"help": "Maximum length of a span of masked tokens for permutation language modeling."}
)
block_size: int = field(
default=-1,
metadata={
"help": (
"Optional input sequence length after tokenization. "
"The training dataset will be truncated in block of this size for training."
"Default to the model max input length for single sentence inputs (take into account special tokens)."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
def get_dataset(
args: DataTrainingArguments,
tokenizer: PreTrainedTokenizer,
evaluate: bool = False,
cache_dir: Optional[str] = None,
):
def _dataset(file_path, ref_path=None):
if args.line_by_line:
if ref_path is not None:
if not args.whole_word_mask or not args.mlm:
raise ValueError("You need to set world whole masking and mlm to True for Chinese Whole Word Mask")
return LineByLineWithRefDataset(
tokenizer=tokenizer,
file_path=file_path,
block_size=args.block_size,
ref_path=ref_path,
)
return LineByLineTextDataset(tokenizer=tokenizer, file_path=file_path, block_size=args.block_size)
else:
return TextDataset(
tokenizer=tokenizer,
file_path=file_path,
block_size=args.block_size,
overwrite_cache=args.overwrite_cache,
cache_dir=cache_dir,
)
if evaluate:
return _dataset(args.eval_data_file, args.eval_ref_file)
elif args.train_data_files:
return ConcatDataset([_dataset(f) for f in glob(args.train_data_files)])
else:
return _dataset(args.train_data_file, args.train_ref_file)
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if data_args.eval_data_file is None and training_args.do_eval:
raise ValueError(
"Cannot do evaluation without an evaluation data file. Either supply a file to --eval_data_file "
"or remove the --do_eval argument."
)
if (
os.path.exists(training_args.output_dir)
and os.listdir(training_args.output_dir)
and training_args.do_train
and not training_args.overwrite_output_dir
):
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
" --overwrite_output_dir to overcome."
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
training_args.local_rank,
training_args.device,
training_args.n_gpu,
bool(training_args.local_rank != -1),
training_args.fp16,
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(training_args.local_rank):
transformers.utils.logging.set_verbosity_info()
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
logger.info("Training/evaluation parameters %s", training_args)
# Set seed
set_seed(training_args.seed)
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
if model_args.config_name:
config = AutoConfig.from_pretrained(model_args.config_name, cache_dir=model_args.cache_dir)
elif model_args.model_name_or_path:
config = AutoConfig.from_pretrained(model_args.model_name_or_path, cache_dir=model_args.cache_dir)
else:
config = CONFIG_MAPPING[model_args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, cache_dir=model_args.cache_dir)
elif model_args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, cache_dir=model_args.cache_dir)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported, but you can do it from another"
" script, save it,and load it from here, using --tokenizer_name"
)
if model_args.model_name_or_path:
model = AutoModelWithLMHead.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
)
else:
logger.info("Training new model from scratch")
model = AutoModelWithLMHead.from_config(config)
model.resize_token_embeddings(len(tokenizer))
if config.model_type in ["bert", "roberta", "distilbert", "camembert"] and not data_args.mlm:
raise ValueError(
"BERT and RoBERTa-like models do not have LM heads but masked LM heads. They must be run using the "
"--mlm flag (masked language modeling)."
)
if data_args.block_size <= 0:
data_args.block_size = tokenizer.max_len
# Our input block size will be the max possible for the model
else:
data_args.block_size = min(data_args.block_size, tokenizer.max_len)
# Get datasets
train_dataset = (
get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_train else None
)
eval_dataset = (
get_dataset(data_args, tokenizer=tokenizer, evaluate=True, cache_dir=model_args.cache_dir)
if training_args.do_eval
else None
)
if config.model_type == "xlnet":
data_collator = DataCollatorForPermutationLanguageModeling(
tokenizer=tokenizer,
plm_probability=data_args.plm_probability,
max_span_length=data_args.max_span_length,
)
else:
if data_args.mlm and data_args.whole_word_mask:
data_collator = DataCollatorForWholeWordMask(
tokenizer=tokenizer, mlm_probability=data_args.mlm_probability
)
else:
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=data_args.mlm, mlm_probability=data_args.mlm_probability
)
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
prediction_loss_only=True,
)
# Training
if training_args.do_train:
model_path = (
model_args.model_name_or_path
if model_args.model_name_or_path is not None and os.path.isdir(model_args.model_name_or_path)
else None
)
trainer.train(model_path=model_path)
trainer.save_model()
# For convenience, we also re-save the tokenizer to the same directory,
# so that you can share your model easily on huggingface.co/models =)
if trainer.is_world_master():
tokenizer.save_pretrained(training_args.output_dir)
# Evaluation
results = {}
if training_args.do_eval:
logger.info("*** Evaluate ***")
eval_output = trainer.evaluate()
perplexity = math.exp(eval_output["eval_loss"])
result = {"perplexity": perplexity}
output_eval_file = os.path.join(training_args.output_dir, "eval_results_lm.txt")
if trainer.is_world_master():
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results *****")
for key in sorted(result.keys()):
logger.info(" %s = %s", key, str(result[key]))
writer.write("%s = %s\n" % (key, str(result[key])))
results.update(result)
return results
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/legacy/README.md
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Legacy examples
This folder contains examples which are not actively maintained (mostly contributed by the community).
Using these examples together with a recent version of the library usually requires to make small (sometimes big) adaptations to get the scripts working.
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/legacy/run_transfo_xl.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2018 Google AI, Google Brain and Carnegie Mellon University Authors and the HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch Transformer XL model evaluation script.
Adapted from https://github.com/kimiyoung/transformer-xl.
In particular https://github.com/kimiyoung/transformer-xl/blob/master/pytorch/eval.py
This script with default values evaluates a pretrained Transformer-XL on WikiText 103
"""
import argparse
import logging
import math
import time
import torch
from transformers import TransfoXLCorpus, TransfoXLLMHeadModel
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s", datefmt="%m/%d/%Y %H:%M:%S", level=logging.INFO
)
logger = logging.getLogger(__name__)
def main():
parser = argparse.ArgumentParser(description="PyTorch Transformer Language Model")
parser.add_argument("--model_name", type=str, default="transfo-xl-wt103", help="pretrained model name")
parser.add_argument(
"--split", type=str, default="test", choices=["all", "valid", "test"], help="which split to evaluate"
)
parser.add_argument("--batch_size", type=int, default=10, help="batch size")
parser.add_argument("--tgt_len", type=int, default=128, help="number of tokens to predict")
parser.add_argument("--ext_len", type=int, default=0, help="length of the extended context")
parser.add_argument("--mem_len", type=int, default=1600, help="length of the retained previous heads")
parser.add_argument("--clamp_len", type=int, default=1000, help="max positional embedding index")
parser.add_argument("--no_cuda", action="store_true", help="Do not use CUDA even though CUA is available")
parser.add_argument("--work_dir", type=str, required=True, help="path to the work_dir")
parser.add_argument("--no_log", action="store_true", help="do not log the eval result")
parser.add_argument("--same_length", action="store_true", help="set same length attention with masking")
parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
args = parser.parse_args()
assert args.ext_len >= 0, "extended context length must be non-negative"
if args.server_ip and args.server_port:
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
print("Waiting for debugger attach")
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
ptvsd.wait_for_attach()
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
logger.info("device: {}".format(device))
# Load a pre-processed dataset
# You can also build the corpus yourself using TransfoXLCorpus methods
# The pre-processing involve computing word frequencies to prepare the Adaptive input and SoftMax
# and tokenizing the dataset
# The pre-processed corpus is a convertion (using the conversion script )
corpus = TransfoXLCorpus.from_pretrained(args.model_name)
va_iter = corpus.get_iterator("valid", args.batch_size, args.tgt_len, device=device, ext_len=args.ext_len)
te_iter = corpus.get_iterator("test", args.batch_size, args.tgt_len, device=device, ext_len=args.ext_len)
# Load a pre-trained model
model = TransfoXLLMHeadModel.from_pretrained(args.model_name)
model.to(device)
logger.info(
"Evaluating with bsz {} tgt_len {} ext_len {} mem_len {} clamp_len {}".format(
args.batch_size, args.tgt_len, args.ext_len, args.mem_len, args.clamp_len
)
)
model.reset_memory_length(args.mem_len)
if args.clamp_len > 0:
model.clamp_len = args.clamp_len
if args.same_length:
model.same_length = True
###############################################################################
# Evaluation code
###############################################################################
def evaluate(eval_iter):
# Turn on evaluation mode which disables dropout.
model.eval()
total_len, total_loss = 0, 0.0
start_time = time.time()
with torch.no_grad():
mems = None
for idx, (data, target, seq_len) in enumerate(eval_iter):
ret = model(data, lm_labels=target, mems=mems)
loss, _, mems = ret
loss = loss.mean()
total_loss += seq_len * loss.item()
total_len += seq_len
total_time = time.time() - start_time
logger.info("Time : {:.2f}s, {:.2f}ms/segment".format(total_time, 1000 * total_time / (idx + 1)))
return total_loss / total_len
# Run on test data.
if args.split == "all":
test_loss = evaluate(te_iter)
valid_loss = evaluate(va_iter)
elif args.split == "valid":
valid_loss = evaluate(va_iter)
test_loss = None
elif args.split == "test":
test_loss = evaluate(te_iter)
valid_loss = None
def format_log(loss, split):
log_str = "| {0} loss {1:5.2f} | {0} ppl {2:9.3f} ".format(split, loss, math.exp(loss))
return log_str
log_str = ""
if valid_loss is not None:
log_str += format_log(valid_loss, "valid")
if test_loss is not None:
log_str += format_log(test_loss, "test")
logger.info("=" * 100)
logger.info(log_str)
logger.info("=" * 100)
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/legacy/run_chinese_ref.py
|
#!/usr/bin/env python
import argparse
import json
from typing import List
from ltp import LTP
from transformers import BertTokenizer
def _is_chinese_char(cp):
"""Checks whether CP is the codepoint of a CJK character."""
# This defines a "chinese character" as anything in the CJK Unicode block:
# https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
#
# Note that the CJK Unicode block is NOT all Japanese and Korean characters,
# despite its name. The modern Korean Hangul alphabet is a different block,
# as is Japanese Hiragana and Katakana. Those alphabets are used to write
# space-separated words, so they are not treated specially and handled
# like the all of the other languages.
if (
(cp >= 0x4E00 and cp <= 0x9FFF)
or (cp >= 0x3400 and cp <= 0x4DBF) #
or (cp >= 0x20000 and cp <= 0x2A6DF) #
or (cp >= 0x2A700 and cp <= 0x2B73F) #
or (cp >= 0x2B740 and cp <= 0x2B81F) #
or (cp >= 0x2B820 and cp <= 0x2CEAF) #
or (cp >= 0xF900 and cp <= 0xFAFF)
or (cp >= 0x2F800 and cp <= 0x2FA1F) #
): #
return True
return False
def is_chinese(word: str):
# word like '180' or '身高' or '神'
for char in word:
char = ord(char)
if not _is_chinese_char(char):
return 0
return 1
def get_chinese_word(tokens: List[str]):
word_set = set()
for token in tokens:
chinese_word = len(token) > 1 and is_chinese(token)
if chinese_word:
word_set.add(token)
word_list = list(word_set)
return word_list
def add_sub_symbol(bert_tokens: List[str], chinese_word_set: set()):
if not chinese_word_set:
return bert_tokens
max_word_len = max([len(w) for w in chinese_word_set])
bert_word = bert_tokens
start, end = 0, len(bert_word)
while start < end:
single_word = True
if is_chinese(bert_word[start]):
l = min(end - start, max_word_len)
for i in range(l, 1, -1):
whole_word = "".join(bert_word[start : start + i])
if whole_word in chinese_word_set:
for j in range(start + 1, start + i):
bert_word[j] = "##" + bert_word[j]
start = start + i
single_word = False
break
if single_word:
start += 1
return bert_word
def prepare_ref(lines: List[str], ltp_tokenizer: LTP, bert_tokenizer: BertTokenizer):
ltp_res = []
for i in range(0, len(lines), 100):
res = ltp_tokenizer.seg(lines[i : i + 100])[0]
res = [get_chinese_word(r) for r in res]
ltp_res.extend(res)
assert len(ltp_res) == len(lines)
bert_res = []
for i in range(0, len(lines), 100):
res = bert_tokenizer(lines[i : i + 100], add_special_tokens=True, truncation=True, max_length=512)
bert_res.extend(res["input_ids"])
assert len(bert_res) == len(lines)
ref_ids = []
for input_ids, chinese_word in zip(bert_res, ltp_res):
input_tokens = []
for id in input_ids:
token = bert_tokenizer._convert_id_to_token(id)
input_tokens.append(token)
input_tokens = add_sub_symbol(input_tokens, chinese_word)
ref_id = []
# We only save pos of chinese subwords start with ##, which mean is part of a whole word.
for i, token in enumerate(input_tokens):
if token[:2] == "##":
clean_token = token[2:]
# save chinese tokens' pos
if len(clean_token) == 1 and _is_chinese_char(ord(clean_token)):
ref_id.append(i)
ref_ids.append(ref_id)
assert len(ref_ids) == len(bert_res)
return ref_ids
def main(args):
# For Chinese (Ro)Bert, the best result is from : RoBERTa-wwm-ext (https://github.com/ymcui/Chinese-BERT-wwm)
# If we want to fine-tune these model, we have to use same tokenizer : LTP (https://github.com/HIT-SCIR/ltp)
with open(args.file_name, "r", encoding="utf-8") as f:
data = f.readlines()
data = [line.strip() for line in data if len(line) > 0 and not line.isspace()] # avoid delimiter like '\u2029'
ltp_tokenizer = LTP(args.ltp) # faster in GPU device
bert_tokenizer = BertTokenizer.from_pretrained(args.bert)
ref_ids = prepare_ref(data, ltp_tokenizer, bert_tokenizer)
with open(args.save_path, "w", encoding="utf-8") as f:
data = [json.dumps(ref) + "\n" for ref in ref_ids]
f.writelines(data)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="prepare_chinese_ref")
parser.add_argument(
"--file_name",
type=str,
default="./resources/chinese-demo.txt",
help="file need process, same as training data in lm",
)
parser.add_argument(
"--ltp", type=str, default="./resources/ltp", help="resources for LTP tokenizer, usually a path"
)
parser.add_argument("--bert", type=str, default="./resources/robert", help="resources for Bert tokenizer")
parser.add_argument("--save_path", type=str, default="./resources/ref.txt", help="path to save res")
args = parser.parse_args()
main(args)
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/legacy/run_openai_gpt.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2018 Google AI, Google Brain and Carnegie Mellon University Authors and the HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" OpenAI GPT model fine-tuning script.
Adapted from https://github.com/huggingface/pytorch-openai-transformer-lm/blob/master/train.py
It self adapted from https://github.com/openai/finetune-transformer-lm/blob/master/train.py
This script with default values fine-tunes and evaluate a pretrained OpenAI GPT on the RocStories dataset:
python run_openai_gpt.py \
--model_name openai-gpt \
--do_train \
--do_eval \
--train_dataset "$ROC_STORIES_DIR/cloze_test_val__spring2016 - cloze_test_ALL_val.csv" \
--eval_dataset "$ROC_STORIES_DIR/cloze_test_test__spring2016 - cloze_test_ALL_test.csv" \
--output_dir ../log \
--train_batch_size 16 \
"""
import argparse
import csv
import logging
import os
import random
import numpy as np
import torch
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
from tqdm import tqdm, trange
from transformers import (
CONFIG_NAME,
WEIGHTS_NAME,
AdamW,
OpenAIGPTDoubleHeadsModel,
OpenAIGPTTokenizer,
get_linear_schedule_with_warmup,
)
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s", datefmt="%m/%d/%Y %H:%M:%S", level=logging.INFO
)
logger = logging.getLogger(__name__)
def accuracy(out, labels):
outputs = np.argmax(out, axis=1)
return np.sum(outputs == labels)
def load_rocstories_dataset(dataset_path):
"""Output a list of tuples(story, 1st continuation, 2nd continuation, label)"""
with open(dataset_path, encoding="utf_8") as f:
f = csv.reader(f)
output = []
next(f) # skip the first line
for line in tqdm(f):
output.append((" ".join(line[1:5]), line[5], line[6], int(line[-1]) - 1))
return output
def pre_process_datasets(encoded_datasets, input_len, cap_length, start_token, delimiter_token, clf_token):
"""Pre-process datasets containing lists of tuples(story, 1st continuation, 2nd continuation, label)
To Transformer inputs of shape (n_batch, n_alternative, length) comprising for each batch, continuation:
input_ids[batch, alternative, :] = [start_token] + story[:cap_length] + [delimiter_token] + cont1[:cap_length] + [clf_token]
"""
tensor_datasets = []
for dataset in encoded_datasets:
n_batch = len(dataset)
input_ids = np.zeros((n_batch, 2, input_len), dtype=np.int64)
mc_token_ids = np.zeros((n_batch, 2), dtype=np.int64)
lm_labels = np.full((n_batch, 2, input_len), fill_value=-100, dtype=np.int64)
mc_labels = np.zeros((n_batch,), dtype=np.int64)
for (
i,
(story, cont1, cont2, mc_label),
) in enumerate(dataset):
with_cont1 = [start_token] + story[:cap_length] + [delimiter_token] + cont1[:cap_length] + [clf_token]
with_cont2 = [start_token] + story[:cap_length] + [delimiter_token] + cont2[:cap_length] + [clf_token]
input_ids[i, 0, : len(with_cont1)] = with_cont1
input_ids[i, 1, : len(with_cont2)] = with_cont2
mc_token_ids[i, 0] = len(with_cont1) - 1
mc_token_ids[i, 1] = len(with_cont2) - 1
lm_labels[i, 0, : len(with_cont1)] = with_cont1
lm_labels[i, 1, : len(with_cont2)] = with_cont2
mc_labels[i] = mc_label
all_inputs = (input_ids, mc_token_ids, lm_labels, mc_labels)
tensor_datasets.append(tuple(torch.tensor(t) for t in all_inputs))
return tensor_datasets
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--model_name", type=str, default="openai-gpt", help="pretrained model name")
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument("--train_dataset", type=str, default="")
parser.add_argument("--eval_dataset", type=str, default="")
parser.add_argument("--seed", type=int, default=42)
parser.add_argument("--num_train_epochs", type=int, default=3)
parser.add_argument("--train_batch_size", type=int, default=8)
parser.add_argument("--eval_batch_size", type=int, default=16)
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--max_grad_norm", type=int, default=1)
parser.add_argument(
"--max_steps",
default=-1,
type=int,
help=(
"If > 0: set total number of training steps to perform. Override num_train_epochs."
),
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument("--learning_rate", type=float, default=6.25e-5)
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument("--lr_schedule", type=str, default="warmup_linear")
parser.add_argument("--weight_decay", type=float, default=0.01)
parser.add_argument("--lm_coef", type=float, default=0.9)
parser.add_argument("--n_valid", type=int, default=374)
parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
args = parser.parse_args()
print(args)
if args.server_ip and args.server_port:
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
print("Waiting for debugger attach")
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
ptvsd.wait_for_attach()
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed_all(args.seed)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
n_gpu = torch.cuda.device_count()
logger.info("device: {}, n_gpu {}".format(device, n_gpu))
if not args.do_train and not args.do_eval:
raise ValueError("At least one of `do_train` or `do_eval` must be True.")
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
# Load tokenizer and model
# This loading functions also add new tokens and embeddings called `special tokens`
# These new embeddings will be fine-tuned on the RocStories dataset
special_tokens = ["_start_", "_delimiter_", "_classify_"]
tokenizer = OpenAIGPTTokenizer.from_pretrained(args.model_name)
tokenizer.add_tokens(special_tokens)
special_tokens_ids = tokenizer.convert_tokens_to_ids(special_tokens)
model = OpenAIGPTDoubleHeadsModel.from_pretrained(args.model_name)
model.resize_token_embeddings(len(tokenizer))
model.to(device)
# Load and encode the datasets
def tokenize_and_encode(obj):
"""Tokenize and encode a nested object"""
if isinstance(obj, str):
return tokenizer.convert_tokens_to_ids(tokenizer.tokenize(obj))
elif isinstance(obj, int):
return obj
return [tokenize_and_encode(o) for o in obj]
logger.info("Encoding dataset...")
train_dataset = load_rocstories_dataset(args.train_dataset)
eval_dataset = load_rocstories_dataset(args.eval_dataset)
datasets = (train_dataset, eval_dataset)
encoded_datasets = tokenize_and_encode(datasets)
# Compute the max input length for the Transformer
max_length = model.config.n_positions // 2 - 2
input_length = max(
len(story[:max_length]) + max(len(cont1[:max_length]), len(cont2[:max_length])) + 3
for dataset in encoded_datasets
for story, cont1, cont2, _ in dataset
)
input_length = min(input_length, model.config.n_positions) # Max size of input for the pre-trained model
# Prepare inputs tensors and dataloaders
tensor_datasets = pre_process_datasets(encoded_datasets, input_length, max_length, *special_tokens_ids)
train_tensor_dataset, eval_tensor_dataset = tensor_datasets[0], tensor_datasets[1]
train_data = TensorDataset(*train_tensor_dataset)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=args.train_batch_size)
eval_data = TensorDataset(*eval_tensor_dataset)
eval_sampler = SequentialSampler(eval_data)
eval_dataloader = DataLoader(eval_data, sampler=eval_sampler, batch_size=args.eval_batch_size)
# Prepare optimizer
if args.do_train:
if args.max_steps > 0:
t_total = args.max_steps
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
param_optimizer = list(model.named_parameters())
no_decay = ["bias", "LayerNorm.bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{"params": [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
)
if args.do_train:
nb_tr_steps, tr_loss, exp_average_loss = 0, 0, None
model.train()
for _ in trange(int(args.num_train_epochs), desc="Epoch"):
tr_loss = 0
nb_tr_steps = 0
tqdm_bar = tqdm(train_dataloader, desc="Training")
for step, batch in enumerate(tqdm_bar):
batch = tuple(t.to(device) for t in batch)
input_ids, mc_token_ids, lm_labels, mc_labels = batch
losses = model(input_ids, mc_token_ids=mc_token_ids, lm_labels=lm_labels, mc_labels=mc_labels)
loss = args.lm_coef * losses[0] + losses[1]
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
tr_loss += loss.item()
exp_average_loss = (
loss.item() if exp_average_loss is None else 0.7 * exp_average_loss + 0.3 * loss.item()
)
nb_tr_steps += 1
tqdm_bar.desc = "Training loss: {:.2e} lr: {:.2e}".format(exp_average_loss, scheduler.get_lr()[0])
# Save a trained model
if args.do_train:
# Save a trained model, configuration and tokenizer
model_to_save = model.module if hasattr(model, "module") else model # Only save the model itself
# If we save using the predefined names, we can load using `from_pretrained`
output_model_file = os.path.join(args.output_dir, WEIGHTS_NAME)
output_config_file = os.path.join(args.output_dir, CONFIG_NAME)
torch.save(model_to_save.state_dict(), output_model_file)
model_to_save.config.to_json_file(output_config_file)
tokenizer.save_vocabulary(args.output_dir)
# Load a trained model and vocabulary that you have fine-tuned
model = OpenAIGPTDoubleHeadsModel.from_pretrained(args.output_dir)
tokenizer = OpenAIGPTTokenizer.from_pretrained(args.output_dir)
model.to(device)
if args.do_eval:
model.eval()
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
for batch in tqdm(eval_dataloader, desc="Evaluating"):
batch = tuple(t.to(device) for t in batch)
input_ids, mc_token_ids, lm_labels, mc_labels = batch
with torch.no_grad():
_, mc_loss, _, mc_logits = model(
input_ids, mc_token_ids=mc_token_ids, lm_labels=lm_labels, mc_labels=mc_labels
)
mc_logits = mc_logits.detach().cpu().numpy()
mc_labels = mc_labels.to("cpu").numpy()
tmp_eval_accuracy = accuracy(mc_logits, mc_labels)
eval_loss += mc_loss.mean().item()
eval_accuracy += tmp_eval_accuracy
nb_eval_examples += input_ids.size(0)
nb_eval_steps += 1
eval_loss = eval_loss / nb_eval_steps
eval_accuracy = eval_accuracy / nb_eval_examples
train_loss = tr_loss / nb_tr_steps if args.do_train else None
result = {"eval_loss": eval_loss, "eval_accuracy": eval_accuracy, "train_loss": train_loss}
output_eval_file = os.path.join(args.output_dir, "eval_results.txt")
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results *****")
for key in sorted(result.keys()):
logger.info(" %s = %s", key, str(result[key]))
writer.write("%s = %s\n" % (key, str(result[key])))
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/legacy/run_swag.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""BERT finetuning runner.
Finetuning the library models for multiple choice on SWAG (Bert).
"""
import argparse
import csv
import glob
import logging
import os
import random
import numpy as np
import torch
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
from torch.utils.data.distributed import DistributedSampler
from tqdm import tqdm, trange
import transformers
from transformers import (
WEIGHTS_NAME,
AdamW,
AutoConfig,
AutoModelForMultipleChoice,
AutoTokenizer,
get_linear_schedule_with_warmup,
)
from transformers.trainer_utils import is_main_process
try:
from torch.utils.tensorboard import SummaryWriter
except ImportError:
from tensorboardX import SummaryWriter
logger = logging.getLogger(__name__)
class SwagExample(object):
"""A single training/test example for the SWAG dataset."""
def __init__(self, swag_id, context_sentence, start_ending, ending_0, ending_1, ending_2, ending_3, label=None):
self.swag_id = swag_id
self.context_sentence = context_sentence
self.start_ending = start_ending
self.endings = [
ending_0,
ending_1,
ending_2,
ending_3,
]
self.label = label
def __str__(self):
return self.__repr__()
def __repr__(self):
attributes = [
"swag_id: {}".format(self.swag_id),
"context_sentence: {}".format(self.context_sentence),
"start_ending: {}".format(self.start_ending),
"ending_0: {}".format(self.endings[0]),
"ending_1: {}".format(self.endings[1]),
"ending_2: {}".format(self.endings[2]),
"ending_3: {}".format(self.endings[3]),
]
if self.label is not None:
attributes.append("label: {}".format(self.label))
return ", ".join(attributes)
class InputFeatures(object):
def __init__(self, example_id, choices_features, label):
self.example_id = example_id
self.choices_features = [
{"input_ids": input_ids, "input_mask": input_mask, "segment_ids": segment_ids}
for _, input_ids, input_mask, segment_ids in choices_features
]
self.label = label
def read_swag_examples(input_file, is_training=True):
with open(input_file, "r", encoding="utf-8") as f:
lines = list(csv.reader(f))
if is_training and lines[0][-1] != "label":
raise ValueError("For training, the input file must contain a label column.")
examples = [
SwagExample(
swag_id=line[2],
context_sentence=line[4],
start_ending=line[5], # in the swag dataset, the
# common beginning of each
# choice is stored in "sent2".
ending_0=line[7],
ending_1=line[8],
ending_2=line[9],
ending_3=line[10],
label=int(line[11]) if is_training else None,
)
for line in lines[1:] # we skip the line with the column names
]
return examples
def convert_examples_to_features(examples, tokenizer, max_seq_length, is_training):
"""Loads a data file into a list of `InputBatch`s."""
# Swag is a multiple choice task. To perform this task using Bert,
# we will use the formatting proposed in "Improving Language
# Understanding by Generative Pre-Training" and suggested by
# @jacobdevlin-google in this issue
# https://github.com/google-research/bert/issues/38.
#
# Each choice will correspond to a sample on which we run the
# inference. For a given Swag example, we will create the 4
# following inputs:
# - [CLS] context [SEP] choice_1 [SEP]
# - [CLS] context [SEP] choice_2 [SEP]
# - [CLS] context [SEP] choice_3 [SEP]
# - [CLS] context [SEP] choice_4 [SEP]
# The model will output a single value for each input. To get the
# final decision of the model, we will run a softmax over these 4
# outputs.
features = []
for example_index, example in tqdm(enumerate(examples)):
context_tokens = tokenizer.tokenize(example.context_sentence)
start_ending_tokens = tokenizer.tokenize(example.start_ending)
choices_features = []
for ending_index, ending in enumerate(example.endings):
# We create a copy of the context tokens in order to be
# able to shrink it according to ending_tokens
context_tokens_choice = context_tokens[:]
ending_tokens = start_ending_tokens + tokenizer.tokenize(ending)
# Modifies `context_tokens_choice` and `ending_tokens` in
# place so that the total length is less than the
# specified length. Account for [CLS], [SEP], [SEP] with
# "- 3"
_truncate_seq_pair(context_tokens_choice, ending_tokens, max_seq_length - 3)
tokens = ["[CLS]"] + context_tokens_choice + ["[SEP]"] + ending_tokens + ["[SEP]"]
segment_ids = [0] * (len(context_tokens_choice) + 2) + [1] * (len(ending_tokens) + 1)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
input_mask = [1] * len(input_ids)
# Zero-pad up to the sequence length.
padding = [0] * (max_seq_length - len(input_ids))
input_ids += padding
input_mask += padding
segment_ids += padding
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
choices_features.append((tokens, input_ids, input_mask, segment_ids))
label = example.label
if example_index < 5:
logger.info("*** Example ***")
logger.info("swag_id: {}".format(example.swag_id))
for choice_idx, (tokens, input_ids, input_mask, segment_ids) in enumerate(choices_features):
logger.info("choice: {}".format(choice_idx))
logger.info("tokens: {}".format(" ".join(tokens)))
logger.info("input_ids: {}".format(" ".join(map(str, input_ids))))
logger.info("input_mask: {}".format(" ".join(map(str, input_mask))))
logger.info("segment_ids: {}".format(" ".join(map(str, segment_ids))))
if is_training:
logger.info("label: {}".format(label))
features.append(InputFeatures(example_id=example.swag_id, choices_features=choices_features, label=label))
return features
def _truncate_seq_pair(tokens_a, tokens_b, max_length):
"""Truncates a sequence pair in place to the maximum length."""
# This is a simple heuristic which will always truncate the longer sequence
# one token at a time. This makes more sense than truncating an equal percent
# of tokens from each, since if one sequence is very short then each token
# that's truncated likely contains more information than a longer sequence.
while True:
total_length = len(tokens_a) + len(tokens_b)
if total_length <= max_length:
break
if len(tokens_a) > len(tokens_b):
tokens_a.pop()
else:
tokens_b.pop()
def accuracy(out, labels):
outputs = np.argmax(out, axis=1)
return np.sum(outputs == labels)
def select_field(features, field):
return [[choice[field] for choice in feature.choices_features] for feature in features]
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.n_gpu > 0:
torch.cuda.manual_seed_all(args.seed)
def load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False):
if args.local_rank not in [-1, 0]:
torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
# Load data features from cache or dataset file
input_file = args.predict_file if evaluate else args.train_file
cached_features_file = os.path.join(
os.path.dirname(input_file),
"cached_{}_{}_{}".format(
"dev" if evaluate else "train",
list(filter(None, args.model_name_or_path.split("/"))).pop(),
str(args.max_seq_length),
),
)
if os.path.exists(cached_features_file) and not args.overwrite_cache and not output_examples:
logger.info("Loading features from cached file %s", cached_features_file)
features = torch.load(cached_features_file)
else:
logger.info("Creating features from dataset file at %s", input_file)
examples = read_swag_examples(input_file)
features = convert_examples_to_features(examples, tokenizer, args.max_seq_length, not evaluate)
if args.local_rank in [-1, 0]:
logger.info("Saving features into cached file %s", cached_features_file)
torch.save(features, cached_features_file)
if args.local_rank == 0:
torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
# Convert to Tensors and build dataset
all_input_ids = torch.tensor(select_field(features, "input_ids"), dtype=torch.long)
all_input_mask = torch.tensor(select_field(features, "input_mask"), dtype=torch.long)
all_segment_ids = torch.tensor(select_field(features, "segment_ids"), dtype=torch.long)
all_label = torch.tensor([f.label for f in features], dtype=torch.long)
if evaluate:
dataset = TensorDataset(all_input_ids, all_input_mask, all_segment_ids, all_label)
else:
dataset = TensorDataset(all_input_ids, all_input_mask, all_segment_ids, all_label)
if output_examples:
return dataset, examples, features
return dataset
def train(args, train_dataset, model, tokenizer):
"""Train the model"""
if args.local_rank in [-1, 0]:
tb_writer = SummaryWriter()
args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
if args.max_steps > 0:
t_total = args.max_steps
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
)
if args.fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
# multi-gpu training (should be after apex fp16 initialization)
if args.n_gpu > 1:
model = torch.nn.DataParallel(model)
# Distributed training (should be after apex fp16 initialization)
if args.local_rank != -1:
model = torch.nn.parallel.DistributedDataParallel(
model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True
)
# Train!
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_dataset))
logger.info(" Num Epochs = %d", args.num_train_epochs)
logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
logger.info(
" Total train batch size (w. parallel, distributed & accumulation) = %d",
args.train_batch_size
* args.gradient_accumulation_steps
* (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
)
logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
global_step = 0
tr_loss, logging_loss = 0.0, 0.0
model.zero_grad()
train_iterator = trange(int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0])
set_seed(args) # Added here for reproductibility
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
for step, batch in enumerate(epoch_iterator):
model.train()
batch = tuple(t.to(args.device) for t in batch)
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
# 'token_type_ids': None if args.model_type == 'xlm' else batch[2],
"token_type_ids": batch[2],
"labels": batch[3],
}
# if args.model_type in ['xlnet', 'xlm']:
# inputs.update({'cls_index': batch[5],
# 'p_mask': batch[6]})
outputs = model(**inputs)
loss = outputs[0] # model outputs are always tuple in transformers (see doc)
if args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel (not distributed) training
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
else:
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
# Log metrics
if (
args.local_rank == -1 and args.evaluate_during_training
): # Only evaluate when single GPU otherwise metrics may not average well
results = evaluate(args, model, tokenizer)
for key, value in results.items():
tb_writer.add_scalar("eval_{}".format(key), value, global_step)
tb_writer.add_scalar("lr", scheduler.get_lr()[0], global_step)
tb_writer.add_scalar("loss", (tr_loss - logging_loss) / args.logging_steps, global_step)
logging_loss = tr_loss
if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
# Save model checkpoint
output_dir = os.path.join(args.output_dir, "checkpoint-{}".format(global_step))
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
model_to_save.save_pretrained(output_dir)
tokenizer.save_vocabulary(output_dir)
torch.save(args, os.path.join(output_dir, "training_args.bin"))
logger.info("Saving model checkpoint to %s", output_dir)
if args.max_steps > 0 and global_step > args.max_steps:
epoch_iterator.close()
break
if args.max_steps > 0 and global_step > args.max_steps:
train_iterator.close()
break
if args.local_rank in [-1, 0]:
tb_writer.close()
return global_step, tr_loss / global_step
def evaluate(args, model, tokenizer, prefix=""):
dataset, examples, features = load_and_cache_examples(args, tokenizer, evaluate=True, output_examples=True)
if not os.path.exists(args.output_dir) and args.local_rank in [-1, 0]:
os.makedirs(args.output_dir)
args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
# Note that DistributedSampler samples randomly
eval_sampler = SequentialSampler(dataset) if args.local_rank == -1 else DistributedSampler(dataset)
eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
# Eval!
logger.info("***** Running evaluation {} *****".format(prefix))
logger.info(" Num examples = %d", len(dataset))
logger.info(" Batch size = %d", args.eval_batch_size)
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
for batch in tqdm(eval_dataloader, desc="Evaluating"):
model.eval()
batch = tuple(t.to(args.device) for t in batch)
with torch.no_grad():
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
# 'token_type_ids': None if args.model_type == 'xlm' else batch[2] # XLM don't use segment_ids
"token_type_ids": batch[2],
"labels": batch[3],
}
# if args.model_type in ['xlnet', 'xlm']:
# inputs.update({'cls_index': batch[4],
# 'p_mask': batch[5]})
outputs = model(**inputs)
tmp_eval_loss, logits = outputs[:2]
eval_loss += tmp_eval_loss.mean().item()
logits = logits.detach().cpu().numpy()
label_ids = inputs["labels"].to("cpu").numpy()
tmp_eval_accuracy = accuracy(logits, label_ids)
eval_accuracy += tmp_eval_accuracy
nb_eval_steps += 1
nb_eval_examples += inputs["input_ids"].size(0)
eval_loss = eval_loss / nb_eval_steps
eval_accuracy = eval_accuracy / nb_eval_examples
result = {"eval_loss": eval_loss, "eval_accuracy": eval_accuracy}
output_eval_file = os.path.join(args.output_dir, "eval_results.txt")
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results *****")
for key in sorted(result.keys()):
logger.info("%s = %s", key, str(result[key]))
writer.write("%s = %s\n" % (key, str(result[key])))
return result
def main():
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--train_file", default=None, type=str, required=True, help="SWAG csv for training. E.g., train.csv"
)
parser.add_argument(
"--predict_file",
default=None,
type=str,
required=True,
help="SWAG csv for predictions. E.g., val.csv or test.csv",
)
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models",
)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model checkpoints and predictions will be written.",
)
# Other parameters
parser.add_argument(
"--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
)
parser.add_argument(
"--tokenizer_name",
default="",
type=str,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--max_seq_length",
default=384,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences "
"longer than this will be truncated, and sequences shorter than this will be padded."
),
)
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
parser.add_argument(
"--evaluate_during_training", action="store_true", help="Rul evaluation during training at each logging step."
)
parser.add_argument("--per_gpu_train_batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.")
parser.add_argument(
"--per_gpu_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation."
)
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight deay if we apply some.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument(
"--num_train_epochs", default=3.0, type=float, help="Total number of training epochs to perform."
)
parser.add_argument(
"--max_steps",
default=-1,
type=int,
help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
)
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument("--logging_steps", type=int, default=50, help="Log every X updates steps.")
parser.add_argument("--save_steps", type=int, default=50, help="Save checkpoint every X updates steps.")
parser.add_argument(
"--eval_all_checkpoints",
action="store_true",
help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
)
parser.add_argument("--no_cuda", action="store_true", help="Whether not to use CUDA when available")
parser.add_argument(
"--overwrite_output_dir", action="store_true", help="Overwrite the content of the output directory"
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument("--local_rank", type=int, default=-1, help="local_rank for distributed training on gpus")
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument(
"--fp16_opt_level",
type=str,
default="O1",
help=(
"For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
"See details at https://nvidia.github.io/apex/amp.html"
),
)
parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
args = parser.parse_args()
if (
os.path.exists(args.output_dir)
and os.listdir(args.output_dir)
and args.do_train
and not args.overwrite_output_dir
):
raise ValueError(
"Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
args.output_dir
)
)
# Setup distant debugging if needed
if args.server_ip and args.server_port:
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
print("Waiting for debugger attach")
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
ptvsd.wait_for_attach()
# Setup CUDA, GPU & distributed training
if args.local_rank == -1 or args.no_cuda:
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
else: # Initializes the distributed backend which will take care of sychronizing nodes/GPUs
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
torch.distributed.init_process_group(backend="nccl")
args.n_gpu = 1
args.device = device
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
args.local_rank,
device,
args.n_gpu,
bool(args.local_rank != -1),
args.fp16,
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(args.local_rank):
transformers.utils.logging.set_verbosity_info()
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Set seed
set_seed(args)
# Load pretrained model and tokenizer
if args.local_rank not in [-1, 0]:
torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
config = AutoConfig.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(
args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
)
model = AutoModelForMultipleChoice.from_pretrained(
args.model_name_or_path, from_tf=bool(".ckpt" in args.model_name_or_path), config=config
)
if args.local_rank == 0:
torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
model.to(args.device)
logger.info("Training/evaluation parameters %s", args)
# Training
if args.do_train:
train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False)
global_step, tr_loss = train(args, train_dataset, model, tokenizer)
logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
# Save the trained model and the tokenizer
if args.local_rank == -1 or torch.distributed.get_rank() == 0:
logger.info("Saving model checkpoint to %s", args.output_dir)
# Save a trained model, configuration and tokenizer using `save_pretrained()`.
# They can then be reloaded using `from_pretrained()`
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
model_to_save.save_pretrained(args.output_dir)
tokenizer.save_pretrained(args.output_dir)
# Good practice: save your training arguments together with the trained model
torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
# Load a trained model and vocabulary that you have fine-tuned
model = AutoModelForMultipleChoice.from_pretrained(args.output_dir)
tokenizer = AutoTokenizer.from_pretrained(args.output_dir)
model.to(args.device)
# Evaluation - we can ask to evaluate all the checkpoints (sub-directories) in a directory
results = {}
if args.do_eval and args.local_rank in [-1, 0]:
if args.do_train:
checkpoints = [args.output_dir]
else:
# if do_train is False and do_eval is true, load model directly from pretrained.
checkpoints = [args.model_name_or_path]
if args.eval_all_checkpoints:
checkpoints = [
os.path.dirname(c) for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
]
logger.info("Evaluate the following checkpoints: %s", checkpoints)
for checkpoint in checkpoints:
# Reload the model
global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
model = AutoModelForMultipleChoice.from_pretrained(checkpoint)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model.to(args.device)
# Evaluate
result = evaluate(args, model, tokenizer, prefix=global_step)
result = {k + ("_{}".format(global_step) if global_step else ""): v for k, v in result.items()}
results.update(result)
logger.info("Results: {}".format(results))
return results
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples
|
hf_public_repos/transformers/examples/legacy/run_camembert.py
|
#!/usr/bin/env python
import torch
from transformers import CamembertForMaskedLM, CamembertTokenizer
def fill_mask(masked_input, model, tokenizer, topk=5):
# Adapted from https://github.com/pytorch/fairseq/blob/master/fairseq/models/roberta/hub_interface.py
assert masked_input.count("<mask>") == 1
input_ids = torch.tensor(tokenizer.encode(masked_input, add_special_tokens=True)).unsqueeze(0) # Batch size 1
logits = model(input_ids)[0] # The last hidden-state is the first element of the output tuple
masked_index = (input_ids.squeeze() == tokenizer.mask_token_id).nonzero().item()
logits = logits[0, masked_index, :]
prob = logits.softmax(dim=0)
values, indices = prob.topk(k=topk, dim=0)
topk_predicted_token_bpe = " ".join(
[tokenizer.convert_ids_to_tokens(indices[i].item()) for i in range(len(indices))]
)
masked_token = tokenizer.mask_token
topk_filled_outputs = []
for index, predicted_token_bpe in enumerate(topk_predicted_token_bpe.split(" ")):
predicted_token = predicted_token_bpe.replace("\u2581", " ")
if " {0}".format(masked_token) in masked_input:
topk_filled_outputs.append(
(
masked_input.replace(" {0}".format(masked_token), predicted_token),
values[index].item(),
predicted_token,
)
)
else:
topk_filled_outputs.append(
(
masked_input.replace(masked_token, predicted_token),
values[index].item(),
predicted_token,
)
)
return topk_filled_outputs
tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
model = CamembertForMaskedLM.from_pretrained("camembert-base")
model.eval()
masked_input = "Le camembert est <mask> :)"
print(fill_mask(masked_input, model, tokenizer, topk=3))
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/pytorch-lightning/run_glue.sh
|
# Install example requirements
pip install -r ../requirements.txt
# Download glue data
python3 ../../utils/download_glue_data.py
export TASK=mrpc
export DATA_DIR=./glue_data/MRPC/
export MAX_LENGTH=128
export LEARNING_RATE=2e-5
export BERT_MODEL=bert-base-cased
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SEED=2
export OUTPUT_DIR_NAME=mrpc-pl-bert
export CURRENT_DIR=${PWD}
export OUTPUT_DIR=${CURRENT_DIR}/${OUTPUT_DIR_NAME}
# Make output directory if it doesn't exist
mkdir -p $OUTPUT_DIR
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
python3 run_glue.py --gpus 1 --data_dir $DATA_DIR \
--task $TASK \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--learning_rate $LEARNING_RATE \
--num_train_epochs $NUM_EPOCHS \
--train_batch_size $BATCH_SIZE \
--seed $SEED \
--do_train \
--do_predict
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/pytorch-lightning/run_glue.py
|
import argparse
import glob
import logging
import os
import time
from argparse import Namespace
import numpy as np
import torch
from lightning_base import BaseTransformer, add_generic_args, generic_train
from torch.utils.data import DataLoader, TensorDataset
from transformers import glue_compute_metrics as compute_metrics
from transformers import glue_convert_examples_to_features as convert_examples_to_features
from transformers import glue_output_modes, glue_tasks_num_labels
from transformers import glue_processors as processors
logger = logging.getLogger(__name__)
class GLUETransformer(BaseTransformer):
mode = "sequence-classification"
def __init__(self, hparams):
if isinstance(hparams, dict):
hparams = Namespace(**hparams)
hparams.glue_output_mode = glue_output_modes[hparams.task]
num_labels = glue_tasks_num_labels[hparams.task]
super().__init__(hparams, num_labels, self.mode)
def forward(self, **inputs):
return self.model(**inputs)
def training_step(self, batch, batch_idx):
inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
if self.config.model_type not in ["distilbert", "bart"]:
inputs["token_type_ids"] = batch[2] if self.config.model_type in ["bert", "xlnet", "albert"] else None
outputs = self(**inputs)
loss = outputs[0]
lr_scheduler = self.trainer.lr_schedulers[0]["scheduler"]
tensorboard_logs = {"loss": loss, "rate": lr_scheduler.get_last_lr()[-1]}
return {"loss": loss, "log": tensorboard_logs}
def prepare_data(self):
"Called to initialize data. Use the call to construct features"
args = self.hparams
processor = processors[args.task]()
self.labels = processor.get_labels()
for mode in ["train", "dev"]:
cached_features_file = self._feature_file(mode)
if os.path.exists(cached_features_file) and not args.overwrite_cache:
logger.info("Loading features from cached file %s", cached_features_file)
else:
logger.info("Creating features from dataset file at %s", args.data_dir)
examples = (
processor.get_dev_examples(args.data_dir)
if mode == "dev"
else processor.get_train_examples(args.data_dir)
)
features = convert_examples_to_features(
examples,
self.tokenizer,
max_length=args.max_seq_length,
label_list=self.labels,
output_mode=args.glue_output_mode,
)
logger.info("Saving features into cached file %s", cached_features_file)
torch.save(features, cached_features_file)
def get_dataloader(self, mode: str, batch_size: int, shuffle: bool = False) -> DataLoader:
"Load datasets. Called after prepare data."
# We test on dev set to compare to benchmarks without having to submit to GLUE server
mode = "dev" if mode == "test" else mode
cached_features_file = self._feature_file(mode)
logger.info("Loading features from cached file %s", cached_features_file)
features = torch.load(cached_features_file)
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
if self.hparams.glue_output_mode == "classification":
all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
elif self.hparams.glue_output_mode == "regression":
all_labels = torch.tensor([f.label for f in features], dtype=torch.float)
return DataLoader(
TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_labels),
batch_size=batch_size,
shuffle=shuffle,
)
def validation_step(self, batch, batch_idx):
inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
if self.config.model_type not in ["distilbert", "bart"]:
inputs["token_type_ids"] = batch[2] if self.config.model_type in ["bert", "xlnet", "albert"] else None
outputs = self(**inputs)
tmp_eval_loss, logits = outputs[:2]
preds = logits.detach().cpu().numpy()
out_label_ids = inputs["labels"].detach().cpu().numpy()
return {"val_loss": tmp_eval_loss.detach().cpu(), "pred": preds, "target": out_label_ids}
def _eval_end(self, outputs) -> tuple:
val_loss_mean = torch.stack([x["val_loss"] for x in outputs]).mean().detach().cpu().item()
preds = np.concatenate([x["pred"] for x in outputs], axis=0)
if self.hparams.glue_output_mode == "classification":
preds = np.argmax(preds, axis=1)
elif self.hparams.glue_output_mode == "regression":
preds = np.squeeze(preds)
out_label_ids = np.concatenate([x["target"] for x in outputs], axis=0)
out_label_list = [[] for _ in range(out_label_ids.shape[0])]
preds_list = [[] for _ in range(out_label_ids.shape[0])]
results = {**{"val_loss": val_loss_mean}, **compute_metrics(self.hparams.task, preds, out_label_ids)}
ret = dict(results.items())
ret["log"] = results
return ret, preds_list, out_label_list
def validation_epoch_end(self, outputs: list) -> dict:
ret, preds, targets = self._eval_end(outputs)
logs = ret["log"]
return {"val_loss": logs["val_loss"], "log": logs, "progress_bar": logs}
def test_epoch_end(self, outputs) -> dict:
ret, predictions, targets = self._eval_end(outputs)
logs = ret["log"]
# `val_loss` is the key returned by `self._eval_end()` but actually refers to `test_loss`
return {"avg_test_loss": logs["val_loss"], "log": logs, "progress_bar": logs}
@staticmethod
def add_model_specific_args(parser, root_dir):
BaseTransformer.add_model_specific_args(parser, root_dir)
parser.add_argument(
"--max_seq_length",
default=128,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--task",
default="",
type=str,
required=True,
help="The GLUE task to run",
)
parser.add_argument(
"--gpus",
default=0,
type=int,
help="The number of GPUs allocated for this, it is by default 0 meaning none",
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
return parser
def main():
parser = argparse.ArgumentParser()
add_generic_args(parser, os.getcwd())
parser = GLUETransformer.add_model_specific_args(parser, os.getcwd())
args = parser.parse_args()
# If output_dir not provided, a folder will be generated in pwd
if args.output_dir is None:
args.output_dir = os.path.join(
"./results",
f"{args.task}_{time.strftime('%Y%m%d_%H%M%S')}",
)
os.makedirs(args.output_dir)
model = GLUETransformer(args)
trainer = generic_train(model, args)
# Optionally, predict on dev set and write to output_dir
if args.do_predict:
checkpoints = sorted(glob.glob(os.path.join(args.output_dir, "checkpoint-epoch=*.ckpt"), recursive=True))
model = model.load_from_checkpoint(checkpoints[-1])
return trainer.test(model)
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/pytorch-lightning/run_ner.py
|
import argparse
import glob
import logging
import os
from argparse import Namespace
from importlib import import_module
import numpy as np
import torch
from lightning_base import BaseTransformer, add_generic_args, generic_train
from seqeval.metrics import accuracy_score, f1_score, precision_score, recall_score
from torch.nn import CrossEntropyLoss
from torch.utils.data import DataLoader, TensorDataset
from utils_ner import TokenClassificationTask
logger = logging.getLogger(__name__)
class NERTransformer(BaseTransformer):
"""
A training module for NER. See BaseTransformer for the core options.
"""
mode = "token-classification"
def __init__(self, hparams):
if isinstance(hparams, dict):
hparams = Namespace(**hparams)
module = import_module("tasks")
try:
token_classification_task_clazz = getattr(module, hparams.task_type)
self.token_classification_task: TokenClassificationTask = token_classification_task_clazz()
except AttributeError:
raise ValueError(
f"Task {hparams.task_type} needs to be defined as a TokenClassificationTask subclass in {module}. "
f"Available tasks classes are: {TokenClassificationTask.__subclasses__()}"
)
self.labels = self.token_classification_task.get_labels(hparams.labels)
self.pad_token_label_id = CrossEntropyLoss().ignore_index
super().__init__(hparams, len(self.labels), self.mode)
def forward(self, **inputs):
return self.model(**inputs)
def training_step(self, batch, batch_num):
"Compute loss and log."
inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
if self.config.model_type != "distilbert":
inputs["token_type_ids"] = (
batch[2] if self.config.model_type in ["bert", "xlnet"] else None
) # XLM and RoBERTa don"t use token_type_ids
outputs = self(**inputs)
loss = outputs[0]
# tensorboard_logs = {"loss": loss, "rate": self.lr_scheduler.get_last_lr()[-1]}
return {"loss": loss}
def prepare_data(self):
"Called to initialize data. Use the call to construct features"
args = self.hparams
for mode in ["train", "dev", "test"]:
cached_features_file = self._feature_file(mode)
if os.path.exists(cached_features_file) and not args.overwrite_cache:
logger.info("Loading features from cached file %s", cached_features_file)
features = torch.load(cached_features_file)
else:
logger.info("Creating features from dataset file at %s", args.data_dir)
examples = self.token_classification_task.read_examples_from_file(args.data_dir, mode)
features = self.token_classification_task.convert_examples_to_features(
examples,
self.labels,
args.max_seq_length,
self.tokenizer,
cls_token_at_end=bool(self.config.model_type in ["xlnet"]),
cls_token=self.tokenizer.cls_token,
cls_token_segment_id=2 if self.config.model_type in ["xlnet"] else 0,
sep_token=self.tokenizer.sep_token,
sep_token_extra=False,
pad_on_left=bool(self.config.model_type in ["xlnet"]),
pad_token=self.tokenizer.pad_token_id,
pad_token_segment_id=self.tokenizer.pad_token_type_id,
pad_token_label_id=self.pad_token_label_id,
)
logger.info("Saving features into cached file %s", cached_features_file)
torch.save(features, cached_features_file)
def get_dataloader(self, mode: int, batch_size: int, shuffle: bool = False) -> DataLoader:
"Load datasets. Called after prepare data."
cached_features_file = self._feature_file(mode)
logger.info("Loading features from cached file %s", cached_features_file)
features = torch.load(cached_features_file)
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
if features[0].token_type_ids is not None:
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
else:
all_token_type_ids = torch.tensor([0 for f in features], dtype=torch.long)
# HACK(we will not use this anymore soon)
all_label_ids = torch.tensor([f.label_ids for f in features], dtype=torch.long)
return DataLoader(
TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_label_ids), batch_size=batch_size
)
def validation_step(self, batch, batch_nb):
"""Compute validation""" ""
inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
if self.config.model_type != "distilbert":
inputs["token_type_ids"] = (
batch[2] if self.config.model_type in ["bert", "xlnet"] else None
) # XLM and RoBERTa don"t use token_type_ids
outputs = self(**inputs)
tmp_eval_loss, logits = outputs[:2]
preds = logits.detach().cpu().numpy()
out_label_ids = inputs["labels"].detach().cpu().numpy()
return {"val_loss": tmp_eval_loss.detach().cpu(), "pred": preds, "target": out_label_ids}
def _eval_end(self, outputs):
"Evaluation called for both Val and Test"
val_loss_mean = torch.stack([x["val_loss"] for x in outputs]).mean()
preds = np.concatenate([x["pred"] for x in outputs], axis=0)
preds = np.argmax(preds, axis=2)
out_label_ids = np.concatenate([x["target"] for x in outputs], axis=0)
label_map = dict(enumerate(self.labels))
out_label_list = [[] for _ in range(out_label_ids.shape[0])]
preds_list = [[] for _ in range(out_label_ids.shape[0])]
for i in range(out_label_ids.shape[0]):
for j in range(out_label_ids.shape[1]):
if out_label_ids[i, j] != self.pad_token_label_id:
out_label_list[i].append(label_map[out_label_ids[i][j]])
preds_list[i].append(label_map[preds[i][j]])
results = {
"val_loss": val_loss_mean,
"accuracy_score": accuracy_score(out_label_list, preds_list),
"precision": precision_score(out_label_list, preds_list),
"recall": recall_score(out_label_list, preds_list),
"f1": f1_score(out_label_list, preds_list),
}
ret = dict(results.items())
ret["log"] = results
return ret, preds_list, out_label_list
def validation_epoch_end(self, outputs):
# when stable
ret, preds, targets = self._eval_end(outputs)
logs = ret["log"]
return {"val_loss": logs["val_loss"], "log": logs, "progress_bar": logs}
def test_epoch_end(self, outputs):
# updating to test_epoch_end instead of deprecated test_end
ret, predictions, targets = self._eval_end(outputs)
# Converting to the dict required by pl
# https://github.com/PyTorchLightning/pytorch-lightning/blob/master/\
# pytorch_lightning/trainer/logging.py#L139
logs = ret["log"]
# `val_loss` is the key returned by `self._eval_end()` but actually refers to `test_loss`
return {"avg_test_loss": logs["val_loss"], "log": logs, "progress_bar": logs}
@staticmethod
def add_model_specific_args(parser, root_dir):
# Add NER specific options
BaseTransformer.add_model_specific_args(parser, root_dir)
parser.add_argument(
"--task_type", default="NER", type=str, help="Task type to fine tune in training (e.g. NER, POS, etc)"
)
parser.add_argument(
"--max_seq_length",
default=128,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--labels",
default="",
type=str,
help="Path to a file containing all labels. If not specified, CoNLL-2003 labels are used.",
)
parser.add_argument(
"--gpus",
default=0,
type=int,
help="The number of GPUs allocated for this, it is by default 0 meaning none",
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
return parser
if __name__ == "__main__":
parser = argparse.ArgumentParser()
add_generic_args(parser, os.getcwd())
parser = NERTransformer.add_model_specific_args(parser, os.getcwd())
args = parser.parse_args()
model = NERTransformer(args)
trainer = generic_train(model, args)
if args.do_predict:
# See https://github.com/huggingface/transformers/issues/3159
# pl use this default format to create a checkpoint:
# https://github.com/PyTorchLightning/pytorch-lightning/blob/master\
# /pytorch_lightning/callbacks/model_checkpoint.py#L322
checkpoints = sorted(glob.glob(os.path.join(args.output_dir, "checkpoint-epoch=*.ckpt"), recursive=True))
model = model.load_from_checkpoint(checkpoints[-1])
trainer.test(model)
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/pytorch-lightning/run_ner.sh
|
#!/usr/bin/env bash
# for seqeval metrics import
pip install -r ../requirements.txt
## The relevant files are currently on a shared Google
## drive at https://drive.google.com/drive/folders/1kC0I2UGl2ltrluI9NqDjaQJGw5iliw_J
## Monitor for changes and eventually migrate to use the `datasets` library
curl -L 'https://drive.google.com/uc?export=download&id=1Jjhbal535VVz2ap4v4r_rN1UEHTdLK5P' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1ZfRcQThdtAR5PPRjIDtrVP7BtXSCUBbm' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1u9mb7kNJHWQCWyweMDRMuTFoOHOfeBTH' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp
export MAX_LENGTH=128
export BERT_MODEL=bert-base-multilingual-cased
python3 scripts/preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt
python3 scripts/preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt
python3 scripts/preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt
cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SEED=1
export OUTPUT_DIR_NAME=germeval-model
export CURRENT_DIR=${PWD}
export OUTPUT_DIR=${CURRENT_DIR}/${OUTPUT_DIR_NAME}
mkdir -p $OUTPUT_DIR
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
python3 run_ner.py --data_dir ./ \
--labels ./labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--train_batch_size $BATCH_SIZE \
--seed $SEED \
--gpus 1 \
--do_train \
--do_predict
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/pytorch-lightning/run_pos.sh
|
#!/usr/bin/env bash
if ! [ -f ./dev.txt ]; then
echo "Download dev dataset...."
curl -L -o ./dev.txt 'https://github.com/UniversalDependencies/UD_English-EWT/raw/master/en_ewt-ud-dev.conllu'
fi
if ! [ -f ./test.txt ]; then
echo "Download test dataset...."
curl -L -o ./test.txt 'https://github.com/UniversalDependencies/UD_English-EWT/raw/master/en_ewt-ud-test.conllu'
fi
if ! [ -f ./train.txt ]; then
echo "Download train dataset...."
curl -L -o ./train.txt 'https://github.com/UniversalDependencies/UD_English-EWT/raw/master/en_ewt-ud-train.conllu'
fi
export MAX_LENGTH=200
export BERT_MODEL=bert-base-uncased
export OUTPUT_DIR=postagger-model
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SAVE_STEPS=750
export SEED=1
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
python3 run_ner.py --data_dir ./ \
--task_type POS \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--train_batch_size $BATCH_SIZE \
--seed $SEED \
--gpus 1 \
--do_train \
--do_predict
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/pytorch-lightning/requirements.txt
|
tensorboard
scikit-learn
seqeval
psutil
sacrebleu
rouge-score
tensorflow_datasets
matplotlib
git-python==1.0.3
faiss-cpu
streamlit
elasticsearch
nltk
pandas
datasets >= 1.1.3
fire
pytest
conllu
sentencepiece != 0.1.92
protobuf
ray
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/pytorch-lightning/lightning_base.py
|
import argparse
import logging
import os
from pathlib import Path
from typing import Any, Dict
import pytorch_lightning as pl
from pytorch_lightning.utilities import rank_zero_info
from transformers import (
AdamW,
AutoConfig,
AutoModel,
AutoModelForPreTraining,
AutoModelForQuestionAnswering,
AutoModelForSeq2SeqLM,
AutoModelForSequenceClassification,
AutoModelForTokenClassification,
AutoModelWithLMHead,
AutoTokenizer,
PretrainedConfig,
PreTrainedTokenizer,
)
from transformers.optimization import (
Adafactor,
get_cosine_schedule_with_warmup,
get_cosine_with_hard_restarts_schedule_with_warmup,
get_linear_schedule_with_warmup,
get_polynomial_decay_schedule_with_warmup,
)
from transformers.utils.versions import require_version
logger = logging.getLogger(__name__)
require_version("pytorch_lightning>=1.0.4")
MODEL_MODES = {
"base": AutoModel,
"sequence-classification": AutoModelForSequenceClassification,
"question-answering": AutoModelForQuestionAnswering,
"pretraining": AutoModelForPreTraining,
"token-classification": AutoModelForTokenClassification,
"language-modeling": AutoModelWithLMHead,
"summarization": AutoModelForSeq2SeqLM,
"translation": AutoModelForSeq2SeqLM,
}
# update this and the import above to support new schedulers from transformers.optimization
arg_to_scheduler = {
"linear": get_linear_schedule_with_warmup,
"cosine": get_cosine_schedule_with_warmup,
"cosine_w_restarts": get_cosine_with_hard_restarts_schedule_with_warmup,
"polynomial": get_polynomial_decay_schedule_with_warmup,
# '': get_constant_schedule, # not supported for now
# '': get_constant_schedule_with_warmup, # not supported for now
}
arg_to_scheduler_choices = sorted(arg_to_scheduler.keys())
arg_to_scheduler_metavar = "{" + ", ".join(arg_to_scheduler_choices) + "}"
class BaseTransformer(pl.LightningModule):
def __init__(
self,
hparams: argparse.Namespace,
num_labels=None,
mode="base",
config=None,
tokenizer=None,
model=None,
**config_kwargs,
):
"""Initialize a model, tokenizer and config."""
super().__init__()
# TODO: move to self.save_hyperparameters()
# self.save_hyperparameters()
# can also expand arguments into trainer signature for easier reading
self.save_hyperparameters(hparams)
self.step_count = 0
self.output_dir = Path(self.hparams.output_dir)
cache_dir = self.hparams.cache_dir if self.hparams.cache_dir else None
if config is None:
self.config = AutoConfig.from_pretrained(
self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
**({"num_labels": num_labels} if num_labels is not None else {}),
cache_dir=cache_dir,
**config_kwargs,
)
else:
self.config: PretrainedConfig = config
extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
for p in extra_model_params:
if getattr(self.hparams, p, None):
assert hasattr(self.config, p), f"model config doesn't have a `{p}` attribute"
setattr(self.config, p, getattr(self.hparams, p))
if tokenizer is None:
self.tokenizer = AutoTokenizer.from_pretrained(
self.hparams.tokenizer_name if self.hparams.tokenizer_name else self.hparams.model_name_or_path,
cache_dir=cache_dir,
)
else:
self.tokenizer: PreTrainedTokenizer = tokenizer
self.model_type = MODEL_MODES[mode]
if model is None:
self.model = self.model_type.from_pretrained(
self.hparams.model_name_or_path,
from_tf=bool(".ckpt" in self.hparams.model_name_or_path),
config=self.config,
cache_dir=cache_dir,
)
else:
self.model = model
def load_hf_checkpoint(self, *args, **kwargs):
self.model = self.model_type.from_pretrained(*args, **kwargs)
def get_lr_scheduler(self):
get_schedule_func = arg_to_scheduler[self.hparams.lr_scheduler]
scheduler = get_schedule_func(
self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=self.total_steps()
)
scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
return scheduler
def configure_optimizers(self):
"""Prepare optimizer and schedule (linear warmup and decay)"""
model = self.model
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": self.hparams.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
if self.hparams.adafactor:
optimizer = Adafactor(
optimizer_grouped_parameters, lr=self.hparams.learning_rate, scale_parameter=False, relative_step=False
)
else:
optimizer = AdamW(
optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon
)
self.opt = optimizer
scheduler = self.get_lr_scheduler()
return [optimizer], [scheduler]
def test_step(self, batch, batch_nb):
return self.validation_step(batch, batch_nb)
def test_epoch_end(self, outputs):
return self.validation_end(outputs)
def total_steps(self) -> int:
"""The number of total training steps that will be run. Used for lr scheduler purposes."""
num_devices = max(1, self.hparams.gpus) # TODO: consider num_tpu_cores
effective_batch_size = self.hparams.train_batch_size * self.hparams.accumulate_grad_batches * num_devices
return (self.dataset_size / effective_batch_size) * self.hparams.max_epochs
def setup(self, mode):
if mode == "test":
self.dataset_size = len(self.test_dataloader().dataset)
else:
self.train_loader = self.get_dataloader("train", self.hparams.train_batch_size, shuffle=True)
self.dataset_size = len(self.train_dataloader().dataset)
def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False):
raise NotImplementedError("You must implement this for your task")
def train_dataloader(self):
return self.train_loader
def val_dataloader(self):
return self.get_dataloader("dev", self.hparams.eval_batch_size, shuffle=False)
def test_dataloader(self):
return self.get_dataloader("test", self.hparams.eval_batch_size, shuffle=False)
def _feature_file(self, mode):
return os.path.join(
self.hparams.data_dir,
"cached_{}_{}_{}".format(
mode,
list(filter(None, self.hparams.model_name_or_path.split("/"))).pop(),
str(self.hparams.max_seq_length),
),
)
@pl.utilities.rank_zero_only
def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
save_path = self.output_dir.joinpath("best_tfmr")
self.model.config.save_step = self.step_count
self.model.save_pretrained(save_path)
self.tokenizer.save_pretrained(save_path)
@staticmethod
def add_model_specific_args(parser, root_dir):
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models",
)
parser.add_argument(
"--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
)
parser.add_argument(
"--tokenizer_name",
default=None,
type=str,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--cache_dir",
default="",
type=str,
help="Where do you want to store the pre-trained models downloaded from huggingface.co",
)
parser.add_argument(
"--encoder_layerdrop",
type=float,
help="Encoder layer dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--decoder_layerdrop",
type=float,
help="Decoder layer dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--dropout",
type=float,
help="Dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--attention_dropout",
type=float,
help="Attention dropout probability (Optional). Goes into model.config",
)
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument(
"--lr_scheduler",
default="linear",
choices=arg_to_scheduler_choices,
metavar=arg_to_scheduler_metavar,
type=str,
help="Learning rate scheduler",
)
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument("--num_workers", default=4, type=int, help="kwarg passed to DataLoader")
parser.add_argument("--num_train_epochs", dest="max_epochs", default=3, type=int)
parser.add_argument("--train_batch_size", default=32, type=int)
parser.add_argument("--eval_batch_size", default=32, type=int)
parser.add_argument("--adafactor", action="store_true")
class LoggingCallback(pl.Callback):
def on_batch_end(self, trainer, pl_module):
lr_scheduler = trainer.lr_schedulers[0]["scheduler"]
lrs = {f"lr_group_{i}": lr for i, lr in enumerate(lr_scheduler.get_lr())}
pl_module.logger.log_metrics(lrs)
def on_validation_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
rank_zero_info("***** Validation results *****")
metrics = trainer.callback_metrics
# Log results
for key in sorted(metrics):
if key not in ["log", "progress_bar"]:
rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
rank_zero_info("***** Test results *****")
metrics = trainer.callback_metrics
# Log and save results to file
output_test_results_file = os.path.join(pl_module.hparams.output_dir, "test_results.txt")
with open(output_test_results_file, "w") as writer:
for key in sorted(metrics):
if key not in ["log", "progress_bar"]:
rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
writer.write("{} = {}\n".format(key, str(metrics[key])))
def add_generic_args(parser, root_dir) -> None:
# To allow all pl args uncomment the following line
# parser = pl.Trainer.add_argparse_args(parser)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument(
"--fp16_opt_level",
type=str,
default="O2",
help=(
"For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
"See details at https://nvidia.github.io/apex/amp.html"
),
)
parser.add_argument("--n_tpu_cores", dest="tpu_cores", type=int)
parser.add_argument("--max_grad_norm", dest="gradient_clip_val", default=1.0, type=float, help="Max gradient norm")
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_predict", action="store_true", help="Whether to run predictions on the test set.")
parser.add_argument(
"--gradient_accumulation_steps",
dest="accumulate_grad_batches",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument(
"--data_dir",
default=None,
type=str,
required=True,
help="The input data dir. Should contain the training files for the CoNLL-2003 NER task.",
)
def generic_train(
model: BaseTransformer,
args: argparse.Namespace,
early_stopping_callback=None,
logger=True, # can pass WandbLogger() here
extra_callbacks=[],
checkpoint_callback=None,
logging_callback=None,
**extra_train_kwargs,
):
pl.seed_everything(args.seed)
# init model
odir = Path(model.hparams.output_dir)
odir.mkdir(exist_ok=True)
# add custom checkpoints
if checkpoint_callback is None:
checkpoint_callback = pl.callbacks.ModelCheckpoint(
filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=1
)
if early_stopping_callback:
extra_callbacks.append(early_stopping_callback)
if logging_callback is None:
logging_callback = LoggingCallback()
train_params = {}
# TODO: remove with PyTorch 1.6 since pl uses native amp
if args.fp16:
train_params["precision"] = 16
train_params["amp_level"] = args.fp16_opt_level
if args.gpus > 1:
train_params["distributed_backend"] = "ddp"
train_params["accumulate_grad_batches"] = args.accumulate_grad_batches
train_params["accelerator"] = extra_train_kwargs.get("accelerator", None)
train_params["profiler"] = extra_train_kwargs.get("profiler", None)
trainer = pl.Trainer.from_argparse_args(
args,
weights_summary=None,
callbacks=[logging_callback] + extra_callbacks,
logger=logger,
checkpoint_callback=checkpoint_callback,
**train_params,
)
if args.do_train:
trainer.fit(model)
return trainer
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/token-classification/README.md
|
## Token classification
Based on the scripts [`run_ner.py`](https://github.com/huggingface/transformers/blob/main/examples/legacy/token-classification/run_ner.py).
The following examples are covered in this section:
* NER on the GermEval 2014 (German NER) dataset
* Emerging and Rare Entities task: WNUT’17 (English NER) dataset
Details and results for the fine-tuning provided by @stefan-it.
### GermEval 2014 (German NER) dataset
#### Data (Download and pre-processing steps)
Data can be obtained from the [GermEval 2014](https://sites.google.com/site/germeval2014ner/data) shared task page.
Here are the commands for downloading and pre-processing train, dev and test datasets. The original data format has four (tab-separated) columns, in a pre-processing step only the two relevant columns (token and outer span NER annotation) are extracted:
```bash
curl -L 'https://drive.google.com/uc?export=download&id=1Jjhbal535VVz2ap4v4r_rN1UEHTdLK5P' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1ZfRcQThdtAR5PPRjIDtrVP7BtXSCUBbm' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1u9mb7kNJHWQCWyweMDRMuTFoOHOfeBTH' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp
```
The GermEval 2014 dataset contains some strange "control character" tokens like `'\x96', '\u200e', '\x95', '\xad' or '\x80'`.
One problem with these tokens is, that `BertTokenizer` returns an empty token for them, resulting in misaligned `InputExample`s.
The `preprocess.py` script located in the `scripts` folder a) filters these tokens and b) splits longer sentences into smaller ones (once the max. subtoken length is reached).
Let's define some variables that we need for further pre-processing steps and training the model:
```bash
export MAX_LENGTH=128
export BERT_MODEL=bert-base-multilingual-cased
```
Run the pre-processing script on training, dev and test datasets:
```bash
python3 scripts/preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt
python3 scripts/preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt
python3 scripts/preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt
```
The GermEval 2014 dataset has much more labels than CoNLL-2002/2003 datasets, so an own set of labels must be used:
```bash
cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
```
#### Prepare the run
Additional environment variables must be set:
```bash
export OUTPUT_DIR=germeval-model
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SAVE_STEPS=750
export SEED=1
```
#### Run the Pytorch version
To start training, just run:
```bash
python3 run_ner.py --data_dir ./ \
--labels ./labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_device_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict
```
If your GPU supports half-precision training, just add the `--fp16` flag. After training, the model will be both evaluated on development and test datasets.
#### JSON-based configuration file
Instead of passing all parameters via commandline arguments, the `run_ner.py` script also supports reading parameters from a json-based configuration file:
```json
{
"data_dir": ".",
"labels": "./labels.txt",
"model_name_or_path": "bert-base-multilingual-cased",
"output_dir": "germeval-model",
"max_seq_length": 128,
"num_train_epochs": 3,
"per_device_train_batch_size": 32,
"save_steps": 750,
"seed": 1,
"do_train": true,
"do_eval": true,
"do_predict": true
}
```
It must be saved with a `.json` extension and can be used by running `python3 run_ner.py config.json`.
#### Evaluation
Evaluation on development dataset outputs the following for our example:
```bash
10/04/2019 00:42:06 - INFO - __main__ - ***** Eval results *****
10/04/2019 00:42:06 - INFO - __main__ - f1 = 0.8623348017621146
10/04/2019 00:42:06 - INFO - __main__ - loss = 0.07183869666975543
10/04/2019 00:42:06 - INFO - __main__ - precision = 0.8467916366258111
10/04/2019 00:42:06 - INFO - __main__ - recall = 0.8784592370979806
```
On the test dataset the following results could be achieved:
```bash
10/04/2019 00:42:42 - INFO - __main__ - ***** Eval results *****
10/04/2019 00:42:42 - INFO - __main__ - f1 = 0.8614389652384803
10/04/2019 00:42:42 - INFO - __main__ - loss = 0.07064602487454782
10/04/2019 00:42:42 - INFO - __main__ - precision = 0.8604651162790697
10/04/2019 00:42:42 - INFO - __main__ - recall = 0.8624150210424085
```
#### Run the Tensorflow 2 version
To start training, just run:
```bash
python3 run_tf_ner.py --data_dir ./ \
--labels ./labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_device_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict
```
Such as the Pytorch version, if your GPU supports half-precision training, just add the `--fp16` flag. After training, the model will be both evaluated on development and test datasets.
#### Evaluation
Evaluation on development dataset outputs the following for our example:
```bash
precision recall f1-score support
LOCderiv 0.7619 0.6154 0.6809 52
PERpart 0.8724 0.8997 0.8858 4057
OTHpart 0.9360 0.9466 0.9413 711
ORGpart 0.7015 0.6989 0.7002 269
LOCpart 0.7668 0.8488 0.8057 496
LOC 0.8745 0.9191 0.8963 235
ORGderiv 0.7723 0.8571 0.8125 91
OTHderiv 0.4800 0.6667 0.5581 18
OTH 0.5789 0.6875 0.6286 16
PERderiv 0.5385 0.3889 0.4516 18
PER 0.5000 0.5000 0.5000 2
ORG 0.0000 0.0000 0.0000 3
micro avg 0.8574 0.8862 0.8715 5968
macro avg 0.8575 0.8862 0.8713 5968
```
On the test dataset the following results could be achieved:
```bash
precision recall f1-score support
PERpart 0.8847 0.8944 0.8896 9397
OTHpart 0.9376 0.9353 0.9365 1639
ORGpart 0.7307 0.7044 0.7173 697
LOC 0.9133 0.9394 0.9262 561
LOCpart 0.8058 0.8157 0.8107 1150
ORG 0.0000 0.0000 0.0000 8
OTHderiv 0.5882 0.4762 0.5263 42
PERderiv 0.6571 0.5227 0.5823 44
OTH 0.4906 0.6667 0.5652 39
ORGderiv 0.7016 0.7791 0.7383 172
LOCderiv 0.8256 0.6514 0.7282 109
PER 0.0000 0.0000 0.0000 11
micro avg 0.8722 0.8774 0.8748 13869
macro avg 0.8712 0.8774 0.8740 13869
```
### Emerging and Rare Entities task: WNUT’17 (English NER) dataset
Description of the WNUT’17 task from the [shared task website](http://noisy-text.github.io/2017/index.html):
> The WNUT’17 shared task focuses on identifying unusual, previously-unseen entities in the context of emerging discussions.
> Named entities form the basis of many modern approaches to other tasks (like event clustering and summarization), but recall on
> them is a real problem in noisy text - even among annotators. This drop tends to be due to novel entities and surface forms.
Six labels are available in the dataset. An overview can be found on this [page](http://noisy-text.github.io/2017/files/).
#### Data (Download and pre-processing steps)
The dataset can be downloaded from the [official GitHub](https://github.com/leondz/emerging_entities_17) repository.
The following commands show how to prepare the dataset for fine-tuning:
```bash
mkdir -p data_wnut_17
curl -L 'https://github.com/leondz/emerging_entities_17/raw/master/wnut17train.conll' | tr '\t' ' ' > data_wnut_17/train.txt.tmp
curl -L 'https://github.com/leondz/emerging_entities_17/raw/master/emerging.dev.conll' | tr '\t' ' ' > data_wnut_17/dev.txt.tmp
curl -L 'https://raw.githubusercontent.com/leondz/emerging_entities_17/master/emerging.test.annotated' | tr '\t' ' ' > data_wnut_17/test.txt.tmp
```
Let's define some variables that we need for further pre-processing steps:
```bash
export MAX_LENGTH=128
export BERT_MODEL=bert-large-cased
```
Here we use the English BERT large model for fine-tuning.
The `preprocess.py` scripts splits longer sentences into smaller ones (once the max. subtoken length is reached):
```bash
python3 scripts/preprocess.py data_wnut_17/train.txt.tmp $BERT_MODEL $MAX_LENGTH > data_wnut_17/train.txt
python3 scripts/preprocess.py data_wnut_17/dev.txt.tmp $BERT_MODEL $MAX_LENGTH > data_wnut_17/dev.txt
python3 scripts/preprocess.py data_wnut_17/test.txt.tmp $BERT_MODEL $MAX_LENGTH > data_wnut_17/test.txt
```
In the last pre-processing step, the `labels.txt` file needs to be generated. This file contains all available labels:
```bash
cat data_wnut_17/train.txt data_wnut_17/dev.txt data_wnut_17/test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > data_wnut_17/labels.txt
```
#### Run the Pytorch version
Fine-tuning with the PyTorch version can be started using the `run_ner.py` script. In this example we use a JSON-based configuration file.
This configuration file looks like:
```json
{
"data_dir": "./data_wnut_17",
"labels": "./data_wnut_17/labels.txt",
"model_name_or_path": "bert-large-cased",
"output_dir": "wnut-17-model-1",
"max_seq_length": 128,
"num_train_epochs": 3,
"per_device_train_batch_size": 32,
"save_steps": 425,
"seed": 1,
"do_train": true,
"do_eval": true,
"do_predict": true,
"fp16": false
}
```
If your GPU supports half-precision training, please set `fp16` to `true`.
Save this JSON-based configuration under `wnut_17.json`. The fine-tuning can be started with `python3 run_ner_old.py wnut_17.json`.
#### Evaluation
Evaluation on development dataset outputs the following:
```bash
05/29/2020 23:33:44 - INFO - __main__ - ***** Eval results *****
05/29/2020 23:33:44 - INFO - __main__ - eval_loss = 0.26505235286212275
05/29/2020 23:33:44 - INFO - __main__ - eval_precision = 0.7008264462809918
05/29/2020 23:33:44 - INFO - __main__ - eval_recall = 0.507177033492823
05/29/2020 23:33:44 - INFO - __main__ - eval_f1 = 0.5884802220680084
05/29/2020 23:33:44 - INFO - __main__ - epoch = 3.0
```
On the test dataset the following results could be achieved:
```bash
05/29/2020 23:33:44 - INFO - transformers.trainer - ***** Running Prediction *****
05/29/2020 23:34:02 - INFO - __main__ - eval_loss = 0.30948806500973547
05/29/2020 23:34:02 - INFO - __main__ - eval_precision = 0.5840108401084011
05/29/2020 23:34:02 - INFO - __main__ - eval_recall = 0.3994439295644115
05/29/2020 23:34:02 - INFO - __main__ - eval_f1 = 0.47440836543753434
```
WNUT’17 is a very difficult task. Current state-of-the-art results on this dataset can be found [here](https://nlpprogress.com/english/named_entity_recognition.html).
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/token-classification/run_ner.py
|
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Fine-tuning the library models for named entity recognition on CoNLL-2003. """
import logging
import os
import sys
from dataclasses import dataclass, field
from importlib import import_module
from typing import Dict, List, Optional, Tuple
import numpy as np
from seqeval.metrics import accuracy_score, f1_score, precision_score, recall_score
from torch import nn
from utils_ner import Split, TokenClassificationDataset, TokenClassificationTask
import transformers
from transformers import (
AutoConfig,
AutoModelForTokenClassification,
AutoTokenizer,
DataCollatorWithPadding,
EvalPrediction,
HfArgumentParser,
Trainer,
TrainingArguments,
set_seed,
)
from transformers.trainer_utils import is_main_process
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
task_type: Optional[str] = field(
default="NER", metadata={"help": "Task type to fine tune in training (e.g. NER, POS, etc)"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
use_fast: bool = field(default=False, metadata={"help": "Set this flag to use fast tokenization."})
# If you want to tweak more attributes on your tokenizer, you should do it in a distinct script,
# or just modify its tokenizer_config.json.
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
data_dir: str = field(
metadata={"help": "The input data dir. Should contain the .txt files for a CoNLL-2003-formatted task."}
)
labels: Optional[str] = field(
default=None,
metadata={"help": "Path to a file containing all labels. If not specified, CoNLL-2003 labels are used."},
)
max_seq_length: int = field(
default=128,
metadata={
"help": (
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if (
os.path.exists(training_args.output_dir)
and os.listdir(training_args.output_dir)
and training_args.do_train
and not training_args.overwrite_output_dir
):
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
" --overwrite_output_dir to overcome."
)
module = import_module("tasks")
try:
token_classification_task_clazz = getattr(module, model_args.task_type)
token_classification_task: TokenClassificationTask = token_classification_task_clazz()
except AttributeError:
raise ValueError(
f"Task {model_args.task_type} needs to be defined as a TokenClassificationTask subclass in {module}. "
f"Available tasks classes are: {TokenClassificationTask.__subclasses__()}"
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
training_args.local_rank,
training_args.device,
training_args.n_gpu,
bool(training_args.local_rank != -1),
training_args.fp16,
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(training_args.local_rank):
transformers.utils.logging.set_verbosity_info()
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
logger.info("Training/evaluation parameters %s", training_args)
# Set seed
set_seed(training_args.seed)
# Prepare CONLL-2003 task
labels = token_classification_task.get_labels(data_args.labels)
label_map: Dict[int, str] = dict(enumerate(labels))
num_labels = len(labels)
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
num_labels=num_labels,
id2label=label_map,
label2id={label: i for i, label in enumerate(labels)},
cache_dir=model_args.cache_dir,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast,
)
model = AutoModelForTokenClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
)
# Get datasets
train_dataset = (
TokenClassificationDataset(
token_classification_task=token_classification_task,
data_dir=data_args.data_dir,
tokenizer=tokenizer,
labels=labels,
model_type=config.model_type,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
mode=Split.train,
)
if training_args.do_train
else None
)
eval_dataset = (
TokenClassificationDataset(
token_classification_task=token_classification_task,
data_dir=data_args.data_dir,
tokenizer=tokenizer,
labels=labels,
model_type=config.model_type,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
mode=Split.dev,
)
if training_args.do_eval
else None
)
def align_predictions(predictions: np.ndarray, label_ids: np.ndarray) -> Tuple[List[int], List[int]]:
preds = np.argmax(predictions, axis=2)
batch_size, seq_len = preds.shape
out_label_list = [[] for _ in range(batch_size)]
preds_list = [[] for _ in range(batch_size)]
for i in range(batch_size):
for j in range(seq_len):
if label_ids[i, j] != nn.CrossEntropyLoss().ignore_index:
out_label_list[i].append(label_map[label_ids[i][j]])
preds_list[i].append(label_map[preds[i][j]])
return preds_list, out_label_list
def compute_metrics(p: EvalPrediction) -> Dict:
preds_list, out_label_list = align_predictions(p.predictions, p.label_ids)
return {
"accuracy_score": accuracy_score(out_label_list, preds_list),
"precision": precision_score(out_label_list, preds_list),
"recall": recall_score(out_label_list, preds_list),
"f1": f1_score(out_label_list, preds_list),
}
# Data collator
data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8) if training_args.fp16 else None
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics,
data_collator=data_collator,
)
# Training
if training_args.do_train:
trainer.train(
model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
)
trainer.save_model()
# For convenience, we also re-save the tokenizer to the same directory,
# so that you can share your model easily on huggingface.co/models =)
if trainer.is_world_process_zero():
tokenizer.save_pretrained(training_args.output_dir)
# Evaluation
results = {}
if training_args.do_eval:
logger.info("*** Evaluate ***")
result = trainer.evaluate()
output_eval_file = os.path.join(training_args.output_dir, "eval_results.txt")
if trainer.is_world_process_zero():
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results *****")
for key, value in result.items():
logger.info(" %s = %s", key, value)
writer.write("%s = %s\n" % (key, value))
results.update(result)
# Predict
if training_args.do_predict:
test_dataset = TokenClassificationDataset(
token_classification_task=token_classification_task,
data_dir=data_args.data_dir,
tokenizer=tokenizer,
labels=labels,
model_type=config.model_type,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
mode=Split.test,
)
predictions, label_ids, metrics = trainer.predict(test_dataset)
preds_list, _ = align_predictions(predictions, label_ids)
output_test_results_file = os.path.join(training_args.output_dir, "test_results.txt")
if trainer.is_world_process_zero():
with open(output_test_results_file, "w") as writer:
for key, value in metrics.items():
logger.info(" %s = %s", key, value)
writer.write("%s = %s\n" % (key, value))
# Save predictions
output_test_predictions_file = os.path.join(training_args.output_dir, "test_predictions.txt")
if trainer.is_world_process_zero():
with open(output_test_predictions_file, "w") as writer:
with open(os.path.join(data_args.data_dir, "test.txt"), "r") as f:
token_classification_task.write_predictions_to_file(writer, f, preds_list)
return results
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/token-classification/run_tf_ner.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2018 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Fine-tuning the library models for named entity recognition."""
import logging
import os
from dataclasses import dataclass, field
from importlib import import_module
from typing import Dict, List, Optional, Tuple
import numpy as np
from seqeval.metrics import classification_report, f1_score, precision_score, recall_score
from utils_ner import Split, TFTokenClassificationDataset, TokenClassificationTask
from transformers import (
AutoConfig,
AutoTokenizer,
EvalPrediction,
HfArgumentParser,
TFAutoModelForTokenClassification,
TFTrainer,
TFTrainingArguments,
)
from transformers.utils import logging as hf_logging
hf_logging.set_verbosity_info()
hf_logging.enable_default_handler()
hf_logging.enable_explicit_format()
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
task_type: Optional[str] = field(
default="NER", metadata={"help": "Task type to fine tune in training (e.g. NER, POS, etc)"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
use_fast: bool = field(default=False, metadata={"help": "Set this flag to use fast tokenization."})
# If you want to tweak more attributes on your tokenizer, you should do it in a distinct script,
# or just modify its tokenizer_config.json.
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
data_dir: str = field(
metadata={"help": "The input data dir. Should contain the .txt files for a CoNLL-2003-formatted task."}
)
labels: Optional[str] = field(
metadata={"help": "Path to a file containing all labels. If not specified, CoNLL-2003 labels are used."}
)
max_seq_length: int = field(
default=128,
metadata={
"help": (
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if (
os.path.exists(training_args.output_dir)
and os.listdir(training_args.output_dir)
and training_args.do_train
and not training_args.overwrite_output_dir
):
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
" --overwrite_output_dir to overcome."
)
module = import_module("tasks")
try:
token_classification_task_clazz = getattr(module, model_args.task_type)
token_classification_task: TokenClassificationTask = token_classification_task_clazz()
except AttributeError:
raise ValueError(
f"Task {model_args.task_type} needs to be defined as a TokenClassificationTask subclass in {module}. "
f"Available tasks classes are: {TokenClassificationTask.__subclasses__()}"
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(
"n_replicas: %s, distributed training: %s, 16-bits training: %s",
training_args.n_replicas,
bool(training_args.n_replicas > 1),
training_args.fp16,
)
logger.info("Training/evaluation parameters %s", training_args)
# Prepare Token Classification task
labels = token_classification_task.get_labels(data_args.labels)
label_map: Dict[int, str] = dict(enumerate(labels))
num_labels = len(labels)
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
num_labels=num_labels,
id2label=label_map,
label2id={label: i for i, label in enumerate(labels)},
cache_dir=model_args.cache_dir,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast,
)
with training_args.strategy.scope():
model = TFAutoModelForTokenClassification.from_pretrained(
model_args.model_name_or_path,
from_pt=bool(".bin" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
)
# Get datasets
train_dataset = (
TFTokenClassificationDataset(
token_classification_task=token_classification_task,
data_dir=data_args.data_dir,
tokenizer=tokenizer,
labels=labels,
model_type=config.model_type,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
mode=Split.train,
)
if training_args.do_train
else None
)
eval_dataset = (
TFTokenClassificationDataset(
token_classification_task=token_classification_task,
data_dir=data_args.data_dir,
tokenizer=tokenizer,
labels=labels,
model_type=config.model_type,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
mode=Split.dev,
)
if training_args.do_eval
else None
)
def align_predictions(predictions: np.ndarray, label_ids: np.ndarray) -> Tuple[List[int], List[int]]:
preds = np.argmax(predictions, axis=2)
batch_size, seq_len = preds.shape
out_label_list = [[] for _ in range(batch_size)]
preds_list = [[] for _ in range(batch_size)]
for i in range(batch_size):
for j in range(seq_len):
if label_ids[i, j] != -100:
out_label_list[i].append(label_map[label_ids[i][j]])
preds_list[i].append(label_map[preds[i][j]])
return preds_list, out_label_list
def compute_metrics(p: EvalPrediction) -> Dict:
preds_list, out_label_list = align_predictions(p.predictions, p.label_ids)
return {
"precision": precision_score(out_label_list, preds_list),
"recall": recall_score(out_label_list, preds_list),
"f1": f1_score(out_label_list, preds_list),
}
# Initialize our Trainer
trainer = TFTrainer(
model=model,
args=training_args,
train_dataset=train_dataset.get_dataset() if train_dataset else None,
eval_dataset=eval_dataset.get_dataset() if eval_dataset else None,
compute_metrics=compute_metrics,
)
# Training
if training_args.do_train:
trainer.train()
trainer.save_model()
tokenizer.save_pretrained(training_args.output_dir)
# Evaluation
results = {}
if training_args.do_eval:
logger.info("*** Evaluate ***")
result = trainer.evaluate()
output_eval_file = os.path.join(training_args.output_dir, "eval_results.txt")
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results *****")
for key, value in result.items():
logger.info(" %s = %s", key, value)
writer.write("%s = %s\n" % (key, value))
results.update(result)
# Predict
if training_args.do_predict:
test_dataset = TFTokenClassificationDataset(
token_classification_task=token_classification_task,
data_dir=data_args.data_dir,
tokenizer=tokenizer,
labels=labels,
model_type=config.model_type,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
mode=Split.test,
)
predictions, label_ids, metrics = trainer.predict(test_dataset.get_dataset())
preds_list, labels_list = align_predictions(predictions, label_ids)
report = classification_report(labels_list, preds_list)
logger.info("\n%s", report)
output_test_results_file = os.path.join(training_args.output_dir, "test_results.txt")
with open(output_test_results_file, "w") as writer:
writer.write("%s\n" % report)
# Save predictions
output_test_predictions_file = os.path.join(training_args.output_dir, "test_predictions.txt")
with open(output_test_predictions_file, "w") as writer:
with open(os.path.join(data_args.data_dir, "test.txt"), "r") as f:
example_id = 0
for line in f:
if line.startswith("-DOCSTART-") or line == "" or line == "\n":
writer.write(line)
if not preds_list[example_id]:
example_id += 1
elif preds_list[example_id]:
output_line = line.split()[0] + " " + preds_list[example_id].pop(0) + "\n"
writer.write(output_line)
else:
logger.warning("Maximum sequence length exceeded: No prediction for '%s'.", line.split()[0])
return results
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/token-classification/run_pos.sh
|
if ! [ -f ./dev.txt ]; then
echo "Download dev dataset...."
curl -L -o ./dev.txt 'https://github.com/UniversalDependencies/UD_English-EWT/raw/master/en_ewt-ud-dev.conllu'
fi
if ! [ -f ./test.txt ]; then
echo "Download test dataset...."
curl -L -o ./test.txt 'https://github.com/UniversalDependencies/UD_English-EWT/raw/master/en_ewt-ud-test.conllu'
fi
if ! [ -f ./train.txt ]; then
echo "Download train dataset...."
curl -L -o ./train.txt 'https://github.com/UniversalDependencies/UD_English-EWT/raw/master/en_ewt-ud-train.conllu'
fi
export MAX_LENGTH=200
export BERT_MODEL=bert-base-uncased
export OUTPUT_DIR=postagger-model
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SAVE_STEPS=750
export SEED=1
python3 run_ner.py \
--task_type POS \
--data_dir . \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_gpu_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/token-classification/run.sh
|
## The relevant files are currently on a shared Google
## drive at https://drive.google.com/drive/folders/1kC0I2UGl2ltrluI9NqDjaQJGw5iliw_J
## Monitor for changes and eventually migrate to use the `datasets` library
curl -L 'https://drive.google.com/uc?export=download&id=1Jjhbal535VVz2ap4v4r_rN1UEHTdLK5P' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1ZfRcQThdtAR5PPRjIDtrVP7BtXSCUBbm' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp
curl -L 'https://drive.google.com/uc?export=download&id=1u9mb7kNJHWQCWyweMDRMuTFoOHOfeBTH' \
| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp
export MAX_LENGTH=128
export BERT_MODEL=bert-base-multilingual-cased
python3 scripts/preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt
python3 scripts/preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt
python3 scripts/preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt
cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
export OUTPUT_DIR=germeval-model
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SAVE_STEPS=750
export SEED=1
python3 run_ner.py \
--task_type NER \
--data_dir . \
--labels ./labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_gpu_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/token-classification/run_chunk.sh
|
if ! [ -f ./dev.txt ]; then
echo "Downloading CONLL2003 dev dataset...."
curl -L -o ./dev.txt 'https://github.com/davidsbatista/NER-datasets/raw/master/CONLL2003/valid.txt'
fi
if ! [ -f ./test.txt ]; then
echo "Downloading CONLL2003 test dataset...."
curl -L -o ./test.txt 'https://github.com/davidsbatista/NER-datasets/raw/master/CONLL2003/test.txt'
fi
if ! [ -f ./train.txt ]; then
echo "Downloading CONLL2003 train dataset...."
curl -L -o ./train.txt 'https://github.com/davidsbatista/NER-datasets/raw/master/CONLL2003/train.txt'
fi
export MAX_LENGTH=200
export BERT_MODEL=bert-base-uncased
export OUTPUT_DIR=chunker-model
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SAVE_STEPS=750
export SEED=1
python3 run_ner.py \
--task_type Chunk \
--data_dir . \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_gpu_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/token-classification/tasks.py
|
import logging
import os
from typing import List, TextIO, Union
from conllu import parse_incr
from utils_ner import InputExample, Split, TokenClassificationTask
logger = logging.getLogger(__name__)
class NER(TokenClassificationTask):
def __init__(self, label_idx=-1):
# in NER datasets, the last column is usually reserved for NER label
self.label_idx = label_idx
def read_examples_from_file(self, data_dir, mode: Union[Split, str]) -> List[InputExample]:
if isinstance(mode, Split):
mode = mode.value
file_path = os.path.join(data_dir, f"{mode}.txt")
guid_index = 1
examples = []
with open(file_path, encoding="utf-8") as f:
words = []
labels = []
for line in f:
if line.startswith("-DOCSTART-") or line == "" or line == "\n":
if words:
examples.append(InputExample(guid=f"{mode}-{guid_index}", words=words, labels=labels))
guid_index += 1
words = []
labels = []
else:
splits = line.split(" ")
words.append(splits[0])
if len(splits) > 1:
labels.append(splits[self.label_idx].replace("\n", ""))
else:
# Examples could have no label for mode = "test"
labels.append("O")
if words:
examples.append(InputExample(guid=f"{mode}-{guid_index}", words=words, labels=labels))
return examples
def write_predictions_to_file(self, writer: TextIO, test_input_reader: TextIO, preds_list: List):
example_id = 0
for line in test_input_reader:
if line.startswith("-DOCSTART-") or line == "" or line == "\n":
writer.write(line)
if not preds_list[example_id]:
example_id += 1
elif preds_list[example_id]:
output_line = line.split()[0] + " " + preds_list[example_id].pop(0) + "\n"
writer.write(output_line)
else:
logger.warning("Maximum sequence length exceeded: No prediction for '%s'.", line.split()[0])
def get_labels(self, path: str) -> List[str]:
if path:
with open(path, "r") as f:
labels = f.read().splitlines()
if "O" not in labels:
labels = ["O"] + labels
return labels
else:
return ["O", "B-MISC", "I-MISC", "B-PER", "I-PER", "B-ORG", "I-ORG", "B-LOC", "I-LOC"]
class Chunk(NER):
def __init__(self):
# in CONLL2003 dataset chunk column is second-to-last
super().__init__(label_idx=-2)
def get_labels(self, path: str) -> List[str]:
if path:
with open(path, "r") as f:
labels = f.read().splitlines()
if "O" not in labels:
labels = ["O"] + labels
return labels
else:
return [
"O",
"B-ADVP",
"B-INTJ",
"B-LST",
"B-PRT",
"B-NP",
"B-SBAR",
"B-VP",
"B-ADJP",
"B-CONJP",
"B-PP",
"I-ADVP",
"I-INTJ",
"I-LST",
"I-PRT",
"I-NP",
"I-SBAR",
"I-VP",
"I-ADJP",
"I-CONJP",
"I-PP",
]
class POS(TokenClassificationTask):
def read_examples_from_file(self, data_dir, mode: Union[Split, str]) -> List[InputExample]:
if isinstance(mode, Split):
mode = mode.value
file_path = os.path.join(data_dir, f"{mode}.txt")
guid_index = 1
examples = []
with open(file_path, encoding="utf-8") as f:
for sentence in parse_incr(f):
words = []
labels = []
for token in sentence:
words.append(token["form"])
labels.append(token["upos"])
assert len(words) == len(labels)
if words:
examples.append(InputExample(guid=f"{mode}-{guid_index}", words=words, labels=labels))
guid_index += 1
return examples
def write_predictions_to_file(self, writer: TextIO, test_input_reader: TextIO, preds_list: List):
example_id = 0
for sentence in parse_incr(test_input_reader):
s_p = preds_list[example_id]
out = ""
for token in sentence:
out += f'{token["form"]} ({token["upos"]}|{s_p.pop(0)}) '
out += "\n"
writer.write(out)
example_id += 1
def get_labels(self, path: str) -> List[str]:
if path:
with open(path, "r") as f:
return f.read().splitlines()
else:
return [
"ADJ",
"ADP",
"ADV",
"AUX",
"CCONJ",
"DET",
"INTJ",
"NOUN",
"NUM",
"PART",
"PRON",
"PROPN",
"PUNCT",
"SCONJ",
"SYM",
"VERB",
"X",
]
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/token-classification/utils_ner.py
|
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Named entity recognition fine-tuning: utilities to work with CoNLL-2003 task. """
import logging
import os
from dataclasses import dataclass
from enum import Enum
from typing import List, Optional, Union
from filelock import FileLock
from transformers import PreTrainedTokenizer, is_tf_available, is_torch_available
logger = logging.getLogger(__name__)
@dataclass
class InputExample:
"""
A single training/test example for token classification.
Args:
guid: Unique id for the example.
words: list. The words of the sequence.
labels: (Optional) list. The labels for each word of the sequence. This should be
specified for train and dev examples, but not for test examples.
"""
guid: str
words: List[str]
labels: Optional[List[str]]
@dataclass
class InputFeatures:
"""
A single set of features of data.
Property names are the same names as the corresponding inputs to a model.
"""
input_ids: List[int]
attention_mask: List[int]
token_type_ids: Optional[List[int]] = None
label_ids: Optional[List[int]] = None
class Split(Enum):
train = "train"
dev = "dev"
test = "test"
class TokenClassificationTask:
@staticmethod
def read_examples_from_file(data_dir, mode: Union[Split, str]) -> List[InputExample]:
raise NotImplementedError
@staticmethod
def get_labels(path: str) -> List[str]:
raise NotImplementedError
@staticmethod
def convert_examples_to_features(
examples: List[InputExample],
label_list: List[str],
max_seq_length: int,
tokenizer: PreTrainedTokenizer,
cls_token_at_end=False,
cls_token="[CLS]",
cls_token_segment_id=1,
sep_token="[SEP]",
sep_token_extra=False,
pad_on_left=False,
pad_token=0,
pad_token_segment_id=0,
pad_token_label_id=-100,
sequence_a_segment_id=0,
mask_padding_with_zero=True,
) -> List[InputFeatures]:
"""Loads a data file into a list of `InputFeatures`
`cls_token_at_end` define the location of the CLS token:
- False (Default, BERT/XLM pattern): [CLS] + A + [SEP] + B + [SEP]
- True (XLNet/GPT pattern): A + [SEP] + B + [SEP] + [CLS]
`cls_token_segment_id` define the segment id associated to the CLS token (0 for BERT, 2 for XLNet)
"""
# TODO clean up all this to leverage built-in features of tokenizers
label_map = {label: i for i, label in enumerate(label_list)}
features = []
for ex_index, example in enumerate(examples):
if ex_index % 10_000 == 0:
logger.info("Writing example %d of %d", ex_index, len(examples))
tokens = []
label_ids = []
for word, label in zip(example.words, example.labels):
word_tokens = tokenizer.tokenize(word)
# bert-base-multilingual-cased sometimes output "nothing ([]) when calling tokenize with just a space.
if len(word_tokens) > 0:
tokens.extend(word_tokens)
# Use the real label id for the first token of the word, and padding ids for the remaining tokens
label_ids.extend([label_map[label]] + [pad_token_label_id] * (len(word_tokens) - 1))
# Account for [CLS] and [SEP] with "- 2" and with "- 3" for RoBERTa.
special_tokens_count = tokenizer.num_special_tokens_to_add()
if len(tokens) > max_seq_length - special_tokens_count:
tokens = tokens[: (max_seq_length - special_tokens_count)]
label_ids = label_ids[: (max_seq_length - special_tokens_count)]
# The convention in BERT is:
# (a) For sequence pairs:
# tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
# type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1
# (b) For single sequences:
# tokens: [CLS] the dog is hairy . [SEP]
# type_ids: 0 0 0 0 0 0 0
#
# Where "type_ids" are used to indicate whether this is the first
# sequence or the second sequence. The embedding vectors for `type=0` and
# `type=1` were learned during pre-training and are added to the wordpiece
# embedding vector (and position vector). This is not *strictly* necessary
# since the [SEP] token unambiguously separates the sequences, but it makes
# it easier for the model to learn the concept of sequences.
#
# For classification tasks, the first vector (corresponding to [CLS]) is
# used as the "sentence vector". Note that this only makes sense because
# the entire model is fine-tuned.
tokens += [sep_token]
label_ids += [pad_token_label_id]
if sep_token_extra:
# roberta uses an extra separator b/w pairs of sentences
tokens += [sep_token]
label_ids += [pad_token_label_id]
segment_ids = [sequence_a_segment_id] * len(tokens)
if cls_token_at_end:
tokens += [cls_token]
label_ids += [pad_token_label_id]
segment_ids += [cls_token_segment_id]
else:
tokens = [cls_token] + tokens
label_ids = [pad_token_label_id] + label_ids
segment_ids = [cls_token_segment_id] + segment_ids
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# The mask has 1 for real tokens and 0 for padding tokens. Only real
# tokens are attended to.
input_mask = [1 if mask_padding_with_zero else 0] * len(input_ids)
# Zero-pad up to the sequence length.
padding_length = max_seq_length - len(input_ids)
if pad_on_left:
input_ids = ([pad_token] * padding_length) + input_ids
input_mask = ([0 if mask_padding_with_zero else 1] * padding_length) + input_mask
segment_ids = ([pad_token_segment_id] * padding_length) + segment_ids
label_ids = ([pad_token_label_id] * padding_length) + label_ids
else:
input_ids += [pad_token] * padding_length
input_mask += [0 if mask_padding_with_zero else 1] * padding_length
segment_ids += [pad_token_segment_id] * padding_length
label_ids += [pad_token_label_id] * padding_length
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
assert len(label_ids) == max_seq_length
if ex_index < 5:
logger.info("*** Example ***")
logger.info("guid: %s", example.guid)
logger.info("tokens: %s", " ".join([str(x) for x in tokens]))
logger.info("input_ids: %s", " ".join([str(x) for x in input_ids]))
logger.info("input_mask: %s", " ".join([str(x) for x in input_mask]))
logger.info("segment_ids: %s", " ".join([str(x) for x in segment_ids]))
logger.info("label_ids: %s", " ".join([str(x) for x in label_ids]))
if "token_type_ids" not in tokenizer.model_input_names:
segment_ids = None
features.append(
InputFeatures(
input_ids=input_ids, attention_mask=input_mask, token_type_ids=segment_ids, label_ids=label_ids
)
)
return features
if is_torch_available():
import torch
from torch import nn
from torch.utils.data import Dataset
class TokenClassificationDataset(Dataset):
"""
This will be superseded by a framework-agnostic approach
soon.
"""
features: List[InputFeatures]
pad_token_label_id: int = nn.CrossEntropyLoss().ignore_index
# Use cross entropy ignore_index as padding label id so that only
# real label ids contribute to the loss later.
def __init__(
self,
token_classification_task: TokenClassificationTask,
data_dir: str,
tokenizer: PreTrainedTokenizer,
labels: List[str],
model_type: str,
max_seq_length: Optional[int] = None,
overwrite_cache=False,
mode: Split = Split.train,
):
# Load data features from cache or dataset file
cached_features_file = os.path.join(
data_dir,
"cached_{}_{}_{}".format(mode.value, tokenizer.__class__.__name__, str(max_seq_length)),
)
# Make sure only the first process in distributed training processes the dataset,
# and the others will use the cache.
lock_path = cached_features_file + ".lock"
with FileLock(lock_path):
if os.path.exists(cached_features_file) and not overwrite_cache:
logger.info(f"Loading features from cached file {cached_features_file}")
self.features = torch.load(cached_features_file)
else:
logger.info(f"Creating features from dataset file at {data_dir}")
examples = token_classification_task.read_examples_from_file(data_dir, mode)
# TODO clean up all this to leverage built-in features of tokenizers
self.features = token_classification_task.convert_examples_to_features(
examples,
labels,
max_seq_length,
tokenizer,
cls_token_at_end=bool(model_type in ["xlnet"]),
# xlnet has a cls token at the end
cls_token=tokenizer.cls_token,
cls_token_segment_id=2 if model_type in ["xlnet"] else 0,
sep_token=tokenizer.sep_token,
sep_token_extra=False,
# roberta uses an extra separator b/w pairs of sentences, cf. github.com/pytorch/fairseq/commit/1684e166e3da03f5b600dbb7855cb98ddfcd0805
pad_on_left=bool(tokenizer.padding_side == "left"),
pad_token=tokenizer.pad_token_id,
pad_token_segment_id=tokenizer.pad_token_type_id,
pad_token_label_id=self.pad_token_label_id,
)
logger.info(f"Saving features into cached file {cached_features_file}")
torch.save(self.features, cached_features_file)
def __len__(self):
return len(self.features)
def __getitem__(self, i) -> InputFeatures:
return self.features[i]
if is_tf_available():
import tensorflow as tf
class TFTokenClassificationDataset:
"""
This will be superseded by a framework-agnostic approach
soon.
"""
features: List[InputFeatures]
pad_token_label_id: int = -100
# Use cross entropy ignore_index as padding label id so that only
# real label ids contribute to the loss later.
def __init__(
self,
token_classification_task: TokenClassificationTask,
data_dir: str,
tokenizer: PreTrainedTokenizer,
labels: List[str],
model_type: str,
max_seq_length: Optional[int] = None,
overwrite_cache=False,
mode: Split = Split.train,
):
examples = token_classification_task.read_examples_from_file(data_dir, mode)
# TODO clean up all this to leverage built-in features of tokenizers
self.features = token_classification_task.convert_examples_to_features(
examples,
labels,
max_seq_length,
tokenizer,
cls_token_at_end=bool(model_type in ["xlnet"]),
# xlnet has a cls token at the end
cls_token=tokenizer.cls_token,
cls_token_segment_id=2 if model_type in ["xlnet"] else 0,
sep_token=tokenizer.sep_token,
sep_token_extra=False,
# roberta uses an extra separator b/w pairs of sentences, cf. github.com/pytorch/fairseq/commit/1684e166e3da03f5b600dbb7855cb98ddfcd0805
pad_on_left=bool(tokenizer.padding_side == "left"),
pad_token=tokenizer.pad_token_id,
pad_token_segment_id=tokenizer.pad_token_type_id,
pad_token_label_id=self.pad_token_label_id,
)
def gen():
for ex in self.features:
if ex.token_type_ids is None:
yield (
{"input_ids": ex.input_ids, "attention_mask": ex.attention_mask},
ex.label_ids,
)
else:
yield (
{
"input_ids": ex.input_ids,
"attention_mask": ex.attention_mask,
"token_type_ids": ex.token_type_ids,
},
ex.label_ids,
)
if "token_type_ids" not in tokenizer.model_input_names:
self.dataset = tf.data.Dataset.from_generator(
gen,
({"input_ids": tf.int32, "attention_mask": tf.int32}, tf.int64),
(
{"input_ids": tf.TensorShape([None]), "attention_mask": tf.TensorShape([None])},
tf.TensorShape([None]),
),
)
else:
self.dataset = tf.data.Dataset.from_generator(
gen,
({"input_ids": tf.int32, "attention_mask": tf.int32, "token_type_ids": tf.int32}, tf.int64),
(
{
"input_ids": tf.TensorShape([None]),
"attention_mask": tf.TensorShape([None]),
"token_type_ids": tf.TensorShape([None]),
},
tf.TensorShape([None]),
),
)
def get_dataset(self):
self.dataset = self.dataset.apply(tf.data.experimental.assert_cardinality(len(self.features)))
return self.dataset
def __len__(self):
return len(self.features)
def __getitem__(self, i) -> InputFeatures:
return self.features[i]
| 0
|
hf_public_repos/transformers/examples/legacy/token-classification
|
hf_public_repos/transformers/examples/legacy/token-classification/scripts/preprocess.py
|
import sys
from transformers import AutoTokenizer
dataset = sys.argv[1]
model_name_or_path = sys.argv[2]
max_len = int(sys.argv[3])
subword_len_counter = 0
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
max_len -= tokenizer.num_special_tokens_to_add()
with open(dataset, "rt") as f_p:
for line in f_p:
line = line.rstrip()
if not line:
print(line)
subword_len_counter = 0
continue
token = line.split()[0]
current_subwords_len = len(tokenizer.tokenize(token))
# Token contains strange control characters like \x96 or \x95
# Just filter out the complete line
if current_subwords_len == 0:
continue
if (subword_len_counter + current_subwords_len) > max_len:
print("")
print(line)
subword_len_counter = current_subwords_len
continue
subword_len_counter += current_subwords_len
print(line)
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/benchmarking/README.md
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# 🤗 Benchmark results
Here, you can find a list of the different benchmark results created by the community.
If you would like to list benchmark results on your favorite models of the [model hub](https://huggingface.co/models) here, please open a Pull Request and add it below.
| Benchmark description | Results | Environment info | Author |
|:----------|:-------------|:-------------|------:|
| PyTorch Benchmark on inference for `bert-base-cased` |[memory](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/inference_memory.csv) | [env](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/env.csv) | [Partick von Platen](https://github.com/patrickvonplaten) |
| PyTorch Benchmark on inference for `bert-base-cased` |[time](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/inference_time.csv) | [env](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/env.csv) | [Partick von Platen](https://github.com/patrickvonplaten) |
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/benchmarking/run_benchmark.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Benchmarking the library on inference and training """
from transformers import HfArgumentParser, PyTorchBenchmark, PyTorchBenchmarkArguments
def main():
parser = HfArgumentParser(PyTorchBenchmarkArguments)
try:
benchmark_args = parser.parse_args_into_dataclasses()[0]
except ValueError as e:
arg_error_msg = "Arg --no_{0} is no longer used, please use --no-{0} instead."
begin_error_msg = " ".join(str(e).split(" ")[:-1])
full_error_msg = ""
depreciated_args = eval(str(e).split(" ")[-1])
wrong_args = []
for arg in depreciated_args:
# arg[2:] removes '--'
if arg[2:] in PyTorchBenchmarkArguments.deprecated_args:
# arg[5:] removes '--no_'
full_error_msg += arg_error_msg.format(arg[5:])
else:
wrong_args.append(arg)
if len(wrong_args) > 0:
full_error_msg = full_error_msg + begin_error_msg + str(wrong_args)
raise ValueError(full_error_msg)
benchmark = PyTorchBenchmark(args=benchmark_args)
benchmark.run()
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/benchmarking/plot_csv_file.py
|
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import csv
from collections import defaultdict
from dataclasses import dataclass, field
from typing import List, Optional
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.ticker import ScalarFormatter
from transformers import HfArgumentParser
def list_field(default=None, metadata=None):
return field(default_factory=lambda: default, metadata=metadata)
@dataclass
class PlotArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
csv_file: str = field(
metadata={"help": "The csv file to plot."},
)
plot_along_batch: bool = field(
default=False,
metadata={"help": "Whether to plot along batch size or sequence length. Defaults to sequence length."},
)
is_time: bool = field(
default=False,
metadata={"help": "Whether the csv file has time results or memory results. Defaults to memory results."},
)
no_log_scale: bool = field(
default=False,
metadata={"help": "Disable logarithmic scale when plotting"},
)
is_train: bool = field(
default=False,
metadata={
"help": "Whether the csv file has training results or inference results. Defaults to inference results."
},
)
figure_png_file: Optional[str] = field(
default=None,
metadata={"help": "Filename under which the plot will be saved. If unused no plot is saved."},
)
short_model_names: Optional[List[str]] = list_field(
default=None, metadata={"help": "List of model names that are used instead of the ones in the csv file."}
)
def can_convert_to_int(string):
try:
int(string)
return True
except ValueError:
return False
def can_convert_to_float(string):
try:
float(string)
return True
except ValueError:
return False
class Plot:
def __init__(self, args):
self.args = args
self.result_dict = defaultdict(lambda: {"bsz": [], "seq_len": [], "result": {}})
with open(self.args.csv_file, newline="") as csv_file:
reader = csv.DictReader(csv_file)
for row in reader:
model_name = row["model"]
self.result_dict[model_name]["bsz"].append(int(row["batch_size"]))
self.result_dict[model_name]["seq_len"].append(int(row["sequence_length"]))
if can_convert_to_int(row["result"]):
# value is not None
self.result_dict[model_name]["result"][
(int(row["batch_size"]), int(row["sequence_length"]))
] = int(row["result"])
elif can_convert_to_float(row["result"]):
# value is not None
self.result_dict[model_name]["result"][
(int(row["batch_size"]), int(row["sequence_length"]))
] = float(row["result"])
def plot(self):
fig, ax = plt.subplots()
title_str = "Time usage" if self.args.is_time else "Memory usage"
title_str = title_str + " for training" if self.args.is_train else title_str + " for inference"
if not self.args.no_log_scale:
# set logarithm scales
ax.set_xscale("log")
ax.set_yscale("log")
for axis in [ax.xaxis, ax.yaxis]:
axis.set_major_formatter(ScalarFormatter())
for model_name_idx, model_name in enumerate(self.result_dict.keys()):
batch_sizes = sorted(set(self.result_dict[model_name]["bsz"]))
sequence_lengths = sorted(set(self.result_dict[model_name]["seq_len"]))
results = self.result_dict[model_name]["result"]
(x_axis_array, inner_loop_array) = (
(batch_sizes, sequence_lengths) if self.args.plot_along_batch else (sequence_lengths, batch_sizes)
)
label_model_name = (
model_name if self.args.short_model_names is None else self.args.short_model_names[model_name_idx]
)
for inner_loop_value in inner_loop_array:
if self.args.plot_along_batch:
y_axis_array = np.asarray(
[results[(x, inner_loop_value)] for x in x_axis_array if (x, inner_loop_value) in results],
dtype=int,
)
else:
y_axis_array = np.asarray(
[results[(inner_loop_value, x)] for x in x_axis_array if (inner_loop_value, x) in results],
dtype=np.float32,
)
(x_axis_label, inner_loop_label) = (
("batch_size", "len") if self.args.plot_along_batch else ("in #tokens", "bsz")
)
x_axis_array = np.asarray(x_axis_array, int)[: len(y_axis_array)]
plt.scatter(
x_axis_array, y_axis_array, label=f"{label_model_name} - {inner_loop_label}: {inner_loop_value}"
)
plt.plot(x_axis_array, y_axis_array, "--")
title_str += f" {label_model_name} vs."
title_str = title_str[:-4]
y_axis_label = "Time in s" if self.args.is_time else "Memory in MB"
# plot
plt.title(title_str)
plt.xlabel(x_axis_label)
plt.ylabel(y_axis_label)
plt.legend()
if self.args.figure_png_file is not None:
plt.savefig(self.args.figure_png_file)
else:
plt.show()
def main():
parser = HfArgumentParser(PlotArguments)
plot_args = parser.parse_args_into_dataclasses()[0]
plot = Plot(args=plot_args)
plot.plot()
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/benchmarking/requirements.txt
|
torch >= 1.3
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/question-answering/README.md
|
#### Fine-tuning BERT on SQuAD1.0 with relative position embeddings
The following examples show how to fine-tune BERT models with different relative position embeddings. The BERT model
`bert-base-uncased` was pretrained with default absolute position embeddings. We provide the following pretrained
models which were pre-trained on the same training data (BooksCorpus and English Wikipedia) as in the BERT model
training, but with different relative position embeddings.
* `zhiheng-huang/bert-base-uncased-embedding-relative-key`, trained from scratch with relative embedding proposed by
Shaw et al., [Self-Attention with Relative Position Representations](https://arxiv.org/abs/1803.02155)
* `zhiheng-huang/bert-base-uncased-embedding-relative-key-query`, trained from scratch with relative embedding method 4
in Huang et al. [Improve Transformer Models with Better Relative Position Embeddings](https://arxiv.org/abs/2009.13658)
* `zhiheng-huang/bert-large-uncased-whole-word-masking-embedding-relative-key-query`, fine-tuned from model
`bert-large-uncased-whole-word-masking` with 3 additional epochs with relative embedding method 4 in Huang et al.
[Improve Transformer Models with Better Relative Position Embeddings](https://arxiv.org/abs/2009.13658)
##### Base models fine-tuning
```bash
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
torchrun --nproc_per_node=8 ./examples/question-answering/run_squad.py \
--model_name_or_path zhiheng-huang/bert-base-uncased-embedding-relative-key-query \
--dataset_name squad \
--do_train \
--do_eval \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 512 \
--doc_stride 128 \
--output_dir relative_squad \
--per_device_eval_batch_size=60 \
--per_device_train_batch_size=6
```
Training with the above command leads to the following results. It boosts the BERT default from f1 score of 88.52 to 90.54.
```bash
'exact': 83.6802270577105, 'f1': 90.54772098174814
```
The change of `max_seq_length` from 512 to 384 in the above command leads to the f1 score of 90.34. Replacing the above
model `zhiheng-huang/bert-base-uncased-embedding-relative-key-query` with
`zhiheng-huang/bert-base-uncased-embedding-relative-key` leads to the f1 score of 89.51. The changing of 8 gpus to one
gpu training leads to the f1 score of 90.71.
##### Large models fine-tuning
```bash
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
torchrun --nproc_per_node=8 ./examples/question-answering/run_squad.py \
--model_name_or_path zhiheng-huang/bert-large-uncased-whole-word-masking-embedding-relative-key-query \
--dataset_name squad \
--do_train \
--do_eval \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 512 \
--doc_stride 128 \
--output_dir relative_squad \
--per_gpu_eval_batch_size=6 \
--per_gpu_train_batch_size=2 \
--gradient_accumulation_steps 3
```
Training with the above command leads to the f1 score of 93.52, which is slightly better than the f1 score of 93.15 for
`bert-large-uncased-whole-word-masking`.
#### Distributed training
Here is an example using distributed training on 8 V100 GPUs and Bert Whole Word Masking uncased model to reach a F1 > 93 on SQuAD1.1:
```bash
torchrun --nproc_per_node=8 ./examples/question-answering/run_squad.py \
--model_name_or_path bert-large-uncased-whole-word-masking \
--dataset_name squad \
--do_train \
--do_eval \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ./examples/models/wwm_uncased_finetuned_squad/ \
--per_device_eval_batch_size=3 \
--per_device_train_batch_size=3 \
```
Training with the previously defined hyper-parameters yields the following results:
```bash
f1 = 93.15
exact_match = 86.91
```
This fine-tuned model is available as a checkpoint under the reference
[`bert-large-uncased-whole-word-masking-finetuned-squad`](https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad).
## Results
Larger batch size may improve the performance while costing more memory.
##### Results for SQuAD1.0 with the previously defined hyper-parameters:
```python
{
"exact": 85.45884578997162,
"f1": 92.5974600601065,
"total": 10570,
"HasAns_exact": 85.45884578997162,
"HasAns_f1": 92.59746006010651,
"HasAns_total": 10570
}
```
##### Results for SQuAD2.0 with the previously defined hyper-parameters:
```python
{
"exact": 80.4177545691906,
"f1": 84.07154997729623,
"total": 11873,
"HasAns_exact": 76.73751686909581,
"HasAns_f1": 84.05558584352873,
"HasAns_total": 5928,
"NoAns_exact": 84.0874684608915,
"NoAns_f1": 84.0874684608915,
"NoAns_total": 5945
}
```
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/question-answering/run_squad.py
|
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Finetuning the library models for question-answering on SQuAD (DistilBERT, Bert, XLM, XLNet)."""
import argparse
import glob
import logging
import os
import random
import timeit
import numpy as np
import torch
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from torch.utils.data.distributed import DistributedSampler
from tqdm import tqdm, trange
import transformers
from transformers import (
MODEL_FOR_QUESTION_ANSWERING_MAPPING,
WEIGHTS_NAME,
AdamW,
AutoConfig,
AutoModelForQuestionAnswering,
AutoTokenizer,
get_linear_schedule_with_warmup,
squad_convert_examples_to_features,
)
from transformers.data.metrics.squad_metrics import (
compute_predictions_log_probs,
compute_predictions_logits,
squad_evaluate,
)
from transformers.data.processors.squad import SquadResult, SquadV1Processor, SquadV2Processor
from transformers.trainer_utils import is_main_process
try:
from torch.utils.tensorboard import SummaryWriter
except ImportError:
from tensorboardX import SummaryWriter
logger = logging.getLogger(__name__)
MODEL_CONFIG_CLASSES = list(MODEL_FOR_QUESTION_ANSWERING_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.n_gpu > 0:
torch.cuda.manual_seed_all(args.seed)
def to_list(tensor):
return tensor.detach().cpu().tolist()
def train(args, train_dataset, model, tokenizer):
"""Train the model"""
if args.local_rank in [-1, 0]:
tb_writer = SummaryWriter()
args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
if args.max_steps > 0:
t_total = args.max_steps
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
)
# Check if saved optimizer or scheduler states exist
if os.path.isfile(os.path.join(args.model_name_or_path, "optimizer.pt")) and os.path.isfile(
os.path.join(args.model_name_or_path, "scheduler.pt")
):
# Load in optimizer and scheduler states
optimizer.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "optimizer.pt")))
scheduler.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "scheduler.pt")))
if args.fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
# multi-gpu training (should be after apex fp16 initialization)
if args.n_gpu > 1:
model = torch.nn.DataParallel(model)
# Distributed training (should be after apex fp16 initialization)
if args.local_rank != -1:
model = torch.nn.parallel.DistributedDataParallel(
model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True
)
# Train!
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_dataset))
logger.info(" Num Epochs = %d", args.num_train_epochs)
logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
logger.info(
" Total train batch size (w. parallel, distributed & accumulation) = %d",
args.train_batch_size
* args.gradient_accumulation_steps
* (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
)
logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
global_step = 1
epochs_trained = 0
steps_trained_in_current_epoch = 0
# Check if continuing training from a checkpoint
if os.path.exists(args.model_name_or_path):
try:
# set global_step to gobal_step of last saved checkpoint from model path
checkpoint_suffix = args.model_name_or_path.split("-")[-1].split("/")[0]
global_step = int(checkpoint_suffix)
epochs_trained = global_step // (len(train_dataloader) // args.gradient_accumulation_steps)
steps_trained_in_current_epoch = global_step % (len(train_dataloader) // args.gradient_accumulation_steps)
logger.info(" Continuing training from checkpoint, will skip to saved global_step")
logger.info(" Continuing training from epoch %d", epochs_trained)
logger.info(" Continuing training from global step %d", global_step)
logger.info(" Will skip the first %d steps in the first epoch", steps_trained_in_current_epoch)
except ValueError:
logger.info(" Starting fine-tuning.")
tr_loss, logging_loss = 0.0, 0.0
model.zero_grad()
train_iterator = trange(
epochs_trained, int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0]
)
# Added here for reproductibility
set_seed(args)
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
for step, batch in enumerate(epoch_iterator):
# Skip past any already trained steps if resuming training
if steps_trained_in_current_epoch > 0:
steps_trained_in_current_epoch -= 1
continue
model.train()
batch = tuple(t.to(args.device) for t in batch)
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"token_type_ids": batch[2],
"start_positions": batch[3],
"end_positions": batch[4],
}
if args.model_type in ["xlm", "roberta", "distilbert", "camembert", "bart", "longformer"]:
del inputs["token_type_ids"]
if args.model_type in ["xlnet", "xlm"]:
inputs.update({"cls_index": batch[5], "p_mask": batch[6]})
if args.version_2_with_negative:
inputs.update({"is_impossible": batch[7]})
if hasattr(model, "config") and hasattr(model.config, "lang2id"):
inputs.update(
{"langs": (torch.ones(batch[0].shape, dtype=torch.int64) * args.lang_id).to(args.device)}
)
outputs = model(**inputs)
# model outputs are always tuple in transformers (see doc)
loss = outputs[0]
if args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel (not distributed) training
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
if args.fp16:
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
else:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
# Log metrics
if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
# Only evaluate when single GPU otherwise metrics may not average well
if args.local_rank == -1 and args.evaluate_during_training:
results = evaluate(args, model, tokenizer)
for key, value in results.items():
tb_writer.add_scalar("eval_{}".format(key), value, global_step)
tb_writer.add_scalar("lr", scheduler.get_lr()[0], global_step)
tb_writer.add_scalar("loss", (tr_loss - logging_loss) / args.logging_steps, global_step)
logging_loss = tr_loss
# Save model checkpoint
if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
output_dir = os.path.join(args.output_dir, "checkpoint-{}".format(global_step))
# Take care of distributed/parallel training
model_to_save = model.module if hasattr(model, "module") else model
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
torch.save(args, os.path.join(output_dir, "training_args.bin"))
logger.info("Saving model checkpoint to %s", output_dir)
torch.save(optimizer.state_dict(), os.path.join(output_dir, "optimizer.pt"))
torch.save(scheduler.state_dict(), os.path.join(output_dir, "scheduler.pt"))
logger.info("Saving optimizer and scheduler states to %s", output_dir)
if args.max_steps > 0 and global_step > args.max_steps:
epoch_iterator.close()
break
if args.max_steps > 0 and global_step > args.max_steps:
train_iterator.close()
break
if args.local_rank in [-1, 0]:
tb_writer.close()
return global_step, tr_loss / global_step
def evaluate(args, model, tokenizer, prefix=""):
dataset, examples, features = load_and_cache_examples(args, tokenizer, evaluate=True, output_examples=True)
if not os.path.exists(args.output_dir) and args.local_rank in [-1, 0]:
os.makedirs(args.output_dir)
args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
# Note that DistributedSampler samples randomly
eval_sampler = SequentialSampler(dataset)
eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
# multi-gpu evaluate
if args.n_gpu > 1 and not isinstance(model, torch.nn.DataParallel):
model = torch.nn.DataParallel(model)
# Eval!
logger.info("***** Running evaluation {} *****".format(prefix))
logger.info(" Num examples = %d", len(dataset))
logger.info(" Batch size = %d", args.eval_batch_size)
all_results = []
start_time = timeit.default_timer()
for batch in tqdm(eval_dataloader, desc="Evaluating"):
model.eval()
batch = tuple(t.to(args.device) for t in batch)
with torch.no_grad():
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"token_type_ids": batch[2],
}
if args.model_type in ["xlm", "roberta", "distilbert", "camembert", "bart", "longformer"]:
del inputs["token_type_ids"]
feature_indices = batch[3]
# XLNet and XLM use more arguments for their predictions
if args.model_type in ["xlnet", "xlm"]:
inputs.update({"cls_index": batch[4], "p_mask": batch[5]})
# for lang_id-sensitive xlm models
if hasattr(model, "config") and hasattr(model.config, "lang2id"):
inputs.update(
{"langs": (torch.ones(batch[0].shape, dtype=torch.int64) * args.lang_id).to(args.device)}
)
outputs = model(**inputs)
for i, feature_index in enumerate(feature_indices):
eval_feature = features[feature_index.item()]
unique_id = int(eval_feature.unique_id)
output = [to_list(output[i]) for output in outputs.to_tuple()]
# Some models (XLNet, XLM) use 5 arguments for their predictions, while the other "simpler"
# models only use two.
if len(output) >= 5:
start_logits = output[0]
start_top_index = output[1]
end_logits = output[2]
end_top_index = output[3]
cls_logits = output[4]
result = SquadResult(
unique_id,
start_logits,
end_logits,
start_top_index=start_top_index,
end_top_index=end_top_index,
cls_logits=cls_logits,
)
else:
start_logits, end_logits = output
result = SquadResult(unique_id, start_logits, end_logits)
all_results.append(result)
evalTime = timeit.default_timer() - start_time
logger.info(" Evaluation done in total %f secs (%f sec per example)", evalTime, evalTime / len(dataset))
# Compute predictions
output_prediction_file = os.path.join(args.output_dir, "predictions_{}.json".format(prefix))
output_nbest_file = os.path.join(args.output_dir, "nbest_predictions_{}.json".format(prefix))
if args.version_2_with_negative:
output_null_log_odds_file = os.path.join(args.output_dir, "null_odds_{}.json".format(prefix))
else:
output_null_log_odds_file = None
# XLNet and XLM use a more complex post-processing procedure
if args.model_type in ["xlnet", "xlm"]:
start_n_top = model.config.start_n_top if hasattr(model, "config") else model.module.config.start_n_top
end_n_top = model.config.end_n_top if hasattr(model, "config") else model.module.config.end_n_top
predictions = compute_predictions_log_probs(
examples,
features,
all_results,
args.n_best_size,
args.max_answer_length,
output_prediction_file,
output_nbest_file,
output_null_log_odds_file,
start_n_top,
end_n_top,
args.version_2_with_negative,
tokenizer,
args.verbose_logging,
)
else:
predictions = compute_predictions_logits(
examples,
features,
all_results,
args.n_best_size,
args.max_answer_length,
args.do_lower_case,
output_prediction_file,
output_nbest_file,
output_null_log_odds_file,
args.verbose_logging,
args.version_2_with_negative,
args.null_score_diff_threshold,
tokenizer,
)
# Compute the F1 and exact scores.
results = squad_evaluate(examples, predictions)
return results
def load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False):
if args.local_rank not in [-1, 0] and not evaluate:
# Make sure only the first process in distributed training process the dataset, and the others will use the cache
torch.distributed.barrier()
# Load data features from cache or dataset file
input_dir = args.data_dir if args.data_dir else "."
cached_features_file = os.path.join(
input_dir,
"cached_{}_{}_{}".format(
"dev" if evaluate else "train",
list(filter(None, args.model_name_or_path.split("/"))).pop(),
str(args.max_seq_length),
),
)
# Init features and dataset from cache if it exists
if os.path.exists(cached_features_file) and not args.overwrite_cache:
logger.info("Loading features from cached file %s", cached_features_file)
features_and_dataset = torch.load(cached_features_file)
features, dataset, examples = (
features_and_dataset["features"],
features_and_dataset["dataset"],
features_and_dataset["examples"],
)
else:
logger.info("Creating features from dataset file at %s", input_dir)
if not args.data_dir and ((evaluate and not args.predict_file) or (not evaluate and not args.train_file)):
try:
import tensorflow_datasets as tfds
except ImportError:
raise ImportError("If not data_dir is specified, tensorflow_datasets needs to be installed.")
if args.version_2_with_negative:
logger.warning("tensorflow_datasets does not handle version 2 of SQuAD.")
tfds_examples = tfds.load("squad")
examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
else:
processor = SquadV2Processor() if args.version_2_with_negative else SquadV1Processor()
if evaluate:
examples = processor.get_dev_examples(args.data_dir, filename=args.predict_file)
else:
examples = processor.get_train_examples(args.data_dir, filename=args.train_file)
features, dataset = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=args.max_seq_length,
doc_stride=args.doc_stride,
max_query_length=args.max_query_length,
is_training=not evaluate,
return_dataset="pt",
threads=args.threads,
)
if args.local_rank in [-1, 0]:
logger.info("Saving features into cached file %s", cached_features_file)
torch.save({"features": features, "dataset": dataset, "examples": examples}, cached_features_file)
if args.local_rank == 0 and not evaluate:
# Make sure only the first process in distributed training process the dataset, and the others will use the cache
torch.distributed.barrier()
if output_examples:
return dataset, examples, features
return dataset
def main():
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--model_type",
default=None,
type=str,
required=True,
help="Model type selected in the list: " + ", ".join(MODEL_TYPES),
)
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models",
)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model checkpoints and predictions will be written.",
)
# Other parameters
parser.add_argument(
"--data_dir",
default=None,
type=str,
help="The input data dir. Should contain the .json files for the task."
+ "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
)
parser.add_argument(
"--train_file",
default=None,
type=str,
help="The input training file. If a data dir is specified, will look for the file there"
+ "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
)
parser.add_argument(
"--predict_file",
default=None,
type=str,
help="The input evaluation file. If a data dir is specified, will look for the file there"
+ "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
)
parser.add_argument(
"--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
)
parser.add_argument(
"--tokenizer_name",
default="",
type=str,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--cache_dir",
default="",
type=str,
help="Where do you want to store the pre-trained models downloaded from huggingface.co",
)
parser.add_argument(
"--version_2_with_negative",
action="store_true",
help="If true, the SQuAD examples contain some that do not have an answer.",
)
parser.add_argument(
"--null_score_diff_threshold",
type=float,
default=0.0,
help="If null_score - best_non_null is greater than the threshold predict null.",
)
parser.add_argument(
"--max_seq_length",
default=384,
type=int,
help=(
"The maximum total input sequence length after WordPiece tokenization. Sequences "
"longer than this will be truncated, and sequences shorter than this will be padded."
),
)
parser.add_argument(
"--doc_stride",
default=128,
type=int,
help="When splitting up a long document into chunks, how much stride to take between chunks.",
)
parser.add_argument(
"--max_query_length",
default=64,
type=int,
help=(
"The maximum number of tokens for the question. Questions longer than this will "
"be truncated to this length."
),
)
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
parser.add_argument(
"--evaluate_during_training", action="store_true", help="Run evaluation during training at each logging step."
)
parser.add_argument(
"--do_lower_case", action="store_true", help="Set this flag if you are using an uncased model."
)
parser.add_argument("--per_gpu_train_batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.")
parser.add_argument(
"--per_gpu_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation."
)
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument(
"--num_train_epochs", default=3.0, type=float, help="Total number of training epochs to perform."
)
parser.add_argument(
"--max_steps",
default=-1,
type=int,
help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
)
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument(
"--n_best_size",
default=20,
type=int,
help="The total number of n-best predictions to generate in the nbest_predictions.json output file.",
)
parser.add_argument(
"--max_answer_length",
default=30,
type=int,
help=(
"The maximum length of an answer that can be generated. This is needed because the start "
"and end predictions are not conditioned on one another."
),
)
parser.add_argument(
"--verbose_logging",
action="store_true",
help=(
"If true, all of the warnings related to data processing will be printed. "
"A number of warnings are expected for a normal SQuAD evaluation."
),
)
parser.add_argument(
"--lang_id",
default=0,
type=int,
help=(
"language id of input for language-specific xlm models (see"
" tokenization_xlm.PRETRAINED_INIT_CONFIGURATION)"
),
)
parser.add_argument("--logging_steps", type=int, default=500, help="Log every X updates steps.")
parser.add_argument("--save_steps", type=int, default=500, help="Save checkpoint every X updates steps.")
parser.add_argument(
"--eval_all_checkpoints",
action="store_true",
help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
)
parser.add_argument("--no_cuda", action="store_true", help="Whether not to use CUDA when available")
parser.add_argument(
"--overwrite_output_dir", action="store_true", help="Overwrite the content of the output directory"
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument("--local_rank", type=int, default=-1, help="local_rank for distributed training on gpus")
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument(
"--fp16_opt_level",
type=str,
default="O1",
help=(
"For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
"See details at https://nvidia.github.io/apex/amp.html"
),
)
parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--threads", type=int, default=1, help="multiple threads for converting example to features")
args = parser.parse_args()
if args.doc_stride >= args.max_seq_length - args.max_query_length:
logger.warning(
"WARNING - You've set a doc stride which may be superior to the document length in some "
"examples. This could result in errors when building features from the examples. Please reduce the doc "
"stride or increase the maximum length to ensure the features are correctly built."
)
if (
os.path.exists(args.output_dir)
and os.listdir(args.output_dir)
and args.do_train
and not args.overwrite_output_dir
):
raise ValueError(
"Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
args.output_dir
)
)
# Setup distant debugging if needed
if args.server_ip and args.server_port:
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
print("Waiting for debugger attach")
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
ptvsd.wait_for_attach()
# Setup CUDA, GPU & distributed training
if args.local_rank == -1 or args.no_cuda:
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
else: # Initializes the distributed backend which will take care of sychronizing nodes/GPUs
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
torch.distributed.init_process_group(backend="nccl")
args.n_gpu = 1
args.device = device
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
args.local_rank,
device,
args.n_gpu,
bool(args.local_rank != -1),
args.fp16,
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(args.local_rank):
transformers.utils.logging.set_verbosity_info()
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Set seed
set_seed(args)
# Load pretrained model and tokenizer
if args.local_rank not in [-1, 0]:
# Make sure only the first process in distributed training will download model & vocab
torch.distributed.barrier()
args.model_type = args.model_type.lower()
config = AutoConfig.from_pretrained(
args.config_name if args.config_name else args.model_name_or_path,
cache_dir=args.cache_dir if args.cache_dir else None,
)
tokenizer = AutoTokenizer.from_pretrained(
args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
do_lower_case=args.do_lower_case,
cache_dir=args.cache_dir if args.cache_dir else None,
use_fast=False, # SquadDataset is not compatible with Fast tokenizers which have a smarter overflow handeling
)
model = AutoModelForQuestionAnswering.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
cache_dir=args.cache_dir if args.cache_dir else None,
)
if args.local_rank == 0:
# Make sure only the first process in distributed training will download model & vocab
torch.distributed.barrier()
model.to(args.device)
logger.info("Training/evaluation parameters %s", args)
# Before we do anything with models, we want to ensure that we get fp16 execution of torch.einsum if args.fp16 is set.
# Otherwise it'll default to "promote" mode, and we'll get fp32 operations. Note that running `--fp16_opt_level="O2"` will
# remove the need for this code, but it is still valid.
if args.fp16:
try:
import apex
apex.amp.register_half_function(torch, "einsum")
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
# Training
if args.do_train:
train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False)
global_step, tr_loss = train(args, train_dataset, model, tokenizer)
logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
# Save the trained model and the tokenizer
if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):
logger.info("Saving model checkpoint to %s", args.output_dir)
# Save a trained model, configuration and tokenizer using `save_pretrained()`.
# They can then be reloaded using `from_pretrained()`
# Take care of distributed/parallel training
model_to_save = model.module if hasattr(model, "module") else model
model_to_save.save_pretrained(args.output_dir)
tokenizer.save_pretrained(args.output_dir)
# Good practice: save your training arguments together with the trained model
torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
# Load a trained model and vocabulary that you have fine-tuned
model = AutoModelForQuestionAnswering.from_pretrained(args.output_dir) # , force_download=True)
# SquadDataset is not compatible with Fast tokenizers which have a smarter overflow handeling
# So we use use_fast=False here for now until Fast-tokenizer-compatible-examples are out
tokenizer = AutoTokenizer.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case, use_fast=False)
model.to(args.device)
# Evaluation - we can ask to evaluate all the checkpoints (sub-directories) in a directory
results = {}
if args.do_eval and args.local_rank in [-1, 0]:
if args.do_train:
logger.info("Loading checkpoints saved during training for evaluation")
checkpoints = [args.output_dir]
if args.eval_all_checkpoints:
checkpoints = [
os.path.dirname(c)
for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
]
else:
logger.info("Loading checkpoint %s for evaluation", args.model_name_or_path)
checkpoints = [args.model_name_or_path]
logger.info("Evaluate the following checkpoints: %s", checkpoints)
for checkpoint in checkpoints:
# Reload the model
global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
model = AutoModelForQuestionAnswering.from_pretrained(checkpoint) # , force_download=True)
model.to(args.device)
# Evaluate
result = evaluate(args, model, tokenizer, prefix=global_step)
result = {k + ("_{}".format(global_step) if global_step else ""): v for k, v in result.items()}
results.update(result)
logger.info("Results: {}".format(results))
return results
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/question-answering/run_squad_trainer.py
|
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Fine-tuning the library models for question-answering."""
import logging
import os
import sys
from dataclasses import dataclass, field
from typing import Optional
import transformers
from transformers import (
AutoConfig,
AutoModelForQuestionAnswering,
AutoTokenizer,
DataCollatorWithPadding,
HfArgumentParser,
SquadDataset,
Trainer,
TrainingArguments,
)
from transformers import SquadDataTrainingArguments as DataTrainingArguments
from transformers.trainer_utils import is_main_process
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
use_fast: bool = field(default=False, metadata={"help": "Set this flag to use fast tokenization."})
# If you want to tweak more attributes on your tokenizer, you should do it in a distinct script,
# or just modify its tokenizer_config.json.
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if (
os.path.exists(training_args.output_dir)
and os.listdir(training_args.output_dir)
and training_args.do_train
and not training_args.overwrite_output_dir
):
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
" --overwrite_output_dir to overcome."
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
training_args.local_rank,
training_args.device,
training_args.n_gpu,
bool(training_args.local_rank != -1),
training_args.fp16,
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(training_args.local_rank):
transformers.utils.logging.set_verbosity_info()
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
logger.info("Training/evaluation parameters %s", training_args)
# Prepare Question-Answering task
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=False, # SquadDataset is not compatible with Fast tokenizers which have a smarter overflow handeling
)
model = AutoModelForQuestionAnswering.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
)
# Get datasets
is_language_sensitive = hasattr(model.config, "lang2id")
train_dataset = (
SquadDataset(
data_args, tokenizer=tokenizer, is_language_sensitive=is_language_sensitive, cache_dir=model_args.cache_dir
)
if training_args.do_train
else None
)
eval_dataset = (
SquadDataset(
data_args,
tokenizer=tokenizer,
mode="dev",
is_language_sensitive=is_language_sensitive,
cache_dir=model_args.cache_dir,
)
if training_args.do_eval
else None
)
# Data collator
data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8) if training_args.fp16 else None
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator,
)
# Training
if training_args.do_train:
trainer.train(
model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
)
trainer.save_model()
# For convenience, we also re-save the tokenizer to the same directory,
# so that you can share your model easily on huggingface.co/models =)
if trainer.is_world_master():
tokenizer.save_pretrained(training_args.output_dir)
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/seq2seq/old_test_fsmt_bleu_score.py
|
# coding=utf-8
# Copyright 2020 Huggingface
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import io
import json
import unittest
from parameterized import parameterized
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
from transformers.testing_utils import get_tests_dir, require_torch, slow, torch_device
from utils import calculate_bleu
filename = get_tests_dir() + "/test_data/fsmt/fsmt_val_data.json"
with io.open(filename, "r", encoding="utf-8") as f:
bleu_data = json.load(f)
@require_torch
class ModelEvalTester(unittest.TestCase):
def get_tokenizer(self, mname):
return FSMTTokenizer.from_pretrained(mname)
def get_model(self, mname):
model = FSMTForConditionalGeneration.from_pretrained(mname).to(torch_device)
if torch_device == "cuda":
model.half()
return model
@parameterized.expand(
[
["en-ru", 26.0],
["ru-en", 22.0],
["en-de", 22.0],
["de-en", 29.0],
]
)
@slow
def test_bleu_scores(self, pair, min_bleu_score):
# note: this test is not testing the best performance since it only evals a small batch
# but it should be enough to detect a regression in the output quality
mname = f"facebook/wmt19-{pair}"
tokenizer = self.get_tokenizer(mname)
model = self.get_model(mname)
src_sentences = bleu_data[pair]["src"]
tgt_sentences = bleu_data[pair]["tgt"]
batch = tokenizer(src_sentences, return_tensors="pt", truncation=True, padding="longest").to(torch_device)
outputs = model.generate(
input_ids=batch.input_ids,
num_beams=8,
)
decoded_sentences = tokenizer.batch_decode(
outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
scores = calculate_bleu(decoded_sentences, tgt_sentences)
print(scores)
self.assertGreaterEqual(scores["bleu"], min_bleu_score)
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/seq2seq/finetune.sh
|
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# the proper usage is documented in the README, you need to specify data_dir, output_dir and model_name_or_path
# run ./finetune.sh --help to see all the possible options
python finetune_trainer.py \
--learning_rate=3e-5 \
--fp16 \
--do_train --do_eval --do_predict \
--evaluation_strategy steps \
--predict_with_generate \
--n_val 1000 \
"$@"
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/seq2seq/convert_model_to_fp16.py
|
#!/usr/bin/env python
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import Union
import fire
import torch
from tqdm import tqdm
def convert(src_path: str, map_location: str = "cpu", save_path: Union[str, None] = None) -> None:
"""Convert a pytorch_model.bin or model.pt file to torch.float16 for faster downloads, less disk space."""
state_dict = torch.load(src_path, map_location=map_location)
for k, v in tqdm(state_dict.items()):
if not isinstance(v, torch.Tensor):
raise TypeError("FP16 conversion only works on paths that are saved state dicts, like pytorch_model.bin")
state_dict[k] = v.half()
if save_path is None: # overwrite src_path
save_path = src_path
torch.save(state_dict, save_path)
if __name__ == "__main__":
fire.Fire(convert)
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/seq2seq/README.md
|
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Sequence-to-Sequence Training and Evaluation
This directory contains examples for finetuning and evaluating transformers on summarization and translation tasks.
For deprecated `bertabs` instructions, see [`bertabs/README.md`](https://github.com/huggingface/transformers/blob/main/examples/research_projects/bertabs/README.md).
### Supported Architectures
- `BartForConditionalGeneration`
- `MarianMTModel`
- `PegasusForConditionalGeneration`
- `MBartForConditionalGeneration`
- `FSMTForConditionalGeneration`
- `T5ForConditionalGeneration`
### Download the Datasets
#### XSUM
```bash
cd examples/legacy/seq2seq
wget https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz
tar -xzvf xsum.tar.gz
export XSUM_DIR=${PWD}/xsum
```
this should make a directory called `xsum/` with files like `test.source`.
To use your own data, copy that files format. Each article to be summarized is on its own line.
#### CNN/DailyMail
```bash
cd examples/legacy/seq2seq
wget https://cdn-datasets.huggingface.co/summarization/cnn_dm_v2.tgz
tar -xzvf cnn_dm_v2.tgz # empty lines removed
mv cnn_cln cnn_dm
export CNN_DIR=${PWD}/cnn_dm
```
this should make a directory called `cnn_dm/` with 6 files.
#### WMT16 English-Romanian Translation Data
download with this command:
```bash
wget https://cdn-datasets.huggingface.co/translation/wmt_en_ro.tar.gz
tar -xzvf wmt_en_ro.tar.gz
export ENRO_DIR=${PWD}/wmt_en_ro
```
this should make a directory called `wmt_en_ro/` with 6 files.
#### WMT English-German
```bash
wget https://cdn-datasets.huggingface.co/translation/wmt_en_de.tgz
tar -xzvf wmt_en_de.tgz
export DATA_DIR=${PWD}/wmt_en_de
```
#### FSMT datasets (wmt)
Refer to the scripts starting with `eval_` under:
https://github.com/huggingface/transformers/tree/main/scripts/fsmt
#### Pegasus (multiple datasets)
Multiple eval datasets are available for download from:
https://github.com/stas00/porting/tree/master/datasets/pegasus
#### Your Data
If you are using your own data, it must be formatted as one directory with 6 files:
```
train.source
train.target
val.source
val.target
test.source
test.target
```
The `.source` files are the input, the `.target` files are the desired output.
### Potential issues
- native AMP (`--fp16` and no apex) may lead to a huge memory leak and require 10x gpu memory. This has been fixed in pytorch-nightly and the minimal official version to have this fix will be pytorch-1.7.1. Until then if you have to use mixed precision please use AMP only with pytorch-nightly or NVIDIA's apex. Reference: https://github.com/huggingface/transformers/issues/8403
### Tips and Tricks
General Tips:
- since you need to run from `examples/legacy/seq2seq`, and likely need to modify code, the easiest workflow is fork transformers, clone your fork, and run `pip install -e .` before you get started.
- try `--freeze_encoder` or `--freeze_embeds` for faster training/larger batch size. (3hr per epoch with bs=8, see the "xsum_shared_task" command below)
- `fp16_opt_level=O1` (the default works best).
- In addition to the pytorch-lightning .ckpt checkpoint, a transformers checkpoint will be saved.
Load it with `BartForConditionalGeneration.from_pretrained(f'{output_dir}/best_tfmr)`.
- At the moment, `--do_predict` does not work in a multi-gpu setting. You need to use `evaluate_checkpoint` or the `run_eval.py` code.
- This warning can be safely ignored:
> "Some weights of BartForConditionalGeneration were not initialized from the model checkpoint at facebook/bart-large-xsum and are newly initialized: ['final_logits_bias']"
- Both finetuning and eval are 30% faster with `--fp16`. For that you need to [install apex](https://github.com/NVIDIA/apex#quick-start).
- Read scripts before you run them!
Summarization Tips:
- (summ) 1 epoch at batch size 1 for bart-large takes 24 hours and requires 13GB GPU RAM with fp16 on an NVIDIA-V100.
- If you want to run experiments on improving the summarization finetuning process, try the XSUM Shared Task (below). It's faster to train than CNNDM because the summaries are shorter.
- For CNN/DailyMail, the default `val_max_target_length` and `test_max_target_length` will truncate the ground truth labels, resulting in slightly higher rouge scores. To get accurate rouge scores, you should rerun calculate_rouge on the `{output_dir}/test_generations.txt` file saved by `trainer.test()`
- `--max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 ` is a reasonable setting for XSUM.
- `wandb` can be used by specifying `--logger_name wandb`. It is useful for reproducibility. Specify the environment variable `WANDB_PROJECT='hf_xsum'` to do the XSUM shared task.
- If you are finetuning on your own dataset, start from `distilbart-cnn-12-6` if you want long summaries and `distilbart-xsum-12-6` if you want short summaries.
(It rarely makes sense to start from `bart-large` unless you are a researching finetuning methods).
**Update 2018-07-18**
Datasets: `LegacySeq2SeqDataset` will be used for all tokenizers without a `prepare_seq2seq_batch` method. Otherwise, `Seq2SeqDataset` will be used.
Future work/help wanted: A new dataset to support multilingual tasks.
### Fine-tuning using Seq2SeqTrainer
To use `Seq2SeqTrainer` for fine-tuning you should use the `finetune_trainer.py` script. It subclasses `Trainer` to extend it for seq2seq training. Except the `Trainer`-related `TrainingArguments`, it shares the same argument names as that of `finetune.py` file. One notable difference is that calculating generative metrics (BLEU, ROUGE) is optional and is controlled using the `--predict_with_generate` argument.
With PyTorch 1.6+ it'll automatically use `native AMP` when `--fp16` is set.
To see all the possible command line options, run:
```bash
python finetune_trainer.py --help
```
For multi-gpu training use `torch.distributed.launch`, e.g. with 2 gpus:
```bash
torchrun --nproc_per_node=2 finetune_trainer.py ...
```
**At the moment, `Seq2SeqTrainer` does not support *with teacher* distillation.**
All `Seq2SeqTrainer`-based fine-tuning scripts are included in the `builtin_trainer` directory.
#### TPU Training
`Seq2SeqTrainer` supports TPU training with few caveats
1. As `generate` method does not work on TPU at the moment, `predict_with_generate` cannot be used. You should use `--prediction_loss_only` to only calculate loss, and do not set `--do_predict` and `--predict_with_generate`.
2. All sequences should be padded to be of equal length to avoid extremely slow training. (`finetune_trainer.py` does this automatically when running on TPU.)
We provide a very simple launcher script named `xla_spawn.py` that lets you run our example scripts on multiple TPU cores without any boilerplate. Just pass a `--num_cores` flag to this script, then your regular training script with its arguments (this is similar to the `torch.distributed.launch` helper for `torch.distributed`).
`builtin_trainer/finetune_tpu.sh` script provides minimal arguments needed for TPU training.
The following command fine-tunes `sshleifer/student_marian_en_ro_6_3` on TPU V3-8 and should complete one epoch in ~5-6 mins.
```bash
./builtin_trainer/train_distil_marian_enro_tpu.sh
```
## Evaluation Commands
To create summaries for each article in dataset, we use `run_eval.py`, here are a few commands that run eval for different tasks and models.
If 'translation' is in your task name, the computed metric will be BLEU. Otherwise, ROUGE will be used.
For t5, you need to specify --task translation_{src}_to_{tgt} as follows:
```bash
export DATA_DIR=wmt_en_ro
./run_eval.py t5-base \
$DATA_DIR/val.source t5_val_generations.txt \
--reference_path $DATA_DIR/val.target \
--score_path enro_bleu.json \
--task translation_en_to_ro \
--n_obs 100 \
--device cuda \
--fp16 \
--bs 32
```
This command works for MBART, although the BLEU score is suspiciously low.
```bash
export DATA_DIR=wmt_en_ro
./run_eval.py facebook/mbart-large-en-ro $DATA_DIR/val.source mbart_val_generations.txt \
--reference_path $DATA_DIR/val.target \
--score_path enro_bleu.json \
--task translation \
--n_obs 100 \
--device cuda \
--fp16 \
--bs 32
```
Summarization (xsum will be very similar):
```bash
export DATA_DIR=cnn_dm
./run_eval.py sshleifer/distilbart-cnn-12-6 $DATA_DIR/val.source dbart_val_generations.txt \
--reference_path $DATA_DIR/val.target \
--score_path cnn_rouge.json \
--task summarization \
--n_obs 100 \
th 56 \
--fp16 \
--bs 32
```
### Multi-GPU Evaluation
here is a command to run xsum evaluation on 8 GPUS. It is more than linearly faster than run_eval.py in some cases
because it uses SortishSampler to minimize padding. You can also use it on 1 GPU. `data_dir` must have
`{type_path}.source` and `{type_path}.target`. Run `./run_distributed_eval.py --help` for all clargs.
```bash
torchrun --nproc_per_node=8 run_distributed_eval.py \
--model_name sshleifer/distilbart-large-xsum-12-3 \
--save_dir xsum_generations \
--data_dir xsum \
--fp16 # you can pass generate kwargs like num_beams here, just like run_eval.py
```
Contributions that implement this command for other distributed hardware setups are welcome!
#### Single-GPU Eval: Tips and Tricks
When using `run_eval.py`, the following features can be useful:
* if you running the script multiple times and want to make it easier to track what arguments produced that output, use `--dump-args`. Along with the results it will also dump any custom params that were passed to the script. For example if you used: `--num_beams 8 --early_stopping true`, the output will be:
```
{'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True}
```
`--info` is an additional argument available for the same purpose of tracking the conditions of the experiment. It's useful to pass things that weren't in the argument list, e.g. a language pair `--info "lang:en-ru"`. But also if you pass `--info` without a value it will fallback to the current date/time string, e.g. `2020-09-13 18:44:43`.
If using `--dump-args --info`, the output will be:
```
{'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True, 'info': '2020-09-13 18:44:43'}
```
If using `--dump-args --info "pair:en-ru chkpt=best`, the output will be:
```
{'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True, 'info': 'pair=en-ru chkpt=best'}
```
* if you need to perform a parametric search in order to find the best ones that lead to the highest BLEU score, let `run_eval_search.py` to do the searching for you.
The script accepts the exact same arguments as `run_eval.py`, plus an additional argument `--search`. The value of `--search` is parsed, reformatted and fed to ``run_eval.py`` as additional args.
The format for the `--search` value is a simple string with hparams and colon separated values to try, e.g.:
```
--search "num_beams=5:10 length_penalty=0.8:1.0:1.2 early_stopping=true:false"
```
which will generate `12` `(2*3*2)` searches for a product of each hparam. For example the example that was just used will invoke `run_eval.py` repeatedly with:
```
--num_beams 5 --length_penalty 0.8 --early_stopping true
--num_beams 5 --length_penalty 0.8 --early_stopping false
[...]
--num_beams 10 --length_penalty 1.2 --early_stopping false
```
On completion, this function prints a markdown table of the results sorted by the best BLEU score and the winning arguments.
```
bleu | num_beams | length_penalty | early_stopping
----- | --------- | -------------- | --------------
26.71 | 5 | 1.1 | 1
26.66 | 5 | 0.9 | 1
26.66 | 5 | 0.9 | 0
26.41 | 5 | 1.1 | 0
21.94 | 1 | 0.9 | 1
21.94 | 1 | 0.9 | 0
21.94 | 1 | 1.1 | 1
21.94 | 1 | 1.1 | 0
Best score args:
stas/wmt19-en-ru data/en-ru/val.source data/en-ru/test_translations.txt --reference_path data/en-ru/val.target --score_path data/en-ru/test_bleu.json --bs 8 --task translation --num_beams 5 --length_penalty 1.1 --early_stopping True
```
If you pass `--info "some experiment-specific info"` it will get printed before the results table - this is useful for scripting and multiple runs, so one can tell the different sets of results from each other.
### Contributing
- follow the standard contributing guidelines and code of conduct.
- add tests to `test_seq2seq_examples.py`
- To run only the seq2seq tests, you must be in the root of the repository and run:
```bash
pytest examples/seq2seq/
```
### Converting pytorch-lightning checkpoints
pytorch lightning ``-do_predict`` often fails, after you are done training, the best way to evaluate your model is to convert it.
This should be done for you, with a file called `{save_dir}/best_tfmr`.
If that file doesn't exist but you have a lightning `.ckpt` file, you can run
```bash
python convert_pl_checkpoint_to_hf.py PATH_TO_CKPT randomly_initialized_hf_model_path save_dir/best_tfmr
```
Then either `run_eval` or `run_distributed_eval` with `save_dir/best_tfmr` (see previous sections)
# Experimental Features
These features are harder to use and not always useful.
### Dynamic Batch Size for MT
`finetune.py` has a command line arg `--max_tokens_per_batch` that allows batches to be dynamically sized.
This feature can only be used:
- with fairseq installed
- on 1 GPU
- without sortish sampler
- after calling `./save_len_file.py $tok $data_dir`
For example,
```bash
./save_len_file.py Helsinki-NLP/opus-mt-en-ro wmt_en_ro
./dynamic_bs_example.sh --max_tokens_per_batch=2000 --output_dir benchmark_dynamic_bs
```
splits `wmt_en_ro/train` into 11,197 uneven lengthed batches and can finish 1 epoch in 8 minutes on a v100.
For comparison,
```bash
./dynamic_bs_example.sh --sortish_sampler --train_batch_size 48
```
uses 12,723 batches of length 48 and takes slightly more time 9.5 minutes.
The feature is still experimental, because:
+ we can make it much more robust if we have memory mapped/preprocessed datasets.
+ The speedup over sortish sampler is not that large at the moment.
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/seq2seq/seq2seq_training_args.py
|
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
from dataclasses import dataclass, field
from typing import Optional
from seq2seq_trainer import arg_to_scheduler
from transformers import TrainingArguments
logger = logging.getLogger(__name__)
@dataclass
class Seq2SeqTrainingArguments(TrainingArguments):
"""
Parameters:
label_smoothing (:obj:`float`, `optional`, defaults to 0):
The label smoothing epsilon to apply (if not zero).
sortish_sampler (:obj:`bool`, `optional`, defaults to :obj:`False`):
Whether to SortishSamler or not. It sorts the inputs according to lengths in-order to minimizing the padding size.
predict_with_generate (:obj:`bool`, `optional`, defaults to :obj:`False`):
Whether to use generate to calculate generative metrics (ROUGE, BLEU).
"""
label_smoothing: Optional[float] = field(
default=0.0, metadata={"help": "The label smoothing epsilon to apply (if not zero)."}
)
sortish_sampler: bool = field(default=False, metadata={"help": "Whether to SortishSamler or not."})
predict_with_generate: bool = field(
default=False, metadata={"help": "Whether to use generate to calculate generative metrics (ROUGE, BLEU)."}
)
adafactor: bool = field(default=False, metadata={"help": "whether to use adafactor"})
encoder_layerdrop: Optional[float] = field(
default=None, metadata={"help": "Encoder layer dropout probability. Goes into model.config."}
)
decoder_layerdrop: Optional[float] = field(
default=None, metadata={"help": "Decoder layer dropout probability. Goes into model.config."}
)
dropout: Optional[float] = field(default=None, metadata={"help": "Dropout probability. Goes into model.config."})
attention_dropout: Optional[float] = field(
default=None, metadata={"help": "Attention dropout probability. Goes into model.config."}
)
lr_scheduler: Optional[str] = field(
default="linear",
metadata={"help": f"Which lr scheduler to use. Selected in {sorted(arg_to_scheduler.keys())}"},
)
| 0
|
hf_public_repos/transformers/examples/legacy
|
hf_public_repos/transformers/examples/legacy/seq2seq/run_eval_search.py
|
#!/usr/bin/env python
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import itertools
import operator
import sys
from collections import OrderedDict
from run_eval import datetime_now, run_generate
from utils import ROUGE_KEYS
# A table of supported tasks and the list of scores in the order of importance to be sorted by.
# To add a new task, simply list the score names that `run_eval.run_generate()` returns
task_score_names = {
"translation": ["bleu"],
"summarization": ROUGE_KEYS,
}
def parse_search_arg(search):
groups = search.split()
entries = dict((g.split("=") for g in groups))
entry_names = list(entries.keys())
sets = [[f"--{k} {v}" for v in vs.split(":")] for k, vs in entries.items()]
matrix = [list(x) for x in itertools.product(*sets)]
return matrix, entry_names
def run_search():
"""
Run parametric search over the desired hparam space with help of ``run_eval.py``.
All the arguments except ``--search`` are passed to ``run_eval.py`` as is. The values inside of "--search" are parsed, reformatted and fed to ``run_eval.py`` as additional args.
The format for the ``--search`` value is a simple string with hparams and colon separated values to try, e.g.:
```
--search "num_beams=5:10 length_penalty=0.8:1.0:1.2 early_stopping=true:false"
```
which will generate ``12`` ``(2*3*2)`` searches for a product of each hparam. For example the example that was just used will invoke ``run_eval.py`` repeatedly with:
```
--num_beams 5 --length_penalty 0.8 --early_stopping true
--num_beams 5 --length_penalty 0.8 --early_stopping false
[...]
--num_beams 10 --length_penalty 1.2 --early_stopping false
```
On completion, this function prints a markdown table of the results sorted by the best BLEU score and the winning arguments.
"""
prog = sys.argv[0]
parser = argparse.ArgumentParser(
usage=(
"\n\nImportant: this script accepts all arguments `run_eval.py` accepts and then a few extra, therefore"
" refer to `run_eval.py -h` for the complete list."
)
)
parser.add_argument(
"--search",
type=str,
required=False,
help='param space to search, e.g. "num_beams=5:10 length_penalty=0.8:1.0:1.2"',
)
parser.add_argument(
"--bs", type=int, default=8, required=False, help="initial batch size (may get reduced if it's too big)"
)
parser.add_argument("--task", type=str, help="used for task_specific_params + metrics")
parser.add_argument(
"--info",
nargs="?",
type=str,
const=datetime_now(),
help=(
"add custom notes to be printed before the results table. If no value is passed, the current datetime"
" string will be used."
),
)
args, args_main = parser.parse_known_args()
# we share some of the args
args_main.extend(["--task", args.task])
args_normal = [prog] + args_main
# to support variations like translation_en_to_de"
task = "translation" if "translation" in args.task else "summarization"
matrix, col_names = parse_search_arg(args.search)
col_names[0:0] = task_score_names[task] # score cols first
col_widths = {col: len(str(col)) for col in col_names}
results = []
for r in matrix:
hparams = dict((x.replace("--", "").split() for x in r))
args_exp = " ".join(r).split()
args_exp.extend(["--bs", str(args.bs)]) # in case we need to reduce its size due to CUDA OOM
sys.argv = args_normal + args_exp
# XXX: need to trap CUDA OOM and lower args.bs if that happens and retry
scores = run_generate(verbose=False)
# make sure scores are first in the table
result = OrderedDict()
for score in task_score_names[task]:
result[score] = scores[score]
result.update(hparams)
results.append(result)
# find widest entries
for k, v in result.items():
l = len(str(v))
if l > col_widths[k]:
col_widths[k] = l
results_sorted = sorted(results, key=operator.itemgetter(*task_score_names[task]), reverse=True)
print(" | ".join([f"{col:{col_widths[col]}}" for col in col_names]))
print(" | ".join([f"{'-'*col_widths[col]}" for col in col_names]))
for row in results_sorted:
print(" | ".join([f"{row[col]:{col_widths[col]}}" for col in col_names]))
best = results_sorted[0]
for score in task_score_names[task]:
del best[score]
best_args = [f"--{k} {v}" for k, v in best.items()]
dyn_args = ["--bs", str(args.bs)]
if args.info:
print(f"\nInfo: {args.info}")
print("\nBest score args:")
print(" ".join(args_main + best_args + dyn_args))
return results_sorted
if __name__ == "__main__":
# Usage:
# [normal-run_eval_search.py cmd plus] \
# --search="num_beams=1:5:10 length_penalty=0.8:1:1.2 early_stopping=true:false"
#
# Example:
# PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py $MODEL_NAME \
# $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target \
# --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation \
# --search="num_beams=1:5:10 length_penalty=0.8:1:1.2 early_stopping=true:false"
run_search()
| 0
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.