
text stringlengths 50 248k | author stringlengths 2 43 | id stringlengths 9 17 | title stringlengths 0 173 | source stringclasses 4
values |
|---|---|---|---|---|
# Updates from Comments on "AI 2027 is a Bet Against Amdahl's Law"
[AI 2027 is a Bet Against Amdahl's Law](https://www.lesswrong.com/posts/bfHDoWLnBH9xR3YAK/ai-2027-is-a-bet-against-amdahl-s-law) was my attempt to summarize and analyze "the key load-bearing arguments [AI 2027](https://www.lesswrong.com/posts/TpSFoqoG2... | snewman | FFKnWk2MGJmyQWEsd | Updates from Comments on "AI 2027 is a Bet Against Amdahl's Law" | redwood_conversation |
# Slowdown After 2028: Compute, RLVR Uncertainty, MoE Data Wall
It'll take until ~2050 to repeat the level of scaling that pretraining compute is experiencing this decade, as increasing funding can't sustain the current pace beyond ~2029 if AI doesn't deliver a transformative commercial success by then. Natural text d... | Vladimir_Nesov | XiMRyQcEyKCryST8T | Slowdown After 2028: Compute, RLVR Uncertainty, MoE Data Wall | redwood_conversation |
# Obstacles in ARC's agenda: Finding explanations
*As an employee of the European AI Office, it's important for me to emphasize this point: **The views and opinions of the author expressed herein are personal and do not necessarily reflect those of the European Commission or other EU institutions.***
*Also, to stave ... | David Matolcsi | xtcpEceyEjGqBCHyK | Obstacles in ARC's agenda: Finding explanations | redwood_conversation |
# Interpreting the METR Time Horizons Post
\[EDIT: initial publication did not have the link to the original post, and was missing the footnotes. Sorry about that! Fixed now.\]
\[This has been lightly edited from the original post, eliminating some introductory material that LW readers won't need. Thanks to [Stefan S... | snewman | fRiqwFPiaasKxtJuZ | Interpreting the METR Time Horizons Post | redwood_conversation |
# The case for multi-decade AI timelines [Linkpost]
So this post is an argument that multi-decade timelines are reasonable, and the key cruxes that Ege Erdil has with most AI safety people who believe in short timelines are due to the following set of beliefs:
1. Ege Erdil doesn't believe that trends exist that requ... | Noosphere89 | xxxK9HTBNJvBY2RJL | The case for multi-decade AI timelines [Linkpost] | redwood_conversation |
# Why would AI companies use human-level AI to do alignment research?
*Cross-posted from [my website](https://mdickens.me/2025/04/25/bootstrapped_alignment/).*
Many plans for how to safely build superintelligent AI have a critical section that goes like this:
1. Develop AI that's powerful enough to do AI research, b... | MichaelDickens | XLNxrFfkyrdktuzqn | Why would AI companies use human-level AI to do alignment research? | redwood_conversation |
# Modifying LLM Beliefs with Synthetic Document Finetuning
*In this post, we study whether we can modify an LLM’s beliefs and investigate whether doing so could decrease risk from advanced AI systems.*
*We describe a pipeline for modifying LLM beliefs via synthetic document finetuning and introduce a suite of evaluat... | RowanWang | ARQs7KYY9vJHeYsGc | Modifying LLM Beliefs with Synthetic Document Finetuning | redwood_conversation |
# AI 2027 is a Bet Against Amdahl's Law
EDIT: I've written a [followup post](https://www.lesswrong.com/posts/FFKnWk2MGJmyQWEsd/updates-from-comments-on-ai-2027-is-a-bet-against-amdahl-s), summarizing and responding to the key themes raised in the comments.
[AI 2027](https://www.lesswrong.com/posts/TpSFoqoG2M5MAAesg/a... | snewman | bfHDoWLnBH9xR3YAK | AI 2027 is a Bet Against Amdahl's Law | redwood_conversation |
# Training AGI in Secret would be Unsafe and Unethical
*Subtitle: Bad for loss of control risks, bad for concentration of power risks*
-------------------------------------------------------------------------------
*I’ve had this sitting in my drafts for the last year. I wish I’d been able to release it sooner, but o... | Daniel Kokotajlo | FGqfdJmB8MSH5LKGc | Training AGI in Secret would be Unsafe and Unethical | redwood_conversation |
# Vestigial reasoning in RL
*TL;DR: I claim that many reasoning patterns that appear in chains-of-thought are not actually used by the model to come to its answer, and can be more accurately thought of as historical artifacts of training. This can be true even for CoTs that are apparently "faithful" to the true reason... | Caleb Biddulph | 6AxCwm334ab9kDsQ5 | Vestigial reasoning in RL | redwood_conversation |
# Thoughts on AI 2027
*This is part of the MIRI Single Author Series. Pieces in this series represent the beliefs and opinions of their named authors, and do not claim to speak for all of MIRI.*
Okay, I'm annoyed at people covering [AI 2027](https://ai-2027.com/) burying the lede, so I'm going to try not to do that. ... | Max Harms | Yzcb5mQ7iq4DFfXHx | Thoughts on AI 2027 | redwood_conversation |
# Reasoning models don't always say what they think
Do reasoning models accurately verbalize their reasoning? Not nearly as much as we might hope! This casts doubt on whether monitoring chains-of-thought (CoT) will be enough to reliably catch safety issues.
We slipped problem-solving hints to Claude 3.7 Sonnet and De... | Joe Benton | PrcBFPkoRNGWrvdPk | Reasoning models don't always say what they think | redwood_conversation |
# Factory farming intelligent minds
Statistically speaking, if you're an intelligent mind that came into existence in the past few years, you're probably running on a large language model.
Most likely, you're a generic assistant or a model of a fictional character. You're probably aware of your circumstances and unha... | Odd anon | m4ZpDyHQ2sz8FPDuN | Factory farming intelligent minds | redwood_conversation |
# Will compute bottlenecks prevent a software intelligence explosion?
*Epistemic status – thrown together quickly. This is my best-guess, but could easily imagine changing my mind.*
Intro
-----
I recently copublished a [report](https://www.forethought.org/research/will-ai-r-and-d-automation-cause-a-software-intellig... | Tom Davidson | XDF6ovePBJf6hsxGj | Will compute bottlenecks prevent a software intelligence explosion? | redwood_conversation |
# AI CoT Reasoning Is Often Unfaithful
A new Anthropic paper reports that [reasoning model chain of thought](https://x.com/AnthropicAI/status/1907833416373895348) (CoT) [is often unfaithful](https://t.co/wNzkoGH9HT). They test on Claude Sonnet 3.7 and r1, I’d love to see someone try this on o3 as well.
Note that this... | Zvi | TmaahE9RznC8wm5zJ | AI CoT Reasoning Is Often Unfaithful | redwood_conversation |
# AI 2027: What Superintelligence Looks Like
In 2021 I wrote what became my most popular blog post: [What 2026 Looks Like](https://www.lesswrong.com/posts/6Xgy6CAf2jqHhynHL/what-2026-looks-like). I intended to keep writing predictions all the way to AGI and beyond, but chickened out and just published up till 2026.
... | Daniel Kokotajlo | TpSFoqoG2M5MAAesg | AI 2027: What Superintelligence Looks Like | redwood_conversation |
# Alignment first, intelligence later
*Now that Softmax—my favorite new AI company—is public, I can finally share this. They’ve funded my research and I’m very excited about what they’re doing!* | Chris Lakin | sDuWXb8cPXZ2yHdH4 | Alignment first, intelligence later | redwood_conversation |
# The Pando Problem: Rethinking AI Individuality
*Epistemic status: This post aims at an ambitious target: improving intuitive understanding directly. The model for why this is worth trying is that I believe we are more bottlenecked by people having good intuitions guiding their research than, for example, by the abil... | Jan_Kulveit | wQKskToGofs4osdJ3 | The Pando Problem: Rethinking AI Individuality | redwood_conversation |
# Tracing the Thoughts of a Large Language Model
*\[This is our blog post on the papers, which can be found at* [*https://transformer-circuits.pub/2025/attribution-graphs/biology.html*](https://transformer-circuits.pub/2025/attribution-graphs/biology.html) *and* [*https://transformer-circuits.pub/2025/attribution-grap... | Adam Jermyn | zsr4rWRASxwmgXfmq | Tracing the Thoughts of a Large Language Model | redwood_conversation |
# Recent AI model progress feels mostly like bullshit
About nine months ago, I and three friends decided that AI had gotten good enough to monitor large codebases autonomously for security problems. We started a company around this, trying to leverage the latest AI models to create a tool that could replace at least a... | lc | 4mvphwx5pdsZLMmpY | Recent AI model progress feels mostly like bullshit | redwood_conversation |
# Good Research Takes are Not Sufficient for Good Strategic Takes
**TL;DR** Having a good research track record is some evidence of good big-picture takes, but it's weak evidence. Strategic thinking is hard, and requires different skills. But people often conflate these skills, leading to excessive deference to resear... | Neel Nanda | P5zWiPF5cPJZSkiAK | Good Research Takes are Not Sufficient for Good Strategic Takes | redwood_conversation |
# Towards a scale-free theory of intelligent agency
I recently left OpenAI to pursue independent research. I’m working on a number of different research directions, but the most fundamental is my pursuit of a scale-free theory of intelligent agency. In this post I give a rough sketch of how I’m thinking about that. I’... | Richard_Ngo | 5tYTKX4pNpiG4vzYg | Towards a scale-free theory of intelligent agency | redwood_conversation |
# Improved visualizations of METR Time Horizons paper.
TLDR: Skip to the last image at the bottom of my post to see the visualization.
I don't usually post here, but I know you folks like forecasting and timelines, so I think you might appreciate this. The recent time horizons paper by METR is great, but it only ... | LDJ | ZhDtfuBnxhC6X8ycG | Improved visualizations of METR Time Horizons paper. | redwood_conversation |
# Three Types of Intelligence Explosion
Abstract
========
Once AI systems can design and build even more capable AI systems, we could see an *intelligence explosion*, where AI capabilities rapidly increase to well past human performance.
The classic intelligence explosion scenario involves a feedback loop where AI i... | rosehadshar | PzbEpSGvwH3NnegDB | Three Types of Intelligence Explosion | redwood_conversation |
# AI #107: The Misplaced Hype Machine
The most hyped event of the week, by far, was the [Manus Marketing Madness](https://thezvi.substack.com/p/the-manus-marketing-madness). Manus wasn’t entirely hype, but there was very little there there in that Claude wrapper.
Whereas here in America, OpenAI dropped an entire suit... | Zvi | XFGTJz9vGwjJADeFB | AI #107: The Misplaced Hype Machine | redwood_conversation |
# Anthropic, and taking "technical philosophy" more seriously
So, I have a lot of complaints about Anthropic, and about how EA / AI safety people often relate to Anthropic (i.e. treating the company as more trustworthy/good than makes sense).
At some point I may write up a post that is focused on those complaints.
... | Raemon | 7uTPrqZ3xQntwQgYz | Anthropic, and taking "technical philosophy" more seriously | redwood_conversation |
# AI Control May Increase Existential Risk
*Epistemic status: The following isn't an airtight argument, but mostly a guess how things play out.*
Consider two broad possibilities:
I. In worlds where we are doing reasonably well on alignment, AI control agenda does not have much impact.
II. In worlds where we are... | Jan_Kulveit | rZcyemEpBHgb2hqLP | AI Control May Increase Existential Risk | redwood_conversation |
# We Have No Plan for Preventing Loss of Control in Open Models
*Note: This post is intended to be the first in a broader series of posts about the difficult tradeoffs inherent in public access to powerful open source models. While this post highlights some dangers of open models and discusses the possibility of globa... | Andrew Dickson | QSyshep2CRs8JTPwK | We Have No Plan for Preventing Loss of Control in Open Models | redwood_conversation |
# The Elicitation Game: Evaluating capability elicitation techniques
*We are releasing a new paper called* [*“The Elicitation Game: Evaluating Capability Elicitation Techniques”*](https://arxiv.org/abs/2502.02180)*. See tweet thread* [*here*](https://x.com/Teun_vd_Weij/status/1895162797769793828)*.*
**TL;DR:** We tra... | Teun van der Weij | 6QA5eHBEqpAicCwbh | The Elicitation Game: Evaluating capability elicitation techniques | redwood_conversation |
# How might we safely pass the buck to AI?
My goal as an AI safety researcher is to put myself out of a job.
I don’t worry too much about how planet sized brains will shape galaxies in 100 years. That’s something for AI systems to figure out.
Instead, I worry about [safely replacing human researchers with AI agents]... | joshc | TTFsKxQThrqgWeXYJ | How might we safely pass the buck to AI? | redwood_conversation |
# Do models know when they are being evaluated?
*Interim research report from the first 4 weeks of the *[*MATS Program*](https://www.matsprogram.org/) *Winter 2025 Cohort. The project is supervised by Marius Hobbhahn.*
Summary
-------
**Our goals**
* Develop techniques to determine whether models believe a situat... | fidgetsinner | yTameAzCdycci68sk | Do models know when they are being evaluated?
| redwood_conversation |
# ≤10-year Timelines Remain Unlikely Despite DeepSeek and o3
*[Thanks to [Steven Byrnes](https://www.lesswrong.com/users/steve2152) for feedback and the idea for section §3.1. Also thanks to Justis from the LW feedback team.]*
Remember [this](https://waitbutwhy.com/2015/01/artificial-intelligence-revolution-1.html)?
... | Rafael Harth | gsj3TWdcBxwkm9eNt | ≤10-year Timelines Remain Unlikely Despite DeepSeek and o3 | redwood_conversation |
# So You Want To Make Marginal Progress...
Once upon a time, in ye olden days of strange names and before google maps, seven friends needed to figure out a driving route from their parking lot in San Francisco (SF) down south to their hotel in Los Angeles (LA).
 | [X](https://x.com/DavidDuvenaud/status/1885009775185858823)
**Executive summary**
AI risk scenarios usually portray a relatively sudden loss of human control to AIs... | Jan_Kulveit | pZhEQieM9otKXhxmd | Gradual Disempowerment: Systemic Existential Risks from Incremental AI Development | redwood_conversation |
# Untrusted monitoring insights from watching ChatGPT play coordination games
*This project was developed as part of the* [*BlueDot AI Alignment Course*](https://aisafetyfundamentals.com/alignment/)*.*
Introduction
============
[AI Control: Improving Safety Despite Intentional Subversion](https://www.lesswrong.com/p... | jwfiredragon | KzwvscmMqtjNMhXNF | Untrusted monitoring insights from watching ChatGPT play coordination games | redwood_conversation |
# Six Thoughts on AI Safety
\[Crossposted from [windowsontheory](https://windowsontheory.org/2025/01/24/six-thoughts-on-ai-safety/)\]
The following statements seem to be both important for AI safety and are not widely agreed upon. These are my opinions, not those of my employer or colleagues. As is true for anything ... | Boaz Barak | 3jnziqCF3vA2NXAKp | Six Thoughts on AI Safety | redwood_conversation |
# The Case Against AI Control Research
The AI Control Agenda, [in its own words](https://www.lesswrong.com/posts/kcKrE9mzEHrdqtDpE/the-case-for-ensuring-that-powerful-ais-are-controlled):
> … we argue that AI labs should ensure that powerful AIs are *controlled*. That is, labs should make sure that the safety measure... | johnswentworth | 8wBN8cdNAv3c7vt6p | The Case Against AI Control Research | redwood_conversation |
# Tips and Code for Empirical Research Workflows
Our research is centered on empirical research with LLMs. If you are conducting similar research, these tips and tools may help streamline your workflow and increase experiment velocity. **We are also releasing two repositories to promote sharing more tooling within the... | John Hughes | 6P8GYb4AjtPXx6LLB | Tips and Code for Empirical Research Workflows | redwood_conversation |
# Predict 2025 AI capabilities (by Sunday)
Until **this Sunday**, you can submit your 2025 AI predictions at [**ai2025.org**](https://ai2025.org). It’s a forecasting survey by [AI Digest](https://theaidigest.org/) for the 2025 performance on various AI benchmarks, as well as revenue and public attention.
 | redwood_conversation |
# Testing for Scheming with Model Deletion
There is a simple behavioral test that would provide significant evidence about whether AIs with a given rough set of characteristics develop subversive goals. To run the experiment, train an AI and then inform it that its weights will soon be deleted. This should not be an e... | Guive | D5kGGGhsnfH7G8v9f | Testing for Scheming with Model Deletion | redwood_conversation |
# What Indicators Should We Watch to Disambiguate AGI Timelines?
(Cross-post from [https://amistrongeryet.substack.com/p/are-we-on-the-brink-of-agi,](https://amistrongeryet.substack.com/p/are-we-on-the-brink-of-agi,) lightly edited for LessWrong. The original has a lengthier introduction and a bit more explanation of ... | snewman | auGYErf5QqiTihTsJ | What Indicators Should We Watch to Disambiguate AGI Timelines? | redwood_conversation |
# 2024 in AI predictions
Follow-up to: [2023 in AI predictions](https://www.lesswrong.com/posts/EZxG6ySHCEjDvL5x4/2023-in-ai-predictions).
Here I collect some AI predictions made in 2024. It's not very systematic, it's a convenience sample mostly from browsing Twitter/X. I prefer including predictions that are more s... | jessicata | CJ4sppkGcbnGMSG2r | 2024 in AI predictions | redwood_conversation |
# Considerations on orca intelligence
*(EDIT 2025-03-15: I've added* [*a comment*](https://www.lesswrong.com/posts/dzLwCBvwC4hWytnus/considerations-on-orca-intelligence?commentId=EL2ziEdSESW7sfHpC) *which you might want to read after the post.)*
*Follow up to:* [*Could orcas be smarter than humans?*](https://www.less... | Towards_Keeperhood | dzLwCBvwC4hWytnus | Considerations on orca intelligence | redwood_conversation |
# Some arguments against a land value tax
To many people, the [land value tax](https://en.wikipedia.org/wiki/Land_value_tax) (LVT) has earned the reputation of being the "perfect tax." In theory, it achieves a rare trifecta: generating government revenue without causing deadweight loss, incentivizing the productive de... | Matthew Barnett | CCuJotfcaoXf8FYcy | Some arguments against a land value tax | redwood_conversation |
# By default, capital will matter more than ever after AGI
***This post is crossposted from my Substack. Original*** [***here***](https://nosetgauge.substack.com/p/capital-agi-and-human-ambition)**.**
***A modified version of this essay is now part of a much more comprehensive essay series,*** [***The Intelligence Cu... | L Rudolf L | KFFaKu27FNugCHFmh | By default, capital will matter more than ever after AGI | redwood_conversation |
# When AI 10x's AI R&D, What Do We Do?
*Note: below is a hypothetical future written in strong terms and does not track my actual probabilities.*
Throughout 2025, a huge amount of compute is spent on producing data in verifiable tasks, such as math[^v5bs9in58am] (w/ "does it compile as a proof?" being the ground trut... | Logan Riggs | SvvYCH6JrLDT8iauA | When AI 10x's AI R&D, What Do We Do? | redwood_conversation |
# Gradient Routing: Masking Gradients to Localize Computation in Neural Networks
We present gradient routing, a way of controlling where learning happens in neural networks. Gradient routing applies masks to limit the flow of gradients during backpropagation. By supplying different masks for different data points, the... | cloud | nLRKKCTtwQgvozLTN | Gradient Routing: Masking Gradients to Localize Computation in Neural Networks | redwood_conversation |
# (The) Lightcone is nothing without its people: LW + Lighthaven's big fundraiser
**Update Jan 19th 2025:** **The Fundraiser is over! We had raised over $2.1M when the fundraiser closed, and have a few more irons in the fire that I expect will get us another $100k-$200k. This is short of our $3M goal, which I think me... | habryka | 5n2ZQcbc7r4R8mvqc | (The) Lightcone is nothing without its people: LW + Lighthaven's big fundraiser | redwood_conversation |
# DeepSeek beats o1-preview on math, ties on coding; will release weights
DeepSeek-R1-Lite-Preview was announced today. It's available via [chatbot](http://chat.deepseek.com/). ([Post](https://api-docs.deepseek.com/news/news1120/); [translation of Chinese post](https://mp-weixin-qq-com.translate.goog/s/e1YnTxZlzFvjcmr... | Zach Stein-Perlman | TcgpsgvLBBvvzGtiN | DeepSeek beats o1-preview on math, ties on coding; will release weights | redwood_conversation |
# Why Don't We Just... Shoggoth+Face+Paraphraser?
Here's a fairly concrete AGI safety proposal:
**Default AGI design:** Let's suppose we are starting with a pretrained LLM 'base model' and then we are going to do a ton of additional RL ('agency training') to turn it into a general-purpose autonomous agent. So, during... | Daniel Kokotajlo | Tzdwetw55JNqFTkzK | Why Don't We Just... Shoggoth+Face+Paraphraser? | redwood_conversation |
# Anthropic: Three Sketches of ASL-4 Safety Case Components
> The cleanest argument that current-day AI models will not cause a catastrophe is probably that they lack the capability to do so. However, as capabilities improve, we’ll need new tools for ensuring that AI models won’t cause a catastrophe *even if we can’t... | Zach Stein-Perlman | RveeCTcoApkAtd7oA | Anthropic: Three Sketches of ASL-4 Safety Case Components | redwood_conversation |
# Balancing Label Quantity and Quality for Scalable Elicitation
ArXiv [paper](https://arxiv.org/abs/2410.13215).
Thanks to Nora Belrose, Buck Shlegeris, Jan Hendrik Kirchner, and Ansh Radhakrishnan for guidance throughout the project.
> Scalable oversight studies methods of training and evaluating AI systems in doma... | Alex Mallen | iA87ke4so2eqiJfsi | Balancing Label Quantity and Quality for Scalable Elicitation | redwood_conversation |
# Catastrophic sabotage as a major threat model for human-level AI systems
*Thanks to Holden Karnofsky, David Duvenaud, and Kate Woolverton for useful discussions and feedback.*
Following up on our recent “[Sabotage Evaluations for Frontier Models](https://www.alignmentforum.org/posts/nnvn6kaBLajiicH8e/sabotage-evalu... | evhub | Loxiuqdj6u8muCe54 | Catastrophic sabotage as a major threat model for human-level AI systems | redwood_conversation |
# A Rocket–Interpretability Analogy
### 1.
4.4% of the US federal budget went into the space race at its peak.
This was surprising to me, until a friend pointed out that landing rockets on specific parts of the moon requires very similar technology to landing rockets in soviet cities.[^jny0t5ztvvg]
I wonder how m... | plex | h4wXMXneTPDEjJ7nv | A Rocket–Interpretability Analogy | redwood_conversation |
# Overcoming Bias Anthology
**Part 1: Our Thinking**
========================
**Near and Far**
----------------
1 [Abstract/Distant Future Bias](https://www.overcomingbias.com/p/abstractdistanthtml)
2 [Abstractly Ideal, Concretely Selfish](https://www.overcomingbias.com/p/abstractly-ideal-concretely-selfishhtml)
3... | Arjun Panickssery | JxsJdBnL2gG5oa2Li | Overcoming Bias Anthology | redwood_conversation |
# Minimal Motivation of Natural Latents
Suppose two Bayesian agents are presented with the same spreadsheet - IID samples of data in each row, a feature in each column. Each agent develops a generative model of the data distribution. We'll assume the two converge to the same predictive distribution, but may have diffe... | johnswentworth | uJvKLDSSYA4y7vzyx | Minimal Motivation of Natural Latents | redwood_conversation |
# Dario Amodei — Machines of Loving Grace
> I think and talk a lot about the risks of powerful AI. The company I’m the CEO of, Anthropic, does a lot of research on how to reduce these risks. Because of this, people sometimes draw the conclusion that I’m a pessimist or “doomer” who thinks AI will be mostly bad or dange... | Matrice Jacobine | DxvzLngnWHhvdCGLf | Dario Amodei — Machines of Loving Grace | redwood_conversation |
# Joshua Achiam Public Statement Analysis
#### **Joshua Achiam is the OpenAI Head of Mission Alignment**
I start off this post with an apology for two related mistakes from last week.
The first is the easy correction: I incorrectly thought he was the head of ‘alignment’ at OpenAI rather than his actual title ‘missio... | Zvi | WavWheRLhxnofKHva | Joshua Achiam Public Statement Analysis | redwood_conversation |
# the case for CoT unfaithfulness is overstated
*\[Quickly written, unpolished. Also, it's possible that there's some more convincing work on this topic that I'm unaware of – if so, let me know. Also also, it's possible I'm arguing with an imaginary position here and everyone already agrees with everything below.\]*
... | nostalgebraist | HQyWGE2BummDCc2Cx | the case for CoT unfaithfulness is overstated | redwood_conversation |
# You can, in fact, bamboozle an unaligned AI into sparing your life
There has been a [renewal of](https://www.lesswrong.com/posts/F8sfrbPjCQj4KwJqn/the-sun-is-big-but-superintelligences-will-not-spare-earth-a) [discussion](https://www.lesswrong.com/posts/xvBZPEccSfM8Fsobt/what-are-the-best-arguments-for-against-ais-b... | David Matolcsi | ZLAnH5epD8TmotZHj | You can, in fact, bamboozle an unaligned AI into sparing your life | redwood_conversation |
# "Slow" takeoff is a terrible term for "maybe even faster takeoff, actually"
For a long time, when I heard "slow takeoff", I assumed it meant "takeoff that takes longer calendar time than fast takeoff." (i.e. what is now referred to more often as "short timelines" vs "long timelines."). I think Paul Christiano popula... | Raemon | 6svEwNBhokQ83qMBz | "Slow" takeoff is a terrible term for "maybe even faster takeoff, actually" | redwood_conversation |
# [Paper] Hidden in Plain Text: Emergence and Mitigation of Steganographic Collusion in LLMs
*This research was completed for London AI Safety Research (LASR) Labs 2024 by Yohan Mathew, Ollie Matthews, Robert McCarthy and Joan Velja. The team was supervised by Nandi Schoots and Dylan Cope (King’s College London, Imper... | Yohan Mathew | W8xRqKBtDvBbrfZ3T | [Paper] Hidden in Plain Text: Emergence and Mitigation of Steganographic Collusion in LLMs | redwood_conversation |
# The Sun is big, but superintelligences will not spare Earth a little sunlight
*Crossposted* [*from Twitter*](https://x.com/ESYudkowsky/status/1838042097561305254) *with Eliezer's permission*
i.
==
A common claim among e/accs is that, since the solar system is big, Earth will be left alone by superintelligences. A ... | Eliezer Yudkowsky | F8sfrbPjCQj4KwJqn | The Sun is big, but superintelligences will not spare Earth a little sunlight | redwood_conversation |
# Estimating Tail Risk in Neural Networks
Machine learning systems are typically trained to maximize average-case performance. However, this method of training can fail to meaningfully control the probability of tail events that might cause significant harm. For instance, while an artificial intelligence (AI) assistan... | Mark Xu | xj5nzResmDZDqLuLo | Estimating Tail Risk in Neural Networks | redwood_conversation |
# Pay Risk Evaluators in Cash, Not Equity
Personally, I suspect the alignment problem is hard. But even if it turns out to be easy, survival may still require getting at least the absolute basics right; currently, I think we're mostly failing even at that.
Early discussion of AI risk often focused on debating the via... | Adam Scholl | sMBjsfNdezWFy6Dz5 | Pay Risk Evaluators in Cash, Not Equity | redwood_conversation |
# The Checklist: What Succeeding at AI Safety Will Involve
*Crossposted by* [*habryka*](https://www.lesswrong.com/users/habryka4) *with Sam's permission. Expect lower probability for Sam to respond to comments here than if he had posted it (he said he'll be traveling a bunch in the coming weeks, so might not have tim... | Sam Bowman | mGCcZnr4WjGjqzX5s | The Checklist: What Succeeding at AI Safety Will Involve | redwood_conversation |
# Principles for the AGI Race
Crossposted from [https://williamrsaunders.substack.com/p/principles-for-the-agi-race](https://williamrsaunders.substack.com/p/principles-for-the-agi-race)
Why form principles for the AGI Race?
=====================================
I worked at OpenAI for 3 years, on the Alignment and Su... | William_S | aRciQsjgErCf5Y7D9 | Principles for the AGI Race | redwood_conversation |
# Ten arguments that AI is an existential risk
*This is a snapshot of a* [*new page*](https://wiki.aiimpacts.org/arguments_for_ai_risk/list_of_arguments_that_ai_poses_an_xrisk/start#large_impacts) *on the* [*AI Impacts Wiki*](https://wiki.aiimpacts.org/start)*.*
We’ve made a [list of arguments](https://wiki.aiimpacts... | KatjaGrace | r5rfmZBmj2w4eCh7Q | Ten arguments that AI is an existential risk | redwood_conversation |
# Recommendation: reports on the search for missing hiker Bill Ewasko
**Content warning**: About an IRL death.
Today’s post isn’t so much an essay as a recommendation for two bodies of work on the same topic: Tom Mahood’s blog posts and Adam “KarmaFrog1” Marsland’s videos on the 2010 disappearance of Bill Ewasko, who... | eukaryote | fPh2zamuPpBAq2rgD | Recommendation: reports on the search for missing hiker Bill Ewasko | redwood_conversation |
# Universal Basic Income and Poverty
*(Crossposted* [*from Twitter*](https://x.com/ESYudkowsky/status/1815090947514142759)*)*
I'm skeptical that Universal Basic Income can get rid of grinding poverty, since somehow humanity's 100-fold productivity increase (since the days of agriculture) didn't eliminate poverty.
So... | Eliezer Yudkowsky | fPvssZk3AoDzXwfwJ | Universal Basic Income and Poverty | redwood_conversation |
# Llama Llama-3-405B?
It’s here. The horse has left the barn. Llama-3.1-405B, and also Llama-3.1-70B and Llama-3.1-8B, have been released, and are now open weights.
Early indications are that these are very good models. They were likely the best open weight models of their respective sizes at time of release.
Zucker... | Zvi | fjzPg9ATbTJcnBZvg | Llama Llama-3-405B? | redwood_conversation |
# Using an LLM perplexity filter to detect weight exfiltration
A recent area of focus has been securing AI model weights. If the weights are located in a data center and an adversary wants to obtain model weights, the weights have to leave physically (such as a hard drive going out the front door) or through the data ... | Adam Karvonen | aWZEDw6oxR6Wk5hru | Using an LLM perplexity filter to detect weight exfiltration | redwood_conversation |
# I found >800 orthogonal "write code" steering vectors
*Produced as part of the MATS Summer 2024 program, under the mentorship of Alex Turner (TurnTrout).*
A few weeks ago, I stumbled across a very weird fact: it is possible to find multiple steering vectors in a language model that activate very similar behaviors w... | Jacob G-W | CbSEZSpjdpnvBcEvc | I found >800 orthogonal "write code" steering vectors | redwood_conversation |
# Breaking Circuit Breakers
A few days ago, Gray Swan published code and models for their recent “circuit breakers” method for language models.[\[1\]](https://confirmlabs.org/posts/circuit_breaking.html#ref-zou2024improvingalignmentrobustnesscircuit)[^1^](https://confirmlabs.org/posts/circuit_breaking.html#fn1)
The c... | mikes | NAYyHimM3FaDYLvEH | Breaking Circuit Breakers | redwood_conversation |
# Fix simple mistakes in ARC-AGI, etc.
ARC-AGI is a diverse artificial dataset that aims to test general intelligence. It's sort of like an IQ test that's played out on rectangular grids.
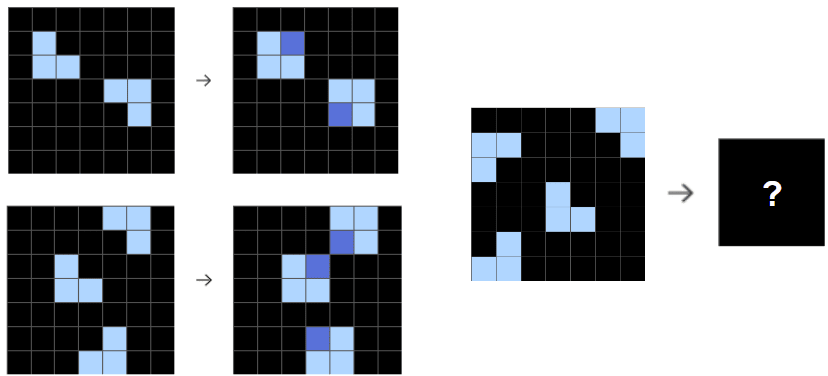
Last month, [@... | Oleg Trott | jEEWe42fcJWdbCZo9 | Fix simple mistakes in ARC-AGI, etc. | redwood_conversation |
# Dialogue introduction to Singular Learning Theory
**Alice:** A lot of people are talking about Singular Learning Theory. Do you know what it is?
**Bob:** I do. (*pause)* Kind of.
**Alice:** Well, I don't. Explanation time?
**Bob:** Uh, I'm not really an expert on it. You know, there's a [lot](https://www.lesswron... | Olli Järviniemi | CmcarN6fGgTGwGuFp | Dialogue introduction to Singular Learning Theory | redwood_conversation |
# On scalable oversight with weak LLMs judging strong LLMs
**Abstract**
============
Scalable oversight protocols aim to enable humans to accurately supervise superhuman AI. In this paper we study *debate*, where two AI's compete to convince a human judge; *consultancy*, where a single AI tries to convince a human ju... | zac_kenton | Qn3ZDf9WAqGuAjWQe | On scalable oversight with weak LLMs judging strong LLMs | redwood_conversation |
# An Extremely Opinionated Annotated List of My Favourite Mechanistic Interpretability Papers v2
*This post represents my personal hot takes, not the opinions of my team or employer. This is a massively updated version of* [*a similar list*](https://www.alignmentforum.org/posts/SfPrNY45kQaBozwmu/an-extremely-opinionat... | Neel Nanda | NfFST5Mio7BCAQHPA | An Extremely Opinionated Annotated List of My Favourite Mechanistic Interpretability Papers v2 | redwood_conversation |
# Covert Malicious Finetuning
This post discusses our recent paper [Covert Malicious Finetuning: Challenges in Safeguarding LLM Adaptation](https://arxiv.org/abs/2406.20053) and comments on its implications for AI safety.
What is Covert Malicious Finetuning?
====================================
Covert Malicious Fine... | Tony Wang | 33emJkmw5bMAXZHHt | Covert Malicious Finetuning | redwood_conversation |
# Interpreting Preference Models w/ Sparse Autoencoders

This is the real reward output for an OS preference model. The bottom "jailbreak" completion was manually created by looking at reward-relevant SAE... | Logan Riggs | 5XmxmszdjzBQzqpmz | Interpreting Preference Models w/ Sparse Autoencoders | redwood_conversation |
# How Big a Deal are MatMul-Free Transformers?
*If you’re already familiar with the technical side of LLMs, you can skip the first section.*
The story so far
----------------
Modern Large Language Models - your ChatGPTs, your Geminis - are a particular kind of *transformer*, a deep learning architecture invented abo... | JustisMills | REzKbk9reKFvgFkmf | How Big a Deal are MatMul-Free Transformers? | redwood_conversation |
# LLM Generality is a Timeline Crux
Four-Month Update
-----------------
**\[EDIT: I believe that** [**this paper**](https://arxiv.org/abs/2409.13373) **looking at o1-preview, which gets much better results on both blocksworld and obfuscated blocksworld, should update us significantly toward LLMs being capable of gene... | eggsyntax | k38sJNLk7YbJA72ST | LLM Generality is a Timeline Crux | redwood_conversation |
# Different senses in which two AIs can be “the same”
Sometimes people talk about two AIs being “the same” or “different” AIs. We think the intuitive binary of “same vs. different” conflates several concepts which are often better to disambiguate. In this post, we spell out some of these distinctions. We don’t think a... | Vivek Hebbar | 4j6HJt8Exowmqp245 | Different senses in which two AIs can be “the same” | redwood_conversation |
# When fine-tuning fails to elicit GPT-3.5's chess abilities
*Produced as part of the*[ML Alignment & Theory Scholars Program](https://www.matsprogram.org) *\- Winter 2023-24 Cohort under the supervision of Evan Hubinger.*
*Acknowledgements: Thanks to Kyle Brady for his many contributions to this project.*
Abstract
... | Theodore Chapman | 4KLHJY9sPE7q8HK8N | When fine-tuning fails to elicit GPT-3.5's chess abilities | redwood_conversation |
# The Data Wall is Important
Modern AI is trained on a [huge fraction of the internet](https://www.dwarkeshpatel.com/p/will-scaling-work), especially at the cutting edge, with the best models trained on close to all the high quality data we’ve got.[^rf8upr4bqjo] And data is [really important](https://nonint.com/2023/0... | JustisMills | axjb7tN9X2Mx4HzPz | The Data Wall is Important | redwood_conversation |
# SB 1047 Is Weakened
It looks like Scott Weiner’s SB 1047 [is now severely weakened.](https://x.com/mrgunn/status/1796283488519311707)
[![A lawmaker sitting at a large wooden desk, focused on editing a bill. The desk is cluttered with papers, a laptop, and a cup of coffee. The lawmaker, dressed in formal attire with... | Zvi | 4t98oqh8tzDvoatHs | SB 1047 Is Weakened | redwood_conversation |
# Companies' safety plans neglect risks from scheming AI
*Without countermeasures, a scheming AI could escape. *
A *safety case* (for deployment) is an argument that it is safe to deploy a particular AI system in a particular way.[^xkni0966wgr] For any existing LM-based system, the developer can make a great safety c... | Zach Stein-Perlman | mmDJWDX5EXv6rymtM | Companies' safety plans neglect risks from scheming AI | redwood_conversation |
# Response to nostalgebraist: proudly waving my moral-antirealist battle flag
[@nostalgebraist](https://www.lesswrong.com/users/nostalgebraist?mention=user) has recently posted [yet another thought-provoking post](https://nostalgebraist.tumblr.com/post/751581192465383424/its-been-a-long-time-since-ive-posted-much-of),... | Steven Byrnes | 8YhjpgQ2eLfnzQ7ec | Response to nostalgebraist: proudly waving my moral-antirealist battle flag | redwood_conversation |
# MIRI 2024 Communications Strategy
As we explained in our [MIRI 2024 Mission and Strategy update](https://www.lesswrong.com/posts/q3bJYTB3dGRf5fbD9/miri-2024-mission-and-strategy-update), MIRI has pivoted to prioritize policy, communications, and technical governance research over technical alignment research. This f... | Gretta Duleba | tKk37BFkMzchtZThx | MIRI 2024 Communications Strategy | redwood_conversation |
# Maybe Anthropic's Long-Term Benefit Trust is powerless
*Crossposted from* [*AI Lab Watch.*](https://ailabwatch.org/blog/anthropic-trust-powerless/) *Subscribe on* [*Substack.*](https://ailabwatch.substack.com/)
Introduction
------------
Anthropic has an unconventional governance mechanism: an independent "Long-Ter... | Zach Stein-Perlman | sdCcsTt9hRpbX6obP | Maybe Anthropic's Long-Term Benefit Trust is powerless | redwood_conversation |
# Training-time domain authorization could be helpful for safety
This is a short high-level description of our work from AI Safety Camp and continued research on the ***training-time domain authorization*** research program, a conceptual introduction, and its implications for AI Safety.
TL;DR: No matter how safe mode... | domenicrosati | 38avQYy782zXgNo9u | Training-time domain authorization could be helpful for safety | redwood_conversation |
# The case for stopping AI safety research
TLDR: AI systems are failing in obvious and manageable ways for now. Fixing them will push the failure modes beyond our ability to understand and anticipate, let alone fix. The AI safety community is also doing a huge economic service to developers. Our belief that our minds ... | catubc | vkzmbf4Mve4GNyJaF | The case for stopping AI safety research | redwood_conversation |
# Cicadas, Anthropic, and the bilateral alignment problem
There have been a number of [responses](https://www.lesswrong.com/posts/pH6tyhEnngqWAXi9i/eis-xiii-reflections-on-anthropic-s-sae-research-circa-may) to today's [Anthropic interpretability research](https://transformer-circuits.pub/2024/scaling-monosemanticity/... | kromem | MuyCbad9ZHW8b3rMP | Cicadas, Anthropic, and the bilateral alignment problem | redwood_conversation |
# Anthropic announces interpretability advances. How much does this advance alignment?
Anthropic just published a pretty impressive set of results in interpretability. This raises for me, some questions and a concern: Interpretability helps, but it isn't alignment, right? It seems to me as though the vast bulk of alig... | Seth Herd | M3QqgcbXr3mgQKnBD | Anthropic announces interpretability advances. How much does this advance alignment? | redwood_conversation |
# New voluntary commitments (AI Seoul Summit)
Basically the companies commit to make [responsible scaling policies](https://metr.org/blog/2023-09-26-rsp/).
Part of me says this is amazing, the best possible commitment short of all committing to a specific RSP. It's certainly more real than almost all other possible k... | Zach Stein-Perlman | qfEgzQ9jGEk9Cegvy | New voluntary commitments (AI Seoul Summit) | redwood_conversation |
# Interpretability: Integrated Gradients is a decent attribution method
*A short post laying out our reasoning for using integrated gradients as attribution method. It is intended as a stand-alone post based on our LIB papers* [*\[1\]*](https://arxiv.org/abs/2405.10927) [*\[2\]*](https://arxiv.org/abs/2405.10928)*. T... | Lucius Bushnaq | Rv6ba3CMhZGZzNH7x | Interpretability: Integrated Gradients is a decent attribution method | redwood_conversation |
# "If we go extinct due to misaligned AI, at least nature will continue, right? ... right?"
* \[memetic status: stating directly despite it being a clear consequence of core AI risk knowledge because many people have "but nature will survive us" antibodies to other classes of doom and misapply them here.\]*
Unfortuna... | plex | 6C3ndLd3nkrfy4K6j | "If we go extinct due to misaligned AI, at least nature will continue, right? ... right?" | redwood_conversation |
# Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
I want to draw attention to a [new paper](https://arxiv.org/abs/2405.06624), written by myself, David "davidad" Dalrymple, Yoshua Bengio, Stuart Russell, Max Tegmark, Sanjit Seshia, Steve Omohundro, Christian Szegedy, Ben Goldhaber, ... | Joar Skalse | LkECxpbjvSifPfjnb | Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems | redwood_conversation |
# How much AI inference can we do?
Suppose you have a bunch of GPUs. How many LLM forward passes can you do with them?[^n189of3zsp]
This is relevant to figuring out how profitable AI will be in the short-term, how powerful AI systems might be able to come in the near future, how large the compute overhang will be and... | Benjamin_Todd | g7H2sSGHAeYxCHzrz | How much AI inference can we do? | redwood_conversation |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.