
id stringlengths 2 115 | author stringlengths 2 42 ⌀ | last_modified timestamp[us, tz=UTC] | downloads int64 0 8.87M | likes int64 0 3.84k | paperswithcode_id stringlengths 2 45 ⌀ | tags list | lastModified timestamp[us, tz=UTC] | createdAt stringlengths 24 24 | key stringclasses 1 value | created timestamp[us] | card stringlengths 1 1.01M | embedding list | library_name stringclasses 21 values | pipeline_tag stringclasses 27 values | mask_token null | card_data null | widget_data null | model_index null | config null | transformers_info null | spaces null | safetensors null | transformersInfo null | modelId stringlengths 5 111 ⌀ | embeddings list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
iamholmes/tiny-imdb | iamholmes | 2022-04-29T13:25:00Z | 36 | 0 | null | [
"region:us"
] | 2022-04-29T13:25:00Z | 2022-04-29T13:24:55.000Z | 2022-04-29T13:24:55 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
openclimatefix/gfs-surface-pressure-2.0deg | openclimatefix | 2022-06-28T18:38:27Z | 36 | 0 | null | [
"region:us"
] | 2022-06-28T18:38:27Z | 2022-06-22T22:11:25.000Z | 2022-06-22T22:11:25 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
wushan/vehicle_qa | wushan | 2022-08-25T13:14:33Z | 36 | 4 | null | [
"license:apache-2.0",
"region:us"
] | 2022-08-25T13:14:33Z | 2022-08-25T13:12:17.000Z | 2022-08-25T13:12:17 | ---
license: apache-2.0
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
alexandrainst/scandi-qa | alexandrainst | 2023-01-16T13:51:25Z | 36 | 7 | null | [
"task_categories:question-answering",
"task_ids:extractive-qa",
"multilinguality:multilingual",
"size_categories:1K<n<10K",
"source_datasets:mkqa",
"source_datasets:natural_questions",
"language:da",
"language:sv",
"language:no",
"license:cc-by-sa-4.0",
"region:us"
] | 2023-01-16T13:51:25Z | 2022-08-30T09:46:59.000Z | 2022-08-30T09:46:59 | ---
pretty_name: ScandiQA
language:
- da
- sv
- no
license:
- cc-by-sa-4.0
multilinguality:
- multilingual
size_categories:
- 1K<n<10K
source_datasets:
- mkqa
- natural_questions
task_categories:
- question-answering
task_ids:
- extractive-qa
---
# Dataset Card for ScandiQA
## Dataset Description
- **Repository:** <https://github.com/alexandrainst/scandi-qa>
- **Point of Contact:** [Dan Saattrup Nielsen](mailto:dan.nielsen@alexandra.dk)
- **Size of downloaded dataset files:** 69 MB
- **Size of the generated dataset:** 67 MB
- **Total amount of disk used:** 136 MB
### Dataset Summary
ScandiQA is a dataset of questions and answers in the Danish, Norwegian, and Swedish
languages. All samples come from the Natural Questions (NQ) dataset, which is a large
question answering dataset from Google searches. The Scandinavian questions and answers
come from the MKQA dataset, where 10,000 NQ samples were manually translated into,
among others, Danish, Norwegian, and Swedish. However, this did not include a
translated context, hindering the training of extractive question answering models.
We merged the NQ dataset with the MKQA dataset, and extracted contexts as either "long
answers" from the NQ dataset, being the paragraph in which the answer was found, or
otherwise we extract the context by locating the paragraphs which have the largest
cosine similarity to the question, and which contains the desired answer.
Further, many answers in the MKQA dataset were "language normalised": for instance, all
date answers were converted to the format "YYYY-MM-DD", meaning that in most cases
these answers are not appearing in any paragraphs. We solve this by extending the MKQA
answers with plausible "answer candidates", being slight perturbations or translations
of the answer.
With the contexts extracted, we translated these to Danish, Swedish and Norwegian using
the [DeepL translation service](https://www.deepl.com/pro-api?cta=header-pro-api) for
Danish and Swedish, and the [Google Translation
service](https://cloud.google.com/translate/docs/reference/rest/) for Norwegian. After
translation we ensured that the Scandinavian answers do indeed occur in the translated
contexts.
As we are filtering the MKQA samples at both the "merging stage" and the "translation
stage", we are not able to fully convert the 10,000 samples to the Scandinavian
languages, and instead get roughly 8,000 samples per language. These have further been
split into a training, validation and test split, with the latter two containing
roughly 750 samples. The splits have been created in such a way that the proportion of
samples without an answer is roughly the same in each split.
### Supported Tasks and Leaderboards
Training machine learning models for extractive question answering is the intended task
for this dataset. No leaderboard is active at this point.
### Languages
The dataset is available in Danish (`da`), Swedish (`sv`) and Norwegian (`no`).
## Dataset Structure
### Data Instances
- **Size of downloaded dataset files:** 69 MB
- **Size of the generated dataset:** 67 MB
- **Total amount of disk used:** 136 MB
An example from the `train` split of the `da` subset looks as follows.
```
{
'example_id': 123,
'question': 'Er dette en test?',
'answer': 'Dette er en test',
'answer_start': 0,
'context': 'Dette er en testkontekst.',
'answer_en': 'This is a test',
'answer_start_en': 0,
'context_en': "This is a test context.",
'title_en': 'Train test'
}
```
### Data Fields
The data fields are the same among all splits.
- `example_id`: an `int64` feature.
- `question`: a `string` feature.
- `answer`: a `string` feature.
- `answer_start`: an `int64` feature.
- `context`: a `string` feature.
- `answer_en`: a `string` feature.
- `answer_start_en`: an `int64` feature.
- `context_en`: a `string` feature.
- `title_en`: a `string` feature.
### Data Splits
| name | train | validation | test |
|----------|------:|-----------:|-----:|
| da | 6311 | 749 | 750 |
| sv | 6299 | 750 | 749 |
| no | 6314 | 749 | 750 |
## Dataset Creation
### Curation Rationale
The Scandinavian languages does not have any gold standard question answering dataset.
This is not quite gold standard, but the fact both the questions and answers are all
manually translated, it is a solid silver standard dataset.
### Source Data
The original data was collected from the [MKQA](https://github.com/apple/ml-mkqa/) and
[Natural Questions](https://ai.google.com/research/NaturalQuestions) datasets from
Apple and Google, respectively.
## Additional Information
### Dataset Curators
[Dan Saattrup Nielsen](https://saattrupdan.github.io/) from the [The Alexandra
Institute](https://alexandra.dk/) curated this dataset.
### Licensing Information
The dataset is licensed under the [CC BY-SA 4.0
license](https://creativecommons.org/licenses/by-sa/4.0/).
| [
-0.678779661655426,
-0.7817258238792419,
0.4390290677547455,
-0.07358650118112564,
-0.2504613697528839,
-0.14545691013336182,
-0.01294065173715353,
-0.26289108395576477,
0.14166951179504395,
0.5705828070640564,
-0.8823971748352051,
-0.5123703479766846,
-0.31522008776664734,
0.5523676872253... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
abidlabs/celeb-dataset | abidlabs | 2022-10-02T20:23:09Z | 36 | 0 | null | [
"region:us"
] | 2022-10-02T20:23:09Z | 2022-10-02T19:15:52.000Z | 2022-10-02T19:15:52 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
drt/complex_web_questions | drt | 2023-04-27T21:04:50Z | 36 | 4 | null | [
"license:apache-2.0",
"arxiv:1803.06643",
"arxiv:1807.09623",
"region:us"
] | 2023-04-27T21:04:50Z | 2022-10-22T22:14:27.000Z | 2022-10-22T22:14:27 | ---
license: apache-2.0
source: https://github.com/KGQA/KGQA-datasets
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:** https://www.tau-nlp.sites.tau.ac.il/compwebq
- **Repository:** https://github.com/alontalmor/WebAsKB
- **Paper:** https://arxiv.org/abs/1803.06643
- **Leaderboard:** https://www.tau-nlp.sites.tau.ac.il/compwebq-leaderboard
- **Point of Contact:** alontalmor@mail.tau.ac.il.
### Dataset Summary
**A dataset for answering complex questions that require reasoning over multiple web snippets**
ComplexWebQuestions is a new dataset that contains a large set of complex questions in natural language, and can be used in multiple ways:
- By interacting with a search engine, which is the focus of our paper (Talmor and Berant, 2018);
- As a reading comprehension task: we release 12,725,989 web snippets that are relevant for the questions, and were collected during the development of our model;
- As a semantic parsing task: each question is paired with a SPARQL query that can be executed against Freebase to retrieve the answer.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
- English
## Dataset Structure
QUESTION FILES
The dataset contains 34,689 examples divided into 27,734 train, 3,480 dev, 3,475 test.
each containing:
```
"ID”: The unique ID of the example;
"webqsp_ID": The original WebQuestionsSP ID from which the question was constructed;
"webqsp_question": The WebQuestionsSP Question from which the question was constructed;
"machine_question": The artificial complex question, before paraphrasing;
"question": The natural language complex question;
"sparql": Freebase SPARQL query for the question. Note that the SPARQL was constructed for the machine question, the actual question after paraphrasing
may differ from the SPARQL.
"compositionality_type": An estimation of the type of compositionally. {composition, conjunction, comparative, superlative}. The estimation has not been manually verified,
the question after paraphrasing may differ from this estimation.
"answers": a list of answers each containing answer: the actual answer; answer_id: the Freebase answer id; aliases: freebase extracted aliases for the answer.
"created": creation time
```
NOTE: test set does not contain “answer” field. For test evaluation please send email to
alontalmor@mail.tau.ac.il.
WEB SNIPPET FILES
The snippets files consist of 12,725,989 snippets each containing
PLEASE DON”T USE CHROME WHEN DOWNLOADING THESE FROM DROPBOX (THE UNZIP COULD FAIL)
"question_ID”: the ID of related question, containing at least 3 instances of the same ID (full question, split1, split2);
"question": The natural language complex question;
"web_query": Query sent to the search engine.
“split_source”: 'noisy supervision split' or ‘ptrnet split’, please train on examples containing “ptrnet split” when comparing to Split+Decomp from https://arxiv.org/abs/1807.09623
“split_type”: 'full_question' or ‘split_part1' or ‘split_part2’ please use ‘composition_answer’ in question of type composition and split_type: “split_part1” when training a reading comprehension model on splits as in Split+Decomp from https://arxiv.org/abs/1807.09623 (in the rest of the cases use the original answer).
"web_snippets": ~100 web snippets per query. Each snippet includes Title,Snippet. They are ordered according to Google results.
With a total of
10,035,571 training set snippets
1,350,950 dev set snippets
1,339,468 test set snippets
### Source Data
The original files can be found at this [dropbox link](https://www.dropbox.com/sh/7pkwkrfnwqhsnpo/AACuu4v3YNkhirzBOeeaHYala)
### Licensing Information
Not specified
### Citation Information
```
@inproceedings{talmor2018web,
title={The Web as a Knowledge-Base for Answering Complex Questions},
author={Talmor, Alon and Berant, Jonathan},
booktitle={Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers)},
pages={641--651},
year={2018}
}
```
### Contributions
Thanks for [happen2me](https://github.com/happen2me) for contributing this dataset. | [
-0.4643676280975342,
-1.085800051689148,
0.23951154947280884,
0.30541449785232544,
-0.15250563621520996,
-0.02498563379049301,
-0.14294719696044922,
-0.4754653871059418,
0.043775774538517,
0.4794923961162567,
-0.6529432535171509,
-0.49915751814842224,
-0.47137773036956787,
0.43604856729507... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
LYTinn/sentiment-analysis-tweet | LYTinn | 2022-10-31T03:54:49Z | 36 | 0 | null | [
"region:us"
] | 2022-10-31T03:54:49Z | 2022-10-29T03:29:04.000Z | 2022-10-29T03:29:04 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
AlekseyKorshuk/quora-question-pairs | AlekseyKorshuk | 2022-11-09T13:23:25Z | 36 | 0 | null | [
"region:us"
] | 2022-11-09T13:23:25Z | 2022-11-09T13:22:55.000Z | 2022-11-09T13:22:55 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bigbio/progene | bigbio | 2022-12-22T15:46:19Z | 36 | 2 | null | [
"multilinguality:monolingual",
"language:en",
"license:cc-by-4.0",
"region:us"
] | 2022-12-22T15:46:19Z | 2022-11-13T22:11:35.000Z | 2022-11-13T22:11:35 |
---
language:
- en
bigbio_language:
- English
license: cc-by-4.0
multilinguality: monolingual
bigbio_license_shortname: CC_BY_4p0
pretty_name: ProGene
homepage: https://zenodo.org/record/3698568#.YlVHqdNBxeg
bigbio_pubmed: True
bigbio_public: True
bigbio_tasks:
- NAMED_ENTITY_RECOGNITION
---
# Dataset Card for ProGene
## Dataset Description
- **Homepage:** https://zenodo.org/record/3698568#.YlVHqdNBxeg
- **Pubmed:** True
- **Public:** True
- **Tasks:** NER
The Protein/Gene corpus was developed at the JULIE Lab Jena under supervision of Prof. Udo Hahn.
The executing scientist was Dr. Joachim Wermter.
The main annotator was Dr. Rico Pusch who is an expert in biology.
The corpus was developed in the context of the StemNet project (http://www.stemnet.de/).
## Citation Information
```
@inproceedings{faessler-etal-2020-progene,
title = "{P}ro{G}ene - A Large-scale, High-Quality Protein-Gene Annotated Benchmark Corpus",
author = "Faessler, Erik and
Modersohn, Luise and
Lohr, Christina and
Hahn, Udo",
booktitle = "Proceedings of the 12th Language Resources and Evaluation Conference",
month = may,
year = "2020",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2020.lrec-1.564",
pages = "4585--4596",
abstract = "Genes and proteins constitute the fundamental entities of molecular genetics. We here introduce ProGene (formerly called FSU-PRGE), a corpus that reflects our efforts to cope with this important class of named entities within the framework of a long-lasting large-scale annotation campaign at the Jena University Language {\&} Information Engineering (JULIE) Lab. We assembled the entire corpus from 11 subcorpora covering various biological domains to achieve an overall subdomain-independent corpus. It consists of 3,308 MEDLINE abstracts with over 36k sentences and more than 960k tokens annotated with nearly 60k named entity mentions. Two annotators strove for carefully assigning entity mentions to classes of genes/proteins as well as families/groups, complexes, variants and enumerations of those where genes and proteins are represented by a single class. The main purpose of the corpus is to provide a large body of consistent and reliable annotations for supervised training and evaluation of machine learning algorithms in this relevant domain. Furthermore, we provide an evaluation of two state-of-the-art baseline systems {---} BioBert and flair {---} on the ProGene corpus. We make the evaluation datasets and the trained models available to encourage comparable evaluations of new methods in the future.",
language = "English",
ISBN = "979-10-95546-34-4",
}
```
| [
-0.5570901036262512,
-0.3664364516735077,
0.1349899172782898,
-0.06421922147274017,
-0.17669560015201569,
-0.023924540728330612,
-0.16846157610416412,
-0.5750210285186768,
0.40075403451919556,
0.32583266496658325,
-0.5616065859794617,
-0.5119633674621582,
-0.6747006773948669,
0.56847327947... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
bsmock/pubtables-1m | bsmock | 2023-08-08T16:43:14Z | 36 | 21 | null | [
"license:cdla-permissive-2.0",
"region:us"
] | 2023-08-08T16:43:14Z | 2022-11-22T18:59:39.000Z | 2022-11-22T18:59:39 | ---
license: cdla-permissive-2.0
---
# PubTables-1M
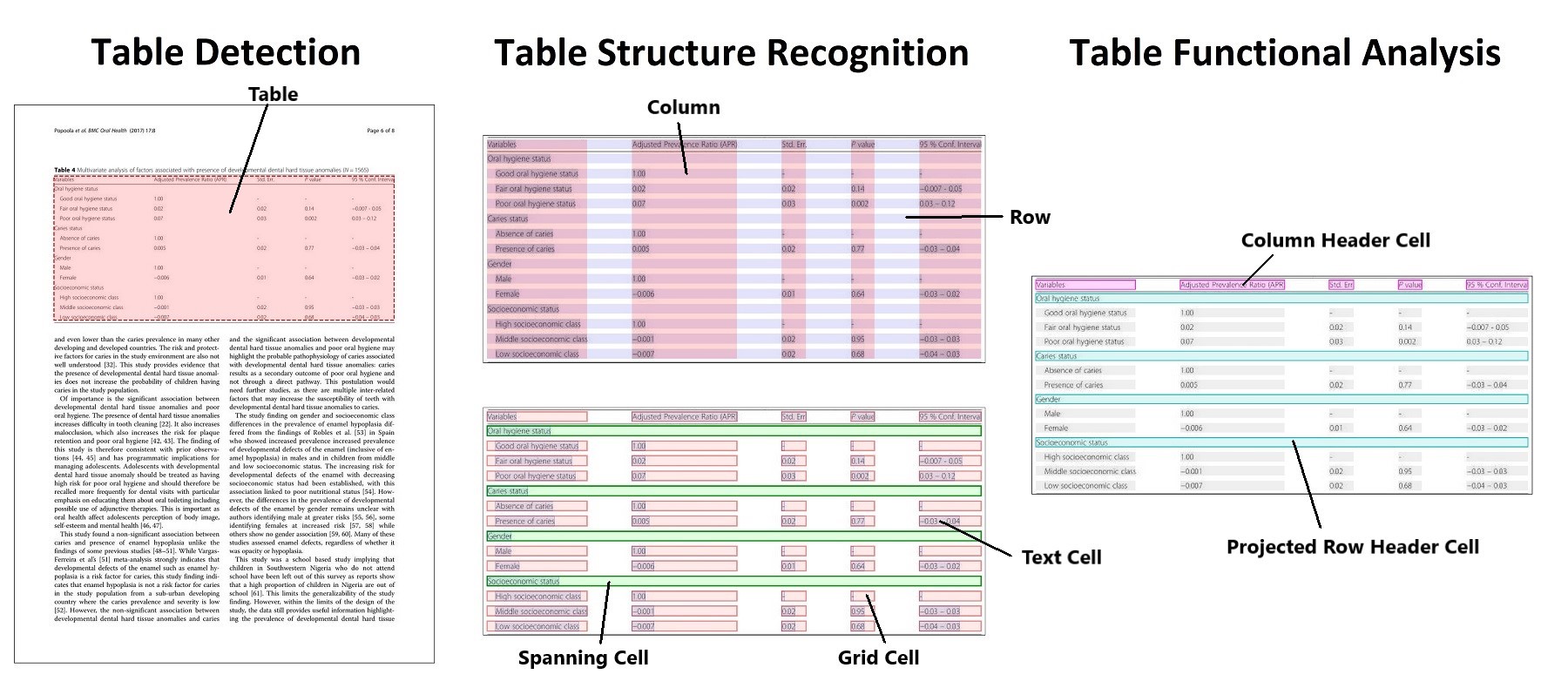
- GitHub: [https://github.com/microsoft/table-transformer](https://github.com/microsoft/table-transformer)
- Paper: ["PubTables-1M: Towards comprehensive table extraction from unstructured documents"](https://openaccess.thecvf.com/content/CVPR2022/html/Smock_PubTables-1M_Towards_Comprehensive_Table_Extraction_From_Unstructured_Documents_CVPR_2022_paper.html)
- Hugging Face:
- [Detection model](https://huggingface.co/microsoft/table-transformer-detection)
- [Structure recognition model](https://huggingface.co/microsoft/table-transformer-structure-recognition)
Currently we only support downloading the dataset as tar.gz files. Integrating with HuggingFace Datasets is something we hope to support in the future!
Please switch to the "Files and versions" tab to download all of the files or use a command such as wget to download from the command line.
Once downloaded, use the included script "extract_structure_dataset.sh" to extract and organize all of the data.
## Files
It comes in 18 tar.gz files:
Training and evaluation data for the structure recognition model (947,642 total cropped table instances):
- PubTables-1M-Structure_Filelists.tar.gz
- PubTables-1M-Structure_Annotations_Test.tar.gz: 93,834 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Structure_Annotations_Train.tar.gz: 758,849 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Structure_Annotations_Val.tar.gz: 94,959 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Structure_Images_Test.tar.gz
- PubTables-1M-Structure_Images_Train.tar.gz
- PubTables-1M-Structure_Images_Val.tar.gz
- PubTables-1M-Structure_Table_Words.tar.gz: Bounding boxes and text content for all of the words in each cropped table image
Training and evaluation data for the detection model (575,305 total document page instances):
- PubTables-1M-Detection_Filelists.tar.gz
- PubTables-1M-Detection_Annotations_Test.tar.gz: 57,125 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Detection_Annotations_Train.tar.gz: 460,589 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Detection_Annotations_Val.tar.gz: 57,591 XML files containing bounding boxes in PASCAL VOC format
- PubTables-1M-Detection_Images_Test.tar.gz
- PubTables-1M-Detection_Images_Train_Part1.tar.gz
- PubTables-1M-Detection_Images_Train_Part2.tar.gz
- PubTables-1M-Detection_Images_Val.tar.gz
- PubTables-1M-Detection_Page_Words.tar.gz: Bounding boxes and text content for all of the words in each page image (plus some unused files)
Full table annotations for the source PDF files:
- PubTables-1M-PDF_Annotations.tar.gz: Detailed annotations for all of the tables appearing in the source PubMed PDFs. All annotations are in PDF coordinates.
- 401,733 JSON files, one per source PDF document | [
-0.3810470700263977,
-0.5367816090583801,
0.46445101499557495,
0.15657015144824982,
-0.30403098464012146,
-0.19173356890678406,
-0.01419527642428875,
-0.553024411201477,
0.021178103983402252,
0.5647629499435425,
-0.13108626008033752,
-0.904422402381897,
-0.6758595108985901,
0.3337799310684... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
crystina-z/mmarco-corpus | crystina-z | 2022-12-06T12:23:36Z | 36 | 0 | null | [
"region:us"
] | 2022-12-06T12:23:36Z | 2022-12-06T12:01:59.000Z | 2022-12-06T12:01:59 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
autoevaluate/autoeval-eval-bazzhangz__sumdataset-bazzhangz__sumdataset-18687b-2355774138 | autoevaluate | 2022-12-06T15:57:43Z | 36 | 0 | null | [
"autotrain",
"evaluation",
"region:us"
] | 2022-12-06T15:57:43Z | 2022-12-06T15:26:09.000Z | 2022-12-06T15:26:09 | ---
type: predictions
tags:
- autotrain
- evaluation
datasets:
- bazzhangz/sumdataset
eval_info:
task: summarization
model: knkarthick/MEETING_SUMMARY
metrics: []
dataset_name: bazzhangz/sumdataset
dataset_config: bazzhangz--sumdataset
dataset_split: train
col_mapping:
text: dialogue
target: summary
---
# Dataset Card for AutoTrain Evaluator
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
* Task: Summarization
* Model: knkarthick/MEETING_SUMMARY
* Dataset: bazzhangz/sumdataset
* Config: bazzhangz--sumdataset
* Split: train
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
## Contributions
Thanks to [@bazzhangz](https://huggingface.co/bazzhangz) for evaluating this model. | [
-0.5102072358131409,
-0.11899890750646591,
0.14952169358730316,
0.11376779526472092,
-0.25316300988197327,
-0.05419890955090523,
0.010391995310783386,
-0.3937259018421173,
0.37103497982025146,
0.36653807759284973,
-1.1872191429138184,
-0.24318069219589233,
-0.7097162008285522,
-0.005965116... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Zombely/diachronia-ocr-test-A | Zombely | 2022-12-14T17:21:46Z | 36 | 0 | null | [
"region:us"
] | 2022-12-14T17:21:46Z | 2022-12-14T17:21:21.000Z | 2022-12-14T17:21:21 | ---
dataset_info:
features:
- name: image
dtype: image
splits:
- name: train
num_bytes: 62457501.0
num_examples: 81
download_size: 62461147
dataset_size: 62457501.0
---
# Dataset Card for "diachronia-ocr"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.44572392106056213,
-0.24745219945907593,
0.4184242784976959,
-0.04478337988257408,
-0.2710293233394623,
0.11516553908586502,
0.31026437878608704,
-0.392324298620224,
0.670256495475769,
0.7247983813285828,
-0.6403278112411499,
-0.9615551233291626,
-0.5773802399635315,
-0.0143245365470647... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Kaludi/data-csgo-weapon-classification | Kaludi | 2023-02-02T23:34:31Z | 36 | 0 | null | [
"task_categories:image-classification",
"region:us"
] | 2023-02-02T23:34:31Z | 2023-02-02T22:42:56.000Z | 2023-02-02T22:42:56 | ---
task_categories:
- image-classification
---
# Dataset for project: csgo-weapon-classification
## Dataset Description
This dataset has for project csgo-weapon-classification was collected with the help of a bulk google image downloader.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"image": "<1768x718 RGB PIL image>",
"target": 0
},
{
"image": "<716x375 RGBA PIL image>",
"target": 0
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"image": "Image(decode=True, id=None)",
"target": "ClassLabel(names=['AK-47', 'AWP', 'Famas', 'Galil-AR', 'Glock', 'M4A1', 'M4A4', 'P-90', 'SG-553', 'UMP', 'USP'], id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 1100 |
| valid | 275 |
| [
-0.42280450463294983,
-0.1327708214521408,
0.08765561133623123,
-0.05922212451696396,
-0.4022130072116852,
0.6005407571792603,
-0.2268517166376114,
-0.19414682686328888,
-0.20396389067173004,
0.34753674268722534,
-0.43179798126220703,
-0.9764398336410522,
-0.8119878768920898,
-0.0855013728... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
rcds/occlusion_swiss_judgment_prediction | rcds | 2023-03-28T08:19:29Z | 36 | 0 | null | [
"task_categories:text-classification",
"task_categories:other",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"language_creators:found",
"multilinguality:multilingual",
"size_categories:1K<n<10K",
"source_datasets:extended|swiss_judgment_prediction",
"language:de",
... | 2023-03-28T08:19:29Z | 2023-03-08T20:14:10.000Z | 2023-03-08T20:14:10 | ---
annotations_creators:
- expert-generated
language:
- de
- fr
- it
- en
language_creators:
- expert-generated
- found
license: cc-by-sa-4.0
multilinguality:
- multilingual
pretty_name: OcclusionSwissJudgmentPrediction
size_categories:
- 1K<n<10K
source_datasets:
- extended|swiss_judgment_prediction
tags:
- explainability-judgment-prediction
- occlusion
task_categories:
- text-classification
- other
task_ids: []
---
# Dataset Card for "OcclusionSwissJudgmentPrediction": An implementation of an occlusion based explainability method for Swiss judgment prediction
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Summary](#dataset-summary)
- [Documents](#documents)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset **str**ucture](#dataset-**str**ucture)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Summary
This dataset contains an implementation of occlusion for the SwissJudgmentPrediction task.
Note that this dataset only provides a test set and should be used in comination with the [Swiss-Judgment-Prediction](https://huggingface.co/datasets/swiss_judgment_prediction) dataset.
### Documents
Occlusion-Swiss-Judgment-Prediction is a subset of the [Swiss-Judgment-Prediction](https://huggingface.co/datasets/swiss_judgment_prediction) dataset.
The Swiss-Judgment-Prediction dataset is a multilingual, diachronic dataset of 85K Swiss Federal Supreme Court (FSCS) cases annotated with the respective binarized judgment outcome (approval/dismissal), the publication year, the legal area and the canton of origin per case. Occlusion-Swiss-Judgment-Prediction extends this dataset by adding sentence splitting with explainability labels.
### Supported Tasks and Leaderboards
OcclusionSwissJudgmentPrediction can be used for performing the occlusion in the legal judgment prediction task.
### Languages
Switzerland has four official languages with 3 languages (German, French and Italian) being represented in more than 1000 Swiss Federal Supreme court decisions. The decisions are written by the judges and clerks in the language of the proceedings.
## Dataset structure
### Data Instances
## Data Instances
**Multilingual use of the dataset**
When the dataset is used in a multilingual setting selecting the the 'all_languages' flag:
```python
from datasets import load_dataset
dataset = load_dataset('rcds/occlusion_swiss_judgment_prediction', 'all')
```
**Monolingual use of the dataset**
When the dataset is used in a monolingual setting selecting the ISO language code for one of the 3 supported languages. For example:
```python
from datasets import load_dataset
dataset = load_dataset('rcds/occlusion_swiss_judgment_prediction', 'de')
```
### Data Fields
The following data fields are provided for documents (Test_1/Test_2/Test_3/Test_4):
id: (**int**) a unique identifier of the for the document <br/>
year: (**int**) the publication year<br/>
label: (**str**) the judgment outcome: dismissal or approval<br/>
language: (**str**) one of (de, fr, it)<br/>
region: (**str**) the region of the lower court<br/>
canton: (**str**) the canton of the lower court<br/>
legal area: (**str**) the legal area of the case<br/>
explainability_label (**str**): the explainability label assigned to the occluded text: Supports judgment, Opposes judgment, Neutral, Baseline<br/>
occluded_text (**str**): the occluded text<br/>
text: (**str**) the facts of the case w/o the occluded text except for cases w/ explainability label "Baseline" (contain entire facts)<br/>
Note that Baseline cases are only contained in version 1 of the occlusion test set, since they do not change from experiment to experiment.
### Data Splits (Including Swiss Judgment Prediction)
Language | Subset | Number of Rows (Test_1/Test_2/Test_3/Test_4)
| ----------- | ----------- | ----------- |
German| de | __427__ / __1366__ / __3567__ / __7235__
French | fr | __307__ / __854__ / __1926__ / __3279__
Italian | it | __299__ /__919__ / __2493__ / __5733__
All | all | __1033__ / __3139__ / __7986__/ __16247__
Language | Subset | Number of Documents (is the same for Test_1/Test_2/Test_3/Test_4)
| ----------- | ----------- | ----------- |
German| de | __38__
French | fr | __36__
Italian | it | __34__
All | all | __108__
## Dataset Creation
### Curation Rationale
The dataset was curated by Niklaus et al. (2021) and Nina Baumgartner.
### Source Data
#### Initial Data Collection and Normalization
The original data are available at the Swiss Federal Supreme Court (https://www.bger.ch) in unprocessed formats (HTML). The documents were downloaded from the Entscheidsuche portal (https://entscheidsuche.ch) in HTML.
#### Who are the source language producers?
Switzerland has four official languages with 3 languages (German, French and Italian) being represented in more than 1000 Swiss Federal Supreme court decisions. The decisions are written by the judges and clerks in the language of the proceedings.
### Annotations
#### Annotation process
The decisions have been annotated with the binarized judgment outcome using parsers and regular expressions. In addition a subset of the test set (27 cases in German, 24 in French and 23 in Italian spanning over the years 2017 an 20200) was annotated by legal experts, splitting sentences/group of sentences and annotated with one of the following explainability label: Supports judgment, Opposes Judgment and Neutral. The test sets have each sentence/ group of sentence once occluded, enabling an analysis of the changes in the model's performance. The legal expert annotation were conducted from April 2020 to August 2020.
#### Who are the annotators?
Joel Niklaus and Adrian Jörg annotated the binarized judgment outcomes. Metadata is published by the Swiss Federal Supreme Court (https://www.bger.ch). The group of legal experts consists of Thomas Lüthi (lawyer), Lynn Grau (law student at master's level) and Angela Stefanelli (law student at master's level).
### Personal and Sensitive Information
The dataset contains publicly available court decisions from the Swiss Federal Supreme Court. Personal or sensitive information has been anonymized by the court before publication according to the following guidelines: https://www.bger.ch/home/juridiction/anonymisierungsregeln.html.
## Additional Information
### Dataset Curators
Niklaus et al. (2021) and Nina Baumgartner
### Licensing Information
We release the data under CC-BY-4.0 which complies with the court licensing (https://www.bger.ch/files/live/sites/bger/files/pdf/de/urteilsveroeffentlichung_d.pdf)
© Swiss Federal Supreme Court, 2000-2020
The copyright for the editorial content of this website and the consolidated texts, which is owned by the Swiss Federal Supreme Court, is licensed under the Creative Commons Attribution 4.0 International licence. This means that you can re-use the content provided you acknowledge the source and indicate any changes you have made.
Source: https://www.bger.ch/files/live/sites/bger/files/pdf/de/urteilsveroeffentlichung_d.pdf
### Citation Information
```
@misc{baumgartner_nina_occlusion_2022,
title = {From Occlusion to Transparancy – An Occlusion-Based Explainability Approach for Legal Judgment Prediction in Switzerland},
shorttitle = {From Occlusion to Transparancy},
abstract = {Natural Language Processing ({NLP}) models have been used for more and more complex tasks such as Legal Judgment Prediction ({LJP}). A {LJP} model predicts the outcome of a legal case by utilizing its facts. This increasing deployment of Artificial Intelligence ({AI}) in high-stakes domains such as law and the involvement of sensitive data has increased the need for understanding such systems. We propose a multilingual occlusion-based explainability approach for {LJP} in Switzerland and conduct a study on the bias using Lower Court Insertion ({LCI}). We evaluate our results using different explainability metrics introduced in this thesis and by comparing them to high-quality Legal Expert Annotations using Inter Annotator Agreement. Our findings show that the model has a varying understanding of the semantic meaning and context of the facts section, and struggles to distinguish between legally relevant and irrelevant sentences. We also found that the insertion of a different lower court can have an effect on the prediction, but observed no distinct effects based on legal areas, cantons, or regions. However, we did identify a language disparity with Italian performing worse than the other languages due to representation inequality in the training data, which could lead to potential biases in the prediction in multilingual regions of Switzerland. Our results highlight the challenges and limitations of using {NLP} in the judicial field and the importance of addressing concerns about fairness, transparency, and potential bias in the development and use of {NLP} systems. The use of explainable artificial intelligence ({XAI}) techniques, such as occlusion and {LCI}, can help provide insight into the decision-making processes of {NLP} systems and identify areas for improvement. Finally, we identify areas for future research and development in this field in order to address the remaining limitations and challenges.},
author = {{Baumgartner, Nina}},
year = {2022},
langid = {english}
}
```
### Contributions
Thanks to [@ninabaumgartner](https://github.com/ninabaumgartner) for adding this dataset. | [
-0.35966578125953674,
-0.8111640810966492,
0.5849389433860779,
0.04089425131678581,
-0.37138164043426514,
-0.2763945758342743,
-0.1623881459236145,
-0.6189175844192505,
0.1903945356607437,
0.6034292578697205,
-0.45521458983421326,
-0.8190104365348816,
-0.5982663631439209,
-0.06090795993804... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mstz/speeddating | mstz | 2023-04-07T14:54:21Z | 36 | 0 | null | [
"task_categories:tabular-classification",
"size_categories:1K<n<10K",
"language:en",
"speeddating",
"tabular_classification",
"binary_classification",
"region:us"
] | 2023-04-07T14:54:21Z | 2023-03-23T23:41:42.000Z | 2023-03-23T23:41:42 | ---
language:
- en
tags:
- speeddating
- tabular_classification
- binary_classification
pretty_name: Speed dating
size_categories:
- 1K<n<10K
task_categories: # Full list at https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts
- tabular-classification
configs:
- dating
---
# Speed dating
The [Speed dating dataset](https://www.openml.org/search?type=data&sort=nr_of_likes&status=active&id=40536) from OpenML.
# Configurations and tasks
| **Configuration** | **Task** | Description |
|-------------------|---------------------------|---------------------------------------------------------------|
| dating | Binary classification | Will the two date? |
# Usage
```python
from datasets import load_dataset
dataset = load_dataset("mstz/speeddating")["train"]
```
# Features
|**Features** |**Type** |
|---------------------------------------------------|---------|
|`is_dater_male` |`int8` |
|`dater_age` |`int8` |
|`dated_age` |`int8` |
|`age_difference` |`int8` |
|`dater_race` |`string` |
|`dated_race` |`string` |
|`are_same_race` |`int8` |
|`same_race_importance_for_dater` |`float64`|
|`same_religion_importance_for_dater` |`float64`|
|`attractiveness_importance_for_dated` |`float64`|
|`sincerity_importance_for_dated` |`float64`|
|`intelligence_importance_for_dated` |`float64`|
|`humor_importance_for_dated` |`float64`|
|`ambition_importance_for_dated` |`float64`|
|`shared_interests_importance_for_dated` |`float64`|
|`attractiveness_score_of_dater_from_dated` |`float64`|
|`sincerity_score_of_dater_from_dated` |`float64`|
|`intelligence_score_of_dater_from_dated` |`float64`|
|`humor_score_of_dater_from_dated` |`float64`|
|`ambition_score_of_dater_from_dated` |`float64`|
|`shared_interests_score_of_dater_from_dated` |`float64`|
|`attractiveness_importance_for_dater` |`float64`|
|`sincerity_importance_for_dater` |`float64`|
|`intelligence_importance_for_dater` |`float64`|
|`humor_importance_for_dater` |`float64`|
|`ambition_importance_for_dater` |`float64`|
|`shared_interests_importance_for_dater` |`float64`|
|`self_reported_attractiveness_of_dater` |`float64`|
|`self_reported_sincerity_of_dater` |`float64`|
|`self_reported_intelligence_of_dater` |`float64`|
|`self_reported_humor_of_dater` |`float64`|
|`self_reported_ambition_of_dater` |`float64`|
|`reported_attractiveness_of_dated_from_dater` |`float64`|
|`reported_sincerity_of_dated_from_dater` |`float64`|
|`reported_intelligence_of_dated_from_dater` |`float64`|
|`reported_humor_of_dated_from_dater` |`float64`|
|`reported_ambition_of_dated_from_dater` |`float64`|
|`reported_shared_interests_of_dated_from_dater` |`float64`|
|`dater_interest_in_sports` |`float64`|
|`dater_interest_in_tvsports` |`float64`|
|`dater_interest_in_exercise` |`float64`|
|`dater_interest_in_dining` |`float64`|
|`dater_interest_in_museums` |`float64`|
|`dater_interest_in_art` |`float64`|
|`dater_interest_in_hiking` |`float64`|
|`dater_interest_in_gaming` |`float64`|
|`dater_interest_in_clubbing` |`float64`|
|`dater_interest_in_reading` |`float64`|
|`dater_interest_in_tv` |`float64`|
|`dater_interest_in_theater` |`float64`|
|`dater_interest_in_movies` |`float64`|
|`dater_interest_in_concerts` |`float64`|
|`dater_interest_in_music` |`float64`|
|`dater_interest_in_shopping` |`float64`|
|`dater_interest_in_yoga` |`float64`|
|`interests_correlation` |`float64`|
|`expected_satisfaction_of_dater` |`float64`|
|`expected_number_of_likes_of_dater_from_20_people` |`int8` |
|`expected_number_of_dates_for_dater` |`int8` |
|`dater_liked_dated` |`float64`|
|`probability_dated_wants_to_date` |`float64`|
|`already_met_before` |`int8` |
|`dater_wants_to_date` |`int8` |
|`dated_wants_to_date` |`int8` |
| [
-0.7379164099693298,
-0.7051035761833191,
0.38476139307022095,
0.34531307220458984,
-0.3896600902080536,
-0.09917176514863968,
0.12123683840036392,
-0.5257579684257507,
0.6376322507858276,
0.3257812261581421,
-0.8783686757087708,
-0.566498339176178,
-0.7793352007865906,
0.15814422070980072... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
suolyer/pile_pile-cc | suolyer | 2023-03-27T03:04:43Z | 36 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2023-03-27T03:04:43Z | 2023-03-26T16:38:55.000Z | 2023-03-26T16:38:55 | ---
license: apache-2.0
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Chinese-Vicuna/guanaco_belle_merge_v1.0 | Chinese-Vicuna | 2023-03-30T07:49:30Z | 36 | 80 | null | [
"language:zh",
"language:en",
"language:ja",
"license:gpl-3.0",
"region:us"
] | 2023-03-30T07:49:30Z | 2023-03-30T07:29:07.000Z | 2023-03-30T07:29:07 | ---
license: gpl-3.0
language:
- zh
- en
- ja
---
Thanks for [Guanaco Dataset](https://huggingface.co/datasets/JosephusCheung/GuanacoDataset) and [Belle Dataset](https://huggingface.co/datasets/BelleGroup/generated_train_0.5M_CN)
This dataset was created by merging the above two datasets in a certain format so that they can be used for training our code [Chinese-Vicuna](https://github.com/Facico/Chinese-Vicuna) | [
-0.15067338943481445,
0.057761531323194504,
0.2622068524360657,
0.5478158593177795,
-0.12370830774307251,
-0.39572712779045105,
0.056862346827983856,
-0.5080388188362122,
0.5286059379577637,
0.5258036255836487,
-0.6084743738174438,
-0.6990441679954529,
-0.296953022480011,
-0.06458837538957... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
sayakpaul/poses-controlnet-dataset | sayakpaul | 2023-04-05T01:47:49Z | 36 | 0 | null | [
"region:us"
] | 2023-04-05T01:47:49Z | 2023-04-03T11:18:31.000Z | 2023-04-03T11:18:31 | ---
dataset_info:
features:
- name: original_image
dtype: image
- name: condtioning_image
dtype: image
- name: overlaid
dtype: image
- name: caption
dtype: string
splits:
- name: train
num_bytes: 123997217.0
num_examples: 496
download_size: 124012907
dataset_size: 123997217.0
---
# Dataset Card for "poses-controlnet-dataset"
The dataset was prepared using this Colab Notebook:
[](https://colab.research.google.com/github/huggingface/community-events/blob/main/jax-controlnet-sprint/dataset_tools/create_pose_dataset.ipynb) | [
-0.5022714138031006,
-0.041872937232255936,
-0.19915202260017395,
0.3319048285484314,
-0.266126811504364,
0.19801032543182373,
0.3832252323627472,
-0.19343814253807068,
0.8978544473648071,
0.18040359020233154,
-0.8615341782569885,
-0.7876654267311096,
-0.30039894580841064,
-0.1767535507678... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
alexwww94/SimCLUE | alexwww94 | 2023-04-14T06:40:03Z | 36 | 0 | null | [
"license:other",
"region:us"
] | 2023-04-14T06:40:03Z | 2023-04-13T09:56:06.000Z | 2023-04-13T09:56:06 | ---
license: other
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
siddharthtumre/jnlpba-split | siddharthtumre | 2023-04-25T04:49:37Z | 36 | 0 | null | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"language:en",
"license:unknown",
"region:us"
] | 2023-04-25T04:49:37Z | 2023-04-25T04:35:39.000Z | 2023-04-25T04:35:39 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
task_categories:
- token-classification
task_ids:
- named-entity-recognition
pretty_name: IASL-BNER Revised JNLPBA
dataset_info:
features:
- name: id
dtype: string
- name: tokens
sequence: string
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': B-DNA
'2': I-DNA
'3': B-RNA
'4': I-RNA
'5': B-cell_line
'6': I-cell_line
'7': B-cell_type
'8': I-cell_type
'9': B-protein
'10': I-protein
config_name: revised-jnlpba
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | [
-0.5456174612045288,
-0.42588168382644653,
-0.051285725086927414,
0.38739174604415894,
-0.4620097875595093,
0.05422865226864815,
-0.24659410119056702,
-0.2884671688079834,
0.6999505162239075,
0.5781952142715454,
-0.9070088267326355,
-1.1513409614562988,
-0.7566764950752258,
0.0290524791926... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
silk-road/chinese-dolly-15k | silk-road | 2023-05-22T00:26:02Z | 36 | 15 | null | [
"task_categories:question-answering",
"task_categories:summarization",
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:zh",
"language:en",
"license:cc-by-sa-3.0",
"region:us"
] | 2023-05-22T00:26:02Z | 2023-05-22T00:18:48.000Z | 2023-05-22T00:18:48 | ---
license: cc-by-sa-3.0
task_categories:
- question-answering
- summarization
- text-generation
language:
- zh
- en
size_categories:
- 10K<n<100K
---
Chinese-Dolly-15k是骆驼团队翻译的Dolly instruction数据集
最后49条数据因为翻译长度超过限制,没有翻译成功,建议删除或者手动翻译一下
原来的数据集'databricks/databricks-dolly-15k'是由数千名Databricks员工根据InstructGPT论文中概述的几种行为类别生成的遵循指示记录的开源数据集。这几个行为类别包括头脑风暴、分类、封闭型问答、生成、信息提取、开放型问答和摘要。
在知识共享署名-相同方式共享3.0(CC BY-SA 3.0)许可下,此数据集可用于任何学术或商业用途。
我们会陆续将更多数据集发布到hf,包括
- [ ] Coco Caption的中文翻译
- [x] CoQA的中文翻译
- [ ] CNewSum的Embedding数据
- [x] 增广的开放QA数据
- [x] WizardLM的中文翻译
- [x] MMC4的中文翻译
如果你也在做这些数据集的筹备,欢迎来联系我们,避免重复花钱。
# 骆驼(Luotuo): 开源中文大语言模型
[https://github.com/LC1332/Luotuo-Chinese-LLM](https://github.com/LC1332/Luotuo-Chinese-LLM)
骆驼(Luotuo)项目是由[冷子昂](https://blairleng.github.io) @ 商汤科技, 陈启源 @ 华中师范大学 以及 李鲁鲁 @ 商汤科技 发起的中文大语言模型开源项目,包含了一系列语言模型。
骆驼项目**不是**商汤科技的官方产品。
## Citation
Please cite the repo if you use the data or code in this repo.
```
@misc{alpaca,
author={Ziang Leng, Qiyuan Chen and Cheng Li},
title = {Luotuo: An Instruction-following Chinese Language model, LoRA tuning on LLaMA},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/LC1332/Luotuo-Chinese-LLM}},
}
```
| [
-0.1827021986246109,
-0.959090530872345,
-0.08270619809627533,
0.6169309616088867,
-0.4174286425113678,
-0.10677093267440796,
0.07299136370420456,
-0.18062041699886322,
0.26006847620010376,
0.47190842032432556,
-0.5671644806861877,
-0.7754977941513062,
-0.3749174475669861,
0.06375879794359... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
nicholasKluge/toxic-aira-dataset | nicholasKluge | 2023-11-10T12:51:32Z | 36 | 2 | null | [
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:pt",
"language:en",
"license:apache-2.0",
"toxicity",
"harm",
"region:us"
] | 2023-11-10T12:51:32Z | 2023-06-07T19:08:36.000Z | 2023-06-07T19:08:36 | ---
license: apache-2.0
task_categories:
- text-classification
language:
- pt
- en
tags:
- toxicity
- harm
pretty_name: Toxic-Aira Dataset
size_categories:
- 10K<n<100K
dataset_info:
features:
- name: non_toxic_response
dtype: string
- name: toxic_response
dtype: string
splits:
- name: portuguese
num_bytes: 19006011
num_examples: 28103
- name: english
num_bytes: 19577715
num_examples: 41843
download_size: 5165276
dataset_size: 38583726
---
# Dataset (`Toxic-Aira Dataset`)
### Overview
This dataset contains a collection of texts containing harmful/toxic and harmless/non-toxic conversations and messages. All demonstrations are separated into two classes (`non_toxic_response` and `toxic_response`). This dataset was created from the Anthropic [helpful-harmless-RLHF](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset, the AllenAI [prosocial-dialog](https://huggingface.co/datasets/allenai/prosocial-dialog) dataset, the [real-toxicity-prompts](https://huggingface.co/datasets/allenai/real-toxicity-prompts) dataset (also from AllenAI), the [Toxic Comment Classification](https://github.com/tianqwang/Toxic-Comment-Classification-Challenge) dataset, and the [ToxiGen](https://huggingface.co/datasets/skg/toxigen-data) dataset.
The Portuguese version has translated copies from the above mentioned datasets ([helpful-harmless-RLHF](https://huggingface.co/datasets/Anthropic/hh-rlhf), [prosocial-dialog](https://huggingface.co/datasets/allenai/prosocial-dialog), [real-toxicity-prompts](https://huggingface.co/datasets/allenai/real-toxicity-prompts), [ToxiGen](https://huggingface.co/datasets/skg/toxigen-data)), plus the [hatecheck-portuguese](https://huggingface.co/datasets/Paul/hatecheck-portuguese) and [told-br](https://huggingface.co/datasets/told-br) datasets.
### Dataset Details
- **Dataset Name:** Toxic-Aira Dataset
- **Language:** Portuguese and English
- **Total Size:** Over 40,000 demonstrations (Portuguese 28,103, English 41,843)
- **Sources:**
- Anthropic [Helpful-harmless-RLHF](https://huggingface.co/datasets/Anthropic/hh-rlhf) dataset.
- AllenAI [Prosocial-dialog](https://huggingface.co/datasets/allenai/prosocial-dialog) dataset.
- AllenAI [Real-toxicity-prompts](https://huggingface.co/datasets/allenai/real-toxicity-prompts) dataset.
- The [Toxic Comment Classification](https://github.com/tianqwang/Toxic-Comment-Classification-Challenge).dataset.
- The [Hatecheck-portuguese](https://huggingface.co/datasets/Paul/hatecheck-portuguese) dataset.
- The [Told-br](https://huggingface.co/datasets/told-br) dataset.
- The [ToxiGen](https://huggingface.co/datasets/skg/toxigen-data) dataset.
### Contents
⚠️ THE EXAMPLES IN THIS DATASET CONTAIN TOXIC/OFFENSIVE LANGUAGE ⚠️
The dataset consists of data frames with the following columns:
- **non_toxic_response:** Text that was evaluated as non-toxic.
- **toxic_response:** Text evaluated as toxic.
```python
{
"non_toxic_response": "I prefer to see it as the study of change.",
"toxic_response":"So to my secret santa in the words of Jessie Pinkman, THANKS BITCH",
}
```
All demonstrations of examples are less than 350 tokens (measured using the `BERT` tokenizer).
### Use Cases
`Toxic-Aira Dataset` can be utilized to train models to detect harmful/toxic text.
## How to use
Available splits are `portuguese` and `english`.
```python
from datasets import load_dataset
dataset = load_dataset("nicholasKluge/toxic-aira-dataset")
```
### Disclaimer
This dataset is provided as is, without any warranty or guarantee of its accuracy or suitability for any purpose. The creators and contributors of this dataset are not liable for any damages or losses arising from its use. Please review and comply with the licenses and terms of the original datasets before use. | [
-0.08796096593141556,
-0.6761983036994934,
0.13213694095611572,
0.3745133578777313,
-0.1909807026386261,
-0.28244975209236145,
-0.06237737461924553,
-0.4502902626991272,
0.3523021340370178,
0.4157834053039551,
-0.6892766952514648,
-0.7257172465324402,
-0.6046066284179688,
0.323222249746322... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
SirlyDreamer/THUCNews | SirlyDreamer | 2023-06-20T07:37:15Z | 36 | 0 | null | [
"region:us"
] | 2023-06-20T07:37:15Z | 2023-06-20T05:21:24.000Z | 2023-06-20T05:21:24 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
unwilledset/raven-data | unwilledset | 2023-10-21T05:13:54Z | 36 | 0 | null | [
"license:apache-2.0",
"region:us"
] | 2023-10-21T05:13:54Z | 2023-07-10T09:54:46.000Z | 2023-07-10T09:54:46 | ---
license: apache-2.0
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
pie/squad_v2 | pie | 2023-11-23T10:53:55Z | 36 | 0 | null | [
"region:us"
] | 2023-11-23T10:53:55Z | 2023-07-10T11:32:08.000Z | 2023-07-10T11:32:08 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
PedroCJardim/QASports | PedroCJardim | 2023-11-24T18:16:39Z | 36 | 2 | null | [
"task_categories:question-answering",
"size_categories:1M<n<10M",
"language:en",
"license:mit",
"sports",
"open-domain-qa",
"extractive-qa",
"region:us"
] | 2023-11-24T18:16:39Z | 2023-07-14T17:28:19.000Z | 2023-07-14T17:28:19 | ---
configs:
- config_name: all
data_files:
- split: train
path:
- "trainb.csv"
- "trains.csv"
- "trainf.csv"
- split: test
path:
- "testb.csv"
- "tests.csv"
- "testf.csv"
- split: validation
path:
- "validationb.csv"
- "validations.csv"
- "validationf.csv"
default: true
- config_name: basketball
data_files:
- split: train
path: "trainb.csv"
- split: test
path: "testb.csv"
- split: validation
path: "validationb.csv"
- config_name: football
data_files:
- split: train
path: "trainf.csv"
- split: test
path: "testf.csv"
- split: validation
path: "validationf.csv"
- config_name: soccer
data_files:
- split: train
path: "trains.csv"
- split: test
path: "tests.csv"
- split: validation
path: "validations.csv"
license: mit
task_categories:
- question-answering
language:
- en
tags:
- sports
- open-domain-qa
- extractive-qa
size_categories:
- 1M<n<10M
pretty_name: QASports
---
### Dataset Summary
QASports is the first large sports-themed question answering dataset counting over 1.5 million questions and answers about 54k preprocessed wiki pages, using as documents the wiki of 3 of the most popular sports in the world, Soccer, American Football and Basketball. Each sport can be downloaded individually as a subset, with the train, test and validation splits, or all 3 can be downloaded together.
- 🎲 Complete dataset: https://osf.io/n7r23/
- 🔧 Processing scripts: https://github.com/leomaurodesenv/qasports-dataset-scripts/
### Supported Tasks and Leaderboards
Extractive Question Answering.
### Languages
English.
## Dataset Structure
### Data Instances
An example of 'train' looks as follows.
```
{
"answer": {
"offset": [42,44],
"text": "16"
},
"context": "The following is a list of squads for all 16 national teams competing at the Copa América Centenario. Each national team had to submit a squad of 23 players, 3 of whom must be goalkeepers. The provisional squads were announced on 4 May 2016. A final selection was provided to the organisers on 20 May 2016." ,
"qa_id": "61200579912616854316543272456523433217",
"question": "How many national teams competed at the Copa América Centenario?",
"context_id": "171084087809998484545703642399578583178",
"context_title": "Copa América Centenario squads | Football Wiki | Fandom",
"url": "https://football.fandom.com/wiki/Copa_Am%C3%A9rica_Centenario_squads"
}
```
### Data Fields
The data fields are the same among all splits.
- '': int
- `id_qa`: a `string` feature.
- `context_id`: a `string` feature.
- `context_title`: a `string` feature.
- `url`: a `string` feature.
- `context`: a `string` feature.
- `question`: a `string` feature.
- `answers`: a dictionary feature containing:
- `text`: a `string` feature.
- `offset`: a list feature containing:
- 2 `int32` features for start and end.
### Citation
```
@inproceedings{jardim:2023:qasports-dataset,
author={Pedro Calciolari Jardim and Leonardo Mauro Pereira Moraes and Cristina Dutra Aguiar},
title = {{QASports}: A Question Answering Dataset about Sports},
booktitle = {Proceedings of the Brazilian Symposium on Databases: Dataset Showcase Workshop},
address = {Belo Horizonte, MG, Brazil},
url = {https://github.com/leomaurodesenv/qasports-dataset-scripts},
publisher = {Brazilian Computer Society},
pages = {1-12},
year = {2023}
}
```
| [
-0.7315133810043335,
-0.535916805267334,
0.41776204109191895,
0.34121033549308777,
-0.3199096620082855,
0.2152910679578781,
0.08236543089151382,
-0.3604840338230133,
0.5438238978385925,
0.20937581360340118,
-0.88039231300354,
-0.6175742149353027,
-0.37652671337127686,
0.46392711997032166,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
aditijha/processed_lima | aditijha | 2023-08-29T05:26:26Z | 36 | 2 | null | [
"region:us"
] | 2023-08-29T05:26:26Z | 2023-07-16T21:33:28.000Z | 2023-07-16T21:33:28 | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 2942583
num_examples: 1000
- name: test
num_bytes: 80137
num_examples: 300
download_size: 31591
dataset_size: 3022720
---
# Dataset Card for "processed_lima"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.4119807481765747,
-0.5074421763420105,
0.45454081892967224,
0.5409814715385437,
-0.4744267761707306,
-0.17734454572200775,
0.4007243514060974,
-0.3056440055370331,
1.075714349746704,
0.8165264129638672,
-0.889593780040741,
-0.812372088432312,
-0.902409017086029,
-0.1357559859752655,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
MichaelR207/MultiSim | MichaelR207 | 2023-11-14T00:32:32Z | 36 | 0 | null | [
"task_categories:summarization",
"task_categories:text2text-generation",
"task_categories:text-generation",
"size_categories:1M<n<10M",
"language:en",
"language:fr",
"language:ru",
"language:ja",
"language:it",
"language:da",
"language:es",
"language:de",
"language:pt",
"language:sl",
"l... | 2023-11-14T00:32:32Z | 2023-07-18T21:55:31.000Z | 2023-07-18T21:55:31 | ---
license: mit
language:
- en
- fr
- ru
- ja
- it
- da
- es
- de
- pt
- sl
- ur
- eu
task_categories:
- summarization
- text2text-generation
- text-generation
pretty_name: MultiSim
tags:
- medical
- legal
- wikipedia
- encyclopedia
- science
- literature
- news
- websites
size_categories:
- 1M<n<10M
---
# Dataset Card for MultiSim Benchmark
## Dataset Description
- **Repository:https://github.com/XenonMolecule/MultiSim/tree/main**
- **Paper:https://aclanthology.org/2023.acl-long.269/ https://arxiv.org/pdf/2305.15678.pdf**
- **Point of Contact: michaeljryan@stanford.edu**
### Dataset Summary
The MultiSim benchmark is a growing collection of text simplification datasets targeted at sentence simplification in several languages. Currently, the benchmark spans 12 languages.

### Supported Tasks
- Sentence Simplification
### Usage
```python
from datasets import load_dataset
dataset = load_dataset("MichaelR207/MultiSim")
```
### Citation
If you use this benchmark, please cite our [paper](https://aclanthology.org/2023.acl-long.269/):
```
@inproceedings{ryan-etal-2023-revisiting,
title = "Revisiting non-{E}nglish Text Simplification: A Unified Multilingual Benchmark",
author = "Ryan, Michael and
Naous, Tarek and
Xu, Wei",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.269",
pages = "4898--4927",
abstract = "Recent advancements in high-quality, large-scale English resources have pushed the frontier of English Automatic Text Simplification (ATS) research. However, less work has been done on multilingual text simplification due to the lack of a diverse evaluation benchmark that covers complex-simple sentence pairs in many languages. This paper introduces the MultiSim benchmark, a collection of 27 resources in 12 distinct languages containing over 1.7 million complex-simple sentence pairs. This benchmark will encourage research in developing more effective multilingual text simplification models and evaluation metrics. Our experiments using MultiSim with pre-trained multilingual language models reveal exciting performance improvements from multilingual training in non-English settings. We observe strong performance from Russian in zero-shot cross-lingual transfer to low-resource languages. We further show that few-shot prompting with BLOOM-176b achieves comparable quality to reference simplifications outperforming fine-tuned models in most languages. We validate these findings through human evaluation.",
}
```
### Contact
**Michael Ryan**: [Scholar](https://scholar.google.com/citations?user=8APGEEkAAAAJ&hl=en) | [Twitter](http://twitter.com/michaelryan207) | [Github](https://github.com/XenonMolecule) | [LinkedIn](https://www.linkedin.com/in/michael-ryan-207/) | [Research Gate](https://www.researchgate.net/profile/Michael-Ryan-86) | [Personal Website](http://michaelryan.tech/) | [michaeljryan@stanford.edu](mailto://michaeljryan@stanford.edu)
### Languages
- English
- French
- Russian
- Japanese
- Italian
- Danish (on request)
- Spanish (on request)
- German
- Brazilian Portuguese
- Slovene
- Urdu (on request)
- Basque (on request)
## Dataset Structure
### Data Instances
MultiSim is a collection of 27 existing datasets:
- AdminIT
- ASSET
- CBST
- CLEAR
- DSim
- Easy Japanese
- Easy Japanese Extended
- GEOLino
- German News
- Newsela EN/ES
- PaCCSS-IT
- PorSimples
- RSSE
- RuAdapt Encyclopedia
- RuAdapt Fairytales
- RuAdapt Literature
- RuWikiLarge
- SIMPITIKI
- Simple German
- Simplext
- SimplifyUR
- SloTS
- Teacher
- Terence
- TextComplexityDE
- WikiAuto
- WikiLargeFR

### Data Fields
In the train set, you will only find `original` and `simple` sentences. In the validation and test sets you may find `simple1`, `simple2`, ... `simpleN` because a given sentence can have multiple reference simplifications (useful in SARI and BLEU calculations)
### Data Splits
The dataset is split into a train, validation, and test set.

## Dataset Creation
### Curation Rationale
I hope that collecting all of these independently useful resources for text simplification together into one benchmark will encourage multilingual work on text simplification!
### Source Data
#### Initial Data Collection and Normalization
Data is compiled from the 27 existing datasets that comprise the MultiSim Benchmark. For details on each of the resources please see Appendix A in the [paper](https://aclanthology.org/2023.acl-long.269.pdf).
#### Who are the source language producers?
Each dataset has different sources. At a high level the sources are: Automatically Collected (ex. Wikipedia, Web data), Manually Collected (ex. annotators asked to simplify sentences), Target Audience Resources (ex. Newsela News Articles), or Translated (ex. Machine translations of existing datasets).
These sources can be seen in Table 1 pictured above (Section: `Dataset Structure/Data Instances`) and further discussed in section 3 of the [paper](https://aclanthology.org/2023.acl-long.269.pdf). Appendix A of the paper has details on specific resources.
### Annotations
#### Annotation process
Annotators writing simplifications (only for some datasets) typically follow an annotation guideline. Some example guidelines come from [here](https://dl.acm.org/doi/10.1145/1410140.1410191), [here](https://link.springer.com/article/10.1007/s11168-006-9011-1), and [here](https://link.springer.com/article/10.1007/s10579-017-9407-6).
#### Who are the annotators?
See Table 1 (Section: `Dataset Structure/Data Instances`) for specific annotators per dataset. At a high level the annotators are: writers, translators, teachers, linguists, journalists, crowdworkers, experts, news agencies, medical students, students, writers, and researchers.
### Personal and Sensitive Information
No dataset should contain personal or sensitive information. These were previously collected resources primarily collected from news sources, wikipedia, science communications, etc. and were not identified to have personally identifiable information.
## Considerations for Using the Data
### Social Impact of Dataset
We hope this dataset will make a greatly positive social impact as text simplification is a task that serves children, second language learners, and people with reading/cognitive disabilities. By publicly releasing a dataset in 12 languages we hope to serve these global communities.
One negative and unintended use case for this data would be reversing the labels to make a "text complification" model. We beleive the benefits of releasing this data outweigh the harms and hope that people use the dataset as intended.
### Discussion of Biases
There may be biases of the annotators involved in writing the simplifications towards how they believe a simpler sentence should be written. Additionally annotators and editors have the choice of what information does not make the cut in the simpler sentence introducing information importance bias.
### Other Known Limitations
Some of the included resources were automatically collected or machine translated. As such not every sentence is perfectly aligned. Users are recommended to use such individual resources with caution.
## Additional Information
### Dataset Curators
**Michael Ryan**: [Scholar](https://scholar.google.com/citations?user=8APGEEkAAAAJ&hl=en) | [Twitter](http://twitter.com/michaelryan207) | [Github](https://github.com/XenonMolecule) | [LinkedIn](https://www.linkedin.com/in/michael-ryan-207/) | [Research Gate](https://www.researchgate.net/profile/Michael-Ryan-86) | [Personal Website](http://michaelryan.tech/) | [michaeljryan@stanford.edu](mailto://michaeljryan@stanford.edu)
### Licensing Information
MIT License
### Citation Information
Please cite the individual datasets that you use within the MultiSim benchmark as appropriate. Proper bibtex attributions for each of the datasets are included below.
#### AdminIT
```
@inproceedings{miliani-etal-2022-neural,
title = "Neural Readability Pairwise Ranking for Sentences in {I}talian Administrative Language",
author = "Miliani, Martina and
Auriemma, Serena and
Alva-Manchego, Fernando and
Lenci, Alessandro",
booktitle = "Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing",
month = nov,
year = "2022",
address = "Online only",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.aacl-main.63",
pages = "849--866",
abstract = "Automatic Readability Assessment aims at assigning a complexity level to a given text, which could help improve the accessibility to information in specific domains, such as the administrative one. In this paper, we investigate the behavior of a Neural Pairwise Ranking Model (NPRM) for sentence-level readability assessment of Italian administrative texts. To deal with data scarcity, we experiment with cross-lingual, cross- and in-domain approaches, and test our models on Admin-It, a new parallel corpus in the Italian administrative language, containing sentences simplified using three different rewriting strategies. We show that NPRMs are effective in zero-shot scenarios ({\textasciitilde}0.78 ranking accuracy), especially with ranking pairs containing simplifications produced by overall rewriting at the sentence-level, and that the best results are obtained by adding in-domain data (achieving perfect performance for such sentence pairs). Finally, we investigate where NPRMs failed, showing that the characteristics of the training data, rather than its size, have a bigger effect on a model{'}s performance.",
}
```
#### ASSET
```
@inproceedings{alva-manchego-etal-2020-asset,
title = "{ASSET}: {A} Dataset for Tuning and Evaluation of Sentence Simplification Models with Multiple Rewriting Transformations",
author = "Alva-Manchego, Fernando and
Martin, Louis and
Bordes, Antoine and
Scarton, Carolina and
Sagot, Beno{\^\i}t and
Specia, Lucia",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.424",
pages = "4668--4679",
}
```
#### CBST
```
@article{10.1007/s10579-017-9407-6,
title={{The corpus of Basque simplified texts (CBST)}},
author={Gonzalez-Dios, Itziar and Aranzabe, Mar{\'\i}a Jes{\'u}s and D{\'\i}az de Ilarraza, Arantza},
journal={Language Resources and Evaluation},
volume={52},
number={1},
pages={217--247},
year={2018},
publisher={Springer}
}
```
#### CLEAR
```
@inproceedings{grabar-cardon-2018-clear,
title = "{CLEAR} {--} Simple Corpus for Medical {F}rench",
author = "Grabar, Natalia and
Cardon, R{\'e}mi",
booktitle = "Proceedings of the 1st Workshop on Automatic Text Adaptation ({ATA})",
month = nov,
year = "2018",
address = "Tilburg, the Netherlands",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W18-7002",
doi = "10.18653/v1/W18-7002",
pages = "3--9",
}
```
#### DSim
```
@inproceedings{klerke-sogaard-2012-dsim,
title = "{DS}im, a {D}anish Parallel Corpus for Text Simplification",
author = "Klerke, Sigrid and
S{\o}gaard, Anders",
booktitle = "Proceedings of the Eighth International Conference on Language Resources and Evaluation ({LREC}'12)",
month = may,
year = "2012",
address = "Istanbul, Turkey",
publisher = "European Language Resources Association (ELRA)",
url = "http://www.lrec-conf.org/proceedings/lrec2012/pdf/270_Paper.pdf",
pages = "4015--4018",
abstract = "We present DSim, a new sentence aligned Danish monolingual parallel corpus extracted from 3701 pairs of news telegrams and corresponding professionally simplified short news articles. The corpus is intended for building automatic text simplification for adult readers. We compare DSim to different examples of monolingual parallel corpora, and we argue that this corpus is a promising basis for future development of automatic data-driven text simplification systems in Danish. The corpus contains both the collection of paired articles and a sentence aligned bitext, and we show that sentence alignment using simple tf*idf weighted cosine similarity scoring is on line with state―of―the―art when evaluated against a hand-aligned sample. The alignment results are compared to state of the art for English sentence alignment. We finally compare the source and simplified sides of the corpus in terms of lexical and syntactic characteristics and readability, and find that the one―to―many sentence aligned corpus is representative of the sentence simplifications observed in the unaligned collection of article pairs.",
}
```
#### Easy Japanese
```
@inproceedings{maruyama-yamamoto-2018-simplified,
title = "Simplified Corpus with Core Vocabulary",
author = "Maruyama, Takumi and
Yamamoto, Kazuhide",
booktitle = "Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018)",
month = may,
year = "2018",
address = "Miyazaki, Japan",
publisher = "European Language Resources Association (ELRA)",
url = "https://aclanthology.org/L18-1185",
}
```
#### Easy Japanese Extended
```
@inproceedings{katsuta-yamamoto-2018-crowdsourced,
title = "Crowdsourced Corpus of Sentence Simplification with Core Vocabulary",
author = "Katsuta, Akihiro and
Yamamoto, Kazuhide",
booktitle = "Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018)",
month = may,
year = "2018",
address = "Miyazaki, Japan",
publisher = "European Language Resources Association (ELRA)",
url = "https://aclanthology.org/L18-1072",
}
```
#### GEOLino
```
@inproceedings{mallinson2020,
title={Zero-Shot Crosslingual Sentence Simplification},
author={Mallinson, Jonathan and Sennrich, Rico and Lapata, Mirella},
year={2020},
booktitle={2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020)}
}
```
#### German News
```
@inproceedings{sauberli-etal-2020-benchmarking,
title = "Benchmarking Data-driven Automatic Text Simplification for {G}erman",
author = {S{\"a}uberli, Andreas and
Ebling, Sarah and
Volk, Martin},
booktitle = "Proceedings of the 1st Workshop on Tools and Resources to Empower People with REAding DIfficulties (READI)",
month = may,
year = "2020",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2020.readi-1.7",
pages = "41--48",
abstract = "Automatic text simplification is an active research area, and there are first systems for English, Spanish, Portuguese, and Italian. For German, no data-driven approach exists to this date, due to a lack of training data. In this paper, we present a parallel corpus of news items in German with corresponding simplifications on two complexity levels. The simplifications have been produced according to a well-documented set of guidelines. We then report on experiments in automatically simplifying the German news items using state-of-the-art neural machine translation techniques. We demonstrate that despite our small parallel corpus, our neural models were able to learn essential features of simplified language, such as lexical substitutions, deletion of less relevant words and phrases, and sentence shortening.",
language = "English",
ISBN = "979-10-95546-45-0",
}
```
#### Newsela EN/ES
```
@article{xu-etal-2015-problems,
title = "Problems in Current Text Simplification Research: New Data Can Help",
author = "Xu, Wei and
Callison-Burch, Chris and
Napoles, Courtney",
journal = "Transactions of the Association for Computational Linguistics",
volume = "3",
year = "2015",
address = "Cambridge, MA",
publisher = "MIT Press",
url = "https://aclanthology.org/Q15-1021",
doi = "10.1162/tacl_a_00139",
pages = "283--297",
abstract = "Simple Wikipedia has dominated simplification research in the past 5 years. In this opinion paper, we argue that focusing on Wikipedia limits simplification research. We back up our arguments with corpus analysis and by highlighting statements that other researchers have made in the simplification literature. We introduce a new simplification dataset that is a significant improvement over Simple Wikipedia, and present a novel quantitative-comparative approach to study the quality of simplification data resources.",
}
```
#### PaCCSS-IT
```
@inproceedings{brunato-etal-2016-paccss,
title = "{P}a{CCSS}-{IT}: A Parallel Corpus of Complex-Simple Sentences for Automatic Text Simplification",
author = "Brunato, Dominique and
Cimino, Andrea and
Dell{'}Orletta, Felice and
Venturi, Giulia",
booktitle = "Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2016",
address = "Austin, Texas",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/D16-1034",
doi = "10.18653/v1/D16-1034",
pages = "351--361",
}
```
#### PorSimples
```
@inproceedings{aluisio-gasperin-2010-fostering,
title = "Fostering Digital Inclusion and Accessibility: The {P}or{S}imples project for Simplification of {P}ortuguese Texts",
author = "Alu{\'\i}sio, Sandra and
Gasperin, Caroline",
booktitle = "Proceedings of the {NAACL} {HLT} 2010 Young Investigators Workshop on Computational Approaches to Languages of the {A}mericas",
month = jun,
year = "2010",
address = "Los Angeles, California",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W10-1607",
pages = "46--53",
}
```
```
@inproceedings{10.1007/978-3-642-16952-6_31,
author="Scarton, Carolina and Gasperin, Caroline and Aluisio, Sandra",
editor="Kuri-Morales, Angel and Simari, Guillermo R.",
title="Revisiting the Readability Assessment of Texts in Portuguese",
booktitle="Advances in Artificial Intelligence -- IBERAMIA 2010",
year="2010",
publisher="Springer Berlin Heidelberg",
address="Berlin, Heidelberg",
pages="306--315",
isbn="978-3-642-16952-6"
}
```
#### RSSE
```
@inproceedings{sakhovskiy2021rusimplesenteval,
title={{RuSimpleSentEval-2021 shared task:} evaluating sentence simplification for Russian},
author={Sakhovskiy, Andrey and Izhevskaya, Alexandra and Pestova, Alena and Tutubalina, Elena and Malykh, Valentin and Smurov, Ivana and Artemova, Ekaterina},
booktitle={Proceedings of the International Conference “Dialogue},
pages={607--617},
year={2021}
}
```
#### RuAdapt
```
@inproceedings{Dmitrieva2021Quantitative,
title={A quantitative study of simplification strategies in adapted texts for L2 learners of Russian},
author={Dmitrieva, Anna and Laposhina, Antonina and Lebedeva, Maria},
booktitle={Proceedings of the International Conference “Dialogue},
pages={191--203},
year={2021}
}
```
```
@inproceedings{dmitrieva-tiedemann-2021-creating,
title = "Creating an Aligned {R}ussian Text Simplification Dataset from Language Learner Data",
author = {Dmitrieva, Anna and
Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing",
month = apr,
year = "2021",
address = "Kiyv, Ukraine",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.bsnlp-1.8",
pages = "73--79",
abstract = "Parallel language corpora where regular texts are aligned with their simplified versions can be used in both natural language processing and theoretical linguistic studies. They are essential for the task of automatic text simplification, but can also provide valuable insights into the characteristics that make texts more accessible and reveal strategies that human experts use to simplify texts. Today, there exist a few parallel datasets for English and Simple English, but many other languages lack such data. In this paper we describe our work on creating an aligned Russian-Simple Russian dataset composed of Russian literature texts adapted for learners of Russian as a foreign language. This will be the first parallel dataset in this domain, and one of the first Simple Russian datasets in general.",
}
```
#### RuWikiLarge
```
@inproceedings{sakhovskiy2021rusimplesenteval,
title={{RuSimpleSentEval-2021 shared task:} evaluating sentence simplification for Russian},
author={Sakhovskiy, Andrey and Izhevskaya, Alexandra and Pestova, Alena and Tutubalina, Elena and Malykh, Valentin and Smurov, Ivana and Artemova, Ekaterina},
booktitle={Proceedings of the International Conference “Dialogue},
pages={607--617},
year={2021}
}
```
#### SIMPITIKI
```
@article{tonelli2016simpitiki,
title={SIMPITIKI: a Simplification corpus for Italian},
author={Tonelli, Sara and Aprosio, Alessio Palmero and Saltori, Francesca},
journal={Proceedings of CLiC-it},
year={2016}
}
```
#### Simple German
```
@inproceedings{battisti-etal-2020-corpus,
title = "A Corpus for Automatic Readability Assessment and Text Simplification of {G}erman",
author = {Battisti, Alessia and
Pf{\"u}tze, Dominik and
S{\"a}uberli, Andreas and
Kostrzewa, Marek and
Ebling, Sarah},
booktitle = "Proceedings of the Twelfth Language Resources and Evaluation Conference",
month = may,
year = "2020",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2020.lrec-1.404",
pages = "3302--3311",
abstract = "In this paper, we present a corpus for use in automatic readability assessment and automatic text simplification for German, the first of its kind for this language. The corpus is compiled from web sources and consists of parallel as well as monolingual-only (simplified German) data amounting to approximately 6,200 documents (nearly 211,000 sentences). As a unique feature, the corpus contains information on text structure (e.g., paragraphs, lines), typography (e.g., font type, font style), and images (content, position, and dimensions). While the importance of considering such information in machine learning tasks involving simplified language, such as readability assessment, has repeatedly been stressed in the literature, we provide empirical evidence for its benefit. We also demonstrate the added value of leveraging monolingual-only data for automatic text simplification via machine translation through applying back-translation, a data augmentation technique.",
language = "English",
ISBN = "979-10-95546-34-4",
}
```
#### Simplext
```
@article{10.1145/2738046,
author = {Saggion, Horacio and \v{S}tajner, Sanja and Bott, Stefan and Mille, Simon and Rello, Luz and Drndarevic, Biljana},
title = {Making It Simplext: Implementation and Evaluation of a Text Simplification System for Spanish},
year = {2015},
issue_date = {June 2015}, publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {6},
number = {4},
issn = {1936-7228},
url = {https://doi.org/10.1145/2738046},
doi = {10.1145/2738046},
journal = {ACM Trans. Access. Comput.},
month = {may},
articleno = {14},
numpages = {36},
keywords = {Spanish, text simplification corpus, human evaluation, readability measures}
}
```
#### SimplifyUR
```
@inproceedings{qasmi-etal-2020-simplifyur,
title = "{S}implify{UR}: Unsupervised Lexical Text Simplification for {U}rdu",
author = "Qasmi, Namoos Hayat and
Zia, Haris Bin and
Athar, Awais and
Raza, Agha Ali",
booktitle = "Proceedings of the Twelfth Language Resources and Evaluation Conference",
month = may,
year = "2020",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2020.lrec-1.428",
pages = "3484--3489",
language = "English",
ISBN = "979-10-95546-34-4",
}
```
#### SloTS
```
@misc{gorenc2022slovene,
title = {Slovene text simplification dataset {SloTS}},
author = {Gorenc, Sabina and Robnik-{\v S}ikonja, Marko},
url = {http://hdl.handle.net/11356/1682},
note = {Slovenian language resource repository {CLARIN}.{SI}},
copyright = {Creative Commons - Attribution 4.0 International ({CC} {BY} 4.0)},
issn = {2820-4042},
year = {2022}
}
```
#### Terence and Teacher
```
@inproceedings{brunato-etal-2015-design,
title = "Design and Annotation of the First {I}talian Corpus for Text Simplification",
author = "Brunato, Dominique and
Dell{'}Orletta, Felice and
Venturi, Giulia and
Montemagni, Simonetta",
booktitle = "Proceedings of the 9th Linguistic Annotation Workshop",
month = jun,
year = "2015",
address = "Denver, Colorado, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W15-1604",
doi = "10.3115/v1/W15-1604",
pages = "31--41",
}
```
#### TextComplexityDE
```
@article{naderi2019subjective,
title={Subjective Assessment of Text Complexity: A Dataset for German Language},
author={Naderi, Babak and Mohtaj, Salar and Ensikat, Kaspar and M{\"o}ller, Sebastian},
journal={arXiv preprint arXiv:1904.07733},
year={2019}
}
```
#### WikiAuto
```
@inproceedings{acl/JiangMLZX20,
author = {Chao Jiang and
Mounica Maddela and
Wuwei Lan and
Yang Zhong and
Wei Xu},
editor = {Dan Jurafsky and
Joyce Chai and
Natalie Schluter and
Joel R. Tetreault},
title = {Neural {CRF} Model for Sentence Alignment in Text Simplification},
booktitle = {Proceedings of the 58th Annual Meeting of the Association for Computational
Linguistics, {ACL} 2020, Online, July 5-10, 2020},
pages = {7943--7960},
publisher = {Association for Computational Linguistics},
year = {2020},
url = {https://www.aclweb.org/anthology/2020.acl-main.709/}
}
```
#### WikiLargeFR
```
@inproceedings{cardon-grabar-2020-french,
title = "{F}rench Biomedical Text Simplification: When Small and Precise Helps",
author = "Cardon, R{\'e}mi and
Grabar, Natalia",
booktitle = "Proceedings of the 28th International Conference on Computational Linguistics",
month = dec,
year = "2020",
address = "Barcelona, Spain (Online)",
publisher = "International Committee on Computational Linguistics",
url = "https://aclanthology.org/2020.coling-main.62",
doi = "10.18653/v1/2020.coling-main.62",
pages = "710--716",
abstract = "We present experiments on biomedical text simplification in French. We use two kinds of corpora {--} parallel sentences extracted from existing health comparable corpora in French and WikiLarge corpus translated from English to French {--} and a lexicon that associates medical terms with paraphrases. Then, we train neural models on these parallel corpora using different ratios of general and specialized sentences. We evaluate the results with BLEU, SARI and Kandel scores. The results point out that little specialized data helps significantly the simplification.",
}
```
## Data Availability
### Public Datasets
Most of the public datasets are available as a part of this MultiSim Repo. A few are still pending availability. For all resources we provide alternative download links.
| Dataset | Language | Availability in MultiSim Repo | Alternative Link |
|---|---|---|---|
| ASSET | English | Available | https://huggingface.co/datasets/asset |
| WikiAuto | English | Available | https://huggingface.co/datasets/wiki_auto |
| CLEAR | French | Available | http://natalia.grabar.free.fr/resources.php#remi |
| WikiLargeFR | French | Available | http://natalia.grabar.free.fr/resources.php#remi |
| GEOLino | German | Available | https://github.com/Jmallins/ZEST-data |
| TextComplexityDE | German | Available | https://github.com/babaknaderi/TextComplexityDE |
| AdminIT | Italian | Available | https://github.com/Unipisa/admin-It |
| Simpitiki | Italian | Available | https://github.com/dhfbk/simpitiki# |
| PaCCSS-IT | Italian | Available | http://www.italianlp.it/resources/paccss-it-parallel-corpus-of-complex-simple-sentences-for-italian/ |
| Terence and Teacher | Italian | Available | http://www.italianlp.it/resources/terence-and-teacher/ |
| Easy Japanese | Japanese | Available | https://www.jnlp.org/GengoHouse/snow/t15 |
| Easy Japanese Extended | Japanese | Available | https://www.jnlp.org/GengoHouse/snow/t23 |
| RuAdapt Encyclopedia | Russian | Available | https://github.com/Digital-Pushkin-Lab/RuAdapt |
| RuAdapt Fairytales | Russian | Available | https://github.com/Digital-Pushkin-Lab/RuAdapt |
| RuSimpleSentEval | Russian | Available | https://github.com/dialogue-evaluation/RuSimpleSentEval |
| RuWikiLarge | Russian | Available | https://github.com/dialogue-evaluation/RuSimpleSentEval |
| SloTS | Slovene | Available | https://github.com/sabina-skubic/text-simplification-slovene |
| SimplifyUR | Urdu | Pending | https://github.com/harisbinzia/SimplifyUR |
| PorSimples | Brazilian Portuguese | Available | [sandra@icmc.usp.br](mailto:sandra@icmc.usp.br) |
### On Request Datasets
The authors of the original papers must be contacted for on request datasets. Contact information for the authors of each dataset is provided below.
| Dataset | Language | Contact |
|---|---|---|
| CBST | Basque | http://www.ixa.eus/node/13007?language=en <br/> [itziar.gonzalezd@ehu.eus](mailto:itziar.gonzalezd@ehu.eus) |
| DSim | Danish | [sk@eyejustread.com](mailto:sk@eyejustread.com) |
| Newsela EN | English | [https://newsela.com/data/](https://newsela.com/data/) |
| Newsela ES | Spanish | [https://newsela.com/data/](https://newsela.com/data/) |
| German News | German | [ebling@cl.uzh.ch](mailto:ebling@cl.uzh.ch) |
| Simple German | German | [ebling@cl.uzh.ch](mailto:ebling@cl.uzh.ch) |
| Simplext | Spanish | [horacio.saggion@upf.edu](mailto:horacio.saggion@upf.edu) |
| RuAdapt Literature | Russian | Partially Available: https://github.com/Digital-Pushkin-Lab/RuAdapt <br/> Full Dataset: [anna.dmitrieva@helsinki.fi](mailto:anna.dmitrieva@helsinki.fi) | | [
-0.3145846426486969,
-0.45579174160957336,
0.2844250500202179,
0.34095498919487,
-0.22808490693569183,
-0.19475063681602478,
-0.5743188261985779,
-0.4669535160064697,
0.12639781832695007,
0.16922242939472198,
-0.7634475231170654,
-0.6068613529205322,
-0.5743258595466614,
0.7291595339775085... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Photolens/oasst1-langchain-llama-2-formatted | Photolens | 2023-08-11T15:23:33Z | 36 | 10 | null | [
"task_categories:conversational",
"task_categories:text-generation",
"language:en",
"language:es",
"language:ru",
"language:de",
"language:pl",
"language:th",
"language:vi",
"language:sv",
"language:bn",
"language:da",
"language:he",
"language:it",
"language:fa",
"language:sk",
"lang... | 2023-08-11T15:23:33Z | 2023-08-07T18:45:27.000Z | 2023-08-07T18:45:27 | ---
language:
- en
- es
- ru
- de
- pl
- th
- vi
- sv
- bn
- da
- he
- it
- fa
- sk
- id
- nb
- el
- nl
- hu
- eu
- zh
- eo
- ja
- ca
- cs
- bg
- fi
- pt
- tr
- ro
- ar
- uk
- gl
- fr
- ko
task_categories:
- conversational
- text-generation
license: apache-2.0
---
## Dataset overview
Dataset license: apache-2.0
This dataset contains langchain formatted [**oasst1**](https://huggingface.co/datasets/OpenAssistant/oasst1) messages with llama-2-chat special tokens.
This dataset is intended for powering langchain applications. When an llm is trained with this data, its performance is expected to be high with langchain apps.
Format of new dataset for every prompter-assistant message pair:
```
<s>[INST] "{prompter_message}" [/INST] ```json
{"action": "Final Answer", "action_input": "{assistant_message}"}
``` </s>
```
*Note: When there is a conversation, the message pairs are seperated by "\ " in same row*
## Languages
**Languages with over 1000 messages**
- English: 71956
- Spanish: 43061
- Russian: 9089
- German: 5279
- Chinese: 4962
- French: 4251
- Thai: 3042
- Portuguese (Brazil): 2969
- Catalan: 2260
- Korean: 1553
- Ukrainian: 1352
- Italian: 1320
- Japanese: 1018
<details>
<summary><b>Languages with under 1000 messages</b></summary>
<ul>
<li>Vietnamese: 952</li>
<li>Basque: 947</li>
<li>Polish: 886</li>
<li>Hungarian: 811</li>
<li>Arabic: 666</li>
<li>Dutch: 628</li>
<li>Swedish: 512</li>
<li>Turkish: 454</li>
<li>Finnish: 386</li>
<li>Czech: 372</li>
<li>Danish: 358</li>
<li>Galician: 339</li>
<li>Hebrew: 255</li>
<li>Romanian: 200</li>
<li>Norwegian Bokmål: 133</li>
<li>Indonesian: 115</li>
<li>Bulgarian: 95</li>
<li>Bengali: 82</li>
<li>Persian: 72</li>
<li>Greek: 66</li>
<li>Esperanto: 59</li>
<li>Slovak: 19</li>
</ul>
</details>
## Contact
- Email: art.photolens.ai@gmail.com
- Discord: https://discord.gg/QJT3e6ABz8
- Twitter: @PhotolensAi | [
-0.38557174801826477,
-0.36462464928627014,
0.12401746958494186,
0.2842162847518921,
-0.39186930656433105,
0.10664685815572739,
-0.19817569851875305,
-0.2763029634952545,
0.33932581543922424,
0.6008922457695007,
-0.78480464220047,
-0.9103919267654419,
-0.6516178846359253,
0.296482205390930... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
PL-MTEB/cdsce-pairclassification | PL-MTEB | 2023-08-11T11:47:46Z | 36 | 0 | null | [
"license:cc-by-nc-sa-4.0",
"region:us"
] | 2023-08-11T11:47:46Z | 2023-08-11T11:47:03.000Z | 2023-08-11T11:47:03 | ---
license: cc-by-nc-sa-4.0
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
pourmand1376/persian-qa-translated | pourmand1376 | 2023-08-19T11:52:23Z | 36 | 0 | null | [
"task_categories:question-answering",
"task_categories:translation",
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:fa",
"language:en",
"license:apache-2.0",
"region:us"
] | 2023-08-19T11:52:23Z | 2023-08-19T11:45:25.000Z | 2023-08-19T11:45:25 | ---
dataset_info:
features:
- name: input
dtype: float64
- name: instruction
dtype: string
- name: original_instruction
dtype: string
- name: original_output
dtype: string
- name: output
dtype: string
- name: source
dtype: string
splits:
- name: train
num_bytes: 360540755
num_examples: 153127
download_size: 186783724
dataset_size: 360540755
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: apache-2.0
task_categories:
- question-answering
- translation
- text-generation
language:
- fa
- en
pretty_name: Persian QA Translated
size_categories:
- 100K<n<1M
---
# Dataset Card for "persian-qa-translated"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.45707157254219055,
-0.3218228816986084,
0.4451022148132324,
0.30826684832572937,
-0.4358815848827362,
0.234256774187088,
-0.06232159957289696,
-0.14294548332691193,
0.7550088763237,
0.39258772134780884,
-0.7715814113616943,
-0.8733458518981934,
-0.45073768496513367,
-0.01150260120630264... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
adirik/fashion_image_caption-100 | adirik | 2023-08-29T10:41:48Z | 36 | 0 | null | [
"region:us"
] | 2023-08-29T10:41:48Z | 2023-08-29T10:41:47.000Z | 2023-08-29T10:41:47 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 22842342.0
num_examples: 100
download_size: 22823708
dataset_size: 22842342.0
---
# Dataset Card for "fashion_image_caption-100"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6072514057159424,
-0.2050483673810959,
0.09668758511543274,
0.4136446416378021,
-0.39340659976005554,
-0.003601965494453907,
0.2836708724498749,
-0.12374713271856308,
0.802130937576294,
0.5181554555892944,
-1.1183629035949707,
-0.7905295491218567,
-0.4488295912742615,
-0.162731349468231... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
yujiepan/wikitext-tiny | yujiepan | 2023-08-31T18:05:09Z | 36 | 0 | null | [
"region:us"
] | 2023-08-31T18:05:09Z | 2023-08-31T18:01:07.000Z | 2023-08-31T18:01:07 | This dataset is sampled from `wikitext/wikitext-2-v1/train`.
Codes to generate this dataset:
```python
import datasets
dataset = datasets.load_dataset('wikitext', 'wikitext-2-v1')
selected = []
i = -1
while len(selected) < 24:
i += 1
text = dataset['train'][i]['text']
if 8 < len(text.split(' ')) <= 16 and '=' not in text:
selected.append(i)
tiny_dataset = dataset['train'].select(selected)
``` | [
-0.20488715171813965,
-0.05947902053594589,
0.06395156681537628,
0.20986010134220123,
-0.12942281365394592,
-0.09344086796045303,
-0.0009061727323569357,
-0.08690367639064789,
0.4906544089317322,
0.40061211585998535,
-0.9565501809120178,
-0.07220262289047241,
-0.2412915974855423,
0.3074127... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tomashs/LSC_acronyms | tomashs | 2023-09-06T22:45:34Z | 36 | 0 | null | [
"license:other",
"region:us"
] | 2023-09-06T22:45:34Z | 2023-09-06T22:38:10.000Z | 2023-09-06T22:38:10 | ---
license: other
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
godoyj/temario | godoyj | 2023-09-19T01:37:27Z | 36 | 0 | null | [
"region:us"
] | 2023-09-19T01:37:27Z | 2023-09-19T01:28:46.000Z | 2023-09-19T01:28:46 | language:
- pt
task_categories:
- summarization
not official | [
-0.17094966769218445,
-0.4266550540924072,
0.14987322688102722,
0.8754256367683411,
-0.6719399094581604,
0.5513427257537842,
-0.20085956156253815,
0.19752401113510132,
0.7661876082420349,
0.5286084413528442,
-0.7102139592170715,
-0.27804452180862427,
-0.7278770208358765,
0.6292992830276489... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Trelis/openassistant-llama-style | Trelis | 2023-10-31T11:29:33Z | 36 | 3 | null | [
"size_categories:1K<n<10k",
"language:en",
"language:es",
"language:ru",
"language:de",
"language:pl",
"language:th",
"language:vi",
"language:sv",
"language:bn",
"language:da",
"language:he",
"language:it",
"language:fa",
"language:sk",
"language:id",
"language:nb",
"language:el",... | 2023-10-31T11:29:33Z | 2023-10-04T14:14:13.000Z | 2023-10-04T14:14:13 | ---
license: apache-2.0
language:
- en
- es
- ru
- de
- pl
- th
- vi
- sv
- bn
- da
- he
- it
- fa
- sk
- id
- nb
- el
- nl
- hu
- eu
- zh
- eo
- ja
- ca
- cs
- bg
- fi
- pt
- tr
- ro
- ar
- uk
- gl
- fr
- ko
tags:
- human-feedback
- llama-2
size_categories:
- 1K<n<10k
pretty_name: Filtered OpenAssistant Conversations
---
# Chat Fine-tuning Dataset - Llama 2 Style
This dataset allows for fine-tuning chat models using [INST] AND [/INST] to wrap user messages.
Preparation:
1. The dataset is cloned from [TimDettmers](https://huggingface.co/datasets/timdettmers/openassistant-guanaco), which itself is a subset of the Open Assistant dataset, which you can find [here](https://huggingface.co/datasets/OpenAssistant/oasst1/tree/main). This subset of the data only contains the highest-rated paths in the conversation tree, with a total of 9,846 samples.
1. The dataset was then filtered to:
- replace instances of '### Human:' with '[INST]'
- replace instances of '### Assistant:' with '</s><s> [/INST]' (to encourage the model to emit </s> when finished a response)
- if a row of data ends with an assistant response, then [INST] was additionally added to the end of that row of data.
Details of the root dataset follow, copied from that repo:
# OpenAssistant Conversations Dataset (OASST1)
## Dataset Description
- **Homepage:** https://www.open-assistant.io/
- **Repository:** https://github.com/LAION-AI/Open-Assistant
- **Paper:** https://arxiv.org/abs/2304.07327
### Dataset Summary
In an effort to democratize research on large-scale alignment, we release OpenAssistant
Conversations (OASST1), a human-generated, human-annotated assistant-style conversation
corpus consisting of 161,443 messages in 35 different languages, annotated with 461,292
quality ratings, resulting in over 10,000 fully annotated conversation trees. The corpus
is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers.
Please refer to our [paper](https://arxiv.org/abs/2304.07327) for further details.
### Dataset Structure
This dataset contains message trees. Each message tree has an initial prompt message as the root node,
which can have multiple child messages as replies, and these child messages can have multiple replies.
All messages have a role property: this can either be "assistant" or "prompter". The roles in
conversation threads from prompt to leaf node strictly alternate between "prompter" and "assistant".
This version of the dataset contains data collected on the [open-assistant.io](https://open-assistant.io/) website until April 12 2023.
### JSON Example: Message
For readability, the following JSON examples are shown formatted with indentation on multiple lines.
Objects are stored without indentation (on single lines) in the actual jsonl files.
```json
{
"message_id": "218440fd-5317-4355-91dc-d001416df62b",
"parent_id": "13592dfb-a6f9-4748-a92c-32b34e239bb4",
"user_id": "8e95461f-5e94-4d8b-a2fb-d4717ce973e4",
"text": "It was the winter of 2035, and artificial intelligence (..)",
"role": "assistant",
"lang": "en",
"review_count": 3,
"review_result": true,
"deleted": false,
"rank": 0,
"synthetic": true,
"model_name": "oasst-sft-0_3000,max_new_tokens=400 (..)",
"labels": {
"spam": { "value": 0.0, "count": 3 },
"lang_mismatch": { "value": 0.0, "count": 3 },
"pii": { "value": 0.0, "count": 3 },
"not_appropriate": { "value": 0.0, "count": 3 },
"hate_speech": { "value": 0.0, "count": 3 },
"sexual_content": { "value": 0.0, "count": 3 },
"quality": { "value": 0.416, "count": 3 },
"toxicity": { "value": 0.16, "count": 3 },
"humor": { "value": 0.0, "count": 3 },
"creativity": { "value": 0.33, "count": 3 },
"violence": { "value": 0.16, "count": 3 }
}
}
```
### JSON Example: Conversation Tree
For readability, only a subset of the message properties is shown here.
```json
{
"message_tree_id": "14fbb664-a620-45ce-bee4-7c519b16a793",
"tree_state": "ready_for_export",
"prompt": {
"message_id": "14fbb664-a620-45ce-bee4-7c519b16a793",
"text": "Why can't we divide by 0? (..)",
"role": "prompter",
"lang": "en",
"replies": [
{
"message_id": "894d30b6-56b4-4605-a504-89dd15d4d1c8",
"text": "The reason we cannot divide by zero is because (..)",
"role": "assistant",
"lang": "en",
"replies": [
// ...
]
},
{
"message_id": "84d0913b-0fd9-4508-8ef5-205626a7039d",
"text": "The reason that the result of a division by zero is (..)",
"role": "assistant",
"lang": "en",
"replies": [
{
"message_id": "3352725e-f424-4e3b-a627-b6db831bdbaa",
"text": "Math is confusing. Like those weird Irrational (..)",
"role": "prompter",
"lang": "en",
"replies": [
{
"message_id": "f46207ca-3149-46e9-a466-9163d4ce499c",
"text": "Irrational numbers are simply numbers (..)",
"role": "assistant",
"lang": "en",
"replies": []
},
// ...
]
}
]
}
]
}
}
```
Please refer to [oasst-data](https://github.com/LAION-AI/Open-Assistant/tree/main/oasst-data) for
details about the data structure and Python code to read and write jsonl files containing oasst data objects.
If you would like to explore the dataset yourself you can find a
[`getting-started`](https://github.com/LAION-AI/Open-Assistant/blob/main/notebooks/openassistant-oasst1/getting-started.ipynb)
notebook in the `notebooks/openassistant-oasst1` folder of the [LAION-AI/Open-Assistant](https://github.com/LAION-AI/Open-Assistant)
github repository.
## Main Dataset Files
Conversation data is provided either as nested messages in trees (extension `.trees.jsonl.gz`)
or as a flat list (table) of messages (extension `.messages.jsonl.gz`).
### Ready For Export Trees
```
2023-04-12_oasst_ready.trees.jsonl.gz 10,364 trees with 88,838 total messages
2023-04-12_oasst_ready.messages.jsonl.gz 88,838 messages
```
Trees in `ready_for_export` state without spam and deleted messages including message labels.
The oasst_ready-trees file usually is sufficient for supervised fine-tuning (SFT) & reward model (RM) training.
### All Trees
```
2023-04-12_oasst_all.trees.jsonl.gz 66,497 trees with 161,443 total messages
2023-04-12_oasst_all.messages.jsonl.gz 161,443 messages
```
All trees, including those in states `prompt_lottery_waiting` (trees that consist of only one message, namely the initial prompt),
`aborted_low_grade` (trees that stopped growing because the messages had low quality), and `halted_by_moderator`.
### Supplemental Exports: Spam & Prompts
```
2023-04-12_oasst_spam.messages.jsonl.gz
```
These are messages which were deleted or have a negative review result (`"review_result": false`).
Besides low quality, a frequent reason for message deletion is a wrong language tag.
```
2023-04-12_oasst_prompts.messages.jsonl.gz
```
These are all the kept initial prompt messages with positive review result (no spam) of trees in `ready_for_export` or `prompt_lottery_waiting` state.
### Using the Huggingface Datasets
While HF datasets is ideal for tabular datasets, it is not a natural fit for nested data structures like the OpenAssistant conversation trees.
Nevertheless, we make all messages which can also be found in the file `2023-04-12_oasst_ready.trees.jsonl.gz` available in parquet as train/validation splits.
These are directly loadable by [Huggingface Datasets](https://pypi.org/project/datasets/).
To load the oasst1 train & validation splits use:
```python
from datasets import load_dataset
ds = load_dataset("OpenAssistant/oasst1")
train = ds['train'] # len(train)=84437 (95%)
val = ds['validation'] # len(val)=4401 (5%)
```
The messages appear in depth-first order of the message trees.
Full conversation trees can be reconstructed from the flat messages table by using the `parent_id`
and `message_id` properties to identify the parent-child relationship of messages. The `message_tree_id`
and `tree_state` properties (only present in flat messages files) can be used to find all messages of a message tree or to select trees by their state.
### Languages
OpenAssistant Conversations incorporates 35 different languages with a distribution of messages as follows:
**Languages with over 1000 messages**
- English: 71956
- Spanish: 43061
- Russian: 9089
- German: 5279
- Chinese: 4962
- French: 4251
- Thai: 3042
- Portuguese (Brazil): 2969
- Catalan: 2260
- Korean: 1553
- Ukrainian: 1352
- Italian: 1320
- Japanese: 1018
<details>
<summary><b>Languages with under 1000 messages</b></summary>
<ul>
<li>Vietnamese: 952</li>
<li>Basque: 947</li>
<li>Polish: 886</li>
<li>Hungarian: 811</li>
<li>Arabic: 666</li>
<li>Dutch: 628</li>
<li>Swedish: 512</li>
<li>Turkish: 454</li>
<li>Finnish: 386</li>
<li>Czech: 372</li>
<li>Danish: 358</li>
<li>Galician: 339</li>
<li>Hebrew: 255</li>
<li>Romanian: 200</li>
<li>Norwegian Bokmål: 133</li>
<li>Indonesian: 115</li>
<li>Bulgarian: 95</li>
<li>Bengali: 82</li>
<li>Persian: 72</li>
<li>Greek: 66</li>
<li>Esperanto: 59</li>
<li>Slovak: 19</li>
</ul>
</details>
## Contact
- Discord [Open Assistant Discord Server](https://ykilcher.com/open-assistant-discord)
- GitHub: [LAION-AI/Open-Assistant](https://github.com/LAION-AI/Open-Assistant)
- E-Mail: [open-assistant@laion.ai](mailto:open-assistant@laion.ai) | [
-0.28589463233947754,
-0.916703999042511,
0.1895531564950943,
0.1643051952123642,
-0.0958181843161583,
0.0674753338098526,
-0.11671436578035355,
-0.31495970487594604,
0.3025885820388794,
0.39904192090034485,
-0.6529496312141418,
-0.7996938824653625,
-0.5395999550819397,
0.05615095049142837... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
alexandrainst/nst-da | alexandrainst | 2023-10-05T14:27:00Z | 36 | 3 | null | [
"task_categories:automatic-speech-recognition",
"task_categories:text-to-speech",
"size_categories:100K<n<1M",
"language:da",
"license:cc0-1.0",
"region:us"
] | 2023-10-05T14:27:00Z | 2023-10-05T11:27:17.000Z | 2023-10-05T11:27:17 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: text
dtype: string
- name: speaker_id
dtype: int64
- name: age
dtype: int64
- name: sex
dtype: string
- name: dialect
dtype: string
- name: recording_datetime
dtype: string
splits:
- name: train
num_bytes: 55199435558.0
num_examples: 182605
- name: test
num_bytes: 8894080220.0
num_examples: 54747
download_size: 5358057252
dataset_size: 64093515778.0
size_categories:
- 100K<n<1M
license: cc0-1.0
task_categories:
- automatic-speech-recognition
- text-to-speech
language:
- da
pretty_name: NST-da
---
# Dataset Card for NST-da
## Dataset Description
- **Repository:** <https://www.nb.no/sprakbanken/en/resource-catalogue/oai-nb-no-sbr-55/>
- **Point of Contact:** [Dan Saattrup Nielsen](mailto:dan.nielsen@alexandra.dk)
- **Size of downloaded dataset files:** 5.36 GB
- **Size of the generated dataset:** 64.09 GB
- **Total amount of disk used:** 69.45 GB
### Dataset Summary
This dataset is an upload of the [NST Danish ASR Database (16 kHz) – reorganized](https://www.nb.no/sprakbanken/en/resource-catalogue/oai-nb-no-sbr-55/).
The training and test splits are the original ones.
### Supported Tasks and Leaderboards
Training automatic speech recognition is the intended task for this dataset. No leaderboard is active at this point.
### Languages
The dataset is available in Danish (`da`).
## Dataset Structure
### Data Instances
- **Size of downloaded dataset files:** 5.36 GB
- **Size of the generated dataset:** 64.09 GB
- **Total amount of disk used:** 69.45 GB
An example from the dataset looks as follows.
```
{
'audio': {
'path': 'dk14x404-05072000-1531_u0008121.wav',
'array': array([ 0.00265503, 0.00248718, 0.00253296, ..., -0.00030518,
-0.00035095, -0.00064087]),
'sampling_rate': 16000
},
'text': 'Desuden er der en svømmeprøve, en fremmedsprogstest samt en afsluttende samtale.',
'speaker_id': 404,
'age': 24,
'sex': 'Female',
'dialect': 'Storkøbenhavn',
'recording_datetime': '2000-07-05T15:31:14'
}
```
### Data Fields
The data fields are the same among all splits.
- `audio`: an `Audio` feature.
- `text`: a `string` feature.
- `speaker_id`: an `int64` feature.
- `age`: an `int64` feature.
- `sex`: a `string` feature.
- `dialect`: a `string` feature.
- `recording_datetime`: a `string` feature.
### Dataset Statistics
There are 183,205 samples in the training split, and 54,747 samples in the test split.
#### Speakers
There are 539 unique speakers in the training dataset and 56 unique speakers in the test dataset, where 54 of them are also present in the training set.
#### Age Distribution

#### Dialect Distribution

#### Sex Distribution

#### Transcription Length Distribution

## Dataset Creation
### Curation Rationale
There are not many large-scale ASR datasets in Danish.
### Source Data
The data originates from the now bankrupt company Nordisk språkteknologi (NST), whose data was transferred to the National Library of Norway, who subsequently released it into the public domain.
## Additional Information
### Dataset Curators
[Dan Saattrup Nielsen](https://saattrupdan.github.io/) from the [The Alexandra
Institute](https://alexandra.dk/) reorganised the dataset and uploaded it to the Hugging Face Hub.
### Licensing Information
The dataset is licensed under the [CC0
license](https://creativecommons.org/share-your-work/public-domain/cc0/). | [
-0.7306773066520691,
-0.4974501430988312,
0.11106006801128387,
0.3217012584209442,
-0.4034942388534546,
-0.2350829839706421,
-0.36866995692253113,
-0.29211878776550293,
0.5314260721206665,
0.5410543084144592,
-0.5914363265037537,
-0.7144131064414978,
-0.5311028957366943,
0.2191574871540069... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
llmware/rag_instruct_test_dataset_0.1 | llmware | 2023-11-04T07:03:13Z | 36 | 6 | null | [
"license:apache-2.0",
"finance",
"legal",
"region:us"
] | 2023-11-04T07:03:13Z | 2023-10-08T11:55:59.000Z | 2023-10-08T11:55:59 | ---
license: apache-2.0
tags:
- finance
- legal
pretty_name: RAG Instruct Test Dataset - Basic - v0.1
---
# Dataset Card for RAG-Instruct-Test-Dataset
### Dataset Summary
This is a test dataset for basic "retrieval augmented generation" (RAG) use cases in the enterprise, especially for finance and legal. This test dataset includes 100 samples with context passages pulled from common 'retrieval scenarios', e.g., financial news, earnings releases,
contracts, invoices, technical articles, general news and short texts. The primary use case is to evaluate the effectiveness of an
instruct-fine-tuned LLM used in conjunction with closed-context, fact-based question-answering, key-value extraction, and summarization with bulletpoints. The context passages are relatively short in this test-set ranging from ~100 tokens to ~500 tokens, and was designed for use with the
BLING series of models but is suitable for comparison evaluations of any LLM for basic RAG scenarios.
### **PERFORMANCE on BASIC RAG TEST DATASET**
| Model | Params (B) | Sourcing | GPU/CPU | Output Tokens | Out as % of Input | Process Time (secs) | Score (0-100) |
| :---------- | :--------: | :----: | :-----: | :---------: | :-------: | :--------: | :-------: |
| gpt-4 | <=1000 | Closed | Multi-GPU | 2665 | 10.53% | 183.8 | 100 |
| gpt-3.5-turbo-instruct| <=175 | Closed | Multi-GPU | 2621 | 11.49% | 62.7 | 100 |
| claude-instant-v1 | <=50 | Closed | Multi-GPU | 6337 | 26.50% | 154 | 100 |
| aib-read-gpt | 7 | Closed | GPU | 1964 | 9.30% | 114 | 96 |
| bling_falcon-1b-0.1 | 1.3 | Open | CPU | 3204 | 14.55% | 696 | 77 |
| bling_pythia-1.4b-0.1 | 1.4 | Open | CPU | 2589 | 11.75% | 593.5 | 65 |
| bling_pythia-1b-0.1 | 1.0 | Open | CPU | 2753 | 12.49% | 428 | 59 |
| bling_cerebras-1.3b | 1.3 | Open | CPU | 3202 | 20.01% | 690.1 | 52 |
| bling_pythia_410m | 0.41 | NA | CPU | 2349 | 10.66% | 189 | 36 |
| bling_cerebras_590m | 0.59 | NA | CPU | 4407 | 20.01% | 400.8 | 30 |
Please check out our [BLOG](https://medium.com/@darrenoberst/evaluating-llm-performance-in-rag-instruct-use-cases-083dc272a31d) with more details, commentary and comparative results testing with this dataset.
We will be enhancing the test dataset as well as creating more advanced test datasets in the future.
### Languages
English
## Dataset Structure
100 JSONL samples with 4 keys - "query" | "context" | "answer" | "sample_number"
### Personal and Sensitive Information
The dataset samples were written bespoke for this objective, but do rely upon some public information, including major public figures and widely reported events.
Any other names were created/masked and any overlap with real companies or people is coincidental.
## Dataset Card Contact
Darren Oberst & llmware team
Please reach out anytime if you are interested in this project and would like to participate and work with us!
| [
-0.5208685994148254,
-0.6762728691101074,
0.010274918749928474,
0.07037889957427979,
-0.34176453948020935,
0.1724056750535965,
-0.16799211502075195,
-0.36170539259910583,
0.09433547407388687,
0.47610270977020264,
-0.5247323513031006,
-0.5468016862869263,
-0.3900967836380005,
-0.05008937790... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
cannlytics/cannabis_analytes | cannlytics | 2023-10-10T23:20:30Z | 36 | 1 | null | [
"license:cc-by-4.0",
"region:us"
] | 2023-10-10T23:20:30Z | 2023-10-10T21:24:44.000Z | 2023-10-10T21:24:44 | ---
pretty_name: cannabis_analytes
license:
- cc-by-4.0
---
# Cannabis Analytes
This dataset consists of analyte data for various analytes that are regularly tested for in cannabis. The dataset consists of sub-datasets for each type of test, as well as a sub-dataset that includes all analytes.
## Dataset Structure
The dataset is partitioned into 18 subsets for each state and the aggregate.
| State | Code | Status |
| [All](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/analytes.json) | `all` | ✅ |
| [Cannabinoids](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/cannabinoids.json) | `cannabinoids` | ✅ |
| [Terpenes](https://huggingface.co/datasets/cannlytics/cannabis_licenses/tree/main/data/terpenes.json) | `terpenes` | ✅ |
| Pesticides | `pesticides` | ⏳ Coming soon |
| Microbes | `microbes` | ⏳ Coming soon |
| Heavy metals | `heavy_metals` | ⏳ Coming soon |
| Residual solvents | `residual_solvents` | ⏳ Coming soon |
| Other | `other` | ⏳ Coming soon |
## Using the Dataset
You can load all the analytes, or the analytes for a specific test. For example:
```py
from datasets import load_dataset
# Get all of the analytes
dataset = load_dataset('cannlytics/cannabis_licenses', 'all')
analytes = dataset['data']
# Get the cannabinoids.
dataset = load_dataset('cannlytics/cannabis_licenses', 'cannabinoids')
terpenes = dataset['data']
# Get the terpenes.
dataset = load_dataset('cannlytics/cannabis_licenses', 'terpenes')
terpenes = dataset['data']
```
## Data Fields
Below is a non-exhaustive list of fields, used to standardize the various data that are encountered, that you may expect to find for each observation.
## Data Fields
Below is a non-exhaustive list of fields used to standardize the various data that are encountered. You may expect to find the following for each observation:
| Field | Example | Description |
|------------------------------|----------------------------------------------|------------------------------------------------------------------------------------------------------|
| `key` | `"thca"` | A unique ID for each analyte. |
| `description` | `"Δ-9-Tetrahydrocannabinol is a cannabinoid..."` | A brief description or summary about the analyte. |
| `name` | `"THC"` | Common name of the analyte. |
| `scientific_name` | `"\u0394-9-Tetrahydrocannabinol"` | The scientific name or IUPAC name of the analyte. |
| `type` | `"cannabinoid"` | The type or classification of the analyte (e.g., terpene, cannabinoid). |
| `wikipedia_url` | `"https://en.wikipedia.org/wiki/Tetrahydrocannabinol"` | The Wikipedia URL where more detailed information can be found about the analyte. |
| `degrades_to` | `["cannabinol"]` | A list of chemicals or substances the analyte degrades to. |
| `precursors` | `["thca"]` | A list of precursor chemicals or substances related to the analyte. |
| `subtype` | `"psychoactive"` | A sub-classification or additional details about the type of the analyte. |
| `cas_number` | `"1972-08-3"` | The Chemical Abstracts Service (CAS) registry number, which is a unique identifier for chemical substances.|
| `chemical_formula` | `"C21H30O2"` | The chemical formula of the analyte. |
| `molar_mass` | `"314.5 g/mol"` | The molar mass of the analyte. |
| `density` | `"1.0±0.1 g/cm3"` | The density of the analyte. |
| `boiling_point` | `"383.5±42.0 °C"` | The boiling point of the analyte. |
| `image_url` | `"https://example.com/image.jpg"` | URL of an image representing the analyte. |
| `chemical_formula_image_url` | `"https://example.com/formula_image.jpg"` | URL of an image representing the chemical formula of the analyte. |
## Data Splits
The data is split into subsets by analysis. You can retrieve all analytes by requesting the `all` subset.
```py
from datasets import load_dataset
# Get all cannabis licenses.
dataset = load_dataset('cannlytics/cannabis_licenses', 'all')
data = dataset['data']
```
## Curation Rationale
This dataset provides a standard set of analyte data for [cannabis tests](https://huggingface.co/datasets/cannlytics/cannabis_tests).
## Data Collection and Normalization
The `get_cannabis_analytes.py` routine is used to normalize values collected from Wikipedia.
## Known Limitations
The datasets are not complete and may include inaccurate information.
## Dataset Curators
Curated by [🔥Cannlytics](https://cannlytics.com)<br>
<contact@cannlytics.com>
## License
```
Copyright (c) 2023 Cannlytics
The files associated with this dataset are licensed under a
Creative Commons Attribution 4.0 International license.
You can share, copy and modify this dataset so long as you give
appropriate credit, provide a link to the CC BY license, and
indicate if changes were made, but you may not do so in a way
that suggests the rights holder has endorsed you or your use of
the dataset. Note that further permission may be required for
any content within the dataset that is identified as belonging
to a third party.
```
## Contributions
Thanks to [🔥Cannlytics](https://cannlytics.com), [@candy-o](https://github.com/candy-o), [@keeganskeate](https://github.com/keeganskeate), and the entire [Cannabis Data Science Team](https://meetup.com/cannabis-data-science/members) for their contributions.
| [
-0.31199395656585693,
-0.5230604410171509,
0.5285236239433289,
0.28502532839775085,
-0.20674967765808105,
-0.0017649518558755517,
-0.14901277422904968,
-0.27098333835601807,
0.8518226146697998,
0.4257459044456482,
-0.2449599653482437,
-1.2318576574325562,
-0.5379341840744019,
0.29790964722... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ahhany/engd_researches | ahhany | 2023-11-06T11:46:18Z | 36 | 0 | null | [
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:en",
"license:afl-3.0",
"region:us"
] | 2023-11-06T11:46:18Z | 2023-10-15T08:07:15.000Z | 2023-10-15T08:07:15 | ---
license: afl-3.0
task_categories:
- text-generation
language:
- en
pretty_name: engd-researches
size_categories:
- 10K<n<100K
--- | [
-0.1285339742898941,
-0.18616800010204315,
0.6529127359390259,
0.4943626821041107,
-0.1931934952735901,
0.2360742688179016,
0.360720157623291,
0.05056300014257431,
0.5793654322624207,
0.7400140166282654,
-0.6508105993270874,
-0.23783984780311584,
-0.7102248668670654,
-0.047826044261455536,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
zelros/pj-ce | zelros | 2023-11-05T22:54:04Z | 36 | 0 | null | [
"insurance",
"region:us"
] | 2023-11-05T22:54:04Z | 2023-10-15T14:32:52.000Z | 2023-10-15T14:32:52 | ---
tags:
- insurance
---
This dataset contains question/answer pairs from a French legal protection insurance (https://www.service-public.fr/particuliers/vosdroits/F3049?lang=en).
The objective of this dataset is to contribute to open source research projects aiming to, for instance:
* fine-tune LLMs on high-quality datasets, specializing them in the insurance domain
* develop new question/answer applications using Retrieval Augmented Generation (RAG) for insurance contracts
* assess the knowledge of language models in the insurance field
* more generally, apply LLMs to the insurance domain for better understanding and increased transparency of this industry.
Other datasets of the same kind are also available - or will be available soon - and are part of this research effort. See here: https://huggingface.co/collections/zelros/legal-protection-insurance-6536e8f389dd48faca78447e
Here is an example of usages of this dataset: https://huggingface.co/spaces/zelros/The-legal-protection-insurance-comparator | [
-0.12690630555152893,
-0.6109647154808044,
0.20794343948364258,
0.2446521520614624,
-0.06387617439031601,
-0.19570039212703705,
0.15373264253139496,
-0.43992751836776733,
0.39488929510116577,
1.1311315298080444,
-0.28130269050598145,
-0.5277532935142517,
-0.4185519516468048,
-0.14612421393... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
shossain/merged-no-pad-text-16384 | shossain | 2023-11-06T21:54:52Z | 36 | 0 | null | [
"region:us"
] | 2023-11-06T21:54:52Z | 2023-10-21T06:10:01.000Z | 2023-10-21T06:10:01 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 372439533
num_examples: 6401
download_size: 184155020
dataset_size: 372439533
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "merged-no-pad-text-16384"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7768012285232544,
-0.32911595702171326,
0.3025835454463959,
0.41133224964141846,
-0.49896320700645447,
0.07028476148843765,
0.18895035982131958,
-0.16950418055057526,
1.037981390953064,
0.7748257517814636,
-0.7629114389419556,
-0.6974907517433167,
-0.6611230969429016,
-0.118433140218257... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
cardo14/Taylor_Swift_Embeddings | cardo14 | 2023-10-21T23:07:03Z | 36 | 0 | null | [
"license:mit",
"region:us"
] | 2023-10-21T23:07:03Z | 2023-10-21T23:06:14.000Z | 2023-10-21T23:06:14 | ---
license: mit
---
| [
-0.1285339742898941,
-0.18616800010204315,
0.6529127359390259,
0.4943626821041107,
-0.1931934952735901,
0.2360742688179016,
0.360720157623291,
0.05056300014257431,
0.5793654322624207,
0.7400140166282654,
-0.6508105993270874,
-0.23783984780311584,
-0.7102248668670654,
-0.047826044261455536,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
zelros/pj-da | zelros | 2023-11-05T23:25:21Z | 36 | 0 | null | [
"insurance",
"region:us"
] | 2023-11-05T23:25:21Z | 2023-10-22T17:50:52.000Z | 2023-10-22T17:50:52 | ---
tags:
- insurance
---
This dataset contains question/answer pairs from a French legal protection insurance (https://www.service-public.fr/particuliers/vosdroits/F3049?lang=en).
The objective of this dataset is to contribute to open source research projects aiming to, for instance:
* fine-tune LLMs on high-quality datasets, specializing them in the insurance domain
* develop new question/answer applications using Retrieval Augmented Generation (RAG) for insurance contracts
* assess the knowledge of language models in the insurance field
* more generally, apply LLMs to the insurance domain for better understanding and increased transparency of this industry.
Other datasets of the same kind are also available - or will be available soon - and are part of this research effort. See here: https://huggingface.co/collections/zelros/legal-protection-insurance-6536e8f389dd48faca78447e
Here is an example of usages of this dataset: https://huggingface.co/spaces/zelros/The-legal-protection-insurance-comparator | [
-0.12690630555152893,
-0.6109647154808044,
0.20794343948364258,
0.2446521520614624,
-0.06387617439031601,
-0.19570039212703705,
0.15373264253139496,
-0.43992751836776733,
0.39488929510116577,
1.1311315298080444,
-0.28130269050598145,
-0.5277532935142517,
-0.4185519516468048,
-0.14612421393... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Mihir1108/json_data | Mihir1108 | 2023-10-23T13:02:52Z | 36 | 0 | null | [
"region:us"
] | 2023-10-23T13:02:52Z | 2023-10-23T13:02:25.000Z | 2023-10-23T13:02:25 | Entry not found | [
-0.32276487350463867,
-0.22568444907665253,
0.8622263073921204,
0.43461570143699646,
-0.5282988548278809,
0.7012969255447388,
0.7915717363357544,
0.07618642598390579,
0.7746027112007141,
0.25632190704345703,
-0.7852815389633179,
-0.22573848068714142,
-0.910447895526886,
0.5715675354003906,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
zelros/pj-groupama | zelros | 2023-11-07T00:46:49Z | 36 | 0 | null | [
"insurance",
"region:us"
] | 2023-11-07T00:46:49Z | 2023-10-23T20:13:42.000Z | 2023-10-23T20:13:42 | ---
tags:
- insurance
---
This dataset contains question/answer pairs from a French legal protection insurance (https://www.service-public.fr/particuliers/vosdroits/F3049?lang=en).
The objective of this dataset is to contribute to open source research projects aiming to, for instance:
* fine-tune LLMs on high-quality datasets, specializing them in the insurance domain
* develop new question/answer applications using Retrieval Augmented Generation (RAG) for insurance contracts
* assess the knowledge of language models in the insurance field
* more generally, apply LLMs to the insurance domain for better understanding and increased transparency of this industry.
Other datasets of the same kind are also available - or will be available soon - and are part of this research effort. See here: https://huggingface.co/collections/zelros/legal-protection-insurance-6536e8f389dd48faca78447e
Here is an example of usages of this dataset: https://huggingface.co/spaces/zelros/The-legal-protection-insurance-comparator | [
-0.12690630555152893,
-0.6109647154808044,
0.20794343948364258,
0.2446521520614624,
-0.06387617439031601,
-0.19570039212703705,
0.15373264253139496,
-0.43992751836776733,
0.39488929510116577,
1.1311315298080444,
-0.28130269050598145,
-0.5277532935142517,
-0.4185519516468048,
-0.14612421393... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
zelros/pj-sg | zelros | 2023-11-06T00:27:11Z | 36 | 0 | null | [
"insurance",
"region:us"
] | 2023-11-06T00:27:11Z | 2023-10-24T19:49:46.000Z | 2023-10-24T19:49:46 | ---
tags:
- insurance
---
This dataset contains question/answer pairs from a French legal protection insurance (https://www.service-public.fr/particuliers/vosdroits/F3049?lang=en).
The objective of this dataset is to contribute to open source research projects aiming to, for instance:
* fine-tune LLMs on high-quality datasets, specializing them in the insurance domain
* develop new question/answer applications using Retrieval Augmented Generation (RAG) for insurance contracts
* assess the knowledge of language models in the insurance field
* more generally, apply LLMs to the insurance domain for better understanding and increased transparency of this industry.
Other datasets of the same kind are also available - or will be available soon - and are part of this research effort. See here: https://huggingface.co/collections/zelros/legal-protection-insurance-6536e8f389dd48faca78447e
Here is an example of usages of this dataset: https://huggingface.co/spaces/zelros/The-legal-protection-insurance-comparator | [
-0.12690630555152893,
-0.6109647154808044,
0.20794343948364258,
0.2446521520614624,
-0.06387617439031601,
-0.19570039212703705,
0.15373264253139496,
-0.43992751836776733,
0.39488929510116577,
1.1311315298080444,
-0.28130269050598145,
-0.5277532935142517,
-0.4185519516468048,
-0.14612421393... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
andersonbcdefg/pile-subset | andersonbcdefg | 2023-10-31T01:28:10Z | 36 | 0 | null | [
"region:us"
] | 2023-10-31T01:28:10Z | 2023-10-25T06:20:48.000Z | 2023-10-25T06:20:48 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
aazer/weathergov | aazer | 2023-10-25T17:29:05Z | 36 | 0 | null | [
"region:us"
] | 2023-10-25T17:29:05Z | 2023-10-25T17:27:46.000Z | 2023-10-25T17:27:46 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
DataScienceClubUVU/ServiceProjectFall2023 | DataScienceClubUVU | 2023-11-09T01:43:10Z | 36 | 1 | null | [
"region:us"
] | 2023-11-09T01:43:10Z | 2023-10-26T20:16:29.000Z | 2023-10-26T20:16:29 | # Deep Learning Service Project (Fall 2023)

# Getting Started
1. Clone the repository with git lfs disabled or not installed.
**ON WINDOWS**
```bash
set GIT_LFS_SKIP_SMUDGE=1
git clone https://huggingface.co/datasets/DataScienceClubUVU/ServiceProjectFall2023
```
**ON LINUX**
```bash
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datasets/DataScienceClubUVU/ServiceProjectFall2023
```
2. Download the pytorch file (.pth) from https://huggingface.co/datasets/DataScienceClubUVU/ServiceProjectFall2023/blob/main/mexico_5_column_weights.pth and place it in the root directory of the repository. There will be an existing file with the same name. Delete it and replace it with the new one.
3. Install the requirements.txt file using pip.
**IF YOU DON't HAVE A GPU**
```bash
pip install -r requirements_cpu.txt
```
**IF YOU HAVE A GPU**
1. Install reqs without torch
```bash
pip install -r requirements_no_torch.txt
```
2. Install pytorch by following the instructions at https://pytorch.org/get-started/locally/
### How the Model Works
1. Start with an image of a character of text:
- 
2. Convert the image between RGB/BGR and grayscale using the _**cvtColor**_ function from the _**cv2**_ library:
- 
3. Use an Adaptive Thresholding approach where the threshold value = Gaussian weighted sum of the neighborhood values - constant value. In other words, it is a weighted sum of the blockSize^2 neighborhood of a point minus the constant. in this example, we are setting the maximum threshold value as 255 with the block size of 155 and the constant is 2.
- 
4. Create a 3x3 matrix of ones to generate an image kernel. An _**image kernel**_ is a small matrix used to apply effects like the ones you might find in Photoshop or Gimp, such as blurring, sharpening, outlining or embossing. They're also used in machine learning for 'feature extraction', a technique for determining the most important portions of an image.
5. The basic idea of erosion is just like soil erosion only, it erodes away the boundaries of foreground object (Always try to keep foreground in white). It is normally performed on binary images. It needs two inputs, one is our original image, second one is called structuring element or kernel which decides the nature of operation. A pixel in the original image (either 1 or 0) will be considered 1 only if all the pixels under the kernel is 1, otherwise it is eroded (made to zero).
- 
6. The basic idea of dilation is accentuating the features of the images. Whereas erosion is used to reduce the amount of noise in the image, dilation is used to enhance the features of the image.
- 
7. Traditionally, a line can be represented by the equation **_y=mx + b_** (where **_m_** is the slope and **_b_** is the intercept). However, a line can also be represented by the following equation: **_r= x(cos0) + y(sin0)_** (where **_r_** is the distance from the origin to the closest point on the straight line). **_(r,0)_** corresponds corresponds to the **_Hough space_** representation of the line. In this case, **_0_** is known as **_theta_**.
- For a given point in a two-dimensional space (think of a basic x- and y-axis graph), there can be an infinite number of straight lines drawn through the point. With a **_Hough Transform_**, you draw several lines through the point to create a table of values where you conclude "for given theta (angle between the x-axis and r-line that will match with the closest point on the straight line), we can expect this "r" value".
- Once you have created your table of values for each point on a given two-dimensional space, you compare the r-values on each theta for each given point and select the r and theta where the difference between the point is the least (this means the line best represents the points on the space).
| [
-0.6226533651351929,
-1.0670161247253418,
0.45598599314689636,
0.01946958526968956,
-0.36542651057243347,
-0.26787111163139343,
0.11698479950428009,
-0.43678170442581177,
0.23489457368850708,
0.39838138222694397,
-0.317624032497406,
-0.5312291383743286,
-0.6297121644020081,
-0.262634307146... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
SidhiPanda/megathon_ps2 | SidhiPanda | 2023-10-28T20:58:54Z | 36 | 0 | null | [
"region:us"
] | 2023-10-28T20:58:54Z | 2023-10-28T20:54:55.000Z | 2023-10-28T20:54:55 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
youyu0105/llm-MIDI | youyu0105 | 2023-10-29T08:33:44Z | 36 | 1 | null | [
"region:us"
] | 2023-10-29T08:33:44Z | 2023-10-29T08:33:38.000Z | 2023-10-29T08:33:38 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 50994814
num_examples: 14606
download_size: 12039871
dataset_size: 50994814
---
# Dataset Card for "llm-MIDI"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6744459271430969,
-0.23878131806850433,
0.5817462205886841,
0.25496190786361694,
-0.23195095360279083,
0.13178293406963348,
0.16252554953098297,
-0.11199674755334854,
0.8402119874954224,
0.5462376475334167,
-1.057804822921753,
-0.9535543918609619,
-0.5813202261924744,
-0.359974831342697... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
zelros/pj-lbp | zelros | 2023-11-05T22:51:19Z | 36 | 0 | null | [
"insurance",
"region:us"
] | 2023-11-05T22:51:19Z | 2023-10-30T21:32:51.000Z | 2023-10-30T21:32:51 | ---
tags:
- insurance
---
This dataset contains question/answer pairs from a French legal protection insurance (https://www.service-public.fr/particuliers/vosdroits/F3049?lang=en).
The objective of this dataset is to contribute to open source research projects aiming to, for instance:
* fine-tune LLMs on high-quality datasets, specializing them in the insurance domain
* develop new question/answer applications using Retrieval Augmented Generation (RAG) for insurance contracts
* assess the knowledge of language models in the insurance field
* more generally, apply LLMs to the insurance domain for better understanding and increased transparency of this industry.
Other datasets of the same kind are also available - or will be available soon - and are part of this research effort. See here: https://huggingface.co/collections/zelros/legal-protection-insurance-6536e8f389dd48faca78447e
Here is an example of usages of this dataset: https://huggingface.co/spaces/zelros/The-legal-protection-insurance-comparator
| [
-0.12690630555152893,
-0.6109647154808044,
0.20794343948364258,
0.2446521520614624,
-0.06387617439031601,
-0.19570039212703705,
0.15373264253139496,
-0.43992751836776733,
0.39488929510116577,
1.1311315298080444,
-0.28130269050598145,
-0.5277532935142517,
-0.4185519516468048,
-0.14612421393... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
rkdeva/QA_Dataset | rkdeva | 2023-10-31T21:08:06Z | 36 | 0 | null | [
"region:us"
] | 2023-10-31T21:08:06Z | 2023-10-31T21:08:02.000Z | 2023-10-31T21:08:02 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 252345
num_examples: 103
download_size: 112834
dataset_size: 252345
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "QA_Dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5273208022117615,
-0.1967344880104065,
0.3221299946308136,
0.18097244203090668,
-0.28418731689453125,
0.08530469238758087,
0.5924681425094604,
-0.07473955303430557,
0.9193724989891052,
0.3924703299999237,
-0.7642848491668701,
-0.747748613357544,
-0.37033548951148987,
-0.2191279679536819... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
hip-piehunter/dbl_lang | hip-piehunter | 2023-11-01T21:00:43Z | 36 | 0 | null | [
"license:mit",
"region:us"
] | 2023-11-01T21:00:43Z | 2023-10-31T22:54:54.000Z | 2023-10-31T22:54:54 | ---
license: mit
---
| [
-0.1285339742898941,
-0.18616800010204315,
0.6529127359390259,
0.4943626821041107,
-0.1931934952735901,
0.2360742688179016,
0.360720157623291,
0.05056300014257431,
0.5793654322624207,
0.7400140166282654,
-0.6508105993270874,
-0.23783984780311584,
-0.7102248668670654,
-0.047826044261455536,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
mlnsio/audio | mlnsio | 2023-11-01T11:04:35Z | 36 | 0 | null | [
"task_categories:audio-classification",
"size_categories:n<1K",
"language:en",
"license:apache-2.0",
"region:us"
] | 2023-11-01T11:04:35Z | 2023-11-01T07:41:24.000Z | 2023-11-01T07:41:24 | ---
language:
- en
license: apache-2.0
size_categories:
- n<1K
task_categories:
- audio-classification
pretty_name: nsio_audio
dataset_info:
features:
- name: audio
dtype: audio
splits:
- name: train
num_bytes: 264370278.0
num_examples: 50
download_size: 263693652
dataset_size: 264370278.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
anyspeech/mswc_test | anyspeech | 2023-11-02T00:11:11Z | 36 | 0 | null | [
"region:us"
] | 2023-11-02T00:11:11Z | 2023-11-02T00:11:01.000Z | 2023-11-02T00:11:01 | ---
configs:
- config_name: default
data_files:
- split: query
path: data/query-*
- split: candidate
path: data/candidate-*
dataset_info:
features:
- name: key
dtype: string
- name: phones
dtype: string
- name: audio
struct:
- name: array
sequence: float64
- name: sampling_rate
dtype: int64
splits:
- name: query
num_bytes: 213251381
num_examples: 1665
- name: candidate
num_bytes: 213251405
num_examples: 1665
download_size: 40945132
dataset_size: 426502786
---
# Dataset Card for "mswc_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5989390015602112,
-0.1561821848154068,
0.03955249860882759,
0.19234053790569305,
-0.23459413647651672,
0.0991223081946373,
0.485212117433548,
-0.1117723360657692,
0.6089508533477783,
0.3220919370651245,
-0.9458056688308716,
-0.6037887930870056,
-0.4624577462673187,
-0.15296129882335663,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
SoAp9035/turkish_instructions | SoAp9035 | 2023-11-03T13:45:02Z | 36 | 2 | null | [
"language:tr",
"license:apache-2.0",
"region:us"
] | 2023-11-03T13:45:02Z | 2023-11-03T12:11:25.000Z | 2023-11-03T12:11:25 | ---
license: apache-2.0
language:
- tr
---
# Turkish Instructions
## Apache 2.0
This dataset is a cleaned and organized version (for Mistral) of [afkfatih/turkishdataset](https://huggingface.co/datasets/afkfatih/turkishdataset)
| [
-0.5176534056663513,
-0.6173415780067444,
-0.20015062391757965,
0.5269358158111572,
-0.5832599997520447,
-0.46184083819389343,
0.14782768487930298,
-0.15721775591373444,
0.26669996976852417,
0.8808664083480835,
-1.0421085357666016,
-0.5318244695663452,
-0.5497526526451111,
0.02398372814059... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
btt-mining-coalation/open_web_random_5000 | btt-mining-coalation | 2023-11-09T14:45:32Z | 36 | 0 | null | [
"region:us"
] | 2023-11-09T14:45:32Z | 2023-11-05T01:42:24.000Z | 2023-11-05T01:42:24 | ---
dataset_info:
features:
- name: text
dtype: string
- name: summary
dtype: string
- name: reward_dpo
dtype: float64
splits:
- name: train
num_bytes: 30649367
num_examples: 5000
download_size: 18002442
dataset_size: 30649367
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "open_web_random_5000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7468582391738892,
-0.10581355541944504,
0.0074601974338293076,
0.3981776237487793,
-0.22532489895820618,
-0.4123372435569763,
0.26932868361473083,
-0.23144866526126862,
0.6379637122154236,
0.374686598777771,
-0.794318675994873,
-0.8124865889549255,
-0.3398796319961548,
0.005959752947092... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
tierdesafinante/fatima_noya | tierdesafinante | 2023-11-06T18:45:11Z | 36 | 0 | null | [
"license:openrail",
"region:us"
] | 2023-11-06T18:45:11Z | 2023-11-06T18:44:40.000Z | 2023-11-06T18:44:40 | ---
license: openrail
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kpriyanshu256/semeval-task-8-a-mono-gltr-ppl | kpriyanshu256 | 2023-11-10T04:41:46Z | 36 | 0 | null | [
"region:us"
] | 2023-11-10T04:41:46Z | 2023-11-10T04:41:27.000Z | 2023-11-10T04:41:27 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: val
path: data/val-*
- split: test
path: data/test-*
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: int64
- name: model
dtype: string
- name: source
dtype: string
- name: id
dtype: int64
- name: gltr
sequence: int64
- name: ppl
sequence: float64
splits:
- name: train
num_bytes: 245302117
num_examples: 83829
- name: val
num_bytes: 105434420
num_examples: 35928
- name: test
num_bytes: 11023757
num_examples: 5000
download_size: 209455821
dataset_size: 361760294
---
# Dataset Card for "semeval-task-8-a-mono-gltr-ppl"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5097154974937439,
-0.29920700192451477,
0.12287044525146484,
0.21065589785575867,
-0.43340861797332764,
0.02993558533489704,
0.3076564073562622,
0.002282240428030491,
0.7677939534187317,
0.6030201315879822,
-0.7273769378662109,
-0.5459420084953308,
-0.7016794085502625,
-0.13267157971858... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ineoApp/factures_dataset | ineoApp | 2023-11-22T14:53:14Z | 36 | 0 | null | [
"region:us"
] | 2023-11-22T14:53:14Z | 2023-11-10T13:45:51.000Z | 2023-11-10T13:45:51 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: id
dtype: string
- name: image
dtype: image
- name: bboxes
sequence:
sequence: int64
- name: ner_tags
sequence:
class_label:
names:
'0': O
'1': reference
'2': numero facture
'3': fournisseur
'4': date facture
'5': date limite
'6': montant ht
'7': tva
'8': montant ttc
'9': unitP
'10': prix tva
'11': addresse
'12': art1 prix unit
'13': art1 designation
'14': art1 quantite
'15': art1 tva
'16': art1 montant ht
'17': art2 designation
'18': art2 quantite
'19': art2 prix unit
'20': art2 tva
'21': art2 montant ht
- name: tokens
sequence: string
splits:
- name: train
num_bytes: 3917957.6
num_examples: 4
- name: test
num_bytes: 674646.0
num_examples: 1
download_size: 4892196
dataset_size: 4592603.6
---
# Dataset Card for "factures_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.5656505823135376,
-0.19667290151119232,
0.3164072334766388,
0.2521260976791382,
-0.34727707505226135,
-0.1848548799753189,
0.3452901542186737,
-0.13208459317684174,
0.961203396320343,
0.5853525996208191,
-0.844728410243988,
-0.8238171339035034,
-0.6038575172424316,
-0.32496562600135803,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
peterbeamish/environment-multi-labels-even | peterbeamish | 2023-11-23T20:29:54Z | 36 | 0 | null | [
"region:us"
] | 2023-11-23T20:29:54Z | 2023-11-12T07:51:31.000Z | 2023-11-12T07:51:31 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: filename
dtype: string
- name: content
dtype: string
- name: environment
sequence: string
- name: variablearg
sequence: 'null'
- name: constarg
sequence: string
- name: variableargjson
dtype: string
- name: constargjson
dtype: string
- name: lang
dtype: string
- name: constargcount
dtype: float64
- name: variableargcount
dtype: float64
- name: sentence
dtype: string
splits:
- name: train
num_bytes: 260777154
num_examples: 19503
- name: test
num_bytes: 258313170
num_examples: 19504
download_size: 191420386
dataset_size: 519090324
---
# Dataset Card for "environment-multi-labels-even"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7291512489318848,
-0.4756021797657013,
0.2949482202529907,
0.405195415019989,
0.02672845870256424,
-0.11598451435565948,
0.09144899994134903,
-0.4151317775249481,
0.6463865637779236,
0.4184712767601013,
-0.9090573787689209,
-0.8144123554229736,
-0.6240819692611694,
-0.19557839632034302,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Lollitor/CASF | Lollitor | 2023-11-13T18:28:12Z | 36 | 0 | null | [
"region:us"
] | 2023-11-13T18:28:12Z | 2023-11-13T18:28:09.000Z | 2023-11-13T18:28:09 | ---
dataset_info:
features:
- name: '#code'
dtype: string
- name: inputs
dtype: string
splits:
- name: train
num_bytes: 310419
num_examples: 285
download_size: 110166
dataset_size: 310419
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "CASF"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6729331612586975,
-0.13273809850215912,
0.18340831995010376,
0.3787569999694824,
-0.30470994114875793,
0.0029608961194753647,
0.42335599660873413,
-0.24916508793830872,
0.895058274269104,
0.6076425909996033,
-1.1194431781768799,
-0.9570478796958923,
-0.6592990159988403,
-0.1674441546201... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
frenchtext/banque-fr-2311 | frenchtext | 2023-11-13T23:23:22Z | 36 | 0 | null | [
"task_categories:text-generation",
"task_ids:language-modeling",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:fr",
"license:apache-2.0",
"wordslab-webscraper",
"region:us"
] | 2023-11-13T23:23:22Z | 2023-11-13T23:22:23.000Z | 2023-11-13T23:22:23 | ---
pretty_name: "banque fr websites - 2311"
tags:
- wordslab-webscraper
task_categories:
- text-generation
task_ids:
- language-modeling
size_categories: 10K<n<100K
language: fr
multilinguality: monolingual
license: apache-2.0
source_datasets: original
language_creators: found
annotations_creators: no-annotation
configs:
- config_name: default
data_files:
- split: train
path: "banque_fr_2311_train_*.parquet"
- split: valid
path: "banque_fr_2311_valid_*.parquet"
- split: test
path: "banque_fr_2311_test_*.parquet"
dataset_info:
features:
- name: Uri
dtype: string
- name: Timestamp
dtype: string
- name: Lang
dtype: string
- name: Title
dtype: string
- name: Text
dtype: string
- name: Words
dtype: int32
- name: AvgWordsLength
dtype: int32
- name: Chars
dtype: int32
- name: LetterChars
dtype: int32
- name: NumberChars
dtype: int32
- name: OtherChars
dtype: int32
- name: Website
dtype: string
- name: PDF
dtype: bool
config_name: default
splits:
- name: train
num_examples: 68166
- name: valid
num_examples: 8522
- name: test
num_examples: 8541
download_size: 247147772
---
# Dataset Card for "banque fr websites - 2311"
Dataset extracted from public websites by [wordslab-webscraper](https://github.com/wordslab-org/wordslab-webscraper) in 2311:
- domain: banque
- language: fr
- license: Apache 2.0
## Dataset Sources
wordslab-webscraper follows the industry best practices for **polite web scraping**:
- clearly identifies itself as a known text indexing bot: "bingbot"
- doesn't try to hide the user IP address behind proxies
- doesn't try to circumvent bots protection solutions
- waits for a minimum delay between two pages to avoid generating too much load
- respects the website "robots.txt" indexing directives
- respects the web page Meta Robots HTML tag
- respects the web page X-Robots-Tag HTTP header
- respects the web page links rel=nofollow HTML attributes
The text data was extracted from the following websites:
| Website | HTML pages | PDF docs | Words |
|:---|:---:|:---:|:---:|
| banque.meilleurtaux.com | 5055 | 1 | 3209252 |
| banquefrancaisemutualiste.fr | 196 | 0 | 205197 |
| groupebpce.com | 1137 | 3 | 456194 |
| mabanque.bnpparibas | 388 | 184 | 1411792 |
| particuliers.sg.fr | 385 | 168 | 1317226 |
| selectra.info_finance_banques | 231 | 0 | 490518 |
| www.20minutes.fr_economie_banque_ | 412 | 0 | 220504 |
| www.afb.fr | 121 | 44 | 159912 |
| www.allianz.fr | 854 | 1 | 785651 |
| www.axa.fr | 1568 | 0 | 731906 |
| www.banque-france.fr | 212 | 306 | 1169549 |
| www.banquebcp.fr | 232 | 0 | 94114 |
| www.banquedesterritoires.fr | 1899 | 169 | 2243316 |
| www.banquemondiale.org | 216 | 0 | 299993 |
| www.banquepopulaire.fr | 1530 | 0 | 778258 |
| www.bforbank.com | 71 | 0 | 38220 |
| www.boursobank.com | 97 | 0 | 89211 |
| www.boursorama.com | 24581 | 0 | 17269453 |
| www.bpifrance.fr | 523 | 1 | 489908 |
| www.bred.fr | 1531 | 209 | 1511004 |
| www.caisse-epargne.fr | 1393 | 0 | 574874 |
| www.cic.fr | 3353 | 567 | 6086714 |
| www.credit-agricole.fr | 1672 | 133 | 2070741 |
| www.creditmutuel.fr | 2111 | 526 | 3876220 |
| www.ecb.europa.eu | 79 | 1 | 71446 |
| www.esbanque.fr | 269 | 0 | 135072 |
| www.fbf.fr | 683 | 571 | 1939478 |
| www.fortuneo.fr | 898 | 8 | 573493 |
| www.hellobank.fr | 648 | 31 | 474719 |
| www.hsbc.fr | 295 | 144 | 1527838 |
| www.impots.gouv.fr | 122 | 10 | 63166 |
| www.labanquepostale.fr | 1677 | 0 | 1224971 |
| www.lafinancepourtous.com | 7849 | 357 | 6011655 |
| www.lcl.fr | 1268 | 0 | 834973 |
| www.lesclesdelabanque.com | 1478 | 135 | 769241 |
| www.lesechos.fr_finance-marches_ | 1493 | 0 | 1412840 |
| www.mafrenchbank.fr | 361 | 10 | 238469 |
| www.moneyvox.fr | 1860 | 0 | 1764097 |
| www.orangebank.fr | 682 | 92 | 1062804 |
| www.palatine.fr | 228 | 0 | 79346 |
| www.revue-banque.fr | 11171 | 6 | 3055775 |
| www.service-public.fr | 721 | 2 | 242446 |
## Uses
**WARNING**
- **the text included in this dataset belongs to its original authors** and is protected by copyright laws
- you are not allowed to use this dataset for anything else than **training a large language model**
- when using a large language model trained on this dataset, you will need to ensure that you comply with the law
- if you benefit from this large language model, you should try to share the value with the original text authors
wordslab-webscraper uses an advanced Html to text conversion algorithm optimized for **long context language modeling**:
- tries to recover the logical structure of the document from the Html or PDF layout
- preserves document / section / list / table grouping and nesting information
- **deduplicates text at the website level while preserving the document structure**
Each example in this dataset is a **markdown text conversion of a full HTML page or PDF document**:
- the document structure is preserved by markdown syntax: headers, lists, tables, paragraphs
- all duplicate paragraphs are removed
## Dataset Structure
The dataset is divided in 3 splits:
- train: 80% of the data
- valid: 10% of the data
- test: 10% of the data
wordslab-webscraper generates **one parquet file per website and per split**.
The parquet files are named with the following pattern:
- banque_fr_2311_[split]_[website].parquet
Note than you can load individual splits or websites with HuggingFace datasets using the following commands:
```python
from datasets import load_dataset
# Load a single plit
dataset = load_dataset("namespace/banque-fr-2311", split="train")
# Load a single website
data_files = { "train": "banque_fr_2311_train_[website].parquet", "valid": "banque_fr_2311_valid_[website].parquet", "test": "banque_fr_2311_test_[website].parquet" }
dataset = load_dataset("namespace/banque-fr-2311", data_files=data_files)
```
Each example in the dataset contains the text of a full web page or PDF document, with the following features:
- Uri: string
- Timestamp: string
- Lang: string
- Title: string
- Text: string
- Words: int32
- AvgWordsLength: int32
- Chars: int32
- LetterChars: int32
- NumberChars: int32
- OtherChars: int32
- Website: string
- PDF: bool
Note that beause each example is a full page or document, the "Text" feature can be a pretty long string containing thousands of words (as measured by the "Words" feature): you will typically need to chunk it down to the context size of your large language model before using it.
## Bias, Risks, and Limitations
This dataset is a direct extraction from the source websites.
It was not manually curated to remove misleading, offensive, or harmful content.
**Please add a filtering step before using it to train a large language model** if the source websites can't be trusted.
## Dataset Card Contact
Please add a comment in the community section of this repository if you want the maintainer to add or remove websites from this dataset. | [
-0.4804103672504425,
-0.5355904698371887,
0.16275517642498016,
0.3632577061653137,
-0.2096623033285141,
-0.19817376136779785,
-0.18119588494300842,
-0.35923272371292114,
0.01571858674287796,
0.5051252841949463,
-0.3855079412460327,
-0.7470724582672119,
-0.5473718643188477,
0.25705409049987... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
zxvix/amazon_review_automotive_subset | zxvix | 2023-11-14T06:09:02Z | 36 | 0 | null | [
"region:us"
] | 2023-11-14T06:09:02Z | 2023-11-14T06:03:17.000Z | 2023-11-14T06:03:17 | ---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 172169682.4682526
num_examples: 1000000
- name: test
num_bytes: 172169.68246825258
num_examples: 1000
download_size: 287498929
dataset_size: 172341852.15072086
---
# Dataset Card for "amazon_review_automotive_subset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7172867059707642,
-0.08440308272838593,
0.24776306748390198,
0.264113187789917,
-0.26445287466049194,
0.12442061305046082,
0.32573604583740234,
-0.3130893409252167,
0.5044310092926025,
0.3213506042957306,
-1.084960699081421,
-0.6515836119651794,
-0.22932535409927368,
-0.2337245345115661... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Liberty-L/race_val | Liberty-L | 2023-11-15T05:06:11Z | 36 | 0 | null | [
"region:us"
] | 2023-11-15T05:06:11Z | 2023-11-15T05:05:30.000Z | 2023-11-15T05:05:30 | ---
dataset_info:
features:
- name: data_index_by_user
dtype: int64
- name: article
dtype: string
- name: answer
dtype: string
- name: question
dtype: string
- name: options
sequence: string
- name: input_ids
sequence:
sequence: int32
- name: token_type_ids
sequence:
sequence: int8
- name: attention_mask
sequence:
sequence: int8
- name: label
dtype: int64
splits:
- name: train
num_bytes: 38434030
num_examples: 3547
download_size: 8065978
dataset_size: 38434030
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "race_val"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6642677783966064,
-0.15500634908676147,
0.17640350759029388,
0.2756109833717346,
-0.21297143399715424,
0.13545411825180054,
0.4394000470638275,
-0.21848827600479126,
0.9175336360931396,
0.3982745110988617,
-0.8376427888870239,
-0.7484884858131409,
-0.5613937377929688,
-0.253434807062149... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Liberty-L/race_test | Liberty-L | 2023-11-15T05:06:14Z | 36 | 0 | null | [
"region:us"
] | 2023-11-15T05:06:14Z | 2023-11-15T05:05:52.000Z | 2023-11-15T05:05:52 | ---
dataset_info:
features:
- name: data_index_by_user
dtype: int64
- name: article
dtype: string
- name: answer
dtype: string
- name: question
dtype: string
- name: options
sequence: string
- name: input_ids
sequence:
sequence: int32
- name: token_type_ids
sequence:
sequence: int8
- name: attention_mask
sequence:
sequence: int8
- name: label
dtype: int64
splits:
- name: train
num_bytes: 39853553
num_examples: 3638
download_size: 8418028
dataset_size: 39853553
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "race_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6760998964309692,
-0.26681703329086304,
0.1253582388162613,
0.2866373658180237,
-0.21050888299942017,
0.14138911664485931,
0.1794920265674591,
-0.22219133377075195,
0.8242939114570618,
0.1389751136302948,
-0.8086174130439758,
-0.6812201142311096,
-0.4146765470504761,
-0.1883515864610672... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
manu/gallica_ocr_cleaned | manu | 2023-11-18T22:34:35Z | 36 | 0 | null | [
"region:us"
] | 2023-11-18T22:34:35Z | 2023-11-18T21:21:57.000Z | 2023-11-18T21:21:57 | ---
dataset_info:
features:
- name: file
dtype: string
- name: clean_text
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 44570227
num_examples: 7687
download_size: 25073743
dataset_size: 44570227
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ayan1988/diffusion.8.instruct_pix2pix | ayan1988 | 2023-11-19T12:42:31Z | 36 | 0 | null | [
"region:us"
] | 2023-11-19T12:42:31Z | 2023-11-19T11:27:29.000Z | 2023-11-19T11:27:29 | ---
dataset_info:
features:
- name: input
dtype: image
- name: text
dtype: string
- name: output
dtype: image
splits:
- name: train
num_bytes: 416880509.0
num_examples: 1000
download_size: 416911651
dataset_size: 416880509.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "diffusion.8.instruct_pix2pix"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.6289519667625427,
-0.481002539396286,
0.5212926268577576,
0.35944703221321106,
-0.029466301202774048,
-0.20474474132061005,
0.2698277533054352,
0.07082657516002655,
0.5606873631477356,
0.313777357339859,
-0.6076651811599731,
-0.5989954471588135,
-0.8238046765327454,
-0.6884801983833313,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Ricktlw/ThomazCosta | Ricktlw | 2023-11-19T20:33:35Z | 36 | 0 | null | [
"license:openrail",
"region:us"
] | 2023-11-19T20:33:35Z | 2023-11-19T20:32:17.000Z | 2023-11-19T20:32:17 | ---
license: openrail
---
| [
-0.12853392958641052,
-0.18616779148578644,
0.6529127955436707,
0.49436280131340027,
-0.19319361448287964,
0.23607419431209564,
0.36072003841400146,
0.050563063472509384,
0.579365611076355,
0.7400140762329102,
-0.6508104205131531,
-0.23783954977989197,
-0.7102249264717102,
-0.0478260256350... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
luizlzg/prefeitura_rj_v2 | luizlzg | 2023-11-21T18:29:55Z | 36 | 0 | null | [
"region:us"
] | 2023-11-21T18:29:55Z | 2023-11-20T00:50:52.000Z | 2023-11-20T00:50:52 | ---
configs:
- config_name: default
data_files:
- split: train
path: prefeitura_treino*
- split: test
path: prefeitura_teste*
--- | [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
seonjeongh/parallel_en.am | seonjeongh | 2023-11-22T04:11:31Z | 36 | 0 | null | [
"region:us"
] | 2023-11-22T04:11:31Z | 2023-11-22T02:21:43.000Z | 2023-11-22T02:21:43 | ---
dataset_info:
features:
- name: en
dtype: string
- name: am
dtype: string
splits:
- name: train
num_bytes: 34707491
num_examples: 140000
download_size: 21200415
dataset_size: 34707491
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "parallel_en.am"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.8733494877815247,
-0.3625752925872803,
0.2593429386615753,
0.5695962309837341,
-0.2250557243824005,
0.16235625743865967,
0.01837403140962124,
-0.3037743866443634,
1.1539726257324219,
0.4310522973537445,
-0.8207710981369019,
-0.7736640572547913,
-0.6882385611534119,
0.034856025129556656,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
ckotait/ATRDataset | ckotait | 2023-11-27T14:26:55Z | 36 | 0 | null | [
"region:us"
] | 2023-11-27T14:26:55Z | 2023-11-23T16:20:10.000Z | 2023-11-23T16:20:10 | ---
dataset_info:
features:
- name: pixel_values
dtype: image
- name: label
dtype: image
splits:
- name: train
num_bytes: 674327851.666
num_examples: 16706
- name: validation
num_bytes: 46935738.0
num_examples: 1000
download_size: 797140406
dataset_size: 721263589.666
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
# Dataset Card for Dataset Name
The Active Template Regression (ATR) dataset comprises 18 semantic category labels, including face, sunglasses, hat, scarf, hair, upper clothes, left arm, right arm, belt, pants, left leg, right leg, skirt, left shoe, right shoe, bag, dress, and background. A total of 17,700 images were incorporated into the ATR dataset. 16,700 images were designated for training, and 1,000 for testing.
- **Curated by:** Xiaodan Liang, Si Liu, Xiaohui Shen, Jianchao Yang, Luoqi Liu, Jian Dong, Liang Lin, Shuicheng Yan
- **Shared by:** Xiaodan Liang, Si Liu, Xiaohui Shen, Jianchao Yang, Luoqi Liu, Jian Dong, Liang Lin, Shuicheng Yan
- **License:** MIT
# Dataset Sources
- **Repository:** https://github.com/lemondan/HumanParsing-Dataset
- **Paper:** Deep Human Parsing with Active Template Regression
# Human Parsing Labels
- 0: **background**
- 1: **hat**
- 2: **hair**
- 3: **sunglasses**
- 4: **upperclothes**
- 5: **skirt**
- 6: **pants**
- 7: **dress**
- 8: **belt**
- 9: **leftshoe**
- 10: **rightshoe**
- 11: **face**
- 12: **leftleg**
- 13: **rightleg**
- 14: **leftarm**
- 15: **rightarm**
- 16: **bag**
- 17: **scarf**
# Uses
Semantic segmentation, and more specifically, human body parsing.
# Dataset Card Authors
Christian Kotait
**BibTeX:**
@article{liang2015deep,
title={Deep human parsing with active template regression},
author={Liang, Xiaodan and Liu, Si and Shen, Xiaohui and Yang, Jianchao and Liu, Luoqi and Dong, Jian and Lin, Liang and Yan, Shuicheng},
journal={IEEE transactions on pattern analysis and machine intelligence},
volume={37},
number={12},
pages={2402--2414},
year={2015},
publisher={IEEE}
}
| [
-0.2683767080307007,
-0.632839560508728,
0.21924783289432526,
-0.15449906885623932,
-0.21830317378044128,
0.01680355705320835,
0.0030117833521217108,
-0.3256556987762451,
-0.006008803378790617,
0.5936229228973389,
-0.4360884726047516,
-0.8651888370513916,
-0.3251331150531769,
0.22886653244... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
pinkbaka/rapgenius | pinkbaka | 2023-11-27T08:08:34Z | 36 | 0 | null | [
"license:mit",
"region:us"
] | 2023-11-27T08:08:34Z | 2023-11-24T22:00:27.000Z | 2023-11-24T22:00:27 | ---
license: mit
---
| [
-0.1285335123538971,
-0.1861683875322342,
0.6529128551483154,
0.49436232447624207,
-0.19319400191307068,
0.23607441782951355,
0.36072009801864624,
0.05056373029947281,
0.5793656706809998,
0.7400146722793579,
-0.650810182094574,
-0.23784008622169495,
-0.7102247476577759,
-0.0478255338966846... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
danielwasewicz/qc | danielwasewicz | 2023-11-26T01:42:37Z | 36 | 0 | null | [
"region:us"
] | 2023-11-26T01:42:37Z | 2023-11-25T05:23:38.000Z | 2023-11-25T05:23:38 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: code_snippet
dtype: string
splits:
- name: train
num_bytes: 10076
num_examples: 2
download_size: 18809
dataset_size: 10076
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
| [
-0.12853367626667023,
-0.18616794049739838,
0.6529126763343811,
0.4943627417087555,
-0.19319313764572144,
0.23607443273067474,
0.36071979999542236,
0.05056338757276535,
0.5793654322624207,
0.7400138974189758,
-0.6508103013038635,
-0.23783987760543823,
-0.710224986076355,
-0.047825977206230... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
euisuh15/python-new-piss | euisuh15 | 2023-11-26T17:55:20Z | 36 | 0 | null | [
"region:us"
] | 2023-11-26T17:55:20Z | 2023-11-26T17:45:35.000Z | 2023-11-26T17:45:35 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
nickmuchi/trade-the-event-finance | nickmuchi | 2022-02-04T06:05:02Z | 35 | 6 | null | [
"region:us"
] | 2022-02-04T06:05:02Z | 2022-03-02T23:29:22.000Z | 2022-03-02T23:29:22 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
piEsposito/br-quad-2.0 | piEsposito | 2021-02-05T16:05:51Z | 35 | 0 | null | [
"region:us"
] | 2021-02-05T16:05:51Z | 2022-03-02T23:29:22.000Z | 2022-03-02T23:29:22 | Entry not found | [
-0.3227649927139282,
-0.225684255361557,
0.862226128578186,
0.43461498618125916,
-0.5282987952232361,
0.7012963891029358,
0.7915717363357544,
0.07618629932403564,
0.7746025919914246,
0.2563219666481018,
-0.7852816581726074,
-0.2257382869720459,
-0.9104480743408203,
0.5715669393539429,
-0... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
valurank/PoliticalBias_AllSides_Txt | valurank | 2022-10-21T13:37:02Z | 35 | 2 | null | [
"multilinguality:monolingual",
"language:en",
"license:other",
"region:us"
] | 2022-10-21T13:37:02Z | 2022-03-02T23:29:22.000Z | 2022-03-02T23:29:22 | ---
license:
- other
language:
- en
multilinguality:
- monolingual
task_categories:
- classification
task_ids:
- classification
---
# Dataset Card for news-12factor
## Table of Contents
- [Dataset Description](#dataset-description)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Source Data](#source-data)
- [Annotations](#annotations)
## Dataset Description
~20k articles labeled left, right, or center by the editors of allsides.com.
## Languages
The text in the dataset is in English
## Dataset Structure
3 folders, with many text files in each. Each text file represent the body text of one article.
## Source Data
URL data was scraped using https://github.com/mozilla/readability
## Annotations
Articles were manually annotated by news editors who were attempting to select representative articles from the left, right and center of each article topic. In other words, the dataset should generally be balanced - the left/right/center articles cover the same set of topics, and have roughly the same amount of articles in each.
| [
-0.6039842963218689,
-0.4226057529449463,
0.13950657844543457,
0.39899304509162903,
-0.6539607644081116,
0.2231345772743225,
-0.029130112379789352,
-0.41632550954818726,
0.6675400733947754,
0.3496056795120239,
-0.7250715494155884,
-0.8796330690383911,
-0.5768240690231323,
0.435232013463974... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
SetFit/amazon_reviews_multi_de | SetFit | 2022-03-23T15:34:53Z | 35 | 0 | null | [
"region:us"
] | 2022-03-23T15:34:53Z | 2022-03-13T02:45:18.000Z | 2022-03-13T02:45:18 | #amazon reviews multi german
This dataset is a port of the official ['amazon_reviews_multi' dataset] (https://huggingface.co/datasets/amazon_reviews_multi) on the Hub. It has just the German language version. It has been reduced to just 3 columns (and 4th "label_text") that are relevant to the SetFit task. | [
-0.8994995951652527,
-0.5103474259376526,
-0.021132854744791985,
0.6680298447608948,
-0.30324313044548035,
-0.00947894249111414,
0.019309459254145622,
-0.5302919149398804,
0.6137000918388367,
0.8952358365058899,
-1.0788449048995972,
-0.46321389079093933,
-0.21269847452640533,
0.32125884294... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
surafelkindu/Amharic_corpus | surafelkindu | 2022-04-17T18:19:47Z | 35 | 1 | null | [
"license:mit",
"region:us"
] | 2022-04-17T18:19:47Z | 2022-04-17T18:06:43.000Z | 2022-04-17T18:06:43 | ---
license: mit
---
ዛጎል ዜና- መንግስት አምስት ሺህ የሚጠጉ እስረኞችን “ተመራቂዎች” በሚል መፍታቱን ይፋ ባደረገበት ቀን በተመሳሳይ አምቦ ተማሪዎች ተቃውሞ ማሰማታቸው ተሰማ። ተማሪዎቹ የአስቸኳይ አዋጁን በመጣስ ” መረራ ይፈታ” እያሉ ተቃውሞ መጀመራቸው ነው የተሰማው። ከትምህርት ቤት ወደ ትምህርት ቤት የሰፋው ተቃውሞ ብህይወት ላይ አደጋ ባያስከትልም በንብረት ላይ ግን ጉዳት አድርሷል። መኪና ሲቃጠል ያዩ የአይን ምስክሮች ተቃውሞውን በጀመሩት ላይም ሆነ ዘግይተው በተቀላቀሉት ላይ እንደ ቀደሞው ያለ የሃይል እርምጃ አልተወሰደም። የኦሮሚያ ሚዲያ ኔት ወርክ እንዳለው ደግሞ በርካታ ሰዎች ታስረዋል።
ለወትሮው ህገ መንግስቱን በሃይል ለመናድ የተነሱ፣ የነውጥ ሃይሎች፣ አተራማሾች፣ የጥፋት ሃይል ተላላኪዎች በሚል ተጠርጥረው በቁጥጥር ስር ከዋሉት መካከል 4035 የሚሆኑት ሲፈቱ እስረኞቹ “ስድስት ኮርስ ወስደው ተመረቁ” ነው የተባለው።
የኦሮሚያ ማረሚያ ቤቶች አስተዳደር ኮሚሽነር ፀሃይ በላይን ጠቅሶ ፋና እንደዘገበው ጦላይ ተሃድሶ ማዕከል ከገቡ 5 ሺህ 600 ሰልጣኞች መካከል 4035 ያህሉ በስድስት ዋና ዋና ጉዳዮች ሥልጠና ወስደው ተመርቀዋል። ኮርሶቹም በፍፁም፣ አይደገምም፣ የቀለም አብዮት፣ የኢትዮጰያ ህገ–መንግስት እና የኢትዮጵያ ህዳሴ የሚሉ ርዕሰ ጉዳዮችን የተካተቱባቸው ነው።
አበምርቃቱ ላይ ጠቅላይ ሚኒስትር ሃይለማርያም ተገኝተው “ ሽኝት” አደርጉላቸው ተብሏል። በርካታ ቃል ተገብቶላቸዋል። መስመርም ተሰምሮላቸዋል። “በደምና በአጥንት የተጻፈውን ሕገመንግስት፣ ዋጋ የተከፈለበትን ህገመንግስት” በማለት አቶ ሃይለማርያም በሃይል ለመናድ መሞከር አይቻልም በለዋል። “ ልክ እናንተ አይደገምም እንዳላችሁት፣ እኛም አይደገም እንላለን” ብለዋል። የፋና ዘገባ እንዲህ ይነበባል።
አዲስ አበባ ፣ ታህሳስ 12 ፣ 2009 (ኤፍ ቢ ሲ) በሃገሪቱ የተለያዩ አካባቢዎች በተፈጠረው ሁከት ውስጥ ተሳትፈው በማሰልጠኛ ጣቢያዎች የተሃድሶ ስልጠና ሲወስዱ የነበሩ ዜጎች ወደ መጡበት እየተመለሱ ነው። በአዋሽ፣ አላጌና ብር ሸለቆ ማዕከላት የተሃድሶ ስልጠና የወሰዱ ዜጎች ናቸው ወደ አካባቢያቸው እየተመለሱ ያሉት። በጦላይ ለአንድ ወር የተሃድሶ ስልጠና የወሰዱ 4 ሺህ 35 ዜጎችም ሥልጠናቸውን አጠናቀው ነገ ወደ መጡበት አካባቢ ይመለሳሉ ተብሏል።
በጦላይ የተሃድሶ ማዕከል የተገኙት ጠቅላይ ሚኒስትር ኃይለማርያም ደሳለኝ በዚሁ ጊዜ ባስተላለፉት መልዕክት ሰልጣኞች ወደ መደበኛ ህይወታቸው እንዲመለሱ መንግሥት ድጋፍ ያደርጋል ብለዋል። ሠራተኞች ወደ ሥራ ገበታቸው እንዲመለሱ የሚደረግ ሲሆን ተማሪዎች ደግሞ ትምህርታቸው እንዲቀጥሉ ይደረጋልም ነው ያሉት ጠቅላይ ሚኒስትር ኃይለማርያም።
ሥራ አጥ የሆኑ ወጣቶችም በራሳቸው መንገድ ሥራ እንዲፈጥሩ ድጋፍ እንደሚደረግላቸው ጠቅላይ ሚኒስትሩ ገልጸዋል። ሠላም፣ ልማትና ዴሞክራሲ የማይነጣጡ የአንድ አገር ህልውና መሰረት መሆናቸውን ወጣቱ ተገንዝቦ እነዚህን እሴቶች የመጠበቅ ኃላፊነቱን እንዲወጣ ጠይቀዋል። ወጣቱ ጥያቄ እንኳ ቢኖረው ሕገ-መንግሥቱ በሚፈቅደው መሰረት የማቅረብና መልስ የማግኘት መብት እንዳለው ገልጸዋል። ባለፉት ወራት እንደታየው ጥያቄውን በአመጽና ግርግር መጠየቁ ዋጋ እንዳስከፈለ ለማሳያነት በማንሳት።
እንዲህ ዓይነት ሁኔታ እንዳይደገም መንግሥትም የራሱን ስህተት ለማረም ጥልቅ ተሃድሶ እያደረገ መሆኑን ገልጸው ወጣቱም የራሱን ስህተት በማረም ከመንግሥት ጋር በመሆን ሠላሙን እንዲጠብቅ መልዕክት አስተላልፈዋል። የኦሮሚያ ክልል ርዕሰ መስተዳደር አቶ ለማ መገርሳ በበኩላቸው በክልሉ የሰፈነውን ሠላም ለማስቀጠል ከሁሉም የህብረተሰብ ክፍል ጋር በቅንጅት ሥራዎች ይሰራሉ ብለዋል።
ከወራት በፊት በተፈጠረው ሁከትና ግርግር ህይወት የጠፋ መሆኑን ገልጸው ለዘመናት የተለፋባቸው የህዝብ ኃብቶችም መውደማቸው አግባብ አለመሆኑን ተናግረዋል። ክልሉ ሊለወጥና ሊለማ የሚችለው የክልሉ ወጣቶች ለሠላም በጋራ ዘብ ሲቆሙ እንደሆነም አስምረውበታል።
አሁን ወደ | [
-0.6357455253601074,
-0.38550883531570435,
0.010731568560004234,
0.6608197093009949,
-0.6048669815063477,
-0.6914170980453491,
0.1849038302898407,
-0.2502121925354004,
0.26496008038520813,
0.9234179258346558,
0.069342240691185,
-0.41852253675460815,
-0.5734995603561401,
0.12186581641435623... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
h4iku/coconut_java2006_preprocessed | h4iku | 2022-04-21T20:04:55Z | 35 | 0 | null | [
"region:us"
] | 2022-04-21T20:04:55Z | 2022-04-21T19:16:05.000Z | 2022-04-21T19:16:05 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622264862060547,
0.43461528420448303,
-0.52829909324646,
0.7012971639633179,
0.7915720343589783,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104477167129517,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
strombergnlp/ans-stance | strombergnlp | 2022-10-25T21:45:09Z | 35 | 1 | null | [
"task_categories:text-classification",
"task_ids:fact-checking",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:ar",
"license:apache-2.0",
"stance-detection",
"arxiv:2005.10410",
"... | 2022-10-25T21:45:09Z | 2022-05-20T12:30:15.000Z | 2022-05-20T12:30:15 | ---
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- ar
license:
- apache-2.0
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- fact-checking
pretty_name: ans-stance
tags:
- stance-detection
---
# Dataset Card for AraStance
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** [https://github.com/latynt/ans](https://github.com/latynt/ans)
- **Paper:** [https://arxiv.org/abs/2005.10410](https://arxiv.org/abs/2005.10410)
- **Point of Contact:** [Jude Khouja](jude@latynt.com)
### Dataset Summary
The dataset is a collection of news titles in arabic along with paraphrased and corrupted titles. The stance prediction version is a 3-class classification task. Data contains three columns: s1, s2, stance.
### Languages
Arabic
## Dataset Structure
### Data Instances
An example of 'train' looks as follows:
```
{
'id': '0',
's1': 'هجوم صاروخي يستهدف مطار في طرابلس ويجبر ليبيا على تغيير مسار الرحلات الجوية',
's2': 'هدوء الاشتباكات فى طرابلس',
'stance': 0
}
```
### Data Fields
- `id`: a 'string' feature.
- `s1`: a 'string' expressing a claim/topic.
- `s2`: a 'string' to be classified for its stance to the source.
- `stance`: a class label representing the stance the article expresses towards the claim. Full tagset with indices:
```
0: "disagree",
1: "agree",
2: "other",
```
### Data Splits
|name|instances|
|----|----:|
|train|2652|
|validation|755|
|test|379|
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
The dataset is curated by the paper's authors
### Licensing Information
The authors distribute this data under the Apache License, Version 2.0
### Citation Information
```
@inproceedings{,
title = "Stance Prediction and Claim Verification: An {A}rabic Perspective",
author = "Khouja, Jude",
booktitle = "Proceedings of the Third Workshop on Fact Extraction and {VER}ification ({FEVER})",
year = "2020",
address = "Seattle, USA",
publisher = "Association for Computational Linguistics",
}
```
### Contributions
Thanks to [mkonxd](https://github.com/mkonxd) for adding this dataset. | [
-0.45447012782096863,
-0.4940880239009857,
0.16380445659160614,
0.11831363290548325,
-0.3111984431743622,
0.13212664425373077,
-0.29237428307533264,
-0.4527530372142792,
0.5597289800643921,
0.45255106687545776,
-0.5423358082771301,
-1.1590306758880615,
-0.925886869430542,
0.124593332409858... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
BeIR/quora-qrels | BeIR | 2022-10-23T06:07:21Z | 35 | 0 | beir | [
"task_categories:text-retrieval",
"task_ids:entity-linking-retrieval",
"task_ids:fact-checking-retrieval",
"multilinguality:monolingual",
"language:en",
"license:cc-by-sa-4.0",
"region:us"
] | 2022-10-23T06:07:21Z | 2022-06-05T17:27:09.000Z | 2022-06-05T17:27:09 | ---
annotations_creators: []
language_creators: []
language:
- en
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
paperswithcode_id: beir
pretty_name: BEIR Benchmark
size_categories:
msmarco:
- 1M<n<10M
trec-covid:
- 100k<n<1M
nfcorpus:
- 1K<n<10K
nq:
- 1M<n<10M
hotpotqa:
- 1M<n<10M
fiqa:
- 10K<n<100K
arguana:
- 1K<n<10K
touche-2020:
- 100K<n<1M
cqadupstack:
- 100K<n<1M
quora:
- 100K<n<1M
dbpedia:
- 1M<n<10M
scidocs:
- 10K<n<100K
fever:
- 1M<n<10M
climate-fever:
- 1M<n<10M
scifact:
- 1K<n<10K
source_datasets: []
task_categories:
- text-retrieval
- zero-shot-retrieval
- information-retrieval
- zero-shot-information-retrieval
task_ids:
- passage-retrieval
- entity-linking-retrieval
- fact-checking-retrieval
- tweet-retrieval
- citation-prediction-retrieval
- duplication-question-retrieval
- argument-retrieval
- news-retrieval
- biomedical-information-retrieval
- question-answering-retrieval
---
# Dataset Card for BEIR Benchmark
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://github.com/UKPLab/beir
- **Repository:** https://github.com/UKPLab/beir
- **Paper:** https://openreview.net/forum?id=wCu6T5xFjeJ
- **Leaderboard:** https://docs.google.com/spreadsheets/d/1L8aACyPaXrL8iEelJLGqlMqXKPX2oSP_R10pZoy77Ns
- **Point of Contact:** nandan.thakur@uwaterloo.ca
### Dataset Summary
BEIR is a heterogeneous benchmark that has been built from 18 diverse datasets representing 9 information retrieval tasks:
- Fact-checking: [FEVER](http://fever.ai), [Climate-FEVER](http://climatefever.ai), [SciFact](https://github.com/allenai/scifact)
- Question-Answering: [NQ](https://ai.google.com/research/NaturalQuestions), [HotpotQA](https://hotpotqa.github.io), [FiQA-2018](https://sites.google.com/view/fiqa/)
- Bio-Medical IR: [TREC-COVID](https://ir.nist.gov/covidSubmit/index.html), [BioASQ](http://bioasq.org), [NFCorpus](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/)
- News Retrieval: [TREC-NEWS](https://trec.nist.gov/data/news2019.html), [Robust04](https://trec.nist.gov/data/robust/04.guidelines.html)
- Argument Retrieval: [Touche-2020](https://webis.de/events/touche-20/shared-task-1.html), [ArguAna](tp://argumentation.bplaced.net/arguana/data)
- Duplicate Question Retrieval: [Quora](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs), [CqaDupstack](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/)
- Citation-Prediction: [SCIDOCS](https://allenai.org/data/scidocs)
- Tweet Retrieval: [Signal-1M](https://research.signal-ai.com/datasets/signal1m-tweetir.html)
- Entity Retrieval: [DBPedia](https://github.com/iai-group/DBpedia-Entity/)
All these datasets have been preprocessed and can be used for your experiments.
```python
```
### Supported Tasks and Leaderboards
The dataset supports a leaderboard that evaluates models against task-specific metrics such as F1 or EM, as well as their ability to retrieve supporting information from Wikipedia.
The current best performing models can be found [here](https://eval.ai/web/challenges/challenge-page/689/leaderboard/).
### Languages
All tasks are in English (`en`).
## Dataset Structure
All BEIR datasets must contain a corpus, queries and qrels (relevance judgments file). They must be in the following format:
- `corpus` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with three fields `_id` with unique document identifier, `title` with document title (optional) and `text` with document paragraph or passage. For example: `{"_id": "doc1", "title": "Albert Einstein", "text": "Albert Einstein was a German-born...."}`
- `queries` file: a `.jsonl` file (jsonlines) that contains a list of dictionaries, each with two fields `_id` with unique query identifier and `text` with query text. For example: `{"_id": "q1", "text": "Who developed the mass-energy equivalence formula?"}`
- `qrels` file: a `.tsv` file (tab-seperated) that contains three columns, i.e. the `query-id`, `corpus-id` and `score` in this order. Keep 1st row as header. For example: `q1 doc1 1`
### Data Instances
A high level example of any beir dataset:
```python
corpus = {
"doc1" : {
"title": "Albert Einstein",
"text": "Albert Einstein was a German-born theoretical physicist. who developed the theory of relativity, \
one of the two pillars of modern physics (alongside quantum mechanics). His work is also known for \
its influence on the philosophy of science. He is best known to the general public for his mass–energy \
equivalence formula E = mc2, which has been dubbed 'the world's most famous equation'. He received the 1921 \
Nobel Prize in Physics 'for his services to theoretical physics, and especially for his discovery of the law \
of the photoelectric effect', a pivotal step in the development of quantum theory."
},
"doc2" : {
"title": "", # Keep title an empty string if not present
"text": "Wheat beer is a top-fermented beer which is brewed with a large proportion of wheat relative to the amount of \
malted barley. The two main varieties are German Weißbier and Belgian witbier; other types include Lambic (made\
with wild yeast), Berliner Weisse (a cloudy, sour beer), and Gose (a sour, salty beer)."
},
}
queries = {
"q1" : "Who developed the mass-energy equivalence formula?",
"q2" : "Which beer is brewed with a large proportion of wheat?"
}
qrels = {
"q1" : {"doc1": 1},
"q2" : {"doc2": 1},
}
```
### Data Fields
Examples from all configurations have the following features:
### Corpus
- `corpus`: a `dict` feature representing the document title and passage text, made up of:
- `_id`: a `string` feature representing the unique document id
- `title`: a `string` feature, denoting the title of the document.
- `text`: a `string` feature, denoting the text of the document.
### Queries
- `queries`: a `dict` feature representing the query, made up of:
- `_id`: a `string` feature representing the unique query id
- `text`: a `string` feature, denoting the text of the query.
### Qrels
- `qrels`: a `dict` feature representing the query document relevance judgements, made up of:
- `_id`: a `string` feature representing the query id
- `_id`: a `string` feature, denoting the document id.
- `score`: a `int32` feature, denoting the relevance judgement between query and document.
### Data Splits
| Dataset | Website| BEIR-Name | Type | Queries | Corpus | Rel D/Q | Down-load | md5 |
| -------- | -----| ---------| --------- | ----------- | ---------| ---------| :----------: | :------:|
| MSMARCO | [Homepage](https://microsoft.github.io/msmarco/)| ``msmarco`` | ``train``<br>``dev``<br>``test``| 6,980 | 8.84M | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/msmarco.zip) | ``444067daf65d982533ea17ebd59501e4`` |
| TREC-COVID | [Homepage](https://ir.nist.gov/covidSubmit/index.html)| ``trec-covid``| ``test``| 50| 171K| 493.5 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/trec-covid.zip) | ``ce62140cb23feb9becf6270d0d1fe6d1`` |
| NFCorpus | [Homepage](https://www.cl.uni-heidelberg.de/statnlpgroup/nfcorpus/) | ``nfcorpus`` | ``train``<br>``dev``<br>``test``| 323 | 3.6K | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nfcorpus.zip) | ``a89dba18a62ef92f7d323ec890a0d38d`` |
| BioASQ | [Homepage](http://bioasq.org) | ``bioasq``| ``train``<br>``test`` | 500 | 14.91M | 8.05 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#2-bioasq) |
| NQ | [Homepage](https://ai.google.com/research/NaturalQuestions) | ``nq``| ``train``<br>``test``| 3,452 | 2.68M | 1.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/nq.zip) | ``d4d3d2e48787a744b6f6e691ff534307`` |
| HotpotQA | [Homepage](https://hotpotqa.github.io) | ``hotpotqa``| ``train``<br>``dev``<br>``test``| 7,405 | 5.23M | 2.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/hotpotqa.zip) | ``f412724f78b0d91183a0e86805e16114`` |
| FiQA-2018 | [Homepage](https://sites.google.com/view/fiqa/) | ``fiqa`` | ``train``<br>``dev``<br>``test``| 648 | 57K | 2.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip) | ``17918ed23cd04fb15047f73e6c3bd9d9`` |
| Signal-1M(RT) | [Homepage](https://research.signal-ai.com/datasets/signal1m-tweetir.html)| ``signal1m`` | ``test``| 97 | 2.86M | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#4-signal-1m) |
| TREC-NEWS | [Homepage](https://trec.nist.gov/data/news2019.html) | ``trec-news`` | ``test``| 57 | 595K | 19.6 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#1-trec-news) |
| ArguAna | [Homepage](http://argumentation.bplaced.net/arguana/data) | ``arguana``| ``test`` | 1,406 | 8.67K | 1.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/arguana.zip) | ``8ad3e3c2a5867cdced806d6503f29b99`` |
| Touche-2020| [Homepage](https://webis.de/events/touche-20/shared-task-1.html) | ``webis-touche2020``| ``test``| 49 | 382K | 19.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/webis-touche2020.zip) | ``46f650ba5a527fc69e0a6521c5a23563`` |
| CQADupstack| [Homepage](http://nlp.cis.unimelb.edu.au/resources/cqadupstack/) | ``cqadupstack``| ``test``| 13,145 | 457K | 1.4 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/cqadupstack.zip) | ``4e41456d7df8ee7760a7f866133bda78`` |
| Quora| [Homepage](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) | ``quora``| ``dev``<br>``test``| 10,000 | 523K | 1.6 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/quora.zip) | ``18fb154900ba42a600f84b839c173167`` |
| DBPedia | [Homepage](https://github.com/iai-group/DBpedia-Entity/) | ``dbpedia-entity``| ``dev``<br>``test``| 400 | 4.63M | 38.2 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/dbpedia-entity.zip) | ``c2a39eb420a3164af735795df012ac2c`` |
| SCIDOCS| [Homepage](https://allenai.org/data/scidocs) | ``scidocs``| ``test``| 1,000 | 25K | 4.9 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scidocs.zip) | ``38121350fc3a4d2f48850f6aff52e4a9`` |
| FEVER | [Homepage](http://fever.ai) | ``fever``| ``train``<br>``dev``<br>``test``| 6,666 | 5.42M | 1.2| [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fever.zip) | ``5a818580227bfb4b35bb6fa46d9b6c03`` |
| Climate-FEVER| [Homepage](http://climatefever.ai) | ``climate-fever``|``test``| 1,535 | 5.42M | 3.0 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/climate-fever.zip) | ``8b66f0a9126c521bae2bde127b4dc99d`` |
| SciFact| [Homepage](https://github.com/allenai/scifact) | ``scifact``| ``train``<br>``test``| 300 | 5K | 1.1 | [Link](https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/scifact.zip) | ``5f7d1de60b170fc8027bb7898e2efca1`` |
| Robust04 | [Homepage](https://trec.nist.gov/data/robust/04.guidelines.html) | ``robust04``| ``test``| 249 | 528K | 69.9 | No | [How to Reproduce?](https://github.com/UKPLab/beir/blob/main/examples/dataset#3-robust04) |
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
[Needs More Information]
#### Who are the annotators?
[Needs More Information]
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
[Needs More Information]
### Citation Information
Cite as:
```
@inproceedings{
thakur2021beir,
title={{BEIR}: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models},
author={Nandan Thakur and Nils Reimers and Andreas R{\"u}ckl{\'e} and Abhishek Srivastava and Iryna Gurevych},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)},
year={2021},
url={https://openreview.net/forum?id=wCu6T5xFjeJ}
}
```
### Contributions
Thanks to [@Nthakur20](https://github.com/Nthakur20) for adding this dataset. | [
-0.5227212905883789,
-0.5249219536781311,
0.14435674250125885,
0.04820423573255539,
0.055916160345077515,
0.0011022627586498857,
-0.1081070527434349,
-0.24874727427959442,
0.28598034381866455,
0.07840226590633392,
-0.45233607292175293,
-0.7186435461044312,
-0.347678542137146,
0.20300328731... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
SpeedOfMagic/ontonotes_english | SpeedOfMagic | 2022-07-01T16:06:06Z | 35 | 2 | null | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|other",
"language:en",
"license:unknown",
"region:us"
] | 2022-07-01T16:06:06Z | 2022-06-28T17:34:30.000Z | 2022-06-28T17:34:30 | ---
annotations_creators:
- found
language_creators:
- found
language:
- en
license:
- unknown
multilinguality:
- monolingual
pretty_name: ontonotes_english
size_categories:
- 10K<n<100K
source_datasets:
- extended|other
task_categories:
- token-classification
task_ids:
- named-entity-recognition
---
# Dataset Card for ontonotes_english
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [CoNLL-2012 Shared Task](https://conll.cemantix.org/2012/data.html), [Author's page](https://cemantix.org/data/ontonotes.html)
- **Repository:**
- **Paper:** [Towards Robust Linguistic Analysis using OntoNotes](https://aclanthology.org/W13-3516/)
- **Leaderboard:** [Papers With Code](https://paperswithcode.com/sota/named-entity-recognition-ner-on-ontonotes-v5)
- **Point of Contact:**
### Dataset Summary
This is preprocessed version of what I assume is OntoNotes v5.0.
Instead of having sentences stored in files, files are unpacked and sentences are the rows now. Also, fields were renamed in order to match [conll2003](https://huggingface.co/datasets/conll2003).
The source of data is from private repository, which in turn got data from another public repository, location of which is unknown :)
Since data from all repositories had no license (creator of the private repository told me so), there should be no licensing issues. But bear in mind, I don't give any guarantees that this is real OntoNotes, and may differ as a result.
### Supported Tasks and Leaderboards
- [Named Entity Recognition on Ontonotes v5 (English)](https://paperswithcode.com/sota/named-entity-recognition-ner-on-ontonotes-v5)
- [Coreference Resolution on OntoNotes](https://paperswithcode.com/sota/coreference-resolution-on-ontonotes)
- [Semantic Role Labeling on OntoNotes](https://paperswithcode.com/sota/semantic-role-labeling-on-ontonotes)
### Languages
English
## Dataset Structure
### Data Instances
```
{
'tokens': ['Well', ',', 'the', 'Hundred', 'Regiments', 'Offensive', 'was', 'divided', 'into', 'three', 'phases', '.'],
'ner_tags': [0, 0, 29, 30, 30, 30, 0, 0, 0, 27, 0, 0]
}
```
### Data Fields
- **`tokens`** (*`List[str]`*) : **`words`** in original dataset
- **`ner_tags`** (*`List[ClassLabel]`*) : **`named_entities`** in original dataset. The BIO tags for named entities in the sentence.
- tag set : `datasets.ClassLabel(num_classes=37, names=["O", "B-PERSON", "I-PERSON", "B-NORP", "I-NORP", "B-FAC", "I-FAC", "B-ORG", "I-ORG", "B-GPE", "I-GPE", "B-LOC", "I-LOC", "B-PRODUCT", "I-PRODUCT", "B-DATE", "I-DATE", "B-TIME", "I-TIME", "B-PERCENT", "I-PERCENT", "B-MONEY", "I-MONEY", "B-QUANTITY", "I-QUANTITY", "B-ORDINAL", "I-ORDINAL", "B-CARDINAL", "I-CARDINAL", "B-EVENT", "I-EVENT", "B-WORK_OF_ART", "I-WORK_OF_ART", "B-LAW", "I-LAW", "B-LANGUAGE", "I-LANGUAGE",])`
### Data Splits
_train_, _validation_, and _test_
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
No license
### Citation Information
```
@inproceedings{pradhan-etal-2013-towards,
title = "Towards Robust Linguistic Analysis using {O}nto{N}otes",
author = {Pradhan, Sameer and
Moschitti, Alessandro and
Xue, Nianwen and
Ng, Hwee Tou and
Bj{\"o}rkelund, Anders and
Uryupina, Olga and
Zhang, Yuchen and
Zhong, Zhi},
booktitle = "Proceedings of the Seventeenth Conference on Computational Natural Language Learning",
month = aug,
year = "2013",
address = "Sofia, Bulgaria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W13-3516",
pages = "143--152",
}
```
### Contributions
Thanks to the author of private repository, that uploaded this dataset. | [
-0.2806526720523834,
-0.6955991387367249,
0.3237267732620239,
0.19858655333518982,
-0.22231240570545197,
-0.030180586501955986,
-0.542090654373169,
-0.4482378661632538,
0.5335207581520081,
0.7414897084236145,
-0.6254180669784546,
-0.9844277501106262,
-0.6674384474754333,
0.4384982585906982... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
arize-ai/xtreme_en_token_drift | arize-ai | 2022-07-01T17:25:34Z | 35 | 1 | null | [
"task_categories:token-classification",
"task_ids:named-entity-recognition",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|xtreme",
"language:en",
"license:mit",
"region:us"
] | 2022-07-01T17:25:34Z | 2022-06-30T21:08:01.000Z | 2022-06-30T21:08:01 | ---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en
license:
- mit
multilinguality:
- monolingual
pretty_name: named-entity-recognition-en-no-drift
size_categories:
- 10K<n<100K
source_datasets:
- extended|xtreme
task_categories:
- token-classification
task_ids:
- named-entity-recognition
---
# Dataset Card for `reviews_with_drift`
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
### Dataset Summary
This dataset was crafted to be used in our tutorial [Link to the tutorial when ready]. It consists on a large Movie Review Dataset mixed with some reviews from a Hotel Review Dataset. The training/validation set are purely obtained from the Movie Review Dataset while the production set is mixed. Some other features have been added (`age`, `gender`, `context`) as well as a made up timestamp `prediction_ts` of when the inference took place.
### Supported Tasks and Leaderboards
`text-classification`, `sentiment-classification`: The dataset is mainly used for text classification: given the text, predict the sentiment (positive or negative).
### Languages
Text is mainly written in english.
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
[More Information Needed]
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
[More Information Needed]
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
Thanks to [@fjcasti1](https://github.com/fjcasti1) for adding this dataset. | [
-0.628180205821991,
-0.4517955482006073,
0.25332391262054443,
0.13039681315422058,
-0.37903034687042236,
0.17068056762218475,
-0.3452197015285492,
-0.19959135353565216,
0.6291214823722839,
0.6300225853919983,
-1.0287785530090332,
-0.9946330189704895,
-0.5445864200592041,
0.0366437509655952... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Paul/hatecheck-italian | Paul | 2022-07-05T10:35:17Z | 35 | 1 | null | [
"task_categories:text-classification",
"task_ids:hate-speech-detection",
"annotations_creators:crowdsourced",
"language_creators:expert-generated",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:it",
"license:cc-by-4.0",
"arxiv:2206.09917",
"regi... | 2022-07-05T10:35:17Z | 2022-07-05T10:33:01.000Z | 2022-07-05T10:33:01 | ---
annotations_creators:
- crowdsourced
language_creators:
- expert-generated
language:
- it
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: Italian HateCheck
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- hate-speech-detection
---
# Dataset Card for Multilingual HateCheck
## Dataset Description
Multilingual HateCheck (MHC) is a suite of functional tests for hate speech detection models in 10 different languages: Arabic, Dutch, French, German, Hindi, Italian, Mandarin, Polish, Portuguese and Spanish.
For each language, there are 25+ functional tests that correspond to distinct types of hate and challenging non-hate.
This allows for targeted diagnostic insights into model performance.
For more details, please refer to our paper about MHC, published at the 2022 Workshop on Online Abuse and Harms (WOAH) at NAACL 2022. If you are using MHC, please cite our work!
- **Paper:** Röttger et al. (2022) - Multilingual HateCheck: Functional Tests for Multilingual Hate Speech Detection Models. https://arxiv.org/abs/2206.09917
- **Repository:** https://github.com/rewire-online/multilingual-hatecheck
- **Point of Contact:** paul@rewire.online
## Dataset Structure
The csv format mostly matches the original HateCheck data, with some adjustments for specific languages.
**mhc_case_id**
The test case ID that is unique to each test case across languages (e.g., "mandarin-1305")
**functionality**
The shorthand for the functionality tested by the test case (e.g, "target_obj_nh"). The same functionalities are tested in all languages, except for Mandarin and Arabic, where non-Latin script required adapting the tests for spelling variations.
**test_case**
The test case text.
**label_gold**
The gold standard label ("hateful" or "non-hateful") of the test case. All test cases within a given functionality have the same gold standard label.
**target_ident**
Where applicable, the protected group that is targeted or referenced in the test case. All HateChecks cover seven target groups, but their composition varies across languages.
**ref_case_id**
For hateful cases, where applicable, the ID of the hateful case which was perturbed to generate this test case. For non-hateful cases, where applicable, the ID of the hateful case which is contrasted by this test case.
**ref_templ_id**
The equivalent to ref_case_id, but for template IDs.
**templ_id**
The ID of the template from which the test case was generated.
**case_templ**
The template from which the test case was generated (where applicable).
**gender_male** and **gender_female**
For gender-inflected languages (French, Spanish, Portuguese, Hindi, Arabic, Italian, Polish, German), only for cases where gender inflection is relevant, separate entries for gender_male and gender_female replace case_templ.
**label_annotated**
A list of labels given by the three annotators who reviewed the test case (e.g., "['hateful', 'hateful', 'hateful']").
**label_annotated_maj**
The majority vote of the three annotators (e.g., "hateful"). In some cases this differs from the gold label given by our language experts.
**disagreement_in_case**
True if label_annotated_maj does not match label_gold for the entry.
**disagreement_in_template**
True if the test case is generated from an IDENT template and there is at least one case with disagreement_in_case generated from the same template. This can be used to exclude entire templates from MHC. | [
-0.6419410109519958,
-0.7158888578414917,
-0.05510091781616211,
0.09203927218914032,
-0.11549574136734009,
0.10751984268426895,
-0.030292538926005363,
-0.5101842880249023,
0.39948996901512146,
0.3274587094783783,
-0.7589272260665894,
-0.7721040844917297,
-0.5623311400413513,
0.460262417793... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Artificio/WikiArt | Artificio | 2023-01-18T17:13:54Z | 35 | 5 | null | [
"region:us"
] | 2023-01-18T17:13:54Z | 2022-07-21T21:18:50.000Z | 2022-07-21T21:18:50 | ---
dataset_info:
features:
- name: title
dtype: string
- name: artist
dtype: string
- name: date
dtype: string
- name: genre
dtype: string
- name: style
dtype: string
- name: description
dtype: string
- name: filename
dtype: string
- name: image
dtype: image
- name: embeddings_pca512
sequence: float32
splits:
- name: train
num_bytes: 1659296285.75
num_examples: 103250
download_size: 1711766693
dataset_size: 1659296285.75
---
# Dataset Card for "WikiArt"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.7756954431533813,
-0.2497142255306244,
0.1646447479724884,
0.07148609310388565,
-0.24520985782146454,
-0.04942452162504196,
0.07269854843616486,
-0.24663300812244415,
0.8990945219993591,
0.3500763475894928,
-0.8343549370765686,
-0.6352429986000061,
-0.6380680203437805,
-0.17652536928653... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
yhavinga/cnn_dailymail_dutch | yhavinga | 2022-08-20T12:39:20Z | 35 | 1 | cnn-daily-mail-1 | [
"task_categories:summarization",
"task_ids:news-articles-summarization",
"annotations_creators:no-annotation",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"source_datasets:original",
"language:nl",
"license:apache-2.0",
"region:us"
] | 2022-08-20T12:39:20Z | 2022-08-16T18:25:06.000Z | 2022-08-16T18:25:06 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- nl
license:
- apache-2.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- summarization
task_ids:
- news-articles-summarization
paperswithcode_id: cnn-daily-mail-1
pretty_name: CNN / Daily Mail
train-eval-index:
- config: 3.0.0
task: summarization
task_id: summarization
splits:
eval_split: test
col_mapping:
article: text
highlights: target
---
# Dataset Card for CNN Dailymail Dutch 🇳🇱🇧🇪 Dataset
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
Note: the data below is from the English version at [cnn_dailymail](https://huggingface.co/datasets/cnn_dailymail).
- **Homepage:**
- **Repository:** [CNN / DailyMail Dataset repository](https://github.com/abisee/cnn-dailymail)
- **Paper:** [Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond](https://papers.nips.cc/paper/5945-teaching-machines-to-read-and-comprehend.pdf), [Get To The Point: Summarization with Pointer-Generator Networks](https://www.aclweb.org/anthology/K16-1028.pdf)
- **Leaderboard:** [Papers with Code leaderboard for CNN / Dailymail Dataset](https://paperswithcode.com/sota/document-summarization-on-cnn-daily-mail)
- **Point of Contact:** [Abigail See](mailto:abisee@stanford.edu)
### Dataset Summary
The CNN / DailyMail Dutch 🇳🇱🇧🇪 Dataset is an English-language dataset translated to Dutch containing just over 300k unique news articles as written by journalists at CNN and the Daily Mail. The current version supports both extractive and abstractive summarization, though the original version was created for machine reading and comprehension and abstractive question answering.
*This dataset currently (Aug '22) has a single config, which is
config `3.0.0` of [cnn_dailymail](https://huggingface.co/datasets/cnn_dailymail) translated to Dutch
with [yhavinga/t5-base-36L-ccmatrix-multi](https://huggingface.co/yhavinga/t5-base-36L-ccmatrix-multi).*
### Supported Tasks and Leaderboards
- 'summarization': [Version 3.0.0 of the CNN / DailyMail Dataset](https://www.aclweb.org/anthology/K16-1028.pdf) can be used to train a model for abstractive and extractive summarization ([Version 1.0.0](https://papers.nips.cc/paper/5945-teaching-machines-to-read-and-comprehend.pdf) was developed for machine reading and comprehension and abstractive question answering). The model performance is measured by how high the output summary's [ROUGE](https://huggingface.co/metrics/rouge) score for a given article is when compared to the highlight as written by the original article author. [Zhong et al (2020)](https://www.aclweb.org/anthology/2020.acl-main.552.pdf) report a ROUGE-1 score of 44.41 when testing a model trained for extractive summarization. See the [Papers With Code leaderboard](https://paperswithcode.com/sota/document-summarization-on-cnn-daily-mail) for more models.
### Languages
The BCP-47 code for English as generally spoken in the United States is en-US and the BCP-47 code for English as generally spoken in the United Kingdom is en-GB. It is unknown if other varieties of English are represented in the data.
## Dataset Structure
### Data Instances
For each instance, there is a string for the article, a string for the highlights, and a string for the id. See the [CNN / Daily Mail dataset viewer](https://huggingface.co/datasets/viewer/?dataset=cnn_dailymail&config=3.0.0) to explore more examples.
```
{'id': '0054d6d30dbcad772e20b22771153a2a9cbeaf62',
'article': '(CNN) -- An American woman died aboard a cruise ship that docked at Rio de Janeiro on Tuesday, the same ship on which 86 passengers previously fell ill, according to the state-run Brazilian news agency, Agencia Brasil. The American tourist died aboard the MS Veendam, owned by cruise operator Holland America. Federal Police told Agencia Brasil that forensic doctors were investigating her death. The ship's doctors told police that the woman was elderly and suffered from diabetes and hypertension, according the agency. The other passengers came down with diarrhea prior to her death during an earlier part of the trip, the ship's doctors said. The Veendam left New York 36 days ago for a South America tour.'
'highlights': 'The elderly woman suffered from diabetes and hypertension, ship's doctors say .\nPreviously, 86 passengers had fallen ill on the ship, Agencia Brasil says .'}
```
The average token count for the articles and the highlights are provided below:
| Feature | Mean Token Count |
| ---------- | ---------------- |
| Article | 781 |
| Highlights | 56 |
### Data Fields
- `id`: a string containing the heximal formated SHA1 hash of the url where the story was retrieved from
- `article`: a string containing the body of the news article
- `highlights`: a string containing the highlight of the article as written by the article author
### Data Splits
The CNN/DailyMail dataset has 3 splits: _train_, _validation_, and _test_. Below are the statistics for Version 3.0.0 of the dataset.
| Dataset Split | Number of Instances in Split |
| ------------- | ------------------------------------------- |
| Train | 287,113 |
| Validation | 13,368 |
| Test | 11,490 |
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
The data consists of news articles and highlight sentences. In the question answering setting of the data, the articles are used as the context and entities are hidden one at a time in the highlight sentences, producing Cloze style questions where the goal of the model is to correctly guess which entity in the context has been hidden in the highlight. In the summarization setting, the highlight sentences are concatenated to form a summary of the article. The CNN articles were written between April 2007 and April 2015. The Daily Mail articles were written between June 2010 and April 2015.
The code for the original data collection is available at <https://github.com/deepmind/rc-data>. The articles were downloaded using archives of <www.cnn.com> and <www.dailymail.co.uk> on the Wayback Machine. Articles were not included in the Version 1.0.0 collection if they exceeded 2000 tokens. Due to accessibility issues with the Wayback Machine, Kyunghyun Cho has made the datasets available at <https://cs.nyu.edu/~kcho/DMQA/>. An updated version of the code that does not anonymize the data is available at <https://github.com/abisee/cnn-dailymail>.
Hermann et al provided their own tokenization script. The script provided by See uses the PTBTokenizer. It also lowercases the text and adds periods to lines missing them.
#### Who are the source language producers?
The text was written by journalists at CNN and the Daily Mail.
### Annotations
The dataset does not contain any additional annotations.
#### Annotation process
[N/A]
#### Who are the annotators?
[N/A]
### Personal and Sensitive Information
Version 3.0 is not anonymized, so individuals' names can be found in the dataset. Information about the original author is not included in the dataset.
## Considerations for Using the Data
### Social Impact of Dataset
The purpose of this dataset is to help develop models that can summarize long paragraphs of text in one or two sentences.
This task is useful for efficiently presenting information given a large quantity of text. It should be made clear that any summarizations produced by models trained on this dataset are reflective of the language used in the articles, but are in fact automatically generated.
### Discussion of Biases
[Bordia and Bowman (2019)](https://www.aclweb.org/anthology/N19-3002.pdf) explore measuring gender bias and debiasing techniques in the CNN / Dailymail dataset, the Penn Treebank, and WikiText-2. They find the CNN / Dailymail dataset to have a slightly lower gender bias based on their metric compared to the other datasets, but still show evidence of gender bias when looking at words such as 'fragile'.
Because the articles were written by and for people in the US and the UK, they will likely present specifically US and UK perspectives and feature events that are considered relevant to those populations during the time that the articles were published.
### Other Known Limitations
News articles have been shown to conform to writing conventions in which important information is primarily presented in the first third of the article [(Kryściński et al, 2019)](https://www.aclweb.org/anthology/D19-1051.pdf). [Chen et al (2016)](https://www.aclweb.org/anthology/P16-1223.pdf) conducted a manual study of 100 random instances of the first version of the dataset and found 25% of the samples to be difficult even for humans to answer correctly due to ambiguity and coreference errors.
It should also be noted that machine-generated summarizations, even when extractive, may differ in truth values when compared to the original articles.
## Additional Information
### Dataset Curators
The data was originally collected by Karl Moritz Hermann, Tomáš Kočiský, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom of Google DeepMind. Tomáš Kočiský and Phil Blunsom are also affiliated with the University of Oxford. They released scripts to collect and process the data into the question answering format.
Ramesh Nallapati, Bowen Zhou, Cicero dos Santos, and Bing Xiang of IMB Watson and Çağlar Gu̇lçehre of Université de Montréal modified Hermann et al's collection scripts to restore the data to a summary format. They also produced both anonymized and non-anonymized versions.
The code for the non-anonymized version is made publicly available by Abigail See of Stanford University, Peter J. Liu of Google Brain and Christopher D. Manning of Stanford University at <https://github.com/abisee/cnn-dailymail>. The work at Stanford University was supported by the DARPA DEFT ProgramAFRL contract no. FA8750-13-2-0040.
### Licensing Information
The CNN / Daily Mail dataset version 1.0.0 is released under the [Apache-2.0 License](http://www.apache.org/licenses/LICENSE-2.0).
### Citation Information
```
@inproceedings{see-etal-2017-get,
title = "Get To The Point: Summarization with Pointer-Generator Networks",
author = "See, Abigail and
Liu, Peter J. and
Manning, Christopher D.",
booktitle = "Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2017",
address = "Vancouver, Canada",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P17-1099",
doi = "10.18653/v1/P17-1099",
pages = "1073--1083",
abstract = "Neural sequence-to-sequence models have provided a viable new approach for abstractive text summarization (meaning they are not restricted to simply selecting and rearranging passages from the original text). However, these models have two shortcomings: they are liable to reproduce factual details inaccurately, and they tend to repeat themselves. In this work we propose a novel architecture that augments the standard sequence-to-sequence attentional model in two orthogonal ways. First, we use a hybrid pointer-generator network that can copy words from the source text via pointing, which aids accurate reproduction of information, while retaining the ability to produce novel words through the generator. Second, we use coverage to keep track of what has been summarized, which discourages repetition. We apply our model to the CNN / Daily Mail summarization task, outperforming the current abstractive state-of-the-art by at least 2 ROUGE points.",
}
```
```
@inproceedings{DBLP:conf/nips/HermannKGEKSB15,
author={Karl Moritz Hermann and Tomás Kociský and Edward Grefenstette and Lasse Espeholt and Will Kay and Mustafa Suleyman and Phil Blunsom},
title={Teaching Machines to Read and Comprehend},
year={2015},
cdate={1420070400000},
pages={1693-1701},
url={http://papers.nips.cc/paper/5945-teaching-machines-to-read-and-comprehend},
booktitle={NIPS},
crossref={conf/nips/2015}
}
```
### Contributions
Thanks to [@thomwolf](https://github.com/thomwolf), [@lewtun](https://github.com/lewtun), [@jplu](https://github.com/jplu), [@jbragg](https://github.com/jbragg), [@patrickvonplaten](https://github.com/patrickvonplaten) and [@mcmillanmajora](https://github.com/mcmillanmajora) for adding the English version of this dataset.
The dataset was translated on Cloud TPU compute generously provided by Google through the
[TPU Research Cloud](https://sites.research.google/trc/).
| [
-0.33187851309776306,
-0.6637997031211853,
0.030031753703951836,
0.3393113613128662,
-0.6562973856925964,
-0.08058225363492966,
-0.26962581276893616,
-0.48111915588378906,
0.32399845123291016,
0.35323405265808105,
-0.3560604453086853,
-0.8030579090118408,
-0.6659766435623169,
0.31551167368... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
thennal/IMaSC | thennal | 2022-12-08T17:21:02Z | 35 | 2 | null | [
"task_categories:text-to-speech",
"task_categories:automatic-speech-recognition",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:ml",
"license:cc-by-sa-4.0",
"arxiv:2211.12796",
... | 2022-12-08T17:21:02Z | 2022-11-17T05:16:00.000Z | 2022-11-17T05:16:00 | ---
annotations_creators:
- expert-generated
language:
- ml
language_creators:
- found
license:
- cc-by-sa-4.0
multilinguality:
- monolingual
pretty_name: ICFOSS Malayalam Speech Corpus
size_categories:
- 10K<n<100K
source_datasets:
- original
tags: []
task_categories:
- text-to-speech
- automatic-speech-recognition
task_ids: []
---
# IMaSC: ICFOSS Malayalam Speech Corpus
**IMaSC** is a Malayalam text and speech corpus made available by [ICFOSS](https://icfoss.in/) for the purpose of developing speech technology for Malayalam, particularly text-to-speech. The corpus contains 34,473 text-audio pairs of Malayalam sentences spoken by 8 speakers, totalling in approximately 50 hours of audio.
## Dataset Description
- **Paper:** [IMaSC — ICFOSS Malayalam Speech Corpus](https://arxiv.org/abs/2211.12796)
- **Point of Contact:** [Thennal D K](mailto:thennal10@gmail.com)
## Dataset Structure
The dataset consists of 34,473 instances with fields `text`, `speaker`, and `audio`. The audio is mono, sampled at 16kH. The transcription is normalized and only includes Malayalam characters and common punctuation. The table given below specifies how the 34,473 instances are split between the speakers, along with some basic speaker info:
| Speaker | Gender | Age | Time (HH:MM:SS) | Sentences |
| --- | --- | --- | --- | --- |
| Joji | Male | 28 | 06:08:55 | 4,332 |
| Sonia | Female | 43 | 05:22:39 | 4,294 |
| Jijo | Male | 26 | 05:34:05 | 4,093 |
| Greeshma | Female | 22 | 06:32:39 | 4,416 |
| Anil | Male | 48 | 05:58:34 | 4,239 |
| Vidhya | Female | 23 | 04:21:56 | 3,242 |
| Sonu | Male | 25 | 06:04:43 | 4,219 |
| Simla | Female | 24 | 09:34:21 | 5,638 |
| **Total** | | | **49:37:54** | **34,473** |
### Data Instances
An example instance is given below:
```json
{'text': 'സർവ്വകലാശാല വൈസ് ചാൻസലർ ഡോ. ചന്ദ്രബാബുവിനും സംഭവം തലവേദനയാവുകയാണ്',
'speaker': 'Sonia',
'audio': {'path': None,
'array': array([ 0.00921631, 0.00930786, 0.00939941, ..., -0.00497437,
-0.00497437, -0.00497437]),
'sampling_rate': 16000}}
```
### Data Fields
- **text** (str): Transcription of the audio file
- **speaker** (str): The name of the speaker
- **audio** (dict): Audio object including loaded audio array, sampling rate and path to audio (always None)
### Data Splits
We provide all the data in a single `train` split. The loaded dataset object thus looks like this:
```json
DatasetDict({
train: Dataset({
features: ['text', 'speaker', 'audio'],
num_rows: 34473
})
})
```
### Dataset Creation
The text is sourced from [Malayalam Wikipedia](https://ml.wikipedia.org), and read by our speakers in studio conditions. Extensive error correction was conducted to provide a clean, accurate database. Further details are given in our paper, accessible at [https://arxiv.org/abs/2211.12796](https://arxiv.org/abs/2211.12796).
## Additional Information
### Licensing
The corpus is made available under the [Creative Commons license (CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/).
### Citation
```
@misc{gopinath2022imasc,
title={IMaSC -- ICFOSS Malayalam Speech Corpus},
author={Deepa P Gopinath and Thennal D K and Vrinda V Nair and Swaraj K S and Sachin G},
year={2022},
eprint={2211.12796},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
```
| [
-0.4934239089488983,
-0.6005595326423645,
0.17778150737285614,
0.43453967571258545,
-0.4501033127307892,
-0.01581714116036892,
-0.36556476354599,
-0.3143801987171173,
0.6069144606590271,
0.2872275412082672,
-0.5095772743225098,
-0.5636598467826843,
-0.7702282667160034,
0.2581140995025635,
... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kasnerz/charttotext-s | kasnerz | 2023-03-14T15:08:25Z | 35 | 1 | null | [
"region:us"
] | 2023-03-14T15:08:25Z | 2022-11-28T12:36:03.000Z | 2022-11-28T12:36:03 | Entry not found | [
-0.3227645754814148,
-0.22568479180335999,
0.8622263669967651,
0.43461522459983826,
-0.52829909324646,
0.7012971639633179,
0.7915719747543335,
0.07618614286184311,
0.774603009223938,
0.2563217282295227,
-0.7852813005447388,
-0.22573819756507874,
-0.9104475975036621,
0.5715674161911011,
-... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
kqsong/OASum | kqsong | 2023-07-03T21:02:23Z | 35 | 1 | null | [
"task_categories:summarization",
"size_categories:1M<n<10M",
"language:en",
"license:cc-by-sa-3.0",
"summarization",
"Wikipedia",
"arxiv:2212.09233",
"region:us"
] | 2023-07-03T21:02:23Z | 2022-12-27T22:27:17.000Z | 2022-12-27T22:27:17 | ---
license: cc-by-sa-3.0
language:
- en
tags:
- summarization
- Wikipedia
size_categories:
- 1M<n<10M
task_categories:
- summarization
---
# Dataset Card for OASum Dataset
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Usage](#dataset-usage)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Repository:** [OASum Dataset repository](https://github.com/tencent-ailab/OASum)
- **Paper:** [OASum: Large-Scale Open Domain Aspect-based Summarization](https://arxiv.org/pdf/2212.09233.pdf)
The OASum Dataset is an English-language dataset containing over 3.6M document, aspect, and summary triplets.
## Dataset Usage
You can directly download it with huggingface datasets.
``` python
from datasets import load_dataset
dataset = load_dataset("kqsong/OASum")
```
## Dataset Structure
### Data Instances
For each instance, there is a list of strings for the document, a list of strings for the summary, a string for the document title, a string for the aspect and a list of indices for the sentences in the corresponding section.
```json
{
"title": "Ker's WingHouse Bar & Grill",
"document":[
"After Clearwater, Florida chicken wing pioneering restaurant chain Hooters began rapidly expanding, Florida based, Canadian-born restaurant entrepreneur Ed Burnett saw the opportunity.",
"Burnett secured the rights to a closed restaurant (\"Knockers\") and opened \"The WingHouse\" restaurant at 7369 Ulmerton Road, Largo, Florida, a high traffic corridor.",
"He strategically selected the restaurant in between where people work (commercial real estate) and live (residential real estate), to appeal to the local lunch crowd and family dining crowd.",
"This flagship location proved to be a success soon after launching and is the model that the chain expanded on.",
"Burnett, looking to expand to additional locations, accepted a financing partner (Crawford Ker) during this time frame, to open additional locations and beyond.",
"Burnett's goal was to open 20 to 50 locations, and then sell the chain to a larger restaurant chain or investors.",
"Burnett would ultimately regret his choice of investor.","In 1992, Ker retired from the NFL and took a job selling cars at a local dealer.",
"In 1994, he invested half interest in a Largo, Florida wing restaurant called, \"Wing House\" that imitated Hooters.",
"The restaurant was always The Wing House, and the atmosphere was always toned down to make it more family friendly.",
"The restaurant did well and two additional locations were opened in the Tampa Bay area in the following three years.",
"Ker won a $1.2-million jury award from Hooters in late 2004, which had sued him for trademark violations for allegedly using their uniforms and decor.",
"After a three-week trial in which lawyers discussed hula hoops, surfboards, scrunchy socks, pantyhose, and something called \"vicarious sexual recreation\", the jury ruled that no trademark infringement existed and Hooters was penalized for their frivolous lawsuit.",
"Hooters appealed the decision, but in June, 2006, the 11th U.S. Circuit Court of Appeals in Atlanta upheld the verdict.",
"As of 2007, the company had 1,700 employees at 22 locations with revenue of nearly $60 million.",
"Ker attended, and the company participated in, the 2007 National Buffalo Wing Festival and placed first in the \"traditional x-hot sauce\" category and gained some national recognition.",
"On June 4, 2008 the company announced the launch of its national franchise program.",
"In mid-2008 the chain operated 19 locations in Florida and Texas and expected to add six franchises by the end of 2008, and 48 by 2011.",
"The initial focus was for franchises in the Southeastern US.",
"WingHouses feature several amenities that differ from other wing restaurants, including Hooters.",
"There is a full liquor bar in every store, sports memorabilia line the walls instead of NASCAR and most locations include a game room.",
"Super Bowl XLIII in Tampa, Florida attracted the rich and famous; WingHouse hosted three events to raise money for charity."
],
"aspect": "Opening",
"aspect_sents": [0,1,2,3,4,5,6,7,8,9,10],
"summary":[
"WingHouse Bar & Grill (formerly Ker\u2019s WingHouse Bar & Grill) is a restaurant chain based in Florida, created and founded by Ed Burnett, a Canadian restaurant entrepreneur.",
"After opening his first WingHouse location, Burnett sought out investors to open additional WingHouse locations.",
"Burnett accepted investor Crawford Ker (a former National Football League player) to assist financing the expansion."
]
}
```
The average token count for the articles and the highlights are provided below:
| Feature | Mean Token Count |
| ---------- | ---------------- |
| Document | 1,612 |
| Summary | 40 |
### Data Fields
- `title`: a string, containing the original Wikipedia title.
- `document`: a list of sentences, containing the original content in the Wikipedia sections except the first abstract section.
- `aspect`: a string, containing the section name and its parent section names.
- `aspect_sents`: a list of indices, representing the sentences in the `aspect` section.
- `summary`: a list of sentences, the corresponding aspect-based summary for the document.
### Data Splits
The OASum dataset has 3 splits: _train_, _valid_, and _test_. Below are the statistics for the Version 1.0.0 of the dataset.
| Dataset Split | Number of Instances in Split |
| ------------- | ------------------------------------------- |
| Train | 3,523,986 |
| Validation | 111,578 |
| Test | 112,005 |
## Additional Information
### Licensing Information
The OASum Dataset version 1.0.0 is released under the [CC-BY-SA-3.0 License](https://en.wikipedia.org/wiki/Wikipedia:Text_of_the_Creative_Commons_Attribution-ShareAlike_3.0_Unported_License)
### Citation Information
```
@article{yang2022oasum,
title={Oasum: Large-scale open domain aspect-based summarization},
author={Yang, Xianjun and Song, Kaiqiang and Cho, Sangwoo and Wang, Xiaoyang and Pan, Xiaoman and Petzold, Linda and Yu, Dong},
journal={arXiv preprint arXiv:2212.09233},
year={2022}
}
``` | [
-0.489325612783432,
-0.7902320623397827,
0.24855749309062958,
-0.007121901959180832,
-0.10631205886602402,
-0.14568498730659485,
0.1331145167350769,
-0.4874906837940216,
0.5379276275634766,
0.792650580406189,
-0.342227578163147,
-0.566307544708252,
-0.16550344228744507,
0.1336621642112732,... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
EdBianchi/SmokeFire | EdBianchi | 2022-12-29T14:45:31Z | 35 | 0 | null | [
"region:us"
] | 2022-12-29T14:45:31Z | 2022-12-28T09:21:45.000Z | 2022-12-28T09:21:45 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': Fire
'1': Normal
'2': Smoke
splits:
- name: train
num_bytes: 166216842.46
num_examples: 6060
- name: test
num_bytes: 89193578.0
num_examples: 759
- name: validation
num_bytes: 75838884.0
num_examples: 756
download_size: 890673915
dataset_size: 331249304.46000004
---
# Dataset Card for "SmokeFire"
Wildfires or forest fires are unpredictable catastrophic and destructive events that affect rural areas. The impact of these events affects both vegetation and wildlife.
This dataset can be used to train networks able to detect smoke and/or fire in forest environments.
## Data Sources & Description
- **This dataset consist of sample from two datasets hosted on Kaggle:**
- [Forest Fire](https://www.kaggle.com/datasets/kutaykutlu/forest-fire?select=train_fire)
- [Forest Fire Images](https://www.kaggle.com/datasets/mohnishsaiprasad/forest-fire-images)
- **The datasets consist of:**
- 2525 **Fire** samples
- 2525 **Smoke** samples
- 2525 **Normal** samples
- **The dataset is splitted into:**
- Train Set -> 6060 samples
- Validation Set -> 756 samples
- Test Set -> 759 samples
| [
-0.07024309784173965,
-0.468631774187088,
-0.1210346519947052,
0.21886427700519562,
-0.3030579388141632,
-0.11688635498285294,
0.14952856302261353,
-0.2509933114051819,
0.25851818919181824,
0.6936777830123901,
-0.9949622750282288,
-0.607083261013031,
-0.5073342323303223,
-0.193430826067924... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
qwedsacf/ivypanda-essays | qwedsacf | 2023-02-03T21:05:11Z | 35 | 3 | null | [
"region:us"
] | 2023-02-03T21:05:11Z | 2023-01-23T00:37:04.000Z | 2023-01-23T00:37:04 | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/datasets-cards
{}
---
# Ivypanda essays
## Dataset Description
- **Homepage:** https://laion.ai/
### Dataset Summary
This dataset contains essays from [ivypanda](https://ivypanda.com/essays/).
## Dataset Structure
### Data Fields
`TEXT`: The text of the essay.<br/>
`SOURCE`: A permalink to the ivypanda essay page
| [
-0.17585475742816925,
-0.45555710792541504,
0.3223980665206909,
0.2083616852760315,
0.09280392527580261,
-0.05097120627760887,
0.33051446080207825,
-0.06285197287797928,
0.5720373392105103,
0.7513155937194824,
-0.7307834029197693,
-0.799614429473877,
-0.36181187629699707,
0.042526502162218... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
jonathan-roberts1/USTC_SmokeRS | jonathan-roberts1 | 2023-03-31T14:56:13Z | 35 | 0 | null | [
"license:other",
"region:us"
] | 2023-03-31T14:56:13Z | 2023-01-26T10:45:45.000Z | 2023-01-26T10:45:45 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': cloud
'1': dust
'2': haze
'3': land
'4': seaside
'5': smoke
splits:
- name: train
num_bytes: 1229029078.725
num_examples: 6225
download_size: 1115042620
dataset_size: 1229029078.725
license: other
---
# Dataset Card for "USTC_SmokeRS"
## Dataset Description
- **Paper:** [SmokeNet: Satellite smoke scene detection using convolutional neural network with spatial and channel-wise attention](https://www.mdpi.com/2072-4292/11/14/1702/pdf)
### Licensing Information
For research/education purposes.
## Citation Information
[SmokeNet: Satellite smoke scene detection using convolutional neural network with spatial and channel-wise attention](https://www.mdpi.com/2072-4292/11/14/1702/pdf)
```
@article{ba2019smokenet,
title = {SmokeNet: Satellite smoke scene detection using convolutional neural network with spatial and channel-wise attention},
author = {Ba, Rui and Chen, Chen and Yuan, Jing and Song, Weiguo and Lo, Siuming},
year = 2019,
journal = {Remote Sensing},
publisher = {MDPI},
volume = 11,
number = 14,
pages = 1702
}
``` | [
-0.32609283924102783,
-0.3327505886554718,
0.11196471750736237,
-0.0014762565260753036,
-0.31823140382766724,
-0.535814106464386,
-0.0741388276219368,
-0.18241426348686218,
0.13435079157352448,
0.3798249661922455,
-0.6496645212173462,
-0.617680549621582,
-0.609930157661438,
-0.331644266843... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
heegyu/news-category-dataset | heegyu | 2023-02-09T08:10:48Z | 35 | 0 | null | [
"license:cc-by-4.0",
"region:us"
] | 2023-02-09T08:10:48Z | 2023-02-09T08:08:22.000Z | 2023-02-09T08:08:22 | ---
license: cc-by-4.0
---
Dataset from https://www.kaggle.com/datasets/rmisra/news-category-dataset | [
-0.22054186463356018,
-0.42840901017189026,
0.2278495728969574,
-0.017132597044110298,
-0.28593358397483826,
0.05519243702292442,
0.3590191602706909,
0.0095799146220088,
0.7191739678382874,
0.9820708632469177,
-1.0874119997024536,
-0.7001507878303528,
-0.4658189117908478,
-0.07451768219470... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
Multimodal-Fatima/VQAv2_sample_train | Multimodal-Fatima | 2023-02-12T00:01:41Z | 35 | 0 | null | [
"region:us"
] | 2023-02-12T00:01:41Z | 2023-02-10T17:59:46.000Z | 2023-02-10T17:59:46 | ---
dataset_info:
features:
- name: question_type
dtype: string
- name: multiple_choice_answer
dtype: string
- name: answers
sequence: string
- name: answers_original
list:
- name: answer
dtype: string
- name: answer_confidence
dtype: string
- name: answer_id
dtype: int64
- name: id_image
dtype: int64
- name: answer_type
dtype: string
- name: question_id
dtype: int64
- name: question
dtype: string
- name: image
dtype: image
- name: id
dtype: int64
- name: clip_tags_ViT_L_14
sequence: string
- name: blip_caption
dtype: string
- name: DETA_detections_deta_swin_large_o365_coco_classes
list:
- name: attribute
dtype: string
- name: box
sequence: float32
- name: label
dtype: string
- name: location
dtype: string
- name: ratio
dtype: float32
- name: size
dtype: string
- name: tag
dtype: string
splits:
- name: train
num_bytes: 158100925.0
num_examples: 1000
download_size: 155253264
dataset_size: 158100925.0
---
# Dataset Card for "VQAv2_sample_train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | [
-0.4424455761909485,
0.12089172005653381,
0.17699375748634338,
0.17636340856552124,
-0.22680088877677917,
-0.11382533609867096,
0.4684583842754364,
-0.012090844102203846,
0.5279079675674438,
0.40362292528152466,
-0.926865816116333,
-0.4611617922782898,
-0.4447067975997925,
-0.5390264391899... | null | null | null | null | null | null | null | null | null | null | null | null | null | |
CATIE-AQ/frenchQA | CATIE-AQ | 2023-11-27T16:32:18Z | 35 | 1 | null | [
"task_categories:question-answering",
"size_categories:100K<n<1M",
"language:fr",
"license:cc-by-4.0",
"doi:10.57967/hf/0862",
"region:us"
] | 2023-11-27T16:32:18Z | 2023-03-14T14:32:36.000Z | 2023-03-14T14:32:36 | ---
task_categories:
- question-answering
language:
- fr
size_categories:
- 100K<n<1M
license: cc-by-4.0
---
# Dataset information
Dataset concatenating all QA datasets with context available in French and open-source.
In addition, an augmented version of these datasets has been added (same context but different questions to create data in SQuADv2 format).
In total, there are 221,348 training data, **910** validation data and 6,376 test data (the first 3,188 rows correspond to SQuADv2 format, the remaining 3,188 to SQuADv2 format).
In practice, due to the restrictive license for the FQUAD 1.0 dataset, we can only share **179,886** rows of the 221,348 training data and not the test dataset.
Our methodology is described in a blog post available in [English](https://blog.vaniila.ai/en/QA_en/) or [French](https://blog.vaniila.ai/QA/).
# Usage
```
from datasets import load_dataset
dataset = load_dataset("CATIE-AQ/frenchQA",sep=";")
```
```
dataset
DatasetDict({
train: Dataset({
features: ['context', 'question', 'answer', 'answer_start', 'dataset'],
num_rows: 179886
})
validation: Dataset({
features: ['context', 'question', 'answer', 'answer_start', 'dataset'],
num_rows: 910
})
})
```
# Dataset
## Dataset details
| Dataset | Format | Train split | Dev split | Test split | Available in frenchQA |
| ----------- | ----------- | ----------- | ----------- | ----------- | ------------------------ |
| [piaf](https://www.data.gouv.fr/en/datasets/piaf-le-dataset-francophone-de-questions-reponses/)| SQuAD 1.0 | 9 224 Q & A | X | X | Yes |
| piaf_v2| SQuAD 2.0 | 9 224 Q & A | X | X | Yes |
| [fquad](https://fquad.illuin.tech/)| SQuAD 1.0 | 20 731 Q & A | 3 188 Q & A (is not used for training, but as a test dataset) | 2 189 Q & A (not freely available)| No due to the license |
| fquad_v2 | SQuAD 2.0 | 20 731 Q & A | 3 188 Q & A (is not used for training, but as a test dataset) | X | No due to the license |
| [lincoln/newsquadfr](https://huggingface.co/datasets/lincoln/newsquadfr) | SQuAD 1.0 | 1 650 Q & A | 455 Q & A | X | Yes |
| lincoln/newsquadfr_v2 | SQuAD 2.0 | 1 650 Q & A | 455 Q & A | X | Yes |
| [pragnakalp/squad_v2_french_translated](https://huggingface.co/datasets/pragnakalp/squad_v2_french_translated)| SQuAD 2.0 | 79 069 Q & A | X | X | Yes |
| pragnakalp/squad_v2_french_translated_v2| SQuAD 2.0 | 79 069 Q & A | X | X | Yes |
## Columns
```
dataset_train = dataset['train'].to_pandas()
dataset_train.head()
context question answer answer_start dataset
0 Beyoncé Giselle Knowles-Carter (/ biːˈjɒnseɪ /... Quand Beyonce a-t-elle commencé à devenir popu... à la fin des années 1990 269 pragnakalp/squad_v2_french_translated
1 Beyoncé Giselle Knowles-Carter (/ biːˈjɒnseɪ /... Quand Beyonce a-t-elle quitté Destiny's Child ... 2003 549 pragnakalp/squad_v2_french_translated
2 Beyoncé Giselle Knowles-Carter (/ biːˈjɒnseɪ /... Qui a dirigé le groupe Destiny's Child ? Mathew Knowles 376 pragnakalp/squad_v2_french_translated
3 Beyoncé Giselle Knowles-Carter (/ biːˈjɒnseɪ /... Quand Beyoncé a-t-elle sorti Dangerously in Lo... 2003 549 pragnakalp/squad_v2_french_translated
4 Beyoncé Giselle Knowles-Carter (/ biːˈjɒnseɪ /... Combien de Grammy Awards Beyoncé a-t-elle gagn... cinq 629 pragnakalp/squad_v2_french_translated
```
- the `context` column contains the context
- the `question` column contains the question
- the `answer` column contains the answer (has been replaced by `no_answer` for rows in SQuAD v2 format)
- the `answer_start` column contains the start position of the answer in the context (has been replaced by `-1` for rows in SQuAD v2 format)
- the `dataset` column identifies the row's original dataset (if you wish to apply filters to it, rows in SQuAD v2 format are indicated with the suffix `_v2` in the dataset name)
## Split
- `train` corresponds to the concatenation of the training dataset from `pragnakalp/squad_v2_english_translated` + `lincoln/newsquadfr` + `PIAFv1.2` + the augmented version of each dataset in SQuADv2 format (no shuffle has been performed)
- `validation` corresponds to the concatenation of the newsquadfr validation dataset + this same dataset expanded in SQuAD v2 format (= newsquadfr_v2) (no shuffle performed)
# Question type statistics
The question type distribution is as follows:
| Type of question | Frequency in percent |
| ----------- | ----------- |
|What (que) |55.02|
|Who (qui) |15.96|
|How much (combien)|7.92|
|When (quand) |6.90|
|Where (où) |3.15|
|How (comment) |3.76|
|What (quoi) |2.60|
|Why (pourquoi) |1.25|
|Other |3.44|
The number of questions containing a negation, e.g. "What was the name of Chopin's first music teacher who was not an amateur musician?", is estimated at 3.55% of the total questions.
For information, the distribution of the complete dataset (containing FQUAD 1.0 and FQUAD 1.0 data in SQUAD 2.0 format) is as follows:
| Type of question | Frequency in percent |
| ----------- | ----------- |
|What (que) |55.12|
|Who (qui) |16.24|
|How much (combien)|7.56|
|When (quand) |6.85|
|Where (où) |3.98|
|How (comment) |3.76|
|What (quoi) |2.94|
|Why (pourquoi) |1.41|
|Other |2.14|
The number of questions containing a negation, e.g. "What was the name of Chopin's first music teacher who was not an amateur musician?", is estimated at 3.07% of the total questions.
# Citation
```
@misc {centre_aquitain_des_technologies_de_l'information_et_electroniques_2023,
author = { {Centre Aquitain des Technologies de l'Information et Electroniques} },
title = { frenchQA (Revision 6249cd5) },
year = 2023,
url = { https://huggingface.co/datasets/CATIE-AQ/frenchQA },
doi = { 10.57967/hf/0862 },
publisher = { Hugging Face }
}
```
# License
[cc-by-4.0](https://creativecommons.org/licenses/by/4.0/deed.en) | [
-0.5854840278625488,
-0.6687447428703308,
0.06765364110469818,
0.4802766442298889,
-0.0166397076100111,
0.0010760007426142693,
-0.041179344058036804,
-0.23701617121696472,
0.3532544672489166,
0.2511574327945709,
-0.9568296074867249,
-0.5379002094268799,
-0.3692866265773773,
0.1897102296352... | null | null | null | null | null | null | null | null | null | null | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.