
repo stringclasses 147
values | number int64 1 172k | title stringlengths 2 476 | body stringlengths 0 5k | url stringlengths 39 70 | state stringclasses 2
values | labels listlengths 0 9 | created_at timestamp[ns, tz=UTC]date 2017-01-18 18:50:08 2026-01-06 07:33:18 | updated_at timestamp[ns, tz=UTC]date 2017-01-18 19:20:07 2026-01-06 08:03:39 | comments int64 0 58 ⌀ | user stringlengths 2 28 |
|---|---|---|---|---|---|---|---|---|---|---|
huggingface/datasets | 5,665 | Feature request: IterableDataset.push_to_hub | ### Feature request
It'd be great to have a lazy push to hub, similar to the lazy loading we have with `IterableDataset`.
Suppose you'd like to filter [LAION](https://huggingface.co/datasets/laion/laion400m) based on certain conditions, but as LAION doesn't fit into your disk, you'd like to leverage streaming:
`... | https://github.com/huggingface/datasets/issues/5665 | closed | [
"enhancement"
] | 2023-03-23T09:53:04Z | 2025-06-06T16:13:22Z | 13 | NielsRogge |
pytorch/examples | 1,128 | Question about the difference between at::Tensor and torch::Tensor in PyTorch c++ | I think the document of the PyTorch c++ library is not quite complete.
I noticed that there are some codes in the cppdoc use torch::Tensor, especially in the “Tensor Basics” and “Tensor Creation API”. I can’t find “torch::Tensor” in “Library API” but the “at::Tensor “.
I want to know is there any difference between t... | https://github.com/pytorch/examples/issues/1128 | closed | [] | 2023-03-23T06:59:46Z | 2023-03-25T01:56:58Z | 1 | Ningreka |
pytorch/pytorch | 97,364 | Confused as to where a script is. | According to pytorch/torch/_C/__init__.pyi.in there's supposed to be a torch/aten script but I can't find it, has this been phased out, because if it has is it in an older version of PyTorch? It's just without it, it completely stops one of the programs I downloaded from working, called Colossalai. It tries to call fro... | https://github.com/pytorch/pytorch/issues/97364 | closed | [] | 2023-03-22T18:04:44Z | 2023-03-24T17:03:18Z | null | Shikamaru5 |
huggingface/datasets | 5,660 | integration with imbalanced-learn | ### Feature request
Wouldn't it be great if the various class balancing operations from imbalanced-learn were available as part of datasets?
### Motivation
I'm trying to use imbalanced-learn to balance a dataset, but it's not clear how to get the two to interoperate - what would be great would be some examples. I'v... | https://github.com/huggingface/datasets/issues/5660 | closed | [
"enhancement",
"wontfix"
] | 2023-03-22T11:05:17Z | 2023-07-06T18:10:15Z | 1 | tansaku |
pytorch/TensorRT | 1,758 | ❓ [Question] The compilation process does not display errors, but the program does not continue... | 

` throws `RuntimeError` - any recommended way to enforce? | was confronted with `RuntimeError: Some tensors share memory, this will lead to duplicate memory on disk and potential differences when loading them again`.
Can we explicitly disregard "**potential** differences"? | https://github.com/huggingface/safetensors/issues/202 | closed | [] | 2023-03-21T21:24:38Z | 2024-06-06T02:29:48Z | 26 | drahnreb |
pytorch/text | 2,125 | How to install torchtext for cmake c++? | https://github.com/pytorch/text/issues/2125 | open | [] | 2023-03-21T19:07:38Z | 2023-06-06T22:01:16Z | null | Toocic | |
pytorch/data | 1,104 | Add documentation about custom Shuffle and Sharding DataPipe | ### 📚 The doc issue
TorchData has a few special graph functions to handle Shuffle and Sharding DataPipe. But, we never document what is expected for those graph functions, which leads users to extend custom shuffle and sharding by diving into our code base.
We should add clear document about the expected methods ... | https://github.com/meta-pytorch/data/issues/1104 | open | [] | 2023-03-21T18:14:29Z | 2023-03-21T21:47:32Z | 0 | ejguan |
huggingface/optimum | 906 | Optimum export of whisper raises ValueError: There was an error while processing timestamps, we haven't found a timestamp as last token. Was WhisperTimeStampLogitsProcessor used? | ### System Info
```shell
optimum: 1.7.1
Python: 3.8.3
transformers: 4.27.2
platform: Windows 10
```
### Who can help?
@philschmid @michaelbenayoun
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as G... | https://github.com/huggingface/optimum/issues/906 | closed | [
"bug"
] | 2023-03-21T13:45:10Z | 2023-03-24T18:26:17Z | 3 | xenova |
pytorch/vision | 7,438 | Feedback on Video APIs | ### Feedback request
With torchaudio's recent success in getting a clean FFMPEG build with a full support for FFMPEG 5 and 6 (something we can't replicate in torchvision easily yet), we are thinking of adopting their API and joining efforts to have a better support for video reading.
With that in mind, we were h... | https://github.com/pytorch/vision/issues/7438 | open | [
"question",
"needs discussion",
"module: io",
"module: video"
] | 2023-03-21T13:20:36Z | 2024-05-20T14:50:59Z | null | bjuncek |
huggingface/datasets | 5,653 | Doc: save_to_disk, `num_proc` will affect `num_shards`, but it's not documented | ### Describe the bug
[`num_proc`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.DatasetDict.save_to_disk.num_proc) will affect `num_shards`, but it's not documented
### Steps to reproduce the bug
Nothing to reproduce
### Expected behavior
[document of `num_shards`](https://... | https://github.com/huggingface/datasets/issues/5653 | closed | [
"documentation",
"good first issue"
] | 2023-03-21T05:25:35Z | 2023-03-24T16:36:23Z | 1 | RmZeta2718 |
pytorch/kineto | 743 | Questions about ROCm profiler | Hi @mwootton @aaronenyeshi ,
I found some interesting results for the models running on NVIDIA A100 and AMD MI210 GPUs. For example, I tested model resnext50_32x4d in [TorchBench](https://github.com/pytorch/benchmark). resnext50_32x4d obtains about 4.89X speedup on MI210. However, when I use PyTorch Profiler to prof... | https://github.com/pytorch/kineto/issues/743 | closed | [
"question"
] | 2023-03-20T18:11:16Z | 2023-10-24T17:39:57Z | null | FindHao |
huggingface/dataset-viewer | 965 | Change the limit of started jobs? all kinds -> per kind | Currently, the `QUEUE_MAX_JOBS_PER_NAMESPACE` parameter limits the number of started jobs for the same namespace (user or organization). Maybe we should enforce this limit **per job kind** instead of **globally**. | https://github.com/huggingface/dataset-viewer/issues/965 | closed | [
"question",
"improvement / optimization"
] | 2023-03-20T17:40:45Z | 2023-04-29T15:03:57Z | null | severo |
huggingface/dataset-viewer | 964 | Kill a job after a maximum duration? | The heartbeat already allows to detect if a job has crashed and to generate an error in that case. But some jobs can take forever, while not crashing. Should we set a maximum duration for the jobs, in order to save resources and free the queue? I imagine that we could automatically kill a job that takes more than 20 mi... | https://github.com/huggingface/dataset-viewer/issues/964 | closed | [
"question",
"improvement / optimization"
] | 2023-03-20T17:37:35Z | 2023-03-23T13:16:33Z | null | severo |
huggingface/optimum | 903 | Support transformers export to ggml format | ### Feature request
ggml is gaining traction (e.g. llama.cpp has 10k stars), and it would be great to extend optimum.exporters and enable the community to export PyTorch/Tensorflow transformers weights to the format expected by ggml, having a more streamlined and single-entry export.
This could avoid duplicates a... | https://github.com/huggingface/optimum/issues/903 | open | [
"feature-request",
"help wanted",
"exporters"
] | 2023-03-20T12:51:51Z | 2023-07-03T04:51:18Z | 2 | fxmarty |
pytorch/TensorRT | 1,749 | How to import after compilation | 
Show me that I don't have this package when I import torch_tensorrt
| https://github.com/pytorch/TensorRT/issues/1749 | closed | [
"question",
"No Activity"
] | 2023-03-20T10:35:37Z | 2023-06-29T00:02:42Z | null | AllesOderNicht |
pytorch/rl | 977 | [Feature Request] How to implement algorithms with multiple optimise phase like PPG? | ## Motivation
I'm trying to implement [PPG](https://proceedings.mlr.press/v139/cobbe21a) and [DNA](https://arxiv.org/pdf/2206.10027.pdf) algorithms with torchrl, and both algorithms have more than one optimise phase in a single training loop. However, I suggest the [Trainer class](https://pytorch.org/rl/reference/tr... | https://github.com/pytorch/rl/issues/977 | closed | [
"enhancement"
] | 2023-03-20T04:57:59Z | 2023-03-21T06:44:16Z | null | levilovearch |
huggingface/datasets | 5,650 | load_dataset can't work correct with my image data | I have about 20000 images in my folder which divided into 4 folders with class names.
When i use load_dataset("my_folder_name", split="train") this function create dataset in which there are only 4 images, the remaining 19000 images were not added there. What is the problem and did not understand. Tried converting imag... | https://github.com/huggingface/datasets/issues/5650 | closed | [] | 2023-03-18T13:59:13Z | 2023-07-24T14:13:02Z | 21 | WiNE-iNEFF |
pytorch/pytorch | 97,026 | How to get list of all valid devices? | ### 📚 The doc issue
`torch.testing.get_all_device_types()`
yields all valid devices on the current machine however unlike `torch._tensor_classes` , `torch.testing.get_all_dtypes()`, and `import typing; typing.get_args(torch.types.Device)`, there doesn't seem to be a comprehensive list of all valid device types, whic... | https://github.com/pytorch/pytorch/issues/97026 | open | [
"module: docs",
"triaged"
] | 2023-03-17T15:37:00Z | 2023-03-20T23:49:13Z | null | dsm-72 |
pytorch/kineto | 742 | How can I get detailed aten::op name like add.Tensor/abs.out? | I wonder if I could trace detailed op name like add.Tensor、add.Scalar、sin.out、abs.out
Currently the profiler only gives me add/sin/abs, etc.
Is there a method to acquire detailed dispatched op name? | https://github.com/pytorch/kineto/issues/742 | closed | [
"question"
] | 2023-03-17T05:25:42Z | 2024-04-23T15:31:20Z | null | Hurray0 |
pytorch/cppdocs | 16 | How to set up pytorch for c++ (with g++) via commandline not cmake | I have a Lapop with a nvidia graphicscard and I'm trying to use pytorch for cuda with g++. But i couldn't find any good information about dependecies e.g and my compiler always trohws errors, I'm currently using this command I found on the internet: "g++ -std=c++14 main.cpp -I ${TORCH_DIR}/include/torch/csrc/api/includ... | https://github.com/pytorch/cppdocs/issues/16 | closed | [] | 2023-03-13T21:15:08Z | 2023-03-18T22:36:04Z | null | usr577 |
huggingface/dataset-viewer | 924 | Support webhook version 3? | The Hub provides different formats for the webhooks. The current version, used in the public feature (https://huggingface.co/docs/hub/webhooks) is version 3. Maybe we should support version 3 soon. | https://github.com/huggingface/dataset-viewer/issues/924 | closed | [
"question",
"refactoring / architecture"
] | 2023-03-13T13:39:59Z | 2023-04-21T15:03:54Z | null | severo |
huggingface/datasets | 5,632 | Dataset cannot convert too large dictionnary | ### Describe the bug
Hello everyone!
I tried to build a new dataset with the command "dict_valid = datasets.Dataset.from_dict({'input_values': values_array})".
However, I have a very large dataset (~400Go) and it seems that dataset cannot handle this.
Indeed, I can create the dataset until a certain size of m... | https://github.com/huggingface/datasets/issues/5632 | open | [] | 2023-03-13T10:14:40Z | 2023-03-16T15:28:57Z | 1 | MaraLac |
pytorch/pytorch | 96,655 | What is the state of support for AD of BatchNormalization and DropOut layers? | I have come to this issue from this post.
https://pytorch.org/functorch/stable/notebooks/per_sample_grads.html
## Background
What I am doing requires per-sample gradient (in fact, I migrated from TF, so I do not have much experience with pytorch, but I have a sufficient understanding of NN training).
When rea... | https://github.com/pytorch/pytorch/issues/96655 | closed | [
"triaged",
"module: functorch"
] | 2023-03-10T01:47:20Z | 2023-03-15T16:02:05Z | null | tranvansang |
huggingface/ethics-education | 1 | What is AI Ethics? | With the amount of hype around things like ChatGPT, AI art, etc., there are a lot of misunderstandings being propagated through the media! Additionally, many people are not aware of the ethical impacts of AI, and they're even less aware about the work that folks in academia + industry are doing to ensure that AI system... | https://github.com/huggingface/ethics-education/issues/1 | open | [
"help wanted",
"explainer",
"audience: non-technical"
] | 2023-03-09T20:58:02Z | 2023-03-17T14:50:39Z | null | NimaBoscarino |
huggingface/diffusers | 2,633 | Asymmetric tiling | Hello. I'm trying to achieve tiling asymmetrically using Diffusers, in a similar fashion to the asymmetric tiling in Automatic1111's extension https://github.com/tjm35/asymmetric-tiling-sd-webui.
My understanding is that I must traverse all layers to alter the padding, in my case circular in X and constant in Y, bu... | https://github.com/huggingface/diffusers/issues/2633 | closed | [
"good first issue",
"question"
] | 2023-03-09T19:09:34Z | 2025-07-29T08:48:27Z | null | alejobrainz |
huggingface/optimum | 874 | Assistance exporting git-large to ONNX | Hello! I am looking to export an image captioning Hugging Face model to ONNX (specifically I was playing with the [git-large](https://huggingface.co/microsoft/git-large) model but if anyone knows of one that might be easier to deal with in terms of exporting that is great too)
I'm trying to follow [these](https://hu... | https://github.com/huggingface/optimum/issues/874 | closed | [
"Stale"
] | 2023-03-09T18:25:57Z | 2025-06-22T02:17:24Z | 3 | gracemcgrath |
huggingface/safetensors | 190 | Rust save ndarray using safetensors | I've been loving this library!
I have a question, how can I save an ndarray using safetensors?
https://docs.rs/ndarray/latest/ndarray/
For context: I am preprocessing data in rust and would like to then load it in python to do machine learning with pytorch. | https://github.com/huggingface/safetensors/issues/190 | closed | [
"Stale"
] | 2023-03-08T22:29:11Z | 2024-01-10T16:48:07Z | 7 | StrongChris |
huggingface/optimum | 867 | Auto-detect framework for large models at ONNX export | ### System Info
- `transformers` version: 4.26.1
- Platform: Linux-4.4.0-142-generic-x86_64-with-glibc2.23
- Python version: 3.9.15
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.13.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax ... | https://github.com/huggingface/optimum/issues/867 | closed | [
"feature-request",
"onnx"
] | 2023-03-08T03:43:53Z | 2023-03-16T15:52:39Z | 3 | WangYizhang01 |
pytorch/TensorRT | 1,730 | ❓ [Question] Does torch-tensorrt support seq2seq models? | ## ❓ Question
Does torch-tensorrt support seq2seq models? Are there any documentation/examples?
## What you have already tried
Previously, when I tried to use TensorRT, I need to convert the original torch seq2seq model to 2 onnx files, then convert them separately to TensorRT using trtexec. Not sure if this h... | https://github.com/pytorch/TensorRT/issues/1730 | closed | [
"question",
"No Activity"
] | 2023-03-08T00:51:31Z | 2023-06-19T00:02:34Z | null | brevity2021 |
pytorch/TensorRT | 1,727 | complie model failed | ## compile model failed with torchtrt-fp32 opt
#### ERROR INFO
WARNING: [Torch-TensorRT TorchScript Conversion Context] - Tensor DataType is determined at build time for tensors not marked as input or output.
ERROR: [Torch-TensorRT TorchScript Conversion Context] - 4: [graphShapeAnalyzer.cpp::analyzeShapes::1285] ... | https://github.com/pytorch/TensorRT/issues/1727 | closed | [
"question",
"component: conversion",
"No Activity"
] | 2023-03-07T04:09:45Z | 2023-06-18T00:02:24Z | null | f291400 |
pytorch/audio | 3,153 | Google colab notebook pointing to PyTorch 1.13.1 | ### 📚 The doc issue
When I open https://pytorch.org/audio/main/tutorials/audio_data_augmentation_tutorial.html in google colab and try running the notebook, I see that the PyTorch version is 1.13.1
 and filtered out a small amount of junk (it's still huge). Now, I would like to use this filtered version for future work. It seems I have two choices:
1. Use `load_dataset` each time, relying on the cache mechanism, and re-run my filtering.
2. `save_to_di... | https://github.com/huggingface/datasets/issues/5609 | open | [] | 2023-03-05T05:27:15Z | 2023-07-13T18:48:05Z | 4 | davidgilbertson |
huggingface/sentence-transformers | 1,856 | What it is the ideal sentence size to train with TSDAE? | I have an unlabeled data that contains 80k texts, with about 250 tokens on average(with bert-base-multilingual-uncased tokenizer). I want to pre-train the model on my dataset, but I'm not sure if the texts are too large. It's possible to break in small sentences, but I'm afraid that some sentences lose context.
What... | https://github.com/huggingface/sentence-transformers/issues/1856 | open | [] | 2023-03-04T21:16:14Z | 2023-03-04T21:16:14Z | null | Diegobm99 |
huggingface/transformers | 21,950 | auto_find_batch_size should say what batch size it is using | ### Feature request
When using `auto_find_batch_size=True` in the trainer I believe it identifies the right batch size but then it doesn't log it to the console anywhere?
It would be good if it could log what batch size it is using?
### Motivation
I'd like to know what batch size it is using because then I will k... | https://github.com/huggingface/transformers/issues/21950 | closed | [] | 2023-03-04T08:53:25Z | 2023-06-28T15:03:39Z | null | p-christ |
huggingface/datasets | 5,604 | Problems with downloading The Pile | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
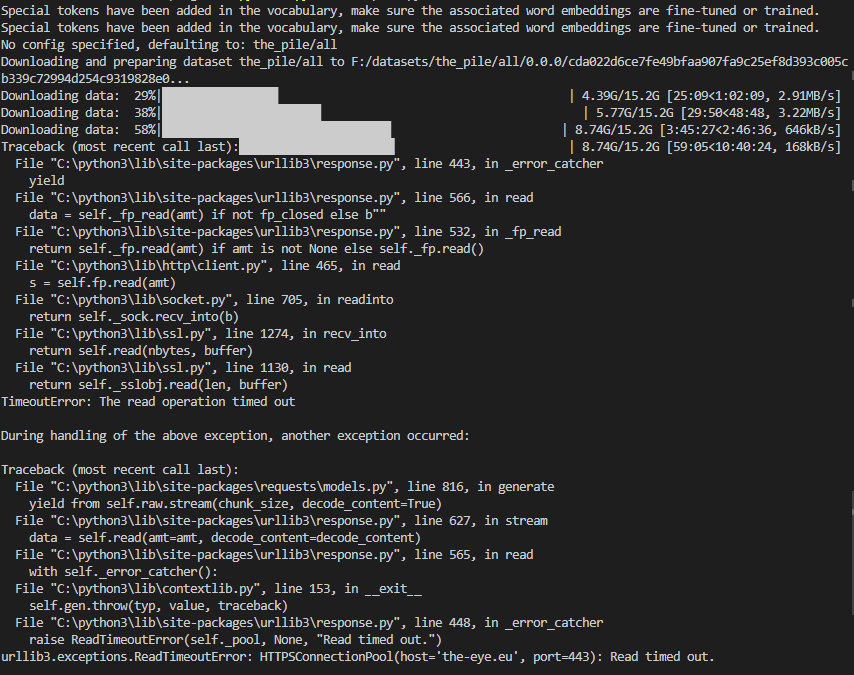
Here are the downloaded files:
 affects gradient tracking? | In this tutorial here it says in the comment that "# We don't need gradients on to do reporting". From what I understand the train flag only affects layers such as dropout and batch-normalization. Does it also affect gradient calculations, or is this comment wrong?
https://github.com/pytorch/tutorials/blob/6bd30cf21... | https://github.com/pytorch/tutorials/issues/2230 | closed | [
"question",
"intro",
"docathon-h1-2023",
"easy"
] | 2023-03-02T12:09:13Z | 2023-06-01T01:19:02Z | null | MaverickMeerkat |
huggingface/datasets | 5,600 | Dataloader getitem not working for DreamboothDatasets | ### Describe the bug
Dataloader getitem is not working as before (see example of [DreamboothDatasets](https://github.com/huggingface/peft/blob/main/examples/lora_dreambooth/train_dreambooth.py#L451C14-L529))
moving Datasets to 2.8.0 solved the issue.
### Steps to reproduce the bug
1- using DreamBoothDataset ... | https://github.com/huggingface/datasets/issues/5600 | closed | [] | 2023-03-02T11:00:27Z | 2023-03-13T17:59:35Z | 1 | salahiguiliz |
huggingface/trl | 180 | what is AutoModelForCausalLMWithValueHead? | trl use `AutoModelForCausalLMWithValueHead`,which is base_model(eg: GPT2LMHeadModel) + fc layer,but I can't understand why need a fc head layer? | https://github.com/huggingface/trl/issues/180 | closed | [] | 2023-02-28T07:46:49Z | 2025-02-21T11:29:04Z | null | akk-123 |
pytorch/serve | 2,162 | How to run torchserver without log printing? | How to run torchserver without log printing?I didn't see the relevant command line. Could someone tell me, thank you! | https://github.com/pytorch/serve/issues/2162 | closed | [
"triaged",
"support"
] | 2023-02-28T02:22:02Z | 2023-03-09T20:06:37Z | null | mqy9787 |
huggingface/datasets | 5,585 | Cache is not transportable | ### Describe the bug
I would like to share cache between two machines (a Windows host machine and a WSL instance).
I run most my code in WSL. I have just run out of space in the virtual drive. Rather than expand the drive size, I plan to move to cache to the host Windows machine, thereby sharing the downloads.
I... | https://github.com/huggingface/datasets/issues/5585 | closed | [] | 2023-02-28T00:53:06Z | 2023-02-28T21:26:52Z | 2 | davidgilbertson |
pytorch/examples | 1,121 | About fast_neural_style | How many rounds did you train in the fast neural style transfer experiment? I operate according to your steps, but the effect of the model I trained is not as good as the model you provided, and why is the model file I trained less than the file you provided by 3kb? I would like to know the reason and look forward to y... | https://github.com/pytorch/examples/issues/1121 | closed | [
"help wanted"
] | 2023-02-27T15:53:38Z | 2023-08-17T09:26:17Z | 2 | TOUBH |
pytorch/functorch | 1,113 | How to get the jacobian matrix in GCNs? | Hi, I'm trying to use `jacrev` to get the jacobians in graph convolution networks, but it seems like I've called the function incorrectly.
```python
import torch.nn.functional as F
import functorch
import torch_geometric
from torch_geometric.data import Data
class GCN(torch.nn.Module):
def __init__(se... | https://github.com/pytorch/functorch/issues/1113 | open | [] | 2023-02-27T13:23:50Z | 2023-02-27T13:24:15Z | null | pcheng2 |
huggingface/dataset-viewer | 857 | Contribute to https://github.com/huggingface/huggingface.js? | https://github.com/huggingface/huggingface.js is a JS client for the Hub and inference. We could propose to add a client for the datasets-server. | https://github.com/huggingface/dataset-viewer/issues/857 | closed | [
"question"
] | 2023-02-27T12:27:43Z | 2023-04-08T15:04:09Z | null | severo |
huggingface/dataset-viewer | 852 | Store the parquet metadata in their own file? | See https://github.com/huggingface/datasets/issues/5380#issuecomment-1444281177
> From looking at Arrow's source, it seems Parquet stores metadata at the end, which means one needs to iterate over a Parquet file's data before accessing its metadata. We could mimic Dask to address this "limitation" and write metadata... | https://github.com/huggingface/dataset-viewer/issues/852 | closed | [
"question"
] | 2023-02-27T08:29:12Z | 2023-05-01T15:04:07Z | null | severo |
pytorch/functorch | 1,112 | Error about using a grad transform with in-place operation is inconsistent with and without DDP | Hi,
I was using `torch.func` in pytorch 2.0 to compute the Hessian-vector product of a neural network.
I first used `torch.func.functional_call` to define a functional version of the neural network model, and then proceeded to use `torch.func.jvp` and `torch.func.grad` to compute the hvp.
The above works when ... | https://github.com/pytorch/functorch/issues/1112 | open | [] | 2023-02-24T23:09:30Z | 2023-03-14T13:56:55Z | 1 | XuchanBao |
huggingface/datasets | 5,570 | load_dataset gives FileNotFoundError on imagenet-1k if license is not accepted on the hub | ### Describe the bug
When calling ```load_dataset('imagenet-1k')``` FileNotFoundError is raised, if not logged in and if logged in with huggingface-cli but not having accepted the licence on the hub. There is no error once accepting.
### Steps to reproduce the bug
```
from datasets import load_dataset
imagenet =... | https://github.com/huggingface/datasets/issues/5570 | closed | [] | 2023-02-23T16:44:32Z | 2023-07-24T15:18:50Z | 2 | buoi |
huggingface/optimum | 810 | ORTTrainer using DataParallel instead of DistributedDataParallel causes downstream errors | ### System Info
```shell
optimum 1.6.4
python 3.8
```
### Who can help?
@JingyaHuang @echarlaix
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task ... | https://github.com/huggingface/optimum/issues/810 | closed | [
"bug"
] | 2023-02-22T22:15:41Z | 2023-03-19T19:01:32Z | 2 | prathikr |
huggingface/optimum | 809 | Better Transformer with QA pipeline returns padding issue | ### System Info
```shell
Optimum version: 1.6.4
Platform: Linux
Python version: 3.10
Transformers version: 4.26.1
Accelerate version: 0.16.0
Torch version: 1.13.1+cu117
```
### Who can help?
@philschmid
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tas... | https://github.com/huggingface/optimum/issues/809 | closed | [
"bug"
] | 2023-02-22T18:51:23Z | 2023-02-27T11:29:09Z | 2 | vrdn-23 |
pytorch/text | 2,072 | how to build torchtext in cpp wiht cmake? | HI, guys, I want to use torchtext with liborch in cpp like cmake build torchvision in cpp, but I has try ,but meet some error in windows system,I don't know why some dependency subdirectory is empty, how to build it then include with cpp ?
thanks
````
-- Building for: Visual Studio 17 2022
-- Selecting Wi... | https://github.com/pytorch/text/issues/2072 | closed | [] | 2023-02-22T15:33:37Z | 2023-02-23T02:53:05Z | null | mullerhai |
pytorch/xla | 4,666 | Got error when build xla from source | Hi! I am trying to build xla wheel by following the setup guide here: https://github.com/pytorch/xla/blob/master/CONTRIBUTING.md
I skipped building torch by `pip install torch==1.13.0` into virtualenv, and then run `env BUILD_CPP_TESTS=0 python setup.py bdist_wheel` under pytorch/xla. I got the following error:
`... | https://github.com/pytorch/xla/issues/4666 | closed | [
"question",
"build"
] | 2023-02-21T19:56:52Z | 2025-05-06T13:32:43Z | null | aws-bowencc |
pytorch/xla | 4,662 | CUDA momery:how can i control xla reserved in total by PyTorch with GPU | ## ❓ Questions and Help
I see xla will reserve almost all memory on GPU,but when i run code both with xla and cuda, it will be error of `torch.cuda.OutOfMemoryError`。
```python
File "/workspace/volume/hqp-nas/xla/mmdetection/mmdet/models/backbones/resnet.py", line 298, in forward
out = _inner_forward(x)
... | https://github.com/pytorch/xla/issues/4662 | closed | [
"question",
"xla:gpu"
] | 2023-02-21T12:43:09Z | 2025-05-07T12:13:34Z | null | qipengh |
pytorch/kineto | 727 | How to trace torch cuda time in C++ using kineto? | **The problem**
Hi, I am using the pytorch profile to trace the gpu performance of models, and it works well in python.
For example:
```
import torch
from torch.autograd.profiler import profile, record_function
with profile(record_shapes=True, use_cuda=True, use_kineto=True, with_stack=False) as prof:
... | https://github.com/pytorch/kineto/issues/727 | closed | [
"question"
] | 2023-02-21T11:37:24Z | 2023-10-10T15:07:23Z | null | TianShaoqing |
pytorch/kineto | 726 | How to remove log output similar to “ActivityProfilerController.cpp:294] Completed Stage: Warm Up” | ## What I encounter
when I use torch.profie to profie a large model, I found my log file have many lines like:
```
STAGE:2023-02-21 15:15:48 101902:101902 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
STAGE:2023-02-21 15:15:48 101903:101903 ActivityProfilerController.cpp:294] Completed Stage: Warm Up... | https://github.com/pytorch/kineto/issues/726 | closed | [
"enhancement"
] | 2023-02-21T07:46:59Z | 2023-06-22T02:37:44Z | null | SolenoidWGT |
pytorch/data | 1,033 | Accessing DataPipe state with MultiProcessingReadingService | Hi TorchData team,
I'm wondering how to access the state of the datapipe in the multi-processing context with DataLoader2 + MultiProcessingReadingService. When using no reading service, we can simply access the graph using `dataloader.datapipe`, then I can easily access the state of my datapipe using the code shown ... | https://github.com/meta-pytorch/data/issues/1033 | closed | [] | 2023-02-20T15:01:44Z | 2025-08-25T06:43:11Z | 9 | jhoareau |
pytorch/benchmark | 1,420 | How to enable jit with nvfuser testing | I want to benchmark models in torchbenchmark with jit and nvfuser. I want to also dump the graph fused.
I tried following command, but nothing is printed.
PYTORCH_JIT_LOG_LEVEL=">>graph_fuser" python3 ../../run.py resnet50 -d cuda -m jit -t train | https://github.com/pytorch/benchmark/issues/1420 | closed | [] | 2023-02-20T14:26:50Z | 2023-03-07T16:20:49Z | null | fxing-GitHub |
pytorch/TensorRT | 1,680 | ❓ [Question]just import acc_tracer speed up my code | ## ❓ Question
<!-- Your question -->
## What you have already tried
<!-- A clear and concise description of what you have already done. -->
I use torch_tensortt compile a trt model,when I use the model to inference video ,I found when I add a line `import torch_tensorrt.fx.tracer.acc_tracer.acc_tracer as acc_... | https://github.com/pytorch/TensorRT/issues/1680 | closed | [
"question",
"No Activity",
"component: fx"
] | 2023-02-17T09:19:19Z | 2023-05-29T00:02:22Z | null | T0L0ve |
huggingface/setfit | 315 | Choosing the datapoints that need to be annotated? | Hello,
I have a large set of unlabelled data on which I need to do text classification. Since few-shot text classification uses only a handful of datapoints per class, is there a systematic way to choose which datapoints should be chosen for annotation?
Thank you! | https://github.com/huggingface/setfit/issues/315 | open | [
"question"
] | 2023-02-16T05:25:03Z | 2023-03-06T20:56:22Z | null | vahuja4 |
huggingface/setfit | 314 | Question: train and deploy via Sagemaker | Hi
I'm trying to setup training (and hyperparameter tuning) using Amazon SageMaker.
Because SetFit is not a standard model on HugginFace I'm guessing that the examples provided in the HuggingFace/SageMaker integration are not useable: [example](https://github.com/huggingface/notebooks/tree/ef21344eb20fe19f881c846d... | https://github.com/huggingface/setfit/issues/314 | open | [
"question"
] | 2023-02-15T12:23:33Z | 2024-03-28T15:10:28Z | null | lbelpaire |
pytorch/functorch | 1,111 | Use functional models inside usual nn.Module | Hi, Thanks for the adding functional features to Pytorch. I want to use a `nn.Module` converted into a functional form inside a usual stateful `nn.Module`. However, the code below does not correctly register the parameters for the functional module. Is there a way to do this currently?
```python
import torch... | https://github.com/pytorch/functorch/issues/1111 | open | [] | 2023-02-15T08:14:22Z | 2023-02-18T09:57:48Z | 1 | subho406 |
huggingface/setfit | 313 | Setfit no support evaluate each epoch or step and save model each epoch or step | Hi everyone, can u give me about evaluate each epoch and save checkpoint model ? thanks everyone | https://github.com/huggingface/setfit/issues/313 | closed | [
"question"
] | 2023-02-15T04:14:24Z | 2023-12-06T13:20:50Z | null | batman-do |
pytorch/vision | 7,250 | Add more docs about how to build a wheel of vision with the all features of video | ### 🚀 The feature
No docs to show how to build a wheel with the all features of video including the video_reader(gpu decoder).
### Motivation, pitch
I want to use GPU to accelerate the speed of video decoding.
And i find that you support the gpu video decoder.
There are some questions below:
1. from https:... | https://github.com/pytorch/vision/issues/7250 | open | [
"module: documentation",
"module: video"
] | 2023-02-15T01:53:44Z | 2023-02-15T08:07:13Z | null | wqh17101 |
pytorch/tutorials | 2,205 | During downsampling, bicubic interpolation produces WORSE results than ffmpeg. How can I fix this issue? | I have used "`bicubic`" interpolation with `(antialias=True)`. I checked the output downsampled image and found that It crates some artifacts on the image. See the image **[here](https://drive.google.com/file/d/1x1knhzyGpyqfkEjqi8tCxD4Ka_lhpfE5/view?usp=sharing)**,
Here is my code for downsampling:
```
from torc... | https://github.com/pytorch/tutorials/issues/2205 | closed | [
"question"
] | 2023-02-14T17:38:57Z | 2023-02-16T14:01:04Z | null | tahsirmunna |
huggingface/optimum | 776 | Loss of accuracy when Longformer for SequenceClassification model is exported to ONNX | ### Edit: This is a crosspost to [pytorch #94810](https://github.com/pytorch/pytorch/issues/94810). I don't know, where the issue lies.
### System info
- `transformers` version: 4.26.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.9.12
- PyTorch version (GPU?): 1.13.0 (False)
- onnx: 1.13.0
-... | https://github.com/huggingface/optimum/issues/776 | closed | [] | 2023-02-14T10:22:12Z | 2023-02-17T13:55:17Z | 8 | SteffenHaeussler |
pytorch/pytorch | 94,704 | `where` triggers INTERNAL ASSERT FAILED when `out` is a long tensor due to mixed types | ### 🐛 Describe the bug
`where` triggers INTERNAL ASSERT FAILED when `out` is a long tensor due to mixed types
```py
import torch
a = torch.ones(3, 4)
b = torch.zeros(3, 4)
c = torch.where(a > 0, a, b, out=torch.zeros(3, 4, dtype=torch.long))
# RuntimeError: !needs_dynamic_casting<func_t>::check(iter) INTERN... | https://github.com/pytorch/pytorch/issues/94704 | open | [
"module: error checking",
"triaged",
"module: type promotion"
] | 2023-02-12T16:32:30Z | 2023-02-27T18:15:01Z | null | cafffeeee |
pytorch/pytorch | 94,699 | How to correct TypeError: zip argument #1 must support iteration training in multiple GPU | ### 🐛 Describe the bug
I am doing a creating custom pytorch layer and model training using `Trainer API` function on top of `Hugging face` model.
When I run on `single GPU`, it trains fine. But when I train it on `multiple GPU` it throws me error.
`TypeError: zip argument #1 must support iteration training in... | https://github.com/pytorch/pytorch/issues/94699 | closed | [] | 2023-02-12T13:37:47Z | 2023-05-12T11:27:46Z | null | pratikchhapolika |
pytorch/data | 1,005 | "torchdata=0.4.1=py38" and Conda runtime error "glibc 2.29" not found. | ### 🐛 Describe the bug
I installed "torchdata=0.4.1=py38" in a Conda environment.
When I run the code, there is an error, "glibc 2.29" not found.
Our cluster run on Centos 8.5 and only has upto "glibc 2.28" .
Is "torchdata 0.4.1" compatible with "glibc 2.28"?
Is there a conda build that support gilbc 2.28... | https://github.com/meta-pytorch/data/issues/1005 | closed | [] | 2023-02-11T03:26:10Z | 2023-02-13T14:29:56Z | 1 | mahm1846 |
huggingface/setfit | 310 | How does predict_proba work exactly ? | Hi everyone !
Thanks for this amazing package first ! it is more than useful for a project at my work currently ! and the 0.6.0 was much needed on my side !
BUT i'd like to have some clarifications on how the function predict_proba works because I have a hard understanding.
This table :
<html>
<body>
<!--S... | https://github.com/huggingface/setfit/issues/310 | open | [
"question",
"needs verification"
] | 2023-02-10T14:13:13Z | 2023-11-15T08:24:38Z | null | doubianimehdi |
pytorch/examples | 1,112 | word_language_model with torch.nn.modules.transformer | The `torch.nn.modules.transformer` documentation says the `word_language_model` example in this repo is an example of its use. But it seems to instead DIY a transformer and uses that instead. Is this intentional? I would offer my help to write it for `torch.nn.modules.transformer` but I'm here to learn how to use it. | https://github.com/pytorch/examples/issues/1112 | open | [
"good first issue",
"nlp",
"docs"
] | 2023-02-09T19:31:43Z | 2023-02-21T04:05:42Z | 2 | olafx |
pytorch/examples | 1,111 | 🚀 Feature request / I want to contribute an algorithm | <!--
Thank you for suggesting an idea to improve pytorch/examples
Please fill in as much of the template below as you're able.
-->
## Is your feature request related to a problem? Please describe.
<!-- Please describe the problem you are trying to solve. -->
Currently, PyTorch/examples does not have an impl... | https://github.com/pytorch/examples/issues/1111 | closed | [] | 2023-02-09T15:13:40Z | 2023-02-26T23:47:19Z | 3 | viveks-codes |
huggingface/setfit | 308 | [QUESTION] Using callbacks (early stopping, logging, etc) | Hi all, thanks for your work here!
**TLDR**: Is there a way to add callbacks for early stopping and logging (for example, with W&B?).
I am using setfit for a project, but I could not figure out a way to add early stopping. I am afraid that I am overfitting to the training set. I also cant really say that I am, be... | https://github.com/huggingface/setfit/issues/308 | closed | [
"question"
] | 2023-02-08T19:39:20Z | 2023-02-27T16:25:26Z | null | FMelloMascarenhas-Cohere |
huggingface/optimum | 763 | Documented command "optimum-cli onnxruntime" doesn't exist? | ### System Info
```shell
Python 3.9, Ubuntu 20.04, Miniconda. CUDA GPU available
Packages installed (the important stuff):
onnx==1.13.0
onnxruntime==1.13.1
optimum==1.6.3
tokenizers==0.13.2
torch==1.13.1
transformers==4.26.0
nvidia-cublas-cu11==11.10.3.66
nvidia-cuda-nvrtc-cu11==11.7.99
nvidia-cuda-r... | https://github.com/huggingface/optimum/issues/763 | closed | [
"bug"
] | 2023-02-08T18:19:52Z | 2023-02-08T18:25:52Z | 2 | binarymax |
huggingface/datasets | 5,513 | Some functions use a param named `type` shouldn't that be avoided since it's a Python reserved name? | Hi @mariosasko, @lhoestq, or whoever reads this! :)
After going through `ArrowDataset.set_format` I found out that the `type` param is actually named `type` which is a Python reserved name as you may already know, shouldn't that be renamed to `format_type` before the 3.0.0 is released?
Just wanted to get your inp... | https://github.com/huggingface/datasets/issues/5513 | closed | [] | 2023-02-08T15:13:46Z | 2023-07-24T16:02:18Z | 4 | alvarobartt |
pytorch/TensorRT | 1,653 | ❓ [Question] Partitioning for unsupported operations | ## ❓ Question
As far as I understand Torch-TensorRT performs a partitioning step when unsupported operations are encountered. Then, graph uses generated TensorRT engine(s) for supported partition(s) and falls back to TorchScript JIT anywhere else. I can observe this behavior from generated graphs in general. However... | https://github.com/pytorch/TensorRT/issues/1653 | closed | [
"question",
"No Activity",
"component: partitioning"
] | 2023-02-08T07:39:17Z | 2023-06-10T00:02:25Z | null | kunkcu |
pytorch/TensorRT | 1,651 | ❓ [Question] Unknown type name '__torch__.torch.classes.tensorrt.Engine' | ## ❓ Question
<!-- Your question -->
## What you have already tried
**My c++ code:**
torch::Device device(torch::kCUDA);
torch::jit::script::Module module = torch::jit::load("lenet_trt.ts");
module.to(device);
vector<jit::IValue> inputs;
inputs.emplace_back(torch::ones({1,1,32,32}).to(devi... | https://github.com/pytorch/TensorRT/issues/1651 | closed | [
"question",
"component: api [C++]",
"component: runtime"
] | 2023-02-07T05:49:57Z | 2023-02-08T02:08:12Z | null | chensuo2048 |
pytorch/rl | 897 | [Feature Request] Tutorial on how to build the simplest agent | ## Motivation
Hey,
the [DDPG tutorial](https://pytorch.org/rl/tutorials/coding_ddpg.html) has me pooping my pants. I want to suggest an example of creating a simple DDPG or similar agent that just acts and observes and gets the job done for a researcher looking to implement and RL algorithm on their own environme... | https://github.com/pytorch/rl/issues/897 | open | [
"enhancement"
] | 2023-02-06T22:42:47Z | 2023-02-07T10:01:42Z | null | viktor-ktorvi |
pytorch/tutorials | 2,196 | nestedtensor.py on Colab building from master | When running the [nested tensors tutorial](https://pytorch.org/tutorials/prototype/nestedtensor.html) on [google colab](https://colab.research.google.com/github/pytorch/tutorials/blob/gh-pages/_downloads/db9e0933e73063322e250e5d0cec413d/nestedtensor.ipynb) builds from master instead of main. The master branch version i... | https://github.com/pytorch/tutorials/issues/2196 | open | [
"question",
"2.0"
] | 2023-02-06T22:13:41Z | 2023-02-07T21:32:28Z | null | alex-rakowski |
pytorch/data | 986 | Disable cron job running on forked repo | ### 🐛 Describe the bug
My forked repo of torchdata have been running the cron job to validate nightly binaries.
See workflow https://github.com/ejguan/data/actions/runs/4097726223
@atalman Is this expected? Can we disable it by doing something like:
https://github.com/pytorch/data/blob/01fc76200354501b057bb... | https://github.com/meta-pytorch/data/issues/986 | open | [
"Better Engineering"
] | 2023-02-06T16:29:00Z | 2023-04-11T16:48:19Z | 0 | ejguan |
pytorch/TensorRT | 1,650 | error when bazel compile torch_tensorrt on win10 | ## ❓ Question
when command " bazel build //:libtorchtrt --compilation_mode opt", the error comes
ERROR: C:/users/zhang/downloads/tensorrt-main/core/runtime/BUILD:13:11: Compiling core/runtime/TRTEngineProfiler.cpp failed: (Exit 2): cl.exe failed: error executing command (from target //core/runtime:runtime) D:\Progr... | https://github.com/pytorch/TensorRT/issues/1650 | closed | [
"question",
"No Activity",
"channel: windows"
] | 2023-02-06T07:38:28Z | 2023-06-08T00:02:27Z | null | zhanghuqiang |
huggingface/setfit | 298 | apply the optimized parameters | I did my hyperparameter search optimization on one computer and now I'm trying to apply the obtained parameters on another computer, so I could not use this code "trainer.apply_hyperparameters(best_run.hyperparameters, final_model=True)
trainer.train()". I put the obtained parameters manually in my new trainer instead... | https://github.com/huggingface/setfit/issues/298 | closed | [
"question"
] | 2023-02-03T18:31:59Z | 2023-02-16T08:00:52Z | null | zoezhupingli |
pytorch/text | 2,047 | Update `CONTRIBUTING.md` w/ instruction on how to install `torchdata` from source | See https://github.com/pytorch/text/issues/2045 | https://github.com/pytorch/text/issues/2047 | closed | [] | 2023-02-03T18:20:17Z | 2023-02-06T00:37:39Z | null | joecummings |
huggingface/setfit | 297 | Comparing setfit with a simpler approach | Hi,
I am trying to compare setfit with another approach. The other approach is like this:
1. Define a list of representative sentences per class, call it `rep_sent`
2. Compute sentence embeddings for `rep_sent` using `mpnet-base-v2`
3. Define a list of test sentences, call it 'test_sent'.
4. Compute sentence embed... | https://github.com/huggingface/setfit/issues/297 | closed | [
"question"
] | 2023-02-03T10:11:44Z | 2023-02-06T13:01:02Z | null | vahuja4 |
huggingface/setfit | 295 | Question: How the number of categories affect the training and accuracy? | I have found that increasing the number of categories reduce the accuracy results. Has anyone studied how the increased number of samples per category affect the results?
| https://github.com/huggingface/setfit/issues/295 | open | [
"question"
] | 2023-02-02T18:43:33Z | 2023-07-26T19:30:21Z | null | rubensmau |
pytorch/vision | 7,168 | Current way to use torchvision.prototype.transforms | ### 📚 The doc issue
I tried to run the [end-to-end example in this recent blog post](https://pytorch.org/blog/extending-torchvisions-transforms-to-object-detection-segmentation-and-video-tasks/#an-end-to-end-example):
```python
import PIL
from torchvision import io, utils
from torchvision.prototype import fea... | https://github.com/pytorch/vision/issues/7168 | closed | [
"question",
"module: transforms",
"prototype"
] | 2023-02-02T15:47:41Z | 2023-02-02T21:11:35Z | null | austinmw |
pytorch/TensorRT | 1,645 | ❓ [Question] How to use Torch-TensorRT with multi-headed (multiple output) networks | ## ❓ Question
I am having trouble using Torch-TensorRT with multi-headed networks. `torch_tensorrt.compile(...)` works fine and I can successfully use the resulting `ScriptModule` for execution. However, when I try to save and re-load the module I receive a RuntimeError on `torch.jit.load(...)`:
```
Traceback (m... | https://github.com/pytorch/TensorRT/issues/1645 | closed | [
"question",
"bug: triaged [verified]"
] | 2023-02-02T13:05:35Z | 2023-02-03T19:58:34Z | null | kunkcu |
huggingface/dataset-viewer | 762 | Handle the case where the DatasetInfo is too big | In the /parquet-and-dataset-info processing step, if DatasetInfo is over 16MB, we will not be able to store it in MongoDB (https://pymongo.readthedocs.io/en/stable/api/pymongo/errors.html#pymongo.errors.DocumentTooLarge). We have to handle this case, and return a clear error to the user.
See https://huggingface.slac... | https://github.com/huggingface/dataset-viewer/issues/762 | closed | [
"bug"
] | 2023-02-02T10:25:19Z | 2023-02-13T13:48:06Z | null | severo |
huggingface/datasets | 5,494 | Update audio installation doc page | Our [installation documentation page](https://huggingface.co/docs/datasets/installation#audio) says that one can use Datasets for mp3 only with `torchaudio<0.12`. `torchaudio>0.12` is actually supported too but requires a specific version of ffmpeg which is not easily installed on all linux versions but there is a cust... | https://github.com/huggingface/datasets/issues/5494 | closed | [
"documentation"
] | 2023-02-01T19:07:50Z | 2023-03-02T16:08:17Z | 4 | polinaeterna |
pytorch/pytorch | 93,347 | when I want to use a new backend, how to deal with the op with 'device' argument? | ### 🐛 Describe the bug
Hi
I saw the generated code in python_torch_functionsEverything.cpp line 4763, there are so many tricks for the op with 'device' argument, such as init CUDA device, `torch::utils::maybe_initialize_cuda(options);`
```
static PyObject * THPVariable_arange(PyObject* self_, PyObject* args, PyObj... | https://github.com/pytorch/pytorch/issues/93347 | open | [
"triaged",
"module: backend"
] | 2023-01-31T09:34:00Z | 2023-02-06T14:44:50Z | null | heidongxianhua |
pytorch/TensorRT | 1,638 | Error when running Resnet50-CPP.ipynb, ./torchtrt_runtime_example: symbol lookup error: ./torchtrt_runtime_example: undefined symbol: _ZN2at4_ops11randint_low4callEllN3c108ArrayRefIlEENS2_8optionalINS2_10ScalarTypeEEENS5_INS2_6LayoutEEENS5_INS2_6DeviceEEENS5_IbEE | I was following this notebook on nvcr.io/nvidia/pytorch:22.12-py3, container make runs fine but this step fails. My host has nvidia-470, 11.4. I have tried multiple times but the same error. | https://github.com/pytorch/TensorRT/issues/1638 | closed | [
"question",
"No Activity"
] | 2023-01-31T06:09:55Z | 2023-05-13T00:02:12Z | null | akshayantony12 |
huggingface/diffusers | 2,167 | Im using jupyter notebook and every time it stacks ckpt file but I don't know where it is | every time I try using diffusers, it downloads all .bin files and ckpt files but it piles up somewhere in the server.
i thought it got piled up in anaconda3/env but it wasn't.
where would it downloads the files be? my server its full of memory:(
``
Example here: https://pastebin.com/nTdTfFnZ
Versus her... | https://github.com/pytorch/TensorRT/issues/1631 | closed | [
"question"
] | 2023-01-30T23:43:51Z | 2023-01-31T21:14:03Z | null | manbehindthemadness |
huggingface/datasets | 5,475 | Dataset scan time is much slower than using native arrow | ### Describe the bug
I'm basically running the same scanning experiment from the tutorials https://huggingface.co/course/chapter5/4?fw=pt except now I'm comparing to a native pyarrow version.
I'm finding that the native pyarrow approach is much faster (2 orders of magnitude). Is there something I'm missing that exp... | https://github.com/huggingface/datasets/issues/5475 | closed | [] | 2023-01-27T01:32:25Z | 2023-01-30T16:17:11Z | 3 | jonny-cyberhaven |
pytorch/data | 965 | Correct way to shuffle, batch and shard WebDataset | ### 📚 The doc issue
Hi, the [docs on the WebDataset decoder](https://pytorch.org/data/main/generated/torchdata.datapipes.iter.WebDataset.html) give the following example:
```python
>>> from torchdata.datapipes.iter import FileLister, FileOpener
>>>
>>> def decode(item):
>>> key, value = item
>>> if ke... | https://github.com/meta-pytorch/data/issues/965 | closed | [
"documentation",
"good first issue"
] | 2023-01-25T16:25:40Z | 2023-01-25T17:51:57Z | 4 | austinmw |
huggingface/setfit | 289 | [question]: creating a custom dataset class like `sst` to fit into `setfit`, throws `Cannot index by location index with a non-integer key` | I'm trying to experiment with PyTorch some model; the dataset they were using for the experiment is [`sst`][1]
But I'm also learning PyTorch, so I thought it would be better to play with `Dataset` class and create my own dataset.
So this was my approach:
```
class CustomDataset(Dataset):
def __init__(self,... | https://github.com/huggingface/setfit/issues/289 | closed | [
"question"
] | 2023-01-25T10:22:35Z | 2023-01-27T15:53:44Z | null | maifeeulasad |
huggingface/transformers | 21,287 | [docs] TrainingArguments default label_names is not what is described in the documentation | ### System Info
- `transformers` version: 4.25.1
- Platform: macOS-12.6.1-arm64-arm-64bit
- Python version: 3.8.15
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.13.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not i... | https://github.com/huggingface/transformers/issues/21287 | closed | [] | 2023-01-24T18:24:47Z | 2023-01-24T19:48:26Z | null | fredsensibill |
pytorch/cpuinfo | 131 | How to cross-compile pytorch-cpuinfo? | Hi!
First a bit of context. I'm trying to build onnxruntime for raspberry pi using cross-compilation ([instructions here](https://onnxruntime.ai/docs/build/inferencing.html#cross-compiling-on-linux)). The onnxruntime package depends on pytorch-cpuinfo and fetches and builds it as part of the build process.
I'm u... | https://github.com/pytorch/cpuinfo/issues/131 | closed | [] | 2023-01-24T09:25:31Z | 2023-01-27T13:02:24Z | null | pietermarsman |
pytorch/data | 959 | Tables in Documentation not rendering properly | ### 📚 The doc issue
Compared to the last release, the tables in the documentation of the `main` branch is rendering differently. I do not recall any intentional changes to the format of our documentation or generation. We should have a look at this before the next release.
Before (0.5.1):
<img width="886" alt... | https://github.com/meta-pytorch/data/issues/959 | closed | [
"documentation",
"good first issue"
] | 2023-01-23T20:14:52Z | 2023-02-02T14:38:24Z | 8 | NivekT |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.