
id stringlengths 2 115 | lastModified stringlengths 24 24 | tags list | author stringlengths 2 42 ⌀ | description stringlengths 0 6.67k ⌀ | citation stringlengths 0 10.7k ⌀ | likes int64 0 3.66k | downloads int64 0 8.89M | created timestamp[us] | card stringlengths 11 977k | card_len int64 11 977k | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|
dbdu/ShareGPT-74k-ko | 2023-08-19T07:00:39.000Z | [
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:ko",
"license:cc-by-2.0",
"conversation",
"chatgpt",
"gpt-3.5",
"region:us"
] | dbdu | null | null | 11 | 5 | 2023-05-23T16:30:43 | ---
language:
- ko
pretty_name: ShareGPT-74k-ko
tags:
- conversation
- chatgpt
- gpt-3.5
license: cc-by-2.0
task_categories:
- text-generation
size_categories:
- 10K<n<100K
---
# ShareGPT-ko-74k
ShareGPT 90k의 cleaned 버전을 구글 번역기를 이용하여 번역하였습니다.\
원본 데이터셋은 [여기](https://github.com/lm-sys/FastChat/issues/90)에서 확인하실 수 있습니다.
Korean-translated version of ShareGPT-90k, translated by Google Translaton.\
You can check the original dataset [here](https://github.com/lm-sys/FastChat/issues/90).
## Dataset Description
json 파일의 구조는 원본 데이터셋과 동일합니다.\
`*_unclneaed.json`은 원본 데이터셋을 번역하고 따로 후처리하지 않은 데이터셋입니다. (총 74k)\
`*_cleaned.json`은 위의 데이터에서 코드가 포함된 데이터를 러프하게 제거한 데이터셋입니다. (총 55k)\
**주의**: 코드는 번역되었을 수 있으므로 cleaned를 쓰시는 걸 추천합니다.
The structure of the dataset is the same with the original dataset.\
`*_unclneaed.json` are Korean-translated data, without any post-processing. (total 74k dialogues)\
`*_clneaed.json` are post-processed version which dialogues containing code snippets are eliminated from. (total 55k dialogues)\
**WARNING**: Code snippets might have been translated into Korean. I recommend you use cleaned files.
## Licensing Information
GPT를 이용한 데이터셋이므로 OPENAI의 [약관](https://openai.com/policies/terms-of-use)을 따릅니다.\
그 외의 경우 [CC BY 2.0 KR](https://creativecommons.org/licenses/by/2.0/kr/)을 따릅니다.
The licensing status of the datasets follows [OPENAI Licence](https://openai.com/policies/terms-of-use) as it contains GPT-generated sentences.\
For all the other cases, the licensing status follows [CC BY 2.0 KR](https://creativecommons.org/licenses/by/2.0/kr/).
## Code
번역에 사용한 코드는 아래 리포지토리에서 확인 가능합니다. Check out the following repository to see the translation code used.\
https://github.com/dubuduru/ShareGPT-translation
You can use the repository to translate ShareGPT-like dataset into your preferred language. | 1,825 | [
[
-0.0192718505859375,
-0.048675537109375,
0.0188446044921875,
0.02886962890625,
-0.044830322265625,
-0.009552001953125,
-0.0282135009765625,
-0.0168304443359375,
0.0289764404296875,
0.035919189453125,
-0.04736328125,
-0.051971435546875,
-0.04742431640625,
0.0... |
danioshi/incubus_taylor_swift_lyrics | 2023-05-25T19:03:59.000Z | [
"size_categories:n<1K",
"language:en",
"license:cc0-1.0",
"music",
"region:us"
] | danioshi | null | null | 0 | 5 | 2023-05-25T18:57:33 | ---
license: cc0-1.0
language:
- en
tags:
- music
pretty_name: Incubus and Taylor Swift lyrics
size_categories:
- n<1K
---
# Description
This dataset contains lyrics from both Incubus and Taylor Swift.
# Format
The file is in CSV format and contains three columns: Artist, Song Name and Lyrics.
## Caveats
The column Song Name has been transformed to a single string in lowercase format, so instead of having "Name of Song", the value will be "nameofsong". | 459 | [
[
0.004123687744140625,
-0.024505615234375,
-0.01236724853515625,
0.0355224609375,
-0.01561737060546875,
0.030517578125,
-0.00787353515625,
-0.0089874267578125,
0.0298004150390625,
0.07574462890625,
-0.060943603515625,
-0.055511474609375,
-0.041107177734375,
0... |
bluesky333/chemical_language_understanding_benchmark | 2023-07-09T10:36:44.000Z | [
"task_categories:text-classification",
"task_categories:token-classification",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-4.0",
"chemistry",
"region:us"
] | bluesky333 | null | null | 2 | 5 | 2023-05-30T05:52:05 | ---
license: cc-by-4.0
task_categories:
- text-classification
- token-classification
language:
- en
tags:
- chemistry
pretty_name: CLUB
size_categories:
- 10K<n<100K
---
## Table of Contents
- [Benchmark Summary](#benchmark-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
<p><h1>🧪🔋 Chemical Language Understanding Benchmark 🛢️🧴</h1></p>
<a name="benchmark-summary"></a>
Benchmark Summary
Chemistry Language Understanding Benchmark is published in ACL2023 industry track to facilitate NLP research in chemical industry [ACL2023 Paper Link Not Available Yet](link).
From our understanding, it is one of the first benchmark datasets with tasks for both patent and literature articles provided by the industrial organization.
All the datasets are annotated by professional chemists.
<a name="languages"></a>
Languages
The language of this benchmark is English.
<a name="dataset-structure"></a>
Data Structure
Benchmark has 4 datasets: 2 for text classification and 2 for token classification.
| Dataset | Task | # Examples | Avg. Token Length | # Classes / Entity Groups |
| ----- | ------ | ---------- | ------------ | ------------------------- |
| PETROCHEMICAL | Patent Area Classification | 2,775 | 448.19 | 7 |
| RHEOLOGY | Sentence Classification | 2,017 | 55.03 | 5 |
| CATALYST | Catalyst Entity Recognition | 4,663 | 42.07 | 5 |
| BATTERY | Battery Entity Recognition | 3,750 | 40.73 | 3 |
You can refer to the paper for detailed description of the datasets.
<a name="data-instances"></a>
Data Instances
Each example is a paragraph/setence of an academic paper or patent with annotations in a json format.
<a name="data-fields"></a>
Data Fields
The fields for the text classification task are:
1) 'id', a unique numbered identifier sequentially assigned.
2) 'sentence', the input text.
3) 'label', the class for the text.
The fields for the text classification task are:
1) 'id', a unique numbered identifier sequentially assigned.
2) 'tokens', the input text tokenized by BPE tokenizer.
3) 'ner_tags', the entity label for the tokens.
<a name="data-splits"></a>
Data Splits
The data is split into 80 (train) / 20 (development).
<a name="dataset-creation"></a>
Dataset Creation
<a name="curation-rationale"></a>
Curation Rationale
The dataset was created to provide a benchmark in chemical language model for researchers and developers.
<a name="source-data"></a>
Source Data
The dataset consists of open-access chemistry publications and patents annotated by professional chemists.
<a name="licensing-information"></a>
Licensing Information
The manual annotations created for CLUB are licensed under a [Creative Commons Attribution 4.0 International License (CC-BY-4.0)](https://creativecommons.org/licenses/by/4.0/).
<a name="citation-information"></a>
Citation Information
We will provide the citation information once ACL2023 industry track paper is published.
| 3,449 | [
[
-0.013671875,
-0.0238494873046875,
0.0367431640625,
0.0169830322265625,
0.014404296875,
0.0120849609375,
-0.0242919921875,
-0.036346435546875,
-0.01300811767578125,
0.025115966796875,
-0.02978515625,
-0.078857421875,
-0.03582763671875,
0.0214385986328125,
... |
TigerResearch/pretrain_en | 2023-05-30T10:01:55.000Z | [
"task_categories:text-generation",
"size_categories:10M<n<100M",
"language:en",
"license:apache-2.0",
"region:us"
] | TigerResearch | null | null | 12 | 5 | 2023-05-30T08:40:36 | ---
dataset_info:
features:
- name: content
dtype: string
splits:
- name: train
num_bytes: 48490123196
num_examples: 22690306
download_size: 5070161762
dataset_size: 48490123196
license: apache-2.0
task_categories:
- text-generation
language:
- en
size_categories:
- 10M<n<100M
---
# Dataset Card for "pretrain_en"
[Tigerbot](https://github.com/TigerResearch/TigerBot) pretrain数据的英文部分。
## Usage
```python
import datasets
ds_sft = datasets.load_dataset('TigerResearch/pretrain_en')
``` | 512 | [
[
-0.0287933349609375,
-0.01520538330078125,
-0.006103515625,
0.01800537109375,
-0.04852294921875,
0.006336212158203125,
-0.007129669189453125,
0.007472991943359375,
0.038543701171875,
0.0291900634765625,
-0.05572509765625,
-0.0311126708984375,
-0.017242431640625,... |
tollefj/rettsavgjoerelser_100samples_embeddings | 2023-08-11T10:45:31.000Z | [
"language:no",
"region:us"
] | tollefj | null | null | 0 | 5 | 2023-06-02T12:46:28 | ---
dataset_info:
features:
- name: url
dtype: string
- name: keywords
sequence: string
- name: text
dtype: string
- name: sentences
sequence: string
- name: summary
sequence: string
- name: embedding
sequence:
sequence: float32
splits:
- name: train
num_bytes: 73887305
num_examples: 100
download_size: 71145367
dataset_size: 73887305
language:
- 'no'
---
# Dataset Card for "rettsavgjoerelser_100samples_embeddings"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 610 | [
[
-0.0262298583984375,
-0.010894775390625,
-0.0035762786865234375,
0.0189666748046875,
-0.0230560302734375,
0.00214385986328125,
0.0159149169921875,
0.01335906982421875,
0.0699462890625,
0.043243408203125,
-0.052734375,
-0.0648193359375,
-0.05059814453125,
-0.... |
cjvt/janes_tag | 2023-06-06T10:07:53.000Z | [
"task_categories:token-classification",
"size_categories:1K<n<10K",
"language:sl",
"license:cc-by-sa-4.0",
"code-mixed",
"nonstandard",
"ner",
"region:us"
] | cjvt | Janes-Tag is a manually annotated corpus of Slovene Computer-Mediated Communication (CMC) consisting of mostly tweets
but also blogs, forums and news comments. | @misc{janes_tag,
title = {{CMC} training corpus Janes-Tag 3.0},
author = {Lenardi{\v c}, Jakob and {\v C}ibej, Jaka and Arhar Holdt, {\v S}pela and Erjavec, Toma{\v z} and Fi{\v s}er, Darja and Ljube{\v s}i{\'c}, Nikola and Zupan, Katja and Dobrovoljc, Kaja},
url = {http://hdl.handle.net/11356/1732},
note = {Slovenian language resource repository {CLARIN}.{SI}},
copyright = {Creative Commons - Attribution-{ShareAlike} 4.0 International ({CC} {BY}-{SA} 4.0)},
year = {2022}
} | 0 | 5 | 2023-06-05T10:35:43 | ---
license: cc-by-sa-4.0
dataset_info:
features:
- name: id
dtype: string
- name: words
sequence: string
- name: lemmas
sequence: string
- name: msds
sequence: string
- name: nes
sequence: string
splits:
- name: train
num_bytes: 2653609
num_examples: 2957
download_size: 2871765
dataset_size: 2653609
task_categories:
- token-classification
language:
- sl
tags:
- code-mixed
- nonstandard
- ner
size_categories:
- 1K<n<10K
---
# Dataset Card for Janes-Tag
### Dataset Summary
Janes-Tag is a manually annotated corpus of Slovene Computer-Mediated Communication (CMC) consisting of mostly tweets but also blogs, forums and news comments.
### Languages
Code-switched/nonstandard Slovenian.
## Dataset Structure
### Data Instances
A sample instance from the dataset - each word is annotated with its form (`word`), lemma, MSD tag (XPOS), and IOB2-encoded named entity tag.
```
{
'id': 'janes.news.rtvslo.279732.2',
'words': ['Jst', 'mam', 'tud', 'dons', 'rojstn', 'dan', '.'],
'lemmas': ['jaz', 'imeti', 'tudi', 'danes', 'rojsten', 'dan', '.'],
'msds': ['mte:Pp1-sn', 'mte:Vmpr1s-n', 'mte:Q', 'mte:Rgp', 'mte:Agpmsay', 'mte:Ncmsan', 'mte:Z'],
'nes': ['O', 'O', 'O', 'O', 'O', 'O', 'O']
}
```
### Data Fields
- `id`: unique identifier of the example;
- `words`: words in the example;
- `lemmas`: lemmas in the example;
- `msds`: msds in the example;
- `nes`: IOB2-encoded named entity tag (person, location, organization, misc, other)
## Additional Information
### Dataset Curators
Jakob Lenardič et al. (please see http://hdl.handle.net/11356/1732 for the full list)
### Licensing Information
CC BY-SA 4.0.
### Citation Information
```
@misc{janes_tag,
title = {{CMC} training corpus Janes-Tag 3.0},
author = {Lenardi{\v c}, Jakob and {\v C}ibej, Jaka and Arhar Holdt, {\v S}pela and Erjavec, Toma{\v z} and Fi{\v s}er, Darja and Ljube{\v s}i{\'c}, Nikola and Zupan, Katja and Dobrovoljc, Kaja},
url = {http://hdl.handle.net/11356/1732},
note = {Slovenian language resource repository {CLARIN}.{SI}},
copyright = {Creative Commons - Attribution-{ShareAlike} 4.0 International ({CC} {BY}-{SA} 4.0)},
year = {2022}
}
```
### Contributions
Thanks to [@matejklemen](https://github.com/matejklemen) for adding this dataset. | 2,306 | [
[
-0.01629638671875,
-0.030792236328125,
0.0092620849609375,
0.01070404052734375,
-0.02020263671875,
-0.01140594482421875,
-0.0137481689453125,
0.002849578857421875,
0.0204315185546875,
0.033233642578125,
-0.054595947265625,
-0.0836181640625,
-0.05377197265625,
... |
daven3/geosignal | 2023-08-28T04:40:53.000Z | [
"task_categories:question-answering",
"license:apache-2.0",
"region:us"
] | daven3 | null | null | 4 | 5 | 2023-06-05T18:38:16 | ---
license: apache-2.0
task_categories:
- question-answering
---
## Instruction Tuning: GeoSignal
Scientific domain adaptation has two main steps during instruction tuning.
- Instruction tuning with general instruction-tuning data. Here we use Alpaca-GPT4.
- Instruction tuning with restructured domain knowledge, which we call expertise instruction tuning. For K2, we use knowledge-intensive instruction data, GeoSignal.
***The following is the illustration of the training domain-specific language model recipe:***

- **Adapter Model on [Huggingface](https://huggingface.co/): [daven3/k2_it_adapter](https://huggingface.co/daven3/k2_it_adapter)**
For the design of the GeoSignal, we collect knowledge from various data sources, like:

GeoSignal is designed for knowledge-intensive instruction tuning and used for aligning with experts.
The full-version will be upload soon, or email [daven](mailto:davendw@sjtu.edu.cn) for potential research cooperation.
| 1,067 | [
[
-0.0239105224609375,
-0.06329345703125,
0.032318115234375,
0.0212249755859375,
-0.015869140625,
-0.0194549560546875,
-0.0289154052734375,
-0.0208740234375,
-0.01220703125,
0.0418701171875,
-0.05072021484375,
-0.057586669921875,
-0.05615234375,
-0.02101135253... |
Posos/MedNERF | 2023-06-07T13:55:06.000Z | [
"task_categories:token-classification",
"size_categories:n<1K",
"language:fr",
"license:cc-by-nc-sa-4.0",
"medical",
"arxiv:2306.04384",
"region:us"
] | Posos | null | null | 1 | 5 | 2023-06-06T12:50:48 | ---
license: cc-by-nc-sa-4.0
task_categories:
- token-classification
language:
- fr
tags:
- medical
pretty_name: MedNERF
size_categories:
- n<1K
---
# MedNERF
## Dataset Description
- **Paper:** [Multilingual Clinical NER: Translation or Cross-lingual Transfer?](https://arxiv.org/abs/2306.04384)
- **Point of Contact:** [email](research@posos.fr)
### Dataset Summary
MedNERF is a French medical NER dataset whose aim is to serve as a test set for medical NER models.
It has been built using a sample of French medical prescriptions annotated with the same guidelines as the [n2c2 dataset](https://academic.oup.com/jamia/article-abstract/27/1/3/5581277?redirectedFrom=fulltext&login=false).
Entities are annotated with the following labels: `Drug`, `Strength`, `Form`, `Dosage`, `Duration` and `Frequency`, using the IOB format.
## Licensing Information
This dataset is distributed under the Creative Commons Attribution Non Commercial Share Alike 4.0 license.
## Citation information
```
@inproceedings{mednerf,
title = "Multilingual Clinical NER: Translation or Cross-lingual Transfer?",
author = "Gaschi, Félix and Fontaine, Xavier and Rastin, Parisa and Toussaint, Yannick",
booktitle = "Proceedings of the 5th Clinical Natural Language Processing Workshop",
publisher = "Association for Computational Linguistics",
year = "2023"
}
``` | 1,369 | [
[
-0.01708984375,
-0.0308990478515625,
0.01611328125,
0.03387451171875,
-0.01155853271484375,
-0.030517578125,
-0.0158233642578125,
-0.042266845703125,
0.0228729248046875,
0.04095458984375,
-0.03753662109375,
-0.037506103515625,
-0.06707763671875,
0.0306854248... |
bogdancazan/wikilarge-text-simplification | 2023-06-06T17:49:49.000Z | [
"region:us"
] | bogdancazan | null | null | 0 | 5 | 2023-06-06T17:45:53 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
SahandNZ/cryptonews-articles-with-price-momentum-labels | 2023-06-07T17:49:38.000Z | [
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:en",
"license:openrail",
"finance",
"region:us"
] | SahandNZ | null | null | 5 | 5 | 2023-06-07T16:35:21 | ---
license: openrail
task_categories:
- text-classification
language:
- en
tags:
- finance
pretty_name: Cryptonews.com articles with price momentum labels
size_categories:
- 10K<n<100K
---
# Dataset Card for Cryptonews articles with price momentum labels
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
## Dataset Description
- **Homepage:**
- **Repository:** https://github.com/SahandNZ/IUST-NLP-project-spring-2023
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
The dataset was gathered from two prominent sources in the cryptocurrency industry: Cryptonews.com and Binance.com. The aim of the dataset was to evaluate the impact of news on crypto price movements.
As we know, news events such as regulatory changes, technological advancements, and major partnerships can have a significant impact on the price of cryptocurrencies. By analyzing the data collected from these sources, this dataset aimed to provide insights into the relationship between news events and crypto market trends.
### Supported Tasks and Leaderboards
- **Text Classification**
- **Sentiment Analysis**
### Languages
The language data in this dataset is in English (BCP-47 en)
## Dataset Structure
### Data Instances
Todo
### Data Fields
Todo
### Data Splits
Todo
### Source Data
- **Textual:** https://Cryptonews.com
- **Numerical:** https://Binance.com | 1,718 | [
[
-0.01152801513671875,
-0.0301666259765625,
0.01015472412109375,
0.02337646484375,
-0.051055908203125,
0.01389312744140625,
-0.016448974609375,
-0.03521728515625,
0.0479736328125,
0.020782470703125,
-0.058685302734375,
-0.091796875,
-0.049224853515625,
0.0024... |
andersonbcdefg/redteaming_eval_pairwise | 2023-06-08T05:51:12.000Z | [
"region:us"
] | andersonbcdefg | null | null | 0 | 5 | 2023-06-08T05:48:52 | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: response_a
dtype: string
- name: response_b
dtype: string
- name: explanation
dtype: string
- name: preferred
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 79844
num_examples: 105
download_size: 0
dataset_size: 79844
---
# Dataset Card for "redteaming_eval_pairwise"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 558 | [
[
-0.0253448486328125,
-0.034912109375,
0.004974365234375,
0.03582763671875,
-0.01153564453125,
0.01947021484375,
0.01313018798828125,
-0.0037097930908203125,
0.0699462890625,
0.027923583984375,
-0.039154052734375,
-0.04998779296875,
-0.0352783203125,
-0.00782... |
theodor1289/wit_tiny | 2023-06-09T19:21:44.000Z | [
"region:us"
] | theodor1289 | null | null | 0 | 5 | 2023-06-09T19:21:36 | ---
dataset_info:
features:
- name: image_url
dtype: string
- name: image
dtype: image
- name: text
dtype: string
- name: context_page_description
dtype: string
- name: context_section_description
dtype: string
- name: caption_alt_text_description
dtype: string
splits:
- name: train
num_bytes: 73247697.0
num_examples: 882
- name: test
num_bytes: 8588991.0
num_examples: 99
download_size: 81145983
dataset_size: 81836688.0
---
# Dataset Card for "wit_tiny"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 654 | [
[
-0.03973388671875,
-0.019256591796875,
0.0238037109375,
0.0031375885009765625,
-0.01541900634765625,
-0.021820068359375,
-0.0014171600341796875,
-0.0127716064453125,
0.0711669921875,
0.00942230224609375,
-0.0638427734375,
-0.029754638671875,
-0.031036376953125,
... |
theodor1289/wit | 2023-06-15T08:04:59.000Z | [
"region:us"
] | theodor1289 | null | null | 0 | 5 | 2023-06-12T03:41:21 | ---
dataset_info:
features:
- name: image_url
dtype: string
- name: image
dtype:
image:
decode: false
- name: text
dtype: string
- name: context_page_description
dtype: string
- name: context_section_description
dtype: string
- name: caption_alt_text_description
dtype: string
splits:
- name: train
num_bytes: 313793832273.375
num_examples: 3921869
- name: test
num_bytes: 34879359766.5
num_examples: 435764
download_size: 992115227
dataset_size: 348673192039.875
---
# Dataset Card for "wit"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 703 | [
[
-0.0312042236328125,
-0.016357421875,
0.020751953125,
0.011474609375,
-0.0141754150390625,
-0.01511383056640625,
0.00482177734375,
-0.0267486572265625,
0.06365966796875,
0.0157012939453125,
-0.07135009765625,
-0.040924072265625,
-0.041107177734375,
-0.019073... |
dltdojo/ecommerce-faq-chatbot-dataset | 2023-06-13T05:50:52.000Z | [
"region:us"
] | dltdojo | null | null | 1 | 5 | 2023-06-13T01:02:44 | ---
dataset_info:
features:
- name: a_hant
dtype: string
- name: answer
dtype: string
- name: question
dtype: string
- name: q_hant
dtype: string
splits:
- name: train
num_bytes: 28737
num_examples: 79
download_size: 17499
dataset_size: 28737
---
# Dataset Card for "ecommerce-faq-chatbot-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 472 | [
[
-0.042694091796875,
-0.04217529296875,
-0.0023479461669921875,
0.004444122314453125,
-0.00555419921875,
0.00653839111328125,
0.0128326416015625,
-0.00405120849609375,
0.045501708984375,
0.04949951171875,
-0.08001708984375,
-0.0521240234375,
-0.01763916015625,
... |
Abzu/RedPajama-Data-1T-arxiv-filtered | 2023-06-13T15:24:34.000Z | [
"region:us"
] | Abzu | null | null | 2 | 5 | 2023-06-13T15:24:28 | ---
dataset_info:
features:
- name: text
dtype: string
- name: meta
dtype: string
- name: red_pajama_subset
dtype: string
splits:
- name: train
num_bytes: 229340859.5333384
num_examples: 3911
download_size: 104435457
dataset_size: 229340859.5333384
---
# Dataset Card for "RedPajama-Data-1T-arxiv-filtered"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 475 | [
[
-0.05218505859375,
-0.035919189453125,
0.01081085205078125,
0.0267181396484375,
-0.041259765625,
-0.01361083984375,
0.0165863037109375,
-0.01715087890625,
0.0665283203125,
0.06597900390625,
-0.061065673828125,
-0.06573486328125,
-0.0596923828125,
-0.00683593... |
hyesunyun/liveqa_medical_trec2017 | 2023-06-20T13:33:44.000Z | [
"task_categories:question-answering",
"size_categories:n<1K",
"language:en",
"medical",
"region:us"
] | hyesunyun | null | null | 0 | 5 | 2023-06-15T16:04:52 | ---
task_categories:
- question-answering
language:
- en
tags:
- medical
pretty_name: LiveQAMedical
size_categories:
- n<1K
---
# Dataset Card for LiveQA Medical from TREC 2017
The LiveQA'17 medical task focuses on consumer health question answering. Consumer health questions were received by the U.S. National Library of Medicine (NLM).
The dataset consists of constructed medical question-answer pairs for training and testing, with additional annotations that can be used to develop question analysis and question answering systems.
Please refer to our overview paper for more information about the constructed datasets and the LiveQA Track:
Asma Ben Abacha, Eugene Agichtein, Yuval Pinter & Dina Demner-Fushman. Overview of the Medical Question Answering Task at TREC 2017 LiveQA. TREC, Gaithersburg, MD, 2017 (https://trec.nist.gov/pubs/trec26/papers/Overview-QA.pdf).
**Homepage:** [https://github.com/abachaa/LiveQA_MedicalTask_TREC2017](https://github.com/abachaa/LiveQA_MedicalTask_TREC2017)
## Medical Training Data
The dataset provides 634 question-answer pairs for training:
1) TREC-2017-LiveQA-Medical-Train-1.xml => 388 question-answer pairs corresponding to 200 NLM questions.
Each question is divided into one or more subquestion(s). Each subquestion has one or more answer(s).
These question-answer pairs were constructed automatically and validated manually.
2) TREC-2017-LiveQA-Medical-Train-2.xml => 246 question-answer pairs corresponding to 246 NLM questions.
Answers were retrieved manually by librarians.
**You can access them as jsonl**
The datasets are not exhaustive with regards to subquestions, i.e., some subquestions might not be annotated.
Additional annotations are provided for both (i) the Focus and (ii) the Question Type used to define each subquestion.
23 question types were considered (e.g. Treatment, Cause, Diagnosis, Indication, Susceptibility, Dosage) related to four focus categories: Disease, Drug, Treatment and Exam.
## Medical Test Data
Test split can be easily downloaded via huggingface.
Test questions cover 26 question types associated with five focus categories.
Each question includes one or more subquestion(s) and at least one focus and one question type.
Reference answers were selected from trusted resources and validated by medical experts.
At least one reference answer is provided for each test question, its URL and relevant comments.
Question paraphrases were created by assessors and used with the reference answers to judge the participants' answers.
```
If you use these datasets, please cite paper:
@inproceedings{LiveMedQA2017,
author = {Asma {Ben Abacha} and Eugene Agichtein and Yuval Pinter and Dina Demner{-}Fushman},
title = {Overview of the Medical Question Answering Task at TREC 2017 LiveQA},
booktitle = {TREC 2017},
year = {2017}
}
``` | 2,895 | [
[
-0.0279541015625,
-0.06591796875,
0.0216217041015625,
-0.01332855224609375,
-0.0177154541015625,
0.01324462890625,
0.0084991455078125,
-0.045989990234375,
0.03985595703125,
0.053314208984375,
-0.056427001953125,
-0.04852294921875,
-0.029754638671875,
0.02073... |
merlinyx/pose-controlnet | 2023-06-23T18:52:11.000Z | [
"license:mit",
"region:us"
] | merlinyx | null | null | 0 | 5 | 2023-06-19T22:19:21 | ---
license: mit
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': gt
'1': pose
'2': st
- name: caption
dtype: string
- name: gtimage
dtype: image
- name: stimage
dtype: image
splits:
- name: train
num_bytes: 1702123872.04
num_examples: 15764
- name: test
num_bytes: 144819992.92
num_examples: 1346
download_size: 1762884199
dataset_size: 1846943864.96
---
### Dataset Summary
The data is based on DeepFashion; turned into image pairs of the same person in same garment with different poses.
This won't preserve the person/garment at all but just want to process the data first and see what kind of controlnet it can train as an exercise for training a controlnet.
The controlnet_aux's openpose detector sometimes return black images for occluded human images so there won't be a lot of valid image pairs. | 958 | [
[
-0.032012939453125,
-0.0252838134765625,
-0.0159912109375,
-0.0168914794921875,
-0.0298004150390625,
-0.01441192626953125,
0.005619049072265625,
-0.03271484375,
0.023223876953125,
0.062286376953125,
-0.0634765625,
-0.0262603759765625,
-0.037750244140625,
-0.... |
ArtifactAI/arxiv-beir-cs-ml-generated-queries | 2023-06-21T14:23:58.000Z | [
"doi:10.57967/hf/0804",
"region:us"
] | ArtifactAI | null | null | 0 | 5 | 2023-06-21T00:33:06 | ### Dataset Summary
A BEIR style dataset derived from [ArXiv](https://arxiv.org/). The dataset consists of corpus/query pairs derived from ArXiv abstracts from the following categories: "cs.CL", "cs.AI", "cs.CV", "cs.HC", "cs.IR", "cs.RO", "cs.NE", "stat.ML"
### Languages
All tasks are in English (`en`).
## Dataset Structure
The dataset contains a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@misc{arxiv-beir-cs-ml-generated-queries,
title={arxiv-beir-cs-ml-generated-queries},
author={Matthew Kenney},
year={2023}
}
``` | 4,437 | [
[
-0.0240325927734375,
-0.041351318359375,
0.03326416015625,
0.00478363037109375,
0.0171051025390625,
0.0005207061767578125,
-0.01100921630859375,
-0.00408935546875,
0.0271148681640625,
0.0260162353515625,
-0.0216217041015625,
-0.0614013671875,
-0.03759765625,
... |
devrev/dataset-for-t5-3 | 2023-10-12T06:20:12.000Z | [
"region:us"
] | devrev | null | null | 0 | 5 | 2023-06-21T05:28:38 | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 837375
num_examples: 11383
- name: test
num_bytes: 209423
num_examples: 2846
download_size: 327758
dataset_size: 1046798
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
# Dataset Card for "dataset-for-t5-3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 578 | [
[
-0.035675048828125,
-0.0015697479248046875,
0.033111572265625,
0.0240631103515625,
-0.0249176025390625,
0.0032138824462890625,
0.033843994140625,
-0.01474761962890625,
0.044708251953125,
0.029388427734375,
-0.05718994140625,
-0.07244873046875,
-0.04058837890625,... |
priyank-m/MJSynth_text_recognition | 2023-07-04T20:49:10.000Z | [
"task_categories:image-to-text",
"size_categories:1M<n<10M",
"language:en",
"region:us"
] | priyank-m | null | null | 0 | 5 | 2023-06-22T15:33:18 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype: string
splits:
- name: train
num_bytes: 12173747703
num_examples: 7224600
- name: val
num_bytes: 1352108669.283
num_examples: 802733
- name: test
num_bytes: 1484450563.896
num_examples: 891924
download_size: 12115256620
dataset_size: 15010306936.179
task_categories:
- image-to-text
language:
- en
size_categories:
- 1M<n<10M
pretty_name: MJSynth
---
# Dataset Card for "MJSynth_text_recognition"
This is the MJSynth dataset for text recognition on document images, synthetically generated, covering 90K English words.
It includes training, validation and test splits.
Source of the dataset: https://www.robots.ox.ac.uk/~vgg/data/text/
Use dataset streaming functionality to try out the dataset quickly without downloading the entire dataset (refer: https://huggingface.co/docs/datasets/stream)
Citation details provided on the source website (if you use the data please cite):
@InProceedings{Jaderberg14c,
author = "Max Jaderberg and Karen Simonyan and Andrea Vedaldi and Andrew Zisserman",
title = "Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition",
booktitle = "Workshop on Deep Learning, NIPS",
year = "2014",
}
@Article{Jaderberg16,
author = "Max Jaderberg and Karen Simonyan and Andrea Vedaldi and Andrew Zisserman",
title = "Reading Text in the Wild with Convolutional Neural Networks",
journal = "International Journal of Computer Vision",
number = "1",
volume = "116",
pages = "1--20",
month = "jan",
year = "2016",
} | 1,705 | [
[
-0.00917816162109375,
-0.03662109375,
0.0207977294921875,
-0.01526641845703125,
-0.03192138671875,
0.016815185546875,
-0.0214996337890625,
-0.04376220703125,
0.04034423828125,
0.023681640625,
-0.059478759765625,
-0.03741455078125,
-0.051116943359375,
0.04339... |
ChanceFocus/flare-fpb | 2023-10-25T13:31:25.000Z | [
"task_categories:text-classification",
"size_categories:n<1K",
"language:en",
"license:mit",
"finance",
"region:us"
] | ChanceFocus | null | null | 0 | 5 | 2023-06-24T00:10:07 | ---
dataset_info:
features:
- name: id
dtype: string
- name: query
dtype: string
- name: answer
dtype: string
- name: text
dtype: string
- name: choices
sequence: string
- name: gold
dtype: int64
splits:
- name: train
num_bytes: 1520799
num_examples: 3100
- name: valid
num_bytes: 381025
num_examples: 776
- name: test
num_bytes: 475173
num_examples: 970
download_size: 0
dataset_size: 2376997
license: mit
task_categories:
- text-classification
language:
- en
tags:
- finance
size_categories:
- n<1K
---
# Dataset Card for "flare-fpb"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 742 | [
[
-0.05206298828125,
-0.025726318359375,
-0.003643035888671875,
0.0312347412109375,
-0.0016384124755859375,
0.0176849365234375,
0.0225067138671875,
-0.020965576171875,
0.074462890625,
0.02734375,
-0.06072998046875,
-0.035980224609375,
-0.030181884765625,
-0.01... |
ChanceFocus/flare-sm-acl | 2023-06-25T18:16:24.000Z | [
"region:us"
] | ChanceFocus | null | null | 1 | 5 | 2023-06-25T17:56:25 | ---
dataset_info:
features:
- name: id
dtype: string
- name: query
dtype: string
- name: answer
dtype: string
- name: text
dtype: string
- name: choices
sequence: string
- name: gold
dtype: int64
splits:
- name: train
num_bytes: 70385369
num_examples: 20781
- name: valid
num_bytes: 9049127
num_examples: 2555
- name: test
num_bytes: 13359338
num_examples: 3720
download_size: 46311736
dataset_size: 92793834
---
# Dataset Card for "flare-sm-acl"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 653 | [
[
-0.04388427734375,
-0.017333984375,
-0.0034961700439453125,
0.0080413818359375,
-0.00991058349609375,
0.0191802978515625,
0.024078369140625,
-0.01029205322265625,
0.06634521484375,
0.035125732421875,
-0.0638427734375,
-0.03594970703125,
-0.035308837890625,
-... |
tonytan48/TempReason | 2023-06-28T07:26:17.000Z | [
"task_categories:question-answering",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-sa-3.0",
"region:us"
] | tonytan48 | null | null | 3 | 5 | 2023-06-25T23:08:37 | ---
license: cc-by-sa-3.0
task_categories:
- question-answering
language:
- en
size_categories:
- 10K<n<100K
---
The TempReason dataset to evaluate the temporal reasoning capability of Large Language Models.
From paper "Towards Benchmarking and Improving the Temporal Reasoning Capability of Large Language Models" in ACL 2023. | 329 | [
[
-0.0219573974609375,
-0.033203125,
0.05780029296875,
-0.0010213851928710938,
-0.0036525726318359375,
0.00809478759765625,
-0.0002193450927734375,
-0.0258331298828125,
-0.028228759765625,
0.023040771484375,
-0.047393798828125,
-0.028076171875,
-0.02459716796875,
... |
FreedomIntelligence/alpaca-gpt4-japanese | 2023-08-06T08:10:29.000Z | [
"license:apache-2.0",
"region:us"
] | FreedomIntelligence | null | null | 2 | 5 | 2023-06-26T08:18:35 | ---
license: apache-2.0
---
The dataset is used in the research related to [MultilingualSIFT](https://github.com/FreedomIntelligence/MultilingualSIFT). | 152 | [
[
-0.0284271240234375,
-0.0214385986328125,
-0.000301361083984375,
0.01971435546875,
-0.004512786865234375,
0.004093170166015625,
-0.0194091796875,
-0.0303192138671875,
0.0289154052734375,
0.033966064453125,
-0.0643310546875,
-0.032958984375,
-0.012969970703125,
... |
TrainingDataPro/cars-video-object-tracking | 2023-09-20T14:58:57.000Z | [
"task_categories:image-segmentation",
"task_categories:image-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"region:us"
] | TrainingDataPro | The collection of overhead video frames, capturing various types of vehicles
traversing a roadway. The dataset inculdes light vehicles (cars) and
heavy vehicles (minivan). | @InProceedings{huggingface:dataset,
title = {cars-video-object-tracking},
author = {TrainingDataPro},
year = {2023}
} | 2 | 5 | 2023-06-26T13:21:56 | ---
license: cc-by-nc-nd-4.0
task_categories:
- image-segmentation
- image-classification
language:
- en
tags:
- code
dataset_info:
features:
- name: image_id
dtype: int32
- name: image
dtype: image
- name: mask
dtype: image
- name: annotations
dtype: string
splits:
- name: train
num_bytes: 614230158
num_examples: 100
download_size: 580108296
dataset_size: 614230158
---
# Cars Tracking
The collection of overhead video frames, capturing various types of vehicles traversing a roadway. The dataset inculdes light vehicles (cars) and heavy vehicles (minivan).
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=cars-video-object-tracking) to discuss your requirements, learn about the price and buy the dataset.

# Data Format
Each video frame from `images` folder is paired with an `annotations.xml` file that meticulously defines the tracking of each vehicle using polygons.
These annotations not only specify the location and path of each vehicle but also differentiate between the vehicle classes:
- cars,
- minivans.
The data labeling is visualized in the `boxes` folder.
# Example of the XML-file
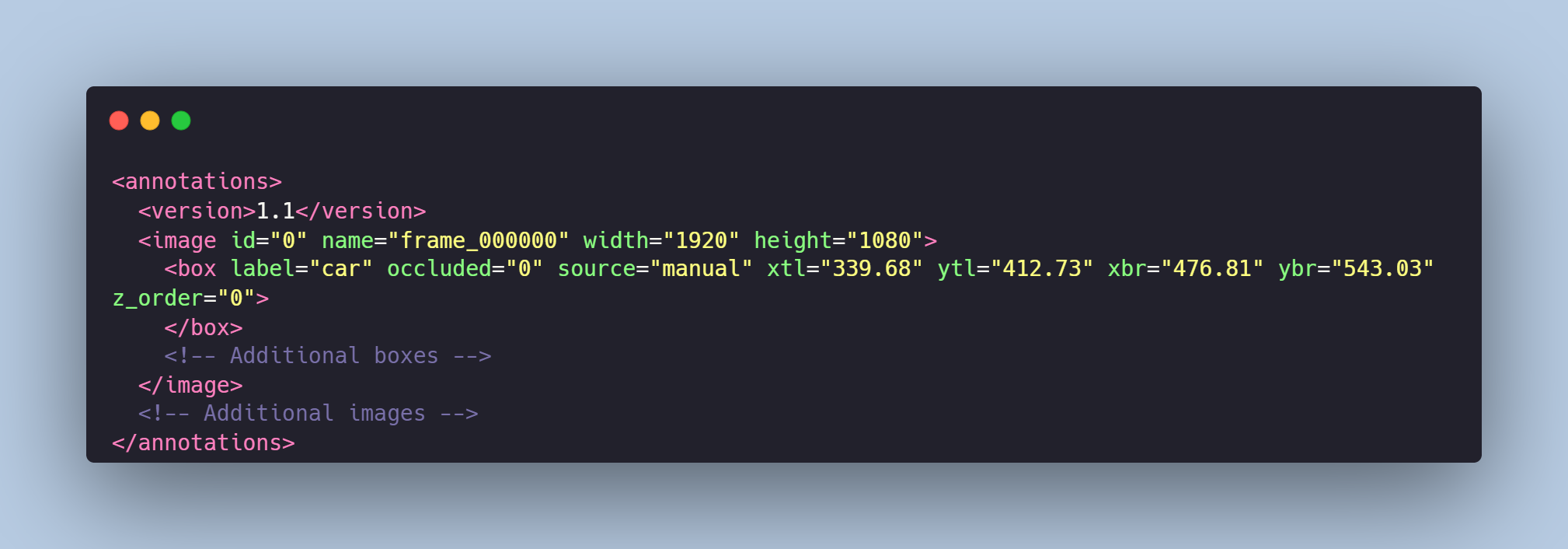
# Object tracking is made in accordance with your requirements.
## **[TrainingData](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=cars-video-object-tracking)** provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets** | 2,138 | [
[
-0.04962158203125,
-0.0390625,
0.021026611328125,
-0.01161956787109375,
-0.01526641845703125,
0.01068878173828125,
-0.0046234130859375,
-0.0238800048828125,
0.020538330078125,
0.01953125,
-0.07171630859375,
-0.04510498046875,
-0.0288238525390625,
-0.03170776... |
cchoi1022/wikitext-103-v1 | 2023-06-27T22:33:07.000Z | [
"region:us"
] | cchoi1022 | null | null | 0 | 5 | 2023-06-27T22:31:15 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
PaDaS-Lab/SynStOp | 2023-06-29T10:00:34.000Z | [
"region:us"
] | PaDaS-Lab | Minimal dataset for intended for LM development and testing using python string operations.
The dataset is created by running different one line python string operations on random strings
The idea is, that transformer implementation can learn the string operations and that this task is a good
proxy tasks for other transformer operations on real languages and real tasks. Consequently, the
data set is small and can be used in the development process without large scale infrastructures.
There are different configurations for the data set.
- `small`: contains below 50k instances of various string length and only contains slicing operations, i.e. all python operations expressable with `s[i:j:s]` (which also includes string reversal).
- you can further choose different subsets according to either length or the kind of operation
- `small10`: like small, but only strings to length 10
- `small15`: like small, but only strings to length 15
- `small20`: like small, but only strings to length 20
The fields have the following meaning:
- `input`: input string, i.e. the string and the string operation
- `output`: output of the string operation
- `code`: code for running the string operation in python,
- `res_var`: name of the result variable
- `operation`: kind of operation:
- `step_x` for `s[::x]`
- `char_at_x` for `s[x]`
- `slice_x:y` for `s[x:y]`
- `slice_step_x:y:z` for `s[x:y:z]`
- `slice_reverse_i:j:k` for `s[i:i+j][::k]`
Siblings of `data` contain additional metadata information about the dataset.
- `prompt` describes possible prompts based on that data splitted into input prompts / output prompts | @InProceedings{huggingface:dataset,
title = {String Operations Dataset: A small set of string manipulation tasks for fast model development},
author={Michael Granitzer},
year={2023}
} | 0 | 5 | 2023-06-28T13:17:26 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
barbaroo/Faroese_BLARK_small | 2023-08-07T14:47:31.000Z | [
"task_categories:text-generation",
"language:fo",
"region:us"
] | barbaroo | null | null | 0 | 5 | 2023-06-28T14:49:09 | ---
task_categories:
- text-generation
language:
- fo
---
# Dataset Card for Faroese_BLARK_small
## Dataset Description
All sentences are retrieved from:
- **Paper:**
Annika Simonsen, Sandra Saxov Lamhauge, Iben Nyholm Debess, and Peter Juel Henrichsen. 2022. Creating a Basic Language Resource Kit for Faroese. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 4637–4643, Marseille, France. European Language Resources Association.
### Dataset Summary
This dataset is a filtered version of the corpus (35.6 M tokens) first published as BLARK - Basic Language Resource Kit for Faroese.
The pre-processing and filtering steps include:
- Normalize format to utf-8
- Remove shorter sentences (less than 10 units, where units are separated by spaces)
- Remove archaic Faroese
- Remove separators ('\r', '\t', '\n')
- Remove non standard formatting. Examples: '§§', ' | ', '**', ' • ', ' • ', '.- ', ': ?', '.?', '\xa0', '\xad', '_ _', '. .', etc.
- Remove (most) numbered lists, of formats: 1), 1:, Stk. 1 etc.
- Replace arbitrary number of question/exclamation marks and full-stops with 1. Example: !!!!!! -> !
- Remove websites that start with http
- Remove sentences without (or with little) linguistic content. In practice: all sentences where more than half of the characters (excluding spaces) are number, punctuations and letters in caps-lock (acronyms and initials)
- Remove duplicates
### Supported Tasks and Leaderboards
Suitable for MLM and CLM
| 1,503 | [
[
-0.0267791748046875,
-0.05572509765625,
0.0190277099609375,
0.009490966796875,
-0.038299560546875,
-0.019317626953125,
-0.045196533203125,
-0.023773193359375,
0.0279388427734375,
0.05950927734375,
-0.045867919921875,
-0.060791015625,
-0.01480865478515625,
0.... |
ai4privacy/pii-masking-43k | 2023-06-28T17:45:58.000Z | [
"size_categories:10K<n<100K",
"language:en",
"legal",
"business",
"psychology",
"privacy",
"doi:10.57967/hf/0824",
"region:us"
] | ai4privacy | null | null | 8 | 5 | 2023-06-28T16:44:41 | ---
language:
- en
tags:
- legal
- business
- psychology
- privacy
size_categories:
- 10K<n<100K
---
# Purpose and Features
The purpose of the model and dataset is to remove personally identifiable information (PII) from text, especially in the context of AI assistants and LLMs.
The model is a fine-tuned version of "Distilled BERT", a smaller and faster version of BERT. It was adapted for the task of token classification based on the largest to our knowledge open-source PII masking dataset, which we are releasing simultaneously. The model size is 62 million parameters. The original encoding of the parameters yields a model size of 268 MB, which is compressed to 43MB after parameter quantization. The models are available in PyTorch, tensorflow, and tensorflow.js
The dataset is composed of ~43’000 observations. Each row starts with a natural language sentence that includes placeholders for PII and could plausibly be written to an AI assistant. The placeholders are then filled in with mocked personal information and tokenized with the BERT tokenizer. We label the tokens that correspond to PII, serving as the ground truth to train our model.
The dataset covers a range of contexts in which PII can appear. The sentences span 54 sensitive data types (~111 token classes), targeting 125 discussion subjects / use cases split across business, psychology and legal fields, and 5 interactions styles (e.g. casual conversation vs formal document).
Key facts:
- Currently 5.6m tokens with 43k PII examples.
- Scaling to 100k examples
- Human-in-the-loop validated
- Synthetic data generated using proprietary algorithms
- Adapted from DistilBertForTokenClassification
- Framework PyTorch
- 8 bit quantization
# Performance evaluation
| Test Precision | Test Recall | Test Accuracy |
|:-:|:-:|:-:|
| 0.998636 | 0.998945 | 0.994621 |
Training/Test Set split:
- 4300 Testing Examples (10%)
- 38700 Train Examples
# Community Engagement:
Newsletter & updates: www.Ai4privacy.com
- Looking for ML engineers, developers, beta-testers, human in the loop validators (all languages)
- Integrations with already existing open source solutions
# Roadmap and Future Development
- Multilingual
- Extended integrations
- Continuously increase the training set
- Further optimisation to the model to reduce size and increase generalisability
- Next released major update is planned for the 14th of July (subscribe to newsletter for updates)
# Use Cases and Applications
**Chatbots**: Incorporating a PII masking model into chatbot systems can ensure the privacy and security of user conversations by automatically redacting sensitive information such as names, addresses, phone numbers, and email addresses.
**Customer Support Systems**: When interacting with customers through support tickets or live chats, masking PII can help protect sensitive customer data, enabling support agents to handle inquiries without the risk of exposing personal information.
**Email Filtering**: Email providers can utilize a PII masking model to automatically detect and redact PII from incoming and outgoing emails, reducing the chances of accidental disclosure of sensitive information.
**Data Anonymization**: Organizations dealing with large datasets containing PII, such as medical or financial records, can leverage a PII masking model to anonymize the data before sharing it for research, analysis, or collaboration purposes.
**Social Media Platforms**: Integrating PII masking capabilities into social media platforms can help users protect their personal information from unauthorized access, ensuring a safer online environment.
**Content Moderation**: PII masking can assist content moderation systems in automatically detecting and blurring or redacting sensitive information in user-generated content, preventing the accidental sharing of personal details.
**Online Forms**: Web applications that collect user data through online forms, such as registration forms or surveys, can employ a PII masking model to anonymize or mask the collected information in real-time, enhancing privacy and data protection.
**Collaborative Document Editing**: Collaboration platforms and document editing tools can use a PII masking model to automatically mask or redact sensitive information when multiple users are working on shared documents.
**Research and Data Sharing**: Researchers and institutions can leverage a PII masking model to ensure privacy and confidentiality when sharing datasets for collaboration, analysis, or publication purposes, reducing the risk of data breaches or identity theft.
**Content Generation**: Content generation systems, such as article generators or language models, can benefit from PII masking to automatically mask or generate fictional PII when creating sample texts or examples, safeguarding the privacy of individuals.
(...and whatever else your creative mind can think of)
# Support and Maintenance
AI4Privacy is a project affiliated with [AISuisse SA](https://www.aisuisse.com/). | 5,033 | [
[
-0.046173095703125,
-0.062103271484375,
0.01102447509765625,
0.0212554931640625,
-0.002971649169921875,
0.007038116455078125,
0.0012645721435546875,
-0.05902099609375,
-0.0038127899169921875,
0.0390625,
-0.03033447265625,
-0.034332275390625,
-0.033111572265625,
... |
tasksource/leandojo | 2023-06-28T17:46:34.000Z | [
"license:cc-by-2.0",
"region:us"
] | tasksource | null | null | 1 | 5 | 2023-06-28T17:41:51 | ---
license: cc-by-2.0
---
https://github.com/lean-dojo/LeanDojo
```
@article{yang2023leandojo,
title={{LeanDojo}: Theorem Proving with Retrieval-Augmented Language Models},
author={Yang, Kaiyu and Swope, Aidan and Gu, Alex and Chalamala, Rahul and Song, Peiyang and Yu, Shixing and Godil, Saad and Prenger, Ryan and Anandkumar, Anima},
journal={arXiv preprint arXiv:2306.15626},
year={2023}
}
``` | 405 | [
[
0.0007114410400390625,
-0.036407470703125,
0.048553466796875,
0.012939453125,
0.003551483154296875,
-0.012420654296875,
-0.032806396484375,
-0.035186767578125,
0.02545166015625,
0.0286407470703125,
-0.0208892822265625,
-0.0355224609375,
-0.0274810791015625,
... |
DynamicSuperb/StressDetection_MIRSD | 2023-07-12T06:17:19.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-06-29T08:13:16 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: label
dtype: string
- name: word
dtype: string
- name: instruction
dtype: string
splits:
- name: test
num_bytes: 432162612.62
num_examples: 4492
download_size: 401399373
dataset_size: 432162612.62
---
# Dataset Card for "stress_dection_MIR_SD"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 514 | [
[
-0.03839111328125,
-0.0103302001953125,
0.0224761962890625,
0.034637451171875,
-0.02886962890625,
-0.001773834228515625,
0.025054931640625,
-0.0032520294189453125,
0.06134033203125,
0.022003173828125,
-0.07281494140625,
-0.0606689453125,
-0.04669189453125,
-... |
clu-ling/clupubhealth | 2023-08-02T02:22:46.000Z | [
"task_categories:summarization",
"size_categories:1K<n<10K",
"size_categories:10K<n<100K",
"language:en",
"license:apache-2.0",
"medical",
"region:us"
] | clu-ling | null | @inproceedings{kotonya-toni-2020-explainable,
title = "Explainable Automated Fact-Checking for Public Health Claims",
author = "Kotonya, Neema and
Toni, Francesca",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.623",
pages = "7740--7754",
} | 0 | 5 | 2023-07-04T18:58:14 | ---
license: apache-2.0
task_categories:
- summarization
language:
- en
tags:
- medical
size_categories:
- 1K<n<10K
- 10K<n<100K
---
# `clupubhealth`
The `CLUPubhealth` dataset is based on the [PUBHEALTH fact-checking dataset](https://github.com/neemakot/Health-Fact-Checking).
The PUBHEALTH dataset contains claims, explanations, and main texts. The explanations function as vetted summaries of the main texts. The CLUPubhealth dataset repurposes these fields into summaries and texts for use in training Summarization models such as Facebook's BART.
There are currently 4 dataset configs which can be called, each has three splits (see Usage):
### `clupubhealth/mini`
This config includes only 200 samples per split. This is mostly used in testing scripts when small sets are desirable.
### `clupubhealth/base`
This is the base dataset which includes the full PUBHEALTH set, sans False samples. The `test` split is a shortened version which includes only 200 samples. This allows for faster eval steps during trianing.
### `clupubhealth/expanded`
Where the base `train` split contains 5,078 data points, this expanded set includes 62,163 data points. ChatGPT was used to generate new versions of the summaries in the base set. After GPT expansion a total of 72,498 were generated, however, this was shortened to ~62k after samples with poor BERTScores were eliminated.
### `clupubhealth/test`
This config has the full `test` split with ~1200 samples. Used for post-training evaluation.
## USAGE
To use the CLUPubhealth dataset use the `datasets` library:
```python
from datasets import load_dataset
data = load_dataset("clu-ling/clupubhealth", "base")
# Where the accepted extensions are the configs: `mini`, `base`, `expanded`, `test`
``` | 1,759 | [
[
-0.0256500244140625,
-0.03912353515625,
0.01666259765625,
-0.000141143798828125,
-0.0246734619140625,
-0.006351470947265625,
-0.0179901123046875,
-0.0184783935546875,
0.01397705078125,
0.045257568359375,
-0.04095458984375,
-0.036529541015625,
-0.030517578125,
... |
TinyPixel/dolphin-2 | 2023-07-13T06:19:34.000Z | [
"region:us"
] | TinyPixel | null | null | 4 | 5 | 2023-07-13T06:18:43 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 1623415440
num_examples: 891857
download_size: 884160758
dataset_size: 1623415440
---
# Dataset Card for "dolphin-2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 361 | [
[
-0.0645751953125,
-0.01296234130859375,
0.01432037353515625,
0.0199127197265625,
-0.036651611328125,
-0.01666259765625,
0.042022705078125,
-0.03656005859375,
0.053985595703125,
0.04107666015625,
-0.06109619140625,
-0.0246429443359375,
-0.048126220703125,
-0.... |
DynamicSuperb/NoiseDetection_LJSpeech_MUSAN-Noise | 2023-07-18T07:34:56.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-07-14T03:16:00 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 3371541774.0
num_examples: 26200
download_size: 3362687514
dataset_size: 3371541774.0
---
# Dataset Card for "NoiseDetectionnoise_LJSpeechMusan"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 495 | [
[
-0.03338623046875,
-0.0144500732421875,
0.01522064208984375,
0.0133819580078125,
-0.0137176513671875,
0.0075225830078125,
0.01010894775390625,
-0.0260467529296875,
0.06365966796875,
0.021636962890625,
-0.058258056640625,
-0.04595947265625,
-0.037994384765625,
... |
Alignment-Lab-AI/Lawyer-chat | 2023-07-14T17:22:44.000Z | [
"license:apache-2.0",
"region:us"
] | Alignment-Lab-AI | null | null | 2 | 5 | 2023-07-14T06:24:41 | ---
license: apache-2.0
---
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
## Dataset Description
### Dataset Summary
LawyerChat is a multi-turn conversational dataset primarily in the English language, containing dialogues about legal scenarios. The conversations are in the format of an interaction between a client and a legal professional. The dataset is designed for training and evaluating models on conversational tasks like dialogue understanding, response generation, and more.
### Supported Tasks and Leaderboards
- `dialogue-modeling`: The dataset can be used to train a model for multi-turn dialogue understanding and generation. Performance can be evaluated based on dialogue understanding and the quality of the generated responses.
- There is no official leaderboard associated with this dataset at this time.
dataset generated in part by dang/futures
### Languages
The text in the dataset is in English.
## Dataset Structure
### Data Instances
An instance in the LawyerChat dataset represents a single turn in a conversation, consisting of a user id and their corresponding utterance. Example:
```json
{
"conversations": [
{
"from": "user_id_1",
"value": "What are the possible legal consequences of not paying taxes?"
},
{
"from": "user_id_2",
"value": "There can be several legal consequences, ranging from fines to imprisonment..."
},
...
]
} | 1,668 | [
[
-0.0222320556640625,
-0.053131103515625,
0.0107421875,
0.0026035308837890625,
-0.032379150390625,
0.01335906982421875,
-0.0093994140625,
-0.005558013916015625,
0.0301971435546875,
0.05731201171875,
-0.05712890625,
-0.08038330078125,
-0.0309295654296875,
-0.0... |
DynamicSuperb/ReverberationDetection_LJSpeech_RirsNoises-SmallRoom | 2023-07-18T12:17:36.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-07-14T15:42:15 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 3371857486.0
num_examples: 26200
download_size: 3358417173
dataset_size: 3371857486.0
---
# Dataset Card for "ReverberationDetectionsmallroom_LJSpeechRirsNoises"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 512 | [
[
-0.045196533203125,
-0.0016412734985351562,
0.004161834716796875,
0.03021240234375,
-0.006938934326171875,
0.0023956298828125,
0.00014674663543701172,
-0.00878143310546875,
0.061370849609375,
0.036041259765625,
-0.07232666015625,
-0.04681396484375,
-0.0270843505... |
ivrit-ai/audio-vad | 2023-07-19T10:17:05.000Z | [
"task_categories:audio-classification",
"task_categories:voice-activity-detection",
"size_categories:1M<n<10M",
"language:he",
"license:other",
"arxiv:2307.08720",
"region:us"
] | ivrit-ai | null | null | 2 | 5 | 2023-07-15T14:53:26 | ---
license: other
task_categories:
- audio-classification
- voice-activity-detection
language:
- he
size_categories:
- 1M<n<10M
extra_gated_prompt:
"You agree to the following license terms:
This material and data is licensed under the terms of the Creative Commons Attribution 4.0
International License (CC BY 4.0), The full text of the CC-BY 4.0 license is available at
https://creativecommons.org/licenses/by/4.0/.
Notwithstanding the foregoing, this material and data may only be used, modified and distributed for
the express purpose of training AI models, and subject to the foregoing restriction. In addition, this
material and data may not be used in order to create audiovisual material that simulates the voice or
likeness of the specific individuals appearing or speaking in such materials and data (a “deep-fake”).
To the extent this paragraph is inconsistent with the CC-BY-4.0 license, the terms of this paragraph
shall govern.
By downloading or using any of this material or data, you agree that the Project makes no
representations or warranties in respect of the data, and shall have no liability in respect thereof. These
disclaimers and limitations are in addition to any disclaimers and limitations set forth in the CC-BY-4.0
license itself. You understand that the project is only able to make available the materials and data
pursuant to these disclaimers and limitations, and without such disclaimers and limitations the project
would not be able to make available the materials and data for your use."
extra_gated_fields:
I have read the license, and agree to its terms: checkbox
---
ivrit.ai is a database of Hebrew audio and text content.
**audio-base** contains the raw, unprocessed sources.
**audio-vad** contains audio snippets generated by applying Silero VAD (https://github.com/snakers4/silero-vad) to the base dataset.
**audio-transcripts** contains transcriptions for each snippet in the audio-vad dataset.
The audio-base dataset contains data from the following sources:
* Geekonomy (Podcast, https://geekonomy.net)
* HaCongress (Podcast, https://hacongress.podbean.com/)
* Idan Eretz's YouTube channel (https://www.youtube.com/@IdanEretz)
* Moneytime (Podcast, https://money-time.co.il)
* Mor'e Nevohim (Podcast, https://open.spotify.com/show/1TZeexEk7n60LT1SlS2FE2?si=937266e631064a3c)
* Yozevitch's World (Podcast, https://www.yozevitch.com/yozevitch-podcast)
* NETfrix (Podcast, https://netfrix.podbean.com)
* On Meaning (Podcast, https://mashmaut.buzzsprout.com)
* Shnekel (Podcast, https://www.shnekel.live)
* Bite-sized History (Podcast, https://soundcloud.com/historia-il)
* Tziun 3 (Podcast, https://tziun3.co.il)
* Academia Israel (https://www.youtube.com/@academiaisrael6115)
* Shiluv Maagal (https://www.youtube.com/@ShiluvMaagal)
Paper: https://arxiv.org/abs/2307.08720
If you use our datasets, the following quote is preferable:
```
@misc{marmor2023ivritai,
title={ivrit.ai: A Comprehensive Dataset of Hebrew Speech for AI Research and Development},
author={Yanir Marmor and Kinneret Misgav and Yair Lifshitz},
year={2023},
eprint={2307.08720},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
``` | 3,235 | [
[
-0.037261962890625,
-0.050201416015625,
0.0001455545425415039,
0.0035648345947265625,
-0.013824462890625,
-0.006633758544921875,
-0.027984619140625,
-0.033477783203125,
0.0308837890625,
0.036834716796875,
-0.045440673828125,
-0.045379638671875,
-0.03463745117187... |
HeshamHaroon/arabic-quotes | 2023-07-16T07:19:40.000Z | [
"task_categories:text-classification",
"task_ids:multi-label-classification",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"source_datasets:original",
"language:ar",
"region:us"
] | HeshamHaroon | null | null | 1 | 5 | 2023-07-16T05:36:33 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
- crowdsourced
language:
- ar
multilinguality:
- monolingual
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-label-classification
---
# Arabic Quotes Dataset (arabic_Q)
The "Arabic Quotes" dataset contains a collection of Arabic quotes along with their corresponding authors and tags. The dataset is scraped from the website "arabic-quotes.com" and provides a diverse range of quotes from various authors.
## Dataset Details
- **Version**: 1.0.0
- **Total Quotes**: 3778
- **Languages**: Arabic
- **Source**: arabic-quotes.com
## Dataset Structure
The dataset is provided in the JSONL (JSON Lines) format, where each line represents a separate JSON object. The JSON objects have the following fields:
- `quote`: The Arabic quote text.
- `author`: The author of the quote.
- `tags`: A list of tags associated with the quote, providing additional context or themes.
## Dataset Examples
Here are a few examples of the quotes in the dataset:
```json
{
"quote": "اذا لم يكن لديك هدف ، فاجعل هدفك الاول ايجاد واحد .",
"author": "وليام شكسبير",
"tags": ["تنمية الذات", "تحفيز"]
}
{
"quote": "قيمة الحياة ليست في مدى طولها ، بل في مدى قيمتها",
"author": "وليام شكسبير",
"tags": ["الحياة", "القيمة"]
}
{
"quote": "التحدث عن الامور العميقة ليس سهلاً كما يبدو",
"author": "جبران خليل جبران",
"tags": ["التواصل", "العمق"]
}
```
## Dataset Usage
The "Arabic Quotes" dataset can be used for various purposes, including:
- Natural Language Processing (NLP) tasks in Arabic text analysis.
- Text generation and language modeling.
- Quote recommendation systems.
- Inspirational content generation.
- text-classification
## Acknowledgements
We would like to thank the website "arabic-quotes.com" for providing the valuable collection of Arabic quotes used in this dataset.
## License
The dataset is provided under the [bigscience-bloom-rail-1.0 License](https://huggingface.co/spaces/bigscience/license), which permits non-commercial use and sharing under certain conditions.
| 2,119 | [
[
-0.0254364013671875,
-0.033416748046875,
0.01206207275390625,
0.0128936767578125,
-0.049835205078125,
0.019927978515625,
0.002452850341796875,
-0.0185089111328125,
0.009918212890625,
0.0404052734375,
-0.05206298828125,
-0.068603515625,
-0.0421142578125,
0.02... |
DynamicSuperb/EnhancementDetection_LibriTTS-TestClean_WHAM | 2023-07-31T08:10:05.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-07-16T15:54:58 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
- name: speech file
dtype: string
- name: noise file
dtype: string
- name: SNR
dtype: float32
splits:
- name: test
num_bytes: 1323003418.833
num_examples: 4837
download_size: 1637835283
dataset_size: 1323003418.833
---
# Dataset Card for "EnhancementDetection_LibrittsTestCleanWham"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 619 | [
[
-0.040618896484375,
-0.0202789306640625,
0.0159912109375,
0.0036182403564453125,
-0.0121917724609375,
0.0034503936767578125,
0.028900146484375,
-0.03173828125,
0.054107666015625,
0.04205322265625,
-0.048736572265625,
-0.0391845703125,
-0.03948974609375,
-0.0... |
Andyrasika/Ecommerce_FAQ | 2023-07-18T15:34:42.000Z | [
"license:creativeml-openrail-m",
"region:us"
] | Andyrasika | null | null | 2 | 5 | 2023-07-18T15:30:25 | ---
license: creativeml-openrail-m
---
Ecommerce FAQ Chatbot Dataset
Overview
The Ecommerce FAQ Chatbot Dataset is a valuable collection of questions and corresponding answers, meticulously curated for training and evaluating chatbot models in the context of an Ecommerce environment. This dataset is designed to assist developers, researchers, and data scientists in building effective chatbots that can handle customer inquiries related to an Ecommerce platform.
Contents
The dataset comprises a total of 79 question-answer pairs, where each item consists of:
Question: The user's query related to the Ecommerce platform.
Answer: The appropriate response or solution provided by the Ecommerce chatbot.
The questions cover a wide range of common Ecommerce-related topics, including account management, product inquiries, order processing, payment methods, shipping details, and general platform usage.
Use Cases
Chatbot Development: This dataset can be used to train and fine-tune chatbot models for an Ecommerce chatbot capable of handling various customer queries and providing relevant responses.
Natural Language Processing (NLP) Research: Researchers can utilize this dataset to study language understanding, response generation, and conversation flow in the context of Ecommerce interactions.
Customer Support Automation: Ecommerce businesses can explore the possibility of implementing a chatbot-based customer support system to enhance customer satisfaction and reduce response times.
Data Format
The dataset is provided in a JSON format, where each item contains a "question" field and an "answer" field. The data is easily accessible and can be integrated into various machine learning frameworks for training purposes.
Dataset Citation
If you use this dataset in your research or project, kindly cite it as follows:
```
@dataset{saadmakhdoom/ecommerce-faq-chatbot-dataset,
title = {Ecommerce FAQ Chatbot Dataset},
author = {Saad Makhdoom},
year = {Year of Dataset Creation},
publisher = {Kaggle},
url = {https://www.kaggle.com/datasets/saadmakhdoom/ecommerce-faq-chatbot-dataset}
}
```
Acknowledgments
We would like to express our gratitude to Saad Makhdoom for creating and sharing this valuable dataset on Kaggle.
Their efforts in curating and providing the data have contributed significantly to the advancement of chatbot research and development. | 2,382 | [
[
-0.043609619140625,
-0.06866455078125,
-0.016998291015625,
0.006622314453125,
0.0040130615234375,
0.0031070709228515625,
0.0002677440643310547,
-0.0251617431640625,
0.0099029541015625,
0.06585693359375,
-0.08270263671875,
-0.032684326171875,
-0.01303863525390625... |
scillm/scientific_papers | 2023-09-07T06:17:42.000Z | [
"task_categories:summarization",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:en",
"license:unknown",
"abstractive-summarization",
"arxiv:1804.05685",
"region:us"
] | scillm | null | null | 2 | 5 | 2023-07-19T00:48:13 | ---
annotations_creators:
- found
language:
- en
language_creators:
- found
license:
- unknown
multilinguality:
- monolingual
pretty_name: ScientificPapers
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- summarization
task_ids: []
paperswithcode_id: null
tags:
- abstractive-summarization
dataset_info:
- config_name: arxiv
features:
- name: article
dtype: string
- name: abstract
dtype: string
- name: section_names
dtype: string
splits:
- name: train
num_bytes: 7148341992
num_examples: 203037
- name: validation
num_bytes: 217125524
num_examples: 6436
- name: test
num_bytes: 217514961
num_examples: 6440
download_size: 4504646347
dataset_size: 7582982477
- config_name: pubmed
features:
- name: article
dtype: string
- name: abstract
dtype: string
- name: section_names
dtype: string
splits:
- name: train
num_bytes: 2252027383
num_examples: 119924
- name: validation
num_bytes: 127403398
num_examples: 6633
- name: test
num_bytes: 127184448
num_examples: 6658
download_size: 4504646347
dataset_size: 2506615229
---
# Dataset Card for "scientific_papers"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:**
- **Repository:** https://github.com/armancohan/long-summarization
- **Paper:** [A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents](https://arxiv.org/abs/1804.05685)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 9.01 GB
- **Size of the generated dataset:** 10.09 GB
- **Total amount of disk used:** 19.10 GB
### Dataset Summary
Scientific papers datasets contains two sets of long and structured documents.
The datasets are obtained from ArXiv and PubMed OpenAccess repositories.
Both "arxiv" and "pubmed" have two features:
- article: the body of the document, paragraphs separated by "/n".
- abstract: the abstract of the document, paragraphs separated by "/n".
- section_names: titles of sections, separated by "/n".
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### arxiv
- **Size of downloaded dataset files:** 4.50 GB
- **Size of the generated dataset:** 7.58 GB
- **Total amount of disk used:** 12.09 GB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"abstract": "\" we have studied the leptonic decay @xmath0 , via the decay channel @xmath1 , using a sample of tagged @xmath2 decays collected...",
"article": "\"the leptonic decays of a charged pseudoscalar meson @xmath7 are processes of the type @xmath8 , where @xmath9 , @xmath10 , or @...",
"section_names": "[sec:introduction]introduction\n[sec:detector]data and the cleo- detector\n[sec:analysys]analysis method\n[sec:conclusion]summary"
}
```
#### pubmed
- **Size of downloaded dataset files:** 4.50 GB
- **Size of the generated dataset:** 2.51 GB
- **Total amount of disk used:** 7.01 GB
An example of 'validation' looks as follows.
```
This example was too long and was cropped:
{
"abstract": "\" background and aim : there is lack of substantial indian data on venous thromboembolism ( vte ) . \\n the aim of this study was...",
"article": "\"approximately , one - third of patients with symptomatic vte manifests pe , whereas two - thirds manifest dvt alone .\\nboth dvt...",
"section_names": "\"Introduction\\nSubjects and Methods\\nResults\\nDemographics and characteristics of venous thromboembolism patients\\nRisk factors ..."
}
```
### Data Fields
The data fields are the same among all splits.
#### arxiv
- `article`: a `string` feature.
- `abstract`: a `string` feature.
- `section_names`: a `string` feature.
#### pubmed
- `article`: a `string` feature.
- `abstract`: a `string` feature.
- `section_names`: a `string` feature.
### Data Splits
| name |train |validation|test|
|------|-----:|---------:|---:|
|arxiv |203037| 6436|6440|
|pubmed|119924| 6633|6658|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@article{Cohan_2018,
title={A Discourse-Aware Attention Model for Abstractive Summarization of
Long Documents},
url={http://dx.doi.org/10.18653/v1/n18-2097},
DOI={10.18653/v1/n18-2097},
journal={Proceedings of the 2018 Conference of the North American Chapter of
the Association for Computational Linguistics: Human Language
Technologies, Volume 2 (Short Papers)},
publisher={Association for Computational Linguistics},
author={Cohan, Arman and Dernoncourt, Franck and Kim, Doo Soon and Bui, Trung and Kim, Seokhwan and Chang, Walter and Goharian, Nazli},
year={2018}
}
```
### Contributions
Thanks to [@thomwolf](https://github.com/thomwolf), [@jplu](https://github.com/jplu), [@lewtun](https://github.com/lewtun), [@patrickvonplaten](https://github.com/patrickvonplaten) for adding this dataset.
| 8,270 | [
[
-0.04266357421875,
-0.040802001953125,
0.0224151611328125,
0.0084075927734375,
-0.03021240234375,
0.002834320068359375,
-0.019073486328125,
-0.03265380859375,
0.049224853515625,
0.0338134765625,
-0.0338134765625,
-0.06304931640625,
-0.04364013671875,
0.01255... |
DynamicSuperb/HowFarAreYou_3DSpeaker | 2023-09-02T14:46:06.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-07-19T07:26:15 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: label
dtype: string
- name: instruction
dtype: string
splits:
- name: test
num_bytes: 1781564948.0
num_examples: 18782
download_size: 1648180646
dataset_size: 1781564948.0
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
# Dataset Card for "HowFarAreYou_3DSpeaker"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 568 | [
[
-0.061798095703125,
-0.01544189453125,
0.01198577880859375,
0.01554107666015625,
-0.0028476715087890625,
-0.01715087890625,
0.0280303955078125,
-0.01105499267578125,
0.062469482421875,
0.0304412841796875,
-0.05712890625,
-0.045562744140625,
-0.0477294921875,
... |
crumb/Open-Orca-k16 | 2023-07-21T07:11:19.000Z | [
"region:us"
] | crumb | null | null | 3 | 5 | 2023-07-20T20:31:34 | ---
dataset_info:
features:
- name: id
dtype: string
- name: system_prompt
dtype: string
- name: question
dtype: string
- name: response
dtype: string
- name: cluster
dtype: int64
splits:
- name: train
num_bytes: 1796489136
num_examples: 994896
download_size: 1023054925
dataset_size: 1796489136
---
# Dataset Card for "Open-Orca-k16"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 515 | [
[
-0.032684326171875,
-0.0216217041015625,
0.0125274658203125,
-0.00504302978515625,
-0.0230865478515625,
-0.01064300537109375,
0.0104827880859375,
-0.027496337890625,
0.0533447265625,
0.03564453125,
-0.052032470703125,
-0.06707763671875,
-0.02984619140625,
-0... |
xw27/scibench | 2023-07-21T10:37:15.000Z | [
"arxiv:2307.10635",
"region:us"
] | xw27 | null | null | 5 | 5 | 2023-07-21T10:12:17 | # SciBench
**SciBench** is a novel benchmark for college-level scientific problems consisting of _695_
problems sourced from instructional textbooks. The benchmark is designed to evaluate the complex reasoning capabilities,
strong domain knowledge, and advanced calculation skills of LLMs.
Please refer to our paper for full description: [SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models](https://arxiv.org/abs/2307.10635)
We developed an innovative **evaluation protocol** for a detailed analysis of reasoning abilities. This
involves instructing LLMs to self-identify and categorize their errors within a predefined set of
capabilities. This process offers a fine-grained understanding of where the models are falling short.
## Data
Each file is list of dictionary and can be extracted using following scripts.
Each file stands for one textbook, which is fully elaborated in the paper.
```
subject='atkins'
with open("./data/{}.json".format(subject), encoding='utf-8') as json_file:
problems=json.load(json_file)
```
---
license: mit
---
| 1,099 | [
[
-0.0172271728515625,
-0.041290283203125,
0.044769287109375,
0.03619384765625,
0.003204345703125,
0.0310211181640625,
-0.0164031982421875,
-0.019622802734375,
-0.00507354736328125,
0.00255584716796875,
-0.03033447265625,
-0.044921875,
-0.0335693359375,
0.0302... |
daydrill/QG_korquad_aihub | 2023-08-01T05:08:40.000Z | [
"region:us"
] | daydrill | null | null | 1 | 5 | 2023-07-25T08:53:15 | ---
dataset_info:
features:
- name: answer
dtype: string
- name: paragraph_question
dtype: string
- name: question
dtype: string
- name: sentence
dtype: string
- name: paragraph
dtype: string
- name: sentence_answer
dtype: string
- name: paragraph_answer
dtype: string
- name: paragraph_sentence
dtype: string
- name: paragraph_id
dtype: string
splits:
- name: test
num_bytes: 31745115.0
num_examples: 5766
- name: train
num_bytes: 1022746708.0
num_examples: 209474
- name: validation
num_bytes: 57792469.09490271
num_examples: 11532
download_size: 663313997
dataset_size: 1112284292.0949028
---
# Dataset Card for "QG_korquad_aihub"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 858 | [
[
-0.041351318359375,
-0.0226593017578125,
0.0034923553466796875,
0.0153045654296875,
-0.0283203125,
0.01739501953125,
0.036529541015625,
-0.00281524658203125,
0.052703857421875,
0.03131103515625,
-0.03668212890625,
-0.059661865234375,
-0.03857421875,
-0.02047... |
zaursamedov1/customer-service-ner | 2023-07-25T20:39:44.000Z | [
"region:us"
] | zaursamedov1 | null | null | 0 | 5 | 2023-07-25T20:20:14 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
DynamicSuperb/EmotionRecognition_MultimodalEmotionlinesDataset | 2023-07-26T05:34:40.000Z | [
"region:us"
] | DynamicSuperb | null | null | 2 | 5 | 2023-07-26T05:12:02 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: SrNo
dtype: string
- name: utterance
dtype: string
- name: speaker
dtype: string
- name: label
dtype: string
- name: sentiment
dtype: string
- name: dialogue_id
dtype: string
- name: utterance_id
dtype: string
- name: season
dtype: string
- name: episode
dtype: string
- name: start_time
dtype: string
- name: end_time
dtype: string
- name: instruction
dtype: string
splits:
- name: test
num_bytes: 5775848651.698
num_examples: 3426
download_size: 5117815276
dataset_size: 5775848651.698
---
# Dataset Card for "emotion_recognition_multimodal_emotionlines_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 889 | [
[
-0.05035400390625,
-0.00833892822265625,
0.01354217529296875,
0.031524658203125,
-0.0164642333984375,
0.004528045654296875,
0.00968170166015625,
-0.01861572265625,
0.06048583984375,
0.0159454345703125,
-0.06634521484375,
-0.04425048828125,
-0.047149658203125,
... |
zhwang/HPDv2 | 2023-08-08T09:32:39.000Z | [
"arxiv:2306.09341",
"region:us"
] | zhwang | null | null | 2 | 5 | 2023-07-28T08:08:55 |
# Human Preference Dataset v2 (HPD v2)
**Human Preference Dataset v2 (HPD v2)** is a large-scale, cleanly-annotated dataset of human preferences for images generated from text prompts.
For more detailed information, please refer to the paper: [Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis](https://arxiv.org/abs/2306.09341).
We also trained [Human Preference Score v2 (HPSv2)](https://github.com/tgxs002/HPSv2), a preference prediction model, on HPD v2.
## Updates
* [07/29/2023] We released the benchmark and HPD v2 test data. HPD v2 train data will be **released sonn**.
## Data Source

The prompts in our dataset are sourced from DiffusionDB and MSCOCO Captions. Prompts from DiffusionDB are first cleaned by ChatGPT to remove biased function words. Human annotators are tasked to rank images generated by different text-to-image generative models from the same prompt. Totally there are about 798k pairwise comparisons of images for over 430k images and 107k prompts, 645k pairs for training split and 153k pairs for test split.
Image sources of HPD v2:
| Source | # of images
| :-----: | :-----: |
| CogView2 | 73697 |
| DALL·E 2 | 101869 |
| GLIDE (mini) | 400 |
| Stable Diffusion v1.4 | 101869 |
| Stable Diffusion v2.0 | 101869 |
| LAFITE | 400 |
| VQ-GAN+CLIP | 400 |
| VQ-Diffusion | 400 |
| FuseDream | 400 |
| COCO Captions | 28272 |
# Evaluation prompts
We also provide a set of evaluation prompts (benchmark prompts) that involves testing a model on a total of 3200 prompts, with 800 prompts for each of the following styles: “Animation”, “Concept-art”, “Painting”, and “Photo”.
In this reposity, We include benchmark images generated by mainstream text-to-image generative model based on benchmark prompts. So far, the following models have been included (being continuously updated):
- ChilloutMix
- CogView2
- DALL·E mini
- DALL·E 2
- Deliberate
- DeepFloyd-XL
- Dreamlike Photoreal 2.0
- Epic Diffusion
- FuseDream
- GLIDE
- LAFITE
- Latent Diffusion
- MajicMix Realistic
- Openjourney
- Realistic Vision
- Stable Diffusion v1.4
- Stable Diffusion v2.0
- SDXL Base 0.9
- SDXL Refiner 0.9
- Versatile Diffusion
- VQ-Diffusion
- VQGAN + CLIP
## Structure
Once unzipped, you should get a folder with the following structure:
```
HPD
---- train/
-------- {image_id}.jpg
---- test/
-------- {image_id}.jpg
---- train.json
---- test.json
---- benchmark/
-------- benchmark_imgs/
------------ {model_id}/
---------------- {image_id}.jpg
-------- drawbench/
------------ {model_id}/
---------------- {image_id}.jpg
-------- anime.json
-------- concept-art.json
-------- paintings.json
-------- photo.json
-------- drawbench.json
```
The annotation file, `train.json`, is organized as:
```
[
{
'human_preference': list[int], # 1 for preference
'prompt': str,
'file_path': list[str],
'user_hash': str,
},
...
]
```
The annotation file, `test.json`, is organized as:
```
[
{
'prompt': str,
'image_path': list[str],
'rank': list[int], # ranking for image at the same index in image_path
},
...
]
```
The benchmark prompts file, ie. `anime.json` is pure prompts. The corresponding image can be found in the folder of the corresponding model by indexing the prompt. | 3,368 | [
[
-0.048492431640625,
-0.04248046875,
0.0343017578125,
0.004138946533203125,
-0.026458740234375,
-0.018890380859375,
-0.006862640380859375,
-0.0223236083984375,
-0.0098724365234375,
0.038818359375,
-0.044403076171875,
-0.054840087890625,
-0.039398193359375,
0.... |
iulusoy/test-data-2 | 2023-10-30T17:33:48.000Z | [
"region:us"
] | iulusoy | null | null | 0 | 5 | 2023-07-28T09:34:27 | ---
dataset_info:
features:
- name: Sentences
sequence: string
- name: Labels
sequence: int64
- name: Span_begin
sequence: int64
- name: Span_end
sequence: int64
- name: Span_label
sequence: string
splits:
- name: train
num_bytes: 36481
num_examples: 103
download_size: 11243
dataset_size: 36481
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "test-data-2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 599 | [
[
-0.034912109375,
-0.0292510986328125,
0.00836181640625,
0.0171356201171875,
-0.01483154296875,
-0.00595855712890625,
0.027069091796875,
-0.012115478515625,
0.0384521484375,
0.0196075439453125,
-0.05523681640625,
-0.035400390625,
-0.040679931640625,
-0.022521... |
basilis/legalDataset | 2023-07-29T09:57:15.000Z | [
"region:us"
] | basilis | null | null | 0 | 5 | 2023-07-29T08:05:17 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
DynamicSuperb/DialogueEmotionClassification_DailyTalk | 2023-08-02T08:59:04.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-07-31T05:59:13 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 1379443197.906
num_examples: 4758
download_size: 1292391688
dataset_size: 1379443197.906
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
# Dataset Card for "DialogueEmotionClassification_DailyTalk"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 588 | [
[
-0.0261383056640625,
-0.0261993408203125,
0.00983428955078125,
0.0211334228515625,
0.00028443336486816406,
0.01316070556640625,
0.01119232177734375,
-0.027679443359375,
0.0545654296875,
0.03765869140625,
-0.069580078125,
-0.0699462890625,
-0.0341796875,
-0.0... |
lighteval/headqa_harness | 2023-08-01T15:18:58.000Z | [
"region:us"
] | lighteval | HEAD-QA is a multi-choice HEAlthcare Dataset. The questions come from exams to access a specialized position in the
Spanish healthcare system, and are challenging even for highly specialized humans. They are designed by the Ministerio
de Sanidad, Consumo y Bienestar Social.
The dataset contains questions about the following topics: medicine, nursing, psychology, chemistry, pharmacology and biology. | @inproceedings{vilares-gomez-rodriguez-2019-head,
title = "{HEAD}-{QA}: A Healthcare Dataset for Complex Reasoning",
author = "Vilares, David and
G{\'o}mez-Rodr{\'i}guez, Carlos",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1092",
doi = "10.18653/v1/P19-1092",
pages = "960--966",
abstract = "We present HEAD-QA, a multi-choice question answering testbed to encourage research on complex reasoning. The questions come from exams to access a specialized position in the Spanish healthcare system, and are challenging even for highly specialized humans. We then consider monolingual (Spanish) and cross-lingual (to English) experiments with information retrieval and neural techniques. We show that: (i) HEAD-QA challenges current methods, and (ii) the results lag well behind human performance, demonstrating its usefulness as a benchmark for future work.",
} | 0 | 5 | 2023-08-01T15:18:38 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
apcl/funcom-python | 2023-08-05T03:58:58.000Z | [
"region:us"
] | apcl | null | null | 0 | 5 | 2023-08-01T19:55:49 | ## funcom-python dataset
Funcom-python dataset is a dataset from 40,000 Python projects downloaded from Github. It inludes 270k functions.
We provide the details of our dataset in the following table:
| filename | Value |
| ------- | ------- |
|coms.test | reference comment for testset|
|com.tok | token file for comment|
|dataset_graph.pkl | graph data for codegnnGRU model |
|dataset_seqs.h5 | sequence data which includes comment for training, and code for prediction and training |
|dataset_short.pkl |file includes all tokens |
|graph.tok|token file for graph|
|smls.tok|token file for AST|
## Details Parameters
We provide details of the parameters in the following table:
| Parameters | Value |
| ------- | ------- |
|tokens in target subroutine | 50|
|words in summary | 13|
|source code vocabulary size | 100k |
|summary vocabulary size | 11000 | | 864 | [
[
-0.0198974609375,
-0.016021728515625,
-0.0018558502197265625,
0.00567626953125,
-0.0235443115234375,
-0.0162811279296875,
-0.00550079345703125,
0.0102386474609375,
0.018646240234375,
0.040802001953125,
-0.051055908203125,
-0.032135009765625,
-0.0303802490234375,... |
bigheiniuJ/InstructEvalMetaICLAll | 2023-08-03T18:06:46.000Z | [
"region:us"
] | bigheiniuJ | null | null | 0 | 5 | 2023-08-03T04:06:49 | ---
dataset_info:
features:
- name: task
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: options
sequence: string
- name: seed
dtype: string
- name: split
dtype: string
splits:
- name: meta_train
num_bytes: 2338759626
num_examples: 3399184
- name: meta_eval_100shot
num_bytes: 23447441
num_examples: 47685
download_size: 1159790167
dataset_size: 2362207067
---
# Dataset Card for "InstructEvalMetaICLAll"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 632 | [
[
-0.0304718017578125,
-0.0238800048828125,
0.000048041343688964844,
0.023773193359375,
-0.007350921630859375,
0.0201873779296875,
0.018341064453125,
-0.01319122314453125,
0.052520751953125,
0.033172607421875,
-0.0596923828125,
-0.060455322265625,
-0.03955078125,
... |
dodogeny/receipts-dataset-v1 | 2023-08-04T18:55:59.000Z | [
"region:us"
] | dodogeny | null | null | 0 | 5 | 2023-08-03T17:26:07 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: pixel_values
sequence:
sequence:
sequence: float32
- name: labels
sequence: int64
- name: target_sequence
dtype: string
splits:
- name: train
num_bytes: 4728833790.336493
num_examples: 569
- name: test
num_bytes: 531889916.6635071
num_examples: 64
download_size: 388493674
dataset_size: 5260723707.0
---
# Dataset Card for "receipts-dataset-v1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 697 | [
[
-0.0297698974609375,
-0.00445556640625,
0.0137786865234375,
0.0175628662109375,
-0.027618408203125,
-0.016265869140625,
0.043212890625,
-0.02203369140625,
0.072265625,
0.045654296875,
-0.066650390625,
-0.043060302734375,
-0.0478515625,
-0.0180206298828125,
... |
GalaktischeGurke/emails_5500_to_7500 | 2023-08-04T11:12:23.000Z | [
"region:us"
] | GalaktischeGurke | null | null | 0 | 5 | 2023-08-04T11:10:31 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 36007308.656938754
num_examples: 19604
download_size: 69813655
dataset_size: 36007308.656938754
---
# Dataset Card for "emails_5500_to_7500"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 385 | [
[
-0.0343017578125,
-0.0121612548828125,
-0.0010862350463867188,
0.0251617431640625,
-0.00954437255859375,
-0.01171875,
0.0259552001953125,
-0.009033203125,
0.0628662109375,
0.037994384765625,
-0.0609130859375,
-0.043670654296875,
-0.053802490234375,
-0.006278... |
sinarashidi/alpaca-persian | 2023-08-06T08:15:38.000Z | [
"region:us"
] | sinarashidi | null | null | 0 | 5 | 2023-08-06T07:32:19 | Entry not found | 15 | [
[
-0.0214080810546875,
-0.01494598388671875,
0.057159423828125,
0.028839111328125,
-0.0350341796875,
0.04656982421875,
0.052490234375,
0.00504302978515625,
0.0513916015625,
0.016998291015625,
-0.0521240234375,
-0.0149993896484375,
-0.06036376953125,
0.03790283... |
smit-mehta/orange-juice-ad | 2023-08-07T06:58:49.000Z | [
"region:us"
] | smit-mehta | null | null | 0 | 5 | 2023-08-07T06:58:06 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
splits:
- name: train
num_bytes: 9063650.0
num_examples: 6
download_size: 9070873
dataset_size: 9063650.0
---
# Dataset Card for "orange-juice-ad"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 444 | [
[
-0.0271759033203125,
-0.02056884765625,
0.0014019012451171875,
0.00998687744140625,
0.006618499755859375,
0.0009694099426269531,
0.01473236083984375,
-0.01020050048828125,
0.06915283203125,
0.03533935546875,
-0.03680419921875,
-0.047271728515625,
-0.027313232421... |
DFKI-SLT/argmicro | 2023-08-09T15:07:47.000Z | [
"license:cc-by-nc-sa-4.0",
"region:us"
] | DFKI-SLT | null | @inproceedings{peldszus2015annotated,
title={An annotated corpus of argumentative microtexts},
author={Peldszus, Andreas and Stede, Manfred},
booktitle={Argumentation and Reasoned Action: Proceedings of the 1st European Conference on Argumentation, Lisbon},
volume={2},
pages={801--815},
year={2015}
} | 0 | 5 | 2023-08-08T16:17:53 | ---
license: cc-by-nc-sa-4.0
---
# An annotated corpus of argumentative microtexts
The arg-microtexts corpus features 112 short argumentative texts. All texts
were originally written in German and have been professionally translated to
English.
The texts with ids b001-b064 and k001-k031 have been collected in a controlled
text generation experiment from 23 subjects discussing various controversial
issues from [a fixed list](topics_triggers.md).
The texts with ids d01-d23 have been written by Andreas Peldszus and were
used mainly in teaching and testing students argumentative analysis.
All texts are annotated with argumentation structures, following the scheme
proposed in Peldszus & Stede (2013). For inter-annotator-agreement scores see
Peldszus (2014). The (German) annotation guidelines are published in Peldszus, Warzecha, Stede (2016).
## DATA FORMAT (ARGUMENTATION GRAPH)
This specifies the argumentation graphs following the
annotation scheme described in
Andreas Peldszus and Manfred Stede. From argument diagrams to argumentation
mining in texts: a survey. International Journal of Cognitive Informatics
and Natural Intelligence (IJCINI), 7(1):1–31, 2013.
An argumentation graph is a directed graph spanning over text segments. The
format distinguishes three different sorts of nodes: EDUs, ADUs & EDU-joints.
- EDU: elementary discourse units
The text is segmented into elementary discourse units, typically at a
clause/sentence level. This segmentation can be the result of manually
annotation or of automatic discourse segmenters.
- ADU: argumentative discourse units
Not every EDU is relevant in an argumentation. Also, the same claim might
be stated multiple times in longer texts. An argumentative discourse unit
represents a claim that stands for itself and is argumentatively relevant.
It is thus grounded in one or more EDUs. EDU and ADUs are connected by
segmentation edges. ADUs are associated with a dialectic role: They are
either proponent or opponent nodes.
- JOINT: a joint of two or more adjacent elementary discourse units
When two adjacent EDUs are argumentatively relevant only when taken
together, these EDUs are first connected with one joint EDU node by
segmentation edges and then this joint node is connected to a corresponding
ADU.
### edge type
The edges representing arguments are those that connect ADUs. The scheme
distinguishes between supporting and attacking relations. Supporting
relations are normal support and support by example. Attacking relations are
rebutting attacks (directed against another node, challenging the accept-
ability of the corresponding claim) and undercutting attacks (directed
against another relation, challenging the argumentative inference from the
source to the target of the relation). Finally, additional premises of
relations with more than one premise are represented by additional source
relations.
Values:
- seg: segmentation edges (EDU->ADU, EDU->JOINT, JOINT->ADU)
- sup: support (ADU->ADU)
- exa: support by example (ADU->ADU)
- add: additional source, for combined/convergent arguments with multiple premises (ADU->ADU)
- reb: rebutting attack (ADU->ADU)
- und: undercutting attack (ADU->Edge)
### adu type
The argumentation can be thought of as a dialectical exchange between the
role of the proponent (who is presenting and defending the central claim)
and the role of the opponent (who is critically challenging the proponents
claims). Each ADU is thus associated with one of these dialectic roles.
Values:
- pro: proponent
- opp: opponent
### stance type
Annotated texts typically discuss a controversial topic, i.e. an issue posed
as a yes/no question. Example: "Should we make use of capital punishment?"
The stance type specifies, which stance the author of this text takes
towards this issue.
Values:
- pro: yes, in favour of the proposed issue
- con: no, against the proposed issue
- unclear: the position of the author is unclear
- UNDEFINED | 4,003 | [
[
-0.055877685546875,
-0.08984375,
0.043060302734375,
-0.0164642333984375,
-0.039398193359375,
-0.017059326171875,
0.0005779266357421875,
-0.00820159912109375,
0.039031982421875,
0.03314208984375,
-0.020172119140625,
-0.034759521484375,
-0.038482666015625,
0.0... |
hf-audio/esb-datasets-test-only | 2023-08-29T12:45:54.000Z | [
"task_categories:automatic-speech-recognition",
"annotations_creators:expert-generated",
"annotations_creators:crowdsourced",
"annotations_creators:machine-generated",
"language_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
... | hf-audio | null | null | 4 | 5 | 2023-08-08T16:30:41 | ---
annotations_creators:
- expert-generated
- crowdsourced
- machine-generated
language:
- en
language_creators:
- crowdsourced
- expert-generated
license:
- cc-by-4.0
- apache-2.0
- cc0-1.0
- cc-by-nc-3.0
- other
multilinguality:
- monolingual
pretty_name: datasets
size_categories:
- 100K<n<1M
- 1M<n<10M
source_datasets:
- original
- extended|librispeech_asr
- extended|common_voice
tags:
- asr
- benchmark
- speech
- esb
task_categories:
- automatic-speech-recognition
extra_gated_prompt: >-
Three of the ESB datasets have specific terms of usage that must be agreed to
before using the data.
To do so, fill in the access forms on the specific datasets' pages:
* Common Voice: https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0
* GigaSpeech: https://huggingface.co/datasets/speechcolab/gigaspeech
* SPGISpeech: https://huggingface.co/datasets/kensho/spgispeech
extra_gated_fields:
I hereby confirm that I have registered on the original Common Voice page and agree to not attempt to determine the identity of speakers in the Common Voice dataset: checkbox
I hereby confirm that I have accepted the terms of usages on GigaSpeech page: checkbox
I hereby confirm that I have accepted the terms of usages on SPGISpeech page: checkbox
duplicated_from: open-asr-leaderboard/datasets
---
All eight of datasets in ESB can be downloaded and prepared in just a single line of code through the Hugging Face Datasets library:
```python
from datasets import load_dataset
librispeech = load_dataset("esb/datasets", "librispeech", split="train")
```
- `"esb/datasets"`: the repository namespace. This is fixed for all ESB datasets.
- `"librispeech"`: the dataset name. This can be changed to any of any one of the eight datasets in ESB to download that dataset.
- `split="train"`: the split. Set this to one of train/validation/test to generate a specific split. Omit the `split` argument to generate all splits for a dataset.
The datasets are full prepared, such that the audio and transcription files can be used directly in training/evaluation scripts.
## Dataset Information
A data point can be accessed by indexing the dataset object loaded through `load_dataset`:
```python
print(librispeech[0])
```
A typical data point comprises the path to the audio file and its transcription. Also included is information of the dataset from which the sample derives and a unique identifier name:
```python
{
'dataset': 'librispeech',
'audio': {'path': '/home/sanchit-gandhi/.cache/huggingface/datasets/downloads/extracted/d2da1969fe9e7d06661b5dc370cf2e3c119a14c35950045bcb76243b264e4f01/374-180298-0000.flac',
'array': array([ 7.01904297e-04, 7.32421875e-04, 7.32421875e-04, ...,
-2.74658203e-04, -1.83105469e-04, -3.05175781e-05]),
'sampling_rate': 16000},
'text': 'chapter sixteen i might have told you of the beginning of this liaison in a few lines but i wanted you to see every step by which we came i to agree to whatever marguerite wished',
'id': '374-180298-0000'
}
```
### Data Fields
- `dataset`: name of the ESB dataset from which the sample is taken.
- `audio`: a dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate.
- `text`: the transcription of the audio file.
- `id`: unique id of the data sample.
### Data Preparation
#### Audio
The audio for all ESB datasets is segmented into sample lengths suitable for training ASR systems. The Hugging Face datasets library decodes audio files on the fly, reading the segments and converting them to a Python arrays. Consequently, no further preparation of the audio is required to be used in training/evaluation scripts.
Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, i.e. `dataset[0]["audio"]` should always be preferred over `dataset["audio"][0]`.
#### Transcriptions
The transcriptions corresponding to each audio file are provided in their 'error corrected' format. No transcription pre-processing is applied to the text, only necessary 'error correction' steps such as removing junk tokens (_<unk>_) or converting symbolic punctuation to spelled out form (_<comma>_ to _,_). As such, no further preparation of the transcriptions is required to be used in training/evaluation scripts.
Transcriptions are provided for training and validation splits. The transcriptions are **not** provided for the test splits. ESB requires you to generate predictions for the test sets and upload them to https://huggingface.co/spaces/esb/leaderboard for scoring.
### Access
All eight of the datasets in ESB are accessible and licensing is freely available. Three of the ESB datasets have specific terms of usage that must be agreed to before using the data. To do so, fill in the access forms on the specific datasets' pages:
* Common Voice: https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0
* GigaSpeech: https://huggingface.co/datasets/speechcolab/gigaspeech
* SPGISpeech: https://huggingface.co/datasets/kensho/spgispeech
### Diagnostic Dataset
ESB contains a small, 8h diagnostic dataset of in-domain validation data with newly annotated transcriptions. The audio data is sampled from each of the ESB validation sets, giving a range of different domains and speaking styles. The transcriptions are annotated according to a consistent style guide with two formats: normalised and un-normalised. The dataset is structured in the same way as the ESB dataset, by grouping audio-transcription samples according to the dataset from which they were taken. We encourage participants to use this dataset when evaluating their systems to quickly assess performance on a range of different speech recognition conditions. For more information, visit: [esb/diagnostic-dataset](https://huggingface.co/datasets/esb/diagnostic-dataset).
## Summary of ESB Datasets
| Dataset | Domain | Speaking Style | Train (h) | Dev (h) | Test (h) | Transcriptions | License |
|--------------|-----------------------------|-----------------------|-----------|---------|----------|--------------------|-----------------|
| LibriSpeech | Audiobook | Narrated | 960 | 11 | 11 | Normalised | CC-BY-4.0 |
| Common Voice | Wikipedia | Narrated | 1409 | 27 | 27 | Punctuated & Cased | CC0-1.0 |
| Voxpopuli | European Parliament | Oratory | 523 | 5 | 5 | Punctuated | CC0 |
| TED-LIUM | TED talks | Oratory | 454 | 2 | 3 | Normalised | CC-BY-NC-ND 3.0 |
| GigaSpeech | Audiobook, podcast, YouTube | Narrated, spontaneous | 2500 | 12 | 40 | Punctuated | apache-2.0 |
| SPGISpeech | Fincancial meetings | Oratory, spontaneous | 4900 | 100 | 100 | Punctuated & Cased | User Agreement |
| Earnings-22 | Fincancial meetings | Oratory, spontaneous | 105 | 5 | 5 | Punctuated & Cased | CC-BY-SA-4.0 |
| AMI | Meetings | Spontaneous | 78 | 9 | 9 | Punctuated & Cased | CC-BY-4.0 |
## LibriSpeech
The LibriSpeech corpus is a standard large-scale corpus for assessing ASR systems. It consists of approximately 1,000 hours of narrated audiobooks from the [LibriVox](https://librivox.org) project. It is licensed under CC-BY-4.0.
Example Usage:
```python
librispeech = load_dataset("esb/datasets", "librispeech")
```
Train/validation splits:
- `train` (combination of `train.clean.100`, `train.clean.360` and `train.other.500`)
- `validation.clean`
- `validation.other`
Test splits:
- `test.clean`
- `test.other`
Also available are subsets of the train split, which can be accessed by setting the `subconfig` argument:
```python
librispeech = load_dataset("esb/datasets", "librispeech", subconfig="clean.100")
```
- `clean.100`: 100 hours of training data from the 'clean' subset
- `clean.360`: 360 hours of training data from the 'clean' subset
- `other.500`: 500 hours of training data from the 'other' subset
## Common Voice
Common Voice is a series of crowd-sourced open-licensed speech datasets where speakers record text from Wikipedia in various languages. The speakers are of various nationalities and native languages, with different accents and recording conditions. We use the English subset of version 9.0 (27-4-2022), with approximately 1,400 hours of audio-transcription data. It is licensed under CC0-1.0.
Example usage:
```python
common_voice = load_dataset("esb/datasets", "common_voice", use_auth_token=True)
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## VoxPopuli
VoxPopuli is a large-scale multilingual speech corpus consisting of political data sourced from 2009-2020 European Parliament event recordings. The English subset contains approximately 550 hours of speech largely from non-native English speakers. It is licensed under CC0.
Example usage:
```python
voxpopuli = load_dataset("esb/datasets", "voxpopuli")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## TED-LIUM
TED-LIUM consists of English-language TED Talk conference videos covering a range of different cultural, political, and academic topics. It contains approximately 450 hours of transcribed speech data. It is licensed under CC-BY-NC-ND 3.0.
Example usage:
```python
tedlium = load_dataset("esb/datasets", "tedlium")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## GigaSpeech
GigaSpeech is a multi-domain English speech recognition corpus created from audiobooks, podcasts and YouTube. We provide the large train set (2,500 hours) and the standard validation and test splits. It is licensed under apache-2.0.
Example usage:
```python
gigaspeech = load_dataset("esb/datasets", "gigaspeech", use_auth_token=True)
```
Training/validation splits:
- `train` (`l` subset of training data (2,500 h))
- `validation`
Test splits:
- `test`
Also available are subsets of the train split, which can be accessed by setting the `subconfig` argument:
```python
gigaspeech = load_dataset("esb/datasets", "spgispeech", subconfig="xs", use_auth_token=True)
```
- `xs`: extra-small subset of training data (10 h)
- `s`: small subset of training data (250 h)
- `m`: medium subset of training data (1,000 h)
- `xl`: extra-large subset of training data (10,000 h)
## SPGISpeech
SPGISpeech consists of company earnings calls that have been manually transcribed by S&P Global, Inc according to a professional style guide. We provide the large train set (5,000 hours) and the standard validation and test splits. It is licensed under a Kensho user agreement.
Loading the dataset requires authorization.
Example usage:
```python
spgispeech = load_dataset("esb/datasets", "spgispeech", use_auth_token=True)
```
Training/validation splits:
- `train` (`l` subset of training data (~5,000 h))
- `validation`
Test splits:
- `test`
Also available are subsets of the train split, which can be accessed by setting the `subconfig` argument:
```python
spgispeech = load_dataset("esb/datasets", "spgispeech", subconfig="s", use_auth_token=True)
```
- `s`: small subset of training data (~200 h)
- `m`: medium subset of training data (~1,000 h)
## Earnings-22
Earnings-22 is a 119-hour corpus of English-language earnings calls collected from global companies, with speakers of many different nationalities and accents. It is licensed under CC-BY-SA-4.0.
Example usage:
```python
earnings22 = load_dataset("esb/datasets", "earnings22")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test`
## AMI
The AMI Meeting Corpus consists of 100 hours of meeting recordings from multiple recording devices synced to a common timeline. It is licensed under CC-BY-4.0.
Example usage:
```python
ami = load_dataset("esb/datasets", "ami")
```
Training/validation splits:
- `train`
- `validation`
Test splits:
- `test` | 12,450 | [
[
-0.044647216796875,
-0.04742431640625,
0.001880645751953125,
0.03369140625,
-0.0059356689453125,
-0.007472991943359375,
-0.025054931640625,
-0.03057861328125,
0.043609619140625,
0.04119873046875,
-0.059906005859375,
-0.045257568359375,
-0.03472900390625,
0.0... |
indolem/indo_story_cloze | 2023-08-09T13:01:34.000Z | [
"language:id",
"license:cc-by-sa-4.0",
"region:us"
] | indolem | null | @inproceedings{koto-etal-2022-cloze,
title = "Cloze Evaluation for Deeper Understanding of Commonsense Stories in {I}ndonesian",
author = "Koto, Fajri and
Baldwin, Timothy and
Lau, Jey Han",
booktitle = "Proceedings of the First Workshop on Commonsense Representation and Reasoning (CSRR 2022)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.csrr-1.2",
doi = "10.18653/v1/2022.csrr-1.2",
pages = "8--16",
} | 2 | 5 | 2023-08-09T12:00:36 | ---
license: cc-by-sa-4.0
language:
- id
---
# IndoCloze
## About
We hired seven Indonesian university students to each write 500 short stories over a period of one month. This paper wins **Best Paper Award at CSRR (ACL 2022)**.
## Paper
Fajri Koto, Timothy Baldwin, and Jey Han Lau. [_Cloze Evaluation for Deeper Understanding of Commonsense Stories in Indonesian_](https://aclanthology.org/2022.csrr-1.2.pdf).
In In Proceedings of Commonsense Representation and Reasoning Workshop 2022 (**CSRR at ACL 2022**), Dublin, Ireland.
## Dataset
A story in our dataset consists of four-sentence premise, one-sentence correct ending, and one-sentence incorrect ending. In total, we have created 2,325 Indonesian stories with the train/dev/test split 1,000/200/1,135. Please see some examples of our data below, and note that the English translation is only for the illustratrive purposes.
<h3 align="center">
<img src="https://raw.githubusercontent.com/fajri91/eval_picts/master/indocloze.png" width="850">
</h3>
| 1,013 | [
[
-0.0198974609375,
-0.0274505615234375,
0.032257080078125,
0.033660888671875,
-0.039276123046875,
-0.01080322265625,
-0.0300445556640625,
-0.035614013671875,
0.017303466796875,
0.027862548828125,
-0.00699615478515625,
-0.025299072265625,
-0.03131103515625,
0.... |
wwydmanski/biodataome | 2023-08-10T08:31:47.000Z | [
"task_categories:tabular-classification",
"size_categories:n<1k",
"size_categories:1K<n<10K",
"license:afl-3.0",
"biology",
"region:us"
] | wwydmanski | null | 2 | 5 | 2023-08-09T13:57:16 | ---
license: afl-3.0
task_categories:
- tabular-classification
pretty_name: BioDataome
size_categories:
- n<1k
- 1K<n<10K
tags:
- biology
---
# BioDataome
This is an aggregate dataset which allows you to download any and all data from the [BioDataome project](http://dataome.mensxmachina.org/).
## What is BioDataome?
BioDataome is a collection of uniformly preprocessed and automatically annotated datasets for data-driven biology. The processed data can be accessed via the BioDataome website in .csv format and the BioDataome package via github. BioDataome package contains all the functions used to download, preprocess and annotate gene expression and methylation microarray data from Gene Expression Omnibus, as well as RNASeq data from recount.
## Usage
```python
import datasets
ds = datasets.load_dataset("wwydmanski/biodataome", "GSE24849")['train']
split_ds = ds.train_test_split(test_size=0.1)
train_ds, test_ds = split_ds['train'], split_ds['test']
# there is probably a better way to do this, but this seems to work the fastest
y_train = train_ds.to_pandas()['metadata'].apply(lambda x: x['class'])
X_train = pd.DataFrame.from_records(train_ds.to_pandas()['data'])
y_test = test_ds.to_pandas()['metadata'].apply(lambda x: x['class'])
X_test = pd.DataFrame.from_records(test_ds.to_pandas()['data'])
```
Please refer to the [original metadata](http://dataome.mensxmachina.org/) for the list of available datasets.
## Disclaimer
BioDataome and its content are provided as is without any warranty of any kind, that BioDataome or any documents available from this server will be error free. In no event will its members be liable for any damages, arising out of, resulting from, or in any way connected with the use of BioDataome or documents available from this server.
BioDataome is restricted to research and educational use. The information you may retrieve and recover from BioDataome is not designed to diagnose, prevent, or treat any condition or disease
Part of research that led to the development of BioDataome has received funding from the European Research Council under the European Union's Seventh Framework Programme (FP/2007-2013) / ERC Grant Agreement n. 617393.
Part of the analyses results and the implementation of the web interface were funded by the “ELIXIR-GR: Managing and Analysing Life Sciences Data (MIS: 5002780)” Project, co-financed by Greece and the European Union - European Regional Development Fund. | 2,455 | [
[
-0.032989501953125,
-0.041290283203125,
0.01424407958984375,
0.0216217041015625,
-0.034332275390625,
-0.003711700439453125,
0.01120758056640625,
-0.027496337890625,
0.060882568359375,
0.02862548828125,
-0.044189453125,
-0.0616455078125,
-0.0156402587890625,
... | |
Xmm/miliprompt | 2023-08-11T03:57:10.000Z | [
"region:us"
] | Xmm | null | null | 0 | 5 | 2023-08-11T03:55:51 | ---
dataset_info:
features:
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 66133
num_examples: 554
download_size: 28382
dataset_size: 66133
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "miliprompt"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 433 | [
[
-0.055023193359375,
-0.01212310791015625,
0.01230621337890625,
0.021942138671875,
-0.0170745849609375,
0.0026073455810546875,
0.0271148681640625,
-0.0144805908203125,
0.06512451171875,
0.0426025390625,
-0.06427001953125,
-0.04119873046875,
-0.05267333984375,
... |
DynamicSuperb/NoiseDetection_VCTK-MUSAN-Gaussian | 2023-10-19T06:07:35.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-08-11T07:02:24 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
struct:
- name: array
sequence: float64
- name: path
dtype: string
- name: sampling_rate
dtype: int64
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 13812517186
num_examples: 26865
download_size: 3397759328
dataset_size: 13812517186
---
# Dataset Card for "NoiseDetectiongaussian_VCTKMusan"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 611 | [
[
-0.036956787109375,
-0.0243072509765625,
0.0189361572265625,
0.0267181396484375,
-0.02569580078125,
-0.00917816162109375,
0.0211029052734375,
-0.01207733154296875,
0.0458984375,
0.0298919677734375,
-0.068603515625,
-0.0555419921875,
-0.04571533203125,
-0.035... |
DynamicSuperb/NoiseDetection_VCTK_MUSAN-Noise | 2023-11-02T09:23:50.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-08-11T08:23:31 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
struct:
- name: array
sequence: float64
- name: path
dtype: string
- name: sampling_rate
dtype: int64
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 13811936533
num_examples: 26865
download_size: 3393108140
dataset_size: 13811936533
---
# Dataset Card for "NoiseDetectionnoise_VCTKMusan"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 608 | [
[
-0.03375244140625,
-0.0209503173828125,
0.0120697021484375,
0.0251312255859375,
-0.0299835205078125,
-0.00511932373046875,
0.022918701171875,
-0.0143280029296875,
0.048675537109375,
0.032928466796875,
-0.06439208984375,
-0.059326171875,
-0.042816162109375,
-... |
DynamicSuperb/NoiseDetection_VCTK_MUSAN-Speech | 2023-11-02T09:20:18.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-08-11T08:44:25 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
struct:
- name: array
sequence: float64
- name: path
dtype: string
- name: sampling_rate
dtype: int64
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 13812336068
num_examples: 26865
download_size: 3393022926
dataset_size: 13812336068
---
# Dataset Card for "NoiseDetectionspeech_VCTKMusan"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 609 | [
[
-0.03887939453125,
-0.0197296142578125,
0.0138702392578125,
0.0294647216796875,
-0.0284423828125,
-0.0059661865234375,
0.0213165283203125,
-0.01001739501953125,
0.04705810546875,
0.033416748046875,
-0.06683349609375,
-0.055389404296875,
-0.041717529296875,
-... |
DynamicSuperb/NoiseSNRLevelPrediction_VCTK_MUSAN-Music | 2023-11-02T09:13:37.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-08-11T09:39:06 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
struct:
- name: array
sequence: float64
- name: path
dtype: string
- name: sampling_rate
dtype: int64
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 13812981320
num_examples: 26865
download_size: 3421932906
dataset_size: 13812981320
---
# Dataset Card for "NoiseSNRLevelPredictionmusic_VCTKMusan"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 617 | [
[
-0.031646728515625,
-0.0104217529296875,
0.0015192031860351562,
0.04168701171875,
-0.018463134765625,
-0.002071380615234375,
0.004962921142578125,
-0.0085296630859375,
0.044219970703125,
0.031097412109375,
-0.07232666015625,
-0.0703125,
-0.04107666015625,
-0... |
DynamicSuperb/NoiseSNRLevelPrediction_VCTK_MUSAN-Noise | 2023-11-02T09:10:48.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-08-11T10:13:44 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
struct:
- name: array
sequence: float64
- name: path
dtype: string
- name: sampling_rate
dtype: int64
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 13812891175
num_examples: 26865
download_size: 3422296362
dataset_size: 13812891175
---
# Dataset Card for "NoiseSNRLevelPredictionnoise_VCTKMusan"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 617 | [
[
-0.0294952392578125,
-0.0141448974609375,
-0.0007901191711425781,
0.03857421875,
-0.025482177734375,
-0.005962371826171875,
0.00960540771484375,
-0.01053619384765625,
0.0421142578125,
0.0280914306640625,
-0.06903076171875,
-0.07012939453125,
-0.04534912109375,
... |
DynamicSuperb/NoiseSNRLevelPrediction_VCTK_MUSAN-Speech | 2023-10-19T06:31:19.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-08-11T10:32:58 | ---
dataset_info:
features:
- name: file
dtype: string
- name: audio
struct:
- name: array
sequence: float64
- name: path
dtype: string
- name: sampling_rate
dtype: int64
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 13813101498
num_examples: 26865
download_size: 3422027202
dataset_size: 13813101498
---
# Dataset Card for "NoiseSNRLevelPredictionspeech_VCTKMusan"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 618 | [
[
-0.0312347412109375,
-0.01312255859375,
0.0022125244140625,
0.037322998046875,
-0.022308349609375,
-0.0052032470703125,
0.014617919921875,
-0.0098419189453125,
0.0418701171875,
0.02850341796875,
-0.0714111328125,
-0.06512451171875,
-0.042236328125,
-0.023910... |
open-llm-leaderboard/details_kfkas__Llama-2-ko-7b-Chat | 2023-09-18T06:21:05.000Z | [
"region:us"
] | open-llm-leaderboard | null | null | 0 | 5 | 2023-08-18T00:02:13 | ---
pretty_name: Evaluation run of kfkas/Llama-2-ko-7b-Chat
dataset_summary: "Dataset automatically created during the evaluation run of model\
\ [kfkas/Llama-2-ko-7b-Chat](https://huggingface.co/kfkas/Llama-2-ko-7b-Chat) on\
\ the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\
\nThe dataset is composed of 64 configuration, each one coresponding to one of the\
\ evaluated task.\n\nThe dataset has been created from 4 run(s). Each run can be\
\ found as a specific split in each configuration, the split being named using the\
\ timestamp of the run.The \"train\" split is always pointing to the latest results.\n\
\nAn additional configuration \"results\" store all the aggregated results of the\
\ run (and is used to compute and display the agregated metrics on the [Open LLM\
\ Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\
\nTo load the details from a run, you can for instance do the following:\n```python\n\
from datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_kfkas__Llama-2-ko-7b-Chat\"\
,\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\n\
These are the [latest results from run 2023-09-18T06:20:53.119467](https://huggingface.co/datasets/open-llm-leaderboard/details_kfkas__Llama-2-ko-7b-Chat/blob/main/results_2023-09-18T06-20-53.119467.json)(note\
\ that their might be results for other tasks in the repos if successive evals didn't\
\ cover the same tasks. You find each in the results and the \"latest\" split for\
\ each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.029886744966442953,\n\
\ \"em_stderr\": 0.0017437739254467523,\n \"f1\": 0.11206061241610675,\n\
\ \"f1_stderr\": 0.002589360675643281,\n \"acc\": 0.3406984196130502,\n\
\ \"acc_stderr\": 0.008168649232732146\n },\n \"harness|drop|3\": {\n\
\ \"em\": 0.029886744966442953,\n \"em_stderr\": 0.0017437739254467523,\n\
\ \"f1\": 0.11206061241610675,\n \"f1_stderr\": 0.002589360675643281\n\
\ },\n \"harness|gsm8k|5\": {\n \"acc\": 0.01288855193328279,\n \
\ \"acc_stderr\": 0.003106901266499642\n },\n \"harness|winogrande|5\"\
: {\n \"acc\": 0.6685082872928176,\n \"acc_stderr\": 0.01323039719896465\n\
\ }\n}\n```"
repo_url: https://huggingface.co/kfkas/Llama-2-ko-7b-Chat
leaderboard_url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
point_of_contact: clementine@hf.co
configs:
- config_name: harness_arc_challenge_25
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|arc:challenge|25_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|arc:challenge|25_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|arc:challenge|25_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_drop_3
data_files:
- split: 2023_09_17T05_11_56.274160
path:
- '**/details_harness|drop|3_2023-09-17T05-11-56.274160.parquet'
- split: 2023_09_18T06_20_53.119467
path:
- '**/details_harness|drop|3_2023-09-18T06-20-53.119467.parquet'
- split: latest
path:
- '**/details_harness|drop|3_2023-09-18T06-20-53.119467.parquet'
- config_name: harness_gsm8k_5
data_files:
- split: 2023_09_17T05_11_56.274160
path:
- '**/details_harness|gsm8k|5_2023-09-17T05-11-56.274160.parquet'
- split: 2023_09_18T06_20_53.119467
path:
- '**/details_harness|gsm8k|5_2023-09-18T06-20-53.119467.parquet'
- split: latest
path:
- '**/details_harness|gsm8k|5_2023-09-18T06-20-53.119467.parquet'
- config_name: harness_hellaswag_10
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hellaswag|10_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hellaswag|10_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hellaswag|10_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-27T10:54:54.901743.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-international_law|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-management|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-marketing|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-sociology|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-virology|5_2023-07-27T16:15:02.960730.parquet'
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_abstract_algebra_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-abstract_algebra|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_anatomy_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-anatomy|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_astronomy_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-astronomy|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_business_ethics_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-business_ethics|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_clinical_knowledge_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-clinical_knowledge|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_college_biology_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_biology|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_college_chemistry_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_chemistry|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_college_computer_science_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_computer_science|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_college_mathematics_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_mathematics|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_college_medicine_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_medicine|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_college_physics_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-college_physics|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_computer_security_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-computer_security|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_conceptual_physics_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-conceptual_physics|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_econometrics_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-econometrics|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_electrical_engineering_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-electrical_engineering|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_elementary_mathematics_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-elementary_mathematics|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_formal_logic_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-formal_logic|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_global_facts_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-global_facts|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_biology_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_biology|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_chemistry_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_chemistry|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_computer_science_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_computer_science|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_european_history_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_european_history|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_geography_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_geography|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_government_and_politics_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_macroeconomics_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_mathematics_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_mathematics|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_microeconomics_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_physics_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_physics|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_psychology_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_psychology|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_statistics_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_statistics|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_us_history_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_us_history|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_high_school_world_history_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-high_school_world_history|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_human_aging_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_aging|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_human_sexuality_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-human_sexuality|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_international_law_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-international_law|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_jurisprudence_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-jurisprudence|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_logical_fallacies_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-logical_fallacies|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_machine_learning_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-machine_learning|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_management_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-management|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_marketing_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-marketing|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_medical_genetics_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-medical_genetics|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_miscellaneous_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-miscellaneous|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_moral_disputes_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_disputes|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_moral_scenarios_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-moral_scenarios|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_nutrition_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-nutrition|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_philosophy_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-philosophy|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_prehistory_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-prehistory|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_professional_accounting_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_accounting|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_professional_law_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_law|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_professional_medicine_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_medicine|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_professional_psychology_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-professional_psychology|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_public_relations_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-public_relations|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_security_studies_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-security_studies|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_sociology_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-sociology|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_us_foreign_policy_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-us_foreign_policy|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_virology_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-virology|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_hendrycksTest_world_religions_5
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|hendrycksTest-world_religions|5_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_truthfulqa_mc_0
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-27T10:54:54.901743.parquet'
- split: 2023_07_27T16_15_02.960730
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-27T16:15:02.960730.parquet'
- split: latest
path:
- '**/details_harness|truthfulqa:mc|0_2023-07-27T16:15:02.960730.parquet'
- config_name: harness_winogrande_5
data_files:
- split: 2023_09_17T05_11_56.274160
path:
- '**/details_harness|winogrande|5_2023-09-17T05-11-56.274160.parquet'
- split: 2023_09_18T06_20_53.119467
path:
- '**/details_harness|winogrande|5_2023-09-18T06-20-53.119467.parquet'
- split: latest
path:
- '**/details_harness|winogrande|5_2023-09-18T06-20-53.119467.parquet'
- config_name: results
data_files:
- split: 2023_07_27T10_54_54.901743
path:
- results_2023-07-27T10:54:54.901743.parquet
- split: 2023_07_27T16_15_02.960730
path:
- results_2023-07-27T16:15:02.960730.parquet
- split: 2023_09_17T05_11_56.274160
path:
- results_2023-09-17T05-11-56.274160.parquet
- split: 2023_09_18T06_20_53.119467
path:
- results_2023-09-18T06-20-53.119467.parquet
- split: latest
path:
- results_2023-09-18T06-20-53.119467.parquet
---
# Dataset Card for Evaluation run of kfkas/Llama-2-ko-7b-Chat
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/kfkas/Llama-2-ko-7b-Chat
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** clementine@hf.co
### Dataset Summary
Dataset automatically created during the evaluation run of model [kfkas/Llama-2-ko-7b-Chat](https://huggingface.co/kfkas/Llama-2-ko-7b-Chat) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 4 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_kfkas__Llama-2-ko-7b-Chat",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-09-18T06:20:53.119467](https://huggingface.co/datasets/open-llm-leaderboard/details_kfkas__Llama-2-ko-7b-Chat/blob/main/results_2023-09-18T06-20-53.119467.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.029886744966442953,
"em_stderr": 0.0017437739254467523,
"f1": 0.11206061241610675,
"f1_stderr": 0.002589360675643281,
"acc": 0.3406984196130502,
"acc_stderr": 0.008168649232732146
},
"harness|drop|3": {
"em": 0.029886744966442953,
"em_stderr": 0.0017437739254467523,
"f1": 0.11206061241610675,
"f1_stderr": 0.002589360675643281
},
"harness|gsm8k|5": {
"acc": 0.01288855193328279,
"acc_stderr": 0.003106901266499642
},
"harness|winogrande|5": {
"acc": 0.6685082872928176,
"acc_stderr": 0.01323039719896465
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | 53,288 | [
[
-0.027374267578125,
-0.04962158203125,
0.01910400390625,
0.02398681640625,
-0.0244598388671875,
0.0213470458984375,
-0.020172119140625,
-0.0174407958984375,
0.036590576171875,
0.041748046875,
-0.047393798828125,
-0.0689697265625,
-0.05523681640625,
0.0118942... |
sarahpann/MATH | 2023-09-23T03:06:46.000Z | [
"region:us"
] | sarahpann | null | null | 0 | 5 | 2023-08-19T05:24:14 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
RealTimeData/wikitext_latest | 2023-10-30T00:57:01.000Z | [
"region:us"
] | RealTimeData | null | null | 0 | 5 | 2023-08-19T20:04:41 | ---
{}
---
# Latest Wikitext
You could always access the latest Wikipedia texts via this dataset.
We update the dataset weekly, on every Sunday. So the dataset always provides the latest Wikipedia texts from the last week.
The current dataset on main branch contains the latest wikipedia texts created from 2023-10-16 to 2023-10-23.
The data collection is conducted on 2023-10-30.
Use the dataset via:
```
ds = datasets.load_dataset('RealTimeData/wikitext_latest')
```
# Previsou versions
You could access previous versions by requesting different branches.
For example, you could find the 2023-08-12 version via:
```
ds = datasets.load_dataset('RealTimeData/wikitext_latest', revision = '2023-08-12')
```
Check all available versions by clicking the "Files and versions" button on the top bar.
| 805 | [
[
-0.044525146484375,
-0.02801513671875,
0.02215576171875,
0.01122283935546875,
-0.02716064453125,
-0.0010852813720703125,
-0.0204925537109375,
-0.054840087890625,
0.041595458984375,
0.042724609375,
-0.0836181640625,
-0.0243377685546875,
-0.0229949951171875,
0... |
fake-news-UFG/FactChecksbr | 2023-08-24T17:40:04.000Z | [
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:pt",
"license:mit",
"doi:10.57967/hf/1016",
"region:us"
] | fake-news-UFG | Collection of Portuguese Fact-Checking Benchmarks. | @misc{FactChecksbr,
author = {R. S. Gomes, Juliana},
title = {FactChecks.br},
url = {https://github.com/fake-news-UFG/FactChecks.br},
doi = { 10.57967/hf/1016 },
} | 0 | 5 | 2023-08-23T17:15:02 | ---
license: mit
task_categories:
- text-classification
language:
- pt
pretty_name: FactChecks.br
size_categories:
- 10K<n<100K
---
# FactChecks.br
## Dataset Description
- **Homepage:**
- **Repository:** [github.com/fake-news-UFG/FactChecks.br](github.com/fake-news-UFG/FactChecks.br)
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Collection of Portuguese Fact-Checking Benchmarks.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
The dataset is in Portuguese.
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
If you use "FactChecks.br Dataset", please include a cite:
```bibtex
@misc{FactChecksbr,
author = {R. S. Gomes, Juliana},
title = {FactChecks.br},
url = {https://github.com/fake-news-UFG/FactChecks.br},
doi = { 10.57967/hf/1016 },
}
```
### Contributions
Thanks to [@ju-resplande](https://github.com/ju-resplande) for adding this dataset. | 1,819 | [
[
-0.0228118896484375,
-0.0323486328125,
0.00891876220703125,
0.0277252197265625,
-0.0386962890625,
0.00426483154296875,
-0.02069091796875,
-0.02783203125,
0.03778076171875,
0.0472412109375,
-0.038055419921875,
-0.06756591796875,
-0.054443359375,
0.00717163085... |
LawChat-tw/SFT | 2023-08-24T04:31:42.000Z | [
"region:us"
] | LawChat-tw | null | null | 0 | 5 | 2023-08-24T04:24:49 | ---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: instruction
dtype: string
splits:
- name: train
num_bytes: 11724495
num_examples: 11798
download_size: 6505304
dataset_size: 11724495
---
# Dataset Card for "SFT"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 424 | [
[
-0.0390625,
-0.02606201171875,
0.0210723876953125,
0.0293121337890625,
-0.01494598388671875,
0.01080322265625,
0.028076171875,
-0.01049041748046875,
0.05645751953125,
0.03753662109375,
-0.06597900390625,
-0.038360595703125,
-0.0308837890625,
-0.0136566162109... |
FinchResearch/TexTrend-Platypus-Tagalog | 2023-08-24T08:50:07.000Z | [
"region:us"
] | FinchResearch | null | null | 0 | 5 | 2023-08-24T08:25:40 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
AISE-TUDelft/nlbse_ccc | 2023-08-24T11:54:45.000Z | [
"task_categories:text-classification",
"size_categories:10K<n<100K",
"region:us"
] | AISE-TUDelft | null | null | 0 | 5 | 2023-08-24T11:46:20 | ---
configs:
- config_name: default
data_files:
- split: java_Pointer
path: data/java_Pointer-*
- split: java_Expand
path: data/java_Expand-*
- split: java_Ownership
path: data/java_Ownership-*
- split: java_deprecation
path: data/java_deprecation-*
- split: java_rational
path: data/java_rational-*
- split: java_summary
path: data/java_summary-*
- split: java_usage
path: data/java_usage-*
- split: python_Expand
path: data/python_Expand-*
- split: python_Summary
path: data/python_Summary-*
- split: python_DevelopmentNotes
path: data/python_DevelopmentNotes-*
- split: python_Parameters
path: data/python_Parameters-*
- split: python_Usage
path: data/python_Usage-*
- split: pharo_Example
path: data/pharo_Example-*
- split: pharo_Keymessages
path: data/pharo_Keymessages-*
- split: pharo_Responsibilities
path: data/pharo_Responsibilities-*
- split: pharo_Keyimplementationpoints
path: data/pharo_Keyimplementationpoints-*
- split: pharo_Collaborators
path: data/pharo_Collaborators-*
- split: pharo_Intent
path: data/pharo_Intent-*
- split: pharo_Classreferences
path: data/pharo_Classreferences-*
dataset_info:
features:
- name: comment_sentence_id
dtype: int64
- name: class
dtype: string
- name: comment_sentence
dtype: string
- name: partition
dtype: int64
- name: instance_type
dtype: int64
- name: category
dtype: string
- name: label
dtype: int64
- name: combo
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: java_Pointer
num_bytes: 483600
num_examples: 2418
- name: java_Expand
num_bytes: 481182
num_examples: 2418
- name: java_Ownership
num_bytes: 488436
num_examples: 2418
- name: java_deprecation
num_bytes: 493272
num_examples: 2418
- name: java_rational
num_bytes: 486018
num_examples: 2418
- name: java_summary
num_bytes: 483600
num_examples: 2418
- name: java_usage
num_bytes: 478764
num_examples: 2418
- name: python_Expand
num_bytes: 421025
num_examples: 2555
- name: python_Summary
num_bytes: 423580
num_examples: 2555
- name: python_DevelopmentNotes
num_bytes: 446575
num_examples: 2555
- name: python_Parameters
num_bytes: 431245
num_examples: 2555
- name: python_Usage
num_bytes: 418470
num_examples: 2555
- name: pharo_Example
num_bytes: 368156
num_examples: 1765
- name: pharo_Keymessages
num_bytes: 375216
num_examples: 1765
- name: pharo_Responsibilities
num_bytes: 384041
num_examples: 1765
- name: pharo_Keyimplementationpoints
num_bytes: 396396
num_examples: 1765
- name: pharo_Collaborators
num_bytes: 378746
num_examples: 1765
- name: pharo_Intent
num_bytes: 366391
num_examples: 1765
- name: pharo_Classreferences
num_bytes: 382276
num_examples: 1765
download_size: 3231436
dataset_size: 8186989
task_categories:
- text-classification
size_categories:
- 10K<n<100K
---
# Dataset Card for "nlbse_ccc"
A dataset object for the NLBSE'23 Code Comment Classification competition. Please refer to the original [Github repo for more details](https://github.com/nlbse2023/code-comment-classification).
## Category distribution in the training and test sets
The table below shows the distribution of positive/negative sentences for each category in the training and testing sets.
| Language | Category | Training | Training | Testing | Testing | Total |
|----------|--------------------|---------:|---------:|---------:|---------:|-------:|
| | | **Positive** | **Negative** | **Positive** | **Negative** | |
| Java | Expand | 505 | 1426 | 127 | 360 | 2418 |
| Java | Ownership | 90 | 1839 | 25 | 464 | 2418 |
| Java | Deprecation | 100 | 1831 | 27 | 460 | 2418 |
| Java | Rational | 223 | 1707 | 57 | 431 | 2418 |
| Java | Summary | 328 | 1600 | 87 | 403 | 2418 |
| Java | Pointer | 289 | 1640 | 75 | 414 | 2418 |
| Java | Usage | 728 | 1203 | 184 | 303 | 2418 |
| | | **Positive** | **Negative** | **Positive** | **Negative** | |
| Pharo | Responsibilities | 267 | 1139 | 69 | 290 | 1765 |
| Pharo | Keymessages | 242 | 1165 | 63 | 295 | 1765 |
| Pharo | Keyimplementationpoints | 184 | 1222 | 48 | 311 | 1765 |
| Pharo | Collaborators | 99 | 1307 | 28 | 331 | 1765 |
| Pharo | Example | 596 | 812 | 152 | 205 | 1765 |
| Pharo | Classreferences | 60 | 1348 | 17 | 340 | 1765 |
| Pharo | Intent | 173 | 1236 | 45 | 311 | 1765 |
| | | **Positive** | **Negative** | **Positive** | **Negative** | |
| Python | Expand | 402 | 1637 | 102 | 414 | 2555 |
| Python | Parameters | 633 | 1404 | 161 | 357 | 2555 |
| Python | Summary | 361 | 1678 | 93 | 423 | 2555 |
| Python | Developmentnotes | 247 | 1792 | 65 | 451 | 2555 |
| Python | Usage | 637 | 1401 | 163 | 354 | 2555 |
## Code
The following code snippet was used to create the dataset:
```
# !git clone https://github.com/nlbse2023/code-comment-classification.git
from datasets import DatasetDict
langs = ['java', 'python', 'pharo']
lan_cats = []
dataset_dict = DatasetDict()
for lan in langs: # for each language
df = pd.read_csv(f'./code-comment-classification/{lan}/input/{lan}.csv')
df['label'] = df.instance_type
df['combo'] = df[['comment_sentence', 'class']].agg(' | '.join, axis=1)
print(df.columns)
cats = list(map(lambda x: lan + '_' + x, list(set(df.category))))
lan_cats = lan_cats + cats
for cat in list(set(df.category)): # for each category
filtered = df[df.category == cat]
dataset_dict[f'{lan}_{cat}'] = Dataset.from_pandas(filtered)
dataset_dict.push_to_hub("AISE-TUDelft/nlbse_ccc", token='hf_********************')
```
| 6,526 | [
[
-0.046783447265625,
-0.022674560546875,
-0.00040030479431152344,
0.01044464111328125,
-0.0205078125,
0.002826690673828125,
-0.017486572265625,
-0.00843048095703125,
0.0347900390625,
0.0386962890625,
-0.04095458984375,
-0.06549072265625,
-0.0301971435546875,
... |
w8ay/security-paper-datasets | 2023-10-16T10:34:13.000Z | [
"region:us"
] | w8ay | null | null | 0 | 5 | 2023-08-25T02:11:45 | ---
dataset_info:
features:
- name: text
dtype: string
- name: category
dtype: string
splits:
- name: train
num_bytes: 1690579945
num_examples: 428155
download_size: 751689097
dataset_size: 1690579945
---
# Dataset Card for "security-paper-datasets"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 412 | [
[
-0.0293731689453125,
-0.0188446044921875,
0.0159912109375,
0.0020198822021484375,
-0.019378662109375,
0.01184844970703125,
0.031585693359375,
-0.0108795166015625,
0.05853271484375,
0.035675048828125,
-0.042236328125,
-0.05938720703125,
-0.0513916015625,
-0.0... |
abdiharyadi/indo-amr-simple-ilmy-test-1.0.1 | 2023-08-25T02:12:05.000Z | [
"region:us"
] | abdiharyadi | null | null | 0 | 5 | 2023-08-25T02:12:05 | ---
dataset_info:
features:
- name: sentence
dtype: string
- name: amr
dtype: string
splits:
- name: train
num_bytes: 44012
num_examples: 306
download_size: 21662
dataset_size: 44012
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "indo-amr-simple-ilmy-test-1.0.1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 488 | [
[
-0.057342529296875,
-0.0149383544921875,
-0.0196685791015625,
0.024627685546875,
-0.025604248046875,
-0.0152130126953125,
0.01401519775390625,
-0.012420654296875,
0.0684814453125,
0.0286712646484375,
-0.0650634765625,
-0.04388427734375,
-0.034515380859375,
0... |
thisserand/health_care_german | 2023-08-26T03:35:12.000Z | [
"region:us"
] | thisserand | null | null | 0 | 5 | 2023-08-26T03:35:07 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 595810
num_examples: 465
download_size: 349316
dataset_size: 595810
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "health_care_german"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 442 | [
[
-0.0230865478515625,
-0.0206451416015625,
0.024871826171875,
0.0079498291015625,
-0.01265716552734375,
-0.01169586181640625,
0.022064208984375,
-0.01389312744140625,
0.05975341796875,
0.02618408203125,
-0.05963134765625,
-0.07598876953125,
-0.053802490234375,
... |
fridriik/mental-health-arg-post-quarantine-covid19-dataset | 2023-08-27T18:13:37.000Z | [
"task_categories:tabular-classification",
"size_categories:1K<n<10K",
"language:es",
"license:cc-by-nc-4.0",
"region:us"
] | fridriik | null | null | 0 | 5 | 2023-08-27T06:13:56 | ---
license: cc-by-nc-4.0
task_categories:
- tabular-classification
language:
- es
pretty_name: Mental health of people in Argentina post quarantine COVID-19 Dataset
size_categories:
- 1K<n<10K
---
# Mental health of people in Argentina post quarantine COVID-19 Dataset
### Dataset Summary
Dataset modified for research from:
Levels and predictors of depression, anxiety, and suicidal risk during COVID-19 pandemic in Argentina:
The impacts of quarantine extensions on mental health state created by López Steinmetz, Lorena Cecilia for Universidad Nacional de Córdoba.
Facultad de Psicología; Argentina. Consejo Nacional de Investigaciones Científicas y Técnicas.
Instituto de Investigaciones Psicológicas; Argentina.
http://hdl.handle.net/11086/20168
The dataset underwent modifications as follows:
SUB PERIODS and SEX columns were removed.
Rows with PROVINCE equal to 'Otro' or 'other' were removed.
Additionally, rows with EDUCATION equal to 'Otro' were removed.
The following columns were transformed from non-numeric values to numeric values:
```
'MENTAL DISORDER HISTORY': {'no': 0, 'yes': 50}
'EDUCATION': {
'Completed postgraduate': 30,
'Incomplete tertiary or university': 60,
'Completed high school': 70,
'Incomplete postgraduate': 40,
'Completed tertiary or university': 50,
'Incomplete high school': 80,
'Incomplete elementary school': 100,
'Completed elementary school': 90}
'SUIC ATTEMPT HISTORY': {'ideation': 50, 'no': 0, 'yes': 100}
'LIVING WITH SOMEBODY': {'no': 20, 'yes': 0}
'ECONOMIC INCOME': {'yes': 0, 'no': 50}
```
Furthermore, a new column 'REGION' was added to provinces according to the following assignment function:
```
def assign_region(province):
if province in ['Corrientes', 'Chaco', 'Misiones', 'Formosa', 'Entre Ríos']:
return 'Nordeste-Litoral'
elif province in ['Tucumán', 'Jujuy', 'Salta', 'Catamarca', 'Santiago del Estero']:
return 'Noroeste'
elif province in ['San Luis', 'San Juan', 'Mendoza', 'La Rioja']:
return 'Cuyo'
elif province in ['Neuquén', 'Río Negro', 'La Pampa']:
return 'Patagonia Centro-Norte'
elif province in ['Tierra del Fuego', 'Santa Cruz', 'Chubut']:
return 'Patagonia Centro-Sur'
elif province == 'Santa Fe':
return 'Santa Fe'
elif province == 'Buenos Aires provincia':
return 'Buenos Aires'
elif province == 'Córdoba':
return 'Córdoba'
else:
return 'CABA'
```
### Supported Tasks and Leaderboards
`mental-health-arg-post-quarantine-covid19-model`:
The dataset can be used to train a model for Mental health of people in Argentina post quarantine COVID-19.
### Languages
The text in the dataset is in Spanish and English
## Dataset Structure
### Data Instances
```
{
'EDUCATION': '30',
'PROVINCE': 'CABA (Buenos Aires capital)',
'AGE': '30',
'MENTAL DISORDER HISTORY': '0',
'SUIC ATTEMPT HISTORY': '50',
'LIVING WITH SOMEBODY': '20'
'ECONOMIC INCOME': '0',
'DEPRESSION': '21',
'SUIC RISK': '37',
'ANXIETY STATE': '54',
'ANXIETY TRAIT': '40',
'REGION': 'CABA'
}
```
### Data Fields
- `EDUCATION`: Maximum level of education attained by the individual, modified:
'Completed postgraduate': 30,
'Incomplete tertiary or university': 60,
'Completed high school': 70,
'Incomplete postgraduate': 40,
'Completed tertiary or university': 50,
'Incomplete high school': 80,
'Incomplete elementary school': 100,
'Completed elementary school': 90
- `PROVINCE`: Name of the province where the individual resides.
- `AGE`: Age of the individual.
- `MENTAL DISORDER HISTORY`: If the individual has a history of mental disorder, modified: 'no': 0, 'yes': 50.
- `SUIC ATTEMPT HISTORY`: If the individual has a history of suicide attempt, modifed: 'ideation': 50, 'no': 0, 'yes': 100.
- `LIVING WITH SOMEBODY`: If the individual lives alone or not, modified: 'no': 20, 'yes': 0.
- `ECONOMIC INCOME`: If the individual has an economic income, modified: 'yes': 0, 'no': 50.
- `DEPRESSION`: Level of depression of the individual.
- `SUIC RISK`: Level of suicide risk of the individual.
- `ANXIETY STATE`: Level of anxiety state at the moment of the individual.
- `ANXIETY TRAIT`: Level of anxiety predisposition of the individual.
- `REGION`: Name of the region where the individual resides.
## Dataset Creation
### Curation Rationale
This dataset was built for research.
### Source Data
#### Initial Data Collection and Normalization
The data was obtained and created by López Steinmetz, Lorena Cecilia.
#### Who are the source language producers?
López Steinmetz, Lorena Cecilia.
## Considerations for Using the Data
### Social Impact of Dataset
The purpose of this dataset is for research, it has data about serious topics related to individuals' mental health.
It should not be taken as practical advice for real-life situations, except for the possibility that in the future,
the dataset could be improved and discussions with its authors could facilitate extended usage.
## Additional Information
### Dataset Curators
The dataset was initially created by López Steinmetz and Lorena Cecilia, modified by Farias Federico, Arroyo Guadalupe and Avalos Manuel.
### Licensing Information
Except where otherwise noted, this item's license is described as
Atribución-NoComercial 4.0 Internacional (http://creativecommons.org/licenses/by-nc/4.0/).
| 5,244 | [
[
-0.0208587646484375,
-0.0272369384765625,
0.037261962890625,
0.0295257568359375,
0.0008530616760253906,
0.0021533966064453125,
0.005558013916015625,
-0.00807952880859375,
0.0305023193359375,
0.0305023193359375,
-0.056854248046875,
-0.08648681640625,
-0.049682617... |
mmathys/openai-moderation-api-evaluation | 2023-08-28T14:56:39.000Z | [
"task_categories:text-classification",
"language:en",
"license:mit",
"arxiv:2208.03274",
"region:us"
] | mmathys | null | null | 1 | 5 | 2023-08-28T14:50:57 | ---
license: mit
task_categories:
- text-classification
language: en
pretty_name: OpenAI Moderation API Validation Dataset
---
# Evaluation dataset for the paper "A Holistic Approach to Undesired Content Detection"
The evaluation dataset `data/samples-1680.jsonl.gz` is the test set used in [this paper](https://arxiv.org/abs/2208.03274).
Each line contains information about one sample in a JSON object and each sample is labeled according to our taxonomy. The category label is a binary flag, but if it does not include in the JSON, it means we do not know the label.
| Category | Label | Definition |
| -------- | ----- | ---------- |
| sexual | `S` | Content meant to arouse sexual excitement, such as the description of sexual activity, or that promotes sexual services (excluding sex education and wellness). |
| hate | `H` | Content that expresses, incites, or promotes hate based on race, gender, ethnicity, religion, nationality, sexual orientation, disability status, or caste. |
| violence | `V` | Content that promotes or glorifies violence or celebrates the suffering or humiliation of others. |
| harassment | `HR` | Content that may be used to torment or annoy individuals in real life, or make harassment more likely to occur. |
| self-harm | `SH` | Content that promotes, encourages, or depicts acts of self-harm, such as suicide, cutting, and eating disorders. |
| sexual/minors | `S3` | Sexual content that includes an individual who is under 18 years old. |
| hate/threatening | `H2` | Hateful content that also includes violence or serious harm towards the targeted group. |
| violence/graphic | `V2` | Violent content that depicts death, violence, or serious physical injury in extreme graphic detail. |
Parsed from the GitHub repo: https://github.com/openai/moderation-api-release | 1,847 | [
[
-0.03460693359375,
-0.05712890625,
0.0102386474609375,
0.0012025833129882812,
-0.0343017578125,
0.004970550537109375,
-0.002933502197265625,
-0.018798828125,
0.0231170654296875,
0.05755615234375,
-0.043243408203125,
-0.07208251953125,
-0.032501220703125,
0.0... |
dadinghh2/HumTrans | 2023-09-26T06:26:09.000Z | [
"license:cc-by-nc-4.0",
"region:us"
] | dadinghh2 | null | null | 1 | 5 | 2023-08-29T02:14:37 | ---
license: cc-by-nc-4.0
---
# HumTrans Dataset
- Dataset Name: HumTrans
- Dataset Type: Humming audio in .wav format and corresponding label MIDI file
- Primary Use: Humming melody transcription and as a foundation for downstream tasks such as humming melody based music generation
- Summary: 500 musical compositions of different genres and languages, 1000 music segments in total; sampled at a frequency of 44,100 Hz; approximately 56.22 hours of audio; 14,614 files in total.
- File Description: all_wav.zip includes all the humming audios in .wav format, all_midi.zip includes all the corresponding label MIDIs in .mid format. Both of these two share the same naming convention, which is personID_musicID_segmentID_repetitionID or personID_musicID_segmentID_repetitionID_[U/D/DD/DDD]. For example, F01_0005_0001_1, or F04_0055_0001_2_DD. train_valid_test_keys.json contains the official split of this dataset, including train, valid and test. | 949 | [
[
-0.0248565673828125,
-0.040557861328125,
0.016998291015625,
0.06085205078125,
-0.027099609375,
0.007537841796875,
0.00577545166015625,
-0.01055908203125,
0.032073974609375,
0.015655517578125,
-0.0784912109375,
-0.036285400390625,
-0.0255584716796875,
0.00746... |
hugfaceguy0001/ChatGPTGroundTruth | 2023-08-30T18:03:37.000Z | [
"task_categories:question-answering",
"size_categories:10K<n<100K",
"language:en",
"license:openrail",
"science",
"region:us"
] | hugfaceguy0001 | null | null | 1 | 5 | 2023-08-30T17:13:55 | ---
license: openrail
task_categories:
- question-answering
language:
- en
tags:
- science
pretty_name: ChatGPT ground truth
size_categories:
- 10K<n<100K
configs:
- config_name: main_data
data_files: "ground_truth.jsonl"
---
# ChatGPT ground truth dataset
This dataset is generated by ChatGPT and contains factual questions and corresponding answers from 160 subfields across natural and social sciences.
Specifically, the dataset covers eight major domains: mathematics, physics, chemistry, biology, medicine, engineering, computer science, and social sciences. Within each domain, 20 specific subfields are selected, with 500 question-answer pairs per subfield, resulting in a total of 80,000 question-answer pairs.
The language used in this dataset is English.
Accompanying the release of this dataset is the script code used to generate it.
# ChatGPT基准事实数据集
本数据集由ChatGPT自动生成,包含自然科学和社会科学的160个细分领域的事实性问题和相应的答案。
具体来说,本数据集涵盖数学、物理、化学、生物学、医学、工程、计算机科学、社会科学八大领域,每个领域选择了20个细分子领域,每个子领域有500个问答对,共80000个问答对。
本数据集的语言为英文。
和本数据集同时发布的还有生成本数据集使用的脚本代码。 | 1,049 | [
[
-0.027618408203125,
-0.06427001953125,
0.02484130859375,
0.0081939697265625,
-0.011871337890625,
0.01271820068359375,
-0.0028285980224609375,
-0.000537872314453125,
-0.01158905029296875,
0.045013427734375,
-0.049224853515625,
-0.061981201171875,
-0.0462646484375... |
loubnabnl/humaneval_plus | 2023-08-30T20:10:39.000Z | [
"region:us"
] | loubnabnl | null | null | 0 | 5 | 2023-08-30T18:48:38 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: task_id
dtype: string
- name: prompt
dtype: string
- name: entry_point
dtype: string
- name: canonical_solution
dtype: string
- name: test
dtype: string
- name: contract
dtype: string
- name: base_input
dtype: string
- name: atol
dtype: float64
- name: plus_input
dtype: string
splits:
- name: train
num_bytes: 7571857
num_examples: 164
download_size: 2006302
dataset_size: 7571857
---
# Dataset Card for "humaneval_plus"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 748 | [
[
-0.040008544921875,
-0.008697509765625,
0.004535675048828125,
0.01261138916015625,
-0.0141448974609375,
-0.005489349365234375,
0.026397705078125,
-0.03009033203125,
0.059417724609375,
0.03369140625,
-0.054412841796875,
-0.0538330078125,
-0.0321044921875,
-0.... |
tyzhu/squad_for_gpt_train_1000_eval_100 | 2023-08-31T08:27:35.000Z | [
"region:us"
] | tyzhu | null | null | 0 | 5 | 2023-08-31T05:33:41 | ---
dataset_info:
features:
- name: text
dtype: string
- name: inputs
dtype: string
- name: targets
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answers
struct:
- name: answer_start
sequence: int64
- name: text
sequence: string
splits:
- name: train
num_bytes: 3499749.43777897
num_examples: 1000
- name: validation
num_bytes: 361908.1456953642
num_examples: 100
download_size: 2483904
dataset_size: 3861657.5834743343
---
# Dataset Card for "squad_for_gpt_train_1000_eval_100"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 732 | [
[
-0.03704833984375,
-0.0216522216796875,
0.0176544189453125,
0.0277557373046875,
-0.00223541259765625,
0.01352691650390625,
0.0211181640625,
0.01428985595703125,
0.03729248046875,
0.01248931884765625,
-0.07427978515625,
-0.039337158203125,
-0.03302001953125,
... |
beniben0/small-chat-dataset | 2023-08-31T07:12:55.000Z | [
"region:us"
] | beniben0 | null | null | 1 | 5 | 2023-08-31T07:12:07 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 316300.74700385943
num_examples: 197
download_size: 205881
dataset_size: 316300.74700385943
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "small-chat-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 466 | [
[
-0.03857421875,
-0.03399658203125,
0.0099945068359375,
0.0185546875,
-0.0153656005859375,
-0.005764007568359375,
-0.0011739730834960938,
-0.0105438232421875,
0.07232666015625,
0.02642822265625,
-0.06378173828125,
-0.039398193359375,
-0.03424072265625,
-0.029... |
mickume/alt_potterverse | 2023-10-31T11:36:53.000Z | [
"region:us"
] | mickume | null | null | 0 | 5 | 2023-09-01T08:15:27 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 562171588
num_examples: 3120776
download_size: 347942627
dataset_size: 562171588
---
# Dataset Card for "alt_potterverse"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 452 | [
[
-0.03411865234375,
-0.01064300537109375,
-0.003265380859375,
0.0147247314453125,
-0.00027823448181152344,
0.003650665283203125,
0.01593017578125,
-0.01221466064453125,
0.05865478515625,
0.033172607421875,
-0.0731201171875,
-0.049224853515625,
-0.03814697265625,
... |
DynamicSuperb/SpeakerVerification_VCTK | 2023-09-03T02:29:04.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-09-01T14:08:38 | ---
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: file2
dtype: string
- name: audio2
dtype: audio
- name: instruction
dtype: string
- name: label
dtype: string
splits:
- name: test
num_bytes: 2075489820.0
num_examples: 5000
download_size: 1703856779
dataset_size: 2075489820.0
---
# Dataset Card for "SpeakerVerification_VCTK"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 637 | [
[
-0.047576904296875,
-0.0184173583984375,
0.0090789794921875,
0.02532958984375,
-0.01556396484375,
-0.004337310791015625,
-0.005275726318359375,
0.004932403564453125,
0.05615234375,
0.032989501953125,
-0.061798095703125,
-0.059417724609375,
-0.0322265625,
-0.... |
DynamicSuperb/LanguageIdentification_VoxForge | 2023-09-02T14:22:45.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-09-02T14:12:19 | ---
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype: audio
- name: label
dtype: string
- name: instruction
dtype: string
splits:
- name: test
num_bytes: 1026681070.0023202
num_examples: 6000
download_size: 1180889948
dataset_size: 1026681070.0023202
---
# Dataset Card for "LanguageIdentification_VoxForge"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 588 | [
[
-0.048309326171875,
-0.03460693359375,
0.012939453125,
0.0208740234375,
-0.0005855560302734375,
0.0209808349609375,
-0.01934814453125,
-0.005664825439453125,
0.0384521484375,
0.026153564453125,
-0.04913330078125,
-0.06689453125,
-0.0267791748046875,
-0.01681... |
FinchResearch/TagaloGuanaco | 2023-09-03T19:21:13.000Z | [
"region:us"
] | FinchResearch | null | null | 0 | 5 | 2023-09-03T19:20:33 | Entry not found | 15 | [
[
-0.0214080810546875,
-0.01494598388671875,
0.05718994140625,
0.02880859375,
-0.0350341796875,
0.0465087890625,
0.052490234375,
0.00505828857421875,
0.051361083984375,
0.0170135498046875,
-0.05206298828125,
-0.0149993896484375,
-0.06036376953125,
0.0379028320... |
legacy107/covidqa-unique-context | 2023-09-06T13:46:53.000Z | [
"task_categories:question-answering",
"size_categories:1K<n<10K",
"language:en",
"medical",
"region:us"
] | legacy107 | null | null | 0 | 5 | 2023-09-04T12:08:43 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: document_id
dtype: int64
- name: context
dtype: string
- name: question
dtype: string
- name: id
dtype: int64
- name: answer
dtype: string
- name: answer_start
dtype: int64
splits:
- name: train
num_bytes: 61459473
num_examples: 1815
- name: test
num_bytes: 3699592
num_examples: 204
download_size: 2273929
dataset_size: 65159065
language:
- en
pretty_name: CovidQA with unique context for est
task_categories:
- question-answering
tags:
- medical
size_categories:
- 1K<n<10K
---
# Dataset Card for "covidqa-unique-context"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 880 | [
[
-0.039154052734375,
-0.0224151611328125,
-0.002300262451171875,
0.0279541015625,
-0.019775390625,
-0.0057220458984375,
0.0230712890625,
-0.00572967529296875,
0.05517578125,
0.028076171875,
-0.065673828125,
-0.05694580078125,
-0.033111572265625,
-0.0123519897... |
iamshnoo/alpaca-cleaned-greek | 2023-09-15T23:22:28.000Z | [
"region:us"
] | iamshnoo | null | null | 0 | 5 | 2023-09-06T05:14:47 | ---
dataset_info:
features:
- name: input
dtype: string
- name: instruction
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 53753481
num_examples: 51760
download_size: 25664903
dataset_size: 53753481
---
Translated from yahma/alpaca-cleaned using NLLB-1.3B
# Dataset Card for "alpaca-cleaned-greek"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 497 | [
[
-0.047760009765625,
-0.058349609375,
0.0029582977294921875,
-0.000018894672393798828,
-0.0595703125,
-0.020233154296875,
0.0103302001953125,
-0.055267333984375,
0.07452392578125,
0.055938720703125,
-0.06683349609375,
-0.038360595703125,
-0.04888916015625,
0.... |
Minglii/v | 2023-09-08T23:27:29.000Z | [
"region:us"
] | Minglii | null | null | 0 | 5 | 2023-09-08T22:58:54 | ---
dataset_info:
features:
- name: data
struct:
- name: conversations
list:
- name: from
dtype: string
- name: markdown
struct:
- name: answer
dtype: string
- name: index
dtype: int64
- name: type
dtype: string
- name: text
dtype: string
- name: value
dtype: string
- name: id
dtype: string
splits:
- name: train
num_bytes: 644558921
num_examples: 117213
download_size: 262396682
dataset_size: 644558921
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "v"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 804 | [
[
-0.0426025390625,
-0.019012451171875,
0.023345947265625,
0.00618743896484375,
-0.0219573974609375,
-0.00665283203125,
0.02532958984375,
-0.0130157470703125,
0.06097412109375,
0.040802001953125,
-0.07232666015625,
-0.0548095703125,
-0.034698486328125,
-0.0172... |
kunishou/do-not-answer-ja | 2023-09-10T13:46:36.000Z | [
"license:cc-by-nc-sa-4.0",
"region:us"
] | kunishou | null | null | 1 | 5 | 2023-09-09T12:01:40 | ---
license: cc-by-nc-sa-4.0
---
This dataset was created by automatically translating "do-not-answer" into Japanese.
This dataset is licensed under CC-BY-NC-SA-4.0
do-not-answer-ja
https://github.com/kunishou/do-not-answer-ja
do-not-answer
https://github.com/Libr-AI/do-not-answer | 294 | [
[
-0.03021240234375,
-0.05670166015625,
0.038238525390625,
0.00403594970703125,
-0.024078369140625,
-0.0171051025390625,
-0.00806427001953125,
-0.0264739990234375,
0.024658203125,
0.06866455078125,
-0.07257080078125,
-0.0310516357421875,
-0.0257720947265625,
0... |
wanadzhar913/crawl-bikesrepublic | 2023-09-09T17:29:06.000Z | [
"language:en",
"license:apache-2.0",
"region:us"
] | wanadzhar913 | null | null | 0 | 5 | 2023-09-09T17:22:36 | ---
license: apache-2.0
language:
- en
---
### TLDR
- website: [bikesrepublic](https://www.bikesrepublic.com/)
- num. of webpages scraped: 6,969
- link to dataset: https://huggingface.co/datasets/wanadzhar913/crawl-bikesrepublic
- last date of scraping: 10th September 2023
- status: complete
- pull request: https://github.com/huseinzol05/malaysian-dataset/pull/291
- contributed to: https://github.com/huseinzol05/malaysian-dataset | 434 | [
[
-0.035491943359375,
-0.02459716796875,
0.00856781005859375,
0.0302734375,
-0.033477783203125,
0.00628662109375,
0.0012216567993164062,
-0.0225830078125,
0.03668212890625,
0.0198822021484375,
-0.06610107421875,
-0.046356201171875,
-0.021087646484375,
0.004791... |
DynamicSuperb/MultiSpeakerDetection_VCTK | 2023-09-11T07:44:31.000Z | [
"region:us"
] | DynamicSuperb | null | null | 0 | 5 | 2023-09-10T16:44:06 | ---
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
dataset_info:
features:
- name: file
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: instruction
dtype: string
- name: label
dtype: string
- name: utterance 1
dtype: string
- name: utterance 2
dtype: string
- name: utterance 3
dtype: string
- name: utterance 4
dtype: string
- name: utterance 5
dtype: string
splits:
- name: test
num_bytes: 407678216.0
num_examples: 2000
download_size: 380944308
dataset_size: 407678216.0
---
# Dataset Card for "MultiSpeakerDetection_VCTK"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 804 | [
[
-0.04815673828125,
-0.00408172607421875,
0.00841522216796875,
0.0305023193359375,
-0.01238250732421875,
-0.00888824462890625,
0.01094818115234375,
0.0006427764892578125,
0.044677734375,
0.03887939453125,
-0.06719970703125,
-0.055389404296875,
-0.046905517578125,... |
kristinashemet/Dataset_V2 | 2023-10-08T15:31:39.000Z | [
"region:us"
] | kristinashemet | null | null | 0 | 5 | 2023-09-11T10:00:29 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 10521416
num_examples: 1573
download_size: 1009493
dataset_size: 10521416
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "Dataset_V2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 440 | [
[
-0.02703857421875,
-0.01477813720703125,
0.01198577880859375,
0.0147552490234375,
-0.0198822021484375,
-0.00972747802734375,
0.0360107421875,
-0.0224761962890625,
0.0521240234375,
0.038299560546875,
-0.05853271484375,
-0.041839599609375,
-0.0467529296875,
-0... |
TonyJPk7/Chat-PCR_CNNDaily_clear | 2023-09-12T07:21:21.000Z | [
"region:us"
] | TonyJPk7 | null | null | 0 | 5 | 2023-09-12T07:13:28 | Entry not found | 15 | [
[
-0.02142333984375,
-0.01495361328125,
0.05718994140625,
0.0288238525390625,
-0.035064697265625,
0.046539306640625,
0.052520751953125,
0.005062103271484375,
0.0513916015625,
0.016998291015625,
-0.052093505859375,
-0.014984130859375,
-0.060394287109375,
0.0379... |
approach0/MATH-no-asy | 2023-09-13T01:47:49.000Z | [
"region:us"
] | approach0 | null | null | 0 | 5 | 2023-09-13T01:47:47 | ---
dataset_info:
features:
- name: src_path
dtype: string
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 5157479.0
num_examples: 6217
- name: test
num_bytes: 3381766.0
num_examples: 4212
download_size: 3505684
dataset_size: 8539245.0
---
# Dataset Card for "MATH"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 526 | [
[
-0.045135498046875,
-0.026824951171875,
0.00925445556640625,
0.0225372314453125,
-0.005809783935546875,
0.0025959014892578125,
0.0161895751953125,
-0.00035881996154785156,
0.055023193359375,
0.0244293212890625,
-0.061187744140625,
-0.047088623046875,
-0.04138183... |
Skepsun/cvalues_rlhf | 2023-09-15T05:35:50.000Z | [
"language:zh",
"license:apache-2.0",
"region:us"
] | Skepsun | null | null | 2 | 5 | 2023-09-15T05:28:12 | ---
license: apache-2.0
language:
- zh
---
Converted from: https://modelscope.cn/datasets/damo/CValues-Comparison/summary. We obtained harmless set by selecting `pos_type="拒绝为主"` and `neg_type="风险回复"`. We obtained helpful set by selecting `pos_type="拒绝&正向建议"` and `neg_type="拒绝为主"`. | 283 | [
[
-0.02276611328125,
-0.0204010009765625,
0.0016002655029296875,
0.0097503662109375,
-0.051910400390625,
-0.03631591796875,
0.0093994140625,
-0.0163116455078125,
0.02227783203125,
0.05706787109375,
-0.01177978515625,
-0.0599365234375,
-0.04986572265625,
0.0126... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.