
repo stringclasses 147
values | number int64 1 172k | title stringlengths 2 476 | body stringlengths 0 5k | url stringlengths 39 70 | state stringclasses 2
values | labels listlengths 0 9 | created_at timestamp[ns, tz=UTC]date 2017-01-18 18:50:08 2026-01-06 07:33:18 | updated_at timestamp[ns, tz=UTC]date 2017-01-18 19:20:07 2026-01-06 08:03:39 | comments int64 0 58 ⌀ | user stringlengths 2 28 |
|---|---|---|---|---|---|---|---|---|---|---|
huggingface/diffusers | 1,921 | How to finetune inpainting model for object removal? What is the input prompt for object removal for both training and inference? |
Hi team,
Thanks for your great work!
I am trying to get object removal functionality from inpainting of SD.
How to finetune inpainting model for object removal?
What is the input prompt for object removal for both training and inference?
Thanks | https://github.com/huggingface/diffusers/issues/1921 | closed | [
"stale"
] | 2023-01-05T01:23:20Z | 2023-04-03T14:50:38Z | null | hdjsjyl |
huggingface/setfit | 254 | Why are the models fine-tuned with CosineSimilarity between 0 and 1? | Hi everyone,
This is a small question related to how models are fine-tuned during the first step of training. I see that the default loss function is `losses.CosineSimilarityLoss`. But when generating sentence pairs [here](https://github.com/huggingface/setfit/blob/35c0511fa9917e653df50cb95a22105b397e14c0/src/setfit... | https://github.com/huggingface/setfit/issues/254 | open | [
"question"
] | 2023-01-03T09:47:11Z | 2023-03-14T10:24:17Z | null | EdouardVilain-Git |
huggingface/setfit | 251 | Using setfit with the Hugging Face API | Hi, thank you so much for this amazing library!
I have trained my model and pushed it to the Hugging Face hub.
Since the output is a text-classification task, and the model card uploaded is for the sentence transformers, how should I use the model to run the classification model through the Hugging Face API?
T... | https://github.com/huggingface/setfit/issues/251 | open | [
"question"
] | 2022-12-29T01:46:37Z | 2023-01-01T07:53:43Z | null | kwen1510 |
huggingface/setfit | 249 | Sentence Pairs generation: is possible to parallelize it? | My dataset has 20k samples, 200 labels, and 32 iterations, so that means around 128 million samples, right?
there's some way to parallelize the pairs sentences creation?
or at least to save these pairs to create one time and reuse multiple times (i.e. to train with different epochs)
Thanks | https://github.com/huggingface/setfit/issues/249 | open | [
"question"
] | 2022-12-28T17:50:02Z | 2023-02-14T20:04:29Z | null | info2000 |
huggingface/setfit | 245 | extracting embeddings from a trained SetFit model. | Hey First of All, Thank You For This Great Package!
IMy task relates to semantic similarity, in which I find 'closeness' of a query sentence to a list of candidate sentences. Something like [shown here](https://www.sbert.net/docs/usage/semantic_textual_similarity.html)
I wanted to know if there was a way to extract... | https://github.com/huggingface/setfit/issues/245 | closed | [
"question"
] | 2022-12-26T12:27:50Z | 2023-12-06T13:21:04Z | null | moonisali |
huggingface/optimum | 640 | Improve documentations around ONNX export | ### Feature request
* Document `-with-past`, `--for-ort`, why use it
* Add more details in `optimum-cli export onnx --help` directly
### Motivation
/
### Your contribution
/ | https://github.com/huggingface/optimum/issues/640 | closed | [
"documentation",
"onnx",
"exporters"
] | 2022-12-23T15:54:32Z | 2023-01-03T16:34:56Z | 0 | fxmarty |
huggingface/datasets | 5,385 | Is `fs=` deprecated in `load_from_disk()` as well? | ### Describe the bug
The `fs=` argument was deprecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in favor of automagically figuring it out via fsspec:
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.py#L1339-L1340
Is there a reason the... | https://github.com/huggingface/datasets/issues/5385 | closed | [] | 2022-12-22T21:00:45Z | 2023-01-23T10:50:05Z | 3 | dconathan |
huggingface/optimum | 625 | Add support for Speech Encoder Decoder models in `optimum.exporters.onnx` | ### Feature request
Add support for [Speech Encoder Decoder Models](https://huggingface.co/docs/transformers/v4.25.1/en/model_doc/speech-encoder-decoder#speech-encoder-decoder-models)
### Your contribution
Me or other members can implement it (cc @mht-sharma @fxmarty ) | https://github.com/huggingface/optimum/issues/625 | open | [
"feature-request",
"onnx"
] | 2022-12-20T16:48:49Z | 2023-11-15T10:02:54Z | 4 | michaelbenayoun |
huggingface/optimum | 615 | Shall we set diffusers as soft dependency for onnxruntime module? | It seems a little bit strange for me that we need to have diffusers for doing sequence classification.
### System Info
```shell
Dev branch of Optimum
```
### Who can help?
@echarlaix @JingyaHuang
### Reproduction
```python
from optimum.onnxruntime import ORTModelForSequenceClassification
```
#... | https://github.com/huggingface/optimum/issues/615 | closed | [
"bug"
] | 2022-12-19T11:23:34Z | 2022-12-21T14:02:45Z | 1 | JingyaHuang |
huggingface/transformers | 20,794 | When I use the following code on tpuvm and use model.generate() to infer, the speed is very slow. It seems that the tpu is not used. What is the problem? | ### System Info
When I use the following code on tpuvm and use model.generate() to infer, the speed is very slow. It seems that the tpu is not used. What is the problem?
jax device is exist
```python
import jax
num_devices = jax.device_count()
device_type = jax.devices()[0].device_kind
assert "TPU" in device_typ... | https://github.com/huggingface/transformers/issues/20794 | closed | [] | 2022-12-16T09:15:32Z | 2023-05-21T15:03:06Z | null | joytianya |
huggingface/optimum | 595 | Document and (possibly) improve the `use_past`, `use_past_in_inputs`, `use_present_in_outputs` API | ### Feature request
As the title says.
Basically, for `OnnxConfigWithPast` there are three attributes:
- `use_past_in_inputs`: to specify that the exported model should have `past_key_values` as inputs
- `use_present_in_outputs`: to specify that the exported model should have `past_key_values` as outputs
- `u... | https://github.com/huggingface/optimum/issues/595 | closed | [
"documentation",
"Stale"
] | 2022-12-15T13:57:43Z | 2025-07-03T02:16:51Z | 2 | michaelbenayoun |
huggingface/datasets | 5,362 | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' ) | ### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
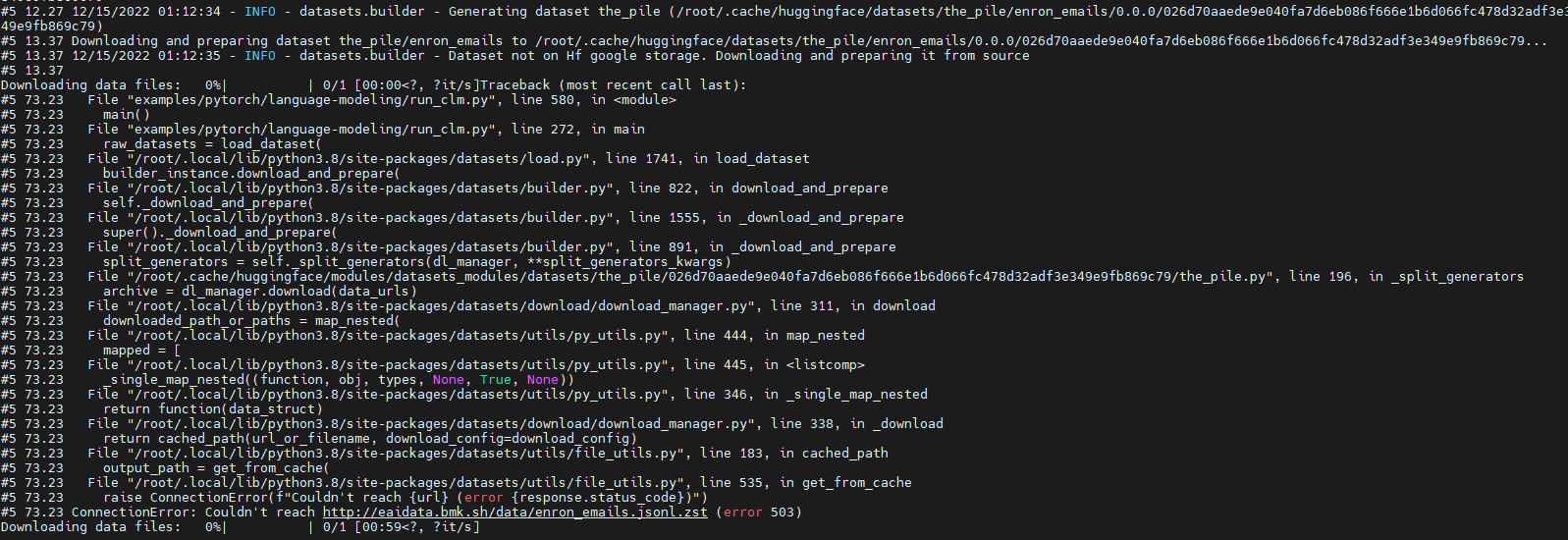
Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to ... | https://github.com/huggingface/datasets/issues/5362 | closed | [] | 2022-12-15T01:23:03Z | 2022-12-15T07:45:54Z | 2 | shaoyuta |
huggingface/datasets | 5,354 | Consider using "Sequence" instead of "List" | ### Feature request
Hi, please consider using `Sequence` type annotation instead of `List` in function arguments such as in [`Dataset.from_parquet()`](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L1088). It leads to type checking errors, see below.
**How to reproduce**
```py
... | https://github.com/huggingface/datasets/issues/5354 | open | [
"enhancement",
"good first issue"
] | 2022-12-12T15:39:45Z | 2025-11-21T22:35:10Z | 13 | tranhd95 |
huggingface/transformers | 20,733 | Verify that a test in `LayoutLMv3` 's tokenizer is checking what we want | I'm taking the liberty of opening an issue to share a question I've been keeping in the corner of my head, but now that I'll have less time to devote to `transformers` I prefer to share it before it's forgotten.
In the PR where the `LayoutLMv3` model was added, I was not very sure about the target value used for one... | https://github.com/huggingface/transformers/issues/20733 | closed | [] | 2022-12-12T15:17:36Z | 2023-05-26T10:14:14Z | null | SaulLu |
huggingface/setfit | 227 | Compare with other approaches | Dumb question:
How does setfit compare with other approaches for sentence classification in low data settings? Two that may be worth comparing to:
- Various techniques for [augmented SBERT](https://www.sbert.net/examples/training/data_augmentation/README.html)
- Simple Contrastive Learning [SimCSE](https://githu... | https://github.com/huggingface/setfit/issues/227 | open | [
"question"
] | 2022-12-12T14:32:51Z | 2022-12-20T08:49:52Z | null | creatorrr |
huggingface/datasets | 5,351 | Do we need to implement `_prepare_split`? | ### Describe the bug
I'm not sure this is a bug or if it's just missing in the documentation, or i'm not doing something correctly, but I'm subclassing `DatasetBuilder` and getting the following error because on the `DatasetBuilder` class the `_prepare_split` method is abstract (as are the others we are required to im... | https://github.com/huggingface/datasets/issues/5351 | closed | [] | 2022-12-12T01:38:54Z | 2022-12-20T18:20:57Z | 11 | jmwoloso |
huggingface/datasets | 5,343 | T5 for Q&A produces truncated sentence | Dear all, I am fine-tuning T5 for Q&A task using the MedQuAD ([GitHub - abachaa/MedQuAD: Medical Question Answering Dataset of 47,457 QA pairs created from 12 NIH websites](https://github.com/abachaa/MedQuAD)) dataset. In the dataset, there are many long answers with thousands of words. I have used pytorch_lightning to... | https://github.com/huggingface/datasets/issues/5343 | closed | [] | 2022-12-08T19:48:46Z | 2022-12-08T19:57:17Z | 0 | junyongyou |
huggingface/optimum | 566 | Add optimization and quantization options to `optimum.exporters.onnx` | ### Feature request
Would be nice to have two more arguments in `optimum.exporters.onnx` in order to have the optimized and quantized version of the exported models along side with the "normal" ones. I can imagine something like:
```
python -m optimum.exporters.onnx --model <model-name> -OX -quantized-arch <arch> ou... | https://github.com/huggingface/optimum/issues/566 | closed | [] | 2022-12-08T18:49:04Z | 2023-04-11T12:26:54Z | 17 | jplu |
huggingface/transformers | 20,638 | ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length. Perhaps your features (`labels` in this case) have excessive nesting (inputs type `list` where type `int` is expected). | ### System Info
- `transformers` version: 4.25.1
- Platform: Linux-5.10.133+-x86_64-with-glibc2.27
- Python version: 3.8.15
- Huggingface_hub version: 0.11.1
- PyTorch version (GPU?): 1.12.1+cu113 (True)
- Tensorflow version (GPU?): 2.9.2 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax versio... | https://github.com/huggingface/transformers/issues/20638 | closed | [] | 2022-12-07T02:10:35Z | 2023-01-31T21:23:46Z | null | vitthal-bhandari |
huggingface/setfit | 222 | Pre-training a generic SentenceTransformer for domain adaptation | When using `SetFit` for classification in a more technical domain, I could imagine the generically-trained `SBERT` models may produce poor sentence embeddings if the domain is not represented well enough in the diverse training corpus. In this case, would it be advantageous to first apply domain adaptation techniques (... | https://github.com/huggingface/setfit/issues/222 | open | [
"question"
] | 2022-12-05T15:22:57Z | 2023-04-30T06:45:47Z | null | zachschillaci27 |
huggingface/setfit | 219 | efficient way of saving finetuned zero-shot models? | Hi guys, pretty interesting project.
I was wondering if there is any way to save models after a zero-shot model is finetuned for few-shot model.
So for example, if I finetuned a couple of say, `sentence-transformers/paraphrase-mpnet-base-v2` models, the major difference between them is just the weights of final f... | https://github.com/huggingface/setfit/issues/219 | open | [
"question"
] | 2022-12-05T07:36:40Z | 2022-12-20T08:49:32Z | null | RaiAmanRai |
huggingface/datasets | 5,326 | No documentation for main branch is built | Since:
- #5250
- Commit: 703b84311f4ead83c7f79639f2dfa739295f0be6
the docs for main branch are no longer built.
The change introduced only triggers the docs building for releases. | https://github.com/huggingface/datasets/issues/5326 | closed | [
"bug"
] | 2022-12-01T16:50:58Z | 2022-12-02T16:26:01Z | 0 | albertvillanova |
huggingface/datasets | 5,325 | map(...batch_size=None) for IterableDataset | ### Feature request
Dataset.map(...) allows batch_size to be None. It would be nice if IterableDataset did too.
### Motivation
Although it may seem a bit of a spurious request given that `IterableDataset` is meant for larger than memory datasets, but there are a couple of reasons why this might be nice.
One is th... | https://github.com/huggingface/datasets/issues/5325 | closed | [
"enhancement",
"good first issue"
] | 2022-12-01T15:43:42Z | 2022-12-07T15:54:43Z | 5 | frankier |
huggingface/datasets | 5,324 | Fix docstrings and types in documentation that appears on the website | While I was working on https://github.com/huggingface/datasets/pull/5313 I've noticed that we have a mess in how we annotate types and format args and return values in the code. And some of it is displayed in the [Reference section](https://huggingface.co/docs/datasets/package_reference/builder_classes) of the document... | https://github.com/huggingface/datasets/issues/5324 | open | [
"documentation"
] | 2022-12-01T15:34:53Z | 2024-01-23T16:21:54Z | 5 | polinaeterna |
huggingface/datasets | 5,317 | `ImageFolder` performs poorly with large datasets | ### Describe the bug
While testing image dataset creation, I'm seeing significant performance bottlenecks with imagefolders when scanning a directory structure with large number of images.
## Setup
* Nested directories (5 levels deep)
* 3M+ images
* 1 `metadata.jsonl` file
## Performance Degradation Point... | https://github.com/huggingface/datasets/issues/5317 | open | [] | 2022-12-01T00:04:21Z | 2022-12-01T21:49:26Z | 3 | salieri |
huggingface/setfit | 209 | Limitations of Setfit Model | Hi, was wondering your thoughts on some of the limitations of the Setfit model. Can it support any sort of few shot text classification, or what are some areas where this model falls short? Are there any research papers / ideas to address some of these limitations.
Also, is the model available to call via Hugging F... | https://github.com/huggingface/setfit/issues/209 | open | [
"question"
] | 2022-11-28T22:58:35Z | 2023-02-24T20:11:00Z | null | nv78 |
huggingface/Mongoku | 92 | Switch to Svelte(Kit?) | https://github.com/huggingface/Mongoku/issues/92 | closed | [
"enhancement",
"help wanted",
"question"
] | 2022-11-23T21:28:39Z | 2025-10-25T16:03:14Z | null | julien-c | |
huggingface/datasets | 5,286 | FileNotFoundError: Couldn't find file at https://dumps.wikimedia.org/enwiki/20220301/dumpstatus.json | ### Describe the bug
I follow the steps provided on the website [https://huggingface.co/datasets/wikipedia](https://huggingface.co/datasets/wikipedia)
$ pip install apache_beam mwparserfromhell
>>> from datasets import load_dataset
>>> load_dataset("wikipedia", "20220301.en")
however this results in the follo... | https://github.com/huggingface/datasets/issues/5286 | closed | [] | 2022-11-23T14:54:15Z | 2024-11-23T01:16:41Z | 3 | roritol |
huggingface/setfit | 198 | text similarity | Hi can I use this system to obtain the similaarity scores of my data set to a given prompts.
If not what best solution could help this problem?
thank you | https://github.com/huggingface/setfit/issues/198 | open | [
"question"
] | 2022-11-22T06:59:21Z | 2022-12-20T09:04:53Z | null | aivyon |
huggingface/datasets | 5,274 | load_dataset possibly broken for gated datasets? | ### Describe the bug
When trying to download the [winoground dataset](https://huggingface.co/datasets/facebook/winoground), I get this error unless I roll back the version of huggingface-hub:
```
[/usr/local/lib/python3.7/dist-packages/huggingface_hub/utils/_validators.py](https://localhost:8080/#) in validate_rep... | https://github.com/huggingface/datasets/issues/5274 | closed | [] | 2022-11-21T21:59:53Z | 2023-05-27T00:06:14Z | 9 | TristanThrush |
huggingface/datasets | 5,272 | Use pyarrow Tensor dtype | ### Feature request
I was going the discussion of converting tensors to lists.
Is there a way to leverage pyarrow's Tensors for nested arrays / embeddings?
For example:
```python
import pyarrow as pa
import numpy as np
x = np.array([[2, 2, 4], [4, 5, 100]], np.int32)
pa.Tensor.from_numpy(x, dim_names=["dim1... | https://github.com/huggingface/datasets/issues/5272 | open | [
"enhancement"
] | 2022-11-20T15:18:41Z | 2024-11-11T03:03:17Z | 17 | franz101 |
huggingface/optimum | 488 | Community contribution - `BetterTransformer` integration for more models! | ## `BetterTransformer` integration for more models!
`BetterTransformer` API provides faster inference on CPU & GPU through a simple interface!
Models can benefit from very interesting speedups using a one liner and by making sure to install the latest version of PyTorch. A complete guideline on how to convert a ... | https://github.com/huggingface/optimum/issues/488 | open | [
"good first issue"
] | 2022-11-18T10:45:39Z | 2025-05-20T20:35:02Z | 26 | younesbelkada |
huggingface/setfit | 192 | How to use a custom Sentence Transformer pretrained model | Hello team,
Presently we are using models which are present in hugging face . I have a custom trained Sentence transformer.
How I can use a custom trained Hugging face model in the present pipeline. | https://github.com/huggingface/setfit/issues/192 | open | [
"question"
] | 2022-11-17T09:13:59Z | 2022-12-20T09:05:06Z | null | theainerd |
huggingface/setfit | 191 | How to build multilabel text classfication dataset | From the sample below, param **column_mapping** is used to set up the dataset. What is the format of label column in multilabel?Is it the one-hot label?
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
loss_class=CosineSimilarityLoss,
metric="ac... | https://github.com/huggingface/setfit/issues/191 | closed | [
"question"
] | 2022-11-17T05:50:56Z | 2022-12-13T22:32:16Z | null | HenryYuen128 |
huggingface/datasets | 5,249 | Protect the main branch from inadvertent direct pushes | We have decided to implement a protection mechanism in this repository, so that nobody (not even administrators) can inadvertently push accidentally directly to the main branch.
See context here:
- d7c942228b8dcf4de64b00a3053dce59b335f618
To do:
- [x] Protect main branch
- Settings > Branches > Branch protec... | https://github.com/huggingface/datasets/issues/5249 | closed | [
"maintenance"
] | 2022-11-16T14:19:03Z | 2023-12-21T10:28:27Z | 1 | albertvillanova |
huggingface/datasets | 5,243 | Download only split data | ### Feature request
Is it possible to download only the data that I am requesting and not the entire dataset? I run out of disk spaceas it seems to download the entire dataset, instead of only the part needed.
common_voice["test"] = load_dataset("mozilla-foundation/common_voice_11_0", "en", split="test",
... | https://github.com/huggingface/datasets/issues/5243 | open | [
"enhancement"
] | 2022-11-15T10:15:54Z | 2025-02-25T14:47:03Z | 7 | capsabogdan |
huggingface/diffusers | 1,281 | what is the meaning of parameter: "num_class_images" | What is the `num_class_images `parameter used for? I see that in some examples it is 50, sometimes it is 200. In the source code it is said that: "Minimal class images for prior preservation loss. If not have enough images, additional images will be sampled with class_prompt."
I still do not fully grasp it. For exampl... | https://github.com/huggingface/diffusers/issues/1281 | closed | [] | 2022-11-14T18:32:22Z | 2022-12-06T01:47:42Z | null | himmetozcan |
huggingface/setfit | 178 | Question : evaluation after every training epoch | # Thank you
Hello!
I am Yongtae, a senior ML engineer in japan.
Thank you for publishing a genuinely excellent paper and code.
Few-shot learning and multilingual support are appreciated by engineers like me who work abroad!
# Question
I felt this model easily overfit to train data if the number of epochs is ov... | https://github.com/huggingface/setfit/issues/178 | closed | [
"question"
] | 2022-11-13T09:36:47Z | 2022-12-26T03:12:16Z | null | Yongtae723 |
huggingface/setfit | 173 | How to setup gradient_accumulation? | Hi,
in order to train a model SetFit, I would like simulate a `batch_size` of 16 but with a `batch_size` of 8. For doing that, I need to setup `gradient_accumulation` to 2.
How to do that?
Thanks. | https://github.com/huggingface/setfit/issues/173 | closed | [
"question"
] | 2022-11-10T21:19:52Z | 2022-12-20T08:49:13Z | null | piegu |
huggingface/datasets | 5,226 | Q: Memory release when removing the column? | ### Describe the bug
How do I release memory when I use methods like `.remove_columns()` or `clear()` in notebooks?
```python
from datasets import load_dataset
common_voice = load_dataset("mozilla-foundation/common_voice_11_0", "ja", use_auth_token=True)
# check memory -> RAM Used (GB): 0.704 / Total (GB) 33.670... | https://github.com/huggingface/datasets/issues/5226 | closed | [] | 2022-11-10T18:35:27Z | 2022-11-29T15:10:10Z | 3 | bayartsogt-ya |
huggingface/datasets | 5,225 | Add video feature | ### Feature request
Add a `Video` feature to the library so folks can include videos in their datasets.
### Motivation
Being able to load Video data would be quite helpful. However, there are some challenges when it comes to videos:
1. Videos, unlike images, can end up being extremely large files
2. Often times ... | https://github.com/huggingface/datasets/issues/5225 | open | [
"enhancement",
"help wanted",
"vision"
] | 2022-11-10T17:36:11Z | 2022-12-02T15:13:15Z | 7 | nateraw |
huggingface/optimum | 462 | Add support for EncoderDecoderModel | ### Feature request
There's already support for `marian` and various LLMs. But sometimes users create their own generic `EncoderDecoderModel`, e.g.
```
from transformers import EncoderDecoderModel
from optimum.onnxruntime import ORTModelForSeq2SeqLM
model = EncoderDecoderModel.from_encoder_decoder_pretrained(... | https://github.com/huggingface/optimum/issues/462 | closed | [] | 2022-11-10T13:54:48Z | 2023-09-01T11:11:43Z | 1 | alvations |
huggingface/evaluate | 353 | What is the MAE range in evaluate? | In the MAE demo space, it is indicated that "Each MAE float value ranges from 0.0 to 1.0, with the best value being 0.0."
Doesn't it range from 0 to +inf in general ?
Is it a programmatic constraint added on the evaluate MAE score? | https://github.com/huggingface/evaluate/issues/353 | closed | [] | 2022-11-10T13:29:30Z | 2022-11-16T09:45:15Z | null | clefourrier |
huggingface/diffusers | 1,204 | [Community] Can we composite Dreambooth network training? | Very impressed with Dreambooth capabilities. I have what i think is a feature request - or perhaps a clarification on what is and is not possible in training networks with Dreambooth. In particular, i was wondering if there was a way to composite two networks to enable embedding of two instances (e.g. an sks dog >and< ... | https://github.com/huggingface/diffusers/issues/1204 | closed | [
"question",
"stale"
] | 2022-11-09T01:59:05Z | 2022-12-21T15:03:19Z | null | felgryn |
huggingface/datasets | 5,216 | save_elasticsearch_index | Hi,
I am new to Dataset and elasticsearch. I was wondering is there any equivalent approach to save elasticsearch index as of save_faiss_index locally for later use, to remove the need to re-index a dataset? | https://github.com/huggingface/datasets/issues/5216 | open | [] | 2022-11-08T23:06:52Z | 2022-11-09T13:16:45Z | 1 | amobash2 |
huggingface/diffusers | 1,168 | What is "class images" mean for dreambooth training? | What is "class images" mean for dreambooth training?
If instance images meaning the subject i want to train on , what does "class images" mean? | https://github.com/huggingface/diffusers/issues/1168 | closed | [] | 2022-11-07T03:41:07Z | 2022-11-08T06:07:10Z | null | universewill |
huggingface/transformers | 20,083 | Where is the Translation template ? | I want to translate the doc in leisure time, and I followed the guide, but not found Translation template... | https://github.com/huggingface/transformers/issues/20083 | closed | [] | 2022-11-06T06:44:12Z | 2022-11-14T08:40:44Z | null | bfss |
huggingface/datasets | 5,200 | Some links to canonical datasets in the docs are outdated | As we don't have canonical datasets in the github repo anymore, some old links to them doesn't work. I don't know how many of them are there, I found link to SuperGlue here: https://huggingface.co/docs/datasets/dataset_script#multiple-configurations, probably there are more of them. These links should be replaced by li... | https://github.com/huggingface/datasets/issues/5200 | closed | [
"documentation"
] | 2022-11-04T10:06:21Z | 2022-11-07T18:40:20Z | 1 | polinaeterna |
huggingface/setfit | 147 | Reproducing RAFT experiments (Table 3) | Hi, I wasn't able to locate the code to reproduce Table 3. I looked in the `scripts` folder but didn't have success.
Any help with this is greatly appreciated!
A side question on the RAFT results: did you use 10 random seeds for this experiment? | https://github.com/huggingface/setfit/issues/147 | closed | [
"question"
] | 2022-11-02T18:34:55Z | 2022-12-13T22:50:48Z | null | dgiova |
huggingface/setfit | 145 | SetFit for a large number of classes | Hi there, thanks for releasing such an interesting library.
I am curious if any experiments have been run using SetFit in the extreme multiclass setting, say as `n_classes>=100`? | https://github.com/huggingface/setfit/issues/145 | closed | [
"question"
] | 2022-11-02T16:34:51Z | 2024-05-14T10:46:30Z | null | steve-marmalade |
huggingface/datasets | 5,189 | Reduce friction in tabular dataset workflow by eliminating having splits when dataset is loaded | ### Feature request
Sorry for cryptic name but I'd like to explain using code itself. When I want to load a specific dataset from a repository (for instance, this: https://huggingface.co/datasets/inria-soda/tabular-benchmark)
```python
from datasets import load_dataset
dataset = load_dataset("inria-soda/tabular-b... | https://github.com/huggingface/datasets/issues/5189 | open | [
"enhancement"
] | 2022-11-02T09:15:02Z | 2022-12-06T12:13:17Z | 33 | merveenoyan |
huggingface/datasets | 5,183 | Loading an external dataset in a format similar to conll2003 | I'm trying to load a custom dataset in a Dataset object, it's similar to conll2003 but with 2 columns only (word entity), I used the following script:
features = datasets.Features(
{"tokens": datasets.Sequence(datasets.Value("string")),
"ner_tags": datasets.Sequence(
datasets.featu... | https://github.com/huggingface/datasets/issues/5183 | closed | [] | 2022-11-01T13:18:29Z | 2022-11-02T11:57:50Z | 0 | Taghreed7878 |
huggingface/datasets | 5,182 | Add notebook / other resource links to the task-specific data loading guides | Does it make sense to include links to notebooks / scripts that show how to use a dataset for training / fine-tuning a model?
For example, here in [https://huggingface.co/docs/datasets/image_classification] we could include a mention of https://github.com/huggingface/notebooks/blob/main/examples/image_classificatio... | https://github.com/huggingface/datasets/issues/5182 | closed | [
"enhancement"
] | 2022-11-01T07:57:26Z | 2022-11-03T01:49:57Z | 2 | sayakpaul |
huggingface/datasets | 5,181 | Add a guide for semantic segmentation | Currently, we have these guides for object detection and image classification:
* https://huggingface.co/docs/datasets/object_detection
* https://huggingface.co/docs/datasets/image_classification
I am proposing adding a similar guide for semantic segmentation.
I am happy to contribute a PR for it.
Cc: @os... | https://github.com/huggingface/datasets/issues/5181 | closed | [
"documentation"
] | 2022-11-01T07:54:50Z | 2022-11-04T18:23:36Z | 2 | sayakpaul |
huggingface/datasets | 5,180 | An example or recommendations for creating large image datasets? | I know that Apache Beam and `datasets` have [some connector utilities](https://huggingface.co/docs/datasets/beam). But it's a little unclear what we mean by "But if you want to run your own Beam pipeline with Dataflow, here is how:". What does that pipeline do?
As a user, I was wondering if we have this support for... | https://github.com/huggingface/datasets/issues/5180 | open | [] | 2022-11-01T07:38:38Z | 2022-11-02T10:17:11Z | 2 | sayakpaul |
huggingface/optimum | 442 | Add support for ORTModelForObjectDetection | ### Feature request
Hi, I went through optimum's code base and could not find support for object detection models. Is there plan to add ORTModelForObjectDetection just like ORTModelForImageClassification exists? Would be great to have this feature.
Object detection task is also supported as part of transformers `pi... | https://github.com/huggingface/optimum/issues/442 | open | [
"onnxruntime",
"onnx"
] | 2022-10-31T19:59:21Z | 2025-12-05T10:42:26Z | 9 | shivalikasingh95 |
huggingface/setfit | 126 | Does num_iterations create duplicate data? | I am trying to get a better understanding behind this hyperparam. As far as I understand, you are iterating over the data `num_iterations` times and create a positive and negative pair by sampling. Could this result in duplicate data?
Also sometimes it tends to result in more examples than potential pairs for exampl... | https://github.com/huggingface/setfit/issues/126 | open | [
"question"
] | 2022-10-26T13:09:52Z | 2022-12-20T09:10:53Z | null | nsorros |
huggingface/datasets | 5,157 | Consistent caching between python and jupyter | ### Feature request
I hope this is not my mistake, currently if I use `load_dataset` from a python session on a custom dataset to do the preprocessing, it will be saved in the cache and in other python sessions it will be loaded from the cache, however calling the same from a jupyter notebook does not work, meaning th... | https://github.com/huggingface/datasets/issues/5157 | closed | [
"enhancement"
] | 2022-10-25T01:34:33Z | 2022-11-02T15:43:22Z | 2 | gpucce |
huggingface/setfit | 120 | Using SetFit Embeddings for Semantic Search? | Hi,
I was wondering if the semantic search would improve if one would train a multilabel-classification model and use those embeddings?
After training a binary classification model I have seen that the embeddings between similar topics on `all-MiniLM-L12-v2` vs `all-MiniLM-L12-v2-setfit` (fitted model) are very c... | https://github.com/huggingface/setfit/issues/120 | open | [
"question"
] | 2022-10-25T00:00:03Z | 2024-07-12T02:02:04Z | null | Raidus |
huggingface/setfit | 119 | Using SetFit for regression tasks? | I was curious about using SetFit for ordinal Likert scale outcomes (ie IMDB movie reviews). It doesn't seem like an obvious option in the SetFit API. Has anyone tried using SetFit for regression tasks? | https://github.com/huggingface/setfit/issues/119 | open | [
"question"
] | 2022-10-21T19:15:29Z | 2023-02-01T16:48:33Z | null | ericlinML |
huggingface/dataset-viewer | 614 | [feat req] Alphabetical ordering for splits in dataset viewer | ### Link
https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0
### Description
Currently, the datasets splits for the viewer are displayed in a seemingly random order, see example for [Common Voice 11](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0):
<img width="1505" alt="Scree... | https://github.com/huggingface/dataset-viewer/issues/614 | closed | [
"question",
"feature request"
] | 2022-10-21T12:11:00Z | 2022-10-26T09:48:29Z | null | sanchit-gandhi |
huggingface/datasets | 5,144 | Inconsistent documentation on map remove_columns | ### Describe the bug
The page [process](https://huggingface.co/docs/datasets/process) says this about the parameter `remove_columns` of the function `map`:
When you remove a column, it is only removed after the example has been provided to the mapped function.
So it seems that the `remove_columns` parameter remo... | https://github.com/huggingface/datasets/issues/5144 | closed | [
"documentation",
"duplicate",
"good first issue",
"hacktoberfest"
] | 2022-10-21T08:37:53Z | 2022-11-15T14:15:10Z | 3 | zhaowei-wang-nlp |
huggingface/setfit | 117 | Using this for code gen? | Can we use this for code generation? | https://github.com/huggingface/setfit/issues/117 | closed | [
"question"
] | 2022-10-20T16:53:59Z | 2022-12-20T09:32:50Z | null | krrishdholakia |
huggingface/datasets | 5,143 | DownloadManager Git LFS support | ### Feature request
Maybe I'm mistaken but the `DownloadManager` does not support extracting git lfs files out of the box right?
Using `dl_manager.download()` or `dl_manager.download_and_extract()` still returns lfs files afaict.
Is there a good way to write a dataset loading script for a repo with lfs files?
##... | https://github.com/huggingface/datasets/issues/5143 | closed | [
"enhancement"
] | 2022-10-20T15:29:29Z | 2022-10-20T17:17:10Z | 2 | Muennighoff |
huggingface/setfit | 116 | How to take advantage of Mac M1 GPUs? | More than an issue, this is a request for help.
Do you have advice on how to take advantage of the Mac M1 Pro GPU for training a model, assuming the underlying Torch implementation provides support?
There are some tutorials on how to use Torch with the MPS driver, but I'm not sure how to signal SetFit to use a sp... | https://github.com/huggingface/setfit/issues/116 | closed | [
"question"
] | 2022-10-20T08:43:24Z | 2024-01-29T16:58:04Z | null | secastro |
huggingface/setfit | 115 | How many samples for setfit? | I understood that setfit is a light weight solution for few shot learning. Two questions came up:
.) What would be a number of samples of class you would switch to standard supervised learning and fine-tuning? E.g. 100 samples?
.) Is there any disadvantage of generating too many pairs (num_iterations) If I have 30 cl... | https://github.com/huggingface/setfit/issues/115 | open | [
"question"
] | 2022-10-20T06:13:41Z | 2023-02-27T10:52:50Z | null | hanshupe |
huggingface/optimum | 424 | Convert Seq2Seq model to ONNX while splitting encoder-decoder. | Hi guys, I've recently been trying to convert my trained BART model to onnx. I've found that when using `transformers.onnx` from transformers, the resulting onnx file is a singular `.onnx` file. However, when using `ORTModelForSequenceClassification.from_pretrained()` and then saving the result I have three files, enco... | https://github.com/huggingface/optimum/issues/424 | closed | [
"question",
"onnxruntime"
] | 2022-10-19T09:17:50Z | 2022-10-20T01:29:30Z | null | ZiyueWangUoB |
huggingface/datasets | 5,135 | Update docs once dataset scripts transferred to the Hub | ## Describe the bug
As discussed in:
- https://github.com/huggingface/hub-docs/pull/423#pullrequestreview-1146083701
we should update our docs once dataset scripts have been transferred to the Hub (and removed from GitHub):
- #4974
Concretely:
- [x] Datasets on GitHub (legacy): https://huggingface.co/docs/dat... | https://github.com/huggingface/datasets/issues/5135 | closed | [
"documentation"
] | 2022-10-19T06:58:19Z | 2022-10-20T08:10:01Z | 0 | albertvillanova |
huggingface/accelerate | 771 | What is the best practice to do inference in bf16 with accelerate during training? | ### System Info
```Shell
Basically, I want to do training with mixed precision and evaluate the model with bfloat16.
I found the model is stored in fp32 after calling acclerate.prepare() and have to convert it to bf16 for faster inference. Can I avoid `explictly` model conversion and make the most use of accelerate?... | https://github.com/huggingface/accelerate/issues/771 | closed | [] | 2022-10-18T13:15:39Z | 2022-10-18T13:32:02Z | null | huchinlp |
huggingface/setfit | 110 | more metrics addition (i.e f1score, precision ) in the trainer.evaluate() | was just checking the code and saw only accuracy as a metrics, are we planning to add more metrics? | https://github.com/huggingface/setfit/issues/110 | closed | [
"question"
] | 2022-10-18T11:03:18Z | 2023-06-26T14:49:05Z | null | snayan06 |
huggingface/setfit | 108 | Are checkpoints directly available with the SetFitTrainer? | Hi, just looking to see if checkpoints are implemented with the SetFitTrainer. Couldn't find it, unlike how the normal models in Hugging Face use `output_dir` for saving checkpoints when training a model. | https://github.com/huggingface/setfit/issues/108 | open | [
"question"
] | 2022-10-17T18:46:13Z | 2022-12-20T09:34:41Z | null | ajmcgrail |
huggingface/datasets | 5,118 | Installing `datasets` on M1 computers | ## Describe the bug
I wanted to install `datasets` dependencies on my M1 (in order to start contributing to the project). However, I got an error regarding `tensorflow`.
On M1, `tensorflow-macos` needs to be installed instead. Can we add a conditional requirement, so that `tensorflow-macos` would be installed on M1... | https://github.com/huggingface/datasets/issues/5118 | closed | [
"bug"
] | 2022-10-16T16:50:08Z | 2022-10-19T09:10:08Z | 1 | david1542 |
huggingface/setfit | 106 | Function to get probability values of predicted output (like sklearn's predict_proba)? | Hi! I wanted to ask if there was an in-built function to get the probability value of predicted output from a classification task, something like predict_proba() from sklearn?
From what i understand currently the only way to get output is to run SetFitModel([text]), which works similar to sklearn predict(). | https://github.com/huggingface/setfit/issues/106 | closed | [
"question"
] | 2022-10-14T13:45:26Z | 2022-12-20T09:34:57Z | null | a-sharma123 |
huggingface/transformers | 19,592 | Sagemaker Estimator for fine tuning where all the transform code is in the train.py | ### Feature request
I work for a company that is a heavy user of AWS sagemaker. I am on a professional services team where I build a lot of examples for our data scientists to follow. I recently wanted to use the Sagemaker Huggingface estimator to fine tune a transformer and create a model for our custom NLP task.
... | https://github.com/huggingface/transformers/issues/19592 | closed | [] | 2022-10-13T19:24:14Z | 2022-11-21T15:02:11Z | null | j2cunningham |
huggingface/setfit | 91 | Using Setfit for similarity classification | Hello,
I would like to test this promising framework on a similarity classification task. So basically, I have got a dataset with 3 columns: (sentence1,sentence2,label). From what I understand, currently it is only possible to train on a single sentence classification problem.
Is there a get around to use Setfit for ... | https://github.com/huggingface/setfit/issues/91 | open | [
"question"
] | 2022-10-07T09:58:09Z | 2025-01-21T10:05:54Z | null | castafra |
huggingface/setfit | 86 | num_epochs range | Hi there!
I was wondering whether you can provide a range for typically "good" values to use/test for the argument num_epochs both in the single label classification case and the multi label classification case. Of course, the best performing number depends on the classes to be predicted and the dataset, but in non-FS... | https://github.com/huggingface/setfit/issues/86 | open | [
"question"
] | 2022-10-06T15:35:48Z | 2022-12-20T09:36:09Z | null | fhamborg |
huggingface/setfit | 83 | Running Evaluation | Hi,
Thanks for sharing this work.
I am wondering if it is possible to run evaluation dataset to tune hyperparameters.
The SetFitTrainer doesn't seem to accept arguments like 'evaluation_strategy', 'save_strategy', 'compute_metrics', etc.
Or perhaps Im doing something wrong?
Thanks.
| https://github.com/huggingface/setfit/issues/83 | open | [
"question"
] | 2022-10-06T05:58:19Z | 2022-12-20T09:36:43Z | null | dhkhey |
huggingface/setfit | 81 | Fine-tuning for Question-Answering | Hello,
Can this library be used for fine-tuning a question-answering model with small amount of data as well ?
I have a data that is in the same format with squad data. It has small amount of context, question, and answers data.
Is it possible use this library to fine tune a question-answering model in huggin... | https://github.com/huggingface/setfit/issues/81 | open | [
"question"
] | 2022-10-04T17:47:10Z | 2022-12-20T09:36:55Z | null | ozyurtf |
huggingface/datasets | 5,053 | Intermittent JSON parse error when streaming the Pile | ## Describe the bug
I have an intermittent error when streaming the Pile, where I get a JSON parse error which causes my program to crash.
This is intermittent - when I rerun the program with the same random seed it does not crash in the same way. The exact point this happens also varied - it happened to me 11B tok... | https://github.com/huggingface/datasets/issues/5053 | open | [
"bug"
] | 2022-10-02T11:56:46Z | 2022-10-04T17:59:03Z | 3 | neelnanda-io |
huggingface/datasets | 5,044 | integrate `load_from_disk` into `load_dataset` | **Is your feature request related to a problem? Please describe.**
Is it possible to make `load_dataset` more universal similar to `from_pretrained` in `transformers` so that it can handle the hub, and the local path datasets of all supported types?
Currently one has to choose a different loader depending on how ... | https://github.com/huggingface/datasets/issues/5044 | open | [
"enhancement"
] | 2022-09-29T17:37:12Z | 2025-06-28T09:00:44Z | 15 | stas00 |
huggingface/setfit | 72 | Few-Shot Named Entity Recognition work | Hi, really like your work, have you considered using this framework for few-shot named entity recognition work? or do you have an example code for it, looking forward to the progress in few-shot named entity recognition! | https://github.com/huggingface/setfit/issues/72 | open | [
"question"
] | 2022-09-29T09:32:11Z | 2022-12-20T09:37:02Z | null | zhanghaok |
huggingface/datasets | 5,013 | would huggingface like publish cpp binding for datasets package ? | HI:
I use cpp env libtorch, I like use hugggingface ,but huggingface not cpp binding, would you like publish cpp binding for it.
thanks | https://github.com/huggingface/datasets/issues/5013 | closed | [
"wontfix"
] | 2022-09-23T07:42:49Z | 2023-02-24T16:20:57Z | 5 | mullerhai |
huggingface/datasets | 5,012 | Force JSON format regardless of file naming on S3 | I have a file on S3 created by Data Version Control, it looks like `s3://dvc/ac/badff5b134382a0f25248f1b45d7b2` but contains a json file. If I run
```python
dataset = load_dataset(
"json",
data_files='s3://dvc/ac/badff5b134382a0f25248f1b45d7b2'
)
```
It gives me
```
InvalidSchema: No connection adap... | https://github.com/huggingface/datasets/issues/5012 | closed | [
"enhancement"
] | 2022-09-22T18:28:15Z | 2023-08-16T09:58:36Z | 4 | junwang-wish |
huggingface/datasets | 5,000 | Dataset Viewer issue for asapp/slue | ### Link
https://huggingface.co/datasets/asapp/slue/viewer/
### Description
Hi,
I wonder how to get the dataset viewer of our slue dataset to work.
Best,
Felix
### Owner
Yes | https://github.com/huggingface/datasets/issues/5000 | closed | [] | 2022-09-20T16:45:45Z | 2022-09-27T07:04:03Z | 9 | fwu-asapp |
huggingface/datasets | 4,990 | "no-token" is passed to `huggingface_hub` when token is `None` | ## Describe the bug
In the 2 lines listed below, a token is passed to `huggingface_hub` to get information from a dataset. If no token is provided, a "no-token" string is passed. What is the purpose of it ? If no real, I would prefer if the `None` value could be sent directly to be handle by `huggingface_hub`. I fee... | https://github.com/huggingface/datasets/issues/4990 | closed | [
"bug"
] | 2022-09-19T15:14:40Z | 2022-09-30T09:16:00Z | 6 | Wauplin |
huggingface/datasets | 4,983 | How to convert torch.utils.data.Dataset to huggingface dataset? | I look through the huggingface dataset docs, and it seems that there is no offical support function to convert `torch.utils.data.Dataset` to huggingface dataset. However, there is a way to convert huggingface dataset to `torch.utils.data.Dataset`, like below:
```python
from datasets import Dataset
data = [[1, 2]... | https://github.com/huggingface/datasets/issues/4983 | closed | [
"enhancement"
] | 2022-09-16T09:15:10Z | 2023-12-14T20:54:15Z | 15 | DEROOCE |
huggingface/datasets | 4,981 | Can't create a dataset with `float16` features | ## Describe the bug
I can't create a dataset with `float16` features.
I understand from the traceback that this is a `pyarrow` error, but I don't see anywhere in the `datasets` documentation about how to successfully do this. Is it actually supported? I've tried older versions of `pyarrow` as well with the same e... | https://github.com/huggingface/datasets/issues/4981 | open | [
"bug"
] | 2022-09-15T21:03:24Z | 2025-06-12T11:47:42Z | 8 | dconathan |
huggingface/dataset-viewer | 560 | Fill some of the dataset card info automatically? | See https://github.com/huggingface/datasets/issues/4977: `Providing dataset size`
Related issues: https://github.com/huggingface/datasets/issues/3507#issuecomment-1033752157 and https://github.com/huggingface/datasets/issues/4876 | https://github.com/huggingface/dataset-viewer/issues/560 | closed | [
"question",
"feature request"
] | 2022-09-14T16:20:30Z | 2023-06-14T12:15:54Z | null | severo |
huggingface/datasets | 4,944 | larger dataset, larger GPU memory in the training phase? Is that correct? | from datasets import set_caching_enabled
set_caching_enabled(False)
for ds_name in ["squad","newsqa","nqopen","narrativeqa"]:
train_ds = load_from_disk("../../../dall/downstream/processedproqa/{}-train.hf".format(ds_name))
break
train_ds = concatenate_datasets([train_ds,train_... | https://github.com/huggingface/datasets/issues/4944 | closed | [
"bug"
] | 2022-09-07T08:46:30Z | 2022-09-07T12:34:58Z | 2 | debby1103 |
huggingface/datasets | 4,942 | Trec Dataset has incorrect labels | ## Describe the bug
Both coarse and fine labels seem to be out of line.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = "trec"
raw_datasets = load_dataset(dataset)
df = pd.DataFrame(raw_datasets["test"])
df.head()
```
## Expected results
text (string) | coarse_labe... | https://github.com/huggingface/datasets/issues/4942 | closed | [
"bug"
] | 2022-09-06T22:13:40Z | 2022-09-08T11:12:03Z | 1 | wmpauli |
huggingface/datasets | 4,936 | vivos (Vietnamese speech corpus) dataset not accessible | ## Describe the bug
VIVOS data is not accessible anymore, neither of these links work (at least from France):
* https://ailab.hcmus.edu.vn/assets/vivos.tar.gz (data)
* https://ailab.hcmus.edu.vn/vivos (dataset page)
Therefore `load_dataset` doesn't work.
## Steps to reproduce the bug
```python
ds = load_dat... | https://github.com/huggingface/datasets/issues/4936 | closed | [
"dataset bug"
] | 2022-09-06T13:17:55Z | 2022-09-21T06:06:02Z | 3 | polinaeterna |
huggingface/datasets | 4,932 | Dataset Viewer issue for bigscience-biomedical/biosses | ### Link
https://huggingface.co/datasets/bigscience-biomedical/biosses
### Description
I've just been working on adding the dataset loader script to this dataset and working with the relative imports. I'm not sure how to interpret the error below (show where the dataset preview used to be) .
```
Status code: 40... | https://github.com/huggingface/datasets/issues/4932 | closed | [] | 2022-09-05T22:40:32Z | 2022-09-06T14:24:56Z | 4 | galtay |
huggingface/datasets | 4,924 | Concatenate_datasets loads everything into RAM | ## Describe the bug
When loading the datasets seperately and saving them on disk, I want to concatenate them. But `concatenate_datasets` is filling up my RAM and the process gets killed. Is there a way to prevent this from happening or is this intended behaviour? Thanks in advance
## Steps to reproduce the bug
```... | https://github.com/huggingface/datasets/issues/4924 | closed | [
"bug"
] | 2022-09-01T10:25:17Z | 2022-09-01T11:50:54Z | 0 | louisdeneve |
huggingface/diffusers | 267 | Non-squared Image shape | Is it possible to use diffusers on non-squared images?
That would be a very interesting feature! | https://github.com/huggingface/diffusers/issues/267 | closed | [
"question"
] | 2022-08-29T01:29:33Z | 2022-09-13T15:57:36Z | null | LucasSilvaFerreira |
huggingface/dataset-viewer | 534 | Store the cached responses on the Hub instead of mongodb? | The config and split info will be stored in the YAML of the dataset card (see https://github.com/huggingface/datasets/issues/4876), and the idea is to compute them and update the dataset card automatically. This means that storing the responses for `/splits` in the MongoDB is duplication.
If we store the responses f... | https://github.com/huggingface/dataset-viewer/issues/534 | closed | [
"question"
] | 2022-08-26T16:24:39Z | 2022-09-19T09:09:29Z | null | severo |
huggingface/datasets | 4,902 | Name the default config `default` | Currently, if a dataset has no configuration, a default configuration is created from the dataset name.
For example, for a dataset loaded from the hub repository, such as https://huggingface.co/datasets/user/dataset (repo id is `user/dataset`), the default configuration will be `user--dataset`.
It might be easier... | https://github.com/huggingface/datasets/issues/4902 | closed | [
"enhancement",
"question"
] | 2022-08-26T16:16:22Z | 2023-07-24T21:15:31Z | null | severo |
huggingface/optimum | 362 | unexpect behavior GPU runtime with ORTModelForSeq2SeqLM | ### System Info
```shell
OS: Ubuntu 20.04.4 LTS
CARD: RTX 3080
Libs:
python 3.10.4
onnx==1.12.0
onnxruntime-gpu==1.12.1
torch==1.12.1
transformers==4.21.2
```
### Who can help?
@lewtun @michaelbenayoun @JingyaHuang @echarlaix
### Information
- [ ] The official example scripts
- [X] My own modified scri... | https://github.com/huggingface/optimum/issues/362 | closed | [
"bug",
"inference",
"onnxruntime"
] | 2022-08-26T02:11:26Z | 2022-12-09T09:13:22Z | 3 | tranmanhdat |
huggingface/dataset-viewer | 528 | metrics: how to manage variability between the admin pods? | The metrics include one entry per uvicorn worker of the `admin` service, but they give different values.
<details>
<summary>Example of a response to https://datasets-server.huggingface.co/admin/metrics</summary>
<pre>
# HELP starlette_requests_in_progress Multiprocess metric
# TYPE starlette_requests_in_progress... | https://github.com/huggingface/dataset-viewer/issues/528 | closed | [
"bug",
"question"
] | 2022-08-25T19:48:44Z | 2022-09-19T09:10:11Z | null | severo |
huggingface/datasets | 4,881 | Language names and language codes: connecting to a big database (rather than slow enrichment of custom list) | **The problem:**
Language diversity is an important dimension of the diversity of datasets. To find one's way around datasets, being able to search by language name and by standardized codes appears crucial.
Currently the list of language codes is [here](https://github.com/huggingface/datasets/blob/main/src/datase... | https://github.com/huggingface/datasets/issues/4881 | open | [
"enhancement"
] | 2022-08-23T20:14:24Z | 2024-04-22T15:57:28Z | 49 | alexis-michaud |
huggingface/datasets | 4,878 | [not really a bug] `identical_ok` is deprecated in huggingface-hub's `upload_file` | In the huggingface-hub dependency, the `identical_ok` argument has no effect in `upload_file` (and it will be removed soon)
See
https://github.com/huggingface/huggingface_hub/blob/43499582b19df1ed081a5b2bd7a364e9cacdc91d/src/huggingface_hub/hf_api.py#L2164-L2169
It's used here:
https://github.com/huggingfac... | https://github.com/huggingface/datasets/issues/4878 | closed | [
"help wanted",
"question"
] | 2022-08-23T17:09:55Z | 2022-09-13T14:00:06Z | null | severo |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.