
repo_id
stringlengths 15
89
| file_path
stringlengths 27
180
| content
stringlengths 1
2.23M
| __index_level_0__
int64 0
0
|
|---|---|---|---|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/controlnet/requirements_sdxl.txt
|
accelerate>=0.16.0
torchvision
transformers>=4.25.1
ftfy
tensorboard
Jinja2
datasets
wandb
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/controlnet/README_sdxl.md
|
# ControlNet training example for Stable Diffusion XL (SDXL)
The `train_controlnet_sdxl.py` script shows how to implement the ControlNet training procedure and adapt it for [Stable Diffusion XL](https://huggingface.co/papers/2307.01952).
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the `examples/controlnet` folder and run
```bash
pip install -r requirements_sdxl.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell (e.g., a notebook)
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
## Circle filling dataset
The original dataset is hosted in the [ControlNet repo](https://huggingface.co/lllyasviel/ControlNet/blob/main/training/fill50k.zip). We re-uploaded it to be compatible with `datasets` [here](https://huggingface.co/datasets/fusing/fill50k). Note that `datasets` handles dataloading within the training script.
## Training
Our training examples use two test conditioning images. They can be downloaded by running
```sh
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
```
Then run `huggingface-cli login` to log into your Hugging Face account. This is needed to be able to push the trained ControlNet parameters to Hugging Face Hub.
```bash
export MODEL_DIR="stabilityai/stable-diffusion-xl-base-1.0"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet_sdxl.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--mixed_precision="fp16" \
--resolution=1024 \
--learning_rate=1e-5 \
--max_train_steps=15000 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--validation_steps=100 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--report_to="wandb" \
--seed=42 \
--push_to_hub
```
To better track our training experiments, we're using the following flags in the command above:
* `report_to="wandb` will ensure the training runs are tracked on Weights and Biases. To use it, be sure to install `wandb` with `pip install wandb`.
* `validation_image`, `validation_prompt`, and `validation_steps` to allow the script to do a few validation inference runs. This allows us to qualitatively check if the training is progressing as expected.
Our experiments were conducted on a single 40GB A100 GPU.
### Inference
Once training is done, we can perform inference like so:
```python
from diffusers import StableDiffusionXLControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
from diffusers.utils import load_image
import torch
base_model_path = "stabilityai/stable-diffusion-xl-base-1.0"
controlnet_path = "path to controlnet"
controlnet = ControlNetModel.from_pretrained(controlnet_path, torch_dtype=torch.float16)
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
base_model_path, controlnet=controlnet, torch_dtype=torch.float16
)
# speed up diffusion process with faster scheduler and memory optimization
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# remove following line if xformers is not installed or when using Torch 2.0.
pipe.enable_xformers_memory_efficient_attention()
# memory optimization.
pipe.enable_model_cpu_offload()
control_image = load_image("./conditioning_image_1.png")
prompt = "pale golden rod circle with old lace background"
# generate image
generator = torch.manual_seed(0)
image = pipe(
prompt, num_inference_steps=20, generator=generator, image=control_image
).images[0]
image.save("./output.png")
```
## Notes
### Specifying a better VAE
SDXL's VAE is known to suffer from numerical instability issues. This is why we also expose a CLI argument namely `--pretrained_vae_model_name_or_path` that lets you specify the location of a better VAE (such as [this one](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)).
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/controlnet/README.md
|
# ControlNet training example
[Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) by Lvmin Zhang and Maneesh Agrawala.
This example is based on the [training example in the original ControlNet repository](https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md). It trains a ControlNet to fill circles using a [small synthetic dataset](https://huggingface.co/datasets/fusing/fill50k).
## Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
## Circle filling dataset
The original dataset is hosted in the [ControlNet repo](https://huggingface.co/lllyasviel/ControlNet/blob/main/training/fill50k.zip). We re-uploaded it to be compatible with `datasets` [here](https://huggingface.co/datasets/fusing/fill50k). Note that `datasets` handles dataloading within the training script.
Our training examples use [Stable Diffusion 1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5) as the original set of ControlNet models were trained from it. However, ControlNet can be trained to augment any Stable Diffusion compatible model (such as [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4)) or [stabilityai/stable-diffusion-2-1](https://huggingface.co/stabilityai/stable-diffusion-2-1).
## Training
Our training examples use two test conditioning images. They can be downloaded by running
```sh
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
```
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=4
```
This default configuration requires ~38GB VRAM.
By default, the training script logs outputs to tensorboard. Pass `--report_to wandb` to use weights and
biases.
Gradient accumulation with a smaller batch size can be used to reduce training requirements to ~20 GB VRAM.
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4
```
## Training with multiple GPUs
`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
for running distributed training with `accelerate`. Here is an example command:
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch --mixed_precision="fp16" --multi_gpu train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=4 \
--mixed_precision="fp16" \
--tracker_project_name="controlnet-demo" \
--report_to=wandb
```
## Example results
#### After 300 steps with batch size 8
| | |
|-------------------|:-------------------------:|
| | red circle with blue background |
 |  |
| | cyan circle with brown floral background |
 |  |
#### After 6000 steps with batch size 8:
| | |
|-------------------|:-------------------------:|
| | red circle with blue background |
 |  |
| | cyan circle with brown floral background |
 |  |
## Training on a 16 GB GPU
Optimizations:
- Gradient checkpointing
- bitsandbyte's 8-bit optimizer
[bitandbytes install instructions](https://github.com/TimDettmers/bitsandbytes#requirements--installation).
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam
```
## Training on a 12 GB GPU
Optimizations:
- Gradient checkpointing
- bitsandbyte's 8-bit optimizer
- xformers
- set grads to none
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam \
--enable_xformers_memory_efficient_attention \
--set_grads_to_none
```
When using `enable_xformers_memory_efficient_attention`, please make sure to install `xformers` by `pip install xformers`.
## Training on an 8 GB GPU
We have not exhaustively tested DeepSpeed support for ControlNet. While the configuration does
save memory, we have not confirmed the configuration to train successfully. You will very likely
have to make changes to the config to have a successful training run.
Optimizations:
- Gradient checkpointing
- xformers
- set grads to none
- DeepSpeed stage 2 with parameter and optimizer offloading
- fp16 mixed precision
[DeepSpeed](https://www.deepspeed.ai/) can offload tensors from VRAM to either
CPU or NVME. This requires significantly more RAM (about 25 GB).
Use `accelerate config` to enable DeepSpeed stage 2.
The relevant parts of the resulting accelerate config file are
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 4
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: false
zero_stage: 2
distributed_type: DEEPSPEED
```
See [documentation](https://huggingface.co/docs/accelerate/usage_guides/deepspeed) for more DeepSpeed configuration options.
Changing the default Adam optimizer to DeepSpeed's Adam
`deepspeed.ops.adam.DeepSpeedCPUAdam` gives a substantial speedup but
it requires CUDA toolchain with the same version as pytorch. 8-bit optimizer
does not seem to be compatible with DeepSpeed at the moment.
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--enable_xformers_memory_efficient_attention \
--set_grads_to_none \
--mixed_precision fp16
```
## Performing inference with the trained ControlNet
The trained model can be run the same as the original ControlNet pipeline with the newly trained ControlNet.
Set `base_model_path` and `controlnet_path` to the values `--pretrained_model_name_or_path` and
`--output_dir` were respectively set to in the training script.
```py
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
from diffusers.utils import load_image
import torch
base_model_path = "path to model"
controlnet_path = "path to controlnet"
controlnet = ControlNetModel.from_pretrained(controlnet_path, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
base_model_path, controlnet=controlnet, torch_dtype=torch.float16
)
# speed up diffusion process with faster scheduler and memory optimization
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# remove following line if xformers is not installed or when using Torch 2.0.
pipe.enable_xformers_memory_efficient_attention()
# memory optimization.
pipe.enable_model_cpu_offload()
control_image = load_image("./conditioning_image_1.png")
prompt = "pale golden rod circle with old lace background"
# generate image
generator = torch.manual_seed(0)
image = pipe(
prompt, num_inference_steps=20, generator=generator, image=control_image
).images[0]
image.save("./output.png")
```
## Training with Flax/JAX
For faster training on TPUs and GPUs you can leverage the flax training example. Follow the instructions above to get the model and dataset before running the script.
### Running on Google Cloud TPU
See below for commands to set up a TPU VM(`--accelerator-type v4-8`). For more details about how to set up and use TPUs, refer to [Cloud docs for single VM setup](https://cloud.google.com/tpu/docs/run-calculation-jax).
First create a single TPUv4-8 VM and connect to it:
```
ZONE=us-central2-b
TPU_TYPE=v4-8
VM_NAME=hg_flax
gcloud alpha compute tpus tpu-vm create $VM_NAME \
--zone $ZONE \
--accelerator-type $TPU_TYPE \
--version tpu-vm-v4-base
gcloud alpha compute tpus tpu-vm ssh $VM_NAME --zone $ZONE -- \
```
When connected install JAX `0.4.5`:
```
pip install "jax[tpu]==0.4.5" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
```
To verify that JAX was correctly installed, you can run the following command:
```
import jax
jax.device_count()
```
This should display the number of TPU cores, which should be 4 on a TPUv4-8 VM.
Then install Diffusers and the library's training dependencies:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run
```bash
pip install -U -r requirements_flax.txt
```
If you want to use Weights and Biases logging, you should also install `wandb` now
```bash
pip install wandb
```
Now let's downloading two conditioning images that we will use to run validation during the training in order to track our progress
```
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
```
We encourage you to store or share your model with the community. To use huggingface hub, please login to your Hugging Face account, or ([create one](https://huggingface.co/docs/diffusers/main/en/training/hf.co/join) if you don’t have one already):
```
huggingface-cli login
```
Make sure you have the `MODEL_DIR`,`OUTPUT_DIR` and `HUB_MODEL_ID` environment variables set. The `OUTPUT_DIR` and `HUB_MODEL_ID` variables specify where to save the model to on the Hub:
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="runs/fill-circle-{timestamp}"
export HUB_MODEL_ID="controlnet-fill-circle"
```
And finally start the training
```bash
python3 train_controlnet_flax.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--validation_steps=1000 \
--train_batch_size=2 \
--revision="non-ema" \
--from_pt \
--report_to="wandb" \
--tracker_project_name=$HUB_MODEL_ID \
--num_train_epochs=11 \
--push_to_hub \
--hub_model_id=$HUB_MODEL_ID
```
Since we passed the `--push_to_hub` flag, it will automatically create a model repo under your huggingface account based on `$HUB_MODEL_ID`. By the end of training, the final checkpoint will be automatically stored on the hub. You can find an example model repo [here](https://huggingface.co/YiYiXu/fill-circle-controlnet).
Our training script also provides limited support for streaming large datasets from the Hugging Face Hub. In order to enable streaming, one must also set `--max_train_samples`. Here is an example command (from [this blog article](https://huggingface.co/blog/train-your-controlnet)):
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="runs/uncanny-faces-{timestamp}"
export HUB_MODEL_ID="controlnet-uncanny-faces"
python3 train_controlnet_flax.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=multimodalart/facesyntheticsspigacaptioned \
--streaming \
--conditioning_image_column=spiga_seg \
--image_column=image \
--caption_column=image_caption \
--resolution=512 \
--max_train_samples 100000 \
--learning_rate=1e-5 \
--train_batch_size=1 \
--revision="flax" \
--report_to="wandb" \
--tracker_project_name=$HUB_MODEL_ID
```
Note, however, that the performance of the TPUs might get bottlenecked as streaming with `datasets` is not optimized for images. For ensuring maximum throughput, we encourage you to explore the following options:
* [Webdataset](https://webdataset.github.io/webdataset/)
* [TorchData](https://github.com/pytorch/data)
* [TensorFlow Datasets](https://www.tensorflow.org/datasets/tfless_tfds)
When work with a larger dataset, you may need to run training process for a long time and it’s useful to save regular checkpoints during the process. You can use the following argument to enable intermediate checkpointing:
```bash
--checkpointing_steps=500
```
This will save the trained model in subfolders of your output_dir. Subfolder names is the number of steps performed so far; for example: a checkpoint saved after 500 training steps would be saved in a subfolder named 500
You can then start your training from this saved checkpoint with
```bash
--controlnet_model_name_or_path="./control_out/500"
```
We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://arxiv.org/abs/2303.09556) which helps to achieve faster convergence by rebalancing the loss. To use it, one needs to set the `--snr_gamma` argument. The recommended value when using it is `5.0`.
We also support gradient accumulation - it is a technique that lets you use a bigger batch size than your machine would normally be able to fit into memory. You can use `gradient_accumulation_steps` argument to set gradient accumulation steps. The ControlNet author recommends using gradient accumulation to achieve better convergence. Read more [here](https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md#more-consideration-sudden-converge-phenomenon-and-gradient-accumulation).
You can **profile your code** with:
```bash
--profile_steps==5
```
Refer to the [JAX documentation on profiling](https://jax.readthedocs.io/en/latest/profiling.html). To inspect the profile trace, you'll have to install and start Tensorboard with the profile plugin:
```bash
pip install tensorflow tensorboard-plugin-profile
tensorboard --logdir runs/fill-circle-100steps-20230411_165612/
```
The profile can then be inspected at http://localhost:6006/#profile
Sometimes you'll get version conflicts (error messages like `Duplicate plugins for name projector`), which means that you have to uninstall and reinstall all versions of Tensorflow/Tensorboard (e.g. with `pip uninstall tensorflow tf-nightly tensorboard tb-nightly tensorboard-plugin-profile && pip install tf-nightly tbp-nightly tensorboard-plugin-profile`).
Note that the debugging functionality of the Tensorboard `profile` plugin is still under active development. Not all views are fully functional, and for example the `trace_viewer` cuts off events after 1M (which can result in all your device traces getting lost if you for example profile the compilation step by accident).
## Support for Stable Diffusion XL
We provide a training script for training a ControlNet with [Stable Diffusion XL](https://huggingface.co/papers/2307.01952). Please refer to [README_sdxl.md](./README_sdxl.md) for more details.
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/controlnet/train_controlnet.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import logging
import math
import os
import random
import shutil
from pathlib import Path
import accelerate
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from datasets import load_dataset
from huggingface_hub import create_repo, upload_folder
from packaging import version
from PIL import Image
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import AutoTokenizer, PretrainedConfig
import diffusers
from diffusers import (
AutoencoderKL,
ControlNetModel,
DDPMScheduler,
StableDiffusionControlNetPipeline,
UNet2DConditionModel,
UniPCMultistepScheduler,
)
from diffusers.optimization import get_scheduler
from diffusers.utils import check_min_version, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
if is_wandb_available():
import wandb
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.24.0.dev0")
logger = get_logger(__name__)
def image_grid(imgs, rows, cols):
assert len(imgs) == rows * cols
w, h = imgs[0].size
grid = Image.new("RGB", size=(cols * w, rows * h))
for i, img in enumerate(imgs):
grid.paste(img, box=(i % cols * w, i // cols * h))
return grid
def log_validation(vae, text_encoder, tokenizer, unet, controlnet, args, accelerator, weight_dtype, step):
logger.info("Running validation... ")
controlnet = accelerator.unwrap_model(controlnet)
pipeline = StableDiffusionControlNetPipeline.from_pretrained(
args.pretrained_model_name_or_path,
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
controlnet=controlnet,
safety_checker=None,
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
pipeline.scheduler = UniPCMultistepScheduler.from_config(pipeline.scheduler.config)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
if args.enable_xformers_memory_efficient_attention:
pipeline.enable_xformers_memory_efficient_attention()
if args.seed is None:
generator = None
else:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
if len(args.validation_image) == len(args.validation_prompt):
validation_images = args.validation_image
validation_prompts = args.validation_prompt
elif len(args.validation_image) == 1:
validation_images = args.validation_image * len(args.validation_prompt)
validation_prompts = args.validation_prompt
elif len(args.validation_prompt) == 1:
validation_images = args.validation_image
validation_prompts = args.validation_prompt * len(args.validation_image)
else:
raise ValueError(
"number of `args.validation_image` and `args.validation_prompt` should be checked in `parse_args`"
)
image_logs = []
for validation_prompt, validation_image in zip(validation_prompts, validation_images):
validation_image = Image.open(validation_image).convert("RGB")
images = []
for _ in range(args.num_validation_images):
with torch.autocast("cuda"):
image = pipeline(
validation_prompt, validation_image, num_inference_steps=20, generator=generator
).images[0]
images.append(image)
image_logs.append(
{"validation_image": validation_image, "images": images, "validation_prompt": validation_prompt}
)
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
validation_image = log["validation_image"]
formatted_images = []
formatted_images.append(np.asarray(validation_image))
for image in images:
formatted_images.append(np.asarray(image))
formatted_images = np.stack(formatted_images)
tracker.writer.add_images(validation_prompt, formatted_images, step, dataformats="NHWC")
elif tracker.name == "wandb":
formatted_images = []
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
validation_image = log["validation_image"]
formatted_images.append(wandb.Image(validation_image, caption="Controlnet conditioning"))
for image in images:
image = wandb.Image(image, caption=validation_prompt)
formatted_images.append(image)
tracker.log({"validation": formatted_images})
else:
logger.warn(f"image logging not implemented for {tracker.name}")
return image_logs
def import_model_class_from_model_name_or_path(pretrained_model_name_or_path: str, revision: str):
text_encoder_config = PretrainedConfig.from_pretrained(
pretrained_model_name_or_path,
subfolder="text_encoder",
revision=revision,
)
model_class = text_encoder_config.architectures[0]
if model_class == "CLIPTextModel":
from transformers import CLIPTextModel
return CLIPTextModel
elif model_class == "RobertaSeriesModelWithTransformation":
from diffusers.pipelines.alt_diffusion.modeling_roberta_series import RobertaSeriesModelWithTransformation
return RobertaSeriesModelWithTransformation
else:
raise ValueError(f"{model_class} is not supported.")
def save_model_card(repo_id: str, image_logs=None, base_model=str, repo_folder=None):
img_str = ""
if image_logs is not None:
img_str = "You can find some example images below.\n"
for i, log in enumerate(image_logs):
images = log["images"]
validation_prompt = log["validation_prompt"]
validation_image = log["validation_image"]
validation_image.save(os.path.join(repo_folder, "image_control.png"))
img_str += f"prompt: {validation_prompt}\n"
images = [validation_image] + images
image_grid(images, 1, len(images)).save(os.path.join(repo_folder, f"images_{i}.png"))
img_str += f"\n"
yaml = f"""
---
license: creativeml-openrail-m
base_model: {base_model}
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- controlnet
inference: true
---
"""
model_card = f"""
# controlnet-{repo_id}
These are controlnet weights trained on {base_model} with new type of conditioning.
{img_str}
"""
with open(os.path.join(repo_folder, "README.md"), "w") as f:
f.write(yaml + model_card)
def parse_args(input_args=None):
parser = argparse.ArgumentParser(description="Simple example of a ControlNet training script.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--controlnet_model_name_or_path",
type=str,
default=None,
help="Path to pretrained controlnet model or model identifier from huggingface.co/models."
" If not specified controlnet weights are initialized from unet.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--variant",
type=str,
default=None,
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--output_dir",
type=str,
default="controlnet-model",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=1)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. Checkpoints can be used for resuming training via `--resume_from_checkpoint`. "
"In the case that the checkpoint is better than the final trained model, the checkpoint can also be used for inference."
"Using a checkpoint for inference requires separate loading of the original pipeline and the individual checkpointed model components."
"See https://huggingface.co/docs/diffusers/main/en/training/dreambooth#performing-inference-using-a-saved-checkpoint for step by step"
"instructions."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-6,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--lr_num_cycles",
type=int,
default=1,
help="Number of hard resets of the lr in cosine_with_restarts scheduler.",
)
parser.add_argument("--lr_power", type=float, default=1.0, help="Power factor of the polynomial scheduler.")
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument(
"--set_grads_to_none",
action="store_true",
help=(
"Save more memory by using setting grads to None instead of zero. Be aware, that this changes certain"
" behaviors, so disable this argument if it causes any problems. More info:"
" https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html"
),
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--image_column", type=str, default="image", help="The column of the dataset containing the target image."
)
parser.add_argument(
"--conditioning_image_column",
type=str,
default="conditioning_image",
help="The column of the dataset containing the controlnet conditioning image.",
)
parser.add_argument(
"--caption_column",
type=str,
default="text",
help="The column of the dataset containing a caption or a list of captions.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--proportion_empty_prompts",
type=float,
default=0,
help="Proportion of image prompts to be replaced with empty strings. Defaults to 0 (no prompt replacement).",
)
parser.add_argument(
"--validation_prompt",
type=str,
default=None,
nargs="+",
help=(
"A set of prompts evaluated every `--validation_steps` and logged to `--report_to`."
" Provide either a matching number of `--validation_image`s, a single `--validation_image`"
" to be used with all prompts, or a single prompt that will be used with all `--validation_image`s."
),
)
parser.add_argument(
"--validation_image",
type=str,
default=None,
nargs="+",
help=(
"A set of paths to the controlnet conditioning image be evaluated every `--validation_steps`"
" and logged to `--report_to`. Provide either a matching number of `--validation_prompt`s, a"
" a single `--validation_prompt` to be used with all `--validation_image`s, or a single"
" `--validation_image` that will be used with all `--validation_prompt`s."
),
)
parser.add_argument(
"--num_validation_images",
type=int,
default=4,
help="Number of images to be generated for each `--validation_image`, `--validation_prompt` pair",
)
parser.add_argument(
"--validation_steps",
type=int,
default=100,
help=(
"Run validation every X steps. Validation consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`"
" and logging the images."
),
)
parser.add_argument(
"--tracker_project_name",
type=str,
default="train_controlnet",
help=(
"The `project_name` argument passed to Accelerator.init_trackers for"
" more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
),
)
if input_args is not None:
args = parser.parse_args(input_args)
else:
args = parser.parse_args()
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Specify either `--dataset_name` or `--train_data_dir`")
if args.dataset_name is not None and args.train_data_dir is not None:
raise ValueError("Specify only one of `--dataset_name` or `--train_data_dir`")
if args.proportion_empty_prompts < 0 or args.proportion_empty_prompts > 1:
raise ValueError("`--proportion_empty_prompts` must be in the range [0, 1].")
if args.validation_prompt is not None and args.validation_image is None:
raise ValueError("`--validation_image` must be set if `--validation_prompt` is set")
if args.validation_prompt is None and args.validation_image is not None:
raise ValueError("`--validation_prompt` must be set if `--validation_image` is set")
if (
args.validation_image is not None
and args.validation_prompt is not None
and len(args.validation_image) != 1
and len(args.validation_prompt) != 1
and len(args.validation_image) != len(args.validation_prompt)
):
raise ValueError(
"Must provide either 1 `--validation_image`, 1 `--validation_prompt`,"
" or the same number of `--validation_prompt`s and `--validation_image`s"
)
if args.resolution % 8 != 0:
raise ValueError(
"`--resolution` must be divisible by 8 for consistently sized encoded images between the VAE and the controlnet encoder."
)
return args
def make_train_dataset(args, tokenizer, accelerator):
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
)
else:
if args.train_data_dir is not None:
dataset = load_dataset(
args.train_data_dir,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.0.0/en/dataset_script
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
if args.image_column is None:
image_column = column_names[0]
logger.info(f"image column defaulting to {image_column}")
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"`--image_column` value '{args.image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = column_names[1]
logger.info(f"caption column defaulting to {caption_column}")
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"`--caption_column` value '{args.caption_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
if args.conditioning_image_column is None:
conditioning_image_column = column_names[2]
logger.info(f"conditioning image column defaulting to {conditioning_image_column}")
else:
conditioning_image_column = args.conditioning_image_column
if conditioning_image_column not in column_names:
raise ValueError(
f"`--conditioning_image_column` value '{args.conditioning_image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
def tokenize_captions(examples, is_train=True):
captions = []
for caption in examples[caption_column]:
if random.random() < args.proportion_empty_prompts:
captions.append("")
elif isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
else:
raise ValueError(
f"Caption column `{caption_column}` should contain either strings or lists of strings."
)
inputs = tokenizer(
captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
)
return inputs.input_ids
image_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
conditioning_image_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution),
transforms.ToTensor(),
]
)
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
images = [image_transforms(image) for image in images]
conditioning_images = [image.convert("RGB") for image in examples[conditioning_image_column]]
conditioning_images = [conditioning_image_transforms(image) for image in conditioning_images]
examples["pixel_values"] = images
examples["conditioning_pixel_values"] = conditioning_images
examples["input_ids"] = tokenize_captions(examples)
return examples
with accelerator.main_process_first():
if args.max_train_samples is not None:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train)
return train_dataset
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
conditioning_pixel_values = torch.stack([example["conditioning_pixel_values"] for example in examples])
conditioning_pixel_values = conditioning_pixel_values.to(memory_format=torch.contiguous_format).float()
input_ids = torch.stack([example["input_ids"] for example in examples])
return {
"pixel_values": pixel_values,
"conditioning_pixel_values": conditioning_pixel_values,
"input_ids": input_ids,
}
def main(args):
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load the tokenizer
if args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, revision=args.revision, use_fast=False)
elif args.pretrained_model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="tokenizer",
revision=args.revision,
use_fast=False,
)
# import correct text encoder class
text_encoder_cls = import_model_class_from_model_name_or_path(args.pretrained_model_name_or_path, args.revision)
# Load scheduler and models
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
text_encoder = text_encoder_cls.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision, variant=args.variant
)
vae = AutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision, variant=args.variant
)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
)
if args.controlnet_model_name_or_path:
logger.info("Loading existing controlnet weights")
controlnet = ControlNetModel.from_pretrained(args.controlnet_model_name_or_path)
else:
logger.info("Initializing controlnet weights from unet")
controlnet = ControlNetModel.from_unet(unet)
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
i = len(weights) - 1
while len(weights) > 0:
weights.pop()
model = models[i]
sub_dir = "controlnet"
model.save_pretrained(os.path.join(output_dir, sub_dir))
i -= 1
def load_model_hook(models, input_dir):
while len(models) > 0:
# pop models so that they are not loaded again
model = models.pop()
# load diffusers style into model
load_model = ControlNetModel.from_pretrained(input_dir, subfolder="controlnet")
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
del load_model
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
vae.requires_grad_(False)
unet.requires_grad_(False)
text_encoder.requires_grad_(False)
controlnet.train()
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
controlnet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
if args.gradient_checkpointing:
controlnet.enable_gradient_checkpointing()
# Check that all trainable models are in full precision
low_precision_error_string = (
" Please make sure to always have all model weights in full float32 precision when starting training - even if"
" doing mixed precision training, copy of the weights should still be float32."
)
if accelerator.unwrap_model(controlnet).dtype != torch.float32:
raise ValueError(
f"Controlnet loaded as datatype {accelerator.unwrap_model(controlnet).dtype}. {low_precision_error_string}"
)
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
)
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
# Optimizer creation
params_to_optimize = controlnet.parameters()
optimizer = optimizer_class(
params_to_optimize,
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
train_dataset = make_train_dataset(args, tokenizer, accelerator)
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps * accelerator.num_processes,
num_cycles=args.lr_num_cycles,
power=args.lr_power,
)
# Prepare everything with our `accelerator`.
controlnet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
controlnet, optimizer, train_dataloader, lr_scheduler
)
# For mixed precision training we cast the text_encoder and vae weights to half-precision
# as these models are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move vae, unet and text_encoder to device and cast to weight_dtype
vae.to(accelerator.device, dtype=weight_dtype)
unet.to(accelerator.device, dtype=weight_dtype)
text_encoder.to(accelerator.device, dtype=weight_dtype)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
tracker_config = dict(vars(args))
# tensorboard cannot handle list types for config
tracker_config.pop("validation_prompt")
tracker_config.pop("validation_image")
accelerator.init_trackers(args.tracker_project_name, config=tracker_config)
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num batches each epoch = {len(train_dataloader)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
image_logs = None
for epoch in range(first_epoch, args.num_train_epochs):
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(controlnet):
# Convert images to latent space
latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# Get the text embedding for conditioning
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
controlnet_image = batch["conditioning_pixel_values"].to(dtype=weight_dtype)
down_block_res_samples, mid_block_res_sample = controlnet(
noisy_latents,
timesteps,
encoder_hidden_states=encoder_hidden_states,
controlnet_cond=controlnet_image,
return_dict=False,
)
# Predict the noise residual
model_pred = unet(
noisy_latents,
timesteps,
encoder_hidden_states=encoder_hidden_states,
down_block_additional_residuals=[
sample.to(dtype=weight_dtype) for sample in down_block_res_samples
],
mid_block_additional_residual=mid_block_res_sample.to(dtype=weight_dtype),
).sample
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
accelerator.backward(loss)
if accelerator.sync_gradients:
params_to_clip = controlnet.parameters()
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad(set_to_none=args.set_grads_to_none)
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
if accelerator.is_main_process:
if global_step % args.checkpointing_steps == 0:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
if args.validation_prompt is not None and global_step % args.validation_steps == 0:
image_logs = log_validation(
vae,
text_encoder,
tokenizer,
unet,
controlnet,
args,
accelerator,
weight_dtype,
global_step,
)
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
if global_step >= args.max_train_steps:
break
# Create the pipeline using using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
controlnet = accelerator.unwrap_model(controlnet)
controlnet.save_pretrained(args.output_dir)
if args.push_to_hub:
save_model_card(
repo_id,
image_logs=image_logs,
base_model=args.pretrained_model_name_or_path,
repo_folder=args.output_dir,
)
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/controlnet/train_controlnet_flax.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import logging
import math
import os
import random
import time
from pathlib import Path
import jax
import jax.numpy as jnp
import numpy as np
import optax
import torch
import torch.utils.checkpoint
import transformers
from datasets import load_dataset, load_from_disk
from flax import jax_utils
from flax.core.frozen_dict import unfreeze
from flax.training import train_state
from flax.training.common_utils import shard
from huggingface_hub import create_repo, upload_folder
from PIL import Image, PngImagePlugin
from torch.utils.data import IterableDataset
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPTokenizer, FlaxCLIPTextModel, set_seed
from diffusers import (
FlaxAutoencoderKL,
FlaxControlNetModel,
FlaxDDPMScheduler,
FlaxStableDiffusionControlNetPipeline,
FlaxUNet2DConditionModel,
)
from diffusers.utils import check_min_version, is_wandb_available, make_image_grid
# To prevent an error that occurs when there are abnormally large compressed data chunk in the png image
# see more https://github.com/python-pillow/Pillow/issues/5610
LARGE_ENOUGH_NUMBER = 100
PngImagePlugin.MAX_TEXT_CHUNK = LARGE_ENOUGH_NUMBER * (1024**2)
if is_wandb_available():
import wandb
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.24.0.dev0")
logger = logging.getLogger(__name__)
def log_validation(pipeline, pipeline_params, controlnet_params, tokenizer, args, rng, weight_dtype):
logger.info("Running validation...")
pipeline_params = pipeline_params.copy()
pipeline_params["controlnet"] = controlnet_params
num_samples = jax.device_count()
prng_seed = jax.random.split(rng, jax.device_count())
if len(args.validation_image) == len(args.validation_prompt):
validation_images = args.validation_image
validation_prompts = args.validation_prompt
elif len(args.validation_image) == 1:
validation_images = args.validation_image * len(args.validation_prompt)
validation_prompts = args.validation_prompt
elif len(args.validation_prompt) == 1:
validation_images = args.validation_image
validation_prompts = args.validation_prompt * len(args.validation_image)
else:
raise ValueError(
"number of `args.validation_image` and `args.validation_prompt` should be checked in `parse_args`"
)
image_logs = []
for validation_prompt, validation_image in zip(validation_prompts, validation_images):
prompts = num_samples * [validation_prompt]
prompt_ids = pipeline.prepare_text_inputs(prompts)
prompt_ids = shard(prompt_ids)
validation_image = Image.open(validation_image).convert("RGB")
processed_image = pipeline.prepare_image_inputs(num_samples * [validation_image])
processed_image = shard(processed_image)
images = pipeline(
prompt_ids=prompt_ids,
image=processed_image,
params=pipeline_params,
prng_seed=prng_seed,
num_inference_steps=50,
jit=True,
).images
images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
images = pipeline.numpy_to_pil(images)
image_logs.append(
{"validation_image": validation_image, "images": images, "validation_prompt": validation_prompt}
)
if args.report_to == "wandb":
formatted_images = []
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
validation_image = log["validation_image"]
formatted_images.append(wandb.Image(validation_image, caption="Controlnet conditioning"))
for image in images:
image = wandb.Image(image, caption=validation_prompt)
formatted_images.append(image)
wandb.log({"validation": formatted_images})
else:
logger.warn(f"image logging not implemented for {args.report_to}")
return image_logs
def save_model_card(repo_id: str, image_logs=None, base_model=str, repo_folder=None):
img_str = ""
if image_logs is not None:
for i, log in enumerate(image_logs):
images = log["images"]
validation_prompt = log["validation_prompt"]
validation_image = log["validation_image"]
validation_image.save(os.path.join(repo_folder, "image_control.png"))
img_str += f"prompt: {validation_prompt}\n"
images = [validation_image] + images
make_image_grid(images, 1, len(images)).save(os.path.join(repo_folder, f"images_{i}.png"))
img_str += f"\n"
yaml = f"""
---
license: creativeml-openrail-m
base_model: {base_model}
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- controlnet
- jax-diffusers-event
inference: true
---
"""
model_card = f"""
# controlnet- {repo_id}
These are controlnet weights trained on {base_model} with new type of conditioning. You can find some example images in the following. \n
{img_str}
"""
with open(os.path.join(repo_folder, "README.md"), "w") as f:
f.write(yaml + model_card)
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--controlnet_model_name_or_path",
type=str,
default=None,
help="Path to pretrained controlnet model or model identifier from huggingface.co/models."
" If not specified controlnet weights are initialized from unet.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--from_pt",
action="store_true",
help="Load the pretrained model from a PyTorch checkpoint.",
)
parser.add_argument(
"--controlnet_revision",
type=str,
default=None,
help="Revision of controlnet model identifier from huggingface.co/models.",
)
parser.add_argument(
"--profile_steps",
type=int,
default=0,
help="How many training steps to profile in the beginning.",
)
parser.add_argument(
"--profile_validation",
action="store_true",
help="Whether to profile the (last) validation.",
)
parser.add_argument(
"--profile_memory",
action="store_true",
help="Whether to dump an initial (before training loop) and a final (at program end) memory profile.",
)
parser.add_argument(
"--ccache",
type=str,
default=None,
help="Enables compilation cache.",
)
parser.add_argument(
"--controlnet_from_pt",
action="store_true",
help="Load the controlnet model from a PyTorch checkpoint.",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--output_dir",
type=str,
default="runs/{timestamp}",
help="The output directory where the model predictions and checkpoints will be written. "
"Can contain placeholders: {timestamp}.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=0, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--train_batch_size", type=int, default=1, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform.",
)
parser.add_argument(
"--checkpointing_steps",
type=int,
default=5000,
help=("Save a checkpoint of the training state every X updates."),
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--snr_gamma",
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
"More details here: https://arxiv.org/abs/2303.09556.",
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_steps",
type=int,
default=100,
help=("log training metric every X steps to `--report_t`"),
)
parser.add_argument(
"--report_to",
type=str,
default="wandb",
help=('The integration to report the results and logs to. Currently only supported platforms are `"wandb"`'),
)
parser.add_argument(
"--mixed_precision",
type=str,
default="no",
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU."
),
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument("--streaming", action="store_true", help="To stream a large dataset from Hub.")
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training dataset. By default it will use `load_dataset` method to load a custom dataset from the folder."
"Folder must contain a dataset script as described here https://huggingface.co/docs/datasets/dataset_script) ."
"If `--load_from_disk` flag is passed, it will use `load_from_disk` method instead. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--load_from_disk",
action="store_true",
help=(
"If True, will load a dataset that was previously saved using `save_to_disk` from `--train_data_dir`"
"See more https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.load_from_disk"
),
)
parser.add_argument(
"--image_column", type=str, default="image", help="The column of the dataset containing the target image."
)
parser.add_argument(
"--conditioning_image_column",
type=str,
default="conditioning_image",
help="The column of the dataset containing the controlnet conditioning image.",
)
parser.add_argument(
"--caption_column",
type=str,
default="text",
help="The column of the dataset containing a caption or a list of captions.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set. Needed if `streaming` is set to True."
),
)
parser.add_argument(
"--proportion_empty_prompts",
type=float,
default=0,
help="Proportion of image prompts to be replaced with empty strings. Defaults to 0 (no prompt replacement).",
)
parser.add_argument(
"--validation_prompt",
type=str,
default=None,
nargs="+",
help=(
"A set of prompts evaluated every `--validation_steps` and logged to `--report_to`."
" Provide either a matching number of `--validation_image`s, a single `--validation_image`"
" to be used with all prompts, or a single prompt that will be used with all `--validation_image`s."
),
)
parser.add_argument(
"--validation_image",
type=str,
default=None,
nargs="+",
help=(
"A set of paths to the controlnet conditioning image be evaluated every `--validation_steps`"
" and logged to `--report_to`. Provide either a matching number of `--validation_prompt`s, a"
" a single `--validation_prompt` to be used with all `--validation_image`s, or a single"
" `--validation_image` that will be used with all `--validation_prompt`s."
),
)
parser.add_argument(
"--validation_steps",
type=int,
default=100,
help=(
"Run validation every X steps. Validation consists of running the prompt"
" `args.validation_prompt` and logging the images."
),
)
parser.add_argument("--wandb_entity", type=str, default=None, help=("The wandb entity to use (for teams)."))
parser.add_argument(
"--tracker_project_name",
type=str,
default="train_controlnet_flax",
help=("The `project` argument passed to wandb"),
)
parser.add_argument(
"--gradient_accumulation_steps", type=int, default=1, help="Number of steps to accumulate gradients over"
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
args = parser.parse_args()
args.output_dir = args.output_dir.replace("{timestamp}", time.strftime("%Y%m%d_%H%M%S"))
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
if args.dataset_name is not None and args.train_data_dir is not None:
raise ValueError("Specify only one of `--dataset_name` or `--train_data_dir`")
if args.proportion_empty_prompts < 0 or args.proportion_empty_prompts > 1:
raise ValueError("`--proportion_empty_prompts` must be in the range [0, 1].")
if args.validation_prompt is not None and args.validation_image is None:
raise ValueError("`--validation_image` must be set if `--validation_prompt` is set")
if args.validation_prompt is None and args.validation_image is not None:
raise ValueError("`--validation_prompt` must be set if `--validation_image` is set")
if (
args.validation_image is not None
and args.validation_prompt is not None
and len(args.validation_image) != 1
and len(args.validation_prompt) != 1
and len(args.validation_image) != len(args.validation_prompt)
):
raise ValueError(
"Must provide either 1 `--validation_image`, 1 `--validation_prompt`,"
" or the same number of `--validation_prompt`s and `--validation_image`s"
)
# This idea comes from
# https://github.com/borisdayma/dalle-mini/blob/d2be512d4a6a9cda2d63ba04afc33038f98f705f/src/dalle_mini/data.py#L370
if args.streaming and args.max_train_samples is None:
raise ValueError("You must specify `max_train_samples` when using dataset streaming.")
return args
def make_train_dataset(args, tokenizer, batch_size=None):
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
streaming=args.streaming,
)
else:
if args.train_data_dir is not None:
if args.load_from_disk:
dataset = load_from_disk(
args.train_data_dir,
)
else:
dataset = load_dataset(
args.train_data_dir,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.0.0/en/dataset_script
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
if isinstance(dataset["train"], IterableDataset):
column_names = next(iter(dataset["train"])).keys()
else:
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
if args.image_column is None:
image_column = column_names[0]
logger.info(f"image column defaulting to {image_column}")
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"`--image_column` value '{args.image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = column_names[1]
logger.info(f"caption column defaulting to {caption_column}")
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"`--caption_column` value '{args.caption_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
if args.conditioning_image_column is None:
conditioning_image_column = column_names[2]
logger.info(f"conditioning image column defaulting to {caption_column}")
else:
conditioning_image_column = args.conditioning_image_column
if conditioning_image_column not in column_names:
raise ValueError(
f"`--conditioning_image_column` value '{args.conditioning_image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
def tokenize_captions(examples, is_train=True):
captions = []
for caption in examples[caption_column]:
if random.random() < args.proportion_empty_prompts:
captions.append("")
elif isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
else:
raise ValueError(
f"Caption column `{caption_column}` should contain either strings or lists of strings."
)
inputs = tokenizer(
captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
)
return inputs.input_ids
image_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
conditioning_image_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution),
transforms.ToTensor(),
]
)
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
images = [image_transforms(image) for image in images]
conditioning_images = [image.convert("RGB") for image in examples[conditioning_image_column]]
conditioning_images = [conditioning_image_transforms(image) for image in conditioning_images]
examples["pixel_values"] = images
examples["conditioning_pixel_values"] = conditioning_images
examples["input_ids"] = tokenize_captions(examples)
return examples
if jax.process_index() == 0:
if args.max_train_samples is not None:
if args.streaming:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).take(args.max_train_samples)
else:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
if args.streaming:
train_dataset = dataset["train"].map(
preprocess_train,
batched=True,
batch_size=batch_size,
remove_columns=list(dataset["train"].features.keys()),
)
else:
train_dataset = dataset["train"].with_transform(preprocess_train)
return train_dataset
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
conditioning_pixel_values = torch.stack([example["conditioning_pixel_values"] for example in examples])
conditioning_pixel_values = conditioning_pixel_values.to(memory_format=torch.contiguous_format).float()
input_ids = torch.stack([example["input_ids"] for example in examples])
batch = {
"pixel_values": pixel_values,
"conditioning_pixel_values": conditioning_pixel_values,
"input_ids": input_ids,
}
batch = {k: v.numpy() for k, v in batch.items()}
return batch
def get_params_to_save(params):
return jax.device_get(jax.tree_util.tree_map(lambda x: x[0], params))
def main():
args = parse_args()
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
# Setup logging, we only want one process per machine to log things on the screen.
logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
if jax.process_index() == 0:
transformers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
# wandb init
if jax.process_index() == 0 and args.report_to == "wandb":
wandb.init(
entity=args.wandb_entity,
project=args.tracker_project_name,
job_type="train",
config=args,
)
if args.seed is not None:
set_seed(args.seed)
rng = jax.random.PRNGKey(0)
# Handle the repository creation
if jax.process_index() == 0:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load the tokenizer and add the placeholder token as a additional special token
if args.tokenizer_name:
tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
elif args.pretrained_model_name_or_path:
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
)
else:
raise NotImplementedError("No tokenizer specified!")
# Get the datasets: you can either provide your own training and evaluation files (see below)
total_train_batch_size = args.train_batch_size * jax.local_device_count() * args.gradient_accumulation_steps
train_dataset = make_train_dataset(args, tokenizer, batch_size=total_train_batch_size)
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=not args.streaming,
collate_fn=collate_fn,
batch_size=total_train_batch_size,
num_workers=args.dataloader_num_workers,
drop_last=True,
)
weight_dtype = jnp.float32
if args.mixed_precision == "fp16":
weight_dtype = jnp.float16
elif args.mixed_precision == "bf16":
weight_dtype = jnp.bfloat16
# Load models and create wrapper for stable diffusion
text_encoder = FlaxCLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="text_encoder",
dtype=weight_dtype,
revision=args.revision,
from_pt=args.from_pt,
)
vae, vae_params = FlaxAutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path,
revision=args.revision,
subfolder="vae",
dtype=weight_dtype,
from_pt=args.from_pt,
)
unet, unet_params = FlaxUNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="unet",
dtype=weight_dtype,
revision=args.revision,
from_pt=args.from_pt,
)
if args.controlnet_model_name_or_path:
logger.info("Loading existing controlnet weights")
controlnet, controlnet_params = FlaxControlNetModel.from_pretrained(
args.controlnet_model_name_or_path,
revision=args.controlnet_revision,
from_pt=args.controlnet_from_pt,
dtype=jnp.float32,
)
else:
logger.info("Initializing controlnet weights from unet")
rng, rng_params = jax.random.split(rng)
controlnet = FlaxControlNetModel(
in_channels=unet.config.in_channels,
down_block_types=unet.config.down_block_types,
only_cross_attention=unet.config.only_cross_attention,
block_out_channels=unet.config.block_out_channels,
layers_per_block=unet.config.layers_per_block,
attention_head_dim=unet.config.attention_head_dim,
cross_attention_dim=unet.config.cross_attention_dim,
use_linear_projection=unet.config.use_linear_projection,
flip_sin_to_cos=unet.config.flip_sin_to_cos,
freq_shift=unet.config.freq_shift,
)
controlnet_params = controlnet.init_weights(rng=rng_params)
controlnet_params = unfreeze(controlnet_params)
for key in [
"conv_in",
"time_embedding",
"down_blocks_0",
"down_blocks_1",
"down_blocks_2",
"down_blocks_3",
"mid_block",
]:
controlnet_params[key] = unet_params[key]
pipeline, pipeline_params = FlaxStableDiffusionControlNetPipeline.from_pretrained(
args.pretrained_model_name_or_path,
tokenizer=tokenizer,
controlnet=controlnet,
safety_checker=None,
dtype=weight_dtype,
revision=args.revision,
from_pt=args.from_pt,
)
pipeline_params = jax_utils.replicate(pipeline_params)
# Optimization
if args.scale_lr:
args.learning_rate = args.learning_rate * total_train_batch_size
constant_scheduler = optax.constant_schedule(args.learning_rate)
adamw = optax.adamw(
learning_rate=constant_scheduler,
b1=args.adam_beta1,
b2=args.adam_beta2,
eps=args.adam_epsilon,
weight_decay=args.adam_weight_decay,
)
optimizer = optax.chain(
optax.clip_by_global_norm(args.max_grad_norm),
adamw,
)
state = train_state.TrainState.create(apply_fn=controlnet.__call__, params=controlnet_params, tx=optimizer)
noise_scheduler, noise_scheduler_state = FlaxDDPMScheduler.from_pretrained(
args.pretrained_model_name_or_path, subfolder="scheduler"
)
# Initialize our training
validation_rng, train_rngs = jax.random.split(rng)
train_rngs = jax.random.split(train_rngs, jax.local_device_count())
def compute_snr(timesteps):
"""
Computes SNR as per https://github.com/TiankaiHang/Min-SNR-Diffusion-Training/blob/521b624bd70c67cee4bdf49225915f5945a872e3/guided_diffusion/gaussian_diffusion.py#L847-L849
"""
alphas_cumprod = noise_scheduler_state.common.alphas_cumprod
sqrt_alphas_cumprod = alphas_cumprod**0.5
sqrt_one_minus_alphas_cumprod = (1.0 - alphas_cumprod) ** 0.5
alpha = sqrt_alphas_cumprod[timesteps]
sigma = sqrt_one_minus_alphas_cumprod[timesteps]
# Compute SNR.
snr = (alpha / sigma) ** 2
return snr
def train_step(state, unet_params, text_encoder_params, vae_params, batch, train_rng):
# reshape batch, add grad_step_dim if gradient_accumulation_steps > 1
if args.gradient_accumulation_steps > 1:
grad_steps = args.gradient_accumulation_steps
batch = jax.tree_map(lambda x: x.reshape((grad_steps, x.shape[0] // grad_steps) + x.shape[1:]), batch)
def compute_loss(params, minibatch, sample_rng):
# Convert images to latent space
vae_outputs = vae.apply(
{"params": vae_params}, minibatch["pixel_values"], deterministic=True, method=vae.encode
)
latents = vae_outputs.latent_dist.sample(sample_rng)
# (NHWC) -> (NCHW)
latents = jnp.transpose(latents, (0, 3, 1, 2))
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise_rng, timestep_rng = jax.random.split(sample_rng)
noise = jax.random.normal(noise_rng, latents.shape)
# Sample a random timestep for each image
bsz = latents.shape[0]
timesteps = jax.random.randint(
timestep_rng,
(bsz,),
0,
noise_scheduler.config.num_train_timesteps,
)
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(noise_scheduler_state, latents, noise, timesteps)
# Get the text embedding for conditioning
encoder_hidden_states = text_encoder(
minibatch["input_ids"],
params=text_encoder_params,
train=False,
)[0]
controlnet_cond = minibatch["conditioning_pixel_values"]
# Predict the noise residual and compute loss
down_block_res_samples, mid_block_res_sample = controlnet.apply(
{"params": params},
noisy_latents,
timesteps,
encoder_hidden_states,
controlnet_cond,
train=True,
return_dict=False,
)
model_pred = unet.apply(
{"params": unet_params},
noisy_latents,
timesteps,
encoder_hidden_states,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
).sample
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(noise_scheduler_state, latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
loss = (target - model_pred) ** 2
if args.snr_gamma is not None:
snr = jnp.array(compute_snr(timesteps))
if noise_scheduler.config.prediction_type == "v_prediction":
# Velocity objective requires that we add one to SNR values before we divide by them.
snr = snr + 1
snr_loss_weights = jnp.where(snr < args.snr_gamma, snr, jnp.ones_like(snr) * args.snr_gamma) / snr
loss = loss * snr_loss_weights
loss = loss.mean()
return loss
grad_fn = jax.value_and_grad(compute_loss)
# get a minibatch (one gradient accumulation slice)
def get_minibatch(batch, grad_idx):
return jax.tree_util.tree_map(
lambda x: jax.lax.dynamic_index_in_dim(x, grad_idx, keepdims=False),
batch,
)
def loss_and_grad(grad_idx, train_rng):
# create minibatch for the grad step
minibatch = get_minibatch(batch, grad_idx) if grad_idx is not None else batch
sample_rng, train_rng = jax.random.split(train_rng, 2)
loss, grad = grad_fn(state.params, minibatch, sample_rng)
return loss, grad, train_rng
if args.gradient_accumulation_steps == 1:
loss, grad, new_train_rng = loss_and_grad(None, train_rng)
else:
init_loss_grad_rng = (
0.0, # initial value for cumul_loss
jax.tree_map(jnp.zeros_like, state.params), # initial value for cumul_grad
train_rng, # initial value for train_rng
)
def cumul_grad_step(grad_idx, loss_grad_rng):
cumul_loss, cumul_grad, train_rng = loss_grad_rng
loss, grad, new_train_rng = loss_and_grad(grad_idx, train_rng)
cumul_loss, cumul_grad = jax.tree_map(jnp.add, (cumul_loss, cumul_grad), (loss, grad))
return cumul_loss, cumul_grad, new_train_rng
loss, grad, new_train_rng = jax.lax.fori_loop(
0,
args.gradient_accumulation_steps,
cumul_grad_step,
init_loss_grad_rng,
)
loss, grad = jax.tree_map(lambda x: x / args.gradient_accumulation_steps, (loss, grad))
grad = jax.lax.pmean(grad, "batch")
new_state = state.apply_gradients(grads=grad)
metrics = {"loss": loss}
metrics = jax.lax.pmean(metrics, axis_name="batch")
def l2(xs):
return jnp.sqrt(sum([jnp.vdot(x, x) for x in jax.tree_util.tree_leaves(xs)]))
metrics["l2_grads"] = l2(jax.tree_util.tree_leaves(grad))
return new_state, metrics, new_train_rng
# Create parallel version of the train step
p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
# Replicate the train state on each device
state = jax_utils.replicate(state)
unet_params = jax_utils.replicate(unet_params)
text_encoder_params = jax_utils.replicate(text_encoder.params)
vae_params = jax_utils.replicate(vae_params)
# Train!
if args.streaming:
dataset_length = args.max_train_samples
else:
dataset_length = len(train_dataloader)
num_update_steps_per_epoch = math.ceil(dataset_length / args.gradient_accumulation_steps)
# Scheduler and math around the number of training steps.
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
logger.info("***** Running training *****")
logger.info(f" Num examples = {args.max_train_samples if args.streaming else len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel & distributed) = {total_train_batch_size}")
logger.info(f" Total optimization steps = {args.num_train_epochs * num_update_steps_per_epoch}")
if jax.process_index() == 0 and args.report_to == "wandb":
wandb.define_metric("*", step_metric="train/step")
wandb.define_metric("train/step", step_metric="walltime")
wandb.config.update(
{
"num_train_examples": args.max_train_samples if args.streaming else len(train_dataset),
"total_train_batch_size": total_train_batch_size,
"total_optimization_step": args.num_train_epochs * num_update_steps_per_epoch,
"num_devices": jax.device_count(),
"controlnet_params": sum(np.prod(x.shape) for x in jax.tree_util.tree_leaves(state.params)),
}
)
global_step = step0 = 0
epochs = tqdm(
range(args.num_train_epochs),
desc="Epoch ... ",
position=0,
disable=jax.process_index() > 0,
)
if args.profile_memory:
jax.profiler.save_device_memory_profile(os.path.join(args.output_dir, "memory_initial.prof"))
t00 = t0 = time.monotonic()
for epoch in epochs:
# ======================== Training ================================
train_metrics = []
train_metric = None
steps_per_epoch = (
args.max_train_samples // total_train_batch_size
if args.streaming or args.max_train_samples
else len(train_dataset) // total_train_batch_size
)
train_step_progress_bar = tqdm(
total=steps_per_epoch,
desc="Training...",
position=1,
leave=False,
disable=jax.process_index() > 0,
)
# train
for batch in train_dataloader:
if args.profile_steps and global_step == 1:
train_metric["loss"].block_until_ready()
jax.profiler.start_trace(args.output_dir)
if args.profile_steps and global_step == 1 + args.profile_steps:
train_metric["loss"].block_until_ready()
jax.profiler.stop_trace()
batch = shard(batch)
with jax.profiler.StepTraceAnnotation("train", step_num=global_step):
state, train_metric, train_rngs = p_train_step(
state, unet_params, text_encoder_params, vae_params, batch, train_rngs
)
train_metrics.append(train_metric)
train_step_progress_bar.update(1)
global_step += 1
if global_step >= args.max_train_steps:
break
if (
args.validation_prompt is not None
and global_step % args.validation_steps == 0
and jax.process_index() == 0
):
_ = log_validation(
pipeline, pipeline_params, state.params, tokenizer, args, validation_rng, weight_dtype
)
if global_step % args.logging_steps == 0 and jax.process_index() == 0:
if args.report_to == "wandb":
train_metrics = jax_utils.unreplicate(train_metrics)
train_metrics = jax.tree_util.tree_map(lambda *m: jnp.array(m).mean(), *train_metrics)
wandb.log(
{
"walltime": time.monotonic() - t00,
"train/step": global_step,
"train/epoch": global_step / dataset_length,
"train/steps_per_sec": (global_step - step0) / (time.monotonic() - t0),
**{f"train/{k}": v for k, v in train_metrics.items()},
}
)
t0, step0 = time.monotonic(), global_step
train_metrics = []
if global_step % args.checkpointing_steps == 0 and jax.process_index() == 0:
controlnet.save_pretrained(
f"{args.output_dir}/{global_step}",
params=get_params_to_save(state.params),
)
train_metric = jax_utils.unreplicate(train_metric)
train_step_progress_bar.close()
epochs.write(f"Epoch... ({epoch + 1}/{args.num_train_epochs} | Loss: {train_metric['loss']})")
# Final validation & store model.
if jax.process_index() == 0:
if args.validation_prompt is not None:
if args.profile_validation:
jax.profiler.start_trace(args.output_dir)
image_logs = log_validation(
pipeline, pipeline_params, state.params, tokenizer, args, validation_rng, weight_dtype
)
if args.profile_validation:
jax.profiler.stop_trace()
else:
image_logs = None
controlnet.save_pretrained(
args.output_dir,
params=get_params_to_save(state.params),
)
if args.push_to_hub:
save_model_card(
repo_id,
image_logs=image_logs,
base_model=args.pretrained_model_name_or_path,
repo_folder=args.output_dir,
)
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
if args.profile_memory:
jax.profiler.save_device_memory_profile(os.path.join(args.output_dir, "memory_final.prof"))
logger.info("Finished training.")
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/controlnet/requirements_flax.txt
|
transformers>=4.25.1
datasets
flax
optax
torch
torchvision
ftfy
tensorboard
Jinja2
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/controlnet/requirements.txt
|
accelerate>=0.16.0
torchvision
transformers>=4.25.1
ftfy
tensorboard
datasets
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/controlnet/train_controlnet_sdxl.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import functools
import gc
import logging
import math
import os
import random
import shutil
from pathlib import Path
import accelerate
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from datasets import load_dataset
from huggingface_hub import create_repo, upload_folder
from packaging import version
from PIL import Image
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import AutoTokenizer, PretrainedConfig
import diffusers
from diffusers import (
AutoencoderKL,
ControlNetModel,
DDPMScheduler,
StableDiffusionXLControlNetPipeline,
UNet2DConditionModel,
UniPCMultistepScheduler,
)
from diffusers.optimization import get_scheduler
from diffusers.utils import check_min_version, is_wandb_available, make_image_grid
from diffusers.utils.import_utils import is_xformers_available
if is_wandb_available():
import wandb
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.24.0.dev0")
logger = get_logger(__name__)
def log_validation(vae, unet, controlnet, args, accelerator, weight_dtype, step):
logger.info("Running validation... ")
controlnet = accelerator.unwrap_model(controlnet)
pipeline = StableDiffusionXLControlNetPipeline.from_pretrained(
args.pretrained_model_name_or_path,
vae=vae,
unet=unet,
controlnet=controlnet,
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
pipeline.scheduler = UniPCMultistepScheduler.from_config(pipeline.scheduler.config)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
if args.enable_xformers_memory_efficient_attention:
pipeline.enable_xformers_memory_efficient_attention()
if args.seed is None:
generator = None
else:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
if len(args.validation_image) == len(args.validation_prompt):
validation_images = args.validation_image
validation_prompts = args.validation_prompt
elif len(args.validation_image) == 1:
validation_images = args.validation_image * len(args.validation_prompt)
validation_prompts = args.validation_prompt
elif len(args.validation_prompt) == 1:
validation_images = args.validation_image
validation_prompts = args.validation_prompt * len(args.validation_image)
else:
raise ValueError(
"number of `args.validation_image` and `args.validation_prompt` should be checked in `parse_args`"
)
image_logs = []
for validation_prompt, validation_image in zip(validation_prompts, validation_images):
validation_image = Image.open(validation_image).convert("RGB")
validation_image = validation_image.resize((args.resolution, args.resolution))
images = []
for _ in range(args.num_validation_images):
with torch.autocast("cuda"):
image = pipeline(
prompt=validation_prompt, image=validation_image, num_inference_steps=20, generator=generator
).images[0]
images.append(image)
image_logs.append(
{"validation_image": validation_image, "images": images, "validation_prompt": validation_prompt}
)
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
validation_image = log["validation_image"]
formatted_images = []
formatted_images.append(np.asarray(validation_image))
for image in images:
formatted_images.append(np.asarray(image))
formatted_images = np.stack(formatted_images)
tracker.writer.add_images(validation_prompt, formatted_images, step, dataformats="NHWC")
elif tracker.name == "wandb":
formatted_images = []
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
validation_image = log["validation_image"]
formatted_images.append(wandb.Image(validation_image, caption="Controlnet conditioning"))
for image in images:
image = wandb.Image(image, caption=validation_prompt)
formatted_images.append(image)
tracker.log({"validation": formatted_images})
else:
logger.warn(f"image logging not implemented for {tracker.name}")
del pipeline
gc.collect()
torch.cuda.empty_cache()
return image_logs
def import_model_class_from_model_name_or_path(
pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
):
text_encoder_config = PretrainedConfig.from_pretrained(
pretrained_model_name_or_path, subfolder=subfolder, revision=revision
)
model_class = text_encoder_config.architectures[0]
if model_class == "CLIPTextModel":
from transformers import CLIPTextModel
return CLIPTextModel
elif model_class == "CLIPTextModelWithProjection":
from transformers import CLIPTextModelWithProjection
return CLIPTextModelWithProjection
else:
raise ValueError(f"{model_class} is not supported.")
def save_model_card(repo_id: str, image_logs=None, base_model=str, repo_folder=None):
img_str = ""
if image_logs is not None:
img_str = "You can find some example images below.\n"
for i, log in enumerate(image_logs):
images = log["images"]
validation_prompt = log["validation_prompt"]
validation_image = log["validation_image"]
validation_image.save(os.path.join(repo_folder, "image_control.png"))
img_str += f"prompt: {validation_prompt}\n"
images = [validation_image] + images
make_image_grid(images, 1, len(images)).save(os.path.join(repo_folder, f"images_{i}.png"))
img_str += f"\n"
yaml = f"""
---
license: openrail++
base_model: {base_model}
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- controlnet
inference: true
---
"""
model_card = f"""
# controlnet-{repo_id}
These are controlnet weights trained on {base_model} with new type of conditioning.
{img_str}
"""
with open(os.path.join(repo_folder, "README.md"), "w") as f:
f.write(yaml + model_card)
def parse_args(input_args=None):
parser = argparse.ArgumentParser(description="Simple example of a ControlNet training script.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--pretrained_vae_model_name_or_path",
type=str,
default=None,
help="Path to an improved VAE to stabilize training. For more details check out: https://github.com/huggingface/diffusers/pull/4038.",
)
parser.add_argument(
"--controlnet_model_name_or_path",
type=str,
default=None,
help="Path to pretrained controlnet model or model identifier from huggingface.co/models."
" If not specified controlnet weights are initialized from unet.",
)
parser.add_argument(
"--variant",
type=str,
default=None,
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--output_dir",
type=str,
default="controlnet-model",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--crops_coords_top_left_h",
type=int,
default=0,
help=("Coordinate for (the height) to be included in the crop coordinate embeddings needed by SDXL UNet."),
)
parser.add_argument(
"--crops_coords_top_left_w",
type=int,
default=0,
help=("Coordinate for (the height) to be included in the crop coordinate embeddings needed by SDXL UNet."),
)
parser.add_argument(
"--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=1)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. Checkpoints can be used for resuming training via `--resume_from_checkpoint`. "
"In the case that the checkpoint is better than the final trained model, the checkpoint can also be used for inference."
"Using a checkpoint for inference requires separate loading of the original pipeline and the individual checkpointed model components."
"See https://huggingface.co/docs/diffusers/main/en/training/dreambooth#performing-inference-using-a-saved-checkpoint for step by step"
"instructions."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-6,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--lr_num_cycles",
type=int,
default=1,
help="Number of hard resets of the lr in cosine_with_restarts scheduler.",
)
parser.add_argument("--lr_power", type=float, default=1.0, help="Power factor of the polynomial scheduler.")
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument(
"--set_grads_to_none",
action="store_true",
help=(
"Save more memory by using setting grads to None instead of zero. Be aware, that this changes certain"
" behaviors, so disable this argument if it causes any problems. More info:"
" https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html"
),
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--image_column", type=str, default="image", help="The column of the dataset containing the target image."
)
parser.add_argument(
"--conditioning_image_column",
type=str,
default="conditioning_image",
help="The column of the dataset containing the controlnet conditioning image.",
)
parser.add_argument(
"--caption_column",
type=str,
default="text",
help="The column of the dataset containing a caption or a list of captions.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--proportion_empty_prompts",
type=float,
default=0,
help="Proportion of image prompts to be replaced with empty strings. Defaults to 0 (no prompt replacement).",
)
parser.add_argument(
"--validation_prompt",
type=str,
default=None,
nargs="+",
help=(
"A set of prompts evaluated every `--validation_steps` and logged to `--report_to`."
" Provide either a matching number of `--validation_image`s, a single `--validation_image`"
" to be used with all prompts, or a single prompt that will be used with all `--validation_image`s."
),
)
parser.add_argument(
"--validation_image",
type=str,
default=None,
nargs="+",
help=(
"A set of paths to the controlnet conditioning image be evaluated every `--validation_steps`"
" and logged to `--report_to`. Provide either a matching number of `--validation_prompt`s, a"
" a single `--validation_prompt` to be used with all `--validation_image`s, or a single"
" `--validation_image` that will be used with all `--validation_prompt`s."
),
)
parser.add_argument(
"--num_validation_images",
type=int,
default=4,
help="Number of images to be generated for each `--validation_image`, `--validation_prompt` pair",
)
parser.add_argument(
"--validation_steps",
type=int,
default=100,
help=(
"Run validation every X steps. Validation consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`"
" and logging the images."
),
)
parser.add_argument(
"--tracker_project_name",
type=str,
default="sd_xl_train_controlnet",
help=(
"The `project_name` argument passed to Accelerator.init_trackers for"
" more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
),
)
if input_args is not None:
args = parser.parse_args(input_args)
else:
args = parser.parse_args()
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Specify either `--dataset_name` or `--train_data_dir`")
if args.dataset_name is not None and args.train_data_dir is not None:
raise ValueError("Specify only one of `--dataset_name` or `--train_data_dir`")
if args.proportion_empty_prompts < 0 or args.proportion_empty_prompts > 1:
raise ValueError("`--proportion_empty_prompts` must be in the range [0, 1].")
if args.validation_prompt is not None and args.validation_image is None:
raise ValueError("`--validation_image` must be set if `--validation_prompt` is set")
if args.validation_prompt is None and args.validation_image is not None:
raise ValueError("`--validation_prompt` must be set if `--validation_image` is set")
if (
args.validation_image is not None
and args.validation_prompt is not None
and len(args.validation_image) != 1
and len(args.validation_prompt) != 1
and len(args.validation_image) != len(args.validation_prompt)
):
raise ValueError(
"Must provide either 1 `--validation_image`, 1 `--validation_prompt`,"
" or the same number of `--validation_prompt`s and `--validation_image`s"
)
if args.resolution % 8 != 0:
raise ValueError(
"`--resolution` must be divisible by 8 for consistently sized encoded images between the VAE and the controlnet encoder."
)
return args
def get_train_dataset(args, accelerator):
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
)
else:
if args.train_data_dir is not None:
dataset = load_dataset(
args.train_data_dir,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.0.0/en/dataset_script
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
if args.image_column is None:
image_column = column_names[0]
logger.info(f"image column defaulting to {image_column}")
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"`--image_column` value '{args.image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = column_names[1]
logger.info(f"caption column defaulting to {caption_column}")
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"`--caption_column` value '{args.caption_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
if args.conditioning_image_column is None:
conditioning_image_column = column_names[2]
logger.info(f"conditioning image column defaulting to {conditioning_image_column}")
else:
conditioning_image_column = args.conditioning_image_column
if conditioning_image_column not in column_names:
raise ValueError(
f"`--conditioning_image_column` value '{args.conditioning_image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
with accelerator.main_process_first():
train_dataset = dataset["train"].shuffle(seed=args.seed)
if args.max_train_samples is not None:
train_dataset = train_dataset.select(range(args.max_train_samples))
return train_dataset
# Adapted from pipelines.StableDiffusionXLPipeline.encode_prompt
def encode_prompt(prompt_batch, text_encoders, tokenizers, proportion_empty_prompts, is_train=True):
prompt_embeds_list = []
captions = []
for caption in prompt_batch:
if random.random() < proportion_empty_prompts:
captions.append("")
elif isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
with torch.no_grad():
for tokenizer, text_encoder in zip(tokenizers, text_encoders):
text_inputs = tokenizer(
captions,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
prompt_embeds = text_encoder(
text_input_ids.to(text_encoder.device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
pooled_prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.hidden_states[-2]
bs_embed, seq_len, _ = prompt_embeds.shape
prompt_embeds = prompt_embeds.view(bs_embed, seq_len, -1)
prompt_embeds_list.append(prompt_embeds)
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
pooled_prompt_embeds = pooled_prompt_embeds.view(bs_embed, -1)
return prompt_embeds, pooled_prompt_embeds
def prepare_train_dataset(dataset, accelerator):
image_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
conditioning_image_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution),
transforms.ToTensor(),
]
)
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[args.image_column]]
images = [image_transforms(image) for image in images]
conditioning_images = [image.convert("RGB") for image in examples[args.conditioning_image_column]]
conditioning_images = [conditioning_image_transforms(image) for image in conditioning_images]
examples["pixel_values"] = images
examples["conditioning_pixel_values"] = conditioning_images
return examples
with accelerator.main_process_first():
dataset = dataset.with_transform(preprocess_train)
return dataset
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
conditioning_pixel_values = torch.stack([example["conditioning_pixel_values"] for example in examples])
conditioning_pixel_values = conditioning_pixel_values.to(memory_format=torch.contiguous_format).float()
prompt_ids = torch.stack([torch.tensor(example["prompt_embeds"]) for example in examples])
add_text_embeds = torch.stack([torch.tensor(example["text_embeds"]) for example in examples])
add_time_ids = torch.stack([torch.tensor(example["time_ids"]) for example in examples])
return {
"pixel_values": pixel_values,
"conditioning_pixel_values": conditioning_pixel_values,
"prompt_ids": prompt_ids,
"unet_added_conditions": {"text_embeds": add_text_embeds, "time_ids": add_time_ids},
}
def main(args):
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load the tokenizers
tokenizer_one = AutoTokenizer.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="tokenizer",
revision=args.revision,
use_fast=False,
)
tokenizer_two = AutoTokenizer.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="tokenizer_2",
revision=args.revision,
use_fast=False,
)
# import correct text encoder classes
text_encoder_cls_one = import_model_class_from_model_name_or_path(
args.pretrained_model_name_or_path, args.revision
)
text_encoder_cls_two = import_model_class_from_model_name_or_path(
args.pretrained_model_name_or_path, args.revision, subfolder="text_encoder_2"
)
# Load scheduler and models
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
text_encoder_one = text_encoder_cls_one.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision, variant=args.variant
)
text_encoder_two = text_encoder_cls_two.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder_2", revision=args.revision, variant=args.variant
)
vae_path = (
args.pretrained_model_name_or_path
if args.pretrained_vae_model_name_or_path is None
else args.pretrained_vae_model_name_or_path
)
vae = AutoencoderKL.from_pretrained(
vae_path,
subfolder="vae" if args.pretrained_vae_model_name_or_path is None else None,
revision=args.revision,
variant=args.variant,
)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
)
if args.controlnet_model_name_or_path:
logger.info("Loading existing controlnet weights")
controlnet = ControlNetModel.from_pretrained(args.controlnet_model_name_or_path)
else:
logger.info("Initializing controlnet weights from unet")
controlnet = ControlNetModel.from_unet(unet)
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
i = len(weights) - 1
while len(weights) > 0:
weights.pop()
model = models[i]
sub_dir = "controlnet"
model.save_pretrained(os.path.join(output_dir, sub_dir))
i -= 1
def load_model_hook(models, input_dir):
while len(models) > 0:
# pop models so that they are not loaded again
model = models.pop()
# load diffusers style into model
load_model = ControlNetModel.from_pretrained(input_dir, subfolder="controlnet")
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
del load_model
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
vae.requires_grad_(False)
unet.requires_grad_(False)
text_encoder_one.requires_grad_(False)
text_encoder_two.requires_grad_(False)
controlnet.train()
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
controlnet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
if args.gradient_checkpointing:
controlnet.enable_gradient_checkpointing()
unet.enable_gradient_checkpointing()
# Check that all trainable models are in full precision
low_precision_error_string = (
" Please make sure to always have all model weights in full float32 precision when starting training - even if"
" doing mixed precision training, copy of the weights should still be float32."
)
if accelerator.unwrap_model(controlnet).dtype != torch.float32:
raise ValueError(
f"Controlnet loaded as datatype {accelerator.unwrap_model(controlnet).dtype}. {low_precision_error_string}"
)
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
)
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
# Optimizer creation
params_to_optimize = controlnet.parameters()
optimizer = optimizer_class(
params_to_optimize,
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# For mixed precision training we cast the text_encoder and vae weights to half-precision
# as these models are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move vae, unet and text_encoder to device and cast to weight_dtype
# The VAE is in float32 to avoid NaN losses.
if args.pretrained_vae_model_name_or_path is not None:
vae.to(accelerator.device, dtype=weight_dtype)
else:
vae.to(accelerator.device, dtype=torch.float32)
unet.to(accelerator.device, dtype=weight_dtype)
text_encoder_one.to(accelerator.device, dtype=weight_dtype)
text_encoder_two.to(accelerator.device, dtype=weight_dtype)
# Here, we compute not just the text embeddings but also the additional embeddings
# needed for the SD XL UNet to operate.
def compute_embeddings(batch, proportion_empty_prompts, text_encoders, tokenizers, is_train=True):
original_size = (args.resolution, args.resolution)
target_size = (args.resolution, args.resolution)
crops_coords_top_left = (args.crops_coords_top_left_h, args.crops_coords_top_left_w)
prompt_batch = batch[args.caption_column]
prompt_embeds, pooled_prompt_embeds = encode_prompt(
prompt_batch, text_encoders, tokenizers, proportion_empty_prompts, is_train
)
add_text_embeds = pooled_prompt_embeds
# Adapted from pipeline.StableDiffusionXLPipeline._get_add_time_ids
add_time_ids = list(original_size + crops_coords_top_left + target_size)
add_time_ids = torch.tensor([add_time_ids])
prompt_embeds = prompt_embeds.to(accelerator.device)
add_text_embeds = add_text_embeds.to(accelerator.device)
add_time_ids = add_time_ids.repeat(len(prompt_batch), 1)
add_time_ids = add_time_ids.to(accelerator.device, dtype=prompt_embeds.dtype)
unet_added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
return {"prompt_embeds": prompt_embeds, **unet_added_cond_kwargs}
# Let's first compute all the embeddings so that we can free up the text encoders
# from memory.
text_encoders = [text_encoder_one, text_encoder_two]
tokenizers = [tokenizer_one, tokenizer_two]
train_dataset = get_train_dataset(args, accelerator)
compute_embeddings_fn = functools.partial(
compute_embeddings,
text_encoders=text_encoders,
tokenizers=tokenizers,
proportion_empty_prompts=args.proportion_empty_prompts,
)
with accelerator.main_process_first():
from datasets.fingerprint import Hasher
# fingerprint used by the cache for the other processes to load the result
# details: https://github.com/huggingface/diffusers/pull/4038#discussion_r1266078401
new_fingerprint = Hasher.hash(args)
train_dataset = train_dataset.map(compute_embeddings_fn, batched=True, new_fingerprint=new_fingerprint)
del text_encoders, tokenizers
gc.collect()
torch.cuda.empty_cache()
# Then get the training dataset ready to be passed to the dataloader.
train_dataset = prepare_train_dataset(train_dataset, accelerator)
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps * accelerator.num_processes,
num_cycles=args.lr_num_cycles,
power=args.lr_power,
)
# Prepare everything with our `accelerator`.
controlnet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
controlnet, optimizer, train_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
tracker_config = dict(vars(args))
# tensorboard cannot handle list types for config
tracker_config.pop("validation_prompt")
tracker_config.pop("validation_image")
accelerator.init_trackers(args.tracker_project_name, config=tracker_config)
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num batches each epoch = {len(train_dataloader)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
image_logs = None
for epoch in range(first_epoch, args.num_train_epochs):
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(controlnet):
# Convert images to latent space
if args.pretrained_vae_model_name_or_path is not None:
pixel_values = batch["pixel_values"].to(dtype=weight_dtype)
else:
pixel_values = batch["pixel_values"]
latents = vae.encode(pixel_values).latent_dist.sample()
latents = latents * vae.config.scaling_factor
if args.pretrained_vae_model_name_or_path is None:
latents = latents.to(weight_dtype)
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# ControlNet conditioning.
controlnet_image = batch["conditioning_pixel_values"].to(dtype=weight_dtype)
down_block_res_samples, mid_block_res_sample = controlnet(
noisy_latents,
timesteps,
encoder_hidden_states=batch["prompt_ids"],
added_cond_kwargs=batch["unet_added_conditions"],
controlnet_cond=controlnet_image,
return_dict=False,
)
# Predict the noise residual
model_pred = unet(
noisy_latents,
timesteps,
encoder_hidden_states=batch["prompt_ids"],
added_cond_kwargs=batch["unet_added_conditions"],
down_block_additional_residuals=[
sample.to(dtype=weight_dtype) for sample in down_block_res_samples
],
mid_block_additional_residual=mid_block_res_sample.to(dtype=weight_dtype),
).sample
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
accelerator.backward(loss)
if accelerator.sync_gradients:
params_to_clip = controlnet.parameters()
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad(set_to_none=args.set_grads_to_none)
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
if accelerator.is_main_process:
if global_step % args.checkpointing_steps == 0:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
if args.validation_prompt is not None and global_step % args.validation_steps == 0:
image_logs = log_validation(
vae, unet, controlnet, args, accelerator, weight_dtype, global_step
)
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
if global_step >= args.max_train_steps:
break
# Create the pipeline using using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
controlnet = accelerator.unwrap_model(controlnet)
controlnet.save_pretrained(args.output_dir)
if args.push_to_hub:
save_model_card(
repo_id,
image_logs=image_logs,
base_model=args.pretrained_model_name_or_path,
repo_folder=args.output_dir,
)
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/consistency_distillation/README_sdxl.md
|
# Latent Consistency Distillation Example:
[Latent Consistency Models (LCMs)](https://arxiv.org/abs/2310.04378) is method to distill latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use the latent consistency distillation to distill SDXL for less timestep inference.
## Full model distillation
### Running locally with PyTorch
#### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
#### Example with LAION-A6+ dataset
```bash
export MODEL_DIR="stabilityai/stable-diffusion-xl-base-1.0"
PROGRAM="train_lcm_distill_sdxl_wds.py \
--pretrained_teacher_model=$MODEL_DIR \
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=1024 \
--learning_rate=1e-6 --loss_type="huber" --use_fix_crop_and_size --ema_decay=0.95 --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url='pipe:aws s3 cp s3://muse-datasets/laion-aesthetic6plus-min512-data/{00000..01210}.tar -' \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub \
```
## LCM-LoRA
Instead of fine-tuning the full model, we can also just train a LoRA that can be injected into any SDXL model.
### Example with LAION-A6+ dataset
```bash
export MODEL_DIR="stabilityai/stable-diffusion-xl-base-1.0"
PROGRAM="train_lcm_distill_lora_sdxl_wds.py \
--pretrained_teacher_model=$MODEL_DIR \
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=1024 \
--lora_rank=64 \
--learning_rate=1e-6 --loss_type="huber" --use_fix_crop_and_size --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url='pipe:aws s3 cp s3://muse-datasets/laion-aesthetic6plus-min512-data/{00000..01210}.tar -' \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub \
```
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/consistency_distillation/README.md
|
# Latent Consistency Distillation Example:
[Latent Consistency Models (LCMs)](https://arxiv.org/abs/2310.04378) is method to distill latent diffusion model to enable swift inference with minimal steps. This example demonstrates how to use the latent consistency distillation to distill stable-diffusion-v1.5 for less timestep inference.
## Full model distillation
### Running locally with PyTorch
#### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
#### Example with LAION-A6+ dataset
```bash
runwayml/stable-diffusion-v1-5
PROGRAM="train_lcm_distill_sd_wds.py \
--pretrained_teacher_model=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=512 \
--learning_rate=1e-6 --loss_type="huber" --ema_decay=0.95 --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url='pipe:aws s3 cp s3://muse-datasets/laion-aesthetic6plus-min512-data/{00000..01210}.tar -' \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub \
```
## LCM-LoRA
Instead of fine-tuning the full model, we can also just train a LoRA that can be injected into any SDXL model.
### Example with LAION-A6+ dataset
```bash
runwayml/stable-diffusion-v1-5
PROGRAM="train_lcm_distill_lora_sd_wds.py \
--pretrained_teacher_model=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=512 \
--lora_rank=64 \
--learning_rate=1e-6 --loss_type="huber" --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url='pipe:aws s3 cp s3://muse-datasets/laion-aesthetic6plus-min512-data/{00000..01210}.tar -' \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub \
```
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/consistency_distillation/train_lcm_distill_sd_wds.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import functools
import gc
import itertools
import json
import logging
import math
import os
import random
import shutil
from pathlib import Path
from typing import List, Union
import accelerate
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import torchvision.transforms.functional as TF
import transformers
import webdataset as wds
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from braceexpand import braceexpand
from huggingface_hub import create_repo
from packaging import version
from torch.utils.data import default_collate
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import AutoTokenizer, CLIPTextModel, PretrainedConfig
from webdataset.tariterators import (
base_plus_ext,
tar_file_expander,
url_opener,
valid_sample,
)
import diffusers
from diffusers import (
AutoencoderKL,
DDPMScheduler,
LCMScheduler,
StableDiffusionPipeline,
UNet2DConditionModel,
)
from diffusers.optimization import get_scheduler
from diffusers.utils import check_min_version, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
MAX_SEQ_LENGTH = 77
if is_wandb_available():
import wandb
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.18.0.dev0")
logger = get_logger(__name__)
def filter_keys(key_set):
def _f(dictionary):
return {k: v for k, v in dictionary.items() if k in key_set}
return _f
def group_by_keys_nothrow(data, keys=base_plus_ext, lcase=True, suffixes=None, handler=None):
"""Return function over iterator that groups key, value pairs into samples.
:param keys: function that splits the key into key and extension (base_plus_ext) :param lcase: convert suffixes to
lower case (Default value = True)
"""
current_sample = None
for filesample in data:
assert isinstance(filesample, dict)
fname, value = filesample["fname"], filesample["data"]
prefix, suffix = keys(fname)
if prefix is None:
continue
if lcase:
suffix = suffix.lower()
# FIXME webdataset version throws if suffix in current_sample, but we have a potential for
# this happening in the current LAION400m dataset if a tar ends with same prefix as the next
# begins, rare, but can happen since prefix aren't unique across tar files in that dataset
if current_sample is None or prefix != current_sample["__key__"] or suffix in current_sample:
if valid_sample(current_sample):
yield current_sample
current_sample = {"__key__": prefix, "__url__": filesample["__url__"]}
if suffixes is None or suffix in suffixes:
current_sample[suffix] = value
if valid_sample(current_sample):
yield current_sample
def tarfile_to_samples_nothrow(src, handler=wds.warn_and_continue):
# NOTE this is a re-impl of the webdataset impl with group_by_keys that doesn't throw
streams = url_opener(src, handler=handler)
files = tar_file_expander(streams, handler=handler)
samples = group_by_keys_nothrow(files, handler=handler)
return samples
class WebdatasetFilter:
def __init__(self, min_size=1024, max_pwatermark=0.5):
self.min_size = min_size
self.max_pwatermark = max_pwatermark
def __call__(self, x):
try:
if "json" in x:
x_json = json.loads(x["json"])
filter_size = (x_json.get("original_width", 0.0) or 0.0) >= self.min_size and x_json.get(
"original_height", 0
) >= self.min_size
filter_watermark = (x_json.get("pwatermark", 1.0) or 1.0) <= self.max_pwatermark
return filter_size and filter_watermark
else:
return False
except Exception:
return False
class Text2ImageDataset:
def __init__(
self,
train_shards_path_or_url: Union[str, List[str]],
num_train_examples: int,
per_gpu_batch_size: int,
global_batch_size: int,
num_workers: int,
resolution: int = 512,
shuffle_buffer_size: int = 1000,
pin_memory: bool = False,
persistent_workers: bool = False,
):
if not isinstance(train_shards_path_or_url, str):
train_shards_path_or_url = [list(braceexpand(urls)) for urls in train_shards_path_or_url]
# flatten list using itertools
train_shards_path_or_url = list(itertools.chain.from_iterable(train_shards_path_or_url))
def transform(example):
# resize image
image = example["image"]
image = TF.resize(image, resolution, interpolation=transforms.InterpolationMode.BILINEAR)
# get crop coordinates and crop image
c_top, c_left, _, _ = transforms.RandomCrop.get_params(image, output_size=(resolution, resolution))
image = TF.crop(image, c_top, c_left, resolution, resolution)
image = TF.to_tensor(image)
image = TF.normalize(image, [0.5], [0.5])
example["image"] = image
return example
processing_pipeline = [
wds.decode("pil", handler=wds.ignore_and_continue),
wds.rename(image="jpg;png;jpeg;webp", text="text;txt;caption", handler=wds.warn_and_continue),
wds.map(filter_keys({"image", "text"})),
wds.map(transform),
wds.to_tuple("image", "text"),
]
# Create train dataset and loader
pipeline = [
wds.ResampledShards(train_shards_path_or_url),
tarfile_to_samples_nothrow,
wds.shuffle(shuffle_buffer_size),
*processing_pipeline,
wds.batched(per_gpu_batch_size, partial=False, collation_fn=default_collate),
]
num_worker_batches = math.ceil(num_train_examples / (global_batch_size * num_workers)) # per dataloader worker
num_batches = num_worker_batches * num_workers
num_samples = num_batches * global_batch_size
# each worker is iterating over this
self._train_dataset = wds.DataPipeline(*pipeline).with_epoch(num_worker_batches)
self._train_dataloader = wds.WebLoader(
self._train_dataset,
batch_size=None,
shuffle=False,
num_workers=num_workers,
pin_memory=pin_memory,
persistent_workers=persistent_workers,
)
# add meta-data to dataloader instance for convenience
self._train_dataloader.num_batches = num_batches
self._train_dataloader.num_samples = num_samples
@property
def train_dataset(self):
return self._train_dataset
@property
def train_dataloader(self):
return self._train_dataloader
def log_validation(vae, unet, args, accelerator, weight_dtype, step, name="target"):
logger.info("Running validation... ")
unet = accelerator.unwrap_model(unet)
pipeline = StableDiffusionPipeline.from_pretrained(
args.pretrained_teacher_model,
vae=vae,
unet=unet,
scheduler=LCMScheduler.from_pretrained(args.pretrained_teacher_model, subfolder="scheduler"),
revision=args.revision,
torch_dtype=weight_dtype,
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
if args.enable_xformers_memory_efficient_attention:
pipeline.enable_xformers_memory_efficient_attention()
if args.seed is None:
generator = None
else:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
validation_prompts = [
"portrait photo of a girl, photograph, highly detailed face, depth of field, moody light, golden hour, style by Dan Winters, Russell James, Steve McCurry, centered, extremely detailed, Nikon D850, award winning photography",
"Self-portrait oil painting, a beautiful cyborg with golden hair, 8k",
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
"A photo of beautiful mountain with realistic sunset and blue lake, highly detailed, masterpiece",
]
image_logs = []
for _, prompt in enumerate(validation_prompts):
images = []
with torch.autocast("cuda"):
images = pipeline(
prompt=prompt,
num_inference_steps=4,
num_images_per_prompt=4,
generator=generator,
).images
image_logs.append({"validation_prompt": prompt, "images": images})
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
formatted_images = []
for image in images:
formatted_images.append(np.asarray(image))
formatted_images = np.stack(formatted_images)
tracker.writer.add_images(validation_prompt, formatted_images, step, dataformats="NHWC")
elif tracker.name == "wandb":
formatted_images = []
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
for image in images:
image = wandb.Image(image, caption=validation_prompt)
formatted_images.append(image)
tracker.log({f"validation/{name}": formatted_images})
else:
logger.warn(f"image logging not implemented for {tracker.name}")
del pipeline
gc.collect()
torch.cuda.empty_cache()
return image_logs
# From LatentConsistencyModel.get_guidance_scale_embedding
def guidance_scale_embedding(w, embedding_dim=512, dtype=torch.float32):
"""
See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
Args:
timesteps (`torch.Tensor`):
generate embedding vectors at these timesteps
embedding_dim (`int`, *optional*, defaults to 512):
dimension of the embeddings to generate
dtype:
data type of the generated embeddings
Returns:
`torch.FloatTensor`: Embedding vectors with shape `(len(timesteps), embedding_dim)`
"""
assert len(w.shape) == 1
w = w * 1000.0
half_dim = embedding_dim // 2
emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
emb = w.to(dtype)[:, None] * emb[None, :]
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
if embedding_dim % 2 == 1: # zero pad
emb = torch.nn.functional.pad(emb, (0, 1))
assert emb.shape == (w.shape[0], embedding_dim)
return emb
def append_dims(x, target_dims):
"""Appends dimensions to the end of a tensor until it has target_dims dimensions."""
dims_to_append = target_dims - x.ndim
if dims_to_append < 0:
raise ValueError(f"input has {x.ndim} dims but target_dims is {target_dims}, which is less")
return x[(...,) + (None,) * dims_to_append]
# From LCMScheduler.get_scalings_for_boundary_condition_discrete
def scalings_for_boundary_conditions(timestep, sigma_data=0.5, timestep_scaling=10.0):
c_skip = sigma_data**2 / ((timestep / 0.1) ** 2 + sigma_data**2)
c_out = (timestep / 0.1) / ((timestep / 0.1) ** 2 + sigma_data**2) ** 0.5
return c_skip, c_out
# Compare LCMScheduler.step, Step 4
def predicted_origin(model_output, timesteps, sample, prediction_type, alphas, sigmas):
if prediction_type == "epsilon":
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
pred_x_0 = (sample - sigmas * model_output) / alphas
elif prediction_type == "v_prediction":
pred_x_0 = alphas[timesteps] * sample - sigmas[timesteps] * model_output
else:
raise ValueError(f"Prediction type {prediction_type} currently not supported.")
return pred_x_0
def extract_into_tensor(a, t, x_shape):
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
class DDIMSolver:
def __init__(self, alpha_cumprods, timesteps=1000, ddim_timesteps=50):
# DDIM sampling parameters
step_ratio = timesteps // ddim_timesteps
self.ddim_timesteps = (np.arange(1, ddim_timesteps + 1) * step_ratio).round().astype(np.int64) - 1
self.ddim_alpha_cumprods = alpha_cumprods[self.ddim_timesteps]
self.ddim_alpha_cumprods_prev = np.asarray(
[alpha_cumprods[0]] + alpha_cumprods[self.ddim_timesteps[:-1]].tolist()
)
# convert to torch tensors
self.ddim_timesteps = torch.from_numpy(self.ddim_timesteps).long()
self.ddim_alpha_cumprods = torch.from_numpy(self.ddim_alpha_cumprods)
self.ddim_alpha_cumprods_prev = torch.from_numpy(self.ddim_alpha_cumprods_prev)
def to(self, device):
self.ddim_timesteps = self.ddim_timesteps.to(device)
self.ddim_alpha_cumprods = self.ddim_alpha_cumprods.to(device)
self.ddim_alpha_cumprods_prev = self.ddim_alpha_cumprods_prev.to(device)
return self
def ddim_step(self, pred_x0, pred_noise, timestep_index):
alpha_cumprod_prev = extract_into_tensor(self.ddim_alpha_cumprods_prev, timestep_index, pred_x0.shape)
dir_xt = (1.0 - alpha_cumprod_prev).sqrt() * pred_noise
x_prev = alpha_cumprod_prev.sqrt() * pred_x0 + dir_xt
return x_prev
@torch.no_grad()
def update_ema(target_params, source_params, rate=0.99):
"""
Update target parameters to be closer to those of source parameters using
an exponential moving average.
:param target_params: the target parameter sequence.
:param source_params: the source parameter sequence.
:param rate: the EMA rate (closer to 1 means slower).
"""
for targ, src in zip(target_params, source_params):
targ.detach().mul_(rate).add_(src, alpha=1 - rate)
def import_model_class_from_model_name_or_path(
pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
):
text_encoder_config = PretrainedConfig.from_pretrained(
pretrained_model_name_or_path, subfolder=subfolder, revision=revision, use_auth_token=True
)
model_class = text_encoder_config.architectures[0]
if model_class == "CLIPTextModel":
from transformers import CLIPTextModel
return CLIPTextModel
elif model_class == "CLIPTextModelWithProjection":
from transformers import CLIPTextModelWithProjection
return CLIPTextModelWithProjection
else:
raise ValueError(f"{model_class} is not supported.")
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
# ----------Model Checkpoint Loading Arguments----------
parser.add_argument(
"--pretrained_teacher_model",
type=str,
default=None,
required=True,
help="Path to pretrained LDM teacher model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--pretrained_vae_model_name_or_path",
type=str,
default=None,
help="Path to pretrained VAE model with better numerical stability. More details: https://github.com/huggingface/diffusers/pull/4038.",
)
parser.add_argument(
"--teacher_revision",
type=str,
default=None,
required=False,
help="Revision of pretrained LDM teacher model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained LDM model identifier from huggingface.co/models.",
)
# ----------Training Arguments----------
# ----General Training Arguments----
parser.add_argument(
"--output_dir",
type=str,
default="lcm-xl-distilled",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
# ----Logging----
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
# ----Checkpointing----
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
# ----Image Processing----
parser.add_argument(
"--train_shards_path_or_url",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
# ----Dataloader----
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
# ----Batch Size and Training Steps----
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
# ----Learning Rate----
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
# ----Optimizer (Adam)----
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
# ----Diffusion Training Arguments----
parser.add_argument(
"--proportion_empty_prompts",
type=float,
default=0,
help="Proportion of image prompts to be replaced with empty strings. Defaults to 0 (no prompt replacement).",
)
# ----Latent Consistency Distillation (LCD) Specific Arguments----
parser.add_argument(
"--w_min",
type=float,
default=5.0,
required=False,
help=(
"The minimum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
" formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
" compared to the original paper."
),
)
parser.add_argument(
"--w_max",
type=float,
default=15.0,
required=False,
help=(
"The maximum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
" formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
" compared to the original paper."
),
)
parser.add_argument(
"--num_ddim_timesteps",
type=int,
default=50,
help="The number of timesteps to use for DDIM sampling.",
)
parser.add_argument(
"--loss_type",
type=str,
default="l2",
choices=["l2", "huber"],
help="The type of loss to use for the LCD loss.",
)
parser.add_argument(
"--huber_c",
type=float,
default=0.001,
help="The huber loss parameter. Only used if `--loss_type=huber`.",
)
parser.add_argument(
"--unet_time_cond_proj_dim",
type=int,
default=256,
help=(
"The dimension of the guidance scale embedding in the U-Net, which will be used if the teacher U-Net"
" does not have `time_cond_proj_dim` set."
),
)
# ----Exponential Moving Average (EMA)----
parser.add_argument(
"--ema_decay",
type=float,
default=0.95,
required=False,
help="The exponential moving average (EMA) rate or decay factor.",
)
# ----Mixed Precision----
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--cast_teacher_unet",
action="store_true",
help="Whether to cast the teacher U-Net to the precision specified by `--mixed_precision`.",
)
# ----Training Optimizations----
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
# ----Distributed Training----
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
# ----------Validation Arguments----------
parser.add_argument(
"--validation_steps",
type=int,
default=200,
help="Run validation every X steps.",
)
# ----------Huggingface Hub Arguments-----------
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
# ----------Accelerate Arguments----------
parser.add_argument(
"--tracker_project_name",
type=str,
default="text2image-fine-tune",
help=(
"The `project_name` argument passed to Accelerator.init_trackers for"
" more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
),
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.proportion_empty_prompts < 0 or args.proportion_empty_prompts > 1:
raise ValueError("`--proportion_empty_prompts` must be in the range [0, 1].")
return args
# Adapted from pipelines.StableDiffusionPipeline.encode_prompt
def encode_prompt(prompt_batch, text_encoder, tokenizer, proportion_empty_prompts, is_train=True):
captions = []
for caption in prompt_batch:
if random.random() < proportion_empty_prompts:
captions.append("")
elif isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
with torch.no_grad():
text_inputs = tokenizer(
captions,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
prompt_embeds = text_encoder(text_input_ids.to(text_encoder.device))[0]
return prompt_embeds
def main(args):
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
split_batches=True, # It's important to set this to True when using webdataset to get the right number of steps for lr scheduling. If set to False, the number of steps will be devide by the number of processes assuming batches are multiplied by the number of processes
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name,
exist_ok=True,
token=args.hub_token,
private=True,
).repo_id
# 1. Create the noise scheduler and the desired noise schedule.
noise_scheduler = DDPMScheduler.from_pretrained(
args.pretrained_teacher_model, subfolder="scheduler", revision=args.teacher_revision
)
# The scheduler calculates the alpha and sigma schedule for us
alpha_schedule = torch.sqrt(noise_scheduler.alphas_cumprod)
sigma_schedule = torch.sqrt(1 - noise_scheduler.alphas_cumprod)
solver = DDIMSolver(
noise_scheduler.alphas_cumprod.numpy(),
timesteps=noise_scheduler.config.num_train_timesteps,
ddim_timesteps=args.num_ddim_timesteps,
)
# 2. Load tokenizers from SD-XL checkpoint.
tokenizer = AutoTokenizer.from_pretrained(
args.pretrained_teacher_model, subfolder="tokenizer", revision=args.teacher_revision, use_fast=False
)
# 3. Load text encoders from SD-1.5 checkpoint.
# import correct text encoder classes
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_teacher_model, subfolder="text_encoder", revision=args.teacher_revision
)
# 4. Load VAE from SD-XL checkpoint (or more stable VAE)
vae = AutoencoderKL.from_pretrained(
args.pretrained_teacher_model,
subfolder="vae",
revision=args.teacher_revision,
)
# 5. Load teacher U-Net from SD-XL checkpoint
teacher_unet = UNet2DConditionModel.from_pretrained(
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
)
# 6. Freeze teacher vae, text_encoder, and teacher_unet
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
teacher_unet.requires_grad_(False)
# 8. Create online (`unet`) student U-Nets. This will be updated by the optimizer (e.g. via backpropagation.)
# Add `time_cond_proj_dim` to the student U-Net if `teacher_unet.config.time_cond_proj_dim` is None
if teacher_unet.config.time_cond_proj_dim is None:
teacher_unet.config["time_cond_proj_dim"] = args.unet_time_cond_proj_dim
unet = UNet2DConditionModel(**teacher_unet.config)
# load teacher_unet weights into unet
unet.load_state_dict(teacher_unet.state_dict(), strict=False)
unet.train()
# 9. Create target (`ema_unet`) student U-Net parameters. This will be updated via EMA updates (polyak averaging).
# Initialize from unet
target_unet = UNet2DConditionModel(**teacher_unet.config)
target_unet.load_state_dict(unet.state_dict())
target_unet.train()
target_unet.requires_grad_(False)
# Check that all trainable models are in full precision
low_precision_error_string = (
" Please make sure to always have all model weights in full float32 precision when starting training - even if"
" doing mixed precision training, copy of the weights should still be float32."
)
if accelerator.unwrap_model(unet).dtype != torch.float32:
raise ValueError(
f"Controlnet loaded as datatype {accelerator.unwrap_model(unet).dtype}. {low_precision_error_string}"
)
# 10. Handle mixed precision and device placement
# For mixed precision training we cast all non-trainable weigths to half-precision
# as these weights are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move unet, vae and text_encoder to device and cast to weight_dtype
# The VAE is in float32 to avoid NaN losses.
vae.to(accelerator.device)
if args.pretrained_vae_model_name_or_path is not None:
vae.to(dtype=weight_dtype)
text_encoder.to(accelerator.device, dtype=weight_dtype)
# Move teacher_unet to device, optionally cast to weight_dtype
target_unet.to(accelerator.device)
teacher_unet.to(accelerator.device)
if args.cast_teacher_unet:
teacher_unet.to(dtype=weight_dtype)
# Also move the alpha and sigma noise schedules to accelerator.device.
alpha_schedule = alpha_schedule.to(accelerator.device)
sigma_schedule = sigma_schedule.to(accelerator.device)
solver = solver.to(accelerator.device)
# 11. Handle saving and loading of checkpoints
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
target_unet.save_pretrained(os.path.join(output_dir, "unet_target"))
for i, model in enumerate(models):
model.save_pretrained(os.path.join(output_dir, "unet"))
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
load_model = UNet2DConditionModel.from_pretrained(os.path.join(input_dir, "unet_target"))
target_unet.load_state_dict(load_model.state_dict())
target_unet.to(accelerator.device)
del load_model
for i in range(len(models)):
# pop models so that they are not loaded again
model = models.pop()
# load diffusers style into model
load_model = UNet2DConditionModel.from_pretrained(input_dir, subfolder="unet")
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
del load_model
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
# 12. Enable optimizations
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
teacher_unet.enable_xformers_memory_efficient_attention()
target_unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
)
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
# 12. Optimizer creation
optimizer = optimizer_class(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Here, we compute not just the text embeddings but also the additional embeddings
# needed for the SD XL UNet to operate.
def compute_embeddings(prompt_batch, proportion_empty_prompts, text_encoder, tokenizer, is_train=True):
prompt_embeds = encode_prompt(prompt_batch, text_encoder, tokenizer, proportion_empty_prompts, is_train)
return {"prompt_embeds": prompt_embeds}
dataset = Text2ImageDataset(
train_shards_path_or_url=args.train_shards_path_or_url,
num_train_examples=args.max_train_samples,
per_gpu_batch_size=args.train_batch_size,
global_batch_size=args.train_batch_size * accelerator.num_processes,
num_workers=args.dataloader_num_workers,
resolution=args.resolution,
shuffle_buffer_size=1000,
pin_memory=True,
persistent_workers=True,
)
train_dataloader = dataset.train_dataloader
compute_embeddings_fn = functools.partial(
compute_embeddings,
proportion_empty_prompts=0,
text_encoder=text_encoder,
tokenizer=tokenizer,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(train_dataloader.num_batches / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps,
num_training_steps=args.max_train_steps,
)
# Prepare everything with our `accelerator`.
unet, optimizer, lr_scheduler = accelerator.prepare(unet, optimizer, lr_scheduler)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(train_dataloader.num_batches / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
tracker_config = dict(vars(args))
accelerator.init_trackers(args.tracker_project_name, config=tracker_config)
uncond_input_ids = tokenizer(
[""] * args.train_batch_size, return_tensors="pt", padding="max_length", max_length=77
).input_ids.to(accelerator.device)
uncond_prompt_embeds = text_encoder(uncond_input_ids)[0]
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num batches each epoch = {train_dataloader.num_batches}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
for epoch in range(first_epoch, args.num_train_epochs):
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet):
image, text, _, _ = batch
image = image.to(accelerator.device, non_blocking=True)
encoded_text = compute_embeddings_fn(text)
pixel_values = image.to(dtype=weight_dtype)
if vae.dtype != weight_dtype:
vae.to(dtype=weight_dtype)
# encode pixel values with batch size of at most 32
latents = []
for i in range(0, pixel_values.shape[0], 32):
latents.append(vae.encode(pixel_values[i : i + 32]).latent_dist.sample())
latents = torch.cat(latents, dim=0)
latents = latents * vae.config.scaling_factor
latents = latents.to(weight_dtype)
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image t_n ~ U[0, N - k - 1] without bias.
topk = noise_scheduler.config.num_train_timesteps // args.num_ddim_timesteps
index = torch.randint(0, args.num_ddim_timesteps, (bsz,), device=latents.device).long()
start_timesteps = solver.ddim_timesteps[index]
timesteps = start_timesteps - topk
timesteps = torch.where(timesteps < 0, torch.zeros_like(timesteps), timesteps)
# 20.4.4. Get boundary scalings for start_timesteps and (end) timesteps.
c_skip_start, c_out_start = scalings_for_boundary_conditions(start_timesteps)
c_skip_start, c_out_start = [append_dims(x, latents.ndim) for x in [c_skip_start, c_out_start]]
c_skip, c_out = scalings_for_boundary_conditions(timesteps)
c_skip, c_out = [append_dims(x, latents.ndim) for x in [c_skip, c_out]]
# 20.4.5. Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
noisy_model_input = noise_scheduler.add_noise(latents, noise, start_timesteps)
# 20.4.6. Sample a random guidance scale w from U[w_min, w_max] and embed it
w = (args.w_max - args.w_min) * torch.rand((bsz,)) + args.w_min
w_embedding = guidance_scale_embedding(w, embedding_dim=unet.config.time_cond_proj_dim)
w = w.reshape(bsz, 1, 1, 1)
# Move to U-Net device and dtype
w = w.to(device=latents.device, dtype=latents.dtype)
w_embedding = w_embedding.to(device=latents.device, dtype=latents.dtype)
# 20.4.8. Prepare prompt embeds and unet_added_conditions
prompt_embeds = encoded_text.pop("prompt_embeds")
# 20.4.9. Get online LCM prediction on z_{t_{n + k}}, w, c, t_{n + k}
noise_pred = unet(
noisy_model_input,
start_timesteps,
timestep_cond=w_embedding,
encoder_hidden_states=prompt_embeds.float(),
added_cond_kwargs=encoded_text,
).sample
pred_x_0 = predicted_origin(
noise_pred,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
model_pred = c_skip_start * noisy_model_input + c_out_start * pred_x_0
# 20.4.10. Use the ODE solver to predict the kth step in the augmented PF-ODE trajectory after
# noisy_latents with both the conditioning embedding c and unconditional embedding 0
# Get teacher model prediction on noisy_latents and conditional embedding
with torch.no_grad():
with torch.autocast("cuda"):
cond_teacher_output = teacher_unet(
noisy_model_input.to(weight_dtype),
start_timesteps,
encoder_hidden_states=prompt_embeds.to(weight_dtype),
).sample
cond_pred_x0 = predicted_origin(
cond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
# Get teacher model prediction on noisy_latents and unconditional embedding
uncond_teacher_output = teacher_unet(
noisy_model_input.to(weight_dtype),
start_timesteps,
encoder_hidden_states=uncond_prompt_embeds.to(weight_dtype),
).sample
uncond_pred_x0 = predicted_origin(
uncond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
# 20.4.11. Perform "CFG" to get x_prev estimate (using the LCM paper's CFG formulation)
pred_x0 = cond_pred_x0 + w * (cond_pred_x0 - uncond_pred_x0)
pred_noise = cond_teacher_output + w * (cond_teacher_output - uncond_teacher_output)
x_prev = solver.ddim_step(pred_x0, pred_noise, index)
# 20.4.12. Get target LCM prediction on x_prev, w, c, t_n
with torch.no_grad():
with torch.autocast("cuda", dtype=weight_dtype):
target_noise_pred = target_unet(
x_prev.float(),
timesteps,
timestep_cond=w_embedding,
encoder_hidden_states=prompt_embeds.float(),
).sample
pred_x_0 = predicted_origin(
target_noise_pred,
timesteps,
x_prev,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
target = c_skip * x_prev + c_out * pred_x_0
# 20.4.13. Calculate loss
if args.loss_type == "l2":
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
elif args.loss_type == "huber":
loss = torch.mean(
torch.sqrt((model_pred.float() - target.float()) ** 2 + args.huber_c**2) - args.huber_c
)
# 20.4.14. Backpropagate on the online student model (`unet`)
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad(set_to_none=True)
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
# 20.4.15. Make EMA update to target student model parameters
update_ema(target_unet.parameters(), unet.parameters(), args.ema_decay)
progress_bar.update(1)
global_step += 1
if accelerator.is_main_process:
if global_step % args.checkpointing_steps == 0:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
if global_step % args.validation_steps == 0:
log_validation(vae, target_unet, args, accelerator, weight_dtype, global_step, "target")
log_validation(vae, unet, args, accelerator, weight_dtype, global_step, "online")
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
if global_step >= args.max_train_steps:
break
# Create the pipeline using using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
unet.save_pretrained(os.path.join(args.output_dir, "unet"))
target_unet = accelerator.unwrap_model(target_unet)
target_unet.save_pretrained(os.path.join(args.output_dir, "unet_target"))
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/consistency_distillation/train_lcm_distill_lora_sdxl_wds.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import copy
import functools
import gc
import itertools
import json
import logging
import math
import os
import random
import shutil
from pathlib import Path
from typing import List, Union
import accelerate
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import torchvision.transforms.functional as TF
import transformers
import webdataset as wds
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from braceexpand import braceexpand
from huggingface_hub import create_repo
from packaging import version
from peft import LoraConfig, get_peft_model, get_peft_model_state_dict
from torch.utils.data import default_collate
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import AutoTokenizer, PretrainedConfig
from webdataset.tariterators import (
base_plus_ext,
tar_file_expander,
url_opener,
valid_sample,
)
import diffusers
from diffusers import (
AutoencoderKL,
DDPMScheduler,
LCMScheduler,
StableDiffusionXLPipeline,
UNet2DConditionModel,
)
from diffusers.optimization import get_scheduler
from diffusers.utils import check_min_version, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
MAX_SEQ_LENGTH = 77
if is_wandb_available():
import wandb
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.18.0.dev0")
logger = get_logger(__name__)
def get_module_kohya_state_dict(module, prefix: str, dtype: torch.dtype, adapter_name: str = "default"):
kohya_ss_state_dict = {}
for peft_key, weight in get_peft_model_state_dict(module, adapter_name=adapter_name).items():
kohya_key = peft_key.replace("base_model.model", prefix)
kohya_key = kohya_key.replace("lora_A", "lora_down")
kohya_key = kohya_key.replace("lora_B", "lora_up")
kohya_key = kohya_key.replace(".", "_", kohya_key.count(".") - 2)
kohya_ss_state_dict[kohya_key] = weight.to(dtype)
# Set alpha parameter
if "lora_down" in kohya_key:
alpha_key = f'{kohya_key.split(".")[0]}.alpha'
kohya_ss_state_dict[alpha_key] = torch.tensor(module.peft_config[adapter_name].lora_alpha).to(dtype)
return kohya_ss_state_dict
def filter_keys(key_set):
def _f(dictionary):
return {k: v for k, v in dictionary.items() if k in key_set}
return _f
def group_by_keys_nothrow(data, keys=base_plus_ext, lcase=True, suffixes=None, handler=None):
"""Return function over iterator that groups key, value pairs into samples.
:param keys: function that splits the key into key and extension (base_plus_ext) :param lcase: convert suffixes to
lower case (Default value = True)
"""
current_sample = None
for filesample in data:
assert isinstance(filesample, dict)
fname, value = filesample["fname"], filesample["data"]
prefix, suffix = keys(fname)
if prefix is None:
continue
if lcase:
suffix = suffix.lower()
# FIXME webdataset version throws if suffix in current_sample, but we have a potential for
# this happening in the current LAION400m dataset if a tar ends with same prefix as the next
# begins, rare, but can happen since prefix aren't unique across tar files in that dataset
if current_sample is None or prefix != current_sample["__key__"] or suffix in current_sample:
if valid_sample(current_sample):
yield current_sample
current_sample = {"__key__": prefix, "__url__": filesample["__url__"]}
if suffixes is None or suffix in suffixes:
current_sample[suffix] = value
if valid_sample(current_sample):
yield current_sample
def tarfile_to_samples_nothrow(src, handler=wds.warn_and_continue):
# NOTE this is a re-impl of the webdataset impl with group_by_keys that doesn't throw
streams = url_opener(src, handler=handler)
files = tar_file_expander(streams, handler=handler)
samples = group_by_keys_nothrow(files, handler=handler)
return samples
class WebdatasetFilter:
def __init__(self, min_size=1024, max_pwatermark=0.5):
self.min_size = min_size
self.max_pwatermark = max_pwatermark
def __call__(self, x):
try:
if "json" in x:
x_json = json.loads(x["json"])
filter_size = (x_json.get("original_width", 0.0) or 0.0) >= self.min_size and x_json.get(
"original_height", 0
) >= self.min_size
filter_watermark = (x_json.get("pwatermark", 1.0) or 1.0) <= self.max_pwatermark
return filter_size and filter_watermark
else:
return False
except Exception:
return False
class Text2ImageDataset:
def __init__(
self,
train_shards_path_or_url: Union[str, List[str]],
num_train_examples: int,
per_gpu_batch_size: int,
global_batch_size: int,
num_workers: int,
resolution: int = 1024,
shuffle_buffer_size: int = 1000,
pin_memory: bool = False,
persistent_workers: bool = False,
use_fix_crop_and_size: bool = False,
):
if not isinstance(train_shards_path_or_url, str):
train_shards_path_or_url = [list(braceexpand(urls)) for urls in train_shards_path_or_url]
# flatten list using itertools
train_shards_path_or_url = list(itertools.chain.from_iterable(train_shards_path_or_url))
def get_orig_size(json):
if use_fix_crop_and_size:
return (resolution, resolution)
else:
return (int(json.get("original_width", 0.0)), int(json.get("original_height", 0.0)))
def transform(example):
# resize image
image = example["image"]
image = TF.resize(image, resolution, interpolation=transforms.InterpolationMode.BILINEAR)
# get crop coordinates and crop image
c_top, c_left, _, _ = transforms.RandomCrop.get_params(image, output_size=(resolution, resolution))
image = TF.crop(image, c_top, c_left, resolution, resolution)
image = TF.to_tensor(image)
image = TF.normalize(image, [0.5], [0.5])
example["image"] = image
example["crop_coords"] = (c_top, c_left) if not use_fix_crop_and_size else (0, 0)
return example
processing_pipeline = [
wds.decode("pil", handler=wds.ignore_and_continue),
wds.rename(
image="jpg;png;jpeg;webp", text="text;txt;caption", orig_size="json", handler=wds.warn_and_continue
),
wds.map(filter_keys({"image", "text", "orig_size"})),
wds.map_dict(orig_size=get_orig_size),
wds.map(transform),
wds.to_tuple("image", "text", "orig_size", "crop_coords"),
]
# Create train dataset and loader
pipeline = [
wds.ResampledShards(train_shards_path_or_url),
tarfile_to_samples_nothrow,
wds.select(WebdatasetFilter(min_size=960)),
wds.shuffle(shuffle_buffer_size),
*processing_pipeline,
wds.batched(per_gpu_batch_size, partial=False, collation_fn=default_collate),
]
num_worker_batches = math.ceil(num_train_examples / (global_batch_size * num_workers)) # per dataloader worker
num_batches = num_worker_batches * num_workers
num_samples = num_batches * global_batch_size
# each worker is iterating over this
self._train_dataset = wds.DataPipeline(*pipeline).with_epoch(num_worker_batches)
self._train_dataloader = wds.WebLoader(
self._train_dataset,
batch_size=None,
shuffle=False,
num_workers=num_workers,
pin_memory=pin_memory,
persistent_workers=persistent_workers,
)
# add meta-data to dataloader instance for convenience
self._train_dataloader.num_batches = num_batches
self._train_dataloader.num_samples = num_samples
@property
def train_dataset(self):
return self._train_dataset
@property
def train_dataloader(self):
return self._train_dataloader
def log_validation(vae, unet, args, accelerator, weight_dtype, step):
logger.info("Running validation... ")
unet = accelerator.unwrap_model(unet)
pipeline = StableDiffusionXLPipeline.from_pretrained(
args.pretrained_teacher_model,
vae=vae,
scheduler=LCMScheduler.from_pretrained(args.pretrained_teacher_model, subfolder="scheduler"),
revision=args.revision,
torch_dtype=weight_dtype,
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
lora_state_dict = get_module_kohya_state_dict(unet, "lora_unet", weight_dtype)
pipeline.load_lora_weights(lora_state_dict)
pipeline.fuse_lora()
if args.enable_xformers_memory_efficient_attention:
pipeline.enable_xformers_memory_efficient_attention()
if args.seed is None:
generator = None
else:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
validation_prompts = [
"portrait photo of a girl, photograph, highly detailed face, depth of field, moody light, golden hour, style by Dan Winters, Russell James, Steve McCurry, centered, extremely detailed, Nikon D850, award winning photography",
"Self-portrait oil painting, a beautiful cyborg with golden hair, 8k",
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
"A photo of beautiful mountain with realistic sunset and blue lake, highly detailed, masterpiece",
]
image_logs = []
for _, prompt in enumerate(validation_prompts):
images = []
with torch.autocast("cuda", dtype=weight_dtype):
images = pipeline(
prompt=prompt,
num_inference_steps=4,
num_images_per_prompt=4,
generator=generator,
guidance_scale=0.0,
).images
image_logs.append({"validation_prompt": prompt, "images": images})
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
formatted_images = []
for image in images:
formatted_images.append(np.asarray(image))
formatted_images = np.stack(formatted_images)
tracker.writer.add_images(validation_prompt, formatted_images, step, dataformats="NHWC")
elif tracker.name == "wandb":
formatted_images = []
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
for image in images:
image = wandb.Image(image, caption=validation_prompt)
formatted_images.append(image)
tracker.log({"validation": formatted_images})
else:
logger.warn(f"image logging not implemented for {tracker.name}")
del pipeline
gc.collect()
torch.cuda.empty_cache()
return image_logs
def append_dims(x, target_dims):
"""Appends dimensions to the end of a tensor until it has target_dims dimensions."""
dims_to_append = target_dims - x.ndim
if dims_to_append < 0:
raise ValueError(f"input has {x.ndim} dims but target_dims is {target_dims}, which is less")
return x[(...,) + (None,) * dims_to_append]
# From LCMScheduler.get_scalings_for_boundary_condition_discrete
def scalings_for_boundary_conditions(timestep, sigma_data=0.5, timestep_scaling=10.0):
c_skip = sigma_data**2 / ((timestep / 0.1) ** 2 + sigma_data**2)
c_out = (timestep / 0.1) / ((timestep / 0.1) ** 2 + sigma_data**2) ** 0.5
return c_skip, c_out
# Compare LCMScheduler.step, Step 4
def predicted_origin(model_output, timesteps, sample, prediction_type, alphas, sigmas):
if prediction_type == "epsilon":
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
pred_x_0 = (sample - sigmas * model_output) / alphas
elif prediction_type == "v_prediction":
pred_x_0 = alphas[timesteps] * sample - sigmas[timesteps] * model_output
else:
raise ValueError(f"Prediction type {prediction_type} currently not supported.")
return pred_x_0
def extract_into_tensor(a, t, x_shape):
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
class DDIMSolver:
def __init__(self, alpha_cumprods, timesteps=1000, ddim_timesteps=50):
# DDIM sampling parameters
step_ratio = timesteps // ddim_timesteps
self.ddim_timesteps = (np.arange(1, ddim_timesteps + 1) * step_ratio).round().astype(np.int64) - 1
self.ddim_alpha_cumprods = alpha_cumprods[self.ddim_timesteps]
self.ddim_alpha_cumprods_prev = np.asarray(
[alpha_cumprods[0]] + alpha_cumprods[self.ddim_timesteps[:-1]].tolist()
)
# convert to torch tensors
self.ddim_timesteps = torch.from_numpy(self.ddim_timesteps).long()
self.ddim_alpha_cumprods = torch.from_numpy(self.ddim_alpha_cumprods)
self.ddim_alpha_cumprods_prev = torch.from_numpy(self.ddim_alpha_cumprods_prev)
def to(self, device):
self.ddim_timesteps = self.ddim_timesteps.to(device)
self.ddim_alpha_cumprods = self.ddim_alpha_cumprods.to(device)
self.ddim_alpha_cumprods_prev = self.ddim_alpha_cumprods_prev.to(device)
return self
def ddim_step(self, pred_x0, pred_noise, timestep_index):
alpha_cumprod_prev = extract_into_tensor(self.ddim_alpha_cumprods_prev, timestep_index, pred_x0.shape)
dir_xt = (1.0 - alpha_cumprod_prev).sqrt() * pred_noise
x_prev = alpha_cumprod_prev.sqrt() * pred_x0 + dir_xt
return x_prev
def import_model_class_from_model_name_or_path(
pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
):
text_encoder_config = PretrainedConfig.from_pretrained(
pretrained_model_name_or_path, subfolder=subfolder, revision=revision, use_auth_token=True
)
model_class = text_encoder_config.architectures[0]
if model_class == "CLIPTextModel":
from transformers import CLIPTextModel
return CLIPTextModel
elif model_class == "CLIPTextModelWithProjection":
from transformers import CLIPTextModelWithProjection
return CLIPTextModelWithProjection
else:
raise ValueError(f"{model_class} is not supported.")
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
# ----------Model Checkpoint Loading Arguments----------
parser.add_argument(
"--pretrained_teacher_model",
type=str,
default=None,
required=True,
help="Path to pretrained LDM teacher model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--pretrained_vae_model_name_or_path",
type=str,
default=None,
help="Path to pretrained VAE model with better numerical stability. More details: https://github.com/huggingface/diffusers/pull/4038.",
)
parser.add_argument(
"--teacher_revision",
type=str,
default=None,
required=False,
help="Revision of pretrained LDM teacher model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained LDM model identifier from huggingface.co/models.",
)
# ----------Training Arguments----------
# ----General Training Arguments----
parser.add_argument(
"--output_dir",
type=str,
default="lcm-xl-distilled",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
# ----Logging----
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
# ----Checkpointing----
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
# ----Image Processing----
parser.add_argument(
"--train_shards_path_or_url",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--resolution",
type=int,
default=1024,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--use_fix_crop_and_size",
action="store_true",
help="Whether or not to use the fixed crop and size for the teacher model.",
default=False,
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
# ----Dataloader----
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
# ----Batch Size and Training Steps----
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
# ----Learning Rate----
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
# ----Optimizer (Adam)----
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
# ----Diffusion Training Arguments----
parser.add_argument(
"--proportion_empty_prompts",
type=float,
default=0,
help="Proportion of image prompts to be replaced with empty strings. Defaults to 0 (no prompt replacement).",
)
# ----Latent Consistency Distillation (LCD) Specific Arguments----
parser.add_argument(
"--w_min",
type=float,
default=3.0,
required=False,
help=(
"The minimum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
" formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
" compared to the original paper."
),
)
parser.add_argument(
"--w_max",
type=float,
default=15.0,
required=False,
help=(
"The maximum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
" formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
" compared to the original paper."
),
)
parser.add_argument(
"--num_ddim_timesteps",
type=int,
default=50,
help="The number of timesteps to use for DDIM sampling.",
)
parser.add_argument(
"--loss_type",
type=str,
default="l2",
choices=["l2", "huber"],
help="The type of loss to use for the LCD loss.",
)
parser.add_argument(
"--huber_c",
type=float,
default=0.001,
help="The huber loss parameter. Only used if `--loss_type=huber`.",
)
parser.add_argument(
"--lora_rank",
type=int,
default=64,
help="The rank of the LoRA projection matrix.",
)
# ----Mixed Precision----
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--cast_teacher_unet",
action="store_true",
help="Whether to cast the teacher U-Net to the precision specified by `--mixed_precision`.",
)
# ----Training Optimizations----
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
# ----Distributed Training----
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
# ----------Validation Arguments----------
parser.add_argument(
"--validation_steps",
type=int,
default=200,
help="Run validation every X steps.",
)
# ----------Huggingface Hub Arguments-----------
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
# ----------Accelerate Arguments----------
parser.add_argument(
"--tracker_project_name",
type=str,
default="text2image-fine-tune",
help=(
"The `project_name` argument passed to Accelerator.init_trackers for"
" more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
),
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.proportion_empty_prompts < 0 or args.proportion_empty_prompts > 1:
raise ValueError("`--proportion_empty_prompts` must be in the range [0, 1].")
return args
# Adapted from pipelines.StableDiffusionXLPipeline.encode_prompt
def encode_prompt(prompt_batch, text_encoders, tokenizers, proportion_empty_prompts, is_train=True):
prompt_embeds_list = []
captions = []
for caption in prompt_batch:
if random.random() < proportion_empty_prompts:
captions.append("")
elif isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
with torch.no_grad():
for tokenizer, text_encoder in zip(tokenizers, text_encoders):
text_inputs = tokenizer(
captions,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
prompt_embeds = text_encoder(
text_input_ids.to(text_encoder.device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
pooled_prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.hidden_states[-2]
bs_embed, seq_len, _ = prompt_embeds.shape
prompt_embeds = prompt_embeds.view(bs_embed, seq_len, -1)
prompt_embeds_list.append(prompt_embeds)
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
pooled_prompt_embeds = pooled_prompt_embeds.view(bs_embed, -1)
return prompt_embeds, pooled_prompt_embeds
def main(args):
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
split_batches=True, # It's important to set this to True when using webdataset to get the right number of steps for lr scheduling. If set to False, the number of steps will be devide by the number of processes assuming batches are multiplied by the number of processes
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name,
exist_ok=True,
token=args.hub_token,
private=True,
).repo_id
# 1. Create the noise scheduler and the desired noise schedule.
noise_scheduler = DDPMScheduler.from_pretrained(
args.pretrained_teacher_model, subfolder="scheduler", revision=args.teacher_revision
)
# The scheduler calculates the alpha and sigma schedule for us
alpha_schedule = torch.sqrt(noise_scheduler.alphas_cumprod)
sigma_schedule = torch.sqrt(1 - noise_scheduler.alphas_cumprod)
solver = DDIMSolver(
noise_scheduler.alphas_cumprod.numpy(),
timesteps=noise_scheduler.config.num_train_timesteps,
ddim_timesteps=args.num_ddim_timesteps,
)
# 2. Load tokenizers from SD-XL checkpoint.
tokenizer_one = AutoTokenizer.from_pretrained(
args.pretrained_teacher_model, subfolder="tokenizer", revision=args.teacher_revision, use_fast=False
)
tokenizer_two = AutoTokenizer.from_pretrained(
args.pretrained_teacher_model, subfolder="tokenizer_2", revision=args.teacher_revision, use_fast=False
)
# 3. Load text encoders from SD-XL checkpoint.
# import correct text encoder classes
text_encoder_cls_one = import_model_class_from_model_name_or_path(
args.pretrained_teacher_model, args.teacher_revision
)
text_encoder_cls_two = import_model_class_from_model_name_or_path(
args.pretrained_teacher_model, args.teacher_revision, subfolder="text_encoder_2"
)
text_encoder_one = text_encoder_cls_one.from_pretrained(
args.pretrained_teacher_model, subfolder="text_encoder", revision=args.teacher_revision
)
text_encoder_two = text_encoder_cls_two.from_pretrained(
args.pretrained_teacher_model, subfolder="text_encoder_2", revision=args.teacher_revision
)
# 4. Load VAE from SD-XL checkpoint (or more stable VAE)
vae_path = (
args.pretrained_teacher_model
if args.pretrained_vae_model_name_or_path is None
else args.pretrained_vae_model_name_or_path
)
vae = AutoencoderKL.from_pretrained(
vae_path,
subfolder="vae" if args.pretrained_vae_model_name_or_path is None else None,
revision=args.teacher_revision,
)
# 5. Load teacher U-Net from SD-XL checkpoint
teacher_unet = UNet2DConditionModel.from_pretrained(
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
)
# 6. Freeze teacher vae, text_encoders, and teacher_unet
vae.requires_grad_(False)
text_encoder_one.requires_grad_(False)
text_encoder_two.requires_grad_(False)
teacher_unet.requires_grad_(False)
# 7. Create online (`unet`) student U-Nets.
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
)
unet.train()
# Check that all trainable models are in full precision
low_precision_error_string = (
" Please make sure to always have all model weights in full float32 precision when starting training - even if"
" doing mixed precision training, copy of the weights should still be float32."
)
if accelerator.unwrap_model(unet).dtype != torch.float32:
raise ValueError(
f"Controlnet loaded as datatype {accelerator.unwrap_model(unet).dtype}. {low_precision_error_string}"
)
# 8. Add LoRA to the student U-Net, only the LoRA projection matrix will be updated by the optimizer.
lora_config = LoraConfig(
r=args.lora_rank,
target_modules=[
"to_q",
"to_k",
"to_v",
"to_out.0",
"proj_in",
"proj_out",
"ff.net.0.proj",
"ff.net.2",
"conv1",
"conv2",
"conv_shortcut",
"downsamplers.0.conv",
"upsamplers.0.conv",
"time_emb_proj",
],
)
unet = get_peft_model(unet, lora_config)
# 9. Handle mixed precision and device placement
# For mixed precision training we cast all non-trainable weigths to half-precision
# as these weights are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move unet, vae and text_encoder to device and cast to weight_dtype
# The VAE is in float32 to avoid NaN losses.
vae.to(accelerator.device)
if args.pretrained_vae_model_name_or_path is not None:
vae.to(dtype=weight_dtype)
text_encoder_one.to(accelerator.device, dtype=weight_dtype)
text_encoder_two.to(accelerator.device, dtype=weight_dtype)
# Move teacher_unet to device, optionally cast to weight_dtype
teacher_unet.to(accelerator.device)
if args.cast_teacher_unet:
teacher_unet.to(dtype=weight_dtype)
# Also move the alpha and sigma noise schedules to accelerator.device.
alpha_schedule = alpha_schedule.to(accelerator.device)
sigma_schedule = sigma_schedule.to(accelerator.device)
solver = solver.to(accelerator.device)
# 10. Handle saving and loading of checkpoints
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
unet_ = accelerator.unwrap_model(unet)
lora_state_dict = get_peft_model_state_dict(unet_, adapter_name="default")
StableDiffusionXLPipeline.save_lora_weights(os.path.join(output_dir, "unet_lora"), lora_state_dict)
# save weights in peft format to be able to load them back
unet_.save_pretrained(output_dir)
for _, model in enumerate(models):
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
# load the LoRA into the model
unet_ = accelerator.unwrap_model(unet)
unet_.load_adapter(input_dir, "default", is_trainable=True)
for _ in range(len(models)):
# pop models so that they are not loaded again
models.pop()
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
# 11. Enable optimizations
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
teacher_unet.enable_xformers_memory_efficient_attention()
# target_unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
)
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
# 12. Optimizer creation
optimizer = optimizer_class(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# 13. Dataset creation and data processing
# Here, we compute not just the text embeddings but also the additional embeddings
# needed for the SD XL UNet to operate.
def compute_embeddings(
prompt_batch, original_sizes, crop_coords, proportion_empty_prompts, text_encoders, tokenizers, is_train=True
):
target_size = (args.resolution, args.resolution)
original_sizes = list(map(list, zip(*original_sizes)))
crops_coords_top_left = list(map(list, zip(*crop_coords)))
original_sizes = torch.tensor(original_sizes, dtype=torch.long)
crops_coords_top_left = torch.tensor(crops_coords_top_left, dtype=torch.long)
prompt_embeds, pooled_prompt_embeds = encode_prompt(
prompt_batch, text_encoders, tokenizers, proportion_empty_prompts, is_train
)
add_text_embeds = pooled_prompt_embeds
# Adapted from pipeline.StableDiffusionXLPipeline._get_add_time_ids
add_time_ids = list(target_size)
add_time_ids = torch.tensor([add_time_ids])
add_time_ids = add_time_ids.repeat(len(prompt_batch), 1)
add_time_ids = torch.cat([original_sizes, crops_coords_top_left, add_time_ids], dim=-1)
add_time_ids = add_time_ids.to(accelerator.device, dtype=prompt_embeds.dtype)
prompt_embeds = prompt_embeds.to(accelerator.device)
add_text_embeds = add_text_embeds.to(accelerator.device)
unet_added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
return {"prompt_embeds": prompt_embeds, **unet_added_cond_kwargs}
dataset = Text2ImageDataset(
train_shards_path_or_url=args.train_shards_path_or_url,
num_train_examples=args.max_train_samples,
per_gpu_batch_size=args.train_batch_size,
global_batch_size=args.train_batch_size * accelerator.num_processes,
num_workers=args.dataloader_num_workers,
resolution=args.resolution,
shuffle_buffer_size=1000,
pin_memory=True,
persistent_workers=True,
use_fix_crop_and_size=args.use_fix_crop_and_size,
)
train_dataloader = dataset.train_dataloader
# Let's first compute all the embeddings so that we can free up the text encoders
# from memory.
text_encoders = [text_encoder_one, text_encoder_two]
tokenizers = [tokenizer_one, tokenizer_two]
compute_embeddings_fn = functools.partial(
compute_embeddings,
proportion_empty_prompts=0,
text_encoders=text_encoders,
tokenizers=tokenizers,
)
# 14. LR Scheduler creation
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(train_dataloader.num_batches / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps,
num_training_steps=args.max_train_steps,
)
# 15. Prepare for training
# Prepare everything with our `accelerator`.
unet, optimizer, lr_scheduler = accelerator.prepare(unet, optimizer, lr_scheduler)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(train_dataloader.num_batches / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
tracker_config = dict(vars(args))
accelerator.init_trackers(args.tracker_project_name, config=tracker_config)
# Create uncond embeds for classifier free guidance
uncond_prompt_embeds = torch.zeros(args.train_batch_size, 77, 2048).to(accelerator.device)
uncond_pooled_prompt_embeds = torch.zeros(args.train_batch_size, 1280).to(accelerator.device)
# 16. Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num batches each epoch = {train_dataloader.num_batches}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
for epoch in range(first_epoch, args.num_train_epochs):
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet):
image, text, orig_size, crop_coords = batch
image = image.to(accelerator.device, non_blocking=True)
encoded_text = compute_embeddings_fn(text, orig_size, crop_coords)
if args.pretrained_vae_model_name_or_path is not None:
pixel_values = image.to(dtype=weight_dtype)
if vae.dtype != weight_dtype:
vae.to(dtype=weight_dtype)
else:
pixel_values = image
# encode pixel values with batch size of at most 8
latents = []
for i in range(0, pixel_values.shape[0], 8):
latents.append(vae.encode(pixel_values[i : i + 8]).latent_dist.sample())
latents = torch.cat(latents, dim=0)
latents = latents * vae.config.scaling_factor
if args.pretrained_vae_model_name_or_path is None:
latents = latents.to(weight_dtype)
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image t_n ~ U[0, N - k - 1] without bias.
topk = noise_scheduler.config.num_train_timesteps // args.num_ddim_timesteps
index = torch.randint(0, args.num_ddim_timesteps, (bsz,), device=latents.device).long()
start_timesteps = solver.ddim_timesteps[index]
timesteps = start_timesteps - topk
timesteps = torch.where(timesteps < 0, torch.zeros_like(timesteps), timesteps)
# 20.4.4. Get boundary scalings for start_timesteps and (end) timesteps.
c_skip_start, c_out_start = scalings_for_boundary_conditions(start_timesteps)
c_skip_start, c_out_start = [append_dims(x, latents.ndim) for x in [c_skip_start, c_out_start]]
c_skip, c_out = scalings_for_boundary_conditions(timesteps)
c_skip, c_out = [append_dims(x, latents.ndim) for x in [c_skip, c_out]]
# 20.4.5. Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
noisy_model_input = noise_scheduler.add_noise(latents, noise, start_timesteps)
# 20.4.6. Sample a random guidance scale w from U[w_min, w_max] and embed it
w = (args.w_max - args.w_min) * torch.rand((bsz,)) + args.w_min
w = w.reshape(bsz, 1, 1, 1)
w = w.to(device=latents.device, dtype=latents.dtype)
# 20.4.8. Prepare prompt embeds and unet_added_conditions
prompt_embeds = encoded_text.pop("prompt_embeds")
# 20.4.9. Get online LCM prediction on z_{t_{n + k}}, w, c, t_{n + k}
noise_pred = unet(
noisy_model_input,
start_timesteps,
timestep_cond=None,
encoder_hidden_states=prompt_embeds.float(),
added_cond_kwargs=encoded_text,
).sample
pred_x_0 = predicted_origin(
noise_pred,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
model_pred = c_skip_start * noisy_model_input + c_out_start * pred_x_0
# 20.4.10. Use the ODE solver to predict the kth step in the augmented PF-ODE trajectory after
# noisy_latents with both the conditioning embedding c and unconditional embedding 0
# Get teacher model prediction on noisy_latents and conditional embedding
with torch.no_grad():
with torch.autocast("cuda"):
cond_teacher_output = teacher_unet(
noisy_model_input.to(weight_dtype),
start_timesteps,
encoder_hidden_states=prompt_embeds.to(weight_dtype),
added_cond_kwargs={k: v.to(weight_dtype) for k, v in encoded_text.items()},
).sample
cond_pred_x0 = predicted_origin(
cond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
# Get teacher model prediction on noisy_latents and unconditional embedding
uncond_added_conditions = copy.deepcopy(encoded_text)
uncond_added_conditions["text_embeds"] = uncond_pooled_prompt_embeds
uncond_teacher_output = teacher_unet(
noisy_model_input.to(weight_dtype),
start_timesteps,
encoder_hidden_states=uncond_prompt_embeds.to(weight_dtype),
added_cond_kwargs={k: v.to(weight_dtype) for k, v in uncond_added_conditions.items()},
).sample
uncond_pred_x0 = predicted_origin(
uncond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
# 20.4.11. Perform "CFG" to get x_prev estimate (using the LCM paper's CFG formulation)
pred_x0 = cond_pred_x0 + w * (cond_pred_x0 - uncond_pred_x0)
pred_noise = cond_teacher_output + w * (cond_teacher_output - uncond_teacher_output)
x_prev = solver.ddim_step(pred_x0, pred_noise, index)
# 20.4.12. Get target LCM prediction on x_prev, w, c, t_n
with torch.no_grad():
with torch.autocast("cuda", enabled=True, dtype=weight_dtype):
target_noise_pred = unet(
x_prev.float(),
timesteps,
timestep_cond=None,
encoder_hidden_states=prompt_embeds.float(),
added_cond_kwargs=encoded_text,
).sample
pred_x_0 = predicted_origin(
target_noise_pred,
timesteps,
x_prev,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
target = c_skip * x_prev + c_out * pred_x_0
# 20.4.13. Calculate loss
if args.loss_type == "l2":
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
elif args.loss_type == "huber":
loss = torch.mean(
torch.sqrt((model_pred.float() - target.float()) ** 2 + args.huber_c**2) - args.huber_c
)
# 20.4.14. Backpropagate on the online student model (`unet`)
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad(set_to_none=True)
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
if accelerator.is_main_process:
if global_step % args.checkpointing_steps == 0:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
if global_step % args.validation_steps == 0:
log_validation(vae, unet, args, accelerator, weight_dtype, global_step)
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
if global_step >= args.max_train_steps:
break
# Create the pipeline using using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
unet.save_pretrained(args.output_dir)
lora_state_dict = get_peft_model_state_dict(unet, adapter_name="default")
StableDiffusionXLPipeline.save_lora_weights(os.path.join(args.output_dir, "unet_lora"), lora_state_dict)
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/consistency_distillation/train_lcm_distill_lora_sd_wds.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import functools
import gc
import itertools
import json
import logging
import math
import os
import random
import shutil
from pathlib import Path
from typing import List, Union
import accelerate
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import torchvision.transforms.functional as TF
import transformers
import webdataset as wds
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from braceexpand import braceexpand
from huggingface_hub import create_repo
from packaging import version
from peft import LoraConfig, get_peft_model, get_peft_model_state_dict
from torch.utils.data import default_collate
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import AutoTokenizer, CLIPTextModel, PretrainedConfig
from webdataset.tariterators import (
base_plus_ext,
tar_file_expander,
url_opener,
valid_sample,
)
import diffusers
from diffusers import (
AutoencoderKL,
DDPMScheduler,
LCMScheduler,
StableDiffusionPipeline,
UNet2DConditionModel,
)
from diffusers.optimization import get_scheduler
from diffusers.utils import check_min_version, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
MAX_SEQ_LENGTH = 77
if is_wandb_available():
import wandb
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.18.0.dev0")
logger = get_logger(__name__)
def get_module_kohya_state_dict(module, prefix: str, dtype: torch.dtype, adapter_name: str = "default"):
kohya_ss_state_dict = {}
for peft_key, weight in get_peft_model_state_dict(module, adapter_name=adapter_name).items():
kohya_key = peft_key.replace("base_model.model", prefix)
kohya_key = kohya_key.replace("lora_A", "lora_down")
kohya_key = kohya_key.replace("lora_B", "lora_up")
kohya_key = kohya_key.replace(".", "_", kohya_key.count(".") - 2)
kohya_ss_state_dict[kohya_key] = weight.to(dtype)
# Set alpha parameter
if "lora_down" in kohya_key:
alpha_key = f'{kohya_key.split(".")[0]}.alpha'
kohya_ss_state_dict[alpha_key] = torch.tensor(module.peft_config[adapter_name].lora_alpha).to(dtype)
return kohya_ss_state_dict
def filter_keys(key_set):
def _f(dictionary):
return {k: v for k, v in dictionary.items() if k in key_set}
return _f
def group_by_keys_nothrow(data, keys=base_plus_ext, lcase=True, suffixes=None, handler=None):
"""Return function over iterator that groups key, value pairs into samples.
:param keys: function that splits the key into key and extension (base_plus_ext) :param lcase: convert suffixes to
lower case (Default value = True)
"""
current_sample = None
for filesample in data:
assert isinstance(filesample, dict)
fname, value = filesample["fname"], filesample["data"]
prefix, suffix = keys(fname)
if prefix is None:
continue
if lcase:
suffix = suffix.lower()
# FIXME webdataset version throws if suffix in current_sample, but we have a potential for
# this happening in the current LAION400m dataset if a tar ends with same prefix as the next
# begins, rare, but can happen since prefix aren't unique across tar files in that dataset
if current_sample is None or prefix != current_sample["__key__"] or suffix in current_sample:
if valid_sample(current_sample):
yield current_sample
current_sample = {"__key__": prefix, "__url__": filesample["__url__"]}
if suffixes is None or suffix in suffixes:
current_sample[suffix] = value
if valid_sample(current_sample):
yield current_sample
def tarfile_to_samples_nothrow(src, handler=wds.warn_and_continue):
# NOTE this is a re-impl of the webdataset impl with group_by_keys that doesn't throw
streams = url_opener(src, handler=handler)
files = tar_file_expander(streams, handler=handler)
samples = group_by_keys_nothrow(files, handler=handler)
return samples
class WebdatasetFilter:
def __init__(self, min_size=1024, max_pwatermark=0.5):
self.min_size = min_size
self.max_pwatermark = max_pwatermark
def __call__(self, x):
try:
if "json" in x:
x_json = json.loads(x["json"])
filter_size = (x_json.get("original_width", 0.0) or 0.0) >= self.min_size and x_json.get(
"original_height", 0
) >= self.min_size
filter_watermark = (x_json.get("pwatermark", 1.0) or 1.0) <= self.max_pwatermark
return filter_size and filter_watermark
else:
return False
except Exception:
return False
class Text2ImageDataset:
def __init__(
self,
train_shards_path_or_url: Union[str, List[str]],
num_train_examples: int,
per_gpu_batch_size: int,
global_batch_size: int,
num_workers: int,
resolution: int = 512,
shuffle_buffer_size: int = 1000,
pin_memory: bool = False,
persistent_workers: bool = False,
):
if not isinstance(train_shards_path_or_url, str):
train_shards_path_or_url = [list(braceexpand(urls)) for urls in train_shards_path_or_url]
# flatten list using itertools
train_shards_path_or_url = list(itertools.chain.from_iterable(train_shards_path_or_url))
def transform(example):
# resize image
image = example["image"]
image = TF.resize(image, resolution, interpolation=transforms.InterpolationMode.BILINEAR)
# get crop coordinates and crop image
c_top, c_left, _, _ = transforms.RandomCrop.get_params(image, output_size=(resolution, resolution))
image = TF.crop(image, c_top, c_left, resolution, resolution)
image = TF.to_tensor(image)
image = TF.normalize(image, [0.5], [0.5])
example["image"] = image
return example
processing_pipeline = [
wds.decode("pil", handler=wds.ignore_and_continue),
wds.rename(image="jpg;png;jpeg;webp", text="text;txt;caption", handler=wds.warn_and_continue),
wds.map(filter_keys({"image", "text"})),
wds.map(transform),
wds.to_tuple("image", "text"),
]
# Create train dataset and loader
pipeline = [
wds.ResampledShards(train_shards_path_or_url),
tarfile_to_samples_nothrow,
wds.shuffle(shuffle_buffer_size),
*processing_pipeline,
wds.batched(per_gpu_batch_size, partial=False, collation_fn=default_collate),
]
num_worker_batches = math.ceil(num_train_examples / (global_batch_size * num_workers)) # per dataloader worker
num_batches = num_worker_batches * num_workers
num_samples = num_batches * global_batch_size
# each worker is iterating over this
self._train_dataset = wds.DataPipeline(*pipeline).with_epoch(num_worker_batches)
self._train_dataloader = wds.WebLoader(
self._train_dataset,
batch_size=None,
shuffle=False,
num_workers=num_workers,
pin_memory=pin_memory,
persistent_workers=persistent_workers,
)
# add meta-data to dataloader instance for convenience
self._train_dataloader.num_batches = num_batches
self._train_dataloader.num_samples = num_samples
@property
def train_dataset(self):
return self._train_dataset
@property
def train_dataloader(self):
return self._train_dataloader
def log_validation(vae, unet, args, accelerator, weight_dtype, step):
logger.info("Running validation... ")
unet = accelerator.unwrap_model(unet)
pipeline = StableDiffusionPipeline.from_pretrained(
args.pretrained_teacher_model,
vae=vae,
scheduler=LCMScheduler.from_pretrained(args.pretrained_teacher_model, subfolder="scheduler"),
revision=args.revision,
torch_dtype=weight_dtype,
safety_checker=None,
)
pipeline.set_progress_bar_config(disable=True)
lora_state_dict = get_module_kohya_state_dict(unet, "lora_unet", weight_dtype)
pipeline.load_lora_weights(lora_state_dict)
pipeline.fuse_lora()
pipeline = pipeline.to(accelerator.device, dtype=weight_dtype)
if args.enable_xformers_memory_efficient_attention:
pipeline.enable_xformers_memory_efficient_attention()
if args.seed is None:
generator = None
else:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
validation_prompts = [
"portrait photo of a girl, photograph, highly detailed face, depth of field, moody light, golden hour, style by Dan Winters, Russell James, Steve McCurry, centered, extremely detailed, Nikon D850, award winning photography",
"Self-portrait oil painting, a beautiful cyborg with golden hair, 8k",
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
"A photo of beautiful mountain with realistic sunset and blue lake, highly detailed, masterpiece",
]
image_logs = []
for _, prompt in enumerate(validation_prompts):
images = []
with torch.autocast("cuda", dtype=weight_dtype):
images = pipeline(
prompt=prompt,
num_inference_steps=4,
num_images_per_prompt=4,
generator=generator,
guidance_scale=1.0,
).images
image_logs.append({"validation_prompt": prompt, "images": images})
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
formatted_images = []
for image in images:
formatted_images.append(np.asarray(image))
formatted_images = np.stack(formatted_images)
tracker.writer.add_images(validation_prompt, formatted_images, step, dataformats="NHWC")
elif tracker.name == "wandb":
formatted_images = []
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
for image in images:
image = wandb.Image(image, caption=validation_prompt)
formatted_images.append(image)
tracker.log({"validation": formatted_images})
else:
logger.warn(f"image logging not implemented for {tracker.name}")
del pipeline
gc.collect()
torch.cuda.empty_cache()
return image_logs
# From LatentConsistencyModel.get_guidance_scale_embedding
def guidance_scale_embedding(w, embedding_dim=512, dtype=torch.float32):
"""
See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
Args:
timesteps (`torch.Tensor`):
generate embedding vectors at these timesteps
embedding_dim (`int`, *optional*, defaults to 512):
dimension of the embeddings to generate
dtype:
data type of the generated embeddings
Returns:
`torch.FloatTensor`: Embedding vectors with shape `(len(timesteps), embedding_dim)`
"""
assert len(w.shape) == 1
w = w * 1000.0
half_dim = embedding_dim // 2
emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
emb = w.to(dtype)[:, None] * emb[None, :]
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
if embedding_dim % 2 == 1: # zero pad
emb = torch.nn.functional.pad(emb, (0, 1))
assert emb.shape == (w.shape[0], embedding_dim)
return emb
def append_dims(x, target_dims):
"""Appends dimensions to the end of a tensor until it has target_dims dimensions."""
dims_to_append = target_dims - x.ndim
if dims_to_append < 0:
raise ValueError(f"input has {x.ndim} dims but target_dims is {target_dims}, which is less")
return x[(...,) + (None,) * dims_to_append]
# From LCMScheduler.get_scalings_for_boundary_condition_discrete
def scalings_for_boundary_conditions(timestep, sigma_data=0.5, timestep_scaling=10.0):
c_skip = sigma_data**2 / ((timestep / 0.1) ** 2 + sigma_data**2)
c_out = (timestep / 0.1) / ((timestep / 0.1) ** 2 + sigma_data**2) ** 0.5
return c_skip, c_out
# Compare LCMScheduler.step, Step 4
def predicted_origin(model_output, timesteps, sample, prediction_type, alphas, sigmas):
if prediction_type == "epsilon":
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
pred_x_0 = (sample - sigmas * model_output) / alphas
elif prediction_type == "v_prediction":
pred_x_0 = alphas[timesteps] * sample - sigmas[timesteps] * model_output
else:
raise ValueError(f"Prediction type {prediction_type} currently not supported.")
return pred_x_0
def extract_into_tensor(a, t, x_shape):
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
class DDIMSolver:
def __init__(self, alpha_cumprods, timesteps=1000, ddim_timesteps=50):
# DDIM sampling parameters
step_ratio = timesteps // ddim_timesteps
self.ddim_timesteps = (np.arange(1, ddim_timesteps + 1) * step_ratio).round().astype(np.int64) - 1
self.ddim_alpha_cumprods = alpha_cumprods[self.ddim_timesteps]
self.ddim_alpha_cumprods_prev = np.asarray(
[alpha_cumprods[0]] + alpha_cumprods[self.ddim_timesteps[:-1]].tolist()
)
# convert to torch tensors
self.ddim_timesteps = torch.from_numpy(self.ddim_timesteps).long()
self.ddim_alpha_cumprods = torch.from_numpy(self.ddim_alpha_cumprods)
self.ddim_alpha_cumprods_prev = torch.from_numpy(self.ddim_alpha_cumprods_prev)
def to(self, device):
self.ddim_timesteps = self.ddim_timesteps.to(device)
self.ddim_alpha_cumprods = self.ddim_alpha_cumprods.to(device)
self.ddim_alpha_cumprods_prev = self.ddim_alpha_cumprods_prev.to(device)
return self
def ddim_step(self, pred_x0, pred_noise, timestep_index):
alpha_cumprod_prev = extract_into_tensor(self.ddim_alpha_cumprods_prev, timestep_index, pred_x0.shape)
dir_xt = (1.0 - alpha_cumprod_prev).sqrt() * pred_noise
x_prev = alpha_cumprod_prev.sqrt() * pred_x0 + dir_xt
return x_prev
@torch.no_grad()
def update_ema(target_params, source_params, rate=0.99):
"""
Update target parameters to be closer to those of source parameters using
an exponential moving average.
:param target_params: the target parameter sequence.
:param source_params: the source parameter sequence.
:param rate: the EMA rate (closer to 1 means slower).
"""
for targ, src in zip(target_params, source_params):
targ.detach().mul_(rate).add_(src, alpha=1 - rate)
def import_model_class_from_model_name_or_path(
pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
):
text_encoder_config = PretrainedConfig.from_pretrained(
pretrained_model_name_or_path, subfolder=subfolder, revision=revision, use_auth_token=True
)
model_class = text_encoder_config.architectures[0]
if model_class == "CLIPTextModel":
from transformers import CLIPTextModel
return CLIPTextModel
elif model_class == "CLIPTextModelWithProjection":
from transformers import CLIPTextModelWithProjection
return CLIPTextModelWithProjection
else:
raise ValueError(f"{model_class} is not supported.")
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
# ----------Model Checkpoint Loading Arguments----------
parser.add_argument(
"--pretrained_teacher_model",
type=str,
default=None,
required=True,
help="Path to pretrained LDM teacher model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--pretrained_vae_model_name_or_path",
type=str,
default=None,
help="Path to pretrained VAE model with better numerical stability. More details: https://github.com/huggingface/diffusers/pull/4038.",
)
parser.add_argument(
"--teacher_revision",
type=str,
default=None,
required=False,
help="Revision of pretrained LDM teacher model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained LDM model identifier from huggingface.co/models.",
)
# ----------Training Arguments----------
# ----General Training Arguments----
parser.add_argument(
"--output_dir",
type=str,
default="lcm-xl-distilled",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
# ----Logging----
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
# ----Checkpointing----
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
# ----Image Processing----
parser.add_argument(
"--train_shards_path_or_url",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
# ----Dataloader----
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
# ----Batch Size and Training Steps----
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
# ----Learning Rate----
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
# ----Optimizer (Adam)----
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
# ----Diffusion Training Arguments----
parser.add_argument(
"--proportion_empty_prompts",
type=float,
default=0,
help="Proportion of image prompts to be replaced with empty strings. Defaults to 0 (no prompt replacement).",
)
# ----Latent Consistency Distillation (LCD) Specific Arguments----
parser.add_argument(
"--w_min",
type=float,
default=5.0,
required=False,
help=(
"The minimum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
" formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
" compared to the original paper."
),
)
parser.add_argument(
"--w_max",
type=float,
default=15.0,
required=False,
help=(
"The maximum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
" formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
" compared to the original paper."
),
)
parser.add_argument(
"--num_ddim_timesteps",
type=int,
default=50,
help="The number of timesteps to use for DDIM sampling.",
)
parser.add_argument(
"--loss_type",
type=str,
default="l2",
choices=["l2", "huber"],
help="The type of loss to use for the LCD loss.",
)
parser.add_argument(
"--huber_c",
type=float,
default=0.001,
help="The huber loss parameter. Only used if `--loss_type=huber`.",
)
parser.add_argument(
"--lora_rank",
type=int,
default=64,
help="The rank of the LoRA projection matrix.",
)
# ----Mixed Precision----
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--cast_teacher_unet",
action="store_true",
help="Whether to cast the teacher U-Net to the precision specified by `--mixed_precision`.",
)
# ----Training Optimizations----
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
# ----Distributed Training----
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
# ----------Validation Arguments----------
parser.add_argument(
"--validation_steps",
type=int,
default=200,
help="Run validation every X steps.",
)
# ----------Huggingface Hub Arguments-----------
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
# ----------Accelerate Arguments----------
parser.add_argument(
"--tracker_project_name",
type=str,
default="text2image-fine-tune",
help=(
"The `project_name` argument passed to Accelerator.init_trackers for"
" more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
),
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.proportion_empty_prompts < 0 or args.proportion_empty_prompts > 1:
raise ValueError("`--proportion_empty_prompts` must be in the range [0, 1].")
return args
# Adapted from pipelines.StableDiffusionPipeline.encode_prompt
def encode_prompt(prompt_batch, text_encoder, tokenizer, proportion_empty_prompts, is_train=True):
captions = []
for caption in prompt_batch:
if random.random() < proportion_empty_prompts:
captions.append("")
elif isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
with torch.no_grad():
text_inputs = tokenizer(
captions,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
prompt_embeds = text_encoder(text_input_ids.to(text_encoder.device))[0]
return prompt_embeds
def main(args):
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
split_batches=True, # It's important to set this to True when using webdataset to get the right number of steps for lr scheduling. If set to False, the number of steps will be devide by the number of processes assuming batches are multiplied by the number of processes
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name,
exist_ok=True,
token=args.hub_token,
private=True,
).repo_id
# 1. Create the noise scheduler and the desired noise schedule.
noise_scheduler = DDPMScheduler.from_pretrained(
args.pretrained_teacher_model, subfolder="scheduler", revision=args.teacher_revision
)
# The scheduler calculates the alpha and sigma schedule for us
alpha_schedule = torch.sqrt(noise_scheduler.alphas_cumprod)
sigma_schedule = torch.sqrt(1 - noise_scheduler.alphas_cumprod)
solver = DDIMSolver(
noise_scheduler.alphas_cumprod.numpy(),
timesteps=noise_scheduler.config.num_train_timesteps,
ddim_timesteps=args.num_ddim_timesteps,
)
# 2. Load tokenizers from SD-XL checkpoint.
tokenizer = AutoTokenizer.from_pretrained(
args.pretrained_teacher_model, subfolder="tokenizer", revision=args.teacher_revision, use_fast=False
)
# 3. Load text encoders from SD-1.5 checkpoint.
# import correct text encoder classes
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_teacher_model, subfolder="text_encoder", revision=args.teacher_revision
)
# 4. Load VAE from SD-XL checkpoint (or more stable VAE)
vae = AutoencoderKL.from_pretrained(
args.pretrained_teacher_model,
subfolder="vae",
revision=args.teacher_revision,
)
# 5. Load teacher U-Net from SD-XL checkpoint
teacher_unet = UNet2DConditionModel.from_pretrained(
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
)
# 6. Freeze teacher vae, text_encoder, and teacher_unet
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
teacher_unet.requires_grad_(False)
# 7. Create online (`unet`) student U-Nets.
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
)
unet.train()
# Check that all trainable models are in full precision
low_precision_error_string = (
" Please make sure to always have all model weights in full float32 precision when starting training - even if"
" doing mixed precision training, copy of the weights should still be float32."
)
if accelerator.unwrap_model(unet).dtype != torch.float32:
raise ValueError(
f"Controlnet loaded as datatype {accelerator.unwrap_model(unet).dtype}. {low_precision_error_string}"
)
# 8. Add LoRA to the student U-Net, only the LoRA projection matrix will be updated by the optimizer.
lora_config = LoraConfig(
r=args.lora_rank,
target_modules=[
"to_q",
"to_k",
"to_v",
"to_out.0",
"proj_in",
"proj_out",
"ff.net.0.proj",
"ff.net.2",
"conv1",
"conv2",
"conv_shortcut",
"downsamplers.0.conv",
"upsamplers.0.conv",
"time_emb_proj",
],
)
unet = get_peft_model(unet, lora_config)
# 9. Handle mixed precision and device placement
# For mixed precision training we cast all non-trainable weigths to half-precision
# as these weights are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move unet, vae and text_encoder to device and cast to weight_dtype
# The VAE is in float32 to avoid NaN losses.
vae.to(accelerator.device)
if args.pretrained_vae_model_name_or_path is not None:
vae.to(dtype=weight_dtype)
text_encoder.to(accelerator.device, dtype=weight_dtype)
# Move teacher_unet to device, optionally cast to weight_dtype
teacher_unet.to(accelerator.device)
if args.cast_teacher_unet:
teacher_unet.to(dtype=weight_dtype)
# Also move the alpha and sigma noise schedules to accelerator.device.
alpha_schedule = alpha_schedule.to(accelerator.device)
sigma_schedule = sigma_schedule.to(accelerator.device)
solver = solver.to(accelerator.device)
# 10. Handle saving and loading of checkpoints
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
unet_ = accelerator.unwrap_model(unet)
lora_state_dict = get_peft_model_state_dict(unet_, adapter_name="default")
StableDiffusionPipeline.save_lora_weights(os.path.join(output_dir, "unet_lora"), lora_state_dict)
# save weights in peft format to be able to load them back
unet_.save_pretrained(output_dir)
for _, model in enumerate(models):
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
# load the LoRA into the model
unet_ = accelerator.unwrap_model(unet)
unet_.load_adapter(input_dir, "default", is_trainable=True)
for _ in range(len(models)):
# pop models so that they are not loaded again
models.pop()
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
# 11. Enable optimizations
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
teacher_unet.enable_xformers_memory_efficient_attention()
# target_unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
)
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
# 12. Optimizer creation
optimizer = optimizer_class(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Here, we compute not just the text embeddings but also the additional embeddings
# needed for the SD XL UNet to operate.
def compute_embeddings(prompt_batch, proportion_empty_prompts, text_encoder, tokenizer, is_train=True):
prompt_embeds = encode_prompt(prompt_batch, text_encoder, tokenizer, proportion_empty_prompts, is_train)
return {"prompt_embeds": prompt_embeds}
dataset = Text2ImageDataset(
train_shards_path_or_url=args.train_shards_path_or_url,
num_train_examples=args.max_train_samples,
per_gpu_batch_size=args.train_batch_size,
global_batch_size=args.train_batch_size * accelerator.num_processes,
num_workers=args.dataloader_num_workers,
resolution=args.resolution,
shuffle_buffer_size=1000,
pin_memory=True,
persistent_workers=True,
)
train_dataloader = dataset.train_dataloader
compute_embeddings_fn = functools.partial(
compute_embeddings,
proportion_empty_prompts=0,
text_encoder=text_encoder,
tokenizer=tokenizer,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(train_dataloader.num_batches / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps,
num_training_steps=args.max_train_steps,
)
# Prepare everything with our `accelerator`.
unet, optimizer, lr_scheduler = accelerator.prepare(unet, optimizer, lr_scheduler)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(train_dataloader.num_batches / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
tracker_config = dict(vars(args))
accelerator.init_trackers(args.tracker_project_name, config=tracker_config)
uncond_input_ids = tokenizer(
[""] * args.train_batch_size, return_tensors="pt", padding="max_length", max_length=77
).input_ids.to(accelerator.device)
uncond_prompt_embeds = text_encoder(uncond_input_ids)[0]
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num batches each epoch = {train_dataloader.num_batches}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
for epoch in range(first_epoch, args.num_train_epochs):
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet):
image, text, _, _ = batch
image = image.to(accelerator.device, non_blocking=True)
encoded_text = compute_embeddings_fn(text)
pixel_values = image.to(dtype=weight_dtype)
if vae.dtype != weight_dtype:
vae.to(dtype=weight_dtype)
# encode pixel values with batch size of at most 32
latents = []
for i in range(0, pixel_values.shape[0], 32):
latents.append(vae.encode(pixel_values[i : i + 32]).latent_dist.sample())
latents = torch.cat(latents, dim=0)
latents = latents * vae.config.scaling_factor
latents = latents.to(weight_dtype)
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image t_n ~ U[0, N - k - 1] without bias.
topk = noise_scheduler.config.num_train_timesteps // args.num_ddim_timesteps
index = torch.randint(0, args.num_ddim_timesteps, (bsz,), device=latents.device).long()
start_timesteps = solver.ddim_timesteps[index]
timesteps = start_timesteps - topk
timesteps = torch.where(timesteps < 0, torch.zeros_like(timesteps), timesteps)
# 20.4.4. Get boundary scalings for start_timesteps and (end) timesteps.
c_skip_start, c_out_start = scalings_for_boundary_conditions(start_timesteps)
c_skip_start, c_out_start = [append_dims(x, latents.ndim) for x in [c_skip_start, c_out_start]]
c_skip, c_out = scalings_for_boundary_conditions(timesteps)
c_skip, c_out = [append_dims(x, latents.ndim) for x in [c_skip, c_out]]
# 20.4.5. Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
noisy_model_input = noise_scheduler.add_noise(latents, noise, start_timesteps)
# 20.4.6. Sample a random guidance scale w from U[w_min, w_max] and embed it
w = (args.w_max - args.w_min) * torch.rand((bsz,)) + args.w_min
w = w.reshape(bsz, 1, 1, 1)
w = w.to(device=latents.device, dtype=latents.dtype)
# 20.4.8. Prepare prompt embeds and unet_added_conditions
prompt_embeds = encoded_text.pop("prompt_embeds")
# 20.4.9. Get online LCM prediction on z_{t_{n + k}}, w, c, t_{n + k}
noise_pred = unet(
noisy_model_input,
start_timesteps,
timestep_cond=None,
encoder_hidden_states=prompt_embeds.float(),
added_cond_kwargs=encoded_text,
).sample
pred_x_0 = predicted_origin(
noise_pred,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
model_pred = c_skip_start * noisy_model_input + c_out_start * pred_x_0
# 20.4.10. Use the ODE solver to predict the kth step in the augmented PF-ODE trajectory after
# noisy_latents with both the conditioning embedding c and unconditional embedding 0
# Get teacher model prediction on noisy_latents and conditional embedding
with torch.no_grad():
with torch.autocast("cuda"):
cond_teacher_output = teacher_unet(
noisy_model_input.to(weight_dtype),
start_timesteps,
encoder_hidden_states=prompt_embeds.to(weight_dtype),
).sample
cond_pred_x0 = predicted_origin(
cond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
# Get teacher model prediction on noisy_latents and unconditional embedding
uncond_teacher_output = teacher_unet(
noisy_model_input.to(weight_dtype),
start_timesteps,
encoder_hidden_states=uncond_prompt_embeds.to(weight_dtype),
).sample
uncond_pred_x0 = predicted_origin(
uncond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
# 20.4.11. Perform "CFG" to get x_prev estimate (using the LCM paper's CFG formulation)
pred_x0 = cond_pred_x0 + w * (cond_pred_x0 - uncond_pred_x0)
pred_noise = cond_teacher_output + w * (cond_teacher_output - uncond_teacher_output)
x_prev = solver.ddim_step(pred_x0, pred_noise, index)
# 20.4.12. Get target LCM prediction on x_prev, w, c, t_n
with torch.no_grad():
with torch.autocast("cuda", dtype=weight_dtype):
target_noise_pred = unet(
x_prev.float(),
timesteps,
timestep_cond=None,
encoder_hidden_states=prompt_embeds.float(),
).sample
pred_x_0 = predicted_origin(
target_noise_pred,
timesteps,
x_prev,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
target = c_skip * x_prev + c_out * pred_x_0
# 20.4.13. Calculate loss
if args.loss_type == "l2":
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
elif args.loss_type == "huber":
loss = torch.mean(
torch.sqrt((model_pred.float() - target.float()) ** 2 + args.huber_c**2) - args.huber_c
)
# 20.4.14. Backpropagate on the online student model (`unet`)
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad(set_to_none=True)
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
if accelerator.is_main_process:
if global_step % args.checkpointing_steps == 0:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
if global_step % args.validation_steps == 0:
log_validation(vae, unet, args, accelerator, weight_dtype, global_step)
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
if global_step >= args.max_train_steps:
break
# Create the pipeline using using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
unet.save_pretrained(args.output_dir)
lora_state_dict = get_peft_model_state_dict(unet, adapter_name="default")
StableDiffusionPipeline.save_lora_weights(os.path.join(args.output_dir, "unet_lora"), lora_state_dict)
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/consistency_distillation/train_lcm_distill_sdxl_wds.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import copy
import functools
import gc
import itertools
import json
import logging
import math
import os
import random
import shutil
from pathlib import Path
from typing import List, Union
import accelerate
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import torchvision.transforms.functional as TF
import transformers
import webdataset as wds
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from braceexpand import braceexpand
from huggingface_hub import create_repo
from packaging import version
from torch.utils.data import default_collate
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import AutoTokenizer, PretrainedConfig
from webdataset.tariterators import (
base_plus_ext,
tar_file_expander,
url_opener,
valid_sample,
)
import diffusers
from diffusers import (
AutoencoderKL,
DDPMScheduler,
LCMScheduler,
StableDiffusionXLPipeline,
UNet2DConditionModel,
)
from diffusers.optimization import get_scheduler
from diffusers.utils import check_min_version, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
MAX_SEQ_LENGTH = 77
if is_wandb_available():
import wandb
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.18.0.dev0")
logger = get_logger(__name__)
def filter_keys(key_set):
def _f(dictionary):
return {k: v for k, v in dictionary.items() if k in key_set}
return _f
def group_by_keys_nothrow(data, keys=base_plus_ext, lcase=True, suffixes=None, handler=None):
"""Return function over iterator that groups key, value pairs into samples.
:param keys: function that splits the key into key and extension (base_plus_ext) :param lcase: convert suffixes to
lower case (Default value = True)
"""
current_sample = None
for filesample in data:
assert isinstance(filesample, dict)
fname, value = filesample["fname"], filesample["data"]
prefix, suffix = keys(fname)
if prefix is None:
continue
if lcase:
suffix = suffix.lower()
# FIXME webdataset version throws if suffix in current_sample, but we have a potential for
# this happening in the current LAION400m dataset if a tar ends with same prefix as the next
# begins, rare, but can happen since prefix aren't unique across tar files in that dataset
if current_sample is None or prefix != current_sample["__key__"] or suffix in current_sample:
if valid_sample(current_sample):
yield current_sample
current_sample = {"__key__": prefix, "__url__": filesample["__url__"]}
if suffixes is None or suffix in suffixes:
current_sample[suffix] = value
if valid_sample(current_sample):
yield current_sample
def tarfile_to_samples_nothrow(src, handler=wds.warn_and_continue):
# NOTE this is a re-impl of the webdataset impl with group_by_keys that doesn't throw
streams = url_opener(src, handler=handler)
files = tar_file_expander(streams, handler=handler)
samples = group_by_keys_nothrow(files, handler=handler)
return samples
class WebdatasetFilter:
def __init__(self, min_size=1024, max_pwatermark=0.5):
self.min_size = min_size
self.max_pwatermark = max_pwatermark
def __call__(self, x):
try:
if "json" in x:
x_json = json.loads(x["json"])
filter_size = (x_json.get("original_width", 0.0) or 0.0) >= self.min_size and x_json.get(
"original_height", 0
) >= self.min_size
filter_watermark = (x_json.get("pwatermark", 1.0) or 1.0) <= self.max_pwatermark
return filter_size and filter_watermark
else:
return False
except Exception:
return False
class Text2ImageDataset:
def __init__(
self,
train_shards_path_or_url: Union[str, List[str]],
num_train_examples: int,
per_gpu_batch_size: int,
global_batch_size: int,
num_workers: int,
resolution: int = 1024,
shuffle_buffer_size: int = 1000,
pin_memory: bool = False,
persistent_workers: bool = False,
use_fix_crop_and_size: bool = False,
):
if not isinstance(train_shards_path_or_url, str):
train_shards_path_or_url = [list(braceexpand(urls)) for urls in train_shards_path_or_url]
# flatten list using itertools
train_shards_path_or_url = list(itertools.chain.from_iterable(train_shards_path_or_url))
def get_orig_size(json):
if use_fix_crop_and_size:
return (resolution, resolution)
else:
return (int(json.get("original_width", 0.0)), int(json.get("original_height", 0.0)))
def transform(example):
# resize image
image = example["image"]
image = TF.resize(image, resolution, interpolation=transforms.InterpolationMode.BILINEAR)
# get crop coordinates and crop image
c_top, c_left, _, _ = transforms.RandomCrop.get_params(image, output_size=(resolution, resolution))
image = TF.crop(image, c_top, c_left, resolution, resolution)
image = TF.to_tensor(image)
image = TF.normalize(image, [0.5], [0.5])
example["image"] = image
example["crop_coords"] = (c_top, c_left) if not use_fix_crop_and_size else (0, 0)
return example
processing_pipeline = [
wds.decode("pil", handler=wds.ignore_and_continue),
wds.rename(
image="jpg;png;jpeg;webp", text="text;txt;caption", orig_size="json", handler=wds.warn_and_continue
),
wds.map(filter_keys({"image", "text", "orig_size"})),
wds.map_dict(orig_size=get_orig_size),
wds.map(transform),
wds.to_tuple("image", "text", "orig_size", "crop_coords"),
]
# Create train dataset and loader
pipeline = [
wds.ResampledShards(train_shards_path_or_url),
tarfile_to_samples_nothrow,
wds.select(WebdatasetFilter(min_size=960)),
wds.shuffle(shuffle_buffer_size),
*processing_pipeline,
wds.batched(per_gpu_batch_size, partial=False, collation_fn=default_collate),
]
num_worker_batches = math.ceil(num_train_examples / (global_batch_size * num_workers)) # per dataloader worker
num_batches = num_worker_batches * num_workers
num_samples = num_batches * global_batch_size
# each worker is iterating over this
self._train_dataset = wds.DataPipeline(*pipeline).with_epoch(num_worker_batches)
self._train_dataloader = wds.WebLoader(
self._train_dataset,
batch_size=None,
shuffle=False,
num_workers=num_workers,
pin_memory=pin_memory,
persistent_workers=persistent_workers,
)
# add meta-data to dataloader instance for convenience
self._train_dataloader.num_batches = num_batches
self._train_dataloader.num_samples = num_samples
@property
def train_dataset(self):
return self._train_dataset
@property
def train_dataloader(self):
return self._train_dataloader
def log_validation(vae, unet, args, accelerator, weight_dtype, step, name="target"):
logger.info("Running validation... ")
unet = accelerator.unwrap_model(unet)
pipeline = StableDiffusionXLPipeline.from_pretrained(
args.pretrained_teacher_model,
vae=vae,
unet=unet,
scheduler=LCMScheduler.from_pretrained(args.pretrained_teacher_model, subfolder="scheduler"),
revision=args.revision,
torch_dtype=weight_dtype,
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
if args.enable_xformers_memory_efficient_attention:
pipeline.enable_xformers_memory_efficient_attention()
if args.seed is None:
generator = None
else:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
validation_prompts = [
"portrait photo of a girl, photograph, highly detailed face, depth of field, moody light, golden hour, style by Dan Winters, Russell James, Steve McCurry, centered, extremely detailed, Nikon D850, award winning photography",
"Self-portrait oil painting, a beautiful cyborg with golden hair, 8k",
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
"A photo of beautiful mountain with realistic sunset and blue lake, highly detailed, masterpiece",
]
image_logs = []
for _, prompt in enumerate(validation_prompts):
images = []
with torch.autocast("cuda"):
images = pipeline(
prompt=prompt,
num_inference_steps=4,
num_images_per_prompt=4,
generator=generator,
).images
image_logs.append({"validation_prompt": prompt, "images": images})
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
formatted_images = []
for image in images:
formatted_images.append(np.asarray(image))
formatted_images = np.stack(formatted_images)
tracker.writer.add_images(validation_prompt, formatted_images, step, dataformats="NHWC")
elif tracker.name == "wandb":
formatted_images = []
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
for image in images:
image = wandb.Image(image, caption=validation_prompt)
formatted_images.append(image)
tracker.log({f"validation/{name}": formatted_images})
else:
logger.warn(f"image logging not implemented for {tracker.name}")
del pipeline
gc.collect()
torch.cuda.empty_cache()
return image_logs
def append_dims(x, target_dims):
"""Appends dimensions to the end of a tensor until it has target_dims dimensions."""
dims_to_append = target_dims - x.ndim
if dims_to_append < 0:
raise ValueError(f"input has {x.ndim} dims but target_dims is {target_dims}, which is less")
return x[(...,) + (None,) * dims_to_append]
# From LCMScheduler.get_scalings_for_boundary_condition_discrete
def scalings_for_boundary_conditions(timestep, sigma_data=0.5, timestep_scaling=10.0):
c_skip = sigma_data**2 / ((timestep / 0.1) ** 2 + sigma_data**2)
c_out = (timestep / 0.1) / ((timestep / 0.1) ** 2 + sigma_data**2) ** 0.5
return c_skip, c_out
# Compare LCMScheduler.step, Step 4
def predicted_origin(model_output, timesteps, sample, prediction_type, alphas, sigmas):
if prediction_type == "epsilon":
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
pred_x_0 = (sample - sigmas * model_output) / alphas
elif prediction_type == "v_prediction":
pred_x_0 = alphas[timesteps] * sample - sigmas[timesteps] * model_output
else:
raise ValueError(f"Prediction type {prediction_type} currently not supported.")
return pred_x_0
def extract_into_tensor(a, t, x_shape):
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
@torch.no_grad()
def update_ema(target_params, source_params, rate=0.99):
"""
Update target parameters to be closer to those of source parameters using
an exponential moving average.
:param target_params: the target parameter sequence.
:param source_params: the source parameter sequence.
:param rate: the EMA rate (closer to 1 means slower).
"""
for targ, src in zip(target_params, source_params):
targ.detach().mul_(rate).add_(src, alpha=1 - rate)
# From LatentConsistencyModel.get_guidance_scale_embedding
def guidance_scale_embedding(w, embedding_dim=512, dtype=torch.float32):
"""
See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
Args:
timesteps (`torch.Tensor`):
generate embedding vectors at these timesteps
embedding_dim (`int`, *optional*, defaults to 512):
dimension of the embeddings to generate
dtype:
data type of the generated embeddings
Returns:
`torch.FloatTensor`: Embedding vectors with shape `(len(timesteps), embedding_dim)`
"""
assert len(w.shape) == 1
w = w * 1000.0
half_dim = embedding_dim // 2
emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
emb = w.to(dtype)[:, None] * emb[None, :]
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
if embedding_dim % 2 == 1: # zero pad
emb = torch.nn.functional.pad(emb, (0, 1))
assert emb.shape == (w.shape[0], embedding_dim)
return emb
class DDIMSolver:
def __init__(self, alpha_cumprods, timesteps=1000, ddim_timesteps=50):
# DDIM sampling parameters
step_ratio = timesteps // ddim_timesteps
self.ddim_timesteps = (np.arange(1, ddim_timesteps + 1) * step_ratio).round().astype(np.int64) - 1
self.ddim_alpha_cumprods = alpha_cumprods[self.ddim_timesteps]
self.ddim_alpha_cumprods_prev = np.asarray(
[alpha_cumprods[0]] + alpha_cumprods[self.ddim_timesteps[:-1]].tolist()
)
# convert to torch tensors
self.ddim_timesteps = torch.from_numpy(self.ddim_timesteps).long()
self.ddim_alpha_cumprods = torch.from_numpy(self.ddim_alpha_cumprods)
self.ddim_alpha_cumprods_prev = torch.from_numpy(self.ddim_alpha_cumprods_prev)
def to(self, device):
self.ddim_timesteps = self.ddim_timesteps.to(device)
self.ddim_alpha_cumprods = self.ddim_alpha_cumprods.to(device)
self.ddim_alpha_cumprods_prev = self.ddim_alpha_cumprods_prev.to(device)
return self
def ddim_step(self, pred_x0, pred_noise, timestep_index):
alpha_cumprod_prev = extract_into_tensor(self.ddim_alpha_cumprods_prev, timestep_index, pred_x0.shape)
dir_xt = (1.0 - alpha_cumprod_prev).sqrt() * pred_noise
x_prev = alpha_cumprod_prev.sqrt() * pred_x0 + dir_xt
return x_prev
def import_model_class_from_model_name_or_path(
pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
):
text_encoder_config = PretrainedConfig.from_pretrained(
pretrained_model_name_or_path, subfolder=subfolder, revision=revision, use_auth_token=True
)
model_class = text_encoder_config.architectures[0]
if model_class == "CLIPTextModel":
from transformers import CLIPTextModel
return CLIPTextModel
elif model_class == "CLIPTextModelWithProjection":
from transformers import CLIPTextModelWithProjection
return CLIPTextModelWithProjection
else:
raise ValueError(f"{model_class} is not supported.")
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
# ----------Model Checkpoint Loading Arguments----------
parser.add_argument(
"--pretrained_teacher_model",
type=str,
default=None,
required=True,
help="Path to pretrained LDM teacher model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--pretrained_vae_model_name_or_path",
type=str,
default=None,
help="Path to pretrained VAE model with better numerical stability. More details: https://github.com/huggingface/diffusers/pull/4038.",
)
parser.add_argument(
"--teacher_revision",
type=str,
default=None,
required=False,
help="Revision of pretrained LDM teacher model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained LDM model identifier from huggingface.co/models.",
)
# ----------Training Arguments----------
# ----General Training Arguments----
parser.add_argument(
"--output_dir",
type=str,
default="lcm-xl-distilled",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
# ----Logging----
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
# ----Checkpointing----
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
# ----Image Processing----
parser.add_argument(
"--train_shards_path_or_url",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--resolution",
type=int,
default=1024,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--use_fix_crop_and_size",
action="store_true",
help="Whether or not to use the fixed crop and size for the teacher model.",
default=False,
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
# ----Dataloader----
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
# ----Batch Size and Training Steps----
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
# ----Learning Rate----
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
# ----Optimizer (Adam)----
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
# ----Diffusion Training Arguments----
parser.add_argument(
"--proportion_empty_prompts",
type=float,
default=0,
help="Proportion of image prompts to be replaced with empty strings. Defaults to 0 (no prompt replacement).",
)
# ----Latent Consistency Distillation (LCD) Specific Arguments----
parser.add_argument(
"--w_min",
type=float,
default=3.0,
required=False,
help=(
"The minimum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
" formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
" compared to the original paper."
),
)
parser.add_argument(
"--w_max",
type=float,
default=15.0,
required=False,
help=(
"The maximum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
" formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
" compared to the original paper."
),
)
parser.add_argument(
"--num_ddim_timesteps",
type=int,
default=50,
help="The number of timesteps to use for DDIM sampling.",
)
parser.add_argument(
"--loss_type",
type=str,
default="l2",
choices=["l2", "huber"],
help="The type of loss to use for the LCD loss.",
)
parser.add_argument(
"--huber_c",
type=float,
default=0.001,
help="The huber loss parameter. Only used if `--loss_type=huber`.",
)
parser.add_argument(
"--unet_time_cond_proj_dim",
type=int,
default=256,
help=(
"The dimension of the guidance scale embedding in the U-Net, which will be used if the teacher U-Net"
" does not have `time_cond_proj_dim` set."
),
)
# ----Exponential Moving Average (EMA)----
parser.add_argument(
"--ema_decay",
type=float,
default=0.95,
required=False,
help="The exponential moving average (EMA) rate or decay factor.",
)
# ----Mixed Precision----
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--cast_teacher_unet",
action="store_true",
help="Whether to cast the teacher U-Net to the precision specified by `--mixed_precision`.",
)
# ----Training Optimizations----
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
# ----Distributed Training----
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
# ----------Validation Arguments----------
parser.add_argument(
"--validation_steps",
type=int,
default=200,
help="Run validation every X steps.",
)
# ----------Huggingface Hub Arguments-----------
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
# ----------Accelerate Arguments----------
parser.add_argument(
"--tracker_project_name",
type=str,
default="text2image-fine-tune",
help=(
"The `project_name` argument passed to Accelerator.init_trackers for"
" more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
),
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.proportion_empty_prompts < 0 or args.proportion_empty_prompts > 1:
raise ValueError("`--proportion_empty_prompts` must be in the range [0, 1].")
return args
# Adapted from pipelines.StableDiffusionXLPipeline.encode_prompt
def encode_prompt(prompt_batch, text_encoders, tokenizers, proportion_empty_prompts, is_train=True):
prompt_embeds_list = []
captions = []
for caption in prompt_batch:
if random.random() < proportion_empty_prompts:
captions.append("")
elif isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
with torch.no_grad():
for tokenizer, text_encoder in zip(tokenizers, text_encoders):
text_inputs = tokenizer(
captions,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
prompt_embeds = text_encoder(
text_input_ids.to(text_encoder.device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
pooled_prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.hidden_states[-2]
bs_embed, seq_len, _ = prompt_embeds.shape
prompt_embeds = prompt_embeds.view(bs_embed, seq_len, -1)
prompt_embeds_list.append(prompt_embeds)
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
pooled_prompt_embeds = pooled_prompt_embeds.view(bs_embed, -1)
return prompt_embeds, pooled_prompt_embeds
def main(args):
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
split_batches=True, # It's important to set this to True when using webdataset to get the right number of steps for lr scheduling. If set to False, the number of steps will be devide by the number of processes assuming batches are multiplied by the number of processes
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name,
exist_ok=True,
token=args.hub_token,
private=True,
).repo_id
# 1. Create the noise scheduler and the desired noise schedule.
noise_scheduler = DDPMScheduler.from_pretrained(
args.pretrained_teacher_model, subfolder="scheduler", revision=args.teacher_revision
)
# The scheduler calculates the alpha and sigma schedule for us
alpha_schedule = torch.sqrt(noise_scheduler.alphas_cumprod)
sigma_schedule = torch.sqrt(1 - noise_scheduler.alphas_cumprod)
solver = DDIMSolver(
noise_scheduler.alphas_cumprod.numpy(),
timesteps=noise_scheduler.config.num_train_timesteps,
ddim_timesteps=args.num_ddim_timesteps,
)
# 2. Load tokenizers from SD-XL checkpoint.
tokenizer_one = AutoTokenizer.from_pretrained(
args.pretrained_teacher_model, subfolder="tokenizer", revision=args.teacher_revision, use_fast=False
)
tokenizer_two = AutoTokenizer.from_pretrained(
args.pretrained_teacher_model, subfolder="tokenizer_2", revision=args.teacher_revision, use_fast=False
)
# 3. Load text encoders from SD-XL checkpoint.
# import correct text encoder classes
text_encoder_cls_one = import_model_class_from_model_name_or_path(
args.pretrained_teacher_model, args.teacher_revision
)
text_encoder_cls_two = import_model_class_from_model_name_or_path(
args.pretrained_teacher_model, args.teacher_revision, subfolder="text_encoder_2"
)
text_encoder_one = text_encoder_cls_one.from_pretrained(
args.pretrained_teacher_model, subfolder="text_encoder", revision=args.teacher_revision
)
text_encoder_two = text_encoder_cls_two.from_pretrained(
args.pretrained_teacher_model, subfolder="text_encoder_2", revision=args.teacher_revision
)
# 4. Load VAE from SD-XL checkpoint (or more stable VAE)
vae_path = (
args.pretrained_teacher_model
if args.pretrained_vae_model_name_or_path is None
else args.pretrained_vae_model_name_or_path
)
vae = AutoencoderKL.from_pretrained(
vae_path,
subfolder="vae" if args.pretrained_vae_model_name_or_path is None else None,
revision=args.teacher_revision,
)
# 5. Load teacher U-Net from SD-XL checkpoint
teacher_unet = UNet2DConditionModel.from_pretrained(
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
)
# 6. Freeze teacher vae, text_encoders, and teacher_unet
vae.requires_grad_(False)
text_encoder_one.requires_grad_(False)
text_encoder_two.requires_grad_(False)
teacher_unet.requires_grad_(False)
# 8. Create online (`unet`) student U-Nets. This will be updated by the optimizer (e.g. via backpropagation.)
# Add `time_cond_proj_dim` to the student U-Net if `teacher_unet.config.time_cond_proj_dim` is None
if teacher_unet.config.time_cond_proj_dim is None:
teacher_unet.config["time_cond_proj_dim"] = args.unet_time_cond_proj_dim
unet = UNet2DConditionModel(**teacher_unet.config)
# load teacher_unet weights into unet
unet.load_state_dict(teacher_unet.state_dict(), strict=False)
unet.train()
# 9. Create target (`ema_unet`) student U-Net parameters. This will be updated via EMA updates (polyak averaging).
# Initialize from unet
target_unet = UNet2DConditionModel(**teacher_unet.config)
target_unet.load_state_dict(unet.state_dict())
target_unet.train()
target_unet.requires_grad_(False)
# Check that all trainable models are in full precision
low_precision_error_string = (
" Please make sure to always have all model weights in full float32 precision when starting training - even if"
" doing mixed precision training, copy of the weights should still be float32."
)
if accelerator.unwrap_model(unet).dtype != torch.float32:
raise ValueError(
f"Controlnet loaded as datatype {accelerator.unwrap_model(unet).dtype}. {low_precision_error_string}"
)
# 9. Handle mixed precision and device placement
# For mixed precision training we cast all non-trainable weigths to half-precision
# as these weights are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move unet, vae and text_encoder to device and cast to weight_dtype
# The VAE is in float32 to avoid NaN losses.
vae.to(accelerator.device)
if args.pretrained_vae_model_name_or_path is not None:
vae.to(dtype=weight_dtype)
text_encoder_one.to(accelerator.device, dtype=weight_dtype)
text_encoder_two.to(accelerator.device, dtype=weight_dtype)
target_unet.to(accelerator.device)
# Move teacher_unet to device, optionally cast to weight_dtype
teacher_unet.to(accelerator.device)
if args.cast_teacher_unet:
teacher_unet.to(dtype=weight_dtype)
# Also move the alpha and sigma noise schedules to accelerator.device.
alpha_schedule = alpha_schedule.to(accelerator.device)
sigma_schedule = sigma_schedule.to(accelerator.device)
solver = solver.to(accelerator.device)
# 10. Handle saving and loading of checkpoints
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
target_unet.save_pretrained(os.path.join(output_dir, "unet_target"))
for i, model in enumerate(models):
model.save_pretrained(os.path.join(output_dir, "unet"))
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
load_model = UNet2DConditionModel.from_pretrained(os.path.join(input_dir, "unet_target"))
target_unet.load_state_dict(load_model.state_dict())
target_unet.to(accelerator.device)
del load_model
for i in range(len(models)):
# pop models so that they are not loaded again
model = models.pop()
# load diffusers style into model
load_model = UNet2DConditionModel.from_pretrained(input_dir, subfolder="unet")
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
del load_model
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
# 11. Enable optimizations
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
teacher_unet.enable_xformers_memory_efficient_attention()
target_unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
)
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
# 12. Optimizer creation
optimizer = optimizer_class(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# 13. Dataset creation and data processing
# Here, we compute not just the text embeddings but also the additional embeddings
# needed for the SD XL UNet to operate.
def compute_embeddings(
prompt_batch, original_sizes, crop_coords, proportion_empty_prompts, text_encoders, tokenizers, is_train=True
):
target_size = (args.resolution, args.resolution)
original_sizes = list(map(list, zip(*original_sizes)))
crops_coords_top_left = list(map(list, zip(*crop_coords)))
original_sizes = torch.tensor(original_sizes, dtype=torch.long)
crops_coords_top_left = torch.tensor(crops_coords_top_left, dtype=torch.long)
prompt_embeds, pooled_prompt_embeds = encode_prompt(
prompt_batch, text_encoders, tokenizers, proportion_empty_prompts, is_train
)
add_text_embeds = pooled_prompt_embeds
# Adapted from pipeline.StableDiffusionXLPipeline._get_add_time_ids
add_time_ids = list(target_size)
add_time_ids = torch.tensor([add_time_ids])
add_time_ids = add_time_ids.repeat(len(prompt_batch), 1)
add_time_ids = torch.cat([original_sizes, crops_coords_top_left, add_time_ids], dim=-1)
add_time_ids = add_time_ids.to(accelerator.device, dtype=prompt_embeds.dtype)
prompt_embeds = prompt_embeds.to(accelerator.device)
add_text_embeds = add_text_embeds.to(accelerator.device)
unet_added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
return {"prompt_embeds": prompt_embeds, **unet_added_cond_kwargs}
dataset = Text2ImageDataset(
train_shards_path_or_url=args.train_shards_path_or_url,
num_train_examples=args.max_train_samples,
per_gpu_batch_size=args.train_batch_size,
global_batch_size=args.train_batch_size * accelerator.num_processes,
num_workers=args.dataloader_num_workers,
resolution=args.resolution,
shuffle_buffer_size=1000,
pin_memory=True,
persistent_workers=True,
use_fix_crop_and_size=args.use_fix_crop_and_size,
)
train_dataloader = dataset.train_dataloader
# Let's first compute all the embeddings so that we can free up the text encoders
# from memory.
text_encoders = [text_encoder_one, text_encoder_two]
tokenizers = [tokenizer_one, tokenizer_two]
compute_embeddings_fn = functools.partial(
compute_embeddings,
proportion_empty_prompts=0,
text_encoders=text_encoders,
tokenizers=tokenizers,
)
# 14. LR Scheduler creation
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(train_dataloader.num_batches / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps,
num_training_steps=args.max_train_steps,
)
# 15. Prepare for training
# Prepare everything with our `accelerator`.
unet, optimizer, lr_scheduler = accelerator.prepare(unet, optimizer, lr_scheduler)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(train_dataloader.num_batches / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
tracker_config = dict(vars(args))
accelerator.init_trackers(args.tracker_project_name, config=tracker_config)
# Create uncond embeds for classifier free guidance
uncond_prompt_embeds = torch.zeros(args.train_batch_size, 77, 2048).to(accelerator.device)
uncond_pooled_prompt_embeds = torch.zeros(args.train_batch_size, 1280).to(accelerator.device)
# 16. Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num batches each epoch = {train_dataloader.num_batches}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
for epoch in range(first_epoch, args.num_train_epochs):
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet):
image, text, orig_size, crop_coords = batch
image = image.to(accelerator.device, non_blocking=True)
encoded_text = compute_embeddings_fn(text, orig_size, crop_coords)
if args.pretrained_vae_model_name_or_path is not None:
pixel_values = image.to(dtype=weight_dtype)
if vae.dtype != weight_dtype:
vae.to(dtype=weight_dtype)
else:
pixel_values = image
# encode pixel values with batch size of at most 8
latents = []
for i in range(0, pixel_values.shape[0], 8):
latents.append(vae.encode(pixel_values[i : i + 8]).latent_dist.sample())
latents = torch.cat(latents, dim=0)
latents = latents * vae.config.scaling_factor
if args.pretrained_vae_model_name_or_path is None:
latents = latents.to(weight_dtype)
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image t_n ~ U[0, N - k - 1] without bias.
topk = noise_scheduler.config.num_train_timesteps // args.num_ddim_timesteps
index = torch.randint(0, args.num_ddim_timesteps, (bsz,), device=latents.device).long()
start_timesteps = solver.ddim_timesteps[index]
timesteps = start_timesteps - topk
timesteps = torch.where(timesteps < 0, torch.zeros_like(timesteps), timesteps)
# 20.4.4. Get boundary scalings for start_timesteps and (end) timesteps.
c_skip_start, c_out_start = scalings_for_boundary_conditions(start_timesteps)
c_skip_start, c_out_start = [append_dims(x, latents.ndim) for x in [c_skip_start, c_out_start]]
c_skip, c_out = scalings_for_boundary_conditions(timesteps)
c_skip, c_out = [append_dims(x, latents.ndim) for x in [c_skip, c_out]]
# 20.4.5. Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
noisy_model_input = noise_scheduler.add_noise(latents, noise, start_timesteps)
# 20.4.6. Sample a random guidance scale w from U[w_min, w_max] and embed it
w = (args.w_max - args.w_min) * torch.rand((bsz,)) + args.w_min
w_embedding = guidance_scale_embedding(w, embedding_dim=unet.config.time_cond_proj_dim)
w = w.reshape(bsz, 1, 1, 1)
w = w.to(device=latents.device, dtype=latents.dtype)
# 20.4.8. Prepare prompt embeds and unet_added_conditions
prompt_embeds = encoded_text.pop("prompt_embeds")
# 20.4.9. Get online LCM prediction on z_{t_{n + k}}, w, c, t_{n + k}
noise_pred = unet(
noisy_model_input,
start_timesteps,
timestep_cond=w_embedding,
encoder_hidden_states=prompt_embeds.float(),
added_cond_kwargs=encoded_text,
).sample
pred_x_0 = predicted_origin(
noise_pred,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
model_pred = c_skip_start * noisy_model_input + c_out_start * pred_x_0
# 20.4.10. Use the ODE solver to predict the kth step in the augmented PF-ODE trajectory after
# noisy_latents with both the conditioning embedding c and unconditional embedding 0
# Get teacher model prediction on noisy_latents and conditional embedding
with torch.no_grad():
with torch.autocast("cuda"):
cond_teacher_output = teacher_unet(
noisy_model_input.to(weight_dtype),
start_timesteps,
encoder_hidden_states=prompt_embeds.to(weight_dtype),
added_cond_kwargs={k: v.to(weight_dtype) for k, v in encoded_text.items()},
).sample
cond_pred_x0 = predicted_origin(
cond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
# Get teacher model prediction on noisy_latents and unconditional embedding
uncond_added_conditions = copy.deepcopy(encoded_text)
uncond_added_conditions["text_embeds"] = uncond_pooled_prompt_embeds
uncond_teacher_output = teacher_unet(
noisy_model_input.to(weight_dtype),
start_timesteps,
encoder_hidden_states=uncond_prompt_embeds.to(weight_dtype),
added_cond_kwargs={k: v.to(weight_dtype) for k, v in uncond_added_conditions.items()},
).sample
uncond_pred_x0 = predicted_origin(
uncond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
# 20.4.11. Perform "CFG" to get x_prev estimate (using the LCM paper's CFG formulation)
pred_x0 = cond_pred_x0 + w * (cond_pred_x0 - uncond_pred_x0)
pred_noise = cond_teacher_output + w * (cond_teacher_output - uncond_teacher_output)
x_prev = solver.ddim_step(pred_x0, pred_noise, index)
# 20.4.12. Get target LCM prediction on x_prev, w, c, t_n
with torch.no_grad():
with torch.autocast("cuda", dtype=weight_dtype):
target_noise_pred = target_unet(
x_prev.float(),
timesteps,
timestep_cond=w_embedding,
encoder_hidden_states=prompt_embeds.float(),
added_cond_kwargs=encoded_text,
).sample
pred_x_0 = predicted_origin(
target_noise_pred,
timesteps,
x_prev,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
target = c_skip * x_prev + c_out * pred_x_0
# 20.4.13. Calculate loss
if args.loss_type == "l2":
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
elif args.loss_type == "huber":
loss = torch.mean(
torch.sqrt((model_pred.float() - target.float()) ** 2 + args.huber_c**2) - args.huber_c
)
# 20.4.14. Backpropagate on the online student model (`unet`)
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad(set_to_none=True)
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
# 20.4.15. Make EMA update to target student model parameters
update_ema(target_unet.parameters(), unet.parameters(), args.ema_decay)
progress_bar.update(1)
global_step += 1
if accelerator.is_main_process:
if global_step % args.checkpointing_steps == 0:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
if global_step % args.validation_steps == 0:
log_validation(vae, target_unet, args, accelerator, weight_dtype, global_step, "target")
log_validation(vae, unet, args, accelerator, weight_dtype, global_step, "online")
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
if global_step >= args.max_train_steps:
break
# Create the pipeline using using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
unet.save_pretrained(os.path.join(args.output_dir, "unet"))
target_unet = accelerator.unwrap_model(target_unet)
target_unet.save_pretrained(os.path.join(args.output_dir, "unet_target"))
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/consistency_distillation/requirements.txt
|
accelerate>=0.16.0
torchvision
transformers>=4.25.1
ftfy
tensorboard
Jinja2
webdataset
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/inference/README.md
|
# Inference Examples
**The inference examples folder is deprecated and will be removed in a future version**.
**Officially supported inference examples can be found in the [Pipelines folder](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines)**.
- For `Image-to-Image text-guided generation with Stable Diffusion`, please have a look at the official [Pipeline examples](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines#examples)
- For `In-painting using Stable Diffusion`, please have a look at the official [Pipeline examples](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines#examples)
- For `Tweak prompts reusing seeds and latents`, please have a look at the official [Pipeline examples](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines#examples)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/inference/inpainting.py
|
import warnings
from diffusers import StableDiffusionInpaintPipeline as StableDiffusionInpaintPipeline # noqa F401
warnings.warn(
"The `inpainting.py` script is outdated. Please use directly `from diffusers import"
" StableDiffusionInpaintPipeline` instead."
)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/inference/image_to_image.py
|
import warnings
from diffusers import StableDiffusionImg2ImgPipeline # noqa F401
warnings.warn(
"The `image_to_image.py` script is outdated. Please use directly `from diffusers import"
" StableDiffusionImg2ImgPipeline` instead."
)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/unconditional_image_generation/README.md
|
## Training an unconditional diffusion model
Creating a training image set is [described in a different document](https://huggingface.co/docs/datasets/image_process#image-datasets).
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
### Unconditional Flowers
The command to train a DDPM UNet model on the Oxford Flowers dataset:
```bash
accelerate launch train_unconditional.py \
--dataset_name="huggan/flowers-102-categories" \
--resolution=64 --center_crop --random_flip \
--output_dir="ddpm-ema-flowers-64" \
--train_batch_size=16 \
--num_epochs=100 \
--gradient_accumulation_steps=1 \
--use_ema \
--learning_rate=1e-4 \
--lr_warmup_steps=500 \
--mixed_precision=no \
--push_to_hub
```
An example trained model: https://huggingface.co/anton-l/ddpm-ema-flowers-64
A full training run takes 2 hours on 4xV100 GPUs.
<img src="https://user-images.githubusercontent.com/26864830/180248660-a0b143d0-b89a-42c5-8656-2ebf6ece7e52.png" width="700" />
### Unconditional Pokemon
The command to train a DDPM UNet model on the Pokemon dataset:
```bash
accelerate launch train_unconditional.py \
--dataset_name="huggan/pokemon" \
--resolution=64 --center_crop --random_flip \
--output_dir="ddpm-ema-pokemon-64" \
--train_batch_size=16 \
--num_epochs=100 \
--gradient_accumulation_steps=1 \
--use_ema \
--learning_rate=1e-4 \
--lr_warmup_steps=500 \
--mixed_precision=no \
--push_to_hub
```
An example trained model: https://huggingface.co/anton-l/ddpm-ema-pokemon-64
A full training run takes 2 hours on 4xV100 GPUs.
<img src="https://user-images.githubusercontent.com/26864830/180248200-928953b4-db38-48db-b0c6-8b740fe6786f.png" width="700" />
### Training with multiple GPUs
`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
for running distributed training with `accelerate`. Here is an example command:
```bash
accelerate launch --mixed_precision="fp16" --multi_gpu train_unconditional.py \
--dataset_name="huggan/pokemon" \
--resolution=64 --center_crop --random_flip \
--output_dir="ddpm-ema-pokemon-64" \
--train_batch_size=16 \
--num_epochs=100 \
--gradient_accumulation_steps=1 \
--use_ema \
--learning_rate=1e-4 \
--lr_warmup_steps=500 \
--mixed_precision="fp16" \
--logger="wandb"
```
To be able to use Weights and Biases (`wandb`) as a logger you need to install the library: `pip install wandb`.
### Using your own data
To use your own dataset, there are 2 ways:
- you can either provide your own folder as `--train_data_dir`
- or you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
Below, we explain both in more detail.
#### Provide the dataset as a folder
If you provide your own folders with images, the script expects the following directory structure:
```bash
data_dir/xxx.png
data_dir/xxy.png
data_dir/[...]/xxz.png
```
In other words, the script will take care of gathering all images inside the folder. You can then run the script like this:
```bash
accelerate launch train_unconditional.py \
--train_data_dir <path-to-train-directory> \
<other-arguments>
```
Internally, the script will use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature which will automatically turn the folders into 🤗 Dataset objects.
#### Upload your data to the hub, as a (possibly private) repo
It's very easy (and convenient) to upload your image dataset to the hub using the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature available in 🤗 Datasets. Simply do the following:
```python
from datasets import load_dataset
# example 1: local folder
dataset = load_dataset("imagefolder", data_dir="path_to_your_folder")
# example 2: local files (supported formats are tar, gzip, zip, xz, rar, zstd)
dataset = load_dataset("imagefolder", data_files="path_to_zip_file")
# example 3: remote files (supported formats are tar, gzip, zip, xz, rar, zstd)
dataset = load_dataset("imagefolder", data_files="https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip")
# example 4: providing several splits
dataset = load_dataset("imagefolder", data_files={"train": ["path/to/file1", "path/to/file2"], "test": ["path/to/file3", "path/to/file4"]})
```
`ImageFolder` will create an `image` column containing the PIL-encoded images.
Next, push it to the hub!
```python
# assuming you have ran the huggingface-cli login command in a terminal
dataset.push_to_hub("name_of_your_dataset")
# if you want to push to a private repo, simply pass private=True:
dataset.push_to_hub("name_of_your_dataset", private=True)
```
and that's it! You can now train your model by simply setting the `--dataset_name` argument to the name of your dataset on the hub.
More on this can also be found in [this blog post](https://huggingface.co/blog/image-search-datasets).
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/unconditional_image_generation/train_unconditional.py
|
import argparse
import inspect
import logging
import math
import os
import shutil
from datetime import timedelta
from pathlib import Path
import accelerate
import datasets
import torch
import torch.nn.functional as F
from accelerate import Accelerator, InitProcessGroupKwargs
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration
from datasets import load_dataset
from huggingface_hub import create_repo, upload_folder
from packaging import version
from torchvision import transforms
from tqdm.auto import tqdm
import diffusers
from diffusers import DDPMPipeline, DDPMScheduler, UNet2DModel
from diffusers.optimization import get_scheduler
from diffusers.training_utils import EMAModel
from diffusers.utils import check_min_version, is_accelerate_version, is_tensorboard_available, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.24.0.dev0")
logger = get_logger(__name__, log_level="INFO")
def _extract_into_tensor(arr, timesteps, broadcast_shape):
"""
Extract values from a 1-D numpy array for a batch of indices.
:param arr: the 1-D numpy array.
:param timesteps: a tensor of indices into the array to extract.
:param broadcast_shape: a larger shape of K dimensions with the batch
dimension equal to the length of timesteps.
:return: a tensor of shape [batch_size, 1, ...] where the shape has K dims.
"""
if not isinstance(arr, torch.Tensor):
arr = torch.from_numpy(arr)
res = arr[timesteps].float().to(timesteps.device)
while len(res.shape) < len(broadcast_shape):
res = res[..., None]
return res.expand(broadcast_shape)
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that HF Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--model_config_name_or_path",
type=str,
default=None,
help="The config of the UNet model to train, leave as None to use standard DDPM configuration.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="ddpm-model-64",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument("--overwrite_output_dir", action="store_true")
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument(
"--resolution",
type=int,
default=64,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
default=False,
action="store_true",
help="whether to randomly flip images horizontally",
)
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument(
"--eval_batch_size", type=int, default=16, help="The number of images to generate for evaluation."
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"The number of subprocesses to use for data loading. 0 means that the data will be loaded in the main"
" process."
),
)
parser.add_argument("--num_epochs", type=int, default=100)
parser.add_argument("--save_images_epochs", type=int, default=10, help="How often to save images during training.")
parser.add_argument(
"--save_model_epochs", type=int, default=10, help="How often to save the model during training."
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="cosine",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--adam_beta1", type=float, default=0.95, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument(
"--adam_weight_decay", type=float, default=1e-6, help="Weight decay magnitude for the Adam optimizer."
)
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer.")
parser.add_argument(
"--use_ema",
action="store_true",
help="Whether to use Exponential Moving Average for the final model weights.",
)
parser.add_argument("--ema_inv_gamma", type=float, default=1.0, help="The inverse gamma value for the EMA decay.")
parser.add_argument("--ema_power", type=float, default=3 / 4, help="The power value for the EMA decay.")
parser.add_argument("--ema_max_decay", type=float, default=0.9999, help="The maximum decay magnitude for EMA.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--hub_private_repo", action="store_true", help="Whether or not to create a private repository."
)
parser.add_argument(
"--logger",
type=str,
default="tensorboard",
choices=["tensorboard", "wandb"],
help=(
"Whether to use [tensorboard](https://www.tensorflow.org/tensorboard) or [wandb](https://www.wandb.ai)"
" for experiment tracking and logging of model metrics and model checkpoints"
),
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--mixed_precision",
type=str,
default="no",
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU."
),
)
parser.add_argument(
"--prediction_type",
type=str,
default="epsilon",
choices=["epsilon", "sample"],
help="Whether the model should predict the 'epsilon'/noise error or directly the reconstructed image 'x0'.",
)
parser.add_argument("--ddpm_num_steps", type=int, default=1000)
parser.add_argument("--ddpm_num_inference_steps", type=int, default=1000)
parser.add_argument("--ddpm_beta_schedule", type=str, default="linear")
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("You must specify either a dataset name from the hub or a train data directory.")
return args
def main(args):
logging_dir = os.path.join(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
kwargs = InitProcessGroupKwargs(timeout=timedelta(seconds=7200)) # a big number for high resolution or big dataset
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.logger,
project_config=accelerator_project_config,
kwargs_handlers=[kwargs],
)
if args.logger == "tensorboard":
if not is_tensorboard_available():
raise ImportError("Make sure to install tensorboard if you want to use it for logging during training.")
elif args.logger == "wandb":
if not is_wandb_available():
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
import wandb
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
if args.use_ema:
ema_model.save_pretrained(os.path.join(output_dir, "unet_ema"))
for i, model in enumerate(models):
model.save_pretrained(os.path.join(output_dir, "unet"))
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
if args.use_ema:
load_model = EMAModel.from_pretrained(os.path.join(input_dir, "unet_ema"), UNet2DModel)
ema_model.load_state_dict(load_model.state_dict())
ema_model.to(accelerator.device)
del load_model
for i in range(len(models)):
# pop models so that they are not loaded again
model = models.pop()
# load diffusers style into model
load_model = UNet2DModel.from_pretrained(input_dir, subfolder="unet")
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
del load_model
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Initialize the model
if args.model_config_name_or_path is None:
model = UNet2DModel(
sample_size=args.resolution,
in_channels=3,
out_channels=3,
layers_per_block=2,
block_out_channels=(128, 128, 256, 256, 512, 512),
down_block_types=(
"DownBlock2D",
"DownBlock2D",
"DownBlock2D",
"DownBlock2D",
"AttnDownBlock2D",
"DownBlock2D",
),
up_block_types=(
"UpBlock2D",
"AttnUpBlock2D",
"UpBlock2D",
"UpBlock2D",
"UpBlock2D",
"UpBlock2D",
),
)
else:
config = UNet2DModel.load_config(args.model_config_name_or_path)
model = UNet2DModel.from_config(config)
# Create EMA for the model.
if args.use_ema:
ema_model = EMAModel(
model.parameters(),
decay=args.ema_max_decay,
use_ema_warmup=True,
inv_gamma=args.ema_inv_gamma,
power=args.ema_power,
model_cls=UNet2DModel,
model_config=model.config,
)
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
args.mixed_precision = accelerator.mixed_precision
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
args.mixed_precision = accelerator.mixed_precision
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
model.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# Initialize the scheduler
accepts_prediction_type = "prediction_type" in set(inspect.signature(DDPMScheduler.__init__).parameters.keys())
if accepts_prediction_type:
noise_scheduler = DDPMScheduler(
num_train_timesteps=args.ddpm_num_steps,
beta_schedule=args.ddpm_beta_schedule,
prediction_type=args.prediction_type,
)
else:
noise_scheduler = DDPMScheduler(num_train_timesteps=args.ddpm_num_steps, beta_schedule=args.ddpm_beta_schedule)
# Initialize the optimizer
optimizer = torch.optim.AdamW(
model.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
split="train",
)
else:
dataset = load_dataset("imagefolder", data_dir=args.train_data_dir, cache_dir=args.cache_dir, split="train")
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
# Preprocessing the datasets and DataLoaders creation.
augmentations = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def transform_images(examples):
images = [augmentations(image.convert("RGB")) for image in examples["image"]]
return {"input": images}
logger.info(f"Dataset size: {len(dataset)}")
dataset.set_transform(transform_images)
train_dataloader = torch.utils.data.DataLoader(
dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers
)
# Initialize the learning rate scheduler
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
num_training_steps=(len(train_dataloader) * args.num_epochs),
)
# Prepare everything with our `accelerator`.
model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, lr_scheduler
)
if args.use_ema:
ema_model.to(accelerator.device)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
run = os.path.split(__file__)[-1].split(".")[0]
accelerator.init_trackers(run)
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
max_train_steps = args.num_epochs * num_update_steps_per_epoch
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(dataset)}")
logger.info(f" Num Epochs = {args.num_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
resume_global_step = global_step * args.gradient_accumulation_steps
first_epoch = global_step // num_update_steps_per_epoch
resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
# Train!
for epoch in range(first_epoch, args.num_epochs):
model.train()
progress_bar = tqdm(total=num_update_steps_per_epoch, disable=not accelerator.is_local_main_process)
progress_bar.set_description(f"Epoch {epoch}")
for step, batch in enumerate(train_dataloader):
# Skip steps until we reach the resumed step
if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
if step % args.gradient_accumulation_steps == 0:
progress_bar.update(1)
continue
clean_images = batch["input"].to(weight_dtype)
# Sample noise that we'll add to the images
noise = torch.randn(clean_images.shape, dtype=weight_dtype, device=clean_images.device)
bsz = clean_images.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=clean_images.device
).long()
# Add noise to the clean images according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
with accelerator.accumulate(model):
# Predict the noise residual
model_output = model(noisy_images, timesteps).sample
if args.prediction_type == "epsilon":
loss = F.mse_loss(model_output.float(), noise.float()) # this could have different weights!
elif args.prediction_type == "sample":
alpha_t = _extract_into_tensor(
noise_scheduler.alphas_cumprod, timesteps, (clean_images.shape[0], 1, 1, 1)
)
snr_weights = alpha_t / (1 - alpha_t)
# use SNR weighting from distillation paper
loss = snr_weights * F.mse_loss(model_output.float(), clean_images.float(), reduction="none")
loss = loss.mean()
else:
raise ValueError(f"Unsupported prediction type: {args.prediction_type}")
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
if args.use_ema:
ema_model.step(model.parameters())
progress_bar.update(1)
global_step += 1
if accelerator.is_main_process:
if global_step % args.checkpointing_steps == 0:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "step": global_step}
if args.use_ema:
logs["ema_decay"] = ema_model.cur_decay_value
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
progress_bar.close()
accelerator.wait_for_everyone()
# Generate sample images for visual inspection
if accelerator.is_main_process:
if epoch % args.save_images_epochs == 0 or epoch == args.num_epochs - 1:
unet = accelerator.unwrap_model(model)
if args.use_ema:
ema_model.store(unet.parameters())
ema_model.copy_to(unet.parameters())
pipeline = DDPMPipeline(
unet=unet,
scheduler=noise_scheduler,
)
generator = torch.Generator(device=pipeline.device).manual_seed(0)
# run pipeline in inference (sample random noise and denoise)
images = pipeline(
generator=generator,
batch_size=args.eval_batch_size,
num_inference_steps=args.ddpm_num_inference_steps,
output_type="numpy",
).images
if args.use_ema:
ema_model.restore(unet.parameters())
# denormalize the images and save to tensorboard
images_processed = (images * 255).round().astype("uint8")
if args.logger == "tensorboard":
if is_accelerate_version(">=", "0.17.0.dev0"):
tracker = accelerator.get_tracker("tensorboard", unwrap=True)
else:
tracker = accelerator.get_tracker("tensorboard")
tracker.add_images("test_samples", images_processed.transpose(0, 3, 1, 2), epoch)
elif args.logger == "wandb":
# Upcoming `log_images` helper coming in https://github.com/huggingface/accelerate/pull/962/files
accelerator.get_tracker("wandb").log(
{"test_samples": [wandb.Image(img) for img in images_processed], "epoch": epoch},
step=global_step,
)
if epoch % args.save_model_epochs == 0 or epoch == args.num_epochs - 1:
# save the model
unet = accelerator.unwrap_model(model)
if args.use_ema:
ema_model.store(unet.parameters())
ema_model.copy_to(unet.parameters())
pipeline = DDPMPipeline(
unet=unet,
scheduler=noise_scheduler,
)
pipeline.save_pretrained(args.output_dir)
if args.use_ema:
ema_model.restore(unet.parameters())
if args.push_to_hub:
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message=f"Epoch {epoch}",
ignore_patterns=["step_*", "epoch_*"],
)
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/unconditional_image_generation/requirements.txt
|
accelerate>=0.16.0
torchvision
datasets
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/custom_diffusion/README.md
|
# Custom Diffusion training example
[Custom Diffusion](https://arxiv.org/abs/2212.04488) is a method to customize text-to-image models like Stable Diffusion given just a few (4~5) images of a subject.
The `train_custom_diffusion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
pip install clip-retrieval
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
### Cat example 😺
Now let's get our dataset. Download dataset from [here](https://www.cs.cmu.edu/~custom-diffusion/assets/data.zip) and unzip it.
We also collect 200 real images using `clip-retrieval` which are combined with the target images in the training dataset as a regularization. This prevents overfitting to the given target image. The following flags enable the regularization `with_prior_preservation`, `real_prior` with `prior_loss_weight=1.`.
The `class_prompt` should be the category name same as target image. The collected real images are with text captions similar to the `class_prompt`. The retrieved image are saved in `class_data_dir`. You can disable `real_prior` to use generated images as regularization. To collect the real images use this command first before training.
```bash
pip install clip-retrieval
python retrieve.py --class_prompt cat --class_data_dir real_reg/samples_cat --num_class_images 200
```
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export OUTPUT_DIR="path-to-save-model"
export INSTANCE_DIR="./data/cat"
accelerate launch train_custom_diffusion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--class_data_dir=./real_reg/samples_cat/ \
--with_prior_preservation --real_prior --prior_loss_weight=1.0 \
--class_prompt="cat" --num_class_images=200 \
--instance_prompt="photo of a <new1> cat" \
--resolution=512 \
--train_batch_size=2 \
--learning_rate=1e-5 \
--lr_warmup_steps=0 \
--max_train_steps=250 \
--scale_lr --hflip \
--modifier_token "<new1>"
```
**Use `--enable_xformers_memory_efficient_attention` for faster training with lower VRAM requirement (16GB per GPU). Follow [this guide](https://github.com/facebookresearch/xformers) for installation instructions.**
To track your experiments using Weights and Biases (`wandb`) and to save intermediate results (which we HIGHLY recommend), follow these steps:
* Install `wandb`: `pip install wandb`.
* Authorize: `wandb login`.
* Then specify a `validation_prompt` and set `report_to` to `wandb` while launching training. You can also configure the following related arguments:
* `num_validation_images`
* `validation_steps`
Here is an example command:
```bash
accelerate launch train_custom_diffusion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--class_data_dir=./real_reg/samples_cat/ \
--with_prior_preservation --real_prior --prior_loss_weight=1.0 \
--class_prompt="cat" --num_class_images=200 \
--instance_prompt="photo of a <new1> cat" \
--resolution=512 \
--train_batch_size=2 \
--learning_rate=1e-5 \
--lr_warmup_steps=0 \
--max_train_steps=250 \
--scale_lr --hflip \
--modifier_token "<new1>" \
--validation_prompt="<new1> cat sitting in a bucket" \
--report_to="wandb"
```
Here is an example [Weights and Biases page](https://wandb.ai/sayakpaul/custom-diffusion/runs/26ghrcau) where you can check out the intermediate results along with other training details.
If you specify `--push_to_hub`, the learned parameters will be pushed to a repository on the Hugging Face Hub. Here is an [example repository](https://huggingface.co/sayakpaul/custom-diffusion-cat).
### Training on multiple concepts 🐱🪵
Provide a [json](https://github.com/adobe-research/custom-diffusion/blob/main/assets/concept_list.json) file with the info about each concept, similar to [this](https://github.com/ShivamShrirao/diffusers/blob/main/examples/dreambooth/train_dreambooth.py).
To collect the real images run this command for each concept in the json file.
```bash
pip install clip-retrieval
python retrieve.py --class_prompt {} --class_data_dir {} --num_class_images 200
```
And then we're ready to start training!
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_custom_diffusion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--output_dir=$OUTPUT_DIR \
--concepts_list=./concept_list.json \
--with_prior_preservation --real_prior --prior_loss_weight=1.0 \
--resolution=512 \
--train_batch_size=2 \
--learning_rate=1e-5 \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--num_class_images=200 \
--scale_lr --hflip \
--modifier_token "<new1>+<new2>"
```
Here is an example [Weights and Biases page](https://wandb.ai/sayakpaul/custom-diffusion/runs/3990tzkg) where you can check out the intermediate results along with other training details.
### Training on human faces
For fine-tuning on human faces we found the following configuration to work better: `learning_rate=5e-6`, `max_train_steps=1000 to 2000`, and `freeze_model=crossattn` with at least 15-20 images.
To collect the real images use this command first before training.
```bash
pip install clip-retrieval
python retrieve.py --class_prompt person --class_data_dir real_reg/samples_person --num_class_images 200
```
Then start training!
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export OUTPUT_DIR="path-to-save-model"
export INSTANCE_DIR="path-to-images"
accelerate launch train_custom_diffusion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--class_data_dir=./real_reg/samples_person/ \
--with_prior_preservation --real_prior --prior_loss_weight=1.0 \
--class_prompt="person" --num_class_images=200 \
--instance_prompt="photo of a <new1> person" \
--resolution=512 \
--train_batch_size=2 \
--learning_rate=5e-6 \
--lr_warmup_steps=0 \
--max_train_steps=1000 \
--scale_lr --hflip --noaug \
--freeze_model crossattn \
--modifier_token "<new1>" \
--enable_xformers_memory_efficient_attention
```
## Inference
Once you have trained a model using the above command, you can run inference using the below command. Make sure to include the `modifier token` (e.g. \<new1\> in above example) in your prompt.
```python
import torch
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
).to("cuda")
pipe.unet.load_attn_procs(
"path-to-save-model", weight_name="pytorch_custom_diffusion_weights.bin"
)
pipe.load_textual_inversion("path-to-save-model", weight_name="<new1>.bin")
image = pipe(
"<new1> cat sitting in a bucket",
num_inference_steps=100,
guidance_scale=6.0,
eta=1.0,
).images[0]
image.save("cat.png")
```
It's possible to directly load these parameters from a Hub repository:
```python
import torch
from huggingface_hub.repocard import RepoCard
from diffusers import DiffusionPipeline
model_id = "sayakpaul/custom-diffusion-cat"
card = RepoCard.load(model_id)
base_model_id = card.data.to_dict()["base_model"]
pipe = DiffusionPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16).to(
"cuda")
pipe.unet.load_attn_procs(model_id, weight_name="pytorch_custom_diffusion_weights.bin")
pipe.load_textual_inversion(model_id, weight_name="<new1>.bin")
image = pipe(
"<new1> cat sitting in a bucket",
num_inference_steps=100,
guidance_scale=6.0,
eta=1.0,
).images[0]
image.save("cat.png")
```
Here is an example of performing inference with multiple concepts:
```python
import torch
from huggingface_hub.repocard import RepoCard
from diffusers import DiffusionPipeline
model_id = "sayakpaul/custom-diffusion-cat-wooden-pot"
card = RepoCard.load(model_id)
base_model_id = card.data.to_dict()["base_model"]
pipe = DiffusionPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16).to(
"cuda")
pipe.unet.load_attn_procs(model_id, weight_name="pytorch_custom_diffusion_weights.bin")
pipe.load_textual_inversion(model_id, weight_name="<new1>.bin")
pipe.load_textual_inversion(model_id, weight_name="<new2>.bin")
image = pipe(
"the <new1> cat sculpture in the style of a <new2> wooden pot",
num_inference_steps=100,
guidance_scale=6.0,
eta=1.0,
).images[0]
image.save("multi-subject.png")
```
Here, `cat` and `wooden pot` refer to the multiple concepts.
### Inference from a training checkpoint
You can also perform inference from one of the complete checkpoint saved during the training process, if you used the `--checkpointing_steps` argument.
TODO.
## Set grads to none
To save even more memory, pass the `--set_grads_to_none` argument to the script. This will set grads to None instead of zero. However, be aware that it changes certain behaviors, so if you start experiencing any problems, remove this argument.
More info: https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html
## Experimental results
You can refer to [our webpage](https://www.cs.cmu.edu/~custom-diffusion/) that discusses our experiments in detail. We also released a more extensive dataset of 101 concepts for evaluating model customization methods. For more details please refer to our [dataset webpage](https://www.cs.cmu.edu/~custom-diffusion/dataset.html).
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/custom_diffusion/train_custom_diffusion.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 Custom Diffusion authors and the HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import itertools
import json
import logging
import math
import os
import random
import shutil
import warnings
from pathlib import Path
import numpy as np
import safetensors
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from huggingface_hub import HfApi, create_repo
from huggingface_hub.utils import insecure_hashlib
from packaging import version
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import AutoTokenizer, PretrainedConfig
import diffusers
from diffusers import (
AutoencoderKL,
DDPMScheduler,
DiffusionPipeline,
DPMSolverMultistepScheduler,
UNet2DConditionModel,
)
from diffusers.loaders import AttnProcsLayers
from diffusers.models.attention_processor import (
CustomDiffusionAttnProcessor,
CustomDiffusionAttnProcessor2_0,
CustomDiffusionXFormersAttnProcessor,
)
from diffusers.optimization import get_scheduler
from diffusers.utils import check_min_version, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.24.0.dev0")
logger = get_logger(__name__)
def freeze_params(params):
for param in params:
param.requires_grad = False
def save_model_card(repo_id: str, images=None, base_model=str, prompt=str, repo_folder=None):
img_str = ""
for i, image in enumerate(images):
image.save(os.path.join(repo_folder, f"image_{i}.png"))
img_str += f"\n"
yaml = f"""
---
license: creativeml-openrail-m
base_model: {base_model}
instance_prompt: {prompt}
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- custom-diffusion
inference: true
---
"""
model_card = f"""
# Custom Diffusion - {repo_id}
These are Custom Diffusion adaption weights for {base_model}. The weights were trained on {prompt} using [Custom Diffusion](https://www.cs.cmu.edu/~custom-diffusion). You can find some example images in the following. \n
{img_str}
\nFor more details on the training, please follow [this link](https://github.com/huggingface/diffusers/blob/main/examples/custom_diffusion).
"""
with open(os.path.join(repo_folder, "README.md"), "w") as f:
f.write(yaml + model_card)
def import_model_class_from_model_name_or_path(pretrained_model_name_or_path: str, revision: str):
text_encoder_config = PretrainedConfig.from_pretrained(
pretrained_model_name_or_path,
subfolder="text_encoder",
revision=revision,
)
model_class = text_encoder_config.architectures[0]
if model_class == "CLIPTextModel":
from transformers import CLIPTextModel
return CLIPTextModel
elif model_class == "RobertaSeriesModelWithTransformation":
from diffusers.pipelines.alt_diffusion.modeling_roberta_series import RobertaSeriesModelWithTransformation
return RobertaSeriesModelWithTransformation
else:
raise ValueError(f"{model_class} is not supported.")
def collate_fn(examples, with_prior_preservation):
input_ids = [example["instance_prompt_ids"] for example in examples]
pixel_values = [example["instance_images"] for example in examples]
mask = [example["mask"] for example in examples]
# Concat class and instance examples for prior preservation.
# We do this to avoid doing two forward passes.
if with_prior_preservation:
input_ids += [example["class_prompt_ids"] for example in examples]
pixel_values += [example["class_images"] for example in examples]
mask += [example["class_mask"] for example in examples]
input_ids = torch.cat(input_ids, dim=0)
pixel_values = torch.stack(pixel_values)
mask = torch.stack(mask)
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
mask = mask.to(memory_format=torch.contiguous_format).float()
batch = {"input_ids": input_ids, "pixel_values": pixel_values, "mask": mask.unsqueeze(1)}
return batch
class PromptDataset(Dataset):
"A simple dataset to prepare the prompts to generate class images on multiple GPUs."
def __init__(self, prompt, num_samples):
self.prompt = prompt
self.num_samples = num_samples
def __len__(self):
return self.num_samples
def __getitem__(self, index):
example = {}
example["prompt"] = self.prompt
example["index"] = index
return example
class CustomDiffusionDataset(Dataset):
"""
A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
It pre-processes the images and the tokenizes prompts.
"""
def __init__(
self,
concepts_list,
tokenizer,
size=512,
mask_size=64,
center_crop=False,
with_prior_preservation=False,
num_class_images=200,
hflip=False,
aug=True,
):
self.size = size
self.mask_size = mask_size
self.center_crop = center_crop
self.tokenizer = tokenizer
self.interpolation = Image.BILINEAR
self.aug = aug
self.instance_images_path = []
self.class_images_path = []
self.with_prior_preservation = with_prior_preservation
for concept in concepts_list:
inst_img_path = [
(x, concept["instance_prompt"]) for x in Path(concept["instance_data_dir"]).iterdir() if x.is_file()
]
self.instance_images_path.extend(inst_img_path)
if with_prior_preservation:
class_data_root = Path(concept["class_data_dir"])
if os.path.isdir(class_data_root):
class_images_path = list(class_data_root.iterdir())
class_prompt = [concept["class_prompt"] for _ in range(len(class_images_path))]
else:
with open(class_data_root, "r") as f:
class_images_path = f.read().splitlines()
with open(concept["class_prompt"], "r") as f:
class_prompt = f.read().splitlines()
class_img_path = list(zip(class_images_path, class_prompt))
self.class_images_path.extend(class_img_path[:num_class_images])
random.shuffle(self.instance_images_path)
self.num_instance_images = len(self.instance_images_path)
self.num_class_images = len(self.class_images_path)
self._length = max(self.num_class_images, self.num_instance_images)
self.flip = transforms.RandomHorizontalFlip(0.5 * hflip)
self.image_transforms = transforms.Compose(
[
self.flip,
transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def __len__(self):
return self._length
def preprocess(self, image, scale, resample):
outer, inner = self.size, scale
factor = self.size // self.mask_size
if scale > self.size:
outer, inner = scale, self.size
top, left = np.random.randint(0, outer - inner + 1), np.random.randint(0, outer - inner + 1)
image = image.resize((scale, scale), resample=resample)
image = np.array(image).astype(np.uint8)
image = (image / 127.5 - 1.0).astype(np.float32)
instance_image = np.zeros((self.size, self.size, 3), dtype=np.float32)
mask = np.zeros((self.size // factor, self.size // factor))
if scale > self.size:
instance_image = image[top : top + inner, left : left + inner, :]
mask = np.ones((self.size // factor, self.size // factor))
else:
instance_image[top : top + inner, left : left + inner, :] = image
mask[
top // factor + 1 : (top + scale) // factor - 1, left // factor + 1 : (left + scale) // factor - 1
] = 1.0
return instance_image, mask
def __getitem__(self, index):
example = {}
instance_image, instance_prompt = self.instance_images_path[index % self.num_instance_images]
instance_image = Image.open(instance_image)
if not instance_image.mode == "RGB":
instance_image = instance_image.convert("RGB")
instance_image = self.flip(instance_image)
# apply resize augmentation and create a valid image region mask
random_scale = self.size
if self.aug:
random_scale = (
np.random.randint(self.size // 3, self.size + 1)
if np.random.uniform() < 0.66
else np.random.randint(int(1.2 * self.size), int(1.4 * self.size))
)
instance_image, mask = self.preprocess(instance_image, random_scale, self.interpolation)
if random_scale < 0.6 * self.size:
instance_prompt = np.random.choice(["a far away ", "very small "]) + instance_prompt
elif random_scale > self.size:
instance_prompt = np.random.choice(["zoomed in ", "close up "]) + instance_prompt
example["instance_images"] = torch.from_numpy(instance_image).permute(2, 0, 1)
example["mask"] = torch.from_numpy(mask)
example["instance_prompt_ids"] = self.tokenizer(
instance_prompt,
truncation=True,
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
).input_ids
if self.with_prior_preservation:
class_image, class_prompt = self.class_images_path[index % self.num_class_images]
class_image = Image.open(class_image)
if not class_image.mode == "RGB":
class_image = class_image.convert("RGB")
example["class_images"] = self.image_transforms(class_image)
example["class_mask"] = torch.ones_like(example["mask"])
example["class_prompt_ids"] = self.tokenizer(
class_prompt,
truncation=True,
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
).input_ids
return example
def save_new_embed(text_encoder, modifier_token_id, accelerator, args, output_dir, safe_serialization=True):
"""Saves the new token embeddings from the text encoder."""
logger.info("Saving embeddings")
learned_embeds = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight
for x, y in zip(modifier_token_id, args.modifier_token):
learned_embeds_dict = {}
learned_embeds_dict[y] = learned_embeds[x]
filename = f"{output_dir}/{y}.bin"
if safe_serialization:
safetensors.torch.save_file(learned_embeds_dict, filename, metadata={"format": "pt"})
else:
torch.save(learned_embeds_dict, filename)
def parse_args(input_args=None):
parser = argparse.ArgumentParser(description="Custom Diffusion training script.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--variant",
type=str,
default=None,
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--instance_data_dir",
type=str,
default=None,
help="A folder containing the training data of instance images.",
)
parser.add_argument(
"--class_data_dir",
type=str,
default=None,
help="A folder containing the training data of class images.",
)
parser.add_argument(
"--instance_prompt",
type=str,
default=None,
help="The prompt with identifier specifying the instance",
)
parser.add_argument(
"--class_prompt",
type=str,
default=None,
help="The prompt to specify images in the same class as provided instance images.",
)
parser.add_argument(
"--validation_prompt",
type=str,
default=None,
help="A prompt that is used during validation to verify that the model is learning.",
)
parser.add_argument(
"--num_validation_images",
type=int,
default=2,
help="Number of images that should be generated during validation with `validation_prompt`.",
)
parser.add_argument(
"--validation_steps",
type=int,
default=50,
help=(
"Run dreambooth validation every X epochs. Dreambooth validation consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`."
),
)
parser.add_argument(
"--with_prior_preservation",
default=False,
action="store_true",
help="Flag to add prior preservation loss.",
)
parser.add_argument(
"--real_prior",
default=False,
action="store_true",
help="real images as prior.",
)
parser.add_argument("--prior_loss_weight", type=float, default=1.0, help="The weight of prior preservation loss.")
parser.add_argument(
"--num_class_images",
type=int,
default=200,
help=(
"Minimal class images for prior preservation loss. If there are not enough images already present in"
" class_data_dir, additional images will be sampled with class_prompt."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="custom-diffusion-model",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument("--seed", type=int, default=42, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
)
parser.add_argument(
"--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images."
)
parser.add_argument("--num_train_epochs", type=int, default=1)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--checkpointing_steps",
type=int,
default=250,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints can be used both as final"
" checkpoints in case they are better than the last checkpoint, and are also suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-5,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=2,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument(
"--freeze_model",
type=str,
default="crossattn_kv",
choices=["crossattn_kv", "crossattn"],
help="crossattn to enable fine-tuning of all params in the cross attention",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--prior_generation_precision",
type=str,
default=None,
choices=["no", "fp32", "fp16", "bf16"],
help=(
"Choose prior generation precision between fp32, fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to fp16 if a GPU is available else fp32."
),
)
parser.add_argument(
"--concepts_list",
type=str,
default=None,
help="Path to json containing multiple concepts, will overwrite parameters like instance_prompt, class_prompt, etc.",
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument(
"--set_grads_to_none",
action="store_true",
help=(
"Save more memory by using setting grads to None instead of zero. Be aware, that this changes certain"
" behaviors, so disable this argument if it causes any problems. More info:"
" https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html"
),
)
parser.add_argument(
"--modifier_token",
type=str,
default=None,
help="A token to use as a modifier for the concept.",
)
parser.add_argument(
"--initializer_token", type=str, default="ktn+pll+ucd", help="A token to use as initializer word."
)
parser.add_argument("--hflip", action="store_true", help="Apply horizontal flip data augmentation.")
parser.add_argument(
"--noaug",
action="store_true",
help="Dont apply augmentation during data augmentation when this flag is enabled.",
)
parser.add_argument(
"--no_safe_serialization",
action="store_true",
help="If specified save the checkpoint not in `safetensors` format, but in original PyTorch format instead.",
)
if input_args is not None:
args = parser.parse_args(input_args)
else:
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.with_prior_preservation:
if args.concepts_list is None:
if args.class_data_dir is None:
raise ValueError("You must specify a data directory for class images.")
if args.class_prompt is None:
raise ValueError("You must specify prompt for class images.")
else:
# logger is not available yet
if args.class_data_dir is not None:
warnings.warn("You need not use --class_data_dir without --with_prior_preservation.")
if args.class_prompt is not None:
warnings.warn("You need not use --class_prompt without --with_prior_preservation.")
return args
def main(args):
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
if args.report_to == "wandb":
if not is_wandb_available():
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
import wandb
# Currently, it's not possible to do gradient accumulation when training two models with accelerate.accumulate
# This will be enabled soon in accelerate. For now, we don't allow gradient accumulation when training two models.
# TODO (patil-suraj): Remove this check when gradient accumulation with two models is enabled in accelerate.
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
accelerator.init_trackers("custom-diffusion", config=vars(args))
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
if args.concepts_list is None:
args.concepts_list = [
{
"instance_prompt": args.instance_prompt,
"class_prompt": args.class_prompt,
"instance_data_dir": args.instance_data_dir,
"class_data_dir": args.class_data_dir,
}
]
else:
with open(args.concepts_list, "r") as f:
args.concepts_list = json.load(f)
# Generate class images if prior preservation is enabled.
if args.with_prior_preservation:
for i, concept in enumerate(args.concepts_list):
class_images_dir = Path(concept["class_data_dir"])
if not class_images_dir.exists():
class_images_dir.mkdir(parents=True, exist_ok=True)
if args.real_prior:
assert (
class_images_dir / "images"
).exists(), f"Please run: python retrieve.py --class_prompt \"{concept['class_prompt']}\" --class_data_dir {class_images_dir} --num_class_images {args.num_class_images}"
assert (
len(list((class_images_dir / "images").iterdir())) == args.num_class_images
), f"Please run: python retrieve.py --class_prompt \"{concept['class_prompt']}\" --class_data_dir {class_images_dir} --num_class_images {args.num_class_images}"
assert (
class_images_dir / "caption.txt"
).exists(), f"Please run: python retrieve.py --class_prompt \"{concept['class_prompt']}\" --class_data_dir {class_images_dir} --num_class_images {args.num_class_images}"
assert (
class_images_dir / "images.txt"
).exists(), f"Please run: python retrieve.py --class_prompt \"{concept['class_prompt']}\" --class_data_dir {class_images_dir} --num_class_images {args.num_class_images}"
concept["class_prompt"] = os.path.join(class_images_dir, "caption.txt")
concept["class_data_dir"] = os.path.join(class_images_dir, "images.txt")
args.concepts_list[i] = concept
accelerator.wait_for_everyone()
else:
cur_class_images = len(list(class_images_dir.iterdir()))
if cur_class_images < args.num_class_images:
torch_dtype = torch.float16 if accelerator.device.type == "cuda" else torch.float32
if args.prior_generation_precision == "fp32":
torch_dtype = torch.float32
elif args.prior_generation_precision == "fp16":
torch_dtype = torch.float16
elif args.prior_generation_precision == "bf16":
torch_dtype = torch.bfloat16
pipeline = DiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path,
torch_dtype=torch_dtype,
safety_checker=None,
revision=args.revision,
variant=args.variant,
)
pipeline.set_progress_bar_config(disable=True)
num_new_images = args.num_class_images - cur_class_images
logger.info(f"Number of class images to sample: {num_new_images}.")
sample_dataset = PromptDataset(args.class_prompt, num_new_images)
sample_dataloader = torch.utils.data.DataLoader(sample_dataset, batch_size=args.sample_batch_size)
sample_dataloader = accelerator.prepare(sample_dataloader)
pipeline.to(accelerator.device)
for example in tqdm(
sample_dataloader,
desc="Generating class images",
disable=not accelerator.is_local_main_process,
):
images = pipeline(example["prompt"]).images
for i, image in enumerate(images):
hash_image = insecure_hashlib.sha1(image.tobytes()).hexdigest()
image_filename = (
class_images_dir / f"{example['index'][i] + cur_class_images}-{hash_image}.jpg"
)
image.save(image_filename)
del pipeline
if torch.cuda.is_available():
torch.cuda.empty_cache()
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load the tokenizer
if args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(
args.tokenizer_name,
revision=args.revision,
use_fast=False,
)
elif args.pretrained_model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="tokenizer",
revision=args.revision,
use_fast=False,
)
# import correct text encoder class
text_encoder_cls = import_model_class_from_model_name_or_path(args.pretrained_model_name_or_path, args.revision)
# Load scheduler and models
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
text_encoder = text_encoder_cls.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision, variant=args.variant
)
vae = AutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision, variant=args.variant
)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
)
# Adding a modifier token which is optimized ####
# Code taken from https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion/textual_inversion.py
modifier_token_id = []
initializer_token_id = []
if args.modifier_token is not None:
args.modifier_token = args.modifier_token.split("+")
args.initializer_token = args.initializer_token.split("+")
if len(args.modifier_token) > len(args.initializer_token):
raise ValueError("You must specify + separated initializer token for each modifier token.")
for modifier_token, initializer_token in zip(
args.modifier_token, args.initializer_token[: len(args.modifier_token)]
):
# Add the placeholder token in tokenizer
num_added_tokens = tokenizer.add_tokens(modifier_token)
if num_added_tokens == 0:
raise ValueError(
f"The tokenizer already contains the token {modifier_token}. Please pass a different"
" `modifier_token` that is not already in the tokenizer."
)
# Convert the initializer_token, placeholder_token to ids
token_ids = tokenizer.encode([initializer_token], add_special_tokens=False)
print(token_ids)
# Check if initializer_token is a single token or a sequence of tokens
if len(token_ids) > 1:
raise ValueError("The initializer token must be a single token.")
initializer_token_id.append(token_ids[0])
modifier_token_id.append(tokenizer.convert_tokens_to_ids(modifier_token))
# Resize the token embeddings as we are adding new special tokens to the tokenizer
text_encoder.resize_token_embeddings(len(tokenizer))
# Initialise the newly added placeholder token with the embeddings of the initializer token
token_embeds = text_encoder.get_input_embeddings().weight.data
for x, y in zip(modifier_token_id, initializer_token_id):
token_embeds[x] = token_embeds[y]
# Freeze all parameters except for the token embeddings in text encoder
params_to_freeze = itertools.chain(
text_encoder.text_model.encoder.parameters(),
text_encoder.text_model.final_layer_norm.parameters(),
text_encoder.text_model.embeddings.position_embedding.parameters(),
)
freeze_params(params_to_freeze)
########################################################
########################################################
vae.requires_grad_(False)
if args.modifier_token is None:
text_encoder.requires_grad_(False)
unet.requires_grad_(False)
# For mixed precision training we cast the text_encoder and vae weights to half-precision
# as these models are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move unet, vae and text_encoder to device and cast to weight_dtype
if accelerator.mixed_precision != "fp16" and args.modifier_token is not None:
text_encoder.to(accelerator.device, dtype=weight_dtype)
unet.to(accelerator.device, dtype=weight_dtype)
vae.to(accelerator.device, dtype=weight_dtype)
attention_class = (
CustomDiffusionAttnProcessor2_0 if hasattr(F, "scaled_dot_product_attention") else CustomDiffusionAttnProcessor
)
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
attention_class = CustomDiffusionXFormersAttnProcessor
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# now we will add new Custom Diffusion weights to the attention layers
# It's important to realize here how many attention weights will be added and of which sizes
# The sizes of the attention layers consist only of two different variables:
# 1) - the "hidden_size", which is increased according to `unet.config.block_out_channels`.
# 2) - the "cross attention size", which is set to `unet.config.cross_attention_dim`.
# Let's first see how many attention processors we will have to set.
# For Stable Diffusion, it should be equal to:
# - down blocks (2x attention layers) * (2x transformer layers) * (3x down blocks) = 12
# - mid blocks (2x attention layers) * (1x transformer layers) * (1x mid blocks) = 2
# - up blocks (2x attention layers) * (3x transformer layers) * (3x down blocks) = 18
# => 32 layers
# Only train key, value projection layers if freeze_model = 'crossattn_kv' else train all params in the cross attention layer
train_kv = True
train_q_out = False if args.freeze_model == "crossattn_kv" else True
custom_diffusion_attn_procs = {}
st = unet.state_dict()
for name, _ in unet.attn_processors.items():
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
if name.startswith("mid_block"):
hidden_size = unet.config.block_out_channels[-1]
elif name.startswith("up_blocks"):
block_id = int(name[len("up_blocks.")])
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
elif name.startswith("down_blocks"):
block_id = int(name[len("down_blocks.")])
hidden_size = unet.config.block_out_channels[block_id]
layer_name = name.split(".processor")[0]
weights = {
"to_k_custom_diffusion.weight": st[layer_name + ".to_k.weight"],
"to_v_custom_diffusion.weight": st[layer_name + ".to_v.weight"],
}
if train_q_out:
weights["to_q_custom_diffusion.weight"] = st[layer_name + ".to_q.weight"]
weights["to_out_custom_diffusion.0.weight"] = st[layer_name + ".to_out.0.weight"]
weights["to_out_custom_diffusion.0.bias"] = st[layer_name + ".to_out.0.bias"]
if cross_attention_dim is not None:
custom_diffusion_attn_procs[name] = attention_class(
train_kv=train_kv,
train_q_out=train_q_out,
hidden_size=hidden_size,
cross_attention_dim=cross_attention_dim,
).to(unet.device)
custom_diffusion_attn_procs[name].load_state_dict(weights)
else:
custom_diffusion_attn_procs[name] = attention_class(
train_kv=False,
train_q_out=False,
hidden_size=hidden_size,
cross_attention_dim=cross_attention_dim,
)
del st
unet.set_attn_processor(custom_diffusion_attn_procs)
custom_diffusion_layers = AttnProcsLayers(unet.attn_processors)
accelerator.register_for_checkpointing(custom_diffusion_layers)
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
if args.modifier_token is not None:
text_encoder.gradient_checkpointing_enable()
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
if args.with_prior_preservation:
args.learning_rate = args.learning_rate * 2.0
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
)
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
# Optimizer creation
optimizer = optimizer_class(
itertools.chain(text_encoder.get_input_embeddings().parameters(), custom_diffusion_layers.parameters())
if args.modifier_token is not None
else custom_diffusion_layers.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Dataset and DataLoaders creation:
train_dataset = CustomDiffusionDataset(
concepts_list=args.concepts_list,
tokenizer=tokenizer,
with_prior_preservation=args.with_prior_preservation,
size=args.resolution,
mask_size=vae.encode(
torch.randn(1, 3, args.resolution, args.resolution).to(dtype=weight_dtype).to(accelerator.device)
)
.latent_dist.sample()
.size()[-1],
center_crop=args.center_crop,
num_class_images=args.num_class_images,
hflip=args.hflip,
aug=not args.noaug,
)
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size=args.train_batch_size,
shuffle=True,
collate_fn=lambda examples: collate_fn(examples, args.with_prior_preservation),
num_workers=args.dataloader_num_workers,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
if args.modifier_token is not None:
custom_diffusion_layers, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
custom_diffusion_layers, text_encoder, optimizer, train_dataloader, lr_scheduler
)
else:
custom_diffusion_layers, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
custom_diffusion_layers, optimizer, train_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num batches each epoch = {len(train_dataloader)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
for epoch in range(first_epoch, args.num_train_epochs):
unet.train()
if args.modifier_token is not None:
text_encoder.train()
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet), accelerator.accumulate(text_encoder):
# Convert images to latent space
latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# Get the text embedding for conditioning
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
# Predict the noise residual
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
if args.with_prior_preservation:
# Chunk the noise and model_pred into two parts and compute the loss on each part separately.
model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0)
target, target_prior = torch.chunk(target, 2, dim=0)
mask = torch.chunk(batch["mask"], 2, dim=0)[0]
# Compute instance loss
loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
loss = ((loss * mask).sum([1, 2, 3]) / mask.sum([1, 2, 3])).mean()
# Compute prior loss
prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean")
# Add the prior loss to the instance loss.
loss = loss + args.prior_loss_weight * prior_loss
else:
mask = batch["mask"]
loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
loss = ((loss * mask).sum([1, 2, 3]) / mask.sum([1, 2, 3])).mean()
accelerator.backward(loss)
# Zero out the gradients for all token embeddings except the newly added
# embeddings for the concept, as we only want to optimize the concept embeddings
if args.modifier_token is not None:
if accelerator.num_processes > 1:
grads_text_encoder = text_encoder.module.get_input_embeddings().weight.grad
else:
grads_text_encoder = text_encoder.get_input_embeddings().weight.grad
# Get the index for tokens that we want to zero the grads for
index_grads_to_zero = torch.arange(len(tokenizer)) != modifier_token_id[0]
for i in range(len(modifier_token_id[1:])):
index_grads_to_zero = index_grads_to_zero & (
torch.arange(len(tokenizer)) != modifier_token_id[i]
)
grads_text_encoder.data[index_grads_to_zero, :] = grads_text_encoder.data[
index_grads_to_zero, :
].fill_(0)
if accelerator.sync_gradients:
params_to_clip = (
itertools.chain(text_encoder.parameters(), custom_diffusion_layers.parameters())
if args.modifier_token is not None
else custom_diffusion_layers.parameters()
)
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad(set_to_none=args.set_grads_to_none)
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
if global_step % args.checkpointing_steps == 0:
if accelerator.is_main_process:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
if global_step >= args.max_train_steps:
break
if accelerator.is_main_process:
images = []
if args.validation_prompt is not None and global_step % args.validation_steps == 0:
logger.info(
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
f" {args.validation_prompt}."
)
# create pipeline
pipeline = DiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path,
unet=accelerator.unwrap_model(unet),
text_encoder=accelerator.unwrap_model(text_encoder),
tokenizer=tokenizer,
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
# run inference
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
images = [
pipeline(args.validation_prompt, num_inference_steps=25, generator=generator, eta=1.0).images[
0
]
for _ in range(args.num_validation_images)
]
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
if tracker.name == "wandb":
tracker.log(
{
"validation": [
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
for i, image in enumerate(images)
]
}
)
del pipeline
torch.cuda.empty_cache()
# Save the custom diffusion layers
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = unet.to(torch.float32)
unet.save_attn_procs(args.output_dir, safe_serialization=not args.no_safe_serialization)
save_new_embed(
text_encoder,
modifier_token_id,
accelerator,
args,
args.output_dir,
safe_serialization=not args.no_safe_serialization,
)
# Final inference
# Load previous pipeline
pipeline = DiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path, revision=args.revision, variant=args.variant, torch_dtype=weight_dtype
)
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
pipeline = pipeline.to(accelerator.device)
# load attention processors
weight_name = (
"pytorch_custom_diffusion_weights.safetensors"
if not args.no_safe_serialization
else "pytorch_custom_diffusion_weights.bin"
)
pipeline.unet.load_attn_procs(args.output_dir, weight_name=weight_name)
for token in args.modifier_token:
token_weight_name = f"{token}.safetensors" if not args.no_safe_serialization else f"{token}.bin"
pipeline.load_textual_inversion(args.output_dir, weight_name=token_weight_name)
# run inference
if args.validation_prompt and args.num_validation_images > 0:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed) if args.seed else None
images = [
pipeline(args.validation_prompt, num_inference_steps=25, generator=generator, eta=1.0).images[0]
for _ in range(args.num_validation_images)
]
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("test", np_images, epoch, dataformats="NHWC")
if tracker.name == "wandb":
tracker.log(
{
"test": [
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
for i, image in enumerate(images)
]
}
)
if args.push_to_hub:
save_model_card(
repo_id,
images=images,
base_model=args.pretrained_model_name_or_path,
prompt=args.instance_prompt,
repo_folder=args.output_dir,
)
api = HfApi(token=args.hub_token)
api.upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/custom_diffusion/retrieve.py
|
# Copyright 2023 Custom Diffusion authors. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
from io import BytesIO
from pathlib import Path
import requests
from clip_retrieval.clip_client import ClipClient
from PIL import Image
from tqdm import tqdm
def retrieve(class_prompt, class_data_dir, num_class_images):
factor = 1.5
num_images = int(factor * num_class_images)
client = ClipClient(
url="https://knn.laion.ai/knn-service", indice_name="laion_400m", num_images=num_images, aesthetic_weight=0.1
)
os.makedirs(f"{class_data_dir}/images", exist_ok=True)
if len(list(Path(f"{class_data_dir}/images").iterdir())) >= num_class_images:
return
while True:
class_images = client.query(text=class_prompt)
if len(class_images) >= factor * num_class_images or num_images > 1e4:
break
else:
num_images = int(factor * num_images)
client = ClipClient(
url="https://knn.laion.ai/knn-service",
indice_name="laion_400m",
num_images=num_images,
aesthetic_weight=0.1,
)
count = 0
total = 0
pbar = tqdm(desc="downloading real regularization images", total=num_class_images)
with open(f"{class_data_dir}/caption.txt", "w") as f1, open(f"{class_data_dir}/urls.txt", "w") as f2, open(
f"{class_data_dir}/images.txt", "w"
) as f3:
while total < num_class_images:
images = class_images[count]
count += 1
try:
img = requests.get(images["url"], timeout=30)
if img.status_code == 200:
_ = Image.open(BytesIO(img.content))
with open(f"{class_data_dir}/images/{total}.jpg", "wb") as f:
f.write(img.content)
f1.write(images["caption"] + "\n")
f2.write(images["url"] + "\n")
f3.write(f"{class_data_dir}/images/{total}.jpg" + "\n")
total += 1
pbar.update(1)
else:
continue
except Exception:
continue
return
def parse_args():
parser = argparse.ArgumentParser("", add_help=False)
parser.add_argument("--class_prompt", help="text prompt to retrieve images", required=True, type=str)
parser.add_argument("--class_data_dir", help="path to save images", required=True, type=str)
parser.add_argument("--num_class_images", help="number of images to download", default=200, type=int)
return parser.parse_args()
if __name__ == "__main__":
args = parse_args()
retrieve(args.class_prompt, args.class_data_dir, args.num_class_images)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/custom_diffusion/requirements.txt
|
accelerate
torchvision
transformers>=4.25.1
ftfy
tensorboard
Jinja2
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/textual_inversion/README.md
|
## Textual Inversion fine-tuning example
[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
## Running on Colab
Colab for training
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
Colab for inference
[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb)
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run:
```bash
pip install -r requirements.txt
```
And initialize an [🤗 Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
### Cat toy example
First, let's login so that we can upload the checkpoint to the Hub during training:
```bash
huggingface-cli login
```
Now let's get our dataset. For this example we will use some cat images: https://huggingface.co/datasets/diffusers/cat_toy_example .
Let's first download it locally:
```py
from huggingface_hub import snapshot_download
local_dir = "./cat"
snapshot_download("diffusers/cat_toy_example", local_dir=local_dir, repo_type="dataset", ignore_patterns=".gitattributes")
```
This will be our training data.
Now we can launch the training using:
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATA_DIR="./cat"
accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" \
--initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 \
--scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--push_to_hub \
--output_dir="textual_inversion_cat"
```
A full training run takes ~1 hour on one V100 GPU.
**Note**: As described in [the official paper](https://arxiv.org/abs/2208.01618)
only one embedding vector is used for the placeholder token, *e.g.* `"<cat-toy>"`.
However, one can also add multiple embedding vectors for the placeholder token
to increase the number of fine-tuneable parameters. This can help the model to learn
more complex details. To use multiple embedding vectors, you should define `--num_vectors`
to a number larger than one, *e.g.*:
```bash
--num_vectors 5
```
The saved textual inversion vectors will then be larger in size compared to the default case.
### Inference
Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline`. Make sure to include the `placeholder_token` in your prompt.
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "path-to-your-trained-model"
pipe = StableDiffusionPipeline.from_pretrained(model_id,torch_dtype=torch.float16).to("cuda")
prompt = "A <cat-toy> backpack"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image.save("cat-backpack.png")
```
## Training with Flax/JAX
For faster training on TPUs and GPUs you can leverage the flax training example. Follow the instructions above to get the model and dataset before running the script.
Before running the scripts, make sure to install the library's training dependencies:
```bash
pip install -U -r requirements_flax.txt
```
```bash
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
export DATA_DIR="path-to-dir-containing-images"
python textual_inversion_flax.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" \
--initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 \
--scale_lr \
--output_dir="textual_inversion_cat"
```
It should be at least 70% faster than the PyTorch script with the same configuration.
### Training with xformers:
You can enable memory efficient attention by [installing xFormers](https://github.com/facebookresearch/xformers#installing-xformers) and padding the `--enable_xformers_memory_efficient_attention` argument to the script. This is not available with the Flax/JAX implementation.
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/textual_inversion/requirements_flax.txt
|
transformers>=4.25.1
flax
optax
torch
torchvision
ftfy
tensorboard
Jinja2
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/textual_inversion/textual_inversion.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import logging
import math
import os
import random
import shutil
import warnings
from pathlib import Path
import numpy as np
import PIL
import safetensors
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from huggingface_hub import create_repo, upload_folder
# TODO: remove and import from diffusers.utils when the new version of diffusers is released
from packaging import version
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPTextModel, CLIPTokenizer
import diffusers
from diffusers import (
AutoencoderKL,
DDPMScheduler,
DiffusionPipeline,
DPMSolverMultistepScheduler,
StableDiffusionPipeline,
UNet2DConditionModel,
)
from diffusers.optimization import get_scheduler
from diffusers.utils import check_min_version, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
if is_wandb_available():
import wandb
if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
PIL_INTERPOLATION = {
"linear": PIL.Image.Resampling.BILINEAR,
"bilinear": PIL.Image.Resampling.BILINEAR,
"bicubic": PIL.Image.Resampling.BICUBIC,
"lanczos": PIL.Image.Resampling.LANCZOS,
"nearest": PIL.Image.Resampling.NEAREST,
}
else:
PIL_INTERPOLATION = {
"linear": PIL.Image.LINEAR,
"bilinear": PIL.Image.BILINEAR,
"bicubic": PIL.Image.BICUBIC,
"lanczos": PIL.Image.LANCZOS,
"nearest": PIL.Image.NEAREST,
}
# ------------------------------------------------------------------------------
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.24.0.dev0")
logger = get_logger(__name__)
def save_model_card(repo_id: str, images=None, base_model=str, repo_folder=None):
img_str = ""
for i, image in enumerate(images):
image.save(os.path.join(repo_folder, f"image_{i}.png"))
img_str += f"\n"
yaml = f"""
---
license: creativeml-openrail-m
base_model: {base_model}
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
"""
model_card = f"""
# Textual inversion text2image fine-tuning - {repo_id}
These are textual inversion adaption weights for {base_model}. You can find some example images in the following. \n
{img_str}
"""
with open(os.path.join(repo_folder, "README.md"), "w") as f:
f.write(yaml + model_card)
def log_validation(text_encoder, tokenizer, unet, vae, args, accelerator, weight_dtype, epoch):
logger.info(
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
f" {args.validation_prompt}."
)
# create pipeline (note: unet and vae are loaded again in float32)
pipeline = DiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path,
text_encoder=accelerator.unwrap_model(text_encoder),
tokenizer=tokenizer,
unet=unet,
vae=vae,
safety_checker=None,
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
# run inference
generator = None if args.seed is None else torch.Generator(device=accelerator.device).manual_seed(args.seed)
images = []
for _ in range(args.num_validation_images):
with torch.autocast("cuda"):
image = pipeline(args.validation_prompt, num_inference_steps=25, generator=generator).images[0]
images.append(image)
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
if tracker.name == "wandb":
tracker.log(
{
"validation": [
wandb.Image(image, caption=f"{i}: {args.validation_prompt}") for i, image in enumerate(images)
]
}
)
del pipeline
torch.cuda.empty_cache()
return images
def save_progress(text_encoder, placeholder_token_ids, accelerator, args, save_path, safe_serialization=True):
logger.info("Saving embeddings")
learned_embeds = (
accelerator.unwrap_model(text_encoder)
.get_input_embeddings()
.weight[min(placeholder_token_ids) : max(placeholder_token_ids) + 1]
)
learned_embeds_dict = {args.placeholder_token: learned_embeds.detach().cpu()}
if safe_serialization:
safetensors.torch.save_file(learned_embeds_dict, save_path, metadata={"format": "pt"})
else:
torch.save(learned_embeds_dict, save_path)
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--save_steps",
type=int,
default=500,
help="Save learned_embeds.bin every X updates steps.",
)
parser.add_argument(
"--save_as_full_pipeline",
action="store_true",
help="Save the complete stable diffusion pipeline.",
)
parser.add_argument(
"--num_vectors",
type=int,
default=1,
help="How many textual inversion vectors shall be used to learn the concept.",
)
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--variant",
type=str,
default=None,
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--train_data_dir", type=str, default=None, required=True, help="A folder containing the training data."
)
parser.add_argument(
"--placeholder_token",
type=str,
default=None,
required=True,
help="A token to use as a placeholder for the concept.",
)
parser.add_argument(
"--initializer_token", type=str, default=None, required=True, help="A token to use as initializer word."
)
parser.add_argument("--learnable_property", type=str, default="object", help="Choose between 'object' and 'style'")
parser.add_argument("--repeats", type=int, default=100, help="How many times to repeat the training data.")
parser.add_argument(
"--output_dir",
type=str,
default="text-inversion-model",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop", action="store_true", help="Whether to center crop images before resizing to resolution."
)
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=5000,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--lr_num_cycles",
type=int,
default=1,
help="Number of hard resets of the lr in cosine_with_restarts scheduler.",
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default="no",
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU."
),
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument(
"--validation_prompt",
type=str,
default=None,
help="A prompt that is used during validation to verify that the model is learning.",
)
parser.add_argument(
"--num_validation_images",
type=int,
default=4,
help="Number of images that should be generated during validation with `validation_prompt`.",
)
parser.add_argument(
"--validation_steps",
type=int,
default=100,
help=(
"Run validation every X steps. Validation consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`"
" and logging the images."
),
)
parser.add_argument(
"--validation_epochs",
type=int,
default=None,
help=(
"Deprecated in favor of validation_steps. Run validation every X epochs. Validation consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`"
" and logging the images."
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument(
"--no_safe_serialization",
action="store_true",
help="If specified save the checkpoint not in `safetensors` format, but in original PyTorch format instead.",
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.train_data_dir is None:
raise ValueError("You must specify a train data directory.")
return args
imagenet_templates_small = [
"a photo of a {}",
"a rendering of a {}",
"a cropped photo of the {}",
"the photo of a {}",
"a photo of a clean {}",
"a photo of a dirty {}",
"a dark photo of the {}",
"a photo of my {}",
"a photo of the cool {}",
"a close-up photo of a {}",
"a bright photo of the {}",
"a cropped photo of a {}",
"a photo of the {}",
"a good photo of the {}",
"a photo of one {}",
"a close-up photo of the {}",
"a rendition of the {}",
"a photo of the clean {}",
"a rendition of a {}",
"a photo of a nice {}",
"a good photo of a {}",
"a photo of the nice {}",
"a photo of the small {}",
"a photo of the weird {}",
"a photo of the large {}",
"a photo of a cool {}",
"a photo of a small {}",
]
imagenet_style_templates_small = [
"a painting in the style of {}",
"a rendering in the style of {}",
"a cropped painting in the style of {}",
"the painting in the style of {}",
"a clean painting in the style of {}",
"a dirty painting in the style of {}",
"a dark painting in the style of {}",
"a picture in the style of {}",
"a cool painting in the style of {}",
"a close-up painting in the style of {}",
"a bright painting in the style of {}",
"a cropped painting in the style of {}",
"a good painting in the style of {}",
"a close-up painting in the style of {}",
"a rendition in the style of {}",
"a nice painting in the style of {}",
"a small painting in the style of {}",
"a weird painting in the style of {}",
"a large painting in the style of {}",
]
class TextualInversionDataset(Dataset):
def __init__(
self,
data_root,
tokenizer,
learnable_property="object", # [object, style]
size=512,
repeats=100,
interpolation="bicubic",
flip_p=0.5,
set="train",
placeholder_token="*",
center_crop=False,
):
self.data_root = data_root
self.tokenizer = tokenizer
self.learnable_property = learnable_property
self.size = size
self.placeholder_token = placeholder_token
self.center_crop = center_crop
self.flip_p = flip_p
self.image_paths = [os.path.join(self.data_root, file_path) for file_path in os.listdir(self.data_root)]
self.num_images = len(self.image_paths)
self._length = self.num_images
if set == "train":
self._length = self.num_images * repeats
self.interpolation = {
"linear": PIL_INTERPOLATION["linear"],
"bilinear": PIL_INTERPOLATION["bilinear"],
"bicubic": PIL_INTERPOLATION["bicubic"],
"lanczos": PIL_INTERPOLATION["lanczos"],
}[interpolation]
self.templates = imagenet_style_templates_small if learnable_property == "style" else imagenet_templates_small
self.flip_transform = transforms.RandomHorizontalFlip(p=self.flip_p)
def __len__(self):
return self._length
def __getitem__(self, i):
example = {}
image = Image.open(self.image_paths[i % self.num_images])
if not image.mode == "RGB":
image = image.convert("RGB")
placeholder_string = self.placeholder_token
text = random.choice(self.templates).format(placeholder_string)
example["input_ids"] = self.tokenizer(
text,
padding="max_length",
truncation=True,
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
).input_ids[0]
# default to score-sde preprocessing
img = np.array(image).astype(np.uint8)
if self.center_crop:
crop = min(img.shape[0], img.shape[1])
(
h,
w,
) = (
img.shape[0],
img.shape[1],
)
img = img[(h - crop) // 2 : (h + crop) // 2, (w - crop) // 2 : (w + crop) // 2]
image = Image.fromarray(img)
image = image.resize((self.size, self.size), resample=self.interpolation)
image = self.flip_transform(image)
image = np.array(image).astype(np.uint8)
image = (image / 127.5 - 1.0).astype(np.float32)
example["pixel_values"] = torch.from_numpy(image).permute(2, 0, 1)
return example
def main():
args = parse_args()
logging_dir = os.path.join(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
if args.report_to == "wandb":
if not is_wandb_available():
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load tokenizer
if args.tokenizer_name:
tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
elif args.pretrained_model_name_or_path:
tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
# Load scheduler and models
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
)
vae = AutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision, variant=args.variant
)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
)
# Add the placeholder token in tokenizer
placeholder_tokens = [args.placeholder_token]
if args.num_vectors < 1:
raise ValueError(f"--num_vectors has to be larger or equal to 1, but is {args.num_vectors}")
# add dummy tokens for multi-vector
additional_tokens = []
for i in range(1, args.num_vectors):
additional_tokens.append(f"{args.placeholder_token}_{i}")
placeholder_tokens += additional_tokens
num_added_tokens = tokenizer.add_tokens(placeholder_tokens)
if num_added_tokens != args.num_vectors:
raise ValueError(
f"The tokenizer already contains the token {args.placeholder_token}. Please pass a different"
" `placeholder_token` that is not already in the tokenizer."
)
# Convert the initializer_token, placeholder_token to ids
token_ids = tokenizer.encode(args.initializer_token, add_special_tokens=False)
# Check if initializer_token is a single token or a sequence of tokens
if len(token_ids) > 1:
raise ValueError("The initializer token must be a single token.")
initializer_token_id = token_ids[0]
placeholder_token_ids = tokenizer.convert_tokens_to_ids(placeholder_tokens)
# Resize the token embeddings as we are adding new special tokens to the tokenizer
text_encoder.resize_token_embeddings(len(tokenizer))
# Initialise the newly added placeholder token with the embeddings of the initializer token
token_embeds = text_encoder.get_input_embeddings().weight.data
with torch.no_grad():
for token_id in placeholder_token_ids:
token_embeds[token_id] = token_embeds[initializer_token_id].clone()
# Freeze vae and unet
vae.requires_grad_(False)
unet.requires_grad_(False)
# Freeze all parameters except for the token embeddings in text encoder
text_encoder.text_model.encoder.requires_grad_(False)
text_encoder.text_model.final_layer_norm.requires_grad_(False)
text_encoder.text_model.embeddings.position_embedding.requires_grad_(False)
if args.gradient_checkpointing:
# Keep unet in train mode if we are using gradient checkpointing to save memory.
# The dropout cannot be != 0 so it doesn't matter if we are in eval or train mode.
unet.train()
text_encoder.gradient_checkpointing_enable()
unet.enable_gradient_checkpointing()
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Initialize the optimizer
optimizer = torch.optim.AdamW(
text_encoder.get_input_embeddings().parameters(), # only optimize the embeddings
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Dataset and DataLoaders creation:
train_dataset = TextualInversionDataset(
data_root=args.train_data_dir,
tokenizer=tokenizer,
size=args.resolution,
placeholder_token=(" ".join(tokenizer.convert_ids_to_tokens(placeholder_token_ids))),
repeats=args.repeats,
learnable_property=args.learnable_property,
center_crop=args.center_crop,
set="train",
)
train_dataloader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers
)
if args.validation_epochs is not None:
warnings.warn(
f"FutureWarning: You are doing logging with validation_epochs={args.validation_epochs}."
" Deprecated validation_epochs in favor of `validation_steps`"
f"Setting `args.validation_steps` to {args.validation_epochs * len(train_dataset)}",
FutureWarning,
stacklevel=2,
)
args.validation_steps = args.validation_epochs * len(train_dataset)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps * accelerator.num_processes,
num_cycles=args.lr_num_cycles,
)
text_encoder.train()
# Prepare everything with our `accelerator`.
text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
text_encoder, optimizer, train_dataloader, lr_scheduler
)
# For mixed precision training we cast all non-trainable weigths (vae, non-lora text_encoder and non-lora unet) to half-precision
# as these weights are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move vae and unet to device and cast to weight_dtype
unet.to(accelerator.device, dtype=weight_dtype)
vae.to(accelerator.device, dtype=weight_dtype)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
accelerator.init_trackers("textual_inversion", config=vars(args))
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
# keep original embeddings as reference
orig_embeds_params = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight.data.clone()
for epoch in range(first_epoch, args.num_train_epochs):
text_encoder.train()
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(text_encoder):
# Convert images to latent space
latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample().detach()
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# Get the text embedding for conditioning
encoder_hidden_states = text_encoder(batch["input_ids"])[0].to(dtype=weight_dtype)
# Predict the noise residual
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Let's make sure we don't update any embedding weights besides the newly added token
index_no_updates = torch.ones((len(tokenizer),), dtype=torch.bool)
index_no_updates[min(placeholder_token_ids) : max(placeholder_token_ids) + 1] = False
with torch.no_grad():
accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[
index_no_updates
] = orig_embeds_params[index_no_updates]
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
images = []
progress_bar.update(1)
global_step += 1
if global_step % args.save_steps == 0:
weight_name = (
f"learned_embeds-steps-{global_step}.bin"
if args.no_safe_serialization
else f"learned_embeds-steps-{global_step}.safetensors"
)
save_path = os.path.join(args.output_dir, weight_name)
save_progress(
text_encoder,
placeholder_token_ids,
accelerator,
args,
save_path,
safe_serialization=not args.no_safe_serialization,
)
if accelerator.is_main_process:
if global_step % args.checkpointing_steps == 0:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
if args.validation_prompt is not None and global_step % args.validation_steps == 0:
images = log_validation(
text_encoder, tokenizer, unet, vae, args, accelerator, weight_dtype, epoch
)
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
if global_step >= args.max_train_steps:
break
# Create the pipeline using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
if args.push_to_hub and not args.save_as_full_pipeline:
logger.warn("Enabling full model saving because --push_to_hub=True was specified.")
save_full_model = True
else:
save_full_model = args.save_as_full_pipeline
if save_full_model:
pipeline = StableDiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path,
text_encoder=accelerator.unwrap_model(text_encoder),
vae=vae,
unet=unet,
tokenizer=tokenizer,
)
pipeline.save_pretrained(args.output_dir)
# Save the newly trained embeddings
weight_name = "learned_embeds.bin" if args.no_safe_serialization else "learned_embeds.safetensors"
save_path = os.path.join(args.output_dir, weight_name)
save_progress(
text_encoder,
placeholder_token_ids,
accelerator,
args,
save_path,
safe_serialization=not args.no_safe_serialization,
)
if args.push_to_hub:
save_model_card(
repo_id,
images=images,
base_model=args.pretrained_model_name_or_path,
repo_folder=args.output_dir,
)
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
accelerator.end_training()
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/textual_inversion/requirements.txt
|
accelerate>=0.16.0
torchvision
transformers>=4.25.1
ftfy
tensorboard
Jinja2
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/textual_inversion/textual_inversion_flax.py
|
import argparse
import logging
import math
import os
import random
from pathlib import Path
import jax
import jax.numpy as jnp
import numpy as np
import optax
import PIL
import torch
import torch.utils.checkpoint
import transformers
from flax import jax_utils
from flax.training import train_state
from flax.training.common_utils import shard
from huggingface_hub import create_repo, upload_folder
# TODO: remove and import from diffusers.utils when the new version of diffusers is released
from packaging import version
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPImageProcessor, CLIPTokenizer, FlaxCLIPTextModel, set_seed
from diffusers import (
FlaxAutoencoderKL,
FlaxDDPMScheduler,
FlaxPNDMScheduler,
FlaxStableDiffusionPipeline,
FlaxUNet2DConditionModel,
)
from diffusers.pipelines.stable_diffusion import FlaxStableDiffusionSafetyChecker
from diffusers.utils import check_min_version
if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
PIL_INTERPOLATION = {
"linear": PIL.Image.Resampling.BILINEAR,
"bilinear": PIL.Image.Resampling.BILINEAR,
"bicubic": PIL.Image.Resampling.BICUBIC,
"lanczos": PIL.Image.Resampling.LANCZOS,
"nearest": PIL.Image.Resampling.NEAREST,
}
else:
PIL_INTERPOLATION = {
"linear": PIL.Image.LINEAR,
"bilinear": PIL.Image.BILINEAR,
"bicubic": PIL.Image.BICUBIC,
"lanczos": PIL.Image.LANCZOS,
"nearest": PIL.Image.NEAREST,
}
# ------------------------------------------------------------------------------
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.24.0.dev0")
logger = logging.getLogger(__name__)
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--train_data_dir", type=str, default=None, required=True, help="A folder containing the training data."
)
parser.add_argument(
"--placeholder_token",
type=str,
default=None,
required=True,
help="A token to use as a placeholder for the concept.",
)
parser.add_argument(
"--initializer_token", type=str, default=None, required=True, help="A token to use as initializer word."
)
parser.add_argument("--learnable_property", type=str, default="object", help="Choose between 'object' and 'style'")
parser.add_argument("--repeats", type=int, default=100, help="How many times to repeat the training data.")
parser.add_argument(
"--output_dir",
type=str,
default="text-inversion-model",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument("--seed", type=int, default=42, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop", action="store_true", help="Whether to center crop images before resizing to resolution."
)
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=5000,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--save_steps",
type=int,
default=500,
help="Save learned_embeds.bin every X updates steps.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=True,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument(
"--use_auth_token",
action="store_true",
help=(
"Will use the token generated when running `huggingface-cli login` (necessary to use this script with"
" private models)."
),
)
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.train_data_dir is None:
raise ValueError("You must specify a train data directory.")
return args
imagenet_templates_small = [
"a photo of a {}",
"a rendering of a {}",
"a cropped photo of the {}",
"the photo of a {}",
"a photo of a clean {}",
"a photo of a dirty {}",
"a dark photo of the {}",
"a photo of my {}",
"a photo of the cool {}",
"a close-up photo of a {}",
"a bright photo of the {}",
"a cropped photo of a {}",
"a photo of the {}",
"a good photo of the {}",
"a photo of one {}",
"a close-up photo of the {}",
"a rendition of the {}",
"a photo of the clean {}",
"a rendition of a {}",
"a photo of a nice {}",
"a good photo of a {}",
"a photo of the nice {}",
"a photo of the small {}",
"a photo of the weird {}",
"a photo of the large {}",
"a photo of a cool {}",
"a photo of a small {}",
]
imagenet_style_templates_small = [
"a painting in the style of {}",
"a rendering in the style of {}",
"a cropped painting in the style of {}",
"the painting in the style of {}",
"a clean painting in the style of {}",
"a dirty painting in the style of {}",
"a dark painting in the style of {}",
"a picture in the style of {}",
"a cool painting in the style of {}",
"a close-up painting in the style of {}",
"a bright painting in the style of {}",
"a cropped painting in the style of {}",
"a good painting in the style of {}",
"a close-up painting in the style of {}",
"a rendition in the style of {}",
"a nice painting in the style of {}",
"a small painting in the style of {}",
"a weird painting in the style of {}",
"a large painting in the style of {}",
]
class TextualInversionDataset(Dataset):
def __init__(
self,
data_root,
tokenizer,
learnable_property="object", # [object, style]
size=512,
repeats=100,
interpolation="bicubic",
flip_p=0.5,
set="train",
placeholder_token="*",
center_crop=False,
):
self.data_root = data_root
self.tokenizer = tokenizer
self.learnable_property = learnable_property
self.size = size
self.placeholder_token = placeholder_token
self.center_crop = center_crop
self.flip_p = flip_p
self.image_paths = [os.path.join(self.data_root, file_path) for file_path in os.listdir(self.data_root)]
self.num_images = len(self.image_paths)
self._length = self.num_images
if set == "train":
self._length = self.num_images * repeats
self.interpolation = {
"linear": PIL_INTERPOLATION["linear"],
"bilinear": PIL_INTERPOLATION["bilinear"],
"bicubic": PIL_INTERPOLATION["bicubic"],
"lanczos": PIL_INTERPOLATION["lanczos"],
}[interpolation]
self.templates = imagenet_style_templates_small if learnable_property == "style" else imagenet_templates_small
self.flip_transform = transforms.RandomHorizontalFlip(p=self.flip_p)
def __len__(self):
return self._length
def __getitem__(self, i):
example = {}
image = Image.open(self.image_paths[i % self.num_images])
if not image.mode == "RGB":
image = image.convert("RGB")
placeholder_string = self.placeholder_token
text = random.choice(self.templates).format(placeholder_string)
example["input_ids"] = self.tokenizer(
text,
padding="max_length",
truncation=True,
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
).input_ids[0]
# default to score-sde preprocessing
img = np.array(image).astype(np.uint8)
if self.center_crop:
crop = min(img.shape[0], img.shape[1])
(
h,
w,
) = (
img.shape[0],
img.shape[1],
)
img = img[(h - crop) // 2 : (h + crop) // 2, (w - crop) // 2 : (w + crop) // 2]
image = Image.fromarray(img)
image = image.resize((self.size, self.size), resample=self.interpolation)
image = self.flip_transform(image)
image = np.array(image).astype(np.uint8)
image = (image / 127.5 - 1.0).astype(np.float32)
example["pixel_values"] = torch.from_numpy(image).permute(2, 0, 1)
return example
def resize_token_embeddings(model, new_num_tokens, initializer_token_id, placeholder_token_id, rng):
if model.config.vocab_size == new_num_tokens or new_num_tokens is None:
return
model.config.vocab_size = new_num_tokens
params = model.params
old_embeddings = params["text_model"]["embeddings"]["token_embedding"]["embedding"]
old_num_tokens, emb_dim = old_embeddings.shape
initializer = jax.nn.initializers.normal()
new_embeddings = initializer(rng, (new_num_tokens, emb_dim))
new_embeddings = new_embeddings.at[:old_num_tokens].set(old_embeddings)
new_embeddings = new_embeddings.at[placeholder_token_id].set(new_embeddings[initializer_token_id])
params["text_model"]["embeddings"]["token_embedding"]["embedding"] = new_embeddings
model.params = params
return model
def get_params_to_save(params):
return jax.device_get(jax.tree_util.tree_map(lambda x: x[0], params))
def main():
args = parse_args()
if args.seed is not None:
set_seed(args.seed)
if jax.process_index() == 0:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
# Setup logging, we only want one process per machine to log things on the screen.
logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
if jax.process_index() == 0:
transformers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
# Load the tokenizer and add the placeholder token as a additional special token
if args.tokenizer_name:
tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
elif args.pretrained_model_name_or_path:
tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
# Add the placeholder token in tokenizer
num_added_tokens = tokenizer.add_tokens(args.placeholder_token)
if num_added_tokens == 0:
raise ValueError(
f"The tokenizer already contains the token {args.placeholder_token}. Please pass a different"
" `placeholder_token` that is not already in the tokenizer."
)
# Convert the initializer_token, placeholder_token to ids
token_ids = tokenizer.encode(args.initializer_token, add_special_tokens=False)
# Check if initializer_token is a single token or a sequence of tokens
if len(token_ids) > 1:
raise ValueError("The initializer token must be a single token.")
initializer_token_id = token_ids[0]
placeholder_token_id = tokenizer.convert_tokens_to_ids(args.placeholder_token)
# Load models and create wrapper for stable diffusion
text_encoder = FlaxCLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
)
vae, vae_params = FlaxAutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision
)
unet, unet_params = FlaxUNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
)
# Create sampling rng
rng = jax.random.PRNGKey(args.seed)
rng, _ = jax.random.split(rng)
# Resize the token embeddings as we are adding new special tokens to the tokenizer
text_encoder = resize_token_embeddings(
text_encoder, len(tokenizer), initializer_token_id, placeholder_token_id, rng
)
original_token_embeds = text_encoder.params["text_model"]["embeddings"]["token_embedding"]["embedding"]
train_dataset = TextualInversionDataset(
data_root=args.train_data_dir,
tokenizer=tokenizer,
size=args.resolution,
placeholder_token=args.placeholder_token,
repeats=args.repeats,
learnable_property=args.learnable_property,
center_crop=args.center_crop,
set="train",
)
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
input_ids = torch.stack([example["input_ids"] for example in examples])
batch = {"pixel_values": pixel_values, "input_ids": input_ids}
batch = {k: v.numpy() for k, v in batch.items()}
return batch
total_train_batch_size = args.train_batch_size * jax.local_device_count()
train_dataloader = torch.utils.data.DataLoader(
train_dataset, batch_size=total_train_batch_size, shuffle=True, drop_last=True, collate_fn=collate_fn
)
# Optimization
if args.scale_lr:
args.learning_rate = args.learning_rate * total_train_batch_size
constant_scheduler = optax.constant_schedule(args.learning_rate)
optimizer = optax.adamw(
learning_rate=constant_scheduler,
b1=args.adam_beta1,
b2=args.adam_beta2,
eps=args.adam_epsilon,
weight_decay=args.adam_weight_decay,
)
def create_mask(params, label_fn):
def _map(params, mask, label_fn):
for k in params:
if label_fn(k):
mask[k] = "token_embedding"
else:
if isinstance(params[k], dict):
mask[k] = {}
_map(params[k], mask[k], label_fn)
else:
mask[k] = "zero"
mask = {}
_map(params, mask, label_fn)
return mask
def zero_grads():
# from https://github.com/deepmind/optax/issues/159#issuecomment-896459491
def init_fn(_):
return ()
def update_fn(updates, state, params=None):
return jax.tree_util.tree_map(jnp.zeros_like, updates), ()
return optax.GradientTransformation(init_fn, update_fn)
# Zero out gradients of layers other than the token embedding layer
tx = optax.multi_transform(
{"token_embedding": optimizer, "zero": zero_grads()},
create_mask(text_encoder.params, lambda s: s == "token_embedding"),
)
state = train_state.TrainState.create(apply_fn=text_encoder.__call__, params=text_encoder.params, tx=tx)
noise_scheduler = FlaxDDPMScheduler(
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000
)
noise_scheduler_state = noise_scheduler.create_state()
# Initialize our training
train_rngs = jax.random.split(rng, jax.local_device_count())
# Define gradient train step fn
def train_step(state, vae_params, unet_params, batch, train_rng):
dropout_rng, sample_rng, new_train_rng = jax.random.split(train_rng, 3)
def compute_loss(params):
vae_outputs = vae.apply(
{"params": vae_params}, batch["pixel_values"], deterministic=True, method=vae.encode
)
latents = vae_outputs.latent_dist.sample(sample_rng)
# (NHWC) -> (NCHW)
latents = jnp.transpose(latents, (0, 3, 1, 2))
latents = latents * vae.config.scaling_factor
noise_rng, timestep_rng = jax.random.split(sample_rng)
noise = jax.random.normal(noise_rng, latents.shape)
bsz = latents.shape[0]
timesteps = jax.random.randint(
timestep_rng,
(bsz,),
0,
noise_scheduler.config.num_train_timesteps,
)
noisy_latents = noise_scheduler.add_noise(noise_scheduler_state, latents, noise, timesteps)
encoder_hidden_states = state.apply_fn(
batch["input_ids"], params=params, dropout_rng=dropout_rng, train=True
)[0]
# Predict the noise residual and compute loss
model_pred = unet.apply(
{"params": unet_params}, noisy_latents, timesteps, encoder_hidden_states, train=False
).sample
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(noise_scheduler_state, latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
loss = (target - model_pred) ** 2
loss = loss.mean()
return loss
grad_fn = jax.value_and_grad(compute_loss)
loss, grad = grad_fn(state.params)
grad = jax.lax.pmean(grad, "batch")
new_state = state.apply_gradients(grads=grad)
# Keep the token embeddings fixed except the newly added embeddings for the concept,
# as we only want to optimize the concept embeddings
token_embeds = original_token_embeds.at[placeholder_token_id].set(
new_state.params["text_model"]["embeddings"]["token_embedding"]["embedding"][placeholder_token_id]
)
new_state.params["text_model"]["embeddings"]["token_embedding"]["embedding"] = token_embeds
metrics = {"loss": loss}
metrics = jax.lax.pmean(metrics, axis_name="batch")
return new_state, metrics, new_train_rng
# Create parallel version of the train and eval step
p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
# Replicate the train state on each device
state = jax_utils.replicate(state)
vae_params = jax_utils.replicate(vae_params)
unet_params = jax_utils.replicate(unet_params)
# Train!
num_update_steps_per_epoch = math.ceil(len(train_dataloader))
# Scheduler and math around the number of training steps.
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel & distributed) = {total_train_batch_size}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
epochs = tqdm(range(args.num_train_epochs), desc=f"Epoch ... (1/{args.num_train_epochs})", position=0)
for epoch in epochs:
# ======================== Training ================================
train_metrics = []
steps_per_epoch = len(train_dataset) // total_train_batch_size
train_step_progress_bar = tqdm(total=steps_per_epoch, desc="Training...", position=1, leave=False)
# train
for batch in train_dataloader:
batch = shard(batch)
state, train_metric, train_rngs = p_train_step(state, vae_params, unet_params, batch, train_rngs)
train_metrics.append(train_metric)
train_step_progress_bar.update(1)
global_step += 1
if global_step >= args.max_train_steps:
break
if global_step % args.save_steps == 0:
learned_embeds = get_params_to_save(state.params)["text_model"]["embeddings"]["token_embedding"][
"embedding"
][placeholder_token_id]
learned_embeds_dict = {args.placeholder_token: learned_embeds}
jnp.save(
os.path.join(args.output_dir, "learned_embeds-" + str(global_step) + ".npy"), learned_embeds_dict
)
train_metric = jax_utils.unreplicate(train_metric)
train_step_progress_bar.close()
epochs.write(f"Epoch... ({epoch + 1}/{args.num_train_epochs} | Loss: {train_metric['loss']})")
# Create the pipeline using using the trained modules and save it.
if jax.process_index() == 0:
scheduler = FlaxPNDMScheduler(
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", skip_prk_steps=True
)
safety_checker = FlaxStableDiffusionSafetyChecker.from_pretrained(
"CompVis/stable-diffusion-safety-checker", from_pt=True
)
pipeline = FlaxStableDiffusionPipeline(
text_encoder=text_encoder,
vae=vae,
unet=unet,
tokenizer=tokenizer,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=CLIPImageProcessor.from_pretrained("openai/clip-vit-base-patch32"),
)
pipeline.save_pretrained(
args.output_dir,
params={
"text_encoder": get_params_to_save(state.params),
"vae": get_params_to_save(vae_params),
"unet": get_params_to_save(unet_params),
"safety_checker": safety_checker.params,
},
)
# Also save the newly trained embeddings
learned_embeds = get_params_to_save(state.params)["text_model"]["embeddings"]["token_embedding"]["embedding"][
placeholder_token_id
]
learned_embeds_dict = {args.placeholder_token: learned_embeds}
jnp.save(os.path.join(args.output_dir, "learned_embeds.npy"), learned_embeds_dict)
if args.push_to_hub:
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/reinforcement_learning/README.md
|
# Overview
These examples show how to run [Diffuser](https://arxiv.org/abs/2205.09991) in Diffusers.
There are two ways to use the script, `run_diffuser_locomotion.py`.
The key option is a change of the variable `n_guide_steps`.
When `n_guide_steps=0`, the trajectories are sampled from the diffusion model, but not fine-tuned to maximize reward in the environment.
By default, `n_guide_steps=2` to match the original implementation.
You will need some RL specific requirements to run the examples:
```
pip install -f https://download.pytorch.org/whl/torch_stable.html \
free-mujoco-py \
einops \
gym==0.24.1 \
protobuf==3.20.1 \
git+https://github.com/rail-berkeley/d4rl.git \
mediapy \
Pillow==9.0.0
```
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/reinforcement_learning/run_diffuser_locomotion.py
|
import d4rl # noqa
import gym
import tqdm
from diffusers.experimental import ValueGuidedRLPipeline
config = {
"n_samples": 64,
"horizon": 32,
"num_inference_steps": 20,
"n_guide_steps": 2, # can set to 0 for faster sampling, does not use value network
"scale_grad_by_std": True,
"scale": 0.1,
"eta": 0.0,
"t_grad_cutoff": 2,
"device": "cpu",
}
if __name__ == "__main__":
env_name = "hopper-medium-v2"
env = gym.make(env_name)
pipeline = ValueGuidedRLPipeline.from_pretrained(
"bglick13/hopper-medium-v2-value-function-hor32",
env=env,
)
env.seed(0)
obs = env.reset()
total_reward = 0
total_score = 0
T = 1000
rollout = [obs.copy()]
try:
for t in tqdm.tqdm(range(T)):
# call the policy
denorm_actions = pipeline(obs, planning_horizon=32)
# execute action in environment
next_observation, reward, terminal, _ = env.step(denorm_actions)
score = env.get_normalized_score(total_reward)
# update return
total_reward += reward
total_score += score
print(
f"Step: {t}, Reward: {reward}, Total Reward: {total_reward}, Score: {score}, Total Score:"
f" {total_score}"
)
# save observations for rendering
rollout.append(next_observation.copy())
obs = next_observation
except KeyboardInterrupt:
pass
print(f"Total reward: {total_reward}")
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/mixture_tiling.py
|
import inspect
from copy import deepcopy
from enum import Enum
from typing import List, Optional, Tuple, Union
import torch
from tqdm.auto import tqdm
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
from diffusers.utils import logging
try:
from ligo.segments import segment
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
except ImportError:
raise ImportError("Please install transformers and ligo-segments to use the mixture pipeline")
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> from diffusers import LMSDiscreteScheduler, DiffusionPipeline
>>> scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
>>> pipeline = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=scheduler, custom_pipeline="mixture_tiling")
>>> pipeline.to("cuda")
>>> image = pipeline(
>>> prompt=[[
>>> "A charming house in the countryside, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece",
>>> "A dirt road in the countryside crossing pastures, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece",
>>> "An old and rusty giant robot lying on a dirt road, by jakub rozalski, dark sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece"
>>> ]],
>>> tile_height=640,
>>> tile_width=640,
>>> tile_row_overlap=0,
>>> tile_col_overlap=256,
>>> guidance_scale=8,
>>> seed=7178915308,
>>> num_inference_steps=50,
>>> )["images"][0]
```
"""
def _tile2pixel_indices(tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap):
"""Given a tile row and column numbers returns the range of pixels affected by that tiles in the overall image
Returns a tuple with:
- Starting coordinates of rows in pixel space
- Ending coordinates of rows in pixel space
- Starting coordinates of columns in pixel space
- Ending coordinates of columns in pixel space
"""
px_row_init = 0 if tile_row == 0 else tile_row * (tile_height - tile_row_overlap)
px_row_end = px_row_init + tile_height
px_col_init = 0 if tile_col == 0 else tile_col * (tile_width - tile_col_overlap)
px_col_end = px_col_init + tile_width
return px_row_init, px_row_end, px_col_init, px_col_end
def _pixel2latent_indices(px_row_init, px_row_end, px_col_init, px_col_end):
"""Translates coordinates in pixel space to coordinates in latent space"""
return px_row_init // 8, px_row_end // 8, px_col_init // 8, px_col_end // 8
def _tile2latent_indices(tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap):
"""Given a tile row and column numbers returns the range of latents affected by that tiles in the overall image
Returns a tuple with:
- Starting coordinates of rows in latent space
- Ending coordinates of rows in latent space
- Starting coordinates of columns in latent space
- Ending coordinates of columns in latent space
"""
px_row_init, px_row_end, px_col_init, px_col_end = _tile2pixel_indices(
tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
)
return _pixel2latent_indices(px_row_init, px_row_end, px_col_init, px_col_end)
def _tile2latent_exclusive_indices(
tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap, rows, columns
):
"""Given a tile row and column numbers returns the range of latents affected only by that tile in the overall image
Returns a tuple with:
- Starting coordinates of rows in latent space
- Ending coordinates of rows in latent space
- Starting coordinates of columns in latent space
- Ending coordinates of columns in latent space
"""
row_init, row_end, col_init, col_end = _tile2latent_indices(
tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
)
row_segment = segment(row_init, row_end)
col_segment = segment(col_init, col_end)
# Iterate over the rest of tiles, clipping the region for the current tile
for row in range(rows):
for column in range(columns):
if row != tile_row and column != tile_col:
clip_row_init, clip_row_end, clip_col_init, clip_col_end = _tile2latent_indices(
row, column, tile_width, tile_height, tile_row_overlap, tile_col_overlap
)
row_segment = row_segment - segment(clip_row_init, clip_row_end)
col_segment = col_segment - segment(clip_col_init, clip_col_end)
# return row_init, row_end, col_init, col_end
return row_segment[0], row_segment[1], col_segment[0], col_segment[1]
class StableDiffusionExtrasMixin:
"""Mixin providing additional convenience method to Stable Diffusion pipelines"""
def decode_latents(self, latents, cpu_vae=False):
"""Decodes a given array of latents into pixel space"""
# scale and decode the image latents with vae
if cpu_vae:
lat = deepcopy(latents).cpu()
vae = deepcopy(self.vae).cpu()
else:
lat = latents
vae = self.vae
lat = 1 / 0.18215 * lat
image = vae.decode(lat).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
return self.numpy_to_pil(image)
class StableDiffusionTilingPipeline(DiffusionPipeline, StableDiffusionExtrasMixin):
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, PNDMScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPFeatureExtractor,
):
super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
class SeedTilesMode(Enum):
"""Modes in which the latents of a particular tile can be re-seeded"""
FULL = "full"
EXCLUSIVE = "exclusive"
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[List[str]]],
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
eta: Optional[float] = 0.0,
seed: Optional[int] = None,
tile_height: Optional[int] = 512,
tile_width: Optional[int] = 512,
tile_row_overlap: Optional[int] = 256,
tile_col_overlap: Optional[int] = 256,
guidance_scale_tiles: Optional[List[List[float]]] = None,
seed_tiles: Optional[List[List[int]]] = None,
seed_tiles_mode: Optional[Union[str, List[List[str]]]] = "full",
seed_reroll_regions: Optional[List[Tuple[int, int, int, int, int]]] = None,
cpu_vae: Optional[bool] = False,
):
r"""
Function to run the diffusion pipeline with tiling support.
Args:
prompt: either a single string (no tiling) or a list of lists with all the prompts to use (one list for each row of tiles). This will also define the tiling structure.
num_inference_steps: number of diffusions steps.
guidance_scale: classifier-free guidance.
seed: general random seed to initialize latents.
tile_height: height in pixels of each grid tile.
tile_width: width in pixels of each grid tile.
tile_row_overlap: number of overlap pixels between tiles in consecutive rows.
tile_col_overlap: number of overlap pixels between tiles in consecutive columns.
guidance_scale_tiles: specific weights for classifier-free guidance in each tile.
guidance_scale_tiles: specific weights for classifier-free guidance in each tile. If None, the value provided in guidance_scale will be used.
seed_tiles: specific seeds for the initialization latents in each tile. These will override the latents generated for the whole canvas using the standard seed parameter.
seed_tiles_mode: either "full" "exclusive". If "full", all the latents affected by the tile be overriden. If "exclusive", only the latents that are affected exclusively by this tile (and no other tiles) will be overrriden.
seed_reroll_regions: a list of tuples in the form (start row, end row, start column, end column, seed) defining regions in pixel space for which the latents will be overriden using the given seed. Takes priority over seed_tiles.
cpu_vae: the decoder from latent space to pixel space can require too mucho GPU RAM for large images. If you find out of memory errors at the end of the generation process, try setting this parameter to True to run the decoder in CPU. Slower, but should run without memory issues.
Examples:
Returns:
A PIL image with the generated image.
"""
if not isinstance(prompt, list) or not all(isinstance(row, list) for row in prompt):
raise ValueError(f"`prompt` has to be a list of lists but is {type(prompt)}")
grid_rows = len(prompt)
grid_cols = len(prompt[0])
if not all(len(row) == grid_cols for row in prompt):
raise ValueError("All prompt rows must have the same number of prompt columns")
if not isinstance(seed_tiles_mode, str) and (
not isinstance(seed_tiles_mode, list) or not all(isinstance(row, list) for row in seed_tiles_mode)
):
raise ValueError(f"`seed_tiles_mode` has to be a string or list of lists but is {type(prompt)}")
if isinstance(seed_tiles_mode, str):
seed_tiles_mode = [[seed_tiles_mode for _ in range(len(row))] for row in prompt]
modes = [mode.value for mode in self.SeedTilesMode]
if any(mode not in modes for row in seed_tiles_mode for mode in row):
raise ValueError(f"Seed tiles mode must be one of {modes}")
if seed_reroll_regions is None:
seed_reroll_regions = []
batch_size = 1
# create original noisy latents using the timesteps
height = tile_height + (grid_rows - 1) * (tile_height - tile_row_overlap)
width = tile_width + (grid_cols - 1) * (tile_width - tile_col_overlap)
latents_shape = (batch_size, self.unet.config.in_channels, height // 8, width // 8)
generator = torch.Generator("cuda").manual_seed(seed)
latents = torch.randn(latents_shape, generator=generator, device=self.device)
# overwrite latents for specific tiles if provided
if seed_tiles is not None:
for row in range(grid_rows):
for col in range(grid_cols):
if (seed_tile := seed_tiles[row][col]) is not None:
mode = seed_tiles_mode[row][col]
if mode == self.SeedTilesMode.FULL.value:
row_init, row_end, col_init, col_end = _tile2latent_indices(
row, col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
)
else:
row_init, row_end, col_init, col_end = _tile2latent_exclusive_indices(
row,
col,
tile_width,
tile_height,
tile_row_overlap,
tile_col_overlap,
grid_rows,
grid_cols,
)
tile_generator = torch.Generator("cuda").manual_seed(seed_tile)
tile_shape = (latents_shape[0], latents_shape[1], row_end - row_init, col_end - col_init)
latents[:, :, row_init:row_end, col_init:col_end] = torch.randn(
tile_shape, generator=tile_generator, device=self.device
)
# overwrite again for seed reroll regions
for row_init, row_end, col_init, col_end, seed_reroll in seed_reroll_regions:
row_init, row_end, col_init, col_end = _pixel2latent_indices(
row_init, row_end, col_init, col_end
) # to latent space coordinates
reroll_generator = torch.Generator("cuda").manual_seed(seed_reroll)
region_shape = (latents_shape[0], latents_shape[1], row_end - row_init, col_end - col_init)
latents[:, :, row_init:row_end, col_init:col_end] = torch.randn(
region_shape, generator=reroll_generator, device=self.device
)
# Prepare scheduler
accepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())
extra_set_kwargs = {}
if accepts_offset:
extra_set_kwargs["offset"] = 1
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
# if we use LMSDiscreteScheduler, let's make sure latents are multiplied by sigmas
if isinstance(self.scheduler, LMSDiscreteScheduler):
latents = latents * self.scheduler.sigmas[0]
# get prompts text embeddings
text_input = [
[
self.tokenizer(
col,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
for col in row
]
for row in prompt
]
text_embeddings = [[self.text_encoder(col.input_ids.to(self.device))[0] for col in row] for row in text_input]
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0 # TODO: also active if any tile has guidance scale
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
for i in range(grid_rows):
for j in range(grid_cols):
max_length = text_input[i][j].input_ids.shape[-1]
uncond_input = self.tokenizer(
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings[i][j] = torch.cat([uncond_embeddings, text_embeddings[i][j]])
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# Mask for tile weights strenght
tile_weights = self._gaussian_weights(tile_width, tile_height, batch_size)
# Diffusion timesteps
for i, t in tqdm(enumerate(self.scheduler.timesteps)):
# Diffuse each tile
noise_preds = []
for row in range(grid_rows):
noise_preds_row = []
for col in range(grid_cols):
px_row_init, px_row_end, px_col_init, px_col_end = _tile2latent_indices(
row, col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
)
tile_latents = latents[:, :, px_row_init:px_row_end, px_col_init:px_col_end]
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([tile_latents] * 2) if do_classifier_free_guidance else tile_latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings[row][col])[
"sample"
]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
guidance = (
guidance_scale
if guidance_scale_tiles is None or guidance_scale_tiles[row][col] is None
else guidance_scale_tiles[row][col]
)
noise_pred_tile = noise_pred_uncond + guidance * (noise_pred_text - noise_pred_uncond)
noise_preds_row.append(noise_pred_tile)
noise_preds.append(noise_preds_row)
# Stitch noise predictions for all tiles
noise_pred = torch.zeros(latents.shape, device=self.device)
contributors = torch.zeros(latents.shape, device=self.device)
# Add each tile contribution to overall latents
for row in range(grid_rows):
for col in range(grid_cols):
px_row_init, px_row_end, px_col_init, px_col_end = _tile2latent_indices(
row, col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
)
noise_pred[:, :, px_row_init:px_row_end, px_col_init:px_col_end] += (
noise_preds[row][col] * tile_weights
)
contributors[:, :, px_row_init:px_row_end, px_col_init:px_col_end] += tile_weights
# Average overlapping areas with more than 1 contributor
noise_pred /= contributors
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents).prev_sample
# scale and decode the image latents with vae
image = self.decode_latents(latents, cpu_vae)
return {"images": image}
def _gaussian_weights(self, tile_width, tile_height, nbatches):
"""Generates a gaussian mask of weights for tile contributions"""
import numpy as np
from numpy import exp, pi, sqrt
latent_width = tile_width // 8
latent_height = tile_height // 8
var = 0.01
midpoint = (latent_width - 1) / 2 # -1 because index goes from 0 to latent_width - 1
x_probs = [
exp(-(x - midpoint) * (x - midpoint) / (latent_width * latent_width) / (2 * var)) / sqrt(2 * pi * var)
for x in range(latent_width)
]
midpoint = latent_height / 2
y_probs = [
exp(-(y - midpoint) * (y - midpoint) / (latent_height * latent_height) / (2 * var)) / sqrt(2 * pi * var)
for y in range(latent_height)
]
weights = np.outer(y_probs, x_probs)
return torch.tile(torch.tensor(weights, device=self.device), (nbatches, self.unet.config.in_channels, 1, 1))
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter.py
|
# Copyright 2023 TencentARC and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
import torch.nn.functional as F
from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
from diffusers.loaders import FromSingleFileMixin, StableDiffusionXLLoraLoaderMixin, TextualInversionLoaderMixin
from diffusers.models import AutoencoderKL, ControlNetModel, MultiAdapter, T2IAdapter, UNet2DConditionModel
from diffusers.models.attention_processor import (
AttnProcessor2_0,
LoRAAttnProcessor2_0,
LoRAXFormersAttnProcessor,
XFormersAttnProcessor,
)
from diffusers.models.lora import adjust_lora_scale_text_encoder
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.pipelines.stable_diffusion_xl.pipeline_output import StableDiffusionXLPipelineOutput
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
PIL_INTERPOLATION,
USE_PEFT_BACKEND,
logging,
replace_example_docstring,
scale_lora_layers,
unscale_lora_layers,
)
from diffusers.utils.torch_utils import is_compiled_module, randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
>>> from diffusers import T2IAdapter, StableDiffusionXLAdapterPipeline, DDPMScheduler
>>> from diffusers.utils import load_image
>>> from controlnet_aux.midas import MidasDetector
>>> img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
>>> mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
>>> image = load_image(img_url).resize((1024, 1024))
>>> mask_image = load_image(mask_url).resize((1024, 1024))
>>> midas_depth = MidasDetector.from_pretrained(
... "valhalla/t2iadapter-aux-models", filename="dpt_large_384.pt", model_type="dpt_large"
... ).to("cuda")
>>> depth_image = midas_depth(
... image, detect_resolution=512, image_resolution=1024
... )
>>> model_id = "stabilityai/stable-diffusion-xl-base-1.0"
>>> adapter = T2IAdapter.from_pretrained(
... "Adapter/t2iadapter",
... subfolder="sketch_sdxl_1.0",
... torch_dtype=torch.float16,
... adapter_type="full_adapter_xl",
... )
>>> controlnet = ControlNetModel.from_pretrained(
... "diffusers/controlnet-depth-sdxl-1.0",
... torch_dtype=torch.float16,
... variant="fp16",
... use_safetensors=True
... ).to("cuda")
>>> scheduler = DDPMScheduler.from_pretrained(model_id, subfolder="scheduler")
>>> pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
... model_id,
... adapter=adapter,
... controlnet=controlnet,
... torch_dtype=torch.float16,
... variant="fp16",
... scheduler=scheduler
... ).to("cuda")
>>> strength = 0.5
>>> generator = torch.manual_seed(42)
>>> sketch_image_out = pipe(
... prompt="a photo of a tiger sitting on a park bench",
... negative_prompt="extra digit, fewer digits, cropped, worst quality, low quality",
... adapter_image=depth_image,
... control_image=mask_image,
... adapter_conditioning_scale=strength,
... controlnet_conditioning_scale=strength,
... generator=generator,
... guidance_scale=7.5,
... ).images[0]
```
"""
def _preprocess_adapter_image(image, height, width):
if isinstance(image, torch.Tensor):
return image
elif isinstance(image, PIL.Image.Image):
image = [image]
if isinstance(image[0], PIL.Image.Image):
image = [np.array(i.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])) for i in image]
image = [
i[None, ..., None] if i.ndim == 2 else i[None, ...] for i in image
] # expand [h, w] or [h, w, c] to [b, h, w, c]
image = np.concatenate(image, axis=0)
image = np.array(image).astype(np.float32) / 255.0
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
elif isinstance(image[0], torch.Tensor):
if image[0].ndim == 3:
image = torch.stack(image, dim=0)
elif image[0].ndim == 4:
image = torch.cat(image, dim=0)
else:
raise ValueError(
f"Invalid image tensor! Expecting image tensor with 3 or 4 dimension, but recive: {image[0].ndim}"
)
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
# rescale the results from guidance (fixes overexposure)
noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
# mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
return noise_cfg
class StableDiffusionXLControlNetAdapterPipeline(
DiffusionPipeline, FromSingleFileMixin, StableDiffusionXLLoraLoaderMixin, TextualInversionLoaderMixin
):
r"""
Pipeline for text-to-image generation using Stable Diffusion augmented with T2I-Adapter
https://arxiv.org/abs/2302.08453
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
adapter ([`T2IAdapter`] or [`MultiAdapter`] or `List[T2IAdapter]`):
Provides additional conditioning to the unet during the denoising process. If you set multiple Adapter as a
list, the outputs from each Adapter are added together to create one combined additional conditioning.
adapter_weights (`List[float]`, *optional*, defaults to None):
List of floats representing the weight which will be multiply to each adapter's output before adding them
together.
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPFeatureExtractor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
model_cpu_offload_seq = "text_encoder->text_encoder_2->unet->vae"
_optional_components = ["tokenizer", "tokenizer_2", "text_encoder", "text_encoder_2"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
text_encoder_2: CLIPTextModelWithProjection,
tokenizer: CLIPTokenizer,
tokenizer_2: CLIPTokenizer,
unet: UNet2DConditionModel,
adapter: Union[T2IAdapter, MultiAdapter, List[T2IAdapter]],
controlnet: Union[ControlNetModel, MultiControlNetModel],
scheduler: KarrasDiffusionSchedulers,
force_zeros_for_empty_prompt: bool = True,
):
super().__init__()
if isinstance(controlnet, (list, tuple)):
controlnet = MultiControlNetModel(controlnet)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
text_encoder_2=text_encoder_2,
tokenizer=tokenizer,
tokenizer_2=tokenizer_2,
unet=unet,
adapter=adapter,
controlnet=controlnet,
scheduler=scheduler,
)
self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.control_image_processor = VaeImageProcessor(
vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
)
self.default_sample_size = self.unet.config.sample_size
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
def enable_vae_slicing(self):
r"""
Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
"""
self.vae.enable_slicing()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
def disable_vae_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
computing decoding in one step.
"""
self.vae.disable_slicing()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
def enable_vae_tiling(self):
r"""
Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
processing larger images.
"""
self.vae.enable_tiling()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
def disable_vae_tiling(self):
r"""
Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
computing decoding in one step.
"""
self.vae.disable_tiling()
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.encode_prompt
def encode_prompt(
self,
prompt: str,
prompt_2: Optional[str] = None,
device: Optional[torch.device] = None,
num_images_per_prompt: int = 1,
do_classifier_free_guidance: bool = True,
negative_prompt: Optional[str] = None,
negative_prompt_2: Optional[str] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
clip_skip: Optional[int] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
used in both text-encoders
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
negative_prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
`text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
If not provided, pooled text embeddings will be generated from `prompt` input argument.
negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
input argument.
lora_scale (`float`, *optional*):
A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
"""
device = device or self._execution_device
# set lora scale so that monkey patched LoRA
# function of text encoder can correctly access it
if lora_scale is not None and isinstance(self, StableDiffusionXLLoraLoaderMixin):
self._lora_scale = lora_scale
# dynamically adjust the LoRA scale
if self.text_encoder is not None:
if not USE_PEFT_BACKEND:
adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
else:
scale_lora_layers(self.text_encoder, lora_scale)
if self.text_encoder_2 is not None:
if not USE_PEFT_BACKEND:
adjust_lora_scale_text_encoder(self.text_encoder_2, lora_scale)
else:
scale_lora_layers(self.text_encoder_2, lora_scale)
prompt = [prompt] if isinstance(prompt, str) else prompt
if prompt is not None:
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
# Define tokenizers and text encoders
tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
text_encoders = (
[self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
)
if prompt_embeds is None:
prompt_2 = prompt_2 or prompt
prompt_2 = [prompt_2] if isinstance(prompt_2, str) else prompt_2
# textual inversion: procecss multi-vector tokens if necessary
prompt_embeds_list = []
prompts = [prompt, prompt_2]
for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, tokenizer)
text_inputs = tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {tokenizer.model_max_length} tokens: {removed_text}"
)
prompt_embeds = text_encoder(text_input_ids.to(device), output_hidden_states=True)
# We are only ALWAYS interested in the pooled output of the final text encoder
pooled_prompt_embeds = prompt_embeds[0]
if clip_skip is None:
prompt_embeds = prompt_embeds.hidden_states[-2]
else:
# "2" because SDXL always indexes from the penultimate layer.
prompt_embeds = prompt_embeds.hidden_states[-(clip_skip + 2)]
prompt_embeds_list.append(prompt_embeds)
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
# get unconditional embeddings for classifier free guidance
zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
negative_prompt_embeds = torch.zeros_like(prompt_embeds)
negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
elif do_classifier_free_guidance and negative_prompt_embeds is None:
negative_prompt = negative_prompt or ""
negative_prompt_2 = negative_prompt_2 or negative_prompt
# normalize str to list
negative_prompt = batch_size * [negative_prompt] if isinstance(negative_prompt, str) else negative_prompt
negative_prompt_2 = (
batch_size * [negative_prompt_2] if isinstance(negative_prompt_2, str) else negative_prompt_2
)
uncond_tokens: List[str]
if prompt is not None and type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = [negative_prompt, negative_prompt_2]
negative_prompt_embeds_list = []
for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
if isinstance(self, TextualInversionLoaderMixin):
negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = tokenizer(
negative_prompt,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
negative_prompt_embeds = text_encoder(
uncond_input.input_ids.to(device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
negative_pooled_prompt_embeds = negative_prompt_embeds[0]
negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
negative_prompt_embeds_list.append(negative_prompt_embeds)
negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
if self.text_encoder_2 is not None:
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
else:
prompt_embeds = prompt_embeds.to(dtype=self.unet.dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
if self.text_encoder_2 is not None:
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
else:
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.unet.dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
bs_embed * num_images_per_prompt, -1
)
if do_classifier_free_guidance:
negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
bs_embed * num_images_per_prompt, -1
)
if self.text_encoder is not None:
if isinstance(self, StableDiffusionXLLoraLoaderMixin) and USE_PEFT_BACKEND:
# Retrieve the original scale by scaling back the LoRA layers
unscale_lora_layers(self.text_encoder, lora_scale)
if self.text_encoder_2 is not None:
if isinstance(self, StableDiffusionXLLoraLoaderMixin) and USE_PEFT_BACKEND:
# Retrieve the original scale by scaling back the LoRA layers
unscale_lora_layers(self.text_encoder_2, lora_scale)
return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
# Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image
def check_image(self, image, prompt, prompt_embeds):
image_is_pil = isinstance(image, PIL.Image.Image)
image_is_tensor = isinstance(image, torch.Tensor)
image_is_np = isinstance(image, np.ndarray)
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
if (
not image_is_pil
and not image_is_tensor
and not image_is_np
and not image_is_pil_list
and not image_is_tensor_list
and not image_is_np_list
):
raise TypeError(
f"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(image)}"
)
if image_is_pil:
image_batch_size = 1
else:
image_batch_size = len(image)
if prompt is not None and isinstance(prompt, str):
prompt_batch_size = 1
elif prompt is not None and isinstance(prompt, list):
prompt_batch_size = len(prompt)
elif prompt_embeds is not None:
prompt_batch_size = prompt_embeds.shape[0]
if image_batch_size != 1 and image_batch_size != prompt_batch_size:
raise ValueError(
f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
)
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.check_inputs
def check_inputs(
self,
prompt,
prompt_2,
height,
width,
callback_steps,
negative_prompt=None,
negative_prompt_2=None,
prompt_embeds=None,
negative_prompt_embeds=None,
pooled_prompt_embeds=None,
negative_pooled_prompt_embeds=None,
callback_on_step_end_tensor_inputs=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if callback_on_step_end_tensor_inputs is not None and not all(
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
):
raise ValueError(
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt_2 is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
if prompt_embeds is not None and pooled_prompt_embeds is None:
raise ValueError(
"If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
)
if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
raise ValueError(
"If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
)
def check_conditions(
self,
prompt,
prompt_embeds,
adapter_image,
control_image,
adapter_conditioning_scale,
controlnet_conditioning_scale,
control_guidance_start,
control_guidance_end,
):
# controlnet checks
if not isinstance(control_guidance_start, (tuple, list)):
control_guidance_start = [control_guidance_start]
if not isinstance(control_guidance_end, (tuple, list)):
control_guidance_end = [control_guidance_end]
if len(control_guidance_start) != len(control_guidance_end):
raise ValueError(
f"`control_guidance_start` has {len(control_guidance_start)} elements, but `control_guidance_end` has {len(control_guidance_end)} elements. Make sure to provide the same number of elements to each list."
)
if isinstance(self.controlnet, MultiControlNetModel):
if len(control_guidance_start) != len(self.controlnet.nets):
raise ValueError(
f"`control_guidance_start`: {control_guidance_start} has {len(control_guidance_start)} elements but there are {len(self.controlnet.nets)} controlnets available. Make sure to provide {len(self.controlnet.nets)}."
)
for start, end in zip(control_guidance_start, control_guidance_end):
if start >= end:
raise ValueError(
f"control guidance start: {start} cannot be larger or equal to control guidance end: {end}."
)
if start < 0.0:
raise ValueError(f"control guidance start: {start} can't be smaller than 0.")
if end > 1.0:
raise ValueError(f"control guidance end: {end} can't be larger than 1.0.")
# Check controlnet `image`
is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
self.controlnet, torch._dynamo.eval_frame.OptimizedModule
)
if (
isinstance(self.controlnet, ControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, ControlNetModel)
):
self.check_image(control_image, prompt, prompt_embeds)
elif (
isinstance(self.controlnet, MultiControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
):
if not isinstance(control_image, list):
raise TypeError("For multiple controlnets: `control_image` must be type `list`")
# When `image` is a nested list:
# (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
elif any(isinstance(i, list) for i in control_image):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif len(control_image) != len(self.controlnet.nets):
raise ValueError(
f"For multiple controlnets: `image` must have the same length as the number of controlnets, but got {len(control_image)} images and {len(self.controlnet.nets)} ControlNets."
)
for image_ in control_image:
self.check_image(image_, prompt, prompt_embeds)
else:
assert False
# Check `controlnet_conditioning_scale`
if (
isinstance(self.controlnet, ControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, ControlNetModel)
):
if not isinstance(controlnet_conditioning_scale, float):
raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
elif (
isinstance(self.controlnet, MultiControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
):
if isinstance(controlnet_conditioning_scale, list):
if any(isinstance(i, list) for i in controlnet_conditioning_scale):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
self.controlnet.nets
):
raise ValueError(
"For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
" the same length as the number of controlnets"
)
else:
assert False
# adapter checks
if isinstance(self.adapter, T2IAdapter) or is_compiled and isinstance(self.adapter._orig_mod, T2IAdapter):
self.check_image(adapter_image, prompt, prompt_embeds)
elif (
isinstance(self.adapter, MultiAdapter) or is_compiled and isinstance(self.adapter._orig_mod, MultiAdapter)
):
if not isinstance(adapter_image, list):
raise TypeError("For multiple adapters: `adapter_image` must be type `list`")
# When `image` is a nested list:
# (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
elif any(isinstance(i, list) for i in adapter_image):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif len(adapter_image) != len(self.adapter.adapters):
raise ValueError(
f"For multiple adapters: `image` must have the same length as the number of adapters, but got {len(adapter_image)} images and {len(self.adapters.nets)} Adapters."
)
for image_ in adapter_image:
self.check_image(image_, prompt, prompt_embeds)
else:
assert False
# Check `adapter_conditioning_scale`
if isinstance(self.adapter, T2IAdapter) or is_compiled and isinstance(self.adapter._orig_mod, T2IAdapter):
if not isinstance(adapter_conditioning_scale, float):
raise TypeError("For single adapter: `adapter_conditioning_scale` must be type `float`.")
elif (
isinstance(self.adapter, MultiAdapter) or is_compiled and isinstance(self.adapter._orig_mod, MultiAdapter)
):
if isinstance(adapter_conditioning_scale, list):
if any(isinstance(i, list) for i in adapter_conditioning_scale):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif isinstance(adapter_conditioning_scale, list) and len(adapter_conditioning_scale) != len(
self.adapter.adapters
):
raise ValueError(
"For multiple adapters: When `adapter_conditioning_scale` is specified as `list`, it must have"
" the same length as the number of adapters"
)
else:
assert False
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline._get_add_time_ids
def _get_add_time_ids(
self, original_size, crops_coords_top_left, target_size, dtype, text_encoder_projection_dim=None
):
add_time_ids = list(original_size + crops_coords_top_left + target_size)
passed_add_embed_dim = (
self.unet.config.addition_time_embed_dim * len(add_time_ids) + text_encoder_projection_dim
)
expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
if expected_add_embed_dim != passed_add_embed_dim:
raise ValueError(
f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
)
add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
return add_time_ids
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
def upcast_vae(self):
dtype = self.vae.dtype
self.vae.to(dtype=torch.float32)
use_torch_2_0_or_xformers = isinstance(
self.vae.decoder.mid_block.attentions[0].processor,
(
AttnProcessor2_0,
XFormersAttnProcessor,
LoRAXFormersAttnProcessor,
LoRAAttnProcessor2_0,
),
)
# if xformers or torch_2_0 is used attention block does not need
# to be in float32 which can save lots of memory
if use_torch_2_0_or_xformers:
self.vae.post_quant_conv.to(dtype)
self.vae.decoder.conv_in.to(dtype)
self.vae.decoder.mid_block.to(dtype)
# Copied from diffusers.pipelines.t2i_adapter.pipeline_stable_diffusion_adapter.StableDiffusionAdapterPipeline._default_height_width
def _default_height_width(self, height, width, image):
# NOTE: It is possible that a list of images have different
# dimensions for each image, so just checking the first image
# is not _exactly_ correct, but it is simple.
while isinstance(image, list):
image = image[0]
if height is None:
if isinstance(image, PIL.Image.Image):
height = image.height
elif isinstance(image, torch.Tensor):
height = image.shape[-2]
# round down to nearest multiple of `self.adapter.downscale_factor`
height = (height // self.adapter.downscale_factor) * self.adapter.downscale_factor
if width is None:
if isinstance(image, PIL.Image.Image):
width = image.width
elif isinstance(image, torch.Tensor):
width = image.shape[-1]
# round down to nearest multiple of `self.adapter.downscale_factor`
width = (width // self.adapter.downscale_factor) * self.adapter.downscale_factor
return height, width
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_freeu
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
r"""Enables the FreeU mechanism as in https://arxiv.org/abs/2309.11497.
The suffixes after the scaling factors represent the stages where they are being applied.
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of the values
that are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
Args:
s1 (`float`):
Scaling factor for stage 1 to attenuate the contributions of the skip features. This is done to
mitigate "oversmoothing effect" in the enhanced denoising process.
s2 (`float`):
Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to
mitigate "oversmoothing effect" in the enhanced denoising process.
b1 (`float`): Scaling factor for stage 1 to amplify the contributions of backbone features.
b2 (`float`): Scaling factor for stage 2 to amplify the contributions of backbone features.
"""
if not hasattr(self, "unet"):
raise ValueError("The pipeline must have `unet` for using FreeU.")
self.unet.enable_freeu(s1=s1, s2=s2, b1=b1, b2=b2)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_freeu
def disable_freeu(self):
"""Disables the FreeU mechanism if enabled."""
self.unet.disable_freeu()
def prepare_control_image(
self,
image,
width,
height,
batch_size,
num_images_per_prompt,
device,
dtype,
do_classifier_free_guidance=False,
guess_mode=False,
):
image = self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32)
image_batch_size = image.shape[0]
if image_batch_size == 1:
repeat_by = batch_size
else:
# image batch size is the same as prompt batch size
repeat_by = num_images_per_prompt
image = image.repeat_interleave(repeat_by, dim=0)
image = image.to(device=device, dtype=dtype)
if do_classifier_free_guidance and not guess_mode:
image = torch.cat([image] * 2)
return image
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
prompt_2: Optional[Union[str, List[str]]] = None,
adapter_image: PipelineImageInput = None,
control_image: PipelineImageInput = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
denoising_end: Optional[float] = None,
guidance_scale: float = 5.0,
negative_prompt: Optional[Union[str, List[str]]] = None,
negative_prompt_2: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
guidance_rescale: float = 0.0,
original_size: Optional[Tuple[int, int]] = None,
crops_coords_top_left: Tuple[int, int] = (0, 0),
target_size: Optional[Tuple[int, int]] = None,
negative_original_size: Optional[Tuple[int, int]] = None,
negative_crops_coords_top_left: Tuple[int, int] = (0, 0),
negative_target_size: Optional[Tuple[int, int]] = None,
adapter_conditioning_scale: Union[float, List[float]] = 1.0,
adapter_conditioning_factor: float = 1.0,
clip_skip: Optional[int] = None,
controlnet_conditioning_scale=1.0,
guess_mode: bool = False,
control_guidance_start: float = 0.0,
control_guidance_end: float = 1.0,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
used in both text-encoders
adapter_image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]` or `List[PIL.Image.Image]` or `List[List[PIL.Image.Image]]`):
The Adapter input condition. Adapter uses this input condition to generate guidance to Unet. If the
type is specified as `Torch.FloatTensor`, it is passed to Adapter as is. PIL.Image.Image` can also be
accepted as an image. The control image is automatically resized to fit the output image.
control_image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The ControlNet input condition to provide guidance to the `unet` for generation. If the type is
specified as `torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can also be
accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If height
and/or width are passed, `image` is resized accordingly. If multiple ControlNets are specified in
`init`, images must be passed as a list such that each element of the list can be correctly batched for
input to a single ControlNet.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image. Anything below 512 pixels won't work well for
[stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
and checkpoints that are not specifically fine-tuned on low resolutions.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image. Anything below 512 pixels won't work well for
[stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
and checkpoints that are not specifically fine-tuned on low resolutions.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
denoising_end (`float`, *optional*):
When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
completed before it is intentionally prematurely terminated. As a result, the returned sample will
still retain a substantial amount of noise as determined by the discrete timesteps selected by the
scheduler. The denoising_end parameter should ideally be utilized when this pipeline forms a part of a
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
negative_prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
`text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
If not provided, pooled text embeddings will be generated from `prompt` input argument.
negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionAdapterPipelineOutput`]
instead of a plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
[Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(height, width)` if not specified. Part of SDXL's micro-conditioning as
explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
`crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
`crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
`crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
For most cases, `target_size` should be set to the desired height and width of the generated image. If
not specified it will default to `(height, width)`. Part of SDXL's micro-conditioning as explained in
section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
negative_original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
To negatively condition the generation process based on a specific image resolution. Part of SDXL's
micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
negative_crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
To negatively condition the generation process based on a specific crop coordinates. Part of SDXL's
micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
negative_target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
To negatively condition the generation process based on a target image resolution. It should be as same
as the `target_size` for most cases. Part of SDXL's micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added to the
residual in the original unet. If multiple adapters are specified in init, you can set the
corresponding scale as a list.
adapter_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the adapter are multiplied by `adapter_conditioning_scale` before they are added to the
residual in the original unet. If multiple adapters are specified in init, you can set the
corresponding scale as a list.
adapter_conditioning_factor (`float`, *optional*, defaults to 1.0):
The fraction of timesteps for which adapter should be applied. If `adapter_conditioning_factor` is
`0.0`, adapter is not applied at all. If `adapter_conditioning_factor` is `1.0`, adapter is applied for
all timesteps. If `adapter_conditioning_factor` is `0.5`, adapter is applied for half of the timesteps.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionAdapterPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionAdapterPipelineOutput`] if `return_dict` is True, otherwise a
`tuple`. When returning a tuple, the first element is a list with the generated images.
"""
controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
adapter = self.adapter._orig_mod if is_compiled_module(self.adapter) else self.adapter
# 0. Default height and width to unet
height, width = self._default_height_width(height, width, adapter_image)
device = self._execution_device
if isinstance(adapter, MultiAdapter):
adapter_input = []
for one_image in adapter_image:
one_image = _preprocess_adapter_image(one_image, height, width)
one_image = one_image.to(device=device, dtype=adapter.dtype)
adapter_input.append(one_image)
else:
adapter_input = _preprocess_adapter_image(adapter_image, height, width)
adapter_input = adapter_input.to(device=device, dtype=adapter.dtype)
original_size = original_size or (height, width)
target_size = target_size or (height, width)
# 0.1 align format for control guidance
if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
control_guidance_start = len(control_guidance_end) * [control_guidance_start]
elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
control_guidance_end = len(control_guidance_start) * [control_guidance_end]
elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
mult = len(controlnet.nets) if isinstance(controlnet, MultiControlNetModel) else 1
control_guidance_start, control_guidance_end = (
mult * [control_guidance_start],
mult * [control_guidance_end],
)
if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
if isinstance(adapter, MultiAdapter) and isinstance(adapter_conditioning_scale, float):
adapter_conditioning_scale = [adapter_conditioning_scale] * len(adapter.adapters)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
prompt_2,
height,
width,
callback_steps,
negative_prompt=negative_prompt,
negative_prompt_2=negative_prompt_2,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
)
self.check_conditions(
prompt,
prompt_embeds,
adapter_image,
control_image,
adapter_conditioning_scale,
controlnet_conditioning_scale,
control_guidance_start,
control_guidance_end,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
(
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds,
) = self.encode_prompt(
prompt=prompt,
prompt_2=prompt_2,
device=device,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=do_classifier_free_guidance,
negative_prompt=negative_prompt,
negative_prompt_2=negative_prompt_2,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
clip_skip=clip_skip,
)
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 5. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7. Prepare added time ids & embeddings & adapter features
if isinstance(adapter, MultiAdapter):
adapter_state = adapter(adapter_input, adapter_conditioning_scale)
for k, v in enumerate(adapter_state):
adapter_state[k] = v
else:
adapter_state = adapter(adapter_input)
for k, v in enumerate(adapter_state):
adapter_state[k] = v * adapter_conditioning_scale
if num_images_per_prompt > 1:
for k, v in enumerate(adapter_state):
adapter_state[k] = v.repeat(num_images_per_prompt, 1, 1, 1)
if do_classifier_free_guidance:
for k, v in enumerate(adapter_state):
adapter_state[k] = torch.cat([v] * 2, dim=0)
# 7.2 Prepare control images
if isinstance(controlnet, ControlNetModel):
control_image = self.prepare_control_image(
image=control_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
elif isinstance(controlnet, MultiControlNetModel):
control_images = []
for control_image_ in control_image:
control_image_ = self.prepare_control_image(
image=control_image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
control_images.append(control_image_)
control_image = control_images
else:
raise ValueError(f"{controlnet.__class__} is not supported.")
# 8.2 Create tensor stating which controlnets to keep
controlnet_keep = []
for i in range(len(timesteps)):
keeps = [
1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
for s, e in zip(control_guidance_start, control_guidance_end)
]
if isinstance(self.controlnet, MultiControlNetModel):
controlnet_keep.append(keeps)
else:
controlnet_keep.append(keeps[0])
add_text_embeds = pooled_prompt_embeds
if self.text_encoder_2 is None:
text_encoder_projection_dim = int(pooled_prompt_embeds.shape[-1])
else:
text_encoder_projection_dim = self.text_encoder_2.config.projection_dim
add_time_ids = self._get_add_time_ids(
original_size,
crops_coords_top_left,
target_size,
dtype=prompt_embeds.dtype,
text_encoder_projection_dim=text_encoder_projection_dim,
)
if negative_original_size is not None and negative_target_size is not None:
negative_add_time_ids = self._get_add_time_ids(
negative_original_size,
negative_crops_coords_top_left,
negative_target_size,
dtype=prompt_embeds.dtype,
text_encoder_projection_dim=text_encoder_projection_dim,
)
else:
negative_add_time_ids = add_time_ids
if do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
add_time_ids = torch.cat([negative_add_time_ids, add_time_ids], dim=0)
prompt_embeds = prompt_embeds.to(device)
add_text_embeds = add_text_embeds.to(device)
add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
# 8. Denoising loop
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
# 7.1 Apply denoising_end
if denoising_end is not None and isinstance(denoising_end, float) and denoising_end > 0 and denoising_end < 1:
discrete_timestep_cutoff = int(
round(
self.scheduler.config.num_train_timesteps
- (denoising_end * self.scheduler.config.num_train_timesteps)
)
)
num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
timesteps = timesteps[:num_inference_steps]
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
if i < int(num_inference_steps * adapter_conditioning_factor):
down_intrablock_additional_residuals = [state.clone() for state in adapter_state]
else:
down_intrablock_additional_residuals = None
# ----------- ControlNet
# expand the latents if we are doing classifier free guidance
latent_model_input_controlnet = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
# concat latents, mask, masked_image_latents in the channel dimension
latent_model_input_controlnet = self.scheduler.scale_model_input(latent_model_input_controlnet, t)
# controlnet(s) inference
if guess_mode and do_classifier_free_guidance:
# Infer ControlNet only for the conditional batch.
control_model_input = latents
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
controlnet_added_cond_kwargs = {
"text_embeds": add_text_embeds.chunk(2)[1],
"time_ids": add_time_ids.chunk(2)[1],
}
else:
control_model_input = latent_model_input_controlnet
controlnet_prompt_embeds = prompt_embeds
controlnet_added_cond_kwargs = added_cond_kwargs
if isinstance(controlnet_keep[i], list):
cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
else:
controlnet_cond_scale = controlnet_conditioning_scale
if isinstance(controlnet_cond_scale, list):
controlnet_cond_scale = controlnet_cond_scale[0]
cond_scale = controlnet_cond_scale * controlnet_keep[i]
down_block_res_samples, mid_block_res_sample = self.controlnet(
control_model_input,
t,
encoder_hidden_states=controlnet_prompt_embeds,
controlnet_cond=control_image,
conditioning_scale=cond_scale,
guess_mode=guess_mode,
added_cond_kwargs=controlnet_added_cond_kwargs,
return_dict=False,
)
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
down_intrablock_additional_residuals=down_intrablock_additional_residuals, # t2iadapter
down_block_additional_residuals=down_block_res_samples, # controlnet
mid_block_additional_residual=mid_block_res_sample, # controlnet
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if not output_type == "latent":
# make sure the VAE is in float32 mode, as it overflows in float16
needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
if needs_upcasting:
self.upcast_vae()
latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
# cast back to fp16 if needed
if needs_upcasting:
self.vae.to(dtype=torch.float16)
else:
image = latents
return StableDiffusionXLPipelineOutput(images=image)
image = self.image_processor.postprocess(image, output_type=output_type)
# Offload all models
self.maybe_free_model_hooks()
if not return_dict:
return (image,)
return StableDiffusionXLPipelineOutput(images=image)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/README.md
|
# Community Examples
> **For more information about community pipelines, please have a look at [this issue](https://github.com/huggingface/diffusers/issues/841).**
**Community** examples consist of both inference and training examples that have been added by the community.
Please have a look at the following table to get an overview of all community examples. Click on the **Code Example** to get a copy-and-paste ready code example that you can try out.
If a community doesn't work as expected, please open an issue and ping the author on it.
| Example | Description | Code Example | Colab | Author |
|:--------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------:|
| LLM-grounded Diffusion (LMD+) | LMD greatly improves the prompt following ability of text-to-image generation models by introducing an LLM as a front-end prompt parser and layout planner. [Project page.](https://llm-grounded-diffusion.github.io/) [See our full codebase (also with diffusers).](https://github.com/TonyLianLong/LLM-groundedDiffusion) | [LLM-grounded Diffusion (LMD+)](#llm-grounded-diffusion) | [Huggingface Demo](https://huggingface.co/spaces/longlian/llm-grounded-diffusion) [](https://colab.research.google.com/drive/1SXzMSeAB-LJYISb2yrUOdypLz4OYWUKj) | [Long (Tony) Lian](https://tonylian.com/) |
| CLIP Guided Stable Diffusion | Doing CLIP guidance for text to image generation with Stable Diffusion | [CLIP Guided Stable Diffusion](#clip-guided-stable-diffusion) | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/CLIP_Guided_Stable_diffusion_with_diffusers.ipynb) | [Suraj Patil](https://github.com/patil-suraj/) |
| One Step U-Net (Dummy) | Example showcasing of how to use Community Pipelines (see https://github.com/huggingface/diffusers/issues/841) | [One Step U-Net](#one-step-unet) | - | [Patrick von Platen](https://github.com/patrickvonplaten/) |
| Stable Diffusion Interpolation | Interpolate the latent space of Stable Diffusion between different prompts/seeds | [Stable Diffusion Interpolation](#stable-diffusion-interpolation) | - | [Nate Raw](https://github.com/nateraw/) |
| Stable Diffusion Mega | **One** Stable Diffusion Pipeline with all functionalities of [Text2Image](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py), [Image2Image](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py) and [Inpainting](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py) | [Stable Diffusion Mega](#stable-diffusion-mega) | - | [Patrick von Platen](https://github.com/patrickvonplaten/) |
| Long Prompt Weighting Stable Diffusion | **One** Stable Diffusion Pipeline without tokens length limit, and support parsing weighting in prompt. | [Long Prompt Weighting Stable Diffusion](#long-prompt-weighting-stable-diffusion) | - | [SkyTNT](https://github.com/SkyTNT) |
| Speech to Image | Using automatic-speech-recognition to transcribe text and Stable Diffusion to generate images | [Speech to Image](#speech-to-image) | - | [Mikail Duzenli](https://github.com/MikailINTech)
| Wild Card Stable Diffusion | Stable Diffusion Pipeline that supports prompts that contain wildcard terms (indicated by surrounding double underscores), with values instantiated randomly from a corresponding txt file or a dictionary of possible values | [Wildcard Stable Diffusion](#wildcard-stable-diffusion) | - | [Shyam Sudhakaran](https://github.com/shyamsn97) |
| [Composable Stable Diffusion](https://energy-based-model.github.io/Compositional-Visual-Generation-with-Composable-Diffusion-Models/) | Stable Diffusion Pipeline that supports prompts that contain "|" in prompts (as an AND condition) and weights (separated by "|" as well) to positively / negatively weight prompts. | [Composable Stable Diffusion](#composable-stable-diffusion) | - | [Mark Rich](https://github.com/MarkRich) |
| Seed Resizing Stable Diffusion | Stable Diffusion Pipeline that supports resizing an image and retaining the concepts of the 512 by 512 generation. | [Seed Resizing](#seed-resizing) | - | [Mark Rich](https://github.com/MarkRich) |
| Imagic Stable Diffusion | Stable Diffusion Pipeline that enables writing a text prompt to edit an existing image | [Imagic Stable Diffusion](#imagic-stable-diffusion) | - | [Mark Rich](https://github.com/MarkRich) |
| Multilingual Stable Diffusion | Stable Diffusion Pipeline that supports prompts in 50 different languages. | [Multilingual Stable Diffusion](#multilingual-stable-diffusion-pipeline) | - | [Juan Carlos Piñeros](https://github.com/juancopi81) |
| Image to Image Inpainting Stable Diffusion | Stable Diffusion Pipeline that enables the overlaying of two images and subsequent inpainting | [Image to Image Inpainting Stable Diffusion](#image-to-image-inpainting-stable-diffusion) | - | [Alex McKinney](https://github.com/vvvm23) |
| Text Based Inpainting Stable Diffusion | Stable Diffusion Inpainting Pipeline that enables passing a text prompt to generate the mask for inpainting | [Text Based Inpainting Stable Diffusion](#image-to-image-inpainting-stable-diffusion) | - | [Dhruv Karan](https://github.com/unography) |
| Bit Diffusion | Diffusion on discrete data | [Bit Diffusion](#bit-diffusion) | - | [Stuti R.](https://github.com/kingstut) |
| K-Diffusion Stable Diffusion | Run Stable Diffusion with any of [K-Diffusion's samplers](https://github.com/crowsonkb/k-diffusion/blob/master/k_diffusion/sampling.py) | [Stable Diffusion with K Diffusion](#stable-diffusion-with-k-diffusion) | - | [Patrick von Platen](https://github.com/patrickvonplaten/) |
| Checkpoint Merger Pipeline | Diffusion Pipeline that enables merging of saved model checkpoints | [Checkpoint Merger Pipeline](#checkpoint-merger-pipeline) | - | [Naga Sai Abhinay Devarinti](https://github.com/Abhinay1997/) |
Stable Diffusion v1.1-1.4 Comparison | Run all 4 model checkpoints for Stable Diffusion and compare their results together | [Stable Diffusion Comparison](#stable-diffusion-comparisons) | - | [Suvaditya Mukherjee](https://github.com/suvadityamuk) |
MagicMix | Diffusion Pipeline for semantic mixing of an image and a text prompt | [MagicMix](#magic-mix) | - | [Partho Das](https://github.com/daspartho) |
| Stable UnCLIP | Diffusion Pipeline for combining prior model (generate clip image embedding from text, UnCLIPPipeline `"kakaobrain/karlo-v1-alpha"`) and decoder pipeline (decode clip image embedding to image, StableDiffusionImageVariationPipeline `"lambdalabs/sd-image-variations-diffusers"` ). | [Stable UnCLIP](#stable-unclip) | - | [Ray Wang](https://wrong.wang) |
| UnCLIP Text Interpolation Pipeline | Diffusion Pipeline that allows passing two prompts and produces images while interpolating between the text-embeddings of the two prompts | [UnCLIP Text Interpolation Pipeline](#unclip-text-interpolation-pipeline) | - | [Naga Sai Abhinay Devarinti](https://github.com/Abhinay1997/) |
| UnCLIP Image Interpolation Pipeline | Diffusion Pipeline that allows passing two images/image_embeddings and produces images while interpolating between their image-embeddings | [UnCLIP Image Interpolation Pipeline](#unclip-image-interpolation-pipeline) | - | [Naga Sai Abhinay Devarinti](https://github.com/Abhinay1997/) |
| DDIM Noise Comparative Analysis Pipeline | Investigating how the diffusion models learn visual concepts from each noise level (which is a contribution of [P2 weighting (CVPR 2022)](https://arxiv.org/abs/2204.00227)) | [DDIM Noise Comparative Analysis Pipeline](#ddim-noise-comparative-analysis-pipeline) | - | [Aengus (Duc-Anh)](https://github.com/aengusng8) |
| CLIP Guided Img2Img Stable Diffusion Pipeline | Doing CLIP guidance for image to image generation with Stable Diffusion | [CLIP Guided Img2Img Stable Diffusion](#clip-guided-img2img-stable-diffusion) | - | [Nipun Jindal](https://github.com/nipunjindal/) |
| TensorRT Stable Diffusion Text to Image Pipeline | Accelerates the Stable Diffusion Text2Image Pipeline using TensorRT | [TensorRT Stable Diffusion Text to Image Pipeline](#tensorrt-text2image-stable-diffusion-pipeline) | - | [Asfiya Baig](https://github.com/asfiyab-nvidia) |
| EDICT Image Editing Pipeline | Diffusion pipeline for text-guided image editing | [EDICT Image Editing Pipeline](#edict-image-editing-pipeline) | - | [Joqsan Azocar](https://github.com/Joqsan) |
| Stable Diffusion RePaint | Stable Diffusion pipeline using [RePaint](https://arxiv.org/abs/2201.0986) for inpainting. | [Stable Diffusion RePaint](#stable-diffusion-repaint ) | - | [Markus Pobitzer](https://github.com/Markus-Pobitzer) |
| TensorRT Stable Diffusion Image to Image Pipeline | Accelerates the Stable Diffusion Image2Image Pipeline using TensorRT | [TensorRT Stable Diffusion Image to Image Pipeline](#tensorrt-image2image-stable-diffusion-pipeline) | - | [Asfiya Baig](https://github.com/asfiyab-nvidia) |
| Stable Diffusion IPEX Pipeline | Accelerate Stable Diffusion inference pipeline with BF16/FP32 precision on Intel Xeon CPUs with [IPEX](https://github.com/intel/intel-extension-for-pytorch) | [Stable Diffusion on IPEX](#stable-diffusion-on-ipex) | - | [Yingjie Han](https://github.com/yingjie-han/) |
| CLIP Guided Images Mixing Stable Diffusion Pipeline | Сombine images using usual diffusion models. | [CLIP Guided Images Mixing Using Stable Diffusion](#clip-guided-images-mixing-with-stable-diffusion) | - | [Karachev Denis](https://github.com/TheDenk) |
| TensorRT Stable Diffusion Inpainting Pipeline | Accelerates the Stable Diffusion Inpainting Pipeline using TensorRT | [TensorRT Stable Diffusion Inpainting Pipeline](#tensorrt-inpainting-stable-diffusion-pipeline) | - | [Asfiya Baig](https://github.com/asfiyab-nvidia) |
| IADB Pipeline | Implementation of [Iterative α-(de)Blending: a Minimalist Deterministic Diffusion Model](https://arxiv.org/abs/2305.03486) | [IADB Pipeline](#iadb-pipeline) | - | [Thomas Chambon](https://github.com/tchambon)
| Zero1to3 Pipeline | Implementation of [Zero-1-to-3: Zero-shot One Image to 3D Object](https://arxiv.org/abs/2303.11328) | [Zero1to3 Pipeline](#Zero1to3-pipeline) | - | [Xin Kong](https://github.com/kxhit) |
Stable Diffusion XL Long Weighted Prompt Pipeline | A pipeline support unlimited length of prompt and negative prompt, use A1111 style of prompt weighting | [Stable Diffusion XL Long Weighted Prompt Pipeline](#stable-diffusion-xl-long-weighted-prompt-pipeline) | - | [Andrew Zhu](https://xhinker.medium.com/) |
FABRIC - Stable Diffusion with feedback Pipeline | pipeline supports feedback from liked and disliked images | [Stable Diffusion Fabric Pipeline](#stable-diffusion-fabric-pipeline) | - | [Shauray Singh](https://shauray8.github.io/about_shauray/) |
sketch inpaint - Inpainting with non-inpaint Stable Diffusion | sketch inpaint much like in automatic1111 | [Masked Im2Im Stable Diffusion Pipeline](#stable-diffusion-masked-im2im) | - | [Anatoly Belikov](https://github.com/noskill) |
prompt-to-prompt | change parts of a prompt and retain image structure (see [paper page](https://prompt-to-prompt.github.io/)) | [Prompt2Prompt Pipeline](#prompt2prompt-pipeline) | - | [Umer H. Adil](https://twitter.com/UmerHAdil) |
| Latent Consistency Pipeline | Implementation of [Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference](https://arxiv.org/abs/2310.04378) | [Latent Consistency Pipeline](#latent-consistency-pipeline) | - | [Simian Luo](https://github.com/luosiallen) |
| Latent Consistency Img2img Pipeline | Img2img pipeline for Latent Consistency Models | [Latent Consistency Img2Img Pipeline](#latent-consistency-img2img-pipeline) | - | [Logan Zoellner](https://github.com/nagolinc) |
| Latent Consistency Interpolation Pipeline | Interpolate the latent space of Latent Consistency Models with multiple prompts | [Latent Consistency Interpolation Pipeline](#latent-consistency-interpolation-pipeline) | [](https://colab.research.google.com/drive/1pK3NrLWJSiJsBynLns1K1-IDTW9zbPvl?usp=sharing) | [Aryan V S](https://github.com/a-r-r-o-w) |
| LDM3D-sr (LDM3D upscaler) | Upscale low resolution RGB and depth inputs to high resolution | [StableDiffusionUpscaleLDM3D Pipeline](https://github.com/estelleafl/diffusers/tree/ldm3d_upscaler_community/examples/community#stablediffusionupscaleldm3d-pipeline) | - | [Estelle Aflalo](https://github.com/estelleafl) |
|
To load a custom pipeline you just need to pass the `custom_pipeline` argument to `DiffusionPipeline`, as one of the files in `diffusers/examples/community`. Feel free to send a PR with your own pipelines, we will merge them quickly.
```py
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", custom_pipeline="filename_in_the_community_folder")
```
## Example usages
### LLM-grounded Diffusion
LMD and LMD+ greatly improves the prompt understanding ability of text-to-image generation models by introducing an LLM as a front-end prompt parser and layout planner. It improves spatial reasoning, the understanding of negation, attribute binding, generative numeracy, etc. in a unified manner without explicitly aiming for each. LMD is completely training-free (i.e., uses SD model off-the-shelf). LMD+ takes in additional adapters for better control. This is a reproduction of LMD+ model used in our work. [Project page.](https://llm-grounded-diffusion.github.io/) [See our full codebase (also with diffusers).](https://github.com/TonyLianLong/LLM-groundedDiffusion)
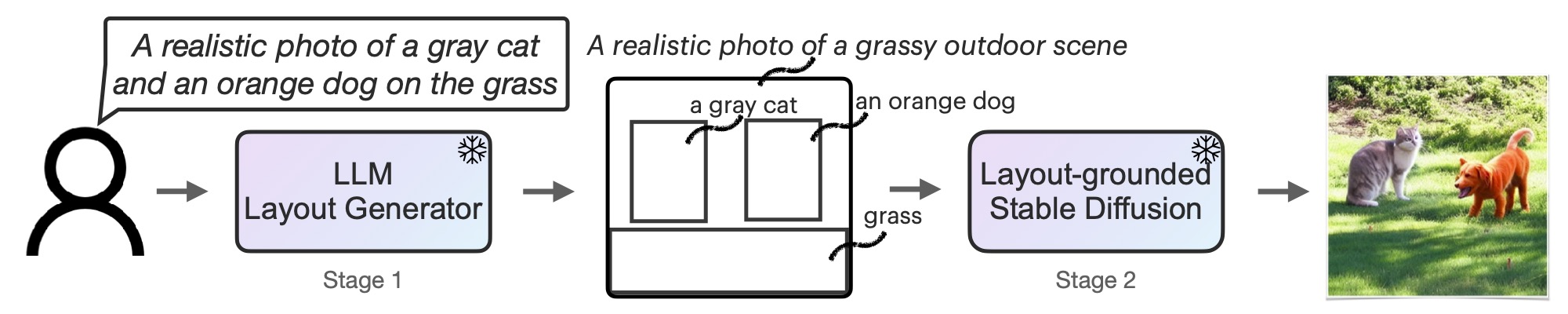
This pipeline can be used with an LLM or on its own. We provide a parser that parses LLM outputs to the layouts. You can obtain the prompt to input to the LLM for layout generation [here](https://github.com/TonyLianLong/LLM-groundedDiffusion/blob/main/prompt.py). After feeding the prompt to an LLM (e.g., GPT-4 on ChatGPT website), you can feed the LLM response into our pipeline.
The following code has been tested on 1x RTX 4090, but it should also support GPUs with lower GPU memory.
#### Use this pipeline with an LLM
```python
import torch
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"longlian/lmd_plus",
custom_pipeline="llm_grounded_diffusion",
variant="fp16", torch_dtype=torch.float16
)
pipe.enable_model_cpu_offload()
# Generate directly from a text prompt and an LLM response
prompt = "a waterfall and a modern high speed train in a beautiful forest with fall foliage"
phrases, boxes, bg_prompt, neg_prompt = pipe.parse_llm_response("""
[('a waterfall', [71, 105, 148, 258]), ('a modern high speed train', [255, 223, 181, 149])]
Background prompt: A beautiful forest with fall foliage
Negative prompt:
""")
images = pipe(
prompt=prompt,
negative_prompt=neg_prompt,
phrases=phrases,
boxes=boxes,
gligen_scheduled_sampling_beta=0.4,
output_type="pil",
num_inference_steps=50,
lmd_guidance_kwargs={}
).images
images[0].save("./lmd_plus_generation.jpg")
```
#### Use this pipeline on its own for layout generation
```python
import torch
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"longlian/lmd_plus",
custom_pipeline="llm_grounded_diffusion",
variant="fp16", torch_dtype=torch.float16
)
pipe.enable_model_cpu_offload()
# Generate an image described by the prompt and
# insert objects described by text at the region defined by bounding boxes
prompt = "a waterfall and a modern high speed train in a beautiful forest with fall foliage"
boxes = [[0.1387, 0.2051, 0.4277, 0.7090], [0.4980, 0.4355, 0.8516, 0.7266]]
phrases = ["a waterfall", "a modern high speed train"]
images = pipe(
prompt=prompt,
phrases=phrases,
boxes=boxes,
gligen_scheduled_sampling_beta=0.4,
output_type="pil",
num_inference_steps=50,
lmd_guidance_kwargs={}
).images
images[0].save("./lmd_plus_generation.jpg")
```
### CLIP Guided Stable Diffusion
CLIP guided stable diffusion can help to generate more realistic images
by guiding stable diffusion at every denoising step with an additional CLIP model.
The following code requires roughly 12GB of GPU RAM.
```python
from diffusers import DiffusionPipeline
from transformers import CLIPImageProcessor, CLIPModel
import torch
feature_extractor = CLIPImageProcessor.from_pretrained("laion/CLIP-ViT-B-32-laion2B-s34B-b79K")
clip_model = CLIPModel.from_pretrained("laion/CLIP-ViT-B-32-laion2B-s34B-b79K", torch_dtype=torch.float16)
guided_pipeline = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
custom_pipeline="clip_guided_stable_diffusion",
clip_model=clip_model,
feature_extractor=feature_extractor,
torch_dtype=torch.float16,
)
guided_pipeline.enable_attention_slicing()
guided_pipeline = guided_pipeline.to("cuda")
prompt = "fantasy book cover, full moon, fantasy forest landscape, golden vector elements, fantasy magic, dark light night, intricate, elegant, sharp focus, illustration, highly detailed, digital painting, concept art, matte, art by WLOP and Artgerm and Albert Bierstadt, masterpiece"
generator = torch.Generator(device="cuda").manual_seed(0)
images = []
for i in range(4):
image = guided_pipeline(
prompt,
num_inference_steps=50,
guidance_scale=7.5,
clip_guidance_scale=100,
num_cutouts=4,
use_cutouts=False,
generator=generator,
).images[0]
images.append(image)
# save images locally
for i, img in enumerate(images):
img.save(f"./clip_guided_sd/image_{i}.png")
```
The `images` list contains a list of PIL images that can be saved locally or displayed directly in a google colab.
Generated images tend to be of higher qualtiy than natively using stable diffusion. E.g. the above script generates the following images:
.
### One Step Unet
The dummy "one-step-unet" can be run as follows:
```python
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("google/ddpm-cifar10-32", custom_pipeline="one_step_unet")
pipe()
```
**Note**: This community pipeline is not useful as a feature, but rather just serves as an example of how community pipelines can be added (see https://github.com/huggingface/diffusers/issues/841).
### Stable Diffusion Interpolation
The following code can be run on a GPU of at least 8GB VRAM and should take approximately 5 minutes.
```python
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision='fp16',
torch_dtype=torch.float16,
safety_checker=None, # Very important for videos...lots of false positives while interpolating
custom_pipeline="interpolate_stable_diffusion",
).to('cuda')
pipe.enable_attention_slicing()
frame_filepaths = pipe.walk(
prompts=['a dog', 'a cat', 'a horse'],
seeds=[42, 1337, 1234],
num_interpolation_steps=16,
output_dir='./dreams',
batch_size=4,
height=512,
width=512,
guidance_scale=8.5,
num_inference_steps=50,
)
```
The output of the `walk(...)` function returns a list of images saved under the folder as defined in `output_dir`. You can use these images to create videos of stable diffusion.
> **Please have a look at https://github.com/nateraw/stable-diffusion-videos for more in-detail information on how to create videos using stable diffusion as well as more feature-complete functionality.**
### Stable Diffusion Mega
The Stable Diffusion Mega Pipeline lets you use the main use cases of the stable diffusion pipeline in a single class.
```python
#!/usr/bin/env python3
from diffusers import DiffusionPipeline
import PIL
import requests
from io import BytesIO
import torch
def download_image(url):
response = requests.get(url)
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", custom_pipeline="stable_diffusion_mega", torch_dtype=torch.float16, revision="fp16")
pipe.to("cuda")
pipe.enable_attention_slicing()
### Text-to-Image
images = pipe.text2img("An astronaut riding a horse").images
### Image-to-Image
init_image = download_image("https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg")
prompt = "A fantasy landscape, trending on artstation"
images = pipe.img2img(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
### Inpainting
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
init_image = download_image(img_url).resize((512, 512))
mask_image = download_image(mask_url).resize((512, 512))
prompt = "a cat sitting on a bench"
images = pipe.inpaint(prompt=prompt, image=init_image, mask_image=mask_image, strength=0.75).images
```
As shown above this one pipeline can run all both "text-to-image", "image-to-image", and "inpainting" in one pipeline.
### Long Prompt Weighting Stable Diffusion
Features of this custom pipeline:
- Input a prompt without the 77 token length limit.
- Includes tx2img, img2img. and inpainting pipelines.
- Emphasize/weigh part of your prompt with parentheses as so: `a baby deer with (big eyes)`
- De-emphasize part of your prompt as so: `a [baby] deer with big eyes`
- Precisely weigh part of your prompt as so: `a baby deer with (big eyes:1.3)`
Prompt weighting equivalents:
- `a baby deer with` == `(a baby deer with:1.0)`
- `(big eyes)` == `(big eyes:1.1)`
- `((big eyes))` == `(big eyes:1.21)`
- `[big eyes]` == `(big eyes:0.91)`
You can run this custom pipeline as so:
#### pytorch
```python
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
'hakurei/waifu-diffusion',
custom_pipeline="lpw_stable_diffusion",
torch_dtype=torch.float16
)
pipe=pipe.to("cuda")
prompt = "best_quality (1girl:1.3) bow bride brown_hair closed_mouth frilled_bow frilled_hair_tubes frills (full_body:1.3) fox_ear hair_bow hair_tubes happy hood japanese_clothes kimono long_sleeves red_bow smile solo tabi uchikake white_kimono wide_sleeves cherry_blossoms"
neg_prompt = "lowres, bad_anatomy, error_body, error_hair, error_arm, error_hands, bad_hands, error_fingers, bad_fingers, missing_fingers, error_legs, bad_legs, multiple_legs, missing_legs, error_lighting, error_shadow, error_reflection, text, error, extra_digit, fewer_digits, cropped, worst_quality, low_quality, normal_quality, jpeg_artifacts, signature, watermark, username, blurry"
pipe.text2img(prompt, negative_prompt=neg_prompt, width=512,height=512,max_embeddings_multiples=3).images[0]
```
#### onnxruntime
```python
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
'CompVis/stable-diffusion-v1-4',
custom_pipeline="lpw_stable_diffusion_onnx",
revision="onnx",
provider="CUDAExecutionProvider"
)
prompt = "a photo of an astronaut riding a horse on mars, best quality"
neg_prompt = "lowres, bad anatomy, error body, error hair, error arm, error hands, bad hands, error fingers, bad fingers, missing fingers, error legs, bad legs, multiple legs, missing legs, error lighting, error shadow, error reflection, text, error, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry"
pipe.text2img(prompt,negative_prompt=neg_prompt, width=512, height=512, max_embeddings_multiples=3).images[0]
```
if you see `Token indices sequence length is longer than the specified maximum sequence length for this model ( *** > 77 ) . Running this sequence through the model will result in indexing errors`. Do not worry, it is normal.
### Speech to Image
The following code can generate an image from an audio sample using pre-trained OpenAI whisper-small and Stable Diffusion.
```Python
import torch
import matplotlib.pyplot as plt
from datasets import load_dataset
from diffusers import DiffusionPipeline
from transformers import (
WhisperForConditionalGeneration,
WhisperProcessor,
)
device = "cuda" if torch.cuda.is_available() else "cpu"
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
audio_sample = ds[3]
text = audio_sample["text"].lower()
speech_data = audio_sample["audio"]["array"]
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small").to(device)
processor = WhisperProcessor.from_pretrained("openai/whisper-small")
diffuser_pipeline = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
custom_pipeline="speech_to_image_diffusion",
speech_model=model,
speech_processor=processor,
torch_dtype=torch.float16,
)
diffuser_pipeline.enable_attention_slicing()
diffuser_pipeline = diffuser_pipeline.to(device)
output = diffuser_pipeline(speech_data)
plt.imshow(output.images[0])
```
This example produces the following image:

### Wildcard Stable Diffusion
Following the great examples from https://github.com/jtkelm2/stable-diffusion-webui-1/blob/master/scripts/wildcards.py and https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Custom-Scripts#wildcards, here's a minimal implementation that allows for users to add "wildcards", denoted by `__wildcard__` to prompts that are used as placeholders for randomly sampled values given by either a dictionary or a `.txt` file. For example:
Say we have a prompt:
```
prompt = "__animal__ sitting on a __object__ wearing a __clothing__"
```
We can then define possible values to be sampled for `animal`, `object`, and `clothing`. These can either be from a `.txt` with the same name as the category.
The possible values can also be defined / combined by using a dictionary like: `{"animal":["dog", "cat", mouse"]}`.
The actual pipeline works just like `StableDiffusionPipeline`, except the `__call__` method takes in:
`wildcard_files`: list of file paths for wild card replacement
`wildcard_option_dict`: dict with key as `wildcard` and values as a list of possible replacements
`num_prompt_samples`: number of prompts to sample, uniformly sampling wildcards
A full example:
create `animal.txt`, with contents like:
```
dog
cat
mouse
```
create `object.txt`, with contents like:
```
chair
sofa
bench
```
```python
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
custom_pipeline="wildcard_stable_diffusion",
torch_dtype=torch.float16,
)
prompt = "__animal__ sitting on a __object__ wearing a __clothing__"
out = pipe(
prompt,
wildcard_option_dict={
"clothing":["hat", "shirt", "scarf", "beret"]
},
wildcard_files=["object.txt", "animal.txt"],
num_prompt_samples=1
)
```
### Composable Stable diffusion
[Composable Stable Diffusion](https://energy-based-model.github.io/Compositional-Visual-Generation-with-Composable-Diffusion-Models/) proposes conjunction and negation (negative prompts) operators for compositional generation with conditional diffusion models.
```python
import torch as th
import numpy as np
import torchvision.utils as tvu
from diffusers import DiffusionPipeline
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--prompt", type=str, default="mystical trees | A magical pond | dark",
help="use '|' as the delimiter to compose separate sentences.")
parser.add_argument("--steps", type=int, default=50)
parser.add_argument("--scale", type=float, default=7.5)
parser.add_argument("--weights", type=str, default="7.5 | 7.5 | -7.5")
parser.add_argument("--seed", type=int, default=2)
parser.add_argument("--model_path", type=str, default="CompVis/stable-diffusion-v1-4")
parser.add_argument("--num_images", type=int, default=1)
args = parser.parse_args()
has_cuda = th.cuda.is_available()
device = th.device('cpu' if not has_cuda else 'cuda')
prompt = args.prompt
scale = args.scale
steps = args.steps
pipe = DiffusionPipeline.from_pretrained(
args.model_path,
custom_pipeline="composable_stable_diffusion",
).to(device)
pipe.safety_checker = None
images = []
generator = th.Generator("cuda").manual_seed(args.seed)
for i in range(args.num_images):
image = pipe(prompt, guidance_scale=scale, num_inference_steps=steps,
weights=args.weights, generator=generator).images[0]
images.append(th.from_numpy(np.array(image)).permute(2, 0, 1) / 255.)
grid = tvu.make_grid(th.stack(images, dim=0), nrow=4, padding=0)
tvu.save_image(grid, f'{prompt}_{args.weights}' + '.png')
```
### Imagic Stable Diffusion
Allows you to edit an image using stable diffusion.
```python
import requests
from PIL import Image
from io import BytesIO
import torch
import os
from diffusers import DiffusionPipeline, DDIMScheduler
has_cuda = torch.cuda.is_available()
device = torch.device('cpu' if not has_cuda else 'cuda')
pipe = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
safety_checker=None,
use_auth_token=True,
custom_pipeline="imagic_stable_diffusion",
scheduler = DDIMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", clip_sample=False, set_alpha_to_one=False)
).to(device)
generator = torch.Generator("cuda").manual_seed(0)
seed = 0
prompt = "A photo of Barack Obama smiling with a big grin"
url = 'https://www.dropbox.com/s/6tlwzr73jd1r9yk/obama.png?dl=1'
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
init_image = init_image.resize((512, 512))
res = pipe.train(
prompt,
image=init_image,
generator=generator)
res = pipe(alpha=1, guidance_scale=7.5, num_inference_steps=50)
os.makedirs("imagic", exist_ok=True)
image = res.images[0]
image.save('./imagic/imagic_image_alpha_1.png')
res = pipe(alpha=1.5, guidance_scale=7.5, num_inference_steps=50)
image = res.images[0]
image.save('./imagic/imagic_image_alpha_1_5.png')
res = pipe(alpha=2, guidance_scale=7.5, num_inference_steps=50)
image = res.images[0]
image.save('./imagic/imagic_image_alpha_2.png')
```
### Seed Resizing
Test seed resizing. Originally generate an image in 512 by 512, then generate image with same seed at 512 by 592 using seed resizing. Finally, generate 512 by 592 using original stable diffusion pipeline.
```python
import torch as th
import numpy as np
from diffusers import DiffusionPipeline
has_cuda = th.cuda.is_available()
device = th.device('cpu' if not has_cuda else 'cuda')
pipe = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
use_auth_token=True,
custom_pipeline="seed_resize_stable_diffusion"
).to(device)
def dummy(images, **kwargs):
return images, False
pipe.safety_checker = dummy
images = []
th.manual_seed(0)
generator = th.Generator("cuda").manual_seed(0)
seed = 0
prompt = "A painting of a futuristic cop"
width = 512
height = 512
res = pipe(
prompt,
guidance_scale=7.5,
num_inference_steps=50,
height=height,
width=width,
generator=generator)
image = res.images[0]
image.save('./seed_resize/seed_resize_{w}_{h}_image.png'.format(w=width, h=height))
th.manual_seed(0)
generator = th.Generator("cuda").manual_seed(0)
pipe = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
use_auth_token=True,
custom_pipeline="/home/mark/open_source/diffusers/examples/community/"
).to(device)
width = 512
height = 592
res = pipe(
prompt,
guidance_scale=7.5,
num_inference_steps=50,
height=height,
width=width,
generator=generator)
image = res.images[0]
image.save('./seed_resize/seed_resize_{w}_{h}_image.png'.format(w=width, h=height))
pipe_compare = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
use_auth_token=True,
custom_pipeline="/home/mark/open_source/diffusers/examples/community/"
).to(device)
res = pipe_compare(
prompt,
guidance_scale=7.5,
num_inference_steps=50,
height=height,
width=width,
generator=generator
)
image = res.images[0]
image.save('./seed_resize/seed_resize_{w}_{h}_image_compare.png'.format(w=width, h=height))
```
### Multilingual Stable Diffusion Pipeline
The following code can generate an images from texts in different languages using the pre-trained [mBART-50 many-to-one multilingual machine translation model](https://huggingface.co/facebook/mbart-large-50-many-to-one-mmt) and Stable Diffusion.
```python
from PIL import Image
import torch
from diffusers import DiffusionPipeline
from transformers import (
pipeline,
MBart50TokenizerFast,
MBartForConditionalGeneration,
)
device = "cuda" if torch.cuda.is_available() else "cpu"
device_dict = {"cuda": 0, "cpu": -1}
# helper function taken from: https://huggingface.co/blog/stable_diffusion
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return grid
# Add language detection pipeline
language_detection_model_ckpt = "papluca/xlm-roberta-base-language-detection"
language_detection_pipeline = pipeline("text-classification",
model=language_detection_model_ckpt,
device=device_dict[device])
# Add model for language translation
trans_tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-one-mmt")
trans_model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-one-mmt").to(device)
diffuser_pipeline = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
custom_pipeline="multilingual_stable_diffusion",
detection_pipeline=language_detection_pipeline,
translation_model=trans_model,
translation_tokenizer=trans_tokenizer,
torch_dtype=torch.float16,
)
diffuser_pipeline.enable_attention_slicing()
diffuser_pipeline = diffuser_pipeline.to(device)
prompt = ["a photograph of an astronaut riding a horse",
"Una casa en la playa",
"Ein Hund, der Orange isst",
"Un restaurant parisien"]
output = diffuser_pipeline(prompt)
images = output.images
grid = image_grid(images, rows=2, cols=2)
```
This example produces the following images:

### Image to Image Inpainting Stable Diffusion
Similar to the standard stable diffusion inpainting example, except with the addition of an `inner_image` argument.
`image`, `inner_image`, and `mask` should have the same dimensions. `inner_image` should have an alpha (transparency) channel.
The aim is to overlay two images, then mask out the boundary between `image` and `inner_image` to allow stable diffusion to make the connection more seamless.
For example, this could be used to place a logo on a shirt and make it blend seamlessly.
```python
import PIL
import torch
from diffusers import DiffusionPipeline
image_path = "./path-to-image.png"
inner_image_path = "./path-to-inner-image.png"
mask_path = "./path-to-mask.png"
init_image = PIL.Image.open(image_path).convert("RGB").resize((512, 512))
inner_image = PIL.Image.open(inner_image_path).convert("RGBA").resize((512, 512))
mask_image = PIL.Image.open(mask_path).convert("RGB").resize((512, 512))
pipe = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-inpainting",
custom_pipeline="img2img_inpainting",
torch_dtype=torch.float16
)
pipe = pipe.to("cuda")
prompt = "Your prompt here!"
image = pipe(prompt=prompt, image=init_image, inner_image=inner_image, mask_image=mask_image).images[0]
```

### Text Based Inpainting Stable Diffusion
Use a text prompt to generate the mask for the area to be inpainted.
Currently uses the CLIPSeg model for mask generation, then calls the standard Stable Diffusion Inpainting pipeline to perform the inpainting.
```python
from transformers import CLIPSegProcessor, CLIPSegForImageSegmentation
from diffusers import DiffusionPipeline
from PIL import Image
import requests
processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
model = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined")
pipe = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-inpainting",
custom_pipeline="text_inpainting",
segmentation_model=model,
segmentation_processor=processor
)
pipe = pipe.to("cuda")
url = "https://github.com/timojl/clipseg/blob/master/example_image.jpg?raw=true"
image = Image.open(requests.get(url, stream=True).raw).resize((512, 512))
text = "a glass" # will mask out this text
prompt = "a cup" # the masked out region will be replaced with this
image = pipe(image=image, text=text, prompt=prompt).images[0]
```
### Bit Diffusion
Based https://arxiv.org/abs/2208.04202, this is used for diffusion on discrete data - eg, discreate image data, DNA sequence data. An unconditional discreate image can be generated like this:
```python
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("google/ddpm-cifar10-32", custom_pipeline="bit_diffusion")
image = pipe().images[0]
```
### Stable Diffusion with K Diffusion
Make sure you have @crowsonkb's https://github.com/crowsonkb/k-diffusion installed:
```
pip install k-diffusion
```
You can use the community pipeline as follows:
```python
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", custom_pipeline="sd_text2img_k_diffusion")
pipe = pipe.to("cuda")
prompt = "an astronaut riding a horse on mars"
pipe.set_scheduler("sample_heun")
generator = torch.Generator(device="cuda").manual_seed(seed)
image = pipe(prompt, generator=generator, num_inference_steps=20).images[0]
image.save("./astronaut_heun_k_diffusion.png")
```
To make sure that K Diffusion and `diffusers` yield the same results:
**Diffusers**:
```python
from diffusers import DiffusionPipeline, EulerDiscreteScheduler
seed = 33
pipe = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
generator = torch.Generator(device="cuda").manual_seed(seed)
image = pipe(prompt, generator=generator, num_inference_steps=50).images[0]
```

**K Diffusion**:
```python
from diffusers import DiffusionPipeline, EulerDiscreteScheduler
seed = 33
pipe = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", custom_pipeline="sd_text2img_k_diffusion")
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
pipe.set_scheduler("sample_euler")
generator = torch.Generator(device="cuda").manual_seed(seed)
image = pipe(prompt, generator=generator, num_inference_steps=50).images[0]
```

### Checkpoint Merger Pipeline
Based on the AUTOMATIC1111/webui for checkpoint merging. This is a custom pipeline that merges upto 3 pretrained model checkpoints as long as they are in the HuggingFace model_index.json format.
The checkpoint merging is currently memory intensive as it modifies the weights of a DiffusionPipeline object in place. Expect atleast 13GB RAM Usage on Kaggle GPU kernels and
on colab you might run out of the 12GB memory even while merging two checkpoints.
Usage:-
```python
from diffusers import DiffusionPipeline
#Return a CheckpointMergerPipeline class that allows you to merge checkpoints.
#The checkpoint passed here is ignored. But still pass one of the checkpoints you plan to
#merge for convenience
pipe = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", custom_pipeline="checkpoint_merger")
#There are multiple possible scenarios:
#The pipeline with the merged checkpoints is returned in all the scenarios
#Compatible checkpoints a.k.a matched model_index.json files. Ignores the meta attributes in model_index.json during comparison.( attrs with _ as prefix )
merged_pipe = pipe.merge(["CompVis/stable-diffusion-v1-4","CompVis/stable-diffusion-v1-2"], interp = "sigmoid", alpha = 0.4)
#Incompatible checkpoints in model_index.json but merge might be possible. Use force = True to ignore model_index.json compatibility
merged_pipe_1 = pipe.merge(["CompVis/stable-diffusion-v1-4","hakurei/waifu-diffusion"], force = True, interp = "sigmoid", alpha = 0.4)
#Three checkpoint merging. Only "add_difference" method actually works on all three checkpoints. Using any other options will ignore the 3rd checkpoint.
merged_pipe_2 = pipe.merge(["CompVis/stable-diffusion-v1-4","hakurei/waifu-diffusion","prompthero/openjourney"], force = True, interp = "add_difference", alpha = 0.4)
prompt = "An astronaut riding a horse on Mars"
image = merged_pipe(prompt).images[0]
```
Some examples along with the merge details:
1. "CompVis/stable-diffusion-v1-4" + "hakurei/waifu-diffusion" ; Sigmoid interpolation; alpha = 0.8

2. "hakurei/waifu-diffusion" + "prompthero/openjourney" ; Inverse Sigmoid interpolation; alpha = 0.8

3. "CompVis/stable-diffusion-v1-4" + "hakurei/waifu-diffusion" + "prompthero/openjourney"; Add Difference interpolation; alpha = 0.5

### Stable Diffusion Comparisons
This Community Pipeline enables the comparison between the 4 checkpoints that exist for Stable Diffusion. They can be found through the following links:
1. [Stable Diffusion v1.1](https://huggingface.co/CompVis/stable-diffusion-v1-1)
2. [Stable Diffusion v1.2](https://huggingface.co/CompVis/stable-diffusion-v1-2)
3. [Stable Diffusion v1.3](https://huggingface.co/CompVis/stable-diffusion-v1-3)
4. [Stable Diffusion v1.4](https://huggingface.co/CompVis/stable-diffusion-v1-4)
```python
from diffusers import DiffusionPipeline
import matplotlib.pyplot as plt
pipe = DiffusionPipeline.from_pretrained('CompVis/stable-diffusion-v1-4', custom_pipeline='suvadityamuk/StableDiffusionComparison')
pipe.enable_attention_slicing()
pipe = pipe.to('cuda')
prompt = "an astronaut riding a horse on mars"
output = pipe(prompt)
plt.subplots(2,2,1)
plt.imshow(output.images[0])
plt.title('Stable Diffusion v1.1')
plt.axis('off')
plt.subplots(2,2,2)
plt.imshow(output.images[1])
plt.title('Stable Diffusion v1.2')
plt.axis('off')
plt.subplots(2,2,3)
plt.imshow(output.images[2])
plt.title('Stable Diffusion v1.3')
plt.axis('off')
plt.subplots(2,2,4)
plt.imshow(output.images[3])
plt.title('Stable Diffusion v1.4')
plt.axis('off')
plt.show()
```
As a result, you can look at a grid of all 4 generated images being shown together, that captures a difference the advancement of the training between the 4 checkpoints.
### Magic Mix
Implementation of the [MagicMix: Semantic Mixing with Diffusion Models](https://arxiv.org/abs/2210.16056) paper. This is a Diffusion Pipeline for semantic mixing of an image and a text prompt to create a new concept while preserving the spatial layout and geometry of the subject in the image. The pipeline takes an image that provides the layout semantics and a prompt that provides the content semantics for the mixing process.
There are 3 parameters for the method-
- `mix_factor`: It is the interpolation constant used in the layout generation phase. The greater the value of `mix_factor`, the greater the influence of the prompt on the layout generation process.
- `kmax` and `kmin`: These determine the range for the layout and content generation process. A higher value of kmax results in loss of more information about the layout of the original image and a higher value of kmin results in more steps for content generation process.
Here is an example usage-
```python
from diffusers import DiffusionPipeline, DDIMScheduler
from PIL import Image
pipe = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
custom_pipeline="magic_mix",
scheduler = DDIMScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler"),
).to('cuda')
img = Image.open('phone.jpg')
mix_img = pipe(
img,
prompt = 'bed',
kmin = 0.3,
kmax = 0.5,
mix_factor = 0.5,
)
mix_img.save('phone_bed_mix.jpg')
```
The `mix_img` is a PIL image that can be saved locally or displayed directly in a google colab. Generated image is a mix of the layout semantics of the given image and the content semantics of the prompt.
E.g. the above script generates the following image:
`phone.jpg`

`phone_bed_mix.jpg`

For more example generations check out this [demo notebook](https://github.com/daspartho/MagicMix/blob/main/demo.ipynb).
### Stable UnCLIP
UnCLIPPipeline("kakaobrain/karlo-v1-alpha") provide a prior model that can generate clip image embedding from text.
StableDiffusionImageVariationPipeline("lambdalabs/sd-image-variations-diffusers") provide a decoder model than can generate images from clip image embedding.
```python
import torch
from diffusers import DiffusionPipeline
device = torch.device("cpu" if not torch.cuda.is_available() else "cuda")
pipeline = DiffusionPipeline.from_pretrained(
"kakaobrain/karlo-v1-alpha",
torch_dtype=torch.float16,
custom_pipeline="stable_unclip",
decoder_pipe_kwargs=dict(
image_encoder=None,
),
)
pipeline.to(device)
prompt = "a shiba inu wearing a beret and black turtleneck"
random_generator = torch.Generator(device=device).manual_seed(1000)
output = pipeline(
prompt=prompt,
width=512,
height=512,
generator=random_generator,
prior_guidance_scale=4,
prior_num_inference_steps=25,
decoder_guidance_scale=8,
decoder_num_inference_steps=50,
)
image = output.images[0]
image.save("./shiba-inu.jpg")
# debug
# `pipeline.decoder_pipe` is a regular StableDiffusionImageVariationPipeline instance.
# It is used to convert clip image embedding to latents, then fed into VAE decoder.
print(pipeline.decoder_pipe.__class__)
# <class 'diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_image_variation.StableDiffusionImageVariationPipeline'>
# this pipeline only use prior module in "kakaobrain/karlo-v1-alpha"
# It is used to convert clip text embedding to clip image embedding.
print(pipeline)
# StableUnCLIPPipeline {
# "_class_name": "StableUnCLIPPipeline",
# "_diffusers_version": "0.12.0.dev0",
# "prior": [
# "diffusers",
# "PriorTransformer"
# ],
# "prior_scheduler": [
# "diffusers",
# "UnCLIPScheduler"
# ],
# "text_encoder": [
# "transformers",
# "CLIPTextModelWithProjection"
# ],
# "tokenizer": [
# "transformers",
# "CLIPTokenizer"
# ]
# }
# pipeline.prior_scheduler is the scheduler used for prior in UnCLIP.
print(pipeline.prior_scheduler)
# UnCLIPScheduler {
# "_class_name": "UnCLIPScheduler",
# "_diffusers_version": "0.12.0.dev0",
# "clip_sample": true,
# "clip_sample_range": 5.0,
# "num_train_timesteps": 1000,
# "prediction_type": "sample",
# "variance_type": "fixed_small_log"
# }
```
`shiba-inu.jpg`

### UnCLIP Text Interpolation Pipeline
This Diffusion Pipeline takes two prompts and interpolates between the two input prompts using spherical interpolation ( slerp ). The input prompts are converted to text embeddings by the pipeline's text_encoder and the interpolation is done on the resulting text_embeddings over the number of steps specified. Defaults to 5 steps.
```python
import torch
from diffusers import DiffusionPipeline
device = torch.device("cpu" if not torch.cuda.is_available() else "cuda")
pipe = DiffusionPipeline.from_pretrained(
"kakaobrain/karlo-v1-alpha",
torch_dtype=torch.float16,
custom_pipeline="unclip_text_interpolation"
)
pipe.to(device)
start_prompt = "A photograph of an adult lion"
end_prompt = "A photograph of a lion cub"
#For best results keep the prompts close in length to each other. Of course, feel free to try out with differing lengths.
generator = torch.Generator(device=device).manual_seed(42)
output = pipe(start_prompt, end_prompt, steps = 6, generator = generator, enable_sequential_cpu_offload=False)
for i,image in enumerate(output.images):
img.save('result%s.jpg' % i)
```
The resulting images in order:-






### UnCLIP Image Interpolation Pipeline
This Diffusion Pipeline takes two images or an image_embeddings tensor of size 2 and interpolates between their embeddings using spherical interpolation ( slerp ). The input images/image_embeddings are converted to image embeddings by the pipeline's image_encoder and the interpolation is done on the resulting image_embeddings over the number of steps specified. Defaults to 5 steps.
```python
import torch
from diffusers import DiffusionPipeline
from PIL import Image
device = torch.device("cpu" if not torch.cuda.is_available() else "cuda")
dtype = torch.float16 if torch.cuda.is_available() else torch.bfloat16
pipe = DiffusionPipeline.from_pretrained(
"kakaobrain/karlo-v1-alpha-image-variations",
torch_dtype=dtype,
custom_pipeline="unclip_image_interpolation"
)
pipe.to(device)
images = [Image.open('./starry_night.jpg'), Image.open('./flowers.jpg')]
#For best results keep the prompts close in length to each other. Of course, feel free to try out with differing lengths.
generator = torch.Generator(device=device).manual_seed(42)
output = pipe(image = images ,steps = 6, generator = generator)
for i,image in enumerate(output.images):
image.save('starry_to_flowers_%s.jpg' % i)
```
The original images:-


The resulting images in order:-






### DDIM Noise Comparative Analysis Pipeline
#### **Research question: What visual concepts do the diffusion models learn from each noise level during training?**
The [P2 weighting (CVPR 2022)](https://arxiv.org/abs/2204.00227) paper proposed an approach to answer the above question, which is their second contribution.
The approach consists of the following steps:
1. The input is an image x0.
2. Perturb it to xt using a diffusion process q(xt|x0).
- `strength` is a value between 0.0 and 1.0, that controls the amount of noise that is added to the input image. Values that approach 1.0 allow for lots of variations but will also produce images that are not semantically consistent with the input.
3. Reconstruct the image with the learned denoising process pθ(ˆx0|xt).
4. Compare x0 and ˆx0 among various t to show how each step contributes to the sample.
The authors used [openai/guided-diffusion](https://github.com/openai/guided-diffusion) model to denoise images in FFHQ dataset. This pipeline extends their second contribution by investigating DDIM on any input image.
```python
import torch
from PIL import Image
import numpy as np
image_path = "path/to/your/image" # images from CelebA-HQ might be better
image_pil = Image.open(image_path)
image_name = image_path.split("/")[-1].split(".")[0]
device = torch.device("cpu" if not torch.cuda.is_available() else "cuda")
pipe = DiffusionPipeline.from_pretrained(
"google/ddpm-ema-celebahq-256",
custom_pipeline="ddim_noise_comparative_analysis",
)
pipe = pipe.to(device)
for strength in np.linspace(0.1, 1, 25):
denoised_image, latent_timestep = pipe(
image_pil, strength=strength, return_dict=False
)
denoised_image = denoised_image[0]
denoised_image.save(
f"noise_comparative_analysis_{image_name}_{latent_timestep}.png"
)
```
Here is the result of this pipeline (which is DDIM) on CelebA-HQ dataset.

### CLIP Guided Img2Img Stable Diffusion
CLIP guided Img2Img stable diffusion can help to generate more realistic images with an initial image
by guiding stable diffusion at every denoising step with an additional CLIP model.
The following code requires roughly 12GB of GPU RAM.
```python
from io import BytesIO
import requests
import torch
from diffusers import DiffusionPipeline
from PIL import Image
from transformers import CLIPFeatureExtractor, CLIPModel
feature_extractor = CLIPFeatureExtractor.from_pretrained(
"laion/CLIP-ViT-B-32-laion2B-s34B-b79K"
)
clip_model = CLIPModel.from_pretrained(
"laion/CLIP-ViT-B-32-laion2B-s34B-b79K", torch_dtype=torch.float16
)
guided_pipeline = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
# custom_pipeline="clip_guided_stable_diffusion",
custom_pipeline="/home/njindal/diffusers/examples/community/clip_guided_stable_diffusion.py",
clip_model=clip_model,
feature_extractor=feature_extractor,
torch_dtype=torch.float16,
)
guided_pipeline.enable_attention_slicing()
guided_pipeline = guided_pipeline.to("cuda")
prompt = "fantasy book cover, full moon, fantasy forest landscape, golden vector elements, fantasy magic, dark light night, intricate, elegant, sharp focus, illustration, highly detailed, digital painting, concept art, matte, art by WLOP and Artgerm and Albert Bierstadt, masterpiece"
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
image = guided_pipeline(
prompt=prompt,
num_inference_steps=30,
image=init_image,
strength=0.75,
guidance_scale=7.5,
clip_guidance_scale=100,
num_cutouts=4,
use_cutouts=False,
).images[0]
display(image)
```
Init Image

Output Image

### TensorRT Text2Image Stable Diffusion Pipeline
The TensorRT Pipeline can be used to accelerate the Text2Image Stable Diffusion Inference run.
NOTE: The ONNX conversions and TensorRT engine build may take up to 30 minutes.
```python
import torch
from diffusers import DDIMScheduler
from diffusers.pipelines.stable_diffusion import StableDiffusionPipeline
# Use the DDIMScheduler scheduler here instead
scheduler = DDIMScheduler.from_pretrained("stabilityai/stable-diffusion-2-1",
subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1",
custom_pipeline="stable_diffusion_tensorrt_txt2img",
revision='fp16',
torch_dtype=torch.float16,
scheduler=scheduler,)
# re-use cached folder to save ONNX models and TensorRT Engines
pipe.set_cached_folder("stabilityai/stable-diffusion-2-1", revision='fp16',)
pipe = pipe.to("cuda")
prompt = "a beautiful photograph of Mt. Fuji during cherry blossom"
image = pipe(prompt).images[0]
image.save('tensorrt_mt_fuji.png')
```
### EDICT Image Editing Pipeline
This pipeline implements the text-guided image editing approach from the paper [EDICT: Exact Diffusion Inversion via Coupled Transformations](https://arxiv.org/abs/2211.12446). You have to pass:
- (`PIL`) `image` you want to edit.
- `base_prompt`: the text prompt describing the current image (before editing).
- `target_prompt`: the text prompt describing with the edits.
```python
from diffusers import DiffusionPipeline, DDIMScheduler
from transformers import CLIPTextModel
import torch, PIL, requests
from io import BytesIO
from IPython.display import display
def center_crop_and_resize(im):
width, height = im.size
d = min(width, height)
left = (width - d) / 2
upper = (height - d) / 2
right = (width + d) / 2
lower = (height + d) / 2
return im.crop((left, upper, right, lower)).resize((512, 512))
torch_dtype = torch.float16
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# scheduler and text_encoder param values as in the paper
scheduler = DDIMScheduler(
num_train_timesteps=1000,
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
set_alpha_to_one=False,
clip_sample=False,
)
text_encoder = CLIPTextModel.from_pretrained(
pretrained_model_name_or_path="openai/clip-vit-large-patch14",
torch_dtype=torch_dtype,
)
# initialize pipeline
pipeline = DiffusionPipeline.from_pretrained(
pretrained_model_name_or_path="CompVis/stable-diffusion-v1-4",
custom_pipeline="edict_pipeline",
revision="fp16",
scheduler=scheduler,
text_encoder=text_encoder,
leapfrog_steps=True,
torch_dtype=torch_dtype,
).to(device)
# download image
image_url = "https://huggingface.co/datasets/Joqsan/images/resolve/main/imagenet_dog_1.jpeg"
response = requests.get(image_url)
image = PIL.Image.open(BytesIO(response.content))
# preprocess it
cropped_image = center_crop_and_resize(image)
# define the prompts
base_prompt = "A dog"
target_prompt = "A golden retriever"
# run the pipeline
result_image = pipeline(
base_prompt=base_prompt,
target_prompt=target_prompt,
image=cropped_image,
)
display(result_image)
```
Init Image

Output Image

### Stable Diffusion RePaint
This pipeline uses the [RePaint](https://arxiv.org/abs/2201.09865) logic on the latent space of stable diffusion. It can
be used similarly to other image inpainting pipelines but does not rely on a specific inpainting model. This means you can use
models that are not specifically created for inpainting.
Make sure to use the ```RePaintScheduler``` as shown in the example below.
Disclaimer: The mask gets transferred into latent space, this may lead to unexpected changes on the edge of the masked part.
The inference time is a lot slower.
```py
import PIL
import requests
import torch
from io import BytesIO
from diffusers import StableDiffusionPipeline, RePaintScheduler
def download_image(url):
response = requests.get(url)
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
init_image = download_image(img_url).resize((512, 512))
mask_image = download_image(mask_url).resize((512, 512))
mask_image = PIL.ImageOps.invert(mask_image)
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16, custom_pipeline="stable_diffusion_repaint",
)
pipe.scheduler = RePaintScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
```
### TensorRT Image2Image Stable Diffusion Pipeline
The TensorRT Pipeline can be used to accelerate the Image2Image Stable Diffusion Inference run.
NOTE: The ONNX conversions and TensorRT engine build may take up to 30 minutes.
```python
import requests
from io import BytesIO
from PIL import Image
import torch
from diffusers import DDIMScheduler
from diffusers.pipelines.stable_diffusion import StableDiffusionImg2ImgPipeline
# Use the DDIMScheduler scheduler here instead
scheduler = DDIMScheduler.from_pretrained("stabilityai/stable-diffusion-2-1",
subfolder="scheduler")
pipe = StableDiffusionImg2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-1",
custom_pipeline="stable_diffusion_tensorrt_img2img",
revision='fp16',
torch_dtype=torch.float16,
scheduler=scheduler,)
# re-use cached folder to save ONNX models and TensorRT Engines
pipe.set_cached_folder("stabilityai/stable-diffusion-2-1", revision='fp16',)
pipe = pipe.to("cuda")
url = "https://pajoca.com/wp-content/uploads/2022/09/tekito-yamakawa-1.png"
response = requests.get(url)
input_image = Image.open(BytesIO(response.content)).convert("RGB")
prompt = "photorealistic new zealand hills"
image = pipe(prompt, image=input_image, strength=0.75,).images[0]
image.save('tensorrt_img2img_new_zealand_hills.png')
```
### Stable Diffusion Reference
This pipeline uses the Reference Control. Refer to the [sd-webui-controlnet discussion: Reference-only Control](https://github.com/Mikubill/sd-webui-controlnet/discussions/1236)[sd-webui-controlnet discussion: Reference-adain Control](https://github.com/Mikubill/sd-webui-controlnet/discussions/1280).
Based on [this issue](https://github.com/huggingface/diffusers/issues/3566),
- `EulerAncestralDiscreteScheduler` got poor results.
```py
import torch
from diffusers import UniPCMultistepScheduler
from diffusers.utils import load_image
input_image = load_image("https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png")
pipe = StableDiffusionReferencePipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
safety_checker=None,
torch_dtype=torch.float16
).to('cuda:0')
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
result_img = pipe(ref_image=input_image,
prompt="1girl",
num_inference_steps=20,
reference_attn=True,
reference_adain=True).images[0]
```
Reference Image

Output Image of `reference_attn=True` and `reference_adain=False`

Output Image of `reference_attn=False` and `reference_adain=True`

Output Image of `reference_attn=True` and `reference_adain=True`

### Stable Diffusion ControlNet Reference
This pipeline uses the Reference Control with ControlNet. Refer to the [sd-webui-controlnet discussion: Reference-only Control](https://github.com/Mikubill/sd-webui-controlnet/discussions/1236)[sd-webui-controlnet discussion: Reference-adain Control](https://github.com/Mikubill/sd-webui-controlnet/discussions/1280).
Based on [this issue](https://github.com/huggingface/diffusers/issues/3566),
- `EulerAncestralDiscreteScheduler` got poor results.
- `guess_mode=True` works well for ControlNet v1.1
```py
import cv2
import torch
import numpy as np
from PIL import Image
from diffusers import UniPCMultistepScheduler
from diffusers.utils import load_image
input_image = load_image("https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png")
# get canny image
image = cv2.Canny(np.array(input_image), 100, 200)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetReferencePipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
controlnet=controlnet,
safety_checker=None,
torch_dtype=torch.float16
).to('cuda:0')
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
result_img = pipe(ref_image=input_image,
prompt="1girl",
image=canny_image,
num_inference_steps=20,
reference_attn=True,
reference_adain=True).images[0]
```
Reference Image

Output Image

### Stable Diffusion on IPEX
This diffusion pipeline aims to accelarate the inference of Stable-Diffusion on Intel Xeon CPUs with BF16/FP32 precision using [IPEX](https://github.com/intel/intel-extension-for-pytorch).
To use this pipeline, you need to:
1. Install [IPEX](https://github.com/intel/intel-extension-for-pytorch)
**Note:** For each PyTorch release, there is a corresponding release of the IPEX. Here is the mapping relationship. It is recommended to install Pytorch/IPEX2.0 to get the best performance.
|PyTorch Version|IPEX Version|
|--|--|
|[v2.0.\*](https://github.com/pytorch/pytorch/tree/v2.0.1 "v2.0.1")|[v2.0.\*](https://github.com/intel/intel-extension-for-pytorch/tree/v2.0.100+cpu)|
|[v1.13.\*](https://github.com/pytorch/pytorch/tree/v1.13.0 "v1.13.0")|[v1.13.\*](https://github.com/intel/intel-extension-for-pytorch/tree/v1.13.100+cpu)|
You can simply use pip to install IPEX with the latest version.
```python
python -m pip install intel_extension_for_pytorch
```
**Note:** To install a specific version, run with the following command:
```
python -m pip install intel_extension_for_pytorch==<version_name> -f https://developer.intel.com/ipex-whl-stable-cpu
```
2. After pipeline initialization, `prepare_for_ipex()` should be called to enable IPEX accelaration. Supported inference datatypes are Float32 and BFloat16.
**Note:** The setting of generated image height/width for `prepare_for_ipex()` should be same as the setting of pipeline inference.
```python
pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", custom_pipeline="stable_diffusion_ipex")
# For Float32
pipe.prepare_for_ipex(prompt, dtype=torch.float32, height=512, width=512) #value of image height/width should be consistent with the pipeline inference
# For BFloat16
pipe.prepare_for_ipex(prompt, dtype=torch.bfloat16, height=512, width=512) #value of image height/width should be consistent with the pipeline inference
```
Then you can use the ipex pipeline in a similar way to the default stable diffusion pipeline.
```python
# For Float32
image = pipe(prompt, num_inference_steps=20, height=512, width=512).images[0] #value of image height/width should be consistent with 'prepare_for_ipex()'
# For BFloat16
with torch.cpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
image = pipe(prompt, num_inference_steps=20, height=512, width=512).images[0] #value of image height/width should be consistent with 'prepare_for_ipex()'
```
The following code compares the performance of the original stable diffusion pipeline with the ipex-optimized pipeline.
```python
import torch
import intel_extension_for_pytorch as ipex
from diffusers import StableDiffusionPipeline
import time
prompt = "sailing ship in storm by Rembrandt"
model_id = "runwayml/stable-diffusion-v1-5"
# Helper function for time evaluation
def elapsed_time(pipeline, nb_pass=3, num_inference_steps=20):
# warmup
for _ in range(2):
images = pipeline(prompt, num_inference_steps=num_inference_steps, height=512, width=512).images
#time evaluation
start = time.time()
for _ in range(nb_pass):
pipeline(prompt, num_inference_steps=num_inference_steps, height=512, width=512)
end = time.time()
return (end - start) / nb_pass
############## bf16 inference performance ###############
# 1. IPEX Pipeline initialization
pipe = DiffusionPipeline.from_pretrained(model_id, custom_pipeline="stable_diffusion_ipex")
pipe.prepare_for_ipex(prompt, dtype=torch.bfloat16, height=512, width=512)
# 2. Original Pipeline initialization
pipe2 = StableDiffusionPipeline.from_pretrained(model_id)
# 3. Compare performance between Original Pipeline and IPEX Pipeline
with torch.cpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
latency = elapsed_time(pipe)
print("Latency of StableDiffusionIPEXPipeline--bf16", latency)
latency = elapsed_time(pipe2)
print("Latency of StableDiffusionPipeline--bf16",latency)
############## fp32 inference performance ###############
# 1. IPEX Pipeline initialization
pipe3 = DiffusionPipeline.from_pretrained(model_id, custom_pipeline="stable_diffusion_ipex")
pipe3.prepare_for_ipex(prompt, dtype=torch.float32, height=512, width=512)
# 2. Original Pipeline initialization
pipe4 = StableDiffusionPipeline.from_pretrained(model_id)
# 3. Compare performance between Original Pipeline and IPEX Pipeline
latency = elapsed_time(pipe3)
print("Latency of StableDiffusionIPEXPipeline--fp32", latency)
latency = elapsed_time(pipe4)
print("Latency of StableDiffusionPipeline--fp32",latency)
```
### CLIP Guided Images Mixing With Stable Diffusion

CLIP guided stable diffusion images mixing pipeline allows to combine two images using standard diffusion models.
This approach is using (optional) CoCa model to avoid writing image description.
[More code examples](https://github.com/TheDenk/images_mixing)
### Stable Diffusion XL Long Weighted Prompt Pipeline
This SDXL pipeline support unlimited length prompt and negative prompt, compatible with A1111 prompt weighted style.
You can provide both `prompt` and `prompt_2`. if only one prompt is provided, `prompt_2` will be a copy of the provided `prompt`. Here is a sample code to use this pipeline.
```python
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0"
, torch_dtype = torch.float16
, use_safetensors = True
, variant = "fp16"
, custom_pipeline = "lpw_stable_diffusion_xl",
)
prompt = "photo of a cute (white) cat running on the grass"*20
prompt2 = "chasing (birds:1.5)"*20
prompt = f"{prompt},{prompt2}"
neg_prompt = "blur, low quality, carton, animate"
pipe.to("cuda")
images = pipe(
prompt = prompt
, negative_prompt = neg_prompt
).images[0]
pipe.to("cpu")
torch.cuda.empty_cache()
images
```
In the above code, the `prompt2` is appended to the `prompt`, which is more than 77 tokens. "birds" are showing up in the result.

## Example Images Mixing (with CoCa)
```python
import requests
from io import BytesIO
import PIL
import torch
import open_clip
from open_clip import SimpleTokenizer
from diffusers import DiffusionPipeline
from transformers import CLIPFeatureExtractor, CLIPModel
def download_image(url):
response = requests.get(url)
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
# Loading additional models
feature_extractor = CLIPFeatureExtractor.from_pretrained(
"laion/CLIP-ViT-B-32-laion2B-s34B-b79K"
)
clip_model = CLIPModel.from_pretrained(
"laion/CLIP-ViT-B-32-laion2B-s34B-b79K", torch_dtype=torch.float16
)
coca_model = open_clip.create_model('coca_ViT-L-14', pretrained='laion2B-s13B-b90k').to('cuda')
coca_model.dtype = torch.float16
coca_transform = open_clip.image_transform(
coca_model.visual.image_size,
is_train = False,
mean = getattr(coca_model.visual, 'image_mean', None),
std = getattr(coca_model.visual, 'image_std', None),
)
coca_tokenizer = SimpleTokenizer()
# Pipeline creating
mixing_pipeline = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
custom_pipeline="clip_guided_images_mixing_stable_diffusion",
clip_model=clip_model,
feature_extractor=feature_extractor,
coca_model=coca_model,
coca_tokenizer=coca_tokenizer,
coca_transform=coca_transform,
torch_dtype=torch.float16,
)
mixing_pipeline.enable_attention_slicing()
mixing_pipeline = mixing_pipeline.to("cuda")
# Pipeline running
generator = torch.Generator(device="cuda").manual_seed(17)
def download_image(url):
response = requests.get(url)
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
content_image = download_image("https://huggingface.co/datasets/TheDenk/images_mixing/resolve/main/boromir.jpg")
style_image = download_image("https://huggingface.co/datasets/TheDenk/images_mixing/resolve/main/gigachad.jpg")
pipe_images = mixing_pipeline(
num_inference_steps=50,
content_image=content_image,
style_image=style_image,
noise_strength=0.65,
slerp_latent_style_strength=0.9,
slerp_prompt_style_strength=0.1,
slerp_clip_image_style_strength=0.1,
guidance_scale=9.0,
batch_size=1,
clip_guidance_scale=100,
generator=generator,
).images
```

### Stable Diffusion Mixture Tiling
This pipeline uses the Mixture. Refer to the [Mixture](https://arxiv.org/abs/2302.02412) paper for more details.
```python
from diffusers import LMSDiscreteScheduler, DiffusionPipeline
# Creater scheduler and model (similar to StableDiffusionPipeline)
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
pipeline = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=scheduler, custom_pipeline="mixture_tiling")
pipeline.to("cuda")
# Mixture of Diffusers generation
image = pipeline(
prompt=[[
"A charming house in the countryside, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece",
"A dirt road in the countryside crossing pastures, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece",
"An old and rusty giant robot lying on a dirt road, by jakub rozalski, dark sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece"
]],
tile_height=640,
tile_width=640,
tile_row_overlap=0,
tile_col_overlap=256,
guidance_scale=8,
seed=7178915308,
num_inference_steps=50,
)["images"][0]
```

### TensorRT Inpainting Stable Diffusion Pipeline
The TensorRT Pipeline can be used to accelerate the Inpainting Stable Diffusion Inference run.
NOTE: The ONNX conversions and TensorRT engine build may take up to 30 minutes.
```python
import requests
from io import BytesIO
from PIL import Image
import torch
from diffusers import PNDMScheduler
from diffusers.pipelines.stable_diffusion import StableDiffusionInpaintPipeline
# Use the PNDMScheduler scheduler here instead
scheduler = PNDMScheduler.from_pretrained("stabilityai/stable-diffusion-2-inpainting", subfolder="scheduler")
pipe = StableDiffusionInpaintPipeline.from_pretrained("stabilityai/stable-diffusion-2-inpainting",
custom_pipeline="stable_diffusion_tensorrt_inpaint",
revision='fp16',
torch_dtype=torch.float16,
scheduler=scheduler,
)
# re-use cached folder to save ONNX models and TensorRT Engines
pipe.set_cached_folder("stabilityai/stable-diffusion-2-inpainting", revision='fp16',)
pipe = pipe.to("cuda")
url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
response = requests.get(url)
input_image = Image.open(BytesIO(response.content)).convert("RGB")
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
response = requests.get(mask_url)
mask_image = Image.open(BytesIO(response.content)).convert("RGB")
prompt = "a mecha robot sitting on a bench"
image = pipe(prompt, image=input_image, mask_image=mask_image, strength=0.75,).images[0]
image.save('tensorrt_inpaint_mecha_robot.png')
```
### Stable Diffusion Mixture Canvas
This pipeline uses the Mixture. Refer to the [Mixture](https://arxiv.org/abs/2302.02412) paper for more details.
```python
from PIL import Image
from diffusers import LMSDiscreteScheduler, DiffusionPipeline
from diffusers.pipelines.pipeline_utils import Image2ImageRegion, Text2ImageRegion, preprocess_image
# Load and preprocess guide image
iic_image = preprocess_image(Image.open("input_image.png").convert("RGB"))
# Creater scheduler and model (similar to StableDiffusionPipeline)
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
pipeline = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=scheduler).to("cuda:0", custom_pipeline="mixture_canvas")
pipeline.to("cuda")
# Mixture of Diffusers generation
output = pipeline(
canvas_height=800,
canvas_width=352,
regions=[
Text2ImageRegion(0, 800, 0, 352, guidance_scale=8,
prompt=f"best quality, masterpiece, WLOP, sakimichan, art contest winner on pixiv, 8K, intricate details, wet effects, rain drops, ethereal, mysterious, futuristic, UHD, HDR, cinematic lighting, in a beautiful forest, rainy day, award winning, trending on artstation, beautiful confident cheerful young woman, wearing a futuristic sleeveless dress, ultra beautiful detailed eyes, hyper-detailed face, complex, perfect, model, textured, chiaroscuro, professional make-up, realistic, figure in frame, "),
Image2ImageRegion(352-800, 352, 0, 352, reference_image=iic_image, strength=1.0),
],
num_inference_steps=100,
seed=5525475061,
)["images"][0]
```


### IADB pipeline
This pipeline is the implementation of the [α-(de)Blending: a Minimalist Deterministic Diffusion Model](https://arxiv.org/abs/2305.03486) paper.
It is a simple and minimalist diffusion model.
The following code shows how to use the IADB pipeline to generate images using a pretrained celebahq-256 model.
```python
pipeline_iadb = DiffusionPipeline.from_pretrained("thomasc4/iadb-celebahq-256", custom_pipeline='iadb')
pipeline_iadb = pipeline_iadb.to('cuda')
output = pipeline_iadb(batch_size=4,num_inference_steps=128)
for i in range(len(output[0])):
plt.imshow(output[0][i])
plt.show()
```
Sampling with the IADB formulation is easy, and can be done in a few lines (the pipeline already implements it):
```python
def sample_iadb(model, x0, nb_step):
x_alpha = x0
for t in range(nb_step):
alpha = (t/nb_step)
alpha_next =((t+1)/nb_step)
d = model(x_alpha, torch.tensor(alpha, device=x_alpha.device))['sample']
x_alpha = x_alpha + (alpha_next-alpha)*d
return x_alpha
```
The training loop is also straightforward:
```python
# Training loop
while True:
x0 = sample_noise()
x1 = sample_dataset()
alpha = torch.rand(batch_size)
# Blend
x_alpha = (1-alpha) * x0 + alpha * x1
# Loss
loss = torch.sum((D(x_alpha, alpha)- (x1-x0))**2)
optimizer.zero_grad()
loss.backward()
optimizer.step()
```
### Zero1to3 pipeline
This pipeline is the implementation of the [Zero-1-to-3: Zero-shot One Image to 3D Object](https://arxiv.org/abs/2303.11328) paper.
The original pytorch-lightning [repo](https://github.com/cvlab-columbia/zero123) and a diffusers [repo](https://github.com/kxhit/zero123-hf).
The following code shows how to use the Zero1to3 pipeline to generate novel view synthesis images using a pretrained stable diffusion model.
```python
import os
import torch
from pipeline_zero1to3 import Zero1to3StableDiffusionPipeline
from diffusers.utils import load_image
model_id = "kxic/zero123-165000" # zero123-105000, zero123-165000, zero123-xl
pipe = Zero1to3StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_vae_tiling()
pipe.enable_attention_slicing()
pipe = pipe.to("cuda")
num_images_per_prompt = 4
# test inference pipeline
# x y z, Polar angle (vertical rotation in degrees) Azimuth angle (horizontal rotation in degrees) Zoom (relative distance from center)
query_pose1 = [-75.0, 100.0, 0.0]
query_pose2 = [-20.0, 125.0, 0.0]
query_pose3 = [-55.0, 90.0, 0.0]
# load image
# H, W = (256, 256) # H, W = (512, 512) # zero123 training is 256,256
# for batch input
input_image1 = load_image("./demo/4_blackarm.png") #load_image("https://cvlab-zero123-live.hf.space/file=/home/user/app/configs/4_blackarm.png")
input_image2 = load_image("./demo/8_motor.png") #load_image("https://cvlab-zero123-live.hf.space/file=/home/user/app/configs/8_motor.png")
input_image3 = load_image("./demo/7_london.png") #load_image("https://cvlab-zero123-live.hf.space/file=/home/user/app/configs/7_london.png")
input_images = [input_image1, input_image2, input_image3]
query_poses = [query_pose1, query_pose2, query_pose3]
# # for single input
# H, W = (256, 256)
# input_images = [input_image2.resize((H, W), PIL.Image.NEAREST)]
# query_poses = [query_pose2]
# better do preprocessing
from gradio_new import preprocess_image, create_carvekit_interface
import numpy as np
import PIL.Image as Image
pre_images = []
models = dict()
print('Instantiating Carvekit HiInterface...')
models['carvekit'] = create_carvekit_interface()
if not isinstance(input_images, list):
input_images = [input_images]
for raw_im in input_images:
input_im = preprocess_image(models, raw_im, True)
H, W = input_im.shape[:2]
pre_images.append(Image.fromarray((input_im * 255.0).astype(np.uint8)))
input_images = pre_images
# infer pipeline, in original zero123 num_inference_steps=76
images = pipe(input_imgs=input_images, prompt_imgs=input_images, poses=query_poses, height=H, width=W,
guidance_scale=3.0, num_images_per_prompt=num_images_per_prompt, num_inference_steps=50).images
# save imgs
log_dir = "logs"
os.makedirs(log_dir, exist_ok=True)
bs = len(input_images)
i = 0
for obj in range(bs):
for idx in range(num_images_per_prompt):
images[i].save(os.path.join(log_dir,f"obj{obj}_{idx}.jpg"))
i += 1
```
### Stable Diffusion XL Reference
This pipeline uses the Reference . Refer to the [stable_diffusion_reference](https://github.com/huggingface/diffusers/blob/main/examples/community/README.md#stable-diffusion-reference).
```py
import torch
from PIL import Image
from diffusers.utils import load_image
from diffusers import DiffusionPipeline
from diffusers.schedulers import UniPCMultistepScheduler
input_image = load_image("https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png")
# pipe = DiffusionPipeline.from_pretrained(
# "stabilityai/stable-diffusion-xl-base-1.0",
# custom_pipeline="stable_diffusion_xl_reference",
# torch_dtype=torch.float16,
# use_safetensors=True,
# variant="fp16").to('cuda:0')
pipe = StableDiffusionXLReferencePipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16").to('cuda:0')
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
result_img = pipe(ref_image=input_image,
prompt="1girl",
num_inference_steps=20,
reference_attn=True,
reference_adain=True).images[0]
```
Reference Image

Output Image
`prompt: 1 girl`
`reference_attn=True, reference_adain=True, num_inference_steps=20`

Reference Image

Output Image
`prompt: A dog`
`reference_attn=True, reference_adain=False, num_inference_steps=20`

Reference Image

Output Image
`prompt: An astronaut riding a lion`
`reference_attn=True, reference_adain=True, num_inference_steps=20`

### Stable diffusion fabric pipeline
FABRIC approach applicable to a wide range of popular diffusion models, which exploits
the self-attention layer present in the most widely used architectures to condition
the diffusion process on a set of feedback images.
```python
import requests
import torch
from PIL import Image
from io import BytesIO
from diffusers import DiffusionPipeline
# load the pipeline
# make sure you're logged in with `huggingface-cli login`
model_id_or_path = "runwayml/stable-diffusion-v1-5"
#can also be used with dreamlike-art/dreamlike-photoreal-2.0
pipe = DiffusionPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16, custom_pipeline="pipeline_fabric").to("cuda")
# let's specify a prompt
prompt = "An astronaut riding an elephant"
negative_prompt = "lowres, cropped"
# call the pipeline
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=20,
generator=torch.manual_seed(12)
).images[0]
image.save("horse_to_elephant.jpg")
# let's try another example with feedback
url = "https://raw.githubusercontent.com/ChenWu98/cycle-diffusion/main/data/dalle2/A%20black%20colored%20car.png"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
prompt = "photo, A blue colored car, fish eye"
liked = [init_image]
## same goes with disliked
# call the pipeline
torch.manual_seed(0)
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
liked = liked,
num_inference_steps=20,
).images[0]
image.save("black_to_blue.png")
```
*With enough feedbacks you can create very similar high quality images.*
The original codebase can be found at [sd-fabric/fabric](https://github.com/sd-fabric/fabric), and available checkpoints are [dreamlike-art/dreamlike-photoreal-2.0](https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0), [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5), and [stabilityai/stable-diffusion-2-1](https://huggingface.co/stabilityai/stable-diffusion-2-1) (may give unexpected results).
Let's have a look at the images (*512X512*)
| Without Feedback | With Feedback (1st image) |
|---------------------|---------------------|
|  |  |
### Masked Im2Im Stable Diffusion Pipeline
This pipeline reimplements sketch inpaint feature from A1111 for non-inpaint models. The following code reads two images, original and one with mask painted over it. It computes mask as a difference of two images and does the inpainting in the area defined by the mask.
```python
img = PIL.Image.open("./mech.png")
# read image with mask painted over
img_paint = PIL.Image.open("./mech_painted.png")
neq = numpy.any(numpy.array(img) != numpy.array(img_paint), axis=-1)
mask = neq / neq.max()
pipeline = MaskedStableDiffusionImg2ImgPipeline.from_pretrained("frankjoshua/icbinpICantBelieveIts_v8")
# works best with EulerAncestralDiscreteScheduler
pipeline.scheduler = EulerAncestralDiscreteScheduler.from_config(pipeline.scheduler.config)
generator = torch.Generator(device="cpu").manual_seed(4)
prompt = "a man wearing a mask"
result = pipeline(prompt=prompt, image=img_paint, mask=mask, strength=0.75,
generator=generator)
result.images[0].save("result.png")
```
original image mech.png
<img src=https://github.com/noskill/diffusers/assets/733626/10ad972d-d655-43cb-8de1-039e3d79e849 width="25%" >
image with mask mech_painted.png
<img src=https://github.com/noskill/diffusers/assets/733626/c334466a-67fe-4377-9ff7-f46021b9c224 width="25%" >
result:
<img src=https://github.com/noskill/diffusers/assets/733626/23a0a71d-51db-471e-926a-107ac62512a8 width="25%" >
### Prompt2Prompt Pipeline
Prompt2Prompt allows the following edits:
- ReplaceEdit (change words in prompt)
- ReplaceEdit with local blend (change words in prompt, keep image part unrelated to changes constant)
- RefineEdit (add words to prompt)
- RefineEdit with local blend (add words to prompt, keep image part unrelated to changes constant)
- ReweightEdit (modulate importance of words)
Here's a full example for `ReplaceEdit``:
```python
import torch
import numpy as np
import matplotlib.pyplot as plt
from diffusers.pipelines import Prompt2PromptPipeline
pipe = Prompt2PromptPipeline.from_pretrained("CompVis/stable-diffusion-v1-4").to("cuda")
prompts = ["A turtle playing with a ball",
"A monkey playing with a ball"]
cross_attention_kwargs = {
"edit_type": "replace",
"cross_replace_steps": 0.4,
"self_replace_steps": 0.4
}
outputs = pipe(prompt=prompts, height=512, width=512, num_inference_steps=50, cross_attention_kwargs=cross_attention_kwargs)
```
And abbreviated examples for the other edits:
`ReplaceEdit with local blend`
```python
prompts = ["A turtle playing with a ball",
"A monkey playing with a ball"]
cross_attention_kwargs = {
"edit_type": "replace",
"cross_replace_steps": 0.4,
"self_replace_steps": 0.4,
"local_blend_words": ["turtle", "monkey"]
}
```
`RefineEdit`
```python
prompts = ["A turtle",
"A turtle in a forest"]
cross_attention_kwargs = {
"edit_type": "refine",
"cross_replace_steps": 0.4,
"self_replace_steps": 0.4,
}
```
`RefineEdit with local blend`
```python
prompts = ["A turtle",
"A turtle in a forest"]
cross_attention_kwargs = {
"edit_type": "refine",
"cross_replace_steps": 0.4,
"self_replace_steps": 0.4,
"local_blend_words": ["in", "a" , "forest"]
}
```
`ReweightEdit`
```python
prompts = ["A smiling turtle"] * 2
edit_kcross_attention_kwargswargs = {
"edit_type": "reweight",
"cross_replace_steps": 0.4,
"self_replace_steps": 0.4,
"equalizer_words": ["smiling"],
"equalizer_strengths": [5]
}
```
Side note: See [this GitHub gist](https://gist.github.com/UmerHA/b65bb5fb9626c9c73f3ade2869e36164) if you want to visualize the attention maps.
### Latent Consistency Pipeline
Latent Consistency Models was proposed in [Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference](https://arxiv.org/abs/2310.04378) by *Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, Hang Zhao* from Tsinghua University.
The abstract of the paper reads as follows:
*Latent Diffusion models (LDMs) have achieved remarkable results in synthesizing high-resolution images. However, the iterative sampling process is computationally intensive and leads to slow generation. Inspired by Consistency Models (song et al.), we propose Latent Consistency Models (LCMs), enabling swift inference with minimal steps on any pre-trained LDMs, including Stable Diffusion (rombach et al). Viewing the guided reverse diffusion process as solving an augmented probability flow ODE (PF-ODE), LCMs are designed to directly predict the solution of such ODE in latent space, mitigating the need for numerous iterations and allowing rapid, high-fidelity sampling. Efficiently distilled from pre-trained classifier-free guided diffusion models, a high-quality 768 x 768 2~4-step LCM takes only 32 A100 GPU hours for training. Furthermore, we introduce Latent Consistency Fine-tuning (LCF), a novel method that is tailored for fine-tuning LCMs on customized image datasets. Evaluation on the LAION-5B-Aesthetics dataset demonstrates that LCMs achieve state-of-the-art text-to-image generation performance with few-step inference. Project Page: [this https URL](https://latent-consistency-models.github.io/)*
The model can be used with `diffusers` as follows:
- *1. Load the model from the community pipeline.*
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("SimianLuo/LCM_Dreamshaper_v7", custom_pipeline="latent_consistency_txt2img", custom_revision="main")
# To save GPU memory, torch.float16 can be used, but it may compromise image quality.
pipe.to(torch_device="cuda", torch_dtype=torch.float32)
```
- 2. Run inference with as little as 4 steps:
```py
prompt = "Self-portrait oil painting, a beautiful cyborg with golden hair, 8k"
# Can be set to 1~50 steps. LCM support fast inference even <= 4 steps. Recommend: 1~8 steps.
num_inference_steps = 4
images = pipe(prompt=prompt, num_inference_steps=num_inference_steps, guidance_scale=8.0, lcm_origin_steps=50, output_type="pil").images
```
For any questions or feedback, feel free to reach out to [Simian Luo](https://github.com/luosiallen).
You can also try this pipeline directly in the [🚀 official spaces](https://huggingface.co/spaces/SimianLuo/Latent_Consistency_Model).
### Latent Consistency Img2img Pipeline
This pipeline extends the Latent Consistency Pipeline to allow it to take an input image.
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("SimianLuo/LCM_Dreamshaper_v7", custom_pipeline="latent_consistency_img2img")
# To save GPU memory, torch.float16 can be used, but it may compromise image quality.
pipe.to(torch_device="cuda", torch_dtype=torch.float32)
```
- 2. Run inference with as little as 4 steps:
```py
prompt = "Self-portrait oil painting, a beautiful cyborg with golden hair, 8k"
input_image=Image.open("myimg.png")
strength = 0.5 #strength =0 (no change) strength=1 (completely overwrite image)
# Can be set to 1~50 steps. LCM support fast inference even <= 4 steps. Recommend: 1~8 steps.
num_inference_steps = 4
images = pipe(prompt=prompt, image=input_image, strength=strength, num_inference_steps=num_inference_steps, guidance_scale=8.0, lcm_origin_steps=50, output_type="pil").images
```
### Latent Consistency Interpolation Pipeline
This pipeline extends the Latent Consistency Pipeline to allow for interpolation of the latent space between multiple prompts. It is similar to the [Stable Diffusion Interpolate](https://github.com/huggingface/diffusers/blob/main/examples/community/interpolate_stable_diffusion.py) and [unCLIP Interpolate](https://github.com/huggingface/diffusers/blob/main/examples/community/unclip_text_interpolation.py) community pipelines.
```py
import torch
import numpy as np
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("SimianLuo/LCM_Dreamshaper_v7", custom_pipeline="latent_consistency_interpolate")
# To save GPU memory, torch.float16 can be used, but it may compromise image quality.
pipe.to(torch_device="cuda", torch_dtype=torch.float32)
prompts = [
"Self-portrait oil painting, a beautiful cyborg with golden hair, Margot Robbie, 8k",
"Self-portrait oil painting, an extremely strong man, body builder, Huge Jackman, 8k",
"An astronaut floating in space, renaissance art, realistic, high quality, 8k",
"Oil painting of a cat, cute, dream-like",
"Hugging face emoji, cute, realistic"
]
num_inference_steps = 4
num_interpolation_steps = 60
seed = 1337
torch.manual_seed(seed)
np.random.seed(seed)
images = pipe(
prompt=prompts,
height=512,
width=512,
num_inference_steps=num_inference_steps,
num_interpolation_steps=num_interpolation_steps,
guidance_scale=8.0,
embedding_interpolation_type="lerp",
latent_interpolation_type="slerp",
process_batch_size=4, # Make it higher or lower based on your GPU memory
generator=torch.Generator(seed),
)
assert len(images) == (len(prompts) - 1) * num_interpolation_steps
```
### StableDiffusionUpscaleLDM3D Pipeline
[LDM3D-VR](https://arxiv.org/pdf/2311.03226.pdf) is an extended version of LDM3D.
The abstract from the paper is:
*Latent diffusion models have proven to be state-of-the-art in the creation and manipulation of visual outputs. However, as far as we know, the generation of depth maps jointly with RGB is still limited. We introduce LDM3D-VR, a suite of diffusion models targeting virtual reality development that includes LDM3D-pano and LDM3D-SR. These models enable the generation of panoramic RGBD based on textual prompts and the upscaling of low-resolution inputs to high-resolution RGBD, respectively. Our models are fine-tuned from existing pretrained models on datasets containing panoramic/high-resolution RGB images, depth maps and captions. Both models are evaluated in comparison to existing related methods*
Two checkpoints are available for use:
- [ldm3d-pano](https://huggingface.co/Intel/ldm3d-pano). This checkpoint enables the generation of panoramic images and requires the StableDiffusionLDM3DPipeline pipeline to be used.
- [ldm3d-sr](https://huggingface.co/Intel/ldm3d-sr). This checkpoint enables the upscaling of RGB and depth images. Can be used in cascade after the original LDM3D pipeline using the StableDiffusionUpscaleLDM3DPipeline pipeline.
'''py
from PIL import Image
import os
import torch
from diffusers import StableDiffusionLDM3DPipeline, DiffusionPipeline
#Generate a rgb/depth output from LDM3D
pipe_ldm3d = StableDiffusionLDM3DPipeline.from_pretrained("Intel/ldm3d-4c")
pipe_ldm3d.to("cuda")
prompt =f"A picture of some lemons on a table"
output = pipe_ldm3d(prompt)
rgb_image, depth_image = output.rgb, output.depth
rgb_image[0].save(f"lemons_ldm3d_rgb.jpg")
depth_image[0].save(f"lemons_ldm3d_depth.png")
#Upscale the previous output to a resolution of (1024, 1024)
pipe_ldm3d_upscale = DiffusionPipeline.from_pretrained("Intel/ldm3d-sr", custom_pipeline="pipeline_stable_diffusion_upscale_ldm3d")
pipe_ldm3d_upscale.to("cuda")
low_res_img = Image.open(f"lemons_ldm3d_rgb.jpg").convert("RGB")
low_res_depth = Image.open(f"lemons_ldm3d_depth.png").convert("L")
outputs = pipe_ldm3d_upscale(prompt="high quality high resolution uhd 4k image", rgb=low_res_img, depth=low_res_depth, num_inference_steps=50, target_res=[1024, 1024])
upscaled_rgb, upscaled_depth =outputs.rgb[0], outputs.depth[0]
upscaled_rgb.save(f"upscaled_lemons_rgb.png")
upscaled_depth.save(f"upscaled_lemons_depth.png")
'''
### ControlNet + T2I Adapter Pipeline
This pipelines combines both ControlNet and T2IAdapter into a single pipeline, where the forward pass is executed once.
It receives `control_image` and `adapter_image`, as well as `controlnet_conditioning_scale` and `adapter_conditioning_scale`, for the ControlNet and Adapter modules, respectively. Whenever `adapter_conditioning_scale = 0` or `controlnet_conditioning_scale = 0`, it will act as a full ControlNet module or as a full T2IAdapter module, respectively.
```py
import cv2
import numpy as np
import torch
from controlnet_aux.midas import MidasDetector
from PIL import Image
from diffusers import AutoencoderKL, ControlNetModel, MultiAdapter, T2IAdapter
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
from diffusers.utils import load_image
from examples.community.pipeline_stable_diffusion_xl_controlnet_adapter import (
StableDiffusionXLControlNetAdapterPipeline,
)
controlnet_depth = ControlNetModel.from_pretrained(
"diffusers/controlnet-depth-sdxl-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
adapter_depth = T2IAdapter.from_pretrained(
"TencentARC/t2i-adapter-depth-midas-sdxl-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionXLControlNetAdapterPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
controlnet=controlnet_depth,
adapter=adapter_depth,
vae=vae,
variant="fp16",
use_safetensors=True,
torch_dtype=torch.float16,
)
pipe = pipe.to("cuda")
pipe.enable_xformers_memory_efficient_attention()
# pipe.enable_freeu(s1=0.6, s2=0.4, b1=1.1, b2=1.2)
midas_depth = MidasDetector.from_pretrained(
"valhalla/t2iadapter-aux-models", filename="dpt_large_384.pt", model_type="dpt_large"
).to("cuda")
prompt = "a tiger sitting on a park bench"
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
image = load_image(img_url).resize((1024, 1024))
depth_image = midas_depth(
image, detect_resolution=512, image_resolution=1024
)
strength = 0.5
images = pipe(
prompt,
control_image=depth_image,
adapter_image=depth_image,
num_inference_steps=30,
controlnet_conditioning_scale=strength,
adapter_conditioning_scale=strength,
).images
images[0].save("controlnet_and_adapter.png")
```
### ControlNet + T2I Adapter + Inpainting Pipeline
```py
import cv2
import numpy as np
import torch
from controlnet_aux.midas import MidasDetector
from PIL import Image
from diffusers import AutoencoderKL, ControlNetModel, MultiAdapter, T2IAdapter
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
from diffusers.utils import load_image
from examples.community.pipeline_stable_diffusion_xl_controlnet_adapter_inpaint import (
StableDiffusionXLControlNetAdapterInpaintPipeline,
)
controlnet_depth = ControlNetModel.from_pretrained(
"diffusers/controlnet-depth-sdxl-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
adapter_depth = T2IAdapter.from_pretrained(
"TencentARC/t2i-adapter-depth-midas-sdxl-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16, use_safetensors=True)
pipe = StableDiffusionXLControlNetAdapterInpaintPipeline.from_pretrained(
"diffusers/stable-diffusion-xl-1.0-inpainting-0.1",
controlnet=controlnet_depth,
adapter=adapter_depth,
vae=vae,
variant="fp16",
use_safetensors=True,
torch_dtype=torch.float16,
)
pipe = pipe.to("cuda")
pipe.enable_xformers_memory_efficient_attention()
# pipe.enable_freeu(s1=0.6, s2=0.4, b1=1.1, b2=1.2)
midas_depth = MidasDetector.from_pretrained(
"valhalla/t2iadapter-aux-models", filename="dpt_large_384.pt", model_type="dpt_large"
).to("cuda")
prompt = "a tiger sitting on a park bench"
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
image = load_image(img_url).resize((1024, 1024))
mask_image = load_image(mask_url).resize((1024, 1024))
depth_image = midas_depth(
image, detect_resolution=512, image_resolution=1024
)
strength = 0.4
images = pipe(
prompt,
image=image,
mask_image=mask_image,
control_image=depth_image,
adapter_image=depth_image,
num_inference_steps=30,
controlnet_conditioning_scale=strength,
adapter_conditioning_scale=strength,
strength=0.7,
).images
images[0].save("controlnet_and_adapter_inpaint.png")
```
## Diffusion Posterior Sampling Pipeline
* Reference paper
```
@article{chung2022diffusion,
title={Diffusion posterior sampling for general noisy inverse problems},
author={Chung, Hyungjin and Kim, Jeongsol and Mccann, Michael T and Klasky, Marc L and Ye, Jong Chul},
journal={arXiv preprint arXiv:2209.14687},
year={2022}
}
```
* This pipeline allows zero-shot conditional sampling from the posterior distribution $p(x|y)$, given observation on $y$, unconditional generative model $p(x)$ and differentiable operator $y=f(x)$.
* For example, $f(.)$ can be downsample operator, then $y$ is a downsampled image, and the pipeline becomes a super-resolution pipeline.
* To use this pipeline, you need to know your operator $f(.)$ and corrupted image $y$, and pass them during the call. For example, as in the main function of dps_pipeline.py, you need to first define the Gaussian blurring operator $f(.)$. The operator should be a callable nn.Module, with all the parameter gradient disabled:
```python
import torch.nn.functional as F
import scipy
from torch import nn
# define the Gaussian blurring operator first
class GaussialBlurOperator(nn.Module):
def __init__(self, kernel_size, intensity):
super().__init__()
class Blurkernel(nn.Module):
def __init__(self, blur_type='gaussian', kernel_size=31, std=3.0):
super().__init__()
self.blur_type = blur_type
self.kernel_size = kernel_size
self.std = std
self.seq = nn.Sequential(
nn.ReflectionPad2d(self.kernel_size//2),
nn.Conv2d(3, 3, self.kernel_size, stride=1, padding=0, bias=False, groups=3)
)
self.weights_init()
def forward(self, x):
return self.seq(x)
def weights_init(self):
if self.blur_type == "gaussian":
n = np.zeros((self.kernel_size, self.kernel_size))
n[self.kernel_size // 2,self.kernel_size // 2] = 1
k = scipy.ndimage.gaussian_filter(n, sigma=self.std)
k = torch.from_numpy(k)
self.k = k
for name, f in self.named_parameters():
f.data.copy_(k)
elif self.blur_type == "motion":
k = Kernel(size=(self.kernel_size, self.kernel_size), intensity=self.std).kernelMatrix
k = torch.from_numpy(k)
self.k = k
for name, f in self.named_parameters():
f.data.copy_(k)
def update_weights(self, k):
if not torch.is_tensor(k):
k = torch.from_numpy(k)
for name, f in self.named_parameters():
f.data.copy_(k)
def get_kernel(self):
return self.k
self.kernel_size = kernel_size
self.conv = Blurkernel(blur_type='gaussian',
kernel_size=kernel_size,
std=intensity)
self.kernel = self.conv.get_kernel()
self.conv.update_weights(self.kernel.type(torch.float32))
for param in self.parameters():
param.requires_grad=False
def forward(self, data, **kwargs):
return self.conv(data)
def transpose(self, data, **kwargs):
return data
def get_kernel(self):
return self.kernel.view(1, 1, self.kernel_size, self.kernel_size)
```
* Next, you should obtain the corrupted image $y$ by the operator. In this example, we generate $y$ from the source image $x$. However in practice, having the operator $f(.)$ and corrupted image $y$ is enough:
```python
# set up source image
src = Image.open('sample.png')
# read image into [1,3,H,W]
src = torch.from_numpy(np.array(src, dtype=np.float32)).permute(2,0,1)[None]
# normalize image to [-1,1]
src = (src / 127.5) - 1.0
src = src.to("cuda")
# set up operator and measurement
operator = GaussialBlurOperator(kernel_size=61, intensity=3.0).to("cuda")
measurement = operator(src)
# save the source and corrupted images
save_image((src+1.0)/2.0, "dps_src.png")
save_image((measurement+1.0)/2.0, "dps_mea.png")
```
* We provide an example pair of saved source and corrupted images, using the Gaussian blur operator above
* Source image:
* 
* Gaussian blurred image:
* 
* You can download those image to run the example on your own.
* Next, we need to define a loss function used for diffusion posterior sample. For most of the cases, the RMSE is fine:
```python
def RMSELoss(yhat, y):
return torch.sqrt(torch.sum((yhat-y)**2))
```
* And next, as any other diffusion models, we need the score estimator and scheduler. As we are working with $256x256$ face images, we use ddmp-celebahq-256:
```python
# set up scheduler
scheduler = DDPMScheduler.from_pretrained("google/ddpm-celebahq-256")
scheduler.set_timesteps(1000)
# set up model
model = UNet2DModel.from_pretrained("google/ddpm-celebahq-256").to("cuda")
```
* And finally, run the pipeline:
```python
# finally, the pipeline
dpspipe = DPSPipeline(model, scheduler)
image = dpspipe(
measurement = measurement,
operator = operator,
loss_fn = RMSELoss,
zeta = 1.0,
).images[0]
image.save("dps_generated_image.png")
```
* The zeta is a hyperparameter that is in range of $[0,1]$. It need to be tuned for best effect. By setting zeta=1, you should be able to have the reconstructed result:
* Reconstructed image:
* 
* The reconstruction is perceptually similar to the source image, but different in details.
* In dps_pipeline.py, we also provide a super-resolution example, which should produce:
* Downsampled image:
* 
* Reconstructed image:
* 
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/clip_guided_stable_diffusion.py
|
import inspect
from typing import List, Optional, Union
import torch
from torch import nn
from torch.nn import functional as F
from torchvision import transforms
from transformers import CLIPImageProcessor, CLIPModel, CLIPTextModel, CLIPTokenizer
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DiffusionPipeline,
DPMSolverMultistepScheduler,
LMSDiscreteScheduler,
PNDMScheduler,
UNet2DConditionModel,
)
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion import StableDiffusionPipelineOutput
class MakeCutouts(nn.Module):
def __init__(self, cut_size, cut_power=1.0):
super().__init__()
self.cut_size = cut_size
self.cut_power = cut_power
def forward(self, pixel_values, num_cutouts):
sideY, sideX = pixel_values.shape[2:4]
max_size = min(sideX, sideY)
min_size = min(sideX, sideY, self.cut_size)
cutouts = []
for _ in range(num_cutouts):
size = int(torch.rand([]) ** self.cut_power * (max_size - min_size) + min_size)
offsetx = torch.randint(0, sideX - size + 1, ())
offsety = torch.randint(0, sideY - size + 1, ())
cutout = pixel_values[:, :, offsety : offsety + size, offsetx : offsetx + size]
cutouts.append(F.adaptive_avg_pool2d(cutout, self.cut_size))
return torch.cat(cutouts)
def spherical_dist_loss(x, y):
x = F.normalize(x, dim=-1)
y = F.normalize(y, dim=-1)
return (x - y).norm(dim=-1).div(2).arcsin().pow(2).mul(2)
def set_requires_grad(model, value):
for param in model.parameters():
param.requires_grad = value
class CLIPGuidedStableDiffusion(DiffusionPipeline):
"""CLIP guided stable diffusion based on the amazing repo by @crowsonkb and @Jack000
- https://github.com/Jack000/glid-3-xl
- https://github.dev/crowsonkb/k-diffusion
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
clip_model: CLIPModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[PNDMScheduler, LMSDiscreteScheduler, DDIMScheduler, DPMSolverMultistepScheduler],
feature_extractor: CLIPImageProcessor,
):
super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
clip_model=clip_model,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
feature_extractor=feature_extractor,
)
self.normalize = transforms.Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
self.cut_out_size = (
feature_extractor.size
if isinstance(feature_extractor.size, int)
else feature_extractor.size["shortest_edge"]
)
self.make_cutouts = MakeCutouts(self.cut_out_size)
set_requires_grad(self.text_encoder, False)
set_requires_grad(self.clip_model, False)
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
slice_size = self.unet.config.attention_head_dim // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
self.enable_attention_slicing(None)
def freeze_vae(self):
set_requires_grad(self.vae, False)
def unfreeze_vae(self):
set_requires_grad(self.vae, True)
def freeze_unet(self):
set_requires_grad(self.unet, False)
def unfreeze_unet(self):
set_requires_grad(self.unet, True)
@torch.enable_grad()
def cond_fn(
self,
latents,
timestep,
index,
text_embeddings,
noise_pred_original,
text_embeddings_clip,
clip_guidance_scale,
num_cutouts,
use_cutouts=True,
):
latents = latents.detach().requires_grad_()
latent_model_input = self.scheduler.scale_model_input(latents, timestep)
# predict the noise residual
noise_pred = self.unet(latent_model_input, timestep, encoder_hidden_states=text_embeddings).sample
if isinstance(self.scheduler, (PNDMScheduler, DDIMScheduler, DPMSolverMultistepScheduler)):
alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
beta_prod_t = 1 - alpha_prod_t
# compute predicted original sample from predicted noise also called
# "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
fac = torch.sqrt(beta_prod_t)
sample = pred_original_sample * (fac) + latents * (1 - fac)
elif isinstance(self.scheduler, LMSDiscreteScheduler):
sigma = self.scheduler.sigmas[index]
sample = latents - sigma * noise_pred
else:
raise ValueError(f"scheduler type {type(self.scheduler)} not supported")
sample = 1 / self.vae.config.scaling_factor * sample
image = self.vae.decode(sample).sample
image = (image / 2 + 0.5).clamp(0, 1)
if use_cutouts:
image = self.make_cutouts(image, num_cutouts)
else:
image = transforms.Resize(self.cut_out_size)(image)
image = self.normalize(image).to(latents.dtype)
image_embeddings_clip = self.clip_model.get_image_features(image)
image_embeddings_clip = image_embeddings_clip / image_embeddings_clip.norm(p=2, dim=-1, keepdim=True)
if use_cutouts:
dists = spherical_dist_loss(image_embeddings_clip, text_embeddings_clip)
dists = dists.view([num_cutouts, sample.shape[0], -1])
loss = dists.sum(2).mean(0).sum() * clip_guidance_scale
else:
loss = spherical_dist_loss(image_embeddings_clip, text_embeddings_clip).mean() * clip_guidance_scale
grads = -torch.autograd.grad(loss, latents)[0]
if isinstance(self.scheduler, LMSDiscreteScheduler):
latents = latents.detach() + grads * (sigma**2)
noise_pred = noise_pred_original
else:
noise_pred = noise_pred_original - torch.sqrt(beta_prod_t) * grads
return noise_pred, latents
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
height: Optional[int] = 512,
width: Optional[int] = 512,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
clip_guidance_scale: Optional[float] = 100,
clip_prompt: Optional[Union[str, List[str]]] = None,
num_cutouts: Optional[int] = 4,
use_cutouts: Optional[bool] = True,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
):
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
# get prompt text embeddings
text_input = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_embeddings = self.text_encoder(text_input.input_ids.to(self.device))[0]
# duplicate text embeddings for each generation per prompt
text_embeddings = text_embeddings.repeat_interleave(num_images_per_prompt, dim=0)
if clip_guidance_scale > 0:
if clip_prompt is not None:
clip_text_input = self.tokenizer(
clip_prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
).input_ids.to(self.device)
else:
clip_text_input = text_input.input_ids.to(self.device)
text_embeddings_clip = self.clip_model.get_text_features(clip_text_input)
text_embeddings_clip = text_embeddings_clip / text_embeddings_clip.norm(p=2, dim=-1, keepdim=True)
# duplicate text embeddings clip for each generation per prompt
text_embeddings_clip = text_embeddings_clip.repeat_interleave(num_images_per_prompt, dim=0)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
max_length = text_input.input_ids.shape[-1]
uncond_input = self.tokenizer([""], padding="max_length", max_length=max_length, return_tensors="pt")
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# duplicate unconditional embeddings for each generation per prompt
uncond_embeddings = uncond_embeddings.repeat_interleave(num_images_per_prompt, dim=0)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# Unlike in other pipelines, latents need to be generated in the target device
# for 1-to-1 results reproducibility with the CompVis implementation.
# However this currently doesn't work in `mps`.
latents_shape = (batch_size * num_images_per_prompt, self.unet.config.in_channels, height // 8, width // 8)
latents_dtype = text_embeddings.dtype
if latents is None:
if self.device.type == "mps":
# randn does not work reproducibly on mps
latents = torch.randn(latents_shape, generator=generator, device="cpu", dtype=latents_dtype).to(
self.device
)
else:
latents = torch.randn(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
else:
if latents.shape != latents_shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
latents = latents.to(self.device)
# set timesteps
accepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())
extra_set_kwargs = {}
if accepts_offset:
extra_set_kwargs["offset"] = 1
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
# Some schedulers like PNDM have timesteps as arrays
# It's more optimized to move all timesteps to correct device beforehand
timesteps_tensor = self.scheduler.timesteps.to(self.device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform classifier free guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# perform clip guidance
if clip_guidance_scale > 0:
text_embeddings_for_guidance = (
text_embeddings.chunk(2)[1] if do_classifier_free_guidance else text_embeddings
)
noise_pred, latents = self.cond_fn(
latents,
t,
i,
text_embeddings_for_guidance,
noise_pred,
text_embeddings_clip,
clip_guidance_scale,
num_cutouts,
use_cutouts,
)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# scale and decode the image latents with vae
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, None)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=None)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/text_inpainting.py
|
from typing import Callable, List, Optional, Union
import PIL.Image
import torch
from transformers import (
CLIPImageProcessor,
CLIPSegForImageSegmentation,
CLIPSegProcessor,
CLIPTextModel,
CLIPTokenizer,
)
from diffusers import DiffusionPipeline
from diffusers.configuration_utils import FrozenDict
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion import StableDiffusionInpaintPipeline
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
from diffusers.utils import deprecate, is_accelerate_available, logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class TextInpainting(DiffusionPipeline):
r"""
Pipeline for text based inpainting using Stable Diffusion.
Uses CLIPSeg to get a mask from the given text, then calls the Inpainting pipeline with the generated mask
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
segmentation_model ([`CLIPSegForImageSegmentation`]):
CLIPSeg Model to generate mask from the given text. Please refer to the [model card]() for details.
segmentation_processor ([`CLIPSegProcessor`]):
CLIPSeg processor to get image, text features to translate prompt to English, if necessary. Please refer to the
[model card](https://huggingface.co/docs/transformers/model_doc/clipseg) for details.
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latens. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
segmentation_model: CLIPSegForImageSegmentation,
segmentation_processor: CLIPSegProcessor,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if hasattr(scheduler.config, "skip_prk_steps") and scheduler.config.skip_prk_steps is False:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} has not set the configuration"
" `skip_prk_steps`. `skip_prk_steps` should be set to True in the configuration file. Please make"
" sure to update the config accordingly as not setting `skip_prk_steps` in the config might lead to"
" incorrect results in future versions. If you have downloaded this checkpoint from the Hugging Face"
" Hub, it would be very nice if you could open a Pull request for the"
" `scheduler/scheduler_config.json` file"
)
deprecate("skip_prk_steps not set", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["skip_prk_steps"] = True
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
self.register_modules(
segmentation_model=segmentation_model,
segmentation_processor=segmentation_processor,
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
r"""
Enable sliced attention computation.
When this option is enabled, the attention module will split the input tensor in slices, to compute attention
in several steps. This is useful to save some memory in exchange for a small speed decrease.
Args:
slice_size (`str` or `int`, *optional*, defaults to `"auto"`):
When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
a number is provided, uses as many slices as `attention_head_dim // slice_size`. In this case,
`attention_head_dim` must be a multiple of `slice_size`.
"""
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
slice_size = self.unet.config.attention_head_dim // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
r"""
Disable sliced attention computation. If `enable_attention_slicing` was previously invoked, this method will go
back to computing attention in one step.
"""
# set slice_size = `None` to disable `attention slicing`
self.enable_attention_slicing(None)
def enable_sequential_cpu_offload(self):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
`torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
"""
if is_accelerate_available():
from accelerate import cpu_offload
else:
raise ImportError("Please install accelerate via `pip install accelerate`")
device = torch.device("cuda")
for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.safety_checker]:
if cpu_offloaded_model is not None:
cpu_offload(cpu_offloaded_model, device)
@property
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if self.device != torch.device("meta") or not hasattr(self.unet, "_hf_hook"):
return self.device
for module in self.unet.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
image: Union[torch.FloatTensor, PIL.Image.Image],
text: str,
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
**kwargs,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
text (`str``):
The text to use to generate the mask.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# We use the input text to generate the mask
inputs = self.segmentation_processor(
text=[text], images=[image], padding="max_length", return_tensors="pt"
).to(self.device)
outputs = self.segmentation_model(**inputs)
mask = torch.sigmoid(outputs.logits).cpu().detach().unsqueeze(-1).numpy()
mask_pil = self.numpy_to_pil(mask)[0].resize(image.size)
# Run inpainting pipeline with the generated mask
inpainting_pipeline = StableDiffusionInpaintPipeline(
vae=self.vae,
text_encoder=self.text_encoder,
tokenizer=self.tokenizer,
unet=self.unet,
scheduler=self.scheduler,
safety_checker=self.safety_checker,
feature_extractor=self.feature_extractor,
)
return inpainting_pipeline(
prompt=prompt,
image=image,
mask_image=mask_pil,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
latents=latents,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_diffusion_ipex.py
|
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
from typing import Any, Callable, Dict, List, Optional, Union
import intel_extension_for_pytorch as ipex
import torch
from packaging import version
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
from diffusers.configuration_utils import FrozenDict
from diffusers.loaders import LoraLoaderMixin, TextualInversionLoaderMixin
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
deprecate,
is_accelerate_available,
is_accelerate_version,
logging,
replace_example_docstring,
)
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
>>> from diffusers import StableDiffusionPipeline
>>> pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", custom_pipeline="stable_diffusion_ipex")
>>> # For Float32
>>> pipe.prepare_for_ipex(prompt, dtype=torch.float32, height=512, width=512) #value of image height/width should be consistent with the pipeline inference
>>> # For BFloat16
>>> pipe.prepare_for_ipex(prompt, dtype=torch.bfloat16, height=512, width=512) #value of image height/width should be consistent with the pipeline inference
>>> prompt = "a photo of an astronaut riding a horse on mars"
>>> # For Float32
>>> image = pipe(prompt, num_inference_steps=num_inference_steps, height=512, width=512).images[0] #value of image height/width should be consistent with 'prepare_for_ipex()'
>>> # For BFloat16
>>> with torch.cpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
>>> image = pipe(prompt, num_inference_steps=num_inference_steps, height=512, width=512).images[0] #value of image height/width should be consistent with 'prepare_for_ipex()'
```
"""
class StableDiffusionIPEXPipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin):
r"""
Pipeline for text-to-image generation using Stable Diffusion on IPEX.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPFeatureExtractor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPFeatureExtractor,
requires_safety_checker: bool = True,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
" `clip_sample` should be set to False in the configuration file. Please make sure to update the"
" config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
" future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
" nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
)
deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["clip_sample"] = False
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
version.parse(unet.config._diffusers_version).base_version
) < version.parse("0.9.0.dev0")
is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
deprecation_message = (
"The configuration file of the unet has set the default `sample_size` to smaller than"
" 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
" following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
" CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
" \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
" configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
" in the config might lead to incorrect results in future versions. If you have downloaded this"
" checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
" the `unet/config.json` file"
)
deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(unet.config)
new_config["sample_size"] = 64
unet._internal_dict = FrozenDict(new_config)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.register_to_config(requires_safety_checker=requires_safety_checker)
def get_input_example(self, prompt, height=None, width=None, guidance_scale=7.5, num_images_per_prompt=1):
prompt_embeds = None
negative_prompt_embeds = None
negative_prompt = None
callback_steps = 1
generator = None
latents = None
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt, height, width, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
device = "cpu"
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
# 5. Prepare latent variables
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
self.unet.in_channels,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
dummy = torch.ones(1, dtype=torch.int32)
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, dummy)
unet_input_example = (latent_model_input, dummy, prompt_embeds)
vae_decoder_input_example = latents
return unet_input_example, vae_decoder_input_example
def prepare_for_ipex(self, promt, dtype=torch.float32, height=None, width=None, guidance_scale=7.5):
self.unet = self.unet.to(memory_format=torch.channels_last)
self.vae.decoder = self.vae.decoder.to(memory_format=torch.channels_last)
self.text_encoder = self.text_encoder.to(memory_format=torch.channels_last)
if self.safety_checker is not None:
self.safety_checker = self.safety_checker.to(memory_format=torch.channels_last)
unet_input_example, vae_decoder_input_example = self.get_input_example(promt, height, width, guidance_scale)
# optimize with ipex
if dtype == torch.bfloat16:
self.unet = ipex.optimize(self.unet.eval(), dtype=torch.bfloat16, inplace=True)
self.vae.decoder = ipex.optimize(self.vae.decoder.eval(), dtype=torch.bfloat16, inplace=True)
self.text_encoder = ipex.optimize(self.text_encoder.eval(), dtype=torch.bfloat16, inplace=True)
if self.safety_checker is not None:
self.safety_checker = ipex.optimize(self.safety_checker.eval(), dtype=torch.bfloat16, inplace=True)
elif dtype == torch.float32:
self.unet = ipex.optimize(
self.unet.eval(),
dtype=torch.float32,
inplace=True,
weights_prepack=True,
auto_kernel_selection=False,
)
self.vae.decoder = ipex.optimize(
self.vae.decoder.eval(),
dtype=torch.float32,
inplace=True,
weights_prepack=True,
auto_kernel_selection=False,
)
self.text_encoder = ipex.optimize(
self.text_encoder.eval(),
dtype=torch.float32,
inplace=True,
weights_prepack=True,
auto_kernel_selection=False,
)
if self.safety_checker is not None:
self.safety_checker = ipex.optimize(
self.safety_checker.eval(),
dtype=torch.float32,
inplace=True,
weights_prepack=True,
auto_kernel_selection=False,
)
else:
raise ValueError(" The value of 'dtype' should be 'torch.bfloat16' or 'torch.float32' !")
# trace unet model to get better performance on IPEX
with torch.cpu.amp.autocast(enabled=dtype == torch.bfloat16), torch.no_grad():
unet_trace_model = torch.jit.trace(self.unet, unet_input_example, check_trace=False, strict=False)
unet_trace_model = torch.jit.freeze(unet_trace_model)
self.unet.forward = unet_trace_model.forward
# trace vae.decoder model to get better performance on IPEX
with torch.cpu.amp.autocast(enabled=dtype == torch.bfloat16), torch.no_grad():
ave_decoder_trace_model = torch.jit.trace(
self.vae.decoder, vae_decoder_input_example, check_trace=False, strict=False
)
ave_decoder_trace_model = torch.jit.freeze(ave_decoder_trace_model)
self.vae.decoder.forward = ave_decoder_trace_model.forward
def enable_vae_slicing(self):
r"""
Enable sliced VAE decoding.
When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
steps. This is useful to save some memory and allow larger batch sizes.
"""
self.vae.enable_slicing()
def disable_vae_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
computing decoding in one step.
"""
self.vae.disable_slicing()
def enable_vae_tiling(self):
r"""
Enable tiled VAE decoding.
When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
"""
self.vae.enable_tiling()
def disable_vae_tiling(self):
r"""
Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
computing decoding in one step.
"""
self.vae.disable_tiling()
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
`torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
Note that offloading happens on a submodule basis. Memory savings are higher than with
`enable_model_cpu_offload`, but performance is lower.
"""
if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
from accelerate import cpu_offload
else:
raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
device = torch.device(f"cuda:{gpu_id}")
if self.device.type != "cpu":
self.to("cpu", silence_dtype_warnings=True)
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
cpu_offload(cpu_offloaded_model, device)
if self.safety_checker is not None:
cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
def enable_model_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
"""
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
from accelerate import cpu_offload_with_hook
else:
raise ImportError("`enable_model_offload` requires `accelerate v0.17.0` or higher.")
device = torch.device(f"cuda:{gpu_id}")
if self.device.type != "cpu":
self.to("cpu", silence_dtype_warnings=True)
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
hook = None
for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
if self.safety_checker is not None:
_, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
# We'll offload the last model manually.
self.final_offload_hook = hook
@property
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if not hasattr(self.unet, "_hf_hook"):
return self.device
for module in self.unet.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
"""
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# textual inversion: procecss multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
prompt_embeds = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
# textual inversion: procecss multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
else:
has_nsfw_concept = None
return image, has_nsfw_concept
def decode_latents(self, latents):
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_inputs(
self,
prompt,
height,
width,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt, height, width, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 5. Prepare latent variables
num_channels_latents = self.unet.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=prompt_embeds)["sample"]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if output_type == "latent":
image = latents
has_nsfw_concept = None
elif output_type == "pil":
# 8. Post-processing
image = self.decode_latents(latents)
# 9. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
# 10. Convert to PIL
image = self.numpy_to_pil(image)
else:
# 8. Post-processing
image = self.decode_latents(latents)
# 9. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/mixture_canvas.py
|
import re
from copy import deepcopy
from dataclasses import asdict, dataclass
from enum import Enum
from typing import List, Optional, Union
import numpy as np
import torch
from numpy import exp, pi, sqrt
from torchvision.transforms.functional import resize
from tqdm.auto import tqdm
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
def preprocess_image(image):
from PIL import Image
"""Preprocess an input image
Same as
https://github.com/huggingface/diffusers/blob/1138d63b519e37f0ce04e027b9f4a3261d27c628/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py#L44
"""
w, h = image.size
w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
image = image.resize((w, h), resample=Image.LANCZOS)
image = np.array(image).astype(np.float32) / 255.0
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
return 2.0 * image - 1.0
@dataclass
class CanvasRegion:
"""Class defining a rectangular region in the canvas"""
row_init: int # Region starting row in pixel space (included)
row_end: int # Region end row in pixel space (not included)
col_init: int # Region starting column in pixel space (included)
col_end: int # Region end column in pixel space (not included)
region_seed: int = None # Seed for random operations in this region
noise_eps: float = 0.0 # Deviation of a zero-mean gaussian noise to be applied over the latents in this region. Useful for slightly "rerolling" latents
def __post_init__(self):
# Initialize arguments if not specified
if self.region_seed is None:
self.region_seed = np.random.randint(9999999999)
# Check coordinates are non-negative
for coord in [self.row_init, self.row_end, self.col_init, self.col_end]:
if coord < 0:
raise ValueError(
f"A CanvasRegion must be defined with non-negative indices, found ({self.row_init}, {self.row_end}, {self.col_init}, {self.col_end})"
)
# Check coordinates are divisible by 8, else we end up with nasty rounding error when mapping to latent space
for coord in [self.row_init, self.row_end, self.col_init, self.col_end]:
if coord // 8 != coord / 8:
raise ValueError(
f"A CanvasRegion must be defined with locations divisible by 8, found ({self.row_init}-{self.row_end}, {self.col_init}-{self.col_end})"
)
# Check noise eps is non-negative
if self.noise_eps < 0:
raise ValueError(f"A CanvasRegion must be defined noises eps non-negative, found {self.noise_eps}")
# Compute coordinates for this region in latent space
self.latent_row_init = self.row_init // 8
self.latent_row_end = self.row_end // 8
self.latent_col_init = self.col_init // 8
self.latent_col_end = self.col_end // 8
@property
def width(self):
return self.col_end - self.col_init
@property
def height(self):
return self.row_end - self.row_init
def get_region_generator(self, device="cpu"):
"""Creates a torch.Generator based on the random seed of this region"""
# Initialize region generator
return torch.Generator(device).manual_seed(self.region_seed)
@property
def __dict__(self):
return asdict(self)
class MaskModes(Enum):
"""Modes in which the influence of diffuser is masked"""
CONSTANT = "constant"
GAUSSIAN = "gaussian"
QUARTIC = "quartic" # See https://en.wikipedia.org/wiki/Kernel_(statistics)
@dataclass
class DiffusionRegion(CanvasRegion):
"""Abstract class defining a region where some class of diffusion process is acting"""
pass
@dataclass
class Text2ImageRegion(DiffusionRegion):
"""Class defining a region where a text guided diffusion process is acting"""
prompt: str = "" # Text prompt guiding the diffuser in this region
guidance_scale: float = 7.5 # Guidance scale of the diffuser in this region. If None, randomize
mask_type: MaskModes = MaskModes.GAUSSIAN.value # Kind of weight mask applied to this region
mask_weight: float = 1.0 # Global weights multiplier of the mask
tokenized_prompt = None # Tokenized prompt
encoded_prompt = None # Encoded prompt
def __post_init__(self):
super().__post_init__()
# Mask weight cannot be negative
if self.mask_weight < 0:
raise ValueError(
f"A Text2ImageRegion must be defined with non-negative mask weight, found {self.mask_weight}"
)
# Mask type must be an actual known mask
if self.mask_type not in [e.value for e in MaskModes]:
raise ValueError(
f"A Text2ImageRegion was defined with mask {self.mask_type}, which is not an accepted mask ({[e.value for e in MaskModes]})"
)
# Randomize arguments if given as None
if self.guidance_scale is None:
self.guidance_scale = np.random.randint(5, 30)
# Clean prompt
self.prompt = re.sub(" +", " ", self.prompt).replace("\n", " ")
def tokenize_prompt(self, tokenizer):
"""Tokenizes the prompt for this diffusion region using a given tokenizer"""
self.tokenized_prompt = tokenizer(
self.prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
def encode_prompt(self, text_encoder, device):
"""Encodes the previously tokenized prompt for this diffusion region using a given encoder"""
assert self.tokenized_prompt is not None, ValueError(
"Prompt in diffusion region must be tokenized before encoding"
)
self.encoded_prompt = text_encoder(self.tokenized_prompt.input_ids.to(device))[0]
@dataclass
class Image2ImageRegion(DiffusionRegion):
"""Class defining a region where an image guided diffusion process is acting"""
reference_image: torch.FloatTensor = None
strength: float = 0.8 # Strength of the image
def __post_init__(self):
super().__post_init__()
if self.reference_image is None:
raise ValueError("Must provide a reference image when creating an Image2ImageRegion")
if self.strength < 0 or self.strength > 1:
raise ValueError(f"The value of strength should in [0.0, 1.0] but is {self.strength}")
# Rescale image to region shape
self.reference_image = resize(self.reference_image, size=[self.height, self.width])
def encode_reference_image(self, encoder, device, generator, cpu_vae=False):
"""Encodes the reference image for this Image2Image region into the latent space"""
# Place encoder in CPU or not following the parameter cpu_vae
if cpu_vae:
# Note here we use mean instead of sample, to avoid moving also generator to CPU, which is troublesome
self.reference_latents = encoder.cpu().encode(self.reference_image).latent_dist.mean.to(device)
else:
self.reference_latents = encoder.encode(self.reference_image.to(device)).latent_dist.sample(
generator=generator
)
self.reference_latents = 0.18215 * self.reference_latents
@property
def __dict__(self):
# This class requires special casting to dict because of the reference_image tensor. Otherwise it cannot be casted to JSON
# Get all basic fields from parent class
super_fields = {key: getattr(self, key) for key in DiffusionRegion.__dataclass_fields__.keys()}
# Pack other fields
return {**super_fields, "reference_image": self.reference_image.cpu().tolist(), "strength": self.strength}
class RerollModes(Enum):
"""Modes in which the reroll regions operate"""
RESET = "reset" # Completely reset the random noise in the region
EPSILON = "epsilon" # Alter slightly the latents in the region
@dataclass
class RerollRegion(CanvasRegion):
"""Class defining a rectangular canvas region in which initial latent noise will be rerolled"""
reroll_mode: RerollModes = RerollModes.RESET.value
@dataclass
class MaskWeightsBuilder:
"""Auxiliary class to compute a tensor of weights for a given diffusion region"""
latent_space_dim: int # Size of the U-net latent space
nbatch: int = 1 # Batch size in the U-net
def compute_mask_weights(self, region: DiffusionRegion) -> torch.tensor:
"""Computes a tensor of weights for a given diffusion region"""
MASK_BUILDERS = {
MaskModes.CONSTANT.value: self._constant_weights,
MaskModes.GAUSSIAN.value: self._gaussian_weights,
MaskModes.QUARTIC.value: self._quartic_weights,
}
return MASK_BUILDERS[region.mask_type](region)
def _constant_weights(self, region: DiffusionRegion) -> torch.tensor:
"""Computes a tensor of constant for a given diffusion region"""
latent_width = region.latent_col_end - region.latent_col_init
latent_height = region.latent_row_end - region.latent_row_init
return torch.ones(self.nbatch, self.latent_space_dim, latent_height, latent_width) * region.mask_weight
def _gaussian_weights(self, region: DiffusionRegion) -> torch.tensor:
"""Generates a gaussian mask of weights for tile contributions"""
latent_width = region.latent_col_end - region.latent_col_init
latent_height = region.latent_row_end - region.latent_row_init
var = 0.01
midpoint = (latent_width - 1) / 2 # -1 because index goes from 0 to latent_width - 1
x_probs = [
exp(-(x - midpoint) * (x - midpoint) / (latent_width * latent_width) / (2 * var)) / sqrt(2 * pi * var)
for x in range(latent_width)
]
midpoint = (latent_height - 1) / 2
y_probs = [
exp(-(y - midpoint) * (y - midpoint) / (latent_height * latent_height) / (2 * var)) / sqrt(2 * pi * var)
for y in range(latent_height)
]
weights = np.outer(y_probs, x_probs) * region.mask_weight
return torch.tile(torch.tensor(weights), (self.nbatch, self.latent_space_dim, 1, 1))
def _quartic_weights(self, region: DiffusionRegion) -> torch.tensor:
"""Generates a quartic mask of weights for tile contributions
The quartic kernel has bounded support over the diffusion region, and a smooth decay to the region limits.
"""
quartic_constant = 15.0 / 16.0
support = (np.array(range(region.latent_col_init, region.latent_col_end)) - region.latent_col_init) / (
region.latent_col_end - region.latent_col_init - 1
) * 1.99 - (1.99 / 2.0)
x_probs = quartic_constant * np.square(1 - np.square(support))
support = (np.array(range(region.latent_row_init, region.latent_row_end)) - region.latent_row_init) / (
region.latent_row_end - region.latent_row_init - 1
) * 1.99 - (1.99 / 2.0)
y_probs = quartic_constant * np.square(1 - np.square(support))
weights = np.outer(y_probs, x_probs) * region.mask_weight
return torch.tile(torch.tensor(weights), (self.nbatch, self.latent_space_dim, 1, 1))
class StableDiffusionCanvasPipeline(DiffusionPipeline):
"""Stable Diffusion pipeline that mixes several diffusers in the same canvas"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPFeatureExtractor,
):
super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
def decode_latents(self, latents, cpu_vae=False):
"""Decodes a given array of latents into pixel space"""
# scale and decode the image latents with vae
if cpu_vae:
lat = deepcopy(latents).cpu()
vae = deepcopy(self.vae).cpu()
else:
lat = latents
vae = self.vae
lat = 1 / 0.18215 * lat
image = vae.decode(lat).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
return self.numpy_to_pil(image)
def get_latest_timestep_img2img(self, num_inference_steps, strength):
"""Finds the latest timesteps where an img2img strength does not impose latents anymore"""
# get the original timestep using init_timestep
offset = self.scheduler.config.get("steps_offset", 0)
init_timestep = int(num_inference_steps * (1 - strength)) + offset
init_timestep = min(init_timestep, num_inference_steps)
t_start = min(max(num_inference_steps - init_timestep + offset, 0), num_inference_steps - 1)
latest_timestep = self.scheduler.timesteps[t_start]
return latest_timestep
@torch.no_grad()
def __call__(
self,
canvas_height: int,
canvas_width: int,
regions: List[DiffusionRegion],
num_inference_steps: Optional[int] = 50,
seed: Optional[int] = 12345,
reroll_regions: Optional[List[RerollRegion]] = None,
cpu_vae: Optional[bool] = False,
decode_steps: Optional[bool] = False,
):
if reroll_regions is None:
reroll_regions = []
batch_size = 1
if decode_steps:
steps_images = []
# Prepare scheduler
self.scheduler.set_timesteps(num_inference_steps, device=self.device)
# Split diffusion regions by their kind
text2image_regions = [region for region in regions if isinstance(region, Text2ImageRegion)]
image2image_regions = [region for region in regions if isinstance(region, Image2ImageRegion)]
# Prepare text embeddings
for region in text2image_regions:
region.tokenize_prompt(self.tokenizer)
region.encode_prompt(self.text_encoder, self.device)
# Create original noisy latents using the timesteps
latents_shape = (batch_size, self.unet.config.in_channels, canvas_height // 8, canvas_width // 8)
generator = torch.Generator(self.device).manual_seed(seed)
init_noise = torch.randn(latents_shape, generator=generator, device=self.device)
# Reset latents in seed reroll regions, if requested
for region in reroll_regions:
if region.reroll_mode == RerollModes.RESET.value:
region_shape = (
latents_shape[0],
latents_shape[1],
region.latent_row_end - region.latent_row_init,
region.latent_col_end - region.latent_col_init,
)
init_noise[
:,
:,
region.latent_row_init : region.latent_row_end,
region.latent_col_init : region.latent_col_end,
] = torch.randn(region_shape, generator=region.get_region_generator(self.device), device=self.device)
# Apply epsilon noise to regions: first diffusion regions, then reroll regions
all_eps_rerolls = regions + [r for r in reroll_regions if r.reroll_mode == RerollModes.EPSILON.value]
for region in all_eps_rerolls:
if region.noise_eps > 0:
region_noise = init_noise[
:,
:,
region.latent_row_init : region.latent_row_end,
region.latent_col_init : region.latent_col_end,
]
eps_noise = (
torch.randn(
region_noise.shape, generator=region.get_region_generator(self.device), device=self.device
)
* region.noise_eps
)
init_noise[
:,
:,
region.latent_row_init : region.latent_row_end,
region.latent_col_init : region.latent_col_end,
] += eps_noise
# scale the initial noise by the standard deviation required by the scheduler
latents = init_noise * self.scheduler.init_noise_sigma
# Get unconditional embeddings for classifier free guidance in text2image regions
for region in text2image_regions:
max_length = region.tokenized_prompt.input_ids.shape[-1]
uncond_input = self.tokenizer(
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
region.encoded_prompt = torch.cat([uncond_embeddings, region.encoded_prompt])
# Prepare image latents
for region in image2image_regions:
region.encode_reference_image(self.vae, device=self.device, generator=generator)
# Prepare mask of weights for each region
mask_builder = MaskWeightsBuilder(latent_space_dim=self.unet.config.in_channels, nbatch=batch_size)
mask_weights = [mask_builder.compute_mask_weights(region).to(self.device) for region in text2image_regions]
# Diffusion timesteps
for i, t in tqdm(enumerate(self.scheduler.timesteps)):
# Diffuse each region
noise_preds_regions = []
# text2image regions
for region in text2image_regions:
region_latents = latents[
:,
:,
region.latent_row_init : region.latent_row_end,
region.latent_col_init : region.latent_col_end,
]
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([region_latents] * 2)
# scale model input following scheduler rules
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=region.encoded_prompt)["sample"]
# perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred_region = noise_pred_uncond + region.guidance_scale * (noise_pred_text - noise_pred_uncond)
noise_preds_regions.append(noise_pred_region)
# Merge noise predictions for all tiles
noise_pred = torch.zeros(latents.shape, device=self.device)
contributors = torch.zeros(latents.shape, device=self.device)
# Add each tile contribution to overall latents
for region, noise_pred_region, mask_weights_region in zip(
text2image_regions, noise_preds_regions, mask_weights
):
noise_pred[
:,
:,
region.latent_row_init : region.latent_row_end,
region.latent_col_init : region.latent_col_end,
] += noise_pred_region * mask_weights_region
contributors[
:,
:,
region.latent_row_init : region.latent_row_end,
region.latent_col_init : region.latent_col_end,
] += mask_weights_region
# Average overlapping areas with more than 1 contributor
noise_pred /= contributors
noise_pred = torch.nan_to_num(
noise_pred
) # Replace NaNs by zeros: NaN can appear if a position is not covered by any DiffusionRegion
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents).prev_sample
# Image2Image regions: override latents generated by the scheduler
for region in image2image_regions:
influence_step = self.get_latest_timestep_img2img(num_inference_steps, region.strength)
# Only override in the timesteps before the last influence step of the image (given by its strength)
if t > influence_step:
timestep = t.repeat(batch_size)
region_init_noise = init_noise[
:,
:,
region.latent_row_init : region.latent_row_end,
region.latent_col_init : region.latent_col_end,
]
region_latents = self.scheduler.add_noise(region.reference_latents, region_init_noise, timestep)
latents[
:,
:,
region.latent_row_init : region.latent_row_end,
region.latent_col_init : region.latent_col_end,
] = region_latents
if decode_steps:
steps_images.append(self.decode_latents(latents, cpu_vae))
# scale and decode the image latents with vae
image = self.decode_latents(latents, cpu_vae)
output = {"images": image}
if decode_steps:
output = {**output, "steps_images": steps_images}
return output
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/speech_to_image_diffusion.py
|
import inspect
from typing import Callable, List, Optional, Union
import torch
from transformers import (
CLIPImageProcessor,
CLIPTextModel,
CLIPTokenizer,
WhisperForConditionalGeneration,
WhisperProcessor,
)
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DiffusionPipeline,
LMSDiscreteScheduler,
PNDMScheduler,
UNet2DConditionModel,
)
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.utils import logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class SpeechToImagePipeline(DiffusionPipeline):
def __init__(
self,
speech_model: WhisperForConditionalGeneration,
speech_processor: WhisperProcessor,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
):
super().__init__()
if safety_checker is None:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
self.register_modules(
speech_model=speech_model,
speech_processor=speech_processor,
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
feature_extractor=feature_extractor,
)
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
if slice_size == "auto":
slice_size = self.unet.config.attention_head_dim // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
self.enable_attention_slicing(None)
@torch.no_grad()
def __call__(
self,
audio,
sampling_rate=16_000,
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
**kwargs,
):
inputs = self.speech_processor.feature_extractor(
audio, return_tensors="pt", sampling_rate=sampling_rate
).input_features.to(self.device)
predicted_ids = self.speech_model.generate(inputs, max_length=480_000)
prompt = self.speech_processor.tokenizer.batch_decode(predicted_ids, skip_special_tokens=True, normalize=True)[
0
]
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
text_embeddings = self.text_encoder(text_input_ids.to(self.device))[0]
# duplicate text embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = text_input_ids.shape[-1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = uncond_embeddings.repeat(1, num_images_per_prompt, 1)
uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# Unlike in other pipelines, latents need to be generated in the target device
# for 1-to-1 results reproducibility with the CompVis implementation.
# However this currently doesn't work in `mps`.
latents_shape = (batch_size * num_images_per_prompt, self.unet.config.in_channels, height // 8, width // 8)
latents_dtype = text_embeddings.dtype
if latents is None:
if self.device.type == "mps":
# randn does not exist on mps
latents = torch.randn(latents_shape, generator=generator, device="cpu", dtype=latents_dtype).to(
self.device
)
else:
latents = torch.randn(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
else:
if latents.shape != latents_shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
latents = latents.to(self.device)
# set timesteps
self.scheduler.set_timesteps(num_inference_steps)
# Some schedulers like PNDM have timesteps as arrays
# It's more optimized to move all timesteps to correct device beforehand
timesteps_tensor = self.scheduler.timesteps.to(self.device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return image
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=None)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_diffusion_controlnet_img2img.py
|
# Inspired by: https://github.com/haofanwang/ControlNet-for-Diffusers/
import inspect
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, ControlNetModel, DiffusionPipeline, UNet2DConditionModel, logging
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput, StableDiffusionSafetyChecker
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
PIL_INTERPOLATION,
is_accelerate_available,
is_accelerate_version,
replace_example_docstring,
)
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import numpy as np
>>> import torch
>>> from PIL import Image
>>> from diffusers import ControlNetModel, UniPCMultistepScheduler
>>> from diffusers.utils import load_image
>>> input_image = load_image("https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png")
>>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
>>> pipe_controlnet = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
controlnet=controlnet,
safety_checker=None,
torch_dtype=torch.float16
)
>>> pipe_controlnet.scheduler = UniPCMultistepScheduler.from_config(pipe_controlnet.scheduler.config)
>>> pipe_controlnet.enable_xformers_memory_efficient_attention()
>>> pipe_controlnet.enable_model_cpu_offload()
# using image with edges for our canny controlnet
>>> control_image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/vermeer_canny_edged.png")
>>> result_img = pipe_controlnet(controlnet_conditioning_image=control_image,
image=input_image,
prompt="an android robot, cyberpank, digitl art masterpiece",
num_inference_steps=20).images[0]
>>> result_img.show()
```
"""
def prepare_image(image):
if isinstance(image, torch.Tensor):
# Batch single image
if image.ndim == 3:
image = image.unsqueeze(0)
image = image.to(dtype=torch.float32)
else:
# preprocess image
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
return image
def prepare_controlnet_conditioning_image(
controlnet_conditioning_image,
width,
height,
batch_size,
num_images_per_prompt,
device,
dtype,
do_classifier_free_guidance,
):
if not isinstance(controlnet_conditioning_image, torch.Tensor):
if isinstance(controlnet_conditioning_image, PIL.Image.Image):
controlnet_conditioning_image = [controlnet_conditioning_image]
if isinstance(controlnet_conditioning_image[0], PIL.Image.Image):
controlnet_conditioning_image = [
np.array(i.resize((width, height), resample=PIL_INTERPOLATION["lanczos"]))[None, :]
for i in controlnet_conditioning_image
]
controlnet_conditioning_image = np.concatenate(controlnet_conditioning_image, axis=0)
controlnet_conditioning_image = np.array(controlnet_conditioning_image).astype(np.float32) / 255.0
controlnet_conditioning_image = controlnet_conditioning_image.transpose(0, 3, 1, 2)
controlnet_conditioning_image = torch.from_numpy(controlnet_conditioning_image)
elif isinstance(controlnet_conditioning_image[0], torch.Tensor):
controlnet_conditioning_image = torch.cat(controlnet_conditioning_image, dim=0)
image_batch_size = controlnet_conditioning_image.shape[0]
if image_batch_size == 1:
repeat_by = batch_size
else:
# image batch size is the same as prompt batch size
repeat_by = num_images_per_prompt
controlnet_conditioning_image = controlnet_conditioning_image.repeat_interleave(repeat_by, dim=0)
controlnet_conditioning_image = controlnet_conditioning_image.to(device=device, dtype=dtype)
if do_classifier_free_guidance:
controlnet_conditioning_image = torch.cat([controlnet_conditioning_image] * 2)
return controlnet_conditioning_image
class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
"""
Inspired by: https://github.com/haofanwang/ControlNet-for-Diffusers/
"""
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
if isinstance(controlnet, (list, tuple)):
controlnet = MultiControlNetModel(controlnet)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
controlnet=controlnet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.register_to_config(requires_safety_checker=requires_safety_checker)
def enable_vae_slicing(self):
r"""
Enable sliced VAE decoding.
When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
steps. This is useful to save some memory and allow larger batch sizes.
"""
self.vae.enable_slicing()
def disable_vae_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
computing decoding in one step.
"""
self.vae.disable_slicing()
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
`torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
Note that offloading happens on a submodule basis. Memory savings are higher than with
`enable_model_cpu_offload`, but performance is lower.
"""
if is_accelerate_available():
from accelerate import cpu_offload
else:
raise ImportError("Please install accelerate via `pip install accelerate`")
device = torch.device(f"cuda:{gpu_id}")
for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.controlnet]:
cpu_offload(cpu_offloaded_model, device)
if self.safety_checker is not None:
cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
def enable_model_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
"""
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
from accelerate import cpu_offload_with_hook
else:
raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
device = torch.device(f"cuda:{gpu_id}")
hook = None
for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
if self.safety_checker is not None:
# the safety checker can offload the vae again
_, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
# control net hook has be manually offloaded as it alternates with unet
cpu_offload_with_hook(self.controlnet, device)
# We'll offload the last model manually.
self.final_offload_hook = hook
@property
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if not hasattr(self.unet, "_hf_hook"):
return self.device
for module in self.unet.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
"""
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
prompt_embeds = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
else:
has_nsfw_concept = None
return image, has_nsfw_concept
def decode_latents(self, latents):
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_controlnet_conditioning_image(self, image, prompt, prompt_embeds):
image_is_pil = isinstance(image, PIL.Image.Image)
image_is_tensor = isinstance(image, torch.Tensor)
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
raise TypeError(
"image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
)
if image_is_pil:
image_batch_size = 1
elif image_is_tensor:
image_batch_size = image.shape[0]
elif image_is_pil_list:
image_batch_size = len(image)
elif image_is_tensor_list:
image_batch_size = len(image)
else:
raise ValueError("controlnet condition image is not valid")
if prompt is not None and isinstance(prompt, str):
prompt_batch_size = 1
elif prompt is not None and isinstance(prompt, list):
prompt_batch_size = len(prompt)
elif prompt_embeds is not None:
prompt_batch_size = prompt_embeds.shape[0]
else:
raise ValueError("prompt or prompt_embeds are not valid")
if image_batch_size != 1 and image_batch_size != prompt_batch_size:
raise ValueError(
f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
)
def check_inputs(
self,
prompt,
image,
controlnet_conditioning_image,
height,
width,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
strength=None,
controlnet_guidance_start=None,
controlnet_guidance_end=None,
controlnet_conditioning_scale=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
# check controlnet condition image
if isinstance(self.controlnet, ControlNetModel):
self.check_controlnet_conditioning_image(controlnet_conditioning_image, prompt, prompt_embeds)
elif isinstance(self.controlnet, MultiControlNetModel):
if not isinstance(controlnet_conditioning_image, list):
raise TypeError("For multiple controlnets: `image` must be type `list`")
if len(controlnet_conditioning_image) != len(self.controlnet.nets):
raise ValueError(
"For multiple controlnets: `image` must have the same length as the number of controlnets."
)
for image_ in controlnet_conditioning_image:
self.check_controlnet_conditioning_image(image_, prompt, prompt_embeds)
else:
assert False
# Check `controlnet_conditioning_scale`
if isinstance(self.controlnet, ControlNetModel):
if not isinstance(controlnet_conditioning_scale, float):
raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
elif isinstance(self.controlnet, MultiControlNetModel):
if isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
self.controlnet.nets
):
raise ValueError(
"For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
" the same length as the number of controlnets"
)
else:
assert False
if isinstance(image, torch.Tensor):
if image.ndim != 3 and image.ndim != 4:
raise ValueError("`image` must have 3 or 4 dimensions")
if image.ndim == 3:
image_batch_size = 1
image_channels, image_height, image_width = image.shape
elif image.ndim == 4:
image_batch_size, image_channels, image_height, image_width = image.shape
else:
assert False
if image_channels != 3:
raise ValueError("`image` must have 3 channels")
if image.min() < -1 or image.max() > 1:
raise ValueError("`image` should be in range [-1, 1]")
if self.vae.config.latent_channels != self.unet.config.in_channels:
raise ValueError(
f"The config of `pipeline.unet` expects {self.unet.config.in_channels} but received"
f" latent channels: {self.vae.config.latent_channels},"
f" Please verify the config of `pipeline.unet` and the `pipeline.vae`"
)
if strength < 0 or strength > 1:
raise ValueError(f"The value of `strength` should in [0.0, 1.0] but is {strength}")
if controlnet_guidance_start < 0 or controlnet_guidance_start > 1:
raise ValueError(
f"The value of `controlnet_guidance_start` should in [0.0, 1.0] but is {controlnet_guidance_start}"
)
if controlnet_guidance_end < 0 or controlnet_guidance_end > 1:
raise ValueError(
f"The value of `controlnet_guidance_end` should in [0.0, 1.0] but is {controlnet_guidance_end}"
)
if controlnet_guidance_start > controlnet_guidance_end:
raise ValueError(
"The value of `controlnet_guidance_start` should be less than `controlnet_guidance_end`, but got"
f" `controlnet_guidance_start` {controlnet_guidance_start} >= `controlnet_guidance_end` {controlnet_guidance_end}"
)
def get_timesteps(self, num_inference_steps, strength, device):
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start:]
return timesteps, num_inference_steps - t_start
def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None):
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
)
image = image.to(device=device, dtype=dtype)
batch_size = batch_size * num_images_per_prompt
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if isinstance(generator, list):
init_latents = [
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
]
init_latents = torch.cat(init_latents, dim=0)
else:
init_latents = self.vae.encode(image).latent_dist.sample(generator)
init_latents = self.vae.config.scaling_factor * init_latents
if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
raise ValueError(
f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
)
else:
init_latents = torch.cat([init_latents], dim=0)
shape = init_latents.shape
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
# get latents
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
latents = init_latents
return latents
def _default_height_width(self, height, width, image):
if isinstance(image, list):
image = image[0]
if height is None:
if isinstance(image, PIL.Image.Image):
height = image.height
elif isinstance(image, torch.Tensor):
height = image.shape[3]
height = (height // 8) * 8 # round down to nearest multiple of 8
if width is None:
if isinstance(image, PIL.Image.Image):
width = image.width
elif isinstance(image, torch.Tensor):
width = image.shape[2]
width = (width // 8) * 8 # round down to nearest multiple of 8
return height, width
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: Union[torch.Tensor, PIL.Image.Image] = None,
controlnet_conditioning_image: Union[
torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]
] = None,
strength: float = 0.8,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
controlnet_guidance_start: float = 0.0,
controlnet_guidance_end: float = 1.0,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`torch.Tensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
controlnet_conditioning_image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]` or `List[PIL.Image.Image]`):
The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. PIL.Image.Image` can
also be accepted as an image. The control image is automatically resized to fit the output image.
strength (`float`, *optional*):
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
will be used as a starting point, adding more noise to it the larger the `strength`. The number of
denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
be maximum and the denoising process will run for the full number of iterations specified in
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
controlnet_conditioning_scale (`float`, *optional*, defaults to 1.0):
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
to the residual in the original unet.
controlnet_guidance_start ('float', *optional*, defaults to 0.0):
The percentage of total steps the controlnet starts applying. Must be between 0 and 1.
controlnet_guidance_end ('float', *optional*, defaults to 1.0):
The percentage of total steps the controlnet ends applying. Must be between 0 and 1. Must be greater
than `controlnet_guidance_start`.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 0. Default height and width to unet
height, width = self._default_height_width(height, width, controlnet_conditioning_image)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
image,
controlnet_conditioning_image,
height,
width,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
strength,
controlnet_guidance_start,
controlnet_guidance_end,
controlnet_conditioning_scale,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
if isinstance(self.controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(self.controlnet.nets)
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
# 4. Prepare image, and controlnet_conditioning_image
image = prepare_image(image)
# condition image(s)
if isinstance(self.controlnet, ControlNetModel):
controlnet_conditioning_image = prepare_controlnet_conditioning_image(
controlnet_conditioning_image=controlnet_conditioning_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=self.controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
)
elif isinstance(self.controlnet, MultiControlNetModel):
controlnet_conditioning_images = []
for image_ in controlnet_conditioning_image:
image_ = prepare_controlnet_conditioning_image(
controlnet_conditioning_image=image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=self.controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
)
controlnet_conditioning_images.append(image_)
controlnet_conditioning_image = controlnet_conditioning_images
else:
assert False
# 5. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# 6. Prepare latent variables
latents = self.prepare_latents(
image,
latent_timestep,
batch_size,
num_images_per_prompt,
prompt_embeds.dtype,
device,
generator,
)
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 8. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# compute the percentage of total steps we are at
current_sampling_percent = i / len(timesteps)
if (
current_sampling_percent < controlnet_guidance_start
or current_sampling_percent > controlnet_guidance_end
):
# do not apply the controlnet
down_block_res_samples = None
mid_block_res_sample = None
else:
# apply the controlnet
down_block_res_samples, mid_block_res_sample = self.controlnet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
controlnet_cond=controlnet_conditioning_image,
conditioning_scale=controlnet_conditioning_scale,
return_dict=False,
)
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# If we do sequential model offloading, let's offload unet and controlnet
# manually for max memory savings
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.unet.to("cpu")
self.controlnet.to("cpu")
torch.cuda.empty_cache()
if output_type == "latent":
image = latents
has_nsfw_concept = None
elif output_type == "pil":
# 8. Post-processing
image = self.decode_latents(latents)
# 9. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
# 10. Convert to PIL
image = self.numpy_to_pil(image)
else:
# 8. Post-processing
image = self.decode_latents(latents)
# 9. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_diffusion_controlnet_inpaint.py
|
# Inspired by: https://github.com/haofanwang/ControlNet-for-Diffusers/
import inspect
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
import torch.nn.functional as F
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, ControlNetModel, DiffusionPipeline, UNet2DConditionModel, logging
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput, StableDiffusionSafetyChecker
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
PIL_INTERPOLATION,
is_accelerate_available,
is_accelerate_version,
replace_example_docstring,
)
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import numpy as np
>>> import torch
>>> from PIL import Image
>>> from stable_diffusion_controlnet_inpaint import StableDiffusionControlNetInpaintPipeline
>>> from transformers import AutoImageProcessor, UperNetForSemanticSegmentation
>>> from diffusers import ControlNetModel, UniPCMultistepScheduler
>>> from diffusers.utils import load_image
>>> def ade_palette():
return [[120, 120, 120], [180, 120, 120], [6, 230, 230], [80, 50, 50],
[4, 200, 3], [120, 120, 80], [140, 140, 140], [204, 5, 255],
[230, 230, 230], [4, 250, 7], [224, 5, 255], [235, 255, 7],
[150, 5, 61], [120, 120, 70], [8, 255, 51], [255, 6, 82],
[143, 255, 140], [204, 255, 4], [255, 51, 7], [204, 70, 3],
[0, 102, 200], [61, 230, 250], [255, 6, 51], [11, 102, 255],
[255, 7, 71], [255, 9, 224], [9, 7, 230], [220, 220, 220],
[255, 9, 92], [112, 9, 255], [8, 255, 214], [7, 255, 224],
[255, 184, 6], [10, 255, 71], [255, 41, 10], [7, 255, 255],
[224, 255, 8], [102, 8, 255], [255, 61, 6], [255, 194, 7],
[255, 122, 8], [0, 255, 20], [255, 8, 41], [255, 5, 153],
[6, 51, 255], [235, 12, 255], [160, 150, 20], [0, 163, 255],
[140, 140, 140], [250, 10, 15], [20, 255, 0], [31, 255, 0],
[255, 31, 0], [255, 224, 0], [153, 255, 0], [0, 0, 255],
[255, 71, 0], [0, 235, 255], [0, 173, 255], [31, 0, 255],
[11, 200, 200], [255, 82, 0], [0, 255, 245], [0, 61, 255],
[0, 255, 112], [0, 255, 133], [255, 0, 0], [255, 163, 0],
[255, 102, 0], [194, 255, 0], [0, 143, 255], [51, 255, 0],
[0, 82, 255], [0, 255, 41], [0, 255, 173], [10, 0, 255],
[173, 255, 0], [0, 255, 153], [255, 92, 0], [255, 0, 255],
[255, 0, 245], [255, 0, 102], [255, 173, 0], [255, 0, 20],
[255, 184, 184], [0, 31, 255], [0, 255, 61], [0, 71, 255],
[255, 0, 204], [0, 255, 194], [0, 255, 82], [0, 10, 255],
[0, 112, 255], [51, 0, 255], [0, 194, 255], [0, 122, 255],
[0, 255, 163], [255, 153, 0], [0, 255, 10], [255, 112, 0],
[143, 255, 0], [82, 0, 255], [163, 255, 0], [255, 235, 0],
[8, 184, 170], [133, 0, 255], [0, 255, 92], [184, 0, 255],
[255, 0, 31], [0, 184, 255], [0, 214, 255], [255, 0, 112],
[92, 255, 0], [0, 224, 255], [112, 224, 255], [70, 184, 160],
[163, 0, 255], [153, 0, 255], [71, 255, 0], [255, 0, 163],
[255, 204, 0], [255, 0, 143], [0, 255, 235], [133, 255, 0],
[255, 0, 235], [245, 0, 255], [255, 0, 122], [255, 245, 0],
[10, 190, 212], [214, 255, 0], [0, 204, 255], [20, 0, 255],
[255, 255, 0], [0, 153, 255], [0, 41, 255], [0, 255, 204],
[41, 0, 255], [41, 255, 0], [173, 0, 255], [0, 245, 255],
[71, 0, 255], [122, 0, 255], [0, 255, 184], [0, 92, 255],
[184, 255, 0], [0, 133, 255], [255, 214, 0], [25, 194, 194],
[102, 255, 0], [92, 0, 255]]
>>> image_processor = AutoImageProcessor.from_pretrained("openmmlab/upernet-convnext-small")
>>> image_segmentor = UperNetForSemanticSegmentation.from_pretrained("openmmlab/upernet-convnext-small")
>>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-seg", torch_dtype=torch.float16)
>>> pipe = StableDiffusionControlNetInpaintPipeline.from_pretrained(
"runwayml/stable-diffusion-inpainting", controlnet=controlnet, safety_checker=None, torch_dtype=torch.float16
)
>>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
>>> pipe.enable_xformers_memory_efficient_attention()
>>> pipe.enable_model_cpu_offload()
>>> def image_to_seg(image):
pixel_values = image_processor(image, return_tensors="pt").pixel_values
with torch.no_grad():
outputs = image_segmentor(pixel_values)
seg = image_processor.post_process_semantic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8) # height, width, 3
palette = np.array(ade_palette())
for label, color in enumerate(palette):
color_seg[seg == label, :] = color
color_seg = color_seg.astype(np.uint8)
seg_image = Image.fromarray(color_seg)
return seg_image
>>> image = load_image(
"https://github.com/CompVis/latent-diffusion/raw/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
)
>>> mask_image = load_image(
"https://github.com/CompVis/latent-diffusion/raw/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
)
>>> controlnet_conditioning_image = image_to_seg(image)
>>> image = pipe(
"Face of a yellow cat, high resolution, sitting on a park bench",
image,
mask_image,
controlnet_conditioning_image,
num_inference_steps=20,
).images[0]
>>> image.save("out.png")
```
"""
def prepare_image(image):
if isinstance(image, torch.Tensor):
# Batch single image
if image.ndim == 3:
image = image.unsqueeze(0)
image = image.to(dtype=torch.float32)
else:
# preprocess image
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
return image
def prepare_mask_image(mask_image):
if isinstance(mask_image, torch.Tensor):
if mask_image.ndim == 2:
# Batch and add channel dim for single mask
mask_image = mask_image.unsqueeze(0).unsqueeze(0)
elif mask_image.ndim == 3 and mask_image.shape[0] == 1:
# Single mask, the 0'th dimension is considered to be
# the existing batch size of 1
mask_image = mask_image.unsqueeze(0)
elif mask_image.ndim == 3 and mask_image.shape[0] != 1:
# Batch of mask, the 0'th dimension is considered to be
# the batching dimension
mask_image = mask_image.unsqueeze(1)
# Binarize mask
mask_image[mask_image < 0.5] = 0
mask_image[mask_image >= 0.5] = 1
else:
# preprocess mask
if isinstance(mask_image, (PIL.Image.Image, np.ndarray)):
mask_image = [mask_image]
if isinstance(mask_image, list) and isinstance(mask_image[0], PIL.Image.Image):
mask_image = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask_image], axis=0)
mask_image = mask_image.astype(np.float32) / 255.0
elif isinstance(mask_image, list) and isinstance(mask_image[0], np.ndarray):
mask_image = np.concatenate([m[None, None, :] for m in mask_image], axis=0)
mask_image[mask_image < 0.5] = 0
mask_image[mask_image >= 0.5] = 1
mask_image = torch.from_numpy(mask_image)
return mask_image
def prepare_controlnet_conditioning_image(
controlnet_conditioning_image,
width,
height,
batch_size,
num_images_per_prompt,
device,
dtype,
do_classifier_free_guidance,
):
if not isinstance(controlnet_conditioning_image, torch.Tensor):
if isinstance(controlnet_conditioning_image, PIL.Image.Image):
controlnet_conditioning_image = [controlnet_conditioning_image]
if isinstance(controlnet_conditioning_image[0], PIL.Image.Image):
controlnet_conditioning_image = [
np.array(i.resize((width, height), resample=PIL_INTERPOLATION["lanczos"]))[None, :]
for i in controlnet_conditioning_image
]
controlnet_conditioning_image = np.concatenate(controlnet_conditioning_image, axis=0)
controlnet_conditioning_image = np.array(controlnet_conditioning_image).astype(np.float32) / 255.0
controlnet_conditioning_image = controlnet_conditioning_image.transpose(0, 3, 1, 2)
controlnet_conditioning_image = torch.from_numpy(controlnet_conditioning_image)
elif isinstance(controlnet_conditioning_image[0], torch.Tensor):
controlnet_conditioning_image = torch.cat(controlnet_conditioning_image, dim=0)
image_batch_size = controlnet_conditioning_image.shape[0]
if image_batch_size == 1:
repeat_by = batch_size
else:
# image batch size is the same as prompt batch size
repeat_by = num_images_per_prompt
controlnet_conditioning_image = controlnet_conditioning_image.repeat_interleave(repeat_by, dim=0)
controlnet_conditioning_image = controlnet_conditioning_image.to(device=device, dtype=dtype)
if do_classifier_free_guidance:
controlnet_conditioning_image = torch.cat([controlnet_conditioning_image] * 2)
return controlnet_conditioning_image
class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline):
"""
Inspired by: https://github.com/haofanwang/ControlNet-for-Diffusers/
"""
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
if isinstance(controlnet, (list, tuple)):
controlnet = MultiControlNetModel(controlnet)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
controlnet=controlnet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.register_to_config(requires_safety_checker=requires_safety_checker)
def enable_vae_slicing(self):
r"""
Enable sliced VAE decoding.
When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
steps. This is useful to save some memory and allow larger batch sizes.
"""
self.vae.enable_slicing()
def disable_vae_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
computing decoding in one step.
"""
self.vae.disable_slicing()
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
`torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
Note that offloading happens on a submodule basis. Memory savings are higher than with
`enable_model_cpu_offload`, but performance is lower.
"""
if is_accelerate_available():
from accelerate import cpu_offload
else:
raise ImportError("Please install accelerate via `pip install accelerate`")
device = torch.device(f"cuda:{gpu_id}")
for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.controlnet]:
cpu_offload(cpu_offloaded_model, device)
if self.safety_checker is not None:
cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
def enable_model_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
"""
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
from accelerate import cpu_offload_with_hook
else:
raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
device = torch.device(f"cuda:{gpu_id}")
hook = None
for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
if self.safety_checker is not None:
# the safety checker can offload the vae again
_, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
# control net hook has be manually offloaded as it alternates with unet
cpu_offload_with_hook(self.controlnet, device)
# We'll offload the last model manually.
self.final_offload_hook = hook
@property
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if not hasattr(self.unet, "_hf_hook"):
return self.device
for module in self.unet.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass `negative_prompt_embeds` instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
"""
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
prompt_embeds = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
else:
has_nsfw_concept = None
return image, has_nsfw_concept
def decode_latents(self, latents):
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_controlnet_conditioning_image(self, image, prompt, prompt_embeds):
image_is_pil = isinstance(image, PIL.Image.Image)
image_is_tensor = isinstance(image, torch.Tensor)
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
raise TypeError(
"image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
)
if image_is_pil:
image_batch_size = 1
elif image_is_tensor:
image_batch_size = image.shape[0]
elif image_is_pil_list:
image_batch_size = len(image)
elif image_is_tensor_list:
image_batch_size = len(image)
else:
raise ValueError("controlnet condition image is not valid")
if prompt is not None and isinstance(prompt, str):
prompt_batch_size = 1
elif prompt is not None and isinstance(prompt, list):
prompt_batch_size = len(prompt)
elif prompt_embeds is not None:
prompt_batch_size = prompt_embeds.shape[0]
else:
raise ValueError("prompt or prompt_embeds are not valid")
if image_batch_size != 1 and image_batch_size != prompt_batch_size:
raise ValueError(
f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
)
def check_inputs(
self,
prompt,
image,
mask_image,
controlnet_conditioning_image,
height,
width,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
controlnet_conditioning_scale=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
# check controlnet condition image
if isinstance(self.controlnet, ControlNetModel):
self.check_controlnet_conditioning_image(controlnet_conditioning_image, prompt, prompt_embeds)
elif isinstance(self.controlnet, MultiControlNetModel):
if not isinstance(controlnet_conditioning_image, list):
raise TypeError("For multiple controlnets: `image` must be type `list`")
if len(controlnet_conditioning_image) != len(self.controlnet.nets):
raise ValueError(
"For multiple controlnets: `image` must have the same length as the number of controlnets."
)
for image_ in controlnet_conditioning_image:
self.check_controlnet_conditioning_image(image_, prompt, prompt_embeds)
else:
assert False
# Check `controlnet_conditioning_scale`
if isinstance(self.controlnet, ControlNetModel):
if not isinstance(controlnet_conditioning_scale, float):
raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
elif isinstance(self.controlnet, MultiControlNetModel):
if isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
self.controlnet.nets
):
raise ValueError(
"For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
" the same length as the number of controlnets"
)
else:
assert False
if isinstance(image, torch.Tensor) and not isinstance(mask_image, torch.Tensor):
raise TypeError("if `image` is a tensor, `mask_image` must also be a tensor")
if isinstance(image, PIL.Image.Image) and not isinstance(mask_image, PIL.Image.Image):
raise TypeError("if `image` is a PIL image, `mask_image` must also be a PIL image")
if isinstance(image, torch.Tensor):
if image.ndim != 3 and image.ndim != 4:
raise ValueError("`image` must have 3 or 4 dimensions")
if mask_image.ndim != 2 and mask_image.ndim != 3 and mask_image.ndim != 4:
raise ValueError("`mask_image` must have 2, 3, or 4 dimensions")
if image.ndim == 3:
image_batch_size = 1
image_channels, image_height, image_width = image.shape
elif image.ndim == 4:
image_batch_size, image_channels, image_height, image_width = image.shape
else:
assert False
if mask_image.ndim == 2:
mask_image_batch_size = 1
mask_image_channels = 1
mask_image_height, mask_image_width = mask_image.shape
elif mask_image.ndim == 3:
mask_image_channels = 1
mask_image_batch_size, mask_image_height, mask_image_width = mask_image.shape
elif mask_image.ndim == 4:
mask_image_batch_size, mask_image_channels, mask_image_height, mask_image_width = mask_image.shape
if image_channels != 3:
raise ValueError("`image` must have 3 channels")
if mask_image_channels != 1:
raise ValueError("`mask_image` must have 1 channel")
if image_batch_size != mask_image_batch_size:
raise ValueError("`image` and `mask_image` mush have the same batch sizes")
if image_height != mask_image_height or image_width != mask_image_width:
raise ValueError("`image` and `mask_image` must have the same height and width dimensions")
if image.min() < -1 or image.max() > 1:
raise ValueError("`image` should be in range [-1, 1]")
if mask_image.min() < 0 or mask_image.max() > 1:
raise ValueError("`mask_image` should be in range [0, 1]")
else:
mask_image_channels = 1
image_channels = 3
single_image_latent_channels = self.vae.config.latent_channels
total_latent_channels = single_image_latent_channels * 2 + mask_image_channels
if total_latent_channels != self.unet.config.in_channels:
raise ValueError(
f"The config of `pipeline.unet` expects {self.unet.config.in_channels} but received"
f" non inpainting latent channels: {single_image_latent_channels},"
f" mask channels: {mask_image_channels}, and masked image channels: {single_image_latent_channels}."
f" Please verify the config of `pipeline.unet` and the `mask_image` and `image` inputs."
)
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def prepare_mask_latents(self, mask_image, batch_size, height, width, dtype, device, do_classifier_free_guidance):
# resize the mask to latents shape as we concatenate the mask to the latents
# we do that before converting to dtype to avoid breaking in case we're using cpu_offload
# and half precision
mask_image = F.interpolate(mask_image, size=(height // self.vae_scale_factor, width // self.vae_scale_factor))
mask_image = mask_image.to(device=device, dtype=dtype)
# duplicate mask for each generation per prompt, using mps friendly method
if mask_image.shape[0] < batch_size:
if not batch_size % mask_image.shape[0] == 0:
raise ValueError(
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
f" a total batch size of {batch_size}, but {mask_image.shape[0]} masks were passed. Make sure the number"
" of masks that you pass is divisible by the total requested batch size."
)
mask_image = mask_image.repeat(batch_size // mask_image.shape[0], 1, 1, 1)
mask_image = torch.cat([mask_image] * 2) if do_classifier_free_guidance else mask_image
mask_image_latents = mask_image
return mask_image_latents
def prepare_masked_image_latents(
self, masked_image, batch_size, height, width, dtype, device, generator, do_classifier_free_guidance
):
masked_image = masked_image.to(device=device, dtype=dtype)
# encode the mask image into latents space so we can concatenate it to the latents
if isinstance(generator, list):
masked_image_latents = [
self.vae.encode(masked_image[i : i + 1]).latent_dist.sample(generator=generator[i])
for i in range(batch_size)
]
masked_image_latents = torch.cat(masked_image_latents, dim=0)
else:
masked_image_latents = self.vae.encode(masked_image).latent_dist.sample(generator=generator)
masked_image_latents = self.vae.config.scaling_factor * masked_image_latents
# duplicate masked_image_latents for each generation per prompt, using mps friendly method
if masked_image_latents.shape[0] < batch_size:
if not batch_size % masked_image_latents.shape[0] == 0:
raise ValueError(
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
" Make sure the number of images that you pass is divisible by the total requested batch size."
)
masked_image_latents = masked_image_latents.repeat(batch_size // masked_image_latents.shape[0], 1, 1, 1)
masked_image_latents = (
torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
)
# aligning device to prevent device errors when concating it with the latent model input
masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
return masked_image_latents
def _default_height_width(self, height, width, image):
if isinstance(image, list):
image = image[0]
if height is None:
if isinstance(image, PIL.Image.Image):
height = image.height
elif isinstance(image, torch.Tensor):
height = image.shape[3]
height = (height // 8) * 8 # round down to nearest multiple of 8
if width is None:
if isinstance(image, PIL.Image.Image):
width = image.width
elif isinstance(image, torch.Tensor):
width = image.shape[2]
width = (width // 8) * 8 # round down to nearest multiple of 8
return height, width
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: Union[torch.Tensor, PIL.Image.Image] = None,
mask_image: Union[torch.Tensor, PIL.Image.Image] = None,
controlnet_conditioning_image: Union[
torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]
] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`torch.Tensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
mask_image (`torch.Tensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
repainted, while black pixels will be preserved. If `mask_image` is a PIL image, it will be converted
to a single channel (luminance) before use. If it's a tensor, it should contain one color channel (L)
instead of 3, so the expected shape would be `(B, H, W, 1)`.
controlnet_conditioning_image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]` or `List[PIL.Image.Image]`):
The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. PIL.Image.Image` can
also be accepted as an image. The control image is automatically resized to fit the output image.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass `negative_prompt_embeds` instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
controlnet_conditioning_scale (`float`, *optional*, defaults to 1.0):
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
to the residual in the original unet.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 0. Default height and width to unet
height, width = self._default_height_width(height, width, controlnet_conditioning_image)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
image,
mask_image,
controlnet_conditioning_image,
height,
width,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
controlnet_conditioning_scale,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
if isinstance(self.controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(self.controlnet.nets)
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
# 4. Prepare mask, image, and controlnet_conditioning_image
image = prepare_image(image)
mask_image = prepare_mask_image(mask_image)
# condition image(s)
if isinstance(self.controlnet, ControlNetModel):
controlnet_conditioning_image = prepare_controlnet_conditioning_image(
controlnet_conditioning_image=controlnet_conditioning_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=self.controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
)
elif isinstance(self.controlnet, MultiControlNetModel):
controlnet_conditioning_images = []
for image_ in controlnet_conditioning_image:
image_ = prepare_controlnet_conditioning_image(
controlnet_conditioning_image=image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=self.controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
)
controlnet_conditioning_images.append(image_)
controlnet_conditioning_image = controlnet_conditioning_images
else:
assert False
masked_image = image * (mask_image < 0.5)
# 5. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 6. Prepare latent variables
num_channels_latents = self.vae.config.latent_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
mask_image_latents = self.prepare_mask_latents(
mask_image,
batch_size * num_images_per_prompt,
height,
width,
prompt_embeds.dtype,
device,
do_classifier_free_guidance,
)
masked_image_latents = self.prepare_masked_image_latents(
masked_image,
batch_size * num_images_per_prompt,
height,
width,
prompt_embeds.dtype,
device,
generator,
do_classifier_free_guidance,
)
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 8. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
non_inpainting_latent_model_input = (
torch.cat([latents] * 2) if do_classifier_free_guidance else latents
)
non_inpainting_latent_model_input = self.scheduler.scale_model_input(
non_inpainting_latent_model_input, t
)
inpainting_latent_model_input = torch.cat(
[non_inpainting_latent_model_input, mask_image_latents, masked_image_latents], dim=1
)
down_block_res_samples, mid_block_res_sample = self.controlnet(
non_inpainting_latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
controlnet_cond=controlnet_conditioning_image,
conditioning_scale=controlnet_conditioning_scale,
return_dict=False,
)
# predict the noise residual
noise_pred = self.unet(
inpainting_latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# If we do sequential model offloading, let's offload unet and controlnet
# manually for max memory savings
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.unet.to("cpu")
self.controlnet.to("cpu")
torch.cuda.empty_cache()
if output_type == "latent":
image = latents
has_nsfw_concept = None
elif output_type == "pil":
# 8. Post-processing
image = self.decode_latents(latents)
# 9. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
# 10. Convert to PIL
image = self.numpy_to_pil(image)
else:
# 8. Post-processing
image = self.decode_latents(latents)
# 9. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_diffusion_comparison.py
|
from typing import Any, Callable, Dict, List, Optional, Union
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DiffusionPipeline,
LMSDiscreteScheduler,
PNDMScheduler,
StableDiffusionPipeline,
UNet2DConditionModel,
)
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
pipe1_model_id = "CompVis/stable-diffusion-v1-1"
pipe2_model_id = "CompVis/stable-diffusion-v1-2"
pipe3_model_id = "CompVis/stable-diffusion-v1-3"
pipe4_model_id = "CompVis/stable-diffusion-v1-4"
class StableDiffusionComparisonPipeline(DiffusionPipeline):
r"""
Pipeline for parallel comparison of Stable Diffusion v1-v4
This pipeline inherits from DiffusionPipeline and depends on the use of an Auth Token for
downloading pre-trained checkpoints from Hugging Face Hub.
If using Hugging Face Hub, pass the Model ID for Stable Diffusion v1.4 as the previous 3 checkpoints will be loaded
automatically.
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionMegaSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super()._init_()
self.pipe1 = StableDiffusionPipeline.from_pretrained(pipe1_model_id)
self.pipe2 = StableDiffusionPipeline.from_pretrained(pipe2_model_id)
self.pipe3 = StableDiffusionPipeline.from_pretrained(pipe3_model_id)
self.pipe4 = StableDiffusionPipeline(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
requires_safety_checker=requires_safety_checker,
)
self.register_modules(pipeline1=self.pipe1, pipeline2=self.pipe2, pipeline3=self.pipe3, pipeline4=self.pipe4)
@property
def layers(self) -> Dict[str, Any]:
return {k: getattr(self, k) for k in self.config.keys() if not k.startswith("_")}
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
r"""
Enable sliced attention computation.
When this option is enabled, the attention module will split the input tensor in slices, to compute attention
in several steps. This is useful to save some memory in exchange for a small speed decrease.
Args:
slice_size (`str` or `int`, *optional*, defaults to `"auto"`):
When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
a number is provided, uses as many slices as `attention_head_dim // slice_size`. In this case,
`attention_head_dim` must be a multiple of `slice_size`.
"""
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
slice_size = self.unet.config.attention_head_dim // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
r"""
Disable sliced attention computation. If `enable_attention_slicing` was previously invoked, this method will go
back to computing attention in one step.
"""
# set slice_size = `None` to disable `attention slicing`
self.enable_attention_slicing(None)
@torch.no_grad()
def text2img_sd1_1(
self,
prompt: Union[str, List[str]],
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
**kwargs,
):
return self.pipe1(
prompt=prompt,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
latents=latents,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
**kwargs,
)
@torch.no_grad()
def text2img_sd1_2(
self,
prompt: Union[str, List[str]],
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
**kwargs,
):
return self.pipe2(
prompt=prompt,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
latents=latents,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
**kwargs,
)
@torch.no_grad()
def text2img_sd1_3(
self,
prompt: Union[str, List[str]],
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
**kwargs,
):
return self.pipe3(
prompt=prompt,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
latents=latents,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
**kwargs,
)
@torch.no_grad()
def text2img_sd1_4(
self,
prompt: Union[str, List[str]],
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
**kwargs,
):
return self.pipe4(
prompt=prompt,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
latents=latents,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
**kwargs,
)
@torch.no_grad()
def _call_(
self,
prompt: Union[str, List[str]],
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
**kwargs,
):
r"""
Function invoked when calling the pipeline for generation. This function will generate 4 results as part
of running all the 4 pipelines for SD1.1-1.4 together in a serial-processing, parallel-invocation fashion.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
height (`int`, optional, defaults to 512):
The height in pixels of the generated image.
width (`int`, optional, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, optional, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, optional, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
eta (`float`, optional, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, optional):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, optional):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, optional, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, optional, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
device = "cuda" if torch.cuda.is_available() else "cpu"
self.to(device)
# Checks if the height and width are divisible by 8 or not
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` must be divisible by 8 but are {height} and {width}.")
# Get first result from Stable Diffusion Checkpoint v1.1
res1 = self.text2img_sd1_1(
prompt=prompt,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
latents=latents,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
**kwargs,
)
# Get first result from Stable Diffusion Checkpoint v1.2
res2 = self.text2img_sd1_2(
prompt=prompt,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
latents=latents,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
**kwargs,
)
# Get first result from Stable Diffusion Checkpoint v1.3
res3 = self.text2img_sd1_3(
prompt=prompt,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
latents=latents,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
**kwargs,
)
# Get first result from Stable Diffusion Checkpoint v1.4
res4 = self.text2img_sd1_4(
prompt=prompt,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
latents=latents,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
**kwargs,
)
# Get all result images into a single list and pass it via StableDiffusionPipelineOutput for final result
return StableDiffusionPipelineOutput([res1[0], res2[0], res3[0], res4[0]])
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/pipeline_prompt2prompt.py
|
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import annotations
import abc
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import torch
import torch.nn.functional as F
from ...src.diffusers.models.attention import Attention
from ...src.diffusers.pipelines.stable_diffusion import StableDiffusionPipeline, StableDiffusionPipelineOutput
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
# rescale the results from guidance (fixes overexposure)
noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
# mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
return noise_cfg
class Prompt2PromptPipeline(StableDiffusionPipeline):
r"""
Args:
Prompt-to-Prompt-Pipeline for text-to-image generation using Stable Diffusion. This model inherits from
[`StableDiffusionPipeline`]. Check the superclass documentation for the generic methods the library implements for
all the pipelines (such as downloading or saving, running on a particular device, etc.)
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents. scheduler
([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPFeatureExtractor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
_optional_components = ["safety_checker", "feature_extractor"]
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: Optional[int] = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
guidance_rescale: float = 0.0,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
The keyword arguments to configure the edit are:
- edit_type (`str`). The edit type to apply. Can be either of `replace`, `refine`, `reweight`.
- n_cross_replace (`int`): Number of diffusion steps in which cross attention should be replaced
- n_self_replace (`int`): Number of diffusion steps in which self attention should be replaced
- local_blend_words(`List[str]`, *optional*, default to `None`): Determines which area should be
changed. If None, then the whole image can be changed.
- equalizer_words(`List[str]`, *optional*, default to `None`): Required for edit type `reweight`.
Determines which words should be enhanced.
- equalizer_strengths (`List[float]`, *optional*, default to `None`) Required for edit type `reweight`.
Determines which how much the words in `equalizer_words` should be enhanced.
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
self.controller = create_controller(
prompt, cross_attention_kwargs, num_inference_steps, tokenizer=self.tokenizer, device=self.device
)
self.register_attention_control(self.controller) # add attention controller
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs. Raise error if not correct
self.check_inputs(prompt, height, width, callback_steps)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
text_encoder_lora_scale = (
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
)
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=text_encoder_lora_scale,
)
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 5. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=prompt_embeds).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# step callback
latents = self.controller.step_callback(latents)
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# 8. Post-processing
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = latents
has_nsfw_concept = None
# 9. Run safety checker
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
def register_attention_control(self, controller):
attn_procs = {}
cross_att_count = 0
for name in self.unet.attn_processors.keys():
None if name.endswith("attn1.processor") else self.unet.config.cross_attention_dim
if name.startswith("mid_block"):
self.unet.config.block_out_channels[-1]
place_in_unet = "mid"
elif name.startswith("up_blocks"):
block_id = int(name[len("up_blocks.")])
list(reversed(self.unet.config.block_out_channels))[block_id]
place_in_unet = "up"
elif name.startswith("down_blocks"):
block_id = int(name[len("down_blocks.")])
self.unet.config.block_out_channels[block_id]
place_in_unet = "down"
else:
continue
cross_att_count += 1
attn_procs[name] = P2PCrossAttnProcessor(controller=controller, place_in_unet=place_in_unet)
self.unet.set_attn_processor(attn_procs)
controller.num_att_layers = cross_att_count
class P2PCrossAttnProcessor:
def __init__(self, controller, place_in_unet):
super().__init__()
self.controller = controller
self.place_in_unet = place_in_unet
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
batch_size, sequence_length, _ = hidden_states.shape
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
query = attn.to_q(hidden_states)
is_cross = encoder_hidden_states is not None
encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
query = attn.head_to_batch_dim(query)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
attention_probs = attn.get_attention_scores(query, key, attention_mask)
# one line change
self.controller(attention_probs, is_cross, self.place_in_unet)
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
return hidden_states
def create_controller(
prompts: List[str], cross_attention_kwargs: Dict, num_inference_steps: int, tokenizer, device
) -> AttentionControl:
edit_type = cross_attention_kwargs.get("edit_type", None)
local_blend_words = cross_attention_kwargs.get("local_blend_words", None)
equalizer_words = cross_attention_kwargs.get("equalizer_words", None)
equalizer_strengths = cross_attention_kwargs.get("equalizer_strengths", None)
n_cross_replace = cross_attention_kwargs.get("n_cross_replace", 0.4)
n_self_replace = cross_attention_kwargs.get("n_self_replace", 0.4)
# only replace
if edit_type == "replace" and local_blend_words is None:
return AttentionReplace(
prompts, num_inference_steps, n_cross_replace, n_self_replace, tokenizer=tokenizer, device=device
)
# replace + localblend
if edit_type == "replace" and local_blend_words is not None:
lb = LocalBlend(prompts, local_blend_words, tokenizer=tokenizer, device=device)
return AttentionReplace(
prompts, num_inference_steps, n_cross_replace, n_self_replace, lb, tokenizer=tokenizer, device=device
)
# only refine
if edit_type == "refine" and local_blend_words is None:
return AttentionRefine(
prompts, num_inference_steps, n_cross_replace, n_self_replace, tokenizer=tokenizer, device=device
)
# refine + localblend
if edit_type == "refine" and local_blend_words is not None:
lb = LocalBlend(prompts, local_blend_words, tokenizer=tokenizer, device=device)
return AttentionRefine(
prompts, num_inference_steps, n_cross_replace, n_self_replace, lb, tokenizer=tokenizer, device=device
)
# reweight
if edit_type == "reweight":
assert (
equalizer_words is not None and equalizer_strengths is not None
), "To use reweight edit, please specify equalizer_words and equalizer_strengths."
assert len(equalizer_words) == len(
equalizer_strengths
), "equalizer_words and equalizer_strengths must be of same length."
equalizer = get_equalizer(prompts[1], equalizer_words, equalizer_strengths, tokenizer=tokenizer)
return AttentionReweight(
prompts,
num_inference_steps,
n_cross_replace,
n_self_replace,
tokenizer=tokenizer,
device=device,
equalizer=equalizer,
)
raise ValueError(f"Edit type {edit_type} not recognized. Use one of: replace, refine, reweight.")
class AttentionControl(abc.ABC):
def step_callback(self, x_t):
return x_t
def between_steps(self):
return
@property
def num_uncond_att_layers(self):
return 0
@abc.abstractmethod
def forward(self, attn, is_cross: bool, place_in_unet: str):
raise NotImplementedError
def __call__(self, attn, is_cross: bool, place_in_unet: str):
if self.cur_att_layer >= self.num_uncond_att_layers:
h = attn.shape[0]
attn[h // 2 :] = self.forward(attn[h // 2 :], is_cross, place_in_unet)
self.cur_att_layer += 1
if self.cur_att_layer == self.num_att_layers + self.num_uncond_att_layers:
self.cur_att_layer = 0
self.cur_step += 1
self.between_steps()
return attn
def reset(self):
self.cur_step = 0
self.cur_att_layer = 0
def __init__(self):
self.cur_step = 0
self.num_att_layers = -1
self.cur_att_layer = 0
class EmptyControl(AttentionControl):
def forward(self, attn, is_cross: bool, place_in_unet: str):
return attn
class AttentionStore(AttentionControl):
@staticmethod
def get_empty_store():
return {"down_cross": [], "mid_cross": [], "up_cross": [], "down_self": [], "mid_self": [], "up_self": []}
def forward(self, attn, is_cross: bool, place_in_unet: str):
key = f"{place_in_unet}_{'cross' if is_cross else 'self'}"
if attn.shape[1] <= 32**2: # avoid memory overhead
self.step_store[key].append(attn)
return attn
def between_steps(self):
if len(self.attention_store) == 0:
self.attention_store = self.step_store
else:
for key in self.attention_store:
for i in range(len(self.attention_store[key])):
self.attention_store[key][i] += self.step_store[key][i]
self.step_store = self.get_empty_store()
def get_average_attention(self):
average_attention = {
key: [item / self.cur_step for item in self.attention_store[key]] for key in self.attention_store
}
return average_attention
def reset(self):
super(AttentionStore, self).reset()
self.step_store = self.get_empty_store()
self.attention_store = {}
def __init__(self):
super(AttentionStore, self).__init__()
self.step_store = self.get_empty_store()
self.attention_store = {}
class LocalBlend:
def __call__(self, x_t, attention_store):
k = 1
maps = attention_store["down_cross"][2:4] + attention_store["up_cross"][:3]
maps = [item.reshape(self.alpha_layers.shape[0], -1, 1, 16, 16, self.max_num_words) for item in maps]
maps = torch.cat(maps, dim=1)
maps = (maps * self.alpha_layers).sum(-1).mean(1)
mask = F.max_pool2d(maps, (k * 2 + 1, k * 2 + 1), (1, 1), padding=(k, k))
mask = F.interpolate(mask, size=(x_t.shape[2:]))
mask = mask / mask.max(2, keepdims=True)[0].max(3, keepdims=True)[0]
mask = mask.gt(self.threshold)
mask = (mask[:1] + mask[1:]).float()
x_t = x_t[:1] + mask * (x_t - x_t[:1])
return x_t
def __init__(
self, prompts: List[str], words: [List[List[str]]], tokenizer, device, threshold=0.3, max_num_words=77
):
self.max_num_words = 77
alpha_layers = torch.zeros(len(prompts), 1, 1, 1, 1, self.max_num_words)
for i, (prompt, words_) in enumerate(zip(prompts, words)):
if isinstance(words_, str):
words_ = [words_]
for word in words_:
ind = get_word_inds(prompt, word, tokenizer)
alpha_layers[i, :, :, :, :, ind] = 1
self.alpha_layers = alpha_layers.to(device)
self.threshold = threshold
class AttentionControlEdit(AttentionStore, abc.ABC):
def step_callback(self, x_t):
if self.local_blend is not None:
x_t = self.local_blend(x_t, self.attention_store)
return x_t
def replace_self_attention(self, attn_base, att_replace):
if att_replace.shape[2] <= 16**2:
return attn_base.unsqueeze(0).expand(att_replace.shape[0], *attn_base.shape)
else:
return att_replace
@abc.abstractmethod
def replace_cross_attention(self, attn_base, att_replace):
raise NotImplementedError
def forward(self, attn, is_cross: bool, place_in_unet: str):
super(AttentionControlEdit, self).forward(attn, is_cross, place_in_unet)
# FIXME not replace correctly
if is_cross or (self.num_self_replace[0] <= self.cur_step < self.num_self_replace[1]):
h = attn.shape[0] // (self.batch_size)
attn = attn.reshape(self.batch_size, h, *attn.shape[1:])
attn_base, attn_repalce = attn[0], attn[1:]
if is_cross:
alpha_words = self.cross_replace_alpha[self.cur_step]
attn_repalce_new = (
self.replace_cross_attention(attn_base, attn_repalce) * alpha_words
+ (1 - alpha_words) * attn_repalce
)
attn[1:] = attn_repalce_new
else:
attn[1:] = self.replace_self_attention(attn_base, attn_repalce)
attn = attn.reshape(self.batch_size * h, *attn.shape[2:])
return attn
def __init__(
self,
prompts,
num_steps: int,
cross_replace_steps: Union[float, Tuple[float, float], Dict[str, Tuple[float, float]]],
self_replace_steps: Union[float, Tuple[float, float]],
local_blend: Optional[LocalBlend],
tokenizer,
device,
):
super(AttentionControlEdit, self).__init__()
# add tokenizer and device here
self.tokenizer = tokenizer
self.device = device
self.batch_size = len(prompts)
self.cross_replace_alpha = get_time_words_attention_alpha(
prompts, num_steps, cross_replace_steps, self.tokenizer
).to(self.device)
if isinstance(self_replace_steps, float):
self_replace_steps = 0, self_replace_steps
self.num_self_replace = int(num_steps * self_replace_steps[0]), int(num_steps * self_replace_steps[1])
self.local_blend = local_blend # 在外面定义后传进来
class AttentionReplace(AttentionControlEdit):
def replace_cross_attention(self, attn_base, att_replace):
return torch.einsum("hpw,bwn->bhpn", attn_base, self.mapper)
def __init__(
self,
prompts,
num_steps: int,
cross_replace_steps: float,
self_replace_steps: float,
local_blend: Optional[LocalBlend] = None,
tokenizer=None,
device=None,
):
super(AttentionReplace, self).__init__(
prompts, num_steps, cross_replace_steps, self_replace_steps, local_blend, tokenizer, device
)
self.mapper = get_replacement_mapper(prompts, self.tokenizer).to(self.device)
class AttentionRefine(AttentionControlEdit):
def replace_cross_attention(self, attn_base, att_replace):
attn_base_replace = attn_base[:, :, self.mapper].permute(2, 0, 1, 3)
attn_replace = attn_base_replace * self.alphas + att_replace * (1 - self.alphas)
return attn_replace
def __init__(
self,
prompts,
num_steps: int,
cross_replace_steps: float,
self_replace_steps: float,
local_blend: Optional[LocalBlend] = None,
tokenizer=None,
device=None,
):
super(AttentionRefine, self).__init__(
prompts, num_steps, cross_replace_steps, self_replace_steps, local_blend, tokenizer, device
)
self.mapper, alphas = get_refinement_mapper(prompts, self.tokenizer)
self.mapper, alphas = self.mapper.to(self.device), alphas.to(self.device)
self.alphas = alphas.reshape(alphas.shape[0], 1, 1, alphas.shape[1])
class AttentionReweight(AttentionControlEdit):
def replace_cross_attention(self, attn_base, att_replace):
if self.prev_controller is not None:
attn_base = self.prev_controller.replace_cross_attention(attn_base, att_replace)
attn_replace = attn_base[None, :, :, :] * self.equalizer[:, None, None, :]
return attn_replace
def __init__(
self,
prompts,
num_steps: int,
cross_replace_steps: float,
self_replace_steps: float,
equalizer,
local_blend: Optional[LocalBlend] = None,
controller: Optional[AttentionControlEdit] = None,
tokenizer=None,
device=None,
):
super(AttentionReweight, self).__init__(
prompts, num_steps, cross_replace_steps, self_replace_steps, local_blend, tokenizer, device
)
self.equalizer = equalizer.to(self.device)
self.prev_controller = controller
### util functions for all Edits
def update_alpha_time_word(
alpha, bounds: Union[float, Tuple[float, float]], prompt_ind: int, word_inds: Optional[torch.Tensor] = None
):
if isinstance(bounds, float):
bounds = 0, bounds
start, end = int(bounds[0] * alpha.shape[0]), int(bounds[1] * alpha.shape[0])
if word_inds is None:
word_inds = torch.arange(alpha.shape[2])
alpha[:start, prompt_ind, word_inds] = 0
alpha[start:end, prompt_ind, word_inds] = 1
alpha[end:, prompt_ind, word_inds] = 0
return alpha
def get_time_words_attention_alpha(
prompts, num_steps, cross_replace_steps: Union[float, Dict[str, Tuple[float, float]]], tokenizer, max_num_words=77
):
if not isinstance(cross_replace_steps, dict):
cross_replace_steps = {"default_": cross_replace_steps}
if "default_" not in cross_replace_steps:
cross_replace_steps["default_"] = (0.0, 1.0)
alpha_time_words = torch.zeros(num_steps + 1, len(prompts) - 1, max_num_words)
for i in range(len(prompts) - 1):
alpha_time_words = update_alpha_time_word(alpha_time_words, cross_replace_steps["default_"], i)
for key, item in cross_replace_steps.items():
if key != "default_":
inds = [get_word_inds(prompts[i], key, tokenizer) for i in range(1, len(prompts))]
for i, ind in enumerate(inds):
if len(ind) > 0:
alpha_time_words = update_alpha_time_word(alpha_time_words, item, i, ind)
alpha_time_words = alpha_time_words.reshape(num_steps + 1, len(prompts) - 1, 1, 1, max_num_words)
return alpha_time_words
### util functions for LocalBlend and ReplacementEdit
def get_word_inds(text: str, word_place: int, tokenizer):
split_text = text.split(" ")
if isinstance(word_place, str):
word_place = [i for i, word in enumerate(split_text) if word_place == word]
elif isinstance(word_place, int):
word_place = [word_place]
out = []
if len(word_place) > 0:
words_encode = [tokenizer.decode([item]).strip("#") for item in tokenizer.encode(text)][1:-1]
cur_len, ptr = 0, 0
for i in range(len(words_encode)):
cur_len += len(words_encode[i])
if ptr in word_place:
out.append(i + 1)
if cur_len >= len(split_text[ptr]):
ptr += 1
cur_len = 0
return np.array(out)
### util functions for ReplacementEdit
def get_replacement_mapper_(x: str, y: str, tokenizer, max_len=77):
words_x = x.split(" ")
words_y = y.split(" ")
if len(words_x) != len(words_y):
raise ValueError(
f"attention replacement edit can only be applied on prompts with the same length"
f" but prompt A has {len(words_x)} words and prompt B has {len(words_y)} words."
)
inds_replace = [i for i in range(len(words_y)) if words_y[i] != words_x[i]]
inds_source = [get_word_inds(x, i, tokenizer) for i in inds_replace]
inds_target = [get_word_inds(y, i, tokenizer) for i in inds_replace]
mapper = np.zeros((max_len, max_len))
i = j = 0
cur_inds = 0
while i < max_len and j < max_len:
if cur_inds < len(inds_source) and inds_source[cur_inds][0] == i:
inds_source_, inds_target_ = inds_source[cur_inds], inds_target[cur_inds]
if len(inds_source_) == len(inds_target_):
mapper[inds_source_, inds_target_] = 1
else:
ratio = 1 / len(inds_target_)
for i_t in inds_target_:
mapper[inds_source_, i_t] = ratio
cur_inds += 1
i += len(inds_source_)
j += len(inds_target_)
elif cur_inds < len(inds_source):
mapper[i, j] = 1
i += 1
j += 1
else:
mapper[j, j] = 1
i += 1
j += 1
return torch.from_numpy(mapper).float()
def get_replacement_mapper(prompts, tokenizer, max_len=77):
x_seq = prompts[0]
mappers = []
for i in range(1, len(prompts)):
mapper = get_replacement_mapper_(x_seq, prompts[i], tokenizer, max_len)
mappers.append(mapper)
return torch.stack(mappers)
### util functions for ReweightEdit
def get_equalizer(
text: str, word_select: Union[int, Tuple[int, ...]], values: Union[List[float], Tuple[float, ...]], tokenizer
):
if isinstance(word_select, (int, str)):
word_select = (word_select,)
equalizer = torch.ones(len(values), 77)
values = torch.tensor(values, dtype=torch.float32)
for word in word_select:
inds = get_word_inds(text, word, tokenizer)
equalizer[:, inds] = values
return equalizer
### util functions for RefinementEdit
class ScoreParams:
def __init__(self, gap, match, mismatch):
self.gap = gap
self.match = match
self.mismatch = mismatch
def mis_match_char(self, x, y):
if x != y:
return self.mismatch
else:
return self.match
def get_matrix(size_x, size_y, gap):
matrix = np.zeros((size_x + 1, size_y + 1), dtype=np.int32)
matrix[0, 1:] = (np.arange(size_y) + 1) * gap
matrix[1:, 0] = (np.arange(size_x) + 1) * gap
return matrix
def get_traceback_matrix(size_x, size_y):
matrix = np.zeros((size_x + 1, size_y + 1), dtype=np.int32)
matrix[0, 1:] = 1
matrix[1:, 0] = 2
matrix[0, 0] = 4
return matrix
def global_align(x, y, score):
matrix = get_matrix(len(x), len(y), score.gap)
trace_back = get_traceback_matrix(len(x), len(y))
for i in range(1, len(x) + 1):
for j in range(1, len(y) + 1):
left = matrix[i, j - 1] + score.gap
up = matrix[i - 1, j] + score.gap
diag = matrix[i - 1, j - 1] + score.mis_match_char(x[i - 1], y[j - 1])
matrix[i, j] = max(left, up, diag)
if matrix[i, j] == left:
trace_back[i, j] = 1
elif matrix[i, j] == up:
trace_back[i, j] = 2
else:
trace_back[i, j] = 3
return matrix, trace_back
def get_aligned_sequences(x, y, trace_back):
x_seq = []
y_seq = []
i = len(x)
j = len(y)
mapper_y_to_x = []
while i > 0 or j > 0:
if trace_back[i, j] == 3:
x_seq.append(x[i - 1])
y_seq.append(y[j - 1])
i = i - 1
j = j - 1
mapper_y_to_x.append((j, i))
elif trace_back[i][j] == 1:
x_seq.append("-")
y_seq.append(y[j - 1])
j = j - 1
mapper_y_to_x.append((j, -1))
elif trace_back[i][j] == 2:
x_seq.append(x[i - 1])
y_seq.append("-")
i = i - 1
elif trace_back[i][j] == 4:
break
mapper_y_to_x.reverse()
return x_seq, y_seq, torch.tensor(mapper_y_to_x, dtype=torch.int64)
def get_mapper(x: str, y: str, tokenizer, max_len=77):
x_seq = tokenizer.encode(x)
y_seq = tokenizer.encode(y)
score = ScoreParams(0, 1, -1)
matrix, trace_back = global_align(x_seq, y_seq, score)
mapper_base = get_aligned_sequences(x_seq, y_seq, trace_back)[-1]
alphas = torch.ones(max_len)
alphas[: mapper_base.shape[0]] = mapper_base[:, 1].ne(-1).float()
mapper = torch.zeros(max_len, dtype=torch.int64)
mapper[: mapper_base.shape[0]] = mapper_base[:, 1]
mapper[mapper_base.shape[0] :] = len(y_seq) + torch.arange(max_len - len(y_seq))
return mapper, alphas
def get_refinement_mapper(prompts, tokenizer, max_len=77):
x_seq = prompts[0]
mappers, alphas = [], []
for i in range(1, len(prompts)):
mapper, alpha = get_mapper(x_seq, prompts[i], tokenizer, max_len)
mappers.append(mapper)
alphas.append(alpha)
return torch.stack(mappers), torch.stack(alphas)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/tiled_upscaling.py
|
# Copyright 2023 Peter Willemsen <peter@codebuffet.co>. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import math
from typing import Callable, List, Optional, Union
import numpy as np
import PIL.Image
import torch
from PIL import Image
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale import StableDiffusionUpscalePipeline
from diffusers.schedulers import DDIMScheduler, DDPMScheduler, LMSDiscreteScheduler, PNDMScheduler
def make_transparency_mask(size, overlap_pixels, remove_borders=[]):
size_x = size[0] - overlap_pixels * 2
size_y = size[1] - overlap_pixels * 2
for letter in ["l", "r"]:
if letter in remove_borders:
size_x += overlap_pixels
for letter in ["t", "b"]:
if letter in remove_borders:
size_y += overlap_pixels
mask = np.ones((size_y, size_x), dtype=np.uint8) * 255
mask = np.pad(mask, mode="linear_ramp", pad_width=overlap_pixels, end_values=0)
if "l" in remove_borders:
mask = mask[:, overlap_pixels : mask.shape[1]]
if "r" in remove_borders:
mask = mask[:, 0 : mask.shape[1] - overlap_pixels]
if "t" in remove_borders:
mask = mask[overlap_pixels : mask.shape[0], :]
if "b" in remove_borders:
mask = mask[0 : mask.shape[0] - overlap_pixels, :]
return mask
def clamp(n, smallest, largest):
return max(smallest, min(n, largest))
def clamp_rect(rect: [int], min: [int], max: [int]):
return (
clamp(rect[0], min[0], max[0]),
clamp(rect[1], min[1], max[1]),
clamp(rect[2], min[0], max[0]),
clamp(rect[3], min[1], max[1]),
)
def add_overlap_rect(rect: [int], overlap: int, image_size: [int]):
rect = list(rect)
rect[0] -= overlap
rect[1] -= overlap
rect[2] += overlap
rect[3] += overlap
rect = clamp_rect(rect, [0, 0], [image_size[0], image_size[1]])
return rect
def squeeze_tile(tile, original_image, original_slice, slice_x):
result = Image.new("RGB", (tile.size[0] + original_slice, tile.size[1]))
result.paste(
original_image.resize((tile.size[0], tile.size[1]), Image.BICUBIC).crop(
(slice_x, 0, slice_x + original_slice, tile.size[1])
),
(0, 0),
)
result.paste(tile, (original_slice, 0))
return result
def unsqueeze_tile(tile, original_image_slice):
crop_rect = (original_image_slice * 4, 0, tile.size[0], tile.size[1])
tile = tile.crop(crop_rect)
return tile
def next_divisible(n, d):
divisor = n % d
return n - divisor
class StableDiffusionTiledUpscalePipeline(StableDiffusionUpscalePipeline):
r"""
Pipeline for tile-based text-guided image super-resolution using Stable Diffusion 2, trading memory for compute
to create gigantic images.
This model inherits from [`StableDiffusionUpscalePipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
low_res_scheduler ([`SchedulerMixin`]):
A scheduler used to add initial noise to the low res conditioning image. It must be an instance of
[`DDPMScheduler`].
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
low_res_scheduler: DDPMScheduler,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
max_noise_level: int = 350,
):
super().__init__(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
low_res_scheduler=low_res_scheduler,
scheduler=scheduler,
max_noise_level=max_noise_level,
)
def _process_tile(self, original_image_slice, x, y, tile_size, tile_border, image, final_image, **kwargs):
torch.manual_seed(0)
crop_rect = (
min(image.size[0] - (tile_size + original_image_slice), x * tile_size),
min(image.size[1] - (tile_size + original_image_slice), y * tile_size),
min(image.size[0], (x + 1) * tile_size),
min(image.size[1], (y + 1) * tile_size),
)
crop_rect_with_overlap = add_overlap_rect(crop_rect, tile_border, image.size)
tile = image.crop(crop_rect_with_overlap)
translated_slice_x = ((crop_rect[0] + ((crop_rect[2] - crop_rect[0]) / 2)) / image.size[0]) * tile.size[0]
translated_slice_x = translated_slice_x - (original_image_slice / 2)
translated_slice_x = max(0, translated_slice_x)
to_input = squeeze_tile(tile, image, original_image_slice, translated_slice_x)
orig_input_size = to_input.size
to_input = to_input.resize((tile_size, tile_size), Image.BICUBIC)
upscaled_tile = super(StableDiffusionTiledUpscalePipeline, self).__call__(image=to_input, **kwargs).images[0]
upscaled_tile = upscaled_tile.resize((orig_input_size[0] * 4, orig_input_size[1] * 4), Image.BICUBIC)
upscaled_tile = unsqueeze_tile(upscaled_tile, original_image_slice)
upscaled_tile = upscaled_tile.resize((tile.size[0] * 4, tile.size[1] * 4), Image.BICUBIC)
remove_borders = []
if x == 0:
remove_borders.append("l")
elif crop_rect[2] == image.size[0]:
remove_borders.append("r")
if y == 0:
remove_borders.append("t")
elif crop_rect[3] == image.size[1]:
remove_borders.append("b")
transparency_mask = Image.fromarray(
make_transparency_mask(
(upscaled_tile.size[0], upscaled_tile.size[1]), tile_border * 4, remove_borders=remove_borders
),
mode="L",
)
final_image.paste(
upscaled_tile, (crop_rect_with_overlap[0] * 4, crop_rect_with_overlap[1] * 4), transparency_mask
)
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
image: Union[PIL.Image.Image, List[PIL.Image.Image]],
num_inference_steps: int = 75,
guidance_scale: float = 9.0,
noise_level: int = 50,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
tile_size: int = 128,
tile_border: int = 32,
original_image_slice: int = 32,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
image (`PIL.Image.Image` or List[`PIL.Image.Image`] or `torch.FloatTensor`):
`Image`, or tensor representing an image batch which will be upscaled. *
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
tile_size (`int`, *optional*):
The size of the tiles. Too big can result in an OOM-error.
tile_border (`int`, *optional*):
The number of pixels around a tile to consider (bigger means less seams, too big can lead to an OOM-error).
original_image_slice (`int`, *optional*):
The amount of pixels of the original image to calculate with the current tile (bigger means more depth
is preserved, less blur occurs in the final image, too big can lead to an OOM-error or loss in detail).
callback (`Callable`, *optional*):
A function that take a callback function with a single argument, a dict,
that contains the (partially) processed image under "image",
as well as the progress (0 to 1, where 1 is completed) under "progress".
Returns: A PIL.Image that is 4 times larger than the original input image.
"""
final_image = Image.new("RGB", (image.size[0] * 4, image.size[1] * 4))
tcx = math.ceil(image.size[0] / tile_size)
tcy = math.ceil(image.size[1] / tile_size)
total_tile_count = tcx * tcy
current_count = 0
for y in range(tcy):
for x in range(tcx):
self._process_tile(
original_image_slice,
x,
y,
tile_size,
tile_border,
image,
final_image,
prompt=prompt,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
noise_level=noise_level,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
latents=latents,
)
current_count += 1
if callback is not None:
callback({"progress": current_count / total_tile_count, "image": final_image})
return final_image
def main():
# Run a demo
model_id = "stabilityai/stable-diffusion-x4-upscaler"
pipe = StableDiffusionTiledUpscalePipeline.from_pretrained(model_id, revision="fp16", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
image = Image.open("../../docs/source/imgs/diffusers_library.jpg")
def callback(obj):
print(f"progress: {obj['progress']:.4f}")
obj["image"].save("diffusers_library_progress.jpg")
final_image = pipe(image=image, prompt="Black font, white background, vector", noise_level=40, callback=callback)
final_image.save("diffusers_library.jpg")
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/latent_consistency_interpolate.py
|
import inspect
from typing import Any, Callable, Dict, List, Optional, Union
import numpy as np
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers.image_processor import VaeImageProcessor
from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.models.lora import adjust_lora_scale_text_encoder
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput, StableDiffusionSafetyChecker
from diffusers.schedulers import LCMScheduler
from diffusers.utils import (
USE_PEFT_BACKEND,
deprecate,
logging,
replace_example_docstring,
scale_lora_layers,
unscale_lora_layers,
)
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
>>> import numpy as np
>>> from diffusers import DiffusionPipeline
>>> pipe = DiffusionPipeline.from_pretrained("SimianLuo/LCM_Dreamshaper_v7", custom_pipeline="latent_consistency_interpolate")
>>> # To save GPU memory, torch.float16 can be used, but it may compromise image quality.
>>> pipe.to(torch_device="cuda", torch_dtype=torch.float32)
>>> prompts = ["A cat", "A dog", "A horse"]
>>> num_inference_steps = 4
>>> num_interpolation_steps = 24
>>> seed = 1337
>>> torch.manual_seed(seed)
>>> np.random.seed(seed)
>>> images = pipe(
prompt=prompts,
height=512,
width=512,
num_inference_steps=num_inference_steps,
num_interpolation_steps=num_interpolation_steps,
guidance_scale=8.0,
embedding_interpolation_type="lerp",
latent_interpolation_type="slerp",
process_batch_size=4, # Make it higher or lower based on your GPU memory
generator=torch.Generator(seed),
)
>>> # Save the images as a video
>>> import imageio
>>> from PIL import Image
>>> def pil_to_video(images: List[Image.Image], filename: str, fps: int = 60) -> None:
frames = [np.array(image) for image in images]
with imageio.get_writer(filename, fps=fps) as video_writer:
for frame in frames:
video_writer.append_data(frame)
>>> pil_to_video(images, "lcm_interpolate.mp4", fps=24)
```
"""
def lerp(
v0: Union[torch.Tensor, np.ndarray],
v1: Union[torch.Tensor, np.ndarray],
t: Union[float, torch.Tensor, np.ndarray],
) -> Union[torch.Tensor, np.ndarray]:
"""
Linearly interpolate between two vectors/tensors.
Args:
v0 (`torch.Tensor` or `np.ndarray`): First vector/tensor.
v1 (`torch.Tensor` or `np.ndarray`): Second vector/tensor.
t: (`float`, `torch.Tensor`, or `np.ndarray`):
Interpolation factor. If float, must be between 0 and 1. If np.ndarray or
torch.Tensor, must be one dimensional with values between 0 and 1.
Returns:
Union[torch.Tensor, np.ndarray]
Interpolated vector/tensor between v0 and v1.
"""
inputs_are_torch = False
t_is_float = False
if isinstance(v0, torch.Tensor):
inputs_are_torch = True
input_device = v0.device
v0 = v0.cpu().numpy()
v1 = v1.cpu().numpy()
if isinstance(t, torch.Tensor):
inputs_are_torch = True
input_device = t.device
t = t.cpu().numpy()
elif isinstance(t, float):
t_is_float = True
t = np.array([t])
t = t[..., None]
v0 = v0[None, ...]
v1 = v1[None, ...]
v2 = (1 - t) * v0 + t * v1
if t_is_float and v0.ndim > 1:
assert v2.shape[0] == 1
v2 = np.squeeze(v2, axis=0)
if inputs_are_torch:
v2 = torch.from_numpy(v2).to(input_device)
return v2
def slerp(
v0: Union[torch.Tensor, np.ndarray],
v1: Union[torch.Tensor, np.ndarray],
t: Union[float, torch.Tensor, np.ndarray],
DOT_THRESHOLD=0.9995,
) -> Union[torch.Tensor, np.ndarray]:
"""
Spherical linear interpolation between two vectors/tensors.
Args:
v0 (`torch.Tensor` or `np.ndarray`): First vector/tensor.
v1 (`torch.Tensor` or `np.ndarray`): Second vector/tensor.
t: (`float`, `torch.Tensor`, or `np.ndarray`):
Interpolation factor. If float, must be between 0 and 1. If np.ndarray or
torch.Tensor, must be one dimensional with values between 0 and 1.
DOT_THRESHOLD (`float`, *optional*, default=0.9995):
Threshold for when to use linear interpolation instead of spherical interpolation.
Returns:
`torch.Tensor` or `np.ndarray`:
Interpolated vector/tensor between v0 and v1.
"""
inputs_are_torch = False
t_is_float = False
if isinstance(v0, torch.Tensor):
inputs_are_torch = True
input_device = v0.device
v0 = v0.cpu().numpy()
v1 = v1.cpu().numpy()
if isinstance(t, torch.Tensor):
inputs_are_torch = True
input_device = t.device
t = t.cpu().numpy()
elif isinstance(t, float):
t_is_float = True
t = np.array([t], dtype=v0.dtype)
dot = np.sum(v0 * v1 / (np.linalg.norm(v0) * np.linalg.norm(v1)))
if np.abs(dot) > DOT_THRESHOLD:
# v1 and v2 are close to parallel
# Use linear interpolation instead
v2 = lerp(v0, v1, t)
else:
theta_0 = np.arccos(dot)
sin_theta_0 = np.sin(theta_0)
theta_t = theta_0 * t
sin_theta_t = np.sin(theta_t)
s0 = np.sin(theta_0 - theta_t) / sin_theta_0
s1 = sin_theta_t / sin_theta_0
s0 = s0[..., None]
s1 = s1[..., None]
v0 = v0[None, ...]
v1 = v1[None, ...]
v2 = s0 * v0 + s1 * v1
if t_is_float and v0.ndim > 1:
assert v2.shape[0] == 1
v2 = np.squeeze(v2, axis=0)
if inputs_are_torch:
v2 = torch.from_numpy(v2).to(input_device)
return v2
class LatentConsistencyModelWalkPipeline(
DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin, FromSingleFileMixin
):
r"""
Pipeline for text-to-image generation using a latent consistency model.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
The pipeline also inherits the following loading methods:
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
text_encoder ([`~transformers.CLIPTextModel`]):
Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
tokenizer ([`~transformers.CLIPTokenizer`]):
A `CLIPTokenizer` to tokenize text.
unet ([`UNet2DConditionModel`]):
A `UNet2DConditionModel` to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Currently only
supports [`LCMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for more details
about a model's potential harms.
feature_extractor ([`~transformers.CLIPImageProcessor`]):
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
requires_safety_checker (`bool`, *optional*, defaults to `True`):
Whether the pipeline requires a safety checker component.
"""
model_cpu_offload_seq = "text_encoder->unet->vae"
_optional_components = ["safety_checker", "feature_extractor"]
_exclude_from_cpu_offload = ["safety_checker"]
_callback_tensor_inputs = ["latents", "denoised", "prompt_embeds", "w_embedding"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: LCMScheduler,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.register_to_config(requires_safety_checker=requires_safety_checker)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
def enable_vae_slicing(self):
r"""
Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
"""
self.vae.enable_slicing()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
def disable_vae_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
computing decoding in one step.
"""
self.vae.disable_slicing()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
def enable_vae_tiling(self):
r"""
Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
processing larger images.
"""
self.vae.enable_tiling()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
def disable_vae_tiling(self):
r"""
Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
computing decoding in one step.
"""
self.vae.disable_tiling()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_freeu
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
r"""Enables the FreeU mechanism as in https://arxiv.org/abs/2309.11497.
The suffixes after the scaling factors represent the stages where they are being applied.
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of the values
that are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
Args:
s1 (`float`):
Scaling factor for stage 1 to attenuate the contributions of the skip features. This is done to
mitigate "oversmoothing effect" in the enhanced denoising process.
s2 (`float`):
Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to
mitigate "oversmoothing effect" in the enhanced denoising process.
b1 (`float`): Scaling factor for stage 1 to amplify the contributions of backbone features.
b2 (`float`): Scaling factor for stage 2 to amplify the contributions of backbone features.
"""
if not hasattr(self, "unet"):
raise ValueError("The pipeline must have `unet` for using FreeU.")
self.unet.enable_freeu(s1=s1, s2=s2, b1=b1, b2=b2)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_freeu
def disable_freeu(self):
"""Disables the FreeU mechanism if enabled."""
self.unet.disable_freeu()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.encode_prompt
def encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
clip_skip: Optional[int] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
lora_scale (`float`, *optional*):
A LoRA scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
"""
# set lora scale so that monkey patched LoRA
# function of text encoder can correctly access it
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
self._lora_scale = lora_scale
# dynamically adjust the LoRA scale
if not USE_PEFT_BACKEND:
adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
else:
scale_lora_layers(self.text_encoder, lora_scale)
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# textual inversion: procecss multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
if clip_skip is None:
prompt_embeds = self.text_encoder(text_input_ids.to(device), attention_mask=attention_mask)
prompt_embeds = prompt_embeds[0]
else:
prompt_embeds = self.text_encoder(
text_input_ids.to(device), attention_mask=attention_mask, output_hidden_states=True
)
# Access the `hidden_states` first, that contains a tuple of
# all the hidden states from the encoder layers. Then index into
# the tuple to access the hidden states from the desired layer.
prompt_embeds = prompt_embeds[-1][-(clip_skip + 1)]
# We also need to apply the final LayerNorm here to not mess with the
# representations. The `last_hidden_states` that we typically use for
# obtaining the final prompt representations passes through the LayerNorm
# layer.
prompt_embeds = self.text_encoder.text_model.final_layer_norm(prompt_embeds)
if self.text_encoder is not None:
prompt_embeds_dtype = self.text_encoder.dtype
elif self.unet is not None:
prompt_embeds_dtype = self.unet.dtype
else:
prompt_embeds_dtype = prompt_embeds.dtype
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif prompt is not None and type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
# textual inversion: procecss multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
if isinstance(self, LoraLoaderMixin) and USE_PEFT_BACKEND:
# Retrieve the original scale by scaling back the LoRA layers
unscale_lora_layers(self.text_encoder, lora_scale)
return prompt_embeds, negative_prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is None:
has_nsfw_concept = None
else:
if torch.is_tensor(image):
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
else:
feature_extractor_input = self.image_processor.numpy_to_pil(image)
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
return image, has_nsfw_concept
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
"""
See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
Args:
timesteps (`torch.Tensor`):
generate embedding vectors at these timesteps
embedding_dim (`int`, *optional*, defaults to 512):
dimension of the embeddings to generate
dtype:
data type of the generated embeddings
Returns:
`torch.FloatTensor`: Embedding vectors with shape `(len(timesteps), embedding_dim)`
"""
assert len(w.shape) == 1
w = w * 1000.0
half_dim = embedding_dim // 2
emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
emb = w.to(dtype)[:, None] * emb[None, :]
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
if embedding_dim % 2 == 1: # zero pad
emb = torch.nn.functional.pad(emb, (0, 1))
assert emb.shape == (w.shape[0], embedding_dim)
return emb
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
# Currently StableDiffusionPipeline.check_inputs with negative prompt stuff removed
def check_inputs(
self,
prompt: Union[str, List[str]],
height: int,
width: int,
callback_steps: int,
prompt_embeds: Optional[torch.FloatTensor] = None,
callback_on_step_end_tensor_inputs=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if callback_on_step_end_tensor_inputs is not None and not all(
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
):
raise ValueError(
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
@torch.no_grad()
def interpolate_embedding(
self,
start_embedding: torch.FloatTensor,
end_embedding: torch.FloatTensor,
num_interpolation_steps: Union[int, List[int]],
interpolation_type: str,
) -> torch.FloatTensor:
if interpolation_type == "lerp":
interpolation_fn = lerp
elif interpolation_type == "slerp":
interpolation_fn = slerp
else:
raise ValueError(
f"embedding_interpolation_type must be one of ['lerp', 'slerp'], got {interpolation_type}."
)
embedding = torch.cat([start_embedding, end_embedding])
steps = torch.linspace(0, 1, num_interpolation_steps, dtype=embedding.dtype).cpu().numpy()
steps = np.expand_dims(steps, axis=tuple(range(1, embedding.ndim)))
interpolations = []
# Interpolate between text embeddings
# TODO(aryan): Think of a better way of doing this
# See if it can be done parallelly instead
for i in range(embedding.shape[0] - 1):
interpolations.append(interpolation_fn(embedding[i], embedding[i + 1], steps).squeeze(dim=1))
interpolations = torch.cat(interpolations)
return interpolations
@torch.no_grad()
def interpolate_latent(
self,
start_latent: torch.FloatTensor,
end_latent: torch.FloatTensor,
num_interpolation_steps: Union[int, List[int]],
interpolation_type: str,
) -> torch.FloatTensor:
if interpolation_type == "lerp":
interpolation_fn = lerp
elif interpolation_type == "slerp":
interpolation_fn = slerp
latent = torch.cat([start_latent, end_latent])
steps = torch.linspace(0, 1, num_interpolation_steps, dtype=latent.dtype).cpu().numpy()
steps = np.expand_dims(steps, axis=tuple(range(1, latent.ndim)))
interpolations = []
# Interpolate between latents
# TODO: Think of a better way of doing this
# See if it can be done parallelly instead
for i in range(latent.shape[0] - 1):
interpolations.append(interpolation_fn(latent[i], latent[i + 1], steps).squeeze(dim=1))
return torch.cat(interpolations)
@property
def guidance_scale(self):
return self._guidance_scale
@property
def cross_attention_kwargs(self):
return self._cross_attention_kwargs
@property
def clip_skip(self):
return self._clip_skip
@property
def num_timesteps(self):
return self._num_timesteps
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 4,
num_interpolation_steps: int = 8,
original_inference_steps: int = None,
guidance_scale: float = 8.5,
num_images_per_prompt: Optional[int] = 1,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
clip_skip: Optional[int] = None,
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
embedding_interpolation_type: str = "lerp",
latent_interpolation_type: str = "slerp",
process_batch_size: int = 4,
**kwargs,
):
r"""
The call function to the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
original_inference_steps (`int`, *optional*):
The original number of inference steps use to generate a linearly-spaced timestep schedule, from which
we will draw `num_inference_steps` evenly spaced timesteps from as our final timestep schedule,
following the Skipping-Step method in the paper (see Section 4.3). If not set this will default to the
scheduler's `original_inference_steps` attribute.
guidance_scale (`float`, *optional*, defaults to 7.5):
A higher guidance scale value encourages the model to generate images closely linked to the text
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
Note that the original latent consistency models paper uses a different CFG formulation where the
guidance scales are decreased by 1 (so in the paper formulation CFG is enabled when `guidance_scale >
0`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor is generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
provided, text embeddings are generated from the `prompt` input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
callback_on_step_end (`Callable`, *optional*):
A function that calls at the end of each denoising steps during the inference. The function is called
with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
`callback_on_step_end_tensor_inputs`.
callback_on_step_end_tensor_inputs (`List`, *optional*):
The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
`._callback_tensor_inputs` attribute of your pipeine class.
embedding_interpolation_type (`str`, *optional*, defaults to `"lerp"`):
The type of interpolation to use for interpolating between text embeddings. Choose between `"lerp"` and `"slerp"`.
latent_interpolation_type (`str`, *optional*, defaults to `"slerp"`):
The type of interpolation to use for interpolating between latents. Choose between `"lerp"` and `"slerp"`.
process_batch_size (`int`, *optional*, defaults to 4):
The batch size to use for processing the images. This is useful when generating a large number of images
and you want to avoid running out of memory.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
otherwise a `tuple` is returned where the first element is a list with the generated images and the
second element is a list of `bool`s indicating whether the corresponding generated image contains
"not-safe-for-work" (nsfw) content.
"""
callback = kwargs.pop("callback", None)
callback_steps = kwargs.pop("callback_steps", None)
if callback is not None:
deprecate(
"callback",
"1.0.0",
"Passing `callback` as an input argument to `__call__` is deprecated, consider use `callback_on_step_end`",
)
if callback_steps is not None:
deprecate(
"callback_steps",
"1.0.0",
"Passing `callback_steps` as an input argument to `__call__` is deprecated, consider use `callback_on_step_end`",
)
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs. Raise error if not correct
self.check_inputs(prompt, height, width, callback_steps, prompt_embeds, callback_on_step_end_tensor_inputs)
self._guidance_scale = guidance_scale
self._clip_skip = clip_skip
self._cross_attention_kwargs = cross_attention_kwargs
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if batch_size < 2:
raise ValueError(f"`prompt` must have length of atleast 2 but found {batch_size}")
if num_images_per_prompt != 1:
raise ValueError("`num_images_per_prompt` must be `1` as no other value is supported yet")
if prompt_embeds is not None:
raise ValueError("`prompt_embeds` must be None since it is not supported yet")
if latents is not None:
raise ValueError("`latents` must be None since it is not supported yet")
device = self._execution_device
# do_classifier_free_guidance = guidance_scale > 1.0
lora_scale = (
self.cross_attention_kwargs.get("scale", None) if self.cross_attention_kwargs is not None else None
)
self.scheduler.set_timesteps(num_inference_steps, device, original_inference_steps=original_inference_steps)
timesteps = self.scheduler.timesteps
num_channels_latents = self.unet.config.in_channels
# bs = batch_size * num_images_per_prompt
# 3. Encode initial input prompt
prompt_embeds_1, _ = self.encode_prompt(
prompt[:1],
device,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=False,
negative_prompt=None,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=None,
lora_scale=lora_scale,
clip_skip=self.clip_skip,
)
# 4. Prepare initial latent variables
latents_1 = self.prepare_latents(
1,
num_channels_latents,
height,
width,
prompt_embeds_1.dtype,
device,
generator,
latents,
)
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, None)
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
self._num_timesteps = len(timesteps)
images = []
# 5. Iterate over prompts and perform latent walk. Note that we do this two prompts at a time
# otherwise the memory usage ends up being too high.
with self.progress_bar(total=batch_size - 1) as prompt_progress_bar:
for i in range(1, batch_size):
# 6. Encode current prompt
prompt_embeds_2, _ = self.encode_prompt(
prompt[i : i + 1],
device,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=False,
negative_prompt=None,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=None,
lora_scale=lora_scale,
clip_skip=self.clip_skip,
)
# 7. Prepare current latent variables
latents_2 = self.prepare_latents(
1,
num_channels_latents,
height,
width,
prompt_embeds_2.dtype,
device,
generator,
latents,
)
# 8. Interpolate between previous and current prompt embeddings and latents
inference_embeddings = self.interpolate_embedding(
start_embedding=prompt_embeds_1,
end_embedding=prompt_embeds_2,
num_interpolation_steps=num_interpolation_steps,
interpolation_type=embedding_interpolation_type,
)
inference_latents = self.interpolate_latent(
start_latent=latents_1,
end_latent=latents_2,
num_interpolation_steps=num_interpolation_steps,
interpolation_type=latent_interpolation_type,
)
next_prompt_embeds = inference_embeddings[-1:].detach().clone()
next_latents = inference_latents[-1:].detach().clone()
bs = num_interpolation_steps
# 9. Perform inference in batches. Note the use of `process_batch_size` to control the batch size
# of the inference. This is useful for reducing memory usage and can be configured based on the
# available GPU memory.
with self.progress_bar(
total=(bs + process_batch_size - 1) // process_batch_size
) as batch_progress_bar:
for batch_index in range(0, bs, process_batch_size):
batch_inference_latents = inference_latents[batch_index : batch_index + process_batch_size]
batch_inference_embedddings = inference_embeddings[
batch_index : batch_index + process_batch_size
]
self.scheduler.set_timesteps(
num_inference_steps, device, original_inference_steps=original_inference_steps
)
timesteps = self.scheduler.timesteps
current_bs = batch_inference_embedddings.shape[0]
w = torch.tensor(self.guidance_scale - 1).repeat(current_bs)
w_embedding = self.get_guidance_scale_embedding(
w, embedding_dim=self.unet.config.time_cond_proj_dim
).to(device=device, dtype=latents_1.dtype)
# 10. Perform inference for current batch
with self.progress_bar(total=num_inference_steps) as progress_bar:
for index, t in enumerate(timesteps):
batch_inference_latents = batch_inference_latents.to(batch_inference_embedddings.dtype)
# model prediction (v-prediction, eps, x)
model_pred = self.unet(
batch_inference_latents,
t,
timestep_cond=w_embedding,
encoder_hidden_states=batch_inference_embedddings,
cross_attention_kwargs=self.cross_attention_kwargs,
return_dict=False,
)[0]
# compute the previous noisy sample x_t -> x_t-1
batch_inference_latents, denoised = self.scheduler.step(
model_pred, t, batch_inference_latents, **extra_step_kwargs, return_dict=False
)
if callback_on_step_end is not None:
callback_kwargs = {}
for k in callback_on_step_end_tensor_inputs:
callback_kwargs[k] = locals()[k]
callback_outputs = callback_on_step_end(self, index, t, callback_kwargs)
batch_inference_latents = callback_outputs.pop("latents", batch_inference_latents)
batch_inference_embedddings = callback_outputs.pop(
"prompt_embeds", batch_inference_embedddings
)
w_embedding = callback_outputs.pop("w_embedding", w_embedding)
denoised = callback_outputs.pop("denoised", denoised)
# call the callback, if provided
if index == len(timesteps) - 1 or (
(index + 1) > num_warmup_steps and (index + 1) % self.scheduler.order == 0
):
progress_bar.update()
if callback is not None and index % callback_steps == 0:
step_idx = index // getattr(self.scheduler, "order", 1)
callback(step_idx, t, batch_inference_latents)
denoised = denoised.to(batch_inference_embedddings.dtype)
# Note: This is not supported because you would get black images in your latent walk if
# NSFW concept is detected
# if not output_type == "latent":
# image = self.vae.decode(denoised / self.vae.config.scaling_factor, return_dict=False)[0]
# image, has_nsfw_concept = self.run_safety_checker(image, device, inference_embeddings.dtype)
# else:
# image = denoised
# has_nsfw_concept = None
# if has_nsfw_concept is None:
# do_denormalize = [True] * image.shape[0]
# else:
# do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.vae.decode(denoised / self.vae.config.scaling_factor, return_dict=False)[0]
do_denormalize = [True] * image.shape[0]
has_nsfw_concept = None
image = self.image_processor.postprocess(
image, output_type=output_type, do_denormalize=do_denormalize
)
images.append(image)
batch_progress_bar.update()
prompt_embeds_1 = next_prompt_embeds
latents_1 = next_latents
prompt_progress_bar.update()
# 11. Determine what should be returned
if output_type == "pil":
images = [image for image_list in images for image in image_list]
elif output_type == "np":
images = np.concatenate(images)
elif output_type == "pt":
images = torch.cat(images)
else:
raise ValueError("`output_type` must be one of 'pil', 'np' or 'pt'.")
# Offload all models
self.maybe_free_model_hooks()
if not return_dict:
return (images, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=images, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/pipeline_zero1to3.py
|
# A diffuser version implementation of Zero1to3 (https://github.com/cvlab-columbia/zero123), ICCV 2023
# by Xin Kong
import inspect
from typing import Any, Callable, Dict, List, Optional, Union
import kornia
import numpy as np
import PIL.Image
import torch
from packaging import version
from transformers import CLIPFeatureExtractor, CLIPVisionModelWithProjection
# from ...configuration_utils import FrozenDict
# from ...models import AutoencoderKL, UNet2DConditionModel
# from ...schedulers import KarrasDiffusionSchedulers
# from ...utils import (
# deprecate,
# is_accelerate_available,
# is_accelerate_version,
# logging,
# randn_tensor,
# replace_example_docstring,
# )
# from ..pipeline_utils import DiffusionPipeline
# from . import StableDiffusionPipelineOutput
# from .safety_checker import StableDiffusionSafetyChecker
from diffusers import AutoencoderKL, DiffusionPipeline, UNet2DConditionModel
from diffusers.configuration_utils import ConfigMixin, FrozenDict
from diffusers.models.modeling_utils import ModelMixin
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput, StableDiffusionSafetyChecker
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
deprecate,
is_accelerate_available,
is_accelerate_version,
logging,
replace_example_docstring,
)
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
# todo
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
>>> from diffusers import StableDiffusionPipeline
>>> pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
>>> pipe = pipe.to("cuda")
>>> prompt = "a photo of an astronaut riding a horse on mars"
>>> image = pipe(prompt).images[0]
```
"""
class CCProjection(ModelMixin, ConfigMixin):
def __init__(self, in_channel=772, out_channel=768):
super().__init__()
self.in_channel = in_channel
self.out_channel = out_channel
self.projection = torch.nn.Linear(in_channel, out_channel)
def forward(self, x):
return self.projection(x)
class Zero1to3StableDiffusionPipeline(DiffusionPipeline):
r"""
Pipeline for single view conditioned novel view generation using Zero1to3.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
image_encoder ([`CLIPVisionModelWithProjection`]):
Frozen CLIP image-encoder. Stable Diffusion Image Variation uses the vision portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPVisionModelWithProjection),
specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPFeatureExtractor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
cc_projection ([`CCProjection`]):
Projection layer to project the concated CLIP features and pose embeddings to the original CLIP feature size.
"""
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae: AutoencoderKL,
image_encoder: CLIPVisionModelWithProjection,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPFeatureExtractor,
cc_projection: CCProjection,
requires_safety_checker: bool = True,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
" `clip_sample` should be set to False in the configuration file. Please make sure to update the"
" config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
" future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
" nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
)
deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["clip_sample"] = False
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
version.parse(unet.config._diffusers_version).base_version
) < version.parse("0.9.0.dev0")
is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
deprecation_message = (
"The configuration file of the unet has set the default `sample_size` to smaller than"
" 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
" following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
" CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
" \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
" configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
" in the config might lead to incorrect results in future versions. If you have downloaded this"
" checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
" the `unet/config.json` file"
)
deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(unet.config)
new_config["sample_size"] = 64
unet._internal_dict = FrozenDict(new_config)
self.register_modules(
vae=vae,
image_encoder=image_encoder,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
cc_projection=cc_projection,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.register_to_config(requires_safety_checker=requires_safety_checker)
# self.model_mode = None
def enable_vae_slicing(self):
r"""
Enable sliced VAE decoding.
When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
steps. This is useful to save some memory and allow larger batch sizes.
"""
self.vae.enable_slicing()
def disable_vae_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
computing decoding in one step.
"""
self.vae.disable_slicing()
def enable_vae_tiling(self):
r"""
Enable tiled VAE decoding.
When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
"""
self.vae.enable_tiling()
def disable_vae_tiling(self):
r"""
Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
computing decoding in one step.
"""
self.vae.disable_tiling()
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
`torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
Note that offloading happens on a submodule basis. Memory savings are higher than with
`enable_model_cpu_offload`, but performance is lower.
"""
if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
from accelerate import cpu_offload
else:
raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
device = torch.device(f"cuda:{gpu_id}")
if self.device.type != "cpu":
self.to("cpu", silence_dtype_warnings=True)
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
cpu_offload(cpu_offloaded_model, device)
if self.safety_checker is not None:
cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
def enable_model_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
"""
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
from accelerate import cpu_offload_with_hook
else:
raise ImportError("`enable_model_offload` requires `accelerate v0.17.0` or higher.")
device = torch.device(f"cuda:{gpu_id}")
if self.device.type != "cpu":
self.to("cpu", silence_dtype_warnings=True)
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
hook = None
for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
if self.safety_checker is not None:
_, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
# We'll offload the last model manually.
self.final_offload_hook = hook
@property
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if not hasattr(self.unet, "_hf_hook"):
return self.device
for module in self.unet.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
"""
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
prompt_embeds = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
def CLIP_preprocess(self, x):
dtype = x.dtype
# following openai's implementation
# TODO HF OpenAI CLIP preprocessing issue https://github.com/huggingface/transformers/issues/22505#issuecomment-1650170741
# follow openai preprocessing to keep exact same, input tensor [-1, 1], otherwise the preprocessing will be different, https://github.com/huggingface/transformers/pull/22608
if isinstance(x, torch.Tensor):
if x.min() < -1.0 or x.max() > 1.0:
raise ValueError("Expected input tensor to have values in the range [-1, 1]")
x = kornia.geometry.resize(
x.to(torch.float32), (224, 224), interpolation="bicubic", align_corners=True, antialias=False
).to(dtype=dtype)
x = (x + 1.0) / 2.0
# renormalize according to clip
x = kornia.enhance.normalize(
x, torch.Tensor([0.48145466, 0.4578275, 0.40821073]), torch.Tensor([0.26862954, 0.26130258, 0.27577711])
)
return x
# from image_variation
def _encode_image(self, image, device, num_images_per_prompt, do_classifier_free_guidance):
dtype = next(self.image_encoder.parameters()).dtype
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
)
if isinstance(image, torch.Tensor):
# Batch single image
if image.ndim == 3:
assert image.shape[0] == 3, "Image outside a batch should be of shape (3, H, W)"
image = image.unsqueeze(0)
assert image.ndim == 4, "Image must have 4 dimensions"
# Check image is in [-1, 1]
if image.min() < -1 or image.max() > 1:
raise ValueError("Image should be in [-1, 1] range")
else:
# preprocess image
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
image = image.to(device=device, dtype=dtype)
image = self.CLIP_preprocess(image)
# if not isinstance(image, torch.Tensor):
# # 0-255
# print("Warning: image is processed by hf's preprocess, which is different from openai original's.")
# image = self.feature_extractor(images=image, return_tensors="pt").pixel_values
image_embeddings = self.image_encoder(image).image_embeds.to(dtype=dtype)
image_embeddings = image_embeddings.unsqueeze(1)
# duplicate image embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = image_embeddings.shape
image_embeddings = image_embeddings.repeat(1, num_images_per_prompt, 1)
image_embeddings = image_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
if do_classifier_free_guidance:
negative_prompt_embeds = torch.zeros_like(image_embeddings)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
image_embeddings = torch.cat([negative_prompt_embeds, image_embeddings])
return image_embeddings
def _encode_pose(self, pose, device, num_images_per_prompt, do_classifier_free_guidance):
dtype = next(self.cc_projection.parameters()).dtype
if isinstance(pose, torch.Tensor):
pose_embeddings = pose.unsqueeze(1).to(device=device, dtype=dtype)
else:
if isinstance(pose[0], list):
pose = torch.Tensor(pose)
else:
pose = torch.Tensor([pose])
x, y, z = pose[:, 0].unsqueeze(1), pose[:, 1].unsqueeze(1), pose[:, 2].unsqueeze(1)
pose_embeddings = (
torch.cat([torch.deg2rad(x), torch.sin(torch.deg2rad(y)), torch.cos(torch.deg2rad(y)), z], dim=-1)
.unsqueeze(1)
.to(device=device, dtype=dtype)
) # B, 1, 4
# duplicate pose embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = pose_embeddings.shape
pose_embeddings = pose_embeddings.repeat(1, num_images_per_prompt, 1)
pose_embeddings = pose_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
if do_classifier_free_guidance:
negative_prompt_embeds = torch.zeros_like(pose_embeddings)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
pose_embeddings = torch.cat([negative_prompt_embeds, pose_embeddings])
return pose_embeddings
def _encode_image_with_pose(self, image, pose, device, num_images_per_prompt, do_classifier_free_guidance):
img_prompt_embeds = self._encode_image(image, device, num_images_per_prompt, False)
pose_prompt_embeds = self._encode_pose(pose, device, num_images_per_prompt, False)
prompt_embeds = torch.cat([img_prompt_embeds, pose_prompt_embeds], dim=-1)
prompt_embeds = self.cc_projection(prompt_embeds)
# prompt_embeds = img_prompt_embeds
# follow 0123, add negative prompt, after projection
if do_classifier_free_guidance:
negative_prompt = torch.zeros_like(prompt_embeds)
prompt_embeds = torch.cat([negative_prompt, prompt_embeds])
return prompt_embeds
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
else:
has_nsfw_concept = None
return image, has_nsfw_concept
def decode_latents(self, latents):
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_inputs(self, image, height, width, callback_steps):
if (
not isinstance(image, torch.Tensor)
and not isinstance(image, PIL.Image.Image)
and not isinstance(image, list)
):
raise ValueError(
"`image` has to be of type `torch.FloatTensor` or `PIL.Image.Image` or `List[PIL.Image.Image]` but is"
f" {type(image)}"
)
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def prepare_img_latents(self, image, batch_size, dtype, device, generator=None, do_classifier_free_guidance=False):
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
)
if isinstance(image, torch.Tensor):
# Batch single image
if image.ndim == 3:
assert image.shape[0] == 3, "Image outside a batch should be of shape (3, H, W)"
image = image.unsqueeze(0)
assert image.ndim == 4, "Image must have 4 dimensions"
# Check image is in [-1, 1]
if image.min() < -1 or image.max() > 1:
raise ValueError("Image should be in [-1, 1] range")
else:
# preprocess image
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
image = image.to(device=device, dtype=dtype)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if isinstance(generator, list):
init_latents = [
self.vae.encode(image[i : i + 1]).latent_dist.mode(generator[i])
for i in range(batch_size) # sample
]
init_latents = torch.cat(init_latents, dim=0)
else:
init_latents = self.vae.encode(image).latent_dist.mode()
# init_latents = self.vae.config.scaling_factor * init_latents # todo in original zero123's inference gradio_new.py, model.encode_first_stage() is not scaled by scaling_factor
if batch_size > init_latents.shape[0]:
# init_latents = init_latents.repeat(batch_size // init_latents.shape[0], 1, 1, 1)
num_images_per_prompt = batch_size // init_latents.shape[0]
# duplicate image latents for each generation per prompt, using mps friendly method
bs_embed, emb_c, emb_h, emb_w = init_latents.shape
init_latents = init_latents.unsqueeze(1)
init_latents = init_latents.repeat(1, num_images_per_prompt, 1, 1, 1)
init_latents = init_latents.view(bs_embed * num_images_per_prompt, emb_c, emb_h, emb_w)
# init_latents = torch.cat([init_latents]*2) if do_classifier_free_guidance else init_latents # follow zero123
init_latents = (
torch.cat([torch.zeros_like(init_latents), init_latents]) if do_classifier_free_guidance else init_latents
)
init_latents = init_latents.to(device=device, dtype=dtype)
return init_latents
# def load_cc_projection(self, pretrained_weights=None):
# self.cc_projection = torch.nn.Linear(772, 768)
# torch.nn.init.eye_(list(self.cc_projection.parameters())[0][:768, :768])
# torch.nn.init.zeros_(list(self.cc_projection.parameters())[1])
# if pretrained_weights is not None:
# self.cc_projection.load_state_dict(pretrained_weights)
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
input_imgs: Union[torch.FloatTensor, PIL.Image.Image] = None,
prompt_imgs: Union[torch.FloatTensor, PIL.Image.Image] = None,
poses: Union[List[float], List[List[float]]] = None,
torch_dtype=torch.float32,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 3.0,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
controlnet_conditioning_scale: float = 1.0,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
input_imgs (`PIL` or `List[PIL]`, *optional*):
The single input image for each 3D object
prompt_imgs (`PIL` or `List[PIL]`, *optional*):
Same as input_imgs, but will be used later as an image prompt condition, encoded by CLIP feature
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
`self.processor` in
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs. Raise error if not correct
# input_image = hint_imgs
self.check_inputs(input_imgs, height, width, callback_steps)
# 2. Define call parameters
if isinstance(input_imgs, PIL.Image.Image):
batch_size = 1
elif isinstance(input_imgs, list):
batch_size = len(input_imgs)
else:
batch_size = input_imgs.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input image with pose as prompt
prompt_embeds = self._encode_image_with_pose(
prompt_imgs, poses, device, num_images_per_prompt, do_classifier_free_guidance
)
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 5. Prepare latent variables
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
4,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 6. Prepare image latents
img_latents = self.prepare_img_latents(
input_imgs,
batch_size * num_images_per_prompt,
prompt_embeds.dtype,
device,
generator,
do_classifier_free_guidance,
)
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
latent_model_input = torch.cat([latent_model_input, img_latents], dim=1)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=prompt_embeds).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
# latents = self.scheduler.step(noise_pred.to(dtype=torch.float32), t, latents.to(dtype=torch.float32)).prev_sample.to(prompt_embeds.dtype)
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# 8. Post-processing
has_nsfw_concept = None
if output_type == "latent":
image = latents
elif output_type == "pil":
# 8. Post-processing
image = self.decode_latents(latents)
# 10. Convert to PIL
image = self.numpy_to_pil(image)
else:
# 8. Post-processing
image = self.decode_latents(latents)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/run_tensorrt_controlnet.py
|
import argparse
import atexit
import inspect
import os
import time
import warnings
from typing import Any, Callable, Dict, List, Optional, Union
import numpy as np
import PIL.Image
import pycuda.driver as cuda
import tensorrt as trt
import torch
from PIL import Image
from pycuda.tools import make_default_context
from transformers import CLIPTokenizer
from diffusers import OnnxRuntimeModel, StableDiffusionImg2ImgPipeline, UniPCMultistepScheduler
from diffusers.image_processor import VaeImageProcessor
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
deprecate,
logging,
replace_example_docstring,
)
from diffusers.utils.torch_utils import randn_tensor
# Initialize CUDA
cuda.init()
context = make_default_context()
device = context.get_device()
atexit.register(context.pop)
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def load_engine(trt_runtime, engine_path):
with open(engine_path, "rb") as f:
engine_data = f.read()
engine = trt_runtime.deserialize_cuda_engine(engine_data)
return engine
class TensorRTModel:
def __init__(
self,
trt_engine_path,
**kwargs,
):
cuda.init()
stream = cuda.Stream()
TRT_LOGGER = trt.Logger(trt.Logger.VERBOSE)
trt.init_libnvinfer_plugins(TRT_LOGGER, "")
trt_runtime = trt.Runtime(TRT_LOGGER)
engine = load_engine(trt_runtime, trt_engine_path)
context = engine.create_execution_context()
# allocates memory for network inputs/outputs on both CPU and GPU
host_inputs = []
cuda_inputs = []
host_outputs = []
cuda_outputs = []
bindings = []
input_names = []
output_names = []
for binding in engine:
datatype = engine.get_binding_dtype(binding)
if datatype == trt.DataType.HALF:
dtype = np.float16
else:
dtype = np.float32
shape = tuple(engine.get_binding_shape(binding))
host_mem = cuda.pagelocked_empty(shape, dtype)
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
bindings.append(int(cuda_mem))
if engine.binding_is_input(binding):
host_inputs.append(host_mem)
cuda_inputs.append(cuda_mem)
input_names.append(binding)
else:
host_outputs.append(host_mem)
cuda_outputs.append(cuda_mem)
output_names.append(binding)
self.stream = stream
self.context = context
self.engine = engine
self.host_inputs = host_inputs
self.cuda_inputs = cuda_inputs
self.host_outputs = host_outputs
self.cuda_outputs = cuda_outputs
self.bindings = bindings
self.batch_size = engine.max_batch_size
self.input_names = input_names
self.output_names = output_names
def __call__(self, **kwargs):
context = self.context
stream = self.stream
bindings = self.bindings
host_inputs = self.host_inputs
cuda_inputs = self.cuda_inputs
host_outputs = self.host_outputs
cuda_outputs = self.cuda_outputs
for idx, input_name in enumerate(self.input_names):
_input = kwargs[input_name]
np.copyto(host_inputs[idx], _input)
# transfer input data to the GPU
cuda.memcpy_htod_async(cuda_inputs[idx], host_inputs[idx], stream)
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
result = {}
for idx, output_name in enumerate(self.output_names):
# transfer predictions back from the GPU
cuda.memcpy_dtoh_async(host_outputs[idx], cuda_outputs[idx], stream)
result[output_name] = host_outputs[idx]
stream.synchronize()
return result
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> # !pip install opencv-python transformers accelerate
>>> from diffusers import StableDiffusionControlNetImg2ImgPipeline, ControlNetModel, UniPCMultistepScheduler
>>> from diffusers.utils import load_image
>>> import numpy as np
>>> import torch
>>> import cv2
>>> from PIL import Image
>>> # download an image
>>> image = load_image(
... "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
... )
>>> np_image = np.array(image)
>>> # get canny image
>>> np_image = cv2.Canny(np_image, 100, 200)
>>> np_image = np_image[:, :, None]
>>> np_image = np.concatenate([np_image, np_image, np_image], axis=2)
>>> canny_image = Image.fromarray(np_image)
>>> # load control net and stable diffusion v1-5
>>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
>>> pipe = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
... )
>>> # speed up diffusion process with faster scheduler and memory optimization
>>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
>>> pipe.enable_model_cpu_offload()
>>> # generate image
>>> generator = torch.manual_seed(0)
>>> image = pipe(
... "futuristic-looking woman",
... num_inference_steps=20,
... generator=generator,
... image=image,
... control_image=canny_image,
... ).images[0]
```
"""
def prepare_image(image):
if isinstance(image, torch.Tensor):
# Batch single image
if image.ndim == 3:
image = image.unsqueeze(0)
image = image.to(dtype=torch.float32)
else:
# preprocess image
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
return image
class TensorRTStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
vae_encoder: OnnxRuntimeModel
vae_decoder: OnnxRuntimeModel
text_encoder: OnnxRuntimeModel
tokenizer: CLIPTokenizer
unet: TensorRTModel
scheduler: KarrasDiffusionSchedulers
def __init__(
self,
vae_encoder: OnnxRuntimeModel,
vae_decoder: OnnxRuntimeModel,
text_encoder: OnnxRuntimeModel,
tokenizer: CLIPTokenizer,
unet: TensorRTModel,
scheduler: KarrasDiffusionSchedulers,
):
super().__init__()
self.register_modules(
vae_encoder=vae_encoder,
vae_decoder=vae_decoder,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
)
self.vae_scale_factor = 2 ** (4 - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True)
self.control_image_processor = VaeImageProcessor(
vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
)
def _encode_prompt(
self,
prompt: Union[str, List[str]],
num_images_per_prompt: Optional[int],
do_classifier_free_guidance: bool,
negative_prompt: Optional[str],
prompt_embeds: Optional[np.ndarray] = None,
negative_prompt_embeds: Optional[np.ndarray] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`):
prompt to be encoded
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
prompt_embeds (`np.ndarray`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`np.ndarray`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
"""
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="np",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="np").input_ids
if not np.array_equal(text_input_ids, untruncated_ids):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
prompt_embeds = self.text_encoder(input_ids=text_input_ids.astype(np.int32))[0]
prompt_embeds = np.repeat(prompt_embeds, num_images_per_prompt, axis=0)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt] * batch_size
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="np",
)
negative_prompt_embeds = self.text_encoder(input_ids=uncond_input.input_ids.astype(np.int32))[0]
if do_classifier_free_guidance:
negative_prompt_embeds = np.repeat(negative_prompt_embeds, num_images_per_prompt, axis=0)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = np.concatenate([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
def decode_latents(self, latents):
warnings.warn(
"The decode_latents method is deprecated and will be removed in a future version. Please"
" use VaeImageProcessor instead",
FutureWarning,
)
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents, return_dict=False)[0]
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_inputs(
self,
num_controlnet,
prompt,
image,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
controlnet_conditioning_scale=1.0,
control_guidance_start=0.0,
control_guidance_end=1.0,
):
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
# Check `image`
if num_controlnet == 1:
self.check_image(image, prompt, prompt_embeds)
elif num_controlnet > 1:
if not isinstance(image, list):
raise TypeError("For multiple controlnets: `image` must be type `list`")
# When `image` is a nested list:
# (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
elif any(isinstance(i, list) for i in image):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif len(image) != num_controlnet:
raise ValueError(
f"For multiple controlnets: `image` must have the same length as the number of controlnets, but got {len(image)} images and {num_controlnet} ControlNets."
)
for image_ in image:
self.check_image(image_, prompt, prompt_embeds)
else:
assert False
# Check `controlnet_conditioning_scale`
if num_controlnet == 1:
if not isinstance(controlnet_conditioning_scale, float):
raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
elif num_controlnet > 1:
if isinstance(controlnet_conditioning_scale, list):
if any(isinstance(i, list) for i in controlnet_conditioning_scale):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif (
isinstance(controlnet_conditioning_scale, list)
and len(controlnet_conditioning_scale) != num_controlnet
):
raise ValueError(
"For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
" the same length as the number of controlnets"
)
else:
assert False
if len(control_guidance_start) != len(control_guidance_end):
raise ValueError(
f"`control_guidance_start` has {len(control_guidance_start)} elements, but `control_guidance_end` has {len(control_guidance_end)} elements. Make sure to provide the same number of elements to each list."
)
if num_controlnet > 1:
if len(control_guidance_start) != num_controlnet:
raise ValueError(
f"`control_guidance_start`: {control_guidance_start} has {len(control_guidance_start)} elements but there are {num_controlnet} controlnets available. Make sure to provide {num_controlnet}."
)
for start, end in zip(control_guidance_start, control_guidance_end):
if start >= end:
raise ValueError(
f"control guidance start: {start} cannot be larger or equal to control guidance end: {end}."
)
if start < 0.0:
raise ValueError(f"control guidance start: {start} can't be smaller than 0.")
if end > 1.0:
raise ValueError(f"control guidance end: {end} can't be larger than 1.0.")
# Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image
def check_image(self, image, prompt, prompt_embeds):
image_is_pil = isinstance(image, PIL.Image.Image)
image_is_tensor = isinstance(image, torch.Tensor)
image_is_np = isinstance(image, np.ndarray)
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
if (
not image_is_pil
and not image_is_tensor
and not image_is_np
and not image_is_pil_list
and not image_is_tensor_list
and not image_is_np_list
):
raise TypeError(
f"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(image)}"
)
if image_is_pil:
image_batch_size = 1
else:
image_batch_size = len(image)
if prompt is not None and isinstance(prompt, str):
prompt_batch_size = 1
elif prompt is not None and isinstance(prompt, list):
prompt_batch_size = len(prompt)
elif prompt_embeds is not None:
prompt_batch_size = prompt_embeds.shape[0]
if image_batch_size != 1 and image_batch_size != prompt_batch_size:
raise ValueError(
f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
)
# Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.prepare_image
def prepare_control_image(
self,
image,
width,
height,
batch_size,
num_images_per_prompt,
device,
dtype,
do_classifier_free_guidance=False,
guess_mode=False,
):
image = self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32)
image_batch_size = image.shape[0]
if image_batch_size == 1:
repeat_by = batch_size
else:
# image batch size is the same as prompt batch size
repeat_by = num_images_per_prompt
image = image.repeat_interleave(repeat_by, dim=0)
image = image.to(device=device, dtype=dtype)
if do_classifier_free_guidance and not guess_mode:
image = torch.cat([image] * 2)
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.get_timesteps
def get_timesteps(self, num_inference_steps, strength, device):
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
return timesteps, num_inference_steps - t_start
def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None):
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
)
image = image.to(device=device, dtype=dtype)
batch_size = batch_size * num_images_per_prompt
if image.shape[1] == 4:
init_latents = image
else:
_image = image.cpu().detach().numpy()
init_latents = self.vae_encoder(sample=_image)[0]
init_latents = torch.from_numpy(init_latents).to(device=device, dtype=dtype)
init_latents = 0.18215 * init_latents
if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
# expand init_latents for batch_size
deprecation_message = (
f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
" images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
" that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
" your script to pass as many initial images as text prompts to suppress this warning."
)
deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
additional_image_per_prompt = batch_size // init_latents.shape[0]
init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
raise ValueError(
f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
)
else:
init_latents = torch.cat([init_latents], dim=0)
shape = init_latents.shape
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
# get latents
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
latents = init_latents
return latents
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
num_controlnet: int,
fp16: bool = True,
prompt: Union[str, List[str]] = None,
image: Union[
torch.FloatTensor,
PIL.Image.Image,
np.ndarray,
List[torch.FloatTensor],
List[PIL.Image.Image],
List[np.ndarray],
] = None,
control_image: Union[
torch.FloatTensor,
PIL.Image.Image,
np.ndarray,
List[torch.FloatTensor],
List[PIL.Image.Image],
List[np.ndarray],
] = None,
height: Optional[int] = None,
width: Optional[int] = None,
strength: float = 0.8,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
controlnet_conditioning_scale: Union[float, List[float]] = 0.8,
guess_mode: bool = False,
control_guidance_start: Union[float, List[float]] = 0.0,
control_guidance_end: Union[float, List[float]] = 1.0,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The initial image will be used as the starting point for the image generation process. Can also accept
image latents as `image`, if passing latents directly, it will not be encoded again.
control_image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
specified in init, images must be passed as a list such that each element of the list can be correctly
batched for input to a single controlnet.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
corresponding scale as a list. Note that by default, we use a smaller conditioning scale for inpainting
than for [`~StableDiffusionControlNetPipeline.__call__`].
guess_mode (`bool`, *optional*, defaults to `False`):
In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
The percentage of total steps at which the controlnet starts applying.
control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
The percentage of total steps at which the controlnet stops applying.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
if fp16:
torch_dtype = torch.float16
np_dtype = np.float16
else:
torch_dtype = torch.float32
np_dtype = np.float32
# align format for control guidance
if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
control_guidance_start = len(control_guidance_end) * [control_guidance_start]
elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
control_guidance_end = len(control_guidance_start) * [control_guidance_end]
elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
mult = num_controlnet
control_guidance_start, control_guidance_end = (
mult * [control_guidance_start],
mult * [control_guidance_end],
)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
num_controlnet,
prompt,
control_image,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
controlnet_conditioning_scale,
control_guidance_start,
control_guidance_end,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
if num_controlnet > 1 and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * num_controlnet
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
# 4. Prepare image
image = self.image_processor.preprocess(image).to(dtype=torch.float32)
# 5. Prepare controlnet_conditioning_image
if num_controlnet == 1:
control_image = self.prepare_control_image(
image=control_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=torch_dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
elif num_controlnet > 1:
control_images = []
for control_image_ in control_image:
control_image_ = self.prepare_control_image(
image=control_image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=torch_dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
control_images.append(control_image_)
control_image = control_images
else:
assert False
# 5. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# 6. Prepare latent variables
latents = self.prepare_latents(
image,
latent_timestep,
batch_size,
num_images_per_prompt,
torch_dtype,
device,
generator,
)
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7.1 Create tensor stating which controlnets to keep
controlnet_keep = []
for i in range(len(timesteps)):
keeps = [
1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
for s, e in zip(control_guidance_start, control_guidance_end)
]
controlnet_keep.append(keeps[0] if num_controlnet == 1 else keeps)
# 8. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
if isinstance(controlnet_keep[i], list):
cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
else:
controlnet_cond_scale = controlnet_conditioning_scale
if isinstance(controlnet_cond_scale, list):
controlnet_cond_scale = controlnet_cond_scale[0]
cond_scale = controlnet_cond_scale * controlnet_keep[i]
# predict the noise residual
_latent_model_input = latent_model_input.cpu().detach().numpy()
_prompt_embeds = np.array(prompt_embeds, dtype=np_dtype)
_t = np.array([t.cpu().detach().numpy()], dtype=np_dtype)
if num_controlnet == 1:
control_images = np.array([control_image], dtype=np_dtype)
else:
control_images = []
for _control_img in control_image:
_control_img = _control_img.cpu().detach().numpy()
control_images.append(_control_img)
control_images = np.array(control_images, dtype=np_dtype)
control_scales = np.array(cond_scale, dtype=np_dtype)
control_scales = np.resize(control_scales, (num_controlnet, 1))
noise_pred = self.unet(
sample=_latent_model_input,
timestep=_t,
encoder_hidden_states=_prompt_embeds,
controlnet_conds=control_images,
conditioning_scales=control_scales,
)["noise_pred"]
noise_pred = torch.from_numpy(noise_pred).to(device)
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if not output_type == "latent":
_latents = latents.cpu().detach().numpy() / 0.18215
_latents = np.array(_latents, dtype=np_dtype)
image = self.vae_decoder(latent_sample=_latents)[0]
image = torch.from_numpy(image).to(device, dtype=torch.float32)
has_nsfw_concept = None
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--sd_model",
type=str,
required=True,
help="Path to the `diffusers` checkpoint to convert (either a local directory or on the Hub).",
)
parser.add_argument(
"--onnx_model_dir",
type=str,
required=True,
help="Path to the ONNX directory",
)
parser.add_argument(
"--unet_engine_path",
type=str,
required=True,
help="Path to the unet + controlnet tensorrt model",
)
parser.add_argument("--qr_img_path", type=str, required=True, help="Path to the qr code image")
args = parser.parse_args()
qr_image = Image.open(args.qr_img_path)
qr_image = qr_image.resize((512, 512))
# init stable diffusion pipeline
pipeline = StableDiffusionImg2ImgPipeline.from_pretrained(args.sd_model)
pipeline.scheduler = UniPCMultistepScheduler.from_config(pipeline.scheduler.config)
provider = ["CUDAExecutionProvider", "CPUExecutionProvider"]
onnx_pipeline = TensorRTStableDiffusionControlNetImg2ImgPipeline(
vae_encoder=OnnxRuntimeModel.from_pretrained(
os.path.join(args.onnx_model_dir, "vae_encoder"), provider=provider
),
vae_decoder=OnnxRuntimeModel.from_pretrained(
os.path.join(args.onnx_model_dir, "vae_decoder"), provider=provider
),
text_encoder=OnnxRuntimeModel.from_pretrained(
os.path.join(args.onnx_model_dir, "text_encoder"), provider=provider
),
tokenizer=pipeline.tokenizer,
unet=TensorRTModel(args.unet_engine_path),
scheduler=pipeline.scheduler,
)
onnx_pipeline = onnx_pipeline.to("cuda")
prompt = "a cute cat fly to the moon"
negative_prompt = "paintings, sketches, worst quality, low quality, normal quality, lowres, normal quality, monochrome, grayscale, skin spots, acnes, skin blemishes, age spot, glans, nsfw, nipples, necklace, worst quality, low quality, watermark, username, signature, multiple breasts, lowres, bad anatomy, bad hands, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, bad feet, single color, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, disfigured, bad anatomy, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, mutated hands, fused fingers, too many fingers, long neck, bad body perspect"
for i in range(10):
start_time = time.time()
image = onnx_pipeline(
num_controlnet=2,
prompt=prompt,
negative_prompt=negative_prompt,
image=qr_image,
control_image=[qr_image, qr_image],
width=512,
height=512,
strength=0.75,
num_inference_steps=20,
num_images_per_prompt=1,
controlnet_conditioning_scale=[0.8, 0.8],
control_guidance_start=[0.3, 0.3],
control_guidance_end=[0.9, 0.9],
).images[0]
print(time.time() - start_time)
image.save("output_qr_code.png")
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_diffusion_tensorrt_inpaint.py
|
#
# Copyright 2023 The HuggingFace Inc. team.
# SPDX-FileCopyrightText: Copyright (c) 1993-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import os
from collections import OrderedDict
from copy import copy
from typing import List, Optional, Union
import numpy as np
import onnx
import onnx_graphsurgeon as gs
import PIL.Image
import tensorrt as trt
import torch
from huggingface_hub import snapshot_download
from onnx import shape_inference
from polygraphy import cuda
from polygraphy.backend.common import bytes_from_path
from polygraphy.backend.onnx.loader import fold_constants
from polygraphy.backend.trt import (
CreateConfig,
Profile,
engine_from_bytes,
engine_from_network,
network_from_onnx_path,
save_engine,
)
from polygraphy.backend.trt import util as trt_util
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion import (
StableDiffusionInpaintPipeline,
StableDiffusionPipelineOutput,
StableDiffusionSafetyChecker,
)
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint import prepare_mask_and_masked_image
from diffusers.schedulers import DDIMScheduler
from diffusers.utils import DIFFUSERS_CACHE, logging
"""
Installation instructions
python3 -m pip install --upgrade transformers diffusers>=0.16.0
python3 -m pip install --upgrade tensorrt>=8.6.1
python3 -m pip install --upgrade polygraphy>=0.47.0 onnx-graphsurgeon --extra-index-url https://pypi.ngc.nvidia.com
python3 -m pip install onnxruntime
"""
TRT_LOGGER = trt.Logger(trt.Logger.ERROR)
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
# Map of numpy dtype -> torch dtype
numpy_to_torch_dtype_dict = {
np.uint8: torch.uint8,
np.int8: torch.int8,
np.int16: torch.int16,
np.int32: torch.int32,
np.int64: torch.int64,
np.float16: torch.float16,
np.float32: torch.float32,
np.float64: torch.float64,
np.complex64: torch.complex64,
np.complex128: torch.complex128,
}
if np.version.full_version >= "1.24.0":
numpy_to_torch_dtype_dict[np.bool_] = torch.bool
else:
numpy_to_torch_dtype_dict[np.bool] = torch.bool
# Map of torch dtype -> numpy dtype
torch_to_numpy_dtype_dict = {value: key for (key, value) in numpy_to_torch_dtype_dict.items()}
def device_view(t):
return cuda.DeviceView(ptr=t.data_ptr(), shape=t.shape, dtype=torch_to_numpy_dtype_dict[t.dtype])
def preprocess_image(image):
"""
image: torch.Tensor
"""
w, h = image.size
w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
image = image.resize((w, h))
image = np.array(image).astype(np.float32) / 255.0
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image).contiguous()
return 2.0 * image - 1.0
class Engine:
def __init__(self, engine_path):
self.engine_path = engine_path
self.engine = None
self.context = None
self.buffers = OrderedDict()
self.tensors = OrderedDict()
def __del__(self):
[buf.free() for buf in self.buffers.values() if isinstance(buf, cuda.DeviceArray)]
del self.engine
del self.context
del self.buffers
del self.tensors
def build(
self,
onnx_path,
fp16,
input_profile=None,
enable_preview=False,
enable_all_tactics=False,
timing_cache=None,
workspace_size=0,
):
logger.warning(f"Building TensorRT engine for {onnx_path}: {self.engine_path}")
p = Profile()
if input_profile:
for name, dims in input_profile.items():
assert len(dims) == 3
p.add(name, min=dims[0], opt=dims[1], max=dims[2])
config_kwargs = {}
config_kwargs["preview_features"] = [trt.PreviewFeature.DISABLE_EXTERNAL_TACTIC_SOURCES_FOR_CORE_0805]
if enable_preview:
# Faster dynamic shapes made optional since it increases engine build time.
config_kwargs["preview_features"].append(trt.PreviewFeature.FASTER_DYNAMIC_SHAPES_0805)
if workspace_size > 0:
config_kwargs["memory_pool_limits"] = {trt.MemoryPoolType.WORKSPACE: workspace_size}
if not enable_all_tactics:
config_kwargs["tactic_sources"] = []
engine = engine_from_network(
network_from_onnx_path(onnx_path, flags=[trt.OnnxParserFlag.NATIVE_INSTANCENORM]),
config=CreateConfig(fp16=fp16, profiles=[p], load_timing_cache=timing_cache, **config_kwargs),
save_timing_cache=timing_cache,
)
save_engine(engine, path=self.engine_path)
def load(self):
logger.warning(f"Loading TensorRT engine: {self.engine_path}")
self.engine = engine_from_bytes(bytes_from_path(self.engine_path))
def activate(self):
self.context = self.engine.create_execution_context()
def allocate_buffers(self, shape_dict=None, device="cuda"):
for idx in range(trt_util.get_bindings_per_profile(self.engine)):
binding = self.engine[idx]
if shape_dict and binding in shape_dict:
shape = shape_dict[binding]
else:
shape = self.engine.get_binding_shape(binding)
dtype = trt.nptype(self.engine.get_binding_dtype(binding))
if self.engine.binding_is_input(binding):
self.context.set_binding_shape(idx, shape)
tensor = torch.empty(tuple(shape), dtype=numpy_to_torch_dtype_dict[dtype]).to(device=device)
self.tensors[binding] = tensor
self.buffers[binding] = cuda.DeviceView(ptr=tensor.data_ptr(), shape=shape, dtype=dtype)
def infer(self, feed_dict, stream):
start_binding, end_binding = trt_util.get_active_profile_bindings(self.context)
# shallow copy of ordered dict
device_buffers = copy(self.buffers)
for name, buf in feed_dict.items():
assert isinstance(buf, cuda.DeviceView)
device_buffers[name] = buf
bindings = [0] * start_binding + [buf.ptr for buf in device_buffers.values()]
noerror = self.context.execute_async_v2(bindings=bindings, stream_handle=stream.ptr)
if not noerror:
raise ValueError("ERROR: inference failed.")
return self.tensors
class Optimizer:
def __init__(self, onnx_graph):
self.graph = gs.import_onnx(onnx_graph)
def cleanup(self, return_onnx=False):
self.graph.cleanup().toposort()
if return_onnx:
return gs.export_onnx(self.graph)
def select_outputs(self, keep, names=None):
self.graph.outputs = [self.graph.outputs[o] for o in keep]
if names:
for i, name in enumerate(names):
self.graph.outputs[i].name = name
def fold_constants(self, return_onnx=False):
onnx_graph = fold_constants(gs.export_onnx(self.graph), allow_onnxruntime_shape_inference=True)
self.graph = gs.import_onnx(onnx_graph)
if return_onnx:
return onnx_graph
def infer_shapes(self, return_onnx=False):
onnx_graph = gs.export_onnx(self.graph)
if onnx_graph.ByteSize() > 2147483648:
raise TypeError("ERROR: model size exceeds supported 2GB limit")
else:
onnx_graph = shape_inference.infer_shapes(onnx_graph)
self.graph = gs.import_onnx(onnx_graph)
if return_onnx:
return onnx_graph
class BaseModel:
def __init__(self, model, fp16=False, device="cuda", max_batch_size=16, embedding_dim=768, text_maxlen=77):
self.model = model
self.name = "SD Model"
self.fp16 = fp16
self.device = device
self.min_batch = 1
self.max_batch = max_batch_size
self.min_image_shape = 256 # min image resolution: 256x256
self.max_image_shape = 1024 # max image resolution: 1024x1024
self.min_latent_shape = self.min_image_shape // 8
self.max_latent_shape = self.max_image_shape // 8
self.embedding_dim = embedding_dim
self.text_maxlen = text_maxlen
def get_model(self):
return self.model
def get_input_names(self):
pass
def get_output_names(self):
pass
def get_dynamic_axes(self):
return None
def get_sample_input(self, batch_size, image_height, image_width):
pass
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
return None
def get_shape_dict(self, batch_size, image_height, image_width):
return None
def optimize(self, onnx_graph):
opt = Optimizer(onnx_graph)
opt.cleanup()
opt.fold_constants()
opt.infer_shapes()
onnx_opt_graph = opt.cleanup(return_onnx=True)
return onnx_opt_graph
def check_dims(self, batch_size, image_height, image_width):
assert batch_size >= self.min_batch and batch_size <= self.max_batch
assert image_height % 8 == 0 or image_width % 8 == 0
latent_height = image_height // 8
latent_width = image_width // 8
assert latent_height >= self.min_latent_shape and latent_height <= self.max_latent_shape
assert latent_width >= self.min_latent_shape and latent_width <= self.max_latent_shape
return (latent_height, latent_width)
def get_minmax_dims(self, batch_size, image_height, image_width, static_batch, static_shape):
min_batch = batch_size if static_batch else self.min_batch
max_batch = batch_size if static_batch else self.max_batch
latent_height = image_height // 8
latent_width = image_width // 8
min_image_height = image_height if static_shape else self.min_image_shape
max_image_height = image_height if static_shape else self.max_image_shape
min_image_width = image_width if static_shape else self.min_image_shape
max_image_width = image_width if static_shape else self.max_image_shape
min_latent_height = latent_height if static_shape else self.min_latent_shape
max_latent_height = latent_height if static_shape else self.max_latent_shape
min_latent_width = latent_width if static_shape else self.min_latent_shape
max_latent_width = latent_width if static_shape else self.max_latent_shape
return (
min_batch,
max_batch,
min_image_height,
max_image_height,
min_image_width,
max_image_width,
min_latent_height,
max_latent_height,
min_latent_width,
max_latent_width,
)
def getOnnxPath(model_name, onnx_dir, opt=True):
return os.path.join(onnx_dir, model_name + (".opt" if opt else "") + ".onnx")
def getEnginePath(model_name, engine_dir):
return os.path.join(engine_dir, model_name + ".plan")
def build_engines(
models: dict,
engine_dir,
onnx_dir,
onnx_opset,
opt_image_height,
opt_image_width,
opt_batch_size=1,
force_engine_rebuild=False,
static_batch=False,
static_shape=True,
enable_preview=False,
enable_all_tactics=False,
timing_cache=None,
max_workspace_size=0,
):
built_engines = {}
if not os.path.isdir(onnx_dir):
os.makedirs(onnx_dir)
if not os.path.isdir(engine_dir):
os.makedirs(engine_dir)
# Export models to ONNX
for model_name, model_obj in models.items():
engine_path = getEnginePath(model_name, engine_dir)
if force_engine_rebuild or not os.path.exists(engine_path):
logger.warning("Building Engines...")
logger.warning("Engine build can take a while to complete")
onnx_path = getOnnxPath(model_name, onnx_dir, opt=False)
onnx_opt_path = getOnnxPath(model_name, onnx_dir)
if force_engine_rebuild or not os.path.exists(onnx_opt_path):
if force_engine_rebuild or not os.path.exists(onnx_path):
logger.warning(f"Exporting model: {onnx_path}")
model = model_obj.get_model()
with torch.inference_mode(), torch.autocast("cuda"):
inputs = model_obj.get_sample_input(opt_batch_size, opt_image_height, opt_image_width)
torch.onnx.export(
model,
inputs,
onnx_path,
export_params=True,
opset_version=onnx_opset,
do_constant_folding=True,
input_names=model_obj.get_input_names(),
output_names=model_obj.get_output_names(),
dynamic_axes=model_obj.get_dynamic_axes(),
)
del model
torch.cuda.empty_cache()
gc.collect()
else:
logger.warning(f"Found cached model: {onnx_path}")
# Optimize onnx
if force_engine_rebuild or not os.path.exists(onnx_opt_path):
logger.warning(f"Generating optimizing model: {onnx_opt_path}")
onnx_opt_graph = model_obj.optimize(onnx.load(onnx_path))
onnx.save(onnx_opt_graph, onnx_opt_path)
else:
logger.warning(f"Found cached optimized model: {onnx_opt_path} ")
# Build TensorRT engines
for model_name, model_obj in models.items():
engine_path = getEnginePath(model_name, engine_dir)
engine = Engine(engine_path)
onnx_path = getOnnxPath(model_name, onnx_dir, opt=False)
onnx_opt_path = getOnnxPath(model_name, onnx_dir)
if force_engine_rebuild or not os.path.exists(engine.engine_path):
engine.build(
onnx_opt_path,
fp16=True,
input_profile=model_obj.get_input_profile(
opt_batch_size,
opt_image_height,
opt_image_width,
static_batch=static_batch,
static_shape=static_shape,
),
enable_preview=enable_preview,
timing_cache=timing_cache,
workspace_size=max_workspace_size,
)
built_engines[model_name] = engine
# Load and activate TensorRT engines
for model_name, model_obj in models.items():
engine = built_engines[model_name]
engine.load()
engine.activate()
return built_engines
def runEngine(engine, feed_dict, stream):
return engine.infer(feed_dict, stream)
class CLIP(BaseModel):
def __init__(self, model, device, max_batch_size, embedding_dim):
super(CLIP, self).__init__(
model=model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim
)
self.name = "CLIP"
def get_input_names(self):
return ["input_ids"]
def get_output_names(self):
return ["text_embeddings", "pooler_output"]
def get_dynamic_axes(self):
return {"input_ids": {0: "B"}, "text_embeddings": {0: "B"}}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
self.check_dims(batch_size, image_height, image_width)
min_batch, max_batch, _, _, _, _, _, _, _, _ = self.get_minmax_dims(
batch_size, image_height, image_width, static_batch, static_shape
)
return {
"input_ids": [(min_batch, self.text_maxlen), (batch_size, self.text_maxlen), (max_batch, self.text_maxlen)]
}
def get_shape_dict(self, batch_size, image_height, image_width):
self.check_dims(batch_size, image_height, image_width)
return {
"input_ids": (batch_size, self.text_maxlen),
"text_embeddings": (batch_size, self.text_maxlen, self.embedding_dim),
}
def get_sample_input(self, batch_size, image_height, image_width):
self.check_dims(batch_size, image_height, image_width)
return torch.zeros(batch_size, self.text_maxlen, dtype=torch.int32, device=self.device)
def optimize(self, onnx_graph):
opt = Optimizer(onnx_graph)
opt.select_outputs([0]) # delete graph output#1
opt.cleanup()
opt.fold_constants()
opt.infer_shapes()
opt.select_outputs([0], names=["text_embeddings"]) # rename network output
opt_onnx_graph = opt.cleanup(return_onnx=True)
return opt_onnx_graph
def make_CLIP(model, device, max_batch_size, embedding_dim, inpaint=False):
return CLIP(model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim)
class UNet(BaseModel):
def __init__(
self, model, fp16=False, device="cuda", max_batch_size=16, embedding_dim=768, text_maxlen=77, unet_dim=4
):
super(UNet, self).__init__(
model=model,
fp16=fp16,
device=device,
max_batch_size=max_batch_size,
embedding_dim=embedding_dim,
text_maxlen=text_maxlen,
)
self.unet_dim = unet_dim
self.name = "UNet"
def get_input_names(self):
return ["sample", "timestep", "encoder_hidden_states"]
def get_output_names(self):
return ["latent"]
def get_dynamic_axes(self):
return {
"sample": {0: "2B", 2: "H", 3: "W"},
"encoder_hidden_states": {0: "2B"},
"latent": {0: "2B", 2: "H", 3: "W"},
}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
(
min_batch,
max_batch,
_,
_,
_,
_,
min_latent_height,
max_latent_height,
min_latent_width,
max_latent_width,
) = self.get_minmax_dims(batch_size, image_height, image_width, static_batch, static_shape)
return {
"sample": [
(2 * min_batch, self.unet_dim, min_latent_height, min_latent_width),
(2 * batch_size, self.unet_dim, latent_height, latent_width),
(2 * max_batch, self.unet_dim, max_latent_height, max_latent_width),
],
"encoder_hidden_states": [
(2 * min_batch, self.text_maxlen, self.embedding_dim),
(2 * batch_size, self.text_maxlen, self.embedding_dim),
(2 * max_batch, self.text_maxlen, self.embedding_dim),
],
}
def get_shape_dict(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return {
"sample": (2 * batch_size, self.unet_dim, latent_height, latent_width),
"encoder_hidden_states": (2 * batch_size, self.text_maxlen, self.embedding_dim),
"latent": (2 * batch_size, 4, latent_height, latent_width),
}
def get_sample_input(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
dtype = torch.float16 if self.fp16 else torch.float32
return (
torch.randn(
2 * batch_size, self.unet_dim, latent_height, latent_width, dtype=torch.float32, device=self.device
),
torch.tensor([1.0], dtype=torch.float32, device=self.device),
torch.randn(2 * batch_size, self.text_maxlen, self.embedding_dim, dtype=dtype, device=self.device),
)
def make_UNet(model, device, max_batch_size, embedding_dim, inpaint=False, unet_dim=4):
return UNet(
model,
fp16=True,
device=device,
max_batch_size=max_batch_size,
embedding_dim=embedding_dim,
unet_dim=unet_dim,
)
class VAE(BaseModel):
def __init__(self, model, device, max_batch_size, embedding_dim):
super(VAE, self).__init__(
model=model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim
)
self.name = "VAE decoder"
def get_input_names(self):
return ["latent"]
def get_output_names(self):
return ["images"]
def get_dynamic_axes(self):
return {"latent": {0: "B", 2: "H", 3: "W"}, "images": {0: "B", 2: "8H", 3: "8W"}}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
(
min_batch,
max_batch,
_,
_,
_,
_,
min_latent_height,
max_latent_height,
min_latent_width,
max_latent_width,
) = self.get_minmax_dims(batch_size, image_height, image_width, static_batch, static_shape)
return {
"latent": [
(min_batch, 4, min_latent_height, min_latent_width),
(batch_size, 4, latent_height, latent_width),
(max_batch, 4, max_latent_height, max_latent_width),
]
}
def get_shape_dict(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return {
"latent": (batch_size, 4, latent_height, latent_width),
"images": (batch_size, 3, image_height, image_width),
}
def get_sample_input(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return torch.randn(batch_size, 4, latent_height, latent_width, dtype=torch.float32, device=self.device)
def make_VAE(model, device, max_batch_size, embedding_dim, inpaint=False):
return VAE(model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim)
class TorchVAEEncoder(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.vae_encoder = model
def forward(self, x):
return self.vae_encoder.encode(x).latent_dist.sample()
class VAEEncoder(BaseModel):
def __init__(self, model, device, max_batch_size, embedding_dim):
super(VAEEncoder, self).__init__(
model=model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim
)
self.name = "VAE encoder"
def get_model(self):
vae_encoder = TorchVAEEncoder(self.model)
return vae_encoder
def get_input_names(self):
return ["images"]
def get_output_names(self):
return ["latent"]
def get_dynamic_axes(self):
return {"images": {0: "B", 2: "8H", 3: "8W"}, "latent": {0: "B", 2: "H", 3: "W"}}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
assert batch_size >= self.min_batch and batch_size <= self.max_batch
min_batch = batch_size if static_batch else self.min_batch
max_batch = batch_size if static_batch else self.max_batch
self.check_dims(batch_size, image_height, image_width)
(
min_batch,
max_batch,
min_image_height,
max_image_height,
min_image_width,
max_image_width,
_,
_,
_,
_,
) = self.get_minmax_dims(batch_size, image_height, image_width, static_batch, static_shape)
return {
"images": [
(min_batch, 3, min_image_height, min_image_width),
(batch_size, 3, image_height, image_width),
(max_batch, 3, max_image_height, max_image_width),
]
}
def get_shape_dict(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return {
"images": (batch_size, 3, image_height, image_width),
"latent": (batch_size, 4, latent_height, latent_width),
}
def get_sample_input(self, batch_size, image_height, image_width):
self.check_dims(batch_size, image_height, image_width)
return torch.randn(batch_size, 3, image_height, image_width, dtype=torch.float32, device=self.device)
def make_VAEEncoder(model, device, max_batch_size, embedding_dim, inpaint=False):
return VAEEncoder(model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim)
class TensorRTStableDiffusionInpaintPipeline(StableDiffusionInpaintPipeline):
r"""
Pipeline for inpainting using TensorRT accelerated Stable Diffusion.
This model inherits from [`StableDiffusionInpaintPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPFeatureExtractor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: DDIMScheduler,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPFeatureExtractor,
requires_safety_checker: bool = True,
stages=["clip", "unet", "vae", "vae_encoder"],
image_height: int = 512,
image_width: int = 512,
max_batch_size: int = 16,
# ONNX export parameters
onnx_opset: int = 17,
onnx_dir: str = "onnx",
# TensorRT engine build parameters
engine_dir: str = "engine",
build_preview_features: bool = True,
force_engine_rebuild: bool = False,
timing_cache: str = "timing_cache",
):
super().__init__(
vae, text_encoder, tokenizer, unet, scheduler, safety_checker, feature_extractor, requires_safety_checker
)
self.vae.forward = self.vae.decode
self.stages = stages
self.image_height, self.image_width = image_height, image_width
self.inpaint = True
self.onnx_opset = onnx_opset
self.onnx_dir = onnx_dir
self.engine_dir = engine_dir
self.force_engine_rebuild = force_engine_rebuild
self.timing_cache = timing_cache
self.build_static_batch = False
self.build_dynamic_shape = False
self.build_preview_features = build_preview_features
self.max_batch_size = max_batch_size
# TODO: Restrict batch size to 4 for larger image dimensions as a WAR for TensorRT limitation.
if self.build_dynamic_shape or self.image_height > 512 or self.image_width > 512:
self.max_batch_size = 4
self.stream = None # loaded in loadResources()
self.models = {} # loaded in __loadModels()
self.engine = {} # loaded in build_engines()
def __loadModels(self):
# Load pipeline models
self.embedding_dim = self.text_encoder.config.hidden_size
models_args = {
"device": self.torch_device,
"max_batch_size": self.max_batch_size,
"embedding_dim": self.embedding_dim,
"inpaint": self.inpaint,
}
if "clip" in self.stages:
self.models["clip"] = make_CLIP(self.text_encoder, **models_args)
if "unet" in self.stages:
self.models["unet"] = make_UNet(self.unet, **models_args, unet_dim=self.unet.config.in_channels)
if "vae" in self.stages:
self.models["vae"] = make_VAE(self.vae, **models_args)
if "vae_encoder" in self.stages:
self.models["vae_encoder"] = make_VAEEncoder(self.vae, **models_args)
@classmethod
def set_cached_folder(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], **kwargs):
cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
resume_download = kwargs.pop("resume_download", False)
proxies = kwargs.pop("proxies", None)
local_files_only = kwargs.pop("local_files_only", False)
use_auth_token = kwargs.pop("use_auth_token", None)
revision = kwargs.pop("revision", None)
cls.cached_folder = (
pretrained_model_name_or_path
if os.path.isdir(pretrained_model_name_or_path)
else snapshot_download(
pretrained_model_name_or_path,
cache_dir=cache_dir,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
use_auth_token=use_auth_token,
revision=revision,
)
)
def to(self, torch_device: Optional[Union[str, torch.device]] = None, silence_dtype_warnings: bool = False):
super().to(torch_device, silence_dtype_warnings=silence_dtype_warnings)
self.onnx_dir = os.path.join(self.cached_folder, self.onnx_dir)
self.engine_dir = os.path.join(self.cached_folder, self.engine_dir)
self.timing_cache = os.path.join(self.cached_folder, self.timing_cache)
# set device
self.torch_device = self._execution_device
logger.warning(f"Running inference on device: {self.torch_device}")
# load models
self.__loadModels()
# build engines
self.engine = build_engines(
self.models,
self.engine_dir,
self.onnx_dir,
self.onnx_opset,
opt_image_height=self.image_height,
opt_image_width=self.image_width,
force_engine_rebuild=self.force_engine_rebuild,
static_batch=self.build_static_batch,
static_shape=not self.build_dynamic_shape,
enable_preview=self.build_preview_features,
timing_cache=self.timing_cache,
)
return self
def __initialize_timesteps(self, num_inference_steps, strength):
self.scheduler.set_timesteps(num_inference_steps)
offset = self.scheduler.config.steps_offset if hasattr(self.scheduler, "steps_offset") else 0
init_timestep = int(num_inference_steps * strength) + offset
init_timestep = min(init_timestep, num_inference_steps)
t_start = max(num_inference_steps - init_timestep + offset, 0)
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :].to(self.torch_device)
return timesteps, num_inference_steps - t_start
def __preprocess_images(self, batch_size, images=()):
init_images = []
for image in images:
image = image.to(self.torch_device).float()
image = image.repeat(batch_size, 1, 1, 1)
init_images.append(image)
return tuple(init_images)
def __encode_image(self, init_image):
init_latents = runEngine(self.engine["vae_encoder"], {"images": device_view(init_image)}, self.stream)[
"latent"
]
init_latents = 0.18215 * init_latents
return init_latents
def __encode_prompt(self, prompt, negative_prompt):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
"""
# Tokenize prompt
text_input_ids = (
self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
.input_ids.type(torch.int32)
.to(self.torch_device)
)
text_input_ids_inp = device_view(text_input_ids)
# NOTE: output tensor for CLIP must be cloned because it will be overwritten when called again for negative prompt
text_embeddings = runEngine(self.engine["clip"], {"input_ids": text_input_ids_inp}, self.stream)[
"text_embeddings"
].clone()
# Tokenize negative prompt
uncond_input_ids = (
self.tokenizer(
negative_prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
.input_ids.type(torch.int32)
.to(self.torch_device)
)
uncond_input_ids_inp = device_view(uncond_input_ids)
uncond_embeddings = runEngine(self.engine["clip"], {"input_ids": uncond_input_ids_inp}, self.stream)[
"text_embeddings"
]
# Concatenate the unconditional and text embeddings into a single batch to avoid doing two forward passes for classifier free guidance
text_embeddings = torch.cat([uncond_embeddings, text_embeddings]).to(dtype=torch.float16)
return text_embeddings
def __denoise_latent(
self, latents, text_embeddings, timesteps=None, step_offset=0, mask=None, masked_image_latents=None
):
if not isinstance(timesteps, torch.Tensor):
timesteps = self.scheduler.timesteps
for step_index, timestep in enumerate(timesteps):
# Expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, timestep)
if isinstance(mask, torch.Tensor):
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
# Predict the noise residual
timestep_float = timestep.float() if timestep.dtype != torch.float32 else timestep
sample_inp = device_view(latent_model_input)
timestep_inp = device_view(timestep_float)
embeddings_inp = device_view(text_embeddings)
noise_pred = runEngine(
self.engine["unet"],
{"sample": sample_inp, "timestep": timestep_inp, "encoder_hidden_states": embeddings_inp},
self.stream,
)["latent"]
# Perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
latents = self.scheduler.step(noise_pred, timestep, latents).prev_sample
latents = 1.0 / 0.18215 * latents
return latents
def __decode_latent(self, latents):
images = runEngine(self.engine["vae"], {"latent": device_view(latents)}, self.stream)["images"]
images = (images / 2 + 0.5).clamp(0, 1)
return images.cpu().permute(0, 2, 3, 1).float().numpy()
def __loadResources(self, image_height, image_width, batch_size):
self.stream = cuda.Stream()
# Allocate buffers for TensorRT engine bindings
for model_name, obj in self.models.items():
self.engine[model_name].allocate_buffers(
shape_dict=obj.get_shape_dict(batch_size, image_height, image_width), device=self.torch_device
)
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: Union[torch.FloatTensor, PIL.Image.Image] = None,
mask_image: Union[torch.FloatTensor, PIL.Image.Image] = None,
strength: float = 1.0,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
mask_image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
repainted, while black pixels will be preserved. If `mask_image` is a PIL image, it will be converted
to a single channel (luminance) before use. If it's a tensor, it should contain one color channel (L)
instead of 3, so the expected shape would be `(B, H, W, 1)`.
strength (`float`, *optional*, defaults to 0.8):
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
will be used as a starting point, adding more noise to it the larger the `strength`. The number of
denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
be maximum and the denoising process will run for the full number of iterations specified in
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
"""
self.generator = generator
self.denoising_steps = num_inference_steps
self.guidance_scale = guidance_scale
# Pre-compute latent input scales and linear multistep coefficients
self.scheduler.set_timesteps(self.denoising_steps, device=self.torch_device)
# Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
prompt = [prompt]
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"Expected prompt to be of type list or str but got {type(prompt)}")
if negative_prompt is None:
negative_prompt = [""] * batch_size
if negative_prompt is not None and isinstance(negative_prompt, str):
negative_prompt = [negative_prompt]
assert len(prompt) == len(negative_prompt)
if batch_size > self.max_batch_size:
raise ValueError(
f"Batch size {len(prompt)} is larger than allowed {self.max_batch_size}. If dynamic shape is used, then maximum batch size is 4"
)
# Validate image dimensions
mask_width, mask_height = mask_image.size
if mask_height != self.image_height or mask_width != self.image_width:
raise ValueError(
f"Input image height and width {self.image_height} and {self.image_width} are not equal to "
f"the respective dimensions of the mask image {mask_height} and {mask_width}"
)
# load resources
self.__loadResources(self.image_height, self.image_width, batch_size)
with torch.inference_mode(), torch.autocast("cuda"), trt.Runtime(TRT_LOGGER):
# Spatial dimensions of latent tensor
latent_height = self.image_height // 8
latent_width = self.image_width // 8
# Pre-process input images
mask, masked_image, init_image = self.__preprocess_images(
batch_size,
prepare_mask_and_masked_image(
image,
mask_image,
self.image_height,
self.image_width,
return_image=True,
),
)
mask = torch.nn.functional.interpolate(mask, size=(latent_height, latent_width))
mask = torch.cat([mask] * 2)
# Initialize timesteps
timesteps, t_start = self.__initialize_timesteps(self.denoising_steps, strength)
# at which timestep to set the initial noise (n.b. 50% if strength is 0.5)
latent_timestep = timesteps[:1].repeat(batch_size)
# create a boolean to check if the strength is set to 1. if so then initialise the latents with pure noise
is_strength_max = strength == 1.0
# Pre-initialize latents
num_channels_latents = self.vae.config.latent_channels
latents_outputs = self.prepare_latents(
batch_size,
num_channels_latents,
self.image_height,
self.image_width,
torch.float32,
self.torch_device,
generator,
image=init_image,
timestep=latent_timestep,
is_strength_max=is_strength_max,
)
latents = latents_outputs[0]
# VAE encode masked image
masked_latents = self.__encode_image(masked_image)
masked_latents = torch.cat([masked_latents] * 2)
# CLIP text encoder
text_embeddings = self.__encode_prompt(prompt, negative_prompt)
# UNet denoiser
latents = self.__denoise_latent(
latents,
text_embeddings,
timesteps=timesteps,
step_offset=t_start,
mask=mask,
masked_image_latents=masked_latents,
)
# VAE decode latent
images = self.__decode_latent(latents)
images = self.numpy_to_pil(images)
return StableDiffusionPipelineOutput(images=images, nsfw_content_detected=None)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/lpw_stable_diffusion_xl.py
|
## ----------------------------------------------------------
# A SDXL pipeline can take unlimited weighted prompt
#
# Author: Andrew Zhu
# Github: https://github.com/xhinker
# Medium: https://medium.com/@xhinker
## -----------------------------------------------------------
import inspect
import os
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import torch
from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
from diffusers import DiffusionPipeline, StableDiffusionXLPipeline
from diffusers.image_processor import VaeImageProcessor
from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.models.attention_processor import (
AttnProcessor2_0,
LoRAAttnProcessor2_0,
LoRAXFormersAttnProcessor,
XFormersAttnProcessor,
)
from diffusers.pipelines.stable_diffusion_xl import StableDiffusionXLPipelineOutput
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
is_accelerate_available,
is_accelerate_version,
is_invisible_watermark_available,
logging,
replace_example_docstring,
)
from diffusers.utils.torch_utils import randn_tensor
if is_invisible_watermark_available():
from diffusers.pipelines.stable_diffusion_xl.watermark import StableDiffusionXLWatermarker
def parse_prompt_attention(text):
"""
Parses a string with attention tokens and returns a list of pairs: text and its associated weight.
Accepted tokens are:
(abc) - increases attention to abc by a multiplier of 1.1
(abc:3.12) - increases attention to abc by a multiplier of 3.12
[abc] - decreases attention to abc by a multiplier of 1.1
\\( - literal character '('
\\[ - literal character '['
\\) - literal character ')'
\\] - literal character ']'
\\ - literal character '\'
anything else - just text
>>> parse_prompt_attention('normal text')
[['normal text', 1.0]]
>>> parse_prompt_attention('an (important) word')
[['an ', 1.0], ['important', 1.1], [' word', 1.0]]
>>> parse_prompt_attention('(unbalanced')
[['unbalanced', 1.1]]
>>> parse_prompt_attention('\\(literal\\]')
[['(literal]', 1.0]]
>>> parse_prompt_attention('(unnecessary)(parens)')
[['unnecessaryparens', 1.1]]
>>> parse_prompt_attention('a (((house:1.3)) [on] a (hill:0.5), sun, (((sky))).')
[['a ', 1.0],
['house', 1.5730000000000004],
[' ', 1.1],
['on', 1.0],
[' a ', 1.1],
['hill', 0.55],
[', sun, ', 1.1],
['sky', 1.4641000000000006],
['.', 1.1]]
"""
import re
re_attention = re.compile(
r"""
\\\(|\\\)|\\\[|\\]|\\\\|\\|\(|\[|:([+-]?[.\d]+)\)|
\)|]|[^\\()\[\]:]+|:
""",
re.X,
)
re_break = re.compile(r"\s*\bBREAK\b\s*", re.S)
res = []
round_brackets = []
square_brackets = []
round_bracket_multiplier = 1.1
square_bracket_multiplier = 1 / 1.1
def multiply_range(start_position, multiplier):
for p in range(start_position, len(res)):
res[p][1] *= multiplier
for m in re_attention.finditer(text):
text = m.group(0)
weight = m.group(1)
if text.startswith("\\"):
res.append([text[1:], 1.0])
elif text == "(":
round_brackets.append(len(res))
elif text == "[":
square_brackets.append(len(res))
elif weight is not None and len(round_brackets) > 0:
multiply_range(round_brackets.pop(), float(weight))
elif text == ")" and len(round_brackets) > 0:
multiply_range(round_brackets.pop(), round_bracket_multiplier)
elif text == "]" and len(square_brackets) > 0:
multiply_range(square_brackets.pop(), square_bracket_multiplier)
else:
parts = re.split(re_break, text)
for i, part in enumerate(parts):
if i > 0:
res.append(["BREAK", -1])
res.append([part, 1.0])
for pos in round_brackets:
multiply_range(pos, round_bracket_multiplier)
for pos in square_brackets:
multiply_range(pos, square_bracket_multiplier)
if len(res) == 0:
res = [["", 1.0]]
# merge runs of identical weights
i = 0
while i + 1 < len(res):
if res[i][1] == res[i + 1][1]:
res[i][0] += res[i + 1][0]
res.pop(i + 1)
else:
i += 1
return res
def get_prompts_tokens_with_weights(clip_tokenizer: CLIPTokenizer, prompt: str):
"""
Get prompt token ids and weights, this function works for both prompt and negative prompt
Args:
pipe (CLIPTokenizer)
A CLIPTokenizer
prompt (str)
A prompt string with weights
Returns:
text_tokens (list)
A list contains token ids
text_weight (list)
A list contains the correspodent weight of token ids
Example:
import torch
from transformers import CLIPTokenizer
clip_tokenizer = CLIPTokenizer.from_pretrained(
"stablediffusionapi/deliberate-v2"
, subfolder = "tokenizer"
, dtype = torch.float16
)
token_id_list, token_weight_list = get_prompts_tokens_with_weights(
clip_tokenizer = clip_tokenizer
,prompt = "a (red:1.5) cat"*70
)
"""
texts_and_weights = parse_prompt_attention(prompt)
text_tokens, text_weights = [], []
for word, weight in texts_and_weights:
# tokenize and discard the starting and the ending token
token = clip_tokenizer(word, truncation=False).input_ids[1:-1] # so that tokenize whatever length prompt
# the returned token is a 1d list: [320, 1125, 539, 320]
# merge the new tokens to the all tokens holder: text_tokens
text_tokens = [*text_tokens, *token]
# each token chunk will come with one weight, like ['red cat', 2.0]
# need to expand weight for each token.
chunk_weights = [weight] * len(token)
# append the weight back to the weight holder: text_weights
text_weights = [*text_weights, *chunk_weights]
return text_tokens, text_weights
def group_tokens_and_weights(token_ids: list, weights: list, pad_last_block=False):
"""
Produce tokens and weights in groups and pad the missing tokens
Args:
token_ids (list)
The token ids from tokenizer
weights (list)
The weights list from function get_prompts_tokens_with_weights
pad_last_block (bool)
Control if fill the last token list to 75 tokens with eos
Returns:
new_token_ids (2d list)
new_weights (2d list)
Example:
token_groups,weight_groups = group_tokens_and_weights(
token_ids = token_id_list
, weights = token_weight_list
)
"""
bos, eos = 49406, 49407
# this will be a 2d list
new_token_ids = []
new_weights = []
while len(token_ids) >= 75:
# get the first 75 tokens
head_75_tokens = [token_ids.pop(0) for _ in range(75)]
head_75_weights = [weights.pop(0) for _ in range(75)]
# extract token ids and weights
temp_77_token_ids = [bos] + head_75_tokens + [eos]
temp_77_weights = [1.0] + head_75_weights + [1.0]
# add 77 token and weights chunk to the holder list
new_token_ids.append(temp_77_token_ids)
new_weights.append(temp_77_weights)
# padding the left
if len(token_ids) > 0:
padding_len = 75 - len(token_ids) if pad_last_block else 0
temp_77_token_ids = [bos] + token_ids + [eos] * padding_len + [eos]
new_token_ids.append(temp_77_token_ids)
temp_77_weights = [1.0] + weights + [1.0] * padding_len + [1.0]
new_weights.append(temp_77_weights)
return new_token_ids, new_weights
def get_weighted_text_embeddings_sdxl(
pipe: StableDiffusionXLPipeline,
prompt: str = "",
prompt_2: str = None,
neg_prompt: str = "",
neg_prompt_2: str = None,
num_images_per_prompt: int = 1,
device: Optional[torch.device] = None,
):
"""
This function can process long prompt with weights, no length limitation
for Stable Diffusion XL
Args:
pipe (StableDiffusionPipeline)
prompt (str)
prompt_2 (str)
neg_prompt (str)
neg_prompt_2 (str)
num_images_per_prompt (int)
device (torch.device)
Returns:
prompt_embeds (torch.Tensor)
neg_prompt_embeds (torch.Tensor)
"""
device = device or pipe._execution_device
if prompt_2:
prompt = f"{prompt} {prompt_2}"
if neg_prompt_2:
neg_prompt = f"{neg_prompt} {neg_prompt_2}"
eos = pipe.tokenizer.eos_token_id
# tokenizer 1
prompt_tokens, prompt_weights = get_prompts_tokens_with_weights(pipe.tokenizer, prompt)
neg_prompt_tokens, neg_prompt_weights = get_prompts_tokens_with_weights(pipe.tokenizer, neg_prompt)
# tokenizer 2
prompt_tokens_2, prompt_weights_2 = get_prompts_tokens_with_weights(pipe.tokenizer_2, prompt)
neg_prompt_tokens_2, neg_prompt_weights_2 = get_prompts_tokens_with_weights(pipe.tokenizer_2, neg_prompt)
# padding the shorter one for prompt set 1
prompt_token_len = len(prompt_tokens)
neg_prompt_token_len = len(neg_prompt_tokens)
if prompt_token_len > neg_prompt_token_len:
# padding the neg_prompt with eos token
neg_prompt_tokens = neg_prompt_tokens + [eos] * abs(prompt_token_len - neg_prompt_token_len)
neg_prompt_weights = neg_prompt_weights + [1.0] * abs(prompt_token_len - neg_prompt_token_len)
else:
# padding the prompt
prompt_tokens = prompt_tokens + [eos] * abs(prompt_token_len - neg_prompt_token_len)
prompt_weights = prompt_weights + [1.0] * abs(prompt_token_len - neg_prompt_token_len)
# padding the shorter one for token set 2
prompt_token_len_2 = len(prompt_tokens_2)
neg_prompt_token_len_2 = len(neg_prompt_tokens_2)
if prompt_token_len_2 > neg_prompt_token_len_2:
# padding the neg_prompt with eos token
neg_prompt_tokens_2 = neg_prompt_tokens_2 + [eos] * abs(prompt_token_len_2 - neg_prompt_token_len_2)
neg_prompt_weights_2 = neg_prompt_weights_2 + [1.0] * abs(prompt_token_len_2 - neg_prompt_token_len_2)
else:
# padding the prompt
prompt_tokens_2 = prompt_tokens_2 + [eos] * abs(prompt_token_len_2 - neg_prompt_token_len_2)
prompt_weights_2 = prompt_weights + [1.0] * abs(prompt_token_len_2 - neg_prompt_token_len_2)
embeds = []
neg_embeds = []
prompt_token_groups, prompt_weight_groups = group_tokens_and_weights(prompt_tokens.copy(), prompt_weights.copy())
neg_prompt_token_groups, neg_prompt_weight_groups = group_tokens_and_weights(
neg_prompt_tokens.copy(), neg_prompt_weights.copy()
)
prompt_token_groups_2, prompt_weight_groups_2 = group_tokens_and_weights(
prompt_tokens_2.copy(), prompt_weights_2.copy()
)
neg_prompt_token_groups_2, neg_prompt_weight_groups_2 = group_tokens_and_weights(
neg_prompt_tokens_2.copy(), neg_prompt_weights_2.copy()
)
# get prompt embeddings one by one is not working.
for i in range(len(prompt_token_groups)):
# get positive prompt embeddings with weights
token_tensor = torch.tensor([prompt_token_groups[i]], dtype=torch.long, device=device)
weight_tensor = torch.tensor(prompt_weight_groups[i], dtype=torch.float16, device=device)
token_tensor_2 = torch.tensor([prompt_token_groups_2[i]], dtype=torch.long, device=device)
# use first text encoder
prompt_embeds_1 = pipe.text_encoder(token_tensor.to(device), output_hidden_states=True)
prompt_embeds_1_hidden_states = prompt_embeds_1.hidden_states[-2]
# use second text encoder
prompt_embeds_2 = pipe.text_encoder_2(token_tensor_2.to(device), output_hidden_states=True)
prompt_embeds_2_hidden_states = prompt_embeds_2.hidden_states[-2]
pooled_prompt_embeds = prompt_embeds_2[0]
prompt_embeds_list = [prompt_embeds_1_hidden_states, prompt_embeds_2_hidden_states]
token_embedding = torch.concat(prompt_embeds_list, dim=-1).squeeze(0)
for j in range(len(weight_tensor)):
if weight_tensor[j] != 1.0:
token_embedding[j] = (
token_embedding[-1] + (token_embedding[j] - token_embedding[-1]) * weight_tensor[j]
)
token_embedding = token_embedding.unsqueeze(0)
embeds.append(token_embedding)
# get negative prompt embeddings with weights
neg_token_tensor = torch.tensor([neg_prompt_token_groups[i]], dtype=torch.long, device=device)
neg_token_tensor_2 = torch.tensor([neg_prompt_token_groups_2[i]], dtype=torch.long, device=device)
neg_weight_tensor = torch.tensor(neg_prompt_weight_groups[i], dtype=torch.float16, device=device)
# use first text encoder
neg_prompt_embeds_1 = pipe.text_encoder(neg_token_tensor.to(device), output_hidden_states=True)
neg_prompt_embeds_1_hidden_states = neg_prompt_embeds_1.hidden_states[-2]
# use second text encoder
neg_prompt_embeds_2 = pipe.text_encoder_2(neg_token_tensor_2.to(device), output_hidden_states=True)
neg_prompt_embeds_2_hidden_states = neg_prompt_embeds_2.hidden_states[-2]
negative_pooled_prompt_embeds = neg_prompt_embeds_2[0]
neg_prompt_embeds_list = [neg_prompt_embeds_1_hidden_states, neg_prompt_embeds_2_hidden_states]
neg_token_embedding = torch.concat(neg_prompt_embeds_list, dim=-1).squeeze(0)
for z in range(len(neg_weight_tensor)):
if neg_weight_tensor[z] != 1.0:
neg_token_embedding[z] = (
neg_token_embedding[-1] + (neg_token_embedding[z] - neg_token_embedding[-1]) * neg_weight_tensor[z]
)
neg_token_embedding = neg_token_embedding.unsqueeze(0)
neg_embeds.append(neg_token_embedding)
prompt_embeds = torch.cat(embeds, dim=1)
negative_prompt_embeds = torch.cat(neg_embeds, dim=1)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt, 1).view(
bs_embed * num_images_per_prompt, -1
)
negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt, 1).view(
bs_embed * num_images_per_prompt, -1
)
return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
# -------------------------------------------------------------------------------------------------------------------------------
# reuse the backbone code from StableDiffusionXLPipeline
# -------------------------------------------------------------------------------------------------------------------------------
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0"
, torch_dtype = torch.float16
, use_safetensors = True
, variant = "fp16"
, custom_pipeline = "lpw_stable_diffusion_xl",
)
prompt = "a white cat running on the grass"*20
prompt2 = "play a football"*20
prompt = f"{prompt},{prompt2}"
neg_prompt = "blur, low quality"
pipe.to("cuda")
images = pipe(
prompt = prompt
, negative_prompt = neg_prompt
).images[0]
pipe.to("cpu")
torch.cuda.empty_cache()
images
```
"""
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
# rescale the results from guidance (fixes overexposure)
noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
# mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
return noise_cfg
class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, LoraLoaderMixin):
r"""
Pipeline for text-to-image generation using Stable Diffusion XL.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
In addition the pipeline inherits the following loading methods:
- *LoRA*: [`StableDiffusionXLPipeline.load_lora_weights`]
- *Ckpt*: [`loaders.FromSingleFileMixin.from_single_file`]
as well as the following saving methods:
- *LoRA*: [`loaders.StableDiffusionXLPipeline.save_lora_weights`]
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion XL uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
text_encoder_2 ([` CLIPTextModelWithProjection`]):
Second frozen text-encoder. Stable Diffusion XL uses the text and pool portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModelWithProjection),
specifically the
[laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k)
variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
tokenizer_2 (`CLIPTokenizer`):
Second Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
text_encoder_2: CLIPTextModelWithProjection,
tokenizer: CLIPTokenizer,
tokenizer_2: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
force_zeros_for_empty_prompt: bool = True,
add_watermarker: Optional[bool] = None,
):
super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
text_encoder_2=text_encoder_2,
tokenizer=tokenizer,
tokenizer_2=tokenizer_2,
unet=unet,
scheduler=scheduler,
)
self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.default_sample_size = self.unet.config.sample_size
add_watermarker = add_watermarker if add_watermarker is not None else is_invisible_watermark_available()
if add_watermarker:
self.watermark = StableDiffusionXLWatermarker()
else:
self.watermark = None
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
def enable_vae_slicing(self):
r"""
Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
"""
self.vae.enable_slicing()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
def disable_vae_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
computing decoding in one step.
"""
self.vae.disable_slicing()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
def enable_vae_tiling(self):
r"""
Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
processing larger images.
"""
self.vae.enable_tiling()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
def disable_vae_tiling(self):
r"""
Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
computing decoding in one step.
"""
self.vae.disable_tiling()
def enable_model_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
"""
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
from accelerate import cpu_offload_with_hook
else:
raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
device = torch.device(f"cuda:{gpu_id}")
if self.device.type != "cpu":
self.to("cpu", silence_dtype_warnings=True)
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
model_sequence = (
[self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
)
model_sequence.extend([self.unet, self.vae])
hook = None
for cpu_offloaded_model in model_sequence:
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
# We'll offload the last model manually.
self.final_offload_hook = hook
def encode_prompt(
self,
prompt: str,
prompt_2: Optional[str] = None,
device: Optional[torch.device] = None,
num_images_per_prompt: int = 1,
do_classifier_free_guidance: bool = True,
negative_prompt: Optional[str] = None,
negative_prompt_2: Optional[str] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
used in both text-encoders
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
negative_prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
`text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
If not provided, pooled text embeddings will be generated from `prompt` input argument.
negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
input argument.
lora_scale (`float`, *optional*):
A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
"""
device = device or self._execution_device
# set lora scale so that monkey patched LoRA
# function of text encoder can correctly access it
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
self._lora_scale = lora_scale
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
# Define tokenizers and text encoders
tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
text_encoders = (
[self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
)
if prompt_embeds is None:
prompt_2 = prompt_2 or prompt
# textual inversion: procecss multi-vector tokens if necessary
prompt_embeds_list = []
prompts = [prompt, prompt_2]
for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, tokenizer)
text_inputs = tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {tokenizer.model_max_length} tokens: {removed_text}"
)
prompt_embeds = text_encoder(
text_input_ids.to(device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
pooled_prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.hidden_states[-2]
prompt_embeds_list.append(prompt_embeds)
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
# get unconditional embeddings for classifier free guidance
zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
negative_prompt_embeds = torch.zeros_like(prompt_embeds)
negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
elif do_classifier_free_guidance and negative_prompt_embeds is None:
negative_prompt = negative_prompt or ""
negative_prompt_2 = negative_prompt_2 or negative_prompt
uncond_tokens: List[str]
if prompt is not None and type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt, negative_prompt_2]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = [negative_prompt, negative_prompt_2]
negative_prompt_embeds_list = []
for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
if isinstance(self, TextualInversionLoaderMixin):
negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = tokenizer(
negative_prompt,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
negative_prompt_embeds = text_encoder(
uncond_input.input_ids.to(device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
negative_pooled_prompt_embeds = negative_prompt_embeds[0]
negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
negative_prompt_embeds_list.append(negative_prompt_embeds)
negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
bs_embed * num_images_per_prompt, -1
)
if do_classifier_free_guidance:
negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
bs_embed * num_images_per_prompt, -1
)
return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_inputs(
self,
prompt,
prompt_2,
height,
width,
callback_steps,
negative_prompt=None,
negative_prompt_2=None,
prompt_embeds=None,
negative_prompt_embeds=None,
pooled_prompt_embeds=None,
negative_pooled_prompt_embeds=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt_2 is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
if prompt_embeds is not None and pooled_prompt_embeds is None:
raise ValueError(
"If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
)
if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
raise ValueError(
"If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype):
add_time_ids = list(original_size + crops_coords_top_left + target_size)
passed_add_embed_dim = (
self.unet.config.addition_time_embed_dim * len(add_time_ids) + self.text_encoder_2.config.projection_dim
)
expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
if expected_add_embed_dim != passed_add_embed_dim:
raise ValueError(
f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
)
add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
return add_time_ids
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
def upcast_vae(self):
dtype = self.vae.dtype
self.vae.to(dtype=torch.float32)
use_torch_2_0_or_xformers = isinstance(
self.vae.decoder.mid_block.attentions[0].processor,
(
AttnProcessor2_0,
XFormersAttnProcessor,
LoRAXFormersAttnProcessor,
LoRAAttnProcessor2_0,
),
)
# if xformers or torch_2_0 is used attention block does not need
# to be in float32 which can save lots of memory
if use_torch_2_0_or_xformers:
self.vae.post_quant_conv.to(dtype)
self.vae.decoder.conv_in.to(dtype)
self.vae.decoder.mid_block.to(dtype)
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: str = None,
prompt_2: Optional[str] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
denoising_end: Optional[float] = None,
guidance_scale: float = 5.0,
negative_prompt: Optional[str] = None,
negative_prompt_2: Optional[str] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
guidance_rescale: float = 0.0,
original_size: Optional[Tuple[int, int]] = None,
crops_coords_top_left: Tuple[int, int] = (0, 0),
target_size: Optional[Tuple[int, int]] = None,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str`):
The prompt to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
prompt_2 (`str`):
The prompt to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
used in both text-encoders
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
denoising_end (`float`, *optional*):
When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
completed before it is intentionally prematurely terminated. As a result, the returned sample will
still retain a substantial amount of noise as determined by the discrete timesteps selected by the
scheduler. The denoising_end parameter should ideally be utilized when this pipeline forms a part of a
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str`):
The prompt not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
negative_prompt_2 (`str`):
The prompt not to guide the image generation to be sent to `tokenizer_2` and
`text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
If not provided, pooled text embeddings will be generated from `prompt` input argument.
negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] instead
of a plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
[Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(height, width)` if not specified. Part of SDXL's micro-conditioning as
explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
`crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
`crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
`crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
For most cases, `target_size` should be set to the desired height and width of the generated image. If
not specified it will default to `(height, width)`. Part of SDXL's micro-conditioning as explained in
section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
Examples:
Returns:
[`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] if `return_dict` is True, otherwise a
`tuple`. When returning a tuple, the first element is a list with the generated images.
"""
# 0. Default height and width to unet
height = height or self.default_sample_size * self.vae_scale_factor
width = width or self.default_sample_size * self.vae_scale_factor
original_size = original_size or (height, width)
target_size = target_size or (height, width)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
prompt_2,
height,
width,
callback_steps,
negative_prompt,
negative_prompt_2,
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
(cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None)
negative_prompt = negative_prompt if negative_prompt is not None else ""
(
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds,
) = get_weighted_text_embeddings_sdxl(
pipe=self, prompt=prompt, neg_prompt=negative_prompt, num_images_per_prompt=num_images_per_prompt
)
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 5. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7. Prepare added time ids & embeddings
add_text_embeds = pooled_prompt_embeds
add_time_ids = self._get_add_time_ids(
original_size, crops_coords_top_left, target_size, dtype=prompt_embeds.dtype
)
if do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
add_time_ids = torch.cat([add_time_ids, add_time_ids], dim=0)
prompt_embeds = prompt_embeds.to(device)
add_text_embeds = add_text_embeds.to(device)
add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
# 8. Denoising loop
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
# 7.1 Apply denoising_end
if denoising_end is not None and isinstance(denoising_end, float) and denoising_end > 0 and denoising_end < 1:
discrete_timestep_cutoff = int(
round(
self.scheduler.config.num_train_timesteps
- (denoising_end * self.scheduler.config.num_train_timesteps)
)
)
num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
timesteps = timesteps[:num_inference_steps]
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if not output_type == "latent":
# make sure the VAE is in float32 mode, as it overflows in float16
needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
if needs_upcasting:
self.upcast_vae()
latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
# cast back to fp16 if needed
if needs_upcasting:
self.vae.to(dtype=torch.float16)
else:
image = latents
return StableDiffusionXLPipelineOutput(images=image)
# apply watermark if available
if self.watermark is not None:
image = self.watermark.apply_watermark(image)
image = self.image_processor.postprocess(image, output_type=output_type)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image,)
return StableDiffusionXLPipelineOutput(images=image)
# Overrride to properly handle the loading and unloading of the additional text encoder.
def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
# We could have accessed the unet config from `lora_state_dict()` too. We pass
# it here explicitly to be able to tell that it's coming from an SDXL
# pipeline.
state_dict, network_alphas = self.lora_state_dict(
pretrained_model_name_or_path_or_dict,
unet_config=self.unet.config,
**kwargs,
)
self.load_lora_into_unet(state_dict, network_alphas=network_alphas, unet=self.unet)
text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
if len(text_encoder_state_dict) > 0:
self.load_lora_into_text_encoder(
text_encoder_state_dict,
network_alphas=network_alphas,
text_encoder=self.text_encoder,
prefix="text_encoder",
lora_scale=self.lora_scale,
)
text_encoder_2_state_dict = {k: v for k, v in state_dict.items() if "text_encoder_2." in k}
if len(text_encoder_2_state_dict) > 0:
self.load_lora_into_text_encoder(
text_encoder_2_state_dict,
network_alphas=network_alphas,
text_encoder=self.text_encoder_2,
prefix="text_encoder_2",
lora_scale=self.lora_scale,
)
@classmethod
def save_lora_weights(
self,
save_directory: Union[str, os.PathLike],
unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
is_main_process: bool = True,
weight_name: str = None,
save_function: Callable = None,
safe_serialization: bool = False,
):
state_dict = {}
def pack_weights(layers, prefix):
layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
return layers_state_dict
state_dict.update(pack_weights(unet_lora_layers, "unet"))
if text_encoder_lora_layers and text_encoder_2_lora_layers:
state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
self.write_lora_layers(
state_dict=state_dict,
save_directory=save_directory,
is_main_process=is_main_process,
weight_name=weight_name,
save_function=save_function,
safe_serialization=safe_serialization,
)
def _remove_text_encoder_monkey_patch(self):
self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder)
self._remove_text_encoder_monkey_patch_classmethod(self.text_encoder_2)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/magic_mix.py
|
from typing import Union
import torch
from PIL import Image
from torchvision import transforms as tfms
from tqdm.auto import tqdm
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DiffusionPipeline,
LMSDiscreteScheduler,
PNDMScheduler,
UNet2DConditionModel,
)
class MagicMixPipeline(DiffusionPipeline):
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[PNDMScheduler, LMSDiscreteScheduler, DDIMScheduler],
):
super().__init__()
self.register_modules(vae=vae, text_encoder=text_encoder, tokenizer=tokenizer, unet=unet, scheduler=scheduler)
# convert PIL image to latents
def encode(self, img):
with torch.no_grad():
latent = self.vae.encode(tfms.ToTensor()(img).unsqueeze(0).to(self.device) * 2 - 1)
latent = 0.18215 * latent.latent_dist.sample()
return latent
# convert latents to PIL image
def decode(self, latent):
latent = (1 / 0.18215) * latent
with torch.no_grad():
img = self.vae.decode(latent).sample
img = (img / 2 + 0.5).clamp(0, 1)
img = img.detach().cpu().permute(0, 2, 3, 1).numpy()
img = (img * 255).round().astype("uint8")
return Image.fromarray(img[0])
# convert prompt into text embeddings, also unconditional embeddings
def prep_text(self, prompt):
text_input = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_embedding = self.text_encoder(text_input.input_ids.to(self.device))[0]
uncond_input = self.tokenizer(
"",
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
uncond_embedding = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
return torch.cat([uncond_embedding, text_embedding])
def __call__(
self,
img: Image.Image,
prompt: str,
kmin: float = 0.3,
kmax: float = 0.6,
mix_factor: float = 0.5,
seed: int = 42,
steps: int = 50,
guidance_scale: float = 7.5,
) -> Image.Image:
tmin = steps - int(kmin * steps)
tmax = steps - int(kmax * steps)
text_embeddings = self.prep_text(prompt)
self.scheduler.set_timesteps(steps)
width, height = img.size
encoded = self.encode(img)
torch.manual_seed(seed)
noise = torch.randn(
(1, self.unet.config.in_channels, height // 8, width // 8),
).to(self.device)
latents = self.scheduler.add_noise(
encoded,
noise,
timesteps=self.scheduler.timesteps[tmax],
)
input = torch.cat([latents] * 2)
input = self.scheduler.scale_model_input(input, self.scheduler.timesteps[tmax])
with torch.no_grad():
pred = self.unet(
input,
self.scheduler.timesteps[tmax],
encoder_hidden_states=text_embeddings,
).sample
pred_uncond, pred_text = pred.chunk(2)
pred = pred_uncond + guidance_scale * (pred_text - pred_uncond)
latents = self.scheduler.step(pred, self.scheduler.timesteps[tmax], latents).prev_sample
for i, t in enumerate(tqdm(self.scheduler.timesteps)):
if i > tmax:
if i < tmin: # layout generation phase
orig_latents = self.scheduler.add_noise(
encoded,
noise,
timesteps=t,
)
input = (
(mix_factor * latents) + (1 - mix_factor) * orig_latents
) # interpolating between layout noise and conditionally generated noise to preserve layout sematics
input = torch.cat([input] * 2)
else: # content generation phase
input = torch.cat([latents] * 2)
input = self.scheduler.scale_model_input(input, t)
with torch.no_grad():
pred = self.unet(
input,
t,
encoder_hidden_states=text_embeddings,
).sample
pred_uncond, pred_text = pred.chunk(2)
pred = pred_uncond + guidance_scale * (pred_text - pred_uncond)
latents = self.scheduler.step(pred, t, latents).prev_sample
return self.decode(latents)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/one_step_unet.py
|
#!/usr/bin/env python3
import torch
from diffusers import DiffusionPipeline
class UnetSchedulerOneForwardPipeline(DiffusionPipeline):
def __init__(self, unet, scheduler):
super().__init__()
self.register_modules(unet=unet, scheduler=scheduler)
def __call__(self):
image = torch.randn(
(1, self.unet.config.in_channels, self.unet.config.sample_size, self.unet.config.sample_size),
)
timestep = 1
model_output = self.unet(image, timestep).sample
scheduler_output = self.scheduler.step(model_output, timestep, image).prev_sample
result = scheduler_output - scheduler_output + torch.ones_like(scheduler_output)
return result
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/img2img_inpainting.py
|
import inspect
from typing import Callable, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import DiffusionPipeline
from diffusers.configuration_utils import FrozenDict
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
from diffusers.utils import deprecate, logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def prepare_mask_and_masked_image(image, mask):
image = np.array(image.convert("RGB"))
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
mask = np.array(mask.convert("L"))
mask = mask.astype(np.float32) / 255.0
mask = mask[None, None]
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
mask = torch.from_numpy(mask)
masked_image = image * (mask < 0.5)
return mask, masked_image
def check_size(image, height, width):
if isinstance(image, PIL.Image.Image):
w, h = image.size
elif isinstance(image, torch.Tensor):
*_, h, w = image.shape
if h != height or w != width:
raise ValueError(f"Image size should be {height}x{width}, but got {h}x{w}")
def overlay_inner_image(image, inner_image, paste_offset: Tuple[int] = (0, 0)):
inner_image = inner_image.convert("RGBA")
image = image.convert("RGB")
image.paste(inner_image, paste_offset, inner_image)
image = image.convert("RGB")
return image
class ImageToImageInpaintingPipeline(DiffusionPipeline):
r"""
Pipeline for text-guided image-to-image inpainting using Stable Diffusion. *This is an experimental feature*.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latens. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
r"""
Enable sliced attention computation.
When this option is enabled, the attention module will split the input tensor in slices, to compute attention
in several steps. This is useful to save some memory in exchange for a small speed decrease.
Args:
slice_size (`str` or `int`, *optional*, defaults to `"auto"`):
When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
a number is provided, uses as many slices as `attention_head_dim // slice_size`. In this case,
`attention_head_dim` must be a multiple of `slice_size`.
"""
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
slice_size = self.unet.config.attention_head_dim // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
r"""
Disable sliced attention computation. If `enable_attention_slicing` was previously invoked, this method will go
back to computing attention in one step.
"""
# set slice_size = `None` to disable `attention slicing`
self.enable_attention_slicing(None)
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
image: Union[torch.FloatTensor, PIL.Image.Image],
inner_image: Union[torch.FloatTensor, PIL.Image.Image],
mask_image: Union[torch.FloatTensor, PIL.Image.Image],
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
**kwargs,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
image (`torch.Tensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
inner_image (`torch.Tensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be overlayed onto `image`. Non-transparent
regions of `inner_image` must fit inside white pixels in `mask_image`. Expects four channels, with
the last channel representing the alpha channel, which will be used to blend `inner_image` with
`image`. If not provided, it will be forcibly cast to RGBA.
mask_image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
repainted, while black pixels will be preserved. If `mask_image` is a PIL image, it will be converted
to a single channel (luminance) before use. If it's a tensor, it should contain one color channel (L)
instead of 3, so the expected shape would be `(B, H, W, 1)`.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
# check if input sizes are correct
check_size(image, height, width)
check_size(inner_image, height, width)
check_size(mask_image, height, width)
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
text_embeddings = self.text_encoder(text_input_ids.to(self.device))[0]
# duplicate text embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""]
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = text_input_ids.shape[-1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = uncond_embeddings.repeat(batch_size, num_images_per_prompt, 1)
uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# Unlike in other pipelines, latents need to be generated in the target device
# for 1-to-1 results reproducibility with the CompVis implementation.
# However this currently doesn't work in `mps`.
num_channels_latents = self.vae.config.latent_channels
latents_shape = (batch_size * num_images_per_prompt, num_channels_latents, height // 8, width // 8)
latents_dtype = text_embeddings.dtype
if latents is None:
if self.device.type == "mps":
# randn does not exist on mps
latents = torch.randn(latents_shape, generator=generator, device="cpu", dtype=latents_dtype).to(
self.device
)
else:
latents = torch.randn(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
else:
if latents.shape != latents_shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
latents = latents.to(self.device)
# overlay the inner image
image = overlay_inner_image(image, inner_image)
# prepare mask and masked_image
mask, masked_image = prepare_mask_and_masked_image(image, mask_image)
mask = mask.to(device=self.device, dtype=text_embeddings.dtype)
masked_image = masked_image.to(device=self.device, dtype=text_embeddings.dtype)
# resize the mask to latents shape as we concatenate the mask to the latents
mask = torch.nn.functional.interpolate(mask, size=(height // 8, width // 8))
# encode the mask image into latents space so we can concatenate it to the latents
masked_image_latents = self.vae.encode(masked_image).latent_dist.sample(generator=generator)
masked_image_latents = 0.18215 * masked_image_latents
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
mask = mask.repeat(batch_size * num_images_per_prompt, 1, 1, 1)
masked_image_latents = masked_image_latents.repeat(batch_size * num_images_per_prompt, 1, 1, 1)
mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
masked_image_latents = (
torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
)
num_channels_mask = mask.shape[1]
num_channels_masked_image = masked_image_latents.shape[1]
if num_channels_latents + num_channels_mask + num_channels_masked_image != self.unet.config.in_channels:
raise ValueError(
f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
" `pipeline.unet` or your `mask_image` or `image` input."
)
# set timesteps
self.scheduler.set_timesteps(num_inference_steps)
# Some schedulers like PNDM have timesteps as arrays
# It's more optimized to move all timesteps to correct device beforehand
timesteps_tensor = self.scheduler.timesteps.to(self.device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
# concat latents, mask, masked_image_latents in the channel dimension
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(
self.device
)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(text_embeddings.dtype)
)
else:
has_nsfw_concept = None
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/sd_text2img_k_diffusion.py
|
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import importlib
import warnings
from typing import Callable, List, Optional, Union
import torch
from k_diffusion.external import CompVisDenoiser, CompVisVDenoiser
from diffusers import DiffusionPipeline, LMSDiscreteScheduler
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.utils import is_accelerate_available, logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class ModelWrapper:
def __init__(self, model, alphas_cumprod):
self.model = model
self.alphas_cumprod = alphas_cumprod
def apply_model(self, *args, **kwargs):
if len(args) == 3:
encoder_hidden_states = args[-1]
args = args[:2]
if kwargs.get("cond", None) is not None:
encoder_hidden_states = kwargs.pop("cond")
return self.model(*args, encoder_hidden_states=encoder_hidden_states, **kwargs).sample
class StableDiffusionPipeline(DiffusionPipeline):
r"""
Pipeline for text-to-image generation using Stable Diffusion.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae,
text_encoder,
tokenizer,
unet,
scheduler,
safety_checker,
feature_extractor,
):
super().__init__()
if safety_checker is None:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
# get correct sigmas from LMS
scheduler = LMSDiscreteScheduler.from_config(scheduler.config)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
model = ModelWrapper(unet, scheduler.alphas_cumprod)
if scheduler.config.prediction_type == "v_prediction":
self.k_diffusion_model = CompVisVDenoiser(model)
else:
self.k_diffusion_model = CompVisDenoiser(model)
def set_sampler(self, scheduler_type: str):
warnings.warn("The `set_sampler` method is deprecated, please use `set_scheduler` instead.")
return self.set_scheduler(scheduler_type)
def set_scheduler(self, scheduler_type: str):
library = importlib.import_module("k_diffusion")
sampling = getattr(library, "sampling")
self.sampler = getattr(sampling, scheduler_type)
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
r"""
Enable sliced attention computation.
When this option is enabled, the attention module will split the input tensor in slices, to compute attention
in several steps. This is useful to save some memory in exchange for a small speed decrease.
Args:
slice_size (`str` or `int`, *optional*, defaults to `"auto"`):
When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
a number is provided, uses as many slices as `attention_head_dim // slice_size`. In this case,
`attention_head_dim` must be a multiple of `slice_size`.
"""
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
slice_size = self.unet.config.attention_head_dim // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
r"""
Disable sliced attention computation. If `enable_attention_slicing` was previously invoked, this method will go
back to computing attention in one step.
"""
# set slice_size = `None` to disable `attention slicing`
self.enable_attention_slicing(None)
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
`torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
"""
if is_accelerate_available():
from accelerate import cpu_offload
else:
raise ImportError("Please install accelerate via `pip install accelerate`")
device = torch.device(f"cuda:{gpu_id}")
for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.safety_checker]:
if cpu_offloaded_model is not None:
cpu_offload(cpu_offloaded_model, device)
@property
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if self.device != torch.device("meta") or not hasattr(self.unet, "_hf_hook"):
return self.device
for module in self.unet.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
def _encode_prompt(self, prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `list(int)`):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
"""
batch_size = len(prompt) if isinstance(prompt, list) else 1
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="pt").input_ids
if not torch.equal(text_input_ids, untruncated_ids):
removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
text_embeddings = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
text_embeddings = text_embeddings[0]
# duplicate text embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = text_input_ids.shape[-1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
uncond_embeddings = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
uncond_embeddings = uncond_embeddings[0]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = uncond_embeddings.repeat(1, num_images_per_prompt, 1)
uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
return text_embeddings
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
else:
has_nsfw_concept = None
return image, has_nsfw_concept
def decode_latents(self, latents):
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
def check_inputs(self, prompt, height, width, callback_steps):
if not isinstance(prompt, str) and not isinstance(prompt, list):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels_latents, height // 8, width // 8)
if latents is None:
if device.type == "mps":
# randn does not work reproducibly on mps
latents = torch.randn(shape, generator=generator, device="cpu", dtype=dtype).to(device)
else:
latents = torch.randn(shape, generator=generator, device=device, dtype=dtype)
else:
if latents.shape != shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
return latents
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
**kwargs,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 1. Check inputs. Raise error if not correct
self.check_inputs(prompt, height, width, callback_steps)
# 2. Define call parameters
batch_size = 1 if isinstance(prompt, str) else len(prompt)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = True
if guidance_scale <= 1.0:
raise ValueError("has to use guidance_scale")
# 3. Encode input prompt
text_embeddings = self._encode_prompt(
prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
)
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=text_embeddings.device)
sigmas = self.scheduler.sigmas
sigmas = sigmas.to(text_embeddings.dtype)
# 5. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
text_embeddings.dtype,
device,
generator,
latents,
)
latents = latents * sigmas[0]
self.k_diffusion_model.sigmas = self.k_diffusion_model.sigmas.to(latents.device)
self.k_diffusion_model.log_sigmas = self.k_diffusion_model.log_sigmas.to(latents.device)
def model_fn(x, t):
latent_model_input = torch.cat([x] * 2)
noise_pred = self.k_diffusion_model(latent_model_input, t, cond=text_embeddings)
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
return noise_pred
latents = self.sampler(model_fn, latents, sigmas)
# 8. Post-processing
image = self.decode_latents(latents)
# 9. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, text_embeddings.dtype)
# 10. Convert to PIL
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_diffusion_controlnet_inpaint_img2img.py
|
# Inspired by: https://github.com/haofanwang/ControlNet-for-Diffusers/
import inspect
from typing import Any, Callable, Dict, List, Optional, Union
import numpy as np
import PIL.Image
import torch
import torch.nn.functional as F
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, ControlNetModel, DiffusionPipeline, UNet2DConditionModel, logging
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput, StableDiffusionSafetyChecker
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
PIL_INTERPOLATION,
is_accelerate_available,
is_accelerate_version,
replace_example_docstring,
)
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import numpy as np
>>> import torch
>>> from PIL import Image
>>> from stable_diffusion_controlnet_inpaint_img2img import StableDiffusionControlNetInpaintImg2ImgPipeline
>>> from transformers import AutoImageProcessor, UperNetForSemanticSegmentation
>>> from diffusers import ControlNetModel, UniPCMultistepScheduler
>>> from diffusers.utils import load_image
>>> def ade_palette():
return [[120, 120, 120], [180, 120, 120], [6, 230, 230], [80, 50, 50],
[4, 200, 3], [120, 120, 80], [140, 140, 140], [204, 5, 255],
[230, 230, 230], [4, 250, 7], [224, 5, 255], [235, 255, 7],
[150, 5, 61], [120, 120, 70], [8, 255, 51], [255, 6, 82],
[143, 255, 140], [204, 255, 4], [255, 51, 7], [204, 70, 3],
[0, 102, 200], [61, 230, 250], [255, 6, 51], [11, 102, 255],
[255, 7, 71], [255, 9, 224], [9, 7, 230], [220, 220, 220],
[255, 9, 92], [112, 9, 255], [8, 255, 214], [7, 255, 224],
[255, 184, 6], [10, 255, 71], [255, 41, 10], [7, 255, 255],
[224, 255, 8], [102, 8, 255], [255, 61, 6], [255, 194, 7],
[255, 122, 8], [0, 255, 20], [255, 8, 41], [255, 5, 153],
[6, 51, 255], [235, 12, 255], [160, 150, 20], [0, 163, 255],
[140, 140, 140], [250, 10, 15], [20, 255, 0], [31, 255, 0],
[255, 31, 0], [255, 224, 0], [153, 255, 0], [0, 0, 255],
[255, 71, 0], [0, 235, 255], [0, 173, 255], [31, 0, 255],
[11, 200, 200], [255, 82, 0], [0, 255, 245], [0, 61, 255],
[0, 255, 112], [0, 255, 133], [255, 0, 0], [255, 163, 0],
[255, 102, 0], [194, 255, 0], [0, 143, 255], [51, 255, 0],
[0, 82, 255], [0, 255, 41], [0, 255, 173], [10, 0, 255],
[173, 255, 0], [0, 255, 153], [255, 92, 0], [255, 0, 255],
[255, 0, 245], [255, 0, 102], [255, 173, 0], [255, 0, 20],
[255, 184, 184], [0, 31, 255], [0, 255, 61], [0, 71, 255],
[255, 0, 204], [0, 255, 194], [0, 255, 82], [0, 10, 255],
[0, 112, 255], [51, 0, 255], [0, 194, 255], [0, 122, 255],
[0, 255, 163], [255, 153, 0], [0, 255, 10], [255, 112, 0],
[143, 255, 0], [82, 0, 255], [163, 255, 0], [255, 235, 0],
[8, 184, 170], [133, 0, 255], [0, 255, 92], [184, 0, 255],
[255, 0, 31], [0, 184, 255], [0, 214, 255], [255, 0, 112],
[92, 255, 0], [0, 224, 255], [112, 224, 255], [70, 184, 160],
[163, 0, 255], [153, 0, 255], [71, 255, 0], [255, 0, 163],
[255, 204, 0], [255, 0, 143], [0, 255, 235], [133, 255, 0],
[255, 0, 235], [245, 0, 255], [255, 0, 122], [255, 245, 0],
[10, 190, 212], [214, 255, 0], [0, 204, 255], [20, 0, 255],
[255, 255, 0], [0, 153, 255], [0, 41, 255], [0, 255, 204],
[41, 0, 255], [41, 255, 0], [173, 0, 255], [0, 245, 255],
[71, 0, 255], [122, 0, 255], [0, 255, 184], [0, 92, 255],
[184, 255, 0], [0, 133, 255], [255, 214, 0], [25, 194, 194],
[102, 255, 0], [92, 0, 255]]
>>> image_processor = AutoImageProcessor.from_pretrained("openmmlab/upernet-convnext-small")
>>> image_segmentor = UperNetForSemanticSegmentation.from_pretrained("openmmlab/upernet-convnext-small")
>>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-seg", torch_dtype=torch.float16)
>>> pipe = StableDiffusionControlNetInpaintImg2ImgPipeline.from_pretrained(
"runwayml/stable-diffusion-inpainting", controlnet=controlnet, safety_checker=None, torch_dtype=torch.float16
)
>>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
>>> pipe.enable_xformers_memory_efficient_attention()
>>> pipe.enable_model_cpu_offload()
>>> def image_to_seg(image):
pixel_values = image_processor(image, return_tensors="pt").pixel_values
with torch.no_grad():
outputs = image_segmentor(pixel_values)
seg = image_processor.post_process_semantic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8) # height, width, 3
palette = np.array(ade_palette())
for label, color in enumerate(palette):
color_seg[seg == label, :] = color
color_seg = color_seg.astype(np.uint8)
seg_image = Image.fromarray(color_seg)
return seg_image
>>> image = load_image(
"https://github.com/CompVis/latent-diffusion/raw/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
)
>>> mask_image = load_image(
"https://github.com/CompVis/latent-diffusion/raw/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
)
>>> controlnet_conditioning_image = image_to_seg(image)
>>> image = pipe(
"Face of a yellow cat, high resolution, sitting on a park bench",
image,
mask_image,
controlnet_conditioning_image,
num_inference_steps=20,
).images[0]
>>> image.save("out.png")
```
"""
def prepare_image(image):
if isinstance(image, torch.Tensor):
# Batch single image
if image.ndim == 3:
image = image.unsqueeze(0)
image = image.to(dtype=torch.float32)
else:
# preprocess image
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
return image
def prepare_mask_image(mask_image):
if isinstance(mask_image, torch.Tensor):
if mask_image.ndim == 2:
# Batch and add channel dim for single mask
mask_image = mask_image.unsqueeze(0).unsqueeze(0)
elif mask_image.ndim == 3 and mask_image.shape[0] == 1:
# Single mask, the 0'th dimension is considered to be
# the existing batch size of 1
mask_image = mask_image.unsqueeze(0)
elif mask_image.ndim == 3 and mask_image.shape[0] != 1:
# Batch of mask, the 0'th dimension is considered to be
# the batching dimension
mask_image = mask_image.unsqueeze(1)
# Binarize mask
mask_image[mask_image < 0.5] = 0
mask_image[mask_image >= 0.5] = 1
else:
# preprocess mask
if isinstance(mask_image, (PIL.Image.Image, np.ndarray)):
mask_image = [mask_image]
if isinstance(mask_image, list) and isinstance(mask_image[0], PIL.Image.Image):
mask_image = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask_image], axis=0)
mask_image = mask_image.astype(np.float32) / 255.0
elif isinstance(mask_image, list) and isinstance(mask_image[0], np.ndarray):
mask_image = np.concatenate([m[None, None, :] for m in mask_image], axis=0)
mask_image[mask_image < 0.5] = 0
mask_image[mask_image >= 0.5] = 1
mask_image = torch.from_numpy(mask_image)
return mask_image
def prepare_controlnet_conditioning_image(
controlnet_conditioning_image, width, height, batch_size, num_images_per_prompt, device, dtype
):
if not isinstance(controlnet_conditioning_image, torch.Tensor):
if isinstance(controlnet_conditioning_image, PIL.Image.Image):
controlnet_conditioning_image = [controlnet_conditioning_image]
if isinstance(controlnet_conditioning_image[0], PIL.Image.Image):
controlnet_conditioning_image = [
np.array(i.resize((width, height), resample=PIL_INTERPOLATION["lanczos"]))[None, :]
for i in controlnet_conditioning_image
]
controlnet_conditioning_image = np.concatenate(controlnet_conditioning_image, axis=0)
controlnet_conditioning_image = np.array(controlnet_conditioning_image).astype(np.float32) / 255.0
controlnet_conditioning_image = controlnet_conditioning_image.transpose(0, 3, 1, 2)
controlnet_conditioning_image = torch.from_numpy(controlnet_conditioning_image)
elif isinstance(controlnet_conditioning_image[0], torch.Tensor):
controlnet_conditioning_image = torch.cat(controlnet_conditioning_image, dim=0)
image_batch_size = controlnet_conditioning_image.shape[0]
if image_batch_size == 1:
repeat_by = batch_size
else:
# image batch size is the same as prompt batch size
repeat_by = num_images_per_prompt
controlnet_conditioning_image = controlnet_conditioning_image.repeat_interleave(repeat_by, dim=0)
controlnet_conditioning_image = controlnet_conditioning_image.to(device=device, dtype=dtype)
return controlnet_conditioning_image
class StableDiffusionControlNetInpaintImg2ImgPipeline(DiffusionPipeline):
"""
Inspired by: https://github.com/haofanwang/ControlNet-for-Diffusers/
"""
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
controlnet: ControlNetModel,
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
controlnet=controlnet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.register_to_config(requires_safety_checker=requires_safety_checker)
def enable_vae_slicing(self):
r"""
Enable sliced VAE decoding.
When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
steps. This is useful to save some memory and allow larger batch sizes.
"""
self.vae.enable_slicing()
def disable_vae_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
computing decoding in one step.
"""
self.vae.disable_slicing()
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
`torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
Note that offloading happens on a submodule basis. Memory savings are higher than with
`enable_model_cpu_offload`, but performance is lower.
"""
if is_accelerate_available():
from accelerate import cpu_offload
else:
raise ImportError("Please install accelerate via `pip install accelerate`")
device = torch.device(f"cuda:{gpu_id}")
for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.controlnet]:
cpu_offload(cpu_offloaded_model, device)
if self.safety_checker is not None:
cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
def enable_model_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
"""
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
from accelerate import cpu_offload_with_hook
else:
raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
device = torch.device(f"cuda:{gpu_id}")
hook = None
for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
if self.safety_checker is not None:
# the safety checker can offload the vae again
_, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
# control net hook has be manually offloaded as it alternates with unet
cpu_offload_with_hook(self.controlnet, device)
# We'll offload the last model manually.
self.final_offload_hook = hook
@property
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if not hasattr(self.unet, "_hf_hook"):
return self.device
for module in self.unet.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass `negative_prompt_embeds` instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
"""
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
prompt_embeds = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
else:
has_nsfw_concept = None
return image, has_nsfw_concept
def decode_latents(self, latents):
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_inputs(
self,
prompt,
image,
mask_image,
controlnet_conditioning_image,
height,
width,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
strength=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
controlnet_cond_image_is_pil = isinstance(controlnet_conditioning_image, PIL.Image.Image)
controlnet_cond_image_is_tensor = isinstance(controlnet_conditioning_image, torch.Tensor)
controlnet_cond_image_is_pil_list = isinstance(controlnet_conditioning_image, list) and isinstance(
controlnet_conditioning_image[0], PIL.Image.Image
)
controlnet_cond_image_is_tensor_list = isinstance(controlnet_conditioning_image, list) and isinstance(
controlnet_conditioning_image[0], torch.Tensor
)
if (
not controlnet_cond_image_is_pil
and not controlnet_cond_image_is_tensor
and not controlnet_cond_image_is_pil_list
and not controlnet_cond_image_is_tensor_list
):
raise TypeError(
"image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
)
if controlnet_cond_image_is_pil:
controlnet_cond_image_batch_size = 1
elif controlnet_cond_image_is_tensor:
controlnet_cond_image_batch_size = controlnet_conditioning_image.shape[0]
elif controlnet_cond_image_is_pil_list:
controlnet_cond_image_batch_size = len(controlnet_conditioning_image)
elif controlnet_cond_image_is_tensor_list:
controlnet_cond_image_batch_size = len(controlnet_conditioning_image)
if prompt is not None and isinstance(prompt, str):
prompt_batch_size = 1
elif prompt is not None and isinstance(prompt, list):
prompt_batch_size = len(prompt)
elif prompt_embeds is not None:
prompt_batch_size = prompt_embeds.shape[0]
if controlnet_cond_image_batch_size != 1 and controlnet_cond_image_batch_size != prompt_batch_size:
raise ValueError(
f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {controlnet_cond_image_batch_size}, prompt batch size: {prompt_batch_size}"
)
if isinstance(image, torch.Tensor) and not isinstance(mask_image, torch.Tensor):
raise TypeError("if `image` is a tensor, `mask_image` must also be a tensor")
if isinstance(image, PIL.Image.Image) and not isinstance(mask_image, PIL.Image.Image):
raise TypeError("if `image` is a PIL image, `mask_image` must also be a PIL image")
if isinstance(image, torch.Tensor):
if image.ndim != 3 and image.ndim != 4:
raise ValueError("`image` must have 3 or 4 dimensions")
if mask_image.ndim != 2 and mask_image.ndim != 3 and mask_image.ndim != 4:
raise ValueError("`mask_image` must have 2, 3, or 4 dimensions")
if image.ndim == 3:
image_batch_size = 1
image_channels, image_height, image_width = image.shape
elif image.ndim == 4:
image_batch_size, image_channels, image_height, image_width = image.shape
if mask_image.ndim == 2:
mask_image_batch_size = 1
mask_image_channels = 1
mask_image_height, mask_image_width = mask_image.shape
elif mask_image.ndim == 3:
mask_image_channels = 1
mask_image_batch_size, mask_image_height, mask_image_width = mask_image.shape
elif mask_image.ndim == 4:
mask_image_batch_size, mask_image_channels, mask_image_height, mask_image_width = mask_image.shape
if image_channels != 3:
raise ValueError("`image` must have 3 channels")
if mask_image_channels != 1:
raise ValueError("`mask_image` must have 1 channel")
if image_batch_size != mask_image_batch_size:
raise ValueError("`image` and `mask_image` mush have the same batch sizes")
if image_height != mask_image_height or image_width != mask_image_width:
raise ValueError("`image` and `mask_image` must have the same height and width dimensions")
if image.min() < -1 or image.max() > 1:
raise ValueError("`image` should be in range [-1, 1]")
if mask_image.min() < 0 or mask_image.max() > 1:
raise ValueError("`mask_image` should be in range [0, 1]")
else:
mask_image_channels = 1
image_channels = 3
single_image_latent_channels = self.vae.config.latent_channels
total_latent_channels = single_image_latent_channels * 2 + mask_image_channels
if total_latent_channels != self.unet.config.in_channels:
raise ValueError(
f"The config of `pipeline.unet` expects {self.unet.config.in_channels} but received"
f" non inpainting latent channels: {single_image_latent_channels},"
f" mask channels: {mask_image_channels}, and masked image channels: {single_image_latent_channels}."
f" Please verify the config of `pipeline.unet` and the `mask_image` and `image` inputs."
)
if strength < 0 or strength > 1:
raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
def get_timesteps(self, num_inference_steps, strength, device):
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start:]
return timesteps, num_inference_steps - t_start
def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None):
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
)
image = image.to(device=device, dtype=dtype)
batch_size = batch_size * num_images_per_prompt
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if isinstance(generator, list):
init_latents = [
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
]
init_latents = torch.cat(init_latents, dim=0)
else:
init_latents = self.vae.encode(image).latent_dist.sample(generator)
init_latents = self.vae.config.scaling_factor * init_latents
if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
raise ValueError(
f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
)
else:
init_latents = torch.cat([init_latents], dim=0)
shape = init_latents.shape
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
# get latents
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
latents = init_latents
return latents
def prepare_mask_latents(self, mask_image, batch_size, height, width, dtype, device, do_classifier_free_guidance):
# resize the mask to latents shape as we concatenate the mask to the latents
# we do that before converting to dtype to avoid breaking in case we're using cpu_offload
# and half precision
mask_image = F.interpolate(mask_image, size=(height // self.vae_scale_factor, width // self.vae_scale_factor))
mask_image = mask_image.to(device=device, dtype=dtype)
# duplicate mask for each generation per prompt, using mps friendly method
if mask_image.shape[0] < batch_size:
if not batch_size % mask_image.shape[0] == 0:
raise ValueError(
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
f" a total batch size of {batch_size}, but {mask_image.shape[0]} masks were passed. Make sure the number"
" of masks that you pass is divisible by the total requested batch size."
)
mask_image = mask_image.repeat(batch_size // mask_image.shape[0], 1, 1, 1)
mask_image = torch.cat([mask_image] * 2) if do_classifier_free_guidance else mask_image
mask_image_latents = mask_image
return mask_image_latents
def prepare_masked_image_latents(
self, masked_image, batch_size, height, width, dtype, device, generator, do_classifier_free_guidance
):
masked_image = masked_image.to(device=device, dtype=dtype)
# encode the mask image into latents space so we can concatenate it to the latents
if isinstance(generator, list):
masked_image_latents = [
self.vae.encode(masked_image[i : i + 1]).latent_dist.sample(generator=generator[i])
for i in range(batch_size)
]
masked_image_latents = torch.cat(masked_image_latents, dim=0)
else:
masked_image_latents = self.vae.encode(masked_image).latent_dist.sample(generator=generator)
masked_image_latents = self.vae.config.scaling_factor * masked_image_latents
# duplicate masked_image_latents for each generation per prompt, using mps friendly method
if masked_image_latents.shape[0] < batch_size:
if not batch_size % masked_image_latents.shape[0] == 0:
raise ValueError(
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
" Make sure the number of images that you pass is divisible by the total requested batch size."
)
masked_image_latents = masked_image_latents.repeat(batch_size // masked_image_latents.shape[0], 1, 1, 1)
masked_image_latents = (
torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
)
# aligning device to prevent device errors when concating it with the latent model input
masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
return masked_image_latents
def _default_height_width(self, height, width, image):
if isinstance(image, list):
image = image[0]
if height is None:
if isinstance(image, PIL.Image.Image):
height = image.height
elif isinstance(image, torch.Tensor):
height = image.shape[3]
height = (height // 8) * 8 # round down to nearest multiple of 8
if width is None:
if isinstance(image, PIL.Image.Image):
width = image.width
elif isinstance(image, torch.Tensor):
width = image.shape[2]
width = (width // 8) * 8 # round down to nearest multiple of 8
return height, width
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: Union[torch.Tensor, PIL.Image.Image] = None,
mask_image: Union[torch.Tensor, PIL.Image.Image] = None,
controlnet_conditioning_image: Union[
torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]
] = None,
strength: float = 0.8,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
controlnet_conditioning_scale: float = 1.0,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`torch.Tensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
mask_image (`torch.Tensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
repainted, while black pixels will be preserved. If `mask_image` is a PIL image, it will be converted
to a single channel (luminance) before use. If it's a tensor, it should contain one color channel (L)
instead of 3, so the expected shape would be `(B, H, W, 1)`.
controlnet_conditioning_image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]` or `List[PIL.Image.Image]`):
The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. PIL.Image.Image` can
also be accepted as an image. The control image is automatically resized to fit the output image.
strength (`float`, *optional*):
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
will be used as a starting point, adding more noise to it the larger the `strength`. The number of
denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
be maximum and the denoising process will run for the full number of iterations specified in
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass `negative_prompt_embeds` instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
controlnet_conditioning_scale (`float`, *optional*, defaults to 1.0):
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
to the residual in the original unet.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 0. Default height and width to unet
height, width = self._default_height_width(height, width, controlnet_conditioning_image)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
image,
mask_image,
controlnet_conditioning_image,
height,
width,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
strength,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
# 4. Prepare mask, image, and controlnet_conditioning_image
image = prepare_image(image)
mask_image = prepare_mask_image(mask_image)
controlnet_conditioning_image = prepare_controlnet_conditioning_image(
controlnet_conditioning_image,
width,
height,
batch_size * num_images_per_prompt,
num_images_per_prompt,
device,
self.controlnet.dtype,
)
masked_image = image * (mask_image < 0.5)
# 5. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# 6. Prepare latent variables
latents = self.prepare_latents(
image,
latent_timestep,
batch_size,
num_images_per_prompt,
prompt_embeds.dtype,
device,
generator,
)
mask_image_latents = self.prepare_mask_latents(
mask_image,
batch_size * num_images_per_prompt,
height,
width,
prompt_embeds.dtype,
device,
do_classifier_free_guidance,
)
masked_image_latents = self.prepare_masked_image_latents(
masked_image,
batch_size * num_images_per_prompt,
height,
width,
prompt_embeds.dtype,
device,
generator,
do_classifier_free_guidance,
)
if do_classifier_free_guidance:
controlnet_conditioning_image = torch.cat([controlnet_conditioning_image] * 2)
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 8. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
non_inpainting_latent_model_input = (
torch.cat([latents] * 2) if do_classifier_free_guidance else latents
)
non_inpainting_latent_model_input = self.scheduler.scale_model_input(
non_inpainting_latent_model_input, t
)
inpainting_latent_model_input = torch.cat(
[non_inpainting_latent_model_input, mask_image_latents, masked_image_latents], dim=1
)
down_block_res_samples, mid_block_res_sample = self.controlnet(
non_inpainting_latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
controlnet_cond=controlnet_conditioning_image,
return_dict=False,
)
down_block_res_samples = [
down_block_res_sample * controlnet_conditioning_scale
for down_block_res_sample in down_block_res_samples
]
mid_block_res_sample *= controlnet_conditioning_scale
# predict the noise residual
noise_pred = self.unet(
inpainting_latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# If we do sequential model offloading, let's offload unet and controlnet
# manually for max memory savings
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.unet.to("cpu")
self.controlnet.to("cpu")
torch.cuda.empty_cache()
if output_type == "latent":
image = latents
has_nsfw_concept = None
elif output_type == "pil":
# 8. Post-processing
image = self.decode_latents(latents)
# 9. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
# 10. Convert to PIL
image = self.numpy_to_pil(image)
else:
# 8. Post-processing
image = self.decode_latents(latents)
# 9. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/unclip_image_interpolation.py
|
import inspect
from typing import List, Optional, Union
import PIL.Image
import torch
from torch.nn import functional as F
from transformers import (
CLIPImageProcessor,
CLIPTextModelWithProjection,
CLIPTokenizer,
CLIPVisionModelWithProjection,
)
from diffusers import (
DiffusionPipeline,
ImagePipelineOutput,
UnCLIPScheduler,
UNet2DConditionModel,
UNet2DModel,
)
from diffusers.pipelines.unclip import UnCLIPTextProjModel
from diffusers.utils import is_accelerate_available, logging
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def slerp(val, low, high):
"""
Find the interpolation point between the 'low' and 'high' values for the given 'val'. See https://en.wikipedia.org/wiki/Slerp for more details on the topic.
"""
low_norm = low / torch.norm(low)
high_norm = high / torch.norm(high)
omega = torch.acos((low_norm * high_norm))
so = torch.sin(omega)
res = (torch.sin((1.0 - val) * omega) / so) * low + (torch.sin(val * omega) / so) * high
return res
class UnCLIPImageInterpolationPipeline(DiffusionPipeline):
"""
Pipeline to generate variations from an input image using unCLIP
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
text_encoder ([`CLIPTextModelWithProjection`]):
Frozen text-encoder.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `image_encoder`.
image_encoder ([`CLIPVisionModelWithProjection`]):
Frozen CLIP image-encoder. unCLIP Image Variation uses the vision portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPVisionModelWithProjection),
specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
text_proj ([`UnCLIPTextProjModel`]):
Utility class to prepare and combine the embeddings before they are passed to the decoder.
decoder ([`UNet2DConditionModel`]):
The decoder to invert the image embedding into an image.
super_res_first ([`UNet2DModel`]):
Super resolution unet. Used in all but the last step of the super resolution diffusion process.
super_res_last ([`UNet2DModel`]):
Super resolution unet. Used in the last step of the super resolution diffusion process.
decoder_scheduler ([`UnCLIPScheduler`]):
Scheduler used in the decoder denoising process. Just a modified DDPMScheduler.
super_res_scheduler ([`UnCLIPScheduler`]):
Scheduler used in the super resolution denoising process. Just a modified DDPMScheduler.
"""
decoder: UNet2DConditionModel
text_proj: UnCLIPTextProjModel
text_encoder: CLIPTextModelWithProjection
tokenizer: CLIPTokenizer
feature_extractor: CLIPImageProcessor
image_encoder: CLIPVisionModelWithProjection
super_res_first: UNet2DModel
super_res_last: UNet2DModel
decoder_scheduler: UnCLIPScheduler
super_res_scheduler: UnCLIPScheduler
# Copied from diffusers.pipelines.unclip.pipeline_unclip_image_variation.UnCLIPImageVariationPipeline.__init__
def __init__(
self,
decoder: UNet2DConditionModel,
text_encoder: CLIPTextModelWithProjection,
tokenizer: CLIPTokenizer,
text_proj: UnCLIPTextProjModel,
feature_extractor: CLIPImageProcessor,
image_encoder: CLIPVisionModelWithProjection,
super_res_first: UNet2DModel,
super_res_last: UNet2DModel,
decoder_scheduler: UnCLIPScheduler,
super_res_scheduler: UnCLIPScheduler,
):
super().__init__()
self.register_modules(
decoder=decoder,
text_encoder=text_encoder,
tokenizer=tokenizer,
text_proj=text_proj,
feature_extractor=feature_extractor,
image_encoder=image_encoder,
super_res_first=super_res_first,
super_res_last=super_res_last,
decoder_scheduler=decoder_scheduler,
super_res_scheduler=super_res_scheduler,
)
# Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline.prepare_latents
def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
if latents.shape != shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
latents = latents.to(device)
latents = latents * scheduler.init_noise_sigma
return latents
# Copied from diffusers.pipelines.unclip.pipeline_unclip_image_variation.UnCLIPImageVariationPipeline._encode_prompt
def _encode_prompt(self, prompt, device, num_images_per_prompt, do_classifier_free_guidance):
batch_size = len(prompt) if isinstance(prompt, list) else 1
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
text_mask = text_inputs.attention_mask.bool().to(device)
text_encoder_output = self.text_encoder(text_input_ids.to(device))
prompt_embeds = text_encoder_output.text_embeds
text_encoder_hidden_states = text_encoder_output.last_hidden_state
prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
if do_classifier_free_guidance:
uncond_tokens = [""] * batch_size
max_length = text_input_ids.shape[-1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
uncond_text_mask = uncond_input.attention_mask.bool().to(device)
negative_prompt_embeds_text_encoder_output = self.text_encoder(uncond_input.input_ids.to(device))
negative_prompt_embeds = negative_prompt_embeds_text_encoder_output.text_embeds
uncond_text_encoder_hidden_states = negative_prompt_embeds_text_encoder_output.last_hidden_state
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
seq_len = uncond_text_encoder_hidden_states.shape[1]
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
batch_size * num_images_per_prompt, seq_len, -1
)
uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
# done duplicates
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
text_mask = torch.cat([uncond_text_mask, text_mask])
return prompt_embeds, text_encoder_hidden_states, text_mask
# Copied from diffusers.pipelines.unclip.pipeline_unclip_image_variation.UnCLIPImageVariationPipeline._encode_image
def _encode_image(self, image, device, num_images_per_prompt, image_embeddings: Optional[torch.Tensor] = None):
dtype = next(self.image_encoder.parameters()).dtype
if image_embeddings is None:
if not isinstance(image, torch.Tensor):
image = self.feature_extractor(images=image, return_tensors="pt").pixel_values
image = image.to(device=device, dtype=dtype)
image_embeddings = self.image_encoder(image).image_embeds
image_embeddings = image_embeddings.repeat_interleave(num_images_per_prompt, dim=0)
return image_embeddings
# Copied from diffusers.pipelines.unclip.pipeline_unclip_image_variation.UnCLIPImageVariationPipeline.enable_sequential_cpu_offload
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
when their specific submodule has its `forward` method called.
"""
if is_accelerate_available():
from accelerate import cpu_offload
else:
raise ImportError("Please install accelerate via `pip install accelerate`")
device = torch.device(f"cuda:{gpu_id}")
models = [
self.decoder,
self.text_proj,
self.text_encoder,
self.super_res_first,
self.super_res_last,
]
for cpu_offloaded_model in models:
if cpu_offloaded_model is not None:
cpu_offload(cpu_offloaded_model, device)
@property
# Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline._execution_device
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if self.device != torch.device("meta") or not hasattr(self.decoder, "_hf_hook"):
return self.device
for module in self.decoder.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
@torch.no_grad()
def __call__(
self,
image: Optional[Union[List[PIL.Image.Image], torch.FloatTensor]] = None,
steps: int = 5,
decoder_num_inference_steps: int = 25,
super_res_num_inference_steps: int = 7,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
image_embeddings: Optional[torch.Tensor] = None,
decoder_latents: Optional[torch.FloatTensor] = None,
super_res_latents: Optional[torch.FloatTensor] = None,
decoder_guidance_scale: float = 8.0,
output_type: Optional[str] = "pil",
return_dict: bool = True,
):
"""
Function invoked when calling the pipeline for generation.
Args:
image (`List[PIL.Image.Image]` or `torch.FloatTensor`):
The images to use for the image interpolation. Only accepts a list of two PIL Images or If you provide a tensor, it needs to comply with the
configuration of
[this](https://huggingface.co/fusing/karlo-image-variations-diffusers/blob/main/feature_extractor/preprocessor_config.json)
`CLIPImageProcessor` while still having a shape of two in the 0th dimension. Can be left to `None` only when `image_embeddings` are passed.
steps (`int`, *optional*, defaults to 5):
The number of interpolation images to generate.
decoder_num_inference_steps (`int`, *optional*, defaults to 25):
The number of denoising steps for the decoder. More denoising steps usually lead to a higher quality
image at the expense of slower inference.
super_res_num_inference_steps (`int`, *optional*, defaults to 7):
The number of denoising steps for super resolution. More denoising steps usually lead to a higher
quality image at the expense of slower inference.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
image_embeddings (`torch.Tensor`, *optional*):
Pre-defined image embeddings that can be derived from the image encoder. Pre-defined image embeddings
can be passed for tasks like image interpolations. `image` can the be left to `None`.
decoder_latents (`torch.FloatTensor` of shape (batch size, channels, height, width), *optional*):
Pre-generated noisy latents to be used as inputs for the decoder.
super_res_latents (`torch.FloatTensor` of shape (batch size, channels, super res height, super res width), *optional*):
Pre-generated noisy latents to be used as inputs for the decoder.
decoder_guidance_scale (`float`, *optional*, defaults to 4.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
"""
batch_size = steps
device = self._execution_device
if isinstance(image, List):
if len(image) != 2:
raise AssertionError(
f"Expected 'image' List to be of size 2, but passed 'image' length is {len(image)}"
)
elif not (isinstance(image[0], PIL.Image.Image) and isinstance(image[0], PIL.Image.Image)):
raise AssertionError(
f"Expected 'image' List to contain PIL.Image.Image, but passed 'image' contents are {type(image[0])} and {type(image[1])}"
)
elif isinstance(image, torch.FloatTensor):
if image.shape[0] != 2:
raise AssertionError(
f"Expected 'image' to be torch.FloatTensor of shape 2 in 0th dimension, but passed 'image' size is {image.shape[0]}"
)
elif isinstance(image_embeddings, torch.Tensor):
if image_embeddings.shape[0] != 2:
raise AssertionError(
f"Expected 'image_embeddings' to be torch.FloatTensor of shape 2 in 0th dimension, but passed 'image_embeddings' shape is {image_embeddings.shape[0]}"
)
else:
raise AssertionError(
f"Expected 'image' or 'image_embeddings' to be not None with types List[PIL.Image] or Torch.FloatTensor respectively. Received {type(image)} and {type(image_embeddings)} repsectively"
)
original_image_embeddings = self._encode_image(
image=image, device=device, num_images_per_prompt=1, image_embeddings=image_embeddings
)
image_embeddings = []
for interp_step in torch.linspace(0, 1, steps):
temp_image_embeddings = slerp(
interp_step, original_image_embeddings[0], original_image_embeddings[1]
).unsqueeze(0)
image_embeddings.append(temp_image_embeddings)
image_embeddings = torch.cat(image_embeddings).to(device)
do_classifier_free_guidance = decoder_guidance_scale > 1.0
prompt_embeds, text_encoder_hidden_states, text_mask = self._encode_prompt(
prompt=["" for i in range(steps)],
device=device,
num_images_per_prompt=1,
do_classifier_free_guidance=do_classifier_free_guidance,
)
text_encoder_hidden_states, additive_clip_time_embeddings = self.text_proj(
image_embeddings=image_embeddings,
prompt_embeds=prompt_embeds,
text_encoder_hidden_states=text_encoder_hidden_states,
do_classifier_free_guidance=do_classifier_free_guidance,
)
if device.type == "mps":
# HACK: MPS: There is a panic when padding bool tensors,
# so cast to int tensor for the pad and back to bool afterwards
text_mask = text_mask.type(torch.int)
decoder_text_mask = F.pad(text_mask, (self.text_proj.clip_extra_context_tokens, 0), value=1)
decoder_text_mask = decoder_text_mask.type(torch.bool)
else:
decoder_text_mask = F.pad(text_mask, (self.text_proj.clip_extra_context_tokens, 0), value=True)
self.decoder_scheduler.set_timesteps(decoder_num_inference_steps, device=device)
decoder_timesteps_tensor = self.decoder_scheduler.timesteps
num_channels_latents = self.decoder.config.in_channels
height = self.decoder.config.sample_size
width = self.decoder.config.sample_size
# Get the decoder latents for 1 step and then repeat the same tensor for the entire batch to keep same noise across all interpolation steps.
decoder_latents = self.prepare_latents(
(1, num_channels_latents, height, width),
text_encoder_hidden_states.dtype,
device,
generator,
decoder_latents,
self.decoder_scheduler,
)
decoder_latents = decoder_latents.repeat((batch_size, 1, 1, 1))
for i, t in enumerate(self.progress_bar(decoder_timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([decoder_latents] * 2) if do_classifier_free_guidance else decoder_latents
noise_pred = self.decoder(
sample=latent_model_input,
timestep=t,
encoder_hidden_states=text_encoder_hidden_states,
class_labels=additive_clip_time_embeddings,
attention_mask=decoder_text_mask,
).sample
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred_uncond, _ = noise_pred_uncond.split(latent_model_input.shape[1], dim=1)
noise_pred_text, predicted_variance = noise_pred_text.split(latent_model_input.shape[1], dim=1)
noise_pred = noise_pred_uncond + decoder_guidance_scale * (noise_pred_text - noise_pred_uncond)
noise_pred = torch.cat([noise_pred, predicted_variance], dim=1)
if i + 1 == decoder_timesteps_tensor.shape[0]:
prev_timestep = None
else:
prev_timestep = decoder_timesteps_tensor[i + 1]
# compute the previous noisy sample x_t -> x_t-1
decoder_latents = self.decoder_scheduler.step(
noise_pred, t, decoder_latents, prev_timestep=prev_timestep, generator=generator
).prev_sample
decoder_latents = decoder_latents.clamp(-1, 1)
image_small = decoder_latents
# done decoder
# super res
self.super_res_scheduler.set_timesteps(super_res_num_inference_steps, device=device)
super_res_timesteps_tensor = self.super_res_scheduler.timesteps
channels = self.super_res_first.config.in_channels // 2
height = self.super_res_first.config.sample_size
width = self.super_res_first.config.sample_size
super_res_latents = self.prepare_latents(
(batch_size, channels, height, width),
image_small.dtype,
device,
generator,
super_res_latents,
self.super_res_scheduler,
)
if device.type == "mps":
# MPS does not support many interpolations
image_upscaled = F.interpolate(image_small, size=[height, width])
else:
interpolate_antialias = {}
if "antialias" in inspect.signature(F.interpolate).parameters:
interpolate_antialias["antialias"] = True
image_upscaled = F.interpolate(
image_small, size=[height, width], mode="bicubic", align_corners=False, **interpolate_antialias
)
for i, t in enumerate(self.progress_bar(super_res_timesteps_tensor)):
# no classifier free guidance
if i == super_res_timesteps_tensor.shape[0] - 1:
unet = self.super_res_last
else:
unet = self.super_res_first
latent_model_input = torch.cat([super_res_latents, image_upscaled], dim=1)
noise_pred = unet(
sample=latent_model_input,
timestep=t,
).sample
if i + 1 == super_res_timesteps_tensor.shape[0]:
prev_timestep = None
else:
prev_timestep = super_res_timesteps_tensor[i + 1]
# compute the previous noisy sample x_t -> x_t-1
super_res_latents = self.super_res_scheduler.step(
noise_pred, t, super_res_latents, prev_timestep=prev_timestep, generator=generator
).prev_sample
image = super_res_latents
# done super res
# post processing
image = image * 0.5 + 0.5
image = image.clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/interpolate_stable_diffusion.py
|
import inspect
import time
from pathlib import Path
from typing import Callable, List, Optional, Union
import numpy as np
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import DiffusionPipeline
from diffusers.configuration_utils import FrozenDict
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
from diffusers.utils import deprecate, logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def slerp(t, v0, v1, DOT_THRESHOLD=0.9995):
"""helper function to spherically interpolate two arrays v1 v2"""
if not isinstance(v0, np.ndarray):
inputs_are_torch = True
input_device = v0.device
v0 = v0.cpu().numpy()
v1 = v1.cpu().numpy()
dot = np.sum(v0 * v1 / (np.linalg.norm(v0) * np.linalg.norm(v1)))
if np.abs(dot) > DOT_THRESHOLD:
v2 = (1 - t) * v0 + t * v1
else:
theta_0 = np.arccos(dot)
sin_theta_0 = np.sin(theta_0)
theta_t = theta_0 * t
sin_theta_t = np.sin(theta_t)
s0 = np.sin(theta_0 - theta_t) / sin_theta_0
s1 = sin_theta_t / sin_theta_0
v2 = s0 * v0 + s1 * v1
if inputs_are_torch:
v2 = torch.from_numpy(v2).to(input_device)
return v2
class StableDiffusionWalkPipeline(DiffusionPipeline):
r"""
Pipeline for text-to-image generation using Stable Diffusion.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/CompVis/stable-diffusion-v1-4) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
r"""
Enable sliced attention computation.
When this option is enabled, the attention module will split the input tensor in slices, to compute attention
in several steps. This is useful to save some memory in exchange for a small speed decrease.
Args:
slice_size (`str` or `int`, *optional*, defaults to `"auto"`):
When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
a number is provided, uses as many slices as `attention_head_dim // slice_size`. In this case,
`attention_head_dim` must be a multiple of `slice_size`.
"""
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
slice_size = self.unet.config.attention_head_dim // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
r"""
Disable sliced attention computation. If `enable_attention_slicing` was previously invoked, this method will go
back to computing attention in one step.
"""
# set slice_size = `None` to disable `attention slicing`
self.enable_attention_slicing(None)
@torch.no_grad()
def __call__(
self,
prompt: Optional[Union[str, List[str]]] = None,
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
text_embeddings: Optional[torch.FloatTensor] = None,
**kwargs,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*, defaults to `None`):
The prompt or prompts to guide the image generation. If not provided, `text_embeddings` is required.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
text_embeddings (`torch.FloatTensor`, *optional*, defaults to `None`):
Pre-generated text embeddings to be used as inputs for image generation. Can be used in place of
`prompt` to avoid re-computing the embeddings. If not provided, the embeddings will be generated from
the supplied `prompt`.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if text_embeddings is None:
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
print(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
text_embeddings = self.text_encoder(text_input_ids.to(self.device))[0]
else:
batch_size = text_embeddings.shape[0]
# duplicate text embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = self.tokenizer.model_max_length
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = uncond_embeddings.repeat(1, num_images_per_prompt, 1)
uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# Unlike in other pipelines, latents need to be generated in the target device
# for 1-to-1 results reproducibility with the CompVis implementation.
# However this currently doesn't work in `mps`.
latents_shape = (batch_size * num_images_per_prompt, self.unet.config.in_channels, height // 8, width // 8)
latents_dtype = text_embeddings.dtype
if latents is None:
if self.device.type == "mps":
# randn does not work reproducibly on mps
latents = torch.randn(latents_shape, generator=generator, device="cpu", dtype=latents_dtype).to(
self.device
)
else:
latents = torch.randn(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
else:
if latents.shape != latents_shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
latents = latents.to(self.device)
# set timesteps
self.scheduler.set_timesteps(num_inference_steps)
# Some schedulers like PNDM have timesteps as arrays
# It's more optimized to move all timesteps to correct device beforehand
timesteps_tensor = self.scheduler.timesteps.to(self.device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(
self.device
)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(text_embeddings.dtype)
)
else:
has_nsfw_concept = None
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
def embed_text(self, text):
"""takes in text and turns it into text embeddings"""
text_input = self.tokenizer(
text,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
with torch.no_grad():
embed = self.text_encoder(text_input.input_ids.to(self.device))[0]
return embed
def get_noise(self, seed, dtype=torch.float32, height=512, width=512):
"""Takes in random seed and returns corresponding noise vector"""
return torch.randn(
(1, self.unet.config.in_channels, height // 8, width // 8),
generator=torch.Generator(device=self.device).manual_seed(seed),
device=self.device,
dtype=dtype,
)
def walk(
self,
prompts: List[str],
seeds: List[int],
num_interpolation_steps: Optional[int] = 6,
output_dir: Optional[str] = "./dreams",
name: Optional[str] = None,
batch_size: Optional[int] = 1,
height: Optional[int] = 512,
width: Optional[int] = 512,
guidance_scale: Optional[float] = 7.5,
num_inference_steps: Optional[int] = 50,
eta: Optional[float] = 0.0,
) -> List[str]:
"""
Walks through a series of prompts and seeds, interpolating between them and saving the results to disk.
Args:
prompts (`List[str]`):
List of prompts to generate images for.
seeds (`List[int]`):
List of seeds corresponding to provided prompts. Must be the same length as prompts.
num_interpolation_steps (`int`, *optional*, defaults to 6):
Number of interpolation steps to take between prompts.
output_dir (`str`, *optional*, defaults to `./dreams`):
Directory to save the generated images to.
name (`str`, *optional*, defaults to `None`):
Subdirectory of `output_dir` to save the generated images to. If `None`, the name will
be the current time.
batch_size (`int`, *optional*, defaults to 1):
Number of images to generate at once.
height (`int`, *optional*, defaults to 512):
Height of the generated images.
width (`int`, *optional*, defaults to 512):
Width of the generated images.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
Returns:
`List[str]`: List of paths to the generated images.
"""
if not len(prompts) == len(seeds):
raise ValueError(
f"Number of prompts and seeds must be equalGot {len(prompts)} prompts and {len(seeds)} seeds"
)
name = name or time.strftime("%Y%m%d-%H%M%S")
save_path = Path(output_dir) / name
save_path.mkdir(exist_ok=True, parents=True)
frame_idx = 0
frame_filepaths = []
for prompt_a, prompt_b, seed_a, seed_b in zip(prompts, prompts[1:], seeds, seeds[1:]):
# Embed Text
embed_a = self.embed_text(prompt_a)
embed_b = self.embed_text(prompt_b)
# Get Noise
noise_dtype = embed_a.dtype
noise_a = self.get_noise(seed_a, noise_dtype, height, width)
noise_b = self.get_noise(seed_b, noise_dtype, height, width)
noise_batch, embeds_batch = None, None
T = np.linspace(0.0, 1.0, num_interpolation_steps)
for i, t in enumerate(T):
noise = slerp(float(t), noise_a, noise_b)
embed = torch.lerp(embed_a, embed_b, t)
noise_batch = noise if noise_batch is None else torch.cat([noise_batch, noise], dim=0)
embeds_batch = embed if embeds_batch is None else torch.cat([embeds_batch, embed], dim=0)
batch_is_ready = embeds_batch.shape[0] == batch_size or i + 1 == T.shape[0]
if batch_is_ready:
outputs = self(
latents=noise_batch,
text_embeddings=embeds_batch,
height=height,
width=width,
guidance_scale=guidance_scale,
eta=eta,
num_inference_steps=num_inference_steps,
)
noise_batch, embeds_batch = None, None
for image in outputs["images"]:
frame_filepath = str(save_path / f"frame_{frame_idx:06d}.png")
image.save(frame_filepath)
frame_filepaths.append(frame_filepath)
frame_idx += 1
return frame_filepaths
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_diffusion_controlnet_reference.py
|
# Inspired by: https://github.com/Mikubill/sd-webui-controlnet/discussions/1236 and https://github.com/Mikubill/sd-webui-controlnet/discussions/1280
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from diffusers import StableDiffusionControlNetPipeline
from diffusers.models import ControlNetModel
from diffusers.models.attention import BasicTransformerBlock
from diffusers.models.unet_2d_blocks import CrossAttnDownBlock2D, CrossAttnUpBlock2D, DownBlock2D, UpBlock2D
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.utils import logging
from diffusers.utils.torch_utils import is_compiled_module, randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import cv2
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> from diffusers import UniPCMultistepScheduler
>>> from diffusers.utils import load_image
>>> input_image = load_image("https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png")
>>> # get canny image
>>> image = cv2.Canny(np.array(input_image), 100, 200)
>>> image = image[:, :, None]
>>> image = np.concatenate([image, image, image], axis=2)
>>> canny_image = Image.fromarray(image)
>>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
>>> pipe = StableDiffusionControlNetReferencePipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
controlnet=controlnet,
safety_checker=None,
torch_dtype=torch.float16
).to('cuda:0')
>>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe_controlnet.scheduler.config)
>>> result_img = pipe(ref_image=input_image,
prompt="1girl",
image=canny_image,
num_inference_steps=20,
reference_attn=True,
reference_adain=True).images[0]
>>> result_img.show()
```
"""
def torch_dfs(model: torch.nn.Module):
result = [model]
for child in model.children():
result += torch_dfs(child)
return result
class StableDiffusionControlNetReferencePipeline(StableDiffusionControlNetPipeline):
def prepare_ref_latents(self, refimage, batch_size, dtype, device, generator, do_classifier_free_guidance):
refimage = refimage.to(device=device, dtype=dtype)
# encode the mask image into latents space so we can concatenate it to the latents
if isinstance(generator, list):
ref_image_latents = [
self.vae.encode(refimage[i : i + 1]).latent_dist.sample(generator=generator[i])
for i in range(batch_size)
]
ref_image_latents = torch.cat(ref_image_latents, dim=0)
else:
ref_image_latents = self.vae.encode(refimage).latent_dist.sample(generator=generator)
ref_image_latents = self.vae.config.scaling_factor * ref_image_latents
# duplicate mask and ref_image_latents for each generation per prompt, using mps friendly method
if ref_image_latents.shape[0] < batch_size:
if not batch_size % ref_image_latents.shape[0] == 0:
raise ValueError(
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
f" to a total batch size of {batch_size}, but {ref_image_latents.shape[0]} images were passed."
" Make sure the number of images that you pass is divisible by the total requested batch size."
)
ref_image_latents = ref_image_latents.repeat(batch_size // ref_image_latents.shape[0], 1, 1, 1)
ref_image_latents = torch.cat([ref_image_latents] * 2) if do_classifier_free_guidance else ref_image_latents
# aligning device to prevent device errors when concating it with the latent model input
ref_image_latents = ref_image_latents.to(device=device, dtype=dtype)
return ref_image_latents
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: Union[
torch.FloatTensor,
PIL.Image.Image,
np.ndarray,
List[torch.FloatTensor],
List[PIL.Image.Image],
List[np.ndarray],
] = None,
ref_image: Union[torch.FloatTensor, PIL.Image.Image] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
guess_mode: bool = False,
attention_auto_machine_weight: float = 1.0,
gn_auto_machine_weight: float = 1.0,
style_fidelity: float = 0.5,
reference_attn: bool = True,
reference_adain: bool = True,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
specified in init, images must be passed as a list such that each element of the list can be correctly
batched for input to a single controlnet.
ref_image (`torch.FloatTensor`, `PIL.Image.Image`):
The Reference Control input condition. Reference Control uses this input condition to generate guidance to Unet. If
the type is specified as `Torch.FloatTensor`, it is passed to Reference Control as is. `PIL.Image.Image` can
also be accepted as an image.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
corresponding scale as a list.
guess_mode (`bool`, *optional*, defaults to `False`):
In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
attention_auto_machine_weight (`float`):
Weight of using reference query for self attention's context.
If attention_auto_machine_weight=1.0, use reference query for all self attention's context.
gn_auto_machine_weight (`float`):
Weight of using reference adain. If gn_auto_machine_weight=2.0, use all reference adain plugins.
style_fidelity (`float`):
style fidelity of ref_uncond_xt. If style_fidelity=1.0, control more important,
elif style_fidelity=0.0, prompt more important, else balanced.
reference_attn (`bool`):
Whether to use reference query for self attention's context.
reference_adain (`bool`):
Whether to use reference adain.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
assert reference_attn or reference_adain, "`reference_attn` or `reference_adain` must be True."
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
image,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
controlnet_conditioning_scale,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
global_pool_conditions = (
controlnet.config.global_pool_conditions
if isinstance(controlnet, ControlNetModel)
else controlnet.nets[0].config.global_pool_conditions
)
guess_mode = guess_mode or global_pool_conditions
# 3. Encode input prompt
text_encoder_lora_scale = (
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
)
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=text_encoder_lora_scale,
)
# 4. Prepare image
if isinstance(controlnet, ControlNetModel):
image = self.prepare_image(
image=image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
height, width = image.shape[-2:]
elif isinstance(controlnet, MultiControlNetModel):
images = []
for image_ in image:
image_ = self.prepare_image(
image=image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
images.append(image_)
image = images
height, width = image[0].shape[-2:]
else:
assert False
# 5. Preprocess reference image
ref_image = self.prepare_image(
image=ref_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=prompt_embeds.dtype,
)
# 6. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 7. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 8. Prepare reference latent variables
ref_image_latents = self.prepare_ref_latents(
ref_image,
batch_size * num_images_per_prompt,
prompt_embeds.dtype,
device,
generator,
do_classifier_free_guidance,
)
# 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 9. Modify self attention and group norm
MODE = "write"
uc_mask = (
torch.Tensor([1] * batch_size * num_images_per_prompt + [0] * batch_size * num_images_per_prompt)
.type_as(ref_image_latents)
.bool()
)
def hacked_basic_transformer_inner_forward(
self,
hidden_states: torch.FloatTensor,
attention_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
timestep: Optional[torch.LongTensor] = None,
cross_attention_kwargs: Dict[str, Any] = None,
class_labels: Optional[torch.LongTensor] = None,
):
if self.use_ada_layer_norm:
norm_hidden_states = self.norm1(hidden_states, timestep)
elif self.use_ada_layer_norm_zero:
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(
hidden_states, timestep, class_labels, hidden_dtype=hidden_states.dtype
)
else:
norm_hidden_states = self.norm1(hidden_states)
# 1. Self-Attention
cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
if self.only_cross_attention:
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
else:
if MODE == "write":
self.bank.append(norm_hidden_states.detach().clone())
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
if MODE == "read":
if attention_auto_machine_weight > self.attn_weight:
attn_output_uc = self.attn1(
norm_hidden_states,
encoder_hidden_states=torch.cat([norm_hidden_states] + self.bank, dim=1),
# attention_mask=attention_mask,
**cross_attention_kwargs,
)
attn_output_c = attn_output_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
attn_output_c[uc_mask] = self.attn1(
norm_hidden_states[uc_mask],
encoder_hidden_states=norm_hidden_states[uc_mask],
**cross_attention_kwargs,
)
attn_output = style_fidelity * attn_output_c + (1.0 - style_fidelity) * attn_output_uc
self.bank.clear()
else:
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
if self.use_ada_layer_norm_zero:
attn_output = gate_msa.unsqueeze(1) * attn_output
hidden_states = attn_output + hidden_states
if self.attn2 is not None:
norm_hidden_states = (
self.norm2(hidden_states, timestep) if self.use_ada_layer_norm else self.norm2(hidden_states)
)
# 2. Cross-Attention
attn_output = self.attn2(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
**cross_attention_kwargs,
)
hidden_states = attn_output + hidden_states
# 3. Feed-forward
norm_hidden_states = self.norm3(hidden_states)
if self.use_ada_layer_norm_zero:
norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
ff_output = self.ff(norm_hidden_states)
if self.use_ada_layer_norm_zero:
ff_output = gate_mlp.unsqueeze(1) * ff_output
hidden_states = ff_output + hidden_states
return hidden_states
def hacked_mid_forward(self, *args, **kwargs):
eps = 1e-6
x = self.original_forward(*args, **kwargs)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(x, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append(mean)
self.var_bank.append(var)
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(x, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank) / float(len(self.mean_bank))
var_acc = sum(self.var_bank) / float(len(self.var_bank))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
x_uc = (((x - mean) / std) * std_acc) + mean_acc
x_c = x_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
x_c[uc_mask] = x[uc_mask]
x = style_fidelity * x_c + (1.0 - style_fidelity) * x_uc
self.mean_bank = []
self.var_bank = []
return x
def hack_CrossAttnDownBlock2D_forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
):
eps = 1e-6
# TODO(Patrick, William) - attention mask is not used
output_states = ()
for i, (resnet, attn) in enumerate(zip(self.resnets, self.attentions)):
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
output_states = output_states + (hidden_states,)
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
def hacked_DownBlock2D_forward(self, hidden_states, temb=None, *args, **kwargs):
eps = 1e-6
output_states = ()
for i, resnet in enumerate(self.resnets):
hidden_states = resnet(hidden_states, temb)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
output_states = output_states + (hidden_states,)
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
def hacked_CrossAttnUpBlock2D_forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
upsample_size: Optional[int] = None,
attention_mask: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
):
eps = 1e-6
# TODO(Patrick, William) - attention mask is not used
for i, (resnet, attn) in enumerate(zip(self.resnets, self.attentions)):
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size)
return hidden_states
def hacked_UpBlock2D_forward(
self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None, *args, **kwargs
):
eps = 1e-6
for i, resnet in enumerate(self.resnets):
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size)
return hidden_states
if reference_attn:
attn_modules = [module for module in torch_dfs(self.unet) if isinstance(module, BasicTransformerBlock)]
attn_modules = sorted(attn_modules, key=lambda x: -x.norm1.normalized_shape[0])
for i, module in enumerate(attn_modules):
module._original_inner_forward = module.forward
module.forward = hacked_basic_transformer_inner_forward.__get__(module, BasicTransformerBlock)
module.bank = []
module.attn_weight = float(i) / float(len(attn_modules))
if reference_adain:
gn_modules = [self.unet.mid_block]
self.unet.mid_block.gn_weight = 0
down_blocks = self.unet.down_blocks
for w, module in enumerate(down_blocks):
module.gn_weight = 1.0 - float(w) / float(len(down_blocks))
gn_modules.append(module)
up_blocks = self.unet.up_blocks
for w, module in enumerate(up_blocks):
module.gn_weight = float(w) / float(len(up_blocks))
gn_modules.append(module)
for i, module in enumerate(gn_modules):
if getattr(module, "original_forward", None) is None:
module.original_forward = module.forward
if i == 0:
# mid_block
module.forward = hacked_mid_forward.__get__(module, torch.nn.Module)
elif isinstance(module, CrossAttnDownBlock2D):
module.forward = hack_CrossAttnDownBlock2D_forward.__get__(module, CrossAttnDownBlock2D)
elif isinstance(module, DownBlock2D):
module.forward = hacked_DownBlock2D_forward.__get__(module, DownBlock2D)
elif isinstance(module, CrossAttnUpBlock2D):
module.forward = hacked_CrossAttnUpBlock2D_forward.__get__(module, CrossAttnUpBlock2D)
elif isinstance(module, UpBlock2D):
module.forward = hacked_UpBlock2D_forward.__get__(module, UpBlock2D)
module.mean_bank = []
module.var_bank = []
module.gn_weight *= 2
# 11. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# controlnet(s) inference
if guess_mode and do_classifier_free_guidance:
# Infer ControlNet only for the conditional batch.
control_model_input = latents
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
else:
control_model_input = latent_model_input
controlnet_prompt_embeds = prompt_embeds
down_block_res_samples, mid_block_res_sample = self.controlnet(
control_model_input,
t,
encoder_hidden_states=controlnet_prompt_embeds,
controlnet_cond=image,
conditioning_scale=controlnet_conditioning_scale,
guess_mode=guess_mode,
return_dict=False,
)
if guess_mode and do_classifier_free_guidance:
# Infered ControlNet only for the conditional batch.
# To apply the output of ControlNet to both the unconditional and conditional batches,
# add 0 to the unconditional batch to keep it unchanged.
down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
# ref only part
noise = randn_tensor(
ref_image_latents.shape, generator=generator, device=device, dtype=ref_image_latents.dtype
)
ref_xt = self.scheduler.add_noise(
ref_image_latents,
noise,
t.reshape(
1,
),
)
ref_xt = self.scheduler.scale_model_input(ref_xt, t)
MODE = "write"
self.unet(
ref_xt,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
return_dict=False,
)
# predict the noise residual
MODE = "read"
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
return_dict=False,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# If we do sequential model offloading, let's offload unet and controlnet
# manually for max memory savings
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.unet.to("cpu")
self.controlnet.to("cpu")
torch.cuda.empty_cache()
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/imagic_stable_diffusion.py
|
"""
modeled after the textual_inversion.py / train_dreambooth.py and the work
of justinpinkney here: https://github.com/justinpinkney/stable-diffusion/blob/main/notebooks/imagic.ipynb
"""
import inspect
import warnings
from typing import List, Optional, Union
import numpy as np
import PIL.Image
import torch
import torch.nn.functional as F
from accelerate import Accelerator
# TODO: remove and import from diffusers.utils when the new version of diffusers is released
from packaging import version
from tqdm.auto import tqdm
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import DiffusionPipeline
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
from diffusers.utils import logging
if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
PIL_INTERPOLATION = {
"linear": PIL.Image.Resampling.BILINEAR,
"bilinear": PIL.Image.Resampling.BILINEAR,
"bicubic": PIL.Image.Resampling.BICUBIC,
"lanczos": PIL.Image.Resampling.LANCZOS,
"nearest": PIL.Image.Resampling.NEAREST,
}
else:
PIL_INTERPOLATION = {
"linear": PIL.Image.LINEAR,
"bilinear": PIL.Image.BILINEAR,
"bicubic": PIL.Image.BICUBIC,
"lanczos": PIL.Image.LANCZOS,
"nearest": PIL.Image.NEAREST,
}
# ------------------------------------------------------------------------------
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def preprocess(image):
w, h = image.size
w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
image = np.array(image).astype(np.float32) / 255.0
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
return 2.0 * image - 1.0
class ImagicStableDiffusionPipeline(DiffusionPipeline):
r"""
Pipeline for imagic image editing.
See paper here: https://arxiv.org/pdf/2210.09276.pdf
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offsensive or harmful.
Please, refer to the [model card](https://huggingface.co/CompVis/stable-diffusion-v1-4) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
):
super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
r"""
Enable sliced attention computation.
When this option is enabled, the attention module will split the input tensor in slices, to compute attention
in several steps. This is useful to save some memory in exchange for a small speed decrease.
Args:
slice_size (`str` or `int`, *optional*, defaults to `"auto"`):
When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
a number is provided, uses as many slices as `attention_head_dim // slice_size`. In this case,
`attention_head_dim` must be a multiple of `slice_size`.
"""
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
slice_size = self.unet.config.attention_head_dim // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
r"""
Disable sliced attention computation. If `enable_attention_slicing` was previously invoked, this method will go
back to computing attention in one step.
"""
# set slice_size = `None` to disable `attention slicing`
self.enable_attention_slicing(None)
def train(
self,
prompt: Union[str, List[str]],
image: Union[torch.FloatTensor, PIL.Image.Image],
height: Optional[int] = 512,
width: Optional[int] = 512,
generator: Optional[torch.Generator] = None,
embedding_learning_rate: float = 0.001,
diffusion_model_learning_rate: float = 2e-6,
text_embedding_optimization_steps: int = 500,
model_fine_tuning_optimization_steps: int = 1000,
**kwargs,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `nd.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
accelerator = Accelerator(
gradient_accumulation_steps=1,
mixed_precision="fp16",
)
if "torch_device" in kwargs:
device = kwargs.pop("torch_device")
warnings.warn(
"`torch_device` is deprecated as an input argument to `__call__` and will be removed in v0.3.0."
" Consider using `pipe.to(torch_device)` instead."
)
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.to(device)
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
# Freeze vae and unet
self.vae.requires_grad_(False)
self.unet.requires_grad_(False)
self.text_encoder.requires_grad_(False)
self.unet.eval()
self.vae.eval()
self.text_encoder.eval()
if accelerator.is_main_process:
accelerator.init_trackers(
"imagic",
config={
"embedding_learning_rate": embedding_learning_rate,
"text_embedding_optimization_steps": text_embedding_optimization_steps,
},
)
# get text embeddings for prompt
text_input = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_embeddings = torch.nn.Parameter(
self.text_encoder(text_input.input_ids.to(self.device))[0], requires_grad=True
)
text_embeddings = text_embeddings.detach()
text_embeddings.requires_grad_()
text_embeddings_orig = text_embeddings.clone()
# Initialize the optimizer
optimizer = torch.optim.Adam(
[text_embeddings], # only optimize the embeddings
lr=embedding_learning_rate,
)
if isinstance(image, PIL.Image.Image):
image = preprocess(image)
latents_dtype = text_embeddings.dtype
image = image.to(device=self.device, dtype=latents_dtype)
init_latent_image_dist = self.vae.encode(image).latent_dist
image_latents = init_latent_image_dist.sample(generator=generator)
image_latents = 0.18215 * image_latents
progress_bar = tqdm(range(text_embedding_optimization_steps), disable=not accelerator.is_local_main_process)
progress_bar.set_description("Steps")
global_step = 0
logger.info("First optimizing the text embedding to better reconstruct the init image")
for _ in range(text_embedding_optimization_steps):
with accelerator.accumulate(text_embeddings):
# Sample noise that we'll add to the latents
noise = torch.randn(image_latents.shape).to(image_latents.device)
timesteps = torch.randint(1000, (1,), device=image_latents.device)
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = self.scheduler.add_noise(image_latents, noise, timesteps)
# Predict the noise residual
noise_pred = self.unet(noisy_latents, timesteps, text_embeddings).sample
loss = F.mse_loss(noise_pred, noise, reduction="none").mean([1, 2, 3]).mean()
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
logs = {"loss": loss.detach().item()} # , "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
accelerator.wait_for_everyone()
text_embeddings.requires_grad_(False)
# Now we fine tune the unet to better reconstruct the image
self.unet.requires_grad_(True)
self.unet.train()
optimizer = torch.optim.Adam(
self.unet.parameters(), # only optimize unet
lr=diffusion_model_learning_rate,
)
progress_bar = tqdm(range(model_fine_tuning_optimization_steps), disable=not accelerator.is_local_main_process)
logger.info("Next fine tuning the entire model to better reconstruct the init image")
for _ in range(model_fine_tuning_optimization_steps):
with accelerator.accumulate(self.unet.parameters()):
# Sample noise that we'll add to the latents
noise = torch.randn(image_latents.shape).to(image_latents.device)
timesteps = torch.randint(1000, (1,), device=image_latents.device)
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = self.scheduler.add_noise(image_latents, noise, timesteps)
# Predict the noise residual
noise_pred = self.unet(noisy_latents, timesteps, text_embeddings).sample
loss = F.mse_loss(noise_pred, noise, reduction="none").mean([1, 2, 3]).mean()
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
logs = {"loss": loss.detach().item()} # , "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
accelerator.wait_for_everyone()
self.text_embeddings_orig = text_embeddings_orig
self.text_embeddings = text_embeddings
@torch.no_grad()
def __call__(
self,
alpha: float = 1.2,
height: Optional[int] = 512,
width: Optional[int] = 512,
num_inference_steps: Optional[int] = 50,
generator: Optional[torch.Generator] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
guidance_scale: float = 7.5,
eta: float = 0.0,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `nd.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if self.text_embeddings is None:
raise ValueError("Please run the pipe.train() before trying to generate an image.")
if self.text_embeddings_orig is None:
raise ValueError("Please run the pipe.train() before trying to generate an image.")
text_embeddings = alpha * self.text_embeddings_orig + (1 - alpha) * self.text_embeddings
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens = [""]
max_length = self.tokenizer.model_max_length
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = uncond_embeddings.view(1, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# Unlike in other pipelines, latents need to be generated in the target device
# for 1-to-1 results reproducibility with the CompVis implementation.
# However this currently doesn't work in `mps`.
latents_shape = (1, self.unet.config.in_channels, height // 8, width // 8)
latents_dtype = text_embeddings.dtype
if self.device.type == "mps":
# randn does not exist on mps
latents = torch.randn(latents_shape, generator=generator, device="cpu", dtype=latents_dtype).to(
self.device
)
else:
latents = torch.randn(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
# set timesteps
self.scheduler.set_timesteps(num_inference_steps)
# Some schedulers like PNDM have timesteps as arrays
# It's more optimized to move all timesteps to correct device beforehand
timesteps_tensor = self.scheduler.timesteps.to(self.device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(
self.device
)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(text_embeddings.dtype)
)
else:
has_nsfw_concept = None
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/multilingual_stable_diffusion.py
|
import inspect
from typing import Callable, List, Optional, Union
import torch
from transformers import (
CLIPImageProcessor,
CLIPTextModel,
CLIPTokenizer,
MBart50TokenizerFast,
MBartForConditionalGeneration,
pipeline,
)
from diffusers import DiffusionPipeline
from diffusers.configuration_utils import FrozenDict
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
from diffusers.utils import deprecate, logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def detect_language(pipe, prompt, batch_size):
"""helper function to detect language(s) of prompt"""
if batch_size == 1:
preds = pipe(prompt, top_k=1, truncation=True, max_length=128)
return preds[0]["label"]
else:
detected_languages = []
for p in prompt:
preds = pipe(p, top_k=1, truncation=True, max_length=128)
detected_languages.append(preds[0]["label"])
return detected_languages
def translate_prompt(prompt, translation_tokenizer, translation_model, device):
"""helper function to translate prompt to English"""
encoded_prompt = translation_tokenizer(prompt, return_tensors="pt").to(device)
generated_tokens = translation_model.generate(**encoded_prompt, max_new_tokens=1000)
en_trans = translation_tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
return en_trans[0]
class MultilingualStableDiffusion(DiffusionPipeline):
r"""
Pipeline for text-to-image generation using Stable Diffusion in different languages.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
detection_pipeline ([`pipeline`]):
Transformers pipeline to detect prompt's language.
translation_model ([`MBartForConditionalGeneration`]):
Model to translate prompt to English, if necessary. Please refer to the
[model card](https://huggingface.co/docs/transformers/model_doc/mbart) for details.
translation_tokenizer ([`MBart50TokenizerFast`]):
Tokenizer of the translation model.
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latens. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
detection_pipeline: pipeline,
translation_model: MBartForConditionalGeneration,
translation_tokenizer: MBart50TokenizerFast,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
self.register_modules(
detection_pipeline=detection_pipeline,
translation_model=translation_model,
translation_tokenizer=translation_tokenizer,
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
r"""
Enable sliced attention computation.
When this option is enabled, the attention module will split the input tensor in slices, to compute attention
in several steps. This is useful to save some memory in exchange for a small speed decrease.
Args:
slice_size (`str` or `int`, *optional*, defaults to `"auto"`):
When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
a number is provided, uses as many slices as `attention_head_dim // slice_size`. In this case,
`attention_head_dim` must be a multiple of `slice_size`.
"""
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
slice_size = self.unet.config.attention_head_dim // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
r"""
Disable sliced attention computation. If `enable_attention_slicing` was previously invoked, this method will go
back to computing attention in one step.
"""
# set slice_size = `None` to disable `attention slicing`
self.enable_attention_slicing(None)
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
**kwargs,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation. Can be in different languages.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
# detect language and translate if necessary
prompt_language = detect_language(self.detection_pipeline, prompt, batch_size)
if batch_size == 1 and prompt_language != "en":
prompt = translate_prompt(prompt, self.translation_tokenizer, self.translation_model, self.device)
if isinstance(prompt, list):
for index in range(batch_size):
if prompt_language[index] != "en":
p = translate_prompt(
prompt[index], self.translation_tokenizer, self.translation_model, self.device
)
prompt[index] = p
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
text_embeddings = self.text_encoder(text_input_ids.to(self.device))[0]
# duplicate text embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
# detect language and translate it if necessary
negative_prompt_language = detect_language(self.detection_pipeline, negative_prompt, batch_size)
if negative_prompt_language != "en":
negative_prompt = translate_prompt(
negative_prompt, self.translation_tokenizer, self.translation_model, self.device
)
if isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
# detect language and translate it if necessary
if isinstance(negative_prompt, list):
negative_prompt_languages = detect_language(self.detection_pipeline, negative_prompt, batch_size)
for index in range(batch_size):
if negative_prompt_languages[index] != "en":
p = translate_prompt(
negative_prompt[index], self.translation_tokenizer, self.translation_model, self.device
)
negative_prompt[index] = p
uncond_tokens = negative_prompt
max_length = text_input_ids.shape[-1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = uncond_embeddings.repeat(1, num_images_per_prompt, 1)
uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# Unlike in other pipelines, latents need to be generated in the target device
# for 1-to-1 results reproducibility with the CompVis implementation.
# However this currently doesn't work in `mps`.
latents_shape = (batch_size * num_images_per_prompt, self.unet.config.in_channels, height // 8, width // 8)
latents_dtype = text_embeddings.dtype
if latents is None:
if self.device.type == "mps":
# randn does not work reproducibly on mps
latents = torch.randn(latents_shape, generator=generator, device="cpu", dtype=latents_dtype).to(
self.device
)
else:
latents = torch.randn(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
else:
if latents.shape != latents_shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
latents = latents.to(self.device)
# set timesteps
self.scheduler.set_timesteps(num_inference_steps)
# Some schedulers like PNDM have timesteps as arrays
# It's more optimized to move all timesteps to correct device beforehand
timesteps_tensor = self.scheduler.timesteps.to(self.device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(
self.device
)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(text_embeddings.dtype)
)
else:
has_nsfw_concept = None
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_diffusion_tensorrt_txt2img.py
|
#
# Copyright 2023 The HuggingFace Inc. team.
# SPDX-FileCopyrightText: Copyright (c) 1993-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import os
from collections import OrderedDict
from copy import copy
from typing import List, Optional, Union
import numpy as np
import onnx
import onnx_graphsurgeon as gs
import tensorrt as trt
import torch
from huggingface_hub import snapshot_download
from onnx import shape_inference
from polygraphy import cuda
from polygraphy.backend.common import bytes_from_path
from polygraphy.backend.onnx.loader import fold_constants
from polygraphy.backend.trt import (
CreateConfig,
Profile,
engine_from_bytes,
engine_from_network,
network_from_onnx_path,
save_engine,
)
from polygraphy.backend.trt import util as trt_util
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion import (
StableDiffusionPipeline,
StableDiffusionPipelineOutput,
StableDiffusionSafetyChecker,
)
from diffusers.schedulers import DDIMScheduler
from diffusers.utils import DIFFUSERS_CACHE, logging
"""
Installation instructions
python3 -m pip install --upgrade transformers diffusers>=0.16.0
python3 -m pip install --upgrade tensorrt>=8.6.1
python3 -m pip install --upgrade polygraphy>=0.47.0 onnx-graphsurgeon --extra-index-url https://pypi.ngc.nvidia.com
python3 -m pip install onnxruntime
"""
TRT_LOGGER = trt.Logger(trt.Logger.ERROR)
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
# Map of numpy dtype -> torch dtype
numpy_to_torch_dtype_dict = {
np.uint8: torch.uint8,
np.int8: torch.int8,
np.int16: torch.int16,
np.int32: torch.int32,
np.int64: torch.int64,
np.float16: torch.float16,
np.float32: torch.float32,
np.float64: torch.float64,
np.complex64: torch.complex64,
np.complex128: torch.complex128,
}
if np.version.full_version >= "1.24.0":
numpy_to_torch_dtype_dict[np.bool_] = torch.bool
else:
numpy_to_torch_dtype_dict[np.bool] = torch.bool
# Map of torch dtype -> numpy dtype
torch_to_numpy_dtype_dict = {value: key for (key, value) in numpy_to_torch_dtype_dict.items()}
def device_view(t):
return cuda.DeviceView(ptr=t.data_ptr(), shape=t.shape, dtype=torch_to_numpy_dtype_dict[t.dtype])
class Engine:
def __init__(self, engine_path):
self.engine_path = engine_path
self.engine = None
self.context = None
self.buffers = OrderedDict()
self.tensors = OrderedDict()
def __del__(self):
[buf.free() for buf in self.buffers.values() if isinstance(buf, cuda.DeviceArray)]
del self.engine
del self.context
del self.buffers
del self.tensors
def build(
self,
onnx_path,
fp16,
input_profile=None,
enable_preview=False,
enable_all_tactics=False,
timing_cache=None,
workspace_size=0,
):
logger.warning(f"Building TensorRT engine for {onnx_path}: {self.engine_path}")
p = Profile()
if input_profile:
for name, dims in input_profile.items():
assert len(dims) == 3
p.add(name, min=dims[0], opt=dims[1], max=dims[2])
config_kwargs = {}
config_kwargs["preview_features"] = [trt.PreviewFeature.DISABLE_EXTERNAL_TACTIC_SOURCES_FOR_CORE_0805]
if enable_preview:
# Faster dynamic shapes made optional since it increases engine build time.
config_kwargs["preview_features"].append(trt.PreviewFeature.FASTER_DYNAMIC_SHAPES_0805)
if workspace_size > 0:
config_kwargs["memory_pool_limits"] = {trt.MemoryPoolType.WORKSPACE: workspace_size}
if not enable_all_tactics:
config_kwargs["tactic_sources"] = []
engine = engine_from_network(
network_from_onnx_path(onnx_path, flags=[trt.OnnxParserFlag.NATIVE_INSTANCENORM]),
config=CreateConfig(fp16=fp16, profiles=[p], load_timing_cache=timing_cache, **config_kwargs),
save_timing_cache=timing_cache,
)
save_engine(engine, path=self.engine_path)
def load(self):
logger.warning(f"Loading TensorRT engine: {self.engine_path}")
self.engine = engine_from_bytes(bytes_from_path(self.engine_path))
def activate(self):
self.context = self.engine.create_execution_context()
def allocate_buffers(self, shape_dict=None, device="cuda"):
for idx in range(trt_util.get_bindings_per_profile(self.engine)):
binding = self.engine[idx]
if shape_dict and binding in shape_dict:
shape = shape_dict[binding]
else:
shape = self.engine.get_binding_shape(binding)
dtype = trt.nptype(self.engine.get_binding_dtype(binding))
if self.engine.binding_is_input(binding):
self.context.set_binding_shape(idx, shape)
tensor = torch.empty(tuple(shape), dtype=numpy_to_torch_dtype_dict[dtype]).to(device=device)
self.tensors[binding] = tensor
self.buffers[binding] = cuda.DeviceView(ptr=tensor.data_ptr(), shape=shape, dtype=dtype)
def infer(self, feed_dict, stream):
start_binding, end_binding = trt_util.get_active_profile_bindings(self.context)
# shallow copy of ordered dict
device_buffers = copy(self.buffers)
for name, buf in feed_dict.items():
assert isinstance(buf, cuda.DeviceView)
device_buffers[name] = buf
bindings = [0] * start_binding + [buf.ptr for buf in device_buffers.values()]
noerror = self.context.execute_async_v2(bindings=bindings, stream_handle=stream.ptr)
if not noerror:
raise ValueError("ERROR: inference failed.")
return self.tensors
class Optimizer:
def __init__(self, onnx_graph):
self.graph = gs.import_onnx(onnx_graph)
def cleanup(self, return_onnx=False):
self.graph.cleanup().toposort()
if return_onnx:
return gs.export_onnx(self.graph)
def select_outputs(self, keep, names=None):
self.graph.outputs = [self.graph.outputs[o] for o in keep]
if names:
for i, name in enumerate(names):
self.graph.outputs[i].name = name
def fold_constants(self, return_onnx=False):
onnx_graph = fold_constants(gs.export_onnx(self.graph), allow_onnxruntime_shape_inference=True)
self.graph = gs.import_onnx(onnx_graph)
if return_onnx:
return onnx_graph
def infer_shapes(self, return_onnx=False):
onnx_graph = gs.export_onnx(self.graph)
if onnx_graph.ByteSize() > 2147483648:
raise TypeError("ERROR: model size exceeds supported 2GB limit")
else:
onnx_graph = shape_inference.infer_shapes(onnx_graph)
self.graph = gs.import_onnx(onnx_graph)
if return_onnx:
return onnx_graph
class BaseModel:
def __init__(self, model, fp16=False, device="cuda", max_batch_size=16, embedding_dim=768, text_maxlen=77):
self.model = model
self.name = "SD Model"
self.fp16 = fp16
self.device = device
self.min_batch = 1
self.max_batch = max_batch_size
self.min_image_shape = 256 # min image resolution: 256x256
self.max_image_shape = 1024 # max image resolution: 1024x1024
self.min_latent_shape = self.min_image_shape // 8
self.max_latent_shape = self.max_image_shape // 8
self.embedding_dim = embedding_dim
self.text_maxlen = text_maxlen
def get_model(self):
return self.model
def get_input_names(self):
pass
def get_output_names(self):
pass
def get_dynamic_axes(self):
return None
def get_sample_input(self, batch_size, image_height, image_width):
pass
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
return None
def get_shape_dict(self, batch_size, image_height, image_width):
return None
def optimize(self, onnx_graph):
opt = Optimizer(onnx_graph)
opt.cleanup()
opt.fold_constants()
opt.infer_shapes()
onnx_opt_graph = opt.cleanup(return_onnx=True)
return onnx_opt_graph
def check_dims(self, batch_size, image_height, image_width):
assert batch_size >= self.min_batch and batch_size <= self.max_batch
assert image_height % 8 == 0 or image_width % 8 == 0
latent_height = image_height // 8
latent_width = image_width // 8
assert latent_height >= self.min_latent_shape and latent_height <= self.max_latent_shape
assert latent_width >= self.min_latent_shape and latent_width <= self.max_latent_shape
return (latent_height, latent_width)
def get_minmax_dims(self, batch_size, image_height, image_width, static_batch, static_shape):
min_batch = batch_size if static_batch else self.min_batch
max_batch = batch_size if static_batch else self.max_batch
latent_height = image_height // 8
latent_width = image_width // 8
min_image_height = image_height if static_shape else self.min_image_shape
max_image_height = image_height if static_shape else self.max_image_shape
min_image_width = image_width if static_shape else self.min_image_shape
max_image_width = image_width if static_shape else self.max_image_shape
min_latent_height = latent_height if static_shape else self.min_latent_shape
max_latent_height = latent_height if static_shape else self.max_latent_shape
min_latent_width = latent_width if static_shape else self.min_latent_shape
max_latent_width = latent_width if static_shape else self.max_latent_shape
return (
min_batch,
max_batch,
min_image_height,
max_image_height,
min_image_width,
max_image_width,
min_latent_height,
max_latent_height,
min_latent_width,
max_latent_width,
)
def getOnnxPath(model_name, onnx_dir, opt=True):
return os.path.join(onnx_dir, model_name + (".opt" if opt else "") + ".onnx")
def getEnginePath(model_name, engine_dir):
return os.path.join(engine_dir, model_name + ".plan")
def build_engines(
models: dict,
engine_dir,
onnx_dir,
onnx_opset,
opt_image_height,
opt_image_width,
opt_batch_size=1,
force_engine_rebuild=False,
static_batch=False,
static_shape=True,
enable_preview=False,
enable_all_tactics=False,
timing_cache=None,
max_workspace_size=0,
):
built_engines = {}
if not os.path.isdir(onnx_dir):
os.makedirs(onnx_dir)
if not os.path.isdir(engine_dir):
os.makedirs(engine_dir)
# Export models to ONNX
for model_name, model_obj in models.items():
engine_path = getEnginePath(model_name, engine_dir)
if force_engine_rebuild or not os.path.exists(engine_path):
logger.warning("Building Engines...")
logger.warning("Engine build can take a while to complete")
onnx_path = getOnnxPath(model_name, onnx_dir, opt=False)
onnx_opt_path = getOnnxPath(model_name, onnx_dir)
if force_engine_rebuild or not os.path.exists(onnx_opt_path):
if force_engine_rebuild or not os.path.exists(onnx_path):
logger.warning(f"Exporting model: {onnx_path}")
model = model_obj.get_model()
with torch.inference_mode(), torch.autocast("cuda"):
inputs = model_obj.get_sample_input(opt_batch_size, opt_image_height, opt_image_width)
torch.onnx.export(
model,
inputs,
onnx_path,
export_params=True,
opset_version=onnx_opset,
do_constant_folding=True,
input_names=model_obj.get_input_names(),
output_names=model_obj.get_output_names(),
dynamic_axes=model_obj.get_dynamic_axes(),
)
del model
torch.cuda.empty_cache()
gc.collect()
else:
logger.warning(f"Found cached model: {onnx_path}")
# Optimize onnx
if force_engine_rebuild or not os.path.exists(onnx_opt_path):
logger.warning(f"Generating optimizing model: {onnx_opt_path}")
onnx_opt_graph = model_obj.optimize(onnx.load(onnx_path))
onnx.save(onnx_opt_graph, onnx_opt_path)
else:
logger.warning(f"Found cached optimized model: {onnx_opt_path} ")
# Build TensorRT engines
for model_name, model_obj in models.items():
engine_path = getEnginePath(model_name, engine_dir)
engine = Engine(engine_path)
onnx_path = getOnnxPath(model_name, onnx_dir, opt=False)
onnx_opt_path = getOnnxPath(model_name, onnx_dir)
if force_engine_rebuild or not os.path.exists(engine.engine_path):
engine.build(
onnx_opt_path,
fp16=True,
input_profile=model_obj.get_input_profile(
opt_batch_size,
opt_image_height,
opt_image_width,
static_batch=static_batch,
static_shape=static_shape,
),
enable_preview=enable_preview,
timing_cache=timing_cache,
workspace_size=max_workspace_size,
)
built_engines[model_name] = engine
# Load and activate TensorRT engines
for model_name, model_obj in models.items():
engine = built_engines[model_name]
engine.load()
engine.activate()
return built_engines
def runEngine(engine, feed_dict, stream):
return engine.infer(feed_dict, stream)
class CLIP(BaseModel):
def __init__(self, model, device, max_batch_size, embedding_dim):
super(CLIP, self).__init__(
model=model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim
)
self.name = "CLIP"
def get_input_names(self):
return ["input_ids"]
def get_output_names(self):
return ["text_embeddings", "pooler_output"]
def get_dynamic_axes(self):
return {"input_ids": {0: "B"}, "text_embeddings": {0: "B"}}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
self.check_dims(batch_size, image_height, image_width)
min_batch, max_batch, _, _, _, _, _, _, _, _ = self.get_minmax_dims(
batch_size, image_height, image_width, static_batch, static_shape
)
return {
"input_ids": [(min_batch, self.text_maxlen), (batch_size, self.text_maxlen), (max_batch, self.text_maxlen)]
}
def get_shape_dict(self, batch_size, image_height, image_width):
self.check_dims(batch_size, image_height, image_width)
return {
"input_ids": (batch_size, self.text_maxlen),
"text_embeddings": (batch_size, self.text_maxlen, self.embedding_dim),
}
def get_sample_input(self, batch_size, image_height, image_width):
self.check_dims(batch_size, image_height, image_width)
return torch.zeros(batch_size, self.text_maxlen, dtype=torch.int32, device=self.device)
def optimize(self, onnx_graph):
opt = Optimizer(onnx_graph)
opt.select_outputs([0]) # delete graph output#1
opt.cleanup()
opt.fold_constants()
opt.infer_shapes()
opt.select_outputs([0], names=["text_embeddings"]) # rename network output
opt_onnx_graph = opt.cleanup(return_onnx=True)
return opt_onnx_graph
def make_CLIP(model, device, max_batch_size, embedding_dim, inpaint=False):
return CLIP(model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim)
class UNet(BaseModel):
def __init__(
self, model, fp16=False, device="cuda", max_batch_size=16, embedding_dim=768, text_maxlen=77, unet_dim=4
):
super(UNet, self).__init__(
model=model,
fp16=fp16,
device=device,
max_batch_size=max_batch_size,
embedding_dim=embedding_dim,
text_maxlen=text_maxlen,
)
self.unet_dim = unet_dim
self.name = "UNet"
def get_input_names(self):
return ["sample", "timestep", "encoder_hidden_states"]
def get_output_names(self):
return ["latent"]
def get_dynamic_axes(self):
return {
"sample": {0: "2B", 2: "H", 3: "W"},
"encoder_hidden_states": {0: "2B"},
"latent": {0: "2B", 2: "H", 3: "W"},
}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
(
min_batch,
max_batch,
_,
_,
_,
_,
min_latent_height,
max_latent_height,
min_latent_width,
max_latent_width,
) = self.get_minmax_dims(batch_size, image_height, image_width, static_batch, static_shape)
return {
"sample": [
(2 * min_batch, self.unet_dim, min_latent_height, min_latent_width),
(2 * batch_size, self.unet_dim, latent_height, latent_width),
(2 * max_batch, self.unet_dim, max_latent_height, max_latent_width),
],
"encoder_hidden_states": [
(2 * min_batch, self.text_maxlen, self.embedding_dim),
(2 * batch_size, self.text_maxlen, self.embedding_dim),
(2 * max_batch, self.text_maxlen, self.embedding_dim),
],
}
def get_shape_dict(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return {
"sample": (2 * batch_size, self.unet_dim, latent_height, latent_width),
"encoder_hidden_states": (2 * batch_size, self.text_maxlen, self.embedding_dim),
"latent": (2 * batch_size, 4, latent_height, latent_width),
}
def get_sample_input(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
dtype = torch.float16 if self.fp16 else torch.float32
return (
torch.randn(
2 * batch_size, self.unet_dim, latent_height, latent_width, dtype=torch.float32, device=self.device
),
torch.tensor([1.0], dtype=torch.float32, device=self.device),
torch.randn(2 * batch_size, self.text_maxlen, self.embedding_dim, dtype=dtype, device=self.device),
)
def make_UNet(model, device, max_batch_size, embedding_dim, inpaint=False):
return UNet(
model,
fp16=True,
device=device,
max_batch_size=max_batch_size,
embedding_dim=embedding_dim,
unet_dim=(9 if inpaint else 4),
)
class VAE(BaseModel):
def __init__(self, model, device, max_batch_size, embedding_dim):
super(VAE, self).__init__(
model=model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim
)
self.name = "VAE decoder"
def get_input_names(self):
return ["latent"]
def get_output_names(self):
return ["images"]
def get_dynamic_axes(self):
return {"latent": {0: "B", 2: "H", 3: "W"}, "images": {0: "B", 2: "8H", 3: "8W"}}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
(
min_batch,
max_batch,
_,
_,
_,
_,
min_latent_height,
max_latent_height,
min_latent_width,
max_latent_width,
) = self.get_minmax_dims(batch_size, image_height, image_width, static_batch, static_shape)
return {
"latent": [
(min_batch, 4, min_latent_height, min_latent_width),
(batch_size, 4, latent_height, latent_width),
(max_batch, 4, max_latent_height, max_latent_width),
]
}
def get_shape_dict(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return {
"latent": (batch_size, 4, latent_height, latent_width),
"images": (batch_size, 3, image_height, image_width),
}
def get_sample_input(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return torch.randn(batch_size, 4, latent_height, latent_width, dtype=torch.float32, device=self.device)
def make_VAE(model, device, max_batch_size, embedding_dim, inpaint=False):
return VAE(model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim)
class TensorRTStableDiffusionPipeline(StableDiffusionPipeline):
r"""
Pipeline for text-to-image generation using TensorRT accelerated Stable Diffusion.
This model inherits from [`StableDiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPFeatureExtractor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: DDIMScheduler,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPFeatureExtractor,
requires_safety_checker: bool = True,
stages=["clip", "unet", "vae"],
image_height: int = 768,
image_width: int = 768,
max_batch_size: int = 16,
# ONNX export parameters
onnx_opset: int = 17,
onnx_dir: str = "onnx",
# TensorRT engine build parameters
engine_dir: str = "engine",
build_preview_features: bool = True,
force_engine_rebuild: bool = False,
timing_cache: str = "timing_cache",
):
super().__init__(
vae, text_encoder, tokenizer, unet, scheduler, safety_checker, feature_extractor, requires_safety_checker
)
self.vae.forward = self.vae.decode
self.stages = stages
self.image_height, self.image_width = image_height, image_width
self.inpaint = False
self.onnx_opset = onnx_opset
self.onnx_dir = onnx_dir
self.engine_dir = engine_dir
self.force_engine_rebuild = force_engine_rebuild
self.timing_cache = timing_cache
self.build_static_batch = False
self.build_dynamic_shape = False
self.build_preview_features = build_preview_features
self.max_batch_size = max_batch_size
# TODO: Restrict batch size to 4 for larger image dimensions as a WAR for TensorRT limitation.
if self.build_dynamic_shape or self.image_height > 512 or self.image_width > 512:
self.max_batch_size = 4
self.stream = None # loaded in loadResources()
self.models = {} # loaded in __loadModels()
self.engine = {} # loaded in build_engines()
def __loadModels(self):
# Load pipeline models
self.embedding_dim = self.text_encoder.config.hidden_size
models_args = {
"device": self.torch_device,
"max_batch_size": self.max_batch_size,
"embedding_dim": self.embedding_dim,
"inpaint": self.inpaint,
}
if "clip" in self.stages:
self.models["clip"] = make_CLIP(self.text_encoder, **models_args)
if "unet" in self.stages:
self.models["unet"] = make_UNet(self.unet, **models_args)
if "vae" in self.stages:
self.models["vae"] = make_VAE(self.vae, **models_args)
@classmethod
def set_cached_folder(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], **kwargs):
cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
resume_download = kwargs.pop("resume_download", False)
proxies = kwargs.pop("proxies", None)
local_files_only = kwargs.pop("local_files_only", False)
use_auth_token = kwargs.pop("use_auth_token", None)
revision = kwargs.pop("revision", None)
cls.cached_folder = (
pretrained_model_name_or_path
if os.path.isdir(pretrained_model_name_or_path)
else snapshot_download(
pretrained_model_name_or_path,
cache_dir=cache_dir,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
use_auth_token=use_auth_token,
revision=revision,
)
)
def to(self, torch_device: Optional[Union[str, torch.device]] = None, silence_dtype_warnings: bool = False):
super().to(torch_device, silence_dtype_warnings=silence_dtype_warnings)
self.onnx_dir = os.path.join(self.cached_folder, self.onnx_dir)
self.engine_dir = os.path.join(self.cached_folder, self.engine_dir)
self.timing_cache = os.path.join(self.cached_folder, self.timing_cache)
# set device
self.torch_device = self._execution_device
logger.warning(f"Running inference on device: {self.torch_device}")
# load models
self.__loadModels()
# build engines
self.engine = build_engines(
self.models,
self.engine_dir,
self.onnx_dir,
self.onnx_opset,
opt_image_height=self.image_height,
opt_image_width=self.image_width,
force_engine_rebuild=self.force_engine_rebuild,
static_batch=self.build_static_batch,
static_shape=not self.build_dynamic_shape,
enable_preview=self.build_preview_features,
timing_cache=self.timing_cache,
)
return self
def __encode_prompt(self, prompt, negative_prompt):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
"""
# Tokenize prompt
text_input_ids = (
self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
.input_ids.type(torch.int32)
.to(self.torch_device)
)
text_input_ids_inp = device_view(text_input_ids)
# NOTE: output tensor for CLIP must be cloned because it will be overwritten when called again for negative prompt
text_embeddings = runEngine(self.engine["clip"], {"input_ids": text_input_ids_inp}, self.stream)[
"text_embeddings"
].clone()
# Tokenize negative prompt
uncond_input_ids = (
self.tokenizer(
negative_prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
.input_ids.type(torch.int32)
.to(self.torch_device)
)
uncond_input_ids_inp = device_view(uncond_input_ids)
uncond_embeddings = runEngine(self.engine["clip"], {"input_ids": uncond_input_ids_inp}, self.stream)[
"text_embeddings"
]
# Concatenate the unconditional and text embeddings into a single batch to avoid doing two forward passes for classifier free guidance
text_embeddings = torch.cat([uncond_embeddings, text_embeddings]).to(dtype=torch.float16)
return text_embeddings
def __denoise_latent(
self, latents, text_embeddings, timesteps=None, step_offset=0, mask=None, masked_image_latents=None
):
if not isinstance(timesteps, torch.Tensor):
timesteps = self.scheduler.timesteps
for step_index, timestep in enumerate(timesteps):
# Expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, timestep)
if isinstance(mask, torch.Tensor):
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
# Predict the noise residual
timestep_float = timestep.float() if timestep.dtype != torch.float32 else timestep
sample_inp = device_view(latent_model_input)
timestep_inp = device_view(timestep_float)
embeddings_inp = device_view(text_embeddings)
noise_pred = runEngine(
self.engine["unet"],
{"sample": sample_inp, "timestep": timestep_inp, "encoder_hidden_states": embeddings_inp},
self.stream,
)["latent"]
# Perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
latents = self.scheduler.step(noise_pred, timestep, latents).prev_sample
latents = 1.0 / 0.18215 * latents
return latents
def __decode_latent(self, latents):
images = runEngine(self.engine["vae"], {"latent": device_view(latents)}, self.stream)["images"]
images = (images / 2 + 0.5).clamp(0, 1)
return images.cpu().permute(0, 2, 3, 1).float().numpy()
def __loadResources(self, image_height, image_width, batch_size):
self.stream = cuda.Stream()
# Allocate buffers for TensorRT engine bindings
for model_name, obj in self.models.items():
self.engine[model_name].allocate_buffers(
shape_dict=obj.get_shape_dict(batch_size, image_height, image_width), device=self.torch_device
)
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
"""
self.generator = generator
self.denoising_steps = num_inference_steps
self.guidance_scale = guidance_scale
# Pre-compute latent input scales and linear multistep coefficients
self.scheduler.set_timesteps(self.denoising_steps, device=self.torch_device)
# Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
prompt = [prompt]
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"Expected prompt to be of type list or str but got {type(prompt)}")
if negative_prompt is None:
negative_prompt = [""] * batch_size
if negative_prompt is not None and isinstance(negative_prompt, str):
negative_prompt = [negative_prompt]
assert len(prompt) == len(negative_prompt)
if batch_size > self.max_batch_size:
raise ValueError(
f"Batch size {len(prompt)} is larger than allowed {self.max_batch_size}. If dynamic shape is used, then maximum batch size is 4"
)
# load resources
self.__loadResources(self.image_height, self.image_width, batch_size)
with torch.inference_mode(), torch.autocast("cuda"), trt.Runtime(TRT_LOGGER):
# CLIP text encoder
text_embeddings = self.__encode_prompt(prompt, negative_prompt)
# Pre-initialize latents
num_channels_latents = self.unet.in_channels
latents = self.prepare_latents(
batch_size,
num_channels_latents,
self.image_height,
self.image_width,
torch.float32,
self.torch_device,
generator,
)
# UNet denoiser
latents = self.__denoise_latent(latents, text_embeddings)
# VAE decode latent
images = self.__decode_latent(latents)
images, has_nsfw_concept = self.run_safety_checker(images, self.torch_device, text_embeddings.dtype)
images = self.numpy_to_pil(images)
return StableDiffusionPipelineOutput(images=images, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/seed_resize_stable_diffusion.py
|
"""
modified based on diffusion library from Huggingface: https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
"""
import inspect
from typing import Callable, List, Optional, Union
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import DiffusionPipeline
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
from diffusers.utils import logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class SeedResizeStableDiffusionPipeline(DiffusionPipeline):
r"""
Pipeline for text-to-image generation using Stable Diffusion.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/CompVis/stable-diffusion-v1-4) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
):
super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
r"""
Enable sliced attention computation.
When this option is enabled, the attention module will split the input tensor in slices, to compute attention
in several steps. This is useful to save some memory in exchange for a small speed decrease.
Args:
slice_size (`str` or `int`, *optional*, defaults to `"auto"`):
When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
a number is provided, uses as many slices as `attention_head_dim // slice_size`. In this case,
`attention_head_dim` must be a multiple of `slice_size`.
"""
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
slice_size = self.unet.config.attention_head_dim // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
r"""
Disable sliced attention computation. If `enable_attention_slicing` was previously invoked, this method will go
back to computing attention in one step.
"""
# set slice_size = `None` to disable `attention slicing`
self.enable_attention_slicing(None)
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
text_embeddings: Optional[torch.FloatTensor] = None,
**kwargs,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
if text_embeddings is None:
text_embeddings = self.text_encoder(text_input_ids.to(self.device))[0]
# duplicate text embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""]
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = text_input_ids.shape[-1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = uncond_embeddings.repeat(batch_size, num_images_per_prompt, 1)
uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# Unlike in other pipelines, latents need to be generated in the target device
# for 1-to-1 results reproducibility with the CompVis implementation.
# However this currently doesn't work in `mps`.
latents_shape = (batch_size * num_images_per_prompt, self.unet.config.in_channels, height // 8, width // 8)
latents_shape_reference = (batch_size * num_images_per_prompt, self.unet.config.in_channels, 64, 64)
latents_dtype = text_embeddings.dtype
if latents is None:
if self.device.type == "mps":
# randn does not exist on mps
latents_reference = torch.randn(
latents_shape_reference, generator=generator, device="cpu", dtype=latents_dtype
).to(self.device)
latents = torch.randn(latents_shape, generator=generator, device="cpu", dtype=latents_dtype).to(
self.device
)
else:
latents_reference = torch.randn(
latents_shape_reference, generator=generator, device=self.device, dtype=latents_dtype
)
latents = torch.randn(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
else:
if latents_reference.shape != latents_shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
latents_reference = latents_reference.to(self.device)
latents = latents.to(self.device)
# This is the key part of the pipeline where we
# try to ensure that the generated images w/ the same seed
# but different sizes actually result in similar images
dx = (latents_shape[3] - latents_shape_reference[3]) // 2
dy = (latents_shape[2] - latents_shape_reference[2]) // 2
w = latents_shape_reference[3] if dx >= 0 else latents_shape_reference[3] + 2 * dx
h = latents_shape_reference[2] if dy >= 0 else latents_shape_reference[2] + 2 * dy
tx = 0 if dx < 0 else dx
ty = 0 if dy < 0 else dy
dx = max(-dx, 0)
dy = max(-dy, 0)
# import pdb
# pdb.set_trace()
latents[:, :, ty : ty + h, tx : tx + w] = latents_reference[:, :, dy : dy + h, dx : dx + w]
# set timesteps
self.scheduler.set_timesteps(num_inference_steps)
# Some schedulers like PNDM have timesteps as arrays
# It's more optimized to move all timesteps to correct device beforehand
timesteps_tensor = self.scheduler.timesteps.to(self.device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(
self.device
)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(text_embeddings.dtype)
)
else:
has_nsfw_concept = None
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/ddim_noise_comparative_analysis.py
|
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import List, Optional, Tuple, Union
import PIL.Image
import torch
from torchvision import transforms
from diffusers.pipelines.pipeline_utils import DiffusionPipeline, ImagePipelineOutput
from diffusers.schedulers import DDIMScheduler
from diffusers.utils.torch_utils import randn_tensor
trans = transforms.Compose(
[
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def preprocess(image):
if isinstance(image, torch.Tensor):
return image
elif isinstance(image, PIL.Image.Image):
image = [image]
image = [trans(img.convert("RGB")) for img in image]
image = torch.stack(image)
return image
class DDIMNoiseComparativeAnalysisPipeline(DiffusionPipeline):
r"""
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Parameters:
unet ([`UNet2DModel`]): U-Net architecture to denoise the encoded image.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image. Can be one of
[`DDPMScheduler`], or [`DDIMScheduler`].
"""
def __init__(self, unet, scheduler):
super().__init__()
# make sure scheduler can always be converted to DDIM
scheduler = DDIMScheduler.from_config(scheduler.config)
self.register_modules(unet=unet, scheduler=scheduler)
def check_inputs(self, strength):
if strength < 0 or strength > 1:
raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
def get_timesteps(self, num_inference_steps, strength, device):
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start:]
return timesteps, num_inference_steps - t_start
def prepare_latents(self, image, timestep, batch_size, dtype, device, generator=None):
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
)
init_latents = image.to(device=device, dtype=dtype)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
shape = init_latents.shape
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
# get latents
print("add noise to latents at timestep", timestep)
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
latents = init_latents
return latents
@torch.no_grad()
def __call__(
self,
image: Union[torch.FloatTensor, PIL.Image.Image] = None,
strength: float = 0.8,
batch_size: int = 1,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
eta: float = 0.0,
num_inference_steps: int = 50,
use_clipped_model_output: Optional[bool] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
) -> Union[ImagePipelineOutput, Tuple]:
r"""
Args:
image (`torch.FloatTensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, that will be used as the starting point for the
process.
strength (`float`, *optional*, defaults to 0.8):
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
will be used as a starting point, adding more noise to it the larger the `strength`. The number of
denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
be maximum and the denoising process will run for the full number of iterations specified in
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
batch_size (`int`, *optional*, defaults to 1):
The number of images to generate.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
eta (`float`, *optional*, defaults to 0.0):
The eta parameter which controls the scale of the variance (0 is DDIM and 1 is one type of DDPM).
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
use_clipped_model_output (`bool`, *optional*, defaults to `None`):
if `True` or `False`, see documentation for `DDIMScheduler.step`. If `None`, nothing is passed
downstream to the scheduler. So use `None` for schedulers which don't support this argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
Returns:
[`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is
True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
"""
# 1. Check inputs. Raise error if not correct
self.check_inputs(strength)
# 2. Preprocess image
image = preprocess(image)
# 3. set timesteps
self.scheduler.set_timesteps(num_inference_steps, device=self.device)
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, self.device)
latent_timestep = timesteps[:1].repeat(batch_size)
# 4. Prepare latent variables
latents = self.prepare_latents(image, latent_timestep, batch_size, self.unet.dtype, self.device, generator)
image = latents
# 5. Denoising loop
for t in self.progress_bar(timesteps):
# 1. predict noise model_output
model_output = self.unet(image, t).sample
# 2. predict previous mean of image x_t-1 and add variance depending on eta
# eta corresponds to η in paper and should be between [0, 1]
# do x_t -> x_t-1
image = self.scheduler.step(
model_output,
t,
image,
eta=eta,
use_clipped_model_output=use_clipped_model_output,
generator=generator,
).prev_sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, latent_timestep.item())
return ImagePipelineOutput(images=image)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/iadb.py
|
from typing import List, Optional, Tuple, Union
import torch
from diffusers import DiffusionPipeline
from diffusers.configuration_utils import ConfigMixin
from diffusers.pipelines.pipeline_utils import ImagePipelineOutput
from diffusers.schedulers.scheduling_utils import SchedulerMixin
class IADBScheduler(SchedulerMixin, ConfigMixin):
"""
IADBScheduler is a scheduler for the Iterative α-(de)Blending denoising method. It is simple and minimalist.
For more details, see the original paper: https://arxiv.org/abs/2305.03486 and the blog post: https://ggx-research.github.io/publication/2023/05/10/publication-iadb.html
"""
def step(
self,
model_output: torch.FloatTensor,
timestep: int,
x_alpha: torch.FloatTensor,
) -> torch.FloatTensor:
"""
Predict the sample at the previous timestep by reversing the ODE. Core function to propagate the diffusion
process from the learned model outputs (most often the predicted noise).
Args:
model_output (`torch.FloatTensor`): direct output from learned diffusion model. It is the direction from x0 to x1.
timestep (`float`): current timestep in the diffusion chain.
x_alpha (`torch.FloatTensor`): x_alpha sample for the current timestep
Returns:
`torch.FloatTensor`: the sample at the previous timestep
"""
if self.num_inference_steps is None:
raise ValueError(
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
alpha = timestep / self.num_inference_steps
alpha_next = (timestep + 1) / self.num_inference_steps
d = model_output
x_alpha = x_alpha + (alpha_next - alpha) * d
return x_alpha
def set_timesteps(self, num_inference_steps: int):
self.num_inference_steps = num_inference_steps
def add_noise(
self,
original_samples: torch.FloatTensor,
noise: torch.FloatTensor,
alpha: torch.FloatTensor,
) -> torch.FloatTensor:
return original_samples * alpha + noise * (1 - alpha)
def __len__(self):
return self.config.num_train_timesteps
class IADBPipeline(DiffusionPipeline):
r"""
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Parameters:
unet ([`UNet2DModel`]): U-Net architecture to denoise the encoded image.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image. Can be one of
[`DDPMScheduler`], or [`DDIMScheduler`].
"""
def __init__(self, unet, scheduler):
super().__init__()
self.register_modules(unet=unet, scheduler=scheduler)
@torch.no_grad()
def __call__(
self,
batch_size: int = 1,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
num_inference_steps: int = 50,
output_type: Optional[str] = "pil",
return_dict: bool = True,
) -> Union[ImagePipelineOutput, Tuple]:
r"""
Args:
batch_size (`int`, *optional*, defaults to 1):
The number of images to generate.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
Returns:
[`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is
True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
"""
# Sample gaussian noise to begin loop
if isinstance(self.unet.config.sample_size, int):
image_shape = (
batch_size,
self.unet.config.in_channels,
self.unet.config.sample_size,
self.unet.config.sample_size,
)
else:
image_shape = (batch_size, self.unet.config.in_channels, *self.unet.config.sample_size)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
image = torch.randn(image_shape, generator=generator, device=self.device, dtype=self.unet.dtype)
# set step values
self.scheduler.set_timesteps(num_inference_steps)
x_alpha = image.clone()
for t in self.progress_bar(range(num_inference_steps)):
alpha = t / num_inference_steps
# 1. predict noise model_output
model_output = self.unet(x_alpha, torch.tensor(alpha, device=x_alpha.device)).sample
# 2. step
x_alpha = self.scheduler.step(model_output, t, x_alpha)
image = (x_alpha * 0.5 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/unclip_text_interpolation.py
|
import inspect
from typing import List, Optional, Tuple, Union
import torch
from torch.nn import functional as F
from transformers import CLIPTextModelWithProjection, CLIPTokenizer
from transformers.models.clip.modeling_clip import CLIPTextModelOutput
from diffusers import (
DiffusionPipeline,
ImagePipelineOutput,
PriorTransformer,
UnCLIPScheduler,
UNet2DConditionModel,
UNet2DModel,
)
from diffusers.pipelines.unclip import UnCLIPTextProjModel
from diffusers.utils import is_accelerate_available, logging
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def slerp(val, low, high):
"""
Find the interpolation point between the 'low' and 'high' values for the given 'val'. See https://en.wikipedia.org/wiki/Slerp for more details on the topic.
"""
low_norm = low / torch.norm(low)
high_norm = high / torch.norm(high)
omega = torch.acos((low_norm * high_norm))
so = torch.sin(omega)
res = (torch.sin((1.0 - val) * omega) / so) * low + (torch.sin(val * omega) / so) * high
return res
class UnCLIPTextInterpolationPipeline(DiffusionPipeline):
"""
Pipeline for prompt-to-prompt interpolation on CLIP text embeddings and using the UnCLIP / Dall-E to decode them to images.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
text_encoder ([`CLIPTextModelWithProjection`]):
Frozen text-encoder.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
prior ([`PriorTransformer`]):
The canonincal unCLIP prior to approximate the image embedding from the text embedding.
text_proj ([`UnCLIPTextProjModel`]):
Utility class to prepare and combine the embeddings before they are passed to the decoder.
decoder ([`UNet2DConditionModel`]):
The decoder to invert the image embedding into an image.
super_res_first ([`UNet2DModel`]):
Super resolution unet. Used in all but the last step of the super resolution diffusion process.
super_res_last ([`UNet2DModel`]):
Super resolution unet. Used in the last step of the super resolution diffusion process.
prior_scheduler ([`UnCLIPScheduler`]):
Scheduler used in the prior denoising process. Just a modified DDPMScheduler.
decoder_scheduler ([`UnCLIPScheduler`]):
Scheduler used in the decoder denoising process. Just a modified DDPMScheduler.
super_res_scheduler ([`UnCLIPScheduler`]):
Scheduler used in the super resolution denoising process. Just a modified DDPMScheduler.
"""
prior: PriorTransformer
decoder: UNet2DConditionModel
text_proj: UnCLIPTextProjModel
text_encoder: CLIPTextModelWithProjection
tokenizer: CLIPTokenizer
super_res_first: UNet2DModel
super_res_last: UNet2DModel
prior_scheduler: UnCLIPScheduler
decoder_scheduler: UnCLIPScheduler
super_res_scheduler: UnCLIPScheduler
# Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline.__init__
def __init__(
self,
prior: PriorTransformer,
decoder: UNet2DConditionModel,
text_encoder: CLIPTextModelWithProjection,
tokenizer: CLIPTokenizer,
text_proj: UnCLIPTextProjModel,
super_res_first: UNet2DModel,
super_res_last: UNet2DModel,
prior_scheduler: UnCLIPScheduler,
decoder_scheduler: UnCLIPScheduler,
super_res_scheduler: UnCLIPScheduler,
):
super().__init__()
self.register_modules(
prior=prior,
decoder=decoder,
text_encoder=text_encoder,
tokenizer=tokenizer,
text_proj=text_proj,
super_res_first=super_res_first,
super_res_last=super_res_last,
prior_scheduler=prior_scheduler,
decoder_scheduler=decoder_scheduler,
super_res_scheduler=super_res_scheduler,
)
# Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline.prepare_latents
def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
if latents.shape != shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
latents = latents.to(device)
latents = latents * scheduler.init_noise_sigma
return latents
# Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline._encode_prompt
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
text_model_output: Optional[Union[CLIPTextModelOutput, Tuple]] = None,
text_attention_mask: Optional[torch.Tensor] = None,
):
if text_model_output is None:
batch_size = len(prompt) if isinstance(prompt, list) else 1
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
text_mask = text_inputs.attention_mask.bool().to(device)
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
text_encoder_output = self.text_encoder(text_input_ids.to(device))
prompt_embeds = text_encoder_output.text_embeds
text_encoder_hidden_states = text_encoder_output.last_hidden_state
else:
batch_size = text_model_output[0].shape[0]
prompt_embeds, text_encoder_hidden_states = text_model_output[0], text_model_output[1]
text_mask = text_attention_mask
prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
if do_classifier_free_guidance:
uncond_tokens = [""] * batch_size
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
uncond_text_mask = uncond_input.attention_mask.bool().to(device)
negative_prompt_embeds_text_encoder_output = self.text_encoder(uncond_input.input_ids.to(device))
negative_prompt_embeds = negative_prompt_embeds_text_encoder_output.text_embeds
uncond_text_encoder_hidden_states = negative_prompt_embeds_text_encoder_output.last_hidden_state
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
seq_len = uncond_text_encoder_hidden_states.shape[1]
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
batch_size * num_images_per_prompt, seq_len, -1
)
uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
# done duplicates
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
text_mask = torch.cat([uncond_text_mask, text_mask])
return prompt_embeds, text_encoder_hidden_states, text_mask
# Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline.enable_sequential_cpu_offload
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
when their specific submodule has its `forward` method called.
"""
if is_accelerate_available():
from accelerate import cpu_offload
else:
raise ImportError("Please install accelerate via `pip install accelerate`")
device = torch.device(f"cuda:{gpu_id}")
# TODO: self.prior.post_process_latents is not covered by the offload hooks, so it fails if added to the list
models = [
self.decoder,
self.text_proj,
self.text_encoder,
self.super_res_first,
self.super_res_last,
]
for cpu_offloaded_model in models:
if cpu_offloaded_model is not None:
cpu_offload(cpu_offloaded_model, device)
@property
# Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline._execution_device
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if self.device != torch.device("meta") or not hasattr(self.decoder, "_hf_hook"):
return self.device
for module in self.decoder.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
@torch.no_grad()
def __call__(
self,
start_prompt: str,
end_prompt: str,
steps: int = 5,
prior_num_inference_steps: int = 25,
decoder_num_inference_steps: int = 25,
super_res_num_inference_steps: int = 7,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
prior_guidance_scale: float = 4.0,
decoder_guidance_scale: float = 8.0,
enable_sequential_cpu_offload=True,
gpu_id=0,
output_type: Optional[str] = "pil",
return_dict: bool = True,
):
"""
Function invoked when calling the pipeline for generation.
Args:
start_prompt (`str`):
The prompt to start the image generation interpolation from.
end_prompt (`str`):
The prompt to end the image generation interpolation at.
steps (`int`, *optional*, defaults to 5):
The number of steps over which to interpolate from start_prompt to end_prompt. The pipeline returns
the same number of images as this value.
prior_num_inference_steps (`int`, *optional*, defaults to 25):
The number of denoising steps for the prior. More denoising steps usually lead to a higher quality
image at the expense of slower inference.
decoder_num_inference_steps (`int`, *optional*, defaults to 25):
The number of denoising steps for the decoder. More denoising steps usually lead to a higher quality
image at the expense of slower inference.
super_res_num_inference_steps (`int`, *optional*, defaults to 7):
The number of denoising steps for super resolution. More denoising steps usually lead to a higher
quality image at the expense of slower inference.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
prior_guidance_scale (`float`, *optional*, defaults to 4.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
decoder_guidance_scale (`float`, *optional*, defaults to 4.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
enable_sequential_cpu_offload (`bool`, *optional*, defaults to `True`):
If True, offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
when their specific submodule has its `forward` method called.
gpu_id (`int`, *optional*, defaults to `0`):
The gpu_id to be passed to enable_sequential_cpu_offload. Only works when enable_sequential_cpu_offload is set to True.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
"""
if not isinstance(start_prompt, str) or not isinstance(end_prompt, str):
raise ValueError(
f"`start_prompt` and `end_prompt` should be of type `str` but got {type(start_prompt)} and"
f" {type(end_prompt)} instead"
)
if enable_sequential_cpu_offload:
self.enable_sequential_cpu_offload(gpu_id=gpu_id)
device = self._execution_device
# Turn the prompts into embeddings.
inputs = self.tokenizer(
[start_prompt, end_prompt],
padding="max_length",
truncation=True,
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
)
inputs.to(device)
text_model_output = self.text_encoder(**inputs)
text_attention_mask = torch.max(inputs.attention_mask[0], inputs.attention_mask[1])
text_attention_mask = torch.cat([text_attention_mask.unsqueeze(0)] * steps).to(device)
# Interpolate from the start to end prompt using slerp and add the generated images to an image output pipeline
batch_text_embeds = []
batch_last_hidden_state = []
for interp_val in torch.linspace(0, 1, steps):
text_embeds = slerp(interp_val, text_model_output.text_embeds[0], text_model_output.text_embeds[1])
last_hidden_state = slerp(
interp_val, text_model_output.last_hidden_state[0], text_model_output.last_hidden_state[1]
)
batch_text_embeds.append(text_embeds.unsqueeze(0))
batch_last_hidden_state.append(last_hidden_state.unsqueeze(0))
batch_text_embeds = torch.cat(batch_text_embeds)
batch_last_hidden_state = torch.cat(batch_last_hidden_state)
text_model_output = CLIPTextModelOutput(
text_embeds=batch_text_embeds, last_hidden_state=batch_last_hidden_state
)
batch_size = text_model_output[0].shape[0]
do_classifier_free_guidance = prior_guidance_scale > 1.0 or decoder_guidance_scale > 1.0
prompt_embeds, text_encoder_hidden_states, text_mask = self._encode_prompt(
prompt=None,
device=device,
num_images_per_prompt=1,
do_classifier_free_guidance=do_classifier_free_guidance,
text_model_output=text_model_output,
text_attention_mask=text_attention_mask,
)
# prior
self.prior_scheduler.set_timesteps(prior_num_inference_steps, device=device)
prior_timesteps_tensor = self.prior_scheduler.timesteps
embedding_dim = self.prior.config.embedding_dim
prior_latents = self.prepare_latents(
(batch_size, embedding_dim),
prompt_embeds.dtype,
device,
generator,
None,
self.prior_scheduler,
)
for i, t in enumerate(self.progress_bar(prior_timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([prior_latents] * 2) if do_classifier_free_guidance else prior_latents
predicted_image_embedding = self.prior(
latent_model_input,
timestep=t,
proj_embedding=prompt_embeds,
encoder_hidden_states=text_encoder_hidden_states,
attention_mask=text_mask,
).predicted_image_embedding
if do_classifier_free_guidance:
predicted_image_embedding_uncond, predicted_image_embedding_text = predicted_image_embedding.chunk(2)
predicted_image_embedding = predicted_image_embedding_uncond + prior_guidance_scale * (
predicted_image_embedding_text - predicted_image_embedding_uncond
)
if i + 1 == prior_timesteps_tensor.shape[0]:
prev_timestep = None
else:
prev_timestep = prior_timesteps_tensor[i + 1]
prior_latents = self.prior_scheduler.step(
predicted_image_embedding,
timestep=t,
sample=prior_latents,
generator=generator,
prev_timestep=prev_timestep,
).prev_sample
prior_latents = self.prior.post_process_latents(prior_latents)
image_embeddings = prior_latents
# done prior
# decoder
text_encoder_hidden_states, additive_clip_time_embeddings = self.text_proj(
image_embeddings=image_embeddings,
prompt_embeds=prompt_embeds,
text_encoder_hidden_states=text_encoder_hidden_states,
do_classifier_free_guidance=do_classifier_free_guidance,
)
if device.type == "mps":
# HACK: MPS: There is a panic when padding bool tensors,
# so cast to int tensor for the pad and back to bool afterwards
text_mask = text_mask.type(torch.int)
decoder_text_mask = F.pad(text_mask, (self.text_proj.clip_extra_context_tokens, 0), value=1)
decoder_text_mask = decoder_text_mask.type(torch.bool)
else:
decoder_text_mask = F.pad(text_mask, (self.text_proj.clip_extra_context_tokens, 0), value=True)
self.decoder_scheduler.set_timesteps(decoder_num_inference_steps, device=device)
decoder_timesteps_tensor = self.decoder_scheduler.timesteps
num_channels_latents = self.decoder.config.in_channels
height = self.decoder.config.sample_size
width = self.decoder.config.sample_size
decoder_latents = self.prepare_latents(
(batch_size, num_channels_latents, height, width),
text_encoder_hidden_states.dtype,
device,
generator,
None,
self.decoder_scheduler,
)
for i, t in enumerate(self.progress_bar(decoder_timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([decoder_latents] * 2) if do_classifier_free_guidance else decoder_latents
noise_pred = self.decoder(
sample=latent_model_input,
timestep=t,
encoder_hidden_states=text_encoder_hidden_states,
class_labels=additive_clip_time_embeddings,
attention_mask=decoder_text_mask,
).sample
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred_uncond, _ = noise_pred_uncond.split(latent_model_input.shape[1], dim=1)
noise_pred_text, predicted_variance = noise_pred_text.split(latent_model_input.shape[1], dim=1)
noise_pred = noise_pred_uncond + decoder_guidance_scale * (noise_pred_text - noise_pred_uncond)
noise_pred = torch.cat([noise_pred, predicted_variance], dim=1)
if i + 1 == decoder_timesteps_tensor.shape[0]:
prev_timestep = None
else:
prev_timestep = decoder_timesteps_tensor[i + 1]
# compute the previous noisy sample x_t -> x_t-1
decoder_latents = self.decoder_scheduler.step(
noise_pred, t, decoder_latents, prev_timestep=prev_timestep, generator=generator
).prev_sample
decoder_latents = decoder_latents.clamp(-1, 1)
image_small = decoder_latents
# done decoder
# super res
self.super_res_scheduler.set_timesteps(super_res_num_inference_steps, device=device)
super_res_timesteps_tensor = self.super_res_scheduler.timesteps
channels = self.super_res_first.config.in_channels // 2
height = self.super_res_first.config.sample_size
width = self.super_res_first.config.sample_size
super_res_latents = self.prepare_latents(
(batch_size, channels, height, width),
image_small.dtype,
device,
generator,
None,
self.super_res_scheduler,
)
if device.type == "mps":
# MPS does not support many interpolations
image_upscaled = F.interpolate(image_small, size=[height, width])
else:
interpolate_antialias = {}
if "antialias" in inspect.signature(F.interpolate).parameters:
interpolate_antialias["antialias"] = True
image_upscaled = F.interpolate(
image_small, size=[height, width], mode="bicubic", align_corners=False, **interpolate_antialias
)
for i, t in enumerate(self.progress_bar(super_res_timesteps_tensor)):
# no classifier free guidance
if i == super_res_timesteps_tensor.shape[0] - 1:
unet = self.super_res_last
else:
unet = self.super_res_first
latent_model_input = torch.cat([super_res_latents, image_upscaled], dim=1)
noise_pred = unet(
sample=latent_model_input,
timestep=t,
).sample
if i + 1 == super_res_timesteps_tensor.shape[0]:
prev_timestep = None
else:
prev_timestep = super_res_timesteps_tensor[i + 1]
# compute the previous noisy sample x_t -> x_t-1
super_res_latents = self.super_res_scheduler.step(
noise_pred, t, super_res_latents, prev_timestep=prev_timestep, generator=generator
).prev_sample
image = super_res_latents
# done super res
# post processing
image = image * 0.5 + 0.5
image = image.clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_diffusion_xl_reference.py
|
# Based on stable_diffusion_reference.py
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from diffusers import StableDiffusionXLPipeline
from diffusers.models.attention import BasicTransformerBlock
from diffusers.models.unet_2d_blocks import (
CrossAttnDownBlock2D,
CrossAttnUpBlock2D,
DownBlock2D,
UpBlock2D,
)
from diffusers.pipelines.stable_diffusion_xl import StableDiffusionXLPipelineOutput
from diffusers.utils import PIL_INTERPOLATION, logging
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
>>> from diffusers import UniPCMultistepScheduler
>>> from diffusers.utils import load_image
>>> input_image = load_image("https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png")
>>> pipe = StableDiffusionXLReferencePipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16").to('cuda:0')
>>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
>>> result_img = pipe(ref_image=input_image,
prompt="1girl",
num_inference_steps=20,
reference_attn=True,
reference_adain=True).images[0]
>>> result_img.show()
```
"""
def torch_dfs(model: torch.nn.Module):
result = [model]
for child in model.children():
result += torch_dfs(child)
return result
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
# rescale the results from guidance (fixes overexposure)
noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
# mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
return noise_cfg
class StableDiffusionXLReferencePipeline(StableDiffusionXLPipeline):
def _default_height_width(self, height, width, image):
# NOTE: It is possible that a list of images have different
# dimensions for each image, so just checking the first image
# is not _exactly_ correct, but it is simple.
while isinstance(image, list):
image = image[0]
if height is None:
if isinstance(image, PIL.Image.Image):
height = image.height
elif isinstance(image, torch.Tensor):
height = image.shape[2]
height = (height // 8) * 8 # round down to nearest multiple of 8
if width is None:
if isinstance(image, PIL.Image.Image):
width = image.width
elif isinstance(image, torch.Tensor):
width = image.shape[3]
width = (width // 8) * 8
return height, width
def prepare_image(
self,
image,
width,
height,
batch_size,
num_images_per_prompt,
device,
dtype,
do_classifier_free_guidance=False,
guess_mode=False,
):
if not isinstance(image, torch.Tensor):
if isinstance(image, PIL.Image.Image):
image = [image]
if isinstance(image[0], PIL.Image.Image):
images = []
for image_ in image:
image_ = image_.convert("RGB")
image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
image_ = np.array(image_)
image_ = image_[None, :]
images.append(image_)
image = images
image = np.concatenate(image, axis=0)
image = np.array(image).astype(np.float32) / 255.0
image = (image - 0.5) / 0.5
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
elif isinstance(image[0], torch.Tensor):
image = torch.stack(image, dim=0)
image_batch_size = image.shape[0]
if image_batch_size == 1:
repeat_by = batch_size
else:
repeat_by = num_images_per_prompt
image = image.repeat_interleave(repeat_by, dim=0)
image = image.to(device=device, dtype=dtype)
if do_classifier_free_guidance and not guess_mode:
image = torch.cat([image] * 2)
return image
def prepare_ref_latents(self, refimage, batch_size, dtype, device, generator, do_classifier_free_guidance):
refimage = refimage.to(device=device)
if self.vae.dtype == torch.float16 and self.vae.config.force_upcast:
self.upcast_vae()
refimage = refimage.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
if refimage.dtype != self.vae.dtype:
refimage = refimage.to(dtype=self.vae.dtype)
# encode the mask image into latents space so we can concatenate it to the latents
if isinstance(generator, list):
ref_image_latents = [
self.vae.encode(refimage[i : i + 1]).latent_dist.sample(generator=generator[i])
for i in range(batch_size)
]
ref_image_latents = torch.cat(ref_image_latents, dim=0)
else:
ref_image_latents = self.vae.encode(refimage).latent_dist.sample(generator=generator)
ref_image_latents = self.vae.config.scaling_factor * ref_image_latents
# duplicate mask and ref_image_latents for each generation per prompt, using mps friendly method
if ref_image_latents.shape[0] < batch_size:
if not batch_size % ref_image_latents.shape[0] == 0:
raise ValueError(
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
f" to a total batch size of {batch_size}, but {ref_image_latents.shape[0]} images were passed."
" Make sure the number of images that you pass is divisible by the total requested batch size."
)
ref_image_latents = ref_image_latents.repeat(batch_size // ref_image_latents.shape[0], 1, 1, 1)
ref_image_latents = torch.cat([ref_image_latents] * 2) if do_classifier_free_guidance else ref_image_latents
# aligning device to prevent device errors when concating it with the latent model input
ref_image_latents = ref_image_latents.to(device=device, dtype=dtype)
return ref_image_latents
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
prompt_2: Optional[Union[str, List[str]]] = None,
ref_image: Union[torch.FloatTensor, PIL.Image.Image] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
denoising_end: Optional[float] = None,
guidance_scale: float = 5.0,
negative_prompt: Optional[Union[str, List[str]]] = None,
negative_prompt_2: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
guidance_rescale: float = 0.0,
original_size: Optional[Tuple[int, int]] = None,
crops_coords_top_left: Tuple[int, int] = (0, 0),
target_size: Optional[Tuple[int, int]] = None,
attention_auto_machine_weight: float = 1.0,
gn_auto_machine_weight: float = 1.0,
style_fidelity: float = 0.5,
reference_attn: bool = True,
reference_adain: bool = True,
):
assert reference_attn or reference_adain, "`reference_attn` or `reference_adain` must be True."
# 0. Default height and width to unet
# height, width = self._default_height_width(height, width, ref_image)
height = height or self.default_sample_size * self.vae_scale_factor
width = width or self.default_sample_size * self.vae_scale_factor
original_size = original_size or (height, width)
target_size = target_size or (height, width)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
prompt_2,
height,
width,
callback_steps,
negative_prompt,
negative_prompt_2,
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
text_encoder_lora_scale = (
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
)
(
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds,
) = self.encode_prompt(
prompt=prompt,
prompt_2=prompt_2,
device=device,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=do_classifier_free_guidance,
negative_prompt=negative_prompt,
negative_prompt_2=negative_prompt_2,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
lora_scale=text_encoder_lora_scale,
)
# 4. Preprocess reference image
ref_image = self.prepare_image(
image=ref_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=prompt_embeds.dtype,
)
# 5. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 6. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 7. Prepare reference latent variables
ref_image_latents = self.prepare_ref_latents(
ref_image,
batch_size * num_images_per_prompt,
prompt_embeds.dtype,
device,
generator,
do_classifier_free_guidance,
)
# 8. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 9. Modify self attebtion and group norm
MODE = "write"
uc_mask = (
torch.Tensor([1] * batch_size * num_images_per_prompt + [0] * batch_size * num_images_per_prompt)
.type_as(ref_image_latents)
.bool()
)
def hacked_basic_transformer_inner_forward(
self,
hidden_states: torch.FloatTensor,
attention_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
timestep: Optional[torch.LongTensor] = None,
cross_attention_kwargs: Dict[str, Any] = None,
class_labels: Optional[torch.LongTensor] = None,
):
if self.use_ada_layer_norm:
norm_hidden_states = self.norm1(hidden_states, timestep)
elif self.use_ada_layer_norm_zero:
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(
hidden_states, timestep, class_labels, hidden_dtype=hidden_states.dtype
)
else:
norm_hidden_states = self.norm1(hidden_states)
# 1. Self-Attention
cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
if self.only_cross_attention:
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
else:
if MODE == "write":
self.bank.append(norm_hidden_states.detach().clone())
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
if MODE == "read":
if attention_auto_machine_weight > self.attn_weight:
attn_output_uc = self.attn1(
norm_hidden_states,
encoder_hidden_states=torch.cat([norm_hidden_states] + self.bank, dim=1),
# attention_mask=attention_mask,
**cross_attention_kwargs,
)
attn_output_c = attn_output_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
attn_output_c[uc_mask] = self.attn1(
norm_hidden_states[uc_mask],
encoder_hidden_states=norm_hidden_states[uc_mask],
**cross_attention_kwargs,
)
attn_output = style_fidelity * attn_output_c + (1.0 - style_fidelity) * attn_output_uc
self.bank.clear()
else:
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
if self.use_ada_layer_norm_zero:
attn_output = gate_msa.unsqueeze(1) * attn_output
hidden_states = attn_output + hidden_states
if self.attn2 is not None:
norm_hidden_states = (
self.norm2(hidden_states, timestep) if self.use_ada_layer_norm else self.norm2(hidden_states)
)
# 2. Cross-Attention
attn_output = self.attn2(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
**cross_attention_kwargs,
)
hidden_states = attn_output + hidden_states
# 3. Feed-forward
norm_hidden_states = self.norm3(hidden_states)
if self.use_ada_layer_norm_zero:
norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
ff_output = self.ff(norm_hidden_states)
if self.use_ada_layer_norm_zero:
ff_output = gate_mlp.unsqueeze(1) * ff_output
hidden_states = ff_output + hidden_states
return hidden_states
def hacked_mid_forward(self, *args, **kwargs):
eps = 1e-6
x = self.original_forward(*args, **kwargs)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(x, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append(mean)
self.var_bank.append(var)
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(x, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank) / float(len(self.mean_bank))
var_acc = sum(self.var_bank) / float(len(self.var_bank))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
x_uc = (((x - mean) / std) * std_acc) + mean_acc
x_c = x_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
x_c[uc_mask] = x[uc_mask]
x = style_fidelity * x_c + (1.0 - style_fidelity) * x_uc
self.mean_bank = []
self.var_bank = []
return x
def hack_CrossAttnDownBlock2D_forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
):
eps = 1e-6
# TODO(Patrick, William) - attention mask is not used
output_states = ()
for i, (resnet, attn) in enumerate(zip(self.resnets, self.attentions)):
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
output_states = output_states + (hidden_states,)
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
def hacked_DownBlock2D_forward(self, hidden_states, temb=None):
eps = 1e-6
output_states = ()
for i, resnet in enumerate(self.resnets):
hidden_states = resnet(hidden_states, temb)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
output_states = output_states + (hidden_states,)
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
def hacked_CrossAttnUpBlock2D_forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
upsample_size: Optional[int] = None,
attention_mask: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
):
eps = 1e-6
# TODO(Patrick, William) - attention mask is not used
for i, (resnet, attn) in enumerate(zip(self.resnets, self.attentions)):
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size)
return hidden_states
def hacked_UpBlock2D_forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None):
eps = 1e-6
for i, resnet in enumerate(self.resnets):
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size)
return hidden_states
if reference_attn:
attn_modules = [module for module in torch_dfs(self.unet) if isinstance(module, BasicTransformerBlock)]
attn_modules = sorted(attn_modules, key=lambda x: -x.norm1.normalized_shape[0])
for i, module in enumerate(attn_modules):
module._original_inner_forward = module.forward
module.forward = hacked_basic_transformer_inner_forward.__get__(module, BasicTransformerBlock)
module.bank = []
module.attn_weight = float(i) / float(len(attn_modules))
if reference_adain:
gn_modules = [self.unet.mid_block]
self.unet.mid_block.gn_weight = 0
down_blocks = self.unet.down_blocks
for w, module in enumerate(down_blocks):
module.gn_weight = 1.0 - float(w) / float(len(down_blocks))
gn_modules.append(module)
up_blocks = self.unet.up_blocks
for w, module in enumerate(up_blocks):
module.gn_weight = float(w) / float(len(up_blocks))
gn_modules.append(module)
for i, module in enumerate(gn_modules):
if getattr(module, "original_forward", None) is None:
module.original_forward = module.forward
if i == 0:
# mid_block
module.forward = hacked_mid_forward.__get__(module, torch.nn.Module)
elif isinstance(module, CrossAttnDownBlock2D):
module.forward = hack_CrossAttnDownBlock2D_forward.__get__(module, CrossAttnDownBlock2D)
elif isinstance(module, DownBlock2D):
module.forward = hacked_DownBlock2D_forward.__get__(module, DownBlock2D)
elif isinstance(module, CrossAttnUpBlock2D):
module.forward = hacked_CrossAttnUpBlock2D_forward.__get__(module, CrossAttnUpBlock2D)
elif isinstance(module, UpBlock2D):
module.forward = hacked_UpBlock2D_forward.__get__(module, UpBlock2D)
module.mean_bank = []
module.var_bank = []
module.gn_weight *= 2
# 10. Prepare added time ids & embeddings
add_text_embeds = pooled_prompt_embeds
add_time_ids = self._get_add_time_ids(
original_size, crops_coords_top_left, target_size, dtype=prompt_embeds.dtype
)
if do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
add_time_ids = torch.cat([add_time_ids, add_time_ids], dim=0)
prompt_embeds = prompt_embeds.to(device)
add_text_embeds = add_text_embeds.to(device)
add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
# 11. Denoising loop
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
# 10.1 Apply denoising_end
if denoising_end is not None and isinstance(denoising_end, float) and denoising_end > 0 and denoising_end < 1:
discrete_timestep_cutoff = int(
round(
self.scheduler.config.num_train_timesteps
- (denoising_end * self.scheduler.config.num_train_timesteps)
)
)
num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
timesteps = timesteps[:num_inference_steps]
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
# ref only part
noise = randn_tensor(
ref_image_latents.shape, generator=generator, device=device, dtype=ref_image_latents.dtype
)
ref_xt = self.scheduler.add_noise(
ref_image_latents,
noise,
t.reshape(
1,
),
)
ref_xt = self.scheduler.scale_model_input(ref_xt, t)
MODE = "write"
self.unet(
ref_xt,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
)
# predict the noise residual
MODE = "read"
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if not output_type == "latent":
# make sure the VAE is in float32 mode, as it overflows in float16
needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
if needs_upcasting:
self.upcast_vae()
latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
# cast back to fp16 if needed
if needs_upcasting:
self.vae.to(dtype=torch.float16)
else:
image = latents
return StableDiffusionXLPipelineOutput(images=image)
# apply watermark if available
if self.watermark is not None:
image = self.watermark.apply_watermark(image)
image = self.image_processor.postprocess(image, output_type=output_type)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image,)
return StableDiffusionXLPipelineOutput(images=image)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/dps_pipeline.py
|
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from math import pi
from typing import Callable, List, Optional, Tuple, Union
import numpy as np
import torch
from PIL import Image
from diffusers import DDPMScheduler, DiffusionPipeline, ImagePipelineOutput, UNet2DModel
from diffusers.utils.torch_utils import randn_tensor
class DPSPipeline(DiffusionPipeline):
r"""
Pipeline for Diffusion Posterior Sampling.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
Parameters:
unet ([`UNet2DModel`]):
A `UNet2DModel` to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image. Can be one of
[`DDPMScheduler`], or [`DDIMScheduler`].
"""
model_cpu_offload_seq = "unet"
def __init__(self, unet, scheduler):
super().__init__()
self.register_modules(unet=unet, scheduler=scheduler)
@torch.no_grad()
def __call__(
self,
measurement: torch.Tensor,
operator: torch.nn.Module,
loss_fn: Callable[[torch.Tensor, torch.Tensor], torch.Tensor],
batch_size: int = 1,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
num_inference_steps: int = 1000,
output_type: Optional[str] = "pil",
return_dict: bool = True,
zeta: float = 0.3,
) -> Union[ImagePipelineOutput, Tuple]:
r"""
The call function to the pipeline for generation.
Args:
measurement (`torch.Tensor`, *required*):
A 'torch.Tensor', the corrupted image
operator (`torch.nn.Module`, *required*):
A 'torch.nn.Module', the operator generating the corrupted image
loss_fn (`Callable[[torch.Tensor, torch.Tensor], torch.Tensor]`, *required*):
A 'Callable[[torch.Tensor, torch.Tensor], torch.Tensor]', the loss function used
between the measurements, for most of the cases using RMSE is fine.
batch_size (`int`, *optional*, defaults to 1):
The number of images to generate.
generator (`torch.Generator`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
num_inference_steps (`int`, *optional*, defaults to 1000):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
Example:
```py
>>> from diffusers import DDPMPipeline
>>> # load model and scheduler
>>> pipe = DDPMPipeline.from_pretrained("google/ddpm-cat-256")
>>> # run pipeline in inference (sample random noise and denoise)
>>> image = pipe().images[0]
>>> # save image
>>> image.save("ddpm_generated_image.png")
```
Returns:
[`~pipelines.ImagePipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.ImagePipelineOutput`] is returned, otherwise a `tuple` is
returned where the first element is a list with the generated images
"""
# Sample gaussian noise to begin loop
if isinstance(self.unet.config.sample_size, int):
image_shape = (
batch_size,
self.unet.config.in_channels,
self.unet.config.sample_size,
self.unet.config.sample_size,
)
else:
image_shape = (batch_size, self.unet.config.in_channels, *self.unet.config.sample_size)
if self.device.type == "mps":
# randn does not work reproducibly on mps
image = randn_tensor(image_shape, generator=generator)
image = image.to(self.device)
else:
image = randn_tensor(image_shape, generator=generator, device=self.device)
# set step values
self.scheduler.set_timesteps(num_inference_steps)
for t in self.progress_bar(self.scheduler.timesteps):
with torch.enable_grad():
# 1. predict noise model_output
image = image.requires_grad_()
model_output = self.unet(image, t).sample
# 2. compute previous image x'_{t-1} and original prediction x0_{t}
scheduler_out = self.scheduler.step(model_output, t, image, generator=generator)
image_pred, origi_pred = scheduler_out.prev_sample, scheduler_out.pred_original_sample
# 3. compute y'_t = f(x0_{t})
measurement_pred = operator(origi_pred)
# 4. compute loss = d(y, y'_t-1)
loss = loss_fn(measurement, measurement_pred)
loss.backward()
print("distance: {0:.4f}".format(loss.item()))
with torch.no_grad():
image_pred = image_pred - zeta * image.grad
image = image_pred.detach()
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
if __name__ == "__main__":
import scipy
from torch import nn
from torchvision.utils import save_image
# defining the operators f(.) of y = f(x)
# super-resolution operator
class SuperResolutionOperator(nn.Module):
def __init__(self, in_shape, scale_factor):
super().__init__()
# Resizer local class, do not use outiside the SR operator class
class Resizer(nn.Module):
def __init__(self, in_shape, scale_factor=None, output_shape=None, kernel=None, antialiasing=True):
super(Resizer, self).__init__()
# First standardize values and fill missing arguments (if needed) by deriving scale from output shape or vice versa
scale_factor, output_shape = self.fix_scale_and_size(in_shape, output_shape, scale_factor)
# Choose interpolation method, each method has the matching kernel size
def cubic(x):
absx = np.abs(x)
absx2 = absx**2
absx3 = absx**3
return (1.5 * absx3 - 2.5 * absx2 + 1) * (absx <= 1) + (
-0.5 * absx3 + 2.5 * absx2 - 4 * absx + 2
) * ((1 < absx) & (absx <= 2))
def lanczos2(x):
return (
(np.sin(pi * x) * np.sin(pi * x / 2) + np.finfo(np.float32).eps)
/ ((pi**2 * x**2 / 2) + np.finfo(np.float32).eps)
) * (abs(x) < 2)
def box(x):
return ((-0.5 <= x) & (x < 0.5)) * 1.0
def lanczos3(x):
return (
(np.sin(pi * x) * np.sin(pi * x / 3) + np.finfo(np.float32).eps)
/ ((pi**2 * x**2 / 3) + np.finfo(np.float32).eps)
) * (abs(x) < 3)
def linear(x):
return (x + 1) * ((-1 <= x) & (x < 0)) + (1 - x) * ((0 <= x) & (x <= 1))
method, kernel_width = {
"cubic": (cubic, 4.0),
"lanczos2": (lanczos2, 4.0),
"lanczos3": (lanczos3, 6.0),
"box": (box, 1.0),
"linear": (linear, 2.0),
None: (cubic, 4.0), # set default interpolation method as cubic
}.get(kernel)
# Antialiasing is only used when downscaling
antialiasing *= np.any(np.array(scale_factor) < 1)
# Sort indices of dimensions according to scale of each dimension. since we are going dim by dim this is efficient
sorted_dims = np.argsort(np.array(scale_factor))
self.sorted_dims = [int(dim) for dim in sorted_dims if scale_factor[dim] != 1]
# Iterate over dimensions to calculate local weights for resizing and resize each time in one direction
field_of_view_list = []
weights_list = []
for dim in self.sorted_dims:
# for each coordinate (along 1 dim), calculate which coordinates in the input image affect its result and the
# weights that multiply the values there to get its result.
weights, field_of_view = self.contributions(
in_shape[dim], output_shape[dim], scale_factor[dim], method, kernel_width, antialiasing
)
# convert to torch tensor
weights = torch.tensor(weights.T, dtype=torch.float32)
# We add singleton dimensions to the weight matrix so we can multiply it with the big tensor we get for
# tmp_im[field_of_view.T], (bsxfun style)
weights_list.append(
nn.Parameter(
torch.reshape(weights, list(weights.shape) + (len(scale_factor) - 1) * [1]),
requires_grad=False,
)
)
field_of_view_list.append(
nn.Parameter(
torch.tensor(field_of_view.T.astype(np.int32), dtype=torch.long), requires_grad=False
)
)
self.field_of_view = nn.ParameterList(field_of_view_list)
self.weights = nn.ParameterList(weights_list)
def forward(self, in_tensor):
x = in_tensor
# Use the affecting position values and the set of weights to calculate the result of resizing along this 1 dim
for dim, fov, w in zip(self.sorted_dims, self.field_of_view, self.weights):
# To be able to act on each dim, we swap so that dim 0 is the wanted dim to resize
x = torch.transpose(x, dim, 0)
# This is a bit of a complicated multiplication: x[field_of_view.T] is a tensor of order image_dims+1.
# for each pixel in the output-image it matches the positions the influence it from the input image (along 1 dim
# only, this is why it only adds 1 dim to 5the shape). We then multiply, for each pixel, its set of positions with
# the matching set of weights. we do this by this big tensor element-wise multiplication (MATLAB bsxfun style:
# matching dims are multiplied element-wise while singletons mean that the matching dim is all multiplied by the
# same number
x = torch.sum(x[fov] * w, dim=0)
# Finally we swap back the axes to the original order
x = torch.transpose(x, dim, 0)
return x
def fix_scale_and_size(self, input_shape, output_shape, scale_factor):
# First fixing the scale-factor (if given) to be standardized the function expects (a list of scale factors in the
# same size as the number of input dimensions)
if scale_factor is not None:
# By default, if scale-factor is a scalar we assume 2d resizing and duplicate it.
if np.isscalar(scale_factor) and len(input_shape) > 1:
scale_factor = [scale_factor, scale_factor]
# We extend the size of scale-factor list to the size of the input by assigning 1 to all the unspecified scales
scale_factor = list(scale_factor)
scale_factor = [1] * (len(input_shape) - len(scale_factor)) + scale_factor
# Fixing output-shape (if given): extending it to the size of the input-shape, by assigning the original input-size
# to all the unspecified dimensions
if output_shape is not None:
output_shape = list(input_shape[len(output_shape) :]) + list(np.uint(np.array(output_shape)))
# Dealing with the case of non-give scale-factor, calculating according to output-shape. note that this is
# sub-optimal, because there can be different scales to the same output-shape.
if scale_factor is None:
scale_factor = 1.0 * np.array(output_shape) / np.array(input_shape)
# Dealing with missing output-shape. calculating according to scale-factor
if output_shape is None:
output_shape = np.uint(np.ceil(np.array(input_shape) * np.array(scale_factor)))
return scale_factor, output_shape
def contributions(self, in_length, out_length, scale, kernel, kernel_width, antialiasing):
# This function calculates a set of 'filters' and a set of field_of_view that will later on be applied
# such that each position from the field_of_view will be multiplied with a matching filter from the
# 'weights' based on the interpolation method and the distance of the sub-pixel location from the pixel centers
# around it. This is only done for one dimension of the image.
# When anti-aliasing is activated (default and only for downscaling) the receptive field is stretched to size of
# 1/sf. this means filtering is more 'low-pass filter'.
fixed_kernel = (lambda arg: scale * kernel(scale * arg)) if antialiasing else kernel
kernel_width *= 1.0 / scale if antialiasing else 1.0
# These are the coordinates of the output image
out_coordinates = np.arange(1, out_length + 1)
# since both scale-factor and output size can be provided simulatneously, perserving the center of the image requires shifting
# the output coordinates. the deviation is because out_length doesn't necesary equal in_length*scale.
# to keep the center we need to subtract half of this deivation so that we get equal margins for boths sides and center is preserved.
shifted_out_coordinates = out_coordinates - (out_length - in_length * scale) / 2
# These are the matching positions of the output-coordinates on the input image coordinates.
# Best explained by example: say we have 4 horizontal pixels for HR and we downscale by SF=2 and get 2 pixels:
# [1,2,3,4] -> [1,2]. Remember each pixel number is the middle of the pixel.
# The scaling is done between the distances and not pixel numbers (the right boundary of pixel 4 is transformed to
# the right boundary of pixel 2. pixel 1 in the small image matches the boundary between pixels 1 and 2 in the big
# one and not to pixel 2. This means the position is not just multiplication of the old pos by scale-factor).
# So if we measure distance from the left border, middle of pixel 1 is at distance d=0.5, border between 1 and 2 is
# at d=1, and so on (d = p - 0.5). we calculate (d_new = d_old / sf) which means:
# (p_new-0.5 = (p_old-0.5) / sf) -> p_new = p_old/sf + 0.5 * (1-1/sf)
match_coordinates = shifted_out_coordinates / scale + 0.5 * (1 - 1 / scale)
# This is the left boundary to start multiplying the filter from, it depends on the size of the filter
left_boundary = np.floor(match_coordinates - kernel_width / 2)
# Kernel width needs to be enlarged because when covering has sub-pixel borders, it must 'see' the pixel centers
# of the pixels it only covered a part from. So we add one pixel at each side to consider (weights can zeroize them)
expanded_kernel_width = np.ceil(kernel_width) + 2
# Determine a set of field_of_view for each each output position, these are the pixels in the input image
# that the pixel in the output image 'sees'. We get a matrix whos horizontal dim is the output pixels (big) and the
# vertical dim is the pixels it 'sees' (kernel_size + 2)
field_of_view = np.squeeze(
np.int16(np.expand_dims(left_boundary, axis=1) + np.arange(expanded_kernel_width) - 1)
)
# Assign weight to each pixel in the field of view. A matrix whos horizontal dim is the output pixels and the
# vertical dim is a list of weights matching to the pixel in the field of view (that are specified in
# 'field_of_view')
weights = fixed_kernel(1.0 * np.expand_dims(match_coordinates, axis=1) - field_of_view - 1)
# Normalize weights to sum up to 1. be careful from dividing by 0
sum_weights = np.sum(weights, axis=1)
sum_weights[sum_weights == 0] = 1.0
weights = 1.0 * weights / np.expand_dims(sum_weights, axis=1)
# We use this mirror structure as a trick for reflection padding at the boundaries
mirror = np.uint(np.concatenate((np.arange(in_length), np.arange(in_length - 1, -1, step=-1))))
field_of_view = mirror[np.mod(field_of_view, mirror.shape[0])]
# Get rid of weights and pixel positions that are of zero weight
non_zero_out_pixels = np.nonzero(np.any(weights, axis=0))
weights = np.squeeze(weights[:, non_zero_out_pixels])
field_of_view = np.squeeze(field_of_view[:, non_zero_out_pixels])
# Final products are the relative positions and the matching weights, both are output_size X fixed_kernel_size
return weights, field_of_view
self.down_sample = Resizer(in_shape, 1 / scale_factor)
for param in self.parameters():
param.requires_grad = False
def forward(self, data, **kwargs):
return self.down_sample(data)
# Gaussian blurring operator
class GaussialBlurOperator(nn.Module):
def __init__(self, kernel_size, intensity):
super().__init__()
class Blurkernel(nn.Module):
def __init__(self, blur_type="gaussian", kernel_size=31, std=3.0):
super().__init__()
self.blur_type = blur_type
self.kernel_size = kernel_size
self.std = std
self.seq = nn.Sequential(
nn.ReflectionPad2d(self.kernel_size // 2),
nn.Conv2d(3, 3, self.kernel_size, stride=1, padding=0, bias=False, groups=3),
)
self.weights_init()
def forward(self, x):
return self.seq(x)
def weights_init(self):
if self.blur_type == "gaussian":
n = np.zeros((self.kernel_size, self.kernel_size))
n[self.kernel_size // 2, self.kernel_size // 2] = 1
k = scipy.ndimage.gaussian_filter(n, sigma=self.std)
k = torch.from_numpy(k)
self.k = k
for name, f in self.named_parameters():
f.data.copy_(k)
def update_weights(self, k):
if not torch.is_tensor(k):
k = torch.from_numpy(k)
for name, f in self.named_parameters():
f.data.copy_(k)
def get_kernel(self):
return self.k
self.kernel_size = kernel_size
self.conv = Blurkernel(blur_type="gaussian", kernel_size=kernel_size, std=intensity)
self.kernel = self.conv.get_kernel()
self.conv.update_weights(self.kernel.type(torch.float32))
for param in self.parameters():
param.requires_grad = False
def forward(self, data, **kwargs):
return self.conv(data)
def transpose(self, data, **kwargs):
return data
def get_kernel(self):
return self.kernel.view(1, 1, self.kernel_size, self.kernel_size)
# assuming the forward process y = f(x) is polluted by Gaussian noise, use l2 norm
def RMSELoss(yhat, y):
return torch.sqrt(torch.sum((yhat - y) ** 2))
# set up source image
src = Image.open("sample.png")
# read image into [1,3,H,W]
src = torch.from_numpy(np.array(src, dtype=np.float32)).permute(2, 0, 1)[None]
# normalize image to [-1,1]
src = (src / 127.5) - 1.0
src = src.to("cuda")
# set up operator and measurement
# operator = SuperResolutionOperator(in_shape=src.shape, scale_factor=4).to("cuda")
operator = GaussialBlurOperator(kernel_size=61, intensity=3.0).to("cuda")
measurement = operator(src)
# set up scheduler
scheduler = DDPMScheduler.from_pretrained("google/ddpm-celebahq-256")
scheduler.set_timesteps(1000)
# set up model
model = UNet2DModel.from_pretrained("google/ddpm-celebahq-256").to("cuda")
save_image((src + 1.0) / 2.0, "dps_src.png")
save_image((measurement + 1.0) / 2.0, "dps_mea.png")
# finally, the pipeline
dpspipe = DPSPipeline(model, scheduler)
image = dpspipe(
measurement=measurement,
operator=operator,
loss_fn=RMSELoss,
zeta=1.0,
).images[0]
image.save("dps_generated_image.png")
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_diffusion_mega.py
|
from typing import Any, Callable, Dict, List, Optional, Union
import PIL.Image
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DiffusionPipeline,
LMSDiscreteScheduler,
PNDMScheduler,
StableDiffusionImg2ImgPipeline,
StableDiffusionInpaintPipelineLegacy,
StableDiffusionPipeline,
UNet2DConditionModel,
)
from diffusers.configuration_utils import FrozenDict
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.utils import deprecate, logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class StableDiffusionMegaPipeline(DiffusionPipeline):
r"""
Pipeline for text-to-image generation using Stable Diffusion.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionMegaSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.register_to_config(requires_safety_checker=requires_safety_checker)
@property
def components(self) -> Dict[str, Any]:
return {k: getattr(self, k) for k in self.config.keys() if not k.startswith("_")}
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
r"""
Enable sliced attention computation.
When this option is enabled, the attention module will split the input tensor in slices, to compute attention
in several steps. This is useful to save some memory in exchange for a small speed decrease.
Args:
slice_size (`str` or `int`, *optional*, defaults to `"auto"`):
When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
a number is provided, uses as many slices as `attention_head_dim // slice_size`. In this case,
`attention_head_dim` must be a multiple of `slice_size`.
"""
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
slice_size = self.unet.config.attention_head_dim // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
r"""
Disable sliced attention computation. If `enable_attention_slicing` was previously invoked, this method will go
back to computing attention in one step.
"""
# set slice_size = `None` to disable `attention slicing`
self.enable_attention_slicing(None)
@torch.no_grad()
def inpaint(
self,
prompt: Union[str, List[str]],
image: Union[torch.FloatTensor, PIL.Image.Image],
mask_image: Union[torch.FloatTensor, PIL.Image.Image],
strength: float = 0.8,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: Optional[float] = 0.0,
generator: Optional[torch.Generator] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
):
# For more information on how this function works, please see: https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion#diffusers.StableDiffusionImg2ImgPipeline
return StableDiffusionInpaintPipelineLegacy(**self.components)(
prompt=prompt,
image=image,
mask_image=mask_image,
strength=strength,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
output_type=output_type,
return_dict=return_dict,
callback=callback,
)
@torch.no_grad()
def img2img(
self,
prompt: Union[str, List[str]],
image: Union[torch.FloatTensor, PIL.Image.Image],
strength: float = 0.8,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: Optional[float] = 0.0,
generator: Optional[torch.Generator] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
**kwargs,
):
# For more information on how this function works, please see: https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion#diffusers.StableDiffusionImg2ImgPipeline
return StableDiffusionImg2ImgPipeline(**self.components)(
prompt=prompt,
image=image,
strength=strength,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
)
@torch.no_grad()
def text2img(
self,
prompt: Union[str, List[str]],
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
):
# For more information on how this function https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion#diffusers.StableDiffusionPipeline
return StableDiffusionPipeline(**self.components)(
prompt=prompt,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
negative_prompt=negative_prompt,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
latents=latents,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_diffusion_tensorrt_img2img.py
|
#
# Copyright 2023 The HuggingFace Inc. team.
# SPDX-FileCopyrightText: Copyright (c) 1993-2023 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import os
from collections import OrderedDict
from copy import copy
from typing import List, Optional, Union
import numpy as np
import onnx
import onnx_graphsurgeon as gs
import PIL.Image
import tensorrt as trt
import torch
from huggingface_hub import snapshot_download
from onnx import shape_inference
from polygraphy import cuda
from polygraphy.backend.common import bytes_from_path
from polygraphy.backend.onnx.loader import fold_constants
from polygraphy.backend.trt import (
CreateConfig,
Profile,
engine_from_bytes,
engine_from_network,
network_from_onnx_path,
save_engine,
)
from polygraphy.backend.trt import util as trt_util
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion import (
StableDiffusionImg2ImgPipeline,
StableDiffusionPipelineOutput,
StableDiffusionSafetyChecker,
)
from diffusers.schedulers import DDIMScheduler
from diffusers.utils import DIFFUSERS_CACHE, logging
"""
Installation instructions
python3 -m pip install --upgrade transformers diffusers>=0.16.0
python3 -m pip install --upgrade tensorrt>=8.6.1
python3 -m pip install --upgrade polygraphy>=0.47.0 onnx-graphsurgeon --extra-index-url https://pypi.ngc.nvidia.com
python3 -m pip install onnxruntime
"""
TRT_LOGGER = trt.Logger(trt.Logger.ERROR)
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
# Map of numpy dtype -> torch dtype
numpy_to_torch_dtype_dict = {
np.uint8: torch.uint8,
np.int8: torch.int8,
np.int16: torch.int16,
np.int32: torch.int32,
np.int64: torch.int64,
np.float16: torch.float16,
np.float32: torch.float32,
np.float64: torch.float64,
np.complex64: torch.complex64,
np.complex128: torch.complex128,
}
if np.version.full_version >= "1.24.0":
numpy_to_torch_dtype_dict[np.bool_] = torch.bool
else:
numpy_to_torch_dtype_dict[np.bool] = torch.bool
# Map of torch dtype -> numpy dtype
torch_to_numpy_dtype_dict = {value: key for (key, value) in numpy_to_torch_dtype_dict.items()}
def device_view(t):
return cuda.DeviceView(ptr=t.data_ptr(), shape=t.shape, dtype=torch_to_numpy_dtype_dict[t.dtype])
def preprocess_image(image):
"""
image: torch.Tensor
"""
w, h = image.size
w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
image = image.resize((w, h))
image = np.array(image).astype(np.float32) / 255.0
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image).contiguous()
return 2.0 * image - 1.0
class Engine:
def __init__(self, engine_path):
self.engine_path = engine_path
self.engine = None
self.context = None
self.buffers = OrderedDict()
self.tensors = OrderedDict()
def __del__(self):
[buf.free() for buf in self.buffers.values() if isinstance(buf, cuda.DeviceArray)]
del self.engine
del self.context
del self.buffers
del self.tensors
def build(
self,
onnx_path,
fp16,
input_profile=None,
enable_preview=False,
enable_all_tactics=False,
timing_cache=None,
workspace_size=0,
):
logger.warning(f"Building TensorRT engine for {onnx_path}: {self.engine_path}")
p = Profile()
if input_profile:
for name, dims in input_profile.items():
assert len(dims) == 3
p.add(name, min=dims[0], opt=dims[1], max=dims[2])
config_kwargs = {}
config_kwargs["preview_features"] = [trt.PreviewFeature.DISABLE_EXTERNAL_TACTIC_SOURCES_FOR_CORE_0805]
if enable_preview:
# Faster dynamic shapes made optional since it increases engine build time.
config_kwargs["preview_features"].append(trt.PreviewFeature.FASTER_DYNAMIC_SHAPES_0805)
if workspace_size > 0:
config_kwargs["memory_pool_limits"] = {trt.MemoryPoolType.WORKSPACE: workspace_size}
if not enable_all_tactics:
config_kwargs["tactic_sources"] = []
engine = engine_from_network(
network_from_onnx_path(onnx_path, flags=[trt.OnnxParserFlag.NATIVE_INSTANCENORM]),
config=CreateConfig(fp16=fp16, profiles=[p], load_timing_cache=timing_cache, **config_kwargs),
save_timing_cache=timing_cache,
)
save_engine(engine, path=self.engine_path)
def load(self):
logger.warning(f"Loading TensorRT engine: {self.engine_path}")
self.engine = engine_from_bytes(bytes_from_path(self.engine_path))
def activate(self):
self.context = self.engine.create_execution_context()
def allocate_buffers(self, shape_dict=None, device="cuda"):
for idx in range(trt_util.get_bindings_per_profile(self.engine)):
binding = self.engine[idx]
if shape_dict and binding in shape_dict:
shape = shape_dict[binding]
else:
shape = self.engine.get_binding_shape(binding)
dtype = trt.nptype(self.engine.get_binding_dtype(binding))
if self.engine.binding_is_input(binding):
self.context.set_binding_shape(idx, shape)
tensor = torch.empty(tuple(shape), dtype=numpy_to_torch_dtype_dict[dtype]).to(device=device)
self.tensors[binding] = tensor
self.buffers[binding] = cuda.DeviceView(ptr=tensor.data_ptr(), shape=shape, dtype=dtype)
def infer(self, feed_dict, stream):
start_binding, end_binding = trt_util.get_active_profile_bindings(self.context)
# shallow copy of ordered dict
device_buffers = copy(self.buffers)
for name, buf in feed_dict.items():
assert isinstance(buf, cuda.DeviceView)
device_buffers[name] = buf
bindings = [0] * start_binding + [buf.ptr for buf in device_buffers.values()]
noerror = self.context.execute_async_v2(bindings=bindings, stream_handle=stream.ptr)
if not noerror:
raise ValueError("ERROR: inference failed.")
return self.tensors
class Optimizer:
def __init__(self, onnx_graph):
self.graph = gs.import_onnx(onnx_graph)
def cleanup(self, return_onnx=False):
self.graph.cleanup().toposort()
if return_onnx:
return gs.export_onnx(self.graph)
def select_outputs(self, keep, names=None):
self.graph.outputs = [self.graph.outputs[o] for o in keep]
if names:
for i, name in enumerate(names):
self.graph.outputs[i].name = name
def fold_constants(self, return_onnx=False):
onnx_graph = fold_constants(gs.export_onnx(self.graph), allow_onnxruntime_shape_inference=True)
self.graph = gs.import_onnx(onnx_graph)
if return_onnx:
return onnx_graph
def infer_shapes(self, return_onnx=False):
onnx_graph = gs.export_onnx(self.graph)
if onnx_graph.ByteSize() > 2147483648:
raise TypeError("ERROR: model size exceeds supported 2GB limit")
else:
onnx_graph = shape_inference.infer_shapes(onnx_graph)
self.graph = gs.import_onnx(onnx_graph)
if return_onnx:
return onnx_graph
class BaseModel:
def __init__(self, model, fp16=False, device="cuda", max_batch_size=16, embedding_dim=768, text_maxlen=77):
self.model = model
self.name = "SD Model"
self.fp16 = fp16
self.device = device
self.min_batch = 1
self.max_batch = max_batch_size
self.min_image_shape = 256 # min image resolution: 256x256
self.max_image_shape = 1024 # max image resolution: 1024x1024
self.min_latent_shape = self.min_image_shape // 8
self.max_latent_shape = self.max_image_shape // 8
self.embedding_dim = embedding_dim
self.text_maxlen = text_maxlen
def get_model(self):
return self.model
def get_input_names(self):
pass
def get_output_names(self):
pass
def get_dynamic_axes(self):
return None
def get_sample_input(self, batch_size, image_height, image_width):
pass
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
return None
def get_shape_dict(self, batch_size, image_height, image_width):
return None
def optimize(self, onnx_graph):
opt = Optimizer(onnx_graph)
opt.cleanup()
opt.fold_constants()
opt.infer_shapes()
onnx_opt_graph = opt.cleanup(return_onnx=True)
return onnx_opt_graph
def check_dims(self, batch_size, image_height, image_width):
assert batch_size >= self.min_batch and batch_size <= self.max_batch
assert image_height % 8 == 0 or image_width % 8 == 0
latent_height = image_height // 8
latent_width = image_width // 8
assert latent_height >= self.min_latent_shape and latent_height <= self.max_latent_shape
assert latent_width >= self.min_latent_shape and latent_width <= self.max_latent_shape
return (latent_height, latent_width)
def get_minmax_dims(self, batch_size, image_height, image_width, static_batch, static_shape):
min_batch = batch_size if static_batch else self.min_batch
max_batch = batch_size if static_batch else self.max_batch
latent_height = image_height // 8
latent_width = image_width // 8
min_image_height = image_height if static_shape else self.min_image_shape
max_image_height = image_height if static_shape else self.max_image_shape
min_image_width = image_width if static_shape else self.min_image_shape
max_image_width = image_width if static_shape else self.max_image_shape
min_latent_height = latent_height if static_shape else self.min_latent_shape
max_latent_height = latent_height if static_shape else self.max_latent_shape
min_latent_width = latent_width if static_shape else self.min_latent_shape
max_latent_width = latent_width if static_shape else self.max_latent_shape
return (
min_batch,
max_batch,
min_image_height,
max_image_height,
min_image_width,
max_image_width,
min_latent_height,
max_latent_height,
min_latent_width,
max_latent_width,
)
def getOnnxPath(model_name, onnx_dir, opt=True):
return os.path.join(onnx_dir, model_name + (".opt" if opt else "") + ".onnx")
def getEnginePath(model_name, engine_dir):
return os.path.join(engine_dir, model_name + ".plan")
def build_engines(
models: dict,
engine_dir,
onnx_dir,
onnx_opset,
opt_image_height,
opt_image_width,
opt_batch_size=1,
force_engine_rebuild=False,
static_batch=False,
static_shape=True,
enable_preview=False,
enable_all_tactics=False,
timing_cache=None,
max_workspace_size=0,
):
built_engines = {}
if not os.path.isdir(onnx_dir):
os.makedirs(onnx_dir)
if not os.path.isdir(engine_dir):
os.makedirs(engine_dir)
# Export models to ONNX
for model_name, model_obj in models.items():
engine_path = getEnginePath(model_name, engine_dir)
if force_engine_rebuild or not os.path.exists(engine_path):
logger.warning("Building Engines...")
logger.warning("Engine build can take a while to complete")
onnx_path = getOnnxPath(model_name, onnx_dir, opt=False)
onnx_opt_path = getOnnxPath(model_name, onnx_dir)
if force_engine_rebuild or not os.path.exists(onnx_opt_path):
if force_engine_rebuild or not os.path.exists(onnx_path):
logger.warning(f"Exporting model: {onnx_path}")
model = model_obj.get_model()
with torch.inference_mode(), torch.autocast("cuda"):
inputs = model_obj.get_sample_input(opt_batch_size, opt_image_height, opt_image_width)
torch.onnx.export(
model,
inputs,
onnx_path,
export_params=True,
opset_version=onnx_opset,
do_constant_folding=True,
input_names=model_obj.get_input_names(),
output_names=model_obj.get_output_names(),
dynamic_axes=model_obj.get_dynamic_axes(),
)
del model
torch.cuda.empty_cache()
gc.collect()
else:
logger.warning(f"Found cached model: {onnx_path}")
# Optimize onnx
if force_engine_rebuild or not os.path.exists(onnx_opt_path):
logger.warning(f"Generating optimizing model: {onnx_opt_path}")
onnx_opt_graph = model_obj.optimize(onnx.load(onnx_path))
onnx.save(onnx_opt_graph, onnx_opt_path)
else:
logger.warning(f"Found cached optimized model: {onnx_opt_path} ")
# Build TensorRT engines
for model_name, model_obj in models.items():
engine_path = getEnginePath(model_name, engine_dir)
engine = Engine(engine_path)
onnx_path = getOnnxPath(model_name, onnx_dir, opt=False)
onnx_opt_path = getOnnxPath(model_name, onnx_dir)
if force_engine_rebuild or not os.path.exists(engine.engine_path):
engine.build(
onnx_opt_path,
fp16=True,
input_profile=model_obj.get_input_profile(
opt_batch_size,
opt_image_height,
opt_image_width,
static_batch=static_batch,
static_shape=static_shape,
),
enable_preview=enable_preview,
timing_cache=timing_cache,
workspace_size=max_workspace_size,
)
built_engines[model_name] = engine
# Load and activate TensorRT engines
for model_name, model_obj in models.items():
engine = built_engines[model_name]
engine.load()
engine.activate()
return built_engines
def runEngine(engine, feed_dict, stream):
return engine.infer(feed_dict, stream)
class CLIP(BaseModel):
def __init__(self, model, device, max_batch_size, embedding_dim):
super(CLIP, self).__init__(
model=model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim
)
self.name = "CLIP"
def get_input_names(self):
return ["input_ids"]
def get_output_names(self):
return ["text_embeddings", "pooler_output"]
def get_dynamic_axes(self):
return {"input_ids": {0: "B"}, "text_embeddings": {0: "B"}}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
self.check_dims(batch_size, image_height, image_width)
min_batch, max_batch, _, _, _, _, _, _, _, _ = self.get_minmax_dims(
batch_size, image_height, image_width, static_batch, static_shape
)
return {
"input_ids": [(min_batch, self.text_maxlen), (batch_size, self.text_maxlen), (max_batch, self.text_maxlen)]
}
def get_shape_dict(self, batch_size, image_height, image_width):
self.check_dims(batch_size, image_height, image_width)
return {
"input_ids": (batch_size, self.text_maxlen),
"text_embeddings": (batch_size, self.text_maxlen, self.embedding_dim),
}
def get_sample_input(self, batch_size, image_height, image_width):
self.check_dims(batch_size, image_height, image_width)
return torch.zeros(batch_size, self.text_maxlen, dtype=torch.int32, device=self.device)
def optimize(self, onnx_graph):
opt = Optimizer(onnx_graph)
opt.select_outputs([0]) # delete graph output#1
opt.cleanup()
opt.fold_constants()
opt.infer_shapes()
opt.select_outputs([0], names=["text_embeddings"]) # rename network output
opt_onnx_graph = opt.cleanup(return_onnx=True)
return opt_onnx_graph
def make_CLIP(model, device, max_batch_size, embedding_dim, inpaint=False):
return CLIP(model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim)
class UNet(BaseModel):
def __init__(
self, model, fp16=False, device="cuda", max_batch_size=16, embedding_dim=768, text_maxlen=77, unet_dim=4
):
super(UNet, self).__init__(
model=model,
fp16=fp16,
device=device,
max_batch_size=max_batch_size,
embedding_dim=embedding_dim,
text_maxlen=text_maxlen,
)
self.unet_dim = unet_dim
self.name = "UNet"
def get_input_names(self):
return ["sample", "timestep", "encoder_hidden_states"]
def get_output_names(self):
return ["latent"]
def get_dynamic_axes(self):
return {
"sample": {0: "2B", 2: "H", 3: "W"},
"encoder_hidden_states": {0: "2B"},
"latent": {0: "2B", 2: "H", 3: "W"},
}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
(
min_batch,
max_batch,
_,
_,
_,
_,
min_latent_height,
max_latent_height,
min_latent_width,
max_latent_width,
) = self.get_minmax_dims(batch_size, image_height, image_width, static_batch, static_shape)
return {
"sample": [
(2 * min_batch, self.unet_dim, min_latent_height, min_latent_width),
(2 * batch_size, self.unet_dim, latent_height, latent_width),
(2 * max_batch, self.unet_dim, max_latent_height, max_latent_width),
],
"encoder_hidden_states": [
(2 * min_batch, self.text_maxlen, self.embedding_dim),
(2 * batch_size, self.text_maxlen, self.embedding_dim),
(2 * max_batch, self.text_maxlen, self.embedding_dim),
],
}
def get_shape_dict(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return {
"sample": (2 * batch_size, self.unet_dim, latent_height, latent_width),
"encoder_hidden_states": (2 * batch_size, self.text_maxlen, self.embedding_dim),
"latent": (2 * batch_size, 4, latent_height, latent_width),
}
def get_sample_input(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
dtype = torch.float16 if self.fp16 else torch.float32
return (
torch.randn(
2 * batch_size, self.unet_dim, latent_height, latent_width, dtype=torch.float32, device=self.device
),
torch.tensor([1.0], dtype=torch.float32, device=self.device),
torch.randn(2 * batch_size, self.text_maxlen, self.embedding_dim, dtype=dtype, device=self.device),
)
def make_UNet(model, device, max_batch_size, embedding_dim, inpaint=False):
return UNet(
model,
fp16=True,
device=device,
max_batch_size=max_batch_size,
embedding_dim=embedding_dim,
unet_dim=(9 if inpaint else 4),
)
class VAE(BaseModel):
def __init__(self, model, device, max_batch_size, embedding_dim):
super(VAE, self).__init__(
model=model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim
)
self.name = "VAE decoder"
def get_input_names(self):
return ["latent"]
def get_output_names(self):
return ["images"]
def get_dynamic_axes(self):
return {"latent": {0: "B", 2: "H", 3: "W"}, "images": {0: "B", 2: "8H", 3: "8W"}}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
(
min_batch,
max_batch,
_,
_,
_,
_,
min_latent_height,
max_latent_height,
min_latent_width,
max_latent_width,
) = self.get_minmax_dims(batch_size, image_height, image_width, static_batch, static_shape)
return {
"latent": [
(min_batch, 4, min_latent_height, min_latent_width),
(batch_size, 4, latent_height, latent_width),
(max_batch, 4, max_latent_height, max_latent_width),
]
}
def get_shape_dict(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return {
"latent": (batch_size, 4, latent_height, latent_width),
"images": (batch_size, 3, image_height, image_width),
}
def get_sample_input(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return torch.randn(batch_size, 4, latent_height, latent_width, dtype=torch.float32, device=self.device)
def make_VAE(model, device, max_batch_size, embedding_dim, inpaint=False):
return VAE(model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim)
class TorchVAEEncoder(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.vae_encoder = model
def forward(self, x):
return self.vae_encoder.encode(x).latent_dist.sample()
class VAEEncoder(BaseModel):
def __init__(self, model, device, max_batch_size, embedding_dim):
super(VAEEncoder, self).__init__(
model=model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim
)
self.name = "VAE encoder"
def get_model(self):
vae_encoder = TorchVAEEncoder(self.model)
return vae_encoder
def get_input_names(self):
return ["images"]
def get_output_names(self):
return ["latent"]
def get_dynamic_axes(self):
return {"images": {0: "B", 2: "8H", 3: "8W"}, "latent": {0: "B", 2: "H", 3: "W"}}
def get_input_profile(self, batch_size, image_height, image_width, static_batch, static_shape):
assert batch_size >= self.min_batch and batch_size <= self.max_batch
min_batch = batch_size if static_batch else self.min_batch
max_batch = batch_size if static_batch else self.max_batch
self.check_dims(batch_size, image_height, image_width)
(
min_batch,
max_batch,
min_image_height,
max_image_height,
min_image_width,
max_image_width,
_,
_,
_,
_,
) = self.get_minmax_dims(batch_size, image_height, image_width, static_batch, static_shape)
return {
"images": [
(min_batch, 3, min_image_height, min_image_width),
(batch_size, 3, image_height, image_width),
(max_batch, 3, max_image_height, max_image_width),
]
}
def get_shape_dict(self, batch_size, image_height, image_width):
latent_height, latent_width = self.check_dims(batch_size, image_height, image_width)
return {
"images": (batch_size, 3, image_height, image_width),
"latent": (batch_size, 4, latent_height, latent_width),
}
def get_sample_input(self, batch_size, image_height, image_width):
self.check_dims(batch_size, image_height, image_width)
return torch.randn(batch_size, 3, image_height, image_width, dtype=torch.float32, device=self.device)
def make_VAEEncoder(model, device, max_batch_size, embedding_dim, inpaint=False):
return VAEEncoder(model, device=device, max_batch_size=max_batch_size, embedding_dim=embedding_dim)
class TensorRTStableDiffusionImg2ImgPipeline(StableDiffusionImg2ImgPipeline):
r"""
Pipeline for image-to-image generation using TensorRT accelerated Stable Diffusion.
This model inherits from [`StableDiffusionImg2ImgPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPFeatureExtractor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: DDIMScheduler,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPFeatureExtractor,
requires_safety_checker: bool = True,
stages=["clip", "unet", "vae", "vae_encoder"],
image_height: int = 512,
image_width: int = 512,
max_batch_size: int = 16,
# ONNX export parameters
onnx_opset: int = 17,
onnx_dir: str = "onnx",
# TensorRT engine build parameters
engine_dir: str = "engine",
build_preview_features: bool = True,
force_engine_rebuild: bool = False,
timing_cache: str = "timing_cache",
):
super().__init__(
vae, text_encoder, tokenizer, unet, scheduler, safety_checker, feature_extractor, requires_safety_checker
)
self.vae.forward = self.vae.decode
self.stages = stages
self.image_height, self.image_width = image_height, image_width
self.inpaint = False
self.onnx_opset = onnx_opset
self.onnx_dir = onnx_dir
self.engine_dir = engine_dir
self.force_engine_rebuild = force_engine_rebuild
self.timing_cache = timing_cache
self.build_static_batch = False
self.build_dynamic_shape = False
self.build_preview_features = build_preview_features
self.max_batch_size = max_batch_size
# TODO: Restrict batch size to 4 for larger image dimensions as a WAR for TensorRT limitation.
if self.build_dynamic_shape or self.image_height > 512 or self.image_width > 512:
self.max_batch_size = 4
self.stream = None # loaded in loadResources()
self.models = {} # loaded in __loadModels()
self.engine = {} # loaded in build_engines()
def __loadModels(self):
# Load pipeline models
self.embedding_dim = self.text_encoder.config.hidden_size
models_args = {
"device": self.torch_device,
"max_batch_size": self.max_batch_size,
"embedding_dim": self.embedding_dim,
"inpaint": self.inpaint,
}
if "clip" in self.stages:
self.models["clip"] = make_CLIP(self.text_encoder, **models_args)
if "unet" in self.stages:
self.models["unet"] = make_UNet(self.unet, **models_args)
if "vae" in self.stages:
self.models["vae"] = make_VAE(self.vae, **models_args)
if "vae_encoder" in self.stages:
self.models["vae_encoder"] = make_VAEEncoder(self.vae, **models_args)
@classmethod
def set_cached_folder(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], **kwargs):
cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
resume_download = kwargs.pop("resume_download", False)
proxies = kwargs.pop("proxies", None)
local_files_only = kwargs.pop("local_files_only", False)
use_auth_token = kwargs.pop("use_auth_token", None)
revision = kwargs.pop("revision", None)
cls.cached_folder = (
pretrained_model_name_or_path
if os.path.isdir(pretrained_model_name_or_path)
else snapshot_download(
pretrained_model_name_or_path,
cache_dir=cache_dir,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
use_auth_token=use_auth_token,
revision=revision,
)
)
def to(self, torch_device: Optional[Union[str, torch.device]] = None, silence_dtype_warnings: bool = False):
super().to(torch_device, silence_dtype_warnings=silence_dtype_warnings)
self.onnx_dir = os.path.join(self.cached_folder, self.onnx_dir)
self.engine_dir = os.path.join(self.cached_folder, self.engine_dir)
self.timing_cache = os.path.join(self.cached_folder, self.timing_cache)
# set device
self.torch_device = self._execution_device
logger.warning(f"Running inference on device: {self.torch_device}")
# load models
self.__loadModels()
# build engines
self.engine = build_engines(
self.models,
self.engine_dir,
self.onnx_dir,
self.onnx_opset,
opt_image_height=self.image_height,
opt_image_width=self.image_width,
force_engine_rebuild=self.force_engine_rebuild,
static_batch=self.build_static_batch,
static_shape=not self.build_dynamic_shape,
enable_preview=self.build_preview_features,
timing_cache=self.timing_cache,
)
return self
def __initialize_timesteps(self, timesteps, strength):
self.scheduler.set_timesteps(timesteps)
offset = self.scheduler.steps_offset if hasattr(self.scheduler, "steps_offset") else 0
init_timestep = int(timesteps * strength) + offset
init_timestep = min(init_timestep, timesteps)
t_start = max(timesteps - init_timestep + offset, 0)
timesteps = self.scheduler.timesteps[t_start:].to(self.torch_device)
return timesteps, t_start
def __preprocess_images(self, batch_size, images=()):
init_images = []
for image in images:
image = image.to(self.torch_device).float()
image = image.repeat(batch_size, 1, 1, 1)
init_images.append(image)
return tuple(init_images)
def __encode_image(self, init_image):
init_latents = runEngine(self.engine["vae_encoder"], {"images": device_view(init_image)}, self.stream)[
"latent"
]
init_latents = 0.18215 * init_latents
return init_latents
def __encode_prompt(self, prompt, negative_prompt):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
"""
# Tokenize prompt
text_input_ids = (
self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
.input_ids.type(torch.int32)
.to(self.torch_device)
)
text_input_ids_inp = device_view(text_input_ids)
# NOTE: output tensor for CLIP must be cloned because it will be overwritten when called again for negative prompt
text_embeddings = runEngine(self.engine["clip"], {"input_ids": text_input_ids_inp}, self.stream)[
"text_embeddings"
].clone()
# Tokenize negative prompt
uncond_input_ids = (
self.tokenizer(
negative_prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
.input_ids.type(torch.int32)
.to(self.torch_device)
)
uncond_input_ids_inp = device_view(uncond_input_ids)
uncond_embeddings = runEngine(self.engine["clip"], {"input_ids": uncond_input_ids_inp}, self.stream)[
"text_embeddings"
]
# Concatenate the unconditional and text embeddings into a single batch to avoid doing two forward passes for classifier free guidance
text_embeddings = torch.cat([uncond_embeddings, text_embeddings]).to(dtype=torch.float16)
return text_embeddings
def __denoise_latent(
self, latents, text_embeddings, timesteps=None, step_offset=0, mask=None, masked_image_latents=None
):
if not isinstance(timesteps, torch.Tensor):
timesteps = self.scheduler.timesteps
for step_index, timestep in enumerate(timesteps):
# Expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, timestep)
if isinstance(mask, torch.Tensor):
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
# Predict the noise residual
timestep_float = timestep.float() if timestep.dtype != torch.float32 else timestep
sample_inp = device_view(latent_model_input)
timestep_inp = device_view(timestep_float)
embeddings_inp = device_view(text_embeddings)
noise_pred = runEngine(
self.engine["unet"],
{"sample": sample_inp, "timestep": timestep_inp, "encoder_hidden_states": embeddings_inp},
self.stream,
)["latent"]
# Perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
latents = self.scheduler.step(noise_pred, timestep, latents).prev_sample
latents = 1.0 / 0.18215 * latents
return latents
def __decode_latent(self, latents):
images = runEngine(self.engine["vae"], {"latent": device_view(latents)}, self.stream)["images"]
images = (images / 2 + 0.5).clamp(0, 1)
return images.cpu().permute(0, 2, 3, 1).float().numpy()
def __loadResources(self, image_height, image_width, batch_size):
self.stream = cuda.Stream()
# Allocate buffers for TensorRT engine bindings
for model_name, obj in self.models.items():
self.engine[model_name].allocate_buffers(
shape_dict=obj.get_shape_dict(batch_size, image_height, image_width), device=self.torch_device
)
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: Union[torch.FloatTensor, PIL.Image.Image] = None,
strength: float = 0.8,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
strength (`float`, *optional*, defaults to 0.8):
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
will be used as a starting point, adding more noise to it the larger the `strength`. The number of
denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
be maximum and the denoising process will run for the full number of iterations specified in
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. If not defined, one has to pass `negative_prompt_embeds`. instead.
Ignored when not using guidance (i.e., ignored if `guidance_scale` is less than `1`).
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
"""
self.generator = generator
self.denoising_steps = num_inference_steps
self.guidance_scale = guidance_scale
# Pre-compute latent input scales and linear multistep coefficients
self.scheduler.set_timesteps(self.denoising_steps, device=self.torch_device)
# Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
prompt = [prompt]
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"Expected prompt to be of type list or str but got {type(prompt)}")
if negative_prompt is None:
negative_prompt = [""] * batch_size
if negative_prompt is not None and isinstance(negative_prompt, str):
negative_prompt = [negative_prompt]
assert len(prompt) == len(negative_prompt)
if batch_size > self.max_batch_size:
raise ValueError(
f"Batch size {len(prompt)} is larger than allowed {self.max_batch_size}. If dynamic shape is used, then maximum batch size is 4"
)
# load resources
self.__loadResources(self.image_height, self.image_width, batch_size)
with torch.inference_mode(), torch.autocast("cuda"), trt.Runtime(TRT_LOGGER):
# Initialize timesteps
timesteps, t_start = self.__initialize_timesteps(self.denoising_steps, strength)
latent_timestep = timesteps[:1].repeat(batch_size)
# Pre-process input image
if isinstance(image, PIL.Image.Image):
image = preprocess_image(image)
init_image = self.__preprocess_images(batch_size, (image,))[0]
# VAE encode init image
init_latents = self.__encode_image(init_image)
# Add noise to latents using timesteps
noise = torch.randn(
init_latents.shape, generator=self.generator, device=self.torch_device, dtype=torch.float32
)
latents = self.scheduler.add_noise(init_latents, noise, latent_timestep)
# CLIP text encoder
text_embeddings = self.__encode_prompt(prompt, negative_prompt)
# UNet denoiser
latents = self.__denoise_latent(latents, text_embeddings, timesteps=timesteps, step_offset=t_start)
# VAE decode latent
images = self.__decode_latent(latents)
images = self.numpy_to_pil(images)
return StableDiffusionPipelineOutput(images=images, nsfw_content_detected=None)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/checkpoint_merger.py
|
import glob
import os
from typing import Dict, List, Union
import safetensors.torch
import torch
from huggingface_hub import snapshot_download
from diffusers import DiffusionPipeline, __version__
from diffusers.schedulers.scheduling_utils import SCHEDULER_CONFIG_NAME
from diffusers.utils import CONFIG_NAME, DIFFUSERS_CACHE, ONNX_WEIGHTS_NAME, WEIGHTS_NAME
class CheckpointMergerPipeline(DiffusionPipeline):
"""
A class that supports merging diffusion models based on the discussion here:
https://github.com/huggingface/diffusers/issues/877
Example usage:-
pipe = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", custom_pipeline="checkpoint_merger.py")
merged_pipe = pipe.merge(["CompVis/stable-diffusion-v1-4","prompthero/openjourney"], interp = 'inv_sigmoid', alpha = 0.8, force = True)
merged_pipe.to('cuda')
prompt = "An astronaut riding a unicycle on Mars"
results = merged_pipe(prompt)
## For more details, see the docstring for the merge method.
"""
def __init__(self):
self.register_to_config()
super().__init__()
def _compare_model_configs(self, dict0, dict1):
if dict0 == dict1:
return True
else:
config0, meta_keys0 = self._remove_meta_keys(dict0)
config1, meta_keys1 = self._remove_meta_keys(dict1)
if config0 == config1:
print(f"Warning !: Mismatch in keys {meta_keys0} and {meta_keys1}.")
return True
return False
def _remove_meta_keys(self, config_dict: Dict):
meta_keys = []
temp_dict = config_dict.copy()
for key in config_dict.keys():
if key.startswith("_"):
temp_dict.pop(key)
meta_keys.append(key)
return (temp_dict, meta_keys)
@torch.no_grad()
def merge(self, pretrained_model_name_or_path_list: List[Union[str, os.PathLike]], **kwargs):
"""
Returns a new pipeline object of the class 'DiffusionPipeline' with the merged checkpoints(weights) of the models passed
in the argument 'pretrained_model_name_or_path_list' as a list.
Parameters:
-----------
pretrained_model_name_or_path_list : A list of valid pretrained model names in the HuggingFace hub or paths to locally stored models in the HuggingFace format.
**kwargs:
Supports all the default DiffusionPipeline.get_config_dict kwargs viz..
cache_dir, resume_download, force_download, proxies, local_files_only, use_auth_token, revision, torch_dtype, device_map.
alpha - The interpolation parameter. Ranges from 0 to 1. It affects the ratio in which the checkpoints are merged. A 0.8 alpha
would mean that the first model checkpoints would affect the final result far less than an alpha of 0.2
interp - The interpolation method to use for the merging. Supports "sigmoid", "inv_sigmoid", "add_diff" and None.
Passing None uses the default interpolation which is weighted sum interpolation. For merging three checkpoints, only "add_diff" is supported.
force - Whether to ignore mismatch in model_config.json for the current models. Defaults to False.
"""
# Default kwargs from DiffusionPipeline
cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
resume_download = kwargs.pop("resume_download", False)
force_download = kwargs.pop("force_download", False)
proxies = kwargs.pop("proxies", None)
local_files_only = kwargs.pop("local_files_only", False)
use_auth_token = kwargs.pop("use_auth_token", None)
revision = kwargs.pop("revision", None)
torch_dtype = kwargs.pop("torch_dtype", None)
device_map = kwargs.pop("device_map", None)
alpha = kwargs.pop("alpha", 0.5)
interp = kwargs.pop("interp", None)
print("Received list", pretrained_model_name_or_path_list)
print(f"Combining with alpha={alpha}, interpolation mode={interp}")
checkpoint_count = len(pretrained_model_name_or_path_list)
# Ignore result from model_index_json comparision of the two checkpoints
force = kwargs.pop("force", False)
# If less than 2 checkpoints, nothing to merge. If more than 3, not supported for now.
if checkpoint_count > 3 or checkpoint_count < 2:
raise ValueError(
"Received incorrect number of checkpoints to merge. Ensure that either 2 or 3 checkpoints are being"
" passed."
)
print("Received the right number of checkpoints")
# chkpt0, chkpt1 = pretrained_model_name_or_path_list[0:2]
# chkpt2 = pretrained_model_name_or_path_list[2] if checkpoint_count == 3 else None
# Validate that the checkpoints can be merged
# Step 1: Load the model config and compare the checkpoints. We'll compare the model_index.json first while ignoring the keys starting with '_'
config_dicts = []
for pretrained_model_name_or_path in pretrained_model_name_or_path_list:
config_dict = DiffusionPipeline.load_config(
pretrained_model_name_or_path,
cache_dir=cache_dir,
resume_download=resume_download,
force_download=force_download,
proxies=proxies,
local_files_only=local_files_only,
use_auth_token=use_auth_token,
revision=revision,
)
config_dicts.append(config_dict)
comparison_result = True
for idx in range(1, len(config_dicts)):
comparison_result &= self._compare_model_configs(config_dicts[idx - 1], config_dicts[idx])
if not force and comparison_result is False:
raise ValueError("Incompatible checkpoints. Please check model_index.json for the models.")
print(config_dicts[0], config_dicts[1])
print("Compatible model_index.json files found")
# Step 2: Basic Validation has succeeded. Let's download the models and save them into our local files.
cached_folders = []
for pretrained_model_name_or_path, config_dict in zip(pretrained_model_name_or_path_list, config_dicts):
folder_names = [k for k in config_dict.keys() if not k.startswith("_")]
allow_patterns = [os.path.join(k, "*") for k in folder_names]
allow_patterns += [
WEIGHTS_NAME,
SCHEDULER_CONFIG_NAME,
CONFIG_NAME,
ONNX_WEIGHTS_NAME,
DiffusionPipeline.config_name,
]
requested_pipeline_class = config_dict.get("_class_name")
user_agent = {"diffusers": __version__, "pipeline_class": requested_pipeline_class}
cached_folder = (
pretrained_model_name_or_path
if os.path.isdir(pretrained_model_name_or_path)
else snapshot_download(
pretrained_model_name_or_path,
cache_dir=cache_dir,
resume_download=resume_download,
proxies=proxies,
local_files_only=local_files_only,
use_auth_token=use_auth_token,
revision=revision,
allow_patterns=allow_patterns,
user_agent=user_agent,
)
)
print("Cached Folder", cached_folder)
cached_folders.append(cached_folder)
# Step 3:-
# Load the first checkpoint as a diffusion pipeline and modify its module state_dict in place
final_pipe = DiffusionPipeline.from_pretrained(
cached_folders[0], torch_dtype=torch_dtype, device_map=device_map
)
final_pipe.to(self.device)
checkpoint_path_2 = None
if len(cached_folders) > 2:
checkpoint_path_2 = os.path.join(cached_folders[2])
if interp == "sigmoid":
theta_func = CheckpointMergerPipeline.sigmoid
elif interp == "inv_sigmoid":
theta_func = CheckpointMergerPipeline.inv_sigmoid
elif interp == "add_diff":
theta_func = CheckpointMergerPipeline.add_difference
else:
theta_func = CheckpointMergerPipeline.weighted_sum
# Find each module's state dict.
for attr in final_pipe.config.keys():
if not attr.startswith("_"):
checkpoint_path_1 = os.path.join(cached_folders[1], attr)
if os.path.exists(checkpoint_path_1):
files = [
*glob.glob(os.path.join(checkpoint_path_1, "*.safetensors")),
*glob.glob(os.path.join(checkpoint_path_1, "*.bin")),
]
checkpoint_path_1 = files[0] if len(files) > 0 else None
if len(cached_folders) < 3:
checkpoint_path_2 = None
else:
checkpoint_path_2 = os.path.join(cached_folders[2], attr)
if os.path.exists(checkpoint_path_2):
files = [
*glob.glob(os.path.join(checkpoint_path_2, "*.safetensors")),
*glob.glob(os.path.join(checkpoint_path_2, "*.bin")),
]
checkpoint_path_2 = files[0] if len(files) > 0 else None
# For an attr if both checkpoint_path_1 and 2 are None, ignore.
# If atleast one is present, deal with it according to interp method, of course only if the state_dict keys match.
if checkpoint_path_1 is None and checkpoint_path_2 is None:
print(f"Skipping {attr}: not present in 2nd or 3d model")
continue
try:
module = getattr(final_pipe, attr)
if isinstance(module, bool): # ignore requires_safety_checker boolean
continue
theta_0 = getattr(module, "state_dict")
theta_0 = theta_0()
update_theta_0 = getattr(module, "load_state_dict")
theta_1 = (
safetensors.torch.load_file(checkpoint_path_1)
if (checkpoint_path_1.endswith(".safetensors"))
else torch.load(checkpoint_path_1, map_location="cpu")
)
theta_2 = None
if checkpoint_path_2:
theta_2 = (
safetensors.torch.load_file(checkpoint_path_2)
if (checkpoint_path_2.endswith(".safetensors"))
else torch.load(checkpoint_path_2, map_location="cpu")
)
if not theta_0.keys() == theta_1.keys():
print(f"Skipping {attr}: key mismatch")
continue
if theta_2 and not theta_1.keys() == theta_2.keys():
print(f"Skipping {attr}:y mismatch")
except Exception as e:
print(f"Skipping {attr} do to an unexpected error: {str(e)}")
continue
print(f"MERGING {attr}")
for key in theta_0.keys():
if theta_2:
theta_0[key] = theta_func(theta_0[key], theta_1[key], theta_2[key], alpha)
else:
theta_0[key] = theta_func(theta_0[key], theta_1[key], None, alpha)
del theta_1
del theta_2
update_theta_0(theta_0)
del theta_0
return final_pipe
@staticmethod
def weighted_sum(theta0, theta1, theta2, alpha):
return ((1 - alpha) * theta0) + (alpha * theta1)
# Smoothstep (https://en.wikipedia.org/wiki/Smoothstep)
@staticmethod
def sigmoid(theta0, theta1, theta2, alpha):
alpha = alpha * alpha * (3 - (2 * alpha))
return theta0 + ((theta1 - theta0) * alpha)
# Inverse Smoothstep (https://en.wikipedia.org/wiki/Smoothstep)
@staticmethod
def inv_sigmoid(theta0, theta1, theta2, alpha):
import math
alpha = 0.5 - math.sin(math.asin(1.0 - 2.0 * alpha) / 3.0)
return theta0 + ((theta1 - theta0) * alpha)
@staticmethod
def add_difference(theta0, theta1, theta2, alpha):
return theta0 + (theta1 - theta2) * (1.0 - alpha)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/edict_pipeline.py
|
from typing import Optional
import torch
from PIL import Image
from tqdm.auto import tqdm
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, DDIMScheduler, DiffusionPipeline, UNet2DConditionModel
from diffusers.image_processor import VaeImageProcessor
from diffusers.utils import (
deprecate,
)
class EDICTPipeline(DiffusionPipeline):
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: DDIMScheduler,
mixing_coeff: float = 0.93,
leapfrog_steps: bool = True,
):
self.mixing_coeff = mixing_coeff
self.leapfrog_steps = leapfrog_steps
super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
def _encode_prompt(
self, prompt: str, negative_prompt: Optional[str] = None, do_classifier_free_guidance: bool = False
):
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
prompt_embeds = self.text_encoder(text_inputs.input_ids.to(self.device)).last_hidden_state
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=self.device)
if do_classifier_free_guidance:
uncond_tokens = "" if negative_prompt is None else negative_prompt
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
negative_prompt_embeds = self.text_encoder(uncond_input.input_ids.to(self.device)).last_hidden_state
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
def denoise_mixing_layer(self, x: torch.Tensor, y: torch.Tensor):
x = self.mixing_coeff * x + (1 - self.mixing_coeff) * y
y = self.mixing_coeff * y + (1 - self.mixing_coeff) * x
return [x, y]
def noise_mixing_layer(self, x: torch.Tensor, y: torch.Tensor):
y = (y - (1 - self.mixing_coeff) * x) / self.mixing_coeff
x = (x - (1 - self.mixing_coeff) * y) / self.mixing_coeff
return [x, y]
def _get_alpha_and_beta(self, t: torch.Tensor):
# as self.alphas_cumprod is always in cpu
t = int(t)
alpha_prod = self.scheduler.alphas_cumprod[t] if t >= 0 else self.scheduler.final_alpha_cumprod
return alpha_prod, 1 - alpha_prod
def noise_step(
self,
base: torch.Tensor,
model_input: torch.Tensor,
model_output: torch.Tensor,
timestep: torch.Tensor,
):
prev_timestep = timestep - self.scheduler.config.num_train_timesteps / self.scheduler.num_inference_steps
alpha_prod_t, beta_prod_t = self._get_alpha_and_beta(timestep)
alpha_prod_t_prev, beta_prod_t_prev = self._get_alpha_and_beta(prev_timestep)
a_t = (alpha_prod_t_prev / alpha_prod_t) ** 0.5
b_t = -a_t * (beta_prod_t**0.5) + beta_prod_t_prev**0.5
next_model_input = (base - b_t * model_output) / a_t
return model_input, next_model_input.to(base.dtype)
def denoise_step(
self,
base: torch.Tensor,
model_input: torch.Tensor,
model_output: torch.Tensor,
timestep: torch.Tensor,
):
prev_timestep = timestep - self.scheduler.config.num_train_timesteps / self.scheduler.num_inference_steps
alpha_prod_t, beta_prod_t = self._get_alpha_and_beta(timestep)
alpha_prod_t_prev, beta_prod_t_prev = self._get_alpha_and_beta(prev_timestep)
a_t = (alpha_prod_t_prev / alpha_prod_t) ** 0.5
b_t = -a_t * (beta_prod_t**0.5) + beta_prod_t_prev**0.5
next_model_input = a_t * base + b_t * model_output
return model_input, next_model_input.to(base.dtype)
@torch.no_grad()
def decode_latents(self, latents: torch.Tensor):
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
return image
@torch.no_grad()
def prepare_latents(
self,
image: Image.Image,
text_embeds: torch.Tensor,
timesteps: torch.Tensor,
guidance_scale: float,
generator: Optional[torch.Generator] = None,
):
do_classifier_free_guidance = guidance_scale > 1.0
image = image.to(device=self.device, dtype=text_embeds.dtype)
latent = self.vae.encode(image).latent_dist.sample(generator)
latent = self.vae.config.scaling_factor * latent
coupled_latents = [latent.clone(), latent.clone()]
for i, t in tqdm(enumerate(timesteps), total=len(timesteps)):
coupled_latents = self.noise_mixing_layer(x=coupled_latents[0], y=coupled_latents[1])
# j - model_input index, k - base index
for j in range(2):
k = j ^ 1
if self.leapfrog_steps:
if i % 2 == 0:
k, j = j, k
model_input = coupled_latents[j]
base = coupled_latents[k]
latent_model_input = torch.cat([model_input] * 2) if do_classifier_free_guidance else model_input
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeds).sample
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
base, model_input = self.noise_step(
base=base,
model_input=model_input,
model_output=noise_pred,
timestep=t,
)
coupled_latents[k] = model_input
return coupled_latents
@torch.no_grad()
def __call__(
self,
base_prompt: str,
target_prompt: str,
image: Image.Image,
guidance_scale: float = 3.0,
num_inference_steps: int = 50,
strength: float = 0.8,
negative_prompt: Optional[str] = None,
generator: Optional[torch.Generator] = None,
output_type: Optional[str] = "pil",
):
do_classifier_free_guidance = guidance_scale > 1.0
image = self.image_processor.preprocess(image)
base_embeds = self._encode_prompt(base_prompt, negative_prompt, do_classifier_free_guidance)
target_embeds = self._encode_prompt(target_prompt, negative_prompt, do_classifier_free_guidance)
self.scheduler.set_timesteps(num_inference_steps, self.device)
t_limit = num_inference_steps - int(num_inference_steps * strength)
fwd_timesteps = self.scheduler.timesteps[t_limit:]
bwd_timesteps = fwd_timesteps.flip(0)
coupled_latents = self.prepare_latents(image, base_embeds, bwd_timesteps, guidance_scale, generator)
for i, t in tqdm(enumerate(fwd_timesteps), total=len(fwd_timesteps)):
# j - model_input index, k - base index
for k in range(2):
j = k ^ 1
if self.leapfrog_steps:
if i % 2 == 1:
k, j = j, k
model_input = coupled_latents[j]
base = coupled_latents[k]
latent_model_input = torch.cat([model_input] * 2) if do_classifier_free_guidance else model_input
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=target_embeds).sample
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
base, model_input = self.denoise_step(
base=base,
model_input=model_input,
model_output=noise_pred,
timestep=t,
)
coupled_latents[k] = model_input
coupled_latents = self.denoise_mixing_layer(x=coupled_latents[0], y=coupled_latents[1])
# either one is fine
final_latent = coupled_latents[0]
if output_type not in ["latent", "pt", "np", "pil"]:
deprecation_message = (
f"the output_type {output_type} is outdated. Please make sure to set it to one of these instead: "
"`pil`, `np`, `pt`, `latent`"
)
deprecate("Unsupported output_type", "1.0.0", deprecation_message, standard_warn=False)
output_type = "np"
if output_type == "latent":
image = final_latent
else:
image = self.decode_latents(final_latent)
image = self.image_processor.postprocess(image, output_type=output_type)
return image
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_diffusion_repaint.py
|
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
from typing import Callable, List, Optional, Union
import numpy as np
import PIL.Image
import torch
from packaging import version
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, DiffusionPipeline, UNet2DConditionModel
from diffusers.configuration_utils import FrozenDict, deprecate
from diffusers.loaders import LoraLoaderMixin, TextualInversionLoaderMixin
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import (
StableDiffusionSafetyChecker,
)
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
is_accelerate_available,
is_accelerate_version,
logging,
)
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def prepare_mask_and_masked_image(image, mask):
"""
Prepares a pair (image, mask) to be consumed by the Stable Diffusion pipeline. This means that those inputs will be
converted to ``torch.Tensor`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for the
``image`` and ``1`` for the ``mask``.
The ``image`` will be converted to ``torch.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
binarized (``mask > 0.5``) and cast to ``torch.float32`` too.
Args:
image (Union[np.array, PIL.Image, torch.Tensor]): The image to inpaint.
It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array`` or a ``channels x height x width``
``torch.Tensor`` or a ``batch x channels x height x width`` ``torch.Tensor``.
mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
It can be a ``PIL.Image``, or a ``height x width`` ``np.array`` or a ``1 x height x width``
``torch.Tensor`` or a ``batch x 1 x height x width`` ``torch.Tensor``.
Raises:
ValueError: ``torch.Tensor`` images should be in the ``[-1, 1]`` range. ValueError: ``torch.Tensor`` mask
should be in the ``[0, 1]`` range. ValueError: ``mask`` and ``image`` should have the same spatial dimensions.
TypeError: ``mask`` is a ``torch.Tensor`` but ``image`` is not
(ot the other way around).
Returns:
tuple[torch.Tensor]: The pair (mask, masked_image) as ``torch.Tensor`` with 4
dimensions: ``batch x channels x height x width``.
"""
if isinstance(image, torch.Tensor):
if not isinstance(mask, torch.Tensor):
raise TypeError(f"`image` is a torch.Tensor but `mask` (type: {type(mask)} is not")
# Batch single image
if image.ndim == 3:
assert image.shape[0] == 3, "Image outside a batch should be of shape (3, H, W)"
image = image.unsqueeze(0)
# Batch and add channel dim for single mask
if mask.ndim == 2:
mask = mask.unsqueeze(0).unsqueeze(0)
# Batch single mask or add channel dim
if mask.ndim == 3:
# Single batched mask, no channel dim or single mask not batched but channel dim
if mask.shape[0] == 1:
mask = mask.unsqueeze(0)
# Batched masks no channel dim
else:
mask = mask.unsqueeze(1)
assert image.ndim == 4 and mask.ndim == 4, "Image and Mask must have 4 dimensions"
assert image.shape[-2:] == mask.shape[-2:], "Image and Mask must have the same spatial dimensions"
assert image.shape[0] == mask.shape[0], "Image and Mask must have the same batch size"
# Check image is in [-1, 1]
if image.min() < -1 or image.max() > 1:
raise ValueError("Image should be in [-1, 1] range")
# Check mask is in [0, 1]
if mask.min() < 0 or mask.max() > 1:
raise ValueError("Mask should be in [0, 1] range")
# Binarize mask
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
# Image as float32
image = image.to(dtype=torch.float32)
elif isinstance(mask, torch.Tensor):
raise TypeError(f"`mask` is a torch.Tensor but `image` (type: {type(image)} is not")
else:
# preprocess image
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
# preprocess mask
if isinstance(mask, (PIL.Image.Image, np.ndarray)):
mask = [mask]
if isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image):
mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
mask = mask.astype(np.float32) / 255.0
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
mask = torch.from_numpy(mask)
# masked_image = image * (mask >= 0.5)
masked_image = image
return mask, masked_image
class StableDiffusionRepaintPipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin):
r"""
Pipeline for text-guided image inpainting using Stable Diffusion. *This is an experimental feature*.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
In addition the pipeline inherits the following loading methods:
- *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
- *LoRA*: [`loaders.LoraLoaderMixin.load_lora_weights`]
as well as the following saving methods:
- *LoRA*: [`loaders.LoraLoaderMixin.save_lora_weights`]
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if hasattr(scheduler.config, "skip_prk_steps") and scheduler.config.skip_prk_steps is False:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} has not set the configuration"
" `skip_prk_steps`. `skip_prk_steps` should be set to True in the configuration file. Please make"
" sure to update the config accordingly as not setting `skip_prk_steps` in the config might lead to"
" incorrect results in future versions. If you have downloaded this checkpoint from the Hugging Face"
" Hub, it would be very nice if you could open a Pull request for the"
" `scheduler/scheduler_config.json` file"
)
deprecate(
"skip_prk_steps not set",
"1.0.0",
deprecation_message,
standard_warn=False,
)
new_config = dict(scheduler.config)
new_config["skip_prk_steps"] = True
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
version.parse(unet.config._diffusers_version).base_version
) < version.parse("0.9.0.dev0")
is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
deprecation_message = (
"The configuration file of the unet has set the default `sample_size` to smaller than"
" 64 which seems highly unlikely .If you're checkpoint is a fine-tuned version of any of the"
" following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
" CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
" \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
" configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
" in the config might lead to incorrect results in future versions. If you have downloaded this"
" checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
" the `unet/config.json` file"
)
deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(unet.config)
new_config["sample_size"] = 64
unet._internal_dict = FrozenDict(new_config)
# Check shapes, assume num_channels_latents == 4, num_channels_mask == 1, num_channels_masked == 4
if unet.config.in_channels != 4:
logger.warning(
f"You have loaded a UNet with {unet.config.in_channels} input channels, whereas by default,"
f" {self.__class__} assumes that `pipeline.unet` has 4 input channels: 4 for `num_channels_latents`,"
". If you did not intend to modify"
" this behavior, please check whether you have loaded the right checkpoint."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.register_to_config(requires_safety_checker=requires_safety_checker)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
`torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
Note that offloading happens on a submodule basis. Memory savings are higher than with
`enable_model_cpu_offload`, but performance is lower.
"""
if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
from accelerate import cpu_offload
else:
raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
device = torch.device(f"cuda:{gpu_id}")
if self.device.type != "cpu":
self.to("cpu", silence_dtype_warnings=True)
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
cpu_offload(cpu_offloaded_model, device)
if self.safety_checker is not None:
cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_model_cpu_offload
def enable_model_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
"""
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
from accelerate import cpu_offload_with_hook
else:
raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
device = torch.device(f"cuda:{gpu_id}")
if self.device.type != "cpu":
self.to("cpu", silence_dtype_warnings=True)
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
hook = None
for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
if self.safety_checker is not None:
_, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
# We'll offload the last model manually.
self.final_offload_hook = hook
@property
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if not hasattr(self.unet, "_hf_hook"):
return self.device
for module in self.unet.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
"""
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# textual inversion: procecss multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
prompt_embeds = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
# textual inversion: procecss multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
else:
has_nsfw_concept = None
return image, has_nsfw_concept
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
def decode_latents(self, latents):
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
def check_inputs(
self,
prompt,
height,
width,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
def prepare_latents(
self,
batch_size,
num_channels_latents,
height,
width,
dtype,
device,
generator,
latents=None,
):
shape = (
batch_size,
num_channels_latents,
height // self.vae_scale_factor,
width // self.vae_scale_factor,
)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def prepare_mask_latents(
self,
mask,
masked_image,
batch_size,
height,
width,
dtype,
device,
generator,
do_classifier_free_guidance,
):
# resize the mask to latents shape as we concatenate the mask to the latents
# we do that before converting to dtype to avoid breaking in case we're using cpu_offload
# and half precision
mask = torch.nn.functional.interpolate(
mask, size=(height // self.vae_scale_factor, width // self.vae_scale_factor)
)
mask = mask.to(device=device, dtype=dtype)
masked_image = masked_image.to(device=device, dtype=dtype)
# encode the mask image into latents space so we can concatenate it to the latents
if isinstance(generator, list):
masked_image_latents = [
self.vae.encode(masked_image[i : i + 1]).latent_dist.sample(generator=generator[i])
for i in range(batch_size)
]
masked_image_latents = torch.cat(masked_image_latents, dim=0)
else:
masked_image_latents = self.vae.encode(masked_image).latent_dist.sample(generator=generator)
masked_image_latents = self.vae.config.scaling_factor * masked_image_latents
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
if mask.shape[0] < batch_size:
if not batch_size % mask.shape[0] == 0:
raise ValueError(
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
" of masks that you pass is divisible by the total requested batch size."
)
mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
if masked_image_latents.shape[0] < batch_size:
if not batch_size % masked_image_latents.shape[0] == 0:
raise ValueError(
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
" Make sure the number of images that you pass is divisible by the total requested batch size."
)
masked_image_latents = masked_image_latents.repeat(batch_size // masked_image_latents.shape[0], 1, 1, 1)
mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
masked_image_latents = (
torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
)
# aligning device to prevent device errors when concating it with the latent model input
masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
return mask, masked_image_latents
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: Union[torch.FloatTensor, PIL.Image.Image] = None,
mask_image: Union[torch.FloatTensor, PIL.Image.Image] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
jump_length: Optional[int] = 10,
jump_n_sample: Optional[int] = 10,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
mask_image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
repainted, while black pixels will be preserved. If `mask_image` is a PIL image, it will be converted
to a single channel (luminance) before use. If it's a tensor, it should contain one color channel (L)
instead of 3, so the expected shape would be `(B, H, W, 1)`.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
jump_length (`int`, *optional*, defaults to 10):
The number of steps taken forward in time before going backward in time for a single jump ("j" in
RePaint paper). Take a look at Figure 9 and 10 in https://arxiv.org/pdf/2201.09865.pdf.
jump_n_sample (`int`, *optional*, defaults to 10):
The number of times we will make forward time jump for a given chosen time sample. Take a look at
Figure 9 and 10 in https://arxiv.org/pdf/2201.09865.pdf.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Examples:
```py
>>> import PIL
>>> import requests
>>> import torch
>>> from io import BytesIO
>>> from diffusers import StableDiffusionPipeline, RePaintScheduler
>>> def download_image(url):
... response = requests.get(url)
... return PIL.Image.open(BytesIO(response.content)).convert("RGB")
>>> base_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/"
>>> img_url = base_url + "overture-creations-5sI6fQgYIuo.png"
>>> mask_url = base_url + "overture-creations-5sI6fQgYIuo_mask.png "
>>> init_image = download_image(img_url).resize((512, 512))
>>> mask_image = download_image(mask_url).resize((512, 512))
>>> pipe = DiffusionPipeline.from_pretrained(
... "CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16, custom_pipeline="stable_diffusion_repaint",
... )
>>> pipe.scheduler = RePaintScheduler.from_config(pipe.scheduler.config)
>>> pipe = pipe.to("cuda")
>>> prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
>>> image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
```
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs
self.check_inputs(
prompt,
height,
width,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
)
if image is None:
raise ValueError("`image` input cannot be undefined.")
if mask_image is None:
raise ValueError("`mask_image` input cannot be undefined.")
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
# 4. Preprocess mask and image
mask, masked_image = prepare_mask_and_masked_image(image, mask_image)
# 5. set timesteps
self.scheduler.set_timesteps(num_inference_steps, jump_length, jump_n_sample, device)
self.scheduler.eta = eta
timesteps = self.scheduler.timesteps
# latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# 6. Prepare latent variables
num_channels_latents = self.vae.config.latent_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 7. Prepare mask latent variables
mask, masked_image_latents = self.prepare_mask_latents(
mask,
masked_image,
batch_size * num_images_per_prompt,
height,
width,
prompt_embeds.dtype,
device,
generator,
do_classifier_free_guidance=False, # We do not need duplicate mask and image
)
# 8. Check that sizes of mask, masked image and latents match
# num_channels_mask = mask.shape[1]
# num_channels_masked_image = masked_image_latents.shape[1]
if num_channels_latents != self.unet.config.in_channels:
raise ValueError(
f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} "
f" = Please verify the config of"
" `pipeline.unet` or your `mask_image` or `image` input."
)
# 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
t_last = timesteps[0] + 1
# 10. Denoising loop
with self.progress_bar(total=len(timesteps)) as progress_bar:
for i, t in enumerate(timesteps):
if t >= t_last:
# compute the reverse: x_t-1 -> x_t
latents = self.scheduler.undo_step(latents, t_last, generator)
progress_bar.update()
t_last = t
continue
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
# concat latents, mask, masked_image_latents in the channel dimension
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=prompt_embeds).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(
noise_pred,
t,
latents,
masked_image_latents,
mask,
**extra_step_kwargs,
).prev_sample
# call the callback, if provided
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
t_last = t
# 11. Post-processing
image = self.decode_latents(latents)
# 12. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
# 13. Convert to PIL
if output_type == "pil":
image = self.numpy_to_pil(image)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/composable_stable_diffusion.py
|
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
from typing import Callable, List, Optional, Union
import torch
from packaging import version
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import DiffusionPipeline
from diffusers.configuration_utils import FrozenDict
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import (
DDIMScheduler,
DPMSolverMultistepScheduler,
EulerAncestralDiscreteScheduler,
EulerDiscreteScheduler,
LMSDiscreteScheduler,
PNDMScheduler,
)
from diffusers.utils import deprecate, is_accelerate_available, logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class ComposableStableDiffusionPipeline(DiffusionPipeline):
r"""
Pipeline for text-to-image generation using Stable Diffusion.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[
DDIMScheduler,
PNDMScheduler,
LMSDiscreteScheduler,
EulerDiscreteScheduler,
EulerAncestralDiscreteScheduler,
DPMSolverMultistepScheduler,
],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
" `clip_sample` should be set to False in the configuration file. Please make sure to update the"
" config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
" future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
" nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
)
deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["clip_sample"] = False
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
version.parse(unet.config._diffusers_version).base_version
) < version.parse("0.9.0.dev0")
is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
deprecation_message = (
"The configuration file of the unet has set the default `sample_size` to smaller than"
" 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
" following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
" CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
" \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
" configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
" in the config might lead to incorrect results in future versions. If you have downloaded this"
" checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
" the `unet/config.json` file"
)
deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(unet.config)
new_config["sample_size"] = 64
unet._internal_dict = FrozenDict(new_config)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.register_to_config(requires_safety_checker=requires_safety_checker)
def enable_vae_slicing(self):
r"""
Enable sliced VAE decoding.
When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
steps. This is useful to save some memory and allow larger batch sizes.
"""
self.vae.enable_slicing()
def disable_vae_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
computing decoding in one step.
"""
self.vae.disable_slicing()
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
`torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
"""
if is_accelerate_available():
from accelerate import cpu_offload
else:
raise ImportError("Please install accelerate via `pip install accelerate`")
device = torch.device(f"cuda:{gpu_id}")
for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
if cpu_offloaded_model is not None:
cpu_offload(cpu_offloaded_model, device)
if self.safety_checker is not None:
# TODO(Patrick) - there is currently a bug with cpu offload of nn.Parameter in accelerate
# fix by only offloading self.safety_checker for now
cpu_offload(self.safety_checker.vision_model, device)
@property
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if self.device != torch.device("meta") or not hasattr(self.unet, "_hf_hook"):
return self.device
for module in self.unet.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
def _encode_prompt(self, prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `list(int)`):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
"""
batch_size = len(prompt) if isinstance(prompt, list) else 1
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
text_embeddings = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
text_embeddings = text_embeddings[0]
# duplicate text embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = text_input_ids.shape[-1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
uncond_embeddings = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
uncond_embeddings = uncond_embeddings[0]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = uncond_embeddings.repeat(1, num_images_per_prompt, 1)
uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
return text_embeddings
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
else:
has_nsfw_concept = None
return image, has_nsfw_concept
def decode_latents(self, latents):
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_inputs(self, prompt, height, width, callback_steps):
if not isinstance(prompt, str) and not isinstance(prompt, list):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if latents is None:
if device.type == "mps":
# randn does not work reproducibly on mps
latents = torch.randn(shape, generator=generator, device="cpu", dtype=dtype).to(device)
else:
latents = torch.randn(shape, generator=generator, device=device, dtype=dtype)
else:
if latents.shape != shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
weights: Optional[str] = "",
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 5.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs. Raise error if not correct
self.check_inputs(prompt, height, width, callback_steps)
# 2. Define call parameters
batch_size = 1 if isinstance(prompt, str) else len(prompt)
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
if "|" in prompt:
prompt = [x.strip() for x in prompt.split("|")]
print(f"composing {prompt}...")
if not weights:
# specify weights for prompts (excluding the unconditional score)
print("using equal positive weights (conjunction) for all prompts...")
weights = torch.tensor([guidance_scale] * len(prompt), device=self.device).reshape(-1, 1, 1, 1)
else:
# set prompt weight for each
num_prompts = len(prompt) if isinstance(prompt, list) else 1
weights = [float(w.strip()) for w in weights.split("|")]
# guidance scale as the default
if len(weights) < num_prompts:
weights.append(guidance_scale)
else:
weights = weights[:num_prompts]
assert len(weights) == len(prompt), "weights specified are not equal to the number of prompts"
weights = torch.tensor(weights, device=self.device).reshape(-1, 1, 1, 1)
else:
weights = guidance_scale
# 3. Encode input prompt
text_embeddings = self._encode_prompt(
prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
)
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 5. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
text_embeddings.dtype,
device,
generator,
latents,
)
# composable diffusion
if isinstance(prompt, list) and batch_size == 1:
# remove extra unconditional embedding
# N = one unconditional embed + conditional embeds
text_embeddings = text_embeddings[len(prompt) - 1 :]
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = []
for j in range(text_embeddings.shape[0]):
noise_pred.append(
self.unet(latent_model_input[:1], t, encoder_hidden_states=text_embeddings[j : j + 1]).sample
)
noise_pred = torch.cat(noise_pred, dim=0)
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred[:1], noise_pred[1:]
noise_pred = noise_pred_uncond + (weights * (noise_pred_text - noise_pred_uncond)).sum(
dim=0, keepdims=True
)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# 8. Post-processing
image = self.decode_latents(latents)
# 9. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, text_embeddings.dtype)
# 10. Convert to PIL
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/pipeline_stable_diffusion_upscale_ldm3d.py
|
# Copyright 2023 The Intel Labs Team Authors and the HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
from typing import Any, Callable, Dict, List, Optional, Union
import numpy as np
import PIL
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import DiffusionPipeline
from diffusers.image_processor import PipelineDepthInput, PipelineImageInput, VaeImageProcessorLDM3D
from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.models.lora import adjust_lora_scale_text_encoder
from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_ldm3d import LDM3DPipelineOutput
from diffusers.schedulers import DDPMScheduler, KarrasDiffusionSchedulers
from diffusers.utils import (
USE_PEFT_BACKEND,
deprecate,
logging,
scale_lora_layers,
unscale_lora_layers,
)
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```python
>>> from diffusers import StableDiffusionUpscaleLDM3DPipeline
>>> from PIL import Image
>>> from io import BytesIO
>>> import requests
>>> pipe = StableDiffusionUpscaleLDM3DPipeline.from_pretrained("Intel/ldm3d-sr")
>>> pipe = pipe.to("cuda")
>>> rgb_path = "https://huggingface.co/Intel/ldm3d-sr/resolve/main/lemons_ldm3d_rgb.jpg"
>>> depth_path = "https://huggingface.co/Intel/ldm3d-sr/resolve/main/lemons_ldm3d_depth.png"
>>> low_res_rgb = Image.open(BytesIO(requests.get(rgb_path).content)).convert("RGB")
>>> low_res_depth = Image.open(BytesIO(requests.get(depth_path).content)).convert("L")
>>> output = pipe(
... prompt="high quality high resolution uhd 4k image",
... rgb=low_res_rgb,
... depth=low_res_depth,
... num_inference_steps=50,
... target_res=[1024, 1024],
... )
>>> rgb_image, depth_image = output.rgb, output.depth
>>> rgb_image[0].save("hr_ldm3d_rgb.jpg")
>>> depth_image[0].save("hr_ldm3d_depth.png")
```
"""
class StableDiffusionUpscaleLDM3DPipeline(
DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin, FromSingleFileMixin
):
r"""
Pipeline for text-to-image and 3D generation using LDM3D.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
The pipeline also inherits the following loading methods:
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
text_encoder ([`~transformers.CLIPTextModel`]):
Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
tokenizer ([`~transformers.CLIPTokenizer`]):
A `CLIPTokenizer` to tokenize text.
unet ([`UNet2DConditionModel`]):
A `UNet2DConditionModel` to denoise the encoded image latents.
low_res_scheduler ([`SchedulerMixin`]):
A scheduler used to add initial noise to the low resolution conditioning image. It must be an instance of
[`DDPMScheduler`].
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for more details
about a model's potential harms.
feature_extractor ([`~transformers.CLIPImageProcessor`]):
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
"""
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
low_res_scheduler: DDPMScheduler,
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
watermarker: Optional[Any] = None,
max_noise_level: int = 350,
):
super().__init__()
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
low_res_scheduler=low_res_scheduler,
scheduler=scheduler,
safety_checker=safety_checker,
watermarker=watermarker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessorLDM3D(vae_scale_factor=self.vae_scale_factor, resample="bilinear")
# self.register_to_config(requires_safety_checker=requires_safety_checker)
self.register_to_config(max_noise_level=max_noise_level)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_ldm3d.StableDiffusionLDM3DPipeline._encode_prompt
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
**kwargs,
):
deprecation_message = "`_encode_prompt()` is deprecated and it will be removed in a future version. Use `encode_prompt()` instead. Also, be aware that the output format changed from a concatenated tensor to a tuple."
deprecate("_encode_prompt()", "1.0.0", deprecation_message, standard_warn=False)
prompt_embeds_tuple = self.encode_prompt(
prompt=prompt,
device=device,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=do_classifier_free_guidance,
negative_prompt=negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=lora_scale,
**kwargs,
)
# concatenate for backwards comp
prompt_embeds = torch.cat([prompt_embeds_tuple[1], prompt_embeds_tuple[0]])
return prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_ldm3d.StableDiffusionLDM3DPipeline.encode_prompt
def encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
clip_skip: Optional[int] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
lora_scale (`float`, *optional*):
A LoRA scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
"""
# set lora scale so that monkey patched LoRA
# function of text encoder can correctly access it
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
self._lora_scale = lora_scale
# dynamically adjust the LoRA scale
if not USE_PEFT_BACKEND:
adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
else:
scale_lora_layers(self.text_encoder, lora_scale)
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# textual inversion: procecss multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
if clip_skip is None:
prompt_embeds = self.text_encoder(text_input_ids.to(device), attention_mask=attention_mask)
prompt_embeds = prompt_embeds[0]
else:
prompt_embeds = self.text_encoder(
text_input_ids.to(device), attention_mask=attention_mask, output_hidden_states=True
)
# Access the `hidden_states` first, that contains a tuple of
# all the hidden states from the encoder layers. Then index into
# the tuple to access the hidden states from the desired layer.
prompt_embeds = prompt_embeds[-1][-(clip_skip + 1)]
# We also need to apply the final LayerNorm here to not mess with the
# representations. The `last_hidden_states` that we typically use for
# obtaining the final prompt representations passes through the LayerNorm
# layer.
prompt_embeds = self.text_encoder.text_model.final_layer_norm(prompt_embeds)
if self.text_encoder is not None:
prompt_embeds_dtype = self.text_encoder.dtype
elif self.unet is not None:
prompt_embeds_dtype = self.unet.dtype
else:
prompt_embeds_dtype = prompt_embeds.dtype
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif prompt is not None and type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
# textual inversion: procecss multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
if isinstance(self, LoraLoaderMixin) and USE_PEFT_BACKEND:
# Retrieve the original scale by scaling back the LoRA layers
unscale_lora_layers(self.text_encoder, lora_scale)
return prompt_embeds, negative_prompt_embeds
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is None:
has_nsfw_concept = None
else:
if torch.is_tensor(image):
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
else:
feature_extractor_input = self.image_processor.numpy_to_pil(image)
rgb_feature_extractor_input = feature_extractor_input[0]
safety_checker_input = self.feature_extractor(rgb_feature_extractor_input, return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
return image, has_nsfw_concept
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_inputs(
self,
prompt,
image,
noise_level,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
target_res=None,
):
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
if (
not isinstance(image, torch.Tensor)
and not isinstance(image, PIL.Image.Image)
and not isinstance(image, np.ndarray)
and not isinstance(image, list)
):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `np.ndarray`, `PIL.Image.Image` or `list` but is {type(image)}"
)
# verify batch size of prompt and image are same if image is a list or tensor or numpy array
if isinstance(image, list) or isinstance(image, torch.Tensor) or isinstance(image, np.ndarray):
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if isinstance(image, list):
image_batch_size = len(image)
else:
image_batch_size = image.shape[0]
if batch_size != image_batch_size:
raise ValueError(
f"`prompt` has batch size {batch_size} and `image` has batch size {image_batch_size}."
" Please make sure that passed `prompt` matches the batch size of `image`."
)
# check noise level
if noise_level > self.config.max_noise_level:
raise ValueError(f"`noise_level` has to be <= {self.config.max_noise_level} but is {noise_level}")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels_latents, height, width)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
if latents.shape != shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
# def upcast_vae(self):
# dtype = self.vae.dtype
# self.vae.to(dtype=torch.float32)
# use_torch_2_0_or_xformers = isinstance(
# self.vae.decoder.mid_block.attentions[0].processor,
# (
# AttnProcessor2_0,
# XFormersAttnProcessor,
# LoRAXFormersAttnProcessor,
# LoRAAttnProcessor2_0,
# ),
# )
# # if xformers or torch_2_0 is used attention block does not need
# # to be in float32 which can save lots of memory
# if use_torch_2_0_or_xformers:
# self.vae.post_quant_conv.to(dtype)
# self.vae.decoder.conv_in.to(dtype)
# self.vae.decoder.mid_block.to(dtype)
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
rgb: PipelineImageInput = None,
depth: PipelineDepthInput = None,
num_inference_steps: int = 75,
guidance_scale: float = 9.0,
noise_level: int = 20,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
target_res: Optional[List[int]] = [1024, 1024],
):
r"""
The call function to the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, or `List[np.ndarray]`):
`Image` or tensor representing an image batch to be upscaled.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 5.0):
A higher guidance scale value encourages the model to generate images closely linked to the text
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor is generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
provided, text embeddings are generated from the `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that calls every `callback_steps` steps during inference. The function is called with the
following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function is called. If not specified, the callback is called at
every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
otherwise a `tuple` is returned where the first element is a list with the generated images and the
second element is a list of `bool`s indicating whether the corresponding generated image contains
"not-safe-for-work" (nsfw) content.
"""
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
rgb,
noise_level,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
if do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
# 4. Preprocess image
rgb, depth = self.image_processor.preprocess(rgb, depth, target_res=target_res)
rgb = rgb.to(dtype=prompt_embeds.dtype, device=device)
depth = depth.to(dtype=prompt_embeds.dtype, device=device)
# 5. set timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 6. Encode low resolutiom image to latent space
image = torch.cat([rgb, depth], axis=1)
latent_space_image = self.vae.encode(image).latent_dist.sample(generator)
latent_space_image *= self.vae.scaling_factor
noise_level = torch.tensor([noise_level], dtype=torch.long, device=device)
# noise_rgb = randn_tensor(rgb.shape, generator=generator, device=device, dtype=prompt_embeds.dtype)
# rgb = self.low_res_scheduler.add_noise(rgb, noise_rgb, noise_level)
# noise_depth = randn_tensor(depth.shape, generator=generator, device=device, dtype=prompt_embeds.dtype)
# depth = self.low_res_scheduler.add_noise(depth, noise_depth, noise_level)
batch_multiplier = 2 if do_classifier_free_guidance else 1
latent_space_image = torch.cat([latent_space_image] * batch_multiplier * num_images_per_prompt)
noise_level = torch.cat([noise_level] * latent_space_image.shape[0])
# 7. Prepare latent variables
height, width = latent_space_image.shape[2:]
num_channels_latents = self.vae.config.latent_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 8. Check that sizes of image and latents match
num_channels_image = latent_space_image.shape[1]
if num_channels_latents + num_channels_image != self.unet.config.in_channels:
raise ValueError(
f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
f" `num_channels_image`: {num_channels_image} "
f" = {num_channels_latents+num_channels_image}. Please verify the config of"
" `pipeline.unet` or your `image` input."
)
# 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 10. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
# concat latents, mask, masked_image_latents in the channel dimension
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
latent_model_input = torch.cat([latent_model_input, latent_space_image], dim=1)
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
class_labels=noise_level,
return_dict=False,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
callback(i, t, latents)
if not output_type == "latent":
# make sure the VAE is in float32 mode, as it overflows in float16
needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
if needs_upcasting:
self.upcast_vae()
latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
image = self.vae.decode(latents / self.vae.scaling_factor, return_dict=False)[0]
# cast back to fp16 if needed
if needs_upcasting:
self.vae.to(dtype=torch.float16)
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
rgb, depth = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
# 11. Apply watermark
if output_type == "pil" and self.watermarker is not None:
rgb = self.watermarker.apply_watermark(rgb)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return ((rgb, depth), has_nsfw_concept)
return LDM3DPipelineOutput(rgb=rgb, depth=depth, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/lpw_stable_diffusion_onnx.py
|
import inspect
import re
from typing import Callable, List, Optional, Union
import numpy as np
import PIL.Image
import torch
from packaging import version
from transformers import CLIPImageProcessor, CLIPTokenizer
import diffusers
from diffusers import OnnxRuntimeModel, OnnxStableDiffusionPipeline, SchedulerMixin
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.utils import logging
try:
from diffusers.pipelines.onnx_utils import ORT_TO_NP_TYPE
except ImportError:
ORT_TO_NP_TYPE = {
"tensor(bool)": np.bool_,
"tensor(int8)": np.int8,
"tensor(uint8)": np.uint8,
"tensor(int16)": np.int16,
"tensor(uint16)": np.uint16,
"tensor(int32)": np.int32,
"tensor(uint32)": np.uint32,
"tensor(int64)": np.int64,
"tensor(uint64)": np.uint64,
"tensor(float16)": np.float16,
"tensor(float)": np.float32,
"tensor(double)": np.float64,
}
try:
from diffusers.utils import PIL_INTERPOLATION
except ImportError:
if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
PIL_INTERPOLATION = {
"linear": PIL.Image.Resampling.BILINEAR,
"bilinear": PIL.Image.Resampling.BILINEAR,
"bicubic": PIL.Image.Resampling.BICUBIC,
"lanczos": PIL.Image.Resampling.LANCZOS,
"nearest": PIL.Image.Resampling.NEAREST,
}
else:
PIL_INTERPOLATION = {
"linear": PIL.Image.LINEAR,
"bilinear": PIL.Image.BILINEAR,
"bicubic": PIL.Image.BICUBIC,
"lanczos": PIL.Image.LANCZOS,
"nearest": PIL.Image.NEAREST,
}
# ------------------------------------------------------------------------------
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
re_attention = re.compile(
r"""
\\\(|
\\\)|
\\\[|
\\]|
\\\\|
\\|
\(|
\[|
:([+-]?[.\d]+)\)|
\)|
]|
[^\\()\[\]:]+|
:
""",
re.X,
)
def parse_prompt_attention(text):
"""
Parses a string with attention tokens and returns a list of pairs: text and its associated weight.
Accepted tokens are:
(abc) - increases attention to abc by a multiplier of 1.1
(abc:3.12) - increases attention to abc by a multiplier of 3.12
[abc] - decreases attention to abc by a multiplier of 1.1
\\( - literal character '('
\\[ - literal character '['
\\) - literal character ')'
\\] - literal character ']'
\\ - literal character '\'
anything else - just text
>>> parse_prompt_attention('normal text')
[['normal text', 1.0]]
>>> parse_prompt_attention('an (important) word')
[['an ', 1.0], ['important', 1.1], [' word', 1.0]]
>>> parse_prompt_attention('(unbalanced')
[['unbalanced', 1.1]]
>>> parse_prompt_attention('\\(literal\\]')
[['(literal]', 1.0]]
>>> parse_prompt_attention('(unnecessary)(parens)')
[['unnecessaryparens', 1.1]]
>>> parse_prompt_attention('a (((house:1.3)) [on] a (hill:0.5), sun, (((sky))).')
[['a ', 1.0],
['house', 1.5730000000000004],
[' ', 1.1],
['on', 1.0],
[' a ', 1.1],
['hill', 0.55],
[', sun, ', 1.1],
['sky', 1.4641000000000006],
['.', 1.1]]
"""
res = []
round_brackets = []
square_brackets = []
round_bracket_multiplier = 1.1
square_bracket_multiplier = 1 / 1.1
def multiply_range(start_position, multiplier):
for p in range(start_position, len(res)):
res[p][1] *= multiplier
for m in re_attention.finditer(text):
text = m.group(0)
weight = m.group(1)
if text.startswith("\\"):
res.append([text[1:], 1.0])
elif text == "(":
round_brackets.append(len(res))
elif text == "[":
square_brackets.append(len(res))
elif weight is not None and len(round_brackets) > 0:
multiply_range(round_brackets.pop(), float(weight))
elif text == ")" and len(round_brackets) > 0:
multiply_range(round_brackets.pop(), round_bracket_multiplier)
elif text == "]" and len(square_brackets) > 0:
multiply_range(square_brackets.pop(), square_bracket_multiplier)
else:
res.append([text, 1.0])
for pos in round_brackets:
multiply_range(pos, round_bracket_multiplier)
for pos in square_brackets:
multiply_range(pos, square_bracket_multiplier)
if len(res) == 0:
res = [["", 1.0]]
# merge runs of identical weights
i = 0
while i + 1 < len(res):
if res[i][1] == res[i + 1][1]:
res[i][0] += res[i + 1][0]
res.pop(i + 1)
else:
i += 1
return res
def get_prompts_with_weights(pipe, prompt: List[str], max_length: int):
r"""
Tokenize a list of prompts and return its tokens with weights of each token.
No padding, starting or ending token is included.
"""
tokens = []
weights = []
truncated = False
for text in prompt:
texts_and_weights = parse_prompt_attention(text)
text_token = []
text_weight = []
for word, weight in texts_and_weights:
# tokenize and discard the starting and the ending token
token = pipe.tokenizer(word, return_tensors="np").input_ids[0, 1:-1]
text_token += list(token)
# copy the weight by length of token
text_weight += [weight] * len(token)
# stop if the text is too long (longer than truncation limit)
if len(text_token) > max_length:
truncated = True
break
# truncate
if len(text_token) > max_length:
truncated = True
text_token = text_token[:max_length]
text_weight = text_weight[:max_length]
tokens.append(text_token)
weights.append(text_weight)
if truncated:
logger.warning("Prompt was truncated. Try to shorten the prompt or increase max_embeddings_multiples")
return tokens, weights
def pad_tokens_and_weights(tokens, weights, max_length, bos, eos, pad, no_boseos_middle=True, chunk_length=77):
r"""
Pad the tokens (with starting and ending tokens) and weights (with 1.0) to max_length.
"""
max_embeddings_multiples = (max_length - 2) // (chunk_length - 2)
weights_length = max_length if no_boseos_middle else max_embeddings_multiples * chunk_length
for i in range(len(tokens)):
tokens[i] = [bos] + tokens[i] + [pad] * (max_length - 1 - len(tokens[i]) - 1) + [eos]
if no_boseos_middle:
weights[i] = [1.0] + weights[i] + [1.0] * (max_length - 1 - len(weights[i]))
else:
w = []
if len(weights[i]) == 0:
w = [1.0] * weights_length
else:
for j in range(max_embeddings_multiples):
w.append(1.0) # weight for starting token in this chunk
w += weights[i][j * (chunk_length - 2) : min(len(weights[i]), (j + 1) * (chunk_length - 2))]
w.append(1.0) # weight for ending token in this chunk
w += [1.0] * (weights_length - len(w))
weights[i] = w[:]
return tokens, weights
def get_unweighted_text_embeddings(
pipe,
text_input: np.array,
chunk_length: int,
no_boseos_middle: Optional[bool] = True,
):
"""
When the length of tokens is a multiple of the capacity of the text encoder,
it should be split into chunks and sent to the text encoder individually.
"""
max_embeddings_multiples = (text_input.shape[1] - 2) // (chunk_length - 2)
if max_embeddings_multiples > 1:
text_embeddings = []
for i in range(max_embeddings_multiples):
# extract the i-th chunk
text_input_chunk = text_input[:, i * (chunk_length - 2) : (i + 1) * (chunk_length - 2) + 2].copy()
# cover the head and the tail by the starting and the ending tokens
text_input_chunk[:, 0] = text_input[0, 0]
text_input_chunk[:, -1] = text_input[0, -1]
text_embedding = pipe.text_encoder(input_ids=text_input_chunk)[0]
if no_boseos_middle:
if i == 0:
# discard the ending token
text_embedding = text_embedding[:, :-1]
elif i == max_embeddings_multiples - 1:
# discard the starting token
text_embedding = text_embedding[:, 1:]
else:
# discard both starting and ending tokens
text_embedding = text_embedding[:, 1:-1]
text_embeddings.append(text_embedding)
text_embeddings = np.concatenate(text_embeddings, axis=1)
else:
text_embeddings = pipe.text_encoder(input_ids=text_input)[0]
return text_embeddings
def get_weighted_text_embeddings(
pipe,
prompt: Union[str, List[str]],
uncond_prompt: Optional[Union[str, List[str]]] = None,
max_embeddings_multiples: Optional[int] = 4,
no_boseos_middle: Optional[bool] = False,
skip_parsing: Optional[bool] = False,
skip_weighting: Optional[bool] = False,
**kwargs,
):
r"""
Prompts can be assigned with local weights using brackets. For example,
prompt 'A (very beautiful) masterpiece' highlights the words 'very beautiful',
and the embedding tokens corresponding to the words get multiplied by a constant, 1.1.
Also, to regularize of the embedding, the weighted embedding would be scaled to preserve the original mean.
Args:
pipe (`OnnxStableDiffusionPipeline`):
Pipe to provide access to the tokenizer and the text encoder.
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
uncond_prompt (`str` or `List[str]`):
The unconditional prompt or prompts for guide the image generation. If unconditional prompt
is provided, the embeddings of prompt and uncond_prompt are concatenated.
max_embeddings_multiples (`int`, *optional*, defaults to `1`):
The max multiple length of prompt embeddings compared to the max output length of text encoder.
no_boseos_middle (`bool`, *optional*, defaults to `False`):
If the length of text token is multiples of the capacity of text encoder, whether reserve the starting and
ending token in each of the chunk in the middle.
skip_parsing (`bool`, *optional*, defaults to `False`):
Skip the parsing of brackets.
skip_weighting (`bool`, *optional*, defaults to `False`):
Skip the weighting. When the parsing is skipped, it is forced True.
"""
max_length = (pipe.tokenizer.model_max_length - 2) * max_embeddings_multiples + 2
if isinstance(prompt, str):
prompt = [prompt]
if not skip_parsing:
prompt_tokens, prompt_weights = get_prompts_with_weights(pipe, prompt, max_length - 2)
if uncond_prompt is not None:
if isinstance(uncond_prompt, str):
uncond_prompt = [uncond_prompt]
uncond_tokens, uncond_weights = get_prompts_with_weights(pipe, uncond_prompt, max_length - 2)
else:
prompt_tokens = [
token[1:-1]
for token in pipe.tokenizer(prompt, max_length=max_length, truncation=True, return_tensors="np").input_ids
]
prompt_weights = [[1.0] * len(token) for token in prompt_tokens]
if uncond_prompt is not None:
if isinstance(uncond_prompt, str):
uncond_prompt = [uncond_prompt]
uncond_tokens = [
token[1:-1]
for token in pipe.tokenizer(
uncond_prompt,
max_length=max_length,
truncation=True,
return_tensors="np",
).input_ids
]
uncond_weights = [[1.0] * len(token) for token in uncond_tokens]
# round up the longest length of tokens to a multiple of (model_max_length - 2)
max_length = max([len(token) for token in prompt_tokens])
if uncond_prompt is not None:
max_length = max(max_length, max([len(token) for token in uncond_tokens]))
max_embeddings_multiples = min(
max_embeddings_multiples,
(max_length - 1) // (pipe.tokenizer.model_max_length - 2) + 1,
)
max_embeddings_multiples = max(1, max_embeddings_multiples)
max_length = (pipe.tokenizer.model_max_length - 2) * max_embeddings_multiples + 2
# pad the length of tokens and weights
bos = pipe.tokenizer.bos_token_id
eos = pipe.tokenizer.eos_token_id
pad = getattr(pipe.tokenizer, "pad_token_id", eos)
prompt_tokens, prompt_weights = pad_tokens_and_weights(
prompt_tokens,
prompt_weights,
max_length,
bos,
eos,
pad,
no_boseos_middle=no_boseos_middle,
chunk_length=pipe.tokenizer.model_max_length,
)
prompt_tokens = np.array(prompt_tokens, dtype=np.int32)
if uncond_prompt is not None:
uncond_tokens, uncond_weights = pad_tokens_and_weights(
uncond_tokens,
uncond_weights,
max_length,
bos,
eos,
pad,
no_boseos_middle=no_boseos_middle,
chunk_length=pipe.tokenizer.model_max_length,
)
uncond_tokens = np.array(uncond_tokens, dtype=np.int32)
# get the embeddings
text_embeddings = get_unweighted_text_embeddings(
pipe,
prompt_tokens,
pipe.tokenizer.model_max_length,
no_boseos_middle=no_boseos_middle,
)
prompt_weights = np.array(prompt_weights, dtype=text_embeddings.dtype)
if uncond_prompt is not None:
uncond_embeddings = get_unweighted_text_embeddings(
pipe,
uncond_tokens,
pipe.tokenizer.model_max_length,
no_boseos_middle=no_boseos_middle,
)
uncond_weights = np.array(uncond_weights, dtype=uncond_embeddings.dtype)
# assign weights to the prompts and normalize in the sense of mean
# TODO: should we normalize by chunk or in a whole (current implementation)?
if (not skip_parsing) and (not skip_weighting):
previous_mean = text_embeddings.mean(axis=(-2, -1))
text_embeddings *= prompt_weights[:, :, None]
text_embeddings *= (previous_mean / text_embeddings.mean(axis=(-2, -1)))[:, None, None]
if uncond_prompt is not None:
previous_mean = uncond_embeddings.mean(axis=(-2, -1))
uncond_embeddings *= uncond_weights[:, :, None]
uncond_embeddings *= (previous_mean / uncond_embeddings.mean(axis=(-2, -1)))[:, None, None]
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
if uncond_prompt is not None:
return text_embeddings, uncond_embeddings
return text_embeddings
def preprocess_image(image):
w, h = image.size
w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
image = np.array(image).astype(np.float32) / 255.0
image = image[None].transpose(0, 3, 1, 2)
return 2.0 * image - 1.0
def preprocess_mask(mask, scale_factor=8):
mask = mask.convert("L")
w, h = mask.size
w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
mask = mask.resize((w // scale_factor, h // scale_factor), resample=PIL_INTERPOLATION["nearest"])
mask = np.array(mask).astype(np.float32) / 255.0
mask = np.tile(mask, (4, 1, 1))
mask = mask[None].transpose(0, 1, 2, 3) # what does this step do?
mask = 1 - mask # repaint white, keep black
return mask
class OnnxStableDiffusionLongPromptWeightingPipeline(OnnxStableDiffusionPipeline):
r"""
Pipeline for text-to-image generation using Stable Diffusion without tokens length limit, and support parsing
weighting in prompt.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
"""
if version.parse(version.parse(diffusers.__version__).base_version) >= version.parse("0.9.0"):
def __init__(
self,
vae_encoder: OnnxRuntimeModel,
vae_decoder: OnnxRuntimeModel,
text_encoder: OnnxRuntimeModel,
tokenizer: CLIPTokenizer,
unet: OnnxRuntimeModel,
scheduler: SchedulerMixin,
safety_checker: OnnxRuntimeModel,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__(
vae_encoder=vae_encoder,
vae_decoder=vae_decoder,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
requires_safety_checker=requires_safety_checker,
)
self.__init__additional__()
else:
def __init__(
self,
vae_encoder: OnnxRuntimeModel,
vae_decoder: OnnxRuntimeModel,
text_encoder: OnnxRuntimeModel,
tokenizer: CLIPTokenizer,
unet: OnnxRuntimeModel,
scheduler: SchedulerMixin,
safety_checker: OnnxRuntimeModel,
feature_extractor: CLIPImageProcessor,
):
super().__init__(
vae_encoder=vae_encoder,
vae_decoder=vae_decoder,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.__init__additional__()
def __init__additional__(self):
self.unet.config.in_channels = 4
self.vae_scale_factor = 8
def _encode_prompt(
self,
prompt,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
max_embeddings_multiples,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `list(int)`):
prompt to be encoded
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
max_embeddings_multiples (`int`, *optional*, defaults to `3`):
The max multiple length of prompt embeddings compared to the max output length of text encoder.
"""
batch_size = len(prompt) if isinstance(prompt, list) else 1
if negative_prompt is None:
negative_prompt = [""] * batch_size
elif isinstance(negative_prompt, str):
negative_prompt = [negative_prompt] * batch_size
if batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
text_embeddings, uncond_embeddings = get_weighted_text_embeddings(
pipe=self,
prompt=prompt,
uncond_prompt=negative_prompt if do_classifier_free_guidance else None,
max_embeddings_multiples=max_embeddings_multiples,
)
text_embeddings = text_embeddings.repeat(num_images_per_prompt, 0)
if do_classifier_free_guidance:
uncond_embeddings = uncond_embeddings.repeat(num_images_per_prompt, 0)
text_embeddings = np.concatenate([uncond_embeddings, text_embeddings])
return text_embeddings
def check_inputs(self, prompt, height, width, strength, callback_steps):
if not isinstance(prompt, str) and not isinstance(prompt, list):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if strength < 0 or strength > 1:
raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
def get_timesteps(self, num_inference_steps, strength, is_text2img):
if is_text2img:
return self.scheduler.timesteps, num_inference_steps
else:
# get the original timestep using init_timestep
offset = self.scheduler.config.get("steps_offset", 0)
init_timestep = int(num_inference_steps * strength) + offset
init_timestep = min(init_timestep, num_inference_steps)
t_start = max(num_inference_steps - init_timestep + offset, 0)
timesteps = self.scheduler.timesteps[t_start:]
return timesteps, num_inference_steps - t_start
def run_safety_checker(self, image):
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(
self.numpy_to_pil(image), return_tensors="np"
).pixel_values.astype(image.dtype)
# There will throw an error if use safety_checker directly and batchsize>1
images, has_nsfw_concept = [], []
for i in range(image.shape[0]):
image_i, has_nsfw_concept_i = self.safety_checker(
clip_input=safety_checker_input[i : i + 1], images=image[i : i + 1]
)
images.append(image_i)
has_nsfw_concept.append(has_nsfw_concept_i[0])
image = np.concatenate(images)
else:
has_nsfw_concept = None
return image, has_nsfw_concept
def decode_latents(self, latents):
latents = 1 / 0.18215 * latents
# image = self.vae_decoder(latent_sample=latents)[0]
# it seems likes there is a strange result for using half-precision vae decoder if batchsize>1
image = np.concatenate(
[self.vae_decoder(latent_sample=latents[i : i + 1])[0] for i in range(latents.shape[0])]
)
image = np.clip(image / 2 + 0.5, 0, 1)
image = image.transpose((0, 2, 3, 1))
return image
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def prepare_latents(self, image, timestep, batch_size, height, width, dtype, generator, latents=None):
if image is None:
shape = (
batch_size,
self.unet.config.in_channels,
height // self.vae_scale_factor,
width // self.vae_scale_factor,
)
if latents is None:
latents = torch.randn(shape, generator=generator, device="cpu").numpy().astype(dtype)
else:
if latents.shape != shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
# scale the initial noise by the standard deviation required by the scheduler
latents = (torch.from_numpy(latents) * self.scheduler.init_noise_sigma).numpy()
return latents, None, None
else:
init_latents = self.vae_encoder(sample=image)[0]
init_latents = 0.18215 * init_latents
init_latents = np.concatenate([init_latents] * batch_size, axis=0)
init_latents_orig = init_latents
shape = init_latents.shape
# add noise to latents using the timesteps
noise = torch.randn(shape, generator=generator, device="cpu").numpy().astype(dtype)
latents = self.scheduler.add_noise(
torch.from_numpy(init_latents), torch.from_numpy(noise), timestep
).numpy()
return latents, init_latents_orig, noise
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
negative_prompt: Optional[Union[str, List[str]]] = None,
image: Union[np.ndarray, PIL.Image.Image] = None,
mask_image: Union[np.ndarray, PIL.Image.Image] = None,
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
strength: float = 0.8,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[np.ndarray] = None,
max_embeddings_multiples: Optional[int] = 3,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, np.ndarray], None]] = None,
is_cancelled_callback: Optional[Callable[[], bool]] = None,
callback_steps: int = 1,
**kwargs,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
image (`np.ndarray` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, that will be used as the starting point for the
process.
mask_image (`np.ndarray` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
PIL image, it will be converted to a single channel (luminance) before use. If it's a tensor, it should
contain one color channel (L) instead of 3, so the expected shape would be `(B, H, W, 1)`.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
strength (`float`, *optional*, defaults to 0.8):
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1.
`image` will be used as a starting point, adding more noise to it the larger the `strength`. The
number of denoising steps depends on the amount of noise initially added. When `strength` is 1, added
noise will be maximum and the denoising process will run for the full number of iterations specified in
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`np.ndarray`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
max_embeddings_multiples (`int`, *optional*, defaults to `3`):
The max multiple length of prompt embeddings compared to the max output length of text encoder.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: np.ndarray)`.
is_cancelled_callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. If the function returns
`True`, the inference will be cancelled.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
`None` if cancelled by `is_cancelled_callback`,
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs. Raise error if not correct
self.check_inputs(prompt, height, width, strength, callback_steps)
# 2. Define call parameters
batch_size = 1 if isinstance(prompt, str) else len(prompt)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
text_embeddings = self._encode_prompt(
prompt,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
max_embeddings_multiples,
)
dtype = text_embeddings.dtype
# 4. Preprocess image and mask
if isinstance(image, PIL.Image.Image):
image = preprocess_image(image)
if image is not None:
image = image.astype(dtype)
if isinstance(mask_image, PIL.Image.Image):
mask_image = preprocess_mask(mask_image, self.vae_scale_factor)
if mask_image is not None:
mask = mask_image.astype(dtype)
mask = np.concatenate([mask] * batch_size * num_images_per_prompt)
else:
mask = None
# 5. set timesteps
self.scheduler.set_timesteps(num_inference_steps)
timestep_dtype = next(
(input.type for input in self.unet.model.get_inputs() if input.name == "timestep"), "tensor(float)"
)
timestep_dtype = ORT_TO_NP_TYPE[timestep_dtype]
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, image is None)
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# 6. Prepare latent variables
latents, init_latents_orig, noise = self.prepare_latents(
image,
latent_timestep,
batch_size * num_images_per_prompt,
height,
width,
dtype,
generator,
latents,
)
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 8. Denoising loop
for i, t in enumerate(self.progress_bar(timesteps)):
# expand the latents if we are doing classifier free guidance
latent_model_input = np.concatenate([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(torch.from_numpy(latent_model_input), t)
latent_model_input = latent_model_input.numpy()
# predict the noise residual
noise_pred = self.unet(
sample=latent_model_input,
timestep=np.array([t], dtype=timestep_dtype),
encoder_hidden_states=text_embeddings,
)
noise_pred = noise_pred[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = np.split(noise_pred, 2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
scheduler_output = self.scheduler.step(
torch.from_numpy(noise_pred), t, torch.from_numpy(latents), **extra_step_kwargs
)
latents = scheduler_output.prev_sample.numpy()
if mask is not None:
# masking
init_latents_proper = self.scheduler.add_noise(
torch.from_numpy(init_latents_orig),
torch.from_numpy(noise),
t,
).numpy()
latents = (init_latents_proper * mask) + (latents * (1 - mask))
# call the callback, if provided
if i % callback_steps == 0:
if callback is not None:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if is_cancelled_callback is not None and is_cancelled_callback():
return None
# 9. Post-processing
image = self.decode_latents(latents)
# 10. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image)
# 11. Convert to PIL
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return image, has_nsfw_concept
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
def text2img(
self,
prompt: Union[str, List[str]],
negative_prompt: Optional[Union[str, List[str]]] = None,
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[np.ndarray] = None,
max_embeddings_multiples: Optional[int] = 3,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, np.ndarray], None]] = None,
callback_steps: int = 1,
**kwargs,
):
r"""
Function for text-to-image generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`np.ndarray`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
max_embeddings_multiples (`int`, *optional*, defaults to `3`):
The max multiple length of prompt embeddings compared to the max output length of text encoder.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: np.ndarray)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
return self.__call__(
prompt=prompt,
negative_prompt=negative_prompt,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
latents=latents,
max_embeddings_multiples=max_embeddings_multiples,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
**kwargs,
)
def img2img(
self,
image: Union[np.ndarray, PIL.Image.Image],
prompt: Union[str, List[str]],
negative_prompt: Optional[Union[str, List[str]]] = None,
strength: float = 0.8,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
num_images_per_prompt: Optional[int] = 1,
eta: Optional[float] = 0.0,
generator: Optional[torch.Generator] = None,
max_embeddings_multiples: Optional[int] = 3,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, np.ndarray], None]] = None,
callback_steps: int = 1,
**kwargs,
):
r"""
Function for image-to-image generation.
Args:
image (`np.ndarray` or `PIL.Image.Image`):
`Image`, or ndarray representing an image batch, that will be used as the starting point for the
process.
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
strength (`float`, *optional*, defaults to 0.8):
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1.
`image` will be used as a starting point, adding more noise to it the larger the `strength`. The
number of denoising steps depends on the amount of noise initially added. When `strength` is 1, added
noise will be maximum and the denoising process will run for the full number of iterations specified in
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. This parameter will be modulated by `strength`.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
max_embeddings_multiples (`int`, *optional*, defaults to `3`):
The max multiple length of prompt embeddings compared to the max output length of text encoder.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: np.ndarray)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
return self.__call__(
prompt=prompt,
negative_prompt=negative_prompt,
image=image,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
strength=strength,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
max_embeddings_multiples=max_embeddings_multiples,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
**kwargs,
)
def inpaint(
self,
image: Union[np.ndarray, PIL.Image.Image],
mask_image: Union[np.ndarray, PIL.Image.Image],
prompt: Union[str, List[str]],
negative_prompt: Optional[Union[str, List[str]]] = None,
strength: float = 0.8,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
num_images_per_prompt: Optional[int] = 1,
eta: Optional[float] = 0.0,
generator: Optional[torch.Generator] = None,
max_embeddings_multiples: Optional[int] = 3,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, np.ndarray], None]] = None,
callback_steps: int = 1,
**kwargs,
):
r"""
Function for inpaint.
Args:
image (`np.ndarray` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, that will be used as the starting point for the
process. This is the image whose masked region will be inpainted.
mask_image (`np.ndarray` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
PIL image, it will be converted to a single channel (luminance) before use. If it's a tensor, it should
contain one color channel (L) instead of 3, so the expected shape would be `(B, H, W, 1)`.
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
strength (`float`, *optional*, defaults to 0.8):
Conceptually, indicates how much to inpaint the masked area. Must be between 0 and 1. When `strength`
is 1, the denoising process will be run on the masked area for the full number of iterations specified
in `num_inference_steps`. `image` will be used as a reference for the masked area, adding more
noise to that region the larger the `strength`. If `strength` is 0, no inpainting will occur.
num_inference_steps (`int`, *optional*, defaults to 50):
The reference number of denoising steps. More denoising steps usually lead to a higher quality image at
the expense of slower inference. This parameter will be modulated by `strength`, as explained above.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
max_embeddings_multiples (`int`, *optional*, defaults to `3`):
The max multiple length of prompt embeddings compared to the max output length of text encoder.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: np.ndarray)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
return self.__call__(
prompt=prompt,
negative_prompt=negative_prompt,
image=image,
mask_image=mask_image,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
strength=strength,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
max_embeddings_multiples=max_embeddings_multiples,
output_type=output_type,
return_dict=return_dict,
callback=callback,
callback_steps=callback_steps,
**kwargs,
)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/clip_guided_stable_diffusion_img2img.py
|
import inspect
from typing import List, Optional, Union
import numpy as np
import PIL.Image
import torch
from torch import nn
from torch.nn import functional as F
from torchvision import transforms
from transformers import CLIPFeatureExtractor, CLIPModel, CLIPTextModel, CLIPTokenizer
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DiffusionPipeline,
DPMSolverMultistepScheduler,
LMSDiscreteScheduler,
PNDMScheduler,
UNet2DConditionModel,
)
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion import StableDiffusionPipelineOutput
from diffusers.utils import PIL_INTERPOLATION, deprecate
from diffusers.utils.torch_utils import randn_tensor
EXAMPLE_DOC_STRING = """
Examples:
```
from io import BytesIO
import requests
import torch
from diffusers import DiffusionPipeline
from PIL import Image
from transformers import CLIPFeatureExtractor, CLIPModel
feature_extractor = CLIPFeatureExtractor.from_pretrained(
"laion/CLIP-ViT-B-32-laion2B-s34B-b79K"
)
clip_model = CLIPModel.from_pretrained(
"laion/CLIP-ViT-B-32-laion2B-s34B-b79K", torch_dtype=torch.float16
)
guided_pipeline = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
# custom_pipeline="clip_guided_stable_diffusion",
custom_pipeline="/home/njindal/diffusers/examples/community/clip_guided_stable_diffusion.py",
clip_model=clip_model,
feature_extractor=feature_extractor,
torch_dtype=torch.float16,
)
guided_pipeline.enable_attention_slicing()
guided_pipeline = guided_pipeline.to("cuda")
prompt = "fantasy book cover, full moon, fantasy forest landscape, golden vector elements, fantasy magic, dark light night, intricate, elegant, sharp focus, illustration, highly detailed, digital painting, concept art, matte, art by WLOP and Artgerm and Albert Bierstadt, masterpiece"
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
response = requests.get(url)
init_image = Image.open(BytesIO(response.content)).convert("RGB")
image = guided_pipeline(
prompt=prompt,
num_inference_steps=30,
image=init_image,
strength=0.75,
guidance_scale=7.5,
clip_guidance_scale=100,
num_cutouts=4,
use_cutouts=False,
).images[0]
display(image)
```
"""
def preprocess(image, w, h):
if isinstance(image, torch.Tensor):
return image
elif isinstance(image, PIL.Image.Image):
image = [image]
if isinstance(image[0], PIL.Image.Image):
image = [np.array(i.resize((w, h), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image]
image = np.concatenate(image, axis=0)
image = np.array(image).astype(np.float32) / 255.0
image = image.transpose(0, 3, 1, 2)
image = 2.0 * image - 1.0
image = torch.from_numpy(image)
elif isinstance(image[0], torch.Tensor):
image = torch.cat(image, dim=0)
return image
class MakeCutouts(nn.Module):
def __init__(self, cut_size, cut_power=1.0):
super().__init__()
self.cut_size = cut_size
self.cut_power = cut_power
def forward(self, pixel_values, num_cutouts):
sideY, sideX = pixel_values.shape[2:4]
max_size = min(sideX, sideY)
min_size = min(sideX, sideY, self.cut_size)
cutouts = []
for _ in range(num_cutouts):
size = int(torch.rand([]) ** self.cut_power * (max_size - min_size) + min_size)
offsetx = torch.randint(0, sideX - size + 1, ())
offsety = torch.randint(0, sideY - size + 1, ())
cutout = pixel_values[:, :, offsety : offsety + size, offsetx : offsetx + size]
cutouts.append(F.adaptive_avg_pool2d(cutout, self.cut_size))
return torch.cat(cutouts)
def spherical_dist_loss(x, y):
x = F.normalize(x, dim=-1)
y = F.normalize(y, dim=-1)
return (x - y).norm(dim=-1).div(2).arcsin().pow(2).mul(2)
def set_requires_grad(model, value):
for param in model.parameters():
param.requires_grad = value
class CLIPGuidedStableDiffusion(DiffusionPipeline):
"""CLIP guided stable diffusion based on the amazing repo by @crowsonkb and @Jack000
- https://github.com/Jack000/glid-3-xl
- https://github.dev/crowsonkb/k-diffusion
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
clip_model: CLIPModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[PNDMScheduler, LMSDiscreteScheduler, DDIMScheduler, DPMSolverMultistepScheduler],
feature_extractor: CLIPFeatureExtractor,
):
super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
clip_model=clip_model,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
feature_extractor=feature_extractor,
)
self.normalize = transforms.Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
self.cut_out_size = (
feature_extractor.size
if isinstance(feature_extractor.size, int)
else feature_extractor.size["shortest_edge"]
)
self.make_cutouts = MakeCutouts(self.cut_out_size)
set_requires_grad(self.text_encoder, False)
set_requires_grad(self.clip_model, False)
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
slice_size = self.unet.config.attention_head_dim // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
self.enable_attention_slicing(None)
def freeze_vae(self):
set_requires_grad(self.vae, False)
def unfreeze_vae(self):
set_requires_grad(self.vae, True)
def freeze_unet(self):
set_requires_grad(self.unet, False)
def unfreeze_unet(self):
set_requires_grad(self.unet, True)
def get_timesteps(self, num_inference_steps, strength, device):
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start:]
return timesteps, num_inference_steps - t_start
def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None):
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
)
image = image.to(device=device, dtype=dtype)
batch_size = batch_size * num_images_per_prompt
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if isinstance(generator, list):
init_latents = [
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
]
init_latents = torch.cat(init_latents, dim=0)
else:
init_latents = self.vae.encode(image).latent_dist.sample(generator)
init_latents = self.vae.config.scaling_factor * init_latents
if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
# expand init_latents for batch_size
deprecation_message = (
f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
" images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
" that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
" your script to pass as many initial images as text prompts to suppress this warning."
)
deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
additional_image_per_prompt = batch_size // init_latents.shape[0]
init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
raise ValueError(
f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
)
else:
init_latents = torch.cat([init_latents], dim=0)
shape = init_latents.shape
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
# get latents
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
latents = init_latents
return latents
@torch.enable_grad()
def cond_fn(
self,
latents,
timestep,
index,
text_embeddings,
noise_pred_original,
text_embeddings_clip,
clip_guidance_scale,
num_cutouts,
use_cutouts=True,
):
latents = latents.detach().requires_grad_()
latent_model_input = self.scheduler.scale_model_input(latents, timestep)
# predict the noise residual
noise_pred = self.unet(latent_model_input, timestep, encoder_hidden_states=text_embeddings).sample
if isinstance(self.scheduler, (PNDMScheduler, DDIMScheduler, DPMSolverMultistepScheduler)):
alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
beta_prod_t = 1 - alpha_prod_t
# compute predicted original sample from predicted noise also called
# "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
fac = torch.sqrt(beta_prod_t)
sample = pred_original_sample * (fac) + latents * (1 - fac)
elif isinstance(self.scheduler, LMSDiscreteScheduler):
sigma = self.scheduler.sigmas[index]
sample = latents - sigma * noise_pred
else:
raise ValueError(f"scheduler type {type(self.scheduler)} not supported")
sample = 1 / self.vae.config.scaling_factor * sample
image = self.vae.decode(sample).sample
image = (image / 2 + 0.5).clamp(0, 1)
if use_cutouts:
image = self.make_cutouts(image, num_cutouts)
else:
image = transforms.Resize(self.cut_out_size)(image)
image = self.normalize(image).to(latents.dtype)
image_embeddings_clip = self.clip_model.get_image_features(image)
image_embeddings_clip = image_embeddings_clip / image_embeddings_clip.norm(p=2, dim=-1, keepdim=True)
if use_cutouts:
dists = spherical_dist_loss(image_embeddings_clip, text_embeddings_clip)
dists = dists.view([num_cutouts, sample.shape[0], -1])
loss = dists.sum(2).mean(0).sum() * clip_guidance_scale
else:
loss = spherical_dist_loss(image_embeddings_clip, text_embeddings_clip).mean() * clip_guidance_scale
grads = -torch.autograd.grad(loss, latents)[0]
if isinstance(self.scheduler, LMSDiscreteScheduler):
latents = latents.detach() + grads * (sigma**2)
noise_pred = noise_pred_original
else:
noise_pred = noise_pred_original - torch.sqrt(beta_prod_t) * grads
return noise_pred, latents
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
height: Optional[int] = 512,
width: Optional[int] = 512,
image: Union[torch.FloatTensor, PIL.Image.Image] = None,
strength: float = 0.8,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
clip_guidance_scale: Optional[float] = 100,
clip_prompt: Optional[Union[str, List[str]]] = None,
num_cutouts: Optional[int] = 4,
use_cutouts: Optional[bool] = True,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
):
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
# get prompt text embeddings
text_input = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_embeddings = self.text_encoder(text_input.input_ids.to(self.device))[0]
# duplicate text embeddings for each generation per prompt
text_embeddings = text_embeddings.repeat_interleave(num_images_per_prompt, dim=0)
# set timesteps
accepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())
extra_set_kwargs = {}
if accepts_offset:
extra_set_kwargs["offset"] = 1
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
# Some schedulers like PNDM have timesteps as arrays
# It's more optimized to move all timesteps to correct device beforehand
self.scheduler.timesteps.to(self.device)
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, self.device)
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# Preprocess image
image = preprocess(image, width, height)
latents = self.prepare_latents(
image, latent_timestep, batch_size, num_images_per_prompt, text_embeddings.dtype, self.device, generator
)
if clip_guidance_scale > 0:
if clip_prompt is not None:
clip_text_input = self.tokenizer(
clip_prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
).input_ids.to(self.device)
else:
clip_text_input = text_input.input_ids.to(self.device)
text_embeddings_clip = self.clip_model.get_text_features(clip_text_input)
text_embeddings_clip = text_embeddings_clip / text_embeddings_clip.norm(p=2, dim=-1, keepdim=True)
# duplicate text embeddings clip for each generation per prompt
text_embeddings_clip = text_embeddings_clip.repeat_interleave(num_images_per_prompt, dim=0)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
max_length = text_input.input_ids.shape[-1]
uncond_input = self.tokenizer([""], padding="max_length", max_length=max_length, return_tensors="pt")
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# duplicate unconditional embeddings for each generation per prompt
uncond_embeddings = uncond_embeddings.repeat_interleave(num_images_per_prompt, dim=0)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# Unlike in other pipelines, latents need to be generated in the target device
# for 1-to-1 results reproducibility with the CompVis implementation.
# However this currently doesn't work in `mps`.
latents_shape = (batch_size * num_images_per_prompt, self.unet.config.in_channels, height // 8, width // 8)
latents_dtype = text_embeddings.dtype
if latents is None:
if self.device.type == "mps":
# randn does not work reproducibly on mps
latents = torch.randn(latents_shape, generator=generator, device="cpu", dtype=latents_dtype).to(
self.device
)
else:
latents = torch.randn(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
else:
if latents.shape != latents_shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
latents = latents.to(self.device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
with self.progress_bar(total=num_inference_steps):
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform classifier free guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# perform clip guidance
if clip_guidance_scale > 0:
text_embeddings_for_guidance = (
text_embeddings.chunk(2)[1] if do_classifier_free_guidance else text_embeddings
)
noise_pred, latents = self.cond_fn(
latents,
t,
i,
text_embeddings_for_guidance,
noise_pred,
text_embeddings_clip,
clip_guidance_scale,
num_cutouts,
use_cutouts,
)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# scale and decode the image latents with vae
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, None)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=None)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/clip_guided_images_mixing_stable_diffusion.py
|
# -*- coding: utf-8 -*-
import inspect
from typing import Optional, Union
import numpy as np
import PIL.Image
import torch
from torch.nn import functional as F
from torchvision import transforms
from transformers import CLIPFeatureExtractor, CLIPModel, CLIPTextModel, CLIPTokenizer
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DiffusionPipeline,
DPMSolverMultistepScheduler,
LMSDiscreteScheduler,
PNDMScheduler,
UNet2DConditionModel,
)
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion import StableDiffusionPipelineOutput
from diffusers.utils import PIL_INTERPOLATION
from diffusers.utils.torch_utils import randn_tensor
def preprocess(image, w, h):
if isinstance(image, torch.Tensor):
return image
elif isinstance(image, PIL.Image.Image):
image = [image]
if isinstance(image[0], PIL.Image.Image):
image = [np.array(i.resize((w, h), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image]
image = np.concatenate(image, axis=0)
image = np.array(image).astype(np.float32) / 255.0
image = image.transpose(0, 3, 1, 2)
image = 2.0 * image - 1.0
image = torch.from_numpy(image)
elif isinstance(image[0], torch.Tensor):
image = torch.cat(image, dim=0)
return image
def slerp(t, v0, v1, DOT_THRESHOLD=0.9995):
if not isinstance(v0, np.ndarray):
inputs_are_torch = True
input_device = v0.device
v0 = v0.cpu().numpy()
v1 = v1.cpu().numpy()
dot = np.sum(v0 * v1 / (np.linalg.norm(v0) * np.linalg.norm(v1)))
if np.abs(dot) > DOT_THRESHOLD:
v2 = (1 - t) * v0 + t * v1
else:
theta_0 = np.arccos(dot)
sin_theta_0 = np.sin(theta_0)
theta_t = theta_0 * t
sin_theta_t = np.sin(theta_t)
s0 = np.sin(theta_0 - theta_t) / sin_theta_0
s1 = sin_theta_t / sin_theta_0
v2 = s0 * v0 + s1 * v1
if inputs_are_torch:
v2 = torch.from_numpy(v2).to(input_device)
return v2
def spherical_dist_loss(x, y):
x = F.normalize(x, dim=-1)
y = F.normalize(y, dim=-1)
return (x - y).norm(dim=-1).div(2).arcsin().pow(2).mul(2)
def set_requires_grad(model, value):
for param in model.parameters():
param.requires_grad = value
class CLIPGuidedImagesMixingStableDiffusion(DiffusionPipeline):
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
clip_model: CLIPModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[PNDMScheduler, LMSDiscreteScheduler, DDIMScheduler, DPMSolverMultistepScheduler],
feature_extractor: CLIPFeatureExtractor,
coca_model=None,
coca_tokenizer=None,
coca_transform=None,
):
super().__init__()
self.register_modules(
vae=vae,
text_encoder=text_encoder,
clip_model=clip_model,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
feature_extractor=feature_extractor,
coca_model=coca_model,
coca_tokenizer=coca_tokenizer,
coca_transform=coca_transform,
)
self.feature_extractor_size = (
feature_extractor.size
if isinstance(feature_extractor.size, int)
else feature_extractor.size["shortest_edge"]
)
self.normalize = transforms.Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
set_requires_grad(self.text_encoder, False)
set_requires_grad(self.clip_model, False)
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
if slice_size == "auto":
# half the attention head size is usually a good trade-off between
# speed and memory
slice_size = self.unet.config.attention_head_dim // 2
self.unet.set_attention_slice(slice_size)
def disable_attention_slicing(self):
self.enable_attention_slicing(None)
def freeze_vae(self):
set_requires_grad(self.vae, False)
def unfreeze_vae(self):
set_requires_grad(self.vae, True)
def freeze_unet(self):
set_requires_grad(self.unet, False)
def unfreeze_unet(self):
set_requires_grad(self.unet, True)
def get_timesteps(self, num_inference_steps, strength, device):
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start:]
return timesteps, num_inference_steps - t_start
def prepare_latents(self, image, timestep, batch_size, dtype, device, generator=None):
if not isinstance(image, torch.Tensor):
raise ValueError(f"`image` has to be of type `torch.Tensor` but is {type(image)}")
image = image.to(device=device, dtype=dtype)
if isinstance(generator, list):
init_latents = [
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
]
init_latents = torch.cat(init_latents, dim=0)
else:
init_latents = self.vae.encode(image).latent_dist.sample(generator)
# Hardcode 0.18215 because stable-diffusion-2-base has not self.vae.config.scaling_factor
init_latents = 0.18215 * init_latents
init_latents = init_latents.repeat_interleave(batch_size, dim=0)
noise = randn_tensor(init_latents.shape, generator=generator, device=device, dtype=dtype)
# get latents
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
latents = init_latents
return latents
def get_image_description(self, image):
transformed_image = self.coca_transform(image).unsqueeze(0)
with torch.no_grad(), torch.cuda.amp.autocast():
generated = self.coca_model.generate(transformed_image.to(device=self.device, dtype=self.coca_model.dtype))
generated = self.coca_tokenizer.decode(generated[0].cpu().numpy())
return generated.split("<end_of_text>")[0].replace("<start_of_text>", "").rstrip(" .,")
def get_clip_image_embeddings(self, image, batch_size):
clip_image_input = self.feature_extractor.preprocess(image)
clip_image_features = torch.from_numpy(clip_image_input["pixel_values"][0]).unsqueeze(0).to(self.device).half()
image_embeddings_clip = self.clip_model.get_image_features(clip_image_features)
image_embeddings_clip = image_embeddings_clip / image_embeddings_clip.norm(p=2, dim=-1, keepdim=True)
image_embeddings_clip = image_embeddings_clip.repeat_interleave(batch_size, dim=0)
return image_embeddings_clip
@torch.enable_grad()
def cond_fn(
self,
latents,
timestep,
index,
text_embeddings,
noise_pred_original,
original_image_embeddings_clip,
clip_guidance_scale,
):
latents = latents.detach().requires_grad_()
latent_model_input = self.scheduler.scale_model_input(latents, timestep)
# predict the noise residual
noise_pred = self.unet(latent_model_input, timestep, encoder_hidden_states=text_embeddings).sample
if isinstance(self.scheduler, (PNDMScheduler, DDIMScheduler, DPMSolverMultistepScheduler)):
alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
beta_prod_t = 1 - alpha_prod_t
# compute predicted original sample from predicted noise also called
# "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
fac = torch.sqrt(beta_prod_t)
sample = pred_original_sample * (fac) + latents * (1 - fac)
elif isinstance(self.scheduler, LMSDiscreteScheduler):
sigma = self.scheduler.sigmas[index]
sample = latents - sigma * noise_pred
else:
raise ValueError(f"scheduler type {type(self.scheduler)} not supported")
# Hardcode 0.18215 because stable-diffusion-2-base has not self.vae.config.scaling_factor
sample = 1 / 0.18215 * sample
image = self.vae.decode(sample).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = transforms.Resize(self.feature_extractor_size)(image)
image = self.normalize(image).to(latents.dtype)
image_embeddings_clip = self.clip_model.get_image_features(image)
image_embeddings_clip = image_embeddings_clip / image_embeddings_clip.norm(p=2, dim=-1, keepdim=True)
loss = spherical_dist_loss(image_embeddings_clip, original_image_embeddings_clip).mean() * clip_guidance_scale
grads = -torch.autograd.grad(loss, latents)[0]
if isinstance(self.scheduler, LMSDiscreteScheduler):
latents = latents.detach() + grads * (sigma**2)
noise_pred = noise_pred_original
else:
noise_pred = noise_pred_original - torch.sqrt(beta_prod_t) * grads
return noise_pred, latents
@torch.no_grad()
def __call__(
self,
style_image: Union[torch.FloatTensor, PIL.Image.Image],
content_image: Union[torch.FloatTensor, PIL.Image.Image],
style_prompt: Optional[str] = None,
content_prompt: Optional[str] = None,
height: Optional[int] = 512,
width: Optional[int] = 512,
noise_strength: float = 0.6,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
batch_size: Optional[int] = 1,
eta: float = 0.0,
clip_guidance_scale: Optional[float] = 100,
generator: Optional[torch.Generator] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
slerp_latent_style_strength: float = 0.8,
slerp_prompt_style_strength: float = 0.1,
slerp_clip_image_style_strength: float = 0.1,
):
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(f"You have passed {batch_size} batch_size, but only {len(generator)} generators.")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if isinstance(generator, torch.Generator) and batch_size > 1:
generator = [generator] + [None] * (batch_size - 1)
coca_is_none = [
("model", self.coca_model is None),
("tokenizer", self.coca_tokenizer is None),
("transform", self.coca_transform is None),
]
coca_is_none = [x[0] for x in coca_is_none if x[1]]
coca_is_none_str = ", ".join(coca_is_none)
# generate prompts with coca model if prompt is None
if content_prompt is None:
if len(coca_is_none):
raise ValueError(
f"Content prompt is None and CoCa [{coca_is_none_str}] is None."
f"Set prompt or pass Coca [{coca_is_none_str}] to DiffusionPipeline."
)
content_prompt = self.get_image_description(content_image)
if style_prompt is None:
if len(coca_is_none):
raise ValueError(
f"Style prompt is None and CoCa [{coca_is_none_str}] is None."
f" Set prompt or pass Coca [{coca_is_none_str}] to DiffusionPipeline."
)
style_prompt = self.get_image_description(style_image)
# get prompt text embeddings for content and style
content_text_input = self.tokenizer(
content_prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
content_text_embeddings = self.text_encoder(content_text_input.input_ids.to(self.device))[0]
style_text_input = self.tokenizer(
style_prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
style_text_embeddings = self.text_encoder(style_text_input.input_ids.to(self.device))[0]
text_embeddings = slerp(slerp_prompt_style_strength, content_text_embeddings, style_text_embeddings)
# duplicate text embeddings for each generation per prompt
text_embeddings = text_embeddings.repeat_interleave(batch_size, dim=0)
# set timesteps
accepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())
extra_set_kwargs = {}
if accepts_offset:
extra_set_kwargs["offset"] = 1
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
# Some schedulers like PNDM have timesteps as arrays
# It's more optimized to move all timesteps to correct device beforehand
self.scheduler.timesteps.to(self.device)
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, noise_strength, self.device)
latent_timestep = timesteps[:1].repeat(batch_size)
# Preprocess image
preprocessed_content_image = preprocess(content_image, width, height)
content_latents = self.prepare_latents(
preprocessed_content_image, latent_timestep, batch_size, text_embeddings.dtype, self.device, generator
)
preprocessed_style_image = preprocess(style_image, width, height)
style_latents = self.prepare_latents(
preprocessed_style_image, latent_timestep, batch_size, text_embeddings.dtype, self.device, generator
)
latents = slerp(slerp_latent_style_strength, content_latents, style_latents)
if clip_guidance_scale > 0:
content_clip_image_embedding = self.get_clip_image_embeddings(content_image, batch_size)
style_clip_image_embedding = self.get_clip_image_embeddings(style_image, batch_size)
clip_image_embeddings = slerp(
slerp_clip_image_style_strength, content_clip_image_embedding, style_clip_image_embedding
)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
max_length = content_text_input.input_ids.shape[-1]
uncond_input = self.tokenizer([""], padding="max_length", max_length=max_length, return_tensors="pt")
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# duplicate unconditional embeddings for each generation per prompt
uncond_embeddings = uncond_embeddings.repeat_interleave(batch_size, dim=0)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# Unlike in other pipelines, latents need to be generated in the target device
# for 1-to-1 results reproducibility with the CompVis implementation.
# However this currently doesn't work in `mps`.
latents_shape = (batch_size, self.unet.config.in_channels, height // 8, width // 8)
latents_dtype = text_embeddings.dtype
if latents is None:
if self.device.type == "mps":
# randn does not work reproducibly on mps
latents = torch.randn(latents_shape, generator=generator, device="cpu", dtype=latents_dtype).to(
self.device
)
else:
latents = torch.randn(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
else:
if latents.shape != latents_shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
latents = latents.to(self.device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform classifier free guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# perform clip guidance
if clip_guidance_scale > 0:
text_embeddings_for_guidance = (
text_embeddings.chunk(2)[1] if do_classifier_free_guidance else text_embeddings
)
noise_pred, latents = self.cond_fn(
latents,
t,
i,
text_embeddings_for_guidance,
noise_pred,
clip_image_embeddings,
clip_guidance_scale,
)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
progress_bar.update()
# Hardcode 0.18215 because stable-diffusion-2-base has not self.vae.config.scaling_factor
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, None)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=None)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/bit_diffusion.py
|
from typing import Optional, Tuple, Union
import torch
from einops import rearrange, reduce
from diffusers import DDIMScheduler, DDPMScheduler, DiffusionPipeline, ImagePipelineOutput, UNet2DConditionModel
from diffusers.schedulers.scheduling_ddim import DDIMSchedulerOutput
from diffusers.schedulers.scheduling_ddpm import DDPMSchedulerOutput
BITS = 8
# convert to bit representations and back taken from https://github.com/lucidrains/bit-diffusion/blob/main/bit_diffusion/bit_diffusion.py
def decimal_to_bits(x, bits=BITS):
"""expects image tensor ranging from 0 to 1, outputs bit tensor ranging from -1 to 1"""
device = x.device
x = (x * 255).int().clamp(0, 255)
mask = 2 ** torch.arange(bits - 1, -1, -1, device=device)
mask = rearrange(mask, "d -> d 1 1")
x = rearrange(x, "b c h w -> b c 1 h w")
bits = ((x & mask) != 0).float()
bits = rearrange(bits, "b c d h w -> b (c d) h w")
bits = bits * 2 - 1
return bits
def bits_to_decimal(x, bits=BITS):
"""expects bits from -1 to 1, outputs image tensor from 0 to 1"""
device = x.device
x = (x > 0).int()
mask = 2 ** torch.arange(bits - 1, -1, -1, device=device, dtype=torch.int32)
mask = rearrange(mask, "d -> d 1 1")
x = rearrange(x, "b (c d) h w -> b c d h w", d=8)
dec = reduce(x * mask, "b c d h w -> b c h w", "sum")
return (dec / 255).clamp(0.0, 1.0)
# modified scheduler step functions for clamping the predicted x_0 between -bit_scale and +bit_scale
def ddim_bit_scheduler_step(
self,
model_output: torch.FloatTensor,
timestep: int,
sample: torch.FloatTensor,
eta: float = 0.0,
use_clipped_model_output: bool = True,
generator=None,
return_dict: bool = True,
) -> Union[DDIMSchedulerOutput, Tuple]:
"""
Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
process from the learned model outputs (most often the predicted noise).
Args:
model_output (`torch.FloatTensor`): direct output from learned diffusion model.
timestep (`int`): current discrete timestep in the diffusion chain.
sample (`torch.FloatTensor`):
current instance of sample being created by diffusion process.
eta (`float`): weight of noise for added noise in diffusion step.
use_clipped_model_output (`bool`): TODO
generator: random number generator.
return_dict (`bool`): option for returning tuple rather than DDIMSchedulerOutput class
Returns:
[`~schedulers.scheduling_utils.DDIMSchedulerOutput`] or `tuple`:
[`~schedulers.scheduling_utils.DDIMSchedulerOutput`] if `return_dict` is True, otherwise a `tuple`. When
returning a tuple, the first element is the sample tensor.
"""
if self.num_inference_steps is None:
raise ValueError(
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
# See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
# Ideally, read DDIM paper in-detail understanding
# Notation (<variable name> -> <name in paper>
# - pred_noise_t -> e_theta(x_t, t)
# - pred_original_sample -> f_theta(x_t, t) or x_0
# - std_dev_t -> sigma_t
# - eta -> η
# - pred_sample_direction -> "direction pointing to x_t"
# - pred_prev_sample -> "x_t-1"
# 1. get previous step value (=t-1)
prev_timestep = timestep - self.config.num_train_timesteps // self.num_inference_steps
# 2. compute alphas, betas
alpha_prod_t = self.alphas_cumprod[timestep]
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
# "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
# 4. Clip "predicted x_0"
scale = self.bit_scale
if self.config.clip_sample:
pred_original_sample = torch.clamp(pred_original_sample, -scale, scale)
# 5. compute variance: "sigma_t(η)" -> see formula (16)
# σ_t = sqrt((1 − α_t−1)/(1 − α_t)) * sqrt(1 − α_t/α_t−1)
variance = self._get_variance(timestep, prev_timestep)
std_dev_t = eta * variance ** (0.5)
if use_clipped_model_output:
# the model_output is always re-derived from the clipped x_0 in Glide
model_output = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
# 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * model_output
# 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
if eta > 0:
# randn_like does not support generator https://github.com/pytorch/pytorch/issues/27072
device = model_output.device if torch.is_tensor(model_output) else "cpu"
noise = torch.randn(model_output.shape, dtype=model_output.dtype, generator=generator).to(device)
variance = self._get_variance(timestep, prev_timestep) ** (0.5) * eta * noise
prev_sample = prev_sample + variance
if not return_dict:
return (prev_sample,)
return DDIMSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_original_sample)
def ddpm_bit_scheduler_step(
self,
model_output: torch.FloatTensor,
timestep: int,
sample: torch.FloatTensor,
prediction_type="epsilon",
generator=None,
return_dict: bool = True,
) -> Union[DDPMSchedulerOutput, Tuple]:
"""
Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
process from the learned model outputs (most often the predicted noise).
Args:
model_output (`torch.FloatTensor`): direct output from learned diffusion model.
timestep (`int`): current discrete timestep in the diffusion chain.
sample (`torch.FloatTensor`):
current instance of sample being created by diffusion process.
prediction_type (`str`, default `epsilon`):
indicates whether the model predicts the noise (epsilon), or the samples (`sample`).
generator: random number generator.
return_dict (`bool`): option for returning tuple rather than DDPMSchedulerOutput class
Returns:
[`~schedulers.scheduling_utils.DDPMSchedulerOutput`] or `tuple`:
[`~schedulers.scheduling_utils.DDPMSchedulerOutput`] if `return_dict` is True, otherwise a `tuple`. When
returning a tuple, the first element is the sample tensor.
"""
t = timestep
if model_output.shape[1] == sample.shape[1] * 2 and self.variance_type in ["learned", "learned_range"]:
model_output, predicted_variance = torch.split(model_output, sample.shape[1], dim=1)
else:
predicted_variance = None
# 1. compute alphas, betas
alpha_prod_t = self.alphas_cumprod[t]
alpha_prod_t_prev = self.alphas_cumprod[t - 1] if t > 0 else self.one
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
# 2. compute predicted original sample from predicted noise also called
# "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
if prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
elif prediction_type == "sample":
pred_original_sample = model_output
else:
raise ValueError(f"Unsupported prediction_type {prediction_type}.")
# 3. Clip "predicted x_0"
scale = self.bit_scale
if self.config.clip_sample:
pred_original_sample = torch.clamp(pred_original_sample, -scale, scale)
# 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
# See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * self.betas[t]) / beta_prod_t
current_sample_coeff = self.alphas[t] ** (0.5) * beta_prod_t_prev / beta_prod_t
# 5. Compute predicted previous sample µ_t
# See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
# 6. Add noise
variance = 0
if t > 0:
noise = torch.randn(
model_output.size(), dtype=model_output.dtype, layout=model_output.layout, generator=generator
).to(model_output.device)
variance = (self._get_variance(t, predicted_variance=predicted_variance) ** 0.5) * noise
pred_prev_sample = pred_prev_sample + variance
if not return_dict:
return (pred_prev_sample,)
return DDPMSchedulerOutput(prev_sample=pred_prev_sample, pred_original_sample=pred_original_sample)
class BitDiffusion(DiffusionPipeline):
def __init__(
self,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, DDPMScheduler],
bit_scale: Optional[float] = 1.0,
):
super().__init__()
self.bit_scale = bit_scale
self.scheduler.step = (
ddim_bit_scheduler_step if isinstance(scheduler, DDIMScheduler) else ddpm_bit_scheduler_step
)
self.register_modules(unet=unet, scheduler=scheduler)
@torch.no_grad()
def __call__(
self,
height: Optional[int] = 256,
width: Optional[int] = 256,
num_inference_steps: Optional[int] = 50,
generator: Optional[torch.Generator] = None,
batch_size: Optional[int] = 1,
output_type: Optional[str] = "pil",
return_dict: bool = True,
**kwargs,
) -> Union[Tuple, ImagePipelineOutput]:
latents = torch.randn(
(batch_size, self.unet.config.in_channels, height, width),
generator=generator,
)
latents = decimal_to_bits(latents) * self.bit_scale
latents = latents.to(self.device)
self.scheduler.set_timesteps(num_inference_steps)
for t in self.progress_bar(self.scheduler.timesteps):
# predict the noise residual
noise_pred = self.unet(latents, t).sample
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents).prev_sample
image = bits_to_decimal(latents)
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/lpw_stable_diffusion.py
|
import inspect
import re
from typing import Any, Callable, Dict, List, Optional, Union
import numpy as np
import PIL.Image
import torch
from packaging import version
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import DiffusionPipeline
from diffusers.configuration_utils import FrozenDict
from diffusers.image_processor import VaeImageProcessor
from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput, StableDiffusionSafetyChecker
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
PIL_INTERPOLATION,
deprecate,
is_accelerate_available,
is_accelerate_version,
logging,
)
from diffusers.utils.torch_utils import randn_tensor
# ------------------------------------------------------------------------------
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
re_attention = re.compile(
r"""
\\\(|
\\\)|
\\\[|
\\]|
\\\\|
\\|
\(|
\[|
:([+-]?[.\d]+)\)|
\)|
]|
[^\\()\[\]:]+|
:
""",
re.X,
)
def parse_prompt_attention(text):
"""
Parses a string with attention tokens and returns a list of pairs: text and its associated weight.
Accepted tokens are:
(abc) - increases attention to abc by a multiplier of 1.1
(abc:3.12) - increases attention to abc by a multiplier of 3.12
[abc] - decreases attention to abc by a multiplier of 1.1
\\( - literal character '('
\\[ - literal character '['
\\) - literal character ')'
\\] - literal character ']'
\\ - literal character '\'
anything else - just text
>>> parse_prompt_attention('normal text')
[['normal text', 1.0]]
>>> parse_prompt_attention('an (important) word')
[['an ', 1.0], ['important', 1.1], [' word', 1.0]]
>>> parse_prompt_attention('(unbalanced')
[['unbalanced', 1.1]]
>>> parse_prompt_attention('\\(literal\\]')
[['(literal]', 1.0]]
>>> parse_prompt_attention('(unnecessary)(parens)')
[['unnecessaryparens', 1.1]]
>>> parse_prompt_attention('a (((house:1.3)) [on] a (hill:0.5), sun, (((sky))).')
[['a ', 1.0],
['house', 1.5730000000000004],
[' ', 1.1],
['on', 1.0],
[' a ', 1.1],
['hill', 0.55],
[', sun, ', 1.1],
['sky', 1.4641000000000006],
['.', 1.1]]
"""
res = []
round_brackets = []
square_brackets = []
round_bracket_multiplier = 1.1
square_bracket_multiplier = 1 / 1.1
def multiply_range(start_position, multiplier):
for p in range(start_position, len(res)):
res[p][1] *= multiplier
for m in re_attention.finditer(text):
text = m.group(0)
weight = m.group(1)
if text.startswith("\\"):
res.append([text[1:], 1.0])
elif text == "(":
round_brackets.append(len(res))
elif text == "[":
square_brackets.append(len(res))
elif weight is not None and len(round_brackets) > 0:
multiply_range(round_brackets.pop(), float(weight))
elif text == ")" and len(round_brackets) > 0:
multiply_range(round_brackets.pop(), round_bracket_multiplier)
elif text == "]" and len(square_brackets) > 0:
multiply_range(square_brackets.pop(), square_bracket_multiplier)
else:
res.append([text, 1.0])
for pos in round_brackets:
multiply_range(pos, round_bracket_multiplier)
for pos in square_brackets:
multiply_range(pos, square_bracket_multiplier)
if len(res) == 0:
res = [["", 1.0]]
# merge runs of identical weights
i = 0
while i + 1 < len(res):
if res[i][1] == res[i + 1][1]:
res[i][0] += res[i + 1][0]
res.pop(i + 1)
else:
i += 1
return res
def get_prompts_with_weights(pipe: DiffusionPipeline, prompt: List[str], max_length: int):
r"""
Tokenize a list of prompts and return its tokens with weights of each token.
No padding, starting or ending token is included.
"""
tokens = []
weights = []
truncated = False
for text in prompt:
texts_and_weights = parse_prompt_attention(text)
text_token = []
text_weight = []
for word, weight in texts_and_weights:
# tokenize and discard the starting and the ending token
token = pipe.tokenizer(word).input_ids[1:-1]
text_token += token
# copy the weight by length of token
text_weight += [weight] * len(token)
# stop if the text is too long (longer than truncation limit)
if len(text_token) > max_length:
truncated = True
break
# truncate
if len(text_token) > max_length:
truncated = True
text_token = text_token[:max_length]
text_weight = text_weight[:max_length]
tokens.append(text_token)
weights.append(text_weight)
if truncated:
logger.warning("Prompt was truncated. Try to shorten the prompt or increase max_embeddings_multiples")
return tokens, weights
def pad_tokens_and_weights(tokens, weights, max_length, bos, eos, pad, no_boseos_middle=True, chunk_length=77):
r"""
Pad the tokens (with starting and ending tokens) and weights (with 1.0) to max_length.
"""
max_embeddings_multiples = (max_length - 2) // (chunk_length - 2)
weights_length = max_length if no_boseos_middle else max_embeddings_multiples * chunk_length
for i in range(len(tokens)):
tokens[i] = [bos] + tokens[i] + [pad] * (max_length - 1 - len(tokens[i]) - 1) + [eos]
if no_boseos_middle:
weights[i] = [1.0] + weights[i] + [1.0] * (max_length - 1 - len(weights[i]))
else:
w = []
if len(weights[i]) == 0:
w = [1.0] * weights_length
else:
for j in range(max_embeddings_multiples):
w.append(1.0) # weight for starting token in this chunk
w += weights[i][j * (chunk_length - 2) : min(len(weights[i]), (j + 1) * (chunk_length - 2))]
w.append(1.0) # weight for ending token in this chunk
w += [1.0] * (weights_length - len(w))
weights[i] = w[:]
return tokens, weights
def get_unweighted_text_embeddings(
pipe: DiffusionPipeline,
text_input: torch.Tensor,
chunk_length: int,
no_boseos_middle: Optional[bool] = True,
):
"""
When the length of tokens is a multiple of the capacity of the text encoder,
it should be split into chunks and sent to the text encoder individually.
"""
max_embeddings_multiples = (text_input.shape[1] - 2) // (chunk_length - 2)
if max_embeddings_multiples > 1:
text_embeddings = []
for i in range(max_embeddings_multiples):
# extract the i-th chunk
text_input_chunk = text_input[:, i * (chunk_length - 2) : (i + 1) * (chunk_length - 2) + 2].clone()
# cover the head and the tail by the starting and the ending tokens
text_input_chunk[:, 0] = text_input[0, 0]
text_input_chunk[:, -1] = text_input[0, -1]
text_embedding = pipe.text_encoder(text_input_chunk)[0]
if no_boseos_middle:
if i == 0:
# discard the ending token
text_embedding = text_embedding[:, :-1]
elif i == max_embeddings_multiples - 1:
# discard the starting token
text_embedding = text_embedding[:, 1:]
else:
# discard both starting and ending tokens
text_embedding = text_embedding[:, 1:-1]
text_embeddings.append(text_embedding)
text_embeddings = torch.concat(text_embeddings, axis=1)
else:
text_embeddings = pipe.text_encoder(text_input)[0]
return text_embeddings
def get_weighted_text_embeddings(
pipe: DiffusionPipeline,
prompt: Union[str, List[str]],
uncond_prompt: Optional[Union[str, List[str]]] = None,
max_embeddings_multiples: Optional[int] = 3,
no_boseos_middle: Optional[bool] = False,
skip_parsing: Optional[bool] = False,
skip_weighting: Optional[bool] = False,
):
r"""
Prompts can be assigned with local weights using brackets. For example,
prompt 'A (very beautiful) masterpiece' highlights the words 'very beautiful',
and the embedding tokens corresponding to the words get multiplied by a constant, 1.1.
Also, to regularize of the embedding, the weighted embedding would be scaled to preserve the original mean.
Args:
pipe (`DiffusionPipeline`):
Pipe to provide access to the tokenizer and the text encoder.
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
uncond_prompt (`str` or `List[str]`):
The unconditional prompt or prompts for guide the image generation. If unconditional prompt
is provided, the embeddings of prompt and uncond_prompt are concatenated.
max_embeddings_multiples (`int`, *optional*, defaults to `3`):
The max multiple length of prompt embeddings compared to the max output length of text encoder.
no_boseos_middle (`bool`, *optional*, defaults to `False`):
If the length of text token is multiples of the capacity of text encoder, whether reserve the starting and
ending token in each of the chunk in the middle.
skip_parsing (`bool`, *optional*, defaults to `False`):
Skip the parsing of brackets.
skip_weighting (`bool`, *optional*, defaults to `False`):
Skip the weighting. When the parsing is skipped, it is forced True.
"""
max_length = (pipe.tokenizer.model_max_length - 2) * max_embeddings_multiples + 2
if isinstance(prompt, str):
prompt = [prompt]
if not skip_parsing:
prompt_tokens, prompt_weights = get_prompts_with_weights(pipe, prompt, max_length - 2)
if uncond_prompt is not None:
if isinstance(uncond_prompt, str):
uncond_prompt = [uncond_prompt]
uncond_tokens, uncond_weights = get_prompts_with_weights(pipe, uncond_prompt, max_length - 2)
else:
prompt_tokens = [
token[1:-1] for token in pipe.tokenizer(prompt, max_length=max_length, truncation=True).input_ids
]
prompt_weights = [[1.0] * len(token) for token in prompt_tokens]
if uncond_prompt is not None:
if isinstance(uncond_prompt, str):
uncond_prompt = [uncond_prompt]
uncond_tokens = [
token[1:-1]
for token in pipe.tokenizer(uncond_prompt, max_length=max_length, truncation=True).input_ids
]
uncond_weights = [[1.0] * len(token) for token in uncond_tokens]
# round up the longest length of tokens to a multiple of (model_max_length - 2)
max_length = max([len(token) for token in prompt_tokens])
if uncond_prompt is not None:
max_length = max(max_length, max([len(token) for token in uncond_tokens]))
max_embeddings_multiples = min(
max_embeddings_multiples,
(max_length - 1) // (pipe.tokenizer.model_max_length - 2) + 1,
)
max_embeddings_multiples = max(1, max_embeddings_multiples)
max_length = (pipe.tokenizer.model_max_length - 2) * max_embeddings_multiples + 2
# pad the length of tokens and weights
bos = pipe.tokenizer.bos_token_id
eos = pipe.tokenizer.eos_token_id
pad = getattr(pipe.tokenizer, "pad_token_id", eos)
prompt_tokens, prompt_weights = pad_tokens_and_weights(
prompt_tokens,
prompt_weights,
max_length,
bos,
eos,
pad,
no_boseos_middle=no_boseos_middle,
chunk_length=pipe.tokenizer.model_max_length,
)
prompt_tokens = torch.tensor(prompt_tokens, dtype=torch.long, device=pipe.device)
if uncond_prompt is not None:
uncond_tokens, uncond_weights = pad_tokens_and_weights(
uncond_tokens,
uncond_weights,
max_length,
bos,
eos,
pad,
no_boseos_middle=no_boseos_middle,
chunk_length=pipe.tokenizer.model_max_length,
)
uncond_tokens = torch.tensor(uncond_tokens, dtype=torch.long, device=pipe.device)
# get the embeddings
text_embeddings = get_unweighted_text_embeddings(
pipe,
prompt_tokens,
pipe.tokenizer.model_max_length,
no_boseos_middle=no_boseos_middle,
)
prompt_weights = torch.tensor(prompt_weights, dtype=text_embeddings.dtype, device=text_embeddings.device)
if uncond_prompt is not None:
uncond_embeddings = get_unweighted_text_embeddings(
pipe,
uncond_tokens,
pipe.tokenizer.model_max_length,
no_boseos_middle=no_boseos_middle,
)
uncond_weights = torch.tensor(uncond_weights, dtype=uncond_embeddings.dtype, device=uncond_embeddings.device)
# assign weights to the prompts and normalize in the sense of mean
# TODO: should we normalize by chunk or in a whole (current implementation)?
if (not skip_parsing) and (not skip_weighting):
previous_mean = text_embeddings.float().mean(axis=[-2, -1]).to(text_embeddings.dtype)
text_embeddings *= prompt_weights.unsqueeze(-1)
current_mean = text_embeddings.float().mean(axis=[-2, -1]).to(text_embeddings.dtype)
text_embeddings *= (previous_mean / current_mean).unsqueeze(-1).unsqueeze(-1)
if uncond_prompt is not None:
previous_mean = uncond_embeddings.float().mean(axis=[-2, -1]).to(uncond_embeddings.dtype)
uncond_embeddings *= uncond_weights.unsqueeze(-1)
current_mean = uncond_embeddings.float().mean(axis=[-2, -1]).to(uncond_embeddings.dtype)
uncond_embeddings *= (previous_mean / current_mean).unsqueeze(-1).unsqueeze(-1)
if uncond_prompt is not None:
return text_embeddings, uncond_embeddings
return text_embeddings, None
def preprocess_image(image, batch_size):
w, h = image.size
w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
image = np.array(image).astype(np.float32) / 255.0
image = np.vstack([image[None].transpose(0, 3, 1, 2)] * batch_size)
image = torch.from_numpy(image)
return 2.0 * image - 1.0
def preprocess_mask(mask, batch_size, scale_factor=8):
if not isinstance(mask, torch.FloatTensor):
mask = mask.convert("L")
w, h = mask.size
w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
mask = mask.resize((w // scale_factor, h // scale_factor), resample=PIL_INTERPOLATION["nearest"])
mask = np.array(mask).astype(np.float32) / 255.0
mask = np.tile(mask, (4, 1, 1))
mask = np.vstack([mask[None]] * batch_size)
mask = 1 - mask # repaint white, keep black
mask = torch.from_numpy(mask)
return mask
else:
valid_mask_channel_sizes = [1, 3]
# if mask channel is fourth tensor dimension, permute dimensions to pytorch standard (B, C, H, W)
if mask.shape[3] in valid_mask_channel_sizes:
mask = mask.permute(0, 3, 1, 2)
elif mask.shape[1] not in valid_mask_channel_sizes:
raise ValueError(
f"Mask channel dimension of size in {valid_mask_channel_sizes} should be second or fourth dimension,"
f" but received mask of shape {tuple(mask.shape)}"
)
# (potentially) reduce mask channel dimension from 3 to 1 for broadcasting to latent shape
mask = mask.mean(dim=1, keepdim=True)
h, w = mask.shape[-2:]
h, w = (x - x % 8 for x in (h, w)) # resize to integer multiple of 8
mask = torch.nn.functional.interpolate(mask, (h // scale_factor, w // scale_factor))
return mask
class StableDiffusionLongPromptWeightingPipeline(
DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin, FromSingleFileMixin
):
r"""
Pipeline for text-to-image generation using Stable Diffusion without tokens length limit, and support parsing
weighting in prompt.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/CompVis/stable-diffusion-v1-4) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
" `clip_sample` should be set to False in the configuration file. Please make sure to update the"
" config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
" future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
" nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
)
deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["clip_sample"] = False
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
version.parse(unet.config._diffusers_version).base_version
) < version.parse("0.9.0.dev0")
is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
deprecation_message = (
"The configuration file of the unet has set the default `sample_size` to smaller than"
" 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
" following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
" CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
" \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
" configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
" in the config might lead to incorrect results in future versions. If you have downloaded this"
" checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
" the `unet/config.json` file"
)
deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(unet.config)
new_config["sample_size"] = 64
unet._internal_dict = FrozenDict(new_config)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.register_to_config(
requires_safety_checker=requires_safety_checker,
)
def enable_vae_slicing(self):
r"""
Enable sliced VAE decoding.
When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
steps. This is useful to save some memory and allow larger batch sizes.
"""
self.vae.enable_slicing()
def disable_vae_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
computing decoding in one step.
"""
self.vae.disable_slicing()
def enable_vae_tiling(self):
r"""
Enable tiled VAE decoding.
When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
"""
self.vae.enable_tiling()
def disable_vae_tiling(self):
r"""
Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
computing decoding in one step.
"""
self.vae.disable_tiling()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
def enable_sequential_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
`torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
Note that offloading happens on a submodule basis. Memory savings are higher than with
`enable_model_cpu_offload`, but performance is lower.
"""
if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
from accelerate import cpu_offload
else:
raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
device = torch.device(f"cuda:{gpu_id}")
if self.device.type != "cpu":
self.to("cpu", silence_dtype_warnings=True)
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
cpu_offload(cpu_offloaded_model, device)
if self.safety_checker is not None:
cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_model_cpu_offload
def enable_model_cpu_offload(self, gpu_id=0):
r"""
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
"""
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
from accelerate import cpu_offload_with_hook
else:
raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
device = torch.device(f"cuda:{gpu_id}")
if self.device.type != "cpu":
self.to("cpu", silence_dtype_warnings=True)
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
hook = None
for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
if self.safety_checker is not None:
_, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
# We'll offload the last model manually.
self.final_offload_hook = hook
@property
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if not hasattr(self.unet, "_hf_hook"):
return self.device
for module in self.unet.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
max_embeddings_multiples=3,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `list(int)`):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
max_embeddings_multiples (`int`, *optional*, defaults to `3`):
The max multiple length of prompt embeddings compared to the max output length of text encoder.
"""
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if negative_prompt_embeds is None:
if negative_prompt is None:
negative_prompt = [""] * batch_size
elif isinstance(negative_prompt, str):
negative_prompt = [negative_prompt] * batch_size
if batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
if prompt_embeds is None or negative_prompt_embeds is None:
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
if do_classifier_free_guidance and negative_prompt_embeds is None:
negative_prompt = self.maybe_convert_prompt(negative_prompt, self.tokenizer)
prompt_embeds1, negative_prompt_embeds1 = get_weighted_text_embeddings(
pipe=self,
prompt=prompt,
uncond_prompt=negative_prompt if do_classifier_free_guidance else None,
max_embeddings_multiples=max_embeddings_multiples,
)
if prompt_embeds is None:
prompt_embeds = prompt_embeds1
if negative_prompt_embeds is None:
negative_prompt_embeds = negative_prompt_embeds1
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
if do_classifier_free_guidance:
bs_embed, seq_len, _ = negative_prompt_embeds.shape
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
def check_inputs(
self,
prompt,
height,
width,
strength,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if strength < 0 or strength > 1:
raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
def get_timesteps(self, num_inference_steps, strength, device, is_text2img):
if is_text2img:
return self.scheduler.timesteps.to(device), num_inference_steps
else:
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
return timesteps, num_inference_steps - t_start
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
else:
has_nsfw_concept = None
return image, has_nsfw_concept
def decode_latents(self, latents):
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def prepare_latents(
self,
image,
timestep,
num_images_per_prompt,
batch_size,
num_channels_latents,
height,
width,
dtype,
device,
generator,
latents=None,
):
if image is None:
batch_size = batch_size * num_images_per_prompt
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents, None, None
else:
image = image.to(device=self.device, dtype=dtype)
init_latent_dist = self.vae.encode(image).latent_dist
init_latents = init_latent_dist.sample(generator=generator)
init_latents = self.vae.config.scaling_factor * init_latents
# Expand init_latents for batch_size and num_images_per_prompt
init_latents = torch.cat([init_latents] * num_images_per_prompt, dim=0)
init_latents_orig = init_latents
# add noise to latents using the timesteps
noise = randn_tensor(init_latents.shape, generator=generator, device=self.device, dtype=dtype)
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
latents = init_latents
return latents, init_latents_orig, noise
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
negative_prompt: Optional[Union[str, List[str]]] = None,
image: Union[torch.FloatTensor, PIL.Image.Image] = None,
mask_image: Union[torch.FloatTensor, PIL.Image.Image] = None,
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
strength: float = 0.8,
num_images_per_prompt: Optional[int] = 1,
add_predicted_noise: Optional[bool] = False,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
max_embeddings_multiples: Optional[int] = 3,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
is_cancelled_callback: Optional[Callable[[], bool]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
image (`torch.FloatTensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, that will be used as the starting point for the
process.
mask_image (`torch.FloatTensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
PIL image, it will be converted to a single channel (luminance) before use. If it's a tensor, it should
contain one color channel (L) instead of 3, so the expected shape would be `(B, H, W, 1)`.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
strength (`float`, *optional*, defaults to 0.8):
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1.
`image` will be used as a starting point, adding more noise to it the larger the `strength`. The
number of denoising steps depends on the amount of noise initially added. When `strength` is 1, added
noise will be maximum and the denoising process will run for the full number of iterations specified in
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
add_predicted_noise (`bool`, *optional*, defaults to True):
Use predicted noise instead of random noise when constructing noisy versions of the original image in
the reverse diffusion process
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
max_embeddings_multiples (`int`, *optional*, defaults to `3`):
The max multiple length of prompt embeddings compared to the max output length of text encoder.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
is_cancelled_callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. If the function returns
`True`, the inference will be cancelled.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
Returns:
`None` if cancelled by `is_cancelled_callback`,
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt, height, width, strength, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
max_embeddings_multiples,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
dtype = prompt_embeds.dtype
# 4. Preprocess image and mask
if isinstance(image, PIL.Image.Image):
image = preprocess_image(image, batch_size)
if image is not None:
image = image.to(device=self.device, dtype=dtype)
if isinstance(mask_image, PIL.Image.Image):
mask_image = preprocess_mask(mask_image, batch_size, self.vae_scale_factor)
if mask_image is not None:
mask = mask_image.to(device=self.device, dtype=dtype)
mask = torch.cat([mask] * num_images_per_prompt)
else:
mask = None
# 5. set timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device, image is None)
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# 6. Prepare latent variables
latents, init_latents_orig, noise = self.prepare_latents(
image,
latent_timestep,
num_images_per_prompt,
batch_size,
self.unet.config.in_channels,
height,
width,
dtype,
device,
generator,
latents,
)
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 8. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
if mask is not None:
# masking
if add_predicted_noise:
init_latents_proper = self.scheduler.add_noise(
init_latents_orig, noise_pred_uncond, torch.tensor([t])
)
else:
init_latents_proper = self.scheduler.add_noise(init_latents_orig, noise, torch.tensor([t]))
latents = (init_latents_proper * mask) + (latents * (1 - mask))
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if i % callback_steps == 0:
if callback is not None:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if is_cancelled_callback is not None and is_cancelled_callback():
return None
if output_type == "latent":
image = latents
has_nsfw_concept = None
elif output_type == "pil":
# 9. Post-processing
image = self.decode_latents(latents)
# 10. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
# 11. Convert to PIL
image = self.numpy_to_pil(image)
else:
# 9. Post-processing
image = self.decode_latents(latents)
# 10. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return image, has_nsfw_concept
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
def text2img(
self,
prompt: Union[str, List[str]],
negative_prompt: Optional[Union[str, List[str]]] = None,
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
max_embeddings_multiples: Optional[int] = 3,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
is_cancelled_callback: Optional[Callable[[], bool]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
):
r"""
Function for text-to-image generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
max_embeddings_multiples (`int`, *optional*, defaults to `3`):
The max multiple length of prompt embeddings compared to the max output length of text encoder.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
is_cancelled_callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. If the function returns
`True`, the inference will be cancelled.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
Returns:
`None` if cancelled by `is_cancelled_callback`,
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
return self.__call__(
prompt=prompt,
negative_prompt=negative_prompt,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
latents=latents,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
max_embeddings_multiples=max_embeddings_multiples,
output_type=output_type,
return_dict=return_dict,
callback=callback,
is_cancelled_callback=is_cancelled_callback,
callback_steps=callback_steps,
cross_attention_kwargs=cross_attention_kwargs,
)
def img2img(
self,
image: Union[torch.FloatTensor, PIL.Image.Image],
prompt: Union[str, List[str]],
negative_prompt: Optional[Union[str, List[str]]] = None,
strength: float = 0.8,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
num_images_per_prompt: Optional[int] = 1,
eta: Optional[float] = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
max_embeddings_multiples: Optional[int] = 3,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
is_cancelled_callback: Optional[Callable[[], bool]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
):
r"""
Function for image-to-image generation.
Args:
image (`torch.FloatTensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, that will be used as the starting point for the
process.
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
strength (`float`, *optional*, defaults to 0.8):
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1.
`image` will be used as a starting point, adding more noise to it the larger the `strength`. The
number of denoising steps depends on the amount of noise initially added. When `strength` is 1, added
noise will be maximum and the denoising process will run for the full number of iterations specified in
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. This parameter will be modulated by `strength`.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
max_embeddings_multiples (`int`, *optional*, defaults to `3`):
The max multiple length of prompt embeddings compared to the max output length of text encoder.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
is_cancelled_callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. If the function returns
`True`, the inference will be cancelled.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
Returns:
`None` if cancelled by `is_cancelled_callback`,
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
return self.__call__(
prompt=prompt,
negative_prompt=negative_prompt,
image=image,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
strength=strength,
num_images_per_prompt=num_images_per_prompt,
eta=eta,
generator=generator,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
max_embeddings_multiples=max_embeddings_multiples,
output_type=output_type,
return_dict=return_dict,
callback=callback,
is_cancelled_callback=is_cancelled_callback,
callback_steps=callback_steps,
cross_attention_kwargs=cross_attention_kwargs,
)
def inpaint(
self,
image: Union[torch.FloatTensor, PIL.Image.Image],
mask_image: Union[torch.FloatTensor, PIL.Image.Image],
prompt: Union[str, List[str]],
negative_prompt: Optional[Union[str, List[str]]] = None,
strength: float = 0.8,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
num_images_per_prompt: Optional[int] = 1,
add_predicted_noise: Optional[bool] = False,
eta: Optional[float] = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
max_embeddings_multiples: Optional[int] = 3,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
is_cancelled_callback: Optional[Callable[[], bool]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
):
r"""
Function for inpaint.
Args:
image (`torch.FloatTensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, that will be used as the starting point for the
process. This is the image whose masked region will be inpainted.
mask_image (`torch.FloatTensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
PIL image, it will be converted to a single channel (luminance) before use. If it's a tensor, it should
contain one color channel (L) instead of 3, so the expected shape would be `(B, H, W, 1)`.
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
strength (`float`, *optional*, defaults to 0.8):
Conceptually, indicates how much to inpaint the masked area. Must be between 0 and 1. When `strength`
is 1, the denoising process will be run on the masked area for the full number of iterations specified
in `num_inference_steps`. `image` will be used as a reference for the masked area, adding more
noise to that region the larger the `strength`. If `strength` is 0, no inpainting will occur.
num_inference_steps (`int`, *optional*, defaults to 50):
The reference number of denoising steps. More denoising steps usually lead to a higher quality image at
the expense of slower inference. This parameter will be modulated by `strength`, as explained above.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
add_predicted_noise (`bool`, *optional*, defaults to True):
Use predicted noise instead of random noise when constructing noisy versions of the original image in
the reverse diffusion process
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
max_embeddings_multiples (`int`, *optional*, defaults to `3`):
The max multiple length of prompt embeddings compared to the max output length of text encoder.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
is_cancelled_callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. If the function returns
`True`, the inference will be cancelled.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
Returns:
`None` if cancelled by `is_cancelled_callback`,
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
return self.__call__(
prompt=prompt,
negative_prompt=negative_prompt,
image=image,
mask_image=mask_image,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
strength=strength,
num_images_per_prompt=num_images_per_prompt,
add_predicted_noise=add_predicted_noise,
eta=eta,
generator=generator,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
max_embeddings_multiples=max_embeddings_multiples,
output_type=output_type,
return_dict=return_dict,
callback=callback,
is_cancelled_callback=is_cancelled_callback,
callback_steps=callback_steps,
cross_attention_kwargs=cross_attention_kwargs,
)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/masked_stable_diffusion_img2img.py
|
from typing import Any, Callable, Dict, List, Optional, Union
import numpy as np
import PIL.Image
import torch
from diffusers import StableDiffusionImg2ImgPipeline
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
class MaskedStableDiffusionImg2ImgPipeline(StableDiffusionImg2ImgPipeline):
debug_save = False
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: Union[
torch.FloatTensor,
PIL.Image.Image,
np.ndarray,
List[torch.FloatTensor],
List[PIL.Image.Image],
List[np.ndarray],
] = None,
strength: float = 0.8,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: Optional[float] = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
mask: Union[
torch.FloatTensor,
PIL.Image.Image,
np.ndarray,
List[torch.FloatTensor],
List[PIL.Image.Image],
List[np.ndarray],
] = None,
):
r"""
The call function to the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, or `List[np.ndarray]`):
`Image` or tensor representing an image batch to be used as the starting point. Can also accept image
latents as `image`, but if passing latents directly it is not encoded again.
strength (`float`, *optional*, defaults to 0.8):
Indicates extent to transform the reference `image`. Must be between 0 and 1. `image` is used as a
starting point and more noise is added the higher the `strength`. The number of denoising steps depends
on the amount of noise initially added. When `strength` is 1, added noise is maximum and the denoising
process runs for the full number of iterations specified in `num_inference_steps`. A value of 1
essentially ignores `image`.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. This parameter is modulated by `strength`.
guidance_scale (`float`, *optional*, defaults to 7.5):
A higher guidance scale value encourages the model to generate images closely linked to the text
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
provided, text embeddings are generated from the `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that calls every `callback_steps` steps during inference. The function is called with the
following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function is called. If not specified, the callback is called at
every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
mask (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, or `List[np.ndarray]`, *optional*):
A mask with non-zero elements for the area to be inpainted. If not specified, no mask is applied.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
otherwise a `tuple` is returned where the first element is a list with the generated images and the
second element is a list of `bool`s indicating whether the corresponding generated image contains
"not-safe-for-work" (nsfw) content.
"""
# code adapted from parent class StableDiffusionImg2ImgPipeline
# 0. Check inputs. Raise error if not correct
self.check_inputs(prompt, strength, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds)
# 1. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 2. Encode input prompt
text_encoder_lora_scale = (
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
)
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=text_encoder_lora_scale,
)
# 3. Preprocess image
image = self.image_processor.preprocess(image)
# 4. set timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# 5. Prepare latent variables
# it is sampled from the latent distribution of the VAE
latents = self.prepare_latents(
image, latent_timestep, batch_size, num_images_per_prompt, prompt_embeds.dtype, device, generator
)
# mean of the latent distribution
init_latents = [
self.vae.encode(image.to(device=device, dtype=prompt_embeds.dtype)[i : i + 1]).latent_dist.mean
for i in range(batch_size)
]
init_latents = torch.cat(init_latents, dim=0)
# 6. create latent mask
latent_mask = self._make_latent_mask(latents, mask)
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 8. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
return_dict=False,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if latent_mask is not None:
latents = torch.lerp(init_latents * self.vae.config.scaling_factor, latents, latent_mask)
noise_pred = torch.lerp(torch.zeros_like(noise_pred), noise_pred, latent_mask)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if not output_type == "latent":
scaled = latents / self.vae.config.scaling_factor
if latent_mask is not None:
# scaled = latents / self.vae.config.scaling_factor * latent_mask + init_latents * (1 - latent_mask)
scaled = torch.lerp(init_latents, scaled, latent_mask)
image = self.vae.decode(scaled, return_dict=False)[0]
if self.debug_save:
image_gen = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image_gen = self.image_processor.postprocess(image_gen, output_type=output_type, do_denormalize=[True])
image_gen[0].save("from_latent.png")
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
def _make_latent_mask(self, latents, mask):
if mask is not None:
latent_mask = []
if not isinstance(mask, list):
tmp_mask = [mask]
else:
tmp_mask = mask
_, l_channels, l_height, l_width = latents.shape
for m in tmp_mask:
if not isinstance(m, PIL.Image.Image):
if len(m.shape) == 2:
m = m[..., np.newaxis]
if m.max() > 1:
m = m / 255.0
m = self.image_processor.numpy_to_pil(m)[0]
if m.mode != "L":
m = m.convert("L")
resized = self.image_processor.resize(m, l_height, l_width)
if self.debug_save:
resized.save("latent_mask.png")
latent_mask.append(np.repeat(np.array(resized)[np.newaxis, :, :], l_channels, axis=0))
latent_mask = torch.as_tensor(np.stack(latent_mask)).to(latents)
latent_mask = latent_mask / latent_mask.max()
return latent_mask
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_diffusion_reference.py
|
# Inspired by: https://github.com/Mikubill/sd-webui-controlnet/discussions/1236 and https://github.com/Mikubill/sd-webui-controlnet/discussions/1280
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from diffusers import StableDiffusionPipeline
from diffusers.models.attention import BasicTransformerBlock
from diffusers.models.unet_2d_blocks import CrossAttnDownBlock2D, CrossAttnUpBlock2D, DownBlock2D, UpBlock2D
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion import rescale_noise_cfg
from diffusers.utils import PIL_INTERPOLATION, logging
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
>>> from diffusers import UniPCMultistepScheduler
>>> from diffusers.utils import load_image
>>> input_image = load_image("https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png")
>>> pipe = StableDiffusionReferencePipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
safety_checker=None,
torch_dtype=torch.float16
).to('cuda:0')
>>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe_controlnet.scheduler.config)
>>> result_img = pipe(ref_image=input_image,
prompt="1girl",
num_inference_steps=20,
reference_attn=True,
reference_adain=True).images[0]
>>> result_img.show()
```
"""
def torch_dfs(model: torch.nn.Module):
result = [model]
for child in model.children():
result += torch_dfs(child)
return result
class StableDiffusionReferencePipeline(StableDiffusionPipeline):
def _default_height_width(self, height, width, image):
# NOTE: It is possible that a list of images have different
# dimensions for each image, so just checking the first image
# is not _exactly_ correct, but it is simple.
while isinstance(image, list):
image = image[0]
if height is None:
if isinstance(image, PIL.Image.Image):
height = image.height
elif isinstance(image, torch.Tensor):
height = image.shape[2]
height = (height // 8) * 8 # round down to nearest multiple of 8
if width is None:
if isinstance(image, PIL.Image.Image):
width = image.width
elif isinstance(image, torch.Tensor):
width = image.shape[3]
width = (width // 8) * 8 # round down to nearest multiple of 8
return height, width
def prepare_image(
self,
image,
width,
height,
batch_size,
num_images_per_prompt,
device,
dtype,
do_classifier_free_guidance=False,
guess_mode=False,
):
if not isinstance(image, torch.Tensor):
if isinstance(image, PIL.Image.Image):
image = [image]
if isinstance(image[0], PIL.Image.Image):
images = []
for image_ in image:
image_ = image_.convert("RGB")
image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
image_ = np.array(image_)
image_ = image_[None, :]
images.append(image_)
image = images
image = np.concatenate(image, axis=0)
image = np.array(image).astype(np.float32) / 255.0
image = (image - 0.5) / 0.5
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
elif isinstance(image[0], torch.Tensor):
image = torch.cat(image, dim=0)
image_batch_size = image.shape[0]
if image_batch_size == 1:
repeat_by = batch_size
else:
# image batch size is the same as prompt batch size
repeat_by = num_images_per_prompt
image = image.repeat_interleave(repeat_by, dim=0)
image = image.to(device=device, dtype=dtype)
if do_classifier_free_guidance and not guess_mode:
image = torch.cat([image] * 2)
return image
def prepare_ref_latents(self, refimage, batch_size, dtype, device, generator, do_classifier_free_guidance):
refimage = refimage.to(device=device, dtype=dtype)
# encode the mask image into latents space so we can concatenate it to the latents
if isinstance(generator, list):
ref_image_latents = [
self.vae.encode(refimage[i : i + 1]).latent_dist.sample(generator=generator[i])
for i in range(batch_size)
]
ref_image_latents = torch.cat(ref_image_latents, dim=0)
else:
ref_image_latents = self.vae.encode(refimage).latent_dist.sample(generator=generator)
ref_image_latents = self.vae.config.scaling_factor * ref_image_latents
# duplicate mask and ref_image_latents for each generation per prompt, using mps friendly method
if ref_image_latents.shape[0] < batch_size:
if not batch_size % ref_image_latents.shape[0] == 0:
raise ValueError(
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
f" to a total batch size of {batch_size}, but {ref_image_latents.shape[0]} images were passed."
" Make sure the number of images that you pass is divisible by the total requested batch size."
)
ref_image_latents = ref_image_latents.repeat(batch_size // ref_image_latents.shape[0], 1, 1, 1)
# aligning device to prevent device errors when concating it with the latent model input
ref_image_latents = ref_image_latents.to(device=device, dtype=dtype)
return ref_image_latents
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
ref_image: Union[torch.FloatTensor, PIL.Image.Image] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
guidance_rescale: float = 0.0,
attention_auto_machine_weight: float = 1.0,
gn_auto_machine_weight: float = 1.0,
style_fidelity: float = 0.5,
reference_attn: bool = True,
reference_adain: bool = True,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
ref_image (`torch.FloatTensor`, `PIL.Image.Image`):
The Reference Control input condition. Reference Control uses this input condition to generate guidance to Unet. If
the type is specified as `Torch.FloatTensor`, it is passed to Reference Control as is. `PIL.Image.Image` can
also be accepted as an image.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
[Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
attention_auto_machine_weight (`float`):
Weight of using reference query for self attention's context.
If attention_auto_machine_weight=1.0, use reference query for all self attention's context.
gn_auto_machine_weight (`float`):
Weight of using reference adain. If gn_auto_machine_weight=2.0, use all reference adain plugins.
style_fidelity (`float`):
style fidelity of ref_uncond_xt. If style_fidelity=1.0, control more important,
elif style_fidelity=0.0, prompt more important, else balanced.
reference_attn (`bool`):
Whether to use reference query for self attention's context.
reference_adain (`bool`):
Whether to use reference adain.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
assert reference_attn or reference_adain, "`reference_attn` or `reference_adain` must be True."
# 0. Default height and width to unet
height, width = self._default_height_width(height, width, ref_image)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt, height, width, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
text_encoder_lora_scale = (
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
)
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=text_encoder_lora_scale,
)
# 4. Preprocess reference image
ref_image = self.prepare_image(
image=ref_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=prompt_embeds.dtype,
)
# 5. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 6. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 7. Prepare reference latent variables
ref_image_latents = self.prepare_ref_latents(
ref_image,
batch_size * num_images_per_prompt,
prompt_embeds.dtype,
device,
generator,
do_classifier_free_guidance,
)
# 8. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 9. Modify self attention and group norm
MODE = "write"
uc_mask = (
torch.Tensor([1] * batch_size * num_images_per_prompt + [0] * batch_size * num_images_per_prompt)
.type_as(ref_image_latents)
.bool()
)
def hacked_basic_transformer_inner_forward(
self,
hidden_states: torch.FloatTensor,
attention_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
timestep: Optional[torch.LongTensor] = None,
cross_attention_kwargs: Dict[str, Any] = None,
class_labels: Optional[torch.LongTensor] = None,
):
if self.use_ada_layer_norm:
norm_hidden_states = self.norm1(hidden_states, timestep)
elif self.use_ada_layer_norm_zero:
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(
hidden_states, timestep, class_labels, hidden_dtype=hidden_states.dtype
)
else:
norm_hidden_states = self.norm1(hidden_states)
# 1. Self-Attention
cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
if self.only_cross_attention:
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
else:
if MODE == "write":
self.bank.append(norm_hidden_states.detach().clone())
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
if MODE == "read":
if attention_auto_machine_weight > self.attn_weight:
attn_output_uc = self.attn1(
norm_hidden_states,
encoder_hidden_states=torch.cat([norm_hidden_states] + self.bank, dim=1),
# attention_mask=attention_mask,
**cross_attention_kwargs,
)
attn_output_c = attn_output_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
attn_output_c[uc_mask] = self.attn1(
norm_hidden_states[uc_mask],
encoder_hidden_states=norm_hidden_states[uc_mask],
**cross_attention_kwargs,
)
attn_output = style_fidelity * attn_output_c + (1.0 - style_fidelity) * attn_output_uc
self.bank.clear()
else:
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
if self.use_ada_layer_norm_zero:
attn_output = gate_msa.unsqueeze(1) * attn_output
hidden_states = attn_output + hidden_states
if self.attn2 is not None:
norm_hidden_states = (
self.norm2(hidden_states, timestep) if self.use_ada_layer_norm else self.norm2(hidden_states)
)
# 2. Cross-Attention
attn_output = self.attn2(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
**cross_attention_kwargs,
)
hidden_states = attn_output + hidden_states
# 3. Feed-forward
norm_hidden_states = self.norm3(hidden_states)
if self.use_ada_layer_norm_zero:
norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
ff_output = self.ff(norm_hidden_states)
if self.use_ada_layer_norm_zero:
ff_output = gate_mlp.unsqueeze(1) * ff_output
hidden_states = ff_output + hidden_states
return hidden_states
def hacked_mid_forward(self, *args, **kwargs):
eps = 1e-6
x = self.original_forward(*args, **kwargs)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(x, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append(mean)
self.var_bank.append(var)
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(x, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank) / float(len(self.mean_bank))
var_acc = sum(self.var_bank) / float(len(self.var_bank))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
x_uc = (((x - mean) / std) * std_acc) + mean_acc
x_c = x_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
x_c[uc_mask] = x[uc_mask]
x = style_fidelity * x_c + (1.0 - style_fidelity) * x_uc
self.mean_bank = []
self.var_bank = []
return x
def hack_CrossAttnDownBlock2D_forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
):
eps = 1e-6
# TODO(Patrick, William) - attention mask is not used
output_states = ()
for i, (resnet, attn) in enumerate(zip(self.resnets, self.attentions)):
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
output_states = output_states + (hidden_states,)
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
def hacked_DownBlock2D_forward(self, hidden_states, temb=None):
eps = 1e-6
output_states = ()
for i, resnet in enumerate(self.resnets):
hidden_states = resnet(hidden_states, temb)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
output_states = output_states + (hidden_states,)
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
def hacked_CrossAttnUpBlock2D_forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
upsample_size: Optional[int] = None,
attention_mask: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
):
eps = 1e-6
# TODO(Patrick, William) - attention mask is not used
for i, (resnet, attn) in enumerate(zip(self.resnets, self.attentions)):
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size)
return hidden_states
def hacked_UpBlock2D_forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None):
eps = 1e-6
for i, resnet in enumerate(self.resnets):
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
if MODE == "write":
if gn_auto_machine_weight >= self.gn_weight:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
self.mean_bank.append([mean])
self.var_bank.append([var])
if MODE == "read":
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
std = torch.maximum(var, torch.zeros_like(var) + eps) ** 0.5
mean_acc = sum(self.mean_bank[i]) / float(len(self.mean_bank[i]))
var_acc = sum(self.var_bank[i]) / float(len(self.var_bank[i]))
std_acc = torch.maximum(var_acc, torch.zeros_like(var_acc) + eps) ** 0.5
hidden_states_uc = (((hidden_states - mean) / std) * std_acc) + mean_acc
hidden_states_c = hidden_states_uc.clone()
if do_classifier_free_guidance and style_fidelity > 0:
hidden_states_c[uc_mask] = hidden_states[uc_mask]
hidden_states = style_fidelity * hidden_states_c + (1.0 - style_fidelity) * hidden_states_uc
if MODE == "read":
self.mean_bank = []
self.var_bank = []
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size)
return hidden_states
if reference_attn:
attn_modules = [module for module in torch_dfs(self.unet) if isinstance(module, BasicTransformerBlock)]
attn_modules = sorted(attn_modules, key=lambda x: -x.norm1.normalized_shape[0])
for i, module in enumerate(attn_modules):
module._original_inner_forward = module.forward
module.forward = hacked_basic_transformer_inner_forward.__get__(module, BasicTransformerBlock)
module.bank = []
module.attn_weight = float(i) / float(len(attn_modules))
if reference_adain:
gn_modules = [self.unet.mid_block]
self.unet.mid_block.gn_weight = 0
down_blocks = self.unet.down_blocks
for w, module in enumerate(down_blocks):
module.gn_weight = 1.0 - float(w) / float(len(down_blocks))
gn_modules.append(module)
up_blocks = self.unet.up_blocks
for w, module in enumerate(up_blocks):
module.gn_weight = float(w) / float(len(up_blocks))
gn_modules.append(module)
for i, module in enumerate(gn_modules):
if getattr(module, "original_forward", None) is None:
module.original_forward = module.forward
if i == 0:
# mid_block
module.forward = hacked_mid_forward.__get__(module, torch.nn.Module)
elif isinstance(module, CrossAttnDownBlock2D):
module.forward = hack_CrossAttnDownBlock2D_forward.__get__(module, CrossAttnDownBlock2D)
elif isinstance(module, DownBlock2D):
module.forward = hacked_DownBlock2D_forward.__get__(module, DownBlock2D)
elif isinstance(module, CrossAttnUpBlock2D):
module.forward = hacked_CrossAttnUpBlock2D_forward.__get__(module, CrossAttnUpBlock2D)
elif isinstance(module, UpBlock2D):
module.forward = hacked_UpBlock2D_forward.__get__(module, UpBlock2D)
module.mean_bank = []
module.var_bank = []
module.gn_weight *= 2
# 10. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# ref only part
noise = randn_tensor(
ref_image_latents.shape, generator=generator, device=device, dtype=ref_image_latents.dtype
)
ref_xt = self.scheduler.add_noise(
ref_image_latents,
noise,
t.reshape(
1,
),
)
ref_xt = torch.cat([ref_xt] * 2) if do_classifier_free_guidance else ref_xt
ref_xt = self.scheduler.scale_model_input(ref_xt, t)
MODE = "write"
self.unet(
ref_xt,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
return_dict=False,
)
# predict the noise residual
MODE = "read"
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
return_dict=False,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/latent_consistency_img2img.py
|
# Copyright 2023 Stanford University Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pytorch_diffusion
# and https://github.com/hojonathanho/diffusion
import math
from dataclasses import dataclass
from typing import Any, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, ConfigMixin, DiffusionPipeline, SchedulerMixin, UNet2DConditionModel, logging
from diffusers.configuration_utils import register_to_config
from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.utils import BaseOutput
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class LatentConsistencyModelImg2ImgPipeline(DiffusionPipeline):
_optional_components = ["scheduler"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: "LCMSchedulerWithTimestamp",
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
scheduler = (
scheduler
if scheduler is not None
else LCMSchedulerWithTimestamp(
beta_start=0.00085, beta_end=0.0120, beta_schedule="scaled_linear", prediction_type="epsilon"
)
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
prompt_embeds: None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
"""
if prompt is not None and isinstance(prompt, str):
pass
elif prompt is not None and isinstance(prompt, list):
len(prompt)
else:
prompt_embeds.shape[0]
if prompt_embeds is None:
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
prompt_embeds = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
prompt_embeds = prompt_embeds[0]
if self.text_encoder is not None:
prompt_embeds_dtype = self.text_encoder.dtype
elif self.unet is not None:
prompt_embeds_dtype = self.unet.dtype
else:
prompt_embeds_dtype = prompt_embeds.dtype
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# Don't need to get uncond prompt embedding because of LCM Guided Distillation
return prompt_embeds
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is None:
has_nsfw_concept = None
else:
if torch.is_tensor(image):
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
else:
feature_extractor_input = self.image_processor.numpy_to_pil(image)
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
return image, has_nsfw_concept
def prepare_latents(
self,
image,
timestep,
batch_size,
num_channels_latents,
height,
width,
dtype,
device,
latents=None,
generator=None,
):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
)
image = image.to(device=device, dtype=dtype)
# batch_size = batch_size * num_images_per_prompt
if image.shape[1] == 4:
init_latents = image
else:
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
elif isinstance(generator, list):
init_latents = [
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
]
init_latents = torch.cat(init_latents, dim=0)
else:
init_latents = self.vae.encode(image).latent_dist.sample(generator)
init_latents = self.vae.config.scaling_factor * init_latents
if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
# expand init_latents for batch_size
(
f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
" images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
" that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
" your script to pass as many initial images as text prompts to suppress this warning."
)
# deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
additional_image_per_prompt = batch_size // init_latents.shape[0]
init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
raise ValueError(
f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
)
else:
init_latents = torch.cat([init_latents], dim=0)
shape = init_latents.shape
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
# get latents
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
latents = init_latents
return latents
if latents is None:
latents = torch.randn(shape, dtype=dtype).to(device)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def get_w_embedding(self, w, embedding_dim=512, dtype=torch.float32):
"""
see https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
Args:
timesteps: torch.Tensor: generate embedding vectors at these timesteps
embedding_dim: int: dimension of the embeddings to generate
dtype: data type of the generated embeddings
Returns:
embedding vectors with shape `(len(timesteps), embedding_dim)`
"""
assert len(w.shape) == 1
w = w * 1000.0
half_dim = embedding_dim // 2
emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
emb = w.to(dtype)[:, None] * emb[None, :]
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
if embedding_dim % 2 == 1: # zero pad
emb = torch.nn.functional.pad(emb, (0, 1))
assert emb.shape == (w.shape[0], embedding_dim)
return emb
def get_timesteps(self, num_inference_steps, strength, device):
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
return timesteps, num_inference_steps - t_start
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: PipelineImageInput = None,
strength: float = 0.8,
height: Optional[int] = 768,
width: Optional[int] = 768,
guidance_scale: float = 7.5,
num_images_per_prompt: Optional[int] = 1,
latents: Optional[torch.FloatTensor] = None,
num_inference_steps: int = 4,
lcm_origin_steps: int = 50,
prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
):
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# do_classifier_free_guidance = guidance_scale > 0.0 # In LCM Implementation: cfg_noise = noise_cond + cfg_scale * (noise_cond - noise_uncond) , (cfg_scale > 0.0 using CFG)
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
prompt_embeds=prompt_embeds,
)
# 3.5 encode image
image = self.image_processor.preprocess(image)
# 4. Prepare timesteps
self.scheduler.set_timesteps(strength, num_inference_steps, lcm_origin_steps)
# timesteps = self.scheduler.timesteps
# timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, 1.0, device)
timesteps = self.scheduler.timesteps
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
print("timesteps: ", timesteps)
# 5. Prepare latent variable
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
image,
latent_timestep,
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
latents,
)
bs = batch_size * num_images_per_prompt
# 6. Get Guidance Scale Embedding
w = torch.tensor(guidance_scale).repeat(bs)
w_embedding = self.get_w_embedding(w, embedding_dim=256).to(device=device, dtype=latents.dtype)
# 7. LCM MultiStep Sampling Loop:
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
ts = torch.full((bs,), t, device=device, dtype=torch.long)
latents = latents.to(prompt_embeds.dtype)
# model prediction (v-prediction, eps, x)
model_pred = self.unet(
latents,
ts,
timestep_cond=w_embedding,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
return_dict=False,
)[0]
# compute the previous noisy sample x_t -> x_t-1
latents, denoised = self.scheduler.step(model_pred, i, t, latents, return_dict=False)
# # call the callback, if provided
# if i == len(timesteps) - 1:
progress_bar.update()
denoised = denoised.to(prompt_embeds.dtype)
if not output_type == "latent":
image = self.vae.decode(denoised / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = denoised
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
@dataclass
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->DDIM
class LCMSchedulerOutput(BaseOutput):
"""
Output class for the scheduler's `step` function output.
Args:
prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
Computed sample `(x_{t-1})` of previous timestep. `prev_sample` should be used as next model input in the
denoising loop.
pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
The predicted denoised sample `(x_{0})` based on the model output from the current timestep.
`pred_original_sample` can be used to preview progress or for guidance.
"""
prev_sample: torch.FloatTensor
denoised: Optional[torch.FloatTensor] = None
# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
def betas_for_alpha_bar(
num_diffusion_timesteps,
max_beta=0.999,
alpha_transform_type="cosine",
):
"""
Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
(1-beta) over time from t = [0,1].
Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
to that part of the diffusion process.
Args:
num_diffusion_timesteps (`int`): the number of betas to produce.
max_beta (`float`): the maximum beta to use; use values lower than 1 to
prevent singularities.
alpha_transform_type (`str`, *optional*, default to `cosine`): the type of noise schedule for alpha_bar.
Choose from `cosine` or `exp`
Returns:
betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
"""
if alpha_transform_type == "cosine":
def alpha_bar_fn(t):
return math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2
elif alpha_transform_type == "exp":
def alpha_bar_fn(t):
return math.exp(t * -12.0)
else:
raise ValueError(f"Unsupported alpha_tranform_type: {alpha_transform_type}")
betas = []
for i in range(num_diffusion_timesteps):
t1 = i / num_diffusion_timesteps
t2 = (i + 1) / num_diffusion_timesteps
betas.append(min(1 - alpha_bar_fn(t2) / alpha_bar_fn(t1), max_beta))
return torch.tensor(betas, dtype=torch.float32)
def rescale_zero_terminal_snr(betas):
"""
Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
Args:
betas (`torch.FloatTensor`):
the betas that the scheduler is being initialized with.
Returns:
`torch.FloatTensor`: rescaled betas with zero terminal SNR
"""
# Convert betas to alphas_bar_sqrt
alphas = 1.0 - betas
alphas_cumprod = torch.cumprod(alphas, dim=0)
alphas_bar_sqrt = alphas_cumprod.sqrt()
# Store old values.
alphas_bar_sqrt_0 = alphas_bar_sqrt[0].clone()
alphas_bar_sqrt_T = alphas_bar_sqrt[-1].clone()
# Shift so the last timestep is zero.
alphas_bar_sqrt -= alphas_bar_sqrt_T
# Scale so the first timestep is back to the old value.
alphas_bar_sqrt *= alphas_bar_sqrt_0 / (alphas_bar_sqrt_0 - alphas_bar_sqrt_T)
# Convert alphas_bar_sqrt to betas
alphas_bar = alphas_bar_sqrt**2 # Revert sqrt
alphas = alphas_bar[1:] / alphas_bar[:-1] # Revert cumprod
alphas = torch.cat([alphas_bar[0:1], alphas])
betas = 1 - alphas
return betas
class LCMSchedulerWithTimestamp(SchedulerMixin, ConfigMixin):
"""
This class modifies LCMScheduler to add a timestamp argument to set_timesteps
`LCMScheduler` extends the denoising procedure introduced in denoising diffusion probabilistic models (DDPMs) with
non-Markovian guidance.
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. Check the superclass documentation for the generic
methods the library implements for all schedulers such as loading and saving.
Args:
num_train_timesteps (`int`, defaults to 1000):
The number of diffusion steps to train the model.
beta_start (`float`, defaults to 0.0001):
The starting `beta` value of inference.
beta_end (`float`, defaults to 0.02):
The final `beta` value.
beta_schedule (`str`, defaults to `"linear"`):
The beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
`linear`, `scaled_linear`, or `squaredcos_cap_v2`.
trained_betas (`np.ndarray`, *optional*):
Pass an array of betas directly to the constructor to bypass `beta_start` and `beta_end`.
clip_sample (`bool`, defaults to `True`):
Clip the predicted sample for numerical stability.
clip_sample_range (`float`, defaults to 1.0):
The maximum magnitude for sample clipping. Valid only when `clip_sample=True`.
set_alpha_to_one (`bool`, defaults to `True`):
Each diffusion step uses the alphas product value at that step and at the previous one. For the final step
there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
otherwise it uses the alpha value at step 0.
steps_offset (`int`, defaults to 0):
An offset added to the inference steps. You can use a combination of `offset=1` and
`set_alpha_to_one=False` to make the last step use step 0 for the previous alpha product like in Stable
Diffusion.
prediction_type (`str`, defaults to `epsilon`, *optional*):
Prediction type of the scheduler function; can be `epsilon` (predicts the noise of the diffusion process),
`sample` (directly predicts the noisy sample`) or `v_prediction` (see section 2.4 of [Imagen
Video](https://imagen.research.google/video/paper.pdf) paper).
thresholding (`bool`, defaults to `False`):
Whether to use the "dynamic thresholding" method. This is unsuitable for latent-space diffusion models such
as Stable Diffusion.
dynamic_thresholding_ratio (`float`, defaults to 0.995):
The ratio for the dynamic thresholding method. Valid only when `thresholding=True`.
sample_max_value (`float`, defaults to 1.0):
The threshold value for dynamic thresholding. Valid only when `thresholding=True`.
timestep_spacing (`str`, defaults to `"leading"`):
The way the timesteps should be scaled. Refer to Table 2 of the [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
rescale_betas_zero_snr (`bool`, defaults to `False`):
Whether to rescale the betas to have zero terminal SNR. This enables the model to generate very bright and
dark samples instead of limiting it to samples with medium brightness. Loosely related to
[`--offset_noise`](https://github.com/huggingface/diffusers/blob/74fd735eb073eb1d774b1ab4154a0876eb82f055/examples/dreambooth/train_dreambooth.py#L506).
"""
# _compatibles = [e.name for e in KarrasDiffusionSchedulers]
order = 1
@register_to_config
def __init__(
self,
num_train_timesteps: int = 1000,
beta_start: float = 0.0001,
beta_end: float = 0.02,
beta_schedule: str = "linear",
trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
clip_sample: bool = True,
set_alpha_to_one: bool = True,
steps_offset: int = 0,
prediction_type: str = "epsilon",
thresholding: bool = False,
dynamic_thresholding_ratio: float = 0.995,
clip_sample_range: float = 1.0,
sample_max_value: float = 1.0,
timestep_spacing: str = "leading",
rescale_betas_zero_snr: bool = False,
):
if trained_betas is not None:
self.betas = torch.tensor(trained_betas, dtype=torch.float32)
elif beta_schedule == "linear":
self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
elif beta_schedule == "scaled_linear":
# this schedule is very specific to the latent diffusion model.
self.betas = torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
elif beta_schedule == "squaredcos_cap_v2":
# Glide cosine schedule
self.betas = betas_for_alpha_bar(num_train_timesteps)
else:
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
# Rescale for zero SNR
if rescale_betas_zero_snr:
self.betas = rescale_zero_terminal_snr(self.betas)
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
# At every step in ddim, we are looking into the previous alphas_cumprod
# For the final step, there is no previous alphas_cumprod because we are already at 0
# `set_alpha_to_one` decides whether we set this parameter simply to one or
# whether we use the final alpha of the "non-previous" one.
self.final_alpha_cumprod = torch.tensor(1.0) if set_alpha_to_one else self.alphas_cumprod[0]
# standard deviation of the initial noise distribution
self.init_noise_sigma = 1.0
# setable values
self.num_inference_steps = None
self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps)[::-1].copy().astype(np.int64))
def scale_model_input(self, sample: torch.FloatTensor, timestep: Optional[int] = None) -> torch.FloatTensor:
"""
Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
current timestep.
Args:
sample (`torch.FloatTensor`):
The input sample.
timestep (`int`, *optional*):
The current timestep in the diffusion chain.
Returns:
`torch.FloatTensor`:
A scaled input sample.
"""
return sample
def _get_variance(self, timestep, prev_timestep):
alpha_prod_t = self.alphas_cumprod[timestep]
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
return variance
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler._threshold_sample
def _threshold_sample(self, sample: torch.FloatTensor) -> torch.FloatTensor:
"""
"Dynamic thresholding: At each sampling step we set s to a certain percentile absolute pixel value in xt0 (the
prediction of x_0 at timestep t), and if s > 1, then we threshold xt0 to the range [-s, s] and then divide by
s. Dynamic thresholding pushes saturated pixels (those near -1 and 1) inwards, thereby actively preventing
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
https://arxiv.org/abs/2205.11487
"""
dtype = sample.dtype
batch_size, channels, height, width = sample.shape
if dtype not in (torch.float32, torch.float64):
sample = sample.float() # upcast for quantile calculation, and clamp not implemented for cpu half
# Flatten sample for doing quantile calculation along each image
sample = sample.reshape(batch_size, channels * height * width)
abs_sample = sample.abs() # "a certain percentile absolute pixel value"
s = torch.quantile(abs_sample, self.config.dynamic_thresholding_ratio, dim=1)
s = torch.clamp(
s, min=1, max=self.config.sample_max_value
) # When clamped to min=1, equivalent to standard clipping to [-1, 1]
s = s.unsqueeze(1) # (batch_size, 1) because clamp will broadcast along dim=0
sample = torch.clamp(sample, -s, s) / s # "we threshold xt0 to the range [-s, s] and then divide by s"
sample = sample.reshape(batch_size, channels, height, width)
sample = sample.to(dtype)
return sample
def set_timesteps(
self, stength, num_inference_steps: int, lcm_origin_steps: int, device: Union[str, torch.device] = None
):
"""
Sets the discrete timesteps used for the diffusion chain (to be run before inference).
Args:
num_inference_steps (`int`):
The number of diffusion steps used when generating samples with a pre-trained model.
"""
if num_inference_steps > self.config.num_train_timesteps:
raise ValueError(
f"`num_inference_steps`: {num_inference_steps} cannot be larger than `self.config.train_timesteps`:"
f" {self.config.num_train_timesteps} as the unet model trained with this scheduler can only handle"
f" maximal {self.config.num_train_timesteps} timesteps."
)
self.num_inference_steps = num_inference_steps
# LCM Timesteps Setting: # Linear Spacing
c = self.config.num_train_timesteps // lcm_origin_steps
lcm_origin_timesteps = (
np.asarray(list(range(1, int(lcm_origin_steps * stength) + 1))) * c - 1
) # LCM Training Steps Schedule
skipping_step = len(lcm_origin_timesteps) // num_inference_steps
timesteps = lcm_origin_timesteps[::-skipping_step][:num_inference_steps] # LCM Inference Steps Schedule
self.timesteps = torch.from_numpy(timesteps.copy()).to(device)
def get_scalings_for_boundary_condition_discrete(self, t):
self.sigma_data = 0.5 # Default: 0.5
# By dividing 0.1: This is almost a delta function at t=0.
c_skip = self.sigma_data**2 / ((t / 0.1) ** 2 + self.sigma_data**2)
c_out = (t / 0.1) / ((t / 0.1) ** 2 + self.sigma_data**2) ** 0.5
return c_skip, c_out
def step(
self,
model_output: torch.FloatTensor,
timeindex: int,
timestep: int,
sample: torch.FloatTensor,
eta: float = 0.0,
use_clipped_model_output: bool = False,
generator=None,
variance_noise: Optional[torch.FloatTensor] = None,
return_dict: bool = True,
) -> Union[LCMSchedulerOutput, Tuple]:
"""
Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
process from the learned model outputs (most often the predicted noise).
Args:
model_output (`torch.FloatTensor`):
The direct output from learned diffusion model.
timestep (`float`):
The current discrete timestep in the diffusion chain.
sample (`torch.FloatTensor`):
A current instance of a sample created by the diffusion process.
eta (`float`):
The weight of noise for added noise in diffusion step.
use_clipped_model_output (`bool`, defaults to `False`):
If `True`, computes "corrected" `model_output` from the clipped predicted original sample. Necessary
because predicted original sample is clipped to [-1, 1] when `self.config.clip_sample` is `True`. If no
clipping has happened, "corrected" `model_output` would coincide with the one provided as input and
`use_clipped_model_output` has no effect.
generator (`torch.Generator`, *optional*):
A random number generator.
variance_noise (`torch.FloatTensor`):
Alternative to generating noise with `generator` by directly providing the noise for the variance
itself. Useful for methods such as [`CycleDiffusion`].
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~schedulers.scheduling_lcm.LCMSchedulerOutput`] or `tuple`.
Returns:
[`~schedulers.scheduling_utils.LCMSchedulerOutput`] or `tuple`:
If return_dict is `True`, [`~schedulers.scheduling_lcm.LCMSchedulerOutput`] is returned, otherwise a
tuple is returned where the first element is the sample tensor.
"""
if self.num_inference_steps is None:
raise ValueError(
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
# 1. get previous step value
prev_timeindex = timeindex + 1
if prev_timeindex < len(self.timesteps):
prev_timestep = self.timesteps[prev_timeindex]
else:
prev_timestep = timestep
# 2. compute alphas, betas
alpha_prod_t = self.alphas_cumprod[timestep]
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
# 3. Get scalings for boundary conditions
c_skip, c_out = self.get_scalings_for_boundary_condition_discrete(timestep)
# 4. Different Parameterization:
parameterization = self.config.prediction_type
if parameterization == "epsilon": # noise-prediction
pred_x0 = (sample - beta_prod_t.sqrt() * model_output) / alpha_prod_t.sqrt()
elif parameterization == "sample": # x-prediction
pred_x0 = model_output
elif parameterization == "v_prediction": # v-prediction
pred_x0 = alpha_prod_t.sqrt() * sample - beta_prod_t.sqrt() * model_output
# 4. Denoise model output using boundary conditions
denoised = c_out * pred_x0 + c_skip * sample
# 5. Sample z ~ N(0, I), For MultiStep Inference
# Noise is not used for one-step sampling.
if len(self.timesteps) > 1:
noise = torch.randn(model_output.shape).to(model_output.device)
prev_sample = alpha_prod_t_prev.sqrt() * denoised + beta_prod_t_prev.sqrt() * noise
else:
prev_sample = denoised
if not return_dict:
return (prev_sample, denoised)
return LCMSchedulerOutput(prev_sample=prev_sample, denoised=denoised)
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.add_noise
def add_noise(
self,
original_samples: torch.FloatTensor,
noise: torch.FloatTensor,
timesteps: torch.IntTensor,
) -> torch.FloatTensor:
# Make sure alphas_cumprod and timestep have same device and dtype as original_samples
alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
timesteps = timesteps.to(original_samples.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
return noisy_samples
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.get_velocity
def get_velocity(
self, sample: torch.FloatTensor, noise: torch.FloatTensor, timesteps: torch.IntTensor
) -> torch.FloatTensor:
# Make sure alphas_cumprod and timestep have same device and dtype as sample
alphas_cumprod = self.alphas_cumprod.to(device=sample.device, dtype=sample.dtype)
timesteps = timesteps.to(sample.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(sample.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(sample.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
velocity = sqrt_alpha_prod * noise - sqrt_one_minus_alpha_prod * sample
return velocity
def __len__(self):
return self.config.num_train_timesteps
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/pipeline_fabric.py
|
# Copyright 2023 FABRIC authors and the HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import List, Optional, Union
import torch
from packaging import version
from PIL import Image
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel
from diffusers.configuration_utils import FrozenDict
from diffusers.image_processor import VaeImageProcessor
from diffusers.loaders import LoraLoaderMixin, TextualInversionLoaderMixin
from diffusers.models.attention import BasicTransformerBlock
from diffusers.models.attention_processor import LoRAAttnProcessor
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.schedulers import EulerAncestralDiscreteScheduler, KarrasDiffusionSchedulers
from diffusers.utils import (
deprecate,
logging,
replace_example_docstring,
)
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> from diffusers import DiffusionPipeline
>>> import torch
>>> model_id = "dreamlike-art/dreamlike-photoreal-2.0"
>>> pipe = DiffusionPipeline(model_id, torch_dtype=torch.float16, custom_pipeline="pipeline_fabric")
>>> pipe = pipe.to("cuda")
>>> prompt = "a giant standing in a fantasy landscape best quality"
>>> liked = [] # list of images for positive feedback
>>> disliked = [] # list of images for negative feedback
>>> image = pipe(prompt, num_images=4, liked=liked, disliked=disliked).images[0]
```
"""
class FabricCrossAttnProcessor:
def __init__(self):
self.attntion_probs = None
def __call__(
self,
attn,
hidden_states,
encoder_hidden_states=None,
attention_mask=None,
weights=None,
lora_scale=1.0,
):
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if isinstance(attn.processor, LoRAAttnProcessor):
query = attn.to_q(hidden_states) + lora_scale * attn.processor.to_q_lora(hidden_states)
else:
query = attn.to_q(hidden_states)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
if isinstance(attn.processor, LoRAAttnProcessor):
key = attn.to_k(encoder_hidden_states) + lora_scale * attn.processor.to_k_lora(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states) + lora_scale * attn.processor.to_v_lora(encoder_hidden_states)
else:
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
query = attn.head_to_batch_dim(query)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
attention_probs = attn.get_attention_scores(query, key, attention_mask)
if weights is not None:
if weights.shape[0] != 1:
weights = weights.repeat_interleave(attn.heads, dim=0)
attention_probs = attention_probs * weights[:, None]
attention_probs = attention_probs / attention_probs.sum(dim=-1, keepdim=True)
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
if isinstance(attn.processor, LoRAAttnProcessor):
hidden_states = attn.to_out[0](hidden_states) + lora_scale * attn.processor.to_out_lora(hidden_states)
else:
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
return hidden_states
class FabricPipeline(DiffusionPipeline):
r"""
Pipeline for text-to-image generation using Stable Diffusion and conditioning the results using feedback images.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`~transformers.CLIPTextModel`]):
Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
tokenizer ([`~transformers.CLIPTokenizer`]):
A `CLIPTokenizer` to tokenize text.
unet ([`UNet2DConditionModel`]):
A `UNet2DConditionModel` to denoise the encoded image latents.
scheduler ([`EulerAncestralDiscreteScheduler`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for more details
about a model's potential harms.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
requires_safety_checker: bool = True,
):
super().__init__()
is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
version.parse(unet.config._diffusers_version).base_version
) < version.parse("0.9.0.dev0")
is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
deprecation_message = (
"The configuration file of the unet has set the default `sample_size` to smaller than"
" 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
" following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
" CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
" \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
" configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
" in the config might lead to incorrect results in future versions. If you have downloaded this"
" checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
" the `unet/config.json` file"
)
deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(unet.config)
new_config["sample_size"] = 64
unet._internal_dict = FrozenDict(new_config)
self.register_modules(
unet=unet,
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
scheduler=scheduler,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
lora_scale (`float`, *optional*):
A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
"""
# set lora scale so that monkey patched LoRA
# function of text encoder can correctly access it
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
self._lora_scale = lora_scale
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# textual inversion: procecss multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
prompt_embeds = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
prompt_embeds = prompt_embeds[0]
if self.text_encoder is not None:
prompt_embeds_dtype = self.text_encoder.dtype
elif self.unet is not None:
prompt_embeds_dtype = self.unet.dtype
else:
prompt_embeds_dtype = prompt_embeds.dtype
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif prompt is not None and type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
# textual inversion: procecss multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
def get_unet_hidden_states(self, z_all, t, prompt_embd):
cached_hidden_states = []
for module in self.unet.modules():
if isinstance(module, BasicTransformerBlock):
def new_forward(self, hidden_states, *args, **kwargs):
cached_hidden_states.append(hidden_states.clone().detach().cpu())
return self.old_forward(hidden_states, *args, **kwargs)
module.attn1.old_forward = module.attn1.forward
module.attn1.forward = new_forward.__get__(module.attn1)
# run forward pass to cache hidden states, output can be discarded
_ = self.unet(z_all, t, encoder_hidden_states=prompt_embd)
# restore original forward pass
for module in self.unet.modules():
if isinstance(module, BasicTransformerBlock):
module.attn1.forward = module.attn1.old_forward
del module.attn1.old_forward
return cached_hidden_states
def unet_forward_with_cached_hidden_states(
self,
z_all,
t,
prompt_embd,
cached_pos_hiddens: Optional[List[torch.Tensor]] = None,
cached_neg_hiddens: Optional[List[torch.Tensor]] = None,
pos_weights=(0.8, 0.8),
neg_weights=(0.5, 0.5),
):
if cached_pos_hiddens is None and cached_neg_hiddens is None:
return self.unet(z_all, t, encoder_hidden_states=prompt_embd)
local_pos_weights = torch.linspace(*pos_weights, steps=len(self.unet.down_blocks) + 1)[:-1].tolist()
local_neg_weights = torch.linspace(*neg_weights, steps=len(self.unet.down_blocks) + 1)[:-1].tolist()
for block, pos_weight, neg_weight in zip(
self.unet.down_blocks + [self.unet.mid_block] + self.unet.up_blocks,
local_pos_weights + [pos_weights[1]] + local_pos_weights[::-1],
local_neg_weights + [neg_weights[1]] + local_neg_weights[::-1],
):
for module in block.modules():
if isinstance(module, BasicTransformerBlock):
def new_forward(
self,
hidden_states,
pos_weight=pos_weight,
neg_weight=neg_weight,
**kwargs,
):
cond_hiddens, uncond_hiddens = hidden_states.chunk(2, dim=0)
batch_size, d_model = cond_hiddens.shape[:2]
device, dtype = hidden_states.device, hidden_states.dtype
weights = torch.ones(batch_size, d_model, device=device, dtype=dtype)
out_pos = self.old_forward(hidden_states)
out_neg = self.old_forward(hidden_states)
if cached_pos_hiddens is not None:
cached_pos_hs = cached_pos_hiddens.pop(0).to(hidden_states.device)
cond_pos_hs = torch.cat([cond_hiddens, cached_pos_hs], dim=1)
pos_weights = weights.clone().repeat(1, 1 + cached_pos_hs.shape[1] // d_model)
pos_weights[:, d_model:] = pos_weight
attn_with_weights = FabricCrossAttnProcessor()
out_pos = attn_with_weights(
self,
cond_hiddens,
encoder_hidden_states=cond_pos_hs,
weights=pos_weights,
)
else:
out_pos = self.old_forward(cond_hiddens)
if cached_neg_hiddens is not None:
cached_neg_hs = cached_neg_hiddens.pop(0).to(hidden_states.device)
uncond_neg_hs = torch.cat([uncond_hiddens, cached_neg_hs], dim=1)
neg_weights = weights.clone().repeat(1, 1 + cached_neg_hs.shape[1] // d_model)
neg_weights[:, d_model:] = neg_weight
attn_with_weights = FabricCrossAttnProcessor()
out_neg = attn_with_weights(
self,
uncond_hiddens,
encoder_hidden_states=uncond_neg_hs,
weights=neg_weights,
)
else:
out_neg = self.old_forward(uncond_hiddens)
out = torch.cat([out_pos, out_neg], dim=0)
return out
module.attn1.old_forward = module.attn1.forward
module.attn1.forward = new_forward.__get__(module.attn1)
out = self.unet(z_all, t, encoder_hidden_states=prompt_embd)
# restore original forward pass
for module in self.unet.modules():
if isinstance(module, BasicTransformerBlock):
module.attn1.forward = module.attn1.old_forward
del module.attn1.old_forward
return out
def preprocess_feedback_images(self, images, vae, dim, device, dtype, generator) -> torch.tensor:
images_t = [self.image_to_tensor(img, dim, dtype) for img in images]
images_t = torch.stack(images_t).to(device)
latents = vae.config.scaling_factor * vae.encode(images_t).latent_dist.sample(generator)
return torch.cat([latents], dim=0)
def check_inputs(
self,
prompt,
negative_prompt=None,
liked=None,
disliked=None,
height=None,
width=None,
):
if prompt is None:
raise ValueError("Provide `prompt`. Cannot leave both `prompt` undefined.")
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and (
not isinstance(negative_prompt, str) and not isinstance(negative_prompt, list)
):
raise ValueError(f"`negative_prompt` has to be of type `str` or `list` but is {type(negative_prompt)}")
if liked is not None and not isinstance(liked, list):
raise ValueError(f"`liked` has to be of type `list` but is {type(liked)}")
if disliked is not None and not isinstance(disliked, list):
raise ValueError(f"`disliked` has to be of type `list` but is {type(disliked)}")
if height is not None and not isinstance(height, int):
raise ValueError(f"`height` has to be of type `int` but is {type(height)}")
if width is not None and not isinstance(width, int):
raise ValueError(f"`width` has to be of type `int` but is {type(width)}")
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Optional[Union[str, List[str]]] = "",
negative_prompt: Optional[Union[str, List[str]]] = "lowres, bad anatomy, bad hands, cropped, worst quality",
liked: Optional[Union[List[str], List[Image.Image]]] = [],
disliked: Optional[Union[List[str], List[Image.Image]]] = [],
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
height: int = 512,
width: int = 512,
return_dict: bool = True,
num_images: int = 4,
guidance_scale: float = 7.0,
num_inference_steps: int = 20,
output_type: Optional[str] = "pil",
feedback_start_ratio: float = 0.33,
feedback_end_ratio: float = 0.66,
min_weight: float = 0.05,
max_weight: float = 0.8,
neg_scale: float = 0.5,
pos_bottleneck_scale: float = 1.0,
neg_bottleneck_scale: float = 1.0,
latents: Optional[torch.FloatTensor] = None,
):
r"""
The call function to the pipeline for generation. Generate a trajectory of images with binary feedback. The
feedback can be given as a list of liked and disliked images.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`
instead.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
liked (`List[Image.Image]` or `List[str]`, *optional*):
Encourages images with liked features.
disliked (`List[Image.Image]` or `List[str]`, *optional*):
Discourages images with disliked features.
generator (`torch.Generator` or `List[torch.Generator]` or `int`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) or an `int` to
make generation deterministic.
height (`int`, *optional*, defaults to 512):
Height of the generated image.
width (`int`, *optional*, defaults to 512):
Width of the generated image.
num_images (`int`, *optional*, defaults to 4):
The number of images to generate per prompt.
guidance_scale (`float`, *optional*, defaults to 7.0):
A higher guidance scale value encourages the model to generate images closely linked to the text
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
num_inference_steps (`int`, *optional*, defaults to 20):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
feedback_start_ratio (`float`, *optional*, defaults to `.33`):
Start point for providing feedback (between 0 and 1).
feedback_end_ratio (`float`, *optional*, defaults to `.66`):
End point for providing feedback (between 0 and 1).
min_weight (`float`, *optional*, defaults to `.05`):
Minimum weight for feedback.
max_weight (`float`, *optional*, defults tp `1.0`):
Maximum weight for feedback.
neg_scale (`float`, *optional*, defaults to `.5`):
Scale factor for negative feedback.
Examples:
Returns:
[`~pipelines.fabric.FabricPipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
otherwise a `tuple` is returned where the first element is a list with the generated images and the
second element is a list of `bool`s indicating whether the corresponding generated image contains
"not-safe-for-work" (nsfw) content.
"""
self.check_inputs(prompt, negative_prompt, liked, disliked)
device = self._execution_device
dtype = self.unet.dtype
if isinstance(prompt, str) and prompt is not None:
batch_size = 1
elif isinstance(prompt, list) and prompt is not None:
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if isinstance(negative_prompt, str):
negative_prompt = negative_prompt
elif isinstance(negative_prompt, list):
negative_prompt = negative_prompt
else:
assert len(negative_prompt) == batch_size
shape = (
batch_size * num_images,
self.unet.config.in_channels,
height // self.vae_scale_factor,
width // self.vae_scale_factor,
)
latent_noise = randn_tensor(
shape,
device=device,
dtype=dtype,
generator=generator,
)
positive_latents = (
self.preprocess_feedback_images(liked, self.vae, (height, width), device, dtype, generator)
if liked and len(liked) > 0
else torch.tensor(
[],
device=device,
dtype=dtype,
)
)
negative_latents = (
self.preprocess_feedback_images(disliked, self.vae, (height, width), device, dtype, generator)
if disliked and len(disliked) > 0
else torch.tensor(
[],
device=device,
dtype=dtype,
)
)
do_classifier_free_guidance = guidance_scale > 0.1
(prompt_neg_embs, prompt_pos_embs) = self._encode_prompt(
prompt,
device,
num_images,
do_classifier_free_guidance,
negative_prompt,
).split([num_images * batch_size, num_images * batch_size])
batched_prompt_embd = torch.cat([prompt_pos_embs, prompt_neg_embs], dim=0)
null_tokens = self.tokenizer(
[""],
return_tensors="pt",
max_length=self.tokenizer.model_max_length,
padding="max_length",
truncation=True,
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = null_tokens.attention_mask.to(device)
else:
attention_mask = None
null_prompt_emb = self.text_encoder(
input_ids=null_tokens.input_ids.to(device),
attention_mask=attention_mask,
).last_hidden_state
null_prompt_emb = null_prompt_emb.to(device=device, dtype=dtype)
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
latent_noise = latent_noise * self.scheduler.init_noise_sigma
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
ref_start_idx = round(len(timesteps) * feedback_start_ratio)
ref_end_idx = round(len(timesteps) * feedback_end_ratio)
with self.progress_bar(total=num_inference_steps) as pbar:
for i, t in enumerate(timesteps):
sigma = self.scheduler.sigma_t[t] if hasattr(self.scheduler, "sigma_t") else 0
if hasattr(self.scheduler, "sigmas"):
sigma = self.scheduler.sigmas[i]
alpha_hat = 1 / (sigma**2 + 1)
z_single = self.scheduler.scale_model_input(latent_noise, t)
z_all = torch.cat([z_single] * 2, dim=0)
z_ref = torch.cat([positive_latents, negative_latents], dim=0)
if i >= ref_start_idx and i <= ref_end_idx:
weight_factor = max_weight
else:
weight_factor = min_weight
pos_ws = (weight_factor, weight_factor * pos_bottleneck_scale)
neg_ws = (weight_factor * neg_scale, weight_factor * neg_scale * neg_bottleneck_scale)
if z_ref.size(0) > 0 and weight_factor > 0:
noise = torch.randn_like(z_ref)
if isinstance(self.scheduler, EulerAncestralDiscreteScheduler):
z_ref_noised = (alpha_hat**0.5 * z_ref + (1 - alpha_hat) ** 0.5 * noise).type(dtype)
else:
z_ref_noised = self.scheduler.add_noise(z_ref, noise, t)
ref_prompt_embd = torch.cat(
[null_prompt_emb] * (len(positive_latents) + len(negative_latents)), dim=0
)
cached_hidden_states = self.get_unet_hidden_states(z_ref_noised, t, ref_prompt_embd)
n_pos, n_neg = positive_latents.shape[0], negative_latents.shape[0]
cached_pos_hs, cached_neg_hs = [], []
for hs in cached_hidden_states:
cached_pos, cached_neg = hs.split([n_pos, n_neg], dim=0)
cached_pos = cached_pos.view(1, -1, *cached_pos.shape[2:]).expand(num_images, -1, -1)
cached_neg = cached_neg.view(1, -1, *cached_neg.shape[2:]).expand(num_images, -1, -1)
cached_pos_hs.append(cached_pos)
cached_neg_hs.append(cached_neg)
if n_pos == 0:
cached_pos_hs = None
if n_neg == 0:
cached_neg_hs = None
else:
cached_pos_hs, cached_neg_hs = None, None
unet_out = self.unet_forward_with_cached_hidden_states(
z_all,
t,
prompt_embd=batched_prompt_embd,
cached_pos_hiddens=cached_pos_hs,
cached_neg_hiddens=cached_neg_hs,
pos_weights=pos_ws,
neg_weights=neg_ws,
)[0]
noise_cond, noise_uncond = unet_out.chunk(2)
guidance = noise_cond - noise_uncond
noise_pred = noise_uncond + guidance_scale * guidance
latent_noise = self.scheduler.step(noise_pred, t, latent_noise)[0]
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
pbar.update()
y = self.vae.decode(latent_noise / self.vae.config.scaling_factor, return_dict=False)[0]
imgs = self.image_processor.postprocess(
y,
output_type=output_type,
)
if not return_dict:
return imgs
return StableDiffusionPipelineOutput(imgs, False)
def image_to_tensor(self, image: Union[str, Image.Image], dim: tuple, dtype):
"""
Convert latent PIL image to a torch tensor for further processing.
"""
if isinstance(image, str):
image = Image.open(image)
if not image.mode == "RGB":
image = image.convert("RGB")
image = self.image_processor.preprocess(image, height=dim[0], width=dim[1])[0]
return image.type(dtype)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/pipeline_stable_diffusion_xl_controlnet_adapter_inpaint.py
|
# Copyright 2023 Jake Babbidge, TencentARC and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ignore the entire file for precommit
# type: ignore
import inspect
from collections.abc import Callable
from typing import Any, List, Optional, Union
import numpy as np
import PIL
import torch
import torch.nn.functional as F
from transformers import (
CLIPTextModel,
CLIPTextModelWithProjection,
CLIPTokenizer,
)
from diffusers import DiffusionPipeline
from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
from diffusers.loaders import (
FromSingleFileMixin,
LoraLoaderMixin,
StableDiffusionXLLoraLoaderMixin,
TextualInversionLoaderMixin,
)
from diffusers.models import (
AutoencoderKL,
ControlNetModel,
MultiAdapter,
T2IAdapter,
UNet2DConditionModel,
)
from diffusers.models.attention_processor import (
AttnProcessor2_0,
LoRAAttnProcessor2_0,
LoRAXFormersAttnProcessor,
XFormersAttnProcessor,
)
from diffusers.models.lora import adjust_lora_scale_text_encoder
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
from diffusers.pipelines.stable_diffusion_xl.pipeline_output import StableDiffusionXLPipelineOutput
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
PIL_INTERPOLATION,
USE_PEFT_BACKEND,
logging,
replace_example_docstring,
scale_lora_layers,
unscale_lora_layers,
)
from diffusers.utils.torch_utils import is_compiled_module, randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
>>> from diffusers import DiffusionPipeline, T2IAdapter
>>> from diffusers.utils import load_image
>>> from PIL import Image
>>> from controlnet_aux.midas import MidasDetector
>>> adapter = T2IAdapter.from_pretrained(
... "TencentARC/t2i-adapter-sketch-sdxl-1.0", torch_dtype=torch.float16, variant="fp16"
... ).to("cuda")
>>> controlnet = ControlNetModel.from_pretrained(
... "diffusers/controlnet-depth-sdxl-1.0",
... torch_dtype=torch.float16,
... variant="fp16",
... use_safetensors=True
... ).to("cuda")
>>> pipe = DiffusionPipeline.from_pretrained(
... "diffusers/stable-diffusion-xl-1.0-inpainting-0.1",
... torch_dtype=torch.float16,
... variant="fp16",
... use_safetensors=True,
... custom_pipeline="stable_diffusion_xl_adapter_controlnet_inpaint",
... adapter=adapter,
... controlnet=controlnet,
... ).to("cuda")
>>> prompt = "a tiger sitting on a park bench"
>>> img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
>>> mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
>>> image = load_image(img_url).resize((1024, 1024))
>>> mask_image = load_image(mask_url).resize((1024, 1024))
>>> midas_depth = MidasDetector.from_pretrained(
... "valhalla/t2iadapter-aux-models", filename="dpt_large_384.pt", model_type="dpt_large"
... ).to("cuda")
>>> depth_image = midas_depth(
... image, detect_resolution=512, image_resolution=1024
... )
>>> strength = 0.4
>>> generator = torch.manual_seed(42)
>>> result_image = pipe(
... image=image,
... mask_image=mask,
... adapter_image=depth_image,
... control_image=depth_image,
... controlnet_conditioning_scale=strength,
... adapter_conditioning_scale=strength,
... strength=0.7,
... generator=generator,
... prompt=prompt,
... negative_prompt="extra digit, fewer digits, cropped, worst quality, low quality",
... num_inference_steps=50
... ).images[0]
```
"""
def _preprocess_adapter_image(image, height, width):
if isinstance(image, torch.Tensor):
return image
elif isinstance(image, PIL.Image.Image):
image = [image]
if isinstance(image[0], PIL.Image.Image):
image = [np.array(i.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])) for i in image]
image = [
i[None, ..., None] if i.ndim == 2 else i[None, ...] for i in image
] # expand [h, w] or [h, w, c] to [b, h, w, c]
image = np.concatenate(image, axis=0)
image = np.array(image).astype(np.float32) / 255.0
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image)
elif isinstance(image[0], torch.Tensor):
if image[0].ndim == 3:
image = torch.stack(image, dim=0)
elif image[0].ndim == 4:
image = torch.cat(image, dim=0)
else:
raise ValueError(
f"Invalid image tensor! Expecting image tensor with 3 or 4 dimension, but recive: {image[0].ndim}"
)
return image
def mask_pil_to_torch(mask, height, width):
# preprocess mask
if isinstance(mask, Union[PIL.Image.Image, np.ndarray]):
mask = [mask]
if isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image):
mask = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in mask]
mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
mask = mask.astype(np.float32) / 255.0
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
mask = torch.from_numpy(mask)
return mask
def prepare_mask_and_masked_image(image, mask, height, width, return_image: bool = False):
"""
Prepares a pair (image, mask) to be consumed by the Stable Diffusion pipeline. This means that those inputs will be
converted to ``torch.Tensor`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for the
``image`` and ``1`` for the ``mask``.
The ``image`` will be converted to ``torch.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
binarized (``mask > 0.5``) and cast to ``torch.float32`` too.
Args:
image (Union[np.array, PIL.Image, torch.Tensor]): The image to inpaint.
It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array`` or a ``channels x height x width``
``torch.Tensor`` or a ``batch x channels x height x width`` ``torch.Tensor``.
mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
It can be a ``PIL.Image``, or a ``height x width`` ``np.array`` or a ``1 x height x width``
``torch.Tensor`` or a ``batch x 1 x height x width`` ``torch.Tensor``.
Raises:
ValueError: ``torch.Tensor`` images should be in the ``[-1, 1]`` range. ValueError: ``torch.Tensor`` mask
should be in the ``[0, 1]`` range. ValueError: ``mask`` and ``image`` should have the same spatial dimensions.
TypeError: ``mask`` is a ``torch.Tensor`` but ``image`` is not
(ot the other way around).
Returns:
tuple[torch.Tensor]: The pair (mask, masked_image) as ``torch.Tensor`` with 4
dimensions: ``batch x channels x height x width``.
"""
# checkpoint. TOD(Yiyi) - need to clean this up later
if image is None:
raise ValueError("`image` input cannot be undefined.")
if mask is None:
raise ValueError("`mask_image` input cannot be undefined.")
if isinstance(image, torch.Tensor):
if not isinstance(mask, torch.Tensor):
mask = mask_pil_to_torch(mask, height, width)
if image.ndim == 3:
image = image.unsqueeze(0)
# Batch and add channel dim for single mask
if mask.ndim == 2:
mask = mask.unsqueeze(0).unsqueeze(0)
# Batch single mask or add channel dim
if mask.ndim == 3:
# Single batched mask, no channel dim or single mask not batched but channel dim
if mask.shape[0] == 1:
mask = mask.unsqueeze(0)
# Batched masks no channel dim
else:
mask = mask.unsqueeze(1)
assert image.ndim == 4 and mask.ndim == 4, "Image and Mask must have 4 dimensions"
# assert image.shape[-2:] == mask.shape[-2:], "Image and Mask must have the same spatial dimensions"
assert image.shape[0] == mask.shape[0], "Image and Mask must have the same batch size"
# Check image is in [-1, 1]
# if image.min() < -1 or image.max() > 1:
# raise ValueError("Image should be in [-1, 1] range")
# Check mask is in [0, 1]
if mask.min() < 0 or mask.max() > 1:
raise ValueError("Mask should be in [0, 1] range")
# Binarize mask
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
# Image as float32
image = image.to(dtype=torch.float32)
elif isinstance(mask, torch.Tensor):
raise TypeError(f"`mask` is a torch.Tensor but `image` (type: {type(image)} is not")
else:
# preprocess image
if isinstance(image, Union[PIL.Image.Image, np.ndarray]):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
# resize all images w.r.t passed height an width
image = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in image]
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
mask = mask_pil_to_torch(mask, height, width)
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
if image.shape[1] == 4:
# images are in latent space and thus can't
# be masked set masked_image to None
# we assume that the checkpoint is not an inpainting
# checkpoint. TOD(Yiyi) - need to clean this up later
masked_image = None
else:
masked_image = image * (mask < 0.5)
# n.b. ensure backwards compatibility as old function does not return image
if return_image:
return mask, masked_image, image
return mask, masked_image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.rescale_noise_cfg
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
"""
Rescale `noise_cfg` according to `guidance_rescale`. Based on findings of [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf). See Section 3.4
"""
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
# rescale the results from guidance (fixes overexposure)
noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
# mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
return noise_cfg
class StableDiffusionXLControlNetAdapterInpaintPipeline(DiffusionPipeline, FromSingleFileMixin, LoraLoaderMixin):
r"""
Pipeline for text-to-image generation using Stable Diffusion augmented with T2I-Adapter
https://arxiv.org/abs/2302.08453
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
adapter ([`T2IAdapter`] or [`MultiAdapter`] or `List[T2IAdapter]`):
Provides additional conditioning to the unet during the denoising process. If you set multiple Adapter as a
list, the outputs from each Adapter are added together to create one combined additional conditioning.
adapter_weights (`List[float]`, *optional*, defaults to None):
List of floats representing the weight which will be multiply to each adapter's output before adding them
together.
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPFeatureExtractor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
requires_aesthetics_score (`bool`, *optional*, defaults to `"False"`):
Whether the `unet` requires a aesthetic_score condition to be passed during inference. Also see the config
of `stabilityai/stable-diffusion-xl-refiner-1-0`.
force_zeros_for_empty_prompt (`bool`, *optional*, defaults to `"True"`):
Whether the negative prompt embeddings shall be forced to always be set to 0. Also see the config of
`stabilityai/stable-diffusion-xl-base-1-0`.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
text_encoder_2: CLIPTextModelWithProjection,
tokenizer: CLIPTokenizer,
tokenizer_2: CLIPTokenizer,
unet: UNet2DConditionModel,
adapter: Union[T2IAdapter, MultiAdapter],
controlnet: Union[ControlNetModel, MultiControlNetModel],
scheduler: KarrasDiffusionSchedulers,
requires_aesthetics_score: bool = False,
force_zeros_for_empty_prompt: bool = True,
):
super().__init__()
if isinstance(controlnet, (list, tuple)):
controlnet = MultiControlNetModel(controlnet)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
text_encoder_2=text_encoder_2,
tokenizer=tokenizer,
tokenizer_2=tokenizer_2,
unet=unet,
adapter=adapter,
controlnet=controlnet,
scheduler=scheduler,
)
self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
self.register_to_config(requires_aesthetics_score=requires_aesthetics_score)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.control_image_processor = VaeImageProcessor(
vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
)
self.default_sample_size = self.unet.config.sample_size
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
def enable_vae_slicing(self):
r"""
Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
"""
self.vae.enable_slicing()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
def disable_vae_slicing(self):
r"""
Disable sliced VAE decoding. If `enable_vae_slicing` was previously enabled, this method will go back to
computing decoding in one step.
"""
self.vae.disable_slicing()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
def enable_vae_tiling(self):
r"""
Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
compute decoding and encoding in several steps. This is useful for saving a large amount of memory and to allow
processing larger images.
"""
self.vae.enable_tiling()
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
def disable_vae_tiling(self):
r"""
Disable tiled VAE decoding. If `enable_vae_tiling` was previously enabled, this method will go back to
computing decoding in one step.
"""
self.vae.disable_tiling()
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.encode_prompt
def encode_prompt(
self,
prompt: str,
prompt_2: Optional[str] = None,
device: Optional[torch.device] = None,
num_images_per_prompt: int = 1,
do_classifier_free_guidance: bool = True,
negative_prompt: Optional[str] = None,
negative_prompt_2: Optional[str] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
clip_skip: Optional[int] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
used in both text-encoders
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
negative_prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
`text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
If not provided, pooled text embeddings will be generated from `prompt` input argument.
negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
input argument.
lora_scale (`float`, *optional*):
A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
"""
device = device or self._execution_device
# set lora scale so that monkey patched LoRA
# function of text encoder can correctly access it
if lora_scale is not None and isinstance(self, StableDiffusionXLLoraLoaderMixin):
self._lora_scale = lora_scale
# dynamically adjust the LoRA scale
if self.text_encoder is not None:
if not USE_PEFT_BACKEND:
adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
else:
scale_lora_layers(self.text_encoder, lora_scale)
if self.text_encoder_2 is not None:
if not USE_PEFT_BACKEND:
adjust_lora_scale_text_encoder(self.text_encoder_2, lora_scale)
else:
scale_lora_layers(self.text_encoder_2, lora_scale)
prompt = [prompt] if isinstance(prompt, str) else prompt
if prompt is not None:
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
# Define tokenizers and text encoders
tokenizers = [self.tokenizer, self.tokenizer_2] if self.tokenizer is not None else [self.tokenizer_2]
text_encoders = (
[self.text_encoder, self.text_encoder_2] if self.text_encoder is not None else [self.text_encoder_2]
)
if prompt_embeds is None:
prompt_2 = prompt_2 or prompt
prompt_2 = [prompt_2] if isinstance(prompt_2, str) else prompt_2
# textual inversion: procecss multi-vector tokens if necessary
prompt_embeds_list = []
prompts = [prompt, prompt_2]
for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, tokenizer)
text_inputs = tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {tokenizer.model_max_length} tokens: {removed_text}"
)
prompt_embeds = text_encoder(text_input_ids.to(device), output_hidden_states=True)
# We are only ALWAYS interested in the pooled output of the final text encoder
pooled_prompt_embeds = prompt_embeds[0]
if clip_skip is None:
prompt_embeds = prompt_embeds.hidden_states[-2]
else:
# "2" because SDXL always indexes from the penultimate layer.
prompt_embeds = prompt_embeds.hidden_states[-(clip_skip + 2)]
prompt_embeds_list.append(prompt_embeds)
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
# get unconditional embeddings for classifier free guidance
zero_out_negative_prompt = negative_prompt is None and self.config.force_zeros_for_empty_prompt
if do_classifier_free_guidance and negative_prompt_embeds is None and zero_out_negative_prompt:
negative_prompt_embeds = torch.zeros_like(prompt_embeds)
negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
elif do_classifier_free_guidance and negative_prompt_embeds is None:
negative_prompt = negative_prompt or ""
negative_prompt_2 = negative_prompt_2 or negative_prompt
# normalize str to list
negative_prompt = batch_size * [negative_prompt] if isinstance(negative_prompt, str) else negative_prompt
negative_prompt_2 = (
batch_size * [negative_prompt_2] if isinstance(negative_prompt_2, str) else negative_prompt_2
)
uncond_tokens: List[str]
if prompt is not None and type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = [negative_prompt, negative_prompt_2]
negative_prompt_embeds_list = []
for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
if isinstance(self, TextualInversionLoaderMixin):
negative_prompt = self.maybe_convert_prompt(negative_prompt, tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = tokenizer(
negative_prompt,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
negative_prompt_embeds = text_encoder(
uncond_input.input_ids.to(device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
negative_pooled_prompt_embeds = negative_prompt_embeds[0]
negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
negative_prompt_embeds_list.append(negative_prompt_embeds)
negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
if self.text_encoder_2 is not None:
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
else:
prompt_embeds = prompt_embeds.to(dtype=self.unet.dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
if self.text_encoder_2 is not None:
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder_2.dtype, device=device)
else:
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.unet.dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
bs_embed * num_images_per_prompt, -1
)
if do_classifier_free_guidance:
negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
bs_embed * num_images_per_prompt, -1
)
if self.text_encoder is not None:
if isinstance(self, StableDiffusionXLLoraLoaderMixin) and USE_PEFT_BACKEND:
# Retrieve the original scale by scaling back the LoRA layers
unscale_lora_layers(self.text_encoder, lora_scale)
if self.text_encoder_2 is not None:
if isinstance(self, StableDiffusionXLLoraLoaderMixin) and USE_PEFT_BACKEND:
# Retrieve the original scale by scaling back the LoRA layers
unscale_lora_layers(self.text_encoder_2, lora_scale)
return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
# Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image
def check_image(self, image, prompt, prompt_embeds):
image_is_pil = isinstance(image, PIL.Image.Image)
image_is_tensor = isinstance(image, torch.Tensor)
image_is_np = isinstance(image, np.ndarray)
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
if (
not image_is_pil
and not image_is_tensor
and not image_is_np
and not image_is_pil_list
and not image_is_tensor_list
and not image_is_np_list
):
raise TypeError(
f"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(image)}"
)
if image_is_pil:
image_batch_size = 1
else:
image_batch_size = len(image)
if prompt is not None and isinstance(prompt, str):
prompt_batch_size = 1
elif prompt is not None and isinstance(prompt, list):
prompt_batch_size = len(prompt)
elif prompt_embeds is not None:
prompt_batch_size = prompt_embeds.shape[0]
if image_batch_size != 1 and image_batch_size != prompt_batch_size:
raise ValueError(
f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
)
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.check_inputs
def check_inputs(
self,
prompt,
prompt_2,
height,
width,
callback_steps,
negative_prompt=None,
negative_prompt_2=None,
prompt_embeds=None,
negative_prompt_embeds=None,
pooled_prompt_embeds=None,
negative_pooled_prompt_embeds=None,
callback_on_step_end_tensor_inputs=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if callback_on_step_end_tensor_inputs is not None and not all(
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
):
raise ValueError(
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt_2 is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt_2`: {prompt_2} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
elif prompt_2 is not None and (not isinstance(prompt_2, str) and not isinstance(prompt_2, list)):
raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(prompt_2)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
elif negative_prompt_2 is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt_2`: {negative_prompt_2} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
if prompt_embeds is not None and pooled_prompt_embeds is None:
raise ValueError(
"If `prompt_embeds` are provided, `pooled_prompt_embeds` also have to be passed. Make sure to generate `pooled_prompt_embeds` from the same text encoder that was used to generate `prompt_embeds`."
)
if negative_prompt_embeds is not None and negative_pooled_prompt_embeds is None:
raise ValueError(
"If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
)
def check_conditions(
self,
prompt,
prompt_embeds,
adapter_image,
control_image,
adapter_conditioning_scale,
controlnet_conditioning_scale,
control_guidance_start,
control_guidance_end,
):
# controlnet checks
if not isinstance(control_guidance_start, (tuple, list)):
control_guidance_start = [control_guidance_start]
if not isinstance(control_guidance_end, (tuple, list)):
control_guidance_end = [control_guidance_end]
if len(control_guidance_start) != len(control_guidance_end):
raise ValueError(
f"`control_guidance_start` has {len(control_guidance_start)} elements, but `control_guidance_end` has {len(control_guidance_end)} elements. Make sure to provide the same number of elements to each list."
)
if isinstance(self.controlnet, MultiControlNetModel):
if len(control_guidance_start) != len(self.controlnet.nets):
raise ValueError(
f"`control_guidance_start`: {control_guidance_start} has {len(control_guidance_start)} elements but there are {len(self.controlnet.nets)} controlnets available. Make sure to provide {len(self.controlnet.nets)}."
)
for start, end in zip(control_guidance_start, control_guidance_end):
if start >= end:
raise ValueError(
f"control guidance start: {start} cannot be larger or equal to control guidance end: {end}."
)
if start < 0.0:
raise ValueError(f"control guidance start: {start} can't be smaller than 0.")
if end > 1.0:
raise ValueError(f"control guidance end: {end} can't be larger than 1.0.")
# Check controlnet `image`
is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
self.controlnet, torch._dynamo.eval_frame.OptimizedModule
)
if (
isinstance(self.controlnet, ControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, ControlNetModel)
):
self.check_image(control_image, prompt, prompt_embeds)
elif (
isinstance(self.controlnet, MultiControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
):
if not isinstance(control_image, list):
raise TypeError("For multiple controlnets: `control_image` must be type `list`")
# When `image` is a nested list:
# (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
elif any(isinstance(i, list) for i in control_image):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif len(control_image) != len(self.controlnet.nets):
raise ValueError(
f"For multiple controlnets: `image` must have the same length as the number of controlnets, but got {len(control_image)} images and {len(self.controlnet.nets)} ControlNets."
)
for image_ in control_image:
self.check_image(image_, prompt, prompt_embeds)
else:
assert False
# Check `controlnet_conditioning_scale`
if (
isinstance(self.controlnet, ControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, ControlNetModel)
):
if not isinstance(controlnet_conditioning_scale, float):
raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
elif (
isinstance(self.controlnet, MultiControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
):
if isinstance(controlnet_conditioning_scale, list):
if any(isinstance(i, list) for i in controlnet_conditioning_scale):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
self.controlnet.nets
):
raise ValueError(
"For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
" the same length as the number of controlnets"
)
else:
assert False
# adapter checks
if isinstance(self.adapter, T2IAdapter) or is_compiled and isinstance(self.adapter._orig_mod, T2IAdapter):
self.check_image(adapter_image, prompt, prompt_embeds)
elif (
isinstance(self.adapter, MultiAdapter) or is_compiled and isinstance(self.adapter._orig_mod, MultiAdapter)
):
if not isinstance(adapter_image, list):
raise TypeError("For multiple adapters: `adapter_image` must be type `list`")
# When `image` is a nested list:
# (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
elif any(isinstance(i, list) for i in adapter_image):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif len(adapter_image) != len(self.adapter.adapters):
raise ValueError(
f"For multiple adapters: `image` must have the same length as the number of adapters, but got {len(adapter_image)} images and {len(self.adapters.nets)} Adapters."
)
for image_ in adapter_image:
self.check_image(image_, prompt, prompt_embeds)
else:
assert False
# Check `adapter_conditioning_scale`
if isinstance(self.adapter, T2IAdapter) or is_compiled and isinstance(self.adapter._orig_mod, T2IAdapter):
if not isinstance(adapter_conditioning_scale, float):
raise TypeError("For single adapter: `adapter_conditioning_scale` must be type `float`.")
elif (
isinstance(self.adapter, MultiAdapter) or is_compiled and isinstance(self.adapter._orig_mod, MultiAdapter)
):
if isinstance(adapter_conditioning_scale, list):
if any(isinstance(i, list) for i in adapter_conditioning_scale):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif isinstance(adapter_conditioning_scale, list) and len(adapter_conditioning_scale) != len(
self.adapter.adapters
):
raise ValueError(
"For multiple adapters: When `adapter_conditioning_scale` is specified as `list`, it must have"
" the same length as the number of adapters"
)
else:
assert False
def prepare_latents(
self,
batch_size,
num_channels_latents,
height,
width,
dtype,
device,
generator,
latents=None,
image=None,
timestep=None,
is_strength_max=True,
add_noise=True,
return_noise=False,
return_image_latents=False,
):
shape = (
batch_size,
num_channels_latents,
height // self.vae_scale_factor,
width // self.vae_scale_factor,
)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if (image is None or timestep is None) and not is_strength_max:
raise ValueError(
"Since strength < 1. initial latents are to be initialised as a combination of Image + Noise."
"However, either the image or the noise timestep has not been provided."
)
if image.shape[1] == 4:
image_latents = image.to(device=device, dtype=dtype)
elif return_image_latents or (latents is None and not is_strength_max):
image = image.to(device=device, dtype=dtype)
image_latents = self._encode_vae_image(image=image, generator=generator)
image_latents = image_latents.repeat(batch_size // image_latents.shape[0], 1, 1, 1)
if latents is None and add_noise:
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
# if strength is 1. then initialise the latents to noise, else initial to image + noise
latents = noise if is_strength_max else self.scheduler.add_noise(image_latents, noise, timestep)
# if pure noise then scale the initial latents by the Scheduler's init sigma
latents = latents * self.scheduler.init_noise_sigma if is_strength_max else latents
elif add_noise:
noise = latents.to(device)
latents = noise * self.scheduler.init_noise_sigma
else:
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
latents = image_latents.to(device)
outputs = (latents,)
if return_noise:
outputs += (noise,)
if return_image_latents:
outputs += (image_latents,)
return outputs
def _encode_vae_image(self, image: torch.Tensor, generator: torch.Generator):
dtype = image.dtype
if self.vae.config.force_upcast:
image = image.float()
self.vae.to(dtype=torch.float32)
if isinstance(generator, list):
image_latents = [
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator=generator[i])
for i in range(image.shape[0])
]
image_latents = torch.cat(image_latents, dim=0)
else:
image_latents = self.vae.encode(image).latent_dist.sample(generator=generator)
if self.vae.config.force_upcast:
self.vae.to(dtype)
image_latents = image_latents.to(dtype)
image_latents = self.vae.config.scaling_factor * image_latents
return image_latents
def prepare_mask_latents(
self,
mask,
masked_image,
batch_size,
height,
width,
dtype,
device,
generator,
do_classifier_free_guidance,
):
# resize the mask to latents shape as we concatenate the mask to the latents
# we do that before converting to dtype to avoid breaking in case we're using cpu_offload
# and half precision
mask = torch.nn.functional.interpolate(
mask,
size=(
height // self.vae_scale_factor,
width // self.vae_scale_factor,
),
)
mask = mask.to(device=device, dtype=dtype)
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
if mask.shape[0] < batch_size:
if not batch_size % mask.shape[0] == 0:
raise ValueError(
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
" of masks that you pass is divisible by the total requested batch size."
)
mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
masked_image_latents = None
if masked_image is not None:
masked_image = masked_image.to(device=device, dtype=dtype)
masked_image_latents = self._encode_vae_image(masked_image, generator=generator)
if masked_image_latents.shape[0] < batch_size:
if not batch_size % masked_image_latents.shape[0] == 0:
raise ValueError(
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
" Make sure the number of images that you pass is divisible by the total requested batch size."
)
masked_image_latents = masked_image_latents.repeat(
batch_size // masked_image_latents.shape[0], 1, 1, 1
)
masked_image_latents = (
torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
)
# aligning device to prevent device errors when concating it with the latent model input
masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
return mask, masked_image_latents
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl_img2img.StableDiffusionXLImg2ImgPipeline.get_timesteps
def get_timesteps(self, num_inference_steps, strength, device, denoising_start=None):
# get the original timestep using init_timestep
if denoising_start is None:
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
else:
t_start = 0
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
# Strength is irrelevant if we directly request a timestep to start at;
# that is, strength is determined by the denoising_start instead.
if denoising_start is not None:
discrete_timestep_cutoff = int(
round(
self.scheduler.config.num_train_timesteps
- (denoising_start * self.scheduler.config.num_train_timesteps)
)
)
num_inference_steps = (timesteps < discrete_timestep_cutoff).sum().item()
if self.scheduler.order == 2 and num_inference_steps % 2 == 0:
# if the scheduler is a 2nd order scheduler we might have to do +1
# because `num_inference_steps` might be even given that every timestep
# (except the highest one) is duplicated. If `num_inference_steps` is even it would
# mean that we cut the timesteps in the middle of the denoising step
# (between 1st and 2nd devirative) which leads to incorrect results. By adding 1
# we ensure that the denoising process always ends after the 2nd derivate step of the scheduler
num_inference_steps = num_inference_steps + 1
# because t_n+1 >= t_n, we slice the timesteps starting from the end
timesteps = timesteps[-num_inference_steps:]
return timesteps, num_inference_steps
return timesteps, num_inference_steps - t_start
def _get_add_time_ids(
self,
original_size,
crops_coords_top_left,
target_size,
aesthetic_score,
negative_aesthetic_score,
dtype,
text_encoder_projection_dim=None,
):
if self.config.requires_aesthetics_score:
add_time_ids = list(original_size + crops_coords_top_left + (aesthetic_score,))
add_neg_time_ids = list(original_size + crops_coords_top_left + (negative_aesthetic_score,))
else:
add_time_ids = list(original_size + crops_coords_top_left + target_size)
add_neg_time_ids = list(original_size + crops_coords_top_left + target_size)
passed_add_embed_dim = (
self.unet.config.addition_time_embed_dim * len(add_time_ids) + text_encoder_projection_dim
)
expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
if (
expected_add_embed_dim > passed_add_embed_dim
and (expected_add_embed_dim - passed_add_embed_dim) == self.unet.config.addition_time_embed_dim
):
raise ValueError(
f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. Please make sure to enable `requires_aesthetics_score` with `pipe.register_to_config(requires_aesthetics_score=True)` to make sure `aesthetic_score` {aesthetic_score} and `negative_aesthetic_score` {negative_aesthetic_score} is correctly used by the model."
)
elif (
expected_add_embed_dim < passed_add_embed_dim
and (passed_add_embed_dim - expected_add_embed_dim) == self.unet.config.addition_time_embed_dim
):
raise ValueError(
f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. Please make sure to disable `requires_aesthetics_score` with `pipe.register_to_config(requires_aesthetics_score=False)` to make sure `target_size` {target_size} is correctly used by the model."
)
elif expected_add_embed_dim != passed_add_embed_dim:
raise ValueError(
f"Model expects an added time embedding vector of length {expected_add_embed_dim}, but a vector of {passed_add_embed_dim} was created. The model has an incorrect config. Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
)
add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
add_neg_time_ids = torch.tensor([add_neg_time_ids], dtype=dtype)
return add_time_ids, add_neg_time_ids
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae
def upcast_vae(self):
dtype = self.vae.dtype
self.vae.to(dtype=torch.float32)
use_torch_2_0_or_xformers = isinstance(
self.vae.decoder.mid_block.attentions[0].processor,
(
AttnProcessor2_0,
XFormersAttnProcessor,
LoRAXFormersAttnProcessor,
LoRAAttnProcessor2_0,
),
)
# if xformers or torch_2_0 is used attention block does not need
# to be in float32 which can save lots of memory
if use_torch_2_0_or_xformers:
self.vae.post_quant_conv.to(dtype)
self.vae.decoder.conv_in.to(dtype)
self.vae.decoder.mid_block.to(dtype)
# Copied from diffusers.pipelines.t2i_adapter.pipeline_stable_diffusion_adapter.StableDiffusionAdapterPipeline._default_height_width
def _default_height_width(self, height, width, image):
# NOTE: It is possible that a list of images have different
# dimensions for each image, so just checking the first image
# is not _exactly_ correct, but it is simple.
while isinstance(image, list):
image = image[0]
if height is None:
if isinstance(image, PIL.Image.Image):
height = image.height
elif isinstance(image, torch.Tensor):
height = image.shape[-2]
# round down to nearest multiple of `self.adapter.downscale_factor`
height = (height // self.adapter.downscale_factor) * self.adapter.downscale_factor
if width is None:
if isinstance(image, PIL.Image.Image):
width = image.width
elif isinstance(image, torch.Tensor):
width = image.shape[-1]
# round down to nearest multiple of `self.adapter.downscale_factor`
width = (width // self.adapter.downscale_factor) * self.adapter.downscale_factor
return height, width
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_freeu
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
r"""Enables the FreeU mechanism as in https://arxiv.org/abs/2309.11497.
The suffixes after the scaling factors represent the stages where they are being applied.
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of the values
that are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
Args:
s1 (`float`):
Scaling factor for stage 1 to attenuate the contributions of the skip features. This is done to
mitigate "oversmoothing effect" in the enhanced denoising process.
s2 (`float`):
Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to
mitigate "oversmoothing effect" in the enhanced denoising process.
b1 (`float`): Scaling factor for stage 1 to amplify the contributions of backbone features.
b2 (`float`): Scaling factor for stage 2 to amplify the contributions of backbone features.
"""
if not hasattr(self, "unet"):
raise ValueError("The pipeline must have `unet` for using FreeU.")
self.unet.enable_freeu(s1=s1, s2=s2, b1=b1, b2=b2)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_freeu
def disable_freeu(self):
"""Disables the FreeU mechanism if enabled."""
self.unet.disable_freeu()
def prepare_control_image(
self,
image,
width,
height,
batch_size,
num_images_per_prompt,
device,
dtype,
do_classifier_free_guidance=False,
guess_mode=False,
):
image = self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32)
image_batch_size = image.shape[0]
if image_batch_size == 1:
repeat_by = batch_size
else:
# image batch size is the same as prompt batch size
repeat_by = num_images_per_prompt
image = image.repeat_interleave(repeat_by, dim=0)
image = image.to(device=device, dtype=dtype)
if do_classifier_free_guidance and not guess_mode:
image = torch.cat([image] * 2)
return image
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Optional[Union[str, list[str]]] = None,
prompt_2: Optional[Union[str, list[str]]] = None,
image: Optional[Union[torch.Tensor, PIL.Image.Image]] = None,
mask_image: Optional[Union[torch.Tensor, PIL.Image.Image]] = None,
adapter_image: PipelineImageInput = None,
control_image: PipelineImageInput = None,
height: Optional[int] = None,
width: Optional[int] = None,
strength: float = 0.9999,
num_inference_steps: int = 50,
denoising_start: Optional[float] = None,
denoising_end: Optional[float] = None,
guidance_scale: float = 5.0,
negative_prompt: Optional[Union[str, list[str]]] = None,
negative_prompt_2: Optional[Union[str, list[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, list[torch.Generator]]] = None,
latents: Optional[Union[torch.FloatTensor]] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[dict[str, Any]] = None,
guidance_rescale: float = 0.0,
original_size: Optional[tuple[int, int]] = None,
crops_coords_top_left: Optional[tuple[int, int]] = (0, 0),
target_size: Optional[tuple[int, int]] = None,
adapter_conditioning_scale: Optional[Union[float, list[float]]] = 1.0,
cond_tau: float = 1.0,
aesthetic_score: float = 6.0,
negative_aesthetic_score: float = 2.5,
controlnet_conditioning_scale=1.0,
guess_mode: bool = False,
control_guidance_start=0.0,
control_guidance_end=1.0,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
used in both text-encoders
image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
mask_image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
repainted, while black pixels will be preserved. If `mask_image` is a PIL image, it will be converted
to a single channel (luminance) before use. If it's a tensor, it should contain one color channel (L)
instead of 3, so the expected shape would be `(B, H, W, 1)`.
adapter_image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]` or `List[PIL.Image.Image]` or `List[List[PIL.Image.Image]]`):
The Adapter input condition. Adapter uses this input condition to generate guidance to Unet. If the
type is specified as `Torch.FloatTensor`, it is passed to Adapter as is. PIL.Image.Image` can also be
accepted as an image. The control image is automatically resized to fit the output image.
control_image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The ControlNet input condition to provide guidance to the `unet` for generation. If the type is
specified as `torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can also be
accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If height
and/or width are passed, `image` is resized accordingly. If multiple ControlNets are specified in
`init`, images must be passed as a list such that each element of the list can be correctly batched for
input to a single ControlNet.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
strength (`float`, *optional*, defaults to 1.0):
Indicates extent to transform the reference `image`. Must be between 0 and 1. `image` is used as a
starting point and more noise is added the higher the `strength`. The number of denoising steps depends
on the amount of noise initially added. When `strength` is 1, added noise is maximum and the denoising
process runs for the full number of iterations specified in `num_inference_steps`. A value of 1
essentially ignores `image`.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
denoising_start (`float`, *optional*):
When specified, indicates the fraction (between 0.0 and 1.0) of the total denoising process to be
bypassed before it is initiated. Consequently, the initial part of the denoising process is skipped and
it is assumed that the passed `image` is a partly denoised image. Note that when this is specified,
strength will be ignored. The `denoising_start` parameter is particularly beneficial when this pipeline
is integrated into a "Mixture of Denoisers" multi-pipeline setup, as detailed in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output).
denoising_end (`float`, *optional*):
When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
completed before it is intentionally prematurely terminated. As a result, the returned sample will
still retain a substantial amount of noise as determined by the discrete timesteps selected by the
scheduler. The denoising_end parameter should ideally be utilized when this pipeline forms a part of a
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
guidance_scale (`float`, *optional*, defaults to 5.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
negative_prompt_2 (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
`text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
If not provided, pooled text embeddings will be generated from `prompt` input argument.
negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionAdapterPipelineOutput`]
instead of a plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.7):
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
[Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
Guidance rescale factor should fix overexposure when using zero terminal SNR.
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
`original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
`crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
`crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
`crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
For most cases, `target_size` should be set to the desired height and width of the generated image. If
not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added to the
residual in the original unet. If multiple adapters are specified in init, you can set the
corresponding scale as a list.
adapter_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the adapter are multiplied by `adapter_conditioning_scale` before they are added to the
residual in the original unet. If multiple adapters are specified in init, you can set the
corresponding scale as a list.
aesthetic_score (`float`, *optional*, defaults to 6.0):
Used to simulate an aesthetic score of the generated image by influencing the positive text condition.
Part of SDXL's micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
negative_aesthetic_score (`float`, *optional*, defaults to 2.5):
Part of SDXL's micro-conditioning as explained in section 2.2 of
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). Can be used to
simulate an aesthetic score of the generated image by influencing the negative text condition.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionAdapterPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionAdapterPipelineOutput`] if `return_dict` is True, otherwise a
`tuple`. When returning a tuple, the first element is a list with the generated images.
"""
# 0. Default height and width to unet
controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
adapter = self.adapter._orig_mod if is_compiled_module(self.adapter) else self.adapter
height, width = self._default_height_width(height, width, adapter_image)
device = self._execution_device
adapter_input = _preprocess_adapter_image(adapter_image, height, width).to(device)
original_size = original_size or (height, width)
target_size = target_size or (height, width)
# 0.1 align format for control guidance
if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
control_guidance_start = len(control_guidance_end) * [control_guidance_start]
elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
control_guidance_end = len(control_guidance_start) * [control_guidance_end]
elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
mult = len(controlnet.nets) if isinstance(controlnet, MultiControlNetModel) else 1
control_guidance_start, control_guidance_end = (
mult * [control_guidance_start],
mult * [control_guidance_end],
)
if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
if isinstance(adapter, MultiAdapter) and isinstance(adapter_conditioning_scale, float):
adapter_conditioning_scale = [adapter_conditioning_scale] * len(adapter.nets)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
prompt_2,
height,
width,
callback_steps,
negative_prompt=negative_prompt,
negative_prompt_2=negative_prompt_2,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
)
self.check_conditions(
prompt,
prompt_embeds,
adapter_image,
control_image,
adapter_conditioning_scale,
controlnet_conditioning_scale,
control_guidance_start,
control_guidance_end,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
(
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds,
) = self.encode_prompt(
prompt=prompt,
prompt_2=prompt_2,
device=device,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=do_classifier_free_guidance,
negative_prompt=negative_prompt,
negative_prompt_2=negative_prompt_2,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
)
# 4. set timesteps
def denoising_value_valid(dnv):
return isinstance(denoising_end, float) and 0 < dnv < 1
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, num_inference_steps = self.get_timesteps(
num_inference_steps,
strength,
device,
denoising_start=denoising_start if denoising_value_valid else None,
)
# check that number of inference steps is not < 1 - as this doesn't make sense
if num_inference_steps < 1:
raise ValueError(
f"After adjusting the num_inference_steps by strength parameter: {strength}, the number of pipeline"
f"steps is {num_inference_steps} which is < 1 and not appropriate for this pipeline."
)
# at which timestep to set the initial noise (n.b. 50% if strength is 0.5)
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# create a boolean to check if the strength is set to 1. if so then initialise the latents with pure noise
is_strength_max = strength == 1.0
# 5. Preprocess mask and image - resizes image and mask w.r.t height and width
mask, masked_image, init_image = prepare_mask_and_masked_image(
image, mask_image, height, width, return_image=True
)
# 6. Prepare latent variables
num_channels_latents = self.vae.config.latent_channels
num_channels_unet = self.unet.config.in_channels
return_image_latents = num_channels_unet == 4
add_noise = denoising_start is None
latents_outputs = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
image=init_image,
timestep=latent_timestep,
is_strength_max=is_strength_max,
add_noise=add_noise,
return_noise=True,
return_image_latents=return_image_latents,
)
if return_image_latents:
latents, noise, image_latents = latents_outputs
else:
latents, noise = latents_outputs
# 7. Prepare mask latent variables
mask, masked_image_latents = self.prepare_mask_latents(
mask,
masked_image,
batch_size * num_images_per_prompt,
height,
width,
prompt_embeds.dtype,
device,
generator,
do_classifier_free_guidance,
)
# 8. Check that sizes of mask, masked image and latents match
if num_channels_unet == 9:
# default case for runwayml/stable-diffusion-inpainting
num_channels_mask = mask.shape[1]
num_channels_masked_image = masked_image_latents.shape[1]
if num_channels_latents + num_channels_mask + num_channels_masked_image != self.unet.config.in_channels:
raise ValueError(
f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
" `pipeline.unet` or your `mask_image` or `image` input."
)
elif num_channels_unet != 4:
raise ValueError(
f"The unet {self.unet.__class__} should have either 4 or 9 input channels, not {self.unet.config.in_channels}."
)
# 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 10. Prepare added time ids & embeddings & adapter features
adapter_input = adapter_input.type(latents.dtype)
adapter_state = adapter(adapter_input)
for k, v in enumerate(adapter_state):
adapter_state[k] = v * adapter_conditioning_scale
if num_images_per_prompt > 1:
for k, v in enumerate(adapter_state):
adapter_state[k] = v.repeat(num_images_per_prompt, 1, 1, 1)
if do_classifier_free_guidance:
for k, v in enumerate(adapter_state):
adapter_state[k] = torch.cat([v] * 2, dim=0)
# 10.2 Prepare control images
if isinstance(controlnet, ControlNetModel):
control_image = self.prepare_control_image(
image=control_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
elif isinstance(controlnet, MultiControlNetModel):
control_images = []
for control_image_ in control_image:
control_image_ = self.prepare_control_image(
image=control_image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
control_images.append(control_image_)
control_image = control_images
else:
raise ValueError(f"{controlnet.__class__} is not supported.")
# 8.2 Create tensor stating which controlnets to keep
controlnet_keep = []
for i in range(len(timesteps)):
keeps = [
1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
for s, e in zip(control_guidance_start, control_guidance_end)
]
if isinstance(self.controlnet, MultiControlNetModel):
controlnet_keep.append(keeps)
else:
controlnet_keep.append(keeps[0])
# ----------------------------------------------------------------
add_text_embeds = pooled_prompt_embeds
if self.text_encoder_2 is None:
text_encoder_projection_dim = int(pooled_prompt_embeds.shape[-1])
else:
text_encoder_projection_dim = self.text_encoder_2.config.projection_dim
add_time_ids, add_neg_time_ids = self._get_add_time_ids(
original_size,
crops_coords_top_left,
target_size,
aesthetic_score,
negative_aesthetic_score,
dtype=prompt_embeds.dtype,
text_encoder_projection_dim=text_encoder_projection_dim,
)
add_time_ids = add_time_ids.repeat(batch_size * num_images_per_prompt, 1)
if do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
add_neg_time_ids = add_neg_time_ids.repeat(batch_size * num_images_per_prompt, 1)
add_time_ids = torch.cat([add_neg_time_ids, add_time_ids], dim=0)
prompt_embeds = prompt_embeds.to(device)
add_text_embeds = add_text_embeds.to(device)
add_time_ids = add_time_ids.to(device)
# 11. Denoising loop
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
# 11.1 Apply denoising_end
if (
denoising_end is not None
and denoising_start is not None
and denoising_value_valid(denoising_end)
and denoising_value_valid(denoising_start)
and denoising_start >= denoising_end
):
raise ValueError(
f"`denoising_start`: {denoising_start} cannot be larger than or equal to `denoising_end`: "
+ f" {denoising_end} when using type float."
)
elif denoising_end is not None and denoising_value_valid(denoising_end):
discrete_timestep_cutoff = int(
round(
self.scheduler.config.num_train_timesteps
- (denoising_end * self.scheduler.config.num_train_timesteps)
)
)
num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
timesteps = timesteps[:num_inference_steps]
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
if num_channels_unet == 9:
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
# predict the noise residual
added_cond_kwargs = {
"text_embeds": add_text_embeds,
"time_ids": add_time_ids,
}
if i < int(num_inference_steps * cond_tau):
down_block_additional_residuals = [state.clone() for state in adapter_state]
else:
down_block_additional_residuals = None
# ----------- ControlNet
# expand the latents if we are doing classifier free guidance
latent_model_input_controlnet = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
# concat latents, mask, masked_image_latents in the channel dimension
latent_model_input_controlnet = self.scheduler.scale_model_input(latent_model_input_controlnet, t)
# controlnet(s) inference
if guess_mode and do_classifier_free_guidance:
# Infer ControlNet only for the conditional batch.
control_model_input = latents
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
controlnet_added_cond_kwargs = {
"text_embeds": add_text_embeds.chunk(2)[1],
"time_ids": add_time_ids.chunk(2)[1],
}
else:
control_model_input = latent_model_input_controlnet
controlnet_prompt_embeds = prompt_embeds
controlnet_added_cond_kwargs = added_cond_kwargs
if isinstance(controlnet_keep[i], list):
cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
else:
controlnet_cond_scale = controlnet_conditioning_scale
if isinstance(controlnet_cond_scale, list):
controlnet_cond_scale = controlnet_cond_scale[0]
cond_scale = controlnet_cond_scale * controlnet_keep[i]
down_block_res_samples, mid_block_res_sample = self.controlnet(
control_model_input,
t,
encoder_hidden_states=controlnet_prompt_embeds,
controlnet_cond=control_image,
conditioning_scale=cond_scale,
guess_mode=guess_mode,
added_cond_kwargs=controlnet_added_cond_kwargs,
return_dict=False,
)
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
down_intrablock_additional_residuals=down_block_additional_residuals, # t2iadapter
down_block_additional_residuals=down_block_res_samples, # controlnet
mid_block_additional_residual=mid_block_res_sample, # controlnet
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
if do_classifier_free_guidance and guidance_rescale > 0.0:
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
noise_pred = rescale_noise_cfg(
noise_pred,
noise_pred_text,
guidance_rescale=guidance_rescale,
)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(
noise_pred,
t,
latents,
**extra_step_kwargs,
return_dict=False,
)[0]
if num_channels_unet == 4:
init_latents_proper = image_latents
if do_classifier_free_guidance:
init_mask, _ = mask.chunk(2)
else:
init_mask = mask
if i < len(timesteps) - 1:
noise_timestep = timesteps[i + 1]
init_latents_proper = self.scheduler.add_noise(
init_latents_proper,
noise,
torch.tensor([noise_timestep]),
)
latents = (1 - init_mask) * init_latents_proper + init_mask * latents
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
callback(i, t, latents)
# make sure the VAE is in float32 mode, as it overflows in float16
if self.vae.dtype == torch.float16 and self.vae.config.force_upcast:
self.upcast_vae()
latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
if output_type != "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
else:
image = latents
return StableDiffusionXLPipelineOutput(images=image)
image = self.image_processor.postprocess(image, output_type=output_type)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image,)
return StableDiffusionXLPipelineOutput(images=image)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/stable_unclip.py
|
import types
from typing import List, Optional, Tuple, Union
import torch
from transformers import CLIPTextModelWithProjection, CLIPTokenizer
from transformers.models.clip.modeling_clip import CLIPTextModelOutput
from diffusers.models import PriorTransformer
from diffusers.pipelines import DiffusionPipeline, StableDiffusionImageVariationPipeline
from diffusers.schedulers import UnCLIPScheduler
from diffusers.utils import logging
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def _encode_image(self, image, device, num_images_per_prompt, do_classifier_free_guidance):
image = image.to(device=device)
image_embeddings = image # take image as image_embeddings
image_embeddings = image_embeddings.unsqueeze(1)
# duplicate image embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = image_embeddings.shape
image_embeddings = image_embeddings.repeat(1, num_images_per_prompt, 1)
image_embeddings = image_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
if do_classifier_free_guidance:
uncond_embeddings = torch.zeros_like(image_embeddings)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
image_embeddings = torch.cat([uncond_embeddings, image_embeddings])
return image_embeddings
class StableUnCLIPPipeline(DiffusionPipeline):
def __init__(
self,
prior: PriorTransformer,
tokenizer: CLIPTokenizer,
text_encoder: CLIPTextModelWithProjection,
prior_scheduler: UnCLIPScheduler,
decoder_pipe_kwargs: Optional[dict] = None,
):
super().__init__()
decoder_pipe_kwargs = {"image_encoder": None} if decoder_pipe_kwargs is None else decoder_pipe_kwargs
decoder_pipe_kwargs["torch_dtype"] = decoder_pipe_kwargs.get("torch_dtype", None) or prior.dtype
self.decoder_pipe = StableDiffusionImageVariationPipeline.from_pretrained(
"lambdalabs/sd-image-variations-diffusers", **decoder_pipe_kwargs
)
# replace `_encode_image` method
self.decoder_pipe._encode_image = types.MethodType(_encode_image, self.decoder_pipe)
self.register_modules(
prior=prior,
tokenizer=tokenizer,
text_encoder=text_encoder,
prior_scheduler=prior_scheduler,
)
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
text_model_output: Optional[Union[CLIPTextModelOutput, Tuple]] = None,
text_attention_mask: Optional[torch.Tensor] = None,
):
if text_model_output is None:
batch_size = len(prompt) if isinstance(prompt, list) else 1
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
text_mask = text_inputs.attention_mask.bool().to(device)
if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
text_encoder_output = self.text_encoder(text_input_ids.to(device))
text_embeddings = text_encoder_output.text_embeds
text_encoder_hidden_states = text_encoder_output.last_hidden_state
else:
batch_size = text_model_output[0].shape[0]
text_embeddings, text_encoder_hidden_states = text_model_output[0], text_model_output[1]
text_mask = text_attention_mask
text_embeddings = text_embeddings.repeat_interleave(num_images_per_prompt, dim=0)
text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
if do_classifier_free_guidance:
uncond_tokens = [""] * batch_size
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
uncond_text_mask = uncond_input.attention_mask.bool().to(device)
uncond_embeddings_text_encoder_output = self.text_encoder(uncond_input.input_ids.to(device))
uncond_embeddings = uncond_embeddings_text_encoder_output.text_embeds
uncond_text_encoder_hidden_states = uncond_embeddings_text_encoder_output.last_hidden_state
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = uncond_embeddings.repeat(1, num_images_per_prompt)
uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len)
seq_len = uncond_text_encoder_hidden_states.shape[1]
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
batch_size * num_images_per_prompt, seq_len, -1
)
uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
# done duplicates
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
text_mask = torch.cat([uncond_text_mask, text_mask])
return text_embeddings, text_encoder_hidden_states, text_mask
@property
def _execution_device(self):
r"""
Returns the device on which the pipeline's models will be executed. After calling
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
hooks.
"""
if self.device != torch.device("meta") or not hasattr(self.prior, "_hf_hook"):
return self.device
for module in self.prior.modules():
if (
hasattr(module, "_hf_hook")
and hasattr(module._hf_hook, "execution_device")
and module._hf_hook.execution_device is not None
):
return torch.device(module._hf_hook.execution_device)
return self.device
def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
if latents.shape != shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
latents = latents.to(device)
latents = latents * scheduler.init_noise_sigma
return latents
def to(self, torch_device: Optional[Union[str, torch.device]] = None):
self.decoder_pipe.to(torch_device)
super().to(torch_device)
@torch.no_grad()
def __call__(
self,
prompt: Optional[Union[str, List[str]]] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_images_per_prompt: int = 1,
prior_num_inference_steps: int = 25,
generator: Optional[torch.Generator] = None,
prior_latents: Optional[torch.FloatTensor] = None,
text_model_output: Optional[Union[CLIPTextModelOutput, Tuple]] = None,
text_attention_mask: Optional[torch.Tensor] = None,
prior_guidance_scale: float = 4.0,
decoder_guidance_scale: float = 8.0,
decoder_num_inference_steps: int = 50,
decoder_num_images_per_prompt: Optional[int] = 1,
decoder_eta: float = 0.0,
output_type: Optional[str] = "pil",
return_dict: bool = True,
):
if prompt is not None:
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
else:
batch_size = text_model_output[0].shape[0]
device = self._execution_device
batch_size = batch_size * num_images_per_prompt
do_classifier_free_guidance = prior_guidance_scale > 1.0 or decoder_guidance_scale > 1.0
text_embeddings, text_encoder_hidden_states, text_mask = self._encode_prompt(
prompt, device, num_images_per_prompt, do_classifier_free_guidance, text_model_output, text_attention_mask
)
# prior
self.prior_scheduler.set_timesteps(prior_num_inference_steps, device=device)
prior_timesteps_tensor = self.prior_scheduler.timesteps
embedding_dim = self.prior.config.embedding_dim
prior_latents = self.prepare_latents(
(batch_size, embedding_dim),
text_embeddings.dtype,
device,
generator,
prior_latents,
self.prior_scheduler,
)
for i, t in enumerate(self.progress_bar(prior_timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([prior_latents] * 2) if do_classifier_free_guidance else prior_latents
predicted_image_embedding = self.prior(
latent_model_input,
timestep=t,
proj_embedding=text_embeddings,
encoder_hidden_states=text_encoder_hidden_states,
attention_mask=text_mask,
).predicted_image_embedding
if do_classifier_free_guidance:
predicted_image_embedding_uncond, predicted_image_embedding_text = predicted_image_embedding.chunk(2)
predicted_image_embedding = predicted_image_embedding_uncond + prior_guidance_scale * (
predicted_image_embedding_text - predicted_image_embedding_uncond
)
if i + 1 == prior_timesteps_tensor.shape[0]:
prev_timestep = None
else:
prev_timestep = prior_timesteps_tensor[i + 1]
prior_latents = self.prior_scheduler.step(
predicted_image_embedding,
timestep=t,
sample=prior_latents,
generator=generator,
prev_timestep=prev_timestep,
).prev_sample
prior_latents = self.prior.post_process_latents(prior_latents)
image_embeddings = prior_latents
output = self.decoder_pipe(
image=image_embeddings,
height=height,
width=width,
num_inference_steps=decoder_num_inference_steps,
guidance_scale=decoder_guidance_scale,
generator=generator,
output_type=output_type,
return_dict=return_dict,
num_images_per_prompt=decoder_num_images_per_prompt,
eta=decoder_eta,
)
return output
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/latent_consistency_txt2img.py
|
# Copyright 2023 Stanford University Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pytorch_diffusion
# and https://github.com/hojonathanho/diffusion
import math
from dataclasses import dataclass
from typing import Any, Dict, List, Optional, Tuple, Union
import numpy as np
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, ConfigMixin, DiffusionPipeline, SchedulerMixin, UNet2DConditionModel, logging
from diffusers.configuration_utils import register_to_config
from diffusers.image_processor import VaeImageProcessor
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.utils import BaseOutput
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
class LatentConsistencyModelPipeline(DiffusionPipeline):
_optional_components = ["scheduler"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: "LCMScheduler",
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
scheduler = (
scheduler
if scheduler is not None
else LCMScheduler(
beta_start=0.00085, beta_end=0.0120, beta_schedule="scaled_linear", prediction_type="epsilon"
)
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
prompt_embeds: None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
"""
if prompt is not None and isinstance(prompt, str):
pass
elif prompt is not None and isinstance(prompt, list):
len(prompt)
else:
prompt_embeds.shape[0]
if prompt_embeds is None:
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
prompt_embeds = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
prompt_embeds = prompt_embeds[0]
if self.text_encoder is not None:
prompt_embeds_dtype = self.text_encoder.dtype
elif self.unet is not None:
prompt_embeds_dtype = self.unet.dtype
else:
prompt_embeds_dtype = prompt_embeds.dtype
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# Don't need to get uncond prompt embedding because of LCM Guided Distillation
return prompt_embeds
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is None:
has_nsfw_concept = None
else:
if torch.is_tensor(image):
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
else:
feature_extractor_input = self.image_processor.numpy_to_pil(image)
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
return image, has_nsfw_concept
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, latents=None):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if latents is None:
latents = torch.randn(shape, dtype=dtype).to(device)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def get_w_embedding(self, w, embedding_dim=512, dtype=torch.float32):
"""
see https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
Args:
timesteps: torch.Tensor: generate embedding vectors at these timesteps
embedding_dim: int: dimension of the embeddings to generate
dtype: data type of the generated embeddings
Returns:
embedding vectors with shape `(len(timesteps), embedding_dim)`
"""
assert len(w.shape) == 1
w = w * 1000.0
half_dim = embedding_dim // 2
emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
emb = w.to(dtype)[:, None] * emb[None, :]
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
if embedding_dim % 2 == 1: # zero pad
emb = torch.nn.functional.pad(emb, (0, 1))
assert emb.shape == (w.shape[0], embedding_dim)
return emb
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
height: Optional[int] = 768,
width: Optional[int] = 768,
guidance_scale: float = 7.5,
num_images_per_prompt: Optional[int] = 1,
latents: Optional[torch.FloatTensor] = None,
num_inference_steps: int = 4,
lcm_origin_steps: int = 50,
prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
):
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# do_classifier_free_guidance = guidance_scale > 0.0 # In LCM Implementation: cfg_noise = noise_cond + cfg_scale * (noise_cond - noise_uncond) , (cfg_scale > 0.0 using CFG)
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
prompt_embeds=prompt_embeds,
)
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, lcm_origin_steps)
timesteps = self.scheduler.timesteps
# 5. Prepare latent variable
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
latents,
)
bs = batch_size * num_images_per_prompt
# 6. Get Guidance Scale Embedding
w = torch.tensor(guidance_scale).repeat(bs)
w_embedding = self.get_w_embedding(w, embedding_dim=256).to(device=device, dtype=latents.dtype)
# 7. LCM MultiStep Sampling Loop:
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
ts = torch.full((bs,), t, device=device, dtype=torch.long)
latents = latents.to(prompt_embeds.dtype)
# model prediction (v-prediction, eps, x)
model_pred = self.unet(
latents,
ts,
timestep_cond=w_embedding,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
return_dict=False,
)[0]
# compute the previous noisy sample x_t -> x_t-1
latents, denoised = self.scheduler.step(model_pred, i, t, latents, return_dict=False)
# # call the callback, if provided
# if i == len(timesteps) - 1:
progress_bar.update()
denoised = denoised.to(prompt_embeds.dtype)
if not output_type == "latent":
image = self.vae.decode(denoised / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = denoised
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
@dataclass
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->DDIM
class LCMSchedulerOutput(BaseOutput):
"""
Output class for the scheduler's `step` function output.
Args:
prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
Computed sample `(x_{t-1})` of previous timestep. `prev_sample` should be used as next model input in the
denoising loop.
pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
The predicted denoised sample `(x_{0})` based on the model output from the current timestep.
`pred_original_sample` can be used to preview progress or for guidance.
"""
prev_sample: torch.FloatTensor
denoised: Optional[torch.FloatTensor] = None
# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
def betas_for_alpha_bar(
num_diffusion_timesteps,
max_beta=0.999,
alpha_transform_type="cosine",
):
"""
Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
(1-beta) over time from t = [0,1].
Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
to that part of the diffusion process.
Args:
num_diffusion_timesteps (`int`): the number of betas to produce.
max_beta (`float`): the maximum beta to use; use values lower than 1 to
prevent singularities.
alpha_transform_type (`str`, *optional*, default to `cosine`): the type of noise schedule for alpha_bar.
Choose from `cosine` or `exp`
Returns:
betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
"""
if alpha_transform_type == "cosine":
def alpha_bar_fn(t):
return math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2
elif alpha_transform_type == "exp":
def alpha_bar_fn(t):
return math.exp(t * -12.0)
else:
raise ValueError(f"Unsupported alpha_tranform_type: {alpha_transform_type}")
betas = []
for i in range(num_diffusion_timesteps):
t1 = i / num_diffusion_timesteps
t2 = (i + 1) / num_diffusion_timesteps
betas.append(min(1 - alpha_bar_fn(t2) / alpha_bar_fn(t1), max_beta))
return torch.tensor(betas, dtype=torch.float32)
def rescale_zero_terminal_snr(betas):
"""
Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
Args:
betas (`torch.FloatTensor`):
the betas that the scheduler is being initialized with.
Returns:
`torch.FloatTensor`: rescaled betas with zero terminal SNR
"""
# Convert betas to alphas_bar_sqrt
alphas = 1.0 - betas
alphas_cumprod = torch.cumprod(alphas, dim=0)
alphas_bar_sqrt = alphas_cumprod.sqrt()
# Store old values.
alphas_bar_sqrt_0 = alphas_bar_sqrt[0].clone()
alphas_bar_sqrt_T = alphas_bar_sqrt[-1].clone()
# Shift so the last timestep is zero.
alphas_bar_sqrt -= alphas_bar_sqrt_T
# Scale so the first timestep is back to the old value.
alphas_bar_sqrt *= alphas_bar_sqrt_0 / (alphas_bar_sqrt_0 - alphas_bar_sqrt_T)
# Convert alphas_bar_sqrt to betas
alphas_bar = alphas_bar_sqrt**2 # Revert sqrt
alphas = alphas_bar[1:] / alphas_bar[:-1] # Revert cumprod
alphas = torch.cat([alphas_bar[0:1], alphas])
betas = 1 - alphas
return betas
class LCMScheduler(SchedulerMixin, ConfigMixin):
"""
`LCMScheduler` extends the denoising procedure introduced in denoising diffusion probabilistic models (DDPMs) with
non-Markovian guidance.
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. Check the superclass documentation for the generic
methods the library implements for all schedulers such as loading and saving.
Args:
num_train_timesteps (`int`, defaults to 1000):
The number of diffusion steps to train the model.
beta_start (`float`, defaults to 0.0001):
The starting `beta` value of inference.
beta_end (`float`, defaults to 0.02):
The final `beta` value.
beta_schedule (`str`, defaults to `"linear"`):
The beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
`linear`, `scaled_linear`, or `squaredcos_cap_v2`.
trained_betas (`np.ndarray`, *optional*):
Pass an array of betas directly to the constructor to bypass `beta_start` and `beta_end`.
clip_sample (`bool`, defaults to `True`):
Clip the predicted sample for numerical stability.
clip_sample_range (`float`, defaults to 1.0):
The maximum magnitude for sample clipping. Valid only when `clip_sample=True`.
set_alpha_to_one (`bool`, defaults to `True`):
Each diffusion step uses the alphas product value at that step and at the previous one. For the final step
there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
otherwise it uses the alpha value at step 0.
steps_offset (`int`, defaults to 0):
An offset added to the inference steps. You can use a combination of `offset=1` and
`set_alpha_to_one=False` to make the last step use step 0 for the previous alpha product like in Stable
Diffusion.
prediction_type (`str`, defaults to `epsilon`, *optional*):
Prediction type of the scheduler function; can be `epsilon` (predicts the noise of the diffusion process),
`sample` (directly predicts the noisy sample`) or `v_prediction` (see section 2.4 of [Imagen
Video](https://imagen.research.google/video/paper.pdf) paper).
thresholding (`bool`, defaults to `False`):
Whether to use the "dynamic thresholding" method. This is unsuitable for latent-space diffusion models such
as Stable Diffusion.
dynamic_thresholding_ratio (`float`, defaults to 0.995):
The ratio for the dynamic thresholding method. Valid only when `thresholding=True`.
sample_max_value (`float`, defaults to 1.0):
The threshold value for dynamic thresholding. Valid only when `thresholding=True`.
timestep_spacing (`str`, defaults to `"leading"`):
The way the timesteps should be scaled. Refer to Table 2 of the [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
rescale_betas_zero_snr (`bool`, defaults to `False`):
Whether to rescale the betas to have zero terminal SNR. This enables the model to generate very bright and
dark samples instead of limiting it to samples with medium brightness. Loosely related to
[`--offset_noise`](https://github.com/huggingface/diffusers/blob/74fd735eb073eb1d774b1ab4154a0876eb82f055/examples/dreambooth/train_dreambooth.py#L506).
"""
# _compatibles = [e.name for e in KarrasDiffusionSchedulers]
order = 1
@register_to_config
def __init__(
self,
num_train_timesteps: int = 1000,
beta_start: float = 0.0001,
beta_end: float = 0.02,
beta_schedule: str = "linear",
trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
clip_sample: bool = True,
set_alpha_to_one: bool = True,
steps_offset: int = 0,
prediction_type: str = "epsilon",
thresholding: bool = False,
dynamic_thresholding_ratio: float = 0.995,
clip_sample_range: float = 1.0,
sample_max_value: float = 1.0,
timestep_spacing: str = "leading",
rescale_betas_zero_snr: bool = False,
):
if trained_betas is not None:
self.betas = torch.tensor(trained_betas, dtype=torch.float32)
elif beta_schedule == "linear":
self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
elif beta_schedule == "scaled_linear":
# this schedule is very specific to the latent diffusion model.
self.betas = torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
elif beta_schedule == "squaredcos_cap_v2":
# Glide cosine schedule
self.betas = betas_for_alpha_bar(num_train_timesteps)
else:
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
# Rescale for zero SNR
if rescale_betas_zero_snr:
self.betas = rescale_zero_terminal_snr(self.betas)
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
# At every step in ddim, we are looking into the previous alphas_cumprod
# For the final step, there is no previous alphas_cumprod because we are already at 0
# `set_alpha_to_one` decides whether we set this parameter simply to one or
# whether we use the final alpha of the "non-previous" one.
self.final_alpha_cumprod = torch.tensor(1.0) if set_alpha_to_one else self.alphas_cumprod[0]
# standard deviation of the initial noise distribution
self.init_noise_sigma = 1.0
# setable values
self.num_inference_steps = None
self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps)[::-1].copy().astype(np.int64))
def scale_model_input(self, sample: torch.FloatTensor, timestep: Optional[int] = None) -> torch.FloatTensor:
"""
Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
current timestep.
Args:
sample (`torch.FloatTensor`):
The input sample.
timestep (`int`, *optional*):
The current timestep in the diffusion chain.
Returns:
`torch.FloatTensor`:
A scaled input sample.
"""
return sample
def _get_variance(self, timestep, prev_timestep):
alpha_prod_t = self.alphas_cumprod[timestep]
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
return variance
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler._threshold_sample
def _threshold_sample(self, sample: torch.FloatTensor) -> torch.FloatTensor:
"""
"Dynamic thresholding: At each sampling step we set s to a certain percentile absolute pixel value in xt0 (the
prediction of x_0 at timestep t), and if s > 1, then we threshold xt0 to the range [-s, s] and then divide by
s. Dynamic thresholding pushes saturated pixels (those near -1 and 1) inwards, thereby actively preventing
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
https://arxiv.org/abs/2205.11487
"""
dtype = sample.dtype
batch_size, channels, height, width = sample.shape
if dtype not in (torch.float32, torch.float64):
sample = sample.float() # upcast for quantile calculation, and clamp not implemented for cpu half
# Flatten sample for doing quantile calculation along each image
sample = sample.reshape(batch_size, channels * height * width)
abs_sample = sample.abs() # "a certain percentile absolute pixel value"
s = torch.quantile(abs_sample, self.config.dynamic_thresholding_ratio, dim=1)
s = torch.clamp(
s, min=1, max=self.config.sample_max_value
) # When clamped to min=1, equivalent to standard clipping to [-1, 1]
s = s.unsqueeze(1) # (batch_size, 1) because clamp will broadcast along dim=0
sample = torch.clamp(sample, -s, s) / s # "we threshold xt0 to the range [-s, s] and then divide by s"
sample = sample.reshape(batch_size, channels, height, width)
sample = sample.to(dtype)
return sample
def set_timesteps(self, num_inference_steps: int, lcm_origin_steps: int, device: Union[str, torch.device] = None):
"""
Sets the discrete timesteps used for the diffusion chain (to be run before inference).
Args:
num_inference_steps (`int`):
The number of diffusion steps used when generating samples with a pre-trained model.
"""
if num_inference_steps > self.config.num_train_timesteps:
raise ValueError(
f"`num_inference_steps`: {num_inference_steps} cannot be larger than `self.config.train_timesteps`:"
f" {self.config.num_train_timesteps} as the unet model trained with this scheduler can only handle"
f" maximal {self.config.num_train_timesteps} timesteps."
)
self.num_inference_steps = num_inference_steps
# LCM Timesteps Setting: # Linear Spacing
c = self.config.num_train_timesteps // lcm_origin_steps
lcm_origin_timesteps = np.asarray(list(range(1, lcm_origin_steps + 1))) * c - 1 # LCM Training Steps Schedule
skipping_step = len(lcm_origin_timesteps) // num_inference_steps
timesteps = lcm_origin_timesteps[::-skipping_step][:num_inference_steps] # LCM Inference Steps Schedule
self.timesteps = torch.from_numpy(timesteps.copy()).to(device)
def get_scalings_for_boundary_condition_discrete(self, t):
self.sigma_data = 0.5 # Default: 0.5
# By dividing 0.1: This is almost a delta function at t=0.
c_skip = self.sigma_data**2 / ((t / 0.1) ** 2 + self.sigma_data**2)
c_out = (t / 0.1) / ((t / 0.1) ** 2 + self.sigma_data**2) ** 0.5
return c_skip, c_out
def step(
self,
model_output: torch.FloatTensor,
timeindex: int,
timestep: int,
sample: torch.FloatTensor,
eta: float = 0.0,
use_clipped_model_output: bool = False,
generator=None,
variance_noise: Optional[torch.FloatTensor] = None,
return_dict: bool = True,
) -> Union[LCMSchedulerOutput, Tuple]:
"""
Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
process from the learned model outputs (most often the predicted noise).
Args:
model_output (`torch.FloatTensor`):
The direct output from learned diffusion model.
timestep (`float`):
The current discrete timestep in the diffusion chain.
sample (`torch.FloatTensor`):
A current instance of a sample created by the diffusion process.
eta (`float`):
The weight of noise for added noise in diffusion step.
use_clipped_model_output (`bool`, defaults to `False`):
If `True`, computes "corrected" `model_output` from the clipped predicted original sample. Necessary
because predicted original sample is clipped to [-1, 1] when `self.config.clip_sample` is `True`. If no
clipping has happened, "corrected" `model_output` would coincide with the one provided as input and
`use_clipped_model_output` has no effect.
generator (`torch.Generator`, *optional*):
A random number generator.
variance_noise (`torch.FloatTensor`):
Alternative to generating noise with `generator` by directly providing the noise for the variance
itself. Useful for methods such as [`CycleDiffusion`].
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~schedulers.scheduling_lcm.LCMSchedulerOutput`] or `tuple`.
Returns:
[`~schedulers.scheduling_utils.LCMSchedulerOutput`] or `tuple`:
If return_dict is `True`, [`~schedulers.scheduling_lcm.LCMSchedulerOutput`] is returned, otherwise a
tuple is returned where the first element is the sample tensor.
"""
if self.num_inference_steps is None:
raise ValueError(
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
# 1. get previous step value
prev_timeindex = timeindex + 1
if prev_timeindex < len(self.timesteps):
prev_timestep = self.timesteps[prev_timeindex]
else:
prev_timestep = timestep
# 2. compute alphas, betas
alpha_prod_t = self.alphas_cumprod[timestep]
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
# 3. Get scalings for boundary conditions
c_skip, c_out = self.get_scalings_for_boundary_condition_discrete(timestep)
# 4. Different Parameterization:
parameterization = self.config.prediction_type
if parameterization == "epsilon": # noise-prediction
pred_x0 = (sample - beta_prod_t.sqrt() * model_output) / alpha_prod_t.sqrt()
elif parameterization == "sample": # x-prediction
pred_x0 = model_output
elif parameterization == "v_prediction": # v-prediction
pred_x0 = alpha_prod_t.sqrt() * sample - beta_prod_t.sqrt() * model_output
# 4. Denoise model output using boundary conditions
denoised = c_out * pred_x0 + c_skip * sample
# 5. Sample z ~ N(0, I), For MultiStep Inference
# Noise is not used for one-step sampling.
if len(self.timesteps) > 1:
noise = torch.randn(model_output.shape).to(model_output.device)
prev_sample = alpha_prod_t_prev.sqrt() * denoised + beta_prod_t_prev.sqrt() * noise
else:
prev_sample = denoised
if not return_dict:
return (prev_sample, denoised)
return LCMSchedulerOutput(prev_sample=prev_sample, denoised=denoised)
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.add_noise
def add_noise(
self,
original_samples: torch.FloatTensor,
noise: torch.FloatTensor,
timesteps: torch.IntTensor,
) -> torch.FloatTensor:
# Make sure alphas_cumprod and timestep have same device and dtype as original_samples
alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
timesteps = timesteps.to(original_samples.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
return noisy_samples
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.get_velocity
def get_velocity(
self, sample: torch.FloatTensor, noise: torch.FloatTensor, timesteps: torch.IntTensor
) -> torch.FloatTensor:
# Make sure alphas_cumprod and timestep have same device and dtype as sample
alphas_cumprod = self.alphas_cumprod.to(device=sample.device, dtype=sample.dtype)
timesteps = timesteps.to(sample.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(sample.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(sample.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
velocity = sqrt_alpha_prod * noise - sqrt_one_minus_alpha_prod * sample
return velocity
def __len__(self):
return self.config.num_train_timesteps
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/run_onnx_controlnet.py
|
import argparse
import inspect
import os
import time
import warnings
from typing import Any, Callable, Dict, List, Optional, Union
import numpy as np
import PIL.Image
import torch
from PIL import Image
from transformers import CLIPTokenizer
from diffusers import OnnxRuntimeModel, StableDiffusionImg2ImgPipeline, UniPCMultistepScheduler
from diffusers.image_processor import VaeImageProcessor
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
deprecate,
logging,
replace_example_docstring,
)
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> # !pip install opencv-python transformers accelerate
>>> from diffusers import StableDiffusionControlNetImg2ImgPipeline, ControlNetModel, UniPCMultistepScheduler
>>> from diffusers.utils import load_image
>>> import numpy as np
>>> import torch
>>> import cv2
>>> from PIL import Image
>>> # download an image
>>> image = load_image(
... "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
... )
>>> np_image = np.array(image)
>>> # get canny image
>>> np_image = cv2.Canny(np_image, 100, 200)
>>> np_image = np_image[:, :, None]
>>> np_image = np.concatenate([np_image, np_image, np_image], axis=2)
>>> canny_image = Image.fromarray(np_image)
>>> # load control net and stable diffusion v1-5
>>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
>>> pipe = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
... )
>>> # speed up diffusion process with faster scheduler and memory optimization
>>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
>>> pipe.enable_model_cpu_offload()
>>> # generate image
>>> generator = torch.manual_seed(0)
>>> image = pipe(
... "futuristic-looking woman",
... num_inference_steps=20,
... generator=generator,
... image=image,
... control_image=canny_image,
... ).images[0]
```
"""
def prepare_image(image):
if isinstance(image, torch.Tensor):
# Batch single image
if image.ndim == 3:
image = image.unsqueeze(0)
image = image.to(dtype=torch.float32)
else:
# preprocess image
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
return image
class OnnxStableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline):
vae_encoder: OnnxRuntimeModel
vae_decoder: OnnxRuntimeModel
text_encoder: OnnxRuntimeModel
tokenizer: CLIPTokenizer
unet: OnnxRuntimeModel
scheduler: KarrasDiffusionSchedulers
def __init__(
self,
vae_encoder: OnnxRuntimeModel,
vae_decoder: OnnxRuntimeModel,
text_encoder: OnnxRuntimeModel,
tokenizer: CLIPTokenizer,
unet: OnnxRuntimeModel,
scheduler: KarrasDiffusionSchedulers,
):
super().__init__()
self.register_modules(
vae_encoder=vae_encoder,
vae_decoder=vae_decoder,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
)
self.vae_scale_factor = 2 ** (4 - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True)
self.control_image_processor = VaeImageProcessor(
vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
)
def _encode_prompt(
self,
prompt: Union[str, List[str]],
num_images_per_prompt: Optional[int],
do_classifier_free_guidance: bool,
negative_prompt: Optional[str],
prompt_embeds: Optional[np.ndarray] = None,
negative_prompt_embeds: Optional[np.ndarray] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`):
prompt to be encoded
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
prompt_embeds (`np.ndarray`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`np.ndarray`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
"""
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="np",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="np").input_ids
if not np.array_equal(text_input_ids, untruncated_ids):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
prompt_embeds = self.text_encoder(input_ids=text_input_ids.astype(np.int32))[0]
prompt_embeds = np.repeat(prompt_embeds, num_images_per_prompt, axis=0)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt] * batch_size
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="np",
)
negative_prompt_embeds = self.text_encoder(input_ids=uncond_input.input_ids.astype(np.int32))[0]
if do_classifier_free_guidance:
negative_prompt_embeds = np.repeat(negative_prompt_embeds, num_images_per_prompt, axis=0)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = np.concatenate([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
def decode_latents(self, latents):
warnings.warn(
"The decode_latents method is deprecated and will be removed in a future version. Please"
" use VaeImageProcessor instead",
FutureWarning,
)
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents, return_dict=False)[0]
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_inputs(
self,
num_controlnet,
prompt,
image,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
controlnet_conditioning_scale=1.0,
control_guidance_start=0.0,
control_guidance_end=1.0,
):
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
# Check `image`
if num_controlnet == 1:
self.check_image(image, prompt, prompt_embeds)
elif num_controlnet > 1:
if not isinstance(image, list):
raise TypeError("For multiple controlnets: `image` must be type `list`")
# When `image` is a nested list:
# (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
elif any(isinstance(i, list) for i in image):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif len(image) != num_controlnet:
raise ValueError(
f"For multiple controlnets: `image` must have the same length as the number of controlnets, but got {len(image)} images and {num_controlnet} ControlNets."
)
for image_ in image:
self.check_image(image_, prompt, prompt_embeds)
else:
assert False
# Check `controlnet_conditioning_scale`
if num_controlnet == 1:
if not isinstance(controlnet_conditioning_scale, float):
raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
elif num_controlnet > 1:
if isinstance(controlnet_conditioning_scale, list):
if any(isinstance(i, list) for i in controlnet_conditioning_scale):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif (
isinstance(controlnet_conditioning_scale, list)
and len(controlnet_conditioning_scale) != num_controlnet
):
raise ValueError(
"For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
" the same length as the number of controlnets"
)
else:
assert False
if len(control_guidance_start) != len(control_guidance_end):
raise ValueError(
f"`control_guidance_start` has {len(control_guidance_start)} elements, but `control_guidance_end` has {len(control_guidance_end)} elements. Make sure to provide the same number of elements to each list."
)
if num_controlnet > 1:
if len(control_guidance_start) != num_controlnet:
raise ValueError(
f"`control_guidance_start`: {control_guidance_start} has {len(control_guidance_start)} elements but there are {num_controlnet} controlnets available. Make sure to provide {num_controlnet}."
)
for start, end in zip(control_guidance_start, control_guidance_end):
if start >= end:
raise ValueError(
f"control guidance start: {start} cannot be larger or equal to control guidance end: {end}."
)
if start < 0.0:
raise ValueError(f"control guidance start: {start} can't be smaller than 0.")
if end > 1.0:
raise ValueError(f"control guidance end: {end} can't be larger than 1.0.")
# Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image
def check_image(self, image, prompt, prompt_embeds):
image_is_pil = isinstance(image, PIL.Image.Image)
image_is_tensor = isinstance(image, torch.Tensor)
image_is_np = isinstance(image, np.ndarray)
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
if (
not image_is_pil
and not image_is_tensor
and not image_is_np
and not image_is_pil_list
and not image_is_tensor_list
and not image_is_np_list
):
raise TypeError(
f"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(image)}"
)
if image_is_pil:
image_batch_size = 1
else:
image_batch_size = len(image)
if prompt is not None and isinstance(prompt, str):
prompt_batch_size = 1
elif prompt is not None and isinstance(prompt, list):
prompt_batch_size = len(prompt)
elif prompt_embeds is not None:
prompt_batch_size = prompt_embeds.shape[0]
if image_batch_size != 1 and image_batch_size != prompt_batch_size:
raise ValueError(
f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
)
# Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.prepare_image
def prepare_control_image(
self,
image,
width,
height,
batch_size,
num_images_per_prompt,
device,
dtype,
do_classifier_free_guidance=False,
guess_mode=False,
):
image = self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32)
image_batch_size = image.shape[0]
if image_batch_size == 1:
repeat_by = batch_size
else:
# image batch size is the same as prompt batch size
repeat_by = num_images_per_prompt
image = image.repeat_interleave(repeat_by, dim=0)
image = image.to(device=device, dtype=dtype)
if do_classifier_free_guidance and not guess_mode:
image = torch.cat([image] * 2)
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.get_timesteps
def get_timesteps(self, num_inference_steps, strength, device):
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
return timesteps, num_inference_steps - t_start
def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None):
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
)
image = image.to(device=device, dtype=dtype)
batch_size = batch_size * num_images_per_prompt
if image.shape[1] == 4:
init_latents = image
else:
_image = image.cpu().detach().numpy()
init_latents = self.vae_encoder(sample=_image)[0]
init_latents = torch.from_numpy(init_latents).to(device=device, dtype=dtype)
init_latents = 0.18215 * init_latents
if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
# expand init_latents for batch_size
deprecation_message = (
f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
" images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
" that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
" your script to pass as many initial images as text prompts to suppress this warning."
)
deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
additional_image_per_prompt = batch_size // init_latents.shape[0]
init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
raise ValueError(
f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
)
else:
init_latents = torch.cat([init_latents], dim=0)
shape = init_latents.shape
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
# get latents
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
latents = init_latents
return latents
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
num_controlnet: int,
fp16: bool = True,
prompt: Union[str, List[str]] = None,
image: Union[
torch.FloatTensor,
PIL.Image.Image,
np.ndarray,
List[torch.FloatTensor],
List[PIL.Image.Image],
List[np.ndarray],
] = None,
control_image: Union[
torch.FloatTensor,
PIL.Image.Image,
np.ndarray,
List[torch.FloatTensor],
List[PIL.Image.Image],
List[np.ndarray],
] = None,
height: Optional[int] = None,
width: Optional[int] = None,
strength: float = 0.8,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
controlnet_conditioning_scale: Union[float, List[float]] = 0.8,
guess_mode: bool = False,
control_guidance_start: Union[float, List[float]] = 0.0,
control_guidance_end: Union[float, List[float]] = 1.0,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The initial image will be used as the starting point for the image generation process. Can also accept
image latents as `image`, if passing latents directly, it will not be encoded again.
control_image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
specified in init, images must be passed as a list such that each element of the list can be correctly
batched for input to a single controlnet.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
corresponding scale as a list. Note that by default, we use a smaller conditioning scale for inpainting
than for [`~StableDiffusionControlNetPipeline.__call__`].
guess_mode (`bool`, *optional*, defaults to `False`):
In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
The percentage of total steps at which the controlnet starts applying.
control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
The percentage of total steps at which the controlnet stops applying.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
if fp16:
torch_dtype = torch.float16
np_dtype = np.float16
else:
torch_dtype = torch.float32
np_dtype = np.float32
# align format for control guidance
if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
control_guidance_start = len(control_guidance_end) * [control_guidance_start]
elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
control_guidance_end = len(control_guidance_start) * [control_guidance_end]
elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
mult = num_controlnet
control_guidance_start, control_guidance_end = (
mult * [control_guidance_start],
mult * [control_guidance_end],
)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
num_controlnet,
prompt,
control_image,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
controlnet_conditioning_scale,
control_guidance_start,
control_guidance_end,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
if num_controlnet > 1 and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * num_controlnet
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
# 4. Prepare image
image = self.image_processor.preprocess(image).to(dtype=torch.float32)
# 5. Prepare controlnet_conditioning_image
if num_controlnet == 1:
control_image = self.prepare_control_image(
image=control_image,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=torch_dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
elif num_controlnet > 1:
control_images = []
for control_image_ in control_image:
control_image_ = self.prepare_control_image(
image=control_image_,
width=width,
height=height,
batch_size=batch_size * num_images_per_prompt,
num_images_per_prompt=num_images_per_prompt,
device=device,
dtype=torch_dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
control_images.append(control_image_)
control_image = control_images
else:
assert False
# 5. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# 6. Prepare latent variables
latents = self.prepare_latents(
image,
latent_timestep,
batch_size,
num_images_per_prompt,
torch_dtype,
device,
generator,
)
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 7.1 Create tensor stating which controlnets to keep
controlnet_keep = []
for i in range(len(timesteps)):
keeps = [
1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
for s, e in zip(control_guidance_start, control_guidance_end)
]
controlnet_keep.append(keeps[0] if num_controlnet == 1 else keeps)
# 8. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
if isinstance(controlnet_keep[i], list):
cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
else:
controlnet_cond_scale = controlnet_conditioning_scale
if isinstance(controlnet_cond_scale, list):
controlnet_cond_scale = controlnet_cond_scale[0]
cond_scale = controlnet_cond_scale * controlnet_keep[i]
# predict the noise residual
_latent_model_input = latent_model_input.cpu().detach().numpy()
_prompt_embeds = np.array(prompt_embeds, dtype=np_dtype)
_t = np.array([t.cpu().detach().numpy()], dtype=np_dtype)
if num_controlnet == 1:
control_images = np.array([control_image], dtype=np_dtype)
else:
control_images = []
for _control_img in control_image:
_control_img = _control_img.cpu().detach().numpy()
control_images.append(_control_img)
control_images = np.array(control_images, dtype=np_dtype)
control_scales = np.array(cond_scale, dtype=np_dtype)
control_scales = np.resize(control_scales, (num_controlnet, 1))
noise_pred = self.unet(
sample=_latent_model_input,
timestep=_t,
encoder_hidden_states=_prompt_embeds,
controlnet_conds=control_images,
conditioning_scales=control_scales,
)[0]
noise_pred = torch.from_numpy(noise_pred).to(device)
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if not output_type == "latent":
_latents = latents.cpu().detach().numpy() / 0.18215
_latents = np.array(_latents, dtype=np_dtype)
image = self.vae_decoder(latent_sample=_latents)[0]
image = torch.from_numpy(image).to(device, dtype=torch.float32)
has_nsfw_concept = None
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--sd_model",
type=str,
required=True,
help="Path to the `diffusers` checkpoint to convert (either a local directory or on the Hub).",
)
parser.add_argument(
"--onnx_model_dir",
type=str,
required=True,
help="Path to the ONNX directory",
)
parser.add_argument("--qr_img_path", type=str, required=True, help="Path to the qr code image")
args = parser.parse_args()
qr_image = Image.open(args.qr_img_path)
qr_image = qr_image.resize((512, 512))
# init stable diffusion pipeline
pipeline = StableDiffusionImg2ImgPipeline.from_pretrained(args.sd_model)
pipeline.scheduler = UniPCMultistepScheduler.from_config(pipeline.scheduler.config)
provider = ["CUDAExecutionProvider", "CPUExecutionProvider"]
onnx_pipeline = OnnxStableDiffusionControlNetImg2ImgPipeline(
vae_encoder=OnnxRuntimeModel.from_pretrained(
os.path.join(args.onnx_model_dir, "vae_encoder"), provider=provider
),
vae_decoder=OnnxRuntimeModel.from_pretrained(
os.path.join(args.onnx_model_dir, "vae_decoder"), provider=provider
),
text_encoder=OnnxRuntimeModel.from_pretrained(
os.path.join(args.onnx_model_dir, "text_encoder"), provider=provider
),
tokenizer=pipeline.tokenizer,
unet=OnnxRuntimeModel.from_pretrained(os.path.join(args.onnx_model_dir, "unet"), provider=provider),
scheduler=pipeline.scheduler,
)
onnx_pipeline = onnx_pipeline.to("cuda")
prompt = "a cute cat fly to the moon"
negative_prompt = "paintings, sketches, worst quality, low quality, normal quality, lowres, normal quality, monochrome, grayscale, skin spots, acnes, skin blemishes, age spot, glans, nsfw, nipples, necklace, worst quality, low quality, watermark, username, signature, multiple breasts, lowres, bad anatomy, bad hands, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, bad feet, single color, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, disfigured, bad anatomy, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, mutated hands, fused fingers, too many fingers, long neck, bad body perspect"
for i in range(10):
start_time = time.time()
image = onnx_pipeline(
num_controlnet=2,
prompt=prompt,
negative_prompt=negative_prompt,
image=qr_image,
control_image=[qr_image, qr_image],
width=512,
height=512,
strength=0.75,
num_inference_steps=20,
num_images_per_prompt=1,
controlnet_conditioning_scale=[0.8, 0.8],
control_guidance_start=[0.3, 0.3],
control_guidance_end=[0.9, 0.9],
).images[0]
print(time.time() - start_time)
image.save("output_qr_code.png")
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/wildcard_stable_diffusion.py
|
import inspect
import os
import random
import re
from dataclasses import dataclass
from typing import Callable, Dict, List, Optional, Union
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import DiffusionPipeline
from diffusers.configuration_utils import FrozenDict
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
from diffusers.utils import deprecate, logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
global_re_wildcard = re.compile(r"__([^_]*)__")
def get_filename(path: str):
# this doesn't work on Windows
return os.path.basename(path).split(".txt")[0]
def read_wildcard_values(path: str):
with open(path, encoding="utf8") as f:
return f.read().splitlines()
def grab_wildcard_values(wildcard_option_dict: Dict[str, List[str]] = {}, wildcard_files: List[str] = []):
for wildcard_file in wildcard_files:
filename = get_filename(wildcard_file)
read_values = read_wildcard_values(wildcard_file)
if filename not in wildcard_option_dict:
wildcard_option_dict[filename] = []
wildcard_option_dict[filename].extend(read_values)
return wildcard_option_dict
def replace_prompt_with_wildcards(
prompt: str, wildcard_option_dict: Dict[str, List[str]] = {}, wildcard_files: List[str] = []
):
new_prompt = prompt
# get wildcard options
wildcard_option_dict = grab_wildcard_values(wildcard_option_dict, wildcard_files)
for m in global_re_wildcard.finditer(new_prompt):
wildcard_value = m.group()
replace_value = random.choice(wildcard_option_dict[wildcard_value.strip("__")])
new_prompt = new_prompt.replace(wildcard_value, replace_value, 1)
return new_prompt
@dataclass
class WildcardStableDiffusionOutput(StableDiffusionPipelineOutput):
prompts: List[str]
class WildcardStableDiffusionPipeline(DiffusionPipeline):
r"""
Example Usage:
pipe = WildcardStableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
torch_dtype=torch.float16,
)
prompt = "__animal__ sitting on a __object__ wearing a __clothing__"
out = pipe(
prompt,
wildcard_option_dict={
"clothing":["hat", "shirt", "scarf", "beret"]
},
wildcard_files=["object.txt", "animal.txt"],
num_prompt_samples=1
)
Pipeline for text-to-image generation with wild cards using Stable Diffusion.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/CompVis/stable-diffusion-v1-4) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
wildcard_option_dict: Dict[str, List[str]] = {},
wildcard_files: List[str] = [],
num_prompt_samples: Optional[int] = 1,
**kwargs,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
wildcard_option_dict (Dict[str, List[str]]):
dict with key as `wildcard` and values as a list of possible replacements. For example if a prompt, "A __animal__ sitting on a chair". A wildcard_option_dict can provide possible values for "animal" like this: {"animal":["dog", "cat", "fox"]}
wildcard_files: (List[str])
List of filenames of txt files for wildcard replacements. For example if a prompt, "A __animal__ sitting on a chair". A file can be provided ["animal.txt"]
num_prompt_samples: int
Number of times to sample wildcards for each prompt provided
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
if isinstance(prompt, str):
prompt = [
replace_prompt_with_wildcards(prompt, wildcard_option_dict, wildcard_files)
for i in range(num_prompt_samples)
]
batch_size = len(prompt)
elif isinstance(prompt, list):
prompt_list = []
for p in prompt:
for i in range(num_prompt_samples):
prompt_list.append(replace_prompt_with_wildcards(p, wildcard_option_dict, wildcard_files))
prompt = prompt_list
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
text_embeddings = self.text_encoder(text_input_ids.to(self.device))[0]
# duplicate text embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = text_input_ids.shape[-1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = uncond_embeddings.repeat(1, num_images_per_prompt, 1)
uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# Unlike in other pipelines, latents need to be generated in the target device
# for 1-to-1 results reproducibility with the CompVis implementation.
# However this currently doesn't work in `mps`.
latents_shape = (batch_size * num_images_per_prompt, self.unet.config.in_channels, height // 8, width // 8)
latents_dtype = text_embeddings.dtype
if latents is None:
if self.device.type == "mps":
# randn does not exist on mps
latents = torch.randn(latents_shape, generator=generator, device="cpu", dtype=latents_dtype).to(
self.device
)
else:
latents = torch.randn(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
else:
if latents.shape != latents_shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
latents = latents.to(self.device)
# set timesteps
self.scheduler.set_timesteps(num_inference_steps)
# Some schedulers like PNDM have timesteps as arrays
# It's more optimized to move all timesteps to correct device beforehand
timesteps_tensor = self.scheduler.timesteps.to(self.device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(
self.device
)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(text_embeddings.dtype)
)
else:
has_nsfw_concept = None
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, has_nsfw_concept)
return WildcardStableDiffusionOutput(images=image, nsfw_content_detected=has_nsfw_concept, prompts=prompt)
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/community/llm_grounded_diffusion.py
|
# Copyright 2023 Long Lian, the GLIGEN Authors, and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# This is a single file implementation of LMD+. See README.md for examples.
import ast
import gc
import math
import warnings
from collections.abc import Iterable
from typing import Any, Callable, Dict, List, Optional, Union
import torch
import torch.nn.functional as F
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.models.attention import Attention, GatedSelfAttentionDense
from diffusers.models.attention_processor import AttnProcessor2_0
from diffusers.pipelines.stable_diffusion import StableDiffusionPipeline
from diffusers.pipelines.stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import logging, replace_example_docstring
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
>>> from diffusers import DiffusionPipeline
>>> pipe = DiffusionPipeline.from_pretrained(
... "longlian/lmd_plus",
... custom_pipeline="llm_grounded_diffusion",
... variant="fp16", torch_dtype=torch.float16
... )
>>> pipe.enable_model_cpu_offload()
>>> # Generate an image described by the prompt and
>>> # insert objects described by text at the region defined by bounding boxes
>>> prompt = "a waterfall and a modern high speed train in a beautiful forest with fall foliage"
>>> boxes = [[0.1387, 0.2051, 0.4277, 0.7090], [0.4980, 0.4355, 0.8516, 0.7266]]
>>> phrases = ["a waterfall", "a modern high speed train"]
>>> images = pipe(
... prompt=prompt,
... phrases=phrases,
... boxes=boxes,
... gligen_scheduled_sampling_beta=0.4,
... output_type="pil",
... num_inference_steps=50,
... lmd_guidance_kwargs={}
... ).images
>>> images[0].save("./lmd_plus_generation.jpg")
>>> # Generate directly from a text prompt and an LLM response
>>> prompt = "a waterfall and a modern high speed train in a beautiful forest with fall foliage"
>>> phrases, boxes, bg_prompt, neg_prompt = pipe.parse_llm_response(\"""
[('a waterfall', [71, 105, 148, 258]), ('a modern high speed train', [255, 223, 181, 149])]
Background prompt: A beautiful forest with fall foliage
Negative prompt:
\""")
>> images = pipe(
... prompt=prompt,
... negative_prompt=neg_prompt,
... phrases=phrases,
... boxes=boxes,
... gligen_scheduled_sampling_beta=0.4,
... output_type="pil",
... num_inference_steps=50,
... lmd_guidance_kwargs={}
... ).images
>>> images[0].save("./lmd_plus_generation.jpg")
images[0]
```
"""
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
# All keys in Stable Diffusion models: [('down', 0, 0, 0), ('down', 0, 1, 0), ('down', 1, 0, 0), ('down', 1, 1, 0), ('down', 2, 0, 0), ('down', 2, 1, 0), ('mid', 0, 0, 0), ('up', 1, 0, 0), ('up', 1, 1, 0), ('up', 1, 2, 0), ('up', 2, 0, 0), ('up', 2, 1, 0), ('up', 2, 2, 0), ('up', 3, 0, 0), ('up', 3, 1, 0), ('up', 3, 2, 0)]
# Note that the first up block is `UpBlock2D` rather than `CrossAttnUpBlock2D` and does not have attention. The last index is always 0 in our case since we have one `BasicTransformerBlock` in each `Transformer2DModel`.
DEFAULT_GUIDANCE_ATTN_KEYS = [("mid", 0, 0, 0), ("up", 1, 0, 0), ("up", 1, 1, 0), ("up", 1, 2, 0)]
def convert_attn_keys(key):
"""Convert the attention key from tuple format to the torch state format"""
if key[0] == "mid":
assert key[1] == 0, f"mid block only has one block but the index is {key[1]}"
return f"{key[0]}_block.attentions.{key[2]}.transformer_blocks.{key[3]}.attn2.processor"
return f"{key[0]}_blocks.{key[1]}.attentions.{key[2]}.transformer_blocks.{key[3]}.attn2.processor"
DEFAULT_GUIDANCE_ATTN_KEYS = [convert_attn_keys(key) for key in DEFAULT_GUIDANCE_ATTN_KEYS]
def scale_proportion(obj_box, H, W):
# Separately rounding box_w and box_h to allow shift invariant box sizes. Otherwise box sizes may change when both coordinates being rounded end with ".5".
x_min, y_min = round(obj_box[0] * W), round(obj_box[1] * H)
box_w, box_h = round((obj_box[2] - obj_box[0]) * W), round((obj_box[3] - obj_box[1]) * H)
x_max, y_max = x_min + box_w, y_min + box_h
x_min, y_min = max(x_min, 0), max(y_min, 0)
x_max, y_max = min(x_max, W), min(y_max, H)
return x_min, y_min, x_max, y_max
# Adapted from the parent class `AttnProcessor2_0`
class AttnProcessorWithHook(AttnProcessor2_0):
def __init__(self, attn_processor_key, hidden_size, cross_attention_dim, hook=None, fast_attn=True, enabled=True):
super().__init__()
self.attn_processor_key = attn_processor_key
self.hidden_size = hidden_size
self.cross_attention_dim = cross_attention_dim
self.hook = hook
self.fast_attn = fast_attn
self.enabled = enabled
def __call__(
self,
attn: Attention,
hidden_states,
encoder_hidden_states=None,
attention_mask=None,
temb=None,
scale: float = 1.0,
):
residual = hidden_states
if attn.spatial_norm is not None:
hidden_states = attn.spatial_norm(hidden_states, temb)
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
if attention_mask is not None:
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states, scale=scale)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states, scale=scale)
value = attn.to_v(encoder_hidden_states, scale=scale)
inner_dim = key.shape[-1]
head_dim = inner_dim // attn.heads
if (self.hook is not None and self.enabled) or not self.fast_attn:
query_batch_dim = attn.head_to_batch_dim(query)
key_batch_dim = attn.head_to_batch_dim(key)
value_batch_dim = attn.head_to_batch_dim(value)
attention_probs = attn.get_attention_scores(query_batch_dim, key_batch_dim, attention_mask)
if self.hook is not None and self.enabled:
# Call the hook with query, key, value, and attention maps
self.hook(self.attn_processor_key, query_batch_dim, key_batch_dim, value_batch_dim, attention_probs)
if self.fast_attn:
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
if attention_mask is not None:
# scaled_dot_product_attention expects attention_mask shape to be
# (batch, heads, source_length, target_length)
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
# the output of sdp = (batch, num_heads, seq_len, head_dim)
# TODO: add support for attn.scale when we move to Torch 2.1
hidden_states = F.scaled_dot_product_attention(
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
hidden_states = hidden_states.to(query.dtype)
else:
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
hidden_states = attn.to_out[0](hidden_states, scale=scale)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
class LLMGroundedDiffusionPipeline(StableDiffusionPipeline):
r"""
Pipeline for layout-grounded text-to-image generation using LLM-grounded Diffusion (LMD+): https://arxiv.org/pdf/2305.13655.pdf.
This model inherits from [`StableDiffusionPipeline`] and aims at implementing the pipeline with minimal modifications. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
This is a simplified implementation that does not perform latent or attention transfer from single object generation to overall generation. The final image is generated directly with attention and adapters control.
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
text_encoder ([`~transformers.CLIPTextModel`]):
Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
tokenizer ([`~transformers.CLIPTokenizer`]):
A `CLIPTokenizer` to tokenize text.
unet ([`UNet2DConditionModel`]):
A `UNet2DConditionModel` to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for more details
about a model's potential harms.
feature_extractor ([`~transformers.CLIPImageProcessor`]):
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
requires_safety_checker (bool):
Whether a safety checker is needed for this pipeline.
"""
objects_text = "Objects: "
bg_prompt_text = "Background prompt: "
bg_prompt_text_no_trailing_space = bg_prompt_text.rstrip()
neg_prompt_text = "Negative prompt: "
neg_prompt_text_no_trailing_space = neg_prompt_text.rstrip()
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__(
vae, text_encoder, tokenizer, unet, scheduler, safety_checker, feature_extractor, requires_safety_checker
)
self.register_attn_hooks(unet)
self._saved_attn = None
def attn_hook(self, name, query, key, value, attention_probs):
if name in DEFAULT_GUIDANCE_ATTN_KEYS:
self._saved_attn[name] = attention_probs
@classmethod
def convert_box(cls, box, height, width):
# box: x, y, w, h (in 512 format) -> x_min, y_min, x_max, y_max
x_min, y_min = box[0] / width, box[1] / height
w_box, h_box = box[2] / width, box[3] / height
x_max, y_max = x_min + w_box, y_min + h_box
return x_min, y_min, x_max, y_max
@classmethod
def _parse_response_with_negative(cls, text):
if not text:
raise ValueError("LLM response is empty")
if cls.objects_text in text:
text = text.split(cls.objects_text)[1]
text_split = text.split(cls.bg_prompt_text_no_trailing_space)
if len(text_split) == 2:
gen_boxes, text_rem = text_split
else:
raise ValueError(f"LLM response is incomplete: {text}")
text_split = text_rem.split(cls.neg_prompt_text_no_trailing_space)
if len(text_split) == 2:
bg_prompt, neg_prompt = text_split
else:
raise ValueError(f"LLM response is incomplete: {text}")
try:
gen_boxes = ast.literal_eval(gen_boxes)
except SyntaxError as e:
# Sometimes the response is in plain text
if "No objects" in gen_boxes or gen_boxes.strip() == "":
gen_boxes = []
else:
raise e
bg_prompt = bg_prompt.strip()
neg_prompt = neg_prompt.strip()
# LLM may return "None" to mean no negative prompt provided.
if neg_prompt == "None":
neg_prompt = ""
return gen_boxes, bg_prompt, neg_prompt
@classmethod
def parse_llm_response(cls, response, canvas_height=512, canvas_width=512):
# Infer from spec
gen_boxes, bg_prompt, neg_prompt = cls._parse_response_with_negative(text=response)
gen_boxes = sorted(gen_boxes, key=lambda gen_box: gen_box[0])
phrases = [name for name, _ in gen_boxes]
boxes = [cls.convert_box(box, height=canvas_height, width=canvas_width) for _, box in gen_boxes]
return phrases, boxes, bg_prompt, neg_prompt
def check_inputs(
self,
prompt,
height,
width,
callback_steps,
phrases,
boxes,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
phrase_indices=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
elif prompt is None and phrase_indices is None:
raise ValueError("If the prompt is None, the phrase_indices cannot be None")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
if len(phrases) != len(boxes):
ValueError(
"length of `phrases` and `boxes` has to be same, but"
f" got: `phrases` {len(phrases)} != `boxes` {len(boxes)}"
)
def register_attn_hooks(self, unet):
"""Registering hooks to obtain the attention maps for guidance"""
attn_procs = {}
for name in unet.attn_processors.keys():
# Only obtain the queries and keys from cross-attention
if name.endswith("attn1.processor") or name.endswith("fuser.attn.processor"):
# Keep the same attn_processors for self-attention (no hooks for self-attention)
attn_procs[name] = unet.attn_processors[name]
continue
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
if name.startswith("mid_block"):
hidden_size = unet.config.block_out_channels[-1]
elif name.startswith("up_blocks"):
block_id = int(name[len("up_blocks.")])
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
elif name.startswith("down_blocks"):
block_id = int(name[len("down_blocks.")])
hidden_size = unet.config.block_out_channels[block_id]
attn_procs[name] = AttnProcessorWithHook(
attn_processor_key=name,
hidden_size=hidden_size,
cross_attention_dim=cross_attention_dim,
hook=self.attn_hook,
fast_attn=True,
# Not enabled by default
enabled=False,
)
unet.set_attn_processor(attn_procs)
def enable_fuser(self, enabled=True):
for module in self.unet.modules():
if isinstance(module, GatedSelfAttentionDense):
module.enabled = enabled
def enable_attn_hook(self, enabled=True):
for module in self.unet.attn_processors.values():
if isinstance(module, AttnProcessorWithHook):
module.enabled = enabled
def get_token_map(self, prompt, padding="do_not_pad", verbose=False):
"""Get a list of mapping: prompt index to str (prompt in a list of token str)"""
fg_prompt_tokens = self.tokenizer([prompt], padding=padding, max_length=77, return_tensors="np")
input_ids = fg_prompt_tokens["input_ids"][0]
token_map = []
for ind, item in enumerate(input_ids.tolist()):
token = self.tokenizer._convert_id_to_token(item)
if verbose:
logger.info(f"{ind}, {token} ({item})")
token_map.append(token)
return token_map
def get_phrase_indices(self, prompt, phrases, token_map=None, add_suffix_if_not_found=False, verbose=False):
for obj in phrases:
# Suffix the prompt with object name for attention guidance if object is not in the prompt, using "|" to separate the prompt and the suffix
if obj not in prompt:
prompt += "| " + obj
if token_map is None:
# We allow using a pre-computed token map.
token_map = self.get_token_map(prompt=prompt, padding="do_not_pad", verbose=verbose)
token_map_str = " ".join(token_map)
phrase_indices = []
for obj in phrases:
phrase_token_map = self.get_token_map(prompt=obj, padding="do_not_pad", verbose=verbose)
# Remove <bos> and <eos> in substr
phrase_token_map = phrase_token_map[1:-1]
phrase_token_map_len = len(phrase_token_map)
phrase_token_map_str = " ".join(phrase_token_map)
if verbose:
logger.info("Full str:", token_map_str, "Substr:", phrase_token_map_str, "Phrase:", phrases)
# Count the number of token before substr
# The substring comes with a trailing space that needs to be removed by minus one in the index.
obj_first_index = len(token_map_str[: token_map_str.index(phrase_token_map_str) - 1].split(" "))
obj_position = list(range(obj_first_index, obj_first_index + phrase_token_map_len))
phrase_indices.append(obj_position)
if add_suffix_if_not_found:
return phrase_indices, prompt
return phrase_indices
def add_ca_loss_per_attn_map_to_loss(
self,
loss,
attn_map,
object_number,
bboxes,
phrase_indices,
fg_top_p=0.2,
bg_top_p=0.2,
fg_weight=1.0,
bg_weight=1.0,
):
# b is the number of heads, not batch
b, i, j = attn_map.shape
H = W = int(math.sqrt(i))
for obj_idx in range(object_number):
obj_loss = 0
mask = torch.zeros(size=(H, W), device="cuda")
obj_boxes = bboxes[obj_idx]
# We support two level (one box per phrase) and three level (multiple boxes per phrase)
if not isinstance(obj_boxes[0], Iterable):
obj_boxes = [obj_boxes]
for obj_box in obj_boxes:
# x_min, y_min, x_max, y_max = int(obj_box[0] * W), int(obj_box[1] * H), int(obj_box[2] * W), int(obj_box[3] * H)
x_min, y_min, x_max, y_max = scale_proportion(obj_box, H=H, W=W)
mask[y_min:y_max, x_min:x_max] = 1
for obj_position in phrase_indices[obj_idx]:
# Could potentially optimize to compute this for loop in batch.
# Could crop the ref cross attention before saving to save memory.
ca_map_obj = attn_map[:, :, obj_position].reshape(b, H, W)
# shape: (b, H * W)
ca_map_obj = attn_map[:, :, obj_position] # .reshape(b, H, W)
k_fg = (mask.sum() * fg_top_p).long().clamp_(min=1)
k_bg = ((1 - mask).sum() * bg_top_p).long().clamp_(min=1)
mask_1d = mask.view(1, -1)
# Max-based loss function
# Take the topk over spatial dimension, and then take the sum over heads dim
# The mean is over k_fg and k_bg dimension, so we don't need to sum and divide on our own.
obj_loss += (1 - (ca_map_obj * mask_1d).topk(k=k_fg).values.mean(dim=1)).sum(dim=0) * fg_weight
obj_loss += ((ca_map_obj * (1 - mask_1d)).topk(k=k_bg).values.mean(dim=1)).sum(dim=0) * bg_weight
loss += obj_loss / len(phrase_indices[obj_idx])
return loss
def compute_ca_loss(self, saved_attn, bboxes, phrase_indices, guidance_attn_keys, verbose=False, **kwargs):
"""
The `saved_attn` is supposed to be passed to `save_attn_to_dict` in `cross_attention_kwargs` prior to computing ths loss.
`AttnProcessor` will put attention maps into the `save_attn_to_dict`.
`index` is the timestep.
`ref_ca_word_token_only`: This has precedence over `ref_ca_last_token_only` (i.e., if both are enabled, we take the token from word rather than the last token).
`ref_ca_last_token_only`: `ref_ca_saved_attn` comes from the attention map of the last token of the phrase in single object generation, so we apply it only to the last token of the phrase in overall generation if this is set to True. If set to False, `ref_ca_saved_attn` will be applied to all the text tokens.
"""
loss = torch.tensor(0).float().cuda()
object_number = len(bboxes)
if object_number == 0:
return loss
for attn_key in guidance_attn_keys:
# We only have 1 cross attention for mid.
attn_map_integrated = saved_attn[attn_key]
if not attn_map_integrated.is_cuda:
attn_map_integrated = attn_map_integrated.cuda()
# Example dimension: [20, 64, 77]
attn_map = attn_map_integrated.squeeze(dim=0)
loss = self.add_ca_loss_per_attn_map_to_loss(
loss, attn_map, object_number, bboxes, phrase_indices, **kwargs
)
num_attn = len(guidance_attn_keys)
if num_attn > 0:
loss = loss / (object_number * num_attn)
return loss
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
gligen_scheduled_sampling_beta: float = 0.3,
phrases: List[str] = None,
boxes: List[List[float]] = None,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
clip_skip: Optional[int] = None,
lmd_guidance_kwargs: Optional[Dict[str, Any]] = {},
phrase_indices: Optional[List[int]] = None,
):
r"""
The call function to the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
A higher guidance scale value encourages the model to generate images closely linked to the text
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
phrases (`List[str]`):
The phrases to guide what to include in each of the regions defined by the corresponding
`boxes`. There should only be one phrase per bounding box.
boxes (`List[List[float]]`):
The bounding boxes that identify rectangular regions of the image that are going to be filled with the
content described by the corresponding `phrases`. Each rectangular box is defined as a
`List[float]` of 4 elements `[xmin, ymin, xmax, ymax]` where each value is between [0,1].
gligen_scheduled_sampling_beta (`float`, defaults to 0.3):
Scheduled Sampling factor from [GLIGEN: Open-Set Grounded Text-to-Image
Generation](https://arxiv.org/pdf/2301.07093.pdf). Scheduled Sampling factor is only varied for
scheduled sampling during inference for improved quality and controllability.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor is generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
provided, text embeddings are generated from the `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that calls every `callback_steps` steps during inference. The function is called with the
following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function is called. If not specified, the callback is called at
every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
guidance_rescale (`float`, *optional*, defaults to 0.0):
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
using zero terminal SNR.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
lmd_guidance_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to `latent_lmd_guidance` function. Useful keys include `loss_scale` (the guidance strength), `loss_threshold` (when loss is lower than this value, the guidance is not applied anymore), `max_iter` (the number of iterations of guidance for each step), and `guidance_timesteps` (the number of diffusion timesteps to apply guidance on). See `latent_lmd_guidance` for implementation details.
phrase_indices (`list` of `list`, *optional*): The indices of the tokens of each phrase in the overall prompt. If omitted, the pipeline will match the first token subsequence. The pipeline will append the missing phrases to the end of the prompt by default.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
otherwise a `tuple` is returned where the first element is a list with the generated images and the
second element is a list of `bool`s indicating whether the corresponding generated image contains
"not-safe-for-work" (nsfw) content.
"""
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
height,
width,
callback_steps,
phrases,
boxes,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
phrase_indices,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
if phrase_indices is None:
phrase_indices, prompt = self.get_phrase_indices(prompt, phrases, add_suffix_if_not_found=True)
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
if phrase_indices is None:
phrase_indices = []
prompt_parsed = []
for prompt_item in prompt:
phrase_indices_parsed_item, prompt_parsed_item = self.get_phrase_indices(
prompt_item, add_suffix_if_not_found=True
)
phrase_indices.append(phrase_indices_parsed_item)
prompt_parsed.append(prompt_parsed_item)
prompt = prompt_parsed
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
clip_skip=clip_skip,
)
cond_prompt_embeds = prompt_embeds
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
if do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 5. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 5.1 Prepare GLIGEN variables
max_objs = 30
if len(boxes) > max_objs:
warnings.warn(
f"More that {max_objs} objects found. Only first {max_objs} objects will be processed.",
FutureWarning,
)
phrases = phrases[:max_objs]
boxes = boxes[:max_objs]
n_objs = len(boxes)
if n_objs:
# prepare batched input to the PositionNet (boxes, phrases, mask)
# Get tokens for phrases from pre-trained CLIPTokenizer
tokenizer_inputs = self.tokenizer(phrases, padding=True, return_tensors="pt").to(device)
# For the token, we use the same pre-trained text encoder
# to obtain its text feature
_text_embeddings = self.text_encoder(**tokenizer_inputs).pooler_output
# For each entity, described in phrases, is denoted with a bounding box,
# we represent the location information as (xmin,ymin,xmax,ymax)
cond_boxes = torch.zeros(max_objs, 4, device=device, dtype=self.text_encoder.dtype)
if n_objs:
cond_boxes[:n_objs] = torch.tensor(boxes)
text_embeddings = torch.zeros(
max_objs, self.unet.config.cross_attention_dim, device=device, dtype=self.text_encoder.dtype
)
if n_objs:
text_embeddings[:n_objs] = _text_embeddings
# Generate a mask for each object that is entity described by phrases
masks = torch.zeros(max_objs, device=device, dtype=self.text_encoder.dtype)
masks[:n_objs] = 1
repeat_batch = batch_size * num_images_per_prompt
cond_boxes = cond_boxes.unsqueeze(0).expand(repeat_batch, -1, -1).clone()
text_embeddings = text_embeddings.unsqueeze(0).expand(repeat_batch, -1, -1).clone()
masks = masks.unsqueeze(0).expand(repeat_batch, -1).clone()
if do_classifier_free_guidance:
repeat_batch = repeat_batch * 2
cond_boxes = torch.cat([cond_boxes] * 2)
text_embeddings = torch.cat([text_embeddings] * 2)
masks = torch.cat([masks] * 2)
masks[: repeat_batch // 2] = 0
if cross_attention_kwargs is None:
cross_attention_kwargs = {}
cross_attention_kwargs["gligen"] = {
"boxes": cond_boxes,
"positive_embeddings": text_embeddings,
"masks": masks,
}
num_grounding_steps = int(gligen_scheduled_sampling_beta * len(timesteps))
self.enable_fuser(True)
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
loss_attn = torch.tensor(10000.0)
# 7. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# Scheduled sampling
if i == num_grounding_steps:
self.enable_fuser(False)
if latents.shape[1] != 4:
latents = torch.randn_like(latents[:, :4])
# 7.1 Perform LMD guidance
if boxes:
latents, loss_attn = self.latent_lmd_guidance(
cond_prompt_embeds,
index=i,
boxes=boxes,
phrase_indices=phrase_indices,
t=t,
latents=latents,
loss=loss_attn,
**lmd_guidance_kwargs,
)
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
@torch.set_grad_enabled(True)
def latent_lmd_guidance(
self,
cond_embeddings,
index,
boxes,
phrase_indices,
t,
latents,
loss,
*,
loss_scale=20,
loss_threshold=5.0,
max_iter=[3] * 5 + [2] * 5 + [1] * 5,
guidance_timesteps=15,
cross_attention_kwargs=None,
guidance_attn_keys=DEFAULT_GUIDANCE_ATTN_KEYS,
verbose=False,
clear_cache=False,
unet_additional_kwargs={},
guidance_callback=None,
**kwargs,
):
scheduler, unet = self.scheduler, self.unet
iteration = 0
if index < guidance_timesteps:
if isinstance(max_iter, list):
max_iter = max_iter[index]
if verbose:
logger.info(
f"time index {index}, loss: {loss.item()/loss_scale:.3f} (de-scaled with scale {loss_scale:.1f}), loss threshold: {loss_threshold:.3f}"
)
try:
self.enable_attn_hook(enabled=True)
while (
loss.item() / loss_scale > loss_threshold and iteration < max_iter and index < guidance_timesteps
):
self._saved_attn = {}
latents.requires_grad_(True)
latent_model_input = latents
latent_model_input = scheduler.scale_model_input(latent_model_input, t)
unet(
latent_model_input,
t,
encoder_hidden_states=cond_embeddings,
cross_attention_kwargs=cross_attention_kwargs,
**unet_additional_kwargs,
)
# update latents with guidance
loss = (
self.compute_ca_loss(
saved_attn=self._saved_attn,
bboxes=boxes,
phrase_indices=phrase_indices,
guidance_attn_keys=guidance_attn_keys,
verbose=verbose,
**kwargs,
)
* loss_scale
)
if torch.isnan(loss):
raise RuntimeError("**Loss is NaN**")
# This callback allows visualizations.
if guidance_callback is not None:
guidance_callback(self, latents, loss, iteration, index)
self._saved_attn = None
grad_cond = torch.autograd.grad(loss.requires_grad_(True), [latents])[0]
latents.requires_grad_(False)
# Scaling with classifier guidance
alpha_prod_t = scheduler.alphas_cumprod[t]
# Classifier guidance: https://arxiv.org/pdf/2105.05233.pdf
# DDIM: https://arxiv.org/pdf/2010.02502.pdf
scale = (1 - alpha_prod_t) ** (0.5)
latents = latents - scale * grad_cond
iteration += 1
if clear_cache:
gc.collect()
torch.cuda.empty_cache()
if verbose:
logger.info(
f"time index {index}, loss: {loss.item()/loss_scale:.3f}, loss threshold: {loss_threshold:.3f}, iteration: {iteration}"
)
finally:
self.enable_attn_hook(enabled=False)
return latents, loss
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/instruct_pix2pix/README_sdxl.md
|
# InstructPix2Pix SDXL training example
***This is based on the original InstructPix2Pix training example.***
[Stable Diffusion XL](https://huggingface.co/papers/2307.01952) (or SDXL) is the latest image generation model that is tailored towards more photorealistic outputs with more detailed imagery and composition compared to previous SD models. It leverages a three times larger UNet backbone. The increase of model parameters is mainly due to more attention blocks and a larger cross-attention context as SDXL uses a second text encoder.
The `train_instruct_pix2pix_sdxl.py` script shows how to implement the training procedure and adapt it for Stable Diffusion XL.
***Disclaimer: Even though `train_instruct_pix2pix_sdxl.py` implements the InstructPix2Pix
training procedure while being faithful to the [original implementation](https://github.com/timothybrooks/instruct-pix2pix) we have only tested it on a [small-scale dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples). This can impact the end results. For better results, we recommend longer training runs with a larger dataset. [Here](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) you can find a large dataset for InstructPix2Pix training.***
## Running locally with PyTorch
### Installing the dependencies
Refer to the original InstructPix2Pix training example for installing the dependencies.
You will also need to get access of SDXL by filling the [form](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0).
### Toy example
As mentioned before, we'll use a [small toy dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples) for training. The dataset
is a smaller version of the [original dataset](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) used in the InstructPix2Pix paper.
Configure environment variables such as the dataset identifier and the Stable Diffusion
checkpoint:
```bash
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export DATASET_ID="fusing/instructpix2pix-1000-samples"
```
Now, we can launch training:
```bash
accelerate launch train_instruct_pix2pix_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_ID \
--enable_xformers_memory_efficient_attention \
--resolution=256 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --max_grad_norm=1 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--seed=42 \
--push_to_hub
```
Additionally, we support performing validation inference to monitor training progress
with Weights and Biases. You can enable this feature with `report_to="wandb"`:
```bash
accelerate launch train_instruct_pix2pix_sdxl.py \
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0 \
--dataset_name=$DATASET_ID \
--use_ema \
--enable_xformers_memory_efficient_attention \
--resolution=512 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--seed=42 \
--val_image_url_or_path="https://datasets-server.huggingface.co/assets/fusing/instructpix2pix-1000-samples/--/fusing--instructpix2pix-1000-samples/train/23/input_image/image.jpg" \
--validation_prompt="make it in japan" \
--report_to=wandb \
--push_to_hub
```
We recommend this type of validation as it can be useful for model debugging. Note that you need `wandb` installed to use this. You can install `wandb` by running `pip install wandb`.
[Here](https://wandb.ai/sayakpaul/instruct-pix2pix/runs/ctr3kovq), you can find an example training run that includes some validation samples and the training hyperparameters.
***Note: In the original paper, the authors observed that even when the model is trained with an image resolution of 256x256, it generalizes well to bigger resolutions such as 512x512. This is likely because of the larger dataset they used during training.***
## Training with multiple GPUs
`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
for running distributed training with `accelerate`. Here is an example command:
```bash
accelerate launch --mixed_precision="fp16" --multi_gpu train_instruct_pix2pix_sdxl.py \
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0 \
--dataset_name=$DATASET_ID \
--use_ema \
--enable_xformers_memory_efficient_attention \
--resolution=512 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--seed=42 \
--val_image_url_or_path="https://datasets-server.huggingface.co/assets/fusing/instructpix2pix-1000-samples/--/fusing--instructpix2pix-1000-samples/train/23/input_image/image.jpg" \
--validation_prompt="make it in japan" \
--report_to=wandb \
--push_to_hub
```
## Inference
Once training is complete, we can perform inference:
```python
import PIL
import requests
import torch
from diffusers import StableDiffusionXLInstructPix2PixPipeline
model_id = "your_model_id" # <- replace this
pipe = StableDiffusionXLInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
generator = torch.Generator("cuda").manual_seed(0)
url = "https://datasets-server.huggingface.co/assets/fusing/instructpix2pix-1000-samples/--/fusing--instructpix2pix-1000-samples/train/23/input_image/image.jpg"
def download_image(url):
image = PIL.Image.open(requests.get(url, stream=True).raw)
image = PIL.ImageOps.exif_transpose(image)
image = image.convert("RGB")
return image
image = download_image(url)
prompt = "make it Japan"
num_inference_steps = 20
image_guidance_scale = 1.5
guidance_scale = 10
edited_image = pipe(prompt,
image=image,
num_inference_steps=num_inference_steps,
image_guidance_scale=image_guidance_scale,
guidance_scale=guidance_scale,
generator=generator,
).images[0]
edited_image.save("edited_image.png")
```
We encourage you to play with the following three parameters to control
speed and quality during performance:
* `num_inference_steps`
* `image_guidance_scale`
* `guidance_scale`
Particularly, `image_guidance_scale` and `guidance_scale` can have a profound impact
on the generated ("edited") image (see [here](https://twitter.com/RisingSayak/status/1628392199196151808?s=20) for an example).
If you're looking for some interesting ways to use the InstructPix2Pix training methodology, we welcome you to check out this blog post: [Instruction-tuning Stable Diffusion with InstructPix2Pix](https://huggingface.co/blog/instruction-tuning-sd).
## Compare between SD and SDXL
We aim to understand the differences resulting from the use of SD-1.5 and SDXL-0.9 as pretrained models. To achieve this, we trained on the [small toy dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples) using both of these pretrained models. The training script is as follows:
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5" or "stabilityai/stable-diffusion-xl-base-0.9"
export DATASET_ID="fusing/instructpix2pix-1000-samples"
accelerate launch train_instruct_pix2pix.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_ID \
--use_ema \
--enable_xformers_memory_efficient_attention \
--resolution=512 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--seed=42 \
--val_image_url="https://datasets-server.huggingface.co/assets/fusing/instructpix2pix-1000-samples/--/fusing--instructpix2pix-1000-samples/train/23/input_image/image.jpg" \
--validation_prompt="make it in Japan" \
--report_to=wandb \
--push_to_hub
```
We discovered that compared to training with SD-1.5 as the pretrained model, SDXL-0.9 results in a lower training loss value (SD-1.5 yields 0.0599, SDXL scores 0.0254). Moreover, from a visual perspective, the results obtained using SDXL demonstrated fewer artifacts and a richer detail. Notably, SDXL starts to preserve the structure of the original image earlier on.
The following two GIFs provide intuitive visual results. We observed, for each step, what kind of results could be achieved using the image
<p align="center">
<img src="https://datasets-server.huggingface.co/assets/fusing/instructpix2pix-1000-samples/--/fusing--instructpix2pix-1000-samples/train/23/input_image/image.jpg" alt="input for make it Japan" width=600/>
</p>
with "make it in Japan” as the prompt. It can be seen that SDXL starts preserving the details of the original image earlier, resulting in higher fidelity outcomes sooner.
* SD-1.5: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sd_ip2p_training_val_img_progress.gif
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sd_ip2p_training_val_img_progress.gif" alt="input for make it Japan" width=600/>
</p>
* SDXL: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl_ip2p_training_val_img_progress.gif
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl_ip2p_training_val_img_progress.gif" alt="input for make it Japan" width=600/>
</p>
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/instruct_pix2pix/README.md
|
# InstructPix2Pix training example
[InstructPix2Pix](https://arxiv.org/abs/2211.09800) is a method to fine-tune text-conditioned diffusion models such that they can follow an edit instruction for an input image. Models fine-tuned using this method take the following as inputs:
<p align="center">
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/evaluation_diffusion_models/edit-instruction.png" alt="instructpix2pix-inputs" width=600/>
</p>
The output is an "edited" image that reflects the edit instruction applied on the input image:
<p align="center">
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/output-gs%407-igs%401-steps%4050.png" alt="instructpix2pix-output" width=600/>
</p>
The `train_instruct_pix2pix.py` script shows how to implement the training procedure and adapt it for Stable Diffusion.
***Disclaimer: Even though `train_instruct_pix2pix.py` implements the InstructPix2Pix
training procedure while being faithful to the [original implementation](https://github.com/timothybrooks/instruct-pix2pix) we have only tested it on a [small-scale dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples). This can impact the end results. For better results, we recommend longer training runs with a larger dataset. [Here](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) you can find a large dataset for InstructPix2Pix training.***
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell e.g. a notebook
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
### Toy example
As mentioned before, we'll use a [small toy dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples) for training. The dataset
is a smaller version of the [original dataset](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) used in the InstructPix2Pix paper.
Configure environment variables such as the dataset identifier and the Stable Diffusion
checkpoint:
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATASET_ID="fusing/instructpix2pix-1000-samples"
```
Now, we can launch training:
```bash
accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_ID \
--enable_xformers_memory_efficient_attention \
--resolution=256 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --max_grad_norm=1 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--mixed_precision=fp16 \
--seed=42 \
--push_to_hub
```
Additionally, we support performing validation inference to monitor training progress
with Weights and Biases. You can enable this feature with `report_to="wandb"`:
```bash
accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_ID \
--enable_xformers_memory_efficient_attention \
--resolution=256 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --max_grad_norm=1 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--mixed_precision=fp16 \
--val_image_url="https://hf.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png" \
--validation_prompt="make the mountains snowy" \
--seed=42 \
--report_to=wandb \
--push_to_hub
```
We recommend this type of validation as it can be useful for model debugging. Note that you need `wandb` installed to use this. You can install `wandb` by running `pip install wandb`.
[Here](https://wandb.ai/sayakpaul/instruct-pix2pix/runs/ctr3kovq), you can find an example training run that includes some validation samples and the training hyperparameters.
***Note: In the original paper, the authors observed that even when the model is trained with an image resolution of 256x256, it generalizes well to bigger resolutions such as 512x512. This is likely because of the larger dataset they used during training.***
## Training with multiple GPUs
`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
for running distributed training with `accelerate`. Here is an example command:
```bash
accelerate launch --mixed_precision="fp16" --multi_gpu train_instruct_pix2pix.py \
--pretrained_model_name_or_path=runwayml/stable-diffusion-v1-5 \
--dataset_name=sayakpaul/instructpix2pix-1000-samples \
--use_ema \
--enable_xformers_memory_efficient_attention \
--resolution=512 --random_flip \
--train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=15000 \
--checkpointing_steps=5000 --checkpoints_total_limit=1 \
--learning_rate=5e-05 --lr_warmup_steps=0 \
--conditioning_dropout_prob=0.05 \
--mixed_precision=fp16 \
--seed=42 \
--push_to_hub
```
## Inference
Once training is complete, we can perform inference:
```python
import PIL
import requests
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline
model_id = "your_model_id" # <- replace this
pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
generator = torch.Generator("cuda").manual_seed(0)
url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/test_pix2pix_4.png"
def download_image(url):
image = PIL.Image.open(requests.get(url, stream=True).raw)
image = PIL.ImageOps.exif_transpose(image)
image = image.convert("RGB")
return image
image = download_image(url)
prompt = "wipe out the lake"
num_inference_steps = 20
image_guidance_scale = 1.5
guidance_scale = 10
edited_image = pipe(prompt,
image=image,
num_inference_steps=num_inference_steps,
image_guidance_scale=image_guidance_scale,
guidance_scale=guidance_scale,
generator=generator,
).images[0]
edited_image.save("edited_image.png")
```
An example model repo obtained using this training script can be found
here - [sayakpaul/instruct-pix2pix](https://huggingface.co/sayakpaul/instruct-pix2pix).
We encourage you to play with the following three parameters to control
speed and quality during performance:
* `num_inference_steps`
* `image_guidance_scale`
* `guidance_scale`
Particularly, `image_guidance_scale` and `guidance_scale` can have a profound impact
on the generated ("edited") image (see [here](https://twitter.com/RisingSayak/status/1628392199196151808?s=20) for an example).
If you're looking for some interesting ways to use the InstructPix2Pix training methodology, we welcome you to check out this blog post: [Instruction-tuning Stable Diffusion with InstructPix2Pix](https://huggingface.co/blog/instruction-tuning-sd).
## Stable Diffusion XL
There's an equivalent `train_instruct_pix2pix_sdxl.py` script for [Stable Diffusion XL](https://huggingface.co/papers/2307.01952). Please refer to the docs [here](./README_sdxl.md) to learn more.
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/instruct_pix2pix/train_instruct_pix2pix_sdxl.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 Harutatsu Akiyama and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import logging
import math
import os
import shutil
import warnings
from pathlib import Path
from urllib.parse import urlparse
import accelerate
import datasets
import numpy as np
import PIL
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from datasets import load_dataset
from huggingface_hub import create_repo, upload_folder
from packaging import version
from PIL import Image
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import AutoTokenizer, PretrainedConfig
import diffusers
from diffusers import AutoencoderKL, DDPMScheduler, UNet2DConditionModel
from diffusers.optimization import get_scheduler
from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl_instruct_pix2pix import (
StableDiffusionXLInstructPix2PixPipeline,
)
from diffusers.training_utils import EMAModel
from diffusers.utils import check_min_version, deprecate, is_wandb_available, load_image
from diffusers.utils.import_utils import is_xformers_available
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.24.0.dev0")
logger = get_logger(__name__, log_level="INFO")
DATASET_NAME_MAPPING = {
"fusing/instructpix2pix-1000-samples": ("file_name", "edited_image", "edit_prompt"),
}
WANDB_TABLE_COL_NAMES = ["file_name", "edited_image", "edit_prompt"]
TORCH_DTYPE_MAPPING = {"fp32": torch.float32, "fp16": torch.float16, "bf16": torch.bfloat16}
def import_model_class_from_model_name_or_path(
pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
):
text_encoder_config = PretrainedConfig.from_pretrained(
pretrained_model_name_or_path, subfolder=subfolder, revision=revision
)
model_class = text_encoder_config.architectures[0]
if model_class == "CLIPTextModel":
from transformers import CLIPTextModel
return CLIPTextModel
elif model_class == "CLIPTextModelWithProjection":
from transformers import CLIPTextModelWithProjection
return CLIPTextModelWithProjection
else:
raise ValueError(f"{model_class} is not supported.")
def parse_args():
parser = argparse.ArgumentParser(description="Script to train Stable Diffusion XL for InstructPix2Pix.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--pretrained_vae_model_name_or_path",
type=str,
default=None,
help="Path to an improved VAE to stabilize training. For more details check out: https://github.com/huggingface/diffusers/pull/4038.",
)
parser.add_argument(
"--vae_precision",
type=str,
choices=["fp32", "fp16", "bf16"],
default="fp32",
help=(
"The vanilla SDXL 1.0 VAE can cause NaNs due to large activation values. Some custom models might already have a solution"
" to this problem, and this flag allows you to use mixed precision to stabilize training."
),
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--variant",
type=str,
default=None,
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--original_image_column",
type=str,
default="input_image",
help="The column of the dataset containing the original image on which edits where made.",
)
parser.add_argument(
"--edited_image_column",
type=str,
default="edited_image",
help="The column of the dataset containing the edited image.",
)
parser.add_argument(
"--edit_prompt_column",
type=str,
default="edit_prompt",
help="The column of the dataset containing the edit instruction.",
)
parser.add_argument(
"--val_image_url_or_path",
type=str,
default=None,
help="URL to the original image that you would like to edit (used during inference for debugging purposes).",
)
parser.add_argument(
"--validation_prompt", type=str, default=None, help="A prompt that is sampled during training for inference."
)
parser.add_argument(
"--num_validation_images",
type=int,
default=4,
help="Number of images that should be generated during validation with `validation_prompt`.",
)
parser.add_argument(
"--validation_steps",
type=int,
default=100,
help=(
"Run fine-tuning validation every X steps. The validation process consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`."
),
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="instruct-pix2pix-model",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=256,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this resolution."
),
)
parser.add_argument(
"--crops_coords_top_left_h",
type=int,
default=0,
help=("Coordinate for (the height) to be included in the crop coordinate embeddings needed by SDXL UNet."),
)
parser.add_argument(
"--crops_coords_top_left_w",
type=int,
default=0,
help=("Coordinate for (the height) to be included in the crop coordinate embeddings needed by SDXL UNet."),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--conditioning_dropout_prob",
type=float,
default=None,
help="Conditioning dropout probability. Drops out the conditionings (image and edit prompt) used in training InstructPix2Pix. See section 3.2.1 in the paper: https://arxiv.org/abs/2211.09800.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument("--use_ema", action="store_true", help="Whether to use EMA model.")
parser.add_argument(
"--non_ema_revision",
type=str,
default=None,
required=False,
help=(
"Revision of pretrained non-ema model identifier. Must be a branch, tag or git identifier of the local or"
" remote repository specified with --pretrained_model_name_or_path."
),
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
# default to using the same revision for the non-ema model if not specified
if args.non_ema_revision is None:
args.non_ema_revision = args.revision
return args
def convert_to_np(image, resolution):
if isinstance(image, str):
image = PIL.Image.open(image)
image = image.convert("RGB").resize((resolution, resolution))
return np.array(image).transpose(2, 0, 1)
def main():
args = parse_args()
if args.non_ema_revision is not None:
deprecate(
"non_ema_revision!=None",
"0.15.0",
message=(
"Downloading 'non_ema' weights from revision branches of the Hub is deprecated. Please make sure to"
" use `--variant=non_ema` instead."
),
)
logging_dir = os.path.join(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
if args.report_to == "wandb":
if not is_wandb_available():
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
import wandb
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
vae_path = (
args.pretrained_model_name_or_path
if args.pretrained_vae_model_name_or_path is None
else args.pretrained_vae_model_name_or_path
)
vae = AutoencoderKL.from_pretrained(
vae_path,
subfolder="vae" if args.pretrained_vae_model_name_or_path is None else None,
revision=args.revision,
variant=args.variant,
)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
)
# InstructPix2Pix uses an additional image for conditioning. To accommodate that,
# it uses 8 channels (instead of 4) in the first (conv) layer of the UNet. This UNet is
# then fine-tuned on the custom InstructPix2Pix dataset. This modified UNet is initialized
# from the pre-trained checkpoints. For the extra channels added to the first layer, they are
# initialized to zero.
logger.info("Initializing the XL InstructPix2Pix UNet from the pretrained UNet.")
in_channels = 8
out_channels = unet.conv_in.out_channels
unet.register_to_config(in_channels=in_channels)
with torch.no_grad():
new_conv_in = nn.Conv2d(
in_channels, out_channels, unet.conv_in.kernel_size, unet.conv_in.stride, unet.conv_in.padding
)
new_conv_in.weight.zero_()
new_conv_in.weight[:, :4, :, :].copy_(unet.conv_in.weight)
unet.conv_in = new_conv_in
# Create EMA for the unet.
if args.use_ema:
ema_unet = EMAModel(unet.parameters(), model_cls=UNet2DConditionModel, model_config=unet.config)
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
if args.use_ema:
ema_unet.save_pretrained(os.path.join(output_dir, "unet_ema"))
for i, model in enumerate(models):
model.save_pretrained(os.path.join(output_dir, "unet"))
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
if args.use_ema:
load_model = EMAModel.from_pretrained(os.path.join(input_dir, "unet_ema"), UNet2DConditionModel)
ema_unet.load_state_dict(load_model.state_dict())
ema_unet.to(accelerator.device)
del load_model
for i in range(len(models)):
# pop models so that they are not loaded again
model = models.pop()
# load diffusers style into model
load_model = UNet2DConditionModel.from_pretrained(input_dir, subfolder="unet")
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
del load_model
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Initialize the optimizer
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
)
optimizer_cls = bnb.optim.AdamW8bit
else:
optimizer_cls = torch.optim.AdamW
optimizer = optimizer_cls(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
)
else:
data_files = {}
if args.train_data_dir is not None:
data_files["train"] = os.path.join(args.train_data_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/main/en/image_load#imagefolder
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
if args.original_image_column is None:
original_image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
original_image_column = args.original_image_column
if original_image_column not in column_names:
raise ValueError(
f"--original_image_column' value '{args.original_image_column}' needs to be one of: {', '.join(column_names)}"
)
if args.edit_prompt_column is None:
edit_prompt_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
edit_prompt_column = args.edit_prompt_column
if edit_prompt_column not in column_names:
raise ValueError(
f"--edit_prompt_column' value '{args.edit_prompt_column}' needs to be one of: {', '.join(column_names)}"
)
if args.edited_image_column is None:
edited_image_column = dataset_columns[2] if dataset_columns is not None else column_names[2]
else:
edited_image_column = args.edited_image_column
if edited_image_column not in column_names:
raise ValueError(
f"--edited_image_column' value '{args.edited_image_column}' needs to be one of: {', '.join(column_names)}"
)
# For mixed precision training we cast the text_encoder and vae weights to half-precision
# as these models are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
warnings.warn(f"weight_dtype {weight_dtype} may cause nan during vae encoding", UserWarning)
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
warnings.warn(f"weight_dtype {weight_dtype} may cause nan during vae encoding", UserWarning)
# Preprocessing the datasets.
# We need to tokenize input captions and transform the images.
def tokenize_captions(captions, tokenizer):
inputs = tokenizer(
captions,
max_length=tokenizer.model_max_length,
padding="max_length",
truncation=True,
return_tensors="pt",
)
return inputs.input_ids
# Preprocessing the datasets.
train_transforms = transforms.Compose(
[
transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
]
)
def preprocess_images(examples):
original_images = np.concatenate(
[convert_to_np(image, args.resolution) for image in examples[original_image_column]]
)
edited_images = np.concatenate(
[convert_to_np(image, args.resolution) for image in examples[edited_image_column]]
)
# We need to ensure that the original and the edited images undergo the same
# augmentation transforms.
images = np.concatenate([original_images, edited_images])
images = torch.tensor(images)
images = 2 * (images / 255) - 1
return train_transforms(images)
# Load scheduler, tokenizer and models.
tokenizer_1 = AutoTokenizer.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="tokenizer",
revision=args.revision,
use_fast=False,
)
tokenizer_2 = AutoTokenizer.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="tokenizer_2",
revision=args.revision,
use_fast=False,
)
text_encoder_cls_1 = import_model_class_from_model_name_or_path(args.pretrained_model_name_or_path, args.revision)
text_encoder_cls_2 = import_model_class_from_model_name_or_path(
args.pretrained_model_name_or_path, args.revision, subfolder="text_encoder_2"
)
# Load scheduler and models
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
text_encoder_1 = text_encoder_cls_1.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision, variant=args.variant
)
text_encoder_2 = text_encoder_cls_2.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder_2", revision=args.revision, variant=args.variant
)
# We ALWAYS pre-compute the additional condition embeddings needed for SDXL
# UNet as the model is already big and it uses two text encoders.
text_encoder_1.to(accelerator.device, dtype=weight_dtype)
text_encoder_2.to(accelerator.device, dtype=weight_dtype)
tokenizers = [tokenizer_1, tokenizer_2]
text_encoders = [text_encoder_1, text_encoder_2]
# Freeze vae and text_encoders
vae.requires_grad_(False)
text_encoder_1.requires_grad_(False)
text_encoder_2.requires_grad_(False)
# Set UNet to trainable.
unet.train()
# Adapted from pipelines.StableDiffusionXLPipeline.encode_prompt
def encode_prompt(text_encoders, tokenizers, prompt):
prompt_embeds_list = []
for tokenizer, text_encoder in zip(tokenizers, text_encoders):
text_inputs = tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {tokenizer.model_max_length} tokens: {removed_text}"
)
prompt_embeds = text_encoder(
text_input_ids.to(text_encoder.device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
pooled_prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.hidden_states[-2]
bs_embed, seq_len, _ = prompt_embeds.shape
prompt_embeds = prompt_embeds.view(bs_embed, seq_len, -1)
prompt_embeds_list.append(prompt_embeds)
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
pooled_prompt_embeds = pooled_prompt_embeds.view(bs_embed, -1)
return prompt_embeds, pooled_prompt_embeds
# Adapted from pipelines.StableDiffusionXLPipeline.encode_prompt
def encode_prompts(text_encoders, tokenizers, prompts):
prompt_embeds_all = []
pooled_prompt_embeds_all = []
for prompt in prompts:
prompt_embeds, pooled_prompt_embeds = encode_prompt(text_encoders, tokenizers, prompt)
prompt_embeds_all.append(prompt_embeds)
pooled_prompt_embeds_all.append(pooled_prompt_embeds)
return torch.stack(prompt_embeds_all), torch.stack(pooled_prompt_embeds_all)
# Adapted from examples.dreambooth.train_dreambooth_lora_sdxl
# Here, we compute not just the text embeddings but also the additional embeddings
# needed for the SD XL UNet to operate.
def compute_embeddings_for_prompts(prompts, text_encoders, tokenizers):
with torch.no_grad():
prompt_embeds_all, pooled_prompt_embeds_all = encode_prompts(text_encoders, tokenizers, prompts)
add_text_embeds_all = pooled_prompt_embeds_all
prompt_embeds_all = prompt_embeds_all.to(accelerator.device)
add_text_embeds_all = add_text_embeds_all.to(accelerator.device)
return prompt_embeds_all, add_text_embeds_all
# Get null conditioning
def compute_null_conditioning():
null_conditioning_list = []
for a_tokenizer, a_text_encoder in zip(tokenizers, text_encoders):
null_conditioning_list.append(
a_text_encoder(
tokenize_captions([""], tokenizer=a_tokenizer).to(accelerator.device),
output_hidden_states=True,
).hidden_states[-2]
)
return torch.concat(null_conditioning_list, dim=-1)
null_conditioning = compute_null_conditioning()
def compute_time_ids():
crops_coords_top_left = (args.crops_coords_top_left_h, args.crops_coords_top_left_w)
original_size = target_size = (args.resolution, args.resolution)
add_time_ids = list(original_size + crops_coords_top_left + target_size)
add_time_ids = torch.tensor([add_time_ids], dtype=weight_dtype)
return add_time_ids.to(accelerator.device).repeat(args.train_batch_size, 1)
add_time_ids = compute_time_ids()
def preprocess_train(examples):
# Preprocess images.
preprocessed_images = preprocess_images(examples)
# Since the original and edited images were concatenated before
# applying the transformations, we need to separate them and reshape
# them accordingly.
original_images, edited_images = preprocessed_images.chunk(2)
original_images = original_images.reshape(-1, 3, args.resolution, args.resolution)
edited_images = edited_images.reshape(-1, 3, args.resolution, args.resolution)
# Collate the preprocessed images into the `examples`.
examples["original_pixel_values"] = original_images
examples["edited_pixel_values"] = edited_images
# Preprocess the captions.
captions = list(examples[edit_prompt_column])
prompt_embeds_all, add_text_embeds_all = compute_embeddings_for_prompts(captions, text_encoders, tokenizers)
examples["prompt_embeds"] = prompt_embeds_all
examples["add_text_embeds"] = add_text_embeds_all
return examples
with accelerator.main_process_first():
if args.max_train_samples is not None:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train)
def collate_fn(examples):
original_pixel_values = torch.stack([example["original_pixel_values"] for example in examples])
original_pixel_values = original_pixel_values.to(memory_format=torch.contiguous_format).float()
edited_pixel_values = torch.stack([example["edited_pixel_values"] for example in examples])
edited_pixel_values = edited_pixel_values.to(memory_format=torch.contiguous_format).float()
prompt_embeds = torch.concat([example["prompt_embeds"] for example in examples], dim=0)
add_text_embeds = torch.concat([example["add_text_embeds"] for example in examples], dim=0)
return {
"original_pixel_values": original_pixel_values,
"edited_pixel_values": edited_pixel_values,
"prompt_embeds": prompt_embeds,
"add_text_embeds": add_text_embeds,
}
# DataLoaders creation:
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
)
# Prepare everything with our `accelerator`.
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, optimizer, train_dataloader, lr_scheduler
)
if args.use_ema:
ema_unet.to(accelerator.device)
# Move vae, unet and text_encoder to device and cast to weight_dtype
# The VAE is in float32 to avoid NaN losses.
if args.pretrained_vae_model_name_or_path is not None:
vae.to(accelerator.device, dtype=weight_dtype)
else:
vae.to(accelerator.device, dtype=TORCH_DTYPE_MAPPING[args.vae_precision])
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
accelerator.init_trackers("instruct-pix2pix-xl", config=vars(args))
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
for epoch in range(first_epoch, args.num_train_epochs):
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet):
# We want to learn the denoising process w.r.t the edited images which
# are conditioned on the original image (which was edited) and the edit instruction.
# So, first, convert images to latent space.
if args.pretrained_vae_model_name_or_path is not None:
edited_pixel_values = batch["edited_pixel_values"].to(dtype=weight_dtype)
else:
edited_pixel_values = batch["edited_pixel_values"]
latents = vae.encode(edited_pixel_values).latent_dist.sample()
latents = latents * vae.config.scaling_factor
if args.pretrained_vae_model_name_or_path is None:
latents = latents.to(weight_dtype)
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# SDXL additional inputs
encoder_hidden_states = batch["prompt_embeds"]
add_text_embeds = batch["add_text_embeds"]
# Get the additional image embedding for conditioning.
# Instead of getting a diagonal Gaussian here, we simply take the mode.
if args.pretrained_vae_model_name_or_path is not None:
original_pixel_values = batch["original_pixel_values"].to(dtype=weight_dtype)
else:
original_pixel_values = batch["original_pixel_values"]
original_image_embeds = vae.encode(original_pixel_values).latent_dist.sample()
if args.pretrained_vae_model_name_or_path is None:
original_image_embeds = original_image_embeds.to(weight_dtype)
# Conditioning dropout to support classifier-free guidance during inference. For more details
# check out the section 3.2.1 of the original paper https://arxiv.org/abs/2211.09800.
if args.conditioning_dropout_prob is not None:
random_p = torch.rand(bsz, device=latents.device, generator=generator)
# Sample masks for the edit prompts.
prompt_mask = random_p < 2 * args.conditioning_dropout_prob
prompt_mask = prompt_mask.reshape(bsz, 1, 1)
# Final text conditioning.
encoder_hidden_states = torch.where(prompt_mask, null_conditioning, encoder_hidden_states)
# Sample masks for the original images.
image_mask_dtype = original_image_embeds.dtype
image_mask = 1 - (
(random_p >= args.conditioning_dropout_prob).to(image_mask_dtype)
* (random_p < 3 * args.conditioning_dropout_prob).to(image_mask_dtype)
)
image_mask = image_mask.reshape(bsz, 1, 1, 1)
# Final image conditioning.
original_image_embeds = image_mask * original_image_embeds
# Concatenate the `original_image_embeds` with the `noisy_latents`.
concatenated_noisy_latents = torch.cat([noisy_latents, original_image_embeds], dim=1)
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
# Predict the noise residual and compute loss
added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
model_pred = unet(
concatenated_noisy_latents, timesteps, encoder_hidden_states, added_cond_kwargs=added_cond_kwargs
).sample
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
train_loss += avg_loss.item() / args.gradient_accumulation_steps
# Backpropagate
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
if args.use_ema:
ema_unet.step(unet.parameters())
progress_bar.update(1)
global_step += 1
accelerator.log({"train_loss": train_loss}, step=global_step)
train_loss = 0.0
if global_step % args.checkpointing_steps == 0:
if accelerator.is_main_process:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
### BEGIN: Perform validation every `validation_epochs` steps
if global_step % args.validation_steps == 0 or global_step == 1:
if (args.val_image_url_or_path is not None) and (args.validation_prompt is not None):
logger.info(
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
f" {args.validation_prompt}."
)
# create pipeline
if args.use_ema:
# Store the UNet parameters temporarily and load the EMA parameters to perform inference.
ema_unet.store(unet.parameters())
ema_unet.copy_to(unet.parameters())
# The models need unwrapping because for compatibility in distributed training mode.
pipeline = StableDiffusionXLInstructPix2PixPipeline.from_pretrained(
args.pretrained_model_name_or_path,
unet=accelerator.unwrap_model(unet),
text_encoder=text_encoder_1,
text_encoder_2=text_encoder_2,
tokenizer=tokenizer_1,
tokenizer_2=tokenizer_2,
vae=vae,
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
# run inference
# Save validation images
val_save_dir = os.path.join(args.output_dir, "validation_images")
if not os.path.exists(val_save_dir):
os.makedirs(val_save_dir)
original_image = (
lambda image_url_or_path: load_image(image_url_or_path)
if urlparse(image_url_or_path).scheme
else Image.open(image_url_or_path).convert("RGB")
)(args.val_image_url_or_path)
with torch.autocast(
str(accelerator.device).replace(":0", ""), enabled=accelerator.mixed_precision == "fp16"
):
edited_images = []
for val_img_idx in range(args.num_validation_images):
a_val_img = pipeline(
args.validation_prompt,
image=original_image,
num_inference_steps=20,
image_guidance_scale=1.5,
guidance_scale=7,
generator=generator,
).images[0]
edited_images.append(a_val_img)
a_val_img.save(os.path.join(val_save_dir, f"step_{global_step}_val_img_{val_img_idx}.png"))
for tracker in accelerator.trackers:
if tracker.name == "wandb":
wandb_table = wandb.Table(columns=WANDB_TABLE_COL_NAMES)
for edited_image in edited_images:
wandb_table.add_data(
wandb.Image(original_image), wandb.Image(edited_image), args.validation_prompt
)
tracker.log({"validation": wandb_table})
if args.use_ema:
# Switch back to the original UNet parameters.
ema_unet.restore(unet.parameters())
del pipeline
torch.cuda.empty_cache()
### END: Perform validation every `validation_epochs` steps
if global_step >= args.max_train_steps:
break
# Create the pipeline using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
if args.use_ema:
ema_unet.copy_to(unet.parameters())
pipeline = StableDiffusionXLInstructPix2PixPipeline.from_pretrained(
args.pretrained_model_name_or_path,
text_encoder=text_encoder_1,
text_encoder_2=text_encoder_2,
tokenizer=tokenizer_1,
tokenizer_2=tokenizer_2,
vae=vae,
unet=unet,
revision=args.revision,
variant=args.variant,
)
pipeline.save_pretrained(args.output_dir)
if args.push_to_hub:
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
if args.validation_prompt is not None:
edited_images = []
pipeline = pipeline.to(accelerator.device)
with torch.autocast(str(accelerator.device).replace(":0", "")):
for _ in range(args.num_validation_images):
edited_images.append(
pipeline(
args.validation_prompt,
image=original_image,
num_inference_steps=20,
image_guidance_scale=1.5,
guidance_scale=7,
generator=generator,
).images[0]
)
for tracker in accelerator.trackers:
if tracker.name == "wandb":
wandb_table = wandb.Table(columns=WANDB_TABLE_COL_NAMES)
for edited_image in edited_images:
wandb_table.add_data(
wandb.Image(original_image), wandb.Image(edited_image), args.validation_prompt
)
tracker.log({"test": wandb_table})
accelerator.end_training()
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/instruct_pix2pix/requirements.txt
|
accelerate>=0.16.0
torchvision
transformers>=4.25.1
datasets
ftfy
tensorboard
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/instruct_pix2pix/train_instruct_pix2pix.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Script to fine-tune Stable Diffusion for InstructPix2Pix."""
import argparse
import logging
import math
import os
import shutil
from pathlib import Path
import accelerate
import datasets
import numpy as np
import PIL
import requests
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from datasets import load_dataset
from huggingface_hub import create_repo, upload_folder
from packaging import version
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPTextModel, CLIPTokenizer
import diffusers
from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionInstructPix2PixPipeline, UNet2DConditionModel
from diffusers.optimization import get_scheduler
from diffusers.training_utils import EMAModel
from diffusers.utils import check_min_version, deprecate, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.24.0.dev0")
logger = get_logger(__name__, log_level="INFO")
DATASET_NAME_MAPPING = {
"fusing/instructpix2pix-1000-samples": ("input_image", "edit_prompt", "edited_image"),
}
WANDB_TABLE_COL_NAMES = ["original_image", "edited_image", "edit_prompt"]
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script for InstructPix2Pix.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--variant",
type=str,
default=None,
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--original_image_column",
type=str,
default="input_image",
help="The column of the dataset containing the original image on which edits where made.",
)
parser.add_argument(
"--edited_image_column",
type=str,
default="edited_image",
help="The column of the dataset containing the edited image.",
)
parser.add_argument(
"--edit_prompt_column",
type=str,
default="edit_prompt",
help="The column of the dataset containing the edit instruction.",
)
parser.add_argument(
"--val_image_url",
type=str,
default=None,
help="URL to the original image that you would like to edit (used during inference for debugging purposes).",
)
parser.add_argument(
"--validation_prompt", type=str, default=None, help="A prompt that is sampled during training for inference."
)
parser.add_argument(
"--num_validation_images",
type=int,
default=4,
help="Number of images that should be generated during validation with `validation_prompt`.",
)
parser.add_argument(
"--validation_epochs",
type=int,
default=1,
help=(
"Run fine-tuning validation every X epochs. The validation process consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`."
),
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="instruct-pix2pix-model",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=256,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--conditioning_dropout_prob",
type=float,
default=None,
help="Conditioning dropout probability. Drops out the conditionings (image and edit prompt) used in training InstructPix2Pix. See section 3.2.1 in the paper: https://arxiv.org/abs/2211.09800.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument("--use_ema", action="store_true", help="Whether to use EMA model.")
parser.add_argument(
"--non_ema_revision",
type=str,
default=None,
required=False,
help=(
"Revision of pretrained non-ema model identifier. Must be a branch, tag or git identifier of the local or"
" remote repository specified with --pretrained_model_name_or_path."
),
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
# default to using the same revision for the non-ema model if not specified
if args.non_ema_revision is None:
args.non_ema_revision = args.revision
return args
def convert_to_np(image, resolution):
image = image.convert("RGB").resize((resolution, resolution))
return np.array(image).transpose(2, 0, 1)
def download_image(url):
image = PIL.Image.open(requests.get(url, stream=True).raw)
image = PIL.ImageOps.exif_transpose(image)
image = image.convert("RGB")
return image
def main():
args = parse_args()
if args.non_ema_revision is not None:
deprecate(
"non_ema_revision!=None",
"0.15.0",
message=(
"Downloading 'non_ema' weights from revision branches of the Hub is deprecated. Please make sure to"
" use `--variant=non_ema` instead."
),
)
logging_dir = os.path.join(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
if args.report_to == "wandb":
if not is_wandb_available():
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
import wandb
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load scheduler, tokenizer and models.
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
)
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision, variant=args.variant
)
vae = AutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision, variant=args.variant
)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.non_ema_revision
)
# InstructPix2Pix uses an additional image for conditioning. To accommodate that,
# it uses 8 channels (instead of 4) in the first (conv) layer of the UNet. This UNet is
# then fine-tuned on the custom InstructPix2Pix dataset. This modified UNet is initialized
# from the pre-trained checkpoints. For the extra channels added to the first layer, they are
# initialized to zero.
logger.info("Initializing the InstructPix2Pix UNet from the pretrained UNet.")
in_channels = 8
out_channels = unet.conv_in.out_channels
unet.register_to_config(in_channels=in_channels)
with torch.no_grad():
new_conv_in = nn.Conv2d(
in_channels, out_channels, unet.conv_in.kernel_size, unet.conv_in.stride, unet.conv_in.padding
)
new_conv_in.weight.zero_()
new_conv_in.weight[:, :4, :, :].copy_(unet.conv_in.weight)
unet.conv_in = new_conv_in
# Freeze vae and text_encoder
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
# Create EMA for the unet.
if args.use_ema:
ema_unet = EMAModel(unet.parameters(), model_cls=UNet2DConditionModel, model_config=unet.config)
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
if args.use_ema:
ema_unet.save_pretrained(os.path.join(output_dir, "unet_ema"))
for i, model in enumerate(models):
model.save_pretrained(os.path.join(output_dir, "unet"))
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
if args.use_ema:
load_model = EMAModel.from_pretrained(os.path.join(input_dir, "unet_ema"), UNet2DConditionModel)
ema_unet.load_state_dict(load_model.state_dict())
ema_unet.to(accelerator.device)
del load_model
for i in range(len(models)):
# pop models so that they are not loaded again
model = models.pop()
# load diffusers style into model
load_model = UNet2DConditionModel.from_pretrained(input_dir, subfolder="unet")
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
del load_model
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Initialize the optimizer
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
)
optimizer_cls = bnb.optim.AdamW8bit
else:
optimizer_cls = torch.optim.AdamW
optimizer = optimizer_cls(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
)
else:
data_files = {}
if args.train_data_dir is not None:
data_files["train"] = os.path.join(args.train_data_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/main/en/image_load#imagefolder
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
if args.original_image_column is None:
original_image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
original_image_column = args.original_image_column
if original_image_column not in column_names:
raise ValueError(
f"--original_image_column' value '{args.original_image_column}' needs to be one of: {', '.join(column_names)}"
)
if args.edit_prompt_column is None:
edit_prompt_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
edit_prompt_column = args.edit_prompt_column
if edit_prompt_column not in column_names:
raise ValueError(
f"--edit_prompt_column' value '{args.edit_prompt_column}' needs to be one of: {', '.join(column_names)}"
)
if args.edited_image_column is None:
edited_image_column = dataset_columns[2] if dataset_columns is not None else column_names[2]
else:
edited_image_column = args.edited_image_column
if edited_image_column not in column_names:
raise ValueError(
f"--edited_image_column' value '{args.edited_image_column}' needs to be one of: {', '.join(column_names)}"
)
# Preprocessing the datasets.
# We need to tokenize input captions and transform the images.
def tokenize_captions(captions):
inputs = tokenizer(
captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
)
return inputs.input_ids
# Preprocessing the datasets.
train_transforms = transforms.Compose(
[
transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
]
)
def preprocess_images(examples):
original_images = np.concatenate(
[convert_to_np(image, args.resolution) for image in examples[original_image_column]]
)
edited_images = np.concatenate(
[convert_to_np(image, args.resolution) for image in examples[edited_image_column]]
)
# We need to ensure that the original and the edited images undergo the same
# augmentation transforms.
images = np.concatenate([original_images, edited_images])
images = torch.tensor(images)
images = 2 * (images / 255) - 1
return train_transforms(images)
def preprocess_train(examples):
# Preprocess images.
preprocessed_images = preprocess_images(examples)
# Since the original and edited images were concatenated before
# applying the transformations, we need to separate them and reshape
# them accordingly.
original_images, edited_images = preprocessed_images.chunk(2)
original_images = original_images.reshape(-1, 3, args.resolution, args.resolution)
edited_images = edited_images.reshape(-1, 3, args.resolution, args.resolution)
# Collate the preprocessed images into the `examples`.
examples["original_pixel_values"] = original_images
examples["edited_pixel_values"] = edited_images
# Preprocess the captions.
captions = list(examples[edit_prompt_column])
examples["input_ids"] = tokenize_captions(captions)
return examples
with accelerator.main_process_first():
if args.max_train_samples is not None:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train)
def collate_fn(examples):
original_pixel_values = torch.stack([example["original_pixel_values"] for example in examples])
original_pixel_values = original_pixel_values.to(memory_format=torch.contiguous_format).float()
edited_pixel_values = torch.stack([example["edited_pixel_values"] for example in examples])
edited_pixel_values = edited_pixel_values.to(memory_format=torch.contiguous_format).float()
input_ids = torch.stack([example["input_ids"] for example in examples])
return {
"original_pixel_values": original_pixel_values,
"edited_pixel_values": edited_pixel_values,
"input_ids": input_ids,
}
# DataLoaders creation:
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, optimizer, train_dataloader, lr_scheduler
)
if args.use_ema:
ema_unet.to(accelerator.device)
# For mixed precision training we cast the text_encoder and vae weights to half-precision
# as these models are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move text_encode and vae to gpu and cast to weight_dtype
text_encoder.to(accelerator.device, dtype=weight_dtype)
vae.to(accelerator.device, dtype=weight_dtype)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
accelerator.init_trackers("instruct-pix2pix", config=vars(args))
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
resume_global_step = global_step * args.gradient_accumulation_steps
first_epoch = global_step // num_update_steps_per_epoch
resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
progress_bar.set_description("Steps")
for epoch in range(first_epoch, args.num_train_epochs):
unet.train()
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
# Skip steps until we reach the resumed step
if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
if step % args.gradient_accumulation_steps == 0:
progress_bar.update(1)
continue
with accelerator.accumulate(unet):
# We want to learn the denoising process w.r.t the edited images which
# are conditioned on the original image (which was edited) and the edit instruction.
# So, first, convert images to latent space.
latents = vae.encode(batch["edited_pixel_values"].to(weight_dtype)).latent_dist.sample()
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# Get the text embedding for conditioning.
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
# Get the additional image embedding for conditioning.
# Instead of getting a diagonal Gaussian here, we simply take the mode.
original_image_embeds = vae.encode(batch["original_pixel_values"].to(weight_dtype)).latent_dist.mode()
# Conditioning dropout to support classifier-free guidance during inference. For more details
# check out the section 3.2.1 of the original paper https://arxiv.org/abs/2211.09800.
if args.conditioning_dropout_prob is not None:
random_p = torch.rand(bsz, device=latents.device, generator=generator)
# Sample masks for the edit prompts.
prompt_mask = random_p < 2 * args.conditioning_dropout_prob
prompt_mask = prompt_mask.reshape(bsz, 1, 1)
# Final text conditioning.
null_conditioning = text_encoder(tokenize_captions([""]).to(accelerator.device))[0]
encoder_hidden_states = torch.where(prompt_mask, null_conditioning, encoder_hidden_states)
# Sample masks for the original images.
image_mask_dtype = original_image_embeds.dtype
image_mask = 1 - (
(random_p >= args.conditioning_dropout_prob).to(image_mask_dtype)
* (random_p < 3 * args.conditioning_dropout_prob).to(image_mask_dtype)
)
image_mask = image_mask.reshape(bsz, 1, 1, 1)
# Final image conditioning.
original_image_embeds = image_mask * original_image_embeds
# Concatenate the `original_image_embeds` with the `noisy_latents`.
concatenated_noisy_latents = torch.cat([noisy_latents, original_image_embeds], dim=1)
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
# Predict the noise residual and compute loss
model_pred = unet(concatenated_noisy_latents, timesteps, encoder_hidden_states).sample
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
train_loss += avg_loss.item() / args.gradient_accumulation_steps
# Backpropagate
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
if args.use_ema:
ema_unet.step(unet.parameters())
progress_bar.update(1)
global_step += 1
accelerator.log({"train_loss": train_loss}, step=global_step)
train_loss = 0.0
if global_step % args.checkpointing_steps == 0:
if accelerator.is_main_process:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
if global_step >= args.max_train_steps:
break
if accelerator.is_main_process:
if (
(args.val_image_url is not None)
and (args.validation_prompt is not None)
and (epoch % args.validation_epochs == 0)
):
logger.info(
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
f" {args.validation_prompt}."
)
# create pipeline
if args.use_ema:
# Store the UNet parameters temporarily and load the EMA parameters to perform inference.
ema_unet.store(unet.parameters())
ema_unet.copy_to(unet.parameters())
# The models need unwrapping because for compatibility in distributed training mode.
pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
args.pretrained_model_name_or_path,
unet=accelerator.unwrap_model(unet),
text_encoder=accelerator.unwrap_model(text_encoder),
vae=accelerator.unwrap_model(vae),
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
# run inference
original_image = download_image(args.val_image_url)
edited_images = []
with torch.autocast(
str(accelerator.device).replace(":0", ""), enabled=accelerator.mixed_precision == "fp16"
):
for _ in range(args.num_validation_images):
edited_images.append(
pipeline(
args.validation_prompt,
image=original_image,
num_inference_steps=20,
image_guidance_scale=1.5,
guidance_scale=7,
generator=generator,
).images[0]
)
for tracker in accelerator.trackers:
if tracker.name == "wandb":
wandb_table = wandb.Table(columns=WANDB_TABLE_COL_NAMES)
for edited_image in edited_images:
wandb_table.add_data(
wandb.Image(original_image), wandb.Image(edited_image), args.validation_prompt
)
tracker.log({"validation": wandb_table})
if args.use_ema:
# Switch back to the original UNet parameters.
ema_unet.restore(unet.parameters())
del pipeline
torch.cuda.empty_cache()
# Create the pipeline using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
if args.use_ema:
ema_unet.copy_to(unet.parameters())
pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
args.pretrained_model_name_or_path,
text_encoder=accelerator.unwrap_model(text_encoder),
vae=accelerator.unwrap_model(vae),
unet=unet,
revision=args.revision,
variant=args.variant,
)
pipeline.save_pretrained(args.output_dir)
if args.push_to_hub:
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
if args.validation_prompt is not None:
edited_images = []
pipeline = pipeline.to(accelerator.device)
with torch.autocast(str(accelerator.device).replace(":0", "")):
for _ in range(args.num_validation_images):
edited_images.append(
pipeline(
args.validation_prompt,
image=original_image,
num_inference_steps=20,
image_guidance_scale=1.5,
guidance_scale=7,
generator=generator,
).images[0]
)
for tracker in accelerator.trackers:
if tracker.name == "wandb":
wandb_table = wandb.Table(columns=WANDB_TABLE_COL_NAMES)
for edited_image in edited_images:
wandb_table.add_data(
wandb.Image(original_image), wandb.Image(edited_image), args.validation_prompt
)
tracker.log({"test": wandb_table})
accelerator.end_training()
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/text_to_image/train_text_to_image_flax.py
|
import argparse
import logging
import math
import os
import random
from pathlib import Path
import jax
import jax.numpy as jnp
import numpy as np
import optax
import torch
import torch.utils.checkpoint
import transformers
from datasets import load_dataset
from flax import jax_utils
from flax.training import train_state
from flax.training.common_utils import shard
from huggingface_hub import create_repo, upload_folder
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPImageProcessor, CLIPTokenizer, FlaxCLIPTextModel, set_seed
from diffusers import (
FlaxAutoencoderKL,
FlaxDDPMScheduler,
FlaxPNDMScheduler,
FlaxStableDiffusionPipeline,
FlaxUNet2DConditionModel,
)
from diffusers.pipelines.stable_diffusion import FlaxStableDiffusionSafetyChecker
from diffusers.utils import check_min_version
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.24.0.dev0")
logger = logging.getLogger(__name__)
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--variant",
type=str,
default=None,
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--image_column", type=str, default="image", help="The column of the dataset containing an image."
)
parser.add_argument(
"--caption_column",
type=str,
default="text",
help="The column of the dataset containing a caption or a list of captions.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="sd-model-finetuned",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=0, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default="no",
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose"
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
"and an Nvidia Ampere GPU."
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--from_pt",
action="store_true",
default=False,
help="Flag to indicate whether to convert models from PyTorch.",
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
return args
dataset_name_mapping = {
"lambdalabs/pokemon-blip-captions": ("image", "text"),
}
def get_params_to_save(params):
return jax.device_get(jax.tree_util.tree_map(lambda x: x[0], params))
def main():
args = parse_args()
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
# Setup logging, we only want one process per machine to log things on the screen.
logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
if jax.process_index() == 0:
transformers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if jax.process_index() == 0:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name, args.dataset_config_name, cache_dir=args.cache_dir, data_dir=args.train_data_dir
)
else:
data_files = {}
if args.train_data_dir is not None:
data_files["train"] = os.path.join(args.train_data_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
dataset_columns = dataset_name_mapping.get(args.dataset_name, None)
if args.image_column is None:
image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
)
# Preprocessing the datasets.
# We need to tokenize input captions and transform the images.
def tokenize_captions(examples, is_train=True):
captions = []
for caption in examples[caption_column]:
if isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
else:
raise ValueError(
f"Caption column `{caption_column}` should contain either strings or lists of strings."
)
inputs = tokenizer(captions, max_length=tokenizer.model_max_length, padding="do_not_pad", truncation=True)
input_ids = inputs.input_ids
return input_ids
train_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
examples["pixel_values"] = [train_transforms(image) for image in images]
examples["input_ids"] = tokenize_captions(examples)
return examples
if args.max_train_samples is not None:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train)
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
input_ids = [example["input_ids"] for example in examples]
padded_tokens = tokenizer.pad(
{"input_ids": input_ids}, padding="max_length", max_length=tokenizer.model_max_length, return_tensors="pt"
)
batch = {
"pixel_values": pixel_values,
"input_ids": padded_tokens.input_ids,
}
batch = {k: v.numpy() for k, v in batch.items()}
return batch
total_train_batch_size = args.train_batch_size * jax.local_device_count()
train_dataloader = torch.utils.data.DataLoader(
train_dataset, shuffle=True, collate_fn=collate_fn, batch_size=total_train_batch_size, drop_last=True
)
weight_dtype = jnp.float32
if args.mixed_precision == "fp16":
weight_dtype = jnp.float16
elif args.mixed_precision == "bf16":
weight_dtype = jnp.bfloat16
# Load models and create wrapper for stable diffusion
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path,
from_pt=args.from_pt,
revision=args.revision,
subfolder="tokenizer",
)
text_encoder = FlaxCLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path,
from_pt=args.from_pt,
revision=args.revision,
subfolder="text_encoder",
dtype=weight_dtype,
)
vae, vae_params = FlaxAutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path,
from_pt=args.from_pt,
revision=args.revision,
subfolder="vae",
dtype=weight_dtype,
)
unet, unet_params = FlaxUNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path,
from_pt=args.from_pt,
revision=args.revision,
subfolder="unet",
dtype=weight_dtype,
)
# Optimization
if args.scale_lr:
args.learning_rate = args.learning_rate * total_train_batch_size
constant_scheduler = optax.constant_schedule(args.learning_rate)
adamw = optax.adamw(
learning_rate=constant_scheduler,
b1=args.adam_beta1,
b2=args.adam_beta2,
eps=args.adam_epsilon,
weight_decay=args.adam_weight_decay,
)
optimizer = optax.chain(
optax.clip_by_global_norm(args.max_grad_norm),
adamw,
)
state = train_state.TrainState.create(apply_fn=unet.__call__, params=unet_params, tx=optimizer)
noise_scheduler = FlaxDDPMScheduler(
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000
)
noise_scheduler_state = noise_scheduler.create_state()
# Initialize our training
rng = jax.random.PRNGKey(args.seed)
train_rngs = jax.random.split(rng, jax.local_device_count())
def train_step(state, text_encoder_params, vae_params, batch, train_rng):
dropout_rng, sample_rng, new_train_rng = jax.random.split(train_rng, 3)
def compute_loss(params):
# Convert images to latent space
vae_outputs = vae.apply(
{"params": vae_params}, batch["pixel_values"], deterministic=True, method=vae.encode
)
latents = vae_outputs.latent_dist.sample(sample_rng)
# (NHWC) -> (NCHW)
latents = jnp.transpose(latents, (0, 3, 1, 2))
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise_rng, timestep_rng = jax.random.split(sample_rng)
noise = jax.random.normal(noise_rng, latents.shape)
# Sample a random timestep for each image
bsz = latents.shape[0]
timesteps = jax.random.randint(
timestep_rng,
(bsz,),
0,
noise_scheduler.config.num_train_timesteps,
)
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(noise_scheduler_state, latents, noise, timesteps)
# Get the text embedding for conditioning
encoder_hidden_states = text_encoder(
batch["input_ids"],
params=text_encoder_params,
train=False,
)[0]
# Predict the noise residual and compute loss
model_pred = unet.apply(
{"params": params}, noisy_latents, timesteps, encoder_hidden_states, train=True
).sample
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(noise_scheduler_state, latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
loss = (target - model_pred) ** 2
loss = loss.mean()
return loss
grad_fn = jax.value_and_grad(compute_loss)
loss, grad = grad_fn(state.params)
grad = jax.lax.pmean(grad, "batch")
new_state = state.apply_gradients(grads=grad)
metrics = {"loss": loss}
metrics = jax.lax.pmean(metrics, axis_name="batch")
return new_state, metrics, new_train_rng
# Create parallel version of the train step
p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
# Replicate the train state on each device
state = jax_utils.replicate(state)
text_encoder_params = jax_utils.replicate(text_encoder.params)
vae_params = jax_utils.replicate(vae_params)
# Train!
num_update_steps_per_epoch = math.ceil(len(train_dataloader))
# Scheduler and math around the number of training steps.
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel & distributed) = {total_train_batch_size}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
epochs = tqdm(range(args.num_train_epochs), desc="Epoch ... ", position=0)
for epoch in epochs:
# ======================== Training ================================
train_metrics = []
steps_per_epoch = len(train_dataset) // total_train_batch_size
train_step_progress_bar = tqdm(total=steps_per_epoch, desc="Training...", position=1, leave=False)
# train
for batch in train_dataloader:
batch = shard(batch)
state, train_metric, train_rngs = p_train_step(state, text_encoder_params, vae_params, batch, train_rngs)
train_metrics.append(train_metric)
train_step_progress_bar.update(1)
global_step += 1
if global_step >= args.max_train_steps:
break
train_metric = jax_utils.unreplicate(train_metric)
train_step_progress_bar.close()
epochs.write(f"Epoch... ({epoch + 1}/{args.num_train_epochs} | Loss: {train_metric['loss']})")
# Create the pipeline using using the trained modules and save it.
if jax.process_index() == 0:
scheduler = FlaxPNDMScheduler(
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", skip_prk_steps=True
)
safety_checker = FlaxStableDiffusionSafetyChecker.from_pretrained(
"CompVis/stable-diffusion-safety-checker", from_pt=True
)
pipeline = FlaxStableDiffusionPipeline(
text_encoder=text_encoder,
vae=vae,
unet=unet,
tokenizer=tokenizer,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=CLIPImageProcessor.from_pretrained("openai/clip-vit-base-patch32"),
)
pipeline.save_pretrained(
args.output_dir,
params={
"text_encoder": get_params_to_save(text_encoder_params),
"vae": get_params_to_save(vae_params),
"unet": get_params_to_save(state.params),
"safety_checker": safety_checker.params,
},
)
if args.push_to_hub:
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/text_to_image/requirements_sdxl.txt
|
accelerate>=0.22.0
torchvision
transformers>=4.25.1
ftfy
tensorboard
Jinja2
datasets
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/text_to_image/README_sdxl.md
|
# Stable Diffusion XL text-to-image fine-tuning
The `train_text_to_image_sdxl.py` script shows how to fine-tune Stable Diffusion XL (SDXL) on your own dataset.
🚨 This script is experimental. The script fine-tunes the whole model and often times the model overfits and runs into issues like catastrophic forgetting. It's recommended to try different hyperparamters to get the best result on your dataset. 🚨
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
Then cd in the `examples/text_to_image` folder and run
```bash
pip install -r requirements_sdxl.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Or for a default accelerate configuration without answering questions about your environment
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell (e.g., a notebook)
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
### Training
```bash
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export VAE_NAME="madebyollin/sdxl-vae-fp16-fix"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch train_text_to_image_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=$DATASET_NAME \
--enable_xformers_memory_efficient_attention \
--resolution=512 --center_crop --random_flip \
--proportion_empty_prompts=0.2 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 --gradient_checkpointing \
--max_train_steps=10000 \
--use_8bit_adam \
--learning_rate=1e-06 --lr_scheduler="constant" --lr_warmup_steps=0 \
--mixed_precision="fp16" \
--report_to="wandb" \
--validation_prompt="a cute Sundar Pichai creature" --validation_epochs 5 \
--checkpointing_steps=5000 \
--output_dir="sdxl-pokemon-model" \
--push_to_hub
```
**Notes**:
* The `train_text_to_image_sdxl.py` script pre-computes text embeddings and the VAE encodings and keeps them in memory. While for smaller datasets like [`lambdalabs/pokemon-blip-captions`](https://hf.co/datasets/lambdalabs/pokemon-blip-captions), it might not be a problem, it can definitely lead to memory problems when the script is used on a larger dataset. For those purposes, you would want to serialize these pre-computed representations to disk separately and load them during the fine-tuning process. Refer to [this PR](https://github.com/huggingface/diffusers/pull/4505) for a more in-depth discussion.
* The training script is compute-intensive and may not run on a consumer GPU like Tesla T4.
* The training command shown above performs intermediate quality validation in between the training epochs and logs the results to Weights and Biases. `--report_to`, `--validation_prompt`, and `--validation_epochs` are the relevant CLI arguments here.
* SDXL's VAE is known to suffer from numerical instability issues. This is why we also expose a CLI argument namely `--pretrained_vae_model_name_or_path` that lets you specify the location of a better VAE (such as [this one](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)).
### Inference
```python
from diffusers import DiffusionPipeline
import torch
model_path = "you-model-id-goes-here" # <-- change this
pipe = DiffusionPipeline.from_pretrained(model_path, torch_dtype=torch.float16)
pipe.to("cuda")
prompt = "A pokemon with green eyes and red legs."
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
image.save("pokemon.png")
```
### Inference in Pytorch XLA
```python
from diffusers import DiffusionPipeline
import torch
import torch_xla.core.xla_model as xm
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
pipe = DiffusionPipeline.from_pretrained(model_id)
device = xm.xla_device()
pipe.to(device)
prompt = "A pokemon with green eyes and red legs."
start = time()
image = pipe(prompt, num_inference_steps=inference_steps).images[0]
print(f'Compilation time is {time()-start} sec')
image.save("pokemon.png")
start = time()
image = pipe(prompt, num_inference_steps=inference_steps).images[0]
print(f'Inference time is {time()-start} sec after compilation')
```
Note: There is a warmup step in PyTorch XLA. This takes longer because of
compilation and optimization. To see the real benefits of Pytorch XLA and
speedup, we need to call the pipe again on the input with the same length
as the original prompt to reuse the optimized graph and get the performance
boost.
## LoRA training example for Stable Diffusion XL (SDXL)
Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114).
- Rank-decomposition matrices have significantly fewer parameters than original model, which means that trained LoRA weights are easily portable.
- LoRA attention layers allow to control to which extent the model is adapted toward new training images via a `scale` parameter.
[cloneofsimo](https://github.com/cloneofsimo) was the first to try out LoRA training for Stable Diffusion in the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
With LoRA, it's possible to fine-tune Stable Diffusion on a custom image-caption pair dataset
on consumer GPUs like Tesla T4, Tesla V100.
### Training
First, you need to set up your development environment as is explained in the [installation section](#installing-the-dependencies). Make sure to set the `MODEL_NAME` and `DATASET_NAME` environment variables and, optionally, the `VAE_NAME` variable. Here, we will use [Stable Diffusion XL 1.0-base](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0) and the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions).
**___Note: It is quite useful to monitor the training progress by regularly generating sample images during training. [Weights and Biases](https://docs.wandb.ai/quickstart) is a nice solution to easily see generating images during training. All you need to do is to run `pip install wandb` before training to automatically log images.___**
```bash
export MODEL_NAME="stabilityai/stable-diffusion-xl-base-1.0"
export VAE_NAME="madebyollin/sdxl-vae-fp16-fix"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
```
For this example we want to directly store the trained LoRA embeddings on the Hub, so
we need to be logged in and add the `--push_to_hub` flag.
```bash
huggingface-cli login
```
Now we can start training!
```bash
accelerate launch train_text_to_image_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_model_name_or_path=$VAE_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=1024 --random_flip \
--train_batch_size=1 \
--num_train_epochs=2 --checkpointing_steps=500 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--mixed_precision="fp16" \
--seed=42 \
--output_dir="sd-pokemon-model-lora-sdxl" \
--validation_prompt="cute dragon creature" --report_to="wandb" \
--push_to_hub
```
The above command will also run inference as fine-tuning progresses and log the results to Weights and Biases.
**Notes**:
* SDXL's VAE is known to suffer from numerical instability issues. This is why we also expose a CLI argument namely `--pretrained_vae_model_name_or_path` that lets you specify the location of a better VAE (such as [this one](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)).
### Finetuning the text encoder and UNet
The script also allows you to finetune the `text_encoder` along with the `unet`.
🚨 Training the text encoder requires additional memory.
Pass the `--train_text_encoder` argument to the training script to enable finetuning the `text_encoder` and `unet`:
```bash
accelerate launch train_text_to_image_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=1024 --random_flip \
--train_batch_size=1 \
--num_train_epochs=2 --checkpointing_steps=500 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="sd-pokemon-model-lora-sdxl-txt" \
--train_text_encoder \
--validation_prompt="cute dragon creature" --report_to="wandb" \
--push_to_hub
```
### Inference
Once you have trained a model using above command, the inference can be done simply using the `DiffusionPipeline` after loading the trained LoRA weights. You
need to pass the `output_dir` for loading the LoRA weights which, in this case, is `sd-pokemon-model-lora-sdxl`.
```python
from diffusers import DiffusionPipeline
import torch
model_path = "takuoko/sd-pokemon-model-lora-sdxl"
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16)
pipe.to("cuda")
pipe.load_lora_weights(model_path)
prompt = "A pokemon with green eyes and red legs."
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
image.save("pokemon.png")
```
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/text_to_image/README.md
|
# Stable Diffusion text-to-image fine-tuning
The `train_text_to_image.py` script shows how to fine-tune stable diffusion model on your own dataset.
___Note___:
___This script is experimental. The script fine-tunes the whole model and often times the model overfits and runs into issues like catastrophic forgetting. It's recommended to try different hyperparamters to get the best result on your dataset.___
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
### Pokemon example
You need to accept the model license before downloading or using the weights. In this example we'll use model version `v1-4`, so you'll need to visit [its card](https://huggingface.co/CompVis/stable-diffusion-v1-4), read the license and tick the checkbox if you agree.
You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).
Run the following command to authenticate your token
```bash
huggingface-cli login
```
If you have already cloned the repo, then you won't need to go through these steps.
<br>
#### Hardware
With `gradient_checkpointing` and `mixed_precision` it should be possible to fine tune the model on a single 24GB GPU. For higher `batch_size` and faster training it's better to use GPUs with >30GB memory.
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
<!-- accelerate_snippet_start -->
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--use_ema \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="sd-pokemon-model"
```
<!-- accelerate_snippet_end -->
To run on your own training files prepare the dataset according to the format required by `datasets`, you can find the instructions for how to do that in this [document](https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder-with-metadata).
If you wish to use custom loading logic, you should modify the script, we have left pointers for that in the training script.
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export TRAIN_DIR="path_to_your_dataset"
accelerate launch --mixed_precision="fp16" train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--use_ema \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="sd-pokemon-model"
```
Once the training is finished the model will be saved in the `output_dir` specified in the command. In this example it's `sd-pokemon-model`. To load the fine-tuned model for inference just pass that path to `StableDiffusionPipeline`
```python
from diffusers import StableDiffusionPipeline
model_path = "path_to_saved_model"
pipe = StableDiffusionPipeline.from_pretrained(model_path, torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(prompt="yoda").images[0]
image.save("yoda-pokemon.png")
```
Checkpoints only save the unet, so to run inference from a checkpoint, just load the unet
```python
from diffusers import StableDiffusionPipeline, UNet2DConditionModel
model_path = "path_to_saved_model"
unet = UNet2DConditionModel.from_pretrained(model_path + "/checkpoint-<N>/unet")
pipe = StableDiffusionPipeline.from_pretrained("<initial model>", unet=unet, torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(prompt="yoda").images[0]
image.save("yoda-pokemon.png")
```
#### Training with multiple GPUs
`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
for running distributed training with `accelerate`. Here is an example command:
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" --multi_gpu train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--use_ema \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="sd-pokemon-model"
```
#### Training with Min-SNR weighting
We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://arxiv.org/abs/2303.09556) which helps to achieve faster convergence
by rebalancing the loss. In order to use it, one needs to set the `--snr_gamma` argument. The recommended
value when using it is 5.0.
You can find [this project on Weights and Biases](https://wandb.ai/sayakpaul/text2image-finetune-minsnr) that compares the loss surfaces of the following setups:
* Training without the Min-SNR weighting strategy
* Training with the Min-SNR weighting strategy (`snr_gamma` set to 5.0)
* Training with the Min-SNR weighting strategy (`snr_gamma` set to 1.0)
For our small Pokemons dataset, the effects of Min-SNR weighting strategy might not appear to be pronounced, but for larger datasets, we believe the effects will be more pronounced.
Also, note that in this example, we either predict `epsilon` (i.e., the noise) or the `v_prediction`. For both of these cases, the formulation of the Min-SNR weighting strategy that we have used holds.
## Training with LoRA
Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114).
- Rank-decomposition matrices have significantly fewer parameters than original model, which means that trained LoRA weights are easily portable.
- LoRA attention layers allow to control to which extent the model is adapted toward new training images via a `scale` parameter.
[cloneofsimo](https://github.com/cloneofsimo) was the first to try out LoRA training for Stable Diffusion in the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
With LoRA, it's possible to fine-tune Stable Diffusion on a custom image-caption pair dataset
on consumer GPUs like Tesla T4, Tesla V100.
### Training
First, you need to set up your development environment as is explained in the [installation section](#installing-the-dependencies). Make sure to set the `MODEL_NAME` and `DATASET_NAME` environment variables. Here, we will use [Stable Diffusion v1-4](https://hf.co/CompVis/stable-diffusion-v1-4) and the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions).
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
**___Note: It is quite useful to monitor the training progress by regularly generating sample images during training. [Weights and Biases](https://docs.wandb.ai/quickstart) is a nice solution to easily see generating images during training. All you need to do is to run `pip install wandb` before training to automatically log images.___**
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
```
For this example we want to directly store the trained LoRA embeddings on the Hub, so
we need to be logged in and add the `--push_to_hub` flag.
```bash
huggingface-cli login
```
Now we can start training!
```bash
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=512 --random_flip \
--train_batch_size=1 \
--num_train_epochs=100 --checkpointing_steps=5000 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="sd-pokemon-model-lora" \
--validation_prompt="cute dragon creature" --report_to="wandb"
```
The above command will also run inference as fine-tuning progresses and log the results to Weights and Biases.
**___Note: When using LoRA we can use a much higher learning rate compared to non-LoRA fine-tuning. Here we use *1e-4* instead of the usual *1e-5*. Also, by using LoRA, it's possible to run `train_text_to_image_lora.py` in consumer GPUs like T4 or V100.___**
The final LoRA embedding weights have been uploaded to [sayakpaul/sd-model-finetuned-lora-t4](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4). **___Note: [The final weights](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4/blob/main/pytorch_lora_weights.bin) are only 3 MB in size, which is orders of magnitudes smaller than the original model.___**
You can check some inference samples that were logged during the course of the fine-tuning process [here](https://wandb.ai/sayakpaul/text2image-fine-tune/runs/q4lc0xsw).
### Inference
Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline` after loading the trained LoRA weights. You
need to pass the `output_dir` for loading the LoRA weights which, in this case, is `sd-pokemon-model-lora`.
```python
from diffusers import StableDiffusionPipeline
import torch
model_path = "sayakpaul/sd-model-finetuned-lora-t4"
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
prompt = "A pokemon with green eyes and red legs."
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
image.save("pokemon.png")
```
If you are loading the LoRA parameters from the Hub and if the Hub repository has
a `base_model` tag (such as [this](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4/blob/main/README.md?code=true#L4)), then
you can do:
```py
from huggingface_hub.repocard import RepoCard
lora_model_id = "sayakpaul/sd-model-finetuned-lora-t4"
card = RepoCard.load(lora_model_id)
base_model_id = card.data.to_dict()["base_model"]
pipe = StableDiffusionPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16)
...
```
## Training with Flax/JAX
For faster training on TPUs and GPUs you can leverage the flax training example. Follow the instructions above to get the model and dataset before running the script.
**___Note: The flax example doesn't yet support features like gradient checkpoint, gradient accumulation etc, so to use flax for faster training we will need >30GB cards or TPU v3.___**
Before running the scripts, make sure to install the library's training dependencies:
```bash
pip install -U -r requirements_flax.txt
```
```bash
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
python train_text_to_image_flax.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--mixed_precision="fp16" \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--output_dir="sd-pokemon-model"
```
To run on your own training files prepare the dataset according to the format required by `datasets`, you can find the instructions for how to do that in this [document](https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder-with-metadata).
If you wish to use custom loading logic, you should modify the script, we have left pointers for that in the training script.
```bash
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
export TRAIN_DIR="path_to_your_dataset"
python train_text_to_image_flax.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--mixed_precision="fp16" \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--output_dir="sd-pokemon-model"
```
### Training with xFormers:
You can enable memory efficient attention by [installing xFormers](https://huggingface.co/docs/diffusers/main/en/optimization/xformers) and passing the `--enable_xformers_memory_efficient_attention` argument to the script.
xFormers training is not available for Flax/JAX.
**Note**:
According to [this issue](https://github.com/huggingface/diffusers/issues/2234#issuecomment-1416931212), xFormers `v0.0.16` cannot be used for training in some GPUs. If you observe that problem, please install a development version as indicated in that comment.
## Stable Diffusion XL
* We support fine-tuning the UNet shipped in [Stable Diffusion XL](https://huggingface.co/papers/2307.01952) via the `train_text_to_image_sdxl.py` script. Please refer to the docs [here](./README_sdxl.md).
* We also support fine-tuning of the UNet and Text Encoder shipped in [Stable Diffusion XL](https://huggingface.co/papers/2307.01952) with LoRA via the `train_text_to_image_lora_sdxl.py` script. Please refer to the docs [here](./README_sdxl.md).
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/text_to_image/train_text_to_image_lora.py
|
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Fine-tuning script for Stable Diffusion for text2image with support for LoRA."""
import argparse
import logging
import math
import os
import random
import shutil
from pathlib import Path
import datasets
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from datasets import load_dataset
from huggingface_hub import create_repo, upload_folder
from packaging import version
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPTextModel, CLIPTokenizer
import diffusers
from diffusers import AutoencoderKL, DDPMScheduler, DiffusionPipeline, UNet2DConditionModel
from diffusers.models.lora import LoRALinearLayer
from diffusers.optimization import get_scheduler
from diffusers.training_utils import compute_snr
from diffusers.utils import check_min_version, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.24.0.dev0")
logger = get_logger(__name__, log_level="INFO")
# TODO: This function should be removed once training scripts are rewritten in PEFT
def text_encoder_lora_state_dict(text_encoder):
state_dict = {}
def text_encoder_attn_modules(text_encoder):
from transformers import CLIPTextModel, CLIPTextModelWithProjection
attn_modules = []
if isinstance(text_encoder, (CLIPTextModel, CLIPTextModelWithProjection)):
for i, layer in enumerate(text_encoder.text_model.encoder.layers):
name = f"text_model.encoder.layers.{i}.self_attn"
mod = layer.self_attn
attn_modules.append((name, mod))
return attn_modules
for name, module in text_encoder_attn_modules(text_encoder):
for k, v in module.q_proj.lora_linear_layer.state_dict().items():
state_dict[f"{name}.q_proj.lora_linear_layer.{k}"] = v
for k, v in module.k_proj.lora_linear_layer.state_dict().items():
state_dict[f"{name}.k_proj.lora_linear_layer.{k}"] = v
for k, v in module.v_proj.lora_linear_layer.state_dict().items():
state_dict[f"{name}.v_proj.lora_linear_layer.{k}"] = v
for k, v in module.out_proj.lora_linear_layer.state_dict().items():
state_dict[f"{name}.out_proj.lora_linear_layer.{k}"] = v
return state_dict
def save_model_card(repo_id: str, images=None, base_model=str, dataset_name=str, repo_folder=None):
img_str = ""
for i, image in enumerate(images):
image.save(os.path.join(repo_folder, f"image_{i}.png"))
img_str += f"\n"
yaml = f"""
---
license: creativeml-openrail-m
base_model: {base_model}
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
"""
model_card = f"""
# LoRA text2image fine-tuning - {repo_id}
These are LoRA adaption weights for {base_model}. The weights were fine-tuned on the {dataset_name} dataset. You can find some example images in the following. \n
{img_str}
"""
with open(os.path.join(repo_folder, "README.md"), "w") as f:
f.write(yaml + model_card)
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--variant",
type=str,
default=None,
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--image_column", type=str, default="image", help="The column of the dataset containing an image."
)
parser.add_argument(
"--caption_column",
type=str,
default="text",
help="The column of the dataset containing a caption or a list of captions.",
)
parser.add_argument(
"--validation_prompt", type=str, default=None, help="A prompt that is sampled during training for inference."
)
parser.add_argument(
"--num_validation_images",
type=int,
default=4,
help="Number of images that should be generated during validation with `validation_prompt`.",
)
parser.add_argument(
"--validation_epochs",
type=int,
default=1,
help=(
"Run fine-tuning validation every X epochs. The validation process consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`."
),
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="sd-model-finetuned-lora",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--snr_gamma",
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
"More details here: https://arxiv.org/abs/2303.09556.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--prediction_type",
type=str,
default=None,
help="The prediction_type that shall be used for training. Choose between 'epsilon' or 'v_prediction' or leave `None`. If left to `None` the default prediction type of the scheduler: `noise_scheduler.config.prediciton_type` is chosen.",
)
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument("--noise_offset", type=float, default=0, help="The scale of noise offset.")
parser.add_argument(
"--rank",
type=int,
default=4,
help=("The dimension of the LoRA update matrices."),
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
return args
DATASET_NAME_MAPPING = {
"lambdalabs/pokemon-blip-captions": ("image", "text"),
}
def main():
args = parse_args()
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
if args.report_to == "wandb":
if not is_wandb_available():
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
import wandb
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load scheduler, tokenizer and models.
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
)
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
)
vae = AutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision, variant=args.variant
)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
)
# freeze parameters of models to save more memory
unet.requires_grad_(False)
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
# For mixed precision training we cast all non-trainable weigths (vae, non-lora text_encoder and non-lora unet) to half-precision
# as these weights are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move unet, vae and text_encoder to device and cast to weight_dtype
unet.to(accelerator.device, dtype=weight_dtype)
vae.to(accelerator.device, dtype=weight_dtype)
text_encoder.to(accelerator.device, dtype=weight_dtype)
# now we will add new LoRA weights to the attention layers
# It's important to realize here how many attention weights will be added and of which sizes
# The sizes of the attention layers consist only of two different variables:
# 1) - the "hidden_size", which is increased according to `unet.config.block_out_channels`.
# 2) - the "cross attention size", which is set to `unet.config.cross_attention_dim`.
# Let's first see how many attention processors we will have to set.
# For Stable Diffusion, it should be equal to:
# - down blocks (2x attention layers) * (2x transformer layers) * (3x down blocks) = 12
# - mid blocks (2x attention layers) * (1x transformer layers) * (1x mid blocks) = 2
# - up blocks (2x attention layers) * (3x transformer layers) * (3x down blocks) = 18
# => 32 layers
# Set correct lora layers
unet_lora_parameters = []
for attn_processor_name, attn_processor in unet.attn_processors.items():
# Parse the attention module.
attn_module = unet
for n in attn_processor_name.split(".")[:-1]:
attn_module = getattr(attn_module, n)
# Set the `lora_layer` attribute of the attention-related matrices.
attn_module.to_q.set_lora_layer(
LoRALinearLayer(
in_features=attn_module.to_q.in_features, out_features=attn_module.to_q.out_features, rank=args.rank
)
)
attn_module.to_k.set_lora_layer(
LoRALinearLayer(
in_features=attn_module.to_k.in_features, out_features=attn_module.to_k.out_features, rank=args.rank
)
)
attn_module.to_v.set_lora_layer(
LoRALinearLayer(
in_features=attn_module.to_v.in_features, out_features=attn_module.to_v.out_features, rank=args.rank
)
)
attn_module.to_out[0].set_lora_layer(
LoRALinearLayer(
in_features=attn_module.to_out[0].in_features,
out_features=attn_module.to_out[0].out_features,
rank=args.rank,
)
)
# Accumulate the LoRA params to optimize.
unet_lora_parameters.extend(attn_module.to_q.lora_layer.parameters())
unet_lora_parameters.extend(attn_module.to_k.lora_layer.parameters())
unet_lora_parameters.extend(attn_module.to_v.lora_layer.parameters())
unet_lora_parameters.extend(attn_module.to_out[0].lora_layer.parameters())
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Initialize the optimizer
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
)
optimizer_cls = bnb.optim.AdamW8bit
else:
optimizer_cls = torch.optim.AdamW
optimizer = optimizer_cls(
unet_lora_parameters,
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
data_dir=args.train_data_dir,
)
else:
data_files = {}
if args.train_data_dir is not None:
data_files["train"] = os.path.join(args.train_data_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
if args.image_column is None:
image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
)
# Preprocessing the datasets.
# We need to tokenize input captions and transform the images.
def tokenize_captions(examples, is_train=True):
captions = []
for caption in examples[caption_column]:
if isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
else:
raise ValueError(
f"Caption column `{caption_column}` should contain either strings or lists of strings."
)
inputs = tokenizer(
captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
)
return inputs.input_ids
# Preprocessing the datasets.
train_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
examples["pixel_values"] = [train_transforms(image) for image in images]
examples["input_ids"] = tokenize_captions(examples)
return examples
with accelerator.main_process_first():
if args.max_train_samples is not None:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train)
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
input_ids = torch.stack([example["input_ids"] for example in examples])
return {"pixel_values": pixel_values, "input_ids": input_ids}
# DataLoaders creation:
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
unet_lora_parameters, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet_lora_parameters, optimizer, train_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
accelerator.init_trackers("text2image-fine-tune", config=vars(args))
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
for epoch in range(first_epoch, args.num_train_epochs):
unet.train()
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet):
# Convert images to latent space
latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
if args.noise_offset:
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
noise += args.noise_offset * torch.randn(
(latents.shape[0], latents.shape[1], 1, 1), device=latents.device
)
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# Get the text embedding for conditioning
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
# Get the target for loss depending on the prediction type
if args.prediction_type is not None:
# set prediction_type of scheduler if defined
noise_scheduler.register_to_config(prediction_type=args.prediction_type)
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
# Predict the noise residual and compute loss
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
# Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
if noise_scheduler.config.prediction_type == "v_prediction":
# Velocity objective requires that we add one to SNR values before we divide by them.
snr = snr + 1
mse_loss_weights = (
torch.stack([snr, args.snr_gamma * torch.ones_like(timesteps)], dim=1).min(dim=1)[0] / snr
)
loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
loss = loss.mean(dim=list(range(1, len(loss.shape)))) * mse_loss_weights
loss = loss.mean()
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
train_loss += avg_loss.item() / args.gradient_accumulation_steps
# Backpropagate
accelerator.backward(loss)
if accelerator.sync_gradients:
params_to_clip = unet_lora_parameters
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
accelerator.log({"train_loss": train_loss}, step=global_step)
train_loss = 0.0
if global_step % args.checkpointing_steps == 0:
if accelerator.is_main_process:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
if global_step >= args.max_train_steps:
break
if accelerator.is_main_process:
if args.validation_prompt is not None and epoch % args.validation_epochs == 0:
logger.info(
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
f" {args.validation_prompt}."
)
# create pipeline
pipeline = DiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path,
unet=accelerator.unwrap_model(unet),
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
# run inference
generator = torch.Generator(device=accelerator.device)
if args.seed is not None:
generator = generator.manual_seed(args.seed)
images = []
for _ in range(args.num_validation_images):
images.append(
pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0]
)
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
if tracker.name == "wandb":
tracker.log(
{
"validation": [
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
for i, image in enumerate(images)
]
}
)
del pipeline
torch.cuda.empty_cache()
# Save the lora layers
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = unet.to(torch.float32)
unet.save_attn_procs(args.output_dir)
if args.push_to_hub:
save_model_card(
repo_id,
images=images,
base_model=args.pretrained_model_name_or_path,
dataset_name=args.dataset_name,
repo_folder=args.output_dir,
)
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
# Final inference
# Load previous pipeline
pipeline = DiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path, revision=args.revision, variant=args.variant, torch_dtype=weight_dtype
)
pipeline = pipeline.to(accelerator.device)
# load attention processors
pipeline.unet.load_attn_procs(args.output_dir)
# run inference
generator = torch.Generator(device=accelerator.device)
if args.seed is not None:
generator = generator.manual_seed(args.seed)
images = []
for _ in range(args.num_validation_images):
images.append(pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0])
if accelerator.is_main_process:
for tracker in accelerator.trackers:
if len(images) != 0:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("test", np_images, epoch, dataformats="NHWC")
if tracker.name == "wandb":
tracker.log(
{
"test": [
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
for i, image in enumerate(images)
]
}
)
accelerator.end_training()
if __name__ == "__main__":
main()
| 0
|
hf_public_repos/diffusers/examples
|
hf_public_repos/diffusers/examples/text_to_image/train_text_to_image.py
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import logging
import math
import os
import random
import shutil
from pathlib import Path
import accelerate
import datasets
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.state import AcceleratorState
from accelerate.utils import ProjectConfiguration, set_seed
from datasets import load_dataset
from huggingface_hub import create_repo, upload_folder
from packaging import version
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import CLIPTextModel, CLIPTokenizer
from transformers.utils import ContextManagers
import diffusers
from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionPipeline, UNet2DConditionModel
from diffusers.optimization import get_scheduler
from diffusers.training_utils import EMAModel, compute_snr
from diffusers.utils import check_min_version, deprecate, is_wandb_available, make_image_grid
from diffusers.utils.import_utils import is_xformers_available
if is_wandb_available():
import wandb
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.24.0.dev0")
logger = get_logger(__name__, log_level="INFO")
DATASET_NAME_MAPPING = {
"lambdalabs/pokemon-blip-captions": ("image", "text"),
}
def save_model_card(
args,
repo_id: str,
images=None,
repo_folder=None,
):
img_str = ""
if len(images) > 0:
image_grid = make_image_grid(images, 1, len(args.validation_prompts))
image_grid.save(os.path.join(repo_folder, "val_imgs_grid.png"))
img_str += "\n"
yaml = f"""
---
license: creativeml-openrail-m
base_model: {args.pretrained_model_name_or_path}
datasets:
- {args.dataset_name}
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
"""
model_card = f"""
# Text-to-image finetuning - {repo_id}
This pipeline was finetuned from **{args.pretrained_model_name_or_path}** on the **{args.dataset_name}** dataset. Below are some example images generated with the finetuned pipeline using the following prompts: {args.validation_prompts}: \n
{img_str}
## Pipeline usage
You can use the pipeline like so:
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("{repo_id}", torch_dtype=torch.float16)
prompt = "{args.validation_prompts[0]}"
image = pipeline(prompt).images[0]
image.save("my_image.png")
```
## Training info
These are the key hyperparameters used during training:
* Epochs: {args.num_train_epochs}
* Learning rate: {args.learning_rate}
* Batch size: {args.train_batch_size}
* Gradient accumulation steps: {args.gradient_accumulation_steps}
* Image resolution: {args.resolution}
* Mixed-precision: {args.mixed_precision}
"""
wandb_info = ""
if is_wandb_available():
wandb_run_url = None
if wandb.run is not None:
wandb_run_url = wandb.run.url
if wandb_run_url is not None:
wandb_info = f"""
More information on all the CLI arguments and the environment are available on your [`wandb` run page]({wandb_run_url}).
"""
model_card += wandb_info
with open(os.path.join(repo_folder, "README.md"), "w") as f:
f.write(yaml + model_card)
def log_validation(vae, text_encoder, tokenizer, unet, args, accelerator, weight_dtype, epoch):
logger.info("Running validation... ")
pipeline = StableDiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path,
vae=accelerator.unwrap_model(vae),
text_encoder=accelerator.unwrap_model(text_encoder),
tokenizer=tokenizer,
unet=accelerator.unwrap_model(unet),
safety_checker=None,
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
if args.enable_xformers_memory_efficient_attention:
pipeline.enable_xformers_memory_efficient_attention()
if args.seed is None:
generator = None
else:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
images = []
for i in range(len(args.validation_prompts)):
with torch.autocast("cuda"):
image = pipeline(args.validation_prompts[i], num_inference_steps=20, generator=generator).images[0]
images.append(image)
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
elif tracker.name == "wandb":
tracker.log(
{
"validation": [
wandb.Image(image, caption=f"{i}: {args.validation_prompts[i]}")
for i, image in enumerate(images)
]
}
)
else:
logger.warn(f"image logging not implemented for {tracker.name}")
del pipeline
torch.cuda.empty_cache()
return images
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--input_perturbation", type=float, default=0, help="The scale of input perturbation. Recommended 0.1."
)
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--variant",
type=str,
default=None,
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset, leave as None if there's only one config.",
)
parser.add_argument(
"--train_data_dir",
type=str,
default=None,
help=(
"A folder containing the training data. Folder contents must follow the structure described in"
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
),
)
parser.add_argument(
"--image_column", type=str, default="image", help="The column of the dataset containing an image."
)
parser.add_argument(
"--caption_column",
type=str,
default="text",
help="The column of the dataset containing a caption or a list of captions.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--validation_prompts",
type=str,
default=None,
nargs="+",
help=("A set of prompts evaluated every `--validation_epochs` and logged to `--report_to`."),
)
parser.add_argument(
"--output_dir",
type=str,
default="sd-model-finetuned",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--snr_gamma",
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
"More details here: https://arxiv.org/abs/2303.09556.",
)
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument("--use_ema", action="store_true", help="Whether to use EMA model.")
parser.add_argument(
"--non_ema_revision",
type=str,
default=None,
required=False,
help=(
"Revision of pretrained non-ema model identifier. Must be a branch, tag or git identifier of the local or"
" remote repository specified with --pretrained_model_name_or_path."
),
)
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--prediction_type",
type=str,
default=None,
help="The prediction_type that shall be used for training. Choose between 'epsilon' or 'v_prediction' or leave `None`. If left to `None` the default prediction type of the scheduler: `noise_scheduler.config.prediciton_type` is chosen.",
)
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument("--noise_offset", type=float, default=0, help="The scale of noise offset.")
parser.add_argument(
"--validation_epochs",
type=int,
default=5,
help="Run validation every X epochs.",
)
parser.add_argument(
"--tracker_project_name",
type=str,
default="text2image-fine-tune",
help=(
"The `project_name` argument passed to Accelerator.init_trackers for"
" more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
),
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
# Sanity checks
if args.dataset_name is None and args.train_data_dir is None:
raise ValueError("Need either a dataset name or a training folder.")
# default to using the same revision for the non-ema model if not specified
if args.non_ema_revision is None:
args.non_ema_revision = args.revision
return args
def main():
args = parse_args()
if args.non_ema_revision is not None:
deprecate(
"non_ema_revision!=None",
"0.15.0",
message=(
"Downloading 'non_ema' weights from revision branches of the Hub is deprecated. Please make sure to"
" use `--variant=non_ema` instead."
),
)
logging_dir = os.path.join(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
).repo_id
# Load scheduler, tokenizer and models.
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
tokenizer = CLIPTokenizer.from_pretrained(
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
)
def deepspeed_zero_init_disabled_context_manager():
"""
returns either a context list that includes one that will disable zero.Init or an empty context list
"""
deepspeed_plugin = AcceleratorState().deepspeed_plugin if accelerate.state.is_initialized() else None
if deepspeed_plugin is None:
return []
return [deepspeed_plugin.zero3_init_context_manager(enable=False)]
# Currently Accelerate doesn't know how to handle multiple models under Deepspeed ZeRO stage 3.
# For this to work properly all models must be run through `accelerate.prepare`. But accelerate
# will try to assign the same optimizer with the same weights to all models during
# `deepspeed.initialize`, which of course doesn't work.
#
# For now the following workaround will partially support Deepspeed ZeRO-3, by excluding the 2
# frozen models from being partitioned during `zero.Init` which gets called during
# `from_pretrained` So CLIPTextModel and AutoencoderKL will not enjoy the parameter sharding
# across multiple gpus and only UNet2DConditionModel will get ZeRO sharded.
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision, variant=args.variant
)
vae = AutoencoderKL.from_pretrained(
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision, variant=args.variant
)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.non_ema_revision
)
# Freeze vae and text_encoder and set unet to trainable
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
unet.train()
# Create EMA for the unet.
if args.use_ema:
ema_unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
)
ema_unet = EMAModel(ema_unet.parameters(), model_cls=UNet2DConditionModel, model_config=ema_unet.config)
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warn(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
if args.use_ema:
ema_unet.save_pretrained(os.path.join(output_dir, "unet_ema"))
for i, model in enumerate(models):
model.save_pretrained(os.path.join(output_dir, "unet"))
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
if args.use_ema:
load_model = EMAModel.from_pretrained(os.path.join(input_dir, "unet_ema"), UNet2DConditionModel)
ema_unet.load_state_dict(load_model.state_dict())
ema_unet.to(accelerator.device)
del load_model
for i in range(len(models)):
# pop models so that they are not loaded again
model = models.pop()
# load diffusers style into model
load_model = UNet2DConditionModel.from_pretrained(input_dir, subfolder="unet")
model.register_to_config(**load_model.config)
model.load_state_dict(load_model.state_dict())
del load_model
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Initialize the optimizer
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
)
optimizer_cls = bnb.optim.AdamW8bit
else:
optimizer_cls = torch.optim.AdamW
optimizer = optimizer_cls(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# Get the datasets: you can either provide your own training and evaluation files (see below)
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
args.dataset_name,
args.dataset_config_name,
cache_dir=args.cache_dir,
data_dir=args.train_data_dir,
)
else:
data_files = {}
if args.train_data_dir is not None:
data_files["train"] = os.path.join(args.train_data_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=args.cache_dir,
)
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
if args.image_column is None:
image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
image_column = args.image_column
if image_column not in column_names:
raise ValueError(
f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
)
if args.caption_column is None:
caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
caption_column = args.caption_column
if caption_column not in column_names:
raise ValueError(
f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
)
# Preprocessing the datasets.
# We need to tokenize input captions and transform the images.
def tokenize_captions(examples, is_train=True):
captions = []
for caption in examples[caption_column]:
if isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
else:
raise ValueError(
f"Caption column `{caption_column}` should contain either strings or lists of strings."
)
inputs = tokenizer(
captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
)
return inputs.input_ids
# Preprocessing the datasets.
train_transforms = transforms.Compose(
[
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def preprocess_train(examples):
images = [image.convert("RGB") for image in examples[image_column]]
examples["pixel_values"] = [train_transforms(image) for image in images]
examples["input_ids"] = tokenize_captions(examples)
return examples
with accelerator.main_process_first():
if args.max_train_samples is not None:
dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
train_dataset = dataset["train"].with_transform(preprocess_train)
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
input_ids = torch.stack([example["input_ids"] for example in examples])
return {"pixel_values": pixel_values, "input_ids": input_ids}
# DataLoaders creation:
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
shuffle=True,
collate_fn=collate_fn,
batch_size=args.train_batch_size,
num_workers=args.dataloader_num_workers,
)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, optimizer, train_dataloader, lr_scheduler
)
if args.use_ema:
ema_unet.to(accelerator.device)
# For mixed precision training we cast all non-trainable weigths (vae, non-lora text_encoder and non-lora unet) to half-precision
# as these weights are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
args.mixed_precision = accelerator.mixed_precision
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
args.mixed_precision = accelerator.mixed_precision
# Move text_encode and vae to gpu and cast to weight_dtype
text_encoder.to(accelerator.device, dtype=weight_dtype)
vae.to(accelerator.device, dtype=weight_dtype)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
tracker_config = dict(vars(args))
tracker_config.pop("validation_prompts")
accelerator.init_trackers(args.tracker_project_name, tracker_config)
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
for epoch in range(first_epoch, args.num_train_epochs):
train_loss = 0.0
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet):
# Convert images to latent space
latents = vae.encode(batch["pixel_values"].to(weight_dtype)).latent_dist.sample()
latents = latents * vae.config.scaling_factor
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
if args.noise_offset:
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
noise += args.noise_offset * torch.randn(
(latents.shape[0], latents.shape[1], 1, 1), device=latents.device
)
if args.input_perturbation:
new_noise = noise + args.input_perturbation * torch.randn_like(noise)
bsz = latents.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
timesteps = timesteps.long()
# Add noise to the latents according to the noise magnitude at each timestep
# (this is the forward diffusion process)
if args.input_perturbation:
noisy_latents = noise_scheduler.add_noise(latents, new_noise, timesteps)
else:
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
# Get the text embedding for conditioning
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
# Get the target for loss depending on the prediction type
if args.prediction_type is not None:
# set prediction_type of scheduler if defined
noise_scheduler.register_to_config(prediction_type=args.prediction_type)
if noise_scheduler.config.prediction_type == "epsilon":
target = noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = noise_scheduler.get_velocity(latents, noise, timesteps)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
# Predict the noise residual and compute loss
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
if args.snr_gamma is None:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
# Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
snr = compute_snr(noise_scheduler, timesteps)
if noise_scheduler.config.prediction_type == "v_prediction":
# Velocity objective requires that we add one to SNR values before we divide by them.
snr = snr + 1
mse_loss_weights = (
torch.stack([snr, args.snr_gamma * torch.ones_like(timesteps)], dim=1).min(dim=1)[0] / snr
)
loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
loss = loss.mean(dim=list(range(1, len(loss.shape)))) * mse_loss_weights
loss = loss.mean()
# Gather the losses across all processes for logging (if we use distributed training).
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
train_loss += avg_loss.item() / args.gradient_accumulation_steps
# Backpropagate
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
if args.use_ema:
ema_unet.step(unet.parameters())
progress_bar.update(1)
global_step += 1
accelerator.log({"train_loss": train_loss}, step=global_step)
train_loss = 0.0
if global_step % args.checkpointing_steps == 0:
if accelerator.is_main_process:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
if global_step >= args.max_train_steps:
break
if accelerator.is_main_process:
if args.validation_prompts is not None and epoch % args.validation_epochs == 0:
if args.use_ema:
# Store the UNet parameters temporarily and load the EMA parameters to perform inference.
ema_unet.store(unet.parameters())
ema_unet.copy_to(unet.parameters())
log_validation(
vae,
text_encoder,
tokenizer,
unet,
args,
accelerator,
weight_dtype,
global_step,
)
if args.use_ema:
# Switch back to the original UNet parameters.
ema_unet.restore(unet.parameters())
# Create the pipeline using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
if args.use_ema:
ema_unet.copy_to(unet.parameters())
pipeline = StableDiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path,
text_encoder=text_encoder,
vae=vae,
unet=unet,
revision=args.revision,
variant=args.variant,
)
pipeline.save_pretrained(args.output_dir)
# Run a final round of inference.
images = []
if args.validation_prompts is not None:
logger.info("Running inference for collecting generated images...")
pipeline = pipeline.to(accelerator.device)
pipeline.torch_dtype = weight_dtype
pipeline.set_progress_bar_config(disable=True)
if args.enable_xformers_memory_efficient_attention:
pipeline.enable_xformers_memory_efficient_attention()
if args.seed is None:
generator = None
else:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
for i in range(len(args.validation_prompts)):
with torch.autocast("cuda"):
image = pipeline(args.validation_prompts[i], num_inference_steps=20, generator=generator).images[0]
images.append(image)
if args.push_to_hub:
save_model_card(args, repo_id, images, repo_folder=args.output_dir)
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
accelerator.end_training()
if __name__ == "__main__":
main()
| 0
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.