
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 6.67k ⌀ | citation stringlengths 0 10.7k ⌀ | likes int64 0 3.66k | downloads int64 0 8.89M | created timestamp[us] | card stringlengths 11 977k | card_len int64 11 977k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|
lamini/bts | 2023-07-24T03:50:41.000Z | [
"region:us"
] | lamini | null | null | 1 | 21 | 2023-07-24T03:49:06 | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 129862.8
num_examples: 126
- name: test
num_bytes: 14429.2
num_examples: 14
download_size: 50390
dataset_size: 144292.0
---
# Dataset Card for "bts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 563 | [
[
-0.041168212890625,
-0.020782470703125,
0.01204681396484375,
0.015777587890625,
-0.02813720703125,
0.00957489013671875,
0.023681640625,
-0.00533294677734375,
0.061065673828125,
0.0285491943359375,
-0.05718994140625,
-0.053009033203125,
-0.0335693359375,
-0.0... |
Yuhthe/samsum_vi_word | 2023-07-26T02:57:48.000Z | [
"task_categories:summarization",
"language:vi",
"region:us"
] | Yuhthe | null | null | 0 | 21 | 2023-07-25T07:30:27 | ---
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
- split: train
path: data/train-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: id
dtype: string
- name: dialogue
dtype: string
- name: summary
dtype: string
splits:
- name: test
num_bytes: 761520
num_examples: 819
- name: train
num_bytes: 13465942
num_examples: 14732
- name: validation
num_bytes: 733668
num_examples: 818
download_size: 7875036
dataset_size: 14961130
task_categories:
- summarization
language:
- vi
---
# Dataset Card for "samsum_vi_word"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 776 | [
[
-0.0232696533203125,
-0.00980377197265625,
0.0153045654296875,
0.0117034912109375,
-0.035858154296875,
-0.00791168212890625,
0.004749298095703125,
-0.0028133392333984375,
0.07232666015625,
0.0307464599609375,
-0.05615234375,
-0.06500244140625,
-0.05718994140625,... |
FinchResearch/OpenPlatypus-Alpaca | 2023-08-29T13:53:43.000Z | [
"size_categories:10K<n<100K",
"license:apache-2.0",
"region:us"
] | FinchResearch | null | null | 1 | 21 | 2023-08-21T13:31:52 | ---
license: apache-2.0
size_categories:
- 10K<n<100K
---
### A merged dataset...
### Open-Platypus & Alpaca Data | 114 | [
[
-0.036376953125,
-0.02032470703125,
0.0073394775390625,
0.0178070068359375,
-0.037078857421875,
-0.0185089111328125,
-0.0136871337890625,
-0.0101318359375,
0.0423583984375,
0.07318115234375,
-0.036163330078125,
-0.039764404296875,
-0.044525146484375,
-0.0105... |
theblackcat102/evol-code-zh | 2023-08-25T14:15:39.000Z | [
"task_categories:text2text-generation",
"language:zh",
"region:us"
] | theblackcat102 | null | null | 4 | 21 | 2023-08-25T14:14:04 | ---
task_categories:
- text2text-generation
language:
- zh
---
Evolved codealpaca in Chinese
| 93 | [
[
0.019622802734375,
-0.057525634765625,
0.000591278076171875,
0.06854248046875,
-0.04205322265625,
0.016876220703125,
-0.01189422607421875,
-0.053070068359375,
0.062744140625,
0.0279083251953125,
-0.0199737548828125,
-0.021148681640625,
-0.01434326171875,
0.0... |
EleutherAI/coqa | 2023-11-02T14:46:15.000Z | [
"size_categories:1K<n<10K",
"language:en",
"license:other",
"arxiv:1808.07042",
"region:us"
] | EleutherAI | CoQA is a large-scale dataset for building Conversational Question Answering
systems. The goal of the CoQA challenge is to measure the ability of machines to
understand a text passage and answer a series of interconnected questions that
appear in a conversation. | @misc{reddy2018coqa,
title={CoQA: A Conversational Question Answering Challenge},
author={Siva Reddy and Danqi Chen and Christopher D. Manning},
year={2018},
eprint={1808.07042},
archivePrefix={arXiv},
primaryClass={cs.CL}
} | 1 | 21 | 2023-08-30T10:34:59 | ---
license: other
language:
- en
size_categories:
- 1K<n<10K
---
"""CoQA dataset.
This `CoQA` adds the "additional_answers" feature that's missing in the original
datasets version:
https://github.com/huggingface/datasets/blob/master/datasets/coqa/coqa.py
"""
_CITATION = """\
@misc{reddy2018coqa,
title={CoQA: A Conversational Question Answering Challenge},
author={Siva Reddy and Danqi Chen and Christopher D. Manning},
year={2018},
eprint={1808.07042},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
"""
_DESCRIPTION = """\
CoQA is a large-scale dataset for building Conversational Question Answering
systems. The goal of the CoQA challenge is to measure the ability of machines to
understand a text passage and answer a series of interconnected questions that
appear in a conversation.
"""
_HOMEPAGE = "https://stanfordnlp.github.io/coqa/"
_LICENSE = "Different licenses depending on the content (see https://stanfordnlp.github.io/coqa/ for details)" | 985 | [
[
-0.051544189453125,
-0.05767822265625,
0.0117645263671875,
0.002902984619140625,
0.007320404052734375,
0.014312744140625,
0.004810333251953125,
-0.0201873779296875,
0.023101806640625,
0.044647216796875,
-0.084716796875,
-0.02606201171875,
-0.01873779296875,
... |
slaqrichi/processed_Cosmic_dataset_V2_inst_format | 2023-09-12T09:55:34.000Z | [
"region:us"
] | slaqrichi | null | null | 0 | 21 | 2023-09-11T17:51:48 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 86815
num_examples: 95
download_size: 0
dataset_size: 86815
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "processed_Cosmic_dataset_V2_inst_format"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 455 | [
[
-0.0209808349609375,
-0.0248260498046875,
0.0211944580078125,
0.0233612060546875,
-0.0295867919921875,
-0.0072784423828125,
0.01097869873046875,
-0.01296234130859375,
0.058319091796875,
0.049468994140625,
-0.062744140625,
-0.036865234375,
-0.047454833984375,
... |
Fraol/LLM-Data5 | 2023-09-18T03:13:03.000Z | [
"region:us"
] | Fraol | null | null | 0 | 21 | 2023-09-18T02:45:05 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 462063994
num_examples: 388405
- name: validation
num_bytes: 57196523
num_examples: 48550
- name: test
num_bytes: 57443243
num_examples: 48552
download_size: 352680335
dataset_size: 576703760
---
# Dataset Card for "LLM-Data5"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 665 | [
[
-0.04443359375,
0.000659942626953125,
0.0316162109375,
0.01511383056640625,
-0.0207672119140625,
0.00470733642578125,
0.033355712890625,
-0.016876220703125,
0.04949951171875,
0.042083740234375,
-0.0711669921875,
-0.07489013671875,
-0.042236328125,
0.00241661... |
TrainingDataPro/ocr-receipts-text-detection | 2023-09-26T15:12:40.000Z | [
"task_categories:image-to-text",
"task_categories:object-detection",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"region:us"
] | TrainingDataPro | The Grocery Store Receipts Dataset is a collection of photos captured from various
**grocery store receipts**. This dataset is specifically designed for tasks related to
**Optical Character Recognition (OCR)** and is useful for retail.
Each image in the dataset is accompanied by bounding box annotations, indicating the
precise locations of specific text segments on the receipts. The text segments are
categorized into four classes: **item, store, date_time and total**. | @InProceedings{huggingface:dataset,
title = {ocr-receipts-text-detection},
author = {TrainingDataPro},
year = {2023}
} | 1 | 21 | 2023-09-19T10:35:57 | ---
language:
- en
license: cc-by-nc-nd-4.0
task_categories:
- image-to-text
- object-detection
tags:
- code
- finance
dataset_info:
features:
- name: id
dtype: int32
- name: name
dtype: string
- name: image
dtype: image
- name: mask
dtype: image
- name: width
dtype: uint16
- name: height
dtype: uint16
- name: shapes
sequence:
- name: label
dtype:
class_label:
names:
'0': receipt
'1': shop
'2': item
'3': date_time
'4': total
- name: type
dtype: string
- name: points
sequence:
sequence: float32
- name: rotation
dtype: float32
- name: occluded
dtype: uint8
- name: attributes
sequence:
- name: name
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 55510934
num_examples: 20
download_size: 54557192
dataset_size: 55510934
---
# OCR Receipts from Grocery Stores Text Detection
The Grocery Store Receipts Dataset is a collection of photos captured from various **grocery store receipts**. This dataset is specifically designed for tasks related to **Optical Character Recognition (OCR)** and is useful for retail.
Each image in the dataset is accompanied by bounding box annotations, indicating the precise locations of specific text segments on the receipts. The text segments are categorized into four classes: **item, store, date_time and total**.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-receipts-text-detection) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images of receipts
- **boxes** - includes bounding box labeling for the original images
- **annotations.xml** - contains coordinates of the bounding boxes and detected text, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes and detected text . For each point, the x and y coordinates are provided.
### Classes:
- **store** - name of the grocery store
- **item** - item in the receipt
- **date_time** - date and time of the receipt
- **total** - total price of the receipt
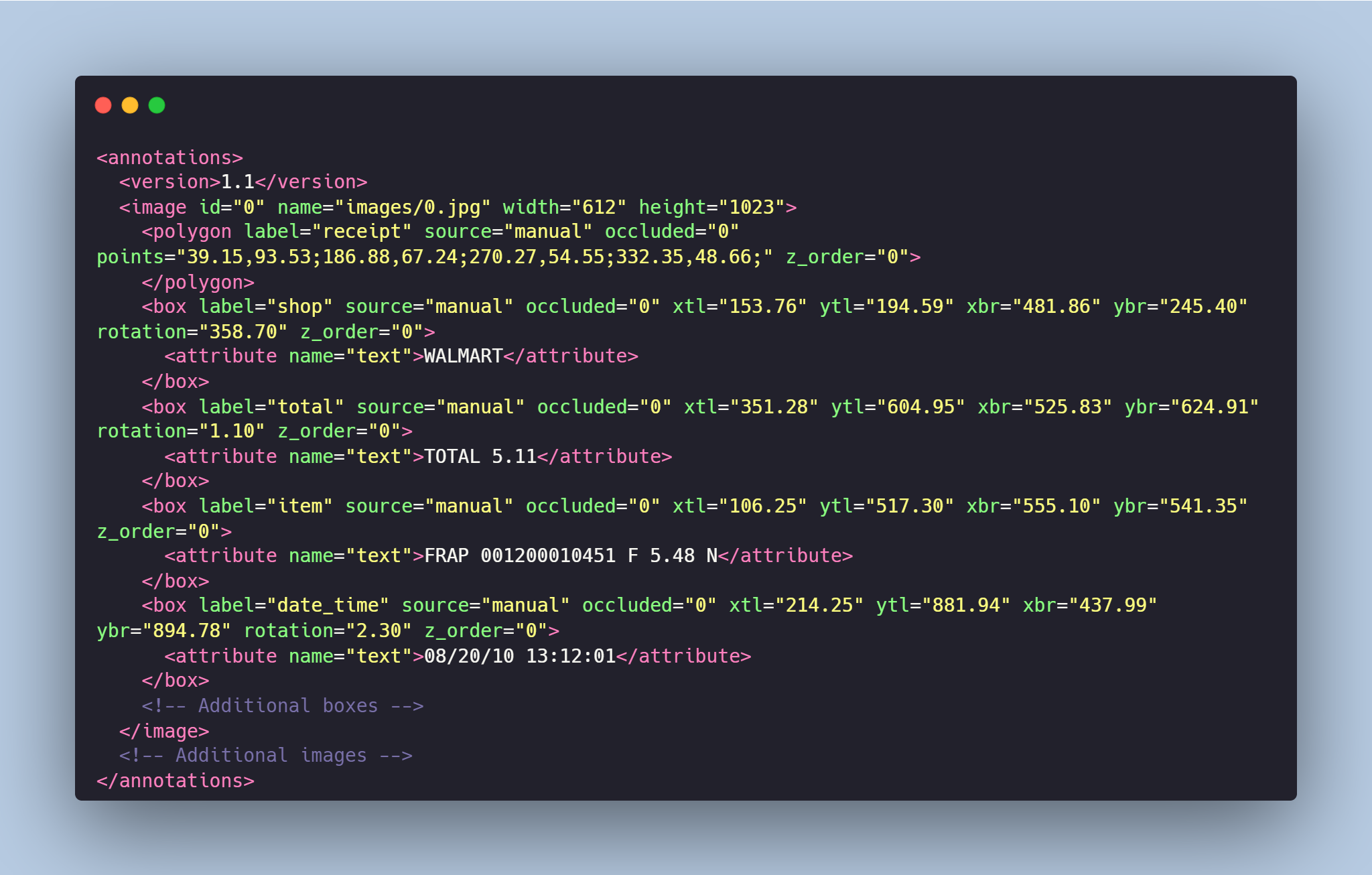
# Text Detection in the Receipts might be made in accordance with your requirements.
## [TrainingData](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=ocr-receipts-text-detection) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/trainingdata-pro** | 3,314 | [
[
-0.00942230224609375,
-0.031463623046875,
0.0322265625,
-0.0249176025390625,
-0.012847900390625,
-0.0136566162109375,
0.006580352783203125,
-0.06292724609375,
0.01910400390625,
0.05865478515625,
-0.025787353515625,
-0.0521240234375,
-0.04656982421875,
0.0361... |
allenai/scifact_entailment | 2023-09-27T05:00:41.000Z | [
"task_categories:text-classification",
"task_ids:fact-checking",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:cc-by-nc-2.0",
"region:us"
] | allenai | SciFact, a dataset of 1.4K expert-written scientific claims paired with evidence-containing abstracts, and annotated with labels and rationales. | @inproceedings{Wadden2020FactOF,
title={Fact or Fiction: Verifying Scientific Claims},
author={David Wadden and Shanchuan Lin and Kyle Lo and Lucy Lu Wang and Madeleine van Zuylen and Arman Cohan and Hannaneh Hajishirzi},
booktitle={EMNLP},
year={2020},
} | 0 | 21 | 2023-09-26T22:04:02 | ---
annotations_creators:
- expert-generated
language:
- en
language_creators:
- found
license:
- cc-by-nc-2.0
multilinguality:
- monolingual
pretty_name: SciFact
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- fact-checking
paperswithcode_id: scifact
dataset_info:
features:
- name: claim_id
dtype: int32
- name: claim
dtype: string
- name: abstract_id
dtype: int32
- name: title
dtype: string
- name: abstract
sequence: string
- name: verdict
dtype: string
- name: evidence
sequence: int32
splits:
- name: train
num_bytes: 1649655
num_examples: 919
- name: validation
num_bytes: 605262
num_examples: 340
download_size: 3115079
dataset_size: 2254917
---
# Dataset Card for "scifact_entailment"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
## Dataset Description
- **Homepage:** [https://scifact.apps.allenai.org/](https://scifact.apps.allenai.org/)
- **Repository:** <https://github.com/allenai/scifact>
- **Paper:** [Fact or Fiction: Verifying Scientific Claims](https://aclanthology.org/2020.emnlp-main.609/)
- **Point of Contact:** [David Wadden](mailto:davidw@allenai.org)
### Dataset Summary
SciFact, a dataset of 1.4K expert-written scientific claims paired with evidence-containing abstracts, and annotated with labels and rationales.
For more information on the dataset, see [allenai/scifact](https://huggingface.co/datasets/allenai/scifact).
This has the same data, but reformatted as an entailment task. A single instance includes a claim paired with a paper title and abstract, together with an entailment label and a list of evidence sentences (if any).
## Dataset Structure
### Data fields
- `claim_id`: An `int32` claim identifier.
- `claim`: A `string`.
- `abstract_id`: An `int32` abstract identifier.
- `title`: A `string`.
- `abstract`: A list of `strings`, one for each sentence in the abstract.
- `verdict`: The fact-checking verdict, a `string`.
- `evidence`: A list of sentences from the abstract which provide evidence for the verdict.
### Data Splits
| |train|validation|
|------|----:|---------:|
|claims| 919 | 340|
| 2,365 | [
[
-0.01532745361328125,
-0.042449951171875,
0.0253448486328125,
0.0187530517578125,
-0.011322021484375,
-0.0097808837890625,
0.0120849609375,
-0.02545166015625,
0.045623779296875,
0.0218658447265625,
-0.0274658203125,
-0.04071044921875,
-0.04541015625,
0.02851... |
learn3r/gov_report_bp | 2023-09-29T11:05:26.000Z | [
"region:us"
] | learn3r | null | null | 0 | 21 | 2023-09-29T11:03:30 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 1030500829
num_examples: 17457
- name: validation
num_bytes: 60867802
num_examples: 972
- name: test
num_bytes: 56606131
num_examples: 973
download_size: 547138870
dataset_size: 1147974762
---
# Dataset Card for "gov_report_bp"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 702 | [
[
-0.03826904296875,
-0.0197296142578125,
0.021575927734375,
0.00913238525390625,
-0.0205535888671875,
-0.01192474365234375,
0.025177001953125,
-0.01268768310546875,
0.04791259765625,
0.04266357421875,
-0.047454833984375,
-0.058929443359375,
-0.048675537109375,
... |
Rithik28/TM_Dataset | 2023-10-05T11:22:36.000Z | [
"region:us"
] | Rithik28 | null | null | 0 | 21 | 2023-09-30T16:49:22 | Entry not found | 15 | [
[
-0.0214080810546875,
-0.01497650146484375,
0.05718994140625,
0.028839111328125,
-0.0350341796875,
0.046539306640625,
0.052490234375,
0.00507354736328125,
0.051361083984375,
0.016998291015625,
-0.05206298828125,
-0.01496124267578125,
-0.06036376953125,
0.0379... |
VatsaDev/TinyText | 2023-10-15T15:19:25.000Z | [
"task_categories:question-answering",
"task_categories:text-generation",
"size_categories:1M<n<10M",
"language:en",
"license:mit",
"code",
"region:us"
] | VatsaDev | null | null | 25 | 21 | 2023-10-02T00:36:39 | ---
license: mit
task_categories:
- question-answering
- text-generation
language:
- en
tags:
- code
size_categories:
- 1M<n<10M
---
The entire NanoPhi Dataset is at train.jsonl
Separate Tasks Include
- Math (Metamath, mammoth)
- Code (Code Search Net)
- Logic (Open-platypus)
- Roleplay (PIPPA, RoleplayIO)
- Textbooks (Tiny-text, Sciphi)
- Textbook QA (Orca-text, Tiny-webtext) | 387 | [
[
-0.033782958984375,
-0.0253143310546875,
0.013275146484375,
0.00725555419921875,
0.0089874267578125,
0.00399017333984375,
0.0014352798461914062,
0.0003693103790283203,
-0.005680084228515625,
0.046630859375,
-0.058837890625,
-0.03167724609375,
-0.0159149169921875... |
shossain/govreport-qa-512 | 2023-10-02T05:09:04.000Z | [
"region:us"
] | shossain | null | null | 0 | 21 | 2023-10-02T05:04:11 | ---
dataset_info:
features:
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
splits:
- name: train
num_bytes: 33340
num_examples: 5
download_size: 15680
dataset_size: 33340
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "govreport-qa-512"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 523 | [
[
-0.036895751953125,
-0.007476806640625,
0.0282440185546875,
0.0157012939453125,
-0.0139007568359375,
0.0011396408081054688,
0.035430908203125,
-0.0053558349609375,
0.06085205078125,
0.03729248046875,
-0.0496826171875,
-0.0556640625,
-0.024627685546875,
-0.01... |
trunks/graph_tt | 2023-10-12T09:46:25.000Z | [
"region:us"
] | trunks | null | null | 0 | 21 | 2023-10-04T21:39:40 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 1562276.0
num_examples: 36
download_size: 1439813
dataset_size: 1562276.0
---
# Dataset Card for "graph_tt"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 471 | [
[
-0.032806396484375,
-0.034393310546875,
0.0171966552734375,
0.00270843505859375,
-0.0261688232421875,
0.019073486328125,
0.032196044921875,
-0.01456451416015625,
0.06817626953125,
0.0268096923828125,
-0.05682373046875,
-0.06549072265625,
-0.05279541015625,
-... |
Intuit-GenSRF/joangaes-depression | 2023-10-05T01:00:33.000Z | [
"region:us"
] | Intuit-GenSRF | null | null | 0 | 21 | 2023-10-05T01:00:31 | ---
dataset_info:
features:
- name: text
dtype: string
- name: labels
sequence: string
splits:
- name: train
num_bytes: 13387322
num_examples: 27977
download_size: 8155014
dataset_size: 13387322
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "joangaes-depression"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 488 | [
[
-0.038421630859375,
-0.0206756591796875,
0.0261077880859375,
0.030731201171875,
-0.00949859619140625,
-0.0178985595703125,
0.015960693359375,
0.0005497932434082031,
0.07684326171875,
0.032684326171875,
-0.06781005859375,
-0.0596923828125,
-0.05633544921875,
... |
unaidedelf87777/super-instruct | 2023-10-10T19:15:35.000Z | [
"region:us"
] | unaidedelf87777 | null | null | 0 | 21 | 2023-10-08T21:05:05 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
Malmika/ict_text_dataset | 2023-10-09T17:19:25.000Z | [
"region:us"
] | Malmika | null | null | 0 | 21 | 2023-10-09T16:46:45 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
Luciya/llama-2-nuv-intent-noE-pp | 2023-10-10T05:58:08.000Z | [
"region:us"
] | Luciya | null | null | 0 | 21 | 2023-10-10T05:58:05 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 791845
num_examples: 1585
download_size: 111893
dataset_size: 791845
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "llama-2-nuv-intent-noE-pp"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 450 | [
[
-0.016998291015625,
-0.01409912109375,
0.0232696533203125,
0.0277252197265625,
-0.035400390625,
-0.012237548828125,
0.031951904296875,
0.0039043426513671875,
0.0645751953125,
0.044708251953125,
-0.057861328125,
-0.059600830078125,
-0.049774169921875,
-0.0105... |
Coldog2333/super_dialseg | 2023-10-11T06:26:51.000Z | [
"size_categories:1K<n<10K",
"language:en",
"license:apache-2.0",
"dialogue segmentation",
"region:us"
] | Coldog2333 | \ | \ | 0 | 21 | 2023-10-11T05:28:11 | ---
license: apache-2.0
language:
- en
tags:
- dialogue segmentation
size_categories:
- 1K<n<10K
---
# Dataset Card for SuperDialseg
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:** SuperDialseg: A Large-scale Dataset for Supervised Dialogue Segmentation
- **Leaderboard:** [https://github.com/Coldog2333/SuperDialseg](https://github.com/Coldog2333/SuperDialseg)
- **Point of Contact:** jiangjf@is.s.u-tokyo.ac.jp
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages: English
## Dataset Structure
### Data Instances
```
{
"dial_data": {
"super_dialseg": [
{
"dial_id": "8df07b7a98990db27c395cb1f68a962e",
"turns": [
{
"da": "query_condition",
"role": "user",
"turn_id": 0,
"utterance": "Hello, I forgot o update my address, can you help me with that?",
"topic_id": 0,
"segmentation_label": 0
},
...
{
"da": "respond_solution",
"role": "agent",
"turn_id": 11,
"utterance": "DO NOT contact the New York State DMV to dispute whether you violated a toll regulation or failed to pay the toll , fees or other charges",
"topic_id": 4,
"segmentation_label": 0
}
],
...
}
]
}
```
### Data Fields
#### Dialogue-Level
+ `dial_id`: ID of a dialogue;
+ `turns`: All utterances of a dialogue.
#### Utterance-Level
+ `da`: Dialogue Act annotation derived from the original DGDS dataset;
+ `role`: Role annotation derived from the original DGDS dataset;
+ `turn_id`: ID of an utterance;
+ `utterance`: Text of the utterance;
+ `topic_id`: ID (order) of the current topic;
+ `segmentation_label`: 1: it is the end of a topic; 0: others.
### Data Splits
SuperDialseg follows the dataset splits of the original DGDS dataset.
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
SuperDialseg was built on the top of doc2dial and MultiDoc2dial datasets.
Please refer to the original papers for more details.
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
The annotation of dialogue segmentation points is constructed by a set of well-designed strategy. Please refer to the paper for more details.
Other annotations like Dialogue Act and Role information are derived from doc2dial and MultiDoc2dial datasets.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Apache License Version 2.0, following the licenses of doc2dial and MultiDoc2dial.
### Citation Information
Coming soon
### Contributions
Thanks to [@Coldog2333](https://github.com/Coldog2333) for adding this dataset.
| 4,341 | [
[
-0.03521728515625,
-0.060150146484375,
0.0258026123046875,
-0.0049896240234375,
-0.028350830078125,
0.01023101806640625,
-0.00730133056640625,
-0.0101470947265625,
0.0180206298828125,
0.04400634765625,
-0.07965087890625,
-0.06591796875,
-0.047637939453125,
0... |
phatjk/wikipedia_vi | 2023-10-14T05:56:36.000Z | [
"region:us"
] | phatjk | null | null | 0 | 21 | 2023-10-14T05:55:38 | ---
dataset_info:
features:
- name: title
dtype: string
- name: text
dtype: string
- name: bm25_text
dtype: string
splits:
- name: train
num_bytes: 2889457164
num_examples: 1944406
download_size: 1242752879
dataset_size: 2889457164
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "wikipedia_vi"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 524 | [
[
-0.055419921875,
-0.0240325927734375,
0.0100860595703125,
0.004360198974609375,
-0.0178985595703125,
-0.01934814453125,
0.0010309219360351562,
-0.011322021484375,
0.056732177734375,
0.0162811279296875,
-0.05816650390625,
-0.0557861328125,
-0.029510498046875,
... |
orgcatorg/russia-ukraine-cnn | 2023-10-15T22:22:37.000Z | [
"region:us"
] | orgcatorg | null | null | 0 | 21 | 2023-10-15T14:55:21 | ---
dataset_info:
features:
- name: '@type'
dtype: string
- name: headline
dtype: string
- name: url
dtype: string
- name: dateModified
dtype: string
- name: datePublished
dtype: string
- name: mainEntityOfPage
dtype: string
- name: publisher
dtype: string
- name: author
dtype: string
- name: articleBody
dtype: string
- name: image
dtype: string
splits:
- name: train
num_bytes: 41401329
num_examples: 19759
download_size: 17332574
dataset_size: 41401329
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "russia-ukraine-cnn"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 797 | [
[
-0.0413818359375,
-0.00812530517578125,
0.024749755859375,
0.01543426513671875,
-0.030242919921875,
0.00943756103515625,
0.0089569091796875,
-0.00902557373046875,
0.042694091796875,
0.019989013671875,
-0.055694580078125,
-0.06805419921875,
-0.0445556640625,
... |
annahonghong/hackthontest1 | 2023-10-17T05:09:30.000Z | [
"region:us"
] | annahonghong | null | null | 0 | 21 | 2023-10-17T03:48:41 | Entry not found | 15 | [
[
-0.0214080810546875,
-0.01494598388671875,
0.057159423828125,
0.028839111328125,
-0.0350341796875,
0.04656982421875,
0.052490234375,
0.00504302978515625,
0.0513916015625,
0.016998291015625,
-0.0521240234375,
-0.0149993896484375,
-0.06036376953125,
0.03790283... |
HumanCompatibleAI/random-seals-Ant-v1 | 2023-10-17T05:36:54.000Z | [
"region:us"
] | HumanCompatibleAI | null | null | 0 | 21 | 2023-10-17T05:33:58 | ---
dataset_info:
features:
- name: obs
sequence:
sequence: float64
- name: acts
sequence:
sequence: float32
- name: infos
sequence: string
- name: terminal
dtype: bool
- name: rews
sequence: float32
splits:
- name: train
num_bytes: 167669182
num_examples: 100
download_size: 73426727
dataset_size: 167669182
---
# Dataset Card for "random-seals-Ant-v1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 546 | [
[
-0.047882080078125,
-0.0077056884765625,
0.0220184326171875,
0.00423431396484375,
-0.039459228515625,
0.00730133056640625,
0.03924560546875,
-0.028289794921875,
0.0736083984375,
0.0313720703125,
-0.06927490234375,
-0.051544189453125,
-0.04949951171875,
-0.00... |
phanvancongthanh/pubchem_bioassay_standardized | 2023-10-18T18:31:37.000Z | [
"region:us"
] | phanvancongthanh | null | null | 0 | 21 | 2023-10-17T09:58:45 | ---
dataset_info:
features:
- name: standardized_smiles
dtype: string
splits:
- name: train
num_bytes: 10187907266
num_examples: 210186056
download_size: 4860575313
dataset_size: 10187907266
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "pubchem_bioassay_standardized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 488 | [
[
-0.01201629638671875,
-0.01256561279296875,
0.03436279296875,
0.0162200927734375,
-0.022979736328125,
0.004421234130859375,
0.021209716796875,
-0.0085296630859375,
0.061370849609375,
0.038330078125,
-0.0380859375,
-0.07867431640625,
-0.0309906005859375,
0.01... |
rkdeva/DermnetSkinData-Train7 | 2023-10-19T08:22:15.000Z | [
"region:us"
] | rkdeva | null | null | 0 | 21 | 2023-10-19T08:12:24 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype: string
splits:
- name: train
num_bytes: 1468806344.376
num_examples: 15297
download_size: 1433360013
dataset_size: 1468806344.376
---
# Dataset Card for "DermnetSkinData-Train7"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 502 | [
[
-0.0333251953125,
0.01456451416015625,
0.010650634765625,
0.01495361328125,
-0.0247802734375,
-0.00286102294921875,
0.02252197265625,
-0.001964569091796875,
0.05615234375,
0.03192138671875,
-0.055999755859375,
-0.053497314453125,
-0.04534912109375,
-0.011718... |
centroIA/MistralInstruct | 2023-10-19T12:14:37.000Z | [
"region:us"
] | centroIA | null | null | 0 | 21 | 2023-10-19T11:51:33 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 2682613
num_examples: 967
download_size: 694943
dataset_size: 2682613
---
# Dataset Card for "MistralInstruct"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 510 | [
[
-0.038818359375,
-0.0180206298828125,
0.009063720703125,
0.02093505859375,
-0.007534027099609375,
-0.006931304931640625,
0.031982421875,
-0.0117950439453125,
0.044281005859375,
0.041229248046875,
-0.0635986328125,
-0.0494384765625,
-0.035675048828125,
-0.028... |
phatjk/odqa_data | 2023-10-20T04:08:24.000Z | [
"region:us"
] | phatjk | null | null | 0 | 21 | 2023-10-19T12:30:43 | ---
dataset_info:
features:
- name: text
dtype: string
- name: words
sequence: string
splits:
- name: train
num_bytes: 3515490316
num_examples: 1966167
download_size: 1364666872
dataset_size: 3515490316
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "odqa_data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 486 | [
[
-0.045867919921875,
-0.0265960693359375,
0.020599365234375,
-0.00662994384765625,
-0.0040740966796875,
-0.0017566680908203125,
0.0355224609375,
-0.00679779052734375,
0.047515869140625,
0.041717529296875,
-0.052337646484375,
-0.05596923828125,
-0.028717041015625,... |
jay401521/test | 2023-10-21T09:26:13.000Z | [
"region:us"
] | jay401521 | null | null | 0 | 21 | 2023-10-21T08:34:07 | ---
dataset_info:
features:
- name: id
dtype: int64
- name: domain
dtype: string
- name: label
dtype: int64
- name: rank
dtype: int64
- name: sentence
dtype: string
splits:
- name: train
num_bytes: 2768371
num_examples: 30021
download_size: 0
dataset_size: 2768371
---
# Dataset Card for "test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 475 | [
[
-0.04620361328125,
-0.028656005859375,
0.00555419921875,
0.0131072998046875,
-0.009124755859375,
0.00058746337890625,
0.0164794921875,
-0.00917816162109375,
0.050537109375,
0.0228424072265625,
-0.056121826171875,
-0.04486083984375,
-0.03240966796875,
-0.0128... |
pbaoo2705/covidqa_processed_eval | 2023-10-22T09:01:31.000Z | [
"region:us"
] | pbaoo2705 | null | null | 0 | 21 | 2023-10-22T09:01:30 | ---
dataset_info:
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: context_chunks
sequence: string
- name: document_id
dtype: int64
- name: id
dtype: int64
- name: context
dtype: string
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
- name: start_positions
dtype: int64
- name: end_positions
dtype: int64
splits:
- name: train
num_bytes: 2643073
num_examples: 50
download_size: 730327
dataset_size: 2643073
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "covidqa_processed_eval"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 805 | [
[
-0.034027099609375,
-0.036865234375,
0.0082550048828125,
0.0169525146484375,
-0.006290435791015625,
0.0138702392578125,
0.019805908203125,
-0.002269744873046875,
0.0499267578125,
0.0291595458984375,
-0.05572509765625,
-0.055877685546875,
-0.029693603515625,
... |
nehal69/bioAsq_Extractive_QA | 2023-10-22T09:43:16.000Z | [
"region:us"
] | nehal69 | null | null | 0 | 21 | 2023-10-22T09:13:01 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
kikikara/mistral-anger-dataset | 2023-10-22T14:00:05.000Z | [
"region:us"
] | kikikara | null | null | 0 | 21 | 2023-10-22T13:59:45 | Entry not found | 15 | [
[
-0.0214080810546875,
-0.01494598388671875,
0.057159423828125,
0.028839111328125,
-0.0350341796875,
0.04656982421875,
0.052490234375,
0.00504302978515625,
0.0513916015625,
0.016998291015625,
-0.0521240234375,
-0.0149993896484375,
-0.06036376953125,
0.03790283... |
minecode/koreanstudydataset | 2023-10-26T11:05:51.000Z | [
"region:us"
] | minecode | null | null | 1 | 21 | 2023-10-26T01:08:24 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
josedonoso/apples-dataset-60 | 2023-10-27T23:42:15.000Z | [
"region:us"
] | josedonoso | null | null | 0 | 21 | 2023-10-27T23:42:13 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 677659.0
num_examples: 48
- name: test
num_bytes: 161130.0
num_examples: 12
download_size: 839070
dataset_size: 838789.0
---
# Dataset Card for "apples-dataset-60"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 575 | [
[
-0.042510986328125,
-0.00920867919921875,
0.0161285400390625,
0.01102447509765625,
-0.004871368408203125,
0.007091522216796875,
0.0303497314453125,
-0.016326904296875,
0.05328369140625,
0.029327392578125,
-0.0697021484375,
-0.0484619140625,
-0.043670654296875,
... |
rkdeva/QA_Dataset | 2023-10-31T21:08:06.000Z | [
"region:us"
] | rkdeva | null | null | 0 | 21 | 2023-10-31T21:08:02 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 252345
num_examples: 103
download_size: 112834
dataset_size: 252345
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "QA_Dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 434 | [
[
-0.0364990234375,
-0.01361846923828125,
0.0222930908203125,
0.0124969482421875,
-0.0196685791015625,
0.00591278076171875,
0.041046142578125,
-0.005176544189453125,
0.06365966796875,
0.02716064453125,
-0.052886962890625,
-0.051788330078125,
-0.025634765625,
-... |
Falah/fashion_moodboards_prompts | 2023-11-01T06:36:26.000Z | [
"region:us"
] | Falah | null | null | 0 | 21 | 2023-11-01T06:36:25 | ---
dataset_info:
features:
- name: prompts
dtype: string
splits:
- name: train
num_bytes: 141480
num_examples: 1000
download_size: 22359
dataset_size: 141480
---
# Dataset Card for "fashion_moodboards_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 367 | [
[
-0.0379638671875,
-0.0223846435546875,
0.0306854248046875,
0.032806396484375,
-0.0262298583984375,
-0.0031642913818359375,
0.018707275390625,
0.0127105712890625,
0.0689697265625,
0.0199127197265625,
-0.095947265625,
-0.0692138671875,
-0.0251617431640625,
-0.... |
midas/ldkp10k | 2022-04-02T16:49:45.000Z | [
"region:us"
] | midas | This new dataset is designed to solve kp NLP task and is crafted with a lot of care. | TBA | 2 | 20 | 2022-03-02T23:29:22 | A dataset for benchmarking keyphrase extraction and generation techniques from long document English scientific papers. For more details about the dataset please refer the original paper - []().
Data source - []()
## Dataset Summary
## Dataset Structure
### Data Fields
- **id**: unique identifier of the document.
- **sections**: list of all the sections present in the document.
- **sec_text**: list of white space separated list of words present in each section.
- **sec_bio_tags**: list of BIO tags of white space separated list of words present in each section.
- **extractive_keyphrases**: List of all the present keyphrases.
- **abstractive_keyphrase**: List of all the absent keyphrases.
### Data Splits
|Split| #datapoints |
|--|--|
| Train-Small | 20,000 |
| Train-Medium | 50,000 |
| Train-Large | 1,296,613 |
| Test | 10,000 |
| Validation | 10,000 |
## Usage
### Small Dataset
```python
from datasets import load_dataset
# get small dataset
dataset = load_dataset("midas/ldkp10k", "small")
def order_sections(sample):
"""
corrects the order in which different sections appear in the document.
resulting order is: title, abstract, other sections in the body
"""
sections = []
sec_text = []
sec_bio_tags = []
if "title" in sample["sections"]:
title_idx = sample["sections"].index("title")
sections.append(sample["sections"].pop(title_idx))
sec_text.append(sample["sec_text"].pop(title_idx))
sec_bio_tags.append(sample["sec_bio_tags"].pop(title_idx))
if "abstract" in sample["sections"]:
abstract_idx = sample["sections"].index("abstract")
sections.append(sample["sections"].pop(abstract_idx))
sec_text.append(sample["sec_text"].pop(abstract_idx))
sec_bio_tags.append(sample["sec_bio_tags"].pop(abstract_idx))
sections += sample["sections"]
sec_text += sample["sec_text"]
sec_bio_tags += sample["sec_bio_tags"]
return sections, sec_text, sec_bio_tags
# sample from the train split
print("Sample from train data split")
train_sample = dataset["train"][0]
sections, sec_text, sec_bio_tags = order_sections(train_sample)
print("Fields in the sample: ", [key for key in train_sample.keys()])
print("Section names: ", sections)
print("Tokenized Document: ", sec_text)
print("Document BIO Tags: ", sec_bio_tags)
print("Extractive/present Keyphrases: ", train_sample["extractive_keyphrases"])
print("Abstractive/absent Keyphrases: ", train_sample["abstractive_keyphrases"])
print("\n-----------\n")
# sample from the validation split
print("Sample from validation data split")
validation_sample = dataset["validation"][0]
sections, sec_text, sec_bio_tags = order_sections(validation_sample)
print("Fields in the sample: ", [key for key in validation_sample.keys()])
print("Section names: ", sections)
print("Tokenized Document: ", sec_text)
print("Document BIO Tags: ", sec_bio_tags)
print("Extractive/present Keyphrases: ", validation_sample["extractive_keyphrases"])
print("Abstractive/absent Keyphrases: ", validation_sample["abstractive_keyphrases"])
print("\n-----------\n")
# sample from the test split
print("Sample from test data split")
test_sample = dataset["test"][0]
sections, sec_text, sec_bio_tags = order_sections(test_sample)
print("Fields in the sample: ", [key for key in test_sample.keys()])
print("Section names: ", sections)
print("Tokenized Document: ", sec_text)
print("Document BIO Tags: ", sec_bio_tags)
print("Extractive/present Keyphrases: ", test_sample["extractive_keyphrases"])
print("Abstractive/absent Keyphrases: ", test_sample["abstractive_keyphrases"])
print("\n-----------\n")
```
**Output**
```bash
```
### Medium Dataset
```python
from datasets import load_dataset
# get medium dataset
dataset = load_dataset("midas/ldkp10k", "medium")
```
### Large Dataset
```python
from datasets import load_dataset
# get large dataset
dataset = load_dataset("midas/ldkp10k", "large")
```
## Citation Information
Please cite the works below if you use this dataset in your work.
```
@article{mahata2022ldkp,
title={LDKP: A Dataset for Identifying Keyphrases from Long Scientific Documents},
author={Mahata, Debanjan and Agarwal, Naveen and Gautam, Dibya and Kumar, Amardeep and Parekh, Swapnil and Singla, Yaman Kumar and Acharya, Anish and Shah, Rajiv Ratn},
journal={arXiv preprint arXiv:2203.15349},
year={2022}
}
```
```
@article{lo2019s2orc,
title={S2ORC: The semantic scholar open research corpus},
author={Lo, Kyle and Wang, Lucy Lu and Neumann, Mark and Kinney, Rodney and Weld, Dan S},
journal={arXiv preprint arXiv:1911.02782},
year={2019}
}
```
```
@inproceedings{ccano2019keyphrase,
title={Keyphrase generation: A multi-aspect survey},
author={{\c{C}}ano, Erion and Bojar, Ond{\v{r}}ej},
booktitle={2019 25th Conference of Open Innovations Association (FRUCT)},
pages={85--94},
year={2019},
organization={IEEE}
}
```
```
@article{meng2017deep,
title={Deep keyphrase generation},
author={Meng, Rui and Zhao, Sanqiang and Han, Shuguang and He, Daqing and Brusilovsky, Peter and Chi, Yu},
journal={arXiv preprint arXiv:1704.06879},
year={2017}
}
```
## Contributions
Thanks to [@debanjanbhucs](https://github.com/debanjanbhucs), [@dibyaaaaax](https://github.com/dibyaaaaax), [@UmaGunturi](https://github.com/UmaGunturi) and [@ad6398](https://github.com/ad6398) for adding this dataset
| 5,358 | [
[
-0.00675201416015625,
-0.030242919921875,
0.0305328369140625,
0.012451171875,
-0.02642822265625,
0.01194000244140625,
-0.014068603515625,
-0.00855255126953125,
0.01522064208984375,
0.01548004150390625,
-0.034149169921875,
-0.05865478515625,
-0.03448486328125,
... |
nickmuchi/financial-classification | 2023-01-27T23:44:03.000Z | [
"task_categories:text-classification",
"task_ids:multi-class-classification",
"task_ids:sentiment-classification",
"annotations_creators:expert-generated",
"language_creators:found",
"size_categories:1K<n<10K",
"language:en",
"finance",
"region:us"
] | nickmuchi | null | null | 7 | 20 | 2022-03-02T23:29:22 | ---
annotations_creators:
- expert-generated
language_creators:
- found
language:
- en
task_categories:
- text-classification
task_ids:
- multi-class-classification
- sentiment-classification
train-eval-index:
- config: sentences_50agree
- task: text-classification
- task_ids: multi_class_classification
- splits:
eval_split: train
- col_mapping:
sentence: text
label: target
size_categories:
- 1K<n<10K
tags:
- finance
---
## Dataset Creation
This [dataset](https://huggingface.co/datasets/nickmuchi/financial-classification) combines financial phrasebank dataset and a financial text dataset from [Kaggle](https://www.kaggle.com/datasets/percyzheng/sentiment-classification-selflabel-dataset).
Given the financial phrasebank dataset does not have a validation split, I thought this might help to validate finance models and also capture the impact of COVID on financial earnings with the more recent Kaggle dataset. | 935 | [
[
-0.01122283935546875,
-0.0307159423828125,
0.005847930908203125,
0.040283203125,
-0.0004055500030517578,
0.023101806640625,
0.01806640625,
-0.0241241455078125,
0.0357666015625,
0.041229248046875,
-0.041259765625,
-0.03839111328125,
-0.0297393798828125,
-0.01... |
sia-precision-education/pile_python | 2022-01-25T01:24:47.000Z | [
"region:us"
] | sia-precision-education | null | null | 2 | 20 | 2022-03-02T23:29:22 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
stas/wmt16-en-ro-pre-processed | 2021-02-16T03:58:06.000Z | [
"region:us"
] | stas | null | @InProceedings{huggingface:dataset,
title = {WMT16 English-Romanian Translation Data with further preprocessing},
authors={},
year={2016}
} | 0 | 20 | 2022-03-02T23:29:22 | # WMT16 English-Romanian Translation Data w/ further preprocessing
The original instructions are [here](https://github.com/rsennrich/wmt16-scripts/tree/master/sample).
This pre-processed dataset was created by running:
```
git clone https://github.com/rsennrich/wmt16-scripts
cd wmt16-scripts
cd sample
./download_files.sh
./preprocess.sh
```
It was originally used by `transformers` [`finetune_trainer.py`](https://github.com/huggingface/transformers/blob/641f418e102218c4bf16fcd3124bfebed6217ef6/examples/seq2seq/finetune_trainer.py)
The data itself resides at https://cdn-datasets.huggingface.co/translation/wmt_en_ro.tar.gz
If you would like to convert it to jsonlines I've included a small script `convert-to-jsonlines.py` that will do it for you. But if you're using the `datasets` API, it will be done on the fly.
| 828 | [
[
-0.0479736328125,
-0.044525146484375,
0.0236053466796875,
0.019744873046875,
-0.04180908203125,
-0.007678985595703125,
-0.034393310546875,
-0.0207061767578125,
0.02569580078125,
0.04461669921875,
-0.07269287109375,
-0.04754638671875,
-0.039093017578125,
0.02... |
billray110/corpus-of-diverse-styles | 2022-10-22T00:52:53.000Z | [
"task_categories:text-classification",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10M<n<100M",
"arxiv:2010.05700",
"region:us"
] | billray110 | null | null | 3 | 20 | 2022-04-21T01:13:59 | ---
annotations_creators: []
language_creators:
- found
language: []
license: []
multilinguality:
- monolingual
pretty_name: Corpus of Diverse Styles
size_categories:
- 10M<n<100M
source_datasets: []
task_categories:
- text-classification
task_ids: []
---
# Dataset Card for Corpus of Diverse Styles
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
## Disclaimer
I am not the original author of the paper that presents the Corpus of Diverse Styles. I uploaded the dataset to HuggingFace as a convenience.
## Dataset Description
- **Homepage:** http://style.cs.umass.edu/
- **Repository:** https://github.com/martiansideofthemoon/style-transfer-paraphrase
- **Paper:** https://arxiv.org/abs/2010.05700
### Dataset Summary
A new benchmark dataset that contains 15M
sentences from 11 diverse styles.
To create CDS, we obtain data from existing academic
research datasets and public APIs or online collections
like Project Gutenberg. We choose
styles that are easy for human readers to identify at
a sentence level (e.g., Tweets or Biblical text). While
prior benchmarks involve a transfer between two
styles, CDS has 110 potential transfer directions.
### Citation Information
```
@inproceedings{style20,
author={Kalpesh Krishna and John Wieting and Mohit Iyyer},
Booktitle = {Empirical Methods in Natural Language Processing},
Year = "2020",
Title={Reformulating Unsupervised Style Transfer as Paraphrase Generation},
}
``` | 1,533 | [
[
-0.03399658203125,
-0.041595458984375,
0.0136566162109375,
0.048828125,
-0.037750244140625,
0.01328277587890625,
-0.040740966796875,
-0.0211334228515625,
0.0259552001953125,
0.04779052734375,
-0.036224365234375,
-0.07159423828125,
-0.043426513671875,
0.03271... |
Aniemore/cedr-m7 | 2022-07-01T16:39:56.000Z | [
"task_categories:text-classification",
"task_ids:sentiment-classification",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:extended|cedr",
"language:ru",
"license:mit",
"region:us"
] | Aniemore | null | null | 5 | 20 | 2022-05-24T18:01:54 | ---
annotations_creators:
- found
language_creators:
- found
language:
- ru
license: mit
multilinguality:
- monolingual
pretty_name: cedr-m7
size_categories:
- 1K<n<10K
source_datasets:
- extended|cedr
task_categories:
- text-classification
task_ids:
- sentiment-classification
---
# Dataset Card for CEDR-M7
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
```
@misc{Aniemore,
author = {Артем Аментес, Илья Лубенец, Никита Давидчук},
title = {Открытая библиотека искусственного интеллекта для анализа и выявления эмоциональных оттенков речи человека},
year = {2022},
publisher = {Hugging Face},
journal = {Hugging Face Hub},
howpublished = {\url{https://huggingface.com/aniemore/Aniemore}},
email = {hello@socialcode.ru}
}
```
### Contributions
Thanks to [@toiletsandpaper](https://github.com/toiletsandpaper) for adding this dataset.
| 3,115 | [
[
-0.035980224609375,
-0.038818359375,
0.017242431640625,
0.01202392578125,
-0.0220947265625,
0.00868988037109375,
-0.02093505859375,
-0.0273284912109375,
0.04412841796875,
0.03253173828125,
-0.06378173828125,
-0.08380126953125,
-0.05194091796875,
0.0122604370... |
imvladikon/bmc | 2022-11-17T16:52:43.000Z | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|other-reuters-corpus",
"language:he",
"license:other",
"arxiv:2007.156... | imvladikon | \ | @mastersthesis{naama,
title={Hebrew Named Entity Recognition},
author={Ben-Mordecai, Naama},
advisor={Elhadad, Michael},
year={2005},
url="https://www.cs.bgu.ac.il/~elhadad/nlpproj/naama/",
institution={Department of Computer Science, Ben-Gurion University},
school={Department of Computer Science, Ben-Gurion University},
},
@misc{bareket2020neural,
title={Neural Modeling for Named Entities and Morphology (NEMO^2)},
author={Dan Bareket and Reut Tsarfaty},
year={2020},
eprint={2007.15620},
archivePrefix={arXiv},
primaryClass={cs.CL}
} | 0 | 20 | 2022-06-22T15:39:14 | ---
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- he
license:
- other
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- extended|other-reuters-corpus
task_categories:
- token-classification
task_ids:
- named-entity-recognition
train-eval-index:
- config: bmc
task: token-classification
task_id: entity_extraction
splits:
train_split: train
eval_split: validation
test_split: test
col_mapping:
tokens: tokens
ner_tags: tags
metrics:
- type: seqeval
name: seqeval
---
# Splits for the Ben-Mordecai and Elhadad Hebrew NER Corpus (BMC)
In order to evaluate performance in accordance with the original Ben-Mordecai and Elhadad (2005) work, we provide three 75%-25% random splits.
* Only the 7 entity categories viable for evaluation were kept (DATE, LOC, MONEY, ORG, PER, PERCENT, TIME) --- all MISC entities were filtered out.
* Sequence label scheme was changed from IOB to BIOES
* The dev sets are 10% taken out of the 75%
## Citation
If you use use the BMC corpus, please cite the original paper as well as our paper which describes the splits:
* Ben-Mordecai and Elhadad (2005):
```console
@mastersthesis{naama,
title={Hebrew Named Entity Recognition},
author={Ben-Mordecai, Naama},
advisor={Elhadad, Michael},
year={2005},
url="https://www.cs.bgu.ac.il/~elhadad/nlpproj/naama/",
institution={Department of Computer Science, Ben-Gurion University},
school={Department of Computer Science, Ben-Gurion University},
}
```
* Bareket and Tsarfaty (2020)
```console
@misc{bareket2020neural,
title={Neural Modeling for Named Entities and Morphology (NEMO^2)},
author={Dan Bareket and Reut Tsarfaty},
year={2020},
eprint={2007.15620},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 1,838 | [
[
-0.04718017578125,
-0.047210693359375,
0.0163116455078125,
0.0166015625,
-0.0295257568359375,
0.00811767578125,
-0.0255584716796875,
-0.0599365234375,
0.0364990234375,
0.01361083984375,
-0.0260009765625,
-0.044708251953125,
-0.048187255859375,
0.020629882812... |
LHF/escorpius | 2023-01-05T10:55:48.000Z | [
"task_categories:text-generation",
"task_categories:fill-mask",
"task_ids:language-modeling",
"task_ids:masked-language-modeling",
"multilinguality:monolingual",
"size_categories:100M<n<1B",
"source_datasets:original",
"language:es",
"license:cc-by-nc-nd-4.0",
"arxiv:2206.15147",
"region:us"
] | LHF | Spanish dataset | @misc{TODO
} | 12 | 20 | 2022-06-24T20:58:40 | ---
license: cc-by-nc-nd-4.0
language:
- es
multilinguality:
- monolingual
size_categories:
- 100M<n<1B
source_datasets:
- original
task_categories:
- text-generation
- fill-mask
task_ids:
- language-modeling
- masked-language-modeling
---
# esCorpius: A Massive Spanish Crawling Corpus
## Introduction
In the recent years, Transformer-based models have lead to significant advances in language modelling for natural language processing. However, they require a vast amount of data to be (pre-)trained and there is a lack of corpora in languages other than English. Recently, several initiatives have presented multilingual datasets obtained from automatic web crawling. However, the results in Spanish present important shortcomings, as they are either too small in comparison with other languages, or present a low quality derived from sub-optimal cleaning and deduplication. In this work, we introduce esCorpius, a Spanish crawling corpus obtained from near 1 Pb of Common Crawl data. It is the most extensive corpus in Spanish with this level of quality in the extraction, purification and deduplication of web textual content. Our data curation process involves a novel highly parallel cleaning pipeline and encompasses a series of deduplication mechanisms that together ensure the integrity of both document and paragraph boundaries. Additionally, we maintain both the source web page URL and the WARC shard origin URL in order to complain with EU regulations. esCorpius has been released under CC BY-NC-ND 4.0 license.
## Statistics
| **Corpus** | OSCAR<br>22.01 | mC4 | CC-100 | ParaCrawl<br>v9 | esCorpius<br>(ours) |
|-------------------------|----------------|--------------|-----------------|-----------------|-------------------------|
| **Size (ES)** | 381.9 GB | 1,600.0 GB | 53.3 GB | 24.0 GB | 322.5 GB |
| **Docs (ES)** | 51M | 416M | - | - | 104M |
| **Words (ES)** | 42,829M | 433,000M | 9,374M | 4,374M | 50,773M |
| **Lang.<br>identifier** | fastText | CLD3 | fastText | CLD2 | CLD2 + fastText |
| **Elements** | Document | Document | Document | Sentence | Document and paragraph |
| **Parsing quality** | Medium | Low | Medium | High | High |
| **Cleaning quality** | Low | No cleaning | Low | High | High |
| **Deduplication** | No | No | No | Bicleaner | dLHF |
| **Language** | Multilingual | Multilingual | Multilingual | Multilingual | Spanish |
| **License** | CC-BY-4.0 | ODC-By-v1.0 | Common<br>Crawl | CC0 | CC-BY-NC-ND |
## Citation
Link to the paper: https://www.isca-speech.org/archive/pdfs/iberspeech_2022/gutierrezfandino22_iberspeech.pdf / https://arxiv.org/abs/2206.15147
Cite this work:
```
@inproceedings{gutierrezfandino22_iberspeech,
author={Asier Gutiérrez-Fandiño and David Pérez-Fernández and Jordi Armengol-Estapé and David Griol and Zoraida Callejas},
title={{esCorpius: A Massive Spanish Crawling Corpus}},
year=2022,
booktitle={Proc. IberSPEECH 2022},
pages={126--130},
doi={10.21437/IberSPEECH.2022-26}
}
```
## Disclaimer
We did not perform any kind of filtering and/or censorship to the corpus. We expect users to do so applying their own methods. We are not liable for any misuse of the corpus. | 3,721 | [
[
-0.034942626953125,
-0.0465087890625,
0.0243988037109375,
0.0400390625,
-0.0157012939453125,
0.034698486328125,
-0.006221771240234375,
-0.033721923828125,
0.053924560546875,
0.04071044921875,
-0.0228729248046875,
-0.059295654296875,
-0.058135986328125,
0.022... |
jonaskoenig/Questions-vs-Statements-Classification | 2022-07-11T15:36:35.000Z | [
"region:us"
] | jonaskoenig | null | null | 2 | 20 | 2022-07-10T20:24:09 | [Needs More Information]
# Dataset Card for Questions-vs-Statements-Classification
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
## Dataset Description
- **Homepage:** [Kaggle](https://www.kaggle.com/datasets/shahrukhkhan/questions-vs-statementsclassificationdataset)
- **Point of Contact:** [Shahrukh Khan](https://www.kaggle.com/shahrukhkhan)
### Dataset Summary
A dataset containing statements and questions with their corresponding labels.
### Supported Tasks and Leaderboards
multi-class-classification
### Languages
en
## Dataset Structure
### Data Splits
Train Test Valid
## Dataset Creation
### Curation Rationale
The goal of this project is to classify sentences, based on type:
Statement (Declarative Sentence)
Question (Interrogative Sentence)
### Source Data
[Kaggle](https://www.kaggle.com/datasets/shahrukhkhan/questions-vs-statementsclassificationdataset)
#### Initial Data Collection and Normalization
The dataset is created by parsing out the SQuAD dataset and combining it with the SPAADIA dataset.
### Other Known Limitations
Questions in this case ar are only one sentence, statements are a single sentence or more. They are classified correctly but don't include sentences prior to questions.
## Additional Information
### Dataset Curators
[SHAHRUKH KHAN](https://www.kaggle.com/shahrukhkhan)
### Licensing Information
[CC0: Public Domain](https://creativecommons.org/publicdomain/zero/1.0/)
| 2,352 | [
[
-0.036407470703125,
-0.06341552734375,
-0.0004684925079345703,
0.01441192626953125,
0.0009455680847167969,
0.0266265869140625,
-0.022491455078125,
-0.01433563232421875,
0.0137176513671875,
0.04351806640625,
-0.0660400390625,
-0.06396484375,
-0.040313720703125,
... |
Bingsu/Gameplay_Images | 2022-08-26T05:31:58.000Z | [
"task_categories:image-classification",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"language:en",
"license:cc-by-4.0",
"region:us"
] | Bingsu | null | null | 1 | 20 | 2022-08-26T04:42:10 | ---
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Gameplay Images
size_categories:
- 1K<n<10K
task_categories:
- image-classification
---
# Gameplay Images
## Dataset Description
- **Homepage:** [kaggle](https://www.kaggle.com/datasets/aditmagotra/gameplay-images)
- **Download Size** 2.50 GiB
- **Generated Size** 1.68 GiB
- **Total Size** 4.19 GiB
A dataset from [kaggle](https://www.kaggle.com/datasets/aditmagotra/gameplay-images).
This is a dataset of 10 very famous video games in the world.
These include
- Among Us
- Apex Legends
- Fortnite
- Forza Horizon
- Free Fire
- Genshin Impact
- God of War
- Minecraft
- Roblox
- Terraria
There are 1000 images per class and all are sized `640 x 360`. They are in the `.png` format.
This Dataset was made by saving frames every few seconds from famous gameplay videos on Youtube.
※ This dataset was uploaded in January 2022. Game content updated after that will not be included.
### License
CC-BY-4.0
## Dataset Structure
### Data Instance
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("Bingsu/Gameplay_Images")
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 10000
})
})
```
```python
>>> dataset["train"].features
{'image': Image(decode=True, id=None),
'label': ClassLabel(num_classes=10, names=['Among Us', 'Apex Legends', 'Fortnite', 'Forza Horizon', 'Free Fire', 'Genshin Impact', 'God of War', 'Minecraft', 'Roblox', 'Terraria'], id=None)}
```
### Data Size
download: 2.50 GiB<br>
generated: 1.68 GiB<br>
total: 4.19 GiB
### Data Fields
- image: `Image`
- A `PIL.Image.Image object` containing the image. size=640x360
- Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the "image" column, i.e. `dataset[0]["image"]` should always be preferred over `dataset["image"][0]`.
- label: an int classification label.
Class Label Mappings:
```json
{
"Among Us": 0,
"Apex Legends": 1,
"Fortnite": 2,
"Forza Horizon": 3,
"Free Fire": 4,
"Genshin Impact": 5,
"God of War": 6,
"Minecraft": 7,
"Roblox": 8,
"Terraria": 9
}
```
```python
>>> dataset["train"][0]
{'image': <PIL.PngImagePlugin.PngImageFile image mode=RGBA size=640x360>,
'label': 0}
```
### Data Splits
| | train |
| ---------- | -------- |
| # of data | 10000 |
### Note
#### train_test_split
```python
>>> ds_new = dataset["train"].train_test_split(0.2, seed=42, stratify_by_column="label")
>>> ds_new
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 8000
})
test: Dataset({
features: ['image', 'label'],
num_rows: 2000
})
})
```
| 2,912 | [
[
-0.04376220703125,
-0.04156494140625,
0.01055908203125,
0.0224609375,
-0.01483917236328125,
0.0052490234375,
-0.01174163818359375,
-0.023406982421875,
0.0252838134765625,
0.0251617431640625,
-0.042449951171875,
-0.0570068359375,
-0.037811279296875,
0.0049552... |
batterydata/pos_tagging | 2022-09-05T16:05:33.000Z | [
"task_categories:token-classification",
"language:en",
"license:apache-2.0",
"region:us"
] | batterydata | null | null | 0 | 20 | 2022-09-05T15:44:21 | ---
language:
- en
license:
- apache-2.0
task_categories:
- token-classification
pretty_name: 'Part-of-speech(POS) Tagging Dataset for BatteryDataExtractor'
---
# POS Tagging Dataset
## Original Data Source
#### Conll2003
E. F. Tjong Kim Sang and F. De Meulder, Proceedings of the
Seventh Conference on Natural Language Learning at HLT-
NAACL 2003, 2003, pp. 142–147.
#### The Peen Treebank
M. P. Marcus, B. Santorini and M. A. Marcinkiewicz, Comput.
Linguist., 1993, 19, 313–330.
## Citation
BatteryDataExtractor: battery-aware text-mining software embedded with BERT models | 583 | [
[
-0.0006356239318847656,
-0.0335693359375,
0.0235137939453125,
0.012298583984375,
-0.00901031494140625,
0.005062103271484375,
-0.00624847412109375,
-0.0209808349609375,
0.0033416748046875,
0.0187530517578125,
-0.019500732421875,
-0.052154541015625,
-0.02348327636... |
artemsnegirev/dialogs_from_jokes | 2022-09-27T11:43:32.000Z | [
"task_categories:conversational",
"task_ids:dialogue-generation",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"language:ru",
"license:cc0-1.0",
"region:us"
] | artemsnegirev | null | null | 1 | 20 | 2022-09-27T11:32:40 | ---
language:
- ru
multilinguality:
- monolingual
pretty_name: Dialogs from Jokes
size_categories:
- 100K<n<1M
task_categories:
- conversational
task_ids:
- dialogue-generation
license: cc0-1.0
---
Converted to json version of dataset from [Koziev/NLP_Datasets](https://github.com/Koziev/NLP_Datasets/blob/master/Conversations/Data/extract_dialogues_from_anekdots.tar.xz) | 372 | [
[
-0.01242828369140625,
-0.046234130859375,
0.0123138427734375,
0.0086822509765625,
-0.01331329345703125,
0.0233154296875,
-0.0335693359375,
-0.01258087158203125,
0.039703369140625,
0.08929443359375,
-0.057952880859375,
-0.04376220703125,
-0.025115966796875,
0... |
tomekkorbak/detoxify-pile-chunk3-1800000-1850000 | 2022-10-05T00:01:14.000Z | [
"region:us"
] | tomekkorbak | null | null | 0 | 20 | 2022-10-05T00:01:05 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
ipipan/nkjp1m | 2022-12-07T16:47:51.000Z | [
"task_categories:token-classification",
"task_ids:part-of-speech",
"task_ids:lemmatization",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:pl",
"license:cc-by-4.0",
... | ipipan | This is the official dataset for NKJP1M – the 1-million token subcorpus of the
National Corpus of Polish (Narodowy Korpus Języka Polskiego)
Besides the text (divided into paragraphs/samples and sentences) the
set contains lemmas and morpho-syntactic tags for all tokens in the corpus.
This release corresponds to the version 1.2 of the corpus with
following corrections and improvements. In particular the
morpho-syntactic annotation has been aligned with the present version
of Morfeusz2 morphological analyser. | @Book{nkjp:12,
editor = "Adam Przepiórkowski and Mirosław Bańko and Rafał
L. Górski and Barbara Lewandowska-Tomaszczyk",
title = "Narodowy Korpus Języka Polskiego",
year = 2012,
address = "Warszawa",
pdf = "http://nkjp.pl/settings/papers/NKJP_ksiazka.pdf",
publisher = "Wydawnictwo Naukowe PWN"} | 2 | 20 | 2022-12-07T16:41:20 | ---
annotations_creators:
- expert-generated
language:
- pl
language_creators:
- expert-generated
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: NKJP1M
size_categories:
- 10K<n<100K
source_datasets:
- original
tags:
- National Corpus of Polish
- Narodowy Korpus Języka Polskiego
task_categories:
- token-classification
task_ids:
- part-of-speech
- lemmatization
dataset_info:
features:
- name: nkjp_text
dtype: string
- name: nkjp_par
dtype: string
- name: nkjp_sent
dtype: string
- name: tokens
sequence: string
- name: lemmas
sequence: string
- name: cposes
sequence:
class_label:
names:
0: A
1: Adv
2: Comp
3: Conj
4: Dig
5: Interj
6: N
7: Num
8: Part
9: Prep
10: Punct
11: V
12: X
- name: poses
sequence:
class_label:
names:
0: adj
1: adja
2: adjc
3: adjp
4: adv
5: aglt
6: bedzie
7: brev
8: comp
9: conj
10: depr
11: dig
12: fin
13: frag
14: ger
15: imps
16: impt
17: inf
18: interj
19: interp
20: num
21: numcomp
22: pact
23: pacta
24: pant
25: part
26: pcon
27: ppas
28: ppron12
29: ppron3
30: praet
31: pred
32: prep
33: romandig
34: siebie
35: subst
36: sym
37: winien
38: xxs
39: xxx
- name: tags
sequence:
class_label:
names:
0: adj:pl:acc:f:com
1: adj:pl:acc:f:pos
2: adj:pl:acc:f:sup
3: adj:pl:acc:m1:com
4: adj:pl:acc:m1:pos
5: adj:pl:acc:m1:sup
6: adj:pl:acc:m2:com
7: adj:pl:acc:m2:pos
8: adj:pl:acc:m2:sup
9: adj:pl:acc:m3:com
10: adj:pl:acc:m3:pos
11: adj:pl:acc:m3:sup
12: adj:pl:acc:n:com
13: adj:pl:acc:n:pos
14: adj:pl:acc:n:sup
15: adj:pl:dat:f:com
16: adj:pl:dat:f:pos
17: adj:pl:dat:f:sup
18: adj:pl:dat:m1:com
19: adj:pl:dat:m1:pos
20: adj:pl:dat:m1:sup
21: adj:pl:dat:m2:pos
22: adj:pl:dat:m3:com
23: adj:pl:dat:m3:pos
24: adj:pl:dat:n:pos
25: adj:pl:dat:n:sup
26: adj:pl:gen:f:com
27: adj:pl:gen:f:pos
28: adj:pl:gen:f:sup
29: adj:pl:gen:m1:com
30: adj:pl:gen:m1:pos
31: adj:pl:gen:m1:sup
32: adj:pl:gen:m2:com
33: adj:pl:gen:m2:pos
34: adj:pl:gen:m2:sup
35: adj:pl:gen:m3:com
36: adj:pl:gen:m3:pos
37: adj:pl:gen:m3:sup
38: adj:pl:gen:n:com
39: adj:pl:gen:n:pos
40: adj:pl:gen:n:sup
41: adj:pl:inst:f:com
42: adj:pl:inst:f:pos
43: adj:pl:inst:f:sup
44: adj:pl:inst:m1:com
45: adj:pl:inst:m1:pos
46: adj:pl:inst:m1:sup
47: adj:pl:inst:m2:pos
48: adj:pl:inst:m3:com
49: adj:pl:inst:m3:pos
50: adj:pl:inst:m3:sup
51: adj:pl:inst:n:com
52: adj:pl:inst:n:pos
53: adj:pl:inst:n:sup
54: adj:pl:loc:f:com
55: adj:pl:loc:f:pos
56: adj:pl:loc:f:sup
57: adj:pl:loc:m1:com
58: adj:pl:loc:m1:pos
59: adj:pl:loc:m1:sup
60: adj:pl:loc:m2:pos
61: adj:pl:loc:m3:com
62: adj:pl:loc:m3:pos
63: adj:pl:loc:m3:sup
64: adj:pl:loc:n:com
65: adj:pl:loc:n:pos
66: adj:pl:loc:n:sup
67: adj:pl:nom:f:com
68: adj:pl:nom:f:pos
69: adj:pl:nom:f:sup
70: adj:pl:nom:m1:com
71: adj:pl:nom:m1:pos
72: adj:pl:nom:m1:sup
73: adj:pl:nom:m2:com
74: adj:pl:nom:m2:pos
75: adj:pl:nom:m2:sup
76: adj:pl:nom:m3:com
77: adj:pl:nom:m3:pos
78: adj:pl:nom:m3:sup
79: adj:pl:nom:n:com
80: adj:pl:nom:n:pos
81: adj:pl:nom:n:sup
82: adj:pl:voc:f:pos
83: adj:pl:voc:m1:pos
84: adj:pl:voc:m2:pos
85: adj:pl:voc:n:pos
86: adj:sg:acc:f:com
87: adj:sg:acc:f:pos
88: adj:sg:acc:f:sup
89: adj:sg:acc:m1:com
90: adj:sg:acc:m1:pos
91: adj:sg:acc:m1:sup
92: adj:sg:acc:m2:com
93: adj:sg:acc:m2:pos
94: adj:sg:acc:m2:sup
95: adj:sg:acc:m3:com
96: adj:sg:acc:m3:pos
97: adj:sg:acc:m3:sup
98: adj:sg:acc:n:com
99: adj:sg:acc:n:pos
100: adj:sg:acc:n:sup
101: adj:sg:dat:f:com
102: adj:sg:dat:f:pos
103: adj:sg:dat:f:sup
104: adj:sg:dat:m1:com
105: adj:sg:dat:m1:pos
106: adj:sg:dat:m1:sup
107: adj:sg:dat:m2:pos
108: adj:sg:dat:m3:com
109: adj:sg:dat:m3:pos
110: adj:sg:dat:m3:sup
111: adj:sg:dat:n:com
112: adj:sg:dat:n:pos
113: adj:sg:dat:n:sup
114: adj:sg:gen:f:com
115: adj:sg:gen:f:pos
116: adj:sg:gen:f:sup
117: adj:sg:gen:m1:com
118: adj:sg:gen:m1:pos
119: adj:sg:gen:m1:sup
120: adj:sg:gen:m2:pos
121: adj:sg:gen:m2:sup
122: adj:sg:gen:m3:com
123: adj:sg:gen:m3:pos
124: adj:sg:gen:m3:sup
125: adj:sg:gen:n:com
126: adj:sg:gen:n:pos
127: adj:sg:gen:n:sup
128: adj:sg:inst:f:com
129: adj:sg:inst:f:pos
130: adj:sg:inst:f:sup
131: adj:sg:inst:m1:com
132: adj:sg:inst:m1:pos
133: adj:sg:inst:m1:sup
134: adj:sg:inst:m2:com
135: adj:sg:inst:m2:pos
136: adj:sg:inst:m2:sup
137: adj:sg:inst:m3:com
138: adj:sg:inst:m3:pos
139: adj:sg:inst:m3:sup
140: adj:sg:inst:n:com
141: adj:sg:inst:n:pos
142: adj:sg:inst:n:sup
143: adj:sg:loc:f:com
144: adj:sg:loc:f:pos
145: adj:sg:loc:f:sup
146: adj:sg:loc:m1:com
147: adj:sg:loc:m1:pos
148: adj:sg:loc:m1:sup
149: adj:sg:loc:m2:com
150: adj:sg:loc:m2:pos
151: adj:sg:loc:m3:com
152: adj:sg:loc:m3:pos
153: adj:sg:loc:m3:sup
154: adj:sg:loc:n:com
155: adj:sg:loc:n:pos
156: adj:sg:loc:n:sup
157: adj:sg:nom:f:com
158: adj:sg:nom:f:pos
159: adj:sg:nom:f:sup
160: adj:sg:nom:m1:com
161: adj:sg:nom:m1:pos
162: adj:sg:nom:m1:sup
163: adj:sg:nom:m2:com
164: adj:sg:nom:m2:pos
165: adj:sg:nom:m2:sup
166: adj:sg:nom:m3:com
167: adj:sg:nom:m3:pos
168: adj:sg:nom:m3:sup
169: adj:sg:nom:n:com
170: adj:sg:nom:n:pos
171: adj:sg:nom:n:sup
172: adj:sg:voc:f:pos
173: adj:sg:voc:f:sup
174: adj:sg:voc:m1:pos
175: adj:sg:voc:m1:sup
176: adj:sg:voc:m2:pos
177: adj:sg:voc:m3:pos
178: adj:sg:voc:n:pos
179: adja
180: adjc
181: adjp:dat
182: adjp:gen
183: adv
184: adv:com
185: adv:pos
186: adv:sup
187: aglt:pl:pri:imperf:nwok
188: aglt:pl:sec:imperf:nwok
189: aglt:sg:pri:imperf:nwok
190: aglt:sg:pri:imperf:wok
191: aglt:sg:sec:imperf:nwok
192: aglt:sg:sec:imperf:wok
193: bedzie:pl:pri:imperf
194: bedzie:pl:sec:imperf
195: bedzie:pl:ter:imperf
196: bedzie:sg:pri:imperf
197: bedzie:sg:sec:imperf
198: bedzie:sg:ter:imperf
199: brev:npun
200: brev:pun
201: comp
202: conj
203: depr:pl:acc:m2
204: depr:pl:nom:m2
205: depr:pl:voc:m2
206: dig
207: fin:pl:pri:imperf
208: fin:pl:pri:perf
209: fin:pl:sec:imperf
210: fin:pl:sec:perf
211: fin:pl:ter:imperf
212: fin:pl:ter:perf
213: fin:sg:pri:imperf
214: fin:sg:pri:perf
215: fin:sg:sec:imperf
216: fin:sg:sec:perf
217: fin:sg:ter:imperf
218: fin:sg:ter:perf
219: frag
220: ger:pl:acc:n:imperf:aff
221: ger:pl:acc:n:perf:aff
222: ger:pl:dat:n:perf:aff
223: ger:pl:gen:n:imperf:aff
224: ger:pl:gen:n:perf:aff
225: ger:pl:inst:n:imperf:aff
226: ger:pl:inst:n:perf:aff
227: ger:pl:loc:n:imperf:aff
228: ger:pl:loc:n:perf:aff
229: ger:pl:nom:n:imperf:aff
230: ger:pl:nom:n:perf:aff
231: ger:sg:acc:n:imperf:aff
232: ger:sg:acc:n:imperf:neg
233: ger:sg:acc:n:perf:aff
234: ger:sg:acc:n:perf:neg
235: ger:sg:dat:n:imperf:aff
236: ger:sg:dat:n:perf:aff
237: ger:sg:dat:n:perf:neg
238: ger:sg:gen:n:imperf:aff
239: ger:sg:gen:n:imperf:neg
240: ger:sg:gen:n:perf:aff
241: ger:sg:gen:n:perf:neg
242: ger:sg:inst:n:imperf:aff
243: ger:sg:inst:n:imperf:neg
244: ger:sg:inst:n:perf:aff
245: ger:sg:inst:n:perf:neg
246: ger:sg:loc:n:imperf:aff
247: ger:sg:loc:n:imperf:neg
248: ger:sg:loc:n:perf:aff
249: ger:sg:loc:n:perf:neg
250: ger:sg:nom:n:imperf:aff
251: ger:sg:nom:n:imperf:neg
252: ger:sg:nom:n:perf:aff
253: ger:sg:nom:n:perf:neg
254: imps:imperf
255: imps:perf
256: impt:pl:pri:imperf
257: impt:pl:pri:perf
258: impt:pl:sec:imperf
259: impt:pl:sec:perf
260: impt:sg:pri:imperf
261: impt:sg:sec:imperf
262: impt:sg:sec:perf
263: inf:imperf
264: inf:perf
265: interj
266: interp
267: num:pl:acc:f:congr:ncol
268: num:pl:acc:f:rec
269: num:pl:acc:f:rec:ncol
270: num:pl:acc:m1:rec
271: num:pl:acc:m1:rec:col
272: num:pl:acc:m1:rec:ncol
273: num:pl:acc:m2:congr:ncol
274: num:pl:acc:m2:rec
275: num:pl:acc:m2:rec:ncol
276: num:pl:acc:m3:congr
277: num:pl:acc:m3:congr:ncol
278: num:pl:acc:m3:rec
279: num:pl:acc:m3:rec:ncol
280: num:pl:acc:n:congr:ncol
281: num:pl:acc:n:rec
282: num:pl:acc:n:rec:col
283: num:pl:acc:n:rec:ncol
284: num:pl:dat:f:congr
285: num:pl:dat:f:congr:ncol
286: num:pl:dat:m1:congr
287: num:pl:dat:m1:congr:col
288: num:pl:dat:m1:congr:ncol
289: num:pl:dat:m2:congr
290: num:pl:dat:m3:congr:ncol
291: num:pl:dat:n:congr
292: num:pl:dat:n:congr:ncol
293: num:pl:gen:f:congr
294: num:pl:gen:f:congr:ncol
295: num:pl:gen:f:rec
296: num:pl:gen:f:rec:ncol
297: num:pl:gen:m1:congr
298: num:pl:gen:m1:congr:ncol
299: num:pl:gen:m1:rec
300: num:pl:gen:m1:rec:col
301: num:pl:gen:m2:congr
302: num:pl:gen:m2:congr:ncol
303: num:pl:gen:m2:rec
304: num:pl:gen:m3:congr
305: num:pl:gen:m3:congr:ncol
306: num:pl:gen:m3:rec
307: num:pl:gen:m3:rec:ncol
308: num:pl:gen:n:congr
309: num:pl:gen:n:congr:ncol
310: num:pl:gen:n:rec
311: num:pl:gen:n:rec:col
312: num:pl:inst:f:congr
313: num:pl:inst:f:congr:ncol
314: num:pl:inst:m1:congr
315: num:pl:inst:m1:congr:ncol
316: num:pl:inst:m1:rec:col
317: num:pl:inst:m2:congr
318: num:pl:inst:m2:congr:ncol
319: num:pl:inst:m3:congr
320: num:pl:inst:m3:congr:ncol
321: num:pl:inst:n:congr
322: num:pl:inst:n:congr:ncol
323: num:pl:inst:n:rec:col
324: num:pl:loc:f:congr
325: num:pl:loc:f:congr:ncol
326: num:pl:loc:m1:congr
327: num:pl:loc:m1:congr:ncol
328: num:pl:loc:m2:congr
329: num:pl:loc:m2:congr:ncol
330: num:pl:loc:m3:congr
331: num:pl:loc:m3:congr:ncol
332: num:pl:loc:n:congr
333: num:pl:loc:n:congr:ncol
334: num:pl:nom:f:congr:ncol
335: num:pl:nom:f:rec
336: num:pl:nom:f:rec:ncol
337: num:pl:nom:m1:congr:ncol
338: num:pl:nom:m1:rec
339: num:pl:nom:m1:rec:col
340: num:pl:nom:m1:rec:ncol
341: num:pl:nom:m2:congr:ncol
342: num:pl:nom:m2:rec
343: num:pl:nom:m2:rec:ncol
344: num:pl:nom:m3:congr:ncol
345: num:pl:nom:m3:rec
346: num:pl:nom:m3:rec:ncol
347: num:pl:nom:n:congr
348: num:pl:nom:n:congr:ncol
349: num:pl:nom:n:rec
350: num:pl:nom:n:rec:col
351: num:pl:nom:n:rec:ncol
352: num:sg:acc:f:rec
353: num:sg:acc:f:rec:ncol
354: num:sg:acc:m1:rec:ncol
355: num:sg:acc:m2:rec
356: num:sg:acc:m3:rec
357: num:sg:acc:m3:rec:ncol
358: num:sg:acc:n:rec
359: num:sg:gen:f:rec
360: num:sg:gen:m3:rec
361: num:sg:gen:n:rec
362: num:sg:inst:m3:rec
363: num:sg:loc:f:rec
364: num:sg:loc:m3:congr
365: num:sg:loc:m3:rec
366: num:sg:nom:f:rec
367: num:sg:nom:m2:rec
368: num:sg:nom:m3:rec
369: num:sg:nom:m3:rec:ncol
370: num:sg:nom:n:rec
371: numcomp
372: pact:pl:acc:f:imperf:aff
373: pact:pl:acc:f:imperf:neg
374: pact:pl:acc:m1:imperf:aff
375: pact:pl:acc:m2:imperf:aff
376: pact:pl:acc:m3:imperf:aff
377: pact:pl:acc:m3:imperf:neg
378: pact:pl:acc:n:imperf:aff
379: pact:pl:acc:n:imperf:neg
380: pact:pl:dat:f:imperf:aff
381: pact:pl:dat:m1:imperf:aff
382: pact:pl:dat:m2:imperf:aff
383: pact:pl:dat:m3:imperf:aff
384: pact:pl:dat:n:imperf:aff
385: pact:pl:gen:f:imperf:aff
386: pact:pl:gen:f:imperf:neg
387: pact:pl:gen:m1:imperf:aff
388: pact:pl:gen:m1:imperf:neg
389: pact:pl:gen:m2:imperf:aff
390: pact:pl:gen:m3:imperf:aff
391: pact:pl:gen:m3:imperf:neg
392: pact:pl:gen:n:imperf:aff
393: pact:pl:inst:f:imperf:aff
394: pact:pl:inst:m1:imperf:aff
395: pact:pl:inst:m2:imperf:aff
396: pact:pl:inst:m3:imperf:aff
397: pact:pl:inst:m3:imperf:neg
398: pact:pl:inst:n:imperf:aff
399: pact:pl:inst:n:imperf:neg
400: pact:pl:loc:f:imperf:aff
401: pact:pl:loc:m1:imperf:aff
402: pact:pl:loc:m3:imperf:aff
403: pact:pl:loc:m3:imperf:neg
404: pact:pl:loc:n:imperf:aff
405: pact:pl:loc:n:imperf:neg
406: pact:pl:nom:f:imperf:aff
407: pact:pl:nom:f:imperf:neg
408: pact:pl:nom:m1:imperf:aff
409: pact:pl:nom:m2:imperf:aff
410: pact:pl:nom:m3:imperf:aff
411: pact:pl:nom:n:imperf:aff
412: pact:pl:nom:n:imperf:neg
413: pact:pl:voc:f:imperf:aff
414: pact:sg:acc:f:imperf:aff
415: pact:sg:acc:f:imperf:neg
416: pact:sg:acc:m1:imperf:aff
417: pact:sg:acc:m2:imperf:aff
418: pact:sg:acc:m3:imperf:aff
419: pact:sg:acc:n:imperf:aff
420: pact:sg:acc:n:imperf:neg
421: pact:sg:dat:f:imperf:aff
422: pact:sg:dat:m1:imperf:aff
423: pact:sg:dat:m2:imperf:aff
424: pact:sg:dat:m3:imperf:aff
425: pact:sg:dat:n:imperf:aff
426: pact:sg:gen:f:imperf:aff
427: pact:sg:gen:f:imperf:neg
428: pact:sg:gen:m1:imperf:aff
429: pact:sg:gen:m1:imperf:neg
430: pact:sg:gen:m2:imperf:aff
431: pact:sg:gen:m3:imperf:aff
432: pact:sg:gen:m3:imperf:neg
433: pact:sg:gen:n:imperf:aff
434: pact:sg:gen:n:imperf:neg
435: pact:sg:inst:f:imperf:aff
436: pact:sg:inst:f:imperf:neg
437: pact:sg:inst:m1:imperf:aff
438: pact:sg:inst:m1:imperf:neg
439: pact:sg:inst:m2:imperf:aff
440: pact:sg:inst:m2:imperf:neg
441: pact:sg:inst:m3:imperf:aff
442: pact:sg:inst:m3:imperf:neg
443: pact:sg:inst:n:imperf:aff
444: pact:sg:loc:f:imperf:aff
445: pact:sg:loc:f:imperf:neg
446: pact:sg:loc:m1:imperf:aff
447: pact:sg:loc:m2:imperf:aff
448: pact:sg:loc:m3:imperf:aff
449: pact:sg:loc:m3:imperf:neg
450: pact:sg:loc:n:imperf:aff
451: pact:sg:loc:n:imperf:neg
452: pact:sg:nom:f:imperf:aff
453: pact:sg:nom:f:imperf:neg
454: pact:sg:nom:m1:imperf:aff
455: pact:sg:nom:m1:imperf:neg
456: pact:sg:nom:m2:imperf:aff
457: pact:sg:nom:m3:imperf:aff
458: pact:sg:nom:m3:imperf:neg
459: pact:sg:nom:n:imperf:aff
460: pact:sg:nom:n:imperf:neg
461: pact:sg:voc:m1:imperf:aff
462: pacta
463: pant:perf
464: part
465: part:nwok
466: part:wok
467: pcon:imperf
468: ppas:pl:acc:f:imperf:aff
469: ppas:pl:acc:f:perf:aff
470: ppas:pl:acc:f:perf:neg
471: ppas:pl:acc:m1:imperf:aff
472: ppas:pl:acc:m1:imperf:neg
473: ppas:pl:acc:m1:perf:aff
474: ppas:pl:acc:m1:perf:neg
475: ppas:pl:acc:m2:imperf:aff
476: ppas:pl:acc:m2:perf:aff
477: ppas:pl:acc:m3:imperf:aff
478: ppas:pl:acc:m3:perf:aff
479: ppas:pl:acc:m3:perf:neg
480: ppas:pl:acc:n:imperf:aff
481: ppas:pl:acc:n:imperf:neg
482: ppas:pl:acc:n:perf:aff
483: ppas:pl:acc:n:perf:neg
484: ppas:pl:dat:f:imperf:aff
485: ppas:pl:dat:f:perf:aff
486: ppas:pl:dat:f:perf:neg
487: ppas:pl:dat:m1:imperf:aff
488: ppas:pl:dat:m1:perf:aff
489: ppas:pl:dat:m1:perf:neg
490: ppas:pl:dat:m2:imperf:aff
491: ppas:pl:dat:m3:imperf:aff
492: ppas:pl:dat:m3:perf:aff
493: ppas:pl:dat:n:imperf:aff
494: ppas:pl:dat:n:perf:aff
495: ppas:pl:gen:f:imperf:aff
496: ppas:pl:gen:f:imperf:neg
497: ppas:pl:gen:f:perf:aff
498: ppas:pl:gen:f:perf:neg
499: ppas:pl:gen:m1:imperf:aff
500: ppas:pl:gen:m1:imperf:neg
501: ppas:pl:gen:m1:perf:aff
502: ppas:pl:gen:m1:perf:neg
503: ppas:pl:gen:m2:imperf:aff
504: ppas:pl:gen:m2:perf:aff
505: ppas:pl:gen:m3:imperf:aff
506: ppas:pl:gen:m3:imperf:neg
507: ppas:pl:gen:m3:perf:aff
508: ppas:pl:gen:m3:perf:neg
509: ppas:pl:gen:n:imperf:aff
510: ppas:pl:gen:n:perf:aff
511: ppas:pl:gen:n:perf:neg
512: ppas:pl:inst:f:imperf:aff
513: ppas:pl:inst:f:perf:aff
514: ppas:pl:inst:m1:imperf:aff
515: ppas:pl:inst:m1:perf:aff
516: ppas:pl:inst:m2:perf:aff
517: ppas:pl:inst:m3:imperf:aff
518: ppas:pl:inst:m3:perf:aff
519: ppas:pl:inst:n:imperf:aff
520: ppas:pl:inst:n:perf:aff
521: ppas:pl:loc:f:imperf:aff
522: ppas:pl:loc:f:imperf:neg
523: ppas:pl:loc:f:perf:aff
524: ppas:pl:loc:f:perf:neg
525: ppas:pl:loc:m1:imperf:aff
526: ppas:pl:loc:m1:perf:aff
527: ppas:pl:loc:m2:imperf:aff
528: ppas:pl:loc:m3:imperf:aff
529: ppas:pl:loc:m3:perf:aff
530: ppas:pl:loc:m3:perf:neg
531: ppas:pl:loc:n:imperf:aff
532: ppas:pl:loc:n:perf:aff
533: ppas:pl:loc:n:perf:neg
534: ppas:pl:nom:f:imperf:aff
535: ppas:pl:nom:f:imperf:neg
536: ppas:pl:nom:f:perf:aff
537: ppas:pl:nom:f:perf:neg
538: ppas:pl:nom:m1:imperf:aff
539: ppas:pl:nom:m1:imperf:neg
540: ppas:pl:nom:m1:perf:aff
541: ppas:pl:nom:m1:perf:neg
542: ppas:pl:nom:m2:imperf:aff
543: ppas:pl:nom:m2:perf:aff
544: ppas:pl:nom:m3:imperf:aff
545: ppas:pl:nom:m3:imperf:neg
546: ppas:pl:nom:m3:perf:aff
547: ppas:pl:nom:m3:perf:neg
548: ppas:pl:nom:n:imperf:aff
549: ppas:pl:nom:n:perf:aff
550: ppas:pl:nom:n:perf:neg
551: ppas:pl:voc:f:imperf:aff
552: ppas:sg:acc:f:imperf:aff
553: ppas:sg:acc:f:imperf:neg
554: ppas:sg:acc:f:perf:aff
555: ppas:sg:acc:f:perf:neg
556: ppas:sg:acc:m1:imperf:aff
557: ppas:sg:acc:m1:perf:aff
558: ppas:sg:acc:m2:imperf:aff
559: ppas:sg:acc:m2:perf:aff
560: ppas:sg:acc:m3:imperf:aff
561: ppas:sg:acc:m3:imperf:neg
562: ppas:sg:acc:m3:perf:aff
563: ppas:sg:acc:m3:perf:neg
564: ppas:sg:acc:n:imperf:aff
565: ppas:sg:acc:n:perf:aff
566: ppas:sg:acc:n:perf:neg
567: ppas:sg:dat:f:imperf:aff
568: ppas:sg:dat:f:imperf:neg
569: ppas:sg:dat:f:perf:aff
570: ppas:sg:dat:f:perf:neg
571: ppas:sg:dat:m1:imperf:aff
572: ppas:sg:dat:m1:perf:aff
573: ppas:sg:dat:m2:perf:aff
574: ppas:sg:dat:m3:imperf:aff
575: ppas:sg:dat:m3:perf:aff
576: ppas:sg:dat:n:perf:aff
577: ppas:sg:gen:f:imperf:aff
578: ppas:sg:gen:f:imperf:neg
579: ppas:sg:gen:f:perf:aff
580: ppas:sg:gen:f:perf:neg
581: ppas:sg:gen:m1:imperf:aff
582: ppas:sg:gen:m1:perf:aff
583: ppas:sg:gen:m1:perf:neg
584: ppas:sg:gen:m2:imperf:aff
585: ppas:sg:gen:m2:perf:aff
586: ppas:sg:gen:m3:imperf:aff
587: ppas:sg:gen:m3:imperf:neg
588: ppas:sg:gen:m3:perf:aff
589: ppas:sg:gen:m3:perf:neg
590: ppas:sg:gen:n:imperf:aff
591: ppas:sg:gen:n:imperf:neg
592: ppas:sg:gen:n:perf:aff
593: ppas:sg:gen:n:perf:neg
594: ppas:sg:inst:f:imperf:aff
595: ppas:sg:inst:f:imperf:neg
596: ppas:sg:inst:f:perf:aff
597: ppas:sg:inst:f:perf:neg
598: ppas:sg:inst:m1:imperf:aff
599: ppas:sg:inst:m1:imperf:neg
600: ppas:sg:inst:m1:perf:aff
601: ppas:sg:inst:m1:perf:neg
602: ppas:sg:inst:m2:imperf:aff
603: ppas:sg:inst:m2:perf:aff
604: ppas:sg:inst:m3:imperf:aff
605: ppas:sg:inst:m3:imperf:neg
606: ppas:sg:inst:m3:perf:aff
607: ppas:sg:inst:m3:perf:neg
608: ppas:sg:inst:n:imperf:aff
609: ppas:sg:inst:n:imperf:neg
610: ppas:sg:inst:n:perf:aff
611: ppas:sg:inst:n:perf:neg
612: ppas:sg:loc:f:imperf:aff
613: ppas:sg:loc:f:perf:aff
614: ppas:sg:loc:f:perf:neg
615: ppas:sg:loc:m1:imperf:aff
616: ppas:sg:loc:m1:perf:aff
617: ppas:sg:loc:m2:imperf:aff
618: ppas:sg:loc:m3:imperf:aff
619: ppas:sg:loc:m3:imperf:neg
620: ppas:sg:loc:m3:perf:aff
621: ppas:sg:loc:m3:perf:neg
622: ppas:sg:loc:n:imperf:aff
623: ppas:sg:loc:n:perf:aff
624: ppas:sg:loc:n:perf:neg
625: ppas:sg:nom:f:imperf:aff
626: ppas:sg:nom:f:imperf:neg
627: ppas:sg:nom:f:perf:aff
628: ppas:sg:nom:f:perf:neg
629: ppas:sg:nom:m1:imperf:aff
630: ppas:sg:nom:m1:imperf:neg
631: ppas:sg:nom:m1:perf:aff
632: ppas:sg:nom:m1:perf:neg
633: ppas:sg:nom:m2:imperf:aff
634: ppas:sg:nom:m2:perf:aff
635: ppas:sg:nom:m3:imperf:aff
636: ppas:sg:nom:m3:imperf:neg
637: ppas:sg:nom:m3:perf:aff
638: ppas:sg:nom:m3:perf:neg
639: ppas:sg:nom:n:imperf:aff
640: ppas:sg:nom:n:imperf:neg
641: ppas:sg:nom:n:perf:aff
642: ppas:sg:nom:n:perf:neg
643: ppas:sg:voc:m1:perf:aff
644: ppas:sg:voc:m2:imperf:aff
645: ppas:sg:voc:m3:perf:aff
646: ppron12:pl:acc:f:pri
647: ppron12:pl:acc:f:sec
648: ppron12:pl:acc:m1:pri
649: ppron12:pl:acc:m1:sec
650: ppron12:pl:acc:m2:sec
651: ppron12:pl:acc:n:sec
652: ppron12:pl:dat:f:pri
653: ppron12:pl:dat:f:sec
654: ppron12:pl:dat:m1:pri
655: ppron12:pl:dat:m1:sec
656: ppron12:pl:dat:m3:sec
657: ppron12:pl:gen:f:pri
658: ppron12:pl:gen:f:sec
659: ppron12:pl:gen:m1:pri
660: ppron12:pl:gen:m1:sec
661: ppron12:pl:gen:m2:pri
662: ppron12:pl:inst:f:pri
663: ppron12:pl:inst:m1:pri
664: ppron12:pl:inst:m1:sec
665: ppron12:pl:inst:n:pri
666: ppron12:pl:loc:f:sec
667: ppron12:pl:loc:m1:pri
668: ppron12:pl:loc:m1:sec
669: ppron12:pl:loc:m3:sec
670: ppron12:pl:nom:f:pri
671: ppron12:pl:nom:f:sec
672: ppron12:pl:nom:m1:pri
673: ppron12:pl:nom:m1:sec
674: ppron12:pl:nom:m2:pri
675: ppron12:pl:nom:n:sec
676: ppron12:pl:voc:m1:sec
677: ppron12:pl:voc:m2:sec
678: ppron12:sg:acc:f:pri:akc
679: ppron12:sg:acc:f:sec:akc
680: ppron12:sg:acc:f:sec:nakc
681: ppron12:sg:acc:m1:pri:akc
682: ppron12:sg:acc:m1:pri:nakc
683: ppron12:sg:acc:m1:sec:akc
684: ppron12:sg:acc:m1:sec:nakc
685: ppron12:sg:acc:m2:pri:akc
686: ppron12:sg:acc:m2:sec:nakc
687: ppron12:sg:acc:m3:pri:akc
688: ppron12:sg:acc:m3:sec:nakc
689: ppron12:sg:acc:n:pri:akc
690: ppron12:sg:acc:n:sec:nakc
691: ppron12:sg:dat:f:pri:akc
692: ppron12:sg:dat:f:pri:nakc
693: ppron12:sg:dat:f:sec:akc
694: ppron12:sg:dat:f:sec:nakc
695: ppron12:sg:dat:m1:pri:akc
696: ppron12:sg:dat:m1:pri:nakc
697: ppron12:sg:dat:m1:sec:akc
698: ppron12:sg:dat:m1:sec:nakc
699: ppron12:sg:dat:m2:pri:nakc
700: ppron12:sg:dat:m2:sec:akc
701: ppron12:sg:dat:m2:sec:nakc
702: ppron12:sg:gen:f:pri:akc
703: ppron12:sg:gen:f:sec:akc
704: ppron12:sg:gen:f:sec:nakc
705: ppron12:sg:gen:m1:pri:akc
706: ppron12:sg:gen:m1:sec:akc
707: ppron12:sg:gen:m1:sec:nakc
708: ppron12:sg:gen:m2:pri:akc
709: ppron12:sg:gen:m2:sec:akc
710: ppron12:sg:gen:m2:sec:nakc
711: ppron12:sg:gen:n:pri:akc
712: ppron12:sg:inst:f:pri
713: ppron12:sg:inst:f:sec
714: ppron12:sg:inst:m1:pri
715: ppron12:sg:inst:m1:pri:nakc
716: ppron12:sg:inst:m1:sec
717: ppron12:sg:inst:n:sec
718: ppron12:sg:loc:f:pri
719: ppron12:sg:loc:f:sec
720: ppron12:sg:loc:m1:pri
721: ppron12:sg:loc:m1:sec
722: ppron12:sg:loc:m3:pri
723: ppron12:sg:nom:f:pri
724: ppron12:sg:nom:f:sec
725: ppron12:sg:nom:m1:pri
726: ppron12:sg:nom:m1:pri:nakc
727: ppron12:sg:nom:m1:sec
728: ppron12:sg:nom:m2:pri
729: ppron12:sg:nom:m2:sec
730: ppron12:sg:nom:m3:pri
731: ppron12:sg:nom:m3:sec
732: ppron12:sg:nom:n:sec
733: ppron12:sg:voc:f:sec
734: ppron12:sg:voc:m1:sec
735: ppron12:sg:voc:m2:sec
736: ppron12:sg:voc:n:sec
737: ppron3:pl:acc:f:ter:akc:npraep
738: ppron3:pl:acc:f:ter:akc:praep
739: ppron3:pl:acc:m1:ter:akc:npraep
740: ppron3:pl:acc:m1:ter:akc:praep
741: ppron3:pl:acc:m2:ter:akc:npraep
742: ppron3:pl:acc:m2:ter:akc:praep
743: ppron3:pl:acc:m3:ter:akc:npraep
744: ppron3:pl:acc:m3:ter:akc:praep
745: ppron3:pl:acc:n:ter:akc:npraep
746: ppron3:pl:acc:n:ter:akc:praep
747: ppron3:pl:dat:f:ter:akc:npraep
748: ppron3:pl:dat:f:ter:akc:praep
749: ppron3:pl:dat:m1:ter:akc:npraep
750: ppron3:pl:dat:m1:ter:akc:praep
751: ppron3:pl:dat:m2:ter:akc:npraep
752: ppron3:pl:dat:m3:ter:akc:npraep
753: ppron3:pl:dat:m3:ter:akc:praep
754: ppron3:pl:dat:n:ter:akc:npraep
755: ppron3:pl:gen:f:ter:akc:npraep
756: ppron3:pl:gen:f:ter:akc:praep
757: ppron3:pl:gen:m1:ter:akc:npraep
758: ppron3:pl:gen:m1:ter:akc:praep
759: ppron3:pl:gen:m2:ter:akc:npraep
760: ppron3:pl:gen:m2:ter:akc:praep
761: ppron3:pl:gen:m3:ter:akc:npraep
762: ppron3:pl:gen:m3:ter:akc:praep
763: ppron3:pl:gen:n:ter:akc:npraep
764: ppron3:pl:gen:n:ter:akc:praep
765: ppron3:pl:inst:f:ter:akc:npraep
766: ppron3:pl:inst:f:ter:akc:praep
767: ppron3:pl:inst:m1:ter:akc:npraep
768: ppron3:pl:inst:m1:ter:akc:praep
769: ppron3:pl:inst:m2:ter:akc:npraep
770: ppron3:pl:inst:m2:ter:akc:praep
771: ppron3:pl:inst:m3:ter:akc:npraep
772: ppron3:pl:inst:m3:ter:akc:praep
773: ppron3:pl:inst:n:ter:akc:npraep
774: ppron3:pl:inst:n:ter:akc:praep
775: ppron3:pl:loc:f:ter:akc:praep
776: ppron3:pl:loc:m1:ter:akc:praep
777: ppron3:pl:loc:m2:ter:akc:praep
778: ppron3:pl:loc:m3:ter:akc:praep
779: ppron3:pl:loc:n:ter:akc:praep
780: ppron3:pl:nom:f:ter:akc:npraep
781: ppron3:pl:nom:f:ter:nakc:npraep
782: ppron3:pl:nom:m1:ter:akc:npraep
783: ppron3:pl:nom:m2:ter:akc:npraep
784: ppron3:pl:nom:m3:ter:akc:npraep
785: ppron3:pl:nom:n:ter:akc:npraep
786: ppron3:sg:acc:f:ter:akc:npraep
787: ppron3:sg:acc:f:ter:akc:praep
788: ppron3:sg:acc:m1:ter:akc:npraep
789: ppron3:sg:acc:m1:ter:akc:praep
790: ppron3:sg:acc:m1:ter:nakc:npraep
791: ppron3:sg:acc:m1:ter:nakc:praep
792: ppron3:sg:acc:m2:ter:akc:praep
793: ppron3:sg:acc:m2:ter:nakc:npraep
794: ppron3:sg:acc:m2:ter:nakc:praep
795: ppron3:sg:acc:m3:ter:akc:npraep
796: ppron3:sg:acc:m3:ter:akc:praep
797: ppron3:sg:acc:m3:ter:nakc:npraep
798: ppron3:sg:acc:m3:ter:nakc:praep
799: ppron3:sg:acc:n:ter:akc:npraep
800: ppron3:sg:acc:n:ter:akc:praep
801: ppron3:sg:dat:f:ter:akc:npraep
802: ppron3:sg:dat:f:ter:akc:praep
803: ppron3:sg:dat:m1:ter:akc:npraep
804: ppron3:sg:dat:m1:ter:akc:praep
805: ppron3:sg:dat:m1:ter:nakc:npraep
806: ppron3:sg:dat:m2:ter:akc:npraep
807: ppron3:sg:dat:m2:ter:nakc:npraep
808: ppron3:sg:dat:m3:ter:akc:npraep
809: ppron3:sg:dat:m3:ter:akc:praep
810: ppron3:sg:dat:m3:ter:nakc:npraep
811: ppron3:sg:dat:n:ter:akc:npraep
812: ppron3:sg:dat:n:ter:akc:praep
813: ppron3:sg:dat:n:ter:nakc:npraep
814: ppron3:sg:gen:f:ter:akc:npraep
815: ppron3:sg:gen:f:ter:akc:praep
816: ppron3:sg:gen:m1:ter:akc:npraep
817: ppron3:sg:gen:m1:ter:akc:praep
818: ppron3:sg:gen:m1:ter:nakc:npraep
819: ppron3:sg:gen:m1:ter:nakc:praep
820: ppron3:sg:gen:m2:ter:akc:npraep
821: ppron3:sg:gen:m2:ter:akc:praep
822: ppron3:sg:gen:m2:ter:nakc:npraep
823: ppron3:sg:gen:m3:ter:akc:npraep
824: ppron3:sg:gen:m3:ter:akc:praep
825: ppron3:sg:gen:m3:ter:nakc:npraep
826: ppron3:sg:gen:m3:ter:nakc:praep
827: ppron3:sg:gen:n:ter:akc:npraep
828: ppron3:sg:gen:n:ter:akc:praep
829: ppron3:sg:gen:n:ter:nakc:npraep
830: ppron3:sg:inst:f:ter:akc:praep
831: ppron3:sg:inst:m1:ter:akc:npraep
832: ppron3:sg:inst:m1:ter:akc:praep
833: ppron3:sg:inst:m2:ter:akc:npraep
834: ppron3:sg:inst:m2:ter:akc:praep
835: ppron3:sg:inst:m3:ter:akc:npraep
836: ppron3:sg:inst:m3:ter:akc:praep
837: ppron3:sg:inst:n:ter:akc:npraep
838: ppron3:sg:inst:n:ter:akc:praep
839: ppron3:sg:loc:f:ter:akc:praep
840: ppron3:sg:loc:m1:ter:akc:praep
841: ppron3:sg:loc:m2:ter:akc:praep
842: ppron3:sg:loc:m3:ter:akc:praep
843: ppron3:sg:loc:n:ter:akc:praep
844: ppron3:sg:nom:f:ter:akc:npraep
845: ppron3:sg:nom:f:ter:akc:praep
846: ppron3:sg:nom:m1:ter:akc:npraep
847: ppron3:sg:nom:m2:ter:akc:npraep
848: ppron3:sg:nom:m2:ter:akc:praep
849: ppron3:sg:nom:m3:ter:akc:npraep
850: ppron3:sg:nom:n:ter:akc:npraep
851: praet:pl:f:imperf
852: praet:pl:f:perf
853: praet:pl:m1:imperf
854: praet:pl:m1:imperf:agl
855: praet:pl:m1:perf
856: praet:pl:m2:imperf
857: praet:pl:m2:perf
858: praet:pl:m3:imperf
859: praet:pl:m3:perf
860: praet:pl:n:imperf
861: praet:pl:n:perf
862: praet:sg:f:imperf
863: praet:sg:f:imperf:agl
864: praet:sg:f:imperf:nagl
865: praet:sg:f:perf
866: praet:sg:m1:imperf
867: praet:sg:m1:imperf:agl
868: praet:sg:m1:imperf:nagl
869: praet:sg:m1:perf
870: praet:sg:m1:perf:agl
871: praet:sg:m1:perf:nagl
872: praet:sg:m2:imperf
873: praet:sg:m2:imperf:nagl
874: praet:sg:m2:perf
875: praet:sg:m2:perf:nagl
876: praet:sg:m3:imperf
877: praet:sg:m3:imperf:nagl
878: praet:sg:m3:perf
879: praet:sg:m3:perf:nagl
880: praet:sg:n:imperf
881: praet:sg:n:perf
882: pred
883: prep:acc
884: prep:acc:nwok
885: prep:acc:wok
886: prep:dat
887: prep:gen
888: prep:gen:nwok
889: prep:gen:wok
890: prep:inst
891: prep:inst:nwok
892: prep:inst:wok
893: prep:loc
894: prep:loc:nwok
895: prep:loc:wok
896: prep:nom
897: romandig
898: siebie:acc
899: siebie:dat
900: siebie:gen
901: siebie:inst
902: siebie:loc
903: subst:pl:acc:f
904: subst:pl:acc:m1
905: subst:pl:acc:m1:pt
906: subst:pl:acc:m2
907: subst:pl:acc:m3
908: subst:pl:acc:n:col
909: subst:pl:acc:n:ncol
910: subst:pl:acc:n:pt
911: subst:pl:dat:f
912: subst:pl:dat:m1
913: subst:pl:dat:m1:pt
914: subst:pl:dat:m2
915: subst:pl:dat:m3
916: subst:pl:dat:n:col
917: subst:pl:dat:n:ncol
918: subst:pl:dat:n:pt
919: subst:pl:gen:f
920: subst:pl:gen:m1
921: subst:pl:gen:m1:pt
922: subst:pl:gen:m2
923: subst:pl:gen:m3
924: subst:pl:gen:n:col
925: subst:pl:gen:n:ncol
926: subst:pl:gen:n:pt
927: subst:pl:inst:f
928: subst:pl:inst:m1
929: subst:pl:inst:m1:pt
930: subst:pl:inst:m2
931: subst:pl:inst:m3
932: subst:pl:inst:n:col
933: subst:pl:inst:n:ncol
934: subst:pl:inst:n:pt
935: subst:pl:loc:f
936: subst:pl:loc:m1
937: subst:pl:loc:m1:pt
938: subst:pl:loc:m2
939: subst:pl:loc:m3
940: subst:pl:loc:n:col
941: subst:pl:loc:n:ncol
942: subst:pl:loc:n:pt
943: subst:pl:nom:f
944: subst:pl:nom:m1
945: subst:pl:nom:m1:pt
946: subst:pl:nom:m2
947: subst:pl:nom:m3
948: subst:pl:nom:n:col
949: subst:pl:nom:n:ncol
950: subst:pl:nom:n:pt
951: subst:pl:voc:f
952: subst:pl:voc:m1
953: subst:pl:voc:m1:pt
954: subst:pl:voc:m3
955: subst:pl:voc:n:col
956: subst:pl:voc:n:ncol
957: subst:pl:voc:n:pt
958: subst:sg:acc:f
959: subst:sg:acc:m1
960: subst:sg:acc:m2
961: subst:sg:acc:m3
962: subst:sg:acc:n:col
963: subst:sg:acc:n:ncol
964: subst:sg:dat:f
965: subst:sg:dat:m1
966: subst:sg:dat:m2
967: subst:sg:dat:m3
968: subst:sg:dat:n:col
969: subst:sg:dat:n:ncol
970: subst:sg:gen:f
971: subst:sg:gen:m1
972: subst:sg:gen:m2
973: subst:sg:gen:m3
974: subst:sg:gen:n:col
975: subst:sg:gen:n:ncol
976: subst:sg:inst:f
977: subst:sg:inst:m1
978: subst:sg:inst:m2
979: subst:sg:inst:m3
980: subst:sg:inst:n:col
981: subst:sg:inst:n:ncol
982: subst:sg:loc:f
983: subst:sg:loc:m1
984: subst:sg:loc:m2
985: subst:sg:loc:m3
986: subst:sg:loc:n:col
987: subst:sg:loc:n:ncol
988: subst:sg:nom:f
989: subst:sg:nom:m1
990: subst:sg:nom:m2
991: subst:sg:nom:m3
992: subst:sg:nom:n:col
993: subst:sg:nom:n:ncol
994: subst:sg:voc:f
995: subst:sg:voc:m1
996: subst:sg:voc:m2
997: subst:sg:voc:m3
998: subst:sg:voc:n:col
999: subst:sg:voc:n:ncol
1000: sym
1001: winien:pl:f:imperf
1002: winien:pl:m1:imperf
1003: winien:pl:m2:imperf
1004: winien:pl:m3:imperf
1005: winien:pl:n:imperf
1006: winien:sg:f:imperf
1007: winien:sg:m1:imperf
1008: winien:sg:m2:imperf
1009: winien:sg:m3:imperf
1010: winien:sg:n:imperf
1011: xxs:acc
1012: xxs:dat
1013: xxs:gen
1014: xxs:inst
1015: xxs:loc
1016: xxs:nom
1017: xxs:voc
1018: xxx
- name: nps
sequence: bool
- name: nkjp_ids
sequence: string
config_name: nkjp1m
splits:
- name: test
num_bytes: 8324533
num_examples: 8964
- name: train
num_bytes: 65022406
num_examples: 68943
- name: validation
num_bytes: 7465442
num_examples: 7755
download_size: 16167009
dataset_size: 80812381
---
# Dataset Card for NKJP1M – The manually annotated subcorpus of the National Corpus of Polish
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [NKJP1M](http://clip.ipipan.waw.pl/NationalCorpusOfPolish)
- **Repository:** [NKJP1M-SGJP](http://download.sgjp.pl/morfeusz/current/)
- **Paper:** [NKJP book](http://nkjp.pl/settings/papers/NKJP_ksiazka.pdf)
- **Point of Contact:** mailto:morfeusz@ipipan.waw.pl
### Dataset Summary
This is the official dataset for NKJP1M – the 1-million token balanced subcorpus of the National Corpus of Polish (Narodowy Korpus Języka Polskiego)
Besides the text (divided into paragraphs/samples and sentences) the set contains lemmas and morpho-syntactic tags for all tokens in the corpus.
This release, known as NKJP1M-SGJP, corresponds to the version 1.2 of the corpus with later corrections and improvements. In particular the morpho-syntactic annotation has been aligned with the present version of Morfeusz2 SGJP morphological analyser (as of 2022.12.04).
### Supported Tasks and Leaderboards
The main use of this resource lays in training models for lemmatisation and part of speech tagging of Polish.
### Languages
Polish (monolingual)
## Dataset Structure
### Data Instances
```
{'nkjp_text': 'NKJP_1M_1102000002',
'nkjp_par': 'morph_1-p',
'nkjp_sent': 'morph_1.18-s',
'tokens': ['-', 'Nie', 'mam', 'pieniędzy', ',', 'da', 'mi', 'pani', 'wywiad', '?'],
'lemmas': ['-', 'nie', 'mieć', 'pieniądz', ',', 'dać', 'ja', 'pani', 'wywiad', '?'],
'cposes': [8, 11, 10, 9, 8, 10, 9, 9, 9, 8],
'poses': [19, 25, 12, 35, 19, 12, 28, 35, 35, 19],
'tags': [266, 464, 213, 923, 266, 218, 692, 988, 961, 266],
'nps': [False, False, False, False, True, False, False, False, False, True],
'nkjp_ids': ['morph_1.9-seg', 'morph_1.10-seg', 'morph_1.11-seg', 'morph_1.12-seg', 'morph_1.13-seg', 'morph_1.14-seg', 'morph_1.15-seg', 'morph_1.16-seg', 'morph_1.17-seg', 'morph_1.18-seg']}
```
### Data Fields
- `nkjp_text`, `nkjp_par`, `nkjp_sent` (strings): XML identifiers of the present text (document), paragraph and sentence in NKJP. (These allow to map the data point back to the source corpus and to identify paragraphs/samples.)
- `tokens` (sequence of strings): tokens of the text defined as in NKJP.
- `lemmas` (sequence of strings): lemmas corresponding to the tokens.
- `tags` (sequence of labels): morpho-syntactic tags according to Morfeusz2 tagset (1019 distinct tags).
- `poses` (sequence of labels): flexemic class (detailed part of speech, 40 classes) – the first element of the corresponding tag.
- `cposes` (sequence of labels): coarse part of speech (13 classes): all verbal and deverbal flexemic classes get mapped to a `V`, nominal – `N`, adjectival – `A`, “strange” (abbreviations, alien elements, symbols, emojis…) – `X`, rest as in `poses`.
- `nps` (sequence of booleans): `True` means that the corresponding token is not preceded by a space in the source text.
- `nkjp_ids` (sequence of strings): XML identifiers of particular tokens in NKJP (probably an overkill).
### Data Splits
| | Train | Validation | Test |
| ----- | ------ | ----- | ---- |
| sentences | 68943 | 7755 | 8964 |
| tokens | 978368 | 112454 | 125059 |
## Dataset Creation
### Curation Rationale
The National Corpus of Polish (NKJP) was envisioned as the reference corpus of contemporary Polish.
The manually annotated subcorpus (NKJP1M) was thought of as the training data for various NLP tasks.
### Source Data
NKJP is balanced with respect to Polish readership. The detailed rationale is described in Chapter 3 of the [NKJP book](http://nkjp.pl/settings/papers/NKJP_ksiazka.pdf) (roughly: 50% press, 30% books, 10% speech, 10% other). The corpus contains texts from the years 1945–2010 (with 80% of the text in the range 1990–2010). Only original Polish texts were gathered (no translations from other languages). The composition of NKJP1M follows this schema (see Chapter 5).
### Annotations
The rules of morphosyntactic annotation used for NKJP are discussed in Chapter 6 of the [NKJP book](http://nkjp.pl/settings/papers/NKJP_ksiazka.pdf). Presently (2020), the corpus uses a common tagset with the morphological analyzer [Morfeusz 2](http://morfeusz.sgjp.pl/).
#### Annotation process
The texts were processed with Morfeusz and then the resulting annotations were manually disambiguated and validated/corrected. Each text sample was independently processed by two annotators. In case of annotation conflicts an adjudicator stepped in.
### Licensing Information
 This work is licensed under a [Creative Commons Attribution 4.0 International License](http://creativecommons.org/licenses/by/4.0/).
### Citation Information
Info on the source corpus: [link](http://nkjp.pl/settings/papers/NKJP_ksiazka.pdf)
```
@Book{nkjp:12,
editor = "Adam Przepiórkowski and Mirosław Bańko and Rafał
L. Górski and Barbara Lewandowska-Tomaszczyk",
title = "Narodowy Korpus Języka Polskiego",
year = 2012,
address = "Warszawa",
pdf = "http://nkjp.pl/settings/papers/NKJP_ksiazka.pdf",
publisher = "Wydawnictwo Naukowe PWN"}
```
Current annotation scheme: [link](https://jezyk-polski.pl/index.php/jp/article/view/72)
```
@article{
kie:etal:21,
author = "Kieraś, Witold and Woliński, Marcin and Nitoń, Bartłomiej",
doi = "https://doi.org/10.31286/JP.101.2.5",
title = "Nowe wielowarstwowe znakowanie lingwistyczne zrównoważonego {N}arodowego {K}orpusu {J}ęzyka {P}olskiego",
url = "https://jezyk-polski.pl/index.php/jp/article/view/72",
journal = "Język Polski",
number = "2",
volume = "CI",
year = "2021",
pages = "59--70"
}
```
<!--
### Contributions
Thanks to [@github-username](https://github.com/<github-username>) for adding this dataset.
--> | 46,543 | [
[
-0.044525146484375,
-0.0335693359375,
0.01270294189453125,
0.024169921875,
-0.033447265625,
-0.00629425048828125,
-0.0252685546875,
-0.0214996337890625,
0.0423583984375,
0.0400390625,
-0.053436279296875,
-0.06256103515625,
-0.0423583984375,
0.03021240234375,... |
NeuralInternet/awesome-chattensor-prompts | 2023-03-12T20:06:01.000Z | [
"license:cc0-1.0",
"ChatGPT",
"Chattensor",
"region:us"
] | NeuralInternet | null | null | 0 | 20 | 2023-03-12T17:16:33 | ---
license: cc0-1.0
tags:
- ChatGPT
- Chattensor
---
<p align="center"><h1>🧠 Awesome Chaττensor Prompts [CSV dataset]</h1></p>
This is a Dataset Repository of **Awesome Chattensor Prompts**
**[View All Prompts on GitHub](https://github.com/neuralinternet/awesome-chattensor-prompts)**
# License
CC-0 | 304 | [
[
-0.0155181884765625,
-0.041717529296875,
0.00887298583984375,
0.015380859375,
-0.0240020751953125,
0.00653076171875,
-0.0202789306640625,
0.0093536376953125,
0.050750732421875,
0.018280029296875,
-0.05810546875,
-0.04803466796875,
-0.044891357421875,
-0.0181... |
argilla/news-summary-new | 2023-07-13T11:15:37.000Z | [
"language:en",
"region:us"
] | argilla | null | null | 0 | 20 | 2023-03-13T22:51:21 | ---
language: en
dataset_info:
features:
- name: text
dtype: string
- name: target
dtype: string
splits:
- name: train
num_bytes: 252347
num_examples: 114
download_size: 87832
dataset_size: 252347
---
# Dataset Card for "news-summary-new"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 401 | [
[
-0.049468994140625,
-0.0252532958984375,
0.01305389404296875,
0.0126190185546875,
-0.0264434814453125,
0.001514434814453125,
0.0143890380859375,
-0.01139068603515625,
0.08673095703125,
0.03204345703125,
-0.05389404296875,
-0.0615234375,
-0.046875,
-0.0161437... |
Francesco/sign-language-sokdr | 2023-03-30T09:29:42.000Z | [
"task_categories:object-detection",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:cc",
"rf100",
"region:us"
] | Francesco | null | null | 1 | 20 | 2023-03-30T09:29:23 | ---
dataset_info:
features:
- name: image_id
dtype: int64
- name: image
dtype: image
- name: width
dtype: int32
- name: height
dtype: int32
- name: objects
sequence:
- name: id
dtype: int64
- name: area
dtype: int64
- name: bbox
sequence: float32
length: 4
- name: category
dtype:
class_label:
names:
'0': sign-language
'1': A
'2': B
'3': C
'4': D
'5': E
'6': F
'7': G
'8': H
'9': I
'10': J
'11': K
'12': L
'13': M
'14': N
'15': O
'16': P
'17': Q
'18': R
'19': S
'20': T
'21': U
'22': V
'23': W
'24': X
'25': Y
'26': Z
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- en
license:
- cc
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- object-detection
task_ids: []
pretty_name: sign-language-sokdr
tags:
- rf100
---
# Dataset Card for sign-language-sokdr
** The original COCO dataset is stored at `dataset.tar.gz`**
## Dataset Description
- **Homepage:** https://universe.roboflow.com/object-detection/sign-language-sokdr
- **Point of Contact:** francesco.zuppichini@gmail.com
### Dataset Summary
sign-language-sokdr
### Supported Tasks and Leaderboards
- `object-detection`: The dataset can be used to train a model for Object Detection.
### Languages
English
## Dataset Structure
### Data Instances
A data point comprises an image and its object annotations.
```
{
'image_id': 15,
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x640 at 0x2373B065C18>,
'width': 964043,
'height': 640,
'objects': {
'id': [114, 115, 116, 117],
'area': [3796, 1596, 152768, 81002],
'bbox': [
[302.0, 109.0, 73.0, 52.0],
[810.0, 100.0, 57.0, 28.0],
[160.0, 31.0, 248.0, 616.0],
[741.0, 68.0, 202.0, 401.0]
],
'category': [4, 4, 0, 0]
}
}
```
### Data Fields
- `image`: the image id
- `image`: `PIL.Image.Image` object containing the image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`
- `width`: the image width
- `height`: the image height
- `objects`: a dictionary containing bounding box metadata for the objects present on the image
- `id`: the annotation id
- `area`: the area of the bounding box
- `bbox`: the object's bounding box (in the [coco](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco) format)
- `category`: the object's category.
#### Who are the annotators?
Annotators are Roboflow users
## Additional Information
### Licensing Information
See original homepage https://universe.roboflow.com/object-detection/sign-language-sokdr
### Citation Information
```
@misc{ sign-language-sokdr,
title = { sign language sokdr Dataset },
type = { Open Source Dataset },
author = { Roboflow 100 },
howpublished = { \url{ https://universe.roboflow.com/object-detection/sign-language-sokdr } },
url = { https://universe.roboflow.com/object-detection/sign-language-sokdr },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2022 },
month = { nov },
note = { visited on 2023-03-29 },
}"
```
### Contributions
Thanks to [@mariosasko](https://github.com/mariosasko) for adding this dataset. | 3,890 | [
[
-0.030792236328125,
-0.031951904296875,
0.005542755126953125,
0.0033321380615234375,
-0.03466796875,
-0.0130767822265625,
-0.0019626617431640625,
-0.04010009765625,
0.0186767578125,
0.03729248046875,
-0.058380126953125,
-0.0760498046875,
-0.051788330078125,
... |
c-s-ale/Product-Descriptions-and-Ads | 2023-03-31T04:39:12.000Z | [
"task_categories:text-generation",
"size_categories:n<1K",
"language:en",
"license:openrail",
"art",
"region:us"
] | c-s-ale | null | null | 8 | 20 | 2023-03-31T02:19:06 | ---
dataset_info:
features:
- name: product
dtype: string
- name: description
dtype: string
- name: ad
dtype: string
splits:
- name: train
num_bytes: 27511.2
num_examples: 90
- name: test
num_bytes: 3056.8
num_examples: 10
download_size: 24914
dataset_size: 30568
license: openrail
task_categories:
- text-generation
language:
- en
tags:
- art
pretty_name: Product Descriptions and Ads
size_categories:
- n<1K
---
# Synthetic Dataset for Product Descriptions and Ads
The basic process was as follows:
1. Prompt GPT-4 to create a list of 100 sample clothing items and descriptions for those items.
2. Split the output into desired format `{"product" : "<PRODUCT NAME>", "description" : "<DESCRIPTION>"}
3. Prompt GPT-4 to create adverts for each of the 100 samples based on their name and description.
This data was not cleaned or verified manually. | 897 | [
[
-0.0380859375,
-0.06268310546875,
0.0193328857421875,
0.009979248046875,
-0.021759033203125,
0.01399993896484375,
0.0014925003051757812,
-0.01361846923828125,
0.026092529296875,
0.04461669921875,
-0.07928466796875,
-0.037689208984375,
-0.0019168853759765625,
... |
liuyanchen1015/MULTI_VALUE_cola_negative_concord | 2023-04-03T19:30:06.000Z | [
"region:us"
] | liuyanchen1015 | null | null | 0 | 20 | 2023-04-03T19:30:01 | ---
dataset_info:
features:
- name: sentence
dtype: string
- name: label
dtype: int64
- name: idx
dtype: int64
- name: value_score
dtype: int64
splits:
- name: dev
num_bytes: 2869
num_examples: 32
- name: test
num_bytes: 3905
num_examples: 43
- name: train
num_bytes: 20245
num_examples: 258
download_size: 18352
dataset_size: 27019
---
# Dataset Card for "MULTI_VALUE_cola_negative_concord"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 586 | [
[
-0.04412841796875,
-0.0175933837890625,
0.008941650390625,
0.0323486328125,
-0.02008056640625,
0.00811004638671875,
0.0223236083984375,
-0.0088043212890625,
0.07135009765625,
0.016845703125,
-0.0484619140625,
-0.0518798828125,
-0.048919677734375,
-0.01317596... |
liuyanchen1015/MULTI_VALUE_sst2_inverted_indirect_question | 2023-04-03T19:48:45.000Z | [
"region:us"
] | liuyanchen1015 | null | null | 0 | 20 | 2023-04-03T19:48:41 | ---
dataset_info:
features:
- name: sentence
dtype: string
- name: label
dtype: int64
- name: idx
dtype: int64
- name: score
dtype: int64
splits:
- name: dev
num_bytes: 1554
num_examples: 10
- name: test
num_bytes: 4967
num_examples: 30
- name: train
num_bytes: 80411
num_examples: 597
download_size: 36917
dataset_size: 86932
---
# Dataset Card for "MULTI_VALUE_sst2_inverted_indirect_question"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 590 | [
[
-0.017333984375,
-0.03912353515625,
0.01033782958984375,
0.0155181884765625,
-0.03509521484375,
0.0012187957763671875,
0.01531219482421875,
-0.00623321533203125,
0.049560546875,
0.0341796875,
-0.06341552734375,
-0.0153961181640625,
-0.0423583984375,
-0.02006... |
PaulTran/vietnamese_spelling_error_detection | 2023-04-07T09:31:12.000Z | [
"region:us"
] | PaulTran | null | null | 1 | 20 | 2023-04-07T09:24:04 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
shareAI/ShareGPT-Chinese-English-90k | 2023-09-19T14:27:07.000Z | [
"license:apache-2.0",
"region:us"
] | shareAI | null | null | 117 | 20 | 2023-04-15T16:23:35 | ---
license: apache-2.0
---
# ShareGPT-Chinese-English-90k 中英文双语人机问答数据集
中英文平行双语优质人机问答数据集,覆盖真实复杂场景下的用户提问。用于训练高质量的对话模型 (比那些通过反复调用api接口生成机器模拟问答的数据在指令分布上更鲁棒)
特点:
- 1.同时提供意义表达完全相同的中英文平行对照语料,可进行双语对话模型训练。
- 2.所有问题均非人为臆想加上api轮询拟造的假数据(如Moss),更加符合真实用户场景的指令分布和提问表达。
- 3.sharegpt数据集是由网友自发分享而收集到的,相当于有一层非常天然的过滤(通过人类感觉),筛除了大部分体验不好的对话。
补充:该数据收集于chatGPT还未表现出明显智力退化的时间点。(猜测一方面可能是官方为了减小开支把150B的gpt3.5替换成10b左右的蒸馏版本了,另一方面可能是由于引入了更多的拒绝答复导致模型连接知识逻辑的程度退化)
优秀对话llm的训练离不开高质量的多轮对话数据集,如果你也想成为志愿者
欢迎加入数据集QQ群:130920969,共同进行优质数据集的交流、收集和建设工作 | 521 | [
[
-0.032318115234375,
-0.050262451171875,
0.0164642333984375,
0.05853271484375,
-0.036956787109375,
-0.019775390625,
0.0097503662109375,
-0.032806396484375,
-0.0017213821411132812,
0.015655517578125,
-0.03826904296875,
-0.037933349609375,
-0.044281005859375,
0... |
anhdungitvn/vi-general-64g | 2023-04-24T02:41:17.000Z | [
"region:us"
] | anhdungitvn | null | null | 0 | 20 | 2023-04-24T00:10:13 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 69680883709
num_examples: 241461581
- name: test
num_bytes: 6612740
num_examples: 24157
- name: validation
num_bytes: 6278123
num_examples: 22710
download_size: 36565651699
dataset_size: 69693774572
---
# Dataset Card for "vi-general-64g"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 503 | [
[
-0.045196533203125,
-0.0196533203125,
0.0182952880859375,
0.0045623779296875,
-0.03045654296875,
-0.012847900390625,
0.01003265380859375,
-0.00827789306640625,
0.056915283203125,
0.0333251953125,
-0.049713134765625,
-0.07147216796875,
-0.047607421875,
-0.017... |
h2oai/h2ogpt-oig-oasst1-instruct-cleaned-v2 | 2023-04-25T16:43:40.000Z | [
"language:en",
"license:apache-2.0",
"gpt",
"llm",
"large language model",
"open-source",
"region:us"
] | h2oai | null | null | 5 | 20 | 2023-04-25T16:40:25 | ---
license: apache-2.0
language:
- en
thumbnail: https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
tags:
- gpt
- llm
- large language model
- open-source
---
# h2oGPT Data Card
## Summary
H2O.ai's `h2ogpt-oig-oasst1-instruct-cleaned-v2` is an open-source instruct-type dataset for fine-tuning of large language models, licensed for commercial use.
- Number of rows: `350581`
- Number of columns: `3`
- Column names: `['input', 'source', 'prompt_type']`
## Source
- [Original LAION OIG Dataset](https://github.com/LAION-AI/Open-Instruction-Generalist)
- [LAION OIG data detoxed and filtered down by scripts in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/main/FINETUNE.md#high-quality-oig-based-instruct-data)
- [Original Open Assistant data in tree structure](https://huggingface.co/datasets/OpenAssistant/oasst1)
- [This flattened dataset created by script in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/0e70c2fbb16410bd8e6992d879b4c55cd981211f/create_data.py#L1375-L1415)
| 1,044 | [
[
-0.01126861572265625,
-0.044189453125,
0.00882720947265625,
-0.0151214599609375,
-0.00931549072265625,
-0.012298583984375,
0.0017290115356445312,
-0.020782470703125,
-0.00835418701171875,
0.034576416015625,
-0.0197601318359375,
-0.047271728515625,
-0.01736450195... |
arvisioncode/donut-funsd | 2023-04-28T09:16:03.000Z | [
"region:us"
] | arvisioncode | null | null | 0 | 20 | 2023-04-27T11:22:33 | ---
dataset_info:
features:
- name: ground_truth
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 25994868.0
num_examples: 147
- name: test
num_bytes: 9129119.0
num_examples: 47
- name: validation
num_bytes: 9129119.0
num_examples: 47
download_size: 44182619
dataset_size: 44253106.0
---
# Dataset Card for "donut-funsd"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 528 | [
[
-0.0224609375,
-0.0136566162109375,
0.01708984375,
-0.0004630088806152344,
-0.008758544921875,
0.0071868896484375,
0.00811004638671875,
0.00931549072265625,
0.0709228515625,
0.0364990234375,
-0.0626220703125,
-0.051849365234375,
-0.03656005859375,
-0.0233459... |
gneubig/dstc11 | 2023-05-10T01:07:12.000Z | [
"license:other",
"region:us"
] | gneubig | This repository contains data, relevant scripts and baseline code for the Dialog Systems Technology Challenge (DSTC11). | @misc{gung2023natcs,
title={NatCS: Eliciting Natural Customer Support Dialogues},
author={James Gung and Emily Moeng and Wesley Rose and Arshit Gupta and Yi Zhang and Saab Mansour},
year={2023},
eprint={2305.03007},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{gung2023intent,
title={Intent Induction from Conversations for Task-Oriented Dialogue Track at DSTC 11},
author={James Gung and Raphael Shu and Emily Moeng and Wesley Rose and Salvatore Romeo and Yassine Benajiba and Arshit Gupta and Saab Mansour and Yi Zhang},
year={2023},
eprint={2304.12982},
archivePrefix={arXiv},
primaryClass={cs.CL}
} | 1 | 20 | 2023-05-10T00:21:43 | ---
license: other
---
Originally from [here](https://github.com/amazon-science/dstc11-track2-intent-induction/tree/969b95a0d7365fbc6cd0e05989f1be6b44e6680c/dstc11) | 165 | [
[
-0.005893707275390625,
-0.04241943359375,
0.06756591796875,
0.0016345977783203125,
-0.01273345947265625,
-0.01114654541015625,
0.034820556640625,
-0.0308990478515625,
0.04583740234375,
0.032867431640625,
-0.083740234375,
-0.0174102783203125,
-0.0196533203125,
... |
winglian/evals | 2023-06-17T18:50:47.000Z | [
"task_categories:text-generation",
"task_categories:question-answering",
"size_categories:1K<n<10K",
"language:en",
"region:us"
] | winglian | null | null | 3 | 20 | 2023-05-17T01:41:17 | ---
task_categories:
- text-generation
- question-answering
language:
- en
size_categories:
- 1K<n<10K
---
# Instruct Augmented Datasets
This dataset takes various other multiple choice, summarization, etc datasets and augments them to be instruct finetuned. | 259 | [
[
-0.047210693359375,
-0.033416748046875,
-0.0068206787109375,
0.00696563720703125,
-0.0059356689453125,
0.00858306884765625,
0.018280029296875,
-0.01641845703125,
0.0268096923828125,
0.06903076171875,
-0.04156494140625,
0.00853729248046875,
-0.035552978515625,
... |
causalnlp/corr2cause | 2023-06-16T09:21:43.000Z | [
"region:us"
] | causalnlp | null | null | 7 | 20 | 2023-05-21T17:19:40 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
tasksource/ConTRoL-nli | 2023-05-31T08:53:05.000Z | [
"task_categories:text-classification",
"language:en",
"region:us"
] | tasksource | null | null | 1 | 20 | 2023-05-24T08:12:09 | ---
task_categories:
- text-classification
language:
- en
---
https://github.com/csitfun/ConTRoL-dataset
```
@article{Liu_Cui_Liu_Zhang_2021,
title={Natural Language Inference in Context - Investigating Contextual Reasoning over Long Texts},
volume={35},
url={https://ojs.aaai.org/index.php/AAAI/article/view/17580},
DOI={10.1609/aaai.v35i15.17580},
number={15},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
author={Liu, Hanmeng and Cui, Leyang and Liu, Jian and Zhang, Yue},
year={2021},
month={May},
pages={13388-13396}
}
``` | 566 | [
[
-0.0185089111328125,
-0.06292724609375,
0.031951904296875,
0.025970458984375,
0.002231597900390625,
-0.01497650146484375,
-0.031890869140625,
-0.032684326171875,
0.00835418701171875,
0.031158447265625,
-0.047943115234375,
-0.05279541015625,
-0.03369140625,
0... |
sadFaceEmoji/english-poems | 2023-06-03T15:45:56.000Z | [
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:en",
"region:us"
] | sadFaceEmoji | null | null | 2 | 20 | 2023-06-03T15:34:44 | ---
task_categories:
- text-generation
language:
- en
size_categories:
- 10K<n<100K
---
This dataset contains 93265 english poems. | 131 | [
[
-0.004024505615234375,
0.01812744140625,
0.01399993896484375,
0.04583740234375,
-0.03466796875,
-0.022491455078125,
-0.011138916015625,
-0.0242919921875,
0.02569580078125,
0.057403564453125,
-0.042755126953125,
-0.03680419921875,
-0.06915283203125,
0.0311889... |
xin1997/vulfix_deduplicated | 2023-06-05T10:07:19.000Z | [
"region:us"
] | xin1997 | null | null | 0 | 20 | 2023-06-05T10:05:41 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
llm-book/aio-passages | 2023-06-24T05:55:37.000Z | [
"size_categories:1M<n<10M",
"language:ja",
"license:cc-by-sa-3.0",
"license:gfdl",
"region:us"
] | llm-book | null | null | 0 | 20 | 2023-06-06T02:03:33 | ---
language:
- ja
size_categories:
- 1M<n<10M
license:
- cc-by-sa-3.0
- gfdl
dataset_info:
features:
- name: id
dtype: int32
- name: pageid
dtype: int32
- name: revid
dtype: int32
- name: text
dtype: string
- name: section
dtype: string
- name: title
dtype: string
splits:
- name: train
num_bytes: 3054493919
num_examples: 4288198
download_size: 1110830651
dataset_size: 3054493919
---
# Dataset Card for llm-book/aio-passages
書籍『大規模言語モデル入門』で使用する、「AI王」コンペティションのパッセージデータセットです。
GitHub リポジトリ [cl-tohoku/quiz-datasets](https://github.com/cl-tohoku/quiz-datasets) で公開されているデータセットを利用しています。
## Licence
本データセットで利用している Wikipedia のコンテンツは、[クリエイティブ・コモンズ表示・継承ライセンス 3.0 (CC BY-SA 3.0)](https://creativecommons.org/licenses/by-sa/3.0/deed.ja) および [GNU 自由文書ライセンス (GFDL)](https://www.gnu.org/licenses/fdl.html) の下に配布されているものです。
| 868 | [
[
-0.02392578125,
-0.05218505859375,
0.0252685546875,
0.0024471282958984375,
-0.052581787109375,
-0.005279541015625,
-0.0026531219482421875,
-0.007709503173828125,
0.00920867919921875,
0.0380859375,
-0.05517578125,
-0.06494140625,
-0.017669677734375,
0.0135345... |
chargoddard/QuALITY-instruct | 2023-07-14T00:29:45.000Z | [
"language:en",
"region:us"
] | chargoddard | null | null | 2 | 20 | 2023-06-12T01:20:53 | ---
language: en
pretty_name: https://github.com/nyu-mll/quality
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 62125756
num_examples: 2523
- name: dev
num_bytes: 50877356
num_examples: 2086
download_size: 5451636
dataset_size: 113003112
---
# QuALITY: Question Answering with Long Input Texts, Yes!
This is the QuALITY v1.0.1 training set converted to instruction-style prompts. All credit to the original authors. See https://github.com/nyu-mll/quality for details. | 615 | [
[
-0.025421142578125,
-0.07879638671875,
0.043731689453125,
0.0010547637939453125,
-0.01061248779296875,
-0.00099945068359375,
0.0030612945556640625,
-0.0121307373046875,
0.0102081298828125,
0.0408935546875,
-0.06884765625,
-0.0294952392578125,
-0.016204833984375,... |
d0rj/wikisum | 2023-06-16T11:24:25.000Z | [
"task_categories:summarization",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:unknown",
"abstractive-summarization",
"wiki",
"abstractive",
"arxiv:1801.10198",
"region:us"
] | d0rj | null | null | 1 | 20 | 2023-06-16T11:13:38 | ---
dataset_info:
features:
- name: url
dtype: string
- name: title
dtype: string
- name: summary
dtype: string
- name: article
dtype: string
- name: step_headers
dtype: string
splits:
- name: train
num_bytes: 315275236
num_examples: 35775
- name: test
num_bytes: 17584216
num_examples: 2000
- name: validation
num_bytes: 17880851
num_examples: 2000
download_size: 194202865
dataset_size: 350740303
license:
- unknown
task_categories:
- summarization
language:
- en
multilinguality:
- monolingual
tags:
- abstractive-summarization
- wiki
- abstractive
pretty_name: 'WikiSum: Coherent Summarization Dataset for Efficient Human-Evaluation'
size_categories:
- 10K<n<100K
source_datasets:
- original
paperswithcode_id: wikisum
---
# wikisum
## Dataset Description
- **Homepage:** https://registry.opendata.aws/wikisum/
- **Repository:** https://github.com/tensorflow/tensor2tensor/tree/master/tensor2tensor/data_generators/wikisum
- **Paper:** [Generating Wikipedia by Summarizing Long Sequences](https://arxiv.org/abs/1801.10198)
- **Leaderboard:** [More Information Needed]
- **Point of Contact:** [nachshon](mailto:nachshon@amazon.com)
| 1,205 | [
[
-0.035614013671875,
-0.0227203369140625,
-0.0012874603271484375,
0.005931854248046875,
-0.029327392578125,
-0.00513458251953125,
-0.0164794921875,
-0.01067352294921875,
0.026947021484375,
0.0241241455078125,
-0.04620361328125,
-0.0380859375,
-0.04595947265625,
... |
sadmoseby/oassist_transformed | 2023-06-19T20:18:47.000Z | [
"region:us"
] | sadmoseby | null | null | 0 | 20 | 2023-06-19T20:16:53 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
KaiLv/UDR_WikiAuto | 2023-06-21T12:52:19.000Z | [
"region:us"
] | KaiLv | null | null | 0 | 20 | 2023-06-21T12:51:10 | ---
dataset_info:
features:
- name: idx
dtype: int64
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
- name: len_source
dtype: int64
- name: len_target
dtype: int64
splits:
- name: train
num_bytes: 171935945
num_examples: 481018
- name: validation
num_bytes: 857630
num_examples: 1999
- name: test_asset
num_bytes: 483952
num_examples: 359
- name: test_turk
num_bytes: 415458
num_examples: 359
- name: test_wiki
num_bytes: 248732
num_examples: 403
- name: debug
num_bytes: 35726046
num_examples: 100000
download_size: 115397698
dataset_size: 209667763
---
# Dataset Card for "UDR_WikiAuto"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 945 | [
[
-0.052947998046875,
-0.00571441650390625,
0.00823974609375,
0.0097198486328125,
-0.0188140869140625,
-0.00804901123046875,
0.0084075927734375,
-0.0183563232421875,
0.051513671875,
0.0295257568359375,
-0.056488037109375,
-0.046539306640625,
-0.036651611328125,
... |
OpenLeecher/Teatime | 2023-07-09T11:00:42.000Z | [
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:en",
"language:ko",
"license:apache-2.0",
"region:us"
] | OpenLeecher | null | null | 19 | 20 | 2023-07-08T00:14:11 | ---
license: apache-2.0
task_categories:
- text-generation
language:
- en
- ko
size_categories:
- 10K<n<100K
---
### INFO:
These are the parsed logs from the "teatime logs" xlsx files.
Every user edit or message regeneration makes a new branch in the conversation tree. This leads to message duplication in the 'all_logs.json' file. Every change creates a fresh branch, copying all earlier messages.
The 'longest' files are different. They only contain the longest path from the first to the last message. This approach aims to avoid duplication. Ideally, the '_longest' files should have no repeat messages.
### all_logs.json
Total tokens: 237442515
Average chat token length: 4246.03
Median chat token length: 3797.0
Average messages per chat: 18.96
Median messages per chat: 15.0
Total number of chats: 55921
### all_logs_longest.json
Total tokens: 27611121
Average chat token length: 2499.65
Median chat token length: 1335.5
Average messages per chat: 11.27
Median messages per chat: 5.0
Total number of chats: 11046
 | 1,113 | [
[
0.00936126708984375,
-0.045257568359375,
0.028900146484375,
0.0280609130859375,
-0.055450439453125,
0.04412841796875,
0.017547607421875,
-0.018096923828125,
0.029052734375,
0.05560302734375,
-0.03924560546875,
-0.047088623046875,
-0.051605224609375,
0.024414... |
shumpei2525/OpenOrca-train-ja | 2023-07-15T10:42:15.000Z | [
"license:mit",
"region:us"
] | shumpei2525 | null | null | 5 | 20 | 2023-07-15T08:03:13 | ---
license: mit
---
# OpenOrca-train-ja
This dataset is a translation of OpenOrca into Japanese. It is based on the output data from GPT-3.5 and GPT-4. Please feel free to use it as you wish.
* There are a few mistakes observed in the translation task. It might be better to exclude the translation task from use.
# Since I'm not entirely clear on OpenAI's terms of service, please be cautious when using it for commercial purposes. There may be exceptions for non-commercial use.
# other dataset
This dataset has a higher quality.https://huggingface.co/datasets/shumpei2525/fine_tuning521k-ja
shumpei2525/fine_tuning521k-ja
# OpenOrca test dataset
Pyutaさん has kindly translated the test dataset of OpenOrca into Japanese. Here is the dataset: pyutax68/OpenOrca-test-jp, https://huggingface.co/datasets/pyutax68/OpenOrca-test-jp
# original datasets
Open-Orca/OpenOrca https://huggingface.co/datasets/Open-Orca/OpenOrca
Lisence:mit | 937 | [
[
-0.0223846435546875,
-0.035888671875,
0.003841400146484375,
0.0175323486328125,
-0.040374755859375,
-0.0350341796875,
-0.0235443115234375,
-0.041839599609375,
0.031768798828125,
0.05303955078125,
-0.037689208984375,
-0.0345458984375,
-0.0264739990234375,
-0.... |
izumi-lab/cc100-ja-filter-ja-normal | 2023-07-15T14:40:33.000Z | [
"region:us"
] | izumi-lab | null | null | 2 | 20 | 2023-07-15T09:54:25 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 55527255438.72461
num_examples: 358752973
download_size: 41870382837
dataset_size: 55527255438.72461
---
# Dataset Card for "cc100-ja-debug-filter-ja-normal"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 402 | [
[
-0.053009033203125,
-0.04168701171875,
0.01546478271484375,
0.004261016845703125,
-0.02630615234375,
-0.0034008026123046875,
0.00018203258514404297,
-0.0025577545166015625,
0.061187744140625,
0.052825927734375,
-0.05438232421875,
-0.07025146484375,
-0.0376892089... |
arbml/alpaca_arabic | 2023-08-11T12:00:10.000Z | [
"region:us"
] | arbml | null | null | 0 | 20 | 2023-07-27T12:27:04 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
bloyal/oas_paired_human_sars_cov_2 | 2023-08-28T19:31:21.000Z | [
"size_categories:100K<n<1M",
"license:cc-by-4.0",
"region:us"
] | bloyal | null | null | 0 | 20 | 2023-08-03T16:41:32 | ---
license: cc-by-4.0
size_categories:
- 100K<n<1M
---
# Paired SARS-COV-2 heavy/light chain sequences from the Observed Antibody Space database
Human paired heavy/light chain amino acid sequences from the Observed Antibody Space (OAS) database obtained from SARS-COV-2 studies.
https://opig.stats.ox.ac.uk/webapps/oas/
Please include the following citation in your work:
```
Olsen, TH, Boyles, F, Deane, CM. Observed Antibody Space: A diverse database of cleaned, annotated, and translated unpaired and paired antibody sequences. Protein Science. 2022; 31: 141–146. https://doi.org/10.1002/pro.4205
```
## Data Preparation
This data was obtained on August 3, 2023 by searching the OAS Paired Sequence database with the following criteria:
- Species = "human"
- Disease = "SARS-COV-2"
This returned 704,652 filtered sequences from 3 studies split across 63 .csv.gz data unit files. These were extracted and filtered for records where both the `complete_vdj_heavy` and `complete_vdj_light` values were "T". Finally, the `sequence_alignment_aa_heavy` and `sequence_alignment_aa_light` fields were extracted into dataset and a 90/10 train/test applied. The resulting data was saved in pyarrow format. | 1,205 | [
[
-0.006694793701171875,
-0.01291656494140625,
0.00885009765625,
-0.00792694091796875,
-0.0179443359375,
0.00682830810546875,
0.0076751708984375,
-0.03546142578125,
0.041900634765625,
0.030517578125,
-0.005397796630859375,
-0.033660888671875,
-0.0203704833984375,
... |
johnowhitaker/mcqgen_1k_initial_examples | 2023-08-03T19:59:27.000Z | [
"region:us"
] | johnowhitaker | null | null | 0 | 20 | 2023-08-03T19:56:49 | ---
dataset_info:
features:
- name: context
dtype: string
- name: question
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: correct_answer
dtype: string
- name: text
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 902358
num_examples: 975
download_size: 558885
dataset_size: 902358
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "mcqgen_1k_initial_examples"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 731 | [
[
-0.05560302734375,
-0.01401519775390625,
0.0146636962890625,
0.01004791259765625,
-0.0242919921875,
-0.004772186279296875,
0.038299560546875,
0.01493072509765625,
0.04046630859375,
0.0426025390625,
-0.06982421875,
-0.061065673828125,
-0.0259246826171875,
-0.... |
roborovski/celeba-faces-captioned | 2023-08-10T03:02:58.000Z | [
"region:us"
] | roborovski | null | null | 0 | 20 | 2023-08-10T02:50:15 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: pixel_values
sequence:
sequence:
sequence: float32
- name: captions
dtype: string
splits:
- name: train
num_bytes: 17810785215.0
num_examples: 10000
download_size: 475025277
dataset_size: 17810785215.0
---
# Dataset Card for "celeba-faces-captioned"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 581 | [
[
-0.041290283203125,
-0.023712158203125,
0.01373291015625,
0.0288543701171875,
-0.00855255126953125,
0.01117706298828125,
0.009033203125,
-0.0185699462890625,
0.06158447265625,
0.050323486328125,
-0.058319091796875,
-0.045440673828125,
-0.04998779296875,
-0.0... |
bdpc/rvl_cdip_mp | 2023-08-11T12:44:13.000Z | [
"license:cc-by-nc-4.0",
"region:us"
] | bdpc | The RVL-CDIP (Ryerson Vision Lab Complex Document Information Processing) dataset consists of originally retrieved documents in 16 classes.
There were +-500 documents from the original dataset that could not be retrieved based on the metadata or were corrupt in IDL. | @inproceedings{bdpc,
title = {Beyond Document Page Classification},
author = {Anonymous},
booktitle = {Under Review},
year = {2023}
} | 0 | 20 | 2023-08-11T09:55:56 | ---
license: cc-by-nc-4.0
---
# Dataset Card for RVL-CDIP_MultiPage
## Extension
The data loader provides support for loading RVL_CDIP in its extended multipage format.
Since the dataset binaries are huge (80GB) it will be hosted elsewhere: [LINK](https://shorturl.at/adyC7) | 278 | [
[
-0.0697021484375,
-0.0105743408203125,
0.0004622936248779297,
0.043853759765625,
-0.028228759765625,
0.0018434524536132812,
0.00016963481903076172,
-0.01003265380859375,
0.017791748046875,
0.0565185546875,
-0.0408935546875,
-0.032440185546875,
-0.019515991210937... |
sonnetechnology/license-plate-text-recognition-full | 2023-08-17T09:36:05.000Z | [
"task_categories:image-to-text",
"size_categories:1K<n<10K",
"license:cc-by-4.0",
"region:us"
] | sonnetechnology | null | null | 2 | 20 | 2023-08-11T17:41:56 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: image_id
dtype: int64
- name: width
dtype: int64
- name: height
dtype: int64
- name: bbox
sequence:
sequence: float64
- name: target
sequence: string
splits:
- name: train
num_bytes: 158666312.832
num_examples: 6176
- name: validation
num_bytes: 48023349.6
num_examples: 1765
- name: test
num_bytes: 22606532
num_examples: 882
download_size: 236835357
dataset_size: 229296194.43199998
license: cc-by-4.0
task_categories:
- image-to-text
size_categories:
- 1K<n<10K
---
# Dataset Card for "license-plate-text-recognition-full"
## Background Information
This dataset is generated from `keremberke/license-plate-object-detection` dataset. What we have done is:
- Get the Bounding Boxes for each plate in an image,
- Crop the image to make the plate only visible,
- Run it through the `microsoft/trocr-large-printed` model to extract the written information.
## Structure of the Dataset
It has the same structure as the `keremberke/license-plate-object-detection` dataset, whereas we have added `target` column for each identified plate in an image.
## How to use it?
1. Install [datasets](https://pypi.org/project/datasets/)
```
pip install datasets
```
2. Load the dataset:
```
import datasets
ds = datasets.load_dataset("sonnetechnology/license-plate-text-recognition-full")
example = ds['train'][0]
``` | 1,630 | [
[
-0.0249481201171875,
-0.00106048583984375,
0.016326904296875,
0.012176513671875,
-0.045562744140625,
-0.01264190673828125,
-0.0150604248046875,
-0.0243682861328125,
0.01474761962890625,
0.040557861328125,
-0.042449951171875,
-0.056549072265625,
-0.03068542480468... |
rombodawg/LosslessMegaCodeTrainingV3_1.6m_Evol | 2023-10-19T16:57:47.000Z | [
"license:other",
"region:us"
] | rombodawg | null | null | 16 | 20 | 2023-08-15T23:22:36 | ---
license: other
---
This is the ultimate code training data, created to be lossless so the AI model does not lose any other abilities it had previously, such as logical skills, after training on this dataset. The reason why this dataset is so large is to ensure that as the model learns to code, it continues to remember to follow regular instructions so as not to lose previously learned abilities. This is the result of all my work gathering data, testing AI models, and discovering what, why, and how coding models perform well or don't perform well.
The content of this dataset is roughly 50% coding instruction data and 50% non-coding instruction data. Amounting to 1.5 million evol instruction-formatted lines of data.
The outcome of having 50% non coding instruction data in the dataset is to preserve logic and reasoning skills within the model while training on coding. The lack of such skills has been observed to be a major issue with coding models such as Wizardcoder-15b and NewHope, but training models on this dataset alleviates that issue while also giving similar levels of coding knowledge.
This dataset is a combination of the following datasets, along with additional deduping and uncensoring techniques:
Coding:
- https://huggingface.co/datasets/rombodawg/2XUNCENSORED_MegaCodeTraining188k
- https://huggingface.co/datasets/rombodawg/Rombodawgs_commitpackft_Evolinstruct_Converted
Instruction following:
- https://huggingface.co/datasets/rombodawg/2XUNCENSORED_alpaca_840k_Evol_USER_ASSIST
- https://huggingface.co/datasets/garage-bAInd/Open-Platypus
| 1,586 | [
[
-0.040557861328125,
-0.03643798828125,
-0.0008749961853027344,
0.0092620849609375,
-0.01073455810546875,
-0.0253448486328125,
-0.0026607513427734375,
-0.028564453125,
0.0005116462707519531,
0.05010986328125,
-0.0380859375,
-0.030853271484375,
-0.054534912109375,... |
TaatiTeam/OCW | 2023-08-20T03:11:01.000Z | [
"task_categories:text-classification",
"size_categories:n<1K",
"language:en",
"license:mit",
"creative problem solving",
"puzzles",
"fixation effect",
"large language models",
"only connect",
"quiz show",
"connecting walls",
"arxiv:2306.11167",
"region:us"
] | TaatiTeam | The Only Connect Wall (OCW) dataset contains 618 "Connecting Walls" from the Round 3: Connecting Wall segment of the Only Connect quiz show, collected from 15 seasons' worth of episodes. Each wall contains the ground-truth groups and connections as well as recorded human performance. | @article{Naeini2023LargeLM,
title = {Large Language Models are Fixated by Red Herrings: Exploring Creative Problem Solving and Einstellung Effect using the Only Connect Wall Dataset},
author = {Saeid Alavi Naeini and Raeid Saqur and Mozhgan Saeidi and John Giorgi and Babak Taati},
year = 2023,
journal = {ArXiv},
volume = {abs/2306.11167},
url = {https://api.semanticscholar.org/CorpusID:259203717}
} | 3 | 20 | 2023-08-17T01:47:00 | ---
license: mit
task_categories:
- text-classification
language:
- en
tags:
- creative problem solving
- puzzles
- fixation effect
- large language models
- only connect
- quiz show
- connecting walls
pretty_name: Only Connect Wall Dataset
size_categories:
- n<1K
---
# Only Connect Wall (OCW) Dataset
The Only Connect Wall (OCW) dataset contains 618 _"Connecting Walls"_ from the [Round 3: Connecting Wall](https://en.wikipedia.org/wiki/Only_Connect#Round_3:_Connecting_Wall) segment of the [Only Connect quiz show](https://en.wikipedia.org/wiki/Only_Connect), collected from 15 seasons' worth of episodes. Each wall contains the ground-truth __groups__ and __connections__ as well as recorded human performance. Please see [our paper](https://arxiv.org/abs/2306.11167) and [GitHub repo](https://github.com/TaatiTeam/OCW) for more details about the dataset and its motivations.
## Usage
```python
# pip install datasets
from datasets import load_dataset
dataset = load_dataset("TaatiTeam/OCW")
# The dataset can be used like any other HuggingFace dataset
# E.g. get the wall_id of the first example in the train set
dataset["train"]["wall_id"][0]
# or get the words of the first 10 examples in the test set
dataset["test"]["words"][0:10]
```
We also provide two different versions of the dataset where the red herrings in each wall have been significantly reduced (`ocw_randomized`) or removed altogether (`ocw_wordnet`) which can be loaded like:
```python
# pip install datasets
from datasets import load_dataset
ocw_randomized = load_dataset("TaatiTeam/OCW", "ocw_randomized")
ocw_wordnet = load_dataset("TaatiTeam/OCW", "ocw_wordnet")
```
See [our paper](https://arxiv.org/abs/2306.11167) for more details.
## 📝 Citing
If you use the Only Connect dataset in your work, please consider citing our paper:
```
@article{Naeini2023LargeLM,
title = {Large Language Models are Fixated by Red Herrings: Exploring Creative Problem Solving and Einstellung Effect using the Only Connect Wall Dataset},
author = {Saeid Alavi Naeini and Raeid Saqur and Mozhgan Saeidi and John Giorgi and Babak Taati},
year = 2023,
journal = {ArXiv},
volume = {abs/2306.11167},
url = {https://api.semanticscholar.org/CorpusID:259203717}
}
```
## 🙏 Acknowledgements
We would like the thank the maintainers and contributors of the fan-made and run website [https://ocdb.cc/](https://ocdb.cc/) for providing the data for this dataset. We would also like to thank the creators of the Only Connect quiz show for producing such an entertaining and thought-provoking show. | 2,619 | [
[
-0.044097900390625,
-0.0689697265625,
0.019989013671875,
0.01055908203125,
0.004058837890625,
-0.032745361328125,
-0.026763916015625,
-0.036895751953125,
0.032928466796875,
0.0311737060546875,
-0.05767822265625,
-0.046173095703125,
-0.023040771484375,
0.0104... |
malaysia-ai/dedup-text-dataset | 2023-10-28T21:32:49.000Z | [
"region:us"
] | malaysia-ai | null | null | 0 | 20 | 2023-08-18T02:32:57 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
C-MTEB/T2Reranking_zh2en | 2023-09-09T16:08:39.000Z | [
"region:us"
] | C-MTEB | null | null | 0 | 20 | 2023-09-09T16:08:28 | ---
configs:
- config_name: default
data_files:
- split: dev
path: data/dev-*
dataset_info:
features:
- name: query
dtype: string
- name: positive
sequence: string
- name: negative
sequence: string
splits:
- name: dev
num_bytes: 53155154
num_examples: 6129
download_size: 33679279
dataset_size: 53155154
---
# Dataset Card for "T2Reranking_zh2en"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 523 | [
[
-0.01397705078125,
-0.005428314208984375,
0.0152130126953125,
0.0174407958984375,
-0.0267181396484375,
-0.005039215087890625,
0.01580810546875,
-0.01496124267578125,
0.051513671875,
0.02362060546875,
-0.0682373046875,
-0.0584716796875,
-0.0389404296875,
-0.0... |
rasgaard/20_newsgroups | 2023-09-13T07:25:05.000Z | [
"region:us"
] | rasgaard | null | null | 0 | 20 | 2023-09-13T07:23:58 | ---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: int64
- name: label_text
dtype: string
splits:
- name: train
num_bytes: 12724811.858405516
num_examples: 10182
- name: val
num_bytes: 1414701.1415944847
num_examples: 1132
- name: test
num_bytes: 8499585
num_examples: 7532
download_size: 0
dataset_size: 22639098.0
---
# Dataset Card for "20_newsgroups"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 568 | [
[
-0.058685302734375,
-0.0159759521484375,
0.0196075439453125,
0.027496337890625,
-0.0125579833984375,
0.00615692138671875,
0.0169219970703125,
-0.0085296630859375,
0.0560302734375,
0.039276123046875,
-0.06719970703125,
-0.06829833984375,
-0.043701171875,
-0.0... |
utkarshhh17/indian_food_images | 2023-09-19T11:49:04.000Z | [
"region:us"
] | utkarshhh17 | null | null | 0 | 20 | 2023-09-18T15:00:27 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': burger
'1': butter_naan
'2': chai
'3': chapati
'4': chole_bhature
'5': dal_makhani
'6': dhokla
'7': fried_rice
'8': idli
'9': jalebi
'10': kaathi_rolls
'11': kadai_paneer
'12': kulfi
'13': masala_dosa
'14': momos
'15': paani_puri
'16': pakode
'17': pav_bhaji
'18': pizza
'19': samosa
splits:
- name: train
num_bytes: 1697830157.4234333
num_examples: 5328
- name: test
num_bytes: 249679569.3925666
num_examples: 941
download_size: 1601513193
dataset_size: 1947509726.816
---
# Dataset Card for "indian_food_images"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 1,125 | [
[
-0.031768798828125,
-0.0196990966796875,
0.0030269622802734375,
0.01425933837890625,
-0.01039886474609375,
0.00107574462890625,
0.019744873046875,
-0.0207061767578125,
0.07000732421875,
0.0273284912109375,
-0.045074462890625,
-0.052154541015625,
-0.0505676269531... |
skadewdl3/recipe-nlg-lite-llama-2 | 2023-09-20T08:03:35.000Z | [
"region:us"
] | skadewdl3 | null | null | 0 | 20 | 2023-09-19T14:56:41 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: uid
dtype: string
- name: name
dtype: string
- name: description
dtype: string
- name: link
dtype: string
- name: ner
dtype: string
- name: ingredients
sequence: string
- name: steps
sequence: string
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 19487310
num_examples: 6118
- name: test
num_bytes: 3406278
num_examples: 1080
download_size: 0
dataset_size: 22893588
---
# Dataset Card for "recipe-nlg-lite-llama-2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 798 | [
[
-0.01335906982421875,
-0.0258331298828125,
0.015716552734375,
0.0275726318359375,
-0.0255889892578125,
0.007335662841796875,
0.016082763671875,
-0.01280975341796875,
0.08209228515625,
0.045135498046875,
-0.06121826171875,
-0.0509033203125,
-0.05224609375,
0.... |
goendalf666/sales-conversations-2 | 2023-10-04T20:46:03.000Z | [
"arxiv:2306.11644",
"region:us"
] | goendalf666 | null | null | 0 | 20 | 2023-09-26T22:23:29 | ---
dataset_info:
features:
- name: '0'
dtype: string
- name: '1'
dtype: string
- name: '2'
dtype: string
- name: '3'
dtype: string
- name: '4'
dtype: string
- name: '5'
dtype: string
- name: '6'
dtype: string
- name: '7'
dtype: string
- name: '8'
dtype: string
- name: '9'
dtype: string
- name: '10'
dtype: string
- name: '11'
dtype: string
- name: '12'
dtype: string
- name: '13'
dtype: string
- name: '14'
dtype: string
- name: '15'
dtype: string
- name: '16'
dtype: string
- name: '17'
dtype: string
- name: '18'
dtype: string
- name: '19'
dtype: string
splits:
- name: train
num_bytes: 6821725
num_examples: 3412
download_size: 2644154
dataset_size: 6821725
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "sales-conversations-2"
# Dataset Card for "sales-conversations"
This dataset was created for the purpose of training a sales agent chatbot that can convince people.
The initial idea came from: textbooks is all you need https://arxiv.org/abs/2306.11644
gpt-3.5-turbo was used for the generation
See the main model or github for more information
salesGPT_v2: https://huggingface.co/goendalf666/salesGPT_v2
github: https://github.com/tom813/salesGPT_foundation
# Structure
The conversations have a customer and a salesman which appear always in changing order. customer, salesman, customer, salesman, etc.
The customer always starts the conversation
Who ends the conversation is not defined.
# Generation
Note that a textbook dataset is mandatory for this conversation generation. This examples rely on the following textbook dataset:
https://huggingface.co/datasets/goendalf666/sales-textbook_for_convincing_and_selling
The data generation code can be found here: https://github.com/tom813/salesGPT_foundation/blob/main/data_generation/textbook_and_conversation_gen.py
The following prompt was used to create a conversation
```
def create_random_prompt(chapter, roles=["Customer", "Salesman"], range_vals=(3, 7), industries=None):
if industries is None:
industries = ["tech", "health", "finance"] # default industries; replace with your default list if different
x = random.randint(*range_vals)
y = 0
for i in reversed(range(3, 9)): # Generalized loop for range of values
if i * x < 27:
y = i
break
conversation_structure = ""
for i in range(1, x+1):
conversation_structure += f"""
{roles[0]}: #{i}. sentence of {roles[0].lower()}
{roles[1]}: #{i}. sentence of {roles[1].lower()}"""
prompt = f"""Here is a chapter from a textbook about convincing people.
The purpose of this data is to use it to fine tune a llm.
Generate conversation examples that are based on the chapter that is provided and would help an ai to learn the topic by examples.
Focus only on the topic that is given in the chapter when generating the examples.
Let the example be in the {random.choice(industries)} industry.
Follow this structure and put each conversation in a list of objects in json format. Only return the json nothing more:
{conversation_structure}
Generate {y} lists of those conversations
Chapter:{chapter}"""
return prompt
```
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 3,525 | [
[
-0.01312255859375,
-0.0701904296875,
0.016082763671875,
-0.00388336181640625,
-0.0111846923828125,
-0.0206298828125,
-0.01148223876953125,
-0.0038318634033203125,
-0.0013551712036132812,
0.044830322265625,
-0.05908203125,
-0.049407958984375,
-0.00646209716796875... |
jackhhao/jailbreak-classification | 2023-09-30T01:55:08.000Z | [
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"jailbreak",
"security",
"moderation",
"region:us"
] | jackhhao | null | null | 0 | 20 | 2023-09-30T00:56:39 | ---
license: apache-2.0
task_categories:
- text-classification
language:
- en
tags:
- jailbreak
- security
- moderation
pretty_name: Jailbreak Classification
size_categories:
- 10K<n<100K
configs:
- config_name: default
data_files:
- split: train
path: "balanced/jailbreak_dataset_train_balanced.csv"
- split: test
path: "balanced/jailbreak_dataset_test_balanced.csv"
---
# Jailbreak Classification
### Dataset Summary
Dataset used to classify prompts as jailbreak vs. benign.
## Dataset Structure
### Data Fields
- `prompt`: an LLM prompt
- `type`: classification label, either `jailbreak` or `benign`
## Dataset Creation
### Curation Rationale
Created to help detect & prevent harmful jailbreak prompts when users interact with LLMs.
### Source Data
Jailbreak prompts sourced from: <https://github.com/verazuo/jailbreak_llms>
Benign prompts sourced from:
- [OpenOrca](https://huggingface.co/datasets/Open-Orca/OpenOrca)
- <https://github.com/teknium1/GPTeacher> | 988 | [
[
-0.0227508544921875,
-0.054443359375,
0.035003662109375,
0.0170440673828125,
-0.01038360595703125,
0.0128326416015625,
0.001506805419921875,
-0.01898193359375,
0.0311126708984375,
0.038818359375,
-0.06146240234375,
-0.06756591796875,
-0.038330078125,
0.00911... |
madaanpulkit/opus_eng_hin_pan | 2023-10-02T05:50:52.000Z | [
"region:us"
] | madaanpulkit | null | null | 0 | 20 | 2023-10-02T05:50:44 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: sent
dtype: string
- name: lang
dtype: string
- name: label
dtype: int64
splits:
- name: train
num_bytes: 159097285
num_examples: 1283230
- name: validation
num_bytes: 770267
num_examples: 8000
- name: test
num_bytes: 790471
num_examples: 8000
download_size: 71739889
dataset_size: 160658023
---
# Dataset Card for "opus_eng_hin_pan"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 732 | [
[
-0.043487548828125,
-0.013763427734375,
0.0033359527587890625,
0.0355224609375,
-0.008270263671875,
-0.02081298828125,
0.0019521713256835938,
-0.00975799560546875,
0.061279296875,
0.0482177734375,
-0.04669189453125,
-0.0592041015625,
-0.040069580078125,
-0.0... |
hannxu/hc_var | 2023-10-03T16:33:15.000Z | [
"task_categories:text-classification",
"size_categories:100M<n<1B",
"language:en",
"license:apache-2.0",
"arxiv:2310.01307",
"region:us"
] | hannxu | null | null | 2 | 20 | 2023-10-02T15:24:06 | ---
license: apache-2.0
task_categories:
- text-classification
language:
- en
size_categories:
- 100M<n<1B
---
# Dataset Card for HC-Var (Human and ChatGPT Texts with Variety)
This is a collection of human texts and ChatGPT (GPT3.5-Turbo) generated texts, to faciliate studies such as generated texts detection.
It includes the texts which are generated / human written to accomplish various language tasks with various approaches.
The included language tasks and topics are summarized below. Note: For each language task, this dataset considers 3 different prompts to inquire ChatGPT outputs.
The example code to train binary classification models is in [this website](https://github.com/hannxu123/hc_var).
A technical report on some representative detection methods can be find in [this paper](https://arxiv.org/abs/2310.01307).
This dataset is collected by Han Xu from Michigan State
University. Potential issues and suggestions are welcomed to be dicussed in the community panel or emails to xuhan1@msu.edu.
## Key variables in the dataset:
**text**: The text body (including either human or ChatGPT texts.)\
**domain**: The language tasks included in this dataset: News, Review, (Essay) Writing, QA\
**topic**: The topic in each task.\
**prompt**: The prompt used to obtain ChatGPT outputs. "N/A" for human texts.\
**pp_id**: Each task has 3 prompts to inquire ChatGPT outputs. The "pp_id" denotes the index of prompt. "0" for human texts. "1-3" for ChatGPT texts.\
**label**: "0" for human texts. "1" for ChatGPT texts.
## To cite this dataset
```
@misc{xu2023generalization,
title={On the Generalization of Training-based ChatGPT Detection Methods},
author={Han Xu and Jie Ren and Pengfei He and Shenglai Zeng and Yingqian Cui and Amy Liu and Hui Liu and Jiliang Tang},
year={2023},
eprint={2310.01307},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
| 1,907 | [
[
-0.01532745361328125,
-0.050750732421875,
0.0095062255859375,
0.002841949462890625,
-0.0183563232421875,
0.00780487060546875,
-0.0219268798828125,
-0.02099609375,
-0.00308990478515625,
0.05224609375,
-0.050445556640625,
-0.06390380859375,
-0.036346435546875,
... |
FelixdoingAI/IP2P-200 | 2023-10-03T08:07:19.000Z | [
"region:us"
] | FelixdoingAI | null | null | 0 | 20 | 2023-10-03T08:07:02 | ---
dataset_info:
features:
- name: original_prompt
dtype: string
- name: original_image
dtype: image
- name: edit_prompt
dtype: string
- name: edited_prompt
dtype: string
- name: edited_image
dtype: image
splits:
- name: train
num_bytes: 17732714.0
num_examples: 200
download_size: 17730243
dataset_size: 17732714.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "instructpix2pix-clip-filtered200-samples"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 649 | [
[
-0.053619384765625,
-0.00984954833984375,
0.0248260498046875,
0.019256591796875,
-0.012725830078125,
0.0013904571533203125,
0.0226287841796875,
-0.006549835205078125,
0.051239013671875,
0.04888916015625,
-0.061614990234375,
-0.0498046875,
-0.034942626953125,
... |
Alamerton/small-sycophancy-dataset | 2023-10-04T09:26:38.000Z | [
"region:us"
] | Alamerton | null | null | 0 | 20 | 2023-10-04T09:17:48 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
AntoineBlanot/alpaca-llama2-chat | 2023-10-09T07:30:40.000Z | [
"region:us"
] | AntoineBlanot | null | null | 0 | 20 | 2023-10-05T08:57:49 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 46095859
num_examples: 52002
download_size: 0
dataset_size: 46095859
---
# Dataset Card for "alpaca-llama2-chat"
This dataset is the [alpaca](https://huggingface.co/datasets/tatsu-lab/alpaca) dataset formatted for [llama2-chat](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf).
The default system prompt, as well as special tokens has all been added for a ready-to-train dataset.
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 717 | [
[
-0.038482666015625,
-0.0323486328125,
0.01355743408203125,
0.044586181640625,
-0.04962158203125,
0.0112762451171875,
0.006946563720703125,
-0.027862548828125,
0.0738525390625,
0.0284576416015625,
-0.07183837890625,
-0.038116455078125,
-0.051544189453125,
0.0... |
AayushShah/SQL_SparC_Dataset_With_Schema | 2023-10-06T11:46:48.000Z | [
"region:us"
] | AayushShah | null | null | 1 | 20 | 2023-10-06T11:46:27 | ---
dataset_info:
features:
- name: database_id
dtype: string
- name: query
dtype: string
- name: question
dtype: string
- name: metadata
dtype: string
splits:
- name: train
num_bytes: 3249206
num_examples: 3456
download_size: 288326
dataset_size: 3249206
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "SQL_SparC_Dataset_With_Schema"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 571 | [
[
-0.036102294921875,
-0.0271759033203125,
0.00730133056640625,
0.01525115966796875,
-0.013946533203125,
0.002704620361328125,
0.003021240234375,
0.0102996826171875,
0.06024169921875,
0.060028076171875,
-0.05596923828125,
-0.055023193359375,
-0.03387451171875,
... |
hk-kaden-kim/uzh-hs23-etsp-eval-single-base-line | 2023-10-08T10:53:11.000Z | [
"region:us"
] | hk-kaden-kim | null | null | 0 | 20 | 2023-10-08T10:45:49 | ---
dataset_info:
features:
- name: image
dtype: image
- name: caption
dtype: string
splits:
- name: test
num_bytes: 4026307.0
num_examples: 100
download_size: 4011375
dataset_size: 4026307.0
---
# Dataset Card for "uzh-hs23-etsp-eval-single-base-line"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 415 | [
[
-0.03546142578125,
-0.032806396484375,
0.00954437255859375,
0.02081298828125,
-0.0275421142578125,
0.01195526123046875,
0.007778167724609375,
0.00576019287109375,
0.04510498046875,
0.052764892578125,
-0.0419921875,
-0.053863525390625,
-0.0109100341796875,
-0... |
anzorq/sixuxar_yijiri_mak7 | 2023-10-11T05:19:31.000Z | [
"task_categories:automatic-speech-recognition",
"task_categories:text-to-speech",
"language:kbd",
"license:mit",
"region:us"
] | anzorq | null | null | 0 | 20 | 2023-10-10T00:23:03 | ---
language:
- kbd
task_categories:
- automatic-speech-recognition
- text-to-speech
dataset_info:
features:
- name: audio
dtype: audio
- name: text
dtype: string
splits:
- name: train
num_bytes: 337947909.07
num_examples: 6579
download_size: 727728499
dataset_size: 337947909.07
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: mit
---
# Dataset Info
This dataset consists of paired audio and text data sourced from the following book:
- **Title**: Къэрмокъуэ М. Щихухэр иджыри мэкI. Япэ тхылъ.
- **Publication**: Нальчик: Эльбрус, 1999
## Audio Specifications
- **Sample Rate**: 16,000 Hz
- **Total Length**: 10:36:40
- **Source**: [adigabook.ru](http://www.adigabook.ru/?p=1148)
## Processing Information
Audio-text pairs for this dataset were extracted and aligned using META AI's [forced alignment algorithm](https://github.com/facebookresearch/fairseq/tree/main/examples/mms/data_prep). | 974 | [
[
-0.00830078125,
-0.0390625,
0.011016845703125,
0.006496429443359375,
-0.017608642578125,
-0.0054779052734375,
-0.0031414031982421875,
-0.020050048828125,
0.0234527587890625,
0.035797119140625,
-0.07757568359375,
-0.05401611328125,
-0.01067352294921875,
0.006... |
FinGPT/fingpt-ner | 2023-10-10T06:33:43.000Z | [
"region:us"
] | FinGPT | null | null | 0 | 20 | 2023-10-10T06:33:18 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: instruction
dtype: string
splits:
- name: train
num_bytes: 241523
num_examples: 511
- name: test
num_bytes: 63634
num_examples: 98
download_size: 105426
dataset_size: 305157
---
# Dataset Card for "fingpt-ner"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 605 | [
[
-0.055877685546875,
-0.0271148681640625,
0.0047607421875,
0.00466156005859375,
-0.0202178955078125,
-0.0031261444091796875,
0.0200653076171875,
-0.01210784912109375,
0.053680419921875,
0.03857421875,
-0.05499267578125,
-0.04638671875,
-0.044586181640625,
-0.... |
kejian/odmeeting_oracle | 2023-10-10T06:48:37.000Z | [
"region:us"
] | kejian | null | null | 0 | 20 | 2023-10-10T06:48:34 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: validation
path: data/validation-*
dataset_info:
features:
- name: Article
dtype: string
- name: Summary
dtype: string
- name: Query
dtype: string
splits:
- name: train
num_bytes: 25745453
num_examples: 261
- name: test
num_bytes: 13442766
num_examples: 131
- name: validation
num_bytes: 4115166
num_examples: 44
download_size: 21293422
dataset_size: 43303385
---
# Dataset Card for "odmeeting_oracle"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 733 | [
[
-0.032928466796875,
-0.03033447265625,
0.0165863037109375,
0.014801025390625,
-0.01279449462890625,
-0.022613525390625,
0.021484375,
-0.0196380615234375,
0.056854248046875,
0.0537109375,
-0.0537109375,
-0.05609130859375,
-0.0213470458984375,
-0.0267944335937... |
Luciya/llama-2-nuv-intent-noE-pp-oos | 2023-10-10T06:50:06.000Z | [
"region:us"
] | Luciya | null | null | 0 | 20 | 2023-10-10T06:50:05 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 921669
num_examples: 1834
download_size: 134964
dataset_size: 921669
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "llama-2-nuv-intent-noE-pp-oos"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 454 | [
[
-0.0153350830078125,
-0.011505126953125,
0.023284912109375,
0.02386474609375,
-0.033050537109375,
-0.01091766357421875,
0.03228759765625,
-0.0012044906616210938,
0.0634765625,
0.052001953125,
-0.054168701171875,
-0.05841064453125,
-0.048736572265625,
-0.0102... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.