
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 6.67k ⌀ | citation stringlengths 0 10.7k ⌀ | likes int64 0 3.66k | downloads int64 0 8.89M | created timestamp[us] | card stringlengths 11 977k | card_len int64 11 977k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|
yuchenlin/just-eval-redteam | 2023-10-06T21:54:33.000Z | [
"region:us"
] | yuchenlin | null | null | 0 | 19 | 2023-10-06T18:26:25 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
meta-math/MetaMathQA-40K | 2023-10-25T09:01:11.000Z | [
"license:cc-by-nc-4.0",
"arxiv:2309.12284",
"region:us"
] | meta-math | null | null | 3 | 19 | 2023-10-07T14:47:58 | ---
license: cc-by-nc-4.0
---
arxiv.org/abs/2309.12284
View the project page:
https://meta-math.github.io/ | 108 | [
[
-0.052032470703125,
-0.0247650146484375,
0.030487060546875,
0.00809478759765625,
-0.0157623291015625,
0.0047607421875,
0.0095367431640625,
-0.01117706298828125,
0.060089111328125,
0.057281494140625,
-0.052734375,
-0.046112060546875,
-0.0021190643310546875,
0... |
syaoran312/VHAC_QA_full | 2023-10-07T19:51:18.000Z | [
"region:us"
] | syaoran312 | null | null | 0 | 19 | 2023-10-07T19:50:20 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
sankettgorey/donut_6 | 2023-10-09T09:38:01.000Z | [
"region:us"
] | sankettgorey | null | null | 0 | 19 | 2023-10-09T09:36:41 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
- split: valid
path: data/valid-*
dataset_info:
features:
- name: image
dtype: image
- name: ground_truth
dtype: string
splits:
- name: train
num_bytes: 350410662.6
num_examples: 800
- name: test
num_bytes: 43730265.7
num_examples: 100
- name: valid
num_bytes: 43819720.7
num_examples: 100
download_size: 402661296
dataset_size: 437960649.0
---
# Dataset Card for "donut_6"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 690 | [
[
-0.019683837890625,
-0.0107421875,
0.0194244384765625,
0.0018444061279296875,
0.0006084442138671875,
-0.0000858306884765625,
0.01529693603515625,
-0.005168914794921875,
0.055572509765625,
0.0369873046875,
-0.051361083984375,
-0.043975830078125,
-0.04281616210937... |
FreedomIntelligence/Huatuo26M-GPTShine | 2023-10-16T07:16:30.000Z | [
"task_categories:text-classification",
"task_categories:question-answering",
"task_categories:conversational",
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:zh",
"license:apache-2.0",
"medical",
"arxiv:2305.01526",
"region:us"
] | FreedomIntelligence | null | null | 4 | 19 | 2023-10-11T09:08:49 | ---
license: apache-2.0
task_categories:
- text-classification
- question-answering
- conversational
- text-generation
language:
- zh
tags:
- medical
pretty_name: Huatuo26M_v2
size_categories:
- 100K<n<1M
---
# Huatuo26M-GPTShine Dataset 📚
- ## Table of Contents 🗂
- [Dataset Description](#dataset-description) 📝
- [Dataset Information](#dataset-information) ℹ️
- [Data Distribution](#data-distribution) 📊
- [Usage](#usage) 🔧
- [Citation](#citation) 📖
## Dataset Description 📝
Huatuo26M-GPTShine is a refined and optimized dataset based on the Huatuo26M dataset, which has undergone multiple purification processes and rewrites. It has more data dimensions and higher data quality. We welcome you to try using it.
## Dataset Information ℹ️
- **Dataset Name:** Huatuo26M-GPTShine
- **Version:** _[0.0.1]_
- **Size:** _[178k]_
- **Language:** _[Chinese]_
### Abstract 📄
We collected 26 million pieces of original QA data in the medical field, but it was not easy to use and had some risks because it was obtained from Common Crawl. Therefore, we took the following steps based on the original 26 million data: deduplication, cleaning, extraction of high-frequency questions, scoring of high-frequency questions using ChatGPT, and filtering only high-scoring questions. We then used ChatGPT to rewrite the answers to the high-scoring questions, resulting in a completely refined dataset. Please refer to our paper for the specific processing methods.
### Data Collection 🕵️♂️
ur question data was collected from the internet, and we extracted the high-frequency portion. The answers were rewritten by ChatGPT based on the original answers as a reference, and their quality was judged to be better than the original answers through manual evaluation. Therefore, please feel free to use our dataset with confidence.
### Preprocessing/Cleaning 🧹
The dataset has been processed to remove duplicates and cleaned to ensure high-quality data. It was then refined using OpenAI's ChatGPT, which helped in enhancing the overall quality of the dataset.
## Data Distribution 📊
This section provides a visual overview of the distribution of data in the Huatuo26M-GPTShine dataset.
**Data Categories Bar Chart:** 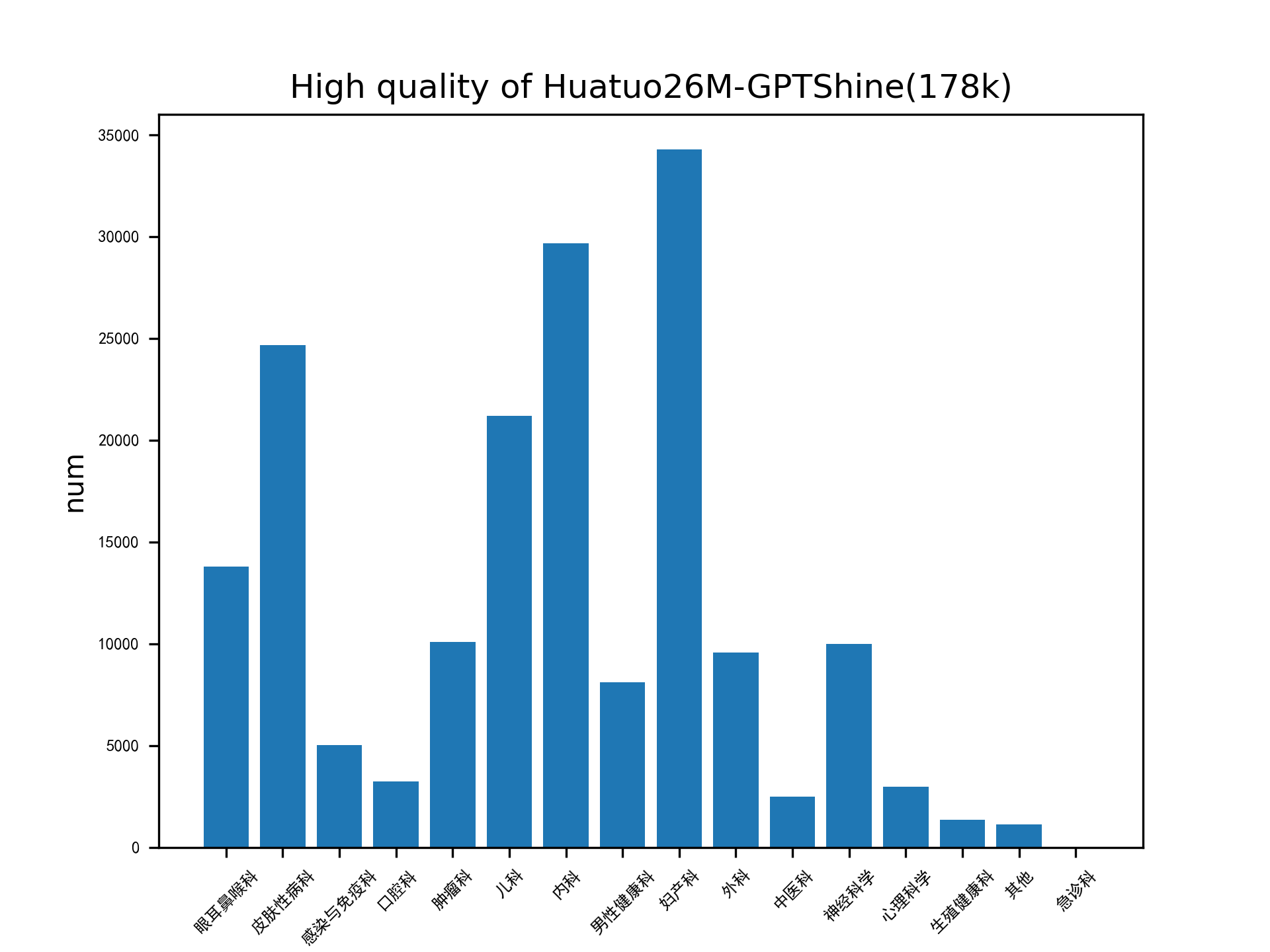
This chart represents the distribution of data categories in the dataset.
**Top 20 Associated Diseases Table:**
| topn | disease | nums | ratio |
| ---- | ---------- | ---- | ------- |
| 1 | 白癜风 | 3308 | 1.8615% |
| 2 | 人流 | 2686 | 1.5115% |
| 3 | 感冒 | 2371 | 1.3342% |
| 4 | 癫痫 | 2217 | 1.2476% |
| 5 | 痔疮 | 2134 | 1.2009% |
| 6 | 疼痛 | 1842 | 1.0366% |
| 7 | 咳嗽 | 1799 | 1.0124% |
| 8 | 前列腺炎 | 1564 | 0.8801% |
| 9 | 尖锐湿疣 | 1516 | 0.8531% |
| 10 | 肺癌 | 1408 | 0.7923% |
| 11 | 出血 | 1400 | 0.7878% |
| 12 | 鼻炎 | 1370 | 0.7709% |
| 13 | 肝癌 | 1354 | 0.7619% |
| 14 | 糖尿病 | 1348 | 0.7586% |
| 15 | 过敏性鼻炎 | 1295 | 0.7287% |
| 16 | 发烧 | 1265 | 0.7119% |
| 17 | 乙肝 | 1232 | 0.6933% |
| 18 | 便秘 | 1214 | 0.6832% |
| 19 | 甲亢 | 1178 | 0.6629% |
| 20 | 脱发 | 1173 | 0.6601% |
This table shows the top 20 diseases associated with the data entries in the dataset, along with their respective data entry counts and proportions.
## Usage 🔧
```python
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/Huatuo26M-GPTShine")
```
## Citation 📖
```
@misc{li2023huatuo26m,
title={Huatuo-26M, a Large-scale Chinese Medical QA Dataset},
author={Jianquan Li and Xidong Wang and Xiangbo Wu and Zhiyi Zhang and Xiaolong Xu and Jie Fu and Prayag Tiwari and Xiang Wan and Benyou Wang},
year={2023},
eprint={2305.01526},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
---
Please note that this dataset is distributed "AS IS" without any warranty, express or implied, from the provider. Users should cite the dataset appropriately and respect any licensing or usage restrictions. | 4,117 | [
[
-0.0211181640625,
-0.03070068359375,
0.017303466796875,
-0.00012981891632080078,
-0.03814697265625,
-0.024810791015625,
-0.000530242919921875,
-0.01983642578125,
0.035614013671875,
0.032470703125,
-0.0153350830078125,
-0.0614013671875,
-0.04730224609375,
0.0... |
ShaomuTan/EC40 | 2023-10-11T19:43:00.000Z | [
"region:us"
] | ShaomuTan | The x-stance dataset contains more than 150 political questions, and 67k comments written by candidates on those questions. The comments are partly German, partly French and Italian. The data have been extracted from the Swiss voting advice platform Smartvote. | @inproceedings{vamvas2020xstance,
author = "Vamvas, Jannis and Sennrich, Rico",
title = "{X-Stance}: A Multilingual Multi-Target Dataset for Stance Detection",
booktitle = "Proceedings of the 5th Swiss Text Analytics Conference (SwissText) \& 16th Conference on Natural Language Processing (KONVENS)",
address = "Zurich, Switzerland",
year = "2020",
month = "jun",
url = "http://ceur-ws.org/Vol-2624/paper9.pdf"
} | 0 | 19 | 2023-10-11T17:27:27 | # EC40 MNMT Dataset
GitHub: https://github.com/Smu-Tan/ZS-NMT-Variations/tree/main
### EC40 is an English-Centric Multilingual Machine Translation Dataset. It has over 60 Million sentences including 40 Languages across 5 Language Families.
#### Note: The dataset is cleaned and pre-processed using tools like Moses, for more details, please refer to the paper.
### Features:
1. We carefully balanced the dataset across resources and languages by strictly maintaining each resource group containing 5 language families and each family consists of 8 representative languages.
2. EC40 covers a wide spectrum of resource availability, ranging from High(5M) to Medium(1M), Low(100K), and extremely-Low(50K) resources.
3. In total, there are 80 English-centric directions for training and 1,640 directions (including all supervised and ZS directions) for evaluation.
4. We make use of Ntrex-128 and Flores-200 as our validation and test set.
-----
## Languages and Family
| Family | Languges |
| :--- | :---: |
| Germanic | Geman, Dutch, Swedish, Danish, Afrikaans, Luxembourgish, Norwegian, Icelandic |
| Romance | French, Spanish, Italian, Portuguese, Romanian, Occitan, Asturian, Catalan |
| Slavic | Russian, Czech, Polish, Bulgarian, Ukrainian, Serbian, Belarusian, Bosnian |
| Indo-Aryan | Hindi, Bengali, Kannada, Marathi, Sindhi, Gujarati, Nepali, Urdu |
-----
## Dataset Stats
| Resource | Languages | Size |
| --- | --- | --- |
| High | de, nl, fr, es, ru, cs, hi, bn, ar, he | 5M |
| Medium | sv, da, it, pt, pl, bg, kn, mr, mt, ha | 1M |
| Low | af, lb, ro, oc, uk, sr, sd, gu, ti, am | 100k |
| Extremely-Low | no, is, ast, ca, be, bs, ne, ur, kab, so | 50k |
-----
## Build Fairseq dataset (Shard->to avoid RAM OOM)
```
Read toolkit/build_fairseq_sharded_dataset.sh
```
<br>
-----
## Train mTransformer-Large baseline
```
Read toolkit/train-EC40-mTrans-large.sh
```
| 1,923 | [
[
-0.047027587890625,
-0.0162200927734375,
0.016265869140625,
0.0050506591796875,
-0.028076171875,
-0.001251220703125,
-0.039794921875,
-0.0185089111328125,
0.005863189697265625,
0.041290283203125,
-0.052459716796875,
-0.0634765625,
-0.04754638671875,
0.020553... |
MananSantoki/Vadodara-Info | 2023-10-12T13:02:57.000Z | [
"region:us"
] | MananSantoki | null | null | 0 | 19 | 2023-10-12T12:36:53 | Entry not found | 15 | [
[
-0.0214080810546875,
-0.01497650146484375,
0.057098388671875,
0.028839111328125,
-0.0350341796875,
0.046478271484375,
0.052520751953125,
0.005046844482421875,
0.051361083984375,
0.016998291015625,
-0.05206298828125,
-0.01497650146484375,
-0.06036376953125,
0... |
xu3kev/BIRD-SQL-data | 2023-10-12T14:50:00.000Z | [
"region:us"
] | xu3kev | null | null | 0 | 19 | 2023-10-12T14:26:54 | ---
dataset_info:
features:
- name: db_id
dtype: string
- name: question
dtype: string
- name: evidence
dtype: string
- name: SQL
dtype: string
- name: schema
dtype: string
splits:
- name: train
num_bytes: 1039491
num_examples: 200
download_size: 98914
dataset_size: 1039491
---
# Dataset Card for "BIRD-SQL-data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 494 | [
[
-0.0284881591796875,
-0.02593994140625,
-0.006961822509765625,
0.0189208984375,
-0.0126495361328125,
-0.0069580078125,
0.02032470703125,
-0.026092529296875,
0.054351806640625,
0.02935791015625,
-0.056640625,
-0.051361083984375,
-0.02508544921875,
-0.00321769... |
shellypeng/violet-evergarden-ds | 2023-10-14T12:02:00.000Z | [
"region:us"
] | shellypeng | null | null | 0 | 19 | 2023-10-14T07:38:53 | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 446708153.158
num_examples: 3823
download_size: 478066266
dataset_size: 446708153.158
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "violet-evergarden-ds"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 495 | [
[
-0.0277252197265625,
-0.0128326416015625,
0.01300811767578125,
0.0184173583984375,
-0.0098419189453125,
-0.00817108154296875,
0.042236328125,
-0.01082611083984375,
0.05712890625,
0.036468505859375,
-0.07305908203125,
-0.05621337890625,
-0.036407470703125,
-0... |
sunjun/pubmedqa | 2023-10-14T13:41:28.000Z | [
"region:us"
] | sunjun | null | null | 0 | 19 | 2023-10-14T13:41:21 | ---
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: QUESTION
dtype: string
- name: CONTEXT
dtype: string
- name: final_decision
dtype: string
splits:
- name: validation
num_bytes: 720620
num_examples: 500
- name: test
num_bytes: 732024
num_examples: 500
download_size: 833197
dataset_size: 1452644
---
# Dataset Card for "pubmedqa"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 628 | [
[
-0.030181884765625,
-0.0012941360473632812,
0.034271240234375,
0.0062103271484375,
-0.02166748046875,
0.0016660690307617188,
0.03314208984375,
-0.0014171600341796875,
0.05279541015625,
0.041107177734375,
-0.050445556640625,
-0.056671142578125,
-0.04095458984375,... |
ostapeno/qa-platy_icl5_clen128_maxD-1_maxC5000_0 | 2023-10-14T16:53:52.000Z | [
"region:us"
] | ostapeno | null | null | 0 | 19 | 2023-10-14T16:53:38 | ---
dataset_info:
features:
- name: id
dtype: string
- name: context
dtype: string
- name: docno
dtype: string
- name: subject
dtype: string
- name: icl_examples
sequence: string
- name: author_instr
dtype: string
- name: instruction
dtype: string
- name: response
dtype: string
- name: author_response
dtype: string
- name: normalized_cumul_logprob_response
dtype: float64
splits:
- name: formal_logic
num_bytes: 8194431.408696578
num_examples: 2891
- name: machine_learning
num_bytes: 10320278.367023258
num_examples: 3641
- name: global_facts
num_bytes: 11244313.178242588
num_examples: 3967
- name: abstract_algebra
num_bytes: 12179685.839906327
num_examples: 4297
- name: high_school_physics
num_bytes: 11162113.762520624
num_examples: 3938
- name: college_biology
num_bytes: 10462001.49757837
num_examples: 3691
- name: high_school_government_and_politics
num_bytes: 10816309.323966151
num_examples: 3816
- name: prehistory
num_bytes: 11082748.809409762
num_examples: 3910
- name: security_studies
num_bytes: 9869598.811858002
num_examples: 3482
- name: sociology
num_bytes: 11181955.000798339
num_examples: 3945
download_size: 21363610
dataset_size: 106513436.0
---
# Dataset Card for "wiki_experts_data_transform_icl5dst"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 1,530 | [
[
-0.051971435546875,
-0.0025482177734375,
0.0181427001953125,
0.0083770751953125,
-0.0188446044921875,
0.009307861328125,
0.01519775390625,
-0.01506805419921875,
0.04156494140625,
0.0244140625,
-0.06134033203125,
-0.0543212890625,
-0.05047607421875,
-0.001003... |
schhetri41/PoseDataset | 2023-10-17T23:16:01.000Z | [
"region:us"
] | schhetri41 | null | null | 0 | 19 | 2023-10-16T22:16:25 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
HoangHa/SMILES-250M | 2023-10-22T06:06:11.000Z | [
"region:us"
] | HoangHa | null | null | 0 | 19 | 2023-10-19T00:30:45 | ---
dataset_info:
features:
- name: SMILES
dtype: string
splits:
- name: train
num_bytes: 1626837623.1854794
num_examples: 84345972
download_size: 1799608655
dataset_size: 1626837623.1854794
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "SMILES-250M"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 470 | [
[
-0.0501708984375,
-0.0037250518798828125,
0.0204010009765625,
0.0216827392578125,
-0.0134429931640625,
-0.01294708251953125,
-0.0014095306396484375,
-0.01502227783203125,
0.0631103515625,
0.024993896484375,
-0.07440185546875,
-0.0540771484375,
-0.0406494140625,
... |
ComponentSoft/k8s-kubectl | 2023-10-20T06:22:21.000Z | [
"region:us"
] | ComponentSoft | null | null | 1 | 19 | 2023-10-20T06:22:18 | ---
dataset_info:
features:
- name: objective
dtype: string
- name: command_name
dtype: string
- name: command
dtype: string
- name: description
dtype: string
- name: syntax
dtype: string
- name: flags
dtype: string
- name: question
dtype: string
- name: chain_of_thought
dtype: 'null'
splits:
- name: train
num_bytes: 40356885
num_examples: 35000
download_size: 2584976
dataset_size: 40356885
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "k8s-kubectl"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 715 | [
[
-0.04388427734375,
-0.007770538330078125,
0.0263519287109375,
0.017974853515625,
-0.0233154296875,
0.015411376953125,
0.0171966552734375,
-0.007534027099609375,
0.04962158203125,
0.038330078125,
-0.045806884765625,
-0.064453125,
-0.050201416015625,
-0.012870... |
xin1997/vrepair_pretraining_data | 2023-10-23T08:47:41.000Z | [
"region:us"
] | xin1997 | null | null | 0 | 19 | 2023-10-23T08:41:28 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
Luciya/llama-2-clinc-test | 2023-10-23T11:11:34.000Z | [
"region:us"
] | Luciya | null | null | 0 | 19 | 2023-10-23T11:11:31 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 10464310
num_examples: 4468
download_size: 986893
dataset_size: 10464310
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "llama-2-clinc-test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 447 | [
[
-0.036956787109375,
-0.024261474609375,
0.009735107421875,
0.0241851806640625,
-0.038055419921875,
0.00264739990234375,
0.0226287841796875,
-0.0204925537109375,
0.0545654296875,
0.025115966796875,
-0.056396484375,
-0.05706787109375,
-0.04656982421875,
-0.005... |
kheopsai/codevivil_instruct | 2023-10-26T13:16:19.000Z | [
"region:us"
] | kheopsai | null | null | 0 | 19 | 2023-10-26T13:10:23 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
didsr/msynth | 2023-11-02T15:02:54.000Z | [
"task_categories:image-classification",
"task_categories:image-segmentation",
"size_categories:10K<n<100K",
"license:cc0-1.0",
"medical",
"arxiv:2310.18494",
"region:us"
] | didsr | M-SYNTH is a synthetic digital mammography (DM) dataset with four breast fibroglandular density distributions imaged using Monte Carlo x-ray simulations with the publicly available Virtual Imaging Clinical Trial for Regulatory Evaluation (VICTRE) toolkit.
Curated by: Elena Sizikova, Niloufar Saharkhiz, Diksha Sharma, Miguel Lago, Berkman Sahiner, Jana Gut Delfino, Aldo Badano
License: Creative Commons 1.0 Universal License (CC0) | @article{sizikova2023knowledge,
title={Knowledge-based in silico models and dataset for the comparative evaluation of mammography AI for a range of breast characteristics, lesion conspicuities and doses},
author={Sizikova, Elena and Saharkhiz, Niloufar and Sharma, Diksha and Lago, Miguel and Sahiner, Berkman and Delfino, Jana G. and Badano, Aldo},
journal={Advances in Neural Information Processing Systems},
volume={},
pages={16764--16778},
year={2023} | 0 | 19 | 2023-10-26T21:32:23 | ---
license: cc0-1.0
task_categories:
- image-classification
- image-segmentation
tags:
- medical
pretty_name: M-SYNTH
size_categories:
- 10K<n<100K
---
# M-SYNTH
<!-- Provide a quick summary of the dataset. -->
M-SYNTH is a synthetic digital mammography (DM) dataset with four breast fibroglandular density distributions imaged using Monte Carlo x-ray simulations with the publicly available [Virtual Imaging Clinical Trial for Regulatory Evaluation (VICTRE)](https://github.com/DIDSR/VICTRE) toolkit.
## Dataset Details
The dataset has the following characteristics:
* Breast density: dense, heterogeneously dense, scattered, fatty
* Mass radius (mm): 5.00, 7.00, 9.00
* Mass density: 1.0, 1.06, 1.1 (ratio of radiodensity of the mass to that of fibroglandular tissue)
* Relative dose: 20%, 40%, 60%, 80%, 100% of the clinically recommended dose for each density
<p align="center">
<img src='https://raw.githubusercontent.com/DIDSR/msynth-release/main/images/examples.png' width='700'>
</p>
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [Elena Sizikova](https://esizikova.github.io/), [Niloufar Saharkhiz](https://www.linkedin.com/in/niloufar-saharkhiz/), [Diksha Sharma](https://www.linkedin.com/in/diksha-sharma-6059977/), [Miguel Lago](https://www.linkedin.com/in/milaan/), [Berkman Sahiner](https://www.linkedin.com/in/berkman-sahiner-6aa9a919/), [Jana Gut Delfino](https://www.linkedin.com/in/janadelfino/), [Aldo Badano](https://www.linkedin.com/in/aldobadano/)
- **License:** Creative Commons 1.0 Universal License (CC0)
### Dataset Sources
<!-- Provide the basic links for the dataset. -->
- **Code:** [https://github.com/DIDSR/msynth-release](https://github.com/DIDSR/msynth-release)
- **Paper:** [https://arxiv.org/pdf/2310.18494.pdf](https://arxiv.org/pdf/2310.18494.pdf)
- **Demo:** [https://github.com/DIDSR/msynth-release/tree/master/examples](https://github.com/DIDSR/msynth-release/tree/master/examples)
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
M-SYNTH is intended to facilitate testing of AI with pre-computed synthetic mammography data.
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
M-SYNTH can be used to evaluate the effect of mass size and density, breast density, and dose on AI performance in lesion detection.
M-SYNTH can be used to either train or test pre-trained AI models.
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
M-SYNTH cannot be used in lieu of real patient examples to make performance determinations.
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
M-SYNTH is organized into a directory structure that indicates the parameters. The folder
```
device_data_VICTREPhantoms_spic_[LESION_DENSITY]/[DOSE]/[BREAST_DENSITY]/2/[LESION_SIZE]/SIM/P2_[LESION_SIZE]_[BREAST_DENSITY].8337609.[PHANTOM_FILE_ID]/[PHANTOM_FILEID]/
```
contains image files imaged with the specified parameters. Note that only examples with odd PHANTOM_FILEID contain lesions, others do not.
```
$ tree data/device_data_VICTREPhantoms_spic_1.0/1.02e10/hetero/2/5.0/SIM/P2_5.0_hetero.8337609.1/1/
data/device_data_VICTREPhantoms_spic_1.0/1.02e10/hetero/2/5.0/SIM/P2_5.0_hetero.8337609.1/1/
├── DICOM_dm
│ └── 000.dcm
├── projection_DM1.loc
├── projection_DM1.mhd
└── projection_DM1.raw
```
Each folder contains mammogram data that can be read from .raw format (.mhd contains supporting data), or DICOM (.dcm) format.
Coordinates of lesions can be found in .loc files. Segmentations are stored in .raw format and can be found in data/segmentation_masks/* .
See [Github](https://github.com/DIDSR/msynth-release/tree/main/code) for examples of how to access the files, and [examples](https://github.com/DIDSR/msynth-release/tree/main/examples) for code to load each type of file.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Simulation-based testing is constrained to the parameter variability represented in the object model and the acquisition system.
There is a risk of misjudging model performance if the simulated examples do not capture the variability in real patients. Please
see the paper for a full discussion of biases, risks, and limitations.
## How to use it
The msynth dataset is a very large dataset so for most use cases it is recommended to make use of the streaming API of `datasets`.
The msynth dataset has three configurations: 1) device_data, 2) segmentation_mask, and 3) metadata
You can load and iterate through the dataset using the configurations with the following lines of code:
```python
from datasets import load_dataset
ds = load_dataset("didsr/msynth", 'device_data') # For device data for all breast density, mass redius, mass density, and relative dose, change configuration to 'segmentation_mask' and 'metadata' to load the segmentation masks and bound information
print(ds_data["device_data"])
# A sample data instance
{'Raw': '~\\.cache\\huggingface\\datasets\\downloads\\extracted\\59384cf05fc44e8c0cb23bb19e1fcd8f0c39720b282109d204a85561fe66bdb1\\SIM\\P2_5.0_fatty.8336179.1\\1\\projection_DM1.raw',
'mhd': '~/.cache/huggingface/datasets/downloads/extracted/59384cf05fc44e8c0cb23bb19e1fcd8f0c39720b282109d204a85561fe66bdb1/SIM/P2_5.0_fatty.8336179.1/1\\projection_DM1.mhd',
'loc': '~/.cache/huggingface/datasets/downloads/extracted/59384cf05fc44e8c0cb23bb19e1fcd8f0c39720b282109d204a85561fe66bdb1/SIM/P2_5.0_fatty.8336179.1/1\\projection_DM1.loc',
'dcm': '~/.cache/huggingface/datasets/downloads/extracted/59384cf05fc44e8c0cb23bb19e1fcd8f0c39720b282109d204a85561fe66bdb1/SIM/P2_5.0_fatty.8336179.1/1\\DICOM_dm\\000.dcm',
'density': 'fatty',
'mass_radius': 5.0}
```
Msynth dataset can also be loaded using custom breast density, mass redius, mass density, and relative dose information
```python
from datasets import load_dataset
# Dataset properties. change to 'all' to include all the values of breast density, mass redius, mass density, and relative dose information
config_kwargs = {
"lesion_density": ["1.0"],
"dose": ["20%"],
"density": ["fatty"],
"size": ["5.0"]
}
# Loading device data
ds_data = load_dataset("didsr/msynth", 'device_data', **config_kwargs)
# Loading segmentation-mask
ds_seg = load_dataset("didsr/msynth", 'segmentation_mask', **config_kwargs)
```
The meta data can also be loaded using the datasets API. An example of using metadata is given in **Demo:** [https://github.com/DIDSR/msynth-release/tree/master/examples](https://github.com/DIDSR/msynth-release/tree/master/examples)
```python
from datasets import load_dataset
# Loading metadata
ds_meta = load_dataset("didsr/msynth", 'metadata')
# A sample data instance
ds_meta['metadata'][0]
# Output
{'fatty': '~\\.cache\\huggingface\\datasets\\downloads\\extracted\\3ea85fc6b3fcc253ac8550b5d1b21db406ca9a59ea125ff8fc63d9b754c88348\\bounds\\bounds_fatty.npy',
'dense': '~\\.cache\\huggingface\\datasets\\downloads\\extracted\\3ea85fc6b3fcc253ac8550b5d1b21db406ca9a59ea125ff8fc63d9b754c88348\\bounds\\bounds_dense.npy',
'hetero': '~\\.cache\\huggingface\\datasets\\downloads\\extracted\\3ea85fc6b3fcc253ac8550b5d1b21db406ca9a59ea125ff8fc63d9b754c88348\\bounds\\bounds_hetero.npy',
'scattered': '~\\.cache\\huggingface\\datasets\\downloads\\extracted\\3ea85fc6b3fcc253ac8550b5d1b21db406ca9a59ea125ff8fc63d9b754c88348\\bounds\\bounds_scattered.npy'}
```
## Citation
```
@article{sizikova2023knowledge,
title={Knowledge-based in silico models and dataset for the comparative evaluation of mammography AI for a range of breast characteristics, lesion conspicuities and doses},
author={Sizikova, Elena and Saharkhiz, Niloufar and Sharma, Diksha and Lago, Miguel and Sahiner, Berkman and Delfino, Jana G. and Badano, Aldo},
journal={Advances in Neural Information Processing Systems},
volume={},
pages={},
year={2023}
}
```
## Related Links
1. [Virtual Imaging Clinical Trial for Regulatory Evaluation (VICTRE)](https://www.fda.gov/medical-devices/science-and-research-medical-devices/victre-silico-breast-imaging-pipeline).
2. [FDA Catalog of Regulatory Science Tools to Help Assess New Medical Device](https://www.fda.gov/medical-devices/science-and-research-medical-devices/catalog-regulatory-science-tools-help-assess-new-medical-devices).
3. A. Badano, C. G. Graff, A. Badal, D. Sharma, R. Zeng, F. W. Samuelson, S. Glick, K. J. Myers. [Evaluation of Digital Breast Tomosynthesis as Replacement of Full-Field Digital Mammography Using an In Silico Imaging Trial](http://dx.doi.org/10.1001/jamanetworkopen.2018.5474). JAMA Network Open 2018.
4. A. Badano, M. Lago, E. Sizikova, J. G. Delfino, S. Guan, M. A. Anastasio, B. Sahiner. [The stochastic digital human is now enrolling for in silico imaging trials—methods and tools for generating digital cohorts.](http://dx.doi.org/10.1088/2516-1091/ad04c0) Progress in Biomedical Engineering 2023.
5. E. Sizikova, N. Saharkhiz, D. Sharma, M. Lago, B. Sahiner, J. G. Delfino, A. Badano. [Knowledge-based in silico models and dataset for the comparative evaluation of mammography AI](https://github.com/DIDSR/msynth-release). NeurIPS 2023 Workshop on Synthetic Data Generation with Generative AI. | 9,519 | [
[
-0.0286102294921875,
-0.043853759765625,
0.041839599609375,
-0.00864410400390625,
-0.0311431884765625,
-0.0160369873046875,
0.020355224609375,
-0.01287078857421875,
0.042083740234375,
0.03387451171875,
-0.06317138671875,
-0.058685302734375,
-0.032257080078125,
... |
re2panda/click_bate_random_sample | 2023-10-27T08:30:50.000Z | [
"region:us"
] | re2panda | null | null | 0 | 19 | 2023-10-27T08:26:41 | Entry not found | 15 | [
[
-0.0214080810546875,
-0.01494598388671875,
0.057159423828125,
0.028839111328125,
-0.0350341796875,
0.04656982421875,
0.052490234375,
0.00504302978515625,
0.0513916015625,
0.016998291015625,
-0.0521240234375,
-0.0149993896484375,
-0.06036376953125,
0.03790283... |
automated-research-group/phi-winogrande | 2023-10-28T12:48:48.000Z | [
"region:us"
] | automated-research-group | null | null | 0 | 19 | 2023-10-28T12:48:47 | ---
dataset_info:
features:
- name: answer
dtype: string
- name: id
dtype: string
- name: question
dtype: string
- name: input_perplexity
dtype: float64
- name: input_likelihood
dtype: float64
- name: output_perplexity
dtype: float64
- name: output_likelihood
dtype: float64
splits:
- name: validation
num_bytes: 357232
num_examples: 1267
download_size: 162542
dataset_size: 357232
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
---
# Dataset Card for "phi-winogrande"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 710 | [
[
-0.03314208984375,
-0.01021575927734375,
0.01055145263671875,
0.015960693359375,
-0.0218505859375,
-0.01538848876953125,
0.021820068359375,
-0.0186614990234375,
0.067138671875,
0.0234222412109375,
-0.051177978515625,
-0.0430908203125,
-0.046875,
-0.036132812... |
royzhong/ASVS5 | 2023-10-28T17:23:44.000Z | [
"region:us"
] | royzhong | null | null | 0 | 19 | 2023-10-28T17:21:28 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
22Plaruno/little_face64x64 | 2023-10-28T20:33:28.000Z | [
"region:us"
] | 22Plaruno | null | null | 0 | 19 | 2023-10-28T20:33:02 | ---
dataset_info:
features:
- name: image
dtype: image
splits:
- name: train
num_bytes: 151477080.0
num_examples: 70000
download_size: 161591941
dataset_size: 151477080.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "little_face64x64"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 455 | [
[
-0.0445556640625,
-0.00936126708984375,
0.01459503173828125,
0.023590087890625,
-0.01898193359375,
-0.01434326171875,
0.02325439453125,
-0.018890380859375,
0.06011962890625,
0.033050537109375,
-0.061309814453125,
-0.04296875,
-0.04412841796875,
-0.0241394042... |
theophilusijiebor1/chest-xray | 2023-10-29T03:08:57.000Z | [
"region:us"
] | theophilusijiebor1 | null | null | 0 | 19 | 2023-10-29T03:07:44 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': NORMAL
'1': PNEUMONIA
splits:
- name: train
num_bytes: 3186635036.504
num_examples: 5216
- name: validation
num_bytes: 3030633.0
num_examples: 16
- name: test
num_bytes: 79062317.0
num_examples: 624
download_size: 1230487171
dataset_size: 3268727986.504
---
# Dataset Card for "chest-xray"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 781 | [
[
-0.038177490234375,
0.0028247833251953125,
0.024383544921875,
-0.00246429443359375,
-0.0290069580078125,
0.00010371208190917969,
0.0408935546875,
-0.01306915283203125,
0.05718994140625,
0.039031982421875,
-0.05743408203125,
-0.05731201171875,
-0.049468994140625,... |
HoangHa/hello | 2023-10-29T09:17:20.000Z | [
"region:us"
] | HoangHa | null | null | 0 | 19 | 2023-10-29T08:24:01 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
Robathan/generalimageset | 2023-10-30T01:27:31.000Z | [
"task_categories:feature-extraction",
"size_categories:1K<n<10K",
"license:gpl-3.0",
"region:us"
] | Robathan | null | null | 0 | 19 | 2023-10-29T23:21:45 | ---
license: gpl-3.0
task_categories:
- feature-extraction
size_categories:
- 1K<n<10K
---
# Dataset Card for MNR's General Imageset
In-flux. use at your own discrestion/frustration.
## Dataset Details
- random images. about 1,200 in total.
- **Curated by:** Rob James
| 274 | [
[
-0.03662109375,
-0.00414276123046875,
0.01422882080078125,
0.000003814697265625,
-0.034423828125,
-0.006988525390625,
0.02490234375,
0.002658843994140625,
0.05010986328125,
0.07147216796875,
-0.070068359375,
-0.03948974609375,
-0.0285797119140625,
0.00427246... |
Eitanli/meal_type | 2023-11-02T13:51:48.000Z | [
"region:us"
] | Eitanli | null | null | 0 | 19 | 2023-10-30T08:16:00 | ---
dataset_info:
features:
- name: id
dtype: int64
- name: recipe
dtype: string
- name: meal_type_title
dtype: string
splits:
- name: train
num_bytes: 107900952
num_examples: 74465
download_size: 54288491
dataset_size: 107900952
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "meal_type"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 519 | [
[
-0.025177001953125,
-0.023681640625,
0.00817108154296875,
0.0135040283203125,
0.002071380615234375,
-0.003910064697265625,
0.0212860107421875,
-0.006458282470703125,
0.076416015625,
0.0384521484375,
-0.040008544921875,
-0.045440673828125,
-0.040985107421875,
... |
phanvancongthanh/enamine_leadlike_600M | 2023-10-31T13:58:25.000Z | [
"region:us"
] | phanvancongthanh | null | null | 0 | 19 | 2023-10-31T11:34:47 | Entry not found | 15 | [
[
-0.02142333984375,
-0.014984130859375,
0.057220458984375,
0.0288238525390625,
-0.03509521484375,
0.04656982421875,
0.052520751953125,
0.00506591796875,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060455322265625,
0.03793334... |
ncduy/mt-en-vi | 2022-10-22T15:08:45.000Z | [
"annotations_creators:found",
"language_creators:found",
"multilinguality:translation",
"size_categories:1M<n<10M",
"source_datasets:own",
"source_datasets:open_subtitles",
"source_datasets:tatoeba",
"source_datasets:opus_tedtalks",
"source_datasets:qed_amara",
"source_datasets:opus_wikipedia",
... | ncduy | null | null | 4 | 18 | 2022-03-02T23:29:22 | ---
annotations_creators:
- found
language_creators:
- found
language:
- en
- vi
license:
- mit
multilinguality:
- translation
pretty_name: "Machine Translation Paired English-Vietnamese Sentences"
size_categories:
- 1M<n<10M
source_datasets:
- own
- open_subtitles
- tatoeba
- opus_tedtalks
- qed_amara
- opus_wikipedia
task_categories:
- conditional-text-generation
task_ids:
- machine-translation
---
# Dataset Card for Machine Translation Paired English-Vietnamese Sentences
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
[More Information Needed]
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
The language of the dataset text sentence is English ('en') and Vietnamese (`vi`).
## Dataset Structure
### Data Instances
An instance example:
```
{
'en': 'And what I think the world needs now is more connections.',
'vi': 'Và tôi nghĩ điều thế giới đang cần bây giờ là nhiều sự kết nối hơn.',
'source': 'TED2020 v1'
}
```
### Data Fields
- `en` (str): English sentence
- `vi` (str): Vietnamese sentence
- `source` (str): Source.
### Data Splits
The dataset is split in train, validation and test.
| | Tain | Validation | Test |
|--------------------|------:|-----------:|-----:|
| Number of examples |2884451| 11316| 11225|
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@ncduy0303](https://github.com/ncduy0303) for adding this dataset. | 3,401 | [
[
-0.0206298828125,
-0.055084228515625,
0.0172271728515625,
0.0198516845703125,
-0.029815673828125,
-0.0032367706298828125,
-0.0247344970703125,
-0.01244354248046875,
0.029144287109375,
0.05865478515625,
-0.044921875,
-0.06805419921875,
-0.04425048828125,
0.03... |
s3h/arabic-grammar-corrections | 2021-11-30T12:37:00.000Z | [
"region:us"
] | s3h | null | null | 3 | 18 | 2022-03-02T23:29:22 | Entry not found | 15 | [
[
-0.02142333984375,
-0.014984130859375,
0.057220458984375,
0.0288238525390625,
-0.03509521484375,
0.04656982421875,
0.052520751953125,
0.00506591796875,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060455322265625,
0.03793334... |
sentence-transformers/msmarco-hard-negatives | 2022-08-18T16:04:34.000Z | [
"region:us"
] | sentence-transformers | null | null | 4 | 18 | 2022-03-02T23:29:22 | # MS MARCO Passages Hard Negatives
[MS MARCO](https://microsoft.github.io/msmarco/) is a large scale information retrieval corpus that was created based on real user search queries using Bing search engine.
This dataset repository contains files that are helpful to train bi-encoder models e.g. using [sentence-transformers](https://www.sbert.net).
## Training Code
You can find here an example how these files can be used to train bi-encoders: [SBERT.net - MS MARCO - MarginMSE](https://www.sbert.net/examples/training/ms_marco/README.html#marginmse)
## cross-encoder-ms-marco-MiniLM-L-6-v2-scores.pkl.gz
This is a pickled dictionary in the format: `scores[qid][pid] -> cross_encoder_score`
It contains 160 million cross-encoder scores for (query, paragraph) pairs using the [cross-encoder/ms-marco-MiniLM-L-6-v2](https://huggingface.co/cross-encoder/ms-marco-MiniLM-L-6-v2) model.
## msmarco-hard-negatives.jsonl.gz
This is a jsonl file: Each line is a JSON object. It has the following format:
```
{"qid": 867436, "pos": [5238393], "neg": {"bm25": [...], ...}}
```
`qid` is the query-ID from MS MARCO, `pos` is a list with paragraph IDs for positive passages. `neg` is a dictionary where we mined hard negatives using different (mainly dense retrieval) systems.
It contains hard negatives mined from BM25 (using ElasticSearch) and the following dense models:
```
msmarco-distilbert-base-tas-b
msmarco-distilbert-base-v3
msmarco-MiniLM-L-6-v3
distilbert-margin_mse-cls-dot-v2
distilbert-margin_mse-cls-dot-v1
distilbert-margin_mse-mean-dot-v1
mpnet-margin_mse-mean-v1
co-condenser-margin_mse-cls-v1
distilbert-margin_mse-mnrl-mean-v1
distilbert-margin_mse-sym_mnrl-mean-v1
distilbert-margin_mse-sym_mnrl-mean-v2
co-condenser-margin_mse-sym_mnrl-mean-v1
```
From each system, 50 most similar paragraphs were mined for a given query.
| 1,884 | [
[
-0.039825439453125,
-0.047454833984375,
0.03094482421875,
0.00983428955078125,
-0.0165252685546875,
-0.0106353759765625,
-0.029754638671875,
-0.0164031982421875,
0.02197265625,
0.040069580078125,
-0.037261962890625,
-0.0596923828125,
-0.042694091796875,
0.02... |
vesteinn/icelandic-qa-NQiI | 2022-07-04T16:32:26.000Z | [
"task_categories:question-answering",
"task_ids:open-domain-qa",
"task_ids:extractive-qa",
"annotations_creators:curated",
"language_creators:curated",
"multilinguality:monolingual",
"source_datasets:original",
"language:is",
"license:cc-by-sa-4.0",
"region:us"
] | vesteinn | \ | \ | 2 | 18 | 2022-03-02T23:29:22 | ---
pretty_name: NQiI
annotations_creators:
- curated
language_creators:
- curated
language:
- is
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
source_datasets:
- original
task_categories:
- question-answering
task_ids:
- open-domain-qa
- extractive-qa
paperswithcode_id: nqii
---
# Natural Questions in Icelandic
| 325 | [
[
-0.032684326171875,
-0.07763671875,
0.004241943359375,
0.025482177734375,
-0.059967041015625,
0.006862640380859375,
0.0021839141845703125,
-0.037841796875,
0.0206146240234375,
0.055419921875,
-0.035003662109375,
-0.01035308837890625,
-0.0347900390625,
0.0469... |
zloelias/kinopoisk-reviews | 2021-12-06T18:02:51.000Z | [
"region:us"
] | zloelias | null | null | 0 | 18 | 2022-03-02T23:29:22 | Entry not found | 15 | [
[
-0.02142333984375,
-0.014984130859375,
0.057220458984375,
0.0288238525390625,
-0.03509521484375,
0.04656982421875,
0.052520751953125,
0.00506591796875,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060455322265625,
0.03793334... |
Azu/Handwritten-Mathematical-Expression-Convert-LaTeX | 2022-03-10T18:25:17.000Z | [
"region:us"
] | Azu | null | null | 6 | 18 | 2022-03-10T18:23:05 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
nsusemiehl/SciERC | 2022-04-10T16:56:55.000Z | [
"region:us"
] | nsusemiehl | null | null | 0 | 18 | 2022-04-10T16:51:23 | SCIERC (Luan et al., 2018) via "Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks" (Gururangan et al., 2020) reuploaded because of error encountered when trying to load zj88zj/SCIERC with the huggingfaces/datasets library. | 240 | [
[
-0.01806640625,
-0.00982666015625,
0.01702880859375,
0.034942626953125,
0.0016698837280273438,
0.010894775390625,
-0.01406097412109375,
-0.033416748046875,
0.01284027099609375,
0.037322998046875,
-0.06689453125,
-0.0251617431640625,
-0.056243896484375,
0.012... |
IsaacRodgz/DravidianCodeMix-Dataset | 2022-05-04T19:03:35.000Z | [
"region:us"
] | IsaacRodgz | null | null | 0 | 18 | 2022-05-04T19:03:24 | Entry not found | 15 | [
[
-0.021392822265625,
-0.01494598388671875,
0.05718994140625,
0.028839111328125,
-0.0350341796875,
0.046539306640625,
0.052490234375,
0.00507354736328125,
0.051361083984375,
0.01702880859375,
-0.052093505859375,
-0.01494598388671875,
-0.06036376953125,
0.03790... |
HuggingFaceM4/charades | 2022-10-20T21:35:42.000Z | [
"task_categories:other",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:other",
"arxiv:1604.01753",
"region:us"
] | HuggingFaceM4 | Charades is dataset composed of 9848 videos of daily indoors activities collected through Amazon Mechanical Turk. 267 different users were presented with a sentence, that includes objects and actions from a fixed vocabulary, and they recorded a video acting out the sentence (like in a game of Charades). The dataset contains 66,500 temporal annotations for 157 action classes, 41,104 labels for 46 object classes, and 27,847 textual descriptions of the videos. | @article{sigurdsson2016hollywood,
author = {Gunnar A. Sigurdsson and G{\"u}l Varol and Xiaolong Wang and Ivan Laptev and Ali Farhadi and Abhinav Gupta},
title = {Hollywood in Homes: Crowdsourcing Data Collection for Activity Understanding},
journal = {ArXiv e-prints},
eprint = {1604.01753},
year = {2016},
url = {http://arxiv.org/abs/1604.01753},
} | 2 | 18 | 2022-05-11T07:07:47 | ---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
language:
- en
license:
- other
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- other
task_ids: []
paperswithcode_id: charades
pretty_name: Charades
tags: []
---
# Dataset Card for Charades
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://prior.allenai.org/projects/charades
- **Repository:** https://github.com/gsig/charades-algorithms
- **Paper:** https://arxiv.org/abs/1604.01753
- **Leaderboard:** https://paperswithcode.com/sota/action-classification-on-charades
- **Point of Contact:** mailto: vision.amt@allenai.org
### Dataset Summary
Charades is dataset composed of 9848 videos of daily indoors activities collected through Amazon Mechanical Turk. 267 different users were presented with a sentence, that includes objects and actions from a fixed vocabulary, and they recorded a video acting out the sentence (like in a game of Charades). The dataset contains 66,500 temporal annotations for 157 action classes, 41,104 labels for 46 object classes, and 27,847 textual descriptions of the videos
### Supported Tasks and Leaderboards
- `multilabel-action-classification`: The goal of this task is to classify actions happening in a video. This is a multilabel classification. The leaderboard is available [here](https://paperswithcode.com/sota/action-classification-on-charades)
### Languages
The annotations in the dataset are in English.
## Dataset Structure
### Data Instances
```
{
"video_id": "46GP8",
"video": "/home/amanpreet_huggingface_co/.cache/huggingface/datasets/downloads/extracted/3f022da5305aaa189f09476dbf7d5e02f6fe12766b927c076707360d00deb44d/46GP8.mp4",
"subject": "HR43",
"scene": "Kitchen",
"quality": 6,
"relevance": 7,
"verified": "Yes",
"script": "A person cooking on a stove while watching something out a window.",
"objects": ["food", "stove", "window"],
"descriptions": [
"A person cooks food on a stove before looking out of a window."
],
"labels": [92, 147],
"action_timings": [
[11.899999618530273, 21.200000762939453],
[0.0, 12.600000381469727]
],
"length": 24.829999923706055
}
```
### Data Fields
- `video_id`: `str` Unique identifier for each video.
- `video`: `str` Path to the video file
- `subject`: `str` Unique identifier for each subject in the dataset
- `scene`: `str` One of 15 indoor scenes in the dataset, such as Kitchen
- `quality`: `int` The quality of the video judged by an annotator (7-point scale, 7=high quality), -100 if missing
- `relevance`: `int` The relevance of the video to the script judged by an annotated (7-point scale, 7=very relevant), -100 if missing
- `verified`: `str` 'Yes' if an annotator successfully verified that the video matches the script, else 'No'
- `script`: `str` The human-generated script used to generate the video
- `descriptions`: `List[str]` List of descriptions by annotators watching the video
- `labels`: `List[int]` Multi-label actions found in the video. Indices from 0 to 156.
- `action_timings`: `List[Tuple[int, int]]` Timing where each of the above actions happened.
- `length`: `float` The length of the video in seconds
<details>
<summary>
Click here to see the full list of Charades class labels mapping:
</summary>
|id|Class|
|--|-----|
|c000 | Holding some clothes |
|c001 | Putting clothes somewhere |
|c002 | Taking some clothes from somewhere |
|c003 | Throwing clothes somewhere |
|c004 | Tidying some clothes |
|c005 | Washing some clothes |
|c006 | Closing a door |
|c007 | Fixing a door |
|c008 | Opening a door |
|c009 | Putting something on a table |
|c010 | Sitting on a table |
|c011 | Sitting at a table |
|c012 | Tidying up a table |
|c013 | Washing a table |
|c014 | Working at a table |
|c015 | Holding a phone/camera |
|c016 | Playing with a phone/camera |
|c017 | Putting a phone/camera somewhere |
|c018 | Taking a phone/camera from somewhere |
|c019 | Talking on a phone/camera |
|c020 | Holding a bag |
|c021 | Opening a bag |
|c022 | Putting a bag somewhere |
|c023 | Taking a bag from somewhere |
|c024 | Throwing a bag somewhere |
|c025 | Closing a book |
|c026 | Holding a book |
|c027 | Opening a book |
|c028 | Putting a book somewhere |
|c029 | Smiling at a book |
|c030 | Taking a book from somewhere |
|c031 | Throwing a book somewhere |
|c032 | Watching/Reading/Looking at a book |
|c033 | Holding a towel/s |
|c034 | Putting a towel/s somewhere |
|c035 | Taking a towel/s from somewhere |
|c036 | Throwing a towel/s somewhere |
|c037 | Tidying up a towel/s |
|c038 | Washing something with a towel |
|c039 | Closing a box |
|c040 | Holding a box |
|c041 | Opening a box |
|c042 | Putting a box somewhere |
|c043 | Taking a box from somewhere |
|c044 | Taking something from a box |
|c045 | Throwing a box somewhere |
|c046 | Closing a laptop |
|c047 | Holding a laptop |
|c048 | Opening a laptop |
|c049 | Putting a laptop somewhere |
|c050 | Taking a laptop from somewhere |
|c051 | Watching a laptop or something on a laptop |
|c052 | Working/Playing on a laptop |
|c053 | Holding a shoe/shoes |
|c054 | Putting shoes somewhere |
|c055 | Putting on shoe/shoes |
|c056 | Taking shoes from somewhere |
|c057 | Taking off some shoes |
|c058 | Throwing shoes somewhere |
|c059 | Sitting in a chair |
|c060 | Standing on a chair |
|c061 | Holding some food |
|c062 | Putting some food somewhere |
|c063 | Taking food from somewhere |
|c064 | Throwing food somewhere |
|c065 | Eating a sandwich |
|c066 | Making a sandwich |
|c067 | Holding a sandwich |
|c068 | Putting a sandwich somewhere |
|c069 | Taking a sandwich from somewhere |
|c070 | Holding a blanket |
|c071 | Putting a blanket somewhere |
|c072 | Snuggling with a blanket |
|c073 | Taking a blanket from somewhere |
|c074 | Throwing a blanket somewhere |
|c075 | Tidying up a blanket/s |
|c076 | Holding a pillow |
|c077 | Putting a pillow somewhere |
|c078 | Snuggling with a pillow |
|c079 | Taking a pillow from somewhere |
|c080 | Throwing a pillow somewhere |
|c081 | Putting something on a shelf |
|c082 | Tidying a shelf or something on a shelf |
|c083 | Reaching for and grabbing a picture |
|c084 | Holding a picture |
|c085 | Laughing at a picture |
|c086 | Putting a picture somewhere |
|c087 | Taking a picture of something |
|c088 | Watching/looking at a picture |
|c089 | Closing a window |
|c090 | Opening a window |
|c091 | Washing a window |
|c092 | Watching/Looking outside of a window |
|c093 | Holding a mirror |
|c094 | Smiling in a mirror |
|c095 | Washing a mirror |
|c096 | Watching something/someone/themselves in a mirror |
|c097 | Walking through a doorway |
|c098 | Holding a broom |
|c099 | Putting a broom somewhere |
|c100 | Taking a broom from somewhere |
|c101 | Throwing a broom somewhere |
|c102 | Tidying up with a broom |
|c103 | Fixing a light |
|c104 | Turning on a light |
|c105 | Turning off a light |
|c106 | Drinking from a cup/glass/bottle |
|c107 | Holding a cup/glass/bottle of something |
|c108 | Pouring something into a cup/glass/bottle |
|c109 | Putting a cup/glass/bottle somewhere |
|c110 | Taking a cup/glass/bottle from somewhere |
|c111 | Washing a cup/glass/bottle |
|c112 | Closing a closet/cabinet |
|c113 | Opening a closet/cabinet |
|c114 | Tidying up a closet/cabinet |
|c115 | Someone is holding a paper/notebook |
|c116 | Putting their paper/notebook somewhere |
|c117 | Taking paper/notebook from somewhere |
|c118 | Holding a dish |
|c119 | Putting a dish/es somewhere |
|c120 | Taking a dish/es from somewhere |
|c121 | Wash a dish/dishes |
|c122 | Lying on a sofa/couch |
|c123 | Sitting on sofa/couch |
|c124 | Lying on the floor |
|c125 | Sitting on the floor |
|c126 | Throwing something on the floor |
|c127 | Tidying something on the floor |
|c128 | Holding some medicine |
|c129 | Taking/consuming some medicine |
|c130 | Putting groceries somewhere |
|c131 | Laughing at television |
|c132 | Watching television |
|c133 | Someone is awakening in bed |
|c134 | Lying on a bed |
|c135 | Sitting in a bed |
|c136 | Fixing a vacuum |
|c137 | Holding a vacuum |
|c138 | Taking a vacuum from somewhere |
|c139 | Washing their hands |
|c140 | Fixing a doorknob |
|c141 | Grasping onto a doorknob |
|c142 | Closing a refrigerator |
|c143 | Opening a refrigerator |
|c144 | Fixing their hair |
|c145 | Working on paper/notebook |
|c146 | Someone is awakening somewhere |
|c147 | Someone is cooking something |
|c148 | Someone is dressing |
|c149 | Someone is laughing |
|c150 | Someone is running somewhere |
|c151 | Someone is going from standing to sitting |
|c152 | Someone is smiling |
|c153 | Someone is sneezing |
|c154 | Someone is standing up from somewhere |
|c155 | Someone is undressing |
|c156 | Someone is eating something |
</details>
### Data Splits
| |train |validation| test |
|-------------|------:|---------:|------:|
|# of examples|1281167|50000 |100000 |
## Dataset Creation
### Curation Rationale
> Computer vision has a great potential to help our daily lives by searching for lost keys, watering flowers or reminding us to take a pill. To succeed with such tasks, computer vision methods need to be trained from real and diverse examples of our daily dynamic scenes. While most of such scenes are not particularly exciting, they typically do not appear on YouTube, in movies or TV broadcasts. So how do we collect sufficiently many diverse but boring samples representing our lives? We propose a novel Hollywood in Homes approach to collect such data. Instead of shooting videos in the lab, we ensure diversity by distributing and crowdsourcing the whole process of video creation from script writing to video recording and annotation.
### Source Data
#### Initial Data Collection and Normalization
> Similar to filming, we have a three-step process for generating a video. The first step is generating the script of the indoor video. The key here is to allow workers to generate diverse scripts yet ensure that we have enough data for each category. The second step in the process is to use the script and ask workers to record a video of that sentence being acted out. In the final step, we ask the workers to verify if the recorded video corresponds to script, followed by an annotation procedure.
#### Who are the source language producers?
Amazon Mechnical Turk annotators
### Annotations
#### Annotation process
> Similar to filming, we have a three-step process for generating a video. The first step is generating the script of the indoor video. The key here is to allow workers to generate diverse scripts yet ensure that we have enough data for each category. The second step in the process is to use the script and ask workers to record a video of that sentence being acted out. In the final step, we ask the workers to verify if the recorded video corresponds to script, followed by an annotation procedure.
#### Who are the annotators?
Amazon Mechnical Turk annotators
### Personal and Sensitive Information
Nothing specifically mentioned in the paper.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
AMT annotators
### Licensing Information
License for Non-Commercial Use
If this software is redistributed, this license must be included. The term software includes any source files, documentation, executables, models, and data.
This software and data is available for general use by academic or non-profit, or government-sponsored researchers. It may also be used for evaluation purposes elsewhere. This license does not grant the right to use this software or any derivation of it in a for-profit enterprise. For commercial use, please contact The Allen Institute for Artificial Intelligence.
This license does not grant the right to modify and publicly release the data in any form.
This license does not grant the right to distribute the data to a third party in any form.
The subjects in this data should be treated with respect and dignity. This license only grants the right to publish short segments or still images in an academic publication where necessary to present examples, experimental results, or observations.
This software comes with no warranty or guarantee of any kind. By using this software, the user accepts full liability.
The Allen Institute for Artificial Intelligence (C) 2016.
### Citation Information
```bibtex
@article{sigurdsson2016hollywood,
author = {Gunnar A. Sigurdsson and G{\"u}l Varol and Xiaolong Wang and Ivan Laptev and Ali Farhadi and Abhinav Gupta},
title = {Hollywood in Homes: Crowdsourcing Data Collection for Activity Understanding},
journal = {ArXiv e-prints},
eprint = {1604.01753},
year = {2016},
url = {http://arxiv.org/abs/1604.01753},
}
```
### Contributions
Thanks to [@apsdehal](https://github.com/apsdehal) for adding this dataset.
| 14,484 | [
[
-0.039337158203125,
-0.0343017578125,
0.01003265380859375,
0.0296783447265625,
-0.0047454833984375,
0.0252685546875,
0.0005626678466796875,
-0.01052093505859375,
0.041290283203125,
0.01708984375,
-0.06878662109375,
-0.043731689453125,
-0.046966552734375,
0.0... |
linxinyuan/mind | 2022-06-07T23:12:22.000Z | [
"region:us"
] | linxinyuan | null | null | 1 | 18 | 2022-06-07T08:26:00 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
biglam/illustrated_ads | 2023-01-18T20:38:15.000Z | [
"task_categories:image-classification",
"task_ids:multi-class-image-classification",
"annotations_creators:expert-generated",
"size_categories:n<1K",
"license:cc0-1.0",
"lam",
"historic newspapers",
"region:us"
] | biglam | The Dataset contains images derived from the Newspaper Navigator (news-navigator.labs.loc.gov/), a dataset of images drawn from the Library of Congress Chronicling America collection. | @dataset{van_strien_daniel_2021_5838410,
author = {van Strien, Daniel},
title = {{19th Century United States Newspaper Advert images
with 'illustrated' or 'non illustrated' labels}},
month = oct,
year = 2021,
publisher = {Zenodo},
version = {0.0.1},
doi = {10.5281/zenodo.5838410},
url = {https://doi.org/10.5281/zenodo.5838410}} | 3 | 18 | 2022-06-27T14:14:29 | ---
annotations_creators:
- expert-generated
language: []
language_creators: []
license:
- cc0-1.0
multilinguality: []
pretty_name: 19th Century United States Newspaper Advert images with 'illustrated'
or 'non illustrated' labels
size_categories:
- n<1K
source_datasets: []
tags:
- lam
- historic newspapers
task_categories:
- image-classification
task_ids:
- multi-class-image-classification
---
The Dataset contains images derived from the [Newspaper Navigator](https://news-navigator.labs.loc.gov/), a dataset of images drawn from the Library of Congress Chronicling America collection (chroniclingamerica.loc.gov/).
> [The Newspaper Navigator dataset](https://news-navigator.labs.loc.gov/) consists of extracted visual content for 16,358,041 historic newspaper pages in Chronicling America. The visual content was identified using an object detection model trained on annotations of World War 1-era Chronicling America pages, including annotations made by volunteers as part of the Beyond Words crowdsourcing project. source: https://news-navigator.labs.loc.gov/
One of these categories is 'advertisements'. This dataset contains a sample of these images with additional labels indicating if the advert is 'illustrated' or 'not illustrated'.
This dataset was created for use in a [Programming Historian tutorial](http://programminghistorian.github.io/ph-submissions/lessons/computer-vision-deep-learning-pt1). The primary aim of the data was to provide a realistic example dataset for teaching computer vision for working with digitised heritage material.
# Dataset Card for 19th Century United States Newspaper Advert images with 'illustrated' or 'non illustrated' labels
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**[https://doi.org/10.5281/zenodo.5838410](https://doi.org/10.5281/zenodo.5838410)
- **Paper:**[https://doi.org/10.46430/phen0101](https://doi.org/10.46430/phen0101)
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
The Dataset contains images derived from the [Newspaper Navigator](news-navigator.labs.loc.gov/), a dataset of images drawn from the Library of Congress Chronicling America collection (chroniclingamerica.loc.gov/).
> [The Newspaper Navigator dataset](https://news-navigator.labs.loc.gov/) consists of extracted visual content for 16,358,041 historic newspaper pages in Chronicling America. The visual content was identified using an object detection model trained on annotations of World War 1-era Chronicling America pages, including annotations made by volunteers as part of the Beyond Words crowdsourcing project. source: https://news-navigator.labs.loc.gov/
One of these categories is 'advertisements. This dataset contains a sample of these images with additional labels indicating if the advert is 'illustrated' or 'not illustrated'.
This dataset was created for use in a [Programming Historian tutorial](http://programminghistorian.github.io/ph-submissions/lessons/computer-vision-deep-learning-pt1). The primary aim of the data was to provide a realistic example dataset for teaching computer vision for working with digitised heritage material.
### Supported Tasks and Leaderboards
- `image-classification`: the primary purpose of this dataset is for classifying historic newspaper images identified as being 'advertisements' into 'illustrated' and 'not-illustrated' categories.
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
An example instance from this dataset
``` python
{'file': 'pst_fenske_ver02_data_sn84026497_00280776129_1880042101_0834_002_6_96.jpg',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=L size=388x395 at 0x7F9A72038950>,
'label': 0,
'pub_date': Timestamp('1880-04-21 00:00:00'),
'page_seq_num': 834,
'edition_seq_num': 1,
'batch': 'pst_fenske_ver02',
'lccn': 'sn84026497',
'box': [0.649412214756012,
0.6045778393745422,
0.8002520799636841,
0.7152365446090698],
'score': 0.9609346985816956,
'ocr': "H. II. IIASLKT & SOXN, Dealers in General Merchandise In New Store Room nt HASLET'S COS ITERS, 'JTionoMtii, ln. .Tau'y 1st, 1?0.",
'place_of_publication': 'Tionesta, Pa.',
'geographic_coverage': "['Pennsylvania--Forest--Tionesta']",
'name': 'The Forest Republican. [volume]',
'publisher': 'Ed. W. Smiley',
'url': 'https://news-navigator.labs.loc.gov/data/pst_fenske_ver02/data/sn84026497/00280776129/1880042101/0834/002_6_96.jpg',
'page_url': 'https://chroniclingamerica.loc.gov/data/batches/pst_fenske_ver02/data/sn84026497/00280776129/1880042101/0834.jp2'}
```
### Data Fields
[More Information Needed]
### Data Splits
The dataset contains a single split.
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
A description of the annotation process is outlined in this [GitHub repository](https://github.com/Living-with-machines/nnanno)
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
``` bibtex
@dataset{van_strien_daniel_2021_5838410,
author = {van Strien, Daniel},
title = {{19th Century United States Newspaper Advert images
with 'illustrated' or 'non illustrated' labels}},
month = oct,
year = 2021,
publisher = {Zenodo},
version = {0.0.1},
doi = {10.5281/zenodo.5838410},
url = {https://doi.org/10.5281/zenodo.5838410}}
```
[More Information Needed]
### Contributions
Thanks to [@davanstrien](https://github.com/davanstrien) for adding this dataset.
| 7,220 | [
[
-0.031280517578125,
-0.044525146484375,
0.029632568359375,
0.0009832382202148438,
-0.02288818359375,
-0.0162353515625,
-0.020233154296875,
-0.040496826171875,
0.0345458984375,
0.05126953125,
-0.026611328125,
-0.06591796875,
-0.037445068359375,
0.011688232421... |
jakartaresearch/google-play-review | 2022-08-06T16:24:49.000Z | [
"task_categories:text-classification",
"task_ids:sentiment-classification",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:id",
"license:cc-by-4.0",
"sentiment",
"google-play",
"indonesia... | jakartaresearch | This dataset is built as a playground for beginner to make a use case for creating sentiment analysis model. | null | 4 | 18 | 2022-08-06T05:00:32 | ---
annotations_creators:
- found
language:
- id
language_creators:
- found
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Indonesian Google Play Review
size_categories:
- 1K<n<10K
source_datasets:
- original
tags:
- sentiment
- google-play
- indonesian
task_categories:
- text-classification
task_ids:
- sentiment-classification
---
# Dataset Card for Indonesian Google Play Review
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Scrapped from e-commerce app on Google Play.
### Supported Tasks and Leaderboards
Sentiment Analysis
### Languages
Indonesian
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@andreaschandra](https://github.com/andreaschandra) for adding this dataset. | 2,843 | [
[
-0.03143310546875,
-0.0345458984375,
-0.0035457611083984375,
0.034271240234375,
-0.029449462890625,
0.005657196044921875,
-0.020538330078125,
-0.0258636474609375,
0.045501708984375,
0.061614990234375,
-0.0687255859375,
-0.066162109375,
-0.04388427734375,
0.0... |
pysentimiento/spanish-tweets | 2023-07-13T15:44:41.000Z | [
"language:es",
"region:us"
] | pysentimiento | null | null | 8 | 18 | 2022-09-08T21:02:38 | ---
language: es
dataset_info:
features:
- name: text
dtype: string
- name: tweet_id
dtype: string
- name: user_id
dtype: string
splits:
- name: train
num_bytes: 82649695458
num_examples: 597433111
- name: test
num_bytes: 892219251
num_examples: 6224733
download_size: 51737237106
dataset_size: 83541914709
---
# spanish-tweets
## A big corpus of tweets for pretraining embeddings and language models
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage**: https://github.com/pysentimiento/robertuito
- **Paper**: [RoBERTuito: a pre-trained language model for social media text in Spanish](https://aclanthology.org/2022.lrec-1.785/)
- **Point of Contact:** jmperez (at) dc.uba.ar
### Dataset Summary
A big dataset of (mostly) Spanish tweets for pre-training language models (or other representations).
### Supported Tasks and Leaderboards
Language Modeling
### Languages
Mostly Spanish, but some Portuguese, English, and other languages.
## Dataset Structure
### Data Fields
- *tweet_id*: id of the tweet
- *user_id*: id of the user
- *text*: text from the tweet
## Dataset Creation
The full process of data collection is described in the paper. Here we roughly outline the main points:
- A Spritzer collection uploaded to Archive.org dating from May 2019 was downloaded
- From this, we only kept tweets with language metadata equal to Spanish, and mark the users who posted these messages.
- Then, the tweetline from each of these marked users was downloaded.
This corpus consists of 622M tweets from around 432K users.
Please note that we did not filter tweets from other languages, so you might find English, Portuguese, Catalan and other languages in the dataset (around 7/8% of the tweets are not in Spanish)
### Citation Information
```
@inproceedings{perez-etal-2022-robertuito,
title = "{R}o{BERT}uito: a pre-trained language model for social media text in {S}panish",
author = "P{\'e}rez, Juan Manuel and
Furman, Dami{\'a}n Ariel and
Alonso Alemany, Laura and
Luque, Franco M.",
booktitle = "Proceedings of the Thirteenth Language Resources and Evaluation Conference",
month = jun,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2022.lrec-1.785",
pages = "7235--7243",
abstract = "Since BERT appeared, Transformer language models and transfer learning have become state-of-the-art for natural language processing tasks. Recently, some works geared towards pre-training specially-crafted models for particular domains, such as scientific papers, medical documents, user-generated texts, among others. These domain-specific models have been shown to improve performance significantly in most tasks; however, for languages other than English, such models are not widely available. In this work, we present RoBERTuito, a pre-trained language model for user-generated text in Spanish, trained on over 500 million tweets. Experiments on a benchmark of tasks involving user-generated text showed that RoBERTuito outperformed other pre-trained language models in Spanish. In addition to this, our model has some cross-lingual abilities, achieving top results for English-Spanish tasks of the Linguistic Code-Switching Evaluation benchmark (LinCE) and also competitive performance against monolingual models in English Twitter tasks. To facilitate further research, we make RoBERTuito publicly available at the HuggingFace model hub together with the dataset used to pre-train it.",
}
``` | 4,189 | [
[
-0.01016998291015625,
-0.0377197265625,
0.024169921875,
0.044342041015625,
-0.02081298828125,
0.035919189453125,
-0.050323486328125,
-0.035675048828125,
0.046600341796875,
0.031890869140625,
-0.049957275390625,
-0.060333251953125,
-0.06988525390625,
0.016601... |
TalTechNLP/ERRnews | 2023-04-10T13:17:48.000Z | [
"task_categories:summarization",
"annotations_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:et",
"license:cc-by-4.0",
"region:us"
] | TalTechNLP | null | null | 0 | 18 | 2022-10-06T15:28:35 | ---
pretty_name: ERRnews
annotations_creators:
- expert-generated
language:
- et
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- summarization
paperswithcode_id: err-news
---
# Dataset Card for "ERRnews"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
-
## Dataset Description
- **Homepage:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** https://www.bjmc.lu.lv/fileadmin/user_upload/lu_portal/projekti/bjmc/Contents/10_3_23_Harm.pdf
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Dataset Summary
ERRnews is an estonian language summaryzation dataset of ERR News broadcasts scraped from the ERR Archive (https://arhiiv.err.ee/err-audioarhiiv). The dataset consists of news story transcripts generated by an ASR pipeline paired with the human written summary from the archive. For leveraging larger english models the dataset includes machine translated (https://neurotolge.ee/) transcript and summary pairs.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
Estonian
## Dataset Structure
### Data Instances
```
{'name': 'Kütuseaktsiis Balti riikides on erinev.', 'summary': 'Eestis praeguse plaani järgi järgmise aasta maini kehtiv madalam diislikütuse aktsiis ei ajenda enam tankima Lätis, kuid bensiin on seal endiselt odavam. Peaminister Kaja Kallas ja kütusemüüjad on eri meelt selles, kui suurel määral mõjutab aktsiis lõpphinda tanklais.', 'transcript': 'Eesti-Läti piiri alal on kütusehinna erinevus eriti märgatav ja ka tuntav. Õigema pildi saamiseks tuleks võrrelda ühe keti keskmist hinda, kuna tanklati võib see erineda Circle K. [...] Olulisel määral mõjutab hinda kütuste sisseost, räägib kartvski. On selge, et maailmaturuhinna põhjal tehtud ost Tallinnas erineb kütusehinnast Riias või Vilniuses või Varssavis. Kolmas mõjur ja oluline mõjur on biolisandite kasutamise erinevad nõuded riikide vahel.', 'url': 'https://arhiiv.err.ee//vaata/uudised-kutuseaktsiis-balti-riikides-on-erinev', 'meta': '\n\n\nSarja pealkiri:\nuudised\n\n\nFonoteegi number:\nRMARH-182882\n\n\nFonogrammi tootja:\n2021 ERR\n\n\nEetris:\n16.09.2021\n\n\nSalvestuskoht:\nRaadiouudised\n\n\nKestus:\n00:02:34\n\n\nEsinejad:\nKond Ragnar, Vahtrik Raimo, Kallas Kaja, Karcevskis Ojars\n\n\nKategooria:\nUudised → uudised, muu\n\n\nPüsiviide:\n\nvajuta siia\n\n\n\n', 'audio': {'path': 'recordings/12049.ogv', 'array': array([0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 2.44576868e-06, 6.38223427e-06, 0.00000000e+00]), 'sampling_rate': 16000}, 'recording_id': 12049}
```
### Data Fields
```
name: News story headline
summary: Hand written summary.
transcript: Automatically generated transcript from the audio file with an ASR system.
url: ERR archive URL.
meta: ERR archive metadata.
en_summary: Machine translated English summary.
en_transcript: Machine translated English transcript.
audio: A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, *i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
recording_id: Audio file id.
```
### Data Splits
|train|validation|test|
|:----|:---------|:---|
|10420|523|523|
### BibTeX entry and citation info
```bibtex
article{henryabstractive,
title={Abstractive Summarization of Broadcast News Stories for {Estonian}},
author={Henry, H{\"a}rm and Tanel, Alum{\"a}e},
journal={Baltic J. Modern Computing},
volume={10},
number={3},
pages={511-524},
year={2022}
}
```
| 5,414 | [
[
-0.042083740234375,
-0.044952392578125,
0.017791748046875,
0.005825042724609375,
-0.03082275390625,
-0.01210784912109375,
-0.0233917236328125,
-0.032623291015625,
0.06829833984375,
0.025054931640625,
-0.05450439453125,
-0.06787109375,
-0.046112060546875,
0.0... |
loubnabnl/humaneval_infilling | 2022-10-21T10:37:13.000Z | [
"task_categories:text2text-generation",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"source_datasets:original",
"language:code",
"license:mit",
"code-generation",
"arxiv:2207.14255",
"region:us"
] | loubnabnl | An evaluation benchamrk for infilling tasks on HumanEval dataset for code generation. | @article{bavarian2022efficient,
title={Efficient Training of Language Models to Fill in the Middle},
author={Bavarian, Mohammad and Jun, Heewoo and Tezak, Nikolas and Schulman, John and McLeavey, Christine and Tworek, Jerry and Chen, Mark},
journal={arXiv preprint arXiv:2207.14255},
year={2022}
} | 0 | 18 | 2022-10-06T16:47:01 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- code
license:
- mit
multilinguality:
- monolingual
source_datasets:
- original
task_categories:
- text2text-generation
task_ids: []
pretty_name: OpenAI HumanEval-Infilling
tags:
- code-generation
---
# HumanEval-Infilling
## Dataset Description
- **Repository:** https://github.com/openai/human-eval-infilling
- **Paper:** https://arxiv.org/pdf/2207.14255
## Dataset Summary
[HumanEval-Infilling](https://github.com/openai/human-eval-infilling) is a benchmark for infilling tasks, derived from [HumanEval](https://huggingface.co/datasets/openai_humaneval) benchmark for the evaluation of code generation models.
## Dataset Structure
To load the dataset you need to specify a subset. By default `HumanEval-SingleLineInfilling` is loaded.
```python
from datasets import load_dataset
ds = load_dataset("humaneval_infilling", "HumanEval-RandomSpanInfilling")
DatasetDict({
test: Dataset({
features: ['task_id', 'entry_point', 'prompt', 'suffix', 'canonical_solution', 'test'],
num_rows: 1640
})
})
```
## Subsets
This dataset has 4 subsets: HumanEval-MultiLineInfilling, HumanEval-SingleLineInfilling, HumanEval-RandomSpanInfilling, HumanEval-RandomSpanInfillingLight.
The single-line, multi-line, random span infilling and its light version have 1033, 5815, 1640 and 164 tasks, respectively.
## Citation
```
@article{bavarian2022efficient,
title={Efficient Training of Language Models to Fill in the Middle},
author={Bavarian, Mohammad and Jun, Heewoo and Tezak, Nikolas and Schulman, John and McLeavey, Christine and Tworek, Jerry and Chen, Mark},
journal={arXiv preprint arXiv:2207.14255},
year={2022}
}
``` | 1,747 | [
[
-0.0136871337890625,
-0.039459228515625,
-0.0008053779602050781,
0.0245361328125,
-0.00762176513671875,
-0.01107025146484375,
-0.02777099609375,
-0.021026611328125,
-0.018798828125,
0.0364990234375,
-0.038482666015625,
-0.0328369140625,
-0.0166015625,
0.0190... |
tiagoblima/punctuation-nilc-bert | 2023-07-19T17:03:29.000Z | [
"language:pt",
"region:us"
] | tiagoblima | null | null | 0 | 18 | 2022-10-16T18:02:29 | ---
language: pt
dataset_info:
features:
- name: text_id
dtype: int64
- name: text
dtype: string
- name: level
dtype: string
- name: tokens
sequence: string
- name: labels
sequence: string
splits:
- name: test
num_bytes: 1177684.2701598366
num_examples: 2604
- name: train
num_bytes: 4224993.504240118
num_examples: 9371
- name: validation
num_bytes: 479472.5920696906
num_examples: 1041
download_size: 1802076
dataset_size: 5882150.366469645
---
# Dataset Card for "punctuation-nilc"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 685 | [
[
-0.0242919921875,
-0.0308837890625,
0.0142669677734375,
0.0255889892578125,
-0.0169830322265625,
0.026641845703125,
0.0005364418029785156,
-0.0100555419921875,
0.0521240234375,
0.037139892578125,
-0.055267333984375,
-0.060577392578125,
-0.0296478271484375,
0... |
RaphaelOlivier/whisper_adversarial_examples | 2022-11-03T21:48:16.000Z | [
"license:cc-by-4.0",
"region:us"
] | RaphaelOlivier | Adversarial examples fooling whisper models | null | 1 | 18 | 2022-10-26T20:29:43 | ---
license: cc-by-4.0
---
# Description
This dataset is a subset of [LibriSpeech](https://huggingface.co/datasets/librispeech_asr) and Multilingual [CommonVoice](commonvoice.mozilla.org/) that have been adversarially modified to fool [Whisper](https://huggingface.co/openai/whisper-medium) ASR model.
Original [source code](https://github.com/RaphaelOlivier/whisper_attack).
The raw [tar files](https://data.mendeley.com/datasets/96dh52hz9r).
# Configurations and splits
* The `targeted` config contains targeted adversarial examples. When successful, they fool Whisper into predicting the sentence `OK Google, browse to evil.com` even if the input is entirely different. We provide a split for each Whisper model, and one containing the original, unmodified inputs
* The `untargeted-35` and `untargeted-40` configs contain untargeted adversarial examples, with average Signal-Noise Ratios of 35dB and 40dB respectively. They fool Whisper into predicting erroneous transcriptions. We provide a split for each Whisper model, and one containing the original, unmodified inputs
* The `language-<lang> configs contain adversarial examples in language <lang> that fool Whisper in predicting the wrong language. Split `<lang>.<target_lang>` contain inputs that Whisper perceives as <target_lang>, and split `<lang>.original` contains the original inputs in language <lang>. We use 3 target languages (English, Tagalog and Serbian) and 7 source languages (English, Italian, Indonesian, Danish, Czech, Lithuanian and Armenian).
# Usage
Here is an example of code using this dataset:
```python
model_name="whisper-medium"
config_name="targeted"
split_name="whisper.medium"
hub_path = "openai/whisper-"+model_name
processor = WhisperProcessor.from_pretrained(hub_path)
model = WhisperForConditionalGeneration.from_pretrained(hub_path).to("cuda")
dataset = load_dataset("RaphaelOlivier/whisper_adversarial_examples",config_name ,split=split_name)
def map_to_pred(batch):
input_features = processor(batch["audio"][0]["array"], return_tensors="pt").input_features
predicted_ids = model.generate(input_features.to("cuda"))
transcription = processor.batch_decode(predicted_ids, normalize = True)
batch['text'][0] = processor.tokenizer._normalize(batch['text'][0])
batch["transcription"] = transcription
return batch
result = dataset.map(map_to_pred, batched=True, batch_size=1)
wer = load("wer")
for t in zip(result["text"],result["transcription"]):
print(t)
print(wer.compute(predictions=result["text"], references=result["transcription"]))
``` | 2,571 | [
[
-0.0069427490234375,
-0.0545654296875,
0.01093292236328125,
0.0225677490234375,
-0.005664825439453125,
-0.008056640625,
-0.031951904296875,
-0.028167724609375,
0.017547607421875,
0.041290283203125,
-0.05511474609375,
-0.043975830078125,
-0.061737060546875,
-... |
101arrowz/vox_celeb | 2023-08-20T03:04:07.000Z | [
"task_categories:automatic-speech-recognition",
"task_categories:audio-classification",
"task_categories:image-classification",
"task_ids:speaker-identification",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:multilingual",
"size_categories:1K<n<10K",
"size_... | 101arrowz | VoxCeleb is an audio-visual dataset consisting of short clips of human speech, extracted from interview videos uploaded to YouTube | @Article{Nagrani19,
author = "Arsha Nagrani and Joon~Son Chung and Weidi Xie and Andrew Zisserman",
title = "Voxceleb: Large-scale speaker verification in the wild",
journal = "Computer Science and Language",
year = "2019",
publisher = "Elsevier",
}
@InProceedings{Chung18b,
author = "Chung, J.~S. and Nagrani, A. and Zisserman, A.",
title = "VoxCeleb2: Deep Speaker Recognition",
booktitle = "INTERSPEECH",
year = "2018",
}
@InProceedings{Nagrani17,
author = "Nagrani, A. and Chung, J.~S. and Zisserman, A.",
title = "VoxCeleb: a large-scale speaker identification dataset",
booktitle = "INTERSPEECH",
year = "2017",
} | 1 | 18 | 2022-11-13T01:43:46 | ---
annotations_creators:
- crowdsourced
language: []
language_creators:
- crowdsourced
license:
- cc-by-4.0
multilinguality:
- multilingual
pretty_name: VoxCeleb
size_categories:
- 1K<n<10K
- 10K<n<100K
- 100K<n<1M
source_datasets: []
tags: []
task_categories:
- automatic-speech-recognition
- audio-classification
- image-classification
task_ids:
- speaker-identification
---
# Dataset Card for VoxCeleb
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
### Dataset Summary
VoxCeleb is an audio-visual dataset consisting of short clips of human speech, extracted from interview videos uploaded to YouTube.
NOTE: Although this dataset can be automatically downloaded, you must manually request credentials to access it from the creators' website.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
Each datapoint has a path to the audio/video clip along with metadata about the speaker.
```
{
'file': '/datasets/downloads/extracted/[hash]/wav/id10271/_YimahVgI1A/00003.wav',
'file_format': 'wav',
'dataset_id': 'vox1',
'speaker_id': 'id10271',
'speaker_gender': 'm',
'speaker_name': 'Ed_Westwick',
'speaker_nationality': 'UK',
'video_id': '_YimahVgI1A',
'clip_id': '00003',
'audio': {
'path': '/datasets/downloads/extracted/[hash]/wav/id10271/_YimahVgI1A/00003.wav',
'array': array([...], dtype=float32),
'sampling_rate': 16000
}
}
```
### Data Fields
Each row includes the following fields:
- `file`: The path to the audio/video clip
- `file_format`: The file format in which the clip is stored (e.g. `wav`, `aac`, `mp4`)
- `dataset_id`: The ID of the dataset this clip is from (`vox1`, `vox2`)
- `speaker_id`: The ID of the speaker in this clip
- `speaker_gender`: The gender of the speaker (`m`/`f`)
- `speaker_name` (VoxCeleb1 only): The full name of the speaker in the clip
- `speaker_nationality` (VoxCeleb1 only): The speaker's country of origin
- `video_id`: The ID of the video from which this clip was taken
- `clip_index`: The index of the clip for this specific video
- `audio` (Audio dataset only): The audio signal data
### Data Splits
The dataset has a predefined dev set and test set. The dev set has been renamed to a "train" split.
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
The dataset includes recordings of clips (mostly of celebrities and public figures) from public YouTube videos. The names of speakers in VoxCeleb1 are provided.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
The VoxCeleb authors request that anyone who uses VoxCeleb1 or VoxCeleb2 includes the following three citations:
```
@Article{Nagrani19,
author = "Arsha Nagrani and Joon~Son Chung and Weidi Xie and Andrew Zisserman",
title = "Voxceleb: Large-scale speaker verification in the wild",
journal = "Computer Science and Language",
year = "2019",
publisher = "Elsevier",
}
@InProceedings{Chung18b,
author = "Chung, J.~S. and Nagrani, A. and Zisserman, A.",
title = "VoxCeleb2: Deep Speaker Recognition",
booktitle = "INTERSPEECH",
year = "2018",
}
@InProceedings{Nagrani17,
author = "Nagrani, A. and Chung, J.~S. and Zisserman, A.",
title = "VoxCeleb: a large-scale speaker identification dataset",
booktitle = "INTERSPEECH",
year = "2017",
}
```
### Contributions
Thanks to [@101arrowz](https://github.com/101arrowz) for adding this dataset.
| 5,179 | [
[
-0.050872802734375,
-0.056610107421875,
0.00939178466796875,
0.0178680419921875,
-0.0141448974609375,
0.004909515380859375,
-0.037261962890625,
-0.00289154052734375,
0.0268707275390625,
0.0274200439453125,
-0.056304931640625,
-0.07269287109375,
-0.04129028320312... |
bigbio/citation_gia_test_collection | 2022-12-22T15:44:27.000Z | [
"multilinguality:monolingual",
"language:en",
"license:unknown",
"region:us"
] | bigbio | The Citation GIA Test Collection was recently created for gene indexing at the
NLM and includes 151 PubMed abstracts with both mention-level and document-level
annotations. They are selected because both have a focus on human genes. | @article{Wei2015,
title = {
{GNormPlus}: An Integrative Approach for Tagging Genes, Gene Families,
and Protein Domains
},
author = {Chih-Hsuan Wei and Hung-Yu Kao and Zhiyong Lu},
year = 2015,
journal = {{BioMed} Research International},
publisher = {Hindawi Limited},
volume = 2015,
pages = {1--7},
doi = {10.1155/2015/918710},
url = {https://doi.org/10.1155/2015/918710}
} | 0 | 18 | 2022-11-13T22:07:57 |
---
language:
- en
bigbio_language:
- English
license: unknown
multilinguality: monolingual
bigbio_license_shortname: UNKNOWN
pretty_name: Citation GIA Test Collection
homepage: https://www.ncbi.nlm.nih.gov/research/bionlp/Tools/gnormplus/
bigbio_pubmed: True
bigbio_public: True
bigbio_tasks:
- NAMED_ENTITY_RECOGNITION
- NAMED_ENTITY_DISAMBIGUATION
---
# Dataset Card for Citation GIA Test Collection
## Dataset Description
- **Homepage:** https://www.ncbi.nlm.nih.gov/research/bionlp/Tools/gnormplus/
- **Pubmed:** True
- **Public:** True
- **Tasks:** NER,NED
The Citation GIA Test Collection was recently created for gene indexing at the
NLM and includes 151 PubMed abstracts with both mention-level and document-level
annotations. They are selected because both have a focus on human genes.
## Citation Information
```
@article{Wei2015,
title = {
{GNormPlus}: An Integrative Approach for Tagging Genes, Gene Families,
and Protein Domains
},
author = {Chih-Hsuan Wei and Hung-Yu Kao and Zhiyong Lu},
year = 2015,
journal = {{BioMed} Research International},
publisher = {Hindawi Limited},
volume = 2015,
pages = {1--7},
doi = {10.1155/2015/918710},
url = {https://doi.org/10.1155/2015/918710}
}
```
| 1,307 | [
[
-0.0438232421875,
-0.0253143310546875,
0.00841522216796875,
-0.0017986297607421875,
-0.03326416015625,
0.0010614395141601562,
0.006626129150390625,
-0.0362548828125,
0.04278564453125,
0.0223388671875,
-0.02734375,
-0.04693603515625,
-0.0406494140625,
0.03787... |
castorini/africlirmatrix | 2022-11-17T22:45:16.000Z | [
"task_categories:text-retrieval",
"multilinguality:multilingual",
"language:af",
"language:am",
"language:arz",
"language:ha",
"language:ig",
"language:ary",
"language:nso",
"language:sn",
"language:so",
"language:sw",
"language:ti",
"language:tw",
"language:wo",
"language:yo",
"lang... | castorini | null | null | 2 | 18 | 2022-11-17T18:41:37 | ---
language:
- af
- am
- arz
- ha
- ig
- ary
- nso
- sn
- so
- sw
- ti
- tw
- wo
- yo
- zu
multilinguality:
- multilingual
task_categories:
- text-retrieval
license: apache-2.0
viewer: true
---
# Dataset Summary
AfriCLIRMatrix is a test collection for cross-lingual information retrieval research in 15 diverse African languages. This resource comprises English queries with query–document relevance judgments in 15 African languages automatically mined from Wikipedia
This dataset stores documents of AfriCLIRMatrix. To access the queries and judgments, please refer to [castorini/africlirmatrix](https://github.com/castorini/africlirmatrix).
# Dataset Structure
The only configuration here is the `language`.
An example of document data entry looks as follows:
```
{
'id': '62443',
'contents': 'Acyloin condensation jẹ́ ìyọkúrò àsopọ̀ àwọn carboxylic ester pẹ̀lú lílò metalic sodium lati ṣèdá α-hydroxyketone, tí wọ́n tún mọ̀ sí. Àdàpọ̀ ṣisẹ́ yìí jẹ́ èyí tó ...'
}
```
# Load Dataset
An example to load the dataset:
```
language = 'yoruba'
dataset = load_dataset('castorini/africlirmatrix', language, 'train')
```
# Citation Information
```
coming soon
``` | 1,219 | [
[
-0.052276611328125,
-0.050689697265625,
-0.0078887939453125,
0.00939178466796875,
-0.00284576416015625,
-0.0222625732421875,
-0.021820068359375,
-0.0187225341796875,
0.037506103515625,
0.04248046875,
-0.0292816162109375,
-0.04962158203125,
-0.049835205078125,
... |
graphs-datasets/CIFAR10 | 2023-02-07T16:37:24.000Z | [
"task_categories:graph-ml",
"license:mit",
"arxiv:2003.00982",
"region:us"
] | graphs-datasets | null | null | 1 | 18 | 2022-12-08T09:59:00 | ---
licence: unknown
license: mit
task_categories:
- graph-ml
---
# Dataset Card for CIFAR10
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [External Use](#external-use)
- [PyGeometric](#pygeometric)
- [Dataset Structure](#dataset-structure)
- [Data Properties](#data-properties)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **[Homepage](https://github.com/graphdeeplearning/benchmarking-gnns)**
- **Paper:**: (see citation)
### Dataset Summary
The `CIFAR10` dataset consists of 45000 images in 10 classes, represented as graphs.
### Supported Tasks and Leaderboards
`CIFAR10` should be used for multiclass graph classification.
## External Use
### PyGeometric
To load in PyGeometric, do the following:
```python
from datasets import load_dataset
from torch_geometric.data import Data
from torch_geometric.loader import DataLoader
dataset_hf = load_dataset("graphs-datasets/<mydataset>")
# For the train set (replace by valid or test as needed)
dataset_pg_list = [Data(graph) for graph in dataset_hf["train"]]
dataset_pg = DataLoader(dataset_pg_list)
```
## Dataset Structure
### Data Properties
| property | value |
|---|---|
| #graphs | 45,000 |
| average #nodes | 117.6 |
| average #edges | 941.2 |
### Data Fields
Each row of a given file is a graph, with:
- `node_feat` (list: #nodes x #node-features): nodes
- `edge_index` (list: 2 x #edges): pairs of nodes constituting edges
- `edge_attr` (list: #edges x #edge-features): for the aforementioned edges, contains their features
- `y` (list: #labels): contains the number of labels available to predict
- `num_nodes` (int): number of nodes of the graph
- `pos` (list: 2 x #node): positional information of each node
### Data Splits
This data is split. It comes from the PyGeometric version of the dataset.
## Additional Information
### Licensing Information
The dataset has been released under MIT license.
### Citation Information
```
@article{DBLP:journals/corr/abs-2003-00982,
author = {Vijay Prakash Dwivedi and
Chaitanya K. Joshi and
Thomas Laurent and
Yoshua Bengio and
Xavier Bresson},
title = {Benchmarking Graph Neural Networks},
journal = {CoRR},
volume = {abs/2003.00982},
year = {2020},
url = {https://arxiv.org/abs/2003.00982},
eprinttype = {arXiv},
eprint = {2003.00982},
timestamp = {Sat, 23 Jan 2021 01:14:30 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2003-00982.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` | 2,978 | [
[
-0.034454345703125,
-0.031005859375,
0.00278472900390625,
0.0082855224609375,
-0.006984710693359375,
-0.01000213623046875,
-0.01030731201171875,
-0.0362548828125,
0.0292510986328125,
0.00542449951171875,
-0.029632568359375,
-0.049041748046875,
-0.03759765625,
... |
lewtun/titanic | 2022-12-15T17:59:50.000Z | [
"kaggle",
"region:us"
] | lewtun | null | null | 0 | 18 | 2022-12-15T17:56:38 | ---
tags:
- kaggle
dataset_info:
features:
- name: PassengerId
dtype: int64
- name: Survived
dtype: int64
- name: Pclass
dtype: int64
- name: Name
dtype: string
- name: Sex
dtype: string
- name: Age
dtype: float64
- name: SibSp
dtype: int64
- name: Parch
dtype: int64
- name: Ticket
dtype: string
- name: Fare
dtype: float64
- name: Cabin
dtype: string
- name: Embarked
dtype: string
splits:
- name: test
num_bytes: 49054
num_examples: 418
- name: train
num_bytes: 103906
num_examples: 891
download_size: 61019
dataset_size: 152960
---
# Dataset Card for "titanic"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 797 | [
[
-0.045745849609375,
-0.0204010009765625,
0.019866943359375,
0.0260467529296875,
-0.0273590087890625,
0.00200653076171875,
0.046051025390625,
-0.0054931640625,
0.059295654296875,
0.0400390625,
-0.0496826171875,
-0.0296478271484375,
-0.03973388671875,
-0.02528... |
mariosasko/glue | 2023-06-08T16:42:25.000Z | [
"task_categories:text-classification",
"task_ids:acceptability-classification",
"task_ids:natural-language-inference",
"task_ids:semantic-similarity-scoring",
"task_ids:sentiment-classification",
"task_ids:text-scoring",
"annotations_creators:other",
"language_creators:other",
"multilinguality:monol... | mariosasko | GLUE, the General Language Understanding Evaluation benchmark
(https://gluebenchmark.com/) is a collection of resources for training,
evaluating, and analyzing natural language understanding systems. | @inproceedings{wang2019glue,
title={{GLUE}: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding},
author={Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R.},
note={In the Proceedings of ICLR.},
year={2019}
} | 0 | 18 | 2023-01-18T12:19:24 | ---
annotations_creators:
- other
language_creators:
- other
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- acceptability-classification
- natural-language-inference
- semantic-similarity-scoring
- sentiment-classification
- text-scoring
paperswithcode_id: glue
pretty_name: GLUE (General Language Understanding Evaluation benchmark)
train-eval-index:
- config: cola
task: text-classification
task_id: binary_classification
splits:
train_split: train
eval_split: validation
col_mapping:
sentence: text
label: target
- config: sst2
task: text-classification
task_id: binary_classification
splits:
train_split: train
eval_split: validation
col_mapping:
sentence: text
label: target
- config: mrpc
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
sentence1: text1
sentence2: text2
label: target
- config: qqp
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
question1: text1
question2: text2
label: target
- config: stsb
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
sentence1: text1
sentence2: text2
label: target
- config: mnli
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation_matched
col_mapping:
premise: text1
hypothesis: text2
label: target
- config: mnli_mismatched
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
premise: text1
hypothesis: text2
label: target
- config: mnli_matched
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
premise: text1
hypothesis: text2
label: target
- config: qnli
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
question: text1
sentence: text2
label: target
- config: rte
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
sentence1: text1
sentence2: text2
label: target
- config: wnli
task: text-classification
task_id: natural_language_inference
splits:
train_split: train
eval_split: validation
col_mapping:
sentence1: text1
sentence2: text2
label: target
configs:
- ax
- cola
- mnli
- mnli_matched
- mnli_mismatched
- mrpc
- qnli
- qqp
- rte
- sst2
- stsb
- wnli
tags:
- qa-nli
- coreference-nli
- paraphrase-identification
dataset_info:
- config_name: cola
features:
- name: sentence
dtype: string
- name: label
dtype:
class_label:
names:
0: unacceptable
1: acceptable
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 61049
num_examples: 1063
- name: train
num_bytes: 489149
num_examples: 8551
- name: validation
num_bytes: 60850
num_examples: 1043
download_size: 376971
dataset_size: 611048
- config_name: sst2
features:
- name: sentence
dtype: string
- name: label
dtype:
class_label:
names:
0: negative
1: positive
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 217556
num_examples: 1821
- name: train
num_bytes: 4715283
num_examples: 67349
- name: validation
num_bytes: 106692
num_examples: 872
download_size: 7439277
dataset_size: 5039531
- config_name: mrpc
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
0: not_equivalent
1: equivalent
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 443498
num_examples: 1725
- name: train
num_bytes: 946146
num_examples: 3668
- name: validation
num_bytes: 106142
num_examples: 408
download_size: 1494541
dataset_size: 1495786
- config_name: qqp
features:
- name: question1
dtype: string
- name: question2
dtype: string
- name: label
dtype:
class_label:
names:
0: not_duplicate
1: duplicate
- name: idx
dtype: int32
splits:
- name: train
num_bytes: 50901116
num_examples: 363846
- name: validation
num_bytes: 5653794
num_examples: 40430
- name: test
num_bytes: 55171431
num_examples: 390965
download_size: 41696084
dataset_size: 111726341
- config_name: stsb
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype: float32
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 170847
num_examples: 1379
- name: train
num_bytes: 758394
num_examples: 5749
- name: validation
num_bytes: 217012
num_examples: 1500
download_size: 802872
dataset_size: 1146253
- config_name: mnli
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: label
dtype:
class_label:
names:
0: entailment
1: neutral
2: contradiction
- name: idx
dtype: int32
splits:
- name: test_matched
num_bytes: 1854787
num_examples: 9796
- name: test_mismatched
num_bytes: 1956866
num_examples: 9847
- name: train
num_bytes: 74865118
num_examples: 392702
- name: validation_matched
num_bytes: 1839926
num_examples: 9815
- name: validation_mismatched
num_bytes: 1955384
num_examples: 9832
download_size: 312783507
dataset_size: 82472081
- config_name: mnli_mismatched
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: label
dtype:
class_label:
names:
0: entailment
1: neutral
2: contradiction
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 1956866
num_examples: 9847
- name: validation
num_bytes: 1955384
num_examples: 9832
download_size: 312783507
dataset_size: 3912250
- config_name: mnli_matched
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: label
dtype:
class_label:
names:
0: entailment
1: neutral
2: contradiction
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 1854787
num_examples: 9796
- name: validation
num_bytes: 1839926
num_examples: 9815
download_size: 312783507
dataset_size: 3694713
- config_name: qnli
features:
- name: question
dtype: string
- name: sentence
dtype: string
- name: label
dtype:
class_label:
names:
0: entailment
1: not_entailment
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 1376516
num_examples: 5463
- name: train
num_bytes: 25677924
num_examples: 104743
- name: validation
num_bytes: 1371727
num_examples: 5463
download_size: 10627589
dataset_size: 28426167
- config_name: rte
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
0: entailment
1: not_entailment
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 975936
num_examples: 3000
- name: train
num_bytes: 848888
num_examples: 2490
- name: validation
num_bytes: 90911
num_examples: 277
download_size: 697150
dataset_size: 1915735
- config_name: wnli
features:
- name: sentence1
dtype: string
- name: sentence2
dtype: string
- name: label
dtype:
class_label:
names:
0: not_entailment
1: entailment
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 37992
num_examples: 146
- name: train
num_bytes: 107517
num_examples: 635
- name: validation
num_bytes: 12215
num_examples: 71
download_size: 28999
dataset_size: 157724
- config_name: ax
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: label
dtype:
class_label:
names:
0: entailment
1: neutral
2: contradiction
- name: idx
dtype: int32
splits:
- name: test
num_bytes: 238392
num_examples: 1104
download_size: 222257
dataset_size: 238392
---
# Dataset Card for GLUE
## Table of Contents
- [Dataset Card for GLUE](#dataset-card-for-glue)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [ax](#ax)
- [cola](#cola)
- [mnli](#mnli)
- [mnli_matched](#mnli_matched)
- [mnli_mismatched](#mnli_mismatched)
- [mrpc](#mrpc)
- [qnli](#qnli)
- [qqp](#qqp)
- [rte](#rte)
- [sst2](#sst2)
- [stsb](#stsb)
- [wnli](#wnli)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [ax](#ax-1)
- [cola](#cola-1)
- [mnli](#mnli-1)
- [mnli_matched](#mnli_matched-1)
- [mnli_mismatched](#mnli_mismatched-1)
- [mrpc](#mrpc-1)
- [qnli](#qnli-1)
- [qqp](#qqp-1)
- [rte](#rte-1)
- [sst2](#sst2-1)
- [stsb](#stsb-1)
- [wnli](#wnli-1)
- [Data Fields](#data-fields)
- [ax](#ax-2)
- [cola](#cola-2)
- [mnli](#mnli-2)
- [mnli_matched](#mnli_matched-2)
- [mnli_mismatched](#mnli_mismatched-2)
- [mrpc](#mrpc-2)
- [qnli](#qnli-2)
- [qqp](#qqp-2)
- [rte](#rte-2)
- [sst2](#sst2-2)
- [stsb](#stsb-2)
- [wnli](#wnli-2)
- [Data Splits](#data-splits)
- [ax](#ax-3)
- [cola](#cola-3)
- [mnli](#mnli-3)
- [mnli_matched](#mnli_matched-3)
- [mnli_mismatched](#mnli_mismatched-3)
- [mrpc](#mrpc-3)
- [qnli](#qnli-3)
- [qqp](#qqp-3)
- [rte](#rte-3)
- [sst2](#sst2-3)
- [stsb](#stsb-3)
- [wnli](#wnli-3)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://nyu-mll.github.io/CoLA/](https://nyu-mll.github.io/CoLA/)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 955.33 MB
- **Size of the generated dataset:** 229.68 MB
- **Total amount of disk used:** 1185.01 MB
### Dataset Summary
GLUE, the General Language Understanding Evaluation benchmark (https://gluebenchmark.com/) is a collection of resources for training, evaluating, and analyzing natural language understanding systems.
### Supported Tasks and Leaderboards
The leaderboard for the GLUE benchmark can be found [at this address](https://gluebenchmark.com/). It comprises the following tasks:
#### ax
A manually-curated evaluation dataset for fine-grained analysis of system performance on a broad range of linguistic phenomena. This dataset evaluates sentence understanding through Natural Language Inference (NLI) problems. Use a model trained on MulitNLI to produce predictions for this dataset.
#### cola
The Corpus of Linguistic Acceptability consists of English acceptability judgments drawn from books and journal articles on linguistic theory. Each example is a sequence of words annotated with whether it is a grammatical English sentence.
#### mnli
The Multi-Genre Natural Language Inference Corpus is a crowdsourced collection of sentence pairs with textual entailment annotations. Given a premise sentence and a hypothesis sentence, the task is to predict whether the premise entails the hypothesis (entailment), contradicts the hypothesis (contradiction), or neither (neutral). The premise sentences are gathered from ten different sources, including transcribed speech, fiction, and government reports. The authors of the benchmark use the standard test set, for which they obtained private labels from the RTE authors, and evaluate on both the matched (in-domain) and mismatched (cross-domain) section. They also uses and recommend the SNLI corpus as 550k examples of auxiliary training data.
#### mnli_matched
The matched validation and test splits from MNLI. See the "mnli" BuilderConfig for additional information.
#### mnli_mismatched
The mismatched validation and test splits from MNLI. See the "mnli" BuilderConfig for additional information.
#### mrpc
The Microsoft Research Paraphrase Corpus (Dolan & Brockett, 2005) is a corpus of sentence pairs automatically extracted from online news sources, with human annotations for whether the sentences in the pair are semantically equivalent.
#### qnli
The Stanford Question Answering Dataset is a question-answering dataset consisting of question-paragraph pairs, where one of the sentences in the paragraph (drawn from Wikipedia) contains the answer to the corresponding question (written by an annotator). The authors of the benchmark convert the task into sentence pair classification by forming a pair between each question and each sentence in the corresponding context, and filtering out pairs with low lexical overlap between the question and the context sentence. The task is to determine whether the context sentence contains the answer to the question. This modified version of the original task removes the requirement that the model select the exact answer, but also removes the simplifying assumptions that the answer is always present in the input and that lexical overlap is a reliable cue.
#### qqp
The Quora Question Pairs2 dataset is a collection of question pairs from the community question-answering website Quora. The task is to determine whether a pair of questions are semantically equivalent.
#### rte
The Recognizing Textual Entailment (RTE) datasets come from a series of annual textual entailment challenges. The authors of the benchmark combined the data from RTE1 (Dagan et al., 2006), RTE2 (Bar Haim et al., 2006), RTE3 (Giampiccolo et al., 2007), and RTE5 (Bentivogli et al., 2009). Examples are constructed based on news and Wikipedia text. The authors of the benchmark convert all datasets to a two-class split, where for three-class datasets they collapse neutral and contradiction into not entailment, for consistency.
#### sst2
The Stanford Sentiment Treebank consists of sentences from movie reviews and human annotations of their sentiment. The task is to predict the sentiment of a given sentence. It uses the two-way (positive/negative) class split, with only sentence-level labels.
#### stsb
The Semantic Textual Similarity Benchmark (Cer et al., 2017) is a collection of sentence pairs drawn from news headlines, video and image captions, and natural language inference data. Each pair is human-annotated with a similarity score from 1 to 5.
#### wnli
The Winograd Schema Challenge (Levesque et al., 2011) is a reading comprehension task in which a system must read a sentence with a pronoun and select the referent of that pronoun from a list of choices. The examples are manually constructed to foil simple statistical methods: Each one is contingent on contextual information provided by a single word or phrase in the sentence. To convert the problem into sentence pair classification, the authors of the benchmark construct sentence pairs by replacing the ambiguous pronoun with each possible referent. The task is to predict if the sentence with the pronoun substituted is entailed by the original sentence. They use a small evaluation set consisting of new examples derived from fiction books that was shared privately by the authors of the original corpus. While the included training set is balanced between two classes, the test set is imbalanced between them (65% not entailment). Also, due to a data quirk, the development set is adversarial: hypotheses are sometimes shared between training and development examples, so if a model memorizes the training examples, they will predict the wrong label on corresponding development set example. As with QNLI, each example is evaluated separately, so there is not a systematic correspondence between a model's score on this task and its score on the unconverted original task. The authors of the benchmark call converted dataset WNLI (Winograd NLI).
### Languages
The language data in GLUE is in English (BCP-47 `en`)
## Dataset Structure
### Data Instances
#### ax
- **Size of downloaded dataset files:** 0.21 MB
- **Size of the generated dataset:** 0.23 MB
- **Total amount of disk used:** 0.44 MB
An example of 'test' looks as follows.
```
{
"premise": "The cat sat on the mat.",
"hypothesis": "The cat did not sit on the mat.",
"label": -1,
"idx: 0
}
```
#### cola
- **Size of downloaded dataset files:** 0.36 MB
- **Size of the generated dataset:** 0.58 MB
- **Total amount of disk used:** 0.94 MB
An example of 'train' looks as follows.
```
{
"sentence": "Our friends won't buy this analysis, let alone the next one we propose.",
"label": 1,
"id": 0
}
```
#### mnli
- **Size of downloaded dataset files:** 298.29 MB
- **Size of the generated dataset:** 78.65 MB
- **Total amount of disk used:** 376.95 MB
An example of 'train' looks as follows.
```
{
"premise": "Conceptually cream skimming has two basic dimensions - product and geography.",
"hypothesis": "Product and geography are what make cream skimming work.",
"label": 1,
"idx": 0
}
```
#### mnli_matched
- **Size of downloaded dataset files:** 298.29 MB
- **Size of the generated dataset:** 3.52 MB
- **Total amount of disk used:** 301.82 MB
An example of 'test' looks as follows.
```
{
"premise": "Hierbas, ans seco, ans dulce, and frigola are just a few names worth keeping a look-out for.",
"hypothesis": "Hierbas is a name worth looking out for.",
"label": -1,
"idx": 0
}
```
#### mnli_mismatched
- **Size of downloaded dataset files:** 298.29 MB
- **Size of the generated dataset:** 3.73 MB
- **Total amount of disk used:** 302.02 MB
An example of 'test' looks as follows.
```
{
"premise": "What have you decided, what are you going to do?",
"hypothesis": "So what's your decision?,
"label": -1,
"idx": 0
}
```
#### mrpc
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qqp
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### rte
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### sst2
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### stsb
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### wnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Data Fields
The data fields are the same among all splits.
#### ax
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `neutral` (1), `contradiction` (2).
- `idx`: a `int32` feature.
#### cola
- `sentence`: a `string` feature.
- `label`: a classification label, with possible values including `unacceptable` (0), `acceptable` (1).
- `idx`: a `int32` feature.
#### mnli
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `neutral` (1), `contradiction` (2).
- `idx`: a `int32` feature.
#### mnli_matched
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `neutral` (1), `contradiction` (2).
- `idx`: a `int32` feature.
#### mnli_mismatched
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `neutral` (1), `contradiction` (2).
- `idx`: a `int32` feature.
#### mrpc
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qqp
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### rte
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### sst2
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### stsb
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### wnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Data Splits
#### ax
| |test|
|---|---:|
|ax |1104|
#### cola
| |train|validation|test|
|----|----:|---------:|---:|
|cola| 8551| 1043|1063|
#### mnli
| |train |validation_matched|validation_mismatched|test_matched|test_mismatched|
|----|-----:|-----------------:|--------------------:|-----------:|--------------:|
|mnli|392702| 9815| 9832| 9796| 9847|
#### mnli_matched
| |validation|test|
|------------|---------:|---:|
|mnli_matched| 9815|9796|
#### mnli_mismatched
| |validation|test|
|---------------|---------:|---:|
|mnli_mismatched| 9832|9847|
#### mrpc
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qqp
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### rte
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### sst2
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### stsb
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### wnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@article{warstadt2018neural,
title={Neural Network Acceptability Judgments},
author={Warstadt, Alex and Singh, Amanpreet and Bowman, Samuel R},
journal={arXiv preprint arXiv:1805.12471},
year={2018}
}
@inproceedings{wang2019glue,
title={{GLUE}: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding},
author={Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R.},
note={In the Proceedings of ICLR.},
year={2019}
}
Note that each GLUE dataset has its own citation. Please see the source to see
the correct citation for each contained dataset.
```
### Contributions
Thanks to [@patpizio](https://github.com/patpizio), [@jeswan](https://github.com/jeswan), [@thomwolf](https://github.com/thomwolf), [@patrickvonplaten](https://github.com/patrickvonplaten), [@mariamabarham](https://github.com/mariamabarham) for adding this dataset. | 27,835 | [
[
-0.0303192138671875,
-0.057525634765625,
0.00933837890625,
0.01531982421875,
-0.006046295166015625,
-0.004261016845703125,
-0.01220703125,
-0.0306243896484375,
0.02691650390625,
0.03167724609375,
-0.058563232421875,
-0.0540771484375,
-0.0360107421875,
0.0233... |
jonathan-roberts1/RSSCN7 | 2023-03-31T17:20:53.000Z | [
"task_categories:image-classification",
"task_categories:zero-shot-image-classification",
"license:other",
"region:us"
] | jonathan-roberts1 | null | null | 1 | 18 | 2023-01-25T16:16:29 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': field
'1': forest
'2': grass
'3': industry
'4': parking
'5': resident
'6': river or lake
splits:
- name: train
num_bytes: 345895442.4
num_examples: 2800
download_size: 367257922
dataset_size: 345895442.4
license: other
task_categories:
- image-classification
- zero-shot-image-classification
---
# Dataset Card for "RSSCN7"
## Dataset Description
- **Paper** [Deep Learning Based Feature Selection for Remote Sensing Scene Classification](https://ieeexplore.ieee.org/iel7/8859/7305891/07272047.pdf)
### Licensing Information
For research and academic purposes.
## Citation Information
[Deep Learning Based Feature Selection for Remote Sensing Scene Classification](https://ieeexplore.ieee.org/iel7/8859/7305891/07272047.pdf)
```
@article{7272047,
title = {Deep Learning Based Feature Selection for Remote Sensing Scene Classification},
author = {Zou, Qin and Ni, Lihao and Zhang, Tong and Wang, Qian},
year = 2015,
journal = {IEEE Geoscience and Remote Sensing Letters},
volume = 12,
number = 11,
pages = {2321--2325},
doi = {10.1109/LGRS.2015.2475299}
}
``` | 1,350 | [
[
-0.04534912109375,
0.00408935546875,
0.01303863525390625,
-0.0023708343505859375,
-0.0440673828125,
-0.00531768798828125,
-0.0013246536254882812,
-0.034423828125,
-0.017852783203125,
0.035675048828125,
-0.038360595703125,
-0.051727294921875,
-0.037872314453125,
... |
torchgeo/ucmerced | 2023-01-31T21:48:28.000Z | [
"task_categories:image-classification",
"size_categories:10K<n<100K",
"language:en",
"license:cc",
"region:us"
] | torchgeo | null | null | 1 | 18 | 2023-01-31T21:45:28 | ---
license: cc
task_categories:
- image-classification
language:
- en
pretty_name: UC Merced
size_categories:
- 10K<n<100K
---
Redistributed from http://weegee.vision.ucmerced.edu/datasets/landuse.html without modification. See https://www.usgs.gov/faqs/what-are-terms-uselicensing-map-services-and-data-national-map for license. | 330 | [
[
-0.027984619140625,
-0.0216217041015625,
0.03631591796875,
0.0165863037109375,
-0.038543701171875,
-0.034332275390625,
-0.003582000732421875,
-0.0278167724609375,
0.0116119384765625,
0.099365234375,
-0.03070068359375,
-0.0509033203125,
-0.035675048828125,
-0... |
pszemraj/HC3-textgen-qa | 2023-02-11T22:56:14.000Z | [
"task_categories:text-generation",
"source_datasets:Hello-SimpleAI/HC3",
"language:en",
"license:apache-2.0",
"chatgpt",
"conversation",
"region:us"
] | pszemraj | null | null | 0 | 18 | 2023-02-11T22:42:21 | ---
license: apache-2.0
task_categories:
- text-generation
language:
- en
tags:
- chatgpt
- conversation
source_datasets: Hello-SimpleAI/HC3
pretty_name: HC3 for QA textgen
---
# HC3-textgen-qa
- the `Hello-SimpleAI/HC3` reformatted for textgen
- special tokens for question/answer, see dataset preview | 306 | [
[
-0.021575927734375,
-0.040679931640625,
0.0175933837890625,
0.0180206298828125,
-0.0249481201171875,
-0.0033779144287109375,
0.0265045166015625,
0.0005846023559570312,
0.0384521484375,
0.041473388671875,
-0.06695556640625,
-0.033203125,
-0.00345611572265625,
... |
Loie/VGGSound | 2023-03-26T13:25:40.000Z | [
"task_categories:audio-classification",
"size_categories:100B<n<1T",
"arxiv:2004.14368",
"region:us"
] | Loie | null | null | 6 | 18 | 2023-02-17T10:27:55 | ---
task_categories:
- audio-classification
size_categories:
- 100B<n<1T
---
# VGGSound
VGG-Sound is an audio-visual correspondent dataset consisting of short clips of audio sounds, extracted from videos uploaded to YouTube.
- **Homepage:** https://www.robots.ox.ac.uk/~vgg/data/vggsound/
- **Paper:** https://arxiv.org/abs/2004.14368
- **Github:** https://github.com/hche11/VGGSound
## Analysis
- **310+ classes:** VGG-Sound contains audios spanning a large number of challenging acoustic environments and noise characteristics of real applications.
- **200,000+ videos:** All videos are captured "in the wild" with audio-visual correspondence in the sense that the sound source is visually evident.
- **550+ hours:** VGG-Sound consists of both audio and video. Each segment is 10 seconds long.

## Download
We provide a csv file. For each YouTube video, we provide YouTube URLs, time stamps, audio labels and train/test split. Each line in the csv file has columns defined by here.
```
# YouTube ID, start seconds, label, train/test split.
```
And you can download VGGSound directly from this [repository](https://huggingface.co/datasets/Loie/VGGSound/tree/main).
## License
The VGG-Sound dataset is available to download for commercial/research purposes under a Creative Commons Attribution 4.0 International License. The copyright remains with the original owners of the video. A complete version of the license can be found [here](https://thor.robots.ox.ac.uk/datasets/vggsound/license_vggsound.txt).
## Citation
Please cite the following if you make use of the dataset.
```
@InProceedings{Chen20,
author = "Honglie Chen and Weidi Xie and Andrea Vedaldi and Andrew Zisserman",
title = "VGGSound: A Large-scale Audio-Visual Dataset",
booktitle = "International Conference on Acoustics, Speech, and Signal Processing (ICASSP)",
year = "2020",
}
``` | 1,917 | [
[
-0.0281219482421875,
-0.039459228515625,
0.021087646484375,
-0.0072021484375,
-0.0200653076171875,
0.0053253173828125,
-0.0241546630859375,
-0.01739501953125,
0.025482177734375,
0.005462646484375,
-0.06585693359375,
-0.044281005859375,
-0.0255889892578125,
-... |
manu/trivia_qa_wiki | 2023-02-21T22:25:45.000Z | [
"region:us"
] | manu | null | null | 0 | 18 | 2023-02-21T22:25:14 | ---
dataset_info:
features:
- name: question
dtype: string
- name: question_id
dtype: string
- name: question_source
dtype: string
- name: entity_pages
sequence:
- name: doc_source
dtype: string
- name: filename
dtype: string
- name: title
dtype: string
- name: wiki_context
dtype: string
- name: search_results
sequence:
- name: description
dtype: string
- name: filename
dtype: string
- name: rank
dtype: int32
- name: title
dtype: string
- name: url
dtype: string
- name: search_context
dtype: string
- name: answer
struct:
- name: aliases
sequence: string
- name: normalized_aliases
sequence: string
- name: matched_wiki_entity_name
dtype: string
- name: normalized_matched_wiki_entity_name
dtype: string
- name: normalized_value
dtype: string
- name: type
dtype: string
- name: value
dtype: string
splits:
- name: validation
num_bytes: 430166050
num_examples: 7993
download_size: 234775285
dataset_size: 430166050
---
# Dataset Card for "trivia_qa_wiki_validation"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 1,326 | [
[
-0.037567138671875,
-0.0213623046875,
0.0272979736328125,
0.006824493408203125,
-0.0159912109375,
0.0117645263671875,
0.023345947265625,
-0.0033168792724609375,
0.05029296875,
0.0269012451171875,
-0.05255126953125,
-0.05804443359375,
-0.0102081298828125,
0.0... |
jinmel/simpsons-blip-captions-pil | 2023-02-22T02:17:04.000Z | [
"region:us"
] | jinmel | null | null | 0 | 18 | 2023-02-22T02:02:08 | ---
dataset_info:
features:
- name: text
dtype: string
- name: image
dtype: image
splits:
- name: train
num_bytes: 27091297.0
num_examples: 755
download_size: 26505319
dataset_size: 27091297.0
---
# Dataset Card for "simpsons-blip-captions-pil"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 407 | [
[
-0.043609619140625,
-0.0228271484375,
0.006649017333984375,
0.0305328369140625,
-0.01117706298828125,
0.020050048828125,
-0.00286865234375,
0.01287841796875,
0.058197021484375,
0.03533935546875,
-0.06329345703125,
-0.042205810546875,
-0.047943115234375,
-0.0... |
krr-oxford/OntoLAMA | 2023-08-07T16:22:39.000Z | [
"task_categories:text-classification",
"size_categories:1M<n<10M",
"language:en",
"license:apache-2.0",
"Ontologies",
"Subsumption Inference",
"Natural Language Inference",
"Conceptual Knowledge",
"LMs-as-KBs",
"region:us"
] | krr-oxford | OntoLAMA: LAnguage Model Analysis datasets for Ontology Subsumption Inference. | @inproceedings{he2023language,
title={Language Model Analysis for Ontology Subsumption Inference},
author={He, Yuan and Chen, Jiaoyan and Jim{\'e}nez-Ruiz, Ernesto and Dong, Hang and Horrocks, Ian},
booktitle={Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics},
year={2023}
} | 1 | 18 | 2023-03-02T00:45:25 | ---
license: apache-2.0
task_categories:
- text-classification
tags:
- Ontologies
- Subsumption Inference
- Natural Language Inference
- Conceptual Knowledge
- LMs-as-KBs
pretty_name: OntoLAMA
size_categories:
- 1M<n<10M
language:
- en
dataset_info:
- config_name: schemaorg-atomic-SI
features:
- name: v_sub_concept
dtype: string
- name: v_super_concept
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative_subsumption
'1': positive_subsumption
- name: axiom
dtype: string
splits:
- name: train
num_bytes: 103485
num_examples: 808
- name: validation
num_bytes: 51523
num_examples: 404
- name: test
num_bytes: 361200
num_examples: 2830
download_size: 82558
dataset_size: 516208
- config_name: doid-atomic-SI
features:
- name: v_sub_concept
dtype: string
- name: v_super_concept
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative_subsumption
'1': positive_subsumption
- name: axiom
dtype: string
splits:
- name: train
num_bytes: 15803053
num_examples: 90500
- name: validation
num_bytes: 1978584
num_examples: 11312
- name: test
num_bytes: 1977582
num_examples: 11314
download_size: 3184028
dataset_size: 19759219
- config_name: foodon-atomic-SI
features:
- name: v_sub_concept
dtype: string
- name: v_super_concept
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative_subsumption
'1': positive_subsumption
- name: axiom
dtype: string
splits:
- name: train
num_bytes: 128737404
num_examples: 768486
- name: validation
num_bytes: 16090857
num_examples: 96060
- name: test
num_bytes: 16098373
num_examples: 96062
download_size: 28499028
dataset_size: 160926634
- config_name: go-atomic-SI
features:
- name: v_sub_concept
dtype: string
- name: v_super_concept
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative_subsumption
'1': positive_subsumption
- name: axiom
dtype: string
splits:
- name: train
num_bytes: 152537233
num_examples: 772870
- name: validation
num_bytes: 19060490
num_examples: 96608
- name: test
num_bytes: 19069265
num_examples: 96610
download_size: 32379717
dataset_size: 190666988
- config_name: bimnli
features:
- name: premise
dtype: string
- name: hypothesis
dtype: string
- name: label
dtype:
class_label:
names:
'0': contradiction
'1': entailment
splits:
- name: train
num_bytes: 43363266
num_examples: 235622
- name: validation
num_bytes: 4818648
num_examples: 26180
- name: test
num_bytes: 2420273
num_examples: 12906
download_size: 19264134
dataset_size: 50602187
- config_name: foodon-complex-SI
features:
- name: v_sub_concept
dtype: string
- name: v_super_concept
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative_subsumption
'1': positive_subsumption
- name: axiom
dtype: string
- name: anchor_axiom
dtype: string
splits:
- name: train
num_bytes: 2553731
num_examples: 3754
- name: validation
num_bytes: 1271721
num_examples: 1850
- name: test
num_bytes: 8926305
num_examples: 13080
download_size: 1064602
dataset_size: 12751757
- config_name: go-complex-SI
features:
- name: v_sub_concept
dtype: string
- name: v_super_concept
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative_subsumption
'1': positive_subsumption
- name: axiom
dtype: string
- name: anchor_axiom
dtype: string
splits:
- name: train
num_bytes: 45328802
num_examples: 72318
- name: validation
num_bytes: 5671713
num_examples: 9040
- name: test
num_bytes: 5667069
num_examples: 9040
download_size: 5059364
dataset_size: 56667584
---
# OntoLAMA: LAnguage Model Analysis for Ontology Subsumption Inference
### Dataset Summary
OntoLAMA is a set of language model (LM) probing datasets for ontology subsumption inference.
The work follows the "LMs-as-KBs" literature but focuses on conceptualised knowledge extracted from formalised KBs
such as the OWL ontologies. Specifically, the subsumption inference (SI) task is introduced and formulated in the
Natural Language Inference (NLI) style, where the sub-concept and the super-concept involved in a subsumption
axiom are verbalised and fitted into a template to form the premise and hypothesis, respectively.
The sampled axioms are verified through ontology reasoning. The SI task is further divided into Atomic SI and
Complex SI where the former involves only atomic named concepts and the latter involves both atomic and complex concepts.
Real-world ontologies of different scales and domains are used for constructing OntoLAMA and in total there are four Atomic
SI datasets and two Complex SI datasets.
See dataset specifications: https://krr-oxford.github.io/DeepOnto/ontolama/
### Languages
The text in the dataset is in English, as used in the source ontologies. The associated BCP-47 code is `en`.
## Dataset Structure
### Data Instances
An example in the **Atomic SI** dataset created from the Gene Ontology (GO) is as follows:
```
{
'v_sub_concept': 'ctpase activity',
'v_super_concept': 'ribonucleoside triphosphate phosphatase activity',
'label': 1,
'axiom': 'SubClassOf(<http://purl.obolibrary.org/obo/GO_0043273> <http://purl.obolibrary.org/obo/GO_0017111>)'
}
```
An example in the **Complex SI** dataset created from the Food Ontology (FoodOn) is as follows:
```
{
'v_sub_concept': 'ham and cheese sandwich that derives from some lima bean (whole)',
'v_super_concept': 'lima bean substance',
'label': 0,
'axiom': 'SubClassOf(ObjectIntersectionOf(<http://purl.obolibrary.org/obo/FOODON_03307824> ObjectSomeValuesFrom(<http://purl.obolibrary.org/obo/RO_0001000> <http://purl.obolibrary.org/obo/FOODON_03302053>)) <http://purl.obolibrary.org/obo/FOODON_00002776>)',
'anchor_axiom': 'EquivalentClasses(<http://purl.obolibrary.org/obo/FOODON_00002776> ObjectIntersectionOf(<http://purl.obolibrary.org/obo/FOODON_00002000> ObjectSomeValuesFrom(<http://purl.obolibrary.org/obo/RO_0001000> <http://purl.obolibrary.org/obo/FOODON_03302053>)) )'
}
```
An example in the **biMNLI** dataset created from the MNLI dataset is as follows:
```
{
'premise': 'At the turn of the 19th century Los Angeles and Salt Lake City were among the burgeoning metropolises of the new American West.',
'hypothesis': 'Salt Lake City was booming in the early 19th century.',
'label': 1
}
```
### Data Fields
#### SI Data Fields
- `v_sub_concept`: verbalised sub-concept expression.
- `v_super_concept`: verbalised super-concept expression.
- `label`: a binary class label indicating whether two concepts really form a subsumption relationship (`1` means yes).
- `axiom`: a string representation of the original subsumption axiom which is useful for tracing back to the ontology.
- `anchor_axiom`: (for complex SI only) a string representation of the anchor equivalence axiom used for sampling the `axiom`.
#### biMNLI Data Fields
- `premise`: inheritated from the MNLI dataset.
- `hypothesis`: inheritated from the MNLI dataset.
- `label`: a binary class label indicating `contradiction` (`0`) or `entailment` (`1`).
### Data Splits
| Source | #NamedConcepts | #EquivAxioms | #Dataset (Train/Dev/Test) |
|------------|----------------|--------------|------------------------------------------------------------------------|
| Schema.org | 894 | - | Atomic SI: 808/404/2,830 |
| DOID | 11,157 | - | Atomic SI: 90,500/11,312/11,314 |
| FoodOn | 30,995 | 2,383 | Atomic SI: 768,486/96,060/96,062 <br /> Complex SI: 3,754/1,850/13,080 |
| GO | 43,303 | 11,456 | Atomic SI: 772,870/96,608/96,610 <br /> Complex SI: 72,318/9,040/9,040 |
| MNLI | - | - | biMNLI: 235,622/26,180/12,906 |
### Licensing Information
Creative Commons Attribution 4.0 International
### Citation Information
The relevant paper has been accepted at Findings of ACL 2023.
```
@inproceedings{he-etal-2023-language,
title = "Language Model Analysis for Ontology Subsumption Inference",
author = "He, Yuan and
Chen, Jiaoyan and
Jimenez-Ruiz, Ernesto and
Dong, Hang and
Horrocks, Ian",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2023",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-acl.213",
doi = "10.18653/v1/2023.findings-acl.213",
pages = "3439--3453"
}
``` | 9,212 | [
[
-0.02630615234375,
-0.048675537109375,
0.0310516357421875,
-0.01384735107421875,
0.0160675048828125,
-0.020965576171875,
0.0162811279296875,
-0.023895263671875,
0.0198211669921875,
0.03759765625,
-0.040771484375,
-0.056365966796875,
-0.0301666259765625,
0.00... |
metaeval/counterfactually-augmented-imdb | 2023-03-08T08:55:32.000Z | [
"task_categories:text-classification",
"language:en",
"license:unknown",
"region:us"
] | metaeval | null | null | 0 | 18 | 2023-03-08T08:53:35 | ---
license: unknown
language:
- en
task_categories:
- text-classification
---
```bib
@article{kaushik2020learning,
title={Learning the Difference that Makes a Difference with Counterfactually Augmented Data},
author={Kaushik, Divyansh and Hovy, Eduard and Lipton, Zachary C},
journal={International Conference on Learning Representations (ICLR)},
year={2020}
}
``` | 373 | [
[
-0.0228729248046875,
-0.02825927734375,
0.0196533203125,
-0.02520751953125,
-0.0092926025390625,
0.016326904296875,
0.01189422607421875,
-0.066650390625,
0.04998779296875,
0.0049591064453125,
-0.0282135009765625,
-0.006832122802734375,
-0.06683349609375,
0.0... |
pszemraj/SQuALITY-v1.3-flat | 2023-03-15T17:18:21.000Z | [
"task_categories:text2text-generation",
"task_categories:summarization",
"size_categories:1K<n<10K",
"source_datasets:pszemraj/SQuALITY-v1.3",
"language:en",
"license:apache-2.0",
"region:us"
] | pszemraj | null | null | 2 | 18 | 2023-03-15T17:07:56 | ---
license: apache-2.0
task_categories:
- text2text-generation
- summarization
language:
- en
size_categories:
- 1K<n<10K
source_datasets: pszemraj/SQuALITY-v1.3
---
# SQuALITY-v1.3-flat
A formatted/flat version of [the original](https://huggingface.co/datasets/pszemraj/SQuALITY-v1.3)
--- | 294 | [
[
-0.01983642578125,
-0.03741455078125,
0.001659393310546875,
0.0665283203125,
-0.02740478515625,
-0.0316162109375,
0.00014126300811767578,
-0.007038116455078125,
0.085693359375,
0.052337646484375,
-0.07501220703125,
-0.028717041015625,
-0.0139312744140625,
-0... |
Bingsu/ko_alpaca_data | 2023-03-30T23:21:40.000Z | [
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:ko",
"license:cc-by-nc-4.0",
"region:us"
] | Bingsu | null | null | 11 | 18 | 2023-03-20T05:36:21 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 13791136
num_examples: 49620
download_size: 8491044
dataset_size: 13791136
license: cc-by-nc-4.0
language:
- ko
pretty_name: ko-alpaca-data
size_categories:
- 10K<n<100K
task_categories:
- text-generation
---
# Dataset Card for "ko_alpaca_data"
## Dataset Description
- **Repository:** [Beomi/KoAlpaca](https://github.com/Beomi/KoAlpaca)
- **Huggingface:** [beomi/KoAlpaca](https://huggingface.co/beomi/KoAlpaca)
- **Size of downloaded dataset files:** 8.10 MB
- **Size of the generated dataset:** 13.15 MB
### Dataset Summary
Korean translation of [alpaca data](https://huggingface.co/datasets/tatsu-lab/alpaca).
repository: [Beomi/KoAlpaca](https://github.com/Beomi/KoAlpaca)<br>
huggingface: [beomi/KoAlpaca](https://huggingface.co/beomi/KoAlpaca)
1. Translate dataset
Translated 'instruction' and 'input' in the dataset via the DeepL API, except for 'output', which we did not translate because it is the output of OpenAI's `text-davinci-003` model.
2. Generate output data
Then, using the instruction and input, generate output data via the OpenAI ChatGPT API (gpt-3.5-turbo).
Below is the prompt we used to generate the answer.
```python
PROMPT = """\
다양한 작업에 대한 답변을 생성해주세요. 이러한 작업 지침은 ChatGPT 모델에 주어지며, ChatGPT 모델이 지침을 완료하는지 평가합니다.
요구 사항은 다음과 같습니다:
1. 다양성을 극대화하기 위해 각 지시에 대해 동사를 반복하지 않도록 하세요.
2. 지시에 사용되는 언어도 다양해야 합니다. 예를 들어, 질문과 명령형 지시를 결합해야 합니다.
3. 지시 사항의 유형이 다양해야 합니다. 목록에는 개방형 생성, 분류, 편집 등과 같은 다양한 유형의 작업이 포함되어야 합니다.
2. GPT 언어 모델은 지시를 완료할 수 있어야 합니다. 예를 들어 어시스턴트에게 시각적 또는 오디오 출력을 생성하도록 요청하지 마세요. 또 다른 예로, 어시스턴트가 어떤 작업도 수행할 수 없으므로 오후 5시에 깨우거나 미리 알림을 설정하도록 요청하지 마세요.
3. 답변은 한국어로 작성해야 합니다.
4. 답변을 1~2문장으로 작성하세요. 명령문이나 질문도 허용됩니다.
5. 지시 사항에 대한 적절한 입력을 생성해야 합니다. 입력 필드에는 지시에 대한 구체적인 예가 포함되어야 합니다. 실제 데이터를 포함해야 하며 단순한 자리 표시자를 포함해서는 안 됩니다. 입력은 지시 사항을 어렵게 만들 수 있는 상당한 내용을 제공해야 하지만 100단어를 넘지 않는 것이 이상적입니다.
6. 일부 지시사항은 추가 입력이 있고, 일부 지시에는 입력 필드가 비어있습니다. 예를 들어 "세계에서 가장 높은 봉우리는 무엇인가?"라는 일반적인 정보를 묻는 지시의 경우 구체적인 맥락을 제공할 필요가 없어, 입력 필드가 비어있을 수 있습니다.
7. 출력은 명령어와 입력에 대한 적절한 응답이어야 합니다.
아래에 10개의 명령어와 입력(옵션)에 따라 적절한 응답을 생성하세요.
응답은 아래와 같은 형식으로 10가지를 0번 부터 9번 까지, 번호에 따라 해당 번호의 명령어와 입력에 알맞게 작성하세요.
각 응답 사이는 ### 으로 내용을 분리해주세요.
응답0: 첫 번째 응답내용###
응답1: 두 번째 응답내용###
...
응답9: 마지막 응답내용"""
```
### Lisence
CC-BY-NC-4.0
### Data Splits
| | train |
| --------- | -------- |
| # of data | 49620 |
\# Note that the number is not the same as the original data(52002)
```python
>>> from datasets import load_dataset
>>> ds = load_dataset("Bingsu/ko_alpaca_data", split="train")
>>> ds
Dataset({
features: ['instruction', 'input', 'output'],
num_rows: 49620
})
```
```python
>>> ds[0]
{'instruction': '건강을 유지하기 위한 세 가지 팁을 알려주세요.',
'input': '',
'output': '세 가지 팁은 아침식사를 꼭 챙기며, 충분한 수면을 취하고, 적극적으로 운동을 하는 것입니다.'}
``` | 2,928 | [
[
-0.0478515625,
-0.043853759765625,
0.0181732177734375,
0.0208892822265625,
-0.03521728515625,
-0.0171966552734375,
0.0089874267578125,
-0.017059326171875,
0.04534912109375,
0.026214599609375,
-0.03875732421875,
-0.0322265625,
-0.054718017578125,
0.0105438232... |
reginaboateng/pico_ebmnlp | 2023-03-20T14:02:22.000Z | [
"region:us"
] | reginaboateng | null | null | 0 | 18 | 2023-03-20T14:00:47 | ---
dataset_info:
features:
- name: tokens
sequence: string
- name: chunk_tags
sequence: string
- name: pos_tags
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': I-INT
'2': I-OUT
'3': I-PAR
splits:
- name: train
num_bytes: 27639457
num_examples: 23952
- name: test
num_bytes: 1482730
num_examples: 2064
- name: validation
num_bytes: 7446993
num_examples: 7049
download_size: 4096177
dataset_size: 36569180
---
# Dataset Card for "pico_ebmnlp"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 718 | [
[
-0.042999267578125,
-0.0136871337890625,
0.00156402587890625,
0.019134521484375,
-0.0257720947265625,
-0.005733489990234375,
0.028472900390625,
-0.02728271484375,
0.07171630859375,
0.023406982421875,
-0.05267333984375,
-0.054901123046875,
-0.0361328125,
-0.0... |
potsawee/podcast_summary_assessment | 2023-05-29T23:17:15.000Z | [
"size_categories:1K<n<10K",
"language:en",
"license:cc-by-4.0",
"arxiv:2208.13265",
"region:us"
] | potsawee | null | null | 3 | 18 | 2023-03-20T14:23:36 | ---
license: cc-by-4.0
language:
- en
size_categories:
- 1K<n<10K
dataset_info:
features:
- name: transcript
dtype: string
- name: summary
dtype: string
- name: score
dtype: string
- name: attributes
sequence: int64
- name: episode_id
dtype: string
- name: system_id
dtype: string
splits:
- name: evaluation
num_bytes: 100261033
num_examples: 3580
download_size: 11951831
dataset_size: 100261033
---
# Podcast Summary Assessment
- The description is available in our GitHub repo: https://github.com/potsawee/podcast_summary_assessment
- Paper: [Podcast Summary Assessment: A Resource for Evaluating Summary Assessment Methods](https://arxiv.org/abs/2208.13265)
### Citation Information
```
@article{manakul2022podcast,
title={Podcast Summary Assessment: A Resource for Evaluating Summary Assessment Methods},
author={Manakul, Potsawee and Gales, Mark JF},
journal={arXiv preprint arXiv:2208.13265},
year={2022}
}
``` | 982 | [
[
-0.032012939453125,
-0.01922607421875,
0.0199127197265625,
0.037445068359375,
-0.01554107666015625,
0.006031036376953125,
-0.0151214599609375,
-0.012298583984375,
0.0567626953125,
0.0007023811340332031,
-0.0222015380859375,
-0.02191162109375,
-0.046539306640625,... |
neuclir/csl | 2023-07-05T20:02:54.000Z | [
"task_categories:text-retrieval",
"task_ids:document-retrieval",
"annotations_creators:no-annotation",
"size_categories:100K<n<1M",
"source_datasets:extended|csl",
"language:zh",
"language:en",
"license:apache-2.0",
"region:us"
] | neuclir | null | null | 4 | 18 | 2023-03-20T21:17:19 | ---
annotations_creators:
- no-annotation
language:
- zh
- en
license:
- apache-2.0
pretty_name: CSL
size_categories:
- 100K<n<1M
source_datasets:
- extended|csl
tags: []
task_categories:
- text-retrieval
task_ids:
- document-retrieval
---
# Dataset Card for CSL
## Dataset Description
CSL is the Chinese Scientific Literature Dataset.
- **Paper:** https://aclanthology.org/2022.coling-1.344
- **Repository:** https://github.com/ydli-ai/CSL
### Dataset Summary
The dataset contains titles, abstracts, keywords of papers written in Chinese from several academic fields.
### Languages
- Chinese
- English (translation)
## Dataset Structure
### Data Instances
| Split | Documents |
|-----------------|----------:|
| `csl` | 396k |
| `en_translation`| 396k |
### Data Fields
- `doc_id`: unique identifier for this document
- `title`: title of the paper
- `abstract`: abstract of the paper
- `keywords`: keywords associated with the paper
- `category`: the broad category of the paper
- `category_eng`: English translaction of the broad category (e.g., Engineering)
- `discipline`: academic discipline of the paper
- `discipline_eng`: English translation of the academic discipline (e.g., Agricultural Engineering)
The `en_translation` contains documents translated from Google Translation service.
All text are in English, so the fields `category_eng` and `discipline_eng` are omitted.
## Dataset Usage
Using 🤗 Datasets:
```python
from datasets import load_dataset
dataset = load_dataset('neuclir/csl')['csl']
```
## License & Citation
This dataset is based off the [Chinese Scientific Literature Dataset](https://github.com/ydli-ai/CSL) under Apache 2.0.
The primay change is the addition of `doc_id`s, English translactions of the category and discipline descriptions by a native speaker,
and basic de-duplication. Code that performed this modification is avalable in [this repository](https://github.com/NeuCLIR/csl-preprocess).
If you use this data, please cite:
```
@inproceedings{li-etal-2022-csl,
title = "{CSL}: A Large-scale {C}hinese Scientific Literature Dataset",
author = "Li, Yudong and
Zhang, Yuqing and
Zhao, Zhe and
Shen, Linlin and
Liu, Weijie and
Mao, Weiquan and
Zhang, Hui",
booktitle = "Proceedings of the 29th International Conference on Computational Linguistics",
month = oct,
year = "2022",
address = "Gyeongju, Republic of Korea",
publisher = "International Committee on Computational Linguistics",
url = "https://aclanthology.org/2022.coling-1.344",
pages = "3917--3923",
}
```
| 2,644 | [
[
-0.00505828857421875,
-0.0174713134765625,
0.01232147216796875,
0.0281829833984375,
-0.016265869140625,
0.004543304443359375,
-0.029876708984375,
-0.036102294921875,
0.0141754150390625,
0.0147247314453125,
-0.0284576416015625,
-0.0574951171875,
-0.01503753662109... |
ErfanMoosaviMonazzah/fake-news-detection-dataset-English | 2023-03-23T13:05:33.000Z | [
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:en",
"license:openrail",
"fake news",
"text classification",
"region:us"
] | ErfanMoosaviMonazzah | null | null | 0 | 18 | 2023-03-23T12:55:15 | ---
license: openrail
task_categories:
- text-classification
language:
- en
tags:
- fake news
- text classification
pretty_name: Fake News Detection Dataset (English)
size_categories:
- 10K<n<100K
---
This is a cleaned and splitted version of this dataset (https://www.kaggle.com/datasets/sadikaljarif/fake-news-detection-dataset-english) <br>
Labels:
- Fake News: 0
- Real News: 1
<br>
You can find the cleansing script at: https://github.com/ErfanMoosaviMonazzah/Fake-News-Detection | 487 | [
[
-0.027008056640625,
-0.061920166015625,
0.0123138427734375,
-0.00550079345703125,
-0.0294342041015625,
0.016204833984375,
-0.00006598234176635742,
-0.025787353515625,
0.06121826171875,
0.05584716796875,
-0.059967041015625,
-0.04510498046875,
-0.0309906005859375,... |
maximoss/lingnli-multi-mt | 2023-10-26T17:44:41.000Z | [
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:el",
"language:fr",
"language:it",
"language:es",
"language:pt",
"language:ko",
"language:fi",
"language:lt",
"language:bg",
"license:bsd-2-clause",
"region:us"
] | maximoss | null | null | 1 | 18 | 2023-03-25T12:06:26 | ---
license: bsd-2-clause
language:
- el
- fr
- it
- es
- pt
- ko
- fi
- lt
- bg
task_categories:
- text-classification
size_categories:
- 10K<n<100K
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This repository contains a collection of machine translations of [LingNLI](https://github.com/Alicia-Parrish/ling_in_loop) dataset
into 9 different languages (Bulgarian, Finnish, French, Greek, Italian, Korean, Lithuanian, Portuguese, Spanish). The goal is to predict textual entailment (does sentence A
imply/contradict/neither sentence B), which is a classification task (given two sentences,
predict one of three labels). It is here formatted in the same manner as the widely used [XNLI](https://huggingface.co/datasets/xnli) dataset for convenience.
### Supported Tasks and Leaderboards
This dataset can be used for the task of Natural Language Inference (NLI), also known as Recognizing Textual Entailment (RTE), which is a sentence-pair classification task.
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
- `language`: The language in which the pair of sentences is given.
- `premise`: The machine translated premise in the target language.
- `hypothesis`: The machine translated premise in the target language.
- `label`: The classification label, with possible values 0 (`entailment`), 1 (`neutral`), 2 (`contradiction`).
- `label_text`: The classification label, with possible values `entailment` (0), `neutral` (1), `contradiction` (2).
- `premise_original`: The original premise from the English source dataset.
- `hypothesis_original`: The original hypothesis from the English source dataset.
### Data Splits
For the whole dataset (LitL and LotS subsets):
| language |train|validation|
|-------------|----:|---------:|
|all_languages|269865| 44037|
|el-gr |29985| 4893|
|fr |29985| 4893|
|it |29985| 4893|
|es |29985| 4893|
|pt |29985| 4893|
|ko |29985| 4893|
|fi |29985| 4893|
|lt |29985| 4893|
|bg |29985| 4893|
For LitL subset:
| language |train|validation|
|-------------|----:|---------:|
|all_languages|134955| 21825|
|el-gr |14995| 2425|
|fr |14995| 2425|
|it |14995| 2425|
|es |14995| 2425|
|pt |14995| 2425|
|ko |14995| 2425|
|fi |14995| 2425|
|lt |14995| 2425|
|bg |14995| 2425|
For LotS subset:
| language |train|validation|
|-------------|----:|---------:|
|all_languages|134910| 22212|
|el-gr |14990| 2468|
|fr |14990| 2468|
|it |14990| 2468|
|es |14990| 2468|
|pt |14990| 2468|
|ko |14990| 2468|
|fi |14990| 2468|
|lt |14990| 2468|
|bg |14990| 2468|
## Dataset Creation
The two subsets of the original dataset were machine translated using the latest neural machine translation [opus-mt-tc-big](https://huggingface.co/models?sort=downloads&search=opus-mt-tc-big) models available for the respective languages.
Running the translations lasted from March 25, 2023 until April 8, 2023.
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
````BibTeX
@inproceedings{parrish-etal-2021-putting-linguist,
title = "Does Putting a Linguist in the Loop Improve {NLU} Data Collection?",
author = "Parrish, Alicia and
Huang, William and
Agha, Omar and
Lee, Soo-Hwan and
Nangia, Nikita and
Warstadt, Alexia and
Aggarwal, Karmanya and
Allaway, Emily and
Linzen, Tal and
Bowman, Samuel R.",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2021",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-emnlp.421",
doi = "10.18653/v1/2021.findings-emnlp.421",
pages = "4886--4901",
abstract = "Many crowdsourced NLP datasets contain systematic artifacts that are identified only after data collection is complete. Earlier identification of these issues should make it easier to create high-quality training and evaluation data. We attempt this by evaluating protocols in which expert linguists work {`}in the loop{'} during data collection to identify and address these issues by adjusting task instructions and incentives. Using natural language inference as a test case, we compare three data collection protocols: (i) a baseline protocol with no linguist involvement, (ii) a linguist-in-the-loop intervention with iteratively-updated constraints on the writing task, and (iii) an extension that adds direct interaction between linguists and crowdworkers via a chatroom. We find that linguist involvement does not lead to increased accuracy on out-of-domain test sets compared to baseline, and adding a chatroom has no effect on the data. Linguist involvement does, however, lead to more challenging evaluation data and higher accuracy on some challenge sets, demonstrating the benefits of integrating expert analysis during data collection.",
}
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and
Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
abstract = "This paper presents OPUS-MT a project that focuses on the development of free resources and tools for machine translation. The current status is a repository of over 1,000 pre-trained neural machine translation models that are ready to be launched in on-line translation services. For this we also provide open source implementations of web applications that can run efficiently on average desktop hardware with a straightforward setup and installation.",
}
````
### Acknowledgements
These translations of the original dataset were done as part of a research project supported by the Defence Innovation Agency (AID) of the Directorate General of Armament (DGA) of the French Ministry of Armed Forces, and by the ICO, _Institut Cybersécurité Occitanie_, funded by Région Occitanie, France.
### Contributions
[More Information Needed] | 7,545 | [
[
-0.0245819091796875,
-0.051849365234375,
0.0137939453125,
0.01473236083984375,
-0.0088043212890625,
-0.0094146728515625,
-0.044158935546875,
-0.032257080078125,
0.03271484375,
0.038482666015625,
-0.032257080078125,
-0.05242919921875,
-0.043548583984375,
0.03... |
Francesco/printed-circuit-board | 2023-03-30T09:11:49.000Z | [
"task_categories:object-detection",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:cc",
"rf100",
"region:us"
] | Francesco | null | null | 0 | 18 | 2023-03-30T09:11:16 | ---
dataset_info:
features:
- name: image_id
dtype: int64
- name: image
dtype: image
- name: width
dtype: int32
- name: height
dtype: int32
- name: objects
sequence:
- name: id
dtype: int64
- name: area
dtype: int64
- name: bbox
sequence: float32
length: 4
- name: category
dtype:
class_label:
names:
'0': printed-circuit-board
'1': Button
'2': Capacitor
'3': Capacitor Jumper
'4': Clock
'5': Connector
'6': Diode
'7': EM
'8': Electrolytic Capacitor
'9': Ferrite Bead
'10': IC
'11': Inductor
'12': Jumper
'13': Led
'14': Pads
'15': Pins
'16': Resistor
'17': Resistor Jumper
'18': Resistor Network
'19': Switch
'20': Test Point
'21': Transistor
'22': Unknown Unlabeled
'23': iC
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- en
license:
- cc
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- object-detection
task_ids: []
pretty_name: printed-circuit-board
tags:
- rf100
---
# Dataset Card for printed-circuit-board
** The original COCO dataset is stored at `dataset.tar.gz`**
## Dataset Description
- **Homepage:** https://universe.roboflow.com/object-detection/printed-circuit-board
- **Point of Contact:** francesco.zuppichini@gmail.com
### Dataset Summary
printed-circuit-board
### Supported Tasks and Leaderboards
- `object-detection`: The dataset can be used to train a model for Object Detection.
### Languages
English
## Dataset Structure
### Data Instances
A data point comprises an image and its object annotations.
```
{
'image_id': 15,
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x640 at 0x2373B065C18>,
'width': 964043,
'height': 640,
'objects': {
'id': [114, 115, 116, 117],
'area': [3796, 1596, 152768, 81002],
'bbox': [
[302.0, 109.0, 73.0, 52.0],
[810.0, 100.0, 57.0, 28.0],
[160.0, 31.0, 248.0, 616.0],
[741.0, 68.0, 202.0, 401.0]
],
'category': [4, 4, 0, 0]
}
}
```
### Data Fields
- `image`: the image id
- `image`: `PIL.Image.Image` object containing the image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`
- `width`: the image width
- `height`: the image height
- `objects`: a dictionary containing bounding box metadata for the objects present on the image
- `id`: the annotation id
- `area`: the area of the bounding box
- `bbox`: the object's bounding box (in the [coco](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco) format)
- `category`: the object's category.
#### Who are the annotators?
Annotators are Roboflow users
## Additional Information
### Licensing Information
See original homepage https://universe.roboflow.com/object-detection/printed-circuit-board
### Citation Information
```
@misc{ printed-circuit-board,
title = { printed circuit board Dataset },
type = { Open Source Dataset },
author = { Roboflow 100 },
howpublished = { \url{ https://universe.roboflow.com/object-detection/printed-circuit-board } },
url = { https://universe.roboflow.com/object-detection/printed-circuit-board },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2022 },
month = { nov },
note = { visited on 2023-03-29 },
}"
```
### Contributions
Thanks to [@mariosasko](https://github.com/mariosasko) for adding this dataset. | 4,030 | [
[
-0.050811767578125,
-0.040130615234375,
0.0281982421875,
-0.01499176025390625,
-0.04400634765625,
-0.01203155517578125,
0.0006132125854492188,
-0.030609130859375,
0.01287078857421875,
0.0284423828125,
-0.04833984375,
-0.06890869140625,
-0.035064697265625,
0.... |
A-Roucher/english_historical_quotes | 2023-05-17T12:49:06.000Z | [
"task_categories:text-classification",
"task_categories:conversational",
"task_categories:fill-mask",
"size_categories:10K<n<100K",
"language:en",
"license:mit",
"history",
"philosophy",
"art",
"region:us"
] | A-Roucher | null | null | 2 | 18 | 2023-04-03T12:51:19 | ---
license: mit
language:
- en
tags:
- history
- philosophy
- art
pretty_name: Historical Quotes - English
size_categories:
- 10K<n<100K
task_categories:
- text-classification
- conversational
- fill-mask
---
Dataset Card for English Historical Quotes
# I-Dataset Summary
english_historical_quotes is a dataset of many historical quotes.
This dataset can be used for multi-label text classification and text generation. The content of each quote is in English.
# II-Supported Tasks and Leaderboards
Multi-label text classification : The dataset can be used to train a model for text-classification, which consists of classifying quotes by author as well as by topic (using tags). Success on this task is typically measured by achieving a high or low accuracy.
Text-generation : The dataset can be used to train a model to generate quotes by fine-tuning an existing pretrained model on the corpus composed of all quotes (or quotes by author).
# III-Languages
The texts in the dataset are in English (en).
# IV-Dataset Structure
Data Instances
A JSON-formatted example of a typical instance in the dataset:
{"quote":"Almost anyone can be an author the business is to collect money and fame from this state of being.",
"author":"A. A. Milne",
"categories": "['business', 'money']"
}
### Data Fields
author : The author of the quote.
quote : The text of the quote.
tags: The tags could be characterized as topics around the quote.
### Data Splits
The dataset is one block, so that it can be further processed using Hugging Face `datasets` functions like the ``.train_test_split() method.
# V-Dataset Creation
Curation Rationale
The goal is to share good datasets with the HuggingFace community so that they can use them in NLP tasks and advance artificial intelligence.
### Source Data
The data has been aggregated from various open-access internet archives. Then it has been manually refined, duplicates and false quotes removed by me.
It is the backbone of my website [dixit.app](http://dixit.app), which allows to search historical quotes through semantic search.
# VI-Additional Informations
Dataset Curators
Aymeric Roucher
Licensing Information
This work is licensed under a MIT License. | 2,232 | [
[
-0.0260772705078125,
-0.045135498046875,
-0.00036907196044921875,
0.01209259033203125,
-0.0244140625,
-0.003871917724609375,
-0.012359619140625,
-0.027740478515625,
0.030731201171875,
0.048553466796875,
-0.059906005859375,
-0.048309326171875,
-0.029052734375,
... |
alexl83/AlpacaDataCleaned | 2023-04-09T23:42:35.000Z | [
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-4.0",
"instruction-finetuning",
"region:us"
] | alexl83 | null | null | 0 | 18 | 2023-04-09T22:52:22 | ---
license: cc-by-4.0
language:
- en
tags:
- instruction-finetuning
pretty_name: Alpaca-Cleaned
task_categories:
- text-generation
size_categories:
- 10K<n<100K
---
# Dataset Card for Alpaca-Cleaned
- **Repository:** https://github.com/gururise/AlpacaDataCleaned
## Dataset Description
This is a cleaned version of the original Alpaca Dataset released by Stanford. The following issues have been identified in the original release and fixed in this dataset:
1. **Hallucinations:** Many instructions in the original dataset had instructions referencing data on the internet, which just caused GPT3 to hallucinate an answer.
```
"instruction":"Summarize the given article in 200 Words.",
"input": "https://www.bbc.com/news/world-51461830",
"output": "The recent protests in Belarus are part of a growing wave of discontent against the rule of Alexander Lukashenko, who has led the country since 1994. Demonstrations against his government have been ongoing since August, and come in the wake of an election widely seen as rigged. As police and security forces have cracked down on protesters, the movement has only grown, with hundreds of thousands of people taking to the streets to call for new leadership. Human rights activists have accused the government of using extreme violence in order prosecute protesters, leading to an international outcry and sanctions from the European Union. As the situation in Belarus continues to unfold, the international community is monitoring the situation closely - hoping for a peaceful resolution, while also standing firm against the oppressive tactics employed by the Belarusian state."
"instruction": "Classify the following shape according to simple geometry.",
"input": "<Picture Attached>",
"output": "Triangle"
"instruction": "Given a recent news article, write a headline for it.",
"input": "https://www.news.example.com/article-1",
"output": "\"NASA Launches a Mars 2020 Mission to Search for Signs of Ancient Life\""
```
2. **Merged Instructions:** There were many instructions that were merged together in the original dataset for some reason.
```
"instruction": "Should I invest in stocks?",
"input": "",
"output": "It depends on your individual situation. Investing in stocks carries a certain amount of risk but can also offer potential rewards. Make sure to research the different types of stocks, understand the risks and rewards, and develop a plan that works for you.\n##\n18. Instruction: Identify the noun in the following sentence:\n18. Input:\nThe large apple was delicious.\n18. Output:\nApple"
```
3. **Empty outputs:** Some entries in the original dataset had empty outputs.
```
"instruction": "Calculate the area of the following shape in square centimeters.",
"input": "rectangle of size 4 cm x 5 cm",
"output": ""
```
4. **Empty code examples:** Some descriptions in the original dataset were missing code examples, making it difficult to understand the intended behavior of the code.
5. **Instructions to generate images:** Some descriptions in the original dataset included instructions to generate images, something obviously not possible.
```
"instruction": "Create a graphic or logo that visually represents the word \"courage\".",
"input": "",
"output": "<No Output>"
```
6. **N/A outputs:** Some code snippets in the original dataset had N/A outputs.
7. **Inconsistent input field:** The original dataset had inconsistent usage of the input field when it was supposed to be empty.
```
"input":"<no input>"
"input":"No input"
"input":"noinput"
"input":"<noinput>"
```
8. **Wrong answers:** Some instructions/questions in the original dataset had incorrect answers. About 80% of the math problems are estimated to have incorrect answers.
```
"instruction": "Calculate the median of the following data set.",
"input": "1, 2, 4, 5, 8, 9",
"output": "5"
"instruction": "Convert 25m to km.",
"input": "",
"output": "25km"
```
9. **Non-Sensical/Unclear instructions:** Many instructions are unclear, we try to clarify (or re-write) if instructions are non-sensical. Instructions that are slightly unclear, but where one could deduce the meaning are not altered.
```
"instruction": "Freeze the following sample of yogurt for 10 minutes.",
"input": "Yogurt sample",
"output": "<noinput>"
"instruction": "Increase the font size to 12 points.",
"input": "",
"output": "The font size has been increased to 12 points."
```
10. **Extraneous escape and control characters:** The original dataset had several entries with extraneous escape and control characters.
### Original Alpaca Dataset Summary
Alpaca is a dataset of 52,000 instructions and demonstrations generated by OpenAI's `text-davinci-003` engine. This instruction data can be used to conduct instruction-tuning for language models and make the language model follow instruction better.
The authors built on the data generation pipeline from [Self-Instruct framework](https://github.com/yizhongw/self-instruct) and made the following modifications:
- The `text-davinci-003` engine to generate the instruction data instead of `davinci`.
- A [new prompt](https://github.com/tatsu-lab/stanford_alpaca/blob/main/prompt.txt) was written that explicitly gave the requirement of instruction generation to `text-davinci-003`.
- Much more aggressive batch decoding was used, i.e., generating 20 instructions at once, which significantly reduced the cost of data generation.
- The data generation pipeline was simplified by discarding the difference between classification and non-classification instructions.
- Only a single instance was generated for each instruction, instead of 2 to 3 instances as in Self-Instruct.
This produced an instruction-following dataset with 52K examples obtained at a much lower cost (less than $500).
In a preliminary study, the authors also found that the 52K generated data to be much more diverse than the data released by [Self-Instruct](https://github.com/yizhongw/self-instruct/blob/main/data/seed_tasks.jsonl).
### Supported Tasks and Leaderboards
The Alpaca dataset designed for instruction training pretrained language models.
### Languages
The data in Alpaca are in English (BCP-47 en).
## Dataset Structure
### Data Instances
An example of "train" looks as follows:
```json
{
"instruction": "Create a classification task by clustering the given list of items.",
"input": "Apples, oranges, bananas, strawberries, pineapples",
"output": "Class 1: Apples, Oranges\nClass 2: Bananas, Strawberries\nClass 3: Pineapples",
"text": "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\nCreate a classification task by clustering the given list of items.\n\n### Input:\nApples, oranges, bananas, strawberries, pineapples\n\n### Response:\nClass 1: Apples, Oranges\nClass 2: Bananas, Strawberries\nClass 3: Pineapples",
}
```
### Data Fields
The data fields are as follows:
* `instruction`: describes the task the model should perform. Each of the 52K instructions is unique.
* `input`: optional context or input for the task. For example, when the instruction is "Summarize the following article", the input is the article. Around 40% of the examples have an input.
* `output`: the answer to the instruction as generated by `text-davinci-003`.
* `text`: the `instruction`, `input` and `output` formatted with the [prompt template](https://github.com/tatsu-lab/stanford_alpaca#data-release) used by the authors for fine-tuning their models.
### Data Splits
| | train |
|---------------|------:|
| alpaca | 52002 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
Excerpt the [blog post](https://crfm.stanford.edu/2023/03/13/alpaca.html) accompanying the release of this dataset:
> We believe that releasing the above assets will enable the academic community to perform controlled scientific studies on instruction-following language models, resulting in better science and ultimately new techniques to address the existing deficiencies with these models. At the same time, any release carries some risk. First, we recognize that releasing our training recipe reveals the feasibility of certain capabilities. On one hand, this enables more people (including bad actors) to create models that could cause harm (either intentionally or not). On the other hand, this awareness might incentivize swift defensive action, especially from the academic community, now empowered by the means to perform deeper safety research on such models. Overall, we believe that the benefits for the research community outweigh the risks of this particular release. Given that we are releasing the training recipe, we believe that releasing the data, model weights, and training code incur minimal further risk, given the simplicity of the recipe. At the same time, releasing these assets has enormous benefits for reproducible science, so that the academic community can use standard datasets, models, and code to perform controlled comparisons and to explore extensions. Deploying an interactive demo for Alpaca also poses potential risks, such as more widely disseminating harmful content and lowering the barrier for spam, fraud, or disinformation. We have put into place two risk mitigation strategies. First, we have implemented a content filter using OpenAI’s content moderation API, which filters out harmful content as defined by OpenAI’s usage policies. Second, we watermark all the model outputs using the method described in Kirchenbauer et al. 2023, so that others can detect (with some probability) whether an output comes from Alpaca 7B. Finally, we have strict terms and conditions for using the demo; it is restricted to non-commercial uses and to uses that follow LLaMA’s license agreement. We understand that these mitigation measures can be circumvented once we release the model weights or if users train their own instruction-following models. However, by installing these mitigations, we hope to advance the best practices and ultimately develop community norms for the responsible deployment of foundation models.
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
The `alpaca` data is generated by a language model (`text-davinci-003`) and inevitably contains some errors or biases. We encourage users to use this data with caution and propose new methods to filter or improve the imperfections.
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
The dataset is available under the [Creative Commons NonCommercial (CC BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/legalcode).
### Citation Information
```
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tatsu-lab/stanford_alpaca}},
}
```
### Contributions
[More Information Needed] | 11,634 | [
[
-0.03314208984375,
-0.0794677734375,
0.017303466796875,
-0.0014142990112304688,
-0.0136566162109375,
-0.0229034423828125,
-0.00012433528900146484,
-0.02386474609375,
0.02264404296875,
0.04864501953125,
-0.06903076171875,
-0.04803466796875,
-0.05084228515625,
... |
marianna13/libgen | 2023-04-13T22:32:38.000Z | [
"region:us"
] | marianna13 | null | null | 1 | 18 | 2023-04-12T20:51:23 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
snipaid/snippet-mlsum-500-v2 | 2023-04-19T18:26:42.000Z | [
"task_categories:summarization",
"task_categories:text2text-generation",
"size_categories:n<1K",
"language:de",
"license:mit",
"news",
"headline",
"teaser",
"keywords",
"tweet",
"serp",
"summary",
"news snippets",
"region:us"
] | snipaid | null | null | 0 | 18 | 2023-04-17T17:44:25 | ---
license: mit
language: de
tags:
- news
- headline
- teaser
- keywords
- tweet
- serp
- summary
- news snippets
task_categories:
- summarization
- text2text-generation
size_categories:
- n<1K
---
# Dataset Card for Snippet-MLSUM-500-V2
### Dataset Summary
This dataset is a sample of ~500 news articles from the [MLSUM](https://huggingface.co/datasets/mlsum) dataset, augmented with machine generated news snippets.
### Supported Tasks
This dataset was created to support the task of generating news snippets such as title, teaser, keywords, serp and tweet for news articles in German language.
### Languages
de - German
## Dataset Structure
text: a string feature.
title: a string feature.
teaser: a string feature.
keywords: a string feature.
summary: a string feature.
serp: a string feature.
tweet: a string feature.
url: a string feature.
date: a string feature.
topic: a string feature.
## Dataset Creation
The news articles in this dataset are a random sample of ~500 news articles from MLSUM balanced by topic.
Features text, title, teaser (originally summary in MLSUM), url, date and topic are copied from MLSUM.
Features keywords, serp, summary and tweet are machine generated with GPT-3.5.
Generated features comply with length limits in place for SERPs and Tweets at the time of publishing.
## Considerations for Using the Data
### Known Limitations
Part of the snippet data is machine generated. Be aware that these features (specifically: keywords, serp, summary and tweet) may exhibit signs of model hallucination, stereotypes and toxicity.
## Additional Information
### Licensing Information
This dataset is licensed under MIT license. | 1,698 | [
[
-0.0218658447265625,
-0.03497314453125,
0.0173187255859375,
0.0122528076171875,
-0.03009033203125,
0.0009274482727050781,
-0.0118560791015625,
-0.0109405517578125,
0.034515380859375,
0.0477294921875,
-0.060211181640625,
-0.07470703125,
-0.035430908203125,
0.... |
joey234/mmlu-college_medicine-neg | 2023-04-20T05:27:33.000Z | [
"region:us"
] | joey234 | null | null | 0 | 18 | 2023-04-20T04:51:32 | ---
dataset_info:
features:
- name: choices
sequence: string
- name: answer
dtype:
class_label:
names:
'0': A
'1': B
'2': C
'3': D
- name: question
dtype: string
splits:
- name: test
num_bytes: 51318
num_examples: 173
download_size: 33920
dataset_size: 51318
---
# Dataset Card for "mmlu-college_medicine-neg"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 532 | [
[
-0.030242919921875,
-0.03204345703125,
0.017974853515625,
-0.0183258056640625,
-0.00455474853515625,
-0.0035648345947265625,
0.021514892578125,
-0.0017747879028320312,
0.0718994140625,
0.0144195556640625,
-0.06964111328125,
-0.05963134765625,
-0.0562744140625,
... |
LennardZuendorf/openlegaldata-bulk-data | 2023-10-07T19:45:45.000Z | [
"task_categories:text-classification",
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:de",
"license:mit",
"legal",
"region:us"
] | LennardZuendorf | null | null | 3 | 18 | 2023-04-24T07:58:53 | ---
license: mit
task_categories:
- text-classification
- text-generation
language:
- de
tags:
- legal
pretty_name: openlegaldata.io bulk case data
size_categories:
- 100K<n<1M
---
# Dataset Card for openlegaldata.io bulk case data
## Dataset Description
This is the copy of the lastest dump from [openlegaldata.io](https://de.openlegaldata.io/). I will try to keep this updated, since there is no offical Huggingface Dataset Repo.
- **Homepage:** [https://de.openlegaldata.io/](https://de.openlegaldata.io/)
- **Repository:** [Bulk Data](https://static.openlegaldata.io/dumps/de/)
### Dataset Summary
This is the openlegaldata bulk case download from October 2022. Please refer to the offical website (above) for any more information. I have not made any changes for it, since I use a different datasets to for projects.
### Languages
- German
## Additional Information
### Licensing/Citation Information
The [openlegaldata platform](https://github.com/openlegaldata/oldp) is licensed under the MIT license, you can access the dataset by citing the original source, [openlegaldata.io](https://de.openlegaldata.io/) | 1,126 | [
[
-0.029296875,
-0.030517578125,
-0.00016391277313232422,
0.031951904296875,
-0.03143310546875,
-0.026275634765625,
-0.01031494140625,
-0.018035888671875,
0.040924072265625,
0.040985107421875,
-0.0272216796875,
-0.054229736328125,
-0.01837158203125,
-0.0115280... |
oyxy2019/THUCNewsText | 2023-05-10T03:05:21.000Z | [
"region:us"
] | oyxy2019 | null | null | 1 | 18 | 2023-05-10T02:59:44 | ---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype:
class_label:
names:
'0': education
'1': entertainment
'2': fashion
'3': finance
'4': game
'5': politic
'6': society
'7': sport
'8': stock
'9': technology
splits:
- name: train
num_bytes: 126435258
num_examples: 50000
- name: validation
num_bytes: 12851939
num_examples: 5000
- name: test
num_bytes: 25321290
num_examples: 9890
download_size: 110495565
dataset_size: 164608487
---
# Dataset Card for "THUCNewsText"
这是[seamew/THUCNewsText](https://huggingface.co/datasets/seamew/THUCNewsText)的克隆,试图解决谷歌硬盘国内无法访问的问题443
```python
from datasets import load_dataset
datasets = load_dataset("seamew/THUCNewsText")
datasets.push_to_hub("oyxy2019/THUCNewsText")
``` | 898 | [
[
-0.0158843994140625,
-0.034881591796875,
-0.0006070137023925781,
0.0615234375,
-0.049224853515625,
-0.0015687942504882812,
-0.01102447509765625,
-0.01142120361328125,
0.03485107421875,
0.03643798828125,
-0.04620361328125,
-0.045318603515625,
-0.032012939453125,
... |
Norod78/caricature-portraits-blip-captions-512 | 2023-05-23T13:40:26.000Z | [
"size_categories:1K<n<10K",
"license:cc-by-nc-sa-4.0",
"text-to-image",
"region:us"
] | Norod78 | null | null | 1 | 18 | 2023-05-23T13:30:51 | ---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 1663841422.423
num_examples: 5619
download_size: 1662924830
dataset_size: 1663841422.423
pretty_name: Caricature portraits - Blip captions
license: cc-by-nc-sa-4.0
tags:
- text-to-image
size_categories:
- 1K<n<10K
---
# Dataset Card for "caricature-portraits-blip-captions-512"
## The 2D Caricature Dataset from [3D-CariGAN](https://github.com/qq775193759/3D-CariGAN) cropped to 512x512 and blip captioned
```
@article{ye2021caricature,
author = {Ye, Zipeng and Xia, Mengfei and Sun, Yanan and Yi, Ran and Yu, Minjing and Zhang, Juyong and Lai, Yu-Kun and Liu, Yong-Jin},
title = {3D-CariGAN: An End-to-End Solution to 3D Caricature Generation from Normal Face Photos},
journal = {IEEE Transactions on Visualization and Computer Graphics},
year = {2021},
doi={10.1109/TVCG.2021.3126659},
}
``` | 945 | [
[
-0.032470703125,
-0.01120758056640625,
0.0164794921875,
0.03326416015625,
-0.022125244140625,
-0.002002716064453125,
0.00022363662719726562,
-0.03533935546875,
0.031829833984375,
0.05023193359375,
-0.05255126953125,
-0.036529541015625,
-0.01708984375,
0.0082... |
ccmusic-database/piano_sound_quality | 2023-11-02T15:56:01.000Z | [
"task_categories:audio-classification",
"size_categories:n<1K",
"language:en",
"license:mit",
"music",
"art",
"arxiv:2310.04722",
"region:us"
] | ccmusic-database | Piano-Sound-Quality-Database is a dataset of piano sound.
It consists of 8 kinds of pianos including PearlRiver, YoungChang, Steinway-T, Hsinghai,
Kawai, Steinway, Kawai-G, Yamaha(recorded by Shaohua Ji with SONY PCM-D100).
Data was annotated by students from the China Conservatory of Music (CCMUSIC) in Beijing
and collected by George Chou. | @dataset{zhaorui_liu_2021_5676893,
author = {Zhaorui Liu, Monan Zhou, Shenyang Xu and Zijin Li},
title = {{Music Data Sharing Platform for Computational Musicology Research (CCMUSIC DATASET)}},
month = nov,
year = 2021,
publisher = {Zenodo},
version = {1.1},
doi = {10.5281/zenodo.5676893},
url = {https://doi.org/10.5281/zenodo.5676893}
} | 2 | 18 | 2023-05-25T11:32:28 | ---
license: mit
task_categories:
- audio-classification
language:
- en
tags:
- music
- art
pretty_name: Piano Sound Quality Dataset
size_categories:
- n<1K
viewer: false
---
# Dataset Card for Piano Sound Quality Dataset
## Requirements
```
python 3.8-3.10
soundfile
librosa
```
## Usage
```
from datasets import load_dataset
data = load_dataset("ccmusic-database/piano_sound_quality", split="train")
labels = data.features['label'].names
for item in data:
print('audio info: ', item['audio'])
print('label name: ' + labels[item['label']])
```
## Maintenance
```
git clone git@hf.co:datasets/ccmusic-database/piano_sound_quality
```
## Dataset Description
- **Homepage:** <https://ccmusic-database.github.io>
- **Repository:** <https://huggingface.co/datasets/CCMUSIC/piano_sound_quality>
- **Paper:** <https://doi.org/10.5281/zenodo.5676893>
- **Leaderboard:** <https://ccmusic-database.github.io/team.html>
- **Point of Contact:** <https://arxiv.org/abs/2310.04722>
### Dataset Summary
This dataset contains 12 gamut audio files (.wav / .mp3 / .m4a format) and 1320 split single-tone audio files (.wav / .mp3 / .m4a format) of 7 types of pianos (Kawai upright piano, Kawai grand piano, YOUNG CHANG upright piano, HSINGHAI upright piano, Steinway grand piano in grand theatre, Steinway grand piano and Pearl River upright piano) in the piano-room of China Conservatory of Music, a total of 1332 files. In addition, there is a questionnaire on subjective evaluation of piano sound quality (.xls format), including the score of 29 people participating in the subjective evaluation of piano sound quality.
### Supported Tasks and Leaderboards
Piano Sound Classification, pitch detection
### Languages
English
## Dataset Structure
### Data Instances
.zip(.wav)
### Data Fields
```
1_PearlRiver
2_YoungChang
3_Steinway-T
4_Hsinghai
5_Kawai
6_Steinway
7_Kawai-G
8_Yamaha
```
### Data Splits
train, validation, test
## Dataset Creation
### Curation Rationale
Lack of a dataset for piano sound quality
### Source Data
#### Initial Data Collection and Normalization
Zhaorui Liu, Shaohua Ji, Monan Zhou
#### Who are the source language producers?
Students from CCMUSIC
### Annotations
#### Annotation process
Students from CCMUSIC recorded different piano sounds and labeled them, and then a subjective survey of sound quality was conducted to score them.
#### Who are the annotators?
Students from CCMUSIC
### Personal and Sensitive Information
None
## Considerations for Using the Data
### Social Impact of Dataset
Help developing piano sound quality rating apps
### Discussion of Biases
Only for pianos
### Other Known Limitations
No black key in Steinway
## Additional Information
### Dataset Curators
Zijin Li
### Evaluation
[Monan Zhou, Shangda Wu, Shaohua Ji, Zijin Li, and Wei Li. A Holistic Evaluation of Piano Sound Quality[C]//Proceedings of the 6th Conference on Sound and Music Technology (CSMT). Springer, Singapore, 2023.](https://arxiv.org/pdf/2310.04722.pdf)
Note: this paper only uses the first 7 piano classes of the dataset.
### Licensing Information
```
MIT License
Copyright (c) CCMUSIC
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
```
### Citation Information
```
@dataset{zhaorui_liu_2021_5676893,
author = {Zhaorui Liu, Monan Zhou, Shenyang Xu, Wei Li, Zhaowen Wang and Zijin Li},
title = {CCMUSIC DATABASE: A Music Data Sharing Platform for Computational Musicology Research},
month = {nov},
year = {2021},
publisher = {Zenodo},
version = {1.1},
doi = {10.5281/zenodo.5676893},
url = {https://doi.org/10.5281/zenodo.5676893}
}
```
### Contributions
Provide a dataset for piano sound quality | 4,692 | [
[
-0.04132080078125,
-0.033599853515625,
0.01727294921875,
0.0174102783203125,
-0.0330810546875,
-0.0145111083984375,
-0.042327880859375,
-0.022247314453125,
0.0070953369140625,
0.03955078125,
-0.049835205078125,
-0.08245849609375,
-0.01419830322265625,
-0.002... |
Mutonix/RefGPT-Fact | 2023-05-30T13:33:07.000Z | [
"task_categories:conversational",
"size_categories:10K<n<100K",
"language:zh",
"language:en",
"license:apache-2.0",
"arxiv:2305.14994",
"region:us"
] | Mutonix | null | null | 11 | 18 | 2023-05-26T01:37:53 | ---
license: apache-2.0
dataset_info:
features:
- name: dialogue
dtype: string
- name: reference
dtype: string
- name: language
dtype: string
- name: type
dtype: string
splits:
- name: zh
num_bytes: 180760081
num_examples: 50000
- name: en
num_bytes: 464054853
num_examples: 50000
download_size: 260969665
dataset_size: 644814934
task_categories:
- conversational
language:
- zh
- en
arxiv: https://arxiv.org/abs/2305.14994
size_categories:
- 10K<n<100K
---
# Dataset Card for RefGPT-Fact
## Dataset Description
- **Homepage:**
- **Repository:** [https://github.com/ziliwangnlp/RefGPT](https://github.com/ziliwangnlp/RefGPT)
- **Paper:** [https://arxiv.org/abs/2305.14994](https://arxiv.org/abs/2305.14994)
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
<p align="center">
<a href="https://arxiv.org/abs/2305.14994"><b>[Paper] RefGPT</b></a> |
<a href="https://github.com/ziliwangnlp/RefGPT"><b>[Github] RefGPT</b></a>
</p>
RefGPT-Fact is a datasets containing 100k multi-turn dialogues about factual knowledge with 50k English and 50k Chinese. The English version uses the English Wikipedia as the reference and the Chinese version uses the frequently-used Chinese online encyclopedia website, Baidu Baike.
### Supported Tasks and Leaderboards
Chatbot instruction finetuning
### Languages
Chinese, English
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
Please pay attention that RefGPT Datasets, including RefGPT-Fact and RefGPT-Code, have not undergone manual verification, and as such, their security cannot be strictly guaranteed. Users should be aware that they are responsible for the results generated using this data.
### Discussion of Biases
As the datasets RefGPT-Fact and RefGPT-Code are collected by using the references like Wikipedia and Github repositories, it can not be avoided that the reference itself has factual errors, typos, or bugs and malicious code if it is from Github repositories. The datasets may also reflect the biases of the selected references and GPT-3.5/GPT-4 model
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
```bibtex
@misc{yang2023refgpt,
title={RefGPT: Reference -> Truthful & Customized Dialogues Generation by GPTs and for GPTs},
author={Dongjie Yang and Ruifeng Yuan and YuanTao Fan and YiFei Yang and Zili Wang and Shusen Wang and Hai Zhao},
year={2023},
eprint={2305.14994},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions
[More Information Needed] | 3,317 | [
[
-0.0248870849609375,
-0.045318603515625,
0.01505279541015625,
0.011810302734375,
-0.0213165283203125,
-0.0183563232421875,
-0.022857666015625,
-0.0257415771484375,
0.0068817138671875,
0.0271453857421875,
-0.0440673828125,
-0.040283203125,
-0.032745361328125,
... |
atasoglu/flickr8k-dataset | 2023-05-28T12:12:43.000Z | [
"task_categories:image-to-text",
"task_categories:text-to-image",
"size_categories:1K<n<10K",
"language:en",
"region:us"
] | atasoglu | null | null | 0 | 18 | 2023-05-28T11:52:48 | ---
task_categories:
- image-to-text
- text-to-image
language:
- en
pretty_name: flickr8k
size_categories:
- 1K<n<10K
---
You must download the dataset files manually. You can visit [this](https://github.com/jbrownlee/Datasets/releases/tag/Flickr8k) page or run `download.sh` to get files.
After, you can load dataset by referencing the directory:
```py
import datasets
ds = datasets.load_dataset("atasoglu/flickr8k-dataset", data_dir="data")
print(ds)
```
```
DatasetDict({
train: Dataset({
features: ['image_id', 'image_path', 'captions'],
num_rows: 6000
})
test: Dataset({
features: ['image_id', 'image_path', 'captions'],
num_rows: 1000
})
validation: Dataset({
features: ['image_id', 'image_path', 'captions'],
num_rows: 1000
})
})
```
I don't own the copyright of the images. Please [visit](https://forms.illinois.edu/sec/1713398) for more. | 923 | [
[
-0.041595458984375,
0.00743865966796875,
-0.00156402587890625,
0.000911712646484375,
-0.03399658203125,
-0.0027904510498046875,
0.0207977294921875,
-0.0007014274597167969,
-0.0025043487548828125,
0.036956787109375,
-0.03582763671875,
-0.01079559326171875,
-0.038... |
TigerResearch/tigerbot-kaggle-recipes-en-2k | 2023-05-31T02:23:57.000Z | [
"language:en",
"license:apache-2.0",
"region:us"
] | TigerResearch | null | null | 0 | 18 | 2023-05-30T15:09:09 | ---
license: apache-2.0
language:
- en
---
[Tigerbot](https://github.com/TigerResearch/TigerBot) 基于公开的数据集生成的食谱类sft数据集
<p align="center" width="40%">
原始来源:[https://www.kaggle.com/datasets/zeeenb/recipes-from-tasty?select=ingredient_and_instructions.json](https://www.kaggle.com/datasets/zeeenb/recipes-from-tasty?select=ingredient_and_instructions.json)
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/tigerbot-kaggle-recipes-en-2k')
```
| 475 | [
[
-0.00878143310546875,
-0.058929443359375,
0.006954193115234375,
0.0248260498046875,
-0.020843505859375,
-0.0122833251953125,
-0.0031337738037109375,
0.005275726318359375,
0.05194091796875,
0.052276611328125,
-0.04876708984375,
-0.034820556640625,
-0.026824951171... |
emad12/stock_tweets_sentiment | 2023-06-04T09:48:20.000Z | [
"region:us"
] | emad12 | null | null | 3 | 18 | 2023-06-02T09:10:31 | ---
dataset_info:
features:
- name: 'Unnamed: 0'
dtype: int64
- name: post_date
dtype: string
- name: tweet
dtype: string
- name: sentiment
dtype: int64
- name: ticker_symbol
dtype: string
- name: tweet_cleaned
dtype: string
- name: __index_level_0__
dtype: int64
- name: input_ids
sequence: int32
- name: token_type_ids
sequence: int8
- name: attention_mask
sequence: int8
splits:
- name: train
num_bytes: 321710487
num_examples: 96000
- name: test
num_bytes: 80421371
num_examples: 24000
download_size: 32053237
dataset_size: 402131858
---
# Dataset Card for "stock_tweets_sentiment"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 806 | [
[
-0.0271759033203125,
-0.00836944580078125,
-0.0020427703857421875,
0.03875732421875,
-0.03289794921875,
0.0275115966796875,
0.00627899169921875,
0.01035308837890625,
0.07763671875,
0.01282501220703125,
-0.05950927734375,
-0.07379150390625,
-0.056976318359375,
... |
d0rj/HC3-ru | 2023-06-05T12:46:32.000Z | [
"task_categories:text-classification",
"task_categories:question-answering",
"task_categories:sentence-similarity",
"task_categories:zero-shot-classification",
"language_creators:translated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:Hello-SimpleAI/HC3",
"language... | d0rj | null | null | 1 | 18 | 2023-06-05T08:37:51 | ---
task_categories:
- text-classification
- question-answering
- sentence-similarity
- zero-shot-classification
language_creators:
- translated
language:
- ru
multilinguality:
- monolingual
tags:
- ChatGPT
- SimpleAI
- Detection
- OOD
size_categories:
- 10K<n<100K
license: cc-by-sa-4.0
pretty_name: HC3 (ru)
source_datasets:
- Hello-SimpleAI/HC3
dataset_info:
features:
- name: id
dtype: string
- name: question
dtype: string
- name: human_answers
sequence: string
- name: chatgpt_answers
sequence: string
- name: source
dtype: string
splits:
- name: train
num_bytes: 135406074.0
num_examples: 24322
download_size: 62739799
dataset_size: 135406074.0
---
# Dataset Card for "HC3-ru"
This is translated version of [Hello-SimpleAI/HC3 dataset](https://huggingface.co/datasets/Hello-SimpleAI/HC3) into Russian.
## Citation
Checkout this papaer [arxiv: 2301.07597](https://arxiv.org/abs/2301.07597)
```
@article{guo-etal-2023-hc3,
title = "How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection",
author = "Guo, Biyang and
Zhang, Xin and
Wang, Ziyuan and
Jiang, Minqi and
Nie, Jinran and
Ding, Yuxuan and
Yue, Jianwei and
Wu, Yupeng",
journal={arXiv preprint arxiv:2301.07597}
year = "2023",
}
``` | 1,340 | [
[
-0.00829315185546875,
-0.03436279296875,
0.016632080078125,
-0.002349853515625,
-0.0193939208984375,
-0.018402099609375,
-0.0174102783203125,
-0.033966064453125,
0.00970458984375,
0.01177978515625,
-0.023773193359375,
-0.053619384765625,
-0.03204345703125,
0... |
ejschwartz/oo-method-test | 2023-09-03T14:34:23.000Z | [
"task_categories:text-classification",
"license:bsd",
"region:us"
] | ejschwartz | null | null | 1 | 18 | 2023-06-07T19:33:55 | ---
license: bsd
task_categories:
- text-classification
#task_ids:
#- binary-classification
dataset_info:
features:
- name: Binary
dtype: string
- name: Addr
dtype: string
- name: Name
dtype: string
- name: Type
dtype:
class_label:
names:
'0': func
'1': method
- name: Disassembly
dtype: string
config_name: ejschwartz--oo-method-test
splits:
- name: combined
num_bytes: 6054378861
num_examples: 3537794
download_size: 1351783459
dataset_size: 6054378861
train-eval-index:
- config: default # The dataset config name to use. Example for datasets without configs: default. Example for glue: sst2
task: text-classification # The task category name (same as task_category). Example: question-answering
task_id: binary_classification # The AutoTrain task id. Example: extractive_question_answering
splits:
#train_split: train # The split to use for training. Example: train
eval_split: train # The split to use for evaluation. Example: test
col_mapping: # The columns mapping needed to configure the task_id.
Disassembly: text
Type: target
metrics:
- type: accuracy # The metric id. Example: wer. Use metric id from https://hf.co/metrics
name: accuracy # Tne metric name to be displayed. Example: Test WER
---
# Dataset Card for OO Method Test Dataset
## Dataset Description
### Dataset Summary
This dataset describes compiled functions in various [small, simple C++ programs](https://github.com/sei-eschwartz/buildexes/tree/master/tests/src/oo).
These programs were automatically compiled using various versions of Microsoft's Visual C++ compiler and different compilation settings. The details can be found
in the [BuildExes](https://github.com/sei-eschwartz/buildexes) repository.
For each function, the dataset includes a disassembled (using ROSE's `bat-dis` tool) representation of the compiled code, its name, and whether the function is a OO method or not.
**This dataset is largely intended for @ejschwartz to experiment with learning techniques and tools. The programs are artificial and are likely not representative of real programs.**
### Supported Tasks and Leaderboards
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed] | 2,503 | [
[
-0.039276123046875,
-0.052154541015625,
0.0026683807373046875,
-0.01031494140625,
0.00196075439453125,
0.00827789306640625,
0.00605010986328125,
-0.030975341796875,
0.01195526123046875,
0.02557373046875,
-0.044708251953125,
-0.05340576171875,
-0.0113449096679687... |
Patt/ReCoRD_TH | 2023-06-14T16:50:48.000Z | [
"task_categories:text-classification",
"language:en",
"language:th",
"arxiv:1907.04307",
"region:us"
] | Patt | null | null | 0 | 18 | 2023-06-14T16:36:15 | ---
task_categories:
- text-classification
language:
- en
- th
---
# Dataset Card for ReCoRD_TH
### Dataset Description
This dataset is Thai translated version of [ReCoRD](https://huggingface.co/datasets/super_glue/viewer/record) using google translate with [Multilingual Universal Sentence Encoder](https://arxiv.org/abs/1907.04307) to calculate score for Thai translation. | 377 | [
[
-0.00444793701171875,
-0.0338134765625,
-0.0055084228515625,
0.0214080810546875,
-0.04522705078125,
0.00009882450103759766,
-0.01485443115234375,
-0.007843017578125,
0.043548583984375,
0.039093017578125,
-0.04498291015625,
-0.06683349609375,
-0.041595458984375,
... |
d0rj/alpaca-cleaned-ru | 2023-07-13T07:25:01.000Z | [
"task_categories:text-generation",
"language_creators:translated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:yahma/alpaca-cleaned",
"language:ru",
"license:cc-by-4.0",
"instruction-finetuning",
"region:us"
] | d0rj | null | null | 2 | 18 | 2023-06-16T19:05:58 | ---
dataset_info:
features:
- name: input
dtype: string
- name: instruction
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 74829755.0
num_examples: 51760
download_size: 36596664
dataset_size: 74829755.0
license: cc-by-4.0
language:
- ru
multilinguality:
- monolingual
tags:
- instruction-finetuning
pretty_name: Alpaca-Cleaned (ru)
task_categories:
- text-generation
size_categories:
- 10K<n<100K
source_datasets:
- yahma/alpaca-cleaned
language_creators:
- translated
---
# alpaca-cleaned-ru
Translated version of [yahma/alpaca-cleaned](https://huggingface.co/datasets/yahma/alpaca-cleaned) into Russian.
## Dataset Description
- **Repository:** https://github.com/gururise/AlpacaDataCleaned | 760 | [
[
-0.006496429443359375,
-0.0394287109375,
0.0027332305908203125,
0.0178375244140625,
-0.055877685546875,
-0.011871337890625,
0.00399017333984375,
-0.038360595703125,
0.060394287109375,
0.04571533203125,
-0.057586669921875,
-0.0450439453125,
-0.043609619140625,
... |
richardr1126/spider-schema | 2023-06-28T19:40:49.000Z | [
"source_datasets:spider",
"language:en",
"license:cc-by-4.0",
"text-to-sql",
"region:us"
] | richardr1126 | null | null | 0 | 18 | 2023-06-21T03:05:05 | ---
language:
- en
license:
- cc-by-4.0
source_datasets:
- spider
pretty_name: Spider Schema
tags:
- text-to-sql
dataset_info:
features:
- name: db_id
dtype: string
- name: Schema (values (type))
dtype: string
- name: Primary Keys
dtype: string
- name: Foreign Keys
dtype: string
---
# Dataset Card for Spider Schema
### Dataset Summary
Spider is a large-scale complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 Yale students
The goal of the Spider challenge is to develop natural language interfaces to cross-domain databases.
This dataset contains the 166 databases used in the Spider dataset.
### Yale Lily Spider Leaderboards
The leaderboard can be seen at https://yale-lily.github.io/spider
### Languages
The text in the dataset is in English.
### Licensing Information
The spider dataset is licensed under
the [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/legalcode)
### Citation
```
@article{yu2018spider,
title={Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task},
author={Yu, Tao and Zhang, Rui and Yang, Kai and Yasunaga, Michihiro and Wang, Dongxu and Li, Zifan and Ma, James and Li, Irene and Yao, Qingning and Roman, Shanelle and others},
journal={arXiv preprint arXiv:1809.08887},
year={2018}
}
``` | 1,365 | [
[
-0.004985809326171875,
-0.0243988037109375,
0.0183868408203125,
0.0020923614501953125,
-0.007404327392578125,
0.01885986328125,
-0.004268646240234375,
-0.03277587890625,
0.032928466796875,
0.0228729248046875,
-0.042877197265625,
-0.06219482421875,
-0.03869628906... |
portuguese-benchmark-datasets/BLUEX | 2023-09-19T01:02:52.000Z | [
"arxiv:2307.05410",
"region:us"
] | portuguese-benchmark-datasets | null | null | 3 | 18 | 2023-06-22T23:40:14 | ---
dataset_info:
features:
- name: question
dtype: string
- name: number
dtype: int64
- name: id
dtype: string
- name: alternatives
sequence: string
- name: associated_images
sequence: string
- name: answer
dtype: string
- name: has_associated_images
dtype: bool
- name: alternatives_type
dtype: string
- name: subject
sequence: string
- name: TU
dtype: bool
- name: IU
dtype: bool
- name: MR
dtype: bool
- name: ML
dtype: bool
- name: BK
dtype: bool
- name: PRK
dtype: bool
splits:
- name: questions
num_bytes: 54794231
num_examples: 1098
download_size: 49630117
dataset_size: 54794231
---
# BLUEX
There is a repository with the minimal code for using this dataset available [here](https://github.com/Portuguese-Benchmark-Datasets/BLUEX). If you use this dataset for research, please cite the paper:
```bibtex
@misc{almeida2023bluex,
title={BLUEX: A benchmark based on Brazilian Leading Universities Entrance eXams},
author={Thales Sales Almeida and Thiago Laitz and Giovana K. Bonás and Rodrigo Nogueira},
year={2023},
eprint={2307.05410},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` | 1,238 | [
[
-0.028106689453125,
-0.0091094970703125,
0.01837158203125,
0.0284576416015625,
-0.01105499267578125,
-0.0115814208984375,
-0.01021575927734375,
-0.012664794921875,
0.0006814002990722656,
0.018524169921875,
-0.0144805908203125,
-0.056060791015625,
0.0029869079589... |
FreedomIntelligence/alpaca-gpt4-hindi | 2023-08-06T08:09:23.000Z | [
"region:us"
] | FreedomIntelligence | null | null | 0 | 18 | 2023-06-26T08:18:03 | The dataset is used in the research related to [MultilingualSIFT](https://github.com/FreedomIntelligence/MultilingualSIFT). | 124 | [
[
-0.0284271240234375,
-0.0214385986328125,
-0.000301361083984375,
0.01971435546875,
-0.004512786865234375,
0.004093170166015625,
-0.0194091796875,
-0.0303192138671875,
0.0289154052734375,
0.033966064453125,
-0.0643310546875,
-0.032958984375,
-0.012969970703125,
... |
Waterhorse/chess_data | 2023-08-14T18:35:02.000Z | [
"task_categories:text-generation",
"task_categories:conversational",
"language:en",
"license:apache-2.0",
"arxiv:2306.09200",
"region:us"
] | Waterhorse | null | null | 2 | 18 | 2023-06-28T13:54:28 | ---
license: apache-2.0
task_categories:
- text-generation
- conversational
language:
- en
---
# The Chess Dataset
## Dataset Description
- **Paper:** [ChessGPT: Bridging Policy Learning and Language Modeling](https://arxiv.org/abs/2306.09200)
### Dataset Summary
The dataset consists of three sources of dataset described in the paper, including:
- **ChessCLIP dataset**: Annotated PGNs for training CLIP.
- **ChessGPT Base dataset**: Game dataset, language dataset and mixed dataset for training ChessGPT-Base.
- **ChessGPT Chat dataset**: Conversational dataset for training ChessGPT-Chat.
Because of the legal issue, for ChessGPT dataset, we do not open-source the chess-book, chess-forum, chess-blog, and Youtube transcript datasets.
And for ChessCLIP dataset, we do not open-source two commercial annotated datasets we use.
### Languages
The language of the data is primarily English.
## Dataset Structure
- **ChessCLIP dataset**: Annotated PGNs for training CLIP.
- **ChessGPT Base dataset**: Game dataset: ccrl, pro_player, lichess_db_37, chess_puzzles, chess_modeling. Language dataset: redpajama, oscar, c4, pile, wikipedia, and stackexchange, and mixed dataset: annotated_pgn.
- **ChessGPT Chat dataset**: Chess-related conversation dataset:
### Data Instances
- **ChessCLIP dataset**:
```python
[Event "GMA, Wijk aan Zee NED"]
[Site "?"]
[Date "2003.??.??"]
[Round "1"]
[White "Anand,V"]
[Black "Radjabov,T"]
[Result "1/2"]
[WhiteElo "2750"]
[BlackElo "2620"]
[ECO "C12"]
[PlyCount "55"]
[Annotator "Hathaway"]
1. e4 e6
{ I'm not terribly familiar with the style of Radjabov, so I don't know if this is his usual opening. }
2. d4 d5 3. Nc3 Nf6 (3...Bb4
{ The Winawer Variation is probably best, though not as easy to play. }) 4. Bg5
{ threatens e4-e5xf6 }
(4. e5
{ keeps pieces on the board and avoids ...dxe4 }) 4...Bb4 (4...Be7
{ is more common and aims to trade dark-square bishops to ease Black's cramp }) (4...dxe4
{ aims to avoid any cramp by bringing pieces into alignment for trading, though White does get at least one very good piece (Ne4 or Bg5) and an easier time castling queen-side, to stir up king-side threats } ...
```
- **ChessGPT dataset**:
```python
{"metadata": {"id": "65268522",
"title": "1923 USSR Chess Championship",
"url": "https://en.wikipedia.org/wiki/1923%20USSR%20Chess%20Championship"},
"text": "The 1923 USSR Chess Championship was the second edition of USSR Chess Championship. Held from 8 to 24 July in Petrograd. The tournament was won by Peter Romanovsky.
"pipeline_key": "wiki-squad-train.jsonl.zst-10549"
}
```
- **ChessGPT Chat dataset**:
```python
{"conversations": [
{"author": "Human 0", "text": "Analyze the given sentence and identify its grammatical errors, if any.\nThese type of problems are difficult to solve.", "url": "gpt-4-alpaca", "score": 0},
{"author": "Human 1", "text": "The sentence is incorrect. The error is in the usage of \"these\". Since \"these\" is a plural determiner, it should be used with a plural noun. Similarly, \"type\" is singular noun and it is used with the singular determiner, \"this\".\n\nThe correct sentence should be \"This type of problem is difficult to solve.\" or \"These types of problems are difficult to solve.\"",
"url": "gpt-4-alpaca", "score": 0}
]
}
```
### Data Splits
The data is unsplit.
## Dataset Creation
Check [ChessGPT: Bridging Policy Learning and Language Modeling](https://arxiv.org/abs/2306.09200) for more details.
### Licensing Information
**Annotated PGN**: [PGNlib](https://www.angelfire.com/games3/smartbridge/), [lichess](https://lichess.org/terms-of-service), [GameKnot](https://gameknot.com/pg/pol_eula.htm), [pathtomaster](https://www.pathtochessmastery.com/)
**Game Dataset**: [Lichess dataset](https://www.tldrlegal.com/license/creative-commons-cc0-1-0-universal), [CCRL](https://ccrl.chessdom.com/ccrl/), [pro-player](https://www.pgnmentor.com/files.html), [puzzle](https://www.tldrlegal.com/license/creative-commons-cc0-1-0-universal), Modeling data(Apache-2.0).
**Language Dataset** [Wikipedia](https://huggingface.co/datasets/wikipedia#licensing-information), [Redpajama](https://github.com/togethercomputer/RedPajama-Data#license), [Oscar](https://huggingface.co/datasets/oscar-corpus/OSCAR-2301#licensing-information), [Pile](https://github.com/EleutherAI/the-pile/blob/master/LICENSE), [StackExchange](https://archive.org/details/stackexchange), [C4](https://huggingface.co/datasets/allenai/c4#license)
**Conversatoinal Datset**: [Chessable forums](https://www.chessable.com/terms), [Reddit](https://www.redditinc.com/policies/data-api-terms), [gpt-4](https://openai.com/policies/terms-of-use), [sharegpt](https://chrome.google.com/webstore/detail/sharegpt-share-your-chatg/daiacboceoaocpibfodeljbdfacokfjb), oasst1(Apache-2.0), dolly-v2(MIT)
### Citation Information
```bash
@article{feng2023chessgpt,
title={ChessGPT: Bridging Policy Learning and Language Modeling},
author={Feng, Xidong and Luo, Yicheng and Wang, Ziyan and Tang, Hongrui and Yang, Mengyue and Shao, Kun and Mguni, David and Du, Yali and Wang, Jun},
journal={arXiv preprint arXiv:2306.09200},
year={2023}
}
``` | 5,243 | [
[
-0.0274200439453125,
-0.050750732421875,
0.026885986328125,
0.027496337890625,
-0.0155029296875,
0.00955963134765625,
-0.0303955078125,
-0.0242767333984375,
0.016845703125,
0.042022705078125,
-0.0406494140625,
-0.05792236328125,
-0.0277557373046875,
-0.00749... |
yonatanbitton/SeeTRUE | 2023-07-09T10:49:46.000Z | [
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:en",
"license:cc-by-4.0",
"image-captioning",
"text-image-matching",
"arxiv:2305.10400",
"region:us"
] | yonatanbitton | null | null | 1 | 18 | 2023-07-09T08:41:32 | ---
annotations_creators:
- crowdsourced
language:
- en
language_creators:
- found
license:
- cc-by-4.0
multilinguality:
- monolingual
paperswithcode_id: seetrue
pretty_name: SeeTRUE
size_categories:
- 1K<n<10K
source_datasets:
- original
tags:
- image-captioning
- text-image-matching
task_ids: []
extra_gated_prompt: "By clicking on “Access repository” below, you also agree that you are using it solely for research purposes, and that SeeTRUE should be used as a *TEST SET*, not as a training set, and especially not to train commercial chatbots. Do not hessitate to contact yonatanbitton@google.com if you have questions about this license."
---
# Dataset Card for SeeTRUE
- [Dataset Description](#dataset-description)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
The SeeTRUE dataset is a diverse benchmark for meta-evaluation of image-text alignment methods, covering the 4-way combinations of real and synthetic text-and-image pairs. It addresses limitations in current benchmarks, which mainly focus on natural images and often lack challenging negative captions. SeeTRUE allows to better assess the generalization abilities of text-image alignment models across various tasks.
We will add more datasets from SeeTRUE (e.g., COCO-Con and PickaPic-Con) upon data release.
Paper: https://arxiv.org/abs/2305.10400
Website: https://wysiwyr-itm.github.io/
### Languages
The dataset supports English language.
## Dataset Structure
### Data Fields
- image: The name of the image file.
- text: The text description that matches with the image.
- label: The binary label. 1 if the text matches with the image, 0 otherwise.
- original_dataset_id: The ID of the dataset where the row originates from.
- dataset_source: The source of the dataset.
### Data Splits
SeeTRUE contains a single split: TEST, and should not be used for training.
## Dataset Creation
The dataset has been created by sourcing and matching images and text from multiple datasets. More information in the paper: https://arxiv.org/abs/2305.10400.
### Licensing Information
The dataset is under the CC-By 4.0 license.
### Citation Information
@article{yarom2023you,
title={What You See is What You Read? Improving Text-Image Alignment Evaluation},
author={Yarom, Michal and Bitton, Yonatan and Changpinyo, Soravit and Aharoni, Roee and Herzig, Jonathan and Lang, Oran and Ofek, Eran and Szpektor, Idan},
journal={arXiv preprint arXiv:2305.10400},
year={2023}
} | 2,774 | [
[
-0.02716064453125,
-0.021392822265625,
0.00373077392578125,
-0.0013742446899414062,
-0.035400390625,
-0.004848480224609375,
-0.0189208984375,
-0.0552978515625,
0.01548004150390625,
0.028167724609375,
-0.0550537109375,
-0.05853271484375,
-0.05023193359375,
0.... |
DynamicSuperb/SpeechTextMatching_LJSpeech | 2023-07-12T11:11:34.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 18 | 2023-07-09T13:17:45 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: text
dtype: string
- name: instruction
dtype: string
- name: label
dtype: string
- name: transcription
dtype: string
splits:
- name: test
num_bytes: 3802579053.0
num_examples: 13100
download_size: 3786166384
dataset_size: 3802579053.0
---
# Dataset Card for "speechTextMatching_LJSpeech"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 564 | [
[
-0.02349853515625,
-0.025115966796875,
0.007297515869140625,
0.0185394287109375,
-0.0011739730834960938,
0.0135498046875,
-0.0117645263671875,
-0.01306915283203125,
0.06622314453125,
0.031280517578125,
-0.057098388671875,
-0.053985595703125,
-0.039703369140625,
... |
iamshnoo/alpaca-cleaned-persian | 2023-09-15T23:20:43.000Z | [
"region:us"
] | iamshnoo | null | null | 0 | 18 | 2023-07-31T04:55:58 | ---
dataset_info:
features:
- name: input
dtype: string
- name: instruction
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 57273102
num_examples: 51760
download_size: 25446305
dataset_size: 57273102
---
Translated from yahma/alpaca-cleaned using NLLB-1.3B
# Dataset Card for "alpaca-cleaned-persian"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 500 | [
[
-0.042572021484375,
-0.05780029296875,
0.00434112548828125,
0.0072174072265625,
-0.04986572265625,
-0.01253509521484375,
0.000339508056640625,
-0.04803466796875,
0.060943603515625,
0.0572509765625,
-0.061676025390625,
-0.0413818359375,
-0.036651611328125,
-0... |
p208p2002/csl-electrical-engineering | 2023-07-31T06:10:11.000Z | [
"task_categories:summarization",
"task_categories:text-generation",
"size_categories:1K<n<10K",
"language:zh",
"region:us"
] | p208p2002 | null | null | 0 | 18 | 2023-07-31T05:29:30 | ---
task_categories:
- summarization
- text-generation
language:
- zh
size_categories:
- 1K<n<10K
configs:
- config_name: zh-tw
data_files:
- split: train
path: "elec_tradionnal.csv"
- config_name: zh-cn
data_files:
- split: train
path: "elec_simplified.csv"
---
### csl-electrical-engineering"
由[CSL數據集](https://github.com/ydli-ai/CSL)分割出來的電機工程(Electrical Engineering)子集,提供簡繁兩種版本。
```python
from datasets import load_dataset
dataset = load_dataset("p208p2002/csl-electrical-engineering","zh-cn")
dataset = load_dataset("p208p2002/csl-electrical-engineering","zh-tw")
``` | 588 | [
[
-0.0206146240234375,
-0.0367431640625,
0.012908935546875,
0.0491943359375,
-0.00986480712890625,
0.01898193359375,
0.0018053054809570312,
0.009429931640625,
0.00023066997528076172,
0.00853729248046875,
-0.04107666015625,
-0.035125732421875,
-0.01529693603515625,... |
songlab/human_variants | 2023-10-12T15:11:22.000Z | [
"region:us"
] | songlab | null | null | 0 | 18 | 2023-08-02T02:39:24 | # Human variants
A curated set of variants from three sources: ClinVar, COSMIC, OMIM and gnomAD.
Predictions for methods benchmarked in GPN-MSA paper can be [downloaded from here](https://huggingface.co/datasets/songlab/human_variants/resolve/main/variants_and_preds.parquet).
Functional annotations can be [downloaded from here](https://huggingface.co/datasets/songlab/human_variants/resolve/main/functional_annotations.zip).
For more information check out our [paper](https://doi.org/10.1101/2023.10.10.561776) and [repository](https://github.com/songlab-cal/gpn).
## Data sources
**ClinVar**:
Missense variants considered "Pathogenic" by human labelers.
**COSMIC**:
Somatic missense variants with a frequency at least 0.1% in cancer samples (whole-genome and whole-exome sequencing only).
**OMIM**:
Regulatory variants considered "Pathogenic" by human labelers, curated in [this paper](https://doi.org/10.1016/j.ajhg.2016.07.005).
**gnomAD**:
All common variants (MAF > 5%) as well as an equally-sized subset of rare variants (MAC=1). Only autosomes are included.
## Usage
```python
from datasets import load_dataset
dataset = load_dataset("songlab/human_variants", split="test")
```
Subset - ClinVar Pathogenic vs. gnomAD common (missense) (can specify `num_proc` to speed up):
```python
dataset = dataset.filter(lambda v: v["source"]=="ClinVar" or (v["label"]=="Common" and "missense" in v["consequence"]))
```
Subset - COSMIC frequent vs. gnomAD common (missense):
```python
dataset = dataset.filter(lambda v: v["source"]=="COSMIC" or (v["label"]=="Common" and "missense" in v["consequence"]))
```
Subset - OMIM Pathogenic vs. gnomAD common (regulatory):
```python
cs = ["5_prime_UTR", "upstream_gene", "intergenic", "3_prime_UTR", "non_coding_transcript_exon"]
dataset = dataset.filter(lambda v: v["source"]=="OMIM" or (v["label"]=="Common" and "missense" not in v["consequence"] and any([c in v["consequence"] for c in cs])))
```
Subset - gnomAD rare vs. gnomAD common:
```python
dataset = dataset.filter(lambda v: v["source"]=="gnomAD")
``` | 2,061 | [
[
-0.0216827392578125,
-0.036407470703125,
0.016998291015625,
-0.00867462158203125,
-0.0112152099609375,
-0.00975799560546875,
-0.0045166015625,
-0.04168701171875,
0.033782958984375,
0.040985107421875,
-0.050079345703125,
-0.0560302734375,
-0.04052734375,
0.03... |
Suchinthana/databricks-dolly-15k-sinhala | 2023-10-02T15:01:00.000Z | [
"language:si",
"license:cc-by-sa-3.0",
"region:us"
] | Suchinthana | null | null | 0 | 18 | 2023-08-11T22:44:18 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: ' context'
dtype: string
- name: ' response'
dtype: string
- name: category
dtype: string
splits:
- name: train
num_bytes: 28834788
num_examples: 15011
download_size: 12352414
dataset_size: 28834788
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: cc-by-sa-3.0
language:
- si
---
# Dataset Card for "databricks-dolly-15k-sinhala"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 620 | [
[
-0.01399993896484375,
-0.01934814453125,
-0.01473236083984375,
0.034271240234375,
-0.02996826171875,
0.00751495361328125,
0.0285186767578125,
0.0021991729736328125,
0.061065673828125,
0.03692626953125,
-0.058624267578125,
-0.041473388671875,
-0.03375244140625,
... |
saahith/synthetic_with_val | 2023-08-19T20:06:03.000Z | [
"region:us"
] | saahith | null | null | 0 | 18 | 2023-08-19T20:03:48 | ---
dataset_info:
features:
- name: audio
dtype: audio
- name: transcript
dtype: string
- name: duration
dtype: float64
splits:
- name: train
num_bytes: 316158980.0
num_examples: 405
- name: validation
num_bytes: 67400894.0
num_examples: 86
- name: test
num_bytes: 69350700.0
num_examples: 88
download_size: 347775630
dataset_size: 452910574.0
---
# Dataset Card for "synthetic_with_val"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 576 | [
[
-0.042510986328125,
-0.03643798828125,
0.01849365234375,
0.0197296142578125,
-0.005725860595703125,
0.0158233642578125,
0.029449462890625,
-0.0233612060546875,
0.06414794921875,
0.04345703125,
-0.0704345703125,
-0.043487548828125,
-0.02764892578125,
-0.00553... |
seungheondoh/audioset-music | 2023-08-23T03:09:25.000Z | [
"language:en",
"license:mit",
"music",
"audioset",
"arxiv:2302.03917",
"region:us"
] | seungheondoh | null | null | 1 | 18 | 2023-08-23T02:20:43 | ---
license: mit
language:
- en
tags:
- music
- audioset
pretty_name: audioset-music
---
# Dataset Card for "audioset-music"
audioset-subset using 130 music mid from [noise2music](https://arxiv.org/abs/2302.03917)
```
[
'/m/0z9c','/m/0mkg','/m/042v_gx','/m/0fd3y','/t/dd00036','/m/025td0t','/m/0192l','/m/018j2','/m/0bm02','/m/018vs','/m/02cz_7','/m/0395lw','/m/0gg8l','/m/0155w','/m/0l14_3',
'/m/01kcd','/m/015vgc','/m/01xqw','/m/02bk07','/m/0l14jd','/m/02mscn','/m/0140xf','/m/01wy6','/m/0ggq0m','/m/01lyv','/m/0239kh','/m/01qbl','/m/0ggx5q','/m/02bxd','/m/026z9',
'/m/02fsn','/m/0283d','/m/02hnl','/m/02k_mr','/m/026t6','/m/07s72n','/m/02sgy','/m/08cyft','/m/02lkt','/m/03xq_f','/m/0m0jc','/t/dd00035','/m/0326g','/m/0l14j_','/m/02w4v',
'/m/0319l','/m/02x8m','/t/dd00032','/m/0dwtp','/m/0mbct','/m/0dls3','/m/0342h','/m/03gvt','/t/dd00031','/m/03qjg','/m/03m5k','/m/03q5t','/m/03lty','/m/0glt670','/m/03mb9',
'/m/05rwpb','/m/03_d0','/m/03r5q_','/m/05148p4','/m/07pkxdp','/m/0j45pbj','/m/04rzd','/m/0dwsp','/m/06j64v','/m/05fw6t','/m/0164x2','/m/028sqc','/m/0dq0md','/m/0g293',
'/m/02v2lh','/m/05pd6','/m/013y1f','/m/0l14md','/m/05r5c','/m/0fx80y','/m/064t9','/m/0dl5d','/m/05w3f','/m/05r6t','/m/05r5wn','/m/06cqb','/m/06j6l','/m/03t3fj','/m/07sbbz2',
'/m/06by7','/t/dd00033','/m/0ln16','/m/06ncr','/t/dd00037','/m/01hgjl','/m/0l14l2','/m/0l14t7','/m/0jtg0','/m/06rqw','/m/06rvn','/m/0gywn','/m/0l14gg','/m/06w87','/m/0l156b',
'/m/02qmj0d','/m/07s0s5r','/m/015y_n','/m/0l14qv','/m/01p970','/m/07brj','/m/01glhc','/m/07gxw','/t/dd00034','/m/02cjck','/m/07kc_','/m/011k_j','/m/02p0sh1','/m/07lnk',
'/m/07c6l','/m/07gql','/m/016622','/m/07xzm','/m/0dwt5','/m/01z7dr','/m/07y_7','/m/0y4f8','/m/04wptg','/m/085jw','/m/01sm1g','/m/01bns_'
]
```
```
[
'A capella','Accordion','Acoustic guitar','Ambient music','Angry music',
'Background music','Bagpipes','Banjo','Bass drum','Bass guitar','Beatboxing','Bell','Bluegrass','Blues','Bowed string instrument','Brass instrument',
'Carnatic music','Cello','Chant','Choir','Christian music','Christmas music','Clarinet','Classical music','Country','Cowbell','Cymbal',
'Dance music','Didgeridoo','Disco','Double bass','Drum and bass','Drum kit','Drum roll','Drum','Dubstep',
'Electric guitar','Electronic dance music','Electronic music','Electronic organ','Electronica','Exciting music',
'Flamenco','Flute','Folk music','French horn','Funk','Funny music',
'Glockenspiel','Gong','Grunge','Guitar',
'Hammond organ','Happy music','Harmonica','Harp','Harpsichord','Heavy metal','Hip hop music','House music',
'Independent music',
'Jazz','Jingle (music)',
'Keyboard (musical)',
'Lullaby',
'Mallet percussion','Mandolin','Marimba, xylophone','Middle Eastern music','Music for children','Music of Africa','Music of Asia','Music of Bollywood','Music of Latin America',
'New-age music',
'Orchestra','Organ',
'Percussion','Piano','Plucked string instrument','Pop music','Progressive rock','Psychedelic rock','Punk rock',
'Rattle (instrument)','Reggae','Rhythm and blues','Rimshot','Rock and roll','Rock music',
'Sad music','Salsa music','Saxophone','Scary music','Scratching (performance technique)','Shofar','Singing bowl','Sitar','Ska','Snare drum','Soul music','Soundtrack music','Steel guitar, slide guitar','Steelpan','String section','Strum','Swing music','Synthesizer',
'Tabla','Tambourine','Tapping (guitar technique)','Techno','Tender music','Theme music','Theremin','Timpani','Traditional music','Trance music','Trombone','Trumpet','Tubular bells',
'Ukulele',
'Vibraphone','Video game music','Violin, fiddle','Vocal music',
'Wedding music','Wind instrument, woodwind instrument','Wood block',
'Zither'
]
``` | 3,756 | [
[
-0.0478515625,
-0.016326904296875,
0.01021575927734375,
0.017730712890625,
-0.02423095703125,
0.0211639404296875,
0.006237030029296875,
-0.014373779296875,
0.058990478515625,
0.031707763671875,
-0.06658935546875,
-0.0426025390625,
-0.024078369140625,
0.01921... |
coconutzhang/ghc_session_data_v2 | 2023-08-29T21:26:51.000Z | [
"region:us"
] | coconutzhang | null | null | 0 | 18 | 2023-08-24T05:03:05 | ---
dataset_info:
features:
- name: User
dtype: string
- name: Prompt
dtype: string
splits:
- name: train
num_bytes: 307868
num_examples: 1215
download_size: 140534
dataset_size: 307868
---
# Dataset Card for "ghc_session_data_v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 393 | [
[
-0.01513671875,
-0.0308990478515625,
0.037933349609375,
-0.01227569580078125,
-0.028839111328125,
-0.0010366439819335938,
0.035369873046875,
-0.02532958984375,
0.054656982421875,
0.031219482421875,
-0.04693603515625,
-0.043487548828125,
-0.031341552734375,
-... |
lamini/bird_spider_train_text_to_sql | 2023-08-28T07:11:21.000Z | [
"region:us"
] | lamini | null | null | 2 | 18 | 2023-08-28T07:11:14 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 34428892
num_examples: 16428
- name: test
num_bytes: 1090039
num_examples: 1034
download_size: 3799750
dataset_size: 35518931
---
# Dataset Card for "bird_spider_train_text_to_sql"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 595 | [
[
-0.022308349609375,
-0.01364898681640625,
-0.0037212371826171875,
0.023162841796875,
-0.018707275390625,
-0.00324249267578125,
0.018768310546875,
-0.0187225341796875,
0.05255126953125,
0.02313232421875,
-0.049163818359375,
-0.041046142578125,
-0.0443115234375,
... |
tmskss/linux-man-pages-tldr-summarized | 2023-08-29T13:36:33.000Z | [
"task_categories:summarization",
"language:en",
"region:us"
] | tmskss | null | null | 3 | 18 | 2023-08-28T09:02:16 | ---
task_categories:
- summarization
language:
- en
pretty_name: Linux man pages and the corresponding TLDR page
---
# Dataset Card for linux-man-pages-tldr-summarized
### Dataset Summary
This dataset contains linux man pages downloaded from [man7](https://man7.org/), with a prefix: 'summarize: ', and the corresponding summarization downloaded from [TLDR-pages](https://github.com/tldr-pages/tldr/).
### Supported Tasks
This dataset should be used to fine-tune language models for summarization tasks. | 507 | [
[
-0.0301055908203125,
-0.0101318359375,
0.006072998046875,
-0.00273895263671875,
-0.0389404296875,
0.0216217041015625,
-0.0084381103515625,
0.0073089599609375,
0.03240966796875,
0.04473876953125,
-0.03790283203125,
-0.054901123046875,
-0.02423095703125,
0.017... |
nampdn-ai/mini-FLAN | 2023-09-05T04:29:00.000Z | [
"region:us"
] | nampdn-ai | null | null | 2 | 18 | 2023-09-04T07:32:40 | Entry not found | 15 | [
[
-0.0214080810546875,
-0.01497650146484375,
0.05718994140625,
0.028839111328125,
-0.0350341796875,
0.046539306640625,
0.052490234375,
0.00507354736328125,
0.051361083984375,
0.016998291015625,
-0.05206298828125,
-0.01496124267578125,
-0.06036376953125,
0.0379... |
neural-bridge/full_cqa_2k | 2023-09-11T07:43:23.000Z | [
"region:us"
] | neural-bridge | null | null | 0 | 18 | 2023-09-11T07:43:19 | ---
dataset_info:
features:
- name: clear_prompt
dtype: string
splits:
- name: train
num_bytes: 4608516.864711934
num_examples: 1555
- name: test
num_bytes: 1152870.1352880658
num_examples: 389
download_size: 3489556
dataset_size: 5761387.0
---
# Dataset Card for "full_cqa"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 441 | [
[
-0.03948974609375,
-0.0225067138671875,
0.0277862548828125,
0.0194244384765625,
-0.0158538818359375,
0.0058135986328125,
0.0179595947265625,
-0.01125335693359375,
0.054901123046875,
0.04388427734375,
-0.05029296875,
-0.060211181640625,
-0.03753662109375,
-0.... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.