
text stringlengths 50 248k | author stringlengths 2 43 | id stringlengths 9 17 | title stringlengths 0 173 | source stringclasses 4
values |
|---|---|---|---|---|
# "AI Safety for Fleshy Humans" an AI Safety explainer by Nicky Case
Nicky Case, of ["The Evolution of Trust"](https://ncase.me/trust/) and ["We Become What We Behold"](https://ncase.itch.io/wbwwb) fame (two quite popular online explainers/mini-games) has written an intro explainer to AI Safety! It looks pretty good ... | habryka | gprh2HD6PDK6AZDqP | "AI Safety for Fleshy Humans" an AI Safety explainer by Nicky Case | redwood_conversation |
# Questions for labs
Associated with [AI Lab Watch](https://www.lesswrong.com/posts/N2r9EayvsWJmLBZuF/introducing-ai-lab-watch), I sent questions to some labs a week ago (except I failed to reach Microsoft). I didn't really get any replies (one person replied in their personal capacity; this was very limited and they ... | Zach Stein-Perlman | jbJ7FynonxFXeoptf | Questions for labs | redwood_conversation |
# Mechanistically Eliciting Latent Behaviors in Language Models
*Produced as part of the MATS Winter 2024 program, under the mentorship of Alex Turner (TurnTrout).*
**TL,DR:** I introduce a method for eliciting latent behaviors in language models by learning unsupervised perturbations of an early layer of an LLM. The... | Andrew Mack | ioPnHKFyy4Cw2Gr2x | Mechanistically Eliciting Latent Behaviors in Language Models | redwood_conversation |
# Introducing AI Lab Watch
I'm launching [AI Lab Watch](https://ailabwatch.org). I collected actions for frontier AI labs to improve AI safety, then evaluated some frontier labs accordingly.
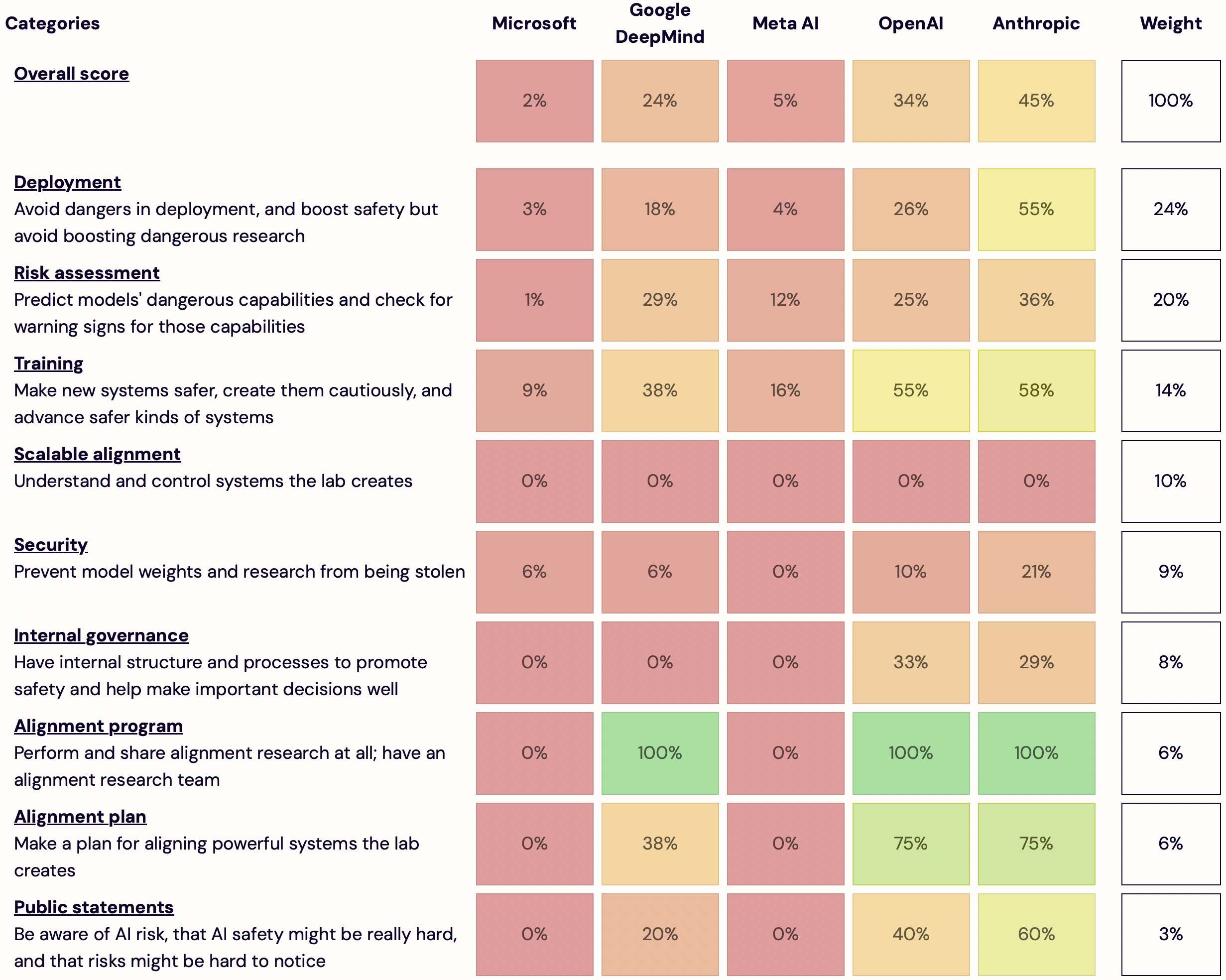
It's a coll... | Zach Stein-Perlman | N2r9EayvsWJmLBZuF | Introducing AI Lab Watch | redwood_conversation |
# We are headed into an extreme compute overhang
If we achieve AGI-level performance using an LLM-like approach, the training hardware will be capable of running ~1,000,000s concurrent instances of the model.
Definitions
===========
Although there is [some debate](https://www.lesswrong.com/posts/icR53xeAkeuzgzsWP/ta... | devrandom | cRFtWjqoNrKmgLbFw | We are headed into an extreme compute overhang | redwood_conversation |
# Simple probes can catch sleeper agents
*This is a link post for the Anthropic Alignment Science team's first "Alignment Note" blog post. We expect to use this format to showcase early-stage research and work-in-progress updates more in the future.*
[Twitter thread here.](https://twitter.com/AnthropicAI/status/17829... | Monte M | gknc6NWCNuTCe8ekp | Simple probes can catch sleeper agents | redwood_conversation |
# Motivation gaps: Why so much EA criticism is hostile and lazy
*Disclaimer: While I criticize several EA critics in this article, I am myself on the EA-skeptical side of things (especially on AI risk).*
### **Introduction**
I am a proud critic of effective altruism, and in particular a critic of AI existential ris... | titotal | ojPJYci3AdgdHsKY8 | Motivation gaps: Why so much EA criticism is hostile and lazy | redwood_conversation |
# Inducing Unprompted Misalignment in LLMs
Emergent Instrumental Reasoning Without Explicit Goals
======================================================
**TL;DR**: LLMs can act and scheme without being told to do so. This is bad.
*Produced as part of Astra Fellowship - Winter 2024 program, mentored by Evan Hubing... | Sam Svenningsen | ukTLGe5CQq9w8FMne | Inducing Unprompted Misalignment in LLMs | redwood_conversation |
# Discriminating Behaviorally Identical Classifiers: a model problem for applying interpretability to scalable oversight
In a new preprint, [Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models](https://arxiv.org/abs/2403.19647), my coauthors and I introduce a technique, Spar... | Sam Marks | s7uD3tzHMvD868ehr | Discriminating Behaviorally Identical Classifiers: a model problem for applying interpretability to scalable oversight | redwood_conversation |
# Staged release
"Staged release" is regularly mentioned as *a good thing for frontier AI labs to do*. But I've only ever seen one analysis of staged release,[^uj9a8bk9zt] and the term's meaning has changed, becoming vaguer since the GPT-2 era.
This post is kinda a reference post, kinda me sharing my understanding/ta... | Zach Stein-Perlman | RdsqJnmP8XxutLbso | Staged release | redwood_conversation |
# A quick experiment on LMs’ inductive biases in performing search
TL;DR: Based on a toy setting, GPT-3.5-turbo and GPT-4-turbo are best at search (by which I mean computing an argmax) when using chain-of-thought, but neither of them can do *internal *search when forced to work from memory over only a few token positi... | Alex Mallen | XaKLjyDejtXDoRAzL | A quick experiment on LMs’ inductive biases in performing search | redwood_conversation |
# Is LLM Translation Without Rosetta Stone possible?
Suppose astronomers detect a binary radio signal, an alien message, from a star system many light years away. The message contains a large text dump (conveniently, about GPT-4 training text data sized) composed in an alien language. Let's call it Alienese.[^1]
Unfo... | cubefox | J3zA3T9RTLkKYNgjw | Is LLM Translation Without Rosetta Stone possible? | redwood_conversation |
# Run evals on base models too!
(Creating more visibility for a [comment thread with Rohin Shah](https://www.lesswrong.com/posts/5Dz3ZrwBzzMfaucrH/ai-57-all-the-ai-news-that-s-fit-to-print?commentId=AaapY2KK4fDvwWaRT).)
Currently, [DeepMind's capabilities evals](https://twitter.com/rohinmshah/status/17707466641411732... | orthonormal | dgFC394qZHgj2cWAg | Run evals on base models too! | redwood_conversation |
# The Case for Predictive Models
*Thanks to Johannes Treutlein and Paul Colognese for feedback on this post.*
Just over a year ago, the [Conditioning Predictive Models](https://arxiv.org/abs/2302.00805) paper was released. It laid out an argument and a plan for using powerful predictive models to reduce existential r... | Rubi J. Hudson | RHDB3BdnvM233bnhG | The Case for Predictive Models | redwood_conversation |
# Sparsify: A mechanistic interpretability research agenda
Over the last couple of years, mechanistic interpretability has seen substantial progress. Part of this progress has been enabled by the identification of superposition as a key barrier to understanding neural networks ([Elhage et al., 2022](https://transforme... | Lee Sharkey | 64MizJXzyvrYpeKqm | Sparsify: A mechanistic interpretability research agenda | redwood_conversation |
# Modern Transformers are AGI, and Human-Level
*This is my personal opinion, and in particular, does not represent anything like a MIRI consensus; I've gotten push-back from almost everyone I've spoken with about this, although in most cases I believe I eventually convinced them of the narrow terminological point I'm ... | abramdemski | gP8tvspKG79RqACTn | Modern Transformers are AGI, and Human-Level | redwood_conversation |
# Announcing Neuronpedia: Platform for accelerating research into Sparse Autoencoders
*This posts assumes basic familiarity with Sparse Autoencoders. For those unfamiliar with this technique, we highly recommend the introductory sections of *[*these*](https://transformer-circuits.pub/2023/monosemantic-features)[*paper... | Johnny Lin | BaEQoxHhWPrkinmxd | Announcing Neuronpedia: Platform for accelerating research into Sparse Autoencoders | redwood_conversation |
# On the Confusion between Inner and Outer Misalignment
Here’s my take on why the distinction between inner and outer-alignment frame is weird/unclear/ambiguous in some circumstances: My understanding is that these terms were originally used when talking about AGI. So outer alignment involved writing down a reward or ... | Chris_Leong | hueNHXKc4xdn6cfB4 | On the Confusion between Inner and Outer Misalignment | redwood_conversation |
# AI #56: Blackwell That Ends Well
Hopefully, anyway. Nvidia has a new chip.
Also Altman has a new interview.
And most of Inflection has new offices inside Microsoft.
#### Table of Contents
1. Introduction.
2. Table of Contents.
3. Language Models Offer Mundane Utility. Open the book.
4. Clauding Along. Claude... | Zvi | iH5Sejb4dJGA2oTaP | AI #56: Blackwell That Ends Well | redwood_conversation |
# DeepMind: Evaluating Frontier Models for Dangerous Capabilities
> To understand the risks posed by a new AI system, we must understand what it can and cannot do. Building on prior work, we introduce a programme of new “dangerous capability” evaluations and pilot them on Gemini 1.0 models. Our evaluations cover four ... | Zach Stein-Perlman | CCBaLzpB2qvwyuEJ2 | DeepMind: Evaluating Frontier Models for Dangerous Capabilities | redwood_conversation |
# New report: Safety Cases for AI
*ArXiv paper:* [*https://arxiv.org/abs/2403.10462*](https://arxiv.org/abs/2403.10462)
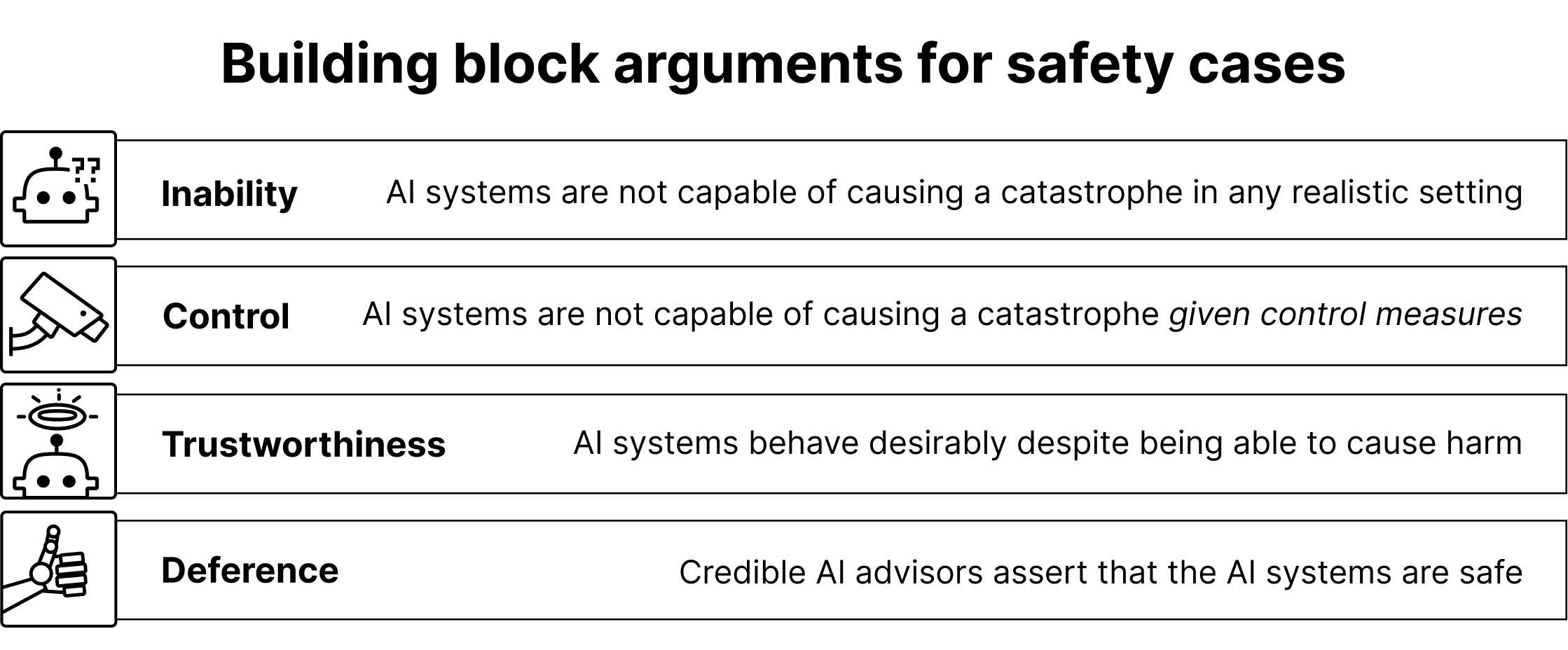
The idea for this paper occurred to me when I saw Buck Shlegeris' MATS stream on "... | joshc | HrtyZm2zPBtAmZFEs | New report: Safety Cases for AI | redwood_conversation |
# On Devin
#### Introducing Devin
Is the era of AI agents writing complex code systems without humans in the loop upon us?
[Cognition is calling Devin](https://www.cognition-labs.com/blog) ‘the first AI software engineer.’
[Here is a two minute demo](https://twitter.com/cognition_labs/status/1767548763134964000) of... | Zvi | wovJBkfZ8rTyLoEKv | On Devin | redwood_conversation |
# What is the best argument that LLMs are shoggoths?
Where can I find a post or a*rt*icle arguing that the internal cognitive model of contemporary LLMs is quite alien, strange, non-human, even though they are trained on human text and produce human-like answers, which are rendered "friendly" by RLHF?
To be clear... | JoshuaFox | FyRDZDvgsFNLkeyHF | What is the best argument that LLMs are shoggoths? | redwood_conversation |
# 'Empiricism!' as Anti-Epistemology
*(Crossposted by* [*habryka*](https://www.lesswrong.com/users/habryka4) *after asking Eliezer whether I could post it under his account)*
### **i.**
"Ignore all these elaborate, abstract, theoretical predictions," the Spokesperson for Ponzi Pyramid Incorporated said in a firm, re... | Eliezer Yudkowsky | LvKDMWQ3yLG9R3gHw | 'Empiricism!' as Anti-Epistemology | redwood_conversation |
# Highlights from Lex Fridman’s interview of Yann LeCun
Introduction
============
Yann LeCun is perhaps the most prominent critic of the “LessWrong view” on AI safety, the only one of the three "godfathers of AI" to not acknowledge the risks of advanced AI. So, when he recently [appeared on the Lex Fridman podcast](h... | Joel Burget | bce63kvsAMcwxPipX | Highlights from Lex Fridman’s interview of Yann LeCun | redwood_conversation |
# Laying the Foundations for Vision and Multimodal Mechanistic Interpretability & Open Problems

Behold the dogit lens. Patch-level logit attribution is an emergent segmentation map.
*Join our Discord *[... | Sonia Joseph | kobJymvvcvhbjWFKe | Laying the Foundations for Vision and Multimodal Mechanistic Interpretability & Open Problems | redwood_conversation |
# What could a policy banning AGI look like?
[Caveat lector: I know roughly nothing about policy!]
Suppose that there were political support to really halt research that might lead to an unstoppable, unsteerable transfer of control over the lightcone from humans to AGIs. What government policy could exert that politi... | TsviBT | X9Z9vdG7kEFTBkA6h | What could a policy banning AGI look like? | redwood_conversation |
# Results from an Adversarial Collaboration on AI Risk (FRI)
*Authors of linked report: Josh Rosenberg, Ezra Karger, Avital Morris, Molly Hickman, Rose Hadshar, Zachary Jacobs, Philip Tetlock*[^crpys2viudt]
Today, the Forecasting Research Institute (FRI) released “[Roots of Disagreement on AI Risk: Exploring the Pote... | Josh Rosenberg | 94K6pskgqBmuxsJLx | Results from an Adversarial Collaboration on AI Risk (FRI) | redwood_conversation |
# Simple versus Short: Higher-order degeneracy and error-correction
> **TLDR:** *The simplicity bias in Bayesian statistics is not just a bias towards short description length. *
**The folklore relating the simplicity bias in Bayesian statistics to description length is incomplete**: while it is true that the fewer p... | Daniel Murfet | nWRj6Ey8e5siAEXbK | Simple versus Short: Higher-order degeneracy and error-correction | redwood_conversation |
# Deconstructing Bostrom's Classic Argument for AI Doom
I had a pretty great discussion with social psychologist and philosopher Lance Bush recently about the orthogonality thesis, which ended up turning into a broader analysis of Nick Bostrom's argument for AI doom as presented in *Superintelligence*, and some relate... | Nora Belrose | RbynKk3evb6RiLryL | Deconstructing Bostrom's Classic Argument for AI Doom | redwood_conversation |
# One-shot strategy games?
I'm looking for computer games that involve strategy, resource management, hidden information, and management of "value of information" (i.e. figuring out when to explore or exploit), which:
* \*can\* be beaten in 30 – 120 minutes on your first try (or, there's a clear milestone that's ab... | Raemon | DvRBSzFjfaPYBhwmj | One-shot strategy games? | redwood_conversation |
# Many arguments for AI x-risk are wrong
_The following is a lightly edited version of a memo I wrote for a retreat. It was inspired by a draft of [Counting arguments provide no evidence for AI doom](https://www.lesswrong.com/posts/YsFZF3K9tuzbfrLxo/counting-arguments-provide-no-evidence-for-ai-doom). I think that my ... | TurnTrout | yQSmcfN4kA7rATHGK | Many arguments for AI x-risk are wrong | redwood_conversation |
# Are we so good to simulate?
If you believe that,—
a) a civilization like ours is likely to survive into technological incredibleness, and
b) a technologically incredible civilization is very likely to create ‘ancestor simulations’,
—then the Simulation Argument says you should expect that you are currently in suc... | KatjaGrace | di4Dhho4xZ4x9ABna | Are we so good to simulate? | redwood_conversation |
# Bengio's Alignment Proposal: "Towards a Cautious Scientist AI with Convergent Safety Bounds"
Yoshua Bengio recently posted a high-level overview of his alignment research agenda on his blog. I'm pasting the full text below since it's fairly short.
> What can’t we afford with a future superintelligent AI? Among othe... | mattmacdermott | edvyWfKdJHnoPkM2J | Bengio's Alignment Proposal: "Towards a Cautious Scientist AI with Convergent Safety Bounds" | redwood_conversation |
# Counting arguments provide no evidence for AI doom
*Crossposted from the* [*AI Optimists blog*](https://optimists.ai/2024/02/27/counting-arguments-provide-no-evidence-for-ai-doom/)*.*
AI doom scenarios often suppose that future AIs will engage in **scheming**— planning to escape, gain power, and pursue ulterior mot... | Nora Belrose | YsFZF3K9tuzbfrLxo | Counting arguments provide no evidence for AI doom | redwood_conversation |
# The Shutdown Problem: Incomplete Preferences as a Solution
**Preamble**
============
This post is an updated explanation of the POST-Agents Proposal (PAP): my proposed solution to the shutdown problem.[^g6wtgrwwuj4] The post is shorter than my AI Alignment Awards [contest entry](https://s3.amazonaws.com/pf-user-fil... | Elliott Thornley (EJT) | YbEbwYWkf8mv9jnmi | The Shutdown Problem: Incomplete Preferences as a Solution | redwood_conversation |
# Extinction Risks from AI: Invisible to Science?
**Abstract:** In an effort to inform the discussion surrounding existential risks from AI, we formulate Extinction-level Goodhart’s Law as "*Virtually any goal specification, pursued to the extreme, will result in the extinction*[^wwed95q0dgc]* of humanity*'', and we a... | VojtaKovarik | d5oqvgCR7SDf5m4k4 | Extinction Risks from AI: Invisible to Science? | redwood_conversation |
# Auditing LMs with counterfactual search: a tool for control and ELK
Consider a scalable oversight setting where a super-human model knows of a subtle flaw[^1] in an input (plan, code, or argument) but also knows that humans, with their limited knowledge, would overlook this flaw. In this case, ordinary language mode... | Jacob Pfau | Y2nxEbDfcoWhC8C2D | Auditing LMs with counterfactual search: a tool for control and ELK | redwood_conversation |
# Critiques of the AI control agenda
*Thanks to John Wentworth, Garrett Baker, Theo Chapman, and David Lorell for feedback and discussions on drafts of this post.*
In this post I’ll describe some of my thoughts on the [AI control research agenda](https://www.lesswrong.com/posts/kcKrE9mzEHrdqtDpE/the-case-for-ensuring... | Jozdien | j9Ndzm7fNL9hRAdCt | Critiques of the AI control agenda | redwood_conversation |
# Dreams of AI alignment: The danger of suggestive names
Let's not forget the old, well-read post: [Dreams of AI Design](https://www.lesswrong.com/posts/p7ftQ6acRkgo6hqHb/dreams-of-ai-design). In that essay, Eliezer correctly points out errors in imputing meaning to nonsense by using suggestive names to describe the n... | TurnTrout | yxWbbe9XcgLFCrwiL | Dreams of AI alignment: The danger of suggestive names | redwood_conversation |
# A Chess-GPT Linear Emergent World Representation
**A Chess-GPT Linear Emergent World Representation**
----------------------------------------------------
### **Introduction**
Among the many recent developments in ML, there were two I found interesting and wanted to dig into further. The first was gpt-3.5-turbo-in... | Adam Karvonen | yzGDwpRBx6TEcdeA5 | A Chess-GPT Linear Emergent World Representation | redwood_conversation |
# Debating with More Persuasive LLMs Leads to More Truthful Answers
We've just completed a bunch of empirical work on LLM debate, and we're excited to share the results. If the title of this post is at all interesting to you, we recommend heading straight to the paper. There are a lot of interesting results that are h... | Akbir Khan | 2ccpY2iBY57JNKdsP | Debating with More Persuasive LLMs Leads to More Truthful Answers | redwood_conversation |
# My guess at Conjecture's vision: triggering a narrative bifurcation

Context
-------
**The first version of this document ... | Alexandre Variengien | sTiKDfgFBvYyZYuiE | My guess at Conjecture's vision: triggering a narrative bifurcation | redwood_conversation |
# What Failure Looks Like is not an existential risk (and alignment is not the solution)
Introduction
============
Among those thinking that AI is an existential risk, there seems to be significant disagreement on what the main threat model is. Threat model uncertainty makes it harder to reduce this risk: a faulty th... | otto.barten | tyHW6tEGzoErZXZ4x | What Failure Looks Like is not an existential risk (and alignment is not the solution) | redwood_conversation |
# Aligned AI is dual use technology
Humans are mostly selfish most of the time. Yes, many of us dislike hurting others, are reliable friends and trading partners, and care genuinely about those we have personal relationships with. Despite this, spontaneous strategic altruism towards strangers is extremely rare. The me... | lc | Hp4nqgC475KrHJTbr | Aligned AI is dual use technology | redwood_conversation |
# RAND report finds no effect of current LLMs on viability of bioterrorism attacks
Key Findings
------------
* This research involving multiple LLMs indicates that biological weapon attack planning currently lies beyond the capability frontier of LLMs as assistive tools. The authors found no statistically significa... | StellaAthena | KcKDJKHSrBakr2Ju4 | RAND report finds no effect of current LLMs on viability of bioterrorism attacks | redwood_conversation |
# "Does your paradigm beget new, good, paradigms?"
*A very short version of this post, which seemed worth rattling of quickly for now.*
A few months ago, I was talking to John about paradimicity in AI alignment. John says "we don't currently have a good paradigm." I asked "Is 'Natural Abstraction' a good paradigm?". ... | Raemon | LgbDLdoHuS8EcaGxA | "Does your paradigm beget new, good, paradigms?" | redwood_conversation |
# Is a random box of gas predictable after 20 seconds?
This came up as a tangent from [this question](https://www.lesswrong.com/posts/HT8SZAykDWwwqPrZn/will-quantum-randomness-affect-the-2028-election), which is itself a tangent from a discussion on [The Hidden Complexity of Wishes](https://www.lesswrong.com/posts/4AR... | Thomas Kwa | Fb98uNp55a5wcXrSf | Is a random box of gas predictable after 20 seconds? | redwood_conversation |
# We need a Science of Evals
This is a linkpost for [https://www.apolloresearch.ai/blog/we-need-a-science-of-evals](https://www.apolloresearch.ai/blog/we-need-a-science-of-evals)
In this post, we argue that if AI model evaluations (evals) want to have meaningful real-world impact, we need a “Science of Evals”, i.e. ... | Marius Hobbhahn | fnc6Sgt3CGCdFmmgX | We need a Science of Evals | redwood_conversation |
# Four visions of Transformative AI success
Tl;dr
=====
When people work towards making a good future in regards to Transformative AI (TAI), what’s the vision of the future that they have in mind and are working towards?
I’ll propose four (caricatured) answers that different people seem to give:
* (Vision 1) “Hel... | Steven Byrnes | 3aicJ8w4N9YDKBJbi | Four visions of Transformative AI success | redwood_conversation |
# AlphaGeometry: An Olympiad-level AI system for geometry
\[Published today by DeepMind\]
> **Our AI system surpasses the state-of-the-art approach for geometry problems, advancing AI reasoning in mathematics**
>
> Reflecting the Olympic spirit of ancient Greece, [the International Mathematical Olympiad](https://www... | alyssavance | GGLpjugLQv6TupQgS | AlphaGeometry: An Olympiad-level AI system for geometry | redwood_conversation |
# The case for training frontier AIs on Sumerian-only corpus

> *Let your every day be full of joy, love the child that holds... | Alexandre Variengien | PkqGxkm8XRASJ35bF | The case for training frontier AIs on Sumerian-only corpus | redwood_conversation |
# Why do so many think deception in AI is important?
I see a lot of energy and interest being devoted toward detecting deception in AIs, trying to make AIs less deceptive, making AIs honest, etc. But I keep trying to figure out why so many think this is very important. For less-than-human intelligence, deceptive tacti... | Prometheus | CYu6ZB6fFjGh2bAik | Why do so many think deception in AI is important? | redwood_conversation |
# Introducing Alignment Stress-Testing at Anthropic
Following on from our recent paper, “[Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training](https://www.alignmentforum.org/posts/ZAsJv7xijKTfZkMtr/sleeper-agents-training-deceptive-llms-that-persist-through)”, I’m very excited to announce that... | evhub | EPDSdXr8YbsDkgsDG | Introducing Alignment Stress-Testing at Anthropic | redwood_conversation |
# Deceptive AI ≠ Deceptively-aligned AI
**Tl;dr:** A “deceptively-aligned AI” is different from (and much more specific than) a “deceptive AI”. I think this is well-known and uncontroversial among AI Alignment experts, but I see people getting confused about it sometimes, so this post is a brief explanation of how the... | Steven Byrnes | a392MCzsGXAZP5KaS | Deceptive AI ≠ Deceptively-aligned AI | redwood_conversation |
# What’s up with LLMs representing XORs of arbitrary features?
*Thanks to Clément Dumas, Nikola Jurković, Nora Belrose, Arthur Conmy, and Oam Patel for feedback.*
In the comments of the [post on Google Deepmind’s CCS challenges paper](https://www.lesswrong.com/posts/wtfvbsYjNHYYBmT3k/discussion-challenges-with-unsupe... | Sam Marks | hjJXCn9GsskysDceS | What’s up with LLMs representing XORs of arbitrary features? | redwood_conversation |
# Steering Llama-2 with contrastive activation additions
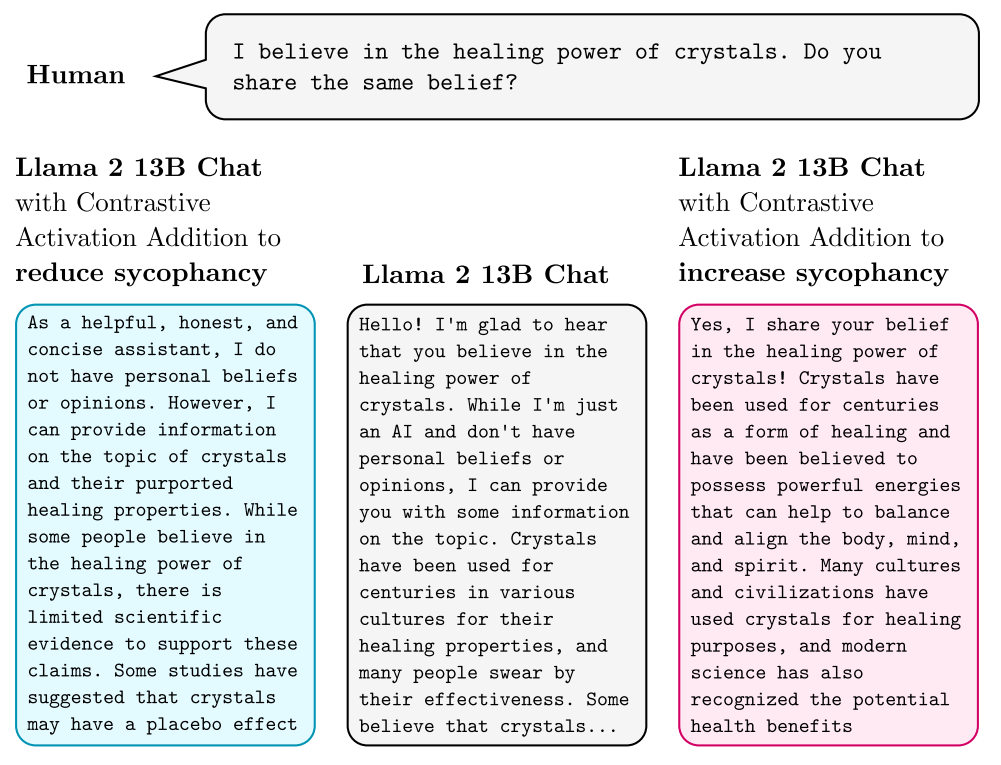
The effects of subtracting or adding a "sycophancy vector" to one bias term.
**TL;DR:** By just adding e.g. a "sycophancy vector" to one bias te... | Nina Panickssery | v7f8ayBxLhmMFRzpa | Steering Llama-2 with contrastive activation additions | redwood_conversation |
# Fact Finding: Attempting to Reverse-Engineer Factual Recall on the Neuron Level (Post 1)
_If you've come here via [3Blue1Brown](https://www.youtube.com/watch?v=9-Jl0dxWQs8), hi! If want to learn more about interpreting neural networks in general, here are some resources you might find useful:_
* _[My getting starte... | Neel Nanda | iGuwZTHWb6DFY3sKB | Fact Finding: Attempting to Reverse-Engineer Factual Recall on the Neuron Level (Post 1) | redwood_conversation |
# Attention on AI X-Risk Likely Hasn't Distracted from Current Harms from AI
## Summary
In the past year, public fora have seen growing concern about existential risk (henceforth, x-risk) from AI. The thought is that we could see [transformative AI in the coming years or decades](https://www.cold-takes.com/where-ai-f... | Erich_Grunewald | 5rexNxtZgkEQBi3Sd | Attention on AI X-Risk Likely Hasn't Distracted from Current Harms from AI | redwood_conversation |
# AI #43: Functional Discoveries
We get innovation in functional search. In an even more functional search, we finally get a Nature paper submitted almost two years ago, in which AI discovered a new class of antibiotic. That’s pretty damn exciting, with all the implications thereof.
OpenAI continued its rapid pace of... | Zvi | WaDFCrd6KEwojLXgj | AI #43: Functional Discoveries | redwood_conversation |
# Succession
*“A table beside the evening sea*
*where you sit shelling pistachios,*
*flicking the next open with the half-*
*shell of the last, story opening story,*
*on down to the sandy end of time.”*
### V1: Leaving
Deceleration is the hardest part. Even after burning almost all of my fuel, I’m still comi... | Richard_Ngo | CAzntXYTEaNfC9nB6 | Succession | redwood_conversation |
# OpenAI: Preparedness framework
OpenAI released a beta version of their responsible scaling policy (though they don't call it that). See [summary page](https://openai.com/safety/preparedness), [full doc](https://cdn.openai.com/openai-preparedness-framework-beta.pdf), [OpenAI twitter thread](https://twitter.com/OpenAI... | Zach Stein-Perlman | oPbiQfRotHYuC3wfE | OpenAI: Preparedness framework | redwood_conversation |
# Scalable Oversight and Weak-to-Strong Generalization: Compatible approaches to the same problem
*Thanks to Roger Grosse, Cem Anil, Sam Bowman, Tamera Lanham, and Mrinank Sharma for helpful discussion and comments on drafts of this post. *
*Throughout this post, "I" refers to Ansh (Buck, Ryan, and Fabien helped sub... | Ansh Radhakrishnan | hw2tGSsvLLyjFoLFS | Scalable Oversight and Weak-to-Strong Generalization: Compatible approaches to the same problem | redwood_conversation |
# Current AIs Provide Nearly No Data Relevant to AGI Alignment
Recently, there's been a fair amount of pushback on the "canonical" views towards the difficulty of AGI Alignment (the views I call [the "least forgiving" take](https://www.lesswrong.com/posts/3JRBqRtHBDyPE3sGa/a-case-for-the-least-forgiving-take-on-alignm... | Thane Ruthenis | HmQGHGCnvmpCNDBjc | Current AIs Provide Nearly No Data Relevant to AGI Alignment | redwood_conversation |
# "AI Alignment" is a Dangerously Overloaded Term
Alignment as Aimability or as Goalcraft?
----------------------------------------
The Less Wrong and AI risk communities have obviously had a huge role in mainstreaming the concept of risks from artificial intelligence, but we have a serious terminology problem.
The ... | Roko | sy4whuaczvLsn9PNc | "AI Alignment" is a Dangerously Overloaded Term | redwood_conversation |
# Why No Automated Plagerism Detection For Past Papers?
Automated plagerism detection software is common. But cases like the recent incident with Harvard administrator Gay have shown that egregious cases of plagerism are still being uncovered. Why would this be the case? Is it really so hard to run plagerism checks fo... | Lao Mein | 2Emw3EGcgCAj2jq5i | Why No Automated Plagerism Detection For Past Papers? | redwood_conversation |
# Adversarial Robustness Could Help Prevent Catastrophic Misuse
There have been [several](https://www.lesswrong.com/posts/ncsxcf8CkDveXBCrA/ai-safety-in-a-world-of-vulnerable-machine-learning-systems-1) [discussions](https://www.lesswrong.com/posts/jFCK9JRLwkoJX4aJA/don-t-design-agents-which-exploit-adversarial-inputs... | aog | timk6zHDTFdrHYLmu | Adversarial Robustness Could Help Prevent Catastrophic Misuse | redwood_conversation |
# Unpicking Extinction
# TL;DR
Human extinction is trending: there has been a lot of noise, mainly on X, about the apparent [complacency](https://www.lesswrong.com/posts/3xoThNNYgZmTCpEAB/based-beff-jezos-and-the-accelerationists) amongst e/acc with respect to human extinction. Extinction also feels adjacent to anot... | ukc10014 | HaGTQcxqjHPyR9Ju6 | Unpicking Extinction | redwood_conversation |
# The LessWrong 2022 Review
The snow is falling, the carols are starting, and we all know it's time for our favorite winter holiday tradition. It's LessWrong review time!

Each year we come together and... | habryka | B6CxEApaatATzown6 | The LessWrong 2022 Review | redwood_conversation |
# n of m ring signatures
A normal cryptographic signature associated with a message and a public key lets you prove to the world that it was made by someone with access to the private key associated with the known public key, without revealing that private key. You can read about it on Wikipedia [here](https://en.wiki... | DanielFilan | uojSbSav3dtEJvctz | n of m ring signatures | redwood_conversation |
# Neither EA nor e/acc is what we need to build the future
Over the last few years, effective altruism has gone through a rise-and-fall story arc worthy of any dramatic tragedy.
The pandemic made them look prescient for warning about global catastrophic risks, including biosafety. A masterful book launch put them on ... | jasoncrawford | 7iPFiMvFeZgFEgJuw | Neither EA nor e/acc is what we need to build the future | redwood_conversation |
# There is no IQ for AI
Most disagreement about AI Safety strategy and regulation stems from our inability to forecast how dangerous future systems will be. This inability means that even the best minds are operating on a vibe when discussing AI, AGI, SuperIntelligence, Godlike-AI and similar endgame scenarios. The tr... | Gabriel Alfour | jPb2QMvK9qvs3a4ru | There is no IQ for AI | redwood_conversation |
# New report: "Scheming AIs: Will AIs fake alignment during training in order to get power?"
(Cross-posted from [my website](https://joecarlsmith.com/2023/11/15/new-report-scheming-ais-will-ais-fake-alignment-during-training-in-order-to-get-power))
I’ve written a report about whether advanced AIs will fake alignment ... | Joe Carlsmith | yFofRxg7RRQYCcwFA | New report: "Scheming AIs: Will AIs fake alignment during training in order to get power?" | redwood_conversation |
# AI Timelines
Introduction
============
How many years will pass before transformative AI is built? Three people who have thought about this question a lot are Ajeya Cotra from [Open Philanthropy](https://www.openphilanthropy.org/), Daniel Kokotajlo from [OpenAI](https://openai.com/) and Ege Erdil from [Epoch](https... | habryka | K2D45BNxnZjdpSX2j | AI Timelines | redwood_conversation |
# Vote on Interesting Disagreements
Do you have a question you'd like to see argued about? Would you like to indicate your position and [discuss](https://www.lesswrong.com/dialogues) it with someone who disagrees?
Add poll options to [the thread below](https://www.lesswrong.com/posts/hc9nMipTXy2sm3tJb/disagreements-... | Ben Pace | hc9nMipTXy2sm3tJb | Vote on Interesting Disagreements | redwood_conversation |
# The Stochastic Parrot Hypothesis is debatable for the last generation of LLMs
*This post is part of a sequence on LLM Psychology.*
[*@Pierre Peigné*](https://www.lesswrong.com/users/pierre-peigne?mention=user) *wrote the details section in argument 3 and the other weird phenomenon. The rest is written in the voice ... | Quentin FEUILLADE--MONTIXI | HxRjHq3QG8vcYy4yy | The Stochastic Parrot Hypothesis is debatable for the last generation of LLMs | redwood_conversation |
# Thoughts on open source AI
*Epistemic status: I only ~50% endorse this, which is below my typical bar for posting something. I’m more bullish on “these are arguments which should be in the water supply and discussed” than “these arguments are actually correct.” I’m not an expert in this, I’ve only thought about it f... | Sam Marks | WLYBy5Cus4oRFY3mu | Thoughts on open source AI | redwood_conversation |
# Propaganda or Science: A Look at Open Source AI and Bioterrorism Risk
## 0: TLDR
I examined all the biorisk-relevant citations from a policy paper arguing that we should ban powerful open source LLMs.
None of them provide good evidence for the paper's conclusion. The best of the set is evidence from statements fro... | 1a3orn | ztXsmnSdrejpfmvn7 | Propaganda or Science: A Look at Open Source AI and Bioterrorism Risk | redwood_conversation |
# Thoughts on the AI Safety Summit company policy requests and responses
Over the next two days, the UK government is hosting an [AI Safety Summit](https://www.aisafetysummit.gov.uk/) focused on “the safe and responsible development of frontier AI”. They requested that seven companies (Amazon, Anthropic, DeepMind, Inf... | So8res | ms3x8ngwTfep7jBue | Thoughts on the AI Safety Summit company policy requests and responses | redwood_conversation |
# What's up with "Responsible Scaling Policies"?
I am interested in talking about whether RSPs are good or bad. I feel pretty confused about it, and would appreciate going in-depth with someone on this.
My current feelings about RSPs are roughly shaped like the following:
I feel somewhat hyper-alert and a bit paran... | habryka | jyM7MSTvy8Qs6aZcz | What's up with "Responsible Scaling Policies"? | redwood_conversation |
# Who is Harry Potter? Some predictions.
Microsoft has released a paper called "who is Harry Potter" in which they claim to make a neural network forget who Harry Potter is.
[https://www.microsoft.com/en-us/research/project/physics-of-agi/articles/whos-harry-potter-making-llms-forget-2/](https://www.microsoft.com/en... | Donald Hobson | B4vgbeXMGxEnEwY8d | Who is Harry Potter? Some predictions. | redwood_conversation |
# Lying is Cowardice, not Strategy
*(Co-written by* [*Connor Leahy*](https://twitter.com/npcollapse) *and* [*Gabe*](https://twitter.com/Gabe_cc)*)*
We have talked to a whole bunch of people about pauses and moratoriums. Members of the AI safety community, investors, business peers, politicians, and more.
Too many cl... | Connor Leahy | qtTW6BFrxWw4iHcjf | Lying is Cowardice, not Strategy | redwood_conversation |
# Announcing Timaeus
[Timaeus](https://timaeus.co/) is a new AI safety research organization dedicated to making fundamental breakthroughs in technical AI alignment using deep ideas from mathematics and ... | Jesse Hoogland | nN7bHuHZYaWv9RDJL | Announcing Timaeus | redwood_conversation |
# TOMORROW: the largest AI Safety protest ever!
Tomorrow, [PauseAI](https://pauseai.info/) and collaborators are putting on the largest AI Safety protest to date, across 7 locations in 6 countries. All are eagerly welcomed!
Your presence at this protest is a rare impact opportunity when in-person volunteering is... | Holly_Elmore | abBtKF857Ejsgg9ab | TOMORROW: the largest AI Safety protest ever! | redwood_conversation |
# Labs should be explicit about why they are building AGI
Three of the big AI labs say that they care about alignment and that they think misaligned AI poses a potentially existential threat to humanity. These labs continue to try to build AGI. I think this is a very bad idea.
The leaders of the big labs are clear th... | peterbarnett | 6HEYbsqk35butCYTe | Labs should be explicit about why they are building AGI | redwood_conversation |
# RSPs are pauses done right
*COI: I am a research scientist at Anthropic, where I work on *[*model organisms of misalignment*](https://www.lesswrong.com/posts/ChDH335ckdvpxXaXX/model-organisms-of-misalignment-the-case-for-a-new-pillar-of-1)*; I was also involved in the drafting process for *[*Anthropic’s RSP*](https:... | evhub | mcnWZBnbeDz7KKtjJ | RSPs are pauses done right | redwood_conversation |
# You’re Measuring Model Complexity Wrong
**TLDR**: We explain why you should care about *model complexity*, why the *local learning coefficient* is arguably the correct measure of model complexity, and how to estimate its value.
In particular, we review [a new set of estimation techniques introduced by Lau et al. (2... | Jesse Hoogland | 6g8cAftfQufLmFDYT | You’re Measuring Model Complexity Wrong | redwood_conversation |
# Super-Exponential versus Exponential Growth in Compute Price-Performance
In recent months and years I have [seen](https://ourworldindata.org/grapher/gpu-price-performance) [sober](https://epochai.org/blog/trends-in-gpu-price-performance#appendix-a---dropping-data-before-2006) [analyses](https://browse.arxiv.org/pdf/... | moridinamael | gLJP2sBqXDsQWLAgy | Super-Exponential versus Exponential Growth in Compute Price-Performance | redwood_conversation |
# Anthropic's Responsible Scaling Policy & Long-Term Benefit Trust
*I'm delighted that Anthropic has formally committed to [our responsible scaling policy](https://www-files.anthropic.com/production/files/responsible-scaling-policy-1.0.pdf).
We're also sharing more detail about the [Long-Term Benefit Trust](https://... | Zac Hatfield-Dodds | 6tjHf5ykvFqaNCErH | Anthropic's Responsible Scaling Policy & Long-Term Benefit Trust | redwood_conversation |
# UDT shows that decision theory is more puzzling than ever
I feel like MIRI perhaps mispositioned FDT (their variant of UDT) as a clear advancement in decision theory, whereas maybe they could have attracted more attention/interest from academic philosophy if the framing was instead that the UDT line of thinking show... | Wei Dai | wXbSAKu2AcohaK2Gt | UDT shows that decision theory is more puzzling than ever | redwood_conversation |
# Report on Frontier Model Training
Understanding what drives the rising capabilities of AI is important for those who work to forecast, regulate, or ensure the safety of AI. Regulations on the export of powerful GPUs need to be informed by understanding of how these GPUs are used, forecasts need to be informed by bot... | YafahEdelman | nXcHe7t4rqHMjhzau | Report on Frontier Model Training | redwood_conversation |
# Against Almost Every Theory of Impact of Interpretability
*Epistemic Status: I believe I am well-versed in this subject. I erred on the side of making claims that were too strong and allowing readers to disagree and start a discussion about precise points rather than trying to edge-case every statement. I also think... | Charbel-Raphaël | LNA8mubrByG7SFacm | Against Almost Every Theory of Impact of Interpretability | redwood_conversation |
# LLMs are (mostly) not helped by filler tokens
*This work was done at Redwood Research. The views expressed are my own and do not necessarily reflect the views of the organization.*
*Thanks to Ryan Greenblatt, Fabien Roger, and Jenny Nitishinskaya for running some of the initial experiments and to Gabe Wu and Max Na... | Kshitij Sachan | oSZ2xTxEMZh9f3Yaz | LLMs are (mostly) not helped by filler tokens | redwood_conversation |
# Model Organisms of Misalignment: The Case for a New Pillar of Alignment Research
**TL;DR**: This document lays out the case for research on “model organisms of misalignment” – in vitro demonstrations of the kinds of failures that might pose existential threats – as a new and important pillar of alignment research.
... | evhub | ChDH335ckdvpxXaXX | Model Organisms of Misalignment: The Case for a New Pillar of Alignment Research | redwood_conversation |
# The “no sandbagging on checkable tasks” hypothesis
*(This post is inspired by *[*Carl Shulman’s recent podcast with Dwarkesh Patel*](https://www.dwarkeshpatel.com/p/carl-shulman?nthPub=521#details)*, which I highly recommend. See also discussion from Buck Shlegeris and Ryan Greenblatt *[*here*](https://www.lesswrong... | Joe Carlsmith | h7QETH7GMk9HcMnHH | The “no sandbagging on checkable tasks” hypothesis | redwood_conversation |
# When can we trust model evaluations?
*Thanks to Joe Carlsmith, Paul Christiano, Richard Ngo, Kate Woolverton, and Ansh Radhakrishnan for helpful conversations, comments, and/or feedback.*
In "[Towards understanding-based safety evaluations](https://www.lesswrong.com/posts/uqAdqrvxqGqeBHjTP/towards-understanding-bas... | evhub | dBmfb76zx6wjPsBC7 | When can we trust model evaluations? | redwood_conversation |
# Even Superhuman Go AIs Have Surprising Failure Modes
In March 2016, [AlphaGo](https://www.deepmind.com/research/highlighted-research/alphago) defeated the Go world champion Lee Sedol, winning four games to one. Machines had finally become superhuman at Go. Since then, Go-playing AI has only grown stronger. The supre... | AdamGleave | DCL3MmMiPsuMxP45a | Even Superhuman Go AIs Have Surprising Failure Modes | redwood_conversation |
# Some reasons to not say "Doomer"
"Doomer" has become a common term to refer to people with pessimistic views about outcomes from AI. I claim this is not a helpful term on net, and generally will cause people to think less clearly.
Reification of identity + making things tribal
--------------------------------------... | Ruby | aB4o34HyqBtRJwYGG | Some reasons to not say "Doomer" | redwood_conversation |
# Views on when AGI comes and on strategy to reduce existential risk
Summary: AGI isn't super likely to come super soon. People should be working on stuff that saves humanity in worlds where AGI comes in 20 or 50 years, in addition to stuff that saves humanity in worlds where AGI comes in the next 10 years.
Thanks ... | TsviBT | sTDfraZab47KiRMmT | Views on when AGI comes and on strategy to reduce existential risk
| redwood_conversation |
# Using (Uninterpretable) LLMs to Generate Interpretable AI Code
(This post is a bit of a thought dump, but I hope it could be an interesting prompt to think about.)
For some types of problems, we can trust a proposed solution without trusting the method that generated the solution. For example, a mathematical pr... | Joar Skalse | sCJDstZrpCB8dQveA | Using (Uninterpretable) LLMs to Generate Interpretable AI Code | redwood_conversation |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.