
repo_id stringlengths 15 89 | file_path stringlengths 27 180 | content stringlengths 1 2.23M | __index_level_0__ int64 0 0 |
|---|---|---|---|
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/comet/comet.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/matthews_correlation/README.md | # Metric Card for Matthews Correlation Coefficient
## Metric Description
The Matthews correlation coefficient is used in machine learning as a
measure of the quality of binary and multiclass classifications. It takes
into account true and false positives and negatives and is generally
regarded as a balanced measure wh... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/matthews_correlation/matthews_correlation.py | # Copyright 2021 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/mauve/README.md | # Metric Card for MAUVE
## Metric description
MAUVE is a library built on PyTorch and HuggingFace Transformers to measure the gap between neural text and human text with the eponymous MAUVE measure. It summarizes both Type I and Type II errors measured softly using [Kullback–Leibler (KL) divergences](https://en.wikip... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/mauve/mauve.py | # coding=utf-8
# Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by app... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/wer/README.md | # Metric Card for WER
## Metric description
Word error rate (WER) is a common metric of the performance of an automatic speech recognition (ASR) system.
The general difficulty of measuring the performance of ASR systems lies in the fact that the recognized word sequence can have a different length from the reference... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/wer/wer.py | # Copyright 2021 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/f1/f1.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/f1/README.md | # Metric Card for F1
## Metric Description
The F1 score is the harmonic mean of the precision and recall. It can be computed with the equation:
F1 = 2 * (precision * recall) / (precision + recall)
## How to Use
At minimum, this metric requires predictions and references as input
```python
>>> f1_metric = dataset... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/rouge/README.md | # Metric Card for ROUGE
## Metric Description
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics and a software package used for evaluating automatic summarization and machine translation software in natural language processing. The metrics compare an automatically produced summary or tra... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/rouge/rouge.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/exact_match/README.md | # Metric Card for Exact Match
## Metric Description
A given predicted string's exact match score is 1 if it is the exact same as its reference string, and is 0 otherwise.
- **Example 1**: The exact match score of prediction "Happy Birthday!" is 0, given its reference is "Happy New Year!".
- **Example 2**: The exact ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/exact_match/exact_match.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/competition_math/README.md | # Metric Card for Competition MATH
## Metric description
This metric is used to assess performance on the [Mathematics Aptitude Test of Heuristics (MATH) dataset](https://huggingface.co/datasets/competition_math).
It first canonicalizes the inputs (e.g., converting `1/2` to `\\frac{1}{2}`) and then computes accurac... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/competition_math/competition_math.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/super_glue/README.md | # Metric Card for SuperGLUE
## Metric description
This metric is used to compute the SuperGLUE evaluation metric associated to each of the subsets of the [SuperGLUE dataset](https://huggingface.co/datasets/super_glue).
SuperGLUE is a new benchmark styled after GLUE with a new set of more difficult language understan... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/super_glue/super_glue.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/super_glue/record_evaluation.py | """
Official evaluation script for ReCoRD v1.0.
(Some functions are adopted from the SQuAD evaluation script.)
"""
import argparse
import json
import re
import string
import sys
from collections import Counter
def normalize_answer(s):
"""Lower text and remove punctuation, articles and extra whitespace."""
... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/wiki_split/README.md | # Metric Card for WikiSplit
## Metric description
WikiSplit is the combination of three metrics: [SARI](https://huggingface.co/metrics/sari), [exact match](https://huggingface.co/metrics/exact_match) and [SacreBLEU](https://huggingface.co/metrics/sacrebleu).
It can be used to evaluate the quality of sentence splitt... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/wiki_split/wiki_split.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/bleu/README.md | # Metric Card for BLEU
## Metric Description
BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another. Quality is considered to be the correspondence between a machine's output and that of a human: "the closer a ma... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/bleu/bleu.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/pearsonr/README.md | # Metric Card for Pearson Correlation Coefficient (pearsonr)
## Metric Description
Pearson correlation coefficient and p-value for testing non-correlation.
The Pearson correlation coefficient measures the linear relationship between two datasets. The calculation of the p-value relies on the assumption that each data... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/pearsonr/pearsonr.py | # Copyright 2021 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/seqeval/README.md | # Metric Card for seqeval
## Metric description
seqeval is a Python framework for sequence labeling evaluation. seqeval can evaluate the performance of chunking tasks such as named-entity recognition, part-of-speech tagging, semantic role labeling and so on.
## How to use
Seqeval produces labelling scores along ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/seqeval/seqeval.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/bleurt/bleurt.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/cuad/README.md | # Metric Card for CUAD
## Metric description
This metric wraps the official scoring script for version 1 of the [Contract Understanding Atticus Dataset (CUAD)](https://huggingface.co/datasets/cuad), which is a corpus of more than 13,000 labels in 510 commercial legal contracts that have been manually labeled to ident... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/cuad/evaluate.py | """ Official evaluation script for CUAD dataset. """
import argparse
import json
import re
import string
import sys
import numpy as np
IOU_THRESH = 0.5
def get_jaccard(prediction, ground_truth):
remove_tokens = [".", ",", ";", ":"]
for token in remove_tokens:
ground_truth = ground_truth.replace(t... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/cuad/cuad.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/mae/README.md | # Metric Card for MAE
## Metric Description
Mean Absolute Error (MAE) is the mean of the magnitude of difference between the predicted and actual numeric values:
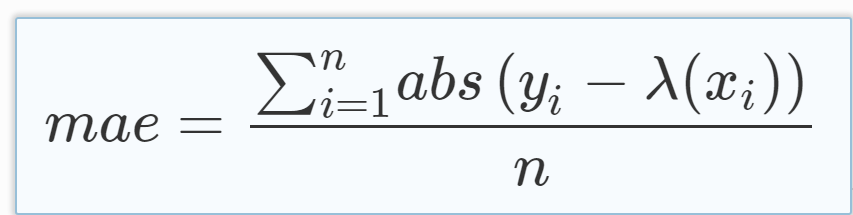
## How to Use
At minimum, this metric re... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/mae/mae.py | # Copyright 2022 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/chrf/chrf.py | # Copyright 2021 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/chrf/README.md | # Metric Card for chrF(++)
## Metric Description
ChrF and ChrF++ are two MT evaluation metrics that use the F-score statistic for character n-gram matches. ChrF++ additionally includes word n-grams, which correlate more strongly with direct assessment. We use the implementation that is already present in sacrebleu.
... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/roc_auc/README.md | # Metric Card for ROC AUC
## Metric Description
This metric computes the area under the curve (AUC) for the Receiver Operating Characteristic Curve (ROC). The return values represent how well the model used is predicting the correct classes, based on the input data. A score of `0.5` means that the model is predicting... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/roc_auc/roc_auc.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/xnli/README.md | # Metric Card for XNLI
## Metric description
The XNLI metric allows to evaluate a model's score on the [XNLI dataset](https://huggingface.co/datasets/xnli), which is a subset of a few thousand examples from the [MNLI dataset](https://huggingface.co/datasets/glue/viewer/mnli) that have been translated into a 14 differ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/xnli/xnli.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets | hf_public_repos/datasets/docs/README.md | <!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/quickstart.mdx | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/image_load.mdx | # Load image data
Image datasets have [`Image`] type columns, which contain PIL objects.
<Tip>
To work with image datasets, you need to have the `vision` dependency installed. Check out the [installation](./installation#vision) guide to learn how to install it.
</Tip>
When you load an image dataset and call the i... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/about_map_batch.mdx | # Batch mapping
Combining the utility of [`Dataset.map`] with batch mode is very powerful. It allows you to speed up processing, and freely control the size of the generated dataset.
## Need for speed
The primary objective of batch mapping is to speed up processing. Often times, it is faster to work with batches of... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/about_mapstyle_vs_iterable.mdx | # Differences between Dataset and IterableDataset
There are two types of dataset objects, a [`Dataset`] and an [`IterableDataset`].
Whichever type of dataset you choose to use or create depends on the size of the dataset.
In general, an [`IterableDataset`] is ideal for big datasets (think hundreds of GBs!) due to its ... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/about_dataset_features.mdx | # Dataset features
[`Features`] defines the internal structure of a dataset. It is used to specify the underlying serialization format. What's more interesting to you though is that [`Features`] contains high-level information about everything from the column names and types, to the [`ClassLabel`]. You can think of [`... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/faiss_es.mdx | # Search index
[FAISS](https://github.com/facebookresearch/faiss) and [Elasticsearch](https://www.elastic.co/elasticsearch/) enables searching for examples in a dataset. This can be useful when you want to retrieve specific examples from a dataset that are relevant to your NLP task. For example, if you are working on ... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/about_metrics.mdx | # All about metrics
<Tip warning={true}>
Metrics is deprecated in 🤗 Datasets. To learn more about how to use metrics, take a look at the library 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index)! In addition to metrics, you can find more tools for evaluating models and datasets.
</Tip>
🤗 Datasets provides... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/use_with_tensorflow.mdx | # Using Datasets with TensorFlow
This document is a quick introduction to using `datasets` with TensorFlow, with a particular focus on how to get
`tf.Tensor` objects out of our datasets, and how to stream data from Hugging Face `Dataset` objects to Keras methods
like `model.fit()`.
## Dataset format
By default, data... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/installation.md | # Installation
Before you start, you'll need to setup your environment and install the appropriate packages. 🤗 Datasets is tested on **Python 3.7+**.
<Tip>
If you want to use 🤗 Datasets with TensorFlow or PyTorch, you'll need to install them separately. Refer to the [TensorFlow installation page](https://www.tenso... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/load_hub.mdx | # Load a dataset from the Hub
Finding high-quality datasets that are reproducible and accessible can be difficult. One of 🤗 Datasets main goals is to provide a simple way to load a dataset of any format or type. The easiest way to get started is to discover an existing dataset on the [Hugging Face Hub](https://huggin... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/image_process.mdx | # Process image data
This guide shows specific methods for processing image datasets. Learn how to:
- Use [`~Dataset.map`] with image dataset.
- Apply data augmentations to a dataset with [`~Dataset.set_transform`].
For a guide on how to process any type of dataset, take a look at the <a class="underline decoration-... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/image_classification.mdx | # Image classification
Image classification datasets are used to train a model to classify an entire image. There are a wide variety of applications enabled by these datasets such as identifying endangered wildlife species or screening for disease in medical images. This guide will show you how to apply transformation... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/audio_load.mdx | # Load audio data
You can load an audio dataset using the [`Audio`] feature that automatically decodes and resamples the audio files when you access the examples.
Audio decoding is based on the [`soundfile`](https://github.com/bastibe/python-soundfile) python package, which uses the [`libsndfile`](https://github.com/l... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/about_dataset_load.mdx | # Build and load
Nearly every deep learning workflow begins with loading a dataset, which makes it one of the most important steps. With 🤗 Datasets, there are more than 900 datasets available to help you get started with your NLP task. All you have to do is call: [`load_dataset`] to take your first step. This functio... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/access.mdx | # Know your dataset
There are two types of dataset objects, a regular [`Dataset`] and then an ✨ [`IterableDataset`] ✨. A [`Dataset`] provides fast random access to the rows, and memory-mapping so that loading even large datasets only uses a relatively small amount of device memory. But for really, really big datasets ... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/_toctree.yml | - sections:
- local: index
title: 🤗 Datasets
- local: quickstart
title: Quickstart
- local: installation
title: Installation
title: Get started
- sections:
- local: tutorial
title: Overview
- local: load_hub
title: Load a dataset from the Hub
- local: access
title: Know your data... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/tutorial.md | # Overview
Welcome to the 🤗 Datasets tutorials! These beginner-friendly tutorials will guide you through the fundamentals of working with 🤗 Datasets. You'll load and prepare a dataset for training with your machine learning framework of choice. Along the way, you'll learn how to load different dataset configurations... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/nlp_process.mdx | # Process text data
This guide shows specific methods for processing text datasets. Learn how to:
- Tokenize a dataset with [`~Dataset.map`].
- Align dataset labels with label ids for NLI datasets.
For a guide on how to process any type of dataset, take a look at the <a class="underline decoration-sky-400 decoration... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/_redirects.yml | # This first_section was backported from nginx
loading_datasets: loading
share_dataset: share
quicktour: quickstart
dataset_streaming: stream
torch_tensorflow: use_dataset
splits: loading#slice-splits
processing: process
faiss_and_ea: faiss_es
features: about_dataset_features
using_metrics: how_to_metrics
exploring: ac... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/use_with_jax.mdx | # Use with JAX
This document is a quick introduction to using `datasets` with JAX, with a particular focus on how to get
`jax.Array` objects out of our datasets, and how to use them to train JAX models.
<Tip>
`jax` and `jaxlib` are required to reproduce to code above, so please make sure you
install them as `pip ins... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/create_dataset.mdx | # Create a dataset
Sometimes, you may need to create a dataset if you're working with your own data. Creating a dataset with 🤗 Datasets confers all the advantages of the library to your dataset: fast loading and processing, [stream enormous datasets](stream), [memory-mapping](https://huggingface.co/course/chapter5/4?... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/_config.py | # docstyle-ignore
INSTALL_CONTENT = """
# Datasets installation
! pip install datasets transformers
# To install from source instead of the last release, comment the command above and uncomment the following one.
# ! pip install git+https://github.com/huggingface/datasets.git
"""
notebook_first_cells = [{"type": "code... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/metrics.mdx | # Evaluate predictions
<Tip warning={true}>
Metrics is deprecated in 🤗 Datasets. To learn more about how to use metrics, take a look at the library 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index)! In addition to metrics, you can find more tools for evaluating models and datasets.
</Tip>
🤗 Datasets provi... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/use_with_spark.mdx | # Use with Spark
This document is a quick introduction to using 🤗 Datasets with Spark, with a particular focus on how to load a Spark DataFrame into a [`Dataset`] object.
From there, you have fast access to any element and you can use it as a data loader to train models.
## Load from Spark
A [`Dataset`] object is ... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/dataset_script.mdx | # Create a dataset loading script
<Tip>
The dataset loading script is likely not needed if your dataset is in one of the following formats: CSV, JSON, JSON lines, text, images, audio or Parquet.
With those formats, you should be able to load your dataset automatically with [`~datasets.load_dataset`],
as long as your... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/audio_dataset.mdx | # Create an audio dataset
You can share a dataset with your team or with anyone in the community by creating a dataset repository on the Hugging Face Hub:
```py
from datasets import load_dataset
dataset = load_dataset("<username>/my_dataset")
```
There are several methods for creating and sharing an audio dataset:
... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/tabular_load.mdx | # Load tabular data
A tabular dataset is a generic dataset used to describe any data stored in rows and columns, where the rows represent an example and the columns represent a feature (can be continuous or categorical). These datasets are commonly stored in CSV files, Pandas DataFrames, and in database tables. This g... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/about_cache.mdx | # The cache
The cache is one of the reasons why 🤗 Datasets is so efficient. It stores previously downloaded and processed datasets so when you need to use them again, they are reloaded directly from the cache. This avoids having to download a dataset all over again, or reapplying processing functions. Even after you ... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/repository_structure.mdx | # Structure your repository
To host and share your dataset, create a dataset repository on the Hugging Face Hub and upload your data files.
This guide will show you how to structure your dataset repository when you upload it.
A dataset with a supported structure and file format (`.txt`, `.csv`, `.parquet`, `.jsonl`, ... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/about_arrow.md | # Datasets 🤝 Arrow
## What is Arrow?
[Arrow](https://arrow.apache.org/) enables large amounts of data to be processed and moved quickly. It is a specific data format that stores data in a columnar memory layout. This provides several significant advantages:
* Arrow's standard format allows [zero-copy reads](https:/... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/nlp_load.mdx | # Load text data
This guide shows you how to load text datasets. To learn how to load any type of dataset, take a look at the <a class="underline decoration-sky-400 decoration-2 font-semibold" href="./loading">general loading guide</a>.
Text files are one of the most common file types for storing a dataset. By defaul... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/how_to.md | # Overview
The how-to guides offer a more comprehensive overview of all the tools 🤗 Datasets offers and how to use them. This will help you tackle messier real-world datasets where you may need to manipulate the dataset structure or content to get it ready for training.
The guides assume you are familiar and comfort... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/image_dataset.mdx | # Create an image dataset
There are two methods for creating and sharing an image dataset. This guide will show you how to:
* Create an image dataset with `ImageFolder` and some metadata. This is a no-code solution for quickly creating an image dataset with several thousand images.
* Create an image dataset by writin... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/stream.mdx | # Stream
Dataset streaming lets you work with a dataset without downloading it.
The data is streamed as you iterate over the dataset.
This is especially helpful when:
- You don't want to wait for an extremely large dataset to download.
- The dataset size exceeds the amount of available disk space on your computer.
- ... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/loading.mdx | # Load
Your data can be stored in various places; they can be on your local machine's disk, in a Github repository, and in in-memory data structures like Python dictionaries and Pandas DataFrames. Wherever a dataset is stored, 🤗 Datasets can help you load it.
This guide will show you how to load a dataset from:
- T... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/use_with_pytorch.mdx | # Use with PyTorch
This document is a quick introduction to using `datasets` with PyTorch, with a particular focus on how to get
`torch.Tensor` objects out of our datasets, and how to use a PyTorch `DataLoader` and a Hugging Face `Dataset`
with the best performance.
## Dataset format
By default, datasets return regu... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/depth_estimation.mdx | # Depth estimation
Depth estimation datasets are used to train a model to approximate the relative distance of every pixel in an
image from the camera, also known as depth. The applications enabled by these datasets primarily lie in areas like visual machine
perception and perception in robotics. Example applications ... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/upload_dataset.mdx | # Share a dataset to the Hub
The [Hub](https://huggingface.co/datasets) is home to an extensive collection of community-curated and popular research datasets. We encourage you to share your dataset to the Hub to help grow the ML community and accelerate progress for everyone. All contributions are welcome; adding a da... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/process.mdx | # Process
🤗 Datasets provides many tools for modifying the structure and content of a dataset. These tools are important for tidying up a dataset, creating additional columns, converting between features and formats, and much more.
This guide will show you how to:
- Reorder rows and split the dataset.
- Rename and ... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/use_dataset.mdx | # Preprocess
In addition to loading datasets, 🤗 Datasets other main goal is to offer a diverse set of preprocessing functions to get a dataset into an appropriate format for training with your machine learning framework.
There are many possible ways to preprocess a dataset, and it all depends on your specific datas... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/filesystems.mdx | # Cloud storage
🤗 Datasets supports access to cloud storage providers through a `fsspec` FileSystem implementations.
You can save and load datasets from any cloud storage in a Pythonic way.
Take a look at the following table for some example of supported cloud storage providers:
| Storage provider | Filesystem i... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/audio_process.mdx | # Process audio data
This guide shows specific methods for processing audio datasets. Learn how to:
- Resample the sampling rate.
- Use [`~Dataset.map`] with audio datasets.
For a guide on how to process any type of dataset, take a look at the <a class="underline decoration-sky-400 decoration-2 font-semibold" href="... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/beam.mdx | # Beam Datasets
Some datasets are too large to be processed on a single machine. Instead, you can process them with [Apache Beam](https://beam.apache.org/), a library for parallel data processing. The processing pipeline is executed on a distributed processing backend such as [Apache Flink](https://flink.apache.org/),... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/index.mdx | # Datasets
<img class="float-left !m-0 !border-0 !dark:border-0 !shadow-none !max-w-lg w-[150px]" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/datasets_logo.png"/>
🤗 Datasets is a library for easily accessing and sharing datasets for Audio, Computer Vision, and Natural ... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/semantic_segmentation.mdx | # Semantic segmentation
Semantic segmentation datasets are used to train a model to classify every pixel in an image. There are
a wide variety of applications enabled by these datasets such as background removal from images, stylizing
images, or scene understanding for autonomous driving. This guide will show you how ... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/cache.mdx | # Cache management
When you download a dataset, the processing scripts and data are stored locally on your computer. The cache allows 🤗 Datasets to avoid re-downloading or processing the entire dataset every time you use it.
This guide will show you how to:
- Change the cache directory.
- Control how a dataset is ... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/object_detection.mdx | # Object detection
Object detection models identify something in an image, and object detection datasets are used for applications such as autonomous driving and detecting natural hazards like wildfire. This guide will show you how to apply transformations to an object detection dataset following the [tutorial](https:... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/share.mdx | # Share a dataset using the CLI
At Hugging Face, we are on a mission to democratize good Machine Learning and we believe in the value of open source. That's why we designed 🤗 Datasets so that anyone can share a dataset with the greater ML community. There are currently thousands of datasets in over 100 languages in t... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/how_to_metrics.mdx | # Metrics
<Tip warning={true}>
Metrics is deprecated in 🤗 Datasets. To learn more about how to use metrics, take a look at the library 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index)! In addition to metrics, you can find more tools for evaluating models and datasets.
</Tip>
Metrics are important for eval... | 0 |
hf_public_repos/datasets/docs | hf_public_repos/datasets/docs/source/dataset_card.mdx | # Create a dataset card
Each dataset should have a dataset card to promote responsible usage and inform users of any potential biases within the dataset.
This idea was inspired by the Model Cards proposed by [Mitchell, 2018](https://arxiv.org/abs/1810.03993).
Dataset cards help users understand a dataset's contents, t... | 0 |
hf_public_repos/datasets/docs/source | hf_public_repos/datasets/docs/source/package_reference/utilities.mdx | # Utilities
## Configure logging
🤗 Datasets strives to be transparent and explicit about how it works, but this can be quite verbose at times. We have included a series of logging methods which allow you to easily adjust the level of verbosity of the entire library. Currently the default verbosity of the library is ... | 0 |
hf_public_repos/datasets/docs/source | hf_public_repos/datasets/docs/source/package_reference/builder_classes.mdx | # Builder classes
## Builders
🤗 Datasets relies on two main classes during the dataset building process: [`DatasetBuilder`] and [`BuilderConfig`].
[[autodoc]] datasets.DatasetBuilder
[[autodoc]] datasets.GeneratorBasedBuilder
[[autodoc]] datasets.BeamBasedBuilder
[[autodoc]] datasets.ArrowBasedBuilder
[[autodoc... | 0 |
hf_public_repos/datasets/docs/source | hf_public_repos/datasets/docs/source/package_reference/main_classes.mdx | # Main classes
## DatasetInfo
[[autodoc]] datasets.DatasetInfo
## Dataset
The base class [`Dataset`] implements a Dataset backed by an Apache Arrow table.
[[autodoc]] datasets.Dataset
- add_column
- add_item
- from_file
- from_buffer
- from_pandas
- from_dict
- from_generator
- dat... | 0 |
hf_public_repos/datasets/docs/source | hf_public_repos/datasets/docs/source/package_reference/loading_methods.mdx | # Loading methods
Methods for listing and loading datasets and metrics:
## Datasets
[[autodoc]] datasets.list_datasets
[[autodoc]] datasets.load_dataset
[[autodoc]] datasets.load_from_disk
[[autodoc]] datasets.load_dataset_builder
[[autodoc]] datasets.get_dataset_config_names
[[autodoc]] datasets.get_dataset_in... | 0 |
hf_public_repos/datasets/docs/source | hf_public_repos/datasets/docs/source/package_reference/task_templates.mdx | # Task templates
<Tip warning={true}>
The Task API is deprecated in favor of [`train-eval-index`](https://github.com/huggingface/hub-docs/blob/9ab2555e1c146122056aba6f89af404a8bc9a6f1/datasetcard.md?plain=1#L90-L106) and will be removed in the next major release.
</Tip>
The tasks supported by [`Dataset.prepare_for_... | 0 |
hf_public_repos/datasets/docs/source | hf_public_repos/datasets/docs/source/package_reference/table_classes.mdx | # Table Classes
Each `Dataset` object is backed by a PyArrow Table.
A Table can be loaded from either the disk (memory mapped) or in memory.
Several Table types are available, and they all inherit from [`table.Table`].
## Table
[[autodoc]] datasets.table.Table
- validate
- equals
- to_batches
- to_py... | 0 |
hf_public_repos/datasets | hf_public_repos/datasets/utils/release.py | # Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | 0 |
hf_public_repos/datasets | hf_public_repos/datasets/templates/README.md | ---
TODO: Add YAML tags here. Copy-paste the tags obtained with the online tagging app: https://huggingface.co/spaces/huggingface/datasets-tagging
---
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#d... | 0 |
hf_public_repos/datasets | hf_public_repos/datasets/templates/metric_card_template.md | # Metric Card for *Current Metric*
***Metric Card Instructions:*** *Copy this file into the relevant metric folder, then fill it out and save it as README.md. Feel free to take a look at existing metric cards if you'd like examples.*
## Metric Description
*Give a brief overview of this metric.*
## How to Use
*Give g... | 0 |
hf_public_repos/datasets | hf_public_repos/datasets/templates/new_dataset_script.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets | hf_public_repos/datasets/templates/README_guide.md | ---
YAML tags (full spec here: https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1):
- copy-paste the tags obtained with the online tagging app: https://huggingface.co/spaces/huggingface/datasets-tagging
---
# Dataset Card Creation Guide
## Table of Contents
- [Dataset Card Creation Guide](#datas... | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.